Эта глава посвящена обработке исключительных ситуаций. Исключительная ситуация (или исключение) — это ошибка, которая возникает во время выполнения программы. Используя С++-подсистему обработки исключительных ситуаций, с такими ошибками вполне можно справляться. При их возникновении во время работы программы автоматически вызывается так называемый обработчик исключений. Теперь программист не должен обеспечивать проверку результата выполнения каждой конкретной операции или функции вручную. В этом-то и состоит принципиальное преимущество системы обработки исключений, поскольку именно она «отвечает» за код обработки ошибок, который прежде приходилось «вручную» вводить в и без того объемные программы.
В этой главе мы также возвращаемся к С++-операторам динамического распределения памяти: new и delete. Как разъяснялось выше в этой книге, если оператор new не может выделить требуемую память, он генерирует исключение. И здесь мы узнаем, как именно обрабатывается такое исключение. Кроме того, вы научитесь перегружать операторы new и delete, что позволит вам определять собственные схемы выделения памяти.
Основы обработки исключительных ситуаций
Обработка исключений — это системные средства, с помощью которых программа может справиться с ошибками времени выполнения.
Управление С++-механизмом обработки исключений зиждется на трех ключевых словах: try, catch и throw. Они образуют взаимосвязанную подсистему, в которой использование одного из них предполагает применение другого. Для начала будет полезно получить общее представление о роли, которую они играют в обработке исключительных ситуаций. Если кратко, то их работа состоит в следующем. Программные инструкции, которые вы считаете нужным проконтролировать на предмет исключений, помещаются в try-блок. Если исключение (т.е. ошибка) таки возникает в этом блоке, оно дает знать о себе выбросом определенного рода информации (с помощью ключевого слова throw). Это выброшенное исключение может быть перехвачено программным путем с помощью catch-блока и обработано соответствующим образом. А теперь подробнее.
Инструкция throw генерирует исключение, которое перехватывается catchинструкцией.
Итак, код, в котором возможно возникновение исключительных ситуаций, должен выполняться в рамках try-блока. (Любая функция, вызываемая из этого try-блока, также подвергается контролю.) Исключения, которые могут быть выброшены контролируемым кодом, перехватываются catch-инструкцией, непосредственно следующей за try-блоком, в котором фиксируются эти «выбросы» исключений. Общий формат try— и catch-блоков выглядит так.
try {
// try-блок (блок кода, подлежащий проверке на наличие ошибок)
}
catch (type1 arg) {
// catch-блок (обработчик исключения типа type1)
}
catch {type2 arg) {
// catch-блок (обработчик исключения типа type2)
}
catch {type3 arg) {
// catch-блок (обработчик исключения типа type3)
}
// …
catch (typeN arg) {
// catch-блок (обработчик исключения типа typeN)
}
Блок try должен содержать код, который, по вашему мнению, должен проверяться на предмет возникновения ошибок. Этот блок может включать лишь несколько инструкций некоторой функции либо охватывать весь код функции main() (в этом случае, по сути, «под колпаком» системы обработки исключений будет находиться вся программа).
После «выброса» исключение перехватывается соответствующей инструкцией catch, которая выполняет его обработку. С одним try-блоком может быть связана не одна, а несколько catch-инструкций. Какая именно из них будет выполнена, определяется типом исключения. Другими словами, будет выполнена та catch-инструкция, тип исключения которой (т.е. тип данных, заданный в catch-инструкции) совпадает с типом сгенерированного исключения (а все остальные будут проигнорированы). После перехвата исключения параметр arg примет его значение. Таким путем могут перехватываться данные любого типа, включая объекты классов, созданных программистом.
Чтобы исключение было перехвачено, необходимо обеспечить его «выброс» в try-блоке.
Общий формат инструкции throw выглядит так:
throw exception;
Здесь с помощью элемента exception задается исключение, сгенерированное инструкцией throw. Если это исключение подлежит перехвату, то инструкция throw должна быть выполнена либо в самом блоке try, либо в любой вызываемой из него функции (т.е. прямо или косвенно).
На заметку. Если в программе обеспечивается «выброс» исключения, для которого не предусмотрена соответствующая catch-инструкция, произойдет аварийное завершение программы, вызываемое стандартной библиотечной функцией terminate(). По умолчанию функция terminate() вызывает функцию abort() для остановки программы, но при желании можно определить собственный обработчик ее завершения. За подробностями относительно обработки этой ситуации следует обратиться к документации, прилагаемой к вашему компилятору.
Рассмотрим простой пример обработки исключений средствами языка C++.
// Простой пример обработки исключений.
#include <iostream>
using namespace std;
int main()
{
cout << «HAЧAЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
throw 99; // генерирование ошибки
cout << «Эта инструкция не будет выполнена.»;
}
catch (int i) {
// перехват ошибки
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
При выполнении эта программа отображает следующие результаты.
НАЧАЛО В try-блоке
Перехват исключения. Его значение равно: 99
КОНЕЦ
Рассмотрим внимательно код этой программы. Как видите, здесь try-блок содержит три инструкции, а инструкция catch(int i) предназначена для обработки исключения целочисленного типа. В этом try-блоке выполняются только две из трех инструкций: cout и throw. После генерирования исключения управление передается catch-выражению, при этом выполнение try-блока прекращается. Необходимо понимать, что catch-инструкция не вызывается, а просто с нее продолжается выполнение программы после «выброса» исключения. (Стек программы автоматически настраивается в соответствии с создавшейся ситуацией.) Поэтому cout-инструкция, следующая после throw-инструкции, никогда не выполнится.
После выполнения catch-блока управление программой передается инструкции, следующей за этим блоком. Поэтому ваш обработчик исключения должен исправить ошибку, вызвавшую его возникновение, чтобы программа могла нормально продолжить выполнение. В случаях, когда ошибку исправить нельзя, catch-блок обычно завершается обращением к функциям exit() или abort(). (Функции exit() и abort() описаны в разделе «Копнем глубже» ниже в этой главе.)
Как упоминалось выше, тип исключения должен совпадать с типом, заданным в catch— инструкции. Например, если в предыдущей программе тип int, указанный в catch— выражении, заменить типом double, то исключение перехвачено не будет, и произойдет аварийное завершение программы. Вот как выглядят последствия внесения такого изменения.
// Этот пример работать не будет.
#include <iostream>
using namespace std;
int main()
{
cout << «НАЧАЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
throw 99; // генерирование ошибки
cout << «Эта инструкция не будет выполнена.»;
}
catch (double i) {
// Перехват исключения типа int не состоится.
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
Такие результаты выполнения этой программы объясняются тем, что исключение целочисленного типа не перехватывается инструкцией catch (double i).
НАЧАЛО
В try-блоке
Abnormal program termination
Функции exit() и abort()
Функции exit() и abort() входят в состав стандартной библиотеки C++ и часто используются в программировании на C++. Обе они обеспечивают завершение программы, но по-разному.
Вызов функции exit() немедленно приводит к «правильному» прекращению программы. («Правильное» окончание означает выполнение стандартной последовательности действий по завершению работы.) Обычно этот способ завершения работы используется для остановки программы при возникновении неисправимой ошибки, которая делает дальнейшее ее выполнение бессмысленным или опасным. Для использования функции exit() требуется включить в программу заголовок <cstdlib>. Ее прототип выглядит так.
void exit(int status);
Поскольку функция exit() вызывает немедленное завершение программы, она не передает управление вызывающему процессу и не возвращает никакого значения. Тем не менее вызывающему процессу в качестве кода завершения передается значение параметра status. По соглашению нулевое значение параметра status говорит об успешном окончании работы программы. Любое другое его значение свидетельствует о завершении программы по ошибке. Для индикации успешного окончания можно также использовать константу EXIT_SUCCESS, а для индикации ошибки— константу EXIT_FAILURE. Эти константы определены в заголовке <cstdlib>.
Прототип функции abort() выглядит так:
void abort();
Аналогично exit() функция abort() вызывает немедленное завершение программы. Но в отличие от функции exit() она не возвращает операционной системе никакой информации о статусе завершения и не выполняет стандартной («правильной») последовательности действий при остановке программы. Для использования функции abort() требуется включить в программу заголовок <cstdlib>. Функцию abort() можно назвать аварийным «стоп-краном» для С++-программы. Ее следует использовать только после возникновения неисправимой ошибки.
Последнее сообщение об аварийном завершении программы (Abnormal program termination) может отличаться от приведенного в результатах выполнения предыдущего примера. Это зависит от используемого вами компилятора.
Исключение, сгенерированное функцией, вызванной из try-блока, может быть перехвачено этим же try-блоком. Рассмотрим, например, следующую вполне корректную программу.
/* Генерирование исключения из функции, вызываемой из try-блока.
*/
#include <iostream>
using namespace std;
void Xtest(int test)
{
cout << «В функции Xtest(), значение test равно: «<< test << «n»;
if(test) throw test;
}
int main()
{
cout << «НАЧАЛОn»;
try {
// начало try-блока
cout << «В trу-блокеn»;
Xtest (0);
Xtest (1);
Xtest (2);
}
catch (int i) {
// перехват ошибки
cout << «Перехват исключения. Его значение равно: «;
cout << i << «n»;
}
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО В try-блоке
Вфункции Xtest(), значение test равно: 0
Вфункции Xtest(), значение test равно: 1
Перехват исключения. Его значение равно: 1
КОНЕЦ
Блок try может быть локализован в рамках функции. В этом случае при каждом ее выполнении запускается и обработка исключений, связанная с этой функцией. Рассмотрим следующую простую программу.
#include <iostream>
using namespace std;
/* Функционирование блоков try/catch возобновляется при каждом входе в функцию.
*/
void Xhandler(int test)
{
try {
if(test) throw test;
}
catch(int i) {
cout << «Перехват! Исключение №: » << i << ‘n’;
}
}
int main()
{
cout << «HAЧАЛОn «;
Xhandler (1);
Xhandler (2);
Xhandler (0);
Xhandler (3);
cout << «КОНЕЦ»;
return 0;
}
При выполнении этой программы отображаются такие результаты.
НАЧАЛО
Перехват! Исключение №:1
Перехват! Исключение №:2
Перехват! Исключение №:3
КОНЕЦ
Как видите, программа сгенерировала три исключения. После каждого исключения функция Xhandler() передавала управление в функцию main(). Когда она снова вызывалась, возобновлялась и обработка исключения.
В общем случае try-блок возобновляет свое функционирование при каждом входе в него. Поэтому try-блок, который является частью цикла, будет запускаться при каждом повторении этого цикла.
Перехват исключений классового типа
Исключение может иметь любой тип, в том числе и тип класса, созданного программистом. В реальных программах большинство исключений имеют именно тип класса, а не встроенный тип. Вероятно, тип класса больше всего подходит для описания ошибки, которая потенциально может возникнуть в программе. Как показано в следующем примере, информация, содержащаяся в объекте класса исключений, позволяет упростить обработку исключений.
// Использование класса исключений.
#include <iostream>
#include <cstring>
using namespace std;
class MyException {
public:
char str_what[80];
MyException() { *str_what =0; }
MyException(char *s) { strcpy(str_what, s);}
};
int main()
{
int a, b;
try {
cout << «Введите числитель и знаменатель: «;
cin >> а >> b;
if( !b) throw MyException(«Делить на нуль нельзя!»);
else
cout << «Частное равно » << a/b << «n»;
}
catch (MyException e) {
// перехват ошибки
cout << e.str_what << «n»;
}
return 0;
}
Вот один из возможных результатов выполнения этой программы.
Введите числитель и знаменатель: 10 0
Делить на нуль нельзя!
После запуска программы пользователю предлагается ввести числитель и знаменатель. Если знаменатель равен нулю, создается объект класса MyException, который содержит информацию о попытке деления на нуль. Таким образом, класс MyException инкапсулирует информацию об ошибке, которая затем используется обработчиком исключений для уведомления пользователя о случившемся.
Безусловно, реальные классы исключений гораздо сложнее класса MyException. Как правило, создание классов исключений имеет смысл в том случае, если они инкапсулируют информацию, которая бы позволила обработчику исключений эффективно справиться с ошибкой и по возможности восстановить работоспособность программы.
Использование нескольких catch-инструкций
Как упоминалось выше, с try-блоком можно связывать не одну, а несколько catch— инструкций. В действительности именно такая практика и является обычной. Но при этом все catch-инструкции должны перехватывать исключения различных типов. Например, в приведенной ниже программе обеспечивается перехват как целых чисел, так и указателей на символы.
