Получение сообщения об ошибке «Нет работоспособного восходящего потока» никогда не бывает приятным. Все, что вам нужно сделать, это сесть, расслабиться и получать удовольствие от использования вашего любимого веб-сайта.
Однако ваши планы могут быть разрушены, когда вы получите это сообщение. Это проблема, связанная с сервером, и чтение этой статьи даст вам больше информации об альтернативе Windows вашему существующему серверу.
Если вы задавались вопросом, как исправить эту ошибку, вам повезло. Ниже приведены несколько общих решений, которые помогут вам навсегда исправить эту ошибку.
Что означает отсутствие здорового восходящего потока?
Восходящий поток определяется в разработке программного обеспечения как действие по отправке исправления или пакета администратору для включения в кодовую базу этого программного обеспечения.
Даже если вы столкнулись с этим сообщением об ошибке на своем компьютере, вы можете даже не знать об этом.
Ошибка «No Healthy Upstream» начинается как программная ошибка, которая препятствует работе определенного приложения.
Как я могу исправить ошибку отсутствия работоспособного восходящего потока?
1. Очистите кеш в браузере вашего компьютера
- В браузере нажмите CTRL+ SHIFT+ DEL.

- Отметьте только кешированные изображения и файлы и нажмите очистить данные.

Для более глубокой очистки браузера используйте CCleaner. Он сканирует ваш браузер, делит ваши данные на более конкретные категории и дает вам обзор всего, что можно безопасно удалить.
2. Перезагрузите компьютер
- Щелкните значок «Пуск».
- Нажмите на значок питания.

- Нажмите «Перезагрузить».

Нет работоспособной ошибки восходящего потока в vCenter
Если нет исправной ошибки восходящего потока, vCenter еще не приспособлен для использования. Поэтому лучше подождать несколько минут, прежде чем получить доступ к vCenter из браузера вашего компьютера.
Недостаточно подготовленный vCenter виноват в большинстве ошибок, связанных с неработоспособным восходящим потоком. Возможно, возникла проблема, которая препятствует правильной работе служб vCenter.
Вы можете исправить эту ошибку в Center следующим образом:
- Выключение Vcenter
- Обновление аппаратной версии виртуальной машины.
- Редактирование настроек Центра. Вы можете сделать это, нажав кнопку параметров виртуальной машины, щелкнув Общие параметры и выбрав ОС VMware Photon.
Убедитесь, что виртуальные машины V7 имеют соответствующую память и вычислительную мощность. Например, vCenter 7 потребляет много ресурсов ЦП и памяти.
Нет здоровой ошибки восходящего потока eBay
В 1995 году американский предприниматель Пьер Омидьяр основал eBay, глобальную онлайн-аукционную и торговую платформу. Ни для кого не секрет, что eBay была одной из первых организаций, запустивших онлайн-рынок, объединяющий потребителей и продавцов.
Малые предприятия и отдельные продавцы одинаково пользуются услугами этого глобального центра электронной коммерции.
Тем не менее, несколько пользователей столкнулись с ошибкой неработоспособного исходящего потока на eBay.
Эта ошибка на компьютере чаще всего вызвана техническими проблемами на eBay и может быть устранена только ими.
Нет здоровой ошибки восходящего потока Spotify
Приложения для потоковой передачи музыки на мобильные устройства стали чрезвычайно интенсивными, но Spotify был на вершине кучи с 2008 года.
Однако даже у Spotify иногда могут возникнуть проблемы.
Если в Spotify нет здоровой ошибки восходящего потока, вот как это исправить.
- Новая поисковая система или сеанс инкогнито/приватный браузер.
- Проверьте, установлена ли последняя версия браузера на вашем компьютере.
- Перезагрузите маршрутизатор.
- Попробуйте другую сеть. Не стесняйтесь связаться с поставщиком услуг предыдущей сети, если он не загружается при вашем новом соединении.
- Услуги могут быть ограничены в общедоступных или совместно используемых сетях (например, в школе или на работе). Вы можете получить дополнительную информацию о сети, связавшись с ответственными за нее людьми.
- Файл вашего хоста также может нуждаться в очистке.
Что такое тайм-аут восходящего потока?
Восходящий поток — это термин компьютерной сети, который относится к передаче данных с локального компьютера или клиента на удаленный хост или сервер.
Вы получаете тайм-аут восходящего потока, когда передача занимает слишком много времени, и система интерпретирует запрос как неудачный.
Мы надеемся, что вы нашли некоторое просветление с этой частью. Пожалуйста, поделитесь своими мыслями в разделе комментариев ниже.
Некоторые пользователи Google Chrome сталкивались с ошибкой No Healthy Upstream. Это довольно странная ошибка, поскольку большинство из нас никогда раньше с ней не сталкивались. Из того, что мы видели, ошибка обычно появляется на таких платформах, как Netflix, Spotify, vCenter, eBay, VMware vCenter, Kubernetes и других. Теперь, в зависимости от точной причины ошибки No Healthy Upstream, может быть несколько способов остановить эту проблему.
Что означает ошибка No Healthy Upstream?
Для тех, кому интересно, апстрим в основном отправляет патч или пакет администратору, чтобы он был добавлен в исходный код программного обеспечения. Итак, когда апстрим неисправен, это означает, что данные не будут отправлены администратору для добавления в источник. В некоторых ситуациях пользователям может потребоваться много времени, чтобы заметить, что на них влияет ошибка No Healthy Upstream. Короче говоря, это программная ошибка, которая препятствует работе определенного приложения.
Исправьте ошибку No Healthy Upstream в Spotify
Это сообщение об ошибке также может появляться, когда речь идет о Spotify, популярном приложении для потоковой передачи музыки.
- Перезагрузите маршрутизатор
- Откройте приватное окно браузера
- Обновите Google Chrome
1]Перезагрузите маршрутизатор.
