Содержание
- Streams, Piping, and Their Error Handling in Node.js
- Explained with examples
- Streams and Buffers in NodeJs
- To handle and manipulate streaming data like a video, a large file, etc. we need streams in Node. Streams module in…
- A Writable Stream
- Stream Piping and Unpiping
- Error Handling for Normal and Piped Streams
- Events Available on a Writable Stream
- drain
- close
- finish
- pipe/unpipe
- Functions Available on a Write Stream
- cork/uncork
- How Error Events Affect Piped Streams In Node.js
- Working with Node.js streams
- Introduction
- Types of streams
- When to use Node.js streams
- The batching process
- Composing streams in Node.js
- Composing writable streams
- Composing readable streams
- Over 200k developers use LogRocket to create better digital experiences
- Composing transform streams
- Piping streams
- Error handling Node.js streams
- Error handling using pipelines
- Error handling using pipes
- Conclusion
- 200’s only Monitor failed and slow network requests in production
Streams, Piping, and Their Error Handling in Node.js
Explained with examples
In the last article, we learned the basics of streams and buffers in Node.js. We also learned about readable streams in Node.js.
If you haven’t read the last article on streams and buffers, read it here:
Streams and Buffers in NodeJs
To handle and manipulate streaming data like a video, a large file, etc. we need streams in Node. Streams module in…
In this article, we will learn about the writable streams, streams piping, and the events and the functions available on a writable stream in Node.js.
A Writable Stream
A writable stream is a stream of data that is created to write some streaming data. For example, creating a write stream to write a text file for some streaming data.
Let’s consider the following example for creating a writable stream in Node.js.
I am using TypeScript instead of JavaScript.
In the above code, we created a write stream to write some streaming data to a file named dump.txt .
Running the above two lines creates a file with the named dump.txt but without any data inside it.
To actually write some data to the file, we need to call the write function of the write stream.
Running the following two write functions on the writeStream variable creates a file named dump.txt and inserts the following text into it.
Stream Piping and Unpiping
In an Express application, the req (request) and res (response) for a request handler are streams. A req is a readable stream of data whereas res is a writable stream of data.
Considering this for an HTTP request, we have to serve a really large file, we can do so by using streams.
The following code in Node represents a similar functionality:
When we request the browser to http://localhost:3000, the request handler is triggered. The handler creates a readStream for file data.txt .
For the data event of readStream , we have called the write method of the res writeStream . Also, on the end event of the readStream , we send a 200 OK status code to the client.
All this code works perfectly and solves the problem well. But there is a shortcut to this problem.
Instead of listening to the data and the end events, we can simply pipe these two streams.
With piping, we simply mean that the two streams are connected. The data that is passed to stream 1 is also passed through stream 2 which is piped to stream 1.
A shorter implementation for the get method using piping is:
With stream piping, the code size is reduced to only one line of code.
In the above code, we piped the read stream from the file to the write stream of the response. This simply means the streaming data from the readStream will be piped and passed through the res write stream.
Similar to the pipe function, there is also an unpipe function on a stream. We can simply call source.unpipe(destination) anytime to stop passing of the data from the source stream to the destination stream.
In the code, we unpiped the stream after 10 milliseconds. Only the data from the read stream that was piped to the res write stream will be sent to the client.
After 10 ms , the res stream will be unpiped from the readStream and we send the 200 status to the client.
As a result of running this code, we do not get the complete content of the data.txt file in the browser.
In my case, the data.txt was 16000 lines of text, but I received only approx. 3800 lines of text on the client size as the stream was unpiped in between sending it to the client.
Error Handling for Normal and Piped Streams
In streams, we handle the errors by creating an error event listener on the stream. The listener gets triggered as soon as an error comes up in the stream.
For the case of error handling in piped streams, let us consider the following code snippet:
For an HTTP request, we created a read stream for a file and we piped it to the HTTP response write stream.
In the code, we closed the read stream in between streaming and this resulted in triggering an error on the write stream for reading from a stream that does not exist anymore.
Running the above code and creating an HTTP request to the endpoint generates the following output:
If we are having a series of piped streams in Node.js, we have to do the error handling for each of the streams individually.
In Node, a pipe does not forward error to the next pipe.
To handle errors in the above case of piped streams, we have to add an error handler on each of the streams like this:
As a result, if any of the streams encounters an error, its corresponding error handler will be triggered and the process will not exit due to unhandled errors.
Events Available on a Writable Stream
The following are the events we can listen for on a writable stream.
drain
Consider we are having a scenario where the stream buffer is full and we want to know when the buffer has some space to continue writing. In such a scenario, we listen to the drain event of the stream.
The drain event triggers as soon as it will appropriate for the stream to resume writing the data.
close
The event is triggered as soon as the stream is closed using the stream.close() function.
finish
The event is triggered after the stream has completed streaming.
pipe/unpipe
The events are triggered as soon as the stream is piped or unpiped by a stream.
Running the following code will give the output as:
Functions Available on a Write Stream
cork/uncork
Consider a scenario where the data flows at a really slow speed and we want some data to get buffered in the stream before using it. We can do so using the cork method on a writable stream.
By calling the cork method, the stream will not write data to the destination and will hold the data in the buffer.
To get the buffer data flushed to the destination, we need to call the uncork method.
In the above code, we corked the stream. As a result, the stream will stop the data flow until it is uncorked.
When uncorked in the nextTick ’s callback, we get 1 2 3 in the buffer of the writable stream being passed to the destination.
Note: If we call the cork() function twice to cork a stream, we have to call the uncork() function twice to enable the data flow from the stream.
Источник
How Error Events Affect Piped Streams In Node.js
Over the weekend, I demonstrated that «error» events don’t have any inherent affect on how individual Streams work in Node.js. In that post, I stressed that I was talking about «individual» streams because multi-stream workflows, that use .pipe(), are somewhat affected by «error» events. The «error» still doesn’t affect the individual streams; but, Node.js will unpipe the streams depending on the source of the error.
If you .pipe() one stream into another, error events emitted from the source stream have no bearing on the workflow (unless handled explicitly by the developer). The only error events that have any affect are those emitted by the target / destination stream. If the target stream emits an error, the source stream will disconnect from it (ie, .unpipe() itself from the target stream).
That said, as we’ve seen before, other than the unpipe response, the error event has no bearing on either stream. This means that after the streams are disconnected, they continue to function normally on their own. To see this in action, I’m going to take one source stream and pipe it into two different target streams. One of the target streams will emit an error event which will cause an .unpipe(); but, the code will demonstrate that all three streams (source + 2 targets) still work like healthy streams.
Since the code is all event-driven, it’s a little hard to follow — I suggest you watch the video. But, when we run the above code, we get the following terminal output:
bens-imac:pipe ben$ node test.js
Source error: StreamError
Unpiped source: true
Target error: StreamError (What)
Target error: StreamError (Written after pipe-break.)
Target error: StreamError (Ended.)
Unsafe Target Buffer: What Written after pipe-break. Ended.
Safe Target Buffer: it be like?
Let’s try to break this down, line by line, so we can see how the error events are affecting the individual streams as well as the stream interactions.
Source error: StreamError
This is the source stream emitting an error when populating the underlying stream buffer. This has no affect at all — not on the source stream and not on the stream pipes.