#include <iostream>
using namespace std;
// Здесь возможен перехват исключений различных типов.
void Xhandler(int test)
{
try {
if(test) throw test;
else throw «Значение равно нулю.»;
}
catch (int i) {
cout << «Перехват! Исключение №: » << i << ‘n’;
}
catch(char *str) {
cout << «Перехват строки: «;
cout << str << ‘n’;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler(1);
Xhandler(2);
Xhandler(0);
Xhandler(3);
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО
Перехват! Исключение №: 1
Перехват! Исключение №: 2
Перехват строки: Значение равно нулю.
Перехват! Исключение №: 3
КОНЕЦ
Как видите, каждая catch-инструкция отвечает только за исключение «своего» типа. В общем случае catch-выражения проверяются в порядке следования, и выполняется только тот catch-блок, в котором тип заданного исключения совпадает с типом сгенерированного исключения. Все остальные catch-блоки игнорируются.
Перехват исключений базового класса
Важно понимать, как выполняются catch-инструкции, связанные с производными классами. Дело в том, что catch-выражение для базового класса «отреагирует совпадением» на исключение любого производного типа (т.е. типа, выведенного из этого базового класса). Следовательно, если нужно перехватывать исключения как базового, так и производного типов, в catch-последовательности catch-инструкцию для производного типа необходимо поместить перед catch-инструкцией для базового типа. В противном случае catch— выражение для базового класса будет перехватывать (помимо «своих») и исключения всех производных классов. Рассмотрим, например, следующую программу:
// Перехват исключений базовых и производных типов.
#include <iostream>
using namespace std;
class В {
};
class D: public В {
};
int main()
{
D derived;
try {
throw derived;
}
catch(B b) {
cout << «Перехват исключения базового класса.n»;
}
catch(D d) {
cout << «Этот перехват никогда не произойдет.n»;
}
return 0;
}
Поскольку здесь объект derived — это объект класса D, который выведен из базового класса В, то исключение типа derived будет всегда перехватываться первым catch— выражением; вторая же catch-инструкция при этом никогда не выполнится. Одни компиляторы отреагируют на такое положение вещей предупреждающим сообщением. Другие могут выдать сообщение об ошибке. В любом случае, чтобы исправить ситуацию, достаточно поменять порядок следования этих catch-инструкций на противоположный.
Варианты обработки исключений
Помимо рассмотренных, существуют и другие С++-средства обработки исключений, которые создают определенные удобства для программистов. О них и пойдет речь в этом разделе.
Перехват всех исключений
Иногда имеет смысл создать обработчик для перехвата всех исключений, а не исключений только определенного типа. Для этого достаточно использовать такой формат catch-блока.
catch (…) {
// Обработка всех исключений
}
Здесь заключенное в круглые скобки многоточие обеспечивает совпадение с любым типом данных.
Использование формата catch(…) иллюстрируется в следующей программе.
// В этой программе перехватываются исключения всех типов.
#include <iostream>
using namespace std;
void Xhandler(int test)
{
try {
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
catch (…) { // перехват всех исключений
cout << «Перехват!n»;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler (0);
Xhandler (1);
Xhandler (2);
cout << «КОНЕЦ»;
return 0;
}
Эта программа генерирует такие результаты.
НАЧАЛО
Перехват!
Перехват!
Перехват!
КОНЕЦ
Как видите, все три throw-исключения перехвачены с помощью одной-единственной
catch-инетрукции.
Зачастую имеет смысл использовать инструкцию catch(…) в качестве последнего «рубежа» catch-последовательности. В этом случае она обеспечивает перехват исключений «всех остальных» типов (т.е. не предусмотренных предыдущими catch-выражениями). Например, рассмотрим еще одну версию предыдущей программы, в которой явным образом обеспечивается перехват исключений целочисленного типа, а перехват всех остальных возможных исключений «взваливается на плечи» инструкции catch(…).
/* Использование формата catch (…) в качестве варианта «все остальное».
*/
#include <iostream>
using namespace std;
void Xhandler(int test)
{
try {
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
catch(int i) {
// перехватывает int-исключение
cout << «Перехват » << i << ‘n’;
}
catch(…) {
// перехватывает все остальные исключения
cout << «Перехват-перехват!n»;
}
}
int main()
{
cout << «НАЧАЛОn»;
Xhandler(0);
Xhandler(1);
Xhandler(2);
cout << «КОНЕЦ»;
return 0;
}
Результаты, сгенерированные при выполнении этой программы, таковы.
НАЧАЛО
Перехват 0
Перехват-перехват!
Перехват-перехват!
КОНЕЦ
Как подтверждает этот пример, использование формата catch(…) в качестве «последнего оплота» catch-последовательности— это удобный способ перехватить все исключения, которые вам не хочется обрабатывать в явном виде. Кроме того, перехватывая абсолютно все исключения, вы предотвращаете возможность аварийного завершения программы, которое может быть вызвано каким-то непредусмотренным (а значит, необработанным) исключением.
Ограничения, налагаемые на тип исключений, генерируемых функциями
Существуют средства, которые позволяют ограничить тип исключений, которые может генерировать функция за пределами своего тела. Можно также оградить функцию от генерирования каких бы то ни было исключений вообще. Для формирования этих ограничений необходимо внести в определение функции throw-выражение. Общий формат определения функции с использованием throw-выражения выглядит так.
тип имя_функции(список_аргументов) throw(список_имен_типов)
{
// . . .
}
Здесь элемент список_имен_типов должен включать только те имена типов данных, которые разрешается генерировать функции (элементы списка разделяются запятыми). Генерирование исключения любого другого типа приведет к аварийному окончанию программы. Если нужно, чтобы функция вообще не могла генерировать исключения, используйте в качестве этого элемента пустой список.
На заметку. При попытке сгенерировать исключение, которое не поддерживается функцией, вызывается стандартная библиотечная функция unexpected(). По умолчанию она вызывает функцию abort(), которая обеспечивает аварийное завершение программы. Но при желании можно задать собственный обработчик процесса завершения. За подробностями обращайтесь к документации, прилагаемой к вашему компилятору.
На примере следующей программы показано, как можно ограничить типы исключений, которые способна генерировать функция.
/* Ограничение типов исключений, генерируемых функцией.
*/
#include <iostream>
using namespace std;
/* Эта функция может генерировать исключения только типа int, char и double.
*/
void Xhandler(int test) throw(int, char, double)
{
if(test==0) throw test; // генерирует int-исключение
if(test==1) throw ‘a’; // генерирует char-исключение
if(test==2) throw 123.23; // генерирует double-исключение
}
int main()
{
cout << «НАЧАЛОn»;
try {
Xhandler(0); // Попробуйте также передать функции Xhandler() аргументы 1 и 2.
}
catch(int i) {
cout << «Перехват int-исключения.n»;
}
catch(char c) {
cout << «Перехват char-исключения.n»;
}
catch(double d) {
cout << «Перехват double-исключения.n»;
}
cout << «КОНЕЦ»;
return 0;
}
В этой программе функция Xhandler() может генерировать исключения только типа int, char и double. При попытке сгенерировать исключение любого другого типа произойдет аварийное завершение программы (благодаря вызову функции unexpected()). Чтобы убедиться в этом, удалите из throw-списка, например, тип int и перезапустите программу.
Важно понимать, что диапазон исключений, разрешенных для генерирования функции, можно ограничивать только типами, генерируемыми ею в try-блоке, из которого была вызвана. Другими словами, любой try-блок, расположенный в теле самой функции, может генерировать исключения любого типа, если они перехватываются в теле той же функции. Ограничение применяется только для ситуаций, когда «выброс» исключений происходит за пределы функции.
Следующее изменение помешает функции Xhandler() генерировать любые изменения.
// Эта функция вообще не может генерировать исключения!
void Xhandler(int test) throw()
{
/* Следующие инструкции больше не работают. Теперь они могут вызвать лишь аварийное завершение программы. */
if(test==0) throw test;
if(test==1) throw ‘a’;
if(test==2) throw 123.23;
}
На заметку. На момент написания этой книги среда Visual C++ не обеспечивала для функции запрет генерировать исключения, тип которых не задан в throw-выражении. Это говорит о нестандартном поведении данной среды. Тем не менее вы все равно можете задавать «ограничивающее» throw-выражение, но оно в этом случае будет играть лишь уведомительную роль.
Повторное генерирование исключения
Для того чтобы повторно сгенерировать исключение в его обработчике, воспользуйтесь throw-инструкцией без указания типа исключения. В этом случае текущее исключение будет передано во внешнюю try/catch-последовательность. Чаще всего причиной для такого выполнения инструкции throw служит стремление позволить доступ к одному исключению нескольким обработчикам. Например, первый обработчик исключений будет сообщать об
одном аспекте исключения, а второй — о другом. Исключение можно повторно сгенерировать только в catch-блоке (или в любой функции, вызываемой из этого блока). При повторном генерировании исключение не будет перехватываться той же catch-инструкцией. Оно распространится на ближайшую try/catch-последовательность.
Повторное генерирование исключения демонстрируется в следующей программе (в данном случае повторно генерируется тип char *).
// Пример повторного генерирования исключения.
#include <iostream>
using namespace std;
void Xhandler()
{
try {
throw «Привет»; // генерирует исключение типа char *
}
catch(char *) { // перехватывает исключение типа char *
cout << «Перехват исключения в функции Xhandler.n»;
throw; // Повторное генерирование исключения типа char *, которое будет перехвачено вне функции Xhandler.
}
}
int main()
{
cout << «НАЧАЛОn»;
try {
Xhandler();
}
catch(char *) {
cout << «Перехват исключения в функции main().n»;
}
cout << «КОНЕЦ»;
return 0;
}
При выполнении эта программа генерирует такие результаты.
НАЧАЛО
Перехват исключения в функции Xhandler.
Перехват исключения в функции main().
КОНЕЦ
Обработка исключений, сгенерированных оператором new
В главе 9 вы узнали, что оператор new генерирует исключение, если не удается удовлетворить запрос на выделение памяти. Поскольку тема исключений рассматривается только в этой главе, описание обработки исключений этого типа было отложено «на потом». Вот теперь настало время об этом поговорить.
Для начала необходимо отметить, что в этом разделе описывается поведение оператора new в соответствии со стандартом C++. Как было отмечено в главе 9, действия, выполняемые системой при неуспешном использовании оператора new, с момента изобретения языка C++ изменялись уже несколько раз. Сначала оператор new возвращал при неудаче значение null. Позже такое поведение было заменено генерированием исключения. Кроме того, несколько раз менялось имя этого исключения. Наконец, было решено, что оператор new будет генерировать исключения по умолчанию, но в качестве альтернативного варианта он может возвращать и нулевой указатель. Следовательно, оператор new в разное время был реализован различными способами. И хотя все современные компиляторы реализуют оператор new в соответствии со стандартом C++, компиляторы более «почтенного» возраста могут содержать отклонения от него. Если приведенные здесь примеры программ не работают с вашим компилятором, обратитесь к документации, прилагаемой к компилятору, и поинтересуйтесь, как именно он реализует
функционирование оператора new.
Согласно стандарту C++ при невозможности удовлетворить запрос на выделение памяти, требуемой оператором new, генерируется исключение типа bad_alloc. Если ваша программа не перехватит его, она будет досрочно завершена. Хотя такое поведение годится для коротких примеров программ, в реальных приложениях необходимо перехватывать это исключение и разумно обрабатывать его. Чтобы получить доступ к исключению типа bad_alloc, нужно включить в программу заголовок <new>.
Рассмотрим пример использования оператора new, заключенного в try/catch-блок для отслеживания неудачных результатов запроса на выделение памяти.
// Обработка исключений, генерируемых оператором new.
#include <iostream>
#include <new>
using namespace std;
int main()
{
int *p, i;
try {
p = new int[32]; // запрос на выделение памяти для 32элементного int-массива
}
catch (bad_alloc ха) {
cout << «Память не выделена.n»;
return 1;
}
for(i=0; i<32; i++) p[i] = i;
for(i=0; i<32; i++ ) cout << p[i] << » «;
delete [] p; // освобождение памяти
return 0;
}
При неудачном выполнении оператора new исключение в этой программе будет перехвачено catch-инструкцией. Этот же подход можно использовать для отслеживания любых ошибок, связанных с использованием оператора new: достаточно заключить каждую new-инструкцию в try-блок.
