Цель и содержание:
приобретение практических навыков
применения нейронных сетей c
использованием пакета Neural
Network
Wizard.
Теоретическое обоснование
Neural Network Wizard 1.7 –
простейший программный эмулятор
нейронных сетей. В Neural Network Wizard реализована
многослойная нейронная сеть, обучаемая
по алгоритму обратного распространения
ошибки (back propagation error). Программа Neural
Network Wizard предназначена для проведения
исследований с целью выбора оптимальной
конфигурации нейронной сети, позволяющей
наилучшим образом решить поставленную
задачу. Результатом работы системы
является файл, который хранит в себе
все параметры полученной нейронной
сети. Далее, на основе этого файла, можно
разрабатывать систему, предназначенную
для решения конкретных задач.
Программа может
применяться для анализа информации,
построения модели процессов и
прогнозирования. Для работы с системой
необходимо проделать следующие операции:
1. Собрать статистику
по процессу.
2. Обучить нейросеть
на приведенных данных.
3. Проверять полученные
результаты.
В результате обучения
нейросеть самостоятельно подберет
такие значения коэффициентов и построит
такую модель, которая наиболее точно
описывает исследуемый процесс.
Программный пакет
Neural Network Wizard может быть использован без
предварительной инсталляции.
Методика и порядок выполнения работы
Прежде чем запускать
программу, необходимо в любом текстовом
редакторе подготовить текстовый файл
с обучающей выборкой. Например, вычислим
косинус. Фрагмент такого файла для
функции Res
= Cos(x)
приведен ниже.
Cos Res
0 1
0.1 0.995
0.4 0.921
0.5 0.878
0.6 0.825
…………..
1.57 0
В первой строке
файла указываются имена входных/выходных
переменных: Cos
– имена входных переменных, Res
– имя выходной переменной. Далее идут
их значения в колонках.
Данные для обучения
нейронной сети должны быть предоставлены
в текстовом файле с разделителями (Tab
или пробел). Количество примеров должно
быть достаточно большим. При этом
необходимо обеспечить, чтобы выборка
была репрезентативной, а данные были
не противоречивы. Вся информация должна
быть представлена в числовом виде. Если
информация представляется в текстовом
виде, то необходимо использовать
какой-либо метод, переводящий текстовую
информацию в числа.
Файл сохраняется
как текстовый с расширением .txt
(Косинус.txt).
После запуска
программы в первом окне задается имя
файла с обучающей выборкой (рисунок
2.1).
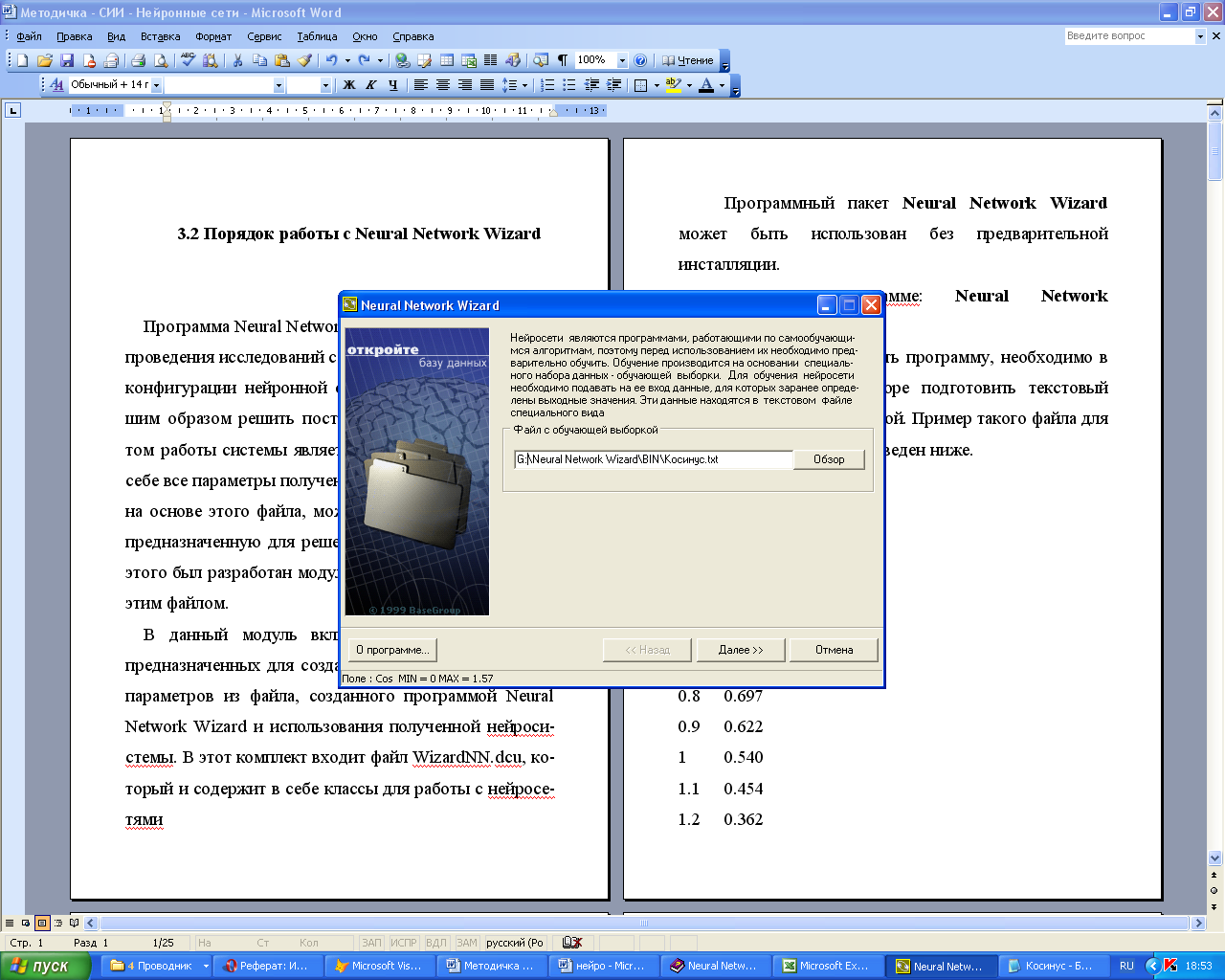
Рисунок 2.1 – Выбор
файла с обучающей выборкой
Кнопка «Далее»
позволяет перейти к следующему окну
(рисунок 2.2). В новом окне перечислен
список доступных полей, взятый из первой
строки указанного файла. Для каждого
из полей необходимо указать, чем является
данная переменная. Если данная переменная
входная, то в группе «Использовать
поле как»
выбирается вариант «Входное», если
выходная – «Целевое». Поля, отмеченные
пометкой «Не использовать» в
обучении и тестировании нейросети
применяться не будут.
На вход нейросети
должна подаваться информация в
нормализованном виде, т.е. это числа в
диапазоне от 0 до 1. Можно выбрать метод
нормализации на вкладке Нормализовать
поле как.
-
(X-MIN)/(MAX-MIN)
– линейная нормализация. -
1/(1+exp(ax))
– экспоненциальная нормализация. -
Авто
– нормализация, основанная на
статистических характеристиках выборки -
Без нормализации
– нормализация не производится.
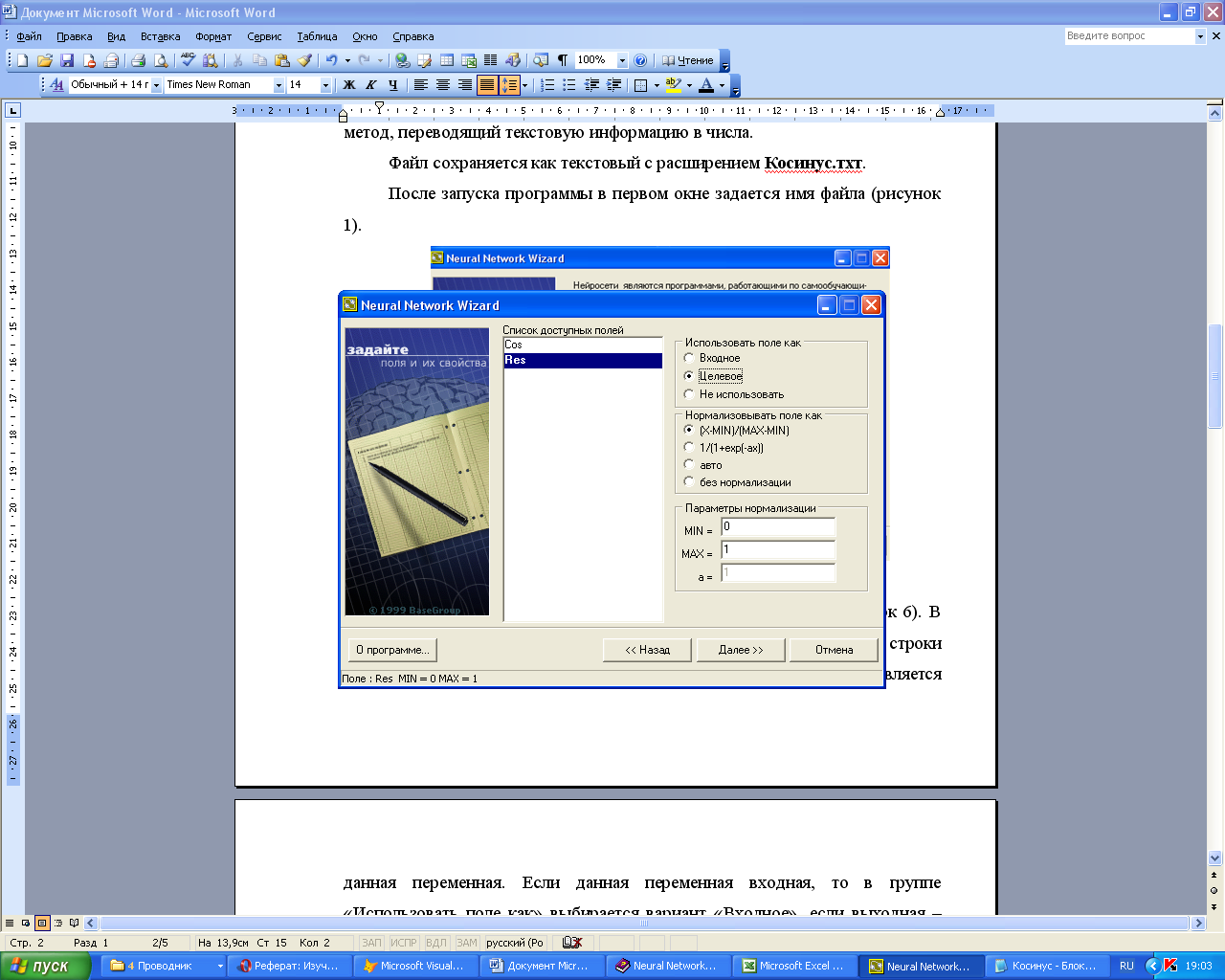
Рисунок 2.2 –
Определение входных и выходных данных
На вкладке Параметры
нормализации
задать значения, используемые в формулах
нормализации.
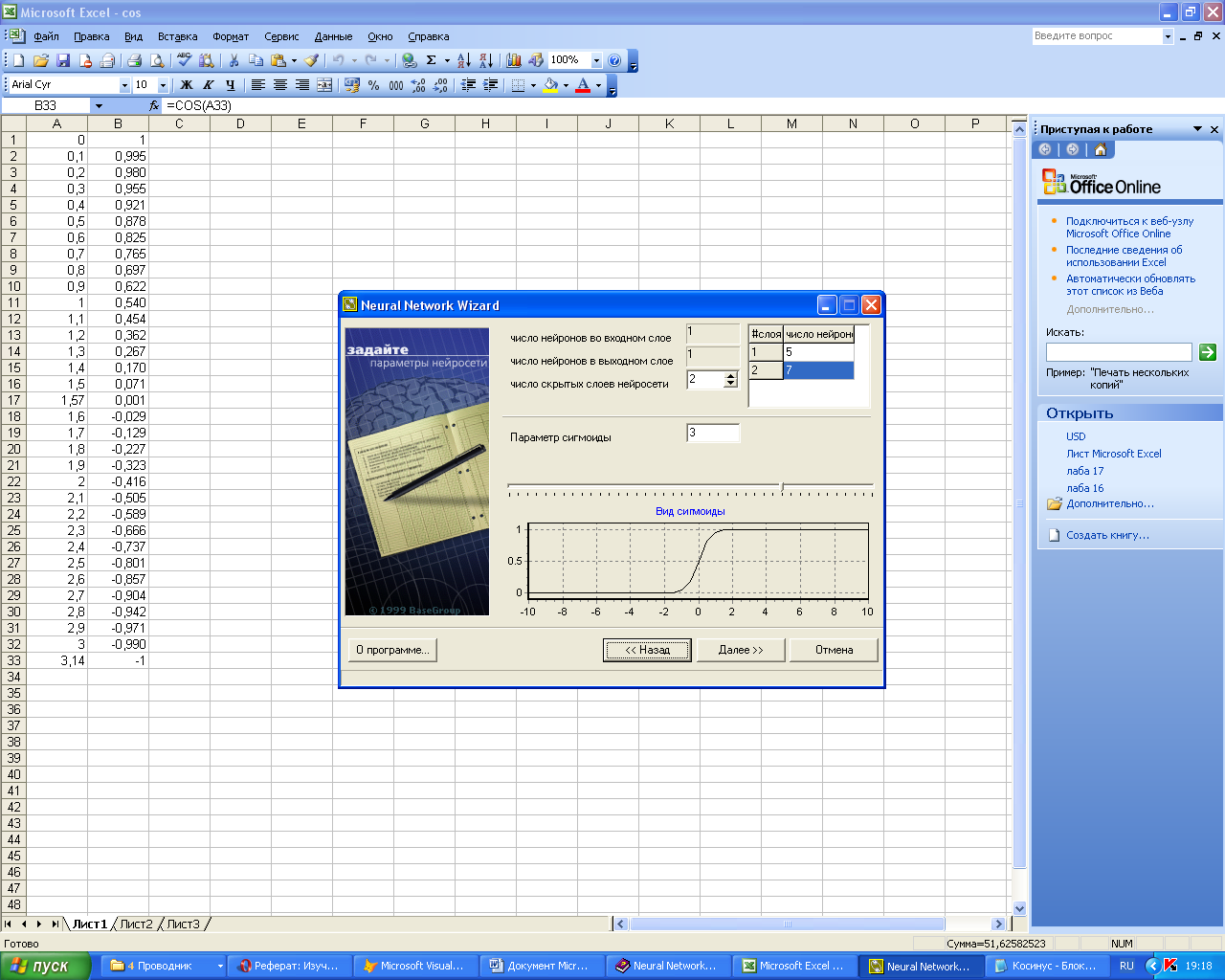
Рисунок 2.3 –
Определение параметров структуры
нейросети.
Кнопка «Далее»
переводит к следующему окну (рисунок
2.3), где определяются структура и параметры
нейросети: количество скрытых слоев,
количество нейронов в каждом слое, а
также вид сигмоидальнойной функции.
Нейронная сеть
состоит из слоев: входного, выходного
и скрытых. Необходимо указать количество
скрытых слоев. Общего правила определения
количества таких слоев нет, обычно
задается 1-3 скрытых слоя. Но считается,
что чем более нелинейная задача, тем
больше скрытых слоев должно быть у
нейронной сети.
В Neural Network Wizard все
элементы предыдущего слоя связаны со
всеми элементами последующего. Количество
нейронов в первом и последнем слое
зависит от того, сколько полей в обучающей
выборке указаны как входные и выходные.
Необходимо задать количество нейронов
в каждом скрытом слое. Общих правил
определения количества нейронов нет,
но необходимо, чтобы число связей между
нейронами было значительно меньше
количества примеров в обучающей выборке.
Иначе нейросеть потеряет способность
к обобщению, а просто «запомнит» все
примеры из обучающей выборки (так
называемый «эффект переобучения»).
Параметр сигмоиды.
Сигмоида применяется для обеспечения
нелинейного преобразования данных. В
противном случае, нейросеть сможет
выделить только линейно разделимые
множества. Чем выше параметр, тем больше
переходная функция походит на пороговую.
Параметр сигмоиды подбирается, фактически,
эмпирически.
В следующем окне
(рисунок 2.4) задаются параметры обучения
и критерии остановки обучения, если она
требуется.
Использовать
для обучения сети % выборки.
Все примеры, подаваемые на вход нейросети,
делятся на 2 множества – обучающее и
тестовое. Заданный процент примеров
будет использоваться в обучающей
выборке. Записи, используемые для
тестирования, выбираются случайно, но
пропорции сохраняются.
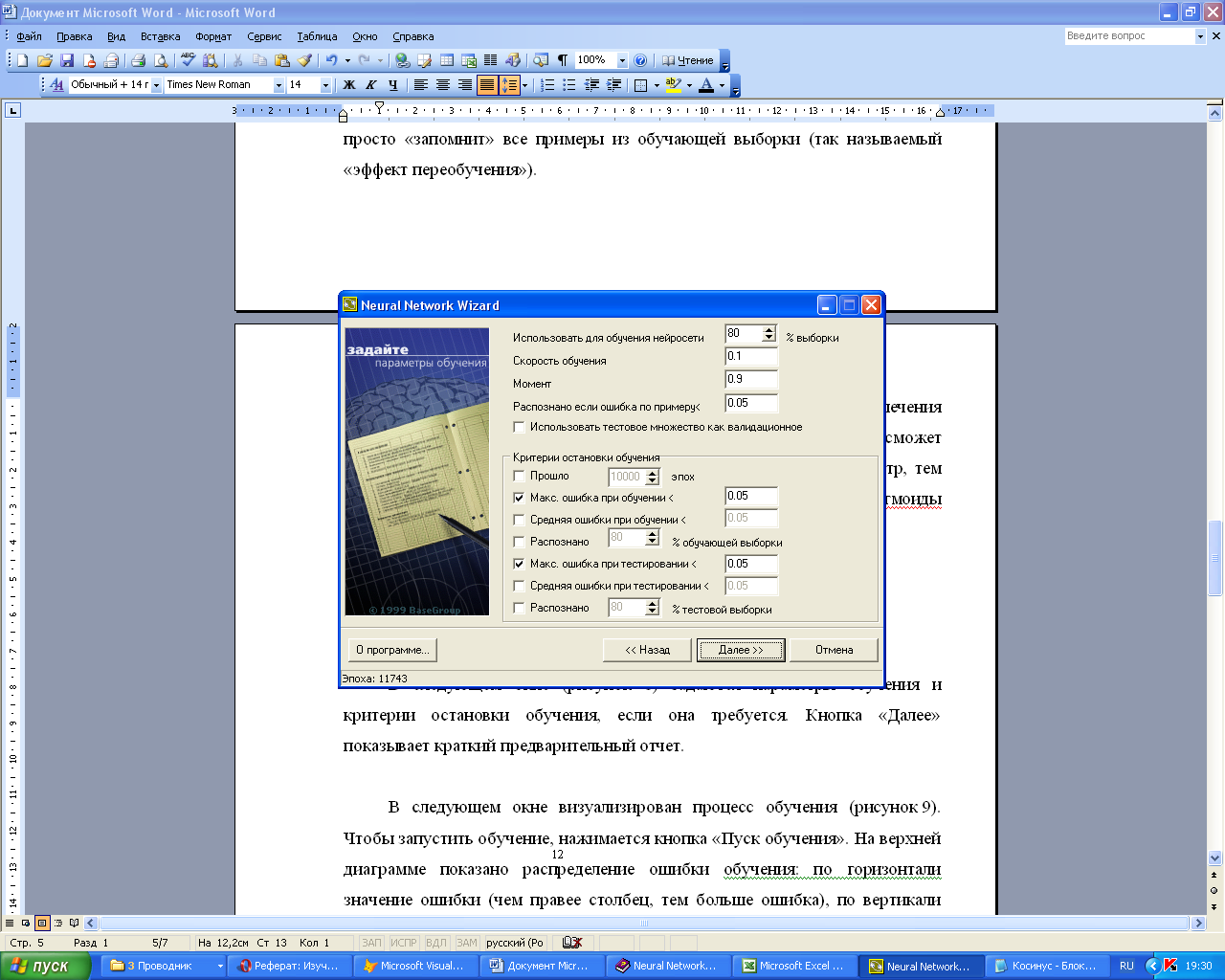
Рисунок 2.4 – Параметры
обучения
Скорость
обучения.
Параметр определяет амплитуду коррекции
весов на каждом шаге обучения.
Момент.
Параметр определяет степень воздействия
i-ой коррекции весов на i+1-ую.
Распознана, если
ошибка по примеру… Если
результат прогнозирования отличается
от значения из обучаемого множества
меньше указанной величины, то пример
считается распознанным.
Использовать
тестовое множество как валидационное.
При установке этого флага обучение
будет прекращено с выдачей сообщения,
как только ошибка на тестовом множестве
начнет увеличиваться. Это помогает
избежать ситуации переобучения нейросети.
Критерии остановки
обучения.
Необходимо определить момент, когда
обучение будет закончено.
Кнопка «Далее»
показывает окно с конфигурацией
нейросистемы, заданные параметры
(рисунок 2.5).
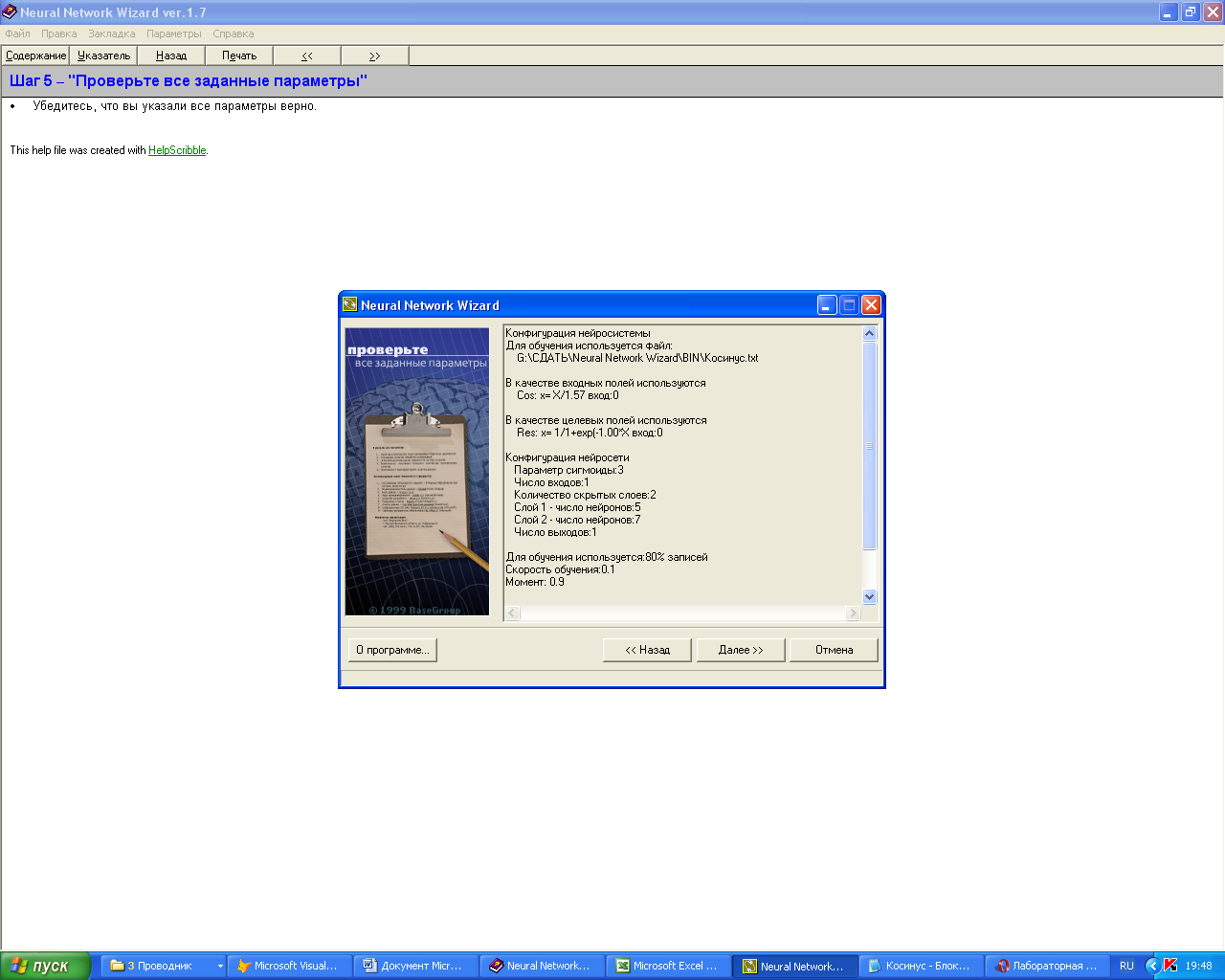
Рисунок 2.5 – Заданные
параметры нейросети
В следующем окне
визуализирован непосредственно сам
процесс обучения (рис. 2.6). Чтобы
запустить обучение, нажимается кнопка
«Пуск обучения».
На верхней диаграмме показано распределение
ошибки обучения: по горизонтали –
значение ошибки (чем правее столбец,
тем больше ошибка), по вертикали –
количество примеров из выборки с данной
ошибкой (чем выше столбец, тем больше
примеров с указанной ошибкой). Зеленые
столбцы – ошибка на рабочей обучающей
выборке, красные – на тестовой. В процессе
обучения столбцы должны стремиться в
левую часть диаграммы.
Ниже диаграммы
отображается распределение примеров
на рабочей и тестовой выборках. На этих
графиках можно отслеживать насколько
результаты, предсказанные нейронной
сетью, совпадают со значениями в обучающей
(слева) и тестовой (справа) выборке.
Каждый пример обозначен на графике
точкой. Если точка попадает на выделенную
линию (диагональ), то нейросеть предсказала
результат с достаточно высокой точностью.
Если точка находится выше диагонали,
значит нейросеть недооценила, ниже –
переоценила. Необходимо добиваться,
чтобы точки располагались как можно
ближе к диагонали.