Один из лучших способов справиться с этой проблемой — перезапустить беспроводной маршрутизатор, если это возможно. Это не займет много усилий, так что давайте посмотрим, что делать.
- Перейдите туда, где находится ваш беспроводной маршрутизатор.
- Нажмите кнопку питания, чтобы выключить его, затем нажмите еще раз, чтобы включить его.
- Кроме того, вы можете перезапустить маршрутизатор, войдя в интерфейс маршрутизатора через веб-браузер, а затем нажав кнопку «Перезагрузить» оттуда.
После выполнения вышеуказанных задач проверьте, не появляется ли по-прежнему ошибка No Healthy Upstream.
2]Откройте приватное окно браузера
В результате нашего тестирования нам удалось выяснить, что использование приватного окна браузера или окна браузера в режиме инкогнито может решить проблему со Spotify.
- На компьютере с Windows 11/10 откройте Google Chrome.
- После того, как вы это сделаете, нажмите кнопку с тремя точками.
- В раскрывающемся меню выберите «Новое окно в режиме инкогнито».
- Теперь должно появиться новое окно.
- Гарантирует, что у него есть значок инкогнито.
- Кроме того, вы можете нажать Ctrl + Shift + n, чтобы открыть окно в режиме инкогнито.
Наконец, посетите Spotify через это окно, войдите в систему, используя свои официальные учетные данные, а затем включите свои любимые мелодии.
3]Обновить браузер
В большинстве случаев простого обновления вашего браузера обычно достаточно, чтобы решить большинство проблем. Как правило, браузер обновляется автоматически, но при необходимости вы можете принудительно выполнить обновление. Этот пост покажет вам, как обновить браузеры Chrome, Edge, Firefox, Opera.
Исправление ошибки No Healthy Upstream на vCenter и eBay
Итак, ошибка No Healthy Upstream может появиться, когда речь идет о vCenter. Вопрос в том, как нам избавиться от этого и снова все исправить? Что ж, мы предлагаем обновить оборудование vCenter, если это возможно, или вы можете выключить его, а затем снова загрузить, чтобы посмотреть, решит ли это проблему.
Несколько пользователей заявили, что вышеуказанные решения работают хорошо, поэтому не стесняйтесь тестировать, чтобы увидеть, какое из них работает.
Как и в случае с eBay, ошибка означает, что вы не сможете выполнять определенные действия, такие как торги, покупка или продажа товаров на платформе. К сожалению, мы не можем решить проблему здесь, поэтому лучше всего подождать, пока eBay исправит себя.
Как исправить ошибку No Healthy Upstream в VMware vCenter
Попробуйте следующие предложения:
- Кнопка «Открыть параметры виртуальной машины» > «Общие параметры» > ОС VMWare Photon. ПОСМОТРИТЕ, поможет ли это.
- Выберите другую конфигурацию с помощью мастера изменения совместимости оборудования.
- Обновите виртуальную машину.
Исправить ошибку No Healthy Upstream в браузере
Исправить ошибку No Healthy Upstream в Google Chrome или любом другом браузере очень просто.
Первое, что вам нужно сделать здесь, это открыть веб-браузер Google Chrome, если вы еще этого не сделали.
- Найдите ярлык Google Chrome на рабочем столе.
- Щелкните правой кнопкой мыши значок и выберите «Открыть».
- Вы также можете дважды щелкнуть ярлык, чтобы открыть браузер.
Кроме того, есть возможность проверить, находится ли значок браузера на панели задач или в меню «Пуск».
Теперь нам необходимо перейти к окну «Очистка данных просмотра» из Google Chrome.
- Нажмите на кнопку с тремя точками.
- В раскрывающемся меню выберите «История».
- После этого в Chrome откроется новая вкладка.
- Найдите «Очистить данные просмотра» на левой панели.
- Нажмите на нее быстро.
- Пожалуйста, установите флажок Кэшированные изображения и файлы.
- Затем выберите «Все время» в разделе «Временной диапазон».
- Наконец, нажмите кнопку «Очистить данные», чтобы завершить задачу.
- Подождите несколько секунд, пока система полностью избавится от ваших данных.
Теперь вы можете проверить, не мешает ли ошибка No Healthy Upstream.
ЧИТАЙТЕ: Unity Web Player установлен, но не работает в Chrome или Firefox
Что означает ошибка восходящего подключения?
Ошибка подключения восходящего потока — это, по сути, общая ошибка, которая обычно возникает, когда посланник пытается перенаправить трафик к службе, которая недоступна. Есть много причин, почему это может произойти.
Что является основной причиной программных ошибок?
Основная причина программных ошибок связана с человеческими ошибками больше, чем с чем-либо еще. Имейте в виду, что код пишется людьми, а, как мы знаем, люди не идеальны, поэтому время от времени случаются ошибки.
Еще одна причина, по которой случаются программные ошибки, может сводиться к сторонним приложениям. Возможно, вы этого не знали, но сторонние инструменты разработки с ошибками могут передавать эти ошибки в создаваемое программное обеспечение. Это, конечно, не обычное явление, но случается, и это то, на что разработчики всегда должны обращать внимание.
Содержание
- get request errors: «no healthy upstream» #9050
- Comments
- 2 способа навсегда исправить ошибку «Нет работоспособного восходящего потока»
- Что означает отсутствие здорового восходящего потока?
- Как я могу исправить ошибку отсутствия работоспособного восходящего потока?
- 1. Очистите кеш в браузере вашего компьютера
- 2. Перезагрузите компьютер
- Нет работоспособной ошибки восходящего потока в vCenter
- Нет здоровой ошибки восходящего потока eBay
- Нет здоровой ошибки восходящего потока Spotify
- Что такое тайм-аут восходящего потока?
get request errors: «no healthy upstream» #9050
Title: get request errors: «no healthy upstream»
Dynamic configuration discovery through control panel.
