Время прочтения
9 мин
Просмотры 37K
Сеть обучалась последние 12 часов. Всё выглядело хорошо: градиенты стабильные, функция потерь уменьшалась. Но потом пришёл результат: все нули, один фон, ничего не распознано. «Что я сделал не так?», — спросил я у компьютера, который промолчал в ответ.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Содержание
0. Как использовать это руководство?
I. Проблемы с набором данных
II. Нормализация данных/Проблемы аугментации
III. Проблемы реализации
IV. Проблемы обучения
0. Как использовать это руководство?
Многое может пойти не так. Но некоторые проблемы встречаются чаще, чем другие. Я обычно начинаю с этого маленького списка как набора экстренной помощи:
- Начните с простой модели, которая точно правильно работает для этого типа данных (например, VGG для изображений). Используйте стандартную функцию потерь, если возможно.
- Отключите все финтифлюшки, например, регуляризацию и аугментацию данных.
- В случае тонкой настройки модели дважды проверьте препроцессинг, чтобы он соответствовал обучению первоначальной модели.
- Удостоверьтесь в правильности входных данных.
- Начните с действительно маленького набора данных (2-20 образцов). Затем расширяйте его, постепенно добавляя новые данные.
- Начните постепенно добавлять обратно все фрагменты, которые были опущены: аугментация/регуляризация, кастомные функции потерь, пробуйте более сложные модели.
Если ничего не помогло, то приступайте к чтению этого длинного списка и проверяйте каждый пункт.
I. Проблемы с набором данных

Источник: http://dilbert.com/strip/2014-05-07
1. Проверьте входные данные
Проверьте, что входные данные имеют смысл. Например, я не раз смешивал в кучу высоту и ширину изображений. Иногда по ошибке отдавал в нейросеть все нули. Или использовал одну и ту же партию снова и снова. Так что напечатайте/посмотрите пару партий входных данных и плановых выходных данных — убедитесь, что всё в порядке.
2. Попробуйте случайные входные значения
Попробуйте передать случайные числа вместо реальных данных и посмотрите, останется ли та же ошибка. Если так, то это верный знак, что ваша сеть на каком-то этапе превращает данные в мусор. Попробуйте отладку слой за слоем (операция за операцией) и посмотрите, где происходит сбой.
3. Проверьте загрузчик данных
С данными всё может быть в порядке, а ошибка в коде, который передаёт входные данные нейросети. Распечатайте и проверьте входные данные первого слоя перед началом его операций.
4. Убедитесь, что вход соединяется с выходом
Проверьте, что несколько образцов входных данных снабжены правильными метками. Также проверьте, что смена местами входных образцов так же отражается на выходных метках.
5. Взаимоотношение между входом и выходом слишком случайно?
Может быть, неслучайные части взаимоотношения между входом и выходом слишком малы по сравнению со случайной частью (кто-то может сказать, что таковы котировки на бирже). То есть вход недостаточно связан с выходом. Тут нет универсального метода, потому что мера случайности зависит от типа данных.
6. Слишком много шума в наборе данных?
Однажды это случилось со мной, когда я стянул набор изображений продуктов питания с сайта. Там было так много плохих меток, что сеть не могла обучаться. Вручную проверьте ряд образцов входных значений и посмотрите, что все метки на месте.
Данный пункт достоин отдельного разговора, потому что эта работа показывает точность выше 50% на базе MNIST при 50% повреждённых меток.
7. Перемешайте набор данных
Если ваши данные не перемешаны и располагаются в определённом порядке (отсортированы по меткам), это может отрицательно отразиться на обучении. Перемешайте набор данных: убедитесь, что перемешиваете вместе и входные данные, и метки.
8. Снизьте несбалансированность классов
Может, в наборе данных тысяча изображений класса А на одно изображение класса Б? Тогда вам может понадобиться сбалансировать функцию потерь или попробовать другие подходы устранения несбалансированности.
9. Достаточно ли образцов для обучения?
Если вы обучаете сеть с нуля (то есть не настраиваете её), то может понадобиться очень много данных. Например, для классификации изображений, говорят, нужна тысяча изображений на каждый класс, а то и больше.
10. Убедитесь в отсутствии партий с единственной меткой
Такое случается в отсортированном наборе данных (то есть первые 10 тыс. образцов содержат одинаковый класс). Легко исправляется перемешиванием набора данных.
11. Уменьшите размер партий
Эта работа указывает, что слишком большие партии могут понизить у модели способность к обобщению.
Дополнение 1. Используйте стандартный набор данных (например, mnist, cifar10)
Спасибо hengcherkeng за это:
При тестировании новой сетевой архитектуры или написании нового кода сначала используйте стандартные наборы данных вместо своих. Потому что для них уже есть много результатов и они гарантированно «разрешимые». Там не будет проблем с шумом в метках, разницей в распределении обучение/тестирование, слишком большой сложностью набора данных и т.д.
II. Нормализация данных/Проблемы аугментации

12. Откалибруйте признаки
Вы откалибровали входные данные на нулевое среднее и единичную дисперсию?
13. Слишком сильная аугментация данных?
Аугментация имеет регуляризующий эффект. Если она слишком сильная, то это вкупе с другими формами регуляризации (L2-регуляризация, dropout и др.) может привести к недообучению нейросети.
14. Проверьте предобработку предварительно обученной модели
Если вы используете уже подготовленную модель, то убедитесь, что используются та же нормализация и предобработка, что и в модели, которую вы обучаете. Например, должен пиксель быть в диапазоне [0, 1], [-1, 1] или [0, 255]?
15. Проверьте предварительную обработку для набора обучение/валидация/тестирование
CS231n указал на типичную ловушку:
«… любую статистику предобработки (например, среднее данных) нужно вычислять на данных для обучения, а потом применять на данных валидации/тестирования. Например, будет ошибкой вычисление среднего и вычитание его из каждого изображения во всём наборе данных, а затем разделение данных на фрагменты для обучения/валидации/тестирования».
Также проверьте на предмет наличия различающейся предварительной обработки каждого образца и партии.
III. Проблемы реализации

Источник: https://xkcd.com/1838/
16. Попробуйте решить более простой вариант задачи
Это поможет определить, где проблема. Например, если целевая выдача — это класс объекта и координаты, попробуйте ограничить предсказание только классом объекта.
17. Поищите правильную функцию потерь «по вероятности»
Снова из бесподобного CS231n: Инициализируйте с небольшими параметрами, без регуляризации. Например, если у нас 10 классов, то «по вероятности» означает, что правильный класс определится в 10% случаев, а функция потерь Softmax — это обратный логарифм к вероятности правильного класса, то есть получается 
После этого попробуйте увеличить силу регуляризации, что должно увеличить функцию потерь.
18. Проверьте функцию потерь
Если вы реализовали свою собственную, проверьте её на баги и добавьте юнит-тесты. У меня часто бывало, что слегка неправильная функция потерь тонко вредила производительности сети.
19. Проверьте входные данные функции потерь
Если вы используете функцию потерь из фреймворка, то убедитесь, что передаёте ей то что нужно. Например, в PyTorch я бы смешал NLLLoss и CrossEntropyLoss, потому что первая требует входных данных softmax, а вторая — нет.
20. Отрегулируйте веса функции потерь
Если ваша функция потерь состоит из нескольких функций, проверьте их соотношение относительно друг друга. Для этого может понадобиться тестирование в разных вариантах соотношений.
21. Отслеживайте другие показатели
Иногда функция потерь — не лучший предиктор того, насколько правильно обучается ваша нейросеть. Если возможно, используйте другие показатели, такие как точность.
22. Проверьте каждый кастомный слой
Вы самостоятельно реализовали какие-то из слоёв сети? Дважды проверьте, что они работают как полагается.
23. Проверьте отсутствие «зависших» слоёв или переменных
Посмотрите, может вы неумышленно отключили обновления градиента каких-то слоёв/переменных.
24. Увеличьте размер сети
Может, выразительной мощности сети недостаточно для усвоения целевой функции. Попробуйте добавить слоёв или больше скрытых юнитов в полностью соединённые слои.
25. Поищите скрытые ошибки измерений
Если ваши входные данные выглядят как  , то легко пропустить ошибку, связанную с неправильными измерениями. Используйте необычные числа для измерений входных данных (например, разные простые числа для каждого измерения) и посмотрите, как они распространяются по сети.
, то легко пропустить ошибку, связанную с неправильными измерениями. Используйте необычные числа для измерений входных данных (например, разные простые числа для каждого измерения) и посмотрите, как они распространяются по сети.
