Вы создали карту сайта, загрузили ее в Google Search Console, но файл не получил статус «Успешно» или «Ок»? А, может, отчет о файлах Sitemap выглядит хорошо, но поисковикиигнорирует ваш файл Sitemap и не собирается индексировать многие страницы из карты сайта. Возникает вопрос, можно ли что-нибудь сделать для улучшения статистики индексирования. Отвечаем — можно, и даже расскажем, как это сделать.
Если у вас еще нет карты сайта и вы хотите узнать, зачем она нужна, ознакомьтесь с нашим вводным интенсивом по созданию файла Sitemap. Здесь мы расскажем о преимуществах использования карты сайта и действенных рекомендациях по работе с ней. Если вы пока не знаете, для чего используют теги <loc> и <lastmod>, что такое карта сайта для видео или файл индекса Sitemap, вводное руководство вам точно пригодится.
В первой части этой статьи перечислены все ошибки, с которыми вы можете столкнуться в отчетах о файлах Sitemap в Google Search Console. Если же вы ищете способ устранить конкретные проблемы, воспользуйтесь содержанием, чтобы перейти к интересующим вас ошибкам.
Во второй части — рекомендации, которые помогут вам извлечь максимальную выгоду из карты сайта. Вы узнаете, как найти мусорные страницы в файле Sitemap, где искать страницы, которые вы могли пропустить и не добавить в карту сайта, и как заставить поисковик проиндексировать как можно больше страниц из файла Sitemap. Поэтому очень советую всем внимательно ознакомиться со второй главой этой статьи.
Исправление ошибок в отчете Sitemap
После загрузки карты сайта в Google в столбце «Статус» можно увидеть, удалось ли поисковику обработать файл. Если ваш файл соответствует всем правилам, появится статус «Успешно». В этой главе мы рассмотрим другие статусы, а именно «Не получено» и «Обнаружены проблемы».
Проблемы со сканированием вашего файла Sitemap
Начнем с самого худшего сценария, когда поисковик не может обработать файл Sitemap. Сначала разберемся с Google — что делать, если статус вашей карты сайта «Не получено».

В этом случае вам придется использовать «Инструмент проверки URL», чтобы выяснить, что может быть причиной проблемы. В инструменте нажмите кнопку «Проверить страницу на сайте» и посмотрите статус получения страницы. Если написано «Успешно», значит ошибка на стороне Google.

Если Google не удалось получить вашу карту сайта, убедитесь, что ничто не блокирует доступ к файлу Sitemap — будь то директивы robots.txt или плагины CMS (да, иногда виноваты они!). Также проверьте, правильно ли введен URL-адрес карты сайта — обратите внимание на протокол и префикс www.
Ошибка «Не получено» может возникнуть как при загрузке отдельной карты сайта, так и в случае загрузки в Google Search Console файла индекса Sitemap. Проблему нужно решить так же, как и с одной картой сайта.
Ошибки в файле индекса Sitemap
Теперь перейдем к случаям, когда поисковики просканировали добавленный вами файл и обнаружили ошибки. И начнем мы с ошибок файла индекса Sitemap.
Файл индекса Sitemap содержит ссылки на несколько карт сайта — поисковой системе необходимо обработать их все, чтобы наконец получить доступ к URL-адресам вашего сайта. В Google Search Console вы получите ошибку «Неполные URL в файле индекса Sitemap», если поисковик не сможет обработать URL-адреса, перечисленные в файле индекса Sitemap. Обычно это означает, что Google не удалось найти одну или несколько ваших карт сайта, потому что вы использовали относительные URL-адреса. Все URL-ы, которые указывают на отдельные карты сайта в файле индекса Sitemap, должны быть абсолютными, иначе Google не сможет их найти.
Кроме того, в вашем файле индекса Sitemap не должны быть указаны другие файлы индекса Sitemap, а только карты сайта. Если вы сделаете так, то получите сообщение «Вложенные файлы индекса Sitemap» в Google Search Console.
И последняя ошибка. В Google она звучит так «Слишком много файлов Sitemap в файле индекса». Это происходит с огромными сайтами, которые содержат более 50 000 карт сайта в одном файле.
Недопустимый размер файла Sitemap и ошибки сжатия
Ограничения по размеру применяются как к файлам индекса Sitemap, так и к отдельным картам сайта. Размер файла Sitemap в несжатом виде не должен превышать 50 МБ, а в карте сайта не должно быть более 50 000 URL-адресов. Если вы не соблюдаете эти правила, то получите ошибку «Превышен максимальный размер файла Sitemap» в Google. Узнать больше о том, как разделить карту сайта на несколько файлов, можно из нашего полного руководства по созданию файла Sitemap.
Карта сайта должна не только не превышать допустимые размеры, но и не быть пустой. Если вы загрузите пустой Sitemap, то получите соответствующую ошибку в консоли.
Я говорила, что допустимый размер карты сайта в несжатом виде должен быть меньше 50 МБ, но часто файлы Sitemap сжимают для экономии пропускной способности канала. Обычно для этой цели используют инструмент gzip, который добавляет расширение gz к файлу. Сообщение об ошибке сжатия или разархивирования в отчете означает, что что-то пошло не так во время процесса сжатия, и вам нужно сделать это еще раз.
