Comments
![]()
yaauie
added a commit
to yaauie/logstash
that referenced
this issue
Apr 19, 2022
![]()
Keys passed to most methods of `ConvertedMap`, based on `IdentityHashMap`
depend on identity and not equivalence, and therefore rely on the keys being
_interned_ strings. In order to avoid hitting the JVM's global String intern
pool (which can have performance problems), operations to normalize a string
to its interned counterpart have traditionally relied on the behaviour of
`FieldReference#from` returning a likely-cached `FieldReference`, that had
an interned `key` and an empty `path`.
This is problematic on two points.
First, when `ConvertedMap` was given data with keys that _were_ valid string
field references representing a nested field (such as `[host][geo][location]`),
the implementation of `ConvertedMap#put` effectively silently discarded the
path components because it assumed them to be empty, and only the key was
kept (`location`).
Second, when `ConvertedMap` was given a map whose keys contained what the
field reference parser considered special characters but _were NOT_
valid field references, the resulting `FieldReference.IllegalSyntaxException`
caused the operation to abort.
Instead of using the `FieldReference` cache, which sits on top of objects whose
`key` and `path`-components are known to have been interned, we introduce an
internment helper on our `ConvertedMap` that is also backed by the global string
intern pool, and ensure that our field references are primed through this pool.
In addition to fixing the `ConvertedMap#newFromMap` functionality, this has
three net effects:
- Our ConvertedMap operations still use strings
from the global intern pool
- We have a new, smaller cache of individual field
names, improving lookup performance
- Our FieldReference cache no longer is flooded
with fragments and therefore is more likely to
remain performant
NOTE: this does NOT create isolated intern pools, as doing so would require
a careful audit of the possible code-paths to `ConvertedMap#putInterned`.
The new cache is limited to 10k strings, and when more are used only
the FIRST 10k strings will be primed into the cache, leaving the
remainder to always hit the global String intern pool.
NOTE: by fixing this bug, we alow events to be created whose fields _CANNOT_
be referenced with the existing FieldReference implementation.
Resolves: elastic#13606
Resolves: elastic#11608
yaauie
added a commit
to yaauie/logstash
that referenced
this issue
Apr 20, 2022
![]()
Keys passed to most methods of `ConvertedMap`, based on `IdentityHashMap`
depend on identity and not equivalence, and therefore rely on the keys being
_interned_ strings. In order to avoid hitting the JVM's global String intern
pool (which can have performance problems), operations to normalize a string
to its interned counterpart have traditionally relied on the behaviour of
`FieldReference#from` returning a likely-cached `FieldReference`, that had
an interned `key` and an empty `path`.
This is problematic on two points.
First, when `ConvertedMap` was given data with keys that _were_ valid string
field references representing a nested field (such as `[host][geo][location]`),
the implementation of `ConvertedMap#put` effectively silently discarded the
path components because it assumed them to be empty, and only the key was
kept (`location`).
Second, when `ConvertedMap` was given a map whose keys contained what the
field reference parser considered special characters but _were NOT_
valid field references, the resulting `FieldReference.IllegalSyntaxException`
caused the operation to abort.
Instead of using the `FieldReference` cache, which sits on top of objects whose
`key` and `path`-components are known to have been interned, we introduce an
internment helper on our `ConvertedMap` that is also backed by the global string
intern pool, and ensure that our field references are primed through this pool.
In addition to fixing the `ConvertedMap#newFromMap` functionality, this has
three net effects:
- Our ConvertedMap operations still use strings
from the global intern pool
- We have a new, smaller cache of individual field
names, improving lookup performance
- Our FieldReference cache no longer is flooded
with fragments and therefore is more likely to
remain performant
NOTE: this does NOT create isolated intern pools, as doing so would require
a careful audit of the possible code-paths to `ConvertedMap#putInterned`.
The new cache is limited to 10k strings, and when more are used only
the FIRST 10k strings will be primed into the cache, leaving the
remainder to always hit the global String intern pool.
