Публикация обновлена 17 ноября 2021 года. Мы добавили опыт и рекомендации экспертов MOZ по исправлению ошибок индексации: “обнаружена, не проиндексирована”, “просканирована, не проиндексирована”.
Вебмастера часто сталкиваются с проблемой отказа индексации страниц Google-поиском. В Search Console появляется ошибка “обнаружена, не проиндексирована”, “просканирована, не проиндексирована”. При этом не указываются ни приблизительные сроки индексации, ни возможные причины, тогда как в других поисковых системах проблемы с индексацией этих же страниц нет. Мы собрали несколько способов, которые помогают вебмастерам быстрее проиндексировать страницы с такой ошибкой.
Что говорит Google об ошибке “обнаружена, не проиндексирована”
Cправка Google указывает, что:

Исходя из этого вебмастеру не нужно предпринимать никаких действий, чтобы проиндексировать страницы. Но по сообщениям на форумах вебмастеров и оптимизаторов сроки индексации могут растягиваться от нескольких недель до никогда.
Так как Google не дает практических путей решения проблемы, вебмастера экспериментируют. Вот самые эффективные методы.
Основные причины и решения ошибок индексации страниц
Некоторые вебмастера полагают, что причиной проблем с индексацией становятся лишь технические факторы страницы. Но это не всегда и в большинстве случаев не так. Простой эксперимент MOZ показал, что 15% страниц популярных интернет-магазинов США не попадают в индекс.
Ошибка: обнаружена, не проиндексирована
Это одна из самых сложных ошибок для устранения, так как причинами может быть что угодно: от качества контента до краулингового бюджета.
Чаще такая ошибка возникает на товарных страницах интернет-магазинов.
Краулинговый бюджет — это максимальное количество страниц одного сайта, которое может просканировать Google за один визит. Большое количество новых и/или обновленных страниц приводит к тому, что Google не справляется с объемом и оставляет остаток на потом.
Вторая распространенная причина появления ошибки — шаблонность страниц. Google определяет, что страницы определенного шаблона на сайте низкого качества, и предпочитает не индексировать их.
Работа с этой ошибкой требует определенных знаний и опыта. Что нужно проверить:
- нет ли определенного шаблона страниц, которые Google не индексирует. Это важно, так как в индекс могут не попадать целые категории товаров;
- очередь новых страниц на индексацию;
- краулинговый бюджет, который вполне могут занимать страницы результатов поиска или фильтров, где Google тратит много времени.
Далее опишем несколько нестандартных решений для ошибки “обнаружена, не проиндексирована”.
1. Перенос на новый URL
Зарубежный вебмастер Дэн Шур (@dan_shure в Твиттере) решил проблему с непроиндексированными страницами путем переноса контента на новый URL. При этом контент оставался неизменным (скопирован), а вот сам URL немного изменен. Для эксперимента вебмастер оставил одну страницу с этой ошибкой без изменений, вторую перенес на новый адрес. Страница на новом URL попала в индекс в течение нескольких часов, а неизмененная страница так и осталась с ошибкой (на тот момент уже более 10 дней).
Вебмастер отмечает, что подача заявок на переобход и отправка URL на индексацию вручную результатов не давали.
Джон Мюллер прокомментировал ситуацию так:
Такая ошибка часто возникает на сайтах, находящихся на грани допустимого качества. Это значит, что вам надо убедить Google в том, что страница стоит добавления в индекс.Для этого сайт должен быть “улетным” (awesome).
Это самая размытая рекомендация Google, потому как указанная характеристика весьма субъективна.
Мюллер предупреждает, что технические манипуляции, чтобы ввести страницу в индекс, не всегда эффективны. Так как добавленная страница может точно также через несколько дней снова вылететь из индекса.
К слову, вторая страница из эксперимента также успешно была проиндексирована после переноса на новый URL.
2. Обновить контент
Другие вебмастера видят проблему в самом контенте, что подтверждает рекомендацию Мюллера. Обнаруженные и не проиндексированные страницы содержат мало контента, он недостаточно информативен и полезен.
Рекомендация: дополнить страницу уникальным контентом в достаточном объеме (от 1000 символов). При этом контент должен быть полезным и информативным, а не техническим дополнением.
3. Проверить контент на уникальность
Мы не знаем, как Google определяет уникальность. Но даже разные инструменты могут показать разный процент проверки одного и того же текста. Ошибку “обнаружена, не проиндексирована” чаще получают страницы с контентом пограничной уникальности. Если какой-то из инструментов показывает низкий процент, стоит доработать страницу, дополнив ее уникальным и полезным текстом.
4. Получить внешнюю ссылку на страницу
Переход по внешним ссылкам — один из методов Google для обнаружения новых страниц. При этом ссылка с хорошего, авторитетного сайта оценивается поиском как голос “за” сайт, что станет дополнительным маркером важности непроиндексированной страницы.
Экспериментировать можно как с внутренними ссылками, прокачав неиндексируемую страницу линками с главной и тематических страниц, так и внешними ссылками.
5. Нагрузка на сервер
Это самый очевидный способ устранения проблемы с индексацией, который работает, но не во всех случаях.
Если страница получила ошибку “обнаружена, не проиндексирована”, стоит проверить хостинг и нагрузку на сервер и устранить причины ее повышения.
Ошибка: просканирована, но пока не проиндексирована
Google указывает, что робот просканировал страницу, но она не внесена в индекс. При этом отправлять повторный запрос на сканирование не надо. Из опыта экспертов MOZ такая ошибка часто вызвана проблемой качества содержания. Учитывая темпы появления новых интернет-магазинов, Google становится более избирательным в том, что вносит в индекс, а что нет.
Если страница получила такой статус, то надо проверить следующее:
- уникальность основных тегов Title и Description. а также основного содержания страницы
- не скопирован ли контент из внешних источников
- не дублируется ли контент в пределах сайта
- заблокирован ли доступ Google к некачественному, неоригинальному контенту на сайте.
Расскажите, случалась ли в вашей практике такая ошибка? Какие методы помогли ее устранить?
Эта статья также доступна на нашем Дзен-канале!

