При создании приложений мы часто сталкиваемся с ошибками, которые необходимо отлаживать. Итак, с помощью логов мы можем легко получить информацию о том, что происходит в приложении, с записью ошибок и необычных обстоятельств. Теперь вам может показаться, что почему бы не использовать оператор System.out.print() в Java.
Проблема с этими утверждениями состоит в том, что сообщения журнала будут печататься только на консоли. Поэтому, как только вы закроете консоль автоматически, все журналы будут потеряны. Они не хранятся постоянно и будут отображаться один за другим, так как это однопоточная среда.
Чтобы избежать таких проблем, логирование в Java упрощается с помощью API, предоставляемого через пакет java.util.logging пакет org.apache.log4j.* .
Компоненты
Компоненты ведения журнала помогают разработчику создавать их, передавать в соответствующее место назначения и поддерживать надлежащий формат. Ниже приведены три компонента:
- Loggers – отвечает за сбор записей журнала и передачу их соответствующему заявителю.
- Appenders или Handlers – они отвечают за запись событий журнала в пункт назначения. Аппендеры форматируют события с помощью макетов перед отправкой результатов.
- Layouts или Formatters – отвечает за определение того, как данные выглядят, когда они появляются в записи журнала.
Вы можете обратиться к изображению ниже для работы всех трех компонентов:

Когда приложение выполняет вызов регистрации, компонент Logger записывает событие в LogRecord и перенаправляет его соответствующему Appender. Затем он форматировал запись, используя формат в соответствии с требуемым форматом. Помимо этого, вы также можете использовать более одного фильтра, чтобы указать, какие Appenders следует использовать для событий.
Логгеры (Logger) в Java – это объекты, которые запускают события журнала. Они создаются и вызываются в коде приложения, где генерируют события журнала перед передачей их следующему компоненту, который является Appender.
Вы можете использовать несколько логгеров в одном классе для ответа на различные события или использовать в иерархии. Они обычно называются с использованием иерархического пространства имен, разделенных точками. Кроме того, все имена Logger должны основываться на классе или имени пакета зарегистрированного компонента.
Кроме того, каждый логгер отслеживает ближайшего существующего предка в пространстве имен, а также имеет связанный с ним «уровень».
Как создать?
Вы должны использовать Logger.getLogger() . Метод getLogger() идентифицирует имя Logger и принимает строку в качестве параметра. Таким образом, если Logger уже существует, он возвращается, в противном случае создается новый.
Синтаксис
static Logger logger = Logger.getLogger(SampleClass.class.getName());
Здесь SampleClass – это имя класса, для которого мы получаем объект Logger.
Пример:
public class Customer{
private static final Logger LOGGER = Logger.getLogger(Customer.class);
public void getCustomerDetails() {
}
}
Уровни
Уровни журналов используются для классификации их по степени серьезности или влиянию на стабильность приложения. Пакет org.apache.log4j.* и java.util.logging предоставляют разные уровни ведения журнала.
Пакет org.apache.log4j.* предоставляет следующие уровни в порядке убывания:
- FATAL;
- ERROR;
- WARN;
- INFO;
- DEBUG.
Пакет java.util.logging предоставляет следующие уровни в порядке убывания:
- SEVERE(HIGHEST LEVEL);
- WARNING;
- INFO;
- CONFIG;
- FINE;
- FINER;
- FINEST(LOWEST LEVEL).
Помимо этого, вышеприведенный пакет также предоставляет два дополнительных уровня ALL и OFF используются для регистрации всех сообщений и отключения регистрации соответственно.
Пример с использованием пакета org.apache.log4j.*
import org.apache.log4j.Logger;
public class Customer {
static Logger logger = Logger.getLogger(Customer.class);
public static void main(String[] args) {
logger.error("ERROR");
logger.warn("WARNING");
logger.fatal("FATAL");
logger.debug("DEBUG");
logger.info("INFO");
System.out.println("Final Output");
}
}
Таким образом, если в нашем файле log4j.properties ваш вывод является корневым логгером уровня WARN, то все сообщения об ошибках с более высоким приоритетом, чем WARN, будут напечатаны, как показано ниже:
Вы также можете установить уровень с помощью метода setLevel() из пакета java.util.logging , как java.util.logging ниже:
logger.setLevel(Level.WARNING);
Пример с использованием пакета java.util.logging
package edureka;
import java.io.IOException;
import java.util.logging.Level;
import java.util.logging.Logger;
import java.util.logging.*;
class EdurekaLogger {
private final static Logger LOGGER = Logger.getLogger(Logger.GLOBAL_LOGGER_NAME);
public void sampleLog()
{
LOGGER.log(Level.WARNING, "Welcome to Edureka!");
}
}
public class Customer {
public static void main(String[] args)
{
EdurekaLogger obj = new EdurekaLogger();
obj.sampleLog();
LogManager slg = LogManager.getLogManager();
Logger log = slg.getLogger(Logger.GLOBAL_LOGGER_NAME);
log.log(Level.WARNING, "Hi! Welcome from Edureka");
}
}
Чтобы включить вход в приложение с помощью пакета org.apache.log4j.* Или пакета java.util.logging , необходимо настроить файл свойств. Далее в этой статье о Logger в Java давайте обсудим файл свойств обоих из них.
Файл свойств пакета Log4j и Java Util
Пример файла свойств Log4j
# Enable Root logger option
log4j.rootLogger=INFO, file, stdout
# Attach appenders to print file
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=E:loglogging.log
log4j.appender.file.MaxFileSize=10MB
log4j.appender.file.MaxBackupIndex=5
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# Attach appenders to print on console
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
- Файл свойств Log4j создается внутри папки src проекта.
