-

-
May 7 2019, 03:35
- IT
- Музыка
- Cancel
Ошибка на единицу
В программировании есть понятие «ошибка на единицу». Так называют не просто ошибку, в результате которой ответ отличается от правильного на единицу, а особую категорию ошибок, вызываемых неправильным учётом первого или последнего элементов набора. Самый характерный пример ошибки на единицу — так называемая ошибка заборного столба. Если вы ставите прямой забор длиной 30 м со столбами через каждые 3 м, то сколько столбов вам необходимо? Очевидный ответ «10» ошибочен: хотя забор состоит из 10 трёхметровых отрезков, число столбов на единицу больше числа отрезков. Правильный ответ — 11 столбов.
Ошибки на единицу очень неприятные, потому что, даже когда учёл их, всегда остаётся лёгкое сомнение в том, что учёл правильно. В нужную ли сторону скомпенсировал? С 5 по 10 число включительно — это сколько дней? А сколько ночей? А не наоборот? Каждый раз приходится останавливаться и думать.
В быту есть множество ситуаций, провоцирующих ошибки на единицу или похожие на них. Больше всего меня раздражает то, как мы говорим о времени суток. Во-первых, мы говорим о ещё не наступившем часе: «пять минут седьмого» означает шесть часов и пять минут, а не семь часов и пять минут. Не забыть применить поправку на единицу, причём в правильную сторону! Во-вторых, мы пишем, к примеру, «17», а говорим «пять», что звучит почти как «пятнадцать». Но нет. Семнадцать — это пять. А пятнадцать — это не семь. И полпятого — это не семнадцать-тридцать, а 16:30.
Очень не люблю договариваться о встрече устно, когда нужно правильно произносить и воспринимать все эти «полпятого». Особенно когда ещё и дата содержит что-нибудь похожее по звучанию, например, «пятница» или «пятое число». В пятницу в четыре или четвёртого числа в пятнадцать часов? Я всегда стараюсь произнести время встречи подробно и однозначно: «в понедельник шестого мая в шестнадцать часов ровно», чтобы минимизировать вероятность ошибки. После того, как договорились устно, у меня есть около десяти секунд, чтобы записать время, иначе я уже не буду уверен, договорился я на четверг в пять или на пятницу в четыре. А ещё есть разные часовые пояса, и разницу между ними нужно тоже применять в правильную сторону — когда надо, прибавлять, а когда надо, отнимать.
А как у вас? Случается ошибаться на единицу, договариваясь о встрече? Бывало ли, что приходили на встречу на час раньше или позже, чем нужно? А не в тот день?
Добавлено 29 мая 2021 в 16:06
Безусловно, наиболее часто используемой инструкцией цикла в C++ является оператор for. Оператор for (также называемый циклом for) предпочтителен, когда у нас есть очевидная переменная цикла, потому что он позволяет нам легко и кратко определять, инициализировать, тестировать и изменять значение переменных цикла.
Начиная с C++11, существует два разных типа циклов for. В этом уроке мы рассмотрим классический оператор for, а новый оператор for на основе диапазона в следующем уроке (10.19 – Циклы for-each), как только рассмотрим некоторые другие необходимые темы, такие как массивы и итераторы.
Оператор for абстрактно выглядит довольно просто:
for (инструкция_инициализации; условие; конечное_выражение)
инструкция;Самый простой способ изначально понять, как работает оператор for, – это преобразовать его в эквивалентный оператор while:
{// обратите внимание на блок здесь
инструкция_инициализации; // используется для определения переменных,
// используемых в цикле
while (условие)
{
инструкция;
конечное_выражение; // используется для изменения переменной цикла перед
// повторным вычислением условия
}
} // переменные, определенные внутри цикла, здесь выходят из области видимостиВычисление операторов for
Оператор for вычисляется в трех частях:
- Сначала выполняется инструкция инициализации. Это происходит только один раз при запуске цикла. Инструкция инициализации обычно используется для определения и инициализации переменных. Эти переменные имеют «область видимости цикла», которая на самом деле является формой области видимости блока, где эти переменные существуют от точки определения до конца инструкции цикла. В нашем эквивалентном цикле
whileвы можете видеть, что инструкция инициализации находится внутри блока, содержащего цикл, поэтому переменные, определенные в инструкции инициализации, выходят за пределы области видимости, когда блок, содержащий цикл, заканчивается. - Во-вторых, для каждой итерации цикла вычисляется условие. Если оно истинно, инструкция выполняется. Если оно принимает значение
false, цикл завершается, и выполнение продолжается со следующей инструкции за пределами цикла. - Наконец, после выполнения инструкции вычисляется конечное выражение. Обычно это выражение используется для увеличения или уменьшения переменных цикла, определенных в инструкции инициализации. После того, как конечное выражение было вычислено, выполнение возвращается ко второму шагу (и условие вычисляется снова).
Давайте посмотрим на пример цикла for и обсудим, как он работает:
#include <iostream>
int main()
{
for (int count{ 1 }; count <= 10; ++count)
std::cout << count << ' ';
return 0;
}Сначала мы объявляем переменную цикла с именем count и инициализируем ее значением 1.
Во-вторых, вычисляется count <= 10, и, поскольку count равно 1, условие вычисляется как true. Следовательно, выполняется инструкция, которая выводит 1 и пробел.
Наконец, вычисляется выражение ++count, которое увеличивает значение count до 2. Затем цикл возвращается ко второму шагу.
Теперь снова вычисляется count <= 10. Поскольку count имеет значение 2, условие вычисляет значение true, поэтому цикл повторяется снова. Инструкция печатает 2 и пробел, и count увеличивается до 3. Цикл продолжает повторяться, пока в конечном итоге count не увеличится до 11, после чего count <= 10 вычисляется как false, и цикл завершается.
Следовательно, эта программа выводит следующий результат:
1 2 3 4 5 6 7 8 9 10В качестве примера давайте преобразуем приведенный выше цикл for в эквивалентный цикл while:
#include <iostream>
int main()
{
{ // блок здесь обеспечивает область видимости блока для count
int count{ 1 }; // наша инструкция инициализации
while (count <= 10) // наше условие
{
std::cout << count << ' '; // наша инструкция
++count; // наше конечное выражение
}
}
}Выглядит не так уж плохо, правда? Обратите внимание, что здесь необходимы внешние фигурные скобки, потому что count выходит за пределы области видимости, когда цикл заканчивается.
Начинающим программистам может быть трудно читать циклы for, однако опытные программисты любят их, потому что они представляют собой очень компактный способ создания циклов со счетчиком со всей необходимой информацией о переменных цикла, условиях цикла и модификаторах счетчиков циклов, представленных заранее в одном месте. Это помогает уменьшить количество ошибок.
Больше примеров циклов
Вот пример функции, которая использует цикл for для вычисления целочисленного возведения в степень:
// возвращает значение base^exponent - берегитесь переполнения!
int pow(int base, int exponent)
{
int total{ 1 };
for (int count{ 0 }; count < exponent; ++count)
total *= base;
return total;
}Эта функция возвращает значение base^exponent (base в степени exponent).
Это цикл for с простым увеличением счетчика на 1, с циклическим увеличением count от 0 до exponent (не включительно).
- Если
exponentравен 0, циклforбудет выполняться 0 раз, и функция вернет 1. - Если
exponentравен 1, циклforвыполнится 1 раз, и функция вернет 1 *base. - Если
exponentравен 2, циклforбудет выполнен 2 раза, и функция вернет 1 *base*base.
Хотя большинство циклов for увеличивают переменную цикла на 1, мы также можем уменьшать ее:
#include <iostream>
int main()
{
for (int count{ 9 }; count >= 0; --count)
std::cout << count << ' ';
return 0;
}Эта программа напечатает следующий результат:
9 8 7 6 5 4 3 2 1 0В качестве альтернативы мы можем с каждой итерацией изменять значение нашей переменной цикла более чем на 1:
#include <iostream>
int main()
{
for (int count{ 9 }; count >= 0; count -= 2)
std::cout << count << ' ';
return 0;
}Эта программа напечатает следующий результат:
9 7 5 3 1Ошибки на единицу
Одна из самых больших проблем, с которыми сталкиваются новички в циклах for (и других циклах, в которых используются счетчики), – это ошибки «на единицу». Ошибки «на единицу» возникают, когда цикл повторяется на один раз больше или на один раз меньше, чем это необходимо.
Например:
#include <iostream>
int main()
{
// упс, мы использовали operator< вместо operator<=
for (unsigned int count{ 1 }; count < 5; ++count)
{
std::cout << count << ' ';
}
return 0;
}Эта программа должна печатать «1 2 3 4 5», но она печатает только «1 2 3 4», потому что мы использовали неправильный оператор отношения.
Хотя наиболее частой причиной этих ошибок является использование неправильного оператора отношения, иногда они могут возникать при использовании префиксного инкремента или префиксного декремента вместо постфиксного инкремента или постфиксного декремента, или наоборот.
Пропущенные выражения
Циклы for можно писать, опуская какие-либо или все инструкции или выражения. Например, в следующем примере мы опустим инструкцию инициализации и конечное выражение, оставив только условие:
#include <iostream>
int main()
{
int count{ 0 };
for ( ; count < 10; ) // нет инструкции инициализации и конечного выражения
{
std::cout << count << ' ';
++count;
}
return 0;
}Этот цикл for дает следующий результат:
0 1 2 3 4 5 6 7 8 9Вместо того чтобы заставлять цикл for выполнять инициализацию и инкремент, мы сделали это вручную. В этом примере мы сделали это исключительно для учебных целей, но бывают случаи, когда необходимо не объявлять переменную цикла (потому что она у вас уже есть) или не инкрементировать ее в конечном выражении (потому что вы увеличиваете ее другим способом).
Хотя вы не часто встретите это, стоит отметить, что следующий пример создает бесконечный цикл:
for (;;)
инструкция;Приведенный выше пример эквивалентен следующему коду:
while (true)
инструкция;Это может показаться немного неожиданным, поскольку вы, вероятно, ожидаете, что пропущенное условное выражение будет обрабатываться как ложное. Однако стандарт C++ явно (и непоследовательно) определяет, что пропущенное условное выражение в цикле for должно рассматриваться как истинное.
Мы рекомендуем полностью избегать этой формы цикла for и вместо нее использовать while (true).
Циклы for с несколькими счетчиками
Хотя циклы for обычно выполняют итерацию только по одной переменной, иногда они должны работать с несколькими переменными. Для этого программист может определить несколько переменных в операторе инициализации, а в конечном выражении может использовать оператор запятой для изменения значений нескольких переменных:
#include <iostream>
int main()
{
for (int x{ 0 }, y{ 9 }; x < 10; ++x, --y)
std::cout << x << ' ' << y << 'n';
return 0;
}Этот цикл определяет и инициализирует две новые переменные: x и y. Он выполняет итерацию по x в диапазоне от 0 до 9, и после каждой итерации x увеличивается, а y уменьшается.
Эта программа дает следующий результат:
0 9
1 8
2 7
3 6
4 5
5 4
6 3
7 2
8 1
9 0Это почти единственное место в C++, где определение нескольких переменных в одном инструкции и использование оператора запятой считается приемлемой практикой.
Лучшая практика
Определение нескольких переменных (в инструкции инициализации) и использование оператора запятой (в конечном выражении) внутри оператора for допустимо.
Вложенные циклы for
Как и другие типы циклов, циклы for могут быть вложены внутрь других циклов. В следующем примере мы вкладываем цикл for внутрь другого цикла for:
#include <iostream>
int main()
{
for (char c{ 'a' }; c <= 'e'; ++c) // внешний цикл для букв
{
std::cout << c; // сначала печатаем нашу букву
for (int i{ 0 }; i < 3; ++i) // внутренний цикл для всех чисел
std::cout << i;
std::cout << 'n';
}
return 0;
}При каждой итерации внешнего цикла внутренний цикл выполняется полностью. Следовательно, на выходе получается:
a012
b012
c012
d012
e012Вот еще несколько подробностей о том, что здесь происходит. Сначала выполняется внешний цикл, и char c инициализируется значением 'a'. Затем вычисляется c <= 'e', что верно, поэтому выполняется тело цикла. Поскольку c установлен в 'a', сначала выводится a. Затем полностью выполняется внутренний цикл (который выводит 0, 1 и 2). Затем печатается символ новой строки. Теперь тело внешнего цикла завершено, поэтому внешний цикл возвращается наверх, c увеличивается до 'b', и условие цикла повторно вычисляется. Поскольку условие цикла по-прежнему выполняется, начинается следующая итерация внешнего цикла. Это напечатает «b012n«. И так далее.
Заключение
Операторы for – это наиболее часто используемый цикл в языке C++. Несмотря на то, что его синтаксис обычно немного сбивает с толку начинающих программистов, вы будете видеть циклы for так часто, что поймете их в кратчайшие сроки!
Операторы for идеально подходят, если у вас есть переменная-счетчик. Если у вас нет счетчика, вероятно, лучше выбрать оператор while.
Лучшая практика
Когда есть очевидная переменная цикла, предпочитайте использовать циклы for вместо циклов while.
Когда нет очевидной переменной цикла, предпочитайте использовать циклы while вместо циклов for.
Небольшой тест
Вопрос 1
Напишите цикл for, который печатает каждое четное число от 0 до 20.
Ответ
for (int count{ 0 }; count <= 20; count += 2) std::cout << count << 'n';
Вопрос 2
Напишите функцию с именем sumTo(), которая принимает целочисленный параметр с именем value и возвращает сумму всех чисел от 1 до value.
Например, sumTo(5) должна вернуть 15, что равно 1 + 2 + 3 + 4 + 5.
Подсказка: при итерации от 1 до входного значения используйте переменную, объявленную вне цикла, для накопления суммы, подобно тому, как в приведенном выше примере pow() используется переменная total для накопления на каждой итерации возвращаемого значения.
Ответ
int sumTo(int value) { int total{ 0 }; for (int count{ 1 }; count <= value; ++count) total += count; return total; }
Вопрос 3
Что не так со следующим циклом for?
// Вывести все числа от 9 до 0
for (unsigned int count{ 9 }; count >= 0; --count)
std::cout << count << ' ';Ответ
Этот цикл
forвыполняется, покаcount >= 0. Другими словами, он выполняется до тех пор, покаcountне станет отрицательной. Однако, поскольку переменнаяcountне имеет знака, она никогда не может стать отрицательной. Следовательно, этот цикл будет работать вечно (ха)! Как правило, рекомендуется избегать использования в циклах беззнаковых переменных без необходимости.
Теги
C++ / CppforLearnCppwhileДля начинающихОбучениеПрограммированиеЦикл
Мы сделали для вас перевод сайта Eat the World, который появился в Сети первого апреля. Его предназначение — объяснить людям, далеким от IT, что такое программирование, через разбор шуток для программистов. Ресурс не только проводит ликбез для «гуманитариев» — начинающим разработчикам он поможет глубже понять суть профессии, а опытным напомнит о всех её прелестях. В любом случае, кем бы вы ни были, вы скорее всего найдёте, над чем посмеяться.
Все шутки располагаются на отдельных страницах и разделены на три основные темы.
Часть I. «Ху из ху» в мире IT
Любое знание стоит воспринимать как подобие семантического дерева: убедитесь в том, что понимаете фундаментальные принципы, то есть ствол и крупные ветки, прежде чем лезть в мелкие листья-детали. Иначе последним не на чем будет держаться.
— Илон Маск
Чем занимаются программисты
— Сколько программистов нужно, чтобы поменять лампочку?
— Ни одного, это проблемы на стороне аппаратного обеспечения.
Программисты занимаются разработкой программного обеспечения. Обслуживание и поддержка правильной работы оборудования — задача системного администратора.
Если вы хорошо знакомы с тяготами жизни IT-специалиста, почитайте нашу шпаргалку по общению с руководством.
Муза любит опаздывать
Руководитель проекта — человек, который думает, что девять женщин могут родить ребёнка за один месяц.
Проектный менеджер головой отвечает за то, чтобы вовремя выпустить продукт. В то время как создание этого продукта — процесс творческий и часто не укладывается в строгие рамки.
Думать вредно
Пользовательский интерфейс как шутка — если тебе приходится давать пояснения, он не так уж хорош.
Пользовательский интерфейс (UI) — это поле взаимодействия пользователя с ПО (например, форма регистрации на сайте). Хорошо спроектированный UI должен быть максимально интуитивным и понятным. Известный специалист Стив Круг говорит, что основной принцип при создании интерфейсов звучит как «не заставляй меня думать».
У нас есть статьи с советами по улучшению интерфейса: часть 1 и часть 2.
Всегда онлайн
Ubuntu — древнее африканское слово, которое означает «я не могу настроить Debian».
Ubuntu и Debian — дистрибутивы Linux, разрабатываемые сообществом Open Source. Ubuntu проще в настройке и использовании, поэтому больше подходит для новичков. Слово «ubuntu» действительно африканское и переводится как «человечность».
Linux-подобными системами часто пользуются системные администраторы при работе с серверами.
Организованная коллекция данных
SQL-запрос заходит в бар, подходит к двум столам и спрашивает: «можно присоединиться?»
Язык запросов SQL (Structured Query Language) используется для создания и модификации баз данных (БД), а также для размещения данных внутри баз и последующего к ним обращения. БД структурированы в виде таблиц, содержащих релевантные данные, которые можно, например, объединить с помощью SQL-запроса.
Предлагаем разобраться в основных моделях баз данных и сравнить популярные системы управления: SQLite, MySQL и PostgreSQL.
Если вы не захотите тестировать продукт, делать это не захотят и ваши пользователи
— Сколько тестировщиков нужно, чтобы поменять лампочку?
— Нисколько, они лишь указали, что в комнате темно. Тестировщики не исправляют проблемы, они их находят.
Роль специалистов по тестированию в процессе разработки состоит в том, чтобы запустить программу в разных средах (браузерах, операционных системах), выявить и локализовать ошибки и баги с целью повысить качество продукта.
Мы начали переводить серию статей про знакомство с фронтенд тестированием, в первой части можно подробнее прочитать про то, что такое тестирование и зачем оно нужно.
Научитесь выбирать слова
SEO-специалист заходит в бар, бары, кабак, вечеринка, отдых, ночной клуб, мини-бар, барный стул, таверна, паб, пиво.
Шутка про специалиста по SEO, который занимается оптимизацией сайта с целью поднять его как можно выше в результатах поиска. Одна из его основных задач — должным образом описать сайт соответственно контенту и определить ключевые слова.
Грамотная поисковая оптимизация определяет часть успеха веб-проекта, но не стоит забывать, что ключ к повышению его эффективности — системный подход. Мы писали об этом ранее.
И это пройдёт
Я буду знать, что конкретно хочу, после того, как это увижу.
Вы можете делать ПО для себя, друзей, компании, на которую работаете, или для своих клиентов в качестве фрилансера. Главное, помните о том, что даже если за время разработки была создана спецификация, близкая к идеальной, единственная вещь, в которой можно быть уверенным — это изменения.
Часть 2. Про будни программиста
Программное обеспечение пожирает мир.
— Марк Андрессен
Первые слова
Начинающий программист заходит в бар, оглядывается и говорит: «Hello, World!»
В книгах и руководствах по программированию распространённая практика — использовать вывод фразы «Hello, World!» для демонстрации базовых концепций языка.
