Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
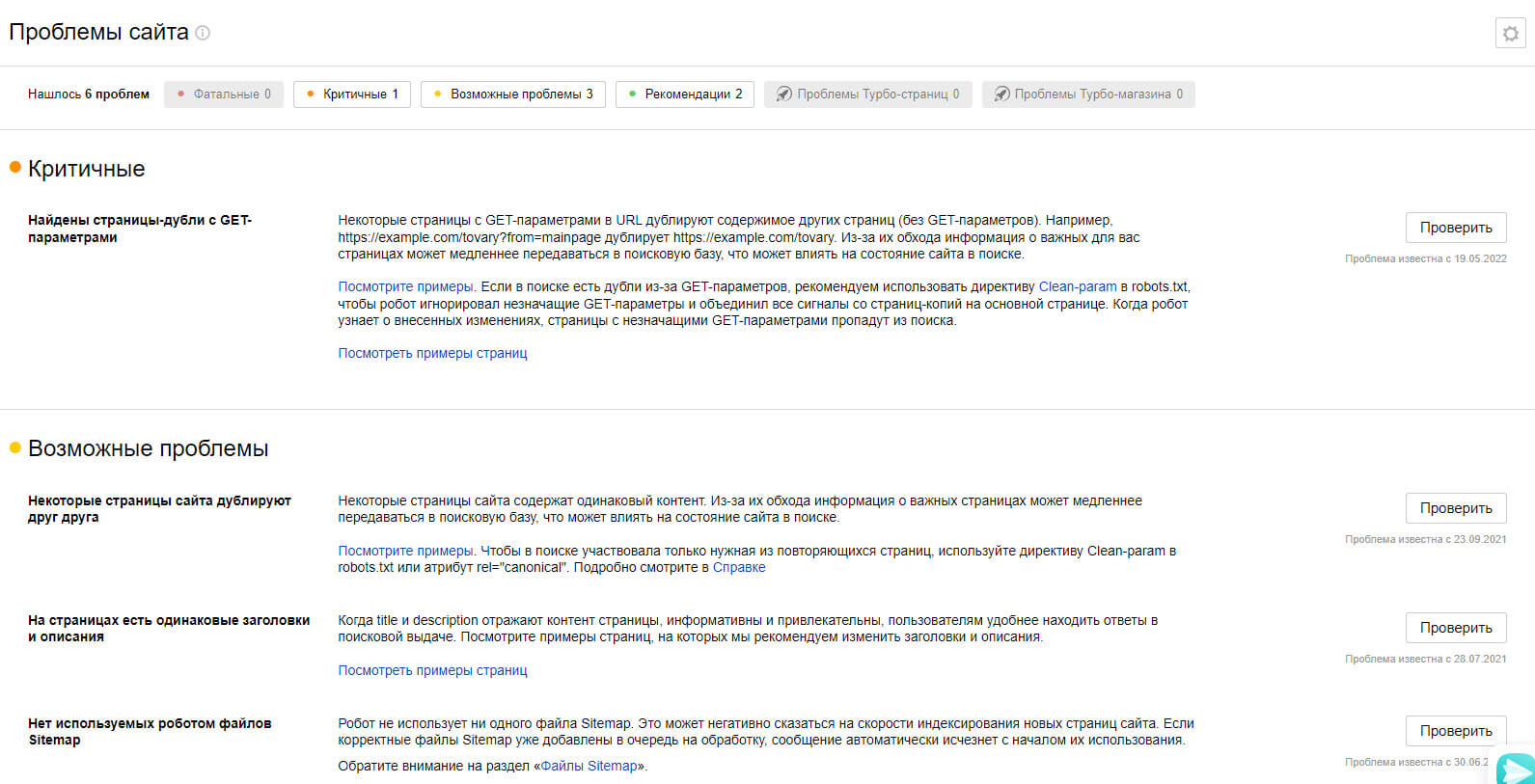
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
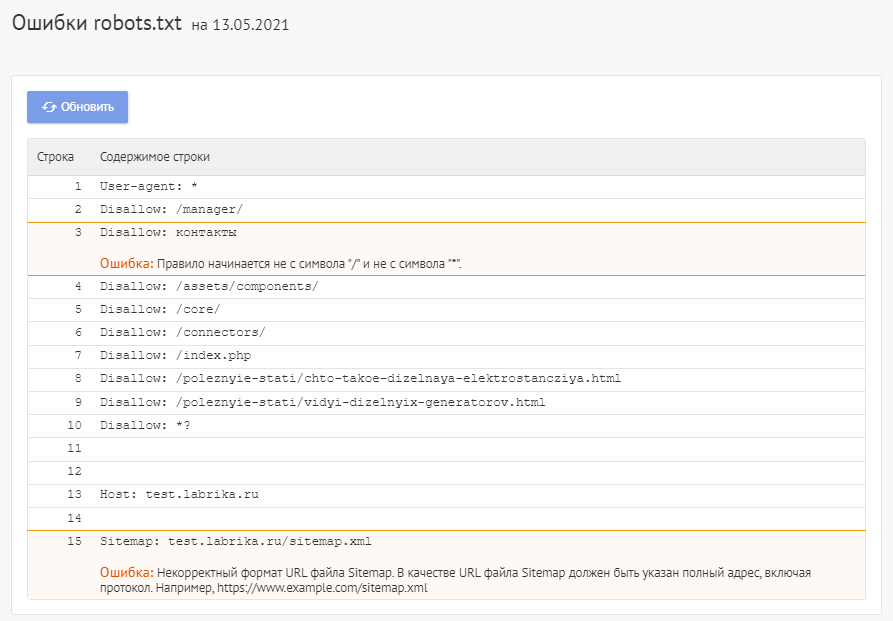
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Вкратце о диагностике сайта
Фатальные
- Сайт закрыт к индексации в файле robots.txt
- Не удалось подключиться к серверу из-за ошибки DNS
- Главная страница сайта возвращает ошибку
- Обнаружены нарушения или проблемы с безопасностью
Критичные
- Долгий ответ сервера
- Большое количество неработающих внутренних ссылок
Возможные проблемы
- Главная страница перенаправляет на другой сайт
- Отсутствуют теги <title>
- Ошибки в файле robots.txt
- Не найден файл robots.txt
- Отсутствуют мета-теги <description>
- Некорректное отображение несуществующих файлов и страниц
- В файле robots.txt задана противоречивая директива Host
- В файле robots.txt не задана директива Host
- Большое количество страниц-дублей
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Файлы Sitemap давно не обновлялись
Рекомендации
- Не задана региональная принадлежность сайта
- Сайт не оптимизирован для мобильных устройств
- Ошибка счётчика Яндекс.Метрики
- Сайт не зарегистрирован в Яндекс.Справочнике
- Отсутствует файл favicon на сайте
- Отсутствуют быстрые ссылки
Вкратце о диагностике сайта
В этой статье мы подробно опишем большинство самых популярных проблем, которые выдает диагностика сайта от Яндекса. Напомним, что раздел диагностики находится в Yandex Webmaster на второй вкладке в левом меню.
Краткую информацию о наличии проблем возможно найти в левом верхнем блоке на главной странице Вебмастера.
Прежде, чем рассказывать о каждой проблеме отдельно, поясним общую информацию. Яндекс разделил все ошибки на 4 вида:
-
Фатальные — то есть, те, которые несовместимы с отображением сайта в поисковой выдаче. Наличие таких ошибок, скорее всего, приведет к полному исключению сайта из поиска. Среди них — запрет индексации, различного рода санкции со стороны поисковиков, серьезное нарушение безопасности или неработоспособность сайта;
-
Критичные — то есть, те, которые серьезно затрудняют удобство пользования сайтом, его корректную работу или индексацию. Наличие таких ошибок вряд ли приведет к исключению ресурса из поисковой выдачи, но может сильно снизить видимость;
-
Возможные — то есть, те, которые влияют на удобство пользователей, отображение и корректную индексацию. Подобные ошибки стоит устранить для улучшения сайта и повышения видимости в органической выдаче. В общем списке сайтов Вебмастера возможные проблемы обозначаются серым восклицательным знаком.

-
Рекомендации — носят исключительно рекомендательный характер. Обычно направлены на улучшение сайта или отображения.

Фатальные проблемы
Решать фатальные проблемы нужно немедленно, иначе они приведут к исключению сайта из поисковой выдачи. Подобные ошибки справедливы не только для Яндекса, но и для всех остальных поисковых систем. Ниже мы опишем каждую из них в отдельности, а так же предложим варианты решения.
Сайт закрыт к индексации в файле robots.txt

«При последнем обращении к файлу robots.txt было обнаружено, что сайт закрыт для индексации. Убедитесь в корректности файла robots.txt, иначе сайт может полностью пропасть из поиска.» © Яндекс Вебмастер
Очень серьезная, но легко решаемая проблема. Причиной ее появления может стать банальная ошибка в синтаксисе файла robots.txt или ненамеренный запрет индексации. Зачастую такую ошибку можно увидеть у новых сайтов, так как разработчики обычно закрывают ресурс для индексации и не всега открывают обратно.
Поправить это очень просто. Открываем свой robots.txt по ссылке ваш_домен/robots.txt и проверяем содержимое. Если в нем расположен код следующего содержания:
User-agent: *
Disallow: /
или
User-agent: Yandex
Disallow: /
То, просто заменяем его на шаблонные инструкции для Вашей CMS или прописываем уникальные вручную.
Подробнее о настройке файла robots.txt
Не удалось подключиться к серверу из-за ошибки DNS