Когда ваш проект начинает расти и у него появляются тысячи публикаций, следует очень внимательно следить за его индексацией, так как сколько бы вы не создавали новых страниц, их отсутствие в поисковом индексе не приведет вам читателя и будет бессмысленным. На минувшем месяце я на одном из своих крупных проектов наткнулся на интересую ситуацию, я выпустил цикл новых статей, отправил их на ручную индексацию Google и забыл, какого же было мое удивление, когда я их не обнаружил в индексе гугла, а в Яндексе все появилось буквально через минуту. Начав копать я обнаружил, что они имеют статус «Страница Обнаружена, не просканирована«. Давайте разбираться из-за чего они получили такой статус и как это исправить.
Что означает статус «Страница Обнаружена, не просканирована»
В Google Search Console есть раздел «Покрытие» в котором вебмастер может отслеживать состояние страниц на его ресурсе:
- Ошибка — Это самое важное из данного представления
- Без ошибок, но есть предупреждения
- Страниц без ошибок — их должно быть максимальное количество
- Исключено — тут нужно особенно изучить все, так как там могут быть проблемы.
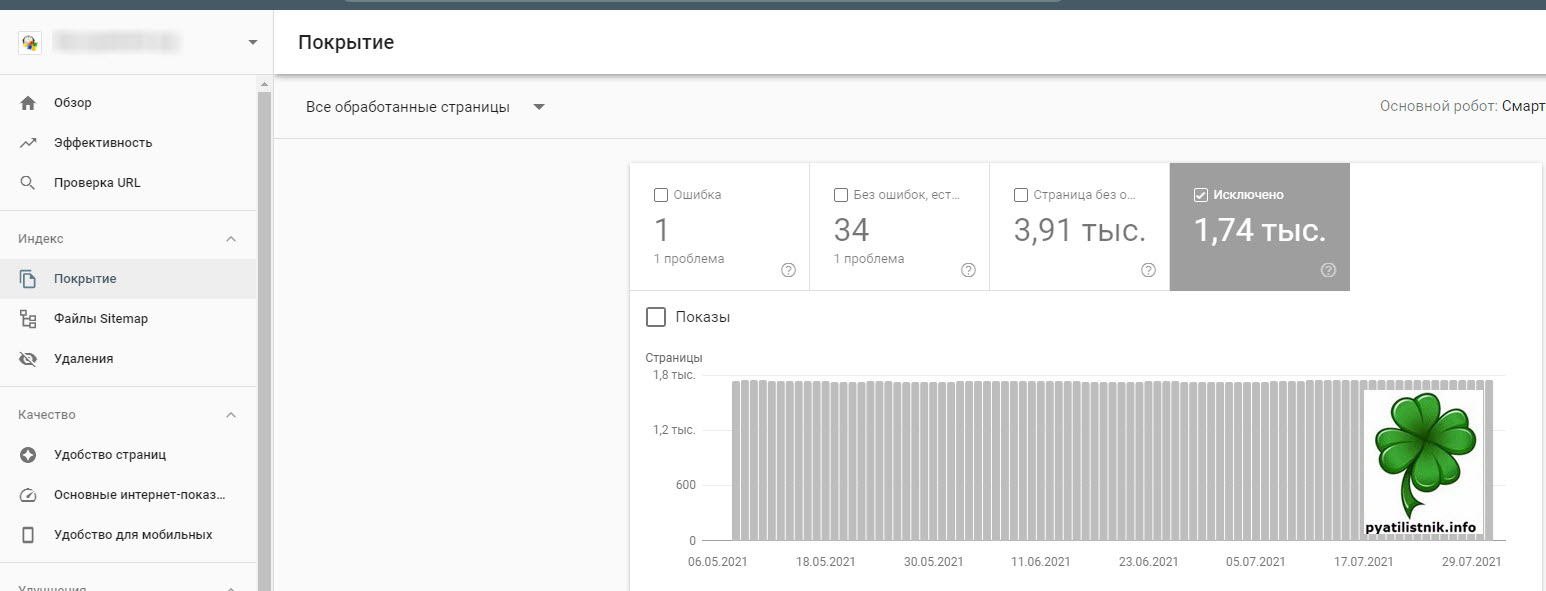
Если пролистать немного ниже, заведомо выбрав пункт «Исключено«, то можно очень детально посмотреть состав исключенных страниц, тут то я и обнаружил раздел с «Страница Обнаружена, не просканирована«.
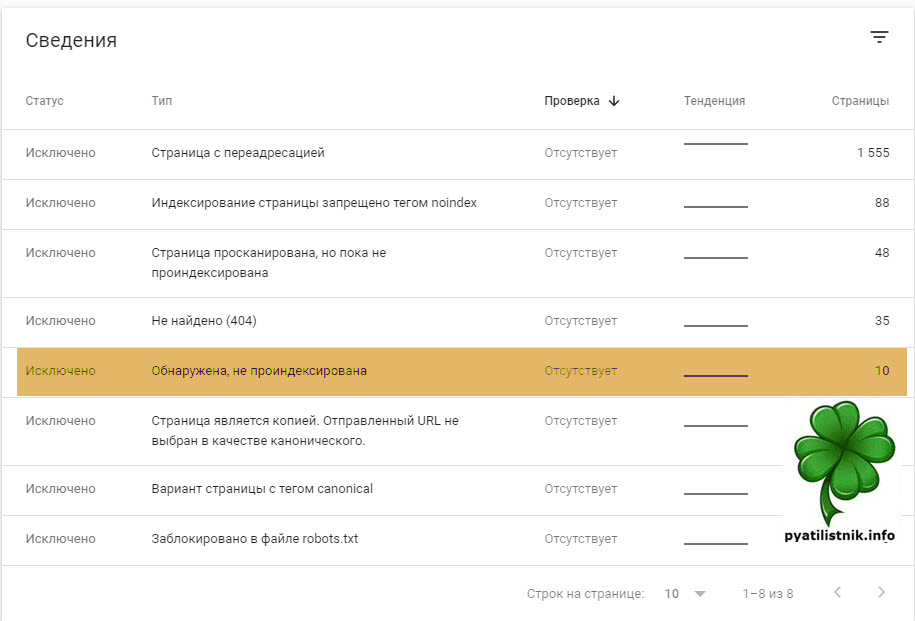
Перейдите в него и вы увидите состав данных страниц, вот мои бывшие примеры:
- http://pyatilistnik.org/how-to-turn-your-photos-into-a-beautiful-movie/
- http://pyatilistnik.org/dell-r740-server-testing/
- http://pyatilistnik.org/netapp-create-aggregate-command-line-howto/
- http://pyatilistnik.org/skachat-ibm-advanced-settings-utility-asu-9-63-dlya-linux/
- http://pyatilistnik.org/how-to-install-the-operating-system-on-the-dell-r740/
- http://pyatilistnik.org/error-rac0509-the-server-temporalily-unavailable/http://pyatilistnik.org/jcp024-lifecycle-controller-in-use/
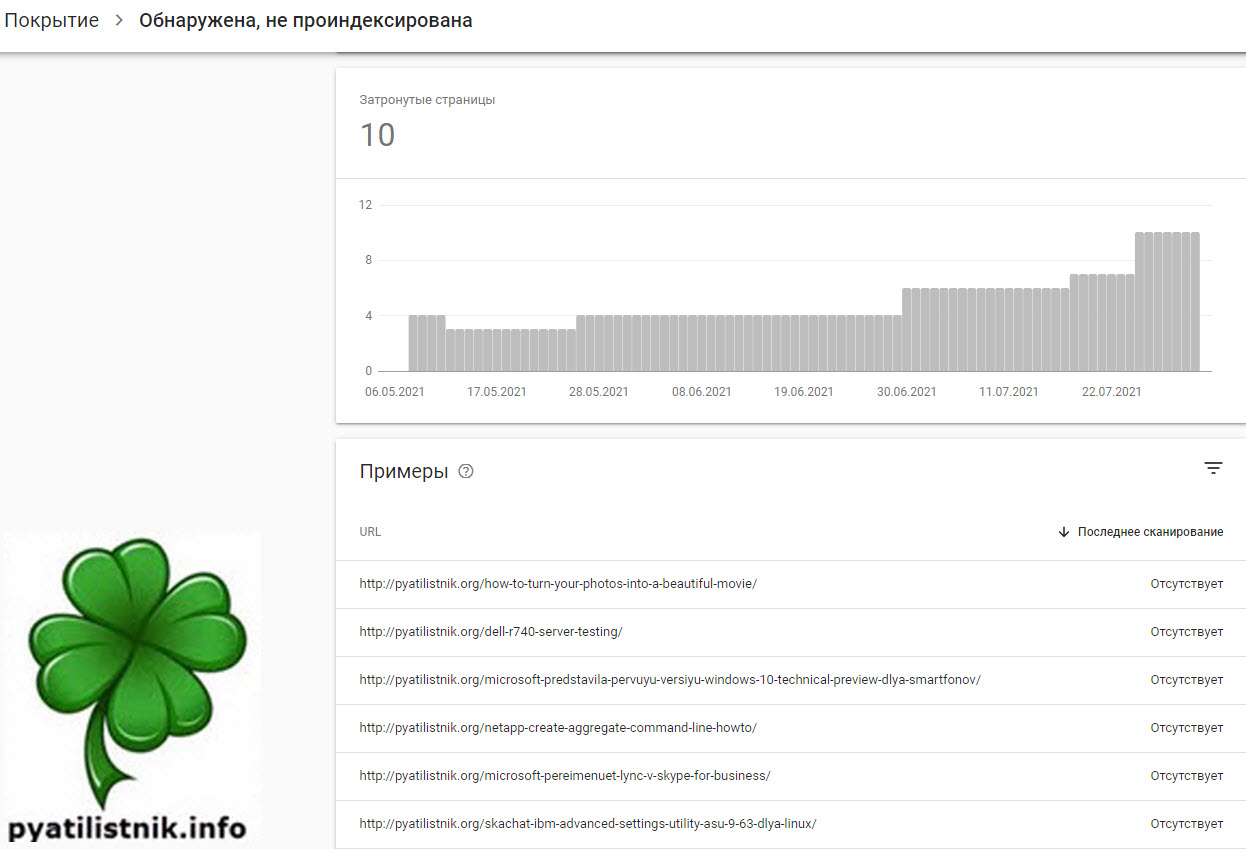
Что значит обнаружена, не проиндексирована — Это сообщение означает, что мы нашли страницу, но пока не добавили ее в индекс Google. Обычно это объясняется тем, что роботу Google не удалось просканировать сайт, поскольку это могло привести к чрезмерной загрузке ресурса, и сканирование было перенесено на более поздний срок. Именно поэтому в отчете не указывается дата последнего сканирования.(https://support.google.com/webmasters/answer/7440203?hl=ru)
Поиск проблем и причин
Когда при индексации вы видите подобный статус страницы, то с большой вероятностью когда пришел Google-bot отвечающий за сканирование ваших страниц, он осознал, что создает большую нагрузку на ваш ресурс. Дабы его не положить он откладывает данный процесс на неизвестное время и старается вас меньше напрягать. Что это значит для нас, это очень плохо, так как страницы не будут индексироваться, значит не будет трафика и далее заработка.
Что делать, нужно смотреть нагрузку на сайт. Первым делом вам необходимо зайти на ваш сервер или хостинг и проанализировать логи. В моем случае, это хостинг. Открыв админку, я увидел сильную нагрузку на сайт и на базу данных, выглядело это вот так. Обычно в пиковые значения нагрузка на БД не превышала 5-6%, что меня очень заинтересовало.
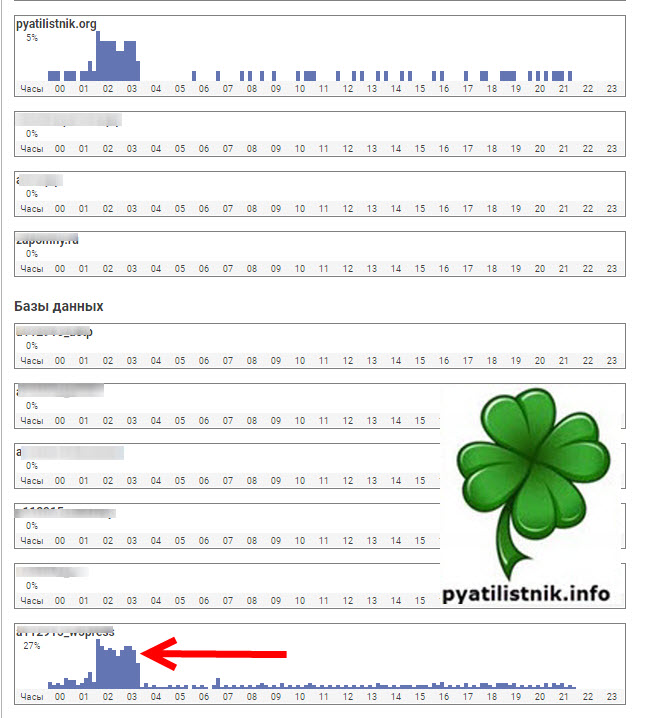
Далее я пошел в отчеты в Google Search Console. Раздел «Настройки — Статистика сканирования«. Нажмите «Открыть отчет«.
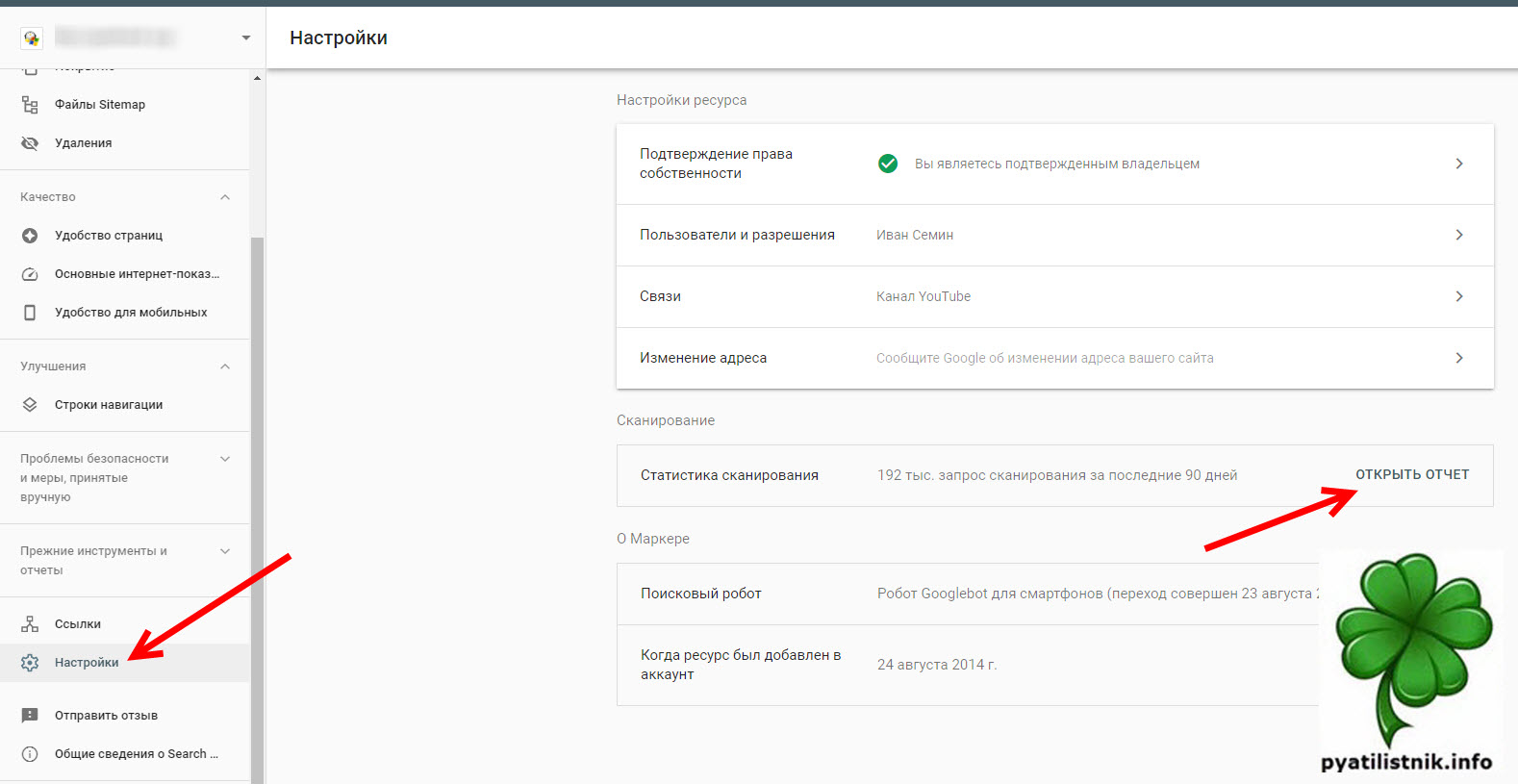
Нас будет интересовать среднее время ответа, это по сути аналог PING, при обращении к хосту. Как видите у меня он в среднем был 260, а затем резко подскочил до 700. Потом то, я нашел причину и он уменьшился, как вы видите по графику, но это успело повлиять на ресурс, и бот стал слегка осторожнее при обходе.
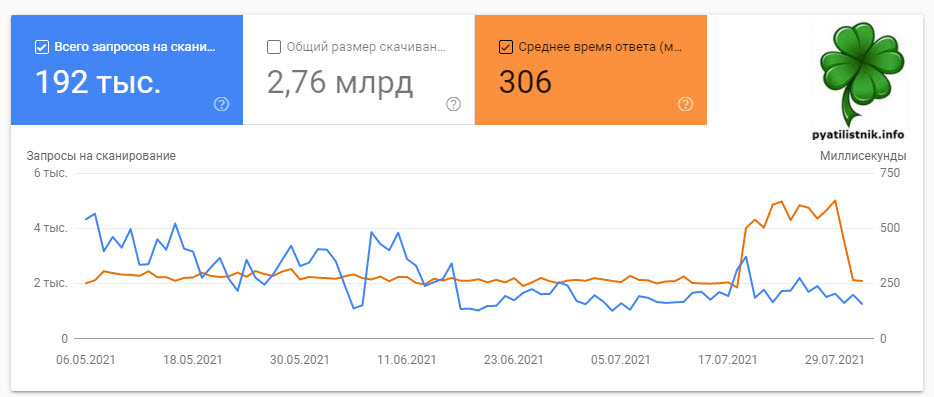
Вспоминая хронологию действий я понял, что причиной всему стало обновление плагина WordPress под названием WP Super Cache. И реально я заметил, что на хостинге в статистике была нагрузка, так как будто сайт работает без кэширующего плагина. Что я сделал, я полностью удалил кэш, а затем провел его тестирование, в итоге штампы совпадают, значит все хорошо.
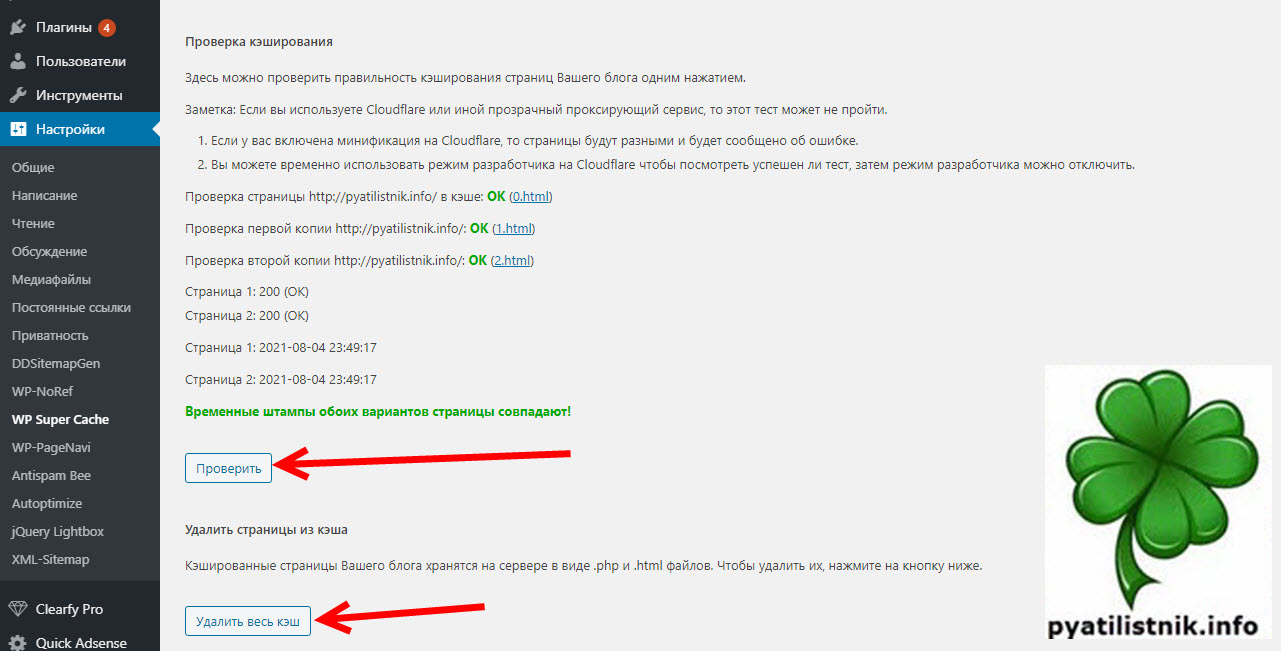
На следующий день я проверил статистику по нагрузке на хостинге, в итоге увидел привычную картину.
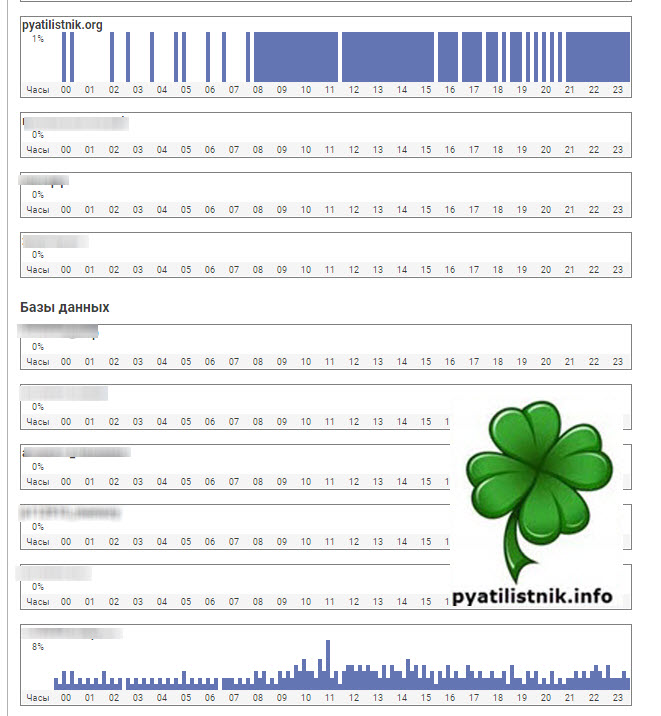