На сайте Hello World Quiz размещена викторина — попробуйте угадать, на каком языке программирования написан скрипт, выводящий привет миру.
Выбор языка программирования
— Тук-тук.
— Кто там?
Очень длинная пауза…
— Java.
Программы, написанные на первых версиях Java, были очень медленными. Одной из главных причин этого была виртуальная машина, тормозящая при выполнении кода.
Есть такое популярное высказывание: «люди не хотят покупать дрель, они хотят дырку в стене». Дрель нужна для того, чтобы выполнить задачу, но главное — какую задачу. То же самое относится к множеству языков программирования.
Популярные ЯП в зависимости от целей разработки:
- веб: Python, PHP, Ruby, JavaScript;
- мобильные приложения под iOS (iPhone, iPad): Objective-C, Swift;
- мобильные приложения под Android: Java;
- операционные системы: C, C++;
- игры: C++.
Код читают не компьютеры, а люди
Когда я это писал, только я и бог знали, что я делаю. Сейчас только бог.
Программисты львиную долю времени проводят, читая код и разбираясь в нём, поэтому важно делать его понятным — как для себя, так и для коллег. Если решение кажется очевидным сейчас, это не значит, что оно останется таким через несколько месяцев или даже недель, тем более для людей, которые придут в проект после вас.
Microsoft делится примером: на Windows XP ещё можно было найти игру «Пинбол 3D», но в более поздние версии она включена не была именно потому, что код не отличался качеством и не сопровождался необходимой документацией. Программисты сами не могли понять, каким образом реализована игра, и в итоге отнять её у пользователей оказалось проще, чем портировать.
Полезные статьи про написание качественного кода: 16 лучших практик, 15 правил, оформление кода на C и на C++, как писать хороший код без обилия комментариев.
От сортировки чисел до искусственного интеллекта
Программист использует слово «алгоритм», когда не хочет объяснять, что он сделал.
Алгоритм — это чёткая инструкция с определённым порядком действий. Результат грамотно реализованного алгоритма всегда будет одним и тем же.
Знание основ по данной теме полезно в любой сфере деятельности. В первую очередь имеет смысл ознакомиться с алгоритмами поиска и сортировки данных — рекомендуем для этого прочитать нашу популярную серию статей для начинающих.
Используйте логику
Муж отправил жену-программиста в магазин и сказал: «возьми батон хлеба. Если там будут яйца, возьми десяток». Жена возвращается с десятью батонами и говорит: «там были яйца».
Ключевое слово в этой шутке — «если…». Оно намекает на оператор if, условную инструкцию, которая присутствует в большинстве языков программирования.
Вот пример алгоритма по завариванию чая с использованием этой инструкции (на естественном языке):
- Если чайник не содержит воды, наполнить чайник.
- Подключить чайник к питанию и включить.
- Если чайник для заварки не пуст, опустошить чайник для заварки.
- Поместить чайные листья в чайник для заварки.
- Если вода в чайнике не кипит, перейти к шагу 5.
- Выключить чайник.
- Налить воду из чайника в чайник для заварки.
Меньше велосипедов
У Чака Норриса есть любимый шаблон проектирования — это «Удар Чака Норриса Ногой с Разворота».
Шаблоны проектирования, или паттерны — проверенные способы решения часто встречающихся проблем. Это не фрагменты кода, которые можно скопипастить в свой проект, а подробное объяснение методов.
Не стоит путать паттерны с алгоритмами: алгоритм предлагает набор инструкций, которые необходимо выполнить в строгом порядке, тогда как паттерн показывает, какой должна быть структура кода для явного описания зависимостей между компонентами.
Зачем тебе два билета в кино, если ты идешь туда один
Оптимист скажет, что стакан наполовину полон, пессимист — что он наполовину пуст. Инженер скажет, что размер стакана в два раза больше, чем нужно.
При создании ПО нужно понимать, на каких девайсах оно будет использоваться, и учитывать ограничения составляющих (в первую очередь CPU — центрального процессора и RAM — оперативной памяти).
Сейчас запоминающие устройства стоят достаточно дёшево, а центральные процессоры отличаются более высокой производительностью в сравнении с теми, которые создавались буквально несколько лет назад. Было посчитано, что сборка iPhone в 1991 году стоила бы порядка $ 3,5 миллионов при стоимости RAM около $ 1,44 миллионов.
Умей работать в команде
Слышал шутку про Git от нескольких человек, и у каждого была своя версия.
Git — популярная система контроля версий (VCS). Одна из возможностей, которые она предоставляет, — хранение локальной копии и создание своей версии репозитория.
Использование VCS обеспечивает удобное взаимодействие между членами команды, а также помогает упорядочить код и другие необходимые материалы. Если вы хотите научиться работать с VCS, прочитайте наше руководство для начинающих и посмотрите подборку из 10 ресурсов для изучения и использования Git.
Среда разработки
Прим. перев. Оригинал с пояснениями
Why programmers like UNIX? unzip, strip, touch, finger, grep, mount, fsck, more, yes, fsck, fsck, fsck, umount, sleep.
UNIX — операционная система, разработанная в Bell Labs в 1969 году. Слова выше — это часть команд, с которыми можно обращаться к ОС. Например, unzip используется для распаковки файлов. Шутка построена на не очень приличной непереводимой игре слов.
Эффективность ОС зависит от технологий, которые используются в конкретном проекте — например, для создания iOS-приложений больше подойдёт macOS. При работе над общим проектом также большое значение имеет выбор интегрированной среды разработки (IDE), системы контроля версий и инструментов для менеджмента (например, Jira).
Как решать проблемы
;
Чемпион по игре в прятки.
Точка с запятой используется в качестве разделителя инструкций во многих языках программирования. Сейчас многофункциональные среды разработки легко обнаруживают его отсутствие, но раньше таких технологий не было, поэтому пропущенный разделитель приходилось искать самостоятельно.
Среду разработки стоит выбирать исходя из используемой технологии — например, для создания iOS-приложений органичным выбором будет XCode. Кроме того, в Сети есть много полезных ресурсов, которые помогут решить возникающие проблемы. Один из самых популярных — Stack Overflow.
Что поставлено на кон
Свинья идёт по дороге. Курица смотрит на неё и говорит: «А давай откроем ресторан!» Свинья смотрит на курицу и отвечает: «Хорошая идея, и как ты хочешь его назвать?» Курица думает и говорит: «Почему бы не назвать „Яичница с беконом“?». «Так не пойдёт, — отвечает свинья, — ведь тогда мне придётся полностью посвятить себя проекту, а ты будешь вовлечена только частично».
Как объясняет Википедия, по методике Scrum в производственном процессе есть определённые роли, разбитые на 2 группы «свиней» и «кур». Свиньи от начала до конца создают продукт, тогда как куры в нём заинтересованы, но им в целом всё равно, будет проект удачным или нет — на них это мало отразится. Требования, пожелания, идеи и влияние кур принимаются во внимание, но им не разрешают непосредственно включаться в ход скрам-проекта.
К «свиньям» относятся владелец продукта (Product Owner), скрам-мастер (Scrum Master) и команда разработки (Development Team). Дополнительные роли «кур» занимают пользователи (Users), клиенты и продавцы (Stakeholders), управляющие (Managers) и эксперты-консультанты (Consulting Experts).
Мудрость толпы
Блондинка, алкоголик и инопланетянин заходят в бар, но это бар Microsoft, поэтому он закрыт.
В 90-х и начале 2000-х Microsoft была закрытой компанией и, как многие крупные корпорации, строго охраняла секреты разработки. В противовес такому подходу появилось движение Open Source, адепты которого создают проекты с открытым исходным кодом.
Сейчас ситуация меняется и Microsoft создаёт некоторые проекты под флагом открытой разработки. Другие крупные компании тоже поддерживают движение — одним из самых активных участников является Google, которая недавно собрала все свои open source проекты под одной http-крышей.
Такой подход имеет положительные стороны не только для пользователей и сторонних разработчиков, но и для самих корпораций: в дополнение к штатным сотрудникам они получают сотни и тысячи волонтёров по всему миру, вовлечённых в создание продукта. Это ускоряет процессы нахождения багов, добавления новых фич и выпуска свежих версий.
У нас есть серия подборок с лучшими проектами, в которых стоит поучаствовать, чтобы примкнуть к движению Open Source: на JavaScript, Java и C#, C и C++, Python.
Главное — не терять голову
Люди делятся на два типа: «я делаю бэкапы» и «я сделаю бэкапы».
Бэкап — это резервное копирование данных, которое в аварийном случае может помочь восстановить ПО. Делать бэкапы — очень хорошая практика.
Совсем недавно сисадмин GitLab случайно удалил 300 ГБ данных, восстановление которых стало возможным благодаря бэкапу, созданному вручную примерно за 6 часов до инцидента. При этом оказалось, что при автоматическом сохранении данных ранее постоянно срабатывала ошибка, но об этом никто не знал.
Чтобы не терять ценные данные, создавайте бэкапы как можно чаще и проверяйте, что система сохранения работает корректно.
Часть 3. Про эти ваши компуктеры
Компьютеры бесполезны. Они могут только давать ответы.
— Пабло Пикассо
Как мы общаемся с компьютерами
На свете существует 10 типов людей: те, кто понимает двоичную систему счисления, и те, кто не понимает.
Классическая бородатая шутка. В двоичной системе есть всего две цифры: 0 и 1. Число 10 — это двоичное представление десятичного числа 2, поэтому в шутке выше упомянуты два типа людей.
Использование бинарного кода — основа компьютерных вычислений, притом очень эффективная. Состояния 0 и 1 могут быть выражены через пониженное и повышенное напряжение.
Представление информации
Прим. перев. Оригинал с пояснениями
A guy walks into a bar and asks for 1.4 root beers. The bartender says «I’ll have to charge you extra, that’s a root beer float».
The guy says «In that case, better make it a double».
Компьютеры используют бинарный код для хранения в памяти потока нулей и единиц. Задача программиста — объяснить машине, как этот поток интерпретировать. К примеру, код 1000001 может хранить букву А или целое число 65.
Попробуем разобраться в шутке. И float, и double — формы представления данных «с плавающей точкой», они используются в компьютере для хранения дробных чисел. Парень заходит в бар и просит налить 1,4 корневого пива (root beer). Бармен ему говорит, что возьмёт с него больше денег, так как он просит шипучку (root beer float). «Тогда лучше налейте двойную порцию (double)» — отвечает парень.
Тип double часто является лучшим выбором в сравнении с float, так как он обеспечивает большую точность (но и занимает больше памяти). Чтобы больше узнать о типах данных, прочитайте нашу статью про статическую и динамическую типизацию.
Ты для меня всегда будешь на первом месте
В компьютерных науках есть две сложности: инвалидация кэша, именование и ошибка на единицу.
Ошибка на единицу, или ошибка неучтённой единицы (off-by-one error) часто встречается, когда программист ошибается, отсчитывая начало последовательности с единицы, как это обычно делают люди. Проблема в том, что индексация массивов во многих языках программирования начинается с нуля, как в шутке выше: 0, 1, 2.
Здесь обыграна известная цитата Фила Карлтона: «В компьютерных науках есть две сложности: инвалидация кэша и именование» («There are only two hard things in Computer Science: cache invalidation and naming things»).
Знай концепции, которые используешь
— Существует ли объектно-ориентированный способ стать богатым?
— Да, наследование.
В 1994 году Стив Джобс давал интервью журналу The Rolling Stone.
Джефф Гуделл: Объясните, пожалуйста, что такое объектно-ориентированный подход, используя простые термины.
Стив Джобс: Объекты похожи на людей. Они живые, дышащие сущности, которые обладают памятью и знаниями о том, как нужно действовать. И вместо того, чтобы взаимодействовать с ними на низком уровне, мы взаимодействуем с ними на очень высоком уровне абстракции.
Например, если для вас я объект-прачка, вы можете передать мне грязную одежду вместе с сообщением «постирай, пожалуйста, мою одежду». Я знаю, где в Сан-Франциско лучшая прачечная. Я говорю по-английски, в карманах у меня доллары. Я выхожу на улицу, ловлю такси и говорю таксисту, чтобы он отвёз меня в нужное место. Я стираю вещи, снова сажусь в такси и возвращаюсь. Я отдаю вам чистую одежду с сообщением: «вот ваша чистая одежда».
Вы понятия не имеете, как и какие шаги я проделал. Вы не знаете о том, что существует прачечная. Возможно, вы говорите по-французски и вы не можете поймать такси — вам нечем за него заплатить, долларов у вас нет. Тем не менее, я знал, как всё это сделать. А вам нет необходимости это знать. Вся комплексность была во мне запрятана, и мы смогли взаимодействовать на высоком уровне абстракции. В этом суть объектов — они сочетают в себе инкапсуляцию структурной сложности и высокоуровневый интерфейс.
Подробнее о принципах ООП можно прочитать в нашей вводной статье.
Рекурсия
Возможно, вы имели в виду: рекурсия.
Если ввести в поиске Google запрос «рекурсия», он взамен предложит вам вывести результаты по тому же самому запросу. Это не ошибка, а шутка, обыгрывающая понятие: рекурсия определяет функцию, которая способна вызывать сама себя.
В поисках соответствий
Вопрос: что одно регулярное выражение говорит другому?
Ответ: .+
Регулярные выражения (Regular Expressions, RegExp) — это формальный язык, который используется для работы с подстроками: с помощью него можно осуществлять, например, поиск и проверку на соответствие шаблону.
Шаблон .+ означает «что угодно», а точнее «любой символ (.) один или более раз (+)».
Новичкам предлагаем прочитать вводную статью по регулярным выражениям.
Кто стоит на защите данных
Заходит хеш-сумма в бар и говорит: «Будьте добры соль».
Одно из базовых правил безопасности — не хранить пароли в незашифрованном виде.
Хеш-сумма (хеш, хеш-код) — это строка фиксированной длины (чаще всего в шестнадцатеричном представлении), в которую преобразовывается текстовый пароль. Например, 7DD987F846400079F4B03C058365A4869047B4A0. Хеши хранятся в базе данных. Имея в распоряжении только хеш, злоумышленник практически никогда не может воспроизвести пароль, установленный пользователем. Хеши используются для идентификации, поиска данных и проверки их на целостность.
Соль — дополнительный параметр, который добавляется к паролю и обеспечивает безопасность генерируемого хеша.
Преодолевая языковой барьер
Прим. перев. Оригинал с пояснениями
Q: According to Sigmund Freud, what comes between fear and sex?
A: Fünf.
Шутка используется для демонстрации лингвистических различий, таких, как специфичные для определенного языка буквы.
В наши дни при создании ПО в подавляющем большинстве случаев нужно ориентироваться на клиентов по всему миру, следовательно, делать его доступным на нескольких языках. Кодировки обычно создаются под конкретный язык или группу языков. Например, Windows-1250 используется для представления текстов, написанных на языках Центральной Европы. Хорошей практикой является использование кодировок, покрывающих большее количество символов, алфавитов и иконок — например, UTF-8.
Предлагаем пройти тест, чтобы узнать, какой язык программирования вам подходит, и начать его изучать 🙂
Источник: Eat the World
Содержание
- 1 Безопасное программирование
- 1.1 Буферы
- 1.1.1 Вычисление размера буфера
- 1.1.2 Определение длины
- 1.1.3 Ошибка на единицу
- 1.1.4 Управляющие символы
- 1.2 Обход каталогов
- 1.3 Форматируемая строка
- 1.4 Длины
- 1.5 Данные из сети
- 1.6 Вызовы функций
- 1.7 Файлы
- 1.1 Буферы
Безопасное программирование
Наиболее рапространённые ошибки при программировании:
Большинство ошибок при программировании, приводящих к уязвимостям в безопасности системы, связаны с предположениями о вероятном поведении кода или данных. Надеемся, что после прочтения этой краткой статьи вы будете более осторожны.
Буферы
Одной из самых распространённых атак является переполнение буфера. Если вы устанавливаете определённую фиксированную длину буфера, а злоумышленнику каким-либо образом удалось вставить в него большее количество данных, то такой код уязвим, т.е.:
char buff[10]; strcpy(buff, user_supplied_data);
Вычисление размера буфера
- Может ли атака вызвать появление в буфере паразитных нулей, что приведет к тому, что strlen выдаст неверное значение?
- Помните: strlen возвращает длину строки без терминального нуля в size_t.
- Помните: sizeof возвращает длину буфера в байтах.
Не полагайтесь на размеры.
Определение длины
Различные функции определяют длину различными способами (в этом примере n это число байт, заданное в аргументах), например:
- strncat добавляет до n байт и присоединяет нуль.
- snprintf добавляет до n-1 байт и присоединяет нуль.
- strncpy обнуляет все байты, а затем добавляет до n байт.
Проверьте описания функций!
Ошибка на единицу
Крайне распространённая ошибка, возникает тогда, когда программист запутался между размером буфера, размером данных и отсчётом от нуля.
- Буфер с размером n имеет индекс от 0 до n-1:
char buffer[10]; buffer[10] = 0x61; /* выход за пределы буфера! */
- Буфер с размером n имеет n-1 свободного места для данных:
char buffer[10]; strcpy(buffer, "EXPLOIT123"); /* теперь буфер не нуль-терминирован */
Буфер с размером MAX_PATH может сохранить MAX_PATH-1 символов.
Управляющие символы
Может ли злоумышленник вставить подстановочные символы в обрабатываемые данные? Наиболее распространёнными примерами являются ‘n’ ‘%s’ ‘%i’ и ».
Обход каталогов
При соединении строк обязательно избавляйтесь от ‘../’ ‘..\’:
buffer1 = "C:\SomeDirectory\Somewhere\"; buffer2 = "..\..\ReactOS\System32\"; strcat(buffer1, buffer2); /* Теперь buffer1 = "C:\SomeDirectory\Somewhere\..\..\ReactOS\System32\" = "C:\ReactOS\System32\" */
Форматируемая строка
Это такая строка, где первый параметр (формат) printf-подобной функции задаётся пользователем.
printf(foo); */ неверно */
printf("%s", foo); */ верно */
Длины
При подсчёте длин, их значения должны быть беззнаковыми (unsigned int, а не int). Беззнаковые числа могут привести к переполнению и переходу через ноль. Числа со знаком могут быть переполнены так, что приобретут отрицательное значение. Распространённая ошибка, которая создаст проблемы при использовании переменных со знаком:
if (length < maxlength) {...}
Отрицательная длина, переданная ‘безопасной’ строковой функции (strncpy) обычно отменяет проверку.
Данные из сети
Данные, полученные из сети, обычно должны быть прочитаны в байтовые массивы, а не в символьные. Символы по умолчанию имеют знак, а это не то, чего хотелось бы.
Вызовы функций
Работа далеко не всех функций заканчивается успешно, проверяйте значения, возвращаемые вашими функцииями! (Это делается во всей кодовой базе).
Файлы
- Если вы хотите открыть файл, на который впоследствии будете полагаться, откройте его с эксклюзивными флагами.
| Переводы блогов |
|---|
| Monstera • Безопасное программирование • Интеллектуальная собственность: Идеология vs Практичность • Интеллектуальная собственность: Основы • Об ОС для настольных компьютеров… • Перспектива: Microsoft и игры • Перспектива: Разработчики вне экосистемы Microsoft • Перспектива: Разработчики и Microsoft • Сценарии использования ReactOS • Цена прогресса |
Пять знаменитых цитат о программировании с объяснениями
Время прочтения
8 мин
Просмотры 13K

