Отладочный лог
Для работы отладочного лога nginx должен быть сконфигурирован с поддержкой
отладки на этапе сборки:
./configure --with-debug ...
Затем нужно задать уровень debug с помощью
директивы error_log:
error_log /path/to/log debug;
Чтобы убедиться, что поддержка отладки сконфигурирована,
необходимо выполнить команду nginx -V:
configure arguments: --with-debug ...
Готовые пакеты для Linux
по умолчанию предоставляют поддержку отладочного лога
при помощи бинарного файла nginx-debug (1.9.8),
который можно запустить при помощи команд
service nginx stop service nginx-debug start
и затем задать уровень debug.
Бинарная версия nginx для Windows всегда собирается с поддержкой отладочного
лога, поэтому понадобится лишь задать уровень debug.
Обратите внимание, что переопределение лога без одновременного указания
уровня debug отключит отладочный лог.
В примере ниже, переопределение лога на уровне
server
отключает отладочный лог для этого сервера:
error_log /path/to/log debug;
http {
server {
error_log /path/to/log;
...
Чтобы избежать этого, следует либо закомментировать строку, переопределяющую
лог, либо добавить определение уровня debug:
error_log /path/to/log debug;
http {
server {
error_log /path/to/log debug;
...
Отладочный лог для определённых клиентов
Можно включить отладочный лог только для
определённых
клиентских адресов:
error_log /path/to/log;
events {
debug_connection 192.168.1.1;
debug_connection 192.168.10.0/24;
}
Запись в кольцевой буфер в памяти
Отладочный лог можно записывать в кольцевой буфер в памяти:
error_log memory:32m debug;
Запись в буфер в памяти на уровне debug
не оказывает существенного влияния на производительность
даже при высоких нагрузках.
В этом случае лог может быть извлечён при помощи
gdb-скрипта, подобного следующему:
set $log = ngx_cycle->log
while $log->writer != ngx_log_memory_writer
set $log = $log->next
end
set $buf = (ngx_log_memory_buf_t *) $log->wdata
dump binary memory debug_log.txt $buf->start $buf->end
Troubleshoot problems and track down bugs in an NGINX or NGINX Plus deployment, with the debugging binary, debug logging, and core dumps.
Introduction
Debugging helps to identify a bug in the program code if something goes wrong. It is generally used in developing or testing third-party or experimental modules.
NGINX debugging features include the debugging log and creation of a core dump file with its further backtrace.
Configuring NGINX Binary For Debugging
First, you will need to enable debugging in NGINX binary. NGINX Plus already provides you with nginx-debug binary while NGINX Open Source requires recompilation.
Configuring NGINX Plus Binary
Starting from Release 8, NGINX Plus ships the nginx-debug binary together with the standard binary. To enable debugging in NGINX Plus, you will need to switch from nginx to nginx-debug binary. Open terminal and run the command:
$ service nginx stop && service nginx-debug start
When finished, enable the debugging log in the configuration file.
Compiling NGINX Open Source Binary
To enable debugging in NGINX Open Source, you will need to recompile it with the --with-debug flag specified in the configure script.
To compile NGINX Open Source with the debug support:
-
Download and unpack NGINX source files, go to the directory with the source files. See Downloading the Sources.
-
Get the list of NGINX configure arguments. Run the command:
$ nginx -V 2>&1 | grep arguments -
Add the
--with-debugoption to the list of configure commands and run the configure script:$ ./configure --with-debug <other configure arguments> -
Compile and install NGINX:
$ sudo make $ sudo make install -
Restart NGINX.
NGINX and Debugging Symbols
Debug symbols helps obtain additional information for debugging, such as functions, variables, data structures, source file and line number information.
NGINX by default is compiled with the “-g” flag that includes debug symbols.
However, if you get the “No symbol table info available” error when you run a backtrace, then debugging symbols are missing and you will need to recompile NGINX with support of debugging symbols.
The exact set of compiler flags depends on the compiler. For example, for the GCC compiler system:
-
include debugging symbols with the “-g” flag
-
make the debugger output easier to understand by disabling compiler optimization with the “-O0” flag:
$ ./configure --with-debug --with-cc-opt='-O0 -g' ...
Enabling Debug Logging in NGINX Configuration
The debugging log records errors and any debugging-related information and is disabled by default. To enable it, make sure NGINX is compiled to support debugging (see Configuring NGINX Binary For Debugging) and then enable it in NGINX configuration file with the debug parameter of the error_log directive. The debugging log may be written to a file, an allocated buffer in memory, stderr output, or to syslog.
It is recommended enabling the debugging log on the ”main“ level of NGINX configuration to get the full picture of what’s going on.
Writing the Debugging Log to a File
Writing the debugging log to a file may slow down performance under high load. Also note that the file can grow very large and quickly eat up disk space. To reduce the negative impact, you can configure the debugging log to be written into a memory buffer, or set the debugging log for particular IP addresses. See Writing the Debugging Log to Memory and Debug Log for Selected IPs for details.
To enable writing the debugging log to a file:
-
Make sure your NGINX is configured with the
--with-debugconfiguration option. Run the command and check if the output contains the--with-debugline:$ nginx -V 2>&1 | grep -- '--with-debug' -
Open NGINX configuration file:
$ sudo vi /etc/nginx/nginx.conf -
Find the error_log directive which is by default located in the
maincontext, and change the logging level todebug. If necessary, change the path to the log file:error_log /var/log/nginx/error.log debug; -
Save the configuration and exit the configuration file.
Writing the Debugging Log to Memory
The debugging log can be written to a memory using a cyclic buffer. The advantage is that logging on the debug level will not have significant impact on performance under high load.
To enable writing the debug log to memory:
-
Make sure your NGINX is configured with the
--with-debugconfiguration option. Run the command and check if the output contains the--with-debugline:$ nginx -V 2>&1 | grep -- '--with-debug' -
In NGINX configuration file, enable a memory buffer for debug logging with the error_log directive specified in the
maincontext:error_log memory:32m debug; ... http { ... }
The log can be extracted from the memory buffer using a script executed in the GDB debugger.
To extract the debugging log from memory:
-
Obtain the PID of NGINX worker process:
-
Launch the GDB debugger:
$ sudo gdb -p <nginx PID obtained at the previous step> -
Copy the script, paste it to GDB and press “Enter”. The script will save the log in the debug_log.txt file located in the current directory:
set $log = ngx_cycle->log while $log->writer != ngx_log_memory_writer set $log = $log->next end set $buf = (ngx_log_memory_buf_t *) $log->wdata dump binary memory debug_log.txt $buf->start $buf->end -
Quit GDB by pressing CTRL+D.
-
Open the file “debug_log.txt” located in the current directory:
$ sudo less debug_log.txt
Debug Log for Selected IPs
It is possible to enable the debugging log for a particular IP address or a range of IP addresses. Logging particular IPs may useful in a production environment as it will not negatively affect performance. The IP address is specified in the debug_connection directive within the events block; the directive can be defined more than once:
error_log /path/to/log;
...
events {
debug_connection 192.168.1.1;
debug_connection 192.168.10.0/24;
}
Debug Log for Each Virtual Host
Generally, the error_log directive is specified in the main context and thus is applied to all other contexts including server and location. But if there is another error_log directive specified inside a particular server or a location block, the global settings will be overridden and such error_log directive will set its own path to the log file and the level of logging.
To set up the debugging log for a particular virtual host, add the error_log directive inside a particular server block, in which set a new path to the log file and the debug logging level:
error_log /path1/to/log debug;
...
http {
...
server {
error_log /path2/to/log debug;
...
}
}
To disable the debugging log per a particular virtual host, specify the error_log directive inside a particular server block, and specify a path to the log file only:
error_log /path/to/log debug;
...
http {
...
server {
error_log /path/to/log;
...
}
}
Enabling Core Dumps
A core dump file helps identify and fix a problem that lead to NGINX crash. Note that a core dump file may contain sensitive information such as passwords and private keys, so ensure that they are treated in a secure manner.
Core dumps can be enabled in two different ways:
- in the operating system
- in the NGINX configuration file
Enabling Core Dumps in the Operating System
Perform the following steps in your operating system:
-
Specify a working directory in which a core dump file will be saved, for example, “/tmp/cores”:
-
Make sure the directory is writable by NGINX worker process:
$ sudo chown root:root /tmp/cores $ sudo chmod 1777 /tmp/cores -
Disable the limit for the maximum size of a core dump file:
If the operation ends up with “Cannot modify limit: operation not permitted”, run the command:
$ sudo sh -c "ulimit -c unlimited && exec su $LOGNAME" -
Enable core dumps for the setuid and setgid processes.
For CentOS 7.0, Debian 8.2, Ubuntu 14.04, run the commands:
$ echo "/tmp/cores/core.%e.%p" | sudo tee /proc/sys/kernel/core_pattern $ sudo sysctl -w fs.suid_dumpable=2 $ sysctl -pFor FreeBSD, run the commands:
$ sudo sysctl kern.sugid_coredump=1 $ sudo sysctl kern.corefile=/tmp/cores/%N.core.%P
Enabling Core Dumps in NGINX Configuration
Skip these steps if you have already configured creation of a core dump file in your operating system.
To enable core dumps in NGINX configuration file:
-
Open the NGINX configuration file:
$ sudo vi /usr/local/etc/nginx/nginx.conf -
Define a directory that will keep core dump files with the working_directory directive. The directive is specified on the main configuration level:
working_directory /tmp/cores/; -
Make sure the directory exists and is writable by NGINX worker process. Open terminal and run the commands:
$ sudo chown root:root /tmp/cores $ sudo chmod 1777 /tmp/cores -
Specify the maximum possible size of the core dump file with the worker_rlimit_core directive. The directive is also specified on the
mainconfiguration level. If the core dump file size exceeds the value, the core dump file will not be created.