Unpiped source: true
This is the source stream reacting to the error event in the unsafeTarget .write() method. It [the source] is unpiping itself from the unsafeTarget. However, the first chunk of data was still written to the unsafeTarget buffer since the error was emitted as part of the write-action.
Target error: StreamError (What)
This is that first chunk getting written to the unsafeTarget buffer, before the .unpipe() call has any affect.
Target error: StreamError (Written after pipe-break.)
Target error: StreamError (Ended.)
Inside the «unpipe» event on the unsafeTarget, we make two more explicit writes to the unsafeTarget stream. This is to demonstrate that the unsafeTarget stream continues to function properly even after the «error» event and the «unpipe» event.
Unsafe Target Buffer: What Written after pipe-break. Ended.
Safe Target Buffer: it be like?
This is the «debug» event on both target streams that outputs the aggregated buffer. As you can see, the source continued to pipe data into the safeTarget even after it [source] was disconnected from the unsafeTarget. Furthermore, the unsafeTarget was able to continue accepting writes after being disconnected from the source.
What we’re seeing here is that «error» events, in Node.js, will disconnect piped-streams. However, the streams in question will continue to work properly. Or perhaps more importantly, will remain open. This means that after streams are unpiped, you probably have to end them explicitly in your error handling.
Want to use code from this post? Check out the license.
Источник
Working with Node.js streams
September 14, 2021 4 min read 1182

Introduction
Streams are one of the major features that most Node.js applications rely on, especially when handling HTTP requests, reading/writing files, and making socket communications. Streams are very predictable since we can always expect data, error, and end events when using streams.
This article will teach Node developers how to use streams to efficiently handle large amounts of data. This is a typical real-world challenge faced by Node developers when they have to deal with a large data source, and it may not be feasible to process this data all at once.
This article will cover the following topics:
Types of streams
The following are four main types of streams in Node.js:
- Readable streams: The readable stream is responsible for reading data from a source file
- Writable streams: The writable stream is responsible for writing data in specific formats to files
- Duplex streams: Duplex streams are streams that implement both readable and writable stream interfaces
- Transform streams: The transform stream is a type of duplex stream that reads data, transforms the data, and then writes the transformed data in a specified format
When to use Node.js streams
Streams come in handy when we are working with files that are too large to read into memory and process as a whole.
For example, consider Node.js streams a good choice if you are working on a video conference/streaming application that would require the transfer of data in smaller chunks to enable high-volume web streaming while avoiding network latency.
The batching process
Batching is a common pattern for data optimization which involves the collection of data in chunks, storing these data in memory, and writing them to disk once all the data are stored in memory.
Let’s take a look at a typical batching process:
Here, all of the data is pushed into an array. When the data event is triggered and once the “end” event is triggered, indicating that we are done receiving the data, we proceed to write the data to a file using the fs.writeFile and Buffer.concat methods.
The major downside with batching is insufficient memory allocation because all the data is stored in memory before writing to disk.
Writing data as we receive it is a more efficient approach to handling large files. This is where streams come in handy.
Composing streams in Node.js
The Node.js fs module exposes some of the native Node Stream API, which can be used to compose streams.
We’ll be covering readable, writable, and transform streams. You can read our blog post about duplex streams in Node.js if you want to learn more about them.
Composing writable streams
A writeable stream is created using the createWriteStream() method, which requires the path of the file to write to as a parameter.
Running the above snippet will create a file named file.txt in your current directory with 20,000 lines of Hello world welcome to Node.js in it.
Composing readable streams
Here, the data event handler will execute each time a chunk of data has been read, while the end event handler will execute once there is no more data.
Running the above snippet will log 20,000 lines of the Hello world welcome to Node.js string from ./file.txt to the console.

Over 200k developers use LogRocket to create better digital experiences
Composing transform streams
Transform streams have both readable and writable features. It allows the processing of input data followed by outputting data in the processed format.
To create a transform stream, we need to import the Transform class from the Node.js stream module. The transform stream constructor accepts a function containing the data processing/transformation logic:
Here, we create a new transform stream containing a function that expects three arguments: the first being the chunk of data, the second is encoding (which comes in handy if the chunk is a string), followed by a callback which gets called with the transformed results.
Running the above snippet will transform all the text in ./file.txt to uppercase then write it to transformedData.txt .
If we run this script and we open the resulting file, we’ll see that all the text has been transformed to uppercase.
Piping streams
Piping streams is a vital technique used to connect multiple streams together. It comes in handy when we need to break down complex processing into smaller tasks and execute them sequentially. Node.js provides a native pipe method for this purpose:
Refer to the code snippet under Composing transform streams for more detail on the above snippet.
Error handling Node.js streams
Error handling using pipelines
Node 10 introduced the Pipeline API to enhance error handling with Node.js streams. The pipeline method accepts any number of streams followed by a callback function that handles any errors in our pipeline and will be executed once the pipeline has been completed:
When using pipeline , the series of streams should be passed sequentially in the order in which they need to be executed.
Error handling using pipes
We can also handle stream errors using pipes as follows:
As seen in the above snippet, we have to create an error event handler for each pipe created. With this, we can keep track of the context for errors, which becomes useful when debugging. The drawback with this technique is its verbosity.
Conclusion
In this article, we’ve explored Node.js streams, when to use them, and how to implement them.
Knowledge of Node.js streams is essential because they are a great tool to rely on when handling large sets of data. Check out the Node.js API docs for more information about streams.
200’s only  Monitor failed and slow network requests in production
Monitor failed and slow network requests in production
 Monitor failed and slow network requests in production
Monitor failed and slow network requests in productionLogRocket is like a DVR for web and mobile apps, recording literally everything that happens while a user interacts with your app. Instead of guessing why problems happen, you can aggregate and report on problematic network requests to quickly understand the root cause.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.
Источник
Introduction
Streams are one of the major features that most Node.js applications rely on, especially when handling HTTP requests, reading/writing files, and making socket communications. Streams are very predictable since we can always expect data, error, and end events when using streams.
This article will teach Node developers how to use streams to efficiently handle large amounts of data. This is a typical real-world challenge faced by Node developers when they have to deal with a large data source, and it may not be feasible to process this data all at once.
This article will cover the following topics:
- Types of streams
- When to adopt Node.js streams
- Batching
- Composing streams in Node.js
- Transforming data with transform streams
- Piping streams
- Error handling Node.js streams
Types of streams
The following are four main types of streams in Node.js:
- Readable streams: The readable stream is responsible for reading data from a source file
- Writable streams: The writable stream is responsible for writing data in specific formats to files
- Duplex streams: Duplex streams are streams that implement both readable and writable stream interfaces
- Transform streams: The transform stream is a type of duplex stream that reads data, transforms the data, and then writes the transformed data in a specified format
When to use Node.js streams
Streams come in handy when we are working with files that are too large to read into memory and process as a whole.
For example, consider Node.js streams a good choice if you are working on a video conference/streaming application that would require the transfer of data in smaller chunks to enable high-volume web streaming while avoiding network latency.
The batching process
Batching is a common pattern for data optimization which involves the collection of data in chunks, storing these data in memory, and writing them to disk once all the data are stored in memory.