Стать программистом значит подписаться на обучение длиной в жизнь. Поток нового – новые функции, новые языки, новые инструменты, новые фреймворки – не иссякает никогда. Но вместе с тем, программирование – на удивление верная традициям сфера, где все основывается на принципах, проверенных временем. Мы ввели в оборот объектно-ориентированное программирование, современные аппаратные решения, искусственный интеллект, однако, несмотря на все эти изменения, многие аксиомы, которые были сформулированы еще в прошлом поколении, оказываются верными и на сегодняшний день.
Эту статью я посвятил разбору нескольких из своих любимых высказываний, касающихся программирования. Единственным критерием, по которому я производил отбор, было требование, чтобы цитате сравнялось не менее двадцати лет. Потому что это только устаревшие технологии быстро становятся непригодными к использованию, тогда как древние заповеди наших предков-программистов долго сохраняют актуальность.
1. О косвенности
«Все проблемы в программировании решаются путём создания дополнительного уровня косвенности» — Дэвид Виллер
Вот вам цитата из книги Computer Science Theory and Application, которую все любят повторять и мало кто любит объяснять. Тем не менее, это одна из моих любимых программерских истин – она метко раскрывает саму суть программирования.
Самый простой способ осмыслить косвенность – представить себе слои. Ну например, представим себе, что у вас есть небольшой проект, в рамках которого нужно поместить компонент А внутрь компонента В:
Оба компонента стандартизированы, так что разобрать их на составляющие и поменять принцип работы не получится. Вы могли бы создать отдельный дополнительный компонент (PlugTwoProngVariant), но это и куча работы, и ненужное дублирование. Есть выход лучше: добавить между этими двумя компонентами слой-адаптер, который успешно взаимодействовал бы с обоими и служил бы между ними посредником.
При все при этом, если бы косвенность исчерпывалась добавлением дополнительных слоев между компонентами, которые иначе не состыкуешь, она была бы, конечно, полезна, но весьма ограничена в применении. Но сама идея того, чтобы решать проблемы, меняя окружение проблемных мест, пронизывает все программирование сверху донизу. Вы сталкиваетесь с ней, когда пытаетесь приладить новую модель данных к старому интерфейсу. Вы сталкиваетесь с ней, когда пытаетесь приладить приложение с legacy-кодом к бэкенду нового веб-сервиса. Вы сталкиваетесь с ней, когда нужно добавить несколько новых высокоуровневых функций вроде логирования и кэширования или скоординировать работу нескольких высокоуровневых сервисов вроде отправки сообщений и проведения транзакций. На самой же вершине этой пирамиды вы приходите к уточенным направлениям вроде машинного обучения (если не можете сами прописать нужное поведение, добавьте еще один слой кода, который решит эту проблему за вас).
Многие скажут вам, что смысл программирования состоит в том, чтобы писать ясные инструкции на языке, который поймет даже самый тупой компьютер. Но цитата Дэвида Виллера предлагает более глубокий взгляд на вопрос. Быть хорошим программистом – значит подниматься по лестнице косвенности, стремясь к самым общим решениям.
Бонусная цитата в тему
Косвенность – мощный инструмент, но за сложность приходится платить. Люди редко приводят то высказывание, которое следует сразу после знаменитой цитаты:
«Обычно это создает новую проблему» — Дэвид Виллер.
Именно благодаря этой истине программисты с давних пор остаются при делах.
2. О простоте
«Простота – предпосылка надежности» — Эдсгер Дейкстра
В мудрых программистах, которые предостерегают нас от усложнения кода без острой необходимости, недостатка нет. Но немногим удалось так явно показать, чем чревата для нас сложность, как пионеру в компьютерных науках Эдсгеру Дейкстра.
Вот в чем тут соль: вы делаете выбор в пользу простоты не просто из желания сделать приятное людям будущего. И не потому что предполагаете возможность повторно использовать этот код в дальнейшем. И не потому что хотите, чтобы он аккуратнее смотрелся на инспекции, и не потому что стремитесь облегчить процесс внесения изменений в будущем (хотя все это, разумеется, ценные преимущества). Вы поступаете так потому, что простота – это предпосылка. Без нее у вас никогда не будет надежного кода, которому можно доверить ведение бизнеса или работу с данными.
Чтобы принять позицию Дейкстра, нам нужно изменить свое понимание того, что такое «хороший код». Это не обязательно самый лаконичный код, или самый быстродействующий, и уж точно не самый заумный. Хороший код – это код, на который можно положиться.
Бонусная цитата в тему
Один из наилучших способов сохранять простоту в коде – помнить, что меньше значит больше. Дейкстра предлагает новую единицу измерения, которая все время будет нам об этом напоминать:
«Если мы хотим подсчитать количество строк кода, следует воспринимать их не как написанные, а как потраченные» — Эдсгер Дейкстра
3. О читабельности и переписывании
«Код сложнее читать, чем писать» — Джоэль Спольски
На первый взгляд, эта цитата Джоэля Спольски, легенды программирования и сооснователя Stack Overflow, кажется разумной, но обманчиво поверхностной. Да, фрагменты кода бывают информационно насыщенными, излишне сжатыми или утомительно длинными. И это относится не только к тому, что писали другие люди. Если вы посмотрите на свои собственные прошлогодние труды, вам понадобится какое-то время, чтобы воссоздать логику, которую вы когда-то знали от и до.
Но наблюдение Спольски разворачивается в нечто интересное. Опасность кода, который с трудом читается, состоит не только в самых очевидных последствиях (его тяжело корректировать и совершенствовать). Есть и другая, большая опасность: сложный для восприятия код кажется хуже, чем есть на самом деле. Фактически, разбираться в чужом коде может показаться такой непосильной задачей, что у вас возникнет искушение совершить то, что Спольски называет грубейшей из всех ошибок – переписать все заново.
Я не говорю, что архитектура системы никогда не выигрывает от подобных переписываний. Разумеется, бывает, что и выигрывает. Но улучшение такого рода дорого обходится. Во всем, что касается тестирования и устранения багов – а это две составляющие разработки, которые отнимают больше времени, чем собственно написание кода – вы возвращаетесь на исходную позицию. Переписывание выглядит заманчиво, потому что укладывается в одно из самых распространенных заблуждений разработчиков – склонность недооценивать трудозатраты на концептуально простые вещи. Именно поэтому 50% времени уходит на заключительные 5% проекта. Элементарные задачи могут отнимать на удивление много времени! А решение проблемы, которую уже решал в прошлом, всегда выглядит проще простого.
Ладно, если переписывать все с нуля, чтобы довести код до совершенства, не следует, то какие есть более удачные альтернативы? Ответ: привлечь каждого разработчика к процессу непрерывного фрагментарного рефакторинга. Так ваш код совершенствуется постоянно, за счет цепочки небольших изменений – реальная выгода с минимальными рисками. Читабельность можно повышать по ходу дела.
Бонусная цитата в тему
Если вы все еще сомневаетесь в важности читабельности, Мартин Фаулер поможет взглянуть на проблему шире:
«Любой дурак может писать код, который будет понятен компьютерам. Хорошие программисты пишут код, который будет понятен людям» — Мартин Фаулер
Иными словами, задача программиста – выдать не просто рабочий код, но код с внутренней логикой.
4. О повторениях
«Не повторяйтесь. Каждый фрагмент знания должен иметь единственное, однозначное, надежное представление в системе» — Энди Хант и Дэвид Томас
Каждый уважающий себя программист знает, что в повторении кроется множество бед. Если вы прописываете одно и то же в нескольких местах, вам приходится больше сил тратить на тестирование и устранение багов. Хуже того, вы создаете условия для возникновения разночтений; например, один фрагмент кода могут впоследствии обновить, а прочие сопутствующие процедуры – не привести в соответствие. Программа с разночтениями – это программа, которой нельзя доверять, а программа, которой нельзя доверять, не может считаться жизнеспособным решением.