Рисунок 2.6 – Обучение
системы
14
Остановка обучения происходит либо
по ранее указанному критерию, либо с
помощью той же кнопки «Пуск обучения».
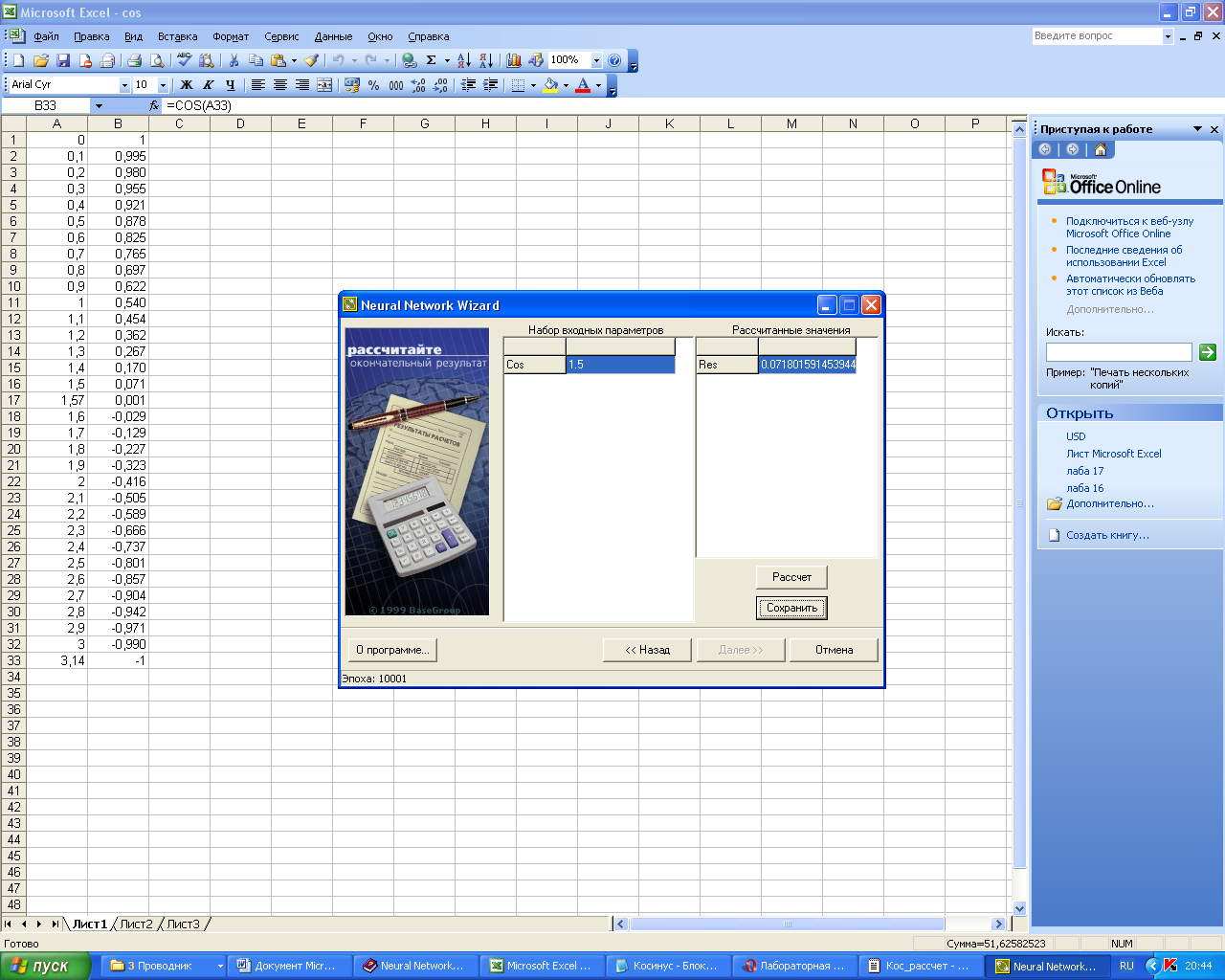
Рисунок 2.7 – Работа
с обученной нейронной сетью
В следующем окне
(рис. 2.7) представляется возможность
оценить точность работы обученной
нейросети в эксплуатационном режиме.
Для этого в левом поле указывается
произвольное значение входного сигнала.
После нажатия на кнопку «Расчет» в
правом поле появляется рассчитанное
сетью значение.
Кнопка «Сохранить»
позволяет записать параметры обученной
сети в виде файла (по умолчанию расширение
файла NNW).
Соседние файлы в папке ЛР методички ИИС
- #
- #
- #
- #
- (XMIN)/(MAX-XMIN) — линейная нормализация.
- 1/(1+exp(-ax)) — экспоненциальная нормализация.
- Авто — нормализация, основанная на статистических характеристиках выборки
- Без нормализации — нормализация не производится
Для рассматриваемого примера входными данными являются X и Y, выходной переменной — Z. Нормализация исходных данных не производится.
2.2. Создание нейронной сети
На следующем шаге в окне представленном на рис.11 задаем параметры конфигурации нейронной сети.
- Число скрытых слоев нейросети — нейронная сеть состоит из нескольких слоев — входного, выходного и скрытых (скрытых слоев может быть несколько). Этот параметр позволяет указать количество скрытых слоев. Общего правила, сколько должно быть таких слоев, нет, обычно задается 1-3 скрытых слоя. Можно говорить, что чем более нелинейная задача, тем больше скрытых слоев должно быть.
- Слои, Число нейронов — этот параметр позволяет задать количество нейронов в каждом скрытом слое. Общих правил определения количества нейронов в скрытых слоях нет, но необходимо, чтобы число связей между нейронами было меньше количества примеров в обучающей выборке.
- Параметр сигмоиды — в Neural Network Wizard в качестве функции активации используется сигмоидальная функция (сигмоида). Сигмоида применяется для обеспечения нелинейного преобразования данных. В противном случае, нейросеть сможет выделить только линейно разделимые множества. Чем выше параметр, тем больше функция активности походит на пороговую функцию. Параметр сигмоиды подбирается экспериментально.
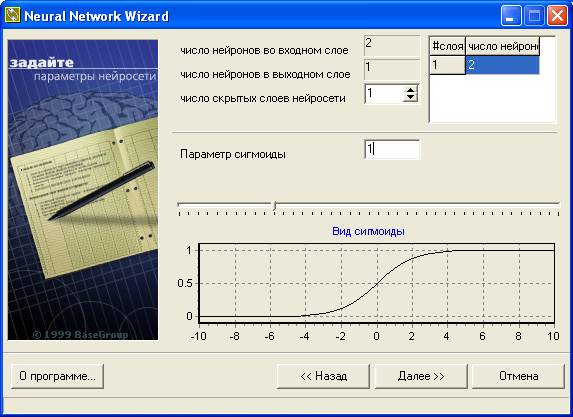
Рис.11. Окно задания параметров нейронной сети
Для рассматриваемого нами примера будет использована сеть с одним скрытым слоем, содержащим 2 нейрона (как известно, задача моделирования функции XOR является нелинейной).
2.3. Обучение сети
После создания нейронной сети необходимо задать параметры обучения в окне на рис.12.
- Использовать для обучения сети % выборки — все примеры, подаваемые на вход нейросети, делятся на 2 множества — обучающее и тестовое. Этот параметр определяет, сколько процентов примеров будут использоваться в обучающей выборке. Записи, используемые для тестирования, выбираются случайно, но пропорции сохраняются.
- Скорость обучения — параметр определяет амплитуду коррекции весов на каждом шаге обучения.
- Момент — параметр определяет степень воздействия i-ой коррекции весов на i+1-ую.
- Распознана, если ошибка по примеру< — если результат прогнозирования отличается от значения из обучаемого множества меньше указанной величины, то пример считается распознанным.
- Использовать тестовое множество как валидационное — при выборе этой опции обучение будет прекращено, как только ошибка на тестовом множестве начнет увеличиваться. Это помогает избежать ситуации переобучения сети.
- Критерии остановки обучения — осуществляется выбор условия завершения процесса обучения нейронной сети.
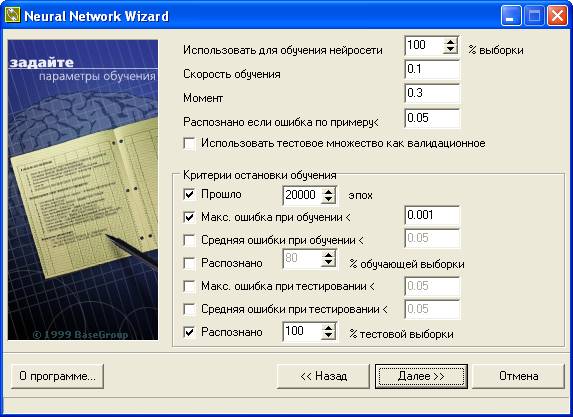
Рис.12. Окно задания параметров обучения
Далее, в окне на рис.13 можно запустить процесс обучения и наблюдать ход обучения нейронной сети
- Пуск обучения/остановка обучения — запуск процесса обучения. В таблице над кнопкой можно наблюдать, как меняется ошибка обучения.
- Распределение ошибки — на диаграмме отображается распределение ошибки. Зеленые столбцы — ошибка на обучающей выборке, красные — на тестовой выборке. Чем правее столбец, тем выше значение ошибки. Шкала от 0 до 1. Чем выше столбец, тем больше примеров с указанной ошибкой.
- Распределение примеров в обучающей/тестовой выборке — на этих графиках можно отслеживать насколько результаты, предсказанные нейронной сетью, совпадают со значениями в обучающей (слева) и тестовой (справа) выборке. Каждый пример обозначен на графике точкой. Если точка попадает на выделенную линию (диагональ), то значит, сеть предсказала результат с достаточно высокой точностью. Если точка находится выше диагонали, значит, сеть недооценила, ниже — переоценила. Необходимо добиваться, чтобы точки располагались как можно ближе к диагонали.
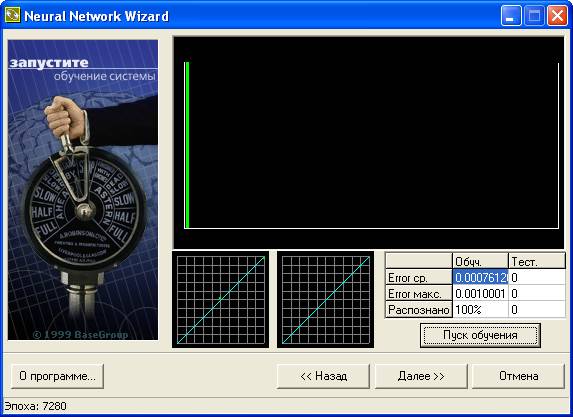
Рис.13. Ход и результаты обучения сети
2.4. Проверка результатов обучения
После того как сеть обучена, можно проверить результаты обучения (рис.14).
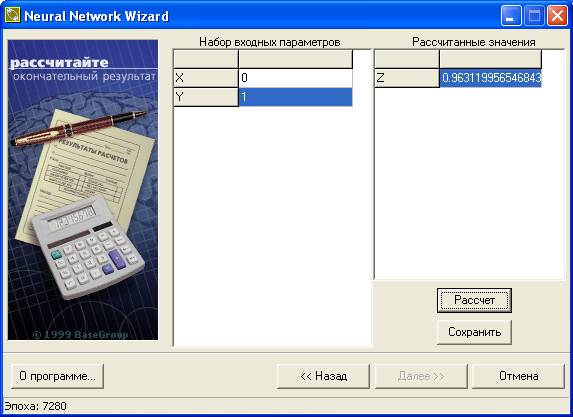
Рис.14. Проверка обучения
Результаты обучения представлены в таблице 4
| X | Y | Целевой выход Z | Выход сети | Ошибка |
|---|---|---|---|---|
| 0 | 0 | 0 | 0,1 | 0,1 |
| 0 | 1 | 1 | 0,96 | 0,004 |
| 1 | 0 | 1 | 0,97 | 0,003 |
| 1 | 1 | 0 | 0 | 0 |
Таблица 4
Пользователь, раз уж ты добрался до этой строки, ты нашёл тут что-то интересное или полезное для себя. Надеюсь, ты просматривал сайт в браузере Firefox, который один правильно отражает формулы, встречающиеся на страницах. Если тебе понравился контент, помоги сайту материально. Отключи, пожалуйста, блокираторы рекламы и нажми на пару баннеров вверху страницы. Это тебе ничего не будет стоить, увидишь ты только то, что уже искал или ищешь, а сайту ты поможешь оставаться на плаву.
Пользуйся браузерами Yandex, Firefox, Opera, Edge — они правильно отражают формулы, встречающиеся на страницах, как в десктопном, так и в мобильном вариантах.
Отключи на минуту блокираторы рекламы и нажми на пару баннеров на странице. Тебе ничего не будет стоить, а сайту поможешь материально.
Программный пакет Neural Network Wizardможет быть использован без предварительной инсталляции.
Путь к программе: Neural Network WizardBinWizard.exe.
Прежде чем запускать программу, необходимо в любом текстовом редакторе подготовить текстовый файл с обучающей выборкой. Пример такого файла для функции res = s1 + s2 приведен ниже.
В первой строке файла указываются имена входных/выходных переменных: s1 и s2 – имена входных переменных, res – имя выходной переменной. Далее идут их значения в колонках.
Файл сохраняется как текстовый с расширением TXT.
В данном окне (рисунок 7) определяются структура и параметры НС: количество скрытых слоев, количество нейронов в каждом слое, а также вид сигмоидной функции.
В следующем окне (рисунок  задаются параметры обучения и критерии остановки обучения, если она требуется. Кнопка «Далее» показывает краткий предварительный отчет.
задаются параметры обучения и критерии остановки обучения, если она требуется. Кнопка «Далее» показывает краткий предварительный отчет.
В следующем окне визуализирован процесс обучения (рисунок 9). Чтобы запустить обучение, нажимается кнопка «Пуск обучения». На верхней диаграмме показано распределение ошибки обучения: по горизонтали значение ошибки (чем правее столбец, тем больше ошибка), по вертикали количество примеров из выборки с данной ошибкой. Зеленые столбцы – ошибка на рабочей обучающей выборке, красные – на тестовой. В процессе обучения столбцы должны стремиться в левую часть диаграммы.




