Сталкиваюсь не первый раз с этой проблемой, закрывал глаза, но сейчас хочу решить эту проблему.
При старте бота изредка выскакивает ошибка, или в работе бота. Выдает ошибку и на vds и на локалке.
Traceback (most recent call last):
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connection.py", line 159, in _new_conn
(self._dns_host, self.port), self.timeout, **extra_kw)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3utilconnection.py", line 57, in create_connection
for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsocket.py", line 748, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11002] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connectionpool.py", line 600, in urlopen
chunked=chunked)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connectionpool.py", line 343, in _make_request
self._validate_conn(conn)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connectionpool.py", line 839, in _validate_conn
conn.connect()
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connection.py", line 301, in connect
conn = self._new_conn()
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connection.py", line 168, in _new_conn
self, "Failed to establish a new connection: %s" % e)
urllib3.exceptions.NewConnectionError: <urllib3.connection.VerifiedHTTPSConnection object at 0x04EAD110>: Failed to establish a new connection: [Errno 11002] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesrequestsadapters.py", line 449, in send
timeout=timeout
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3connectionpool.py", line 638, in urlopen
_stacktrace=sys.exc_info()[2])
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesurllib3utilretry.py", line 398, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='api.vk.com', port=443): Max retries exceeded with url: /method/stats.trackVisitor (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x04EAD110>: Failed to establish a new connection: [Errno 11002] getaddrinfo failed'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/Bogdan/PycharmProjects/?/---.py", line 1, in <module>
from --- import *
File "C:UsersBogdanPycharmProjects?---.py", line 24, in <module>
from --- import *
File "C:UsersBogdanPycharmProjects?---.py", line 122, in <module>
vk._auth_token()
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesvk_apivk_api.py", line 209, in _auth_token
if not reauth and self._check_token():
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesvk_apivk_api.py", line 501, in _check_token
self.method('stats.trackVisitor')
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesvk_apivk_api.py", line 602, in method
values
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesrequestssessions.py", line 581, in post
return self.request('POST', url, data=data, json=json, **kwargs)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesrequestssessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesrequestssessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "C:UsersBogdanAppDataLocalProgramsPythonPython37-32libsite-packagesrequestsadapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='api.vk.com', port=443): Max retries exceeded with url: /method/stats.trackVisitor (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x04EAD110>: Failed to establish a new connection: [Errno 11002] getaddrinfo failed'))Python is a simple, minimalistic, and easy-to-comprehend programming language that is globally-accepted and universally-used today. Its simple, easy-to-learn syntax can sometimes lead Python developers – especially those who are newer to the language – into missing some of its subtleties and underestimating the power of the diverse Python language.
One of the most popular error messages that new developers encounter when using requests library in Python is the “Max retries exceeded with URL” (besides timeout errors). While it seems simple, sometimes this somewhat vague error message can make even advanced Python developers scratching their head for a few good hours.
This article will show you what causes “Max retries exceeded with URL” error and a few ways to debug it.
Max retries exceeded with URL is a common error, you will encounter it when using requests library to make a request. The error indicates that the request cannot be made successfully. Usually, the verbose error message should look like the output below
Traceback (most recent call last): File "/home/nl/example.py", line 17, in <module> page1 = requests.get(ap) File "/usr/local/lib/python2.7/dist-packages/requests/api.py", line 55, in get return request('get', url, **kwargs) File "/usr/local/lib/python2.7/dist-packages/requests/api.py", line 44, in request return session.request(method=method, url=url, **kwargs) File "/usr/local/lib/python2.7/dist-packages/requests/sessions.py", line 383, in request resp = self.send(prep, **send_kwargs) File "/usr/local/lib/python2.7/dist-packages/requests/sessions.py", line 486, in send r = adapter.send(request, **kwargs) File "/usr/local/lib/python2.7/dist-packages/requests/adapters.py", line 378, in send raise ConnectionError(e) requests.exceptions.ConnectionError: HTTPSConnectionPool(host='localhost.com', port=443): Max retries exceeded with url: /api (Caused by <class 'socket.gaierror'>: [Errno -2] Name or service not known)Code language: JavaScript (javascript)
Sometimes, the error message may look slightly different, like below :
Code language: HTML, XML (xml)
requests.exceptions.ConnectionError(MaxRetryError("HTTPSConnectionPool(host='api.example.com', port=443): Max retries exceeded with url: /api.json ( Caused by <class 'socket.error'>: [Errno 10054] An existing connection was forcibly closed by the remote host)",),)
Code language: JavaScript (javascript)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=8001): Max retries exceeded with url: /api (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x10f96ecc0>: Failed to establish a new connection: [Errno 61] Connection refused'))
Code language: JavaScript (javascript)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.example.com', port=80): Max retries exceeded with url: /api (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000008EC69AAA90>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
Code language: JavaScript (javascript)
requests.exceptions.SSLError: HTTPSConnectionPool(host='example.com', port=443): Max retries exceeded with url: /api (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:997)')))
The error message usually begins with requests.exceptions.ConnectionError, which tell us that there is something bad happened when requests was trying to connect. Sometimes, the exception is requests.exceptions.SSLError which is obviously a SSL-related problem.
