Счет числительными (ошибка)
-

Alexwall
- interested

- Сообщения: 4
- Зарегистрирован: 27 дек 2013, 15:24
- Версия LabVIEW: 2012
- Контактная информация:



Счет числительными (ошибка)
Суть задания такова:
Напишите программу, которая записывает введенное двухзначное число
строкой соответствующих числительных.
Указание: обратите внимание, что числительные от 21 до 99
получаются написанием перед числительным для чисел от 1 до 9 слова,
обозначающего десятки – двадцать, тридцать, …, девяносто.
Исключение составляет 0 и числа от 10 до 19.
Поэтому имеет смысл анализировать цифры двузначного числа по
отдельности.
Выбор числительных организуйте при помощи структуры Case Structure.
Если к терминалу условия подключить данные типа целое число, то
станет возможно создавать случаи, соответствующие различным
значениям этого числа, или даже диапазонам значений. Новые случаи
создаются из контекстного меню структуры Add Case After или Add Case
Before.
Проверку состояния элементов управления организуйте, используя цикл
While Loop с задержкой 100 мс.

Как понял так сделал…как сделать чтобы ошибку не выдавало? И правильно ли это?
- Вложения
-
- 1.vi
- Как понял так сделал…
- (9.05 КБ) 144 скачивания
-

dadreamer
- professor
- Сообщения: 3836
- Зарегистрирован: 17 фев 2013, 16:33
- Награды: 4
- Версия LabVIEW: 2.5 — 2022
- Благодарил (а): 9 раз
- Поблагодарили: 89 раз
- Контактная информация:


Re: Счет числительными (ошибка)
Сообщение
dadreamer » 27 дек 2013, 16:19
Alexwall писал(а):как сделать чтобы ошибку не выдавало?
No case for some selector values
A Case structure must have a case corresponding to every possible value of the selector. An easy way to fill this requirement is to specify a default case or cases whose selector values include ranges to or from infinity.
Если подали число на Case, то нужно определить все варианты (случаи) для этого числа, либо определить критичные для вас случаи, а для остальных сделать один вариант и назначить его Default (по умолчанию).
-
IvanLis
- guru
- Сообщения: 5376
- Зарегистрирован: 02 дек 2009, 17:44
- Награды: 7
- Версия LabVIEW: 2015, 2016
- Откуда: СССР
- Благодарил (а): 25 раз
- Поблагодарили: 72 раза


Re: Счет числительными (ошибка)
Сообщение
IvanLis » 27 дек 2013, 16:21
Alexwall писал(а):Как понял так сделал…как сделать чтобы ошибку не выдавало? И правильно ли это?
Во первых, необходимо указать «значение по умолчанию» в Case структуре.
Во вторых, как может получится при целочисленном делении на 10, остаток 12 и т.д. (больше 10)?
-
Alexwall
- interested
- Сообщения: 4
- Зарегистрирован: 27 дек 2013, 15:24
- Версия LabVIEW: 2012
- Контактная информация:
Re: Счет числительными (ошибка)
Сообщение
Alexwall » 27 дек 2013, 18:18
IvanLis писал(а):
Alexwall писал(а):Как понял так сделал…как сделать чтобы ошибку не выдавало? И правильно ли это?
Во первых, необходимо указать «значение по умолчанию» в Case структуре.
Во вторых, как может получится при целочисленном делении на 10, остаток 12 и т.д. (больше 10)?
А как сделать «значение по умолчанию?». Я просто только не давно начал изучать LabView не все знаю.
Вот я тоже долго думал, никак не могу сделать.
-
dadreamer
- professor
- Сообщения: 3836
- Зарегистрирован: 17 фев 2013, 16:33
- Награды: 4
- Версия LabVIEW: 2.5 — 2022
- Благодарил (а): 9 раз
- Поблагодарили: 89 раз
- Контактная информация:
-
Alexwall
- interested
- Сообщения: 4
- Зарегистрирован: 27 дек 2013, 15:24
- Версия LabVIEW: 2012
-
Контактная информация:
Re: Счет числительными (ошибка)
Сообщение
Alexwall » 27 дек 2013, 19:23
dadreamer писал(а):ПКМ на Case:
Спасибо.
Я вот никак додумать не могу, с помощью какой функции выделить значения от 10 до 19
-
Alexwall
- interested
- Сообщения: 4
- Зарегистрирован: 27 дек 2013, 15:24
- Версия LabVIEW: 2012
- Контактная информация:
Re: Счет числительными (ошибка)
Сообщение
Alexwall » 27 дек 2013, 22:53
IvanLis писал(а):
Alexwall писал(а):Я вот никак додумать не могу, с помощью какой функции выделить значения от 10 до 19
Прежде чем «городить огород» посмотрели бы как это уже реализовано в других языках и отталкивались от этого.