Проблемы со сканированием URL-адресов в карте сайта
По ряду причин поисковики могут не просканировать некоторые URL-адреса, которые указаны в карте сайта. Давайте разберемся со всеми подобными ошибками.
«Файл Sitemap содержит URL, доступ к которым заблокирован в файле robots.txt» — ошибка довольно простая, поскольку поисковики укажут вам на заблокированные URL-адреса. Все зависит от того, хотите ли вы, чтобы эти URL-ы были проиндексированы. Если да, то вам придется снять блокировку, в другом случае необходимо удалить адреса из карты сайта.
Еще одна довольно очевидная проблема, которая не позволяет Google сканировать страницу, — это код ответа, отличный от 200 ОК. В отчете поисковиков это называется ошибкой HTTP, и точный код указывается для каждой отдельной страницы. Кроме консолей вебмастеров, проверить коды ответа URL-адресов из вашей карты сайта можно с помощью инструмента «Аудит сайта» от SE Ranking.
Всю необходимую информацию ищите в разделе «Код ответа сервера».

Google также выделяет другие не такие очевидные и простые ошибки. Кратко пройдемся по каждой из них.
Ошибка «URL недоступны» означает, что поисковик обнаружил вашу карту сайта в указанном месте, но не смог получить все URL-адреса из списка. В этом случае вам снова нужно использовать «Инструмент проверки URL» и проверять доступность для сканирования каждого проблемного URL-а.
Ошибка «Переход по URL не выполнен» возникает либо из-за того, что вы использовали относительные URL-адреса в карте сайта вместо абсолютных, либо из-за проблем с редиректами. Цепочки и циклы редиректов, временные редиректы, которые используют вместо постоянного перенаправления, а также HTML- и JS-редиректы могут привести к этим ошибкам.
Google Search Console не указывает, что именно может быть причиной проблемы. Поэтому вам нужно использовать другие инструменты, чтобы понять, какие ошибки необходимо исправить. Например, в инструменте «Аудит сайта» SE Ranking есть специальный раздел «Редиректы», где можно проверить, есть ли на вашем сайте какие-либо проблемы с перенаправлениями.
Если инструмент обнаружит какие-либо ошибки, вы получите всю необходимую информацию по каждой из них — щелкнув на количество страниц, можно узнать, на какой странице есть проблема и как она связана с другими страницами сайта.

Ошибка «Нельзя использовать URL» означает, что ваша карта сайта содержит URL-адреса, которые находятся на более высоком уровне или в другом домене по сравнению с файлом Sitemap. Например, если ваша карта сайта находится по адресу: vashsajt.com/category1/sitemap.xml и вы добавили в нее страницу, адрес которой: vashsajt.com/stranitsa1, поисковики не смогут получить к ней доступ.
Что касается разных доменов, помните, что для Google версии сайта на HTTP и HTTPS, а также с www и без www считаются разными. Поэтому, если ваша карта сайта находится по адресу http://www.vashsajt.com/sitemap.xml, URL вида https://vashsajt.com/stranitsa1 будет считаться некорректным.
Если вы недавно перешли на HTTPS, обязательно создайте новую карту сайта с HTTPS URL-адресами. Инструмент «Аудит сайта» SE Ranking напомнит вам об этом.

Google считает, что вы указали неправильные URL
Также стоит обратить внимание на еще одну ошибку, которую выделяет Google. Если вы добавите URL без префикса www в свою карту сайта, адрес которой содержит www, вы получите ошибку «Несоответствующий путь». То же самое касается файла Sitemap с www и URL-адресом без соответствующего префикса. Даже если ваш сайт доступен как с префиксом www, так и без него, не нужно путать эти вещи в карте сайта. Если ваш файл Sitemap находится по адресу: https://example.com/sitemap.xml, ни один из URL-ов, которые она содержит, не должен включать www. Если ваша карта сайта находится по адресу: https://www.example.com/sitemap.xml, все перечисленные в ней URL-ы должны включать www.
Синтаксические ошибки в карте сайта
В большинстве случаев вам не нужно беспокоиться о синтаксических ошибках в карте сайта — создав файл Sitemap с помощью одного из специальных сервисов, вы можете быть уверены, что с тегами и атрибутами не будет проблем. Однако, если вы самостоятельно сделали карту сайта, то можете столкнуться с одной из ниже описанных ошибок.
- «Недопустимое значение тега». Значение тега — это то, что вы указываете между начальным и конечным тегами — URL-адрес между тегами <loc>, или дата, которую вы определяете с помощью тега <lastmod>. Ошибка возникает, когда вы указываете недопустимое значение в карте сайта, например, устанавливаете приоритет вне диапазона от 0,0 до 1,0.
- «Неверное значение атрибута». Значение атрибута указывается после знака равенства (=) в кавычках. В следующей строке кода перечислены различные языковые версии страницы в файле Sitemap.