26. Исследуйте Gradient Checking
Если вы самостоятельно реализовали Gradient Descent, то с помощью Gradient Checking можно убедиться в корректной обратной связи. Дополнительная информация: 1, 2, 3.
IV. Проблемы обучения

Источник: http://carlvondrick.com/ihog/
27. Решите задачу для действительно маленького набора данных
Переобучите сеть на маленьком наборе данных и убедитесь в её работе. Например, обучите её всего с 1-2 примерами и посмотрите, способна ли сеть различать объекты. Переходите к большему количеству образцов для каждого класса.
28. Проверьте инициализацию весов
Если не уверены, используйте инициализацию Ксавьера или Хе. К тому же, ваша инициализация может вывести на плохой локальный минимум, так что испытайте другую инициализацию, может поможет.
29. Измените гиперпараметры
Может вы используете плохой набор гиперпараметров. Если возможно, попробуйте grid search.
30. Уменьшите регуляризацию
Из-за слишком сильной регуляризации сеть может конкретно недообучиться. Уменьшите регуляризацию, такую как dropout, batch norm, L2-регуляризацию weight/bias и др. В отличном курсе «Практическое глубинное обучение для программистов» Джереми Говард рекомендует в первую очередь избавиться от недообучения. То есть нужно достаточно переообучить сеть на исходных данных, и только затем бороться с переобучением.
31. Дайте время
Может сети нужно больше времени на обучение, прежде чем она начнёт делать осмысленные предсказания. Если функция потерь стабильно уменьшается, дайте ей обучиться чуть подольше.
32. Переходите от режима обучения в режим тестирования
В некоторых фреймворках слои Batch Norm, Dropout и другие ведут себя по-разному во время обучения и тестирования. Переключение в подходящий режим может помочь вашей сети начать делать правильные прогнозы.
33. Визуализируйте обучение
- Отслеживайте активации, веса и обновления для каждого слоя. Убедитесь, что отношения их величин совпадают. Например, отношение величины обновлений к параметрам (весам и смещениям) должно равняться 1e-3.
- Рассмотрите библиотеки визуализации вроде Tensorboard и Crayon. В крайнем случае, можно просто печатать значения весов/сдвигов/активаций.
- Будьте осторожны с активациями сетей со средним намного больше нуля. Попробуйте Batch Norm или ELU.
- Deeplearning4j указал, на что смотреть в гистограммах весов и сдвигов:
«Для весов эти гистограммы должны иметь примерно гауссово (нормальное) распределение, спустя какое-то время. Гистограммы сдвигов обычно начинаются с нуля и обычно заканчиваются на уровне примерно гауссова распределения (единственное исключение — LSTM). Следите за параметрами, которые отклоняются на плюс/минус бесконечность. Следите за сдвигами, которые становятся слишком большими. Иногда такое случается в выходном слое для классификации, если распределение классов слишком несбалансировано».
- Проверяйте обновления слоёв, они должны иметь нормальное распределение.
34. Попробуйте иной оптимизатор
Ваш выбор оптимизатора не должен мешать нейросети обучаться, если только вы не выбрали конкретно плохие гиперпараметры. Но правильный оптимизатор для задачи может помочь получить наилучшее обучение за кратчайшее время. Научная статья с описанием того алгоритма, который вы используете, должна упомянуть и оптимизатор. Если нет, я предпочитаю использовать Adam или простой SGD.
Прочтите отличную статью Себастьяна Рудера, чтобы узнать больше об оптимизаторах градиентного спуска.
35. Взрыв/исчезновение градиентов
- Проверьте обновления слоя, поскольку очень большие значения могут указывать на взрывы градиентов. Может помочь клиппинг градиента.
- Проверьте активации слоя. Deeplearning4j даёт отличный совет: «Хорошее стандартное отклонение для активаций находится в районе от 0,5 до 2,0. Значительный выход за эти рамки может указывать на взрыв или исчезновение активаций».
36. Ускорьте/замедлите обучение
Низкая скорость обучения приведёт к очень медленному схождению модели.
Высокая скорость обучения сначала быстро уменьшит функцию потерь, а потом вам будет трудно найти хорошее решение.
Поэкспериментируйте со скоростью обучению, ускоряя либо замедляя её в 10 раз.
37. Устранение состояний NaN
Состояния NaN (Non-a-Number) гораздо чаще встречаются при обучении RNN (насколько я слышал). Некоторые способы их устранения:
- Уменьшите скорость обучения, особенно если NaN появляются в первые 100 итераций.
- Нечисла могут возникнуть из-за деления на ноль, взятия натурального логарифма нуля или отрицательного числа.
- Рассел Стюарт предлагает хорошие советы, что делать в случае появления NaN.
- Попробуйте оценить сеть слой за слоем и посмотреть, где появляются NaN.
Обучение нейронных сетей
Перед использованием нейронной сети ее необходимо обучить.
Процесс обучения нейронной сети заключается в подстройке ее внутренних параметров под конкретную задачу.
Алгоритм работы нейронной сети является итеративным, его шаги называют эпохами или циклами.
Эпоха — одна итерация в процессе обучения, включающая предъявление всех примеров из обучающего множества и, возможно, проверку качества обучения на контрольном множестве.
Процесс обучения осуществляется на обучающей выборке.
Обучающая выборка включает входные значения и соответствующие им выходные значения набора данных. В ходе обучения нейронная сеть находит некие зависимости выходных полей от входных.
Таким образом, перед нами ставится вопрос — какие входные поля (признаки) нам необходимо использовать. Первоначально выбор осуществляется эвристически, далее количество входов может быть изменено.
Сложность может вызвать вопрос о количестве наблюдений в наборе данных. И хотя существуют некие правила, описывающие связь между необходимым количеством наблюдений и размером сети, их верность не доказана.
Количество необходимых наблюдений зависит от сложности решаемой задачи. При увеличении количества признаков количество наблюдений возрастает нелинейно, эта проблема носит название «проклятие размерности». При недостаточном количестве данных рекомендуется использовать линейную модель.
Аналитик должен определить количество слоев в сети и количество нейронов в каждом слое.
Далее необходимо назначить такие значения весов и смещений, которые смогут минимизировать ошибку решения. Веса и смещения автоматически настраиваются таким образом, чтобы минимизировать разность между желаемым и полученным на выходе сигналами, которая называется ошибка обучения.
Ошибка обучения для построенной нейронной сети вычисляется путем сравнения выходных и целевых (желаемых) значений. Из полученных разностей формируется функция ошибок.
Функция ошибок — это целевая функция, требующая минимизации в процессе управляемого обучения нейронной сети.
С помощью функции ошибок можно оценить качество работы нейронной сети во время обучения. Например, часто используется сумма квадратов ошибок.
От качества обучения нейронной сети зависит ее способность решать поставленные перед ней задачи.
Переобучение нейронной сети
При обучении нейронных сетей часто возникает серьезная трудность, называемая проблемой переобучения (overfitting).
Переобучение, или чрезмерно близкая подгонка — излишне точное соответствие нейронной сети конкретному набору обучающих примеров, при котором сеть теряет способность к обобщению.
Переобучение возникает в случае слишком долгого обучения, недостаточного числа обучающих примеров или переусложненной структуры нейронной сети.
Переобучение связано с тем, что выбор обучающего (тренировочного) множества является случайным. С первых шагов обучения происходит уменьшение ошибки. На последующих шагах с целью уменьшения ошибки (целевой функции) параметры подстраиваются под особенности обучающего множества. Однако при этом происходит «подстройка» не под общие закономерности ряда, а под особенности его части — обучающего подмножества. При этом точность прогноза уменьшается.
Один из вариантов борьбы с переобучением сети — деление обучающей выборки на два множества (обучающее и тестовое).
На обучающем множестве происходит обучение нейронной сети. На тестовом множестве осуществляется проверка построенной модели. Эти множества не должны пересекаться.
С каждым шагом параметры модели изменяются, однако постоянное уменьшение значения целевой функции происходит именно на обучающем множестве. При разбиении множества на два мы можем наблюдать изменение ошибки прогноза на тестовом множестве параллельно с наблюдениями над обучающим множеством. Какое-то количество шагов ошибки прогноза уменьшается на обоих множествах. Однако на определенном шаге ошибка на тестовом множестве начинает возрастать, при этом ошибка на обучающем множестве продолжает уменьшаться. Этот момент считается концом реального или настоящего обучения, с него и начинается переобучение.
Описанный процесс проиллюстрирован на рис. 11.2.

Рис.
11.2.
Процесс обучений сети. Явление переобучения
На первом шаге ошибки прогноза для обучающего и тестового множества одинаковы. На последующих шагах значения обеих ошибок уменьшаются, однако с семидесятого шага ошибка на тестовом множестве начинает возрастать, т.е. начинается процесс переобучения сети.