In step:
2019-11-15 19:00:43: update cluster timeout and change config version.
2019-11-15 21:17:03: get A lot of request errors, grpc-status: 14, grpc-message: no healthy upstream
Deploying 21 envoy nodes, two of them had this error.
Envoy restart or reload node returns to normal.
Envoy version: 1.11.2
[2019-11-15 19:00:43.206][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 14, upstream conne
ct error or disconnect/reset before headers. reset reason: connection termination
[2019-11-15 19:03:03.399][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 14, upstream conne
ct error or disconnect/reset before headers. reset reason: connection termination
[2019-11-15 19:08:36.138][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 13,
[2019-11-15 19:08:36.620][23415][info][upstream] [source/server/lds_api.cc:60] lds: add/update listener ‘grpc-listener’
[2019-11-15 19:08:36.621][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster app.xxx starting warming
[2019-11-15 19:08:36.625][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster app.xxx starting warming
[2019-11-15 19:08:36.626][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster app.xxx starting warming
[2019-11-15 19:08:36.626][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster app.xxx starting warming
[2019-11-15 19:08:36.627][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:495] add/update cluster app.xxx starting warming
[2019-11-15 19:08:36.627][23415][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 19:08:36.627][23415][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 19:08:36.627][23415][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 19:08:36.627][23415][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 19:08:36.627][23415][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 19:08:52.511][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 14, upstream connect error or disconnect/reset before headers. reset reason: connection termination
[2019-11-15 21:01:22.203][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 13,
[2019-11-15 21:17:03.937][23415][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:87] gRPC config stream closed: 13,
[2019-11-15 21:17:03.937][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster app.xxx complete
[2019-11-15 21:17:03.938][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster app.xxx complete
[2019-11-15 21:17:03.938][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster app.xxx complete
[2019-11-15 21:17:03.938][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster app.xxx complete
[2019-11-15 21:17:03.939][23415][info][upstream] [source/common/upstream/cluster_manager_impl.cc:507] warming cluster app.xxx complete
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:238] initializing epoch 7 (hot restart version=11.104)
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:240] statically linked extensions:
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:242] access_loggers: envoy.file_access_log,envoy.http_grpc_access_log
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:245] filters.http: envoy.buffer,envoy.cors,envoy.csrf,envoy.ext_authz,envoy.fault,envoy.filters.http.dynamic_forward_proxy,envoy.filters.http.grpc_http1_reverse_bridge,envoy.filters.http.header_to_metadata,envoy.filters.http.jwt_authn,envoy.filters.http.original_src,envoy.filters.http.rbac,envoy.filters.http.tap,envoy.grpc_http1_bridge,envoy.grpc_json_transcoder,envoy.grpc_web,envoy.gzip,envoy.health_check,envoy.http_dynamo_filter,envoy.ip_tagging,envoy.lua,envoy.rate_limit,envoy.router,envoy.squash
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:248] filters.listener: envoy.listener.original_dst,envoy.listener.original_src,envoy.listener.proxy_protocol,envoy.listener.tls_inspector
[2019-11-15 21:41:03.451][3324][info][main] [source/server/server.cc:251] filters.network: envoy.client_ssl_auth,envoy.echo,envoy.ext_authz,envoy.filters.network.dubbo_proxy,envoy.filters.network.mysql_proxy,envoy.filters.network.rbac,envoy.filters.network.sni_cluster,envoy.filters.network.thrift_proxy,envoy.filters.network.zookeeper_proxy,envoy.http_connection_manager,envoy.mongo_proxy,envoy.ratelimit,envoy.redis_proxy,envoy.tcp_proxy
[2019-11-15 21:41:03.452][3324][info][main] [source/server/server.cc:253] stat_sinks: envoy.dog_statsd,envoy.metrics_service,envoy.stat_sinks.hystrix,envoy.statsd
[2019-11-15 21:41:03.452][3324][info][main] [source/server/server.cc:255] tracers: envoy.dynamic.ot,envoy.lightstep,envoy.tracers.datadog,envoy.tracers.opencensus,envoy.zipkin
[2019-11-15 21:41:03.452][3324][info][main] [source/server/server.cc:258] transport_sockets.downstream: envoy.transport_sockets.alts,envoy.transport_sockets.tap,raw_buffer,tls
[2019-11-15 21:41:03.452][3324][info][main] [source/server/server.cc:261] transport_sockets.upstream: envoy.transport_sockets.alts,envoy.transport_sockets.tap,raw_buffer,tls
[2019-11-15 21:41:03.452][3324][info][main] [source/server/server.cc:267] buffer implementation: old (libevent)
[2019-11-15 21:41:03.458][23415][warning][main] [source/server/server.cc:574] shutting down admin due to child startup
[2019-11-15 21:41:03.458][23415][warning][main] [source/server/server.cc:580] terminating parent process
[2019-11-15 21:41:03.459][3324][info][main] [source/server/server.cc:322] admin address: 0.0.0.0:9901
[2019-11-15 21:41:03.460][3324][info][main] [source/server/server.cc:432] runtime: layers:
- name: base
static_layer:
<> - name: admin
admin_layer:
<>
[2019-11-15 21:41:03.460][3324][warning][runtime] [source/common/runtime/runtime_impl.cc:497] Skipping unsupported runtime layer: name: «base»
static_layer <
>
[2019-11-15 21:41:03.460][3324][info][config] [source/server/configuration_impl.cc:61] loading 0 static secret(s)
[2019-11-15 21:41:03.460][3324][info][config] [source/server/configuration_impl.cc:67] loading 2 cluster(s)
[2019-11-15 21:41:03.462][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:124] cm init: initializing secondary clusters