The exception then followed by a more detailed string about the error, which could be Failed to establish a new connection: [Errno 61] Connection refused, [Errno 11001] getaddrinfo failed, [Errno 10054] An existing connection was forcibly closed by the remote host or [Errno -2] Name or service not known. These messages were produced by the underlying system library which requests called internally. Based on these texts, we can further isolate and fix the problems.
Double-check the URL
There are a possibility that your requested URL wrong. It may be malformed or leading to a non-existent endpoint. In reality, this is usually the case among Python beginners. Seasoned developers can also encounter this error, especially when the URL is parsed from a webpage, which can be a relative URL or schemeless URL.
One way to further debug this is to prepare the URL in advance, then print it before actually making a connection.
Code language: PHP (php)
# ... url = soup.find("#linkout").href print(url) # prints out "/api" which is a non-valid URL r = requests.get(url)
Unstable internet connection / server overload
The underlying problem may be related to your own connection or the server you’re trying to connect to. Unstable internet connection may cause packet loss between network hops, leading to unsuccessful connection. There are times the server has received so many requests that it cannot process them all, therefore your requests won’t receive a response.
In this case, you can try increasing retry attempts and disable keep-alive connections to see if the problems go away. The amount of time spent for each request will certainly increase too, but that’s a trade-off you must accept. Better yet, find a more reliable internet connection.
Code language: PHP (php)
import requests requests.adapters.DEFAULT_RETRIES = 5 # increase retries number s = requests.session() s.keep_alive = False # disable keep alive s.get(url)
Increase request timeout
Another way that you can avoid “Max retries exceeded with URL” error, especially when the server is busy handling a huge number of connections, is to increase the amount of time requests library waits for a response from the server. In other words, you wait longer for a response, but increase the chance for a request to successfully finishes. This method can also be applied when the server is in a location far away from yours.
In order to increase request timeout, simply pass the time value in seconds to the get or post method :
r = requests.get(url, timeout=3)
You can also pass a tuple to timeout with the first element being a connect timeout (the time it allows for the client to establish a connection to the server), and the second being a read timeout (the time it will wait on a response once your client has established a connection).
If the request establishes a connection within 2 seconds and receives data within 5 seconds of the connection being established, then the response will be returned as it was before. If the request times out, then the function will raise a Timeout exception:
Code language: JavaScript (javascript)
requests.get('https://api.github.com', timeout=(2, 5))
Apply backoff factor
backoff_factor is an urllib3 argument, the library which requests relies on to initialize a network connection. Below is an example where we use backoff_factor to slow down the requests to the servers whenever there’s a failed one.
Code language: JavaScript (javascript)
import requests from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry session = requests.Session() retry = Retry(connect=3, backoff_factor=1) adapter = HTTPAdapter(max_retries=retry) session.mount('http://', adapter) session.mount('https://', adapter) session.get(url)
According to urllib3 documentation, backoff_factor is base value which the library use to calculate sleep interval between retries. Specifically, urllib3 will sleep for {backoff factor} * (2 ^ ({number of total retries} - 1)) seconds after every failed connection attempt.
For example, If the backoff_factor is 0.1, then sleep() will sleep for 0.0s, 0.2s, 0.4s, … between retries. By default, backoff is disabled (set to 0). It will also force a retry if the status code returned is 500, 502, 503 or 504.
You can customize Retry to have even more granular control over retries. Other notable options are:
- total – Total number of retries to allow.
- connect – How many connection-related errors to retry on.
- read – How many times to retry on read errors.
- redirect – How many redirects to perform.
- _methodwhitelist – Set of uppercased HTTP method verbs that we should retry on.
- _statusforcelist – A set of HTTP status codes that we should force a retry on.
- _backofffactor – A backoff factor to apply between attempts.
- _raise_onredirect – Whether, if the number of redirects is exhausted, to raise a
MaxRetryError, or to return a response with a response code in the 3xx range. - raise_on_status – Similar meaning to _raise_onredirect: whether we should raise an exception, or return a response, if status falls in _statusforcelist range and retries have been exhausted.
We hope that the article helped you successfully debugged “Max retries exceeded with URL” error in Python requests library, as well as avoid encountering it in the future. We’ve also written a few other guides for fixing common Python errors, such as Timeout in Python requests, Python Unresolved Import in VSCode or “IndexError: List Index Out of Range” in Python. If you have any suggestion, please feel free to leave a comment below.
![]()
hi,
for example:
>>> requests.get('http://localhost:1111')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "requests/api.py", line 55, in get
return request('get', url, **kwargs)
File "requests/api.py", line 44, in request
return session.request(method=method, url=url, **kwargs)
File "requests/sessions.py", line 312, in request
resp = self.send(prep, **send_kwargs)
File "requests/sessions.py", line 413, in send
r = adapter.send(request, **kwargs)
File "requests/adapters.py", line 223, in send
raise ConnectionError(e)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 61] Connection refused)
(assuming nothing is listening on port 1111)
the exception says «Max retries exceeded». i found this confusing because i did not specify any retry-related params. in fact, i am unable to find any documentation about specifying the retry-count. after going through the code, it seems that urllib3 is the underlying transport, and it is called with max_retries=0 (so in fact there are no retries). and requests simply wraps the exception. so it is understandable, but it confuses the end-user (end-developer)? i think something better should be done here, especially considering that it is very easy to get this error.
![]()
Requests wraps the exception for the users convenience. The original exception is part of the message although the Traceback is misleading. I’ll think about how to improve this.