<url><loc>https://example.com</loc><xhtml:link rel=”alternate” hreflang=”gb” href=”https://example.com”/><xhtml:link rel=”alternate” hreflang=”fr” href=”https://example.com/fr”/></url>
Здесь “alternate”, “gb” и “fr” являются значениями атрибутов, но “gb” используется неправильно. Вы не можете указать в hreflangs только код страны — он должен сочетаться с кодом языка, например, “en-gb”.
- «Неправильно введена дата». Все довольно просто — вы использовали неправильный формат даты для тега <lastmod>. Единственный допустимый формат:
2005-02-21 2005-02-21T18:00:15+00:00
- «Недопустимый URL». Как вы могли догадаться, эта ошибка означает, что нужно искать опечатки в добавленных URL-адресах. Напомню, что все URL-ы в вашей карте сайта должны быть абсолютными.
- Ошибки «Отсутствует атрибут XML» и «Отсутствует тег XML» тоже довольно очевидны. Отсутствие обязательных тегов и атрибутов (urlset, url, loc, xmlns) недопустимо — их нужно добавить, чтобы ваша карта сайта работала должным образом.
- «Недопустимый XML: слишком много тегов». Эта ошибка может возникнуть, если вы используете один из тегов несколько раз. Например, вы указали два разных адреса или две даты изменения для одного URL. В этом случае вам необходимо удалить повторяющийся тег.
<url> <loc>http://www.example.com/</loc> <lastmod>2021-01-01</lastmod> <lastmod>2021-02-01</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url>
- «Неправильно указано пространство имен». Пространство имен, указанное в вашем теге <urlset>, должно быть одним из принятых протоколов. В настоящее время используется следующий протокол:
Обычные файлы Sitemap — xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9”
Файлы Sitemap для новостей — xmlns:news=”http://www.google.com/schemas/sitemap-news/0.9″
Файлы Sitemap для видео — xmlns:video=”http://www.google.com/schemas/sitemap-video/1.1″
Файлы Sitemap для изображений — xmlns:image:=”http://www.google.com/schemas/sitemap-image/1.1″
Напомню, что специальные карты сайта для новостей, картинок и видео поддерживает только Google.
Если вы использовали неправильный протокол для своей карты сайта, вы получите ошибку «Неподдерживаемый формат файла» в Google Search Console. Она также может появиться из-за других всевозможных синтаксических ошибок, таких как использование неправильных кавычек (принимаются только прямые одинарные или двойные), отсутствие тега кодировки или некорректный префикс UTF-8.

Также Google выделяет несколько ошибок, связанных с файлом Sitemap для видео: «Слишком большой/маленький значок видео», «Адреса видео и страницы воспроизведения совпадают», «URL видео указывает на страницу воспроизведения». Вы можете найти более подробную информацию об этих ошибках здесь.
Чтобы избежать синтаксических ошибок, перед отправкой файла Sitemap используйте один из сервисов проверки карты сайта, подобных этому. Инструменты будут выделять проблемы, которые необходимо исправить.
После устранения всех ошибок в файле Sitemap нужно повторно загрузить обновленную карту сайта в Google Search Console.
Такие действия заставят Google повторно просканировать ваш сайт и, наконец, проиндексировать страницы, которые они не смогли просканировать из-за ошибок.
Загруженные vs проиндексированные URL-адреса
Ваша карта сайта и файл индекса Sitemap могут получить статус «Успешно» или «Ок», но на этом ваша работа не заканчивается.
Давайте сначала разберем, что делать дальше в Google Search Console. Щелкните на значок диаграммы рядом с количеством выявленных URL-адресов, чтобы перейти к отчету об индексировании. Как только вы начнете анализировать его, вы скорее всего заметите, что не все отправленные страницы были проиндексированы.

Это нормально, когда страницы исключаются из индексации — Google не может оценить и проиндексировать все страницы вашего сайта, о которых он знает. Более того, почти на каждом сайте есть страницы, которые вебмастера не хотят индексировать: страницы защищенные паролем, служебные страницы и дубли. Что не нормально, так это наличие ошибок и предупреждений в вашем отчете об индексировании. Также недопустимо, чтобы количество исключенных страниц во много раз превышало количество страниц без ошибок.
Так почему же поисковики не могут проиндексировать страницы, которые были добавлены в карту сайта? В большинстве случаев это происходит, когда вы добавляете туда страницы, которых в карте сайта быть не должно. Возможно, поисковики просто не могут проиндексировать страницу из-за директивы noindex. Кроме того, поисковики могут запутаться, действительно ли вы хотите, чтобы страница была проиндексирована — например, когда вы добавляете неканонические страницы в карту сайта.
Все подобные ошибки можно найти в разных вкладках «Отчета об индексировании» в Google Search Console. Но их удобнее проверять с помощью инструмента «Аудит сайта» SE Ranking — если на вашем сайте есть подобные проблемы, вы легко найдете их все в разделе «Сканирование» в «Отчете об ошибках».

Удалите из карты сайта неиндексируемые и неканонические страницы. А если страницы были по ошибке помечены как неиндексируемые и неканонические, решите эту проблему.