Прогноз на тестовом множестве является проверкой работоспособности построенной модели. Ошибка на тестовом множестве может являться ошибкой прогноза, если тестовое множество максимально приближено к текущему моменту.
Список шагов для устранения проблем, связанных с обучением, обобщением и оптимизацией модели глубокого обучения и отладки нейронной сети.

Программный код машинного обучения не совсем похож на другие программные решения. Поэтому он может быть достаточно сложен для отладки. Даже для простых нейронных сетей прямого распространения необходимо принять несколько решений об архитектуре сети, инициализации весов и оптимизации нейросети. На всех этих этапах в концепции обучения и их реализации в виде кода модели могут вкрасться коварные ошибки.
Чейз Робертс в статье «Как делать юнит тесты для машинного обучения» (англ.) выделил три основных типа ловушек:
- Код никогда не падает, вызывает исключения или даже замедляется.
- Пока сеть тренируется, потери не перестают снижаются.
- Значения сходятся через несколько часов, но приводят к плохим результатам.
Что же с этим делать? Эта статья предоставит структуру, которая поможет вам отладить ваши нейронные сети.
1. Начните с простого
Нейронную сеть со сложной архитектурой, регуляризацией и планировщиком скорости обучения будет сложнее отлаживать, чем простую сеть. Этот пункт может представляться несколько надуманным, ведь он не имеет отношения к отладке имеющейся нейросети. Но он важен для тех, кто хочет со старта контролировать ситуацию.
Создайте сначала простую модель
Создайте небольшую сеть с одним скрытым слоем и убедитесь, что все работает правильно. Постепенно усложняя модель, проверяйте, работает ли каждый аспект структуры (дополнительный слой, параметр и т. д.).
Обучите модель на одной точке из массива данных
В качестве быстрой проверки работоспособности используйте одну или две точки тренировочных данных. Нейросеть должна немедленно переобучаться до 100% точности. Если модель не может «воспроизвести» такой малый объем данных, она либо слишком мала, чтобы их аппроксимировать, либо уже имеется ошибка. Итак, вы убедились: модель работает. Прежде чем двигаться дальше, попробуйте потренировать ее один или несколько периодов дискретизации (epoch).
2. Потери
Потери модели (loss) – основной критерий оценки производительности и собственный критерий нейросети, по которому определяется важность какого-либо параметра, поэтому убедитесь в следующем:
- Функция потерь соответствует задаче (например, категориальная кросс-энтропия для задачи классификации или focal loss для несбалансированных классов).
- Функция потерь измеряется по правильной шкале. Если вы используете более одного типа функции потерь (MSE, feature loss, L1), важно проверить, что все потери масштабируются до одного порядка.
Обратите внимание на начальные потери – соответствует ли их порядок модели, начинающейся со случайных предположений. В Стэндфордском курсе CS231n Андрей Карпатый предлагает следующее: «Убедитесь, что вы получаете ожидаемые потери при инициализации малыми параметрами. Регуляризацию сначала лучше уменьшить до нуля. Так, для CIFAR-10 с классификатором Softmax мы ожидаем, что начальные потери будут 2.302. У нас 10 классов, значит, вероятность диффузии составляет 0.1. Потеря Softmax является отрицательным логарифмом от вероятности. То есть потери равны –ln(0.1) = 2.302»
Для бинарного случая выполняется аналогичный расчет для каждого из классов. Допустим, данные на 20% состоят из нулей и 80% – из единиц. Ожидаемая начальная потеря составляет –0.2ln(0.5)–0.8ln(0.5) = 0.693. Если исходные потери много больше 1, нейронная сеть не сбалансирована должным образом (т. е. плохо инициализирована), или данные не нормализованы.
3. Проверьте промежуточные выходы слоев и соединения
Для отладки нейронной сети бывает полезным понимать внутреннюю динамику и ту индивидуальную роль, которую играют промежуточные слои и межсоединения. Вы можете столкнуться с ошибками:
- Некорректные выражения для обновлений градиента.
- Отсутствие обновлений вычисленных весов.
- Исчезающие или лавинообразно нарастающие градиенты.
Если значение градиента равно нулю, это может означать, что скорость обучения в оптимизаторе слишком мала. Или то, что вы столкнулись с первой из перечисленных ошибок.
Помимо просмотра абсолютных значений обновлений градиента, обязательно следите за величинами активаций, весов и обновлениями каждого слоя. Например, величина обновлений параметров (весов и смещений) должна составлять 1-e3.
Существует явление, называемое «умирающий ReLU» или «проблема исчезающего градиента». Оно происходит, когда нейроны обучаются с большим отрицательным смещением весов. В этом случае нейроны больше не активируются ни на одной из точек данных. Вы можете использовать проверку градиента для отслеживания таких ошибок, аппроксимируя градиент численным образом. Для этого ознакомьтесь с соответствующими разделами CS231n (раз и два) и специальным уроком Эндрю Ына.
Что касается визуализации нейронной сети, Файзан Шейх описал три основных группы методов:
- Предварительные методы. Простые методы, показывающие общую структуру тренируемой модели с печатью форм и фильтров индивидуальных слоев нейросети и параметров каждого слоя.
- Методы, основанные на активации. В этих методах расшифровывается активация отдельных нейронов и групп нейронов.
- Методы, основанные на градиенте. Эти методы стремятся к манипуляции градиентами, которые формируются при проходах вперед и назад при обучении модели (включая карты значимости и карты активации классов).
Существует множество полезных инструментов для визуализации активаций и соединений отдельных слоев, например, ConX и TensorBoard. Здесь представлен пример визуализацией нейросети, сделанной с помощью ConX:
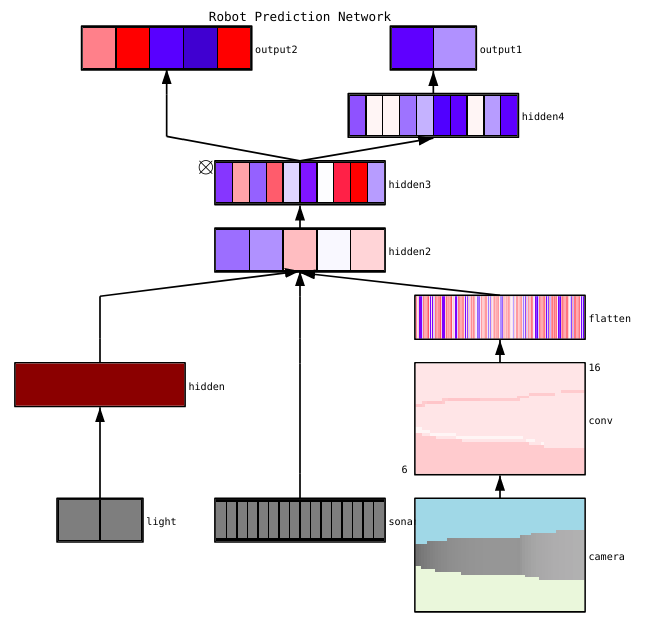
Если для вас важны вопросы отладки нейронной сети, обрабатывающей изображения, ознакомьтесь с красочной публикацией Эрика Риппела «Визуализация частей сверточных нейронных сетей с использованием Keras и кошек» (англ.).
4. Диагностика параметров
Нейронные сети имеют огромное число параметров для настройки, к тому же взаимосвязанных, что затрудняет их оптимизацию. Обратите внимание: эта сфера является областью активных исследований. Так что изложенные ниже рекомендации – лишь начальные точки.
Размер батча (mini-batch)
С одной стороны, размер пакета должен быть довольно большим, чтобы сделать оценку ошибки градиента. С другой, батч должен быть довольно мал, чтобы градиентный спуск мог регуляризовать нейросеть. Слишком малые размеры батча заставляют процесс обучения быстро сходиться за счет шума и могут приводить к трудностям оптимизации.
В публикации «Об использовании крупных батчей для глубокого обучения: разрыв в обобщении и острые минимумы» (англ.) говорится: «На практике наблюдалось, что при использовании крупных батчей качество модели ухудшалось. Это было определено по способности модели к обобщению. Исследуя причину ухудшения, мы представили численные доказательства того, что метод крупных батчей имеет тенденцию сходиться к резким минимизаторам функций обучения и тестирования. А резкие минимумы, как известно, приводят к худшей обобщающей способности. Напротив, методы с малыми батчами сходятся к плоским минимизаторам. Эксперименты подтверждают мнение, что такое поведение обусловлено внутренним шумом при оценке градиента».
