It sort of is something to do with how the human brain works. We’re wired to be «good enough» for tasks that don’t usually require engineering-grade precision. There’s a reason why the cases we have the most trouble dealing with are called «edge» cases.
Probably the best way to avoid off-by-one errors is encapsulation. For example, instead of using a for loop that iterates a collection by index (from 0 to count — 1), use a for-each style loop with all the logic of where to stop built into the enumerator. That way you only have to get the bounds right once, when writing the enumerator, instead of every time you loop over the collection.
answered Feb 2, 2011 at 18:10
![]()
Mason WheelerMason Wheeler
81.7k24 gold badges234 silver badges309 bronze badges
2
There is something special about how brain handles borders and edges.
While it’s easier for the brain to think in terms of ranges and spaces, focusing on an edge seems to require somewhat more of attention. Here is how it happens, momentary loss of attention or insufficient concentration and you missed the border.
Another slight addition to the problem is that different programming environments have different indexation systems starting at either 0 or 1 which might add confusion to the people actively exposed to the both types of environments.
answered Feb 2, 2011 at 18:12
I believe it is due to context switching. In our day to day lives we tend to use 1-based indexes. Because of this our brain is unable to burn the correct behavior into long term memory.
answered Feb 2, 2011 at 18:10
![]()
ChaosPandionChaosPandion
6,2852 gold badges33 silver badges33 bronze badges
2
From Wikipedia, the free encyclopedia
An off-by-one error or off-by-one bug (known by acronyms OBOE, OBO, OB1 and OBOB) is a logic error involving the discrete equivalent of a boundary condition. It often occurs in computer programming when an iterative loop iterates one time too many or too few. This problem could arise when a programmer makes mistakes such as using «is less than or equal to» where «is less than» should have been used in a comparison, or fails to take into account that a sequence starts at zero rather than one (as with array indices in many languages). This can also occur in a mathematical context.
Cases[edit]
Looping over arrays[edit]
Consider an array of items, and items m through n (inclusive) are to be processed. How many items are there? An intuitive answer may be n − m, but that is off by one, exhibiting a fencepost error; the correct answer is
(n – m) + 1.
For this reason, ranges in computing are often represented by half-open intervals; the range from m to n (inclusive) is represented by the range from m (inclusive) to n + 1 (exclusive) to avoid fencepost errors. For example, a loop that iterates five times (from 0 to 4 inclusive) can be written as a half-open interval from 0 to 5:
for (index = 0; index < 5; index++) { /* Body of the loop */ }
The loop body is executed first of all with index equal to 0; index then becomes 1, 2, 3, and finally 4 on successive iterations. At that point, index becomes 5, so index < 5 is false and the loop ends. However, if the comparison used were <= (less than or equal to), the loop would be carried out six times: index takes the values 0, 1, 2, 3, 4, and 5. Likewise, if index were initialized to 1 rather than 0, there would only be four iterations: index takes the values 1, 2, 3, and 4. Both of these alternatives can cause off-by-one errors.
Another such error can occur if a do-while loop is used in place of a while loop (or vice versa.) A do-while loop is guaranteed to run at least once.
Array-related confusion may also result from differences in programming languages. Numbering from 0 is most common, but some languages start array numbering with 1. Pascal has arrays with user-defined indices. This makes it possible to model the array indices after the problem domain.
Fencepost error[edit]

A straight fence with n sections has n+1 posts.
A fencepost error (occasionally called a telegraph pole, lamp-post, or picket fence error) is a specific type of off-by-one error. An early description of this error appears in the works of Vitruvius.[1] The following problem illustrates the error:
If you build a straight fence 30 feet long with posts spaced 3 feet apart, how many posts do you need?
The common answer of 10 posts is wrong. This response comes from dividing the length of the fence by the spacing apart from each post, with the quotient being erroneously classified as the number of posts. In actuality, the fence has 10 sections and 11 posts.
In this scenario, a fence with n sections will have n + 1 posts. Conversely, if the fence contains n posts, it will contain n − 1 sections. This relationship is important to consider when dealing with the reverse error. The reverse error occurs when the number of posts is known and the number of sections is assumed to be the same. Depending on the design of the fence, this assumption can be correct or incorrect.
The following problem demonstrates the reverse error:
If you have n posts, how many sections are there between them?
The interpretation for the fence’s design changes the answer to this problem. The correct number of sections for a fence is n − 1 if the fence is a free-standing line segment bounded by a post at each of its ends (e.g., a fence between two passageway gaps), n if the fence forms one complete, free-standing loop (e.g., enclosure accessible by surmounting, such as a boxing ring), or n + 1 if posts do not occur at the ends of a line-segment-like fence (e.g., a fence between and wall-anchored to two buildings). The precise problem definition must be carefully considered, as the setup for one situation may give the wrong answer for other situations. Fencepost errors come from counting things rather than the spaces between them, or vice versa, or by neglecting to consider whether one should count one or both ends of a row.
Fencepost errors can also occur in units other than length. For example, the Time Pyramid, consisting of 120 blocks placed at 10-year intervals between blocks, is scheduled to take 1,190 years to build (not 1,200), from the installation of the first block to the last block. One of the earliest fencepost errors involved time, where the Julian calendar originally calculated leap years incorrectly, due to counting inclusively rather than exclusively, yielding a leap year every three years rather than every four.
«Fencepost error» can, in rare occasions, refer to an error induced by unexpected regularities in input values,[2] which can (for instance) completely thwart a theoretically efficient binary tree or hash function implementation. This error involves the difference between expected and worst case behaviours of an algorithm.
In larger numbers, being off by one is often not a major issue. In smaller numbers, however, and specific cases where accuracy is paramount committing an off-by-one error can be disastrous. Sometimes such an issue will also be repeated and, therefore, worsened, by someone passing on an incorrect calculation if the following person makes the same kind of mistake again (of course, the error might also be reversed).
An example of this error can occur in the computational language MATLAB with the linspace() linear interpolation function, whose parameters are (lower value, upper value, number of values) and not (lower value, upper value, number of increments). A programmer who misunderstands the third parameter to be the number of increments might hope that linspace(0,10,5) would achieve a sequence [0, 2, 4, 6, 8, 10] but instead would get [0, 2.5, 5, 7.5, 10].
Security implications[edit]
A common off-by-one error which results in a security-related bug is caused by misuse of the C standard library strncat routine. A common misconception with strncat is that the guaranteed null termination will not write beyond the maximum length. In reality it will write a terminating null character one byte beyond the maximum length specified. The following code contains such a bug:
void foo (char *s) { char buf[15]; memset(buf, 0, sizeof(buf)); strncat(buf, s, sizeof(buf)); // Final parameter should be: sizeof(buf)-1 }
Off-by-one errors are common in using the C library because it is not consistent with respect to whether one needs to subtract 1 byte – functions like fgets() and strncpy will never write past the length given them (fgets() subtracts 1 itself, and only retrieves (length − 1) bytes), whereas others, like strncat will write past the length given them. So the programmer has to remember for which functions they need to subtract 1.
On some systems (little endian architectures in particular) this can result in the overwriting of the least significant byte of the frame pointer. This can cause an exploitable condition where an attacker can hijack the local variables for the calling routine.
One approach that often helps avoid such problems is to use variants of these functions that calculate how much to write based on the total length of the buffer, rather than the maximum number of characters to write. Such functions include strlcat and strlcpy, and are often considered «safer» because they make it easier to avoid accidentally writing past the end of a buffer. (In the code example above, calling strlcat(buf, s, sizeof(buf)) instead would remove the bug.)
See also[edit]
- Boundary-value analysis
- Pigeonhole principle
- Rounding error
- Zero-based numbering
References[edit]
Citations[edit]
- ^ Moniot, Robert K., Who first described the «fence-post error?», Fordham University, archived from the original on 2016-03-05, retrieved 2016-07-07.
- ^ Raymond, Eric. «The Jargon File». Retrieved 17 May 2021.
Sources[edit]
- An earlier version of this article was based on fencepost error at FOLDOC, used with permission.
- Dijkstra, Edsger Wybe (May 2, 2008). «Why numbering should start at zero (EWD 831)». E. W. Dijkstra Archive. University of Texas at Austin. Retrieved 2011-03-16.
- In the Common Weakness Enumeration system this issue is listed as CWE-193: Off-by-one Error
Further reading[edit]
- Parker, Matt (2021). Humble Pi: When Math Goes Wrong in the Real World. Riverhead Books. ISBN 978-0593084694.
Содержание
- what is an “off-by-one error” java
- Logic error — Wikipedia
- How do I fix this Java error?
- What is an off-by-one error in an array?
- How do you avoid off-by-one error?
- What does fencepost error mean?
- What is a runtime error?
- What is the meaning of off-by-one?
- What is an off-by-one error Give an example from your own programming experience?
- How do you count fence posts?
- What are the 3 types of programming errors?
- What are runtime errors in Java?
- What is difference between compile time and runtime error?
- How do I fix runtime error?
- What is an example of a runtime error?
- How do I fix runtime error on my website?
- Why do we get runtime errors?
- Why is Java a logical error?
- Why are Java errors easy to spot?
- What happens when a user inputs a string format when the computer is expecting an integer?
- What is an error in a program?
- What is runtime error?
- What happens if a program accidentally adds two variables when he or she meant to divide them?
- What is an off by one error?
- Why are off by one errors not visible?
- What happens when you write off by one error?
- Why does an array get off by one?