- log4j.appender.file = org.apache.log4j.RollingFileAppender -> Печатает все журналы в файле
- log4j.appender.stdout = org.apache.log4j.ConsoleAppender -> Печатает все журналы в консоли
- log4j.appender.file.File = D: loglogging.log -> Указывает расположение файла журнала
- log4j.appender.file.MaxFileSize = 10 МБ -> Максимальный размер файла журнала до 10 МБ
- log4j.appender.file.MaxBackupIndex = 5 -> Ограничивает количество файлов резервных копий до 5
- log4j.appender.file.layout = org.apache.log4j.PatternLayout -> Указывает шаблон, в котором журналы будут печататься в файл журнала.
- log4j.appender.file.layout.ConversionPattern =% d {гггг-ММ-дд ЧЧ: мм: сс}% -5p% c {1}:% L -% m% n -> Устанавливает шаблон преобразования по умолчанию.
Пример файла свойств пакета Java Util
handlers= java.util.logging.ConsoleHandler .level= WARNING # Output will be stored in the default directory java.util.logging.FileHandler.pattern = %h/java%u.log java.util.logging.FileHandler.limit = 60000 java.util.logging.FileHandler.count = 1 java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter # Level of logs will be limited to WARNING and above. java.util.logging.ConsoleHandler.level = WARNING java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
Здесь
- java.util.logging.FileHandler.pattern =% h / java% u.log -> Файлы журнала будут записаны в C: TEMPjava1.log
- java.util.logging.FileHandler.limit = 50000 -> Максимальная сумма, которую регистратор записывает в один файл в байтах.
- java.util.logging.FileHandler.count = 1 -> Указывает количество выходных файлов
- java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter -> Упоминает форматер, используемый для форматирования. Здесь используется XML Formatter.
- java.util.logging.ConsoleHandler.level = WARNING -> Устанавливает уровень журнала по умолчанию для WARNING
- java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter -> Указывает форматер, используемый всеми ConsoleHandler. Здесь используется SimpleFormatter.
Регистрация событий
Чтобы регистрировать события в Java, вы должны убедиться, что вы назначаете уровень, чтобы легко отфильтровать события. Чтобы назначить уровень и упомянуть сообщение, вы можете использовать следующие методы:
Способ 1
logger.log(Level.INFO, “Display message”);
Here, level is INFO and the message to be printed is "Display Message".
Способ 2
logger.info(“Display message”);
Чтобы убедиться, что Logger регистрирует только события, которые находятся на уровне или выше уровня INFO, вы можете использовать метод setLevel(), описанный выше.
Appender или Handlers
Appender или Handlers отвечают за запись событий журнала в пункт назначения. Каждый регистратор имеет доступ к нескольким обработчикам и получает сообщение журнала от регистратора. Затем Appenders используют средства форматирования или макеты для форматирования событий и отправки их в соответствующее место назначения.
Appender можно отключить с помощью метода setLevel (Level.OFF). Два наиболее стандартных обработчика в пакете java.util.logging :
- FileHandler: записать сообщение журнала в файл.
- ConsoleHandler: записывает сообщение журнала в консоль.
Layout или Formatters
Используются для форматирования и преобразования данных в журнале событий. Каркасы журналов предоставляют макеты для HTML, XML, Syslog, JSON, простого текста и других журналов.
![]()
Давайте научимся следить за выполнением логики в нашей программе, для этого мы научимся использовать логирование, поймем зачем оно и где используется.
Шаг 0. Обзор
Логирование – не используя термины википедии, то это возможность следить за процесом выполнения бизнес-логики проекта.
Зачем нужно логирование и что оно даёт?
Допустим у вас есть WEB-проект, и он что-то делает, сейчас не важно что именно. Допустим это интернет магазин, на котором при оформлении заказа нужно отправить на почту покупателю отчет о его покупке, но почтовый сервер вышел из строя, и программно письмо не отправилось.
Вы, как человек который администрирует магазин начнет разбераться в чем же проблема. Неопытный человек будет долго искать проблему, а опытный сразу полезет в логи сервера, но там все логи сервера и найти то что нужно вам сложно.

В этом случае решение следующее, выводить нужные вам логи в отдельный файл. Но как понять, какие из всех логов, которые сыпятся в общий лог сервера нужны вам? Для этого нужно реализовать свою систему логирования, где вы сможите указать какие логи куда выводить, или же настроить уровни логирования.
В данном уроке мы рассмотрим как сконфигурировать и начать использовать Log4j.
Шаг 1. Создаем проект и добавляем завимости
Запускаем всеми любимую Intellij IDEA и тыкаем New Project выбираем Maven Module и называем его :

Теперь в pom.xml жлбавим зависимость:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
Это все зависимости, которые надо было подключить.
Шаг 2. Создание примитивной логики для примера
Давайте создадим класс в котором была бы бизнес-логика, назовем его OrderLogic:
package com.devcolibri.logpack;
public class OrderLogic {
public void doOrder(){
// какае-то логика
System.out.println("Заказ оформлен!");
addToCart();
}
private void addToCart() {
// добавление товара в корзину
System.out.println("Товар добавлен в корзину");
}
}
Хочу обратить ваше внимание на то, что логика данного проекта не важна, так как мы рассматриваем логирование, для этого я и подготовил примитивную логику класса OrderLogic.
И теперь создаем Main класс:
package com.devcolibri.logpack;
public class Main {
private static OrderLogic logic;
public static void main(String[] args) {
logic = new OrderLogic();
logic.doOrder();
}
}
В результате выполнения данного кода, мы получим следующее:
Заказ оформлен! Товар добавлен в корзину
Как видите пока ничего нового.