Например здесь: http://www.num2word.ru/?
Исходники: [url]view-source:http://www.num2word.ru/?[/url]
Все равно ничего не понимаю…с 0 до 9 и с 20 по 99 выводит…а с 10 до 19 вообще никак. Не понимаю.
-
- 3 Ответы
- 590 Просмотры
-
Последнее сообщение Artem.spb
17 сен 2022, 18:38
-
- 1 Ответы
- 512 Просмотры
-
Последнее сообщение alerm
16 ноя 2022, 23:42
|
Основы программирования в LabView
Как это работает? Очень просто — на поле диаграммы ставится рамочка Case structure, сверху в ней есть переключатель случаев — Рассмотрим пример: Здесь в зависимости от шкалы происходит или не происходит пересчет градусов по Цельсию в градусы по Фаренгейту. В принципе, тут было бы достаточно функции Select, но у Case structure более широкие возможности — ведь внутрь рамки можно добавить еще много чего более сложного:) Плюс, выбор осуществить можно не из двух, а гораздо большего числа случаев, что с помощью той же Select организовать можно, но довольно коряво. Туннели В Case structure можно использовать туннели. При этом, если подать что-то на вход, то туннель появится для всех случаев. Можно использовать, можно не использовать — по желанию. С выходными туннелями несколько сложнее. Их тоже можно не подключать в каждой подпрограмме. При этом туннель будет отображаться в виде белых квадратных скобок. Если в каждом случае что-то (не обязательно одно и то же, главное чтобы тип данных совпадал) будет подключено к туннелю, то квадратик туннеля будет заполнен сплошным цветом. Если щелкнуть по туннелю правой кнопкой мыши и выбрать Use Default If Unwired, то для случаев с не подключенным туннелем, будет использоваться значение из дефолтного случая (как нетрудно догадаться по названию опции).
Оригинальный источник материала: |
|
 структура Case позволяет осуществить выбор одного из двух (или более) случаев, и выполнить в зависимости от этого выбора нужную подпрограмму. Case structure похожа на конструкцию if…then…else в обычных текстовых языках программирования (а еще больше на Select case:)
структура Case позволяет осуществить выбор одного из двух (или более) случаев, и выполнить в зависимости от этого выбора нужную подпрограмму. Case structure похожа на конструкцию if…then…else в обычных текстовых языках программирования (а еще больше на Select case:)Я уверен, что вы уже знакомы с основами SQL CASE, поэтому я не буду мучит вас длинным введением. Давайте углубимся в понимание того, что происходит под капотом.
1. SQL CASE не всегда оценивается последовательно
Выражения в SQL CASE по большей части оцениваются последовательно или слева направо. Хотя совсем другое дело, когда они используются с агрегатными функциями. Давайте рассмотрим пример:
-- сначала оценивается агрегатная функция и генерирует ошибку
DECLARE @value INT = 0;
SELECT CASE WHEN @value = 0 THEN 1 ELSE MAX(1/@value) END;
Вышеприведенный код выглядит обычно. Если я спрошу вас, какой результат будет получен, вы, вероятно, ответите 1. Визуальная проверка скажет нам это, поскольку переменная @value установлена в 0. Если @value равна 0, то результат равен 1.
Но не в этом случае. Вот действительный результат, полученный в SQL Server Management Studio:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
Но почему?
Когда условное выражение использует агрегатные функции типа MAX() в SQL CASE, они оцениваются в первую очередь. Таким образом, MAX(1/@value) вызывает ошибку деления на нуль, поскольку @value равна 0.
Ситуация становится еще более неприятной, когда скрыта. Я объясню это позже.
2. Простое выражение SQL CASE оценивается многократно
Ну и что?
Хороший вопрос. Действительно, здесь вообще нет никаких проблем, если вы используете литералы или простые выражения. Но если вы используете подзапросы в качестве условного выражения, вы сильно удивитесь.
Прежде, чем проверять пример ниже, лучше восстановить отсюда копию базы данных. Мы будем использовать её в последующих примерах.
Теперь рассмотрим следующий очень простой пример:
SELECT TOP 1 manufacturerID FROM SportsCars
Очень простой, правда? Он возвращает 1 строку с одним столбцом данных. STATISTICS IO показывает минимальное число логических чтений.