- Off-by-one errors in Java lexer implemented in Java #136
- Comments
- 10: Обработка ошибок с помощью исключений
- Основные исключения
- Аргументы исключения
- Ловля исключения
- Блок try
- Обработчики исключений
- Прерывание против возобновления
- Создание ваших собственных исключений
- Спецификация исключения
- Перехват любого исключения
- Повторное выбрасывание исключений
- Стандартные исключения Java
- Особый случай RuntimeException
- Выполнение очистки с помощью finally
- Для чего нужно finally?
- Ловушка: потерянное исключение
- Ограничения исключений
- Конструкторы
- Совпадение исключений
- Руководство по исключениям
- Резюме
- Упражнения
what is an “off-by-one error” java

An off-by-one error (OBOE), also commonly known as an OBOB (off-by-one bug), or OB1 error is a logic error involving the discrete equivalent of a boundary condition. It often occurs in computer programming when an iterative loop iterates one time too many or too few.
Logic error — Wikipedia
How do I fix this Java error?
An off-by-one error is for example when you write intend to perform a loop n times and write something like: for (int i = 1; i 
What is an off-by-one error in an array?
in an array, and there is a loop over the array, an off-by-one error means that either there is one iteration too few to cover all elements, or one too many. In the first case, one element of the array is left out, in the second the index of the array will be outside its dimensions.
How do you avoid off-by-one error?
Probably the best way to avoid off-by-one errors is encapsulation. For example, instead of using a for loop that iterates a collection by index (from 0 to count — 1), use a for-each style loop with all the logic of where to stop built into the enumerator.
What does fencepost error mean?
What Does Fencepost Error Mean? A fencepost error is a specific type of off-by-one error that has to do with unlikely or misunderstood algorithms for development. Fencepost errors are also known as telegraph pole errors and lamppost errors.
What is a runtime error?
A runtime error is a software or hardware problem that prevents Internet Explorer from working correctly. Runtime errors can be caused when a website uses HTML code that’s incompatible with the web browser functionality. Original product version: Internet Explorer. Original KB number: 822521.
What is the meaning of off-by-one?
An off-by-one error or off-by-one bug (known by acronyms OBOE, OBO, OB1 and OBOB) is a logic error involving the discrete equivalent of a boundary condition. It often occurs in computer programming when an iterative loop iterates one time too many or too few.
What is an off-by-one error Give an example from your own programming experience?
An off-by-one error is when you expect something to be of value N, but in reality it ends up being N-1 or N+1. For example, you were expecting the program to perform an operation 10 times, but it ends up performing 9 or 11 times (one too few or one too many times).
How do you count fence posts?
Number of posts = (fence length / post spacing) + 1 (round the result up) Number of sections = number of posts — 1. Post length = fence height * 1.5. Total number of rails = number of rails per section * number of sections.
What are the 3 types of programming errors?
When developing programs there are three types of error that can occur:syntax errors.logic errors.runtime errors.
What are runtime errors in Java?
A runtime error in Java is an application error that occurs during the execution of a program. A runtime error occurs when a program is syntactically correct but contains an issue that is only detected during program execution.
What is difference between compile time and runtime error?
A compile-time error generally refers to the errors that correspond to the semantics or syntax. A runtime error refers to the error that we encounter during the code execution during runtime. We can easily fix a compile-time error during the development of code. A compiler cannot identify a runtime error.
How do I fix runtime error?
How to Fix a Runtime ErrorRestart the computer. . Update the program to its latest version. . Fully delete the program, and then reinstall it. . Install the latest Microsoft Visual C++ Redistributable package. . Use SFC scannow to repair corrupted Windows files. . Run System Restore to return your computer to a previous state.More items. •
What is an example of a runtime error?
Common examples include dividing by zero, referencing missing files, calling invalid functions, or not handling certain input correctly. NOTE: Runtime errors are commonly called referred to as «bugs,» and are often found during the debugging process, before the software is released.
How do I fix runtime error on my website?
How can I fix the Runtime server error for Chrome?Is the website down? . Delete cookies for the page you can’t log in to. . Clear Chrome’s brower data. . Reset Google Chrome. . Remove credentials. . Reinstall Google Chrome.
Why do we get runtime errors?
A memory leak is the most common cause of a runtime error on a Windows computer. It occurs when a program incorrectly manages the memory allocations, such as consuming more RAM without freeing it. A memory leak also occurs when the running code cannot access an object stored in the memory.
Why is Java a logical error?
Logical errors are also called Semantic Errors. These errors are caused due to an incorrect idea or concept used by a programmer while coding.
Why are Java errors easy to spot?
These kind of errors are easy to spot and rectify because the java compiler finds them for you. The compiler will tell you which piece of code in the program got in trouble and its best guess as to what you did wrong.
What happens when a user inputs a string format when the computer is expecting an integer?
For example: if the user inputs a data of string format when the computer is expecting an integer, there will be a runtime error.
What is an error in a program?
Error is an illegal operation performed by the user which results in the abnormal working of the program. Programming errors often remain undetected until the program is compiled or executed. Some of the errors inhibit the program from getting compiled or executed. Thus errors should be removed before compiling and executing.
What is runtime error?
Runtime errors occur when a program does not contain any syntax errors but asks the computer to do something that the computer is unable to reliably do. During compilation, the compiler has no technique to detect these kinds of errors. It is the JVM (Java Virtual Machine) which detects it while the program is running.
What happens if a program accidentally adds two variables when he or she meant to divide them?
For example: if a programmer accidentally adds two variables when he or she meant to divide them, the program will give no error and will execute successfully but with an incorrect result.
What is an off by one error?
Off-by-one errors arise when you don’t correctly account for the boundary conditions of a problem. It’s easy to reason about the first step, and the repeated step in the middle. It’s sometimes tricky to correctly reason about the last step—that is, when to stop iterating the repeated step in the middle.
Why are off by one errors not visible?
Often the off-by-one errors in other areas are not as visible as they are in Computer Programming because only one or two people will become aware of them. Also, they have occurred often enough that, where an off-by-one error is critical, we have procedures in place to make sure they don’t occur.
What happens when you write off by one error?
If the program gets past your team and into production, many, many people can become aware of the problem cause by this one off-by-one error, even though most will not be aware that it was an off-by-one error, it still becomes a highly visible problem .
Why does an array get off by one?
Probably the most common reason for off by one errors is forgetting that collection types, ie arrays, are referenced by an offset, or how far it is from the beginning or 1st element, not by count. The 1st element of an array is array [0], the second is array [1] and so on. The last element of an array is not array [ sizeof (array) ], but array [ sizeof (array) -1 ]. For example, an array with 6 elements, array [6], sizeof (array) == 6 but the last element is array [5]. But even using array [ sizeof (array) -1 ] can cause an error if the array is empty (sizeof (array) == 0) because that results in array [-1
Источник
Off-by-one errors in Java lexer implemented in Java #136
I’m getting what looks like an off-by-one error in token positions. In this source file being parsed, in this line:
I get the following token positions from the lexer implemented in Java:
Notice how the \u is reported as \ in the STRING_LITERAL . Conversely, with the lexer implemented in Python, I get this:
which looks correct; the \u is correctly shown and the subsequent column positions agree with what I see in an editor.
The text was updated successfully, but these errors were encountered:
Drat. I guess there is a problem here.
Well, one thing that needs to be investigated is whether the absolute offsets are wrong. You see, as I describe in the recent blog posts, internally, the tokens only store absolute offsets, beginOffset , endOffset and that’s inclusive/exclusive. I mean, if the absolute offsets are correct, but the line/column is wrong, then the bug is in translating the absolute offset to line/column. If the beginOffset/endOffset is incorrect, then the bug is something else. So maybe you could help me by answering that question.
In any case, we’ll figure this out. This is probably a rather superficial glitch.
Actually, I tried to investigate this a bit more and I think that the problem is here:
https://github.com/javacc21/javacc21/blob/master/src/ftl/java/Lexer.java.ftl#L733
That block of code, by the way, from line 724 to line 744, is the code that implements this JAVA_UNICODE_ESCAPE thing, you know, things like u31FB or something like that. But it’s kind of a weird thing, because the u unicode escape applies if the number of consecutive backslashes preceding the u is odd, not if it is even. (I would say in passing that this kind of thing can be really sort of annoying to get right and is the kind of place where bugs do tend to lurk. )
But anyway, I think (I haven’t really checked but you’re in a better position to check!) that the problem is line 733, the index++ is wrong. I suspect that if you comment that line out, everything will be fine. You see, it is incorrectly incrementing the index variable, which causes it to skip over the u in this case — you know, the case here where we have an even number of backslashes before the u, so that we do NOT have a unicode escape.
Anyway, if you comment out that line and do a full rebuild, the problem may go away. (I think it will but I would not bet my life on this!) I did comment out the line and run all tests and everything seems to work okay.
OK, I’ll try that. Thanks!
I commented out that line and those problems went away, but there still seem to be some pertaining to TAB characters. For example, in this file [not sure if uploading to Gist will have munged it], I get the following tokens in the Java version:
vs. Python version:
Now, in the source, lines 651-653 start with a single tab character. Are you counting these as 8 column positions? If so, then line 653 (and hence the multi-line comment) should end at column 11 as reported in Python, but the Java version reports 8 for the end column.
Источник
10: Обработка ошибок с помощью исключений
Основная философия Java в том, что “плохо сформированный код не будет работать”.
