From BetaArchive Wiki
Jump to:navigation, search
Article ID: 270848
Article Last Modified on 2/26/2007
- Microsoft Exchange 2000 Server Standard Edition
This article was previously published under Q270848
SYMPTOMS
The Eseutil utility may not work when you use the /d or /p option with the /t option, and you may receive the following error message:
Operation terminated with error -1023 (JET_errInvalidPath, Invalid File Path) after 0.437 seconds.
The number of seconds in this error message varies according to the time and the server.
If you use Event Viewer to view the application event log, an event ID 490 error message that has a source of ESE98 is displayed that states the following:
ESEUTIL (2660) An attempt to open the file «f:sharetemp.edb» for read / write access failed with system error 3 (0x00000003): «The system cannot find the path specified. «. The open file operation will fail with error -1023 (0xfffffc01).
For more information, click http://search.support.microsoft.com/search/?adv=1.
The drive letter, path, and file name in the preceding error message (f:sharetemp.edb) may differ.
CAUSE
This issue can occur if the /t option is specified incorrectly.
RESOLUTION
To resolve this issue, use the correct syntax when you use the /t option in the Eseutil utility.
MORE INFORMATION
The format for the /t option used in conjunction with the /d or /p option is the following
/tdrive:[path]file_name[.edb]
where the path and file extension are optional.
The following is an example of an Eseutil utility command-line format that works:
eseutil /d c:program filesexchsrvrmdbdatapriv1.edb /tc:tempdb.edb
You must create a folder on the drive C named «Temp» before the following format example can work:
eseutil /d c:program filesexchsrvrmdbdatapriv1.edb /tc:temptempdb.edb
If you do not create a folder named Temp before you run the preceding command, the Eseutil utility returns the -1023 error message.
You must use a valid drive letter and path for the /t option to work correctly. If you want to use a mapped drive (\server_nameshared_dir) and map the drive to drive F, use the following syntax:
eseutil /d c:program filesexchsrvrmdbdatapriv1.edb /tf:tempdb.edb
The following format is incorrect, and results in a -1023 error message:
eseutil /d c:program filesexchsrvrmdbdatapriv1.edb /tf:shared_dirtempdb.edb
For additional information about how to use the /t option with the Eseutil or Edbutil utilities on Microsoft Exchange Server 4.0, 5.0, or 5.5, click the article number below to view the article in the Microsoft Knowledge Base:
184738 XADM: Error -1811 Running Edbutil or Eseutil With /T Option
Additional query words: exch2kp2w
Keywords: kberrmsg kbprb KB270848
How do I resolve the error «ERROR: 1023 DETAIL: Serializable isolation violation on table in Redshift»?
Last updated: 2022-10-10
If I run concurrent Amazon Redshift operations in different sessions, I get the message «ERROR: 1023 DETAIL: Serializable isolation violation on table in Redshift.» How do I resolve this error?
Short description
Concurrent write operations in Amazon Redshift must be serializable. This means that it must be possible for the transactions to run serially in at least one order that produces the same results as if the transactions were run concurrently. For more information, see Serializable isolation.
Use one or all of the following methods to resolve serializable isolation errors:
- Move operations that don’t have to be in the same transaction for atomicity so that they are outside the transaction
- Force serialization by locking all tables in each session
- Use snapshot isolation for concurrent transactions
Resolution
Move operations that don’t have to be in the same transaction for atomicity so that they are outside the transaction
Use this method when individual operations inside two transactions cross-reference each other in a way that might affect the outcome of the other transaction. For example, assume that two sessions each start a transaction:
Session1_Redshift = # BEGIN;Session2_Redshift = # BEGIN;The result of the SELECT statement in each transaction might be affected by the INSERT statement in the other. If run serially, in any order, the result of one SELECT statement always returns one more row than if the transactions run concurrently. Because there is no order where the operations can be run serially that can produce the same result as when run concurrently, the last operation that is run results in a serializable isolation error:
Session1_redshift=# select * from tab1;
Session1_redshift =# insert into tab2 values (1);Session2_redshift =# insert into tab1 values (1);
Session2_redshift =# select * from tab2;If the result of the SELECT statements isn’t important (that is, the atomicity of the operations in the transactions isn’t important), move the SELECT statements so that they are outside their transactions. For example:
Session1_Redshift=# BEGIN;
Session1_Redshift = # insert into tab1 values (1)
Session1_Redshift = # END;
Session1_Redshift # select * from tab2;Session2_Redshift # select * from tab1;
Session2_Redshift =# BEGIN;
Session2_Redshift = # insert into tab2 values (1)
Session2_Redshift = # END;In these examples, there are no cross-references in the transactions. The two INSERT statements don’t affect each other. Because there’s at least one order where the transactions can run serially and produce the same result as if run concurrently, the transactions are serializable.
