
-
#1
Девайс: SSD Silicon Power P34A80 NVMe M.2 1 Tb. Использовался и в ПК, и иногда в доке ASUS Arion.
Под спойлером собственно инфа по S.M.A.R.T. из CrystalDiskInfo:

На диске VST/сэмплы/контактовые библы. Т.е. данные, в принципе, восстановимы и уникальными не являются, если что. Critical warning пока не ругается, однако, стоит ли мне начинать переживать?
Накопал данные, что гарантия на этот SSD аж 5 лет. Оно как вообще работает, интересно?
-
#3
@Jafaroff, все нормально, но бесперебойник компу не помешает. Выполните chkdsk /f
-
#4
Я не был бы столь оптимистичен. Если начали сыпаться Media Errors — ничего хорошего в этом нет…
стоит ли мне начинать переживать?
Смотрите за смартом, насколько будет прогрессировать количество Media Errors, если на диске что-то есть важное, бакапы не помешают, да и они вообще никогда не мешают, особенно в случаях с использованием SSD.
Оно как вообще работает, интересно?
Если в чеке от магазина прописано 5 лет, значит, если что, в магазин сдавать. Если прописано меньше, то остальное к производителю.
-
#5
Я не был бы столь оптимистичен. Если начали сыпаться Media Errors — ничего хорошего в этом нет…
Эти ошибки не критичны — причины их появления, обычно, некорректное завершение работы. Но не известны ни динамика, ни начальные значения — пустое.
А вот количество переназначенных секторов действительно имеет значение. Но данная величина не показана, но сама диагностика говорит что все ОК. Никакой гарантии не надо.
Наблюдение за рав величинами без пороговых значений сродни наблюдению за кругами в лужах.
-
#6
причины их появления, обычно, некорректное завершение работы.
Каким образом Вы установите по какой именно причине посыпались ошибки media errors, а если не от некорректного завершения работы? Мой пример, при наличии пары десятков некорректных завершений — media errors 0. А банальное гугление по media errors расскажет, как у людей умирали самсунги с появлением и нарастанием media errors при остаточном ресурсе 100%.
-
#7
как у людей умирали самсунги.
У самсунгов своя история. Тут это при чем?
-
#8
но бесперебойник компу не помешает
Вообще, я удивился этой цифре чуток, если честно, она не от ПК скорее всего, а от дока NVMe/USB возникла, думаю.
Собственно, вот:
E:>chkdsk /f
Тип файловой системы: NTFS.
Не удается заблокировать текущий диск.
Невозможно выполнить команду Chkdsk на этом томе, т.к. том используется другим
процессом. Чтобы запустить Chkdsk, вначале следует отключить этот том.
ВCE ОТКРЫТЫЕ ДЕСКРИПТОРЫ ТОМА БУДУТ ДАЛЕЕ НЕВЕРНЫ.
Подтверждаете отключение тома? [Y(да)/N(нет)] y
Том отключен. ВCE ОТКРЫТЫЕ ДЕСКРИПТОРЫ ТОМА СТАЛИ НЕВЕРНЫ.
Метка тома: VST&Samples SSD.
Этап 1. Проверка базовой структуры файловой системы…
Обработано записей файлов: 1058048.
Проверка файлов завершена.
Длительность фазы (Проверка записи файла): 6.82 с.
Обработано больших файловых записей: 3560.
Длительность фазы (Восстановление потерянной файловой записи): 0.00 мс.
Обработано поврежденных файловых записей: 0.
Длительность фазы (Проверка поврежденной файловой записи): 0.38 мс.
Этап 2. Проверка связей имен файлов…
Обработано записей повторного анализа: 228.
Обработано записей индекса: 1122442.
Проверка индексов завершена.
Длительность фазы (Проверка индексов): 8.52 с.
Проверено неиндексированных файлов: 0.
Длительность фазы (Переподключение потерянного элемента): 343.38 мс.
Восстановлено неиндексированных файлов в утерянное и найденное: 0.
Длительность фазы (Восстановление потерянного элемента в раздел «Потерянные и найденные»): 1.02 мс.
Обработано записей повторного анализа: 228.
Длительность фазы (Проверка точки повторного анализа и ИД объекта): 4.38 мс.
Этап 3. Проверка дескрипторов безопасности…
Проверка дескрипторов безопасности завершена.
Длительность фазы (Проверка дескриптора безопасности): 1.41 мс.
Обработано файлов данных: 32197.
Длительность фазы (Проверка атрибута данных): 0.42 мс.
Windows проверила файловую систему и не обнаружила проблем.
Дальнейшие действия не требуются.
1000072191 КБ всего на диске.
656934876 КБ в 443629 файлах.
124260 КБ в 32199 индексах.
64 КБ в поврежденных секторах.
1154859 КБ используется системой.
65536 КБ занято под файл журнала.
341858132 КБ свободно на диске.
4096 байт в каждой единице распределения.
Всего единиц распределения на диске: 250018047.
Доступно единиц распределения на диске: 85464533.
Общая длительность: 15.70 с (15706 мс).
-
#10
@Jafaroff, заодно не забудьте провереть актуальность прошивки — апдейтами решаются проблемы.
-
#11
SP есть собственный диагностический пакет
Воспользовался им. Сделал быструю и полную проверку родным софтом — он ничего не нашёл, badblocks тоже 0. По поводу здоровья диска SP Toolbox даёт цифру в 99,79%, по шкале Critical/Warning/Good в упор до Good, прошивка самая свежая. В общем, судя по всему, тревога отменяется, раз родная софтина ничего не предвещает плохого. Да и, в общем-то, CrystalDiskInfo не особо ругался.
Спасибо
Кстати, хотел спросить совета, тоже к вопросу о хранилищах и носителях.
Я купил ноутбук Lenovo Legion S7 (Ryzen 7 5800H, 1 TB SSD NVMe, 32 GB RAM, 3050 Ti 4 GB и прочее). Думал все VST/сэмплы/библы держать как раз на том SSD NVMe M.2 1 TB, который как раз в шапке и указан был, с использованием внешнего дока ASUS Arion на USB 3.2g2. В работе выяснилось, что это не очень-то и удобно (каждый раз присоединять к ноутбуку док), в итоге пихнул всё рабочее на SSD самого ноутбука.
Теперь осталось решить вопрос — куда закинуть все свои рабочие проекты? Нормально ли для этого использовать как раз имеющиеся ASUS Arion + тот Silicon Power P34A80 NVMe M.2 1 TB? Была мысль купить внешний USB HDD 3.0 там, допустим, но тогда, получается, будет зря валяться док и SSD. Данные все, мои, разумеется, не будут находиться в единственном экземпляре на доке с SSD, они у меня продублированы на 2 жёстких диска 5400, лежащих на полке.
-
#12
куда закинуть все свои рабочие проекты?
Если есть и не нужен привод ДВД, можно его заменить на адаптер для SSD. У меня в ноуте два места под SSD, плюс — я сделал такую замену, оч удобно. А привод ДВД есть внешний.