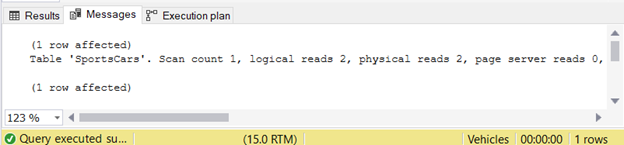
Рис.1. Логические чтения таблицы SportsCars до использования запроса в качестве подзапроса в SQL CASE
Замечание для непосвященных. Чем больше логических чтений, тем медленнее запрос. О логических чтениях можно почитать здесь.
План выполнения тоже показывает простой процесс:
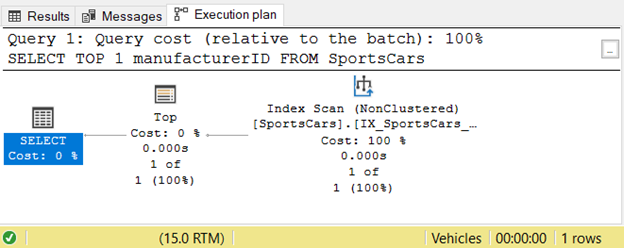
Рис.2. План выполнения для запроса к SportsCar до его использования как подзапроса в SQL CASE
Давайте теперь поместим этот запрос в выражение CASE:
-- Использование подзапроса в SQL CASE
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE (SELECT TOP 1 manufacturerID FROM SportsCars)
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Анализ
Скрестите пальцы, поскольку сейчас логические чтения увеличатся в 4 раза.

Рис.3. Логические чтения после использования подзапроса в SQL CASE
Удивительно! По сравнению всего с двумя логическими чтениями на рис.1 мы получили в 4 раза больше. Таким образом, запрос стал в 4 раза медленнее. Как это могло произойти? Мы видим подзапрос только в одном месте.
Но это не конец истории. Посмотрите план выполнения:
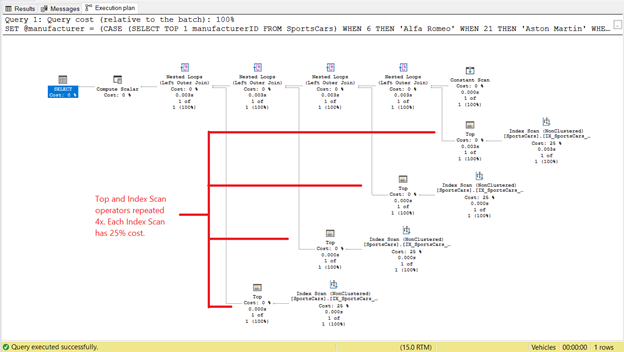
Рис.4. План выполнения после использования простого запроса в качестве выражения подзапроса в SQL CASE
Мы видим 4 экземпляра операторов Top и Index Scan на рис.4. Если каждый Top и Index Scan потребляет 2 логических чтения, это объясняет, почему число логических чтений стало 8 на рис.3. И, поскольку каждый Top и Index Scan имеют 25% стоимости, это подтверждает сказанное.
Но это еще не все. Свойства оператора Compute Scalar показывают, как обрабатывается весь оператор.

Рис.5. Свойства Compute Scalar показывают 4 выражения CASE WHEN
Мы видим 3 выражения CASE WHEN в свойстве Defined Values оператора Compute Scalar. Это выглядит так, как будто простое выражение CASE стало поисковым выражением CASE типа:
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 6 THEN 'Alfa Romeo'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 21 THEN 'Aston Martin'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 64 THEN 'Ferrari'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Хорошее исправление? Давайте посмотрим логические чтения в STATISTICS IO:

Рис.6. Логические чтения после извлечения подзапроса из выражения CASE
Мы видим меньше логических чтений в модифицированном запросе. Извлечение подзапроса и присвоение результата переменной получается значительно лучше. Что насчет плана выполнения? Посмотрите ниже:
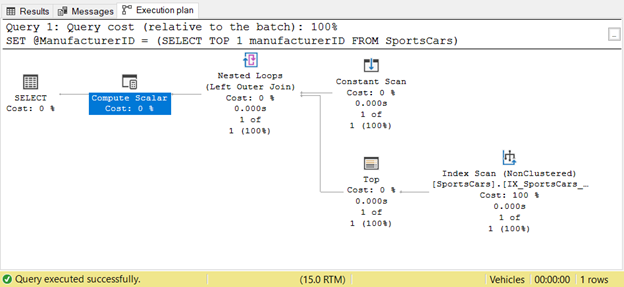
Рис.7. План выполнения после извлечения подзапроса из выражения CASE
Оператор Top и Index Scan появляются однажды, а не 4 раза. Замечательно!
