From Wikipedia, the free encyclopedia
The base rate fallacy, also called base rate neglect[1] or base rate bias, is a type of fallacy in which people tend to ignore the base rate (i.e., general prevalence) in favor of the individuating information (i.e., information pertaining only to a specific case).[2]
Base rate neglect is a specific form of the more general extension neglect.
False positive paradox[edit]
An example of the base rate fallacy is the false positive paradox. This paradox describes situations where there are more false positive test results than true positives. For example, if a facial recognition camera can identify wanted criminals 99% accurately, but analyzes 10,000 people a day, the high accuracy is outweighed by the number of tests, and the program’s list of criminals will likely have far more false positives than true. The probability of a positive test result is determined not only by the accuracy of the test but also by the characteristics of the sampled population.[3] When the prevalence, the proportion of those who have a given condition, is lower than the test’s false positive rate, even tests that have a very low risk of giving a false positive in an individual case will give more false than true positives overall.[4] The paradox surprises most people.[5]
It is especially counter-intuitive when interpreting a positive result in a test on a low-prevalence population after having dealt with positive results drawn from a high-prevalence population.[4] If the false positive rate of the test is higher than the proportion of the new population with the condition, then a test administrator whose experience has been drawn from testing in a high-prevalence population may conclude from experience that a positive test result usually indicates a positive subject, when in fact a false positive is far more likely to have occurred.
Examples[edit]
Example 1: Disease[edit]
High-incidence population[edit]
| Number of people |
Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
400 (true positive) |
30 (false positive) |
430 |
| Test negative |
0 (false negative) |
570 (true negative) |
570 |
| Total | 400 | 600 | 1000 |
Imagine running an infectious disease test on a population A of 1000 persons, of which 40% are infected. The test has a false positive rate of 5% (0.05) and no false negative rate. The expected outcome of the 1000 tests on population A would be:
- Infected and test indicates disease (true positive)
- 1000 × 40/100 = 400 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 40/100 × 0.05 = 30 people would receive a false positive
- The remaining 570 tests are correctly negative.
So, in population A, a person receiving a positive test could be over 93% confident (400/30 + 400) that it correctly indicates infection.
Low-incidence population[edit]
| Number of people |
Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
20 (true positive) |
49 (false positive) |
69 |
| Test negative |
0 (false negative) |
931 (true negative) |
931 |
| Total | 20 | 980 | 1000 |
Now consider the same test applied to population B, of which only 2% are infected. The expected outcome of 1000 tests on population B would be:
- Infected and test indicates disease (true positive)
- 1000 × 2/100 = 20 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 2/100 × 0.05 = 49 people would receive a false positive
- The remaining 931 tests are correctly negative.
In population B, only 20 of the 69 total people with a positive test result are actually infected. So, the probability of actually being infected after one is told that one is infected is only 29% (20/20 + 49) for a test that otherwise appears to be «95% accurate».
A tester with experience of group A might find it a paradox that in group B, a result that had usually correctly indicated infection is now usually a false positive. The confusion of the posterior probability of infection with the prior probability of receiving a false positive is a natural error after receiving a health-threatening test result.
Example 2: Drunk drivers[edit]
- A group of police officers have breathalyzers displaying false drunkenness in 5% of the cases in which the driver is sober. However, the breathalyzers never fail to detect a truly drunk person. One in a thousand drivers is driving drunk. Suppose the police officers then stop a driver at random to administer a breathalyzer test. It indicates that the driver is drunk. We assume you do not know anything else about them. How high is the probability they really are drunk?
Many would answer as high as 95%, but the correct probability is about 2%.
An explanation for this is as follows: on average, for every 1,000 drivers tested,
- 1 driver is drunk, and it is 100% certain that for that driver there is a true positive test result, so there is 1 true positive test result
- 999 drivers are not drunk, and among those drivers there are 5% false positive test results, so there are 49.95 false positive test results
Therefore, the probability that one of the drivers among the 1 + 49.95 = 50.95 positive test results really is drunk is  .
.
The validity of this result does, however, hinge on the validity of the initial assumption that the police officer stopped the driver truly at random, and not because of bad driving. If that or another non-arbitrary reason for stopping the driver was present, then the calculation also involves the probability of a drunk driver driving competently and a non-drunk driver driving (in-)competently.
More formally, the same probability of roughly 0.02 can be established using Bayes’s theorem. The goal is to find the probability that the driver is drunk given that the breathalyzer indicated they are drunk, which can be represented as

where D means that the breathalyzer indicates that the driver is drunk. Bayes’s theorem tells us that

We were told the following in the first paragraph:

- and




As you can see from the formula, one needs p(D) for Bayes’ theorem, which one can compute from the preceding values using the law of total probability:

which gives

Plugging these numbers into Bayes’ theorem, one finds that

Example 3: Terrorist identification[edit]
In a city of 1 million inhabitants, let there be 100 terrorists and 999,900 non-terrorists. To simplify the example, it is assumed that all people present in the city are inhabitants. Thus, the base rate probability of a randomly selected inhabitant of the city being a terrorist is 0.0001, and the base rate probability of that same inhabitant being a non-terrorist is 0.9999. In an attempt to catch the terrorists, the city installs an alarm system with a surveillance camera and automatic facial recognition software.
The software has two failure rates of 1%:
- The false negative rate: If the camera scans a terrorist, a bell will ring 99% of the time, and it will fail to ring 1% of the time.
- The false positive rate: If the camera scans a non-terrorist, a bell will not ring 99% of the time, but it will ring 1% of the time.
Suppose now that an inhabitant triggers the alarm. What is the probability that the person is a terrorist? In other words, what is P(T | B), the probability that a terrorist has been detected given the ringing of the bell? Someone making the ‘base rate fallacy’ would infer that there is a 99% probability that the detected person is a terrorist. Although the inference seems to make sense, it is actually bad reasoning, and a calculation below will show that the probability of a terrorist is actually near 1%, not near 99%.
The fallacy arises from confusing the natures of two different failure rates. The ‘number of non-bells per 100 terrorists’ and the ‘number of non-terrorists per 100 bells’ are unrelated quantities. One does not necessarily equal the other, and they don’t even have to be almost equal. To show this, consider what happens if an identical alarm system were set up in a second city with no terrorists at all. As in the first city, the alarm sounds for 1 out of every 100 non-terrorist inhabitants detected, but unlike in the first city, the alarm never sounds for a terrorist. Therefore, 100% of all occasions of the alarm sounding are for non-terrorists, but a false negative rate cannot even be calculated. The ‘number of non-terrorists per 100 bells’ in that city is 100, yet P(T | B) = 0%. There is zero chance that a terrorist has been detected given the ringing of the bell.
Imagine that the first city’s entire population of one million people pass in front of the camera. About 99 of the 100 terrorists will trigger the alarm—and so will about 9,999 of the 999,900 non-terrorists. Therefore, about 10,098 people will trigger the alarm, among which about 99 will be terrorists. The probability that a person triggering the alarm actually is a terrorist is only about 99 in 10,098, which is less than 1%, and very, very far below our initial guess of 99%.
The base rate fallacy is so misleading in this example because there are many more non-terrorists than terrorists, and the number of false positives (non-terrorists scanned as terrorists) is so much larger than the true positives (terrorists scanned as terrorists).
Multiple practitioners have argued that as the base rate of terrorism is extremely low, using data mining and predictive algorithms to identify terrorists cannot feasibly work due to the false positive paradox.[6][7][8][9] Estimates of the number of false positives for each accurate result vary from over ten thousand[9] to one billion;[7] consequently, investigating each lead would be cost and time prohibitive.[6][8] The level of accuracy required to make these models viable is likely unachievable. Foremost the low base rate of terrorism also means there is a lack of data with which to make an accurate algorithm.[8] Further, in the context of detecting terrorism false negatives are highly undesirable and thus must be minimised as much as possible, however this requires increasing sensitivity at the cost of specificity, increasing false positives.[9] It is also questionable whether the use of such models by law enforcement would meet the requisite burden of proof given that over 99% of results would be false positives.[9]
Findings in psychology[edit]
In experiments, people have been found to prefer individuating information over general information when the former is available.[10][11][12]
In some experiments, students were asked to estimate the grade point averages (GPAs) of hypothetical students. When given relevant statistics about GPA distribution, students tended to ignore them if given descriptive information about the particular student even if the new descriptive information was obviously of little or no relevance to school performance.[11] This finding has been used to argue that interviews are an unnecessary part of the college admissions process because interviewers are unable to pick successful candidates better than basic statistics.
Psychologists Daniel Kahneman and Amos Tversky attempted to explain this finding in terms of a simple rule or «heuristic» called representativeness. They argued that many judgments relating to likelihood, or to cause and effect, are based on how representative one thing is of another, or of a category.[11] Kahneman considers base rate neglect to be a specific form of extension neglect.[13] Richard Nisbett has argued that some attributional biases like the fundamental attribution error are instances of the base rate fallacy: people do not use the «consensus information» (the «base rate») about how others behaved in similar situations and instead prefer simpler dispositional attributions.[14]
There is considerable debate in psychology on the conditions under which people do or do not appreciate base rate information.[15][16] Researchers in the heuristics-and-biases program have stressed empirical findings showing that people tend to ignore base rates and make inferences that violate certain norms of probabilistic reasoning, such as Bayes’ theorem. The conclusion drawn from this line of research was that human probabilistic thinking is fundamentally flawed and error-prone.[17] Other researchers have emphasized the link between cognitive processes and information formats, arguing that such conclusions are not generally warranted.[18][19]
Consider again Example 2 from above. The required inference is to estimate the (posterior) probability that a (randomly picked) driver is drunk, given that the breathalyzer test is positive. Formally, this probability can be calculated using Bayes’ theorem, as shown above. However, there are different ways of presenting the relevant information. Consider the following, formally equivalent variant of the problem:
- 1 out of 1000 drivers are driving drunk. The breathalyzers never fail to detect a truly drunk person. For 50 out of the 999 drivers who are not drunk the breathalyzer falsely displays drunkenness. Suppose the policemen then stop a driver at random, and force them to take a breathalyzer test. It indicates that they are drunk. We assume you don’t know anything else about them. How high is the probability they really are drunk?
In this case, the relevant numerical information—p(drunk), p(D | drunk), p(D | sober)—is presented in terms of natural frequencies with respect to a certain reference class (see reference class problem). Empirical studies show that people’s inferences correspond more closely to Bayes’ rule when information is presented this way, helping to overcome base-rate neglect in laypeople[19] and experts.[20] As a consequence, organizations like the Cochrane Collaboration recommend using this kind of format for communicating health statistics.[21] Teaching people to translate these kinds of Bayesian reasoning problems into natural frequency formats is more effective than merely teaching them to plug probabilities (or percentages) into Bayes’ theorem.[22] It has also been shown that graphical representations of natural frequencies (e.g., icon arrays, hypothetical outcome plots) help people to make better inferences.[22][23][24][25]
Why are natural frequency formats helpful? One important reason is that this information format facilitates the required inference because it simplifies the necessary calculations. This can be seen when using an alternative way of computing the required probability p(drunk|D):

where N(drunk ∩ D) denotes the number of drivers that are drunk and get a positive breathalyzer result, and N(D) denotes the total number of cases with a positive breathalyzer result. The equivalence of this equation to the above one follows from the axioms of probability theory, according to which N(drunk ∩ D) = N × p (D | drunk) × p (drunk). Importantly, although this equation is formally equivalent to Bayes’ rule, it is not psychologically equivalent. Using natural frequencies simplifies the inference because the required mathematical operation can be performed on natural numbers, instead of normalized fractions (i.e., probabilities), because it makes the high number of false positives more transparent, and because natural frequencies exhibit a «nested-set structure».[26][27]
Not every frequency format facilitates Bayesian reasoning.[27][28] Natural frequencies refer to frequency information that results from natural sampling,[29] which preserves base rate information (e.g., number of drunken drivers when taking a random sample of drivers). This is different from systematic sampling, in which base rates are fixed a priori (e.g., in scientific experiments). In the latter case it is not possible to infer the posterior probability p (drunk | positive test) from comparing the number of drivers who are drunk and test positive compared to the total number of people who get a positive breathalyzer result, because base rate information is not preserved and must be explicitly re-introduced using Bayes’ theorem.
See also[edit]
- Base rate
- Bayesian probability
- Bayes’ theorem
- Data dredging
- Inductive argument
- List of cognitive biases
- List of paradoxes
- Misleading vividness
- Prevention paradox
- Prosecutor’s fallacy, a mistake in reasoning that involves ignoring a low prior probability
- Simpson’s paradox, another error in statistical reasoning dealing with comparing groups
- Stereotype
- Intuitive statistics
References[edit]
- ^ Welsh, Matthew B.; Navarro, Daniel J. (2012). «Seeing is believing: Priors, trust, and base rate neglect». Organizational Behavior and Human Decision Processes. 119 (1): 1–14. doi:10.1016/j.obhdp.2012.04.001. hdl:2440/41190. ISSN 0749-5978.
- ^ «Logical Fallacy: The Base Rate Fallacy». Fallacyfiles.org. Retrieved 2013-06-15.
- ^ Rheinfurth, M. H.; Howell, L. W. (March 1998). Probability and Statistics in Aerospace Engineering (PDF). NASA. p. 16.
MESSAGE: False positive tests are more probable than true positive tests when the overall population has a low prevalence of the disease. This is called the false-positive paradox.
- ^ a b Vacher, H. L. (May 2003). «Quantitative literacy — drug testing, cancer screening, and the identification of igneous rocks». Journal of Geoscience Education: 2.
At first glance, this seems perverse: the less the students as a whole use steroids, the more likely a student identified as a user will be a non-user. This has been called the False Positive Paradox
— Citing: Gonick, L.; Smith, W. (1993). The cartoon guide to statistics. New York: Harper Collins. p. 49. - ^ Madison, B. L. (August 2007). «Mathematical Proficiency for Citizenship». In Schoenfeld, A. H. (ed.). Assessing Mathematical Proficiency. Mathematical Sciences Research Institute Publications (New ed.). Cambridge University Press. p. 122. ISBN 978-0-521-69766-8.
The correct [probability estimate…] is surprising to many; hence, the term paradox.
- ^ a b Munk, Timme Bisgaard (1 September 2017). «100,000 false positives for every real terrorist: Why anti-terror algorithms don’t work». First Monday. 22 (9). doi:10.5210/fm.v22i9.7126.
- ^ a b Schneier, Bruce. «Why Data Mining Won’t Stop Terror». Wired. ISSN 1059-1028. Retrieved 2022-08-30.
- ^ a b c Jonas, Jeff; Harper, Jim (2006-12-11). «Effective Counterterrorism and the Limited Role of Predictive Data Mining». CATO Institute. Retrieved 2022-08-30.
- ^ a b c d Sageman, Marc (2021-02-17). «The Implication of Terrorism’s Extremely Low Base Rate». Terrorism and Political Violence. 33 (2): 302–311. doi:10.1080/09546553.2021.1880226. ISSN 0954-6553. S2CID 232341781.
- ^ Bar-Hillel, Maya (1980). «The base-rate fallacy in probability judgments» (PDF). Acta Psychologica. 44 (3): 211–233. doi:10.1016/0001-6918(80)90046-3.
- ^ a b c Kahneman, Daniel; Amos Tversky (1973). «On the psychology of prediction». Psychological Review. 80 (4): 237–251. doi:10.1037/h0034747. S2CID 17786757.
- ^ Kahneman, Daniel; Amos Tversky (1985). «Evidential impact of base rates». In Daniel Kahneman, Paul Slovic & Amos Tversky (ed.). Judgment under uncertainty: Heuristics and biases. Science. Vol. 185. pp. 153–160. Bibcode:1974Sci…185.1124T. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- ^ Kahneman, Daniel (2000). «Evaluation by moments, past and future». In Daniel Kahneman and Amos Tversky (ed.). Choices, Values and Frames. ISBN 0-521-62749-4.
- ^ Nisbett, Richard E.; E. Borgida; R. Crandall; H. Reed (1976). «Popular induction: Information is not always informative». In J. S. Carroll & J. W. Payne (ed.). Cognition and social behavior. Vol. 2. pp. 227–236. ISBN 0-470-99007-4.
- ^ Koehler, J. J. (2010). «The base rate fallacy reconsidered: Descriptive, normative, and methodological challenges». Behavioral and Brain Sciences. 19: 1–17. doi:10.1017/S0140525X00041157. S2CID 53343238.
- ^ Barbey, A. K.; Sloman, S. A. (2007). «Base-rate respect: From ecological rationality to dual processes». Behavioral and Brain Sciences. 30 (3): 241–254, discussion 255–297. doi:10.1017/S0140525X07001653. PMID 17963533. S2CID 31741077.