How SSDs Fail – NVMe™ SSD Management, Error Reporting, and Logging Capabilities
How SSDs Fail – NVMe™ SSD Management, Error Reporting, and Logging Capabilities

By Jonmichael Hands, NVMe MWG Co-Chair, Intel
NVMe™ technology was built from the ground up for SSDs, and the original NVMe specification included a standard SMART (Self-Monitoring, Analysis and Reporting Technology) log that monitored errors, device health, and endurance. At the time, SAS/SATA drives had SMART capability, but it was vendor specific (tools had to parse data by vendor) and the data wasn’t widely trusted. I can’t understate how important this was in NVMe architecture– creating an industry standard SMART log page that contained the most common information needed to monitor an SSD. Ultimately, it was a tool to help vendors maintain accountability for accurate and correct data reporting.
Many capabilities have been built into NVMe technology since, including enhance error reporting, logging, management, debug, and telemetry. These capabilities can be built into tools ranging from open source management tools to OEM management consoles to help support monitor the status and health of the SSD (like notifying users when an SSD failure occurs). More importantly, customers want to ensure smooth and normal operation of their SSD and be able to understand where and why things are failing and when it does happen.
Management tools, log pages, endurance monitoring and more can help identify and pinpoint when a device fails, the number of errors and type of errors. These errors could include hardware failure, integrity errors, media errors, temperature issues and more. Before we dive into specifics on the capabilities of NVMe technology, it is important to understand how SSDs fail, then we can use the tools to help predict and prevent them. SSD failures generally fall into these categories
- System incompatibility – In this situation, there is nothing wrong with the SSD, but compatibility bugs are preventing normal operation. An example would be a system hang or no enumeration of the SSD. A customer would generally return an SSD to the manufacturer if this happened.
- SSD Endurance – SSD endurance is finite and writing data will eventually wear out an SSD. Good news is that this can be accurately predicted and modeled by understanding the workload and the SSD, and NVMe technology can report the statistics to monitor this in real time.
- Firmware errors – SSD firmware is complex and must handle many corner cases of workloads and states for transferring data. SSD vendors try to eliminate as many firmware issues as possible prior to going to production, but perfect validation and verification can’t catch all firmware issues. Firmware failures account for the majority of SSD failures!
- Media Errors – there are many different classes of SSDs, some with end-to-end data protection, power loss protection, and redundancy within the SSD media through RAID, XOR, or other technologies. But NAND flash and other storage and memory classes do have failures, and too many will cause the SSD to stop functioning
- Hardware errors – capacitors, resistors, and power management circuits can fail. These are rarer but are more catastrophic when they do happen.
Log Pages
Log Pages are maintained in the SSD and can be read by host software at any time. Below are the various log pages NVMe technology utilizes:
- Error Log Page
The Error Log Pages are used to log all errors so that no errors go unreported or missing. NVMe drives maintain an error log page that records all errors that happen. This log page maintains important information regarding the number of errors, which queue they came from, and which data and namespaces were affected. This is critical into identifying problematic drives and root causing what in the system may be causing errors.
- SMART Log Page
The SMART log page is used to report on general health information about the drive. Its main health indicator is called the critical warning, which warns of a problem in the drive. The NVMe drive will then inform the host on the type of issue. Issues could mean the drive is in a degraded or read only mode due to media errors, the drive is currently exceeding the temperature threshold or there could be a hardware failure. The SMART log page also works to summarize the error log page for media or data integrity errors and lists the number of unsafe shutdowns caused by power loss events. Lastly, the SMART page is useful to monitor endurance. By checking the SMART Percentage Used field, a system integrator can view the SSD life left as an easy to read percentage of total life used/available. To best utilize this feature, vendors can set an available spares field to send a notification to the host when spares are below a certain threshold.
- Persistent Event Log
Added in the NVMe 1.4 specification, the Persistent Event Log can be compared to a black box recorder for the SSD. This works to log events occurring on the SSD such as errors, updating firmware, formatting, and more so that they are legible to humans and timestamped. This is extremely useful to an OEM or OS vendor looking to identify and manage their device and pinpoint when a specific event or failure happened. Those interested in learning more about the Persistent Event Log can visit the “Changes in NVMe Revision 1.4” webpage.

- Telemetry – adding debug capability to NVMe technology
Telemetry enables SSD vendors / manufactures to collect internal logs upon device failure. Standard human readable logs are encouraged here due to IP and internal data collection sensitivity from customers. The command can be either host or controller initiated, but generally makes sense for a host (customer in this case) to read out the telemetry log when a device fails and send that to an SSD vendor or OEM that they purchased it from for further analysis. As we saw from the introduction, firmware issues are a major cause of SSD failures, and a telemetry log allows vendors to get to the root cause when failures occur in the field.
Event and Error Reporting
Along with log pages, many NVMe specification features work to report errors and operation failures. These reports help identify each specific type of error and how to recover the controller, drive and operating system.
- Asynchronous Event Request
Asynchronous events are used to notify host software of the status, error and health information of various events. NVMe controllers or drives report an event to the host software when an error occurs, attributes on the drive change, a SMART change, or a management event is completed. The most important capability here is for the NVMe controller (drive in most cases) can notify the host asynchronously when a critical warning happens, and the operating system or system console can immediately report this to the user. To find out more details about the types of events defined, visit page 96 of the NVMe 1.4 specification.
- Operation failures
The NVMe specification includes a section dedicated to the error reporting and recovery for use of the controller/drive, driver and operating system use. This is mostly used for device drivers and host software systems to identify critical failures of the NVM subsystems and NVMe controllers. This section can be found on page 400 of the NVMe 1.4 specification.
- Rebuild Assist
Rebuild assist was added as an option in the NVMe 1.4 specification. Rebuild Assist defines a new Get LBA Status capability that identifies potentially unrecoverable LBAs to the host. This status is used to determine what LBAs on a device need recovered by the host from another location and re-written. One of the top use cases for rebuild assist can help replace background data scrubs for SSDs, since the SSD firmware is generally already doing this analysis internally and now has a way to report this to the host. The host generally has redundant copies of data and now has an opportunity to recover the data from a valid copy.
Management
Management capability of NVMe Management Interface™ (NVMe-MI™) technology is critical for enterprise, cloud, and data center deployments. These are especially useful for OEMs that support multiple operating systems and benefit from one management console, which is a value add to end customers.
- NVMe-MI Specification
The NVMe-MI specification manages NVMe SSDs outside of the operating system through the SMBUS/MCTP and PCIe/VDMs interface. NVMe-MI architecture uses baseboard management controllers to check inventory, monitory for errors, track SMART log and endurance and report these through a management console. To learn more about the NVMe-MI specification, we invite you to read our NVMe-MI technology blog for a more in-depth explanation of its features and benefits. NVMe-MI really sets the NVMe standard apart from other storage interfaces by providing an entire specification dedicated to management of the storage devices.

Testing
Testing features are useful to conduct diagnostics and ensure NVMe technology has been properly implemented.
- Device Self-Test Command
The Device Self-Test command feature, defined on page 107 of the NVMe 1.4 specification, allows the host to start either a short or long self-test to be run for offline diagnostics. OEMs, ODMS and system integrators often use this command feature when integrating a new NVMe SSD into a larger system. One example would be at a system integrator or factory, they obtain SSDs from an SSD vendor and put them into a larger server, and then proceed to run the self-test command to ensure the drives are all functioning correctly. The NVMe specification includes an informative figure containing an example device self-test, pictured below.