[2019-11-15 21:41:03.463][3324][info][config] [source/server/configuration_impl.cc:71] loading 0 listener(s)
[2019-11-15 21:41:03.463][3324][info][config] [source/server/configuration_impl.cc:96] loading tracing configuration
[2019-11-15 21:41:03.463][3324][info][config] [source/server/configuration_impl.cc:116] loading stats sink configuration
[2019-11-15 21:41:03.463][3324][info][main] [source/server/server.cc:516] starting main dispatch loop
[2019-11-15 21:41:03.468][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:144] cm init: initializing cds
[2019-11-15 21:41:03.469][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:489] add/update cluster app.xxx during init
[2019-11-15 21:41:03.470][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:489] add/update cluster app.xxx during init
[2019-11-15 21:41:03.471][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:489] add/update cluster app.xxx during init
[2019-11-15 21:41:03.471][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:489] add/update cluster app.xxx during init
[2019-11-15 21:41:03.472][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:489] add/update cluster app.xxx during init
[2019-11-15 21:41:03.472][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:124] cm init: initializing secondary clusters
[2019-11-15 21:41:03.475][3324][info][upstream] [source/common/upstream/cluster_manager_impl.cc:148] cm init: all clusters initialized
[2019-11-15 21:41:03.475][3324][info][main] [source/server/server.cc:500] all clusters initialized. initializing init manager
[2019-11-15 21:41:03.479][3324][info][upstream] [source/server/lds_api.cc:60] lds: add/update listener ‘grpc-listener’
[2019-11-15 21:41:03.480][3324][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 21:41:03.480][3324][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 21:41:03.480][3324][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 21:41:03.481][3324][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 21:41:03.481][3324][warning][misc] [source/common/protobuf/utility.cc:199] Using deprecated option ‘envoy.api.v2.route.CorsPolicy.allow_origin_regex’ from file route.proto. This configuration will be removed from Envoy soon. Please see https://www.envoyproxy.io/docs/envoy/latest/intro/deprecated for details.
[2019-11-15 21:41:03.481][3324][info][config] [source/server/listener_manager_impl.cc:761] all dependencies initialized. starting workers
Normal node: 
Abnormal node: 
The text was updated successfully, but these errors were encountered:
Источник
2 способа навсегда исправить ошибку «Нет работоспособного восходящего потока»
Получение сообщения об ошибке «Нет работоспособного восходящего потока» никогда не бывает приятным. Все, что вам нужно сделать, это сесть, расслабиться и получать удовольствие от использования вашего любимого веб-сайта.
Однако ваши планы могут быть разрушены, когда вы получите это сообщение. Это проблема, связанная с сервером, и чтение этой статьи даст вам больше информации об альтернативе Windows вашему существующему серверу.
Если вы задавались вопросом, как исправить эту ошибку, вам повезло. Ниже приведены несколько общих решений, которые помогут вам навсегда исправить эту ошибку.
Что означает отсутствие здорового восходящего потока?
Восходящий поток определяется в разработке программного обеспечения как действие по отправке исправления или пакета администратору для включения в кодовую базу этого программного обеспечения.
Даже если вы столкнулись с этим сообщением об ошибке на своем компьютере, вы можете даже не знать об этом.
Ошибка «No Healthy Upstream» начинается как программная ошибка, которая препятствует работе определенного приложения.
Как я могу исправить ошибку отсутствия работоспособного восходящего потока?
1. Очистите кеш в браузере вашего компьютера
- В браузере нажмите CTRL + SHIFT + DEL .
- Отметьте только кешированные изображения и файлы и нажмите очистить данные.
Для более глубокой очистки браузера используйте CCleaner. Он сканирует ваш браузер, делит ваши данные на более конкретные категории и дает вам обзор всего, что можно безопасно удалить.
2. Перезагрузите компьютер
- Щелкните значок «Пуск».
- Нажмите на значок питания.
- Нажмите «Перезагрузить».
Нет работоспособной ошибки восходящего потока в vCenter
Если нет исправной ошибки восходящего потока, vCenter еще не приспособлен для использования. Поэтому лучше подождать несколько минут, прежде чем получить доступ к vCenter из браузера вашего компьютера.
Недостаточно подготовленный vCenter виноват в большинстве ошибок, связанных с неработоспособным восходящим потоком. Возможно, возникла проблема, которая препятствует правильной работе служб vCenter.
Вы можете исправить эту ошибку в Center следующим образом:
- Выключение Vcenter
- Обновление аппаратной версии виртуальной машины.
- Редактирование настроек Центра. Вы можете сделать это, нажав кнопку параметров виртуальной машины, щелкнув Общие параметры и выбрав ОС VMware Photon.
Убедитесь, что виртуальные машины V7 имеют соответствующую память и вычислительную мощность. Например, vCenter 7 потребляет много ресурсов ЦП и памяти.
Нет здоровой ошибки восходящего потока eBay
В 1995 году американский предприниматель Пьер Омидьяр основал eBay, глобальную онлайн-аукционную и торговую платформу. Ни для кого не секрет, что eBay была одной из первых организаций, запустивших онлайн-рынок, объединяющий потребителей и продавцов.
Малые предприятия и отдельные продавцы одинаково пользуются услугами этого глобального центра электронной коммерции.
Тем не менее, несколько пользователей столкнулись с ошибкой неработоспособного исходящего потока на eBay.
Эта ошибка на компьютере чаще всего вызвана техническими проблемами на eBay и может быть устранена только ими.
Нет здоровой ошибки восходящего потока Spotify
Приложения для потоковой передачи музыки на мобильные устройства стали чрезвычайно интенсивными, но Spotify был на вершине кучи с 2008 года.
Однако даже у Spotify иногда могут возникнуть проблемы.
