Модуль ngx_http_proxy_module позволяет передавать
запросы другому серверу.
Пример конфигурации
location / {
proxy_pass http://localhost:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
Директивы
| Синтаксис: |
proxy_bind
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 0.8.22.
Задаёт локальный IP-адрес с необязательным портом (1.11.2),
который будет использоваться в исходящих соединениях с проксируемым сервером.
В значении параметра допустимо использование переменных (1.3.12).
Специальное значение off (1.3.12) отменяет действие
унаследованной с предыдущего уровня конфигурации
директивы proxy_bind, позволяя системе
самостоятельно выбирать локальный IP-адрес и порт.
Параметр transparent (1.11.0) позволяет
задать нелокальный IP-aдрес, который будет использоваться в
исходящих соединениях с проксируемым сервером,
например, реальный IP-адрес клиента:
proxy_bind $remote_addr transparent;
Для работы параметра
обычно требуется
запустить рабочие процессы nginx с привилегиями
суперпользователя.
В Linux этого не требуется (1.13.8), так как если
указан параметр transparent, то рабочие процессы
наследуют capability CAP_NET_RAW из главного процесса.
Также необходимо настроить таблицу маршрутизации ядра
для перехвата сетевого трафика с проксируемого сервера.
| Синтаксис: |
proxy_buffer_size
|
|---|---|
| Умолчание: |
proxy_buffer_size 4k|8k; |
| Контекст: |
http, server, location
|
Задаёт размер буфера, в который будет читаться
первая часть ответа, получаемого от проксируемого сервера.
В этой части ответа находится, как правило, небольшой заголовок ответа.
По умолчанию размер одного буфера равен размеру страницы памяти.
В зависимости от платформы это или 4K, или 8K,
однако его можно сделать меньше.
| Синтаксис: |
proxy_buffering
|
|---|---|
| Умолчание: |
proxy_buffering on; |
| Контекст: |
http, server, location
|
Разрешает или запрещает использовать буферизацию ответов проксируемого сервера.
Если буферизация включена, то nginx принимает ответ проксируемого сервера
как можно быстрее, сохраняя его в буферы, заданные директивами
proxy_buffer_size и proxy_buffers.
Если ответ не вмещается целиком в память, то его часть может быть записана
на диск во временный файл.
Запись во временные файлы контролируется директивами
proxy_max_temp_file_size и
proxy_temp_file_write_size.
Если буферизация выключена, то ответ синхронно передаётся клиенту сразу же
по мере его поступления.
nginx не пытается считать весь ответ проксируемого сервера.
Максимальный размер данных, который nginx может принять от сервера
за один раз, задаётся директивой proxy_buffer_size.
Буферизация может быть также включена или выключена путём передачи
значения “yes” или “no” в поле
“X-Accel-Buffering” заголовка ответа.
Эту возможность можно запретить с помощью директивы
proxy_ignore_headers.
| Синтаксис: |
proxy_buffers
|
|---|---|
| Умолчание: |
proxy_buffers 8 4k|8k; |
| Контекст: |
http, server, location
|
Задаёт число и размер буферов
для одного соединения,
в которые будет читаться ответ, получаемый от проксируемого сервера.
По умолчанию размер одного буфера равен размеру страницы.
В зависимости от платформы это или 4K, или 8K.
| Синтаксис: |
proxy_busy_buffers_size
|
|---|---|
| Умолчание: |
proxy_busy_buffers_size 8k|16k; |
| Контекст: |
http, server, location
|
При включённой буферизации ответов
проксируемого сервера, ограничивает суммарный размер
буферов, которые могут быть заняты для отправки ответа клиенту, пока
ответ ещё не прочитан целиком.
Оставшиеся буферы тем временем могут использоваться для чтения ответа
и, при необходимости, буферизации части ответа во временный файл.
По умолчанию размер ограничен величиной двух буферов, заданных
директивами proxy_buffer_size и proxy_buffers.
| Синтаксис: |
proxy_cache
|
|---|---|
| Умолчание: |
proxy_cache off; |
| Контекст: |
http, server, location
|
Задаёт зону разделяемой памяти, используемой для кэширования.
Одна и та же зона может использоваться в нескольких местах.
В значении параметра можно использовать переменные (1.7.9).
Параметр off запрещает кэширование, унаследованное
с предыдущего уровня конфигурации.
| Синтаксис: |
proxy_cache_background_update
|
|---|---|
| Умолчание: |
proxy_cache_background_update off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.11.10.
Позволяет запустить фоновый подзапрос
для обновления просроченного элемента кэша,
в то время как клиенту возвращается устаревший закэшированный ответ.
Использование устаревшего закэшированного ответа в момент его обновления
должно быть
разрешено.
| Синтаксис: |
proxy_cache_bypass
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Задаёт условия, при которых ответ не будет браться из кэша.
Если значение хотя бы одного из строковых параметров непустое и не равно “0”,
то ответ не берётся из кэша:
proxy_cache_bypass $cookie_nocache $arg_nocache$arg_comment; proxy_cache_bypass $http_pragma $http_authorization;
Можно использовать совместно с директивой proxy_no_cache.
| Синтаксис: |
proxy_cache_convert_head
|
|---|---|
| Умолчание: |
proxy_cache_convert_head on; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.9.7.
Разрешает или запрещает преобразование метода “HEAD”
в “GET” для кэширования.
Если преобразование выключено, то
необходимо, чтобы ключ кэширования
включал в себя $request_method.
| Синтаксис: |
proxy_cache_key
|
|---|---|
| Умолчание: |
proxy_cache_key $scheme$proxy_host$request_uri; |
| Контекст: |
http, server, location
|
Задаёт ключ для кэширования, например,
proxy_cache_key "$host$request_uri $cookie_user";
По умолчанию значение директивы близко к строке
proxy_cache_key $scheme$proxy_host$uri$is_args$args;
| Синтаксис: |
proxy_cache_lock
|
|---|---|
| Умолчание: |
proxy_cache_lock off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.1.12.
Если включено, одновременно только одному запросу будет позволено
заполнить новый элемент кэша, идентифицируемый согласно директиве
proxy_cache_key, передав запрос на проксируемый сервер.
Остальные запросы этого же элемента будут либо ожидать
появления ответа в кэше, либо освобождения блокировки
этого элемента, в течение времени, заданного директивой
proxy_cache_lock_timeout.
| Синтаксис: |
proxy_cache_lock_age
|
|---|---|
| Умолчание: |
proxy_cache_lock_age 5s; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.8.
Если последний запрос, переданный на проксируемый сервер
для заполнения нового элемента кэша,
не завершился за указанное время,
на проксируемый сервер может быть передан ещё один запрос.
| Синтаксис: |
proxy_cache_lock_timeout
|
|---|---|
| Умолчание: |
proxy_cache_lock_timeout 5s; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.1.12.
Задаёт таймаут для proxy_cache_lock.
По истечении указанного времени
запрос будет передан на проксируемый сервер,
однако ответ не будет закэширован.
До версии 1.7.8 такой ответ мог быть закэширован.
| Синтаксис: |
proxy_cache_max_range_offset
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.11.6.
Задаёт смещение в байтах для запросов с указанием диапазона запрашиваемых байт
(byte-range requests).
Если диапазон находится за указанным смещением,
range-запрос будет передан на проксируемый сервер
и ответ не будет закэширован.
| Синтаксис: |
proxy_cache_methods
|
|---|---|
| Умолчание: |
proxy_cache_methods GET HEAD; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 0.7.59.
Если метод запроса клиента указан в этой директиве,
то ответ будет закэширован.
Методы “GET” и “HEAD” всегда добавляются
в список, но тем не менее рекомендуется перечислять их явно.
См. также директиву proxy_no_cache.
| Синтаксис: |
proxy_cache_min_uses
|
|---|---|
| Умолчание: |
proxy_cache_min_uses 1; |
| Контекст: |
http, server, location
|
Задаёт число запросов, после которого ответ будет закэширован.
| Синтаксис: |
proxy_cache_path
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http
|
Задаёт путь и другие параметры кэша.
Данные кэша хранятся в файлах.
Именем файла в кэше является результат функции MD5
от ключа кэширования.
Параметр levels задаёт уровни иерархии кэша:
можно задать от 1 до 3 уровней, на каждом уровне допускаются значения 1 или 2.
Например, при использовании
proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=one:10m;
имена файлов в кэше будут такого вида:
/data/nginx/cache/c/29/b7f54b2df7773722d382f4809d65029c
Кэшируемый ответ сначала записывается во временный файл, а потом этот файл
переименовывается.
Начиная с версии 0.8.9 временные файлы и кэш
могут располагаться на разных файловых системах.
Однако нужно учитывать,
что в этом случае вместо дешёвой операции переименовывания в пределах
одной файловой системы файл копируется с одной файловой системы на другую.
Поэтому лучше, если кэш будет находиться на той же файловой
системе, что и каталог с временными файлами.
Какой из каталогов будет использоваться для временных файлов
определяется параметром use_temp_path (1.7.10).
Если параметр не задан или установлен в значение “on”,
то будет использоваться каталог, задаваемый директивой
proxy_temp_path для данного location.
Если параметр установлен в значение “off”,
то временные файлы будут располагаться непосредственно в каталоге кэша.
Кроме того, все активные ключи и информация о данных хранятся в зоне
разделяемой памяти, имя и размер которой
задаются параметром keys_zone.
Зоны размером в 1 мегабайт достаточно для хранения около 8 тысяч ключей.
Как часть
коммерческой подписки
в зоне разделяемой памяти также хранится расширенная
информация о кэше,
поэтому для хранения аналогичного количества ключей необходимо указывать
больший размер зоны.
Например
зоны размером в 1 мегабайт достаточно для хранения около 4 тысяч ключей.
Если к данным кэша не обращаются в течение времени, заданного параметром
inactive, то данные удаляются, независимо от их свежести.
По умолчанию inactive равен 10 минутам.
Специальный процесс “cache manager” следит за максимальным размером кэша,
заданным параметром max_size,
а также за минимальным объёмом свободного места на файловой системе с кэшем,
заданным параметром min_free (1.19.1).
При превышении максимального размера кэша
или недостаточном объёме свободного места
процесс удаляет наименее востребованные данные.
Удаление данных происходит итерациями, настраиваемыми параметрами (1.11.5)
manager_files,
manager_threshold и
manager_sleep.
За одну итерацию загружается не более manager_files
элементов (по умолчанию 100).
Время работы одной итерации ограничено параметром
manager_threshold (по умолчанию 200 миллисекунд).
Между итерациями делается пауза на время, заданное параметром
manager_sleep (по умолчанию 50 миллисекунд).
Через минуту после старта активируется специальный процесс “cache loader”,
который загружает в зону кэша информацию о ранее закэшированных данных,
хранящихся на файловой системе.
Загрузка также происходит итерациями.
За одну итерацию загружается не более loader_files
элементов (по умолчанию 100).
Кроме того, время работы одной итерации ограничено параметром
loader_threshold (по умолчанию 200 миллисекунд).
Между итерациями делается пауза на время, заданное параметром
loader_sleep (по умолчанию 50 миллисекунд).
Кроме того,
следующие параметры доступны как часть
коммерческой подписки:
-
purger=on|off -
Указывает, будут ли записи в кэше, соответствующие
маске,
удалены с диска при помощи процесса “cache purger” (1.7.12).
Установка параметра в значениеon
(по умолчаниюoff)
активирует процесс “cache purger”, который
проходит по всем записям в кэше
и удаляет записи, соответствующие этой маске. -
purger_files=число -
Задаёт число элементов, которые будут сканироваться за одну итерацию (1.7.12).
По умолчаниюpurger_filesравен 10. -
purger_threshold=время -
Задаёт продолжительность одной итерации (1.7.12).
По умолчаниюpurger_thresholdравен 50 миллисекундам. -
purger_sleep=время -
Задаёт паузу между итерациями (1.7.12).
По умолчаниюpurger_sleepравен 50 миллисекундам.
В версиях 1.7.3, 1.7.7 и 1.11.10 формат заголовка кэша был изменён.
При обновлении на более новую версию nginx
ранее закэшированные ответы будут считаться недействительными.
| Синтаксис: |
proxy_cache_purge строка ...;
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.5.7.
Задаёт условия, при которых запрос будет считаться запросом
на очистку кэша.
Если значение хотя бы одного из строковых параметров непустое и не равно “0”,
то запись в кэше с соответствующим
ключом кэширования удаляется.
В результате успешной операции возвращается ответ с кодом
204 (No Content).
Если ключ кэширования
запроса на очистку заканчивается
звёздочкой (“*”), то все записи в кэше, соответствующие
этой маске, будут удалены из кэша.
Тем не менее, эти записи будут оставаться на диске или до момента удаления
из-за отсутствия обращения к данным,
или до обработки их процессом “cache purger” (1.7.12),
или до попытки клиента получить к ним доступ.
Пример конфигурации:
proxy_cache_path /data/nginx/cache keys_zone=cache_zone:10m;
map $request_method $purge_method {
PURGE 1;
default 0;
}
server {
...
location / {
proxy_pass http://backend;
proxy_cache cache_zone;
proxy_cache_key $uri;
proxy_cache_purge $purge_method;
}
}
Функциональность доступна как часть
коммерческой подписки.
| Синтаксис: |
proxy_cache_revalidate
|
|---|---|
| Умолчание: |
proxy_cache_revalidate off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.5.7.
Разрешает ревалидацию просроченных элементов кэша при помощи
условных запросов с полями заголовка
“If-Modified-Since” и “If-None-Match”.
| Синтаксис: |
proxy_cache_use_stale
|
|---|---|
| Умолчание: |
proxy_cache_use_stale off; |
| Контекст: |
http, server, location
|
Определяет, в каких случаях можно использовать
устаревший закэшированный ответ.
Параметры директивы совпадают с параметрами
директивы proxy_next_upstream.
Параметр error также позволяет использовать
устаревший закэшированный ответ при невозможности выбора
проксированного сервера для обработки запроса.
Кроме того, дополнительный параметр updating
разрешает использовать устаревший закэшированный ответ,
если на данный момент он уже обновляется.
Это позволяет минимизировать число обращений к проксированным серверам
при обновлении закэшированных данных.
Использование устаревшего закэшированного ответа
может также быть разрешено непосредственно в заголовке ответа
на определённое количество секунд после того, как ответ устарел (1.11.10).
Такой способ менее приоритетен, чем задание параметров директивы.
-
Расширение
“stale-while-revalidate”
поля заголовка “Cache-Control” разрешает
использовать устаревший закэшированный ответ,
если на данный момент он уже обновляется. -
Расширение
“stale-if-error”
поля заголовка “Cache-Control” разрешает
использовать устаревший закэшированный ответ в случае ошибки.
Чтобы минимизировать число обращений к проксированным серверам при
заполнении нового элемента кэша, можно воспользоваться директивой
proxy_cache_lock.
| Синтаксис: |
proxy_cache_valid [
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Задаёт время кэширования для разных кодов ответа.
Например, директивы
proxy_cache_valid 200 302 10m; proxy_cache_valid 404 1m;
задают время кэширования 10 минут для ответов с кодами 200 и 302
и 1 минуту для ответов с кодом 404.
Если указано только время кэширования,
proxy_cache_valid 5m;
то кэшируются только ответы 200, 301 и 302.
Кроме того, можно кэшировать любые ответы с помощью параметра
any:
proxy_cache_valid 200 302 10m; proxy_cache_valid 301 1h; proxy_cache_valid any 1m;
Параметры кэширования могут также быть заданы непосредственно
в заголовке ответа.
Такой способ приоритетнее, чем задание времени кэширования с помощью директивы.
-
Поле заголовка “X-Accel-Expires” задаёт время кэширования
ответа в секундах.
Значение 0 запрещает кэшировать ответ.
Если значение начинается с префикса@, оно задаёт абсолютное
время в секундах с начала эпохи, до которого ответ может быть закэширован. -
Если в заголовке нет поля “X-Accel-Expires”,
параметры кэширования определяются по полям заголовка
“Expires” или “Cache-Control”. -
Ответ, в заголовке которого есть поле “Set-Cookie”,
не будет кэшироваться. -
Ответ, в заголовке которого есть поле “Vary”
со специальным значением “*”,
не будет кэшироваться (1.7.7).
Ответ, в заголовке которого есть поле “Vary”
с другим значением, будет закэширован
с учётом соответствующих полей заголовка запроса (1.7.7).
Обработка одного или более из этих полей заголовка может быть отключена
при помощи директивы proxy_ignore_headers.
| Синтаксис: |
proxy_connect_timeout
|
|---|---|
| Умолчание: |
proxy_connect_timeout 60s; |
| Контекст: |
http, server, location
|
Задаёт таймаут для установления соединения с проксированным сервером.
Необходимо иметь в виду, что этот таймаут обычно не может превышать 75 секунд.
| Синтаксис: |
proxy_cookie_domain proxy_cookie_domain
|
|---|---|
| Умолчание: |
proxy_cookie_domain off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.1.15.
Задаёт текст, который нужно изменить в атрибуте domain
полей “Set-Cookie” заголовка ответа проксируемого сервера.
Предположим, проксируемый сервер вернул поле заголовка
“Set-Cookie” с атрибутом
“domain=localhost”.
Директива
proxy_cookie_domain localhost example.org;
перепишет данный атрибут в виде
“domain=example.org”.
Точка в начале строк домен и замена,
а равно как и в атрибуте domain игнорируется.
Регистр значения не имеет.
В строках домен и замена можно использовать
переменные:
proxy_cookie_domain www.$host $host;
Директиву также можно задать при помощи регулярных выражений.
При этом домен должен начинаться с символа
“~”.
Регулярное выражение может содержать именованные и позиционные выделения,
а замена ссылаться на них:
proxy_cookie_domain ~.(?P<sl_domain>[-0-9a-z]+.[a-z]+)$ $sl_domain;
На одном уровне может быть указано
несколько директив proxy_cookie_domain:
proxy_cookie_domain localhost example.org; proxy_cookie_domain ~.([a-z]+.[a-z]+)$ $1;
Если к куке могут быть применены несколько директив,
будет выбрана первая из них.
Параметр off отменяет действие
унаследованных с предыдущего уровня конфигурации
директив proxy_cookie_domain.
| Синтаксис: |
proxy_cookie_flags
|
|---|---|
| Умолчание: |
proxy_cookie_flags off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.19.3.
Задаёт один или несколько флагов для куки.
В качестве куки
можно использовать текст, переменные и их комбинации.
В качестве флага
можно использовать текст, переменные и их комбинации (1.19.8).
Параметры
secure,
httponly,
samesite=strict,
samesite=lax,
samesite=none
добавляют соответствующие флаги.
Параметры
nosecure,
nohttponly,
nosamesite
удаляют соответствующие флаги.
Куки также можно задать при помощи регулярных выражений.
При этом кука должна начинаться с символа
“~”.
На одном уровне конфигурации может быть указано
несколько директив proxy_cookie_flags:
proxy_cookie_flags one httponly; proxy_cookie_flags ~ nosecure samesite=strict;
Если к куке могут быть применены несколько директив,
будет выбрана первая из них.
В данном примере флаг httponly
добавляется к куке one,
для остальных кук
добавляется флаг samesite=strict и
удаляется флаг secure.
Параметр off отменяет действие всех директив
proxy_cookie_flags
на данном уровне.
| Синтаксис: |
proxy_cookie_path proxy_cookie_path
|
|---|---|
| Умолчание: |
proxy_cookie_path off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.1.15.
Задаёт текст, который нужно изменить в атрибуте path
полей “Set-Cookie” заголовка ответа проксируемого сервера.
Предположим, проксируемый сервер вернул поле заголовка
“Set-Cookie” с атрибутом
“path=/two/some/uri/”.
Директива
proxy_cookie_path /two/ /;
перепишет данный атрибут в виде
“path=/some/uri/”.
В строках путь и замена можно использовать
переменные:
proxy_cookie_path $uri /some$uri;
Директиву также можно задать при помощи регулярных выражений.
При этом путь должен начинаться либо с символа
“~”, если при сравнении следует учитывать регистр символов,
либо с символов “~*”, если регистр символов учитывать
не нужно.
Регулярное выражение может содержать именованные и позиционные выделения,
а замена ссылаться на них:
proxy_cookie_path ~*^/user/([^/]+) /u/$1;
На одном уровне может быть указано
несколько директив proxy_cookie_path:
proxy_cookie_path /one/ /; proxy_cookie_path / /two/;
Если к куке могут быть применены несколько директив,
будет выбрана первая из них.
Параметр off отменяет действие
унаследованных с предыдущего уровня конфигурации
директив proxy_cookie_path.
| Синтаксис: |
proxy_force_ranges
|
|---|---|
| Умолчание: |
proxy_force_ranges off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.7.
Включает поддержку диапазонов запрашиваемых байт (byte-range)
для кэшированных и некэшированных ответов проксируемого сервера
вне зависимости от наличия поля “Accept-Ranges”
в заголовках этих ответов.
| Синтаксис: |
proxy_headers_hash_bucket_size
|
|---|---|
| Умолчание: |
proxy_headers_hash_bucket_size 64; |
| Контекст: |
http, server, location
|
Задаёт размер корзины для хэш-таблиц,
используемых директивами proxy_hide_header
и proxy_set_header.
Подробнее настройка хэш-таблиц обсуждается в отдельном
документе.
| Синтаксис: |
proxy_headers_hash_max_size
|
|---|---|
| Умолчание: |
proxy_headers_hash_max_size 512; |
| Контекст: |
http, server, location
|
Задаёт максимальный размер хэш-таблиц,
используемых директивами proxy_hide_header и
proxy_set_header.
Подробнее настройка хэш-таблиц обсуждается в отдельном
документе.
| Синтаксис: |
proxy_hide_header
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
По умолчанию
nginx не передаёт клиенту поля заголовка “Date”,
“Server”, “X-Pad” и
“X-Accel-…” из ответа проксированного сервера.
Директива proxy_hide_header задаёт дополнительные поля,
которые не будут передаваться.
Если же передачу полей нужно разрешить, можно воспользоваться
директивой proxy_pass_header.
| Синтаксис: |
proxy_http_version
|
|---|---|
| Умолчание: |
proxy_http_version 1.0; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.1.4.
Задаёт версию протокола HTTP для проксирования.
По умолчанию используется версия 1.0.
Для работы
постоянных
соединений и
проверки подлинности
NTLM рекомендуется версия 1.1.
| Синтаксис: |
proxy_ignore_client_abort
|
|---|---|
| Умолчание: |
proxy_ignore_client_abort off; |
| Контекст: |
http, server, location
|
Определяет, закрывать ли соединение с проксированным сервером
в случае, если клиент закрыл соединение, не дождавшись ответа.
| Синтаксис: |
proxy_ignore_headers
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Запрещает обработку некоторых полей заголовка из ответа проксированного сервера.
В директиве можно указать поля “X-Accel-Redirect”,
“X-Accel-Expires”, “X-Accel-Limit-Rate” (1.1.6),
“X-Accel-Buffering” (1.1.6),
“X-Accel-Charset” (1.1.6), “Expires”,
“Cache-Control”, “Set-Cookie” (0.8.44)
и “Vary” (1.7.7).
Если не запрещено, обработка этих полей заголовка заключается в следующем:
-
“X-Accel-Expires”, “Expires”,
“Cache-Control”, “Set-Cookie”
и “Vary”
задают параметры кэширования ответа; -
“X-Accel-Redirect” производит
внутреннее
перенаправление на указанный URI; -
“X-Accel-Limit-Rate” задаёт
ограничение
скорости передачи ответа клиенту; -
“X-Accel-Buffering” включает или выключает
буферизацию ответа; -
“X-Accel-Charset” задаёт желаемую
кодировку
ответа.
| Синтаксис: |
proxy_intercept_errors
|
|---|---|
| Умолчание: |
proxy_intercept_errors off; |
| Контекст: |
http, server, location
|
Определяет, передавать ли клиенту проксированные ответы с кодом
больше либо равным 300,
или же перехватывать их и перенаправлять на обработку nginx’у с помощью
директивы error_page.
| Синтаксис: |
proxy_limit_rate
|
|---|---|
| Умолчание: |
proxy_limit_rate 0; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.7.
Ограничивает скорость чтения ответа от проксируемого сервера.
Скорость задаётся в байтах в секунду.
Значение 0 отключает ограничение скорости.
Ограничение устанавливается на запрос,
поэтому, если nginx одновременно
откроет два соединения к проксируемому серверу,
суммарная скорость будет вдвое выше заданного ограничения.
Ограничение работает только в случае, если включена
буферизация ответов проксируемого сервера.
| Синтаксис: |
proxy_max_temp_file_size
|
|---|---|
| Умолчание: |
proxy_max_temp_file_size 1024m; |
| Контекст: |
http, server, location
|
Если включена буферизация ответов
проксируемого сервера, и ответ не вмещается целиком в буферы,
заданные директивами proxy_buffer_size и
proxy_buffers, часть ответа может быть записана во временный файл.
Эта директива задаёт максимальный размер временного файла.
Размер данных, сбрасываемых во временный файл за один раз, задаётся
директивой proxy_temp_file_write_size.
Значение 0 отключает возможность буферизации ответов во временные файлы.
Данное ограничение не распространяется на ответы,
которые будут закэшированы
или сохранены на диске.
| Синтаксис: |
proxy_method
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Задаёт HTTP-метод, который будет использоваться
в передаваемых на проксируемый сервер запросах вместо метода
из клиентского запроса.
В значении параметра допустимо использование переменных (1.11.6).
| Синтаксис: |
proxy_next_upstream
|
|---|---|
| Умолчание: |
proxy_next_upstream error timeout; |
| Контекст: |
http, server, location
|
Определяет, в каких случаях запрос будет передан следующему серверу:
error- произошла ошибка соединения с сервером, передачи ему запроса или
чтения заголовка ответа сервера; timeout- произошёл таймаут во время соединения с сервером,
передачи ему запроса или чтения заголовка ответа сервера; invalid_header- сервер вернул пустой или неверный ответ;
http_500- сервер вернул ответ с кодом 500;
http_502- сервер вернул ответ с кодом 502;
http_503- сервер вернул ответ с кодом 503;
http_504- сервер вернул ответ с кодом 504;
http_403- сервер вернул ответ с кодом 403;
http_404- сервер вернул ответ с кодом 404;
http_429- сервер вернул ответ с кодом 429 (1.11.13);
non_idempotent- обычно запросы с
неидемпотентным
методом
(POST,LOCK,PATCH)
не передаются на другой сервер,
если запрос серверу группы уже был отправлен (1.9.13);
включение параметра явно разрешает повторять подобные запросы; off- запрещает передачу запроса следующему серверу.
Необходимо понимать, что передача запроса следующему серверу возможна
только при условии, что клиенту ещё ничего не передавалось.
То есть, если ошибка или таймаут возникли в середине передачи ответа
клиенту, то исправить это уже невозможно.
Директива также определяет, что считается
неудачной
попыткой работы с сервером.
Случаи error, timeout и
invalid_header
всегда считаются неудачными попытками, даже если они не указаны в директиве.
Случаи http_500, http_502,
http_503, http_504
и http_429
считаются неудачными попытками, только если они указаны в директиве.
Случаи http_403 и http_404
никогда не считаются неудачными попытками.
Передача запроса следующему серверу может быть ограничена по
количеству попыток
и по времени.
| Синтаксис: |
proxy_next_upstream_timeout
|
|---|---|
| Умолчание: |
proxy_next_upstream_timeout 0; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.5.
Ограничивает время, в течение которого возможна передача запроса
следующему серверу.
Значение 0 отключает это ограничение.
| Синтаксис: |
proxy_next_upstream_tries
|
|---|---|
| Умолчание: |
proxy_next_upstream_tries 0; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.5.
Ограничивает число допустимых попыток для передачи запроса
следующему серверу.
Значение 0 отключает это ограничение.
| Синтаксис: |
proxy_no_cache
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Задаёт условия, при которых ответ не будет сохраняться в кэш.
Если значение хотя бы одного из строковых параметров непустое и не равно “0”,
то ответ не будет сохранён:
proxy_no_cache $cookie_nocache $arg_nocache$arg_comment; proxy_no_cache $http_pragma $http_authorization;
Можно использовать совместно с директивой proxy_cache_bypass.
| Синтаксис: |
proxy_pass
|
|---|---|
| Умолчание: |
— |
| Контекст: |
location, if в location, limit_except
|
Задаёт протокол и адрес проксируемого сервера, а также необязательный URI,
на который должен отображаться location.
В качестве протокола можно указать
“http” или “https”.
Адрес может быть указан в виде доменного имени или IP-адреса,
и необязательного порта:
proxy_pass http://localhost:8000/uri/;
или в виде пути UNIX-сокета, который указывается после слова
“unix” и заключается в двоеточия:
proxy_pass http://unix:/tmp/backend.socket:/uri/;
Если доменному имени соответствует несколько адресов, то все они будут
использоваться по очереди (round-robin).
Кроме того, в качестве адреса можно указать
группу серверов.
В значении параметра можно использовать переменные.
В этом случае, если адрес указан в виде доменного имени,
имя ищется среди описанных групп серверов
и если не найдено, то определяется с помощью
resolver’а.
URI запроса передаётся на сервер так:
-
Если директива
proxy_passуказана с URI,
то при передаче запроса серверу часть
нормализованного
URI запроса, соответствующая location, заменяется на URI,
указанный в директиве:location /name/ { proxy_pass http://127.0.0.1/remote/; } -
Если директива
proxy_passуказана без URI,
то при обработке первоначального запроса на сервер передаётся
URI запроса в том же виде, в каком его прислал клиент,
а при обработке изменённого URI —
нормализованный URI запроса целиком:location /some/path/ { proxy_pass http://127.0.0.1; }До версии 1.1.12,
еслиproxy_passуказана без URI,
в ряде случаев при изменении URI на сервер мог передаваться
URI первоначального запроса вместо изменённого URI.
В ряде случаев часть URI запроса, подлежащую замене, выделить невозможно:
-
Если location задан регулярным выражением,
а также в именованных location’ах.В этих случаях
proxy_passследует указывать без URI. -
Если внутри проксируемого location с помощью директивы
rewrite изменяется
URI, и именно с этой конфигурацией будет обрабатываться запрос
(break):location /name/ { rewrite /name/([^/]+) /users?name=$1 break; proxy_pass http://127.0.0.1; }В этом случае URI, указанный в директиве, игнорируется, и на сервер
передаётся изменённый URI запроса целиком. -
При использовании переменных в
proxy_pass:location /name/ { proxy_pass http://127.0.0.1$request_uri; }В этом случае если в директиве указан URI,
он передаётся на сервер как есть,
заменяя URI первоначального запроса.
Проксирование WebSocket требует особой
настройки и поддерживается начиная с версии 1.3.13.
| Синтаксис: |
proxy_pass_header
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Разрешает передавать от проксируемого сервера клиенту
запрещённые для передачи поля заголовка.
| Синтаксис: |
proxy_pass_request_body
|
|---|---|
| Умолчание: |
proxy_pass_request_body on; |
| Контекст: |
http, server, location
|
Позволяет запретить передачу исходного тела запроса
на проксируемый сервер.
location /x-accel-redirect-here/ {
proxy_method GET;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_pass ...
}
См. также директивы proxy_set_header и
proxy_pass_request_headers.
| Синтаксис: |
proxy_pass_request_headers
|
|---|---|
| Умолчание: |
proxy_pass_request_headers on; |
| Контекст: |
http, server, location
|
Позволяет запретить передачу полей заголовка исходного запроса на
проксируемый сервер.
location /x-accel-redirect-here/ {
proxy_method GET;
proxy_pass_request_headers off;
proxy_pass_request_body off;
proxy_pass ...
}
См. также директивы proxy_set_header и
proxy_pass_request_body.
| Синтаксис: |
proxy_read_timeout
|
|---|---|
| Умолчание: |
proxy_read_timeout 60s; |
| Контекст: |
http, server, location
|
Задаёт таймаут при чтении ответа проксированного сервера.
Таймаут устанавливается не на всю передачу ответа,
а только между двумя операциями чтения.
Если по истечении этого времени проксируемый сервер ничего не передаст,
соединение закрывается.
| Синтаксис: |
proxy_redirect proxy_redirect proxy_redirect
|
|---|---|
| Умолчание: |
proxy_redirect default; |
| Контекст: |
http, server, location
|
Задаёт текст, который нужно изменить в полях заголовка
“Location” и “Refresh” в ответе
проксируемого сервера.
Предположим, проксируемый сервер вернул поле заголовка
“Location: http://localhost:8000/two/some/uri/”.
Директива
proxy_redirect http://localhost:8000/two/ http://frontend/one/;
перепишет эту строку в виде
“Location: http://frontend/one/some/uri/”.
В заменяемой строке можно не указывать имя сервера:
proxy_redirect http://localhost:8000/two/ /;
тогда будут подставлены основное имя сервера и порт, если он отличен от 80.
Стандартная замена, задаваемая параметром default,
использует параметры директив
location и
proxy_pass.
Поэтому две нижеприведённые конфигурации одинаковы:
location /one/ {
proxy_pass http://upstream:port/two/;
proxy_redirect default;
location /one/ {
proxy_pass http://upstream:port/two/;
proxy_redirect http://upstream:port/two/ /one/;
Параметр default недопустим, если в proxy_pass
используются переменные.
В строке замена можно использовать переменные:
proxy_redirect http://localhost:8000/ http://$host:$server_port/;
В строке перенаправление тоже можно использовать (1.1.11)
переменные:
proxy_redirect http://$proxy_host:8000/ /;
Директиву также можно задать (1.1.11) при помощи регулярных выражений.
При этом перенаправление должно начинаться либо с символа
“~”, если при сравнении следует учитывать регистр символов,
либо с символов “~*”, если регистр символов учитывать
не нужно.
Регулярное выражение может содержать именованные и позиционные выделения,
а замена ссылаться на них:
proxy_redirect ~^(http://[^:]+):d+(/.+)$ $1$2; proxy_redirect ~*/user/([^/]+)/(.+)$ http://$1.example.com/$2;
На одном уровне может быть указано
несколько директив proxy_redirect:
proxy_redirect default; proxy_redirect http://localhost:8000/ /; proxy_redirect http://www.example.com/ /;
Если к полям заголовка в ответе проксируемого сервера
могут быть применены несколько директив,
будет выбрана первая из них.
Параметр off отменяет действие
унаследованных с предыдущего уровня конфигурации
директив proxy_redirect.
С помощью этой директивы можно также добавлять имя хоста к относительным
перенаправлениям, выдаваемым проксируемым сервером:
proxy_redirect / /;
| Синтаксис: |
proxy_request_buffering
|
|---|---|
| Умолчание: |
proxy_request_buffering on; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.11.
Разрешает или запрещает использовать буферизацию тела запроса клиента.
Если буферизация включена, то тело запроса полностью
читается
от клиента перед отправкой запроса на проксируемый сервер.
Если буферизация выключена, то тело запроса отправляется
на проксируемый сервер сразу же по мере его поступления.
В этом случае запрос не может быть передан
следующему серверу,
если nginx уже начал отправку тела запроса.
Если для отправки тела исходного запроса используется HTTP/1.1
и передача данных частями (chunked transfer encoding),
то тело запроса буферизуется независимо от значения директивы,
если для проксирования также не
включён HTTP/1.1.
| Синтаксис: |
proxy_send_lowat
|
|---|---|
| Умолчание: |
proxy_send_lowat 0; |
| Контекст: |
http, server, location
|
При установке директивы в ненулевое значение nginx будет пытаться минимизировать
число операций отправки на исходящих соединениях с проксируемым сервером либо
при помощи флага NOTE_LOWAT метода
kqueue,
либо при помощи параметра сокета SO_SNDLOWAT,
с указанным размером.
Эта директива игнорируется на Linux, Solaris и Windows.
| Синтаксис: |
proxy_send_timeout
|
|---|---|
| Умолчание: |
proxy_send_timeout 60s; |
| Контекст: |
http, server, location
|
Задаёт таймаут при передаче запроса проксированному серверу.
Таймаут устанавливается не на всю передачу запроса,
а только между двумя операциями записи.
Если по истечении этого времени проксируемый сервер не примет новых данных,
соединение закрывается.
| Синтаксис: |
proxy_set_body
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Позволяет переопределить тело запроса, передаваемое на проксируемый сервер.
В качестве значения можно использовать текст, переменные и их комбинации.
| Синтаксис: |
proxy_set_header
|
|---|---|
| Умолчание: |
proxy_set_header Host $proxy_host; proxy_set_header Connection close; |
| Контекст: |
http, server, location
|
Позволяет переопределять или добавлять поля заголовка запроса,
передаваемые проксируемому серверу.
В качестве значения можно использовать текст, переменные и их комбинации.
Директивы наследуются с предыдущего уровня конфигурации при условии, что
на данном уровне не описаны свои директивы proxy_set_header.
По умолчанию переопределяются только два поля:
proxy_set_header Host $proxy_host; proxy_set_header Connection close;
Если включено кэширование, поля заголовка
“If-Modified-Since”,
“If-Unmodified-Since”,
“If-None-Match”,
“If-Match”,
“Range”
и
“If-Range”
исходного запроса не передаются на проксируемый сервер.
Неизменённое поле заголовка запроса “Host” можно передать так:
proxy_set_header Host $http_host;
Однако, если это поле отсутствует в заголовке запроса клиента, то ничего
передаваться не будет.
В этом случае лучше воспользоваться переменной $host — её
значение равно имени сервера в поле “Host”
заголовка запроса, или же основному имени сервера, если поля нет:
proxy_set_header Host $host;
Кроме того, можно передать имя сервера вместе с портом проксируемого сервера:
proxy_set_header Host $host:$proxy_port;
Если значение поля заголовка — пустая строка, то поле вообще
не будет передаваться проксируемому серверу:
proxy_set_header Accept-Encoding "";
| Синтаксис: |
proxy_socket_keepalive
|
|---|---|
| Умолчание: |
proxy_socket_keepalive off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.15.6.
Конфигурирует поведение “TCP keepalive”
для исходящих соединений к проксируемому серверу.
По умолчанию для сокета действуют настройки операционной системы.
Если указано значение “on”, то
для сокета включается параметр SO_KEEPALIVE.
| Синтаксис: |
proxy_ssl_certificate
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.8.
Задаёт файл с сертификатом в формате PEM
для аутентификации на проксируемом HTTPS-сервере.
Начиная с версии 1.21.0 в имени файла можно использовать переменные.
| Синтаксис: |
proxy_ssl_certificate_key
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.8.
Задаёт файл с секретным ключом в формате PEM
для аутентификации на проксируемом HTTPS-сервере.
Вместо файла можно указать значение
engine:имя:id (1.7.9),
которое загружает ключ с указанным id
из OpenSSL engine с заданным именем.
Начиная с версии 1.21.0 в имени файла можно использовать переменные.
| Синтаксис: |
proxy_ssl_ciphers
|
|---|---|
| Умолчание: |
proxy_ssl_ciphers DEFAULT; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.5.6.
Описывает разрешённые шифры для запросов к проксируемому HTTPS-серверу.
Шифры задаются в формате, поддерживаемом библиотекой OpenSSL.
Полный список можно посмотреть с помощью команды
“openssl ciphers”.
| Синтаксис: |
proxy_ssl_conf_command
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.19.4.
Задаёт произвольные конфигурационные
команды
OpenSSL
при установлении соединения с проксируемым HTTPS-сервером.
Директива поддерживается при использовании OpenSSL 1.0.2 и выше.
На одном уровне может быть указано
несколько директив proxy_ssl_conf_command.
Директивы наследуются с предыдущего уровня конфигурации при условии, что
на данном уровне не описаны
свои директивы proxy_ssl_conf_command.
Следует учитывать, что изменение настроек OpenSSL напрямую
может привести к неожиданному поведению.
| Синтаксис: |
proxy_ssl_crl
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Указывает файл с отозванными сертификатами (CRL)
в формате PEM, используемыми при проверке
сертификата проксируемого HTTPS-сервера.
| Синтаксис: |
proxy_ssl_name
|
|---|---|
| Умолчание: |
proxy_ssl_name $proxy_host; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Позволяет переопределить имя сервера, используемое при
проверке
сертификата проксируемого HTTPS-сервера, а также для
передачи его через SNI
при установлении соединения с проксируемым HTTPS-сервером.
По умолчанию используется имя хоста из URL’а, заданного
директивой proxy_pass.
| Синтаксис: |
proxy_ssl_password_file
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.8.
Задаёт файл с паролями от
секретных ключей,
где каждый пароль указан на отдельной строке.
Пароли применяются по очереди в момент загрузки ключа.
| Синтаксис: |
proxy_ssl_protocols
|
|---|---|
| Умолчание: |
proxy_ssl_protocols TLSv1 TLSv1.1 TLSv1.2; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.5.6.
Разрешает указанные протоколы для запросов к проксируемому HTTPS-серверу.
| Синтаксис: |
proxy_ssl_server_name
|
|---|---|
| Умолчание: |
proxy_ssl_server_name off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Разрешает или запрещает передачу имени сервера через
расширение
Server Name Indication протокола TLS (SNI, RFC 6066)
при установлении соединения с проксируемым HTTPS-сервером.
| Синтаксис: |
proxy_ssl_session_reuse
|
|---|---|
| Умолчание: |
proxy_ssl_session_reuse on; |
| Контекст: |
http, server, location
|
Определяет, использовать ли повторно SSL-сессии при
работе с проксированным сервером.
Если в логах появляются ошибки
“SSL3_GET_FINISHED:digest check failed”,
то можно попробовать выключить
повторное использование сессий.
| Синтаксис: |
proxy_ssl_trusted_certificate
|
|---|---|
| Умолчание: |
— |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Задаёт файл с доверенными сертификатами CA в формате PEM,
используемыми при проверке
сертификата проксируемого HTTPS-сервера.
| Синтаксис: |
proxy_ssl_verify
|
|---|---|
| Умолчание: |
proxy_ssl_verify off; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Разрешает или запрещает проверку сертификата проксируемого HTTPS-сервера.
| Синтаксис: |
proxy_ssl_verify_depth
|
|---|---|
| Умолчание: |
proxy_ssl_verify_depth 1; |
| Контекст: |
http, server, location
|
Эта директива появилась в версии 1.7.0.
Устанавливает глубину проверки в цепочке сертификатов
проксируемого HTTPS-сервера.
| Синтаксис: |
proxy_store
|
|---|---|
| Умолчание: |
proxy_store off; |
| Контекст: |
http, server, location
|
Разрешает сохранение на диск файлов.
Параметр on сохраняет файлы в соответствии с путями,
указанными в директивах
alias или
root.
Параметр off запрещает сохранение файлов.
Кроме того, имя файла можно задать явно с помощью строки с переменными:
proxy_store /data/www$original_uri;
Время изменения файлов выставляется согласно полученному полю
“Last-Modified” в заголовке ответа.
Ответ сначала записывается во временный файл, а потом этот файл
переименовывается.
Начиная с версии 0.8.9 временный файл и постоянное место хранения ответа
могут располагаться на разных файловых системах.
Однако нужно учитывать,
что в этом случае вместо дешёвой операции переименовывания в пределах
одной файловой системы файл копируется с одной файловой системы на другую.
Поэтому лучше, если сохраняемые файлы будут находиться на той же файловой
системе, что и каталог с временными файлами, задаваемый директивой
proxy_temp_path для данного location.
Директиву можно использовать для создания локальных копий статических
неизменяемых файлов, например, так:
location /images/ {
root /data/www;
error_page 404 = /fetch$uri;
}
location /fetch/ {
internal;
proxy_pass http://backend/;
proxy_store on;
proxy_store_access user:rw group:rw all:r;
proxy_temp_path /data/temp;
alias /data/www/;
}
или так:
location /images/ {
root /data/www;
error_page 404 = @fetch;
}
location @fetch {
internal;
proxy_pass http://backend;
proxy_store on;
proxy_store_access user:rw group:rw all:r;
proxy_temp_path /data/temp;
root /data/www;
}
| Синтаксис: |
proxy_store_access
|
|---|---|
| Умолчание: |
proxy_store_access user:rw; |
| Контекст: |
http, server, location
|
Задаёт права доступа для создаваемых файлов и каталогов, например,
proxy_store_access user:rw group:rw all:r;
Если заданы какие-либо права для group или
all, то права для user
указывать необязательно:
proxy_store_access group:rw all:r;
| Синтаксис: |
proxy_temp_file_write_size
|
|---|---|
| Умолчание: |
proxy_temp_file_write_size 8k|16k; |
| Контекст: |
http, server, location
|
Ограничивает размер данных, сбрасываемых во временный файл
за один раз, при включённой буферизации ответов проксируемого сервера
во временные файлы.
По умолчанию размер ограничен двумя буферами, заданными
директивами proxy_buffer_size и proxy_buffers.
Максимальный размер временного файла задаётся директивой
proxy_max_temp_file_size.
| Синтаксис: |
proxy_temp_path
|
|---|---|
| Умолчание: |
proxy_temp_path proxy_temp; |
| Контекст: |
http, server, location
|
Задаёт имя каталога для хранения временных файлов с данными,
полученными от проксируемых серверов.
В каталоге может использоваться иерархия подкаталогов до трёх уровней.
Например, при такой конфигурации
proxy_temp_path /spool/nginx/proxy_temp 1 2;
временный файл будет следующего вида:
/spool/nginx/proxy_temp/7/45/00000123457
См. также параметр use_temp_path директивы
proxy_cache_path.
Встроенные переменные
В модуле ngx_http_proxy_module есть встроенные переменные,
которые можно использовать для формирования заголовков с помощью директивы
proxy_set_header:
$proxy_host- имя и порт проксируемого сервера, как указано в
директиве proxy_pass; $proxy_port- порт проксируемого сервера, как указано в
директиве proxy_pass, или стандартный порт протокола; -
$proxy_add_x_forwarded_for - поле заголовка запроса клиента “X-Forwarded-For”
и добавленная к нему через запятую переменная$remote_addr.
Если же поля “X-Forwarded-For” в заголовке запроса клиента нет,
то переменная$proxy_add_x_forwarded_for
равна переменной$remote_addr.
Время прочтения
6 мин
Просмотры 21K
Является ли ошибкой ответ 5хх, если его никто не видит? [1]

