-
#1
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего

Последнее редактирование: 24 Фев 2021
-
#2
вопрос — а на куя?
а не усе, снято))) 2 минуты на загрузку эт РИП)))
-
#4
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего
Посмотреть вложение 172172
Хайв на ссд накати,у меня есть фермы с флешками а есть с ссд,на ссд проблем нету,можешь попробовать обычный жёсткий,но я хз не пробовал какая там скорость загрузки
-
#5
Такая-же проблема. Собрал/разобрал риг и стал появлятся переодически LA. При подключении ещё одной карты в риг LA идет выше и выше пока карта не отвалится или риг целиком. Заменил райзер, риг и карта перестал отваливаться, но шестую карту повесить не могу.
-
#6
ни на одном из ригов ЛА не был еще выше 40 секунд — и это считаю я, долго… а тут тема про 2 минуты…
флешка? или 486sx-40 проц?
-
#7
Такая-же проблема. Собрал/разобрал риг и стал появлятся переодически LA. При подключении ещё одной карты в риг LA идет выше и выше пока карта не отвалится или риг целиком. Заменил райзер, риг и карта перестал отваливаться, но шестую карту повесить не могу.
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
-
#8
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
Спасибо, попробую
-
#9
Там в соседней теме пишут что рейв/хайв это круто.
Вы из одной секты или разные?
-
#10
Такое чувство что никто не понимает что такое load average в линуксе. Это просто загрузка системы. Открой top, посмотри что грузит проц. Если ничего, вероятно, затык из-за io (файловой системы). Как уже сказали, посмотри выключены ли логи.
-
#11
здравствуйте как понизить лоад авэредж. вставлял карты по очереди, менял первую вставленую карту на другую, повышал напряжение до 900 на всех и все бес толку. пулл хайв, майнер тимрэд сейчас 1,9 но он постоянно скачет от 1,8 до 2,5 приблизительно,, я так понимаю что какая то из карт вешается? ну так я и разгон уменьшал и напругу повышал ничего
Посмотреть вложение 172172
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
-
#12
1. Обнови до последней версии.
2. Снизь разгон нулевой карты. Инкорректов не должно быть совсем.
3. Замени флешку на SSD.
-
#13
В случае «плохого» Load Average тебе сама ОС его подсветит красным.
-
#14
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
И еще amd -info скрин.
-
#15
1. Обнови до последней версии.
2. Снизь разгон нулевой карты. Инкорректов не должно быть совсем.
3. Замени флешку на SSD
обновлен.инкорект нулевой не из за разгона у нее чипы перегреваются не удачная конструкция асуса) а насчет флешки я сам грешил попробую заменить но нет под рукой не ссд не флешки лишней ,если ты думаешь что вот проблема, то нет, я убирал эту карту из рига, не чего не изменилось, кстате не по теме карты асус стрикс идет с завода бе з прокладок причем три чипа даже не обдуваются кто нибудь их модернизировал?по ка спасает большой куллер на обратную сторону платы
А ну покажи табличку тюнинга любой 570-й. Что там еще прописано.
все на скрине
Попробуйте ластиком потереть дорожки золотые на видеокартах а так же на концах райзера которые в мать вставляются и оперативку можно за одно,все с обоих сторон
попробую тоже0 а вдруг
отключил закрузка просела но не на долго до 1,3 потом снова 2,9
-
#17
Такое чувство что никто не понимает что такое load average в линуксе. Это просто загрузка системы. Открой top, посмотри что грузит проц. Если ничего, вероятно, затык из-за io (файловой системы). Как уже сказали, посмотри выключены ли логи.
что значит открой тоП?
-
#19
Попробуй ничего не прописывать в даунвольт памяти. Никаких vddci и mvdd. И посмотри как будет с LA. В самом майнере никаких доп. комманд нет?
Последнее редактирование: 24 Фев 2021
-
#20
вроде как бы и не грузит не чего спасибо кстате не знал про эту команду, что выходит? флэшка?



Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя облачные инстансы на основании этой и ряда других метрик. Но на Linux она окутана некой тайной. Отслеживание средней нагрузки на Linux — это задача, работающая в непрерываемом состоянии сна (uninterruptible sleep state). Почему? Я никогда не встречал объяснений. В этой статье я хочу разгадать эту тайну, и создать референс по средним значениям нагрузки для всех, кто пытается их интерпретировать.
Средние значения нагрузки в Linux — это «средние значения нагрузки системы», показывающие потребность в исполняемых потоках (задачах) в виде усреднённого количества исполняемых и ожидающих потоков. Это мера нагрузки, которая может превышать обрабатываемую системой в данный момент. Большинство инструментов показывает три средних значения: для 1, 5 и 15 минут:
$ uptime
16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46
top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603Некоторые интерпретации:
- Если значения равны 0.0, то система в состоянии простоя.
- Если среднее значение для 1 минуты выше, чем для 5 или 15, то нагрузка растёт.
- Если среднее значение для 1 минуты ниже, чем для 5 или 15, то нагрузка снижается.
- Если значения нагрузки выше, чем количество процессоров, то у вас могут быть проблемы с производительностью (в зависимости от ситуации).
По этому набору из трёх значений вы можете оценить динамику нагрузки, что безусловно полезно. Также эти метрики полезны, когда требуется какая-то одна оценка потребности в ресурсах, например, для автоматического масштабирования облачных сервисов. Но чтобы разобраться с ними подробнее, нужно обратиться и к другим метрикам. Само по себе значение в диапазоне 23—25 ничего не значит, но обретает смысл, если известно количество процессоров, и если речь идёт о нагрузке, относящейся к процессору.
Вместо того, чтобы заниматься отладкой средних значений нагрузки, я обычно переключаюсь на другие метрики. Об этом мы поговорим ближе к концу статьи, в главе «Более подходящие метрики».
История
Изначально средние значения нагрузки показывают только потребность в ресурсах процессора: количество выполняемых и ожидающих выполнения процессов. В RFC 546 есть хорошее описание под названием «TENEX Load Averages», август 1973:
[1] Средняя нагрузка TENEX — это мера потребности в ресурсах CPU. Это среднее количество исполняемых процессов в течение определённого времени. Например, если часовая средняя нагрузка равна 10, то это означает (для однопроцессорной системы), что в любой момент времени в течение этого часа 1 процесс выполняется, а 9 готовы к выполнению (то есть не блокированы для ввода/вывода) и ждут, когда процессор освободится.
