Ошибка превышения лимита памяти : Обычно это происходит, когда не установлен лимит памяти. Это означает, что программа пытается выделить больше памяти, чем лимит памяти для конкретной задачи. Например, если предел памяти составляет 256 МБ , то нет необходимости писать код, требующий более 256 МБ памяти. Как правило, все онлайн-платформы имеют одинаковый лимит памяти в 256 МБ . Может быть еще много причин, из-за которых может возникнуть эта ошибка.
Программа 1:
Ниже приведена программа C++ для объявления глобального одномерного массива размером 10 7 :
Объяснение: Этот код будет успешно скомпилирован и выведет 9999999 , поскольку глобально объявлен одномерный массив размером 10 7 .
Программа 2: Ниже приведена программа на C++ для объявления глобального одномерного массива размером 10 8 :
C++
#include <bits/stdc++.h>
using namespace std;
const int N = 1e8;
int a[N];
int main()
{
for (int i = 0; i < N; ++i) {
a[i] = i;
}
cout << a[N - 1];
return 0;
}
Выход:
Memory Limit Exceeded
или же
Segmentation Fault (SIGSEGV)
Объяснение: в приведенной выше программе пользователи получат ограничение памяти и превышение в виде ошибки, но некоторые онлайн-платформы также могут выдавать ошибку в виде ошибки сегментации ( SIGSEGV ). Это связано с тем, что пользователи могут объявить глобальный одномерный массив только размером 10 7 , не более того. Здесь один объявил глобальный одномерный массив размером 10 8 и, следовательно, имеет место ошибка, поскольку происходит превышение предела памяти (MLE).
Примечание:
- Обратите внимание, что попытка превысить лимит памяти может иногда приводить к другим ошибкам.
- Например, если пользователи используют malloc в C для выделения памяти. Если malloc терпит неудачу из-за того, что пользователь пытается выделить слишком много, он просто возвращает нулевой указатель, который, если его не проверить, вероятно, вызовет ошибку времени выполнения, когда пользователь попытается его использовать.
- Точно так же попытка выделить слишком много памяти в C++ с помощью new вызовет SIGABRT и выдаст ошибку времени выполнения.
Improve Article
Save Article
Improve Article
Save Article
Memory Limit Exceeded Error: It typically occurs when no memory limit has been set. It means that the program is trying to allocate more memory than the memory limit for the particular problem. For Example, if the memory limit is 256 MB, then there is no need to write code that requires more than 256 MB of memory. Generally, all online platforms have the same memory limit as 256 MB. There might be many more reasons due to which this error can occur.
Program 1:
Below is the C++ program to declaring a global 1D array of size 107:
C++
#include <bits/stdc++.h>
using namespace std;
const int N = 1e7;
int a[N];
int main()
{
for (int i = 0; i < N; ++i) {
a[i] = i;
}
cout << a[N - 1];
return 0;
}
Explanation: This code will successfully compile and output is 9999999 because the 1-D array has been declared globally of size 107.
Program 2: Below is the C++ program to declare a global 1D array of size 108:
C++
#include <bits/stdc++.h>
using namespace std;
const int N = 1e8;
int a[N];
int main()
{
for (int i = 0; i < N; ++i) {
a[i] = i;
}
cout << a[N - 1];
return 0;
}
Output:
Memory Limit Exceeded
or
Segmentation Fault (SIGSEGV)
Explanation: In the above program, the users will get a memory limit and exceed as an error, but some online platforms can also give an error as a Segmentation Fault(SIGSEGV). This is because users can only declare a global 1-D array of size 107, not more than that. Here, one declared a global 1-D array of size 108 and therefore has an error as the memory limit exceeded (MLE) occurs.
Note:
- Note that trying to exceed the memory limit may sometimes result in other errors.
- An example would be if users are using malloc in C to allocate memory. If malloc fails because the user is trying to allocate too much, it simply returns a null pointer which, unless checked for it, would probably cause a Run Time Error when the user tries to use it.