How Can You Get Involved?
As we have seen, NVMe technology has a robust suite of features and capabilities to help monitor, manage and deploy NVMe SSDs at scale. As an open standards organization, NVM Express is constantly improving and getting real feedback from SSD vendors, OEMs, ODMs, and hyperscale cloud service providers on what matters in real world deployments. To keep up with this feedback and the evolving storage landscape, NVM Express updates its specifications by adding needed features such as Persistent Event Log, the NVMe Management Interface and more. This year, we look forward to continuing to augment NVM Express technology and making the end-user experience both simple and seamless.
Members interested in contributing their expertise to the NVM Express specifications are encouraged to join one of our NVM Express Working Groups.
In my fallback server I have a Samsung 970 evo disk that reports the following:
root@lair ~]# smartctl -a /dev/nvme0
smartctl 7.0 2018-12-30 r4883 [x86_64-linux-3.10.0-1062.1.2.el7.x86_64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: Samsung SSD 970 EVO 500GB
Serial Number: S466NB0K405934V
Firmware Version: 1B2QEXE7
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 500,107,862,016 [500 GB]
Unallocated NVM Capacity: 0
Controller ID: 4
Number of Namespaces: 1
Namespace 1 Size/Capacity: 500,107,862,016 [500 GB]
Namespace 1 Utilization: 229,721,784,320 [229 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 5481b24802
Local Time is: Thu Oct 10 13:14:44 2019 CEST
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x005f): Comp Wr_Unc DS_Mngmt Wr_Zero Sav/Sel_Feat Timestmp
Maximum Data Transfer Size: 512 Pages
Warning Comp. Temp. Threshold: 85 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 6.20W — — 0 0 0 0 0 0
1 + 4.30W — — 1 1 1 1 0 0
2 + 2.10W — — 2 2 2 2 0 0
3 — 0.0400W — — 3 3 3 3 210 1200
4 — 0.0050W — — 4 4 4 4 2000 8000
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 37 Celsius
Available Spare: 94%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 10,122,289 [5.18 TB]
Data Units Written: 34,031,482 [17.4 TB]
Host Read Commands: 212,554,037
Host Write Commands: 1,166,877,653
Controller Busy Time: 4,563
Power Cycles: 40
Power On Hours: 10,440
Unsafe Shutdowns: 8
Media and Data Integrity Errors: 12
Error Information Log Entries: 14
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 37 Celsius
Temperature Sensor 2: 42 Celsius
Error Information (NVMe Log 0x01, max 64 entries)
No Errors Logged
I know how to read smart data for sata disks, but I have no experience with nvme. I am worried about the
Media and Data Integrity Errors: 12
Yesterday I noticed that there were a few errors reported, but after reading the whole disk with dd the error count increased to 11, another dd read today added one more error.
Does this mean that my NVME SSD is dying? It is not much over one year old and pretty lightly used. Should I get it replaced? Is this a warranty case?
Вы тут: Главная → Popular → Как разобраться в атрибутах SMART вашего SSD и перестать бояться за ресурс диска
Владея твердотельным накопителем несколько лет, вы уже вряд ли беспокоитесь о сроке его службы, однако износ SSD волнует умы всех новичков. Чтобы развеять их сомнения, сегодня я покопаюсь в отчетах SMART своих дисков, а с гиками мы будем вычислять ресурс NAND и мультипликатор WA.