Example:
worker_processes auto;
error_log /var/log/nginx/error.log debug;
working_directory /tmp/cores/;
worker_rlimit_core 500M;
events {
...
}
http {
...
}
With these settings, a core dump file will be created in the “/tmp/cores/” directory, and only if its size does not exceed 500 megabytes.
Obtaining Backtrace From a Core Dump File
Backtraces provide information from a core dump file about what was wrong when a program crashed.
To get a backtrace from a core dump file:
-
Open a core dump file with the GDB debugger using the pattern:
$ sudo gdb <nginx_executable_path> <coredump_file_path> -
Type-in the “backtrace command to get a stack trace from the time of the crash:
If the “backtrace” command resulted with the “No symbol table info available” message, you will need to recompile NGINX binary to include debugging symbols. See NGINX and Debugging Symbols.
Dumping NGINX Configuration From a Running Process
You can extract the current NGINX configuration from the master process in memory. This can be useful when you need to:
- verify which configuration has been loaded
- restore a previous configuration if the version on disk has been accidentally removed or overwritten
The configuration dump can be obtained with a GDB script provided that your NGINX has the debug support.
-
Make sure your NGINX is built with the debug support (the
--with-debugconfigure option in the list of the configure arguments). Run the command and check if the output contains the--with-debugline:$ nginx -V 2>&1 | grep -- '--with-debug' -
Obtain the PID of NGINX worker process:
-
Launch the GDB debugger:
$ sudo gdb -p <nginx PID obtained at the previous step> -
Copy and paste the script to GDB and press “Enter”. The script will save the configuration in the nginx_conf.txt file in the current directory:
set $cd = ngx_cycle->config_dump set $nelts = $cd.nelts set $elts = (ngx_conf_dump_t*)($cd.elts) while ($nelts-- > 0) set $name = $elts[$nelts]->name.data printf "Dumping %s to nginx_conf.txtn", $name append memory nginx_conf.txt $elts[$nelts]->buffer.start $elts[$nelts]->buffer.end end -
Quit GDB by pressing CTRL+D.
-
Open the file nginx_conf.txt located in the current directory:
Asking for help
When asking for help with debugging, please provide the following information:
-
NGINX version, compiler version, and configure parameters. Run the command:
-
Current full NGINX configuration. See Dumping NGINX Configuration From a Running Process
-
The debugging log. See Enabling Debug Logging in NGINX Configuration
-
The obtained backtrace. See Enabling Core Dumps, Obtaining Backtrace
By default, Nginx logs only standard errors to default Nginx error log file or a file specified by error_log directive in site-specific server configuration.
We can control many aspects about error logging which will help us debug our Nginx configuration.
Important: After any change to any Nginx configuration file, you must test and reload Nginx configuration for changes to take effect. On Ubuntu, you can simply run nginx -t && service nginx reload command.
Before we proceed…
I believe, we never break something that we never code! So before you copy-paste any Nginx config, make sure you remove unwanted codes. Also, every time you upgrade Nginx, update your config files also to use latest Nginx offering.
And before we proceed, please read these official articles: common Nginx Pitfalls, if-is-evil, location-directive & Nginx’s request processing. You might end up fixing your problem using them alone.
Alright… looks like you need some serious debugging… Lets go ahead!
Debug only rewrite rules
Most of the time, you will be needing this only. Specially when you are seeing 404 or unexpected pages.
server {
#other config
error_log /var/logs/nginx/example.com.error.log;
rewrite_log on;
#other config
}
rewrite_log is simply a flag. When turned on, it will send rewrite related log messages insideerror_log file with [notice] level.
So once you turn it on, start looking for log messages in error_log file.
Set Nginx log-level to debug
Following example adds debug log-level which logs most to specified path:
server {
#other config
error_log /var/logs/nginx/example.com.error.log debug;
#other config
}
debug will log maximum messages. You can find other possible values here.
Note: Do NOT forget to revert debug-level for error_log on a *very* high traffic site. error_log may end up eating all your available disk space and cause your server to crash!
Set Nginx to log errors from your IP only
When you will set log-level to debug, your error log will log so many messages for every request that it will become meaningless if you are debugging a high-traffic site on a live-server.
To force Nginx to log errors from only your IP, add the following line to events{..} block inside /etc/nginx/nginx.conf
Make sure you replace 1.2.3.4 with your own public IP. You can find your public IP here.
events {
debug_connection 1.2.3.4;
}
You can find more details on this here.
Nginx Location Specific Error logs
In Nginx, we use location{..} block all over.
To debug parts of an application, you can specify error_log directive inside one or more location{..} block.
server {
#other config
error_log /var/logs/nginx/example.com.error.log;
location /admin/ {
error_log /var/logs/nginx/admin-error.log debug;
}
#other config
}
Above will debug only /admin/ part of you application and error logs will be recorded to a different file.
You can combine location-specific error_log with debug_connection to gain more control over debug logs.
Debug using Nginx’s HttpEchoModule
HttpEchoModule is a separate Nginx module which can help you debug in altogether different way. This module doesn’t come bundled with Nginx.
You need to recompile Nginx to use this. For Ubuntu users, there is a launchpad repo.
I recently came across this and I am yet to use it for debugging on a project. When I will do it, I will post details about it.
Using Perl/Lua Language for Nginx config
If you are still having a tough time and you config Nginx regularly, should consider using other languages for Nginx configuration.
There is a Nginx module for Perl language and one for Lua language.
As I am very bad at learning new languages, chances are less that I will ever write more on this. But it might be fun if you already know or can easily learn Perl/Lua.
More…
- How Nginx’s location-if works!
- Maintaining, Optimizing & Debugging WordPress-Nginx Setup
Содержание
- Отладочный лог
- Отладочный лог для определённых клиентов
- Запись в кольцевой буфер в памяти
- Debugging NGINX
- Introduction
- Configuring NGINX Binary For Debugging
- Configuring NGINX Plus Binary
- Compiling NGINX Open Source Binary
- NGINX and Debugging Symbols
- Enabling Debug Logging in NGINX Configuration
- Writing the Debugging Log to a File
- Writing the Debugging Log to Memory
- Extracting Debug Log From Memory
- Debug Log for Selected IPs
- Debug Log for Each Virtual Host
- Enabling Core Dumps
- Enabling Core Dumps in the Operating System
- Enabling Core Dumps in NGINX Configuration
- Obtaining Backtrace From a Core Dump File
- Dumping NGINX Configuration From a Running Process
- Asking for help
- Основная функциональность
- Пример конфигурации
- Директивы

Отладочный лог
Для работы отладочного лога nginx должен быть сконфигурирован с поддержкой отладки на этапе сборки:
Затем нужно задать уровень debug с помощью директивы error_log:
Чтобы убедиться, что поддержка отладки сконфигурирована, необходимо выполнить команду nginx -V :
Готовые пакеты для Linux по умолчанию предоставляют поддержку отладочного лога при помощи бинарного файла nginx-debug (1.9.8), который можно запустить при помощи команд
и затем задать уровень debug . Бинарная версия nginx для Windows всегда собирается с поддержкой отладочного лога, поэтому понадобится лишь задать уровень debug .
Обратите внимание, что переопределение лога без одновременного указания уровня debug отключит отладочный лог. В примере ниже, переопределение лога на уровне server отключает отладочный лог для этого сервера:
Чтобы избежать этого, следует либо закомментировать строку, переопределяющую лог, либо добавить определение уровня debug :
Отладочный лог для определённых клиентов
Можно включить отладочный лог только для определённых клиентских адресов:
Запись в кольцевой буфер в памяти
Отладочный лог можно записывать в кольцевой буфер в памяти:
Запись в буфер в памяти на уровне debug не оказывает существенного влияния на производительность даже при высоких нагрузках. В этом случае лог может быть извлечён при помощи gdb -скрипта, подобного следующему:
Источник
Debugging NGINX
Troubleshoot problems and track down bugs in an NGINX or NGINX Plus deployment, with the debugging binary, debug logging, and core dumps.
Introduction
Debugging helps to identify a bug in the program code if something goes wrong. It is generally used in developing or testing third-party or experimental modules.
NGINX debugging features include the debugging log and creation of a core dump file with its further backtrace.
Configuring NGINX Binary For Debugging
First, you will need to enable debugging in NGINX binary. NGINX Plus already provides you with nginx-debug binary while NGINX Open Source requires recompilation.
Configuring NGINX Plus Binary
Starting from Release 8, NGINX Plus ships the nginx-debug binary together with the standard binary. To enable debugging in NGINX Plus, you will need to switch from nginx to nginx-debug binary. Open terminal and run the command:
When finished, enable the debugging log in the configuration file.
Compiling NGINX Open Source Binary
To enable debugging in NGINX Open Source, you will need to recompile it with the —with-debug flag specified in the configure script.
To compile NGINX Open Source with the debug support:
Download and unpack NGINX source files, go to the directory with the source files. See Downloading the Sources.
Get the list of NGINX configure arguments. Run the command:
Add the —with-debug option to the list of configure commands and run the configure script:
Compile and install NGINX:
NGINX and Debugging Symbols
Debug symbols helps obtain additional information for debugging, such as functions, variables, data structures, source file and line number information.
NGINX by default is compiled with the “-g” flag that includes debug symbols.
However, if you get the “No symbol table info available” error when you run a backtrace, then debugging symbols are missing and you will need to recompile NGINX with support of debugging symbols.