Скорость обучения
При низкой скорости обучения процесс рискует застрять в локальных минимумах. Слишком высокая скорость обучения приведет к расхождению процесса оптимизации, так как вы можете «перепрыгнуть» через узкую, но глубокую часть функции потерь. Рассмотрите вопрос планирования скорости обучения, чтобы правильно снижать скорость обучения по мере тренировки нейросети. В курсе CS231n имеется раздел, посвященный методикам реализации процедуры отжига при настройке скорости обучения. Многие фреймворки используют планировщики скорости обучения или схожие стратегии. Приведем здесь ссылки на соответствующие разделы документации: Keras, TensorFlow, PyTorch, MXNet.
Ограничение нормы градиента (gradient clipping)
Gradient clipping предполагает ограничение параметров градиента в процессе обратного распространения по максимальному значению или максимальной норме. Этот подход полезен для устранения взрывных градиентов.
Пакетная нормализация
Пакетная нормализация используется для нормализации входных данных каждого слоя, чтобы бороться с проблемой внутреннего ковариантного сдвига. Наиболее распространенные ошибки, связанные с пакетной нормализацией, описаны в соответствующей публикации Дишэнка Банзала.
Стохастический градиентный спуск
Существует несколько разновидностей стохастического градиентного спуска (СГС), использующих импульс, адаптивные скорости обучения и обновления Нестерова. Но ни одна из этих разновидностей не выигрывает одновременно и по эффективности обучения, и по его обобщению (см. обзор алгоритмов оптимизации градиентного спуска и эксперимент SDG > Adam). Рекомендуемой отправной точкой является Adam или простой СГС с импульсом Нестерова.
Регуляризация
Регуляризация имеет решающее значение для построения обобщаемой модели. Она добавляет штраф за сложность модели или экстремальные значения параметров. Это значительно уменьшает дисперсию модели без существенного увеличения ее смещения.
Важное замечание дается в курсе CS231n: «Часто функция потерь представляет собой сумму потерь данных и потерь регуляризации (например, штраф L2 по весам). Опасность в том, что потеря регуляризации может превысить потерю данных. В этом случае градиенты будут исходить в основном от компонента, обусловленного регуляризацией. Он обычно имеет более простое выражение градиента. Это может маскировать неправильную реализацию градиента потери данных». В таком случае вы должны отключить регуляризацию и независимо проверить градиент потери данных.
Исключение (dropout)
Исключение – еще одна техника, позволяющая регуляризовать вашу нейросеть и избежать переобучения. Использование дропаута в процессе обучения заключается в ограничении числа активных нейронов при помощи вероятностного гиперпараметра. В результате нейросети требуется использовать другое подмножество параметров для пакета, на котором происходит обучение. Исключение уменьшает изменение определенных параметров, которые начинают доминировать над другими. То есть более обученные нейроны получают в сети больший вес.
Теперь важное предупреждение, если вы используете вместе дропаут и пакетную нормализацию. Будьте осторожны с порядком выполнения этих операций или совместным использованием. В этом вопросе пока не найден консенсус. Некоторые идеи на этот счет можно найти в следующей публикации.
Легко недооценивать важность документации ваших экспериментов до тех пор пока вы не забудете какие скорости обучения и веса классов вы ранее использовали. Важно иметь возможность легко отслеживать, просматривать и воспроизводить предыдущие эксперименты. Это уменьшает объем повторяемых работ и упрощает процесс отладки нейронной сети.
Ручное документирование информации практически всегда трудоемко. Поэтому пригодятся такие инструменты, как Comet.ml, помогающие автоматически отслеживать наборы данных, изменения кода, историю экспериментов и производственные модели. В том числе и такие ключевые сведения о вашей модели, как гиперпараметры, показатели производительности и детали программного окружения.
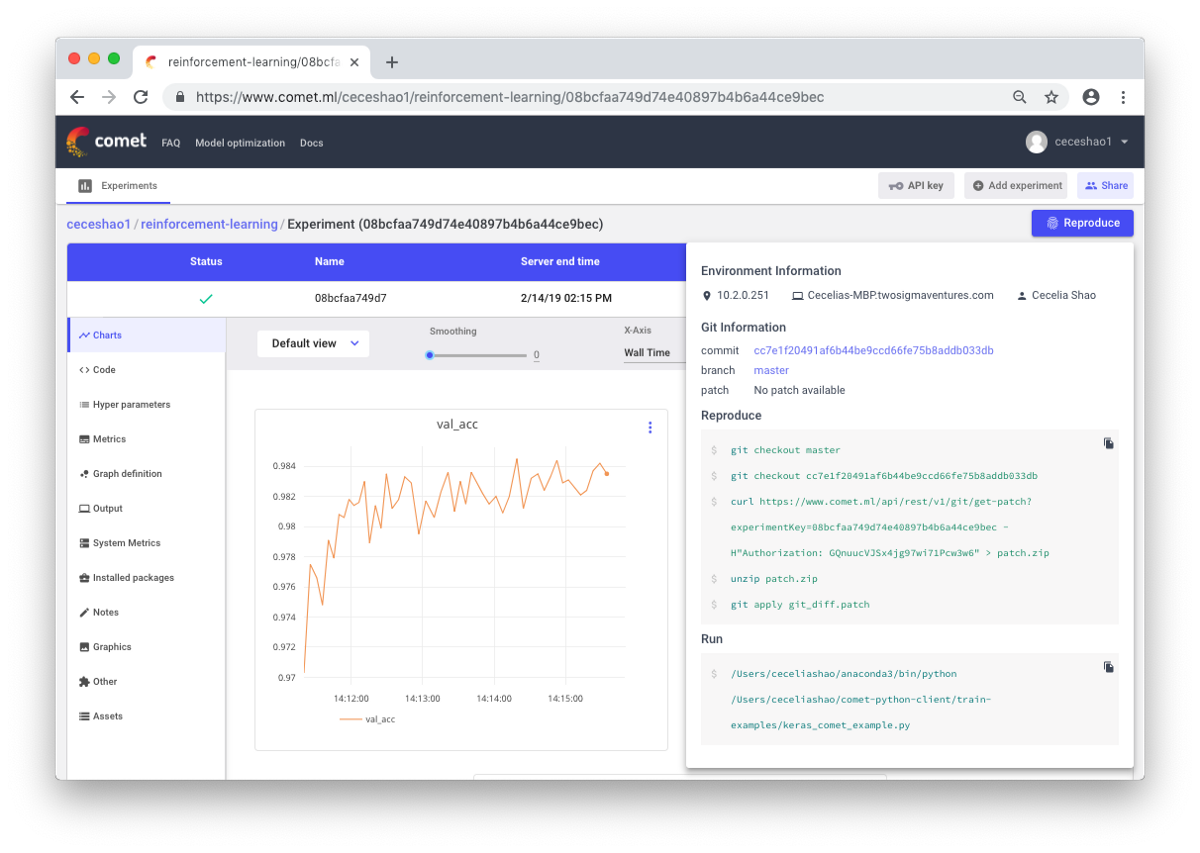
Нейросеть может быть чувствительной к небольшим изменениям данных, параметров и версий пакетов. Это может приводить к падению производительности модели. Отслеживание вашей работы – первый шаг, который вы можете предпринять, чтобы стандартизировать рабочую среду.
Источник
Вам также будут интересны:
- Нейронные сети: наиболее полные и понятные видеолекции
- Deep Learning: 15 лучших книг по глубинному обучению
- 7 трюков для глубокого обучения, о которых вы не знали
Нейронные сети считаются универсальными моделями в машинном обучении, поскольку позволяют решать широкий класс задач. Однако, при их использовании могут возникать различные проблемы.
Содержание
- 1 Взрывающийся и затухающий градиент
- 1.1 Определение
- 1.2 Причины
- 1.3 Способы определения
- 1.3.1 Взрывающийся градиент
- 1.3.2 Затухающий градиент
- 1.4 Способы устранения
- 1.4.1 Использование другой функции активации
- 1.4.1.1 Tanh
- 1.4.1.2 ReLU
- 1.4.1.3 Softplus
- 1.4.2 Изменение модели
- 1.4.3 Использование Residual blocks
- 1.4.4 Регуляризация весов
- 1.4.5 Обрезание градиента
- 1.4.1 Использование другой функции активации
- 2 См. также
- 3 Примечания
- 4 Источники
Взрывающийся и затухающий градиент
Определение
Напомним, что градиентом в нейронных сетях называется вектор частных производных функции потерь по весам нейронной сети. Таким образом, он указывает на направление наибольшего роста этой функции для всех весов по совокупности. Градиент считается в процессе тренировки нейронной сети и используется в оптимизаторе весов для улучшения качества модели.