«При попытке скачать данные с сайта не удалось подключиться к серверу из-за ошибки DNS. Если роботы не смогут получить доступ к серверу, сайт может полностью пропасть из поиска. Возможно, пользователи также не могут попасть на сайт.» © Яндекс Вебмастер
Данная проблема решается уже не так быстро, как предыдущая. Суть ее проста. Индексирующий робот Яндекса попросту не смог получить доступ к сайту. То есть, корректная индексация уже невозможна. Если краулер, при повторных обращениях, будет продолжать получать ошибку, то сайт рано или поздно исключат из поиска.
В данном конкретном случае, лучше всего будет обратиться к разработчикам сайта или хост-провайдеру (регистратору доменного имени.) Если Вы не профессионал, то можете потерять много драгоценного времени в попытках разобраться в произошедшем. Помните, что фатальные ошибки нужно решать незамедлительно.
Главная страница сайта возвращает ошибку

«При обращении к главной странице сайта не удалось получить HTTP-код 200 OK. Поскольку страница недоступна для робота, она может быть исключена из результатов поиска.» © Яндекс Вебмастер
При обращении к главной странице сайта робот ожидает ответ 200 ОК. Только при его получении продолжается корректная индексация.
Если Вы столкнулись с вышеупомянутой проблемой, то вот несколько причин ее появления.
-
Неверно настроен ответ главной страницы. К примеру, главная может отдавать 404 Not Found или 403. Что для нее не корректно. Определить ответ можно в Яндекс Вебмастере, при помощи инструмента «проверка ответа сервера«;
-
Для главной страницы может быть настроен 301 редирект;
-
Главная страница сайта может технически отсутствовать, что редкость.
Решается проблема путем проверки наличия страницы и ее ответа. Для разработчиков сайта устранить данную ошибку не составит никакого труда.
Обнаружены нарушения или проблемы с безопасностью

«Сайт может угрожать безопасности пользователя, или на нём были обнаружены нарушения правил поисковой системы. Наличие этой проблемы негативно сказывается на положении сайта в результатах поиска.» © Яндекс Вебмастер
Одна из самых сложно решаемых проблем. Причин ее появления может быть множество. Вот основные из них:
-
Сайт был взломан и на нем находится вредоносный код. Это может быть вирусный рекламный баннер, вставки iframe, различного рода трояны, а так же множество другой гадости;
-
Сбор, обработка или передача данных пользователей сделана насколько некорректно, что индексирующий робот заподозрил в этом мошеннические намерения;
-
Сайт не соответствует правилам поисковой системы. То есть, имеет запрещенный контент, обманывает или вводит в заблуждение пользователей, подменяет материал и т.д.;
Стоит сказать, что данная проблема может появляться у очень молодых сайтов из-за темного прошлого доменного имени. Обязательно проверяйте домен перед покупкой.
Однако, не стоит беспокоиться и переделывать сайт, если Вы уверены в его корректной работе. Подобное сообщение может появляться по ошибке. Если это так, то оно автоматически пропадет через несколько обновлений.
Критичные проблемы
На критичные проблемы стоит сразу обратить внимание и начать искать решение. Их появление скорее всего не приведет к исключению из поиска, однако может серьезно повлиять на видимость сайта.
Долгий ответ сервера

«При обращении к серверу среднее время ответа превышает 3 секунды. Долгая загрузка страниц затрудняет работу с сайтом.» © Яндекс Вебмастер
Это одна из основных причин неполной (некорректной) индексации. Робот отводит на каждый сайт определенное количество секунд, после чего переходит к следующем ресурсу. Если ответ сервера слишком долгий, то времени на загрузку страниц может просто не остаться.
Что бы решить эту проблему, необходимо обратиться к администратору сервера или хост-провайдеру. Возможно, Вашему сайту просто не хватает выделенных для работы ресурсов.
Если данное сообщение появилось, а потом пропало без видимых причин, не стоит его игнорировать. Обязательно проверьте скорость ответа сервера, а так же параметры загрузки сайта. Наличие подобной проблемы влияет на индексацию вне зависимости от того, есть сообщение в Вебмастере или его нету.
Большое количество неработающих внутренних ссылок

«На сайте не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.» © Яндекс Вебмастер
Причиной возникновения подобной проблемы может служить некорректный перенос разделов, страниц или сайта в целом. Так же, к этому может привести сбой в работе каталога, фильтра, пагинации или другого блока связанного со ссылками.
Определить точное количество неработающих ссылок и увидеть детали можно в разделе «Внутренние ссылки» Яндекс Вебмастера.
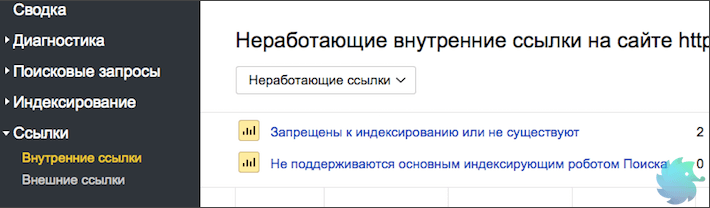
В этом блоке подробно описываются причины, поэтому Вам останется только устранить проблемы внутри сайта.
Возможные проблемы
Несмотря на название, возможные проблемы все же являются серьезными изъянами с точки зрения SEO. Они не приведут к исключению ресурса из поиска, а так же слабо повлияют на позиции и видимость. Однако их устранение может привести к подъему поискового трафика и более лояльному отношению поисковиков.
Главная страница перенаправляет на другой сайт

«При обращении к главной странице робот получает перенаправление на другой сайт, что делает невозможным её индексирование.» © Яндекс Вебмастер
Данную проблему Яндекс относит к разделу «Возможные», однако с нашей точки зрения это серьезная ошибка. Речь сейчас не идет о перенаправлении на зеркала или «склейку». Только редирект на сторонний сайт.
При корректном обращении к главной странице краулер должен получать ответ 200 ОК, что означает, что страница доступна пользователям и ее можно индексировать. В случае получения 301 Redirect, робот не только отправляется на сторонний ресурс, но и получает тревожный сигнал, что сайт мог быть взломан или вводит пользователей в заблуждение. То есть, Вы уже рискуете попасть под фильтры безопасности.
Сразу проверьте ответ сервера, если это будет не 200 ОК — ищите и устраняйте причину. В случае получения 301 Redirect рекомендуем заглянуть в файл .htaccess и проверить его на наличие редиректа.
Отсутствуют теги <title>

«Значительная часть страниц не содержит тег <title>, или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.» © Яндекс Вебмастер
Очень серьезное упущение с точки зрения поискового продвижения. Заголовки <title></title> являются одним из основных факторов внутренней оптимизации, которые влияют на ранжирование страницы.
Ранее этому заголовку мы посвятили полноценную статью. В ней разложено по полочкам все, что нужно знать о данном теге с точки зрения SEO.
Безусловно, Яндекс самостоятельно выберет текст для ссылки при построении поисковой выдачи и без сниппета Вы не останетесь, однако Ваша конкурентоспособность с точки зрения SEO сильно упадет.
Ошибки в файле robots.txt

«Файл robots.txt содержит ошибки. Это может привести к некорректному обходу и индексированию сайта.» © Яндекс Вебмастер
Данный файл представляет из себя список инструкций для индексирующего робота. Именно в нем определяется, что нужно загружать в базу, а что игнорировать. Находится он в корневой папке сайта и доступен по адресу www.ваш_домен.ru/robots.txt.
Большинство ошибок в robots.txt, обычно, связаны с синтаксисом прописываемых в нем инструкций. Лишняя точка, слэш или пробел могут привести к некорректному распознанию команды.
Поэтому, при появлении данной проблемы сразу открывайте свой роботс и начинайте проверять синтаксис. В этом деле Вам может помочь сервис «Анализ robots.txt» находящийся во вкладке «Инструменты» Яндекс Вебмастера.
Подробнее об ошибках и настройке файла robots.txt
Не найден файл robots.txt

«Робот не смог получить доступ к файлу robots.txt при последнем обращении. Из-за отсутствия параметров индексирования и инструкций в поиск могут попасть нежелательные страницы.» © Яндекс Вебмастер
Суть проблемы понятна из названия. Что бы решить ее, необходимо просто добавить robots.txt в корневой каталог Вашего сайта. Сделать это можно через FTP или при помощи различного рода плагинов.
Если Вы используете популярную CMS, то мы готовы предложить шаблонные решения. Однако, обратите внимание, что шаблоны инструкций не гарантируют корректность индексации и отсутствие мусора. У каждого сайта будут свои особенности и подводные камни.
Подробнее о настройке файла robots.txt
Отсутствуют мета-теги <description>

«Значительная часть страниц сайта не содержит мета-тег <description>, или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.» © Яндекс Вебмастер
Это одна из самых распространенных проблем, с которой сталкивается практически каждый SEO специалист. Для ее решения необходимо просто добавить недостающие <description>.
Узнать полный список страниц с отсутствующими тегами Вы можете перейдя по ссылке «Ознакомьтесь» в описании проблемы.
Отсутствие meta тега <description> сильно влияет на корректность отображения сниппетов. Поэтому тянуть с решением проблемы не стоит.
Если подобная ошибка появилась у Интернет-магазина, сайта-каталога или другого крупного ресурса, то для ее решения есть стандартные плагины, которые формируют meta description автоматически. Пользоваться такими плагинами мы советуем в крайнем случае, так как результат работы не всегда удовлетворителен.
Подробнее о description и правилах заполнения
Некорректное отображение несуществующих файлов и страниц

«Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 Not Found, что может негативно сказаться на индексировании сайта роботом. Настройте возврат кода 404 на запрос несуществующих страниц.» © Яндекс Вебмастер
Проще говоря, у Вас попросту отсутствует или некорректно работает страница 404. Что бы разобраться в этом, необходимо перейти на несуществующий раздел. Сделать это можно введя любой некорректный URL, к примеру «ваш_домен.ру/none12345».
Если Вы видите перед собой неизвестную ошибку, белый экран, сообщение хост-провайдера или другую информацию, которая к сайту не относится — у Вас просто нету данной страницы. Шаблон для нее необходимо сделать в CMS сайта. Это напрямую относится к разработке и дизайну сайта, поэтому работы стоит поручить верстальщику.
Если Вы видите оформленную страницу 404 своего сайта, тогда проблема в ответе сервера. Нужно понимать, что надпись «404 — страница не найдена» не означает, что сайт действительно отдает «404 Not Found», скорее всего, результатом будет 200 ОК.
Проверить ответ сервера Вы можете в разделе «Проверка ответов сервера» во вкладке «Инструменты» Яндекс Вебмастера.
Создание страницы 404 Not Found и настройка ответа сервера полностью зависят от конкретного сайта, поэтому сделать пошаговую инструкцию просто невозможно.
Подробнее о странице 404 с точки зрения SEO
В файле robots.txt задана противоречивая директива Host

«В директиве Host указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы указания директивы Host были учтены, идентичные директивы должны присутствовать в файлах robots.txt всех зеркал сайта.» © Яндекс Вебмастер
Суть проблемы в следующем. Есть два зеркала. У обоих есть файл robots.txt, в котором указаны различные параметры инструкции HOST.
Решение очень простое. Необходимо указать во всех HOST одно главное зеркало. Это нужно, что бы у робота не оставалось сомнений, какое из зеркал основное.
Бывает так, что файл robots.txt один и инструкции попросту не могут различаться. В таком случае нужно подождать и сообщение пропадет.
В файле robots.txt не задана директива Host

«Для корректного определения главного зеркала сайта рекомендуется задать соответствующую директиву Host в файлах robots.txt всех зеркал сайта. В случае ее отсутствия главное зеркало может быть выбрано автоматически.» © Яндекс Вебмастер
Помимо прочих инструкций в файле robots.txt для агента Яндекса необходимо указывать директиву host. Пример директивы приведен на рисунке ниже.

Синтаксис ее крайне прост. Сначала пишется служебное слово «Host:», далее через пробел вставляется главное зеркало сайта. При этом нужно учесть, что протокол http не пишется. Добавляется только https при его наличии. Убедитесь, что зеркало выставленное в Яндекс Вебмастере и других host (у сайтов-зеркал) соответствует указываемому в robots.txt. В противном случае Вы получите ошибку, о которой говорится выше.
Подробнее о директиве host
Большое количество страниц дублей

«На сайте обнаружено большое количество одинаковых страниц, это усложняет индексирование сайта. Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt.» © Яндекс Вебмастер
Достаточно серьезная проблема, которая для решения, зачастую, требует квалифицированной помощи программиста. Страницы-дубли, по сути, представляют собой различные URL, которые ведут на одну и ту же страницу. (Реже, это несколько абсолютно одинаковых html файлов с разными URL)
Когда индексирующий робот попадает на сайт, он старается обойти все доступные URL адреса и загрузить по ним уникальный контент. Если робот переходит по адресу и «видит» уже загруженную ранее страницу, то он исключает ее из поиска как дубликат, при этом теряя драгоценное время обхода.
Определить наличие дублей возможно в Яндекс Вебмастере. Необходимо зайти в раздел «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы». Тут будут представлены все исключенные из поиска разделы, в том числе и по причине дублирования. Для того, что бы долго не искать, можно настроить фильтр по статусу. (нажать на значок воронки рядом с заголовком)

После того, как все страницы будут отсортированы, Вы сможете увидеть имеющиеся дубликаты, о которых знает Яндекс.
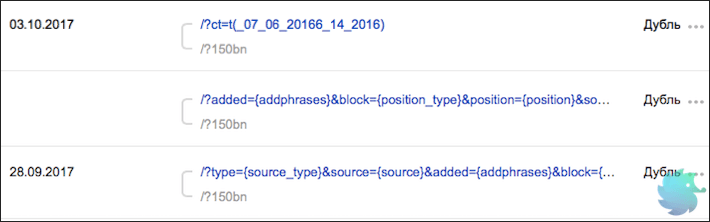
Для решения данной проблемы необходимо, в первую очередь, определить причину появления дублей. Их может быть несколько.
-
При создании страницы, в CMS генерируется технический адрес, который обычно имеет вид «post=3333&action=edit» или любой другой не ЧПУ. Вы не хотите видеть подобный URL и создаете для страницы человекочитаемый адрес. Таким образом статья становится доступна по 2 адресам. В этом случае необходимо скрыть все технические адреса в robots.txt при помощи маски;
-
На сайте имеются динамические URL, которые дополняются различными префиксами в зависимости от выбранных параметров, поиска, сортировки и т.д. Их так же необходимо скрывать при помощи маски в robots или отказаться от динамических URL;
-
Во время настройки рекламы, для получения данных о клиенте и источнике, часто используются дублирующие ссылки с параметрами. Такие URL нужно сразу закрывать в robots.txt во избежание попадания в индекс;
-
Некоторые системы управления могут отображать страницу по нескольким человекочитаемым URL. К примеру, страница может быть доступна по всем 3-м адресам: «/page1/», «/page1.php», «/page1.html». Исключаются подобные дубли так же при помощи маски.
После того, как дубли будут закрыты для индексации, предупреждение пропадет автоматически. Но, не стоит думать, что это произойдет в первую неделю. Подобное сообщение может держаться месяцами.
Нет используемых роботом файлов Sitemap

«Робот не использует ни одного файла Sitemap. Это может негативно сказаться на скорости индексирования новых страниц сайта. Если корректные файлы Sitemap уже добавлены в очередь на обработку, сообщение автоматически исчезнет с началом их использования.» © Яндекс Вебмастер
Это длинное сообщение описывает всего лишь отсутствие sitemap.xml. Что бы поправить ситуацию нужно просто создать данный файл и разместить его в корневом каталоге Вашего сайта. Ранее мы подробно рассказывали, как это сделать.
После создания необходимо зайти в Яндекс Вебмастер -> «Индексирование» — > «Файлы Sitemap» -> «Добавить карту». В этом же разделе возможно отследить корректность индексации и в случае необходимости обновить.
После того, как робот увидит sitemap сообщение о проблеме пропадет автоматически.
Обнаружены ошибки в файлах Sitemap

«В одном или нескольких файлах Sitemap обнаружены ошибки, которые могут повлиять на обработку файлов индексирующим роботом.» © Яндекс Вебмастер
В случае возникновения данной проблемы воспользуйтесь сервисом анализа sitemap.xml, который находится прямо в Яндекс Вебмастере. («Инструменты»-> «Анализ файлов Sitemap»).
Если ошибку не удается выявить, проще всего создать новую карту сайта. Как это сделать, подробно описывали ранее.
Если sitemap генерируется при помощи плагинов, обратите внимание на поля, которые находятся в итоговом файле. В отличии от Google, Яндекс не воспринимает инструкцию <image:image> и может сообщать об ошибке.
Файлы Sitemap давно не обновлялись

«В файлах Sitemap не обнаружено никаких изменений с undefined. Проверьте, не нужно ли обновить файлы Sitemap.»© Яндекс Вебмастер
Тут все просто. Необходимо обновить все имеющиеся на сайте файлы sitemap.xml. Причем сделать это нужно корректно. Вот лишь несколько ошибок, которые допускают при обновлении карты сайта.
-
Даты изменения страниц не соответствуют реальному обновлению страниц. Подобная ошибка происходит в тот момент, когда Вы используете online сервис. В таком случае все даты изменения могут быть одинаковыми и не соответствовать фактическим. Это заставляет поисковую систему повторно загружать один и тот же материал, что приводит к пустой трате времени;
-
Все страницы имеют один и тот же приоритет. В таком случае данный параметр sitemap.xml просто перестает иметь какой-либо смысл;
-
Вероятная частота изменения не соответствует действительной. Не стоит писать, что Ваши страницы обновляются каждый час. Обмануть поисковую систему не удастся и преимущества Вы не получите, но вот возможность корректного указания частоты обновления утратите.
Подробнее о создании sitemap.xml
Рекомендации
Этот раздел носит исключительно информационный характер, однако мы советуем соблюсти все его требования.
Не задана региональная принадлежность сайта

«В разделе «Региональность» регион сайта не задан явно, это может осложнить ранжирование. Если ваш сайт интересен пользователям вне зависимости от региона, выберите в разделе вариант «Нет региона».» © Яндекс Вебмастер
У данной проблемы есть две стороны медали. С одной — присвоение региона не является обязательной процедурой и Яндекс сам может определить его. С другой — если регион определен некорректно, то Вы можете получить нерелевантный трафик или же вообще лишиться его.
Поэтому мы настоятельно рекомендуем присваивать регион каждому сайту. Стоит отметить, что есть ряд ресурсов, которые не имеют региональной привязки. В таком случае необходимо сообщить Яндексу, что региона Вы не имеете.
Подробнее о том, как выбрать и присвоить регион.
Сайт не оптимизирован для мобильных

«По результатам работы алгоритма, определяющего, насколько сайт подходит для мобильных устройств, сайт не удалось признать оптимизированным.» © Яндекс Вебмастер
Сегодня эта проблема должна находиться уже среди критичных. Поисковые системы не раз говорили о том, что будут занижать сайты не имеющие мобильной версии. С каждым годом процентное соотношение трафика с мобильных устройств растет, поэтому мобильная адаптация должна быть у всех.
Насколько корректно Ваш сайт адаптирован под мобильные телефоны и планшеты Вы можете определить с помощью официального сервиса Яндекса — «Проверка мобильных страниц» . Располагается он в разделе «Инструменты» Яндекс Вебмастера.
Ошибка счётчика Яндекс.Метрики

«Яндекс.Метрика помогает отслеживать источники трафика, получать детальную статистику о посещаемости и качестве страниц сайта, а также анализировать видеозаписи действий посетителей.» © Яндекс Вебмастер
Тут все просто. Скорее всего код Яндекс Метрики был установлен некорректно или не на все страницы.
Если Вы зайдете в счетчики и увидите красный значок слева от сайта — данные в Метрику не поступают. Нажмите на него.

