������������� ������� ��������� ��������� ���������� (man-��)
m_pullup (9)
BSD mandoc
NAME
mbuf - memory management in the kernel IPC subsystem
SYNOPSIS
#include <sys/param.h>
#include <sys/systm.h>
#include <sys/mbuf.h>
Mbuf allocation macros
MGET (struct mbuf *mbuf int how short type);
MGETHDR (struct mbuf *mbuf int how short type);
MCLGET (struct mbuf *mbuf int how);
Fo MEXTADD
Fa struct mbuf *mbuf
Fa caddr_t buf
Fa u_int size
Fa void (*free)(void *opt_args)
Fa void *opt_args
Fa short flags
Fa int type
Fc Fn MEXTFREE struct mbuf *mbuf
MFREE (struct mbuf *mbuf struct mbuf *successor);
Mbuf utility macros
mtod (struct mbuf *mbuf type);
M_ALIGN (struct mbuf *mbuf u_int len);
MH_ALIGN (struct mbuf *mbuf u_int len);
int
M_LEADINGSPACE (struct mbuf *mbuf);
int
M_TRAILINGSPACE (struct mbuf *mbuf);
M_MOVE_PKTHDR (struct mbuf *to struct mbuf *from);
M_PREPEND (struct mbuf *mbuf int len int how);
MCHTYPE (struct mbuf *mbuf u_int type);
int
M_WRITABLE (struct mbuf *mbuf);
Mbuf allocation functions
struct mbuf *
m_get (int how int type);
struct mbuf *
m_getm (struct mbuf *orig int len int how int type);
struct mbuf *
m_getcl (int how short type int flags);
struct mbuf *
m_getclr (int how int type);
struct mbuf *
m_gethdr (int how int type);
struct mbuf *
m_free (struct mbuf *mbuf);
void
m_freem (struct mbuf *mbuf);
Mbuf utility functions
void
m_adj (struct mbuf *mbuf int len);
void
m_align (struct mbuf *mbuf int len);
int
m_append (struct mbuf *mbuf int len c_caddr_t cp);
struct mbuf *
m_prepend (struct mbuf *mbuf int len int how);
struct mbuf *
m_copyup (struct mbuf *mbuf int len int dstoff);
struct mbuf *
m_pullup (struct mbuf *mbuf int len);
struct mbuf *
m_pulldown (struct mbuf *mbuf int offset int len int *offsetp);
struct mbuf *
m_copym (struct mbuf *mbuf int offset int len int how);
struct mbuf *
m_copypacket (struct mbuf *mbuf int how);
struct mbuf *
m_dup (struct mbuf *mbuf int how);
void
m_copydata (const struct mbuf *mbuf int offset int len caddr_t buf);
void
m_copyback (struct mbuf *mbuf int offset int len caddr_t buf);
struct mbuf *
Fo m_devget
Fa char *buf
Fa int len
Fa int offset
Fa struct ifnet *ifp
Fa void (*copy)(char *from, caddr_t to, u_int len)
Fc Ft void
m_cat (struct mbuf *m struct mbuf *n);
u_int
m_fixhdr (struct mbuf *mbuf);
void
m_dup_pkthdr (struct mbuf *to struct mbuf *from);
void
m_move_pkthdr (struct mbuf *to struct mbuf *from);
u_int
m_length (struct mbuf *mbuf struct mbuf **last);
struct mbuf *
m_split (struct mbuf *mbuf int len int how);
int
m_apply (struct mbuf *mbuf int off int len int (*f)(void *arg, void *data, u_int len) void *arg);
struct mbuf *
m_getptr (struct mbuf *mbuf int loc int *off);
struct mbuf *
m_defrag (struct mbuf *m0 int how);
struct mbuf *
m_unshare (struct mbuf *m0 int how);
DESCRIPTION
An
Vt mbuf
is a basic unit of memory management in the kernel IPC subsystem.
Network packets and socket buffers are stored in
Vt mbufs .
A network packet may span multiple
Vt mbufs
arranged into a
Vt mbuf chain
(linked list),
which allows adding or trimming
network headers with little overhead.
While a developer should not bother with
Vt mbuf
internals without serious
reason in order to avoid incompatibilities with future changes, it
is useful to understand the general structure of an
Vt mbuf .
An
Vt mbuf
consists of a variable-sized header and a small internal
buffer for data.
The total size of an
Vt mbuf ,
MSIZE
is a constant defined in
In sys/param.h .
The
Vt mbuf
header includes:
- m_next
-
(Vt struct mbuf
)
A pointer to the next
Vt mbufin the
Vt mbuf chain . - m_nextpkt
-
(Vt struct mbuf
)
A pointer to the next
Vt mbuf chainin the queue.
- m_data
-
(Vt caddr_t
)
A pointer to data attached to this
Vt mbuf . - m_len
-
(Vt int
)
The length of the data.
- m_type
-
(Vt short
)
The type of the data.
- m_flags
-
(Vt int
)
The
Vt mbufflags.
The
Vt mbuf
flag bits are defined as follows:
/* mbuf flags */ #define M_EXT 0x0001 /* has associated external storage */ #define M_PKTHDR 0x0002 /* start of record */ #define M_EOR 0x0004 /* end of record */ #define M_RDONLY 0x0008 /* associated data marked read-only */ #define M_PROTO1 0x0010 /* protocol-specific */ #define M_PROTO2 0x0020 /* protocol-specific */ #define M_PROTO3 0x0040 /* protocol-specific */ #define M_PROTO4 0x0080 /* protocol-specific */ #define M_PROTO5 0x0100 /* protocol-specific */ #define M_PROTO6 0x4000 /* protocol-specific (avoid M_BCAST conflict) */ #define M_FREELIST 0x8000 /* mbuf is on the free list */ /* mbuf pkthdr flags (also stored in m_flags) */ #define M_BCAST 0x0200 /* send/received as link-level broadcast */ #define M_MCAST 0x0400 /* send/received as link-level multicast */ #define M_FRAG 0x0800 /* packet is fragment of larger packet */ #define M_FIRSTFRAG 0x1000 /* packet is first fragment */ #define M_LASTFRAG 0x2000 /* packet is last fragment */
The available
Vt mbuf
types are defined as follows:
/* mbuf types */ #define MT_DATA 1 /* dynamic (data) allocation */ #define MT_HEADER MT_DATA /* packet header */ #define MT_SONAME 8 /* socket name */ #define MT_CONTROL 14 /* extra-data protocol message */ #define MT_OOBDATA 15 /* expedited data */
If the
M_PKTHDR
flag is set, a
Vt struct pkthdr Va m_pkthdr
is added to the
Vt mbuf
header.
It contains a pointer to the interface
the packet has been received from
(Vt struct ifnet *rcvif
)
and the total packet length
(Vt int len
)
Optionally, it may also contain an attached list of packet tags
(Vt struct m_tag
)
See
mbuf_tags9
for details.
Fields used in offloading checksum calculation to the hardware are kept in
m_pkthdr
as well.
See
Sx HARDWARE-ASSISTED CHECKSUM CALCULATION
for details.
If small enough, data is stored in the internal data buffer of an
Vt mbuf .
If the data is sufficiently large, another
Vt mbuf
may be added to the
Vt mbuf chain ,
or external storage may be associated with the
Vt mbuf .
MHLEN
bytes of data can fit into an
Vt mbuf
with the
M_PKTHDR
flag set,
MLEN
bytes can otherwise.
If external storage is being associated with an
Vt mbuf ,
the
m_ext
header is added at the cost of losing the internal data buffer.
It includes a pointer to external storage, the size of the storage,
a pointer to a function used for freeing the storage,
a pointer to an optional argument that can be passed to the function,
and a pointer to a reference counter.
An
Vt mbuf
using external storage has the
M_EXT
flag set.
The system supplies a macro for allocating the desired external storage
buffer,
MEXTADD
The allocation and management of the reference counter is handled by the
subsystem.
The system also supplies a default type of external storage buffer called an
Vt mbuf cluster .
Vt Mbuf clusters
can be allocated and configured with the use of the
MCLGET
macro.
Each
Vt mbuf cluster
is
MCLBYTES
in size, where MCLBYTES is a machine-dependent constant.
The system defines an advisory macro
MINCLSIZE
which is the smallest amount of data to put into an
Vt mbuf cluster .
It is equal to the sum of
MLEN
and
MHLEN
It is typically preferable to store data into the data region of an
Vt mbuf ,
if size permits, as opposed to allocating a separate
Vt mbuf cluster
to hold the same data.
Macros and Functions
There are numerous predefined macros and functions that provide the
developer with common utilities.
- Fn mtod mbuf type
-
Convert an
Fa mbufpointer to a data pointer.
The macro expands to the data pointer cast to the pointer of the specified
Fa type .Note
It is advisable to ensure that there is enough contiguous data in
Fa mbuf .See
m_pullup ();for details.
- Fn MGET mbuf how type
-
Allocate an
Vt mbufand initialize it to contain internal data.
Fa mbufwill point to the allocated
Vt mbufon success, or be set to
NULLon failure.
The
Fa howargument is to be set to
M_TRYWAITor
M_DONTWAITIt specifies whether the caller is willing to block if necessary.
If
Fa howis set to
M_TRYWAITa failed allocation will result in the caller being put
to sleep for a designated
kern.ipc.mbuf_wait
(sysctl8tunable)
number of ticks.
A number of other functions and macros related to
Vt mbufshave the same argument because they may
at some point need to allocate new
Vt mbufs .Programmers should be careful not to confuse the
Vt mbufallocation flag
M_DONTWAITwith the
malloc(9)allocation flag,
M_NOWAITThey are not the same.
- Fn MGETHDR mbuf how type
-
Allocate an
Vt mbufand initialize it to contain a packet header
and internal data.
See
MGET ();for details.
- Fn MCLGET mbuf how
-
Allocate and attach an
Vt mbuf clusterto
Fa mbuf .If the macro fails, the
M_EXTflag will not be set in
Fa mbuf . - Fn M_ALIGN mbuf len
-
Set the pointer
Fa mbuf->m_datato place an object of the size
Fa lenat the end of the internal data area of
Fa mbuf ,long word aligned.
Applicable only if
Fa mbufis newly allocated with
MGET ();or
m_get (.); - Fn MH_ALIGN mbuf len
-
Serves the same purpose as
M_ALIGN ();does, but only for
Fa mbufnewly allocated with
MGETHDR ();or
m_gethdr (,);or initialized by
m_dup_pkthdr ();or
m_move_pkthdr (.); - Fn m_align mbuf len
-
Services the same purpose as
M_ALIGN ();but handles any type of mbuf.
- Fn M_LEADINGSPACE mbuf
-
Returns the number of bytes available before the beginning
of data in
Fa mbuf . - Fn M_TRAILINGSPACE mbuf
-
Returns the number of bytes available after the end of data in
Fa mbuf . - Fn M_PREPEND mbuf len how
-
This macro operates on an
Vt mbuf chain .It is an optimized wrapper for
m_prepend ();that can make use of possible empty space before data
(e.g. left after trimming of a link-layer header).
The new
Vt mbuf chainpointer or
NULLis in
Fa mbufafter the call.
- Fn M_MOVE_PKTHDR to from
-
Using this macro is equivalent to calling
m_move_pkthdr (to from .); - Fn M_WRITABLE mbuf
-
This macro will evaluate true if
Fa mbufis not marked
M_RDONLYand if either
Fa mbufdoes not contain external storage or,
if it does,
then if the reference count of the storage is not greater than 1.
The
M_RDONLYflag can be set in
Fa mbuf->m_flags .This can be achieved during setup of the external storage,
by passing the
M_RDONLYbit as a
Fa flagsargument to the
MEXTADD ();macro, or can be directly set in individual
Vt mbufs . - Fn MCHTYPE mbuf type
-
Change the type of
Fa mbufto
Fa type .This is a relatively expensive operation and should be avoided.
The functions are:
- Fn m_get how type
-
A function version of
MGET ();for non-critical paths.
- Fn m_getm orig len how type
-
Allocate
Fa lenbytes worth of
Vt mbufsand
Vt mbuf clustersif necessary and append the resulting allocated
Vt mbuf chainto the
Vt mbuf chainFa orig ,
if it is
non- NULLIf the allocation fails at any point,
free whatever was allocated and return
NULLIf
Fa origis
non- NULLit will not be freed.
It is possible to use
m_getm ();to either append
Fa lenbytes to an existing
Vt mbufor
Vt mbuf chain(for example, one which may be sitting in a pre-allocated ring)
or to simply perform an all-or-nothing
Vt mbufand
Vt mbuf clusterallocation.
- Fn m_gethdr how type
-
A function version of
MGETHDR ();for non-critical paths.
- Fn m_getcl how type flags
-
Fetch an
Vt mbufwith a
Vt mbuf clusterattached to it.
If one of the allocations fails, the entire allocation fails.
This routine is the preferred way of fetching both the
Vt mbufand
Vt mbuf clustertogether, as it avoids having to unlock/relock between allocations.
Returns
NULLon failure.
- Fn m_getclr how type
-
Allocate an
Vt mbufand zero out the data region.
- Fn m_free mbuf
-
Frees
Vt mbuf .Returns
m_nextof the freed
Vt mbuf .
The functions below operate on
Vt mbuf chains .
- Fn m_freem mbuf
-
Free an entire
Vt mbuf chain ,including any external storage.
- Fn m_adj mbuf len
-
Trim
Fa lenbytes from the head of an
Vt mbuf chainif
Fa lenis positive, from the tail otherwise.
- Fn m_append mbuf len cp
-
Append
Vt lenbytes of data
Vt cpto the
Vt mbuf chain .Extend the mbuf chain if the new data does not fit in
existing space. - Fn m_prepend mbuf len how
-
Allocate a new
Vt mbufand prepend it to the
Vt mbuf chain ,handle
M_PKTHDRproperly.
NoteIt does not allocate any
Vt mbuf clusters ,so
Fa lenmust be less than
MLENor
MHLENdepending on the
M_PKTHDRflag setting.
- Fn m_copyup mbuf len dstoff
-
Similar to
m_pullup ();but copies
Fa lenbytes of data into a new mbuf at
Fa dstoffbytes into the mbuf.
The
Fa dstoffargument aligns the data and leaves room for a link layer header.
Returns the new
Vt mbuf chainon success,
and frees the
Vt mbuf chainand returns
NULLon failure.
NoteThe function does not allocate
Vt mbuf clusters ,so
Fa len + dstoffmust be less than
MHLEN - Fn m_pullup mbuf len
-
Arrange that the first
Fa lenbytes of an
Vt mbuf chainare contiguous and lay in the data area of
Fa mbuf ,so they are accessible with
mtod (mbuf type .);It is important to remember that this may involve
reallocating some mbufs and moving data so all pointers
referencing data within the old mbuf chain
must be recalculated or made invalid.
Return the new
Vt mbuf chainon success,
NULLon failure
(the
Vt mbuf chainis freed in this case).
NoteIt does not allocate any
Vt mbuf clusters ,so
Fa lenmust be less than
MHLEN - Fn m_pulldown mbuf offset len offsetp
-
Arrange that
Fa lenbytes between
Fa offsetand
Fa offset + lenin the
Vt mbuf chainare contiguous and lay in the data area of
Fa mbuf ,so they are accessible with
mtod (mbuf type .);Fa len must be smaller than, or equal to, the size of an
Vt mbuf cluster .
Return a pointer to an intermediate
Vt mbufin the chain containing the requested region;
the offset in the data region of the
Vt mbuf chainto the data contained in the returned mbuf is stored in
Fa *offsetp .If
Fa offpis NULL, the region may be accessed using
mtod (mbuf type .);If
Fa offpis non-NULL, the region may be accessed using
mtod (mbuf uint8_t + *offsetp .);The region of the mbuf chain between its beginning and
Fa offis not modified, therefore it is safe to hold pointers to data within
this region before calling
m_pulldown (.); - Fn m_copym mbuf offset len how
-
Make a copy of an
Vt mbuf chainstarting
Fa offsetbytes from the beginning, continuing for
Fa lenbytes.
If
Fa lenis
M_COPYALLcopy to the end of the
Vt mbuf chain .Note
The copy is read-only, because the
Vt mbuf clustersare not copied, only their reference counts are incremented.
- Fn m_copypacket mbuf how
-
Copy an entire packet including header, which must be present.
This is an optimized version of the common case
m_copym (mbuf 0 M_COPYALL how .);Note
the copy is read-only, because the
Vt mbuf clustersare not copied, only their reference counts are incremented.
- Fn m_dup mbuf how
-
Copy a packet header
Vt mbuf chaininto a completely new
Vt mbuf chain ,including copying any
Vt mbuf clusters .Use this instead of
m_copypacket ();when you need a writable copy of an
Vt mbuf chain . - Fn m_copydata mbuf offset len buf
-
Copy data from an
Vt mbuf chainstarting
Fa offbytes from the beginning, continuing for
Fa lenbytes, into the indicated buffer
Fa buf . - Fn m_copyback mbuf offset len buf
-
Copy
Fa lenbytes from the buffer
Fa bufback into the indicated
Vt mbuf chain ,starting at
Fa offsetbytes from the beginning of the
Vt mbuf chain ,extending the
Vt mbuf chainif necessary.
NoteIt does not allocate any
Vt mbuf clusters ,just adds
Vt mbufsto the
Vt mbuf chain .It is safe to set
Fa offsetbeyond the current
Vt mbuf chainend: zeroed
Vt mbufswill be allocated to fill the space.
- Fn m_length mbuf last
-
Return the length of the
Vt mbuf chain ,and optionally a pointer to the last
Vt mbuf . - Fn m_dup_pkthdr to from how
-
Upon the function’s completion, the
Vt mbufFa to
will contain an identical copy of
Fa from->m_pkthdrand the per-packet attributes found in the
Vt mbuf chainFa from .
The
Vt mbufFa from
must have the flag
M_PKTHDRinitially set, and
Fa tomust be empty on entry.
- Fn m_move_pkthdr to from
-
Move
m_pkthdrand the per-packet attributes from the
Vt mbuf chainFa from
to the
Vt mbufFa to .
The
Vt mbufFa from
must have the flag
M_PKTHDRinitially set, and
Fa tomust be empty on entry.
Upon the function’s completion,
Fa fromwill have the flag
M_PKTHDRand the per-packet attributes cleared.
- Fn m_fixhdr mbuf
-
Set the packet-header length to the length of the
Vt mbuf chain . - Fn m_devget buf len offset ifp copy
-
Copy data from a device local memory pointed to by
Fa bufto an
Vt mbuf chain .The copy is done using a specified copy routine
Fa copy ,or
bcopy ();if
Fa copyis
NULL - Fn m_cat m n
-
Concatenate
Fa nto
Fa m .Both
Vt mbuf chainsmust be of the same type.
Fa Nis still valid after the function returned.
NoteIt does not handle
M_PKTHDRand friends.
- Fn m_split mbuf len how
-
Partition an
Vt mbuf chainin two pieces, returning the tail:
all but the first
Fa lenbytes.
In case of failure, it returns
NULLand attempts to restore the
Vt mbuf chainto its original state.
- Fn m_apply mbuf off len f arg
-
Apply a function to an
Vt mbuf chain ,at offset
Fa off ,for length
Fa lenbytes.
Typically used to avoid calls to
m_pullup ();which would otherwise be unnecessary or undesirable.
Fa argis a convenience argument which is passed to the callback function
Fa f .Each time
f ();is called, it will be passed
Fa arg ,a pointer to the
Fa datain the current mbuf, and the length
Fa lenof the data in this mbuf to which the function should be applied.