- Similarly, trying to allocate too much memory in C++ using new would cause a SIGABRT and give Run Time Error.
|
Shamil1 Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
||||
|
1 |
||||
|
01.03.2017, 12:43. Показов 2255. Ответов 28 Метки нет (Все метки)
Есть некая acm: И нулевая задача: Сумма двух целых чисел Time limit = 3 секунд(ы) Memory limit = 33000 Kb Оба числа не превосходят 1 000 000 000 по модулю. Подсказка: если у вас не получается решить задачу, обратитесь к эталонным решениям К сожалению эталонное решение на Haskell отсутствует. Я решил так:
Моё решение не принимается с ошибкой «Memory limit». В чём может быть причина? з.ы. Какой стандартной функцией можно заменить самопальный scanInt? Не стал использовать функцию words из-за опасений, что будет медленней работать. В C# комбинация split + int.parse работает в 10 раз медленней, чем самопальный scanInt, который не создаёт новых список строк.
2 |

|
Programming Эксперт 94731 / 64177 / 26122 Регистрация: 12.04.2006 Сообщений: 116,782 |
01.03.2017, 12:43 |
|
28 |
|
Антикодер 1796 / 860 / 48 Регистрация: 15.09.2012 Сообщений: 3,056 |
|
|
01.03.2017, 13:38 |
2 |
|
Не стал использовать функцию words из-за опасений, что будет медленней работать. Может ByteString поможет? Можно попробовать вывести тестовые значения с помощью
1 |
|
Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
|
|
01.03.2017, 13:49 [ТС] |
3 |
|
words преобразует строку в список строк. То есть, для каждой строки возвращаемого списка выполняются выделение памяти и копирование. Я хочу избежать этих ненужных накладных расходов. read s читает строку s до конца. Мне нужна функция, которая будет читать до первого пробела. Чтобы, когда в строке несколько чисел, разделённых пробелами, можно было запускать эту функцию и получать числа, пока строка не закончится.
0 |
|
Антикодер 1796 / 860 / 48 Регистрация: 15.09.2012 Сообщений: 3,056 |
|
|
01.03.2017, 14:16 |
4 |
|
toInt = Data.Char (digitToInt) Надо точно знать, что тесты на вход подают только целые числа через пробел в указанном диапазоне. Потому что я не нашёл комбинацию, которая вызывает расход памяти в >33 МБ. Поэтому проще эталонное решение посмотреть и по нему уже найти проблему.
0 |
|
_Ivana 4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
||||||||
|
01.03.2017, 14:59 |
5 |
|||||||
|
Shamil1, 1) пишите типы функций, помогает 2) вы читаете лайн, а там ввод каждого нового значения на новой строке. Поэтому в Эс1 у вас сидит только первое значение, а вы пытаетесь пропарсить из него второе — но ваша функция на пустой строке валится и поэтому все плохо 3) у вас слишком нагроможден кот. Даже если оставить вашу идею со сканинтом, то ее можно переписать так
4) но в подобных задачках ввод/вывод не является боттлнеком по скорости/оптимальности, поэтому проще сделать так:
ЗЫ наивное чтение инпута в хаскеле тоже ленивое, как и все прочее по-умолчанию. Поэтому вот это
words преобразует строку в список строк. То есть, для каждой строки возвращаемого списка выполняются выделение памяти и копирование. Я хочу избежать этих ненужных накладных расходов. имхо не соответствует действительности — будет прочитано ровно столько вордов, сколько надо, и безо всяких лишних накладных расходов. ЗЗЫ мою реализацию scInt по-хорошему тоже надо переписать на возврат Мэйби, чтобы она не кидала эррор а в случае пустой строки или отсутствия числа в начале строки возвращала Нафинг. Но я оставлю это вам на самостоятельное несложное упражнение, ибо сам считаю ненужным писать эту функцию по причинам, изложенным выше
3 |

") И можете впихнуть в нее разбор строки посимвольно с накоплением результата через десятичные разряды, или же вообще прикрутить к ней Парсек/Аттопарсек или еще какую громоздкую монструозную ерунду.
И можете впихнуть в нее разбор строки посимвольно с накоплением результата через десятичные разряды, или же вообще прикрутить к ней Парсек/Аттопарсек или еще какую громоздкую монструозную ерунду.|
Антикодер 1796 / 860 / 48 Регистрация: 15.09.2012 Сообщений: 3,056 |
|
|
01.03.2017, 15:18 |
6 |
|
s1 <- getContents а откуда появится символ конца файла? Тесты в виде файлов будут подаваться на вход?