Этого бага можно было бы избежать с методом GetTeamUniform()
Однако повторы сеют хаос не только в коде. Данная версия хорошо всем известного принципа DRY (Don’t Repeat Yourself / Не потворяйтесь) толкует принцип устранения дубликатов расширительно, охватывая и другие места, куда могут пробраться повторы. Сейчас разговор идет уже не о дубликатах в коде – мы говорим в том числе и о повторах в масштабах всей системы. А системы кодируют знания в различных форматах. В частности это:
- Операторы
- Комментарии к коду
- Документация для разработчиков или клиентов
- Схемы данных (например, таблицы базы данных)
- Прочие спецификации – планы тестирования, документы по организации процессов, правила сборки
Все эти группы могут пересекаться по своему содержимому. И когда это происходит, возникает риск того, что они начнут транслировать разные версии одной реальности. Скажем, как быть, если в документации описана одна модель работы, а само приложение следует другой? Что в этом случае считать держателем истины? А что если таблицы в базе данных не соответствуют модели данных из кода? Или если комментарии к коду описывают операцию или алгоритм, которые в корне отличаются от реальной имплементации? Каждая система нуждается в единственном надежном представлении, на которое опирается всё остальное.
Кстати говоря, не следует думать, что конфликты между претендентами на истину случаются только в небольших проектах или являются следствием низкого качества кода. Один из самых лучших примеров, который полыхнул у всех на виду – битва между XHTML и HTML5. Одна сторона утверждала, что спецификации – это и есть официальная правильная версия, а браузеры должны под нее подстроиться. Другой лагерь возражал, что именно поведение браузеров должно считаться стандартом де-факто – ведь именно так проектировщики всё себе и представляли, когда писали веб-страницы. В конечном итоге, победила та версия истины, которую продвигали браузеры. С тех пор HTML5 – это то, что браузеры реально делают, включая допустимые короткие пути и ошибки.
Бонусная цитата в тему
Возможность того, что код и комментарии к нему вступят в противоречие друг с другом, породила оживленные дискуссии: чего вообще больше от комментариев – пользы или вреда? Сторонники экстремального программирования относятся к ним с откровенным недоверием.
«Код никогда не лжет, а вот с комментариями такое случается» — Рон Джеффрис
5. О сложных проблемах
«В компьютерных науках есть только две сложные проблемы – аннулирование кэша и придумывание названий» — Фил Карлтон
С виду эта цитата кажется просто программисткой шуткой, забавной, но ничем не выделяющейся из прочих. Каждый может прочувствовать контраст между чем-то, что звучит как сложная задача (аннулирование кэша), и чем-то, что звучит как сущий пустяк (придумывание названий). Любой программист хоть раз убивал целые часы на какую-нибудь до смешного мелкую проблему – два параметра, проставленных не в том порядке, переменную, которая где-то с большой буквы, а где-то нет (спасибо, JavaScript!). Пока людям для достижения своих целей приходится работать совместно с компьютерами, программирование всегда будет представлять собой смесь высокоуровневого системного планирования и дурацких опечаток.
Но если вчитаться в слова Фила Картона повнимательнее, мы обнаружим здесь больше простора для размышлений. Придумывать названия сложно не просто потому, что из таких маленьких головных болей у программиста то и дело вся жизнь идет кувырком. Дело тут еще и в том, что названия – это одна из граней основной задачи программиста, проектирования программ. Иными словами, как вообще пишется ясный, аккуратный и непротиворечивый код?
Существует много разновидностей плохих названий. Все мы встречались с переменными, которые нарекли в честь типов данных (myString, obj), сокращений (pc, то есть product catalog), какой-нибудь незначительной детали имплементации (swappable_name, formUserInput) или же вообще оставили безымянными (ret_value, tempArray). Легко попасться в ловушку и назвать переменную исходя из того, что вы сейчас с ней делаете, а не из ее содержимого. А со значениями логических типов данных вообще беда: что подразумевает progress – что прогресс уже начался, что нужно отобразить информацию о прогрессе в интерфейсе или вообще что-то третье?

Источник: CommitStrip.com
Перевод
«results_tmp_2? Это что еще за?.. Ты что, весь мир ненавидишь? Нельзя так называть переменные!» — «Ну, мне нужно было на время сохранить результаты запроса… И я уже один раз так делал, вот и получается results_tmp_2. Стараюсь не пренебрегать семантикой»
Но названия переменных – это еще только начало. Когда вы начинаете придумывать имена классам, встает вопрос о том, как разбивать код на независимые части. Названия публичных членов определяют, каково будет представление интерфейса, с помощью которого разные части приложения будут взаимодействовать между собой. Закрепляя за фрагментом кода название, вы не просто описываете, что он может делать – вы устанавливаете, что он будет делать.
Бонусная цитата в тему
«В компьютерных науках есть только две сложные проблемы – аннулирование кэша, придумывание названий и ошибка на единицу» — Леон Бамбрик

Здравствуйте, уважаемые коллеги форекс-программисты!
В сегодняшнем уроке, по вашим просьбам, мы подробно разберём работу с массивами и циклами посредством языка MQL4.
Циклы служат для многократного повторения какого-то участка кода, а массивы – для хранения неограниченного количества структур данных с их последующей обработкой в цикле.
Начнём с циклов. Поскольку обращение к элементам массива, как правило, осуществляется с использованием циклов, то научимся сначала работать с ними, а потом перейдем к массивам.
MQL4 программирование — Массивы и циклы
Циклы
Цикл while

Синтаксис цикла while в MQL4 имеет следующий вид:
while (<условие>)
{
<тело цикла>;
}
Тело цикла в данном случае будет выполняться, пока истинно условие в круглых скобках. Если это условие на момент выполнения цикла окажется ложным, то тело цикла не выполнится ни одного раза. В качестве примера выведем в журнал терминала целые числа от 1 до 5, каждое с новой строки. Код будет выглядеть так:
int i = 1;
while (i <= 5)
{
Print( i );
i++;
}
Исходя из условий задачи, мы сначала определили целочисленную переменную i и присвоили ей значение 1. В операторе цикла while проверяем, меньше или равно 5 значение переменной i. Если да, то выполняется тело цикла: значение печатается в журнал и увеличивается на единицу. После первой итерации в журнал выведено число «1», а значение переменной i равно двум. Спустя несколько итераций переменная i стала равна шести, условие i<=5 ложно. Следовательно, тело цикла выполняться больше не будет.
Цикл for

Этот вид цикла работает аналогично уже рассмотренному while. Здесь тело цикла выполняется, пока некое условие истинно. Однако в самом операторе можно задать действия, которые совершаются до начала цикла (например, инициализировать переменную-счётчик), а также после выполнения каждой итерации (увеличение или уменьшение счётчика). Такой вид цикла предназначен прежде всего для ситуаций, когда нам заранее известно число итераций. Синтаксис цикла for в языке MQL4 таков:
for(выражение1; выражение2; выражение3)
{
<тело цикла>;
}
- выражение1 – инициализация цикла, как правило, это объявление и инициализация счётчика итераций;
- выражение2 – условие продолжения цикла, пока оно истинно, тело цикла выполняется;
- выражение3 – выражение, вычисляемое после каждой итерации, обычно здесь происходит изменение счётчика итераций.
Рассмотрим цикл for на следующем примере: найдём сумму целых чисел от 1 до 1000.
int sum=0; // переменная для суммы чисел
for(int i=1; i<=1000; i++)
sum+=i; // прибавляем к текущему значению суммы очередное число
Print("Сумма чисел от 1 до 100: ",i);
Мы объявили переменную sum для записи в неё текущей суммы чисел и проинициализировали её нулевым значением.
В операторе for переменная i выступает в качестве счётчика итераций. Мы объявили и проинициализировали её начальным значением «1». Нам требуется, чтобы цикл выполнялся 1000 раз, то есть пока переменная i меньше или равна 1000. Условие продолжения цикла примет вид i<=1000. После каждой итерации нам надо увеличить счётчик на единицу. Запишем через точку с запятой i++.
Тело цикла представляет всего один оператор sum+=i, что эквивалентно записи sum=sum+i. Поэтому операторные скобки «{ }» здесь не нужны. В теле цикла значение переменной sum увеличивается на значение переменной i, в которой на текущей итерации содержится очередное число от 1 до 1000. В итоге после тысячи выполнений тела цикла переменная sum будет содержать сумму всех целых чисел от 1 до 1000.
Любое из трех или все выражения в операторе for(выражение1; выражение2; выражение3) могут отсутствовать. Нельзя опускать только разделяющие выражения точки с запятыми, то есть в записи всегда должны быть оба символа «;». Например, запись for(;;) представляет собой бесконечный цикл. Выражение1 и выражение3 могут состоять из нескольких выражений, объединенных оператором запятая «,».
Решим такую задачу. Напечатаем в журнал числа от 1 до 5 и от 5 до 1 одновременно в одном цикле. При этом тело цикла должно состоять только из одного вызова функции Print().
for(int i=1, j=5; i<=5; i++, j--)
Print(i," ",j);
Как видите, тело цикла выполняется 5 раз, при этом переменная i изменяется от 1 до 5, а переменная j от 5 до 1. Результат выполнения выглядит следующим образом:
5 1 4 2 3 3 2 4 1 5
Заметьте, что наряду с инкрементом, то есть увеличением переменной i на единицу, здесь мы использовали и декремент, то есть уменьшали на единицу переменную j.
Запишем вывод в цикле пяти целых чисел от 1 до 5 в журнал следующим образом:
int n=1;
for(;n<=5;)
{
Print(n);
n++;
}
Здесь мы объявили переменную-счётчик до оператора цикла, а её инкрементацию поместили в тело цикла.
Счётчик в цикле for может увеличиваться или уменьшаться на любое значение, а не только на единицу. Тем самым можно реализовать цикл с шагом. Выведем, например, в журнал все нечётные числа от 1 до 10. Для этого будем увеличивать счётчик после каждой итерации на 2, начиная с единицы:
for(int i=1; i<=10; i+=2) Print(i);
В данном случае переменная-счётчик последовательно примет значения 1, 3, 5, 7, 9, 11, а в журнал выведет 1, 3, 5, 7, 9.
Цикл do while