Ваши отчеты в комментариях придадут картине объема и послужат для моего статистического анализа. Этот материал входит в серию из четырех статей:
- Как работает NAND, от чего зависит срок ее службы, почему он отличается у разных типов памяти, как с этим борются изготовители SSD
- Ситуация на рынке флэш-памяти, современные накопители с 2D NAND и 3D NAND
- Как интерпретировать атрибуты SMART для анализа объемов записи на диск и его срока жизни (эта запись)
- Какой объем данных записывается на диск в повседневной работе (анализ предоставленных вами данных)
[+] Сегодня в большой программе
Контроллер SSD ведет учет параметров SMART. Ресурс накопителя определяется и гарантируется по объему записи операционной системы, вне зависимости от реального объема записи во флэш-память. Соответствующий атрибут SMART называется по-разному, но все вертится вокруг Host Writes. Вы можете посмотреть отчет SMART фирменной утилитой или сторонними программами.
Программы изготовителей
Преимущества: верные описания атрибутов SMART в соответствии с документацией, управление фирменными технологиями
В фирменных утилитах описания атрибутов всегда соответствуют действительности. Кроме того, программы изготовителей SSD всегда показывают десятичные ИД атрибутов и нередко только их указывают в документации. В зависимости от производителя, программы отличаются интерфейсом, функциональными возможностями и принципами работы. Но у всех объем записи можно увидеть, даже не открывая атрибуты SMART.
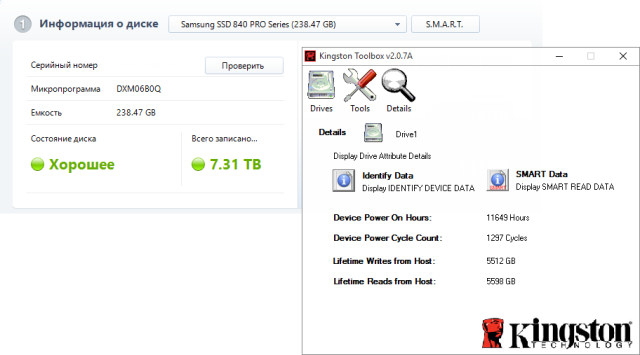
Увеличить рисунок
Управление фирменными технологиями возможно только в родных утилитах. У Samsung хорошее ПО: обновление прошивки, резервная область – все работает четко. Со службой RAPID, которая перехватывает запись, ни разу было проблем. Я даже забыл о ее существовании и заинтересовался, что же это у меня потребляет столько памяти  Но в интерфейсе регулярно встречаются нестыковки.
Но в интерфейсе регулярно встречаются нестыковки.
Увеличить рисунок
У некоторых изготовителей не просто утилиты, а целыe программные комплексы. У Crucial год назад даже самой простенькой программы не было, зато теперь Storage Executive весом 120MB!
Так или иначе, все самое интересное в параметрах SMART, а их всегда можно посмотреть в любой профильной программе.
Сторонние утилиты
Преимущества: универсальность, малые размеры
Я не буду ходить дальше CrystalDiskInfo (CDI), которая вполне всеядна, но может спотыкаться на новых дисках, особенно когда параметры SMART не задокументированы производителем. Ошибки разработчика тоже нельзя сбрасывать со счетов, поэтому всегда скачивайте свежую версию.1
У CDI есть несколько тонкостей, которые раскрыты в инструкции по сбору данных.
Как правильно просматривать и собирать данные SMART в CrystalDiskInfo
Чтобы ориентироваться в цифрах, включите десятичные значения: Сервис → Дополнительно → RAW-значения → 10 [DEC].
Чтобы исключить ошибки перевода атрибутов SMART, поставьте: Язык → SMART по-английски.
Копирование текста
При стандартных настройках в отчет попадает много шума, но от него легко избавиться.
- Сервис → Скрыть серийный номер
- Правка → Опции копирования → снять все флажки
- Ctrl + C
Скриншот
Растяните окно по вертикали, чтобы были видны все атрибуты → PrtScr.
Как ориентироваться в данных SMART
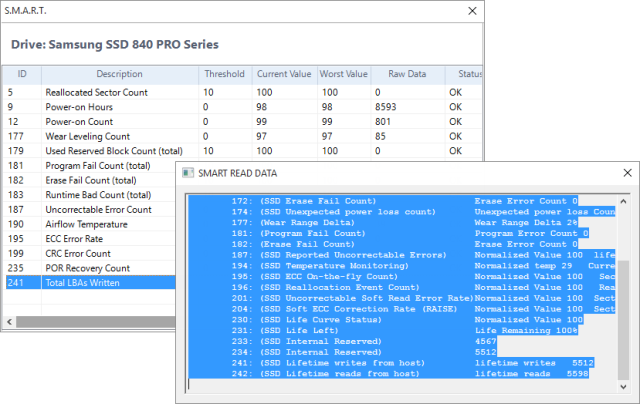
Проще всего объяснить на примере атрибута часов работы в Samsung 840 Pro.
![]()
- Атрибут (Attribute). В большинстве случаев название атрибута говорит само за себя. Особые случаи будем разбирать ниже.
- RAW-значения (RAW Values). Если вы не забыли выставить десятичные значения ↑, все будет понятно. Мой диск Samsung проработал 8671 час.
- Текущее (Current). Для большинства атрибутов – это оставшийся ресурс в процентах. Год непрерывной работы съел лишь 2% ресурса.
- Наихудшее (Worst). Худшее из всех зафиксированных значений. Для большинства атрибутов равно текущему, но не для температуры, например.
- Порог (Threshold). Минимально допустимое значение. При его достижении диск считается ненадежным и может выйти из строя.
Что означают данные SMART, связанные со сроком службы SSD
Фирменные и сторонние утилиты выводят упрощенные сведения, и зачастую этого достаточно.
Но у SMART много интересных атрибутов, поэтому давайте разбираться. Чтобы не гадать, нужно сверяться с документацией, которая идет в комплекте с фирменной утилитой в справке или прилагается в PDF, либо выложена в разделе поддержки на сайте изготовителя. Конечно, там все на английском, поэтому использую только английские название атрибутов, несмотря на локализацию CDI.
Список ссылок на документацию SMART производителей SSD
Добавляйте в комментариях ссылки на описание атрибутов ваших дисков.
- Samsung (справка к утилите Magician, веб-сайт)
- Kingston (SandForce)
- Crucial (M5xx, M600, MXxxx)
Атрибуты объема записи в NAND
Давайте посмотрим, как определяют ключевой параметр разные изготовители.
Total LBAs Written / Total Host Sector Writes
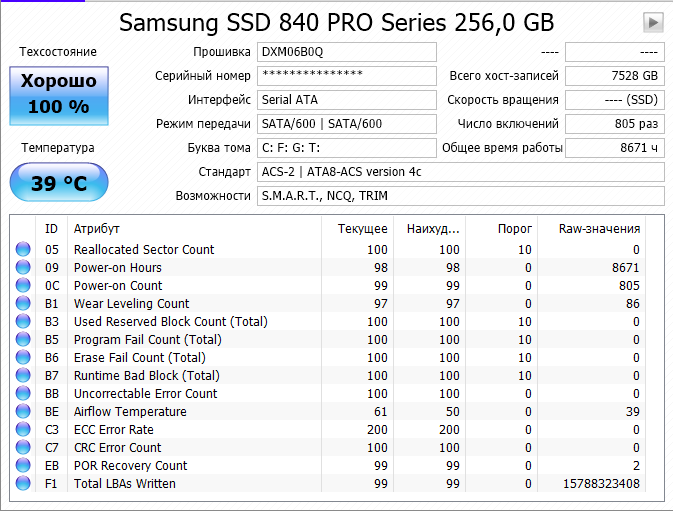
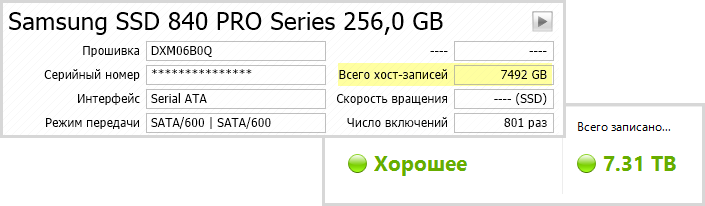
Некоторые изготовители считают количество блоков LBA (Samsung, Crucial). Чтобы получить значение в байтах, надо умножить на 512. На Samsung 840 Pro записано 7.3TB.
![]()
Здесь попутно указывается текущее значение [в процентах], поэтому можно грубо оценить износ накопителя. Но для оценки срока жизни есть специальные атрибуты, которые мы рассмотрим ниже.
Lifetime Writes from Host
Этот атрибут используется в дисках на SF. Указывается значение в гигабайтах2 или в байтах, по количеству цифр понятно. На Kingston Hyper-X 3K записано 5.5TB
![]()
Заметьте, что здесь процент износа оценить невозможно.
Атрибуты износа и срока службы NAND
В SMART всех дисков есть конкретный показатель износа или процент оставшегося здоровья SSD.
Percent Lifetime Remaining / SSD Life Left
Оставшийся процент жизни SSD. 5.5TB – ничто.