Оптимизируйте карту сайта с подсказками от Google
Убедившись, что с вашей картой сайта все в порядке, изучите «Отчет об индексировании», чтобы найти случаи, когда ваше мнение о странице расходится с Google.
- На вкладке «Без ошибок, есть предупреждения» обратите внимание на страницы, которые были проиндексированы, несмотря на директиву noindex. Скорее всего, Google был прав, и вам нужно удалить тег noindex из этих страниц или из вашего X-Robots-Tag.
- На вкладке «Страница без ошибок» посмотрите внимательно на проиндексированные, но не отправленные в файл Sitemap страницы — вы можете добавить их в карту сайта, так как Google считает их качественными. В то же время, если Google проиндексировал ваше «Пользовательское соглашение», которое вы не включили в карту сайта, можно ничего не делать. Также следите за дублями страниц, которые были проиндексированы, но отсутствовали в вашей карте сайта — такие случаи часто возникают из-за проблем с пагинацией и обработкой параметров URL-адресов.
- Наконец, перейдите на вкладку «Исключено». Большинство страниц здесь исключены из индексации в соответствии с вашими собственными директивами, например старые страницы 404, страницы, заблокированные robots.txt, неиндексируемые и неканонические страницы. Обратите внимание на канонические страницы, которые Google решил не индексировать, — поисковая система считает, что на вашем сайте есть альтернативы получше. Тщательно изучите каждый случай и решите, действительно ли страница более ценна, чем ее дубли — исправьте свои теги canonical, если Google был прав. Если вы по-прежнему считаете, что страницу нужно проиндексировать, вам придется поработать над ее содержанием, профилем бэклинков и внутренней линковкой, чтобы убедить Google в обратном.
На вкладке «Исключено» можно увидеть еще две интересные категории страниц: «Просканированы, но пока не проиндексированы», и «Обнаружены, не проиндексированы». Оба типа обычно определяют некачественные страницы с малым содержанием, которые Google не хочет показывать пользователям. В первом случае страница была по крайней мере просканирована, а затем признана некачественной. А во втором случае поисковик даже не потратил краулинговый бюджет на страницу. Тщательно проанализируйте все такие страницы и посмотрите, что вы можете сделать, чтобы повысить их ценность: поработайте над контентом, взаимодействием с пользователем, внутренней линковкой и т. д.
Заключение
Благодаря разнообразию инструментов для создания карты сайта сделать файл Sitemap очень легко. Однако, если вы просто воспользуетесь одним из случайных инструментов и проигнорируете рекомендации по созданию карты сайта, то наверняка получите отчет о файле Sitemap с большим количеством ошибок, или отправите через карту сайта множество некачественных страниц на рассмотрение поисковикам.
Я надеюсь, что это руководство помогло вам исправить каждую ошибку в отчете о файле Sitemap. А воспользовавшись советами из второй части этого руководства, вы сможете оставить в карте сайта только качественные страницы и убрать все те, которые поисковики все равно не захотят индексировать. Если у вас остались вопросы, не стесняйтесь оставлять их в комментариях ниже.
Даша — контент-маркетолог и редактор в SE Ranking. Пишет статьи о SEO и диджитал-маркетинге. Любит разбираться в сложных вещах и описывать их просто и доступно. В свободное от блога время Даша путешествует, изучает искусство фотографии и посещает картинные галереи.
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
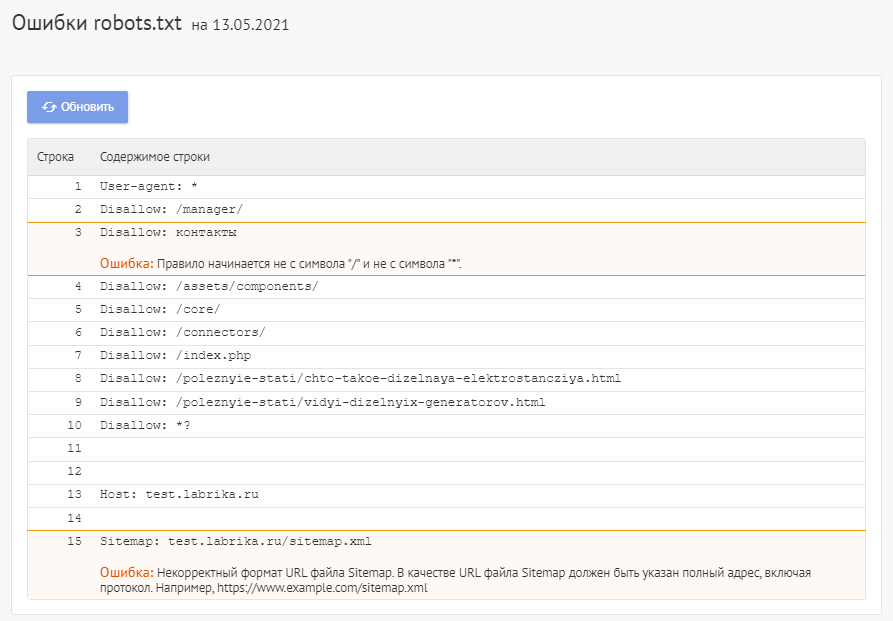
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
URL недоступны
Google не удалось просканировать адреса из файла Sitemap. Проверьте, доступны ли URL в нем нашему роботу, с помощью этого инструмента.