Шаг 3. Конфигурируем Log4j
Чтобы гибко управлять логированием стоит создать в resources/ файл log4j.properties:

Теперь в этот файл добавим пару строк конфигураций:
# Уровень логирования
log4j.rootLogger=INFO, file
# Апендер для работы с файлами
log4j.appender.file=org.apache.log4j.RollingFileAppender
# Путь где будет создаваться лог файл
log4j.appender.file.File=C:\TMP\log_file.log
# Указываем максимальный размер файла с логами
log4j.appender.file.MaxFileSize=1MB
# Конфигурируем шаблон вывода логов в файл
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
Теперь давайте более детальней разберем строку формирования шаблона:
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
Значения:
%d{yyyy-MM-dd HH:mm:ss} – выводит дату в формате 2014-01-14 23:55:57
%-5p – выводит уровень лога (ERROR, DEBUG, INFO …), цифра 5 означает что всегда использовать 5 символов остальное дополнится пробелами, а минус (-), то что позиционирование по левой стороне.
%c{1} – категория, в скобках указывается сколько уровней выдавать. Так как у нас 1 уровень то писаться будет только имя класса.
%L – номер строки в которой произошёл вызов записи в лог.
%m – сообщение, которое передали в лог.
%n – переход на новую строку.
Шаг 4. Добавляем примитивное логирование
Теперь в класс OrderLogic добави логирование и посмотрим на результат:
package com.devcolibri.logpack;
import org.apache.log4j.Logger;
public class OrderLogic {
// Инициализация логера
private static final Logger log = Logger.getLogger(OrderLogic.class);
public void doOrder(){
// какае-то логика
System.out.println("Заказ оформлен!");
// логируем инфо
log.info("Это информационное сообщение!");
addToCart();
}
private void addToCart() {
// добавление товара в корзину
System.out.println("Товар добавлен в корзину");
// логируем ошибку
log.error("Это сообщение ошибки");
}
}
Теперь давайте запустим код опять. Мы получим тот же результат, вот только уже по пути C://TMP/ будет лежать файл log_file.log со следующим содержимым:
2014-01-14 23:55:57 INFO OrderLogic:12 - Это информационное сообщение! 2014-01-14 23:55:57 ERROR OrderLogic:19 - Это сообщение ошибки
- None Found
When it comes to troubleshooting application performance, the more information you have the better. Java logs combined with JVM metrics and traces give you full visibility into your Java applications. Logging in your Java applications can be achieved in multiple ways – for example, you can just write data to a file, but there are far better ways on how to do that, as we explained in our Java logging tutorial.
Today, we will look into Log4j 2, the latest version of the widely known Log4j library developed under the Apache Software Foundation.
However, before diving into that, let’s address an issue that impacted the community using this framework. On December 9, 2021, a critical vulnerability was disclosed and nicknamed Log4Shell. The vulnerability was registered on the National Vulnerability Database as CVE-2021-44228 with a severity code of 10 and allows a system running Apache Log4j 2 version 2.14.1 or below to be compromised, giving an attacker full control to execute arbitrary code on the vulnerable server. In our recent blog post about the Log4jShell vulnerability, we explained how you would know if you are affected by the problem, what steps to follow to fix it, and what we, at Sematext, have done to protect our system and users.
What Is Log4j 2 and Why Should You Use It
Log4j 2 and its predecessor the Log4j are the most common and widely known logging framework for Java. Log4j 2 promises to improve the first version of the Log4j library and fix some of the issues identified in the Logback framework. Read our Logback tutorial if you’re curious to learn more about how this library works.
It also supports asynchronous logging. For the purpose of this tutorial I created a simple Java project that uses Log4j 2, you can find it in our Github account. Keep in mind that the Log4j 1.x is deprecated and no longer maintained, so when choosing the logging library of your choice you should go for Log4j 2.x.
Let’s start with the code that we will be using for the test:
package com.sematext.blog.logging;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Log4JDefaultConfig {
private static final Logger
LOGGER = LogManager.getLogger(Log4JDefaultConfig.class);
public static void main(String[] args) { LOGGER.info("This is an INFO level log message!");
LOGGER.error("This is an ERROR level log message!");
}
}
For the code to compile we need two dependencies – the Log4j 2 API and the Core. Our build.gradle includes the following:
dependencies {
implementation 'org.apache.logging.log4j:log4j-api:2.13.3'
implementation 'org.apache.logging.log4j:log4j-core:2.13.3'
}
Things are quite simple here – we get the Logger instance by using the Log4j 2 LogManager class and its getLogger method. Once we have that we use the info and error methods of the Logger to write the log records. We could of course use SLF4J and we will in one of the examples. For now, though, let’s stick to the pure Log4j 2 API.
In comparison to the java.util.logging we don’t have to do any setup. By default, Log4j 2 will use the ConsoleAppender to write the log message to the console. The log record will be printed using the PatternLayout attached to the mentioned ConsoleAppander with the pattern defined as follows: %d{HH:mm:ss.SSS} [%t] %-5level %logger{36} – %msg%n. However, the root logger is defined for ERROR level. That means, that by default, ERROR level logs and beyond will be only visible. Log messages with level INFO, DEBUG, TRACE will not be visible.
There are multiple conditions when Log4j 2 will use the default configuration, but in general, you can expect it to kick in when no log4j.configurationFile property is present in the application startup parameters and when this property doesn’t point to a valid configuration file. In addition no log4j2-test.[properties|xml|yaml|jsn] files are present in the classpath and no log4j2.[properties|xml|yaml|jsn] files are present in the classpath. Yes, that means that you can easily have different logging configurations for tests, different configurations as the default for your codebase, and then use the log4j.configurationFile property and point to a configuration for a given environment.