0 |
|
4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
|
|
01.03.2017, 15:23 |
7 |
|
Да хоть в виде чего угодно — хоть в виде файла (только надо взывать к hGetContents, с префиксом хандле
1 |
|
Антикодер 1796 / 860 / 48 Регистрация: 15.09.2012 Сообщений: 3,056 |
|
|
01.03.2017, 15:26 |
8 |
|
…
0 |
|
4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
|
|
01.03.2017, 15:29 |
9 |
|
XRuZzz, не расстраивайте меня, мы же с вами не первый день знакомы ЗЫ плюсовый цин делает примерно то же самое, о чем мы ведем здесь речь.
1 |
|
Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
|
|
01.03.2017, 16:34 [ТС] |
10 |
|
вы читаете лайн, а там ввод каждого нового значения на новой строке. Поэтому в Эс1 у вас сидит только первое значение, а вы пытаетесь пропарсить из него второе — но ваша функция на пустой строке валится и поэтому все плохо По условию числа должны быть в той же строке. Ваш вариант валится с той же ошибкой.
where (a,b) = break isSpace s Про создание ненужной промежуточной строки я писал выше.
но в подобных задачках ввод/вывод не является боттлнеком по скорости/оптимальности Если есть желание сравнивать время с другими участниками, то вполне может стать «боттлнеком». Я сталкивался с задачами, в которых решение занимает меньше времени, чем ввод.
имхо не соответствует действительности — будет прочитано ровно столько вордов, сколько надо, и безо всяких лишних накладных расходов. Дело в том, что мне не нужно читать ни одного ворда. Мне нужны только сами числа, а не их строковые эквиваленты.
мою реализацию scInt по-хорошему тоже надо переписать на возврат Мэйби, чтобы она не кидала эррор а в случае пустой строки или отсутствия числа в начале строки возвращала Нафинг В данном случае обработка ошибок — это лишнее, так как формат входных данных строго задан.
у вас слишком нагроможден кот Функции solve, input, output нужны обязательно, так как я не хочу, чтобы одна функция выполняла разные функции (в смысле, решала разные задачи). А вот от scInt я бы с удовольствием избавился.
0 |
|
4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
|
|
01.03.2017, 17:06 |
11 |
|
Ваш вариант валится с той же ошибкой
Проверил на рекстестере — ничего не валится
Я сталкивался с задачами, в которых решение занимает меньше времени, чем ввод. Ну да, например сабжевая задача
Про создание ненужной промежуточной строки я писал выше.
Дело в том, что мне не нужно читать ни одного ворда. Мне нужны только сами числа, а не их строковые эквиваленты. Я тоже писал выше про ленивое чтение. Могу еще волшебное слово лист-фьюжн написать. Но вы же все равно не читаете Добавлено через 18 минут
0 |
|
Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
|
|
01.03.2017, 17:13 [ТС] |
12 |
|
Проверил на рекстестере — ничего не валится Мой вариант тоже не валится. Я бы не стал пытаться сдать код, который не выполняется. Как я писал выше, проблема в том, что решение не принимается конкретной icm по ссылке.
Я тоже писал выше про ленивое чтение. Если в строке 10 тыс. чисел (как в другой задаче), то при выполнении Вашего кода создастся 10 тыс. строк (10 тыс. раз будет выполняться выделение памяти и копирование из исходной строки). Каким образом ленивое чтение может на это повлиять? Речь идёт не об экономии памяти, а об экономии времени.
0 |
|
_Ivana 4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
||||
|
01.03.2017, 17:21 |
13 |
|||
|
Как я писал выше, проблема в том, что решение не принимается конкретной icm по ссылке. Проблема конкретной ицм по ссылке
Фантазии из мира C# и прочее бла-бла-бла…. Волшебным образом, если
угодно
http://rextester.com/NQHQO55366
0 |
|
Модератор
33878 / 18905 / 3981 Регистрация: 12.02.2012 Сообщений: 31,695 Записей в блоге: 13 |
|
|
01.03.2017, 17:24 |
14 |
|
Я бы тоже хотел поучаствовать, но не вполне понимаю постановку. Нужно просто сложить два числа, читаемых как строки с консоли? Не используя преобразование в тип Integer?