The function should return zero to indicate success;
otherwise, if an error is indicated, then
m_apply ();will return the error and stop iterating through the
Vt mbuf chain . - Fn m_getptr mbuf loc off
-
Return a pointer to the mbuf containing the data located at
Fa locbytes from the beginning of the
Vt mbuf chain .The corresponding offset into the mbuf will be stored in
Fa *off . - Fn m_defrag m0 how
-
Defragment an mbuf chain, returning the shortest possible
chain of mbufs and clusters.
If allocation fails and this can not be completed,
NULLwill be returned and the original chain will be unchanged.
Upon success, the original chain will be freed and the new
chain will be returned.
Fa howshould be either
M_TRYWAITor
M_DONTWAITdepending on the caller’s preference.
This function is especially useful in network drivers, where
certain long mbuf chains must be shortened before being added
to TX descriptor lists. - Fn m_unshare m0 how
-
Create a version of the specified mbuf chain whose
contents can be safely modified without affecting other users.
If allocation fails and this operation can not be completed,
NULLwill be returned.
The original mbuf chain is always reclaimed and the reference
count of any shared mbuf clusters is decremented.
Fa howshould be either
M_TRYWAITor
M_DONTWAITdepending on the caller’s preference.
As a side-effect of this process the returned
mbuf chain may be compacted.This function is especially useful in the transmit path of
network code, when data must be encrypted or otherwise
altered prior to transmission.
HARDWARE-ASSISTED CHECKSUM CALCULATION
This section currently applies to TCP/IP only.
In order to save the host CPU resources, computing checksums is
offloaded to the network interface hardware if possible.
The
m_pkthdr
member of the leading
Vt mbuf
of a packet contains two fields used for that purpose,
Vt int Va csum_flags
and
Vt int Va csum_data .
The meaning of those fields depends on the direction a packet flows in,
and on whether the packet is fragmented.
Henceforth,
csum_flags
or
csum_data
of a packet
will denote the corresponding field of the
m_pkthdr
member of the leading
Vt mbuf
in the
Vt mbuf chain
containing the packet.
On output, checksum offloading is attempted after the outgoing
interface has been determined for a packet.
The interface-specific field
ifnet.if_data.ifi_hwassist
(see
ifnet(9))
is consulted for the capabilities of the interface to assist in
computing checksums.
The
csum_flags
field of the packet header is set to indicate which actions the interface
is supposed to perform on it.
The actions unsupported by the network interface are done in the
software prior to passing the packet down to the interface driver;
such actions will never be requested through
csum_flags
The flags demanding a particular action from an interface are as follows:
- CSUM_IP
-
The IP header checksum is to be computed and stored in the
corresponding field of the packet.
The hardware is expected to know the format of an IP header
to determine the offset of the IP checksum field. - CSUM_TCP
-
The TCP checksum is to be computed.
(See below.) - CSUM_UDP
-
The UDP checksum is to be computed.
(See below.)
Should a TCP or UDP checksum be offloaded to the hardware,
the field
csum_data
will contain the byte offset of the checksum field relative to the
end of the IP header.
In this case, the checksum field will be initially
set by the TCP/IP module to the checksum of the pseudo header
defined by the TCP and UDP specifications.
For outbound packets which have been fragmented
by the host CPU, the following will also be true,
regardless of the checksum flag settings:
-
all fragments will have the flag
M_FRAGset in their
m_flagsfield;
-
the first and the last fragments in the chain will have
M_FIRSTFRAGor
M_LASTFRAGset in their
m_flagscorrespondingly;
-
the first fragment in the chain will have the total number
of fragments contained in its
csum_datafield.
The last rule for fragmented packets takes precedence over the one
for a TCP or UDP checksum.
Nevertheless, offloading a TCP or UDP checksum is possible for a
fragmented packet if the flag
CSUM_IP_FRAGS
is set in the field
ifnet.if_data.ifi_hwassist
associated with the network interface.
However, in this case the interface is expected to figure out
the location of the checksum field within the sequence of fragments
by itself because
csum_data
contains a fragment count instead of a checksum offset value.
On input, an interface indicates the actions it has performed
on a packet by setting one or more of the following flags in
csum_flags
associated with the packet:
- CSUM_IP_CHECKED
- The IP header checksum has been computed.
- CSUM_IP_VALID
-
The IP header has a valid checksum.
This flag can appear only in combination with
CSUM_IP_CHECKED - CSUM_DATA_VALID
-
The checksum of the data portion of the IP packet has been computed
and stored in the field
csum_datain network byte order.
- CSUM_PSEUDO_HDR
-
Can be set only along with
CSUM_DATA_VALIDto indicate that the IP data checksum found in
csum_dataallows for the pseudo header defined by the TCP and UDP specifications.
Otherwise the checksum of the pseudo header must be calculated by
the host CPU and added to
csum_datato obtain the final checksum to be used for TCP or UDP validation purposes.
If a particular network interface just indicates success or
failure of TCP or UDP checksum validation without returning
the exact value of the checksum to the host CPU, its driver can mark
CSUM_DATA_VALID
and
CSUM_PSEUDO_HDR
in
csum_flags
and set
csum_data
to
0xFFFF
hexadecimal to indicate a valid checksum.
It is a peculiarity of the algorithm used that the Internet checksum
calculated over any valid packet will be
0xFFFF
as long as the original checksum field is included.
For inbound packets which are IP fragments, all
csum_data
fields will be summed during reassembly to obtain the final checksum
value passed to an upper layer in the
csum_data
field of the reassembled packet.
The
csum_flags
fields of all fragments will be consolidated using logical AND
to obtain the final value for
csum_flags
Thus, in order to successfully
offload checksum computation for fragmented data,
all fragments should have the same value of
csum_flags
STRESS TESTING
When running a kernel compiled with the option
MBUF_STRESS_TEST
the following
sysctl(8)
-controlled options may be used to create
various failure/extreme cases for testing of network drivers
and other parts of the kernel that rely on
Vt mbufs .
- net.inet.ip.mbuf_frag_size
-
Causes
ip_output ();to fragment outgoing
Vt mbuf chainsinto fragments of the specified size.
Setting this variable to 1 is an excellent way to
test the long
Vt mbuf chainhandling ability of network drivers.
- kern.ipc.m_defragrandomfailures
-
Causes the function
m_defrag ();to randomly fail, returning
NULLAny piece of code which uses
m_defrag ();should be tested with this feature.
RETURN VALUES
See above.
SEE ALSO
ifnet(9),
mbuf_tags9
HISTORY
Vt Mbufs
appeared in an early version of
BSD .
Besides being used for network packets, they were used
to store various dynamic structures, such as routing table
entries, interface addresses, protocol control blocks, etc.
In more recent
Fx use of
Vt mbufs
is almost entirely limited to packet storage, with
uma(9)
zones being used directly to store other network-related memory.
Historically, the
Vt mbuf
allocator has been a special-purpose memory allocator able to run in
interrupt contexts and allocating from a special kernel address space map.
As of
Fx 5.3 ,
the
Vt mbuf
allocator is a wrapper around
uma(9),
allowing caching of
Vt mbufs ,
clusters, and
Vt mbuf
+ cluster pairs in per-CPU caches, as well as bringing other benefits of
slab allocation.
AUTHORS
The original
manual page was written by Yar Tikhiy.
The
uma(9)
Vt mbuf
allocator was written by Bosko Milekic.
Index
- NAME
- SYNOPSIS
-
- Mbuf allocation macros
- Mbuf utility macros
- Mbuf allocation functions
- Mbuf utility functions
- DESCRIPTION
-
- Macros and Functions
- HARDWARE-ASSISTED CHECKSUM CALCULATION
- STRESS TESTING
- RETURN VALUES
- SEE ALSO
- HISTORY
- AUTHORS
|
Header pointers needs to be reinitialized in icmp_error after m_pullup calls:
Date: Thu Sep 28 15:06:28 2017 -0700
Reinitialize mtod derived protocol header pointers in icmp_error after calling m_pullup
diff --git a/sys/netinet/ip_icmp.c b/sys/netinet/ip_icmp.c
index 5983b3386af..4f466236864 100644
--- a/sys/netinet/ip_icmp.c
+++ b/sys/netinet/ip_icmp.c
@@ -237,6 +237,12 @@ icmp_error(struct mbuf *n, int type, int code, uint32_t dest, int mtu)
if (n->m_len < oiphlen + sizeof(struct tcphdr) &&
((n = m_pullup(n, oiphlen + sizeof(struct tcphdr))) == NULL))
goto freeit;
+
+ /*
+ * Reinitialize pointers derived from mbuf data pointer,
+ * after calling m_pullup
+ */
+ oip = mtod(n, struct ip *);
th = (struct tcphdr *)((caddr_t)oip + oiphlen);
tcphlen = th->th_off << 2;
if (tcphlen < sizeof(struct tcphdr))
@@ -248,6 +254,14 @@ icmp_error(struct mbuf *n, int type, int code, uint32_t dest, int mtu)
if (n->m_len < oiphlen + tcphlen &&
((n = m_pullup(n, oiphlen + tcphlen)) == NULL))
goto freeit;
+
+ /*
+ * Reinitialize pointers derived from mbuf data pointer,
+ * after calling m_pullup
+ */
+ oip = mtod(n, struct ip *);
+ th = (struct tcphdr *)((caddr_t)oip + oiphlen);
+
icmpelen = max(tcphlen, min(V_icmp_quotelen,
ntohs(oip->ip_len) - oiphlen));
} else if (oip->ip_p == IPPROTO_SCTP) {
@@ -262,6 +276,12 @@ icmp_error(struct mbuf *n, int type, int code, uint32_t dest, int mtu)
if (n->m_len < oiphlen + sizeof(struct sctphdr) &&
(n = m_pullup(n, oiphlen + sizeof(struct sctphdr))) == NULL)
goto freeit;
+
+ /*
+ * Reinitialize pointers derived from mbuf data pointer,
+ * after calling m_pullup
+ */
+ oip = mtod(n, struct ip *);
icmpelen = max(sizeof(struct sctphdr),
min(V_icmp_quotelen, ntohs(oip->ip_len) - oiphlen));
sh = (struct sctphdr *)((caddr_t)oip + oiphlen);
@@ -272,7 +292,15 @@ icmp_error(struct mbuf *n, int type, int code, uint32_t dest, int mtu)
if (n->m_len < oiphlen + sizeof(struct sctphdr) + 8 &&
(n = m_pullup(n, oiphlen + sizeof(struct sctphdr) + 8)) == NULL)
goto freeit;
+
+ /*
+ * Reinitialize pointers derived from mbuf data pointer,
+ * after calling m_pullup
+ */
+ oip = mtod(n, struct ip *);
+ sh = (struct sctphdr *)((caddr_t)oip + oiphlen);
ch = (struct sctp_chunkhdr *)(sh + 1);
+
if (ch->chunk_type == SCTP_INITIATION) {
icmpelen = max(sizeof(struct sctphdr) + 8,
min(V_icmp_quotelen, ntohs(oip->ip_len) - oiphlen));
A commit references this bug: Author: ae Date: Fri Sep 29 06:24:45 UTC 2017 New revision: 324098 URL: https://svnweb.freebsd.org/changeset/base/324098 Log: Some mbuf related fixes in icmp_error() * check mbuf length before doing mtod() and accessing to IP header; * update oip pointer and all depending pointers after m_pullup(); * remove extra checks and extra parentheses, wrap long lines; PR: 222670 Reported by: Prabhakar Lakhera MFC after: 1 week Changes: head/sys/netinet/ip_icmp.c
A commit references this bug:
Author: ae
Date: Mon Oct 9 08:50:04 UTC 2017
New revision: 324426
URL: https://svnweb.freebsd.org/changeset/base/324426
Log:
MFC r324098:
Some mbuf related fixes in icmp_error()
* check mbuf length before doing mtod() and accessing to IP header;
* update oip pointer and all depending pointers after m_pullup();
* remove extra checks and extra parentheses, wrap long lines;
PR: 222670
Changes:
_U stable/11/
stable/11/sys/netinet/ip_icmp.c
|

NAME¶
mbuf — memory
management in the kernel IPC subsystem
SYNOPSIS¶
#include
<sys/param.h>
#include <sys/systm.h>
#include <sys/mbuf.h>
Mbuf allocation macros¶
MGET(struct
mbuf *mbuf, int
how, short
type);
MGETHDR(struct
mbuf *mbuf, int
how, short
type);
int
MCLGET(struct
mbuf *mbuf, int
how);
MEXTADD(struct mbuf
*mbuf, caddr_t buf, u_int
size, void (*free)(void *opt_arg1, void
*opt_arg2), void *opt_arg1, void
*opt_arg2, short flags, int
type);
Mbuf utility macros¶
mtod(struct
mbuf *mbuf,
type);
M_ALIGN(struct
mbuf *mbuf, u_int
len);
MH_ALIGN(struct
mbuf *mbuf, u_int
len);
int
M_LEADINGSPACE(struct
mbuf *mbuf);
int
M_TRAILINGSPACE(struct
mbuf *mbuf);
M_MOVE_PKTHDR(struct
mbuf *to, struct mbuf
*from);
M_PREPEND(struct
mbuf *mbuf, int
len, int how);
MCHTYPE(struct
mbuf *mbuf, short
type);
int
M_WRITABLE(struct
mbuf *mbuf);
Mbuf allocation functions¶
struct mbuf *
m_get(int
how, short
type);
struct mbuf *
m_get2(int
size, int how,
short type,
int flags);
struct mbuf *
m_getm(struct
mbuf *orig, int
len, int how,
short type);
struct mbuf *
m_getjcl(int
how, short type,
int flags,
int size);
struct mbuf *
m_getcl(int
how, short type,
int flags);
struct mbuf *
m_getclr(int
how, short
type);
struct mbuf *
m_gethdr(int
how, short
type);
struct mbuf *
m_free(struct
mbuf *mbuf);
void
m_freem(struct
mbuf *mbuf);
Mbuf utility functions¶
void
m_adj(struct
mbuf *mbuf, int
len);
void
m_align(struct
mbuf *mbuf, int
len);
int
m_append(struct
mbuf *mbuf, int
len, c_caddr_t
cp);
struct mbuf *
m_prepend(struct
mbuf *mbuf, int
len, int how);
struct mbuf *
m_copyup(struct
mbuf *mbuf, int
len, int
dstoff);
struct mbuf *
m_pullup(struct
mbuf *mbuf, int
len);
struct mbuf *
m_pulldown(struct
mbuf *mbuf, int
offset, int len,
int *offsetp);
struct mbuf *
m_copym(struct
mbuf *mbuf, int
offset, int len,
int how);
struct mbuf *
m_copypacket(struct
mbuf *mbuf, int
how);
struct mbuf *
m_dup(struct
mbuf *mbuf, int
how);
void
m_copydata(const
struct mbuf *mbuf, int
offset, int len,
caddr_t buf);
void
m_copyback(struct
mbuf *mbuf, int
offset, int len,
caddr_t buf);
struct mbuf *
m_devget(char *buf,
int len, int offset,
struct ifnet *ifp, void (*copy)(char
*from, caddr_t to, u_int len));
void
m_cat(struct
mbuf *m, struct mbuf
*n);
void
m_catpkt(struct
mbuf *m, struct mbuf
*n);
u_int
m_fixhdr(struct
mbuf *mbuf);
void
m_dup_pkthdr(struct
mbuf *to, struct mbuf
*from);
void
m_move_pkthdr(struct
mbuf *to, struct mbuf
*from);
u_int
m_length(struct
mbuf *mbuf, struct mbuf
**last);
struct mbuf *
m_split(struct
mbuf *mbuf, int
len, int how);
int
m_apply(struct
mbuf *mbuf, int
off, int len,
int (*f)(void *arg, void *data,
u_int len), void
*arg);
struct mbuf *
m_getptr(struct
mbuf *mbuf, int
loc, int *off);
struct mbuf *
m_defrag(struct
mbuf *m0, int
how);
struct mbuf *
m_collapse(struct
mbuf *m0, int how,
int maxfrags);
struct mbuf *
m_unshare(struct
mbuf *m0, int
how);
DESCRIPTION¶
An mbuf is a basic unit of memory management
in the kernel IPC subsystem. Network packets and socket buffers are stored
in mbufs. A network packet may span multiple
mbufs arranged into a mbuf chain
(linked list), which allows adding or trimming network headers with little
overhead.
While a developer should not bother with
mbuf internals without serious reason in order to
avoid incompatibilities with future changes, it is useful to understand the
general structure of an mbuf.
An mbuf consists of a variable-sized header
and a small internal buffer for data. The total size of an
mbuf, MSIZE, is a constant
defined in <sys/param.h>.
The mbuf header includes:
- m_next
- (struct mbuf *) A pointer to the next
mbuf in the mbuf chain. - m_nextpkt
- (struct mbuf *) A pointer to the next
mbuf chain in the queue. - m_data
- (caddr_t) A pointer to data attached to this
mbuf. - m_len
- (int) The length of the data.
- m_type
- (short) The type of the data.
- m_flags
- (int) The mbuf flags.
The mbuf flag bits are defined as
follows:
/* mbuf flags */ #define M_EXT 0x00000001 /* has associated external storage */ #define M_PKTHDR 0x00000002 /* start of record */ #define M_EOR 0x00000004 /* end of record */ #define M_RDONLY 0x00000008 /* associated data marked read-only */ #define M_PROTO1 0x00001000 /* protocol-specific */ #define M_PROTO2 0x00002000 /* protocol-specific */ #define M_PROTO3 0x00004000 /* protocol-specific */ #define M_PROTO4 0x00008000 /* protocol-specific */ #define M_PROTO5 0x00010000 /* protocol-specific */ #define M_PROTO6 0x00020000 /* protocol-specific */ #define M_PROTO7 0x00040000 /* protocol-specific */ #define M_PROTO8 0x00080000 /* protocol-specific */ #define M_PROTO9 0x00100000 /* protocol-specific */ #define M_PROTO10 0x00200000 /* protocol-specific */ #define M_PROTO11 0x00400000 /* protocol-specific */ #define M_PROTO12 0x00800000 /* protocol-specific */ /* mbuf pkthdr flags (also stored in m_flags) */ #define M_BCAST 0x00000010 /* send/received as link-level broadcast */ #define M_MCAST 0x00000020 /* send/received as link-level multicast */
The available mbuf types are defined as
follows:
/* mbuf types */ #define MT_DATA 1 /* dynamic (data) allocation */ #define MT_HEADER MT_DATA /* packet header */ #define MT_SONAME 8 /* socket name */ #define MT_CONTROL 14 /* extra-data protocol message */ #define MT_OOBDATA 15 /* expedited data */
The available external buffer types are defined as follows:
/* external buffer types */ #define EXT_CLUSTER 1 /* mbuf cluster */ #define EXT_SFBUF 2 /* sendfile(2)'s sf_bufs */ #define EXT_JUMBOP 3 /* jumbo cluster 4096 bytes */ #define EXT_JUMBO9 4 /* jumbo cluster 9216 bytes */ #define EXT_JUMBO16 5 /* jumbo cluster 16184 bytes */ #define EXT_PACKET 6 /* mbuf+cluster from packet zone */ #define EXT_MBUF 7 /* external mbuf reference (M_IOVEC) */ #define EXT_NET_DRV 252 /* custom ext_buf provided by net driver(s) */ #define EXT_MOD_TYPE 253 /* custom module's ext_buf type */ #define EXT_DISPOSABLE 254 /* can throw this buffer away w/page flipping */ #define EXT_EXTREF 255 /* has externally maintained ref_cnt ptr */
If the M_PKTHDR flag is set, a
struct pkthdr m_pkthdr is added
to the mbuf header. It contains a pointer to the
interface the packet has been received from (struct
ifnet *rcvif), and the total packet length
(int len). Optionally, it may
also contain an attached list of packet tags (struct
m_tag). See mbuf_tags(9) for details. Fields used in
offloading checksum calculation to the hardware are kept in
m_pkthdr as well. See
HARDWARE-ASSISTED
CHECKSUM CALCULATION for details.