Вне зависимости от того, как долго и тщательно программное обеспечение проверяется перед запуском, часть проблем проявляется только в рабочем окружении. Например, race condition от параллельного обслуживания большого количества клиентов или исключения при валидации непредвиденных данных от пользователя. В результате эти проблемы могут привести к 5хх ошибкам.
HTTP 5хх ответы зачастую возвращаются пользователям и могут нанести ущерб репутации компании даже за короткий промежуток времени. В то же время, отладить проблему на рабочем сервере зачастую очень непросто. Даже простое извлечение проблемной сессии из логов может превратиться в поиск иголки в стоге сена. И даже если будут собраны все необходимые логи со всех рабочих серверов — этого может быть недостаточно для понимания причин проблемы.
Для облегчения процесса поиска и отладки могут быть использованы некоторые полезные приёмы в случае, когда NGINX используется для проксирования или балансировки приложения. В этой статье будет рассмотрено особое использование директивы error_page в применении к типичной инфраструктуре приложения с проксированием через NGINX.
Сервер отладки
Сервер отладки (отладочный сервер, Debug Server) — специальный сервер, на который перенаправляются запросы, вызывающие ошибки на рабочих серверах. Это достигается использованием того преимущества, что NGINX может детектировать 5xx ошибки, возвращаемые из upstream и перенаправлять приводящие к ошибкам запросы из разных групп upstream на отладочный сервер. А так как отладочный сервер будет обрабатывать только запросы, приводящие к ошибкам, то в логах будет информация, относящаяся исключительно к ошибкам. Таким образом, проблема поиска иголок в стоге сена сводится к горстке иголок.
Так как отладочный сервер не обслуживает рабочие клиентские запросы, то нет нужды затачивать его на производительность. Вместо этого, на нём можно включить максимальное логирование и добавить инструменты диагностики на любой вкус. Например:
- Запуск приложения в режиме отладки
- Включение подробного логирования на сервере
- Добавление профилирования приложения
- Подсчет ресурсов использованных сервером
Инструменты отладки обычно отключаются для рабочих серверов, так как зачастую замедляют работу приложения. Однако, для отладочного сервера их можно безопасно включить. Ниже приведён пример инфраструктуры приложения с отладочным сервером.
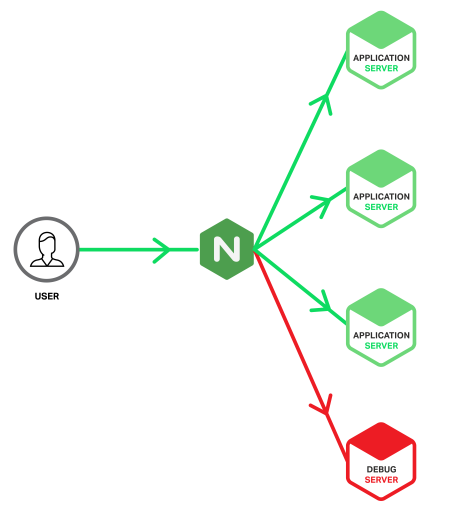
В идеальном мире, процесс конфигурирования и выделение ресурсов для отладочного сервера не должен отличаться от процесса настройки обычного рабочего сервера. Но если сделать сервер отладки в виде виртуальной машины, то в этом могут быть свои преимущества (например, клонирование и копирование для автономной аналитики). Однако, в таком случае, существует риск, что сервер может быть перегружен в случае возникновения серьёзной проблемы, которая вызовет внезапный всплеск ошибок 5xx. В NGINX Plus этого можно избежать с помощью параметра max_conns для ограничения количества параллельных соединений (ниже будет приведён пример конфигурации).
Так как сервер отладки загружен не так, как рабочий сервер, то не все ошибки 5xx могут воспроизводиться. В такой ситуации можно предположить, что вы достигли предела масштабирования приложения и исчерпали ресурсы, и никакой ошибки в самом приложении нет. Независимо от основной причины, использование отладочного сервера поможет улучшить взаимодействие с пользователем и предостеречь его от 5xx ошибок.
Конфигурация
Ниже приведен простой пример конфигурации сервера отладки для приема запросов, которые привели к 5xx ошибке на одном из основных серверов.
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
}
В блоке upstream app_server указаны адреса рабочих серверов. Далее указывается один адрес сервера отладки в upstream debug_server.
Первый блок location настраивает простое проксирование с помощью директивы proxy_pass для балансировки серверов приложения в upstream app_server (в примере не указан алгоритм балансировки, поэтому используется стандартный алгоритм Round Robin). Включенная директива proxy_intercept_errors означает, что любой ответ с HTTP статусом 300 или выше будет обрабатываться с помощью директивы error_page. В нашем примере перехватываются только 500, 503 и 504 ошибки и передаются на обработку в блок location @debug. Все остальные ответы, такие как 404, отсылаются пользователю без изменений.
В блоке @debug происходят два действия: во-первых, проксирование в группу upstream debug_server, которая, разумеется, содержит сервер отладки; во-вторых, запись access_log и error_log в отдельные файлы. Изолируя сообщения, сгенерированные ошибочными запросами на рабочие сервера, можно легко соотнести их с ошибками, которые сгенерируются на самом отладочном сервере.
Отметим, что директива access_log ссылается на отдельный формат логирования — detailed. Этот формат можно определить, указав в директиве log_format на уровне http следующие значения:
log_format detailed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_length $request_time '
'$upstream_response_length $upstream_response_time '
'$upstream_status';
Формат detailed расширяет формат по умолчанию combined добавлением пяти переменных, которые предоставляют дополнительную информацию о запросе к отладочному серверу и его ответе.
$request_length– полный размер запроса, включая заголовки и тело, в байтах$request_time– время обработки запроса, в миллисекундах$upstream_response_length– длинна ответа полученного от отладочного сервера, в байтах$upstream_response_time– время затраченное на получение ответа от отладочного сервера, в миллисекундах$upstream_status– код статуса ответа от отладочного сервера
Перечисленные выше дополнительные поля в логе очень полезны для детектирования некорректных запросов и запросов с большим временем выполнения. Последние могут указывать на неверные таймауты в приложении или другие межпроцессные коммуникационные проблемы.
Идемпотентность при переотправке запросов
Возможно, в некоторых случаях, хочется избежать перенаправления запросов на сервер отладки. Например, если в приложении произошла ошибка при попытке изменить несколько записей в базе данных, то новый запрос может повторить обращение к базе данных и внести изменения ещё раз. Это может привести к беспорядку в базе данных.
Поэтому безопасно переотправлять запрос можно только в случае, если он идемпотентный – то есть запрос, при повторных отправках которого, результат будет один и тот же. HTTP GET, PUT, и DELETE методы идемпотентны, в то время как POST – нет. Однако, стоит отметить, что идемпотентность HTTP методов может зависеть от реализации приложения и отличаться от формально определенных.
Есть три варианта как обрабатывать идемпотентность на отладочном сервере:
- Запустить отладочный сервер в режиме read-only для базы данных. В таком случае переотправка запросов безопасна, так как не вносит никаких изменений. Логирование запросов на отладочном сервере будет происходить без изменений, но меньше информации будет доступно для диагностики проблемы (из-за режима read-only).
- Переотправлять на отладочный сервер только идемпотентные запросы.
- Развернуть второй отладочный сервер в режиме read-only для базы данных и переотправлять на него неидемпотентные запросы, а идемпотентные продолжать отправлять на основной сервер отладки. В таком случае будут обрабатываться все запросы, но потребуется дополнительная настройка.
Для полноты картины, рассмотрим конфигурацию для третьего варианта:
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
upstream readonly_server {
server 172.16.0.10 max_conns=20;
}
map $request_method $debug_location {
'POST' @readonly;
'LOCK' @readonly;
'PATCH' @readonly;
default @debug;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 $debug_location;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
location @readonly {
proxy_pass http://readonly_server;
access_log /var/log/nginx/access_readonly_server.log detailed;
error_log /var/log/nginx/error_readonly_server.log;
}
}
Используя директиву map с переменной $request_method, в зависимости от идемпотентности метода, устанавливается значение новой переменной $debug_location. При срабатывании директивы error_page вычисляется переменная $debug_location, и определяется, на какой именно отладочный сервер будет переотправляться запрос.
Нередко для повторной отправки неудавшихся запросов на остальные сервера в upstream (перед отправкой на отладочный сервер) используется директива proxy_next_upstream. Хотя, как правило, это используется для ошибок на сетевом уровне, но возможно также расширение и для 5xx ошибок. Начиная с версии NGINX 1.9.13 неидемпотентные запросы, которые приводят к ошибкам 5xx, не переотправляются по умолчанию. Для включения такого поведения, нужно добавить параметр non_idempotent в директиве proxy_next_upstream. Такое же поведение реализовано в NGINX Plus начиная с версии R9 (апрель 2016г.).
location / {
proxy_pass http://app_server;
proxy_next_upstream http_500 http_503 http_504 non_idempotent;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
Заключение
Не стоит игнорировать ошибки 5хх. Если вы используете модель DevOps, экспериментируете с Continuous Delivery или просто желаете уменьшить риск при обновлениях — NGINX предоставляет инструменты, которые могут помочь лучше реагировать на возникающие проблемы.
I have a Sinatra application hosted with Unicorn, and nginx in front of it. When the Sinatra application errors out (returns 500), I’d like to serve a static page, rather than the default «Internal Server Error». I have the following nginx configuration:
server {
listen 80 default;
server_name *.example.com;
root /home/deploy/www-frontend/current/public;
location / {
proxy_pass_header Server;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_connect_timeout 5;
proxy_read_timeout 240;
proxy_pass http://127.0.0.1:4701/;
}
error_page 500 502 503 504 /50x.html;
}
The error_page directive is there, and I have sudo’d as www-data (Ubuntu) and verified I can cat the file, thus it’s not a permission problem. With the above config file, and service nginx reload, the page I receive on error is still the same «Internal Server Error».
What’s my error?
asked Jan 3, 2012 at 16:10
![]()
error_page handles errors that are generated by nginx. By default, nginx will return whatever the proxy server returns regardless of http status code.
What you’re looking for is proxy_intercept_errors
This directive decides if nginx will intercept responses with HTTP
status codes of 400 and higher.By default all responses will be sent as-is from the proxied server.
If you set this to on then nginx will intercept status codes that are
explicitly handled by an error_page directive. Responses with status
codes that do not match an error_page directive will be sent as-is
from the proxied server.
![]()
Golu
4165 silver badges16 bronze badges
answered Jan 3, 2012 at 16:48
![]()
Stephen EmslieStephen Emslie
10.1k9 gold badges31 silver badges28 bronze badges
3
You can set proxy_intercept_errors especially for that location
location /some/location {
proxy_pass_header Server;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_connect_timeout 5;
proxy_read_timeout 240;
proxy_pass http://127.0.0.1:4701/;
proxy_intercept_errors on; # see http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_intercept_errors
error_page 400 500 404 ... other statuses ... =200 /your/path/for/custom/errors;
}
and you can set instead 200 other status what you need
![]()
Trenton
1,3981 gold badge9 silver badges7 bronze badges
answered Dec 24, 2012 at 17:58
![]()
3
People who are using FastCGI as their upstream need this parameter turned on
fastcgi_intercept_errors on;
For my PHP application, I am using it in my upstream configuration block
location ~ .php$ { ## Execute PHP scripts
fastcgi_pass php-upstream;
fastcgi_intercept_errors on;
error_page 500 /500.html;
}
answered Nov 22, 2017 at 4:40
![]()
Aftab NaveedAftab Naveed
3,5723 gold badges25 silver badges40 bronze badges
As mentioned by Stephen in this response, using proxy_intercept_errors on; can work.
Though in my case, as seen in this answer, using uwsgi_intercept_errors on; did the trick…
![]()
answered Feb 13, 2017 at 22:29
![]()
ppythonppython
4756 silver badges19 bronze badges
Is it possible to change the fallback error_page based on the response of the upstream proxy?
upstream serverA {
server servera.com;
}
upstream serverB {
server serverb.com;
}
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for
proxy_set_header Host $host;
proxy_pass http://serverA;
proxy_intercept_errors on;
# if serverA returns 'hard' 404
# IE returns X-HARD-404=true header
return 404;
# else I would like to fallback to server-b
error_page 403 404 500 502 504 = @serverB;
}
The reason I would like to do this is to an issue with our setup. Usually we send a request to server-a and if that returns a 404, we ask server-b to return the page. In this case, we do not want server-b to return its page, and we want to explicitly return a 404 without trying server-b.
asked Jun 19, 2014 at 21:57
![]()
Nathan LeeNathan Lee
1311 silver badge5 bronze badges
You could also serve the error page direct from nginx.
If serverA gives a 404, send 404.html from /your/nginx/html/directory/ without involving serverB
server {
listen 80;
location / {
proxy_pass http://serverA/;
proxy_intercept_errors on;
proxy_redirect off;
error_page 404 /404.html;
}
location /404.html {
root /your/nginx/html/directory/;
}
}
answered Jun 20, 2014 at 11:35
![]()
John AuldJohn Auld
5942 silver badges6 bronze badges
You could try this:
location / {
...
error_page 404 = @check_header;
error_page 403 500 502 504 = @serverB;
}
location @check_header {
if ($upstream_http_x_hard_404) {
return 404;
}
return 403;
error_page 403 = @serverB;
}
answered Jun 20, 2014 at 11:03
![]()
Alexey TenAlexey Ten
8,11031 silver badges35 bronze badges
If a 5xx happens and no one is around to see it, is it still an error?

