 Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Навожу короткую инструкция по мониторингу физических дисков под хардварным LSI 2108 RAID контроллером. Так же эта инструкция может пригодиться для мониторинга дисков под HP/Compaq Smart Array Controller, Areca SATA[/SAS] RAID controller и другими, используя инструмент smart в сочетании с специализированными программами. Перечень контроллеров, за которыми можно мониторить физические диски используя smartctl наведен здесь.
Немного о HDD интерфейсах
Аббревиатуры:
SCSI— Small Computer System Interface
SAS— Serial Attached SCSI
SATA — Serial ATA
ATA — AT Attachment
Чтобы визуально понять как выглядят те, или иные интерфейсы навожу картинки.
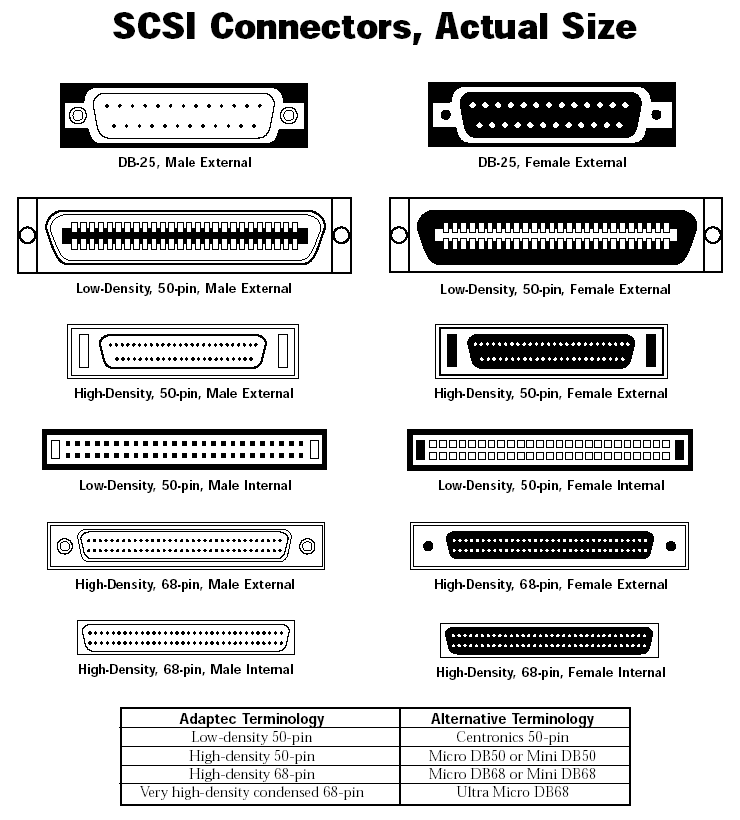

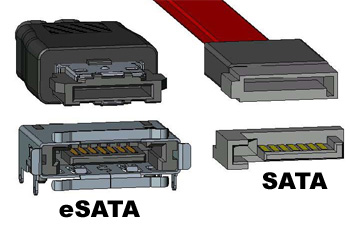

С интерфейсами все понятно, переходим к практике.
Мониторинг дисков используя megacli
Смотрим какие у нас есть диски.
root@il-nv-s06:~# lshw -c disk
*-disk:0
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.0.0
bus info: scsi@0:2.0.0
logical name: /dev/sda
version: 2.90
serial: 0074df64060b7e521510538600800403
size: 2791GiB (2996GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=02712922-3f89-4077-8a1b-2ed197f3c54c
*-disk:1
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.1.0
bus info: scsi@0:2.1.0
logical name: /dev/sdb
version: 2.90
serial: 00405d940d100d0a1810538600800403
size: 54GiB (58GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=992168b5-1ecd-4e43-ab0f-f2e0b945ab27
*-disk:2
description: SCSI Disk
product: SMC2108
vendor: SMC
physical id: 2.2.0
bus info: scsi@0:2.2.0
logical name: /dev/sdc
version: 2.90
serial: 00074cce4a116a071810538600800403
size: 7446GiB (7995GB)
capabilities: gpt-1.00 partitioned partitioned:gpt
configuration: ansiversion=5 guid=92c542ab-7199-4525-89e3-057744b8397d
SMC2108 — означает, что у нас Supermicro MC2108 контроллер. Так же можно убедиться, что у нас Megaraid контроллер используя эту команду.
root@il-nv-s06:~# cat /proc/devices | grep mega 250 megaraid_sas_ioctl
Как видим, у нас LSI SAS MegaRAID контроллер, диски которого можно мониторить используя smartctl или же используя специализированную утилиту megacli. Для начала присмотримся к megacli. В стандартных репозиториях ее нет, но можно скачать с официального сайта и собрать с исходников. Но я рекомендую использовать специальный репозиторий (за который хочу сказать ОГРОМНОЕ спасибо) в котором есть почти весь набор специализированных утилиты под любой тип аппаратных рейдов.
root@il-nv-s06:~# echo 'deb http://hwraid.le-vert.net/ubuntu precise main' > /etc/apt/sources.list.d/raid.list root@il-nv-s06:~# wget -O - http://hwraid.le-vert.net/debian/hwraid.le-vert.net.gpg.key | sudo apt-key add - root@il-nv-s06:~# apt-get update root@il-nv-s06:~# apt-get install megacli
Перечень всех доступных в репозитории утилит наведен здесь
Проверяем на ошибки физический диск megaraid используя megacli.
root@il-nv-s06:~# megacli -pdinfo -physdrv [4:0] -aALL Enclosure Device ID: 4 Slot Number: 0 Drive's position: DiskGroup: 0, Span: 0, Arm: 0 Enclosure position: 1 Device Id: 0 WWN: 5000C5002130CD08 Sequence Number: 2 Media Error Count: 38 Other Error Count: 0 Predictive Failure Count: 0 Last Predictive Failure Event Seq Number: 0 PD Type: SAS Raw Size: 931.512 GB [0x74706db0 Sectors] Non Coerced Size: 931.012 GB [0x74606db0 Sectors] Coerced Size: 930.390 GB [0x744c8000 Sectors] Sector Size: 0 Firmware state: Online, Spun Up Device Firmware Level: 0005 Shield Counter: 0 Successful diagnostics completion on : N/A SAS Address(0): 0x5000c5002130cd09 SAS Address(1): 0x0 Connected Port Number: 0(path0) Inquiry Data: SEAGATE ST31000424SS 00059WK1D042 FDE Capable: Not Capable FDE Enable: Disable Secured: Unsecured Locked: Unlocked Needs EKM Attention: No Foreign State: None Device Speed: 6.0Gb/s Link Speed: 6.0Gb/s Media Type: Hard Disk Device Drive: Not Certified Drive Temperature :29C (84.20 F) PI Eligibility: No Drive is formatted for PI information: No PI: No PI Port-0 : Port status: Active Port's Linkspeed: 6.0Gb/s Port-1 : Port status: Active Port's Linkspeed: Unknown Drive has flagged a S.M.A.R.T alert : No
Как видим, на первом физическом диске есть «Media Error Count: 38». Это означает, что запасные(зарезервированные) сектора для remap(замены) битых секторов диска — закончились. И нужно проводить замену диска.