Альтернативная форма оператора new — nothrow
Стандарт C++ при неудачной попытке выделения памяти вместо генерирования исключения также позволяет оператору new возвращать значение null. Эта форма использования оператора new особенно полезна при компиляции старых программ с применением современного С++-компилятора. Это средство также очень полезно при замене вызовов функции malloc() оператором new. (Это обычная практика при переводе С- кода на язык C++.) Итак, этот формат оператора new выглядит следующим образом.
p_var = new(nothrow) тип;
Здесь элемент p_var— это указатель на переменную типа тип. Этот nothrow-формат оператора new работает подобно оригинальной версии оператора new, которая использовалась несколько лет назад. Поскольку оператор new (nothrow) возвращает при неудаче значение null, его можно «внедрить» в старый код программы, не прибегая к обработке исключений. Однако в новых программах на C++ все же лучше иметь дело с исключениями.
В следующем примере показано, как используется альтернативный вариант new (nothrow). Нетрудно догадаться, что перед вами вариация на тему предыдущей программы.
// Использование nothrow-версии оператора new.
#include <iostream>
#include <new>
using namespace std;
int main()
{
int *p, i;
p = new(nothrow) int[32]; // использование nothrow-версии
if(!p) {
cout << «Память не выделена.n»;
return 1;
}
for(i=0; i<32; i++) p[i] = i;
for(i=0; i<32; i++ ) cout << p[i] << » «;
delete [] p; // освобождение памяти
return 0;
}
Здесь при использовании nothrow-версии после каждого запроса на выделение памяти необходимо проверять значение указателя, возвращаемого оператором new.
Перегрузка операторов new и delete
Поскольку new и delete — операторы, их также можно перегружать. Несмотря на то что перегрузку операторов мы рассматривали в главе 13, тема перегрузки операторов new и delete была отложена до знакомства с темой исключений, поскольку правильно перегруженная версия оператора new (та, которая соответствует стандарту C++) должна в случае неудачи генерировать исключение типа bad_alloc. По ряду причин вам имеет смысл создать собственную версию оператора new. Например, создайте процедуры выделения памяти, которые, если область кучи окажется исчерпанной, автоматически начинают использовать дисковый файл в качестве виртуальной памяти. В любом случае реализация перегрузки этих операторов не сложнее перегрузки любых других.
Ниже приводится скелет функций, которые перегружают операторы new и delete.
// Выделение памяти для объекта.
void *operator new(size_t size)
{
/* В случае невозможности выделить память генерируется исключение типа bad_alloc. Конструктор вызывается автоматически. */
return pointer_to_memory;
}
// Удаление объекта.
void operator delete(void *p)
{
/* Освобождается память, адресуемая указателем р. Деструктор вызывается автоматически. */
}
Тип size_t специально определен, чтобы обеспечить хранение размера максимально возможной области памяти, которая может быть выделена для объекта. (Тип size_t, по сути,
—это целочисленный тип без знака.) Параметр size определяет количество байтов памяти, необходимых для хранения объекта, для которого выделяется память. Другими словами, это объем памяти, который должна выделить ваша версия оператора new. Перегруженная функция new должна возвращать указатель на выделяемую ею память или генерировать исключение типа bad_alloc в случае возникновении ошибки. Помимо этих ограничений, перегруженная функция new может выполнять любые нужные действия. При выделении памяти для объекта с помощью оператора new (его исходной версии или вашей собственной) автоматически вызывается конструктор объекта.
Функция delete получает указатель на область памяти, которую необходимо освободить. Затем она должна вернуть эту область памяти системе. При удалении объекта автоматически вызывается его деструктор.
Чтобы выделить память для массива объектов, а затем освободить ее, необходимо использовать следующие форматы операторов new и delete.
// Выделение памяти для массива объектов.
void *operator new[](size_t size)
{
/* В случае невозможности выделить память генерируется исключение типа bad_alloc. Каждый конструктор вызывается автоматически. */
return pointer_to_memory;
}
// Удаление массива объектов.
void operator delete[](void *p)
{
/* Освобождается память, адресуемая указателем р. При этом автоматически вызывается деструктор для каждого элемента массива. */
}
При выделении памяти для массива автоматически вызывается конструктор каждого объекта, а при освобождении массива автоматически вызывается деструктор каждого объекта. Это значит, что для выполнения этих действий не нужно явным образом программировать их.
Операторы new и delete, как правило, перегружаются относительно класса. Ради простоты в следующем примере используется не новая схема распределения памяти, а перегруженные функции new и delete, которые просто вызывают С-ориентированные функции выделения памяти malloc() и free(). (В своем собственном приложении вы вольны реализовать любой метод выделения памяти.)
Чтобы перегрузить операторы new и delete для конкретного класса, достаточно сделать эти перегруженные операторные функции членами этого класса. В следующем примере программы операторы new и delete перегружаются для класса three_d. Эта перегрузка позволяет выделить память для объектов и массивов объектов, а затем освободить ее.
// Демонстрация перегруженных операторов new и delete.
#include <iostream>
#include <new>
#include <cstdlib>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты
public:
three_d() {
x = у = z = 0;
cout << «Создание объекта 0, 0, 0n»;
}
three_d(int i, int j, int k) {
x = i;
у = j;
z = k;
cout << «Создание объекта » << i << «, «;
cout << j << «, » << k;
cout << ‘n’;
}
~three_d() { cout << «Разрушение объектаn»; }
void *operator new(size_t size);
void *operator new[](size_t size);
void operator delete(void *p);
void operator delete[](void *p);
void show();
};
// Перегрузка оператора new для класса three_d.
void *three_d::operator new(size_t size)
{
void *p;
cout <<«Выделение памяти для объекта класса three_d.n»;
р = malloc(size);
// Генерирование исключения в случае неудачного выделения памяти.
if(!р) {
bad_alloc ba;
throw ba;
}
return р;
}
// Перегрузка оператора new для массива объектов типа three_d.
void *three_d::operator new[](size_t size)
{
void *p;
cout <<«Выделение памяти для массива three_d-oбъeктoв.»;
cout << «n»;
// Генерирование исключения при неудаче.
р = malloc(size);
if(!р) {
bad_alloc ba;
throw ba;
}
return p;
}
// Перегрузка оператора delete для класса three_d.
void three_d::operator delete(void *p)
{
cout << «Удаление объекта класса three_d.n»;
free(p);
}
// Перегрузка оператора delete для массива объектов типа three_d.
void three_d::operator delete[](void *p)
{
cout << «Удаление массива объектов типа three_d.n»;
free(р);
}
// Отображение координат X, Y, Z.
void three_d::show()
{
cout << x << «, «;
cout << у << «, «;
cout << z << «n»;
}
int main()
{
three_d *p1, *p2;
try {
p1 = new three_d[3]; // выделение памяти для массива
р2 = new three_d(5, 6, 7); // выделение памяти для объекта
}
catch (bad_alloc ba) {
cout << «Ошибка при выделении памяти.n»;
return 1;
}
p1[1].show();
p2->show();
delete [] p1; // удаление массива
delete р2; // удаление объекта
return 0;
}
При выполнении эта программа генерирует такие результаты.
Выделение памяти для массива three_d-oбъeктoв.
Создание объекта 0, 0, 0
Создание объекта 0, 0, 0
Создание объекта 0, 0, 0
Выделение памяти для объекта класса three_d.
Создание объекта 5, 6, 7
0, 0, 0
5, б, 7
Разрушение объекта
Разрушение объекта
Разрушение объекта
Удаление массива объектов типа three_d.
Разрушение объекта
Удаление объекта класса three_d.
Первые три сообщения Создание объекта 0, 0, 0 выданы конструктором класса three_d (который не имеет параметров) при выделении памяти для трехэлементного массива. Как упоминалось выше, при выделении памяти для массива автоматически вызывается конструктор каждого элемента. Сообщение Создание объекта 5, б, 7 выдано конструктором класса three_d (который принимает три аргумента) при выделении памяти для одного объекта. Первые три сообщения Разрушение объекта выданы деструктором в результате удаления трехэлементного массива, поскольку при этом автоматически вызывался деструктор каждого элемента массива. Последнее сообщение Разрушение объекта выдано при удалении одного объекта класса three_d. Важно понимать, что, если операторы new и delete перегружены для конкретного класса, то в результате их использования для данных других типов будут задействованы оригинальные версии операторов new и delete. Это
означает, что при добавлении в функцию main() следующей строки будет выполнена стандартная версия оператора new.
int *f = new int; // Используется стандартная версия оператора new.
И еще. Операторы new и delete можно перегружать глобально. Для этого достаточно объявить их операторные функции вне классов. В этом случае стандартные версии С++- операторов new и delete игнорируются вообще, и во всех запросах на выделение памяти используются их перегруженные версии. Безусловно, если вы при этом определите версию операторов new и delete для конкретного класса, то эти «классовые» версии будут применяться при выделении памяти (и ее освобождении) для объектов этого класса. Во всех же остальных случаях будут использоваться глобальные операторные функции.
Перегрузка nothrow-версии оператора new
Можно также создать перегруженные nothrow-версии операторов new и delete. Для этого используйте такие схемы.
// Перегрузка nothrow-версии оператора new.
void *operator new(size_t size, const nothrow_t &n)
{
// Выделение памяти.
if(success) return pointer_to_memory;
else return 0;
}
// Перегрузка nothrow-версии оператора new для массива.
void *operator new[](size_t size, const nothrow_t &n)
{
// Выделение памяти.
if(success) return pointer_to_memory;
else return 0;
}
// Перегрузка nothrow-версии оператора delete.
void operator delete(void *p, const nothrow_t &n)
{
// Освобождение памяти.
}
// Перегрузка nothrow-версии оператора delete для массива.
void operator delete[](void *p, const nothrow_t &n)
{
// Освобождение памяти.
}
Тип nothrow_t определяется в заголовке <new>. Параметр типа nothrow_t не используется. В качестве упражнения поэкспериментируйте с nothrow-версиями операторов new и delete самостоятельно.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Обработка исключительных ситуаций. Методы и способы идентификации сбоев и ошибок.
Конструкция try..catch..finally
Иногда при выполнении программы возникают ошибки, которые трудно предусмотреть или предвидеть, а иногда и вовсе невозможно. Например, при передачи файла по сети может неожиданно оборваться сетевое подключение. такие ситуации называются исключениями. Язык C# предоставляет разработчикам возможности для обработки таких ситуаций. Для этого в C# предназначена конструкция try…catch…finally.
try { } catch { } finally { }
При использовании блока try…catch..finally вначале пытаются выполниться инструкции в блоке try. Если в этом блоке не возникло исключений, то после его выполнения начинает выполняться блок finally. И затем конструкция try..catch..finally завершает свою работу.
Если же в блоке try вдруг возникает исключение, то обычный порядок выполнения останавливается, и среда CLR (Common Language Runtime) начинает искать блок catch, который может обработать данное исключение. Если нужный блок catch найден, то он выполняется, и после его завершения выполняется блок finally.
Если нужный блок catch не найден, то при возникновении исключения программа аварийно завершает свое выполнение.
Рассмотрим следующий пример:
class Program { static void Main(string[] args) { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае происходит деление числа на 0, что приведет к генерации исключения. И при запуске приложения в режиме отладки мы увидим в Visual Studio окошко, которое информирует об исключении:

В этом окошке мы видим, что возникло исключение, которое представляет тип System.DivideByZeroException, то есть попытка деления на ноль. С помощью пункта View Details можно посмотреть более детальную информацию об исключении.
И в этом случае единственное, что нам остается, это завершить выполнение программы.
Чтобы избежать подобного аварийного завершения программы, следует использовать для обработки исключений конструкцию try…catch…finally. Так, перепишем пример следующим образом:
class Program { static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); } finally { Console.WriteLine("Блок finally"); } Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае у нас опять же возникнет исключение в блоке try, так как мы пытаемся разделить на ноль. И дойдя до строки
выполнение программы остановится. CLR найдет блок catch и передаст управление этому блоку.
После блока catch будет выполняться блок finally.
Возникло исключение!
Блок finally
Конец программы
Таким образом, программа по-прежнему не будет выполнять деление на ноль и соответственно не будет выводить результат этого деления, но теперь она не будет аварийно завершаться, а исключение будет обрабатываться в блоке catch.
Следует отметить, что в этой конструкции обязателен блок try. При наличии блока catch мы можем опустить блок finally:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); }
И, наоборот, при наличии блока finally мы можем опустить блок catch и не обрабатывать исключение:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } finally { Console.WriteLine("Блок finally"); }
Однако, хотя с точки зрения синтаксиса C# такая конструкция вполне корректна, тем не менее, поскольку CLR не сможет найти нужный блок catch, то исключение не будет обработано, и программа аварийно завершится.
