Ошибка ORA-0600 является внутренним кодом ошибки для программных исключений Oracle. Её возникновение указывает на то, что процесс столкнулся на низком уровне с неожиданным условием.
Ошибка ORA-0600 включает список аргументов в квадратных скобках:
ORA-00600 "internal error code, arguments: [%a], [%b], [%c], [%d], [%e]"
Первым аргументом является внутренний номер сообщения или символьная строка. Этот аргумент и номер версии базы данных является первостепенным в идентификации первопричины и потенциального воздействия на базу данных. Остальные аргументы используются, что бы предоставить дополнительную информацию (например, значения внутренних переменных и т.д.).
В зависимости от вида первого аргумента, в Oracle имеются два типа ошибок ORA-0600:
- первый аргумент является числом, которое отражает исходный компонент или слой, в котором происходит ошибка.
- первый аргумент является мнемоникой, которая указывает на исходный модуль, где произошла ошибка. Этот тип внутренней ошибки более предпочтителен в настоящее время.
Категории ошибок ORA-0600 ранжированные по номеру
В следующей таблице приведена информация относительно внутренних числовых кодов ошибок ORA-0600, используемых в Oracle.
Читать далее…
Категории ошибок ORA-0600 ранжированные по мнемонике
Следующая таблица детализирует возможные мнемоники ошибок ORA-0600.
Читать далее…
Справочник ошибок ORA-0600
ORA-00600: internal error code, arguments: [1113]
Последствия:
Сбой процесса, возможный сбой экземпляра.
Версия:
от 6.0 до 9.2
Причины возникновения:
Попытка освободить state object, хотя он уже находиться в свободных списках. Нарушение целостности в памяти SGA или из-за bug в плохом управлении state objects.
Действия:
Проанализировать дамп PMON, установить заплатки на bug.
ORA-00600: internal error code, arguments: [4193], [a], [b]
Аргументы:
[a] – Номер изменения (SCN) записи в серменте отката (Undo), [b] SCN записи в журнале повторного выполнения (Redo)
Последствия:
Сбой процесса, возможное повреждение сегмента отката, невозможность продолжения наката журналов на STANDBY.
Версия:
от 6.0 до 10.1
Источник:
KERNEL TRANSACTION UNDO
Причины возникновения:
Было обнаружено несоответствие между журнальной записью и записью в сегменте отката.
Действия:
Перейти на новую версию Oracle (10.2.0.5, 11.2.0.1); Восстановить экземпляр из резервной копии.
ORA-00600: internal error code, arguments: [12333], [a], [b],[c],[d]
Последствия:
Отказ процесса. Физического искажения нет.
Версия:
от 6.0 до 9.2
Источник:
USER/ORACLE INTERFACE LAYER
Причины возникновения:
В результате сетевой ошибки получены плохие данные, приложение клиента послало неправильные данные, данные в сетевом буфере были записаны поверх, всевозможные bug (столбцы LONG).
Действия:
Проверить сетевое соединение и настройки NLS, заменить версию клиента Net на более новую.
ORA-00600: internal error code, arguments: [13001]
Последствия:
Физического искажения нет.
Версия:
от 8.0 до 10.2
Причины возникновения:
Возникает при удалении строк из таблицы, в случаях когда запись уже удалена. Такое обычно происходит если в таблице есть внешний ключ на столбец в этой же таблице. По своей сути не является полноценной ошибкой.
Действия:
Переделать внешний ключ.
ORA-00600: internal error code, arguments: [15419], [a]
Последствия:
Отказ процесса. Физического искажения нет.
Версия:
от 7.0 до 10.1
Источник:
Kernel Kompilation pl/sql Compiler
Причины возникновения:
Всевозможные bug. Для большей информации смотреть дополнительные ошибки в trc файле. Bug: 2829071, 2588469, 2437995
Действия:
Установить заплатки на bug. Если не помогает, модифицируйте PL/SQL код.
ORA-00600: internal error code, arguments: [15735], [a], [b]
Аргумент:
[a] — значение parallel_execution_message_size в котором нуждается запрос, [b] — текущее значение parallel_execution_message_size
Последствия:
Ошибка с записью в trace файл. Физического искажения нет.
Версия:
от 10.1 до 10.2
Причины возникновения:
BUG:5462624.
Действия:
Открыть trc файл ошибки. Найти sql оператор. Для таблиц этого оператора выполнить запрос select table_name, degree from dba_tables where table_name = ». Выбрать таблицы у которых degree ‘1’. Выполнить для каждой таблицы команду alter table noparallel. В качестве второго способа можно порекомендовать увеличить значение параметра parallel_execution_message_size.
ORA-00600: internal error code, arguments: [16607]
Последствия:
Сбой процесса, повреждения данных нет.
Версия:
от 8.0 до 10.1
Источник:
Kernel Generic Library cache Subordinate set/cache manager
Причины возникновения:
Была произведена попытка получить подчиненный элемент, но при поиске, куча памяти для данного элемента не была закреплена.
Действия:
Установить заплатки на bug.
ORA-00600: internal error code, arguments: [17090],[a], [b],[c],[d]
Последствия:
Отказ процесса. Физического искажения нет.
Версия:
от 7.0 до 8.1
Источник:
GENERIC CODE LAYER
Причины возникновения:
Всевозможные bug.
Действия:
Уничтожьте сеанс и связанный с ним процесс.
ORA-00600: internal error code, arguments: [17271], [instantiation space leak]
Последствия:
Сбой процесса. Повреждения данных нет.
Версия:
до 10.2.0.5
Источник:
Kernel Generic Instantiation manager
Причины возникновения:
Исключение возникает при попытке Oracle деинстанцировать (уничтожить экземпляр) разделяемый объект (курсор) во время выхода из сеанса. В этот момент, Oracle проходит связанный список разделяемых объектов для деинстанцирования, и находит, что объект был помечен как не разделяемый. Этого не должно быть, поэтому возникает исключение. Может проявляться при работе с распределёнными базами данных.
Действия:
Игнорировать ошибку. Если ошибка повторяется, то идентифицировать курсор в trace файле и переделать, или поставить последний патч Oracle закрывающий баги.
ORA-00600: internal error code, arguments: [25012], [a], [b]
Аргумент:
[a] — номер табличного пространства, [b] — относительный номер файла БД
Последствия:
Возможно физическое искажение.
Версия:
от 8.0 до 10.1
Источник:
KERNEL FILE MANAGEMENT TABLESPACE COMPONENT
Причины возникновения:
Всевозможные bug ( 4305391, 3915343, 3900237, 3771508, 3751874, 3430832, 3258674, 3150268, 3070856, 2531519, 2526334, 2287815, 2214167, 2212389, 2189615, 2184731, 1968815, 1949273, 1872985).
Действия:
Установить заплатки на bug.
ORA-00600: internal error code, arguments: [ktspgsb-1]
Последствия:
Повреждение данных.
Версия:
До 10.2.0.5
Причины возникновения:
Ошибка возникает если в объекте (таблице) присутствуют логически повреждённые блоки. Выполнение команд (TRUNCATE, INSERT и т.д.) применительно к объекту приводит к этой ошибке.
Действия:
Пересоздание объекта.
ORA-00600: internal error code, arguments: [pfri.c: pfri8: plio mismatch ]
Причины возникновения:
Несоответствие создания экземпляра PL/SQL объекта. Вероятнее всего возникает из-за инвалидации PL/SQL объекта (bug 9691456, зафиксирован в 11.2.0.2). Проявлялась в триггере на версии 10.2.0.5.