Версия на ietf.org ведёт на PDF-скан графика, нарисованного вручную в июле 1973, демонстрирующего, что эта метрика используется десятилетиями:
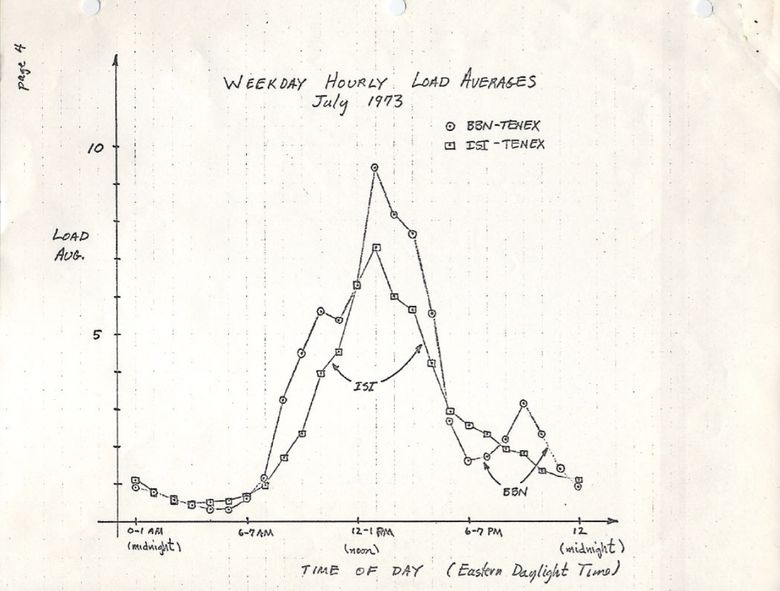
source: https://tools.ietf.org/html/rfc546
Сегодня можно найти в сети исходный код старых операционных систем. Вот фрагмент из TENEX (начало 1970’s) SCHED.MAC, на макроассемблере DEC:
NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAIN
GS RJAV,NRJAVS ;EXPONENTIAL AVERAGES OF NUMBER OF ACTIVE PROCESSES
[...]
;UPDATE RUNNABLE JOB AVERAGES
DORJAV: MOVEI 2,^D5000
MOVEM 2,RJATIM ;SET TIME OF NEXT UPDATE
MOVE 4,RJTSUM ;CURRENT INTEGRAL OF NBPROC+NGPROC
SUBM 4,RJAVS1 ;DIFFERENCE FROM LAST UPDATE
EXCH 4,RJAVS1
FSC 4,233 ;FLOAT IT
FDVR 4,[5000.0] ;AVERAGE OVER LAST 5000 MS
[...]
;TABLE OF EXP(-T/C) FOR T = 5 SEC.
EXPFF: EXP 0.920043902 ;C = 1 MIN
EXP 0.983471344 ;C = 5 MIN
EXP 0.994459811 ;C = 15 MINА вот фрагмент из современной Linux (include/linux/sched/loadavg.h):
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */В Linux тоже жёстко прописаны константы на 1, 5 и 15 минут.
Аналогичные метрики были и в более старых системах, включая Multics, которая содержала экспоненциальное среднее значение очереди планируемых заданий (exponential scheduling queue average).
Три числа
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие скользящие суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:

Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Непрерываемые задачи Linux
Когда в Linux впервые появились средние значения нагрузки, они отражали только потребность в ресурсах процессора, как и в других ОС. Но позднее они претерпели изменения, в них включили не только выполняемые задачи, но и те, что находятся в непрерываемом состоянии (TASK_UNINTERRUPTIBLE или nr_uninterruptible). Это состояние используется ветвями кода, которые хотят избежать прерывания по сигналам, в том числе задачами, блокированными дисковым вводом/выводом, и некоторыми блокировками. Вы могли уже сталкиваться с этим состоянием: оно отображается как состояние «D» в выходных данных ps и top. На странице ps(1) его называют «uninterruptible sleep (usually IO)».
Внедрение непрерываемого состояния означает, что в Linux средние значения нагрузок могут увеличиваться из-за дисковой (или NFS) нагрузки ввода/вывода, а не только ресурсов процессора. Всех, кто знаком с другими ОС и их средними нагрузками на процессор, включение этого состояния поначалу сильно смущает.
Зачем? Зачем это было сделано в Linux?
Существует несметное количество статей по средним нагрузкам, многие из которых упоминают про nr_uninterruptible в Linux. Но я не видел ни одного объяснения, или хотя бы серьёзного предположения, почему начали учитывать это состояние. Лично я предположил бы, что оно должно отражать более общие потребности в ресурсах, а не только применительно к процессору.
В поисках древнего патча для Linux
Легко понять, почему в Linux что-то меняется: просматриваешь историю git-коммитов для нужного файла и читаешь описания изменений. Я просмотрел историю на loadavg.c, но изменение, добавляющее неизменяемое состояние, датировано более ранним числом, чем файл, содержащий код из более раннего файла. Я проверил другой файл, но это ничего не дало: код «скакал» по разным файлам. Надеясь на удачу, я задампил git log -p по всему Github-репозиторию Linux, содержащему 4 Гб текста, и начал читать с конца, отыскивая место, где впервые появился этот код. Это мне тоже не помогло. Самое старое изменение в репозитории датировано 2005-м, когда Линус импортировал Linux 2.6.12-rc2, а искомое изменение было внесено ещё раньше.
Есть старинные репозитории Linux (1 и 2), но и в них отсутствует описание этого изменения. Стараясь найти хотя бы дату его внедрения, я изучил архив на kernel.org и обнаружил, что оно было в 0.99.15, а в 0.99.13 ещё не было. Однако версия 0.99.14 отсутствовала. Мне удалось её отыскать и подтвердить, что искомое изменение появилось в Linux 0.99.14, в ноябре 1993. Я надеялся, что мне поможет описание этого релиза, но и здесь я не нашёл объяснения:
«Изменения в последнем официальном релизе (p13) слишком многочисленны, чтобы их перечислять (или даже вспомнить)…» — Линус
Он упомянул лишь основные изменения, не связанные со средним значением нагрузки.