Let’s take a look at a typical batching process:
const fs = require("fs");
const https = require("https");
const url = "some file url";
https.get(url, (res) => {
const chunks = [];
res
.on("data", (data) => chunks.push(data))
.on("end", () =>
fs.writeFile("file.txt", Buffer.concat(chunks), (err) => {
err ? console.error(err) : console.log("saved successfully!");
})
);
});
Here, all of the data is pushed into an array. When the data event is triggered and once the “end” event is triggered, indicating that we are done receiving the data, we proceed to write the data to a file using the fs.writeFile and Buffer.concat methods.
The major downside with batching is insufficient memory allocation because all the data is stored in memory before writing to disk.
Writing data as we receive it is a more efficient approach to handling large files. This is where streams come in handy.
Composing streams in Node.js
The Node.js fs module exposes some of the native Node Stream API, which can be used to compose streams.
We’ll be covering readable, writable, and transform streams. You can read our blog post about duplex streams in Node.js if you want to learn more about them.
Composing writable streams
const fs = require("fs");
const fileStream = fs.createWriteStream('./file.txt')
for (let i = 0; i <= 20000; i++) {
fileStream.write("Hello world welcome to Node.jsn"
);
}
A writeable stream is created using the createWriteStream() method, which requires the path of the file to write to as a parameter.
Running the above snippet will create a file named file.txt in your current directory with 20,000 lines of Hello world welcome to Node.js in it.
Composing readable streams
const fs = require("fs");
const fileStream = fs.createReadStream("./file.txt");
fileStream
.on("data", (data) => {
console.log("Read data:", data.toString());
})
.on("end", () => { console.log("No more data."); });
Here, the data event handler will execute each time a chunk of data has been read, while the end event handler will execute once there is no more data.
Running the above snippet will log 20,000 lines of the Hello world welcome to Node.js string from ./file.txt to the console.
Composing transform streams
Transform streams have both readable and writable features. It allows the processing of input data followed by outputting data in the processed format.
To create a transform stream, we need to import the Transform class from the Node.js stream module. The transform stream constructor accepts a function containing the data processing/transformation logic:
const fs = require("fs");
const { Transform } = require("stream");
const fileStream= fs.createReadStream("./file.txt");
const transformedData= fs.createWriteStream("./transformedData.txt");
const uppercase = new Transform({
transform(chunk, encoding, callback) {
callback(null, chunk.toString().toUpperCase());
},
});
fileStream.pipe(uppercase).pipe(transformedData);
Here, we create a new transform stream containing a function that expects three arguments: the first being the chunk of data, the second is encoding (which comes in handy if the chunk is a string), followed by a callback which gets called with the transformed results.
Running the above snippet will transform all the text in ./file.txt to uppercase then write it to transformedData.txt.
If we run this script and we open the resulting file, we’ll see that all the text has been transformed to uppercase.
Piping streams
Piping streams is a vital technique used to connect multiple streams together. It comes in handy when we need to break down complex processing into smaller tasks and execute them sequentially. Node.js provides a native pipe method for this purpose:
fileStream.pipe(uppercase).pipe(transformedData);
Refer to the code snippet under Composing transform streams for more detail on the above snippet.
Error handling Node.js streams
Error handling using pipelines
Node 10 introduced the Pipeline API to enhance error handling with Node.js streams. The pipeline method accepts any number of streams followed by a callback function that handles any errors in our pipeline and will be executed once the pipeline has been completed:
pipeline(...streams, callback)
const fs = require("fs");
const { pipeline, Transform } = require("stream");
pipeline(
streamA,
streamB,
streamC,
(err) => {
if (err) {
console.error("An error occured in pipeline.", err);
} else {
console.log("Pipeline execcution successful");
}
}
);
When using pipeline, the series of streams should be passed sequentially in the order in which they need to be executed.
Error handling using pipes
We can also handle stream errors using pipes as follows:
const fs = require("fs");
const fileStream= fs.createReadStream("./file.txt");
let b = otherStreamType()
let c = createWriteStream()
fileStream.on('error', function(e){handleError(e)})
.pipe(b)
.on('error', function(e){handleError(e)})
.pipe(c)
.on('error', function(e){handleError(e)});
As seen in the above snippet, we have to create an error event handler for each pipe created. With this, we can keep track of the context for errors, which becomes useful when debugging. The drawback with this technique is its verbosity.
Conclusion
In this article, we’ve explored Node.js streams, when to use them, and how to implement them.
Knowledge of Node.js streams is essential because they are a great tool to rely on when handling large sets of data. Check out the Node.js API docs for more information about streams.
200’s only Monitor failed and slow network requests in production
Deploying a Node-based web app or website is the easy part. Making sure your Node instance continues to serve resources to your app is where things get tougher. If you’re interested in ensuring requests to the backend or third party services are successful, try LogRocket.  https://logrocket.com/signup/
https://logrocket.com/signup/
LogRocket is like a DVR for web and mobile apps, recording literally everything that happens while a user interacts with your app. Instead of guessing why problems happen, you can aggregate and report on problematic network requests to quickly understand the root cause.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.
Have you been using Node.js for a while and only until now have you heard about the word pipe? You tried checking the documentation but still can’t figure out what it means or does? In this article, I will clarify those doubts by explaining what .pipe or piping is and how to use it in Node.js. To ensure you understand the article, previous knowledge about streams is strongly recommended.
What Does .pipe() Method Do?
The method .pipe was added in v0.9.4 of Node.js and its purpose is to attach a writeable stream to a readable stream allowing to pass the readable stream data to the writeable stream. One good way to understand this concept is by thinking about PVC pipes and connecting two pipes.

For the sake of explanation, let’s assume the first PVC pipe is a readable stream and the second pipe is a writeable stream. The method .pipe will be the orange pipe fitting which will connect both pipes allow for the water, or the data, to flow from one pipe to another.
How to Use The .pipe() Method?
In this pipe implementation, we are going to create a simple HTTP server that will read data from a file and send the response to the client.
1. Let’s start by creating the HTTP server using the http package that returns some data.
const http = require('http');
http.createServer(function(req, res) {
res.write('hello!');
res.end();
}).listen(8080);
Let’s make sure it works, by making a request to our server using curl.
curl localhost:8080
Or another option is to open a new tab http://localhost:8080/. Once you make the request, you should receive “hello!”.
We are going to pause for a second. Let’s recall the anatomy of an HTTP transaction. An HTTP transaction is made of a server, created by the method createServer which in itself is an EventEmitter. When an HTTP request hits the server, node calls the request handler using the req and res objects, which are request and response respectively, for dealing with the transaction.
The req or request object is an instance of the IncomingMessage object. The IncomingMessage object is a child object of a ReadableStream.
The res or response object is an instance of the ServerResponse object. The ServerResponse object is a child object of a WriteableStream.
Therefore, we know we have a writeable and a readable stream.
2. We are going to create a data.txt file in the same directory folder, and save some information. For the sake of making things clear, I will save the following text: “This is data from the data.txt file”.
3. Remove the existing logic from the event handler.
4. We are going to read the content of the data.txt file using the fs package using fs.createReadStream. The fs.createReadStream will return a ReadableStream. We are going to use that ReadableStream to pipe or pass the data from data.txt file to the response object, which is a WriteableStream.
const http = require('http');
const fs = require('fs');
http.createServer(function(req, res) {
// generete readable stream to read content of data.txt
const readStream = fs.createReadStream(__dirname + '/data.txt');
// pass readable stream data, which are the content of data.txt, to the
// response object, which is a writeable stream
readStream.pipe(res);
}).listen(8080);Once updated the event handler’s logic, make a request to http://localhost:8080/ and you should see data.txt data.