Идеальное время для поимки ошибки — это время компиляции, прежде чем вы попробуете даже запустить программу. Однако не все ошибки могут быть определены во время компиляции. Оставшиеся проблемы должны быть обработаны во время выполнения, с помощью некоторого правила, которая позволяет источнику ошибки передавать соответствующую информацию приемщику, который будет знать, как правильно обрабатывать затруднение.
В C и других ранних языках могло быть несколько таких правил, и они обычно устанавливались соглашениями, а не являлись частью языка программирования. Обычно вы возвращали специальное значение или устанавливали флаг, а приемщику предлагалось взглянуть на это значение или на флаг и определить, было ли что-нибудь неправильно. Однако, по прошествии лет, было обнаружено, что программисты, использующие библиотеки, имеют тенденцию думать о себе, как о непогрешимых, например: “Да, ошибки могут случаться с другими, но не в моем коде”. Так что, не удивительно, что они не проверяют состояние ошибки (а иногда состояние ошибки бывает слишком глупым, чтобы проверять [51] ). Если вы всякий раз проверяли состояние ошибки при вызове метода, ваш код мог превратиться нечитаемый ночной кошмар. Поскольку программисты все еще могли уговорить систему в этих языках, они были стойки к принятию правды: Этот подход обработки ошибок имел большие ограничения при создании больших, устойчивых, легких в уходе программ.
Решением является упор на причинную натуру обработки ошибок и усиление правил. Это действительно имеет долгую историю, так как реализация обработки исключений возвращает нас к операционным системам 1960-х и даже к бейсиковому “ on error goto ” (переход по ошибке). Но исключения C++ основывались на Ada, а Java напрямую базируется на C++ (хотя он больше похож на Object Pascal).
Слово “исключение” используется в смысле “Я беру исключение из этого”. В том месте, где возникает проблема, вы можете не знать, что делать с ней, но вы знаете, что вы не можете просто весело продолжать; вы должны остановиться и кто-то, где-то должен определить, что делать. Но у вас нет достаточно информации в текущем контексте для устранения проблемы. Так что вы передаете проблему в более высокий контекст, где кто-то будет достаточно квалифицированным, чтобы принять правильное решение (как в цепочке команд).
Другая, более значимая выгода исключений в том, что они очищают код обработки ошибок. Вместо проверки всех возможных ошибок и выполнения этого в различных местах вашей программы, вам более нет необходимости проверять место вызова метода (так как исключение гарантирует, что кто-то поймает его). И вам необходимо обработать проблему только в одном месте, называемом обработчик исключения. Это сохранит ваш код и разделит код, описывающий то, что вы хотите сделать, от кода, который выполняется, если что-то случается не так. В общем, чтение, запись и отладка кода становится яснее при использовании исключений, чем при использовании старого способа обработки ошибок.
Так как обработка исключений навязывается компилятором Java, то есть так много примеров, которые могут быть написаны в этой книге без изучения обработки исключений. Эта глава вводит вас в код, который вам необходим для правильной обработки исключений, и способы, которыми вы можете генерировать свои собственные исключения, если ваш метод испытывает затруднения.
Основные исключения
Исключительное состояние — это проблема, которая мешает последовательное исполнение метода или ограниченного участка, в котором вы находитесь. Важно различать исключительные состояния и обычные проблемы, в которых вы имеете достаточно информации в текущем контексте, чтобы как-то справиться с трудностью. В исключительном состоянии вы не можете продолжать обработку, потому что вы не имете необходимой информации, чтобы разобраться с проблемой в текущем контексте. Все, что вы можете сделать — это выйти из текущего контекста и отослать эту проблему к высшему контексту. Это то, что случается, когда вы выбрасываете исключение.
Простой пример — деление. Если вы делите на ноль, стоит проверить, чтобы убедиться, что вы пройдете вперед и выполните деление. Но что это значит, что делитель равен нулю? Может быть, вы знаете, в контексте проблемы вы пробуете решить это в определенном методе, как поступать с делителем, равным нулю. Но если это не ожидаемое значение, вы не можете это определить внутри и раньше должны выбросить исключение, чем продолжать свой путь.
Когда вы выбрасываете исключение, случается несколько вещей. Во-первых, создается объект исключения тем же способом, что и любой Java объект: в куче, с помощью new . Затем текущий путь выполнения (который вы не можете продолжать) останавливается, и ссылка на объект исключения выталкивается из текущего контекста. В этот момент вступает механизм обработки исключений и начинает искать подходящее место для продолжения выполнения программы. Это подходящее место — обработчик исключения, чья работа — извлечь проблему, чтобы программа могла попробовать другой способ, либо просто продолжиться.
Простым примером выбрасывания исключения является рассмотрение ссылки на объект, называемой t . Возможно, что вы можете передать ссылку, которая не была инициализирована, так что вы можете пожелать проверить ее перед вызовом метода, использующего эту ссылку на объект. Вы можете послать информацию об ошибке в больший контекст с помощью создания объекта, представляющего вашу информацию и “выбросить” его из вашего контекста. Это называется выбрасыванием исключения. Это выглядит так:
Здесь выбрасывается исключение, которое позволяет вам — в текущем контексте — отказаться от ответственности, думая о будущем решении. Оно магически обработается где-то в другом месте. Где именно будет скоро показано.
Аргументы исключения
Как и многие объекты в Java, вы всегда создаете исключения в куче, используя new , который резервирует хранилище и вызывает конструктор. Есть два конструктора для всех стандартных исключений: первый — конструктор по умолчанию, и второй принимает строковый аргумент, так что вы можете поместить подходящую информацию в исключение:
Эта строка позже может быть разложена при использовании различных методов, как скоро будет показано.
Ключевое слово throw является причиной несколько относительно магических вещей. Обычно, вы сначала используете new для создания объекта, который соответствует ошибочному состоянию. Вы передаете результирующую ссылку в throw . Объект, в результате, “возвращается” из метода, даже если метод обычно не возвращает этот тип объекта. Простой способ представлять себе обработку исключений, как альтернативный механизм возврата, хотя вы будете иметь трудности, если будете использовать эту аналогию и далее. Вы можете также выйти из обычного блока, выбросив исключение. Но значение будет возвращено, и произойдет выход из метода или блока.
Любое подобие обычному возврату из метода здесь заканчивается, потому что куда вы возвращаетесь, полностью отличается от того места, куда вы вернетесь при нормальном вызове метода. (Вы закончите в соответствующем обработчике исключения, который может быть очень далеко — на много уровней ниже по стеку вызова — от того места, где выброшено исключение.)
В дополнение, вы можете выбросить любой тип Выбрасываемого(Throwable) объекта, который вы хотите. Обычно вы будете выбрасывать различные классы исключений для каждого различного типа ошибок. Информация об ошибке представлена и внутри объекта исключения, и выбранным типом исключения, так что кто-то в большем контексте может определить, что делать с вашим исключением. (Часто используется только информация о типе объекта исключения и ничего значащего не хранится в объекте исключения.)
Ловля исключения
Если метод выбросил исключение, он должен предполагать, что исключение будет “поймано” и устранено. Один из преимуществ обработки исключений Java в том, что это позволяет вам концентрироваться на проблеме, которую вы пробуете решить в одном месте, а затем принимать меры по ошибкам из этого кода в другом месте.
Чтобы увидеть, как ловятся исключения, вы должны сначала понять концепцию критического блока . Он является секцией кода, которая может произвести исключение и за которым следует код, обрабатывающий это исключение.
Блок try
Если вы находитесь внутри метода, и вы выбросили исключение (или другой метод, вызванный вами внутри этого метода, выбросил исключение), такой метод перейдет в процесс бросания. Если вы не хотите быть выброшенными из метода, вы можете установить специальный блок внутри такого метода для поимки исключения. Он называется блок проверки, потому что вы “проверяете” ваши различные методы, вызываемые здесь. Блок проверки — это обычный блок, которому предшествует ключевое слово try :
Если вы внимательно проверяли ошибки в языке программирования, который не поддерживает исключений, вы окружали каждый вызов метода кодом установки и проверки ошибки, даже если вы вызывали один и тот же метод несколько раз. С обработкой исключений вы помещаете все в блок проверки и ловите все исключения в одном месте. Это означает, что ваш код становится намного легче для написания и легче для чтения, поскольку цель кода — не смешиваться с проверкой ошибок.
Обработчики исключений
Конечно, выбрасывание исключения должно где-то заканчиваться. Это “место” — обработчик исключения , и есть один обработчик для каждого типа исключения, которые вы хотите поймать. Обработчики исключений следуют сразу за блоком проверки и объявляются ключевым словом catch :
Каждое catch предложение (обработчик исключения) как меленький метод, который принимает один и только один аргумент определенного типа. Идентификаторы ( id1 , id2 и так далее) могут быть использованы внутри обработчика, как аргумент метода. Иногда вы нигде не используете идентификатор, потому что тип исключения дает вам достаточно информации, чтобы разобраться с исключением, но идентификатор все равно должен быть.
Обработчики должны располагаться прямо после блока проверки. Если выброшено исключение, механизм обработки исключений идет охотится за первым обработчиком с таким аргументом, тип которого совпадает с типом исключения. Затем происходит вход в предложение catch, и рассматривается обработка исключения. Поиск обработчика, после остановки на предложении catch, заканчивается. Выполняется только совпавшее предложение catch; это не как инструкция switch , в которой вам необходим break после каждого case , чтобы предотвратить выполнение оставшейся части.
Обратите внимание, что внутри блока проверки несколько вызовов различных методов может генерировать одно и тоже исключение, но вам необходим только один обработчик.