По дате мне удалось найти архивы почтовой рассылки kernel и конкретный патч, но более старое письмо было датировано аж июнем 1995:
«Во время работы над системой, позволяющей эффективнее масштабировать почтовые архивы, я случайно уничтожил текущие архивы (ай-ой)».
Я начал ощущать себя проклятым. К счастью мне удалось обнаружить старые архивы почтовой рассылки linux-devel, вытащенные из серверного бэкапа, зачастую хранящиеся как архивы дайджестов. Я просмотрел более 6000 дайджестов, содержащих свыше 98 000 писем, из которых 30 000 относились к 1993 году. Но ничего не нашёл. Казалось, исходное описание патча потеряно навеки, и ответа на вопрос «зачем» мы уже не получим.
Происхождение непрерываемости
Но вдруг на сайте oldlinux.org в архивированном файле почтового ящика за 1993 я нашёл это:
From: Matthias Urlichs <urlichs@smurf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
Ядро считает только "исполняемые" процессы при вычислении среднего значения нагрузки. Мне это не нравится. Проблема в том, что процессы, которые подкачиваются или ожидают в "быстром", то есть непрерываемом, вводе/выводе, тоже потребляют ресурсы.
Это нелогично, что средняя нагрузка снижается, когда вы заменяете диск с быстрой подкачкой на диск с медленной подкачкой…
В любом случае, следующий патч сделает среднее значение нагрузки более соответствующим субъективной скорости системы. И что ещё важнее, нагрузка всё ещё будет равна нулю, когда никто ничего не делает. ;-)
--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}
--
Matthias Urlichs XLink-POP N|rnberg | EMail: urlichs@smurf.sub.org
Schleiermacherstra_e 12 Unix+Linux+Mac | Phone: ...please use email.
90491 N|rnberg (Germany) Consulting+Networking+Programming+etc'ing 42Было просто невероятно прочитать о размышлениях 24-летней давности, ставших причиной этого изменения. Письмо подтвердило, что изменение в метрике должно было учитывать потребности и в других ресурсах системы, а не только процессора. Linux перешла от «средней нагрузки на процессор» к чему-то вроде «средней нагрузки на систему».
Упомянутый пример с диском с более медленной подкачкой не лишён смысла: снижая производительность системы, потребность в ресурсах (исполняемые и ждущие очереди процессы) должна расти. Однако средние значения нагрузки снижались, потому что они учитывали только состояния выполнения процессора (CPU running states), но не состояния подкачки (swapping states). Маттиас вполне справедливо считал это нелогичным, и потому исправил.
Непрерываемость сегодня
Но разве средние значения нагрузки в Linux иногда не поднимаются слишком высоко, что уже нельзя объяснить дисковым вводом/выводом? Да, это так, хотя я предполагаю, что это следствие новой ветви кода, использующей TASK_UNINTERRUPTIBLE, не существовавшего в 1993-м. В Linux 0.99.14 было 13 ветвей кода, которые напрямую использовали TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние подкачки позднее убрали из Linux). Сегодня в Linux 4.12 почти 400 ветвей, использующих TASK_UNINTERRUPTIBLE, включая некоторые примитивы блокировки. Вероятно, что одна из этих ветвей не должна учитываться в среднем значении нагрузки. Я проверю, так ли это, когда снова увижу, что значение слишком высокое, и посмотрю, можно ли это исправить.
Я написал Маттиасу и спросил, что он думает 24 года спустя о своём изменении среднего значения нагрузки. Он ответил через час:
«Суть «средней нагрузки» — предоставить численную оценку занятости системы с точки зрения человека. TASK_UNINTERRUPTIBLE означает (означало?), что процесс ожидает чего-то вроде чтения с диска, что влияет на нагрузку системы. Система, сильно зависящая от диска, может быть очень тормозной, но при этом среднее значение TASK_RUNNING будет в районе 0,1, что совершенно бесполезно».
Так что Маттиас до сих пор уверен в правильности этого шага, как минимум относительно того, для чего предназначался TASK_UNINTERRUPTIBLE.
Но сегодня TASK_UNINTERRUPTIBLE соответствует большему количеству вещей. Нужно ли нам менять средние значения нагрузки, чтобы они отражали потребности в ресурсах только процессора и диска? Peter Zijstra уже прислал мне хорошую идею: учитывать в средней нагрузке task_struct->in_iowait вместо TASK_UNINTERRUPTIBLE, потому что это точнее соответствует вводу/выводу диска. Однако это поднимает другой вопрос: чего мы хотим на самом деле? Хотим ли мы измерять потребности в системных ресурсах в виде потоков выполнения, или нам нужны физические ресурсы? Если первое, то нужно учитывать непрерываемые блокировки, потому что эти потоки потребляют ресурсы системы. Они не находятся в состоянии простоя. Так что среднее значение нагрузки в Linux, вероятно, уже работает как нужно.
Чтобы лучше разобраться с непрерываемыми ветвями кода, я хотел бы измерить их в действии. Потом можно оценить разные примеры, измерить затраченное время и понять, есть ли в этом смысл.
Измерение непрерываемых задач
Вот внепроцессорный (off-CPU) флейм-график с production-сервера, охватывающий 60 секунд и показывающий только стеки ядра, на котором я оставил только состояние TASK_UNINTERRUPTIBLE (SVG).
График отражает много примеров непрерываемых ветвей кода:

Если вы не знакомы с флейм-графиками: можете покликать по блокам, изучить целиком стеки, отображающиеся как колонки из блоков. Размер оси Х пропорционален времени, потраченному на блокирование вне процессора, а порядок сортировки (слева направо) не имеет значения. Для внепроцессорных стеков выбран голубой цвет (для внутрипроцессорных стеков я использую тёплые цвета), а вариации насыщенности обозначают разные фреймы.
Я сгенерировал график с помощью своего инструмента offcputime из bcc (для работы ему нужны eBPF-возможности Linux 4.8+), а также приложения для создания флейм-графиков:
# ./bcc/tools/offcputime.py -K --state 2 -f 60 > out.stacks
# awk '{ print $1, $2 / 1000 }' out.stacks | ./FlameGraph/flamegraph.pl --color=io --countname=ms > out.offcpu.svgb>Для изменения выходных данных с микросекунд на миллисекунды я использую awk. Offcputime «—state 2» соответствует TASK_UNINTERRUPTIBLE (см. sched.h), это опция, которую я добавил ради этой статьи. Впервые это сделал Джозеф Бачик с его инструментом kernelscope, который тоже использует bcc и флейм-графики. В своих примерах я показываю лишь стеки ядра, но offcputime.py поддерживает и пользовательские стеки.