Only Works With Readable Streams
Remember, the pipe method can only be used in readable streams. Don’t let yourself fool by your IDE in case it suggests the pipe method in a writeable stream.
In case you attempt using the .pipe method using a writeable stream, like in the example below:
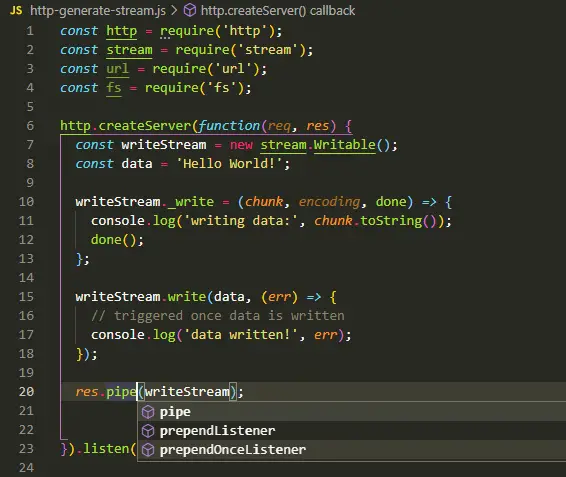
At the moment of executing this code, it will throw the following error.
Error [ERR_STREAM_CANNOT_PIPE]: Cannot pipe, not readable
Pushing Data No Matter Readable Stream’s Flowing Mode
If you are familiar with readable streams, you will know there are two modes in which data flows, flowing and paused mode. You can use the pause() or resume() method to update the flowing mode.
const http = require('http');
const fs = require('fs');
http.createServer(function(req, res) {
const readStream = fs.createReadStream(__dirname + '/data.txt');
readStream.on('data', function(chunk) {
console.log('this is the data from file', chunk);
});
readStream.pause();
console.log('on pause: readable flowing', readStream.readableFlowing);
readStream.resume();
console.log('on resume: readable flowing', readStream.readableFlowing);
res.write('Hello!')
res.end();
}).listen(8080);
If you run the example above, you will only read data from the data.txt file whenever the readable stream flowing mode is set to true which is enabled by using the resume() method. If the flowing mode is set to false, it will never read the content of the data.txt file.
However, when using the pipe method the flowing mode will automatically be set to true ensuring the data is passed from one stream to another. We can confirm this if we try to pause the flowing mode prior to piping both streams.
const http = require('http');
const fs = require('fs');
http.createServer(function(req, res) {
// generete readable stream to read content of data.txt
const readStream = fs.createReadStream(__dirname + '/data.txt');
readStream.on('data', function(chunk) {
console.log('this is the data from file', chunk);
});
readStream.pause();
console.log('on pause: readable flowing', readStream.readableFlowing);
readStream.pipe(res);
}).listen(8080);After making a request to the server, we will still receive the content from the data.txt file.
Don’t Confuse The pipe Method With The Event pipe
If you have never heard of the word “pipe” or “piping” when working with streams, there is a slight chance you could find the wrong information if you go to Node.js documentation and start finding for the word “pipe”. When you do a quick search, you will find two options.
- Event “pipe”
- Readable.pipe
If you find the first option, you will notice it is an event listener that writeable streams can set when a readable stream uses the pipe method to pass the data from one stream to another. The event pipe is only available on writeable streams. We are going to use our simple server API to demonstrate the event pipes.
const http = require('http');
const fs = require('fs');
http.createServer(function(req, res) {
const readStream = fs.createReadStream(__dirname + '/data.txt');
// setting pipe event listener before triggering the pipe method in the readable stream
// otherwise, the pipe event listener won't be triggered if set after triggering the pipe method
res.on('pipe', function(src) {
console.log('Triggered the pipe event listener whenever a source readable stream pipes the writeable stream');
});
readStream.pipe(res);
}).listen(8080);In other words, calling the pipe method on the readable stream causes the pipe event listener to be triggered on the writeable stream.
It is important to mention to define the pipe event listener prior to calling the pipe method from the readable stream. Attempting to call the pipe method prior to setting the event listener in the writeable stream won’t work.
Why You Should Use .pipe Method?
Streams are one of the most powerful and fundamental concepts of Node.js applications. They allow us to handle data in a more efficient way as pieces of data can be transported in smaller chunks preventing you from running out of memory and maintaining good performance in your applications.
Therefore, using the pipe method is an effective and easy solution to push data between streams. In that way, we avoid storing too much data that needs to be manipulated or modified all at the same time. Also, the code will be shorter, elegant, and easy to follow.
Was this article helpful?
Share your thoughts by replying on Twitter of Become A Better Programmer or to personal my Twitter account.
Данный документ является вольным переводом stream-handbook и охватывает основы создания node.js приложений с использованием потоков. По сравнению с источником — обновлены некоторые главы с учетом 2016 года, добавлено объяснение различий между разными версиями API, убраны устаревшие модули и добавлены новые, изменена структура повествования.
Таким образом, надеюсь, в результате получился актуальный современный учебник по потоковому API в node.js. Жду ваших комментариев и замечаний.
Оглавление
- Вступление
- Почему мы должны использовать потоки
- Основы
- .pipe()
- Потоки на чтение (readable)
- Создание потока на чтение
- Использование потока на чтение
- Потоки на запись (writeable)
- Создание потока на запись
- Отправка данных в поток на запись
- Дуплексные потоки (duplex)
- Трансформирующие потоки (transform)
- Различия в реализации потоков
- streams1: устаревшее API
- streams2: второе поколение
- streams3: стабильная реализация
- Дополнительно
- Встроенные потоки
- Сторонние потоки
- Список модулей
- Примеры использования
- Мощные комбинации
- Создание распределенной сети
- Клиент-серверный RPC
- Собственная реализация socket.io
- Заключение
Вступление
Нам нужен способ взаимодействия между программами, наподобие того как садовый шланг можно подключать к разным сегментам и изменять направление воды. То же самое можно сделать с вводом-выводом данных
Дуглас Макилрой. 11 октября 1964

Потоки пришли к нам из первых дней эпохи Unix и зарекомендовали себя в течении многих десятилетий как надежный способ создания сложных систем из маленьких компонентов, которые делают что-то одно, но делают это хорошо. В Unix потоки реализуются в оболочке с помощью знака | (pipe). В node встроенный модуль потоков используется в базовых библиотеках, кроме этого его можно подключать в свой код. Подобно Unix, в node основной метод модуля потоков называется .pipe(). Он позволяет соединять потоки с разной скоростью передачи данных таким образом что данные не будут потеряны.
Потоки помогают разделять ответственность, поскольку позволяют вынести все взаимодействие в отдельный интерфейс, который может быть использован повторно. Вы сможете подключить вывод одного потока на ввод другого, и использовать библиотеки которые будут работать с подобными интерфейсами на более высоком уровне.
Потоки — важный элемент микроархитектурного дизайна и философии UNIX, но кроме этого есть еще достаточное количество важных абстракций для рассмотрения. Всегда помните своего врага (технический долг) и ищите наиболее подходящие для решения задач абстракции.