Так же я проверил скорость загрузки сайта в Google через сервис, в итоге все вернулось в зеленую зону.
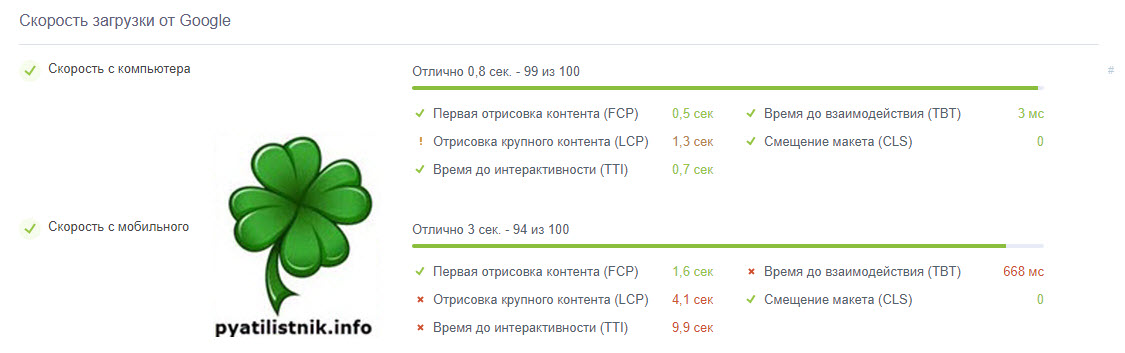
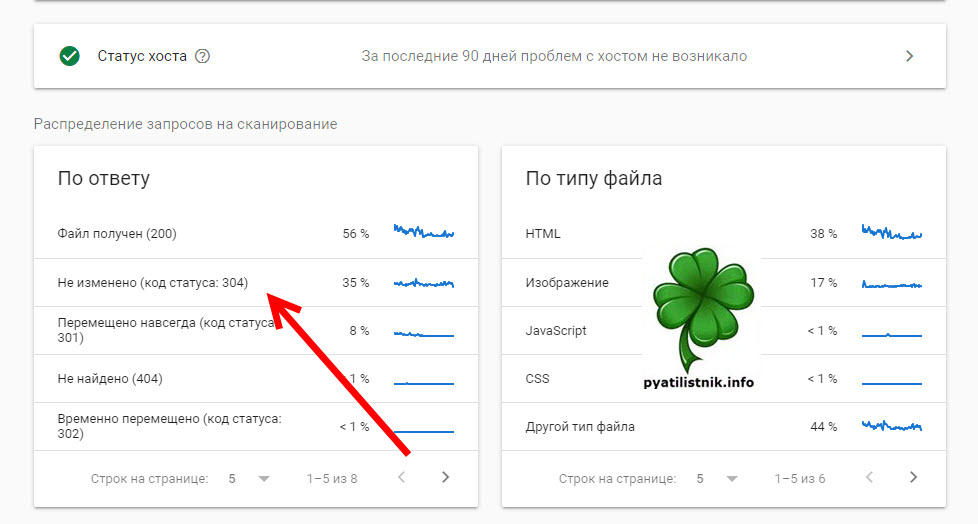
Дополнительно
- Обязательно учитывайте свой краулинговый бюджет сайта, постарайтесь, чтобы у вас если страницы не изменяются, то отдавался 304 код и заголовок Last Modified. Это можно увидеть в отчете.
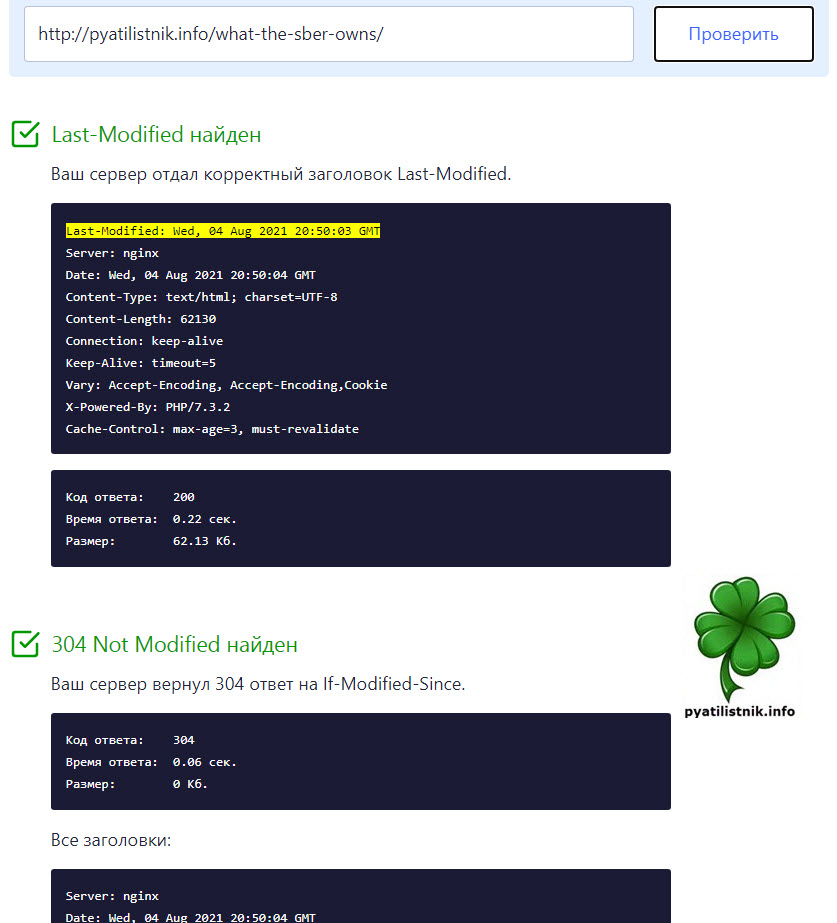
Проверить заголовок Last Modified можно на вот этом ресурсе «https://lastmodified.ru/«. Например, я проверю статью «Какими компаниями владеет Сбербанк».
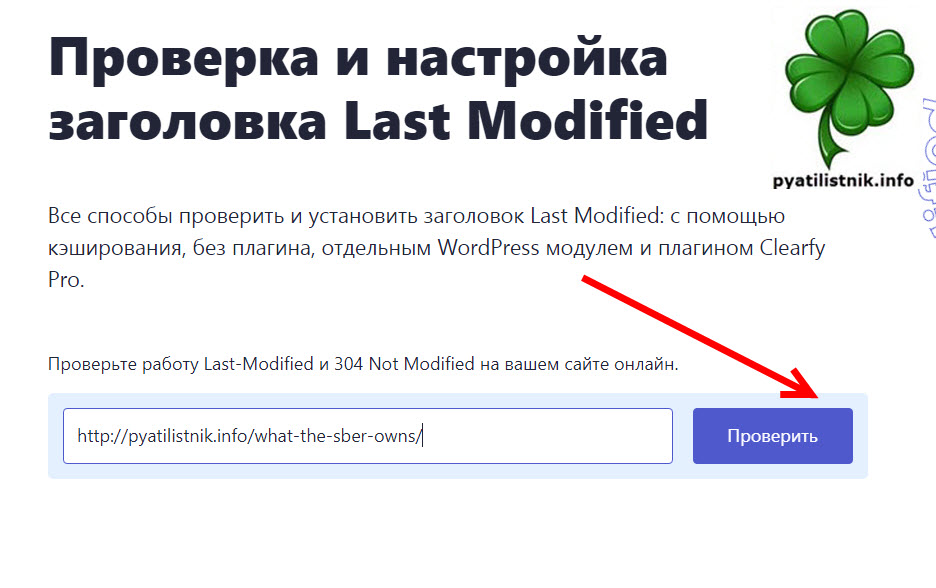
Ваш сервер отдал корректный заголовок Last-Modified.
Last-Modified: Wed, 04 Aug 2021 20:50:03 GMT Server: nginx Date: Wed, 04 Aug 2021 20:50:04 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 62130 Connection: keep-alive Keep-Alive: timeout=5 Vary: Accept-Encoding, Accept-Encoding,Cookie X-Powered-By: PHP/7.3.2 Cache-Control: max-age=3, must-revalidateКод ответа: 200 Время ответа: 0.22 сек. Размер: 62.13 Кб.
- Уменьшите количество 404 страниц, удостоверьтесь, что они не индексируются
- Создайте правильный файл robots.txt, чтобы исключить от индексации разные технические страницы.
- Постарайтесь нарастить ссылочную массу, на страницы у которых статус «Страница Обнаружена, не просканирована»
- Создайте карту сайта в формате XML
- Попробуйте уменьшить количество страниц, если среди них есть незначимые
Через некоторое время ваши выпавшие из индексации страницы появятся в индексе, можете периодических их пытаться засунуть в ручную Google Search Console через кабинет.
Перевод статьи с портала MOZ
Отчет об индексировании от Google дает SEO-специалистам уникальную возможность понять, как происходит краулинг и индексирование страниц. Эта функция очень удобна для диагностики технических проблем, возникающих у клиентов.
В отчете встречается много разных «статусов», которые предоставляют веб-мастерам подробную информацию о том, как Google обрабатывает контент их сайта. И хотя большинство статусов дают понимание о решениях Google по краулингу и индексированию, один из них остается неясным. Речь идет о статусе «Crawled — currently not indexed» («Просканировано, но не проиндексировано).
Обращая внимание на подобные отчеты и выявив причины возникновения ошибок, можно будет с уверенностью ответить на вопрос «Почему сайт не индексируется в Google?».
Появления статуса «Crawled — currently not indexed» вызывает у владельцев сайтов много вопросов. Одно из преимуществ крупной компании — это возможность работать с большим объемом данных. Поэтому после появления этого статуса в нескольких учетных записях мы начали отслеживать тенденции по указанным URL-адресам.
Определение Google
Для начала давайте посмотрим, какое определение этому статусу дает сам Google. Согласно официальным документам Google, за непонятной фразой скрывается следующее: «Страница была просканирована Google, но не проиндексирована. Возможно, она будет проиндексирована в будущем; нет необходимости повторно отправлять этот URL для краулинга».
Итак, мы можем сделать следующие выводы:
1. Google может получить доступ к странице.
2. Google потратил время на сканирование страницы.
3. После сканирования Google решил не индексировать страницу.
Чтобы лучше понять этот статус, нужно подумать о причинах, по которым Google решил отказать странице в индексации. Очевидно, что Google без труда находит страницу, но почему-то не считает ее достаточно полезной для включения в поисковую выдачу.
Получать отказ в индексировании от Google всегда неприятно, особенно если вы не понимаете, что сделали не так. Ниже мы рассмотрим несколько наиболее распространенных причин, по которым этот загадочный статус может быть присвоен вашему сайту.
1. Ложная тревога
Приоритет: низкий
Прежде всего нелишним будет сделать несколько выборочных проверок URL-адресов, получивших статус «Crawled — currently not indexed». Нередко можно найти URL-адреса, которые отмечены как исключенные, но тем не менее присутствуют в поисковой выдаче Google.
Например, вот URL-адрес, получивший такой статус в отчете для нашего веб-сайта: https://gofishdigital.com/meetup/
Однако, используя оператор поиска по сайту, мы обнаруживаем, что URL по-прежнему включен в индекс Google. Вы можете сделать это, добавив site: перед URL, как показано на рисунке ниже.