The exact set of compiler flags depends on the compiler. For example, for the GCC compiler system:
include debugging symbols with the “-g” flag
make the debugger output easier to understand by disabling compiler optimization with the “-O0” flag:
Enabling Debug Logging in NGINX Configuration
The debugging log records errors and any debugging-related information and is disabled by default. To enable it, make sure NGINX is compiled to support debugging (see Configuring NGINX Binary For Debugging) and then enable it in NGINX configuration file with the debug parameter of the error_log directive. The debugging log may be written to a file, an allocated buffer in memory, stderr output, or to syslog.
It is recommended enabling the debugging log on the ”main“ level of NGINX configuration to get the full picture of what’s going on.
Writing the Debugging Log to a File
Writing the debugging log to a file may slow down performance under high load. Also note that the file can grow very large and quickly eat up disk space. To reduce the negative impact, you can configure the debugging log to be written into a memory buffer, or set the debugging log for particular IP addresses. See Writing the Debugging Log to Memory and Debug Log for Selected IPs for details.
To enable writing the debugging log to a file:
Make sure your NGINX is configured with the —with-debug configuration option. Run the command and check if the output contains the —with-debug line:
Open NGINX configuration file:
Find the error_log directive which is by default located in the main context, and change the logging level to debug . If necessary, change the path to the log file:
Save the configuration and exit the configuration file.
Writing the Debugging Log to Memory
The debugging log can be written to a memory using a cyclic buffer. The advantage is that logging on the debug level will not have significant impact on performance under high load.
To enable writing the debug log to memory:
Make sure your NGINX is configured with the —with-debug configuration option. Run the command and check if the output contains the —with-debug line:
In NGINX configuration file, enable a memory buffer for debug logging with the error_log directive specified in the main context:
The log can be extracted from the memory buffer using a script executed in the GDB debugger.
To extract the debugging log from memory:
Obtain the PID of NGINX worker process:
Launch the GDB debugger:
Copy the script, paste it to GDB and press “Enter”. The script will save the log in the debug_log.txt file located in the current directory:
Quit GDB by pressing CTRL+D.
Open the file “debug_log.txt” located in the current directory:
Debug Log for Selected IPs
It is possible to enable the debugging log for a particular IP address or a range of IP addresses. Logging particular IPs may useful in a production environment as it will not negatively affect performance. The IP address is specified in the debug_connection directive within the events block; the directive can be defined more than once:
Debug Log for Each Virtual Host
Generally, the error_log directive is specified in the main context and thus is applied to all other contexts including server and location. But if there is another error_log directive specified inside a particular server or a location block, the global settings will be overridden and such error_log directive will set its own path to the log file and the level of logging.
To set up the debugging log for a particular virtual host, add the error_log directive inside a particular server block, in which set a new path to the log file and the debug logging level:
To disable the debugging log per a particular virtual host, specify the error_log directive inside a particular server block, and specify a path to the log file only:
Enabling Core Dumps
A core dump file helps identify and fix a problem that lead to NGINX crash. Note that a core dump file may contain sensitive information such as passwords and private keys, so ensure that they are treated in a secure manner.
Core dumps can be enabled in two different ways:
- in the operating system
- in the NGINX configuration file
Enabling Core Dumps in the Operating System
Perform the following steps in your operating system:
Specify a working directory in which a core dump file will be saved, for example, “/tmp/cores”:
Make sure the directory is writable by NGINX worker process:
Disable the limit for the maximum size of a core dump file:
If the operation ends up with “Cannot modify limit: operation not permitted”, run the command:
Enable core dumps for the setuid and setgid processes.
For CentOS 7.0, Debian 8.2, Ubuntu 14.04, run the commands:
For FreeBSD, run the commands:
Enabling Core Dumps in NGINX Configuration
Skip these steps if you have already configured creation of a core dump file in your operating system.
To enable core dumps in NGINX configuration file:
Open the NGINX configuration file:
Define a directory that will keep core dump files with the working_directory directive. The directive is specified on the main configuration level:
Make sure the directory exists and is writable by NGINX worker process. Open terminal and run the commands:
Specify the maximum possible size of the core dump file with the worker_rlimit_core directive. The directive is also specified on the main configuration level. If the core dump file size exceeds the value, the core dump file will not be created.
With these settings, a core dump file will be created in the “/tmp/cores/” directory, and only if its size does not exceed 500 megabytes.
Obtaining Backtrace From a Core Dump File
Backtraces provide information from a core dump file about what was wrong when a program crashed.
To get a backtrace from a core dump file:
Open a core dump file with the GDB debugger using the pattern:
Type-in the “backtrace command to get a stack trace from the time of the crash:
If the “backtrace” command resulted with the “No symbol table info available” message, you will need to recompile NGINX binary to include debugging symbols. See NGINX and Debugging Symbols.
Dumping NGINX Configuration From a Running Process
You can extract the current NGINX configuration from the master process in memory. This can be useful when you need to:
- verify which configuration has been loaded
- restore a previous configuration if the version on disk has been accidentally removed or overwritten
The configuration dump can be obtained with a GDB script provided that your NGINX has the debug support.
Make sure your NGINX is built with the debug support (the —with-debug configure option in the list of the configure arguments). Run the command and check if the output contains the —with-debug line:
Obtain the PID of NGINX worker process:
Launch the GDB debugger:
Copy and paste the script to GDB and press “Enter”. The script will save the configuration in the nginx_conf.txt file in the current directory:
Quit GDB by pressing CTRL+D.
Open the file nginx_conf.txt located in the current directory:
Asking for help
When asking for help with debugging, please provide the following information:
NGINX version, compiler version, and configure parameters. Run the command:
Источник
Основная функциональность
Пример конфигурации
Директивы
| Синтаксис: | accept_mutex on | off ; |
|---|---|
| Умолчание: | |
| Контекст: | events |
Если accept_mutex включён, рабочие процессы будут принимать новые соединения по очереди. В противном случае о новых соединениях будет сообщаться сразу всем рабочим процессам, и при низкой интенсивности поступления новых соединений часть рабочих процессов может работать вхолостую.
Нет необходимости включать accept_mutex на системах, поддерживающих флаг EPOLLEXCLUSIVE (1.11.3), или при использовании reuseport.
До версии 1.11.3 по умолчанию использовалось значение on .
| Синтаксис: | accept_mutex_delay время ; |
|---|---|
| Умолчание: | |
| Контекст: | events |
При включённом accept_mutex задаёт максимальное время, в течение которого рабочий процесс вновь попытается начать принимать новые соединения, если в настоящий момент новые соединения принимает другой рабочий процесс.
| Синтаксис: | daemon on | off ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Определяет, будет ли nginx запускаться в режиме демона. Используется в основном для разработки.
| Синтаксис: | debug_connection адрес | CIDR | unix: ; |
|---|---|
| Умолчание: | — |
| Контекст: | events |
Включает отладочный лог для отдельных клиентских соединений. Для остальных соединений используется уровень лога, заданный директивой error_log. Отлаживаемые соединения задаются IPv4 или IPv6 (1.3.0, 1.2.1) адресом или сетью. Соединение может быть также задано при помощи имени хоста. Отладочный лог для соединений через UNIX-сокеты (1.3.0, 1.2.1) включается параметром “ unix: ”.
Для работы директивы необходимо сконфигурировать nginx с параметром —with-debug , см. “Отладочный лог”.
| Синтаксис: | debug_points abort | stop ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Эта директива используется для отладки.
В случае обнаружения внутренней ошибки, например, утечки сокетов в момент перезапуска рабочих процессов, включение debug_points приводит к созданию core-файла ( abort ) или остановке процесса ( stop ) с целью последующей диагностики с помощью системного отладчика.
| Синтаксис: | env переменная [= значение ]; |
|---|---|
| Умолчание: | |
| Контекст: | main |
По умолчанию nginx удаляет все переменные окружения, унаследованные от своего родительского процесса, кроме переменной TZ. Эта директива позволяет сохранить часть унаследованных переменных, поменять им значения или же создать новые переменные окружения. Эти переменные затем:
- наследуются во время обновления исполняемого файла на лету;
- используются модулем ngx_http_perl_module;
- используются рабочими процессами. Следует иметь в виду, что управление поведением системных библиотек подобным образом возможно не всегда, поскольку зачастую библиотеки используют переменные только во время инициализации, то есть ещё до того, как их можно задать с помощью данной директивы. Исключением из этого является упомянутое выше обновление исполняемого файла на лету.
Если переменная TZ не описана явно, то она всегда наследуется и всегда доступна модулю ngx_http_perl_module.
Переменная окружения NGINX используется для внутренних целей nginx и не должна устанавливаться непосредственно самим пользователем.
| Синтаксис: | error_log файл [ уровень ]; |
|---|---|
| Умолчание: | |
| Контекст: | main , http , mail , stream , server , location |
Конфигурирует запись в лог. На одном уровне конфигурации может использоваться несколько логов (1.5.2). Если на уровне конфигурации main запись лога в файл явно не задана, то используется файл по умолчанию.
Первый параметр задаёт файл , который будет хранить лог. Специальное значение stderr выбирает стандартный файл ошибок. Запись в syslog настраивается указанием префикса “ syslog: ”. Запись в кольцевой буфер в памяти настраивается указанием префикса “ memory: ” и размера буфера и как правило используется для отладки (1.7.11).
Второй параметр определяет уровень лога и может принимать одно из следующих значений: debug , info , notice , warn , error , crit , alert или emerg . Уровни лога, указанные выше, перечислены в порядке возрастания важности. При установке определённого уровня в лог попадают все сообщения указанного уровня и уровней большей важности. Например, при стандартном уровне error в лог попадают сообщения уровней error , crit , alert и emerg . Если этот параметр не задан, используется error .
Для работы уровня лога debug необходимо сконфигурировать nginx с —with-debug , см. “Отладочный лог”.