Так же нужно мониторить следующие параметры используя команду:
root@il-nv-s06:~# megacli -LdPdInfo -aALL | grep -E "(Id|State |Bad Blocks|Firmware state|Error Count|Predictive Failure Count)" # Первый виртуальный диск - он же /dev/sda Virtual Drive: 0 (Target Id: 0) # Статус RAID-a (Degraded - если проблема с одним из дисков; Optimal - нормальный статус) State : Degraded # Наличие бедблоков на виртуальном диске Bad Blocks Exist: No # ID физического диска Device Id: 14 # Количество ошибок, которые нет возможности исправить - самый важный компонент Media Error Count: 0 # Количество иных ошибок не связанных с бедблоками Other Error Count: 0 # Определение количества возможных ошибок Predictive Failure Count: 0 # Статус физического диска (Rebuild - добавляется в RAID; Online - в RAID-e) # Также есть "Failed", "Online, Spun Up", "Online, Spun Down", "Unconfigured(bad)", "Unconfigured(good), Spun down","Hotspare, Spun down", "Hotspare, Spun up" or "not Online". Firmware state: Rebuild Device Id: 1 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Device Id: 2 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Device Id: 3 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Virtual Drive: 1 (Target Id: 1) State : Optimal Bad Blocks Exist: No Device Id: 13 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Media Type: Solid State Device Device Id: 12 Media Error Count: 0 Other Error Count: 0 Predictive Failure Count: 0 Firmware state: Online, Spun Up Media Type: Solid State Device
Теперь напишем маленький скрипт для мониторинга всех нужных параметров включая BBU.
root@il-nv-s06:~# cat megaraid.sh
#!/bin/bash
#Вся информация по физическим и логическим дискам
VD_PDID_ERRORS=`megacli -ldpdinfo -aALL | grep -E "(Id|State |Media Error|Firmware state)"`
#Вся информация по батарее
BBU_OUT=`megacli -AdpBbuCmd -aAll | grep -E "(Full Charge|^Max Error|Battery State)"`
while read line
do
#Ловим название (ID) логического диска
VD=`echo ${line} | grep -Eo "Virtual Drive: [0-9]"`
#Ловим название (ID) физического диска
PD_ID=`echo ${line} | grep -E "Device Id:"`
#Ловим важные ошибки физических дисков
PD_ERRORS=`echo ${line} | grep -E "(Media Error)"`
#Ловим статус рейда
RAID_STAT=`echo ${line} | grep -E "State"`
#Ловим статус прошивки
PD_FIRMWARE=`echo ${line} | grep -E "Firmware"`
if [ -n "${VD}" ]
then
DRIVE="${VD} ==> "
elif [ -n "${RAID_STAT}" ]
then
VD_RAID_STAT=`echo "${RAID_STAT}" | awk '{print $3}'`
VD_RAID="${DRIVE}${RAID_STAT} ==> "
#Если статус рейда отличается от нормального - число ошибок растет
if [ ${VD_RAID_STAT} != 'Optimal' ]
then
#echo "Raid with problem"
VDRIVE_WITH_FAIL="${VD_RAID}
${VDRIVE_WITH_FAIL}"
let "ERROR_COUNT += 1"
fi
elif [ -n "${PD_ID}" ]
then
PD_DRIVE="${DRIVE}${PD_ID} ==> "
elif [ -n "${PD_ERRORS}" ]
then
#Если есть ошибка - ловим их количество
PD_ERR=${PD_DRIVE}${PD_ERRORS}
let "ERROR_COUNT +=`echo ${PD_ERRORS} | awk '{print $4}'`"
TRAP=`echo ${PD_ERRORS} | awk '{print $4}'`
if [ ${TRAP} -ne 0 ]
then
DISK_WITH_FAIL="${PD_ERR}
${DISK_WITH_FAIL}"
fi
elif [ -n "${PD_FIRMWARE}" ]
then
#Проверяем или прошивка в порядке, если нет - число ошибок растет
PD_FIRM_STATUS=`echo "${PD_FIRMWARE}" | cut --delimiter=":" -f2 | sed 's/ //g'`
PD_FIRM=${PD_DRIVE}${PD_FIRMWARE}
if [ ${PD_FIRM_STATUS} != "Online,SpunUp" ]
then
#echo "PD firmware with problem"
PDFIRM_WITH_FAIL="${PD_FIRM}
${PDFIRM_WITH_FAIL}"
let "ERROR_COUNT += 1"
fi
fi
done <<< "${VD_PDID_ERRORS}"
while read bbu_log
do
BBU_STATE=`echo ${bbu_log} | grep -E "Battery State"`
BBU_ERROR=`echo ${bbu_log} | grep -E "Max Error"`
BBU_CHARGE=`echo ${bbu_log} | grep -E "Full Charge"`
if [ -n "${BBU_STATE}" ]
then
BBU_ST=`echo "${BBU_STATE}" | awk '{print $3}'`
#echo ${BBU_ST}
if [ ${BBU_ST} = "Unknown" ]
then
#echo "Battery status is Unknown"
let "ERROR_COUNT = 250"
BBUSU_WITH_FAIL="${BBU_STATE}"
elif [ ${BBU_ST} != "Optimal" ]
then
#echo "Battery STATUS is BAD"
BBUS_WITH_FAIL="${BBU_STATE}"
let "ERROR_COUNT = 251"
fi
elif [ -n "${BBU_ERROR}" ]
then
BBU_ER=`echo ${BBU_ERROR} | awk '{print $4}'`
#echo ${BBU_ER}
if [ "${BBU_ER}" -ge "11" ]
then
#echo "Battery has ERRORS"
BBUE_WITH_FAIL="${BBU_ERROR}"
let "ERROR_COUNT = 252"
fi
elif [ -n "${BBU_CHARGE}" ]
then
BBU_CHAR=`echo ${BBU_CHARGE} | awk '{print $4}'`
#echo ${BBU_CHAR}
if [ "${BBU_CHAR}" -lt "675" ]
then
#echo "Battery has low CHARGE"
BBUC_WITH_FAIL="${BBU_CHARGE}"
let "ERROR_COUNT = 253"
fi
fi
done <<< "${BBU_OUT}"
if [[ -n $1 ]] && [ $1 == 'log' ]
then
echo "${VDRIVE_WITH_FAIL}
${DISK_WITH_FAIL}
${PDFIRM_WITH_FAIL}
${BBUS_WITH_FAIL}
${BBUSU_WITH_FAIL}
${BBUE_WITH_FAIL}
${BBUC_WITH_FAIL} "
else
echo $ERROR_COUNT
fi
exit 0
Данный скрипт проверяет все диски на наличие проблем с прошивкой,состояние рейда,ошибки физических дисков и состояние батареи. Если есть проблема с батареей — код выхода скрипта будет больше 250, если проблемы с остальными устройствами, то будет выведено только количество ошибок. Скрипт запускается без аргументов. Если добавить аргумент log, будет выведено текст с указанием проблемного элемента. Проверяем работу скрипта:
root@il-nv-s06:~# ./megaraid.sh 252 root@il-nv-s06:~# ./megaraid.sh log Max Error = 14 %
Как видим у нас проблема с батареей (BBU) и ее нужно заменить.
По роботе с magacli есть целая книга-руководство.
Из полезных команд:
# Просмотр журнала событий BBU, где можно найти информацию по проверкам и автоисправлению битых секторов megacli -fwtermlog -dsply -aall > /tmp/ttylog.txt # Полная информация о всех адаптеров контроллера megacli -AdpAllInfo -aALL # Полная информация о настройках и дисках megacli -CfgDsply -aALL # Информация о последних событиях, где можно найти информацию о сбои в работе дисков megacli -AdpEventLog -GetLatest 4000 -f events.log -aALL megacli -AdpEventLog -GetEvents -f events.log -aALL # Информация о всех доступных корпусах контроллера megacli -EncInfo -aALL # Список всех логических дисков и типе RAID-а в котором они собраны megacli -LDInfo -Lall -aALL # Список всех физических дисков megacli -PDList -aALL # Информация о конкретном физическом диске # Типовая комманда megacli -pdinfo -physdrv [E1:S2] -aALL # E1 - Enclosure Device ID: 1, S2 - Slot Number: 2 # To get it need to run - megacli -LdPdInfo -aALL | grep -E "ID|Slot" megacli -pdinfo -physdrv [4:2] -aALL # Засветить диск #Start blinking megacli -PdLocate -start -physdrv[4:3] -aALL megacli -PdLocate -start -physdrv[4:2] -aALL megacli -PdLocate -start -physdrv[4:1] -aALL #Stop blinking megacli -PdLocate -stop -physdrv[4:1] -aALL megacli -PdLocate -stop -physdrv[4:2] -aALL megacli -PdLocate -stop -physdrv[4:3] -aALL # Проверка состояния BBU (Battery Backup Unit) megacli -adpbbucmd -aall # Посмотреть прогресс добавления диска в RAID megacli -pdrbld -showprog -physdrv[4:0] -aAll
Мониторинг дисков используя smartctl
Для этого нам понадобиться тот же megacli, используя который, мы узнаем ID физических дисков и соответствующие им логические носители. Начнем.