На заметку: Не используйте подзапрос в качестве условия в операторе CASE. Если необходимо получить значение, поместите сначала результат подзапроса в переменную. Затем используйте эту переменную в выражении CASE.
Эти три встроенные функции тайно преобразуются в SQL CASE
Есть секрет, и SQL CASE имеет к нему отношение. Если вы не знаете, как ведут себя эти 3 функции, вы не будете знать, что совершаете ошибку, которую мы пытались избежать в пунктах №1 и №2 выше. Вот они:
- IIF
- COALESCE
- CHOOSE
Давайте рассмотрим их по очереди.
IIF
Я использовал Immediate IF, или IIF, в Visual Basic и Visual Basic for Applications. Это является также эквивалентом тернарного оператор в C#: <условие> ? <результат, если истинно> : <результат, если ложно>.
Эта функция принимает условие и возвращает 1 из 2 аргументов в зависимости от результатов условия. И эта функция также имеется в T-SQL.
Но это просто обертка более длинного выражения CASE. Откуда нам это известно? Давайте проверим пример.
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) =
'McLaren Senna', 'Yes', 'No');
Результатом этого запроса является ‘No’. Однако проверьте план выполнения, а также свойства Compute Scalar.
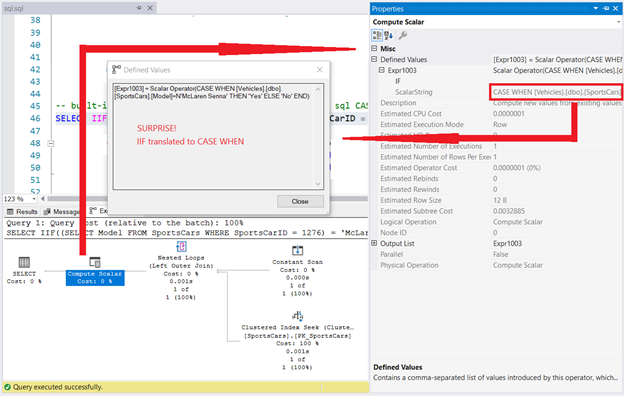
Рис.8. IIF оказывается CASE WHEN в плане выполнения
Поскольку IIF является CASE WHEN, как вы думаете, что произойдет, если выполнить что-то подобное этому?
DECLARE @averageCost MONEY = 1000000.00;
DECLARE @noOfPayments TINYINT = 0; -- умышленно вызвать ошибку
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'SF90 Spider', 83333.33,MIN(@averageCost / @noOfPayments));
Будет получена ошибка деления на нуль, если @noOfPayments равен нулю. То же самое происходило в первом случае, рассмотренном ранее.
Вы можете спросить, что вызывает эту ошибку, поскольку результатом запроса является TRUE, и должно получиться 83333.33. Опять вернитесь к случаю 1.
Таким образом, если вы столкнулись с такой ошибкой при использовании IIF, виноват SQL CASE.
COALESCE
COALESCE — это также сокращенная форма выражения SQL CASE. Она оценивает список значений и возвращает первое не-NULL значение. Вот пример, который показывает, что подзапрос вычисляется дважды.
SELECT
COALESCE(m.Manufacturer + ' ','') + sc.Model AS Car
FROM SportsCars sc
LEFT JOIN Manufacturers m ON sc.ManufacturerID = m.ManufacturerID
Давайте посмотрим план выполнения и свойство Defined Values оператора Compute Scalar.
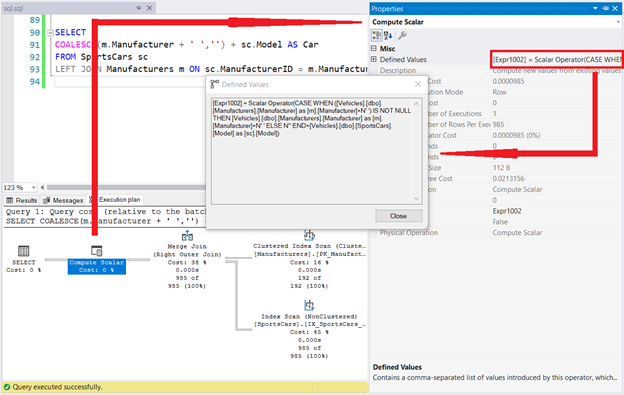
Рис.9. COALESCE преобразуется в SQL CASE в плане выполнения
Разумеется SQL CASE. Нигде не упоминается COALESCE в окне Defined Values. Это доказывает тайный секрет этой функции.