Как отмечалось ранее, если условие продолжения цикла c предусловием (while) изначально ложно, то тело цикла не выполнится ни разу. Однако есть задачи, которые требуют выполнения цикла по крайней мере однократно. Для этих целей существует цикл, тело которого выполнится хотя бы один раз независимо от условия. Синтаксис цикла do while или, как его еще называют, цикл с постусловием в MQL4 имеет следующий вид:
do
{
<тело цикла>;
}
while (<условие>);
Выполним ту же задачу с выводом целых чисел от 1 до 5 с помощью цикла do while:
int i=1;
do
{
Print(i);
i++;
}
while(i<=5);
Сначала мы объявили переменную-счётчик i и инициализировали её значением 1 согласно условию задачи. Затем сразу выполнилось тело цикла. В журнал было выведено значение переменной i, которое на тот момент было равно единице, следом значение переменной i увеличилось на единицу, а уже потом состоялась проверка условия i<=5. Так как 2 меньше 5, то цикл продолжился, пока значение переменной i не стало равняться шести. Обратите внимание, что инкремент счётчика в теле цикла мы производим после вывода его значения в журнал. Если мы будем делать это до вывода в журнал, то нам необходимо уменьшить начальное значение счётчика и изменить условие. В этом случае цикл будет выглядеть так:
int i=0;
do
{
i++;
Print(i);
}
while(i<5);
Любопытно, что в языке MQL4 операцию инкремента можно выполнять прямо в вызове функции, при этом надо помнить, что постфиксный инкремент (i++) увеличивает значение переменной на единицу сразу после использования этой переменной в выражении, а префиксный инкремент (++i) увеличивает значение переменной на единицу непосредственно перед использованием этой переменной в выражении. Теперь наши примеры можно записать компактнее:
int i=1; do Print(i++); while(i<=5);
Здесь функция Print() выводит в журнал значение переменной i, а следом происходит увеличение i на единицу (инкремент):
int i=0; do Print(++i); while(i<5);
При вызове функции Print() сначала происходит увеличение переменной i на единицу, а потом значение i выводится в журнал.
Разберём пример посложнее. Напишем советник, который после прикрепления его к графику начинает обрабатывать поступающие тики не сразу, а спустя какое-то время, заданное нами в секундах. При этом советник должен сообщать с помощью комментария на графике, сколько секунд осталось до его запуска. Очевидно, что такую задержку надо поместить внутрь обработчика OnInit(), так как эта функция выполняется при инициализации советника.
//+------------------------------------------------------------------+
//| Expert initialization function |
//+------------------------------------------------------------------+
int OnInit()
{
uint begin=GetTickCount(),// запоминаем значение функции GetTickCount()
passed_seconds, // прошло секунд
pause=10; // пауза в секундах
Comment(""); // очищаем комментарий на графике, выводя пустую строку
do
{
passed_seconds=(GetTickCount()-begin)/1000;// прошло секунд со старта
Comment("Советник начнёт работу через:",pause-passed_seconds);
}
while(passed_seconds<pause);// тело цикла выполняется пока количество
// прошедших секунд меньше паузы в секундах
Comment(""); // очищаем комментарий на графике, выводя пустую строку
return(INIT_SUCCEEDED);
}
В данном коде мы реализовали задержку с выводом оставшегося до запуска времени в секундах при помощи цикла do while. Функция GetTickCount() возвращает количество миллисекунд, прошедших с момента старта системы. Мы использовали её для вычисления количества прошедших и оставшихся секунд.
Операторы break и continue

Операторы break и continue могут использоваться в теле цикла любого типа.
С помощью оператора break можно немедленно прервать выполнение тела цикла без каких-либо дополнительных условий. Управление при этом передаётся первому следующему за циклом оператору. Рассмотрим такую реализацию знакомой нам задачи вывода целых чисел от 1 до 5 в журнал терминала:
int i=1;
while(true)
{
Print(i);
i++;
if(i>5) break;
}
Здесь мы имеем бесконечный цикл while, так как условие в круглых скобках всегда истинно. В теле цикла осуществляется вывод в журнал текущего значения переменной i и её инкрементация. Как только значение i станет равным шести, оператор break прервёт выполнение цикла. Тут стоит сделать одно важное замечание. Если цикл предполагает большое число итераций или была допущена ошибка, из-за которой цикл стал бесконечным, программа может не отвечать, «зависнуть». Чтобы избежать такой ситуации, в условие продолжения цикла добавляют вызов функции IsStopped(), которая возвращает истину (true), если от терминала поступила команда завершить выполнение mql4-программы (например, была нажата кнопка «Стоп» при работе в тестере). Учитывая это, наш пример будет правильнее записать так:
while(!IsStopped)
{
Print(i);
i++;
if(i>5) break;
}
Это всё тот же бесконечный цикл, но выполняется он, пока не будет прерван оператором break или пока не поступит команда от терминала на завершение программы.
Надо заметить, что язык MQL4 позволяет прерывать цикл внутри функции еще и оператором return. Например:
void PrintNumber()
{
int i=1;
while(!IsStopped)
{
Print(i);
i++;
if(i>5) return;
}
}
В данном случае оператор return прервёт цикл и передаст управление в то место программы, откуда была вызвана функция PrintNumber().
Оператор continue прерывает текущую итерацию цикла и начинает новую. Все операторы в теле цикла, идущие за оператором continue, не будут выполнены. Для иллюстрации работы оператора немного модифицируем нашу задачу с выводом в журнал целых чисел от 1 до 5. Выведем все числа, кроме 2.
for(int i=1; i<=5; i++)
{
if(i==2) continue;
Print(i);
}
1 2 3 4 5
Вывод числа «2» будет пропущен.
Оператор continue удобно применять, если тело цикла довольно большое. Можно не усложнять конструкции ветвления внутри цикла, а сразу пропустить все последующие операторы и перейти к новой итерации.
Массивы

Массивы присутствуют практически во всех языках программирования, и MQL4 не стал исключением. По сути, массив – это совокупность переменных одного типа с одним именем, но при этом каждая переменная имеет свой уникальный номер. Например, нам нужны три целочисленные переменные. Мы можем объявить их следующим образом:
В таком случае к каждой переменной можно обращаться по её уникальному имени. Например, присвоим переменным какие-то значения:
Var1=35; Var2=8; Var3=21;
С другой стороны, переменные можно задать как массив из трёх элементов:
Обращаться же к этим переменным следует по их общему имени и номеру в массиве:
Var[0]=35;
Var[1]=8;
Var[2]=21;Номер переменной в массиве называют индексом (от латинского index – указательный палец). При объявлении массива в квадратных скобках указывается его размер (количество элементов), а при обращении к переменной – индекс элемента.
Обратите внимание, что нумерация элементов в массиве начинается с нуля, а не с единицы. Это обстоятельство часто служит причиной ошибок и вызывает вопросы, особенно у начинающих программистов. Массив, как и обычная переменная, – это область памяти, имеющая своё начало – адрес. В случае с массивами доступ к каждому элементу по индексу задаётся как смещение от начала. Тогда адрес первого элемента совпадает с адресом всего массива, то есть смещение равно нулю. Адрес второго элемента – это адрес первого плюс одно смещение на размер первого элемента. Адрес второго – это два смещения и т. д.
Статические и динамические массивы

Размер статических массивов устанавливается на этапе компиляции и больше в ходе выполнения программы не меняется. Пример объявления статического массива:
Здесь мы объявили массив из десяти целочисленных элементов, память под которые выделит компилятор.
Массивы, размер которых можно изменять в процессе выполнения программы, называются динамическими. Вместе с изменением размера массива память либо выделяется, либо освобождается динамически. Пример объявления динамического массива:
Получается, если в квадратных скобках не указан размер массива, то он будет объявлен как динамический. В данном случае мы объявили динамический массив целочисленных элементов. Чтобы использовать массив, надо задать его размер с помощью функции ArrayResize():
Теперь массив Array состоит из 10 элементов с индексами от 0 до 9.
У данной функции есть третий необязательный параметр reserve_size. С помощью него можно задать размер массива «с запасом». Например, первый вызов функции в виде ArrayResize(Array, 10, 1000) увеличит размер массива до 10 элементов, но физически память под массив будет выделена, как если бы он содержал 1010 элементов. То есть память под 1000 элементов оказывается в резерве. Теперь при увеличении или уменьшении размера массива в пределах 1010 элементов физического распределения памяти не будет. Если же размер увеличить, скажем, до 1011, то выделится еще 1000 резервных элементов, и так далее. Поскольку физическое распределение памяти – процесс достаточно медленный, то в случае, если предполагается частое изменение размера массива в программе, третий параметр функции ArrayResize() будет весьма полезен.
В языке MQL4 все элементы массива инициализируются при его объявлении нулевым значением: для числовых массивов – это ноль, для строковых – пустая строка, для массива логических значений – это false. Однако есть ситуации, когда массив надо проинициализировать определёнными значениями. Для статических массивов это можно сделать в момент объявления массива следующим образом:
int Numbers[5] = {3, 21, 72, 1, 8};
Здесь каждому из пяти элементов с индексами от 0 до 4 присваиваются по порядку значения в фигурных скобках. Можно проинициализировать схожим образом все элементы массива одним значением:
Все пять элементов массива примут значение 82.
Динамические массивы инициализировать таким образом нельзя. Даже если вы объявите массив:
int Numbers[] = {3, 21, 72, 1, 8};
то компилятор определит его как статический и автоматически установит размер по количеству значений в фигурных скобках.
Чтобы инициализировать динамический массив, можно использовать функции ArrayInitialize() или ArrayFill(). Первая заполняет указанным значением весь массив, вторая может заполнить только часть массива. Но таким образом можно инициализировать или заполнить лишь массивы простых типов, массив, например, строк придётся заполнять в цикле, перебирая все элементы по индексу и присваивая каждому нужное значение. Как это сделать, поговорим в следующем разделе.
Использование циклов при работе с массивами

Поскольку элементы массива последовательно пронумерованы, то обработку массивов удобно вести с использованием циклов: производить действия над всеми элементами массива или его частями, искать элемент с нужными характеристиками, упорядочивать элементы внутри массива по какому-то критерию. Наиболее часто встречающаяся операция, применяемая к массиву – это перебор в цикле его значений, которую называют итерацией по массиву.
Решим задачу.
Имеется список слов: память, машина, пицца, вода, ножницы, кот, батарейка, удочка, гром, стол, флаг, телефон, зонт, документ. Необходимо найти все слова, длина которых больше пяти символов, и вывести в журнал все эти слова, а также общее количество таких слов.
Для обработки слов создадим массив строк и запишем слова в него:
string Words[]={"машина", "пицца", "вода", "ножницы", "кот", "батарейка", "удочка", "гром", "стол", "флаг", "телефон", "зонт", "документ"};
int size=ArraySize(Words);
int n=0;
for(int i=0; i<size; i++)
{
if(StringLen(Words[i])>5)
{
Print(Words[i]);
n++;
}
}
if(n>0) Print("Количество слов, длина которых больше пяти: ",n);
В этом примере нам понадобилась дополнительная переменная size, в которую мы поместили найденный с помощью функции ArraySize() размер массива. Было бы нерационально на каждой итерации вызывать функцию, чтобы сравнить полученное значение со счётчиком. Хотя в данном случае неважно, в каком направлении обходить элементы массива. Поэтому можно обойтись и без дополнительной переменной, обходя массив в обратном порядке:
int n=0;
for(int i=ArraySize(Words)-1; i>=0; i--)
if(StringLen(Words[i])>5)
{
Print(Words[i]);
n++;
}
if(n>0) Print("Количество слов, длина которых больше пяти: ",n);
Следующая задача: удалить элемент с указанным индексом из динамического массива целых чисел.
double Array[]; // подготовим массив для демонстрации работы алгоритма
int size=21; // зададим ему размер в 21 элемент
int removed_element=17; // индекс удаляемого элемента
Print("Новый Размер:", ArrayResize(Array,size));
for(int i=0; i<size; i++) // заполним массив числами от 100, до 120
Array[i]=i+100.0;
if(removed_element<size) // индекс удаляемого элемента не выходит за пределы массива
{
Print("Будет удалён элемент с индексом ", removed_element,", имеющий значение ", Array[removed_element]);
for(int i=removed_element+1; i<size; i++) // сдвинем все элементы за удаляемым влево на один
Array[i-1]=Array[i];
size=ArrayResize(Array,size-1); // уменьшим размер массива на единицу, тем самым отсечём ненужный последний элемент
Print("Новый размер массива: ", size);
for(int i=size-1; i>=0; i--) // выведем в журнал все элементы массива
{
Print("Array[",i,"]=",Array[i]);
}
}
else
Print("Индекс удаляемого элемента находится за пределами массива");
Передача массива в функцию

Массивы можно передавать в функции только по ссылке, то есть в функцию передаётся только адрес существующего массива, а не его копия. Функция не может вернуть и сам массив. Она только производит действия над массивом в целом или над его отдельными элементами. Таким образом, если аргумент функции представляет собой массив, то перед его именем необходимо писать знак «&» (амперсанд), как знак того, что аргумент передаётся по ссылке, а после имени – пустые квадратные скобки «[]», указывающие на то, что аргумент представляет из себя массив.
Давайте решим предыдущую задачу с использованием функции, которая будет удалять из переданного по ссылке массива элемент с указанным индексом.
double Array[]; // подготовим массив для демонстрации работы нашей будущей функции
int size=21;
ArrayResize(Array,size);
for(int i=0; i<size; i++) // заполним массив числами от 100, до 120
Array[i]=i+100.0;
if( RemoveFromArray(Array, 17) )
for(int i=ArraySize(Array)-1; i>=0; i--) // выведем в журнал все элементы массива
Print("Array[",i,"]=",Array[i]);
Напишем функцию, которая будет удалять указанный элемент.
//+------------------------------------------------------------------+
//| Удаляет элемент динамического массива с указанным индексом |
//| и возвращает "true", если удаление прошло удачно, в противном |
//| случае возвращает false |
//+------------------------------------------------------------------+
bool RemoveFromArray(double &array[], int index)
{
int size=ArraySize(array);
if(index<size) // индекс удаляемого элемента не выходит за пределы массива
{
for(int i=index+1; i<size; i++) // сдвинем все элементы за удаляемым влево на один
array[i-1]=array[i];
size=ArrayResize(array,size-1); // уменьшим размер массива на единицу, тем самым отсечём ненужный последний элемент
return(true); // возвратим истину, так как удаление прошло успешно
}
else
{
Print("Индекс удаляемого элемента находится за пределами массива");
return(false);// возвратим ложь, так как удаление прошло неудачно
}
}
Если по каким-то причинам вы не хотите изменять исходный массив, а все действия собираетесь производить с копией массива, то можно воспользоваться функцией ArrayCopy(), которая копирует содержимое одного массива в другой. Массив-приёмник, естественно, должен быть объявлен и иметь тот же тип, что массив-источник. В связи с тем, что операция копирования занимает какое-то время, старайтесь использовать эту функцию, когда это действительно необходимо в рамках вашей задачи.
Многомерные массивы