Директива может быть указана на уровне stream начиная с версии 1.7.11 и на уровне mail начиная с версии 1.9.0.
| Синтаксис: | events < . > |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Предоставляет контекст конфигурационного файла, в котором указываются директивы, влияющие на обработку соединений.
| Синтаксис: | include файл | маска ; |
|---|---|
| Умолчание: | — |
| Контекст: | любой |
Включает в конфигурацию другой файл или файлы, подходящие под заданную маску. Включаемые файлы должны содержать синтаксически верные директивы и блоки.
| Синтаксис: | load_module файл ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Эта директива появилась в версии 1.9.11.
Загружает динамический модуль.
| Синтаксис: | lock_file файл ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Для реализации accept_mutex и сериализации доступа к разделяемой памяти nginx использует механизм блокировок. На большинстве систем блокировки реализованы с помощью атомарных операций, и эта директива игнорируется. Для остальных систем применяется механизм файлов блокировок. Эта директива задаёт префикс имён файлов блокировок.
| Синтаксис: | master_process on | off ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Определяет, будут ли запускаться рабочие процессы. Эта директива предназначена для разработчиков nginx.
| Синтаксис: | multi_accept on | off ; |
|---|---|
| Умолчание: | |
| Контекст: | events |
Если multi_accept выключен, рабочий процесс за один раз будет принимать только одно новое соединение. В противном случае рабочий процесс за один раз будет принимать сразу все новые соединения.
Директива игнорируется в случае использования метода обработки соединений kqueue, т.к. данный метод сам сообщает число новых соединений, ожидающих приёма.
| Синтаксис: | pcre_jit on | off ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Эта директива появилась в версии 1.1.12.
Разрешает или запрещает использование JIT-компиляции (PCRE JIT) для регулярных выражений, известных на момент парсинга конфигурации.
Использование PCRE JIT способно существенно ускорить обработку регулярных выражений.
Для работы JIT необходима библиотека PCRE версии 8.20 или выше, собранная с параметром конфигурации —enable-jit . При сборке библиотеки PCRE вместе с nginx ( —with-pcre= ), для включения поддержки JIT необходимо использовать параметр конфигурации —with-pcre-jit .
| Синтаксис: | pid файл ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Задаёт файл , в котором будет храниться номер (PID) главного процесса.
| Синтаксис: | ssl_engine устройство ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Задаёт название аппаратного SSL-акселератора.
| Синтаксис: | thread_pool имя threads = число [ max_queue = число ]; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Эта директива появилась в версии 1.7.11.
Задаёт имя и параметры пула потоков, используемого для многопоточной обработки операций чтения и отправки файлов без блокирования рабочего процесса.
Параметр threads задаёт число потоков в пуле.
Если все потоки из пула заняты выполнением заданий, новое задание будет ожидать своего выполнения в очереди. Параметр max_queue ограничивает число заданий, ожидающих своего выполнения в очереди. По умолчанию в очереди может находиться до 65536 заданий. При переполнении очереди задание завершается с ошибкой.
| Синтаксис: | timer_resolution интервал ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Уменьшает разрешение таймеров времени в рабочих процессах, за счёт чего уменьшается число системных вызовов gettimeofday() . По умолчанию gettimeofday() вызывается после каждой операции получения событий из ядра. При уменьшении разрешения gettimeofday() вызывается только один раз за указанный интервал .
Внутренняя реализация интервала зависит от используемого метода:
- фильтр EVFILT_TIMER при использовании kqueue ;
- timer_create() при использовании eventport ;
- и setitimer() во всех остальных случаях.
| Синтаксис: | use метод ; |
|---|---|
| Умолчание: | — |
| Контекст: | events |
Задаёт метод , используемый для обработки соединений. Обычно нет необходимости задавать его явно, поскольку по умолчанию nginx сам выбирает наиболее эффективный метод.
| Синтаксис: | user пользователь [ группа ]; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Задаёт пользователя и группу, с правами которого будут работать рабочие процессы. Если группа не задана, то используется группа, имя которой совпадает с именем пользователя.
| Синтаксис: | worker_aio_requests число ; |
|---|---|
| Умолчание: | |
| Контекст: | events |
Эта директива появилась в версиях 1.1.4 и 1.0.7.
При использовании aio совместно с методом обработки соединений epoll, задаёт максимальное число ожидающих обработки операций асинхронного ввода-вывода для одного рабочего процесса.
| Синтаксис: | worker_connections число ; |
|---|---|
| Умолчание: | |
| Контекст: | events |
Задаёт максимальное число соединений, которые одновременно может открыть рабочий процесс.
Следует иметь в виду, что в это число входят все соединения (в том числе, например, соединения с проксируемыми серверами), а не только соединения с клиентами. Стоит также учитывать, что фактическое число одновременных соединений не может превышать действующего ограничения на максимальное число открытых файлов, которое можно изменить с помощью worker_rlimit_nofile.
| Синтаксис: | worker_cpu_affinity маска_CPU . ; worker_cpu_affinity auto [ маска_CPU ]; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Привязывает рабочие процессы к группам процессоров. Каждая группа процессоров задаётся битовой маской разрешённых к использованию процессоров. Для каждого рабочего процесса должна быть задана отдельная группа. По умолчанию рабочие процессы не привязаны к конкретным процессорам.
привязывает каждый рабочий процесс к отдельному процессору, тогда как
привязывает первый рабочий процесс к CPU0/CPU2, а второй — к CPU1/CPU3. Второй пример пригоден для hyper-threading.
Специальное значение auto (1.9.10) позволяет автоматически привязать рабочие процессы к доступным процессорам:
С помощью необязательной маски можно ограничить процессоры, доступные для автоматической привязки:
Директива доступна только на FreeBSD и Linux.
| Синтаксис: | worker_priority число ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Задаёт приоритет планирования рабочих процессов подобно тому, как это делается командой nice : отрицательное число означает более высокий приоритет. Диапазон возможных значений, как правило, варьируется от -20 до 20.
| Синтаксис: | worker_processes число | auto ; |
|---|---|
| Умолчание: | |
| Контекст: | main |
Задаёт число рабочих процессов.
Оптимальное значение зависит от множества факторов, включая (но не ограничиваясь ими) число процессорных ядер, число жёстких дисков с данными и картину нагрузок. Если затрудняетесь в выборе правильного значения, можно начать с установки его равным числу процессорных ядер (значение “ auto ” пытается определить его автоматически).
Параметр auto поддерживается только начиная с версий 1.3.8 и 1.2.5.
| Синтаксис: | worker_rlimit_core размер ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Изменяет ограничение на наибольший размер core-файла ( RLIMIT_CORE ) для рабочих процессов. Используется для увеличения ограничения без перезапуска главного процесса.
| Синтаксис: | worker_rlimit_nofile число ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Изменяет ограничение на максимальное число открытых файлов ( RLIMIT_NOFILE ) для рабочих процессов. Используется для увеличения ограничения без перезапуска главного процесса.
| Синтаксис: | worker_shutdown_timeout время ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Эта директива появилась в версии 1.11.11.
Задаёт таймаут в секундах для плавного завершения рабочих процессов. По истечении указанного времени nginx попытается закрыть все открытые соединения для ускорения завершения.
| Синтаксис: | working_directory каталог ; |
|---|---|
| Умолчание: | — |
| Контекст: | main |
Задаёт каталог, который будет текущим для рабочего процесса. Основное применение — запись core-файла, в этом случае рабочий процесс должен иметь права на запись в этот каталог.
Источник
Introduction
NGINX has wide range of debugging features, including detailed debug log.
Note
Most debugging nits are only activated when NGINX compiled with —with-debug configure argument.
Debugging log
See a debugging log in documentation for details.
To activate debugging log you have to compile NGINX with —with-debug configure option and set debug level in error_log directive.
It’s possible to debug only connections from specified addresses via debug_connection directive.
Note
In hard cases (e.g. debugging event method related problems) it’s good idea to obtain full debugging log by setting debug level in global error_log.
Core dump
To obtain core dump you usually have to tune your OS. Though NGINX simplifies some typical cases and usually adding
worker_rlimit_core 500M; working_directory /path/to/cores/;
to nginx.conf is enough. Then run gdb to obtain backtrace as usual, e.g.
gdb /path/to/nginx /path/to/cores/nginx.core backtrace full
If your gdb backtrace warns that No symbol table info available. then you will need to recompile NGINX with the appropriate compiler flags for debugging symbols.
The exact flags required depend on the compiler used. If you use GCC, the flag -g enables the inclusion of debugging symbols.
Additionally disabling compiler optimization using -O0 will make the debugger output easier to understand.
CFLAGS="-g -O0" ./configure ....
Socket leaks
Sometimes socket leaks happen.
This usually results in [alert] 15248#0: open socket #123 left in connection 456 messages in error log on NGINX reload/restart/shutdown.
To debug add
to nginx.conf and configure core dumps (see above).
This will result in abort() call once NGINX detects leak and core dump.
Something like this in gdb should be usefull (assuming 456 is connection number from error message from the process which dumped core):
set $c = &ngx_cycle->connections[456] p $c->log->connection p *$c set $r = (ngx_http_request_t *) $c->data p *$r
In particular, p $c->log->connection will print connection number as used in logs.
It will be possible to grep debug log for relevant lines, e.g.
fgrep ' *12345678 ' /path/to/error_log;
Asking for help
When asking for help with debugging please provide:
nginx -Voutput- full config
- debug log
- backtrace (if NGINX exits on signal)
Время прочтения
6 мин
Просмотры 21K
Является ли ошибкой ответ 5хх, если его никто не видит? [1]

Вне зависимости от того, как долго и тщательно программное обеспечение проверяется перед запуском, часть проблем проявляется только в рабочем окружении. Например, race condition от параллельного обслуживания большого количества клиентов или исключения при валидации непредвиденных данных от пользователя. В результате эти проблемы могут привести к 5хх ошибкам.