Ниже диаграммы отображается распределение примеров на рабочей и тестовой выборках. Каждый пример изображен здесь точкой. Чем ближе точка к диагонали, тем точнее НС предсказала ее значение.
Остановка обучения происходит либо по ранее указанному критерию, либо с помощью той же кнопки «Пуск обучения».
В следующем окне (рисунок 10) представляется возможность оценить точность работы НС в эксплуатационном режиме. Для этого в левом поле указывается произвольное значение входного сигнала. После нажатия на кнопку «Расчет» в правом поле появляется рассчитанное сетью значение выходного.
Кнопка «Сохранить» позволяет записать параметры обученной сети в виде файла (по умолчанию расширение файла NNW).
В данном файле кроме прочих параметров указаны:
Epoch – количество эпох (циклов) обучения,
Layer_* — количество нейронов в соответствующем слое (нейроны нумеруются от 0 до N-1),
W_i_j_k – веса синапсов (i = номер слоя — 2, j – номер нейрона, k – номер синапса данного нейрона).
Цель и содержание: приобретение практических навыков применения нейронных сетей c использованием пакета Neural Network Wizard.
Теоретическое обоснование
Neural Network Wizard 1.7 – простейший программный эмулятор нейронных сетей. В Neural Network Wizard реализована многослойная нейронная сеть, обучаемая по алгоритму обратного распространения ошибки (back propagation error). Программа Neural Network Wizard предназначена для проведения исследований с целью выбора оптимальной конфигурации нейронной сети, позволяющей наилучшим образом решить поставленную задачу. Результатом работы системы является файл, который хранит в себе все параметры полученной нейронной сети. Далее, на основе этого файла, можно разрабатывать систему, предназначенную для решения конкретных задач.
Программа может применяться для анализа информации, построения модели процессов и прогнозирования. Для работы с системой необходимо проделать следующие операции:
1. Собрать статистику по процессу.
2. Обучить нейросеть на приведенных данных.
3. Проверять полученные результаты.
В результате обучения нейросеть самостоятельно подберет такие значения коэффициентов и построит такую модель, которая наиболее точно описывает исследуемый процесс.
Программный пакет Neural Network Wizard может быть использован без предварительной инсталляции.
Методика и порядок выполнения работы
Прежде чем запускать программу, необходимо в любом текстовом редакторе подготовить текстовый файл с обучающей выборкой. Например, вычислим косинус. Фрагмент такого файла для функции Res = Cos(x) приведен ниже.
В первой строке файла указываются имена входных/выходных переменных: Cos – имена входных переменных, Res – имя выходной переменной. Далее идут их значения в колонках.
Данные для обучения нейронной сети должны быть предоставлены в текстовом файле с разделителями (Tab или пробел). Количество примеров должно быть достаточно большим. При этом необходимо обеспечить, чтобы выборка была репрезентативной, а данные были не противоречивы. Вся информация должна быть представлена в числовом виде. Если информация представляется в текстовом виде, то необходимо использовать какой-либо метод, переводящий текстовую информацию в числа.
Файл сохраняется как текстовый с расширением .txt (Косинус.txt).
После запуска программы в первом окне задается имя файла с обучающей выборкой (рисунок 2.1).