NOTE: by fixing this bug, we alow events to be created whose fields _CANNOT_
be referenced with the existing FieldReference implementation.
Resolves: elastic#13606
Resolves: elastic#11608
yaauie
added a commit
to yaauie/logstash
that referenced
this issue
Apr 25, 2022
![]()
Keys passed to most methods of `ConvertedMap`, based on `IdentityHashMap`
depend on identity and not equivalence, and therefore rely on the keys being
_interned_ strings. In order to avoid hitting the JVM's global String intern
pool (which can have performance problems), operations to normalize a string
to its interned counterpart have traditionally relied on the behaviour of
`FieldReference#from` returning a likely-cached `FieldReference`, that had
an interned `key` and an empty `path`.
This is problematic on two points.
First, when `ConvertedMap` was given data with keys that _were_ valid string
field references representing a nested field (such as `[host][geo][location]`),
the implementation of `ConvertedMap#put` effectively silently discarded the
path components because it assumed them to be empty, and only the key was
kept (`location`).
Second, when `ConvertedMap` was given a map whose keys contained what the
field reference parser considered special characters but _were NOT_
valid field references, the resulting `FieldReference.IllegalSyntaxException`
caused the operation to abort.
Instead of using the `FieldReference` cache, which sits on top of objects whose
`key` and `path`-components are known to have been interned, we introduce an
internment helper on our `ConvertedMap` that is also backed by the global string
intern pool, and ensure that our field references are primed through this pool.
In addition to fixing the `ConvertedMap#newFromMap` functionality, this has
three net effects:
- Our ConvertedMap operations still use strings
from the global intern pool
- We have a new, smaller cache of individual field
names, improving lookup performance
- Our FieldReference cache no longer is flooded
with fragments and therefore is more likely to
remain performant
NOTE: this does NOT create isolated intern pools, as doing so would require
a careful audit of the possible code-paths to `ConvertedMap#putInterned`.
The new cache is limited to 10k strings, and when more are used only
the FIRST 10k strings will be primed into the cache, leaving the
remainder to always hit the global String intern pool.
NOTE: by fixing this bug, we alow events to be created whose fields _CANNOT_
be referenced with the existing FieldReference implementation.
Resolves: elastic#13606
Resolves: elastic#11608
yaauie
added a commit
to yaauie/logstash
that referenced
this issue
Apr 25, 2022
![]()
Keys passed to most methods of `ConvertedMap`, based on `IdentityHashMap`
depend on identity and not equivalence, and therefore rely on the keys being
_interned_ strings. In order to avoid hitting the JVM's global String intern
pool (which can have performance problems), operations to normalize a string
to its interned counterpart have traditionally relied on the behaviour of
`FieldReference#from` returning a likely-cached `FieldReference`, that had
an interned `key` and an empty `path`.
This is problematic on two points.
First, when `ConvertedMap` was given data with keys that _were_ valid string
field references representing a nested field (such as `[host][geo][location]`),
the implementation of `ConvertedMap#put` effectively silently discarded the
path components because it assumed them to be empty, and only the key was
kept (`location`).
Second, when `ConvertedMap` was given a map whose keys contained what the
field reference parser considered special characters but _were NOT_
valid field references, the resulting `FieldReference.IllegalSyntaxException`
caused the operation to abort.
Instead of using the `FieldReference` cache, which sits on top of objects whose
`key` and `path`-components are known to have been interned, we introduce an
internment helper on our `ConvertedMap` that is also backed by the global string
intern pool, and ensure that our field references are primed through this pool.
In addition to fixing the `ConvertedMap#newFromMap` functionality, this has
three net effects:
- Our ConvertedMap operations still use strings
from the global intern pool
- We have a new, smaller cache of individual field
names, improving lookup performance
- Our FieldReference cache no longer is flooded
with fragments and therefore is more likely to
remain performant
NOTE: this does NOT create isolated intern pools, as doing so would require
a careful audit of the possible code-paths to `ConvertedMap#putInterned`.