Обработка исключений и условные конструкции
Ряд исключительных ситуаций может быть предвиден разработчиком. Например, пусть программа предусматривает ввод числа и вывод его квадрата:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x = Int32.Parse(Console.ReadLine()); x *= x; Console.WriteLine("Квадрат числа: " + x); Console.Read(); }
Если пользователь введет не число, а строку, какие-то другие символы, то программа выпадет в ошибку. С одной стороны, здесь как раз та ситуация, когда можно применить блок try..catch, чтобы обработать возможную ошибку. Однако гораздо оптимальнее было бы проверить допустимость преобразования:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x; string input = Console.ReadLine(); if (Int32.TryParse(input, out x)) { x *= x; Console.WriteLine("Квадрат числа: " + x); } else { Console.WriteLine("Некорректный ввод"); } Console.Read(); }
Метод Int32.TryParse() возвращает true, если преобразование можно осуществить, и false — если нельзя. При допустимости преобразования переменная x будет содержать введенное число. Так, не используя try…catch можно обработать возможную исключительную ситуацию.
С точки зрения производительности использование блоков try..catch более накладно, чем применение условных конструкций. Поэтому по возможности вместо try..catch лучше использовать условные конструкции на проверку исключительных ситуаций.
Блок catch и фильтры исключений
Определение блока catch
За обработку исключения отвечает блок catch, который может иметь следующие формы:
-
Обрабатывает любое исключение, которое возникло в блоке try. Выше уже был продемонстрирован пример подобного блока.
catch { // выполняемые инструкции }
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch.
catch (тип_исключения) { // выполняемые инструкции }
Например, обработаем только исключения типа DivideByZeroException:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); }
Однако если в блоке try возникнут исключения каких-то других типов, отличных от DivideByZeroException, то они не будут обработаны.
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch. А вся информация об исключении помещается в переменную данного типа.
catch (тип_исключения имя_переменной) { // выполняемые инструкции }
Например:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException ex) { Console.WriteLine($"Возникло исключение {ex.Message}"); }
Фактически этот случай аналогичен предыдущему за тем исключением, что здесь используется переменная. В данном случае в переменную ex, которая представляет тип DivideByZeroException, помещается информация о возникшем исключени. И с помощью свойства Message мы можем получить сообщение об ошибке.
Если нам не нужна информация об исключении, то переменную можно не использовать как в предыдущем случае.
Фильтры исключений
Фильтры исключений позволяют обрабатывать исключения в зависимости от определенных условий. Для их применения после выражения catch идет выражение when, после которого в скобках указывается условие:
В этом случае обработка исключения в блоке catch производится только в том случае, если условие в выражении when истинно. Например:
int x = 1; int y = 0; try { int result = x / y; } catch(DivideByZeroException) when (y==0 && x == 0) { Console.WriteLine("y не должен быть равен 0"); } catch(DivideByZeroException ex) { Console.WriteLine(ex.Message); }
В данном случае будет выброшено исключение, так как y=0. Здесь два блока catch, и оба они обрабатывают исключения типа DivideByZeroException, то есть по сути все исключения, генерируемые при делении на ноль. Но поскольку для первого блока указано условие y == 0 && x == 0, то оно не будет обрабатывать исключение — условие, указанное после оператора when возвращает false. Поэтому CLR будет дальше искать соответствующие блоки catch далее и для обработки исключения выберет второй блок catch. В итоге если мы уберем второй блок catch, то исключение вобще не будет обрабатываться.
Типы исключений. Класс Exception
Базовым для всех типов исключений является тип Exception. Этот тип определяет ряд свойств, с помощью которых можно получить информацию об исключении.
-
InnerException: хранит информацию об исключении, которое послужило причиной текущего исключения
-
Message: хранит сообщение об исключении, текст ошибки
-
Source: хранит имя объекта или сборки, которое вызвало исключение
-
StackTrace: возвращает строковое представление стека вызывов, которые привели к возникновению исключения
-
TargetSite: возвращает метод, в котором и было вызвано исключение
Например, обработаем исключения типа Exception:
static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); Console.WriteLine($"Метод: {ex.TargetSite}"); Console.WriteLine($"Трассировка стека: {ex.StackTrace}"); } Console.Read(); }

Однако так как тип Exception является базовым типом для всех исключений, то выражение catch (Exception ex) будет обрабатывать все исключения, которые могут возникнуть.
Но также есть более специализированные типы исключений, которые предназначены для обработки каких-то определенных видов исключений. Их довольно много, я приведу лишь некоторые:
-
DivideByZeroException: представляет исключение, которое генерируется при делении на ноль
-
ArgumentOutOfRangeException: генерируется, если значение аргумента находится вне диапазона допустимых значений
-
ArgumentException: генерируется, если в метод для параметра передается некорректное значение
-
IndexOutOfRangeException: генерируется, если индекс элемента массива или коллекции находится вне диапазона допустимых значений
-
InvalidCastException: генерируется при попытке произвести недопустимые преобразования типов
-
NullReferenceException: генерируется при попытке обращения к объекту, который равен null (то есть по сути неопределен)
И при необходимости мы можем разграничить обработку различных типов исключений, включив дополнительные блоки catch:
static void Main(string[] args) { try { int[] numbers = new int[4]; numbers[7] = 9; // IndexOutOfRangeException int x = 5; int y = x / 0; // DivideByZeroException Console.WriteLine($"Результат: {y}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException ex) { Console.WriteLine(ex.Message); } Console.Read(); }
В данном случае блоки catch обрабатывают исключения типов IndexOutOfRangeException, DivideByZeroException и Exception. Когда в блоке try возникнет исключение, то CLR будет искать нужный блок catch для обработки исключения. Так, в данном случае на строке
происходит обращение к 7-му элементу массива. Однако поскольку в массиве только 4 элемента, то мы получим исключение типа IndexOutOfRangeException. CLR найдет блок catch, который обрабатывает данное исключение, и передаст ему управление.
Следует отметить, что в данном случае в блоке try есть ситуация для генерации второго исключения — деление на ноль. Однако поскольку после генерации IndexOutOfRangeException управление переходит в соответствующий блок catch, то деление на ноль int y = x / 0 в принципе не будет выполняться, поэтому исключение типа DivideByZeroException никогда не будет сгенерировано.
Однако рассмотрим другую ситуацию:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } Console.Read(); }
В данном случае в блоке try генерируется исключение типа InvalidCastException, однако соответствующего блока catch для обработки данного исключения нет. Поэтому программа аварийно завершит свое выполнение.
Мы также можем определить для InvalidCastException свой блок catch, однако суть в том, что теоретически в коде могут быть сгенерированы сами различные типы исключений. А определять для всех типов исключений блоки catch, если обработка исключений однотипна, не имеет смысла. И в этом случае мы можем определить блок catch для базового типа Exception:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); } Console.Read(); }
И в данном случае блок catch (Exception ex){} будет обрабатывать все исключения кроме DivideByZeroException и IndexOutOfRangeException. При этом блоки catch для более общих, более базовых исключений следует помещать в конце — после блоков catch для более конкретный, специализированных типов. Так как CLR выбирает для обработки исключения первый блок catch, который соответствует типу сгенерированного исключения. Поэтому в данном случае сначала обрабатывается исключение DivideByZeroException и IndexOutOfRangeException, и только потом Exception (так как DivideByZeroException и IndexOutOfRangeException наследуется от класса Exception).
Создание классов исключений
Если нас не устраивают встроенные типы исключений, то мы можем создать свои типы. Базовым классом для всех исключений является класс Exception, соответственно для создания своих типов мы можем унаследовать данный класс.
Допустим, у нас в программе будет ограничение по возрасту:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (Exception ex) { Console.WriteLine($"Ошибка: {ex.Message}"); } Console.Read(); } } class Person { private int age; public string Name { get; set; } public int Age { get { return age; } set { if (value < 18) { throw new Exception("Лицам до 18 регистрация запрещена"); } else { age = value; } } } }
В классе Person при установке возраста происходит проверка, и если возраст меньше 18, то выбрасывается исключение. Класс Exception принимает в конструкторе в качестве параметра строку, которое затем передается в его свойство Message.
Но иногда удобнее использовать свои классы исключений. Например, в какой-то ситуации мы хотим обработать определенным образом только те исключения, которые относятся к классу Person. Для этих целей мы можем сделать специальный класс PersonException:
class PersonException : Exception { public PersonException(string message) : base(message) { } }
По сути класс кроме пустого конструктора ничего не имеет, и то в конструкторе мы просто обращаемся к конструктору базового класса Exception, передавая в него строку message. Но теперь мы можем изменить класс Person, чтобы он выбрасывал исключение именно этого типа и соответственно в основной программе обрабатывать это исключение:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (PersonException ex) { Console.WriteLine("Ошибка: " + ex.Message); } Console.Read(); } } class Person { private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена"); else age = value; } } }
Однако необязательно наследовать свой класс исключений именно от типа Exception, можно взять какой-нибудь другой производный тип. Например, в данном случае мы можем взять тип ArgumentException, который представляет исключение, генерируемое в результате передачи аргументу метода некорректного значения:
class PersonException : ArgumentException { public PersonException(string message) : base(message) { } }
Каждый тип исключений может определять какие-то свои свойства. Например, в данном случае мы можем определить в классе свойство для хранения устанавливаемого значения:
class PersonException : ArgumentException { public int Value { get;} public PersonException(string message, int val) : base(message) { Value = val; } }
В конструкторе класса мы устанавливаем это свойство и при обработке исключения мы его можем получить:
class Person { public string Name { get; set; } private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена", value); else age = value; } } } class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 13 }; } catch (PersonException ex) { Console.WriteLine($"Ошибка: {ex.Message}"); Console.WriteLine($"Некорректное значение: {ex.Value}"); } Console.Read(); } }
Поиск блока catch при обработке исключений
Если код, который вызывает исключение, не размещен в блоке try или помещен в конструкцию try..catch, которая не содержит соответствующего блока catch для обработки возникшего исключения, то система производит поиск соответствующего обработчика исключения в стеке вызовов.
Например, рассмотрим следующую программу:
using System; namespace HelloApp { class Program { static void Main(string[] args) { try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); } Console.WriteLine("Конец метода Main"); Console.Read(); } } class TestClass { public static void Method1() { try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); } Console.WriteLine("Конец метода Method1"); } static void Method2() { try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); } Console.WriteLine("Конец метода Method2"); } } }
В данном случае стек вызовов выглядит следующим образом: метод Main вызывает метод Method1, который, в свою очередь, вызывает метод Method2. И в методе Method2 генерируется исключение DivideByZeroException. Визуально стек вызовов можно представить следующим образом:

Внизу стека метод Main, с которого началось выполнение, и на самом верху метод Method2.
Что будет происходить в данном случае при генерации исключения?
-
Метод Main вызывает метод Method1, а тот вызывает метод Method2, в котором генерируется исключение DivideByZeroException.
-
Система видит, что код, который вызывал исключение, помещен в конструкцию try..catch
try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); }
Система ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако такого блока catch нет.
-
Система опускается в стеке вызовов в метод Method1, который вызывал Method2. Здесь вызов Method2 помещен в конструкцию try..catch
try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); }
Система также ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако здесь также подобный блок catch отсутствует.
-
Система далее опускается в стеке вызовов в метод Main, который вызывал Method1. Здесь вызов Method1 помещен в конструкцию try..catch
try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
Система снова ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. И в данном случае ткой блок найден.
-
Система наконец нашла нужный блок catch в методе Main, для обработки исключения, которое возникло в методе Method2 — то есть к начальному методу, где непосредственно возникло исключение. Но пока данный блок catch НЕ выполняется. Система поднимается обратно по стеку вызовов в самый верх в метод Method2 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method2"); }
-
Далее система возвращается по стеку вызовов вниз в метод Method1 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method1"); }
-
Затем система переходит по стеку вызовов вниз в метод Main и выполняет в нем найденный блок catch и последующий блок finally:
catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
-
Далее выполняется код, который идет в методе Main после конструкции try..catch:
Console.WriteLine("Конец метода Main");
Стоит отметить, что код, который идет после конструкции try…catch в методах Method1 и Method2, не выполняется, потому что обработчик исключения найден именно в методе Main.
Консольный вывод программы:
Блок finally в Method2
Блок finally в Method1
Catch в Main: Попытка деления на нуль.