Таким образом, если вы обнаружили статус «Crawled — currently not indexed» у URL-адреса, рекомендуется начать с оператора поиска по сайту, чтобы наверняка убедиться, проиндексирован он или нет. Иногда появление такого статуса — ложная тревога о статусе индексации в Google.
Решение: ничего делать не нужно. Все хорошо.
2. Адреса RSS-каналов
Приоритет: низкий
Один из достаточно распространенных случаев, с которыми нам приходилось сталкиваться. Если на вашем сайте используется RSS-канал, возможно, вы обнаружите у URL-адресов статус «Crawled — currently not indexed». Часто к этим URL-адресам будет добавлена строка /feed/. В отчете это выглядит следующим образом:

Google нашел эти URL-адреса RSS-каналов, связанных с основной страницей, затем просканировал, но не проиндексировал.
Связывание часто происходит с использованием элемента rel=alternate. Плагины WordPress, такие как Yoast, могут автоматически генерировать подобные URL.
Решение: ничего делать не нужно. Все хорошо.
Скорее всего, Google выборочно не индексирует эти URL-адреса, и вовсе не напрасно. Если вы перейдете по адресу RSS-канала, то увидите XML-документ, подобный приведенному ниже:

Хотя этот документ полезен для RSS-каналов, обычным пользователям он совершенно без надобности. Именно поэтому Google не индексирует такие URL-адреса.
3. Разбитые на страницы URL-адреса
Приоритет: низкий
Еще одна распространенная причина появления статуса «Crawled — currently not indexed» — разбивка на страницы. В отчете мы часто наблюдаем большое количество разбитых на страницы URL-адресов. На рисунке ниже приведено несколько URL-адресов с крупного сайта интернет-магазина:

Решение: ничего делать не нужно. Все хорошо.
Для полного краулинга сайта Google должен сканировать все разбитые на страницы URL-адреса. Это могут быть страницы с довольно важным контентом, например, с категориями или описанием продуктов. Однако поисковой системе вовсе не обязательно индексировать все подобные URL-адреса.
Тем не менее нужно удостовериться, что вы сами не препятствуете сканированию отдельных страниц. Убедитесь, что все ваши страницы имеют самореферентный канонический тег и не содержат nofollow-тегов. Подобная разбивка позволяет Google сканировать другие ключевые страницы вашего сайта.
4. Отсутствующие продукты
Приоритет: средний
После выборочной проверки отдельных страниц, перечисленных в отчете, мы обнаружили еще одну общую проблему многих клиентов. Речь идет об URL-адресах, содержащих текст «товары с истекшим сроком годности» или «нет в наличии». Похоже, что на сайтах интернет-магазинов Google проверяет наличие определенного продукта. Если выясняется, что продукта нет в наличии, Google убирает страницу из индекса.
С точки зрения пользовательского опыта, это действительно имеет смысл, поскольку Google сканирует и исключает из индекса товары, которые пользователи не могут приобрести.
Однако, если данные продукты доступны на вашем сайте, исключение из индекса сулит неприятные последствия. Если страница не была проиндексирована, ваш контент не получает никакого рейтинга.
Кроме того, Google не просто проверяет видимый контент на странице. Бывали случаи, когда видимый контент никоим образом не указывал на отсутствие того или иного продукта. Однако при проверке структурированных данных мы видим, что для свойства Availability («Доступность») установлено значение OutOfStock («Нет на складе»).

Похоже, что Google использует не только видимый контент, но и структурированные данные о доступности того или иного продукта. Поэтому важно проверять оба источника данных. Если проблема имеет массовый характер, Google не проиндексирует не только страницы, но и сайт в целом.
Решение: проверьте наличие продуктов на складе.
Если вы обнаружите, что ваш продукт, который на самом деле есть в наличии, почему-то исключен из индекса, это повод проверить и другие продукты, указанные в отчете. Проведите сканирование своего сайта с помощью инструментов извлечения, таких как Screaming Frog SEO Spider.
Например, если вы хотите увидеть все ваши URL-адреса, где присутствует значение OutOfStock, используйте регулярное выражение «availability»:».
С помощью «class=»redactor-autoparser-object»>http://schema.org/OutOfStock» автоматически отобразятся все URL-адреса с этим значением:

Вы можете экспортировать этот список и перекрестные ссылки с данными о наличии товара, используя Excel или инструменты бизнес-аналитики. Это позволит вам быстро найти расхождения между структурированными данными на вашем сайте и продуктами, которые действительно есть в наличии. Аналогичным образом можно обнаружить случаи, когда ваш видимый контент указывает, что срок годности продуктов истек.
5. Переадресация 301
Приоритет: средний
Конечный URL — еще один тип адресов в зоне риска. Мы часто видим, что Google сканирует конечный URL, но не включает его в индекс. Однако, посмотрев на поисковую выдачу, мы обнаружим, что Google индексирует перенаправленный URL. Поскольку перенаправленный URL индексируется, конечный URL-адрес добавляется в отчет «Crawled — currently not indexed».

Проблема в том, что Google, вероятно, еще не распознает переадресацию. В результате он рассматривает конечный URL как «дубликат» перенаправленного URL.
Решение: создайте временный файл sitemap.xml.
Если подобное происходит на большом количестве URL-адресов или сайт полностью не индексируется в Google, стоит принять меры для отправки в Google более сильных сигналов консолидации. Проблема может указывать на то, что Google своевременно не распознает ваши переадресации, что приводит к появлению сигналов о неконсолидированном контенте.
Одним из вариантов может стать создание временного файла sitemap. Это поможет значительно ускорить сканирование перенаправленных URL-адресов. Именно такую стратегию рекомендовал Джон Мюллер в одной из предыдущих статей.
Как сделать временную карту сайта с конечными URL адресами для редиректов:
1. Экспортируйте все URL-адреса из отчета «Crawled — currently not indexed».
2. Сопоставьте их в Excel с предварительно настроенными редиректами.
3. Найдите все переадресации, у которых в области «Crawled — currently not indexed» находится конечный URL.
4. С помощью Screaming Frog создайте статический файл sitemap.xml этих URL-адресов.
5. Загрузите sitemap и просмотрите отчет в Search Console.
Google будет сканировать URL-адреса во временном файле sitemap.xml чаще, что приведет к более быстрой консолидации редиректов.
6. Контент низкого качества
Приоритет: средний
Иногда мы видим в отчете URL-адреса с контентом очень низкого качества. На таких страницах могут быть правильно настроены все технические элементы и внутренние ссылки, однако им недостает фактического контента, что также замечает Google. Ниже приведен пример страницы с информацией о продукте, на которой очень мало уникального текста:

Этой странице был присвоен статус «Crawled — Currently Not Indexed». Наиболее вероятная причина — низкое качество контента.
Google посчитал ее либо недостаточно полезной, либо дубликатом другой страницы. В результате страница была удалена из индекса.

Вот еще один пример: Google просканировал страницу с отзывом на сайте Go Fish Digital (рисунок выше). Хотя этот контент является уникальным для нашего сайта, но Google, вероятно, не считает, что страница из одного предложения с рекомендацией заслуживает индексации.
Поэтому Google принял решение исключить страницу из индекса по причине низкого качества контента.
Решение: добавьте больше контента или настройте сигналы индексации.
Следующие шаги зависят от того, насколько важно для вас проиндексировать те или иные страницы.
Если вы считаете, что страница обязательно должна попасть в индекс, добавьте больше уникального контента. В этом случае Google посчитает страницу достаточно полезной и проиндексирует ее.
Если тот или иной контент, на ваш взгляд, не нуждается в индексации, встает совершенно другой вопрос: следует ли вам предпринять дополнительные меры и убедительно показать, что данный контент не следует индексировать. Ведь, как мы помним, статус «Crawled —currently not indexed» указывает на то, что контент был просканирован и мог быть включен в индекс, но Google решил этого не делать.
Однако Google применяет эту логику не ко всем страницам низкого качества. Вы можете выполнить общий поиск по сайту с помощью оператора site:, чтобы найти проиндексированный контент, который соответствует приведенным выше критериям низкого качества. Если обнаружится, что большое количество таких страниц появляется в индексе, вы можете предпринять ряд мер, таких как тег noindex, ошибка 404 или полное удаление внутренних ссылок.
7. Дублированный (неуникальный) контент
Приоритет: высокий
Среди наших клиентов данная проблема встречается наиболее часто. Если Google посчитает ваш контент дублированным, он может сканировать его, но не включать в индекс. Это один из способов, с помощью которых Google избегает дублирования поисковой выдачи. Удаляя подобный контент, Google обеспечивает пользователям широкий выбор уникальных страниц. Иногда в отчете URL-адреса получают статус «дубликатов» (Duplicate, Google chose different canonical than user). Тем не менее не каждая страница является дублирующей в строгом смысле этого слова.
Эта проблема особенно актуальна для интернет-магазинов. Ключевые страницы, например, с описанием продукта, часто содержат контент, аналогичный или похожий на многие другие страницы в интернете. Если Google обнаружит, что по содержанию или структуре ваши страницы слишком похожи на страницы других сайтов, он может исключить их из индекса.
Решение: добавьте в дублированный контент уникальные элементы.
Если вы считаете, что это относится к вашему сайту, проведите следующую проверку:
1. Скопируйте сниппет потенциального дублированного текста и вставьте его в Google.
2. Добавьте в конец URL-адреса (в браузере) следующую строку: &num=100. Отобразятся первые 100 результатов.
3. Используйте функцию «Поиск», чтобы увидеть, появляется ли ваш результат среди первой сотни. Если нет, вероятно, он был удален из индекса.
4. Вернитесь к URL-адресу (в браузере) и добавьте следующую строку: &filter=0. Это должно показать вам нефильтрованные результаты Google (спасибо Патрику Стоксу за совет).
5. Используйте функцию «Поиск», чтобы найти ваш URL. Если теперь ваша страница появляется в выдаче, это говорит о том, что ваш контент удаляется фильтром из индекса.
6. Повторите процесс для нескольких URL-адресов с потенциально дублированным или очень похожим контентом, которые получили статус «Crawled — currently not indexed».