0 |
|
_Ivana 4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
||||
|
01.03.2017, 17:31 |
15 |
|||
|
Ахда, забыл написать вариант с «пожирающим память и время вордсом»
Добавлено через 5 минут
0 |
|
Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
|
|
01.03.2017, 17:42 [ТС] |
16 |
|
Фантазии из мира C# и прочее бла-бла-бла…. Скажите, код Так как s — неизменяемый объект, то в качестве b можно использовать хвост s. Достаточно сохранить в стеке ссылку на этот хвост. Добавлено через 6 минут
Я бы тоже хотел поучаствовать, но не вполне понимаю постановку. Две проблемы (разные и независимые): 1. Основная 2. Другая
0 |
|
4814 / 2275 / 287 Регистрация: 01.03.2013 Сообщений: 5,936 Записей в блоге: 26 |
|
|
01.03.2017, 17:43 |
17 |
|
Только не байты из s, а новый лист — потому что все приведенные варианты работают не с байтстрингами как таковыми, а со списками чаров. Как реализовано взятие начала подсписка длинного списка я не в курсе, может и новым выделением памяти с копированием, а может и каким-то хитрым вариантом функциональной датаструкчи без копирования. Но даже если будет копирование, имхо это блохи — вы отщипываете подсписочек от списка, читаете его в инт, потом отщипываете следующий… Хвост никуда не копируется (он даже не генерируется без нужды), а отщипленное пошло в дело, остатки собрались сборщиком.
0 |
|
Curry 4736 / 2992 / 462 Регистрация: 01.06.2013 Сообщений: 6,296 Записей в блоге: 9 |
||||
|
01.03.2017, 18:19 |
18 |
|||
|
Прочитать числа из String в «полувелосипедном режиме» можно ещё через readDec, на любителя. Там беззнаковые числа и возвращается не Maybe, а список из одного кортежа, или пустой — древняя штука, раритет. А вопрос кто съел «Memory limit = 33000 Kb» в
конкретной icm по ссылке так и остался открытым. Не по теме: У меня сейчас, чего то интернет тормозит, наверно по этому я по ссылке не увидел где там haskell, хоть и зарегался. Добавлено через 1 минуту
Есть ли ли в Haskell стандартная функция, которая парсит Int и при этом не съедает всю строку? readDec как раз, но беззнаковая. Добавлено через 15 минут
2 |
|
Модератор 2969 / 2108 / 450 Регистрация: 26.03.2015 Сообщений: 8,238 |
|
|
01.03.2017, 18:43 [ТС] |
19 |
|
У меня сейчас, чего то интернет тормозит, наверно по этому я по ссылке не увидел где там haskell, хоть и зарегался. Если выбрать в меню «сдать», то откроется форма для отправки решения. Там есть выпадающий список с подписью «компилятор» с элементом «Haskell GC 6.8.2».
0 |
|
Curry 4736 / 2992 / 462 Регистрация: 01.06.2013 Сообщений: 6,296 Записей в блоге: 9 |
||||
|
01.03.2017, 18:52 |
20 |
|||
|
Если выбрать в меню «сдать», то откроется форма для отправки решения. Сейчас, вроде, получше с интернетом стало. Нажал «Сдать», ввёл строку почти как у _Ivana, но короче
И тоже «Memory limit». Косяк у них, там, в МФТИ.
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
01.03.2017, 18:52 |
|
20 |
Навигация: Главная страница/Система ejudge/Использование/Вердикты тестирования/Ошибка превышения лимита памяти
Английское название: Memory Limit Exceeded, ML
Ошибка диагностируется, если в процессе работы тестирующая программа потребила больше памяти, чем указано в ограничениях задачи. Обоснованность диагностирования этой ошибки вызывает дискуссии (см. далее).
Разные тестирующие системы подходят к ограничению памяти для работающей программы по-разному. В ejudge ограничение памяти реализуется с помощью установки ограничения на размер виртуального адресного пространства и размер стека (см. ulimit). Таким образом, тестируемая программа не может превысить установленные ограничения.
Диагностирование ошибки превышения ограничения по памяти в системе ejudge работает, толко если установлен патч к ядру Linux. Если патч не установлен, превышение ограничения по памяти будет диагностировано как ошибка времени выполнения. Кроме того, система ejudge позволяет отключить диагностирование данной ошибки даже если патч к ядру установлен.
Хотя диагностирование данной ошибки может быть полезно для участников для отладки их решений, в большистве ситуаций граница между ошибкой при выполнении программы и ошибкой превышения ограничения по памяти оказывается очень размытой.
Например, если превышен максимальный размер стека из-за того, что программа вошла в бесконечную рекурсию, то такая ситуация должна скорее рассматриваться как ошибка при выполнении программы. Но с другой стороны, если программа попыталась выделить слишком много памяти в стеке (например, из-за слишком большого локального массива), такая ситуация должна рассматриваться как превышение ограничения по памяти. Естественно, невозможно простым способом четко различить эти две ситуации.