Что касается вышеприведённого графика: он отображает только 926 мс из 60 секунд, проведённые в состоянии непрерываемого сна. Это добавляет к нашим средним значениям нагрузки всего 0,015. Это время, потраченное некоторыми cgroup-ветвями, но на этом сервере не выполняется много дисковых операций ввода/вывода.
А вот более интересный график, охватывающий только 10 секунд (SVG):

Более широкая башня справа относится к блокируемому systemd-journal в proc_pid_cmdline_read() (чтение /proc/PID/cmdline), что добавляет к среднему значению нагрузки 0,07. Слева более широкая башня page fault, тоже заканчивающаяся на rwsem_down_read_failed() (добавляет к средней нагрузке 0,23). Я окрасил эти функции пурпурным цветом с помощью поисковой фичи в моём инструменте. Вот фрагмент кода из rwsem_down_read_failed():
/* wait to be given the lock */
while (true) {
set_task_state(tsk, TASK_UNINTERRUPTIBLE);
if (!waiter.task)
break;
schedule();
}Это код получения блокировки, использующий TASK_UNINTERRUPTIBLE. В Linux есть прерываемые и непрерываемые версии функций получения мьютексов (mutex acquire functions) (например, mutex_lock() и mutex_lock_interruptible(), down() и down_interruptible() для семафоров). Прерываемые версии позволяют прерывать задачи по сигналу, а затем будить для продолжения обработки прежде, чем будет получена блокировка. Время, потраченное на сон в непрерываемой блокировке, обычно мало добавляет к среднему значению нагрузки, и в данном случае прибавка достигает 0,3. Если бы было гораздо больше, то стоило бы выяснить, можно ли уменьшить конфликты при блокировках (например, я начинаю копаться в systemd-journal и proc_pid_cmdline_read()!), чтобы улучшить производительность и снизить среднее значение нагрузки.
Имеет ли смысл учитывать эти ветви кода в средней нагрузке? Я бы сказал, да. Эти потоки остановлены посреди выполнения и заблокированы. Они не простаивают. Им требуются ресурсы, хотя бы и программные, а не аппаратные.
Анализируем средние значения нагрузки в Linux
Можно ли полностью разложить на компоненты среднее значение нагрузки? Вот пример: на простаивающей 8-процессорной системе я запустил tar для архивирования нескольких незакэшированных файлов. Приложение потратило несколько минут, по большей части оно было блокировано операциями чтения с диска. Вот статистика, из трёх разных окон терминала:
terma$ pidstat -p `pgrep -x tar` 60
Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU)
10:15:51 PM UID PID %usr %system %guest %CPU CPU Command
10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tar
termb$ iostat -x 60
[...]
avg-cpu: %user %nice %system %iowait %steal %idle
0.54 0.00 4.03 8.24 0.09 87.10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21
xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47
xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65
md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00
termc$ uptime
22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05
[...]
termc$ uptime
22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06Я также построил внепроцессорный флейм-график исключительно для непрерываемого состояния (SVG):
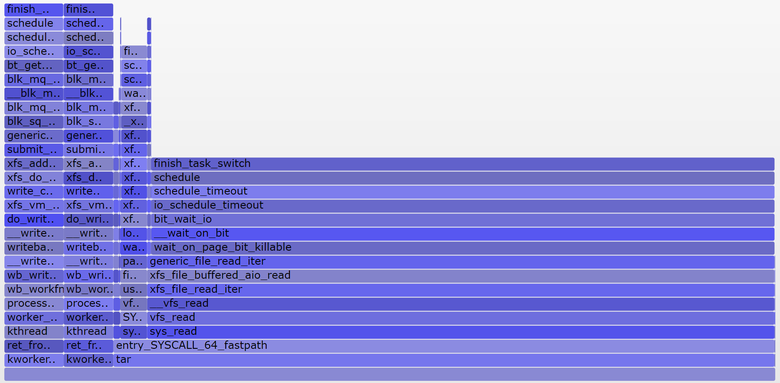
Средняя нагрузка в последнюю минуту составила 1,19. Давайте разложим на составляющие:
- 0,33 — процессорное время tar (pidstat)
- 0,67 — непрерываемые чтения с диска, предположительно (на графике 0,69, полагаю, что для него сбор данных начался чуть позже и охватывает немного другой временной диапазон)
- 0,04 — прочие потребители процессора (пользователь mpstat + система, минус потребление процессора tar’ом из pidstat)
- 0,11 — непрерываемый дисковый ввод/вывод воркеров ядра, сбросы на диск (на графике две башни слева)
В сумме получается 1,15. Не хватает ещё 0,04. Частично сюда могут входить округления и ошибки измерения сдвигов интервала, но в основном это может быть из-за того, что средняя нагрузка представляет собой экспоненциально затухающую скользящую сумму, в то время как другие используемые метрики (pidstat, iostat) являются обычными средними. До 1,19 одноминутная средняя нагрузка равнялась 1,25, значит что-то из перечисленного всё ещё тянет метрику вверх. Насколько? Согласно моим ранним графикам, на одноминутной отметке 62 % метрики приходилось на текущую минуту, а остальное — на предыдущую. Так что 0,62 x 1,15 + 0,38 x 1,25 = 1,18. Достаточно близко к полученному 1,19.
В этой системе работу выполняет один поток (tar), плюс ещё немного времени тратится потоками воркеров ядра, так что отчёт Linux о средней нагрузке на уровне 1,19 выглядит обоснованно. Если бы я измерял «среднюю нагрузку на процессор», то мне показали бы только 0,37 (расчётное значение из mpstat), что корректно только для процессорных ресурсов, но не учитывает тот факт, что нужно обрабатывать более одного потока.
Надеюсь, этот пример показал вам, что эти числа берутся не с потолка (процессор + непререрываемые), и вы можете сами разложить их на составляющие.