Узнаем ID всех физических дисков за мегарейд контроллером ну и номера соответствующих логических дисков.
root@il-nv-s06:~# megacli -LdPdInfo -aALL | grep Id Virtual Drive: 0 (Target Id: 0) Device Id: 0 Device Id: 1 Device Id: 2 Device Id: 3 Virtual Drive: 1 (Target Id: 1) Device Id: 13 Device Id: 12 Virtual Drive: 2 (Target Id: 2) Device Id: 11 Device Id: 10 Device Id: 9 Device Id: 6 Device Id: 7 Device Id: 8
Расшифрую эту команду:
- -LdPdInfo — получить информацию(Info) по логическим (Ld) и физическим(Pd) устройствам …
- -aALL — … на всех адаптерах
Теперь видно, что у нас три логических(виртуальных) диска в которые входят по несколько физических дисков с соответствующими ID. Посмотрим на сервере, сколько у нас есть дисков:
root@il-nv-s06:~# ls /dev/sd[a-Z] /dev/sda /dev/sdb /dev/sdc
Все верно, у нас три логических диска в системе. Проводим аналогию с выводом команды megacli:
- Virtual Drive: 0 == /dev/sda и в него входит 4 физических диска с ID=0,1,2,3
- Virtual Drive: 1 == /dev/sdb и в него входит 2 физических диска с ID=13,12
- Virtual Drive: 2 == /dev/sdc и в него входит 6 физических дисков с ID=6,7,8,9,10,11
Теперь нам осталось запустить SMART проверку по каждому с дисков используя собранные данные.
root@il-nv-s06:~# cat smartcheck.sh #!/bin/bash echo "=============================================" echo "================== /dev/sda =================" echo "=============================================" smartctl -d megaraid,0 -a /dev/sda smartctl -d megaraid,1 -a /dev/sda smartctl -d megaraid,2 -a /dev/sda smartctl -d megaraid,3 -a /dev/sda echo "=============================================" echo "================== /dev/sdb =================" echo "=============================================" smartctl -d megaraid,13 -a /dev/sdb smartctl -d megaraid,12 -a /dev/sdb echo "=============================================" echo "================== /dev/sdc =================" echo "=============================================" smartctl -d megaraid,11 -a /dev/sdc smartctl -d megaraid,10 -a /dev/sdc smartctl -d megaraid,9 -a /dev/sdc smartctl -d megaraid,6 -a /dev/sdc smartctl -d megaraid,7 -a /dev/sdc smartctl -d megaraid,8 -a /dev/sdc
К примеру возьмем первый диск.
root@il-nv-s06:~# smartctl -d megaraid,0 -a /dev/sda
smartctl 5.41 2011-06-09 r3365 [x86_64-linux-3.8.0-26-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net
Vendor: SEAGATE
Product: ST31000424SS
Revision: 0005
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Logical block size: 512 bytes
Logical Unit id: 0x5000c5002130cd0b
Serial number: 9WK1D0420000C1051TRW
Device type: disk
Transport protocol: SAS
Local Time is: Fri Feb 7 20:24:25 2014 IST
Device supports SMART and is Enabled
Temperature Warning Enabled
SMART Health Status: OK
Current Drive Temperature: 29 C
Drive Trip Temperature: 68 C
Manufactured in week 32 of year 2010
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 30
Specified load-unload count over device lifetime: 300000
Accumulated load-unload cycles: 2
Elements in grown defect list: 0
Vendor (Seagate) cache information
Blocks sent to initiator = 920579338
Blocks received from initiator = 3734205770
Blocks read from cache and sent to initiator = 2669309657
Number of read and write commands whose size <= segment size = 101596876 Number of read and write commands whose size > segment size = 1211
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 24230.63
number of minutes until next internal SMART test = 20
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 3033913199 210 0 3033913409 3033913469 39052.656 60
write: 0 0 0 0 0 4141.743 0
verify: 75533051 10 0 75533061 75533061 1001.100 0
Non-medium error count: 14
[GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on']
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background long Completed - 24200 - [- - -]
Long (extended) Self Test duration: 11100 seconds [185.0 minutes]
Как видим у нас есть 60 ошибок с которыми не смогла справиться система исправления ошибок.
Немного расшифрую выводу ошибок:
Журнал ошибок (если он доступен) отображается в отдельных строках:
- write error counters — ошибки записи
- read error counters — ошибки считывания
- verify error counters (отображаются только когда не нулевое значение) — ошибки выполнения
- non-medium error counter (определенное число) — число восстанавливаемых ошибок отличных от ошибок записи/считывания/выполнения
Так же может выводиться детальное описание последних ошибок с кодом, если устройство его поддерживает(если нет поддержки — выводиться сообщение «Error Events logging not supported»). К примеру:
Error 3 occurred at disk power-on lifetime: 23855 hours (993 days + 23 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 10 51 08 4c 08 0f e0 Error: IDNF at LBA = 0x000f084c = 985164 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ca 00 08 4c 08 0f 00 08 19d+06:08:39.873 WRITE DMA ca 00 08 5c 05 0f 00 08 19d+06:08:39.873 WRITE DMA c8 00 10 9c a0 25 00 08 19d+06:08:39.866 READ DMA c8 00 08 94 a0 25 00 08 19d+06:08:39.866 READ DMA c8 00 08 8c a0 25 00 08 19d+06:08:39.862 READ DMA
Каждая из ошибок имеет различные коды. Оригинал описания кодов взято из мануала по SCSI Seagate дискам:
Errors Corrected by ECC, fast [Errors corrected without substantial delay: 00h]. An error correction was applied to get perfect data (a.k.a. ECC on-the-fly). «Without substantial delay» means the correction did not postpone reading of later sectors (e.g. a revolution was not lost). The counter is incremented once for each logical block that requires correction. Two different blocks corrected during the same command are counted as two events.
Errors Corrected by ECC: delayed [Errors corrected with possible delays: 01h]. An error code or algorithm (e.g. ECC, checksum) is applied in order to get perfect data with substantial delay. «With possible delay» means the correction took longer than a sector time so that reading/writing of subsequent sectors was delayed (e.g. a lost revolution). The counter is incremented once for each logical block that requires correction. A block with a double error that is correctable counts as one event and two different blocks corrected during the same command count as two events.
Error corrected by rereads/rewrites [Total (e.g. rewrites and rereads): 02h]. This parameter code specifies the counter counting the number of errors that are corrected by applying retries. This counts errors recovered, not the number of retries. If five retries were required to recover one block of data, the counter increments by one, not five. The counter is incremented once for each logical block that is recovered using retries. If an error is not recoverable while applying retries and is recovered by ECC, it isn’t counted by this counter; it will be counted by the counter specified by parameter code 01h — Errors Corrected With Possible Delays.
Total errors corrected [Total errors corrected: 03h]. This counter counts the total of parameter code errors 00h, 01h and 02h (i.e. error corrected by ECC: fast and delayed plus errors corrected by rereads and rewrites). There is no «double counting» of data errors among these three counters. The sum of all correctable errors can be reached by adding parameter code 01h and 02h errors, not by using this total. [The author does not understand the previous sentence from the Seagate manual.]
Correction algorithm invocations [Total times correction algorithm processed: 04h]. This parameter code specifies the counter that counts the total number of retries, or «times the retry algorithm is invoked». If after five attempts a counter 02h type error is recovered, then five is added to this counter. If three retries are required to get stable ECC syndrome before a counter 01h type error is corrected, then those three retries are also counted here. The number of retries applied to unsuccessfully recover an error (counter 06h type error) are also counted by this counter.
Gigabytes processed {10^9} [Total bytes processed: 05h]. This parameter code specifies the counter that counts the total number of bytes either successfully or unsuccessfully read, written or verified (depending on the log page) from the drive. If a transfer terminates early because of an unrecoverable error, only the logical blocks up to and including the one with the uncorrected data are counted. [smartmontools divides this counter by 10^9 before displaying it with three digits to the right of the decimal point. This makes this 64 bit counter easier to read.]
Total uncorrected errors [Total uncorrected errors: 06h]. This parameter code specifies the counter that contains the total number of blocks for which an uncorrected data error has occurred.
С всего этого нас интересует параметр Total uncorrected errors который показывает количество не исправленных ошибок. Если это число велико, то нужно запускать long тест и проверить, дополнительно, параметры физического диска в Megaraid контроллере.