С другой стороны, например, в языке C функция malloc возвращает NULL, если память выделить не удалось. Если тестируемая программа не проверяет результат функции malloc на NULL и получает ошибку доступа по нулевому указателю, то это типичная ошибка программиста и должна рассматриваться как ошибка при выполнении программы. И наоборот, программа может отлавливать ситуации, когда malloc возвращает NULL, и модифицировать свое поведение (например, почистив хеш-таблицу).

Решая задачу Преобразование последовательности, столкнулся с превышением памяти на 23 тесте. Решал двумя способами:
1 способ (Используя словарь, прошёл 23 теста, 23 мб)
import java.util.*;
import java.io.*;
import java.util.stream.Collectors;
public class SequenceTransform {
public static void main(String[] args) throws IOException {
Scanner scan = new Scanner(new File("input.txt"));
PrintWriter pw = new PrintWriter(new File("output.txt"));
List<Integer> seq = new ArrayList<>(); // сама последовательность
Map<Integer, Integer> eachCount = new HashMap<>(); // словарь ( число - кол-во)
int n = scan.nextInt(); // кол-во чисел
int num;
for(int i = 0; i < n; i++) {
num = scan.nextInt();
seq.add(num);
if (!eachCount.containsKey(num)){ // добавление в словарь числа, либо увеличение его кол-ва
eachCount.put(num,1);
} else {
eachCount.put(num, eachCount.get(num) + 1);
}
}
// сортировка словаря и получение самого частого числа
List<Map.Entry<Integer, Integer>> sorted = new ArrayList<>(eachCount.entrySet());
int max = sorted.stream().sorted((a,b) -> {
if (a.getValue() != b.getValue())
return b.getValue() - a.getValue();
else
return a.getKey() - b.getKey();
}).limit(1).collect(Collectors.toList()).get(0).getKey();
int max_count = eachCount.get(max);
// удаление(как и сказано в условии) max'a и вставка в конец
seq.removeIf(a -> a == max);
for (int i = 0; i < max_count; i++)
seq.add(max);
seq.forEach(pw::println);
pw.close();
}
}2 способ (Используя массив для подсчета кол-ва, прошел 13 тестов, 22 мб)
import java.util.*;
import java.io.*;
import java.util.stream.Collectors;
public class SequenceTransform {
public static void main(String[] args) throws IOException {
Scanner scan = new Scanner(new File("input.txt"));
PrintWriter pw = new PrintWriter(new File("output.txt"));
int N = scan.nextInt();
List<Integer> seq = new ArrayList<>();
final int million = 1000000;
int[] count = new int[million * 2 + 1]; // два миллиона эл-ов, так как в условии сказано, что числа в диапазоне [-10^6; 10^6]
for (int i = 0; i < N; i++){
int num = scan.nextInt();
seq.add(num);
count[million + num]+=1;
}
int[] max = {0,0};
for (int i = 0; i < count.length; i++){
if (max[1] < count[i]){
max[0] = i;
max[1] = count[i];
}
}
int max_num = max[0] - million;
seq.removeIf(a -> a == max_num);
for (int i = 0; i < max[1]; i++)
seq.add(max_num);
seq.forEach(pw::println);
pw.close();
}
}Текущая попытка( 16 мб, 23 теста)
import java.util.*;
import java.io.*;
public class SequenceTransform {
static int nexInt(Reader reader) throws IOException{
String c = Character.toString( (char) reader.read());
String Int = "";
while (!c.equals(" ") && !c.equals("n") && !c.equals("uFFFF")){
if (!c.equals("r")) Int = Int.concat(c);
c = Character.toString( (char) reader.read());
}
return Integer.valueOf(Int);
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader (new FileReader("input.txt"));
PrintWriter pw = new PrintWriter(new File("output.txt"));
Map<Integer, Integer> eachCount = new HashMap<>();
int n = nexInt(br);
int[] seq = new int[n];
for(int i = 0; i < n; i++) {
int num = nexInt(br);
seq[i] = (num);
if (!eachCount.containsKey(num)){
eachCount.put(num,1);
} else {
eachCount.put(num, eachCount.get(num) + 1);
}
}
List<Map.Entry<Integer, Integer>> sorted = new ArrayList<>(eachCount.entrySet());
Map.Entry<Integer, Integer> max = sorted.get(0);
Map.Entry<Integer, Integer> el;
for (int i = 0; i < sorted.size(); i++){
el = sorted.get(i);
if (max.getValue().compareTo(el.getValue()) <= 0){
if (max.getValue().compareTo(el.getValue()) != 0)
max = el;
else if (max.getKey().compareTo(el.getKey()) > 0)
max = el;
}
}
int maxkey = max.getKey();
int maxvalue = max.getValue();
int[] ans = new int[n];
int j = 0;
for (int i = 0; i < n; i++){ // Новый массив, в котором самый частый элемент находится в конце.