Но это не все. Сколько раз вы увидели [Vehicles].[dbo].[Styles].[Style] в окне Defined Values? ДВАЖДЫ! Это согласуется с официальной документацией Microsoft. Представьте, что один из аргументов в COALESCE является подзапросом. Тогда получаем удвоение логических чтений и замедление выполнения.
CHOOSE
Наконец, CHOOSE. Она подобна функции CHOOSE в MS Access. Она возвращает одно значение из списка значений на основе позиции индекса. Она также действует как индекс массива.
Давайте посмотрим, сможем ли мы получить трансформацию в SQL CASE в примере. Проверьте нижеприведенный код:
;WITH McLarenCars AS
(
SELECT
CASE
WHEN sc.Model IN ('Artura','Speedtail','P1/ P1 GTR','P1 LM') THEN '1'
ELSE '2'
END AS [type]
,sc.Model
,s.Style
FROM SportsCars sc
INNER JOIN Styles s ON sc.StyleID = s.StyleID
WHERE sc.ManufacturerID = 108
)
SELECT
Model
,Style
,CHOOSE([Type],'Hybrid','Gasoline') AS [type]
FROM McLarenCars
Это наш пример с CHOOSE. Теперь давайте посмотрим план выполнения и свойство Defined Values в операторе Compute Scalar:

Рис.10. Как видно в плане выполнения CHOOSE преобразуется в SQL CASE
Вы видите ключевое слово CHOOSE в окне Defined Values на рис.10? Как насчет CASE WHEN?
Подобно предыдущим примерам, эта функция CHOOSE есть просто оболочка для более длинного выражения CASE. И поскольку запрос имеет 2 пункта для CHOOSE, ключевые слова CASE WHEN появляются дважды. Смотрите в окне Defined Values красные прямоугольники.
Однако CASE WHEN появлялось более двух раз. Это происходит из-за выражения CASE во внутреннем запросе CTE. Если посмотреть внимательно, эта часть внутреннего запроса также появляется дважды.
На заметку
Теперь, когда все секреты раскрыты, что мы узнали?
- SQL CASE ведет себя иначе, когда используются агрегатные функции. Будьте внимательны при передаче аргументов в агрегатные функции типа MIN, MAX или COUNT.
- Простое выражение CASE будет оцениваться несколько раз. Имейте это в виду и избегайте передачи подзапроса. Хотя это синтаксически корректно, это повредит производительности.
- IIF, CHOOSE и COALESCE имеют грязные секреты. Помните это, передавая значения в эти функции. Это вызовет преобразование к SQL CASE. В зависимости от значений вы можете получить ошибку или ухудшить производительность.
Надеюсь, что различие в поведении SQL CASE было полезным для вас.
Перевод статьи «SQL Case Statement Tutorial – With When-Then Clause Example Queries».
Выражение СASE — это, по сути, SQL-версия условной логики. Это выражение может использоваться примерно так же, как if-предложения в языках программирования вроде JavaScript, хотя его структура немного отличается.
Данные для примера
Представьте, что вы преподаете литературу в школе. ваши ученики должны написать сочинение.
Вы создали следующую таблицу, чтобы отслеживать, кто из учеников уже сдал сочинение (там же проставляются оценки). Если ученик еще не сдал сочинение, в графе оценок значится NULL.
| STUDENT_ID | NAME | SUBMITTED_ESSAY | GRADE |
|---|---|---|---|
| 1 | Джон | TRUE | 86 |
| 2 | Саид | TRUE | 90 |
| 3 | Алиса | FALSE | NULL |
| 4 | Ной | TRUE | 68 |
| 5 | Элеанор | TRUE | 95 |
| 6 | Акико | FALSE | NULL |
| 7 | Отто | TRUE | 76 |
| 8 | Джамал | TRUE | 85 |
| 9 | Кьяра | TRUE | 88 |
| 10 | Клементина | FALSE | NULL |
Как написать выражение CASE в SQL
Допустим, вы хотели бы выводить ученикам сообщения о том, сдали они сочинение или нет. Чтобы получить статус каждого ученика, вы можете просто выбрать столбец submitted_essay, но тогда в сообщении будет только TRUE или FALSE, а это не очень читабельно.
Вместо этого вы можете использовать выражение CASE и вывоить разные сообщения, основываясь на статусе в submitted_essay.
Базовая структура выражения CASE:
CASE WHEN... THEN... END
Использование CASE WHEN, THEN и END является обязательным, а ELSE и AS — опцональным. Выражение СASE должно идти внутри инструкции SELECT.