Прерывание против возобновления
Есть две основные модели в теории обработки исключений. При прерывании (которое поддерживает Java и C++), вы предполагаете, что ошибка критична и нет способа вернуться туда, где возникло исключение. Кто бы ни выбросил исключение, он решил, что нет способа спасти ситуацию, и он не хочет возвращаться обратно.
Альтернатива называется возобновлением — это означает, что обработчик исключения может что-то сделать для исправления ситуации, а затем повторно вызовет придирчивый метод, предполагая, что вторая попытка будет удачной. Если вы хотите возобновления, это означает, что вы все еще надеетесь продолжить выполнение после обработки исключения. В этом случае ваше исключение больше похоже на вызов метода, в котором вы должны произвести настройку ситуации в Java, после чего возможно возобновление. (То есть, не выбрасывать исключение; вызвать метод, который исправит проблему.) Альтернатива — поместить ваш блок try внутри цикла while , который производит повторный вход в блок try , пока не будет получен удовлетворительный результат.
Исторически программисты используют операционные системы, которые поддерживают обработку ошибок с возобновлением, в конечном счете, заканчивающуюся использованием прерывающего кода и пропуском возобновления. Так что, хотя возобновление на первый взгляд кажется привлекательнее, оно не так полезно на практике. Вероятно, главная причина — это с оединение таких результатов: ваш обработчик часто должен знать, где брошено исключение и содержать не характерный специфический код для места выброса. Это делает код трудным для написания и ухода, особенно для больших систем, где исключения могут быть сгенерированы во многих местах.
Создание ваших собственных исключений
Вы не ограничены в использовании существующих Java исключений. Это очень важно, потому что часто вам будет нужно создавать свои собственные исключения, чтобы объявить специальную ошибку, которую способна создавать ваша библиотека, но это не могли предвидеть, когда создавалась иерархия исключений Java.
Для создания вашего собственного класса исключения вы обязаны наследовать его от исключения существующего типа, предпочтительно от того, которое наиболее близко подходит для вашего нового исключения (однако, часто это невозможно). Наиболее простой способ создать новый тип исключения — это просто создать конструктор по умолчанию для вас, так чтобы он совсем не требовал кода:
Когда компилятор создает конструктор по умолчанию, он автоматически (и невидимо) вызывает конструктор по умолчанию базового класса. Конечно, в этом случае у вас нет конструктора SimpleException(String) , но на практике он не используется часто. Как вы увидите, наиболее важная вещь в использовании исключений — это имя класса, так что чаще всего подходят такие исключения, как показаны выше.
Вот результат, который печатается на консоль стандартной ошибки — поток для записи в System.err . Чаще всего это лучшее место для направления информации об ошибках, чем System.out , который может быть перенаправлен. Если вы посылаете вывод в System.err , он не может быть перенаправлен, в отличие от System.out , так что пользователю легче заметить его.
Создание класса исключения, который также имеет конструктор, принимающий String , также достаточно просто:
Дополнительный код достаточно мал — добавлено два конструктора, которые определяют способы создания MyException . Во втором конструкторе явно вызывается конструктор базового класса с аргументом String с помощью использования ключевого слова super .
Информация трассировки направляется в System.err , так как это лучше, поскольку она будет выводиться, даже если System.out будет перенаправлен.
Программа выводит следующее:
Вы можете увидеть недостаток деталей в этих сообщениях MyException , выбрасываемых из f( ) .
Процесс создания вашего собственного исключения может быть развит больше. Вы можете добавить дополнительные конструкторы и члены:
Бал добавлен член — данные i , вместе с методами, которые читают его значение и дополнительные конструкторы, которые устанавливают его. Вод результат работы:
Так как исключение является просто еще одним видом объекта, вы можете продолжать этот процесс наращивания мощность ваших классов исключений. Однако запомните, что все это украшение может быть потеряно для клиентского программиста, использующего ваш пакет, так как он может просто взглянуть на выбрасываемое исключение и ничего более. (Это способ чаще всего используется в библиотеке исключений Java.)
Спецификация исключения
В Java, вам необходимо проинформировать клиентских программистов, которые вызывают ваши методы, что метод может выбросить исключение. Это достаточно цивилизованный метод, поскольку тот, кто производит вызов, может точно знать какой код писать для поимки всех потенциальных исключений. Конечно, если доступен исходный код, клиентский программист может открыть программу и посмотреть на инструкцию throw , но часто библиотеки не поставляются с исходными текстами. Для предотвращения возникновения этой проблемы Java обеспечивает синтаксис (и навязывает вам этот синтаксис), позволяющий вам правильно сказать клиентскому программисту, какое исключение выбрасывает этот метод, так что клиентский программист может обработать его. Это спецификация исключения и это часть объявления метода, добавляемая после списка аргументов.
Спецификация исключения использует дополнительное ключевое слово throws , за которым следует за список потенциальных типов исключений. Так что определение вашего метода может выглядеть так:
Если вы скажете
это будет означать, что исключения не выбрасываются из этого метода. (Кроме исключения, типа RuntimeException , которое может быть выброшено в любом месте — это будет описано позже.)
Вы не можете обмануть спецификацию исключения — если ваш метод является причиной исключения и не обрабатывает его, компилятор обнаружит это и скажет вам что вы должны либо обработать исключение, либо указать с помощью спецификации исключения, что оно может быть выброшено из вашего метода. При введении ограничений на спецификацию исключений с верху вниз, Java гарантирует, что исключение будет корректно обнаружено во время компиляции[52].
Есть одно место, в котором вы можете обмануть: вы можете заявить о выбрасывании исключения, которого на самом деле нет. Компилятор получит ваши слова об этом и заставит пользователя вашего метода думать, что это исключение на самом деле выбрасывается. Это имеет благотворный эффект на обработчика этого исключения, так как вы на самом деле позже можете начать выбрасывать это исключение и это не потребует изменения существующего кода. Также важно создание абстрактного базового класса и интерфейсов , наследующих классам или реализующим многие требования по выбрасыванию исключений.
Перехват любого исключения
Можно создать обработчик, ловящий любой тип исключения. Вы сделаете это, перехватив исключение базового типа Exception (есть другие типы базовых исключений, но Exception — это базовый тип, которому принадлежит фактически вся программная активность):
Это поймает любое исключение, так что, если вы используете его, вы будете помещать его в конце вашего списка обработчиков для предотвращения перехвата любого обработчика исключения, который мог управлять течением.
Так как класс Exception — это базовый класс для всех исключений, которые важны для программиста, вы не получите достаточно специфической информации об исключении, но вы можете вызвать метод, который пришел из его базового типа Throwable :
String getMessage( )
String getLocalizedMessage ( )
Получает подробное сообщение или сообщение, отрегулированное по его месту действия.
String toString( )
Возвращает короткое описание Throwable, включая подробности сообщения, если они есть.
void printStackTrace( )
void printStackTrace(PrintStream)
void printStackTrace ( PrintWriter )
Печатает Throwable и трассировку вызовов Throwable. Вызов стека показывает последовательность вызовов методов, которые подвели вас к точке, в которой было выброшено исключение. Первая версия печатает в поток стандартный поток ошибки, второй и третий печатают в выбранный вами поток (в Главе 11, вы поймете, почему есть два типа потоков).
Throwable fillInStackTrace ( )
Запись информации в этот Throwable объекте о текущем состоянии кадра стека. Это полезно, когда приложение вновь выбрасывает ошибки или исключение (дальше об этом будет подробнее).
Кроме этого вы имеете некоторые другие метода, наследуемые от базового типа Throwable Object (базовый тип для всего). Один из них, который может быть удобен для исключений, это getClass( ) , который возвращает объектное представление класса этого объекта. Вы можете опросить у объекта этого Класса его имя с помощью getName( ) или toString( ) . Вы также можете делать более изощренные вещи с объектом Класса, которые не нужны в обработке ошибок. Объект Class будет изучен позже в этой книге.
Вот пример, показывающий использование основных методов Exception :
Вывод этой программы:
Вы можете заметить, что методы обеспечивают больше информации — каждый из них дополняет предыдущий.
Повторное выбрасывание исключений
Иногда вам будет нужно вновь выбросить исключение, которое вы только что поймали, обычно это происходит, когда вы используете Exception , чтобы поймать любое исключение. Так как вы уже имеете ссылку на текущее исключение, вы можете просто вновь бросить эту ссылку:
Повторное выбрасывание исключения является причиной того, что исключение переходит в обработчик следующего, более старшего контекста. Все остальные предложения catch для того же самого блока try игнорируются. Кроме того, все, что касается объекта исключения, сохраняется, так что обработчик старшего контекста, который поймает исключение этого специфического типа, может получить всю информацию из этого объекта.
Если вы просто заново выбросите текущее исключение, то информация, которую вы печатаете об этом исключении, в printStackTrace( ) будет принадлежать источнику исключения, а не тому месту, откуда вы его вновь выбросили. Если вы хотите установить новый стек информации трассировки, вы можете сделать это, вызвав функцию fillInStackTrace( ) , которая возвращает объект исключения, для которого текущий стек наполняется информацией для старого объекта исключения. Вот как это выглядит:
Важные строки помечены комментарием с числами. При раскомментированной строке 17 (как показано), на выходе получаем:
Так что стек трассировки исключения всегда помнит исходное место, не имеет значения, сколько прошло времени перед повторным выбрасыванием.
Если закомментировать строку 17, а строку 18 раскомментировать, будет использоваться функция fillInStackTrace( ) , и получим результат:
Поскольку fillInStackTrace( ) в строке 18 становится новой исходной точкой исключения.