Почему мы должны использовать потоки
Ввод-вывод в node асинхронен, поэтому взаимодействие с диском и сетью происходит через различные способы управления асинхронным кодом (обещания, генераторы, функции обратного вызова и т.п.). Следующий код отдает файл браузеру через функцию обратного вызова (callback):
|
|
Этот код работает, но он буферизирует весь data.txt в память при каждом запросе. Если data.txt достаточно большой, ваша программа начнет потреблять слишком много оперативной памяти, особенно при большом количестве подключений пользователей с медленными каналами связи.
При этом пользователи останутся недовольными, ведь им придется ждать пока весь файл не будет считан в память на сервере перед отправкой.
К счастью, оба аргумента (req, res) являются потоками, а это значит что мы можем переписать код с использованием fs.createReadStream() вместо fs.readFile():
|
|
Теперь .pipe() самостоятельно слушает события 'data' и'end' потока созданного через fs.createReadStream(). Этот код не только чище, но теперь и data.txt доставляется по частям по мере чтения его с диска.
Использование .pipe() имеет ряд других преимуществ, например автоматическая обработка скорости ввода-вывода — node.js не будет буферизировать лишние части файла в память пока предыдущие части не отправлены клиенту с медленным соединением.
А если мы хотим еще больше ускорить отправку файла? Добавим сжатие:
|
|
Теперь наш файл cжимается для браузеров, которые поддерживают gzip или deflate! Мы просто отдаем модулю opressor всю логику обработки content-encoding и забываем про нее.
После того как вы ознакомитесь с API потоков, вы сможете писать потоковые модули и соединять их как кусочки лего, вместо того чтобы изобретать свои велосипеды и пытаться запомнить все способы взаимодействия между компонентами системы.
Потоки делают программирование в node.js простым, элегантным и компонуемым.
Основы
Существует 4 вида потоков:
- на чтение (readable)
- на запись (writeable)
- трансформирующие (transform)
- дуплексные (duplex)
Начиная с версии node.js v0.12 в стабильном состоянии заморожена версия APIv3 (streams3) — именно его описывает официальная документация. Все виды потоков, и различия в реализации API между ними будут рассмотрены ниже.
pipe()
Любой поток может использовать.pipe() для соединения входов с выходами.
.pipe() это просто функция, которая берет поток на чтение src и соединяет его вывод с вводом потока на запись dst:
|
|
.pipe(dst) возвращает dst, так что вы можете связывать сразу несколько потоков:
|
|
или то же самое:
|
|
Аналогично в Unix вы можете связать утилиты вместе:
|
|
Потоки на чтение (readable)
Поток на чтение производит данные, которые с помощью .pipe() могут быть переданы в поток на запись, трансформирующий или дуплексный поток:
|
|
Создание потока на чтение
Давайте создадим считываемый поток!
|
|
|
|
Тут rs.push(null) сообщает потребителю, что rs закончил вывод данных.
Заметьте, мы отправили содержимое в поток на чтение rs ДО привязывания его к process.stdout, но сообщение все равно появилось в консоли. Когда вы посылаете с помощью .push() данные в поток на чтение, они буферизируются до тех пор пока потребитель не будет готов их прочитать.
Тем не менее, в большинстве случаев будет лучше если мы не будем их буферизировать совсем, вместо этого будем генерировать их только когда данные запрашиваются потребителем.
Мы можем посылать данные кусками, определив функцию ._read:
|
|
|
|
Теперь мы помещаем буквы от 'a' до 'z' включительно, но только тогда когда потребитель будет готов их прочитать.
Метод _read также получает в первом аргументе параметр size, который указывает сколько байт потребитель хочет прочитать — он необязательный, так что ваша реализация потока может его игнорировать.
Обратите внимание, вы также можете использовать util.inherits() для наследования от базового потока, но такой подход может быть непонятен тому кто будет читать ваш код.
Чтобы продемонстрировать, что наш метод _read вызовется только когда потребитель запросит данные, добавим задержку в наш поток:
|
|
Запустив программу, мы увидим, что если мы запросим 5 байт — _read () вызовется 5 раз:
|
|
Задержка через setTimeout необходима, так как операционной системе требуется определенное время чтобы послать сигнал о закрытии конвейера.
Обработчик process.stdout.on('error', fn) также необходим, поскольку операционная система пошлет SIGPIPE нашему процессу когда утилите head больше не будет нужен результат нашей программы (в этом случае будет вызвано событие EPIPE в потоке process.stdout).
Эти усложнения необходимы при взаимодействии с конвейером в операционной системе, но в случае реализации потоков чисто в коде они будут обработаны автоматически.
Если вы хотите создать читаемый поток, который выдает произвольные форматы данных вместо строк и буферов — убедитесь что вы его инициализировали с соответствующей опцией: Readable ({ objectMode: true }).
Использование потока на чтение
В большинстве случаев мы будем подключать такой поток к другому потоку, созданному нами или модулями наподобие through, concat-stream. Но иногда может потребоваться использовать его напрямую.
|
|
|
|
Когда данные становятся доступными, возникает событие 'readable', и вы можете вызвать .read() чтобы получить следующую порцию данных из буффера.
Когда поток завершится, .read() вернет null, потому что не останется доступных для чтения байтов.
Вы можете запросить определенное количество байтов: .read(n). Указание необходимого размера носит рекомендательный характер, и не сработает для потоков возвращающих объекты. Однако, все базовые потоки обязаны поддерживать данную опцию.
Пример чтения в буффер порциями по 3 байта:
|
|
Но, при запуске этого примера мы получим не все данные:
|
|
Это произошло потому что последняя порция данных осталась во внутреннем буфере, и нам надо “подопнуть” их. Сделаем мы это сообщив с помощью .read(0) что нам надо больше чем только что полученные 3 байта данных:
|
|
Теперь наш код работает как и ожидалось:
|
|
В случае, если вы получили больше данных чем вам требуется — можно использовать .unshift() чтобы вернуть их назад. Использование .unshift() помогает нам предотвратить получение ненужных частей.
К примеру, создадим парсер который разделяет абзац на строки с делителем — переносом строки:
|
|
|
|
Код выше приведен только для примера, если вам действительно нужно будет разбить строку — лучше будет воспользоваться специализированным модулем split и не изобретать велосипед.
Потоки на запись (writeable)
В поток на запись можно послать данные используя .pipe(), но прочитать их уже не получится:
|
|
Создание потока на запись
Просто определяем методом ._write(chunk, enc, next), и теперь в наш поток можно передавать данные:
|
|
|
|
Первый аргумент, chunk, это данные которые посылает отправитель.
Второй аргумент, enc, это строка с названием кодировки. Она используется только в случае когда опция opts.decodeString установлена в false, и вы отправляете строку.
Третий аргумент, next(err), является функцией обратного вызова (callback), сообщающей отправителю что можно послать еще данные. Если вы вызовите ее с параметром err, в потоке будет создано событие 'error'.
В случае если поток из которого вы читаете передает строки, они будут преобразовываться в Buffer. Чтобы отключить преобразование — создайте поток на запись с соответствующим параметром: Writable({ decodeStrings: false }).