Force serialization by locking all tables in each session
The LOCK command blocks operations that might result in serializable isolation errors. When you use the LOCK command, be sure to do the following:
- Lock all tables affected by the transaction, including those affected by read-only SELECT statements inside the transaction.
- Lock tables in the same order regardless of the order that operations are performed in.
- Lock all tables at the beginning of the transaction, before performing any operations.
Use snapshot isolation for concurrent transactions
The SERIALIZABLE option implements strict serialization, where a transaction might fail if the result can’t be mapped to a serial order of the concurrently running transactions.
The SNAPSHOT ISOLATION option allows higher concurrency, where concurrent modifications to different rows in the same table can complete successfully.
Transactions continue to operate on the latest committed version, or a snapshot, of the database.
Snapshot isolation is set on the database using the ISOLATION LEVEL parameter in the CREATE DATABASE or ALTER DATABASE command.
To view the concurrency model that your database is using, run the following example STV_DB_ISOLATION_LEVEL query:
SELECT * FROM stv_db_isolation_level;
The database can then be altered to SNAPSHOT ISOLATION:
ALTER DATABASE sampledb ISOLATION LEVEL SNAPSHOT;Consider the following when altering the isolation level of a database:
- You must have the superuser or CREATE DATABASE privilege for the current database to change the database isolation level.
- You can’t alter the isolation level of the DEV database environment.
- You can’t alter the isolation level within a transaction block.
- The alter isolation level command fails if other users are connected to the database.
- The alter isolation level command can alter the isolation level settings of the current session.
Did this article help?
Do you need billing or technical support?
AWS support for Internet Explorer ends on 07/31/2022. Supported browsers are Chrome, Firefox, Edge, and Safari.
Learn more »
In this article, I will explain what causes an ERROR 1023 (Serializable isolation violation) in Redshift and how I dealt with it in a novel way.
Redshift’s use cases
Redshift’s design targets fast reads of flattened data. Historical data is typically loaded during off peak hours, stored in a flattened manner (no normalization), and queried for near real time display of data.
Redshift is not optimized for writes due to limitations in its scheduler, lack of dynamic scaling, lack of separation of duties between storage and compute resources, and more basically because it’s a columnar store that doesn’t have row level locking. As a result, an optimal use case involves loading data in batches during a daily/nightly maintenance window and only storing data through the previous day.
If you try to do intraday updates, you will have to deal with periods of high CPU and IO from the writes slowing down your queries. If you store your data in a star or snowflake schema, you’ll also run into issues with Redshift’s serializable isolation limitations if you have multiple jobs normalizing data to the same dimension tables.
When using an ODBC connector, those errors will look similar to this:
System.Data.Odbc.OdbcException: ERROR [HY000] [Amazon][RedShift ODBC] (30) Error occurred while trying to execute a query: ERROR: 1023 DETAIL: Serializable isolation violation on table - 1256109, transactions forming the cycle are: 15749004, 15748971, 15748625, 15748970, 15749497 (pid:8238) at System.Data.Odbc.OdbcConnection.HandleError(OdbcHandle hrHandle, RetCode retcode)
If you’re using Microsoft SQL Server Integration Services (SSIS) your messages may look closer to this:
Executed as user: NT ServiceSQLSERVERAGENT. Microsoft (R) SQL Server Execute Package Utility Version 11.0.5058.0 for 64-bit Copyright (C) Microsoft Corporation. All rights reserved. Started: 7:01:01 AM Error: 2017-03-14 07:30:23.84 Code: 0xC002F304 Source: Populate fact tables Populate fact tables Description: An error occurred with the following error message: "ERROR: XX000: 1023". End Error DTExec: The package execution returned DTSER_FAILURE (1). Started: 7:01:01 AM Finished: 8:41:03 AM Elapsed: 6002.32 seconds. The package execution failed. The step failed.