Мониторинг дисков используя smartd
Предыдущие способы мониторинга дисков были ручными, т.е. нужно вручную запускать проверку дисков находясь на конкретном сервере, или же настроить систему мониторинга, которая будет использовать написанные выше скрипты для сбора информации о состоянии дисков. Но есть еще один способ мониторинга — это использование демона smartd, который будет отправлять нам письма о проблемных дисках. Детально о настройках демона smartd можно почитать здесь
Для начала добавим демон в автозагрузку.
root@il-nv-s06:~# cat /etc/default/smartmontools start_smartd=yes smartd_opts="--interval=3600"
Так же было добавлено интервал запуска проверок. Далее нам нужно добавить диски на мониторинг, для чего служит файл smartd.conf.
root@il-nv-s06:~# cat /etc/smartd.conf #Диски, которые нужно мониторить /dev/sda -d megaraid,0 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,1 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,2 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sda -d megaraid,3 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdb -d megaraid,13 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdb -d megaraid,12 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,11 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,10 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,9 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,6 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,7 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) /dev/sdc -d megaraid,8 -o on -S on -m your@emailaddress.com -M diminishing -a -s (S/../.././00|L/../../7/03) root@il-nv-s06:~# /etc/init.d/smartd restart
Немного расшифрую вывод. Для все дисков включено запуск офлайн тестов (-o on) для обновление и сохранения значений атрибутов (-S on). Так же добавлена проверка всех текущих параметров (-а) и назначено запуск дополнительных коротких тестов каждый день в полночь (S/../.././00) и долгих тестов каждое воскресенье с 3 часов ночи (L/../../7/03). Если будет проблема хотя бы с одной из метрик — будет отправлено письмо на соответствующий адрес (-m your@emailaddress.com). При этом письма будут отправляться систематически — 1,2,4,8,16,… дни (-M diminishing), пока проблема не будет устранена.
В следующей статье я постараюсь описать решение проблемы с батареей Megaraid та и любого другого RAID-контролера. Потом поговорим о мониторинге дисков под HP контроллером (HP/Compaq SmartArray)
Модераторы: Trinity admin`s, Free-lance moderator`s
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Появились тормоза при работе с базами 1с, в логах контроллера (LSI 9211-4i) вылезла ошибка «Controller ID: 0 PD Predictive failure: 0». После запустил «check consistency» и огорчился…. многочисленные повторяющиеся ошибки:
«Controller ID: 0 Unexpected sense: PD = 0-No defect spare location available»,
«Controller ID: 0 Consistency Check detected uncorrectable multiple medium errors: (PD -:-:-1 Location 0x4e36990, VD 0)»,
«Controller ID: 0 Unexpected sense: PD = -:-:0-Peripheral device write fault», «Controller ID: 0 Unexpected sense: PD = -:-:0-Unrecovered read error»
«Controller ID: 0 PD Predictive failure: -:-:0»
Полный лог в файле.
На 1 диске Media Error Count: 39, на 0 диске Media Error Count: 0
Контроллер пишет статус «оптимал»
Судя по ошибкам, проблемы сразу на двух дисках. Очень интересует мнение профессионалов, что лучше сделать в данной ситуации? Возможна ли замена только первого диска на котором Media Error Count: 39?
- Вложения
-
-
- DC1_1_17_2017.txt
- лог
- (1.39 МБ) 619 скачиваний
-

Tert
- Advanced member
- Сообщения: 4233
- Зарегистрирован: 19 янв 2003, 08:09
- Откуда: Москва
- Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Tert » 17 янв 2017, 10:23
zaki
Попробуйте заменить кабель от контроллера к дискам.
Если не поможет, то скорее всего надо менять диск. Проверьте его фирменной утилитой Seagate.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 17 янв 2017, 11:35
1)Подскажите пожалуйста, какие именно ошибки указывают на замену кабеля. Не пойму, что и как сломалось в кабеле, т.к. 2 недели назад было все в порядке.
2)Можно поменять только первый диск (id1), где Media Error Count: 39?
Второй диск (id0) можно оставить или нет? По сообщениям ему прогнозируется отказ, проблемы с чтением и записью. На сколько критичны эти предупреждения для данного контроллера и диска?
-
Tert
- Advanced member
- Сообщения: 4233
- Зарегистрирован: 19 янв 2003, 08:09
- Откуда: Москва
- Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Tert » 17 янв 2017, 13:36
zaki
Media Error — это ошибки, возникающие при передаче. Поэтому разумно вначале проверить путь, по которому идут эти данные.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 18 янв 2017, 12:01
По кабелю все понятно…. Еще интересует Ваше мнение по дискам, т.к. ошибок достаточно….
-
Tert
- Advanced member
- Сообщения: 4233
- Зарегистрирован: 19 янв 2003, 08:09
- Откуда: Москва
- Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Tert » 18 янв 2017, 14:56
zaki
О дисках Seagate вас должно интересовать только мнение этой программы ![]() .
.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 19 янв 2017, 10:50
Согласен, но SeaTools for Windows видит только Logical Volume! Эта прога не знает контроллер LSI 9211-4i и не показывает смарт хардов. Программа Hard Disk Sentinel знает контроллер LSI 9211-4i и показывает всю информацию по хардам.
-

Stranger03
- Сотрудник Тринити

- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:

Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Stranger03 » 19 янв 2017, 12:56
zaki писал(а):Согласен, но SeaTools for Windows видит только Logical Volume! Нужна прога, которая знает контроллер LSI 9211-4i и покажет смарт хардов.
Если я правильно понимаю, то LSI 9211-4i — это HBA с возможностью создания простых уровней РАИД массивов, аля Intel ICH. Если бы вы на контроллере не стали делать массивов, а прокинули диски, то софт Сегейта смог бы увидеть физические диски. Но как только на уровне контроллера вы сделали массив, то ни один софт не увидит физический диск. Для этого вам нужен другой контроллер в режиме HBA.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 19 янв 2017, 14:35
Stranger03 писал(а): Если бы вы на контроллере не стали делать массивов, а прокинули диски, то софт Сегейта смог бы увидеть физические диски. Но как только на уровне контроллера вы сделали массив, то ни один софт не увидит физический диск. Для этого вам нужен другой контроллер в режиме HBA.
Софт Сегейта вне массива видит диски, но у меня задача удаленно мониторить состояние смарт дисков состоящих в массиве.
Физические диски в созданном массиве на контроллере LSI 9211-4i видит программа Hard Disk Sentinel Professional Portable v4.71, проверено лично 10 минут назад.
-
Tert
- Advanced member
- Сообщения: 4233
- Зарегистрирован: 19 янв 2003, 08:09
- Откуда: Москва
- Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Tert » 19 янв 2017, 14:41
zaki
С помощью SeaTools надо однократно проверить подозрительный диск, подключив его к другому контроллеру.
Если программа говорит, что диск сбойный, то можете смело нести его в гарантию.
Всякие сторонние программы для гарантийщиков Seagate показателем работоспособности диска не являются.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 19 янв 2017, 15:08
Tert писал(а):zaki
С помощью SeaTools надо однократно проверить подозрительный диск, подключив его к другому контроллеру.
Если программа говорит, что диск сбойный, то можете смело нести его в гарантию.Всякие сторонние программы для гарантийщиков Seagate показателем работоспособности диска не являются.
Гарантия в данный момент не интересует, но спасибо за совет.
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
-
Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Stranger03 » 20 янв 2017, 08:24
zaki писал(а):Софт Сегейта вне массива видит диски, но у меня задача удаленно мониторить состояние смарт дисков состоящих в массиве.
В этом нет никакого смысла. В утилите управления контроллером настройте алерты на почту. Что будет с диском, прога сообщит, в логах будет все видно.
-
zaki
- Junior member
- Сообщения: 13
- Зарегистрирован: 16 янв 2017, 22:58
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
zaki » 20 янв 2017, 12:27
Stranger03 писал(а):
В этом нет никакого смысла. В утилите управления контроллером настройте алерты на почту. Что будет с диском, прога сообщит, в логах будет все видно.
Утилита контроллера давно настроена, логи приходят на почту. Вопрос заключался в том, чтобы в подробностях посмотреть состояние диска (параметры смарт и др.), утилита присылает обобщенную информацию (типо: у диска 0 намечаются проблемы и т.д.)
-
Tert
- Advanced member
- Сообщения: 4233
- Зарегистрирован: 19 янв 2003, 08:09
- Откуда: Москва
- Контактная информация:
Re: Проблема с 2 дисками в RAID1 (LSI 9211-4i)
Сообщение
Tert » 23 янв 2017, 14:30
zaki
Диски, объединенные в массивы, на аппаратных RAID контроллерах обычно недоступны для мониторинга сторонними утилитами.
Только утилитой RAID контроллера. Но обычно этого достаточно.
Вернуться в «Массивы — Технические вопросы, решение проблем.»
Перейти
- Серверы
- ↳ Серверы — Конфигурирование
- ↳ Конфигурации сервера для 1С
- ↳ Серверы — Решение проблем
- ↳ Серверы — ПО, Unix подобные системы
- ↳ Серверы — ПО, Windows система, приложения.