HTTP 5хх ответы зачастую возвращаются пользователям и могут нанести ущерб репутации компании даже за короткий промежуток времени. В то же время, отладить проблему на рабочем сервере зачастую очень непросто. Даже простое извлечение проблемной сессии из логов может превратиться в поиск иголки в стоге сена. И даже если будут собраны все необходимые логи со всех рабочих серверов — этого может быть недостаточно для понимания причин проблемы.
Для облегчения процесса поиска и отладки могут быть использованы некоторые полезные приёмы в случае, когда NGINX используется для проксирования или балансировки приложения. В этой статье будет рассмотрено особое использование директивы error_page в применении к типичной инфраструктуре приложения с проксированием через NGINX.
Сервер отладки
Сервер отладки (отладочный сервер, Debug Server) — специальный сервер, на который перенаправляются запросы, вызывающие ошибки на рабочих серверах. Это достигается использованием того преимущества, что NGINX может детектировать 5xx ошибки, возвращаемые из upstream и перенаправлять приводящие к ошибкам запросы из разных групп upstream на отладочный сервер. А так как отладочный сервер будет обрабатывать только запросы, приводящие к ошибкам, то в логах будет информация, относящаяся исключительно к ошибкам. Таким образом, проблема поиска иголок в стоге сена сводится к горстке иголок.
Так как отладочный сервер не обслуживает рабочие клиентские запросы, то нет нужды затачивать его на производительность. Вместо этого, на нём можно включить максимальное логирование и добавить инструменты диагностики на любой вкус. Например:
- Запуск приложения в режиме отладки
- Включение подробного логирования на сервере
- Добавление профилирования приложения
- Подсчет ресурсов использованных сервером
Инструменты отладки обычно отключаются для рабочих серверов, так как зачастую замедляют работу приложения. Однако, для отладочного сервера их можно безопасно включить. Ниже приведён пример инфраструктуры приложения с отладочным сервером.
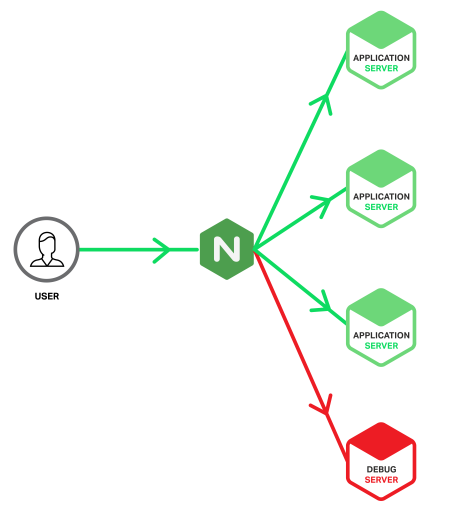
В идеальном мире, процесс конфигурирования и выделение ресурсов для отладочного сервера не должен отличаться от процесса настройки обычного рабочего сервера. Но если сделать сервер отладки в виде виртуальной машины, то в этом могут быть свои преимущества (например, клонирование и копирование для автономной аналитики). Однако, в таком случае, существует риск, что сервер может быть перегружен в случае возникновения серьёзной проблемы, которая вызовет внезапный всплеск ошибок 5xx. В NGINX Plus этого можно избежать с помощью параметра max_conns для ограничения количества параллельных соединений (ниже будет приведён пример конфигурации).
Так как сервер отладки загружен не так, как рабочий сервер, то не все ошибки 5xx могут воспроизводиться. В такой ситуации можно предположить, что вы достигли предела масштабирования приложения и исчерпали ресурсы, и никакой ошибки в самом приложении нет. Независимо от основной причины, использование отладочного сервера поможет улучшить взаимодействие с пользователем и предостеречь его от 5xx ошибок.
Конфигурация
Ниже приведен простой пример конфигурации сервера отладки для приема запросов, которые привели к 5xx ошибке на одном из основных серверов.
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
}
В блоке upstream app_server указаны адреса рабочих серверов. Далее указывается один адрес сервера отладки в upstream debug_server.
Первый блок location настраивает простое проксирование с помощью директивы proxy_pass для балансировки серверов приложения в upstream app_server (в примере не указан алгоритм балансировки, поэтому используется стандартный алгоритм Round Robin). Включенная директива proxy_intercept_errors означает, что любой ответ с HTTP статусом 300 или выше будет обрабатываться с помощью директивы error_page. В нашем примере перехватываются только 500, 503 и 504 ошибки и передаются на обработку в блок location @debug. Все остальные ответы, такие как 404, отсылаются пользователю без изменений.
В блоке @debug происходят два действия: во-первых, проксирование в группу upstream debug_server, которая, разумеется, содержит сервер отладки; во-вторых, запись access_log и error_log в отдельные файлы. Изолируя сообщения, сгенерированные ошибочными запросами на рабочие сервера, можно легко соотнести их с ошибками, которые сгенерируются на самом отладочном сервере.
Отметим, что директива access_log ссылается на отдельный формат логирования — detailed. Этот формат можно определить, указав в директиве log_format на уровне http следующие значения:
log_format detailed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_length $request_time '
'$upstream_response_length $upstream_response_time '
'$upstream_status';
Формат detailed расширяет формат по умолчанию combined добавлением пяти переменных, которые предоставляют дополнительную информацию о запросе к отладочному серверу и его ответе.
$request_length– полный размер запроса, включая заголовки и тело, в байтах$request_time– время обработки запроса, в миллисекундах$upstream_response_length– длинна ответа полученного от отладочного сервера, в байтах$upstream_response_time– время затраченное на получение ответа от отладочного сервера, в миллисекундах$upstream_status– код статуса ответа от отладочного сервера
Перечисленные выше дополнительные поля в логе очень полезны для детектирования некорректных запросов и запросов с большим временем выполнения. Последние могут указывать на неверные таймауты в приложении или другие межпроцессные коммуникационные проблемы.
Идемпотентность при переотправке запросов
Возможно, в некоторых случаях, хочется избежать перенаправления запросов на сервер отладки. Например, если в приложении произошла ошибка при попытке изменить несколько записей в базе данных, то новый запрос может повторить обращение к базе данных и внести изменения ещё раз. Это может привести к беспорядку в базе данных.
Поэтому безопасно переотправлять запрос можно только в случае, если он идемпотентный – то есть запрос, при повторных отправках которого, результат будет один и тот же. HTTP GET, PUT, и DELETE методы идемпотентны, в то время как POST – нет. Однако, стоит отметить, что идемпотентность HTTP методов может зависеть от реализации приложения и отличаться от формально определенных.
Есть три варианта как обрабатывать идемпотентность на отладочном сервере:
- Запустить отладочный сервер в режиме read-only для базы данных. В таком случае переотправка запросов безопасна, так как не вносит никаких изменений. Логирование запросов на отладочном сервере будет происходить без изменений, но меньше информации будет доступно для диагностики проблемы (из-за режима read-only).
- Переотправлять на отладочный сервер только идемпотентные запросы.
- Развернуть второй отладочный сервер в режиме read-only для базы данных и переотправлять на него неидемпотентные запросы, а идемпотентные продолжать отправлять на основной сервер отладки. В таком случае будут обрабатываться все запросы, но потребуется дополнительная настройка.
Для полноты картины, рассмотрим конфигурацию для третьего варианта:
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
upstream readonly_server {
server 172.16.0.10 max_conns=20;
}
map $request_method $debug_location {
'POST' @readonly;
'LOCK' @readonly;
'PATCH' @readonly;
default @debug;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 $debug_location;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
location @readonly {
proxy_pass http://readonly_server;
access_log /var/log/nginx/access_readonly_server.log detailed;
error_log /var/log/nginx/error_readonly_server.log;
}
}
Используя директиву map с переменной $request_method, в зависимости от идемпотентности метода, устанавливается значение новой переменной $debug_location. При срабатывании директивы error_page вычисляется переменная $debug_location, и определяется, на какой именно отладочный сервер будет переотправляться запрос.
Нередко для повторной отправки неудавшихся запросов на остальные сервера в upstream (перед отправкой на отладочный сервер) используется директива proxy_next_upstream. Хотя, как правило, это используется для ошибок на сетевом уровне, но возможно также расширение и для 5xx ошибок. Начиная с версии NGINX 1.9.13 неидемпотентные запросы, которые приводят к ошибкам 5xx, не переотправляются по умолчанию. Для включения такого поведения, нужно добавить параметр non_idempotent в директиве proxy_next_upstream. Такое же поведение реализовано в NGINX Plus начиная с версии R9 (апрель 2016г.).
location / {
proxy_pass http://app_server;
proxy_next_upstream http_500 http_503 http_504 non_idempotent;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
Заключение
Не стоит игнорировать ошибки 5хх. Если вы используете модель DevOps, экспериментируете с Continuous Delivery или просто желаете уменьшить риск при обновлениях — NGINX предоставляет инструменты, которые могут помочь лучше реагировать на возникающие проблемы.
NGINX is one of the most widely used reverse proxy servers, web servers, and load balancers. It has capabilities like TLS offloading, can do health checks for backends, and offers support for HTTP2, gRPC, WebSocket, and most TCP-based protocols.
When running a tool like NGINX, which generally sits in front of your applications, it’s important to understand how to debug issues. And because you need to see the logs, you have to understand the different NGINX logging mechanisms. In addition to the errors in your application or web server, you need to look into NGINX performance issues, as they can lead to SLA breaches, negative user experience, and more.
In this article, we’ll explore the types of logs that NGINX provides and how to properly configure them to make troubleshooting easier.
What Are NGINX Logs?
NGINX logs are the files that contain information related to the tasks performed by the NGINX server, such as who tried to access which resources and whether there were any errors or issues that occured.