Смысл средних значений нагрузки в Linux
Я вырос на операционных системах, в которых средние значения нагрузок относились только к процессору, так что Linux-вариант всегда меня напрягал. Возможно, настоящая проблема заключается в том, что термин «средняя нагрузка» так же неоднозначен, как «ввод-вывод». Какой именно ввод/вывод? Диска? Файловой системы? Сети?.. Аналогично, средние нагрузки чего? Процессора? Системы? Эти уточнения помогли мне понять:
- В Linux средние нагрузки — это (или пытаются быть) «средние значения нагрузки на систему», систему в целом. Они измеряют количество выполняемых потоков и ожидающих своей очереди (процессор, диск, непрерываемые блокировки). Иными словами, эта метрика отражает количество потоков, которые не простаивают полностью. Преимущество: учитывается потребность в разных ресурсах.
- В других ОС средние нагрузки — это «средние значения нагрузки на процессор». Они измеряют количество потоков, выполняемых и готовых к выполнению в процессоре. Преимущество: проще в понимании и обосновании (только для процессоров).
Есть и другой возможный тип метрики: «средние значения нагрузки на физические ресурсы», куда входит нагрузка только на физические ресурсы (процессор и диск).
Возможно, когда-нибудь мы начнём учитывать в Linux и другие нагрузки, и позволим пользователям выбирать, что они хотят видеть: средние нагрузки на процессор, на диск, на сеть и так далее. Или вообще использовать всё вместе.
Что такое «хорошие» или «плохие» средние нагрузки?
Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
Более подходящие метрики
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
- использование каждого процессора (per-CPU utilization): например, используя
mpstat -P ALL 1. - использование процессора для каждого процесса (per-process CPU utilization): например,
top, pidstat 1и так далее. - задержка очереди выполнения (диспетчера) для каждого потока (per-thread run queue (scheduler) latency): например, в /proc/PID/schedstats, delaystats, perf sched
- задержка очереди выполнения процессора (CPU run queue latency): например, в
/proc/schedstat,perf sched, моём инструменте runqlat bcc. - длина очереди выполнения процессора (CPU run queue length): например, используя vmstat 1 и колонку ‘r’, или мой инструмент
runqlen bcc.
Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция schedstats (sysctl kernel.sched_schedstats) стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
$ awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug
task PID tree-key switches prio wait-time sum-exec sum-sleep
systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope
ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 /
kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 /
migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 /
lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 /
watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 /
cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 /
xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 /
khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 /
[...]
dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service
dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service
dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/
[...]Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация. Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим.
Заключение
В 1993 году Linux-инженер обнаружил нелогичную работу средних значений нагрузки, и с помощью трёхстрочного патча навсегда изменил их с «со средних нагрузок на процессор» на «средние нагрузки на систему». С тех пор учитываются задачи в непрерываемом состоянии, так что средние нагрузки отражают потребность не только в процессорных, но и в дисковых ресурсах. Обновлённые метрики подсчитывают количество работающих и ожидающих работы процессов (ожидающих освобождения процессора, дисков и снятия непрерываемых блокировок). Они выводятся в виде трёх экспоненциально затухающих скользящих сумм, в уравнениях которых используются константы в 1, 5 и 15 минут. Эти три значения позволяют видеть динамику нагрузки, а самое большое из них может использоваться для относительного сравнения с ними самими.
С тех пор в ядре Linux всё активнее использовалось непрерываемое состояние, и сегодня оно включает в себя примитивы непрерываемой блокировки. Если считать среднее значение нагрузки мерой потребности в ресурсах в виде выполняемых и ожидающих потоков (а не просто потоков, которым нужны аппаратные ресурсы), то эта метрика уже работает так, как нам нужно.
Я откопал патч, с которым было внесено это изменение в Linux в 1993-м — его было на удивление трудно найти, — содержащий исходное объяснение его автора. Также с помощью bcc/eBPF я замерил на современной Linux-системе трейсы стеков и длительность нахождения в непрерываемом состоянии, и отобразил это на внепроцессорном флем-графике. На нём отражено много примеров состояний непрерываемого сна, такой график можно генерировать, когда нужно объяснить необычно высокие средние значения нагрузки. Также я предложил вместо них использовать другие метрики, позволяющие глубже понять работу системы.
В заключение процитирую комментарий из топа kernel/sched/loadavg.c исходного кода Linux:
Этот файл содержит волшебные биты, необходимые для вычисления глобального среднего значения нагрузки. Это глупое число, но люди считают его важным. Мы потратили много сил, чтобы эта метрика работала на больших машинах и tickless-ядрах.
Ссылки
- Saltzer, J., and J. Gintell. “The Instrumentation of Multics,” CACM, August 1970 (объясняет экспоненциальные значения).
- Ссылка на команду system_performance_graph в Multics (использует одноминутное среднеее).
- Исходный код TENEX (среднее значение нагрузки в SCHED.MAC).
- RFC 546 «TENEX Load Averages for July 1973» (объясняет измерение потребности в ресурсах процессора).
- Bobrow, D., et al. “TENEX: A Paged Time Sharing System for the PDP-10,” Communications of the ACM, March 1972 (объясняет три метрики средней нагрузки).
- Gunther, N. «UNIX Load Average Part 1: How It Works» PDF (объясняет экспоненциальные вычисления).
- Письмо Линуса по поводу Linux 0.99 patchlevel 14.
- Письмо об изменении в среднем значении нагрузки на oldlinux.org (в alan-old-funet-lists/kernel.1993.gz, а не в linux-директориях, где я сначала искал).
- Исходны код Linux kernel/sched.c до и после внесения изменения: 0.99.13, 0.99.14.
- Архивы релизов Linux 0.99 на kernel.org.
- Текущий код среднего значения нагрузки в Linux: loadavg.c, loadavg.h
- Аналитические инструменты bcc, включая мой offcputime, использованный для трейсинга TASK_UNINTERRUPTIBLE.
- Флейм-графики, использованные для визуализации непрерываемых ветвей.

С необходимостью правильно оценить нагрузку на систему сталкивается каждый системный администратор. Если говорить о Linux-системах, то одним из основных терминов, с которым придется столкнуться начинающему администратору окажется Load Average (средняя загрузка). Однако, если говорить о русскоязычном сегменте сети интернет, описание данного параметра сводится к общим малозначащим фразам, в то время как за этими простыми цифрами кроется глубокий пласт информации о работе системы.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если обратиться к популярным источникам (Википедия), то можно найти примерно следующее:
Средняя загрузка — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут, чем ниже, тем лучше. В UNIX это среднее значение вычислительной работы, которую выполняет система.