- ↳ Серверы — ПО, Базы Данных и их использование
- ↳ Серверы — FAQ
- Дисковые массивы, RAID, SCSI, SAS, SATA, FC
- ↳ Массивы — RAID технологии.
- ↳ Массивы — Технические вопросы, решение проблем.
- ↳ Массивы — FAQ
- Майнинг, плоттинг, фарминг (Добыча криптовалют)
- ↳ Proof Of Work
- ↳ Proof Of Space
- Кластеры — вычислительные и отказоустойчивые ( SMP, vSMP, NUMA, GRID , NAS, SAN)
- ↳ Кластеры, Аппаратная часть
- ↳ Deep Learning и AI
- ↳ Кластеры, Программное обеспечение
- ↳ Кластеры, параллельные файловые системы
- Медиа технологии, и цифровое ТВ, IPTV, DVB
- ↳ Станции видеомонтажа, графические системы, рендеринг.
- ↳ Видеонаблюдение
- ↳ Компоненты Digital TV решений
- ↳ Студийные системы, производство ТВ, Кино и рекламы
- Инфраструктурное ПО и его лицензирование
- ↳ Виртуализация
- ↳ Облачные технологии
- ↳ Резервное копирования / Защита / Сохранение данных
- Сетевые решения
- ↳ Сети — Вопросы конфигурирования сети
- ↳ Сети — Технические вопросы, решение проблем
- Общие вопросы
- ↳ Обсуждение общих вопросов
- ↳ Приколы нашего IT городка
- ↳ Регистрация на форуме

Когда нужно обеспечить быстродействие и надежность дисковой системы, а также возможность горячей замены дисков без выключения сервера, большую помощь окажут дисковые контроллеры с кэш памятью и защитным аккумулятором, такие как MegaRAID. Новые версии этих контроллеров есть на сайте https://www.broadcom.com/products/storage/raid-controllers.
Для надежной работы дисковой системы сервера необходимо настроить мониторинг контроллера и подключенных к ним дисков. В этой статье вы найдете практическое руководство, которое позволит вам организовать такой мониторинг для контроллера MegaRAID с помощью Zabbix.
При этом вы будете использовать программу zabbix_sender, с помощью которой, без преувеличения, можно настроить мониторинг практически чего угодно. В данном случае для получения данных мониторинга мы будем использовать программу MegaCli.
Приемы, описанные в этой статье, вы сможете использовать для мониторинга других контроллеров или устройств, если не найдете для них готовых шаблонов на сайте https://www.zabbix.com/integrations.
Установка программы MegaCli
Вы можете загрузить архив с программой MegaCli для многих платформ, включая Linux и Windows, на сайте https://www.broadcom.com, например, по этой ссылке: https://docs.broadcom.com/docs/12351587. Мы расскажем о том, как установить программу MegaCli в ОС Debian 11 из репозитория le-vert.net, где есть утилиты для различных контроллеров RAID. Также приведем инструкцию по установке для CentOS и FreeBSD.
Установка MegaCli в ОС Debian 11
Чтобы установить программу MegaCli в ОС Debian 11, нужно подключить репозиторий le-vert.net. Для этот добавьте в файл /etc/apt/ sources.list следующую строку:
deb http://hwraid.le-vert.net/debian bullseye mainПосле этого добавьте ключ, обновите пакеты и установите программу:
# wget -O - http://hwraid.le-vert.net/debian/hwraid.le-vert.net.gpg.key | apt-key add -
# apt update
# apt install megacliПосле установки проверьте версию программы:
# megacli -v
MegaCLI SAS RAID Management Tool Ver 8.07.14 Dec 16, 2013
(c)Copyright 2013, LSI Corporation, All Rights Reserved.Обратите внимание, что мы запускаем программу megacli, а не MegaCli.
После установки можно отключить репозиторий. Для этого закройте в файле /etc/apt/sources.list символом комментария добавленную строку и обновите пакеты:
# apt updateУстановка MegaCli в CentOS
Если нужно установить программу MegaCli в CentOS, прежде всего скачайте нужный пакет:
# wget --user=hetzner --password=download http://download.hetzner.de/tools/LSI/tools/MegaCLI/8.07.14_MegaCLI.zipДалее установите утилиту unzip, если ее нет на сервере:
# yum install unzipРаспакуйте пакет и установите программу megacli следующим образом:
# unzip 8.07.14_MegaCLI.zip
# cd Linux
# rpm -i MegaCli-8.07.14-1.noarch.rpm
# ln -s /opt/MegaRAID/MegaCli/MegaCli64 /usr/bin/megacliПроверьте версию установленной программы:
# megacli -V
MegaCLI SAS RAID Management Tool Ver 8.07.14 Dec 16, 2013
(c)Copyright 2013, LSI Corporation, All Rights Reserved.Установка MegaCli в ОС FreeBSD
Выполните установку MegaCli из портов ОС FreeBSD. Для этого сначала обновите порты:
# portsnap fetch updateЗатем установите программу MegaCli следующим образом:
# cd /usr/ports/sysutils/megacli
# make installПроверьте версию установленной программы:
# MegaCli -vОбратите внимание, что в отличие от Debian и CentOS, в командном приглашении FreeBSD нужно запускать команду MegaCli, а не megacli.
Мониторинг состояния массива RAID с контроллером MegaRAID вручную
Прежде чем мы займемся настройкой мониторинга дискового массива RAID с контроллером MegaRAID с помощью Zabbix, выполним основные процедуры диагностики вручную из командной строки.
Проверка состояния массива RAID
Для проверки массива RAID, созданного контроллером как виртуальное дисковое устройство, используйте команду megacli с параметром -LDInfo (в ОС FreeBSD запустите команду MageCli):
# megacli -LDInfo -LALL -aALLЭта команда покажет важную информацию о виртуальном дисковом устройстве (RAID-массиве):
Adapter 0 -- Virtual Drive Information:
Virtual Drive: 0 (Target Id: 0)
Name :
RAID Level : Primary-1, Secondary-0, RAID Level Qualifier-0
Size : 557.861 GB
Sector Size : 512
Mirror Data : 557.861 GB
State : Optimal
Strip Size : 64 KB
Number Of Drives : 2
Span Depth : 1
Default Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU
Current Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU
Default Access Policy: Read/Write
Current Access Policy: Read/Write
Disk Cache Policy : Disabled
Encryption Type : None
Is VD Cached: No
Number of Dedicated Hot Spares: 1
0 : EnclId - 4 SlotId - 2В данном случае сконфигурировано зеркало из двух дисков объемом 557.861 ГБайт каждый.
Если массив находится в оптимальном состоянии, и данные останутся в сохранности при выходе из строя одного из дисков, то значение параметра State будет равно Optimal.
Также обратите внимание на параметр политики кэширования Current Cache Policy.
Если ваш контроллер оснащен аккумулятором, защищающим кэш-память контроллера от внезапного отключения электропитания, то по умолчанию при нормальном заряде и емкости аккумулятора контроллер использует отложенный режим записи WriteBack.
В этом случае контроллер сообщает о том, что данные записаны, сразу после того, как они оказываются в кэше контроллера, еще до завершения фактической записи данных на диск. Этот режим сильно ускоряет запись данных, но он безопасен только при нормальном состоянии аккумулятора.
Если аккумулятор контроллера разряжен в результате запуска периодической тренировки или в результате исчерпания ресурса, то режим отложенной записи WriteBack отключается и включается режим прямой записи WriteThrough:
Default Cache Policy: WriteBack, ReadAheadNone, Direct, No Write Cache if Bad BBU
Current Cache Policy: WriteThrough, ReadAheadNone, Direct, No Write Cache if Bad BBUВ этом режиме контроллер будет дожидаться завершения процесса записи на диск перед тем, как сообщить программе о завершении операции записи.
Политика дискового контроллера Default Cache Policy, установленная по умолчанию, предполагает отключение кэша записи при неисправном или разряженном аккумуляторе. Если кэш не отключить, что в случае аварии с электропитанием можно потерять данные, находящиеся в кэше, но еще не записанные на диск. В этом случае велика вероятность повреждения файловой системы.
Проверка состояния аккумулятора
Дисковый контроллер MegaRAID может быть оснащен блоком батарейного (на самом деле аккумуляторного) питания (рис. 1).