NGINX provides two types of logs: access logs and error logs. Before we show you how to configure them, let’s look at the possible log types and different log levels.
Here is the most basic NGINX configuration:
http{
server {
listen 80;
server_name example.com www.example.com;
access_log /var/log/nginx/access.log combined;
root /var/www/virtual/big.server.com/htdocs;
}
}
For this server, we opened port 80. The server name is “example.com www.example.com.” You can see the access and error log configurations, as well as the root of the directive, which defines from where to serve the files.
What Are NGINX Access Logs?
NGINX access logs are files that have the information of all the resources that a client is accessing on the NGINX server, such as details about what is being accessed and how it responded to the requests, including client IP address, response status code, user agent, and more. All requests sent to NGINX are logged into NGINX logs just after the requests are processed.
Here are some important NGINX access log fields you should be aware of:
- remote_addr: The IP address of the client that requested the resource
- http_user_agent: The user agent in use that sent the request
- time_local: The local time zone of the server
- request: What resource was requested by the client (an API path or any file)
- status: The status code of the response
- body_bytes_sent: The size of the response in bytes
- request_time: The total time spent processing the request
- remote_user: Information about the user making the request
- http_referer: The IP address of the HTTP referer
- gzip_ratio: The compression ratio of gzip, if gzip is enabled
NGINX Access Log Location
You can find the access logs in the logs/access.log file and change their location by using the access_log directive in the NGINX configuration file.
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]]; access_log /var/log/nginx/access.log combined
By changing the path field in the access_log directive, you can also change where you want to save your access logs.
An NGINX access log configuration can be overridden by another configuration at a lower level. For example:
http {
access_log /var/log/nginx/access.log main;
server {
listen 8000;
location /health {
access_log off; # <----- this WILL work
proxy_pass http://app1server;
}
}
}
Here, any calls to /health will not be logged, as the access logs are disabled for this path. All the other calls will be logged to the access log. There is a global config, as well as different local configs. The same goes for the other configurations that are in the NGINX config files.
How to Enable NGINX Access Logs
Most of the time, NGINX access logs are enabled by default. To enable them manually, you can use the access_log directive as follows:
access_log /var/log/nginx/access.log combined
The first parameter is the location of the file, and the second is the log format. If you put the access_log directive in any of the server directories, it will start the access logging.
Setting Up NGINX Custom Log Format
To easily predefine the NGINX access log format and use it along with the access_log directive, use the log_format directive:
log_format upstream_time '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"'
'rt=$request_time uct="$upstream_connect_time" uht="$upstream_header_time" urt="$upstream_response_time"';
Most of the fields here are self explanatory, but if you want to learn more, look up NGINX configurations for logging. You can specify the log formats in an HTTP context in the /etc/nginx/nginx.conf file and then use them in a server context.
By default, NGINX access logs are written in a combined format, which looks something like this:
log_format combined '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';
Once you have defined the log formats, you can use them with the access_log directive, like in the following examples:
server {
access_log /var/log/nginx/access.log combined
access_log /var/log/nginx/access.log upstream_time #defined in the first format
…
}
Formatting the Logs as JSON
Logging to JSON is useful when you want to ship the NGINX logs, as JSON makes log parsing very easy. Since you have key-value information, it will be simpler for the consumer to understand. Otherwise, the parse has to understand the format NGINX is logging.
NGINX 1.11.8 comes with an escape=json setting, which helps you define the NGINX JSON log format. For example:
log_format json_combined escape=json
'{'
'"time_local":"$time_local",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"status": "$status",'
'"body_bytes_sent":"$body_bytes_sent",'
'"http_referrer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"request_time":"$request_time"'
'}';
You can now use this predefined log format in JSON with the access_log directive to get the logs in JSON.
You can also use an open-source NGINX module, like https://github.com/jiaz/nginx-http-json-log, to do the JSON logging.
Configuring NGINX Conditional Logging
Sometimes, you want to write logs only when a certain condition is met. NGINX calls this conditional logging. For example:
map $remote_addr $log_enable {
"192.168.4.1" 0;
"192.168.4.2" 0;
"192.168.4.3" 0;
"192.168.4.4" 0;
default 1;
}
access_log /var/log/nginx/access.log combined if=$log_enable
This means that whenever the request comes from the IPs 192.168.4.1 to 192.168.4.4, the access logs will not be populated. For every other IP, the logs will be recorded.
You can use conditional logging with NGINX in multiple scenarios. For example, if you are under attack and can identify the IPs of the attacker, you can log the requests to a different file. This allows you to process the file and get relevant information about the attack later.
How to View NGINX Access Logs
Linux utilities, like LESS or TAIL, allow you to view NGINX logs easily. You can also see the NGINX access logs’ location from the configuration files. With newer systems that are running systemd, the journalctl feature can tail the logs. To see the logs, use this command:
journalctl -fu nginx.service
You can also tail the log locations, as shown here:
tail -f /var/log/nginx/access.log
It’s also possible to use journalctl, but this will show all the logs together, which can be a bit confusing.
How to Disable Access Logs
To disable an NGINX access log, pass the off argument to the access_log directive:
access_log off;
This can be useful when there are too many logs, which can overload the disk IO and, in rare cases, impact the performance of your NGINX server. However, disabling NGINX access logs is not usually recommended, as it can make troubleshooting difficult.
What Are NGINX Error Logs?
NGINX error logs are the files where all information about errors will be logged, including permission errors or any NGINX configuration-related access errors. While access logs are used to see the HTTP requests received by the server, error logs bring more value, as when there is an issue, they will show exactly what happened and provide detailed information about the issue.
Whenever there is an error with the requests, or when there are NGINX glitches, these issues will be recorded in the error log files configured in the NGINX configuration file.
Where Are the NGINX Error Logs Stored?
The location of NGINX error logs can be configured in the error_log directive in the NGINX configuration. By default, these logs are in the /var/log/nginx directory. You can configure the location separately for different server components that you can run in the NGINX configuration.
The default location is:
/var/log/nginx/error.log
NGINX Error Logs Configuration
NGINX error logs configuration is in the same place as access_log. You can use the error_log directive to enable and configure the log levels and the location of the log file. Here is the configuration line to enable the error_log:
error_log log_file_location log_level;
NGINX Error Log Levels
NGINX has eight log levels for different degrees of severity and verbosity:
- emerg: These are the emergency logs. They mean that the system is unusable.
- alert: An immediate action is required.
- crit: A critical condition occurred.
- error: An error or failure occurred while processing a request.
- warn: There was an unexpected event, or something needs to be fixed, but NGINX fulfilled the request as expected.
- notice: Something normal, but important, has happened, and it needs to be noted.
- info: These are messages that give you information about the process.
- debug: These are messages that help with debugging and troubleshooting. They are generally not enabled unless needed because they create a lot of noise.
Note that the log_level parameter is a threshold, as every log level includes the previous log levels as well. For example, if your log level is 6 (notice), your logs will contain entries from levels 1 through 6.
Enable Debug Logging and Other Levels
You can specify the log level with the error_log directive using the log_level argument. As the log level number increases, the logs will contain more information. If the application misbehaves, you can enable the debug logs to aid you in the troubleshooting process. With the extra information they provide, you will be able to pinpoint the issue more easily. You can read about this more in the NGINX documentation.
Keeping NGINX debug logs enabled continuously is not recommended, as it will make logs very noisy and large by printing information that is generally unnecessary. If you see an issue, you can change the log level on the fly, solve the problem, then revert it back to a stricter severity.
Logging to Multiple Files
You can forward NGINX error logs to separate files based on the different log levels. In the configuration below, you send logs to all the specified log directives based on the log severity level.
error_log /var/log/nginx/error.info info; error_log /var/log/nginx/error.crit crit;
This configuration can be very useful when looking at the different log levels separately or if you want your logging agent to label these logs based on filenames. You can selectively discard the error logs based on their severity.
How to Check NGINX Error Logs
You can view NGINX error logs the same way as access logs: for example, by using TAIL, LESS, or other utilities. Below is an example of how to do it with TAIL using the location of the error_logs that you have set. These logs are also present in journalctl logs, but there, they will be a combination of access_log and error_logs.
tail -f /var/log/nginx/error.log
How to Disable Error Logs
Disabling NGINX error logs can be tricky, as there is no off option in error_log. Similar to access_log in the lower configuration levels, you can use error_log false at the higher level configurations.
error_log off;
For the lower levels, you can forward the logs to /dev/null:
error_log /dev/null;
How to Send NGINX Logs to Syslog
NGINX can also ship your logs to log aggregators using syslog. This can be useful when you are logging other system/service logs in syslog or using syslog to export the logs. You can implement this with the syslog: prefix, which can be used with both access_log and error_logs. You can also use this prefix instead of the file path in the access_log and error_log directives.
Syslog can help you concentrate your NGINX logs in one place by forwarding them to a centralized logging solution:
error_log syslog:unix/var/log/nginx.sock debug
You can also send the logs to different syslog servers by defining the syslog server parameter to point to the IP or hostname and port of the syslog server.
error_log syslog:server=192.168.100.1 debug access_log syslog:server=[127.0.0.1]:9992, facility=local1,tag=nginx,severity=debug;
In the above configuration for access_log, the logs are forwarded to the local syslog server, with the service name as local1, since syslog doesn’t have an option for NGINX.
Syslog has various options for keeping the forwarded logs segregated:
- Facility: Identifies who is logging to syslog.
- Severity: Specifies the log levels.
- Tag: Identifies the message sender or any other information that you want to send; default is NGINX.
NGINX Logging in Kubernetes Environments
In Kubernetes, NGINX Ingress runs as a pod. All the logs for the NGINX Ingress pods are sent to standard output and error logs. However, if you want to see the logs, you have to log in to the pod or use the kubectl commands, which is not a very practical solution.