The new cache is limited to 10k strings, and when more are used only
the FIRST 10k strings will be primed into the cache, leaving the
remainder to always hit the global String intern pool.
NOTE: by fixing this bug, we alow events to be created whose fields _CANNOT_
be referenced with the existing FieldReference implementation.
Resolves: elastic#13606
Resolves: elastic#11608
yaauie
added a commit
that referenced
this issue
May 24, 2022
![]()
![]()
* add failing tests for Event.new with field that look like field references
* fix: correctly handle FieldReference-special characters in field names.
Keys passed to most methods of `ConvertedMap`, based on `IdentityHashMap`
depend on identity and not equivalence, and therefore rely on the keys being
_interned_ strings. In order to avoid hitting the JVM's global String intern
pool (which can have performance problems), operations to normalize a string
to its interned counterpart have traditionally relied on the behaviour of
`FieldReference#from` returning a likely-cached `FieldReference`, that had
an interned `key` and an empty `path`.
This is problematic on two points.
First, when `ConvertedMap` was given data with keys that _were_ valid string
field references representing a nested field (such as `[host][geo][location]`),
the implementation of `ConvertedMap#put` effectively silently discarded the
path components because it assumed them to be empty, and only the key was
kept (`location`).
Second, when `ConvertedMap` was given a map whose keys contained what the
field reference parser considered special characters but _were NOT_
valid field references, the resulting `FieldReference.IllegalSyntaxException`
caused the operation to abort.
Instead of using the `FieldReference` cache, which sits on top of objects whose
`key` and `path`-components are known to have been interned, we introduce an
internment helper on our `ConvertedMap` that is also backed by the global string
intern pool, and ensure that our field references are primed through this pool.
In addition to fixing the `ConvertedMap#newFromMap` functionality, this has
three net effects:
- Our ConvertedMap operations still use strings
from the global intern pool
- We have a new, smaller cache of individual field
names, improving lookup performance
- Our FieldReference cache no longer is flooded
with fragments and therefore is more likely to
remain performant
NOTE: this does NOT create isolated intern pools, as doing so would require
a careful audit of the possible code-paths to `ConvertedMap#putInterned`.
The new cache is limited to 10k strings, and when more are used only
the FIRST 10k strings will be primed into the cache, leaving the
remainder to always hit the global String intern pool.
NOTE: by fixing this bug, we alow events to be created whose fields _CANNOT_
be referenced with the existing FieldReference implementation.
Resolves: #13606
Resolves: #11608
* field_reference: support escape sequences
Adds a `config.field_reference.escape_style` option and a companion
command-line flag `--field-reference-escape-style` allowing a user
to opt into one of two proposed escape-sequence implementations for field
reference parsing:
- `PERCENT`: URI-style `%`+`HH` hexadecimal encoding of UTF-8 bytes
- `AMPERSAND`: HTML-style `&#`+`DD`+`;` encoding of decimal Unicode code-points
The default is `NONE`, which does _not_ proccess escape sequences.
With this setting a user effectively cannot reference a field whose name
contains FieldReference-reserved characters.