Если в Spotify нет здоровой ошибки восходящего потока, вот как это исправить.
- Новая поисковая система или сеанс инкогнито/приватный браузер.
- Проверьте, установлена ли последняя версия браузера на вашем компьютере.
- Перезагрузите маршрутизатор.
- Попробуйте другую сеть. Не стесняйтесь связаться с поставщиком услуг предыдущей сети, если он не загружается при вашем новом соединении.
- Услуги могут быть ограничены в общедоступных или совместно используемых сетях (например, в школе или на работе). Вы можете получить дополнительную информацию о сети, связавшись с ответственными за нее людьми.
- Файл вашего хоста также может нуждаться в очистке.
Что такое тайм-аут восходящего потока?
Восходящий поток — это термин компьютерной сети, который относится к передаче данных с локального компьютера или клиента на удаленный хост или сервер.
Вы получаете тайм-аут восходящего потока, когда передача занимает слишком много времени, и система интерпретирует запрос как неудачный.
Мы надеемся, что вы нашли некоторое просветление с этой частью. Пожалуйста, поделитесь своими мыслями в разделе комментариев ниже.
Источник
Trending
Spotify users left frustrated at new ‘No Healthy Upstream’ error message when using the streaming platforms Web Player, but is there a fix?
For millions of people around the world, Spotify is how we enjoy our favourite artists.
Unfortunately, when an unexpected error gets in the way of our music, it can be incredibly frustrating.
It appears that Spotify is experiencing some technical difficulties today, with thousands of users being met with an unexpected ‘No Healthy Upstream’ error message when using the streaming service.
- BLM: Edward Colston’s statue has a new place on Google Maps following Bristol protest
This content could not be loaded
@SpotifyCares having a «No healthy upstream» error pop up when trying to access web player on google chrome on my laptop, would you be able to help with this issue?
— Whitney Marie (@butteredt0as7) April 8, 2020
No Healthy Upstream error message
At the time of writing, there is not any meaningful information on the Spotify community page as to what the ‘No Healthy Upstream’ actually means.
However, some users are suggesting that this is related to an access issue as a similar problem occurred back in late-2019.
- INSTAGRAM: How to find the Guess The Lyrics Filter – test your song knowledge!
Is there a fix to ‘No Healthy Upstream’ error?
Currently, there isn’t a known fix for the error message, but the issue seems to be on Spotify’s end – not users.
However, this only seems to be an issue for those users using the site through the Web Player.
So, if you have the option available, move over to the dedicated Spotify app or through third-party applications, like a games console, and it should work fine there.
- TWITTER: Why is block Katie Hopkins trending again in the UK?
Is this a temporary issue?
Yes, throughout the morning the Spotify Web Player has been returning to normal and then crashing again.
It doesn’t appear that users can do much to help the issue apart from switching over to the app.
Whilst some users have reported that the issue was resolved after 15-20 minutes, others have said that the same error has been reoccurring every hour or so.
It would help if there was an official statement on the issue from Spotify, so if the problem persists than keep an eye out on their Twitter.
In other news, Why is Bono at Biden’s State Of the Union Address? Is he a US citizen?
Have something to tell us about this article? Let us know
Trending
Spotify users left frustrated at new ‘No Healthy Upstream’ error message when using the streaming platforms Web Player, but is there a fix?
For millions of people around the world, Spotify is how we enjoy our favourite artists.
Unfortunately, when an unexpected error gets in the way of our music, it can be incredibly frustrating.
It appears that Spotify is experiencing some technical difficulties today, with thousands of users being met with an unexpected ‘No Healthy Upstream’ error message when using the streaming service.
- BLM: Edward Colston’s statue has a new place on Google Maps following Bristol protest
This content could not be loaded
@SpotifyCares having a «No healthy upstream» error pop up when trying to access web player on google chrome on my laptop, would you be able to help with this issue?
— Whitney Marie (@butteredt0as7) April 8, 2020
No Healthy Upstream error message
At the time of writing, there is not any meaningful information on the Spotify community page as to what the ‘No Healthy Upstream’ actually means.
However, some users are suggesting that this is related to an access issue as a similar problem occurred back in late-2019.
- INSTAGRAM: How to find the Guess The Lyrics Filter – test your song knowledge!
Is there a fix to ‘No Healthy Upstream’ error?
Currently, there isn’t a known fix for the error message, but the issue seems to be on Spotify’s end – not users.
However, this only seems to be an issue for those users using the site through the Web Player.
So, if you have the option available, move over to the dedicated Spotify app or through third-party applications, like a games console, and it should work fine there.
- TWITTER: Why is block Katie Hopkins trending again in the UK?
Is this a temporary issue?
Yes, throughout the morning the Spotify Web Player has been returning to normal and then crashing again.
It doesn’t appear that users can do much to help the issue apart from switching over to the app.
Whilst some users have reported that the issue was resolved after 15-20 minutes, others have said that the same error has been reoccurring every hour or so.
It would help if there was an official statement on the issue from Spotify, so if the problem persists than keep an eye out on their Twitter.
In other news, Why is Bono at Biden’s State Of the Union Address? Is he a US citizen?
Have something to tell us about this article? Let us know
Istio service mesh offers a multitude of solutions at network level 7 (L7) to define traffic routing, security, and application monitoring in a cloud environment. However, given the complexity of cloud-based networks, the host of devices involved, and the difficulty of visualizing effective changes made by Istio, it’s hard to debug the unpopular «no healthy upstream» error messages that often show up in Envoy logs.
This article attempts some pain relief in the form of quick guidance on how to respond to emergency calls demanding a resolution to «no healthy upstream» error messages and related errors such as «Applications in the Mesh are not available» or «Istio is broken.»
In my experience, 90% of these issues are caused by configuration problems in either the network or Istio. This article shows some troubleshooting tools you can use to identify such problems quickly, in the context of two recent cases that a Red Hat customer escalated to us.