Переход по URL не выполнен
Google не удалось просканировать все URL, указанные в файле Sitemap. Возможные причины:
- При переходе по URL слишком много раз выполняется переадресация, и поисковые роботы Google останавливаются, не достигая цели. Рекомендуем заменить все URL переадресации на адреса непосредственно тех страниц, которые нужно просканировать.
- Если вы все время применяете переадресацию с одной страницы на другую, используйте постоянную переадресацию.
- Рекомендуем отказаться от переадресации с помощью JavaScript или метатега refresh.
- Роботам Google не удается просканировать относительные URL в вашем файле Sitemap. По возможности используйте абсолютные ссылки вместо относительных. Например, для перехода на другую страницу своего сайта указывайте URL
https://www.example.com/mypage.html, а не простоmypage.html.
Нельзя использовать URL
Некоторые из перечисленных вами URL находятся в другом домене или на более высоком уровне по сравнению с файлом Sitemap.
Более высокий уровень. Если файл расположен по адресу http://www.example.com/mysite/sitemap.xml, то недействительны следующие URL:
http://www.example.com/– находится на более высоком уровне, чем файл Sitemap;http://www.example.com/yoursite/– находится в соседнем каталоге (необходимо перейти на более высокий уровень, а затем на более низкий).
Другой домен. Убедитесь, что все URL начинаются с того же домена, в котором хранится ваш файл Sitemap. Например, если файл расположен по адресу http://www.example.com/sitemap.xml, то недействительны следующие URL:
http://example.com/– отсутствует www в начале.www.example.com/– нет префикса протокола (http).https://www.example.com/– указан префикс протокола https вместо http.
Ошибка сжатия
Произошла ошибка при попытке восстановить сжатый файл Sitemap. Выполните повторное сжатие файла (например, с помощью gzip), после чего загрузите его на сайт и повторно отправьте в Google.
Пустой Sitemap
В файле Sitemap отсутствуют URL. Исправьте это.
Превышен максимальный размер файла Sitemap
Размер файла Sitemap в несжатом виде превышает 50 МБ. Разбейте его на несколько файлов и укажите их в индексе Sitemap, а затем отправьте нам этот индекс.
Неверное значение атрибута
У атрибута в теге XML недопустимое значение. Проверьте файлы Sitemap и убедитесь, что в них есть все необходимые атрибуты с действительными значениями (согласно техническим требованиям к таким файлам), а также что отсутствуют опечатки.
Неправильно введена дата
Как минимум одна дата в файле Sitemap имеет неверный формат или значение. Даты должны быть в формате кодировки даты и времени W3C. Время можно не указывать. Введите все даты в одном из допустимых форматов W3C:
2005-02-21 2005-02-21T18:00:15+00:00
Время задавать не требуется (по умолчанию устанавливается значение 00:00:00Z), однако если вы все же делаете это, не забудьте указать часовой пояс.
Недопустимое значение тега
В файле Sitemap содержится один или несколько тегов с недопустимым значением. Проверьте спецификации для соответствующего типа файла Sitemap (индекс, стандартный, видео и т. п.).
Недопустимый URL
В файле Sitemap указан недействительный URL. Возможно, он содержит недопустимые символы (пробелы, кавычки и т. д.) или ошибки, например имеет префикс htp:// вместо http://.
Убедитесь, что URL в файле Sitemap указаны в правильной кодировке и должным образом экранированы. Проверьте, нет ли недопустимых символов, таких как пробелы и кавычки. Кроме того, можно вставить URL в браузер и посмотреть, будет ли загружена страница.
Неполные URL в файле индекса Sitemap
Для некоторых файлов Sitemap, перечисленных в файле индекса Sitemap, не указаны полные URL. Google выполняет поиск файлов Sitemap в том же каталоге, в котором находится индекс. Например, если индекс расположен по адресу http://www.example.com/folder1/sitemap_index.xml и указывает на файл sitemap.xml (без символа / впереди), то Google ищет этот файл Sitemap по адресу http://www.example.com/folder1/sitemap.xml. Если найти его не удается, показывается сообщение об ошибке.
Добавьте в индекс Sitemap полные URL всех нужных файлов Sitemap и отправьте его ещё раз.
Недопустимый XML: слишком много тегов
В файле Sitemap имеются повторяющиеся теги. Например, следующая запись станет причиной ошибки, поскольку тег <loc> повторяется в ней дважды:
<url> <loc>http://www.example.com/</loc> <loc>http://www.example.com/page1.html</loc> <lastmod>2005-01-01</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url>
В сообщении об ошибке указываются тег и номер строки, в которой он находится. Удалите повторяющийся тег и отправьте файл Sitemap ещё раз.
Отсутствует атрибут XML
В одном из тегов в файле Sitemap отсутствует обязательный атрибут. Просмотрите файлы Sitemap и убедитесь, что все обязательные атрибуты на месте. Исправьте найденные ошибки в значениях атрибутов и ещё раз отправьте файл Sitemap.