SELECT name, CASE WHEN submitted_essay IS TRUE THEN 'сочинение сдано!' ELSE 'сдай сочинение!' END AS status FROM students;
В приведенном выше примере мы выбрали имена учеников, а затем вывели разные сообщения в столбце status, основываясь на значении submitted_essay. Результирующая таблица выглядит так:
| NAME | STATUS |
|---|---|
| Акико | сдай сочинение! |
| Клементина | сдай сочинение! |
| Алиса | сдай сочинение! |
| Саид | сочинение сдано! |
| Элеанор | сочинение сдано! |
| Отто | сочинение сдано! |
| Ной | сочинение сдано! |
| Кьяра | сочинение сдано! |
| Джон | сочинение сдано! |
| Джамал | сочинение сдано! |
Усложняем пример
Идем дальше. Допустим, вы хотели бы включить в сообщение побольше информации. Если ученик уже сдал сочинение, вы хотели бы добавить в сообщение его оценку, а если нет — напомнить, что сочинение еще не сдано. Здесь нам пригодятся предложения WHEN/THEN.
SELECT name, essay_grade, CASE WHEN essay_grade >= 80 THEN 'молодец' WHEN essay_grade < 80 THEN 'можешь лучше' ELSE 'сдай сочинение!' END AS teacher_comment FROM students;
В этом примере кода мы вывели имена учеников, их оценки, а также комментарии, соответствующие оценкам.
После первого предложения WHEN/THEN вы можете добавить сколько угодно других WHEN/THEN, а также предложение ELSE, покрывающее все неучтенные случаи. Это аналог логики if... else if... else в JavaScript (или if... elif... else в Python и т. д.).
Обратите внимание, что в этом случае предложение ELSE призвано захватить все сочинения с оценками NULL (т. е. еще не сданные сочинения), но в других ситуациях для проверки, является ли значение null, вы могли бы использовать IS NULL.
Не забывайте ставить END в конце вашего CASE-выражения!
В таблице представлены результаты этого запроса:
| NAME | ESSAY_GRADE | TEACHER_COMMENT |
|---|---|---|
| Акико | NULL | сдай сочинение! |
| Клементина | NULL | сдай сочинение! |
| Алиса | NULL | сдай сочинение! |
| Саид | 90 | молодец |
| Элеанор | 95 | молодец |
| Отто | 76 | можешь лучше |
| Ной | 68 | можешь лучше |
| Кьяра | 88 | молодец |
| Джон | 86 | молодец |
| Джамал | 85 | молодец |
Заключение
Выражения CASE легко понять и изучить. Их применение — это лаконичный способ внести ясность в ваши SQL-запросы.
Contents
- 1 Usage
- 1.1 Supported data types
- 1.1.1 Boolean Case Structure
- 1.1.2 Integer Case Structure
- 1.1.2.1 Range selector
- 1.1.2.2 Radix
- 1.1.3 Enum Case Structure
- 1.1.3.1 Range selector
- 1.1.3.2 Add Case for Every Value
- 1.1.4 String Case Structure
- 1.1.4.1 Case Insensitive Match
- 1.1.4.2 Range selector
- 1.1.5 Error Case Structure
- 1.1.5.1 Multiple error cases
- 1.2 Subdiagram Label
- 1.3 Keyboard shortcuts
- 1.1 Supported data types
- 2 Best practice
- 3 Tips and tricks
- 4 History
- 5 See also
- 6 External links
| Object information | |
|---|---|
| Owning palette(s) | Structures palette |
| Type | Structure |
| Requires | Basic Development Environment |
| Icon |
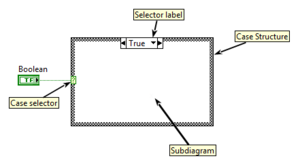
Components of a Case Structure
A Case Structure is a primitive Structure that can have multiple Subdiagrams (also known as «Cases»), one of which is selectively executed at runtime. A selector value determines which case is executed at runtime. The Structure autmatically adapts to the data type connected to the Case selector and must have exactly one Subdiagram for each possible value of the connected data type, or a Default case to handle undefined values.
Usage
Supported data types
The Case Structure automatically adapts to following data types:
- Boolean
- Integer
- Enum
- String
- Error Cluster
Some features are only available for specific data types.
Boolean Case Structure
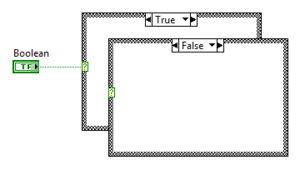
Case Structure with Boolean value
The Boolean Case Structure is the default Structure when placed from the Functions Palette. It has exactly two cases: True and False.
Integer Case Structure
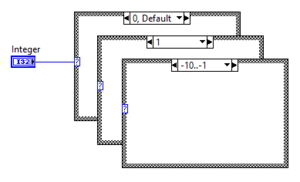
Case Structure with Integer value
The Integer Case Structure uses an Integer as selector value and can have as many cases as the specific Integer type supports.