После прочтения данного абзаца никаких новых знаний, кроме того, что масло таки масляное (средняя загрузка — среднее значение загрузки) не возникает и понимания ситуации не прибавляется. Чем ниже, тем лучше, но насколько ниже и относительно чего.
Посмотреть текущую загрузку системы можно командной
uptimeТакже ее значения выводят утилиты top и htop, а также множество других инструментов. В ответ мы получим что-то вроде:
load average: 0,12, 0,10, 0,03Много это или мало? Хорошо или плохо? Давайте разбираться.
Чтобы понять, что такое загрузка системы следует обратиться к логике работы центрального процессора. Вне зависимости от того, мощный у вас процессор или слабый, многоядерный или нет, он выполняет некий программный код для некоторых процессов. Если процесс один, то вопросов нет, а вот когда их несколько? Надо как-то распределять ресурсы между ними и, желательно, равномерно, чтобы один процесс, «дорвавшись» до CPU, не оставил без вычислений другие.
Здесь можно провести аналогию, когда несколько игроков хотят поиграть на одной приставке. Что обычно делают в таких случаях? Договариваются о времени, скажем каждый играет по 15 минут, затем дает поиграть другому.
Процессор поступает аналогичным образом. Каждому нуждающемуся в вычислениях процессу выделяется некий промежуток времени, который зависит от типа процессора и системы, если говорить о современных процессорах Intel, то это значение обычно составляет 10 мс и называется тиком. Каждый тик процессорное время отдается какому-то одному процессу в порядке очереди, но если процесс имеет повышенный или пониженный приоритет, то он, соответственно получит большее или меньшее количество тиков.
Количество использованных тиков, в первом приближении, и представляет загрузку системы. В Linux для оценки загрузки используется интервал в 500 тиков (5 секунд), при этом учитываются как работающие процессы (использованные тики), так и ожидающие (которым не хватило тика, либо они не смогли его использовать, ожидая завершения иной операции).
Если мы используем все тики за указанный промежуток времени и у нас не будет ожидающих сводного тика процессов, то мы получим загрузку процессора на 100% или load average (LA) равное 1.
Давайте рассмотрим следующую схему:
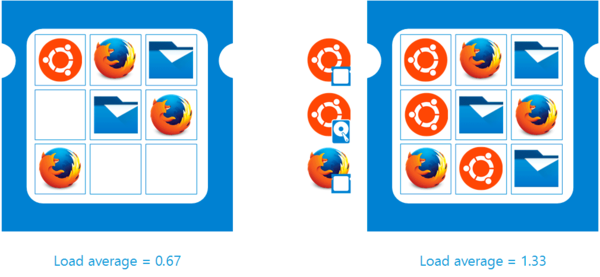 Для простоты мы будем использовать в расчетах более короткий интервал — 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Для простоты мы будем использовать в расчетах более короткий интервал — 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Справа показана ситуация, когда каждый тик был занят своим процессом, но некоторые процессы так и не получили своего тика или не смогли получить, например, ждали окончания операции ввода-вывода. В таком случае загрузка процессора составит все те же 100%, но load average вырастет до 1,33, указывая на наличие очереди.
Чтобы лучше понять ситуацию давайте представим себе небольшой супермаркет, касса представляет собой аналог процессора, тик — среднее время обслуживания покупателя (скажем, 1 минута), а процессы — это покупатели. В разгар рабочего дня людей в магазине немного, и вы спокойно прошли на свободную кассу, рассчитались и пошли по своим делам. Это хорошо, но как оценить нагрузку на кассу? Для этого нужно взять некий промежуток времени, допустим 10 минут. Если за 10 минут в магазине кроме вас было еще три человека, то средняя загрузка составит 0,4.
А теперь зайдем в магазин вечером, все кассы заняты, и чтобы оплатить покупки придется ждать. Теперь если за 10 минут касса обслужила 10 человек и еще 10 стоят в очереди, то средняя загрузка будет равна 2, хотя касса загружена всего на 100%.
Вернемся к процессору и еще одному моменту, процессам, ожидающим окончания операций ввода-вывода (диск, сеть и т.п.). Во многих источниках указывается, что такие процессы искажают результат load average и мы можем получить высокие значения LA при отсутствии загрузки процессора. Да, это так. Посмотрим на еще одну схему ниже:
 Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Если продолжать аналогию с супермаркетом, то похожая ситуация возникает, когда вы уже подошли к кассе и уже собрались выгружать продукты на ленту, но ваша супруга говорит вам, что она забыла купить хлеб, и вы тут стойте, а она сбегает. Собственно, все что вам остается до того, как она принесет хлеб, это стоять рядом с кассой и ждать, пропуская тех, кто находится в очереди позади вас.
Искажают ли такие процессы значение load average? На наш взгляд нет. Следует понимать, что средняя загрузка — это не показатель производительности процессора, не результат бенчмарка, не текущая нагрузка, а отношение числа процессов, которым требуются вычислительные ресурсы системы к имеющимся в наличии ресурсам.
Т.е. если у нас имеется 1 процессор и 500 тиков, но за это время процессорные ресурсы требуются тысяче процессов, то нагрузка у нас явно вдвое превышает имеющиеся ресурсы. И то, что часть процессов ждут жесткий диск и процессор работает вхолостую, не говорит о том, что система находится в простое, наоборот, она не может обработать нагрузку, правда по другой, не зависящей от процессора причине.
Пользователю ведь все равно по какой причине тормозит сайт или приложение, тем более что недостаток дисковых ресурсов обычно выражается подвисании приложения, в то время как при недостатке процессорных оно просто начинает тормозить.
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов (тиков). Для одного процессора (одного процессорного ядра) использование всех имеющихся ресурсов обозначает load average = 1. Причем это будет справедливо и для Core i7 и для Pentium I, хотя производительность у этих двух процессоров разная.
Теперь перейдем к многопроцессорности и многоядерности. При появлении второго процессора или второго ядра у нас появляются дополнительные вычислительные ресурсы, т.е. же самые 500 тиков. Но за эти 500 тиков система уже может обработать уже 1000 запросов, что покажет нам load average = 2.