Если поток на чтение передает объекты — явно укажите это в параметрах: Writable({ objectMode: true }).
Отправка данных в поток на запись
Чтобы передать данные в поток на запись — вызовите .write(data), где data это набор данных которые вы хотите записать.
|
|
Если вы хотите сообщить что вы закончили запись — вызовите .end() (или .end(data) чтобы отправить еще немного данных перед завершением):
|
|
|
|
Не беспокойтесь о синхронизации данных и буферизации, .write() вернет false если в буфере скопилось данных больше чем указывалось в параметре opts.highWaterMark при создании потока. В этом случае следует подождать события 'drain', которое сигнализирует о том что данные можно снова писать.
Дуплексные потоки (duplex)
Дуплексные потоки наследуют методы как от потоков на чтение, так и от потоков на запись. Это позволяет им действовать в обоих направлениях — читать данные, и записывать их в обе стороны. В качестве аналогии можно привести телефон. Если вам требуется сделать что-нибудь типа такого:
|
|
значит вам нужен дуплексный поток.
Трансформирующие потоки (transform)
Трансформирующие потоки это частный случай дуплексных потоков (в обоих случаях они могут использоваться как для записи, так и чтения). Разница в том, что в случае трансформации отдаваемые данные так или иначе зависят от того что подается на вход.
Возможно, вы также встречали второе название таких потоков — “сквозные” (“through streams”). В любом случае, это просто фильтры которые преобразовывают входящие данные и отдают их.
Различия в реализации потоков
streams1: устаревшее API
В первых версиях node.js существовал классический (streams1) интерфейс потоков. Интерфейс поддерживал добавление данных в поток (push-режим), однако потребитель мог только слушать события data и end, буферизация не поддерживалась и данные легко было потерять. Разработчики вручную контролировали поток вызывая .pause() и .resume(). На текущий момент его практически нигде не используют. Если вы все таки работаете с подобным потоком — вам пригодится несколько практик.
К примеру, чтобы избежать установки слушателей "data" и "end" подойдет модуль through:
|
|
|
|
а для буферизации всего содержимого потока сойдет concat-stream:
|
|
|
|
У классических потоков на чтение для остановки и продолжения есть методы .pause() и .resume(), но их использования следует избегать. Если вам необходим этот функционал — рекомендуется не создавать логику самостоятельно, а использовать модуль through.
streams2: второе поколение
В node.js v0.10 появилось второе поколение потоков (streams2). Эти потоки всегда запускаются в режиме паузы, и у потребителей уже есть возможность запросить данные вызвав .read(numBytes) (pull-режим), присутствует буферизация. Ключевая особенность данного API — поток автоматически переключается в классический режим в целях совместимости если назначить обработчики на data и end. При этом поток снимается с режима паузы и отключается возможность использовать pull-режим. На момент написания статьи (11.07.2016) многие неактуальные модули работают в данном режиме, однако активно развивающиеся модули перешли на третье поколение.
streams3: стабильная реализация
Начиная с node.js v0.11, концепция потоков переработана и признана стабильной — в официальной документации описывается именно поведение streams3. По умолчанию потоки все еще запускаются в режиме паузы а назначение обработчиков снимает их с паузы. Однако, если использовать .pause() и вызвать метод .read() — соответствующие данные будут возвращены. Таким образом, потоки поддерживают как pull режим, так и push. При этом, можно смело использовать модули с streams2 так как они совместимы.
Дополнительно
Вы прочитали про базовые понятия касающиеся потоков, если вы хотите узнать больше — обратитесь к актуальной документация по потокам. В случае если вам понадобится сделать API streams2 потоков совместимым с “классическим” API streams1 (например, при использовании устаревших версий node.js)- используйте модуль readable-stream. Просто подключите его в свой проект: require('readable-stream') вместо require('stream').
Встроенные потоки
Эти потоки поставляются с node.js и могут быть использованы без подключения дополнительных библиотек.
process
process.stdin
Поток на чтение содержит стандартный системный поток ввода для вашей программы.
По умолчанию он находится в режиме паузы, но после первого вызова .resume() он начнет исполняться в
следующем системном тике.
Если process.stdin указывает на терминал (проверяется вызовомtty.isatty()), тогда входящие данные будут буферизироваться построчно. Вы можете выключить построчную буферизацию вызвав process.stdin.setRawMode(true). Однако, имейте ввиду что в этом случае обработчики системных нажатий (таких как^C и ^D) будут удалены.
process.stdout
Поток на запись, содержащий стандартный системный вывод для вашей программы. Посылайте туда данные, если вам нужно передать их в stdout.
process.stderr
Поток на запись, содержащий стандартный системный вывод ошибок для вашей программы. Посылайте туда данные, если вам нужно передать их в stderr.
child_process.spawn()
Данная функция запускает процесс, и возвращает объект содержащий stderr/stdin/stdout потоки данного процесса.
fs.createReadStream()
Поток на чтение, содержащий указанный файл. Используйте, если вам надо прочесть большой файл без больших затрат ресурсов.
fs.createWriteStream()
Поток на запись, позволяющий сохранить переданные данные в файл.
net
net.connect()
Данная функция вернет дуплексный поток, который позволяет подключиться к удаленному хосту по протоколу tcp.
Все данные которые вы будете в него записывать будут буферизироваться до тех пор, пока не возникнет событие 'connect'.
net.createServer()
Создает сервер для обработки входящих соединений. Параметром передается функция обратного вызова (callback), которая вызывается при создании соединения, и содержит поток на запись.
|
|
http.request()
Создает поток на чтение, позволяющий сделать запрос к веб-серверу и вернуть результат.
http.createServer()
Создает сервер для обработки входящих веб-запросов. Параметром передается функция обратного вызова (callback), которая вызывается при создании соединения, и содержит поток на запись.
zlib.createGzip()
Трансформирующий поток, который отдает на выходе запакованный gzip.
zlib.createGunzip()
Трансформирующий поток, распаковывает gzip-поток.
zlib.createDeflate()
zlib.createInflate()
Сторонние потоки
Список модулей
Ниже приведен список npm-модулей, работающих с потоками. Список является далеко не полным, постоянно появляются новые модули и их нет возможности отслеживать. Цель данной таблицы — дать представление о “кирпичиках”, из которых вы можете собрать свое приложение. Не стесняйтесь проходить по ссылкам и изучать документацию, там есть более подробное описание и примеры использования.