Действия:
Приведение PL/SQL объекта в нормальный статус.

Oracle database is the most popular database among the database industry because of its accuracy and performance. It is a Relational database management system (RDBMS) and capable to store and manage lots of new entries in a sufficient manner and why so it is one of popular database.
The majority of getting errors related to Oracle database increases if you do not have enough knowledge of Oracle. Yes, it is a fact and due to having less knowledge of using Oracle database, users get different errors messages and one of them is the ora-00600 internal error code.
One more issue with this error is that it can normally generate along with arguments encloses in a square bracket, and here occurs the critical situation because the meaning of these enclosed arguments alters with the version of the database. It is very difficult for a database administrator to verify the reason for the database error. This error also gets more difficult when more than one ORA-00600 error occurs because due to this the generated trace files and log files become large in number.
If you are the one who got this error then do not worry, you have come to the right place. I am saying so because here you will get to know how to fix ora-00600 internal error code.
Why ORA-00600 Error Occurs?
There are several causes due to which ORA_00600 internal error code occurs. It is a generic internal error number to execute Oracle program. This error indicates that the process has some unexpected conditions. The first argument is internal message number and the other arguments are several names, character strings and numbers. However, the number may change the meaning of different Oracle versions. Here are some of the reasons of getting this error:
#1: File Corruption: When an Oracle supported file has been corrupted then you may get ora-00600 internal error code.
#2: Timeouts: While connecting with the database the timeout occurred or the query runs for a long time and timeout occurs then this internal error code takes place.
#3: Failed Data Checks In the Memory: Due to the failed data checks in the memory, ora-00600 internal error code occurs.
#4: Hardware/Memory/IO: When the hardware is incompatible or the memory is full in Oracle version and you still work on it may cause this error to take place.
#5: Incorrectly Restored Files: When the Oracle files are restored in an improper way then this error will occur.
There are several reasons for ORA-00600 error like compatibility issues to database block error. Sometimes, this kind of error remains unsolvable. However, it is quite difficult to find the root cause of this error.
Several reasons are there ways with the help of which you will be able to fix ora-00600 internal error code. Here, I have tried my best to let you know how to resolve ora-00600 internal error code. Here are some of the major solutions you should try:
Fix #1: Writes Error Message In Alert Log & Trace File
The very first option you can try to fix ora-00600 internal error code is to write error message and trace file in alert.log file. The Oracle engine will write the error in alert.log file. The trace file location will find in alert.log file.
Fix #2: Try Other Solutions Based On Error Code Examples
You may get several errors reported within the space of a few minutes that starts with the ORA-00600 error. Well, apart from fixing ora-00600 error, you can check trace files and alert logs. Another solution you can try is to find the source of the issue is important. Most of the time, you will not be able to find the source by checking the alert or trace the alert logs. Also, these errors will not give you clear information about what has happened with the server.
Here are some great examples that might help the Oracle developers or users and DBAs to restore this issue:
Example #1:
ORA-00600: internal error code, arguments: [kxtotolc_lobopt], [], [], [], [], [], [], [], [], [], [], []
00600. 00000 – “internal error code, arguments: [%s], [%s], [%s], [%s], [%s], [%s], [%s], [%s]”
Cause of this error: This example is the generic internal error number for Oracle program exceptions. Also, this error indicates that a process has encountered an exceptional condition.
How To Fix This Issue
If you are updating or inserting the CLOB column value as null with the use of merge statement and the merge the statement table has trigger. The same null CLOB column value if you try to update or insert CLOB value in another table with the use of trigger then you will get ora-00600 internal error code. You will also notice that the session is closed automatically, you will also get this error in both Oracle 11g as well as 12c.
Below are the steps to fix this issue:
- First of all, you have to create a table CLOB_ table(sno number, c_clob clob);
- Next, you have to create table table test_Clob_table_stg as select * from test_Clob_table;
- After this, you are required to create a trigger on Clob_table table and then you have to insert data in staging table test_Clob_table_stg using trigger:
CREATE OR REPLACE trigger test_Clob_table_trg AFTER INSERT ON Clob_table
FOR EACH ROW
DECLARE
BEGIN
INSERT INTO test_Clob_table_stg VALUES(:new.sno,:new.c_clob);
EXCEPTION
WHEN others THEN
NULL;
END;
/
- You have to then run the below query.
MERGE INTO Clob_table a USING (
select 1 AS sno, null AS C_CLOB from dual) b
ON (a.sno = b.sno)
WHEN MATCHED THEN
UPDATE SET C_CLOB = b.C_CLOB
WHEN NOT MATCHED THEN
INSERT (a.sno,a.C_CLOB) VALUES (b.sno,b.C_CLOB);
Example #2:
Error Code:
ORA-00600: internal error code, arguments: [15851], [3], [3499], [2], [1], [], [], [], [], [], [], []
ORA-00600: internal error code, arguments: [15851], [3], [3499], [2], [1], [], [], [], [], [], [], []
ORA-06502: PL/SQL: numeric or value error: character string buffer too small
ORA-06512: at “SIEBEL_ODS.MS_CCM_UTILITIES”, line 2866
ORA-04088: error during execution of trigger ‘SIEBEL_ODS.MS_CCM_TI_INVESTIGATION’
00600. 00000 – “internal error code, arguments: [%s], [%s], [%s], [%s], [%s], [%s], [%s], [%s]”
Cause of this example: This example is the generic internal error number for Oracle program exceptions. This error message indicates that a process has encountered an exceptional condition.
How To Fix This Issue:
The other function used in trigger has variable size issue because you got this error, this trigger has created on merge statement table that is sued in “_P” package. This error won’t track the error log tables until if you run all the statement outside of the package, you get error in si_application_error_log.
Example #3:
SQL Error: ORA-00600: internal error code, arguments: [13013], [5001], [158796], [30437895], [0], [30437895], [17], [], [], [], [], []
How To Fix This Issue:
You can create index on one table for improving the performance of query, on same table you are updating data in some stages.
This will work and improve the performance in local examples and customer testing examples, but users get ora-00600 internal error code in UAT after applying the patch, whenever users has done update statement stage flow. You will get the below update statement highlighted in trace file with the error message, it helped users to debug the issue and also you will get some more information in alert log for an internal error.
Query to trace file with error message:
UPDATE MS_ITC_AUDIT_V SET STATUS = ’38’, AUDIT_STATUS = ’38’ WHERE AUDIT_ID = :B1 AND INSTANCE_ID = (SELECT MAX(INSTANCE_ID) FROM MS_ITC_AUDIT_V WHERE AUDIT_ID = :B1 );
Ultimate Solution: Try Oracle File Repair Tool To Fix ORA-00600 Internal Error Code
Apart from all these solutions that are mentioned above, if you are unable to fix ora-00600 error then you can try Oracle File Repair Tool. This tool will allow you to fix this error and recover Oracle database easily. This tool has some great features that will let you know how to fix ora-00600 internal error code. I am sure that you will not get disappointed after trying this tool. All you have to do is to download and install this tool and follow the step by step instructions to fix and recover oracle database that shows ora-00600 internal error code.


Steps To Fix ORA-00600 Internal error Code
Step 1: Search the Initial screen of Stellar Phoenix Oracle Repair & Recovery with a pop-up window showing options to select or search corrupt Oracle databases on your computer.