| ESCAPE STYLE | `[` | `]` |
| ------------ | ------- | ------- |
| `NONE` | _N/A_ | _N/A_ |
| `PERCENT` | `%5B` | `%5D` |
| `AMPERSAND` | `[` | `]` |
* fixup: no need to double-escape HTML-ish escape sequences in docs
* Apply suggestions from code review
Co-authored-by: Karol Bucek <kares@users.noreply.github.com>
* field-reference: load escape style in runner
* docs: sentences over semiciolons
* field-reference: faster shortcut for PERCENT escape mode
* field-reference: escape mode control downcase
* field_reference: more s/experimental/technical preview/
* field_reference: still more s/experimental/technical preview/
Co-authored-by: Karol Bucek <kares@users.noreply.github.com>
Problem
Logstash is getting several error messages like the following:
[ERROR][logstash.codecs.json ][main] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unexpected end-of-input: was expecting closing quote for a string value
[ERROR][logstash.codecs.json ][main] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Unrecognized token ‘RMF’: was expecting (‘true’, ‘false’ or ‘null’)
[ERROR][logstash.codecs.json ][main] JSON parse error, original data now in message field {:error=>#<LogStash::Json::ParserError: Invalid numeric value: Leading zeroes not allowed
Resolving The Problem
Edit the Logstash pipeline configuration file and change from:
input {
tcp {
port => 8080
codec => «json»
}
}
to
input {
tcp {
port => 8080
codec => «json_lines»
}
}
Document Location
Worldwide
[{«Business Unit»:{«code»:»BU058″,»label»:»IBM Infrastructure w/TPS»},»Product»:{«code»:»SSTQCD»,»label»:»IBM Z Common Data Provider»},»Component»:»»,»Platform»:[{«code»:»PF035″,»label»:»z/OS»}],»Version»:»All Versions»,»Edition»:»»,»Line of Business»:{«code»:»LOB35″,»label»:»Mainframe SW»}}]
For the last couple of weeks, I have been running behind a Logstash issue, where thousands of JSON parsing errors were logged after the whole ELK stack was upgraded to 7.15.
This caused the
/var partition to be filled up within a very short time:
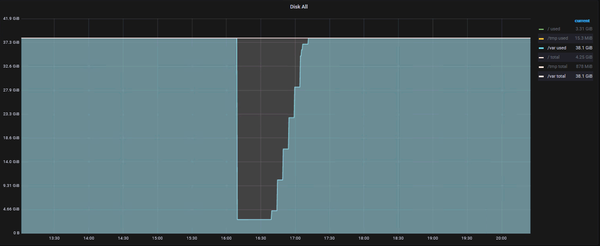
Even after clearing (emptying) /var/log/syslog, it didn’t even take 30 minutes, until more than 30GB of errors were written and filling up the partition again.
The local syslog log file (/var/log/syslog) contained thousands of
errors, indicating JSON parsing errors from Logstash:
Oct 20 11:17:46 log01 logstash[3628473]: [2021-10-20T11:17:46,964][ERROR][logstash.codecs.json ][main][6becfe14a36e9ff58e20a97f0820ea946e3122df132f9ddd7c5d61b99c609832] JSON parse error, original data now in message field {:message=>»Unexpected end-of-input: was expecting closing quote for a string valuen at [Source: (String)»{«@timestamp»:»2021-10-20T11:17:46.960783+02:00″,»@version»:»1″,»message»:» [2021-10-20T11:17:46,960][ERROR][logstash.codecs.json ][main][6becfe14a36e9ff58e20a97f0820ea946e3122df132f9ddd7c5d61b99c609832] JSON parse error, original data now in message field {:message=>\»Unexpected end-of-input in character escape sequence\\n at [Source: (String)\\\»{\\\»@timestamp\\\»:\\\»2021-10-20T11:17:46.956975+02:00\\\»,\\\»@version\\\»:\\\»1\\\»,\\\»message\\\»:\\\» [2021-10-20T11:17:46,955][ERROR][logs»[truncated 7596 chars]; line: 1, column: 16193]», :exception=>LogStash::Json::ParserError, :data=>»{«@timestamp»:»2021-10-20T11:17:46.960783+02:00″,»@version»:»1″,»message»:» [2021-10-20T11:17:46,960][ERROR][logstash.codecs.json ][main][6becfe14a36e9ff58e20a97f0820ea946e3122df132f9ddd7c5d61b99c609832] JSON parse error, original data now in message field {:message=>\»Unexpected end-of-input in character escape sequence\\n at [Source: (String)\\\»{\\\»@timestamp\\\»:\\\»2021-10-20T11:17:46.956975+02:00\\\»,\\\»@version\\\»:\\\»1\\\»,\\\»message\\\»:\\\» [2021-10-20T11:17:46,955][ERROR][logstash.codecs.json ][main][6becfe14a36e9ff58e20a97f0820ea946e3122df132f9ddd7c5d61b99c609832] JSON parse error, original data now in message field {:message=>\\\\\\\»Unexpected end-of-input: was expecting closing quote for a string value\\\\\\\\n at [Source: (String)
[…]
Help was requested on the public Elastic discussion forum (find source of events causing Logstash errors), with the goal to identify which application or program would cause these errors — but nobody answered. An additional support ticket with the Elastic support was also created.