| through | Простой способ создания дуплексного потока или конвертации “классического” в современный | ||
| from | Аналог through, только для создания потока для чтения | ||
| pause-stream | Позволяет буферизировать поток и получать результат буфера в произвольный момент | ||
| concat-stream | Буферизирует поток в один общий буфер. concat(cb) принимает параметром только один аргумент — функцию cb(body), которая вернет body когда поток завершится |
||
| duplex, duplexer | Создание дуплексного потока | ||
| emit-stream | Конвертирует события (event-emitter) в поток, и обратно | ||
| invert-stream | Создает из двух потоков один, “соединяя” вход первого потока с выходом второго и наоборот | ||
| map-stream | Создает трансформирующий поток для заданной асинхронной функции | ||
| remote-events | Позволяет объединять несколько эмиттеров событий в единый поток | ||
| buffer-stream | Дуплексный поток, буферизирующий проходящие через него данные | ||
| highland | Управление асинхронным кодом с использованием потоков | ||
| auth-stream | Добавление слоя авторизации для доступа к потокам | ||
| mux-demux | Создание мультифункциональных потоков на основе любых текстовых. | ||
| stream-router | Роутер для потоков, созданных с помощью mux-demux |
||
| multi-channel-mdm | Создание постоянных потоков (каналов) из потоков mux-demux |
||
| crdt, delta-stream, scuttlebutt | Данная коллекция потоков предполагает, что операции над данными всегда возвращают один и тот же результат вне зависимости от порядка этих операций | ||
| request | Создание http-запросов | ||
| reconnect-core | Базовый настраиваемый интерфейс для переподключения потоков при возникновении проблем в сети | ||
| kv | Абстрактный поток, предоставляющий враппер для доступа к различным key-value хранилищам | ||
| trumpet | Трансформация html-текста с использованием css-селекторов | ||
| JSONStream | Преобразование JSON.parse и JSON.stringify. Примеры использования — обработка большого объема JSON-данных при недостаточном количестве оперативной памяти, обработка json “на лету” при получении его через медленные каналы, и т.п. |
||
| shoe | Трансляция вебсокет событий. | ||
| dnode | Данный модуль дает вам возможность вызывать удаленные функции (RPC) через любой поток | ||
| tap | Фреймворк для тестирования node.js на основе потоков. | ||
| stream-spec | Способ описания спецификации потоков, для автоматизации их тестирования. |
Примеры использования
pause-stream позволяет буферизировать поток и получать результат буфера в произвольный момент:
|
|
В данном примере concat-stream вернет строку "beep boop" только после того как вызовется cs.end(). Результат работы программы — перевод строки в верхний регистр:
|
|
|
|
Следующий пример с concat-stream обработает строку с параметрами, и вернет их уже в JSON:
|
|
|
|
В данном примере используются JSONStream и emit-stream и net. Будет создан сервер который автоматически отправит все события клиенту:
|
|
Клиент, со своей стороны, может автоматически конвертировать приходящие данные обратно в события:
|
|
Данная программа создаст из stdin и stdout дуплексный поток с помощью invert-stream:
|
|
|
|
Для создания потока, работающего с датами, тут мы используем mux-demux:
|
|
Мощные комбинации
Статья была бы не полной без рассказа о той магии, которую можно совершать используя комбинации различных потоков. Давайте рассмотрим некоторые из них.
Создание распределенной сети
Модуль scuttlebutt может быть использован для синхронизации состояния между узлами mesh-сети, где узлы непосредственно не связаны между собой и нет единого мастера (аналог торрент-клиента).
Под капотом у scuttlebutt используется широко известный в узких кругах протокол gossip, который гарантирует что все узлы будут возвращать последнее актуальное значение.
Используя интерфейс scuttlebutt/model, мы можем создавать клиентов и связывать их между собой:
|
|
Мы создали сеть в форме ненаправленного графа, которая выглядит так:
|
|
Узлы a и e напрямую не соединены, но если мы выполним команду:
|
|
то увидим что узел a будет доступен узлу e через узлы bи d. Учитывая то, что scuttlebutt использует простой потоковый интерфейс, и все узлы гарантированно получат данные — мы можем соединить любой процесс, сервер или транспорт которые поддерживают обработку строк.
Давайте создадим более реалистичный пример. В нем мы будем соединяться через сеть, и увеличивать счетчик каждые 320 миллисекунд на всех узлах:
|
|
Теперь создадим клиента, который подключается к серверу, получает обновления и выводит их на экран:
|
|
Клиент получился чуть-чуть сложнее, так как ему приходится ждать обновления от остальных участников прежде чем убедиться что он может увеличить счетчик.
После того как мы запустим сервер и несколько клиентов — мы увидим изменения счетчика наподобие такого:
|
|
Время от времени на некоторых узлах мы будем замечать что значения повторяются:
|
|
Это происходит потому, что мы не предоставили достаточно данных алгоритму для разрешения временных конфликтов, и ему сложнее поддерживать синхронизацию всех узлов. К сожалению, дальнейшее развитие примера выходит за пределы данной статьи, поэтому рекомендуем самостоятельно изучить scuttlebutt.
Обратите внимание, что в вышеприведенных примерах сервер это всего лишь еще один узел с теми же привилегиями что и остальные клиенты. Понятия “клиент” и “сервер” не затрагивают способы синхронизации данных, в данном сервер это “тот кто первым создал соединение”. Подобные протоколы называют “симметричными”, еще один пример подобного протокола можно посмотреть в реализации модуля dnode.
Клиент-серверный RPC
Для примера, создадим простой сервер dnode:
|
|
потом напишем клиента, который вызывает метод сервера .transform():
|
|
После запуска, клиент выведет следующий текст:
|
|
Клиент послал 'beep' на сервер, запросив выполнение метода .transform(), сервер вернул результат.
Интерфейс, который предоставляет dnode, является дуплексным потоком. Таким образом, так как и клиент и сервер подключены друг к другу (c.pipe(d).pipe(c)), запросы можно выполнять в обе стороны.
dnode раскрывает себя во всей красе когда вы начинаете передавать аргументы к предоставленным методам. Посмотрим на обновленную версию предыдущего сервера:
|
|
Вот обновленный клиент:
|
|
После запуска клиента, мы увидим:
|
|
Сервер увидел аргумент, и выполнил функцию с ним!
Основная идея такая: вы просто кладете функцию в объект, и на другой стороне земного шара вызываете идентичную функцию с нужными вам аргументами. Вместо того чтобы выполниться локально, данные передаются на сервер и функция возвращает результат удаленного выполнения. Это просто работает.
dnode работает через потоки как в node.js, так и в браузере. Удобно комбинировать потоки через mux-demux для создания мультиплексного потока, работающего в обе стороны.
Собственная реализация socket.io
Мы можем создать собственное API для генерации событий через websocket с использованием потоков.
Сперва, используем shoe для создания серверного обработчика вебсокетов, и emit-stream чтобы превратить эмиттер событий в поток, который генерирует объекты.
Далее, поток с объектами мы подключаем к JSONStream, с целью преобразовать объект в строку готовую для передачи в сеть.
|
|
Теперь мы можем прозрачно генерировать события используя метод эмиттера ev. К примеру, несколько событий через разные промежутки времени:
|
|
Наконец, экземпляр shoe привяжем к http-серверу:
|
|
Между тем, на стороне браузера поток от shoe содержащий json обрабатывается и получившиеся объекты передаются в eventStream(). Таким образом, eventStream() возвращает эмиттер который генерирует переданные сервером события:
|
|
Используем browserify для генерации кода в браузере, чтобы мы могли делать require() прямо в файле:
|
|
Подключаем <script src="/bundle.js"></script> в html-страницу, открываем ее в браузере и наслаждаемся серверными событиями которые отображаются в браузере.
Заключение
Начав использовать потоки и планировать с их помощью процесс разработки программ, вы заметите что стали больше полагаться на маленькие переиспользуемые компоненты которым не нужно ничего кроме общего интерфейса потоков. Вместо маршрутизации сообщений через глобальную систему событий и настройки обработчиков вы сфокусируетесь на разбиении приложения на мелкие компоненты, хорошо выполняющими какую-то одну задачу.