Wear Leveling Count / Media Wearout Indicator
Износ NAND. У Samsung (на картинке) и Intel соответственно этот атрибут отражает количество пройденных циклов перезаписи (RAW Values) и текущий уровень жизни SSD в процентах.
![]()
Ниже с помощью этого показателя мы определим ресурс NAND в 840 Pro и 840 EVO.
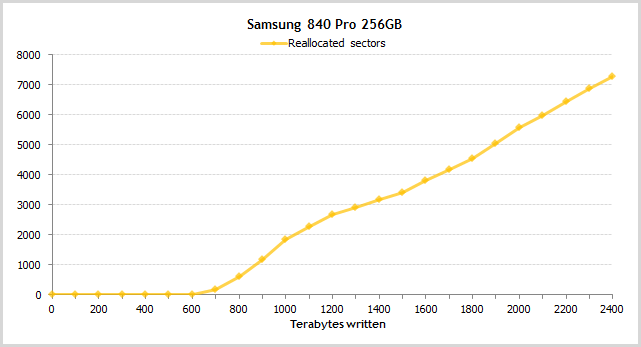
Used Reserved Block Count (total) и Reallocated Sector Count
Количества использованных резервных блоков и переназначенных секторов. Чтобы здесь испортить идеальные показатели, нужно очень много записывать. Так, победитель эксперимента над шестью SSD 840 Pro начал заметно использовать резервные блоки только после записи 600TB. Обратите внимание, что WLC опустился до нуля на 500TB.
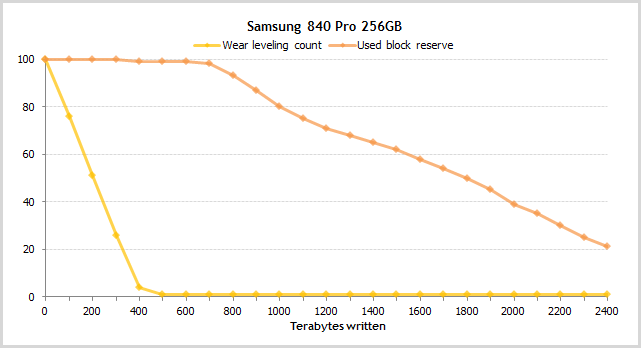
А вот так на картинках хорошо видна связь количества использованных резервных блоков и переназначенных секторов.
Вычисляем ресурс NAND (количество циклов перезаписи)
Зная число пройденных циклов и процент износа, можно подсчитать количество циклов P/E, которые выдерживает память. По науке, надо последовательно записать терабайт десять, сопоставляя каждое падение счетчика WLC на единицу с объемом записанных данных. Но можно прикинуть, усреднив значения двух 840 Pro с MLC NAND, которые у нас с братом из одной партии. Для сравнения с ними добавлены два 840 EVO 120GB с самым большим износом из комментариев
| Модель Samsung |
Износ (WLC) |
Записано |
Пройдено циклов P/E | Ресурс циклов P/E3 | Ресурс записи в NAND4 |
|---|---|---|---|---|---|
| 840 Pro | 3% | 7.3TB | 86 | Среднее: 3058 | Среднее: 250TB |
| 840 Pro | 2% | 5.2TB | 65 | ||
| 840 EVO | 7% | 10.3TB | 75 | Среднее: 1123 | Среднее: 160TB |
| 840 EVO | 8% | 14TB | 94 |
Таблица высвечивает пару любопытных особенностей:
- Samsung не озвучивала выносливость флэш-памяти 840 Pro в циклах P/E, в отличие от Kingston. Но ресурс NAND у обоих накопителей одинаковый – 3 000 циклов или 3K.
- У 840 EVO ресурс памяти соответствует TLC NAND — 1 000 циклов. Ожидаемо, расчетный ресурс записи в терабайтах ниже, чем у 840 PRO, но не в три раза.
Из результатов эксперимента выше видно, что даже израсходовав ресурс, во флэш-память можно записать очень много данных. Но на практике при нуле процентов жизни диск надо срочно менять.
Вычисляем мультипликатор увеличения записи
Вы уже видели эти показатели выше глазами CDI в контексте срока жизни SSD, но сейчас я хочу обратить ваше внимание на атрибуты без описаний, причем в фирменной утилите.

О назначении параметров я догадался сам, а потом нашел подтверждения в сети (это как раз тот случай, когда легче искать информацию по десятичному номеру атрибута утилиты изготовителя). Обратите внимание, что значения атрибутов 234 и 241 совпадают, т.е. 234 – это тоже объем записи на диск. Значение 233 меньше, а диск – SandForce, главной особенностью которого является сжатие данных контроллером. Все сходится!
Атрибут 233 – это NAND Writes!
Если диск выводит объем записи во флэш-память, можно вычислить соотношение физической записи в NAND к логической записи ОС — мультипликатор WA.
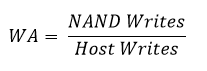
Для накопителя Kingston WA=4567/5512=0.8. Он меньше 1, т.е. сжатие действительно экономит ресурс SSD. В презентациях SandForce заявляла 0.5, впрочем.
Давайте теперь посмотрим на диск без сжатия – типичный для 2015-2016 годов накопитель на MLC NAND 16nm с контроллером Marvell на примере Crucial MX100.5 В отсутствие сжатия идеальное значение WA равно 1. У Crucial мультипликатор вычисляется немного сложнее.
| ИД | Атрибут | RAW-значение |
|---|---|---|
| 247 | Host program page count | 277655968 |
| 248 | Background program page count | 2665992986 |
ИД 247 – это операции программирования ячеек, исходящие от ОС, т.е. аналог Host Writes. ИД 248 – это операции контроллера в дополнение к записям ОС. Поэтому NAND Writes = ИД 247 + ИД 248. В документации формула дается после упрощения дроби: WA=1+(ИД 248/ИД 247).
Даже без вычислений видно, что физических операций на порядок больше логических записей ОС. Точный WA= (277655968+2665992986)/277655968=10.6. Это многовато, на форумах Crucial я не видел WA>6. Скорее всего, такой большой мультипликатор связан с условиями эксплуатации диска – он регулярно забивался скачанными фильмами на протяжении большей части службы. Но, думаю, сценарий “один диск SSD 256GB в ноутбуке” достаточно распространен.
3 года назад, опираясь на характеристики HyperX 3K при записи «один объем диска в день», я оценивал срок службы накопителя в 8 лет. Тогда я брал WA=10, а фактический мультипликатор оказался в 12 раз меньше. Однако для более нового SSD Crucial десятикратное увеличение объема записи в NAND оказалось реальностью. Переходим к объемам записи.
Какой объем записи гарантируют изготовители
Я уже поднимал этот вопрос, но за несколько лет технологии изменились. Давайте посмотрим на гарантийные сроки и объем записи в дисках трех изготовителей памяти и одного ОЕМа.
В таблице все диски укомплектованы 2D NAND за исключением Samsung серий 850 и 950. TBW (Terabytes Written) – означает общий объем записи в TB. Гарантия может ограничиваться сроком или объемом записи.
| Изготовитель / Модель |
Гарантийный срок |
Гарантийный объем |
|---|---|---|
| Samsung | ||
| 950 Pro 256/512GB | 5 лет | 200/400TBW |
| 850 Pro 128&256/512+GB | 10 лет | 150/300TBW |
| 850 EVO 120&250/500+GB | 5 лет | 75/150TBW |
| 840 Pro 128/256/512GB 6 | 5 лет | 73TBW |
| Crucial | ||
| MX200 250/500/1000GB | 3 года | 80/160/320TBW |
| MX100 128/256/512GB 7 | 3 года | 72TBW |
| Intel | ||
| 750 Series 400/800/1200GB | 5 лет | 125TBW 8 |
| 730 Series 240/480GB | 5 лет | 89/125TBW 9 |
| Kingston | ||
| HyperX Savage 120/240/480/960GB | 3 года | 113/306/416/681TBW |
| V300 120/240/480GB | 3 года | 64/128/256TBW |
Как вы заметили, некоторые изготовители дают гарантию в объеме дневной записи. В начале 2013 года в потребительских дисках 128GB гарантировали 3-5 лет при объеме записи 20GB в день.
В 2016 году минимальная гарантия для диска объемом 256GB составляет около 73TB – это 5 лет по 40GB записи в день. (Kingston неизменно щедрее изготовителей NAND). Если вы покупаете более емкий диск, как правило, возрастает и гарантийный объем записи, а вот срок – реже.
Сколько записывается на SSD
В следующей таблице я свел данные об использовании SSD, до которых дотянулись руки. Они эксплуатируются в одном настольном ПК и трех разных ноутбуках. Никто их не бережет и не жалеет, файлы подкачки не отключает, временные файлы не переносит. Оба 840 Pro служат системными дисками и хранят личные файлы (кроме видео), Kingston – это полигон для виртуальных машин и второй файл подкачки, а Crucial выступал даже хранилищем фильмов.
| Samsung 840 Pro 256GB |
Samsung 840 Pro 256GB |
Samsung 840 EVO 120GB |
Kingston Hyper-X 3K 120GB |
Crucial MX100 256GB |
PLEXTOR 128M5Pro 128GB |
|
|---|---|---|---|---|---|---|
| Текущий срок службы диска (лет) | 2.25 | 2.25 | 2 | 3.25 | 1.25 | 2.25 |
| Применено мифов | 0 | 0 | 0 | 0 | 0 | 0 |
| Запись всего | 7.3TB | 5.0TB | 1.6TB | 5.5TB | 4.1TB | 5.7TB |
| Запись в год | 3.2TB | 2.2TB | 0.8TB | 1.7TB | 3.3TB | 2.5TB |
| Запись в день | 9GB | 6GB | 2GB | 5GB | 9GB | 7GB |
| Ресурс NAND диска (лет)10 | 22.8 | 33.2 | — | 45.3 | 21.8 | — |
Износ флэш-памяти – это последнее, от чего умрут диски из таблицы. Им гарантируется 20-40GB записи в день, но ни один даже до 10GB не дотягивает! А ведь у современных SSD гарантийные объемы еще выше.
Покажите свой SMART!
Практически все мифы по оптимизации SSD нацелены на снижение объема записи, и приверженцы мифологии утешают себя хотя бы тем, что продлевают жизнь диску. Но на практике до гарантийных пределов добраться очень нелегко, даже если скачивать в день по фильму в разрешении Full HD.
Уверен, всем нам будет интересно сравнить свои показатели с другими. Публикуйте в комментариях отчеты своих дисков!
- Правильно соберите данные SMART (скриншот каждого SSD и текст).
- В данных SMART рядом с названием диска впишите срок использования SSD и сколько мифов вы к нему применили.
- Выложите SMART на PasteBin (пример), а скриншот — на фотохостинг.
- Опубликуйте прямые ссылки (не используйте BBCode!). Если у вас есть ссылка на расшифровку SMART вашего диска, добавьте ее – я внесу в статью.
Внимание! Сбор отчетов для анализа прекращен. Вы все равно можете опубликовать свой отчет, особенно при наличии вопросов об атрибутах SMART.
Наряду с отчетом расскажите об условиях эксплуатации диска, примененных мифах и впечатлениях от владения SSD.
Question m2 ssd media and data integrity errors (smart)
-
Thread starterash_X
-
Start dateDec 4, 2021
-
- Mar 19, 2021
-
- 16
-
- 0
-
- 10
- 0