В процессе обратного распространения ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это в свою очередь может сделать нестабильным алгоритм обучения нейронной сети. В таком случае элементы градиента могут переполнить тип данных, в котором они хранятся. Такое явление называется взрывающимся градиентом (англ. exploding gradient).
Существует аналогичная обратная проблема, когда в процессе обучения при обратном распространении ошибки через слои нейронной сети градиент становится все меньше. Это приводит к тому, что веса при обновлении изменяются на слишком малые значения, и обучение проходит неэффективно или останавливается, то есть алгоритм обучения не сходится. Это явление называется затухающим градиентом (англ. vanishing gradient).
Таким образом, увеличение числа слоев нейронной сети с одной стороны увеличивает ее способности к обучению и расширяет ее возможности, но с другой стороны может порождать данную проблему. Поэтому для решения сложных задач с помощью нейронных сетей необходимо уметь определять и устранять ее.
Причины
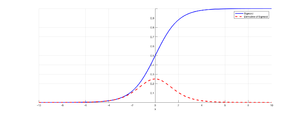
Рисунок 1. График сигмоиды и ее производной[1]
Такая проблема может возникнуть при использовании нейронных сетях классической функцией активации (англ. activation function) сигмоиды (англ. sigmoid):
$sigma(x) = frac{1}{1 + e^{-x}}.$
Эта функция часто используется, поскольку множество ее возможных значений — отрезок $[0, 1]$ — совпадает с возможными значениями вероятностной меры, что делает более удобным ее предсказание. Также график сигмоиды соответствует многим естественным процессам, показывающим рост с малых значений, который ускоряется с течением времени, и достигающим своего предела[2] (например, рост популяции).
Пусть сеть состоит из подряд идущих нейронов с функцией активации $sigma(x)$; функция потерть (англ. loss function) $L(y) = MSE(y, hat{y}) = (y — hat{y})^2$ (англ. MSE — Mean Square Error); $u_d$ — значение, поступающее на вход нейрону на слое $d$; $w_d$ — вес нейрона на слое $d$; $y$ — выход из последнего слоя. Оценим частные производные по весам такой нейронной сети на каждом слое. Оценка для производной сигмоиды видна из рисунка 1.
$frac{partial(L(y))}{partial(w_d)} = frac{partial(L(y))}{partial(y)} cdot frac{partial(y)}{partial(w_d)} = 2 (y — hat{y}) cdot sigma'(w_d u_d) u_d leq 2 (y — hat{y}) cdot frac{1}{4} u_d$
$frac{partial(L(y))}{partial(w_{d — 1})} = frac{partial(L(y))}{partial(w_d)} cdot frac{partial(w_d)}{partial(w_{d — 1})} leq 2 (y — hat{y}) cdot (frac{1}{4})^2 u_d u_{d-1}$
$ldots$
Откуда видно, что оценка элементов градиента растет экспоненциально при рассмотрении частных производных по весам слоев в направлении входа в нейронную сеть (уменьшения номера слоя). Это в свою очередь может приводить либо к экспоненциальному росту градиента от слоя к слою, когда входные значения нейронов — числа, по модулю большие $1$, либо к затуханию, когда эти значения — числа, по модулю меньшие $1$.
Однако, входные значения скрытых слоев есть выходные значения функций активаций предшествующих им слоев. В частности, сигмоида насыщается (англ. saturates) при стремлении аргумента к $+infty$ или $-infty$, то есть имеет там конечный предел. Это приводит к тому, что более отдаленные слои обучаются медленнее, так как увеличение или уменьшение аргумента насыщенной функции вносит малые изменения, и градиент становится все меньше. Это и есть проблема затухающего градиента.
Способы определения
Взрывающийся градиент
Возникновение проблемы взрывающегося градиента можно определить по следующим признакам:
- Модель плохо обучается на данных, что отражается в высоком значении функции потерь.
- Модель нестабильна, что отражается в значительных скачках значения функции потерь.
- Значение функции потерь принимает значение
NaN.
Более непрозрачные признаки, которые могут подтвердить возникновение проблемы:
- Веса модели растут экспоненциально.
- Веса модели принимают значение
NaN.
Затухающий градиент
Признаки проблемы затухающего градиента:
- Точность модели растет медленно, при этом возможно раннее срабатывание критерия останова, так как алгоритм может решить, что дальнейшее обучение не будет оказывать существенного влияния.
- Градиент ближе к концу показывает более сильные изменения, в то время как градиент ближе к началу почти не показывает никакие изменения.
- Веса модели уменьшаются экспоненциально во время обучения.
- Веса модели стремятся к $0$ во время обучения.
Способы устранения
Использование другой функции активации
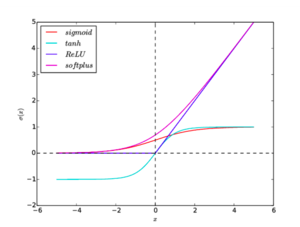
Рисунок 2. Графики функций активации: sigmoid, tanh, ReLU, softplus
Как уже упоминалось выше, подверженность нейронной сети проблемам взрывающегося или затухающего градиента во многом зависит от свойств используемых функций активации. Поэтому правильный их подбор важен для предотвращения описываемых проблем.
Tanh
$tanh(x) = frac{e^x — e^{-x}}{e^x + e^{-x}}$
Функция аналогична сигмоиде, но множество возможных значений: $[-1, 1]$. Градиенты при этом сосредоточены около $0$,. Однако, эта функция также насыщается в обоих направлениях, поэтому также может приводить к проблеме затухающего градиента.
ReLU
$h(x) = max(0, x)$
Функция проста для вычисления и имеет производную, равную либо $1$, либо $0$. Также есть мнение, что именно эта функция используется в биологических нейронных сетях. При этом функция не насыщается на любых положительных значениях, что делает градиент более чувствительным к отдаленным слоям.
Недостатком функции является отсутствие производной в нуле, что можно устранить доопределением производной в нуле слева или справа. Также эту проблему устраняет использование гладкой аппроксимации, Softplus.
Существуют модификации ReLU:
- Noisy ReLU: $h(x) = max(0, x + varepsilon), varepsilon sim N(0, sigma(x))$.
- Parametric ReLU: $h(x) = begin{cases} x & x > 0 \ beta x & text{otherwise} end{cases}$.
- Leaky ReLU: Paramtetric ReLU со значением $beta = 0.01$.
Softplus
$h(x) = ln(1 + e^x)$
Гладкий, везде дифференцируемый аналог функции ReLU, следовательно, наследует все ее преимущества. Однако, эта функция более сложна для вычисления. Эмпирически было выявлено, что по качеству не превосходит ReLU.
Графики всех функций активации приведены на рисунок 2.
Изменение модели
Для решения проблемы может оказаться достаточным сокращение числа слоев. Это связано с тем, что частные производные по весам растут экспоненциально в зависимости от глубины слоя.
В рекуррентных нейронных сетях можно воспользоваться техникой обрезания обратного распространения ошибки по времени, которая заключается в обновлении весов с определенной периодичностью.
Использование Residual blocks
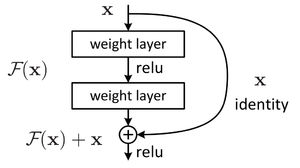
Рисунок 3. Устройство residual block[3]
В данной конструкции вывод нейрона подается как следующему нейрону, так и нейрону на расстоянии 2-3 слоев впереди, который суммирует его с выходом предшествующего нейрона, а функция активации в нем — ReLU (см. рисунок 3). Такая связка называется shortcut. Это позволяет при обратном распространении ошибки значениям градиента в слоях быть более чувствительным к градиенту в слоях, с которыми связаны с помощью shortcut, то есть расположенными несколько дальше следующего слоя.
Регуляризация весов
Регуляризация заключается в том, что слишком большие значения весов будут увеличивать функцию потерь. Таким образом, в процессе обучения нейронная сеть помимо оптимизации ответа будет также минимизировать веса, не позволяя им становиться слишком большими.
Обрезание градиента
Образание заключается в ограничении нормы градиента. То есть если норма градиента превышает заранее выбранную величину $T$, то следует масштабировать его так, чтобы его норма равнялась этой величине:
$nabla_{clipped} = begin{cases} nabla & || nabla || leq T \ frac{T}{|| nabla ||} cdot nabla & text{otherwise} end{cases}.$
См. также
- Нейронные сети, перцептрон
- Обратное распространение ошибки
- Регуляризация
- Глубокое обучение
- Сверточные нейронные сети
Примечания
- ↑ towardsdatascience.com — Derivative of the sigmoid function
- ↑ wikipedia.org — Sigmoid function, Applications
- ↑ wikipedia.org — Residual neural network
Источники
- Курс Machine Learning, ИТМО, 2020;
- towardsdatascience.com — The vanishing exploding gradient problem in deep neural networks;
- machinelearningmastery.com — Exploding gradients in neural networks.