На рис. 2 показан литий-ионный аккумулятор упомянутого выше блока. Новые версии контроллеров оснащаются не литий-ионными аккумуляторами, а супер-конденсаторами (ионисторами), имеющими большой срок службы.

Для проверки состояния аккумулятора используйте следующую команду:
# megacli -AdpBbuCmd -aAllЭта команда выведет на консоль довольно обширную информацию. На что нужно обратить внимание в первую очередь?
Прежде всего, параметр Battery State должен быть равен Optimal. Если это не так, то с контроллером что-то случилось. В лучшем случае поможет запуск обучения аккумулятора, в худшем — блок аккумулятора придется заменить.
Если контроллер по какой-то причине не запустил автоматическое обучение, может появиться строка с сообщением о необходимости запуска обучения вручную:
Battery State: Degraded(Need Attention)
A manual learn is required.В этом случае запустите обучение с помощью такой команды:
# megacli -AdpBbuCmd -BbuLearn -aAllЕсли обучение запустилось, вы увидите сообщение на консоли:
Adapter 0: BBU Learn Succeeded.Теперь чтобы отслеживать процесс обучения, время от времени выдавайте команду «megacli -AdpBbuCmd -aAll». Контролируйте состояние заряда или разряда аккумулятора Charging Status, запрос цикла обучения Learn Cycle Requested, его активность Learn Cycle Active и текущее состояние обучения Learn Cycle Status:
Charging Status : Discharging
Learn Cycle Requested : Yes
Learn Cycle Active : Yes
Learn Cycle Status : OKЗаметим, что обучение может выполняться долго, не один час, так что запаситесь терпением. Со временем, после того как аккумулятор в процессе обучения полностью разрядится, начнется его зарядка. Статус Charging Status изменится на Charging.
Еще один важный параметр аккумуляторного блока, это количество циклов обучения Cycle Count. Его можно посмотреть так:
# megacli -AdpBbuCmd -aAll | grep "Cycle Count"
Cycle Count: 4062Этот параметр показывает степень износа аккумуляторов. В приведенном выше примере аккумуляторный блок давно нужно было заменить.
Просмотр свойств контроллера
Следующая команда выведет на консоль информацию обо всех дисковых контроллерах MegaRAID, установленных на сервере:
# megacli -AdpAllinfo -aAllЗдесь можно увидеть название контроллера Product Name и его серийный номер Serial No, что может пригодиться при обращении в сервис.
Вы можете узнать, оснащен ли контроллер блоком аккумуляторов (поле BBU) и определить размер кэш памяти, количество и состояние сконфигурированных виртуальных дисков Virtual Drives, количество и состояние физических дисков Disks, возможности контроллера и его параметры по умолчанию.
Подробное описание этой информации выходит за рамки нашей статьи. Хорошее описание команды megacli можно найти в руководстве MegaRAID SAS Software User Guide, доступном по адресу https://docs.broadcom.com/docs/12353236.
Просмотр свойств дисков
Со временем жесткие диски, как и диски SSD, могут выходить из строя. Если на сервере установлен контроллер MegaRAID, то список подключенных физических дисков и их состояние можно легко узнать так:
# megacli -PDList -aAllПосле запуска команды на консоли появится множество различных параметров и их значения. Параметр Enclosure Device ID содержит идентификатор места расположения, по которому вы сможете адресоваться к диску при выполнении с ним различных операций. Вам также потребуется номер слота Slot Number.
Ниже мы показали команды, с помощью которых можно быстро узнать упомянутый выше идентификатор и номер:
# megacli -PDList -aAll | grep "Enclosure Device ID"
Enclosure Device ID: 252
Enclosure Device ID: 252
Enclosure Device ID: 252
# megacli -PDList -aAll | grep "Slot Number"
Slot Number: 0
Slot Number: 1
Slot Number: 2Параметр Firmware state очень важен — анализируя его, можно узнать состояние диска:
# megacli -PDList -aAll | grep "Firmware state"
Firmware state: Unconfigured(bad)
Firmware state: Online, Spun Up
Firmware state: Online, Spun UpЗдесь видно, что первый диск, для которого Enclosure Device ID равен 252, а номер слота Slot Number находится в аварийном состоянии и не сконфигурирован для работы в массиве. Остальные два диска работают нормально.
Если вам нужен новый диск на замену, то типы дисков, подключенных к контроллеру, можно узнать так:
# megacli -PDList -aAll | grep "Inquiry Data"
Inquiry Data: SEAGATE ST3600057SS 00063SL098QA
Inquiry Data: SEAGATE ST3600057SS 00063SL09XZ1
Inquiry Data: SEAGATE ST3600057SS 00063SL09EVPКак видите, используются диски Seagate, указана модель и серийный номер. Для замены нужно приобрести такой же или совместимы диск.
Чтобы посмотреть детальную информацию о диске, укажите следующей команде идентификатор Enclosure Device ID и номер слота Slot Number:
# megacli -PDInfo -PhysDrv[252:0] -aAllБудет полезной информация о количестве ошибок на диске:
# megacli -PDInfo -PhysDrv[252:0] -aAll | grep Error
Media Error Count: 3
Other Error Count: 2Если появились такие ошибки, то диск скоро может выйти из строя.
Контроллер время от времени запускает тестовое чтение дисков (Patrol Read) с целью обнаружения потенциальных проблем.
С помощью следующих двух команд вы можете инициировать запуск тестового чтения и посмотреть его состояние:
# megacli -AdpPR Start -aAll
# megacli -AdpPR Info -aAllДругие полезные команды
Если вы заменили вышедший из строя диск, контроллер автоматически запускает перенос на него данных. Эта операция называется CopyBack, а ее состояние можно узнать следующим образом:
# megacli -PDCpyBk -ShowProg -PhysDrv[252:0] -aAll
Copyback Progress on Device at Enclosure 4, Slot 0 Completed 28% in 192 Minutes.Также может оказаться полезной команда добавления диска в горячий резерв:
# megacli -PDHSP -set -PhysDrv[252:3] -a0При выходе из строя одного из дисков массива его роль будет играть резервный диск, причем копирование данных на него запустится автоматически.
И, наконец, приведем еще одну полезную команду — чтение журнала контроллера:
# megacli -AdpAlILog -aAll > lsi_log.txtСодержимое журнала будет записано в файл, который можно проанализировать или отдать для анализа в сервис.
Программа zabbix_sender
Программа с названием zabbix_sender позволяет передавать данные на сервер Zabbix без использования агента zabbix_agent. Если подготовить для нее данные в виде текстового файла, то она сможет передать сразу несколько элементов данных на сервер Zabbix через порт 10050.
Установка программы zabbix_sender
Во второй статье нашей серии про Zabbix мы рассказывали о том, как установить программу zabbix_sender. Нужно установить репозиторий Zabbix, а затем выполнить установку:
# wget https://repo.zabbix.com/zabbix/6.2/debian/pool/main/z/zabbix-release/zabbix-release_6.2-1+debian11_all.deb
# dpkg -i zabbix-release_6.2-1+debian11_all.deb
# apt update
# apt install zabbix-senderПосле установки проверьте версию zabbix_sender:
# zabbix_sender -VЕсли на сервере установлена ОС FreeBSD, то программа zabbix_sender будет установлена вместе с агентом Zabbix из порта /usr/ports/net-mgmt/zabbix6-agent.
Подготовка файла с данными для zabbix_sender
Если вам нужно передать на сервер Zabbix несколько элементов данных, то нужно подготовить текстовый файл такого вида:
d207 lsi.isOptimal 1
d207 lsi.WriteBack 0
d207 lsi.OnlineDriveCount 2
d207 lsi.HotspareDriveCount 0
d207 lsi.BatteryReplacementRequired No
d207 lsi.RemainingCapacityLow Yes
d207 lsi.RaidDriveHasErrors 1
d207 lsi.PredictiveFailureCount 0
d207 lsi.CycleCount 107Здесь в каждой строке следует указать через пробел имя хоста, как оно было задано при добавлении в мониторинг, далее имя элемента данных, указанное в шаблоне, созданном для мониторинга этих элементов данных, а также значение элемента данных.
В данном случае в файл записаны данные, полученные от контроллера MegaRAID с помощью утилиты megacli и скрипта, составленного на языке Perl.