Класс Throwable должен появиться в спецификации исключения для g( ) и main( ) , потому что fillInStackTrace( ) производит ссылку на объект Throwable . Так как Throwable — это базовый класс для Exception , можно получить объект, который является Throwable , но не Exception , так что обработчик для Exception в main( ) может промахнуться. Чтобы убедится, что все в порядке, компилятор навязывает спецификацию исключения для Throwable . Например, исключение в следующем примере не перехватывается в main( ) :
Также возможно вновь выбросить исключение, отличающееся от того, которое вы поймали. Если вы делаете это, вы получаете сходный эффект, как если бы вы использовали fillInStackTrace( ) — информация об оригинальном состоянии исключения теряется, а то, с чем вы остаетесь — это информация, относящаяся к новому throw :
Вот что напечатается:
Конечное исключение знает только то, что оно произошло в main( ) , а не в f( ) .
Вам никогда не нужно заботится об очистке предыдущего исключения или что другое исключение будет иметь значение. Они являются объектами, базирующимися в куче и создающимися с помощью new , так что сборщик мусора автоматически очистит их все.
Стандартные исключения Java
Класс Java Throwable описывает все, что может быть выброшено как исключение. Есть два основных типа объектов Throwable (“тип” = “наследуется от”). Error представляет ошибки времени компиляции и системные ошибки, о поимке которых вам не нужно беспокоиться (за исключением особых случаев). Exception — основной тип, который может быть выброшен из любого стандартного метода библиотеки классов Java и из вашего метода, что случается во время работы. Так что основной тип, интересующий программистов Java — это Exception .
Лучший способ получить обзор исключений — просмотреть HTML документацию Java, которую можно загрузить с java.sun.com. Это стоит сделать один раз, чтобы почувствовать разнообразие исключений, но вы скоро увидите, что нет никакого специального отличия одного исключения от другого кроме его имени. Кроме того, число исключений в Java увеличивается, поэтому бессмысленно перечислять их в книге. Каждая новая библиотека, получаемая от третьих производителей, вероятно, имеет свои собственные исключения. Важно понимать концепцию и то, что вы должны делать с исключением.
Основная идея в том, что имя исключения представляет возникшую проблему, и имя исключения предназначено для самообъяснения. Не все исключения определены в java.lang , некоторые создаются для поддержки других библиотек, таких как util , net и io , как вы можете видеть по полому имени класса или по их наследованию. Например, все исключения I/O наследуются от java.io.IOException .
Особый случай RuntimeException
Первый пример в этой главе был:
Это может быть немного пугающим: думать, что вы должны проверять на null каждую ссылку, передаваемую в метод (так как вы не можете знать, что при вызове была передана правильная ссылка). К счастью вам не нужно это, поскольку Java выполняет стандартную проверку во время выполнения за вас и, если вы вызываете метод для null ссылки, Java автоматически выбросит NullPointerException . Так что приведенную выше часть кода всегда излишняя.
Есть целая группа типов исключений, которые относятся к такой категории. Они всегда выбрасываются Java автоматически и вам не нужно включать их в вашу спецификацию исключений. Что достаточно удобно, что они все сгруппированы вместе и относятся к одному базовому классу, называемому RuntimeException , который является великолепным примером наследования: он основывает род типов, которые имеют одинаковые характеристики и одинаковы в поведении. Также вам никогда не нужно писать спецификацию исключения, объявляя, что метод может выбросить RuntimeException , так как это просто предполагается. Так как они указывают на ошибки, вы, фактически, никогда не выбрасываете RuntimeException — это делается автоматически. Если вы заставляете ваш код выполнять проверку на RuntimeException s, он может стать грязным. Хотя вы обычно не ловите RuntimeExceptions , в ваших собственных пакетах вы можете по выбору выбрасывать некоторые из RuntimeException .
Что случится, если вы не выбросите это исключение? Так как компилятор не заставляет включать спецификацию исключений для этого случая, достаточно правдоподобно, что RuntimeException могут принизывать насквозь ваш метод main( ) и не ловится. Чтобы увидеть, что случится в этом случае, попробуйте следующий пример:
Вы уже видели, что RuntimeException (или любое, унаследованное от него) — это особый случай, так как компилятор не требует спецификации этих типов.
Вот что получится при выводе:
Так что получим такой ответ: Если получаем RuntimeException , все пути ведут к выходу из main( ) без поимки, для такого исключения вызывается printStackTrace( ) , и происходит выход из программы.
Не упускайте из виду, что вы можете только игнорировать RuntimeException в вашем коде, так как вся другая обработка внимательно ограничивается компилятором. Причина в том, что RuntimeException представляют ошибки программы:
- Ошибка, которую вы не можете поймать (получение null ссылки, передаваемой в ваш метод клиентским программистом, например).
- Ошибки, которые вы, как программист, должны проверять в вашем коде (такие как ArrayIndexOutOfBoundsException , где вы должны обращать внимание на размер массива).
Вы можете увидеть какая огромная выгода от этих исключений, так как они помогают процессу отладки.
Интересно заметить, что вы не можете классифицировать обработку исключений Java, как инструмент с одним предназначением. Да, он предназначен для обработки этих надоедливых ошибок времени выполнения, которые будут случаться, потому что ограничения накладываются вне кода управления, но он также важен для определенных типов ошибок программирования, которые компилятор не может отследить.
Выполнение очистки с помощью finally
Часто есть такие места кода, которые вы хотите выполнить независимо от того, было ли выброшено исключение в блоке try , или нет. Это обычно относится к некоторым операциям, отличным от утилизации памяти (так как об этом заботится сборщик мусора). Для достижения этого эффекта вы используете предложение finally [53] в конце списка всех обработчиков исключений. Полная картина секции обработки исключений выглядит так:
Для демонстрации, что предложение finally всегда отрабатывает, попробуйте эту программу:
Эта программа также дает подсказку, как вы можете поступить с фактом, что исключения в Java (как и исключения в C++) не позволяют вам возвратится обратно в то место, откуда оно выброшено, как обсуждалось ранее. Если вы поместите ваш блок try в цикл, вы сможете создать состояние, которое должно будет встретиться, прежде чем вы продолжите программу. Вы также можете добавить статический счетчик или какое-то другое устройство, позволяющее циклу опробовать различные подходы, прежде чем сдаться. Этим способом вы можете построить лучший уровень живучести вашей программы.
Вот что получается на выводе:
Независимо от того, было выброшено исключение или не, предложение finally выполняется всегда.
Для чего нужно finally?
В языках без сборщика мусора и без автоматического вызова деструктора [54] , finally очень важно, потому что оно позволяет программисту гарантировать освобождение памяти независимо от того, что случилось в блоке try . Но Java имеет сборщик мусора, так что освобождение памяти, фактически, не является проблемой. Также, язык не имеет деструкторов для вызова. Так что, когда вам нужно использовать finally в Java?
finally необходимо, когда вам нужно что-то установить, отличное от блока памяти, в его оригинальное состояние. Это очистка определенного вида, такое как открытие файла или сетевого соединения, рисование на экране или даже переключение во внешний мир, как смоделировано в следующем примере:
Цель этого примера — убедится, что переключатель выключен, когда main( ) будет завершена, так что sw.off( ) помешена в конце блока проверки и в каждом обработчике исключения. Но возможно, что будет выброшено исключение, которое не будет поймано здесь, так что sw.off( ) будет пропущено. Однако с помощью finally вы можете поместить очищающий код для блока проверки только в одном месте:
Здесь sw.off( ) была перемещена только в одно место, где она гарантировано отработает не зависимо от того, что случится.
Даже в случае исключения, не пойманного в этом случае набором предложений catch , finally будет выполнено прежде, чем механизм обработки исключений продолжит поиск обработчика на более высоком уровне:
Вывод этой программы показывает что происходит:
Инструкция finally также будет исполнена в ситуации, когда используются инструкции break и continue . Обратите внимание, что наряду с помеченным break и помеченным continue , finally подавляет необходимость в использовании инструкции goto в Java.
Ловушка: потерянное исключение
Вообще, реализация исключений Java достаточно выдающееся, но, к сожалению, есть недостаток. Хотя исключения являются индикаторами кризиса в вашей программе и не должны игнорироваться, возможна ситуация, при которой исключение просто потеряется. Это случается при определенной конфигурации использования предложения finally :
Вот что получаем на выходе:
Вы можете видеть, что нет свидетельств о VeryImportantException , которое просто заменилось HoHumException в предложении finally . Это достаточно серьезная ловушка, так как это означает, что исключения могут быть просто потеряны и далее в более узких и трудно определимых ситуациях, чем показано выше. В отличие от Java, C++ трактует ситуации, в которых второе исключение выбрасывается раньше, чем обработано первое, как ошибку программирования. Надеюсь, что будущие версии Java решат эту проблему (с другой стороны, вы всегда окружаете метод, который выбрасывает исключение, такой как dispose( ) , предложением try-catch ).
Ограничения исключений
Когда вы перегружаете метод, вы можете выбросить только те исключения, которые указаны в версии базового класса этого метода. Это полезное ограничение, так как это означает, что код, работающий с базовым классом, будет автоматически работать с любым другим объектом, наследованным от базового класса (конечно, это фундаментальная концепция ООП), включая исключения.