No matter how rigorously or how long you test your software, there’s nothing like the production environment to uncover bugs. Whether it’s caused by a weird race condition that happens only under the unpredictable concurrency patterns of live traffic, or an input validation blow‑up for data you couldn’t imagine a user ever typing, “throwing a 500” is a big deal.
HTTP 5xx error messages are highly visible to your users, highly embarrassing for the business, and can lead to reputational damage in a very short space of time. Furthermore, debugging them in your production environment can be extremely difficult. For starters, the sheer volume of log data can make the job of isolating a problematic session like searching for a needle in a haystack. And even when you have collated logs from all components, you may still not have enough data to understand the problem.
When using NGINX as a reverse proxy or load balancer for your application, there are a number of features that can assist you with debugging in a production environment. In this blog post we will describe a specific use of the error_page directive as we explore a typical reverse proxy application infrastructure, with a twist.
Introducing the Debug Server
The twist is that we’re going to set up a special application server – we’ll call it the Debug Server – and feed it only requests that have caused errors on a regular application server. We’re taking advantage of how NGINX can detect 5xx errors coming back from an upstream application server and retry the responsible requests with a different upstream group, in our case the one containing the Debug Server. This means that Debug Server only receives requests that have already produced errors, so its log files contain only erroneous events, ready for investigation. This reduces the scope of your needle search from a haystack to merely a handful of needles.
Unlike the main application servers, the Debug Server does not have to be built for performance. Therefore you can enable all of the available logging and diagnostic tools at your disposal, such as:
- Running your application in debug mode, with full stack trace enabled
- Debug logging of application servers
- Application profiling, so that interprocess timeouts can be identified
- Logging of server resource usage
Debugging tools like these are usually reserved for a development environment, because production environments are tuned for performance. However, as the Debug Server only ever receives erroneous requests, you can safely enable debug mode on as many components as possible.
Here’s what our application infrastructure looks like.
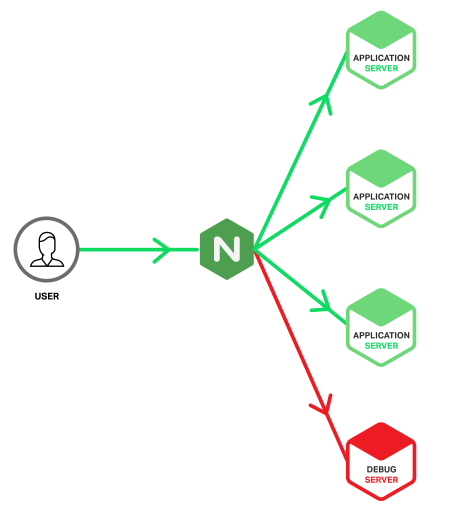
Ideally, the provisioning and configuration of the Debug Server is identical to the application servers, but there are also benefits from building the Debug Server as a virtual machine so that it can be cloned and copied for offline analysis. However, this does carry the risk that the server might be overwhelmed if a significant problem produces a sudden spike of 5xx errors. With NGINX Plus you can protect the Debug Server from such spikes by including the max_conns parameter on the server directive to limit the number of concurrent connections sent to it (see the sample configuration below).
Furthermore, because the Debug Server is not as heavily loaded as the main application servers, not everything that generates a 5xx on an application server will cause one on the Debug Server. Such situations may suggest that you are reaching the scaling limits of the main application servers and that resource exhaustion rather than a software bug is responsible. Regardless of the root cause, such situations improve the user experience by saving them from a 5xx error.
Configuration
The following sample NGINX configuration shows how we can configure the Debug Server to receive requests that have already generated a 5xx error on a main application server.
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
}The first thing we do is specify the addresses of our application servers in the upstream app_server block. Then we specify the single address of our Debug Server in the upstream debug_server block.
The first location block configures a simple reverse proxy, using the proxy_pass directive to load balance requests across the application servers in our app_server upstream group (we don’t specify a load‑balancing algorithm, so the default Round Robin algorithm is used). The proxy_intercept_errors directive means that any response with HTTP code 300 or greater is handled by the error_page directive. In our configuration we are intercepting only 500, 503, and 504 errors, and passing them to the @debug location. Any other response codes, such as 404s, are sent back to the client unmodified.
The location @debug block does two things. First, it proxies all requests to the debug_server upstream group, which of course contains our special Debug Server. Second, it writes duplicate log entries into separate access and error log files. By isolating messages generated for erroneous requests on the application servers from regular access messages, you can more easily correlate the errors with those generated on the Debug Server itself.
Note that the access_log directive references a special log format, called detailed. We define the format by including the following log_format directive in the top‑level http context, above the server block.
log_format detailed '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent "$http_referer" '
'"$http_user_agent" $request_length $request_time '
'$upstream_response_length $upstream_response_time '
'$upstream_status';The detailed format extends the default combined format with a further five variables which provide more information about the requests forwarded to the Debug Server and its responses.
$request_length– Total size of the request, including header and body, in bytes$request_time– Request processing time, in milliseconds$upstream_response_length– Length of the response obtained from the Debug Server, in bytes$upstream_response_time– Time spent receiving the response from the Debug Server, in milliseconds$upstream_status– Status code of the response from the Debug Server
These additional fields in the log are very helpful in detecting both malformed and long‑running requests. The latter may point to timeouts within the application or other interprocess communication problems.
Consider Idempotency when Retrying Requests
There are times when you might not want to send failed requests to the Debug Server. For example, if your application or API failed partway through a request that involved making changes to multiple database records, then retrying the request could end up repeating database actions that already completed successfully. This can leave your database in a bigger mess than if you had not retried the failed request at all.
It is safe to retry a request only if it is idempotent – that is, it always has the same result no matter how many times you make it. HTTP GET, PUT, and DELETE requests are defined as idempotent, whereas POST is not (it is nonidempotent). However, exactly what HTTP methods are idempotent for your application may vary from the official definition.
The issue of idempotency gives us three options for our Debug Server:
- Run the Debug Server with a read‑only database connection; repeating requests is safe because no changes are possible anyway. We still log the requests that caused a
5xxerror but there is less diagnostic information available from the Debug Server with which to investigate the root cause. - Send only idempotent requests to the Debug Server. This isolates requests that caused a
5xxerror, but not if they used thePOSTmethod. - Deploy a second Debug Server with a read‑only database connection and send the nonidempotent requests to it, while continuing to send idempotent requests to the primary Debug Server. This captures all the failed requests but requires a second server and more configuration.
In the interests of completeness, let’s look at the configuration for option 3, with changes from the previous configuration highlighted.
upstream app_server {
server 172.16.0.1;
server 172.16.0.2;
server 172.16.0.3;
}
upstream debug_server {
server 172.16.0.9 max_conns=20;
}
upstream readonly_server {
server 172.16.0.10 max_conns=20;
}
map $request_method $debug_location {
'POST' @readonly;
'LOCK' @readonly;
'PATCH' @readonly;
default @debug;
}
server {
listen *:80;
location / {
proxy_pass http://app_server;
proxy_intercept_errors on;
error_page 500 503 504 $debug_location;
}
location @debug {
proxy_pass http://debug_server;
access_log /var/log/nginx/access_debug_server.log detailed;
error_log /var/log/nginx/error_debug_server.log;
}
location @readonly {
proxy_pass http://readonly_server;
access_log /var/log/nginx/access_readonly_server.log detailed;
error_log /var/log/nginx/error_readonly_server.log;
}
}With our new read‑only Debug Server in place, the map directive uses the $request_method variable to set a new variable, $debug_location, based on the idempotency of the request method. When we hit the error_page directive, we use the $debug_location variable to direct processing of the request to the Debug Server appropriate for the HTTP method used in the request.
It is common to use the proxy_next_upstream directive to have NGINX retry a failed request on the remaining servers in the upstream group (before trying the Debug Server). Though typically used for network‑level errors, it can also be extended to 5xx errors. In NGINX Open Source 1.9.13 and later, nonidempotent requests that fail with 5xx errors are not retried by default. If it’s acceptable to retry nonidempotent requests, add the non_idempotent parameter to the proxy_next_upstream directive. This behavior and the new parameter are also enabled in NGINX Plus R9 and later.
location / {
proxy_pass http://app_server;
proxy_next_upstream http_500 http_503 http_504 non_idempotent;
proxy_intercept_errors on;
error_page 500 503 504 @debug;
}Conclusion
Throwing a 500 is a big deal. Whether you’re running a DevOps model, experimenting with continuous delivery, or simply wanting to mitigate the risk of a big bang upgrade, NGINX provides you with the tools that can help you react better to issues in the wild.
To try out a Debug Server in your own NGINX Plus environment, start your free 30‑day trial today or contact us to discuss your use cases.

Free O’Reilly eBook: The Complete NGINX Cookbook
Updated for 2022 – Your Guide to Everything NGINX
Содержание
- Module ngx_http_proxy_module
- Example Configuration
- Directives
- Embedded Variables

Module ngx_http_proxy_module
The ngx_http_proxy_module module allows passing requests to another server.
Example Configuration
Directives
| Syntax: | proxy_bind address [ transparent ] | off ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 0.8.22.
Makes outgoing connections to a proxied server originate from the specified local IP address with an optional port (1.11.2). Parameter value can contain variables (1.3.12). The special value off (1.3.12) cancels the effect of the proxy_bind directive inherited from the previous configuration level, which allows the system to auto-assign the local IP address and port.
The transparent parameter (1.11.0) allows outgoing connections to a proxied server originate from a non-local IP address, for example, from a real IP address of a client:
In order for this parameter to work, it is usually necessary to run nginx worker processes with the superuser privileges. On Linux it is not required (1.13.8) as if the transparent parameter is specified, worker processes inherit the CAP_NET_RAW capability from the master process. It is also necessary to configure kernel routing table to intercept network traffic from the proxied server.
| Syntax: | proxy_buffer_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the size of the buffer used for reading the first part of the response received from the proxied server. This part usually contains a small response header. By default, the buffer size is equal to one memory page. This is either 4K or 8K, depending on a platform. It can be made smaller, however.
| Syntax: | proxy_buffering on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Enables or disables buffering of responses from the proxied server.
When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives.
When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive.
Buffering can also be enabled or disabled by passing “ yes ” or “ no ” in the “X-Accel-Buffering” response header field. This capability can be disabled using the proxy_ignore_headers directive.
| Syntax: | proxy_buffers number size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the number and size of the buffers used for reading a response from the proxied server, for a single connection. By default, the buffer size is equal to one memory page. This is either 4K or 8K, depending on a platform.
| Syntax: | proxy_busy_buffers_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
When buffering of responses from the proxied server is enabled, limits the total size of buffers that can be busy sending a response to the client while the response is not yet fully read. In the meantime, the rest of the buffers can be used for reading the response and, if needed, buffering part of the response to a temporary file. By default, size is limited by the size of two buffers set by the proxy_buffer_size and proxy_buffers directives.
| Syntax: | proxy_cache zone | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Defines a shared memory zone used for caching. The same zone can be used in several places. Parameter value can contain variables (1.7.9). The off parameter disables caching inherited from the previous configuration level.
| Syntax: | proxy_cache_background_update on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.11.10.
Allows starting a background subrequest to update an expired cache item, while a stale cached response is returned to the client. Note that it is necessary to allow the usage of a stale cached response when it is being updated.
| Syntax: | proxy_cache_bypass string . ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Defines conditions under which the response will not be taken from a cache. If at least one value of the string parameters is not empty and is not equal to “0” then the response will not be taken from the cache:
Can be used along with the proxy_no_cache directive.
| Syntax: | proxy_cache_convert_head on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.9.7.
Enables or disables the conversion of the “ HEAD ” method to “ GET ” for caching. When the conversion is disabled, the cache key should be configured to include the $request_method .
| Syntax: | proxy_cache_key string ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Defines a key for caching, for example
By default, the directive’s value is close to the string
| Syntax: | proxy_cache_lock on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.1.12.
When enabled, only one request at a time will be allowed to populate a new cache element identified according to the proxy_cache_key directive by passing a request to a proxied server. Other requests of the same cache element will either wait for a response to appear in the cache or the cache lock for this element to be released, up to the time set by the proxy_cache_lock_timeout directive.
| Syntax: | proxy_cache_lock_age time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.8.
If the last request passed to the proxied server for populating a new cache element has not completed for the specified time , one more request may be passed to the proxied server.
| Syntax: | proxy_cache_lock_timeout time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.1.12.
Sets a timeout for proxy_cache_lock. When the time expires, the request will be passed to the proxied server, however, the response will not be cached.
Before 1.7.8, the response could be cached.
| Syntax: | proxy_cache_max_range_offset number ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.11.6.
Sets an offset in bytes for byte-range requests. If the range is beyond the offset, the range request will be passed to the proxied server and the response will not be cached.
| Syntax: | proxy_cache_methods GET | HEAD | POST . ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 0.7.59.
If the client request method is listed in this directive then the response will be cached. “ GET ” and “ HEAD ” methods are always added to the list, though it is recommended to specify them explicitly. See also the proxy_no_cache directive.
| Syntax: | proxy_cache_min_uses number ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the number of requests after which the response will be cached.
| Syntax: | proxy_cache_path path [ levels = levels ] [ use_temp_path = on | off ] keys_zone = name : size [ inactive = time ] [ max_size = size ] [ min_free = size ] [ manager_files = number ] [ manager_sleep = time ] [ manager_threshold = time ] [ loader_files = number ] [ loader_sleep = time ] [ loader_threshold = time ] [ purger = on | off ] [ purger_files = number ] [ purger_sleep = time ] [ purger_threshold = time ]; |
|---|---|
| Default: | — |
| Context: | http |
Sets the path and other parameters of a cache. Cache data are stored in files. The file name in a cache is a result of applying the MD5 function to the cache key. The levels parameter defines hierarchy levels of a cache: from 1 to 3, each level accepts values 1 or 2. For example, in the following configuration
file names in a cache will look like this:
A cached response is first written to a temporary file, and then the file is renamed. Starting from version 0.8.9, temporary files and the cache can be put on different file systems. However, be aware that in this case a file is copied across two file systems instead of the cheap renaming operation. It is thus recommended that for any given location both cache and a directory holding temporary files are put on the same file system. The directory for temporary files is set based on the use_temp_path parameter (1.7.10). If this parameter is omitted or set to the value on , the directory set by the proxy_temp_path directive for the given location will be used. If the value is set to off , temporary files will be put directly in the cache directory.
In addition, all active keys and information about data are stored in a shared memory zone, whose name and size are configured by the keys_zone parameter. One megabyte zone can store about 8 thousand keys.
As part of commercial subscription, the shared memory zone also stores extended cache information, thus, it is required to specify a larger zone size for the same number of keys. For example, one megabyte zone can store about 4 thousand keys.
Cached data that are not accessed during the time specified by the inactive parameter get removed from the cache regardless of their freshness. By default, inactive is set to 10 minutes.
The special “cache manager” process monitors the maximum cache size set by the max_size parameter, and the minimum amount of free space set by the min_free (1.19.1) parameter on the file system with cache. When the size is exceeded or there is not enough free space, it removes the least recently used data. The data is removed in iterations configured by manager_files , manager_threshold , and manager_sleep parameters (1.11.5). During one iteration no more than manager_files items are deleted (by default, 100). The duration of one iteration is limited by the manager_threshold parameter (by default, 200 milliseconds). Between iterations, a pause configured by the manager_sleep parameter (by default, 50 milliseconds) is made.
A minute after the start the special “cache loader” process is activated. It loads information about previously cached data stored on file system into a cache zone. The loading is also done in iterations. During one iteration no more than loader_files items are loaded (by default, 100). Besides, the duration of one iteration is limited by the loader_threshold parameter (by default, 200 milliseconds). Between iterations, a pause configured by the loader_sleep parameter (by default, 50 milliseconds) is made.
Additionally, the following parameters are available as part of our commercial subscription:
purger = on | off Instructs whether cache entries that match a wildcard key will be removed from the disk by the cache purger (1.7.12). Setting the parameter to on (default is off ) will activate the “cache purger” process that permanently iterates through all cache entries and deletes the entries that match the wildcard key. purger_files = number Sets the number of items that will be scanned during one iteration (1.7.12). By default, purger_files is set to 10. purger_threshold = number Sets the duration of one iteration (1.7.12). By default, purger_threshold is set to 50 milliseconds. purger_sleep = number Sets a pause between iterations (1.7.12). By default, purger_sleep is set to 50 milliseconds.
In versions 1.7.3, 1.7.7, and 1.11.10 cache header format has been changed. Previously cached responses will be considered invalid after upgrading to a newer nginx version.
| Syntax: | proxy_cache_purge string . ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.5.7.
Defines conditions under which the request will be considered a cache purge request. If at least one value of the string parameters is not empty and is not equal to “0” then the cache entry with a corresponding cache key is removed. The result of successful operation is indicated by returning the 204 (No Content) response.
If the cache key of a purge request ends with an asterisk (“ * ”), all cache entries matching the wildcard key will be removed from the cache. However, these entries will remain on the disk until they are deleted for either inactivity, or processed by the cache purger (1.7.12), or a client attempts to access them.
| Syntax: | proxy_cache_revalidate on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.5.7.
Enables revalidation of expired cache items using conditional requests with the “If-Modified-Since” and “If-None-Match” header fields.
| Syntax: | proxy_cache_use_stale error | timeout | invalid_header | updating | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | off . ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Determines in which cases a stale cached response can be used during communication with the proxied server. The directive’s parameters match the parameters of the proxy_next_upstream directive.
The error parameter also permits using a stale cached response if a proxied server to process a request cannot be selected.
Additionally, the updating parameter permits using a stale cached response if it is currently being updated. This allows minimizing the number of accesses to proxied servers when updating cached data.
Using a stale cached response can also be enabled directly in the response header for a specified number of seconds after the response became stale (1.11.10). This has lower priority than using the directive parameters.
- The “stale-while-revalidate” extension of the “Cache-Control” header field permits using a stale cached response if it is currently being updated.
- The “stale-if-error” extension of the “Cache-Control” header field permits using a stale cached response in case of an error.
To minimize the number of accesses to proxied servers when populating a new cache element, the proxy_cache_lock directive can be used.
| Syntax: | proxy_cache_valid [ code . ] time ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Sets caching time for different response codes. For example, the following directives
set 10 minutes of caching for responses with codes 200 and 302 and 1 minute for responses with code 404.
If only caching time is specified
then only 200, 301, and 302 responses are cached.
In addition, the any parameter can be specified to cache any responses:
Parameters of caching can also be set directly in the response header. This has higher priority than setting of caching time using the directive.
- The “X-Accel-Expires” header field sets caching time of a response in seconds. The zero value disables caching for a response. If the value starts with the @ prefix, it sets an absolute time in seconds since Epoch, up to which the response may be cached.
- If the header does not include the “X-Accel-Expires” field, parameters of caching may be set in the header fields “Expires” or “Cache-Control”.
- If the header includes the “Set-Cookie” field, such a response will not be cached.
- If the header includes the “Vary” field with the special value “ * ”, such a response will not be cached (1.7.7). If the header includes the “Vary” field with another value, such a response will be cached taking into account the corresponding request header fields (1.7.7).
Processing of one or more of these response header fields can be disabled using the proxy_ignore_headers directive.
| Syntax: | proxy_connect_timeout time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Defines a timeout for establishing a connection with a proxied server. It should be noted that this timeout cannot usually exceed 75 seconds.
| Syntax: | proxy_cookie_domain off ; proxy_cookie_domain domain replacement ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.1.15.
Sets a text that should be changed in the domain attribute of the “Set-Cookie” header fields of a proxied server response. Suppose a proxied server returned the “Set-Cookie” header field with the attribute “ domain=localhost ”. The directive
will rewrite this attribute to “ domain=example.org ”.
A dot at the beginning of the domain and replacement strings and the domain attribute is ignored. Matching is case-insensitive.
The domain and replacement strings can contain variables:
The directive can also be specified using regular expressions. In this case, domain should start from the “
” symbol. A regular expression can contain named and positional captures, and replacement can reference them:
Several proxy_cookie_domain directives can be specified on the same level:
If several directives can be applied to the cookie, the first matching directive will be chosen.
The off parameter cancels the effect of the proxy_cookie_domain directives inherited from the previous configuration level.
| Syntax: | proxy_cookie_flags off | cookie [ flag . ]; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.19.3.
Sets one or more flags for the cookie. The cookie can contain text, variables, and their combinations. The flag can contain text, variables, and their combinations (1.19.8). The secure , httponly , samesite=strict , samesite=lax , samesite=none parameters add the corresponding flags. The nosecure , nohttponly , nosamesite parameters remove the corresponding flags.
The cookie can also be specified using regular expressions. In this case, cookie should start from the “
Several proxy_cookie_flags directives can be specified on the same configuration level:
If several directives can be applied to the cookie, the first matching directive will be chosen. In the example, the httponly flag is added to the cookie one , for all other cookies the samesite=strict flag is added and the secure flag is deleted.
The off parameter cancels the effect of the proxy_cookie_flags directives inherited from the previous configuration level.
| Syntax: | proxy_cookie_path off ; proxy_cookie_path path replacement ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.1.15.
Sets a text that should be changed in the path attribute of the “Set-Cookie” header fields of a proxied server response. Suppose a proxied server returned the “Set-Cookie” header field with the attribute “ path=/two/some/uri/ ”. The directive
will rewrite this attribute to “ path=/some/uri/ ”.
The path and replacement strings can contain variables:
The directive can also be specified using regular expressions. In this case, path should either start from the “
” symbol for a case-sensitive matching, or from the “
* ” symbols for case-insensitive matching. The regular expression can contain named and positional captures, and replacement can reference them:
Several proxy_cookie_path directives can be specified on the same level:
If several directives can be applied to the cookie, the first matching directive will be chosen.
The off parameter cancels the effect of the proxy_cookie_path directives inherited from the previous configuration level.
| Syntax: | proxy_force_ranges on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.7.
Enables byte-range support for both cached and uncached responses from the proxied server regardless of the “Accept-Ranges” field in these responses.
| Syntax: | proxy_headers_hash_bucket_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the bucket size for hash tables used by the proxy_hide_header and proxy_set_header directives. The details of setting up hash tables are provided in a separate document.
| Syntax: | proxy_headers_hash_max_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the maximum size of hash tables used by the proxy_hide_header and proxy_set_header directives. The details of setting up hash tables are provided in a separate document.
| Syntax: | proxy_hide_header field ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
By default, nginx does not pass the header fields “Date”, “Server”, “X-Pad”, and “X-Accel-. ” from the response of a proxied server to a client. The proxy_hide_header directive sets additional fields that will not be passed. If, on the contrary, the passing of fields needs to be permitted, the proxy_pass_header directive can be used.
| Syntax: | proxy_http_version 1.0 | 1.1 ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.1.4.
Sets the HTTP protocol version for proxying. By default, version 1.0 is used. Version 1.1 is recommended for use with keepalive connections and NTLM authentication.
| Syntax: | proxy_ignore_client_abort on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Determines whether the connection with a proxied server should be closed when a client closes the connection without waiting for a response.
| Syntax: | proxy_ignore_headers field . ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Disables processing of certain response header fields from the proxied server. The following fields can be ignored: “X-Accel-Redirect”, “X-Accel-Expires”, “X-Accel-Limit-Rate” (1.1.6), “X-Accel-Buffering” (1.1.6), “X-Accel-Charset” (1.1.6), “Expires”, “Cache-Control”, “Set-Cookie” (0.8.44), and “Vary” (1.7.7).
If not disabled, processing of these header fields has the following effect:
- “X-Accel-Expires”, “Expires”, “Cache-Control”, “Set-Cookie”, and “Vary” set the parameters of response caching;
- “X-Accel-Redirect” performs an internal redirect to the specified URI;
- “X-Accel-Limit-Rate” sets the rate limit for transmission of a response to a client;
- “X-Accel-Buffering” enables or disables buffering of a response;
- “X-Accel-Charset” sets the desired charset of a response.
| Syntax: | proxy_intercept_errors on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Determines whether proxied responses with codes greater than or equal to 300 should be passed to a client or be intercepted and redirected to nginx for processing with the error_page directive.
| Syntax: | proxy_limit_rate rate ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.7.
Limits the speed of reading the response from the proxied server. The rate is specified in bytes per second. The zero value disables rate limiting. The limit is set per a request, and so if nginx simultaneously opens two connections to the proxied server, the overall rate will be twice as much as the specified limit. The limitation works only if buffering of responses from the proxied server is enabled.
| Syntax: | proxy_max_temp_file_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
When buffering of responses from the proxied server is enabled, and the whole response does not fit into the buffers set by the proxy_buffer_size and proxy_buffers directives, a part of the response can be saved to a temporary file. This directive sets the maximum size of the temporary file. The size of data written to the temporary file at a time is set by the proxy_temp_file_write_size directive.
The zero value disables buffering of responses to temporary files.
This restriction does not apply to responses that will be cached or stored on disk.
| Syntax: | proxy_method method ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Specifies the HTTP method to use in requests forwarded to the proxied server instead of the method from the client request. Parameter value can contain variables (1.11.6).
| Syntax: | proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | non_idempotent | off . ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Specifies in which cases a request should be passed to the next server:
error an error occurred while establishing a connection with the server, passing a request to it, or reading the response header; timeout a timeout has occurred while establishing a connection with the server, passing a request to it, or reading the response header; invalid_header a server returned an empty or invalid response; http_500 a server returned a response with the code 500; http_502 a server returned a response with the code 502; http_503 a server returned a response with the code 503; http_504 a server returned a response with the code 504; http_403 a server returned a response with the code 403; http_404 a server returned a response with the code 404; http_429 a server returned a response with the code 429 (1.11.13); non_idempotent normally, requests with a non-idempotent method ( POST , LOCK , PATCH ) are not passed to the next server if a request has been sent to an upstream server (1.9.13); enabling this option explicitly allows retrying such requests; off disables passing a request to the next server.
One should bear in mind that passing a request to the next server is only possible if nothing has been sent to a client yet. That is, if an error or timeout occurs in the middle of the transferring of a response, fixing this is impossible.
The directive also defines what is considered an unsuccessful attempt of communication with a server. The cases of error , timeout and invalid_header are always considered unsuccessful attempts, even if they are not specified in the directive. The cases of http_500 , http_502 , http_503 , http_504 , and http_429 are considered unsuccessful attempts only if they are specified in the directive. The cases of http_403 and http_404 are never considered unsuccessful attempts.
Passing a request to the next server can be limited by the number of tries and by time.
| Syntax: | proxy_next_upstream_timeout time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.5.
Limits the time during which a request can be passed to the next server. The 0 value turns off this limitation.
| Syntax: | proxy_next_upstream_tries number ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.5.
Limits the number of possible tries for passing a request to the next server. The 0 value turns off this limitation.
| Syntax: | proxy_no_cache string . ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Defines conditions under which the response will not be saved to a cache. If at least one value of the string parameters is not empty and is not equal to “0” then the response will not be saved:
Can be used along with the proxy_cache_bypass directive.
| Syntax: | proxy_pass URL ; |
|---|---|
| Default: | — |
| Context: | location , if in location , limit_except |
Sets the protocol and address of a proxied server and an optional URI to which a location should be mapped. As a protocol, “ http ” or “ https ” can be specified. The address can be specified as a domain name or IP address, and an optional port:
or as a UNIX-domain socket path specified after the word “ unix ” and enclosed in colons:
If a domain name resolves to several addresses, all of them will be used in a round-robin fashion. In addition, an address can be specified as a server group.
Parameter value can contain variables. In this case, if an address is specified as a domain name, the name is searched among the described server groups, and, if not found, is determined using a resolver.
A request URI is passed to the server as follows:
- If the proxy_pass directive is specified with a URI, then when a request is passed to the server, the part of a normalized request URI matching the location is replaced by a URI specified in the directive:
Before version 1.1.12, if proxy_pass is specified without a URI, the original request URI might be passed instead of the changed URI in some cases.
In some cases, the part of a request URI to be replaced cannot be determined:
- When location is specified using a regular expression, and also inside named locations.
In these cases, proxy_pass should be specified without a URI.
When the URI is changed inside a proxied location using the rewrite directive, and this same configuration will be used to process a request ( break ):
In this case, the URI specified in the directive is ignored and the full changed request URI is passed to the server.
When variables are used in proxy_pass :
WebSocket proxying requires special configuration and is supported since version 1.3.13.
| Syntax: | proxy_pass_header field ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Permits passing otherwise disabled header fields from a proxied server to a client.
| Syntax: | proxy_pass_request_body on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Indicates whether the original request body is passed to the proxied server.
| Syntax: | proxy_pass_request_headers on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Indicates whether the header fields of the original request are passed to the proxied server.
| Syntax: | proxy_read_timeout time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Defines a timeout for reading a response from the proxied server. The timeout is set only between two successive read operations, not for the transmission of the whole response. If the proxied server does not transmit anything within this time, the connection is closed.
| Syntax: | proxy_redirect default ; proxy_redirect off ; proxy_redirect redirect replacement ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets the text that should be changed in the “Location” and “Refresh” header fields of a proxied server response. Suppose a proxied server returned the header field “ Location: http://localhost:8000/two/some/uri/ ”. The directive
will rewrite this string to “ Location: http://frontend/one/some/uri/ ”.
A server name may be omitted in the replacement string:
then the primary server’s name and port, if different from 80, will be inserted.
The default replacement specified by the default parameter uses the parameters of the location and proxy_pass directives. Hence, the two configurations below are equivalent:
The default parameter is not permitted if proxy_pass is specified using variables.
A replacement string can contain variables:
A redirect can also contain (1.1.11) variables:
The directive can be specified (1.1.11) using regular expressions. In this case, redirect should either start with the “
” symbol for a case-sensitive matching, or with the “
* ” symbols for case-insensitive matching. The regular expression can contain named and positional captures, and replacement can reference them:
Several proxy_redirect directives can be specified on the same level:
If several directives can be applied to the header fields of a proxied server response, the first matching directive will be chosen.
The off parameter cancels the effect of the proxy_redirect directives inherited from the previous configuration level.
Using this directive, it is also possible to add host names to relative redirects issued by a proxied server:
| Syntax: | proxy_request_buffering on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.11.
Enables or disables buffering of a client request body.
When buffering is enabled, the entire request body is read from the client before sending the request to a proxied server.
When buffering is disabled, the request body is sent to the proxied server immediately as it is received. In this case, the request cannot be passed to the next server if nginx already started sending the request body.
When HTTP/1.1 chunked transfer encoding is used to send the original request body, the request body will be buffered regardless of the directive value unless HTTP/1.1 is enabled for proxying.
| Syntax: | proxy_send_lowat size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
If the directive is set to a non-zero value, nginx will try to minimize the number of send operations on outgoing connections to a proxied server by using either NOTE_LOWAT flag of the kqueue method, or the SO_SNDLOWAT socket option, with the specified size .
This directive is ignored on Linux, Solaris, and Windows.
| Syntax: | proxy_send_timeout time ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets a timeout for transmitting a request to the proxied server. The timeout is set only between two successive write operations, not for the transmission of the whole request. If the proxied server does not receive anything within this time, the connection is closed.
| Syntax: | proxy_set_body value ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
Allows redefining the request body passed to the proxied server. The value can contain text, variables, and their combination.
| Syntax: | proxy_set_header field value ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Allows redefining or appending fields to the request header passed to the proxied server. The value can contain text, variables, and their combinations. These directives are inherited from the previous configuration level if and only if there are no proxy_set_header directives defined on the current level. By default, only two fields are redefined:
If caching is enabled, the header fields “If-Modified-Since”, “If-Unmodified-Since”, “If-None-Match”, “If-Match”, “Range”, and “If-Range” from the original request are not passed to the proxied server.
An unchanged “Host” request header field can be passed like this:
However, if this field is not present in a client request header then nothing will be passed. In such a case it is better to use the $host variable — its value equals the server name in the “Host” request header field or the primary server name if this field is not present:
In addition, the server name can be passed together with the port of the proxied server:
If the value of a header field is an empty string then this field will not be passed to a proxied server:
| Syntax: | proxy_socket_keepalive on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.15.6.
Configures the “TCP keepalive” behavior for outgoing connections to a proxied server. By default, the operating system’s settings are in effect for the socket. If the directive is set to the value “ on ”, the SO_KEEPALIVE socket option is turned on for the socket.
| Syntax: | proxy_ssl_certificate file ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.7.8.
Specifies a file with the certificate in the PEM format used for authentication to a proxied HTTPS server.
Since version 1.21.0, variables can be used in the file name.
| Syntax: | proxy_ssl_certificate_key file ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.7.8.
Specifies a file with the secret key in the PEM format used for authentication to a proxied HTTPS server.
The value engine : name : id can be specified instead of the file (1.7.9), which loads a secret key with a specified id from the OpenSSL engine name .
Since version 1.21.0, variables can be used in the file name.
| Syntax: | proxy_ssl_ciphers ciphers ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.5.6.
Specifies the enabled ciphers for requests to a proxied HTTPS server. The ciphers are specified in the format understood by the OpenSSL library.
The full list can be viewed using the “ openssl ciphers ” command.
| Syntax: | proxy_ssl_conf_command name value ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.19.4.
Sets arbitrary OpenSSL configuration commands when establishing a connection with the proxied HTTPS server.
The directive is supported when using OpenSSL 1.0.2 or higher.
Several proxy_ssl_conf_command directives can be specified on the same level. These directives are inherited from the previous configuration level if and only if there are no proxy_ssl_conf_command directives defined on the current level.
Note that configuring OpenSSL directly might result in unexpected behavior.
| Syntax: | proxy_ssl_crl file ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Specifies a file with revoked certificates (CRL) in the PEM format used to verify the certificate of the proxied HTTPS server.
| Syntax: | proxy_ssl_name name ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Allows overriding the server name used to verify the certificate of the proxied HTTPS server and to be passed through SNI when establishing a connection with the proxied HTTPS server.
By default, the host part of the proxy_pass URL is used.
| Syntax: | proxy_ssl_password_file file ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.7.8.
Specifies a file with passphrases for secret keys where each passphrase is specified on a separate line. Passphrases are tried in turn when loading the key.
| Syntax: | proxy_ssl_protocols [ SSLv2 ] [ SSLv3 ] [ TLSv1 ] [ TLSv1.1 ] [ TLSv1.2 ] [ TLSv1.3 ]; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.5.6.
Enables the specified protocols for requests to a proxied HTTPS server.
| Syntax: | proxy_ssl_server_name on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Enables or disables passing of the server name through TLS Server Name Indication extension (SNI, RFC 6066) when establishing a connection with the proxied HTTPS server.
| Syntax: | proxy_ssl_session_reuse on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Determines whether SSL sessions can be reused when working with the proxied server. If the errors “ SSL3_GET_FINISHED:digest check failed ” appear in the logs, try disabling session reuse.
| Syntax: | proxy_ssl_trusted_certificate file ; |
|---|---|
| Default: | — |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Specifies a file with trusted CA certificates in the PEM format used to verify the certificate of the proxied HTTPS server.
| Syntax: | proxy_ssl_verify on | off ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Enables or disables verification of the proxied HTTPS server certificate.
| Syntax: | proxy_ssl_verify_depth number ; |
|---|---|
| Default: | |
| Context: | http , server , location |
This directive appeared in version 1.7.0.
Sets the verification depth in the proxied HTTPS server certificates chain.
| Syntax: | proxy_store on | off | string ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Enables saving of files to a disk. The on parameter saves files with paths corresponding to the directives alias or root. The off parameter disables saving of files. In addition, the file name can be set explicitly using the string with variables:
The modification time of files is set according to the received “Last-Modified” response header field. The response is first written to a temporary file, and then the file is renamed. Starting from version 0.8.9, temporary files and the persistent store can be put on different file systems. However, be aware that in this case a file is copied across two file systems instead of the cheap renaming operation. It is thus recommended that for any given location both saved files and a directory holding temporary files, set by the proxy_temp_path directive, are put on the same file system.
This directive can be used to create local copies of static unchangeable files, e.g.:
| Syntax: | proxy_store_access users : permissions . ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Sets access permissions for newly created files and directories, e.g.:
If any group or all access permissions are specified then user permissions may be omitted:
| Syntax: | proxy_temp_file_write_size size ; |
|---|---|
| Default: | |
| Context: | http , server , location |
Limits the size of data written to a temporary file at a time, when buffering of responses from the proxied server to temporary files is enabled. By default, size is limited by two buffers set by the proxy_buffer_size and proxy_buffers directives. The maximum size of a temporary file is set by the proxy_max_temp_file_size directive.
| Syntax: | proxy_temp_path path [ level1 [ level2 [ level3 ]]]; |
|---|---|
| Default: | |
| Context: | http , server , location |
Defines a directory for storing temporary files with data received from proxied servers. Up to three-level subdirectory hierarchy can be used underneath the specified directory. For example, in the following configuration
a temporary file might look like this:
See also the use_temp_path parameter of the proxy_cache_path directive.
Embedded Variables
The ngx_http_proxy_module module supports embedded variables that can be used to compose headers using the proxy_set_header directive:
$proxy_host name and port of a proxied server as specified in the proxy_pass directive; $proxy_port port of a proxied server as specified in the proxy_pass directive, or the protocol’s default port; $proxy_add_x_forwarded_for the “X-Forwarded-For” client request header field with the $remote_addr variable appended to it, separated by a comma. If the “X-Forwarded-For” field is not present in the client request header, the $proxy_add_x_forwarded_for variable is equal to the $remote_addr variable.
Источник
NGINX Basics
Go to the Table of Contents or What’s next? section.
- ≡ NGINX Basics
- Directories and files
- Commands
- Processes
- CPU pinning
- Shutdown of worker processes
- Configuration syntax
- Comments
- End of lines
- Variables, Strings, and Quotes
- Directives, Blocks, and Contexts
- External files
- Measurement units
- Regular expressions with PCRE
- Enable syntax highlighting
- Connection processing
- Event-Driven architecture
- Multiple processes
- Simultaneous connections
- HTTP Keep-Alive connections
- sendfile, tcp_nodelay, and tcp_nopush
- Request processing stages
- Server blocks logic
- Handle incoming connections
- Matching location
- rewrite vs return
- URL redirections
- try_files directive
- if, break, and set
- root vs alias
- internal directive
- External and internal redirects
- allow and deny
- uri vs request_uri
- Compression and decompression
- What is the best NGINX compression gzip level?
- Hash tables
- Server names hash table
- Log files
- Conditional logging
- Manually log rotation
- Error log severity levels
- How to log the start time of a request?
- How to log the HTTP request body?
- NGINX upstream variables returns 2 values
- Reverse proxy
- Passing requests
- Trailing slashes
- Passing headers to the backend
- Importance of the Host header
- Redirects and X-Forwarded-Proto
- A warning about the X-Forwarded-For
- Improve extensibility with Forwarded
- Response headers
- Load balancing algorithms
- Backend parameters
- Upstream servers with SSL
- Round Robin
- Weighted Round Robin
- Least Connections
- Weighted Least Connections
- IP Hash
- Generic Hash
- Other methods
- Rate limiting
- Variables
- Directives, keys, and zones
- Burst and nodelay parameters
- NAXSI Web Application Firewall
- OWASP ModSecurity Core Rule Set (CRS)
- Core modules
- ngx_http_geo_module
- 3rd party modules
- ngx_set_misc
- ngx_http_geoip_module
Directories and files
If you compile NGINX with default parameters all files and directories are available from
/usr/local/nginxlocation.
For upstream NGINX packaging paths can be as follows (it depends on the type of system/distribution):
-
/etc/nginx— is the default configuration root for the NGINX service- other locations:
/usr/local/etc/nginx,/usr/local/nginx/conf
- other locations:
-
/etc/nginx/nginx.conf— is the default configuration entry point used by the NGINX services, includes the top-level http block and all other configuration contexts and files- other locations:
/usr/local/etc/nginx/nginx.conf,/usr/local/nginx/conf/nginx.conf
- other locations:
-
/usr/share/nginx— is the default root directory for requests, containshtmldirectory and basic static files- other locations:
html/in root directory
- other locations:
-
/var/log/nginx— is the default log (access and error log) location for NGINX- other locations:
logs/in root directory
- other locations:
-
/var/cache/nginx— is the default temporary files location for NGINX- other locations:
/var/lib/nginx
- other locations:
-
/etc/nginx/conf— contains custom/vhosts configuration files- other locations:
/etc/nginx/conf.d,/etc/nginx/sites-enabled(I can’t stand this debian/apache-like convention)
- other locations:
-
/var/run/nginx— contains information about NGINX process(es)- other locations:
/usr/local/nginx/logs,logs/in root directory
- other locations:
See also Installation and Compile-Time Options — Files and Permissions.
Commands
🔖 Use reload option to change configurations on the fly — Base Rules — P2
nginx -h— shows the helpnginx -v— shows the NGINX versionnginx -V— shows the extended information about NGINX: version, build parameters, and configuration argumentsnginx -t— tests the NGINX configurationnginx -c <filename>— sets configuration file (default:/etc/nginx/nginx.conf)nginx -p <directory>— sets prefix path (default:/etc/nginx/)nginx -T— tests the NGINX configuration and prints the validated configuration on the screennginx -s <signal>— sends a signal to the NGINX master process:stop— discontinues the NGINX process immediatelyquit— stops the NGINX process after it finishes processing
inflight requestsreload— reloads the configuration without stopping processesreopen— instructs NGINX to reopen log files
nginx -g <directive>— sets global directives out of configuration file
Some useful snippets for management of the NGINX daemon:
-
testing configuration:
/usr/sbin/nginx -t -c /etc/nginx/nginx.conf /usr/sbin/nginx -t -q -g 'daemon on; master_process on;' # ; echo $? /usr/local/etc/rc.d/nginx status
-
starting daemon:
/usr/sbin/nginx -g 'daemon on; master_process on;' service nginx start systemctl start nginx /usr/local/etc/rc.d/nginx start # You can also start NGINX from start-stop-daemon script: /sbin/start-stop-daemon --quiet --start --exec /usr/sbin/nginx --background --retry QUIT/5 --pidfile /run/nginx.pid
-
stopping daemon:
# graceful shutdown (waiting for the worker processes to finish serving current requests) /usr/sbin/nginx -s quit # fast shutdown (kill connections immediately) /usr/sbin/nginx -s stop service nginx stop systemctl stop nginx /usr/local/etc/rc.d/nginx stop # You can also stop NGINX from start-stop-daemon script: /sbin/start-stop-daemon --quiet --stop --retry QUIT/5 --pidfile /run/nginx.pid
-
reloading daemon:
/usr/sbin/nginx -g 'daemon on; master_process on;' -s reload service nginx reload systemctl reload nginx /usr/local/etc/rc.d/nginx reload kill -HUP $(cat /var/run/nginx.pid) kill -HUP $(pgrep -f "nginx: master")
-
restarting daemon:
service nginx restart systemctl restart nginx /usr/local/etc/rc.d/nginx restart
Something about testing configuration:
You cannot test half-baked configurations. For example, you defined a server section for your domain in a separate file. Any attempt to test such a file will throw errors. The file has to be complete in all respects.
Configuration syntax
🔖 Organising Nginx configuration — Base Rules — P2
🔖 Format, prettify and indent your Nginx code — Base Rules — P2
NGINX uses a micro programming language in the configuration files. This language’s design is heavily influenced by Perl and Bourne Shell. Configuration syntax, formatting and definitions follow a so-called C-style convention. For me, NGINX configuration has a simple and very transparent structure.
Comments
NGINX configuration files don’t support comment blocks, they only accept # at the beginning of a line for a comment.
End of lines
Lines containing directives must end with a semicolon (;), otherwise NGINX will fail to load the configuration and report an error.
Variables, Strings, and Quotes
Variables start with $ and that get set automaticaly for each request. The ability to set variables at runtime and control logic flow based on them is part of the rewrite module and not a general feature of NGINX. By default, we cannot modify built-in variables like $host or $request_uri.
There are some directives that do not support variables, e.g.
access_log(is really the exception because can contain variables with restrictions) orerror_log. Variables probably can’t be (and shouldn’t be because they are evaluated in the run-time during the processing of each request and rather costly compared to plain static configuration) declared anywhere, with very few exceptions:rootdirective can contains variables,server_namedirective only allows strict$hostnamebuilt-in value as a variable-like notation (but it’s more like a magic constant). If you use variables inifcontext, you can only set them inifconditions (and maybe rewrite directives). Don’t try to use them elsewhere.
To assign value to the variable you should use a set directive:
See
if,break, andsetsection to learn more about variables.
Some interesting things about variables:
Make sure to read the agentzh’s Nginx Tutorials — it’s about NGINX tips & tricks. This guy is a NGINX Guru and creator of the OpenResty. In these tutorials he describes, amongst other things, variables in great detail. I also recommend nginx built-in variables post.
- the most variables in NGINX only exist at runtime, not during configuration time
- the scope of variables spreads out all over configuration
- variable assignment occurs when requests are actually being served
- variable have exactly the same lifetime as the corresponding request
- each request does have its own version of all those variables’ containers (different containers values)
- requests do not interfere with each other even if they are referencing a variable with the same name
- the assignment operation is only performed in requests that access location
Strings may be inputted without quotes unless they include blank spaces, semicolons or curly braces, then they need to be escaped with backslashes or enclosed in single/double quotes.
Quotes are required for values which are containing space(s) and/or some other special characters, otherwise NGINX will not recognize them. You can either quote or -escape some special characters like " " or ";" in strings (characters that would make the meaning of a statement ambiguous). So the following instructions are the same:
# 1) add_header My-Header "nginx web server;"; # 2) add_header My-Header nginx web server;;
Variables in quoted strings are expanded normally unless the $ is escaped.
Directives, Blocks, and Contexts
Read this great article about the NGINX configuration inheritance model by Martin Fjordvald.
Configuration options are called directives. We have four types of directives:
-
standard directive — one value per context:
-
array directive — multiple values per context:
error_log /var/log/nginx/localhost/localhost-error.log warn;
-
action directive — something which does not just configure:
rewrite ^(.*)$ /msie/$1 break;
-
try_filesdirective:try_files $uri $uri/ /test/index.html;
Valid directives begin with a variable name and then state an argument or series of arguments separated by spaces.
Directives are organised into groups known as blocks or contexts. Generally, context is a block directive that can have other directives inside braces. It appears to be organised in a tree-like structure, defined by sets of brackets — { and }.
The curly braces actually denote a new configuration context.
As a general rule, if a directive is valid in multiple nested scopes, a declaration in a broader context will be passed on to any child contexts as default values. The children contexts can override these values at will.
Directives placed in the configuration file outside of any contexts are considered to be in the global/main context.
Special attention should be paid to some strange behavior associated with some directives. For more information please see Set the HTTP headers with add_header and proxy_*_header directives properly rule.
Directives can only be used in the contexts that they were designed for. NGINX will error out on reading a configuration file with directives that are declared in the wrong context.
If you want to review all directives see alphabetical index of directives.
Contexts can be layered within one another (a level of inheritance). Their structure looks like this:
Global/Main Context
|
|
+-----» Events Context
|
|
+-----» HTTP Context
| |
| |
| +-----» Server Context
| | |
| | |
| | +-----» Location Context
| |
| |
| +-----» Upstream Context
|
|
+-----» Mail Context
The most important contexts are shown in the following description. These will be the ones that you will be dealing with for the most part:
-
global— contains global configuration directives; is used to set the settings for NGINX globally and is the only context that is not surrounded by curly braces -
events— configuration for the events module; is used to set global options for connection processing; contains directives that affect connection processing are specified -
http— controls all the aspects of working with the HTTP module and holds directives for handling HTTP and HTTPS traffic; directives in this context can be grouped into:- HTTP client directives
- HTTP file I/O directives
- HTTP hash directives
- HTTP socket directives
-
server— defines virtual host settings and describes a logical separation of a set of resources associated with a particular domain or IP address -
location— define directives to handle client request and indicates a URI that comes either from the client or from an internal redirect -
upstream— define a pool of back-end servers that NGINX can proxy the request; commonly used for defining either a web server cluster for load balancing
NGINX also provides other contexts (e.g. used for mapping) such as:
-
map— is used to set the value of a variable depending on the value of another variable. It provides a mapping of one variable’s values to determine what the second variable should be set to -
geo— is used to specify a mapping. However, this mapping is specifically used to categorize client IP addresses. It sets the value of a variable depending on the connecting IP address -
types— is used to map MIME types to the file extensions that should be associated with them -
if— provide conditional processing of directives defined within, execute the instructions contained if a given test returnstrue -
limit_except— is used to restrict the use of certain HTTP methods within a location context
Look also at the graphic below. It presents the most important contexts with reference to the configuration:

For HTTP, NGINX lookup starts from the http block, then through one or more server blocks, followed by the location block(s).
External files
include directive may appear inside any contexts to perform conditional inclusion. It attaching another file, or files matching the specified mask:
include /etc/nginx/proxy.conf; # or: include /etc/nginx/conf/*.conf;
You cannot use variables in NGINX config file includes. This is because includes are processed before any variables are evaluated.
See also this:
Variables should not be used as template macros. Variables are evaluated in the run-time during the processing of each request, so they are rather costly compared to plain static configuration. Using variables to store static strings is also a bad idea. Instead, a macro expansion and «include» directives should be used to generate configs more easily and it can be done with the external tools, e.g. sed + make or any other common template mechanism.
Measurement units
It is recommended to always specify a suffix for the sake of clarity and consistency.
Sizes can be specified in:
- without a suffix: Bytes
korK: KilobytesmorM: MegabytesgorG: Gigabytes
Time intervals can be specified in:
- without a suffix: Seconds
ms: Millisecondss: Secondsm: Minutesh: Hoursd: Daysw: WeeksM: Months (30 days)y: Years (365 days)
proxy_read_timeout 20; # =20s, default
Some of the time intervals can be specified only with a seconds resolution. You should also remember about this:
Multiple units can be combined in a single value by specifying them in the order from the most to the least significant, and optionally separated by whitespace. For example,
1h 30mspecifies the same time as90mor5400s.
Regular expressions with PCRE
🔖 Enable PCRE JIT to speed up processing of regular expressions — Performance — P2
Before start reading next chapters you should know what regular expressions are and how they works (they are not a black magic really). I recommend two great and short write-ups about regular expressions created by Jonny Fox:
- Regex tutorial — A quick cheatsheet by examples
- Regex cookbook — Top 10 Most wanted regex
Why? Regular expressions can be used in both the server_name and location (also in other) directives, and sometimes you must have a great skills of reading them. I think you should create the most readable regular expressions that do not become spaghetti code — impossible to debug and maintain.
NGINX uses the PCRE library to perform complex manipulations with your location blocks and use the powerful rewrite directive. To use a regular expression for string matching, it first needs to be compiled, which is usually done at the configuration phase.
You can also enable pcre_jit to dynamic translation during execution (at run time) rather than prior to execution. This option can improve performance, however, in some cases pcre_jit may have a negative effect. So, before enabling it, I recommend you to read this great document: PCRE Performance Project.
Below is also something interesting about regular expressions and PCRE:
- Learn PCRE in Y minutes
- PCRE Regex Cheatsheet
- Regular Expression Cheat Sheet — PCRE
- Regex cheatsheet
- Regular expressions in Perl
- Regexp Security Cheatsheet
- A regex cheatsheet for all those regex haters (and lovers)
You can also use external tools for testing regular expressions. For more please see online tools chapter.
If you’re good at it, check these very nice and brainstorming regex challenges:
- RegexGolf
- Regex Crossword
Enable syntax highlighting
vi/vim
# 1) Download vim plugin for NGINX: # Official NGINX vim plugin: mkdir -p ~/.vim/syntax/ wget "http://www.vim.org/scripts/download_script.php?src_id=19394" -O ~/.vim/syntax/nginx.vim # Improved NGINX vim plugin (incl. syntax highlighting) with Pathogen: mkdir -p ~/.vim/{autoload,bundle}/ curl -LSso ~/.vim/autoload/pathogen.vim https://tpo.pe/pathogen.vim echo -en "nexecute pathogen#infect()n" >> ~/.vimrc git clone https://github.com/chr4/nginx.vim ~/.vim/bundle/nginx.vim # 2) Set location of NGINX config files: cat > ~/.vim/filetype.vim << __EOF__ au BufRead,BufNewFile /etc/nginx/*,/etc/nginx/conf.d/*,/usr/local/nginx/conf/*,*/conf/nginx.conf if &ft == '' | setfiletype nginx | endif __EOF__
It may be interesting for you: Highlight insecure SSL configuration in Vim.
Sublime Text
Install cabal — system for building and packaging Haskell libraries and programs (on Ubuntu):
add-apt-repository -y ppa:hvr/ghc apt-get update apt-get install -y cabal-install-1.22 ghc-7.10.2 # Add this to the main configuration file of your shell: export PATH=$HOME/.cabal/bin:/opt/cabal/1.22/bin:/opt/ghc/7.10.2/bin:$PATH source $HOME/.<shellrc> cabal update
-
nginx-lint:git clone https://github.com/temoto/nginx-lint cd nginx-lint && cabal install --global
-
sublime-nginx+SublimeLinter-contrib-nginx-lint:Bring up the Command Palette and type
install. Among the commands you should see Package Control: Install Package. Typenginxto install sublime-nginx and after that do the above again for install SublimeLinter-contrib-nginx-lint: typeSublimeLinter-contrib-nginx-lint.
Processes
🔖 Adjust worker processes — Performance — P3
🔖 Improve debugging by disable daemon, master process, and all workers except one — Debugging — P4
NGINX has one master process and one or more worker processes. It has also cache loader and cache manager processes but only if you enable caching.
The main purposes of the master process is to read and evaluate configuration files, as well as maintain the worker processes (respawn when a worker dies), handle signals, notify workers, opens log files, and, of course binding to ports.
Master process should be started as root user, because this will allow NGINX to open sockets below 1024 (it needs to be able to listen on port 80 for HTTP and 443 for HTTPS).
To defines the number of worker processes you should set
worker_processesdirective.
The worker processes do the actual processing of requests and get commands from master process. They runs in an event loop (registering events and responding when one occurs), handle network connections, read and write content to disk, and communicate with upstream servers. These are spawned by the master process, and the user and group will as specified (unprivileged).
The worker processes spend most of the time just sleeping and waiting for new events (they are in
Sstate intop).
The following signals can be sent to the NGINX master process:
| SIGNAL | NUM | DESCRIPTION |
|---|---|---|
TERM, INT |
15, 2 | quick shutdown |
QUIT |
3 | graceful shutdown |
KILL |
9 | halts a stubborn process |
HUP |
1 | configuration reload, start new workers, gracefully shutdown the old worker processes |
USR1 |
10 | reopen the log files |
USR2 |
12 | upgrade executable on the fly |
WINCH |
28 | gracefully shutdown the worker processes |
There’s no need to control the worker processes yourself. However, they support some signals too:
| SIGNAL | NUM | DESCRIPTION |
|---|---|---|
TERM, INT |
15, 2 | quick shutdown |
QUIT |
3 | graceful shutdown |
USR1 |
10 | reopen the log files |
CPU pinning
Moreover, it is important to mention about worker_cpu_affinity directive (it’s only supported on GNU/Linux). CPU affinity is used to control which CPUs NGINX utilizes for individual worker processes. By default, worker processes are not bound to any specific CPUs. What’s more, system might schedule all worker processes to run on the same CPU which may not be efficient enough.
CPU affinity is represented as a bitmask (given in hexadecimal), with the lowest order bit corresponding to the first logical CPU and the highest order bit corresponding to the last logical CPU.
Here you will find an amazing explanation of this. There is a worker_cpu_affinity configuration generator for NGINX. After all, I would recommend to let the OS scheduler to do the work because there is no reason to ever set it up during normal operation.
Shutdown of worker processes
This should come in useful if you want to tweak NGINX’s shutdown process, particularly if other servers or load balancers are relying upon predictable restart times or if it takes a long time to close worker processes.
The worker_shutdown_timeout directive configures a timeout to be used when gracefully shutting down worker processes. When the timer expires, NGINX will try to close all the connections currently open to facilitate shutdown.
NGINX’s Maxim Dounin explains:
The
worker_shutdown_timeoutdirective is not expected to delay shutdown if there are no active connections. It was introduced to limit possible time spent in shutdown, that is, to ensure fast enough shutdown even if there are active connections.
When a worker process enters the «exiting» state, it does a few things:
- mark itself as an exiting process
- set a shutdown timer, if
worker_shutdown_timeoutis defined - close listening sockets
- close idle connections
Then, if the shutdown timer was set, after the worker_shutdown_timeout interval, all connections are closed.
By default, NGINX to wait for and process additional data from a client before fully closing a connection, but only if heuristics suggests that a client may be sending more data.
Sometimes, you can see nginx: worker process is shutting down in your log file. The problem occurs when reloading the configuration — where NGINX usually exits the existing worker processes gracefully, but at times, it takes hours to close these processes. Every config reload may dropping a zombie workers, permanently eating up all of your system’s memory. In this case, fast shutdown of worker processes might be a solution.
In addition, setting worker_shutdown_timeout also solve the issue:
worker_shutdown_timeout 60s;
Test connection timeouts and how long your request is processed by a server, next adjust the worker_shutdown_timeout value to these values. 60 seconds is a value with a solid supply and nothing valid should last longer than that.
In my experience, if you have multiple workers in a shutting down state, maybe you should first look at the loaded modules that may cause problems with hanging worker processes.
Connection processing
NGINX supports a variety of connection processing methods which depends on the platform used.
In general there are four types of event multiplexing:
select— is anachronism and not recommended but installed on all platforms as a fallbackpoll— is anachronism and not recommended
And the most efficient implementations of non-blocking I/O:
epoll— recommend if you’re using GNU/Linuxkqueue— recommend if you’re using BSD (it is technically superior toepoll)
The select method can be enabled or disabled using the --with-select_module or --without-select_module configuration parameter. Similarly, the poll method can be enabled or disabled using the --with-poll_module or --without-poll_module configuration parameter.
epollis an efficient method of processing connections available on Linux 2.6+.kqueueis an efficient method of processing connections available on FreeBSD 4.1+, OpenBSD 2.9+, and NetBSD 2.0+.
There is normally no need to specify it explicitly, because NGINX will by default use the most efficient method. But if you want to set this:
There are also great resources (also makes comparisons) about them:
- Kqueue: A generic and scalable event notification facility
- poll vs select vs event-based
- select/poll/epoll: practical difference for system architects
- Scalable Event Multiplexing: epoll vs. kqueue
- Async IO on Linux: select, poll, and epoll
- A brief history of select(2)
- Select is fundamentally broken
- Epoll is fundamentally broken
- I/O Multiplexing using epoll and kqueue System Calls
- Benchmarking BSD and Linux
- The C10K problem
Look also at libevent benchmark (read about libevent – an event notification library):

This infographic comes from daemonforums — An interesting benchmark (kqueue vs. epoll).
You may also view why big players uses NGINX on FreeBSD instead of on GNU/Linux:
- FreeBSD NGINX Performance
- Why did Netflix use NGINX and FreeBSD to build their own CDN?
NGINX means connections as follows (the following status information is provided by ngx_http_stub_status_module):
-
Active connections — the current number of active (open) client connections including waiting connections and connections to backends
- accepts — the total number of accepted client connections
- handled — the total number of handled connections. Generally, the parameter value is the same as
acceptsunless some resource limits have been reached (for example, theworker_connectionslimit) - requests — the total number of client requests
-
Reading — the current number of connections where NGINX is reading the request header
-
Writing — the current number of connections where NGINX is writing the response back to the client (reads request body, processes request, or writes response to a client)
-
Waiting — the current number of idle client connections waiting for a request, i.e. connection still opened waiting for either a new request, or the keepalive expiration (actually it is Active — (Reading + Writing))
Waiting connections those are keepalive connections. They are usually not a problem but if you want to reduce them set the lower value of the
keepalive_timeoutdirective.
Be sure to recommend to read this:
Writing connections counter increasing might indicate one of the following:
- crashed or killed worker processes. This is unlikely in your case though, as this would also result in other values growing as well, notably
Waiting- a real socket leak somewhere. These usually results in sockets in
CLOSE_WAITstate (in a waiting state for the FIN packet terminating the connection), try looking atnetstatoutput withoutgrep -v CLOSE_WAITfilter. Leaked sockets are reported by NGINX during graceful shutdown of a worker process (for example, after a configuration reload) — if there are any leaked sockets, NGINX will writeopen socket ... left in connection ...alerts to the error logTo further investigate things, please do the following:
- upgrade to the latest mainline versions, without any 3rd party modules, and check if you are able to reproduce the issue
- try disabling HTTP/2 to see if it fixes the issue
- check if you are seeing
open socket ... left in connection ...(socket leaks) alerts on configuration reload
See also Debugging socket leaks (from this handbook).
Event-Driven architecture
Thread Pools in NGINX Boost Performance 9x! — this official article is an amazing explanation about thread pools and generally about handling connections. I also recommend Inside NGINX: How We Designed for Performance & Scale. Both are really great.
NGINX uses Event-Driven architecture which heavily relies on Non-Blocking I/O. One advantage of non-blocking/asynchronous operations is that you can maximize the usage of a single CPU as well as memory because is that your thread can continue it’s work in parallel. The end result is that even as load increases, memory and CPU usage remain manageable.
There is a perfectly good and brief summary about non-blocking I/O and multi-threaded blocking I/O by Werner Henze. I also recommend asynchronous vs non-blocking by Daniel Earwicker.
Take a look at this simple drawing:

This infographic comes from Kansas State Polytechnic website.
Blocking I/O system calls (a) do not return until the I/O is complete. Nonblocking I/O system calls return immediately. The process is later notified when the I/O is complete.
There are forms of I/O and examples of POSIX functions:
| Blocking | Non-blocking | Asynchronous |
|---|---|---|
write, read |
write, read + poll/select |
aio_write, aio_read |
Look also what the official documentation says about it:
It’s well known that NGINX uses an asynchronous, event‑driven approach to handling connections. This means that instead of creating another dedicated process or thread for each request (like servers with a traditional architecture), it handles multiple connections and requests in one worker process. To achieve this, NGINX works with sockets in a non‑blocking mode and uses efficient methods such as epoll and kqueue.
Because the number of full‑weight processes is small (usually only one per CPU core) and constant, much less memory is consumed and CPU cycles aren’t wasted on task switching. The advantages of such an approach are well‑known through the example of NGINX itself. It successfully handles millions of simultaneous requests and scales very well.
I must not forget to mention here about Non-Blocking and 3rd party modules (also from official documentation):
Unfortunately, many third‑party modules use blocking calls, and users (and sometimes even the developers of the modules) aren’t aware of the drawbacks. Blocking operations can ruin NGINX performance and must be avoided at all costs.
To handle concurrent requests with a single worker process NGINX uses the reactor design pattern. Basically, it’s a single-threaded but it can fork several processes to utilize multiple cores.
However, NGINX is not a single threaded application. Each of worker processes is single-threaded and can handle thousands of concurrent connections. Workers are used to get request parallelism across multiple cores. When a request blocks, that worker will work on another request.
NGINX does not create a new process/thread for each connection/requests but it starts several worker threads during start. It does this asynchronously with one thread, rather than using multi-threaded programming (it uses an event loop with asynchronous I/O).
That way, the I/O and network operations are not a very big bottleneck (remember that your CPU would spend a lot of time waiting for your network interfaces, for example). This results from the fact that NGINX only use one thread to service all requests. When requests arrive at the server, they are serviced one at a time. However, when the code serviced needs other thing to do it sends the callback to the other queue and the main thread will continue running (it doesn’t wait).
Now you see why NGINX can handle a large amount of requests perfectly well (and without any problems).
For more information take a look at following resources:
- Asynchronous, Non-Blocking I/O
- Asynchronous programming. Blocking I/O and non-blocking I/O
- Blocking I/O and non-blocking I/O
- Non-blocking I/O
- About High Concurrency, NGINX architecture and internals
- A little holiday present: 10,000 reqs/sec with Nginx!
- Nginx vs Apache: Is it fast, if yes, why?
- How is Nginx handling its requests in terms of tasks or threading?
- Why nginx is faster than Apache, and why you needn’t necessarily care
- How we scaled nginx and saved the world 54 years every day
Finally, look at these great preview:

Both infographic comes from Inside NGINX: How We Designed for Performance & Scale.
Multiple processes
NGINX uses only asynchronous I/O, which makes blocking a non-issue. The only reason NGINX uses multiple processes is to make full use of multi-core, multi-CPU, and hyper-threading systems. NGINX requires only enough worker processes to get the full benefit of symmetric multiprocessing (SMP).
From official documentation:
The NGINX configuration recommended in most cases — running one worker process per CPU core — makes the most efficient use of hardware resources.
NGINX uses a custom event loop which was designed specifically for NGINX — all connections are processed in a highly efficient run-loop in a limited number of single-threaded processes called workers. Worker processes accept new requests from a shared listen socket and execute a loop. There’s no specialized distribution of connections to the workers in NGINX; this work is done by the OS kernel mechanisms which notifies a workers.
Upon startup, an initial set of listening sockets is created. workers then continuously accept, read from and write to the sockets while processing HTTP requests and responses. — from The Architecture of Open Source Applications — NGINX.
Multiplexing works by using a loop to increment through a program chunk by chunk operating on one piece of data/new connection/whatever per connection/object per loop iteration. It is all based on events multiplexing like epoll() or kqueue(). Within each worker NGINX can handle many thousands of concurrent connections and requests per second.
See Nginx Internals presentation as a lot of great stuff about the internals of the NGINX.
NGINX does not fork a process or thread per connection (like Apache) so memory usage is very conservative and extremely efficient in the vast majority of cases. NGINX is a faster and consumes less memory than Apache and performs very well under load. It is also very friendly for CPU because there’s no ongoing create-destroy pattern for processes or threads.
Finally and in summary:
- uses Non-Blocking «Event-Driven» architecture
- uses the single-threaded reactor pattern to handle concurrent requests
- uses highly efficient loop for connection processing
- is not a single threaded application because it starts multiple worker processes (to handle multiple connections and requests) during start
Simultaneous connections
Okay, so how many simultaneous connections can be processed by NGINX?
worker_processes * worker_connections = max connections
According to this: if you are running 4 worker processes with 4,096 worker connections per worker, you will be able to serve 16,384 connections. Of course, these are the NGINX settings limited by the kernel (number of connections, number of open files, or number of processes).
At this point, I would like to mention about Understanding socket and port in TCP. It is a great and short explanation. I also recommend to read Theoretical maximum number of open TCP connections that a modern Linux box can have.
I’ve seen some admins does directly translate the sum of worker_processes and worker_connections into the number of clients that can be served simultaneously. In my opinion, it is a mistake because certain of clients (e.g. browsers which have different values for this) opens a number of parallel connections (see this to confirm my words). Clients typically establish 4-8 TCP connections so that they can download resources in parallel (to download various components that compose a web page, for example, images, scripts, and so on). This increases the effective bandwidth and reduces latency.
That is a HTTP/1.1 limit (6-8) of concurrent HTTP calls. The best solution to improve performance (without upgrade the hardware and use cache at the middle (e.g. CDN, Varnish)) is using HTTP/2 (RFC 7540 [IETF]) instead of HTTP/1.1.
HTTP/2 multiplex many HTTP requests on a single connection. When HTTP/1.1 has a limit of 6-8 roughly, HTTP/2 does not have a standard limit but say: «It is recommended that this value (
SETTINGS_MAX_CONCURRENT_STREAMS) be no smaller than 100» (RFC 7540). That number is better than 6-8.
Additionally, you must know that the worker_connections directive includes all connections per worker (e.g. connection structures are used for listen sockets, internal control sockets between NGINX processes, connections with proxied servers, and for upstream connections), not only incoming connections from clients.
Be aware that every worker connection (in the sleeping state) needs 256 bytes of memory, so you can increase it easily.
The number of connections is especially limited by the maximum number of open files (RLIMIT_NOFILE) on your system (you can read about file descriptors and file handlers on this great explanation). The reason is that the operating system needs memory to manage each open file, and memory is a limited resource. This limitation only affects the limits for the current process. The limits of the current process are bequeathed to children processes too, but each process has a separate count.
To change the limit of the maximum file descriptors (that can be opened by a single worker process) you can also edit the worker_rlimit_nofile directive. With this, NGINX provides very powerful dynamic configuration capabilities with no service restarts.
The number of file descriptors is not the only one limitation of the number of connections — remember also about the kernel network (TCP/IP stack) parameters and the maximum number of processes.
I don’t like this piece of the NGINX documentation. Maybe I’m missing something but it says the worker_rlimit_nofile is a limit on the maximum number of open files for worker processes. I believe it is associated to a single worker process.
If you set RLIMIT_NOFILE to 25,000 and worker_rlimit_nofile to 12,000, NGINX sets (only for workers) the maximum open files limit as a worker_rlimit_nofile. But the master process will have a set value of RLIMIT_NOFILE. Default value of worker_rlimit_nofile directive is none so by default NGINX sets the initial value of maximum open files from the system limits.
# On GNU/Linux (or /usr/lib/systemd/system/nginx.service): grep "LimitNOFILE" /lib/systemd/system/nginx.service LimitNOFILE=5000 grep "worker_rlimit_nofile" /etc/nginx/nginx.conf worker_rlimit_nofile 256; PID SOFT HARD 24430 5000 5000 24431 256 256 24432 256 256 24433 256 256 24434 256 256 # To check fds on FreeBSD: sysctl kern.maxfiles kern.maxfilesperproc kern.openfiles kern.maxfiles: 64305 kern.maxfilesperproc: 57870 kern.openfiles: 143
This is also controlled by the OS because the worker is not the only process running on the server. It would be very bad if your workers used up all of the file descriptors available to all processes, don’t set your limits so that is possible.
In my opinion, relying on the RLIMIT_NOFILE (and alternatives on other systems) than worker_rlimit_nofile value is more understandable and predictable. To be honest, it doesn’t really matter which method is used to set, but you should keep a constant eye on the priority of the limits.
If you don’t set the
worker_rlimit_nofiledirective manually, then the OS settings will determine how many file descriptors can be used by NGINX.
I think that the chance of running out of file descriptors is minimal, but it might be a big problem on a high traffic websites.
Ok, so how many fds are opens by NGINX?
- one file handler for the client’s active connection
- one file handler for the proxied connection (that will open a socket handling these requests to remote or local host/process)
- one file handler for opening file (e.g. static file)
- other file handlers for internal connections, shared libraries, log files, and sockets
Also important is:
NGINX can use up to two file descriptors per full-fledged connection.
Look also at these diagrams:
-
1 file handler for connection with client and 1 file handler for static file being served by NGINX:
# 1 connection, 2 file handlers +-----------------+ +----------+ | | | | 1 | | | CLIENT <---------------> NGINX | | | | ^ | +----------+ | | | | 2 | | | | | | | | | +------v------+ | | | STATIC FILE | | | +-------------+ | +-----------------+ -
1 file handler for connection with client and 1 file handler for a open socket to the remote or local host/process:
# 2 connections, 2 file handlers +-----------------+ +----------+ | | +-----------+ | | 1 | | 2 | | | CLIENT <---------------> NGINX <---------------> BACKEND | | | | | | | +----------+ | | +-----------+ +-----------------+ -
2 file handlers for two simultaneous connections from the same client (1, 4), 1 file handler for connection with other client (3), 2 file handlers for static files (2, 5), and 1 file handler for a open socket to the remote or local host/process (6), so in total it is 6 file descriptors:
# 4 connections, 6 file handlers 4 +-----------------------+ | +--------|--------+ +-----v----+ | | | | | 1 | v | 6 | CLIENT <-----+---------> NGINX <---------------+ | | | | ^ | +-----v-----+ +----------+ | | | | | | 3 | | 2 | 5 | | BACKEND | +----------+ | | | | | | | | | | | | +-----------+ | CLIENT <----+ | +------v------+ | | | | | STATIC FILE | | +----------+ | +-------------+ | +-----------------+
In the first two examples: we can take that NGINX needs 2 file handlers for full-fledged connection (but still uses 2 worker connections). In the third example NGINX can take still 2 file handlers for every full-fledged connection (also if client uses parallel connections).
So, to conclude, I think that the correct value of worker_rlimit_nofile per all connections of worker should be greater than worker_connections.
In my opinion, the safe value of worker_rlimit_nofile (and system limits) is:
# 1 file handler for 1 connection:
worker_connections + (shared libs, log files, event pool, etc.) = worker_rlimit_nofile
# 2 file handlers for 1 connection:
(worker_connections * 2) + (shared libs, log files, event pool, etc.) = worker_rlimit_nofile
That is probably how many files can be opened by each worker and should have a value greater than to the number of connections per worker (according to the above formula).
In the most articles and tutorials we can see that this parameter has a value similar to the maximum number (or even more) of all open files by the NGINX. If we assume that this parameter applies to each worker separately these values are altogether excessive.
However, after a deeper reflection they are rational because they allow one worker to use all the file descriptors so that they are not confined to other workers if something happens to them. Remember though that we are still limited by the connections per worker. May I remind you that any connection opens at least one file.
So, moving on, the maximum number of open files by the NGINX should be:
(worker_processes * worker_connections * 2) + (shared libs, log files, event pool, etc.) = max open files
To serve 16,384 connections by all workers (4,096 connections for each worker), and bearing in mind about the other handlers used by NGINX, a reasonably value of max files handlers in this case may be 35,000. I think it’s more than enough.
Given the above to change/improve the limitations you should:
-
Edit the maximum, total, global number of file descriptors the kernel will allocate before choking (this step is optional, I think you should change this only for a very very high traffic):
# Find out the system-wide maximum number of file handles: sysctl fs.file-max # Shows the current number of all file descriptors in kernel memory: # first value: <allocated file handles> # second value: <unused-but-allocated file handles> # third value: <the system-wide maximum number of file handles> # fs.file-max sysctl fs.file-nr # Set it manually and temporarily: sysctl -w fs.file-max=150000 # Set it permanently: echo "fs.file-max = 150000" > /etc/sysctl.d/99-fs.conf # And load new values of kernel parameters: sysctl -p # for /etc/sysctl.conf sysctl --system # for /etc/sysctl.conf and all of the system configuration files
-
Edit the system-wide value of the maximum file descriptor number that can be opened by a single process:
-
for non-systemd systems:
# Set the maximum number of file descriptors for the users logged in via PAM: # /etc/security/limits.conf nginx soft nofile 35000 nginx hard nofile 35000
-
for systemd systems:
# Set the maximum number (hard limit) of file descriptors for the services started via systemd: # /etc/systemd/system.conf - global config (default values for all units) # /etc/systemd/user.conf - this specifies further per-user restrictions # /lib/systemd/system/nginx.service - default unit for the NGINX service # /etc/systemd/system/nginx.service - for your own instance of the NGINX service [Service] # ... LimitNOFILE=35000 # Reload a unit file and restart the NGINX service: systemctl daemon-reload && systemct restart nginx
-
-
Adjusts the system limit on number of open files for the NGINX worker. The maximum value can not be greater than
LimitNOFILE(in this example: 35,000). You can change it at any time:# Set the limit for file descriptors for a single worker process (change it as needed): # nginx.conf within the main context worker_rlimit_nofile 10000; # You need to reload the NGINX service: nginx -s reload
To show the current hard and soft limits applying to the NGINX processes (with nofile, LimitNOFILE, or worker_rlimit_nofile):
for _pid in $(pgrep -f "nginx: [master,worker]") ; do echo -en "$_pid " grep "Max open files" /proc/${_pid}/limits | awk '{print $4" "$5}' done | xargs printf '%6s %10st%sn%6s %10st%sn' "PID" "SOFT" "HARD"
or use the following:
# To determine the OS limits imposed on a process, read the file /proc/$pid/limits. # $pid corresponds to the PID of the process: for _pid in $(pgrep -f "nginx: [master,worker]") ; do echo -en ">>> $_pid\n" cat /proc/$_pid/limits done
To list the current open file descriptors for each NGINX process:
for _pid in $(pgrep -f "nginx: [master,worker]") ; do _fds=$(find /proc/${_pid}/fd/*) _fds_num=$(echo "$_fds" | wc -l) echo -en "nn##### PID: $_pid ($_fds_num fds) #####nn" # List all files from the proc/{pid}/fd directory: echo -en "$_fdsnn" # List all open files (log files, memory mapped files, libs): lsof -as -p $_pid | awk '{if(NR>1)print}' done
You should also remember about the following rules:
-
worker_rlimit_nofileserves to dynamically change the maximum file descriptors the NGINX worker processes can handle, which is typically defined with the system’s soft limit (ulimit -Sn) -
worker_rlimit_nofileworks only at the process level, it’s limited to the system’s hard limit (ulimit -Hn) -
if you have SELinux enabled, you will need to run
setsebool -P httpd_setrlimit 1so that NGINX has permissions to set its rlimit. To diagnose SELinux denials and attempts you can usesealert -a /var/log/audit/audit.log, oraudit2whyandaudit2allowtools
To sum up this example:
- each of the NGINX processes (master + workers) have the ability to create up to 35,000 files
- for all workers, the maximum number of file descriptors is 140,000 (
LimitNOFILEper worker) - for each worker, the initial/current number of file descriptors is 10,000 (
worker_rlimit_nofile)
nginx: master process = LimitNOFILE (35,000)
_ nginx: worker process = LimitNOFILE (35,000), worker_rlimit_nofile (10,000)
_ nginx: worker process = LimitNOFILE (35,000), worker_rlimit_nofile (10,000)
_ nginx: worker process = LimitNOFILE (35,000), worker_rlimit_nofile (10,000)
_ nginx: worker process = LimitNOFILE (35,000), worker_rlimit_nofile (10,000)
= master (35,000), all workers:
- 140,000 by LimitNOFILE
- 40,000 by worker_rlimit_nofile
Look also at this great article about Optimizing Nginx for High Traffic Loads.
HTTP Keep-Alive connections
🔖 Activate the cache for connections to upstream servers — Performance — P2
Before starting this section I recommend to read the following articles:
- HTTP Keepalive Connections and Web Performance
- Optimizing HTTP: Keep-alive and Pipelining
- Evolution of HTTP — HTTP/0.9, HTTP/1.0, HTTP/1.1, Keep-Alive, Upgrade, and HTTPS
The original model of HTTP, and the default one in HTTP/1.0, is short-lived connections. Each HTTP request is completed on its own connection; this means a TCP handshake happens before each HTTP request, and these are serialized. The client creates a new TCP connection for each transaction (and the connection is torn down after the transaction completes).
HTTP Keep-Alive connection or persistent connection is the idea of using a single TCP connection to send and receive multiple HTTP requests/responses (Keep Alive’s work between requests), as opposed to opening a new connection for every single request/response pair.
When using keep alive the browser does not have to make multiple connections (keep in mind that establishing connections is expensive) but uses the already established connection and controls how long that stays active/open. So, the keep alive is a way to reduce the overhead of creating the connection, as, most of the time, a user will navigate through the site etc. (plus the multiple requests from a single page, to download css, javascript, images etc.).
It takes a 3-way handshake to establish a TCP connection, so, when there is a perceivable latency between the client and the server, keepalive would greatly speed things up by reusing existing connections.
This mechanism hold open the TCP connection between the client and the server after an HTTP transaction has completed. It’s important because NGINX needs to close connections from time to time, even if you configure NGINX to allow infinite keep alive timeouts and a huge amount of acceptable requests per connection, to return results and as well errors and success messages.

Persistent connection model keeps connections opened between successive requests, reducing the time needed to open new connections. The HTTP pipelining model goes one step further, by sending several successive requests without even waiting for an answer, reducing much of the latency in the network.

This infographic comes from Mozilla MDN — Connection management in HTTP/1.x.
However, at present, browsers are not using pipelined HTTP requests. For more information please see Why is pipelining disabled in modern browsers?.
Look also at this example that shows how a Keep-Alive header could be used:
Client Proxy Server
| | |
+- Keep-Alive: timeout=600 -->| |
| Connection: Keep-Alive | |
| +- Keep-Alive: timeout=1200 -->|
| | Connection: Keep-Alive |
| | |
| |<-- Keep-Alive: timeout=300 --+
| | Connection: Keep-Alive |
|<- Keep-Alive: timeout=5000 -+ |
| Connection: Keep-Alive | |
| | |
NGINX official documentation says:
All connections are independently negotiated. The client indicates a timeout of 600 seconds (10 minutes), but the proxy is only prepared to retain the connection for at least 120 seconds (2 minutes). On the link between proxy and server, the proxy requests a timeout of 1200 seconds and the server reduces this to 300 seconds. As this example shows, the timeout policies maintained by the proxy are different for each connection. Each connection hop is independent.
Keepalive connections reduce overhead, especially when SSL/TLS is in use but they also have drawbacks; even when idling they consume server resources, and under heavy load, DoS attacks can be conducted. In such cases, using non-persistent connections, which are closed as soon as they are idle, can provide better performance. So, Keep-Alives will improve SSL/TLS performance by quite a big deal if clients are doing multiple requests but if you don’t have the resources to handle them then they kill your servers.
NGINX closes keepalive connections when the
worker_connectionslimit is reached (connections are kept in the cache till the origin server closes them).
To better understand how Keep-Alive works, please see amazing explanation by Barry Pollard.
NGINX provides the two layers to enable Keep-Alive:
Client layer
-
the maximum number of keepalive requests a client can make over a given connection, which means a client can make e.g. 256 successfull requests inside one keepalive connection:
# Default: 100 keepalive_requests 256;
-
server will close connection after this time. A higher number may be required when there is a larger amount of traffic to ensure there is no frequent TCP connection re-initiated. If you set it lower, you are not utilizing keep-alives on most of your requests slowing down client:
# Default: 75s keepalive_timeout 10s; # Or tell the browser when it should close the connection by adding an optional second timeout # in the header sent to the browser (some browsers do not care about the header): keepalive_timeout 10s 25s;
Increase this to allow the keepalive connection to stay open longer, resulting in faster subsequent requests. However, setting this too high will result in the waste of resources (mainly memory) as the connection will remain open even if there is no traffic, potentially: significantly affecting performance. I think this should be as close to your average response time as possible. You could also decrease little by little the timeout (75s -> 50s, then later 25s…) and see how the server behaves.
Upstream layer
-
the number of idle keepalive connections that remain open for each worker process. The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are preserved in the cache of each worker process (when this number is exceeded, the least recently used connections are closed):
# Default: disable keepalive 32;
NGINX, by default, only talks on HTTP/1.0 to the upstream servers. To keep TCP connection alive both upstream section and origin server should be configured to not finalise the connection.
Please keep in mind that keepalive is a feature of HTTP 1.1, NGINX uses HTTP 1.0 per default for upstreams.
Connection won’t be reused by default because keepalive in the upstream section means no keepalive (each time you can see TCP stream number increases per every request to origin server).
HTTP keepalive enabled in NGINX upstream servers reduces latency thus improves performance and it reduces the possibility that the NGINX runs out of ephemeral ports.
The connections parameter should be set to a number small enough to let upstream servers process new incoming connections as well.
Update your upstream configuration to use keepalive:
upstream bk_x8080 { ... # Sets the maximum number of idle keepalive connections to upstream servers # that are preserved in the cache of each worker process. keepalive 16; }
And enable the HTTP/1.1 protocol in all upstream requests:
server { ... location / { # Default is HTTP/1, keepalive is only enabled in HTTP/1.1: proxy_http_version 1.1; # Remove the Connection header if the client sends it, # it could be "close" to close a keepalive connection: proxy_set_header Connection ""; proxy_pass http://bk_x8080; } } ... }
There are two basic cases when keeping connections alive is really beneficial:
- fast backends, which produce responses is a very short time, comparable to a TCP handshake
- distant backends, when a TCP handshake takes a long time, comparable to a backend response time
Look at the test:
- without keepalive for upstream:
wrk -c 500 -t 6 -d 60s -R 15000 -H "Host: example.com" https://example.com/ Running 1m test @ https://example.com/ 6 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 24.13s 10.68s 49.55s 59.06% Req/Sec 679.21 42.44 786.00 78.95% 228421 requests in 1.00m, 77.98MB read Socket errors: connect 0, read 0, write 0, timeout 1152 Non-2xx or 3xx responses: 4 Requests/sec: 3806.96 Transfer/sec: 1.30MB
- with keepalive for upstream:
wrk -c 500 -t 6 -d 60s -R 15000 -H "Host: example.com" https://example.com/ Running 1m test @ https://example.com/ 6 threads and 500 connections Thread Stats Avg Stdev Max +/- Stdev Latency 23.40s 9.53s 47.25s 60.67% Req/Sec 0.86k 50.19 0.94k 60.00% 294148 requests in 1.00m, 100.41MB read Socket errors: connect 0, read 0, write 0, timeout 380 Requests/sec: 4902.24 Transfer/sec: 1.67MB
sendfile, tcp_nodelay, and tcp_nopush
Before you start reading please review:
- Nginx optimization, understanding SENDFILE, TCP_NODELAY and TCP_NOPUSH
- Nginx Tutorial #2: Performance
As you’re making these changes, keep careful watch on your network traffic and see how each tweak impacts congestion.
sendfile
By default, NGINX handles file transmission itself and copies the file into the buffer before sending it. Enabling the
sendfiledirective eliminates the step of copying the data into the buffer and enables direct copying data from one file descriptor to another.
Normally, when a file needs to be sent, the following steps are required:
malloc— allocate a local buffer for storing object dataread— retrieve and copy the object into the local bufferwrite— copy the object from the local buffer into the socket buffer
Look at this great explanation (from Nginx Tutorial #2: Performance):
This involves two context switches (read, write) which make a second copy of the same object unnecessary. As you may see, it is not the optimal way. Thankfully, there is another system call that improves sending files, and it’s called (surprise, surprise!):
sendfile(2). This call retrieves an object to the file cache, and passes the pointers (without copying the whole object) straight to the socket descriptor. Netflix states that usingsendfile(2)increased the network throughput from 6Gbps to 30Gbps.
When a file is transferred by a process, the kernel first buffers the data and then sends the data to the process buffers. The process, in turn, sends the data to the destination.
NGINX employs a solution that uses the sendfile system call to perform a zero-copy data flow from disk to socket and saves context switching from userspace on read/write. sendfile tell how NGINX buffers or reads the file (trying to stuff the contents directly into the network slot, or buffer its contents first).
This method is an improved method of data transfer, in which data is copied between file descriptors within the OS kernel space, that is, without transferring data to the application buffers. No additional buffers or data copies are required, and the data never leaves the kernel memory address space.
In my opinion enabling this really won’t make any difference unless NGINX is reading from something which can be mapped into the virtual memory space like a file (i.e. the data is in the cache). But please… do not let me influence you — you should in the first place be keeping an eye on this document: Optimizing TLS for High–Bandwidth Applications in FreeBSD [pdf].
By default NGINX disable the use of sendfile:
# http, server, location, if in location contexts # To turn on sendfile (my recommendation): sendfile on; # To turn off sendfile: sendfile off; # default
Look also at sendfile_max_chunk directive. NGINX documentation say:
When set to a non-zero value, limits the amount of data that can be transferred in a single
sendfile()call. Without the limit, one fast connection may seize the worker process entirely.
On fast local connection sendfile() in Linux may send tens of megabytes per one syscall blocking other connections. sendfile_max_chunk allows to limit the maximum size per one sendfile() operation. So, with this NGINX can reduce the maximum time spent in blocking sendfile() calls, since NGINX won’t try to send the whole file at once, but will do it in chunks. For example:
sendfile on; sendfile_max_chunk 512k;
tcp_nodelay
I recommend to read The Caveats of TCP_NODELAY and Rethinking the TCP Nagle Algorithm [pdf]. These great papers describes very interesting topics about TCP_NODELAY and TCP_NOPUSH.
tcp_nodelay is used to manage Nagle’s algorithm which is one mechanism for improving TCP efficiency by reducing the number of small packets sent over the network. If you set tcp_nodelay on;, NGINX adds the TCP_NODELAY options when opening a new socket.
The option only affects keep-alive connections. Otherwise there is 100ms delay when NGINX sends response tail in the last incomplete TCP packet. Additionally, it is enabled on SSL connections, for unbuffered proxying, and for WebSocket proxying.
Maybe you should think about enabling Nagle’s algorithm (tcp_nodelay off;) but it really depends on what is your specific workload and dominant traffic patterns on a service. tcp_nodelay on; is more reasonable for the modern web, the whole delay business of TCP was reasonable for terminals. Typically LANs have less issues with traffic congestion as compared to the WANs. The Nagle algorithm is most effective if TCP/IP traffic is generated sporadically by user input, not by applications using stream oriented protocols like a HTTP traffic.
So, for me, the recipe is simple:
- bulk sends or HTTP traffic
- applications that require lower latency
- non-interactive type of traffic
There is no need for using Nagle’s algorithm.
You should also know the Nagle’s algorithm author’s interesting comment:
If you’re doing bulk file transfers, you never hit that problem. If you’re sending enough data to fill up outgoing buffers, there’s no delay. If you send all the data and close the TCP connection, there’s no delay after the last packet. If you do send, reply, send, reply, there’s no delay. If you do bulk sends, there’s no delay. If you do send, send, reply, there’s a delay.
The real problem is ACK delays. The 200ms «ACK delay» timer is a bad idea that someone at Berkeley stuck into BSD around 1985 because they didn’t really understand the problem. A delayed ACK is a bet that there will be a reply from the application level within 200ms. TCP continues to use delayed ACKs even if it’s losing that bet every time.
I think if you are dealing with non-interactive type of traffic or bulk transfers such as HTTP/web traffic then enabling TCP_NODELAY to disable Nagle’s algorithm may be useful (is the default behavior of the NGINX). This is especially relevant if you’re running applications or environments that only sometimes have highly interactive traffic and chatty protocols.
By default NGINX enable the use of TCP_NODELAY option:
# http, server, location contexts # To turn on tcp_nodelay and at the same time to disable Nagle’s algorithm # (my recommendation, unless you turn tcp_nopush on): tcp_nodelay on; # default # To turn off tcp_nodelay and at the same time to enable Nagle’s algorithm: tcp_nodelay off;
tcp_nopush
This option is only available if you are using sendfile (NGINX uses tcp_nopush for requests served with sendfile). It causes NGINX to attempt to send its HTTP response head in one packet, instead of using partial frames. This is useful for prepending headers before calling sendfile, or for throughput optimization.
Normally, using
tcp_nopushalong withsendfileis very good. However, there are some cases where it can slow down things (specially from cache systems), so, run your own tests and find if it’s useful in that way.
tcp_nopush enables TCP_CORK (more specifically, the TCP_NOPUSH socket option on FreeBSD or the TCP_CORK socket option on Linux) which aggressively accumulates data and which tells TCP to wait for the application to remove the cork before sending any packets.
If TCP_NOPUSH/TCP_CORK (are not the same!) is enabled in a socket, it will not send data until the buffer fills to a fixed limit (allows application to control building of packet, e.g pack a packet with full HTTP response). To read more about it and get into the details of this option please read TCP_CORK: More than you ever wanted to know.
Once, I read that tcp_nopush is opposite to tcp_nodelay. I don’t agree with that because, as I understand it, the first one aggregates data based on buffer pressure instead whereas Nagle’s algorithm aggregates data while waiting for a return ACK, which the latter option disables.
It may appear that tcp_nopush and tcp_nodelay are mutually exclusive but if all directives are turned on, NGINX manages them very wisely:
- ensure packages are full before sending them to the client
- for the last packet,
tcp_nopushwill be removed, allowing TCP to send it immediately, without the 200ms delay
And let’s also remember (take a look at Tony Finch notes — this guy developed a kernel patch for FreeBSD which makes TCP_NOPUSH work like TCP_CORK):
- on Linux,
sendfile()depends on theTCP_CORKsocket option to avoid undesirable packet boundaries - FreeBSD has a similar option called
TCP_NOPUSH - when
TCP_CORKis turned off any buffered data is sent immediately, but this is not the case forTCP_NOPUSH
By default NGINX disable the use of TCP_NOPUSH option:
# http, server, location contexts # To turn on tcp_nopush (my recommendation): tcp_nopush on; # To turn off tcp_nopush: tcp_nopush off; # default
Mixing all together
There are many opinions on this. My recommendation is to set all to on. However, I quote an interesting comment (Mixing sendfile, tcp_nodelay and tcp_nopush illogical?) that should dispel any doubts:
When set indicates to always queue non-full frames. Later the user clears this option and we transmit any pending partial frames in the queue. This is meant to be used alongside
sendfile()to get properly filled frames when the user (for example) must write out headers with awrite()call first and then usesendfileto send out the data parts.TCP_CORKcan be set together withTCP_NODELAYand it is stronger thanTCP_NODELAY.
Summarizing:
tcp_nodelay on;is generaly at the odds withtcp_nopush on;as they are mutually exclusive- NGINX has special behavior that if you have
sendfile on;, it usesTCP_NOPUSHfor everything but the last package - and then turns
TCP_NOPUSHoff and enablesTCP_NODELAYto avoid 200ms ACK delay
So in fact, the most important changes are listed below:
sendfile on; tcp_nopush on; # with this, the tcp_nodelay does not really matter
Request processing stages
When building filtering rules (e.g. with
allow/deny) you should always remember to test them and to know what happens at each of the phases (which modules are used). For additional information about the potential problems, look at allow and deny section and Take care about your ACL rules — Hardening — P1.
There can be altogether 11 phases when NGINX handles (processes) a request:
-
NGX_HTTP_POST_READ_PHASE— first phase, read the request header- example modules: ngx_http_realip_module
-
NGX_HTTP_SERVER_REWRITE_PHASE— implementation of rewrite directives defined in a server block; to change request URI using PCRE regular expressions, return redirects, and conditionally select configurations- example modules: ngx_http_rewrite_module
-
NGX_HTTP_FIND_CONFIG_PHASE— replace the location according to URI (location lookup) -
NGX_HTTP_REWRITE_PHASE— URI transformation on location level- example modules: ngx_http_rewrite_module
-
NGX_HTTP_POST_REWRITE_PHASE— URI transformation post-processing (the request is redirected to a new location)- example modules: ngx_http_rewrite_module
-
NGX_HTTP_PREACCESS_PHASE— authentication preprocessing request limit, connection limit (access restriction)- example modules: ngx_http_limit_req_module, ngx_http_limit_conn_module, ngx_http_realip_module
-
NGX_HTTP_ACCESS_PHASE— verification of the client (the authentication process, limiting access)- example modules: ngx_http_access_module, ngx_http_auth_basic_module
-
NGX_HTTP_POST_ACCESS_PHASE— access restrictions check post-processing phase, the certification process, processingsatisfy anydirective- example modules: ngx_http_access_module, ngx_http_auth_basic_module
-
NGX_HTTP_PRECONTENT_PHASE— generating content- example modules: ngx_http_try_files_module
-
NGX_HTTP_CONTENT_PHASE— content processing- example modules: ngx_http_index_module, ngx_http_autoindex_module, ngx_http_gzip_module
-
NGX_HTTP_LOG_PHASE— log processing- example modules: ngx_http_log_module
You may feel lost now (me too…) so I let myself put this great and simple preview:

This infographic comes from Inside NGINX official library.
On every phase you can register any number of your handlers. Each phase has a list of handlers associated with it.
I recommend to read a great explanation about HTTP request processing phases in Nginx and, of course, official Development guide. I have also prepared a simple diagram that can help you understand what modules are used in each phase. It also contains short descriptions from official development guide:

Server blocks logic
NGINX does have server blocks (like a virtual hosts in an Apache) that use
listendirective to bind to TCP sockets andserver_namedirective to identify virtual hosts.
It’s a short example of two server block contexts with several regular expressions:
http { index index.html; root /var/www/example.com/default; server { listen 10.10.250.10:80; server_name www.example.com; access_log logs/example.access.log main; root /var/www/example.com/public; location ~ ^/(static|media)/ { ... } location ~* /[0-9][0-9](-.*)(.html)$ { ... } location ~* .(jpe?g|png|gif|ico)$ { ... } location ~* (?<begin>.*app)/(?<end>.+.php)$ { ... } ... } server { listen 10.10.250.11:80; server_name "~^(api.)?example.com api.de.example.com"; access_log logs/example.access.log main; location ~ ^(/[^/]+)/api(.*)$ { ... } location ~ ^/backend/id/([a-z].[a-z]*) { ... } ... } }
Handle incoming connections
🔖 Define the listen directives with address:port pair — Base Rules — P1
🔖 Prevent processing requests with undefined server names — Base Rules — P1
🔖 Never use a hostname in a listen or upstream directives — Base Rules — P1
🔖 Use exact names in a server_name directive if possible — Performance — P2
🔖 Separate listen directives for 80 and 443 ports — Base Rules — P3
🔖 Use only one SSL config for the listen directive — Base Rules — P3
NGINX uses the following logic to determining which virtual server (server block) should be used:
-
Match the
address:portpair to thelistendirective — that can be multiple server blocks withlistendirectives of the same specificity that can handle the requestNGINX use the
address:portcombination for handle incoming connections. This pair is assigned to thelistendirective.The
listendirective can be set to:-
an IP address/port combination (
127.0.0.1:80;) -
a lone IP address, if only address is given, the port
80is used (127.0.0.1;) — becomes127.0.0.1:80; -
a lone port which will listen to every interface on that port (
80;or*:80;) — becomes0.0.0.0:80; -
the path to a UNIX domain socket (
unix:/var/run/nginx.sock;)
If the
listendirective is not present then either*:80is used (runs with the superuser privileges), or*:8000otherwise.To play with
listendirective NGINX must follow the following steps:-
NGINX translates all incomplete
listendirectives by substituting missing values with their default values (see above) -
NGINX attempts to collect a list of the server blocks that match the request most specifically based on the
address:port -
If any block that is functionally using
0.0.0.0, will not be selected if there are matching blocks that list a specific IP -
If there is only one most specific match, that server block will be used to serve the request
-
If there are multiple server blocks with the same level of matching, NGINX then begins to evaluate the
server_namedirective of each server block
Look at this short example:
# From client side: GET / HTTP/1.0 Host: api.random.com # From server side: server { # This block will be processed: listen 192.168.252.10; # --> 192.168.252.10:80 ... } server { listen 80; # --> *:80 --> 0.0.0.0:80 server_name api.random.com; ... }
-
-
Match the
Hostheader field against theserver_namedirective as a string (the exact names hash table) -
Match the
Hostheader field against theserver_namedirective with a
wildcard at the beginning of the string (the hash table with wildcard names starting with an asterisk)
If one is found, that block will be used to serve the request. If multiple matches are found, the longest match will be used to serve the request.
- Match the
Hostheader field against theserver_namedirective with a
wildcard at the end of the string (the hash table with wildcard names ending with an asterisk)
If one is found, that block is used to serve the request. If multiple matches are found, the longest match will be used to serve the request.
- Match the
Hostheader field against theserver_namedirective as a regular expression
The first
server_namewith a regular expression that matches theHostheader will be used to serve the request.
-
If all the
Hostheaders doesn’t match, then direct to thelistendirective marked asdefault_server(makes the server block answer all the requests that doesn’t match any server block) -
If all the
Hostheaders doesn’t match and there is nodefault_server,
direct to the first server with alistendirective that satisfies first step -
Finally, NGINX goes to the
locationcontext
This list is based on Mastering Nginx — The virtual server section.
Matching location
🔖 Make an exact location match to speed up the selection process — Performance — P3
For each request, NGINX goes through a process to choose the best location block that will be used to serve that request.
The location block enables you to handle several types of URIs/routes (Layer 7 routing based on URL), within a server block. Syntax looks like:
location optional_modifier location_match { ... }
location_match in the above defines what NGINX should check the request URI against. The optional_modifier below will cause the associated location block to be interpreted as follows (the order doesn’t matter at this moment):
-
(none): if no modifiers are present, the location is interpreted as a prefix match. To determine a match, the location will now be matched against the beginning of the URI -
=: is an exact match, without any wildcards, prefix matching or regular expressions; forces a literal match between the request URI and the location parameter -
~: if a tilde modifier is present, this location must be used for case sensitive matching (RE match) -
~*: if a tilde and asterisk modifier is used, the location must be used for case insensitive matching (RE match) -
^~: assuming this block is the best non-RE match, a carat followed by a tilde modifier means that RE matching will not take place
And now, a short introduction to determines location priority:
-
the exact match is the best priority (processed first); ends search if match
-
the prefix match is the second priority; there are two types of prefixes:
^~and(none), if this match used the^~prefix, searching stops -
the regular expression match has the lowest priority; there are two types of prefixes:
~and~*; in the order they are defined in the configuration file -
if regular expression searching yielded a match, that result is used, otherwise, the match from prefix searching is used
So, look at this example, it comes from the Nginx documentation — ngx_http_core_module:
location = / {
# Matches the query / only.
[ configuration A ]
}
location / {
# Matches any query, since all queries begin with /, but regular
# expressions and any longer conventional blocks will be
# matched first.
[ configuration B ]
}
location /documents/ {
# Matches any query beginning with /documents/ and continues searching,
# so regular expressions will be checked. This will be matched only if
# regular expressions don't find a match.
[ configuration C ]
}
location ^~ /images/ {
# Matches any query beginning with /images/ and halts searching,
# so regular expressions will not be checked.
[ configuration D ]
}
location ~* .(gif|jpg|jpeg)$ {
# Matches any request ending in gif, jpg, or jpeg. However, all
# requests to the /images/ directory will be handled by
# Configuration D.
[ configuration E ]
}
To help you understand how does location match works:
- Nginx location match tester
- Nginx location match visible
- NGINX Regular Expression Tester
The process of choosing NGINX location block is as follows (a detailed explanation):
- NGINX searches for an exact match. If a
=modifier (e.g.location = foo { ... }) exactly matches the request URI, this specific location block is chosen right away
- this block is processed
- match-searching stops
- Prefix-based NGINX location matches (no regular expression). Each location will be checked against the request URI. If no exact (meaning no
=modifier) location block is found, NGINX will continue with non-exact prefixes. It starts with the longest matching prefix location for this URI, with the following approach:
-
In case the longest matching prefix location has the
^~modifier (e.g.location ^~ foo { ... }), NGINX will stop its search right away and choose this location- the block of the longest (most explicit) of those matches is processed
- match-searching stops
-
Assuming the longest matching prefix location doesn’t use the
^~modifier, the match is temporarily stored and the process continues
I’m not sure about the order. In the official documentation it is not clearly indicated and external guides explain it differently. It seems logical to check the longest matching prefix location first.
- As soon as the longest matching prefix location is chosen and stored, NGINX continues to evaluate the case-sensitive (e.g.
location ~ foo { ... }) and insensitive regular expression (e.g.location ~* foo { ... }) locations. The first regular expression location that fits the URI is selected right away to process the request
- the block of the first matching regex found (when parsing the config-file top-to-bottom) is processed
- match-searching stops
- If no regular expression locations are found that match the request URI, the previously stored prefix location (e.g.
location foo { ... }) is selected to serve the request
location /kind of a catch all location- the block of the longest (most explicit) of those matches is processed
- match-searching stops
You should also know, that the non-regex match-types are fully declarative — order of definition in the config doesn’t matter — but the winning regex-match (if processing even gets that far) is entirely based on its order of entry in the config file.
In order, to better understand how this process work, please see this short cheatsheet that will allow you to design your location blocks in a predictable way:

I recommend to use external tools for testing regular expressions. For more please see online tools chapter.
Ok, so here’s a more complicated configuration:
server { listen 80; server_name xyz.com www.xyz.com; location ~ ^/(media|static)/ { root /var/www/xyz.com/static; expires 10d; } location ~* ^/(media2|static2) { root /var/www/xyz.com/static2; expires 20d; } location /static3 { root /var/www/xyz.com/static3; } location ^~ /static4 { root /var/www/xyz.com/static4; } location = /api { proxy_pass http://127.0.0.1:8080; } location / { proxy_pass http://127.0.0.1:8080; } location /backend { proxy_pass http://127.0.0.1:8080; } location ~ logo.xcf$ { root /var/www/logo; expires 48h; } location ~* .(png|ico|gif|xcf)$ { root /var/www/img; expires 24h; } location ~ logo.ico$ { root /var/www/logo; expires 96h; } location ~ logo.jpg$ { root /var/www/logo; expires 48h; } }
And look the table with the results:
| URL | LOCATIONS FOUND | FINAL MATCH |
|---|---|---|
/ |
1) prefix match for / |
/ |
/css |
1) prefix match for / |
/ |
/api |
1) exact match for /api |
/api |
/api/ |
1) prefix match for / |
/ |
/backend |
1) prefix match for /2) prefix match for /backend |
/backend |
/static |
1) prefix match for / |
/ |
/static/header.png |
1) prefix match for /2) case sensitive regex match for ^/(media|static)/ |
^/(media|static)/ |
/static/logo.jpg |
1) prefix match for /2) case sensitive regex match for ^/(media|static)/ |
^/(media|static)/ |
/media2 |
1) prefix match for /2) case insensitive regex match for ^/(media2|static2) |
^/(media2|static2) |
/media2/ |
1) prefix match for /2) case insensitive regex match for ^/(media2|static2) |
^/(media2|static2) |
/static2/logo.jpg |
1) prefix match for /2) case insensitive regex match for ^/(media2|static2) |
^/(media2|static2) |
/static2/logo.png |
1) prefix match for /2) case insensitive regex match for ^/(media2|static2) |
^/(media2|static2) |
/static3/logo.jpg |
1) prefix match for /static32) prefix match for /3) case sensitive regex match for logo.jpg$ |
logo.jpg$ |
/static3/logo.png |
1) prefix match for /static32) prefix match for /3) case insensitive regex match for .(png|ico|gif|xcf)$ |
.(png|ico|gif|xcf)$ |
/static4/logo.jpg |
1) priority prefix match for /static42) prefix match for / |
/static4 |
/static4/logo.png |
1) priority prefix match for /static42) prefix match for / |
/static4 |
/static5/logo.jpg |
1) prefix match for /2) case sensitive regex match for logo.jpg$ |
logo.jpg$ |
/static5/logo.png |
1) prefix match for /2) case insensitive regex match for .(png|ico|gif|xcf)$ |
.(png|ico|gif|xcf)$ |
/static5/logo.xcf |
1) prefix match for /2) case sensitive regex match for logo.xcf$ |
logo.xcf$ |
/static5/logo.ico |
1) prefix match for /2) case insensitive regex match for .(png|ico|gif|xcf)$ |
.(png|ico|gif|xcf)$ |
rewrite vs return
Generally there are two ways of implementing redirects in NGINX: with rewrite and return directives.
These directives (comes from the ngx_http_rewrite_module) are very useful but (from the NGINX documentation) the only 100% safe things which may be done inside if in a location context are:
return ...;rewrite ... last;
Anything else may possibly cause unpredictable behaviour, including potential SIGSEGV.
rewrite directive
The rewrite directives are executed sequentially in order of their appearance in the configuration file. It’s slower (but still extremely fast) than a return and returns HTTP 302 in all cases, irrespective of permanent.
The rewrite directive just changes the request URI, not the response of request. Importantly only the part of the original url that matches the regex is rewritten. It can be used for temporary url changes.
I sometimes used rewrite to capture elementes in the original URL, change or add elements in the path, and in general when I do something more complex:
location / { ... rewrite ^/users/(.*)$ /user.php?username=$1 last; # or: rewrite ^/users/(.*)/items$ /user.php?username=$1&page=items last; }
You must know that rewrite returns only code 301 or 302.
rewrite directive accept optional flags:
-
break— basically completes processing of rewrite directives, stops processing, and breakes location lookup cycle by not doing any location lookup and internal jump at all-
if you use
breakflag insidelocationblock:- no more parsing of rewrite conditions
- internal engine continues to parse the current
locationblock
Inside a location block, with
break, NGINX only stops processing anymore rewrite conditions. -
if you use
breakflag outsidelocationblock:- no more parsing of rewrite conditions
- internal engine goes to the next phase (searching for
locationmatch)
Outside a location block, with
break, NGINX stops processing anymore rewrite conditions.
-
-
last— basically completes processing of rewrite directives, stops processing, and starts a search for a new location matching the changed URI-
if you use
lastflag insidelocationblock:- no more parsing of rewrite conditions
- internal engine starts to look for another location match based on the result of the rewrite result
- no more parsing of rewrite conditions, even on the next location match
Inside a location block, with last, NGINX stops processing anymore rewrite conditions and then starts to look for a new matching of location block. NGINX also ignores any rewrites in the new location block.
-
if you use
lastflag outsidelocationblock:- no more parsing of rewrite conditions
- internal engine goes to the next phase (searching for
locationmatch)
Outside a location block, with
last, NGINX stops processing anymore rewrite conditions.
-
-
redirect— returns a temporary redirect with the 302 HTTP response code -
permanent— returns a permanent redirect with the 301 HTTP response code
Note:
- that outside location blocks,
lastandbreakare effectively the same - processing of rewrite directives at server level may be stopped via
break, but the location lookup will follow anyway
This explanation is based on the awesome answer by Pothi Kalimuthu to nginx url rewriting: difference between break and last.
Official documentation has a great tutorials about Creating NGINX Rewrite Rules and Converting rewrite rules. I also recommend Clean Url Rewrites Using Nginx.
Finally, look at the difference between last and break flags in action:
lastdirective:

breakdirective:

This infographic comes from Internal rewrite — nginx by Ivan Dabic.
return directive
🔖 Use return directive for URL redirection (301, 302) — Base Rules — P2
🔖 Use return directive instead of rewrite for redirects — Performance — P2
The other way is a return directive. It’s faster than rewrite because there is no regexp that has to be evaluated. It’s stops processing and returns HTTP 301 (by default) to a client (tells NGINX to respond directly to the request), and the entire url is rerouted to the url specified.
I use return directive in the following cases:
-
force redirect from http to https:
server { ... return 301 https://example.com$request_uri; }
-
redirect from www to non-www and vice versa:
server { ... # It's only example. You shouldn't use 'if' statement in the following case: if ($host = www.example.com) { return 301 https://example.com$request_uri; } }
-
close the connection and log it internally:
server { ... return 444; }
-
send 4xx HTTP response for a client without any other actions:
server { ... if ($request_method = POST) { return 405; } # or: if ($invalid_referer) { return 403; } # or: if ($request_uri ~ "^/app/(.+)$") { return 403; } # or: location ~ ^/(data|storage) { return 403; } }
-
and sometimes for reply with HTTP code without serving a file or response body:
server { ... # NGINX will not allow a 200 with no response body (200's need to be with a resource in the response. # '204 No Content' is meant to say "I've completed the request, but there is no body to return"): return 204 "it's all okay"; # Or without body: return 204; # Because default Content-Type is application/octet-stream, browser will offer to "save the file". # If you want to see reply in browser you should add properly Content-Type: # add_header Content-Type text/plain; }
To the last example: be careful if you’re using such a configuration to do a healthcheck. While a 204 HTTP code is semantically perfect for a healthcheck (success indication with no content), some services do not consider it a success.
URL redirections
🔖 Use return directive for URL redirection (301, 302) — Base Rules — P2
🔖 Use return directive instead of rewrite for redirects — Performance — P2
HTTP allows servers to redirect a client request to a different location. This is useful when moving content to a new URL, when deleting pages or when changing domain names or merging websites.
URL redirection is done for various reasons:
- for URL shortening
- to prevent broken links when web pages are moved
- to allow multiple domain names belonging to the same owner to refer to a single web site
- to guide navigation into and out of a website
- for privacy protection
- for hostile purposes such as phishing attacks or malware distribution
It comes from Wikipedia — URL redirection.
I recommend to read:
- Redirections in HTTP
- 301 101: How Redirects Work
- Modify 301/302 response body (from this handbook)
- Redirect POST request with payload to external endpoint (from this handbook)
try_files directive
We have one more very interesting and important directive: try_files (from the ngx_http_core_module). This directive tells NGINX to check for the existence of a named set of files or directories (checks files conditionally breaking on success).
I think the best explanation comes from the official documentation:
try_fileschecks the existence of files in the specified order and uses the first found file for request processing; the processing is performed in the current context. The path to a file is constructed from the file parameter according to the root and alias directives. It is possible to check directory’s existence by specifying a slash at the end of a name, e.g.$uri/. If none of the files were found, an internal redirect to the uri specified in the last parameter is made.
Generally it may check files on disk, redirect to proxies or internal locations, and return error codes, all in one directive.
Take a look at the following example:
server { ... root /var/www/example.com; location / { try_files $uri $uri/ /frontend/index.html; } location ^~ /images { root /var/www/static; try_files $uri $uri/ =404; } ...
-
default root directory for all locations is
/var/www/example.com -
location /— matches all locations without more specific locations, e.g. exact names-
try_files $uri— when you receive a URI that’s matched by this block try$urifirstFor example:
https://example.com/tools/en.js— NGINX will try to check if there’s a file inside/toolscalleden.js, if found it, serve it in the first place. -
try_files $uri $uri/— if you didn’t find the first condition try the URI as a directoryFor example:
https://example.com/backend/— NGINX will try first check if a file calledbackendexists, if can’t find it then goes to second check$uri/and see if there’s a directory calledbackendexists then it will try serving it. -
try_files $uri $uri/ /frontend/index.html— if a file and directory not found, NGINX sends/frontend/index.html
-
-
location ^~ /images— handle any query beginning with/imagesand halts searching-
default root directory for this location is
/var/www/static -
try_files $uri— when you receive a URI that’s matched by this block try$urifirstFor example:
https://example.com/images/01.gif— NGINX will try to check if there’s a file inside/imagescalled01.gif, if found it, serve it in the first place. -
try_files $uri $uri/— if you didn’t find the first condition try the URI as a directoryFor example:
https://example.com/images/— NGINX will try first check if a file calledimagesexists, if can’t find it then goes to second check$uri/and see if there’s a directory calledimagesexists then it will try serving it. -
try_files $uri $uri/ =404— if a file and directory not found, NGINX sendsHTTP 404(Not Found)
-
On the other hand, try_files is relatively primitive. When encountered, NGINX will look for any of the specified files physically in the directory matched by the location block. If they don’t exist, NGINX does an internal redirect to the last entry in the directive.
Additionally, think about dont’t check for the existence of directories:
# Use this to take out an extra filesystem stat(): try_files $uri @index; # Instead of this: try_files $uri $uri/ @index;
if, break and set
🔖 Avoid checks server_name with if directive — Performance — P2
The ngx_http_rewrite_module also provides additional directives:
-
break— stops processing, if is specified inside thelocation, further processing of the request continues in this location:# It's useful for: if ($slow_resp) { limit_rate 50k; break; }
-
if— you can useifinside aserverbut not the other way around, also notice that you shouldn’t useifinsidelocationas it may not work as desired. For example,ifstatements aren’t a good way of setting custom headers because they may cause statements outside the if block to be ignored. The NGINX docs says:There are cases where you simply cannot avoid using an
if, for example if you need to test a variable which has no equivalent directive.You should also remember about this:
The
ifcontext in NGINX is provided by the rewrite module and this is the primary intended use of this context. Since NGINX will test conditions of a request with many other purpose-made directives,ifshould not be used for most forms of conditional execution. This is such an important note that the NGINX community has created a page called if is evil (yes, it’s really evil and in most cases not needed).A long time ago I found this:
That’s actually not true and shows you don’t understand the problem with it. When the
ifstatement ends withreturndirective, there is no problem and it’s safe to use.On the other hand, official documentation say:
Directive if has problems when used in location context, in some cases it doesn’t do what you expect but something completely different instead. In some cases it even segfaults. It’s generally a good idea to avoid it if possible.
-
set— sets a value for the specified variable. The value can contain text, variables, and their combination
Example of usage if and set directives:
# It comes from: https://gist.github.com/jrom/1760790: if ($request_uri = /) { set $test A; } if ($host ~* example.com) { set $test "${test}B"; } if ($http_cookie !~* "auth_token") { set $test "${test}C"; } if ($test = ABC) { proxy_pass http://cms.example.com; break; }
root vs alias
Placing a
rootoraliasdirective in a location block overrides therootoraliasdirective that was applied at a higher scope.
With alias you can map to another file name. With root forces you to name your file on the server. In the first case, NGINX replaces the string prefix e.g /robots.txt in the URL path with e.g. /var/www/static/robots.01.txt and then uses the result as a filesystem path. In the second, NGINX inserts the string e.g. /var/www/static/ at the beginning of the URL path and then uses the result as a file system path.
Look at this. There is a difference, when the alias is for a whole directory will work:
location ^~ /data/ { alias /home/www/static/data/; }
But the following code won’t do:
location ^~ /data/ { root /home/www/static/data/; }
This would have to be:
location ^~ /data/ { root /home/www/static/; }
The root directive is typically placed in server and location blocks. Placing a root directive in the server block makes the root directive available to all location blocks within the same server block.
This directive tells NGINX to take the request url and append it behind the specified directory. For example, with the following configuration block:
server { server_name example.com; listen 10.250.250.10:80; index index.html; root /var/www/example.com; location / { try_files $uri $uri/ =404; } location ^~ /images { root /var/www/static; try_files $uri $uri/ =404; } }
NGINX will map the request made to:
http://example.com/images/logo.pnginto the file path/var/www/static/images/logo.pnghttp://example.com/contact.htmlinto the file path/var/www/example.com/contact.htmlhttp://example.com/about/us.htmlinto the file path/var/www/example.com/about/us.html
Like you want to forward all requests which start /static and your data present in /var/www/static you should set:
- first path:
/var/www - last path:
/static - full path:
/var/www/static
location <last path> { root <first path>; ... }
NGINX documentation on the alias directive suggests that it is better to use root over alias when the location matches the last part of the directive’s value.
The alias directive can only be placed in a location block. The following is a set of configurations for illustrating how the alias directive is applied:
server { server_name example.com; listen 10.250.250.10:80; index index.html; root /var/www/example.com; location / { try_files $uri $uri/ =404; } location ^~ /images { alias /var/www/static; try_files $uri $uri/ =404; } }
NGINX will map the request made to:
http://example.com/images/logo.pnginto the file path/var/www/static/logo.pnghttp://example.com/images/ext/img.pnginto the file path/var/www/static/ext/img.pnghttp://example.com/contact.htmlinto the file path/var/www/example.com/contact.htmlhttp://example.com/about/us.htmlinto the file path/var/www/example.com/about/us.html
When location matches the last part of the directive’s value it is better to use the root directive (it seems like an arbitrary style choice because authors don’t justify that instruction at all). Look at this example from the official documentation:
location /images/ { alias /data/w3/images/; } # Better solution: location /images/ { root /data/w3; }
internal directive
This directive specifies that the location block is internal. In other words,
the specified resource cannot be accessed by external requests.
On the other hand, it specifies how external redirections, i.e. locations like http://example.com/app.php/some-path should be handled; while set, they should return 404, only allowing internal redirections. In brief, this tells NGINX it’s not accessible from the outside (it doesn’t redirect anything).
Conditions handled as internal redirections are listed in the documentation for internal directive. Specifies that a given location can only be used for internal requests and are the following:
- requests redirected by the
error_page,index,random_index, andtry_filesdirectives - requests redirected by the
X-Accel-Redirectresponse header field from an upstream server - subrequests formed by the
include virtualcommand of thengx_http_ssi_module module, by thengx_http_addition_modulemodule directives, and byauth_requestandmirrordirectives - requests changed by the
rewritedirective
Example 1:
error_page 404 /404.html; location = /404.html { internal; }
Example 2:
The files are served from the directory /srv/hidden-files by the path prefix /hidden-files/. Pretty straightforward. The internal declaration tells NGINX that this path is accessible only through rewrites in the NGINX config, or via the X-Accel-Redirect header in proxied responses.
To use this, just return an empty response which contains that header. The content of the header should be the location you want to redirect to:
location /hidden-files/ { internal; alias /srv/hidden-files/; }
Example 3:
Another use case for internal redirects in NGINX is to hide credentials. Often you need to make requests to 3rd party services. For example, you want to send text messages or access a paid maps server. It would be the most efficient to send these requests directly from your JavaScript front end. However, doing so means you would have to embed an access token in the front end. This means savvy users could extract this token and make requests on your account.
An easy fix is to make an endpoint in your back end which initiates the actual request. We could make use of an HTTP client library inside the back end. However, this will again tie up workers, especially if you expect a barrage of requests and the 3rd party service is responding very slowly.
location /external-api/ { internal; set $redirect_uri "$upstream_http_redirect_uri"; set $authorization "$upstream_http_authorization"; # For performance: proxy_buffering off; # Pass on secret from backend: proxy_set_header Authorization $authorization; # Use URI determined by backend: proxy_pass $redirect_uri; }
Examples 2 and 3 (both are great!) comes from How to use internal redirects in NGINX.
There is a limit of 10 internal redirects per request to prevent request processing cycles that can occur in incorrect configurations. If this limit is reached, the error HTTP 500 Internal Server Error is returned. In such cases, the
rewrite or internal redirection cyclemessage can be seen in the error log.
Look also at Authentication Based on Subrequest Result from the official documentation.
External and internal redirects
External redirects originate directly from the client. So, if the client fetched https://example.com/directory it would be directly fall into preceding location block.
Internal redirect means that it doesn’t send a 302 response to the client, it simply performs an implicit rewrite of the url and attempts to process it as though the user typed the new url originally.
The internal redirect is different from the external redirect defined by HTTP response code 302 and 301, client browser won’t update its URI addresses.
To begin rewriting internally, we should explain the difference between redirects and internal rewrite. When source points to a destination that is out of source domain that is what we call redirect as your request will go from source to outside domain/destination.
With internal rewrite you would be, basically, doing the same only the destination is local path under same domain and not the outside location.
There is also great explanation about internal redirects:
The internal redirection (e.g. via the
echo_execorrewritedirective) is an operation that makes NGINX jump from one location to another while processing a request (are very similar togotostatement in the C language). This «jumping» happens completely within the server itself.
There are two different kinds of internal requests:
-
internal redirects — redirects the client requests internally. The URI is
changed, and the request may therefore match another location block and
become eligible for different settings. The most common case of internal
redirects is when using therewritedirective, which allows you to rewrite the
request URI -
sub-requests — additional requests that are triggered internally to generate (insert or append to the body of the original request) content that is complementary to the main request (
additionorssimodules)
allow and deny
🔖 Take care about your ACL rules — Hardening — P1
🔖 Reject unsafe HTTP methods — Hardening — P1
Both comes from the ngx_http_access_module module and allows limiting access to certain client addresses. You can combining allow/deny rules.
denywill always return 403 error code.
The easiest path would be to start out by denying all access, then only granting access to those locations you want. For example:
location / { # without 'satisfy any' both should be passed: satisfy any; allow 192.168.0/0/16; deny all; # sh -c "echo -n 'user:' >> /etc/nginx/.secret" # sh -c "openssl passwd -apr1 >> /etc/nginx/.secret" auth_basic "Restricted Area"; auth_basic_user_file /etc/nginx/.secret; root /usr/share/nginx/html; index index.html index.htm; }
Putting satisfy any; in your configuration tells NGINX to accept either http authentication, or IP restriction. By default, when you define both, it will expect both.
See also this answer:
As you’ve found, it isn’t advisable to but the auth settings at the server level because they will apply to all locations. While it is possible to turn basic auth off there doesn’t appear to be a way to clear an existing IP whitelist.
A better solution would be to add the authentication to the / location so that it isn’t inherited by /hello.
The problem comes if you have other locations that require the basic auth and IP whitelisting in which case it might be worth considering moving the auth components to an include file or nesting them under /.
Both directives may work unexpectedly! Look at the following example:
server { server_name example.com; deny all; location = /test { return 200 "it's all okay"; more_set_headers 'Content-Type: text/plain'; } }
If you generate a reqeust:
curl -i https://example.com/test
HTTP/2 200
date: Wed, 11 Nov 2018 10:02:45 GMT
content-length: 13
server: Unknown
content-type: text/plain
it's all okay
Why? Look at Request processing stages chapter. That’s because NGINX process request in phases, and rewrite phase (where return belongs) goes before access phase (where deny works).
uri vs request_uri
🔖 Use
$request_urito avoid using regular expressions — Performance — P2
$request_uri is the original request (for example /foo/bar.php?arg=baz includes arguments and can’t be modified) but $uri refers to the altered URI so $uri is not equivalent to $request_uri.
See this great and short explanation by Richard Smith:
The
$urivariable is set to the URI that NGINX is currently processing — but it is also subject to normalisation, including:
- removal of the
?and query string- consecutive
/characters are replace by a single/- URL encoded characters are decoded
The value of
$request_uriis always the original URI and is not subject to any of the above normalisations.Most of the time you would use
$uri, because it is normalised. Using$request_uriin the wrong place can cause URL encoded characters to become doubly encoded.
Both excludes the schema (https:// and the port (implicit 443) in both examples above) as defined by RFC 2616 — http URL [IETF] for the URL:
http_URL = "http(s):" "//" host [ ":" port ] [ abs_path [ "?" query ]]
Take a look at the following table:
| URL | $request_uri |
$uri |
|---|---|---|
https://example.com/foo |
/foo |
/foo |
https://example.com/foo/bar |
/foo/bar |
/foo/bar |
https://example.com/foo/bar/ |
/foo/bar/ |
/foo/bar/ |
https://example.com/foo/bar? |
/foo/bar? |
/foo/bar |
https://example.com/foo/bar?do=test |
/foo/bar?do=test |
/foo/bar |
https://example.com/rfc2616-sec3.html#sec3.2 |
/rfc2616-sec3.html |
/rfc2616-sec3.html |
Another way to repeat the location is to use the proxy_pass directive which is quite easy:
location /app/ { proxy_pass http://127.0.0.1:5000; # or: proxy_pass http://127.0.0.1:5000/api/app/; }
| LOCATION | proxy_pass |
REQUEST | RECEIVED BY UPSTREAM |
|---|---|---|---|
/app/ |
http://localhost:5000/api$request_uri |
/app/foo?bar=baz |
/api/webapp/foo?bar=baz |
/app/ |
http://localhost:5000/api$uri |
/app/foo?bar=baz |
/api/webapp/foo |
Compression and decompression
🔖 Mitigation of CRIME/BREACH attacks — Hardening Rules — P2
By default, NGINX compresses responses only with MIME type text/html using the gzip method. So, if you send request with Accept-Encoding: gzip header you will not see the Content-Encoding: gzip in the response.
To enable gzip compression:
To compress responses with other MIME types, include the gzip_types directive and list the additional types:
gzip_types text/plain text/css text/xml text/javascript application/x-javascript application/xml;
Remember: by default, NGINX doesn’t compress image files using its per-request gzip module.
I also highly recommend you read this (it’s interesting observation about gzip and performance by Barry Pollard):
To be honest gzip is not very processor intensive these days and gzipping on the fly (and then unzipping in the browser) is often the norm. It’s something web browsers are very good at.
So unless you are getting huge volumes of traffic you’ll probably not notice any performance or CPU load impact due to on the fly gzipping for most web files.
To test HTTP and Gzip compression I recommend two external tools:
- HTTP Compression Test
- HTTP Gzip Compression Test
NGINX also compress large files and avoid the temptation to compress smaller files (such as images, executables, etc.), because very small files barely benefit from compression. You can tell NGINX not to compress files smaller than e.g. 128 bytes:
For more information see Finding the Nginx gzip_comp_level Sweet Spot.
Compressing resources on-the-fly adds CPU-load and latency (wait for the compression to be done) every time a resource is served. NGINX also provides static compression with static module. It is better, for 2 reasons:
- you don’t have to gzip for each request
- you can use a higher gzip level
For example:
# Enable static gzip compression: location ^~ /assets/ { gzip_static on; ... }
You should put the gzip_static on; inside the blocks that configure static files, but if you’re only running one site, it’s safe to just put it in the http block.
NGINX does not automatically compress the files for you. You will have to do this yourself.
To compress files manually:
cd assets/ while IFS='' read -r -d '' _fd; do gzip -N4c ${_fd} > ${_fd}.gz done < <(find . -maxdepth 1 -type f -regex ".*.(css|js|jpg|gif|png|jpeg)" -print0)
So, for example, to service a request for /foo/bar/file, NGINX tries to find and send the file /foo/bar/file.gz that directly, so no extra CPU-cost or latency is added to your requests, speeding up the serving of your app.
What is the best NGINX compression gzip level?
The level of gzip compression simply determines how compressed the data is on a scale from 1-9, where 9 is the most compressed. The trade-off is that the most compressed data usually requires the most work to compress/decompress but look also at this great answer. Author explains that the level of gzip compression doesn’t affect the difficulty to decompress.
I think the ideal compression level seems to be between 4 and 6. The following directive set how much files will be compressed:
Hash tables
Before start reading this chapter I recommend Hash tables explained.
To assist with the rapid processing of requests, NGINX uses hash tables. NGINX hash, though in principle is same as typical hash lists, but it has significant differences.
They are not meant for applications that add and remove elements dynamicall but are specifically designed to hold set of init time elements arranged in hash list. All elements that are put in the hash list are known while creating the hash list itself. No dynamic addtion or deletion is possible here.
This hash table is constructed and compiled during restart or reload and afterwards it’s running very fast. Main purpose seems to be speeding up the lookup of one time added elements.
Look at the Setting up hashes from official documentation:
To quickly process static sets of data such as server names, map directive’s values, MIME types, names of request header strings, NGINX uses hash tables. During the start and each re-configuration NGINX selects the minimum possible sizes of hash tables such that the bucket size that stores keys with identical hash values does not exceed the configured parameter (hash bucket size). The size of a table is expressed in buckets. The adjustment is continued until the table size exceeds the hash max size parameter. Most hashes have the corresponding directives that allow changing these parameters.
I also recommend Optimizations section and nginx — Hashing scheme explanation.
Some important information (based on this amazing research by brablc):
-
the general recommendation would be to keep both values as small as possible and as less collisions as possible (during startup and with each reconfiguration, NGINX selects the smallest possible size for the hash tables)
-
it depends on your setup, you can reduce the number of server from the table and
reloadthe NGINX instead ofrestart -
if NGINX gave out communication about the need for increasing
hash_max_sizeorhash_bucket_size, then it is first necessary to increase the first parameter -
bigger
hash_max_sizeuses more memory, biggerhash_bucket_sizeuses more CPU cycles during lookup and more transfers from main memory to cache. If you have enough memory increasehash_max_sizeand try to keephash_bucket_sizeas low as possible -
each hash table entry consumes space in a bucket. The space required is the length of the key (with some overhead to store the domain’s actual length as well), e.g. domain name
Since
stage.api.example.comis 21 characters, all entries consume at least 24 bytes in a bucket, and most consume 32 bytes or more. -
as you increase the number of entries, you have to increase the size of the hash table and/or the number of hash buckets in the table
If NGINX complains increase
hash_max_sizefirst as long as it complains. If the number exceeds some big number (32769 for instance), increasehash_bucket_sizeto multiple of default value on your platform as long as it complains. If it does not complain anymore, decreasehash_max_sizeback as long as it does not complain. Now you have the best setup for your set of server names (each set of server names may need different setup). -
with a hash bucket size of 64 or 128, a bucket is full after 4 or 5 entries hash to it
-
hash_max_sizeis not related to number of server names directly, if number of servers doubles, you may need to increasehash_max_size10 times or even more to avoid collisions. If you cannot avoid them, you have to increasehash_bucket_size -
if you have
hash_max_sizeless than 10000 and smallhash_bucket_size, you can expect long loading time because NGINX would try to find optimal hash size in a loop (see src/core/ngx_hash.c) -
if you have
hash_max_sizebigger than 10000, there will be only 1000 loops performed before it would complain
Server names hash table
The hash with the names of servers are controlled by the following directives (inside http context):
-
server_names_hash_max_size— sets the maximum size of the server names hash tables; default value: 512 -
server_names_hash_bucket_size— sets the bucket size for the server names hash tables; default values: 32, 64, or 128 (the default value depends on the size of the processor’s cache line)Parameter
server_names_hash_bucket_sizeis always equalized to the size, multiple to the size of the line of processor cache.
If server name is defined as too.long.server.name.example.com then NGINX will fail to start and display the error message like:
nginx: [emerg] could not build server_names_hash, you should increase server_names_hash_bucket_size: 64
To fix this, you should reload the NGINX or increase the server_names_hash_bucket_size directive value to the next power of two (in this case to 128).
If a large number of server names are defined, and NGINX complained with the following error:
nginx: [emerg] could not build the server_names_hash, you should increase either server_names_hash_max_size: 512 or server_names_hash_bucket_size: 32
Try to set the server_names_hash_max_size to a number close to the number of server names. Only if this does not help, or if NGINX’s start time is unacceptably long, try to increase the server_names_hash_bucket_size parameter.
Log files
🔖 Use custom log formats — Debugging — P4
Log files are a critical part of the NGINX management. It writes information about client requests in the access log right after the request is processed (in the last phase: NGX_HTTP_LOG_PHASE).
By default:
- the access log is located in
logs/access.log, but I suggest you take it to/var/log/nginxdirectory - data is written in the predefined
combined/mainformat access.logstores record of each request and log format is fully configurableerror.logcontains important operational messages
It is the equivalent to the following configuration:
# In nginx.conf (default log format): http { ... log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; # but I suggest you change: log_format main '$remote_addr - $remote_user [$time_local] ' '"$request_method $scheme://$host$request_uri ' '$server_protocol" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" ' '$request_time'; }
For more information please see Configuring Logging.
Set
access log off;to completely turns off logging.
If you don’t want 404 errors to show in your NGINX error logs, you should set
log_not_found off;.
If you want to enable logging of subrequests into
access_log, you should setlog_subrequest on;and change the default logging format (you have to log$urito see the difference). There is great explanation about how to identify subrequests in NGINX log files.
I also recommend to read:
- ngx_http_log_module
- ngx_http_upstream_module
Conditional logging
Sometimes certain entries are there just to fill up the logs or are cluttering them. I sometimes exclude requests — by client IP or whatever else — when I want to debug log files more effective.
So, in this example, if the $error_codes variable’s value is 0 — then log nothing (default action), but if 1 (e.g. 404 or 503 from backend) — to save this request to the log:
# Define map in the http context: http { ... map $status $error_codes { default 1; ~^[23] 0; } ... # Add if condition to the access log: access_log /var/log/nginx/example.com-access.log combined if=$error_codes; }
Manually log rotation
🔖 Configure log rotation policy — Base Rules — P1
NGINX will re-open its logs in response to the USR1 signal:
cd /var/log/nginx mv access.log access.log.0 kill -USR1 $(cat /var/run/nginx.pid) && sleep 1 # >= gzip-1.6: gzip -k access.log.0 # With any version: gzip < access.log.0 > access.log.0.gz # Test integrity and remove if test passed: gzip -t access.log.0 && rm -fr access.log.0
Error log severity levels
You can’t specify your own format, but in NGINX build-in several level’s of
error_log-ing.
The following is a list of all severity levels:
| TYPE | DESCRIPTION |
|---|---|
debug |
information that can be useful to pinpoint where a problem is occurring |
info |
informational messages that aren’t necessary to read but may be good to know |
notice |
something normal happened that is worth noting |
warn |
something unexpected happened, however is not a cause for concern |
error |
something was unsuccessful, contains the action of limiting rules (default) |
crit |
important problems that need to be addressed |
alert |
severe situation where action is needed promptly |
emerg |
the system is in an unusable state and requires immediate attention |
For example: if you set crit error log level, messages of crit, alert, and emerg levels are logged.
For debug logging to work, NGINX needs to be built with
--with-debug.
Default values for the error level:
- in the main section —
error - in the HTTP section —
crit - in the server section —
crit
How to log the start time of a request?
The most logging information requires the request to complete (status code, bytes sent, durations, etc). If you want to log the start time of a request in NGINX you should apply a patch that exposes request start time as a variable.
The $time_local variable contains the time when the log entry is written so when the HTTP request header is read, NGINX does a lookup of the associated virtual server configuration. If the virtual server is found, the request goes through six phases:
- server rewrite phase
- location phase
- location rewrite phase (which can bring the request back to the previous phase)
- access control phase
try_filesphase- log phase
Since the log phase is the last one, $time_local variable is much more close to the end of the request than it’s start.
How to log the HTTP request body?
Nginx doesn’t parse the client request body unless it really needs to, so it usually does not fill the $request_body variable.
The exceptions are when:
- it sends the request to a proxy
- or a fastcgi server
So you really need to either add the proxy_pass or fastcgi_pass directives to your block.
# 1) Set log format: log_format req_body_logging '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" "$request_body"'; # 2) Limit the request body size: client_max_body_size 1k; client_body_buffer_size 1k; client_body_in_single_buffer on; # 3) Put the log format: server { ... location /api/v4 { access_log logs/access_req_body.log req_body_logging; proxy_pass http://127.0.0.1; ... } location = /post.php { access_log /var/log/nginx/postdata.log req_body_logging; fastcgi_pass php_cgi; ... } }
For this, you can also use echo module. To log a request body, what we need is to use the echo_read_request_body directive and the $request_body variable (contains the request body of the echo module).
echo_read_request_bodyexplicitly reads request body so that the$request_bodyvariable will always have non-empty values (unless the body is so big that it has been saved by NGINX to a local temporary file).
http { log_format req_body_logging '$request_body'; access_log /var/log/nginx/access.log req_body_logging; ... server { location / { echo_read_request_body; ... } ... } }
NGINX upstream variables returns 2 values
For example:
upstream_addr 192.168.50.201:8080 : 192.168.50.201:8080
upstream_bytes_received 427 : 341
upstream_connect_time 0.001 : 0.000
upstream_header_time 0.003 : 0.001
upstream_response_length 0 : 0
upstream_response_time 0.003 : 0.001
upstream_status 401 : 200
Below is a short description of each of them:
$upstream_addr— keeps the IP address and port, or the path to the UNIX-domain socket of the upstream server. If several servers were contacted during request processing, their addresses are separated by commas, e.g.192.168.1.1:80, 192.168.1.2:80, unix:/tmp/sock. If an internal redirect from one server group to another happens, initiated byX-Accel-Redirectorerror_page, then the server addresses from different groups are separated by colons, e.g.192.168.1.1:80, 192.168.1.2:80, unix:/tmp/sock : 192.168.10.1:80, 192.168.10.2:80$upstream_cache_status— keeps the status of accessing a response cache (0.8.3). The status can be eitherMISS,BYPASS,EXPIRED,STALE,UPDATING,REVALIDATED, orHIT$upstream_connect_time— time spent on establishing a connection with an upstream server$upstream_cookie_— cookie with the specified name sent by the upstream server in theSet-Cookieresponse header field (1.7.1). Only the cookies from the response of the last server are saved$upstream_header_time— time between establishing a connection and receiving the first byte of the response header from the upstream server$upstream_http_— keep server response header fields. For example, theServerresponse header field is available through the$upstream_http_servervariable. The rules of converting header field names to variable names are the same as for the variables that start with the$http_prefix. Only the header fields from the response of the last server are saved$upstream_response_length— keeps the length of the response obtained from the upstream server (0.7.27); the length is kept in bytes. Lengths of several responses are separated by commas and colons like addresses in the$upstream_addrvariable$upstream_response_time— time between establishing a connection and receiving the last byte of the response body from the upstream server$upstream_status— keeps status code of the response obtained from the upstream server. Status codes of several responses are separated by commas and colons like addresses in the$upstream_addrvariable
Official documentation say:
[…] If several servers were contacted during request processing, their addresses are separated by commas. […] If an internal redirect from one server group to another happens, initiated by “X-Accel-Redirect” or error_page, then the server addresses from different groups are separated by colons
This means that it made multiple requests to a backend, most likely you either have a bare proxy_pass host that resolves to different IPs (frequently the case with something like Amazon ELB as an origin), are you have a configured upstream that has multiple servers. Unless disabled, the proxy module will make round robin attempts against all healthy backends. This can be configured from proxy_next_upstream_* directives.
For example if this is not the desired behavior, you can just do (specifies in which cases a request should be passed to the next server):
# One should bear in mind that passing a request to the next server is only possible # if nothing has been sent to a client yet. That is, if an error or timeout occurs # in the middle of the transferring of a response, fixing this is impossible. proxy_next_upstream off;
For more information please see ngx_http_upstream_module and proxy_next_upstream.
Reverse proxy
After reading this chapter, please see: Rules: Reverse Proxy.
This is one of the greatest feature of the NGINX. In simplest terms, a reverse proxy is a server that comes in-between internal applications and external clients, forwarding client requests to the appropriate server. It takes a client request, passes it on to one or more servers, and subsequently delivers the server’s response back to the client.
Official NGINX documentation says:
Proxying is typically used to distribute the load among several servers, seamlessly show content from different websites, or pass requests for processing to application servers over protocols other than HTTP.
You can also read a very good explanation about What’s the difference between proxy server and reverse proxy server.
A reverse proxy can off load much of the infrastructure concerns of a high-volume distributed web application.

This infographic comes from Jenkins with NGINX — Reverse proxy with https.
This allow you to have NGINX reverse proxy requests to unicorns, mongrels, webricks, thins, or whatever you really want to have run your servers.
Reverse proxy gives you number of advanced features such as:
- load balancing, failover, and transparent maintenance of the backend servers
- increased security (e.g. SSL termination, hide upstream configuration)
- increased performance (e.g. caching, load balancing)
- simplifies the access control responsibilities (single point of access and maintenance)
- centralised logging and auditing (single point of maintenance)
- add/remove/modify HTTP headers
In my opinion, the two most important things related to the reverse proxy are:
- the way of requests forwarded to the backend
- the type of headers forwarded to the backend
If we talking about security of the proxy server look at this recommendations about Guidelines on Securing Public Web Servers [NIST]. This document is a good starting point. Is old but still has interesting solutions and suggestions.
There is a great explanation about the benefits of improving security through the use of a reverse proxy server.
A reverse proxy gives you a couple things that may make your server more secure:
- a place to monitor and log what is going on separate from the web server
- a place to filter separate from your web server if you know that some area of your system is vulnerable. Depending on the proxy you may be able to filter at the application level
- another place to implement ACLs and rules if you cannot be expressive enough for some reason on your web server
- a separate network stack that will not be vulnerable in the same ways as your web server. This is particularly true if your proxy is from a different vendor
- a reverse proxy with no filtering does not automatically protect you against everything, but if the system you need to protect is high-value then adding a reverse proxy may be worth the costs support and performance costs
Another great answer about best practices for reverse proxy implementation:
In my experience some of the most important requirements and mitigations, in no particular order, are:
- make sure that your proxy, back-end web (and DB) servers cannot establish direct outbound (internet) connections (including DNS and SMTP, and particularly HTTP). This means (forward) proxies/relays for required outbound access, if required
- make sure your logging is useful (§9.1 in the above), and coherent. You may have logs from multiple devices (router, firewall/IPS/WAF, proxy, web/app servers, DB servers). If you can’t quickly, reliably and deterministically link records across each device together, you’re doing it wrong. This means NTP, and logging any or all of: PIDs, TIDs, session-IDs, ports, headers, cookies, usernames, IP addresses and maybe more (and may mean some logs contain confidential information)
- understand the protocols, and make deliberate, informed decisions: including cipher/TLS version choice, HTTP header sizes, URL lengths, cookies. Limits should be implemented on the reverse-proxy. If you’re migrating to a tiered architecture, make sure the dev team are in the loop so that problems are caught as early as possible
- run vulnerability scans from the outside, or get someone to do it for you. Make sure you know your footprint and that the reports highlight deltas, as well as the theoretical TLS SNAFU du-jour
- understand the modes of failure. Sending users a bare default «HTTP 500 — the wheels came off» when you have load or stability problems is sloppy
- monitoring, metrics and graphs: having normal and historic data is invaluable when investigating anomalies, and for capacity planning
- tuning: from TCP time-wait to listen backlog to SYN-cookies, again you need to make make deliberate, informed decisions
- follow basic OS hardening guidelines, consider the use of chroot/jails, host-based IDS, and other measures, where available
Passing requests
🔖 Use pass directive compatible with backend protocol — Reverse Proxy — P1
When NGINX proxies a request, it sends the request to a specified proxied server, fetches the response, and sends it back to the client.
It is possible to proxy requests to:
-
an HTTP servers (e.g. NGINX, Apache, or other) with
proxy_passdirective:upstream bk_front { server 192.168.252.20:8080 weight=5; server 192.168.252.21:8080 } server { location / { proxy_pass http://bk_front; } location /api { proxy_pass http://192.168.21.20:8080; } location /info { proxy_pass http://localhost:3000; } location /ra-client { proxy_pass http://10.0.11.12:8080/guacamole/; } location /foo/bar/ { proxy_pass http://www.example.com/url/; } ... }
-
a non-HTTP servers (e.g. PHP, Node.js, Python, Java, or other) with
proxy_passdirective (as a fallback) or directives specially designed for this:-
fastcgi_passwhich passes a request to a FastCGI server (PHP FastCGI Example):server { ... location ~ ^/.+.php(/|$) { fastcgi_pass 127.0.0.1:9000; include /etc/nginx/fcgi_params; } ... }
-
uwsgi_passwhich passes a request to a uWSGI server (Nginx support uWSGI):server { location / { root html; uwsgi_pass django_cluster; uwsgi_param UWSGI_SCRIPT testapp; include /etc/nginx/uwsgi_params; } ... }
-
scgi_passwhich passes a request to an SCGI server:server { location / { scgi_pass 127.0.0.1:4000; include /etc/nginx/scgi_params; } ... }
-
memcached_passwhich passes a request to a Memcached server:server { location / { set $memcached_key "$uri?$args"; memcached_pass memc_instance:4004; error_page 404 502 504 = @memc_fallback; } location @memc_fallback { proxy_pass http://backend; } ... }
-
redis_passwhich passes a request to a Redis server (HTTP Redis):server { location / { set $redis_key $uri; redis_pass redis_instance:6379; default_type text/html; error_page 404 = /fallback; } location @fallback { proxy_pass http://backend; } ... }
-
The proxy_pass and other *_pass directives specifies that all requests which match the location block should be forwarded to the specific socket, where the backend app is running.
However, more complex apps may need additional directives:
proxy_pass— seengx_http_proxy_moduledirectives explanationfastcgi_pass— seengx_http_fastcgi_moduledirectives explanationuwsgi_pass— seengx_http_uwsgi_moduledirectives explanationscgi_pass— seengx_http_scgi_moduledirectives explanationmemcached_pass— seengx_http_memcached_moduledirectives explanationredis_pass— seengx_http_redis_moduledirectives explanation
Trailing slashes
🔖 Be careful with trailing slashes in proxy_pass directive — Reverse Proxy — P3
If you have something like:
location /public/ { proxy_pass http://bck_testing_01; }
And go to http://example.com/public, NGINX will automatically redirect you to http://example.com/public/.
Look also at this example:
location /foo/bar/ { # proxy_pass http://example.com/url/; proxy_pass http://192.168.100.20/url/; }
If the URI is specified along with the address, it replaces the part of the request URI that matches the location parameter. For example, here the request with the /foo/bar/page.html URI will be proxied to http://www.example.com/url/page.html.
If the address is specified without a URI, or it is not possible to determine the part of URI to be replaced, the full request URI is passed (possibly, modified).
Here is an example with trailing slash in location, but no trailig slash in proxy_pass:
location /foo/ { proxy_pass http://127.0.0.1:8080/bar; }
See how bar and path concatenates. If one go to http://yourserver.com/foo/path/id?param=1 NGINX will proxy request to http://127.0.0.1/barpath/id?param=1.
As stated in NGINX documentation if proxy_pass used without URI (i.e. without path after server:port) NGINX will put URI from original request exactly as it was with all double slashes, ../ and so on.
Look also at the configuration snippets: Using trailing slashes.
Below are additional examples:
| LOCATION | PROXY_PASS | REQUEST | RECEIVED BY UPSTREAM |
|---|---|---|---|
/app/ |
http://localhost:5000/api/ |
/app/foo?bar=baz |
/api/foo?bar=baz |
/app/ |
http://localhost:5000/api |
/app/foo?bar=baz |
/apifoo?bar=baz |
/app |
http://localhost:5000/api/ |
/app/foo?bar=baz |
/api//foo?bar=baz |
/app |
http://localhost:5000/api |
/app/foo?bar=baz |
/api/foo?bar=baz |
/app |
http://localhost:5000/api |
/appfoo?bar=baz |
/apifoo?bar=baz |
In other words:
You usually always want a trailing slash, never want to mix with and without trailing slash, and only want without trailing slash when you want to concatenate a certain path component together (which I guess is quite rarely the case). Note how query parameters are preserved.
Passing headers to the backend
🔖 Set the HTTP headers with add_header and proxy_*_header directives properly — Base Rules — P1
🔖 Remove support for legacy and risky HTTP headers — Hardening — P1
🔖 Always pass Host, X-Real-IP, and X-Forwarded headers to the backend — Reverse Proxy — P2
🔖 Use custom headers without X- prefix — Reverse Proxy — P3
By default, NGINX redefines two header fields in proxied requests:
-
the
Hostheader is re-written to the value defined by the$proxy_hostvariable. This will be the IP address or name and port number of the upstream, directly as defined by theproxy_passdirective -
the
Connectionheader is changed toclose. This header is used to signal information about the particular connection established between two parties. In this instance, NGINX sets this tocloseto indicate to the upstream server that this connection will be closed once the original request is responded to. The upstream should not expect this connection to be persistent
When NGINX proxies a request, it automatically makes some adjustments to the request headers it receives from the client:
-
NGINX drop empty headers. There is no point of passing along empty values to another server; it would only serve to bloat the request
-
NGINX, by default, will consider any header that contains underscores as invalid. It will remove these from the proxied request. If you wish to have NGINX interpret these as valid, you can set the
underscores_in_headersdirective toon, otherwise your headers will never make it to the backend server. Underscores in header fields are allowed (RFC 7230, sec. 3.2.), but indeed uncommon
It is important to pass more than just the URI if you expect the upstream server handle the request properly. The request coming from NGINX on behalf of a client will look different than a request coming directly from a client.
Please read Managing request headers from the official wiki.
In NGINX does support arbitrary request header field. Last part of a variable name is the field name converted to lower case with dashes replaced by underscores:
$http_name_of_the_header_key
If you have X-Real-IP = 127.0.0.1 in header, you can use $http_x_real_ip to get 127.0.0.1.
Use the proxy_set_header directive to sets headers that sends to the backend servers.
HTTP headers are used to transmit additional information between client and server.
add_headersends headers to the client (browser) and will work on successful requests only, unless you set upalwaysparameter.proxy_set_headersends headers to the backend server. If the value of a header field is an empty string then this field will not be passed to a proxied server.
It’s also important to distinguish between request headers and response headers. Request headers are for traffic inbound to the webserver or backend app. Response headers are going the other way (in the HTTP response you get back using client, e.g. curl or browser).
Ok, so look at the following short explanation about proxy directives (for more information about valid header values please see this rule):
-
proxy_http_version— defines the HTTP protocol version for proxying, by default it it set to 1.0. For Websockets and keepalive connections you need to use the version 1.1: -
proxy_cache_bypass— sets conditions under which the response will not be taken from a cache:proxy_cache_bypass $http_upgrade;
-
proxy_intercept_errors— means that any response with HTTP code 300 or greater is handled by theerror_pagedirective and ensures that if the proxied backend returns an error status, NGINX will be the one showing the error page (as opposed to the error page on the backend side). If you want certain error pages still being delivered from the upstream server, then simply don’t specify theerror_page <code>on the reverse proxy (without this, NGINX will forward the error page coming from the upstream server to the client):proxy_intercept_errors on; error_page 404 /404.html; # from proxy # To bypass error intercepting (if you have proxy_intercept_errors on): # 1 - don't specify the error_page 404 on the reverse proxy # 2 - go to the @debug location error_page 500 503 504 @debug; location @debug { proxy_intercept_errors off; proxy_pass http://backend; }
-
proxy_set_header— allows redefining or appending fields to the request header passed to the proxied server-
UpgradeandConnection— these header fields are required if your application is using Websockets:proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade";
-
Host— the$hostvariable in the following order of precedence contains: host name from the request line, or host name from the Host request header field, or the server name matching a request: NGINX usesHostheader forserver_namematching. It does not use TLS SNI. This means that for an SSL server, NGINX must be able to accept SSL connection, which boils down to having certificate/key. The cert/key can be any, e.g. self-signed:proxy_set_header Host $host;
-
X-Real-IP— forwards the real visitor remote IP address to the proxied server:proxy_set_header X-Real-IP $remote_addr;
-
X-Forwarded-For— is the conventional way of identifying the originating IP address of the user connecting to the web server coming from either a HTTP proxy or load balancer:proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
-
X-Forwarded-Proto— identifies the protocol (HTTP or HTTPS) that a client used to connect to your proxy or load balancer:proxy_set_header X-Forwarded-Proto $scheme;
-
X-Forwarded-Host— defines the original host requested by the client:proxy_set_header X-Forwarded-Host $host;
-
X-Forwarded-Port— defines the original port requested by the client:proxy_set_header X-Forwarded-Port $server_port;
-
If you want to read about custom headers, take a look at Why we need to deprecate x prefix for HTTP headers? and this great answer by BalusC.
Importance of the Host header
🔖 Set and pass Host header only with $host variable — Reverse Proxy — P2
The Host header tells the webserver which virtual host to use (if set up). You can even have the same virtual host using several aliases (domains and wildcard-domains). This why the host header exists. The host header specifies which website or web application should process an incoming HTTP request.
In NGINX, $host equals $http_host, lowercase and without the port number (if present), except when HTTP_HOST is absent or is an empty value. In that case, $host equals the value of the server_name directive of the server which processed the request.
But look at this:
An unchanged
Hostrequest header field can be passed with$http_host. However, if this field is not present in a client request header then nothing will be passed. In such a case it is better to use the$hostvariable — its value equals the server name in theHostrequest header field or the primary server name if this field is not present.
For example, if you set Host: MASTER:8080, $host will be «master» (while $http_host will be MASTER:8080 as it just reflects the whole header).
Look also at $10k host header and What is a Host Header Attack?.
Redirects and X-Forwarded-Proto
🔖 Don’t use X-Forwarded-Proto with $scheme behind reverse proxy — Reverse Proxy — P1
This header is very important because it prevent a redirect loop. When used inside HTTPS server block each HTTP response from the proxied server will be rewritten to HTTPS. Look at the following example:
- Client sends the HTTP request to the Proxy
- Proxy sends the HTTP request to the Server
- Server sees that the URL is
http:// - Server sends back 3xx redirect response telling the Client to connect to
https:// - Client sends an HTTPS request to the Proxy
- Proxy decrypts the HTTPS traffic and sets the
X-Forwarded-Proto: https - Proxy sends the HTTP request to the Server
- Server sees that the URL is
http://but also sees thatX-Forwarded-Protois https and trusts that the request is HTTPS - Server sends back the requested web page or data
This explanation comes from Purpose of the X-Forwarded-Proto HTTP Header.
In step 6 above, the Proxy is setting the HTTP header X-Forwarded-Proto: https to specify that the traffic it received is HTTPS. In step 8, the Server then uses the X-Forwarded-Proto to determine if the request was HTTP or HTTPS.
You can read about how to set it up correctly here:
- Set correct scheme passed in X-Forwarded-Proto
- Don’t use X-Forwarded-Proto with $scheme behind reverse proxy — Reverse Proxy — P1
A warning about the X-Forwarded-For
🔖 Set properly values of the X-Forwarded-For header — Reverse Proxy — P1
I think we should just maybe stop for a second. X-Forwarded-For is a one of the most important header that has the security implications.
Where a connection passes through a chain of proxy servers, X-Forwarded-For can give a comma-separated list of IP addresses with the first being the furthest downstream (that is, the user).
The HTTP X-Forwarded-For accepts two directives as mentioned above and described below:
<client>— it is the IP address of the client<proxy>— it is the proxies that request has to go through. If there are multiple proxies then the IP addresses of each successive proxy is listed
Syntax:
X-Forwarded-For: <client>, <proxy1>, <proxy2>
X-Forwarded-For should not be used for any Access Control List (ACL) checks because it can be spoofed by attackers. Use the real IP address for this type of restrictions. HTTP request headers such as X-Forwarded-For, True-Client-IP, and X-Real-IP are not a robust foundation on which to build any security measures, such as access controls.
Set properly values of the X-Forwarded-For header (from this handbook) — see this for more detailed information on how to set properly values of the X-Forwarded-For header.
But that’s not all. Behind a reverse proxy, the user IP we get is often the reverse proxy IP itself. If you use other HTTP server working between proxy and app server you should also set the correct mechanism for interpreting values of this header.
I recommend to read this amazing explanation by Nick M.
-
Pass headers from proxy to the backend layer:
- Always pass Host, X-Real-IP, and X-Forwarded headers to the backend
- Set properly values of the X-Forwarded-For header (from this handbook)
-
NGINX (backend) — modify the
set_real_ip_fromandreal_ip_headerdirectives:For this, the
http_realip_modulemust be installed (--with-http_realip_module).First of all, you should add the following lines to the configuration:
# Add these to the set_real_ip.conf, there are the real IPs where your traffic # is coming from (front proxy/lb): set_real_ip_from 192.168.20.10; # IP address of master set_real_ip_from 192.168.20.11; # IP address of slave # You can also add an entire subnet: set_real_ip_from 192.168.40.0/24; # Defines a request header field used to send the address for a replacement, # in this case we use X-Forwarded-For: real_ip_header X-Forwarded-For; # The real IP from your client address that matches one of the trusted addresses # is replaced by the last non-trusted address sent in the request header field: real_ip_recursive on; # Include it to the appropriate context: server { include /etc/nginx/set_real_ip.conf; ... }
-
NGINX — add/modify and set log format:
log_format combined-1 '$remote_addr forwarded for $http_x_real_ip - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"'; # or: log_format combined-2 '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/example.com/access.log combined-1;
This way, e.g. the
$_SERVER['REMOTE_ADDR']will be correctly filled up in PHP fastcgi. You can test it with the following script:# tls_check.php <?php echo '<pre>'; print_r($_SERVER); echo '</pre>'; exit; ?>
And send request to it:
curl -H Cache-Control: no-cache -ks https://example.com/tls-check.php?${RANDOM} | grep "HTTP_X_FORWARDED_FOR|HTTP_X_REAL_IP|SERVER_ADDR|REMOTE_ADDR" [HTTP_X_FORWARDED_FOR] => 172.217.20.206 [HTTP_X_REAL_IP] => 172.217.20.206 [SERVER_ADDR] => 192.168.10.100 [REMOTE_ADDR] => 192.168.10.10
Improve extensibility with Forwarded
Since 2014, the IETF has approved a standard header definition for proxy, called Forwarded, documented here [IETF] and here that should be use instead of X-Forwarded headers. This is the one you should use reliably to get originating IP in case your request is handled by a proxy. Official NGINX documentation also gives you how to Using the Forwarded header.
In general, the proxy headers (Forwarded or X-Forwarded-For) are the right way to get your client IP only when you are sure they come to you via a proxy. If there is no proxy header or no usable value in, you should default to the REMOTE_ADDR server variable.
Response headers
🔖 Set the HTTP headers with add_header and proxy_*_header directives properly — Base Rules — P1
add_header directive allows you to define an arbitrary response header (mostly for informational/debugging purposes) and value to be included in all response codes which are equal to:
- 2xx series: 200, 201, 204, 206
- 3xx series: 301, 302, 303, 304, 307, 308
For example:
add_header Custom-Header Value;
To change (adding or removing) existing headers you should use a headers-more-nginx-module module.
There is one thing you must watch out for if you use add_header directive (also applies to proxy_*_header directives). See the following explanations:
- Nginx add_header configuration pitfall
- Be very careful with your add_header in Nginx! You might make your site insecure
This situation is described in the official documentation:
There could be several
add_headerdirectives. These directives are inherited from the previous level if and only if there are noadd_headerdirectives defined on the current level.
However — and this is important — as you now have defined a header in your server context, all the remaining headers defined in the http context will no longer be inherited. Means, you’ve to define them in your server context again (or alternatively ignore them if they’re not important for your site).
At the end, summary about directives to manipulate headers:
proxy_set_headeris to sets or remove a request header (and pass it or not to the backend)add_headeris to add header to responseproxy_hide_headeris to hide a response header
We also have the ability to manipulate request and response headers using the headers-more-nginx-module module:
more_set_headers— replaces (if any) or adds (if not any) the specified output headersmore_clear_headers— clears the specified output headersmore_set_input_headers— very much likemore_set_headersexcept that it operates on input headers (or request headers)more_clear_input_headers— very much likemore_clear_headersexcept that it operates on input headers (or request headers)
The following figure describes the modules and directives responsible for manipulating HTTP request and response headers:

Load balancing algorithms
Load Balancing is in principle a wonderful thing really. You can find out about it when you serve tens of thousands (or maybe more) of requests every second. Of course, load balancing is not the only reason — think also about maintenance tasks without downtime.
Generally load balancing is a technique used to distribute the workload across multiple computing resources and servers. I think you should always use this technique also if you have a simple app or whatever else what you’re sharing with other.
The configuration is very simple. NGINX includes a ngx_http_upstream_module to define backends (groups of servers or multiple server instances). More specifically, the upstream directive is responsible for this.
upstreamdefines the load balancing pool, only provide a list of servers, some kind of weight, and other parameters related to the backend layer.
Backend parameters
🔖 Tweak passive health checks — Load Balancing — P3
🔖 Don’t disable backends by comments, use down parameter — Load Balancing — P4
Before we start talking about the load balancing techniques you should know something about server directive. It defines the address and other parameters of a backend servers.
This directive accepts the following options:
-
weight=<num>— sets the weight of the origin server, e.g.weight=10 -
max_conns=<num>— limits the maximum number of simultaneous active connections from the NGINX proxy server to an upstream server (default value:0= no limit), e.g.max_conns=8- if you set
max_conns=4the 5th will be rejected - if the server group does not reside in the shared memory (
zonedirective), the limitation works per each worker process
- if you set
-
max_fails=<num>— the number of unsuccessful attempts to communicate with the backend (default value:1,0disables the accounting of attempts), e.g.max_fails=3; -
fail_timeout=<time>— the time during which the specified number of unsuccessful attempts to communicate with the server should happen to consider the server unavailable (default value:10 seconds), e.g.fail_timeout=30s; -
zone <name> <size>— defines shared memory zone that keeps the group’s configuration and run-time state that are shared between worker processes, e.g.zone backend 32k; -
backup— if server is marked as a backup server it does not receive requests unless both of the other servers are unavailable -
down— marks the server as permanently unavailable
Upstream servers with SSL
Setting up SSL termination on NGINX is also very simple using the SSL module. For this you need to use upstream module, and proxy module also. A very good case study is also given here.
For more information please read Securing HTTP Traffic to Upstream Servers from the official documentation.
Round Robin
It’s the simpliest load balancing technique. Round Robin has the list of servers and forwards each request to each server from the list in order. Once it reaches the last server, the loop again jumps to the first server and start again.
upstream bck_testing_01 { # with default weight for all (weight=1) server 192.168.250.220:8080; server 192.168.250.221:8080; server 192.168.250.222:8080; }

Weighted Round Robin
In Weighted Round Robin load balancing algorithm, each server is allocated with a weight based on its configuration and ability to process the request.
This method is similar to the Round Robin in a sense that the manner by which requests are assigned to the nodes is still cyclical, albeit with a twist. The node with the higher specs will be apportioned a greater number of requests.
upstream bck_testing_01 { server 192.168.250.220:8080 weight=3; server 192.168.250.221:8080; # default weight=1 server 192.168.250.222:8080; # default weight=1 }

Least Connections
This method tells the load balancer to look at the connections going to each server and send the next connection to the server with the least amount of connections.
upstream bck_testing_01 { least_conn; # with default weight for all (weight=1) server 192.168.250.220:8080; server 192.168.250.221:8080; server 192.168.250.222:8080; }
For example: if clients D10, D11 and D12 attempts to connect after A4, C2 and C8 have already disconnected but A1, B3, B5, B6, C7 and A9 are still connected, the load balancer will assign client D10 to server 2 instead of server 1 and server 3. After that, client D11 will be assign to server 1 and client D12 will be assign to server 2.

Weighted Least Connections
This is, in general, a very fair distribution method, as it uses the ratio of the number of connections and the weight of a server. The server in the cluster with the lowest ratio automatically receives the next request.
upstream bck_testing_01 { least_conn; server 192.168.250.220:8080 weight=3; server 192.168.250.221:8080; # default weight=1 server 192.168.250.222:8080; # default weight=1 }
For example: if clients D10, D11 and D12 attempts to connect after A4, C2 and C8 have already disconnected but A1, B3, B5, B6, C7 and A9 are still connected, the load balancer will assign client D10 to server 2 or 3 (because they have a least active connections) instead of server 1. After that, client D11 and D12 will be assign to server 1 because it has the biggest weight parameter.

IP Hash
The IP Hash method uses the IP of the client to create a unique hash key and associates the hash with one of the servers. This ensures that a user is sent to the same server in future sessions (a basic kind of session persistence) except when this server is unavailable. If one of the servers needs to be temporarily removed, it should be marked with the down parameter in order to preserve the current hashing of client IP addresses.
This technique is especially helpful if actions between sessions has to be kept alive e.g. products put in the shopping cart or when the session state is of concern and not handled by shared memory of the application.
upstream bck_testing_01 { ip_hash; # with default weight for all (weight=1) server 192.168.250.220:8080; server 192.168.250.221:8080; server 192.168.250.222:8080; }

Generic Hash
This technique is very similar to the IP Hash but for each request the load balancer calculates a hash that is based on the combination of a text string, variable, or a combination you specify, and associates the hash with one of the servers.
upstream bck_testing_01 { hash $request_uri; # with default weight for all (weight=1) server 192.168.250.220:8080; server 192.168.250.221:8080; server 192.168.250.222:8080; }
For example: load balancer calculate hash from the full original request URI (with arguments). Clients A4, C7, C8 and A9 sends requests to the /static location and will be assign to server 1. Similarly clients A1, C2, B6 which get /sitemap.xml resource they will be assign to server 2. Clients B3 and B5 sends requests to the /api/v4 and they will be assign to server 3.

Other methods
It is similar to the Generic Hash method because you can also specify a unique hash identifier but the assignment to the appropriate server is under your control. I think it’s a somewhat primitive method and I wouldn’t say it is a full load balancing technique, but in some cases it is very useful.
Mainly this helps reducing the mess on the configuration made by a lot of
locationblocks with similar configurations.
First of all, create a map:
map $request_uri $bck_testing_01 { default "192.168.250.220:8080"; /api/v4 "192.168.250.220:8080"; /api/v3 "192.168.250.221:8080"; /static "192.168.250.222:8080"; /sitemap.xml "192.168.250.222:8080"; }
And add proxy_pass directive:
server { ... location / { proxy_pass http://$bck_testing_01; } ... }
Rate limiting
🔖 Limit concurrent connections — Hardening — P1
**🔖 Use limit_conn to improve limiting the download speed — Performance — P3
NGINX has a default module to setup rate limiting. For me, it’s one of the most useful protect feature but sometimes really hard to understand.
I think, in case of doubt, you should read up on the following documents:
- Rate Limiting with NGINX and NGINX Plus
- NGINX rate-limiting in a nutshell
- NGINX Rate Limiting
- How to protect your web site from HTTP request flood, DoS and brute-force attacks
Rate limiting rules are useful for:
- traffic shaping
- traffic optimising
- slow down the rate of incoming requests
- protect http requests flood
- protect against slow http attacks
- prevent consume a lot of bandwidth
- mitigating ddos attacks
- protect brute-force attacks
Variables
NGINX has following variables (unique keys) that can be used in a rate limiting rules. For example:
| VARIABLE | DESCRIPTION |
|---|---|
$remote_addr |
client address |
$binary_remote_addr |
client address in a binary form, it is smaller and saves space then remote_addr |
$server_name |
name of the server which accepted a request |
$request_uri |
full original request URI (with arguments) |
$query_string |
arguments in the request line |
Please see official documentation for more information about variables.
Directives, keys, and zones
NGINX also provides following keys:
| KEY | DESCRIPTION |
|---|---|
limit_req_zone |
stores the current number of excessive requests |
limit_conn_zone |
stores the maximum allowed number of connections |
And directives:
| DIRECTIVE | DESCRIPTION |
|---|---|
limit_req |
in combination with a limit_conn_zone sets the shared memory zone and the maximum burst size of requests |
limit_conn |
in combination with a limit_req_zone sets the shared memory zone and the maximum allowed number of (simultaneous) connections to the server per a client IP |
Keys are used to store the state of each IP address and how often it has accessed a limited object. This information are stored in shared memory available from all NGINX worker processes.
You can enable the dry run mode with
limit_req_dry_run on;. In this mode, requests processing rate is not limited, however, in the shared memory zone, the number of excessive requests is accounted as usual.
Both keys also provides response status parameters indicating too many requests or connections with specific http code (default 503).
limit_req_status <value>limit_conn_status <value>
For example, if you want to set the desired logging level for cases when the server limits the number of connections:
# Add this to http context: limit_req_status 429; # Set your own error page for 429 http code: error_page 429 /rate_limit.html; location = /rate_limit.html { root /usr/share/www/http-error-pages/sites/other; internal; }
And create this file:
cat > /usr/share/www/http-error-pages/sites/other/rate_limit.html << __EOF__ HTTP 429 Too Many Requests __EOF__
Rate limiting rules also have zones that lets you define a shared space in which to count the incoming requests or connections.
All requests or connections coming into the same space will be counted in the same rate limit. This is what allows you to limit per URL, per IP, or anything else. In HTTP/2 and SPDY, each concurrent request is considered a separate connection.
The zone has two required parts:
<name>— is the zone identifier<size>— is the zone size
Example:
<key> <variable> zone=<name>:<size>;
State information for about 16,000 IP addresses takes 1 megabyte. So 1 kilobyte zone has 16 IP addresses.
The range of zones is as follows:
-
http context
-
server context
server { ... zone=<name>; -
location directive
location /api { ... zone=<name>;
All rate limiting rules (definitions) should be added to the NGINX
httpcontext.
Remember also about this answer:
If your are loading a website, you are not loading only this site, but assets as well. Nginx will think of them as independent connections. You have 10r/s defined and a burst size of 5. Therefore after 10 Requests/s the next requests will be delayed for rate limiting purposes. If the burst size (5) gets exceeded the following requests will receive a 503 error.
limit_req_zone key lets you set rate parameter (optional) — it defines the rate limited URL(s).
See also examples (all comes from this handbook):
- Limiting the rate of requests with burst mode
- Limiting the rate of requests with burst mode and nodelay
- Limiting the rate of requests per IP with geo and map
- Limiting the number of connections
Burst and nodelay parameters
For enable queue you should use limit_req or limit_conn directives (see above). limit_req also provides optional parameters:
| PARAMETER | DESCRIPTION |
|---|---|
burst=<num> |
sets the maximum number of excessive requests that await to be processed in a timely manner; maximum requests as rate * burst in burst seconds |
nodelay |
it imposes a rate limit without constraining the allowed spacing between requests; default NGINX would return 503 response and not handle excessive requests |
nodelayparameters are only useful when you also set aburst.
Without nodelay NGINX would wait (no 503 response) and handle excessive requests with some delay.
NAXSI Web Application Firewall
- NAXSI
- NAXSI, a web application firewall for Nginx
NAXSI is an open-source, high performance, low rules maintenance WAF for NGINX and is usually referred to as a Positive model application Firewall. It is an open-source WAF (Web Application Firewall), providing high performances, and low rules maintenance Web Application Firewall module.
OWASP ModSecurity Core Rule Set (CRS)
- OWASP Core Rule Set
- OWASP Core Rule Set — Official documentation
The OWASP ModSecurity Core Rule Set (CRS) is a set of generic attack detection rules for use with ModSecurity or compatible web application firewalls. The CRS aims to protect web applications from a wide range of attacks, including the OWASP Top Ten, with a minimum of false alerts.
Core modules
ngx_http_geo_module
Documentation:
ngx_http_geo_module
This module makes available variables, whose values depend on the IP address of the client. When combined with GeoIP module allows for very elaborate rules serving content according to the geolocation context.
By default, the IP address used for doing the lookup is $remote_addr, but it is possible to specify an another variable.
If the value of a variable does not represent a valid IP address then the
255.255.255.255address is used.
Performance
Look at this (from official documentation):
Since variables are evaluated only when used, the mere existence of even a large number of declared
geovariables does not cause any extra costs for request processing.
This module (watch out: don’t mistake this module for the GeoIP) builds in-memory radix tree when loading configs. This is the same data structure as used in routing, and lookups are really fast. If you have many unique values per networks, then this long load time is caused by searching duplicates of data in array. Otherwise, it may be caused by insertions to a radix tree.
Examples
See Use geo/map modules instead of allow/deny from this handbook.
# The variable created is $trusted_ips: geo $trusted_ips { default 0; 192.0.0.0/24 0; 8.8.8.8 1; } server { if ( $trusted_ips = 1 ) { return 403; } ... }
If the value of a variable does not represent a valid IP address then the
255.255.255.255address is used.
You can also test IP ranges, for example:
# Create geo-ranges.conf: 127.0.0.0-127.255.255.255 loopback; # Add geo definition: geo $geo_ranges { ranges; default default; include geo-ranges.conf; 10.255.0.0-10.255.255.255 internal; }
3rd party modules
Not all external modules can work properly with your currently NGINX version. You should read the documentation of each module before adding it to the modules list. You should also to check what version of module is compatible with your NGINX release. What’s more, be careful before adding modules on production. Some of them can cause strange behaviors, increased memory and CPU usage, and also reduce the overall performance of NGINX.
Before installing external modules please read Event-Driven architecture section to understand why poor quality 3rd party modules may reduce NGINX performance.
If you have running NGINX on your server, and if you want to add new modules, you’ll need to compile them against the same version of NGINX that’s currently installed (
nginx -v) and to make new module compatible with the existing NGINX binary, you need to use the same compile flags (nginx -V). For more please see How to Compile Dynamic NGINX Modules.
If you use, e.g.
--with-stream=dynamic, then all thosestream_xxxmodules must also be built as NGINX dynamic modules. Otherwise you would definitely see those linker errors.
ngx_set_misc
Documentation:
ngx_set_misc
ngx_http_geoip_module
Documentation:
ngx_http_geoip_modulengx_http_geoip2_module
This module allows real-time queries against the Max Mind GeoIP database. It uses the old version of API, still very common on OS distributions. For using the new version of GeoIP API, see geoip2 module.
The Max Mind GeoIP database is a map of IP network address assignments to geographical locales that can be useful — though approximate — in identifying the physical location with which an IP host address is associated on a relatively granular level.
Performance
The GeoIP module sets multiple variables and by default NGINX parses and loads geoip data into memory once the config file only on (re)start or SIGHUP.
GeoIP lookups come from a distributed database rather than from a dynamic server, so unlike DNS, the worst-case performance hit is minimal. Additionally, from a performance point of view, you should not worry, as geoip database are stored in memory (at the reading configuration phase) and NGINX doing lookups very fast.
GeoIP module creates (and assigns values to) variables based on the IP address of the request client and one of Maxmind GeoIP databases. One of the common uses is to set the country of the end-user as a NGINX variable.
Variables in NGINX are evaluated only on demand. If $geoip_* variable was not used during the request processing, then geoip db was not lookuped. So, if you don’t call the geoip variable on your app the geoip module wont be executed at all. The only inconvenience of using really large geobases is config reading time.
Examples
See Restricting access by geographical location from this handbook.
With the advent of Microservices™, ingress routing and routing between services has been an every-increasing demand. I currently default to nginx for this — with no plausible reason or experience to back this decision, just because it seems to be the most used tool currently.
However, the often needed proxy_pass directive has driven me crazy because of it’s — to me unintuitive — behavior. So I decided to take notes on how it works and what is possible with it, and how to circumvent some of it’s quirks.
First, a note on https
By default proxy_pass does not verify the certificate of the endpoint if it is https (how can this be the default behavior, really?!). This can be useful internally, but usually you want to do this very explicitly. And in case that you use publicly routed endpoints, which I have done in the past, make sure to set proxy_ssl_verify to on. You can also authenticate against the upstream server that you proxy_pass to using client certificates and more, make sure to have a look at the available options at https://docs.nginx.com/nginx/admin-guide/security-controls/securing-http-traffic-upstream/.
A simple example
A proxy_pass is usually used when there is an nginx instance that handles many things, and delegates some of those requests to other servers. Some examples are ingress in a Kubernetes cluster that spreads requests among the different microservices that are responsible for the specific locations. Or you can use nginx to directly deliver static files for a frontend, while some server-side rendered content or API is delivered by a WebApp such as ASP.NET Core or flask.
Let’s imagine we have a WebApp running on http://localhost:5000 and want it to be available on http://localhost:8080/webapp/, here’s how we would do it in a minimal nginx.conf:
daemon off;
events {
}
http {
server {
listen 8080;
location /webapp/ {
proxy_pass http://127.0.0.1:5000/api/;
}
}
}
You can save this to a file, e.g. nginx.conf, and run it with
nginx -c $(pwd)/nginx.conf.
Now, you can access http://localhost:8080/webapp/ and all requests will be forwarded to http://localhost:5000/api/.
Note how the /webapp/ prefix is «cut away» by nginx. That’s how locations work: They cut off the part specified in the location specification, and pass the rest on to the «upstream». «upstream» is called whatever is behind the nginx.
To slash or not to slash
Except for when you use variables in the proxy_pass upstream definition, as we will learn below, the location and upstream definition are very simply tied together. That’s why you need to be aware of the slashes, because some strange things can happen when you don’t get it right.
Here is a handy table that shows you how the request will be received by your WebApp, depending on how you write the location and proxy_pass declarations. Assume all requests go to http://localhost:8080:
In other words: You usually always want a trailing slash, never want to mix with and without trailing slash, and only want without trailing slash when you want to concatenate a certain path component together (which I guess is quite rarely the case). Note how query parameters are preserved!
$uri and $request_uri
You have to ways to circumvent that the location is cut off: First, you can simply repeat the location in the proxy_pass definition, which is quite easy:
location /webapp/ {
proxy_pass http://127.0.0.1:5000/api/webapp/;
}
That way, your upstream WebApp will receive /api/webapp/foo?bar=baz in the above examples.
Another way to repeat the location is to use $uri or $request_uri. The difference is that $request_uri preserves the query parameters, while $uri discards them:
Note how in the proxy_pass definition, there is no slash between «api» and $request_uri or $uri. This is because a full URI will always include a leading slash, which would lead to a double-slash if you wrote «api/$uri».
Capture regexes
While this is not exclusive to proxy_pass, I find it generally handy to be able to use regexes to forward parts of a request to an upstream WebApp, or to reformat it. Example: Your public URI should be http://localhost:8080/api/cart/items/123, and your upstream API handles it in the form of http://localhost:5000/cart_api?items=123. In this case, or more complicated ones, you can use regex to capture parts of the request uri and transform it in the desired format.
location ~ ^/api/cart/([a-z]*)/(.*)$ {
proxy_pass http://127.0.0.1:5000/cart_api?$1=$2;
}
Use try_files with a WebApp as fallback
A use-case I came across was that I wanted nginx to handle all static files in a folder, and if the file is not available, forward the request to a backend. For example, this was the case for a Vue single-page-application (SPA) that is delivered through flask — because the master HTML needs some server-side tuning — and I wanted to handle nginx the static files instead of flask. (This is recommended by the official gunicorn docs.)
You might have everything for your SPA except for your index.html available at /app/wwwroot/, and http://localhost:5000/ will deliver your server-tuned index.html.
Here’s how you can do this:
location /spa/ {
root /app/wwwroot/;
try_files $uri @backend;
}
location @backend {
proxy_pass http://127.0.0.1:5000;
}
Note that you can not specify any paths in the proxy_pass directive in the @backend for some reason. Nginx will tell you:
nginx: [emerg] "proxy_pass" cannot have URI part in location given by regular expression, or inside named location, or inside "if" statement, or inside "limit_except" block in /home/daniel/projects/nginx_blog/nginx.conf:28
That’s why your backend should receive any request and return the index.html for it, or at least for the routes that are handled by the frontend’s router.
Let nginx start even when not all upstream hosts are available
One reason that I used 127.0.0.1 instead of localhost so far, is that nginx is very picky about hostname resolution. For some unexplainable reason, nginx will try to resolve all hosts defined in proxy_pass directives on startup, and fail to start when they are not reachable. However, especially in microservice environments, it is very fragile to require all upstream services to be available at the time the ingress, load balancer or some intermediate router starts.
You can circumvent nginx’s requirement for all hosts to be available at startup by using variables inside the proxy_pass directives. HOWEVER, for some unfathomable reason, if you do so, you require a dedicated resolver directive to resolve these paths. For Kubernetes, you can use kube-dns.kube-system here. For other environments, you can use your internal DNS or for publicly routed upstream services you can even use a public DNS such as 1.1.1.1 or 8.8.8.8.
Additionally, using variables in proxy_pass changes completely how URIs are passed on to the upstream. When just changing
proxy_pass https://localhost:5000/api/;
to
set $upstream https://localhost:5000;
proxy_pass $upstream/api/;
… which you might think should result in exactly the same, you might be surprised. The former will hit your upstream server with /api/foo?bar=baz with our example request to /webapp/foo?bar=baz. The latter, however, will hit your upstream server with /api/. No foo. No bar. And no baz. 
We need to fix this by putting the request together from two parts: First, the path after the location prefix, and second the query parameters. The first part can be captured using the regex we learned above, and the second (query parameters) can be forwarded using the built-in variables $is_args and $args. If we put it all together, we will end up with a config like this:
daemon off;
events {
}
http {
server {
access_log /dev/stdout;
error_log /dev/stdout;
listen 8080;
# My home router in this case:
resolver 192.168.178.1;
location ~ ^/webapp/(.*)$ {
# Use a variable so that localhost:5000 might be down while nginx starts:
set $upstream http://localhost:5000;
# Put together the upstream request path using the captured component after the location path, and the query parameters:
proxy_pass $upstream/api/$1$is_args$args;
}
}
}
While localhost is not a great example here, it works with your service’s arbitrary DNS names, too. I find this very valuable in production, because having an nginx refuse to start because of a probably very unimportant service can be quite a hassle while wrangling a production issue. However, it makes the location directive much more complex. From a simple location /webapp/ with a proxy_pass http://localhost/api/ it has become this behemoth. I think it’s worth it, though.
Better logging format for proxy_pass
To debug issues, or simply to have enough information at hand when investigating issues in the future, you can maximize the information about what is going on in your location that uses proxy_pass.
I found this handy log_format, which I enhanced with a custom variable $upstream, as we have defined above. If you always call your variables $upstream in all your locations that use proxy_pass, you can use this log_format and have often much needed information in your log:
log_format upstream_logging '[$time_local] $remote_addr - $remote_user - $server_name to: $upstream: $request upstream_response_time $upstream_response_time msec $msec request_time $request_time';
Here is a full example:
daemon off;
events {
}
http {
log_format upstream_logging '[$time_local] $remote_addr - $remote_user - $server_name to: "$upstream": "$request" upstream_response_time $upstream_response_time msec $msec request_time $request_time';
server {
listen 8080;
location /webapp/ {
access_log /dev/stdout upstream_logging;
set $upstream http://127.0.0.1:5000/api/;
proxy_pass $upstream;
}
}
}
However, I have not found a way to log the actual URI that is forwarded to $upstream, which would be one of the most important things to know when debugging proxy_pass issues.
Conclusion
I hope that you have found helpful information in this article that you can put to good use in your development and production nginx configurations.