Массивы, в которых каждый элемент имеет один индекс, называются одномерными. До этого мы рассматривали только одномерные массивы. Если же каждый элемент массива имеет более одного индекса – то мы имеем дело с многомерным массивом.
Запись вида:
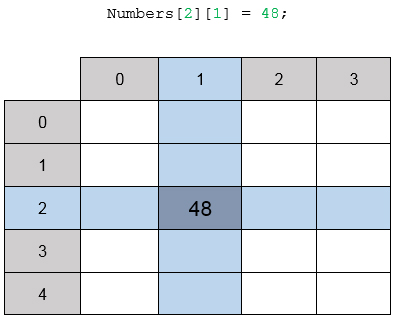
объявляет двумерный массив или, другими словами, массив пяти массивов по четыре элемента. Визуально двумерный массив можно представить как таблицу, в данном случае из пяти строк и четырёх столбцов. Элементы двумерного массива можно представить как ячейки таблицы. Строка и столбец, на пересечении которых располагается ячейка – это индексы элемента массива. Например, выражение Numbers[2][1]=48 можно интерпретировать так: в ячейку таблицы на третьей строке во втором столбце записали число «48» (помним, что индексация в каждом измерении массива начинается с нуля).
Так как у каждого элемента массива Numbers два индекса, то перебор всех его значений надо осуществлять с помощью двух циклов, причём один будет вложен в другой. Например, следующий код присваивает всем элементам массива значение «10», кроме элемента Numbers[2][1], которому присваивается значение «48»:
for(int i=0; i<5; i++)
for(int j=0; j<4; j++)
{
if(i==2 && j==1)
Numbers[i][j]=48;
else
Numbers[i][j]=10;
}
Язык MQL4 поддерживает не более четырёх измерений у массива:
double Prices[8][2][5] // пример трёхмерного массива double Levels[4][3][1][6] // четырёхмерный массив
Многомерные массивы также могут быть статическими или динамическими. Важной особенностью многомерных динамических массивов в MQL4 является тот факт, что они могут быть динамическими только в первом измерении, все следующие измерения являются статическими, и их размер должен быть явно указан при объявлении массива.
double Prices[][2][5]; // правильноe объявление трёхмерного динамического массива double Prices[][][5]; // неправильное объявление
Отсюда следует, что с помощью функции ArrayResize() можно менять только размер первого измерения массива:
double Prices[][2][5]; int new_size = ArrayResize(Prices,10);
Надо учитывать, что в этом случае функция ArrayResize() вернёт общий размер элементов массива, то есть new_size станет равным 100 (10*2*5).
На практике большинство задач, с которыми вам придётся столкнуться, вряд ли потребует использования массивов, размерность которых превышает 2. Двумерные динамические массивы, например, хорошо подходят для обработки табличных данных, поэтому встречаются намного чаще, чем другие многомерные массивы. Однако иногда требуется, чтобы была возможность изменять размер двумерного массива в обоих измерениях. Например, в процессе выполнения программы нам может понадобиться массив Numbers[Rows][Columns], где Rows и Columns – это переменные, но мы можем задать с помощью переменной только размер первого измерения. Обойти это ограничение можно с помощью простого трюка: свернуть оба измерения массива в одно. То есть объявить одномерный динамический массив и установить его размер равным произведению Rows*Columns, а второе измерение определять с помощью простой формулы row*Columns+column, где row и column – координаты ячейки в «виртуальной таблице», а Columns – это размер второго измерения (количество столбцов).
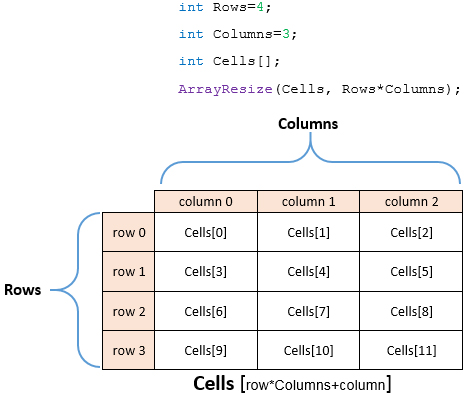
Для того, чтобы было удобнее использовать одномерный динамический массив в качестве двумерного, напишем «обёртку» в виде структуры, в которой будем хранить и сам массив, и его свойства, а также методы для обращения к элементам массива с помощью двух индексов.
struct int2DArray
{
private:
int rows; // количество строк
int columns; // количество столбцов
int Values[]; // одномерный динамический массив
int GetIndex(int row, int col) {return(row*columns+col);}; // возвращает индекс ячейки в массиве
public:
int Create(int row, int col); // устанавливает массиву размер, необходимый для хранения ячеек
int Get(int row, int col) {return(Values[GetIndex(row,col)]);}; // возвращает содержимое ячейки (row,col)
void Set(int row, int col, int value) {Values[GetIndex(row,col)]=value;}; // записывает значение в ячейку (row,col)
int AddRows(int amount); // добавляет строку к двумерному массиву
int Rows() {return(rows);}; // возвращает число строк в массиве
int Columns() {return(columns);}; // возвращает число строк в массиве
};
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
int int2DArray::Create(int row, int col)
{
int size=row*col;
if(size<=0)
return(EMPTY);
rows=row;
columns=col;
ArrayFree(Values);
ArrayResize(Values,size);
ArrayInitialize(Values,0);
return(size);
}
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
int int2DArray::AddRows(int amount)
{
int new_size=ArrayResize(Values,ArraySize(Values)+amount*columns);
rows+=amount;
return(new_size);
}
//+------------------------------------------------------------------+
//| Expert initialization function |
//+------------------------------------------------------------------+
int OnInit()
{
// Объявим переменную структуры:
int2DArray Array;
// Зададим размер массива в 10 строк и 5 столбцов:
int size=Array.Create(10,5);
// Все ячейки проинициализированы нулевым значением, а их общее количество - пятьдесят:
Print("Размер массива=",size);
// Заполним ячейки (0;3), (5;0), (8;4) какими-то ненулевыми значениями
Array.Set(0,3,9);
Array.Set(5,0,18);
Array.Set(8,4,3);
// Убедимся в том, что заполнились именно те ячейки, индексы которых мы указали в методе Set:
for(int i=0; i<Array.Rows(); i++)
for(int j=0; j<Array.Columns(); j++)
{
PrintFormat("Array[%d,%d]=%d",i,j,Array.Get(i,j));
}
// Добавим 2 строки в "массив". Так как общее число столбцов у нас пять, то физически в конец одномерного массива добавятся 2*5=10 элементов.
Array.AddRows(2);
// Заполним ячейки (10;3), (11;4) какими-то ненулевыми значениями
Array.Set(10,3,4);
Array.Set(11,4,31);
// Убедимся в том, что заполнились именно те ячейки, индексы которых мы указали в методе Set:
for(int i=0; i<Array.Rows(); i++)
for(int j=0; j<Array.Columns(); j++)
{
PrintFormat("Array[%d,%d]=%d",i,j,Array.Get(i,j));
}
return(INIT_SUCCEEDED);
}
Подобные структуры можно написать и для массивов других типов. Универсальную структуру, подходящую для использования массивов любого типа, к сожалению, создать не получится.
«Ошибка на единицу»

Одна из самых распространённых ошибок при работе с циклами for и другими, если они используют счётчик – это так называемая «ошибка неучтённой единицы» или «ошибка на единицу». Возникает она из-за неправильного использования операторов сравнения. Например, цикл
for(int i=1; i<=5; i++)
Print(i);
выполнится 5 раз, а цикл
for(int i=1; i<5; i++) Print(i);
будет выполнен всего 4 раза. Во втором случае при значении 5 переменной i условие i<5 будет ложным, значит, тело цикла при этом значении выполнено не будет. Важно помнить, что цикл выполняется только тогда, когда условие его продолжения истинно. «Ошибка неучтённой единицы» наибольшую опасность представляет в контексте работы с массивами. Так как индексация элементов массива начинается с нуля, то индекс последнего элемента на единицу меньше размера самого массива. Если из-за «неучтённой единицы» цикл итерации по массиву выполнится на один раз больше требуемого, то программа прекратит работу из-за критической ошибки. Произойдёт так называемый «выход за пределы массива»:
int Numbers[]; int size=ArrayResize(Numbers,100); for(int i=0; i<=size; i++) // необходимо использовать строгое условие i<size Print(Numbers[i]);
Здесь переменная size равна размеру массива, то есть 100. На последней итерации цикла счётчик i примет значение 100, но элемента с таким индексом в массиве нет, последний имеет индекс 99. Поэтому условие продолжения цикла должно быть строгим – i<size.
Быстрая сортировка составных данных с помощью массива ссылок

Рассмотрим интересный пример использования массивов для построения индексов в стиле базы данных. В арсенале языка MQL4 имеется функция ArraySort() для сортировки числовых массивов по первому измерению. Отсортировать, скажем, массив структур или объектов по какому-то числовому элементу с помощью функции ArraySort() нельзя. Казалось бы, единственный выход – писать функцию сортировки с физическим обменом местами элементов массива структур. Но можно создать двумерный динамический числовой массив, в который достаточно скопировать нужные значения для сортировки, и индекс элементов, которым принадлежат эти данные в массиве-источнике. Отсортировав такой массив по первому измерению, мы можем потом обращаться к нужному элементу в массиве-источнике через индекс во втором измерении. Физической сортировки массива-источника не произойдёт. Давайте рассмотрим подобную сортировку на конкретном примере. Только мы будем сортировать не какой-то массив структур, а информацию об открытых ордерах, даже не копируя её в массив.
Определим критерии сортировки в виде перечисления:
enum field
{
fOrderOpenTime, // Время открытия
fOrderType, // Тип
fOrderLots, // Объём
fOrderOpenPrice, // Цена открытия
fOrderStopLoss, // S/L
fOrderTakeProfit, // T/P
fOrderCommission, // Комиссия
fOrderSwap, // Своп
fOrderProfit // Прибыль
};
Напишем функцию, которая строит индекс по переданному критерию сортировки:
//+------------------------------------------------------------------+
//| |
//+------------------------------------------------------------------+
void BuildIndex(field criterion, int &out[])
{
double Index[][2];
int size=OrdersTotal(); // общее количество ордеров
ArrayResize(Index,size);
for(int i=size-1; i>=0; i--) // перебор всех ордеров
if(OrderSelect(i,SELECT_BY_POS,MODE_TRADES))
{
Index[i][1]=OrderTicket();
switch(criterion)
{
case fOrderOpenTime:
Index[i][0]=double(OrderOpenTime());
break;
case fOrderType:
Index[i][0]=OrderType();
break;
case fOrderLots:
Index[i][0]=OrderLots();
break;
case fOrderOpenPrice:
Index[i][0]=OrderOpenPrice();
break;
case fOrderStopLoss:
Index[i][0]=OrderStopLoss();
break;
case fOrderTakeProfit:
Index[i][0]=OrderTakeProfit();
break;
case fOrderCommission:
Index[i][0]=OrderCommission();
break;
case fOrderSwap:
Index[i][0]=OrderSwap();
break;
case fOrderProfit:
Index[i][0]=OrderProfit();
break;
}
}
ArraySort(Index);// сортируем по первому измерению
ArrayResize(out,size);
// копируем тикеты в переданный массив в отсортированном порядке
for(int i=0; i<size; i++)
out[i]=int(Index[i][1]);
}
//+------------------------------------------------------------------+
//| Expert initialization function |
//+------------------------------------------------------------------+
int OnInit()
{
/* Перед вызовом функции надо объявить массив, в который функция поместит ссылки на ордера в отсортированном порядке. Очевидно, что в качестве таких ссылок будут использованы тикеты,– уникальные идентификаторы ордеров. */
int Tickets[];
/* Вызываем функцию. В качестве критерия указываем прибыль ордера, то есть сортировку будем производить по текущей прибыли ордеров от наименьшей к наибольшей: */
BuildIndex(fOrderProfit, Tickets);
// Выведем в журнал информацию об открытых ордерах, отсортированную по прибыли.
// перебираем массив тикетов
for(int i = ArraySize(Tickets) -1; i>=0; i--)
{
// выбираем ордер с указанным тикетом
if(OrderSelect(Tickets[i],SELECT_BY_TICKET))
{
int digits=int(SymbolInfoInteger(OrderSymbol(),SYMBOL_DIGITS));
// формируем и выводим в журнал строку с информацией по выбранному ордеру
Print(OrderTicket()," | ",
TimeToString(OrderOpenTime())," | ",
(OrderType()==OP_BUY)?"buy":"sell"," | ",
DoubleToStr(OrderLots(),2)," | ",
OrderSymbol()," | ",
DoubleToStr(OrderOpenPrice(),digits)," | ",
DoubleToStr(OrderStopLoss(),digits)," | ",
DoubleToStr(OrderTakeProfit(),digits)," | ",
DoubleToStr(OrderCommission(),2)," | ",
DoubleToStr(OrderSwap(),2)," | ",
DoubleToStr(OrderProfit(),2));
}
}
return(INIT_SUCCEEDED);
}
Фрагмент журнала с результатами работы:
Крайнее правое число после разделителя – это текущая прибыль ордера. Как видите, строки отсортированы именно по этому значению.
Заключение

В этом уроке мы рассмотрели использование циклов при работе с массивами. Заодно вспомнили и закрепили основные сведения о самих массивах и циклах, изучили особенности их реализации в языке MQL4, разобрали типичные примеры и приёмы программирования массивов и циклов.
Тема на форуме
С уважением, Юрий Лосев aka lsv107
Tlap.com