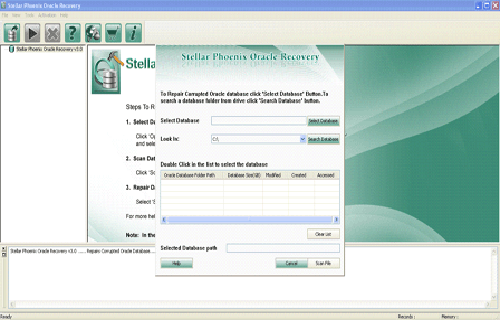
Step 2: Click Scan File to initiate the scan process after selecting the oracle database. The recoverable database objects get listed in left-side pane.
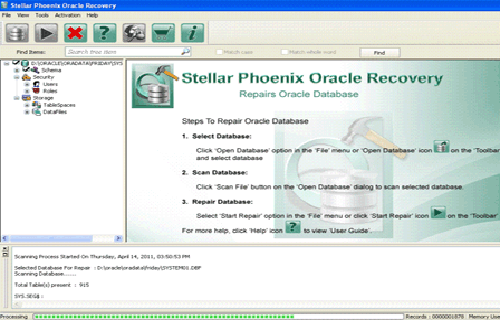
Step 3: Click an object to see its preview.

Step 4: : Click Start Repair in the icon bar to start the repair process. A pop-up window is displayed which show the steps needed to perform further. Click next and continue.

Step 5: Give the user name, password and path of the blank database where you want to save the repaired database objects.

Step 6: Repairing and restoring various database objects after establishing a connection with blank oracle database.

Final Words
I hope after going through this blog and trying the ways to fix ora-00600 internal error code, you will be able to fix it and recover the Oracle database easily. I have tried my best to provide you the best solution I can. Hope these will not let you down in any manner. All the best to you.

Jacob Martin is a technology enthusiast having experience of more than 4 years with great interest in database administration. He is expertise in related subjects like SQL database, Access, Oracle & others. Jacob has Master of Science (M.S) degree from the University of Dallas. He loves to write and provide solutions to people on database repair. Apart from this, he also loves to visit different countries in free time.
In my previous article i have explained about the most common error ORA-12154.In This article i will try to explain another most common error which has been searched approximately 50000 times in a month by oracle developers. While working with a database and performing different scenarios of database every developer or dba might have faced error called as ORA-00600: internal error code.While working with databases i have frequently faced ORA-00600: internal error code and struggled to solve and debug this issue.I would like to share my experience working and debugging with this error.
“ORA-600 error has been searched on google approximately 50 k times per month”

The generic error code will be displayed as :
ORA-00600: internal error code, arguments: [%s], [%s],[%s], [%s], [%s]
where %s stands for string.
Why ORA-00600 error will come?
There are multiple reasons for which this error will occur.Actually ORA-00600 is generic internal error number for oracle program exceptions.This actually indicates that the process has unexpected conditions.The first argument is internal message number and other arguments are various numbers,names and character strings.The numbers may change meanings of different oracle versions.There should be multiple reasons of this error.I will mention few of them:
Reason 1 :
Timeouts
While connecting with the database the timeout occurred or the query is running for long time and timeout occurred then this error will come.
Reason 2:
File Corruption
When any oracle supported file has been corrupted then this error will come.
Reason 3:
Hardware/Memory/IO
When the memory is full or hardware is not compatible with oracle version then this error will come.
Reason 4:
Failed Data checks in the memory
Because of failed data checks in the memory this error will occur.
Reason 5:
Incorrectly restored files.
If the oracle internal files restored not properly then this error will come.
There should be lot of reasons for ORA-00600 like compatibility problem to data block error.Most of the times these kind of errors remains unresolved.We can not be able to find the root cause of this issue.We need to call oracle support to resolve this issue in 60-70 percent of times.
NO TIME TO READ CLICK HERE TO GET THIS ARTICLE
Resolution of Error :
There is no specific reason for which ” ORA-00600: internal error code “error will come.For these kind of internal errors following activities is done by oracle engine :
1.Writes Error message in Alert Log :
The oracle engine will write the error in alert.log file.
2.Trace file :
Write detailed message in trace file.The trace file location will find in alert.log file.
3.Often you will see multiple errors reported within the space of a few minutes, typically starting with an ORA-600. It is usually, but not always, the case that the first is the significant error and the others are side effects.
If you are facing these kind of error first step is to check trace files and alert logs.There is no way to resolve these kind of issues so we need to do trial and error to resolve this issue.Finding the source of the problem is important. Sometimes you won’t be finding the source by checking the alert or trace logs. And neither these errors give you clear information about what exactly has happened with your server.
Following are some examples where i have faced this error and resolved.These examples might help developers and DBAs to resolve this issue.
Example 1 :
Error Code :
ORA-00600: internal error code, arguments: [15851], [3], [3499], [2], [1], [], [], [], [], [], [], []
ORA-00600: internal error code, arguments: [15851], [3], [3499], [2], [1], [], [], [], [], [], [], []
ORA-06502: PL/SQL: numeric or value error: character string buffer too small
ORA-06512: at “SIEBEL_ODS.MS_CCM_UTILITIES”, line 2866
ORA-04088: error during execution of trigger ‘SIEBEL_ODS.MS_CCM_TI_INVESTIGATION’
00600. 00000 – “internal error code, arguments: [%s], [%s], [%s], [%s], [%s], [%s], [%s], [%s]”
*Cause: This is the generic internal error number for Oracle program
exceptions. This indicates that a process has encountered an
exceptional condition.
*Action: Report as a bug – the first argument is the internal error number
Resolution :
one of the function used in trigger has variable size issue due to this we got above error,
this trigger created on merge statement table used in “_P” package. This error we will not track in any of the error log tables until if you run each and every statement outside of the package, we got socket error in si_application_error_log.
Example 2 :
ORA-00600: internal error code, arguments: [kxtotolc_lobopt], [], [], [], [], [], [], [], [], [], [], []
00600. 00000 – “internal error code, arguments: [%s], [%s], [%s], [%s], [%s], [%s], [%s], [%s]”
*Cause: This is the generic internal error number for Oracle program
exceptions. This indicates that a process has encountered an
exceptional condition.
*Action: Report as a bug – the first argument is the internal error number
Resolution :
If we are inserting/updating CLOB column value as null using merge statement, and merge statement table has trigger,same null CLOB column value if we try to insert/update CLOB value in another table using trigger then we will get the above error,also session is automatically closed, we got this error in both Oracle 11g and 12c.
Steps :
1) create table Clob_table(sno number, c_clob clob);
2) create table test_Clob_table_stg as select * from test_Clob_table;
3) Create a trigger on Clob_table table and insert data in staging table test_Clob_table_stg using trriger
CREATE OR REPLACE trigger test_Clob_table_trg AFTER INSERT ON Clob_table
FOR EACH ROW
DECLARE
BEGIN
INSERT INTO test_Clob_table_stg VALUES(:new.sno,:new.c_clob);
EXCEPTION
WHEN others THEN
NULL;
END;
/
4) Run the below query.
MERGE INTO Clob_table a USING (
select 1 AS sno, null AS C_CLOB from dual) b
ON (a.sno = b.sno)
WHEN MATCHED THEN
UPDATE SET C_CLOB = b.C_CLOB
WHEN NOT MATCHED THEN
INSERT (a.sno,a.C_CLOB) VALUES (b.sno,b.C_CLOB);
Example 3 :
SQL Error: ORA-00600: internal error code, arguments: [13013], [5001], [158796], [30437895], [0], [30437895], [17], [], [], [], [], []
Resolution :
We have created index on one table to improve performance of query, on same table we are updating data in some stages.