Если вы продолжаете замечать, что URL-адреса удаляются фильтром из индекса, необходимо сделать контент более уникальным.
Универсального средства для таких случаев не существует, но мы можем предложить несколько вариантов:
1. Перепишите контент на самых важных страницах, чтобы сделать его более уникальным.
2. Используйте динамические свойства для автоматической вставки уникального контента на страницу.
3. Удалите большие куски шаблонного текста. Иногда страница признается дубликатом именно по этой причине.
4. Если ваш сайт зависит от пользовательского контента, повысьте требования к уникальности текстов. Это может помочь предотвратить случаи, когда пользователи размещают один и тот же контент на нескольких страницах или доменах.
8. Скрытый контент
Приоритет: высокий
В некоторых случаях Google может сканировать контент, к которому у него не должно быть доступа. Если Google находит URL-адреса, на которых ведется разработка, он может включить их в отчет. Однажды мы столкнулись с тем, что Google сканировал субдомен, предназначенный для задач JIRA. Это вызвало тотальный обход сайта, содержащего страницы, совершенно не предназначенные для индексации.
Таким образом, Google тратит время на сканирование (и, возможно, индексацию) URL-адресов, которые не предназначены для обычных пользователей. Это может иметь серьезные последствия для краулингового бюджета сайта.
Решение: примите меры для краулинга и индексации.
Это решение будет полностью зависеть от ситуации и того, к чему Google может получить доступ. Как правило, первым делом необходимо выяснить, как Google смог обнаружить скрытые URL-адреса, особенно если это произошло через структуру внутренних ссылок.
Начните сканирование с домашней страницы основного субдомена и проверьте, может ли Screaming Frog получить доступ к скрытым субдоменам стандартным способом. Если да, то можно с уверенностью сказать, что робот Google мог использовать аналогичную лазейку. Вы можете ограничить доступ Google, удалив все внутренние ссылки на этот контент.
Следующим шагом может стать проверка статусов URL-адресов, которые должны быть исключены из индекса. Справляется ли Google с этой задачей, или некоторые из адресов все же были проиндексированы? Если Google не индексирует большой объем данного контента, вы можете настроить файл robots.txt так, чтобы он сразу блокировал сканирование. В противном случае используйте теги noindex, атрибуты canonical и страницы, защищенные паролем.
Пример: дублированный пользовательский контент
В качестве живого примера можно привести случай, когда мы диагностировали проблему на сайте клиента. Этот сайт очень похож на интернет-магазин, поскольку большая часть его контента состоит из страниц с описанием продуктов. Тем не менее все такие описания являются пользовательским контентом.
Третьим лицам разрешено создавать листинги продуктов на этом сайте. Однако очень часто пользователи составляют слишком короткие описания, что расценивается как контент низкого качества. По этой причине страницы с описанием продуктов от пользователей стали попадать в отчет «Crawled — currently not indexed». Таким образом, страницы, способные генерировать органический трафик, были вовсе исключены из индекса, что имело ряд неприятных последствий.
После проведения диагностики мы обнаружили, что страницам с описанием продуктов существенно не хватало уникального контента. Все исключенные страницы содержали не более одного абзаца уникального текста. Кроме того, основное содержание всех страниц представляло собой один и тот же шаблон. Из-за недостатка уникальности шаблонного текста Google мог рассматривать страницы как дубликаты. В результате они были исключены из индекса с присвоением статуса «Crawled — currently not indexed».
Совместно с клиентом мы решили, какой неуникальный контент необходимо убрать со страниц описания продукта. Мы удалили одинаковое содержание с тысяч страниц. Это привело к значительному уменьшению URL-адресов со статусом «Crawled — currently not indexed», так как Google начал рассматривать каждую страницу как более уникальную.

Заключение
Надеюсь, наша статья поможет SEO-специалистам лучше понять загадочный статус «Crawled — currently not indexed», который появляется в Отчете об индексировании. Конечно, могут быть и другие причины, по которым Google классифицирует URL-адреса подобным образом, однако мы привели наиболее распространенные среди наших клиентов случаи.
Таким образом, Отчет об индексации является одним из самых мощных инструментов Search Console. Мы настоятельно рекомендуем с ним ознакомиться, поскольку во многом благодаря этому инструменту мы своевременно обнаруживаем все аномалии краулинга и индексирования, особенно на крупных сайтах. Если вы сталкивались с другими причинами попадания URL-адресов в отчет «Crawled — currently not indexed», сообщите об этом в комментариях!
Об авторе:
Крис Лонг -— старший SEO-менеджер в Go Fish Digital. Крис работает с уникальными проблемами и сложными ситуациями, чтобы через глубокое понимание алгоритмов Google и веб-технологий помочь своим клиентам улучшить органический трафик. Крис сотрудничает с Moz, Search Engine Land и The Next Web. Он также выступает на тематических конференциях, таких как SMX East и State Of Search. Вы можете связаться с Крисом в Twitter и LinkedIn.
Автор: Кристофер Лонг
Ссылка на оригинал: https://moz.com/blog/crawled-currently-not-indexed-coverage-status
P.s. Мы стараемся регулярно готовить для вас полезный контент. Для того чтобы не пропустить очередную статью в нашем блоге, подписывайтесь на наш telegram-канал: T.me/seoantteam
Автор: Томек Рудзки (Tomek Rudzki) – специалист по техническому SEO, R&D-менеджер Onely.
В справочной документации Google определяет этот статус так:
«Страница просканирована, но пока не проиндексирована. В дальнейшем она может быть проиндексирована, а может и остаться в текущем состоянии; вновь отправлять этот URL на сканирование не нужно».
Обычно это объяснение не сильно помогает, особенно если это касается важной для бизнеса страницы. Google не проясняет, что именно случилось, и что может сделать владелец сайта. Он лишь говорит, что Googlebot просканировал страницу, но по какой-то причине решил ее не индексировать.
Согласно нашим данным, статус «Страница просканирована, но пока не проиндексирована» – это самая частая ошибка в отчете об индексировании. Это значит, что вы или уже сталкивались с ней, или столкнетесь в будущем.
Очень важно решить эту проблему максимально быстро: если страница не проиндексирована, она не будет появляться в результатах поиска и не получит органического трафика из Google.
В этой статье мы рассмотрим возможные причины возникновения этой ошибки и разберемся, как их устранить.
Где найти этот статус
Этот статус можно увидеть в отчете об индексировании и в инструменте проверки URL в Search Console.
Отчет об индексировании
URL со статусом «Страница просканирована, но пока не проиндексирована» относится к категории исключенных, и Google не считает отсутствие этой страницы в индексе ошибкой.
В Справке этот статус определяется так:
«Исключено. Страница не проиндексирована, скорее всего потому, что таково было ваше решение. В частности, это может быть связано с тем, что страница исключена вами при помощи директивы noindex или является копией уже проиндексированной канонической страницы».
Прим. ред.: интересно, что в англоязычной версии Справки упор делается на решение Google, а не владельца сайта: «These pages are typically not indexed, and we think that is appropriate. These pages are either duplicate of indexed pages, or blocked from indexing by some mechanism on your site, or otherwise not indexed for a reason that we think is not an error». При переводе этот смысл потерялся, но именно на него ориентируется автор статьи.
После клика по статусу «Страница просканирована, но пока не проиндексирована» отображается список всех таких URL. В первую очередь нужно будет заняться теми страницами, которые являются наиболее ценными для сайта.
Отчет также можно выгрузить. Однако экспортировать можно лишь до 1000 URL. Если затронуто больше страниц, то можно увеличить количество экспортируемых URL, отфильтровав их по Sitemap. Например, если у сайта два файла Sitemap, в каждом из которых по 1000 URL, то их можно будет скачать по отдельности.
Инструмент проверки URL
Найти страницы со статусом «Страница просканирована, но пока не проиндексирована» также можно с помощью инструмента проверки URL в Search Console.
Верхний раздел отчета показывает, может ли страница быть найдена в Google. Если в отчете об индексировании проверяемый URL отнесен к категории «Исключено», то инструмент сообщит, что страница отсутствует в индексе, но это не связано с ошибкой.
Ошибка в отчетности: страница на самом деле может быть проиндексирована
Заметив статус «Страница просканирована, но пока не проиндексирована», первое, что нужно сделать – проверить, действительно ли страницы нет в индексе. Нередко можно увидеть, что страница помечена как просканированная, тогда как инструмент проверки URL показывает, что на самом деле она проиндексирована.
Инструмент проверки URL также позволяет получить более детальную информацию о конкретной странице, включая:
- Ошибки индексации;
- Ошибки структурированных данных;
- Оптимизация для мобильных и т.д.
Также можно просмотреть загруженные ресурсы (например, JavaScript), запросить индексацию и увидеть обработанную версию страницы.
Важно помнить, что данные о статусе индексации страницы в отчете об индексировании и инструменте проверки URL могут не совпадать. Согласно Google, это связано с тем, что в отчете об индексировании данные обновляются немного по-другому и медленнее, чем в инструменте проверки URL. Однако это не всегда задержка. Иногда это баг в работе отчетности.
В сентябре мы заметили, что некоторые из наших проиндексированных статей получили статус «Страница просканирована, но не проиндексирована» в Search Console. Это определенно не было задержкой, поскольку также были затронуты и более старые статьи.
Вскоре после этого на проблему обратили внимание и другие специалисты, в том числе Лили Рэй (Lily Ray):
Others have already tweeted about this, but I’m seeing many examples of URLs in GSC’s «Crawled, Not Indexed» report (with recent crawl dates) that are, in fact, indexed URLs.
Inspecting individual URLs often results in the below message.
Thoughts @danielwaisberg @googlesearchc? pic.twitter.com/i1XfcvldEq
— Lily Ray 😏 (@lilyraynyc) 28 сентября 2021 г.
Что делать в такой ситуации и какому отчету доверять
Как правило, инструмент проверки URL показывает более актуальные данные, чем отчет об индексировании. Поэтому, выбирая между этими двумя отчетами, ориентируйтесь на данные инструмента проверки URL.
Причины возникновения такой ошибки и как ее устранить
Теперь давайте перейдем к сути проблемы: почему появляется этот статус, и что можно сделать, чтобы страницы были проиндексированы.
Google не дает четкого ответа, почему страница получила такой статус, но есть несколько возможных причин, по которым он может появиться. В их числе:
- Задержка индексации
- Страница не соответствует стандартам качества
- Страница была деиндексирована
- Проблема с архитектурой сайта
- Проблемы с дублированным контентом
Задержка индексации
Для индексации нужно время. Интернет бесконечно велик, и Google должен определить, какие страницы будут проиндексированы в первую очередь.
В своей статье Ultimate Guide to Indexing SEO мы показали, сколько времени обычно требуется страницам на популярных сайтах для индексации. Вот некоторые результаты из нашего исследования:
- Google индексирует только 56% индексируемых URL через 1 день после публикации.
- Через 2 недели индексируется 87% URL-адресов.
Если вы только что опубликовали страницу, вполне нормально, если она пока не проиндексирована. Нужно немного подождать, и она появится в индексе.
Решение
Вы не можете повлиять на сканирование и индексирование страницы в краткосрочной перспективе, но есть несколько вещей, которые помогут сайту в более долгосрочном периоде:
- Создайте стратегию индексирования, чтобы помочь Google приоритизировать нужные страницы на сайте. Для этого следует решить, какие страницы должны индексироваться, и выбрать лучшие методы сообщить об этом Google.
- Убедитесь, что на те страницы, которые для вас важны, есть внутренние ссылки. Это поможет Google найти эти страницы и лучше понять их контекст.
- Создайте хорошо оптимизированную карту сайта. Перечислите в ней самые ценные URL. Google будет использовать этот файл в качестве дорожной карты и сможет быстрее находить страницы.
Страница не соответствует стандартам качества
Google не может индексировать все страницы в интернете. Хранилище ограничено и поэтому необходимо фильтровать низкокачественный контент.
Цель Google – предоставлять пользователям страницы высокого качества, которые лучше всего отвечают их намерению. Это значит, что если страница более низкого качества, то Google может ее проигнорировать, чтобы оставить место для более качественного контента. И мы ожидаем, что в будущем стандарты качества будут лишь ужесточаться.
Решение
Как владелец сайта, вы должны убедиться, что каждая страница содержит контент высокого качества. Проверьте, может ли страница удовлетворить намерение пользователя, и добавьте качественный контент при необходимости.
В справочном руководстве по ключевым обновлениям Google предлагает список вопросов, которые помогают определить ценность контента. Вот некоторые из них:
- Размещены ли на сайте оригинальные материалы (факты, репортажи, исследования, аналитика)?
- Содержит ли ваш сайт глубокую аналитику или интересные и неочевидные факты?
- Если взят контент из других источников, то переработан ли он в достаточной мере, чтобы представлять существенную ценность в таком виде?
- Готовы ли вы поделиться такой страницей с друзьями, добавить ее в закладки или порекомендовать другим пользователям?
Кроме того, вы можете воспользоваться советами по качественному контенту из Руководства для асессоров Google. Хотя этот документ ориентирован прежде всего на асессоров, чтобы они могли оценивать качество сайтов, вебмастера могут использовать его для улучшения собственных ресурсов.
UGC-контент
Генерируемый пользователями контент тоже может быть проблемой с точки зрения качества. Например, у вас есть форум, и кто-то задает вопрос. Если на момент сканирования ответов в теме не было, то Google может квалифицировать эту страницу как низкокачественный контент – несмотря на то, что такие ответы могут появиться в будущем.
Как защититься от такой ситуации?
Сервис вопросов и ответов Quora разработал отличную стратегию на этот случай: любой неотвеченный вопрос имеет префикс /unanswered/ в URL. Например:
Файл robots.txt блокирует все страницы с префиксом /unanswered/. В итоге Googlebot не может их сканировать. Как только в теме появляется ответ, URL меняется и становится доступным для сканирования.
Таким образом Quora блокирует доступ к потенциально низкокачественному контенту, генерируемому пользователями.
Google удалил страницу из индекса
URL может получить статус «Страница просканирована, но не проиндексирована», если страница была проиндексирована, но со временем Google решил удалить ее из индекса.
Почему страницы могут выпадать из индекса? Google может заменять их на более качественный контент.
Index selection, while it’s largely about (RAM/flash/disk) space, it’s tightly tied to quality of content. If we have tons of free space available, we’re more likely to index crappier content. If we don’t, we might deindex stuff to make space for higher quality docs. pic.twitter.com/jRMkEqdft0
— Gary 鯨理/경리 Illyes (@methode) 15 мая 2020 г.
Также важно следить за обновлениями поисковых алгоритмов. Деиндексация может стать результатом одного из таких апдейтов.
Выпадение страниц из индекса также может быть связано со сбоем на стороне Google. Такие ситуации тоже возможны. Например, Google как-то удалил из индекса сайт Search Engine Land потому что ошибочно решил, что он был взломан.
Решение
Решение для деиндексированных страниц тесно связано с их качеством. Следите за тем, чтобы страница предоставляла качественный и актуальный контент. Не думайте, что если страница проиндексирована, то больше ничего с ней делать не нужно. Продолжайте отслеживать и внедряйте изменения и улучшения при необходимости.
«Если после определенного ключевого обновления эффективность страниц снизилась, это не значит, что с ними что-то не так. Они не нарушают наши рекомендации для вебмастеров, и к ним не применялись никакие меры – ни вручную, ни автоматически. Ключевые обновления не нацелены на конкретные страницы и сайты. Они предназначены для того, чтобы наши системы могли в целом лучше оценивать контент», — объяснили в Google.
Прим. ред. В англоязычной версии документа, опять же, смысл немного другой: «Убедитесь, что предлагаете максимально качественный контент. Это то, что наши алгоритмы стремятся вознаграждать».
После устранения проблем отправьте запрос на повторную индексацию этих URL, чтобы Google быстрее увидел изменения.
Проблемы с архитектурой сайта
Когда сотрудника Google Джона Мюллера спросили о возможных причинах, по которым страница может иметь статус «просканирована, но пока не проиндексирована», он упомянул еще одну возможную причину – плохую структуру сайта.
You can’t force pages to be indexed — it’s normal that we don’t index all pages on all websites. It’s not an issue with «that page», it’s more site-wide. Creating a good site structure and making sure the site is of the highest quality possible is essentially the direction.
— 🐐 John 🐐 (@JohnMu) 28 июня 2021 г.
Например, на сайте есть страница хорошего качества, но Google может найти ее только через файл Sitemap. Googlebot может посетить эту страницу и просканировать ее, но поскольку внутренних ссылок нет, он может решить, что эта страница менее ценная, чем другие. На сайте нет никакой семантической или структурной информации, которая помогла бы ему должным образом оценить страницу. И это может быть одной из причин, по которой Google решил сосредоточиться на других страницах, а эту оставить без индексации после сканирования.
Решение
Хорошая архитектура сайта является ключом к тому, чтобы максимально увеличить шансы на индексацию. Продуманная структура позволяет роботам поисковых систем обнаруживать контент и лучше понимать взаимосвязь между страницами.
Вот почему так важно обеспечить хорошую архитектуру сайта и внутренние ссылки на ту страницу, которую нужно проиндексировать.
Дублированный контент
В октябре 2021 года SEO-консультант Адам Гент (Adam Gent) поделился интересным кейсом. Его страница получала статус «Просканирована, но пока не проиндексирована», поскольку Google посчитал ее дубликатом.
Google хочет предоставлять уникальный и ценный контент своим пользователям. Поэтому, когда при сканировании он видит, что некоторые страницы идентичны или практически идентичны, то может индексировать лишь одну из них.
Обычно страницы, не попавшие в индекс по этой причине, в отчете об индексировании получают статус «Страница является копией», однако не всегда. Иногда Google присваивает им статус «Страница просканирована, но пока не проиндексирована».
Почему Google может выбирать этот статус, до конца не понятно. Одно из возможных объяснений состоит в том, что этот статус может измениться в будущем, когда Google увидит, что есть более подходящий URL.
Также причина может быть в ошибке: Google может попросту ошибиться при назначении статуса. Такая ситуация более сложная, поскольку статус «Страница просканирована, но пока не проиндексирована» не дает столько информации, как специальный статус для дублированного контента.
Как проверить, показывается ли дубликат в результатах поиска:
- Перейдите на страницу, которая не проиндексирована, и скопируйте небольшой фрагмент текста.
- Возьмите его в кавычки и выполните поиск по этому запросу в Google.
- Проанализируйте результаты. Если в выдаче присутствует другой URL с этим текстом, значит ваша страница не индексируется, потому что Google выбрал другой URL.
Решение
Прежде всего, убедитесь, что создаете оригинальные страницы. Если необходимо, добавьте уникальный контент.
К сожалению, избежать появления дублированного контента не всегда возможно (например, если есть мобильная и десктопная версия сайта). У нас не так много контроля над тем, что появляется в результатах поиска, но мы можем дать Google некие подсказки о том, какая версия является оригиналом.
Если вы видите, что Google индексирует много дублированного контента, то проверьте следующие элементы:
- Канонические теги. Эти HTML-теги сообщают поисковым системам, какие версии страниц являются оригиналами.
- Внутренние ссылки. Убедитесь, что внутренние ссылки указывают на оригинальный контент. Google может использовать это как индикатор важности страницы.
- Файлы Sitemap. Убедитесь, что в них содержится только каноническая версия страницы.
Помните, что это только подсказки, и Google не обязан им следовать. В случае, описанном Адамом Гентом, Google выбрал для индексации RSS-фид, хотя многие сигналы указывали на другой URL. Адам решил проблему, настроив ошибку 404, чтобы оставалась только оригинальная версия. Он также настроил HTTP-заголовок X-Robots-Tag на всех URL фидов таким образом, чтобы запретить их индексацию.
«Страница просканирована, но пока не проиндексирована» vs «Обнаружена, не проиндексирована»
Статус «Страница просканирована, но пока не проиндексирована» часто путают с другой проблемой индексации в отчете об индексировании: «Обнаружена, не проиндексирована».
Оба статуса показывают, что страница не проиндексирована. Однако в первом случае Google уже посетил страницу, а во втором – поисковик знает об URL, но пока его не просканировал.
Если вы видите статус «Обнаружена, не проиндексирована», попробуйте выяснить, почему Google не смог или не захотел просканировать эту страницу. Например, этот статус может указывать на проблемы с качеством сайта в целом, бюджетом сканирования или перегрузкой сервера.
Подводим итоги
Статус «Страница просканирована, но пока не проиндексирована» часто связывают с качеством страницы, но в действительности он может указывать на множество других проблем, таких как плохая архитектура сайта или дублированный контент.
Что сделать, чтобы избавиться от этого статуса:
- Добавьте на страницы уникальный и ценный контент. После этого отправьте заявку на повторное сканирование. Так поисковик сможет быстрее заметить изменения.
- Проверьте архитектуру сайта и убедитесь, что на ценные страницы есть внутренние ссылки.
- Решите, какие страницы должны и не должны индексироваться Google. Помогите поисковой системе приоритизировать более ценные URL.
Не позволяйте своему контенту оставаться незамеченным. Узнайте о том, что попало в графу «Исключено» в Google Search Console в отчете «Покрытие» и исправьте.
Google Search Console позволяет пользователю посмотреть на свой сайт так, как его видит Google.
Вы получите информацию о производительности сайта, имеющихся брешах в безопасности; о краулинге, о том, как индексируется сайт и т.п.
Часть отчета, помеченная как «Исключено» в Google Search Console «Покрытие» предоставляет детальную информацию об индексации страниц сайта.
Узнайте, почему некоторые страницы вашего ресурса попадают в графу «Исключено» в Google Search Console и как это исправить.
Что показывает графа «Покрытие»
Отчет Google Search Console «Покрытие» показывает подробную информацию об индексации веб-страниц вашего сайта. Они могут попасть в одну из следующих четырех «корзин»:
- Ошибка: Страницы, которые Google не может проиндексировать. Вы должны просмотреть этот отчет, поскольку Google считает, что вы, возможно, хотите, чтобы эти страницы были проиндексированы.
- Без ошибок, есть предупреждения: Страницы, которые Google индексирует, но есть некоторые проблемы, которые вам следует устранить.
- Страница без ошибок: Страницы, которые Google индексирует.
- «Исключено»: Страницы, которые исключены из индекса.