Ошибка на единицу
-
Ошибка на единицу или ошибка неучтённой единицы (англ. off-by-one error) — логическая ошибка в алгоритме, включающая в частности дискретный вариант нарушения граничных условий.
Ошибка часто встречается в программировании, когда количество итераций пошагового цикла оказывается на единицу меньше или больше необходимого. Например, программист при сравнении указывает «меньше или равно», вместо «меньше», или ошибается, отсчитывая начало последовательности не с нуля, а с единицы (индексация массивов во многих языках программирования начинается с нуля).
Источник: Википедия
Связанные понятия
В математике деление на два, деление пополам — это математическая операция, частный случай деления. Древние египтяне отличали деление на два от деления на другие числа, поскольку их алгоритм умножения использовал деление на два как один из промежуточных этапов. В XVI веке некоторые математики предложили рассматривать деление на два как операцию, отличающуюся от деления на другие числа. В современном программировании также иногда выделяют деление именно на два.
Денормализованные числа (англ. denormalized numbers) или субнормальные числа (англ. subnormal numbers) — вид чисел с плавающей запятой, определённый в стандарте IEEE 754. При записи в форматах float, double, long double их экспонента будет записана как 0. Для получения их значения не требуется использование неявной единицы; мантисса просто умножается на наименьшую для данного формата экспоненту.
Строковое ядро — это ядерная функция, определённая на строках, т.е. конечных последовательностях символов, которые не обязательно имеют одну и ту же длину. Строковые ядра можно интуитивно понимать как функции, измеряющие похожесть пар строк — чем больше похожи две строки a и b, тем больше значение строкового ядра K(a, b).
Удаление общих подвыражений (англ. Common subexpression elimination или CSE) — оптимизация компилятора, которая ищет в программе вычисления, выполняемые более одного раза на рассматриваемом участке, и удаляет вторую и последующие одинаковые операции, если это возможно и эффективно. Данная оптимизация требует проведения анализа потока данных для нахождения избыточных вычислений и практически всегда улучшает время выполнения программы в случае применения.
Таблица поиска (англ. lookup table) — это структура данных, обычно массив или ассоциативный массив, используемая с целью заменить вычисления на операцию простого поиска. Увеличение скорости может быть значительным, так как получить данные из памяти зачастую быстрее, чем выполнить трудоёмкие вычисления.
Двоичный алгоритм поиска подстроки (также bitap algorithm, shift-or algorithm) — алгоритм поиска подстроки, использующий тот факт, что в современных компьютерах битовый сдвиг и побитовое ИЛИ являются атомарными операциями. По сути, это примитивный алгоритм поиска с небольшой оптимизацией, благодаря которой за одну операцию производится до 32 сравнений одновременно (или до 64, в зависимости от разрядности машины). Легко переделывается на приблизительный поиск.
Би́товое поле (англ. bit field) в программировании — некоторое количество бит, расположенных последовательно в памяти, значение которых процессор не способен прочитать из-за особенностей аппаратной реализации.
Цифрово́й компара́тор или компара́тор ко́дов логическое устройство с двумя словарными входами, на которые подаются два разных двоичных слова равной в битах длины и обычно с тремя двоичными выходами, на которые выдаётся признак сравнения входных слов, — первое слово больше второго, меньше или слова равны. При этом выходы «больше», «меньше» имеют смысл, если входные слова кодируют числа в том или ином машинном представлении.
Универса́льное хеши́рование (англ. Universal hashing) — это вид хеширования, при котором используется не одна конкретная хеш-функция, а происходит выбор из заданного семейства по случайному алгоритму. Такой подход обеспечивает равномерное хеширование: для очередного ключа вероятности помещения его в любую ячейку совпадают. Известно несколько семейств универсальных хеш-функций, которые имеют многочисленные применения в информатике, в частности в хеш-таблицах, вероятностных алгоритмах и криптографии…
Обратный код (англ. ones’ complement) — метод вычислительной математики, позволяющий вычесть одно число из другого, используя только операцию сложения над натуральными числами. Ранее метод использовался в механических калькуляторах (арифмометрах). Многие ранние компьютеры, включая CDC 6600, LINC, PDP-1 и UNIVAC 1107, использовали обратный код. Большинство современных компьютеров используют дополнительный код.
Нуль-терминированная строка или C-строка (от названия языка Си) или ASCIIZ-строка — способ представления строк в языках программирования, при котором вместо введения специального строкового типа используется массив символов, а концом строки считается первый встретившийся специальный нуль-символ (NUL из кода ASCII, со значением 0).
Прямой код — способ представления двоичных чисел с фиксированной запятой в компьютерной арифметике. Главным образом используется для записи неотрицательных чисел. В случае использования прямого кода для чисел как положительных, так и отрицательных, то есть чисел, запись которых подразумевает возможность использования знака минус (знаковых чисел), хранимые цифровые разряды числа дополняются знаковым разрядом.
Вариативный шаблон или шаблон с переменным числом аргументов в программировании — шаблон с заранее неизвестным числом аргументов, которые формируют один или несколько так называемых пакетов параметров.
Структурированная обработка исключений (англ. SEH — Structured Exception Handling) — механизм обработки программных и аппаратных исключений в операционной системе Microsoft Windows, позволяющий программистам контролировать обработку исключений, а также являющийся отладочным средством.
Оптимизация запросов — это 1) функция СУБД, осуществляющая поиск оптимального плана выполнения запросов из всех возможных для заданного запроса, 2) процесс изменения запроса и/или структуры БД с целью уменьшения использования вычислительных ресурсов при выполнении запроса. Один и тот же результат может быть получен СУБД различными способами (планами выполнения запросов), которые могут существенно отличаться как по затратам ресурсов, так и по времени выполнения. Задача оптимизации заключается в нахождении…
Таблица — это совокупность связанных данных, хранящихся в структурированном виде в базе данных. Она состоит из столбцов и строк.
Код Хэ́мминга — вероятно, наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Построен применительно к двоичной системе счисления. Позволяет исправлять одиночную ошибку (ошибка в одном бите) и находить двойную.
Сравне́ние в программировании — общее название ряда операций над па́рами значений одного типа, реализующих математические отношения равенства и порядка. В языках высокого уровня такие операции, чаще всего, возвращают булево значение («истина» или «ложь»).
Символьный тип (Сhar) — тип данных, предназначенный для хранения одного символа (управляющего или печатного) в определённой кодировке. Может являться как однобайтовым (для стандартной таблицы символов), так и многобайтовым (к примеру, для Юникода). Основным применением является обращение к отдельным знакам строки.
Компромисс времени и памяти (англ. Space-time trade-off, «выбор оптимального соотношения „место-время“» (англ. space-time trade-off), или, иначе, «выбор оптимального соотношения „время-память“» (англ. time-memory trade-off)) — компромиссный подход к решению ряда задач в информатике, при котором используется обратное соотношение требуемого объёма памяти и скорости выполнения программы: время вычислений может быть увеличено за счёт уменьшения используемой памяти или, наоборот, снижено за счёт увеличения…
Поточный алгоритм (англ. streaming algorithm) — алгоритм для обработки последовательности данных в один или малое число проходов.
Тест на следующий бит (англ. next-bit test) — тест, служащий для проверки генераторов псевдо-случайных чисел на криптостойкость. Тест гласит, что не должно существовать полиномиального алгоритма, который, зная первые k битов случайной последовательности, сможет предсказать k+1 бит с вероятностью, неравной ½.
Дополнительный код (англ. two’s complement, иногда twos-complement) — наиболее распространённый способ представления отрицательных целых чисел в компьютерах. Он позволяет заменить операцию вычитания на операцию сложения и сделать операции сложения и вычитания одинаковыми для знаковых и беззнаковых чисел, чем упрощает архитектуру ЭВМ. В англоязычной литературе обратный код называют первым дополнением, а дополнительный код называют вторым дополнением.
Каламбур типизации является прямым нарушением типобезопасности. Традиционно возможность построить каламбур типизации связывается со слабой типизацией, но и некоторые сильно типизированные языки или их реализации предоставляют такие возможности (как правило, используя в связанных с ними идентификаторах слова unsafe или unchecked). Сторонники типобезопасности утверждают, что «необходимость» каламбуров типизации является мифом.
Блочный код — в информатике тип канального кодирования. Он увеличивает избыточность сообщения так, чтобы в приёмнике можно было расшифровать его с минимальной (теоретически нулевой) погрешностью, при условии, что скорость передачи информации (количество передаваемой информации в битах в секунду) не превысила бы канальную производительность.
Динамическим называется массив, размер которого может изменяться во время исполнения программы. Возможность изменения размера отличает динамический массив от статического, размер которого задаётся на момент компиляции программы. Для изменения размера динамического массива язык программирования, поддерживающий такие массивы, должен предоставлять встроенную функцию или оператор. Динамические массивы дают возможность более гибкой работы с данными, так как позволяют не прогнозировать хранимые объёмы…
Циклическая база данных (англ. Round-robin Database, RRD) — база данных, объём хранимых данных которой не меняется со временем, поскольку количество записей постоянно, в процессе сохранения данных они используются циклически. Как правило, используется для хранения информации, которая перезаписывается через равные интервалы времени.
Гистогра́мма в математической статистике — это функция, приближающая плотность вероятности некоторого распределения, построенная на основе выборки из него.
Сумматор с сохранением переноса (англ. carry-save adder) — является видом цифровых сумматоров, используемых в компьютерной микроархитектуре для вычисления суммы трёх или более n-битных чисел в двоичной системе счисления. Он отличается от других цифровых сумматоров тем, что его выходные два числа той же размерности, что и входные, одно из которых является частной суммой битов, а другое является последовательностью битов переноса.
Поиск клонов в исходном коде — анализ исходного кода с помощью различных алгоритмов, с целью обнаружения клонированного кода, который может иметь вредоносный характер.
Двоичное дерево поиска (англ. binary search tree, BST) — это двоичное дерево, для которого выполняются следующие дополнительные условия (свойства дерева поиска)…
Массив (в некоторых языках программирования также таблица, ряд, матрица) — структура данных, хранящая набор значений (элементов массива), идентифицируемых по индексу или набору индексов, принимающих целые (или приводимые к целым) значения из некоторого заданного непрерывного диапазона. Одномерный массив можно рассматривать как реализацию абстрактного типа данных вектор.
Основная теорема о рекуррентных соотношениях (англ. Master theorem) используется в анализе алгоритмов для получения асимптотической оценки рекурсивных соотношений (рекуррентных уравнений), часто возникающих при анализе алгоритмов типа «разделяй и властвуй» (divide and conquer), например, при оценке времени их выполнения. Теорема была популяризована в книге Алгоритмы: построение и анализ (Томас Кормен, Чарльз Лейзерстон, Рональд Ривест, Клиффорд Штайн), в которой она была введена и доказана.
Система типов Си — реализация понятия типа данных в языке программирования Си. Сам язык предоставляет базовые арифметические типы, а также синтаксис для создания массивов и составных типов. Некоторые заголовочные файлы из стандартной библиотеки Си содержат определения типов с дополнительными свойствами.
Сравнение с обменом (англ. compare and set, compare and swap, CAS) — атомарная инструкция, сравнивающая значение в памяти с одним из аргументов, и в случае успеха записывающая второй аргумент в память. Поддерживается в семействах процессоров x86, Itanium, Sparc и других.
В теории информации теорема Шеннона об источнике шифрования (или теорема бесшумного шифрования) устанавливает предел максимального сжатия данных и числовое значение энтропии Шеннона.
В компьютерных науках ку́ча — это специализированная структура данных типа дерево, которая удовлетворяет свойству кучи: если B является узлом-потомком узла A, то ключ(A) ≥ ключ(B). Из этого следует, что элемент с наибольшим ключом всегда является корневым узлом кучи, поэтому иногда такие кучи называют max-кучами (в качестве альтернативы, если сравнение перевернуть, то наименьший элемент будет всегда корневым узлом, такие кучи называют min-кучами). Не существует никаких ограничений относительно того…
Подробнее: Куча (структура данных)
Поиск подстроки в строке — одна из простейших задач поиска информации. Применяется в виде встроенной функции в текстовых редакторах, СУБД, поисковых машинах, языках программирования и т. п.
Алгоритм Гёрцеля (англ. Goertzel algorithm) — это специальная реализация дискретного преобразования Фурье (ДПФ) в форме рекурсивного фильтра. Данный алгоритм был предложен Джеральдом Гёрцелем в 1958 году. В отличие от быстрого преобразования Фурье, вычисляющего все частотные компоненты ДПФ, алгоритм Гёрцеля позволяет эффективно вычислить значение одного частотного компонента.
Хронологическая база данных — база данных, содержащая исторические (хронологические) данные, то есть данные, относящиеся к прошлым и, возможно, к будущим периодам времени. Обычная, нехронологическая база данных содержит только текущие данные.
Пифагор — функционально-потоковый язык программирования, предназначенный для разработки переносимых (архитектурно-независимых) параллельных программ.
Очередь с приоритетом (англ. priority queue) — абстрактный тип данных в программировании, поддерживающий две обязательные операции — добавить элемент и извлечь максимум(минимум). Предполагается, что для каждого элемента можно вычислить его приоритет — действительное число или в общем случае элемент линейно упорядоченного множества.
Фибоначчиева система счисления — смешанная система счисления для целых чисел на основе чисел Фибоначчи F2=1, F3=2, F4=3, F5=5, F6=8 и т. д.