- ^ Tversky, A.; Kahneman, D. (1974). «Judgment under Uncertainty: Heuristics and Biases». Science. 185 (4157): 1124–1131. Bibcode:1974Sci…185.1124T. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- ^ Cosmides, Leda; John Tooby (1996). «Are humans good intuitive statisticians after all? Rethinking some conclusions of the literature on judgment under uncertainty». Cognition. 58: 1–73. CiteSeerX 10.1.1.131.8290. doi:10.1016/0010-0277(95)00664-8. S2CID 18631755.
- ^ a b Gigerenzer, G.; Hoffrage, U. (1995). «How to improve Bayesian reasoning without instruction: Frequency formats». Psychological Review. 102 (4): 684. CiteSeerX 10.1.1.128.3201. doi:10.1037/0033-295X.102.4.684.
- ^ Hoffrage, U.; Lindsey, S.; Hertwig, R.; Gigerenzer, G. (2000). «Medicine: Communicating Statistical Information». Science. 290 (5500): 2261–2262. doi:10.1126/science.290.5500.2261. hdl:11858/00-001M-0000-0025-9B18-3. PMID 11188724. S2CID 33050943.
- ^ Akl, E. A.; Oxman, A. D.; Herrin, J.; Vist, G. E.; Terrenato, I.; Sperati, F.; Costiniuk, C.; Blank, D.; Schünemann, H. (2011). Schünemann, Holger (ed.). «Using alternative statistical formats for presenting risks and risk reductions». The Cochrane Database of Systematic Reviews. 2011 (3): CD006776. doi:10.1002/14651858.CD006776.pub2. PMC 6464912. PMID 21412897.
- ^ a b Sedlmeier, P.; Gigerenzer, G. (2001). «Teaching Bayesian reasoning in less than two hours». Journal of Experimental Psychology: General. 130 (3): 380–400. doi:10.1037/0096-3445.130.3.380. hdl:11858/00-001M-0000-0025-9504-E. PMID 11561916.
- ^ Brase, G. L. (2009). «Pictorial representations in statistical reasoning». Applied Cognitive Psychology. 23 (3): 369–381. doi:10.1002/acp.1460. S2CID 18817707.
- ^ Edwards, A.; Elwyn, G.; Mulley, A. (2002). «Explaining risks: Turning numerical data into meaningful pictures». BMJ. 324 (7341): 827–830. doi:10.1136/bmj.324.7341.827. PMC 1122766. PMID 11934777.
- ^ Kim, Yea-Seul; Walls, Logan A.; Krafft, Peter; Hullman, Jessica (2 May 2019). «A Bayesian Cognition Approach to Improve Data Visualization». Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems: 1–14. doi:10.1145/3290605.3300912. ISBN 9781450359702. S2CID 57761146.
- ^ Girotto, V.; Gonzalez, M. (2001). «Solving probabilistic and statistical problems: A matter of information structure and question form». Cognition. 78 (3): 247–276. doi:10.1016/S0010-0277(00)00133-5. PMID 11124351. S2CID 8588451.
- ^ a b Hoffrage, U.; Gigerenzer, G.; Krauss, S.; Martignon, L. (2002). «Representation facilitates reasoning: What natural frequencies are and what they are not». Cognition. 84 (3): 343–352. doi:10.1016/S0010-0277(02)00050-1. PMID 12044739. S2CID 9595672.
- ^ Gigerenzer, G.; Hoffrage, U. (1999). «Overcoming difficulties in Bayesian reasoning: A reply to Lewis and Keren (1999) and Mellers and McGraw (1999)». Psychological Review. 106 (2): 425. doi:10.1037/0033-295X.106.2.425. hdl:11858/00-001M-0000-0025-9CB4-8.
- ^ Kleiter, G. D. (1994). «Natural Sampling: Rationality without Base Rates». Contributions to Mathematical Psychology, Psychometrics, and Methodology. Recent Research in Psychology. pp. 375–388. doi:10.1007/978-1-4612-4308-3_27. ISBN 978-0-387-94169-1.
External links[edit]
- The Base Rate Fallacy The Fallacy Files
From Wikipedia, the free encyclopedia
The base rate fallacy, also called base rate neglect[1] or base rate bias, is a type of fallacy in which people tend to ignore the base rate (i.e., general prevalence) in favor of the individuating information (i.e., information pertaining only to a specific case).[2]
Base rate neglect is a specific form of the more general extension neglect.
False positive paradox[edit]
An example of the base rate fallacy is the false positive paradox. This paradox describes situations where there are more false positive test results than true positives. For example, if a facial recognition camera can identify wanted criminals 99% accurately, but analyzes 10,000 people a day, the high accuracy is outweighed by the number of tests, and the program’s list of criminals will likely have far more false positives than true. The probability of a positive test result is determined not only by the accuracy of the test but also by the characteristics of the sampled population.[3] When the prevalence, the proportion of those who have a given condition, is lower than the test’s false positive rate, even tests that have a very low risk of giving a false positive in an individual case will give more false than true positives overall.[4] The paradox surprises most people.[5]
It is especially counter-intuitive when interpreting a positive result in a test on a low-prevalence population after having dealt with positive results drawn from a high-prevalence population.[4] If the false positive rate of the test is higher than the proportion of the new population with the condition, then a test administrator whose experience has been drawn from testing in a high-prevalence population may conclude from experience that a positive test result usually indicates a positive subject, when in fact a false positive is far more likely to have occurred.
Examples[edit]
Example 1: Disease[edit]
High-incidence population[edit]
| Number of people |
Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
400 (true positive) |
30 (false positive) |
430 |
| Test negative |
0 (false negative) |
570 (true negative) |
570 |
| Total | 400 | 600 | 1000 |
Imagine running an infectious disease test on a population A of 1000 persons, of which 40% are infected. The test has a false positive rate of 5% (0.05) and no false negative rate. The expected outcome of the 1000 tests on population A would be:
- Infected and test indicates disease (true positive)
- 1000 × 40/100 = 400 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 40/100 × 0.05 = 30 people would receive a false positive
- The remaining 570 tests are correctly negative.
So, in population A, a person receiving a positive test could be over 93% confident (400/30 + 400) that it correctly indicates infection.
Low-incidence population[edit]
| Number of people |
Infected | Uninfected | Total |
|---|---|---|---|
| Test positive |
20 (true positive) |
49 (false positive) |
69 |
| Test negative |
0 (false negative) |
931 (true negative) |
931 |
| Total | 20 | 980 | 1000 |
Now consider the same test applied to population B, of which only 2% are infected. The expected outcome of 1000 tests on population B would be:
- Infected and test indicates disease (true positive)
- 1000 × 2/100 = 20 people would receive a true positive
- Uninfected and test indicates disease (false positive)
- 1000 × 100 – 2/100 × 0.05 = 49 people would receive a false positive
- The remaining 931 tests are correctly negative.
In population B, only 20 of the 69 total people with a positive test result are actually infected. So, the probability of actually being infected after one is told that one is infected is only 29% (20/20 + 49) for a test that otherwise appears to be «95% accurate».
A tester with experience of group A might find it a paradox that in group B, a result that had usually correctly indicated infection is now usually a false positive. The confusion of the posterior probability of infection with the prior probability of receiving a false positive is a natural error after receiving a health-threatening test result.
Example 2: Drunk drivers[edit]
- A group of police officers have breathalyzers displaying false drunkenness in 5% of the cases in which the driver is sober. However, the breathalyzers never fail to detect a truly drunk person. One in a thousand drivers is driving drunk. Suppose the police officers then stop a driver at random to administer a breathalyzer test. It indicates that the driver is drunk. We assume you do not know anything else about them. How high is the probability they really are drunk?
Many would answer as high as 95%, but the correct probability is about 2%.
An explanation for this is as follows: on average, for every 1,000 drivers tested,
- 1 driver is drunk, and it is 100% certain that for that driver there is a true positive test result, so there is 1 true positive test result
- 999 drivers are not drunk, and among those drivers there are 5% false positive test results, so there are 49.95 false positive test results
Therefore, the probability that one of the drivers among the 1 + 49.95 = 50.95 positive test results really is drunk is .
The validity of this result does, however, hinge on the validity of the initial assumption that the police officer stopped the driver truly at random, and not because of bad driving. If that or another non-arbitrary reason for stopping the driver was present, then the calculation also involves the probability of a drunk driver driving competently and a non-drunk driver driving (in-)competently.
More formally, the same probability of roughly 0.02 can be established using Bayes’s theorem. The goal is to find the probability that the driver is drunk given that the breathalyzer indicated they are drunk, which can be represented as
where D means that the breathalyzer indicates that the driver is drunk. Bayes’s theorem tells us that
We were told the following in the first paragraph:
- and
As you can see from the formula, one needs p(D) for Bayes’ theorem, which one can compute from the preceding values using the law of total probability:
which gives
Plugging these numbers into Bayes’ theorem, one finds that
Example 3: Terrorist identification[edit]
In a city of 1 million inhabitants, let there be 100 terrorists and 999,900 non-terrorists. To simplify the example, it is assumed that all people present in the city are inhabitants. Thus, the base rate probability of a randomly selected inhabitant of the city being a terrorist is 0.0001, and the base rate probability of that same inhabitant being a non-terrorist is 0.9999. In an attempt to catch the terrorists, the city installs an alarm system with a surveillance camera and automatic facial recognition software.
The software has two failure rates of 1%:
- The false negative rate: If the camera scans a terrorist, a bell will ring 99% of the time, and it will fail to ring 1% of the time.
- The false positive rate: If the camera scans a non-terrorist, a bell will not ring 99% of the time, but it will ring 1% of the time.
Suppose now that an inhabitant triggers the alarm. What is the probability that the person is a terrorist? In other words, what is P(T | B), the probability that a terrorist has been detected given the ringing of the bell? Someone making the ‘base rate fallacy’ would infer that there is a 99% probability that the detected person is a terrorist. Although the inference seems to make sense, it is actually bad reasoning, and a calculation below will show that the probability of a terrorist is actually near 1%, not near 99%.
The fallacy arises from confusing the natures of two different failure rates. The ‘number of non-bells per 100 terrorists’ and the ‘number of non-terrorists per 100 bells’ are unrelated quantities. One does not necessarily equal the other, and they don’t even have to be almost equal. To show this, consider what happens if an identical alarm system were set up in a second city with no terrorists at all. As in the first city, the alarm sounds for 1 out of every 100 non-terrorist inhabitants detected, but unlike in the first city, the alarm never sounds for a terrorist. Therefore, 100% of all occasions of the alarm sounding are for non-terrorists, but a false negative rate cannot even be calculated. The ‘number of non-terrorists per 100 bells’ in that city is 100, yet P(T | B) = 0%. There is zero chance that a terrorist has been detected given the ringing of the bell.
Imagine that the first city’s entire population of one million people pass in front of the camera. About 99 of the 100 terrorists will trigger the alarm—and so will about 9,999 of the 999,900 non-terrorists. Therefore, about 10,098 people will trigger the alarm, among which about 99 will be terrorists. The probability that a person triggering the alarm actually is a terrorist is only about 99 in 10,098, which is less than 1%, and very, very far below our initial guess of 99%.
The base rate fallacy is so misleading in this example because there are many more non-terrorists than terrorists, and the number of false positives (non-terrorists scanned as terrorists) is so much larger than the true positives (terrorists scanned as terrorists).
Multiple practitioners have argued that as the base rate of terrorism is extremely low, using data mining and predictive algorithms to identify terrorists cannot feasibly work due to the false positive paradox.[6][7][8][9] Estimates of the number of false positives for each accurate result vary from over ten thousand[9] to one billion;[7] consequently, investigating each lead would be cost and time prohibitive.[6][8] The level of accuracy required to make these models viable is likely unachievable. Foremost the low base rate of terrorism also means there is a lack of data with which to make an accurate algorithm.[8] Further, in the context of detecting terrorism false negatives are highly undesirable and thus must be minimised as much as possible, however this requires increasing sensitivity at the cost of specificity, increasing false positives.[9] It is also questionable whether the use of such models by law enforcement would meet the requisite burden of proof given that over 99% of results would be false positives.[9]
Findings in psychology[edit]
In experiments, people have been found to prefer individuating information over general information when the former is available.[10][11][12]
In some experiments, students were asked to estimate the grade point averages (GPAs) of hypothetical students. When given relevant statistics about GPA distribution, students tended to ignore them if given descriptive information about the particular student even if the new descriptive information was obviously of little or no relevance to school performance.[11] This finding has been used to argue that interviews are an unnecessary part of the college admissions process because interviewers are unable to pick successful candidates better than basic statistics.
Psychologists Daniel Kahneman and Amos Tversky attempted to explain this finding in terms of a simple rule or «heuristic» called representativeness. They argued that many judgments relating to likelihood, or to cause and effect, are based on how representative one thing is of another, or of a category.[11] Kahneman considers base rate neglect to be a specific form of extension neglect.[13] Richard Nisbett has argued that some attributional biases like the fundamental attribution error are instances of the base rate fallacy: people do not use the «consensus information» (the «base rate») about how others behaved in similar situations and instead prefer simpler dispositional attributions.[14]
There is considerable debate in psychology on the conditions under which people do or do not appreciate base rate information.[15][16] Researchers in the heuristics-and-biases program have stressed empirical findings showing that people tend to ignore base rates and make inferences that violate certain norms of probabilistic reasoning, such as Bayes’ theorem. The conclusion drawn from this line of research was that human probabilistic thinking is fundamentally flawed and error-prone.[17] Other researchers have emphasized the link between cognitive processes and information formats, arguing that such conclusions are not generally warranted.[18][19]
Consider again Example 2 from above. The required inference is to estimate the (posterior) probability that a (randomly picked) driver is drunk, given that the breathalyzer test is positive. Formally, this probability can be calculated using Bayes’ theorem, as shown above. However, there are different ways of presenting the relevant information. Consider the following, formally equivalent variant of the problem:
- 1 out of 1000 drivers are driving drunk. The breathalyzers never fail to detect a truly drunk person. For 50 out of the 999 drivers who are not drunk the breathalyzer falsely displays drunkenness. Suppose the policemen then stop a driver at random, and force them to take a breathalyzer test. It indicates that they are drunk. We assume you don’t know anything else about them. How high is the probability they really are drunk?
In this case, the relevant numerical information—p(drunk), p(D | drunk), p(D | sober)—is presented in terms of natural frequencies with respect to a certain reference class (see reference class problem). Empirical studies show that people’s inferences correspond more closely to Bayes’ rule when information is presented this way, helping to overcome base-rate neglect in laypeople[19] and experts.[20] As a consequence, organizations like the Cochrane Collaboration recommend using this kind of format for communicating health statistics.[21] Teaching people to translate these kinds of Bayesian reasoning problems into natural frequency formats is more effective than merely teaching them to plug probabilities (or percentages) into Bayes’ theorem.[22] It has also been shown that graphical representations of natural frequencies (e.g., icon arrays, hypothetical outcome plots) help people to make better inferences.[22][23][24][25]
Why are natural frequency formats helpful? One important reason is that this information format facilitates the required inference because it simplifies the necessary calculations. This can be seen when using an alternative way of computing the required probability p(drunk|D):
where N(drunk ∩ D) denotes the number of drivers that are drunk and get a positive breathalyzer result, and N(D) denotes the total number of cases with a positive breathalyzer result. The equivalence of this equation to the above one follows from the axioms of probability theory, according to which N(drunk ∩ D) = N × p (D | drunk) × p (drunk). Importantly, although this equation is formally equivalent to Bayes’ rule, it is not psychologically equivalent. Using natural frequencies simplifies the inference because the required mathematical operation can be performed on natural numbers, instead of normalized fractions (i.e., probabilities), because it makes the high number of false positives more transparent, and because natural frequencies exhibit a «nested-set structure».[26][27]
Not every frequency format facilitates Bayesian reasoning.[27][28] Natural frequencies refer to frequency information that results from natural sampling,[29] which preserves base rate information (e.g., number of drunken drivers when taking a random sample of drivers). This is different from systematic sampling, in which base rates are fixed a priori (e.g., in scientific experiments). In the latter case it is not possible to infer the posterior probability p (drunk | positive test) from comparing the number of drivers who are drunk and test positive compared to the total number of people who get a positive breathalyzer result, because base rate information is not preserved and must be explicitly re-introduced using Bayes’ theorem.
See also[edit]
- Base rate
- Bayesian probability
- Bayes’ theorem
- Data dredging
- Inductive argument
- List of cognitive biases
- List of paradoxes
- Misleading vividness
- Prevention paradox
- Prosecutor’s fallacy, a mistake in reasoning that involves ignoring a low prior probability
- Simpson’s paradox, another error in statistical reasoning dealing with comparing groups
- Stereotype
- Intuitive statistics
References[edit]
- ^ Welsh, Matthew B.; Navarro, Daniel J. (2012). «Seeing is believing: Priors, trust, and base rate neglect». Organizational Behavior and Human Decision Processes. 119 (1): 1–14. doi:10.1016/j.obhdp.2012.04.001. hdl:2440/41190. ISSN 0749-5978.