Значит ли это, что производительность выросла в два раза? Нет! Производительность зависит от того, сколько вычислений способен произвести процессор в течении одного тика. Понятно, что более мощный процессор выполнит за этот промежуток времени больше вычислений, но оба из них сделают одинаковое число тиков (для каждого процессорного ядра). В многопроцессорных (многоядерных) системах часть процессорного времени вместо вычислений занимают задачи межпроцессорного взаимодействия, переключения контекста и т.д. Поэтому появление второго ядра никогда не даст 100% прироста производительности, но всегда позволяет обработать вдвое большее количество запросов.
Это хорошо видно на примере технологии Hyper-threading, которая позволяет сделать из одного физического ядра процессора два виртуальных. Физическая производительность ядра процессора, т.е. количество производимых им вычислений в единицу времени не меняется, но появляется, хоть и виртуальное, но второе ядро, а это еще 500 тиков. Как показывают тесты, прирост производительности от Hyper-threading составляет 15-30%, что еще раз подтверждает старую поговорку, что лучше плохо ехать, чем хорошо стоять. Второе ядро, хоть и виртуальное, позволяет обрабатывать вычислительные запросы тех процессов, которые в одноядерном варианте стояли бы в очереди.
Непонимание этого момента приводит к тому, что load average ошибочно связывают не с доступностью и достаточностью вычислительных ресурсов, а с производительностью процессора, что приводит к неверным выводам.
Например, переводчик довольно неплохой статьи на Хабре делает ошибочный вывод в отношении Hyper-threading:
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
А Википедия вообще написала полную ерунду (что для технических статей там совсем не редкость):
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения). И если на компьютере есть несколько процессоров, то такой характеристике верить нельзя. Располагая двумя процессорами, можно (теоретически) одновременно выполнять в два раза большее число программ. Это означает, что средняя нагрузка 2.00 (на двухпроцессорном компьютере) будет эквивалентна средней нагрузке 1.00 (на однопроцессорном компьютере). На самом деле это не совсем так. Из-за дополнительной нагрузки, вызванной планированием и некоторыми другими факторами, двухпроцессорный компьютер не обеспечивает удвоения быстродействия по сравнению с однопроцессорным вариантом.
Убедиться, что это не так довольно легко. Если запустить бесконечный цикл командой
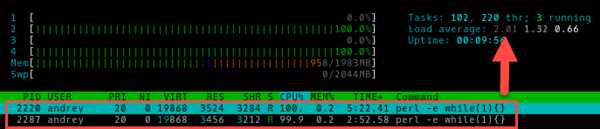
perl -e 'while(1){}'то мы обеспечим полную загрузку одного процессорного ядра и load average = 1 (в данный момент смотрим только на первые, минутные показания данного параметра).
 Два процесса:
Два процесса:
 Четыре:
Четыре:
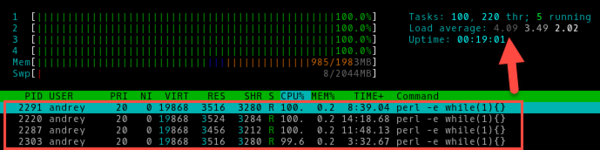 Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
Запустим пятый процесс:
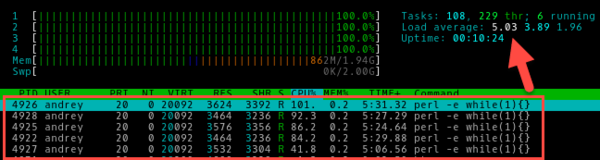 Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Теперь касательно HyperThreading, виртуализации и т.п. случаев, когда процессор, с которым работает система далеко не соответствует физическому процессору, искусственно создадим данную ситуацию. Для этого запустим на хосте параллельно с виртуальной машиной какой-нибудь ресурсоемкий процесс, например, кодирование видео. Виртуальная машина будет рассчитывать на 4 полных процессорных ядра, а по факту получит в лучшем случае половину их производительности. Проверим?
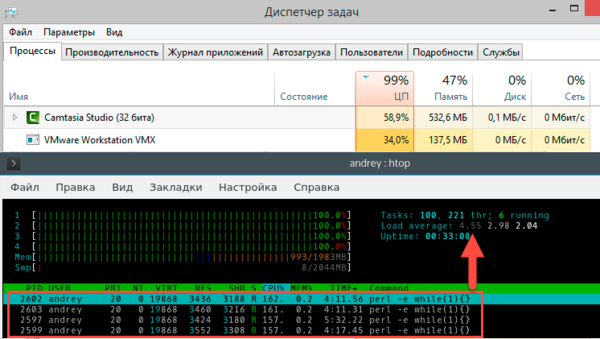 На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов — 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд — нет.
На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов — 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд — нет.
Теперь уберем стороннюю нагрузку. Гипервизор тут же передаст максимум ресурсов виртуальной машине.
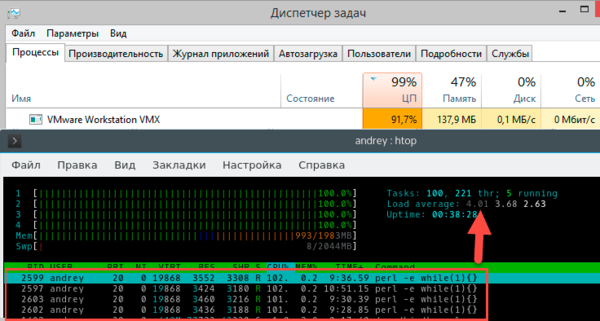 Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Какие выводы мы можем сделать из этого примера? Что значение load average корректно отражает загрузку системы даже в тех условиях, когда иные показатели не дают корректного представления о происходящих процессах. Так нагрузка на CPU в 157% явно противоречит здравому смыслу, а вот LA = 4,55 вполне реально отражает ситуацию. Поэтому никаких корректив на виртуальные ядра, виртуализацию и т.п. вносить не надо. Load average является относительной величиной и от реальной производительности CPU не зависит в тоже время показывая наличие или дефицит вычислительных ресурсов.
Теперь разберемся с самими цифрами. Мы получаем три значения load average для промежутков в 1, 5 и 15 минут. Как гласит та же Википедия — это средние значения за указанный промежуток времени, что снова неправильно. Для отображения load average используется экспоненциально взвешенная скользящая средняя, подобный тип кривых используется для для сглаживания краткосрочных колебаний и выделения основных тенденций или циклов.