You also have to find a way to ship the logs from the containers. You can do this with any logging agent that is running in the Kubernetes environment. These agents run as pods and mount the file system that NGINX runs on, reading the logs from there.
How to See the NGINX Ingress Logs
Use the kubectl logs command to see the NGINX logs as streams:
$ kubectl logs -f nginx-ingress-pod-name -n namespace.
It’s important to understand that pods can come and go, so the approach to debugging issues in the Kubernetes environment is a bit different than in VM or baremetal-based environments. In Kubernetes, the logging agent should be able to discover the NGINX Ingress pods, then scrape the logs from there. Also, the log aggregator should show the logs of the pods that were killed and discover any new pod that comes online.
NGINX Logging and Analysis with Sematext
NGINX log integration with Sematext
Sematext Logs is a log aggregation and management tool with great support for NGINX logs. Its auto-discovery feature is helpful, particularly when you have multiple machines. Simply create an account with Sematext, create the NGINX Logs App and install the Sematext Agent. Once you’re set up, you get pre-built, out-of-the-box dashboards and the option to build your own custom dashboards.
Sematext Logs is part of Sematext Cloud, a full-stack monitoring solution that gives you all you need when it comes to observability. By correlating NGINX logs and metrics, you’ll get a more holistic view of your infrastructure, which helps you identify and solve issues quickly.
Using anomaly-detection algorithms, Sematext Cloud informs you in advance of any potential issues. These insights into your infrastructure help you prevent issues and troubleshoot more efficiently. With Sematext Cloud, you can also collect logs and metrics from a wide variety of tools, including HAProxy, Apache Tomcat, JVM, and Kubernetes. By integrating with other components of your infrastructure, this tool is a one-stop solution for all your logging and monitoring needs.
If you’d like to learn more about Sematext Logs, and how they can help you manage your NGINX logs, then check out this short video below:
If you’re interested in how Sematext compares to other log management tools, read our review of the top NGINX log analyzers.
Conclusion
Managing, troubleshooting, and debugging large-scale NGINX infrastructures can be challenging, especially if you don’t have a proper way of looking into logs and metrics. It’s important to understand NGINX access and error logs, but if you have hundreds of machines, this will take a substantial amount of time. You need to be able to see the logs aggregated in one place.
Performance issues are also more common than you think. For example, you may not see anything in the error logs, but your APIs continue to degrade. To look into this properly, you need effective dashboarding around NGINX performance metrics, like response code and response time.
Sematext Logs can help you tackle these problems so you can troubleshoot more quickly. Sign up for our free trial today.
Author Bio

Gaurav Yadav
Gaurav has been involved with systems and infrastructure for almost 6 years now. He has expertise in designing underlying infrastructure and observability for large-scale software. He has worked on Docker, Kubernetes, Prometheus, Mesos, Marathon, Redis, Chef, and many more infrastructure tools. He is currently working on Kubernetes operators for running and monitoring stateful services on Kubernetes. He also likes to write about and guide people in DevOps and SRE space through his initiatives Learnsteps and Letusdevops.
(britespanbuildings)
При работе с веб-сервером Nginx одной из самых распространенных задач является проверка журналов отладки. Знание того, как включить и интерпретировать журналы отладки, очень полезно для устранения проблем с приложением или сервером, поскольку эти журналы предоставляют подробную информацию об отладке. В Nginx вы можете включить журналы отладки для изучения восходящего взаимодействия и внутреннего поведения.
Nginx отслеживает его событий в двух журналов: журналы ошибок и журналов доступа. Прежде чем двигаться дальше, давайте разберемся с базовой концепцией журналов ошибок и журналов отладки.
Содержание
- Что такое журналы ошибок в Nginx
- Что такое журналы доступа в Nginx
- Как включить журналы ошибок в Nginx
- Контекст error_log в Nginx
- Синтаксис error_log в Nginx:
- Как включить журнал доступа в Nginx
- Контекст access_log в Nginx
- Синтаксис access_log в Nginx
- Как просмотреть error_log в Nginx
- Как просмотреть access_log в Nginx
- Заключение
Что такое журналы ошибок в Nginx
Любые ошибки, с которыми сталкивается Nginx, такие как неожиданная остановка или возникновение проблем, связанных с восходящим соединением или временем соединения, записываются в журналы ошибок. Журналы ошибок записывают информацию, относящуюся к проблемам сервера и приложений.
Что такое журналы доступа в Nginx
Nginx регистрирует все клиентские запросы в журналах доступа вскоре после их обработки. Информация о доступном файле, браузере, который использует клиент, о том, как Nginx отреагировал на запрос, и IP-адресах клиентов можно найти в журналах доступа. Данные журналов доступа можно использовать для анализа трафика и отслеживания использования сайта с течением времени.
Этот пост покажет вам, как включить журналы ошибок и доступ к журналам для целей отладки в Nginx. Итак, начнем!
Как включить журналы ошибок в Nginx
Нажмите » CTRL + ALT + T «, чтобы открыть терминал. После этого выполните приведенную ниже команду, чтобы открыть файл конфигурации nginx, чтобы включить журнал ошибок в файле конфигурации Nginx:
$ sudo nano /etc/nginx/nginx.conf
Ваш файл конфигурации Nginx будет как-то выглядеть так:
В файл журнала ошибок Nginx записывает сообщения об общих сбоях сервера и проблемах, связанных с приложением. Если у вас есть проблемы, связанные с вашим веб-приложением, то в первую очередь можно найти решения в журнале ошибок. В Nginx директива error_log включает и настраивает местоположение журнала ошибок и уровень журнала.
Контекст error_log в Nginx
«Error_log директива» может быть добавлен в сервере {}, HTTP {}, местоположения {} блока.
Синтаксис error_log в Nginx:
error_log [log_file_path] [log_level]
Для настройки error_log необходимо добавить путь к файлу журнала и установить уровень журнала. Если вы не установите второй параметр, error_log примет значение » error » в качестве уровня журнала по умолчанию:
error_log /var/log/nginx/error.log;
Аргумент log_level определяет уровень ведения журнала. Вот список log_level, используемых директивой error_log :
- debug: уровень журнала » отладка » устанавливается для отладки сообщений.
- warn:» warn » устанавливается как log_level для уведомления о предупреждениях.
- info: этот log_level помогает журналу ошибок предоставлять информационные сообщения.
- error: Ошибки, возникающие в процессе обработкив виде запроса.
- alerts: предупреждения — это тип уведомления, для которого требуется немедленное действие.
- crit: он решает проблемы, которые необходимо решить.
- emerg: ситуация, требующая немедленных действий.
Директива error_log по умолчанию определена в блоке http {}. Однако вы также можете разместить его внутри блока location {} или server.
Теперь мы добавим приведенную ниже строку в наш серверный блок, чтобы включить журналы ошибок с » debug » log_level:
error_log /var/log/nginx/example.error.log debug;
Как включить журнал доступа в Nginx
Nginx добавляет новое событие в журнал доступа всякий раз, когда обрабатывается клиентский запрос. Эти журналы хранят местоположение посетителей, информацию о просматриваемой ими веб-странице и количество времени, проведенного на странице. Каждая запись события включает метку времени, а также различные сведения о ресурсах, запрошенных клиентом.
Директива формата журнала позволяет вам определять формат ваших регистрируемых сообщений. Директива access_log используется для включения местоположения файла журнала и его формата. По умолчанию журнал доступа включен в блоке http {}.
Контекст access_log в Nginx
» Access_log» директива может быть добавлена в сервере {}, {} HTTP, местоположения {} блока.
Синтаксис access_log в Nginx
access_log [log_file_path] [log_format]
Если вы не укажете » log_format «, тогда access_log включит » комбинированный » access_format по умолчанию. Однако вы можете настроить формат журнала следующим образом:
log_format main ‘$remote_addr — $remote_user [$time_local] «$request» ‘
‘$status $body_bytes_sent «$http_referer» ‘
‘»$http_user_agent» «$http_x_forwarded_for»‘;
После настройки формата журнала вы можете добавить следующую строку в блок http {} для включения журнала доступа:
access_log /var/log/nginx/access.log main;
Чтобы добавить access_log в блок server {}, следуйте синтаксису, приведенному ниже:
access_log /var/log/nginx/example.access.log main;
Вы можете отключить журнал доступа; если у вас загруженный веб-сайт или на вашем сервере мало ресурсов. Для этого вы должны установить «off» в качестве значения access_log:
После настройки error_log или access_log в конкретном блоке нажмите » CTRL + O «, чтобы сохранить добавленные строки:
Теперь в вашем терминале выполните команду » nginx » с параметром » -t «, чтобы проверить файл конфигурации Nginx и его контекст:
В конце концов, перезапустите службу Nginx, и все готово!
$ sudo systemctl restart nginx
Чтобы проверить, включены ли журналы и работают ли они, проверьте каталог журналов Nginx:
Из выходных данных вы можете увидеть, что в нашей системе включены журналы доступа и ошибок:
Как просмотреть error_log в Nginx
Вы можете использовать команду » cat » для извлечения содержимого error_log из файла » /var/log/nginx/error.log «:
$ sudo cat /var/log/nginx/error.log
Как просмотреть access_log в Nginx
Чтобы проверить содержимое access_log, выполните команду » cat » и укажите свой каталог access_log:
$ sudo cat /var/log/nginx/access.log
Заключение
Nginx включает настраиваемые параметры отладки, которые используются для сбора информации, которая помогает вам понять поведение вашего веб-сервера. Nginx предоставляет два файла для регистрации данных веб-сервера: error_logs и access_logs, где error_logs записывает неожиданные или информативные сообщения, а access_logs хранит информацию, относящуюся к запросам клиентов. В этом посте мы объяснили error_logs, access_logs и то, как вы можете включить error_logs и access_logs в Nginx.