A simple test – running the above code gives the following output:
09:27:10.312 [main] ERROR com.sematext.blog.logging.Log4JDefaultConfig - This is an ERROR level log message!
Of course, such default behavior will not be enough for almost anything apart from a simple code, so let’s see what we can do about it.
Log4j 2 can be configured in one of the two ways:
- By using the configuration file. By default, Log4j 2 understands configuration written in Java properties files and XML files, but you can also include additional dependencies to work with JSON or YAML. In this blog post, we will use this method.
- Programmatically by creating the ConfigurationFactory and Configuration implementations, or by using the exposed APIs in the Configuration interface or by calling internal Logger methods.
Let’s create a simple, old fashioned XML configuration file first just to print the time, level, and the message associated with the log record. Log4j 2 requires us to call that file log4j2.xml. We put it in the resources folder of our example project and run it. This time the output looks as follows:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
Let’s stay here for a minute or two and discuss what we did here. We started with the Configuration definition. In this element, we defined that all the status-related messages will be logged with the WARN level – status=”WARN”.
Next, we defined the appender. The Appender is responsible for delivering the LogEvent to its destination. You can have multiple of those. In our case the Appenders section contains a single appender of the Console type:
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
</Console>
We set its name, which we will use a bit later, we say that the target is the standard system output – SYSTEM_OUT. We also provided the pattern for the PatternLayout which defines the way our LogEvent will be formatted in the Console appender.
The last section defines the Loggers. We define the configuration of different loggers that we defined in our code or in the libraries that we are using. In our case this section only contains the Root logger definition:
<Root level="info"> <AppenderRef ref="Console"/> </Root>
The Root logger definition tells Log4j to use that configuration when a dedicated configuration for a logger is not found. In our Root logger definition, we say that the default log level should be set to INFO and the log events should be sent to the appender with the name Console.
If we run the example code mentioned above with our new XML configuration the output will be as follows:
09:29:58.735 INFO - This is an INFO level log message!
09:29:58.737 ERROR - This is an ERROR level log message!
Just as we expected we have both log messages present in the console.
If we would like to use the properties file instead of the XML one we could just create a log4j2.properties file and include it in the classpath or just use the log4j.configuration property and point it to the properties file of our choice. To achieve similar results as we got with the XML based configuration we would use the following properties:
appender.console.type = Console
appender.console.name = STDOUT
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{HH:mm:ss.SSS} %-5level - %msg%n rootLogger.level = info
rootLogger.appenderRef.stdout.ref = STDOUT
It is less verbose and works, but is also less flexible if you want to use slightly more complicated functionalities.
Log4j 2 Logger
The Logger is the main entity that our application uses to create LogRecord, so basically to log what we want to output as the log message. Creating the Logger is very simple. In the majority of the cases it will be a private, static object inside a class, for example:
private static final Logger LOGGER = LogManager.getLogger(SomeFancyClassName.class);
The above part of the code uses the Log4j 2 classes to create the Logger object, but you can also base the initialization on SLF4J, so you can always change the logging framework of your choice:
private static final Logger LOGGER = LoggerFactory.getLogger(SomeFancyClassName.class);
No matter which method of initialization we will chose, once we have the Logger instance we can use it to generate our log events:
LOGGER.info("This is an INFO level log message");
Log4j 2 Log Levels
A log level or log severity is a piece of information telling how important a given log event is. It is a simple, yet very powerful way of distinguishing log events from each other. If the log levels are used properly in your application all you need is to look at the severity first. It will tell you if you can continue sleeping during the on-call night or you need to jump out of bed right away and hit another personal best in running between your bedroom and laptop in the living room.
You can think of the log levels as a way to filter the critical information about your system state and the one that is purely informative. The log levels can help in reducing the information noise and reduce alert fatigue.
If you’re new to the concept of logging levels, we recommend you have a look at our tutorial on log levels, where we explain in great detail how they work and the best ways to use them.
Log4j 2 Appenders
Log4j 2 appender is responsible for delivering LogEvents to their destination. Some appenders only send LogEvents while others wrap other appenders to provide additional functionality. Let’s look at some of the appenders available in Log4j 2. Keep in mind that this is not a full list of appenders and to see all of them look at Log4j 2 appenders documentation.
The not-so-full list of appenders in Log4j 2:
- ConsoleAppender – writes the data to System.out or System.err with the default begin the first one (a Java best practice when logging in containers)
- FileAppender – appender that uses the FileManager to write the data to a defined file
- RollingFileAppender – appender that writes data to a defined file and rolls over the file according to a defined policy
- MemoryMappedFileAppender – added in version 2.1, uses memory-mapped files and relies on the operating system virtual memory manager to synchronize the changes in the file with the storage device
- FlumeAppender – appender that writes data to Apache Flume
- CassandraAppender – appender that writes data to Apache Cassandra
- JDBCAppender – writes data to a database using standard JDBC driver
- HTTPAppender – writes data to a defined HTTP endpoint
- KafkaAppender – writes data to Apache Kafka
- SyslogAppender – writes data to a Syslog compatible destination
- ZeroMQAppender – writes data to ZeroMQ
- AsyncAppender – encapsulates another appender and uses a different thread to write data, which results in asynchronous logging
Appender Configuration
Let’s now look at a few examples of how we can configure appenders for Log4j 2.
Using Multiple Appenders – File and Console Together
Now let’s look at the File appender to see how to log the log messages to the console and file at the same time.
Let’s assume we have the following use case – we would like to set up our application to log everything to a file so we can use it for shipping data to an external log management and analysis solution such as Sematext Logs and we would also like to have the logs from com.sematext.blog loggers printed to the console.