Verify that your code is bug free
There’s a saying among writers that «All writing is re-writing» — that is, the greater part of writing is revising. For programmers (or at least data scientists) the expression could be re-phrased as «All coding is debugging.»
Any time you’re writing code, you need to verify that it works as intended. The best method I’ve ever found for verifying correctness is to break your code into small segments, and verify that each segment works. This can be done by comparing the segment output to what you know to be the correct answer. This is called unit testing. Writing good unit tests is a key piece of becoming a good statistician/data scientist/machine learning expert/neural network practitioner. There is simply no substitute.
You have to check that your code is free of bugs before you can tune network performance! Otherwise, you might as well be re-arranging deck chairs on the RMS Titanic.
There are two features of neural networks that make verification even more important than for other types of machine learning or statistical models.
-
Neural networks are not «off-the-shelf» algorithms in the way that random forest or logistic regression are. Even for simple, feed-forward networks, the onus is largely on the user to make numerous decisions about how the network is configured, connected, initialized and optimized. This means writing code, and writing code means debugging.
-
Even when a neural network code executes without raising an exception, the network can still have bugs! These bugs might even be the insidious kind for which the network will train, but get stuck at a sub-optimal solution, or the resulting network does not have the desired architecture. (This is an example of the difference between a syntactic and semantic error.)
This Medium post, «How to unit test machine learning code,» by Chase Roberts discusses unit-testing for machine learning models in more detail. I borrowed this example of buggy code from the article:
def make_convnet(input_image):
net = slim.conv2d(input_image, 32, [11, 11], scope="conv1_11x11")
net = slim.conv2d(input_image, 64, [5, 5], scope="conv2_5x5")
net = slim.max_pool2d(net, [4, 4], stride=4, scope='pool1')
net = slim.conv2d(input_image, 64, [5, 5], scope="conv3_5x5")
net = slim.conv2d(input_image, 128, [3, 3], scope="conv4_3x3")
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.conv2d(input_image, 128, [3, 3], scope="conv5_3x3")
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.conv2d(input_image, 32, [1, 1], scope="conv6_1x1")
return net
Do you see the error? Many of the different operations are not actually used because previous results are over-written with new variables. Using this block of code in a network will still train and the weights will update and the loss might even decrease — but the code definitely isn’t doing what was intended. (The author is also inconsistent about using single- or double-quotes but that’s purely stylistic.)
The most common programming errors pertaining to neural networks are
- Variables are created but never used (usually because of copy-paste errors);
- Expressions for gradient updates are incorrect;
- Weight updates are not applied;
- Loss functions are not measured on the correct scale (for example, cross-entropy loss can be expressed in terms of probability or logits)
- The loss is not appropriate for the task (for example, using categorical cross-entropy loss for a regression task).
- Dropout is used during testing, instead of only being used for training.
- Make sure you’re minimizing the loss function $L(x)$, instead of minimizing $-L(x)$.
- Make sure your loss is computed correctly.
Unit testing is not just limited to the neural network itself. You need to test all of the steps that produce or transform data and feed into the network. Some common mistakes here are
NAorNaNorInfvalues in your data creatingNAorNaNorInfvalues in the output, and therefore in the loss function.- Shuffling the labels independently from the samples (for instance, creating train/test splits for the labels and samples separately);
- Accidentally assigning the training data as the testing data;
- When using a train/test split, the model references the original, non-split data instead of the training partition or the testing partition.
- Forgetting to scale the testing data;
- Scaling the testing data using the statistics of the test partition instead of the train partition;
- Forgetting to un-scale the predictions (e.g. pixel values are in [0,1] instead of [0, 255]).
- Here’s an example of a question where the problem appears to be one of model configuration or hyperparameter choice, but actually the problem was a subtle bug in how gradients were computed. Is this drop in training accuracy due to a statistical or programming error?
For the love of all that is good, scale your data
The scale of the data can make an enormous difference on training. Sometimes, networks simply won’t reduce the loss if the data isn’t scaled. Other networks will decrease the loss, but only very slowly. Scaling the inputs (and certain times, the targets) can dramatically improve the network’s training.
- Prior to presenting data to a neural network, standardizing the data to have 0 mean and unit variance, or to lie in a small interval like $[-0.5, 0.5]$ can improve training. This amounts to pre-conditioning, and removes the effect that a choice in units has on network weights. For example, length in millimeters and length in kilometers both represent the same concept, but are on different scales. The exact details of how to standardize the data depend on what your data look like.
-
Data normalization and standardization in neural networks
- Why does $[0,1]$ scaling dramatically increase training time for feed forward ANN (1 hidden layer)?
- Batch or Layer normalization can improve network training. Both seek to improve the network by keeping a running mean and standard deviation for neurons’ activations as the network trains. It is not well-understood why this helps training, and remains an active area of research.
- «Understanding Batch Normalization» by Johan Bjorck, Carla Gomes, Bart Selman
- «Towards a Theoretical Understanding of Batch Normalization» by Jonas Kohler, Hadi Daneshmand, Aurelien Lucchi, Ming Zhou, Klaus Neymeyr, Thomas Hofmann
- «How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)» by Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, Aleksander Madry
Crawl Before You Walk; Walk Before You Run
Wide and deep neural networks, and neural networks with exotic wiring, are the Hot Thing right now in machine learning. But these networks didn’t spring fully-formed into existence; their designers built up to them from smaller units. First, build a small network with a single hidden layer and verify that it works correctly. Then incrementally add additional model complexity, and verify that each of those works as well.
-
Too few neurons in a layer can restrict the representation that the network learns, causing under-fitting. Too many neurons can cause over-fitting because the network will «memorize» the training data.
Even if you can prove that there is, mathematically, only a small number of neurons necessary to model a problem, it is often the case that having «a few more» neurons makes it easier for the optimizer to find a «good» configuration. (But I don’t think anyone fully understands why this is the case.) I provide an example of this in the context of the XOR problem here: Aren’t my iterations needed to train NN for XOR with MSE < 0.001 too high?.
-
Choosing the number of hidden layers lets the network learn an abstraction from the raw data. Deep learning is all the rage these days, and networks with a large number of layers have shown impressive results. But adding too many hidden layers can make risk overfitting or make it very hard to optimize the network.
-
Choosing a clever network wiring can do a lot of the work for you. Is your data source amenable to specialized network architectures? Convolutional neural networks can achieve impressive results on «structured» data sources, image or audio data. Recurrent neural networks can do well on sequential data types, such as natural language or time series data. Residual connections can improve deep feed-forward networks.
Neural Network Training Is Like Lock Picking
To achieve state of the art, or even merely good, results, you have to set up all of the parts configured to work well together. Setting up a neural network configuration that actually learns is a lot like picking a lock: all of the pieces have to be lined up just right. Just as it is not sufficient to have a single tumbler in the right place, neither is it sufficient to have only the architecture, or only the optimizer, set up correctly.
Tuning configuration choices is not really as simple as saying that one kind of configuration choice (e.g. learning rate) is more or less important than another (e.g. number of units), since all of these choices interact with all of the other choices, so one choice can do well in combination with another choice made elsewhere.
This is a non-exhaustive list of the configuration options which are not also regularization options or numerical optimization options.
All of these topics are active areas of research.
-
The network initialization is often overlooked as a source of neural network bugs. Initialization over too-large an interval can set initial weights too large, meaning that single neurons have an outsize influence over the network behavior.
-
The key difference between a neural network and a regression model is that a neural network is a composition of many nonlinear functions, called activation functions. (See: What is the essential difference between neural network and linear regression)
Classical neural network results focused on sigmoidal activation functions (logistic or $tanh$ functions). A recent result has found that ReLU (or similar) units tend to work better because the have steeper gradients, so updates can be applied quickly. (See: Why do we use ReLU in neural networks and how do we use it?) One caution about ReLUs is the «dead neuron» phenomenon, which can stymie learning; leaky relus and similar variants avoid this problem. See
-
Why can’t a single ReLU learn a ReLU?
-
My ReLU network fails to launch
There are a number of other options. See: Comprehensive list of activation functions in neural networks with pros/cons
- Residual connections are a neat development that can make it easier to train neural networks. «Deep Residual Learning for Image Recognition»
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun In: CVPR. (2016). Additionally, changing the order of operations within the residual block can further improve the resulting network. «Identity Mappings in Deep Residual Networks» by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Non-convex optimization is hard
The objective function of a neural network is only convex when there are no hidden units, all activations are linear, and the design matrix is full-rank — because this configuration is identically an ordinary regression problem.