Блок finally в Main
Конец метода Main
Генерация исключения и оператор throw
Обычно система сама генерирует исключения при определенных ситуациях, например, при делении числа на ноль. Но язык C# также позволяет генерировать исключения вручную с помощью оператора throw. То есть с помощью этого оператора мы сами можем создать исключение и вызвать его в процессе выполнения.
Например, в нашей программе происходит ввод строки, и мы хотим, чтобы, если длина строки будет больше 6 символов, возникало исключение:
static void Main(string[] args) { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch (Exception e) { Console.WriteLine($"Ошибка: {e.Message}"); } Console.Read(); }
После оператора throw указывается объект исключения, через конструктор которого мы можем передать сообщение об ошибке. Естественно вместо типа Exception мы можем использовать объект любого другого типа исключений.
Затем в блоке catch сгенерированное нами исключение будет обработано.
Подобным образом мы можем генерировать исключения в любом месте программы. Но существует также и другая форма использования оператора throw, когда после данного оператора не указывается объект исключения. В подобном виде оператор throw может использоваться только в блоке catch:
try { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch { Console.WriteLine("Возникло исключение"); throw; } } catch (Exception ex) { Console.WriteLine(ex.Message); }
В данном случае при вводе строки с длиной больше 6 символов возникнет исключение, которое будет обработано внутренним блоком catch. Однако поскольку в этом блоке используется оператор throw, то исключение будет передано дальше внешнему блоку catch.
Методы поиска ошибок в программах
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования [7.6, 7.11]. Отказ может быть результатом следующих причин:
- ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
- спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
- проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
- программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
- непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
- спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
- организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
- неадекватность спецификации требований конечным пользователям;
- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
- несоответствие требований заказчика к отдельным и общим свойствам ПО;
- некорректность описания функциональных характеристик;
- необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
- с определением интерфейса пользователя со средой;
- с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
- с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
- с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
- с некорректным описанием алгоритмов модулей;
- с определением условий возникновения возможных ошибок в программе;
- с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
- бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
- неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
- нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
- использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;
- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
- логические и функциональные ошибки;
- ошибки вычислений и времени выполнения;
- ошибки вводавывода и манипулирования данными;
- ошибки интерфейсов;
- ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с необеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибкаотказ» выполняются следующие действия:
- идентификация изъянов в технологиях проектирования и программирования;
- взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
- классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;
- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
- проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
- сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
- разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка-отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
- аппаратный, при котором общесистемное ПО не работоспособно;
- информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
- эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
- программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
Аннотация: Попытка классификации ошибок. Сообщение об ошибке с помощью возвращаемого значения. Исключительные ситуации. Обработка исключительных ситуаций, операторы try и catch.
Виды ошибок
Существенной частью любой программы является обработка ошибок.
Прежде чем перейти к описанию средств языка Си++, предназначенных
для обработки ошибок, остановимся немного на том,какие, собственно, ошибки
мы будем рассматривать.
Ошибки компиляции пропустим:пока все они не исправлены,
программа не готова, и запустить ее нельзя. Здесь мы будем рассматривать
только ошибки, происходящие во время выполнения программы.
Первый вид ошибок, который всегда приходит в голову – это ошибки
программирования. Сюда относятся ошибки в алгоритме, в логике
программы и чисто программистские ошибки. Ряд возможных ошибок
мы называли ранее (например, при работе с указателями), но гораздо
больше вы узнаете на собственном горьком опыте.
Теоретически возможно написать программу без таких ошибок. Во
многом язык Си++ помогает предотвратить ошибки во время выполнения
программы,осуществляя строгий контроль на стадии компиляции.
Вообще, чем строже контроль на стадии компиляции, тем меньше ошибок
остается при выполнении программы.
Перечислим некоторые средства языка, которые помогут избежать ошибок:
-
Контроль типов. Случаи использования недопустимых операций
и смешения несовместимых типов будут обнаружены компилятором. - Обязательное объявление имен до их использования. Невозможно
вызвать функцию с неверным числом аргументов. При изменении определения
переменной или функции легко обнаружить все места, где она
используется. - Ограничение видимости имен, контексты имен. Уменьшается возможность
конфликтов имен, неправильного переопределения имен.
Самым важным средством уменьшения вероятности ошибок является
объектно-ориентированный подход к программированию, который поддерживает
язык Си++. Наряду с преимуществами объектного программирования,
о которых мы говорили ранее, построение программы из классов позволяет
отлаживать классы по отдельности и строить программы из надежных
составных «кирпичиков», используя одни и те же классы многократно.
Несмотря на все эти положительные качества языка, остается «простор»
для написания ошибочных программ. По мере рассмотрения
свойств языка, мы стараемся давать рекомендации, какие возможности
использовать, чтобы уменьшить вероятность ошибки.
Лучше исходить из того, что идеальных программ не существует, это
помогает разрабатывать более надежные программы. Самое главное –
обеспечить контроль данных, а для этого необходимо проверять в программе
все, что может содержать ошибку. Если в программе предполагается
какое-то условие, желательно проверить его, хотя бы в начальной
версии программы, до того, как можно будет на опыте убедиться, что это
условие действительно выполняется. Важно также проверять указатели,
передаваемые в качестве аргументов, на равенство нулю; проверять, не
выходят ли индексы за границы массива и т.п.
Ну и решающими качествами, позволяющими уменьшить количество ошибок,
являются внимательность, аккуратность и опыт.
Второй вид ошибок – «предусмотренные», запланированные ошибки.
Если разрабатывается программа диалога с пользователем, такая
программа обязана адекватно реагировать и обрабатывать неправильные
нажатия клавиш. Программа чтения текста должна учитывать возможные
синтаксические ошибки. Программа передачи данных по телефонной линии
должна обрабатывать помехи и возможные сбои при передаче. Такие ошибки – это, вообще говоря, не ошибки с точки зрения программы, а
плановые ситуации, которые она обрабатывает.
Третий вид ошибок тоже в какой-то мере предусмотрен. Это исключительные
ситуации, которые могут иметь место, даже если в программе
нет ошибок . Например, нехватка памяти для создания нового объекта.
Или сбой диска при извлечении информации из базы данных.
Именно обработка двух последних видов ошибок и рассматривается в последующих
разделах. Граница между ними довольно условна. Например,
для большинства программ сбой диска – исключительная ситуация, но
для операционной системы сбой диска должен быть предусмотрен и должен
обрабатываться. Скорее два типа можно разграничить по тому, какая
реакция программы должна быть предусмотрена. Если после плановых ошибок программа должна продолжать работать, то после исключительных
ситуаций надо лишь сохранить уже вычисленные данные и завершить программу.
Возвращаемое значение как признак ошибки
Простейший способ сообщения об ошибках предполагает использование возвращаемого значения функции или метода. Функция сохранения
объекта в базе данных может возвращать логическое значение: true в
случае успешного сохранения, false – в случае ошибки.
class Database
{
public:
bool SaveObject(const Object& obj);
};
Соответственно, вызов метода должен выглядеть так:
if (database.SaveObject(my_obj) == false ){
//обработка ошибки
}
Обработка ошибки, разумеется, зависит от конкретной программы.
Типична ситуация, когда при многократно вложенных вызовах функций
обработка происходит на несколько уровней выше, чем уровень, где ошибка произошла. В таком случае результат, сигнализирующий об ошибке,
придется передавать во всех вложенных вызовах.
int main()
{
if (fun1()==false ) //обработка ошибки
return 1;
}
bool
fun1()
{
if (fun2()==false )
return false ;
return true ;
}
bool
fun2()
{
if (database.SaveObject(obj)==false )
return false ;
return true ;
}
Если функция или метод должны возвращать какую-то величину в качестве
результата, то особое, недопустимое, значение этой величины используется в
качестве признака ошибки. Если метод возвращает указатель,
выдача нулевого указателя применяется в качестве признака ошибки. Если
функция вычисляет положительное число, возврат — 1 можно использовать
в качестве признака ошибки.
Иногда невозможно вернуть признак ошибки в качестве возвращаемого значения.
Примером является конструктор объекта, который не может вернуть значение. Как же сообщить о том, что во время инициализации объекта что-то было не так?
Распространенным решением является дополнительный атрибут
объекта – флаг, отражающий состояние объекта. Предположим, конструктор
класса Database должен соединиться с сервером базы данных.
class Database
{
public :
Database(const char *serverName);
...
bool Ok(void) const {return okFlag;};
private :
bool okFlag;
};
Database::Database(const char*serverName)
{
if (connect(serverName)==true )
okFlag =true ;
else
okFlag =false ;
}
int main()
{
Database database("db-server");
if (!database.Ok()){
cerr <<"Ошибка соединения с базой данных"<<endl;
return 0;
}
return 1;
}
Лучше вместо метода Ok, возвращающего значение флага okFlag,
переопределить операцию ! (отрицание).
class Database
{
public :
bool operator !()const {return !okFlag;};
};
Тогда проверка успешности соединения с базой данных будет выглядеть так:
if (!database){
cerr <<"Ошибка соединения с базой
данных"<<endl;
}
Следует отметить, что лучше избегать такого построения классов,
при котором возможны ошибки в конструкторе. Из конструктора можно
выделить соединение с сервером базы данных в отдельный метод Open:
class Database
{
public :
Database();
bool Open(const char*serverName);
}
и тогда отпадает необходимость в операции ! или методе Ok().
Использование возвращаемого значения в качестве признака ошибки –
метод почти универсальный. Он применяется, прежде всего, для обработки
запланированных ошибочных ситуаций. Этот метод имеет ряд
недостатков. Во-первых, приходится передавать признак ошибки через
вложенные вызовы функций. Во-вторых, возникают неудобства, если
метод или функция уже возвращают значение, и приходится либо модифицировать
интерфейс, либо придумывать специальное » ошибочное »
значение. В-третьих, логика программы оказывается запутанной из-за
сплошных условных операторов if с проверкой на ошибочное значение.
Исключительные ситуации и надежное программирование
Любая программа при своей работе может вызвать исключительную ситуацию.
Это может быть, например, неверный ввод чисел, извлечение корня из отрицательного числа, деление на ноль, нехватка ресурсов (оперативной памяти, дисковой памяти, внешних устройств).
Программист может обрабатывать такие ситуации, используя структуры типа If <ошибка> Then <обработка>
Однако в этом случае алгоритм решения основной задачи обрастает многочисленными проверками и блоками обработки ошибок. Из этой ситуации в Delphi имеется простой и элегантный выход – механизм обработки исключительных ситуаций.
Исключительная ситуация (exception) – это любая ошибка или ошибочное условие, возникающее в процессе выполнения программы. Когда программа обнаруживает ошибку, она генерирует исключительную ситуацию. При этом нормальный ход выполнения программы прерывается, и управление передается специальной части кода, которая выполнят обработку этой исключительной ситуации. После обработки исключительной ситуации возврат в точку ее возникновения не происходит, а выполняются действия, следующие за телом обработчика.
Этот механизм успешно работает даже тогда, когда исключительную ситуацию генерирует вызываемая подпрограмма, а обрабатывает вызывающая. В итоге удается отделить смысловую часть алгоритмов от обработчиков ошибок; программа становится более простой, понятной и отказоустойчивой.
Для практической реализации механизма обработки исключительных ситуаций в Object Pascal введены специальные языковые конструкции try…except…end, try…finally…end и оператор raise.
Исключительные ситуации в Object Pascal описываются классами. Каждый класс соответствует определенному типу исключительных ситуаций. Когда возникает исключительная ситуация, создается объект соответствующего класс, который переносит информацию об этой ситуации из места возникновения в место обработки.
Классы исключительных ситуаций образуют иерархию, корнем которой является класс Exception. Класс Exception описывает самый общий тип исключительных ситуаций, а его наследники – конкретные виды таких ситуаций. Например, класс EOutOfMemory порожден от Exception и описывает ситуацию, когда исчерпана свободная оперативная память.
Примеры классов исключительных ситуаций:
|
EInOutError |
ошибка доступа к устройству ввода/вывода, код ошибки в поле ErrorCode |
|
EOutOfMemory |
нехватка оперативной памяти |
|
EIntError |
общий класс исключительных ситуаций целочисленной арифметики и включает в себя |
|
EDivByZero |
деление на ноль |
|
ERangeError |
выход за границы диапазона |
|
EIntOverFlow |
переполнение |
|
EMathError |
общий класс исключительных ситуаций вещественной математике включает в себя |
|
..EInvalidOp |
..неверный код операции вещественной математики |
|
..EZeroDivide |
..деление на ноль |
|
..EOverFlow |
..переполнение |
|
..EUnderFlow |
..исчезновение порядка |
|
EInvalidPointer |
попытка освободить недействительный указатель |
|
EConvertError |
ошибка преобразования данных с помощью функций IntToStr, StrToInt, StrToFloot, StrToDoleTime |
|
EStackOverFlow |
переполненного стека |
|
EExternalException |
исключительная ситуация ОС, не соответствующая ни одному из стандартных классов |
Наследование классов позволяет создавать семейства родственных исключительных ситуаций:
Type EMathError = Class(Exception);
EInvalidOp = Class(EMathError).