Алгоритм Петерсона — алгоритм параллельного программирования для взаимного исключения потоков исполнения кода, разработанный Гарри Петерсоном в 1981 г. Хотя изначально был сформулирован для 2-поточного случая, алгоритм может быть обобщён для произвольного количества потоков. Алгоритм условно называется программным, так как не основан на использовании специальных команд процессора для запрета прерываний, блокировки шины памяти и т. д., используются только общие переменные памяти и цикл для ожидания…
В математике и информатике подстановка — это операция синтаксической замены подтермов данного терма другими термами, согласно определённым правилам. Обычно речь идёт о подстановке терма вместо переменной.
Подробнее: Подстановка
Блочная сортировка (Карманная сортировка, корзинная сортировка, англ. Bucket sort) — алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков (карманов, корзин) так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше (или меньше), чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем…
Распределением регистров в процессе компиляции называется отображение множества большого числа переменных фрагмента компьютерной программы (виртуальных регистров промежуточного представления) на, как правило, небольшое множество физических регистров микропроцессора. Распределение регистров может выполняться в отдельно взятом базовом блоке (локальное распределение регистров) или во всей процедуре (глобальное распределение регистров).
В языках программирования объявле́ние (англ. declaration) включает в себя указание идентификатора, типа, а также других аспектов элементов языка, например, переменных и функций. Объявление используется, чтобы уведомить компилятор о существовании элемента; это весьма важно для многих языков (например, таких как Си), требующих объявления переменных перед их использованием.
Подробнее: Объявление (информатика)
Литерал (англ. literal ) — запись в исходном коде компьютерной программы, представляющая собой фиксированное значение. Литералами также называют представление значения некоторого типа данных.
1.
Часть 6.
Циклические операторы
2. Операторы цикла
ОПЕРАТОРЫ ЦИКЛА
Операторы цикла используются
для организации многократно
повторяющихся вычислений.
— цикл с параметром for.
— цикл с предусловием while,
— цикл с постусловием do while
3. Цикл с параметром for
ЦИКЛ С ПАРАМЕТРОМ FOR
Оператор цикла состоит из заголовка цикла и тела цикла.
Тело цикла – оператор, который будет повторно
выполняться.
Заголовок – это ключевое слово FOR, после которого в
круглых скобках записаны 3 выражения, разделенные
точкой с запятой. Первое выражение вычисляется один
раз до начала выполнения цикла; второе – условие цикла.
Тело цикла будет повторяться до тех пор пока условие
истинно. Третье выражение вычисляется после каждого
повторения тела цикла.
Оператор FOR реализует фундаментальный принцип
вычислений в программировании – итерацию
(повторение).
4. Цикл с параметром for
ЦИКЛ С ПАРАМЕТРОМ FOR
Цикл с параметром имеет следующую структуру:
for (<инициализация>; <выражение>; <модификации>) <оператор>;
Инициализация используется для объявления и присвоения начальных значений
величинам, используемым в цикле.
В этой части можно записать несколько операторов, разделенных запятой.
Областью действия переменных, объявленных в части инициализации цикла,
является цикл и вложенные блоки.
Выражение определяет условие выполнения цикла:
— если его результат истинен, цикл выполняется.
Истинность выражения проверяется перед каждым выполнением тела цикла,
таким образом, цикл с параметром реализован как цикл с предусловием.
Модификации выполняются после каждой итерации цикла и служат обычно для
изменения параметров цикла.
В части модификаций можно записать несколько операторов через запятую.
Оператор (простой или составной) представляет собой тело цикла.
5.
6.
Пример: найти сумму целых чисел от 1 до 100
int sum=0;
int i;
for (i=0; i<100; ++i)
sum=sum+i;
Любая
из частей оператора for (инициализация, выражение, модификация,
оператор) может отсутствовать, но точку с запятой, определяющую позицию
пропускаемой части, надо оставить.
Пример: найти сумму целых чисел от 1 до 100
Вариант 1: int sum=0;
int i=0;
for (; i<100; ) {sum=sum+i; ++i;}
Вариант 2: int sum=0;
int i=0;
for (; ; ) {if (i>=100) break; sum=sum+i; i=i+1;}
7.
Задача. Вывести на экран квадраты и кубы целых чисел
от 1 до 8.
начало
задать начальное значение
переменной цикла
i = 1;
проверить, все ли сделали
i <= 8?
да
i2 = i * i;
i3 = i2 * i;
i, i2, i3
i = i + 1;
нет
конец
вычисляем
квадрат и куб
вывод
результата
перейти к
следующему i
7
8.
8
Алгоритм (с блоком «цикл»)
начало
i = 1,8
блок «цикл»
конец
i2 = i * i;
i3 = i2 * i;
i, i2, i3
тело цикла
9.
9
Программа
main()
{
int i, i2, i3;
переменная цикла
начальное
значение
заголовок
цикла
конечное
значение
цикл
изменение на
for (i=1;
(i=1; i<=8;
i<=8; i++)
i++)
for
каждом шаге:
i=i+1
{{ начало цикла
i2 === i*i;
i*i; цикл работает, пока это
i2
i2
i*i;
тело цикла
условие верно
i3 === i2*i;
i2*i;
i3
i3
i2*i;
cout<<i<<”t”<<i2<<”t”<<i3<<”t”;
cout<<i<<”t”<<i2<<”t”<<i3<<”t”;
cout<<i<<”t”<<i2<<”t”<<i3<<”t”;
}}
конец цикла
ровные
}
столбики
10.
10
Цикл с уменьшением переменной
Задача. Вывести на экран квадраты и кубы целых чисел
от 8 до 1 (в обратном порядке).
Особенность: переменная цикла должна уменьшаться.
Решение:
for ( i = 8; i >= 1; i — )
{
i2 = i*i;
i3 = i2*i;
printf(«%4d %4d %4dn», i, i2, i3);
}
11.
12.
13.
13
Цикл с переменной
for (начальные значения;
условие продолжения цикла;
изменение на каждом шаге)
{
// тело цикла
}
Примеры:
for (a = 2; a < b; a+=2) { … }
for (a = 2, b = 4; a < b; a+=2) { … }
for (a = 1; c < d; x++) { … }
for (; c < d; x++) { … }
for (; c < d; ) { … }
14.
14
Цикл с переменной
Особенности:
• условие проверяется в начале очередного шага цикла,
если оно ложно цикл не выполняется;
• изменения (третья часть в заголовке) выполняются в
конце очередного шага цикла;
• если условие никогда не станет ложным, цикл может
продолжаться бесконечно (зацикливание)
for(i=1; i<8; i++) { i—; }
!
Не рекомендуется менять переменную
цикла в теле цикла!
• если в теле цикла один оператор, скобки {} можно не
ставить:
for (i = 1; i < 8; i++) a += b;
15.
15
Какой результат выполнения цикла?
a = 1;
for(i=1; i<4; i++) a++;
a= 4
a = 1;
for(i=1; i<4; i++) a = a+i;
a= 7
a = 1; b=2;
for(i=3; i >= 1; i—)a += b;
a= 7
a = 1;
for(i=1; i >= 3; i—)a = a+1;
a = 1;
for(i=1; i<= 4; i—)a ++;
a= 1
зацикливание
16. Ошибка неучтенной единицы
ОШИБКА НЕУЧТЕННОЙ ЕДИНИЦЫ
Одна из самых больших проблем с которой приходится сталкиваться начинающим
программистам в циклах for (а также и в других типах циклов) — это ошибка на
единицу (или «ошибка неучтенной единицы»). Она возникает, когда цикл
повторяется на 1 раз больше или на 1 раз меньше нужного количества итераций.
Это обычно происходит из-за того, что в условии используется некорректный
оператор сравнения (например, > вместо >= или наоборот). Как правило, эти
ошибки трудно отследить, так как компилятор не будет жаловаться на них,
программа будет работать, но её результаты будут неправильными.
При написании циклов for помните, что цикл будет выполняться до тех пор, пока
условие является истинным. Рекомендуется тестировать циклы, используя разные
значения для проверки работоспособности цикла. Хорошей практикой является
проверять циклы с помощью данных ввода (чисел, символов и прочего), которые
заставляют цикл выполниться 0, 1 и 2 раза. Если цикл работает исправно, значит
всё ОК.
Правило: Тестируйте свои циклы, используя входные данные, которые заставляют
цикл выполниться 0, 1 и 2 раза.
17. Объявления переменных в цикле for
ОБЪЯВЛЕНИЯ ПЕРЕМЕННЫХ В ЦИКЛЕ FOR
18. Пример: найти сумму четных чисел от 0 до 10.
#include <iostream.h>
void main()
{int n,sum;
for (n=0, sum=0; n<=10; n+=2)
{ sum+=n;
cout<<“промежуточный результат: n=“;
cout<<n<<“tsum=“<<sum<<“n”;}
cout<<“nОкончательный результат: n=“<<n;
cout<<“tsum=“<<sum<<“n”;}
19. В спортзал ежедневно приходит какое-то количество посетителей. Необходимо предложить пользователю ввести такие данные: сколько
человек посетило спортзал
за день, ввести возраст каждого посетителя и в итоге показать возраст самого
старшего и самого молодого из них, а так же посчитать средний возраст
посетителей.
20.
20
Задания
Ввести a и b и вывести квадраты и кубы чисел от a до b.
Пример:
Введите границы интервала:
4 6
4 16
64
5 25 125
6 36 216
Вывести квадраты и кубы 10 чисел следующей
последовательности: 1, 2, 4, 7, 11, 16, …
Пример:
1
1
1
2
4
8
4
16
64
…
46 2116 97336
21.
Оператор break завершает выполнение
цикла
Оператор continue заставляет пропустит
остаток тела цикла и перейти к
следующей итерации (повторению)
22.
23.
24. Пример: найти сумму всех целых чисел от 0 до 100, которые не делятся на 7.
int sum=0;
for (int i=1; i<=100; i=i+1)
{ if (i%7==0) continue;
sum=sum+i;}
25. Задания для самостоятельного выполнения.
1.
2.
3.
4.
5.
6.
Вывести на экран кубы целых чисел от 10 до 100.
Вычислите сумму ряда S = 1 + 1/x + 1/2x + 1/3x +
… 1/nx, для n и х введённых с клавиатуры.
Вычислить значение n! для n введённого с
клавиатуры.
Вычислить A(A+1)(A+2)…(A+N), для A и N введённых
с клавиатуры.
Найти максимальное число среди N
вещественных чисел, введенных с клавиатуры
Вычислить сумму ряда Y = 1! + 2! + 3! + … n!, для n
введённого с клавиатуры.
26. Вложенные циклы
ВЛОЖЕННЫЕ ЦИКЛЫ
Циклы могут быть простые или вложенные (кратные, циклы в цикле).
Вложенными могут быть циклы любых типов: while, do while, for.
Структура вложенных циклов на примере типа for приведена ниже:
for(i=1;i<ik;i++)
{…
for (j=10; j>jk;j- -)
{…for(k=1;k<kk;j+=2){…} 3 2
1
…}
…}
Каждый внутренний цикл должен быть полностью вложен во все внешние
циклы.
— «Пересечения» циклов не допускается.
27.
Рассмотрим пример использования вложенных циклов, который
позволит вывести на экран следующую таблицу:
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
2
#include <iostream.h>
int main()
{ for (int i=1; i<=4;++i,cout<<endI) //внешний цикл
for (int j= 1; j<=5; ++j)
//внутренний цикл
cout<<«2t»;
//тело внутреннего цикла
return 0;}
Внешний цикл определяет количество строк, выводимых на экран. В блоке
модификации данного цикла стоят два оператора.
Первый ++/ будет увеличивать значение i на единицу после каждого выполнения
внутреннего цикла, а второй -cout <<endl будет переводить выходной поток на
новую строку.
Внутренний цикл является телом внешнего цикла.
Внутренний цикл определяет, сколько чисел нужно вывести в каждой строке, а в
теле внутреннего цикла выводится нужное число.
28.
Рассмотрим еще один пример использования вложенных циклов, который
позволит вывести на экран следующую таблицу:
#include <iostream.h>
1
1
1
1
3
3
3
3
5
5
5
7
7
9
int main()
{ for (int i=1; i<=5; ++i, cout<<endl) //внешний цикл
for(int j=1;j<=2*i-1;j+=2) //внутренний цикл
cout<<j<<«t»;
//тело внутреннего цикла
return 0;}
В данном случае таблица состоит из пяти строчек, в каждой из которых печатаются
только нечетные числа.
Последнее нечетное число в строчке зависит от ее номера.
Эта зависимость выражается через формулу k =2i-l (зависимость проверить
самостоятельно), где к — последнее число в строке, ;i — номер текущей строки.
Внешний цикл следит за номером текущей строки i а внутренний цикл будет
печатать нечетные числа из диапазона от 1 до 2i-I.
29. Пример: написать программу для нахождения следующей суммы
3
4
y (n 2 m 2 )
n 1 m 2
#include <iostream.h>
main()
{ int n,y,m;
for (n=1,y=0; n<=3; n++)
for(m=2;m<=4;m++)
{y+=(n*n+m*m);
cout<<“n=“<<n<<“ t”;
cout<<“m=“<<m<<“ t y=”<<y<<endl;}
cout<<“Ответ:у=“<<y;
}
Ответ: у=129
30. задание
ЗАДАНИЕ
5
5
5
5
Вывести на экран числа в виде следующих
таблиц:
1.)
2.)
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5
5 5
5 5 5
5 5 5
5
31. Цикл с предусловием WHILE (пока)
Общая форма:
while (условие) тело цикла;
Оператор while организует выполнение
цикла до тех пор пока логическое
выражение (условие) не примет значение
ложь.
32. Пример: найти сумму чисел от 1 до 5.
void main()
{ int n=1, sum=0;
while (n<=5)
{sum+=n;
n++;
}
cout<<“S=“<<s<<endl;
}
33.
— если условие B во время работы цикла не будет изменяться, то
возможна ситуация зацикливания, то есть невозможность
выхода из цикла.
Внутри тела должны находиться операторы, приводящие к изменению
значения выражения В так, чтобы цикл мог завершиться.
Рассмотрим программу вывода на экран целых чисел из интервала от 1 до n.
#include <iostream.h>
int main()
{ int n, i=1;
cout <<«n=»; cin >>n;
while (i<=n) //пока i меньше или равно n
{ cout<<i<<«t»;
//выводим на экран значение i
++i;}//увеличиваем i на единицу
return 0;}
Замечание: используя операцию постфиксного инкремента, тело цикла
можно заменить одной командой cout <<;’++ <<«t».
34. Цикл с постусловием do while
ЦИКЛ С ПОСТУСЛОВИЕМ DO WHILE
В отличие от цикла while условие завершения цикла проверяется после
выполнения тела цикла.
Формат цикла do while:
do S while (В);
В — выражение, истинность которого проверяется (условие завершения
цикла);
S — тело цикла: один оператор (простой или блок).
Сначала выполняется оператор S, а затем анализируется значение
выражения В:
— если оно истинно, то управление передается оператору S,
— если ложно — цикл завершается и управление передается на оператор,
следующий за условием В.
35. Пример(do while): программа вывода на экран целых чисел из интервала от 1 до п.
#include <iostream.h>
int main()
{int n, i=1;
cout <<«n=»; cin >>n;
do //выводим на экран i, а замет увеличиваем
сout<<i++<<«t»; //ее значении на единицу
while (i<=n); //до тех пор пока i меньше или равна n
return 0;}
36. Пример(do while): прочитать символы, вводимые с клавиатуры до тех пор, пока не будет введен символ *
#include <iostream.h>
#include<conio.h>
int main()
{char ch;
do ch=getch();
while (ch!=‘*’);
return 0;}
37. Пример(do while): составить блок-схему и написать программу для нахождения суммы нечетных чисел от 0 до 10
#include <iostream.h>
void main()
{int n=1, s=0;
do
{s+=n;
n+=2;}
while (n<=10);
cout<<“n=“<<n<<“ts=“<<s<<endl;
return 0;}
38. Использование операторов цикла
ИСПОЛЬЗОВАНИЕ ОПЕРАТОРОВ ЦИКЛА
Программа, которая выводит на экран квадраты всех целых чисел от А до В
(А и В целые числа, при этом А<В).
Необходимо перебрать все целые числа из интервала от А до В.
Эти числа представляют собой упорядоченную последовательность, в которой
каждое число отличается от предыдущего на 1.
#include <iostream.h>
#include <iostream.h>
int main()
int main()
{ int a, b;
{ int a, b;
cout <<«a=»; cin >>a;
cout <<«a=»; cin >>a;
cout <<«b=»; cin >>b;
cout <<«b=»; cin >>b;
int i=a;
int i=a;
while (i<=b)
do cout<<i*i++<<«t»;
cout<<i*i++<<«t»;.
while (i<=b);
return 0;}
return 0;}
Выражение i*i++ (значение которого выводится на экран в теле каждого из циклов)
С учетом приоритета в начале выполнится операция умножение, результат которой
будет помещен в выходной поток, а затем постфиксный инкремент увеличит значение i
на 1.
39. задание
ЗАДАНИЕ
Написать программу, которая выводит на экран
квадраты всех четных чисел из диапазона от А до
В (А и В целые числа, при этом А<В).
(решить с помощью трех оператора цикла);