Если он не станет зеленым, то просто переустановите счетчик. Для этого нужно:
-
Перейти в настройки нажав на значок шестеренки в правой части экрана;
-
Переходим на вкладку «Код счетчика» и копируем его;
-
Открываем шаблон, который формирует страницы сайта и вставляем в него код;
-
Переходим в метрику и нажимаем на красный кружок со стрелочкой. Он должен стать зеленым.
В случае, если Вы уверены, что код размещен правильно, но данные так и не поступают — обратитесь в службу поддержки или подробно ознакомьтесь с процессом установки счетчика.
Сайт не зарегистрирован в Яндекс.Справочнике

«Сайт не добавлен в Яндекс.Справочник. Если у вас есть офисы или филиалы, добавьте их в справочник, чтобы улучшить внешний вид сайта в поиске и региональное ранжирование. Если офисов и филиалов нет, явно укажите «Нет региона» в подразделе «Вебмастер» раздела настройки региональности.» © Яндекс Вебмастер
С точки зрения SEO, регистрация сайта в Яндекс Справочнике может дополнить сниппет такой полезной информацией, как телефон, адрес и режим работы. По брендовым запросам справа от сниппета начнет появляться карта с адресом и подробной информацией о фирме. Такие сниппеты любят пользователи, поэтому стоить уделить 15 минут на регистрацию.
Зарегистрироваться проще некуда. Это совершенно бесплатно.
-
Заходим в Яндекс Аккаунт и переходим по ссылке: https://yandex.ru/sprav/add/;
-
Вводим информацию о компании и нажимаем «Добавить организацию»;
-
Ожидаем одобрения модераторов. (Обычно проблем с этим не возникает)
После успешной модерации информация появится в выдаче через несколько обновлений.
Отсутствует файл favicon на сайте

«Не найден файл с изображением, которое должно отображаться во вкладке браузера и может быть показано возле названия сайта в поиске.» © Яндекс Вебмастер
Файл favicon.ico это небольшая картинка, которая отображается во вкладке браузера.

Favicon имеет расширение .ico и располагается в корневой папке сайта или шаблона.
Кроме отображения во вкладке, данное изображение присутствует в поисковой выдаче рядом со ссылкой на сайт. Именно поэтому о нем сообщает Яндекс.
Сделать favicon очень просто. Для этого нужно создать рисунок квадратной формы, после чего воспользоваться одним из множество online генераторов. Примеры таких сервисов:
-
http://pr-cy.ru/favicon/
-
http://www.favicon.ru
-
http://www.favicon.by
-
Множество других.
Скачайте получившийся файл, назовите его favicon.ico и разместите в корневой папке сайта. Несколько раз обновите браузер и Ваше изображение появится во вкладке рядом с доменом. В поисковой выдаче favicon обновится в течение 2-3 недель.
Отсутствуют быстрые ссылки

«В некоторых случаях в результатах поиска возможно отображение быстрых ссылок в сниппете сайта, что улучшает его видимость и количество переходов. Ссылки формируются полностью автоматически, роботы регулярно оценивают возможность показа быстрых ссылок.» © Яндекс Вебмастер
Это исключительно информационное сообщение, так как напрямую повлиять на вывод быстрых ссылок Вы не можете. Напомним, что последние располагаются под основным сниппетом сайта в органической выдаче. На рисунке ниже приведен пример быстрых ссылок для сайта компании Apple.
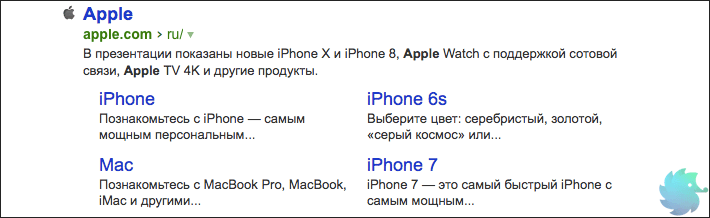
Но, несмотря на то, что напрямую влияния Вы не имеете, возможно «помочь» роботу определить быстрые ссылки. Делается это путем создания корректной древовидной структуры сайта. То есть, выделить основные разделы, сгруппировать в них подразделы и корректно связать все перелинковкой.
В этом случае Яндекс сможет с большей вероятностью определить основные разделы и сформировать блок быстрых ссылок.
I set up a website a few weeks ago and I’m trying to get Google to crawl it. When logging into Google’s Search Console (Webmaster Tools) and within:
Crawl > Crawl Errors
It reports:
Google couldn’t crawl your site because we were unable to access your
site’s robots.txt file. More Info.
In the «More info» link, Google says I don’t need a robots.txt file, so I’m not sure what I need to do to make the site indexed on Google.
Does this affect my site being indexed? How can I fix this issue?
![]()
John Conde♦
85.9k26 gold badges142 silver badges239 bronze badges
asked Mar 9, 2016 at 18:20
![]()
1
You do not need a robots.txt file for the site to enter Google’s index.
Since Google checks every site for a robots.txt your site is returning a 404 error which will return notifications with crawl errors. Simply ignore this error or create an emptyrobots.txt so that your website returns 200 OK status.
It should be noted that a site returning a 404 status is not an ERROR implying that your site requires fixing, for pages that do not exist then a server responding with a 404 status means the server is working as intended.
![]()
Simon Hayter
32.7k7 gold badges57 silver badges116 bronze badges
answered Mar 9, 2016 at 18:25
![]()
grggrg
3,1871 gold badge17 silver badges23 bronze badges
4
After reading the questions and comments, I would suggest doing any of the following:
-
Create an robots.txt with only one line in it. Maybe something like this:
# it works
-
Or if you don’t really want a robots.txt file, then configure your server so that all requests to robots.txt result in an HTTP 410 status code, meaning the file is gone and it should not be requested ever again.
If your server is apache, you can easily add the following contents to .htaccess in the document root folder of your site, or inside the directory tags where the directory is the document root in the main server configuration.
RewriteEngine On
RewriteRule ^robots.txt$ - [R=410,NC,L]
This will cause any request to robots.txt (regardless of letter casing) to produce an HTTP 410 status code.
I added a forward slash before the dot in the file name to make the dot a literal character instead of a rule-processing character.
The advantage to having a plain robots.txt file as opposed to no robots.txt file is that your error logs won’t be filled up with requests to robots.txt.
answered Mar 10, 2016 at 5:05
![]()
1
I set up a website a few weeks ago and I’m trying to get Google to crawl it. When logging into Google’s Search Console (Webmaster Tools) and within:
Crawl > Crawl Errors
It reports:
Google couldn’t crawl your site because we were unable to access your
site’s robots.txt file. More Info.
In the «More info» link, Google says I don’t need a robots.txt file, so I’m not sure what I need to do to make the site indexed on Google.
Does this affect my site being indexed? How can I fix this issue?
![]()
John Conde♦
85.9k26 gold badges142 silver badges239 bronze badges
asked Mar 9, 2016 at 18:20
![]()
1
You do not need a robots.txt file for the site to enter Google’s index.
Since Google checks every site for a robots.txt your site is returning a 404 error which will return notifications with crawl errors. Simply ignore this error or create an emptyrobots.txt so that your website returns 200 OK status.
It should be noted that a site returning a 404 status is not an ERROR implying that your site requires fixing, for pages that do not exist then a server responding with a 404 status means the server is working as intended.
![]()
Simon Hayter
32.7k7 gold badges57 silver badges116 bronze badges
answered Mar 9, 2016 at 18:25
![]()
grggrg
3,1871 gold badge17 silver badges23 bronze badges
4
After reading the questions and comments, I would suggest doing any of the following:
-
Create an robots.txt with only one line in it. Maybe something like this:
# it works
-
Or if you don’t really want a robots.txt file, then configure your server so that all requests to robots.txt result in an HTTP 410 status code, meaning the file is gone and it should not be requested ever again.
If your server is apache, you can easily add the following contents to .htaccess in the document root folder of your site, or inside the directory tags where the directory is the document root in the main server configuration.
RewriteEngine On
RewriteRule ^robots.txt$ - [R=410,NC,L]
This will cause any request to robots.txt (regardless of letter casing) to produce an HTTP 410 status code.
I added a forward slash before the dot in the file name to make the dot a literal character instead of a rule-processing character.
The advantage to having a plain robots.txt file as opposed to no robots.txt file is that your error logs won’t be filled up with requests to robots.txt.
answered Mar 10, 2016 at 5:05
![]()
1
В самом начале SEO-продвижения сайта специалист обязан «уведомить» поисковые системы о наличии сайта в индексе и оценить, какие проблемы отображает Яндекс или Google по своим стандартам. Сайт добавляется в Вебмастер – сервис Яндекса, в котором содержится панель инструментов для оценки качества индексации сайта. Этот инструмент находится по URL-адресу: https://webmaster.yandex.ru/. Верификация осуществляется тремя способами:
- Добавление соответствующего кода в тег «head».
- Размещение файла Вебмастера сайта в корневой папке проекта.
- Добавление TXT-записи верификации в DNS домена сайта.
Если домен новый и ни разу не проверялся Яндексом, необходимо подождать несколько дней, чтобы сформировался предварительный отчет и на панели можно было обнаружить ошибки. Их необходимо устранять в кратчайшие сроки.
В данной статье рассмотрим самые частые ошибки Вебмастера Яндекса и приведём рекомендации по их устранению.
Содержание:
- Категории проблем
- Фатальные ошибки
- Критичные ошибки
- Возможные ошибки
- Рекомендации
- Вывод
Категории проблем
Ошибки проверяемого сайта указаны в разделе «Диагностика сайта». Существует 4 категории ошибок, которые фиксирует Яндекс и сообщает об этом пользователю:
- Фатальные — отображаются возможные проблемы с подключением сайта к серверу, его корректной настройкой, доступностью для последующего индексирования, соблюдением правил безопасности и общих правил поисковой системы.
- Критичные — выдаются проблемы с настройкой SSL-сертификата (он отвечает за безопасное HTTPS-соединение, важный фактор в SEO-оптимизации), ссылками с 404-ошибкой и скоростью ответа сервера на запрос.
- Возможные — потенциальные проблемы, которые влияют на общее качество сайта для потенциальных пользователей и скорость обхода отдельных страниц сайта – правильная настройка XML-карты, наличие файла robots.txt, разрешение на обход внутренних страниц через статистику из Метрики (настройка параллельного отслеживания данных со счетчика статистики), наличие дублирующихся страниц.
- Рекомендации — общая информация для улучшения представления сайта в поиске.
Как правило, все ошибки и рекомендации важно закрывать и исправлять, а при выполнении вовремя уведомлять системы через кнопку «Проверить». Также рекомендуется отправить отредактированные страницы на переобход (раздел «Индексирование», далее – «Переобход страниц»).
Рассмотрим подробнее все варианты и пути для исправления.
Фатальные ошибки
Уведомления о наличии такого рода проблем могут появляться в следующих ситуациях:
«Главная страница возвращает ошибку»