After having tried lots of different configuration options, including disabling the «codec => json» setting on the Logstash input or in general disabling JSON parsing (which worked, but resulted in our logs not being split into needed fields anymore), Logstash was finally downgraded to 7.12.1.
And what a change this was! Since Logstash was downgraded from 7.15.2 to 7.12.1, the massive error logging stopped, and the disk usage on the /var partition remained stable (within the expected growth):
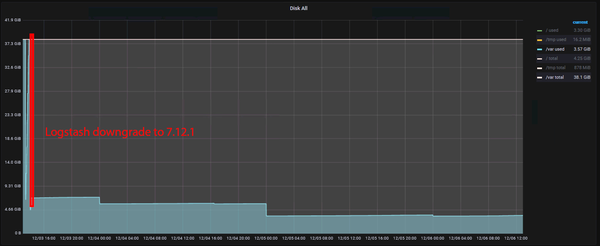
But not only the disk usage remained very steady, with only a few occasional Logstash errors being logged, we also saw a sharp decrease of CPU and network usage (towards Elasticsearch):
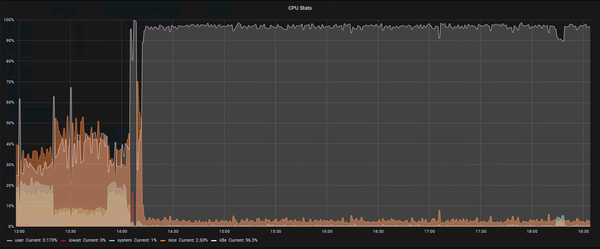
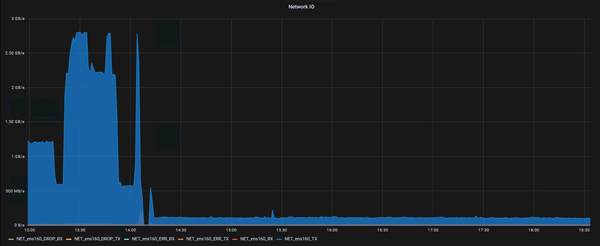
The graphs all look very good — but are there any downsides? So far we have discovered no downsides at all. We are still getting all the logs (= we are not missing any logs), the events are correctly JSON parsed and split into fields, indexing in Elasticsearch works was it should. Yet, there are no more mass-errors being logged and performance is better (on a large factor).
This leads to the conclusion that between Logstash 7.12.1 and 7.15.x (we have seen this mass error happening on Logstash 7.15.0-2) must be a bug in Logstash itself. What exactly is yet unknown and we hope the Elastic support might find the cause of it. For now we will stick with the 7.12 version.
Looping logs
Updated December 8th, 2021
Further analysis and discussion with Elastic support showed indeed a different logging behaviour between Logstash 7.12 and 7.15. Logstash’s JSON codec changed the logging event in case of parsing errors:
- 7.12: logger.info(«JSON parse failure. Falling back to plain-text» … )
- 7.15: logger.error(«JSON parse error, original data now in message field» … )
An initial JSON parsing error (1) is therefore logged by Logstash to syslog and is written into /var/log/syslog (2). One particular configuration in our environment is that we use rsyslogd (3) to format syslog events to JSON and then forward it to — you guessed it — Logstash (4). By just looking at the logged error message (which contains partial JSON data, too) it doesn’t need a JSON genius to guess that Logstash will AGAIN throw a JSON parsing error when the forwarded syslog entry reaches the Logstash input (5).