In all other cases, the optimization problem is non-convex, and non-convex optimization is hard. The challenges of training neural networks are well-known (see: Why is it hard to train deep neural networks?). Additionally, neural networks have a very large number of parameters, which restricts us to solely first-order methods (see: Why is Newton’s method not widely used in machine learning?). This is a very active area of research.
-
Setting the learning rate too large will cause the optimization to diverge, because you will leap from one side of the «canyon» to the other. Setting this too small will prevent you from making any real progress, and possibly allow the noise inherent in SGD to overwhelm your gradient estimates. See:
- How can change in cost function be positive?
-
Gradient clipping re-scales the norm of the gradient if it’s above some threshold. I used to think that this was a set-and-forget parameter, typically at 1.0, but I found that I could make an LSTM language model dramatically better by setting it to 0.25. I don’t know why that is.
-
Learning rate scheduling can decrease the learning rate over the course of training. In my experience, trying to use scheduling is a lot like regex: it replaces one problem («How do I get learning to continue after a certain epoch?») with two problems («How do I get learning to continue after a certain epoch?» and «How do I choose a good schedule?»). Other people insist that scheduling is essential. I’ll let you decide.
-
Choosing a good minibatch size can influence the learning process indirectly, since a larger mini-batch will tend to have a smaller variance (law-of-large-numbers) than a smaller mini-batch. You want the mini-batch to be large enough to be informative about the direction of the gradient, but small enough that SGD can regularize your network.
-
There are a number of variants on stochastic gradient descent which use momentum, adaptive learning rates, Nesterov updates and so on to improve upon vanilla SGD. Designing a better optimizer is very much an active area of research. Some examples:
- No change in accuracy using Adam Optimizer when SGD works fine
- How does the Adam method of stochastic gradient descent work?
- Why does momentum escape from a saddle point in this famous image?
-
When it first came out, the Adam optimizer generated a lot of interest. But some recent research has found that SGD with momentum can out-perform adaptive gradient methods for neural networks. «The Marginal Value of Adaptive Gradient Methods in Machine Learning» by Ashia C. Wilson, Rebecca Roelofs, Mitchell Stern, Nathan Srebro, Benjamin Recht
-
But on the other hand, this very recent paper proposes a new adaptive learning-rate optimizer which supposedly closes the gap between adaptive-rate methods and SGD with momentum. «Closing the Generalization Gap of Adaptive Gradient Methods in Training Deep Neural Networks» by Jinghui Chen, Quanquan Gu
Adaptive gradient methods, which adopt historical gradient information to automatically adjust the learning rate, have been observed to generalize worse than stochastic gradient descent (SGD) with momentum in training deep neural networks. This leaves how to close the generalization gap of adaptive gradient methods an open problem. In this work, we show that adaptive gradient methods such as Adam, Amsgrad, are sometimes «over adapted». We design a new algorithm, called Partially adaptive momentum estimation method (Padam), which unifies the Adam/Amsgrad with SGD to achieve the best from both worlds. Experiments on standard benchmarks show that Padam can maintain fast convergence rate as Adam/Amsgrad while generalizing as well as SGD in training deep neural networks. These results would suggest practitioners pick up adaptive gradient methods once again for faster training of deep neural networks.
-
Specifically for triplet-loss models, there are a number of tricks which can improve training time and generalization. See: In training a triplet network, I first have a solid drop in loss, but eventually the loss slowly but consistently increases. What could cause this?
Regularization
Choosing and tuning network regularization is a key part of building a model that generalizes well (that is, a model that is not overfit to the training data). However, at the time that your network is struggling to decrease the loss on the training data — when the network is not learning — regularization can obscure what the problem is.
When my network doesn’t learn, I turn off all regularization and verify that the non-regularized network works correctly. Then I add each regularization piece back, and verify that each of those works along the way.
This tactic can pinpoint where some regularization might be poorly set. Some examples are
-
$L^2$ regularization (aka weight decay) or $L^1$ regularization is set too large, so the weights can’t move.
-
Two parts of regularization are in conflict. For example, it’s widely observed that layer normalization and dropout are difficult to use together. Since either on its own is very useful, understanding how to use both is an active area of research.
- «Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift» by Xiang Li, Shuo Chen, Xiaolin Hu, Jian Yang
- «Adjusting for Dropout Variance in Batch Normalization and Weight Initialization» by Dan Hendrycks, Kevin Gimpel.
- «Self-Normalizing Neural Networks» by Günter Klambauer, Thomas Unterthiner, Andreas Mayr and Sepp Hochreiter
Keep a Logbook of Experiments
When I set up a neural network, I don’t hard-code any parameter settings. Instead, I do that in a configuration file (e.g., JSON) that is read and used to populate network configuration details at runtime. I keep all of these configuration files. If I make any parameter modification, I make a new configuration file. Finally, I append as comments all of the per-epoch losses for training and validation.
The reason that I’m so obsessive about retaining old results is that this makes it very easy to go back and review previous experiments. It also hedges against mistakenly repeating the same dead-end experiment. Psychologically, it also lets you look back and observe «Well, the project might not be where I want it to be today, but I am making progress compared to where I was $k$ weeks ago.»
As an example, I wanted to learn about LSTM language models, so I decided to make a Twitter bot that writes new tweets in response to other Twitter users. I worked on this in my free time, between grad school and my job. It took about a year, and I iterated over about 150 different models before getting to a model that did what I wanted: generate new English-language text that (sort of) makes sense. (One key sticking point, and part of the reason that it took so many attempts, is that it was not sufficient to simply get a low out-of-sample loss, since early low-loss models had managed to memorize the training data, so it was just reproducing germane blocks of text verbatim in reply to prompts — it took some tweaking to make the model more spontaneous and still have low loss.)
Verify that your code is bug free
There’s a saying among writers that «All writing is re-writing» — that is, the greater part of writing is revising. For programmers (or at least data scientists) the expression could be re-phrased as «All coding is debugging.»
Any time you’re writing code, you need to verify that it works as intended. The best method I’ve ever found for verifying correctness is to break your code into small segments, and verify that each segment works. This can be done by comparing the segment output to what you know to be the correct answer. This is called unit testing. Writing good unit tests is a key piece of becoming a good statistician/data scientist/machine learning expert/neural network practitioner. There is simply no substitute.
You have to check that your code is free of bugs before you can tune network performance! Otherwise, you might as well be re-arranging deck chairs on the RMS Titanic.
There are two features of neural networks that make verification even more important than for other types of machine learning or statistical models.
-
Neural networks are not «off-the-shelf» algorithms in the way that random forest or logistic regression are. Even for simple, feed-forward networks, the onus is largely on the user to make numerous decisions about how the network is configured, connected, initialized and optimized. This means writing code, and writing code means debugging.
-
Even when a neural network code executes without raising an exception, the network can still have bugs! These bugs might even be the insidious kind for which the network will train, but get stuck at a sub-optimal solution, or the resulting network does not have the desired architecture. (This is an example of the difference between a syntactic and semantic error.)
This Medium post, «How to unit test machine learning code,» by Chase Roberts discusses unit-testing for machine learning models in more detail. I borrowed this example of buggy code from the article:
def make_convnet(input_image):
net = slim.conv2d(input_image, 32, [11, 11], scope="conv1_11x11")
net = slim.conv2d(input_image, 64, [5, 5], scope="conv2_5x5")
net = slim.max_pool2d(net, [4, 4], stride=4, scope='pool1')
net = slim.conv2d(input_image, 64, [5, 5], scope="conv3_5x5")
net = slim.conv2d(input_image, 128, [3, 3], scope="conv4_3x3")
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.conv2d(input_image, 128, [3, 3], scope="conv5_3x3")
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.conv2d(input_image, 32, [1, 1], scope="conv6_1x1")
return net
Do you see the error? Many of the different operations are not actually used because previous results are over-written with new variables. Using this block of code in a network will still train and the weights will update and the loss might even decrease — but the code definitely isn’t doing what was intended. (The author is also inconsistent about using single- or double-quotes but that’s purely stylistic.)
The most common programming errors pertaining to neural networks are
- Variables are created but never used (usually because of copy-paste errors);
- Expressions for gradient updates are incorrect;
- Weight updates are not applied;
- Loss functions are not measured on the correct scale (for example, cross-entropy loss can be expressed in terms of probability or logits)
- The loss is not appropriate for the task (for example, using categorical cross-entropy loss for a regression task).
- Dropout is used during testing, instead of only being used for training.
- Make sure you’re minimizing the loss function $L(x)$, instead of minimizing $-L(x)$.