Этот пример демонстрирует виды налагаемых ограничений (времени компиляции) на исключения:
В Inning вы можете увидеть, что и конструктор, и метод event( ) говорят о том, что они будут выбрасывать исключение, но они не делают этого. Это допустимо, потому что это позволяет вам заставить пользователя ловить любое исключение, которое может быть добавлено и перегруженной версии метода event( ) . Эта же идея применена к абстрактным методам, как видно в atBat( ) .
Интересен interface Storm , потому что он содержит один метод ( event( ) ), который определен в Inning , и один метод, которого там нет. Оба метода выбрасывают новый тип исключения: RainedOut . Когда StormyInning расширяет Inning и реализует Storm , вы увидите, что метод event( ) в Storm не может изменить исключение интерфейса event( ) в Inning . Кроме того, в этом есть здравый смысл, потому что, в противном случае, вы никогда не узнаете, что поймали правильную вещь, работая с базовым классом. Конечно, если метод, описанный как интерфейс, не существует в базовом классе, такой как rainHard( ) , то нет проблем, если он выбросит исключения.
Ограничения для исключений не распространяются на конструкторы. Вы можете видеть в StormyInning , что конструктор может выбросить все, что хочет, не зависимо от того, что выбрасывает конструктор базового класса. Но, так как конструктор базового класса всегда, так или иначе, должен вызываться (здесь автоматически вызывается конструктор по умолчанию), конструктор наследованного класса должен объявить все исключения конструктора базового класса в своей спецификации исключений. Заметьте, что конструктор наследованного класса не может ловить исключения, выброшенные конструктором базового класса.
Причина того, что StormyInning.walk( ) не будет компилироваться в том, что она выбрасывает исключение, которое Inning.walk( ) не выбрасывает. Если бы это допускалось, то вы могли написать код, вызывающий Inning.walk( ) , и не иметь обработчика для любого исключения, а затем, когда вы заменили объектом класса, унаследованного от Inning , могло начать выбрасываться исключение и ваш код сломался бы. При ограничивании методов наследуемого класса в соответствии со спецификацией исключений методов базового класса замена объектов допустима.
Перегрузка метода event( ) показывает, что версия метода наследованного класса может не выбрасывать исключение, даже если версия базового класса делает это. Опять таки это хорошо, так как это не нарушит ни какой код, который написан с учетом версии базового класса с выбрасыванием исключения. Сходная логика применима и к atBat( ) , которая выбрасывает PopFoul — исключение, унаследованное от Foul , выбрасываемое версией базового класса в методе atBat( ) . Таким образом, если кто-то напишет код, который работает с классом Inning и вызывает atBat( ) , он должен ловить исключение Foul . Так как PopFoul наследуется от Foul , обработчик исключения также поймает PopFoul .
Последнее, что нас интересует — это main( ) . Здесь вы можете видеть, что если вы имеете дело с объектом StormyInning , компилятор заставит вас ловить только те исключения, которые объявлены для этого класса, но если вы выполните приведение к базовому типу, то компилятор (что совершенно верно) заставит вас ловить исключения базового типа. Все эти ограничения производят более устойчивый код обработки исключений [55] .
Полезно понимать, что хотя спецификация исключений навязываются компилятором во время наследования, спецификация исключений не является частью метода типа, который включает только имя метода и типы аргументов. Поэтому вы не можете перегрузить метод, основываясь на спецификации исключений. Кроме того, только потому, что спецификация исключений существует в версии метода базового класса, это не означает, что она должна существовать в версии метода наследованного класса. Это немного отличается от правил наследования, по которым метод базового класса должен также существовать в наследуемом классе. Есть другая возможность: “спецификации исключения интерфейса” для определенного метода может сузиться во время наследования и перегрузки, но он не может расшириться — это точно противоречит правилам для интерфейса класса при наследовании.
Конструкторы
Когда пишете код с исключениями, обычно важно, чтобы вы всегда спрашивали: “Если случится исключение, будет ли оно правильно очищено?” Большую часть времени вы этим сохраните, но в конструкторе есть проблемы. Конструктор переводит объект в безопасное начальное состояние, но он может выполнить некоторые операции — такие как открытие файла — которые не будут очищены, пока пользователь не закончит работать с объектом и не вызовет специальный очищающий метод. Если вы выбросили исключение из конструктора, это очищающее поведение может не сработать правильно. Это означает, что вы должны быть особенно осторожными при написании конструктора.
Так как вы только изучили о finally , вы можете подумать, что это корректное решение. Но это не так просто, потому что finally выполняет очищающий код каждый раз, даже в ситуации, в которой вы не хотите, чтобы выполнялся очищающий код до тех пор, пока не будет вызван очищающий метод. Таким образом, если вы выполняете очистку в finally , вы должны установить некоторый флаг, когда конструктор завершается нормально, так что вам не нужно ничего делать в блоке finally , если флаг установлен. Потому что это обычно не элегантное решение (вы соединяете ваш код в одном месте с кодом в другом месте), так что лучше попробовать предотвратить выполнение такого рода очистки в finally , если вы не вынуждены это делать.
В приведенном ниже примере класс, называемый InputFile , при создании открывает файл и позволяет вам читать его по одной строке (конвертируя в String ). Он использует классы FileReader и BufferedReader из стандартной библиотеки Java I/O, которая будет обсуждаться в Главе 11, но которая достаточно проста, что вы, вероятно, не будете иметь трудностей в понимании основ ее использования:
Конструктор для InputFile получает аргумент String , который является именем файла, который вы открываете. Внутри блока try создается FileReader с использование имени файла. FileReader не очень полезен до тех пор, пока вы не используете его для создания BufferedReader , с которым вы фактически можете общаться — обратите внимание, что в этом одна из выгод InputFile , который комбинирует эти два действия.
Если конструктор FileReader завершится неудачно, он выбросит FileNotFoundException , которое должно быть поймано отдельно, потому что это тот случай, когда вам не надо закрывать файл, так как его открытие закончилось неудачно. Любое другое предложение catch должно закрыть файл, потому что он был открыт до того, как произошел вход в предложение catch. (Конечно это ненадежно, если более одного метода могут выбросить FileNotFoundException . В этом случае вы можете захотеть разбить это на несколько блоков try .) Метод close( ) может выбросить исключение, так что он проверяется и ловится, хотя он в блоке другого предложения catch — это просто другая пара фигурных скобок для компилятора Java. После выполнения локальных операций исключение выбрасывается дальше, потому что конструктор завершился неудачей, и вы не захотите объявить, что объект правильно создан и имеет силу.
В этом примере, который не использует вышеупомянутую технику флагов, предложение finally определенно это не то место для закрытия файла, так как он будет закрываться всякий раз по завершению конструктора. Так как вы хотим, чтобы файл был открыт для использования все время жизни объекта InputFile , этот метод не подходит.
Метод getLine( ) возвращает String , содержащую следующую строку файла. Он вызывает readLine( ) , который может выбросить исключение, но это исключение ловится, так что getLine( ) не выбрасывает никаких исключений. Одна из проблем разработки исключений заключается в том, обрабатывать ли исключение полностью на этом уровне, обрабатывать ли его частично и передавать то же исключение (или какое-то другое) или просто передавать его дальше. Дальнейшая передача его, в подходящих случаях, может сильно упростить код. Метод getLine( ) превратится в:
Но, конечно, теперь вызывающий код несет ответственность за обработку любого исключения IOException , которое может возникнуть .
Метод cleanup( ) должен быть вызван пользователем, когда закончится использование объекта InputFile . Это освободит ресурсы системы (такие как указатель файла), которые используются объектами BufferedReader и/или FileReader [56] . Вам не нужно делать этого до тех пор, пока вы не закончите работать с объектом InputFile . Вы можете подумать о перенесении такой функциональности в метод finalize( ) , но как показано в Главе 4, вы не можете всегда быть уверены, что будет вызвана finalize( ) (даже если вы можете быть уверены, что она будет вызвана, вы не будете знать когда). Это обратная сторона Java: вся очистка — отличающаяся от очистки памяти — не происходит автоматически, так что вы должны информировать клиентского программиста, что он отвечает за это и, возможно, гарантировать возникновение такой очистки с помощью finalize( ) .
В Cleanup.java InputFile создается для открытия того же исходного файла, который создает программа, файл читается по строкам, а строки нумеруются. Все исключения ловятся в основном в main( ) , хотя вы можете выбрать лучшее решение.
Польза от этого примера в том, что он показывает вам, почему исключения введены именно в этом месте книги — вы не можете работать с основами ввода/вывода, не используя исключения. Исключения настолько интегрированы в программирование на Java, особенно потому, что компилятор навязывает их, что вы можете выполнить ровно столько, не зная их, сколько может сделать, работая с ними.
Совпадение исключений
Когда выброшено исключение, система обработки исключений просматривает “ближайшие” обработчики в порядке их записи. Когда он находит совпадение, исключение считается обработанным и дальнейшего поиска не производится.
Для совпадения исключения не требуется точного соответствия между исключением и его обработчиком. Объект наследованного класса будет совпадать обработчику базового класса, как показано в этом примере:
Исключение Sneeze будет поймано первым предложением catch , с которым оно совпадает — конечно, это первое предложение. Конечно, если вы удалите первое предложение catch, оставив только:
Код все равно будет работать, потому что он ловит базовый класс Sneeze . Другими словами, catch(Annoyance e) будет ловить Annoyance или любой другой класс, наследованный от него. Это полезно, потому что, если вы решите добавить еще унаследованных исключений в метод, то код клиентского программиста не будет требовать изменений до тех пор, пока клиент ловит исключения базового класса.