В примерах вы можете легко заменить JSONStream на stream-serializer чтобы получить немного другой способ преобразования в строку. Вы можете добавить дополнительный слой чтобы обрабатывать потери связи с помощью reconnect-core. Если вы захотите использовать события с областью видимости — вы вставите дополнительный поток с поддержкой eventemitter2. В случае если вам потребуется изменить поведение некоторых частей потока вы сможете пропустить его через mux-demux и разделить на отдельные каналы каждый со своей логикой.
С течением времени, при изменении требований к приложению, вы легко сможете заменять устаревшие компоненты новыми, с гораздо меньшим риском получить в результате неработающую систему.
Over the weekend, I demonstrated that «error» events don’t have any inherent affect on how individual Streams work in Node.js. In that post, I stressed that I was talking about «individual» streams because multi-stream workflows, that use .pipe(), are somewhat affected by «error» events. The «error» still doesn’t affect the individual streams; but, Node.js will unpipe the streams depending on the source of the error.
If you .pipe() one stream into another, error events emitted from the source stream have no bearing on the workflow (unless handled explicitly by the developer). The only error events that have any affect are those emitted by the target / destination stream. If the target stream emits an error, the source stream will disconnect from it (ie, .unpipe() itself from the target stream).
That said, as we’ve seen before, other than the unpipe response, the error event has no bearing on either stream. This means that after the streams are disconnected, they continue to function normally on their own. To see this in action, I’m going to take one source stream and pipe it into two different target streams. One of the target streams will emit an error event which will cause an .unpipe(); but, the code will demonstrate that all three streams (source + 2 targets) still work like healthy streams.
// Include module references.
var stream = require( "stream" );
var util = require( "util" );
var chalk = require( "chalk" );
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// I am a reabable stream in object-mode.
function Source() {
stream.Readable.call(
this,
{
objectMode: true
}
);
this._source = [ "What", "it", "be", "like?" ];
}
util.inherits( Source, stream.Readable );
Source.prototype._read = function( sizeIsIgnored ) {
// Emit an error every time we're asked to read data from the underlying source.
// --
// NOTE: You would never want to do this - I am only doing this to
// demonstrate the interplay between Readable streams and error events.
this.emit( "error", new Error( "StreamError" ) );
while ( this._source.length ) {
if ( ! this.push( this._source.shift() ) ) {
break;
}
}
if ( ! this._source.length ) {
this.push( null );
}
};
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// I am a writable stream in object-mode that may or may not emit errors (based on
// the instantiation arguments).
function Target( doEmitError ) {
stream.Writable.call(
this,
{
objectMode: true
}
);
this._emitError = ( doEmitError === true );
this._buffer = "";
this.on(
"finish",
function handleFinish() {
this.emit( "debug", this._buffer );
}
);
}
util.inherits( Target, stream.Writable );
Target.prototype._write = function( chunk, encoding, writeDone ) {
this._buffer += ( chunk + " " );
// Emit an error every time we go to write data into the running buffer.
// --
// NOTE: You would never want to do this - I am only doing this to
// demonstrate the interplay between Readable streams and error events.
if ( this._emitError ) {
this.emit( "error", new Error( "StreamError (" + chunk + ")" ) );
}
writeDone();
};
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// Create an instance of our readable stream.
var source = new Source();
var unsafeTarget = new Target( true );
var safeTarget = new Target( false );
// Debug errors on the source.
source.on(
"error",
function handleSourceError( error ) {
console.log( chalk.magenta( "Source error:", error.message ) );
}
);
// Debug errors on the target.
// --
// NOTE: We're only doing this for one of the targets since we know that the
// "safeTarget" will not emit any errors in this demo.
unsafeTarget.on(
"error",
function handleSourceError( error ) {
console.log( chalk.cyan( "Target error:", error.message ) );
}
);
// When the target emits the error, the source is going to disconnect itself from
// the destination.
unsafeTarget.on(
"unpipe",
function handleTargetUnpipe( stream ) {
console.log( chalk.yellow( "Unpiped source:", ( stream === source ) ) );
// At this point, the two streams have been disconnected. BUT, the two streams
// should continue to function 100% correctly. The errors have done nothing but
// interrupted the pipe-connection. As such, we can still write to the target.
this.write( "Written after pipe-break." );
this.end( "Ended." );
}
);
// Debug the state of the buffer when the UNSAFE target ends.
unsafeTarget.on(
"debug",
function handleUnsafeTargetDebug( buffer ) {
console.log( chalk.green( "Unsafe Target Buffer:", buffer ) );
}
);
// Debug the state of the buffer when the SAFE target ends.
safeTarget.on(
"debug",
function handleSafeTargetDebug( buffer ) {
console.log( chalk.green( "Safe Target Buffer:", buffer ) );
}
);
// ---------------------------------------------------------- //
// ---------------------------------------------------------- //
// Pipe the source into both the unsafe and safe targets.
source.pipe( unsafeTarget );
source.pipe( safeTarget );
Since the code is all event-driven, it’s a little hard to follow — I suggest you watch the video. But, when we run the above code, we get the following terminal output:
bens-imac:pipe ben$ node test.js
Source error: StreamError
Unpiped source: true
Target error: StreamError (What)
Target error: StreamError (Written after pipe-break.)
Target error: StreamError (Ended.)
Unsafe Target Buffer: What Written after pipe-break. Ended.
Safe Target Buffer: it be like?
Let’s try to break this down, line by line, so we can see how the error events are affecting the individual streams as well as the stream interactions.
Source error: StreamError
This is the source stream emitting an error when populating the underlying stream buffer. This has no affect at all — not on the source stream and not on the stream pipes.
Unpiped source: true
This is the source stream reacting to the error event in the unsafeTarget .write() method. It [the source] is unpiping itself from the unsafeTarget. However, the first chunk of data was still written to the unsafeTarget buffer since the error was emitted as part of the write-action.
Target error: StreamError (What)
This is that first chunk getting written to the unsafeTarget buffer, before the .unpipe() call has any affect.
Target error: StreamError (Written after pipe-break.)
Target error: StreamError (Ended.)
Inside the «unpipe» event on the unsafeTarget, we make two more explicit writes to the unsafeTarget stream. This is to demonstrate that the unsafeTarget stream continues to function properly even after the «error» event and the «unpipe» event.
Unsafe Target Buffer: What Written after pipe-break. Ended.
Safe Target Buffer: it be like?
This is the «debug» event on both target streams that outputs the aggregated buffer. As you can see, the source continued to pipe data into the safeTarget even after it [source] was disconnected from the unsafeTarget. Furthermore, the unsafeTarget was able to continue accepting writes after being disconnected from the source.
What we’re seeing here is that «error» events, in Node.js, will disconnect piped-streams. However, the streams in question will continue to work properly. Or perhaps more importantly, will remain open. This means that after streams are unpiped, you probably have to end them explicitly in your error handling.
Want to use code from this post?
Check out the license.
I believe in love. I believe in compassion. I believe in human rights. I believe that we can afford to give more of these gifts to the world around us because it costs us nothing to be decent and kind and understanding. And, I want you to know that when you land on this site, you are accepted for who you are, no matter how you identify, what truths you live, or whatever kind of goofy shit makes you feel alive! Rock on with your bad self!