![]()
I think need a auto retry to ignore few error
![]()
I agree this is quite confusing. Requests never retries (it sets the retries=0 for urllib3’s HTTPConnectionPool), so the error would be much more obvious without the HTTPConnectionPool/MaxRetryError stuff. I didn’t realize requests used urllib3 till just now, when I had to dive into the source code of both libraries to help me figure out how many retries it was doing:
ConnectionError(MaxRetryError("HTTPSConnectionPool(host='api.venere.com', port=443):
Max retries exceeded with url: /xhi-1.0/services/XHI_HotelAvail.json (
Caused by <class 'socket.error'>: [Errno 10054]
An existing connection was forcibly closed by the remote host)",),)
Ideally the exception would just look something like this:
ConnectionError(<class 'socket.error'>: [Errno 10054]
An existing connection was forcibly closed by the remote host))
![]()
That would be ideal. The issue is with wrapping these exceptions like we do. They make for a great API but a poor debugging experience. I have an idea for how to fix it though and preserve all the information
![]()
We’d also need to consider the case where a user does configure retries, in which case this exception is appropriate.
![]()
@Lukasa, I’m not sure you do need to consider that — Kenneth said here that Requests explicitly shouldn’t support retries as part of its API.
![]()
Right, but there’s no way to prevent a user from actually doing so.
My plan, for the record, is to traverse as far downwards as possible to the lowest level exception and use that instead. The problem with @benhoyt ‘s example is that it seems the socket error exception is unavailable to us. (Just by looking at what he has pasted. I haven’t tried to reproduce it yet and play with it.)
![]()
@gabor ‘s example actually makes this easy to reproduce. Catching the exception that’s raised, I did the following:
>>> e
ConnectionError(MaxRetryError("HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 111] Connection refused)",),)
>>> e.args
(MaxRetryError("HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 111] Connection refused)",),)
>>> e.args[0].args
("HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 111] Connection refused)",)
>>> e.args[0].args[0]
"HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 111] Connection refused)"
>>> isinstance(e.args[0].args[0], str)
True
So the best we could do is only use the message stored in e.args[0].args[0] which could potentially be confusing as well, but probably less so than what @benhoyt encountered. Either way, we will not parse error messages to try to get more or less details because that would just be utter insanity.
![]()
@sigmavirus24, I agree string parsing in exceptions is a terrible idea. However, urllib3’s MaxRetryError already exposes a reason attribute which contains the underlying exception (see source code). So you can get what you want with e.args[0].reason.
So continuing with the example above, e.args[0].reason is an instance of socket.error:
>>> requests.get('http://localhost:1111')
Traceback (most recent call last):
...
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 10061] No connection could be made because the target machine actively refused it)
>>> e = sys.last_value
>>> e
ConnectionError(MaxRetryError("HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 10061] No connection could be made because the target machine actively refused it)",),)
>>> e.args[0]
MaxRetryError("HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 10061] No connection could be made because the target machine actively refused it)",)
>>> e.args[0].reason
error(10061, 'No connection could be made because the target machine actively refused it')
![]()
Nice catch @benhoyt. I’m not as familiar with urllib3 as I would like to be.
![]()
If it really looks as you showed ie.
requests.exceptions.ConnectionError: HTTPConnectionPool(host='localhost', port=1111): Max retries exceeded with url: / (Caused by <class 'socket.error'>: [Errno 61] Connection refused)
then I couldn’t dream of better exception, really.
![]()
@piotr-dobrogost, the main problem (for me) was the fact that it talks about «max retries exceeded», when there’s no retrying involved at all. At first I thought it was the web service I was using saying that, so I contacted them. Then, digging further, I discovered this was a urllib3 quirk. So you can see the confusion.
![]()
Have you missed (Caused by <class 'socket.error'>: [Errno 61] Connection refused) part of the exception?
![]()
Yeah, you’re right — it’s all there. But as I mentioned, I missed that at first, because the MaxRetryError is a red herring.
![]()
This max retries thing always drives me mad. Does anybody mind if I dive in and see if I can’t put a PR together to squash the retries message?
I don’t mean to appear out of nowhere, but I use requests tons in the Python work we do at Cloudant. We get pages that include the retries thing, and it can be a red herring.
![]()
The answer is maybe.
The problem is that, while by default we don’t perform any retries, you can configure Requests to automatically retry failed requests. In those situations, the MaxRetryError we’ve wrapped is totally reasonable. If you can come up with a solution that leaves the MaxRetryError in place when it ought to be, but removes it when you can guarantee no retry attempts have been made, we’ll consider it. =)
![]()
@Lukasa thanks, I’m refreshing myself on the backlog here. If I get a chance to dive in I will definitely reach out.
![]()
It almost seems to me as if the right place for the change is in urllib3? MaxRetryError makes sense to raise in the context of automatic retries, but in the case of zero retries (perhaps the naive requests experience) it can be confusing.
In urllib3 it seems the confusing errors can be triggered here via requests. It’d almost be nice to only raise a MaxRetryError when retries==0 and max_retries!=0. If max_retries==0 instead raise a plain RequestError was raised instead.
I see the urllib3 as used by requests exists in an included package — just curious, why is that? Anyways, these were just a few ideas I wanted to toss out there. I’m still catching up on the codebases.