Yet again, another error is logged in syslog, which is then again picked up by Logstash, which creates another error, which is logged, … A classical case of a loop. The following drawing should explain this visually:
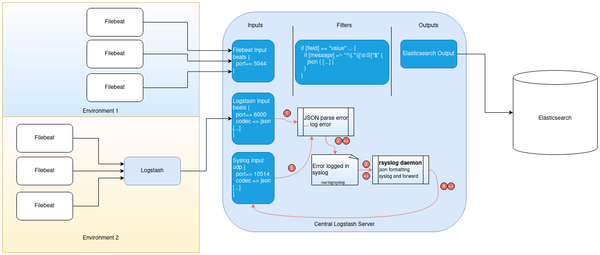
So right now we are working on a way to prevent Logstash actually writing into syslog — and keep its own dedicated log file. This would prevent the loop to be triggered and only the initial JSON parse error would be logged (which would be fine).
Another alternative workaround would be to drop the Logstash syslog lines as soon as they arrive in the LS input:
filter {
if «log01» in [sysloghost] and «logstash» in [programname] {
drop { }
}
}
But of course this uses performance, too.
Disabling logging to syslog
Updated January 3rd 2022
As described in the previous update, the suspected reason was that errors were logged to syslog and then picked up by Logstash again, hence creating a loop. To disable logging to syslog, the following log4j setting needs to be disabled (commented):
root@logstash:~# grep «console.ref» /etc/logstash/log4j2.properties
#rootLogger.appenderRef.console.ref = ${sys:ls.log.format}_console # Disabled logging to syslog
After another Logstash restart, all Logstash related logs (including errors) are now logged in a dedicated log file under /var/log/logstash/logstash-plain.log.
This did the trick! Syslog doesn’t pick up any Logstash logs anymore and the JSON parse errors are gone. This can be nicely seen in the disk usage of the /var partition:
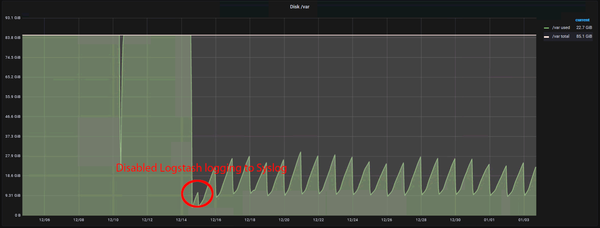
Add a comment
Show form to leave a comment
Comments (newest first)
No comments yet.
1 answer to this question.
Hi@akhtar,
You may get this error if you used codec as JSON in your Logstash configuration file. So edit the Logstash pipeline configuration file and switch from codec json to json_lines.
![]()
answered
Jun 18, 2020
by
MD
• 95,420 points
Related Questions In DevOps Tools
- All categories
-

ChatGPT
(4) -
Apache Kafka
(84) -
Apache Spark
(596) -
Azure
(131) -
Big Data Hadoop
(1,907) -
Blockchain
(1,673) -
C#
(141) -
C++
(271) -
Career Counselling
(1,060) -
Cloud Computing
(3,446) -
Cyber Security & Ethical Hacking
(147) -
Data Analytics
(1,266) -
Database
(855) -
Data Science
(75) -
DevOps & Agile
(3,575) -
Digital Marketing
(111) -
Events & Trending Topics
(28) -
IoT (Internet of Things)
(387) -
Java
(1,247) -
Kotlin
(8) -
Linux Administration
(389) -
Machine Learning
(337) -
MicroStrategy
(6) -
PMP
(423) -
Power BI
(516) -
Python
(3,188) -
RPA
(650) -
SalesForce
(92) -
Selenium
(1,569) -
Software Testing
(56) -
Tableau
(608) -
Talend
(73) -
TypeSript
(124) -
Web Development
(3,002) -
Ask us Anything!
(66) -
Others
(1,938) -
Mobile Development
(263)
























Subscribe to our Newsletter, and get personalized recommendations.
Already have an account? Sign in.