I’ll use the same example application that looks as follows:
package com.sematext.blog.logging;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class Log4j2 { private static final Logger
LOGGER = LogManager.getLogger(Log4j2.class);
public static void main(String[] args) {
LOGGER.info("This is an INFO level log message!");
LOGGER.error("This is an ERROR level log message!");
}
}
The log4j2.xml will look as follows:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
</Console>
<File name="File" fileName="/tmp/log4j2.log" append="true">
<PatternLayout>
<Pattern>%d{HH:mm:ss.SSS} [%t] %-5level - %msg%n</Pattern>
</PatternLayout>
</File>
</Appenders>
<Loggers>
<Logger name="com.sematext.blog" level="info" additivity="true">
<AppenderRef ref="Console"/>
</Logger>
<Root level="info">
<AppenderRef ref="File"/>
</Root>
</Loggers>
</Configuration>
You can see that I have two appenders defined – one called Console that appends the data to the System.out or System.err. The second one is called File. I provided a fileName configuration property to tell the appender where the data should be written and I said that I want to append the data to the end of the file. Keep in mind that those two appenders have slightly different patterns – the File one also logs the thread, while the Console one doesn’t.
We also have two Loggers defined. We have the root logger that appends the data to our File appender. It does that for all the log events with the INFO log level and higher. We also have a second Logger defined with the name of com.sematext.blog, which appends the data using the Console appender as well with the INFO level.
After running the above code we will see the following output on the console:
15:19:54.730 INFO - This is an INFO level log message! 15:19:54.732 ERROR - This is an ERROR level log message!
And the following output in the /tmp/log4j2.log file:
15:19:54.730 [main] INFO - This is an INFO level log message! 15:19:54.732 [main] ERROR - This is an ERROR level log message!
You can see that the times are exactly the same, the lines are different though just as our patterns are.
In the normal production environment, you would probably use the Rolling File appender to roll over the files daily or when they will reach a certain size.
Syslog Appender
One of the useful appenders is the SyslogAppender that enables sending the log events generated by our application to a Syslog compatible destination. That can be your local Syslog server, remote Syslog server in your organization, or even one exposed as a part of a log centralization solution such as Sematext Logs.
For example, the following configuration would send out log messages to the Syslog server exposed as a part of Sematext Cloud:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="warn">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d %level [%t] %c - %m%n"/>
</Console>
<Syslog
name="Syslog"
host="logsene-syslog-receiver.sematext.com"
port="514"
protocol="TCP"
format="RFC5424"
appName="ab6253c2-f76s-23s1-5dwx-d221dswf232s"
facility="LOCAL0"
mdcId="mdc"
newLine="true"/>
</Appenders>
<Loggers>
<Root level="debug">
<AppenderRef ref="Console"/>
<AppenderRef ref="Syslog"/>
</Root>
</Loggers>
</Configuration>
You can see that we have two appenders defined. One is the already known – the Console appender writes the log events to the standard output. The second is the Syslog appender that sends data to Syslog compatible destinations available at logsene-syslog-receiver.sematext.com. We also included some configuration properties like port, protocol, and format. As you can see, sending log events from your Java application to Syslog is really simple.
Custom Appenders
If the appenders that come out of the box with Log4j 2 are not enough we can create our own implementations. We just need to extend one of the abstract appender classes, like AbstractAppender for example and implement the append and createAppender method. For example:
package com.sematext.blog.logging;
import org.apache.logging.log4j.core.Appender;
import org.apache.logging.log4j.core.Core;
import org.apache.logging.log4j.core.Filter;
import org.apache.logging.log4j.core.LogEvent;
import org.apache.logging.log4j.core.appender.AbstractAppender;
import org.apache.logging.log4j.core.config.plugins.Plugin;
import org.apache.logging.log4j.core.config.plugins.PluginAttribute;
import org.apache.logging.log4j.core.config.plugins.PluginElement;
import org.apache.logging.log4j.core.config.plugins.PluginFactory;
@Plugin(name="TestAppender", category=Core.CATEGORY_NAME, elementType=Appender.ELEMENT_TYPE)
public class TestAppender extends AbstractAppender {
protected TestAppender(String name, Filter filter) {
super(name, filter, null, false, null);
}
@PluginFactory
public static TestAppender createAppender(@PluginAttribute("name") String name, @PluginElement("Filter") Filter filter) {
return new TestAppender(name, filter);
}
@Override
public void append(LogEvent event) {
// do some custom append code
}
}
You can see that I created the TestAppender class that extends the AbstractAppender. The append methodis the one responsible for processing the LogEvent objects. The createAppender method is responsible for creating the instance of our appender. We alsoused the @Plugin and @PluginFactory annotations to tell Log4j how to create the appender itself.
Finally, we just need to configure Log4j to include our plugin. We do it as follows:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN" xmlns:xi="http://www.w3.org/2001/XInclude" packages="com.sematext.blog.logging">
<Appenders>
<TestAppender name="TestAppender" />
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="TestAppender"/>
</Root>
</Loggers>
</Configuration>
You can see that we’ve added our appender. The key thing to remember is to include the packages section in the root Configuration tag, so that Log4j knows where to look for the plugin.
Log4j 2 Layouts
Layout is used by the appender to format a LogEvent into a form that is defined.
By default, there are a few layouts available in Log4j 2 (some of them require additional runtime dependencies):
- Pattern – uses a string pattern to format log events (learn more about the Pattern layout)
- CSV – the layout for writing data in the CSV format
- GELF – layout for writing events in the Graylog Extended Log Format 1.1
- HTML – layout for writing data in the HTML format
- JSON – layout for writing data in JSON
- RFC5424 – writes the data in accordance with RFC 5424 – the extended Syslog format
- Serialized – serializes log events into a byte array using Java serialization
- Syslog – formats log events into Syslog compatible format
- XML – layout for writing data in the XML format
- YAML – layout for writing data in the YAML format
The PatternLayout
The Log4j PatternLayout is a powerful tool. It allows us to structure logs events without the need of writing any code – we only need to define the pattern that we will use and include that in our configuration. It is that simple.