Рисунок 2.1 – Выбор файла с обучающей выборкой
На вход нейросети должна подаваться информация в нормализованном виде, т.е. это числа в диапазоне от 0 до 1. Можно выбрать метод нормализации на вкладке Нормализовать поле как.
(X-MIN)/(MAX-MIN) – линейная нормализация.
1/(1+exp(ax)) – экспоненциальная нормализация.
Авто – нормализация, основанная на статистических характеристиках выборки
Без нормализации – нормализация не производится.

Рисунок 2.2 – Определение входных и выходных данных
На вкладке Параметры нормализации задать значения, используемые в формулах нормализации.

Рисунок 2.3 – Определение параметров структуры нейросети.
Кнопка «Далее» переводит к следующему окну (рисунок 2.3), где определяются структура и параметры нейросети: количество скрытых слоев, количество нейронов в каждом слое, а также вид сигмоидальнойной функции.
Нейронная сеть состоит из слоев: входного, выходного и скрытых. Необходимо указать количество скрытых слоев. Общего правила определения количества таких слоев нет, обычно задается 1-3 скрытых слоя. Но считается, что чем более нелинейная задача, тем больше скрытых слоев должно быть у нейронной сети.
В Neural Network Wizard все элементы предыдущего слоя связаны со всеми элементами последующего. Количество нейронов в первом и последнем слое зависит от того, сколько полей в обучающей выборке указаны как входные и выходные. Необходимо задать количество нейронов в каждом скрытом слое. Общих правил определения количества нейронов нет, но необходимо, чтобы число связей между нейронами было значительно меньше количества примеров в обучающей выборке. Иначе нейросеть потеряет способность к обобщению, а просто «запомнит» все примеры из обучающей выборки (так называемый «эффект переобучения»).
Параметр сигмоиды. Сигмоида применяется для обеспечения нелинейного преобразования данных. В противном случае, нейросеть сможет выделить только линейно разделимые множества. Чем выше параметр, тем больше переходная функция походит на пороговую. Параметр сигмоиды подбирается, фактически, эмпирически.
В следующем окне (рисунок 2.4) задаются параметры обучения и критерии остановки обучения, если она требуется.
Использовать для обучения сети % выборки. Все примеры, подаваемые на вход нейросети, делятся на 2 множества – обучающее и тестовое. Заданный процент примеров будет использоваться в обучающей выборке. Записи, используемые для тестирования, выбираются случайно, но пропорции сохраняются.

Рисунок 2.4 – Параметры обучения
Скорость обучения. Параметр определяет амплитуду коррекции весов на каждом шаге обучения.
Момент. Параметр определяет степень воздействия i-ой коррекции весов на i+1-ую.
Распознана, если ошибка по примеру… Если результат прогнозирования отличается от значения из обучаемого множества меньше указанной величины, то пример считается распознанным.
Критерии остановки обучения. Необходимо определить момент, когда обучение будет закончено.
Кнопка «Далее» показывает окно с конфигурацией нейросистемы, заданные параметры (рисунок 2.5).

Рисунок 2.5 – Заданные параметры нейросети
В следующем окне визуализирован непосредственно сам процесс обучения (рис. 2.6). Чтобы запустить обучение, нажимается кнопка «Пуск обучения». На верхней диаграмме показано распределение ошибки обучения: по горизонтали – значение ошибки (чем правее столбец, тем больше ошибка), по вертикали – количество примеров из выборки с данной ошибкой (чем выше столбец, тем больше примеров с указанной ошибкой). Зеленые столбцы – ошибка на рабочей обучающей выборке, красные – на тестовой. В процессе обучения столбцы должны стремиться в левую часть диаграммы.
Ниже диаграммы отображается распределение примеров на рабочей и тестовой выборках. На этих графиках можно отслеживать насколько результаты, предсказанные нейронной сетью, совпадают со значениями в обучающей (слева) и тестовой (справа) выборке. Каждый пример обозначен на графике точкой. Если точка попадает на выделенную линию (диагональ), то нейросеть предсказала результат с достаточно высокой точностью. Если точка находится выше диагонали, значит нейросеть недооценила, ниже – переоценила. Необходимо добиваться, чтобы точки располагались как можно ближе к диагонали.

Рисунок 2.6 – Обучение системы
Остановка обучения происходит либо по ранее указанному критерию, либо с помощью той же кнопки «Пуск обучения».

Рисунок 2.7 – Работа с обученной нейронной сетью
В следующем окне (рис. 2.7) представляется возможность оценить точность работы обученной нейросети в эксплуатационном режиме. Для этого в левом поле указывается произвольное значение входного сигнала. После нажатия на кнопку «Расчет» в правом поле появляется рассчитанное сетью значение.
Кнопка «Сохранить» позволяет записать параметры обученной сети в виде файла (по умолчанию расширение файла NNW).
Сеть обучалась последние 12 часов. Всё выглядело хорошо: градиенты стабильные, функция потерь уменьшалась. Но потом пришёл результат: все нули, один фон, ничего не распознано. «Что я сделал не так?», — спросил я у компьютера, который промолчал в ответ.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Многое может пойти не так. Но некоторые проблемы встречаются чаще, чем другие. Я обычно начинаю с этого маленького списка как набора экстренной помощи:
- Начните с простой модели, которая точно правильно работает для этого типа данных (например, VGG для изображений). Используйте стандартную функцию потерь, если возможно.
- Отключите все финтифлюшки, например, регуляризацию и аугментацию данных.
- В случае тонкой настройки модели дважды проверьте препроцессинг, чтобы он соответствовал обучению первоначальной модели.
- Удостоверьтесь в правильности входных данных.
- Начните с действительно маленького набора данных (2-20 образцов). Затем расширяйте его, постепенно добавляя новые данные.
- Начните постепенно добавлять обратно все фрагменты, которые были опущены: аугментация/регуляризация, кастомные функции потерь, пробуйте более сложные модели.
1. Проверьте входные данные
Проверьте, что входные данные имеют смысл. Например, я не раз смешивал в кучу высоту и ширину изображений. Иногда по ошибке отдавал в нейросеть все нули. Или использовал одну и ту же партию снова и снова. Так что напечатайте/посмотрите пару партий входных данных и плановых выходных данных — убедитесь, что всё в порядке.
2. Попробуйте случайные входные значения
Попробуйте передать случайные числа вместо реальных данных и посмотрите, останется ли та же ошибка. Если так, то это верный знак, что ваша сеть на каком-то этапе превращает данные в мусор. Попробуйте отладку слой за слоем (операция за операцией) и посмотрите, где происходит сбой.
3. Проверьте загрузчик данных
С данными всё может быть в порядке, а ошибка в коде, который передаёт входные данные нейросети. Распечатайте и проверьте входные данные первого слоя перед началом его операций.
4. Убедитесь, что вход соединяется с выходом
Проверьте, что несколько образцов входных данных снабжены правильными метками. Также проверьте, что смена местами входных образцов так же отражается на выходных метках.
5. Взаимоотношение между входом и выходом слишком случайно?
Может быть, неслучайные части взаимоотношения между входом и выходом слишком малы по сравнению со случайной частью (кто-то может сказать, что таковы котировки на бирже). То есть вход недостаточно связан с выходом. Тут нет универсального метода, потому что мера случайности зависит от типа данных.
6. Слишком много шума в наборе данных?
Однажды это случилось со мной, когда я стянул набор изображений продуктов питания с сайта. Там было так много плохих меток, что сеть не могла обучаться. Вручную проверьте ряд образцов входных значений и посмотрите, что все метки на месте.
Данный пункт достоин отдельного разговора, потому что эта работа показывает точность выше 50% на базе MNIST при 50% повреждённых меток.
7. Перемешайте набор данных
Если ваши данные не перемешаны и располагаются в определённом порядке (отсортированы по меткам), это может отрицательно отразиться на обучении. Перемешайте набор данных: убедитесь, что перемешиваете вместе и входные данные, и метки.
8. Снизьте несбалансированность классов
Может, в наборе данных тысяча изображений класса А на одно изображение класса Б? Тогда вам может понадобиться сбалансировать функцию потерь или попробовать другие подходы устранения несбалансированности.
9. Достаточно ли образцов для обучения?
Если вы обучаете сеть с нуля (то есть не настраиваете её), то может понадобиться очень много данных. Например, для классификации изображений, говорят, нужна тысяча изображений на каждый класс, а то и больше.
10. Убедитесь в отсутствии партий с единственной меткой
Такое случается в отсортированном наборе данных (то есть первые 10 тыс. образцов содержат одинаковый класс). Легко исправляется перемешиванием набора данных.
11. Уменьшите размер партий
Эта работа указывает, что слишком большие партии могут понизить у модели способность к обобщению.
Дополнение 1. Используйте стандартный набор данных (например, mnist, cifar10)
При тестировании новой сетевой архитектуры или написании нового кода сначала используйте стандартные наборы данных вместо своих. Потому что для них уже есть много результатов и они гарантированно «разрешимые». Там не будет проблем с шумом в метках, разницей в распределении обучение/тестирование, слишком большой сложностью набора данных и т.д.

12. Откалибруйте признаки
Вы откалибровали входные данные на нулевое среднее и единичную дисперсию?
13. Слишком сильная аугментация данных?
Аугментация имеет регуляризующий эффект. Если она слишком сильная, то это вкупе с другими формами регуляризации (L2-регуляризация, dropout и др.) может привести к недообучению нейросети.
14. Проверьте предобработку предварительно обученной модели
Если вы используете уже подготовленную модель, то убедитесь, что используются та же нормализация и предобработка, что и в модели, которую вы обучаете. Например, должен пиксель быть в диапазоне [0, 1], [-1, 1] или [0, 255]?
15. Проверьте предварительную обработку для набора обучение/валидация/тестирование
«… любую статистику предобработки (например, среднее данных) нужно вычислять на данных для обучения, а потом применять на данных валидации/тестирования. Например, будет ошибкой вычисление среднего и вычитание его из каждого изображения во всём наборе данных, а затем разделение данных на фрагменты для обучения/валидации/тестирования».
Также проверьте на предмет наличия различающейся предварительной обработки каждого образца и партии.
16. Попробуйте решить более простой вариант задачи
Это поможет определить, где проблема. Например, если целевая выдача — это класс объекта и координаты, попробуйте ограничить предсказание только классом объекта.
17. Поищите правильную функцию потерь «по вероятности»
Снова из бесподобного CS231n: Инициализируйте с небольшими параметрами, без регуляризации. Например, если у нас 10 классов, то «по вероятности» означает, что правильный класс определится в 10% случаев, а функция потерь Softmax — это обратный логарифм к вероятности правильного класса, то есть получается
После этого попробуйте увеличить силу регуляризации, что должно увеличить функцию потерь.
18. Проверьте функцию потерь
Если вы реализовали свою собственную, проверьте её на баги и добавьте юнит-тесты. У меня часто бывало, что слегка неправильная функция потерь тонко вредила производительности сети.
19. Проверьте входные данные функции потерь
Если вы используете функцию потерь из фреймворка, то убедитесь, что передаёте ей то что нужно. Например, в PyTorch я бы смешал NLLLoss и CrossEntropyLoss, потому что первая требует входных данных softmax, а вторая — нет.
20. Отрегулируйте веса функции потерь
Если ваша функция потерь состоит из нескольких функций, проверьте их соотношение относительно друг друга. Для этого может понадобиться тестирование в разных вариантах соотношений.
21. Отслеживайте другие показатели
Иногда функция потерь — не лучший предиктор того, насколько правильно обучается ваша нейросеть. Если возможно, используйте другие показатели, такие как точность.
22. Проверьте каждый кастомный слой
Вы самостоятельно реализовали какие-то из слоёв сети? Дважды проверьте, что они работают как полагается.
23. Проверьте отсутствие «зависших» слоёв или переменных
Посмотрите, может вы неумышленно отключили обновления градиента каких-то слоёв/переменных.
24. Увеличьте размер сети
Может, выразительной мощности сети недостаточно для усвоения целевой функции. Попробуйте добавить слоёв или больше скрытых юнитов в полностью соединённые слои.
25. Поищите скрытые ошибки измерений
Если ваши входные данные выглядят как , то легко пропустить ошибку, связанную с неправильными измерениями. Используйте необычные числа для измерений входных данных (например, разные простые числа для каждого измерения) и посмотрите, как они распространяются по сети.
26. Исследуйте Gradient Checking
Если вы самостоятельно реализовали Gradient Descent, то с помощью Gradient Checking можно убедиться в корректной обратной связи. Дополнительная информация: 1, 2, 3.
27. Решите задачу для действительно маленького набора данных
Переобучите сеть на маленьком наборе данных и убедитесь в её работе. Например, обучите её всего с 1-2 примерами и посмотрите, способна ли сеть различать объекты. Переходите к большему количеству образцов для каждого класса.
28. Проверьте инициализацию весов
Если не уверены, используйте инициализацию Ксавьера или Хе. К тому же, ваша инициализация может вывести на плохой локальный минимум, так что испытайте другую инициализацию, может поможет.
29. Измените гиперпараметры
Может вы используете плохой набор гиперпараметров. Если возможно, попробуйте grid search.
30. Уменьшите регуляризацию
Из-за слишком сильной регуляризации сеть может конкретно недообучиться. Уменьшите регуляризацию, такую как dropout, batch norm, L2-регуляризацию weight/bias и др. В отличном курсе «Практическое глубинное обучение для программистов» Джереми Говард рекомендует в первую очередь избавиться от недообучения. То есть нужно достаточно переообучить сеть на исходных данных, и только затем бороться с переобучением.
31. Дайте время
Может сети нужно больше времени на обучение, прежде чем она начнёт делать осмысленные предсказания. Если функция потерь стабильно уменьшается, дайте ей обучиться чуть подольше.
32. Переходите от режима обучения в режим тестирования
В некоторых фреймворках слои Batch Norm, Dropout и другие ведут себя по-разному во время обучения и тестирования. Переключение в подходящий режим может помочь вашей сети начать делать правильные прогнозы.
33. Визуализируйте обучение
- Отслеживайте активации, веса и обновления для каждого слоя. Убедитесь, что отношения их величин совпадают. Например, отношение величины обновлений к параметрам (весам и смещениям) должно равняться 1e-3.
- Рассмотрите библиотеки визуализации вроде Tensorboard и Crayon. В крайнем случае, можно просто печатать значения весов/сдвигов/активаций.
- Будьте осторожны с активациями сетей со средним намного больше нуля. Попробуйте Batch Norm или ELU. указал, на что смотреть в гистограммах весов и сдвигов:
«Для весов эти гистограммы должны иметь примерно гауссово (нормальное) распределение, спустя какое-то время. Гистограммы сдвигов обычно начинаются с нуля и обычно заканчиваются на уровне примерно гауссова распределения (единственное исключение — LSTM). Следите за параметрами, которые отклоняются на плюс/минус бесконечность. Следите за сдвигами, которые становятся слишком большими. Иногда такое случается в выходном слое для классификации, если распределение классов слишком несбалансировано».
- Проверяйте обновления слоёв, они должны иметь нормальное распределение.
34. Попробуйте иной оптимизатор
Ваш выбор оптимизатора не должен мешать нейросети обучаться, если только вы не выбрали конкретно плохие гиперпараметры. Но правильный оптимизатор для задачи может помочь получить наилучшее обучение за кратчайшее время. Научная статья с описанием того алгоритма, который вы используете, должна упомянуть и оптимизатор. Если нет, я предпочитаю использовать Adam или простой SGD.
Прочтите отличную статью Себастьяна Рудера, чтобы узнать больше об оптимизаторах градиентного спуска.
35. Взрыв/исчезновение градиентов
- Проверьте обновления слоя, поскольку очень большие значения могут указывать на взрывы градиентов. Может помочь клиппинг градиента.
- Проверьте активации слоя. Deeplearning4j даёт отличный совет: «Хорошее стандартное отклонение для активаций находится в районе от 0,5 до 2,0. Значительный выход за эти рамки может указывать на взрыв или исчезновение активаций».
36. Ускорьте/замедлите обучение
Низкая скорость обучения приведёт к очень медленному схождению модели.
Высокая скорость обучения сначала быстро уменьшит функцию потерь, а потом вам будет трудно найти хорошее решение.
Поэкспериментируйте со скоростью обучению, ускоряя либо замедляя её в 10 раз.
37. Устранение состояний NaN
Состояния NaN (Non-a-Number) гораздо чаще встречаются при обучении RNN (насколько я слышал). Некоторые способы их устранения:
Читайте также:
- Ошибка 418c при запуске компьютера
- Серийный номер сертификата эцп где посмотреть
- Почему из за cd rom тормозит компьютер
- Как установить файл wgt на часы
- Как отсортировать csv файл python
3.1. Краткое описание программы Neural Network Wizard 1.7
Программа Neural Network Wizard предназначена для проведения исследований с целью выбора оптимальной конфигурации нейронной сети, позволяющей наилучшим образом решить поставленную задачу. Результатом работы системы является файл, который хранит в себе все параметры полученной нейронной сети. Далее, на основе этого файла, можно разрабатывать систему, предназначенную для решения конкретных задач. Для этого был разработан модуль, позволяющий работать с этим файлом. В данный модуль включено несколько классов, предназначенных для создания нейросети, загрузки ее параметров из файла, созданного программой Neural Network Wizard, и использования полученной нейросистемы. В этот комплект входит файл WizardNN.dcu, который и содержит в себе классы для работы с нейросетями.
Свойства:
InputValues[inputName:string]:double – значения входов нейросети;
OutputValues[inputName:string]:double – значения выходов нейросети;
InputsList : TstringList – список названий входов нейросети;
OutputsList : TStringList – список названий выходов нейросети.
Методы:
Create – конструктор класса;
LoadFromWizardFile(FileName:string) – чтение параметров нейросети из файла Neural Network Wizard;
Compute – расчет с использованием нейросети.
3.2. Изучение принципов работы программного эмулятора
нейрокомпьютера Neural Network Wizard 1.7
Neural Network Wizard 1.7 – программный эмулятор нейрокомпьютера. В Neural Network Wizard реализована многослойная нейронная сеть, обучаемая по алгоритму обратного распространения ошибки. Программа может применяться для анализа информации, построения модели процессов и прогнозирования. Для работы с системой необходимо проделать следующие операции:
- осуществить сбор статистики по процессу;
- выполнить обучение нейросети на приведенных данных;
- произвести проверку полученных результатов.
3.2.1. Сбор статистики по процессу
Данные для обучения нейронной сети должны быть предоставлены в текстовом файле с разделителями (Tab или пробел). Количество примеров должно быть достаточно большим. При этом необходимо обеспечить, чтобы выборка была репрезентативной. Кроме того, нужно обеспечить, чтобы данные были не противоречивы. Вся информация должна быть представлена в числовом виде. Причем, это касается всех данных. Если информация представляется в текстовом виде, то необходимо использовать какой-либо метод, переводящий текстовую информацию в числа.
Можно добиться хороших результатов, если провести предобработку данных. Если текстовую информацию можно как-то ранжировать, то необходимо это учитывать. Например, если вы кодируете информацию о городах, то можно ранжировать и по численности населения и задать соответствующую кодировку: Москва = 1, Санкт-Петербург = 2, Нижний Новгород = 3 и т.д. Если же данные не могут быть упорядочены, то можно задать им произвольные номера. Вообще, лучше при кодировании входной информации увеличивать расстояние между объектами (Москва = 1, Санкт-Петербург = 11, Нижний Новгород = 21) и определять результат по расстоянию между значением, полученным из нейросети, и кодом объекта. В нашем случае, если нейросеть выдала результат 7,2, значит это Санкт-Петербург.
3.2.2. Описание процесса обучения нейросети
на приведенных данных
При обучении нейросети нужно учитывать несколько факторов.
1. Если вы будете подавать на вход противоречивые данные, то нейросеть может вообще никогда ничему не научиться. Она будет не в состоянии понять, почему в одном случае 2+2=4, а во втором 2+2=5. Необходимо избавиться от противоречивых данных в обучающей и тестовой выборке.
2. Количество связей между нейронами должно быть меньше примеров в обучающей выборке, иначе нейросеть не обучится, а «запомнит» все приведенные примеры.
3. Если слишком долго обучать нейросеть, то она может «переобучиться». Необходимо определять момент, когда процесс будет считаться завершенным.
В целом, нет четких правил, как нужно обучать нейросеть, чтобы получить наилучший результат.
3.2.3. Проверка полученных результатов
В результате обучения нейросеть самостоятельно подберет такие значения коэффициентов и построит такую модель, которая наиболее точно описывает исследуемый процесс.
Для примера рассмотрим процесс обучения нейронной сети арифметике, а точнее, сложению двух чисел. Рассмотрим решение этой проблемы по шагам.
Шаг 1. Выбрать файл с «обучающей выборкой…». Информация, содержащаяся в этом файле, используется для обучения нейросети. Вы можете открыть txt-файл для обучения или nnw-файл – обученную нейросеть (см. рисунок 1).
На вход необходимо подать следующую информацию:
S1 S2 RES
0 0 0
1 1 2
1 2 3
2 2 4
3 3 6
4 4 8
2 4 6
5 5 10
6 6 12
7 7 14
8 8 16
9 9 18
9 10 19
10 9 19
10 10 20
2 3 5
6 1 7
1 5 6
3 8 11
9 7 16
8 9 17
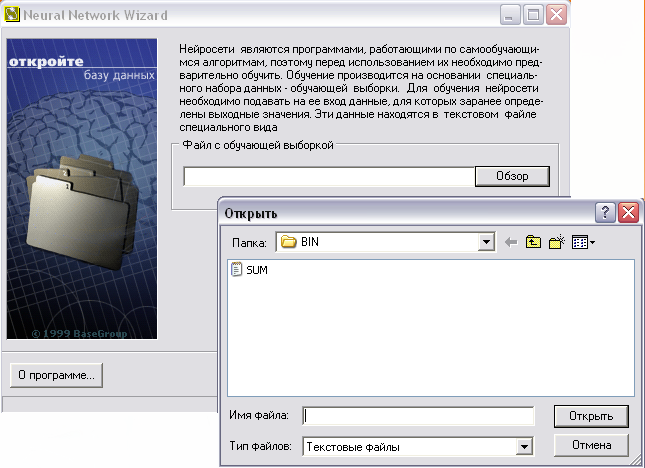
Рис. 1. Выбор файла с обучающей выборкой
Шаг 2. Выберите поле в списке и укажите, как его обрабатывать. «Использовать поле как…». Нейронная сеть состоит их входного, выходного и скрытых слоев. Количество нейронов в первом и последнем слое зависит от того, сколько полей вы определите как входные и выходные. Поля, отмеченные пометкой «не использовать», в обучении и тестировании нейросети применяться не будут.
«Нормализовать поле как…». На вход нейросети должна подаваться информация в нормализованном виде, т.е. в виде чисел в диапазоне от 0 до 1. Вы можете выбрать метод нормализации:
(X-MIN)/(MAX-MIN) – линейная нормализация;
1/(1+exp(ax)) – экспоненциальная нормализация;
авто – нормализация, основанная на статистических характеристиках выборки;
без нормализации – нормализация не производится.
«Параметры нормализации…». Задайте значения, используемые в формулах нормализации.
Указываем, что поле RES – целевое. Т.е. нейросеть будет пытаться определить, каким образом значения полей S1 и S2 влияют на поле RES (см. рис. 2).
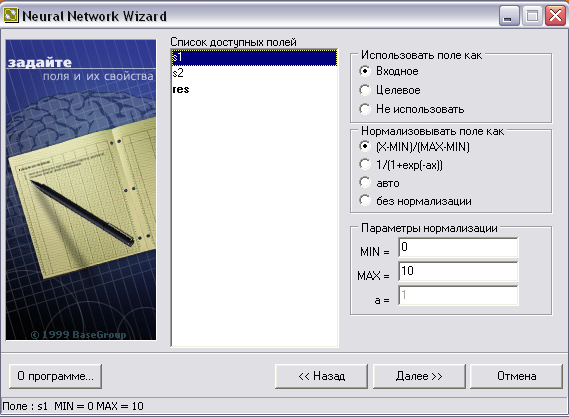
Рис. 2. Список доступных полей
Шаг 3. Определяем конфигурацию нейронной сети.
«Число слоев нейросети…». Нейронная сеть состоит из слоев – входного, выходного и скрытых. Необходимо указать количество скрытых слоев. Общего правила, определяющего, сколько должно быть таких слоев, нет, обычно задается 1-3 скрытых слоя. Можно говорить, что чем более нелинейная задача, тем больше скрытых слоев должно быть.
Зададим количество скрытых слоев – 1.
«Слои, Число нейронов…». В Neural Network Wizard все элементы предыдущего слоя связаны со всеми элементами последующего. Количество нейронов в первом и последнем слое зависит от того, сколько полей вы указали как входные и выходные. Количество нейронов в каждом скрытом слое необходимо задать. Общих правил определения количества нейронов нет, но необходимо, чтобы число связей между нейронами было меньше количества примеров в обучающей выборке. Иначе нейросеть потеряет способность к обобщению и просто «запомнит» все примеры из обучающей выборки. Тогда при тестировании на примерах, присутствующих в обучающей выборке, она будет демонстрировать прекрасные результаты, а на реальных данных – очень плохие.
Количество элементов в 1-ом слое – 2.
«Параметр сигмоиды…». Сигмоида применяется для обеспечения нелинейного преобразования данных. В противном случае, нейросеть сможет выделить только линейно разделимые множества. Чем выше параметр, тем больше переходная функция походит на пороговую. Параметр сигмоиды подбирается, фактически, эмпирически. Выбор параметра сигмоиды поясняется рисунком 3.

Рис. 3. Выбор параметра сигмоиды
Шаг 4. Определяем параметры обучения. Остановить обучение по прошествии 10000 эпох (см. рис. 4).
«Использовать для обучения сети выборки…». Все примеры, подаваемые на вход нейросети, делятся на 2 множества – обучающее и тестовое. Задайте, сколько процентов примеров будут использоваться в обучающей выборке. Записи, используемые для тестирования, выбираются случайно, но пропорции сохраняются.
«Скорость обучения…». Параметр определяет амплитуду коррекции весов на каждом шаге обучения.
«Момент…». Параметр определяет степень воздействия i-ой коррекции весов на i+1-ую.
«Распознана, если ошибка по примеру…». Если результат прогнозирования отличается от значения из обучаемого множества меньше указанной величины, то пример считается распознанным.
«Использовать тестовое множество как валидационное…». При установке этого флага обучение будет прекращено с выдачей сообщения, как только ошибка на тестовом множестве начнет увеличиваться. Это помогает избежать ситуации переобучения нейросети.
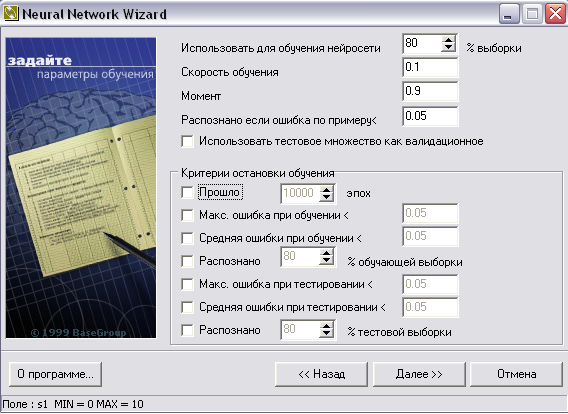
Рис. 4. Определение окончания процесса обучения
«Критерии остановки обучения…». Необходимо определить момент, когда обучение будет закончено.
Шаг 5. Проверяем правильность конфигурации сети и параметров обучения (см. рис. 5). Убедитесь, что вы указали все параметры верно.
Шаг 6. Запускаем систему на обучение, в процессе которого система построит модель операции сложения (см. рис. 6).

Рис. 5. Проверка правильности конфигурации сети
и параметров обучения

Рис. 6. Первый этап построения модели операции сложения
«Пуск обучения/остановка обучения…». Запустите процесс. В таблице над кнопкой вы можете наблюдать, как меняется ошибка обучения.
«Распределение ошибки…». В диаграмме отображается распределение ошибки. Зеленые столбцы – ошибка на обучающей выборке, красные – на тестовой выборке. Чем правее столбец, тем выше значение ошибки. Шкала от 0 до 1. Чем выше столбец, тем больше примеров с указанной ошибкой.
«Распределение примеров в обучающей/тестовой выборке…». На этих графиках вы можете отслеживать, насколько результаты, предсказанные нейронной сетью, совпадают со значениями в обучающей (слева) и тестовой (справа) выборке. Каждый пример обозначен на графике точкой. Если точка попадает на выделенную линию (диагональ), то значит нейросеть предсказала результат с достаточно высокой точностью. Если точка находится выше диагонали, значит нейросеть недооценила, ниже – переоценила. Необходимо добиваться, чтобы точки располагались как можно ближе к диагонали.
Шаг 7. По окончанию обучения мы можем тестировать полученную модель. Вводим начальные параметры и рассчитываем результат (см. рис.7).
В наборе входных параметров введите цифры и нажмите на кнопку «Расчет». В таблице «Рассчитанные параметры» вы получите результат. Необходимо иметь в виду, что бессмысленно проверять нейросеть на цифрах, выходящих за границы обучаемой и тестовой выборки. Если вы учили нейросеть складывать числа от 0 до 10, то необходимо на этих цифрах нейросеть и тестировать.

Рис. 7. Ввод начальных параметров и расчет результатов
Если результаты вас устраивают, то нажмите на кнопку «Сохранить». Neural Network Wizard сохранить все параметры и настройки в файле с расширением nnw.
4. Вопросы и задания для самооценки
- Каковы основные определения в теории интеллектуализированных систем? Что из себя представляет технология инженерии знаний?
- Какова основная терминология в области разработки интеллектуализированными системами? Какие типы классификаций интеллектуализированных систем распространены в последние годы?
- Что составляет проблемную область искусственного интеллекта? В чем состоят основные аспекты системного анализа предметной области на применимость технологии интеллектуализированных систем? Что входит в понятийную структуру предметной области?
- Каким образом осуществляется представление данных в компьютере? Особенности представления знаний интеллектуализированных систем. В чем принципиальное отличие представления данных и знаний в ЭВМ? Каковы классификация и состав знаний в интеллектуализированных системах?
- Что из себя представляют: знаковые представления понятий; схемы и формулы понятий; экстенсионал и интенсивная понятий; абстрагирование понятий; обобщение и специализация понятий?
- Что включает в себя декларативное и процедурное представления знаний? В чем состоит семантическая модель представления знаний?
- Каково основное содержание фреймовой модели представления знаний? Какова основная схема приобретения знаний?
- Каково содержание логической модели представления знаний?
- В чем состоит технология продукционной модели знаний?
- Какие существуют стратегии получения знаний при разработке интеллектуализированных систем? Какова классификация и содержание методов извлечения знаний?
- Каковы модели приобретения знаний (их сходство и отличие)?
- Что понимается под нечеткими знаниями (нечеткими множествами)? Что называется точкой перехода нечетких множеств?
- Какова роль функции принадлежности?
- Как определяется объединение, дополнение, разность, отображение, отношение в теории нечетких множеств?
- Какова роль лингвистической переменной в представлении знаний? Что такое терм-множества при описании знаний?
- Какова схема методов пополнения знаний?
- Что представляют собой псевдофизические логики?
- Как осуществляется пополнение знаний на основе сценариев?
- Какова основная схема взаимодействия базы знаний с внешней средой? Какие основные операции осуществляются над базой знаний при ее пополнении?
- Каково содержание архитектуры системы работы со знаниями?
- Какие существуют методы логического вывода пополнения знаний? Как осуществляется обобщение знаний?
- Как осуществляется классификация знаний? Каковы экстенсиональный и интенсиональный аспекты классификации?
- Что такое таксономия и мерономия?
- Опишите назначение и принцип действия машины Р. Луллия. Что такое «интеллектуальное математическое моделирование»?
- В чем суть модели лабиринтного поиска и эвристического метода? Чем отличаются нейрокибернетические методы от методов кибернетики «черного ящика»?
- В чем смысл терминов «восходящее» и «нисходящее» направления искусственного интеллекта? Что такое «эволюционное программирование»?
- Какой, по вашему мнению, метод представления знаний используется в человеческом мозге? Приведите примеры формализованных и неформализованных знаний.
- Дайте определение и сформулируйте назначение экспертной системы. Приведите примеры известных вам экспертных систем. Что такое «оболочка экспертной системы»?
- Каким, по вашему мнению, должен быть коллектив разработчиков экспертной системы? Перечислите и охарактеризуйте стадии и этапы разработки экспертных систем.
- Постройте таблицы значимости для булевых функций «И» и «ИЛИ». Графическим способом подберите веса и пороги однонейронного персептрона, реализующего функции «И» и «ИЛИ».
- Постройте двухслойный персептрон, реализующий функцию «Исключающее ИЛИ».
- Составьте программу обучения однонейронного персептрона с помощью правил Хебба и дельта-правила. С помощью составленной программы попытайтесь обучить одно-нейронный персептрон логическим операциям «И», «ИЛИ», «Исключающее ИЛИ».
- Спроектируйте и обучите нейросеть (используя ниже приведенную последовательность операций) прогнозированию курса американского доллара по отношению к российскому рублю.
А) Возьмите из сети Internet и изобразите графически данные по изменению курса доллара за последние три месяца.
В) По данным двух первых месяцев методом окон обучите нейросеть прогнозированию курса доллара на один день вперед.
С) Определите среднеквадратичную ошибку прогноза, используя в качестве тестовых примеров данные последнего месяца.
D) Введите в нейросеть дополнительный входной нейрон, в котором закодируйте день недели прогнозируемого дня. Повторите пункты B – C.
Е) В дополнительном нейроне сети закодируйте данные о солнечной активности, взятые из сети Internet.
F) Повторите пункты B – C.
G) В дополнительном нейроне сети закодируйте сведения о фазах Луны и повторите пункты B – C.
H) Сравните среднеквадратичные ошибки прогноза на тестовых выборках, сделайте заключение о степени влияния на курс доллара исследованных факторов.
- Нарисуйте схему RBF-сети с минимальным числом нейронов, способную моделировать функции «И», «ИЛИ», «Исключающее ИЛИ».
Библиографический список
- Гаскаров Д.В. Интеллектуальные информационные системы: учебник для вузов. – М.: Высшая школа, 2003. – 431 с.
- Ясницкий Л.Н. Введение в искусственный интеллект: учебное пособие для студ. высш. учеб. заведений. – М.: Академия, 2005. – 176 с.
Учебно-методическое издание
Сергей Евгеньевич Меньшенин
Современные информационные технологии.
Изучение принципов работы программного эмулятора
нейрокомпьютера Neural Network Wizard 1.7
Учебно-методическое пособие по дисциплинам
«Интеллектуальные информационные системы» и
«Системы искусственного интеллекта»
Р едактор Т.П. Дмитриева
едактор Т.П. Дмитриева
Темплан 2006 г. Подписано в печать 23.11.2006.
Формат 60×84 1/16.
Печ. л.
3,72
Уч. изд. л.
3,75
Тираж 50 экз.
Южно-Российский государственный технический университет
А
дрес ун-та: 346428, г. Новочеркасск, ул. Просвещения, 132
Время прочтения
9 мин
Просмотры 37K
Сеть обучалась последние 12 часов. Всё выглядело хорошо: градиенты стабильные, функция потерь уменьшалась. Но потом пришёл результат: все нули, один фон, ничего не распознано. «Что я сделал не так?», — спросил я у компьютера, который промолчал в ответ.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Содержание
0. Как использовать это руководство?
I. Проблемы с набором данных
II. Нормализация данных/Проблемы аугментации
III. Проблемы реализации
IV. Проблемы обучения
0. Как использовать это руководство?
Многое может пойти не так. Но некоторые проблемы встречаются чаще, чем другие. Я обычно начинаю с этого маленького списка как набора экстренной помощи:
- Начните с простой модели, которая точно правильно работает для этого типа данных (например, VGG для изображений). Используйте стандартную функцию потерь, если возможно.
- Отключите все финтифлюшки, например, регуляризацию и аугментацию данных.
- В случае тонкой настройки модели дважды проверьте препроцессинг, чтобы он соответствовал обучению первоначальной модели.
- Удостоверьтесь в правильности входных данных.
- Начните с действительно маленького набора данных (2-20 образцов). Затем расширяйте его, постепенно добавляя новые данные.
- Начните постепенно добавлять обратно все фрагменты, которые были опущены: аугментация/регуляризация, кастомные функции потерь, пробуйте более сложные модели.
Если ничего не помогло, то приступайте к чтению этого длинного списка и проверяйте каждый пункт.
I. Проблемы с набором данных