Если вы пробуете “маскировать” исключения наследованного класса, помещая первым предложение catch для базового класса, как здесь:
компилятор выдаст вам сообщение об ошибке, так как catch-предложение Sneeze никогда не будет достигнуто.
Руководство по исключениям
Используйте исключения для:
- Исправления проблем и нового вызова метода, который явился причиной исключения.
- Исправления вещей и продолжения без повторной попытки метода.
- Подсчета какого-то альтернативного результата вместо того, который должен был вычислить метод.
- Выполнения того, что вы можете в текущем контексте и повторного выброса того же исключения в более старший контекст.
- Выполнения того, что вы можете в текущем контексте и повторного выброса другого исключения в более старший контекст.
- Прекращения программы .
- Упрощения. (Если ваша схема исключений делает вещи более сложными, то это приводит к тягостному и мучительному использованию.)
- Создать более безопасные библиотеки и программы. (Для краткосрочной инвестиции — для отладки — и для долгосрочной инвестиции (Для устойчивости приложения).)
Резюме
Улучшение перекрытия ошибок является мощнейшим способом, который увеличивает устойчивость вашего кода. Перекрытие ошибок является фундаментальной концепцией для каждой написанной вами программы, но это особенно важно в Java, где одна из главнейших целей — это создание компонент программ для других. Для создание помехоустойчивой системы каждый компонент должен быть помехоустойчивым.
Цель обработки исключений в Java состоит в упрощении создания больших, надежных программ при использовании меньшего кода, насколько это возможно, и с большей уверенностью, что ваше приложение не имеет не отлавливаемых ошибок.
Исключения не ужасно сложны для изучения и это одна из тех особенностей, которая обеспечивает немедленную и значительную выгоду для вашего проекта. К счастью, Java ограничивает все аспекты исключений, так что это гарантирует, что они будут использоваться совместно и разработчиком библиотеки, и клиентским программистом.
Упражнения
Решения для выбранных упражнений могут быть найдены в электронной документации The Thinking in Java Annotated Solution Guide, доступной за малую плату на www.BruceEckel.com.
- Создайте класс с main( ) , который выбрасывает объект, класса Exception внутри блока try . Передайте конструктору Exception аргумент String . Поймайте исключение внутри предложение catch и напечатайте аргумент String . Добавьте предложение finally и напечатайте сообщение, чтобы убедится, что вы были там.
- Создайте ваш собственный класс исключений, используя ключевое слово extends . Напишите конструктор для этого класса, который принимает аргумент String , и хранит его внутри объекта в ссылке String . Напишите метод, который печатает хранящийся String . Создайте предложение try-catch для наблюдения своего собственного исключения.
- Напишите класс с методом, который выбрасывает исключение типа, созданного в Упражнении 2. Попробуйте откомпилировать его без спецификации исключения, чтобы посмотреть, что скажет компилятор. Добавьте соответствующую спецификацию исключения. Испытайте ваш класс и его исключение в блоке try-catch.
- Определите ссылку на объект и инициализируйте ее значением null . Попробуйте вызвать метод по этой ссылке. Не окружайте код блоком try-catch , чтобы поймать исключение.
- Создайте класс с двумя методами f( ) и g( ) . В g( ) выбросите исключение нового типа, который вы определили. В f( ) вызовите g( ) , поймайте его исключение и, в предложении catch , выбросите другое исключение (второго определенного вами типа). Проверьте ваш код в main( ) .
- Создайте три новых типа исключений. Напишите класс с методом, который выбрасывает все три исключения. В main( ) вызовите метод, но используйте только единственное предложение catch , которое будет ловить все три вида исключений.
- Напишите код для генерации и поимки ArrayIndexOutOfBoundsException .
- Создайте свое собственное поведение по типу возобновления, используя цикл while , который будет повторяться, пока исключение больше не будет выбрасываться.
- Создайте трехуровневую иерархию исключений. Теперь создайте базовый класс A , с методом, который выбрасывает исключение базового класса вашей иерархии. Наследуйте B от A и перегрузите метод так, чтобы он выбрасывал исключение второго уровня в вашей иерархии. Повторите то же самое, унаследовав класс C от B . В main( ) создайте C и приведите его к A , затем вызовите метод.
- Покажите, что конструктор наследуемого класса не может ловить исключения, брошенные конструктором базового класса .
- Покажите, что OnOffSwitch.java может завершиться неудачей при выбрасывании RuntimeException внутри блока try .
- Покажите, что WithFinally.java не завершится неудачей при выбрасывании RuntimeException в блоке try .
- Измените Упражнение 6, добавив предложение finally . Проверьте, что предложение finally выполняется даже, если выбрасывается NullPointerException .
- Создайте пример, в котором вы используете флаг для управления вызовом кода очистки, как описано во втором параграфе под заголовком “Конструкторы”.
- Измените StormyInning.java , добавив тип исключения UmpireArgument и метод, который его выбрасывает. Проверьте измененную иерархию.
- Удалите первый catch в Human.java и проверьте, что код все равно компилируется и правильно работает.
- Добавьте второй уровень потерь исключения в LostMessage.java , так чтобы HoHumException заменялось третьим исключением.
- В Главе 5 найдите две программы, называемые Assert.java и измените их, чтобы они выбрасывали свои собственные исключения вместо печать в System.err . Это исключение должно быть внутренним классом, расширяющим RuntimeException .
- Добавьте подходящий набор исключений в c08:GreenhouseControls.java .
[51] C программист может посмотреть на возвращаемое значение printf( ) , как пример этого.
[52] Это значительное улучшение, по сравнению с обработкой исключений в C++, которая не ловит нарушения спецификации исключений до времени выполнения, хотя это не очень полезно.
[53] Обработка исключений в C++ не имеет предложения finally , поэтому в C++ освобождение происходит в деструкторах, чтобы завершить такой род очистки.
[54] Деструктор — это функция, которая всегда вызывается, когда объект более не используется. Вы всегда знаете точно, где совершен вызов деструктора. C++ имеет автоматический вызов деструктора, но Object Pascal из Delphi версии 1 и 2 не делает этого (что изменяет значение и использование концепции деструкторов в этом языке).
[55] ISO C++ добавил сходное ограничение, которое требует, чтобы исключение наследуемого метода были теми же или наследовались от тех же, что и выбрасываемые методом базового класса. Это первый случай, в котором C++ реально способен проверить спецификацию исключений во время компиляции.
[56] В C++ деструктор должен это обрабатывать за вас.
Источник
Уязвимость «off-by-one» (завышение/занижение на единицу) – это достаточно старая проблема. Вот перевод описания из английской версии Википедии:
Ошибка off-by-one (off-by-one error, OBOE) это логическая ошибка, возникающая при использовании дискретного эквивалента граничных условий. Подобные ошибки нередки в компьютерном программировании, когда цикл итерации повторяется на один раз больше или меньше, чем следует. Как правило, проблема возникает, если программист не учитывает, что последовательность начинается с нуля, а не с единицы (как, например, с индексами массивов в некоторых языках программирования) или ошибочно использует в сравнении «меньше или равно» вместо «меньше».
Подобные ошибки позволяют проводить DoS-атаки или даже выполнять произвольный код. В интернете есть множество ресурсов, на которых объясняется, как эксплуатировать «переполнение кучи на одну позицию» (“off-by-one heap overflow”).
Но почему «Ошибка на одну позицию 2.0»?
Читая свою ленту на Твиттере, я заметил нечто весьма интересное. Сообщение (tweet), отправленное с официального корпоративного аккаунта, содержало сокращенную ссылку (bit.ly), которая вела на сайт, распространяющий потенциально опасное приложение.

Если внимательно посмотреть на снимок экрана, обнаружатся две похожие ссылки, сокращенные с помощью сервиса bit.ly. В одной из них пропущена буква d. Отсюда и название – «Ошибка на одну позицию 2.0».
В результате элементарной ошибки копирования новая ссылка ведет совершенно не на тот сайт, на который должна была бы. На всякий случай я решил проверить ссылку на сайте http://web-sniffer.net.
Вот сайт, на который попадаешь по ссылке в сообщении Twitter:
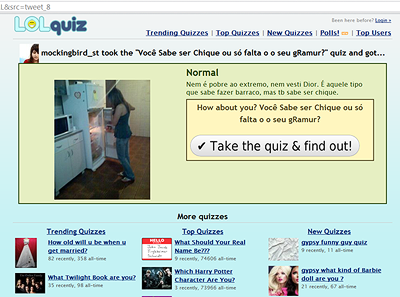
Судя по присутствию слова quiz в названии сайта (LOLquiz), он предлагает разного рода викторины. Однако выглядит он подозрительно. По моему опыту, многие сайты, похожие на этот, используются для вредоносных целей.
Поэтому я решил продолжить расследование и кликнул по ссылке на выбранную случайным образом викторину:
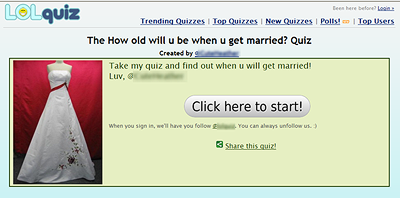
Войдя в тестовый аккаунт Twitter на тестовом компьютере, я кликнул по кнопке подтверждения участия в викторине. На той же странице было написано, что регистрация означает согласие на подписку на ленту сообщений в Twitter, принадлежащую владельцам сайта.