ERROR: 1023 DETAIL: Serializable isolation violation on table
Basically, a serializable isolation violation in Redshift means that two jobs were writing to the same table concurrently.
I could add that this would okay as long as the multiple jobs had the same results regardless of what order they ran in (serializable). However, it’s not really possible to have them be serializable if you have concurrent jobs creating new rows in a dimension table with an auto-incrementing key.
Although one could argue that one shouldn’t perform normalization on Redshift, if you’re required to do this, we need to prevent two jobs from inserting new rows into the dimension table at the same time.
If you’re using a star schema, it’s quite normal for many fact tables to reference a single dimension table. As a result, the ETL jobs that load these fact tables will need to insert new keys into the same table. If these jobs every run concurrently, you’ll end up with serializable isolation violation errors.
Redshift’s recommendation
In the Redshift world, you will want to have the ETL jobs for these multiple fact tables that normalize to the same dimension tables scheduled in serial. This is how you would load data in the once a day maintenance window scenario.
If you’re forced to schedule these jobs independently where run times may overlap, or if you’re intentionally trying to run these jobs somewhat in parallel, you may consider an alternative solution.
Redshift’s documentation recommends the following:
Force serialization by having each session lock all tables
You can use the LOCK command to force operations to occur serially by blocking operations to tables that would result in serializable isolation errors.
To force serialization while avoiding deadlock, make sure to do the following:
-
Lock all tables affected by the transaction, including those affected by read-only SELECT statements inside the transaction.
-
Lock tables in the same order regardless of the order of operations to be performed.
-
Lock all tables at the beginning of the transaction, before performing any operations.
However, this seems like a horrible idea to do on a production system. You don’t really want to lock a dimension table for reads and writes the entire time that you’re ETL job is loading data.
The semaphore solution (my recommendation)
I was thinking, if only there was a way to pass a semaphore, I could force the jobs to take turns writing to the dimension table and I wouldn’t have to lock the entire dimension table for reads and writes.
I decided to use a shared table and table locking to act as a semaphore whenever writing to a dimension table. Locking a shared “dummy” table prevents needlessly locking the dimension table itself.
For example, for my table named “dimtable” in the “prod” schema, I will use this snippet of SQL anytime I write to the table:
BEGIN; LOCK public.dimtable_lock; -- Write to prod.dimtable END;
This allows us to prevent concurrent writes of the dimension table without preventing reads of the dimension table. This isn’t perfect because If you’re writing to the dimension table and query the table to include the new records, in theory, this should also be a serializable isolation violation. However, in my case, it seemed a better solution than locking the dimension table completely against reads.
Troubleshooting serializable isolation issues:
I’ve found that this is the best query to dig into the cause of the 1023 error.
If your error message is like this:
Serializable isolation violation on table - 1809923, transactions forming the cycle are: 41329759, 41329414 (pid:11276)Then take the above transaction xid’s (41329759, 41329414) and paste them into this query:
WITH pids AS ( SELECT DISTINCT pid FROM svl_qlog WHERE xid IN (41329759, 41329414) ) SELECT a.* FROM svl_qlog a INNER JOIN pids b ON(a.pid = b.pid) ORDER BY starttime;
The pid indicates the session. You’ll see the queries that overlap between the sessions and which ones were aborted, and the transaction that was undone.

Extensible Storage Engine Utility or Eseutil is a built-in Microsoft utility designed to help Exchange and IT administrators repair inconsistent, corrupt, or damaged Exchange databases (EDB). It allows administrators to efficiently deal with Exchange database corruption issues and restore the database and user mailboxes when the backup isn’t available or becomes obsolete.
Sometimes, the utility fails to repair a corrupt or damaged Exchange database or defragment a database due to permission issues, insufficient storage space, or limitations. In such cases, you may encounter various Eseutil errors. In this article, we have discussed some common Eseutil errors and the solutions to resolve them.