Non-integer values (Fixed-point, Single Precision, Double Precision, Extended Precision) are rounded according to IEEE 754-1985.
Complex numbers (Complex Single, Complex Double, Complex Extended) are not supported and will break the VI.
Range selector
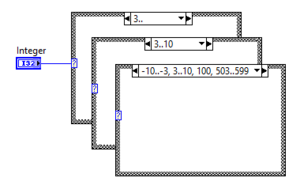
Using range selectors on an Integer Case Structure
Integer cases can have ranges.
| Type | Selector | Description |
|---|---|---|
| Range (open) | 3.. | Executes if the value is greater than or equal to 3 |
| Range (closed) | 3..10 | Executes if the value is greater than or equal to 3 and lower than or equal to 10 |
| List | 3, 5, 7 | Executes if the value is either 3, 5 or 7 |
Ranges are automatically sorted in ascending order by LabVIEW.
Radix
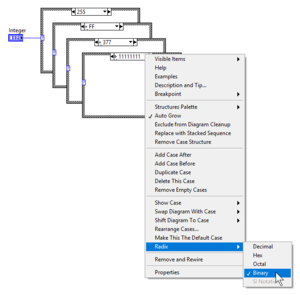
Change Radix on an Integer Case Structure
The default representation for Integer values is Decimal. This representation can be changed to Decimal, Hex, Octal or Binary from the right-click menu option Radix.
Enum Case Structure
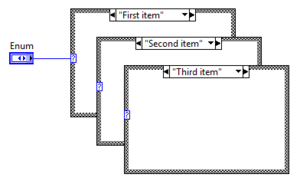
Case Structure with Enum value
The Enum Case Structure uses the string interpretation of the value to label cases. Internally, however, LabVIEW uses the Integer representation to select cases. Renaming Enum values has no effect on the Case Structure.
Range selector
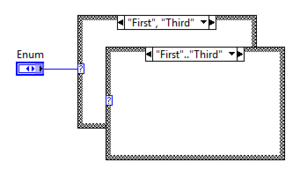
Use range selectors with Enum Case Structures
Enum Case Structures support range selectors similar to the Integer Case Structure:
| Type | Selector | Description |
|---|---|---|
| Range (open) | «First».. | Executes if the value is greater than or equal to «First». |
| Range (closed) | «First»..»Third» | Executes if the value is greater than or equal to «First» and lower than or equal to «Third». |
| List | «First», «Third» | Executes if the value is «First» or «Third». |
Values are automatically sorted by their Integer representation and not by name.
Add Case for Every Value
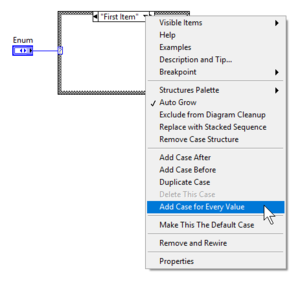
Because Enums have a finite amount of values, LabVIEW provides a simple way to add cases for every value via the right-click menu option Add Case for Every Value. This automatically adds cases for all missing values.
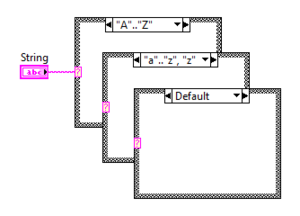
String Case Structure
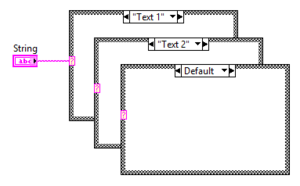
Case Structure with String value
The string Case Structure uses a case-sensitive string as selector value.
Case Insensitive Match
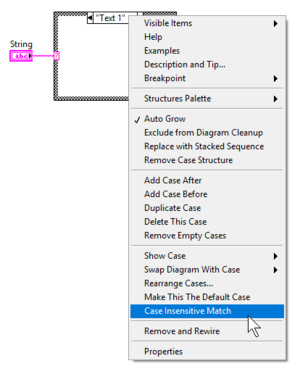
Enable Case Insensitive Match
By default the Case Structure does a case sensitive match. This behavior can be changed by using the Case Insensitive Match option from the right-click menu.
From LabVIEW 2015 onward, the Case Structure shows «A=a» at the bottom left corner if Case Insensitive Match is enabled.