Let’s start with a simple configuration that will write log the time of the event and the message. The configuration would look as follows:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
And the output of running a sample code would be as follows:
13:44:28.397 This is an INFO level log message!
You can see two things there – the %d and the %msg variables. The %d one is responsible for the log event date, the %msg is responsible for the message that we passed as the log event. As you can see the date related to the event can be further configured using patterns. You can learn about that in the documentation related to PatternLayout.
But of course the %d and the %msg variables are not everything that we can use. We have used the logger name, the class, include exceptions, configure highlighting color, location of the message and many, many more. All of them are described in the documentation related to PatternLayout. But just to give you a more sophisticated example here is another configuration:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%-5level] %c:%L [PID:%pid] - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
This time the log event that is generated by Log4j 2 will look as follows:
13:56:16.502 [INFO ] com.sematext.blog.logging.Log4j2:10 [PID:44993] - This is an INFO level log message!
You can see that in addition to the date and message we also have the level of the message, the class and the line where the log event was produced. We even included the process identifier.
The HTML Layout
If we would like to have our logs be formatted in HTML we could use the following configuration:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<HTMLLayout>
</HTMLLayout>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
The output of running the example code with the above configuration is quite verbose and looks as follows:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html>
<head>
<meta charset="UTF-8"/>
<title>Log4j Log Messages</title>
<style type="text/css">
<!-- body, table {font-family:arial,sans-serif; font-size: medium ;}th {background: #336699; color: #FFFFFF; text-align: left;} -->
</style>
</head>
<body bgcolor="#FFFFFF" topmargin="6" leftmargin="6">
<hr size="1" noshade="noshade">
Log session start time Wed Jul 01 15:45:08 CEST 2020
<br>
<br>
<table cellspacing="0" cellpadding="4" border="1" bordercolor="#224466" width="100%">
<tr>
<th>Time</th>
<th>Thread</th>
<th>Level</th>
<th>Logger</th>
<th>Message</th>
</tr>
<tr>
<td>652</td>
<td title="main thread">main</td>
<td title="Level">INFO</td>
<td title="com.sematext.blog.logging.Log4j2 logger">com.sematext.blog.logging.Log4j2</td>
<td title="Message">This is an INFO level log message!</td>
</tr>
<tr>
<td>653</td>
<td title="main thread">main</td>
<td title="Level"><font color="#993300"><strong>ERROR</strong></font></td>
<td title="com.sematext.blog.logging.Log4j2 logger">com.sematext.blog.logging.Log4j2</td>
<td title="Message">This is an ERROR level log message!</td>
</tr>
</table>
<br>
</body>
</html>
Log4j 2 Filters
The Filter allows log events to be checked to determine if or how they should be published. A filter execution can end with one of three values – ACCEPT, DENY, or NEUTRAL.
Filters can be configured in one of the following locations:
- Directly in the Configuration for context – wide filters
- In the Logger for the logger specific filtering
- In the Appender for appender specific filtering
- In the Appender reference to determine if the log event should reach a given appender
There are a few out-of-the-box filters and we can also develop our own filters. The ones that are available out of the box are:
- Burst – provides a mechanism to control the rate at which log events are processed and discards them silently if a limit is hit
- Composite – provides a mechanism to combine multiple filters
- Threshold – allows filtering on the log level of the log event
- Dynamic Threshold – similar to Threshold filter, but allows to include additional attributes, for example, user
- Map – allows filtering of data that is in a MapMessage
- Marker – compares the Marker defined in the filter with the Marker in the log event and filters on the basis of that
- No Marker – allows checking for Marker existence in the log event and filter on the basis of that information
- Regex – filters on the basis of the defined regular expression
- Script – executes a script that should return a boolean result
- Structured Data – allows filtering on the id, type, and message of the log event
- Thread Context Map – allows filtering against data that are in the current context
- Time – allows restricting log events to a certain time
The Threshold Filter
For example, if we would like to include all logs with level WARN or higher we could use the ThresholdFilter with the following configuration:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level - %msg%n"/>
<ThresholdFilter level="WARN" onMatch="ACCEPT" onMismatch="DENY"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
Running our example code with the above Log4j 2 configuration would result in the following output:
16:34:30.797 ERROR - This is an ERROR level log message!
Log4j 2 Garbage Free Logging
With Log4j 2.6 a partially implemented garbage-free logging was introduced. The framework reuses objects stored in ThreadLocal and tries to reuse buffers when converting text to bytes.
With the 2.6 version of the framework, two properties are used to control the garbage-free logging capabilities of Log4j 2. The log4j2.enableThreadlocals which is by default set to true for non-web applications and the log4j2.enableDirectEncoders which is also set to true by default are the ones that enable optimizations in Log4j 2.
With the 2.7 version of the framework, the third property was added – the log4j2.garbagefreeThreadContextMap. If set to true the ThreadContext map will also use a garbage-free approach. By default, this property is set to false.
There is a set of limitations when it comes to garbage-free logging in Log4j 2. Not all filters, appenders, and layouts are available. If you decide to use it check Log4j 2 documentation on that topic.
For mission-critical systems tuning the Java garbage collection process is crucial for stability and efficiency. Having a logging library that can potentially generate a lot of distinct String instances, support garbage-free logging is a feature that is welcomed by a lot of developers and DevOps.
Log4j 2 Asynchronous Logging
The asynchronous logging is a new addition to Log4j 2. The aim is to return to the application from the Logger.log method call as soon as possible by executing the logging operation in a separate thread.