- ^ «Logical Fallacy: The Base Rate Fallacy». Fallacyfiles.org. Retrieved 2013-06-15.
- ^ Rheinfurth, M. H.; Howell, L. W. (March 1998). Probability and Statistics in Aerospace Engineering (PDF). NASA. p. 16.
MESSAGE: False positive tests are more probable than true positive tests when the overall population has a low prevalence of the disease. This is called the false-positive paradox.
- ^ a b Vacher, H. L. (May 2003). «Quantitative literacy — drug testing, cancer screening, and the identification of igneous rocks». Journal of Geoscience Education: 2.
At first glance, this seems perverse: the less the students as a whole use steroids, the more likely a student identified as a user will be a non-user. This has been called the False Positive Paradox
— Citing: Gonick, L.; Smith, W. (1993). The cartoon guide to statistics. New York: Harper Collins. p. 49. - ^ Madison, B. L. (August 2007). «Mathematical Proficiency for Citizenship». In Schoenfeld, A. H. (ed.). Assessing Mathematical Proficiency. Mathematical Sciences Research Institute Publications (New ed.). Cambridge University Press. p. 122. ISBN 978-0-521-69766-8.
The correct [probability estimate…] is surprising to many; hence, the term paradox.
- ^ a b Munk, Timme Bisgaard (1 September 2017). «100,000 false positives for every real terrorist: Why anti-terror algorithms don’t work». First Monday. 22 (9). doi:10.5210/fm.v22i9.7126.
- ^ a b Schneier, Bruce. «Why Data Mining Won’t Stop Terror». Wired. ISSN 1059-1028. Retrieved 2022-08-30.
- ^ a b c Jonas, Jeff; Harper, Jim (2006-12-11). «Effective Counterterrorism and the Limited Role of Predictive Data Mining». CATO Institute. Retrieved 2022-08-30.
- ^ a b c d Sageman, Marc (2021-02-17). «The Implication of Terrorism’s Extremely Low Base Rate». Terrorism and Political Violence. 33 (2): 302–311. doi:10.1080/09546553.2021.1880226. ISSN 0954-6553. S2CID 232341781.
- ^ Bar-Hillel, Maya (1980). «The base-rate fallacy in probability judgments» (PDF). Acta Psychologica. 44 (3): 211–233. doi:10.1016/0001-6918(80)90046-3.
- ^ a b c Kahneman, Daniel; Amos Tversky (1973). «On the psychology of prediction». Psychological Review. 80 (4): 237–251. doi:10.1037/h0034747. S2CID 17786757.
- ^ Kahneman, Daniel; Amos Tversky (1985). «Evidential impact of base rates». In Daniel Kahneman, Paul Slovic & Amos Tversky (ed.). Judgment under uncertainty: Heuristics and biases. Science. Vol. 185. pp. 153–160. Bibcode:1974Sci…185.1124T. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- ^ Kahneman, Daniel (2000). «Evaluation by moments, past and future». In Daniel Kahneman and Amos Tversky (ed.). Choices, Values and Frames. ISBN 0-521-62749-4.
- ^ Nisbett, Richard E.; E. Borgida; R. Crandall; H. Reed (1976). «Popular induction: Information is not always informative». In J. S. Carroll & J. W. Payne (ed.). Cognition and social behavior. Vol. 2. pp. 227–236. ISBN 0-470-99007-4.
- ^ Koehler, J. J. (2010). «The base rate fallacy reconsidered: Descriptive, normative, and methodological challenges». Behavioral and Brain Sciences. 19: 1–17. doi:10.1017/S0140525X00041157. S2CID 53343238.
- ^ Barbey, A. K.; Sloman, S. A. (2007). «Base-rate respect: From ecological rationality to dual processes». Behavioral and Brain Sciences. 30 (3): 241–254, discussion 255–297. doi:10.1017/S0140525X07001653. PMID 17963533. S2CID 31741077.
- ^ Tversky, A.; Kahneman, D. (1974). «Judgment under Uncertainty: Heuristics and Biases». Science. 185 (4157): 1124–1131. Bibcode:1974Sci…185.1124T. doi:10.1126/science.185.4157.1124. PMID 17835457. S2CID 143452957.
- ^ Cosmides, Leda; John Tooby (1996). «Are humans good intuitive statisticians after all? Rethinking some conclusions of the literature on judgment under uncertainty». Cognition. 58: 1–73. CiteSeerX 10.1.1.131.8290. doi:10.1016/0010-0277(95)00664-8. S2CID 18631755.
- ^ a b Gigerenzer, G.; Hoffrage, U. (1995). «How to improve Bayesian reasoning without instruction: Frequency formats». Psychological Review. 102 (4): 684. CiteSeerX 10.1.1.128.3201. doi:10.1037/0033-295X.102.4.684.
- ^ Hoffrage, U.; Lindsey, S.; Hertwig, R.; Gigerenzer, G. (2000). «Medicine: Communicating Statistical Information». Science. 290 (5500): 2261–2262. doi:10.1126/science.290.5500.2261. hdl:11858/00-001M-0000-0025-9B18-3. PMID 11188724. S2CID 33050943.
- ^ Akl, E. A.; Oxman, A. D.; Herrin, J.; Vist, G. E.; Terrenato, I.; Sperati, F.; Costiniuk, C.; Blank, D.; Schünemann, H. (2011). Schünemann, Holger (ed.). «Using alternative statistical formats for presenting risks and risk reductions». The Cochrane Database of Systematic Reviews. 2011 (3): CD006776. doi:10.1002/14651858.CD006776.pub2. PMC 6464912. PMID 21412897.
- ^ a b Sedlmeier, P.; Gigerenzer, G. (2001). «Teaching Bayesian reasoning in less than two hours». Journal of Experimental Psychology: General. 130 (3): 380–400. doi:10.1037/0096-3445.130.3.380. hdl:11858/00-001M-0000-0025-9504-E. PMID 11561916.
- ^ Brase, G. L. (2009). «Pictorial representations in statistical reasoning». Applied Cognitive Psychology. 23 (3): 369–381. doi:10.1002/acp.1460. S2CID 18817707.
- ^ Edwards, A.; Elwyn, G.; Mulley, A. (2002). «Explaining risks: Turning numerical data into meaningful pictures». BMJ. 324 (7341): 827–830. doi:10.1136/bmj.324.7341.827. PMC 1122766. PMID 11934777.
- ^ Kim, Yea-Seul; Walls, Logan A.; Krafft, Peter; Hullman, Jessica (2 May 2019). «A Bayesian Cognition Approach to Improve Data Visualization». Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems: 1–14. doi:10.1145/3290605.3300912. ISBN 9781450359702. S2CID 57761146.
- ^ Girotto, V.; Gonzalez, M. (2001). «Solving probabilistic and statistical problems: A matter of information structure and question form». Cognition. 78 (3): 247–276. doi:10.1016/S0010-0277(00)00133-5. PMID 11124351. S2CID 8588451.
- ^ a b Hoffrage, U.; Gigerenzer, G.; Krauss, S.; Martignon, L. (2002). «Representation facilitates reasoning: What natural frequencies are and what they are not». Cognition. 84 (3): 343–352. doi:10.1016/S0010-0277(02)00050-1. PMID 12044739. S2CID 9595672.
- ^ Gigerenzer, G.; Hoffrage, U. (1999). «Overcoming difficulties in Bayesian reasoning: A reply to Lewis and Keren (1999) and Mellers and McGraw (1999)». Psychological Review. 106 (2): 425. doi:10.1037/0033-295X.106.2.425. hdl:11858/00-001M-0000-0025-9CB4-8.
- ^ Kleiter, G. D. (1994). «Natural Sampling: Rationality without Base Rates». Contributions to Mathematical Psychology, Psychometrics, and Methodology. Recent Research in Psychology. pp. 375–388. doi:10.1007/978-1-4612-4308-3_27. ISBN 978-0-387-94169-1.
External links[edit]
- The Base Rate Fallacy The Fallacy Files
Когнитивные искажения (от лат. cognitiо «познание») – это то, что касается каждого человека вне зависимости от уровня его образования и социального положения.
Наш мозг – это главный орган центральной нервной системы, загадка которого не разгадана учеными до сих пор. Он содержит около 86 миллиардов нейронов, которые регулируют всю деятельность человека.

Наверное, и неудивительно, что мозг иногда обманывает нас, так что порой кажется, что он живет отдельной жизнью.
Так это или нет – мы, возможно, узнаем в будущем, а пока давайте рассмотрим наиболее частые когнитивные искажения, или ошибки мышления, которые встречаются в жизни каждого.
Это поможет вам не только осознать причины тех или иных своих действий, но и даст понимание некоторых поступков окружающих вас людей.
Ошибки мышления
Данная статья будет интересна не только любителям психологии, но и всем, кому интересно саморазвитие.
-
Ошибка базового процента
Довольно часто мы игнорируем реальную статистику, отдавая предпочтение собственному опыту. Например, вы обратились в автосервис, который, в конечном счете, не смог починить вашу машину.
После этого ваш мозг будет считать данный сервис плохим даже несмотря на то, что вам достоверно известно о сотнях машин, которые были там полностью отремонтированы. Ничего не поделаешь, личный опыт для мозга важнее статистики.
-
Отклонение внимания
Мозгу свойственно замечать только то, что вам нравится, или что вас интересует. Например, если вы парикмахер, то новая прическа вашего коллеги будет тут же детально изучена, в то время как другие даже не обратят на нее внимание.
Если вы любите модные бренды, то любая новая сумка знакомого вызовет у вас интерес. То же самое касается и праздников. Так что если вас кто-то не поздравил, не спешите обижаться, – наверняка это было сделано не намеренно. Все дело в когнитивном искажении под названием «Отклонение внимания».
-
Феномен «Дверь в лицо»
Известный американский психолог Роберт Чалдини рассказывал, как однажды на улице к нему подошёл мальчик и предложил купить билеты на какое-то мероприятие. Один билет стоил 5 долларов.
Чалдини вежливо отказался. Тогда мальчик предложил ему купить плитки шоколада всего лишь по доллару за штуку. После того как Чалдини купил пару плиток, он осознал, что им манипулировали, так как:
- он не любит шоколад и ему нужны деньги;
- он остался с двумя ненужными ему шоколадками и без денег.
Чалдини отправился на встречу с коллегами, с которыми обсудил произошедшее. В результате совещания была разработана серия экспериментов, позже ставшая классической.
Итак, «Дверь в лицо» – это социально-психологический феномен, который заключается в том, что люди склонны идти на уступку и соглашаться с малопривлекательным предложением в том случае, если оно им предлагается сразу после их отказа от другой более тяжелой просьбы.
-
Иллюзия частоты
Мозг не замечает многие вещи, которые нас окружают до тех пор, пока они нас не заинтересуют. Например, вам нужно купить детскую коляску, и вы остановились на каком-то бренде.
Внезапно вы обнаруживаете, что колясок этого бренда начало встречаться очень много. Это иллюзия. На самом деле просто вы начали обращать на них внимание, а не они резко распространились. Таковы результаты когнитивного искажения.
-
Эффект мнимой правды
Это один из самых популярных инструментов пропаганды во всем мире. Давно известно, что если повторять ложь достаточно долго, достаточно громко и достаточно часто – люди начнут верить лжи.
Если человеку 100 раз сказать, что он свинья, то на 101раз он захрюкает.
Умельцы весьма эффективно применяют этот феномен. Приведем безобидный пример. Некто хочет, чтобы его считали умным, поэтому он, цитирует, допустим, древнегреческого философа:
– Как говорил Протагор – «Человек есть мера всех вещей».
В следующий раз он повторяет это несколько иначе:
– Как я говорил в прошлый раз, – «Человек есть мера всех вещей».
И, наконец, в третий раз он заявляет:
– Как я обычно говорю, – «Человек есть мера всех вещей».
Вроде бы все правильно, но используя это когнитивное искажение, вам навязали ложную мысль, будто автором фразы является этот Некто, который хочет, чтобы его считали умным.
-
Эффект знакомства с объектом
Пожалуй, вся реклама, существующая в мире, работает на этот эффект мышления. Дело в том, что из нескольких незнакомых объектов мы обязательно отдадим предпочтение тому, о котором знаем хотя бы что-то.
Например, вам нужен крем для рук. Придя в магазин, вы почти наверняка возьмете тот крем, о котором хотя бы раз где-то слышали (например, в рекламе), чем тот, о котором вы вообще ничего не знаете.
-
Эвристика доступности
Наверняка у многих бывали такие случаи, когда знакомый уезжал в столицу и умело там пристраивался, вследствие чего у вас формировалось убеждение, что все жители столицы – это хорошо обеспеченные люди, работающие в крутых компаниях.
Так вот эта ошибка мышления возникает потому, что наш мозг оценивает частоту или возможность события по легкости, с которой примеры или случаи приходят на ум, т. е. легче вспоминаются.
Или, например, человек оценивает степень риска возникновения инфаркта у людей среднего возраста, припоминая подобные случаи среди своих знакомых.
-
Эффект контекста
Эффект контекста используется маркетологами для того, чтобы спровоцировать вас на покупку чего-то, что вам вовсе не нужно. Именно поэтому выкладка товара в магазине делается не просто для удобства, а с обязательным использованием эффекта контекста.
Одна дама сумела чрезвычайно выгодно продать свою квартиру потому, что перед приездом покупателя она готовила ароматные сдобные булочки. Входя в свою потенциальную квартиру, клиент ощущал тепло и такой приятный домашний аромат, что мозг просто не мог не попасть в ловушку контекста.
Таким образом, при помощи этого нехитрого когнитивного искажения ловкая барышня сумела провернуть выгодную сделку.
-
Склонность к негативу
Мы подсознательно переоцениваем значение отрицательных вещей. Собственно именно по этой причине плохие новости всегда будут иметь гораздо бо́льшую аудиторию, чем хорошие.
Не случайно слова журналистки известной новостной службы «Редакция требует крови!» стали мемом и вовсе не так далеки от действительности. Редакции действительно нужно «больше крови», так как это гарантирует кратное увеличение просмотров.
-
Эффект якоря
Эффект якоря – это особенность оценки числовых значений, которая смещает оценку в сторону начального приближения.
Например, вам нужно купить пальто. Вы заходите в магазин, находите подходящую вам модель, а после примерки узнаете, что она стоит 500$. Для вас это дорого, и вы уже собираетесь уходить, как вдруг к вам подбегает консультант.
Уточнив, подошло ли вам пальто, консультант говорит, что это уникальная серия, состоящая из всего 80 экземпляров. Более того, на эту модель сегодня действует скидка «Минус 50%».
Именно здесь и срабатывает эффект якоря, роль которого в данном случае играет число 500. С большой долей вероятности клиент в такой ситуации совершит покупку, даже не задумываясь о том, что для такого пальто даже 250$ – большая цена.
Интересен факт, что эффект якоря работает вне зависимости от того, знаете вы о нем, или нет. То же самое наблюдается и с правилом взаимного обмена.
-
Эффект фрейминга
Эффект фрейминга (от англ. frame рамка, обрамление) – это когнитивное искажение, при котором форма подачи информации влияет на ее восприятие человеком.
В качестве классического примера данного эффекта нередко приводят выражение: «Стакан наполовину пуст или наполовину полон». Речь идет об одном и том же явлении, но отношение к нему из-за подачи информации меняется.
В одном из экспериментов участникам показывали видеозаписи с автомобильными авариями. После этого им задавали вопрос: «С какой скоростью ехали машины, когда столкнулись друг с другом?».
В каждой группе вопросы немного отличались: глагол «столкнулись» заменялся на «врезались», «налетели», «задели», «ударились».
В результате было установлено, что изменения в постановке вопроса оказывали влияние на оценку скорости автомобилей, несмотря на то, что всем респондентам показывали один и тот же ролик.
-
Восприятие выбора
Замечено, что сначала мы делаем выбор, а потом мозг пытается его оправдать. Причем чем бессмысленнее выбор, тем больше мы его защищаем.
В качестве примера можно привести попытки найти неявные плюсы в покупке и тем самым её оправдать при наличии другого, более подходящего товара, который по каким-то причинам не был приобретён.
К слову сказать, именно по этому принципу работают деструктивные секты и различные финансовые пирамиды. В какой-то степени этот эффект похож на стокгольмский синдром, когда жертва оправдывает агрессора. Кстати, мы уже рассказывали про 10 необычных психических синдромов в отдельной статье.
-
Предпочтение нулевого риска
Это предпочтение контролируемой, но потенциально более вредоносной (вследствие более частого её возникновения) ситуации перед обратной.
Происходит это по причине переоценки возможности контроля. То есть человек со своей стороны считает, что он полностью избавляется от риска (на самом деле не имея полного контроля), в то время как со стороны статистики это является снижением до нуля лишь одного, причем не самого большого риска.
Например, большинство людей предпочли бы уменьшить вероятность терактов до нуля вместо снижения аварийности на дорогах, даже несмотря на то, что второй эффект давал бы гораздо больше сохранённых жизней.