Нас интересует графа «Исключено». Так что же она значит?
Дело в том, что Google не индексирует страницы, которые попали в категорию «Исключено» или «Ошибка». Но эти две категории, тем не менее, имеют существенное отличие друг от друга:
- Google считает, что страницы в графе «Ошибка» должны быть проиндексированы, но сделать это, впрочем, не представляет возможным – до тех пор, пока ошибки не будут изучены лично вами. Например, неиндексируемые страницы на базе языка разметки XML попадают в категорию Ошибка.
- Что касаемо «Исключено»: Google действительно убежден в том, что страницы в этой категории не должны индексироваться – вне зависимости от того, есть ли у них проблемы, которые можно решить. Они неликвидны.

Однако Google не всегда стратифицирует их правильно, и страницы, которые должны быть проиндексированы, попадают в «Исключено». Вместо «Ошибка».
К счастью, Google Search Console сообщает пользователю о причинах помещения страниц в ту или иную категорию.
Именно поэтому «благим делом» считается тщательный анализ страниц во всех четырех категориях. Но пока вернемся к страницам из категории «Исключено».
Почему страницы попадают в «Исключено»
Всего Google Search Console показывает 15 возможных причин, по которым веб-страницы попадают в группу «Исключено». Давайте рассмотрим каждую из них подробнее.
Исключено тегом noindex
Речь об URL-адресах, которые имеют тег noindex.
Google полагает, что вы на самом деле хотите исключить эти страницы из индексации в принципе, поскольку не указали их в XML sitemap. К ним, как правило, относятся: страницы для входа в личный кабинет, профиля пользователей, поисковые результаты.

Что можно сделать:
- Перепроверьте эти URL-адреса еще раз, чтобы убедиться, что вы точно хотите исключить их из индексации Google.
- Проверьте, присутствует ли тег noindex в этих ссылках.
Страница просканирована, но пока не проиндексирована
Google обратил внимание на страницы, но все еще не проиндексировал их.
Как говорится в пояснении от самого сервиса: «URL-адреса, находящиеся в этой категории, могут быть проиндексированы в будущем, а могут и не быть; нет необходимости повторно отправлять запрос на индексацию».
Многие SEO-специалисты неоднократно отмечали, что у сайта могут быть серьезные проблемы с качеством, если многие полезные и адекватные страницы попадают в раздел «Страница просканирована, но пока не проиндексирована».
Это может означать, что Google просмотрел эти страницы и считает, что они не представляют достаточной ценности для индексации.

Что можно сделать:
- Пересмотрите свой ресурс с точки зрения качества исполнения и обратите внимание на E-A-T.
Обнаружена, не проиндексирована
Как говорится в документации Google, страница под заголовком «Обнаружена, не проиндексирована» была найдена Google, но еще не проиндексирована.
Google не стал просматривать страницу, чтобы не перегружать сервер. Большое количество страниц в этом списке может свидетельствовать о том, что у вашего сайта проблемы с краулинговым бюджетом.

Что можно сделать:
- Проверьте состояние сервера.
Не найдено (404)
Это страницы, которые при запросе Google выдают ошибку 404.
Это не URL-адреса, «предоставленные лично» поисковой машине (например, файлом sitemap). Это Google самостоятельно обнаружил эти страницы (например, через другой сайт, который ссылается на уже несуществующую страницу).

Что можно сделать:
- Проанализируйте эти страницы и решите, следует ли прибегать к 301 редиректу на актуальный и рабочий сайт.
Ошибка 404
Ошибка 404 – код ответа сервера, который указывает, что он (сервер) не смог найти запрошенный URL-адрес.
Также под «Ошибка 404» часто подразумевается страница, практически не содержащая никакого контента, и на которой можно найти только ходовые фразы в духе «извините», «ошибка», «не найдено» и т.д.

Что можно сделать:
- Для страниц с откровенно плохим содержанием добавьте уникальный контент, чтобы Google начал распознавать этот URL обособленно.
- Не забудьте выгрузить все 404 из Google Search Console.
Страница с переадресацией
Все переадресованные страницы на вашем сайте попадают в раздел «Исключено», где вы можете внимательно их изучить.

Что можно сделать:
- Внимательно просмотрите все страницы, чтобы убедиться в правильности редиректа.
- Некоторые плагины WordPress могут автоматически производить редирект при изменении URL – следует периодически просматривать такие страницы.
Страница является копией. Канонический вариант не выбран пользователем
Google считает, что URL-адреса с этой меткой являются дубликатами и, следовательно, не должны индексироваться.
Такое случается, если вы забыли установить атрибут тега link rel=canonical тег для нужного адреса. Google сам выбрал каноническую страницу: основываясь на других моментах.