![]()
Whether or not the fix belongs in urllib3 is totally down to @shazow. Given that urllib3 by default does retry (3 times IIRC), it may be that he wants to keep urllib3’s behaviour as is. Pinging him to get his input.
We vendor urllib3 to avoid some dependency issues. Essentially, it means we’re always operating against a known version of urllib3. This has been discussed at excruciating length in #1384 and #1812 if you want the gritty details.
![]()
Phew gritty but informative. @shazow these are just a few thoughts I had — raising a RequestError rather than MaxRetryError as above. Really I think I better understand the MaxRetryError after checking out urlopen.
Double edit: Really even just a kwarg so one can raise MaxRetryError(retries=0) and alter the message on retries==0.
![]()
How about a retries=False which would disable retries altogether and always raise the original exception instead of MaxRetryError?
![]()
Being able to distinguish between asking urlopen for no retries and having it count down to 0 on the number of retries would be useful. It is jarring seeing the MaxRetryError when you did not ask for retries.
![]()
If anyone would like to do a patch+test for this, it would be appreciated. 
![]()
@shazow great, I’d be game to if I can find the cycles. I’ll ping if I have anything.
![]()
![]()
^I was wondering whether there was any patch released ? This issue seems to be an year old.
![]()
Not as far as I’m aware. =)
![]()
retries=False should raise the original exception as of v1.9, no wrapping.
![]()
![]()
![]()
Yeah this has been fixed I think
requests.get('http://localhost:11211') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "requests/api.py", line 60, in get return request('get', url, **kwargs) File "requests/api.py", line 49, in request return session.request(method=method, url=url, **kwargs) File "requests/sessions.py", line 457, in request resp = self.send(prep, **send_kwargs) File "requests/sessions.py", line 569, in send r = adapter.send(request, **kwargs) File "requests/adapters.py", line 407, in send raise ConnectionError(err, request=request) requests.exceptions.ConnectionError: ('Connection aborted.', error(61, 'Connection refused'))
![]()
Could you please tell me how this has been resolved, since i am too getting connection refused problem at my end. In my python script i am trying to connect RPC server
![]()
@SiddheshS This issue was fixed by rewording some exceptions: it has nothing to do with the actual connection refused error. To ask for help with a problem you should consider using Stack Overflow.
![]()
I encountered the same problem . it happened occasionally. how to fix,is there anyone can help me ? .thanks.
requests.exceptions.ConnectionError: HTTPSConnectionPool(host=’api.xxxx.com’, port=443): Max retries exceeded with url: /v2/goods/?category=0&sort_type=2&page_size=3&page_num=13&t=0&count=110 (Caused by NewConnectionError(‘<requests.packages.urllib3.connection.VerifiedHTTPSConnection object at 0x7f033a2c2590>: Failed to establish a new connection: [Errno 110] Connection timed out’,))
Traceback (most recent call last):
File «test.py», line 335, in
main()
File «test.py», line 290, in main
result = get_goods_info()
File «test.py», line 67, in get_goods_info
result = requests.get(url)
File «/usr/local/lib/python2.7/site-packages/requests/api.py», line 69, in get
return request(‘get’, url, params=params, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/api.py», line 50, in request
response = session.request(method=method, url=url, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/sessions.py», line 468, in request
resp = self.send(prep, *_send_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/sessions.py», line 576, in send
r = adapter.send(request, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/adapters.py», line 423, in send
raise ConnectionError(e, request=request)
![]()
@nkjulia The connection attempt is timing out, which suggests that the remote server is overloaded or that your connection timeout is too low.
![]()
I also misguided by this….
![]()
@kevinburke how did your issue resolved after getting connection refused error ? Could you please advice buddy. TIA
![]()
Ignore my post mate. I had multiple version of pythons in my machine due to which it wasn’t able to pick the right one and was throwing error. Posting this thinking it may be helpful for someone.
![]()
I encountered the same problem . it happened occasionally. how to fix,is there anyone can help me ? .thanks.
requests.exceptions.ConnectionError: HTTPSConnectionPool(host=’api.xxxx.com’, port=443): Max retries exceeded with url: /v2/goods/?category=0&sort_type=2&page_size=3&page_num=13&t=0&count=110 (Caused by NewConnectionError(‘<requests.packages.urllib3.connection.VerifiedHTTPSConnection object at 0x7f033a2c2590>: Failed to establish a new connection: [Errno 110] Connection timed out’,))
Traceback (most recent call last):
File «test.py», line 335, in
main()
File «test.py», line 290, in main
result = get_goods_info()
File «test.py», line 67, in get_goods_info
result = requests.get(url)
File «/usr/local/lib/python2.7/site-packages/requests/api.py», line 69, in get
return request(‘get’, url, params=params, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/api.py», line 50, in request
response = session.request(method=method, url=url, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/sessions.py», line 468, in request
resp = self.send(prep, *_send_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/sessions.py», line 576, in send
r = adapter.send(request, *_kwargs)
File «/usr/local/lib/python2.7/site-packages/requests/adapters.py», line 423, in send
raise ConnectionError(e, request=request)
If this issue has been solved,please give me some advise.
![]()
psf
locked as resolved and limited conversation to collaborators
Dec 27, 2018
A few months ago we announced the beginning of rate-limiting in the Clarizen One API (read more here https://success.clarizen.com/hc/en-us/articles/360012223839-API-Updates-for-Developers). This created some reaction by our customers, and some requested guidance on how to change their custom applications to handle the new policy.