It’s important to understand a few aspects of this customer’s architecture. The customer is running services in separate Red Hat OpenShift clusters, some of which are in the customer’s own on-premises infrastructure, while others span several countries in the EU region. Each OpenShift cluster has its own instance of a Red Hat OpenShift Service Mesh, Red Hat’s productized Istio service.
Kubernetes services make both intramesh and intermesh requests. But a service in this customer’s configuration always makes a local call. Integration and routing between services in the different clusters are performed by the mesh via a set of VirtualService, DestinationRule, and ServiceEntry resources that redirect the local call to a remote service.
A duplicate service
In our first real-life example, the customer complained that the service mesh somehow was causing cluster-to-cluster communications to fail, and reported the «no healthy upstream» message.
To identify a problem related to Istio configuration, I always use Istio’s Kiali console to visualize the network state and pinpoint where issues are occurring. Kiali allows you to «play back» network behavior, a nice feature that is very helpful if you’re dealing with a problem that is not occurring right now. Whether or not I discover the problematic service, I turn next to checking the logs of the Envoy proxy via either Kiali or OpenShift (using an oc logs <pod_name> -c istio-proxy commmand). The aim in both cases is to find the service for which the «no healthy upstream» error appears.
In this case, Kiali showed that 95% of the traffic to the destination service destination.mynamespace.svc.cluster.local was failing. My next resource was the istioctl command, which can provide a quick view of the state of the Envoy proxy and whether its configuration was updated correctly by Istio:
$ istioctl proxy-status
NAME CDS LDS EDS RDS PILOT VERSION
...
service-source-v1-74f955bd84-9lmnf.mynamespace SYNCED SYNCED SYNCED SYNCED istiod-86798869b8-bqw7c 1.5.0
...Getting confirmation from the output that the mesh managed to keep all relevant service Envoy proxies up to date, I then checked the cluster names configured on the Envoy proxy of the client service pod. I focused only on the clusters related to the outbound service host for which logs showed the «no healthy upstream» message:
$ istioctl proxy-config cluster -i istio-system service-source-v1-74f955bd84- 9lmnf.mynamespace --fqdn service-destination.mynamespace.svc.cluster.local -o json | jq -r .[].name
outbound|80||service-destination.mynamespace.svc.cluster.local
inbound|80|9180-tcp|service-destination.mynamespace.svc.cluster.local outbound|80|v1|service-destination.mynamespace.svc.cluster.local
outbound|80|v2|service-destination.mynamespace.svc.cluster.localIn the output, I noticed that the Istio configuration had defined two services (v1 and v2) for the cluster in question: outbound|80|v2|service-destination.mynamespace.svc.cluster.local. I then checked for the available endpoints for the v2 service:
$ istioctl proxy-config endpoints service-source-v1-74f955bd84-9lmnf.mynamespace --cluster "outbound|80|v2|service-destination.mynamespace.svc.cluster.local" ENDPOINT STATUS OUTLIER CHECK CLUSTER
172.17.0.28:9180 HEALTHY OK outbound|80|v2|service destination.mynamespace.svc.cluster.local
172.17.0.29:9180 HEALTHY OK outbound|80|v2|service destination.mynamespace.svc.cluster.localThen I proceeded to check the endpoints for v1. However, for the v1 service for outbound|80|v2|service destination.mynamespace, the mesh has no endpoints, and therefore no pods:
$ istioctl proxy-config endpoints teachstore-course-v1-74f965bd84-8lmnf.development 2
cluster "outbound|80|v`|service-destination.mynamespace.svc.cluster.local" ENDPOINT STATUS OUTLIER CHECK CLUSTERThis misconfiguration caused the «no healthy upstream» errors.
Checking the VirtualService for the destination, I noticed that 5% of the traffic is routed to v2, which agrees with what I saw also in Kiali, while 95% is routed to v1, which also explains why the customer saw 95% failures with the «no healthy upstream» message.
All the customer needed to do to fix the problem was to deploy service v1 or update the VirtualService to distribute all requests to v2.
Duplicate Envoy clusters
In a follow-up escalation, the «no healthy upstream» issue came up again. We followed the same troubleshooting approach as in the previous example, but in this case there was no VirtualService.
We saw multiple ServiceEntry definitions for multiple country destinations. We found it puzzling that all country destinations, apart from the one reported, had requests directed correctly. The following check verified that all clusters were reported as healthy except service-destination.remote-namespace.ocp4.customdomain.com:
$ oc exec istio-egressgateway-6567f7d756-4gvh8 -- curl localhost:15000/clusters |egrep 'health|remote-service-destination.remote-namespace.ocp4.customdomain.com'In this case I looked for a log entry like:
outbound|443||remote-service-destination.remote namespace.ocp4.customdomain.com::10.128.2.21:443::health_flags::/failed_active_hcHaving verified the cluster as unhealthy, I turned to Istiod to ensure that no errors were being reported against this cluster. The Istiod pod reported:
2022-05-13T12:27:51.262316Z info ads Push finished: 5.709679819s { "ProxyStatus": {
"pilot_duplicate_envoy_clusters": {
"outbound|443||remote-service-destination.remote-namespace.ocp4.customdomain.com": {
"proxy": "e2e-871-remote-namespace-c58f7f7f6-vljr6.e2e-871-remote namespace",
"message": "Duplicate cluster outbound|53||remote-service destination.remote-namespace.ocp4.customdomain.com found while pushing CDS" }
},This output indicates that Istiod was trying to apply a cluster configuration for which there was a duplicate. This information prompted me to check the applied ServiceEntry resources, which quickly revealed that there had been duplicate definitions for remote-service-destination.remote-namespace.ocp4.customdomain.com.