Что можно сделать:
- Проверьте эти URL-адреса, чтобы узнать, какую из страниц Google выбрал канонической.
Страница является копией. Канонические версии страницы, выбранные Google и пользователем, не совпадают
В этом случае вы указали канонический тег для страницы, но, несмотря на это, Google выбрал в качестве предпочитаемого ресурса другой сайт. Как итог: выбранный Google URL индексируется, а выбранный пользователем — нет.
Что можно сделать:
- Проверьте URL-адрес, чтобы узнать, какой сайт был выбран каноническим.
- Изучите все поводы, которые заставили Google выбрать неправильный канонический (например, могли повлиять внешние ссылки).
Страница является копией. Отправленный URL не выбран в качестве канонического
Разница между вышеописанным и этим статусом заключается в том, что в последнем случае URL-адрес был отправлен в Google для индексации, но при этом у него не был указан тег link rel=canonical. Это дает повод поисковой машине считать, что другой URL будет смотреться более уместно в качестве каноничного.
Как результат: индексируется адрес, выбранный Google, а не отправленный вами.
Что можно сделать:
- Проверьте URL, чтобы узнать, какой канон выбрал Google.
Вариант страницы с тегом canonical
Это дубликаты страниц, которые Google распознает как канонические URL.
Что можно сделать:
- В большинстве случаев вмешательство не требуется. Не переживайте.
Заблокировано в файле robots.txt
Страницы, закрытые мета-тегом robots.txt.
При анализе этого блока следует помнить, что Google все еще может индексировать такие страницы (и отображать их в урезанном, «неполноценном» виде). Но только в том случае, если поисковик Google найдет ссылку на них – например, на других сайтах.
Что можно сделать:
- Проверьте, закрыты ли страницы для индексации.
- Добавьте тег noindex и удалите страницы из robots.txt.
Заблокирован инструментом удаления страниц
В этом отчете перечислены страницы, удаление которых было запрошено инструментом Removal.
Следует помнить, что эта утилита удаляет страницы из результатов поиска только временно (на 90 дней) и не препятствует им индексироваться.
Что можно сделать:
- Проверьте, действительно ли должны эти страницы быть удалены. Или иметь тег noindex.
Страница не проиндексирована вследствие ошибки 401
В случае с этими URL Googlebot не смог получить доступ к страницам из-за запроса на авторизацию (ошибка 401).
Если эти страницы не должны быть доступны без авторизации, вам не нужно ничего делать. Google просто информирует вас о том, с чем он столкнулся.

Что можно сделать:
- Проверьте, действительно ли эти страницы должны (или не должны) требовать авторизации.
Страница заблокирована из-за ошибки 403
Эта ошибка обычно свидетельствует о том, что проблема на стороне сервера. Она появляется, когда предоставленные полученные данные не соответствуют действительности. Ее очень желательно исправить, либо и вовсе – заблокировать страницу с помощью robots.txt или noindex.
Внезапные и огромные всплески количества исключенных страниц могут указывать на серьезные проблемы сайта.
Что можно узнать о страницах из категории «Исключено»
Различные ошибки, которые выдает вам Google Search Console после проведенного аудита, могут свидетельствовать о разных вещах. Так, например:
- Большое количество страниц с ошибкой 404 может указывать на неудачную миграцию: когда URL-адреса были изменены, но перелинковка не реализована (или реализована крайне неудачно).
- Большое количество страниц с пометкой «Страница просканирована, но пока не проиндексирована» или «Обнаружена, не проиндексирована» может указывать на то, что ваш ресурс был взломан. Обязательно просмотрите все ваши страницы, чтобы проверить, действительно ли они принадлежат вам или появились в результате взлома (взломанные страницы часто сопровождаются визуальными, графическими багами. Например, обилием китайских иероглифов).
- Большой количество страниц с пометкой «Индексирование страницы запрещено тегом noindex» также может указывать на неудачную миграцию. Такое часто случается, когда у нового сайта остаются прежние теги noindex, что были у прошлого сайта.
Благодаря разделу «Исключено» в отчете GSC «Покрытие», вы можете узнать многое о вашем сайте и о том, как Googlebot взаимодействует с ним.
Независимо от того, являетесь ли вы начинающим SEO-специалистом или уже имеете несколько лет опыта за спиной, сделайте проверку Google Search Console своей привычкой.
Это поможет вам обнаружить различные технические SEO-проблемы до того, как они превратятся в настоящие катастрофы.
Источник: https://www.searchenginejournal.com/excluded-pages-google-search-console/453226/
Подробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Даже если Google нашёл и просканировал страницу, это не означает, что она обязательно будет проиндексирована.
Но главное, что вы должны понять и запомнить: нет необходимости в том, чтобы абсолютно все страницы вашего сайты были проиндексированы. Вместо этого убедитесь, что в индекс включены все важные и полезные для пользователей страницы с качественным контентом.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
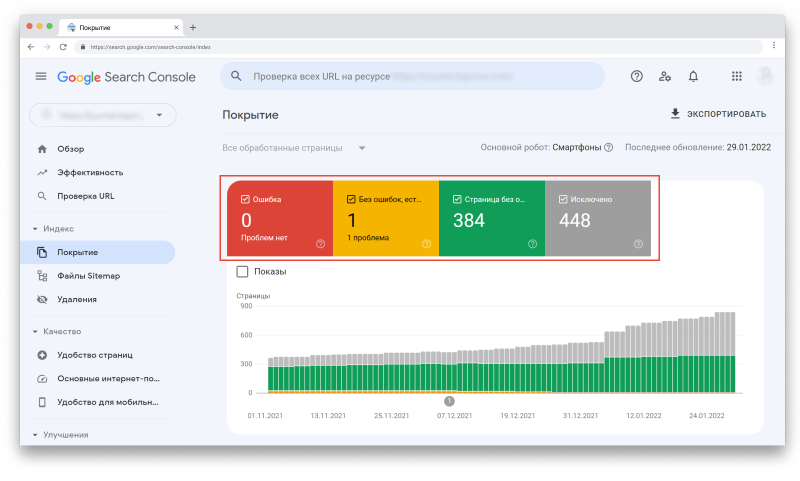
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).
Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
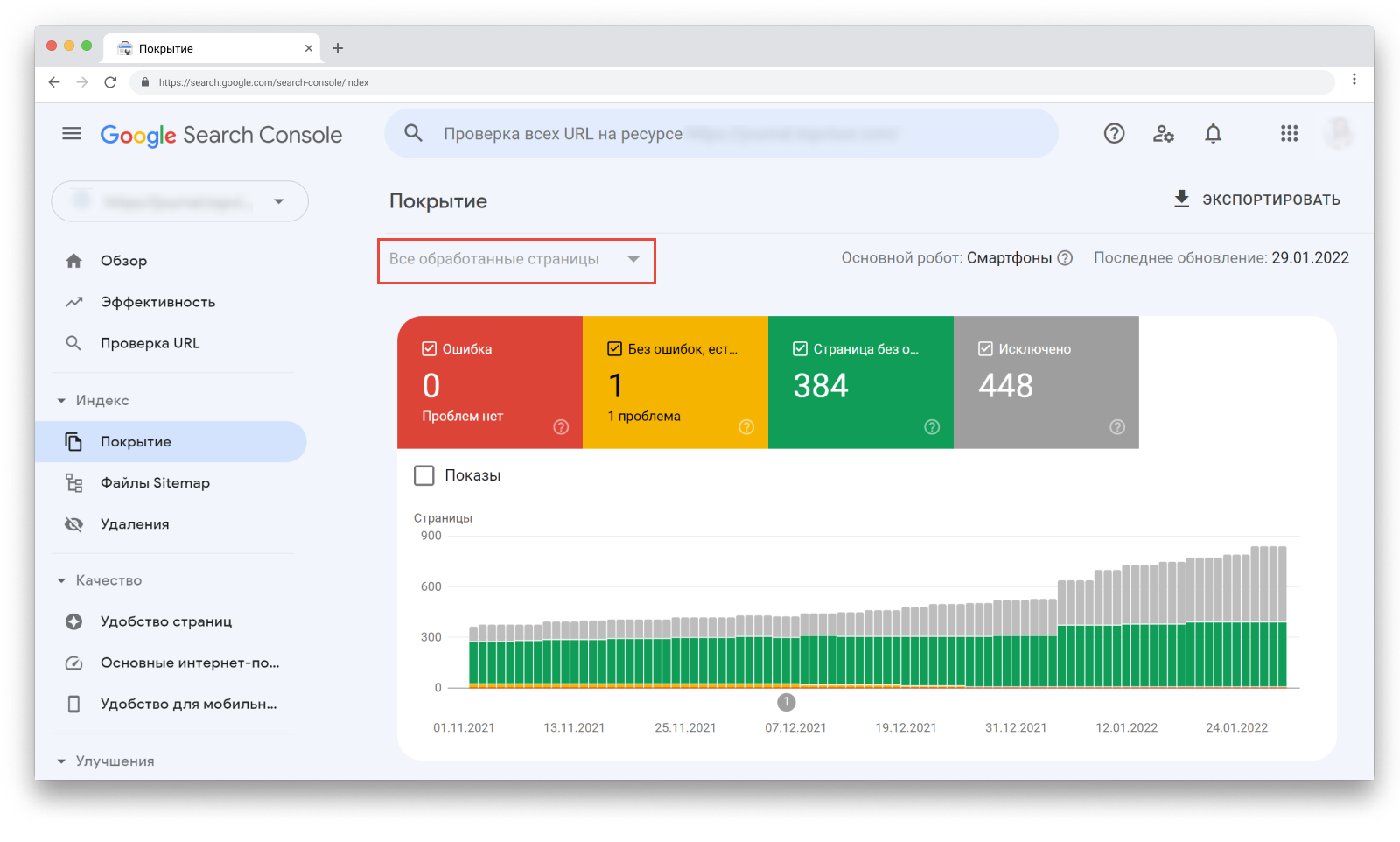
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
В чём разница?
Первый обычно включает в себя больше URL-адресов и многие из них попадают в секцию «Исключено». Это происходит потому, что карта сайта включает только индексируемые URL, в то время как сайты обычно содержат множество страниц, которые не должны быть проиндексированы.
Как пример — URL с параметрами на сайтах eCommerce. Googlebot может найти их разными способами, но не в карте сайта.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:

Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
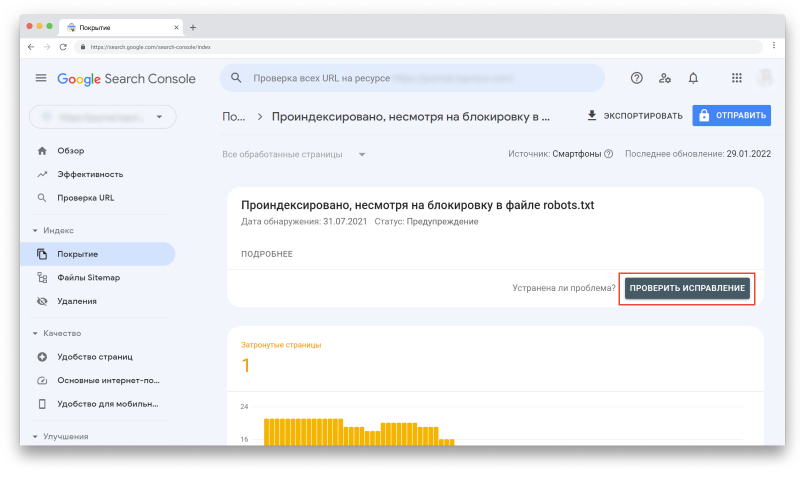
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
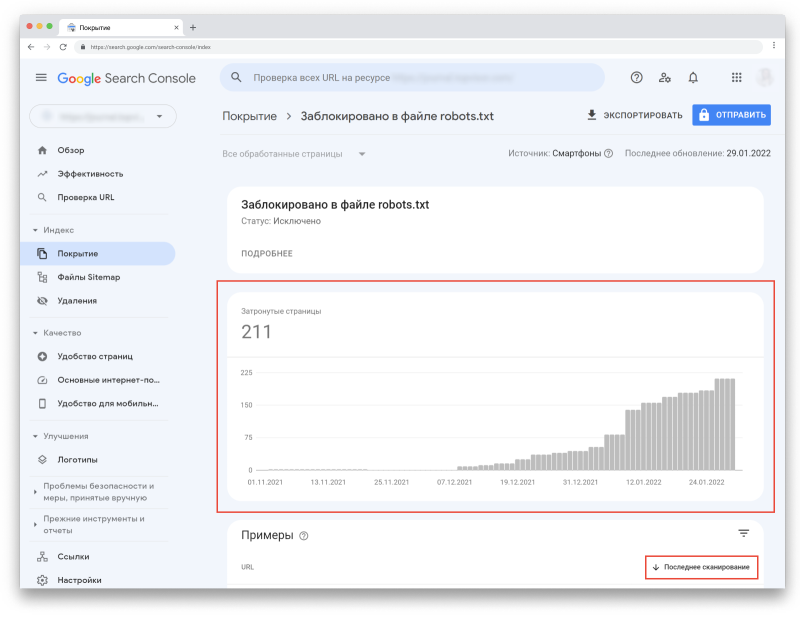
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:

Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.
Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Для постоянного редиректа убедитесь, что вы настроили перенаправление на ближайшую альтернативную страницу, а не на Главную. Редирект страницы с 404 ошибкой на Главную может определять её как soft 404.
@JohnMu what does Google do when a site redirects all its 404s to the homepage? Seeing more and more sites do this and it’s such an anti-pattern.
— Joost de Valk (@jdevalk) January 7, 2019
Yeah, it’s not a great practice (confuses users), and we mostly treat them as 404s anyway (they’re soft-404s), so there’s no upside. It’s not critically broken/bad, but additional complexity for no good reason — make a better 404 page instead.
— ? John ? (@JohnMu) January 8, 2019
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
«Страница просканирована, но пока не проиндексирована» — статус, который нередко присваивается в поисковой системе Google. При этом владельцу сайта не сообщается о причинах выставления такого статуса и каких-либо действиях для его изменения.
Google только оповещает, что индексация, возможно, будет позже или не будет вообще. Это не особо обнадёживает, особенно если страничка имеет большое значение для бизнеса и её нужно продвигать.
В этой статье разбираемся, что делать, если возникла такая ошибка.
Где посмотреть статус
Статус необходимо искать в отчёте об индексировании в Search Console. Поисковик не считает, что в этих страницах произошла ошибка, а потому относит их к категории исключённых.
Если кликнуть по статусу «Страница просканирована, но пока не проиндексирована», покажется список всех страничек, которые были просканированы ботом, но почему-то не прошли индексацию. Для поиска таких страничек также используют инструмент проверки URL в Search Console.
Ошибки в отчёте
Если вы заметили, что страничка получила такой статус, сначала необходимо убедиться, действительно ли это так. В отчётности бывают ошибки. Здесь и пригодится инструмент проверки URL. В нём представлено больше сведений о страничках сайта. Например, ошибки индексации, ошибки структурированных данных, наличие мобильной версии и т.д.
Различие информации в отчёте об индексации и инструменте проверки URL может быть вызвано как особенностями работы систем — в инструменте проверки сведения обновляются быстрее, чем в отчётности, так и багом.
Так кому доверять в таких случаях? Обычно в инструменте проверки URL представлены более «свежие» данные, поэтому ориентироваться следует именно на него.
Почему возникает ошибка и как её исправить
В Google конкретного ответа на этот вопрос не найти. Однако имеется ряд причин, которые потенциально могли привести к появлению такого статуса. Среди них:
- время на индексацию;
- низкое качество страничек;
- деиндексация;
- неправильная архитектура сайта;
- дублирование контента.
Время на индексацию
Индексация не проводится за одну секунду, этот процесс требует времени. Google сам определяет, какие страницы надо проиндексировать первым делом. Если страничка была опубликована только что, не стоит ждать, что её тут же проиндексируют.
Повлиять на скорость сканирования и индексации здесь и сейчас вы не можете. Но чтобы в будущем ваши страницы попадали в индекс быстрее, можно пользоваться следующими правилами:
- Разработать стратегию индексирования. Это даст краулерам поисковика понимание, какие странички надо обходить первым делом.
- Проверить наличие внутренних ссылок на особенно важные страницы. Благодаря этому поисковик быстрее найдёт эти странички и лучше поймёт их содержимое.
- Разработать карту сайта. В неё надо внести наиболее важные URL. Для Google это станет своеобразным навигатором, с помощью которого система будет искать странички быстрее.
Несоответствие стандартам качества
Поисковик не может индексировать все существующие страницы, так как его лимиты тоже ограничены. Соответственно, он сортирует их по соответствию стандартам качества. Тратить ресурсы на некачественные странички не имеет смысла, поэтому они отсеиваются и не индексируются.
Вероятно, причина ошибки кроется как раз в низком качестве контента. Соответственно, необходимо проверить, отвечает ли страница требованиям поисковика и способна ли в полной мере удовлетворить запрос пользователя.
Google даёт вопросы, которые помогут понять, насколько качественный контент вы предлагаете. Вопросы касаются следующих моментов:
- оригинальность размещённых материалов;
- наличие глубокой аналитики или полезных неочевидных фактов;
- степень проработанности контента, полученного из сторонних источников;
- готовность делиться представленной информацией, сохранять её и т.д.
UGC-контент
Это контент, который создают пользователи. И он тоже может влиять на качество страницы. Допустим, кто-то задаёт вопрос по материалу, а на момент обхода странички краулером ответов на него нет. Тогда Google может посчитать её низкокачественной, даже несмотря на то, что ответы могут появиться в дальнейшем.
Для борьбы с такими ситуациями можно воспользоваться идеей сервиса Quora. Там все неотвеченные вопросы маркируются префиксом /unanswered/. Файл robots.txt скрывает странички с таким префиксом от роботов. Когда на вопрос отвечают, префикс убирается, и страница оказывается доступной для индексации.
Деиндексация
Причиной появления статуса о сканировании, но отсутствии индексации может быть то, что Google почему-то убрал страничку из индекса. Часто такое происходит, когда поисковик решает заменить её на более полезную. Кроме того, к такому итогу может привести изменение алгоритмов поисковика. И, конечно, нельзя исключать вероятность сбоев на стороне поисковой системы.
Если поисковик удалил страницу из индекса, необходимо проанализировать её на предмет соответствия требованиям качества. Также учитывайте, что даже ранее проиндексированная страница может спустя какое-то время выпасть из индекса. То есть работать над контентом надо постоянно. Следите за актуальностью информации и своевременно обновляйте её.
Неправильная архитектура сайта
Непродуманная архитектура тоже может стать причиной непопадания страничек в индекс. Допустим, на сайте есть качественная страница, но обнаружить её можно только через Sitemap. Вероятно, краулер найдёт её и просканирует, но из-за отсутствия внутренних ссылок, он примет решение, что эта страничка представляет меньшую ценность, чем другие.
На сайте отсутствует какая-либо структурная информация, которая бы способствовала полноценной оценке странички. Соответственно, робот может оставить её без индексирования.
Проблема решается выстраиванием правильной, чёткой архитектуры.
Дубликаты
Дубли страниц не нравятся поисковикам, так как не считаются ценными и полезными. Для Google важно предоставлять пользователям уникальный контент, который будет полезен.
Соответственно, если краулер встречает две одинаковые или почти одинаковые страницы, он индексирует только какую-то одну. Чаще всего дубли получают статус «Страница является копией», но так происходит не всегда.
Работайте над устранением дублей или уникализацией контента на страничках с похожим содержимым.
Необходимо отличать статус «Страница просканирована, но пока не проиндексирована» и «Обнаружена, не проиндексирована». Первый значит, что робот выполнил сканирование, но индексация не состоялась. А второй — что страничка в принципе не была просканирована.
То есть система знает об этом URL, но сканирования не было. В этом случае следует узнать, почему Google не сканировал страничку. Возможно, причина в низком качестве контента, бюджете сканирования или перегруженности сервера.
Это перевод статьи с ресурса searchenginejournal.com.
Перевод сделан в режиме machine translation + постредактура.
Это мой небольшой проект, с помощью которого я обучаю движок машинного перевода и переводческую память. Постараюсь находить больше новых и интересных статей для перевода.
Статья ниже оказалась сложной для перевода, но так как я сам столкнулся с проблемой индексации, пришлось разобраться. Способ, упомянутый здесь помог.
Джон Мюллер из Google делится своими мыслями на тему «Обнаружена, не проиндексировано» в консоли поиска.
/ 9 ноября 2021 / На чтение 5 мин.
Джон Мюллер из Google предложил дополнительную информацию об этом надоедливом сообщении «Обнаружена, не проиндексировано» в Google Search Console. Мюллер ответил на серию твитов о том, что происходит в Google, когда они предпочитают не индексировать URL.
Баг в индексации Google?
В Twitter и Facebook ведутся многочисленные обсуждения уведомлений о том, что URL-адрес был обнаружен, но не проиндексирован, потому что это мешает работать с контентом и видеть, что он отклоняется Google.
Специалист по поисковому маркетингу Дэн Шур (@dan_shure) начал ветку в Твиттере на эту тему, рассказывая, как новая статья была обнаружена, но не проиндексирована.
Дэн привел пример сайта-клиента, который опубликовал две статьи, и через несколько дней он отображался как обнаруженный, но в настоящее время не проиндексирован.
Они отправили URL-адреса для повторного сканирования, но Google, по сути, отвернулся от этих страниц, отказываясь их индексировать.
Может ли URL-адрес быть заблокирован после обнаружения?
Поэтому Дэн высказывает идею о том, что, возможно, сам URL-адрес после того, как он был обнаружен и не проиндексирован, сжигается на этом этапе, и в данном случае он решил удалить старый URL-адрес и привязать содержимое к новому URL-адресу.
Это действительно хорошая идея — отказаться от старого URL-адреса и, по сути, повторить попытку с другим URL-адресом.
«Итак, к прошлой пятнице мы ждали более 10 дней (даже новые сообщения индексировались)
Я подумал, а не на самом ли деле * URL * «сломался»?
Поэтому мы удалили одно из сообщений, скопировали / вставили точно такой же контент и повторно опубликовали на новой странице с немного другим URL-адресом и новой датой публикации»
«Сообщение по-новому URL (но с таким же содержанием) индексируется немедленно (даже не отправляя его в GSC) всего за несколько часов.
другой пост, который мы оставили в покое, все же не был проиндексирован.
Сейчас мы собираемся переместить его на новый URL / дату и посмотреть, произойдет ли то же самое».
Дэн пришел к выводу, что в этом URL-адресе что-то было.
«Мы знаем, что Google индексирует контент, используя URL-адрес в качестве основного «идентификатора», с которым связаны все сигналы … так что это может иметь смысл, если URL-адрес получает «Обнаружена, не проиндексировано» на первом проходе, он получает своего рода «звоночек/метку» «- можете попробовать что-нибудь из того, что сделали мы, если столкнетесь с такой проблемой»
Ничего нового на тему «Обнаружена, не проиндексировано»
Джон Мюллер из Google задался вопросом, сбивает ли с толку людей этот инструмент и стоит ли Google просто удалить его.
We know Google indexes content using the URL as basically the main «id» by which all signals are associated.. so it could make sense if a URL gets «Discovered but not indexed» on the first pass it gets some sort of «ding» — maybe something to try if you run into this problem /5
Балансирование на грани индексирования
Мюллер признал, что иногда один и тот же контент индексируется по-новому URL-адресу в ситуациях, когда сайт «балансирует на грани индексации», что может намекать на множество причин, например на общее качество сайта.
«Да, такое может случиться. Но также может случиться так, что он снова выпадает через неделю или выпадает другой URL.
Если вы балансируете на грани индексации, всегда есть колебания.
По сути, это означает, что вам нужно убедить Google, что этот сайт стоит индексации».
«Поскольку у нас нет понимания URL-адреса (он не индексируется), мы должны изучить остальную часть сайта, чтобы лучше понять его потенциальный контекст внутри сайта и в остальной части сети. Это то, чего ждал интернет? Или это просто еще один красный виджет?»
Когда его попросили объяснить, как убедить Google проиндексировать что-то, Джон Мюллер ответил:
«Крутизна. Много крутизны. Все виды крутизны. И добавить еще крутизны».
Что такое крутизна?
Быть крутым имеет смысл и не требует объяснений. Но это как-то расплывчато.
Я предпочитаю что-то вроде: не делай того, что делают все остальные, просто делай так, как тебе кажется лучше.
Или что-то вроде: создайте что-нибудь, что вас взволновало бы, когда вы были новичком в этой теме.
Больше не значит лучше
Вся эта идея «в десять раз лучше» мотивирует, но наивна, потому что больше не значит лучше.
Другой распространенной ошибкой является копирование конкурентов, использование тех же ключевых слов и синонимов (как будто в их ключевых словах есть волшебство), потому что это порождает лишь существенно переписанный контент.
Принц прославился не тем, что копировал Майкла Джексона, верно?
Так почему же SEO специалисты так стремятся черпать вдохновение из того, что уже входит в первую десятку? Имеет смысл видеть, что ранжирует Google, но это теряет смысл, когда SEO специалист начинает переписывать то, что уже ранжируется.
Если вы знаете тему и хорошо разбираетесь в ней, то почему бы не попробовать не смотреть на то, что делают конкуренты, а просто сделать все, что в ваших силах? Возможно, Google сможет распознать одиночный голос на вашем сайте, кто-то назовет его классным и, вероятно, у него не будет проблем с индексированием.
Цитата
Прочтите обсуждение в Twitter:
Может ли «Обнаружена, не проиндексировано» поместить URL-адрес в своего рода «черный список»?
Could «Discovered — but currently not indexed» put a URL in some sort of ‘blacklist’?
Thought I’d share something strange and interesting that happened w/a few blog posts of a client..
(1/5) (I hate doing threads but this needs a little detail) 👇🏻
Спасибо, что прочитали до конца.
Если вы нашли какие-то неточности в переводе или ошибки, пишите в комментариях.