-
#1
Media and Data Integrity Errors 1856
What does it say about my SSD? Is it gonna fail soon?
Its health is 100%, bought it one month ago and it works fine (apart from not being recognized after cold boot), total host writes and reads are 1140 and 950 gbs, so not that much (ssd storage is on 1tb)

-
- Mar 16, 2013
-
- 161,377
-
- 13,435
-
- 176,090
- 24,454
-
#2
What does the manufacturers testing tool say?
-
- Mar 19, 2021
-
- 16
-
- 0
-
- 10
- 0
-
#3
Make/model of this drive?
What does the manufacturers testing tool say?
Kingston A2000 1Tb M2 Nvme drive
Kingston SSD Manager: No Firmware Update Available, same amount of media and data integrity errors but in 16th DEC (0x0740)
SSD Wear Indicator 100%, SSD Spare Blocks 100%, Failures None, Warnings None, Overall Healthy, Temperature 43C.
So it doesnt indicate anything wrong.
In fact AIDA claims Media and Data Integrity Errors with ! sign. But says Status: OK Value is normal.
-
- Mar 16, 2013
-
- 161,377
-
- 13,435
-
- 176,090
- 24,454
-
#4
- There is a 0.2% chance your drive will become fatally faulty in the next 60 days
- There is a 42% chance your drive will become fatally faulty in the next 60 days
- There is a 92% chance your drive will become fatally faulty in the next 60 days
What, if anything, would you differently if given just one of those statements, vs the other 2?
-
- Mar 19, 2021
-
- 16
-
- 0
-
- 10
- 0
-
#5
Here’s 3 statements:
- There is a 0.2% chance your drive will become fatally faulty in the next 60 days
- There is a 42% chance your drive will become fatally faulty in the next 60 days
- There is a 92% chance your drive will become fatally faulty in the next 60 days
What, if anything, would you differently if given just one of those statements, vs the other 2?
So basically you dont know? Just wanna know if that Media Errors thing mean that drive is corrupted or faulty and do I need to RMA it.
-
- Mar 16, 2013
-
- 161,377
-
- 13,435
-
- 176,090
- 24,454
-
#6
So basically you dont know? Just wanna know if that Media Errors thing mean that drive is corrupted or faulty and do I need to RMA it.
Contact them about an RMA. It may be nothing, it may be serious.
But the result of my 3 statements was…..»You should be doing the same thing, no matter which one we out here said».
Your particular device can die at any time, no matter what the software says or doesn’t say.
Always be prepared for your drive to die in the next 0.25 sec.
| Thread starter | Similar threads | Forum | Replies | Date |
|---|---|---|---|---|
|
T
|
Question adding a new M.2 SSD to my motherboard causes PC to receive a boot error | Storage | 6 | Feb 1, 2023 |
|
|
[SOLVED] Repairing Disc Errors This May Take Over an Hour to Complete? | Storage | 22 | Jan 31, 2023 |
|
|
Question USB flash drive capacity went down after creating W11 installation media | Storage | 2 | Jan 31, 2023 |
|
K
|
Question Recommend a storage media for 2TB of data. | Storage | 6 | Nov 14, 2022 |
|
C
|
Question Best medias for long term storage of files ? | Storage | 10 | Nov 2, 2022 |
|
C
|
Question Question durability DVD Mdisc media | Storage | 20 | Oct 2, 2022 |
|
|
Question Hashsum question ? | Storage | 9 | Sep 9, 2022 |
|
D
|
Question SSD reaches 76% health. High Temp. No Error. Beep sounds? #230 Media Wearout Indicator | Storage | 5 | Aug 16, 2022 |
|
|
Question Cant change the «This Drive is read only» or «this media is write protected» | Storage | 11 | May 26, 2022 |
|
I
|
Question Is there any easy personal multi-bay cloud media storage hardware? | Storage | 4 | May 3, 2022 |



- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics

В прошлых частях цикла мы рассказывали про историю накопителей, о применяемых интерфейсах и форм-факторах, а также про организацию на физическом уровне. Пятая же часть посвящена «мозгу» современного твердотельного накопителя.
Контроллер современного накопителя — маленький компьютер, который принимает стандартизированные команды и выполняет соответствующие действия с подконтрольным ему хранилищем. При этом внутреннее устройство контроллера может быть любым.
У Intel есть накопитель P4618 6.4 TB, который представляется системе как два накопителя по 3.2 TB. Аналогичное встречается и среди жестких дисков. Накопители Seagate с технологией MACH.2 — это два диска, «заключенные» в одном корпусе и объединенные единым контроллером.
Контроллер — достаточно сложное устройство, которое в зависимости от предназначения диска выполняет различные задачи по управлению данными. Например, базы данных часто требуют от накопителя запись непосредственно в энергонезависимую память, минуя кэш, и в этом случае серверный SATA SSD будет быстрее, чем пользовательский NVMe. Из-за большой вариативности контроллеров не будем вдаваться в детали конкретных устройств, а поговорим об общих принципах работы современного твердотельного накопителя.
Особенности записи