Запуск программы zabbix_sender
Для запуска программы zabbix_sender с целью передачи содержимого файла со значениями параметров мы используем следующую команду:
/usr/bin/zabbix_sender -vv -z xxx.xxx.xxx.xxx -i /home/frolov/zabbix_lsi/zabbix_data.txtЗдесь вместо xxx.xxx.xxx.xxx в параметре -z нужно указать адрес IP вашего сервера Zabbix. Параметр -vv позволяет при запуске программы увидеть на консоли детали выполнения операции. И, наконец, параметр -i задает путь к файлу со значениями элементов данных.
Программа check_lsi.pl для сбора и отправки данных мониторинга MegaRAID
Чтобы получить данные от контроллера MegaRAID, сформировать текстовый файла с результатами мониторинга и отправить эти данные на сервер Zabbix с помощью программы zabbix_sender, мы подготовили программу check_lsi.pl.
Эту программу, а также соответствующий шаблон check_lsi.xml для Zabbix вы найдете на GitHub по адресу https://github.com/AlexandreFrolov/shop2you_zabbix_monitoring.
Расскажем кратко о программе check_lsi.pl.
Инициализация
На этапе инициализации программа check_lsi.pl получает первые три параметра командной строки:
my $zabbix_server_ip = $ARGV[0];
my $hostname = $ARGV[1];
if($ARGV[2] eq 'debug') { $debug = 1; } else { $debug = 0; }Через первый параметр программе передается адреса IP серверов Zabbix, на которые нужно отправить данные мониторинга контроллера MegaRAID и подключенных к нему дисков. Если серверов Zabbix несколько, разделите адреса запятой.
Второй параметр задает имя хоста, к которому подключен контроллер. Это имя должно совпадать с именем соответствующего хоста на сервере Zabbix.
И, наконец, третий параметр позволяет включить вывод отладочной информации на консоль, и при обычном запуске он не используется.
Также при инициализации программа check_lsi.pl определяет версию ОС, на которой ее запустили. В зависимости от версии программа записывает в переменную $zabbix_sender различные пути для Linux и FreeBSD.
Получение состояния MegaRAID и дисков
На этапе получения состояния контроллера и дисков программа выдает команду megacli с параметром -LDInfo, о которой мы говорили выше:
my $cmd;
$cmd = "$bin_megacli -LDInfo -LALL -aALL";
my @rqout = ();
@rqout = split /n/, `$cmd`;
my $isOptimal = 0;
my $WriteBack = 0;
foreach my $line (@rqout)
{
next if ($line eq "" or !defined $line);
if($line=~/State/ && $line=~/Optimal/) { $isOptimal = 1; }
if($line=~/Current Cache Policy/ && $line=~/WriteBack/) { $WriteBack = 1; }
}Здесь программа проверяет, находится ли дисковый массив в оптимальном состоянии, и используется ли режим отложенной записи. Результат сохраняется в переменных isOptimal и WriteBack, соответственно.
Проверка состояния дисков
Далее программа выдает команду megacli с параметром -PDList для получения информации обо всех дисках:
$cmd = "$bin_megacli -PDList -aALL";В программе определяются переменные:
my $MediaErrorCount = 0; // количество ошибок на диске
my $OtherErrorCount = 0; // количество прочих ошибок
my $PredictiveFailureCount = 0; // счетчик предупреждений о возможных сбоях
my $OnlineDriveCount = 0; // счетчик дисков в состоянии онлайн
my $HotspareDriveCount = 0; // счетчик дисков горячего резерва
my $DeviceId = 0; // идентификатор диска
my $raid_drive_has_errors = 0; // признак наличия ошибок в на диске
my $HasPredictiveFailureCount = 0; // признак наличия предупреждений о возможных сбояхПрограмма предпринимает несколько попыток выдачи команды -PDList:
my $retry_count = 2;
do
{
@rqout = ();
@rqout = split /n/, `$cmd`;
my $responce_array_size = $#rqout;
if ($responce_array_size < 3) # PDList cmd failed
{
$retry_count -= 1;
sleep(10);
}
else
{
$retry_count = 0;
}
} while ($retry_count > 0);Если команда выполнилась успешно, программа анализирует полученные от нее данные и устанавливает соответствующим образом состояние перечисленных выше переменных:
foreach my $line (@rqout)
{
if($line=~/Device Id/)
{
($str, $DeviceId) = split(/:/, $line);
$MediaErrorCount = 0;
$OtherErrorCount = 0;
$PredictiveFailureCount = 0;
}
if($line=~/Media Error Count/) { ($str, $MediaErrorCount) = split(/:/, $line); }
if($line=~/Other Error Count/) { ($str, $OtherErrorCount) = split(/:/, $line); }
if($line=~/Predictive Failure Count/) { ($str, $PredictiveFailureCount) = split(/:/, $line); }
if($MediaErrorCount != 0 || $OtherErrorCount != 0 || $PredictiveFailureCount != 0)
{
$drive_with_errors{$DeviceId} = { MediaErrorCount => $MediaErrorCount, OtherErrorCount => $OtherErrorCount, PredictiveFailureCount => $PredictiveFailureCount };
$raid_drive_has_errors = 1;
}
if($PredictiveFailureCount != 0)
{
$HasPredictiveFailureCount = 1;
}
if($line=~/Firmware state/ && $line=~/Online/) { $OnlineDriveCount += 1; }
if($line=~/Firmware state/ && $line=~/Hotspare/) { $HotspareDriveCount += 1; }
}Проверка состояния блока аккумуляторов
Для получения состояния блока аккумуляторов, установленных на контроллере MegaRAID, программа выдает команду megacli с параметром -AdpBbuCmd:
$cmd = "$bin_megacli -AdpBbuCmd -aAll";
@rqout = ();
@rqout = split /n/, `$cmd`;
my $BatteryReplacementRequired = 'No';
my $RemainingCapacityLow = 'No';
my $CycleCount=0;
foreach my $line (@rqout)
{
if ($debug) { print $line."n"; }
if($line=~/Battery Replacement required/) { ($str, $BatteryReplacementRequired) = split(/:/, $line); }
if($line=~/Remaining Capacity Low/) { ($str, $RemainingCapacityLow) = split(/:/, $line); }
if($line=~/Cycle Count/) { ($str,$CycleCount) = split(/:/, $line); }
}По результатам анализа программа записывает в переменную BatteryReplacementRequired строку «Yes», если есть необходимость замены блока аккумуляторов.
В переменная RemainingCapacityLow будет записано предупреждение, если емкость аккумуляторной батареи стала низкой.
Что касается переменной CycleCount, то в ней сохраняется текущее значение счетчика циклов обучения аккумуляторного блока.
Запись данных в файл и отправка на сервер Zabbix
Теперь, когда все данных подготовлены, программа check_lsi.pl записывает их в файл:
open(my $fh, '>', $zabbix_sender_data_file) or die "Не могу открыть '$zabbix_sender_data_file' $!";
print $fh $hostname." lsi.isOptimal ".$isOptimal."n";
print $fh $hostname." lsi.WriteBack ".$WriteBack."n";
print $fh $hostname." lsi.OnlineDriveCount ".$OnlineDriveCount."n";
print $fh $hostname." lsi.HotspareDriveCount ".$HotspareDriveCount."n";
print $fh $hostname." lsi.BatteryReplacementRequired ".$BatteryReplacementRequired."n";
print $fh $hostname." lsi.RemainingCapacityLow ".$RemainingCapacityLow."n";
print $fh $hostname." lsi.RaidDriveHasErrors ".$raid_drive_has_errors."n";
print $fh $hostname." lsi.PredictiveFailureCount ".$HasPredictiveFailureCount."n";
print $fh $hostname." lsi.CycleCount ".$CycleCount."n";
close $fh;После этого файл отправляется на все серверы Zabbix, адреса которых были заданы в командной строке через запятую:
my @zabbix_server_ip_array = split(',', $zabbix_server_ip);
foreach my $server_ip (@zabbix_server_ip_array)
{
my $trap_cmd = $zabbix_sender.' -vv -z '.$server_ip.' -i '.$zabbix_sender_data_file;
my @trapout = ();
@trapout = split /n/, `$trap_cmd`;
}Запуск check_lsi.pl через crontab
Для запуска программы check_lsi.pl мы используем crontab. В этом примере проверка запускается каждый час:
0 * * * * /usr/bin/perl /home/frolov/zabbix_lsi/check_lsi.pl xxx.xxx.xxx.xx1,xxx.xxx.xxx.xx2 d207В командной строке заданы адреса IP двух серверов Zabbix, на которые отправляются данные, а также имя хоста, на котором установлен контроллер MegaCLI.