Или другой пример – ятрофобия (боязнь врачей). Многие люди боятся осложнений медицинских вмешательств больше, чем заболевания и смерти в результате самих этих заболеваний, которые возникают из-за отсутствия лечения.
-
Эффект морального доверия
Человек, относительно которого известно, что у него нет предубеждений, имеет в будущем большие шансы проявить эти предубеждения.
Иными словами, если все (в том числе и он сам) считают человека безгрешным, то возникает иллюзия, что любое его действие также будет безгрешным.
-
Селективное восприятие
Селективное восприятие (лат. selectio «выбирать») – это склонность людей уделять внимание тем элементам окружения, которые согласуются с их ожиданиями, и игнорировать остальные.
В классическом эксперименте зрители просматривали видео особо ожесточённого матча по американскому футболу между Принстонским университетом и Дартмутским колледжем.
Зрители из Принстона заметили почти в два раза больше нарушений, совершённых дартмутской командой, чем зрители из Дартмута. Один зритель из Дартмута вовсе не заметил ни одного нарушения со стороны «своей» команды.
Это когнитивное искажение также играет огромную роль в психологии рекламы.
-
Слепое пятно в отношении искажений
Последняя ошибка мышления, или когнитивное искажение, которое мы рассмотрим, – это слепое пятно в отношении искажений.
Это не что иное, как более лёгкое обнаружение недостатков у других людей, нежели у себя. То есть, все перечисленные когнитивные искажения присутствуют у каждого человека, однако мы «в чужом глазу видим соринку, а в своём и бревна не замечаем».
Наверняка и после прочтения этой статьи у большинства зрителей появится ощущение, что я, дескать, знаю все это и так, и, конечно же, меня все эти когнитивные искажения не касаются. На самом же деле они касаются всех.

Но теперь возникает закономерный вопрос: что же делать со всеми этими ошибками? Ответ прост: перечитывайте статью и вникайте в суть перечисленных когнитивных искажений или ошибок мышления.
Чем больше вы будете осознавать факт существования когнитивных искажений, тем больше вероятность, что вы будете принимать правильные решения и делать верный выбор.
Теперь вы знаете, что такое когнитивные искажения и как они влияют на нашу жизнь. Если вам понравилась статья, – поделитесь ею с друзьями и подписывайтесь на сайт interesnyefakty.org. С нами всегда интересно!
Понравился пост? Нажми любую кнопку:

Содержание
Введение. О чем эта статья
Цели и дисклеймеры
Часть 1. Хороший продукт
Часть 2. Пользовательский опыт (UX). Что это?
Часть 3. Архитектура выбора
Часть 4. Архитектор выбора
Часть 5. Когнитивные искажения и Пользовательский опыт
Ссылка на полную версию UX CORE (105 примеров использования когнитивных искажений в менеджменте команд и продуктов)
Часть 6. Наши дни
Часть 7. Не только искажения
Часть 8. Эпилог
Часть 9. Материал, качественно дополняющий эту статью
Введение. О чем эта статья
В этой статье мы поговорим о когнитивной психологии, поведенческой экономике и об ошибках (искажениях) нашего мозга. Мы посмотрим как понимание ошибок мозга и моделей человеческого поведения может помочь нам обеспечить высококачественный пользовательский опыт (UX) в цифровых продуктах. В основном, мы поговорим о программном обеспечении для мобайл и десктоп платформ. Внимательный же читатель сможет применить эти знания широко за рамками как этих платформ, так и программного обеспечения вообще.
Последние десять лет моим основным хобби было изучение того, как люди принимают решения. Этот путь привел меня к изучению широкого спектра когнитивных наук, в частности, когнитивной психологии и неврологии.
В какой-то момент своей жизни я перепрофилировался из технического специалиста в IT-сфере, коим я проработал около 6 лет (LAN/WAN/DevOps/InfoSec), в Product Manager-а. Моей основной деятельностью на этой должности является анализ ожиданий и принятых решений пользователей с целью создания более комфортного и желанного продукта.
Проверка и оценка практической пользы информации этой статьи заняла около пяти лет работы в разных компаниях и проектах различной степени сложности (от вебсайтов-визиток, до разработки первой в мире левитирующей камеры, экосистемы для киберспортивных дисциплин, тотализатор для киберспорта, ПО для гражданской авиации и крупнейшей в мире платформы цифрового издательства). В сумме я проработал более чем с сотней специалистов различного профессионального уровня, что принесло колоссальную пользу в виде ряда подтвержденных и опровергнутых концептов; лишь полезная часть которых будет описана далее.
Цели и дисклеймеры
Изложенный здесь материал лучше всего будет понятен опытным специалистам в IT-сфере, занимающимися разработкой и дизайном ПО на регулярной основе. Тем не менее, пользу от этого материала почерпнет любой читатель вне зависимости от рода деятельности.
Цели, которыми я задаюсь в этой статье выглядят так:
- показать четкие доказательства важности глубоких знаний в психологии для работы в качестве менеджера по продукту;
- дать определение понятию UX (Пользовательский опыт) с позиции психологии и поделиться наиважнейшим источником знаний для создания качественного UX;
- показать механизм оценки «грамотности» продакт менеджеров (и не только);
- побудить инвесторов больше инвестировать в продукты, в основе которых лежит когнитивная психология и поведенческая экономика;
- предоставить продакт менеджерам дополнительные аргументы в поддержку их идей, которые, часто являясь верными, увы, блокируются техническими специалистами из-за непонимания полной картины и «технического» склада ума;
- показать с другого угла «скучные» исследования, которые «пылятся» на полках библиотек, акцентируя чрезвычайную важность этих материалов для будущего разработки ПО;
- побудить психологов и экономистов взглянуть в сторону продакт менеджмента как возможной опции смены карьерного направления. Мир IT нуждается в вас гораздо больше, чем в диванных аналитиках и псведо-менеджерах с MBA и PMP.
Я намеренно опускаю такие бизнес вопросы как «целесообразность создания продукта», «анализ рынка», «анализ конкурентов» и прочие, так как они имеют мало общего с UX. Продукт может быть качественным вне зависимости от спроса, от целесообразности его выпуска на рынок и силы конкурентов.
Я с глубоким уважением отношусь ко всем, чьи имена появляются в этой статье. Я бесконечно рад возможности ознакомиться с трудами, мыслями и идеями этих людей.
Размер статьи выдался куда больше, чем я ожидал. Тем не менее, вы получите доступ к синопсисам наиважнейших исследований в неврологии и когнитивных науках, проведенных за последние 70 с лишним лет. Детальное изучение этих исследований и сопоставление их с условиями «реального мира» заняло бы у вас, по меньшей мере, два года регулярного обучения.
Часть 1. Хороший продукт
Мы не будем вдаваться в абстрактные рассуждения о том, что такое продукт, а-ля «это то, что приносит пользу его владельцу, рынку и конечным потребителям». Много людей будут не согласны с идеей, что качественный продукт может оставаться качественным даже провалившись на рынке, поэтому я отдельно скажу пару слов об этом.
Итак, чуть выше я убрал вопросы про рынки, конкурентов и целесообразность продукта, потому что я исхожу из того, что качественный продукт – это, прежде всего, продукт без внутренних противоречий. Такой продукт идеально связан как «идеологическими» его составляющими (история создания, его миссия, все использованные изображения, текстовые и печатные материалы используемые для его разработки и продвижения и прочее), так и техническими (back end, пользовательский интерфейс, элементы взаимодействия и дизайн, бизнес цвета, инструкции для работы службы поддержки клиентов, tone of voice of the company и много другого).
При всем при этом важно понимать, что качественный продукт может выйти на рынок, оказаться никому не нужным, стать историей и тем не менее быть качественным продуктом.
Причин неудачи может быть широкое множество, например:
- неудачный тайминг (изменилась коньюнктура на рынке, люди еще не осознали всю серьезность проблемы, решаемой продуктом и т.п.);
- человеческий фактор (утечки внутри компании, уборщица, опрокинувшая ведро рядом с серверами в день релиза и т.п.);
- слабые управленческие навыки руководства (основатели компании слишком поздно начали обсуждать распределение прибыли, что создало конфликты; чрезмерный нажим на команду разработчиков повлек массовые увольнения и сорвал переговоры об инвестировании и пр.)
- банальное невезение, важность которого повально игнорируется как новичками, так и экспертами в бизнесе (Черные Лебеди Н. Нассима Талеба).
Поэтому, для того, чтобы не вдаваться в унылые философские спекуляции по бизнес вопросам, в этой статье мы будем о них помнить, временами будем к ним «прикасаться», но не будем на них фокусироваться.
Часть 2. Пользовательский Опыт (UX). Что это?
Так как на данный момент понятие UX гораздо чаще относят к UI дизайну, моим «оппонентом» в обсуждении данного вопроса будет Джо Натоли. Джо — ветеран-дизайнер с опытом работы более 30 лет, один из самых популярных в мире IT экспертов по UXD (User Experience Design), автор ряда книг, а также самых популярных видео-курсов по UX на Udemy. Натоли провел более тридцати лет консультируя по вопросам дизайна пользовательского опыта (UXD) компании из списка Fortune 100, 500 и правительственные организации. На своем вебсайте он называет себя «User Experience Evangelist», значит, я могу ссылаться на его утверждения, высказанные публично в его книгах и видеоуроках.
В одном из своих уроков, где господин Натоли объясняет понятие User Experience, он ссылается на Питера Мерхольца:
«Питер Мерхольц, который является деловым партнером Джесси Джеймса Гарретта (автора термина «Пользовательский опыт» и книги «Элементы пользовательского опыта — Библии UX всех времен»), говорит, что пользовательский интерфейс (UI) является компонентом пользовательского опыта. Но есть гораздо больше, и это гораздо большее включает в себя вещи, которые имеют отношение к когнитивной науке. Это связано с людьми: что они хотят, что им нужно, что они хотят использовать и почему они реагируют на вещи так, как они реагируют.»
Другой UXD эксперт – Билл ДэРушэ (Старший продакт менеджер / Workflow Experience Lead at Zendesk). В обсуждении UXD говорит следующее: «Для UXD… даже не нужен экран. UXD — это любое взаимодействие с любым продуктом, любым элементом, любой системой ».
Просмотрев все доступные материалы выше упомянутых, а также ряда других UXD специалистов, я заметил одну важную закономерность — они постоянно используют научные достижения когнитивных психологов, неврологов и поведенческих экономистов. Практически вся идеологическая часть, весь “back end” их речей основывается на когнитивных науках, однако, на это редко делается акцент. Чаще всего они не хотят «усложнять» материал для слушателя и слишком часто используют фразы, типа «мы используем те вещи, которые понимаем», что ставит грубые рамки, не позволяющие учитывать множество важных факторов.
К примеру, даже, если у нас есть доступ к приложению, мы практически никогда не будем его использовать, если ожидаемые от нас действия идут в разрез с ценностями социально-культурной среды, с которой мы себя отождествляем. Другой же UXD специалист может тонко заметить это, сказав: «Чтобы быть приемлемым, визуальный дизайн должен соответствовать социально-культурным ценностям», что звучит красиво, однако, не показывает всей картины, которую нужно учитывать в принятии решений по продукту.
Прошу заметить, я ни в коем случае не говорю, что книги и видеоуроки бесполезны. На данный момент, для того, чтобы человек понял что такое UX и как с ним работать, ему необходимо пройти через множество разбросанных материалов в книгах и видеоуроках. Я же в этой статье хочу показать научные истоки, на основе которых все эти книги и уроки создаются.
Итак, практически все UXD эксперты сходятся во мнении, что UX — это понятие, выходящее широко за рамки интерфейсов. Их общее мнение сводится к тому, что UX — это фактический опыт, получаемый пользователем при его интеракции с продуктом/компанией.
В силу же того, что опыт- это результат интерпретации чувств, возникающих у человека при интеракции с продуктом/компанией,
создание пользовательского опыта – это психологическая игра с целью подталкивания пользователя к определенной мысли, эмоции, действию или выбору. И здесь мы вплотную подходим к такому понятию как “архитектура выбора”.
Часть 3. Архитектура Выбора
Понятие «архитектура выбора» популяризировалось после совместного труда Ричарда Талера и Касса Санстейна над Теорией Подталкивания. Вместе они написали книгу «Подталкивание» (англ. Nudge Theory), которая позволила множеству разных специалистов, ответственных за «создание выбора» для пользователей, взглянуть на свою работу под новым углом. Чтобы читатель понимал значимость вышеуказанных персон, приведу здесь их краткое описание:
Касс Санстейн – со-автор теории подталкивания. После выхода книги ≪Подталкивание≫ президент Обама предложил Санстейну место в Отделе информации и регуляторной политики. Это дало исследователю широкие возможности внедрять идеи психологии и поведенческой экономики в работу правительственных учреждений. 10 сентября 2009 года Санстейн был назначен на пост главы OIRA, которое является частью Административно-бюджетного управления Администрации президента. OIRA осуществляет надзор за реализацией государственной политики и рассматривает проекты нормативных актов. Пост главы OIRA считается одним из наиболее влиятельных, учитывая его возможность влиять на тексты принимаемых законов. СМИ неофициально называют этот пост regulatory czar. OIRA Санстейн возглавлял до 21 августа 2012 года.
В августе 2013 года Санстейн вошел в состав комиссии по надзору за АНБ (англ. Review Group on Intelligence and Communications Technology). Кроме него в комиссии еще два бывших работника Белого Дома: крупейший специалист по контртерроризму и кибервойнам Ричард Алан Кларк и бывший заместитель директора ЦРУ.
Ричард Талер — автор «Теории Подталкивания», лауреат премии по экономике памяти Альфреда Нобеля 2017 года за вклад в область поведенческой экономики. При правительстве Великобритании было создано новое подразделение, чья цель применять принципы поведенческой науки к решению государственных задач. Официальное название подразделения — ≪Группа поведенческого инсайта≫, но чаще и в правительстве, и за его пределами ее называют ≪Группа подталкивания≫. Талер является одним из советников этой группы.
Итак, эти господа много лет работали над теорией, в которой тщательно описали как можно «подтолкнуть» человека к определенному выбору, используя когнитивные искажения (о них мы поговорим совсем скоро). Идея и описанные методы настолько понравились руководствам разных стран (не только США и Англии), что были созданы специальные гос.подразделения с целью редактирования законопроектов для подталкивания граждан к более здоровому образу жизни и более здоровой пище не ограничивая их в выборе.
Даже сейчас тысячи ученых ежедневно работают на правительства, изучая работу человеческого мозга и свойственные ему ошибки с целью оптимизировать наш выбор, дать нам возможность выбирать «лучшее» там, где это возможно и при этом не ограничивать наш выбор.
Фактически, архитектура выбора – это
описание мыслей и когнитивных искажений, которым подвержена целевая аудитория
– с одной стороны, и
решения по расстановке элементов участвующих в выборе
– с другой.
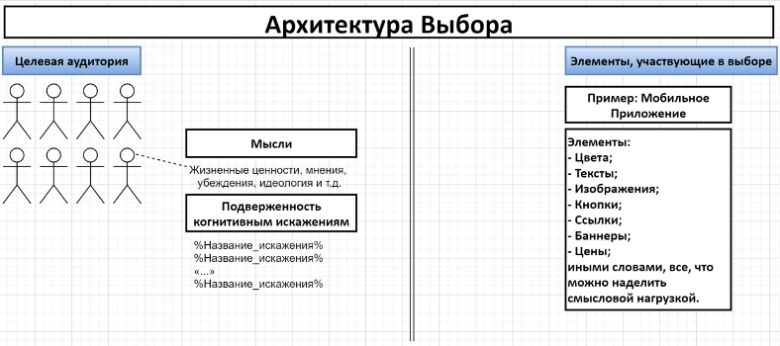
При грамотном понимании обеих частей этого уравнения, архитектор выбора может плавно подтолкнуть пользователя/потребителя в нужном для компании направлении.
Часть 4. Архитектор Выбора
Понятие «Архитектор выбора» ввели Санстейн и Талер, описав его следующим образом:
«Архитектор выбора — это тот, кто отвечает за организацию контекста, в котором человек принимает решения».
Талер и Санстейн доказывали эффективность «подталкивания» на примере принятия решений при разработке законопроектов. В таком контексте, работа архитектора выбора крайне сложна, так как на него налагаются колоссальные юридические и моральные ограничения.
Нас же с вами интересует IT сфера, в частности, разработка разного рода приложений. В этой сфере тоже имеются определенные ограничения, однако, их гораздо меньше, что дает возможность архитектору выбора реализовать весь свой научный потенциал.
В такой компании несложно понять, кто является архитектором выбора. Это тот, кто занимается «организацией контекста, в котором человек (пользователь) принимает решения в приложении», либо просто Product Manager.