Проблема отображается, если главная страница не выдает корректный ответ сервера — «200 ОК», это можно проверить в разделе «Инструменты» — «Проверка ответа сервера». Причины могут быть разные — страница закрыта от индексации, произошел сбой в настройке сервера, главная страница перенаправлена на другую страницу (для нее настроен редирект).
Для исправления необходимо проверить файл robots.txt на наличие правила «Disallow» для главной страницы или убрать тег noindex в метатеге robots в коде главной страницы.
«Не удалось подключиться к серверу из-за ошибки DNS»

Это означает, что при индексировании поисковый робот не смог получить IP-адрес сервера, на котором расположены файлы сайта. Адрес присваивается хостинг-провайдером и указывается в панели управления DNS-записями. При корректной настройке ответ сервера для ресурса – «200 ОК». В случае неполадки следует обращаться к хостинг-провайдеру.
«Сайт закрыт от индексирования в файле robots.txt»

Зачастую такая ошибка возникает после переноса готового проекта с тестового домена (откуда велась разработка) на основной. В файле robots.txt обычно в таких случаях прописывается правило «Disallow: /», означающая закрытие от индексации абсолютно всех страниц сайта. Чтобы устранить эту ошибку, требуется просто удалить эту строку из файла для всех элементов User-Agent.
«Обнаружены нарушения или проблемы с безопасностью»

В эту категорию фатальных проблем попадают сайты, замеченные за нарушениями, которые противоречат правилам поисковиков, среди таких нарушений могут быть:
- переспамленные SEO-тексты;
- обман Яндекса с целью манипуляции выдачей в топе поиска;
- чрезмерная закупка SEO-ссылок — наличие большого количества внешних ссылок, закупленных в течение недавнего времени;
- дорвеи — наличие сквозного веб-ресурса, который за счет мощного трафика перенаправляет пользователей на продвигаемый сайт;
- майнинг
- малополезный контент;
- фишинг — сбор конфиденциальной информации, логинов, паролей, данных для связи
- «черные» и «серые» методы продвижения, связанные с манипуляцией поведенческими факторами или большим количеством автоматических переходов (накрутка ботами), применяемая не только некоторыми SEO-оптимизаторами, но и недобросовестными конкурентами.
Чтобы узнать точный ответ, что именно исправлять, необходимо перейти в раздел «Безопасность и нарушения» и нажать на кнопку с вопросительным знаком. Далее от SEO-шника требуется внимательно исправить ошибку, чтобы после устранения проблемы в том же разделе нажать кнопку «Я всё исправил». Проблем должна исчезнуть, в противном случае придется ждать минимум 3 месяца.
Критичные ошибки
Рассматриваемые проблемы могут стать причиной понижения позиций по продвигаемым запросам по отдельным страницам или для всего сайта.
«Долгий ответ сервера»

В данном случае страницы долго отвечают на запросы поискового робота. Для проверки скорости прямо в Вебмастере можно использовать инструмент «Проверка ответа сервера». Оптимальное время для корректной работы — не более 3-х секунд. В противном случае необходимо настроить кэширование ресурса, устранить ошибки и добавить ресурс на хостинге, а также сократить число запросов к базе данных.
«Некорректная настройка SSL-сертификата»

Для безопасного соединения ресурса с пользователем с возможностью предоставления информации используется SSL-сертификат, обеспечивающий защищенное HTTPS-соединение. Критическая проблема может появиться в следующих случаях:
- Истек срок действия — требуется продление;
- Сертификат был аннулирован по причине проблем в удостоверяющем центре — заменить на корректный и работающий на всех популярных браузерах;
- Сертификат оформлен на дублирующийся домен — заменить на актуальный адрес и заодно настроить перенаправление;
- Использование самописного SSL — заменить на один из популярных и работающих.
«Найдены страницы-дубли с GET-параметрами»

К проблеме относятся дубли страницы с одинаковым содержимым, но доступные по разным URL-адресам. Это или страницы без перенаправления на правильный адрес или содержащие GET-параметр, связанный с динамической ссылкой для сервера.
Для исправления необходимо добавить правило «Clean-param:» в файл robots.txt или разместить в теге «head» атрибут rel=”canonical” с отображением правильной версии страницы. Проблема «уходит» автоматически через несколько дней.
Возможные ошибки
Самый распространенный вид, к которым относятся небольшие проблемы при SEO-оптимизации.
«Не найден файл robots.txt»

Данный файл нужен для определения правил индексирования для поисковых роботов, что можно включать в выдачу, а что — нельзя. Иногда бывает, что Вебмастер может случайно сообщить об ошибке, даже если файл размещен в корневой системе сайта. В таком случае нужно нажать кнопку «Проверить» и в течение 2-3 дней уведомление удалится.
«Обнаружены ошибки в файле robots.txt»

Необходимо через Вебмастер проверить на наличие ошибок файл robots.txt, который закрывает часть страниц от индексирования. Для исправления требуется еще раз проверить документ на правильную настройку директив.
«Нет используемых роботом файлов Sitemap»

Sitemap.xml представляет собой список всех страниц сайта, который считывает поисковая система, загружая в свою базу новые страницы. Для устранения проблемы нужно создать и загрузить на сервере файл (через специальные сервисы, например SiteAnalyzer, а также стандартный SEO-плагин в CMS), указать в панели Вебмастера ссылку на карту («Индексирование» — «Файлы Sitemap»), а также скопировать путь к файлу и отметить в файле robots.txt.
«Обнаружены ошибки в Sitemap»

В Вебмастере есть компонент «Анализ файлов Sitemap», с помощью которого можно проверить все строки файла на ошибки и устранить их. Вносить изменения рекомендуется, даже несмотря на то, что при наличии проблем поисковая система не блокирует весь файл, а игнорирует незнакомые инструкции.
«Отсутствуют элемент title и метатег description»

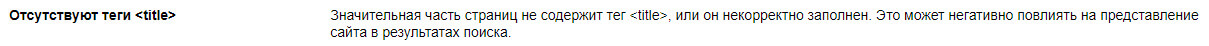
Теги title и description необходимы для соответствия ресурса запросу пользователя. С их помощью поисковая систем формирует сниппет — краткое описание сайта в выдаче. Метатеги обязательны к заполнению.
«На страницах имеются одинаковые заголовки и описания»

Метатеги title и description должны быть не только заполнены, но и различимы между собой. Рекомендация исчезнет после изменений и последующей проверки роботом, рекомендуется указать ссылки на измененные страницы в разделе для переобхода.
«Файл favicon недоступен для робота»

В данном случае иконка не всегда показывается в результатах поиска (в зависимости от браузера). Посмотрите причину: ответ сервера не «200 ОК» — проверьте ссылку, причина может быть в неправильном значении данных в параметре type.
Рекомендации
В этой категории отображаются предложения по улучшению позиций сайта.
«В результатах поиска найдены поддомены»

Если в проекте имеются региональные поддомены, их также нужно добавлять в Вебмастер в качестве отдельных ресурсов, а в разделе «Региональность» присвоить геопривязку через карточку компании в Яндекс.Бизнес и добавление ссылки на страницу «Контакты», где указан фактический адрес. Для поддоменов дополнительная верификация не требуется – достаточно просто добавить проект на уже подтвержденный аккаунт для основного зеркала сайта.
«Не задана региональная принадлежность сайта»

В блоке «Региональность» нужно указать регион (город или субъект), чтобы лучше отображать продвигаемый сайт по геозависимым запросам, когда пользователь ищет товар или услугу, не указывая регион в поисковой строке, а находясь в нем.
«В Бизнесе подготовлена карточка организации»

Сервис «Яндекс.Бизнес», с помощью которого можно создавать карточки компании для отображения, например, в картах, может автоматически сформировать профиль на основе контента, особенно это относится к новым сайтам. В данном случае необходимо проверить и подтвердить содержимое карточки.
«Не указаны регионы в Яндекс Бизнесе»