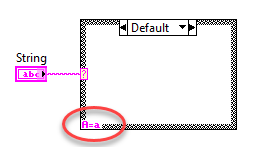
Range selector
Using range selectors on string type Case Structures
String Case Structures support ranges similar to Integer Case Structures, but with added complexity due to the nature of strings. Note that ranges are matched using the ASCII character set.
| Type | Selector | Description (standard) | Description (Case Insensitive Match) |
|---|---|---|---|
| Exact match | «a» | Executes if the value is exactly «a» | Executes if the value is either «a» or «A» |
| Range (open) | «a».. | Executes if the value is greater than or equal to «a» | Executes if the value is greater than or equal to «A» (lower on the ASCII table) |
| Range (closed) | «a»..»z» | Executes if the value is greater than or equal to «a» and lower than «z» (not including «z») | Executes if the value is greater than or equal to «A» and lower than «z» (not including «z») |
| List | «a», «o», «z» | Executes if the value is either «a», «o» or «z» | Executes if the value is either «A», «a», «O», «o», «Z» or «z» |
Ranges are automatically sorted in ascending order by LabVIEW.
Error Case Structure
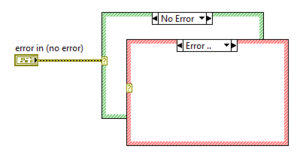
Case Structure with Error Cluster
The error case structure is like the Boolean case structure but can be controlled by the error state of an Error cluster. The border of the error case is red and the non-error case is green.
Multiple error cases
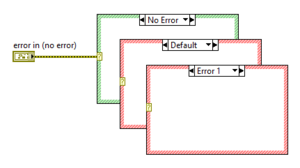
Since LabVIEW 2019 it is possible to have multiple error cases for specific error codes. Previously this was only possible by unbundling the code element from the Error Cluster and connect it to an Integer Case Structure inside the error case. Error codes are handled like Integer values and therefore can specify range selectors:
| Type | Selector | Description |
|---|---|---|
| All Errors | Error .. | Executes for any error |
| Range (open) | Error 3.. | Executes if the error code is greater than or equal to 3 |
| Range (closed) | Error 3..10 | Executes if the error code is greater than or equal to 3 and lower than or equal to 10 |
| List | Error 3, 5, 7 | Executes if the error code is either 3, 5 or 7 |
A Default case is required when using error ranges.
Subdiagram Label
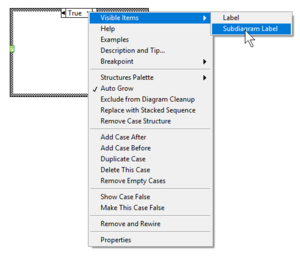
The Subdiagram Label adds a label at top of each Subdiagram. It is hidden by default and can be shown via the right-click menu option Visible Items >> Subdiagram Label.
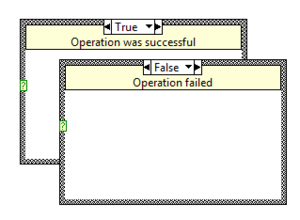
While the position of the label is fixed, its height can be adjusted for each Subdiagram.
Keyboard shortcuts
- <Shift-Enter> creates a new case after the current case.
- <Ctrl-Shift-Enter> duplicates the current case.
Best practice
- Use Lookup Tables instead of Case Structures to return values from a constant non-consecutive list of items (i.e. error code => error message).
- If two cases perform the same operation, remove one case and use the range selector instead.
- Use Subdiagram labels instead of free labels to document Subdiagrams.
- Use Linked Input Tunnels for data wires that must be wired through all cases (changed or unchanged).
- Use the Match Pattern function or Match Regular Expression function instead of range selectors for string Case Structures.
- Set output terminals to Use Default Value if only some cases need to return values.
- Do not connect data wires if they are not used inside the Case Structure. Those wires should be wired around the Structure.
- Do not add a Default case for Enum values if the Structure is supposed to handle all values at all times.
- Do not use Case Structures to disable code (i.e. by wiring a False constant), use the Diagram Disable Structure instead.
Tips and tricks
- Wire an error cluster to a Case Structure to turn it into an Error Case Structure.
History
| Version | Change(s) | Comment |
|---|---|---|

|
Added support for multiple error cases in Error Case Structures. | This feature was requested on the LabVIEW Idea Exchange by Hueter on 19.01.2010 and later confirmed by Darren to be included in LabVIEW 2019 on 30.05.2019. [1] |

|
Added an indicator for the Case Structure if Case Insensitive Match is enabled. | This feature was requested on the LabVIEW Idea Exchange by Matthias_H on 08.08.2014 and later confirmed by Darren to be included in LabVIEW 2015 on 17.08.2015. [2] |
See also
- CaseStructure class
- State Machine
External links
- National Instruments: Execution Structures in LabVIEW