Организация контекста, в котором пользователи принимают решения – это ключевая обязанность Product Manager-а. Для создания лучших условий для выбора и подталкивания пользователей к выбору выгодному бизнесу, Product Manager обязан знать модели человеческого поведения и, что наиболее важно, отклонения в этом поведении. Именно такие систематические отклонения в восприятии, мышлении и поведении человека называются «когнитивными искажениями». Их можно считать «bug-ами», потому что бОльшая часть этих искажений описывает сбои в обработке и анализе информации.
Часть 5. Когнитивные Искажения и Пользовательский Опыт
Итак, мы дошли до основного материала статьи.
Далее я выложу ряд известных науке когнитивных искажений, которые были научно выведенны и задокументированны. Отдельной ссылкой я выложил онлайн инструмент, который я назвал «UX CORE». В нем вы сможете найти 105 когнитивных искажений с примерами их использования в менеджменте и в разработке приложений.
Для структурирования материала я использовал «Кодекс когнитивных искажений», категоризированный и структурированный Бастером Бэнсоном в 2016м году (по ссылке выше дизайн Джона Манукяна III). Помимо новой формы презентации искажений, к каждому из них я добавил пример использования в разработке программного обеспечения, а в некоторых случаях- в управлении командой. Были учтены самые современные практики по управлению командами и компаниями (PMP, PMI ACP), а также разработке продукта.
Многие примеры, которые я описал далее, довольно радикальны. Это было сделано намеренно, т.к. в соответствии с эффектом контраста, такие примеры запоминаются лучше. Основная цель примеров – дать пищу для размышлений. Я не стремился добиться их абсолютной точности, т.к. для такого примера необходимо тщательное описание рабочей ситуации и поставленной задачи, а это заняло бы десятки страниц материала. Я глубоко убежден, что данная работа поможет читателям узнать для себя много нового и сделать определенные выводы.
Клики на названия искажений в таблице открывают поп-апы. Все ссылки в поп-апах открываются в новых вкладках браузера, поэтому можете серфить контент спокойно, не беспокоясь случайно что-то закрыть.
Итак, как верно заметил Бастер Бенсон, суть изложенных когнитивных искажений в том, чтобы помочь нам решить 4 проблемы:
- Работа с большим объемом данных. Когда много информации;
- Расплывчатость, недостаточность данных. Когда не хватает смысла;
- Недостаточно времени. Когда быстро реагируем;
- Разные приоритеты по информации. Когда запоминаем и вспоминаем.
Каждое когнитивное искажение существует по определенной причине — в основном, чтобы мозг сохранял энергию и тратил меньше времени на раздумья. Когда смотришь на искажения с точки зрения проблемы, которую они помогают решить, становится легче понять почему они существуют, чем они полезны и на какие компромиссы в связи с этим нам приходится соглашаться.
#1 Эвристика доступности [P]
Процесс, при котором человек оценивает частоту или вероятность события по легкости, с которой примеры или случаи приходят на ум, т.е. легче вспоминаются.
В разработке приложений понимание этого искажения необходимо для последовательного проектирования интерфейсов, дизайна контента и коммуникации с пользователем. Если действие, которое нам нужно, чтобы пользователь совершил, ассоциируется у него с чем-либо негативным (особенно, если это освещается или освещалось в СМИ не так давно), вероятность того, что действие будет совершено сильно снижается. Понимание этого позволяет проектировать контент (текст, изображения и т.д.), так, чтобы он ассоциировался у человека только с тем, что нам нужно. Это же искажение позволяет нам задуматься над текущей коньюнктурой в мире и на рынке, чтобы выбрать наиболее удобную «тональность» наших сообщений.
Другой пример: биткоины и разного рода ICO. Тема криптовалют так часто негативно форсировалась в СМИ, что в какой-то момент инвесторы просто решили избегать всего, что с этим связано, не вдаваясь в детали. Простые же пользователи поняли, что их ослепленность повышенной волатилностью этих рынков не привела ни к чему хорошему. Хайп по этой теме сошел на нет, а множество действительно качественных блокчейн-проектов столкнулись с серъезными сложностями в развитии из-за сильно искаженной репутации всего, что ассоциируется с блокчейном, биткоином и крипто в целом.
Последний пример — это то, что я выбрал тему проектирования ПО и блокчейн технологий для описания эвристики доступности. Первая тема очевидна для меня в силу моей профессии (product manager), вторая же тема просто с легкостью пришла мне на ум, когда я задал себе вопрос: «Какое направление в IT было полно хайпа, а потом быстро сошло на нет?».
#4 Эффект знакомства с объектом [P]
Психологический феномен выражения симпатии к объекту только на основании имеющегося знакомства с ним. Чем чаще человек видит кого-то, тем приятнее и привлекательнее ему кажется этот человек.
Важно подчеркнуть, что речь идет не только о людях, а об объектах вообще.
Предположим, у нас есть успешное приложение, которое мы хотим продвинуть в Испании. Если мы используем в наших цифровых промо-материалах описание нашего приложения в цветах Испанского флага (ненавязчиво, конечно), это даст ощущение «знакомого» у испаноязычных читателей. Другой пример – мы размещаем очень блеклое, монохромное изображение «Саграда Фамилия» на фон белой страницы, на которой на испанском описываются преимущества нашего приложения. Если в текст добавить величественные, высокопарные слова вкупэ с фоновым изображением, они вполне дадут эффект «знакомства» и повысят вероятность конвертации потенциальных пользователей в фактических.
Другой пример: мы используем в нашем приложении стандартные кнопки, стандартных для нас цветов и размеров, и весь наш интерфейс «универсален». Приходит день, когда нам нужно оповестить наших пользователей о новых функциях приложения. Мы можем сделать это ненавязчиво, используя стандартный pop-up, с такими же кнопками которые используются в других частях приложения. Либо, наоборот, если нам нужно заострить внимание пользователя таким образом, чтобы у него было стойкое чувство новизны – мы отходим от нашей стандартной системы и используем слегка другой цвет окна и слегка другой размер кнопок в поп-апе. При виде такого окна, самое первое что придет в голову нашего пользователя – это ощущение «новизны», интенсивность которого будет пропорциональна тому, как долго пользователь использует наше приложение.
#6 Забывание без подсказок [P]
Является неспособностью вспомнить воспоминание из-за отсутствия стимулов или сигналов, которые присутствовали во время кодирования памяти.
В контексте приложения мы можем использовать наши знания об этом искажении с целью «напоминаний» пользователю о том, что он может сделать с системой.
Приведу простой пример на онлайн тотализаторе, где множество пользователей делают ставки. Очевидно, что «средний» пользователь как выигрывает, так и проигрывает. В интересах бизнеса правильно будет «поддержать» такого пользователя в тот сложный момент, когда он все проиграл. Так как в сознании игрока, который пережил серию «поражений» — одни поражения, система может напомнить ему о целом ряде побед по некоему паттерну, оживив в нем всю ту серию хороших воспоминаний, которые он испытал. Это может быть сделано ненавязчиво, сообщением типа «Уважаемый %username%, мы просто хотели напомнить вам о невероятно успешной серии ваших побед, продлившейся три дня подряд на играх %game_names%». Навязчиво? Возможно. Изменим сообщение на «Вы попали в топ 20% наших игроков, благодаря вашей серии побед в %game_name%!». Уже не так навязчиво, это уже статистика . Конечно, делать это не этично с точки зрения морали. Поэтому букмекерские конторы и казино, работающие под лицензиями Malta Gaming Authority (MGA), Кюрасао и других, заранее соглашаются, что не будут подталкивать игроков к острым азартным действиям. В любом случае, приведенный пример наглядно иллюстрирует как можно извлечь пользу для бизнеса, зная о такой простой ошибке нашего мозга.
#11 Ошибка базового процента [P]
Это ошибка в мышлении, когда сталкиваясь с общей информацией о частоте некоторого события (базовый процент) и специфической информацией об этом событии, человек имеет склонность игнорировать первое и фокусироваться на втором. Например: люди верят показаниям теста, сигнализирующем о наличии редкой болезни, сразу, не принимая во внимание, что редкая болезнь, вообще говоря, редкая. Либо другой пример: страх террористов и полетов на самолете. Суть в том, что наш мозг склонен преувеличивать частный случай в ущерб статистике.
Понимание этой ошибки дает нам возможность более внимательно подходить к разработке текстового контента для приложений. Так, сообщение, описывающее потенциально негативный исход в случае выполнения какого-либо действия, будет по-разному воспринято пользователями:
«Вы собираетесь запустить процесс дефрагментации диска. С вероятностью 99% операция пройдет успешно.»
«Вы собираетесь запустить процесс дефрагментации диска. Есть 1% вероятности, что жесткий диск будет уничтожен, а ваши данные безвозвратно потеряны.»
Кстати, именно по этой причине очень важно предоставлять качественную техподдержку. Разочарованный пользователь, который не смог найти разумное объяснение происшедшей ошибке в программе, может оставить негативный отзыв о приложении. И это нанесет гораздо более крупный вред продукту, чем может показаться на первый взгляд.
Когда люди видят 15,800 хвалебных отзывов и 50 крайне негативных отзывов в перемешку с ними, они склонны считать продукт менее ценным, непропорционально тому факту, что негативных отзывов меньше 0.1%.
#13 Эффект юмора [P]
Смешные вещи легче запомнить, чем не юмористические, что может быть объяснено увеличенным временем когнитивной обработки, чтобы понять юмор, или эмоциональным возбуждением, вызванным юмором.
Лучший пример использования юмора — это вездесущие мемы. Множество крупных IT-компаний используют мемы для того, чтобы продвигать свои продукты, и «эффект юмора» — это именно то, на что они делают ставку.
Здесь очень важно понять, что речь идет о запоминании юморных вещей, но не о позитивном отношении к ним. Так, если в процессе работы над важным действием (заполнение формы, сохранение данных), пользователь попадает на страницу ошибки (500 (Internal server error), 502 (Bad gateway), 503 (Service unavailable), 504 (Gateway timeout) ), то юмор типа «Хо хо! Наши пираты работают над ошибкой и скоро все будет восстановлено!» будет не к месту. В этом случае юмор будет замечен,
запомнен
, и, вероятнее всего, вызовет гнев пользователя так, что это событие запомнится лучше. Если подобное событие произойдет несколько раз за месяц, в соответствии с эвристикой доступности, в следующий раз подумав о качестве нашего продукта пользователь с высокой вероятностью даст негативную оценку. Даже если в 99% случаев приложение справлялось с задачей (ошибка базового процента).
Хорошим пользовательским опытом в данной ситуации будет считаться страница с ошибкой, где компания принимает вину на себя, объясняет суть ошибки и оповещает о том, что скоро все восстановится и страница сама обновится.
#21 Ошибка различения [P]
Это тенденция рассматривать два варианта как более отличительные при оценке их одновременно, чем при оценке их отдельно.
Понимание этой ошибки дает нам возможность по-разному подходить к разработке информационной структуры для нашего приложения. К примеру, если мы хотим, чтобы пользователь четко видел отличия одного сервисного плана от другого, мы можем поместить сервисные планы в ряд с указанием характеристик и цены каждого (вы видели такое на многих вебсайтах в разделе «Цена»). Если же нам нужно, чтобы пользователь считал наши сервисные планы «почти одинаковыми» (не важно по какой причине), тогда мы можем вместо размещения их горизонтально в таблице, разместить их вертикально — друг под другом. Это не позволит пользователю одновременно оценивать отличия сервисных планов, т.к. придется скролить страницу, и тем самым повысится вероятность того, что мы добъемся своей цели. Эта ошибка также является одной из причин, по которой онлайн тотализаторы и разного рода казино не показывают «сумму депозита», «выигрыши» и «проигрыши» на одной странице. Это удобно для пользователя, но не отвечает бизнес целям проекта, т.к. пользователь будет придавать бОльшее значение различиям между победами и поражениями. При этом не важно, чему он придаст бОльшее значение. Сам факт того, что у пользователя появятся чувства и мысли, которые не поддаются контролю, создаст риски для бизнеса.
#36 Пренебрежение вероятностью [P]
Когнитивное искажение, согласно которому человек склонен к игнорированию малых вероятностей при принятии решений в условиях неопределенности. Небольшие риски обычно либо полностью игнорируются, либо сильно недооцениваются. Континуум между крайностями игнорируется. Как объясняет Рольф Добелли, причина, по которой это происходит, заключается в том, что мы не обладаем интуитивным пониманием риска и поэтому плохо различаем разные угрозы. По сути, чем более серьезна угроза и эмоциональнее тема (напр. Радиоактивность), тем менее обнадеживающим представляется снижение риска.
Использование этого искажения ежедневно приносит сотни миллионов долларов разным казино и тотализаторам по всему миру. Это искажение также является причиной, по которой мы склонны нажимать на «Я принимаю условия лицензионного соглашения» по факту его не прочитав. Понимание этого искажения позволяет компаниям доносить важную информацию до пользователей в такой форме, при которой он с высокой вероятностью проигнорируют риск. Либо, наоборот, мы можем подтолкнуть пользователя к нужным нам действиям используя специфические формулировки.
К примеру, зная что наши пользователи игнорируют вероятность полной потери данных, мы можем подтолкнуть их к созданию бэкапов сообщением вида «Уважаемый %user_name%, в последний раз вы создавали бэкап ваших данных 571 день назад. Мы настоятельно рекомендуем создать бэкап чтобы избежать риска полной безвозвратной потери ваших данных.». Здесь мы ничего не говорим о вероятности потери. Она могла постоянно быть равной 0.1%, но написав сообщение с призывом к эмоциям («полной безвозвратной потери ваших данных») и конвертируя условные 19 месяцев в 571 день, мы с большей вероятностью добьемся действия пользователя (бэкап системы).
Ссылка на полную версию UX CORE (105 примеров использования когнитивных искажений в менеджменте команд и продуктов)
Повторюсь, что все что я здесь написал служит исключительно примером, и в каждой отдельно взятой ситуации, для выявления лучшего решения необходим будет комплексный подход. Более того, практически в любой решаемой задаче необходимо учитывать широкий спектр искажений, а не одно конкретное.
Также, очевидно, еще одной важной «переменной» в процессе создания архитектуры выбора являются бизнес цели. И эти бизнес цели, вместе с налагаемыми юридическими и моральными ограничениями, должны учитываться при проектировании решений.
В завершении, я бы хотел рассказать об ошибке GI JOE задокументированной профессором Лори Сантос буквально несколько лет назад. Ошибка касается широко распространенного утверждения, что «знать – это уже пол дела», что, однако, не имеет научных оснований и является ложным утверждением. На самом деле, одного лишь знания недостаточно, чтобы изменить модель нашего поведения. Настоящие перемены невозможны без наших целенаправленных действий. Вы можете выучить наизусть все когнитивные искажения и механизм их работы, но, если вы не меняете модель своего поведения под полученными знаниями, ценность ваших «знаний» снижается. Более того, подобное «знание» не будет «крепким», вам придется регулярно возвращаться к таблице и повторять написанное, чтобы не забыть. Если же вы не только поймете, но и предпримите определенные действия для усвоения материала, изменения вашего образа мыслей, вашей жизни, тогда самые лучшие решения по продукту, удивительным образом станут для вас крайне очевидными.
Часть 6. Наши дни
К сожалению, нехватка хороших продакт менеджеров является главным препятствием для создания качественных продуктов на рынке. Ситуация усложняется тем, что большинство компаний еще не до конца понимают разницу между Product Manager-ом и Product Owner—ом, иногда, даже, прописывая их в вакансиях через «/».
На данный момент, взглянув на рынок и на требования к продакт менеджерам «лучших компаний», можно обнаружить описания и «опросники», на которые ответит почти каждый, кто прошел PMI-ACP. По сути, отсутствие четкого понимания роли Product Manager-а приводит к тому, что на них вваливаются обязанности Project Manager—ов, Scrum Master-ов, и других.
Оговорюсь, что речь идет в первую очередь о странах СНГ, хотя на европейском рынке абсолютной ясности по поводу продакт менеджеров; как их найти, как интервьюировать, и чего от них ожидать — тоже нет.
Полагаю, с США дела обстоят лучше, т.к. развитие продакт менеджмента идет именно оттуда.
Другая проблема на пути к созданию качественных продуктов — это, конечно же эго непосредственных руководителей, под которыми работают продакт менеджеры. Раздутое эго особенно часто встречается у технических специалистов – со-владельцев продукта. Такие «менеджеры» обычно, полагают, что их знания программирования позволяющие написать функциональную часть продукта, также являются доказательством того, что они хорошие продакт менеджеры. По сути, такое руководство чаще других подвергается эффекту Даннинга-Крюгера и эффекту слепого пятна. Работа с таким руководством по-умолчанию увеличивает сложность работы продакт менеджера. Теперь, когда ему нужно разработать решение для задачи, помимо выполнения фактической работы, он, заодно, вынужденно «придумывает велосипед» и «соус», под которым все это дело нужно закрутить и подать руководству так, чтобы их хрупкое эго могло согласиться с предлагаемым решением.