Проблема относится к профилю в «Яндекс.Бизнесе». Необходимо выполнить все условия для правильного отображения карточки:
- данные заполнены на 90% и более (получена специальная «галочка» о том, что владелец компании подтвердил все указанные данные);
- указано главное зеркало сайта;
- с момента создания карточки прошло больше 1 недели.
Если все условия выполнены, рекомендация пропадет из раздела диагностики.
«Файл favicon не найден»

В качестве рекомендации может выпасть не только отсутствие favicon, но и его правильный формат – с расширением «.svg» или размером от 120х120 пикселей.
«Сайт не оптимизирован для мобильных устройств»

Чтобы увидеть замечания, необходимо перейти в раздел «Инструменты» — «Проверка мобильных страниц» и ознакомиться с рекомендациями от Яндекса, которые мешают корректному отображению мобильной версии сайта. Если все изменения были сделаны или ошибок не обнаружено, можно нажать кнопку «Проверить» для дополнительного анализа со стороны робота.
Вывод
При обнаружении ошибок в Яндекс.Вебмастере особое внимание уделите фатальным и критическим ошибкам – они напрямую влияют на работоспособность сайта и могут обрушить позиции сайта по продвигаемым запросам на несколько страниц вниз. Для устранения ошибок желательно привлекать технического специалиста (программиста или разработчика). Возможные проблемы относятся больше к компетенции SEO-специалистов и требуют чуть больше времени на исправления — все зависит от размера сайта.
К рекомендациям также следует присматриваться, чтобы успешно конкурировать с сайтами в топе поиска и улучшать коммерческие и поведенческие факторы.
Если ошибиться при создании файла robots.txt, то он может оказаться бесполезным для поисковых роботов. Появится риск неверной передачи поисковым роботам нужных команд, что приведет к снижению рейтинга, изменению пользовательских показателей виртуальной площадки. Даже если сайт работает хорошо и является полноценным, проверка robots.txt ему не помешает, а только сделает его работу лучше.
Из этой статьи вы узнаете:
- Для чего нужна проверка robots.txt
- Как осуществляется проверка robots.txt в Google
- 15 ошибок при проверке файла robots.txt
- Как правильно составить файл, чтобы проверка robots.txt не выявляла ошибок
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.

Как проводится проверка robots.txt Яндексом
- Проверить файл поможет специальный сервис Яндекс.Вебмастера «Анализ robots.txt». Найти его можно по ссылке: http://webmaster.yandex.ru/robots.xml
Чтобы войти в сервис, понадобится авторизация в системе. Если вы еще не проходили процедуру регистрации, то вам поможет пошаговая инструкция «Добавить сайт в Яндекс Вебмастер».
- В предлагаемую форму вам нужно ввести содержимое файла robots.txt, который нужно проверить на наличие ошибок. Есть два способа ввода данных:
- Заходите на сайт, используя ссылку http://ваш-сайт.ру/robots.txt, копируете содержимое в пустое поле сервиса (при отсутствии файла robots.txt вам обязательно нужно его создать!);
- Вставляете ссылку на проверяемый файл в поле «Имя хоста», нажимаете «Загрузить robots.txt с сайта» или Enter.
- Запуск проверки осуществляется нажатием команды «Проверить».
- После того как проверка запущена, можно провести анализ результатов.
После начала проверки анализатор разбирает каждую строку содержимого поля «Текст robots.txt» и анализирует директивы, которые он содержит. Кроме того, вы узнаете, будет ли робот обходить страницы из поля «Список URL».

Составлять файл robots.txt, подходящий для вашего ресурса, можно редактированием правил. Не забывайте, что сам файл ресурса при этом остается неизменным. Для вступления изменений в силу понадобится самостоятельная загрузка новой версии файла на сайт.
При проверке директив разделов, которые предназначены для робота Яндекса (User-agent: Yandex или User-agent:*), анализатор руководствуется правилами использования robots.txt. Остальные разделы проверяются в соответствии с требованиями стандарта. Когда анализатор разбирает файл, то выводит сообщение о найденных ошибках, предупреждает, если в написании правил есть неточности, перечисляет, какие части файла предназначены для робота Яндекса.
Анализатор может посылать сообщения двух типов: ошибки и предупреждения.
Сообщение об ошибке выводится, если какая-либо строка, секция или весь файл не могут быть обработаны анализатором вследствие наличия серьезных синтаксических ошибок, которые допустили при составлении директив.
В предупреждении, как правило, сообщается об отклонении от правил, исправление которого анализатором невозможно, или о наличии потенциальной проблемы (ее может и не оказаться), причина которой – случайная опечатка или неточное составленные правила.
Сообщение об ошибке «Этот URL не принадлежит вашему домену» говорит о том, что в списке URL содержится адрес одного из зеркал вашего ресурса, к примеру, http://example.com вместо http://www.example.com (формально эти URL различны). Нужно, чтобы подлежащие проверке адреса относились к сайту, файл robots.txt которого анализируется.
Как осуществляется проверка robots.txt в Google
Инструмент Google Search Console позволяет вам провести проверку того, содержится ли в файле robots.txt запрет на сканирование роботом Googlebot определенных URL на вашем ресурсе. К примеру, у вас есть изображение, которое вы не хотите видеть в результатах поисковой выдачи Google по картинкам. С помощью инструмента вы узнаете, имеет ли робот Googlebot-Image доступ к этому изображению.
Для этого следует указать интересующий URL. После этого происходит обработка файла robots.txt инструментом проверки, аналогичная проверка роботом Googlebot. Это дает возможность определить, доступен ли этот адрес.
Процедура проверки:
- После выбора вашего ресурса в Google Search Console перейдите к инструменту проверки, который выдаст вам содержание файла robots.txt. Выделенный текст – это ошибки в синтаксисе или логические. Их количество указывается под окном редактирования.
- В нижней части страницы интерфейса вы увидите специальное окно, в которое нужно ввести URL.
- Справа появится меню, из которого необходимо выбрать робота.
- Нажмите на кнопку «Проверить».
- Если в результате проверки выводится сообщение с текстом «доступен», это значит, что роботам Google разрешено посещать указанную страницу. Статус «недоступен» говорит о том, что доступ к ней роботам закрыт.
- Если нужно, вы можете изменить меню и провести новую проверку. Внимание! Автоматического внесения изменений в файл robots.txt на вашем ресурсе не произойдет.
- Скопируйте изменения и внесите их в файл robots.txt на вашем веб-сервере.