What is the API rate-limit and why did Clarizen add it?
Clarizen API is used extensively by our customers; many of them built custom applications and custom integrations that use Clarizen’s advanced API query language and backend calculations to implement complex scenarios to automate their business workflows. 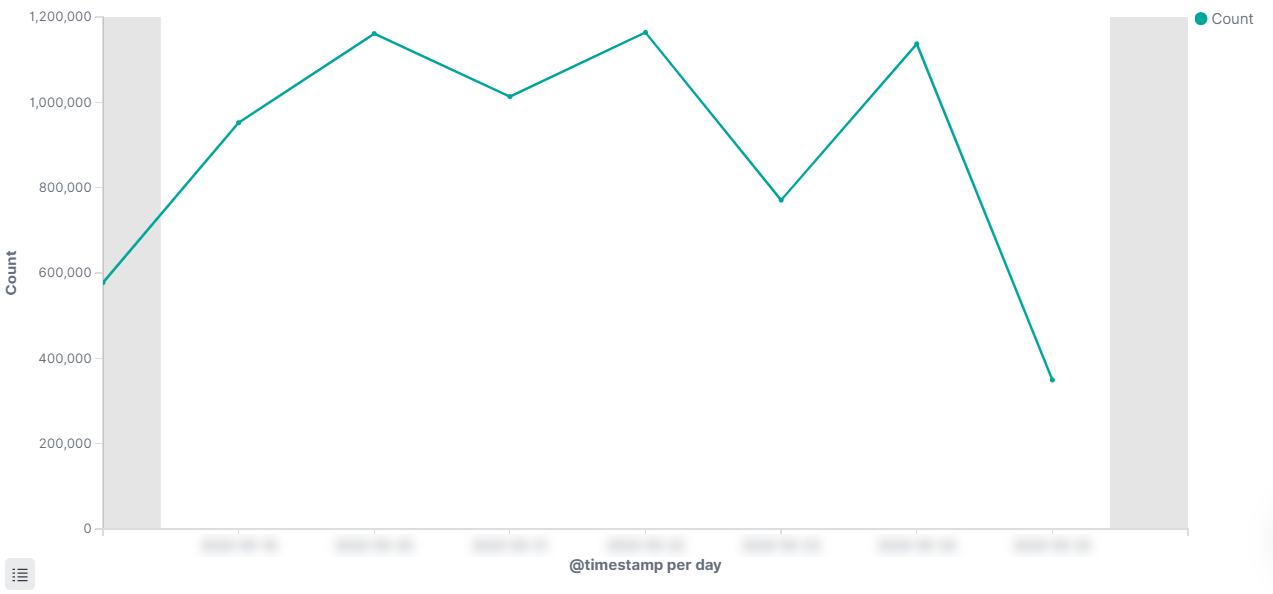 An avarage week of API usage in one datacenter
An avarage week of API usage in one datacenter
Our API is scalable and performs well, but even with the best hardware and software, without setting limits, customers can create a load that will affect the performance and user experience of their tenant and sometimes even on other tenants These are the types of issues you may see on the backend with such loads:
- Exhausted thread-pools
- Creating bottlenecks in DB connection pools
- Increasing the risk for locks and even deadlocks in the DB or other types of resources
Over time we discovered that some clients can create heavy loads on the API. At some point we even saw thousands of calls per second coming from a single client! 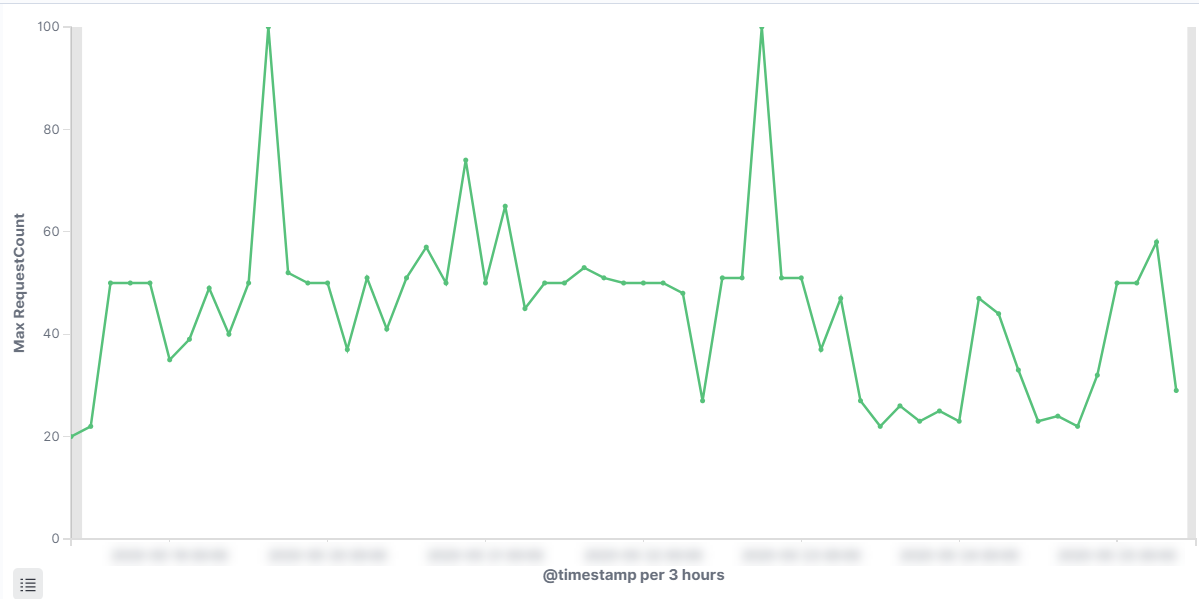 Max API calls per sec from a single client in an average week
Max API calls per sec from a single client in an average week
So one good way to fix these issues is to avoid them in the first place, hence rate-limits were introduced.