Istio administrative tools reveal the source of errors
A «no healthy upstream» error can be caused by Istio, a misconfigured network device, or actual network outages. Thus, it is difficult for the mesh operations team to pinpoint the cause or even predict its occurrence, because DevOps teams may unwittingly apply an incorrect configuration. This article provided guidance on how to establish the cause of such errors, determining whether they are or are not due to Istio configuration.
Even greater benefits can be realized when, as in the case of the customer in this example, the operations team applies observability monitoring and alerts against such occurrences, so that the team can be aware in advance of the issue and inform the relevant teams before an escalation occurs.
Last updated:
January 4, 2023
After upgrading to vCenter 7 Update 1 , when I tried to browse vCenter HTML5 UI, I faced “no healthy upstream” error. I could access to vCenter Management Interface (VAMI) https://vCenter-IPaddress:5480 without any issues. I could also connect to vCenter Server through SSH but I realized couple of vCenter Server services could not start.
You can also check the details status of services by connecting to vCenter through SSH and run the following command:
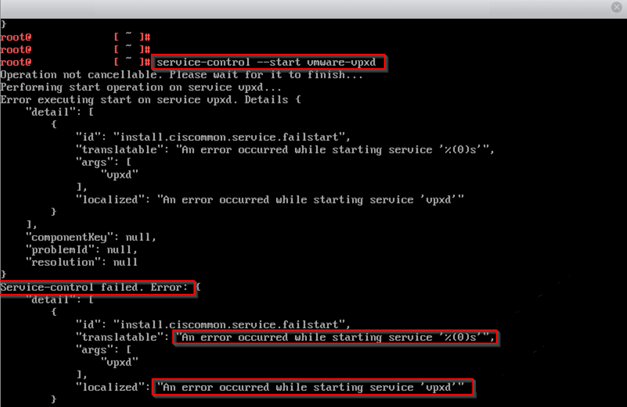
#service-control --list Then I tried to force to start services by below commands:
#service-control --start --all
#service-control –-start {service-name}After waiting for a while, I got the underneath error.
After spending couple of hours reading logs and a bit of googling, I have been pointed towards different answers. First of all I went through all DNS, NTP and IP checks and in my case everything was working as it should.
In my scenario, vCenter’s SSL certificate were
replaced with a valid signed certificate and it was one of the reason that
points me to check certification validity. Beside this SSL certificate, there
are couple of other certificates that vCenter server uses. To get familiar with
vSphere certificates you can read the following vSphere documentation:
https://docs.vmware.com/en/VMware-vSphere/7.0/com.vmware.vsphere.authentication.doc/GUID-3AF7757E-A30E-4EEC-8A41-28DA72102520.html
In my case “Trusted root certificate, Machine SSL Certificate and SMS” were still valid . But ” Machine, vpxd, vpxd-extension and vsphere-webclient” were expired.
You can check the validity of each certificate by running below commands in vCenter server:
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store TRUSTED_ROOTS --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store MACHINE_SSL_CERT --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store SMS --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store machine --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store vpxd --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store vpxd-extension --text | less
# /usr/lib/vmware-vmafd/bin/vecs-cli entry list --store vsphere-webclient --text | lessBelow you can find the expired certificate screen shot:

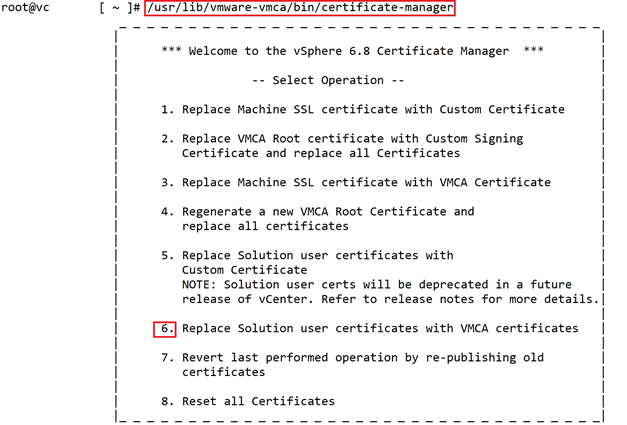
In this case you need to update the expired certificates with use of vCenter certificate manager through running following command on vCenter CLI.
#/usr/lib/vmware-vmca/bin/certificate-managerchoose number 6 to replace Solution User certificates.
Then you need to answer the required information
- Do you wish to generate all certificates using configuration file : Option[Y/N] ? : Y
- Please provide valid SSO and VC privileged user credential to perform certificate operations.Enter username [Administrator@vsphere.local]:
Note: this is an example how to address each question you need to fill it out based on your environment.
- Enter proper value for ‘Country’ [Default value : US] :US
- Enter proper value for ‘Name’ [Default value : CA] : CA
- Enter proper value for ‘Organization’ [Default value : VMware] : “ vElements lab”
- Enter proper value for ‘OrgUnit’ [Default value : VMware Engineering] : VELEMENTSIT
- Enter proper value for ‘State’ [Default value : California]: California
- Enter proper value for ‘Locality’ [Default value : Palo Alto] : Palo Alto
- Enter proper value for ‘IPAddress’ (Provide comma separated values for multiple IP addresses) [optional] : you can press Enter or provide the required information
- Enter proper value for ‘Email’ [Default value : email@acme.com] : Press Enter
- Enter proper value for ‘Hostname’ (Provide comma separated values for multiple Hostname entries) [Enter valid Fully Qualified DomainName(FQDN), For Example : example.domain.com] : vc.velements.net
- Enter proper value for VMCA ‘Name’ : vc.velements.net You are going to regenerate Solution User Certificates using VMCA
- Continue operation : Option[Y/N] ? : Y
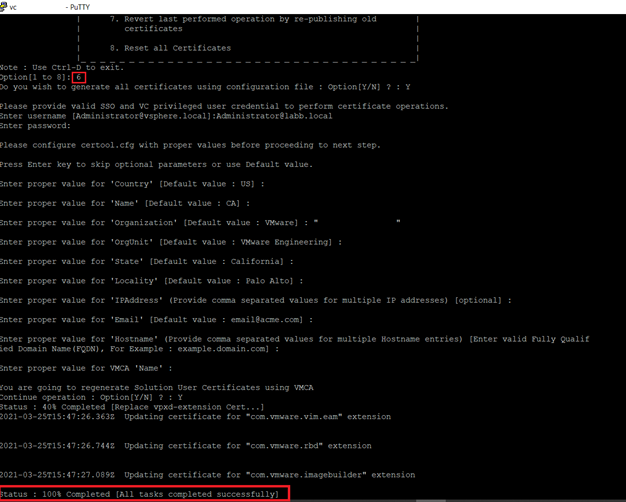
After I successfully updated the certificates , vCenter
services got started and I could reach the vCenter UI.