Блоки и страницы в NAND-памяти. Источник
Хранилище твердотельного накопителя состоит из множества полевых транзисторов, соединенных друг с другом. При таком подходе чтение и запись выполняются страницами данных, размер которых обычно 4 КиБ. Таким образом, изменение одного бита на диске приводит к необходимости перезаписать всю страницу данных. Эта проблема называется усилением записи (Write Amplification).
Кроме того, твердотельные накопители не могут обновить данные в странице. Обновление страницы производится в четыре шага:
- Чтение данных из страницы в буфер.
- Изменение данных в странице.
- Очистка страницы данных.
- Запись обновленных данных из буфера.
Контроллер умеет записывать страницы данных, а стирать только блоки — последовательность страниц. Обычно блок состоит из 64 страниц данных. В поставленных условиях и при конечном ресурсе перезаписи ячеек накопителя контроллеру нужно проводить операции записи и стирания аккуратно.
Износостойкость

Выравнивание износа. Источник
Современные накопители построены на базе ячеек TLC, ресурс которых в разы меньше, чем у накопителей с ячейками SLC и MLC. Если какая-то программа в ОС будет постоянно перезаписывать маленький файл, а контроллер будет «наивно» обновлять одну страницу данных, то вскоре блок с этой страницей исчерпает ресурс. Исчерпание ресурса будет отображено в показателях накопителя, что неизбежно приведет к беспокойству системного администратора.
Во избежание сильного износа единичных блоков накопителя применяются технологии выравнивания износа (Wear Leveling). При этом обновление данных выполняется без очистки страницы накопителя и выглядит так:
- Чтение данных из страницы в буфер.
- Изменение данных в странице.
- Запись обновленных данных из буфера в «чистую» страницу.
- Старая страница помечается как «грязная».
Очистка блока происходит после того, как все страницы отмечены «грязными». Возникает закономерный вопрос: как поведет себя накопитель, когда не останется «чистых» страниц и не будет блоков, готовых к очистке? Ответ прост: избыточность (over provisioning) и сборка мусора (garbage collection).
Балансировка износа
В каком-то смысле производитель накопителей обманывает нас дважды. Первый раз использует десятичные приставки вместо двоичных: 480 ГБ — это 447 ГиБ. А второй раз, когда фактический объем накопителя больше, чем доступно пользователю. Часть объема зарезервирована производителем для внутренних нужд контроллера. Такой резерв называется запасной областью (spare).
Таким образом, у контроллера всегда есть немного свободного пространства, которое может быть использовано для внутренних процессов. Хотя точных данных нет, в различных источниках утверждается, что для контроллера резервируется от 7 до 28 % объема накопителя.
Увеличение объема зарезервированной области уменьшает доступный объем, но чаще всего повышает производительность диска. Для увеличения spare-области достаточно оставить часть накопителя неразмеченным. Однако если хочется экстрима и сделать все «по уму», то можно уменьшить объем видимого пользователю пространства через ключ -N утилиты hdparm.
Как бы то ни было, вернуть зарезервированную производителем область в собственное пользование не получится.