Например, скользящие средние широко применяются в финансовом анализе, для выделения общих тенденций движения курсов валют и акций, позволяя отбросить так называемый «биржевой шум» и понять общие тренды рынка.
 То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения).
Именно усредненные по особому алгоритму значения позволяют нам окинуть ситуацию взглядом вширь и вглубь и разглядеть за деревьями лес. В этом отношении временные значения load average представляют собой не время, за которое посчитали среднее значение, а период времени относительно которого проводится усреднение.
Благодаря автору Хабра ZloyHobbit, который не поленился изучить исходный код Linux, можно точно смоделировать различные значения load average при заданной модели нагрузки. Мы смоделировали ситуацию, когда первые 30 минут единственное ядро CPU было нагружено на 100%, без ждущих в очереди процессов, в последующие полчаса нагрузка была полностью снята.
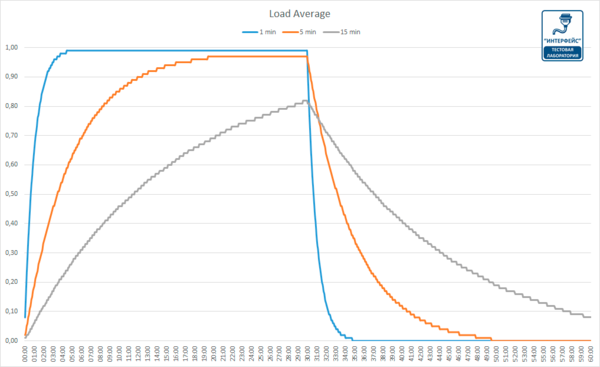
Как видим, разные периоды усреднения дают совершенно различные результаты, так LA 1 (1 min), начинает показывать реальные значения где-то через 4 минуты, LA 5 для отражения текущей нагрузки потребовалось уже 20 минут, а LA 15 за полчаса полной загрузки вышла только на 0,8.
О чем это говорит и как интерпретировать данные значения? Можно сказать, что LA 1 представляет собой недавнее прошлое (несколько минут назад), LA 5 прошлое (полчаса-час) и LA 15 отдаленное прошлое (несколько часов).
Теперь, располагая этим багажом знаний, мы можем правильно интерпретировать простые, на первый взгляд, три числа load average.
Для примера возьмем такое значение:
load average: 0.99 0.75 0.35Это говорит о том, что имеет место достаточно кратковременный (около десятка минут) всплеск нагрузки, при этом вычислительных ресурсов пока достаточно.
А вот значение:
load average: 0.00 0.36 0.59Говорит о том, что не так давно система испытывала значительные нагрузки в течении довольно продолжительного времени (полчаса-час).
А вот такая картина:
load average: 4.55 4.22 4.18Для четырехядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов).
Как видим, load average, несмотря всего на три цифры, способна представить системному администратору огромный пласт информации о фактической загрузке системы на протяжении последних нескольких часов.
Теперь самое время дать ответы на вопросы, поставленные нами в начале статьи: «Много это или мало? Хорошо или плохо? » Для одного ядра мы считаем приемлемыми следующие значения:
- LA 1 — может превышать 1.00, свидетельствуя о кратковременной пиковой нагрузке на систему.
- LA 5 — не должен превышать 1.00, в противном случае налицо явный недостаток вычислительных ресурсов.
- LA 15 — максимальное значение 0.7 — 0.8, но в любом случае не выше 1.0, в противном случае вы можете получить в три часа ночи звонок от руководства с вопросом: » А что это с нашим сервером???»
На многоядерной (многопроцессорной) системе значения load average следует откорректировать пропорционально числу ядер. Узнать их количество можно командой
nprocили
cat /proc/cpuinfo | grep "cpu cores"Так, например, с учетом вышесказанного, для четырехядерной системы LA 15 не должен превышать 3.00, для двухядерной 1.5, а для одноядерной 0.75.
Теперь, понимая, что такое load average и каким образом формируются его значения вы всегда сможете быстро оценить производительность собственной системы и вовремя принять меры если в работе вашего сервера возникнут узкие места.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Portnov писал(а): ↑
01.12.2008 21:43
Ну ясно что раз загрузка не в ЦПУ, значит она в подсистеме ввода-вывода. Запустите iotop, посмотрите чего он скажет.
Под подозрением прямота собственно той явы…
iotop в etch не нашел, только в ленни.
вывод iostat
Код: Выделить всё
iostat -x
Linux 2.6.18-6-amd64 (gs) 01.12.2008
avg-cpu: %user %nice %system %iowait %steal %idle
5,48 0,02 1,79 0,03 0,00 92,68
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0,12 0,62 0,16 1,70 6,58 67,59 39,80 0,06 32,56 3,81 0,71
sr0 0,00 0,00 0,00 0,00 0,00 0,00 35,39 0,00 189,58 173,09 0,00что за sr0?? с таким await большим
vmstat
Код: Выделить всё
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
4 0 72 1754472 49516 919752 0 0 2 15 7 21 6 2 93 0netstat
Код: Выделить всё
netstat -i
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth2 1500 0 17207523 0 0 0 17530201 0 0 0 BMRU
lo 16436 0 54904505 0 0 0 54904505 0 0 0 LRUpmstat (почему цпу1 intr/s = 0??)
Код: Выделить всё
mpstat -P ALL
Linux 2.6.18-6-amd64 (gs) 01.12.2008
21:51:51 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
21:51:51 all 5,48 0,02 1,73 0,03 0,00 0,06 0,00 92,68 282,46
21:51:51 0 5,30 0,02 1,74 0,03 0,01 0,10 0,00 92,80 282,46
21:51:51 1 5,67 0,03 1,71 0,02 0,00 0,02 0,00 92,56 0,00без джавы все чики-пики.и так ясно что линейка виновата. вопрос в том как ее оптимизировать до нормальной работы. винда справляллась на ура и единая проблема была ( при запуске 4-х серваков) активный свопинг, поскольку больше четырех гиг оперативки увидеть не могла. потому появлялись тормоза в работе. с увеличением RAM до 8 гиг и переходом на Дебиан 64 все тормоза ПРОПАЛИ. мож и правда кривизна джавы, но мож кто натолкнет на оптимизацию какуюто?