How the rate-limit works?
Clarizen looks at users from two angles, as an individual doing operations in the applications, and as a member of a tenant (organization) performing operation on behalf of the organization they belong to. Most of the cases that involve API usage coming from the organization level of the operation — for example, syncing the currency rates from a financial system with Clarizen. So simply put, the way our rate-limit works is that we count the amount of API calls made in a sliding window of 1 second from any user of your organization. This however has some exclusions:
- Any API call coming from the UI
- Any API call coming from Clarizen internal tools and integration platform
What happens when my API call reaches the limit
If your API client triggers more requests than allowed in a single second, you will get a response with an HTTP status code 429 (too many requests).
Here is an example of a response:
1 2 3 4 5 6 7 8 9 10 11 |
HTTP/1.1 429 Too Many Requests
Cache-Control: no-cache, no-store
Pragma: no-cache
Content-Type: application/json; charset=utf-8
Expires: -1
Retry-After: 1
Content-Length: 121
Date: Mon, 25 May 2020 07:52:16 GMT
Connection: keep-alive
{"statusCode":"Too Many Requests","message":"API calls quota exceeded! maximum admitted 25 per Second.","retryAfter":"1"}
|
What you should understand from this is that the API client code you write should now be aware of such restrictions and should protect itself.
How to avoid 429 Too Many Requests
The first thing you need to understand is that there is no magic here, you have to design your API clients so that they will not flood the API. This is generally true to any API you consume, and specifically the Clarizen API.
One of the most popular techniques to remedy the rate-limit response is by adding some kind of retry mechanism with backoffs (delays) between the attempts. The delay can be fixed so the same amount of time is waited for every time, or it can be with some randomization (known as exponantial backoff)
The following example show a C# program that calls the Clarizen API and simply runs in a loop until the call succeeds with some delay between each iteration. If the maximum amount of retries is reached, we just throw an exception (remember, there is no silver bullet).
Another option is to use a library that does a return logic for you. In the .NET ecosystem, Polly is a very powerful and popular option:
Last, it’s worth mentioning the popular Ekin.Clarizen library that provides a .NET Wrapper for Clarizen API v2.0. If you are using Ekin.Clarizen then you would use
Final words
API rate-limiting is a widely used and standard way to protect APIs from being flooded. I understand that it makes the client code more complex, and that it requires more work to protect your code from the new reality. At the same time, I’m sure and hope that you now understand that in the end this was introduced to give the best user experience possible for Clarizen users. With a simple change to your code and a bit of planning, you can easily tweak your code to make sure you won’t see any failures in your applications.
This post is licensed under CC BY 4.0 by Tamir Dresher.
Requests: You need not explicitly call close(). request will automatically close after finished because it bases on urlopen (this is why resp.raw.closed is True), This is the simplified code after i watched session.py and adapters.py:
from urllib3 import PoolManager
import time
manager = PoolManager(10)
conn = manager.connection_from_host('host1.example.com')
conn2 = manager.connection_from_host('host2.example.com')
res = conn.urlopen(url="http://host1.example.com/",method="get")
print(len(manager.pools))
manager.clear()
print(len(manager.pools))
print(res.closed)
#2
#0
#True
Then what did the __exit__ do? It uses to clear PoolManager(self.poolmanager=PoolManager(...)) and proxy.
# session.py
def __exit__(self, *args): #line 423
self.close()
def close(self): #line 733
for v in self.adapters.values():
v.close()
# adapters.py
# v.close()
def close(self): #line 307
self.poolmanager.clear()
for proxy in self.proxy_manager.values():
proxy.clear()
So when should you need to use close() , as the note said Releases the connection back to the pool, because DEFAULT_POOLSIZE = 10(http/https are independent). That means if you want to access more than 10 website with one session , you can chose to close some you do not need otherwise manager will close connection from the first to the newest when you have one more. But actually you need not to care about this , you can specify pool size and it would not waste much time to rebuild connection
aiohttp aiohttp.ClientSession() is using one TCPConnector for all requests. When it triggered __aexit__ , self._connector will be closed.