Имена классов исключительных ситуаций принято начинать с буквы Е.
Можно объявить собственный класс исключительной ситуации:
Type
EMyException = class(Exception)
MyErrorCode: Integer;
End.
Обработка исключительных ситуаций
Генерация исключительной ситуации
Когда подпрограмма сталкивается с неразрешимой для нее проблемой, она генерирует исключительную ситуацию соответствующего класса, чтобы ее могла обрабатывать подпрограмма.
Например: Raise EOutOfMemory.Create(‘нет памяти»);
Для того, чтобы отловить и обрабатывать эту ситуацию в вызывающей подпрограмме организуется так называемый защитный блок:
Try
..{защищаемые операторы}
except
..{операторы обработки исключительных ситуаций}
end;
Между символами Try и Except помещаются смысловые операторы, которые пишутся для «правильной» корректной работы.
Если при выполнении любого из них возникает исключительная ситуация, то управление передается оператору, следующуму за словом Except.
Операторы между словами Except и End образуют секцию обработки исключительной ситуации. Эта секция пропускается при нормальном выполнении программы.
|
|
|
|
Нормальная ситуация |
Исключительная ситуация |


Можно использовать вложенные защитные блоки.
Исключительная ситуация вложенного защитного блока обрабатываются вложенной копией Except…End. Если такая обработка не выполнена, то управление передается внешней секции Except…End.
Распознавание исключительной ситуации
Распознавание класса исключительной ситуации выполняется с помощью конструкции On<класс исключительной ситуации> Do<оператор>. Например:
try {вычисление}
except
..On EZeroDivide Do {обработка /0}
..On EMathError Do {обработка других ошибок веществ. математики}
…
Поиск обработчика исключительной ситуации выполняется последовательно до тех пор, пока класс исключительной ситуации не станет совместимым с классом, указанным в операторе On. После этого выполняется оператор за словом Do и управление передается за секцию Except…End.
Порядок операторов On существенен.
Для отлавливания всех исключительных ситуаций, не описанных в конструкциях On…Do… применяется обработчик по умолчанию (default exception handler). Он записывается в секции Except после всех операторов On и начинается со слова Else.
Пример:
Function StrProc (S: String): Integer;
Begin
..Result := StrToInt(s);
..If (Result<0) Or (Result>100) Then
..Raise EConvertError.Greate(S+» не %»);
End;
Function IncProcStr (S: String): String;
Begin
..Try
….Result :=IntToStr(StrToProc(S) + 1);
..Except
….On EConvertError Do Result :=»0″;
..End;
End;
Возобновление исключительной ситуации
Когда защищенный блок не может обрабатывать исключительную ситуацию полностью, он выполняет частичную обработку и возобновляет исключительную ситуацию, чтобы ее обработал внешний защитный блок
Try
…
Except
..On EZeroDivide Do
..Begin
….…
….Raise;
..End;
End;
Защита выделенных ресурсов от пропадания
Ресурсы, выделяемые по запросам приложения операционной системой Windows должны после их использования программой корректно освобождаться независимо ни от каких исключительных ситуаций. Для этого в Delphi предусмотрен еще один вариант защитного блока:
(выделение ресурса)
Try
..(использование ресурса)
Finally
..(освобождение ресурса)
End;
Секция Finally…End называется секцией очистки. Она выполняется во всех случаях. Если в секции Try…Finally генерируется исключительная ситуация, то сначала выполняется секция очистки, а затем управление передается внешнему защищенному блоку.
Этот защищенный блок работает аналогично и при других выходах из него (Break, Continue, Exit).
Аналогично вышесказанному возможны вложенные блоки Try. .. Finally. .. End.
|
|
к обработчику искл. ситуации |
|
Нормальный ход вычислений |
Возникновение исключительной ситуации |


Проект и его отладка в среде Delphi
Создаваемая программа в среде Windows называется приложением (Application). Обычно каждое работающее в данный момент приложение имеет окно на рабочем столе и значок на панели задач (в нижней части экрана).
Созданное приложение – это достаточно сложная задача, которая разбивается на несколько более простых частей (модулей, файлов, форм и т.д.) Совокупность этих частей разрабатываемого приложения составляет проект. Проект, как правило, создается и разрабатывается в отдельном подкаталоге, содержащим все его части. Компилятор обрабатывает все части проекта и строит из них выполняемый файл.
Минимальный проект содержит:
главный файл проекта – текстовый файл с расширением DPR;
файл описания формы – двоичный или текстовый файл с расширением DFM;
файл программного модуля – текстовый файл с расширением PAS.
Пример: Project1.DPR; Unit1.pas,Form1.DFM.
Project1.DPR содержит главный программный блок. Он подключает все другие модули и содержит операторы для запуска приложения.
Program Project1;
Uses Forms,
Unit1 in «Unit1.pas» {Form1};
{*.RES} – подключает значок приложения
Begin
Application.Initialize;
Application.CreateForm(TForm1, Form1);
Application.Run;
End.
Unit1.pas содержащий исходный код формы на языке Object Pascal, методы обработки событий, генерируемых формой и ее компонентами.
Unit1
Interface
Uses Windows, Forms;
Type TForm1 = class(TForm)
Button1: TButton;
…
Private
…
Public
…
End;
Var
Form1: TForm;
implementation
{$R *.DFM} подключение двоичного файла формы.
Procedure TForm1.Button1Click(Sender: TObject);
Begin
Edit1.Text := «пример»;
End:
Procedure TForm1.Button1Click(…);
Begin
Close;
End;
Файл Form1.DFM содержит описание формы с компонентами, а также содержит начальные значения свойств, установленных с помощью инспектора объектов. В текстовом виде его содержимое имеет следующий вид:
Object Form1: TForm
Left=200
Top=108
Width=435
Heigtht=300
…
End.
При старте Delphi автоматически создается новый проект, в котором программистом добавляются на форму компоненты и задаются для них обработчики событий. Для сохранения проекта следует выполнить команду главного меню: File-Save All.
Компиляция проекта выполняется по команде Project-Compile (или Ctrl-F9), при этом из каждого программного модуля создается файл с расширением DCU (Delphi Compiled Unit). Затем выполняется сборка проекта из DCU файлов в выполняемый EXE-файл приложения.
Запуск приложения выполняется по команде меню Run-Run (или F9)
Отладка приложений
В разрабатываемой программе могут существовать ошибки. Все возможные ошибки подразделяют на 3 группы:
синтаксические ошибки,
ошибки времени выполнения программы (run time errors),
логические (смысловые) ошибки.
Синтаксические ошибки – это ошибки в правилах написания операторов языка Object Pascal.
Например, написано «=» вместо «:=» (т.е. пропущено «:»).
Они обнаруживаются при компиляции, и их список выводится на панель сообщений.
Ошибки времени выполнения проявляются в виде исключительных ситуаций, которые приостанавливают работу приложения.
Например:
Var List : TStringList;
Begin
List := nil;
List.Add;
…
End;
Если это приложение запущено из среды Delphi, то его работа приостанавливается и вам выдается сообщение об этом. Вы можете продолжить работу приложения с помощью команды Run-Run, либо прервать его командой Run-Program Reset (Ctrl-F2)
Логические ошибки самые сложные и трудноуловимые. На их поиск уходит почти все время отладки. Delphi содержит развитые средства отладки:
средства трассировки;
контрольные точки;
просмотр значений переменных.
Средства трассировки. По команде Run-Run to Cursor (F4) программа выполняется до строки, в которой располагается текстовый курсор. По команде Trace Into (F7) программа выполняется по шагам, т.е. трассируется. Если в строке записан вызов подпрограммы, то начинается трассировка этой подпрограммы.
С помощью команды Step Over (F8) можно выполнить строку без захода в вызываемые подпрограммы.
Контрольные точки позволяют остановить программу в нужном месте, чтобы затем изучить ее состояние и найти ошибку. Контрольные точка устанавливается щелчком мыши на левом поле выбранной строки (или клавишей F5). При этом строка отобразится на красном фоне. С контрольной точкой может быть связано условие, т.е. выражение, имеющее логический тип.
С помощью команды Watches в линию View можно открыть окно просмотра переменных. В редакторе можно добавить переменную в окно просмотра с помощью команды AddWatch at Cursor (Ctrl-F5). Существует возможность изменения (модификации) значений переменных с помощью команды Evaluate/Modify. При отладке вложенных и рекурсивных подпрограмм полезно знать всю цепочку вложенных вызовов и значения параметров. Это смотрится в окне Call Stack, выбираем в меню View. Если требуется запускать отлаженные приложения не из среды Delphi, то полезно в определенных точках ставить вызов функции Beep, которая генерирует звуковой сигнал (как и в Post).
Для отладки также можно использовать подпрограмму ShowMessage(«строка»), которая в заданных точках позволяет контролировать выполнение программы.Программирование управляющих элементов
окна приложения Windows
Элементы графического интерфейса
Окно приложения Windows может содержать ряд стандартных управляющих элементов. В Delphi эти управляющие элементы задаются как компоненты со страницы Standard, Additional, Win 95, Dialogs. Рассмотрим наиболее употребляемые элементы.
Кнопки
Эти компоненты создают иллюзию нажимающейся кнопки. Стандартная кнопка создается с помощью команды компонента Button, расположенной в палитре компонентов на странице Standard.
Основные его свойства:
Cancel – если True, то кнопка срабатывает по нажатию Esc (кнопка отмены).
Caption – определяет текст на кнопке. Если текст содержит символ &, то он не отображается, а обеспечивает подчеркивание следующего символа. Подчеркнутый символ используется в комбинации с кнопкой Alt для активизации кнопки с клавиатуры.
Default – кнопка ввода, кнопка, которая срабатывает по нажатию клавиши Enter (если True, то кнопка срабатывает по нажатию Enter).
Modal Result – если не равно нулю, то нажатие кнопки обеспечивает закрытие модального окна.
Окна диалога бывают модальные и немодальные.
Модальное окно служит для взаимодействия с пользователем в режиме неделимого действия. Оно не позволяет переключиться на другие окна своего приложения до тех пор, пока работа с ним не будет завершена.
Немодальные – предоставляют пользователю свободу выбора, позволяя переключаться на другие окна приложения и выполнять ввод данных параллельно с другими операциями.
Когда пользователь нажимает кнопку с помощью мыши или клавиатуры, в компоненте Button возникает событие OnClick. Определив для него обработчик, можно реализовать ответную реакцию программы.
Кнопки с картинками
На странице Additional расположен компонент BitBtn, который обладает теми же возможностями, что и Button, но кроме текста может содержать небольшой точечный рисунок.
|
Свойства: |
Gryph – картинка на кнопке NumGryph – количество образов кнопки на картинке. Delphi рисует один из образов в зависимости от состояния кнопки. Layout – положение картинки относительно текста. Margin, Spacing ……. Kind – задает кнопку стандартного вида |
Украшение окна картинкой выполняется с помощью компонента Image на странице Additional.
|
По кнопке Load можно загрузить: |
точечный рисунок (bitmap) метафайл (metafile) значок (icon) |
Текстовые надписи выполняются с помощью компонента Label, со страницы Standard.
|
Свойства: |
Caption – текст надписи Align – выравнивание компонента Alignment – расположения текста в компоненте Transparent – если True, то текст прозрачен Word-wrap – если True, то с переносом слов AutoSize – автоматическая подгонка размера |
Рельефные кнопки и бордюры – с помощью компонента Bevel на странице Additional.
Управляющие элементы для ввода данных
Независимый переключатель CheckBox на странице Standard.
|
Свойства: |
State – текст составлен Caption – текст Checked – включен ли |
Зависимые переключатели Radio Button на странице Standard.