Процесс «сбора мусора». Источник
Помимо балансирования износа, в контроллерах в фоновом режиме часто проходит процесс «сбора мусора» (garbage collection). В ходе него с нескольких блоков собираются актуальные страницы и помещаются в один блок. Затем исходные блоки очищаются, так как в них не осталось страниц с данным.
Важно отметить, что сборщик мусора занимается перекладыванием данных в хранилище, чтобы было как можно больше чистых блоков. При этом он не может понять, что на файловой системе какой-то файл отмечен удаленным, так как контроллер накопителя не умеет работать в терминах файловых систем.
Для решения этой проблемы в каждом из протоколов есть команда, позволяющая уведомить контроллер об удалении файла. Для NVMe — это deallocate, для SATA — TRIM, а для SCSI — unmap. Суть каждой их этих команд одинакова: пометить страницы с удаленным файлом как «грязные».
Контроллеру приходится постоянно беспокоиться о состоянии страниц хранилища. При этом напрашивается очевидная оптимизация: если операционная система пытается считать данные со страниц, на которых нет данных, то вместо операции чтения можно просто генерировать необходимое количество нулей.
Это легко подтверждается с помощью эксперимента. Проводим Secure Erase для накопителя и запускаем тесты на случайное чтение с глубиной очереди 64. Затем «забиваем» накопитель с помощью последовательной записи, желательно дважды. И повторяем тесты.
В наших тестах использовался SSD-накопитель Micron 7300 1.92 TB, подключенный по PCIe 3.0 x4. Третья версия PCI Express по четырем линиям способна пропускать 3940 МБ/с или 3757 МиБ/с. Мы, конечно, не достигли предела, но надо полагать, это из-за накладных расходов на протокол NVMe. Тем не менее, видно, что чтение с диска без данных «упирается» в предел 3400 МиБ/с. После заполнения диска на 15% результаты тестов стали хуже.
Несмотря на то, что контроллер накопителя всегда пытается сделать как лучше, иногда системному администратору стоит взглянуть на показатели диска своими глазами.
Показатели
Вне зависимости от интерфейса накопителя SSD имеют набор показателей состояния, которые могут быть считаны системным администратором. Для SATA-накопителей используются показатели S.M.A.R.T., которые не стандартизированы. Отсутствие стандарта приводит к появлению различных трактовок одного показателя.
Рассмотрим вывод утилиты smartctl на примере Intel S4510.
# smartctl -iA /dev/sda
smartctl 7.3 (build date Jan 1 2021) [x86_64-linux-4.15.0-51-generic] (local build)
Copyright (C) 2002-21, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Intel S4510/S4610/S4500/S4600 Series SSDs
Device Model: INTEL SSDSC2KB480G8
Serial Number: ThereIsNoSerialHere
LU WWN Device Id: 5 5cd2e4 14fd823b7
Firmware Version: XCV10100
User Capacity: 480,103,981,056 bytes [480 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
TRIM Command: Available, deterministic, zeroed
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.2, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Mon Jul 5 14:30:43 2021 MSK
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0032 100 100 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 21345
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 76
170 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0
171 Program_Fail_Count 0x0032 100 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0032 100 100 000 Old_age Always - 0
174 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always - 48
175 Power_Loss_Cap_Test 0x0033 100 100 010 Pre-fail Always - 2625 (76 65535)
183 SATA_Downshift_Count 0x0032 100 100 000 Old_age Always - 0
184 End-to-End_Error_Count 0x0033 100 100 090 Pre-fail Always - 0
187 Uncorrectable_Error_Cnt 0x0032 100 100 000 Old_age Always - 0
190 Drive_Temperature 0x0022 080 080 000 Old_age Always - 20 (Min/Max 11/21)
192 Unsafe_Shutdown_Count 0x0032 100 100 000 Old_age Always - 48
194 Temperature_Celsius 0x0022 100 100 000 Old_age Always - 20
197 Pending_Sector_Count 0x0012 100 100 000 Old_age Always - 0
199 CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
225 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always - 67625
226 Workld_Media_Wear_Indic 0x0032 100 100 000 Old_age Always - 276
227 Workld_Host_Reads_Perc 0x0032 100 100 000 Old_age Always - 84
228 Workload_Minutes 0x0032 100 100 000 Old_age Always - 1280413
232 Available_Reservd_Space 0x0033 100 100 010 Pre-fail Always - 0
233 Media_Wearout_Indicator 0x0032 100 100 000 Old_age Always - 0
234 Thermal_Throttle_Status 0x0032 100 100 000 Old_age Always - 0/0
235 Power_Loss_Cap_Test 0x0033 100 100 010 Pre-fail Always - 2625 (76 65535)
241 Host_Writes_32MiB 0x0032 100 100 000 Old_age Always - 67625
242 Host_Reads_32MiB 0x0032 100 100 000 Old_age Always - 359222
243 NAND_Writes_32MiB 0x0032 100 100 000 Old_age Always - 477803
Для нашего диска интересны следующие параметры:
- 5 Reallocated_Sector_Ct — количество секторов с нулевым ресурсом.
- 187 Uncorrectable_Error_Cnt — количество ошибок, которые не удалось исправить при помощи кодов коррекции.
- 233 Media_Wearout_Indicator — процент износа диска.
- 243 NAND_Writes_32MiB — объем данных, который был записан на диск за все время.
Уже в этом списке видны проблемы отсутствия стандартов. Так, параметр Host_Writes_32MiB встречается дважды: под номером 225 и под номером 241.
С точки зрения износа исправного диска интересен показатель 233 Media_Wearout_Indicator, так как при достижении числа 1023 накопитель программно заблокируется и будет доступен в режиме только для чтения.
Показатели S.M.A.R.T — это особенность протокола SATA. Для NVMe-накопителей есть NVMe log, который также считывается программой smartctl. Аналогичный вывод можно получить с помощью команды nvme smart-log.
# smartctl -iA /dev/nvme0n1
smartctl 7.3 (build date Jan 1 2021) [x86_64-linux-4.15.0-51-generic] (local build)
Copyright (C) 2002-21, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Number: INTEL SSDPF2NV153TZ
Serial Number: ThereIsNoSerialToo
Firmware Version: ACV10024
PCI Vendor/Subsystem ID: 0x8086
IEEE OUI Identifier: 0x5cd2e4
Total NVM Capacity: 15,362,991,415,296 [15.3 TB]
Unallocated NVM Capacity: 0
Controller ID: 0
NVMe Version: 1.3
Number of Namespaces: 128
Namespace 1 Size/Capacity: 15,362,991,415,296 [15.3 TB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 5cd2e4 71434b0400
Local Time is: Mon Jul 5 14:31:34 2021 MSK
=== START OF SMART DATA SECTION ===
SMART/Health Information (NVMe Log 0x02)
Critical Warning: 0x00
Temperature: 28 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 0%
Data Units Read: 77,871,643 [39.8 TB]
Data Units Written: 148,394,810 [75.9 TB]
Host Read Commands: 5,737,206,704
Host Write Commands: 1,802,643,030
Controller Busy Time: 81
Power Cycles: 5
Power On Hours: 146
Unsafe Shutdowns: 1
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
# nvme smart-log /dev/nvme0n1
Smart Log for NVME device:nvme0n1 namespace-id:ffffffff
critical_warning : 0
temperature : 29 C
available_spare : 100%
available_spare_threshold : 10%
percentage_used : 0%
data_units_read : 77,871,643
data_units_written : 148,394,810
host_read_commands : 5,737,206,704
host_write_commands : 1,802,643,030
controller_busy_time : 81
power_cycles : 5
power_on_hours : 148
unsafe_shutdowns : 1
media_errors : 0
num_err_log_entries : 0
Warning Temperature Time : 0
Critical Composite Temperature Time : 0
Thermal Management T1 Trans Count : 0
Thermal Management T2 Trans Count : 0
Thermal Management T1 Total Time : 0
Thermal Management T2 Total Time : 0В выводе NVMe накопителя меньше непонятных показателей, но все равно есть место разночтениям. Легко предположить, что параметр percentage_used отвечает за объем занятого пользователем пространства на диске, но это не так. Этот параметр эквивалентен Media_Wearout_Indicator и обозначает износ накопителя.
Не стоит забывать, что предоставляемые показатели и поведение контроллера реализуется прошивкой, которая может быть обновлена.
Перепрошивка
О прошивке твердотельных накопителей задумываются нечасто. В лучшем случае после покупки «накатывают» свежую версию и забывают до конца жизни накопителя.
Как бы то ни было, обновления прошивки редко приносят какие-то значительные и заметные для пользователя нововведения. Прошивка, как и любое другое программное обеспечение, может содержать ошибки, в том числе критические. К счастью, это происходит редко, а потому нет надобности постоянно поддерживать актуальность прошивок на всех используемых накопителях.
Хотя NVMe можно перепрошить через команды fw-download и fw-commit, чаще всего обновление прошивки производится через утилиты, предоставляемые производителем накопителя. Во избежание потенциально деструктивных действий мы не будем публиковать точные команды, а порекомендуем обратиться к официальной инструкции от производителя.
Заключение
Контроллеры накопителей — сложные устройства, которые управляют не менее сложными процессами, которые проходят внутри твердотельных накопителей. Мы рассмотрели только самые интересные процессы в общих чертах.
Если вам хочется больше погрузиться в особенности работы с NVMe, рекомендуем статью про пространства имен NVMe.

-
#1
Hi everyone,
I have a HP EX920 NVMe PCIE 3.0 SSD 256GB SSD installed on my Inspiron 5000 laptop, the kids are using it. In the past few days, they said they can’t install programs, can’t executing existing program and a lot of missing dll issues. So I tried it and a lot of files can’t be read also. Here is the report on the SSD: I didn’t see any SMART error, but the «Media Errors» concerns me. Is the driver dying?
Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T.)
Available Space Below Threshold: OK
Temperature Exceeded Critical Threshold: OK
Device Reliablity Degraded: OK
Media In Read Only Mode: OK
Volatile Memory Backup Device Failed: OK
Drive Temperature: 54 °C
Warning Temperature Threshold: 70 °C
Critical Temperature Threshold: 80 °C
Time Above Warning Temperature Threshold: 3 minutes
Time Above Critical Temperature Threshold: 0 minutes
Spare Capacity Available: 90%
Device Health: 100%
Power Cycles: 1082
Power On Hours: 867 hours
Unsafe Shutdowns: 19
Media Errors: 1127674
Total Host Reads: 2783 GBytes
Total Host Writes: 2545 GBytes

-
#2
I’d be concerned, that number is pretty high. As per definition of Media Errors:
Contains the number of occurrences where the controller detected an unrecovered data integrity error. Errors such as uncorrectable ECC, CRC checksum failure, or LBA tag mismatch are included in this field.
-
#3
And it keeps growing. I formatted the drive and did a clean install of windows, the number still growing.
Time to tslk to HP. Thank you.
I’d be concerned, that number is pretty high. As per definition of Media Errors: