![]()
Error handling is an essential part of RxJs, as we will need it in just about any reactive program that we write.
Error handling in RxJS is likely not as well understood as other parts of the library, but it’s actually quite simple to understand if we focus on understanding first the Observable contract in general.
In this post, we are going to provide a complete guide containing the most common error handling strategies that you will need in order to cover most practical scenarios, starting with the basics (the Observable contract).
Table Of Contents
In this post, we will cover the following topics:
- The Observable contract and Error Handling
- RxJs subscribe and error callbacks
- The catchError Operator
- The Catch and Replace Strategy
- throwError and the Catch and Rethrow Strategy
- Using catchError multiple times in an Observable chain
- The finalize Operator
- The Retry Strategy
- Then retryWhen Operator
- Creating a Notification Observable
- Immediate Retry Strategy
- Delayed Retry Strategy
- The delayWhen Operator
- The timer Observable creation function
- Running Github repository (with code samples)
- Conclusions
So without further ado, let’s get started with our RxJs Error Handling deep dive!
The Observable Contract and Error Handling
In order to understand error handling in RxJs, we need to first understand that any given stream can only error out once. This is defined by the Observable contract, which says that a stream can emit zero or more values.
The contract works that way because that is just how all the streams that we observe in our runtime work in practice. Network requests can fail, for example.
A stream can also complete, which means that:
- the stream has ended its lifecycle without any error
- after completion, the stream will not emit any further values
As an alternative to completion, a stream can also error out, which means that:
- the stream has ended its lifecycle with an error
- after the error is thrown, the stream will not emit any other values
Notice that completion or error are mutually exclusive:
- if the stream completes, it cannot error out afterwards
- if the streams errors out, it cannot complete afterwards
Notice also that there is no obligation for the stream to complete or error out, those two possibilities are optional. But only one of those two can occur, not both.
This means that when one particular stream errors out, we cannot use it anymore, according to the Observable contract. You must be thinking at this point, how can we recover from an error then?
RxJs subscribe and error callbacks
To see the RxJs error handling behavior in action, let’s create a stream and subscribe to it. Let’s remember that the subscribe call takes three optional arguments:
- a success handler function, which is called each time that the stream emits a value
- an error handler function, that gets called only if an error occurs. This handler receives the error itself
- a completion handler function, that gets called only if the stream completes
Completion Behavior Example
If the stream does not error out, then this is what we would see in the console:
HTTP response {payload: Array(9)}
HTTP request completed.
As we can see, this HTTP stream emits only one value, and then it completes, which means that no errors occurred.
But what happens if the stream throws an error instead? In that case, we will see the following in the console instead:

As we can see, the stream emitted no value and it immediately errored out. After the error, no completion occurred.
Limitations of the subscribe error handler
Handling errors using the subscribe call is sometimes all that we need, but this error handling approach is limited. Using this approach, we cannot, for example, recover from the error or emit an alternative fallback value that replaces the value that we were expecting from the backend.
Let’s then learn a few operators that will allow us to implement some more advanced error handling strategies.
The catchError Operator
In synchronous programming, we have the option to wrap a block of code in a try clause, catch any error that it might throw with a catch block and then handle the error.
Here is what the synchronous catch syntax looks like:
This mechanism is very powerful because we can handle in one place any error that happens inside the try/catch block.
The problem is, in Javascript many operations are asynchronous, and an HTTP call is one such example where things happen asynchronously.
RxJs provides us with something close to this functionality, via the RxJs catchError Operator.
How does catchError work?
As usual and like with any RxJs Operator, catchError is simply a function that takes in an input Observable, and outputs an Output Observable.
With each call to catchError, we need to pass it a function which we will call the error handling function.
The catchError operator takes as input an Observable that might error out, and starts emitting the values of the input Observable in its output Observable.
If no error occurs, the output Observable produced by catchError works exactly the same way as the input Observable.
What happens when an error is thrown?
However, if an error occurs, then the catchError logic is going to kick in. The catchError operator is going to take the error and pass it to the error handling function.
That function is expected to return an Observable which is going to be a replacement Observable for the stream that just errored out.
Let’s remember that the input stream of catchError has errored out, so according to the Observable contract we cannot use it anymore.
This replacement Observable is then going to be subscribed to and its values are going to be used in place of the errored out input Observable.
The Catch and Replace Strategy
Let’s give an example of how catchError can be used to provide a replacement Observable that emits fallback values:
Let’s break down the implementation of the catch and replace strategy:
- we are passing to the catchError operator a function, which is the error handling function
- the error handling function is not called immediately, and in general, it’s usually not called
- only when an error occurs in the input Observable of catchError, will the error handling function be called
- if an error happens in the input stream, this function is then returning an Observable built using the
of([])function - the
of()function builds an Observable that emits only one value ([]) and then it completes - the error handling function returns the recovery Observable (
of([])), that gets subscribed to by the catchError operator - the values of the recovery Observable are then emitted as replacement values in the output Observable returned by catchError
As the end result, the http$ Observable will not error out anymore! Here is the result that we get in the console:
HTTP response []
HTTP request completed.
As we can see, the error handling callback in subscribe() is not invoked anymore. Instead, here is what happens:
- the empty array value
[]is emitted - the
http$Observable is then completed
As we can see, the replacement Observable was used to provide a default fallback value ([]) to the subscribers of http$, despite the fact that the original Observable did error out.
Notice that we could have also added some local error handling, before returning the replacement Observable!
And this covers the Catch and Replace Strategy, now let’s see how we can also use catchError to rethrow the error, instead of providing fallback values.
The Catch and Rethrow Strategy
Let’s start by noticing that the replacement Observable provided via catchError can itself also error out, just like any other Observable.
And if that happens, the error will be propagated to the subscribers of the output Observable of catchError.
This error propagation behavior gives us a mechanism to rethrow the error caught by catchError, after handling the error locally. We can do so in the following way:
Catch and Rethrow breakdown
Let’s break down step-by-step the implementation of the Catch and Rethrow Strategy:
- just like before, we are catching the error, and returning a replacement Observable
- but this time around, instead of providing a replacement output value like
[], we are now handling the error locally in the catchError function - in this case, we are simply logging the error to the console, but we could instead add any local error handling logic that we want, such as for example showing an error message to the user
- We are then returning a replacement Observable that this time was created using throwError
- throwError creates an Observable that never emits any value. Instead, it errors out immediately using the same error caught by catchError
- this means that the output Observable of catchError will also error out with the exact same error thrown by the input of catchError
- this means that we have managed to successfully rethrow the error initially thrown by the input Observable of catchError to its output Observable
- the error can now be further handled by the rest of the Observable chain, if needed
If we now run the code above, here is the result that we get in the console:

As we can see, the same error was logged both in the catchError block and in the subscription error handler function, as expected.
Using catchError multiple times in an Observable chain
Notice that we can use catchError multiple times at different points in the Observable chain if needed, and adopt different error strategies at each point in the chain.
We can, for example, catch an error up in the Observable chain, handle it locally and rethrow it, and then further down in the Observable chain we can catch the same error again and this time provide a fallback value (instead of rethrowing):
If we run the code above, this is the output that we get in the console:
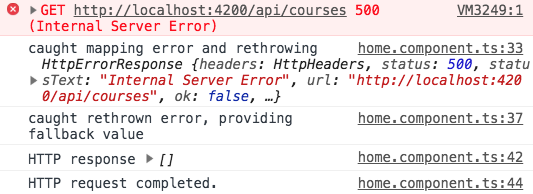
As we can see, the error was indeed rethrown initially, but it never reached the subscribe error handler function. Instead, the fallback [] value was emitted, as expected.
The Finalize Operator
Besides a catch block for handling errors, the synchronous Javascript syntax also provides a finally block that can be used to run code that we always want executed.
The finally block is typically used for releasing expensive resources, such as for example closing down network connections or releasing memory.
Unlike the code in the catch block, the code in the finally block will get executed independently if an error is thrown or not:
RxJs provides us with an operator that has a similar behavior to the finally functionality, called the finalize Operator.
Note: we cannot call it the finally operator instead, as finally is a reserved keyword in Javascript
Finalize Operator Example
Just like the catchError operator, we can add multiple finalize calls at different places in the Observable chain if needed, in order to make sure that the multiple resources are correctly released:
Let’s now run this code, and see how the multiple finalize blocks are being executed:

Notice that the last finalize block is executed after the subscribe value handler and completion handler functions.
The Retry Strategy
As an alternative to rethrowing the error or providing fallback values, we can also simply retry to subscribe to the errored out Observable.
Let’s remember, once the stream errors out we cannot recover it, but nothing prevents us from subscribing again to the Observable from which the stream was derived from, and create another stream.
Here is how this works:
- we are going to take the input Observable, and subscribe to it, which creates a new stream
- if that stream does not error out, we are going to let its values show up in the output
- but if the stream does error out, we are then going to subscribe again to the input Observable, and create a brand new stream
When to retry?
The big question here is, when are we going to subscribe again to the input Observable, and retry to execute the input stream?
- are we going to retry that immediately?
- are we going to wait for a small delay, hoping that the problem is solved and then try again?
- are we going to retry only a limited amount of times, and then error out the output stream?
In order to answer these questions, we are going to need a second auxiliary Observable, which we are going to call the Notifier Observable. It’s the Notifier
Observable that is going to determine when the retry attempt occurs.
The Notifier Observable is going to be used by the retryWhen Operator, which is the heart of the Retry Strategy.
RxJs retryWhen Operator Marble Diagram
To understand how the retryWhen Observable works, let’s have a look at its marble diagram:

Notice that the Observable that is being re-tried is the 1-2 Observable in the second line from the top, and not the Observable in the first line.
The Observable on the first line with values r-r is the Notification Observable, that is going to determine when a retry attempt should occur.
Breaking down how retryWhen works
Let’s break down what is going in this diagram:
- The Observable 1-2 gets subscribed to, and its values are reflected immediately in the output Observable returned by retryWhen
- even after the Observable 1-2 is completed, it can still be re-tried
- the notification Observable then emits a value
r, way after the Observable 1-2 has completed - The value emitted by the notification Observable (in this case
r) could be anything - what matters is the moment when the value
rgot emitted, because that is what is going to trigger the 1-2 Observable to be retried - the Observable 1-2 gets subscribed to again by retryWhen, and its values are again reflected in the output Observable of retryWhen
- The notification Observable is then going to emit again another
rvalue, and the same thing occurs: the values of a newly subscribed 1-2 stream are going to start to get reflected in the output of retryWhen - but then, the notification Observable eventually completes
- at that moment, the ongoing retry attempt of the 1-2 Observable is completed early as well, meaning that only the value 1 got emitted, but not 2
As we can see, retryWhen simply retries the input Observable each time that the Notification Observable emits a value!
Now that we understand how retryWhen works, let’s see how we can create a Notification Observable.
Creating a Notification Observable
We need to create the Notification Observable directly in the function passed to the retryWhen operator. This function takes as input argument an Errors Observable, that emits as values the errors of the input Observable.
So by subscribing to this Errors Observable, we know exactly when an error occurs. Let’s now see how we could implement an immediate retry strategy using the Errors Observable.
Immediate Retry Strategy
In order to retry the failed observable immediately after the error occurs, all we have to do is return the Errors Observable without any further changes.
In this case, we are just piping the tap operator for logging purposes, so the Errors Observable remains unchanged:
Let’s remember, the Observable that we are returning from the retryWhen function call is the Notification Observable!
The value that it emits is not important, it’s only important when the value gets emitted because that is what is going to trigger a retry attempt.
Immediate Retry Console Output
If we now execute this program, we are going to find the following output in the console:

As we can see, the HTTP request failed initially, but then a retry was attempted and the second time the request went through successfully.
Let’s now have a look at the delay between the two attempts, by inspecting the network log:

As we can see, the second attempt was issued immediately after the error occurred, as expected.
Delayed Retry Strategy
Let’s now implement an alternative error recovery strategy, where we wait for example for 2 seconds after the error occurs, before retrying.
This strategy is useful for trying to recover from certain errors such as for example failed network requests caused by high server traffic.
In those cases where the error is intermittent, we can simply retry the same request after a short delay, and the request might go through the second time without any problem.
The timer Observable creation function
To implement the Delayed Retry Strategy, we will need to create a Notification Observable whose values are emitted two seconds after each error occurrence.
Let’s then try to create a Notification Observable by using the timer creation function. This timer function is going to take a couple of arguments:
- an initial delay, before which no values will be emitted
- a periodic interval, in case we want to emit new values periodically
Let’s then have a look at the marble diagram for the timer function:

As we can see, the first value 0 will be emitted only after 3 seconds, and then we have a new value each second.
Notice that the second argument is optional, meaning that if we leave it out our Observable is going to emit only one value (0) after 3 seconds and then complete.
This Observable looks like its a good start for being able to delay our retry attempts, so let’s see how we can combine it with the retryWhen and delayWhen operators.
The delayWhen Operator
One important thing to bear in mind about the retryWhen Operator, is that the function that defines the Notification Observable is only called once.
So we only get one chance to define our Notification Observable, that signals when the retry attempts should be done.
We are going to define the Notification Observable by taking the Errors Observable and applying it the delayWhen Operator.
Imagine that in this marble diagram, the source Observable a-b-c is the Errors Observable, that is emitting failed HTTP errors over time:

delayWhen Operator breakdown
Let’s follow the diagram, and learn how the delayWhen Operator works:
- each value in the input Errors Observable is going to be delayed before showing up in the output Observable
- the delay per each value can be different, and is going to be created in a completely flexible way
- in order to determine the delay, we are going to call the function passed to delayWhen (called the duration selector function) per each value of the input Errors Observable
- that function is going to emit an Observable that is going to determine when the delay of each input value has elapsed
- each of the values a-b-c has its own duration selector Observable, that will eventually emit one value (that could be anything) and then complete
- when each of these duration selector Observables emits values, then the corresponding input value a-b-c is going to show up in the output of delayWhen
- notice that the value
bshows up in the output after the valuec, this is normal - this is because the
bduration selector Observable (the third horizontal line from the top) only emitted its value after the duration selector Observable ofc, and that explains whycshows up in the output beforeb
Delayed Retry Strategy implementation
Let’s now put all this together and see how we can retry consecutively a failing HTTP request 2 seconds after each error occurs:
Let’s break down what is going on here:
- let’s remember that the function passed to retryWhen is only going to be called once
- we are returning in that function an Observable that will emit values whenever a retry is needed
- each time that there is an error, the delayWhen operator is going to create a duration selector Observable, by calling the timer function
- this duration selector Observable is going to emit the value 0 after 2 seconds, and then complete
- once that happens, the delayWhen Observable knows that the delay of a given input error has elapsed
- only once that delay elapses (2 seconds after the error occurred), the error shows up in the output of the notification Observable
- once a value gets emitted in the notification Observable, the retryWhen operator will then and only then execute a retry attempt
Retry Strategy Console Output
Let’s now see what this looks like in the console! Here is an example of an HTTP request that was retried 5 times, as the first 4 times were in error:

And here is the network log for the same retry sequence:

As we can see, the retries only happened 2 seconds after the error occurred, as expected!
And with this, we have completed our guided tour of some of the most commonly used RxJs error handling strategies available, let’s now wrap things up and provide some running sample code.
Running Github repository (with code samples)
In order to try these multiple error handling strategies, it’s important to have a working playground where you can try handling failing HTTP requests.
This playground contains a small running application with a backend that can be used to simulate HTTP errors either randomly or systematically. Here is what the application looks like:

Conclusions
As we have seen, understanding RxJs error handling is all about understanding the fundamentals of the Observable contract first.
We need to keep in mind that any given stream can only error out once, and that is exclusive with stream completion; only one of the two things can happen.
In order to recover from an error, the only way is to somehow generate a replacement stream as an alternative to the errored out stream, like it happens in the case of the catchError or retryWhen Operators.
I hope that you have enjoyed this post, if you would like to learn a lot more about RxJs, we recommend checking the RxJs In Practice Course course, where lots of useful patterns and operators are covered in much more detail.
Also, if you have some questions or comments please let me know in the comments below and I will get back to you.
To get notified of upcoming posts on RxJs and other Angular topics, I invite you to subscribe to our newsletter:
If you are just getting started learning Angular, have a look at the Angular for Beginners Course:

Содержание
- Name already in use
- angular / aio / content / guide / observables.md
- Introduction
- First examples
- Purity
- Values
- Observable
- Pull versus Push
- Observables as generalizations of functions
- Anatomy of an Observable
- Creating Observables
- Subscribing to Observables
- Executing Observables
- Disposing Observable Executions
- Observer
- Subscription
- Subject
- Multicasted Observables
- Reference counting
- BehaviorSubject
- ReplaySubject
- AsyncSubject
- Operators
- What are operators?
- Instance operators versus static operators
- Marble diagrams
- Choose an operator
- Categories of operators
- Creation Operators
- Transformation Operators
- Filtering Operators
- Combination Operators
- Multicasting Operators
- Error Handling Operators
- Utility Operators
- Conditional and Boolean Operators
- Mathematical and Aggregate Operators
- Scheduler
- Scheduler Types
- Using Schedulers
Name already in use
angular / aio / content / guide / observables.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
Copy raw contents
Copy raw contents
Using observables to pass values
Observables provide support for passing messages between parts of your application. They are used frequently in Angular and are a technique for event handling, asynchronous programming, and handling multiple values.
The observer pattern is a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of state changes. This pattern is similar (but not identical) to the publish/subscribe design pattern.
Observables are declarative —that is, you define a function for publishing values, but it is not executed until a consumer subscribes to it. The subscribed consumer then receives notifications until the function completes, or until they unsubscribe.
An observable can deliver multiple values of any type —literals, messages, or events, depending on the context. The API for receiving values is the same whether the values are delivered synchronously or asynchronously. Because setup and teardown logic are both handled by the observable, your application code only needs to worry about subscribing to consume values, and when done, unsubscribing. Whether the stream was keystrokes, an HTTP response, or an interval timer, the interface for listening to values and stopping listening is the same.
Because of these advantages, observables are used extensively within Angular, and for application development as well.
Basic usage and terms
As a publisher, you create an Observable instance that defines a subscriber function. This is the function that is executed when a consumer calls the subscribe() method. The subscriber function defines how to obtain or generate values or messages to be published.
To execute the observable you have created and begin receiving notifications, you call its subscribe() method, passing an observer. This is a JavaScript object that defines the handlers for the notifications you receive. The subscribe() call returns a Subscription object that has an unsubscribe() method, which you call to stop receiving notifications.
Here’s an example that demonstrates the basic usage model by showing how an observable could be used to provide geolocation updates.
A handler for receiving observable notifications implements the Observer interface. It is an object that defines callback methods to handle the three types of notifications that an observable can send:
| Notification type | Details |
|---|---|
| next | Required. A handler for each delivered value. Called zero or more times after execution starts. |
| error | Optional. A handler for an error notification. An error halts execution of the observable instance. |
| complete | Optional. A handler for the execution-complete notification. Delayed values can continue to be delivered to the next handler after execution is complete. |
An observer object can define any combination of these handlers. If you don’t supply a handler for a notification type, the observer ignores notifications of that type.
An Observable instance begins publishing values only when someone subscribes to it. You subscribe by calling the subscribe() method of the instance, passing an observer object to receive the notifications.
In order to show how subscribing works, we need to create a new observable. There is a constructor that you use to create new instances, but for illustration, we can use some methods from the RxJS library that create simple observables of frequently used types:
| RxJS methods | Details |
|---|---|
| of(. items) | Returns an Observable instance that synchronously delivers the values provided as arguments. |
| from(iterable) | Converts its argument to an Observable instance. This method is commonly used to convert an array to an observable. |
Here’s an example of creating and subscribing to a simple observable, with an observer that logs the received message to the console:
Alternatively, the subscribe() method can accept callback function definitions in line, for next , error , and complete handlers. For example, the following subscribe() call is the same as the one that specifies the predefined observer:
In either case, a next handler is required. The error and complete handlers are optional.
NOTE:
A next() function could receive, for instance, message strings, or event objects, numeric values, or structures, depending on context. As a general term, we refer to data published by an observable as a stream. Any type of value can be represented with an observable, and the values are published as a stream.
Use the Observable constructor to create an observable stream of any type. The constructor takes as its argument the subscriber function to run when the observable’s subscribe() method executes. A subscriber function receives an Observer object, and can publish values to the observer’s next() method.
For example, to create an observable equivalent to the of(1, 2, 3) above, you could do something like this:
To take this example a little further, we can create an observable that publishes events. In this example, the subscriber function is defined inline.
Now you can use this function to create an observable that publishes keydown events:
A typical observable creates a new, independent execution for each subscribed observer. When an observer subscribes, the observable wires up an event handler and delivers values to that observer. When a second observer subscribes, the observable then wires up a new event handler and delivers values to that second observer in a separate execution.
Sometimes, instead of starting an independent execution for each subscriber, you want each subscription to get the same values —even if values have already started emitting. This might be the case with something like an observable of clicks on the document object.
Multicasting is the practice of broadcasting to a list of multiple subscribers in a single execution. With a multicasting observable, you don’t register multiple listeners on the document, but instead re-use the first listener and send values out to each subscriber.
When creating an observable you should determine how you want that observable to be used and whether or not you want to multicast its values.
Let’s look at an example that counts from 1 to 3, with a one-second delay after each number emitted.
Notice that if you subscribe twice, there will be two separate streams, each emitting values every second. It looks something like this:
Changing the observable to be multicasting could look something like this:
Multicasting observables take a bit more setup, but they can be useful for certain applications. Later we will look at tools that simplify the process of multicasting, allowing you to take any observable and make it multicasting.
Because observables produce values asynchronously, try/catch will not effectively catch errors. Instead, you handle errors by specifying an error callback on the observer. Producing an error also causes the observable to clean up subscriptions and stop producing values. An observable can either produce values (calling the next callback), or it can complete, calling either the complete or error callback.
Error handling (and specifically recovering from an error) is covered in more detail in a later section.
Источник
Introduction
RxJS is a library for composing asynchronous and event-based programs by using observable sequences. It provides one core type, the Observable, satellite types (Observer, Schedulers, Subjects) and operators inspired by Array#extras (map, filter, reduce, every, etc) to allow handling asynchronous events as collections.
Think of RxJS as Lodash for events.
ReactiveX combines the Observer pattern with the Iterator pattern and functional programming with collections to fill the need for an ideal way of managing sequences of events.
The essential concepts in RxJS which solve async event management are:
- Observable: represents the idea of an invokable collection of future values or events.
- Observer: is a collection of callbacks that knows how to listen to values delivered by the Observable.
- Subscription: represents the execution of an Observable, is primarily useful for cancelling the execution.
- Operators: are pure functions that enable a functional programming style of dealing with collections with operations like map , filter , concat , flatMap , etc.
- Subject: is the equivalent to an EventEmitter, and the only way of multicasting a value or event to multiple Observers.
- Schedulers: are centralized dispatchers to control concurrency, allowing us to coordinate when computation happens on e.g. setTimeout or requestAnimationFrame or others.
First examples
Normally you register event listeners.
Using RxJS you create an observable instead.
Purity
What makes RxJS powerful is its ability to produce values using pure functions. That means your code is less prone to errors.
Normally you would create an impure function, where other pieces of your code can mess up your state.
Using RxJS you isolate the state.
The scan operator works just like reduce for arrays. It takes a value which is exposed to a callback. The returned value of the callback will then become the next value exposed the next time the callback runs.
RxJS has a whole range of operators that helps you control how the events flow through your observables.
This is how you would allow at most one click per second, with plain JavaScript:
Values
You can transform the values passed through your observables.
Here’s how you can add the current mouse x position for every click, in plain JavaScript:
Observable
Observables are lazy Push collections of multiple values. They fill the missing spot in the following table:
| Single | Multiple | |
|---|---|---|
| Pull | Function | Iterator |
| Push | Promise | Observable |
Example. The following is an Observable that pushes the values 1 , 2 , 3 immediately (synchronously) when subscribed, and the value 4 after one second has passed since the subscribe call, then completes:
To invoke the Observable and see these values, we need to subscribe to it:
Which executes as such on the console:
Pull versus Push
Pull and Push are two different protocols that describe how a data Producer can communicate with a data Consumer.
What is Pull? In Pull systems, the Consumer determines when it receives data from the data Producer. The Producer itself is unaware of when the data will be delivered to the Consumer.
Every JavaScript Function is a Pull system. The function is a Producer of data, and the code that calls the function is consuming it by «pulling» out a single return value from its call.
ES2015 introduced generator functions and iterators ( function* ), another type of Pull system. Code that calls iterator.next() is the Consumer, «pulling» out multiple values from the iterator (the Producer).
| Producer | Consumer | |
|---|---|---|
| Pull | Passive: produces data when requested. | Active: decides when data is requested. |
| Push | Active: produces data at its own pace. | Passive: reacts to received data. |
What is Push? In Push systems, the Producer determines when to send data to the Consumer. The Consumer is unaware of when it will receive that data.
Promises are the most common type of Push system in JavaScript today. A Promise (the Producer) delivers a resolved value to registered callbacks (the Consumers), but unlike functions, it is the Promise which is in charge of determining precisely when that value is «pushed» to the callbacks.
RxJS introduces Observables, a new Push system for JavaScript. An Observable is a Producer of multiple values, «pushing» them to Observers (Consumers).
- A Function is a lazily evaluated computation that synchronously returns a single value on invocation.
- A generator is a lazily evaluated computation that synchronously returns zero to (potentially) infinite values on iteration.
- A Promise is a computation that may (or may not) eventually return a single value.
- An Observable is a lazily evaluated computation that can synchronously or asynchronously return zero to (potentially) infinite values from the time it’s invoked onwards.
Observables as generalizations of functions
Contrary to popular claims, Observables are not like EventEmitters nor are they like Promises for multiple values. Observables may act like EventEmitters in some cases, namely when they are multicasted using RxJS Subjects, but usually they don’t act like EventEmitters.
Observables are like functions with zero arguments, but generalize those to allow multiple values.
Consider the following:
We expect to see as output:
You can write the same behavior above, but with Observables:
And the output is the same:
This happens because both functions and Observables are lazy computations. If you don’t call the function, the console.log(‘Hello’) won’t happen. Also with Observables, if you don’t «call» it (with subscribe ), the console.log(‘Hello’) won’t happen. Plus, «calling» or «subscribing» is an isolated operation: two function calls trigger two separate side effects, and two Observable subscribes trigger two separate side effects. As opposed to EventEmitters which share the side effects and have eager execution regardless of the existence of subscribers, Observables have no shared execution and are lazy.
Subscribing to an Observable is analogous to calling a Function.
Some people claim that Observables are asynchronous. That is not true. If you surround a function call with logs, like this:
You will see the output:
And this is the same behavior with Observables:
And the output is:
Which proves the subscription of foo was entirely synchronous, just like a function.
Observables are able to deliver values either synchronously or asynchronously.
What is the difference between an Observable and a function? Observables can «return» multiple values over time, something which functions cannot. You can’t do this:
Functions can only return one value. Observables, however, can do this:
With synchronous output:
But you can also «return» values asynchronously:
- func.call() means «give me one value synchronously«
- observable.subscribe() means «give me any amount of values, either synchronously or asynchronously«
Anatomy of an Observable
Observables are created using Rx.Observable.create or a creation operator, are subscribed to with an Observer, execute to deliver next / error / complete notifications to the Observer, and their execution may be disposed. These four aspects are all encoded in an Observable instance, but some of these aspects are related to other types, like Observer and Subscription.
Core Observable concerns:
- Creating Observables
- Subscribing to Observables
- Executing the Observable
- Disposing Observables
Creating Observables
Rx.Observable.create is an alias for the Observable constructor, and it takes one argument: the subscribe function.
The following example creates an Observable to emit the string ‘hi’ every second to an Observer.
Observables can be created with create , but usually we use the so-called creation operators, like of , from , interval , etc.
In the example above, the subscribe function is the most important piece to describe the Observable. Let’s look at what subscribing means.
Subscribing to Observables
The Observable observable in the example can be subscribed to, like this:
It is not a coincidence that observable.subscribe and subscribe in Observable.create(function subscribe(observer) <. >) have the same name. In the library, they are different, but for practical purposes you can consider them conceptually equal.
This shows how subscribe calls are not shared among multiple Observers of the same Observable. When calling observable.subscribe with an Observer, the function subscribe in Observable.create(function subscribe(observer) <. >) is run for that given Observer. Each call to observable.subscribe triggers its own independent setup for that given Observer.
Subscribing to an Observable is like calling a function, providing callbacks where the data will be delivered to.
This is drastically different to event handler APIs like addEventListener / removeEventListener . With observable.subscribe , the given Observer is not registered as a listener in the Observable. The Observable does not even maintain a list of attached Observers.
A subscribe call is simply a way to start an «Observable execution» and deliver values or events to an Observer of that execution.
Executing Observables
The code inside Observable.create(function subscribe(observer) <. >) represents an «Observable execution», a lazy computation that only happens for each Observer that subscribes. The execution produces multiple values over time, either synchronously or asynchronously.
There are three types of values an Observable Execution can deliver:
- «Next» notification: sends a value such as a Number, a String, an Object, etc.
- «Error» notification: sends a JavaScript Error or exception.
- «Complete» notification: does not send a value.
Next notifications are the most important and most common type: they represent actual data being delivered to an Observer. Error and Complete notifications may happen only once during the Observable Execution, and there can only be either one of them.
These constraints are expressed best in the so-called Observable Grammar or Contract, written as a regular expression:
In an Observable Execution, zero to infinite Next notifications may be delivered. If either an Error or Complete notification is delivered, then nothing else can be delivered afterwards.
The following is an example of an Observable execution that delivers three Next notifications, then completes:
Observables strictly adhere to the Observable Contract, so the following code would not deliver the Next notification 4 :
It is a good idea to wrap any code in subscribe with try / catch block that will deliver an Error notification if it catches an exception:
Disposing Observable Executions
Because Observable Executions may be infinite, and it’s common for an Observer to want to abort execution in finite time, we need an API for canceling an execution. Since each execution is exclusive to one Observer only, once the Observer is done receiving values, it has to have a way to stop the execution, in order to avoid wasting computation power or memory resources.
When observable.subscribe is called, the Observer gets attached to the newly created Observable execution. This call also returns an object, the Subscription :
The Subscription represents the ongoing execution, and has a minimal API which allows you to cancel that execution. Read more about the Subscription type here. With subscription.unsubscribe() you can cancel the ongoing execution:
When you subscribe, you get back a Subscription, which represents the ongoing execution. Just call unsubscribe() to cancel the execution.
Each Observable must define how to dispose resources of that execution when we create the Observable using create() . You can do that by returning a custom unsubscribe function from within function subscribe() .
For instance, this is how we clear an interval execution set with setInterval :
Just like observable.subscribe resembles Observable.create(function subscribe() <. >) , the unsubscribe we return from subscribe is conceptually equal to subscription.unsubscribe . In fact, if we remove the ReactiveX types surrounding these concepts, we’re left with rather straightforward JavaScript.
The reason why we use Rx types like Observable, Observer, and Subscription is to get safety (such as the Observable Contract) and composability with Operators.
Observer
What is an Observer? An Observer is a consumer of values delivered by an Observable. Observers are simply a set of callbacks, one for each type of notification delivered by the Observable: next , error , and complete . The following is an example of a typical Observer object:
To use the Observer, provide it to the subscribe of an Observable:
Observers are just objects with three callbacks, one for each type of notification that an Observable may deliver.
Observers in RxJS may also be partial. If you don’t provide one of the callbacks, the execution of the Observable will still happen normally, except some types of notifications will be ignored, because they don’t have a corresponding callback in the Observer.
The example below is an Observer without the complete callback:
When subscribing to an Observable, you may also just provide the callbacks as arguments, without being attached to an Observer object, for instance like this:
Internally in observable.subscribe , it will create an Observer object using the first callback argument as the next handler. All three types of callbacks may be provided as arguments:
Subscription
What is a Subscription? A Subscription is an object that represents a disposable resource, usually the execution of an Observable. A Subscription has one important method, unsubscribe , that takes no argument and just disposes the resource held by the subscription. In previous versions of RxJS, Subscription was called «Disposable».
A Subscription essentially just has an unsubscribe() function to release resources or cancel Observable executions.
Subscriptions can also be put together, so that a call to an unsubscribe() of one Subscription may unsubscribe multiple Subscriptions. You can do this by «adding» one subscription into another:
When executed, we see in the console:
Subscriptions also have a remove(otherSubscription) method, in order to undo the addition of a child Subscription.
Subject
What is a Subject? An RxJS Subject is a special type of Observable that allows values to be multicasted to many Observers. While plain Observables are unicast (each subscribed Observer owns an independent execution of the Observable), Subjects are multicast.
A Subject is like an Observable, but can multicast to many Observers. Subjects are like EventEmitters: they maintain a registry of many listeners.
Every Subject is an Observable. Given a Subject, you can subscribe to it, providing an Observer, which will start receiving values normally. From the perspective of the Observer, it cannot tell whether the Observable execution is coming from a plain unicast Observable or a Subject.
Internally to the Subject, subscribe does not invoke a new execution that delivers values. It simply registers the given Observer in a list of Observers, similarly to how addListener usually works in other libraries and languages.
Every Subject is an Observer. It is an object with the methods next(v) , error(e) , and complete() . To feed a new value to the Subject, just call next(theValue) , and it will be multicasted to the Observers registered to listen to the Subject.
In the example below, we have two Observers attached to a Subject, and we feed some values to the Subject:
With the following output on the console:
Since a Subject is an Observer, this also means you may provide a Subject as the argument to the subscribe of any Observable, like the example below shows:
Which executes as:
With the approach above, we essentially just converted a unicast Observable execution to multicast, through the Subject. This demonstrates how Subjects are the only way of making any Observable execution be shared to multiple Observers.
There are also a few specializations of the Subject type: BehaviorSubject , ReplaySubject , and AsyncSubject .
Multicasted Observables
A «multicasted Observable» passes notifications through a Subject which may have many subscribers, whereas a plain «unicast Observable» only sends notifications to a single Observer.
A multicasted Observable uses a Subject under the hood to make multiple Observers see the same Observable execution.
Under the hood, this is how the multicast operator works: Observers subscribe to an underlying Subject, and the Subject subscribes to the source Observable. The following example is similar to the previous example which used observable.subscribe(subject) :
multicast returns an Observable that looks like a normal Observable, but works like a Subject when it comes to subscribing. multicast returns a ConnectableObservable , which is simply an Observable with the connect() method.
The connect() method is important to determine exactly when the shared Observable execution will start. Because connect() does source.subscribe(subject) under the hood, connect() returns a Subscription, which you can unsubscribe from in order to cancel the shared Observable execution.
Reference counting
Calling connect() manually and handling the Subscription is often cumbersome. Usually, we want to automatically connect when the first Observer arrives, and automatically cancel the shared execution when the last Observer unsubscribes.
Consider the following example where subscriptions occur as outlined by this list:
- First Observer subscribes to the multicasted Observable
- The multicasted Observable is connected
- The next value 0 is delivered to the first Observer
- Second Observer subscribes to the multicasted Observable
- The next value 1 is delivered to the first Observer
- The next value 1 is delivered to the second Observer
- First Observer unsubscribes from the multicasted Observable
- The next value 2 is delivered to the second Observer
- Second Observer unsubscribes from the multicasted Observable
- The connection to the multicasted Observable is unsubscribed
To achieve that with explicit calls to connect() , we write the following code:
If we wish to avoid explicit calls to connect() , we can use ConnectableObservable’s refCount() method (reference counting), which returns an Observable that keeps track of how many subscribers it has. When the number of subscribers increases from 0 to 1 , it will call connect() for us, which starts the shared execution. Only when the number of subscribers decreases from 1 to 0 will it be fully unsubscribed, stopping further execution.
refCount makes the multicasted Observable automatically start executing when the first subscriber arrives, and stop executing when the last subscriber leaves.
Below is an example:
Which executes with the output:
The refCount() method only exists on ConnectableObservable, and it returns an Observable , not another ConnectableObservable.
BehaviorSubject
One of the variants of Subjects is the BehaviorSubject , which has a notion of «the current value». It stores the latest value emitted to its consumers, and whenever a new Observer subscribes, it will immediately receive the «current value» from the BehaviorSubject .
BehaviorSubjects are useful for representing «values over time». For instance, an event stream of birthdays is a Subject, but the stream of a person’s age would be a BehaviorSubject.
In the following example, the BehaviorSubject is initialized with the value 0 which the first Observer receives when it subscribes. The second Observer receives the value 2 even though it subscribed after the value 2 was sent.
ReplaySubject
A ReplaySubject is similar to a BehaviorSubject in that it can send old values to new subscribers, but it can also record a part of the Observable execution.
A ReplaySubject records multiple values from the Observable execution and replays them to new subscribers.
When creating a ReplaySubject , you can specify how many values to replay:
You can also specify a window time in milliseconds, besides of the buffer size, to determine how old the recorded values can be. In the following example we use a large buffer size of 100 , but a window time parameter of just 500 milliseconds.
With the following output where the second Observer gets events 3 , 4 and 5 that happened in the last 500 milliseconds prior to its subscription:
AsyncSubject
The AsyncSubject is a variant where only the last value of the Observable execution is sent to its observers, and only when the execution completes.
The AsyncSubject is similar to the last() operator, in that it waits for the complete notification in order to deliver a single value.
Operators
RxJS is mostly useful for its operators, even though the Observable is the foundation. Operators are the essential pieces that allow complex asynchronous code to be easily composed in a declarative manner.
What are operators?
Operators are methods on the Observable type, such as .map(. ) , .filter(. ) , .merge(. ) , etc. When called, they do not change the existing Observable instance. Instead, they return a new Observable, whose subscription logic is based on the first Observable.
An Operator is a function which creates a new Observable based on the current Observable. This is a pure operation: the previous Observable stays unmodified.
An Operator is essentially a pure function which takes one Observable as input and generates another Observable as output. Subscribing to the output Observable will also subscribe to the input Observable. In the following example, we create a custom operator function that multiplies each value received from the input Observable by 10:
Notice that a subscribe to output will cause input Observable to be subscribed. We call this an «operator subscription chain».
Instance operators versus static operators
What is an instance operator? Typically when referring to operators, we assume instance operators, which are methods on Observable instances. For instance, if the operator multiplyByTen would be an official instance operator, it would look roughly like this:
Instance operators are functions that use the this keyword to infer what is the input Observable.
Notice how the input Observable is not a function argument anymore, it is assumed to be the this object. This is how we would use such instance operator:
What is a static operator? Besides instance operators, static operators are functions attached to the Observable class directly. A static operator uses no this keyword internally, but instead relies entirely on its arguments.
Static operators are pure functions attached to the Observable class, and usually are used to create Observables from scratch.
The most common type of static operators are the so-called Creation Operators. Instead of transforming an input Observable to an output Observable, they simply take a non-Observable argument, like a number, and create a new Observable.
A typical example of a static creation operator would be the interval function. It takes a number (not an Observable) as input argument, and produces an Observable as output:
Another example of a creation operator is create , which we have been using extensively in previous examples. See the list of all static creation operators here.
However, static operators may be of different nature than simply creation. Some Combination Operators may be static, such as merge , combineLatest , concat , etc. These make sense as static operators because they take multiple Observables as input, not just one, for instance:
Marble diagrams
To explain how operators work, textual descriptions are often not enough. Many operators are related to time, they may for instance delay, sample, throttle, or debounce value emissions in different ways. Diagrams are often a better tool for that. Marble Diagrams are visual representations of how operators work, and include the input Observable(s), the operator and its parameters, and the output Observable.
In a marble diagram, time flows to the right, and the diagram describes how values («marbles») are emitted on the Observable execution.
Below you can see the anatomy of a marble diagram.

Throughout this documentation site, we extensively use marble diagrams to explain how operators work. They may be really useful in other contexts too, like on a whiteboard or even in our unit tests (as ASCII diagrams).
Choose an operator
Categories of operators
There are operators for different purposes, and they may be categorized as: creation, transformation, filtering, combination, multicasting, error handling, utility, etc. In the following list you will find all the operators organized in categories.
Creation Operators
Transformation Operators
Filtering Operators
Combination Operators
Multicasting Operators
Error Handling Operators
Utility Operators
Conditional and Boolean Operators
Mathematical and Aggregate Operators
Scheduler
What is a Scheduler? A scheduler controls when a subscription starts and when notifications are delivered. It consists of three components.
- A Scheduler is a data structure. It knows how to store and queue tasks based on priority or other criteria.
- A Scheduler is an execution context. It denotes where and when the task is executed (e.g. immediately, or in another callback mechanism such as setTimeout or process.nextTick, or the animation frame).
- A Scheduler has a (virtual) clock. It provides a notion of «time» by a getter method now() on the scheduler. Tasks being scheduled on a particular scheduler will adhere only to the time denoted by that clock.
A Scheduler lets you define in what execution context will an Observable deliver notifications to its Observer.
In the example below, we take the usual simple Observable that emits values 1 , 2 , 3 synchronously, and use the operator observeOn to specify the async scheduler to use for delivering those values.
Which executes with the output:
Notice how the notifications got value. were delivered after just after subscribe , which is different to the default behavior we have seen so far. This is because observeOn(Rx.Scheduler.async) introduces a proxy Observer between Observable.create and the final Observer. Let’s rename some identifiers to make that distinction obvious in the example code:
The proxyObserver is created in observeOn(Rx.Scheduler.async) , and its next(val) function is approximately the following:
The async Scheduler operates with a setTimeout or setInterval , even if the given delay was zero. As usual, in JavaScript, setTimeout(fn, 0) is known to run the function fn earliest on the next event loop iteration. This explains why got value 1 is delivered to the finalObserver after just after subscribe happened.
The schedule() method of a Scheduler takes a delay argument, which refers to a quantity of time relative to the Scheduler’s own internal clock. A Scheduler’s clock need not have any relation to the actual wall-clock time. This is how temporal operators like delay operate not on actual time, but on time dictated by the Scheduler’s clock. This is specially useful in testing, where a virtual time Scheduler may be used to fake wall-clock time while in reality executing scheduled tasks synchronously.
Scheduler Types
The async Scheduler is one of the built-in schedulers provided by RxJS. Each of these can be created and returned by using static properties of the Scheduler object.
| Scheduler | Purpose |
|---|---|
| null | By not passing any scheduler, notifications are delivered synchronously and recursively. Use this for constant-time operations or tail recursive operations. |
| Rx.Scheduler.queue | Schedules on a queue in the current event frame (trampoline scheduler). Use this for iteration operations. |
| Rx.Scheduler.asap | Schedules on the micro task queue, which uses the fastest transport mechanism available, either Node.js’ process.nextTick() or Web Worker MessageChannel or setTimeout or others. Use this for asynchronous conversions. |
| Rx.Scheduler.async | Schedules work with setInterval . Use this for time-based operations. |
Using Schedulers
You may have already used schedulers in your RxJS code without explicitly stating the type of schedulers to be used. This is because all Observable operators that deal with concurrency have optional schedulers. If you do not provide the scheduler, RxJS will pick a default scheduler by using the principle of least concurrency. This means that the scheduler which introduces the least amount of concurrency that satisfies the needs of the operator is chosen. For example, for operators returning an observable with a finite and small number of messages, RxJS uses no Scheduler, i.e. null or undefined . For operators returning a potentially large or infinite number of messages, queue Scheduler is used. For operators which use timers, async is used.
Because RxJS uses the least concurrency scheduler, you can pick a different scheduler if you want to introduce concurrency for performance purpose. To specify a particular scheduler, you can use those operator methods that take a scheduler, e.g., from([10, 20, 30], Rx.Scheduler.async) .
Static creation operators usually take a Scheduler as argument. For instance, from(array, scheduler) lets you specify the Scheduler to use when delivering each notification converted from the array . It is usually the last argument to the operator. The following static creation operators take a Scheduler argument:
- bindCallback
- bindNodeCallback
- combineLatest
- concat
- empty
- from
- fromPromise
- interval
- merge
- of
- range
- throw
- timer
Use subscribeOn to schedule in what context will the subscribe() call happen. By default, a subscribe() call on an Observable will happen synchronously and immediately. However, you may delay or schedule the actual subscription to happen on a given Scheduler, using the instance operator subscribeOn(scheduler) , where scheduler is an argument you provide.
Use observeOn to schedule in what context will notifications be delivered. As we saw in the examples above, instance operator observeOn(scheduler) introduces a mediator Observer between the source Observable and the destination Observer, where the mediator schedules calls to the destination Observer using your given scheduler .
Instance operators may take a Scheduler as argument.
Time-related operators like bufferTime , debounceTime , delay , auditTime , sampleTime , throttleTime , timeInterval , timeout , timeoutWith , windowTime all take a Scheduler as the last argument, and otherwise operate by default on the Rx.Scheduler.async Scheduler.
Other instance operators that take a Scheduler as argument: cache , combineLatest , concat , expand , merge , publishReplay , startWith .
Notice that both cache and publishReplay accept a Scheduler because they utilize a ReplaySubject. The constructor of a ReplaySubjects takes an optional Scheduler as the last argument because ReplaySubject may deal with time, which only makes sense in the context of a Scheduler. By default, a ReplaySubject uses the queue Scheduler to provide a clock.
Источник
What is a Subject? An RxJS Subject is a special type of Observable that allows values to be multicasted to many Observers. While plain Observables are unicast (each subscribed Observer owns an independent execution of the Observable), Subjects are multicast.
A Subject is like an Observable, but can multicast to many Observers. Subjects are like EventEmitters: they maintain a registry of many listeners.
Every Subject is an Observable. Given a Subject, you can subscribe to it, providing an Observer, which will start receiving values normally. From the perspective of the Observer, it cannot tell whether the Observable execution is coming from a plain unicast Observable or a Subject.
Internally to the Subject, subscribe does not invoke a new execution that delivers values. It simply registers the given Observer in a list of Observers, similarly to how addListener usually works in other libraries and languages.
Every Subject is an Observer. It is an object with the methods next(v), error(e), and complete(). To feed a new value to the Subject, just call next(theValue), and it will be multicasted to the Observers registered to listen to the Subject.
In the example below, we have two Observers attached to a Subject, and we feed some values to the Subject:
import { Subject } from 'rxjs'; const subject = new Subject<number>(); subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); subject.next(1); subject.next(2); // Logs: // observerA: 1 // observerB: 1 // observerA: 2 // observerB: 2
Since a Subject is an Observer, this also means you may provide a Subject as the argument to the subscribe of any Observable, like the example below shows:
import { Subject, from } from 'rxjs'; const subject = new Subject<number>(); subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); const observable = from([1, 2, 3]); observable.subscribe(subject); // You can subscribe providing a Subject // Logs: // observerA: 1 // observerB: 1 // observerA: 2 // observerB: 2 // observerA: 3 // observerB: 3
With the approach above, we essentially just converted a unicast Observable execution to multicast, through the Subject. This demonstrates how Subjects are the only way of making any Observable execution be shared to multiple Observers.
There are also a few specializations of the Subject type: BehaviorSubject, ReplaySubject, and AsyncSubject.
Multicasted Observables
A «multicasted Observable» passes notifications through a Subject which may have many subscribers, whereas a plain «unicast Observable» only sends notifications to a single Observer.
A multicasted Observable uses a Subject under the hood to make multiple Observers see the same Observable execution.
Under the hood, this is how the multicast operator works: Observers subscribe to an underlying Subject, and the Subject subscribes to the source Observable. The following example is similar to the previous example which used observable.subscribe(subject):
import { from, Subject, multicast } from 'rxjs'; const source = from([1, 2, 3]); const subject = new Subject(); const multicasted = source.pipe(multicast(subject)); // These are, under the hood, `subject.subscribe({...})`: multicasted.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); multicasted.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); // This is, under the hood, `source.subscribe(subject)`: multicasted.connect();
multicast returns an Observable that looks like a normal Observable, but works like a Subject when it comes to subscribing. multicast returns a ConnectableObservable, which is simply an Observable with the connect() method.
The connect() method is important to determine exactly when the shared Observable execution will start. Because connect() does source.subscribe(subject) under the hood, connect() returns a Subscription, which you can unsubscribe from in order to cancel the shared Observable execution.
Reference counting
Calling connect() manually and handling the Subscription is often cumbersome. Usually, we want to automatically connect when the first Observer arrives, and automatically cancel the shared execution when the last Observer unsubscribes.
Consider the following example where subscriptions occur as outlined by this list:
- First Observer subscribes to the multicasted Observable
- The multicasted Observable is connected
- The
nextvalue0is delivered to the first Observer - Second Observer subscribes to the multicasted Observable
- The
nextvalue1is delivered to the first Observer - The
nextvalue1is delivered to the second Observer - First Observer unsubscribes from the multicasted Observable
- The
nextvalue2is delivered to the second Observer - Second Observer unsubscribes from the multicasted Observable
- The connection to the multicasted Observable is unsubscribed
To achieve that with explicit calls to connect(), we write the following code:
import { interval, Subject, multicast } from 'rxjs'; const source = interval(500); const subject = new Subject(); const multicasted = source.pipe(multicast(subject)); let subscription1, subscription2, subscriptionConnect; subscription1 = multicasted.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); // We should call `connect()` here, because the first // subscriber to `multicasted` is interested in consuming values subscriptionConnect = multicasted.connect(); setTimeout(() => { subscription2 = multicasted.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); }, 600); setTimeout(() => { subscription1.unsubscribe(); }, 1200); // We should unsubscribe the shared Observable execution here, // because `multicasted` would have no more subscribers after this setTimeout(() => { subscription2.unsubscribe(); subscriptionConnect.unsubscribe(); // for the shared Observable execution }, 2000);
If we wish to avoid explicit calls to connect(), we can use ConnectableObservable’s refCount() method (reference counting), which returns an Observable that keeps track of how many subscribers it has. When the number of subscribers increases from 0 to 1, it will call connect() for us, which starts the shared execution. Only when the number of subscribers decreases from 1 to 0 will it be fully unsubscribed, stopping further execution.
refCount makes the multicasted Observable automatically start executing when the first subscriber arrives, and stop executing when the last subscriber leaves.
Below is an example:
import { interval, Subject, multicast, refCount } from 'rxjs'; const source = interval(500); const subject = new Subject(); const refCounted = source.pipe(multicast(subject), refCount()); let subscription1, subscription2; // This calls `connect()`, because // it is the first subscriber to `refCounted` console.log('observerA subscribed'); subscription1 = refCounted.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); setTimeout(() => { console.log('observerB subscribed'); subscription2 = refCounted.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); }, 600); setTimeout(() => { console.log('observerA unsubscribed'); subscription1.unsubscribe(); }, 1200); // This is when the shared Observable execution will stop, because // `refCounted` would have no more subscribers after this setTimeout(() => { console.log('observerB unsubscribed'); subscription2.unsubscribe(); }, 2000); // Logs // observerA subscribed // observerA: 0 // observerB subscribed // observerA: 1 // observerB: 1 // observerA unsubscribed // observerB: 2 // observerB unsubscribed
The refCount() method only exists on ConnectableObservable, and it returns an Observable, not another ConnectableObservable.
BehaviorSubject
One of the variants of Subjects is the BehaviorSubject, which has a notion of «the current value». It stores the latest value emitted to its consumers, and whenever a new Observer subscribes, it will immediately receive the «current value» from the BehaviorSubject.
BehaviorSubjects are useful for representing «values over time». For instance, an event stream of birthdays is a Subject, but the stream of a person’s age would be a BehaviorSubject.
In the following example, the BehaviorSubject is initialized with the value 0 which the first Observer receives when it subscribes. The second Observer receives the value 2 even though it subscribed after the value 2 was sent.
import { BehaviorSubject } from 'rxjs'; const subject = new BehaviorSubject(0); // 0 is the initial value subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); subject.next(1); subject.next(2); subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); subject.next(3); // Logs // observerA: 0 // observerA: 1 // observerA: 2 // observerB: 2 // observerA: 3 // observerB: 3
ReplaySubject
A ReplaySubject is similar to a BehaviorSubject in that it can send old values to new subscribers, but it can also record a part of the Observable execution.
A ReplaySubject records multiple values from the Observable execution and replays them to new subscribers.
When creating a ReplaySubject, you can specify how many values to replay:
import { ReplaySubject } from 'rxjs'; const subject = new ReplaySubject(3); // buffer 3 values for new subscribers subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); subject.next(1); subject.next(2); subject.next(3); subject.next(4); subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); subject.next(5); // Logs: // observerA: 1 // observerA: 2 // observerA: 3 // observerA: 4 // observerB: 2 // observerB: 3 // observerB: 4 // observerA: 5 // observerB: 5
You can also specify a window time in milliseconds, besides of the buffer size, to determine how old the recorded values can be. In the following example we use a large buffer size of 100, but a window time parameter of just 500 milliseconds.
import { ReplaySubject } from 'rxjs'; const subject = new ReplaySubject(100, 500 /* windowTime */); subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); let i = 1; setInterval(() => subject.next(i++), 200); setTimeout(() => { subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); }, 1000); // Logs // observerA: 1 // observerA: 2 // observerA: 3 // observerA: 4 // observerA: 5 // observerB: 3 // observerB: 4 // observerB: 5 // observerA: 6 // observerB: 6 // ...
AsyncSubject
The AsyncSubject is a variant where only the last value of the Observable execution is sent to its observers, and only when the execution completes.
import { AsyncSubject } from 'rxjs'; const subject = new AsyncSubject(); subject.subscribe({ next: (v) => console.log(`observerA: ${v}`), }); subject.next(1); subject.next(2); subject.next(3); subject.next(4); subject.subscribe({ next: (v) => console.log(`observerB: ${v}`), }); subject.next(5); subject.complete(); // Logs: // observerA: 5 // observerB: 5
The AsyncSubject is similar to the last() operator, in that it waits for the complete notification in order to deliver a single value.
Void subject
Sometimes the emitted value doesn’t matter as much as the fact that a value was emitted.
For instance, the code below signals that one second has passed.
const subject = new Subject<string>(); setTimeout(() => subject.next('dummy'), 1000);
Passing a dummy value this way is clumsy and can confuse users.
By declaring a void subject, you signal that the value is irrelevant. Only the event itself matters.
const subject = new Subject<void>(); setTimeout(() => subject.next(), 1000);
A complete example with context is shown below:
import { Subject } from 'rxjs'; const subject = new Subject(); // Shorthand for Subject<void> subject.subscribe({ next: () => console.log('One second has passed'), }); setTimeout(() => subject.next(), 1000);
Before version 7, the default type of Subject values was any. Subject<any> disables type checking of the emitted values, whereas Subject<void> prevents accidental access to the emitted value. If you want the old behavior, then replace Subject with Subject<any>.