NGINX logging is often overlooked as a critical part of the web service and is commonly referenced only when an error occurs. But it’s important to understand from the beginning how to configure NGINX logs and what information is considered most important.
Within NGINX there are two types of logs available, the error log and the access log. How then would you configure the error and access logs and in what format should be used? Read on to learn all about how NGINX logging works!
Prerequisites
To follow along with this tutorial, it is necessary to have a recent working NGINX installation, ideally version 1.21.1 or higher. In this tutorial, Ubuntu is used to host the NGINX installation. To view formatted JSON log file output in the terminal you may want to install the jq utility
Learning the NGINX Logging System
The NGINX logging system has quite a few moving parts. Logging is made up of log formats (how logs are stored) and an NGNIX configuration file (nginx.conf) to enable and tune how logs are generated.
First, let’s cover the NGINX configuration file. An NGNIX configuration file defines a hierarchy of sections that are referred to as contexts within the NGINX documentation. These contexts are made up of a combination of the following, although not all available contexts are listed below.
- The “main” context is the root of the nginx.conf file
- The
httpcontext - Multiple
servercontexts - Multiple
locationcontexts
Inside one or more of these contexts is where you can define access_log and error_log configuration items, or directives. A logging directive defines how NGINX is supposed to record logs under each context.
NGINX Logs Logging Directive Structure
Logging directives are defined under each context with the log name, the location to store the log, and the level of log data to store.
<log name> <log location> <logging level>;- Log Location – You can store logs in three different areas; a file e.g.
/var/log/nginx/error.log, syslog e.g.syslog:server=unix:/var/log/nginx.sockor cyclic memory buffer e.g.memory:32m. - Logging Levels – The available levels are
debug,info,notice,warn,error,crit,alert, oremergwith the default beingerror. Thedebuglevel may not be available unless NGINX was compiled with the--with-debugflag.
Allowed Logging Directive Contexts
Both the error_log and access_log directives are allowed in only certain contexts. error_log is allowed in the main, http, mail, stream, server, and location contexts. While the access_log directive is allowed in http, server, location, if in location, and limit_exept contexts.
Logging directives override higher-up directives. For example, the
error_logdirective specified in alocationcontext will override the same directive specified in thehttpcontext.
You can see an example configuration below that contains various defined directives below.
# Log to a file on disk with all errors of the level warn and higher
error_log /var/log/nginx/error.log warn;
http {
access_log /var/log/nginx/access.log combined;
server {
access_log /var/log/nginx/domain1.access.log combined;
location {
# Log to a local syslog server as a local7 facility, tagged as nginx, and with the level of notice and higher
error_log syslog:server=unix:/var/log/nginx.sock,facility=local7,tag=nginx notice;
}
}
server {
access_log /var/log/nginx/domain2.access.log combined;
location {
# Log all info and higher error messages directly into memory, but max out at 32 Mb
error_log memory:32m info;
}
}
}
Log Formats and the Access Log Directive
Beyond just NGINX error logs, each access request to NGINX is logged. An access request could be anything from requesting a web page to a specific image. As you might surmise, there is a lot of data that can be included in the logged requests.
To record general NGINX request activity, NGNIX relies on access logs using the access_log directive. Unlike the error_log directive which has a standard format, you can configure NGINX access logs to store in a particular format.
The Default access_log Log Format
NGNIX can record access log data in many different ways through log formats. By default, that log format is called combined. When you don’t specify a log format in the NGINX configuration file, NGNIX will log all requested according to the following schema.
'$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"'Below, you can see an example of the combined format in practice.
127.0.0.1 - - [10/Oct/2020:15:10:20 -0600] "HEAD / HTTP/1.1" 200 0 "<https://example.com>" "Mozilla/5.0..."Defining Custom access_log Formats via log_format Directive
The default combined NGINX log format may work perfectly well for your needs, but what if you would like to add additional data, such as upstream service information, or use this in JSON format instead? You’ll need to define a custom log format using the log_format directive.
The log_format directive allows you to define multiple different access_log formats to be used across the various contexts in the configuration file.
An example of defining a log format is below which specifies many different fields and variables. This example defines a JSON logging format, you may choose to display various fields.
Check out all available variables via the NGINX documentation.
The json text displayed after the log_format directive is merely the name that is referenced by any access_log directive that wishes to use this format. By using log_format, multiple logging output formats may be defined and used by any combination of access_log directives throughout the NGINX configuration file.
log_format json escape=json '{ "time": "$time_iso8601", '
'"remote_addr": "$remote_addr", '
'"remote_user": "$remote_user", '
'"ssl_protocol_cipher": "$ssl_protocol/$ssl_cipher", '
'"body_bytes_sent": "$body_bytes_sent", '
'"request_time": "$request_time", '
'"status": "$status", '
'"request": "$request", '
'"request_method": "$request_method", '
'"http_referrer": "$http_referer", '
'"http_x_forwarded_for": "$http_x_forwarded_for", '
'"http_cf_ray": "$http_cf_ray", '
'"host": "$host", '
'"server_name": "$server_name", '
'"upstream_address": "$upstream_addr", '
'"upstream_status": "$upstream_status", '
'"upstream_response_time": "$upstream_response_time", '
'"upstream_response_length": "$upstream_response_length", '
'"upstream_cache_status": "$upstream_cache_status", '
'"http_user_agent": "$http_user_agent" }';
The
log_formatmay only be used in thehttpcontext, but referenced by anyaccess_logdirective regardless of location.
Escaping Log Output
When you define log format via JSON, for example, you’ll sometimes need to escape variables defined in JSON to be treated as literal elements in the NGNIX configuration file. To do that, you can use various escape formats such as default, json, and none. If the escape command is omitted, the default format is used.
default– Double-quotes, “”, and all characters with ISO values less than 32 and greater than 126 will be escaped as “x##”. If no variable value is found, then a hyphen (-) will be logged.json– All disallowed characters in the JSON string format will be escaped.none– All escaping of values is disabled.
You’ll see a great example of NGNIX escaping all JSON variables in the example above using the json escape format (escape=json).
Configuring access_log Directives
For NGNIX to become recording access activity using the fancy log format you defined earlier, you must enable it using the access_log directive
Once you’ve defined the log format, you must enable the log inside of the NGINX configuration file much like the error_log directive.
An example of a typical access_log directive is shown below where it sends access logs in the json log_format, as previously defined, and to a file (/var/log/nginx/access.log). Then the special off parameter disables access logging in a specific context where the directive is included.
access_log /var/log/nginx/domain.access.log json;
access_log off;Perhaps you have defined an access_log for a domain. How would you go about seeing the output from the below directive?
access_log /var/log/nginx/domain.access.log json;To demonstrate NGINX sending log output as defined by the access_log directive, first run the Linux cat command to grab the file contents and pipe the output to the tail command to show only a single line. Then finally, pass the single line to the jq utility to nicely format the JSON output.
cat /var/log/nginx/domain.access.log | tail -n 1 | jqLike the
error_log, both thememoryandsyslogformats work in addition to the standard file output.
Configuring NGINX to Buffer Disk Writes
Since there is typically far more information output from access logging than error logging, additional abilities for compression and buffering of the log data to disk writes are included, but enabled by default. To avoid constant disk writes and potential request blocking of the webserver while waiting for disk IO, tell NGINX to buffer disk writes.
An example of an access_log directive defining the gzip, buffer, and flush parameters is shown below.
access_log /var/log/nginx/domain.access.log gzip=7 buffer=64k flush=3m;buffer– A buffer temporarily stores data, before sending it elsewhere. The default buffer size is64kwhich you can redefine by specifying a size along with the directive, i.e.buffer=32kinstead of justbuffer.gzip– Defines a level of GZIP compression to use from1to9, with 9 being the slowest but highest level of compression. For example,gzipdefaults to1but you will set (gzip=9) the compression to the highest.
If you use
gzipbut notbuffer, you’ll buffer the writes by default. Since the nature of GZIP compression means log entries cannot be streamed to disk, disk buffering is required.
flush– To avoid holding on to in-memory logs indefinitely for infrequently accessed sites, you’ll specify aflushtime to write any logging data to disk after that time threshold is met. For example, withflush=5myou force all logged data to be written to disk, even if the buffer has not filled.
Logging Access Entries Conditionally
There are times when you will only want to log a particular access request. For example, instead of logging all requests including HTTP/200 (successful requests), perhaps you’d like to only log HTTP/404 (file not found requests). If so, you can define a logging condition in the access_log directive using the if parameter.
The if= parameter of the access_log directive looks for values passed in by the associated variable that are not “0” or an empty string to continue with logging.
As an example, perhaps you’d like to force NGNIX to only log only HTTP access requests starting with a 4 for the HTTP code.
In the NGINX configuration file:
Define a map directive to assign a variable with the value of either 0 or 1 depending n the evaluated condition. The first regular expression looks for all HTTP statuses that do not start with 4. The default condition is the fallback for all values that do not meet that requirement.
map $status $logged {
~^[1235] 0;
default 1;
}The
mapdirective must be defined at thehttpcontext level. You may use themapdirective output variable, shown below as$logged, further in the configuration file and not confined to thehttpcontext level.
Once you have defined the map directive which will assign a value of 0 or 1 to the $logged variable, you can then use this variable in conditions as shown below. Here, using the if parameter, you’re telling NGINX to only log activity to the access_404.log file if it sees a request starting with 4.
access_log /var/log/nginx/access_404.log json if=$logged;Conclusion
Now that you know how to log errors and access requests in a variety of ways, you can start monitoring your NGINX installation for issues and also for user-facing problems.
What’s next? Try taking the results of the logs and ingesting those into a SIEM application for analysis!