Группа зависимых переключателей RadioGroup на странице Standard заменяет группу компонентов RadioButton.
|
Свойства |
Items – массив надписей. ItemIndex – номер активного переключателя |
Однострочный редактор Edit на странице Standard служит для ввода строки текста.
|
Свойства |
PasswordChar – если не #0, то этот символ отображается вместо символов текста; Text – редактируемый текст. ReadOnly (False – True) – запрет редактирования; однако можно копировать текст в буфер обмена |
Многострочный редактор Memo на странице Standard.
|
Свойства |
Scrollbars – видимость полос прокрутки. WordWrap – перенос слов. Lines – строка текста (TStrings) ReadOnly |
Редактор с шаблоном Mask Edit со страницы Standard позволяет вводить строку разрешенных символов в разрешенных позициях (дата, время, телефон )
Кнопки увеличения-уменьшения числовых значений Up Down на странице Standard.
Выпадающий список Combo Box страница Standard.
Список ListBox
|
Свойства |
Items – элементы списка ItemIndex – порядковый номер выбранного элемента Text – текст в строке |
Страницы с закладкой PageControl на странице Windows 95.
|
Свойства |
ActivePage, Pages – массив страниц (объектов типа TTabSheet) Page Count. – количество страниц PageIndex – номер страницы |
(По правой кнопке включается меню – New Page)
Закладки – TabControl – рядом с Page Control. Это одна страница со множеством закладок
|
Свойства |
Tabs – массив названий закладок TabIndex – номер закладки. |
Средства работы с базами данных в Delphi
В основе работы с базами лежит механизм Borland Database Engine (BDE) – (ядро баз данных), который обеспечивает подключение приложения к базе данных.
База данных (БД) – это множество файлов, предназначенных для хранения информации о некоторой предметной области. Файлы одной базы собираются в одном каталоге, которому назначается сокращенное имя – псевдоним.
Абстрагируясь от формата отдельных файлов, можно считать, что база данных состоит из таблиц. Таблица содержит информацию о множестве идентичных по структуре объектов. Элементами таблицы являются записи. Записи соответствуют строкам таблицы. Число записей произвольно. Записи состоят из полей. Поля соответствуют колонкам таблицы. Каждое поле имеет имя и тип. Структура полей задается жестко при создании таблицы. Между таблицами устанавливаются отношения, поэтому база называется реляционной (от слова relation – отношение).
Для быстрого доступа записи в таблице упорядочиваются по значению одного или нескольких полей. Список полей, задающих порядок записей, называется индексом (Index), а сами поля – ключевыми (Index fields). Один из индексов называется первичным (primary). Значение его должно быть уникально для каждой записи. Остальные индексы являются вторичными (secondary). Они задают альтернативные способы упорядочивания записей и могут быть не уникальными.
Компонент Table обеспечивает доступ к таблице БД.
Компонент DataSource позволяет легко переключать программные средства на обработку другой БД путем его подключения к другой таблице.
Системы, которые обеспечивают доступ к базам данных и управление ими называются системами управления базами данных (СУБД).
Примеры (СУБД): dBase, Paradox, Oracle.
СУБД обеспечивает абстракцию таблиц данных от их физического представления на диске. Таблицы же могут представляться в виде одного или нескольких файлов.
В настоящее время получили распространение СУБД с так называемой архитектурой клиент-сервер. Это InterBase, Informix, Oracle, Sybase.
В архитектуре клиент-сервер СУБД – это сервер, он находится на производительном файловом сервере. Приложение, работающее с данными – это клиент; он выполняется на локальном компьютере. Клиент запрашивает у сервера данные на специальном языке SQL (Structured Query Language).
Приложение языка SQL – это команда запрос серверу выполнить операцию с базой данных, например, произвести выборку (select) или обновление (update) записей. Этот запрос передается по сети серверу БД, который обрабатывает его и возвращает клиенту готовый результат. Пример:
SELEСT * from Orders WHERE CustNo =1221.
Существует множество форматов БД. Borland Database Engine (BDF) – это промежуточный слой между файлами баз данных и приложениями, работающими с ними. BDE обеспечивает эффективную поддержку всех наиболее популярных форматов баз данных (Paradox, dBase, Informix, Oracle, Sybase, MS SQL Server).
Программа BDE инсталлируется вместе со средой Delphi и тесно с ней интегрирована.
Соединение с различными базами данных осуществляются с помощью псевдонимов.
Псевдоним – это известное приложению BDE имя БД, с которым BDE ассоциируются параметры, используемые для соединения с базами данных на диске. Это:
тип (формат) БД
маршрут (локальный или сетевой ) к БД
режим открытия и другие параметры
Псевдоним можно создавать с помощью любой из трех утилей:
BDE Configurator (основная функция )
Database DeskTop
Database Explorer
Существуют следующие компоненты для работы с БД :
множество данных (DataSet);
визуальные компоненты БД;
источники данных DataSource.
Компонент Table обеспечивает доступ к таблице любой СУБД.
Компонент Query инкапсулирует в себе запрос к БД на языке SQL, результат которого – это логическая таблица, формируемая из строк и столбцов таблиц баз данных.
DBGraph, DBEdit, DBImage, DBCheckBox – и так далее – в основном дублируют известные управляющие элементы диалоговых окон. Отличие в том, что данные для них берутся из таблиц и в таблицы помещаются.
DBSource – играет роль соединителя между данными (БД) и визуальными компонентами.
Типичными операциями над БД являются сортировка по индексу, фильтрация.
Перемещение между записями.
Методы
First
Last
Next
Prior
MoveBy(Count) – относительное перемещение
Свойства
BOF и EOF.
OrdersTable.First ……….
Редактирование записей выполняется с помощью методов.
Edit
Cancel – отмена
Post
Пример:
Edit ;
Field Valises [‘Sole Date»]:=Now ;
Post.
Вставка записи производится методом Insert, а удаление – методом Delete
Создание отчетов по БД
Отчет – это печатный документ, который содержит выборочную и зачастую обобщенную информацию по базе данных, представленную в дробном для анализа виде.
Для создания отчетов используется компонент QReport, или автономное приложение ReportSmith. Практикум
Техническое обеспечение автоматизированных систем
Цель работы
приобретение навыков получения информации об установленном оборудовании и установки режимов функционирования технических устройств компьютера.
Порядок выполнения
1. Одним из способов открыть «Панель управления»
а) Кнопка «Пуск на панели задач» – «Настройка» – «Панель управления»
б) Пиктограмма «Мой компьютер» на «Рабочем столе» – «Панель управления»
2. Открыть компонент «Система», посмотреть и выяснить
а) конфигурацию системы и компьютера
б) список установленного в системе оборудования
в) драйверы управления этими устройствами
г) используемые в системе профили оборудования
д) параметры системы на вкладке «Быстродействие»
3. Открыть компонент «Клавиатура» и выяснить
а) тип используемой клавиатуры
б) используемые языки
в) способ переключения раскладки клавиатуры
г) основной язык
4. Открыть компонент «Мультимедиа» и выяснить
а) какие устройства мультимедиа установлены на компьютере
б) параметры имеющихся устройств и драйверов к ним
в) возможности настройки мультимедиа- компонентов
5. В компоненте «Мышь» изучить
а) конфигурацию кнопок мыши
б) изменение скорости двойного нажатия (и протестировать)
в) схемы указателей мыши
г) изменение скорости перемещения указателя (и протестировать)
6. В разделе «Принтеры» выяснить
а) какие принтеры установлены в системе
б) какой из установленных принтеров используется для печати по умолчанию
в) имеются ли в очереди какие-либо печатаемые документы
д) ТОЛЬКО ПО СОГЛАСОВАНИЮ С ПЕРСОНАЛОМ УЧЕБНОЙ
ЛАБОРАТОРИИ
установить другой принтер и сделать его используемым по умолчанию
е) отправить на печать какой-либо документ и посмотреть очередь печати принтера
ж) отменить печать текущего документа
з) очистить очередь печати принтера
7. С помощью компонента «Управление электропитанием» изучить используемую в данной системе схему управления электропитанием и выяснить моменты отключения дисплея и дисков
8. Оформить отчет.
Содержание отчета
- Общие сведения о системе: тип процессора, объем памяти, наименование и версия используемой операционной системы.
- Список имеющихся в системе устройств и их характеристики.
- Используемые драйверы управления основными устройствами.
- Установленные в системе принтеры; какой из них используется по умолчанию.
- Конфигурация мыши и клавиатуры.
- Конфигурация видеосистемы.
- Используется ли на компьютере управление электропитанием. Если да, то указать схему управления.
- Выводы и заключение.
Программная среда Турбо-Паскаль
Цель работы
Приобретение навыков работы в среде Турбо-Паскаль: установка, настройка минимальной конфигурации под DOS, выполнение отладки примеров программ, пошаговый режим, просмотр переменных, стека и регистров.
Порядок выполнения
1. Запустить окно DOS из меню «Пуск»-«Программы».
2. Скопировать архив BP71.rar и программу архивации RAR.EXE в папку C:PSAS из папки D:DISK_A. Перейти в папку C:PSAS. С помощью архиватора развернуть архив в текущей папке.
3. Выполнить загрузку программной среды: Перейти в папку BP71BIN и запустить программу TPX.EXE.
4. Открыть меню «options», «directories», посмотреть и установить путь к файлам «units directories» (C:PSASBP71UNITS).
5. Открыть меню «file», «change dir…» и перейти в папку «examples».
6. По очереди для каждого примера
а) Загрузить текст примера в программную среду
б) Скомпилировать пример.(например, fib8087)
в) Запустить пример в отладочном режиме.
г) С помощью меню «debug» установить режимы просмотра значений переменных, регистров и стека программы.
д) выполнить программу по шагам.
7. Выйти из программной среды ТурбоПаскаль.
8. С помощью архиватора RAR.EXE выполнить архивацию папки EXAMPLES (включая имя папки и подкаталоги) в архив 2_113XXX_Фамилия_дата (например: 2_113018_Иванов_15_сентября).
9. В отчете представить перечень командных строк MS DOS, посланных в режиме командной строки для выполнения задания, названия и краткую аннотацию рассмотренных примеров.
Создание приложения в среде программирования Delphi
Цель работы
Освоение средств быстрого проектирования среды программирования Delphi. Приобретение навыков работы с программными компонентами, их свойствами и методами. Знакомство со средствами отладки пользовательских приложений.
Содержание
- 1 Методы обработки ошибок
- 2 Исключения
- 3 Классификация исключений
- 3.1 Проверяемые исключения
- 3.2 Error
- 3.3 RuntimeException
- 4 Обработка исключений
- 4.1 try-catch-finally
- 4.2 Обработка исключений, вызвавших завершение потока
- 4.3 Информация об исключениях
- 5 Разработка исключений
- 6 Исключения в Java7
- 7 Примеры исключений
- 8 Гарантии безопасности
- 9 Источники
Методы обработки ошибок
1. Не обрабатывать.
2. Коды возврата. Основная идея — в случае ошибки возвращать специальное значение, которое не может быть корректным. Например, если в методе есть операция деления, то придется проверять делитель на равенство нулю. Также проверим корректность аргументов a и b:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return null;
}
//...
if (Math.abs(b) < EPS) {
return null;
} else {
return a / b;
}
}
При вызове метода необходимо проверить возвращаемое значение:
Double d = f(a, b); if (d != null) { //... } else { //... }
Минусом такого подхода является необходимость проверки возвращаемого значения каждый раз при вызове метода. Кроме того, не всегда возможно определить тип ошибки.
3.Использовать флаг ошибки: при возникновении ошибки устанавливать флаг в соответствующее значение:
boolean error; Double f(Double a, Double b) { if ((a == null) || (b == null)) { error = true; return null; } //... if (Math.abs(b) < EPS) { error = true; return b; } else { return a / b; } }
error = false; Double d = f(a, b); if (error) { //... } else { //... }
Минусы такого подхода аналогичны минусам использования кодов возврата.
4.Можно вызвать метод обработки ошибки и возвращать то, что вернет этот метод.
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return nullPointer();
}
//...
if (Math.abs(b) < EPS) {
return divisionByZero();
} else {
return a / b;
}
}
Но в таком случае не всегда возможно проверить корректность результата вызова основного метода.
5.В случае ошибки просто закрыть программу.
if (Math.abs(b) < EPS) { System.exit(0); return this; }
Это приведет к потере данных, также невозможно понять, в каком месте возникла ошибка.
Исключения
В Java возможна обработка ошибок с помощью исключений:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
throw new IllegalArgumentException("arguments of f() are null");
}
//...
return a / b;
}
Проверять b на равенство нулю уже нет необходимости, так как при делении на ноль метод бросит непроверяемое исключение ArithmeticException.