Отсутствует тег XML
В одной или нескольких записях в файле Sitemap отсутствует обязательный тег. В сообщении об ошибке указывается номер строки, с которой связана проблема. Сведения об обязательных тегах можно найти в этой статье.
Отсутствует URL значка видео
В некоторых записях о видео нет ссылки на значок. Убедитесь, что в тегах <video:thumbnail_loc> указаны URL всех значков видео.
Отсутствует название видео
В некоторых записях о видео отсутствует название. Убедитесь, что в тегах <video:title> указаны названия всех видео.
Вложенные файлы индекса Sitemap
В одной или нескольких записях файла индекса Sitemap указан его собственный URL или URL другого файла индекса Sitemap. Файл индекса Sitemap может содержать ссылки только на обычные файлы Sitemap, а не на индексы.
Удалите записи, указывающие на индексы Sitemap, и повторно отправьте файл.
Ошибка синтаксического анализа
Google не удалось выполнить синтаксический анализ XML-контента вашего файла Sitemap.
Зачастую это происходит из-за неэкранированных символов в URL. Во всех файлах XML в любых значениях данных (включая URL) необходимо экранировать символы &, ‘, «, <, > и некоторые другие. Проверьте, правильно ли выполнено экранирование в URL.
Временная ошибка
Файл Sitemap не удалось обработать из-за временной ошибки системы. Как правило, при этой ошибке отправлять файл заново нет необходимости. Робот Google попробует получить его позже. Если это сообщение об ошибке будет отображаться даже через несколько часов, отправьте файл Sitemap ещё раз.
Слишком много файлов Sitemap
В файле индекса упомянуто более 50 000 файлов Sitemap. Разделите его на несколько, в каждом из которых должно быть указано не более 50 000 файлов Sitemap.
Слишком много URL
В файле Sitemap упомянуто более 50 000 URL. Разделите его на несколько, в каждом из которых должно быть указано до 50 000 адресов. Для удобства можно создать файл индекса Sitemap.
Неподдерживаемый формат файла
Вы создали некорректный файл.
Чтобы избежать самых частых ошибок XML, проверьте следующее:
- В файлах Sitemap должны быть правильные заголовки. Например, если файл содержит информацию о видео, заголовок должен быть следующим:
<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:video="http://www.google.com/schemas/sitemap-video/1.1"> - Пространство имен в заголовке должно иметь вид http://www.sitemaps.org/schemas/sitemap/0.9 (не .9).
- Все атрибуты XML нужно заключать в одинарные (‘) или двойные («) кавычки, которые должны быть только прямыми. Обратите внимание, что текстовые редакторы, например Microsoft Word, могут автоматически менять кавычки на фигурные.
Несоответствующий путь: отсутствует префикс www
Путь к файлу Sitemap не содержит префикс www (пример: http://example.com/sitemap.xml), однако этот префикс есть в URL, которые перечислены в файле (пример: http://www.example.com/myfile.html).
Удалите префикс www из всех URL внутри файла.
Несоответствующий путь: имеется префикс www
Путь к файлу Sitemap содержит префикс www (пример: http://www.example.com/sitemap.xml), однако этого префикса нет в URL, которые перечислены в файле (пример: http://example.com/myfile.xml).
Добавьте префикс www во все URL внутри файла.
Неправильно указано пространство имен
В корневом элементе файла Sitemap неверно задано или отсутствует пространство имен, содержится орфографическая ошибка или неправильный URL.
Убедитесь, что пространство имен задано правильно с учетом типа файла. Ниже приведены примеры.
- Файл Sitemap:
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" - Файл Sitemap для видео:
xmlns:video="http://www.google.com/schemas/sitemap-video/1.1" - Файл индекса Sitemap:
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> - Другие типы файлов Sitemap
Файл Sitemap начинается с пробела
Ваш файл Sitemap начинается с пробела, а не с объявления пространства имен. Файлы XML должны начинаться с декларации XML, в которой указана используемая версия XML.
Указанная проблема не помешает Google обработать ваш файл Sitemap, однако лучше удалить пробел, чтобы файл соответствовал стандарту XML и сообщение об этой ошибке больше не появлялось.
Ошибка HTTP [код ошибки]
При попытке скачать файл Sitemap произошла ошибка HTTP уровня 400. В сообщении о ней будет указан код статуса (например, 404). Убедитесь, что URL файла Sitemap записан верно и файл находится в указанном месте. Затем повторно отправьте его в Google.
Общая ошибка HTTP
Произошла ошибка HTTP, которую невозможно отнести ни к одной из приведенных в этом списке. Вы можете воспользоваться инструментом проверки URL, чтобы воспроизвести ошибку, однако она может быть временной. Подождите немного и посмотрите, будет ли она повторяться при дополнительных попытках сканирования.