It worked fine and improved performance in local instances and customer testing instance, but we got above error in UAT after applying patch, whenever they has done update statement stage flow. After 3 days of debugging ,we suspect some data blocks are corrupted in UAT due that we got the error and then we dropped the newly index and check the flow, it worked fine. We got the below update statement highlighted in trace file with error message, it helped us to debug the issue and also we will get some more information in alert log for any internal error.
Query for the same :
UPDATE MS_ITC_AUDIT_V SET STATUS = ’38’, AUDIT_STATUS = ’38’ WHERE AUDIT_ID = :B1 AND INSTANCE_ID = (SELECT MAX(INSTANCE_ID) FROM MS_ITC_AUDIT_V WHERE AUDIT_ID = :B1 );
These are some examples of the ORA-00600: internal error code.Hope you like this article.If you like this article dont forget to share it with everyone.
How to deal with ORA-600 Internal Errors
PURPOSE
This note provides a description of how to handle ORA-600 Internal Errors.It is intended to be used by the Database Administrator when reporting ORA-600 Internal Errors to Oracle Support.
TROUBLESHOOTING STEPS
How to deal with ORA-600 Internal Errors
Unless you are able to identify the cause and possible fix for an ORA-600 error using the references mentioned below, it should be considered as a potentially serious issue and reported to Oracle Support for identification.
As mentioned in note:146580.1 every ORA-600 error will generate a trace file. The name and location of the trace file is also written to the alert.log. To help Oracle Support determine what caused the ORA-600 you should open a Service Request and supply the following information:
-
The database alert log located in BACKGROUND_DUMP_DEST (for Oracle Real Application Clusters supply the alert log for all instances in the environment):
SQL> show parameter background_dump_dest
-
The trace file mentioned in the alert log.
- In case of multiple occurrences of the same ORA-600 error (ie. identical first arguments) you should only supply the first 2 or 3 trace files but do not delete any of the remaining traces as they might be required at a later stage.
- In case of multiple different ORA-600 errors you should only supply the trace file from the first error. Oracle Support will request any other file that may be needed.
- For Oracle RDBMS 11g, provide both the trace file and the incident trace file referenced
- Recent changes to the system environment, eg. hardware modifications, operating system upgrades, restore of datafiles, power failures, etc.
-
Use RDA (Remote Diagnostic Agent) to collect important information:
note:314422.1 «Remote Diagnostic Agent (RDA) 4 — Getting Started»
ORA-600 errors are raised from the kernel code of the Oracle RDBMS software when an internal inconsistency is detected or an unexpected condition is met. This situation is not necessarily a bug as it might be caused by problems with the Operating System, lack of resources, hardware failures, etc.
With the ORA-600 error comes a list of arguments in square brackets. The first of these arguments tells us from where in the code the error was caught and thus is the key information in identifying the problem. This argument is either a number or a character string. The remaining arguments are used to supply further information (e.g. values of internal variables etc).
Whenever an ORA-600 error is raised a trace file is generated and an entry written to the alert.log with details of the trace file location. Starting with Oracle Database 11g Release 1, the diagnosability infrastructure was introduced which places the trace and core files into a location controlled by the DIAGNOSTIC_DEST initialization parameter when an incident, such as an ORA-600 is created. For earlier versions, the trace file will be written to either USER_DUMP_DEST (if the error was caught in a user process) or BACKGROUND_DUMP_DEST (if the error was caught in a background process like PMON or SMON). The trace file contains vital information about what led to the error condition.
The purpose of this troubleshooting article is to provide an insight into key areas of internal
600/7445 trace files to assist in deriving to a known bug or to highlight what might be needed
by ORACLE Support to progress an issue further. Whilst the article can be used to some
extent on 11g it is primarily written for versions <V10204 due to :-
a) The worked example is based on a bug fixed in V10204 and higher releases
b) The alert/trace file structure in 11g has changed
The article will make reference to other notes so that the traces for 11g can also
be proactively reviewed if wished.
The nature of Internal errors means no one approach can guarantee getting to a solution but again
the intention is to provide an indication on notes that support make available to customers and
a simple workflow process that assists for a vast majority of SRs. A simple example is illustrated
to generate a known bug that is harmless to the database when generated, that said it
should ONLY be used on a TEST database as it’s not encouraged to willingly raise such errors in
‘LIVE’ environments. This example will then be used to highlight various sections and how each
section can be useful for general 600/7445 analysis and again to provide the best chance of
identifying a known bugfix should one be available.
The article also makes links to a number of others for completeness including Note:232963.1
should a testcase be required as is the ideal case for all internal errors but understandably
is not always possible dependent on the problem area. Tests were made on SUN but the
bug is not platform specific, it may however show slightly different messages within the alert
log and for Windows based platforms some tools/notes might not be applicable. However this
does not distract from the primary aim of how a trace file can be analyzed.
An Internal Error whether ORA-00600 or ORA-07445 can fall into many categories :-
Issue reproducible and testcase can be provided
Issue reproducible but no simple testcase perhaps due to code being oracle SQL, 3rd party SQL
Issue not reproducible but persistent and formulates to some pattern e.g. once a day
Issue not reproducible and random pattern to occurrences
By definition if an issue is not reproducible at will in a customer environment a testcase may
be very difficult to obtain but should always be attempted where possible.
These are a simplified subset, depending on root cause there can be many 600/7445 errors.
Typically the argument(s) of the error when unique should mean each are different problems
but if occurring on same timestamp or one always soon follows another there might be some
relationship and this will be for support to determine.
TROUBLESHOOTING STEPS
Worked Example
——————
A real life example will follow and a working methodology will then be provided. Conclusions
will then be made at the end of the analysis and some standard questions will be commented
on that should always be appropriate to analysis of Internal errors and perhaps any SR raised
into support. The bug number identified will be reported in a later section so as to show the
workflow/analysis methodology used without knowing the solution in advance. This article
is only suitable for <V10204 databases in terms of the testcase as the bug it relates to
if fixed in the V10204PSR and higher RDBMS versions. The article is still appropriate as an
introduction to analysis for 11g RDBMS and we will mention the main differences for when an internal error is seen in 11g. Due to the nature of Internal errors it is possible that the error
is reported differently between versions/PSRs/platforms making analysis more complex. The
example and trace results for this article came from V10201/64bitSUN but the same principles
apply to all.
sqlplus scott/tiger
drop table a;
drop table b;
create table A(col11 number, col12 number);
create table B(col21 number, col22 number);
insert into a values (-3,-7);
insert into a values (null,-1);
insert into b values ( -7,-3);
update a sET col11 =
(select avg(b.col22) keep (dense_rank first order by (col22)) FROM b where
b.col21= a.col12);
The UPDATE will fail at session level with ORA-03113 error. A trace file will also be written
to the UDUMP destination of the database and will now be highlighted, where appropriate
if a section can be found using keyword searches in the trace it will be mentioned.
Before any analysis of UDUMP/BDUMP traces take place there should be an understanding of
how the error(s) are reported in the alert log.
ALERT LOG
—————
As this is a worked example we know what to expect in advance but the alert and an understanding
of what actions take place around an internal error can be fundamental to resolution. It is
certainly possible for internal errors to be a consequence of a problem rather than the cause.