There are several benefits and drawbacks of using asynchronous logging. The benefits are:
- Higher peak throughput
- Lower logging response time latency
There are also drawbacks:
- Complicated error handling
- Will not give a higher performance on machines with low CPU count
- If you log more than the appender can process, the speed of logging will be dedicated by the slowest appender because of the queue filling up
If at this point you still think about turning on asynchronous logging you need to be aware that additional runtime dependencies are needed. Log4j 2 uses the Disruptor library and requires it as the runtime dependency. You also need to set the log4j2.contextSelector system property to org.apache.logging.log4j.core.async.AsyncLoggerContextSelector.
Log4j 2 Thread Context
Log4j combines the Mapped Diagnostic Context with the Nested Diagnostic Context in the Thread Context. But let’s discuss each of those separately for a moment.
The Mapped Diagnostic Context or MDC is basically a map that can be used to store the context data of the particular thread where the context is running. For example, we can store the user identifier or the step of the algorithm. In the Log4j 2 instead of MDC, we will be using the Thread Context. Thread Context is used to associate multiple events with limited numbers of information.
The Nested Diagnostic Context or NDC is similar to MDC, but can be used to distinguish interleaved log output from different sources, so in situations where a server or application handles multiple clients at once. In Log4j 2 instead of NDC we will use Thread Context Stack.
Let’s see how we can work with it. What we would like to do is add additional information to our log messages – the user name and the step of the algorithm. This could be done by using the Thread Context in the following way:
package com.sematext.blog.logging;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.ThreadContext;
public class Log4j2ThreadContext {
private static final Logger
LOGGER = LogManager.getLogger(Log4j2ThreadContext.class);
public static void main(String[] args) {
ThreadContext.put("user", "rafal.kuc@sematext.com");
LOGGER.info("This is the first INFO level log message!");
ThreadContext.put("executionStep", "one");
LOGGER.info("This is the second INFO level log message!");
ThreadContext.put("executionStep", "two");
LOGGER.info("This is the third INFO level log message!");
}
}
For our additional information from the Thread Context to be displayed in the log messages, we need a different configuration. The configuration that we used to achieve this look as follows:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%X{user}] [%X{executionStep}] %-5level - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info"> <AppenderRef ref="Console"/> </Root>
</Loggers>
</Configuration>
You can see that we’ve added the [%X{user}] [%X{executionStep}] part to our pattern. This means that we will take the user and executionStep property values from the Thread Context and include that. If we would like to include all that are present we would just add %X.
The output of running the above code with the above configuration would be as follows:
18:05:40.181 [rafal.kuc@sematext.com] [] INFO - This is the first INFO level log message! 18:05:40.183 [rafal.kuc@sematext.com] [one] INFO - This is the second INFO level log message! 18:05:40.183 [rafal.kuc@sematext.com] [two] INFO - This is the third INFO level log message!
You can see that when the context information is available it is written along with the log messages. It will be present until it is changed or cleared.
What Is a Marker
Markers are named objects that are used to enrich the data. While the Thread Context is used to provide additional information for the log events, the Markers can be used to mark a single log statement. You can imagine marking a log event with the IMPORTANT marker, which will mean that the appender should for example store the event in a separate log file.
How to do that? Look at the following code example that uses filtering to achieve that:
package com.sematext.blog.logging;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.Marker;
import org.slf4j.MarkerFactory;
public class Log4J2MarkerFiltering {
private static Logger LOGGER = LoggerFactory.getLogger(Log4J2MarkerFiltering.class);
private static final Marker IMPORTANT = MarkerFactory.getMarker("IMPORTANT");
public static void main(String[] args) {
LOGGER.info("This is a log message that is not important!");
LOGGER.info(IMPORTANT, "This is a very important log message!");
}
}
The above example uses SLF4J as the API of choice and Log4j 2 as the logging framework. That means that our dependencies section of the Gradle build file looks like this:
dependencies {
implementation 'org.slf4j:slf4j-api:1.7.30'
implementation 'org.apache.logging.log4j:log4j-api:2.13.3'
implementation 'org.apache.logging.log4j:log4j-core:2.13.3'
implementation 'org.apache.logging.log4j:log4j-slf4j-impl:2.13.3'
}
There are two important things in the above code example. First of all, we are creating a static Marker:
private static final Marker IMPORTANT = MarkerFactory.getMarker(“IMPORTANT”);
We use the MarkerFactory class to do that by calling its getMarker method and providing the name of the marker. Usually, you would set up those markers in a separate, common class that your whole code can access.
Finally, to provide the Marker to the Logger we use the appropriate logging method of the Logger class and provide the marker as the first argument:
LOGGER.info(IMPORTANT, "This is a very important log message!");
After running the code the console will show the following output:
12:51:25.905 INFO - This is a log message that is not important! 12:51:25.907 INFO - This is a very important log message!
While the file that is created by the File appender will contain the following log message:
12:51:25.907 [main] INFO - This is a very important log message!
Exactly what we wanted!
Keep in mind that Markers are not only available in Log4j (read our Log4j tutorial to learn more about this library). As you can see in the above example, they come from the SLF4J, so the SLF4J compatible frameworks should support them. If you’re curious about what libraries match, you should check out our SLF4J tutorial.
Java Logging with Log Management Tools: How Sematext Logs Can Help
Now that we know how to use and configure logging with Log4j 2 in our Java application you may be overwhelmed by how many logs your applications will produce. This is especially true for large, distributed applications.
You may get away with logging to a file and only using them when troubleshooting is needed, but working with huge amounts of data quickly becomes unmanageable and you should end up using a log management solution to centralize and monitor your logs. You can either go for an in-house solution based on the open-source software or use one of the products available on the market like Sematext Logs.