Слишком большой значок видео
Значок видео, указанный в файле Sitemap, слишком велик. Измените его размер до 160 x 120 пикселей. При необходимости обновите файл Sitemap и повторно отправьте его в Google. Подробнее о том, как добавить в файл Sitemap информацию о видео…
Слишком маленький значок видео
Значок видео, указанный в файле Sitemap, слишком мал. Измените его размер до 160 x 120 пикселей. При необходимости обновите файл Sitemap. Подробнее о том, как добавить в файл Sitemap информацию о видео…
Адреса видео и страницы воспроизведения совпадают
URL видео и страницы проигрывателя, указанные в файле Sitemap для видео, не должны совпадать. Если используются одновременно тег <video:player_loc> и тег <video:content_loc>, то URL в них должны различаться. Подробнее о том, как добавить в файл Sitemap информацию о видео…
URL видео указывает на страницу воспроизведения
URL в теге <video:content_loc> в файле Sitemap для видео указывает на страницу, где размещен проигрыватель. Подробнее о том, как добавить в файл Sitemap информацию о видео…
Файл Sitemap содержит URL, доступ к которым заблокирован в файле robots.txt
Роботу Google не удалось обработать файл Sitemap, поскольку доступ к нему или его содержанию запрещен в файле robots.txt. Воспользуйтесь инструментом проверки URL, чтобы выяснить, на какой именно файл влияет блокировка доступа, и внесите в директивы robots.txt необходимые изменения.
Плагин Yoast WordPress SEO является одним из самых популярных и популярных плагинов SEO для WordPress. Помимо возможности добавления настраиваемого метаописания, заголовка и других оптимизаций на странице, он также предлагает множество других дополнительных функций. Некоторые из дополнительных функций, такие как добавление хлебных крошек, перенаправление изображений вложений для публикации, XML-карта сайта, проверка инструментов веб-мастеров и т. Д., Помогают пользователям использовать один плагин для всех целей SEO. К сожалению, функция XML Sitemap может создать некоторые проблемы для вашего сайта WordPress. В этой статье давайте рассмотрим возможные проблемы с XML Sitemap с плагином Yoast WordPress SEO.
Включение XML Sitemap в плагине Yoast SEO
После установки и активации плагина перейдите в меню «SEO> XML Sitemaps», чтобы увидеть текущий статус Sitemap. Перед тем, как читать «Вы можете найти свой XML-файл Sitemap здесь, убедитесь, что установлен статус« Включено »и есть кнопка« XML Sitemap »с текстом:»

Включить XML Sitemap в плагине Yoast WordPress SEO
Если Sitemap отключен, кнопка «XML Sitemap» автоматически исчезнет.
Возможные ошибки карты сайта с плагином Yoast WordPress SEO
Ниже приведены возможные ошибки, связанные с XML Sitemap, на основе нашего опыта:
- Карта сайта вообще не работает
- Ошибка 404 Страница не найдена
- внутренняя ошибка сервера 500
- xml не перенаправляет на sitemap_index.xml
- Пользовательские записи / категории Sitemap не найдены
- Автор / дата перенаправление архивов на домашнюю страницу
Возможные исправления описаны в следующих разделах.
1. Карта сайта вообще не работает
Если вы видите, что файл Sitemap не открывается или отображается белая страница, попробуйте следующее:
- Отключите XML Sitemap в плагине Yoast.
- Перейдите в «Настройки»> «Постоянные ссылки» и сохраните изменения.
- Включите XML Sitemap в плагине Yoast снова.
Иногда также может помочь изменение структуры постоянных ссылок и ее сброс.
2. Ошибка 404 «Страница не найдена»
Если XML-карта сайта указывает на ошибку 404 Page Not Found, Yoast рекомендует добавить фрагмент кода для решения проблемы. В самом плагине Yoast SEO есть возможность изменить файл .htaccess в разделе «SEO> Инструменты> Редактор файлов».
Для серверов Apache с установленным WordPress в «/ public_html» добавьте приведенный ниже код до начала перезаписи постоянных ссылок WordPress.
# Start Yoast SEO - Sitemap Fix for Normal WordPress Install RewriteEngine On RewriteBase / RewriteRule ^sitemap_index.xml$ /index.php?sitemap=1 [L] RewriteRule ^locations.kml$ /index.php?sitemap=wpseo_local_kml [L] RewriteRule ^geo_sitemap.xml$ /index.php?sitemap=geo [L] RewriteRule ^([^/]+?)-sitemap([0-9]+)?.xml$ /index.php?sitemap=$1&sitemap_n=$2 [L] RewriteRule ^([a-z]+)?-?sitemap.xsl$ /index.php?xsl=$1 [L] # END Yoast SEO - Sitemap Fix for Normal WordPress Install
Если у вас установлен WordPress в подпапке, добавьте приведенный ниже код в файл .htaccess. Подкаталог в этом примере — «wordpress», который вы можете изменить на собственное имя подкаталога.