Источник: http://dilbert.com/strip/2014-05-07
1. Проверьте входные данные
Проверьте, что входные данные имеют смысл. Например, я не раз смешивал в кучу высоту и ширину изображений. Иногда по ошибке отдавал в нейросеть все нули. Или использовал одну и ту же партию снова и снова. Так что напечатайте/посмотрите пару партий входных данных и плановых выходных данных — убедитесь, что всё в порядке.
2. Попробуйте случайные входные значения
Попробуйте передать случайные числа вместо реальных данных и посмотрите, останется ли та же ошибка. Если так, то это верный знак, что ваша сеть на каком-то этапе превращает данные в мусор. Попробуйте отладку слой за слоем (операция за операцией) и посмотрите, где происходит сбой.
3. Проверьте загрузчик данных
С данными всё может быть в порядке, а ошибка в коде, который передаёт входные данные нейросети. Распечатайте и проверьте входные данные первого слоя перед началом его операций.
4. Убедитесь, что вход соединяется с выходом
Проверьте, что несколько образцов входных данных снабжены правильными метками. Также проверьте, что смена местами входных образцов так же отражается на выходных метках.
5. Взаимоотношение между входом и выходом слишком случайно?
Может быть, неслучайные части взаимоотношения между входом и выходом слишком малы по сравнению со случайной частью (кто-то может сказать, что таковы котировки на бирже). То есть вход недостаточно связан с выходом. Тут нет универсального метода, потому что мера случайности зависит от типа данных.
6. Слишком много шума в наборе данных?
Однажды это случилось со мной, когда я стянул набор изображений продуктов питания с сайта. Там было так много плохих меток, что сеть не могла обучаться. Вручную проверьте ряд образцов входных значений и посмотрите, что все метки на месте.
Данный пункт достоин отдельного разговора, потому что эта работа показывает точность выше 50% на базе MNIST при 50% повреждённых меток.
7. Перемешайте набор данных
Если ваши данные не перемешаны и располагаются в определённом порядке (отсортированы по меткам), это может отрицательно отразиться на обучении. Перемешайте набор данных: убедитесь, что перемешиваете вместе и входные данные, и метки.
8. Снизьте несбалансированность классов
Может, в наборе данных тысяча изображений класса А на одно изображение класса Б? Тогда вам может понадобиться сбалансировать функцию потерь или попробовать другие подходы устранения несбалансированности.
9. Достаточно ли образцов для обучения?
Если вы обучаете сеть с нуля (то есть не настраиваете её), то может понадобиться очень много данных. Например, для классификации изображений, говорят, нужна тысяча изображений на каждый класс, а то и больше.
10. Убедитесь в отсутствии партий с единственной меткой
Такое случается в отсортированном наборе данных (то есть первые 10 тыс. образцов содержат одинаковый класс). Легко исправляется перемешиванием набора данных.
11. Уменьшите размер партий
Эта работа указывает, что слишком большие партии могут понизить у модели способность к обобщению.
Дополнение 1. Используйте стандартный набор данных (например, mnist, cifar10)
Спасибо hengcherkeng за это:
При тестировании новой сетевой архитектуры или написании нового кода сначала используйте стандартные наборы данных вместо своих. Потому что для них уже есть много результатов и они гарантированно «разрешимые». Там не будет проблем с шумом в метках, разницей в распределении обучение/тестирование, слишком большой сложностью набора данных и т.д.
II. Нормализация данных/Проблемы аугментации

12. Откалибруйте признаки
Вы откалибровали входные данные на нулевое среднее и единичную дисперсию?
13. Слишком сильная аугментация данных?
Аугментация имеет регуляризующий эффект. Если она слишком сильная, то это вкупе с другими формами регуляризации (L2-регуляризация, dropout и др.) может привести к недообучению нейросети.
14. Проверьте предобработку предварительно обученной модели
Если вы используете уже подготовленную модель, то убедитесь, что используются та же нормализация и предобработка, что и в модели, которую вы обучаете. Например, должен пиксель быть в диапазоне [0, 1], [-1, 1] или [0, 255]?
15. Проверьте предварительную обработку для набора обучение/валидация/тестирование
CS231n указал на типичную ловушку:
«… любую статистику предобработки (например, среднее данных) нужно вычислять на данных для обучения, а потом применять на данных валидации/тестирования. Например, будет ошибкой вычисление среднего и вычитание его из каждого изображения во всём наборе данных, а затем разделение данных на фрагменты для обучения/валидации/тестирования».
Также проверьте на предмет наличия различающейся предварительной обработки каждого образца и партии.
III. Проблемы реализации

Источник: https://xkcd.com/1838/
16. Попробуйте решить более простой вариант задачи
Это поможет определить, где проблема. Например, если целевая выдача — это класс объекта и координаты, попробуйте ограничить предсказание только классом объекта.
17. Поищите правильную функцию потерь «по вероятности»
Снова из бесподобного CS231n: Инициализируйте с небольшими параметрами, без регуляризации. Например, если у нас 10 классов, то «по вероятности» означает, что правильный класс определится в 10% случаев, а функция потерь Softmax — это обратный логарифм к вероятности правильного класса, то есть получается 
После этого попробуйте увеличить силу регуляризации, что должно увеличить функцию потерь.
18. Проверьте функцию потерь
Если вы реализовали свою собственную, проверьте её на баги и добавьте юнит-тесты. У меня часто бывало, что слегка неправильная функция потерь тонко вредила производительности сети.
19. Проверьте входные данные функции потерь
Если вы используете функцию потерь из фреймворка, то убедитесь, что передаёте ей то что нужно. Например, в PyTorch я бы смешал NLLLoss и CrossEntropyLoss, потому что первая требует входных данных softmax, а вторая — нет.
20. Отрегулируйте веса функции потерь
Если ваша функция потерь состоит из нескольких функций, проверьте их соотношение относительно друг друга. Для этого может понадобиться тестирование в разных вариантах соотношений.
21. Отслеживайте другие показатели
Иногда функция потерь — не лучший предиктор того, насколько правильно обучается ваша нейросеть. Если возможно, используйте другие показатели, такие как точность.
22. Проверьте каждый кастомный слой
Вы самостоятельно реализовали какие-то из слоёв сети? Дважды проверьте, что они работают как полагается.
23. Проверьте отсутствие «зависших» слоёв или переменных
Посмотрите, может вы неумышленно отключили обновления градиента каких-то слоёв/переменных.
24. Увеличьте размер сети
Может, выразительной мощности сети недостаточно для усвоения целевой функции. Попробуйте добавить слоёв или больше скрытых юнитов в полностью соединённые слои.
25. Поищите скрытые ошибки измерений
Если ваши входные данные выглядят как  , то легко пропустить ошибку, связанную с неправильными измерениями. Используйте необычные числа для измерений входных данных (например, разные простые числа для каждого измерения) и посмотрите, как они распространяются по сети.
, то легко пропустить ошибку, связанную с неправильными измерениями. Используйте необычные числа для измерений входных данных (например, разные простые числа для каждого измерения) и посмотрите, как они распространяются по сети.
26. Исследуйте Gradient Checking
Если вы самостоятельно реализовали Gradient Descent, то с помощью Gradient Checking можно убедиться в корректной обратной связи. Дополнительная информация: 1, 2, 3.
IV. Проблемы обучения

Источник: http://carlvondrick.com/ihog/
27. Решите задачу для действительно маленького набора данных
Переобучите сеть на маленьком наборе данных и убедитесь в её работе. Например, обучите её всего с 1-2 примерами и посмотрите, способна ли сеть различать объекты. Переходите к большему количеству образцов для каждого класса.
28. Проверьте инициализацию весов
Если не уверены, используйте инициализацию Ксавьера или Хе. К тому же, ваша инициализация может вывести на плохой локальный минимум, так что испытайте другую инициализацию, может поможет.
29. Измените гиперпараметры
Может вы используете плохой набор гиперпараметров. Если возможно, попробуйте grid search.
30. Уменьшите регуляризацию
Из-за слишком сильной регуляризации сеть может конкретно недообучиться. Уменьшите регуляризацию, такую как dropout, batch norm, L2-регуляризацию weight/bias и др. В отличном курсе «Практическое глубинное обучение для программистов» Джереми Говард рекомендует в первую очередь избавиться от недообучения. То есть нужно достаточно переообучить сеть на исходных данных, и только затем бороться с переобучением.
31. Дайте время
Может сети нужно больше времени на обучение, прежде чем она начнёт делать осмысленные предсказания. Если функция потерь стабильно уменьшается, дайте ей обучиться чуть подольше.
32. Переходите от режима обучения в режим тестирования
В некоторых фреймворках слои Batch Norm, Dropout и другие ведут себя по-разному во время обучения и тестирования. Переключение в подходящий режим может помочь вашей сети начать делать правильные прогнозы.
33. Визуализируйте обучение
- Отслеживайте активации, веса и обновления для каждого слоя. Убедитесь, что отношения их величин совпадают. Например, отношение величины обновлений к параметрам (весам и смещениям) должно равняться 1e-3.
- Рассмотрите библиотеки визуализации вроде Tensorboard и Crayon. В крайнем случае, можно просто печатать значения весов/сдвигов/активаций.
- Будьте осторожны с активациями сетей со средним намного больше нуля. Попробуйте Batch Norm или ELU.
- Deeplearning4j указал, на что смотреть в гистограммах весов и сдвигов:
«Для весов эти гистограммы должны иметь примерно гауссово (нормальное) распределение, спустя какое-то время. Гистограммы сдвигов обычно начинаются с нуля и обычно заканчиваются на уровне примерно гауссова распределения (единственное исключение — LSTM). Следите за параметрами, которые отклоняются на плюс/минус бесконечность. Следите за сдвигами, которые становятся слишком большими. Иногда такое случается в выходном слое для классификации, если распределение классов слишком несбалансировано».
- Проверяйте обновления слоёв, они должны иметь нормальное распределение.
34. Попробуйте иной оптимизатор
Ваш выбор оптимизатора не должен мешать нейросети обучаться, если только вы не выбрали конкретно плохие гиперпараметры. Но правильный оптимизатор для задачи может помочь получить наилучшее обучение за кратчайшее время. Научная статья с описанием того алгоритма, который вы используете, должна упомянуть и оптимизатор. Если нет, я предпочитаю использовать Adam или простой SGD.
Прочтите отличную статью Себастьяна Рудера, чтобы узнать больше об оптимизаторах градиентного спуска.
35. Взрыв/исчезновение градиентов
- Проверьте обновления слоя, поскольку очень большие значения могут указывать на взрывы градиентов. Может помочь клиппинг градиента.
- Проверьте активации слоя. Deeplearning4j даёт отличный совет: «Хорошее стандартное отклонение для активаций находится в районе от 0,5 до 2,0. Значительный выход за эти рамки может указывать на взрыв или исчезновение активаций».
36. Ускорьте/замедлите обучение
Низкая скорость обучения приведёт к очень медленному схождению модели.
Высокая скорость обучения сначала быстро уменьшит функцию потерь, а потом вам будет трудно найти хорошее решение.
Поэкспериментируйте со скоростью обучению, ускоряя либо замедляя её в 10 раз.
37. Устранение состояний NaN
Состояния NaN (Non-a-Number) гораздо чаще встречаются при обучении RNN (насколько я слышал). Некоторые способы их устранения:
- Уменьшите скорость обучения, особенно если NaN появляются в первые 100 итераций.
- Нечисла могут возникнуть из-за деления на ноль, взятия натурального логарифма нуля или отрицательного числа.
- Рассел Стюарт предлагает хорошие советы, что делать в случае появления NaN.
- Попробуйте оценить сеть слой за слоем и посмотреть, где появляются NaN.