if (maxkey != seq[i]){
ans[j] = seq[i];
j++;
}
}
for (int i = n - maxvalue; i < n ; i++){
ans[i] = maxkey;
}
for (int x : ans)
pw.print(x + " ");
pw.close();
}
}
Возникли вопросы:
Как сервер подсчитывает память?
Как сократить расходы памяти, потому что первое решение не особо затратное?
-
Вопрос заданболее трёх лет назад
-
847 просмотров
Пригласить эксперта
В первом способе слишком много абстракций. Когда речь заходит о критической экономии памяти нужно сразу забывать про существовании Stream API, стараться не использовать autoboxing и пытаться эффективней использовать ресурсы. На то они и олимпиадные задачки, чтобы писать все сортировки руками вместо однострочных стримов и пр.
Что можно сделать:
- закрывать сканер после чтения (не закрыв он так и будет висеть у тебя в памяти, которой может не хватить допустим в середине алгоритма)
- открывать writer в самом конце (тоже самое что и со сканером, тем более что он тебе абсолютно не нужен в начале выполнения)
- заменить мапу на массив, убрать использование объекта Integer (со списком тоже желательно, но боттлнек твоего первого способа именно её использование, поэтому если заменишь правильно не сломав логику, то должно хватить.)
- не использовать стримы
По поводу подсчёта памяти сервером скорее всего просто запускают виртуалку с -Xmx16m параметром и реагируют на OutOfMemoryError, но это не точно.
ps Ты не можешь сравнивать Integer таким образом a.getValue() != b.getValue(). Integer суть объект, нужно использовать equals. А ещё в задании сказано разделять числа в output пробелами, а не переходами на новую строку, но это так, к слову.
Scanner убери и юзай BufferedReader
-
Показать ещё
Загружается…
10 февр. 2023, в 00:15
1000 руб./в час
09 февр. 2023, в 22:06
500 руб./за проект
09 февр. 2023, в 22:01
50000 руб./за проект
Минуточку внимания
Просматривая журналы работы сайта вы можете увидеть очень частую ошибку нехватки WordPress. Обычно это этом пишет предупреждение: PHP Warning: Use of undefined constant ‘WP_MEMORY_LIMIT’ — assumed ‘‘WP_MEMORY_LIMIT’’ (this will throw an Error in a future version of PHP) То есть Вы видите ошибку исчерпания разрешенного объема памяти в WordPress? Это одна из самых распространенных ошибок WordPress , и вы можете легко исправить ее, увеличив лимит памяти php в WordPress. В этой статье мы покажем вам, как исправить ошибку исчерпания памяти WordPress, увеличив память PHP.
Содержание
1
Что такое ошибка исчерпания памяти WordPress?
WordPress написан на PHP, который является серверным языком программирования. Каждому веб-сайту нужен хостинг-сервер WordPress для его правильной работы.
Веб-серверы такие же, как и любой другой компьютер. Им нужна память для эффективного запуска нескольких приложений одновременно. Администраторы серверов выделяют определенный объем памяти для различных приложений, включая PHP.
Когда вашему коду WordPress требуется больше памяти, чем выделенная по умолчанию память, вы увидите эту ошибку.
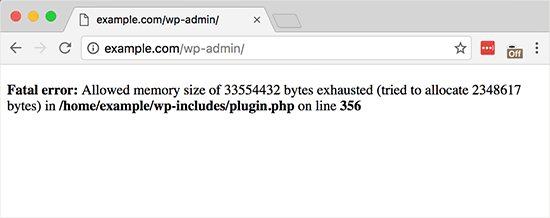
|
Fatal error: Allowed memory size of 33554432 bytes exhausted (tried to allocate 2348617 bytes) in /home4/xxx/public_html/wp—includes/plugin.php on line xxx |
По умолчанию WordPress автоматически пытается увеличить лимит памяти PHP, если он меньше 64 МБ. Однако 64 МБ часто бывает недостаточно.