Edit: s.request() is set up a connection from host but it did not get response. await resp.text() can only be done after got response, if you did not do such step(wait for response), you will exit without having response.
if connector is None: #line 132
connector = TCPConnector(loop=loop)
...
self._connector = connector #line 151
# connection timeout
try:
with CeilTimeout(real_timeout.connect,loop=self._loop):
assert self._connector is not None
conn = await self._connector.connect(
req,
traces=traces,
timeout=real_timeout
)
...
async def close(self) -> None:
if not self.closed:
if self._connector is not None and self._connector_owner:
self._connector.close()
self._connector = None
...
async def __aexit__(self,
...) -> None:
await self.close()
This is code to show what i said
import asyncio
import aiohttp
import time
async def get():
async with aiohttp.ClientSession() as s:
# The response is already closed after this `with` block.
# Why would it need to be used as a context manager?
resp = await s.request('GET', 'https://www..com')
resp2 = await s.request('GET', 'https://www.github.com')
print("resp:",resp._closed)
print("resp:",resp._connection)
print("resp2:",resp2._closed)
print("resp2:",resp2._connection)
s.close()
print(s.closed)
c = await resp.text()
d = await resp2.text()
print()
print(s._connector)
print("resp:",resp._closed)
print("resp:",resp._connection)
print("resp2:",resp2._closed)
print("resp2:",resp2._connection)
loop = asyncio.get_event_loop()
loop.run_until_complete(get()) # Python 3.5 +
#dead loop
The “Max retries exceeded with url” error thrown sometimes by the requests library in Python falls under two classes of errors: requests.exceptions.ConnectionError (most common) and requests.exceptions.SSLError. In this article, we will discuss the causes of the error, how to reproduce it, and, importantly, how to solve the error.
The error occurs when the requests library cannot successfully send requests to the issued site. This happens because of different reasons. Here are the common ones. of them:
- Wrong URL – A typo maybe (go to Solution 1),
- Failure to verify SSL certificate (Solution 2),
- Using requests with no or unstable internet connection (Solution 3), and
- Sending too many requests or server too busy (Solution 4)
Wrong URL – A typo?
There is a chance that the URL you requested was incorrect. It could be distorted because of a typo. For example, suppose we want to send a get request to “https://www.example.com” (which is a valid URL), but instead, we issued the URL: “https://www.example.cojkm” (we used .cojkm in the domain extension instead of .com).
|
import requests url = ‘https://www.example.cojkm’ response = requests.get(url) print(response) |
Output:
requests.exceptions.ConnectionError: HTTPSConnectionPool(host='www.example.cojkm', port=443): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.VerifiedHTTPSConnection object at 0x7fd5b5d33100>: Failed to establish a new connection: [Errno 111] Connection refused'))
Failure to verify the SSL certificate
The requests library, by default, implements SSL certificate verification to ensure you are making a secure connection. If the certificates can’t be verified, you end up with an error like this:
requests.exceptions.SSLError: [Errno 1] _ssl.c:503: error:14090086:SSL routines:SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
Using requests with no or unstable internet connection
The requests package sends and receives data via the web; therefore, the internet connection should be available and stable. If you have no or unstable internet, requests will throw an error like this:
Error: requests.exceptions.ConnectionError: HTTPSConnectionPool(host=’www.example.com’, port=443): Max retries exceeded with url: / (Caused by NewConnectionError(‘<urllib3.connection.VerifiedHTTPSConnection object at 0x7f7f5fadb100>: Failed to establish a new connection: [Errno -3] Temporary failure in name resolution’))
Sending too many requests/ server overload
Some websites blocks connections when so many requests are made so fast. Another problem related to this is when the server is overloaded – managing a large number of connections at the same time. In this case, requests.get() throws an error like this:
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.srgfesrsergserg.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x0000008EC69AAA90>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
Solutions to requests Max Retries Exceeded With Url Error
In this section, we will cover some solutions to solve the “Max Retries Exceeded With Url” Error caused by the above reasons.
Solution 1: Double check URL
Ensure that you have a correct and valid URL. Consider a valid URL mentioned earlier: “https://www.example.com“. “Max retries exceeded with url” error mostly when incorrect edits are done around www and top-level domain name (e.g., .com).
Another error arises when the scheme/protocol (https) is incorrectly edited: requests.exceptions.InvalidSchema. If the second-level domain (in our case, “example”) is wrongly edited, we will be directed to a different website altogether, and if the site does not exist, we get a 404 response.
Other wrong URLS that leads to “Max retries exceeded with url” is “wwt.example.com” and “https://www.example.com “(a white space after .com).
Solution 2: Solving SSLError
As mentioned, the error is caused by an untrusted SSL certificate. The quickest fix is to set the attribute verify=False on requests.get(). This tells requests to send a request without verifying the SSL certificate.
|
requests.get(‘https://example.com’, verify=False) |
Please be aware that the certificate won’t be verified; therefore, your application will be exposed to security threats like man-in-the-middle attacks. It is best to avoid this method for scripts used at the production level.
Solution 3: Solving the “Max retries exceeded with url” error related to an unstable connection
This solution fits cases when you have intermittent connection outages. In these cases, we want requests to be able to carry out many tries on requests before throwing an error. For this case, we can use two solutions:
- Issue timeout argument in requests.get(), or
- Retry connections on connections-related errors
Solution 3a: Issue timeout argument in requests.get()
If the server is overloaded, we can use a timeout to wait longer for a response. This will increase the chance of a request finishing successfully.
|
import requests url = ‘https://www.example.com’ response = requests.get(url, timeout=7) print(response) |
The code above will wait 7 seconds for the requests package to connect to the site and read the source.
Alternatively, you can pass a timeout as a 2-element tuple where the first element is connection timeout (time to establish a connection to the server) and the second value is read timeout (time allowed for the client to read data from the server)
|
requests.get(‘https://api.github.com’, timeout=(3, 7)) |
When the above line is used, a connection must be established within 3 seconds, and data read within 7 seconds; otherwise, requests raise Timeout Error.