Также я бы хотел показать другую сторону когнитивных искажений, а именно: их колоссальный, недооцененный потенциал который они таят в себе для HR специалистов. Хотя, увы, у меня не было возможности поработать с грамотными HR специалистами, я уверен, что они где-то есть и при внимательном изучении искажений, им удастся создать новые процедуры для более качественного отбора кадров. Полагаю, наиболее бюрократизированным организациям будет сложно представить, как можно интегрировать когнитивные искажения в процесс поиска сотрудников. Однако, для более «свободных» компаний, готовых эксперементировать, я бы порекомендовал использовать знания искажений для выявления «слабых мест» кандидатов. Помимо этого, эти знания дадут возможность определить «гибкость» кандидата. В определенных случаях, можно даже проанализировать «хрупкость эго» кандидата, проверив его склонность к эффекту слепого пятна.
Вообще, такие искажения как эффект сверхуверенности, иррациональное усиление и эффект обратного действия, довольно просто могут быть «протестированы», и в случае адекватной реакции кандидата, с высокой вероятностью, смогут сэкономить очень много человекочасов поисков «нужных людей». Видя все эти возможности и понимая, что они не используются из-за дичайшей человеческой лени, становится грустно, и тем не менее, я уверен, что найдутся люди, публичные авторитеты, которые смогут подтолкнуть наше IT сообщество к развитию в нужную сторону, подальше от бюрократии и поближе к науке.
Часть 7. Не только искажения
Я бы также хотел затронуть те аспекты знаний продакт менеджера, которым в этой статье было уделено мало внимания, но, которые не менее важны для понимания, чем искажения.
Конечно, глубокие познания в когнитивных искажениях, как мы видим, играют существенную роль в менеджменте, разработке и управлении продуктами, однако, наивно будет утверждать, что этих знаний достаточно для успеха продукта.
Так, менеджеру не следует забывать о важности бизнеса и выгоды, которую бизнес преследует. В основе любого бизнес продукта лежит стремление увеличить прибыль либо уменьшить издержки. И понимание того, как именно компания хочет это сделать, очень важно для продакт менеджера при проектировании любого решения. Для этого продакт менеджер должен следить за решениями компаний-партнеров и конкурентов, изучать их стиль ведения работы; то, как они поддерживают коммуникацию с пользователями и как пользователи эту коммуникацию воспринимают. Если продукт нацелен на получение прибыли, необходимо понимать механики ценообразования, существующие бизнес модели, их преимущества и ограничения.
Помимо знаний о бизнесе, и функционировании компаний, очевидно, необходимы знания в юридической сфере. Продакт менеджер обязан знать закон и современные ограничения, которые налагаются на IT продукты, в достаточной мере, чтобы, в случае необходимости, обращаться к юристам с проверкой лишь мелких деталей, а не общей идеи, на которую уже было потрачено существенное время.
Отдельным пунктом идут познания о наиболее распространенных социальных культурах и субкультурах, религиях, образе жизни на разных континентах, международных праздниках, памятных датах и тысяче других вещей, составляющих общую конъюнктуру мира на момент разработки продукта или его особенности.
В определенных случаях, менеджеру могут даже понадобиться знания о существующих вооруженных и/или идеологических конфликтах в регионах.
Также, очевидно, продакт менеджер должен быть более чем продвинутым пользователем современных вебсайтов и мобильных приложений, иметь хорошее представление и опыт работы с принципами и практиками Agile, а также понимать техническую составляющую проекта. Технические знания- такие, как основы front-end и back-end программирования и систем работы баз данных, тоже очень важны, потому что решения, разрабатываемые с учетом технических тонкостей проекта, в конечном итоге экономят десятки, а в некоторых случаях сотни человекочасов.
Все это и многое другое — те самые детали, которые важно учитывать с самого начала, и отсутствие которых, часто, выясняется слишком поздно и стоит дорого.
Без внимания к деталям, невозможно добиться высокого качества.
Важность деталей и умение с ними работать в наше время гораздо более важны, чем общие идеи.
Часть 8. Эпилог
В заключительной части я бы хотел объяснить, почему из всех знаний, которые важны для продакт менеджера, я особенно выделил психологию, в частности, критическую важность понимания когнитивных искажений.
Причина же в том, что из всех перечисленных выше аспектов знаний продакт менеджера, психологическая составляющая — это не что-то, что можно легко «понять», «принять» и «стать лучше». У широкого множества людей, которые захотят использовать знания когнитивных искажений в своей регулярной работе возникнут внутренние противоречия, борьба со своими прежними «установками». Иными словами, человеческое эго не позволит принять легкие и очевидные правильные ответы, так как для их «принятия» придется менять устоявшуюся модель мышления и поведения — выходить из зоны своего психологического комфорта.
Попробую объяснить иначе. Вне зависимости от идеологической составляющей вашей жизни, вашего «стиля» и публичного образа, вы можете в любой момент записаться на курсы по SCRUM, изучить этот фреймворк, почитать о нескольких других, понять идеи Agile и устроиться работать проект менеджером в какую-то компанию. Вы также можете пройти пару онлайн курсов и подтянуть ваши знания по front-end и back-end программированию, понять принципы работы баз данных, и это займет у вас буквально месяц. Еще за месяц вы можете сами выучить HTML и CSS, поиграть с разметкой, собрать несколько макетов и понять общую идею работы Javascript.
По сути, вы можете месяца за три собрать достаточно знаний для понимания технической составляющей проекта, и этого более чем хватит для начинающего продакт менеджера. Для понимания трендов вы можете скачать самые последние приложения, пройти по списку самых популярных онлайн платформ, зарегистрироваться на producthunt, betalist, techcrunch и всегда быть в курсе происходящего. Новостной информационный пробел легко восполнить регулярно читая Google News и hackernoon.
Однако, когда мы затрагиваем психологическую составляющую работы, ситуация немного меняется. Решения по разрабатываемым особенностям продукта принимаются, в первую очередь, с опорой на понимание наших пользователей, их ожиданий и забот. Здесь психология играет ключевую роль, поэтому «абстрактное» понимание вопроса (как в случае с тех. составляющей) не подойдет. Для применения когнитивных искажений совершенно не достаточно прочесть эту статью или просмотреть их все в таблице. Не хватит даже чтения нескольких книг или просмотра пары видео курсов.
Чтобы по-настоящему «применить» эти знания и создать красивое решение, которое учтет ошибки нашего мозга, необходимо не просто помнить об этих ошибках, но и вовлечь их в свою жизнь. А подобное вовлечение, не может не привести к изменению своей линии поведения, идеологии и жизненных взглядов.
Именно поэтому тем, для кого эта статья была просто «прикольной статьей», будет лучше продолжать жить так же, как они жили, а те, для кого бОльшая часть написанного здесь была очевидной из-за своей логичности, могут задуматься над тем, чтобы построить свою карьеру вокруг продакт менеджмента. Именно вы являетесь теми, кто в какой-то момент поможет перевернуть страницу черствого, грубого софта, который заполонил рынок и приведет всех нас в новый мир, где проектировка любого продукта начинается с чувств эмпатии и сострадания к пользователям. Именно вы способны создавать революционные продукты, методологии и практики разработки качественного ПО.
Завершить статью я хочу провокационной мыслью.
А что, если изучение когнитивных искажений в раннем возрасте (скажем, в университетах) – это прямой способ сделать наше общество более сознательным, чувственным и сопереживающим?
Что, если именно изучение искажений и пользовательского опыта, является ключом к обеспечению рациональности (суть – отсуствие противоречий по Д. Канеману) индивида?
Как говорит сам Д. Канеман: «Чем бы ни занималась организация, она является фабрикой по производству суждений и решений». И рано или поздно, из-за необходимости повышения качества этих производимых суждений и решений, подход к разработке продуктов и менеджменту компании будет базироваться на эмпатии и сострадании, а методы сухого анализа данных будут применяться гораздо реже.
Человек же, по количеству произведенных суждений и решений не уступает ни одной компании в мире (вопрос сознательности оставляем за рамками). Нам не обязательно ждать, когда крупные компании дадут «публичное добро» на использование когнитивных искажений как основны для разработки разных решений. Мы можем использовать эти знания для изменения нашей жизни уже сейчас.
В любом случае, для того, чтобы идеи стали популярны, их должны обсуждать общепризнанные авторитеты. Обсуждать чаще и больше. Вреда от этого точно не будет, а потенциальную пользу переоценить невозможно.
Большое спасибо за проявленный интерес.
Искренне надеюсь, что эта статья дала вам пищу для размышлений.
Я буду очень рад познакомиться с людьми со схожими интересами, поэтому, если вы изучаете когнитивные науки и/или их применение в разработке продуктов – добавляйтесь ко мне в LinkedIn или Facebook.
Также я всегда открыт для обсуждения новых идей. Чем амбициознее, тем лучше. Пишите.
Буду рад помочь всем, что в моих силах.
Часть 9. Материал, качественно дополняющий эту статью
- Даниел Канеман – Думай медленно… Решай быстро;
- Николас Нассим Талеб – Черный Лебедь;
- Касс Санстейн и Ричард Талер – Подталкивание;
- Ричард Дэвидсон – Как эмоции управляют мозгом;
- Михай Чиксентмихайи – Поток;
- Джим Коллинз – От хорошего к великому;
- Jesse James Garrett — The Elements of User Experience (2nd Edition);
- William Lidwell — Universal Principles of Design;
- James Clear – Atomic Habits;
- Erin Meyer – The Culture Map;
- Joe Natoli – UX Design Fundamentals Udemy Video;
- Joe Natoli — UX & Web Design Master Course: Strategy, Design, Development Udemy Video;
Эта статья была написана в период объявленного карантина из-за пандемии коронавируса (COVID-19) в Армении, г. Ереван. Я очень рад, что статья оказалась полезна многим людям, которые успели ознакомиться с разными частями написанного материала в период моей работы над ней.
Оригинал статьи
Английская версия
По любым вопросам и предложениям пишите, буду рад помочь: alexanyanwolf@gmail.com / www.linkedin.com/in/alexanyan / www.facebook.com/AlexanyanWolf
Статистическая формальная ошибка
Ошибка базовой ставки, также называемая базовой пренебрежение оценкой или отклонение базовой ставки, является ошибкой. При представлении связанной информации базовой ставки (т. Е. Общей информации о распространенности) и конкретной информации (т. Е. Информации, относящейся только к конкретному случаю) люди склонны игнорировать базовую ставку в пользу индивидуальной информации, вместо правильного объединения двух.
Пренебрежение базовой скоростью — это конкретная форма более общего пренебрежения расширением.
Содержание
- 1 Ложноположительный парадокс
- 2 Примеры
- 2.1 Пример 1: Болезнь
- 2.1.1 Население с высокой заболеваемостью
- 2.1.2 Население с низкой заболеваемостью
- 2.2 Пример 2: Водители в нетрезвом виде
- 2.3 Пример 3: Идентификация террористов
- 2.1 Пример 1: Болезнь
- 3 Выводы по психологии
- 4 См. Также
- 5 Ссылки
- 6 Внешние ссылки
Парадокс ложных срабатываний
Примером ошибки базовой ставки является то, насколько удивлены люди парадоксом ложных срабатываний, ситуации, когда имеется больше ложноположительных результатов теста, чем истинно-положительных. Например, это может быть так, что из 1000 человек, прошедших тестирование на инфекцию, 50 из них дали положительный результат на наличие инфекции, но это связано с тем, что у 10 действительно она была и у 40 ошибочных результатов тестов, потому что только 10 человек из тех, кто прошел тестирование, действительно инфицированы. но тест иногда дает ложные результаты. Вероятность положительного результата теста определяется не только точностью теста, но и характеристиками выборки. Когда распространенность, доля тех, у кого есть данное заболевание, ниже, чем уровень ложноположительных результатов теста, даже тесты, которые имеют очень низкий шанс дать ложноположительный результат в отдельном случае, будут давать больше ложных результатов. чем истинных положительных результатов в целом. Парадокс удивляет большинство людей.
Это особенно противоречит интуиции при интерпретации положительного результата теста на низкой распространенности популяции после того, как имеешь дело с положительными результатами, полученными из высокой распространенности. численность населения. Если ложноположительный уровень теста выше, чем доля новой популяции с заболеванием, то администратор теста, чей опыт был получен в результате тестирования в популяции с высокой распространенностью, может сделать вывод из Опыт, что положительный результат теста обычно указывает на положительный результат, тогда как на самом деле ложноположительный результат гораздо более вероятен.
Примеры
Пример 1: Болезнь
Население с высокой заболеваемостью
| Количество. людей | Инфицированные | Незараженные | Всего |
|---|---|---|---|
| Тест. положительный | 400. (истинно положительный) | 30. (ложноположительный) | 430 |
| Тест. отрицательный | 0. (ложноотрицательный) | 570. (истинно отрицательный) | 570 |
| Всего | 400 | 600 | 1000 |
Представьте, что вы проводите тест на инфекционное заболевание в популяции A из 1000 человек, 40% из которых инфицированы. Уровень ложноположительных результатов теста составляет 5% (0,05), а количество ложноотрицательных результатов отсутствует. ожидаемый результат из 1000 тестов в популяции A будет:
- инфицировано, и тест указывает на болезнь (истинно положительный )
- 1000 × 40/100 = 400 человек получат истинно положительный результат
- Незараженные и тест указывает на болезнь (ложноположительный)
- 1000 × 100 — 40/100 × 0,05 = 30 человек получат ложноположительный результат
- Остальные 570 тестов правильно отрицательны.
Итак, в популяции A человек, получивший положительный результат теста, может быть уверен более чем на 93% (400/30 + 400), что он правильно указывает на инфекцию.
Население с низкой заболеваемостью
| Количество. людей | Зараженные | Неинфицированные | Всего |
|---|---|---|---|
| Тест. положительный | 20. (истинно положительный) | 49. (ложноположительный) | 69 |
| Тест. отрицательный | 0. (ложноотрицательный) | 931. (истинно отрицательный) | 931 |
| Итого | 20 | 980 | 1000 |
Теперь рассмотрим тот же тест, примененный к популяции B, в которой инфицировано только 2%. ожидаемый результат 1000 тестов в популяции B будет:
- Заражено a -й тест указывает на болезнь (истинно положительный )
- 1000 × 2/100 = 20 человек получат истинно положительный результат
- Неинфицированные, а тест указывает на болезнь (ложноположительный)
- 1000 × 100 — 2 / 100 × 0,05 = 49 человек получат ложноположительный результат
- Остальные 931 (= 1000 — (49 + 20)) теста являются правильно отрицательными.
В популяции B только 20 из 69 человек с положительным результатом теста результат действительно заражены. Таким образом, вероятность действительно заразиться после того, как кому-то сказали, что он инфицирован, составляет всего 29% (20/20 + 49) для теста, который в противном случае кажется «точным на 95%».
Тестировщик, имеющий опыт работы с группой A, может найти парадокс в том, что в группе B результат, который обычно правильно указывал на инфекцию, теперь обычно является ложноположительным. Смешение апостериорной вероятности заражения с априорной вероятностью получения ложноположительного результата является естественной ошибкой после получения угрожающего здоровью результата теста.
Пример 2: Пьяные водители
- У группы полицейских есть алкотестеры, показывающие ложное опьянение в 5% случаев, когда водитель трезв. Однако алкотестеры всегда обнаруживают по-настоящему пьяного человека. Один из тысячи водителей водит машину в нетрезвом виде. Предположим, полицейские наугад останавливают водителя, чтобы провести тест алкотестера. Это указывает на то, что водитель пьян. Мы предполагаем, что вы ничего о них не знаете. Насколько высока вероятность того, что они действительно пьяны?
Многие ответят как 95%, но правильная вероятность составляет около 2%.
Объяснение этому следующее: в среднем на каждую 1000 протестированных водителей
- 1 водитель находится в состоянии алкогольного опьянения, и 100% уверенности в том, что для этого драйвера существует истинно положительный результат теста, поэтому имеется 1 истинно положительный результат теста
- 999 водителей не находятся в состоянии алкогольного опьянения, и среди этих водителей имеется 5% ложноположительных результатов испытаний, поэтому имеется 49,95 ложноположительных результатов испытаний
Следовательно, вероятность того, что один из водители среди положительных результатов теста 1 + 49,95 = 50,95 действительно пьяны 1 / 50,95 ≈ 0,019627 { displaystyle 1 / 50.95 приблизительно 0,019627}.
Однако достоверность этого результата зависит от достоверности Из первоначального предположения, что полицейский остановил водителя действительно случайно, а не из-за плохого вождения. Если присутствовала та или иная непроизвольная причина остановки водителя, то в расчет также включается вероятность того, что водитель в состоянии алкогольного опьянения будет управлять автомобилем грамотно, а водитель в нетрезвом виде водит (не) компетентно.