Файл шаблона для мониторинга MegaCLI
Шаблон для программы check_lsi.pl вы найдете по адресу https://github.com/AlexandreFrolov/shop2you_zabbix_monitoring/blob/main/check_lsi.xml. Вам необходимо подключить этот шаблон к серверу, на котором установлен контроллер MegaCLI.
На рис. 3 показаны элементы данных, определенных в этом шаблоне.

Как видите, здесь имеются все элементы, которые получает и отправляет на сервер Zabbix только что описанная программа check_lsi.pl.
В шаблоне также определены триггеры (рис. 4).

Очень высокая степень важности (High) задана для триггеров, указывающих на деградацию массива RAID, а также на снижение количества дисков в состоянии Online ниже двух (в нашем случае используется зеркало из двух дисков и третий диск горячего резерва).
Менее важные триггеры указывают на необходимость замены блока аккумуляторов.
Также обратите внимание на триггер No LSI heartbeats within last 1.5 hour, для срабатывания которого проверяется следующее выражение:
nodata(/Shop2YOU LSI/lsi.isOptimal,5400s)=1Триггер срабатывает, если данные мониторинга не приходили от сервера дольше чем полтора часа. Так как мы запускаем программу check_lsi.pl через задание crontab раз в час, то этот триггер сообщит нам, что по какой-то причине мониторинг состояния контроллера и дисков не отработал.
Для других триггеров установлена минимальная степень важности Information. Например, триггеры BBU Remaining Capacity Low и Mode changed from WriteBack to WriteThrough могут срабатывать при периодическом выполнении цикла обучения, когда аккумулятор сначала разряжается, а потом снова заряжается. Нет необходимости обращать внимание системного администратора на запуск процесса обучения.
Если сработал триггер Predictive Failure Count, то это также не приведет к немедленному риску потери информации, однако является поводом для более глубокого анализа состояния контроллера и массива.
Аналогично, сообщение Some Raid Drives has Errors сообщает, что на дисках есть ошибки, но сами по себе диски с ошибками могут работать довольно долго (а могут и быстро выйти из строя).
Разумеется, для мониторинга своей системы вы можете установить другие степени важности триггеров, а также выбрать другую периодичность запуска программы check_lsi.pl.
Автор: Александр Фролов.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Процесс замены вышедшего из строя физического диска на сервере с аппаратным RAID контроллером

Прежде всего определим тип RAID-контроллера.
В данном примере будет рассмотрен вариант с LSI, для других типов будут отдельные статьи, когда под рукой окажется свободный котроллер другой модели.
00:1f.2 RAID bus controller: Intel Corporation C600/X79 series chipset SATA RAID Controller (rev 06)
07:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS 2108 [Liberator] (rev 05)
После определения типа контроллера приступим к установке утилиты для работы с ним.
(ПО обновляется, поэтому актуальную версию проверяйте на официальном сайте LSI.)
Проверяем состояние RAID
State : Degraded
Выводим информацию о состоянии дисков:
Enclosure Device ID: 25
Slot Number: 12
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3SJKY0825BA58
Enclosure Device ID: 25
Slot Number: 13
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3SJSY0825BA58
Enclosure Device ID: 25
Slot Number: 14
Media Error Count: 0
Other Error Count: 1233
Firmware state: Failed
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3SSL60825BA58
Enclosure Device ID: 25
Slot Number: 15
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ47FF1
Enclosure Device ID: 25
Slot Number: 16
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ47GS5
Enclosure Device ID: 25
Slot Number: 17
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ684J5
Enclosure Device ID: 25
Slot Number: 18
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ60R8S
Enclosure Device ID: 25
Slot Number: 19
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ47JG1
Enclosure Device ID: 25
Slot Number: 20
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ47FKV
Enclosure Device ID: 25
Slot Number: 21
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ67CCL
Enclosure Device ID: 25
Slot Number: 22
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: SEAGATE ST3300657SS 00086SJ67CLB
Enclosure Device ID: 25
Slot Number: 23
Media Error Count: 0
Other Error Count: 0
Firmware state: Online, Spun Up
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3R65E0825BA58
Как видно из лога, то проблема с одним из дисков:
Enclosure Device ID: 25
Slot Number: 14
Media Error Count: 0
Other Error Count: 1233
Firmware state: Failed
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3SSL60825BA58
Также можно вывести полную информацию по дискам подключенным к контроллеру:
...
Enclosure Device ID: 25
Slot Number: 14
Drive's postion: DiskGroup: 0, Span: 1, Arm: 0
Enclosure position: 0
Device Id: 29
WWN: 5000C50043E6C068
Sequence Number: 3
Media Error Count: 0
Other Error Count: 1233
Predictive Failure Count: 136
Last Predictive Failure Event Seq Number: 69159
PD Type: SAS
Raw Size: 279.396 GB [0x22ecb25c Sectors]
Non Coerced Size: 278.896 GB [0x22dcb25c Sectors]
Coerced Size: 278.464 GB [0x22cee000 Sectors]
Firmware state: Failed
Device Firmware Level: BA58
Shield Counter: 0
Successful diagnostics completion on : N/A
SAS Address(0): 0x5000c50043e6c069
SAS Address(1): 0x0
Connected Port Number: 0(path0)
Inquiry Data: IBM-ESXSST3300657SS BA586SJ3SSL60825BA58
IBM FRU/CRU: 44W2235
FDE Enable: Disable
Secured: Unsecured
Locked: Unlocked
Needs EKM Attention: No
Foreign State: None
Device Speed: 6.0Gb/s
Link Speed: 6.0Gb/s
Media Type: Hard Disk Device
Drive Temperature :28C (82.40 F)
PI Eligibility: No
Drive is formatted for PI information: No
PI: No PI
Drive's write cache : Disabled
Port-0 :
Port status: Active
Port's Linkspeed: 6.0Gb/s
Port-1 :
Port status: Active
Port's Linkspeed: Unknown
Drive has flagged a S.M.A.R.T alert : Yes
Enclosure Device ID — идентификатор блока;Slot Number — Номер слота физического диска.
Заменяем проблемный диск
Если диск в состоянии Online (в нашем случае Failed), то переводим в состояние Offline.
Adapter: 0: EnclId-25 SlotId-14 state changed to OffLine.
Отметим диск, как извлеченный
EnclId-25 SlotId-14 is marked Missing.
Получаем информацию об извлеченном(-ых) диске(-ах):
Adapter 0 - Missing Physical drives
No. Array Row Size Expected
0 1 0 285148 MB
Подсвечиваем диск, который требуется заменить:
Adapter: 0: Device at EnclId-25 SlotId-14 -- PD Locate Start Command was successfully sent to Firmware
Если возникла проблема с подсветкой, то используем лампочку активности в качестве индикации:
Adapter 0: Set Use Disk Activity For Locate to Enabled success.
Удаляем диск из RAID
Prepare for removal Success
После этого выполняем процедуру физической замены диска(-ов).
В случае с новым диском, если он содержит метаданные от старого RAID массива, эти данные необходимо затереть.
Проверяем их наличие:
megacli -CfgForeign -Scan -a0
Если таковые имеются, то удаляем следующей их командой:
(к счастью у меня такого добра не обнаружилось)
megacli -CfgForeign -Сlear -a0
Выполняем замену (нам потребуются значения параметров Array и Row из предыдущего пункта)
Adapter: 0: Physical drive in array 1 at row 0 is not missing.
И запускаем Rebuild нового диска:
Cannot Rebuild Physical Drive at Enclosure - 25, Slot - 14.
FW error description:
The specified device is in a state that doesn't support the requested command.
Если получаем эту ошибку при выполнении команды, то Rebuild запустился автоматически.
Проверяем статус Rebuild и оставшееся время до окончания:
Rebuild Progress on Device at Enclosure 25, Slot 14 Completed 38% in 10 Minutes.
Ну и не забываем отключить индикацию диска:
Adapter: 0: Device at EnclId-25 SlotId-14 -- PD Locate Stop Command was successfully sent to Firmware
Бонусы
Отключение звукового оповещения до перезагрузки
megacli -AdpSetProp AlarmSilence -a0
Включение и выключение звукового оповещения навсегда:
megacli -AdpSetProp AlarmEnbl -a0
megacli -AdpSetProp AlarmDsbl -a0
Проверка приоритета ребилда:
Adapter 0: Rebuild Rate = 30%
Изменяем приоритет ребилда в % соотношении:
Adapter 0: Set rebuild rate to 80% success.