# Start Yoast SEO - Sitemap Fix for Subdirectory WordPress Install RewriteEngine On RewriteBase /wordpress/ RewriteRule ^sitemap_index.xml$ /wordpress/index.php?sitemap=1 [L] RewriteRule ^locations.kml$ /wordpress/index.php?sitemap=wpseo_local_kml [L] RewriteRule ^geo_sitemap.xml$ /wordpress/index.php?sitemap=wpseo_local [L] RewriteRule ^([^/]+?)-sitemap([0-9]+)?.xml$ /wordpress/index.php?sitemap=$1&sitemap_n=$2 [L] # END Yoast SEO - Sitemap Fix for Subdirectory WordPress Install
Если вы используете сервер Nginx, добавьте приведенный ниже код в файл конфигурации сервера Nginx:
# Yoast Sitemap Fix
location ~ ([^/]*)sitemap(.*).x(m|s)l$ {
## this redirects sitemap.xml to /sitemap_index.xml
rewrite ^/sitemap.xml$ /sitemap_index.xml permanent;
## this makes the XML sitemaps work
rewrite ^/([a-z]+)?-?sitemap.xsl$ /index.php?xsl=$1 last;
rewrite ^/sitemap_index.xml$ /index.php?sitemap=1 last;
rewrite ^/([^/]+?)-sitemap([0-9]+)?.xml$ /index.php?sitemap=$1&sitemap_n=$2 last;
## The following lines are optional for the premium extensions
## News SEO
rewrite ^/news-sitemap.xml$ /index.php?sitemap=wpseo_news last;
## Local SEO
rewrite ^/locations.kml$ /index.php?sitemap=wpseo_local_kml last;
rewrite ^/geo-sitemap.xml$ /index.php?sitemap=wpseo_local last;
## Video SEO
rewrite ^/video-sitemap.xsl$ /index.php?xsl=video last;
}
3. 500 Внутренняя ошибка сервера
Ошибка внутреннего сервера 500 может произойти либо при нажатии на файл «sitemap_index.xml», либо при нажатии на отдельную часть файла Sitemap в файле индекса, например «post-sitemap.xml». В большинстве сценариев это связано с ограничением времени выполнения сценария PHP на уровне хоста. Чтобы сократить время выполнения, вы можете уменьшить количество записей в каждом файле Sitemap. По умолчанию количество записей в каждом файле Sitemap ограничено 1000 в плагине Yoast WordPress SEO. Но 1000 также вызывает внутреннюю ошибку сервера в большинстве сред общего хостинга, таких как Bluehost.

Уменьшить количество записей в файлах Sitemap
Так что уменьшите макс. записей на файл Sitemap до 300 или 400 и проверьте, что все файлы Sitemap доступны в индексе Sitemap. При изменении количества записей все отдельные файлы Sitemap, такие как сообщения, теги и категории, будут соответствующим образом реструктурированы. Следовательно, настоятельно рекомендуется повторно отправить ваш Sitemap в Google и другие поисковые системы после завершения количества записей.
4. Sitemap.xml не перенаправляет на Sitemap_index.xml
К файлу Sitemap по умолчанию для сайта WordPress можно получить доступ по URL-адресу «http://yoursite.com/sitemap.xml». Но плагин Yoast не создает файл sitemap.xml, а динамически создает файл индекса Sitemap. Доступ к индексному файлу можно получить по URL-адресу «http://yoursite.com/sitemap_index.xml». Файл индекса Sitemap содержит все отдельные файлы Sitemap, как показано в следующем примере:

Пример файла индекса Sitemap XML Yoast
Обычно «sitemap.xml» автоматически перенаправляет на «sitemap_index.xml». Но в некоторых случаях файл Sitemap не выполняет перенаправление, и для этой цели необходимо добавить перенаправление вручную. Добавьте приведенный ниже код в файл .htaccess.
Redirect 301 /sitemap.xml /sitemap_index.xml
Вы также можете добавить перенаправление с помощью плагинов, таких как перенаправление, непосредственно из панели администратора WordPress или через свою учетную запись хостинга. Если вы используете сервер Nginx, обратитесь к разделу 2 выше, чтобы исправить ошибку 404 page not found, которая также имеет перенаправление с sitemap.xml на sitemap_index.xml.
5. Файлы Sitemap для настраиваемых сообщений или категорий не найдены
Когда вы используете пользовательские сообщения / категории / теги, плагин Yoast SEO имеет настройку для включения или отключения соответствующих файлов Sitemap. Перейдите к «SEO> XML-карты сайта» и проверьте на вкладках «Типы сообщений» и «Таксономии», чтобы включить или отключить необходимые карты сайта. Например, у нас есть настраиваемая таксономия с именем «Категории часто задаваемых вопросов», отключение которой приведет к удалению соответствующего файла Sitemap из файла индекса.

Включение или отключение настраиваемых файлов Sitemap
6. Перенаправление архива автора или даты на домашнюю страницу
Когда один автор управляет всем блогом, нет необходимости в отдельном архиве авторов Sitemap. Это сделано для того, чтобы избежать дублирования контента под двумя разными URL-адресами страницы архива автора, а также на странице индекса блога. Точно так же для блога с одним автором весь архив дат, архив авторов и страница индекса блога будут иметь одинаковое содержание.
Когда вы отключили архивы авторов и архивы на основе даты в разделе «SEO> Название и мета», эти архивные страницы будут перенаправляться на вашу домашнюю страницу. Проверьте настройки и включите или отключите архивы в соответствии с вашими потребностями.

Перенаправить архивы автора и даты на домашнюю страницу