Более формально такая же вероятность примерно 0,02 может быть установлена с помощью теоремы Байеса. Цель состоит в том, чтобы найти вероятность того, что водитель пьян, учитывая, что алкотестер показал, что он пьян, что может быть представлено как
- p (пьяный ∣ D) { displaystyle p ( mathrm {drunk} mid D)}
где D означает, что алкотестер показывает, что водитель пьян. Теорема Байеса говорит нам, что
- p (d r u n k ∣ D) = p (D ∣ d r u n k) p (d r u n k) p (D). { displaystyle p ( mathrm {drunk} mid D) = { frac {p (D mid mathrm {drunk}) , p ( mathrm {drunk})} {p (D)}}.}.
В первом абзаце нам сказали следующее:
- p (пьяный) = 0,001, { displaystyle p ( mathrm {drunk}) = 0,001,}
- p (трезвый) = 0,999, { displaystyle p ( mathrm {sober}) = 0,999,}
- p (D ∣ drunk) = 1,00, { displaystyle p (D mid mathrm {drunk}) = 1,00,}и
- p (D трезвый) = 0,05. { displaystyle p (D mid mathrm {sober}) = 0,05.}
Как видно из формулы, для теоремы Байеса требуется p (D), которую можно вычислить из предыдущих значений с помощью закон полной вероятности :
- p (D) = p (D ∣ пьяный) p (пьяный) + p (D ∣ трезвый) p (трезвый) { displaystyle p (D) = p (D mid mathrm {drunk}) , p ( mathrm {drunk}) + p (D mid mathrm {sober}) , p ( mathrm {sober})}
, что дает
- p (D) = (1,00 × 0,001) + (0,05 × 0,999) = 0,05095. { displaystyle p (D) = (1,00 times 0,001) + (0,05 times 0,999) = 0,05095.}
Подставляя эти числа в теорему Байеса, мы получаем, что
- p (drunk ∣ D) = 1,00 × 0,001 0,05095 = 0,019627. { displaystyle p ( mathrm {drunk} mid D) = { frac {1,00 times 0,001} {0,05095}} = 0,019627.}
Пример 3: идентификация террориста
В городе 1 миллион жителей пусть будет 100 террористов и 999 900 нетеррористов. Для упрощения примера предполагается, что все люди, присутствующие в городе, являются его жителями. Таким образом, базовая вероятность того, что случайно выбранный житель города является террористом, равна 0,0001, а базовая вероятность того, что этот же житель не является террористом, равна 0,9999. В попытке поймать террористов город устанавливает систему сигнализации с камерой наблюдения и автоматическим программным обеспечением для распознавания лиц.
. Программное обеспечение имеет два уровня отказов по 1%:
- Уровень ложных отрицательных результатов: если камера сканирует террориста, звонок будет звонить в 99% случаев, и он не будет звонить в 1% случаев.
- Частота ложных срабатываний: если камера сканирует человека, не являющегося террористом, звонок не будет звонит 99% времени, но он будет звонить 1% времени.
Предположим теперь, что житель вызывает тревогу. Какова вероятность того, что это террорист? Другими словами, что такое P (T | B), вероятность того, что террорист был обнаружен при звонке в колокол? Кто-то, делающий «ошибку базовой ставки», сделает вывод о том, что с вероятностью 99% обнаруженный человек является террористом. Хотя этот вывод кажется логичным, на самом деле это неверное рассуждение, и приведенный ниже расчет покажет, что вероятность того, что они террористы, на самом деле составляет около 1%, а не около 99%.
Заблуждение возникает из-за смешения природы двух разных уровней отказов. «Количество не-колоколов на 100 террористов» и «количество нетеррористов на 100 колоколов» не связаны между собой. Один не обязательно равен другому, и они даже не обязательно должны быть почти равными. Чтобы продемонстрировать это, представьте, что произойдет, если во втором городе, где террористов вообще нет, была бы установлена идентичная система сигнализации. Как и в первом городе, тревога звучит для 1 из каждых 100 обнаруженных жителей, не являющихся террористами, но, в отличие от первого города, тревога никогда не звучит для террористов. Таким образом, 100% всех случаев срабатывания сигнализации относятся к нетеррористам, но ложноотрицательный показатель даже не может быть подсчитан. «Число нетеррористов на 100 колоколов» в этом городе равно 100, но P (T | B) = 0%. При звонке в колокол вероятность того, что террорист был обнаружен, равна нулю.
Представьте себе, что перед камерой проходит весь миллион жителей первого города. Около 99 из 100 террористов вызовут тревогу, равно как и около 9 999 из 999 900 нетеррористов. Таким образом, тревогу сработают около 10 098 человек, среди которых около 99 — террористы. Таким образом, вероятность того, что человек, вызвавший тревогу, на самом деле является террористом, составляет всего около 99 из 10 098, что меньше 1% и очень, очень сильно ниже нашего первоначального предположения в 99%.
Ошибка базовой ставки в этом примере вводит в заблуждение, потому что нетеррористов намного больше, чем террористов, а количество ложных срабатываний (нетеррористы сканируются как террористы) намного больше, чем истинных срабатываний ( реальное количество террористов).
Выводы по психологии
В ходе экспериментов было обнаружено, что люди предпочитают индивидуальную информацию общей информации, когда первая доступна.
В некоторых экспериментах студентов просили оценить средний балл (GPA) гипотетических студентов. Получая соответствующую статистику о распределении среднего балла, учащиеся, как правило, игнорировали ее, если давали описательную информацию о конкретном учащемся, даже если новая описательная информация явно не имела отношения к успеваемости в школе или не имела никакого отношения к ней. Этот вывод был использован, чтобы доказать, что собеседования являются ненужной частью процесса поступления в колледж, потому что интервьюеры не могут выбрать успешных кандидатов лучше, чем базовая статистика.
Психологи Дэниел Канеман и Амос Тверски попытались объяснить это открытие с помощью простого правила или «эвристики», называемого репрезентативностью.. Они утверждали, что многие суждения, касающиеся вероятности или причины и следствия, основаны на том, насколько одно репрезентативно для другого или для категории. Канеман считает, что пренебрежение базовой ставкой является особой формой пренебрежения расширением. Ричард Нисбетт утверждал, что некоторые предубеждения при атрибуции, такие как фундаментальная ошибка атрибуции являются примерами ошибки базовой ставки: люди не используют «консенсусную информацию» («базовую оценку») о том, как другие вели себя в аналогичных ситуациях, а вместо этого предпочитают более простые диспозиционные атрибуции.
В психологии ведутся серьезные споры об условиях, при которых люди ценят или не ценят информацию о базовой ставке. Исследователи программы эвристики и систематических ошибок подчеркнули эмпирические данные, показывающие, что люди склонны игнорировать базовые ставки и делать выводы, нарушающие определенные нормы вероятностного рассуждения, такие как теорема Байеса. Вывод, сделанный на основании этого направления исследований, заключался в том, что вероятностное мышление человека в корне ошибочно и подвержено ошибкам. Другие исследователи подчеркнули связь между когнитивными процессами и форматами информации, утверждая, что такие выводы обычно не являются обоснованными.
Еще раз рассмотрим пример 2, приведенный выше. Требуемый вывод заключается в оценке (апостериорной) вероятности того, что (случайно выбранный) водитель находится в состоянии алкогольного опьянения, при условии, что тест алкотестера положительный. Формально эту вероятность можно рассчитать с помощью теоремы Байеса, как показано выше. Однако существуют разные способы представления соответствующей информации. Рассмотрим следующий формально эквивалентный вариант проблемы:
- 1 из 1000 водителей водит машину в нетрезвом виде. Алкотестеры никогда не перестают определять по-настоящему пьяного человека. Для 50 из 999 водителей, не находящихся в состоянии алкогольного опьянения, алкотестер ложно показывает состояние опьянения. Предположим, полицейские наугад останавливают водителя и заставляют его пройти тест алкотестера. Это указывает на то, что они пьяны. Мы предполагаем, что вы ничего о них не знаете. Насколько высока вероятность, что они действительно пьяны?
В этом случае соответствующая числовая информация — p (пьяный), p (D | пьяный), p (D | трезвый) — представлена в виде собственных частот относительно к определенному эталонному классу (см. проблема эталонного класса ). Эмпирические исследования показывают, что выводы людей в большей степени соответствуют правилу Байеса, когда информация представлена таким образом, что помогает преодолеть пренебрежение базовой оценкой со стороны непрофессионалов и экспертов. Как следствие, такие организации, как Cochrane Collaboration, рекомендуют использовать такой формат для передачи статистики здравоохранения. Учить людей переводить подобные байесовские задачи мышления в форматы собственных частот более эффективно, чем просто учить их подставлять вероятности (или проценты) в теорему Байеса. Также было показано, что графическое представление собственных частот (например, массив значков) помогает людям делать более точные выводы.
Почему полезны форматы собственных частот? Одна из важных причин заключается в том, что этот формат информации облегчает требуемый вывод, поскольку упрощает необходимые вычисления. Это можно увидеть, используя альтернативный способ вычисления требуемой вероятности p (пьяный | D):
- p (пьян ∣ D) = N (пьян ∩ D) N (D) = 1 51 = 0,0196 { displaystyle p ( mathrm {drunk} mid D) = { frac {N ( mathrm {drunk} cap D)} {N (D)}} = { frac {1} {51}} = 0,0196}
где N (пьяный ∩ D) обозначает количество пьяных водителей, получивших положительный результат алкотестера, а N (D) обозначает общее количество случаев с положительным результатом алкотестера. Эквивалентность этого уравнения предыдущему следует из аксиом теории вероятностей, согласно которой N (drunk ∩ D) = N × p (D | drunk) × p (drunk). Важно отметить, что хотя это уравнение формально эквивалентно правилу Байеса, психологически оно не эквивалентно. Использование собственных частот упрощает вывод, поскольку требуемая математическая операция может выполняться с натуральными числами, а не с нормализованными дробями (т. Е. Вероятностями), поскольку это делает большое количество ложных срабатываний более прозрачным, и поскольку собственные частоты демонстрируют «вложенный набор» структура «.
Не каждый частотный формат позволяет использовать байесовские рассуждения. Собственные частоты относятся к информации о частоте, которая является результатом естественной выборки, которая сохраняет информацию о базовой скорости (например, количество пьяных водителей при выборке случайной выборки водителей). Это отличается от систематической выборки, в которой базовые ставки фиксируются априори (например, в научных экспериментах). В последнем случае невозможно вывести апостериорную вероятность p (пьяный | положительный тест) из сравнения количества пьяных водителей с положительным результатом теста по сравнению с общим количеством людей, получивших положительный результат алкотестера, потому что информация о базовой скорости не сохраняется и должен быть явно повторно введен с использованием теоремы Байеса.
См. Также
- Байесовская вероятность
- Теорема Байеса
- Извлечение данных
- Индуктивный аргумент
- Список когнитивных предубеждений
- Список парадоксов
- Вводящая в заблуждение яркость
- Парадокс предотвращения
- Заблуждение прокурора, ошибка в рассуждениях, включающая игнорирование низкой априорной вероятности
- парадокса Симпсона, еще одна ошибка в статистических рассуждениях, касающихся сравнения групп
- стереотип
Ссылки
Внешние ссылки
- Ошибка базовой ставки Файлы ошибок
Что такое ошибка базовой ставки?
Ошибка базовой ставки или пренебрежение базовой ставкой – это когнитивная ошибка, при которой слишком мало веса придается базовой или исходной вероятности (например, вероятности A при заданном B). В поведенческих финансах ошибка базовой ставки – это склонность людей ошибочно оценивать вероятность ситуации, не принимая во внимание все соответствующие данные. Вместо этого инвесторы могут уделять больше внимания новой информации, не осознавая, как это влияет на исходные предположения.
Ключевые выводы
- Ошибка базовой ставки – это когда базовый или исходный вес или вероятность либо игнорируются, либо считаются второстепенными.
- Эта «ошибка» трейдера тщательно изучается, поскольку часто эмоциональные факторы, такие как ошибка базовой ставки, определяют направление рынка.
- Поведенческое финансирование включает изучение ошибки базовой ставки и ее рыночных эффектов.
Понимание ошибки базовой ставки
При рассмотрении информации о базовой ставке существуют две категории при определении вероятности в определенных ситуациях. Первое – это общая вероятность, а второе – информация по конкретному событию, например, на сколько базисных пунктов сместился рынок, на какой процент компании снизилась ее корпоративная прибыль или сколько раз компания меняла руководство. Инвесторы часто склонны придавать большее значение этой информации о конкретном событии в контексте ситуации, иногда полностью игнорируя базовые ставки.
Хотя часто информация о конкретном событии важна в краткосрочной перспективе, особенно для трейдеров или участников коротких продаж, она может казаться больше, чем требуется для инвесторов, пытающихся предсказать долгосрочную траекторию движения акций. Например, инвестор может пытаться определить вероятность того, что компания превзойдет свою группу конкурентов и станет лидером отрасли.
Краткий обзор
Существует множество примеров, когда эмоции и психология сильно влияют на решения инвесторов, заставляя людей вести себя непредсказуемым образом.
В то время как база информации – прочное финансовое положение компании, стабильные темпы роста, менеджмент с подтвержденным послужным списком и отрасль с высоким спросом – все указывает на ее способность преуспевать, слабая прибыль за квартал может отбросить инвесторов, заставив их думаю, что это меняет курс компании. Как это часто бывает, это может быть просто небольшой скачок в его общем росте.
Особое внимание: поведенческие финансы
Поведенческие финансы – это относительно новая область, которая стремится объединить поведенческую и когнитивную психологическую теорию с традиционной экономикой и финансами, чтобы объяснить, почему люди принимают нерациональные финансовые решения. Согласно традиционной финансовой теории, мир и его участники по большей части являются логическими «максимизаторами богатства».
Одним из таких примеров является чрезмерная реакция на рыночное событие, поскольку она тесно связана с концепцией ошибки базовой ставки. Согласно рыночной эффективности, новая информация должна быстро отражаться в цене ценной бумаги. Однако действительность противоречит этой теории. Часто участники рынка слишком остро реагируют на новую информацию, такую как изменение процентных ставок, что оказывает более сильное, чем необходимо, влияние на цену ценной бумаги или класса активов. Такие скачки цен обычно не являются постоянными и имеют тенденцию к снижению со временем.
Ошибка базового процента
- Ошибка базового процента (другие названия: заблуждение базового процента или игнорирование базового уровня) — это ошибка в мышлении, когда сталкиваясь с общей информацией о частоте некоторого события (базовый процент) и специфической информацией об этом событии, человек имеет склонность игнорировать первое и фокусироваться на втором.
Источник: Википедия
Связанные понятия
Байесовская игра (англ. Bayesian game) или игра с неполной информацией (англ. incomplete information game) в теории игр характеризуются неполнотой информации о соперниках (их возможных стратегиях и выигрышах), при этом у игроков есть веры относительно этой неопределённости. Байесовскую игру можно преобразовать в игру полной, но несовершенной информации, если принять допущение об общем априорном распределении. В отличие от неполной информации, несовершенная информация включает знание стратегий и выигрышей…
Машина вероятности – математическая модель вычислительного устройства, в работе которого участвует некоторый случайный процесс. Различные варианты понятия «Машины вероятности» являются обобщениями понятий «автомата детерминированного», «Тьюринга машина», «автомата бесконечного». Рассматривались, например, такие понятия «машины вероятности», как: 1)Машина Тьюринга (или другой детерминированный автомат) с входом, к которому присоединен бернуллиевский датчик, выдающий символ 1 и 0 с вероятностью p и…
Парадокс мальчика и девочки также известен в теории вероятностей как «Парадокс девочки и мальчика», «Дети мистера Смита» и «Проблемы миссис Смит». Впервые задача была сформулирована в 1959 году, когда Мартин Гарднер опубликовал один из самых ранних вариантов этого парадокса в журнале Scientific American под названием «The Two Children Problem», где привёл следующую формулировку…
Ложный вызов, ложная тревога — обман или ошибочное сообщение о чрезвычайной ситуации, в результате чего возникает ненужная паника и / или вызов аварийных служб (например скорой медицинской помощи, полиции) к месту, где они не нужны. Ложные вызовы могут возникать также в результате срабатывания сигнализации в жилище, детектора дыма, аварийной сигнализации на предприятии и в теории обнаружения сигнала. Ложные тревоги отвлекают аварийные службы от истинных чрезвычайных ситуаций, которые могли бы в конечном…
Тест на следующий бит (англ. next-bit test) — тест, служащий для проверки генераторов псевдо-случайных чисел на криптостойкость. Тест гласит, что не должно существовать полиномиального алгоритма, который, зная первые k битов случайной последовательности, сможет предсказать k+1 бит с вероятностью, неравной ½.