Below you can also find other solutions I found
when I was googling
Suggested answers to check
- Upgrade VMware Hardware version and choose the
correct OS for vCenter
Note: Take a snapshot from
vCenter Server VM before hardware version upgrade, as it’s none reversible task to previous versions.
- Shutdown the vCenter > right click on the VM
> Compatibility > Upgrade VM Compatibility. - Right click on the vCenter and choose Edit
settings > VM Options > General Options > Select VMware Photon OS - Check DNS (you should be able to resolve FQDN
names from vCenter) - Check NTP (Time should be synced and correct
between ESXi hosts and vCenter Server) - vCenter Server IP address should be set Static
All of the services which are set to Automatic start are running without any errors or warnings. Hopefully this will help you to solve your issue.

I recently faced this issue when downgrading HPE Simplivity Node, we were using Center v7 U2, and we have to shut down everything for this host downgrade.
after the downgrade and adding additional SimpliVity node deployment was done, we tried to turn on vCenter but we cannot see GUI it says “no healthy upstream” and it looks like vpxd service not starting.

we tried to ssh to vCenter and try to restart “vmware-vpxd” several times, later we logged a case with VMware, immediately they called us and taken server remotely. and add esxi server IP to hosfile, I dont know why he did that. may be he wants vCenter to communicate with Esxi host properly kindly check this link for reference
later he relogged in to vCenter through ssh and tried to stop and restart all service and on another ssh he watch which service is up and running with in minutes issue got fixed. i will be pasting logs below for your reference.
SSH Connection 1
[email protected] [ /etc ]# vi hosts
[email protected] [ /etc ]# cat hosts
# Begin /etc/hosts (network card version)
10.9.8.120
127.0.0.1 localhost.localdomain
127.0.0.1 localhost
# End /etc/hosts (network card version)
[email protected] [ /etc ]# service-control –stop –all && service-control –start –all
Operation not cancellable. Please wait for it to finish…
Performing stop operation on service observability…
Successfully stopped service observability
Performing stop operation on service vmware-pod…
Successfully stopped service vmware-pod
Performing stop operation on service vmware-vdtc…
Successfully stopped service vmware-vdtc
Performing stop operation on profile: ALL…
Successfully stopped service vmware-vmon
Successfully stopped profile: ALL.
Performing stop operation on service vmcad…
Successfully stopped service vmcad
Performing stop operation on service vmdird…
Successfully stopped service vmdird
Performing stop operation on service vmafdd…
Successfully stopped service vmafdd
Performing stop operation on service lwsmd…
Successfully stopped service lwsmd
Operation not cancellable. Please wait for it to finish…
Performing start operation on service lwsmd…
Successfully started service lwsmd
Performing start operation on service vmafdd…
Successfully started service vmafdd
Performing start operation on service vmdird…
Successfully started service vmdird
Performing start operation on service vmcad…
Successfully started service vmcad
Performing start operation on profile: ALL…
Successfully started service vmware-vmon
Successfully started profile: ALL.
Performing start operation on service observability…
Successfully started service observability
Performing start operation on service vmware-vdtc…
Successfully started service vmware-vdtc
Performing start operation on service vmware-pod…
Successfully started service vmware-pod
[email protected] [ /etc ]#
SSH Connection 2
[email protected] [ ~ ]# watch service-control –status
Every 2.0s: service-control –status localhost: Thu Mar 31 16:17:48 2022
Running:
applmgmt lookupsvc lwsmd observability observability-vapi pschealth vlcm vmafdd vmcad vmdird vmonapi vmware-analytics vmware-certificateauthority vmware-certificatemanagement vmware-cis-license vm
ware-content-library vmware-eam vmware-envoy vmware-hvc vmware-infraprofile vmware-perfcharts vmware-pod vmware-postgres-archiver vmware-rhttpproxy vmware-sca vmware-sps vmware-statsmonitor vmware-
stsd vmware-topologysvc vmware-trustmanagement vmware-updatemgr vmware-vapi-endpoint vmware-vdtc vmware-vmon vmware-vpostgres vmware-vpxd vmware-vpxd-svcs vmware-vsan-health vmware-vsm vsphere-ui v
stats vtsdb wcp
Stopped:
vmcam vmware-imagebuilder vmware-netdumper vmware-rbd-watchdog vmware-vcha
Kudos to VMware team who fixed this issue, this way all of the services required for vCenter to start is up and running,
it is weird that some of the community members and blog post recommended to reset Bios time of Esxi node is correct and synchronized with vCenter, for us we already corrected Bios and (HPE) Intelligent provisioning time to same one because in future we may face issue with logs time stamp.
I Hope using above method might have fix your issue, or if you have any opinion about any good method let me know.

Related Posts
Comments

Subscribe For Instant News, Updates, and Discounts