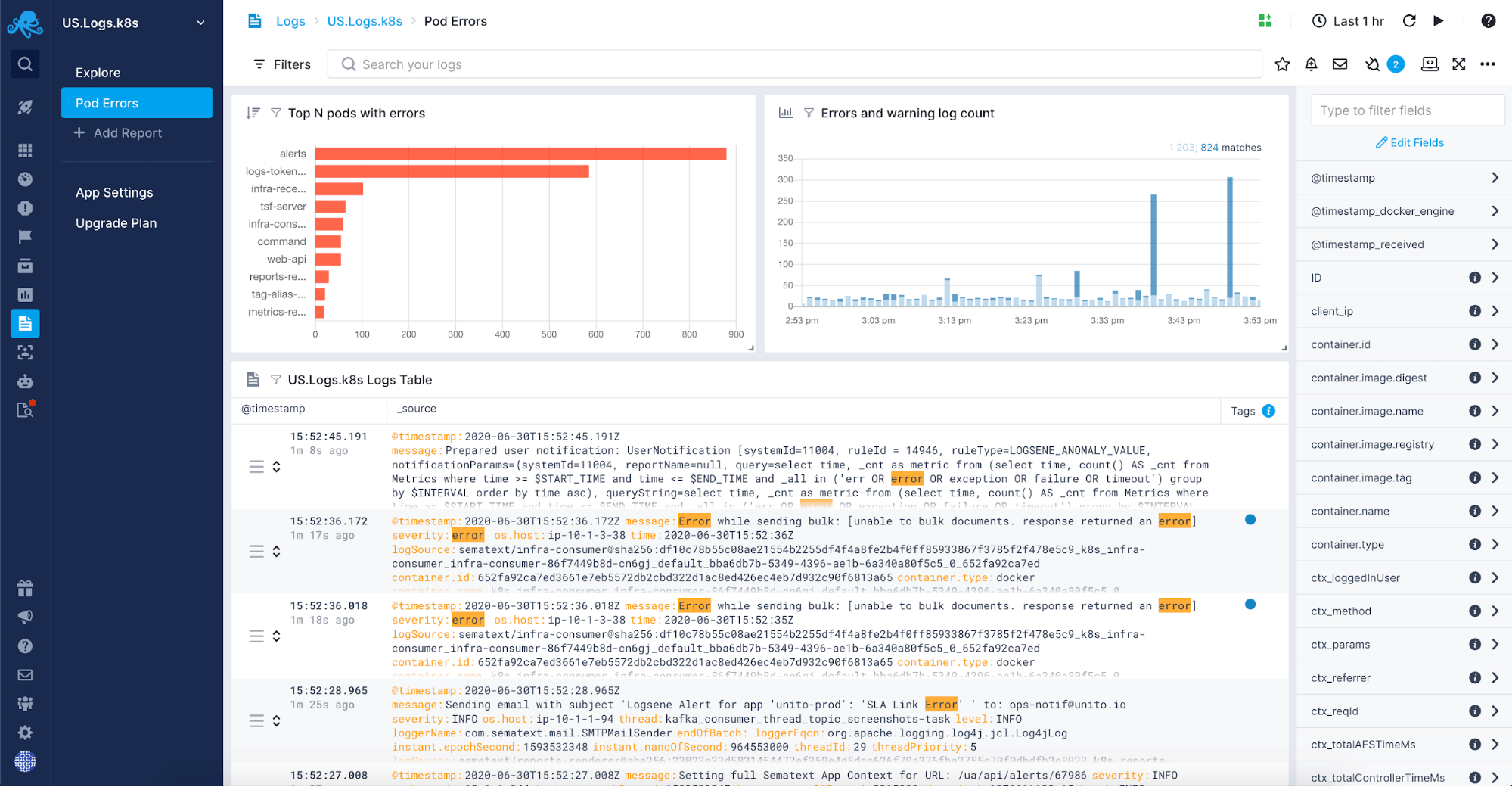
A fully-managed log monitoring and centralization solution such as Sematext Logs will give you the freedom of not needing to manage yet another, usually quite complex, part of your infrastructure. It will allow you to manage a plethora of sources for your logs. If you want to see how Sematext stacks up against similar tools, we wrote in-depth comparisons to help you understand the options available out there. Read our reviews of the best cloud logging services, log analysis software, and log management solutions.
You may want to include logs like JVM garbage collection logs in your managed log solution. After turning them on for your applications and systems working on the JVM you will want to have them in a single place for correlation, analysis, and to help you tune the garbage collection in the JVM instances. Alert on logs, aggregate the data, save and re-run the queries, hook up your favorite incident management software.
Using a log management solution is just one way to make your job easier and faster. You can read more tips about how to efficiently write Java logs from our blog post about Java logging best practices.
Want to know more? Check out this quick video on how Sematext Logs works, and how you can utilize it to manage your infrastructure without all the headache.
Wrapping up
Logging is invaluable when troubleshooting Java applications. In fact, logging is invaluable in troubleshooting in general, no matter if that is a Java application or a hardware switch or firewall. Both the software and hardware give us a look into how they are working in the form of parametrized logs enriched with contextual information.
In this article, we introduced you to Log4j 2.x, the state of art Java logging library allowing you to turn on efficient and highly configurable logging to your projects. We’ve learned how to include it, how to turn it on, configure log events formats and destinations.
I hope this article gave you an idea on how to deal with Java application logs using Log4j 2.x and why you should start working with that library right away if you haven’t already. And don’t forget, the key to efficient application logging is using a good log management tool. Try Sematext Logs to see how much easier things could be. There’s a 14-day free trial available for you to explore all its features.
Good luck!