Эффект социальной желательности (social desirability bias, SDB) — термин в социологических исследованиях, описывающий тип предвзятости в ответах респондентов, что является тенденцией опрашиваемых давать такие ответы, которые, с их точки зрения, выглядят предпочтительнее в глазах окружающих. Такая тенденция может выражается в преувеличении положительных и желательных качеств и поведения и преуменьшении негативных, нежелательных. Этот феномен создает множество проблем в исследованиях, основанных на…
Причинность по Грэнджеру (англ. Granger causality) — понятие, используемое в эконометрике (анализе временных рядов), формализующее понятие причинно-следственной связи между временными рядами. Причинность по Грэнджеру является необходимым, но не достаточным условием причинно-следственной связи.
Безопасность информационных потоков — набор требований и правил, направленных на определение того, какие информационные потоки в системе являются разрешёнными, а какие нет. Данная модель не является самостоятельной, и используется в дополнение к мандатной или дискреционной модели управления доступа.
Теорема о конце света (англ. Doomsday argument, буквально «Аргумент судного дня» — сокращённо далее DA, нет устоявшегося перевода на русский язык, обычно используют английское название или сокращение DA) — это вероятностное рассуждение, которое претендует на то, чтобы предсказывать будущее время существования человеческой расы, исходя только из оценки числа живших до сих пор людей. Исходя из предположения, что живущие сейчас люди находятся в случайном месте всей хронологии человеческой истории, велики…
Теория обнаружения сигнала (ТОС) — современный психофизический метод, учитывающий вероятностный характер обнаружения стимула, в котором наблюдатель рассматривается как активный субъект принятия решения в ситуации неопределённости. Теория обнаружения сигнала описывает сенсорный процесс как двухступенчатый: процесс отображения физической энергии стимула в интенсивность ощущения и процесс принятия решения субъектом.
Социа́льное доказа́тельство (англ. Social proof), или информационное социальное влияние (англ. informational social influence) — психологическое явление, происходящее, когда некоторые люди не могут определить предпочтительный способ поведения в сложных ситуациях. Предполагая, что окружающие лучше знакомы с ситуацией, такие люди считают их поведение предпочтительным. Это явление часто используется для сознательной манипуляции поведением других.
Лемма разветвления (англ. Forking lemma) — лемма в области криптографических исследований.
Эффект Валинса — осознаваемое ощущение физиологических изменений при актуализации эмоциональной реакции.
Системати́ческая оши́бка вы́жившего (англ. survivorship bias) — разновидность систематической ошибки отбора, когда по одной группе («выжившим») есть много данных, а по другой («погибшим») — практически нет, в результате чего исследователи пытаются искать общие черты среди «выживших» и упускают из вида, что не менее важная информация скрывается среди «погибших».
Демпстера-Шафера теория — математическая теория очевидностей (свидетельств) (), основанная на функции доверия (belief functions) и функции правдоподобия (plausible reasoning), которые используются, чтобы скомбинировать отдельные части информации (свидетельства) для вычисления вероятности события. Теория была развита Артуром П. Демпстером и Гленном Шафером.
Эффект опознаваемой жертвы — разновидность когнитивного искажения, суть которого в том, что среди людей существует тенденция оказывать более щедрую помощь отдельному индивиду (жертве), чьи затруднительные жизненные обстоятельства можно наблюдать напрямую, нежели неопределённой группе лиц с аналогичными проблемами. По подобному принципу этот эффект также наблюдается при присвоении большей меры ответственности правонарушителю, чья личность была установлена, даже если его личность не несёт никакой значимой…
Эффект интервьюера — в современной социологии все погрешности, которые связаны с влиянием интервьюера на качество получаемых от респондента данных.
Эффект спящего — психологический феномен, связанный с убеждением. Это отсроченный рост влияния сообщения, которое сопровождалось обесценивающим стимулом (например, контраргументом или получением сообщения из источника, не вызывающего доверия). Суть феномена в отсроченном разделении содержания сообщения и источника информации.
Оккамово обучение в теории вычислительного обучения является моделью алгоритмического обучения, где целью обучения является получение сжатого представления имеющихся тренировочных данных. Метод тесно связан с почти корректным обучением (ПК обучение, англ. Probably Approximately Correct learning, PAC learning), где учитель оценивает прогнозирующую способность тестового набора.
Модель бинарного выбора — применяемая в эконометрике модель зависимости бинарной переменной (принимающей всего два значения — 0 и 1) от совокупности факторов. Построение обычной линейной регрессии для таких переменных теоретически некорректно, так как условное математическое ожидание таких переменных равно вероятности того, что зависимая переменная примет значение 1, а линейная регрессия допускает и отрицательные значения и значения выше 1. Поэтому обычно используются некоторые интегральные функции…
В психологии эвристика беглости — это ментальная эвристика, в которой, если один объект обрабатывается плавнее или быстрее другого,то этот объект имеет более высокое значение в отношении рассматриваемого вопроса. Другими словами, чем более умело или изящно идея передается, тем вероятней, что её следует рассматривать серьезно, независимо от того, логична она или нет.
Субъективная вероятность — степень личной веры агента (субъекта) в возможность наступления некоторого события.
Модель отказов (англ. fault model) представляет собой инженерную модель конструкции или оборудования, которое может работать неправильно. Исходя из модели, разработчик или пользователь могут предсказать последствия конкретных отказов. Модели отказов могут быть использованы практически во всех видах инженерной деятельности.
Робастность (англ. robustness, от robust — «крепкий», «сильный», «твёрдый», «устойчивый») — свойство статистического метода, характеризующее независимость влияния на результат исследования различного рода выбросов, устойчивости к помехам. Выбросоустойчивый (робастный) метод — метод, направленный на выявление выбросов, снижение их влияния или исключение их из выборки.
Приня́тие жела́емого за действи́тельное — формирование убеждений и принятие решений в соответствии с тем, что является приятным человеку, вместо апелляции к имеющимся доказательствам, рациональности или реальности.
Эффект свидетеля, эффект постороннего, синдром Дженовезе — психологический эффект, проявляющийся в том, что люди, оказавшиеся свидетелями чрезвычайной ситуации (ДТП, преступления или других), не пытаются помочь пострадавшим. Установлено, что вероятность того, что кто-нибудь из свидетелей начнёт помогать пострадавшим, тем меньше, чем больше людей станут просто стоять и смотреть. Другими словами, каждый из очевидцев считает, что помочь пострадавшим должен не он, а кто-то другой. Наоборот, единственный…
Эвристика доступности (англ. availability heuristic) — это интуитивный процесс, в котором человек «оценивает частоту или возможность события по легкости, с которой примеры или случаи приходят на ум», т. е. легче вспоминаются. При подобной оценке человек полагается на ограниченное количество примеров или случаев. Это упрощает комплексную задачу оценки вероятности и прогнозирования значимости события до простых суждений, основанных на собственных воспоминаниях, поэтому такой процесс является необъективным…
Шкала Ликерта, или (неверно) Лайкерта (англ. Likert scale (/ˈlɪkərt/ ), шкала суммарных оценок) — психометрическая шкала, которая часто используется в опросниках и анкетных исследованиях (разработана в 1932 году Ренсисом Ликертом). При работе со шкалой испытуемый оценивает степень своего согласия или несогласия с каждым суждением, от «полностью согласен» до «полностью не согласен». Сумма оценок каждого отдельного суждения позволяет выявить установку испытуемого по какому-либо вопросу. Предполагается…
Слепота́ невнима́ния (англ. Inattentional Blindness) или Перцепти́вная слепота (англ. Perceptual blindness), также часто неточно переводится как ложная слепота) — это психологическая неспособность обращать внимание на какой-либо объект, которая не относится к проблемам со зрением и носит исключительно психологический характер. Явление также может быть определено как неспособность индивида увидеть неожиданно возникший в поле зрения раздражитель.
Случайность имеет множество применений в области науки, искусства, статистики, криптографии, игр, азартных игр, и других областях. Например, случайное распределение в рандомизированных контролируемых исследованиях помогает ученым проверять гипотезы, а также случайные и псевдослучайные числа находят применение в видео-играх, таких как видеопокер.
Подробнее: Применения случайности
Коэффициент Байеса — это байесовская альтернатива проверке статистических гипотез. Байесовское сравнение моделей — это метод выбора моделей на основе коэффициентов Байеса. Обсуждаемые модели являются статистическими моделями. Целью коэффициента Байеса является количественное выражение поддержки модели по сравнению с другой моделью, независимо от того, верны модели или нет. Техническое определение понятия «поддержка» в контексте байесовского вывода дано ниже.
Склонность к подтверждению своей точки зрения или предвзятость подтверждения (англ. confirmation bias) — тенденция человека искать и интерпретировать такую информацию или отдавать предпочтение такой информации, которая согласуется с его точкой зрения, убеждением или гипотезой.
Дифференциальная приватность — совокупность методов, которые обеспечивают максимально точные запросы в статистическую базу данных при одновременной минимизации возможности идентификации отдельных записей в ней.
Пять почему — техника, используемая для изучения причинно-следственных связей, лежащих в основе той или иной проблемы. Основной задачей техники является поиск первопричины возникновения дефекта или проблемы с помощью повторения одного вопроса — «Почему?». Каждый последующий вопрос задаётся к ответам на предыдущий вопрос. Количество «5» подобрано эмпирическим путём и считается достаточным для нахождения решения типичных проблем.
Выявленное предпочтение — предпочтение, информация о котором получена в результате наблюдения за поведением экономического агента. Концепция выявленных предпочтений — это один из методов моделирования потребительского поведения в условиях определённости, который был предложен в 1938 году американским экономистом Полом Самуэльсоном. Метод основан на том, что у агентов имеются определённые устойчивые предпочтения, в соответствии с которыми они осуществляют выбор.
Подробнее: Выявленные предпочтения
Задача о разорении игрока — задача из области теории вероятностей. Подробно рассматривалась российским математиком А. Н. Ширяевым в монографии «Вероятность».
Семплирование по Гиббсу — алгоритм для генерации выборки совместного распределения множества случайных величин. Он используется для оценки совместного распределения и для вычисления интегралов методом Монте-Карло. Этот алгоритм является частным случаем алгоритма Метрополиса-Гастингса и назван в честь физика Джозайи Гиббса.
Закон необходимого разнообразия (англ. The Law of Requisite Variety) — кибернетический закон, сформулированный Уильямом Россом Эшби и формально доказанный в работе «Введение в кибернетику».
Нулевая гипотеза — принимаемое по умолчанию предположение о том, что не существует связи между двумя наблюдаемыми событиями, феноменами. Так, нулевая гипотеза считается верной до того момента, пока нельзя доказать обратное. Опровержение нулевой гипотезы, то есть приход к заключению о том, что связь между двумя событиями, феноменами существует, — главная задача современной науки. Статистика как наука даёт чёткие условия, при наступлении которых нулевая гипотеза может быть отвергнута.
В теории информации теорема Шеннона об источнике шифрования (или теорема бесшумного шифрования) устанавливает предел максимального сжатия данных и числовое значение энтропии Шеннона.
Эффе́кт телеско́па — это понятие в когнитивной психологии, означающее временное смещение события, при котором люди воспринимают события, произошедшие недавно более отдаленными, а события, которые случились давно — более близкими. Вначале этот эффект был известен, как «обратный телескоп» (события, являющиеся новыми для определённого периода времени) и уже позже — «прямой телескоп» (события, являющиеся старыми для определённого периода времени). Между «обратным» и «прямым» телескопом существует точка…
Отношение шансов — характеристика, применяемая в математической статистике (на русском обозначается аббревиатурой «ОШ», на английском «OR» от odds ratio) для количественного описания тесноты связи признака А с признаком Б в некоторой статистической популяции.
Игровое заблуждение (англ. Ludic fallacy) — когнитивное искажение, которое выражается как злоупотребление играми и моделями для моделирования реальных ситуаций. Термин введен американским экономистом ливанского происхождения Нассимом Талебом в изданной в 2007 году книге «Чёрный лебедь. Под знаком непредсказуемости». Название ошибки происходит от латинского слова ludus — «игра».
Новостные ценности, также называемые новостными критериями, определяют охват освещения новости средствами массовой информации, а также интерес, проявляемый к новости аудиторией. Новостные ценности не универсальны и могут значительно отличаться в зависимости от культур. На Западе решения о выборе и приоритете тех или иных событий для освещения принимаются редакторами, которые, в свою очередь, опираются на опыт и интуицию. Однако исследования, проведенные Дж. Галтунг и М. Руж показали: существуют факторы…
Реактивное сопротивление — мотивационное состояние, возникающее в ситуации, когда какое-либо внешнее условие (другой человек, предложение, или правило) ограничивает свободу или создает угрозу ограничения проявлений индивида. Главная задача такого поведения — восстановление утраченной или ограниченной свободы.
«Проклятие знания» (англ. curse of knowledge) — одно из когнитивных искажений в мышлении человека (см. их список); термин, предложенный психологом Робином Хогартом для обозначения психологического феномена, заключающегося в том, что более информированным людям чрезвычайно сложно рассматривать какую-либо проблему с точки зрения менее информированных людей.
Алгоритм Петерсона — алгоритм параллельного программирования для взаимного исключения потоков исполнения кода, разработанный Гарри Петерсоном в 1981 г. Хотя изначально был сформулирован для 2-поточного случая, алгоритм может быть обобщён для произвольного количества потоков. Алгоритм условно называется программным, так как не основан на использовании специальных команд процессора для запрета прерываний, блокировки шины памяти и т. д., используются только общие переменные памяти и цикл для ожидания…
Двоичная, бинарная или дихотомическая классификация — это задача классификации элементов заданного множества в две группы (предсказание, какой из групп принадлежит каждый элемент множества) на основе правила классификации. Контекст, в котором требуется решение, имеет ли объект некоторое качественное свойство, некоторые специфичные характеристики или некоторую типичную двоичную классификацию, включает…
Фидуциальный вывод (от лат. fides: вера, доверие), как разновидность статистического вывода, был впервые предложен сэром Р. Э. Фишером.
Мы обманываем сами себя и не замечаем этого. Но искажение информации происходит не специально, таким образом наш мозг помогает нам быстрее адаптироваться и сохранять энергию. Ежедневно мы перерабатываем очень много информации, начиная от погоды за окном до всяких мыслей перед сном. Чтобы не утонуть в потоке данных, наш мозг самостоятельно выбирает важную информацию и отбрасывает ненужную, используя определенные приемы. Благодаря исследованиям ученых были выявлены основные ошибки нашего мышления, которые мы можем самостоятельно исправить.
Эвристика доступности
Наш мозг присваивает любым данным ярлыки, основываясь на уже имеющихся воспоминаниях и знаниях. Работает это так: если возникают определенные воспоминания, то это важно. А обычно мы запоминаем то, что нас тронуло: что-то случилось с близкими, впечатлило путешествие, попробовали необычное блюдо. В итоге всю информацию мы воспринимаем через призму собственного опыта. К примеру, знакомый уехал жить в другой город, устроился на хорошую работу и стал много зарабатывать. И теперь нам кажется, что многие люди в том городе имеют высокие зарплаты и живут лучше.
Ошибка базового процента
Мы обращаем больше внимания на единичные случаи и совсем не воспринимаем статистику в целом. Например, мы узнали, что 5% людей, сделавших прививку от гриппа, все равно заболели. В результате мы будем считать, что прививка малоэффективна, хотя она спасает миллионы людей от болезни. Но наше когнитивное искажение не опирается на статистику.
Отклонение внимания
Мы замечаем то, что нам интересно. И это само по себе логично. Например, девушка интересуется модой и обожает покупать вещи. Она первая заметит, если коллега придет с новой сумочкой на работу. Тот, кто не любит праздники, будет забывать поздравлять окружающих.
Эффект знакомства с объектом
Мы автоматически выбираем тот объект, который покажется нам знакомым. И чем больше мы владеем информацией об объекте, тем сильнее он нам будет нравиться. По этому принципу работает реклама. Когда мы приходим в магазин и видим продукт, о котором мы уже слышали, то у нас возникает больше доверия к нему. Затем мы приобретаем этот продукт несколько раз и не хотим пробовать другой, так как этот уже проверенный.
Эффект контекста
Окружающая обстановка влияет на наше восприятие привычных вещей. Например, читать книги удобнее в тише с хорошим освещением, чем в шумном метро. Или же находясь в красивом ресторане и в приятной атмосфере, мы готовы заплатить больше денег за блюдо, которое могли бы купить в другом месте намного дешевле.
Склонность к негативу
Мы любим преувеличивать значения отрицательных вещей. Поэтому нам так нравятся детективы, документальные фильмы, ток-шоу со скандалами. Часто один неверный поступок человека может перечеркнуть все хорошее, что было до этого. Эта та ложка дегтя, которая в наших глазах портит всю репутацию на корню.
Для того чтобы предотвратить ошибки нашего мышления, необходимо развивать результат-ориентированное мышление. Пройдите прямо сейчас короткий бесплатный онлайн-курс «Личная ответственность за результат: результат-ориентированное мышление», в котором вы узнаете эффективные техники по прокачке своих способностей за короткий срок.