Сказав это, давайте посмотрим, как легко увеличить лимит памяти PHP в WordPress, чтобы избежать ошибки исчерпания памяти.
Лимит памяти PHP в WordPress
Сначала вам нужно отредактировать файл wp-config.php на вашем сайте WordPress. Он находится в корневой папке вашего сайта WordPress, и вам нужно будет использовать FTP-клиент или файловый менеджер в панели управления веб-хостингом.
Затем вам нужно вставить этот код в файл wp-config.php непосредственно перед строкой, которая гласит: «Все, прекратите редактирование! Удачного ведения блога».
|
define( ‘WP_MEMORY_LIMIT’, ‘256M’ ); |
Этот код указывает WordPress увеличить лимит памяти PHP до 256 МБ. Когда вы закончите, вам нужно сохранить изменения и загрузить файл wp-config.php обратно на ваш сервер. Теперь вы можете посетить свой сайт WordPress, и ошибка исчерпания памяти должна исчезнуть.
Узнайте, сколько памяти выделено сайту
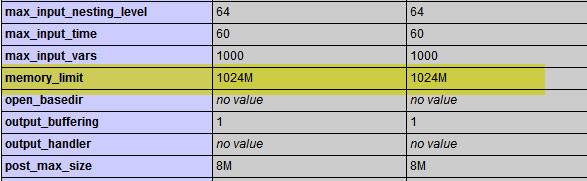
Хотя сама эта часть не очень важна , те, кто хочет узнать Лимит Памяти , могут изучить этот раздел. Прежде всего, нам нужно узнать, сколько МБ (мегабайт) ограничивает память вашего сайта. В этом методе, который чаще всего используется для определения предела памяти; Создайте новый файл с именем « view-php-info.php» на своем сервере/сервере и добавьте в него приведенный ниже код.
После создания нового файла перейдите по URL-адресу нового файла , который вы создали в своем браузере/браузере, то есть по адресу http://www.yourwebsite.com/view-php-info.php. Когда вы перейдете по указанному нами адресу, вы увидите таблицу, как показано на рисунке ниже. из этой таблицы Найдите вкладку memory_limit. Это значение показывает текущий лимит памяти вашего сайта.
Ограничение памяти для обучения — WordPress
Еще один способ узнать лимит памяти — использовать плагин WP-Memory-Usage. Этот плагин не только показывает «ограничение памяти» , но также показывает использование вашей памяти и версию php, которую вы используете. Описанный выше процесс может показаться немного сложным. Вот почему я рекомендую использовать плагин.
Сколько памяти для работы вам нужно?
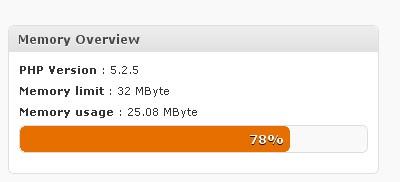
Лимит памяти, который WordPress назначает по умолчанию, то есть по умолчанию ограничен 32 мб. Если вы используете слишком много плагинов или ваш трафик увеличился, вашему сайту потребуется 64 МБ или более лимита памяти. Когда вы откроете свой сайт в первый раз, проблем не возникнет. Однако со временем, с появлением новых надстроек и увеличением количества посетителей, вы столкнетесь с этой проблемой, с которой сталкивается каждый веб-мастер.
Если вы не знаете, сколько памяти вы будете использовать, мы считаем полезным использовать плагин WP-Memory-Usage . Установите и запустите плагин, затем проверьте раздел « Использование памяти ». Если вкладка использования памяти окрашена в красный цвет, это будет означать, что вам необходимо увеличить лимит памяти.
Итак, как увеличить «Предел памяти WordPress»?
Сразу напомню, что тема эта очень и очень простая. Это метод, который вы можете использовать более чем одним способом. Рекомендую все способы.
1- Увеличение лимита памяти через файл Config.php:
В этом методе подключитесь к серверу вашего сайта WordPress через FTP , откройте файл « wp-config.php» в его основном каталоге и добавьте в него следующий код. Могу сказать, что это один из самых используемых методов. В этом процессе мы увеличили лимит памяти с 32 МБ , который определен по умолчанию, до 64 МБ . Вы увидите, что ошибка ограничения памяти исчезнет после выполнения этой операции.