Solution 3b: Retry connections on connections-related errors
The requests use the Retry utility in urllib3 (urllib3.util.Retry) to retry connections. We will use the following code to send requests (explained after).
|
import requests from requests.adapters import HTTPAdapter, Retry import time def send_request(url, n_retries=4, backoff_factor=0.9, status_codes=[504, 503, 502, 500, 429]): sess = requests.Session() retries = Retry(connect=n_retries, backoff_factor=backoff_factor, status_forcelist=status_codes) sess.mount(«https://», HTTPAdapter(max_retries=retries)) sess.mount(«http://», HTTPAdapter(max_retries=retries)) response = sess.get(url) return response |
We have used the following parameters on urllib3.util.Retry class:
- connect – the number of connection-related tries. By default, send_request() will make 4 tries plus 1 (an original request which happens immediately).
- backoff_factor – determines delays between retries. The sleeping time is computed with the formula {backoff_factor} * (2 ^ ({retry_number} – 1)). We will work on an example for this argument when calling the function.
- status_forcelist – retry for all connections that resulted in 504, 503, 502, 400, and 429 status codes only (Read more about status codes in https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)
Let’s now call our function and time the execution.
|
# start the timer start_time = time.time() # send a request to GitHub API url = «https://api.github.com/users» response = send_request(url) # print the status code print(response.status_code) # end timer end_time = time.time() # compute the run time print(«Run time: «, end_time—start_time) |
Output:
200 Run time: 0.8597214221954346
The connection was completed successfully (status 200) taking 0.86 of a second to finish. To see the implementation of backoff, let’s try to send a request to a server that does not exist, catch an exception when it occurs and compute execution time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
try: # start execution timer start_time = time.time() url = «http://localhost/6000» # call send_request() method to send a request to the url # this will never be successful because there is no server running # on port 6000. response = send_request(url) print(response.status_code) except Exception as e: # Catch any exception — execution will end here because # requests can’t connect to http://localhost/6000 print(«Error Name: «, e.__class__.__name__) print(«Error Message: «, e) finally: # Pick end time end_time = time.time() # Calculate the time taken to execute. print(«Run time: «, end_time—start_time) |
Output:
Error Name: ConnectionError
Error Message: HTTPConnectionPool(host='localhost', port=80): Max retries exceeded with url: /6000 (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f06a5862a00>: Failed to establish a new connection: [Errno 111] Connection refused'))
Run time: 12.61784315109253
After 4 retries (plus 1 original request) with a backoff_factor=0.9, the execution time was 12.6 seconds. Let’s use the formula we saw earlier to compute sleeping time.
sleeping_time = {backoff_factor} * (2 ^ ({retry_number} – 1))
There are 5 requests in total
- First request (which is made immediately) – 0 seconds sleeping,
- First retry ( which is also sent immediately after the failure of the first request) – 0 seconds sleeping,
- Second retry -> 0.9*(2^(2-1)) = 0.9*2 = 1.8 seconds of sleeping,
- Third retry -> 0.9*(2^(3-1)) = 0.9*4 = 3.6 seconds of sleeping time, and,
- Fourth retry -> 0.9*(2^(4-1)) = 0.9*8 = 7.2 seconds.
That is a total of 12.6 seconds of sleeping time implemented by urllib3.util.Retry. The actual execution time is 12.61784315109253 seconds. The 0.01784315109253 difference, which is not accounted for, is attributable to the DNC and general computer power latency.
Solution 4: Using headers when sending requests
Some websites blocks web crawlers. They notice that a bot is sending requests based on headers passed. For example, let’s run this code and turn on the verbose to see what happened behind the hoods.
|
import http.client # turn verbose on http.client.HTTPConnection.debuglevel = 1 import requests url = ‘https://www.example.com’ response = requests.get(url) |
Output (truncated):
send: b'GET / HTTP/1.1rnHost: www.example.comrnUser-Agent: python-requests/2.28.1rnAccept-Encoding: gzip, deflaternAccept: */*rnConnection: keep-alivernrn' reply: 'HTTP/1.1 200 OKrn'
In that log, you can see that User-Agent is python-requests v2.28.1 and not a real browser. With such identification, you might get blocked and get the “Max retries exceeded with url” error. To avoid this, we need to pass our actual browser as a user-agent. You can go to the following link to get some headers: http://myhttpheader.com/. In that link, my user-agent is “Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0”. Let’s now use that user agent instead.
|
import http.client # Turn verbose on. http.client.HTTPConnection.debuglevel = 1 import requests headers = {‘User-Agent’:‘Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0’} url = ‘https://www.example.com’ response = requests.get(url, timeout=5, headers=headers) |
Output (truncated)
send: b'GET / HTTP/1.1rnHost: www.example.comrnUser-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0rnAccept-Encoding: gzip, deflaternAccept: */*rnConnection: keep-alivernrn' reply: 'HTTP/1.1 200 OKrn'
Conclusion
The “Max retries exceeded with url” error is caused by an invalid URL, server overloading, failed SSL verification, unstable internet connection, and an attempt to send many requests to a server. In this article, we discussed solutions for all these problems using examples.
The key is always to understand the kind of error you have and then pick the appropriate solution.