Удивительно, но, пройдя по ссылке, я снова оказался в Twitter, и мне было предложено разрешить некому приложению доступ к моей учетной записи, как видно на снимке экрана ниже:

В своей тестовой учетной записи я авторизовал приложение и был перенаправлен на ту самую викторину, в которой собирался принять участие:

Но каковы были функции того приложения?
Разрешив установку этого приложения, я тем самым предоставил ему права на чтение и запись моего аккаунта в Twitter, как видно на снимке экрана ниже:

Как только приложение получило доступ к моему аккаунту, оно автоматически подписалось на ленту учетной записи lolquiz в Twitter. Эта особенность поведения программы описана на сайте одним предложением, набранным очень мелким шрифтом, и при первом просмотре сайта я его не заметил.
Теперь мой тестовый аккаунт «следует» в Twitter за авторами этого потенциально опасного приложения.
Если посмотреть на число подписчиков на сообщения этой учетной записи, окажется, что права доступа к своим аккаунтам дали этому приложению более 300 000(!) пользователей. Я уверен, что большинство из них не читали набранную мелким шрифтом информацию о функции этого приложения по автоматической подписке на ленту сообщений в Twitter, принадлежащую владельцам сайта.

Пока что никаких сообщений не было. Поэтому я решил попробовать ответить на вопросы викторины и посмотреть, произойдет ли что-нибудь после этого:

Как только вы заканчиваете отвечать на вопросы, приложение рассылает подписчикам вашего аккаунта сообщение с вашими результатами. Если кто-то из них захочет попробовать принять участие в викторине, ему тоже придется дать приложению доступ к своей учетной записи в Twitter, и он тоже автоматически станет подписчиком «lolquiz» и разошлет сообщение о своих результатах своим подписчикам и т.д. Это приводит к вирусному распространению приложения.
Интересно, что автор этого приложения сам является подписчиком двух аналогичных лент в Twitter.
Простой поиск на Twitter выдает множество аналогичных сообщений от других пользователей:

Остается непонятной настоящая цель, ради которой создавалось это приложение, которое (на данный момент) является не вредоносным, но потенциально опасным.
Авторы приложения утверждают, что вы всегда можете отписаться от их ленты сообщений, но не упоминают о том факте, что при этом у приложения сохранятся права на чтение и запись в вашей ленте Twitter. Отписаться от их ленты можно, отправив им сообщение напрямую (Direct Message), но это не приводит к удалению приложения или к прекращению автоматической рассылки сообщений.

Подобные приложения-викторины очень распространены в сети Facebook, а теперь они, очевидно, заполонили и Twitter. Эта викторина, судя по всему, появилась в 2009 году.
Если авторы приложения решат разместить на сайте что-то более опасное (или если он будет взломан с размещением вредоносных ссылок), это может привести к куда более серьезной проблеме, которая затронет сотни тысяч пользователей. Ведь авторы приложения могут посылать какие угодно сообщения с вашего аккаунта в Twitter.
Мой пост о фальшивом антивирусе, распространяемом через Twitter, дает прекрасный пример того, что может произойти.
Мне кажется, это со всей очевидностью показывает, насколько опасными могут быть сервисы по сокращению интернет-адресов: банальная ошибка копирования текста может привести к тому, что по ссылке будет открываться совершенно другой веб-сайт, в то время как при использовании обычных ссылок в большинстве случаев подобная ошибка приведет лишь к сообщению «404 – Страница не найдена».
It sort of is something to do with how the human brain works. We’re wired to be «good enough» for tasks that don’t usually require engineering-grade precision. There’s a reason why the cases we have the most trouble dealing with are called «edge» cases.
Probably the best way to avoid off-by-one errors is encapsulation. For example, instead of using a for loop that iterates a collection by index (from 0 to count — 1), use a for-each style loop with all the logic of where to stop built into the enumerator. That way you only have to get the bounds right once, when writing the enumerator, instead of every time you loop over the collection.
answered Feb 2, 2011 at 18:10
![]()
Mason WheelerMason Wheeler
81.7k24 gold badges234 silver badges309 bronze badges
2
There is something special about how brain handles borders and edges.
While it’s easier for the brain to think in terms of ranges and spaces, focusing on an edge seems to require somewhat more of attention. Here is how it happens, momentary loss of attention or insufficient concentration and you missed the border.
Another slight addition to the problem is that different programming environments have different indexation systems starting at either 0 or 1 which might add confusion to the people actively exposed to the both types of environments.
answered Feb 2, 2011 at 18:12
I believe it is due to context switching. In our day to day lives we tend to use 1-based indexes. Because of this our brain is unable to burn the correct behavior into long term memory.
answered Feb 2, 2011 at 18:10
![]()
ChaosPandionChaosPandion
6,2852 gold badges33 silver badges33 bronze badges
2
An Off-By-One Error (OBOE) is common among any system in which discrete elements are found. In programming and computer science, these errors pop up often during loops and memory allocation. Off-by-one errors happen when there are n-many elements expected and either n+1 or n-1 elements are present.
Termination conditions set using <= instead of < and iterators initialized to non-zero values are two common causes of OBOE’s. Lower-level languages like C — those requiring manual memory management — also subject developers to OBOE cases where terminators, EOF, and similar characters are automatically appended after certain operations.
Example: Off-By-One For Loop
Languages like Python make it easier to avoid off-by-0ne errors through easy reference-based loops. Older iterator-based syntaxes — where static termination conditions are defined — leave much more responsibility in the hands of the developer. Consider the following loops written in JavaScript:
// define a value for n
let n = 5;
// A: loops n-many times
for (let i = 0; i < n; i++){}
// B: loops n-1 times
for (let i = 1; i < n; i++){}
// C: loops n+1 times
for (let i = 0; i <= n; i++){}
n-times
In the first loop A we see the value of i incremented until it is of value n-1 such that a value of n terminates the loop. This produces a loop of n values because our iterator i is initialized to a starting value of 0 such that 0, 1, 2, 3, 4 are 5 unique values, equal to the value assigned to n.
n-1 times
In the second loop B we see the value of i incremented until it is of value n-1 as well. However, in this case, i was initialized with a value of 0 such that the only valid values are 1, 2, 3, 4 or 4 total — 1 fewer than the value 5 which is assigned to n.
n+1 times
In the third loop C, we see the value of i incremented until it is <= the value of n which, in this case, will continue the loop until i reaches a value of 6. This includes the values 0, 1, 2, 3, 4, 5 given i was initialized to 0 such that there are a total of 6 or n+1 elements given the value of n is 6.
Example: Index Errors
In cases where one accesses elements of an array iteratively OBOE’s result from using the <= operator or initializing a iterator to a non-zero value. Depending on the language, these issues may or may not cause an issue. Let’s take a look at an example in Python:
# define a list of 6 total values
n = [0, 1, 2, 3, 4, 5]
# Define an iterator variable
i = 0
while i <= len(n):
# print the value of i
print("i = ", i)
# print the value of the ith element of n
print("n[i] = ", n[i])
# increment the iterator
i += 1
Here we have a list of 6 values and enter a while loop that will access each element via the iterator variable i which gets incremented each iteration via the i += 1 segment. The printout is as follows:
i = 0
n[i] = 0
i = 1
n[i] = 1
i = 2
n[i] = 2
i = 3
n[i] = 3
i = 4
n[i] = 4
i = 5
n[i] = 5
i = 6
Traceback (most recent call last):
File "C:/Users/pc/Desktop/mercator/scatch.py", line 13, in <module>
print("n[i] = ", n[i])
IndexError: list index out of range
Here we see no issue in incrementing the value of i to 6 but when we try to access the 6th element of n we cause a IndexError exception — keep in mind our list is 0-indexed. This code tries to access an element of n that doesn’t exist and Python throws an exception as a result. Let’s consider a similar example using JavaScript:
// Create an array of 6 elements
let n = [0, 1, 2, 3, 4, 5]
// iterate until i <= 6
for (let i = 0; i <= n.length; i++){
console.log("i = ", i);
console.log("i = ", n[i]);
}
The logic is identical to the above Python code but written here in JavaScript syntax. We have an array n with 6 items and we loop until our iterator i‘s value is greater than 6. This produces the following output to the console:
i = 0 n[i] = 0 i = 1 n[i] = 1 i = 2 n[i] = 2 i = 3 n[i] = 3 i = 4 n[i] = 4 i = 5 n[i] = 5 i = 6 n[i] = undefined
The last line where the n[i] syntax was used attempts to access an element of n that doesn’t exist. JavaScript doesn’t throw an exception here however and simply returns an undefined object. This can be useful in cases where crashes should be avoided but also infuriating in cases where one would expect such a logical error to cause an issue.
Common Causes
In languages like C, there are certain functions like strcat in which the first n characters of a source string are used to create a second string. However, this function also appends a terminator character after the operation such that there must be n+1 bytes available in a buffer allocated for the copy operation. Aside from such less common issues, the following checklist is a good guide for avoiding off-by-one errors:
- Iterators that are initialized to non-zero values
- Termination conditions that use
==or<=operators
Final Thoughts
Off-By-One errors are often products of simple typos but can also reflect larger logical flaws. Loop conditions and iterator initialization values are common causes but certainly not exclusive sources of OBOE’s. OBOE’s aren’t exclusive to computer programming and can appear in general calculations as well.
Consider the case of creating a fence that spans 25ft such that there is a fencepost every foot. How many total fence posts would be needed? An easy mistake is to answer 25 posts — there will be 25 posts needed for each 1ft span but there will also be an initial post needed to start. This would bring the total to 25 + 1 post!