Errors in file xxxx/xxxx_ora_24779.trc:
ORA-07445: exception encountered: core dump [_memcpy()+592] [SIGSEGV]
[Address not mapped to object] [0xFFFFFFFF7B180000] [] []
ORA-00600: internal error code, arguments: [kgh_heap_sizes:ds],
[0xFFFFFFFF7B179E98], [], [], [], [], [], []
ORA-07445: exception encountered: core dump [_memcpy()+592] [SIGSEGV]
[Address not mapped to object] [0xFFFFFFFF7B180000] [] []
ORA-00600: internal error code, arguments: [kghGetHpSz1], [0xFFFFFFFF7B179EA8]
The errors continue in the alert and as we can see >1 error is raised but all are reported
to be within the same tracefile.
There will be cases where >1 error and >1 trace exist but this is
beyond the scope of this ‘Introduction’.
Various sections of the trace are now reported based on this example, not all 600/7445 traces
will allow for each section to be reviewed. Again this is a very simple example and often a
combination of traces will need to be understood which is beyond the scope of this article.
Section 1 : Trace header information
-------------------------------------
xxxx/xxxx_ora_24779.trc
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 — 64bit Production
With the Partitioning, OLAP and Data Mining options
ORACLE_HOME = xxxxxx
System name: SunOS
Node name: xxxxxx
Release: 5.8
Version: Generic_117350-38
Machine: sun4u
Instance name: xxxxx
Redo thread mounted by this instance: 1
Oracle process number: 15
Unix process pid: 24779, image: oracle@xxxxx (TNS V1-V3)
This section gives general information on the machine/instance and version of RDBMS where the internal error has been seen, whilst important its certainly does not really contain much to narrow bug searches as this info is customer/machine specific where as a bug itself should really hold information generic to all customers.
Section 2 : The 600 or 7445 internal error
------------------------------------------
*** SESSION ID:(143.5) 2006-07-18 10:45:03.004
Exception signal: 11 (SIGSEGV), code: 1 (Address not mapped to object), addr: 0xffffffff7b280000,
PC: [0xffffffff7b700b58, memcpy()+1196]
*** 2006-07-18 10:45:03.008
ksedmp: internal or fatal error
ORA-07445: exception encountered: core dump [memcpy()+1196] [SIGSEGV] [Address not mapped to object]
[0xFFFFFFFF7B280000] [] []
This article is not written to show the differences between ORA-00600/ORA-07445 errors in any detail.
The basic difference between these two errors, is that
an ORA-600 is a trapped error condition in the Oracle code that should not occur, whereasan ORA-7445 is an untrapped
error condition detected by the operating system.
Section 3 : Current SQL statement
---------------------------------
Current SQL statement for this session:
update a sET col11 =
(select avg(b.col22) keep (dense_rank first order by (col22)) FROM b where b.col21= a.col12);
Not all internal issues will show a current SQL statement and there is no simple reason why this is the case. If this does happen it is recommended to try and use all other sections to narrow the search space down. When present in an internal (600/7445) trace file it should always be locatable using a search in the trace file of 'Current SQL' and should be the first hit found.
In addition there maybe a ‘PLSQL Call Stack’ that pinpoints the schema.object and line number for an internal issue.
Section 4 : Call Stack Trace
-----------------------------
The call stack within the trace file is seen
as follows :-
----- Call Stack Trace -----
calling call entry argument values in hex
location type point (? means dubious value)
-------------------- -------- -------------------- ----------------------------
ksedmp()+744 CALL ksedst() 000000840 ?
FFFFFFFF7FFE7D5C ?
000000000 ?
FFFFFFFF7FFE4850 ?
FFFFFFFF7FFE35B8 ?
FFFFFFFF7FFE3FB8 ?
ssexhd()+1000 CALL ksedmp() 000106000 ? 106324A04 ?
106324000 ? 000106324 ?
000106000 ? 106324A04 ?
sigacthandler()+44 PTR_CALL 0000000000000000 000380007 ?
FFFFFFFF7FFEB9A0 ?
000000067 ? 000380000 ?
00000000B ? 106324A00 ?
_memcpy()+592 PTR_CALL 0000000000000000 00000000B ?
FFFFFFFF7FFEB9A0 ?
FFFFFFFF7FFEB6C0 ?
FFFFFFFFFFFFFFFF ?
000000004 ? 000000000 ?
ksxb1bqb()+36 FRM_LESS __1cY__nis_writeCol FFFFFFFF7B2F0000 ?
dStartFile6FpcpnNdi FFFFFFFF7B35EE90 ?
rectory_obj__i_()+3 FFFFFFFFFFFE6DA0 ?
75 FFFFFFFFFFFFFFFF ?
000000004 ? 000000000 ?
kxhrPack()+1088 CALL ksxb1bqb() FFFFFFFF7B0F7220 ?
FFFFFFFF7B354BBF ?
FFFFFFFFFFFF1070 ?
FFFFFFFF7B2E5D60 ?
FFFFFFFF7B0F7220 ?
000001FF0 ?
qescaInsert()+280 CALL kxhrPack() 000000080 ?
FFFFFFFF7B34A5E8 ?
The stack function is the first column on each line, and so reads:
ksedmp ssexhd sigacthandler memcpy ksxb1bqb .....
For clarity the full stack trace is summarised to :-
Function List (to Full stack) (to Summary stack)
ksedmp ssexhd sigacthandler memcpy ksxb1bqb kxhrPack
qescaInsert subsr3 evaopn2 upderh upduaw kdusru
kauupd updrow qerupRowProcedure qerupFetch updaul updThreePhaseExe
updexe opiexe kpoal8 opiodr ttcpip opitsk opiino opiodr opidrv
sou2o opimai_real main start
There is no automated tool for customers to get into this
form. Note:211909.1 reports a further example
of ORA-7445 stack analysis.
The call stack can be very powerful to narrow a problem down to known issues
but if used incorrectly will generate many hits totally unrelated to the
problem being encountered.
As the functions and their purpose are ORACLE proprietry this article can only give pointers towards good practice and these include :-
a) Ignore function names that are before the 600/7445 error so for this worked example searches on 'ksedmp','ssexhd' or 'sigacthandler' will not benefit.
The top most routines are for error handling, so this is
why the failing function 'memcpy()' is not at the top of
the stack, and why the top most functions can be ignored.
b) Ignore calls towards the end of the call stack
c) Try a number of different searches based on the failing function from the 600/7445 and 4-5 functions after
In this case a useful 'My ORACLE Support' (MOS) search would be : memcpy ksxb1bqb kxhrPack qescaInsert subsr3
Section 5 : Session Information
-------------------------------
SO: 392b5a188, type: 4, owner: 392a5a5b8, flag: INIT/-/-/0x00
(session) sid: 143 trans: 3912d2f78, creator: 392a5a5b8, flag: (41) USR/- BSY/-/-/-/-/-
DID: 0001-000F-0000000F, short-term DID: 0000-0000-00000000
txn branch: 0
oct: 6, prv: 0, sql: 38d8c05b0, psql: 38d8c0b20, user: 173/SCOTT
O/S info: user: xxxxxx, term: pts/21, ospid: 24482, machine: xxxxxx
program: sqlplus@xxxxxx (TNS V1-V3)
application name: SQL*Plus, hash value=3669949024
last wait for 'SQL*Net message from client' blocking sess=0x0 seq=282 wait_time=830 seconds since wait started=1
A 600/7445 trace should always have a 'Call stack Trace' whether it contains function names or not, after this follows 'PROCESS STATE' information and in this we can search on keyword 'session'.
The first hit should take us to the section of the trace file that shows where the error came from and the session/user affected (above they have been blanked to xxxxxx). In many cases we will see user, terminal and machine information that can often be useful for any issue that needs to be reproduced for further investigation. On many occasions an internal error will be reported in alert logs and the DBA will not necessarily have been informed by any users of the database/application that they encountered a problem.