Common Eseutil Errors List
Before we begin with the error list, let’s understand the two different Eseutil database recovery modes to repair corrupt databases.
- Soft Recovery
In the Soft Recovery process (Eseutil /r), transaction logs are replayed on the database to bring it back from a Dirty Shutdown state to a consistent or Clean Shutdown state. Once the database is clean, it can be remounted on the server and users can access their mailboxes.
- Hard Recovery
Hard Recovery (Eseutil /p) is used when transaction logs are missing, deleted, or unavailable. It helps recover an inconsistent or corrupt Exchange database from a Dirty Shutdown state to a Clean Shutdown state by purging the database’s irrecoverable mailboxes or mail items.
When you run Soft Recovery or Hard Recovery on a corrupt or inconsistent database, you may encounter one of the several Eseutil errors discussed below.
Tip: Always backup the database before using Eseutil for database repair.
1. Eseutil Error 1003
The error 1003 or JET_errInvalidParameter -1003 appears when you run Soft Recovery on the corrupt or inconsistent database copy. The error reads as follows:
Initiating RECOVERY mode...
Logfile base name: C:Program FilesMicrosoftExchange ServerV15MailboxMailbox Databasee00
Log files: C:Program FilesMicrosoftExchange ServerV15MailboxMailbox Database
System files: C:Program FilesMicrosoftExchange ServerV15Mailbox
Database Directory: C:Program FilesMicrosoftExchange ServerV15MailboxMailbox Database
Operation terminated with error -1003 (JET_errInvalidParameter, Invalid API parameter) after x.xx seconds.
The error code 1003 may appear due to an invalid API parameter is being used or for the following reasons:
- Low Storage: During database repair, you must have at least 110% free storage of the database size to store the temp database file during the repair process. If the disk storage is low, the utility may fail to create the temporary copy for database repair and display the error 1003.
- IPV6: In some cases, the error may also appear if the IPV6 is not enabled on the network adapter.
2. Eseutil /d Error -1808
The error code 1808 or JET_errDiskFull -1808 is a disk space-related Eseutil error that prevents the utility from defragmenting the database file due to low storage space. It appears when the utility fails to defragment the Exchange database file after a repair or recovery session or while performing regular database maintenance tasks.
The error reads as follows:
Operation terminated with error -1808 (Jet_err DiskFull, no space left on Disk) after x.xx seconds
3. Eseutil /r Checksum Error 1018 on Database Page
The checksum JET_errReadVerifyFailure -1018 or checksum error on the database page appears when a consistency check (Eseutil /g) or Exchange database recovery fails. The error is usually caused when the database is corrupted due to hardware-related issues or failure.
The error message reads as follows:
Operation terminated with error -1018 /jet_errreadverifyfailure, checksum="" error="" after x.xx seconds. /jet_errreadverifyfailure
4. Eseutil Bad Checksum Error Count
The bad checksum counts are displayed when the user or administrator runs the checksum check using Eseutil /K parameter. Bad checksum counts indicate a problem with the database content or file. For example, the database or the STM file you are checking is damaged or corrupt.
The command output is displayed as follows:
XXXX pages seen
XX bad checksums
XXXX uninitialized pages
The operation was completed successfully in x.xxx seconds.
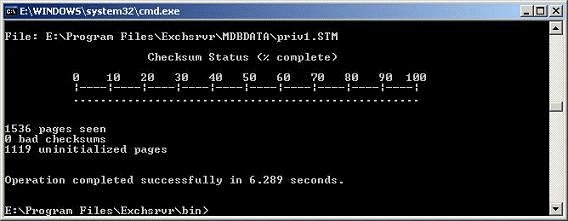
Besides bad checksums, another related checksum error may also appear – “Eseutil Checksum Failed with Microsoft Eseutil Return Error Code -1.”
In such a case, try Soft Recovery. If it fails, perform Hard Recovery to fix the database. Then run an integrity check to check the database for bad checksums or checksum errors. Make sure the bad checksum count is 0.
5. Eseutil /r Terminated with Error -566
When the dbtime on a database page is smaller than the dbtime before in the record, the Soft Recovery fails with the error code -566 or JET_errDbTimeTooOld -566.
The error message reads as follows:
Initiating RECOVERY mode...