определить(‘WP_MEMORY_LIMIT’, ’64M’);
2- Увеличение лимита памяти через файл .htaccess:
Подключитесь к вашему файлу .htaccess через FTP или cPanel , как описано выше, и добавьте следующую строку в ваш файл .htaccess . В этом методе, добавив следующую строку в файл .htaccess, мы увеличили значение ограничения памяти в 32 МБ, назначенное по умолчанию (по умолчанию), до 64 МБ .
php_value memory_limit 64M
3- Увеличение лимита памяти через файл Php.ini :
Многие хостинговые компании блокируют доступ к файлу php.ini для своих пользователей. Это может произойти, особенно если речь идет о виртуальном хостинге. Если у вас есть разрешение на доступ к файлу php.ini , вы можете самостоятельно выполнить следующий метод. Как я объяснил в первом пункте , создайте новый файл с именем view-php-info.php на своем сервере и найдите вкладку « Загруженный файл конфигурации» . Вы можете найти расположение вашего файла php.ini здесь.

Поиск местоположения файла WordPress Php.ini
Если вы узнали расположение вашего файла php.ini , войдите в этот файл и измените значение ограничения памяти с 32 МБ на 64 МБ или, если хотите, на 128 МБ в соответствии с вашими потребностями. Если на вашей странице php.ini нет вкладки memory_limit, в конце страницы memory_limit = 64M; Выполните операцию, добавив фразу. Не забудьте после добавления сохраниться и перезапустить сервер Apache командой httpd restart .
Примечание: Если это решение не работает для вас, это означает, что ваш поставщик услуг веб-хостинга не позволяет WordPress увеличивать лимит памяти PHP. Вам нужно будет попросить своего веб-хостинг-провайдера увеличить лимит памяти PHP вручную.
Это все, мы надеемся, что эта статья помогла вам решить ошибку исчерпания памяти WordPress, увеличив лимит памяти PHP.
PHP поставляется с настройками по умолчанию, которые обычно подходят для большинства веб-сайтов. Иногда потребности сайта приводят к необходимости изменить эти настройки PHP. Например, вашему сайту может потребоваться увеличить лимит памяти для завершения процесса.
![]()
Содержание
- Ошибка PHP о недостатке памяти
- Увеличение лимита памяти в php.ini
- Увеличение лимита памяти в .htaccess
- Увеличение лимита памяти в php скрипте
- Увеличение лимита памяти в WordPress
Ошибка PHP о недостатке памяти
PHP позволяет использовать стандартный объем памяти. Иногда веб-сайту требуется больше памяти, чем установлено по умолчанию. В этом можно увеличить его, чтобы он соответствовал потребностям вашего сайта.
Также иногда может возникать ошибка, указывающую на то, что лимит памяти достигнут. Она может выглядеть следующим образом:
Fatal error: Allowed memory size of 83260710 bytes exhausted (tried to allocate 4062 bytes)Увеличение лимита памяти в php.ini
Открываем на редактирование файл php.ini, по умолчанию /etc/php.ini
в секции [PHP] редактируем или добавляем параметр memory_limit
[PHP]
memory_limit = 256Mпосле этого необходимо перезапустить веб-свервер (к примеру apache)
в случае с использование php-fpm требуется перезапустить только его
Увеличение лимита памяти в .htaccess
Apache позволяет передавать параметры php с использованием .htaccess, без необходимости перезапускать сервер.
Для этого в в корне сайта добавляем (желательно как можно ближе к началу) следующий текст
php_value memory_limit 128MПосле сохранения изменений настройки вступят в силу.
Увеличение лимита памяти в php скрипте
Изменения лимита памяти возможно так же в самом PHP скрипте. Аналогично в самом начале скрипта добавляем строку
ini_set('memory_limit', '128M');После сохранения изменений, при следующем запуске изменения вступят в силу.
Увеличение лимита памяти в WordPress
При использовании WordPress, настройки в файле php.ini могут не сработать, так как WordPress переопределяет их в файле wp-config.php. Чтобы исправить это, необходимо в файле wp-config.php, указать конкретный лимит памяти. Например:
define( 'WP_MEMORY_LIMIT', '128M' );
define( 'WP_MAX_MEMORY_LIMIT', '128M' );
/** Sets up WordPress vars and included files. */
require_once(ABSPATH . 'wp-settings.php');