This section can often also show 3rd party sessions e.g. TOAD/PLSQL or even where the client is another ORACLE product e.g. FORMS/APPS and even if just a client process e.g. EXP/RMAN. This can be another powerful method of narrowing a problem down, in the case of a problem coming from 3rd party software it is important to determine wherever possible if an issue can be reproduced in SQLPLUS.
Section 6 : Explain Plan Information
-------------------------------------
============
Plan Table
============
---------------------------------------+-----------------------------------+
| Id | Operation | Name | Rows | Bytes | Cost | Time |
---------------------------------------+-----------------------------------+
| 0 | UPDATE STATEMENT | | | | 3 | |
| 1 | UPDATE | A | | | | |
| 2 | TABLE ACCESS FULL | A | 2 | 52 | 3 | 00:00:01 |
| 3 | SORT AGGREGATE | | 1 | 26 | | |
| 4 | TABLE ACCESS FULL | B | 1 | 26 | 3 | 00:00:01 |
---------------------------------------+-----------------------------------+
This section can be found in the 600/7445 trace (when present) using the case
sensitive search 'Explain plan' and will be the first hit unless the SQL for
example contained the same string.
In this section the 'Plan Table' for the failing SQL will be reported and
especially for CBO related internal errors might give a pointer to finding
a workaround. For this worked example nothing really can be used but we might
for example see the plan using a 'hash join' and if so a possible w/a to
try would be hash_join_enabled=false. Caution should be used here, permanent
workarounds should only be set in place if matching to a known bug and the
implications are understood.
Section 7 : Current Cursor Information
--------------------------------------
Current cursor: 4, pgadep: 0
Open cursors(pls, sys, hwm, max): 11(3, 7, 50, 50)
NULL 6 SYNTAX 0 PARSE 0 BOUND 5 FETCH 0 ROW 0
Cached frame pages(total, free):
4k(61, 58), 8k(10, 10), 16k(1, 1), 32k(0, 0)
pgactx: 38d2c9e98 ctxcbk: 38d2c9b30 ctxqbc: 0 ctxrws: 38e751110
This can be found using the case sensitive search in the trace file for 'Current cursor:' [do not include the quotes], this section will either tie up with the current SQL statement reported in the 600/7445 or when there is no SQL statement reported it 'might' assist in further analysis.
Once the current cursor is known the information on this can be found using the search 'Cursor#X' where X is the value shown e.g in this case 4.
However this is >=10.2 specific
and so it should be noted that prior to 10.2
use the search 'Cursor X '.
Cursor#4(ffffffff7b231828) state=BOUND curiob=ffffffff7b2456f8
curflg=4c fl2=0 par=0 ses=392b5a188
sqltxt(38d8c05b0)=update a sET col11 =
(select avg(b.col22) keep (dense_rank first order by (col22)) FROM b where b.col21= a.col12)
hash=e2ef469857c74a273b881c20276493b5
parent=38eabc4b8 maxchild=01 plk=38f664f50 ppn=nll
If a SQL statement is using BIND variables it is the cursor information that often proves useful at isolating the values used in the SQL which again can be the key to reproducing a problem if data specific.
ORA-00600/ORA-07445 Analysis : General Guidelines
--------------------------------------------------
Now that the sections have been explained we need to ensure we use as systematic a procedure as possible to determine if a known issue/bug exists. It should be clear that a 600/7445 trace contains far more information but if the above sections together with what follows cannot conclude to a known issue it is recommended that a SR is raised to support.
Three useful documents types can assist here :-
OERI notes
———-
An ‘OERI’ article is a document provided where possible to customers that provides a brief meaning of the error/impact and known bugs relating to the 600/7445. The quickest way to find this information from MOS is to search as :
a) 7445 <1st argument> oeri
or
b) 600 <1st argument> oeri
So if the internal error was 600[12333] the search is:600 12333 oeri
So for this article and worked example the search would be : 7445 memcpy oeri
Equally the 600/7445 tool as per Note:153788.1 can be used and if the trace file is submitted into this tool an OERI note will be reported where published. If the testcase is attempted on a WINDOWS platform the error reported in the alert and trace may not be the same and the tool might not return any hits. Finding a suitable example for all platforms is beyond the scope of this document.
So for the latter search we should find Note:310531.1, it should be noted that not all bugs associated with an error will be tagged but ideally they would be.
It should also be clear from the notes seen in this type of search that ORA-600[x]/7445[y] does not mean only one bug can attribute to the Internal error.
BUG.8 notes
————
If the OERI or if a search gets a hit to a bug there maybe a link to a note where the MOS Noteid is <BUGNO>.8
For this worked example Note:5162852.8 exists, also to illustrate their purpose we can take for example Note:4451759.8
These articles are automatically generated when a bug becomes fixed and will typically include :-
—Product affected
—Range of releases the bug/error is believe appropriate to
—Known affected version(s)
—Fixed version
Together with the ‘symptoms’ of the bug and where possible workarounds. This information is also in the bug itself but the note provides this into a much clearer form.
Patch Set : List of Bugfixes by Problem Type Articles
——————————————————
When a PSR is released ORACLE ensures there is an article that summarises all the bugfixes made into that PSR, this articles allows a quick search to customers to see if there is an ORA-600/ORA-7445 error of the same type in the PSR. As mentioned earlier in the OERI section just because there is a fix for the same type, it does not guarantee that the problem is the same.
For example if one of these PSR notes mentions ORA-00600[729] it means that the fix relates to one specifc way this error can be encountered, it does not stop 600[729] occurring for other reasons and even with the latest PSR applied to a given RDBMS release the internal error could occur due to a new unknown bug.
These documents can be found in MOS using a search with keywords like :-
<version> patch set bug fixes problem type
So if we are looking to see what fixes are made into the V92070 PSR we would use
the six keywords : 9.2.0.7 patch set bug fixes problem type
MOS will produce many hits but then the internet browsers search function can be used to search on the string ‘9.2.0.7’ to quickly isolate the note which in this case is Note:308894.1
It is recommended to search always on the highest PSR available for the version you are running on since the note will then also contain links to the previous PSRs.
ORA-00600/ORA-07445 Analysis : Keyword Searches
————————————————
This is the stage of the article where we need to use the research gathered from trace files and known MOS notes to see if we can use the MOS knowledge base to determine if the internal error is a known bug. It was commented that Section4 of a trace file can be very powerful here but again it is impossible to provide one unique way to search the knowledge bases. Instead we will use the worked example and will give some recommendations for 'bad' and 'good' search practices.
Bad Searches Practices
———————-
a) Using first few calls of stack trace e.g ksedmp ssexhd sigacthandler memcpy
b) Use of MOS ‘Advanced Search’ and using the ‘using any of the words’ option
The reason this is a poor search method is that it is likely too many hits will be returned especially if keywords like 600/7445 are used. The default search functionality is an AND base search where all keywords must be present and this provides for better searches and fewer unrelated hits.
c) Using all of the stack trace. As explained above a default MOS search will find hits that contain all the keywords and using the whole stack allows a real risk of getting zero hits returned.