If small enough, data is stored in the internal data buffer of an
mbuf. If the data is sufficiently large, another
mbuf may be added to the mbuf
chain, or external storage may be associated with the
mbuf. MHLEN bytes of data can
fit into an mbuf with the
M_PKTHDR flag set, MLEN
bytes can otherwise.
If external storage is being associated with an
mbuf, the m_ext header is added
at the cost of losing the internal data buffer. It includes a pointer to
external storage, the size of the storage, a pointer to a function used for
freeing the storage, a pointer to an optional argument that can be passed to
the function, and a pointer to a reference counter. An
mbuf using external storage has the
M_EXT flag set.
The system supplies a macro for allocating the desired external
storage buffer, MEXTADD.
The allocation and management of the reference counter is handled
by the subsystem.
The system also supplies a default type of external storage buffer
called an mbuf cluster. Mbuf
clusters can be allocated and configured with the use of the
MCLGET macro. Each mbuf
cluster is MCLBYTES in size, where MCLBYTES is
a machine-dependent constant. The system defines an advisory macro
MINCLSIZE, which is the smallest amount of data to
put into an mbuf cluster. It is equal to
MHLEN plus one. It is typically preferable to store
data into the data region of an mbuf, if size permits,
as opposed to allocating a separate mbuf cluster to
hold the same data.
Macros and Functions¶
There are numerous predefined macros and functions that provide
the developer with common utilities.
mtod(mbuf,
type)- Convert an mbuf pointer to a data pointer. The macro
expands to the data pointer cast to the specified
type. Note: It is advisable to
ensure that there is enough contiguous data in mbuf.
See
m_pullup()
for details. MGET(mbuf,
how, type)- Allocate an mbuf and initialize it to contain
internal data. mbuf will point to the allocated
mbuf on success, or be set to
NULLon failure. The how
argument is to be set toM_WAITOKor
M_NOWAIT. It specifies whether the caller is
willing to block if necessary. A number of other functions and macros
related to mbufs have the same argument because they
may at some point need to allocate new mbufs. MGETHDR(mbuf,
how, type)- Allocate an mbuf and initialize it to contain a
packet header and internal data. SeeMGET() for
details. MEXTADD(mbuf,
buf, size,
free, opt_arg1,
opt_arg2, flags,
type)- Associate externally managed data with mbuf. Any
internal data contained in the mbuf will be discarded, and the
M_EXTflag will be set. The
buf and size arguments are the
address and length, respectively, of the data. The
free argument points to a function which will be
called to free the data when the mbuf is freed; it is only used if
type isEXT_EXTREF. The
opt_arg1 and opt_arg2
arguments will be passed unmodified to free. The
flags argument specifies additional
mbuf flags; it is not necessary to specify
M_EXT. Finally, the type
argument specifies the type of external data, which controls how it will
be disposed of when the mbuf is freed. In most
cases, the correct value isEXT_EXTREF. MCLGET(mbuf,
how)- Allocate and attach an mbuf cluster to
mbuf. On success, a non-zero value returned;
otherwise, 0. Historically, consumers would check for success by testing
theM_EXTflag on the mbuf, but this is now
discouraged to avoid unnecessary awareness of the implementation of
external storage in protocol stacks and device drivers. M_ALIGN(mbuf,
len)- Set the pointer mbuf->m_data to place an object
of the size len at the end of the internal data area
of mbuf, long word aligned. Applicable only if
mbuf is newly allocated with
MGET() orm_get(). MH_ALIGN(mbuf,
len)- Serves the same purpose as
M_ALIGN() does, but
only for mbuf newly allocated with
MGETHDR() orm_gethdr(),
or initialized by
m_dup_pkthdr()
or
m_move_pkthdr(). m_align(mbuf,
len)- Services the same purpose as
M_ALIGN() but handles
any type of mbuf. M_LEADINGSPACE(mbuf)- Returns the number of bytes available before the beginning of data in
mbuf. M_TRAILINGSPACE(mbuf)- Returns the number of bytes available after the end of data in
mbuf. M_PREPEND(mbuf,
len, how)- This macro operates on an mbuf chain. It is an
optimized wrapper form_prepend() that can make
use of possible empty space before data (e.g. left after trimming of a
link-layer header). The new mbuf chain pointer or
NULLis in mbuf after the
call. M_MOVE_PKTHDR(to,
from)- Using this macro is equivalent to calling
m_move_pkthdr(to,
from). M_WRITABLE(mbuf)- This macro will evaluate true if mbuf is not marked
M_RDONLYand if either mbuf
does not contain external storage or, if it does, then if the reference
count of the storage is not greater than 1. The
M_RDONLYflag can be set in
mbuf->m_flags. This can be achieved during setup
of the external storage, by passing theM_RDONLY
bit as a flags argument to the
MEXTADD() macro, or can be directly set in
individual mbufs. MCHTYPE(mbuf,
type)- Change the type of mbuf to
type. This is a relatively expensive operation and
should be avoided.
The functions are:
m_get(how,
type)- A function version of
MGET()
for non-critical paths. m_get2(size,
how, type,
flags)- Allocate an mbuf with enough space to hold specified
amount of data. m_getm(orig,
len, how,
type)- Allocate len bytes worth of
mbufs and mbuf clusters if
necessary and append the resulting allocated mbuf
chain to the mbuf chain
orig, if it is
non-NULL. If the
allocation fails at any point, free whatever was allocated and return
NULL. If orig is
non-NULL, it will not be
freed. It is possible to usem_getm() to either
append len bytes to an existing
mbuf or mbuf chain (for
example, one which may be sitting in a pre-allocated ring) or to simply
perform an all-or-nothing mbuf and
mbuf cluster allocation. m_gethdr(how,
type)- A function version of
MGETHDR() for non-critical
paths. m_getcl(how,
type, flags)- Fetch an mbuf with a mbuf
cluster attached to it. If one of the allocations fails, the entire
allocation fails. This routine is the preferred way of fetching both the
mbuf and mbuf cluster
together, as it avoids having to unlock/relock between allocations.
ReturnsNULLon failure. m_getjcl(how,
type, flags,
size)- This is like
m_getcl() but it the size of the
cluster allocated will be large enough for size
bytes. m_getclr(how,
type)- Allocate an mbuf and zero out the data region.
m_free(mbuf)- Frees mbuf. Returns m_next of
the freed mbuf.
The functions below operate on mbuf
chains.
m_freem(mbuf)- Free an entire mbuf chain, including any external
storage. m_adj(mbuf,
len)- Trim len bytes from the head of an
mbuf chain if len is positive,
from the tail otherwise. m_append(mbuf,
len, cp)- Append len bytes of data cp to
the mbuf chain. Extend the mbuf chain if the new
data does not fit in existing space. m_prepend(mbuf,
len, how)- Allocate a new mbuf and prepend it to the
mbuf chain, handleM_PKTHDR
properly. Note: It does not allocate any
mbuf clusters, so len must be
less thanMLENorMHLEN,
depending on theM_PKTHDRflag setting. m_copyup(mbuf,
len, dstoff)- Similar to
m_pullup() but copies
len bytes of data into a new mbuf at
dstoff bytes into the mbuf. The
dstoff argument aligns the data and leaves room for
a link layer header. Returns the new mbuf chain on
success, and frees the mbuf chain and returns
NULLon failure. Note: The
function does not allocate mbuf clusters, so
len + dstoff must be less than
MHLEN. m_pullup(mbuf,
len)- Arrange that the first len bytes of an
mbuf chain are contiguous and lay in the data area
of mbuf, so they are accessible with
mtod(mbuf,
type). It is important to remember that this may
involve reallocating some mbufs and moving data so all pointers
referencing data within the old mbuf chain must be recalculated or made
invalid. Return the new mbuf chain on success,
NULLon failure (the mbuf
chain is freed in this case). Note: It does not
allocate any mbuf clusters, so
len must be less than or equal to
MHLEN. m_pulldown(mbuf,
offset, len,
offsetp)- Arrange that len bytes between
offset and offset + len in the
mbuf chain are contiguous and lay in the data area
of mbuf, so they are accessible with
mtod(mbuf,
type). len must be smaller
than, or equal to, the size of an mbuf cluster.
Return a pointer to an intermediate mbuf in the
chain containing the requested region; the offset in the data region of
the mbuf chain to the data contained in the returned
mbuf is stored in *offsetp. If
offsetp is NULL, the region may be accessed using
mtod(mbuf,
type). If offsetp is non-NULL,
the region may be accessed using
mtod(mbuf,
uint8_t) + *offsetp. The region of the mbuf chain
between its beginning and offset is not modified,
therefore it is safe to hold pointers to data within this region before
callingm_pulldown(). m_copym(mbuf,
offset, len,
how)- Make a copy of an mbuf chain starting
offset bytes from the beginning, continuing for
len bytes. If len is
M_COPYALL, copy to the end of the
mbuf chain. Note: The copy is
read-only, because the mbuf clusters are not copied,
only their reference counts are incremented. m_copypacket(mbuf,
how)- Copy an entire packet including header, which must be present. This is an
optimized version of the common case
m_copym(mbuf,
0, M_COPYALL,
how). Note: the copy is read-only,
because the mbuf clusters are not copied, only their
reference counts are incremented. m_dup(mbuf,
how)- Copy a packet header mbuf chain into a completely
new mbuf chain, including copying any
mbuf clusters. Use this instead of
m_copypacket() when you need a writable copy of an
mbuf chain. m_copydata(mbuf,
offset, len,
buf)- Copy data from an mbuf chain starting
off bytes from the beginning, continuing for
len bytes, into the indicated buffer
buf. m_copyback(mbuf,
offset, len,
buf)- Copy len bytes from the buffer
buf back into the indicated mbuf
chain, starting at offset bytes from the
beginning of the mbuf chain, extending the
mbuf chain if necessary. Note: It
does not allocate any mbuf clusters, just adds
mbufs to the mbuf chain. It is
safe to set offset beyond the current
mbuf chain end: zeroed mbufs
will be allocated to fill the space. m_length(mbuf,
last)- Return the length of the mbuf chain, and optionally
a pointer to the last mbuf. m_dup_pkthdr(to,
from, how)- Upon the function’s completion, the mbuf
to will contain an identical copy of
from->m_pkthdr and the per-packet attributes
found in the mbuf chain from.
The mbuf from must have the
flagM_PKTHDRinitially set, and
to must be empty on entry. m_move_pkthdr(to,
from)- Move m_pkthdr and the per-packet attributes from the
mbuf chain from to the
mbuf to. The
mbuf from must have the flag
M_PKTHDRinitially set, and
to must be empty on entry. Upon the function’s
completion, from will have the flag
M_PKTHDRand the per-packet attributes
cleared. m_fixhdr(mbuf)- Set the packet-header length to the length of the mbuf
chain. m_devget(buf,
len, offset,
ifp, copy)- Copy data from a device local memory pointed to by
buf to an mbuf chain. The copy
is done using a specified copy routine copy, or
bcopy()
if copy isNULL. m_cat(m,
n)- Concatenate n to m. Both
mbuf chains must be of the same type.
n is not guaranteed to be valid after
m_cat() returns.m_cat()
does not update any packet header fields or free mbuf tags. m_catpkt(m,
n)- A variant of
m_cat() that operates on packets.
Both m and n must contain
packet headers. n is not guaranteed to be valid
afterm_catpkt() returns. m_split(mbuf,
len, how)- Partition an mbuf chain in two pieces, returning the
tail: all but the first len bytes. In case of
failure, it returnsNULLand attempts to restore
the mbuf chain to its original state. m_apply(mbuf,
off, len,
f, arg)- Apply a function to an mbuf chain, at offset
off, for length len bytes.
Typically used to avoid calls tom_pullup() which
would otherwise be unnecessary or undesirable. arg
is a convenience argument which is passed to the callback function
f.Each time
f() is
called, it will be passed arg, a pointer to the
data in the current mbuf, and the length
len of the data in this mbuf to which the function
should be applied.The function should return zero to indicate
success; otherwise, if an error is indicated, then
m_apply()
will return the error and stop iterating through the
mbuf chain. m_getptr(mbuf,
loc, off)- Return a pointer to the mbuf containing the data located at
loc bytes from the beginning of the
mbuf chain. The corresponding offset into the mbuf
will be stored in *off. m_defrag(m0,
how)- Defragment an mbuf chain, returning the shortest possible chain of mbufs
and clusters. If allocation fails and this can not be completed,
NULLwill be returned and the original chain will
be unchanged. Upon success, the original chain will be freed and the new
chain will be returned. how should be either
M_WAITOKorM_NOWAIT,
depending on the caller’s preference.This function is especially useful in network drivers, where
certain long mbuf chains must be shortened before being added to TX
descriptor lists. m_collapse(m0,
how, maxfrags)- Defragment an mbuf chain, returning a chain of at most
maxfrags mbufs and clusters. If allocation fails or
the chain cannot be collapsed as requested,NULL
will be returned, with the original chain possibly modified. As with
m_defrag(),
how should be one of
M_WAITOKorM_NOWAIT. m_unshare(m0,
how)- Create a version of the specified mbuf chain whose contents can be safely
modified without affecting other users. If allocation fails and this
operation can not be completed,NULLwill be
returned. The original mbuf chain is always reclaimed and the reference
count of any shared mbuf clusters is decremented.
how should be either
M_WAITOKorM_NOWAIT,
depending on the caller’s preference. As a side-effect of this process the
returned mbuf chain may be compacted.This function is especially useful in the transmit path of
network code, when data must be encrypted or otherwise altered prior to
transmission.
HARDWARE-ASSISTED CHECKSUM CALCULATION¶
This section currently applies to TCP/IP only. In order to save
the host CPU resources, computing checksums is offloaded to the network
interface hardware if possible. The m_pkthdr member of
the leading mbuf of a packet contains two fields used
for that purpose, int csum_flags
and int csum_data. The meaning
of those fields depends on the direction a packet flows in, and on whether
the packet is fragmented. Henceforth, csum_flags or
csum_data of a packet will denote the corresponding
field of the m_pkthdr member of the leading
mbuf in the mbuf chain
containing the packet.
On output, checksum offloading is attempted after the outgoing
interface has been determined for a packet. The interface-specific field
ifnet.if_data.ifi_hwassist (see
ifnet(9)) is consulted for the capabilities of the
interface to assist in computing checksums. The
csum_flags field of the packet header is set to
indicate which actions the interface is supposed to perform on it. The
actions unsupported by the network interface are done in the software prior
to passing the packet down to the interface driver; such actions will never
be requested through csum_flags.
The flags demanding a particular action from an interface are as
follows:
CSUM_IP- The IP header checksum is to be computed and stored in the corresponding
field of the packet. The hardware is expected to know the format of an IP
header to determine the offset of the IP checksum field. CSUM_TCP- The TCP checksum is to be computed. (See below.)
CSUM_UDP- The UDP checksum is to be computed. (See below.)
Should a TCP or UDP checksum be offloaded to the hardware, the
field csum_data will contain the byte offset of the
checksum field relative to the end of the IP header. In this case, the
checksum field will be initially set by the TCP/IP module to the checksum of
the pseudo header defined by the TCP and UDP specifications.
On input, an interface indicates the actions it has performed on a
packet by setting one or more of the following flags in
csum_flags associated with the packet:
CSUM_IP_CHECKED- The IP header checksum has been computed.
CSUM_IP_VALID- The IP header has a valid checksum. This flag can appear only in
combination withCSUM_IP_CHECKED. CSUM_DATA_VALID- The checksum of the data portion of the IP packet has been computed and
stored in the field csum_data in network byte
order. CSUM_PSEUDO_HDR- Can be set only along with
CSUM_DATA_VALIDto
indicate that the IP data checksum found in
csum_data allows for the pseudo header defined by
the TCP and UDP specifications. Otherwise the checksum of the pseudo
header must be calculated by the host CPU and added to
csum_data to obtain the final checksum to be used
for TCP or UDP validation purposes.
If a particular network interface just indicates success or
failure of TCP or UDP checksum validation without returning the exact value
of the checksum to the host CPU, its driver can mark
CSUM_DATA_VALID and
CSUM_PSEUDO_HDR in csum_flags,
and set csum_data to 0xFFFF
hexadecimal to indicate a valid checksum. It is a peculiarity of the
algorithm used that the Internet checksum calculated over any valid packet
will be 0xFFFF as long as the original checksum
field is included.
STRESS TESTING¶
When running a kernel compiled with the option
MBUF_STRESS_TEST, the following
sysctl(8)-controlled options may be used to create various
failure/extreme cases for testing of network drivers and other parts of the
kernel that rely on mbufs.
- net.inet.ip.mbuf_frag_size
- Causes
ip_output()
to fragment outgoing mbuf chains into fragments of
the specified size. Setting this variable to 1 is an excellent way to test
the long mbuf chain handling ability of network
drivers. - kern.ipc.m_defragrandomfailures
- Causes the function
m_defrag()
to randomly fail, returningNULL. Any piece of
code which usesm_defrag() should be tested with
this feature.
RETURN VALUES¶
See above.
SEE ALSO¶
ifnet(9), mbuf_tags(9)
HISTORY¶
Mbufs appeared in an early version of
BSD. Besides being used for network packets, they
were used to store various dynamic structures, such as routing table
entries, interface addresses, protocol control blocks, etc. In more recent
FreeBSD use of mbufs is almost
entirely limited to packet storage, with uma(9) zones
being used directly to store other network-related memory.
Historically, the mbuf allocator has been a
special-purpose memory allocator able to run in interrupt contexts and
allocating from a special kernel address space map. As of
FreeBSD 5.3, the mbuf
allocator is a wrapper around uma(9), allowing caching of
mbufs, clusters, and mbuf +
cluster pairs in per-CPU caches, as well as bringing other benefits of slab
allocation.
The original mbuf manual page was written
by Yar Tikhiy. The uma(9)
mbuf allocator was written by
Bosko Milekic.
Эта статья будет полезна системным администраторам и программистам, работающим в ядре FreeBSD. Осмыслив изложенное здесь, можно понять, почему же бывает паника по kmem, что такое состояние
keglim
/
zoneli
, как читать непонятные циферки в выводе
vmstat -m
/
vmstat -z
, и что же такое эти самые
mbuf
и
nmbclusters
. Программистам, приступающим к работе не в сетевой подсистеме, всё равно будет интересно узнать о дополнительных интерфейсах, помимо привычных
malloc()
/
free()
, и отличиях этих стандартных функций.
Поскольку эта статья — введение в комплекс связанных обширных тем, она предполагает наличие некоторых базовых понятий (например, чем виртуальная память отличается от физической), и не углубляется в некоторые специфичные вещи (типа packet secondary zone), особенно появившиеся не так давно.
| Операционная система делает три вещи — управляет оборудованием, распределяет память и мешает работе программиста. Причем ни с первым, ни со вторым она обычно не справляется.
(с) фольклор |
Виртуальная память и адресное пространство
Рассмотрим традиционное распределение виртуальной памяти процесса на i386 (рисовано по картинке Matthew Dillon псевдографикой):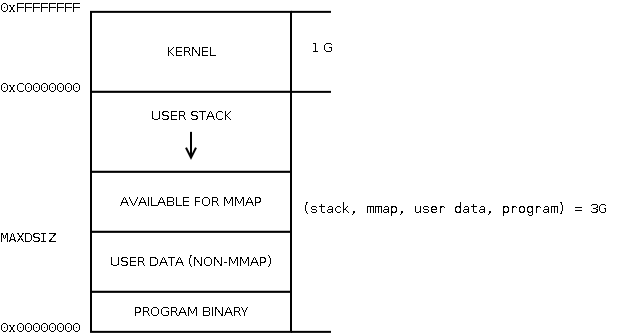
То, что относится к процессу, нас не интересует, а интересует сейчас та часть, которая KERNEL. Эта часть, которая при параметрах компиляции по умолчанию на i386 составляет 1 Гб — общая для всех процессов на машине, и при этом присутствует (отображается) в адресном пространстве каждого из них. Представим себе, что у нас работает 10 процессов на машине архитектуры i386 с 40 Гб физической памяти (Нет, это не опечатка. Представьте). Тогда каждый процесс мог бы использовать полные доступные ему 2^32 = 4 Гб виртуальной памяти, и все 10 поместились бы в 40 Гб физической? Нет, потому что каждому доступно только 3 Гб адресного пространства — и если они съедят доступную им память по полной, и то же самое сделает ядро, будет всего 31 Гб в сумме.
Откуда эти цифры берутся? Один элемент таблицы страниц, то есть описывающий 1 страницу памяти, занимает 4 байта на i386. Размер страницы — 4 Кб. Один уровень таблицы страниц занимает опять же 1 страницу, т.е. 4 Кб — это 1024 записи, итого охватывающих 4 Мб виртуальной памяти (далее используется следующий уровень таблицы страниц). Вот об этих страницах каталогов, охватывающих по 4 Мб, и идёт речь в
KVA_PAGES
. В случае PAE цифры другие, там один элемент 8 байт, а 1 уровень каталога страниц занимает 4 страницы, охватывая 2 Мб виртуальной памяти — поэтому цифры
KVA_PAGES
умножаются на 2. Подробнее можно посмотреть в файлах
pmap.h
,
param.h
,
vmparam.h
в
/sys/i386/include/
(или аналоге для другой архитектуры), в районе определений с зубодробительными именами типа
VADDR(KPTDI+NKPDE-1, NPTEPG-1)
.
Этот подход, когда память ядра находится в том же адресном пространстве процесса, не уникален для FreeBSD, и применяется во всех современных ОС, разве что граница по умолчанию может варьироваться (в Windows NT было 2 Гб). Её можно задать при компиляции ядра, например,
options KVA_PAGES=384
выделит ядру 1.5 Гб, оставив процессам всего 2.5; задается в единицах по 4 Мб и должно быть кратно 16 Мб (т.е. 256, 260, 264 и т.д.). Отсюда понятно, что если в ядре есть большой потребитель памяти, типа
mdconfig -t malloc
или ZFS, то адресного пространства ядра может запросто не хватить, даже если на машине еще есть гора свободной памяти. На amd64, понятное дело, ядру отвели 512 Гб пространства (это же просто виртуальные адреса, чего с ними мелочиться), так что проблем по этой причине там уже не возникнет.
Но это всего лишь виртуальные адреса, а дальше у нас реальная память. Почти вся принадлежащая ядру память не подлежит вытеснению в swap (представьте, например, что при обработке прерывания от сетевухи понадобилась лежащая в свопе ядерная память, а своп где-то на сетевом диске), но некоторые исключения всё-таки есть, типа буферов анонимных пайпов (это которые
sort | head
, например). Кроме того, память приложений, которой было сказано
mlock()
, также является запрещенной к свопингу (см.
memorylocked
в
ulimit
). Вся память, которая не может быть отправлена в своп, видна в
top
как Wired. Память же ядра, которая нас будет интересовать дальше, называется kmem. К сожалению, по указанным выше причинам, нельзя сказать, что
WIRED == KMEM
. Иными словами, kmem — память тоже виртуальная. Собственно, kmem — не единственный регион памяти ядра (есть и другие
vm_map
, размеры которых управляются, например,
kern.ipc.maxpipekva
,
kern.nbuf
,
kern.nswbuf
и др.). Просто именно из этого региона выделяется память для UMA и
malloc()
, о которых речь будет идти дальше. Размер kmem считается по такой формуле:
vm.kmem_size = min(max(max(VM_KMEM_SIZE, Physical_memory / VM_KMEM_SIZE_SCALE), VM_KMEM_SIZE_MIN), VM_KMEM_SIZE_MAX)
Выглядит страшно, но смысл очень простой. Рассмотрим как пример какой-нибудь Первопень™, стоящий на подоконнике, c 80 Мб ОЗУ:
vm.kvm_size: 1073737728 1 Гб минус 1 страница: полный размер памяти ядра vm.kvm_free: 947908608 совсем нераспределенных адресов памяти ядра vm.kmem_size_scale: 3 vm.kmem_size_max: 335544320 320 Мб: константа для автотюнинга vm.kmem_size_min: 0 vm.kmem_size: 25165824 24 Мб: выбранный при загрузке макс. размер kmem vm.kmem_map_size: 15175680 занято в kmem vm.kmem_map_free: 9539584 свободно в kmem
Первые два параметра, хотя и называются KVM (kernel virtual memory), обозначают kernel virtual address space (KVA). Считаются они так:
kvm_size = VM_MAX_KERNEL_ADDRESS — KERNBASE; kvm_free = VM_MAX_KERNEL_ADDRESS — kernel_vm_end;
Большими буквами в коде BSD-стиля принято обозначать константы, задаваемые только при компиляции (а также макросы) — это те самые размеры в 1 Гб, рассмотренные выше. В переменной
kernel_vm_end
ядро хранит конец используемой части KVM (расширяется при необходимости). Теперь о вычислении
vm.kmem_size
на примере. Сначала доступная память машины делится на
vm.kmem_size_scale
, получаем 24 Мб. Далее, kmem не может быть больше
vm.kmem_size_max
и меньше
vm.kmem_size_min
. В примере
vm.kmem_size_min
нулевой, в этом случае используется константа VM_KMEM_SIZE на этапе компиляции (она составляет 12 Мб для всех платформ). Разумеется, настройки
vm.kmem_size_min
и
vm.kmem_size_max
предназначены для автоподбора (одно и то же ядро/loader.conf может грузиться на разном железе), поэтому
vm.kmem_size
может быть задан явно, в этом случае он перекроет собой
vm.kmem_size_max
. Хотя и здесь предусмотрена страховка — он не может быть больше двух размеров физической памяти. Ближайшая машина с amd64 рапортует, что на ней
vm.kmem_size_scale
равен 1, и
kmem_size
равен почти что всем 4 Гб ОЗУ (хотя занято в нем куда меньше).
Подробнее о виртуальной памяти в современных ОС можно почитать на http://www.intuit.ru/department/os/osintro/ (первые главы).
Slab-аллокатор UMA и ядерный malloc
Почему такое внимание было уделено kmem, в отличие от остальных регионов памяти ядра? Потому что именно он используется для привычного
malloc()
и нового slab-аллокатора UMA. Зачем был нужен новый? Рассмотрим, как выглядела память в какой-то момент времени работы при традиционных аллокаторах:
...->|<-- 40 байт -->|<-- 97 байт -->|<-- 50 байт -->|<-- 20 байт -->|<-- 80 байт --->|<-- 250 байт -->|<-...
занято дырка занято занято дырка занято
Здесь в какой-то момент времени было 6 объектов, потом 2 освободилось. Теперь, если где-либо делается запрос
malloc(100)
, то аллокатор будет вынужден не только оставить неиспользованными дыры от старых объектов суммой 177 байт, но и последовательно перебрать все эти свободные области только затем, чтобы увидеть, что запрашиваемые 100 байт туда не влезут. А теперь представьте, что на машину непрерывно прибывают со скоростью 100 Мбит/с пакеты самого разного размера? Память под них очень быстро станет фрагментированной, с большими потерями и затратами времени на поиск.
Конечно, с этим довольно быстро стали бороться — деревья и другие приемы вместо линейного поиска, округления размеров, разные пулы для объектов сильно отличающихся размеров, и т.д. Но основным средством оставались всяческие кэши в разных подсистемах, фактически, собственные небольшие аллокаторы — чтоб поменьше обращаться к системному. А когда прикладные программисты (имеются в виду в том числе подсистемы-потребители в ядре) начинают писать свои аллокаторы памяти, это плохо. И не тем, что свой аллокатор скорее всего будет похуже, а тем, что не учитывались интересы других подсистем — много памяти висело в зарезервированных пулах (сейчас не используем, а другим бы эта память пригодилась), паттерны нагрузки тоже не учитывали соседей.
Наиболее продвинутым решением, которое используется в общем случае и сейчас — когда slab-аллокаторы использовать нельзя — являются аллокаторы, выделяющие память блоками с округлением до 2^n байт. То есть, для
malloc(50)
будет выделен кусок в 64 байт, а для
malloc(97)
— кусок в 128 байт. Блоки группируются между собой в пулах по размеру, что позволяет избежать проблем с фрагментацией и поисков — ценой потерь памяти, могущих достигать 50%. Стандартный
malloc(9)
ядра, появившийся еще в 4.4BSD, был сделан именно так. Рассмотрим его интерфейс подробнее.
MALLOC_DEFINE(M_NETGRAPH_HOOK, "netgraph_hook", "netgraph hook structures"); hook = malloc(sizeof(*hook), M_NETGRAPH_HOOK, M_NOWAIT | M_ZERO); free(hook, M_NETGRAPH_HOOK);
Если ваш тип malloc используется где-то еще за пределами одного файла, то кроме
MALLOC_DEFINE(M_FOO, «foo», «foo module mem»)
потребуется еще
MALLOC_DECLARE(M_FOO)
— см. определение этих макросов:
#define MALLOC_DEFINE(type, shortdesc, longdesc)
struct malloc_type type[1] = {
...
#define MALLOC_DECLARE(type)
extern struct malloc_type type[1]
(в старом коде был еще макрос
MALLOC()
в дополнение к функции, сразу приводивший типы, не так давно его отовсюду выпилили)
Как видно, по сравнению с привычными
malloc()
/
free()
в прикладных приложениях, здесь указывается еще один аргумент: тип malloc, определяемый где-нибудь в начале макросом
MALLOC_DEFINE()
; а для самого
malloc()
еще и флаги. Что это за тип? Он предназначен для ведения статистики. Аллокатор отслеживает, сколько для каждого типа сейчас выделено объектов, байт, и каких размеров блоков. Системный администратор может запустить команду
vmstat -m
и увидеть такую информацию:
- Type: название подсистемы из MALLOC_DEFINE
- InUse: сколько сейчас выделено объектов для этой подсистемы
- MemUse: сколько эта подсистема заняла памяти (выводится всегда в килобайтах с округлением вниз)
- Requests: сколько всего было запросов на выделение объектов для этой подсистемы с момента загрузки
- Size(s): размеры блоков, используемые для объектов этой подсистемы
Например:
$ vmstat -m
Type InUse MemUse HighUse Requests Size(s)
sigio 2 1K — 4 32
filedesc 92 31K — 256346 16,32,64,128,256,512,1024,2048,4096
kenv 93 7K — 94 16,32,64,128,4096
kqueue 4 6K — 298093 128,1024,4096
proc-args 47 3K — 881443 16,32,64,128,256
devbuf 233 5541K — 376 16,32,64,128,256,512,1024,2048,4096
CAM dev queue 1 1K — 1 64
Здесь нужно отметить, что округления блоков идут до 2^n только размера страницы, дальше идет округление до целого числа страниц. То есть на запрос в 10 Кб будет выделено 12 Кб, а не 16.
Остается рассмотреть только флаги вызова
malloc()
.
M_ZERO
понятен из названия — выделяемая память будет сразу заполнена нулями. Более важны два других взаимоисключающих флага, один из которых обязательно должен быть указан:
- M_NOWAIT — выделить память из доступного сейчас подмножества. Если её сейчас там не хватает, malloc() вернет NULL. Ситуация очень вероятная, поэтому её надо всегда обрабатывать (в отличие от поведения malloc() в юзерленде). Этот флаг обязателен при вызове из контекста прерывания — то есть, например, при обработке пакета в сети.
- M_WAITOK — если сейчас памяти не хватает, вызвавший тред останавливается и ждет, когда она появится. Поэтому этот флаг нельзя использовать в контексте прерывания, но можно, например, в контексте syscall — то есть по запросу от пользовательского процесса. С этим флагом malloc() никогда не вернет NULL, а всегда выдаст память (может ждать и очень долго) — если памяти не хватает совсем, система говорит panic: kmem_malloc(размер): kmem_map too small
Следует обратить внимание, что эта паника, как правило, возникает не в той подсистеме, которая всю память сожрала. Типичный пример из жизни: небольшой роутер падает в такую панику в UFS с запросом в 16384 байта — это какой-то процесс хочет прочитать что-то с диска, и для блока с диска вызывается
malloc(16384, …, M_WAITOK)
— памяти в kmem больше нет, всё, сохраняется корка. После ребута делаем
vmstat -m -M /var/crash/vmcore.1
и видим, что всю память сожрал NAT на базе
libalias
— просто он с
M_NOWAIT
обламывался в получении еще памяти, а система пока жила.
Еще в конце 80-х начались исследования специальных аллокаторов, предназначенных для отдельных подсистем. Они показывали результаты лучше общего аллокатора, но страдали от указанных в начале этого раздела недостатков — плохое взаимодействие с другими подсистемами. Самый важный полученный в ислледованиях вывод: «…a customized segregated-storage allocator — one that has a priori knowledge of the most common allocation sizes — is usually optimal in both space and time».
И вот в 1994 году, опираясь на этот вывод, Jeff Bonwick из Sun Microsystems придумал (и реализовал в Solaris) так называемый Slab Allocator (название отсылает к плитке шоколада, которая делится на дольки). Суть идеи: каждая подсистема, которая использует много объектов одинакового типа (а значит, одинакового размера), вместо заведения своих собственных кэшей регистрируется в slab-аллокаторе. А тот сам управляет размером кэшей, исходя из общего количества свободной памяти. Почему кэшей? Потому что аллокатор при регистрации принимает функции конструктора и деструктора объекта, и возвращает при аллокации уже инициализированный объект. Он может инициализировать некоторое их количество заранее, да и при
free()
объект может быть лишь частично деинициализирован, просто возвращаясь в кэш и будучи немедленно готовым к следующей аллокации.
«Плитка», которая обычно составляет страницу виртуальной памяти, разбивается на объекты, которые плотно упакованы. Например, если размер объекта 72 байта, их помещается 58 штук на одной странице, и неиспользованным остается лишь «хвост» в 64 байта — впустую тратится всего лишь 1.5% объема. Обычно в этом хвосте находится заголовок slab с битовой картой, какие из объектов свободны, какие выделены:
<---------------- Page (UMA_SLAB_SIZE) ------------------> ___________________________________________________________ | _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ___________ | ||i||i||i||i||i||i||i||i||i||i||i||i||i||i||i| |slab header|| i == item ||_||_||_||_||_||_||_||_||_||_||_||_||_||_||_| |___________|| |___________________________________________________________|
Реализация slab во FreeBSD называется UMA (Universal Memory Allocator) и документирован в
zone(9)
. Потребитель вызывает
uma_zcreate()
для создания зоны — коллекции объектов одинакового типа/размера, из которой и будут происходить выделения (она и является кэшом). С точки зрения системного администратора наиболее важным является то, что для зоны может быть установлен лимит с помощью
uma_zone_set_max()
. Зона не вырастет больше лимита, и если аллокация выполнялась с помощью
M_WAITOK
в syscall для пользовательского процесса, то он повиснет в
top
в состоянии
keglim
(в предыдущих версиях оно называлось
zoneli
) — до тех пор, пока не появится свободных элементов.
Текущее состояние UMA системный администратор может посмотреть в
vmstat -z
:
$ vmstat -z ITEM SIZE LIMIT USED FREE REQUESTS FAILURES UMA Kegs: 128, 0, 90, 0, 90, 0 UMA Zones: 480, 0, 90, 6, 90, 0 UMA Slabs: 64, 0, 514, 17, 2549, 0 UMA RCntSlabs: 104, 0, 117, 31, 134, 0 UMA Hash: 128, 0, 5, 25, 7, 0 16: 16, 0, 2239, 400, 82002734, 0 32: 32, 0, 688, 442, 78043255, 0 64: 64, 0, 2676, 1100, 1368912, 0 128: 128, 0, 2074, 656, 1953603, 0 256: 256, 0, 706, 329, 5848258, 0 512: 512, 0, 100, 100, 3069552, 0 1024: 1024, 0, 49, 39, 327074, 0 2048: 2048, 0, 294, 26, 623, 0 4096: 4096, 0, 127, 38, 481418, 0 socket: 416, 3078, 62, 109, 999707, 0 |
Значение полей:
|
Как заметили об универсальности разработчики Facebook: «If it isn’t general purpose, it isn’t good enough». Мы во FreeBSD любим разрабатывать универсальные вещи — GEOM, netgraph и много чего еще… И именно новый универсальный аллокатор для пользовательских приложений
jemalloc
и был взят разработчиками Facebook и Firefox 3. Подробнее о том, как сейчас обстоят дела на фронте масштабируемых аллокаторов, можно прочитать в их заметке http://www.facebook.com/note.php?note_id=480222803919
В примере можно заметить, почему UMA называется universal — потому что использует свои зоны даже для своих же собственных структур, а кроме того,
malloc()
сейчас реализован поверх того же UMA — имена зон от «16» до «4096». Дотошный читатель, однако, обратит внимание, что здесь размеры блоков только по 4096 включительно, а выделять-то можно и больше — и будет прав. Объекты большего размера выделяются внутренней функцией
uma_large_malloc()
— и, к сожалению, в общей статистике зон они не учитываются. Можно обнаружить, что результат
vmstat -m | sed -E ‘s/.* ([0-9]+)K.*/1/g’ | awk ‘{s+=$1}END{print s}’
не совпадает с
vmstat -z | awk -F'[:,]’ ‘/^[0-9]+:/ {s += $2*($4+$5)} END {print s}’
именно по этой причине. Впрочем, даже если просуммировать
vmstat -m
и всех остальных зон, всё равно это будет неточное значение размера kmem из-за выравниваний на кратное число страниц, потерь в UMA на хвосты страниц, и т.д. Поэтому на живой системе удобнее пользоваться
sysctl vm.kmem_map_size vm.kmem_map_free
, оставив упражнения с
awk
для посмертного анализа корок.
Кстати, возвращаясь к примеру с паниковавшим маленьким роутером: если бы в ядерном libalias вызывался не
malloc()
, а
uma_zalloc()
(принимает 2 аргумента — зону и те же флаги
M_NOWAIT/M_WAITOK
), то, во-первых, размер элемента не округлялся бы до 128 байт, и в ту же память влезало бы большее количество трансляций. Во-вторых, можно было бы выставить лимит этой зоне и избежать бесконтрольного захвата памяти libalias’ом вообще.
Подробнее о slab-аллокаторах можно прочитать в публикации «The Slab Allocator: An Object-Caching Kernel Memory Allocator», Jeff Bonwick, Sun Microsystems (в сети доступна в PDF), и в
man uma
(он же
man zone
).
Память сетевой подсистемы: mbuf
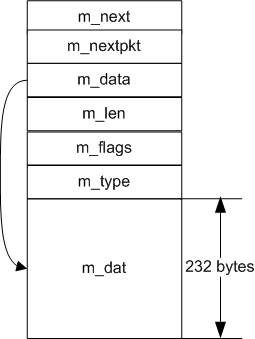
Рис. 1. Структура mbuf (размер посчитан для 32-битных архитектур)
Итак, было описано, что фрагментация памяти плохо влияет на производительность аллокатора, что с этим можно бороться либо ценой потерь памяти из-за округления размера вверх, либо с использованием slab-аллокаторов, когда имеется множество объектов одного типа/размера. А теперь посмотрим, что же происходит в сетевой подсистеме? Мало того, что прибывающие пакеты очень сильно варьируются в размерах, есть куда более серьезная проблема: в течение жизни пакета его размер изменяется — добавляются и удаляются заголовки, бывает необходимо разбиение пользовательских данных на сегменты, сбор их обратно при чтении в большой буфер пользовательского процесса, и т.п.
Для решения всех этих имеющихся тогда, в 80-е годы, проблем разом, в BSD было введен концепт mbuf (memory buffer) — структуры данных небольшого фиксированного размера. Эти буферы объединялись в связные списки, и данные пакета, таким образом, оказывались размазаны по цепочке из нескольких mbuf. Поскольку размер фиксирован, нет проблем с аллокатором, являвшимся надстройкой над стандартным (в наше время, понятное дело, их выделяет UMA). Поскольку это связный список, добавить ему в голову еще один mbuf с заголовком более низкого уровня (IP или L2) не составляет проблем.
Физически mbuf, как видно из рисунка 1, представляет из себя буфер определенного размера, в начале которого имеется фиксированный заголовок. Поля (не менялись уже многие годы) служат для связи нескольких mbuf в списках, указывают тип содержимого, флаги, фактическую длину содержащихся данных и указатель на их начало. Понятное дело, что, например, для «отрезания» IP-заголовка можно просто увеличить указатель начала данных на 20 байт, а длину содержимого уменьшить на 20 байт — тогда данные в начале буфера станут как бы свободными, без всякого перемещения байтов пакета в памяти (это сравнительно затратная операция). А для удаления данных из конца вообще достаточно только уменьшить длину, не трогая указатель.
Исторически, размер одного mbuf составлял 128 байт, включая этот фиксированный заголовок. Применялся он в сетевой подсистеме практически для всего — адреса, пути, записи таблицы маршрутизации… Потому и название универсальное, а не только про пакеты. Потом все эти усложнения кода «всё-в-одном» повычистили, и из имеющихся типов осталось только относящееся к сокетам (помимо собственно данных пакетов это, например, OOB data или ancillary data в
struct cmsghdr
). Кроме того, за годы постепенно добавляются новые поля в переменной части mbuf, и поэтому с FreeBSD 4 размер mbuf (константа
MSIZE
в
param.h
) составляет уже 256 байт.

Рис. 2. Очередь из двух mbuf chain по 2 mbuf каждая, в первой состояние после m_prepend()/MH_ALIGN
Как показано на рисунке 2, mbuf связываются в цепочки (mbuf chain) с использованием поля
m_next
. Все связанные таким образом mbuf обрабатываются как единый объект — то есть единый пакет данных. Многие функции обработки mbuf оперируют именно всей цепочкой. Далее, несколько независимых пакетов связываются между собой с помощью поля
m_nextpkt
(имеет смысл, понятное дело, только в головном mbuf пакета). В документации нередко один пакет (цепочку по m_next) называют chain, а связь нескольких mbuf chain по
m_nextpkt
называют queue, очередь — потому что таким образом они помещаются в исходящую очередь интерфейса, во входную очередь обработки, входящий или исходящий буфер сокета тоже есть очередь, и т.д.
Пакет обычно размещается в mbuf chain так, что первый mbuf имеет установленный флаг
M_PKTHDR
, отмечающий наличие в нем дополнительной структуры
m_pkthdr
. Она не является частью самого пакета, но описывает его для системы. Вот её основные поля:
- rcvif — указатель на интерфейс (struct ifnet), где пакет был получен (или NULL, если он создан локально). Это поле не изменяется в течение всей жизни пакета, и его проверяет ipfw recv (соответственно, проверка валидна даже на out-проходе).
- header — указатель на заголовок самого пакета
- len — полная длина пакета
- csum_flags, csum_data — данные по контрольной сумме пакета (валидна, невалидна, надо пересчитать, расчет выполняется железом, и т.д.)
- tags — заголовок списка mbuf_tags(9) пакета. В тегах каждая подсистема может хранить какую-то информацию, которую не требуется включать в каждый pkthdr. Например, там может храниться информация IPSEC, MAC labels, теги ipfw и pf, и др.
Кроме них, время от времени в
pkthdr
разрешается включать и другие поля, если они малы по размеру, и при этом важны для быстродействия, например, номер VLAN-тега в
ether_vtag
, или информацию для TCP segmentation offloading, и т.д. Ведь, как можно видеть из рисунка, включение
pkthdr
в головном mbuf цепочки — уменьшает в нём доступное для данных место.
Внимательный читатель на этом месте уже подсчитал, что для хранения полноразмерного Ethernet-пакета потребуется целых 7 mbuf, а при старых размерах в первоначальной реализации — и вообще 15. Жить с этим можно, но не слишком ли это неудобно и медленно, когда основная часть пакета всё-таки распиливания не требует? Это поняли еще в 80-е годы, и первоначальная реализация mbuf была изменена для поддержки хранения больших объемов данных вне mbuf (и, например, поле смещения, говорившее, где начинаются данные, было изменено на указатель
m_data
, который может показывать в нужное место). Была предусмотрена возможность использования различных типов внешних хранилищ, поэтому флаг
M_EXT
стал не просто говорить о наличии внешнего хранилища, а обозначать наличие в mbuf еще одного заголовка —
struct m_ext
. При этом теряется возможность использовать для хранения данных внутреннее пространство (
m_dat
) в самом mbuf, однако приобретается возможность использования одной и той же копии данных внешнего буфера во многих mbuf — при этом просто увеличивается счетчик ссылок (на него указывает поле
ref_cnt
) этого внешнего буфера. Другие поля
struct m_ext
указывают размер, тип внешнего хранилища, и данные для той подсистемы, которая этот тип обрабатывает.

Рис. 3. Поля mbuf (для FreeBSD 7.4/i386) при установленных флагах M_PKTHDR (слева) и M_EXT (справа)
Для ряда типов внешних буферов администратору доступны настройки, задающие их количество:
tunable Размер одного Количество по умолчанию kern.ipc.nmbclusters 2048 1024 + maxusers * 64 kern.ipc.nmbjumbop page (4096) nmbclusters / 2 kern.ipc.nmbjumbo9 9216 nmbjumbop / 2 kern.ipc.nmbjumbo16 16384 nmbjumbo9 / 2 kern.ipc.nsfbufs page (4096) 512 + maxusers * 16
Хотя расширяемость (поддержка более одного типа) была сделана сразу, долгое время единственным типом внешних данных был так называемый mbuf cluster — область данных размером
MCLBYTES
(см.
param.h
), обычно это ровно половина страницы, 2048 байт. Система предпочитает помещать данные в кластер, если запрашиваемый размер превышает половину доступного размера в головном mbuf (т.е. 100 байт для версии 7.4/i386, показанной на рисунках).
Максимальное число этих кластеров в системе и задается широко известным
sysctl kern.ipc.nmbclusters
. При этом при общих расчетах памяти следует помнить, что на каждый кластер всегда приходится еще и как минимум один ссылающийся на него просто mbuf. Здесь же объяснение, почему на машину, где исчерпались mbuf clusters, невозможно даже зайти по ssh — ведь они используются для любых операций с сетью (хотя можно, конечно, попробовать отправлять очень мелкие пакеты).
Стандартный mbuf cluster остается типом по умолчанию и сейчас, но появились и другие. Прежде всего, конечно, это буфера
sendfile(2)
, регулируемые
sysctl kern.ipc.nsfbufs
(если это число равно нулю, для этой архитектуры настройка не требуется). Их тюнинг актуален для тех, кто держит нагруженные сервера с раздачей статики, например с nginx или каким-нибудь ftpd, умеющим
sendfile()
(например, штатным
ftpd
из базовой системы FreeBSD).
Кроме того, начиная с FreeBSD 6.3 доступны другие типы кластеров, предназначенные для поддержки jumbo frames размером 9 Кб и 16 Кб, а также специальный тип кластера размером с одну страницу (4 Кб). Последний нужен для экономии памяти (не выделять слишком большие буфера, если не нужно) в локальном IPC (127.0.0.1) и не очень больших пакетах при больших MTU (линки с jumbo frames).
Наиболее часто встречающиеся очереди mbuf, с которыми приходится иметь дело администратору — это буфера сокетов приложений. Буфер сокета — это просто небольшая структура, имеющая несколько управляющих переменных, типа своего размера, и собственно указатель на очередь mbuf. Буферов у каждого сокета два штуки, на прием (recv) и передачу (send). Операции в ядре по выставлению размера буферов выполняются функцией
sbreserve()
(программисты, в норме следует использовать не её, а
soreserve()
, ставящую watermark’и для обоих сразу). Создавалась и используется она в предположении, что под сокет реально резервируется какое-то место, никому больше недоступное, но на самом деле она только лишь проверяет лимиты — то есть неиспользованное до лимита в сокете место доступно другим приложениям. В противном случае, ядерной памяти бы просто не хватило при большом числе сокетов в системе.
Проверяемых лимитов на размер буфера сокета всего два. Это глобальный
sysctl kern.ipc.maxsockbuf
(не может быть уменьшен ниже размера одного mbuf + кластера, т.е.
MSIZE + MCLBYTES
= 2304 байт) и соответствующий лимит ресурсов пользователя (см.
ulimit
). Применяются они, однако, не так просто, как может показаться на первый взгляд. Дело в том, что цифру лимита можно трактовать двояко — как реальное число помещающихся в буфер байт (это интересует автора приложения) и как размер выделенных системой ресурсов (это интересует администратора). Какой вариант используется? Оба. Прежде всего, будет отказано в выделении размера, превышающего
kern.ipc.maxsockbuf * MCLBYTES / (MSIZE + MCLBYTES)
— как видно, здесь учтены неиспользуемые mbuf, когда данные лежат в кластерах. Затем, если пройдена проверка на лимит ресурсов пользователя, в переменную
sb_hiwat
заносится запрошенное количество байт, но в
sb_mbmax
пишется значение, вычисляемое по такой формуле:
sb_mbmax = min(запрос * kern.ipc.sockbuf_waste_factor, kern.ipc.maxsockbuf)
Таким образом, поскольку с
sb_mbmax
сравнивается полный размер всех mbuf и кластеров, включая накладные расходы на внутренние заголовки и теряемые области, то реальных ресурсов не будет выделено больше лимита. [На самом деле, всё несколько сложнее, бывают readonly mbuf (когда одна физическая копия данных принадлежит нескольким буферам), и, например,
sbspace()
может вернуть отрицательное значение. Но эти темы выходят за объем поста.]
Состояние
sk_buff
в Linux после:
1)
skb_reserve()

2)
skb_put()
3)
skb_push()
По теме буферов осталось заметить только разницу между несколькими переменными, кочующими по хаутушкам о тюнинге. Есть
kern.ipc.maxsockbuf
, задающий глобальный лимит, а есть переменные
recvspace
и
sendspace
у каждого протокола (например,
net.inet.tcp.sendspace
). Эти переменные — всего лишь значение по умолчанию, используемое при создании сокета. Приложение с помощью вызова
setsockopt()
легко может перекрыть эти значения своими, в пределах лимитов (впрочем, программистам следует помнить, что нет смысла ставить буфер меньше, чем
MSIZE + MCLBYTES
).
Прежде, чем переходить к теме интерфейсов программиста к mbuf, окинем еще раз взглядом их архитектуру, рассмотрим достоинства и недостатки. Здесь полезно сравнить их с аналогом в Linux, структурой
sk_buff
, которая представляет собой один непрерывный кусок памяти заранее выделенного максимального размера. Некий размер в начале sk_buff резервируется под заголовки пакета, которые постепенно туда добавляются (см. рисунок справа). Поскольку пакет непрерывен, то огромным плюсом sk_buff является простота. Каждый, кто писал модули к iptables, знает, что пакет есть просто массив байт, просто берешь по нужному смещению и всё. Соответственно, минусом mbuf является сложность работы — необходимо постоянно помнить, что пакет может быть «размазан» по цепочке буферов, вызывать
m_pullup()
, дабы удостовериться, что заголовки пакета непрерывны (в худшем случае это может повлечь за собой выделение памяти и копирование части байт), и т.д. В некоторых случаях иметь не-непрерывный буфер вообще невозможно либо слишком трудоемко, тогда данные приходится копировать в отдельный непрерывный буфер (так делается, например, в портированном из юзерленда libalias, что несколько снижает его производительность), если они не находятся целиком в mbuf или кластере.
Однако, простота sk_buff в определенных случаях оборачивается минусом — поскольку размеры задаются один раз, обычно в месте выделения, при необходимости вместить больше заголовков, чем было рассчитано автором кода, приходится перетряхивать все такие места при любом серьезном изменении (на самом деле, не только поэтому, а еще и потому что там все возможные варианты протоколов сделаны в
union
, и т.д., в общем, обычный линуксовый стиль «о долговременном не думаем»). В mbuf такой проблемы (как и проблемы с размерами/экономией выделенной памяти) просто не существует. В результате неожиданно завернуть пакет в еще один туннель, или соорудить что-то еще более нетривиальное типа
netgraph
— в линуксе стоит гораздо более тяжелых усилий. При этом, наличие mbuf cluster’ов всё же до некоторой степени упрощает жизнь, хотя со всем историческим наследием дизайн mbuf’ов и нельзя назвать полностью удачным. Но перейдем к использованию того, что уже есть.
Поскольку интерфейсы для работы с mbuf описаны в системной документации, нет смысла повторять маны и приводить полные определения функций и макросов. Рассмотрим наиболее важные из них.
- mget() и MGET() — выделить один mbuf. Принимаются те же флаги, что и в malloc(), хотя в старом коде можно видеть их аналоги M_TRYWAIT и M_DONTWAIT
- MGETHDR() и m_gethdr() — выделить mbuf с заголовком пакета (pkthdr)
- MCLGET() и m_getcl() — получить сразу mbuf и прицепленный к нему кластер
- m_free() — освободить один mbuf
- m_freem() — освободить цепочку mbuf
Макросы не всегда эквивалентны соответствующим функциями, иногда они могут включать незначительные отличия (например,
MCLGET()
может вернуть просто mbuf без установленного
M_EXT
, если не удалось выделить кластер, а
m_getcl()
вернет NULL и в этом случае).
Далее обратимся снова к рисунку 2. На нем в первой цепочке видно два mbuf, в первом заголовки, во втором — пользовательские данные. Здесь следует обратить внимание, что заголовки находятся в конце области данных mbuf. Как добиться этого эффекта? В зависимости от того, что было в начале, можно использовать разные функции/макросы. В типичном случае приписывания заголовков следует использовать оптимизированный макрос
M_PREPEND()
, который проверит наличие запрошенной длины (в которую потом пользователь поместит заголовки) в свободном месте в начале mbuf. Если его там нет, будет вызвана
m_prepend()
для прицепления нового пустого mbuf в голову цепочки. Последняя учтет, заголовок ли это пакета, при необходимости сделает
M_MOVE_PKTHDR()
для перемещения его в новый головной mbuf, и вызовет
MH_ALIGN()
или
M_ALIGN()
для собственно выравнивания указателя на данные в конец.
Для доступа к данным используется макрос
mtod()
. Если это нужно для доступа к заголовкам, предварительно следует вызвать
m_pullup()
, которая удостоверится, что данные запрошенной длины от начала цепочки — непрерывны и лежат в одном mbuf, при необходимости выделив его (и если ей не удастся, ipfw, например, напишет на консоль загадочное «pullup failed»). Обратите внимание, что только в одном mbuf (т.е. не более 200 байт по рисункам выше) — встречается ошибка, когда ею пытаются сделать непрерывным весь пакет. Для такой цели существует
m_copydata()
, которую надобно снабдить буфером, куда она скопирует пакет (или его часть по запрошенному смещению/длине). Чтобы положить данные из такого буфера обратно в цепочку (расширяя её при необходимости), предусмотрен
m_copyback()
.
Если же непрерывность не требуется, можно воспользоваться
m_getptr()
для получения указателя/смещения mbuf, в котором лежит N-ный байт пакета в цепочке. О длине цепочки расскажет
m_length()
, а о свободном месте в одном mbuf — макросы
M_LEADINGSPACE()
и
M_TRAILINGSPACE()
. Добавить места, обрезав данные, можно с помощью
m_adj()
. Интересной функцией является также
m_apply()
, обходящая всю цепочку и вызывающая callback-функцию пользователя для каждого участка данных. Подобным образом, например, вызывается MD5_Update() и считается сигнатура TCP-пакета.
Есть и оперирующие цепочками функции:
m_cat()
для объединения,
m_split()
для разрезания,
m_copym()
для получения read-only копии цепочки увеличением счетчиков ссылок на кластерах (
m_unshare()
из разделяемой read-only копии скопирует в свою, приватную). Если данные кажутся слишком размазанными —
m_defrag()
сожмет цепочку в минимальное количество mbuf’ов и кластеров.
Подробнее обо всех этих (и других) интерфейсах можно прочитать в
mbuf(9)
и в книге «The Design and Implementation of the FreeBSD Operating System», by Marshall Kirk McKusick, George V. Neville-Neil (которая настоятельно рекомендуется к прочтению вообще всем, кому нужно писать в ядре).
Пятерки,Макросы и функции, связанные с mbuf
следующим образом:



1. Mbstat — глобальная переменная.
Ниже приведены различные статистические данные, хранящиеся в глобальной структуре mbstat.
struct mbstat {
u_long m_mbufs; / * mbufs, полученные из пула страниц * / Получение количества mbufs из пула страниц (не используется)
u_long m_clusters; / * кластеры, полученные из пула страниц * / Получение кластеров из пула страниц
u_long m_spare; / * запасное поле * / оставшееся место (не используется)
u_long m_clfree; / * свободные кластеры * / Свободные кластеры
u_long m_drops; / * раз не удалось найти место * / Сколько раз не удалось найти место (неиспользуемое)
u_long m_wait; / * раз ожидал пробел * / Сколько раз ожидал пробел (неиспользованный)
u_long m_drain; / * время слива протоколов для пространства * / Вызов функции слива протокола для освобождения пространства
/Время
u_short m_mtypes [256]; / * выделение mbuf для конкретного типа * / Текущий номер выделения mbuf:
/ MT_XXX индекс
};
2. Получите mbuf
Макрос MGET。Например, вызов MGET для выделения mbuf целевого адреса системного вызова sendto выглядит следующим образом:
MGET(m, M_WAIT, MT_SONAME);
If ( m == NULL)
Return (ENOBUFS);
Прототип макроса MGET выглядит следующим образом: MBUFLOCK для защиты функций и макросов от прерывания.
#define MGET(m, how, type) {
// mbtypes [type] преобразует тип mbuf в тип, требуемый MALLOC, например M_MBUF, M_SOCKET и т. д.
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how));
if (m) {
(m)->m_type = (type);
// MBUFLOCK изменяет приоритет процессора, предотвращает прерывание работы сетевого процессора и защищает общие ресурсы
MBUFLOCK(mbstat.m_mtypes[type]++;)
(m)->m_next = (struct mbuf *)NULL;
(m)->m_nextpkt = (struct mbuf *)NULL;
// # define m_dat M_dat.M_databuf резервирует место для pkthdr и m_ext
(m)->m_data = (m)->m_dat;
(m)->m_flags = 0;
} else
// Пытаемся перераспределить, главный вопрос, откуда берется выделенная память? Увидим позже
(m) = m_retry((how), (type));
}MGET сначала вызывает макрос ядра MALLOC, который выполняется общим распределителем памяти ядра.。Массив mbtypes преобразует значение MT_xxx mbuf в соответствующее значение M_xxx. Если выделение выполнено успешно, m_type устанавливается равным значению в параметре.
MBUFLOCK используется для отслеживания и подсчета структуры ядра каждого типа mbuf плюс 1 (mbstat)。Когда это предложение выполняется, макрос MBUFLOCK принимает его в качестве параметра для изменения приоритета процессора, а затем восстанавливает приоритет до исходного значения. Это предотвращает прерывание сетевыми устройствами при выполнении оператора mbstat.m_mtypes [type] ++, потому что mbufs могут быть выделены на различных уровнях ядра. Рассмотрим такую систему, которая использует три шага для реализации операции ++ в c: (1) загрузить текущее значение в регистр; (2) добавить 1 в регистр; (3) сохранить значение регистра в памяти. Предположим, что значение счетчика 77 и MGET выполняется на уровне сокета. Предположим, что выполняются шаги 1 и 2 (значение регистра 78), и происходит прерывание устройства. Если драйвер устройства также выполняет MGET для получения того же типа mbuf, возьмите значение (77) в памяти, добавьте 1 (78) и сохраните его обратно в память. Когда шаг 3 прерванного MGET продолжает выполняться, он сохраняет значение регистра (78) в памяти. Но счетчик должен быть 79 вместо 78, поэтому счетчик уничтожен.
m_next и m_nextptk установлены на нулевые указатели。
Указатель данных m_data установлен так, чтобы указывать на начальный адрес 108-байтового буфера mbuf, а флаг m_flags установлен в 0。
Если вызов выделения памяти ядра завершился неудачно, вызовите m_retry. Первый параметр — M_WAIT или M_DONTWAIT.
3. Выделите mbuf
struct mbuf *
m_get(nowait, type)
int nowait, type;
{
register struct mbuf *m;
MGET(m, nowait, type);
return (m);
}
Этот вызов указывает параметрыЗначение nowait — M_WAIT или M_DONTWAIT., Это зависит от того, нужно ли ждать, когда память станет недоступной. Например, когда уровень сокета запрашивает выделение mbuf для хранения целевого адреса системного вызова sendto, он указывает M_WAIT, потому что здесь нет проблем с блокировкой. Но когда драйвер устройства Ethernet запрашивает выделение mbuf для хранения полученного кадра, он указывает M_DONTWAIT, потому что он выполняется как обработка прерывания устройства и не может перейти в состояние сна для ожидания mbuf. В этом случае, если память недоступна, драйверу устройства лучше сбросить фрейм.
4. Функция m_retry
/*
* When MGET failes, ask protocols to free space when short of memory,
* then re-attempt to allocate an mbuf.
*/
struct mbuf *
m_retry(i, t)
int i, t;
{
register struct mbuf *m;
// Вызов функции регистрации протокола для освобождения памяти
m_reclaim();
// Устанавливаем m_retrydefine в NULL, чтобы NULL возвращался напрямую, но как гарантировать, что m_retry в этом MGET возвращает
// NULL, и последняя возвращается эта функция? #Define заменяется во время предварительной компиляции.
// Ключ к этому в том, что MGET - это макрос, а не функция.
#define m_retry(i, t) (struct mbuf *)0
MGET(m, i, t);
#undef m_retry
return (m);
}5. m_reclaim
// Эта функция циклически вызывает функцию слива протокола для выделения памяти
m_reclaim()
{
register struct domain *dp;
register struct protosw *pr;
// Повышаем приоритет процессора без прерывания сетевой обработки
int s = splimp();
for (dp = domains; dp; dp = dp->dom_next)
for (pr = dp->dom_protosw; pr < dp->dom_protoswNPROTOSW; pr++)
if (pr->pr_drain)
(*pr->pr_drain)();
// Восстанавливаем приоритет процессора
splx(s);
mbstat.m_drain++;
}6. Макрос MGETHDR
// Выделяем mbuf заголовка пакета для инициализации m_data и m_flags
#define MGETHDR(m, how, type) {
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how));
if (m) {
(m)->m_type = (type);
MBUFLOCK(mbstat.m_mtypes[type]++;)
(m)->m_next = (struct mbuf *)NULL;
(m)->m_nextpkt = (struct mbuf *)NULL;
(m)->m_data = (m)->m_pktdat;
(m)->m_flags = M_PKTHDR;
} else
(m) = m_retryhdr((how), (type));
}7. Функция m_devget
/*
* Routine to copy from device local memory into mbufs.
*/
struct mbuf *
m_devget(buf, totlen, off0, ifp, copy)
char *buf;
int totlen, off0;
struct ifnet *ifp;
void (*copy)();
{
...
}Когда интерфейс получает кадр Ethernet, драйвер установки вызывает функцию m_devget для создания связанного списка mbuf и копирует кадр в устройстве в этот связанный список. В зависимости от длины полученного кадра (за исключением заголовка Ethernet) он может выдаватьЧетыре разных связанных списка mbuf.
Рисунок 9 Первые два буфера mbuf, созданные m_devget
Mbuf слева на рисунке 9 используется, когда длина данных составляет от 0 до 84 байтов., На рисунке предполагается, что имеется 52 байта данных: 20 байтов заголовка IP и 32 байта заголовка TCP (стандартные 20 байтов заголовка TCP + 12 байтов параметров TCP), но не включают данные TCP. Поскольку данные mbuf, возвращаемые m_devget, начинаются с заголовка IP, фактическое минимальное значение m_len mbuf составляет 28:20 байтов заголовка IP + 8 байтов заголовка UDP + 0 байтов данных UDP (UDP выбран здесь, потому что заголовок UDP больше Заголовок TCP меньше). Для входного кадра первые 16 байтов части данных mbuf зарезервированы и не используются, а для выходного кадра первые 16 байтов выделяются 14-байтовому заголовку Ethernet. Две функции icmp_reflect и tcp_respond генерируют ответ, принимая полученный mbuf в качестве вывода. В этих двух случаях полученная дейтаграмма должна быть меньше 84 байтов, поэтому легко зарезервировать 16 байт пространства впереди. Выделение 16 байтов вместо 14 означает сохранение заголовка IP в mbuf с выравниванием длинных байтов.
Mbuf справа на рисунке 9 используется для данных длиной от 85 до 100 байтов.В это время он все еще хранится в mbuf заголовка пакета, но нет 16-байтового зарезервированного пространства, и данные сохраняются непосредственно с начала массива m_pktdat.
Рисунок 10 Третий тип mbuf, созданный m_devget
На рисунке 10 показан третий буфер mbuf, созданный m_devget.Если размер данных составляет от 101 до 207 байтов, требуется два буфера буфера. Первые 100 байтов хранятся в первом mbuf (включая заголовок пакета), а оставшиеся данные хранятся во втором mbuf. Точно так же нет зарезервированного 16-байтового пространства в первом mubf.
Рисунок 11 Четвертый mbuf, созданный m_devget
На рисунке 11 показан четвертый буфер mbuf, созданный m_devget., Если данные превышают или равны 208 байтам (208 байтов могут использоваться в третьем типе mbuf, лично чувствую), следует использовать один или несколько кластеров. В примере на рисунке 11 предполагается, что Ethernet имеет размер 1500. Если используется 1024-байтовый кластер, требуются два буфера буфера, помеченных как M_EXT.



8. Макросы mtod и dtom
Макросы mtod и dtom используются для упрощения выражения структуры mbuf.
#define mtod(m, t) ((t) ((m)->m_data))mtod («mbuf на данные») возвращает указатель на данные mbuf и назначает указатель на указанный тип. Например код:
struct mbuf *m;
struct ip *ip;
ip = mtod(m, struct ip *);
ip->ip_v = IPVERSION;Укажите ip на данные (m_data), хранящиеся в mbuf, а затем обратитесь к заголовку IP через указатель ip. Когда структура C (обычно заголовок протокола) хранится в mbuf, указатель на структуру может быть получен с помощью макроса; аналогично, когда данные существуют в mbuf или кластере, макрос также может использоваться для получения указателя данных.
#define dtom(x) ((struct mbuf *) ((int)(x) &~(MSIZE-1)))Dtom («данные в mbuf») получает указатель данных, хранящийся в любом месте mbuf, и возвращает указатель самой структуры mubf. Например, если мы знаем, что ip указывает на область данных mbuf, в следующей последовательности предложений начальный адрес этого mubf присваивается m.
struct mbuf *m;
struct ip *ip;
m = dtom(ip);Мы знаем, что MSIZE (128) — это степень двойки, и распределитель памяти ядра всегда выделяет непрерывные блоки хранения байтов MSIZE для mbuf. Dtom определяет только начальную позицию mbuf, очищая младшие биты указателя в параметре.
У макроса dtom есть проблема: когда его параметры указывают на кластер или кластер, поскольку нет указателя от кластера обратно на структуру mbuf, dtom нельзя использовать. На этом этапе пригодится другая функция m_pullup.
9. Функция m_pullup
①. Функция m_pullup и заголовок непрерывного протокола
Функция m_pullup имеет две цели. Первый — когда протокол (IP, ICMP, IGMP, UDP или TCP) обнаруживает, что длина данных (m_len) в первом mbuf меньше минимальной длины заголовка протокола (например: IP — 20, UDP — 8, TCP — 20. ), вызов m_pullup основан на предположении, что оставшаяся часть заголовка протокола хранится в следующем mbuf связанного списка. m_pullup переупорядочивает связанный список mbuf так, чтобы первые N байтов данных постоянно сохранялись в первом mbuf связанного списка. N — параметр этой функции, он должен быть меньше или равен 100 (потому что первый mbuf имеет не более 100 байт). Если первые N байтов постоянно хранятся в первом mbuf, можно использовать mtod и dtom. Например, в процедуре ввода IP-адреса будет встречаться следующий код:
if (m->m_len < sizeof (struct ip) &&
(m = m_pullup(m, sizeof (struct ip))) == 0) {
ipstat.ips_toosmall++;
goto next;
}
ip = mtod(m, struct ip *);Если данные в первом mbuf меньше 20 байт (стандартный размер IP-заголовка), вызывается m_pullup. Функция m_pullup не работает по двум причинам: а. Если ей нужны другие буферы mbuf и вызов MGET завершается неудачно; b. Если общее количество данных во всем связанном списке m_pullup меньше требуемого количества последовательных байтов (то есть значение параметра N, в данном случае это 20 ). Приведенный выше код m_pullup редко вызывается в реальных ситуациях, потому что в первом mbuf есть не менее 100 последовательных байтов из заголовка IP, а заголовок IP имеет максимум 60 байтов, за которыми следуют 40 байтов. Заголовок TCP (заголовок других протоколов, таких как ICMP и UDP, составляет менее 40 байт).
②. Фрагментация и реорганизация функции m_pullup и IP
Второе использование функции m_pullup — реорганизация IP и TCP. Предположим, что IP получает пакет длиной 296, который является фрагментом большой IP-дейтаграммы. Mbuf, переданный от драйвера устройства на вход IP, выглядит как mbuf, показанный на рисунке 11: в кластере хранится 296 байт данных. Мы показываем это на рисунке 12.

Рисунок 12 IP-фрагмент длиной 296
Алгоритм IP-фрагментации хранит каждый фрагмент в двусвязном списке и использует исходный и целевой IP-адреса в IP-заголовке для хранения прямых и обратных указателей на связанный список (конечно, эти два IP-адреса должны храниться в заголовке связанного списка) Поскольку их необходимо снова поместить в реструктурированную дейтаграмму IP, в исходной главе 10 этот вопрос обсуждается подробно).
Но если IP-заголовок находится в кластере, как показано на рисунке 12, эти указатели связанного списка будут храниться в этом кластере, и когда связанный список будет пройден позже, указатель на IP-заголовок (то есть указатель на начало кластера) не может быть Преобразуется в указатель на mubf. Это проблема, о которой мы упоминали ранее в этой статье: если m_data указывает на кластер, макрос dtom не может использоваться, поскольку нет указателя на mbuf из кластера. IP-фрагментация. Чтобы решить эту проблему, при получении фрагмента, если он хранится в кластере, процедура фрагментации IP всегда вызывает m_pullup и помещает 20-байтовый IP-заголовок в свой mbuf. код показан ниже:
if (ip->ip_off &~ IP_DF) {
if (m->m_flags & M_EXT) { /* XXX */
if ((m = m_pullup(m, sizeof (struct ip))) == 0) {
ipstat.ips_toosmall++;
goto next;
}
ip = mtod(m, struct ip *);
}
Рисунок 13 IP-пакет длиной 296 после m_pullup
На рисунке 13 алгоритм фрагментации IP сохраняет указатель на заголовок IP в mbuf слева, и dtom можно использовать для преобразования этого указателя в указатель на сам mbuf.
③. Реорганизация TCP позволяет избежать вызова m_pullup
Вместо вызова функции m_pullup используется другой метод повторной сборки сегментов TCP. Это связано с тем, что вызов m_pullup является дорогостоящим: выделяется память и данные копируются из одного мегабайта в один мегабайт. TCP старается максимально избегать дублирования данных.
Около половины данных TCP — это объемные данные (каждый сегмент имеет 512 или более байтов данных); другая половина — интерактивные данные (90% сегмента составляет менее 10 байтов данных). Поэтому, когда TCP получает сегмент от IP, он обычно имеет формат, показанный слева на рисунке 10 (небольшой объем интерактивных данных, хранящихся в самом mbuf) или формат, показанный на рисунке 11 (пакетные данные, хранящиеся в кластере). ). Когда сегменты TCP прибывают не по порядку, они сохраняются TCP в двусвязном списке. Как и при фрагментации IP, поля в заголовке IP используются для хранения указателей на связанный список.Поскольку эти поля больше не нужны после того, как TCP получит дейтаграмму IP, это вполне возможно. Но когда IP-заголовок хранится в кластере, это вызовет ту же проблему при преобразовании указателя связанного списка в соответствующий указатель mbuf.(Рисунок 12)。
Чтобы решить эту проблему, TCP сохраняет указатель mbuf в некоторых неиспользуемых полях в заголовке TCP и предоставляет указатель из кластера обратно в mbuf, чтобы избежать вызова m_pullup для каждого сегмента вне последовательности. Если заголовок IP содержится в области данных mbuf(Рисунок 13), Этот обратный указатель бесполезен, потому что макрос dtom может указывать на начало mbuf через этот указатель связанного списка.
Резюме по использованию m_pullup
Большинство установочных драйверов не разделяют первую часть (часть заголовка) IP-дейтаграммы на несколько буферов. Если предположить, что заголовки протоколов могут храниться рядом друг с другом, возможность вызова m_pullup в каждом протоколе (IP, ICMP, IGMP, UDP и TCP) очень мала. Если вызывается m_pullup, обычно это связано с тем, что дейтаграмма IP слишком мала, и если при вызове m_pullup возвращается ошибка, дейтаграмма отбрасывается.
Для каждого полученного IP-фрагмента m_pullup вызывается, когда IP-дейтаграмма сохраняется в кластере. Это означает, что m_pullup необходимо вызывать почти для каждого полученного сегмента, потому что большинство сегментов имеют длину более 208 байт.
Пока сегмент TCP не фрагментирован по IP, и сегмент TCP получен, нет необходимости вызывать m_pullup независимо от того, находится ли он вне очереди. Это одна из причин избегать фрагментации IP-адресов TCP.
6. Пример анализа: общие открытые методы mbuf в Net / 3
Далее будет представлено несколько общих структур данных на основе mbuf.
Цепочка mbuf: связанный список mbuf, связанный указателем m_next.
Связанный список (очередь) цепочек mbuf только с одним указателем на заголовок. Цепочка mbuf связана указателем m_nextpkt в первом mubf каждой цепочки. Как показано на рисунке 16, примером этой структуры данных является буфер передачи и приемный буфер сокета.
Рисунок 16 Связанный список цепочки mbuf с указателем только на заголовок
Два верхних буфера буфера образуют первую запись в этой очереди, а три нижних буфера буфера образуют вторую запись в этой очереди. Для протокола на основе записей, такого как UDP, мы можем встретить несколько записей в каждой очереди. Но для таких протоколов, как TCP, у него нет границы записи, и мы можем найти только одну запись для каждой очереди (цепочка mbuf может содержать несколько mbuf).
Добавление mbuf к первой записи очереди требует обхода всех mbuf первой записи, пока не встретится mbuf с пустым m_next. Чтобы добавить в эту очередь цепочку mbuf, содержащую новую запись, необходимо найти первый mbuf всех записей, пока он не встретит запись, в которой m_nextpkt пуст.
Связанный список цепочек mbuf с указателями на начало и конец. На рисунке 17 показан этот тип связного списка. Мы встретим его в очереди интерфейса.
Рисунок 17 Связанный список с указателем головы и указателем хвоста
Для двустороннего кругового связанного списка, как показано на рисунке 18, мы встретим эту структуру данных в IP-фрагментации и повторной сборке, блоке управления протоколом и очереди сегментов TCP вне последовательности.
Рисунок 18 Двусторонний круговой список
m_copy и счетчик ссылок на кластер
Один из очевидных способов использования кластеров — уменьшить количество буферов в буфере, когда требуется большой объем данных. Например, если вы не используете кластеры, вам нужно 10 МБУФОВ, чтобы содержать 1024 байта данных (100 + 8 * 108 + 60). Выделение и связывание 10 МБУФ дороже, чем выделение 1024-байтового кластера МБФ. Но потенциальный недостаток кластеров — это бесполезная трата места. В нашем примере для использования кластера (2048 + 128) требуется 2176 байтов, а 1280 байтов не могут использовать пространство кластера.
Еще одно преимущество кластеров состоит в том, что кластер может использоваться несколькими буферами mbuf. Если приложение выполняет запись и записывает 4096 байт в сокет TCP, предполагая, что буфер отправки сокета пуст, а окно интерфейса имеет размер не менее 4096, будут выполняться следующие операции. Уровень сокетов помещает первые 2048 байтов данных в кластер и вызывает подпрограмму отправки протокола. Процедура отправки TCP добавляет этот mbuf в свой буфер отправки, как показано на рисунке 19, а затем вызывает tcp_output. Структура socket содержит структуру sockbuf, в которой хранится заголовок связанного списка цепочки mbuf буфера отправки: so_snd.sb_mb.
Рисунок 19 Буфер отправки сокета TCP, содержащий 2048 байтов данных
Предполагая, что максимальный сегмент TCP (MSS) этого соединения (Ethernet) равен 1460, tcp_output создает сегмент для отправки данных, содержащий первые 1460 байтов. Он также создает mbuf, содержащий заголовки IP и TCP, резервирует 16 байтов пространства для заголовка канального уровня и передает эту цепочку mbuf на выход IP. Цепочка mbuf в конце очереди вывода интерфейса показана на рисунке 20. Для протокола TCP, поскольку это надежный протокол, он должен поддерживать копию отправленных данных (хранящихся в своем буфере отправки) до тех пор, пока данные не будут подтверждены другой стороной; для протокола UDP нет необходимости сохранять копию, поэтому это Буфер mbuf хранится в буфере отправки.
Рисунок 20 Сегмент сообщения в буфере отправки сокета TCP и очереди вывода интерфейса
В этом примере tcp_output вызывает функцию m_copy для запроса копии 1460 байтов данных, начиная с начала буфера отправки. Но поскольку данные хранятся в кластере, m_copy создает mbuf в правом нижнем углу рисунка 20 и инициализирует его, указывая на правильную позицию существующего кластера, в примере — на начальную позицию кластера. Длина данных этого mbuf составляет 1460 байтов, хотя в кластере хранятся еще 588 байтов. Длина нижней цепочки mbuf на рисунке 20 составляет 1514, включая заголовок Ethernet, заголовок IP и заголовок TCP.
Примечание: mbuf в правой нижней части рисунка 20 содержит заголовок пакета, потому что он скопирован из mbuf выше на рисунке 20, но поскольку этот mbuf не является первым mbuf в цепочке m_pkthdr.len и заголовок пакета в заголовке пакета Поле m_pkthdr.rcvif можно игнорировать.
Такой способ совместного использования кластеров не позволяет ядру копировать данные из одного буфера в другой, что снижает накладные расходы. Это достигается путем предоставления счетчика ссылок для каждого кластера.
Продолжая наш пример, поскольку оставшиеся 588 байтов в кластере отправляющего буфера не могут сформировать сегмент сообщения, tcp_out возвращается после отправки 1460-байтового сегмента сообщения на IP (в главе 26 исходной книги подробно описывается tcp_output при этом условии. Детали отправки данных, я не буду здесь в первую очередь вдаваться в подробности). Уровень сокетов продолжает обрабатывать данные из процесса приложения: оставшиеся 2048 байтов сохраняются в новом mbuf с кластером, процедура отправки TCP вызывается снова, и новый mbuf добавляется к буферу отправки сокета. Поскольку tcp_output может отправить полный сегмент сообщения, он создает другой связанный список mbuf с заголовком протокола и 1460 байтами данных. Параметр m_copy указывает начальное смещение и длину 1460 байтов данных в буфере отправки (1460 байтов). Как показано на рисунке 21, и предположим, что эта цепочка mbuf находится в очереди вывода интерфейса (длина первого mbuf в этой цепочке отражает заголовок Ethernet, заголовок IP и заголовок TCP).
На этот раз 1460 байтов данных поступают из двух кластеров: первые 588 байтов — из первого кластера в буфере передачи, а следующие 872 байта — из второго кластера в буфере передачи. Он использует два буфера буфера для хранения 1460 байтов, но m_copy по-прежнему не копирует 1460 байтов данных, ссылаясь на существующий кластер.
Рисунок 21 Цепочка mbuf, используемая для отправки 1460-байтового сегмента TCP
Имя функции m_copy подразумевает физическую копию данных, но если данные находятся в кластере, они просто ссылаются на кластер вместо копирования.
Вышеупомянутое примерно представляет поток данных из процесса в очередь вывода интерфейса.Тщательное понимание и сглаживание потока обработки данных очень поможет понять следующий текст.
C++ (Cpp) m_pullup — 5 examples found. These are the top rated real world C++ (Cpp) examples of m_pullup extracted from open source projects. You can rate examples to help us improve the quality of examples.
Programming Language: C++ (Cpp)
Method/Function: m_pullup
Examples at hotexamples.com: 5
void
udp_input(struct mbuf *m, ...)
{
struct ip *ip;
struct udphdr *uh;
struct inpcb *inp = NULL;
struct mbuf *opts = NULL;
struct ip save_ip;
int iphlen, len;
va_list ap;
u_int16_t savesum;
union {
struct sockaddr sa;
struct sockaddr_in sin;
#ifdef INET6
struct sockaddr_in6 sin6;
#endif /* INET6 */
} srcsa, dstsa;
#ifdef INET6
struct ip6_hdr *ip6;
#endif /* INET6 */
#ifdef IPSEC
struct m_tag *mtag;
struct tdb_ident *tdbi;
struct tdb *tdb;
int error, s;
#endif /* IPSEC */
va_start(ap, m);
iphlen = va_arg(ap, int);
va_end(ap);
udpstat.udps_ipackets++;
switch (mtod(m, struct ip *)->ip_v) {
case 4:
ip = mtod(m, struct ip *);
#ifdef INET6
ip6 = NULL;
#endif /* INET6 */
srcsa.sa.sa_family = AF_INET;
break;
#ifdef INET6
case 6:
ip = NULL;
ip6 = mtod(m, struct ip6_hdr *);
srcsa.sa.sa_family = AF_INET6;
break;
#endif /* INET6 */
default:
goto bad;
}
IP6_EXTHDR_GET(uh, struct udphdr *, m, iphlen, sizeof(struct udphdr));
if (!uh) {
udpstat.udps_hdrops++;
return;
}
/* Check for illegal destination port 0 */
if (uh->uh_dport == 0) {
udpstat.udps_noport++;
goto bad;
}
/*
* Make mbuf data length reflect UDP length.
* If not enough data to reflect UDP length, drop.
*/
len = ntohs((u_int16_t)uh->uh_ulen);
if (ip) {
if (m->m_pkthdr.len - iphlen != len) {
if (len > (m->m_pkthdr.len - iphlen) ||
len < sizeof(struct udphdr)) {
udpstat.udps_badlen++;
goto bad;
}
m_adj(m, len - (m->m_pkthdr.len - iphlen));
}
}
#ifdef INET6
else if (ip6) {
/* jumbograms */
if (len == 0 && m->m_pkthdr.len - iphlen > 0xffff)
len = m->m_pkthdr.len - iphlen;
if (len != m->m_pkthdr.len - iphlen) {
udpstat.udps_badlen++;
goto bad;
}
}
#endif
else /* shouldn't happen */
goto bad;
/*
* Save a copy of the IP header in case we want restore it
* for sending an ICMP error message in response.
*/
if (ip)
save_ip = *ip;
/*
* Checksum extended UDP header and data.
* from W.R.Stevens: check incoming udp cksums even if
* udpcksum is not set.
*/
savesum = uh->uh_sum;
#ifdef INET6
if (ip6) {
/* Be proactive about malicious use of IPv4 mapped address */
if (IN6_IS_ADDR_V4MAPPED(&ip6->ip6_src) ||
IN6_IS_ADDR_V4MAPPED(&ip6->ip6_dst)) {
/* XXX stat */
goto bad;
}
/*
* In IPv6, the UDP checksum is ALWAYS used.
*/
if (uh->uh_sum == 0) {
udpstat.udps_nosum++;
goto bad;
}
if ((m->m_pkthdr.csum_flags & M_UDP_CSUM_IN_OK) == 0) {
if (m->m_pkthdr.csum_flags & M_UDP_CSUM_IN_BAD) {
udpstat.udps_badsum++;
udpstat.udps_inhwcsum++;
goto bad;
}
if ((uh->uh_sum = in6_cksum(m, IPPROTO_UDP,
iphlen, len))) {
udpstat.udps_badsum++;
goto bad;
}
} else {
m->m_pkthdr.csum_flags &= ~M_UDP_CSUM_IN_OK;
udpstat.udps_inhwcsum++;
}
} else
#endif /* INET6 */
if (uh->uh_sum) {
if ((m->m_pkthdr.csum_flags & M_UDP_CSUM_IN_OK) == 0) {
if (m->m_pkthdr.csum_flags & M_UDP_CSUM_IN_BAD) {
udpstat.udps_badsum++;
udpstat.udps_inhwcsum++;
m_freem(m);
return;
}
if ((uh->uh_sum = in4_cksum(m, IPPROTO_UDP,
iphlen, len))) {
udpstat.udps_badsum++;
m_freem(m);
return;
}
} else {
m->m_pkthdr.csum_flags &= ~M_UDP_CSUM_IN_OK;
udpstat.udps_inhwcsum++;
}
} else
udpstat.udps_nosum++;
#ifdef IPSEC
if (udpencap_enable && udpencap_port &&
uh->uh_dport == htons(udpencap_port)) {
u_int32_t spi;
int skip = iphlen + sizeof(struct udphdr);
if (m->m_pkthdr.len - skip < sizeof(u_int32_t)) {
/* packet too short */
m_freem(m);
return;
}
m_copydata(m, skip, sizeof(u_int32_t), (caddr_t) &spi);
/*
* decapsulate if the SPI is not zero, otherwise pass
* to userland
*/
if (spi != 0) {
if ((m = m_pullup(m, skip)) == NULL) {
udpstat.udps_hdrops++;
return;
}
/* remove the UDP header */
bcopy(mtod(m, u_char *),
mtod(m, u_char *) + sizeof(struct udphdr), iphlen);
m_adj(m, sizeof(struct udphdr));
skip -= sizeof(struct udphdr);
espstat.esps_udpencin++;
ipsec_common_input(m, skip, offsetof(struct ip, ip_p),
srcsa.sa.sa_family, IPPROTO_ESP, 1);
return;
}
}
int
ipsec_filter(struct mbuf **mp, int dir, int flags)
{
int error, i;
struct ip *ip;
KASSERT(encif != NULL, ("%s: encif is null", __func__));
KASSERT(flags & (ENC_IN|ENC_OUT),
("%s: invalid flags: %04x", __func__, flags));
if ((encif->if_drv_flags & IFF_DRV_RUNNING) == 0)
return (0);
if (flags & ENC_IN) {
if ((flags & ipsec_filter_mask_in) == 0)
return (0);
} else {
if ((flags & ipsec_filter_mask_out) == 0)
return (0);
}
/* Skip pfil(9) if no filters are loaded */
if (1
#ifdef INET
&& !PFIL_HOOKED(&V_inet_pfil_hook)
#endif
#ifdef INET6
&& !PFIL_HOOKED(&V_inet6_pfil_hook)
#endif
) {
return (0);
}
i = min((*mp)->m_pkthdr.len, max_protohdr);
if ((*mp)->m_len < i) {
*mp = m_pullup(*mp, i);
if (*mp == NULL) {
printf("%s: m_pullup failedn", __func__);
return (-1);
}
}
error = 0;
ip = mtod(*mp, struct ip *);
switch (ip->ip_v) {
#ifdef INET
case 4:
error = pfil_run_hooks(&V_inet_pfil_hook, mp,
encif, dir, NULL);
break;
#endif
#ifdef INET6
case 6:
error = pfil_run_hooks(&V_inet6_pfil_hook, mp,
encif, dir, NULL);
break;
#endif
default:
printf("%s: unknown IP versionn", __func__);
}
/*
* If the mbuf was consumed by the filter for requeueing (dummynet, etc)
* then error will be zero but we still want to return an error to our
* caller so the null mbuf isn't forwarded further.
*/
if (*mp == NULL && error == 0)
return (-1); /* Consumed by the filter */
if (*mp == NULL)
return (error);
if (error != 0)
goto bad;
return (error);
bad:
m_freem(*mp);
*mp = NULL;
return (error);
}
/*
* Ip input routine. Checksum and byte swap header. If fragmented
* try to reassamble. If complete and fragment queue exists, discard.
* Process options. Pass to next level.
*/
ipintr()
{
register struct ip *ip;
register struct mbuf *m;
struct mbuf *m0;
register int i;
register struct ipq *fp;
register struct in_ifaddr *ia;
struct ifnet *ifp;
int hlen, s;
/* IOdebug( "ipintr: called" ); */
next:
/*
* Get next datagram off input queue and get IP header
* in first mbuf.
*/
s = splimp();
IF_DEQUEUEIF(&ipintrq, m, ifp);
splx(s);
if (m == NULL)
{
/* IOdebug( "ipintr: no more mbufs" ); */
return;
}
/*
* If no IP addresses have been set yet but the interfaces
* are receiving, can't do anything with incoming packets yet.
*/
if (in_ifaddr == NULL)
goto bad;
ipstat.ips_total++;
if ((m->m_off > MMAXOFF || m->m_len < sizeof (struct ip)) &&
(m = m_pullup(m, sizeof (struct ip))) == 0) {
ipstat.ips_toosmall++;
goto next;
}
ip = mtod(m, struct ip *);
hlen = ip->ip_hl << 2;
if (hlen < sizeof(struct ip)) { /* minimum header length */
ipstat.ips_badhlen++;
goto bad;
}
if (hlen > m->m_len) {
if ((m = m_pullup(m, hlen)) == 0) {
ipstat.ips_badhlen++;
goto next;
}
ip = mtod(m, struct ip *);
}
if (ipcksum)
if (ip->ip_sum = in_cksum(m, hlen)) {
ipstat.ips_badsum++;
/* IOdebug( "ipintr: bad checksum" ); */
goto bad;
}
/*
* Convert fields to host representation.
*/
ip->ip_len = ntohs((u_short)ip->ip_len);
if (ip->ip_len < hlen) {
ipstat.ips_badlen++;
goto bad;
}
ip->ip_id = ntohs(ip->ip_id);
ip->ip_off = ntohs((u_short)ip->ip_off);
/*
* Check that the amount of data in the buffers
* is as at least much as the IP header would have us expect.
* Trim mbufs if longer than we expect.
* Drop packet if shorter than we expect.
*/
i = -(u_short)ip->ip_len;
m0 = m;
for (;;) {
i += m->m_len;
if (m->m_next == 0)
break;
m = m->m_next;
}
if (i != 0) {
if (i < 0) {
ipstat.ips_tooshort++;
m = m0;
goto bad;
}
if (i <= m->m_len)
m->m_len -= i;
else
m_adj(m0, -i);
}
m = m0;
/*
* Process options and, if not destined for us,
* ship it on. ip_dooptions returns 1 when an
* error was detected (causing an icmp message
* to be sent and the original packet to be freed).
*/
ip_nhops = 0; /* for source routed packets */
if (hlen > sizeof (struct ip) && ip_dooptions(ip, ifp))
goto next;
/*
* Check our list of addresses, to see if the packet is for us.
*/
/* IOdebug( "ipintr: checking address" ); */
for (ia = in_ifaddr; ia; ia = ia->ia_next) {
#define satosin(sa) ((struct sockaddr_in *)(sa))
if (IA_SIN(ia)->sin_addr.s_addr == ip->ip_dst.s_addr)
goto ours;
if (
#ifdef DIRECTED_BROADCAST
ia->ia_ifp == ifp &&
#endif
(ia->ia_ifp->if_flags & IFF_BROADCAST)) {
u_long t;
if (satosin(&ia->ia_broadaddr)->sin_addr.s_addr ==
ip->ip_dst.s_addr)
goto ours;
if (ip->ip_dst.s_addr == ia->ia_netbroadcast.s_addr)
goto ours;
/*
* Look for all-0's host part (old broadcast addr),
* either for subnet or net.
*/
t = ntohl(ip->ip_dst.s_addr);
if (t == ia->ia_subnet)
goto ours;
if (t == ia->ia_net)
goto ours;
}
}
if (ip->ip_dst.s_addr == (u_long)INADDR_BROADCAST)
goto ours;
if (ip->ip_dst.s_addr == INADDR_ANY)
goto ours;
/*
* Not for us; forward if possible and desirable.
*/
ip_forward(ip, ifp);
/* IOdebug( "ipintr: not for us" ); */
goto next;
ours:
/* IOdebug( "ipintr: ours" ); */
/*
* If offset or IP_MF are set, must reassemble.
* Otherwise, nothing need be done.
* (We could look in the reassembly queue to see
* if the packet was previously fragmented,
* but it's not worth the time; just let them time out.)
*/
if (ip->ip_off &~ IP_DF) {
/*
* Look for queue of fragments
* of this datagram.
*/
for (fp = ipq.next; fp != &ipq; fp = fp->next)
if (ip->ip_id == fp->ipq_id &&
ip->ip_src.s_addr == fp->ipq_src.s_addr &&
ip->ip_dst.s_addr == fp->ipq_dst.s_addr &&
ip->ip_p == fp->ipq_p)
goto found;
fp = 0;
found:
/*
* Adjust ip_len to not reflect header,
* set ip_mff if more fragments are expected,
* convert offset of this to bytes.
*/
ip->ip_len -= hlen;
((struct ipasfrag *)ip)->ipf_mff = 0;
if (ip->ip_off & IP_MF)
((struct ipasfrag *)ip)->ipf_mff = 1;
ip->ip_off <<= 3;
/*
* If datagram marked as having more fragments
* or if this is not the first fragment,
* attempt reassembly; if it succeeds, proceed.
*/
if (((struct ipasfrag *)ip)->ipf_mff || ip->ip_off)
{
/* IOdebug( "ipintr: attempting reassembly" ); */
ipstat.ips_fragments++;
ip = ip_reass((struct ipasfrag *)ip, fp);
if (ip == NULL)
{
/* IOdebug( "ipintr: attempt failed" ); */
goto next;
}
m = dtom(ip);
}
else
if (fp)
ip_freef(fp);
} else
ip->ip_len -= hlen;
/*
* Switch out to protocol's input routine.
*/
/* IOdebug( "ipintr: handling packet of len %d", ip->ip_len ); */
(*inetsw[ip_protox[ip->ip_p]].pr_input)(m, ifp);
/* IOdebug( "ipintr: handled" ); */
goto next;
bad:
/* IOdebug( "ipintr: bad input" ); */
m_freem(m);
goto next;
}
/*
* IPX input routine. Pass to next level.
*/
void
ipxintr()
{
struct ipx *ipx;
struct mbuf *m;
struct ipxpcb *ipxp;
struct ipx_ifaddr *ia;
int len, s;
next:
/*
* Get next datagram off input queue and get IPX header
* in first mbuf.
*/
s = splimp();
IF_DEQUEUE(&ipxintrq, m);
splx(s);
if (m == NULL) {
return;
}
ipxstat.ipxs_total++;
if ((m->m_flags & M_EXT || m->m_len < sizeof(struct ipx)) &&
(m = m_pullup(m, sizeof(struct ipx))) == 0) {
ipxstat.ipxs_toosmall++;
goto next;
}
/*
* Give any raw listeners a crack at the packet
*/
for (ipxp = ipxrawcbtable.ipxpt_queue.cqh_first;
ipxp != (struct ipxpcb *)&ipxrawcbtable.ipxpt_queue;
ipxp = ipxp->ipxp_queue.cqe_next) {
struct mbuf *m1 = m_copy(m, 0, (int)M_COPYALL);
if (m1)
ipx_input(m1, ipxp);
}
ipx = mtod(m, struct ipx *);
len = ntohs(ipx->ipx_len);
/*
* Check that the amount of data in the buffers
* is as at least much as the IPX header would have us expect.
* Trim mbufs if longer than we expect.
* Drop packet if shorter than we expect.
*/
if (m->m_pkthdr.len < len) {
ipxstat.ipxs_tooshort++;
goto bad;
}
if (m->m_pkthdr.len > len) {
if (m->m_len == m->m_pkthdr.len) {
m->m_len = len;
m->m_pkthdr.len = len;
} else
m_adj(m, len - m->m_pkthdr.len);
}
if (ipxcksum && ipx->ipx_sum != 0xffff) {
if (ipx->ipx_sum != ipx_cksum(m, len)) {
ipxstat.ipxs_badsum++;
goto bad;
}
}
/*
* Propagated (Netbios) packets (type 20) has to be handled
* different. :-(
*/
if (ipx->ipx_pt == IPXPROTO_NETBIOS) {
if (ipxnetbios) {
ipx_output_type20(m);
goto next;
} else
goto bad;
}
/*
* Is this a directed broadcast?
*/
if (ipx_hosteqnh(ipx_broadhost,ipx->ipx_dna.ipx_host)) {
if ((!ipx_neteq(ipx->ipx_dna, ipx->ipx_sna)) &&
(!ipx_neteqnn(ipx->ipx_dna.ipx_net, ipx_broadnet)) &&
(!ipx_neteqnn(ipx->ipx_sna.ipx_net, ipx_zeronet)) &&
(!ipx_neteqnn(ipx->ipx_dna.ipx_net, ipx_zeronet)) ) {
/*
* If it is a broadcast to the net where it was
* received from, treat it as ours.
*/
for (ia = ipx_ifaddr.tqh_first; ia;
ia = ia->ia_list.tqe_next)
if((ia->ia_ifa.ifa_ifp == m->m_pkthdr.rcvif) &&
ipx_neteq(ia->ia_addr.sipx_addr,
ipx->ipx_dna))
goto ours;
/*
* Look to see if I need to eat this packet.
* Algorithm is to forward all young packets
* and prematurely age any packets which will
* by physically broadcasted.
* Any very old packets eaten without forwarding
* would die anyway.
*
* Suggestion of Bill Nesheim, Cornell U.
*/
if (ipx->ipx_tc < IPX_MAXHOPS) {
ipx_forward(m);
goto next;
}
}
/*
* Is this our packet? If not, forward.
*/
} else {
for (ia = ipx_ifaddr.tqh_first; ia; ia = ia->ia_list.tqe_next)
if (ipx_hosteq(ipx->ipx_dna, ia->ia_addr.sipx_addr) &&
(ipx_neteq(ipx->ipx_dna, ia->ia_addr.sipx_addr) ||
ipx_neteqnn(ipx->ipx_dna.ipx_net, ipx_zeronet)))
break;
if (ia == NULL) {
ipx_forward(m);
goto next;
}
}
ours:
/*
* Locate pcb for datagram.
*/
ipxp = ipx_pcblookup(&ipx->ipx_sna, ipx->ipx_dna.ipx_port,
IPX_WILDCARD);
/*
* Switch out to protocol's input routine.
*/
if (ipxp) {
ipxstat.ipxs_delivered++;
if ((ipxp->ipxp_flags & IPXP_ALL_PACKETS) == 0)
switch (ipx->ipx_pt) {
case IPXPROTO_SPX:
spx_input(m, ipxp);
goto next;
}
ipx_input(m, ipxp);
} else
goto bad;
goto next;
bad:
m_freem(m);
goto next;
}
int
gre_output(struct ifnet *ifp, struct mbuf *m, struct sockaddr *dst,
struct rtentry *rt)
{
int error = 0;
struct gre_softc *sc = (struct gre_softc *) (ifp->if_softc);
struct greip *gh = NULL;
struct ip *inp = NULL;
u_int8_t ip_tos = 0;
u_int16_t etype = 0;
struct mobile_h mob_h;
struct m_tag *mtag;
if ((ifp->if_flags & IFF_UP) == 0 ||
sc->g_src.s_addr == INADDR_ANY || sc->g_dst.s_addr == INADDR_ANY) {
m_freem(m);
error = ENETDOWN;
goto end;
}
/* Try to limit infinite recursion through misconfiguration. */
for (mtag = m_tag_find(m, PACKET_TAG_GRE, NULL); mtag;
mtag = m_tag_find(m, PACKET_TAG_GRE, mtag)) {
if (!bcmp((caddr_t)(mtag + 1), &ifp, sizeof(struct ifnet *))) {
IF_DROP(&ifp->if_snd);
m_freem(m);
error = EIO;
goto end;
}
}
mtag = m_tag_get(PACKET_TAG_GRE, sizeof(struct ifnet *), M_NOWAIT);
if (mtag == NULL) {
IF_DROP(&ifp->if_snd);
m_freem(m);
error = ENOBUFS;
goto end;
}
bcopy(&ifp, (caddr_t)(mtag + 1), sizeof(struct ifnet *));
m_tag_prepend(m, mtag);
m->m_flags &= ~(M_BCAST|M_MCAST);
#if NBPFILTER >0
if (ifp->if_bpf)
bpf_mtap_af(ifp->if_bpf, dst->sa_family, m, BPF_DIRECTION_OUT);
#endif
if (sc->g_proto == IPPROTO_MOBILE) {
if (ip_mobile_allow == 0) {
IF_DROP(&ifp->if_snd);
m_freem(m);
error = EACCES;
goto end;
}
if (dst->sa_family == AF_INET) {
struct mbuf *m0;
int msiz;
/*
* Make sure the complete IP header (with options)
* is in the first mbuf.
*/
if (m->m_len < sizeof(struct ip)) {
m = m_pullup(m, sizeof(struct ip));
if (m == NULL) {
IF_DROP(&ifp->if_snd);
error = ENOBUFS;
goto end;
} else
inp = mtod(m, struct ip *);
if (m->m_len < inp->ip_hl << 2) {
m = m_pullup(m, inp->ip_hl << 2);
if (m == NULL) {
IF_DROP(&ifp->if_snd);
error = ENOBUFS;
goto end;
}
}
}
inp = mtod(m, struct ip *);
bzero(&mob_h, MOB_H_SIZ_L);
mob_h.proto = (inp->ip_p) << 8;
mob_h.odst = inp->ip_dst.s_addr;
inp->ip_dst.s_addr = sc->g_dst.s_addr;
/*
* If the packet comes from our host, we only change
* the destination address in the IP header.
* Otherwise we need to save and change the source.
*/
if (inp->ip_src.s_addr == sc->g_src.s_addr) {
msiz = MOB_H_SIZ_S;
} else {
mob_h.proto |= MOB_H_SBIT;
mob_h.osrc = inp->ip_src.s_addr;
inp->ip_src.s_addr = sc->g_src.s_addr;
msiz = MOB_H_SIZ_L;
}
HTONS(mob_h.proto);
mob_h.hcrc = gre_in_cksum((u_int16_t *) &mob_h, msiz);
/* Squeeze in the mobility header */
if ((m->m_data - msiz) < m->m_pktdat) {
/* Need new mbuf */
MGETHDR(m0, M_DONTWAIT, MT_HEADER);
if (m0 == NULL) {
IF_DROP(&ifp->if_snd);
m_freem(m);
error = ENOBUFS;
goto end;
}
M_MOVE_HDR(m0, m);
m0->m_len = msiz + (inp->ip_hl << 2);
m0->m_data += max_linkhdr;
m0->m_pkthdr.len = m->m_pkthdr.len + msiz;
m->m_data += inp->ip_hl << 2;
m->m_len -= inp->ip_hl << 2;
bcopy((caddr_t) inp, mtod(m0, caddr_t),
sizeof(struct ip));
m0->m_next = m;
m = m0;
} else { /* we have some space left in the old one */
m->m_data -= msiz;
m->m_len += msiz;
m->m_pkthdr.len += msiz;
bcopy(inp, mtod(m, caddr_t),
inp->ip_hl << 2);
}
/* Copy Mobility header */
inp = mtod(m, struct ip *);
bcopy(&mob_h, (caddr_t)(inp + 1), (unsigned) msiz);
inp->ip_len = htons(ntohs(inp->ip_len) + msiz);
} else { /* AF_INET */
Приветствую уважаемую публику.
Была старая тема про правильную настройку серверов FreeBSD, шейпирующих и NAT’ящих абонентов, но сходу её не нашёл, поэтому открываю новую.
Имею проблему с таким сервером.
Итак, сервер FreeBSD 7.3-STABLE i386 с pf(NAT), ipfw(ACL) и dummynet (shaping).
Пропускает порядка 1500 клиентов, трафик порядка 400-500 Мбит/сек (60kpps), количество сессий PF порядка 300 тысяч.
В течении года загрузка постепенно подобралась к LA 2-3 (на Core2Duo), поменял процессор на Core2Quad.
И настала жопа.
Загрузка не только не уменьшилась, она ещё больше возросла, начались задержки и потери пакетов.
Установка драйверов от Яндекса не помогла.
Игры настройками sysctl net.isr.direct 1/0, dev.em.X.int_delay; привязка cpuset’ом процессов dummynet и emX_xxx к определённым ядрам не приносят практически никакого значимого результата.
Немного помогает уборка следующих правил файервола из ipfw — потери и задержки пакетов уходят, хотя загрузка всё равно высокая:
03000 760849293 645265414446 pipe tablearg ip from any to table(4) xmit vlan3050 // Incoming traffic shaping 03000 802815983 576003644433 pipe tablearg ip from table(5) to any xmit em0 // Outgoing traffic shaping
В цифрах это будет вот так:
em0: Excessive collisions = 0 em0: Excessive collisions = 0 em0: Sequence errors = 0 em0: Sequence errors = 0 em0: Defer count = 0 em0: Defer count = 0 em0: Missed Packets = 24553 em0: Missed Packets = 24553 em0: Receive No Buffers = 4547 em0: Receive No Buffers = 4547 em0: Receive Length Errors = 0 em0: Receive Length Errors = 0 em0: Receive errors = 0 em0: Receive errors = 0 em0: Crc errors = 0 em0: Crc errors = 0 em0: Alignment errors = 0 em0: Alignment errors = 0 em0: Collision/Carrier extension errors = 0 em0: Collision/Carrier extension errors = 0 em0: watchdog timeouts = 0 em0: watchdog timeouts = 0 em0: XON Rcvd = 0 em0: XON Rcvd = 0 em0: XON Xmtd = 0 em0: XON Xmtd = 0 em0: XOFF Rcvd = 0 em0: XOFF Rcvd = 0 em0: XOFF Xmtd = 0 em0: XOFF Xmtd = 0 em0: Good Packets Rcvd = 10419220831 em0: Good Packets Rcvd = 10419220831 em0: Good Packets Xmtd = 9848872653 em0: Good Packets Xmtd = 9848872653 em0: TSO Contexts Xmtd = 7362 em0: TSO Contexts Xmtd = 7362 em0: TSO Contexts Failed = 0 em0: TSO Contexts Failed = 0
root@Bastinda:/root/nasscripts (344) netstat -i -I em0 -dh 1 input (em0) output packets errs bytes packets errs bytes colls drops 60K 0 61M 43K 0 21M 0 0 61K 0 60M 44K 0 22M 0 0 60K 0 59M 44K 0 22M 0 0 60K 0 60M 43K 0 22M 0 0 49K 0 47M 36K 0 19M 0 0 56K 1.8K 54M 42K 0 23M 0 0 54K 0 54M 39K 0 19M 0 0 55K 0 53M 40K 0 21M 0 0 55K 0 55M 40K 0 20M 0 0 54K 0 52M 40K 0 20M 0 0 56K 1 55M 40K 0 20M 0 0 56K 0 55M 41K 0 21M 0 0 57K 0 56M 41K 0 21M 0 0 57K 0 57M 41K 0 21M 0 0 59K 0 59M 43K 0 22M 0 0 61K 0 62M 44K 0 22M 0 0
root@Bastinda:/root/nasscripts (399) netstat -i -dh 1 input (Total) output packets errs bytes packets errs bytes colls drops 146K 0 109M 146K 0 132M 0 0 147K 0 110M 145K 0 129M 0 0 147K 0 111M 146K 0 127M 0 0 142K 0 108M 140K 0 124M 0 0 140K 0 106M 137K 0 118M 0 0 145K 0 112M 141K 0 125M 0 0 141K 0 107M 139K 0 121M 0 0 143K 0 109M 139K 0 121M 0 0 142K 0 107M 139K 0 120M 0 0 135K 0 101M 133K 0 116M 0 0
Интересно, что удаление правил файервола, связанных с шейпером, процесс dummynet всё равно продолжает потреблять ресурсы процессора:
last pid: 80781; load averages: 4.69, 4.85, 4.99 up 4+20:50:51 20:55:56 162 processes: 9 running, 135 sleeping, 18 waiting CPU 0: 0.0% user, 0.0% nice, 86.1% system, 0.0% interrupt, 13.9% idle CPU 1: 1.5% user, 0.0% nice, 88.6% system, 2.0% interrupt, 7.9% idle CPU 2: 0.0% user, 0.0% nice, 81.3% system, 2.0% interrupt, 16.7% idle CPU 3: 0.0% user, 0.0% nice, 78.9% system, 2.0% interrupt, 19.1% idle Mem: 53M Active, 1355M Inact, 485M Wired, 29M Cache, 199M Buf, 79M Free Swap: 8192M Total, 8192M Free PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND 25 root 43 - 0K 8K RUN 1 34.6H 92.58% [em0_rx0_0] 26 root 43 - 0K 8K CPU1 0 34.6H 91.16% [em0_rx0_1] 30 root 43 - 0K 8K CPU3 3 33.8H 68.80% [em1_rx0_1] 29 root 43 - 0K 8K WAIT 2 33.8H 66.26% [em1_rx0_0] 5 root 8 - 0K 8K RUN 0 784:55 21.39% [thread taskq] 38 root -68 - 0K 8K - 2 30.5H 17.38% [dummynet] 11 root 171 ki31 0K 8K CPU2 2 63.3H 16.80% [idle: cpu2] 10 root 171 ki31 0K 8K RUN 3 80.8H 16.16% [idle: cpu3] 13 root 171 ki31 0K 8K RUN 0 59.8H 7.28% [idle: cpu0] 12 root 171 ki31 0K 8K RUN 1 65.9H 6.05% [idle: cpu1] 15 root -32 - 0K 8K WAIT 3 157:18 2.10% [swi4: clock] 27 root 16 - 0K 8K WAIT 3 76:39 1.56% [swi16: em1_tx] 23 root 16 - 0K 8K WAIT 1 79:29 1.37% [swi16: em0_tx] root@Bastinda:/root/nasscripts (342)
root@Bastinda:/root/nasscripts (343) sysctl net.isr net.isr.swi_count: 53881 net.isr.drop: 0 net.isr.queued: 75222 net.isr.deferred: 0 net.isr.directed: 205468560 net.isr.count: 205468478 net.isr.direct: 1
3 users Load 4.76 4.74 4.78 18 окт 21:14 Mem:KB REAL VIRTUAL VN PAGER SWAP PAGER Tot Share Tot Share Free in out in out Act 60360 5924 359628 7036 161668 count All 388820 9176 4624800 18788 pages Proc: Interrupts r p d s w Csw Trp Sys Int Sof Flt cow 9093 total 1 116 170k 4 169 1094 7866 zfod atkbd0 1 ozfod atapci1+ 1 95.2%Sys 0.7%Intr 0.0%User 0.0%Nice 4.0%Idle %ozfod skc0 irq24 | | | | | | | | | | | daefr 1995 cpu0: time ================================================ prcfr 549 em0 irq256 33 dtbuf totfr 546 em1 irq257 Namei Name-cache Dir-cache 100000 desvn react 1995 cpu1: time Calls hits % hits % 88426 numvn pdwak 2004 cpu2: time 25000 frevn pdpgs 2004 cpu3: time intrn Disks ad6 493080 wire KB/t 0.00 56020 act tps 0 1338324 inact MB/s 0.00 6128 cache %busy 0 155540 free
root@Bastinda:/root/nasscripts (397) netstat -m 8702/9733/18435 mbufs in use (current/cache/total) 8699/9695/18394/262144 mbuf clusters in use (current/cache/total/max) 8695/8841 mbuf+clusters out of packet secondary zone in use (current/cache) 0/178/178/12800 4k (page size) jumbo clusters in use (current/cache/total/max) 0/347/347/6400 9k jumbo clusters in use (current/cache/total/max) 0/0/0/3200 16k jumbo clusters in use (current/cache/total/max) 19629K/25658K/45287K bytes allocated to network (current/cache/total) 0/0/0 requests for mbufs denied (mbufs/clusters/mbuf+clusters) 0/0/0 requests for jumbo clusters denied (4k/9k/16k) 0/7/10240 sfbufs in use (current/peak/max) 0 requests for sfbufs denied 0 requests for sfbufs delayed 0 requests for I/O initiated by sendfile 0 calls to protocol drain routines
grep -v ^# /etc/sysctl.conf | sort dev.em.0.rx_abs_int_delay=1800 dev.em.0.rx_int_delay=900 dev.em.0.tx_abs_int_delay=1800 dev.em.0.tx_int_delay=900 dev.em.1.rx_abs_int_delay=1800 dev.em.1.rx_int_delay=900 dev.em.1.rx_kthreads=2 dev.em.1.rx_kthreads=2 dev.em.1.tx_abs_int_delay=1800 dev.em.1.tx_int_delay=900 kern.ipc.maxsockbuf=2097152 kern.ipc.nmbclusters=262144 kern.ipc.somaxconn=4096 kern.maxfiles=20480 # For PPP kern.polling.user_frac=25 kern.timecounter.hardware=HPET net.inet.carp.log=6 net.inet.carp.preempt=1 net.inet.ip.dummynet.expire=0 net.inet.ip.dummynet.hash_size=1024 net.inet.ip.dummynet.io_fast=1 net.inet.ip.fastforwarding=1 net.inet.ip.fw.one_pass=0 net.inet.ip.process_options=0 net.inet.ip.random_id=1 net.inet.ip.redirect=0 net.inet.ip.stealth=1 net.inet.tcp.delayed_ack=0 net.inet.tcp.drop_synfin=1 net.inet.tcp.recvspace=65228 net.inet.tcp.sendspace=65228 net.inet.tcp.syncookies=1 net.inet.udp.maxdgram=57344 net.inet.udp.recvspace=65228 net.link.ether.inet.log_arp_wrong_iface=0
Конфигурация шейперов (на примере):
# Login 1239282656, ID 20, Tariff 2, Bandwidth 1024 Kb/s, IP 10.54.3.8/29' /sbin/ipfw -q pipe 20 config bw 1126Kb/s mask dst-ip 0xFFFFFFFF queue 100 gred 0.002/17/51/0.1 /sbin/ipfw -q pipe 10020 config bw 1126Kb/s mask src-ip 0xFFFFFFFF queue 100 gred 0.002/17/51/0.1
root@Bastinda:/root/nasscripts (372) sysctl net.inet.ip.dummynet net.inet.ip.dummynet.debug: 0 net.inet.ip.dummynet.pipe_byte_limit: 1048576 net.inet.ip.dummynet.pipe_slot_limit: 100 net.inet.ip.dummynet.io_pkt_drop: 8885604 net.inet.ip.dummynet.io_pkt_fast: 992352269 net.inet.ip.dummynet.io_pkt: 2310923696 net.inet.ip.dummynet.io_fast: 1 net.inet.ip.dummynet.tick_lost: 0 net.inet.ip.dummynet.tick_diff: 8941128 net.inet.ip.dummynet.tick_adjustment: 6792058 net.inet.ip.dummynet.tick_delta_sum: 314 net.inet.ip.dummynet.tick_delta: 0 net.inet.ip.dummynet.red_max_pkt_size: 1500 net.inet.ip.dummynet.red_avg_pkt_size: 512 net.inet.ip.dummynet.red_lookup_depth: 256 net.inet.ip.dummynet.max_chain_len: 16 net.inet.ip.dummynet.expire: 0 net.inet.ip.dummynet.search_steps: -1984046616 net.inet.ip.dummynet.searches: -1984043600 net.inet.ip.dummynet.extract_heap: 0 net.inet.ip.dummynet.ready_heap: 272 net.inet.ip.dummynet.hash_size: 1024
root@Bastinda:/root/nasscripts (361) grep -v ^# /boot/loader.conf | sort autoboot_delay="1" hw.em.rxd=4096 hw.em.txd=4096 ichsmb_load="YES" if_sk_load="YES" kern.ipc.nsfbufs=10240 net.inet.tcp.syncache.bucketlimit=100 net.inet.tcp.syncache.hashsize=1024 net.inet.tcp.tcbhashsize=16384 # Set the value of TCBHASHSIZE vm.kmem_size=768M vm.kmem_size_max=1G
em0@pci0:13:0:0: class=0x020000 card=0x108c15d9 chip=0x108c8086 rev=0x03 hdr=0x00 vendor = 'Intel Corporation' device = 'Intel Corporation 82573E Gigabit Ethernet Controller (Copper) (82573E)' class = network subclass = ethernet em1@pci0:15:0:0: class=0x020000 card=0x109a15d9 chip=0x109a8086 rev=0x00 hdr=0x00 vendor = 'Intel Corporation' device = 'Intel PRO/1000 PL Network Adaptor (82573L)' class = network subclass = ethernet
Что можно в данном случае сделать?
Изменено 18 октября, 2010 пользователем Dyr