Исключения позволяют:
- разделить обработку ошибок и сам алгоритм;
- не загромождать код проверками возвращаемых значений;
- обрабатывать ошибки на верхних уровнях, если на текущем уровне не хватает данных для обработки. Например, при написании универсального метода чтения из файла невозможно заранее предусмотреть реакцию на ошибку, так как эта реакция зависит от использующей метод программы;
- классифицировать типы ошибок, обрабатывать похожие исключения одинаково, сопоставлять специфичным исключениям определенные обработчики.
Каждый раз, когда при выполнении программы происходит ошибка, создается объект-исключение, содержащий информацию об ошибке, включая её тип и состояние программы на момент возникновения ошибки.
После создания исключения среда выполнения пытается найти в стеке вызовов метод, который содержит код, обрабатывающий это исключение. Поиск начинается с метода, в котором произошла ошибка, и проходит через стек в обратном порядке вызова методов. Если не было найдено ни одного подходящего обработчика, выполнение программы завершается.
Таким образом, механизм обработки исключений содержит следующие операции:
- Создание объекта-исключения.
- Заполнение stack trace’а этого исключения.
- Stack unwinding (раскрутка стека) в поисках нужного обработчика.
Классификация исключений
Класс Java Throwable описывает все, что может быть брошено как исключение. Наследеники Throwable — Exception и Error — основные типы исключений. Также RuntimeException, унаследованный от Exception, является существенным классом.
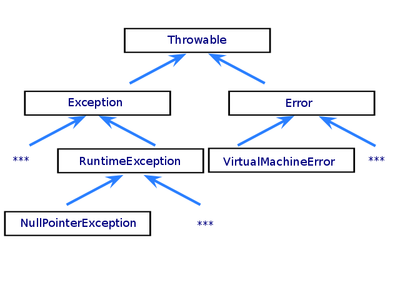
Иерархия стандартных исключений
Проверяемые исключения
Наследники класса Exception (кроме наслеников RuntimeException) являются проверяемыми исключениями(checked exception). Как правило, это ошибки, возникшие по вине внешних обстоятельств или пользователя приложения – неправильно указали имя файла, например. Эти исключения должны обрабатываться в ходе работы программы, поэтому компилятор проверяет наличие обработчика или явного описания тех типов исключений, которые могут быть сгенерированы некоторым методом.
Все исключения, кроме классов Error и RuntimeException и их наследников, являются проверяемыми.
Error
Класс Error и его подклассы предназначены для системных ошибок. Свои собственные классы-наследники для Error писать (за очень редкими исключениями) не нужно. Как правило, это действительно фатальные ошибки, пытаться обработать которые довольно бессмысленно (например OutOfMemoryError).
RuntimeException
Эти исключения обычно возникают в результате ошибок программирования, такие как ошибки разработчика или неверное использование интерфейса приложения. Например, в случае выхода за границы массива метод бросит OutOfBoundsException. Такие ошибки могут быть в любом месте программы, поэтому компилятор не требует указывать runtime исключения в объявлении метода. Теоретически приложение может поймать это исключение, но разумнее исправить ошибку.
Обработка исключений
Чтобы сгенерировать исключение используется ключевое слово throw. Как и любой объект в Java, исключения создаются с помощью new.
if (t == null) { throw new NullPointerException("t = null"); }
Есть два стандартных конструктора для всех исключений: первый — конструктор по умолчанию, второй принимает строковый аргумент, поэтому можно поместить подходящую информацию в исключение.
Возможна ситуация, когда одно исключение становится причиной другого. Для этого существует механизм exception chaining. Практически у каждого класса исключения есть конструктор, принимающий в качестве параметра Throwable – причину исключительной ситуации. Если же такого конструктора нет, то у Throwable есть метод initCause(Throwable), который можно вызвать один раз, и передать ему исключение-причину.
Как и было сказано раньше, определение метода должно содержать список всех проверяемых исключений, которые метод может бросить. Также можно написать более общий класс, среди наследников которого есть эти исключения.
void f() throws InterruptedException, IOException { //...
try-catch-finally
Код, который может бросить исключения оборачивается в try-блок, после которого идут блоки catch и finally (Один из них может быть опущен).
try { // Код, который может сгенерировать исключение }
Сразу после блока проверки следуют обработчики исключений, которые объявляются ключевым словом catch.
try { // Код, который может сгенерировать исключение } catch(Type1 id1) { // Обработка исключения Type1 } catch(Type2 id2) { // Обработка исключения Type2 }
Сatch-блоки обрабатывают исключения, указанные в качестве аргумента. Тип аргумента должен быть классом, унаследованного от Throwable, или самим Throwable. Блок catch выполняется, если тип брошенного исключения является наследником типа аргумента и если это исключение не было обработано предыдущими блоками.
Код из блока finally выполнится в любом случае: при нормальном выходе из try, после обработки исключения или при выходе по команде return.
NB: Если JVM выйдет во время выполнения кода из try или catch, то finally-блок может не выполниться. Также, например, если поток выполняющий try или catch код остановлен, то блок finally может не выполниться, даже если приложение продолжает работать.
Блок finally удобен для закрытия файлов и освобождения любых других ресурсов. Код в блоке finally должен быть максимально простым. Если внутри блока finally будет брошено какое-либо исключение или просто встретится оператор return, брошенное в блоке try исключение (если таковое было брошено) будет забыто.
import java.io.IOException; public class ExceptionTest { public static void main(String[] args) { try { try { throw new Exception("a"); } finally { throw new IOException("b"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println(ex.getMessage()); } } }
После того, как было брошено первое исключение — new Exception("a") — будет выполнен блок finally, в котором будет брошено исключение new IOException("b"), именно оно будет поймано и обработано. Результатом его выполнения будет вывод в консоль b. Исходное исключение теряется.
Обработка исключений, вызвавших завершение потока
При использовании нескольких потоков бывают ситуации, когда поток завершается из-за исключения. Для того, чтобы определить с каким именно, начиная с версии Java 5 существует интерфейс Thread.UncaughtExceptionHandler. Его реализацию можно установить нужному потоку с помощью метода setUncaughtExceptionHandler. Можно также установить обработчик по умолчанию с помощью статического метода Thread.setDefaultUncaughtExceptionHandler.
Интерфейс Thread.UncaughtExceptionHandler имеет единственный метод uncaughtException(Thread t, Throwable e), в который передается экземпляр потока, завершившегося исключением, и экземпляр самого исключения. Когда поток завершается из-за непойманного исключения, JVM запрашивает у потока UncaughtExceptionHandler, используя метод Thread.getUncaughtExceptionHandler(), и вызвает метод обработчика – uncaughtException(Thread t, Throwable e). Все исключения, брошенные этим методом, игнорируются JVM.
Информация об исключениях
-
getMessage(). Этот метод возвращает строку, которая была первым параметром при создании исключения; -
getCause()возвращает исключение, которое стало причиной текущего исключения; -
printStackTrace()печатает stack trace, который содержит информацию, с помощью которой можно определить причину исключения и место, где оно было брошено.
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
Все методы выводятся в обратном порядке вызовов. В примере исключение IllegalStateException было брошено в методе getBookIds, который был вызван в main. «Caused by» означает, что исключение NullPointerException является причиной IllegalStateException.
Разработка исключений
Чтобы определить собственное проверяемое исключение, необходимо создать наследника класса java.lang.Exception. Желательно, чтобы у исключения был конструкор, которому можно передать сообщение:
public class FooException extends Exception { public FooException() { super(); } public FooException(String message) { super(message); } public FooException(String message, Throwable cause) { super(message, cause); } public FooException(Throwable cause) { super(cause); } }
Исключения в Java7
- обработка нескольких типов исключений в одном
catch-блоке:
catch (IOException | SQLException ex) {...}
В таких случаях параметры неявно являются final, поэтому нельзя присвоить им другое значение в блоке catch.
Байт-код, сгенерированный компиляцией такого catch-блока будет короче, чем код нескольких catch-блоков.
-
Tryс ресурсами позволяет прямо вtry-блоке объявлять необходимые ресурсы, которые по завершению блока будут корректно закрыты (с помощью методаclose()). Любой объект реализующийjava.lang.AutoCloseableможет быть использован как ресурс.
static String readFirstLineFromFile(String path) throws IOException { try (BufferedReader br = new BufferedReader(new FileReader(path))) { return br.readLine(); } }
В приведенном примере в качестве ресурса использутся объект класса BufferedReader, который будет закрыт вне зависимосити от того, как выполнится try-блок.
Можно объявлять несколько ресурсов, разделяя их точкой с запятой:
public static void viewTable(Connection con) throws SQLException { String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES"; try (Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query)) { //Work with Statement and ResultSet } catch (SQLException e) { e.printStackTrace; } }
Во время закрытия ресурсов тоже может быть брошено исключение. В try-with-resources добавленна возможность хранения «подавленных» исключений, и брошенное try-блоком исключение имеет больший приоритет, чем исключения получившиеся во время закрытия. Получить последние можно вызовом метода getSuppressed() от исключения брошенного try-блоком.
- Перебрасывание исключений с улучшенной проверкой соответствия типов.
Компилятор Java SE 7 тщательнее анализирует перебрасываемые исключения. Рассмотрим следующий пример:
static class FirstException extends Exception { } static class SecondException extends Exception { } public void rethrowException(String exceptionName) throws Exception { try { if ("First".equals(exceptionName)) { throw new FirstException(); } else { throw new SecondException(); } } catch (Exception ex) { throw e; } }
В примере try-блок может бросить либо FirstException, либо SecondException. В версиях до Java SE 7 невозможно указать эти исключения в декларации метода, потому что catch-блок перебрасывает исключение ex, тип которого — Exception.
В Java SE 7 вы можете указать, что метод rethrowException бросает только FirstException и SecondException. Компилятор определит, что исключение Exception ex могло возникнуть только в try-блоке, в котором может быть брошено FirstException или SecondException. Даже если тип параметра catch — Exception, компилятор определит, что это экземпляр либо FirstException, либо SecondException:
public void rethrowException(String exceptionName) throws FirstException, SecondException { try { // ... } catch (Exception e) { throw e; } }
Если FirstException и SecondException не являются наследниками Exception, то необходимо указать и Exception в объявлении метода.
Примеры исключений
- любая операция может бросить
VirtualMachineError. Как правило это происходит в результате системных сбоев. -
OutOfMemoryError. Приложение может бросить это исключение, если, например, не хватает места в куче, или не хватает памяти для того, чтобы создать стек нового потока. -
IllegalArgumentExceptionиспользуется для того, чтобы избежать передачи некорректных значений аргументов. Например:
public void f(Object a) { if (a == null) { throw new IllegalArgumentException("a must not be null"); } }
IllegalStateExceptionвозникает в результате некорректного состояния объекта. Например, использование объекта перед тем как он будет инициализирован.
Гарантии безопасности
При возникновении исключительной ситуации, состояния объектов и программы могут удовлетворять некоторым условиям, которые определяются различными типами гарантий безопасности:
- Отсутствие гарантий (no exceptional safety). Если было брошено исключение, то не гарантируется, что все ресурсы будут корректно закрыты и что объекты, методы которых бросили исключения, могут в дальнейшем использоваться. Пользователю придется пересоздавать все необходимые объекты и он не может быть уверен в том, что может переиспозовать те же самые ресурсы.
- Отсутствие утечек (no-leak guarantee). Объект, даже если какой-нибудь его метод бросает исключение, освобождает все ресурсы или предоставляет способ сделать это.
- Слабые гарантии (weak exceptional safety). Если объект бросил исключение, то он находится в корректном состоянии, и все инварианты сохранены. Рассмотрим пример:
class Interval { //invariant: left <= right double left; double right; //... }
Если будет брошено исключение в этом классе, то тогда гарантируется, что ивариант «левая граница интервала меньше правой» сохранится, но значения left и right могли измениться.
- Сильные гарантии (strong exceptional safety). Если при выполнении операции возникает исключение, то это не должно оказать какого-либо влияния на состояние приложения. Состояние объектов должно быть таким же как и до вызовов методов.
- Гарантия отсутствия исключений (no throw guarantee). Ни при каких обстоятельствах метод не должен генерировать исключения. В Java это невозможно, например, из-за того, что
VirtualMachineErrorможет произойти в любом месте, и это никак не зависит от кода. Кроме того, эту гарантию практически невозможно обеспечить в общем случае.
Источники
- Обработка ошибок и исключения — Сайт Георгия Корнеева
- Лекция Георгия Корнеева — Лекториум
- The Java Tutorials. Lesson: Exceptions
- Обработка исключений — Википедия
- Throwable (Java Platform SE 7 ) — Oracle Documentation
- try/catch/finally и исключения — www.skipy.ru