Good Searches Practices
————————
It should be noted that more than one search might actually be needed to get a feeling for what bugs/notes are relevant to the customers issue. The scope of what can be searched will depend on if a problem is reproducible.
a) Isolating a good section of the ‘Call Stack’ from Section4
b) If SQL is known then look at SQL to see if there is something special on the SQL e.g for this worked example we know dense_rank is being used and this is not common SQL
c) If a problem is reproducible and an explain plan is available look at the plan to see if there is something that can be changed at session level. An example was reported in Section6 and if a parameter is seen to make a query work this parameter can then become a very useful keyword for determining if a known bug exists.
d) Using the RDBMS version as keyword can sometimes show if any bugs exist that contain a oneoff fix for the same internal error argument but caution is needed as it is not a guarantee that the bug will cover the same cause.
With this information in mind the two searches :-
memcpy ksxb1bqb kxhrPack qescaInsert subsr3
memcpy dense_rank
both get very few bug hits and BUG:5162852 is quickly identified.
Worked Example for 11g
———————————
The general principles of internal 600/7445 error analysis holds
true for 11g but there are some differences in how traces get reported.
To illustrate Note.808071.1 provides an excellent testcase to reproduce
the error ORA-00600[16613]. As stated already if there is a desire to
reproduce this error so that the alert/trace can be looked at in a proactive
manner then it should ONLY be used on a TEST database.
The example will not be reported in the same detail but instead we can use
it to highlight the key differences.
After the error has been reproduced we need to look at the alert log which
can be located via :-
show parameter dump_dest
background_dump_dest string c:appdiagrdbmsorclorcltrace
core_dump_dest string c:appdiagrdbmsorclorclcdump
user_dump_dest string c:appdiagrdbmsorclorcltrace
It is the background and user destinations for the ‘trace’ directory that we will
need to look.
Tue Nov 15 09:33:59 2011
Errors in file c:appdiagrdbmsorclorcltraceorcl_ora_3896.trc (incident=74841):
ORA-00600: internal error code, arguments: [16613], [0x37D727F8], [2], [], [], [], [], []
Incident details in: c:appdiagrdbmsorclorclincidentincdir_74841orcl_ora_3896_i74841.trc
For more details on how critical/internal errors are reported within 11g Note.443536.1
can be used. For further analysis of the ORA-00600 we are interested in the ‘Incident Trace’
and the full path to this file is still provided by the alert log. Such traces can also
be located via ‘ADRCI’ but is beyond the scope of this article.
If we look at the appropriate incident trace file we will see very similar traces to
the 10.2 example and the same analytical approach to these traces can be followed.
To provide 11g files to support it is vital to provide the appropriate incident traces
and Note.443529.1/Note.411.1 can be reviewed but again is outside of the scope
of how to try and diagnose the internal error itself.
ORA-00600/ORA-07445 Analysis : Key Questions
——————————————————————-
If trying to research an Internal error before raising a SR to ORACLE Support the following
questions will help avoid further questions from analysts. These questions are asked in the
MOS template when raising a SR and if answered as clearly as possible this can greatly assist
in getting to a solution.
Is the error reproducible?
If an issue is reproducible where possible it should also be tested from SQLPLUS
(ref Section 5). It is possible that a known bug/new bug might only occur on JDBC
based clients for example and time needs to be spent understanding the minimum
configuration needed to reproduce a problem.
If an issue is indeed reproducible in a controlled manner a testcase for the majority
of issues should be possible and if a SR or pre-analysis is not matched to a known bug
very rarely can a problem be fixed from a trace file alone. For this reason please be
aware of Note:232963.1
Has this worked before?
If functionality that was working has just stopped it would tend to suggest either some
issue of data within one or more objects or some more significant change. If a 600/7445
is seen within Development particularly on higher PSRs/releases it could well be that
you have found a new bug. Again depending on reproducibility a testcase ideally would
be required.
Has any new change been made recently e.g new code/new PSR or DB version/higher DB load?
Rarely do 600/7445 errors just start to occur due to a database being open for a certain
amount of time. Even a small change of init/spfile parameters can influence how the database operates
so if any change is known it is better to mention asap no matter how small.
What is frequency of the error, when did it start?
On many occasions a 600/7445 will be seen as a oneoff and not to be seen again. If pre-analysis
cannot be matched to a known issue and if in any doubt about an error a SR should always
be raised. It is however necessary to be aware that if the error is a oneoff or sporadic there is a
tradeoff between impact of error and further analysis, as covered below.
On other occasions we might see the error on the hour or some consistent period of time, in
these cases root cause might be some job that runs or linked to an ORACLE process that
gets invoked at certain times. Finding some pattern can sometimes be vital to solving an issue
and knowing when an issue truly started is very important to analysis.
What is the known visible impact?
Of course any 600/7445 [or any issue for all product support] should be raised as a SR to
ORACLE if there is any concern. Sometimes an Internal errors impact is very clear in that
we might see an error in a controlled manner only when a session logsoff the database or the
database closes down. It is equally possible that a database may seem to be running stable
with no users reporting problems and only by proactively looking at the alert can errors be seen.
In all cases if a SR is raised to Support we will need to try and assess the impact of a given
error and to make a confirmation asap if linked to something serious within the database eg corruption.
In many cases of analysis there soon becomes a tradeoff between seeing the error in the alert
and the further diagnostics needed to try and get to the root cause. For this reason if an error
is a oneoff or very infrequent and determined not to visibly affect users a decision may need to
be made on how far to go especially if running on a desupported release or not on the latest PSR.
The above questions relate to Support asking this information from the customer, one of the key questions asked by customers to Support is :-
‘Why am I being asked to go to the latest PSR when a bug has not been identified?’
The primary answers for this are twofold :-
a) Note:209768.1 explains the backport policy for new bugs. So if Support could not match analysis to a known issue, a new bug can be filed. Sometimes Development can release ‘diagnostics patches’ to better analyze new issue but it’s recommended to use it on latest patchset. Also if on older PSRs it is far more likely for the customer to be running with >1 ‘oneoff’ fix placing the customer into a configuration that is probably not seen with many other customers.
b) Perhaps more importantly each PSR contains many fixes and can solve many issues without
Support being able to determine why. For this reason the latest PSR is seen as a statistically faster
option to solve a problem when an error cannot be matched to a known bug.
Of course if considering the latest PSR appropriate backups and testing need to be made in advance.
Summary and Conclusions
—————————
The article can be summarised into key sections :-
1. Most importantly always raise a SR if anything is unclear
2. Consider the ORA600/7445 tool : Note:153788.1
3. Make use of the key articles surrounding internal errors ie OERI notes and BUGTAGS
4. Understand basic trace information to be able to use MOS better for ‘efficient’ searching
5. If a SR is to be be raised provide as much information as possible based on the MOS
template questions as these will often be vital to solving the SR.
In conclusion 600/7445 errors are not hopefully a common event to be seen by DBA’s and
analysis of these errors is not something that would be expected by themselves. However it is often of
interest to many customers as to what is looked at within support and how we make a formal analysis.
Therefore the articles purpose is to highlight some of these processes with the hope that some
self analysis can be made and to assist customer/support interaction on these issues.
Troubleshooting
Problem
Under stress, Oracle 11g might create the []ORA-00600[] internal error code.
Symptom
The exception is similar to the following information:
ORA-00600: internal error code, arguments: [kgkprrpicknext1],
[18], [16], [], [], [], [], []
========= Dump for incident 37785 (ORA 600 [kgkprrpicknext1])
========
*** 2008-03-07 22:04:08.465
—— Current SQL Statement for this session
(sql_id=1upn36hp032kg) ——
/* SQL Analyze(636,1) */ select /*+ full(t) no_parallel(t)
no_parallel_index(t)
Resolving The Problem
Contact Oracle support and reference the 6651027 fix.