Logfile base name: e01
Log files:
System files:
Database Directory: I:Program FilesMicrosoftExchange ServerVxxMailboxMBXDB01MBXDB01.edb
Performing soft recovery...
Operation terminated with error -541 (JET_errLogFileSizeMismatch, actual log file size does not match JET_paramLogFileSize) after 1.485 seconds
6. Eseutil /r Error 1119
The error 1119 or JET_errReadLostFlushVerifyFailure -1119 is displayed when the database page read from the storage media had a previous write not represented on the database page.
The error is caused when the drive has file system issues or the storage media has failed. The complete error message reads as follows:
Operation terminated with error -1119 (JET_errReadLostFlushVerifyFailure, The database page read from disk had a previous write not represented on the page.) after XXXX.xxx seconds.
7. Eseutil Jet Error LV Corrupted Jet Error -1526
JET_errLVCorrupted -1526 is an Eseutil error that occurs when a user tries to mount the database but fails due to a corrupt or damaged log file. It occurs when the Eseutil detects corruption in a long-value tree.
You can follow our previous guide to resolve JET_errLVCorrupted -1526 error.
8. Eseutil /d Error 555
The JET_errGivenLogFileHasBadSignature -555 is an Eseutil error that indicates a problem with the restore log file. The log file is either damaged or has a bad signature. It appears when the user runs Eseutil /d command to defragment an Exchange database file.
In such a case, you can perform Soft Recovery (eseutil /r ) on the database to fix it.
9. Eseutil Failure Writing to Log File
The error -501 JET_errLogFileCorrupt or failure writing to log file occurs when hardware corrupts I/O at writing or lost flush lead to unstable log. This may happen when the hard drive, controller, or hardware stops responding to the commands, or there’s a conflict caused by programs, such as antivirus that may lock the Active Directory log files.
How to Prevent and Resolve Eseutil Errors?
Before using Eseutil to recover or defragment the Exchange database, you must check and meet the prerequisites required to run the Eseutil.
Prerequisites
To ensure Eseutil does not fail or result in the errors mentioned above, check the following:
- The user account used to execute Eseutil commands should be an Exchange administrator.
- The Exchange database file must be offline and not mounted on the server.
- The drive where the database file is stored should have 110% free disk space than the database file size. You can move large files or folders that are not required to a different volume or external drive to free up space.
- Check the storage media for any disk errors and fix them using CHKDSK.
- Check and enable IPv6 on your network adapter.
After fulfilling the prerequisites the errors still appear or Eseutil fails to recover the database, it may be due to one or more of the following reasons:
- The database is severely corrupt or damaged, beyond the capabilities of Eseutil.
- The STM file is unavailable or does not match the Exchange database you are trying to repair.
- The drive where the database is stored does not have enough space to hold a temporary copy of the database for repair.
Quick Solutions to Resolve Eseutil Jet Database Errors
- Restart the server and try again. This may provide you access if caused by temporary hardware or software-related issue. However, consider upgrading the firmware and replacing the controller or disk, if the issue isn’t fixed.
- There’s a conflict between the apps that might be locking the files required to perform certain operations. For instance, antivirus software may scan logs and lock them until the scan is finished resulting in jet database errors. You can temporarily disable the antivirus or add an exception for log and database folders.
- Disable third-party apps from the startup items list and then restart the server.
- Install and use UPS for power supply.
- Install disk controller with battery backup.
- Disable write-back cache on drive controller.
- Remove/reinstall the Active directory on the domain controller.
- Verify driver stack.
- If the Jet database error appeared after Soft Recovery, try Hard Recovery after taking the database backup.
Use Advanced Exchange Recovery Tool for Database Repair
If the Eseutil errors are not resolved or the utility fails to repair the database, you can use an advanced third-party Exchange server recovery software, such as Stellar Repair for Exchange. The software can repair severely corrupt or damaged databases without transaction logs and restore all the mailboxes.
Furthermore, you can use the software to save recovered mailboxes from a repaired database (EDB) to PST files or export them directly to your Exchange Server mailbox database with complete integrity and precision. You can also export the mailboxes from repaired Exchange EDB files directly to Office 365 in a few clicks.