На что нужно обратить внимание:
- Сохранения сделанных в редакторе изменений на веб-сервере не происходит. Понадобится копирование полученного кода и вставки его в файл robots.txt.
- Получить результаты проверки файла robots.txt инструментом могут только агенты пользователя Google и роботы, относящиеся к Google (к примеру, робот Googlebot). При этом гарантии того, что интерпретация содержания вашего файла роботами других поисковых систем будет аналогичной, нет.
15 ошибок при проверке файла robots.txt
Ошибка 1. Перепутанные инструкции
Наиболее распространенная ошибка в файле robots.txt – перепутанные инструкции. К примеру:
- User-agent: /
- Disallow: Yandex
Правильный вариант такой:
- User-agent: Yandex
- Disallow: /
Ошибка 2. Указание нескольких каталогов в одной инструкции Disallow
Часто владельцы Интернет-ресурсов стараются прописать все каталоги, которые они хотят запретить индексировать, в одной инструкции Disallow.
Disallow: /css/ /cgi-bin/ /images/
Такая запись не соответствует требованиям стандарта, предсказать, какой будет обработка ее разными роботами, невозможно. Одни из них могут проигнорировать пробелы. Их интерпретация записи будет такой: «Disallow: /css/cgi-bin/images/». Другими может быть использована лишь первая или последняя папка. Третьи и вовсе могут отбросить инструкцию, не поняв ее.
Есть вероятность того, что обработка этой конструкции будет именно такой, на которую рассчитывал мастер, но все же лучше написать правильно:
- Disallow: /css/
- Disallow: /cgi-bin/
- Disallow: /images/
Ошибка 3. В имени файла присутствуют заглавные буквы
Правильное название файла — robots.txt, а не Robots.txt или ROBOTS.TXT.
Ошибка 4. Написание имени файла как robot.txt вместо robots.txt
Запомните, правильно называть файл robots.txt.
Ошибка 5. Оставление строки в User-agent пустой
Неправильный вариант:
- User-agent:
- Disallow:
Верно:
- User-agent: *
- Disallow:
Ошибка 6. Написание Url в директиве Host
URL нужно указывать, не используя аббревиатуру протокола передачи гипертекста (http://) и закрывающий слеш (/).
Неверная запись:
- User-agent: Yandex
- Disallow: /cgi-bin
- Host: http://www.site.ru/
Правильный вариант:
- User-agent: Yandex
- Disallow: /cgi-bin
- Host: www.site.ru
Корректным использование директивы host является только для робота Яндекса.
Ошибка 7. Использование в инструкции Disallow символов подстановки
Иногда, чтобы указать все файлы file1.html, file2.html, file3.html и т.д, веб-мастер может написать:
- User-agent: *
- Disallow: file*.html
Но делать этого нельзя, поскольку у некоторых роботов отсутствует поддержка символов подстановки.
Ошибка 8. Использование для написания комментариев и инструкций одной строки
Стандарт разрешает такие записи:
Disallow: /cgi-bin/ #запрещаем роботам индексировать cgi-bin
Раньше обработка таких строк некоторыми роботами была невозможна. Может быть, в настоящее время ни у одного поисковика не возникнет с этим проблем, но стоит ли идти на риск? Лучше размещать комментарии на отдельной строке.
Ошибка 9. Редирект на страницу 404-й ошибки
Нередко, если сайт не имеет файла robots.txt, то при его запросе поисковик будет переадресовывать на другую страницу. Иногда при этом не происходит отдачи статуса 404 Not Found. Роботу приходится самому разбираться, что он получил — robots.txt или обычный html-файл. Это не является проблемой, но лучше, если в корне сайта будет размещен пустой файл robots.txt.
Ошибка 10. Использование заглавных букв – признак плохого стиля
USER-AGENT: GOOGLEBOT
DISALLOW:
Хоть в стандарте и не регламентирована чувствительность robots.txt к регистру, нередко она имеет место у имен файлов и директорий. Кроме того, если файл robots.txt написан полностью заглавными буквами, то это считается плохим стилем.
User-agent: googlebot
Disallow:
Ошибка 11. Перечисление всех файлов
Неправильным будет перечислять каждый файл в директории в отдельности:
- User-agent: *
- Disallow: /AL/Alabama.html
- Disallow: /AL/AR.html
- Disallow: /Az/AZ.html
- Disallow: /Az/bali.html
- Disallow: /Az/bed-breakfast.html
Правильным будет закрытие от индексации полностью всей директории:
- User-agent: *
- Disallow: /AL/
- Disallow: /Az/
Ошибка 12. Использование дополнительных директив в секции *
Может иметь место неправильная реакция некоторых роботов на использование дополнительных директив. Поэтому применение их в секции «*» является нежелательным.
Если директива не является стандартной (как, например, «Host»), то для нее лучше создать специальную секцию.
Неверный вариант:
- User-agent: *
- Disallow: /css/
- Host: www.example.com
Правильно будет написать:
- User-agent: *
- Disallow: /css/
- User-agent: Yandex
- Disallow: /css/
- Host: www.example.com
Ошибка 13. Отсутствие инструкции Disallow
Даже при желании использовать дополнительную директиву и не устанавливать никакой запрет, рекомендуется указывать пустой Disallow. В стандарте указана обязательность инструкции Disallow, при ее отсутствии робот может «неправильно вас понять».
Неправильно:
- User-agent: Yandex
- Host: www.example.com
Правильно:
- User-agent: Yandex
- Disallow:
- Host: www.example.com
Ошибка 14. Неиспользование слешей, когда указывается директория
Каковы будут действия робота в этом случае?
- User-agent: Yandex
- Disallow: john
Согласно стандарту, индексация не будет проведена для как для файла, так и для директории с именем «john». Чтобы указать только директорию, нужно написать:
- User-agent: Yandex
- Disallow: /john/
Ошибка 15. Неправильное написание HTTP-заголовка
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Если заголовок будет написан неправильно, то обработка файла некоторыми роботами будет невозможна.
Как правильно составить файл, чтобы проверка robots.txt не выявляла ошибок
Каким должен быть правильный файл robots.txt для Интернет-ресурса? Рассмотрим его структуру:
1. User-agent
Эта директива является основной, она определяет, для каких роботов написаны правила.
Если для любого робота, пишем:
User-agent: *
Если для конкретного бота:
User-agent: GoogleBot
Стоит отметить, что регистр символов не имеет значения в robots.txt. К примеру, юзер-агент для Google можно записать и так:
user-agent: googlebot
Приведем таблицу основных юзер-агентов различных поисковиков.
|
Бот |
Функция |
|
|
|
|
Googlebot |
основной индексирующий робот Google |
|
Googlebot-News |
Google Новости |
|
Googlebot-Image |
Google Картинки |
|
Googlebot-Video |
видео |
|
Mediapartners-Google |
Google AdSense, Google Mobile AdSense |
|
Mediapartners |
Google AdSense, Google Mobile AdSense |
|
AdsBot-Google |
проверка качества целевой страницы |
|
AdsBot-Google-Mobile-Apps |
Робот Google для приложений |
|
Яндекс |
|
|
YandexBot |
основной индексирующий робот Яндекса |
|
YandexImages |
Яндекс.Картинки |
|
YandexVideo |
Яндекс.Видео |
|
YandexMedia |
мультимедийные данные |
|
YandexBlogs |
робот поиска по блогам |
|
YandexAddurl |
робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
|
YandexFavicons |
робот, индексирующий пиктограммы сайтов (favicons) |
|
YandexDirect |
Яндекс.Директ |
|
YandexMetrika |
Яндекс.Метрика |
|
YandexCatalog |
Яндекс.Каталог |
|
YandexNews |
Яндекс.Новости |
|
YandexImageResizer |
робот мобильных сервисов |
|
Bing |
|
|
Bingbot |
основной индексирующий робот Bing |
|
Yahoo! |
|
|
Slurp |
основной индексирующий робот Yahoo! |
|
Mail.Ru |
|
|
Mail.Ru |
основной индексирующий робот Mail.Ru |
2. Disallow и Allow
Disallow позволяет запретить индексирование страниц и разделов Интернет-ресурса.
Allow служит для принудительного открытия их для индексирования.
Но пользоваться ими достаточно непросто.
Во-первых, нужно ознакомиться с дополнительными операторами и правилами их использования. К ним относятся: *, $ и #.
- * —любое количество символов, даже их отсутствие. Ставить этот оператор в конце строки не обязательно, подразумевается, что она там стоит по умолчанию;
- $ — показывает, что стоящий перед ним символ должен быть последним;
- # — этот оператор служит для обозначения комментария, любая информация после него роботом в расчет не берется.
Как пользоваться этими операторами:
- Disallow: *?s=
- Disallow: /category/$
Не могут быть проиндексированы такие ссылки:
- http://site.ru/?s rel=»nofollow»=
- http://site.ru/?s=keyword rel=»nofollow»
- http://site.ru/page/?s=keyword rel=»nofollow»
- http://site.ru/category/ rel=»nofollow»
Эти ссылки, наоборот, открыты для индексации:
- http://site.ru/category/cat1/ rel=»nofollow»
- http://site.ru/category-folder/ rel=»nofollow»
Во-вторых, необходимо понимание того, как выполняются правила, вложенные в файл robots.txt.
Не имеет значения, в каком порядке записаны директивы. Определение наследования правил (что открыть или закрыть от индексации) осуществляется по указанным директориям. Приведем пример.
Allow: *.css
Disallow: /template/
- http://site.ru/template/ rel=»nofollow» — закрыто от индексирования
- http://site.ru/template/style.css rel=»nofollow» — закрыто от индексирования
- http://site.ru/style.css rel=»nofollow» — открыто для индексирования
- http://site.ru/theme/style.css rel=»nofollow» — открыто для индексирования
Если необходимо открыть для индексации все файлы .css, то нужно будет дополнительно указать это для каждой папки, доступ к которой закрыт. В нашем случае:
- Allow: *.css
- Allow: /template/*.css
- Disallow: /template/
Напомним еще раз: не важно, в каком порядке записаны директивы.
3. Sitemap
Эта директива указывает путь к XML-файлу Sitemap. URL-адрес имеет такой же вид, что и в адресной строке.
К примеру,
Sitemap: http://site.ru/sitemap.xml rel=»nofollow»
Указание директивы Sitemap возможно в любом месте файла robots.txt, при этом не требуется привязывать ее к конкретному user-agent. Разрешается указывать несколько правил Sitemap.
4. Host
Эта директива указывает главное зеркало ресурса (как правило, с www или без www). Помните: при указании главного зеркала пишется не http://, а https://. В случае необходимости указывается и порт.
Поддержка этой директивы возможна только ботами Яндекса и Mail.Ru. Другие роботы, в том числе и GoogleBot, эту команду не учитывают. Прописывать host можно только один раз!
Пример 1:
Host: site.ru
Пример 2:
5. Crawl-delay
Позволяет установить, через какой промежуток времени роботу нужно скачивать страницы ресурса. Директиву поддерживают роботы Яндекса, Mail.Ru, Bing, Yahoo. При установке интервала можно использовать как целые значения, так и дробные, используя в качестве разделителя применяется точка. Единица измерения — секунды.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если нагрузка на сайт небольшая, то нет необходимости в установке этого правила. Но если результатом индексирования роботом страниц является превышение лимитов или серьезное увеличение нагрузки, приводящее к перебоям в работе сервера, то использование этой директивы целесообразно: оно позволяет снизить нагрузку.
Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии. Оптимальное значение для каждого ресурса свое. Сначала рекомендуется ставить небольшие значения (0.1, 0.2, 0.5), затем постепенно увеличивая их. Для роботов поисковиков, не особо важных для результатов продвижения (к примеру, Mail.Ru, Bing и Yahoo), можно сразу устанавливать значения, бóльшие, нежели для роботов Яндекса.
6. Clean-param
Эта директива нужна для сообщения краулеру (поисковому роботу) о ненужности индексации URL-адресов с указанными параметрами. Для правила указываются два аргумента: параметр и URL раздела. Яндекс поддерживает директиву.
Пример 1:
http://site.ru/articles/?author_id=267539 — не подвергнется индексации
Пример 2:
http://site.ru/articles/?author_id=267539&sid=0995823627 — не подвергнется индексации
Яндексом также рекомендовано использование этой директивы, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source utm_medium utm_campaign
7. Другие параметры
Расширенная спецификация robots.txt содержит еще такие параметры: Request-rate и Visit-time. Но в настоящее время отсутствует поддержка их ведущими поисковиками.
Директивы нужны для следующего:
- Request-rate: 1/5 — разрешает загрузку не более 1 страницы за 5 секунд
- Visit-time: 0600-0845 — разрешает загрузку страниц только с 6 утра до 8:45 по Гринвичу
Для правильной настройки файла robots.txt рекомендуем использовать такой алгоритм:
1)Запретите индексировать админку сайта;
2)Закройте доступ роботам к личному кабинету, страницам авторизации и регистрации;
3)Запретите индексировать корзину, формы заказа, данные по доставке и заказам;
4) Закройте от индексирования ajax, json-скрипты;
5) Запретите индексировать папку cgi;
6) Запретите индексировать плагины, темы оформления, js, css для роботов всех поисковых систем, кроме Яндекса и Google;
7) Закройте доступ роботам к функционалу поиска;
 Запретите индексировать служебные разделы, не являющиеся ценными для ресурса в поиске (ошибка 404, список авторов);
Запретите индексировать служебные разделы, не являющиеся ценными для ресурса в поиске (ошибка 404, список авторов);
9)Закройте от индексирования технические дубли страниц и страницы, контент которых в той или иной степени дублирует содержимое других страниц (календари, архивы, RSS);
10) Запретите индексировать страницы с параметрами фильтров, сортировки, сравнения;
11) Запретите индексировать страницы с параметрами UTM-меток и сессий;
12) Используйте для проверки того, что проиндексировал Яндекс и Google, параметр «site:». Для этого в строку поиска введите «site:site.ru». Если в поисковой выдаче есть страницы, которые не нужно индексировать, добавьте их в robots.txt;
13)Пропишите правила Sitemap и Host;
14) Если необходимо, укажите Crawl-Delay и Clean-Param;
15)Проведите проверку корректности файла robots.txt, используя инструменты Google и Яндекса;
16) Через 14 дней проведите повторную проверку, чтобы убедиться в отсутствии в выдаче поисковых систем страниц, которые не должны индексироваться. Если таковые имеются, повторите все указанные выше пункты.
Проверка файла robots.txt имеет смысл, только если ваш сайт в порядке. Определить это поможет аудит сайта, проводимый квалифицированными специалистами.
Надеемся, что наша статья о бизнес-идеях, окажется вам полезной. А если вы уже определились с направлением деятельности и активно занимаетесь развитием и продвижением своего проекта, то советуем пройти аудит сайта, чтобы представлять реальную картину возможностей вашего ресурса.
Robots.txt — это текстовый файл, который показывает поисковым роботам, как сканировать ваш сайт. Он защищает сайт и сервер от перегрузки из-за запросов поисковых роботов.
Если вы хотите заблокировать работу поисковых роботов, важно убедиться в корректности настроек. Это особенно важно, если вы используете динамические URL или другие методы, которые в теории генерируют бесконечное количество страниц.