Related Information
[{«Product»:{«code»:»SSEQTP»,»label»:»WebSphere Application Server»},»Business Unit»:{«code»:»BU053″,»label»:»Cloud & Data Platform»},»Component»:»DB Connections/Connection Pooling»,»Platform»:[{«code»:»PF002″,»label»:»AIX»},{«code»:»PF010″,»label»:»HP-UX»},{«code»:»PF012″,»label»:»IBM i»},{«code»:»PF016″,»label»:»Linux»},{«code»:»PF027″,»label»:»Solaris»},{«code»:»PF033″,»label»:»Windows»}],»Version»:»7.0″,»Edition»:»Base;Express;Network Deployment»,»Line of Business»:{«code»:»LOB45″,»label»:»Automation»}},{«Product»:{«code»:»SS7K4U»,»label»:»WebSphere Application Server for z/OS»},»Business Unit»:{«code»:»BU053″,»label»:»Cloud & Data Platform»},»Component»:»DB Connections/Connection Pooling»,»Platform»:[{«code»:»»,»label»:»»}],»Version»:»7.0″,»Edition»:»»,»Line of Business»:{«code»:»LOB45″,»label»:»Automation»}}]
Эта ошибка возникает в случае несоответствия между REDO записями и сегментами отката (записями UNDO). Обычно эта ошибка имеет как минимум 2 дополнительных параметра в квадратных скобках:
- Первый параметр показывает максимальный номер записи UNDO в сегменте отката.
- Второй параметр показывает номер записи UNDO в блоке REDO.
Например так:
ORA-00600: internal error code, arguments: [4194], [19], [33], [], [], []
Действия
Для решения этой проблемы необходимо пересоздать табличное пространство UNDO. Для начала переключим управление откатом на режим, в котором используются сегменты (rollback_segment), расположенные в системном табличном пространстве (SYSTEM). Соединяемся с простаивающим экземпляром БД, запускаем его и останавливаемся перед этапом монтирования. Создаем конфигурационный файл PFILE из SPFILE и останавливаем БД.
startup nomount; create pfile from spfile; shutdown immediate
В полученном PFILE комментируем строку undo_tablespace=UNDOTBS1 и добавляем строку undo_management=MANUAL. Вот так:
undo_management=MANUAL #undo_tablespace=UNDOTBS1
Для упрощения, просто обновляем SPFILE на основе отредактированного PFILE и монтируем БД.
startup nomount; create spfile from pfile; alter database mount;
Удаляем табличное пространство UNDO и создаем новое.
-- удаление старого табличного пространства alter database datafile 'ORACLE_BASE/oradata/SID/undotbs01.dbf' offline drop; alter database open; drop tablespace UNDOTBS1 INCLUDING CONTENTS and datafiles; -- создание нового табличного пространства CREATE UNDO TABLESPACE undotbs DATAFILE 'ORACLE_BASE/oradata/SID/undotbs02.dbf' SIZE 100M; shutdown immediate
Возвращаем обратно параметр конфигурационного файла.
#undo_management=MANUAL undo_tablespace=UNDOTBS1
Пересоздаем из него SPFILE и запускаем БД.
startup nomount; create spfile from pfile; shutdown immediate startup
ORA-00600:
internal error code, arguments: [kcratr_nab_less_than_odr],
[1],[12], [29106], [29107], [], [], [], [], [],
[], []
ORA-00600 is an internal error which can be
because of multiple reasons. To know more about this, you can refer to my
previous post regarding ORA-600 Oracle Database Error.
 |
| ORA-00600 kcratr_nab_less_than_odr |
Here in this case, I was unable to open the
database since it was failing with ORA-00600 after trying to go ahead of mount
stage. See below,
Microsoft Windows [Version 6.1.7601]
Copyright (c) 2009 Microsoft Corporation. All rights reserved.
C:UsersB@by>sqlplus
SQL*Plus: Release 11.2.0.1.0 Production on Thu May 3 11:53:46 2018
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Enter user-name: sys@orcl as sysdba
Enter password:
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
SQL> select name,open_mode from v$database;
NAME OPEN_MODE
--------- --------------------
ORCL MOUNTED
SQL> alter database open;
alter database open
*
ERROR at line 1:
ORA-00600: internal error code, arguments: [kcratr_nab_less_than_odr], [1],
[12], [29106], [29107], [], [], [], [], [], [], []
To resolve the problem here, I tried a few
steps but can’t guarantee that the same will work everywhere. Any way you can
try the same at your own risk (not on production, for that refer Oracle
Support).
1. Shut down the
database again and bring it to mount stage to check if everything’s fine till
that point.
SQL> shut immediate;
ORA-01109: database not open
Database dismounted.
ORACLE instance shut down.
SQL> exit
C:UsersB@by>set ORACLE_SID=ORCL
C:UsersB@by>sqlplus
SQL*Plus: Release 11.2.0.1.0 Production on Thu May 3 11:57:37 2018
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Enter user-name: sys as sysdba
Enter password:
Connected to an idle instance.
SQL> startup;
ORACLE instance started.
Total System Global Area 1252663296 bytes
Fixed Size 2175328 bytes
Variable Size 889196192 bytes
Database Buffers 352321536 bytes
Redo Buffers 8970240 bytes
Database mounted.
2. Check for the
CURRENT Redo log member and perform Shutdown abort. Then again bring the
database to mount stage to perform recovery using backup controlfile file. Also
you need to manually copy the controlfile as well after you shut down the database
in order to keep things backed up.
SQL> show parameter control
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
control_file_record_keep_time integer 7
control_files string C:APPGYANORADATAORCLCONTR
OL01.CTL, C:APPGYANFLASH_RE
COVERY_AREAORCLCONTROL02.CTL
control_management_pack_access string DIAGNOSTIC+TUNING
SQL>
SQL> select a.member, a.group#, b.status from v$logfile a ,v$log b where a.group
#=b.group# and b.status='CURRENT' ;
MEMBER GROUP# STATUS
------------------------------------------- --------- --------------
C:APPGYANORADATAORCLREDO03.LOG 3 CURRENT
3. Shut down the
database using SHUTDOWN ABORT command and bring it up to mount stage.
SQL> shutdown abort
ORACLE instance shut down.
SQL> startup mount;
ORACLE instance started.
Total System Global Area 1252663296 bytes
Fixed Size 2175328 bytes
Variable Size 889196192 bytes
Database Buffers 352321536 bytes
Redo Buffers 8970240 bytes
Database mounted.
4. Now perform the
recovery using controlfile backup. It will ask for the logfile to recover the
database. Provide the complete path for the logfile which was CURRENT.
SQL> recover database using backup controlfile until cancel;
ORA-00279: change 1181684 generated at 04/13/2018 22:53:32 needed for thread 1
ORA-00289: suggestion :
C:APPGYANFLASH_RECOVERY_AREAORCLARCHIVELOG2018_05_03O1_MF_1_12_%U_.ARC
ORA-00280: change 1181684 for thread 1 is in sequence #12
Specify log: {<RET>=suggested | filename | AUTO | CANCEL}
C:appgyanoradataorclredo03.log
Log applied.
Media recovery complete.
SQL>
5. If it goes well
like this till this point, you can now try opening your database using
RESETLOGS option.
SQL> alter database open resetlogs;
Database altered.
6. Check the
OPEN_MODE of your database now.
SQL> select name, open_mode from V$database;
NAME OPEN_MODE
--------- --------------------
ORCL READ WRITE
I hope this helps !!