В этом гайде рассматриваются самые распространенные проблемы с файлом robots.txt, их влияние на сайт и ранжирование в поисковой выдаче, а также способы решения.
Но для начала поговорим подробнее о robots.txt и его альтернативах.
Что такое файл robots.txt
Robots.txt — это файл в простом текстовом формате. Он размещается в корневом каталоге сайта (самый верхний каталог в иерархии). Если файл размещен в другом каталоге, поисковые роботы будут его игнорировать. Несмотря на всю мощь robots.txt, выглядит он как простой текстовый документ. А создать его можно за пару секунд в любом текстовом редакторе.
Выполнять функции robots.txt могут и его альтернативы. Например, метатеги. Их можно размещать в код отдельной страницы.
Можно использовать и HTTP-заголовок X-Robots-Tag, который задает настройки на уровне страницы.
Что делает robots.txt
Файл robots.txt можно использовать для множества целей. Вот несколько самых популярных.
Блокировка сканирования поисковыми роботами определенных страниц
Они все еще могут появляться в поисковой выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
Блокировка медиафайлов для отображения в результатах поиска
Под медиафайлами понимаются изображения, видео и аудиофайлы. Если для файла предусмотрен общий доступ, он будет отображаться, но приватный контент не попадет в поисковую выдачу.

Блокировка файлов ресурсов с неважными внешними скриптами
Если у страницы заблокирован файл ресурсов, поисковые роботы посчитают, что его не существовало вовсе. Это может сказаться на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах поиска. Для этого придется добавить метатег noindex в верхнюю часть страницы.
Насколько опасны ошибки с Robots.txt
Ошибки в robots.txt приводят к определенным последствиям, но обычно не трагичным. А приведение файла в порядок позволит быстро и полностью восстановиться.
Как отмечает сам Google, у поисковых роботов достаточно гибкие алгоритмы. Поэтому незначительные ошибки в файле robots.txt никак не сказываются на их работе. В худшем случае неправильная или неподдерживаемая директива будет проигнорирована. Но если вы знаете, что в файле есть ошибки, их стоит исправить.
Шесть главных ошибок robots.txt
Если ранжирование сайта в поисковой выдаче изменилось странным образом, стоит проверить файл robots.txt. Рассмотрим шесть популярных ошибок подробно.
Ошибка № 1. Robots.txt находится не в корневом каталоге
Поисковые роботы могут найти файл robots.txt только если он расположен в корневом каталоге. Поэтому домен, например, .ru, и название файла robots.txt в URL должна разделять одна косая черта.
Если есть дополнительная папка, скорее всего, поисковые роботы не увидят файл. Сайт в этом случае функционирует так, как будто файла robots.txt нет совсем.
Чтобы исправить эту ошибку, перенесите robots.txt в корневой каталог. Для этого потребуется доступ к серверу. Некоторые системы управления содержимым по умолчанию загружают файл в подпапку с медиафайлами или подобные. Чтобы файл попал в нужное место, придется обойти эту настройку.
Ошибка № 2. Неправильное использование символа-джокера или символа подстановки
Символ-джокер — это символ, используемый для замены других символов или их последовательностей. Robots.txt поддерживает два символа-джокера:
- Звездочка, или астериск (*). Она представляет любые варианты допустимого символа. Своего рода аналог карты джокера.
- Значок доллара $. Обозначает конец URL, позволяет добавлять правила к последней части URL, например, файловое расширение.
При использовании символов-джокеров стоит придерживаться минимализма. Они могут потенциально наложить ограничения на большую часть сайта. Неправильное использование астерикса может привести к блокировке поискового робота. Чтобы решить проблему с неправильным символом-джокером, нужно его найти и переместить или удалить.
Ошибка № 3. Тег noindex в robots.txt
Эта ошибка часто встречается у сайтов, которым уже несколько лет. Google в сентябре 2019 года перестал выполнять команды метатега noindex в файле robots.txt.

Если ваш файл был создан до этой даты или содержит метатег noindex, скорее всего, страницы будут индексироваться Google.
Чтобы решить проблему, примените альтернативный метод. Вы можете добавить метатег robots в элемент страницы <head>, чтобы остановить индексацию.
Ошибка № 4. Блокировка скриптов и страниц стилей
Ограничение доступа к внутреннему JavaScript коду и Cascading Style Sheets (CSS) для поисковых роботов кажется логичным шагом. Однако поисковым роботам Google требуется доступ к CSS и JavaScript файлам, чтобы корректно сканировать HTML и PHP страницы.
Если страницы сайта странно отображаются в поисковой выдаче, проверьте, не заблокирован ли доступ поискового робота к этим внутренним файлам. Удалите соответствующую строку из файла robots.txt.
Если же вам нужна блокировка определенных файлов, вставьте исключение, которое даст поисковым роботам доступ только к нужным материалам.
Ошибка № 5. Отсутствует ссылка на файл sitemap.xml
Этот пункт относится к SEO больше всего. Файл sitemap.xml дает роботам информацию о структуре сайта и его главных страницах. Поэтому есть смысл добавить его в файл robots.txt. Его поисковые роботы Google сканируют в первую очередь.
Строго говоря, это не ошибка, и в большинстве случаев отсутствие ссылки на sitemap в robots.txt не должно влиять на функциональность и внешний вид сайта. Но если вы хотите улучшить продвижение, дополните файл robots.txt
Ошибка № 6. Доступ к страницам в разработке
Запрет сканирования поисковыми роботами рабочих страниц — серьезная ошибка. Как и предоставление им доступа к страницам, находящимся в разработке. Включите запрещающие инструкции в файл robots.txt, если сайт находится на реконструкции. Тогда пользователи не увидят «сырой» вариант.
Кстати, не забудьте убрать соответствующую строчку из файла, когда закончите. Это довольно распространенная ошибка, которая не позволит поисковым роботам правильно сканировать и индексировать сайт
Если ваш сайт еще находится в разработке, но вы видите реальный трафик, или, наоборот, запущенный сайт плохо ранжируется, проверьте строчку User-Agent в файле robots.txt.
User-Agent: *
Disallow: /
Наличие косой черты в строке Disallow делает сайт невидимым для поисковых роботов. Корректируйте строку в соответствии с нужным вам эффектом.
Как восстановиться после ошибок в robots.txt
Если ошибка в файле robots.txt повлияла на отображение в поисковой выдаче, самое главное — скорректировать файл и подтвердить, что новые правила дают нужный эффект. Проверить это можно с помощью инструментов для сканирования, например, Screaming Frog.

Когда убедитесь, что robots.txt работает верно, запросите повторное сканирование поисковыми роботами. В этом поможет Google Search Console. Добавьте обновленный файл sitemap и запросите повторное сканирование страниц, которые пострадали.
К сожалению, нет конкретного срока, в который поисковый робот проведет сканирование и страницы начнут нормально отображаться в поисковой выдаче. Все, что остается — быстро выполнить необходимые шаги и ждать, когда поисковый робот просканирует сайт.
Профилактика важнее всего
Ошибки с файлом robots.txt решаются относительно просто, но лучшим лекарством от них станет профилактика. Редактируйте файл аккуратно, привлекая опытных разработчиков, дважды все проверяйте и, если это актуально, послушайте мнение второго специалиста.
Если есть возможность, протестируйте изменения в песочнице, прежде чем применять их на реальном сервере.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
Это позволит избежать непроизвольных ошибок. И помните, если самое страшное уже случилось, не поддавайтесь панике. Проанализируйте проблему, внесите необходимые изменения в файл robots.txt и отправьте запрос на повторное сканирование. Скорее всего, нескольких дней будет достаточно, чтобы вернуться на прежние позиции в поисковой выдаче.