- Make sure your loss is computed correctly.
Unit testing is not just limited to the neural network itself. You need to test all of the steps that produce or transform data and feed into the network. Some common mistakes here are
NAorNaNorInfvalues in your data creatingNAorNaNorInfvalues in the output, and therefore in the loss function.- Shuffling the labels independently from the samples (for instance, creating train/test splits for the labels and samples separately);
- Accidentally assigning the training data as the testing data;
- When using a train/test split, the model references the original, non-split data instead of the training partition or the testing partition.
- Forgetting to scale the testing data;
- Scaling the testing data using the statistics of the test partition instead of the train partition;
- Forgetting to un-scale the predictions (e.g. pixel values are in [0,1] instead of [0, 255]).
- Here’s an example of a question where the problem appears to be one of model configuration or hyperparameter choice, but actually the problem was a subtle bug in how gradients were computed. Is this drop in training accuracy due to a statistical or programming error?
For the love of all that is good, scale your data
The scale of the data can make an enormous difference on training. Sometimes, networks simply won’t reduce the loss if the data isn’t scaled. Other networks will decrease the loss, but only very slowly. Scaling the inputs (and certain times, the targets) can dramatically improve the network’s training.
- Prior to presenting data to a neural network, standardizing the data to have 0 mean and unit variance, or to lie in a small interval like $[-0.5, 0.5]$ can improve training. This amounts to pre-conditioning, and removes the effect that a choice in units has on network weights. For example, length in millimeters and length in kilometers both represent the same concept, but are on different scales. The exact details of how to standardize the data depend on what your data look like.
-
Data normalization and standardization in neural networks
- Why does $[0,1]$ scaling dramatically increase training time for feed forward ANN (1 hidden layer)?
- Batch or Layer normalization can improve network training. Both seek to improve the network by keeping a running mean and standard deviation for neurons’ activations as the network trains. It is not well-understood why this helps training, and remains an active area of research.
- «Understanding Batch Normalization» by Johan Bjorck, Carla Gomes, Bart Selman
- «Towards a Theoretical Understanding of Batch Normalization» by Jonas Kohler, Hadi Daneshmand, Aurelien Lucchi, Ming Zhou, Klaus Neymeyr, Thomas Hofmann
- «How Does Batch Normalization Help Optimization? (No, It Is Not About Internal Covariate Shift)» by Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, Aleksander Madry
Crawl Before You Walk; Walk Before You Run
Wide and deep neural networks, and neural networks with exotic wiring, are the Hot Thing right now in machine learning. But these networks didn’t spring fully-formed into existence; their designers built up to them from smaller units. First, build a small network with a single hidden layer and verify that it works correctly. Then incrementally add additional model complexity, and verify that each of those works as well.
-
Too few neurons in a layer can restrict the representation that the network learns, causing under-fitting. Too many neurons can cause over-fitting because the network will «memorize» the training data.
Even if you can prove that there is, mathematically, only a small number of neurons necessary to model a problem, it is often the case that having «a few more» neurons makes it easier for the optimizer to find a «good» configuration. (But I don’t think anyone fully understands why this is the case.) I provide an example of this in the context of the XOR problem here: Aren’t my iterations needed to train NN for XOR with MSE < 0.001 too high?.
-
Choosing the number of hidden layers lets the network learn an abstraction from the raw data. Deep learning is all the rage these days, and networks with a large number of layers have shown impressive results. But adding too many hidden layers can make risk overfitting or make it very hard to optimize the network.
-
Choosing a clever network wiring can do a lot of the work for you. Is your data source amenable to specialized network architectures? Convolutional neural networks can achieve impressive results on «structured» data sources, image or audio data. Recurrent neural networks can do well on sequential data types, such as natural language or time series data. Residual connections can improve deep feed-forward networks.
Neural Network Training Is Like Lock Picking
To achieve state of the art, or even merely good, results, you have to set up all of the parts configured to work well together. Setting up a neural network configuration that actually learns is a lot like picking a lock: all of the pieces have to be lined up just right. Just as it is not sufficient to have a single tumbler in the right place, neither is it sufficient to have only the architecture, or only the optimizer, set up correctly.
Tuning configuration choices is not really as simple as saying that one kind of configuration choice (e.g. learning rate) is more or less important than another (e.g. number of units), since all of these choices interact with all of the other choices, so one choice can do well in combination with another choice made elsewhere.
This is a non-exhaustive list of the configuration options which are not also regularization options or numerical optimization options.
All of these topics are active areas of research.
-
The network initialization is often overlooked as a source of neural network bugs. Initialization over too-large an interval can set initial weights too large, meaning that single neurons have an outsize influence over the network behavior.
-
The key difference between a neural network and a regression model is that a neural network is a composition of many nonlinear functions, called activation functions. (See: What is the essential difference between neural network and linear regression)
Classical neural network results focused on sigmoidal activation functions (logistic or $tanh$ functions). A recent result has found that ReLU (or similar) units tend to work better because the have steeper gradients, so updates can be applied quickly. (See: Why do we use ReLU in neural networks and how do we use it?) One caution about ReLUs is the «dead neuron» phenomenon, which can stymie learning; leaky relus and similar variants avoid this problem. See
-
Why can’t a single ReLU learn a ReLU?
-
My ReLU network fails to launch
There are a number of other options. See: Comprehensive list of activation functions in neural networks with pros/cons
- Residual connections are a neat development that can make it easier to train neural networks. «Deep Residual Learning for Image Recognition»
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun In: CVPR. (2016). Additionally, changing the order of operations within the residual block can further improve the resulting network. «Identity Mappings in Deep Residual Networks» by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Non-convex optimization is hard
The objective function of a neural network is only convex when there are no hidden units, all activations are linear, and the design matrix is full-rank — because this configuration is identically an ordinary regression problem.
In all other cases, the optimization problem is non-convex, and non-convex optimization is hard. The challenges of training neural networks are well-known (see: Why is it hard to train deep neural networks?). Additionally, neural networks have a very large number of parameters, which restricts us to solely first-order methods (see: Why is Newton’s method not widely used in machine learning?). This is a very active area of research.
-
Setting the learning rate too large will cause the optimization to diverge, because you will leap from one side of the «canyon» to the other. Setting this too small will prevent you from making any real progress, and possibly allow the noise inherent in SGD to overwhelm your gradient estimates. See:
- How can change in cost function be positive?
-
Gradient clipping re-scales the norm of the gradient if it’s above some threshold. I used to think that this was a set-and-forget parameter, typically at 1.0, but I found that I could make an LSTM language model dramatically better by setting it to 0.25. I don’t know why that is.
-
Learning rate scheduling can decrease the learning rate over the course of training. In my experience, trying to use scheduling is a lot like regex: it replaces one problem («How do I get learning to continue after a certain epoch?») with two problems («How do I get learning to continue after a certain epoch?» and «How do I choose a good schedule?»). Other people insist that scheduling is essential. I’ll let you decide.
-
Choosing a good minibatch size can influence the learning process indirectly, since a larger mini-batch will tend to have a smaller variance (law-of-large-numbers) than a smaller mini-batch. You want the mini-batch to be large enough to be informative about the direction of the gradient, but small enough that SGD can regularize your network.
-
There are a number of variants on stochastic gradient descent which use momentum, adaptive learning rates, Nesterov updates and so on to improve upon vanilla SGD. Designing a better optimizer is very much an active area of research. Some examples:
- No change in accuracy using Adam Optimizer when SGD works fine
- How does the Adam method of stochastic gradient descent work?
- Why does momentum escape from a saddle point in this famous image?
-
When it first came out, the Adam optimizer generated a lot of interest. But some recent research has found that SGD with momentum can out-perform adaptive gradient methods for neural networks. «The Marginal Value of Adaptive Gradient Methods in Machine Learning» by Ashia C. Wilson, Rebecca Roelofs, Mitchell Stern, Nathan Srebro, Benjamin Recht
-
But on the other hand, this very recent paper proposes a new adaptive learning-rate optimizer which supposedly closes the gap between adaptive-rate methods and SGD with momentum. «Closing the Generalization Gap of Adaptive Gradient Methods in Training Deep Neural Networks» by Jinghui Chen, Quanquan Gu
Adaptive gradient methods, which adopt historical gradient information to automatically adjust the learning rate, have been observed to generalize worse than stochastic gradient descent (SGD) with momentum in training deep neural networks. This leaves how to close the generalization gap of adaptive gradient methods an open problem. In this work, we show that adaptive gradient methods such as Adam, Amsgrad, are sometimes «over adapted». We design a new algorithm, called Partially adaptive momentum estimation method (Padam), which unifies the Adam/Amsgrad with SGD to achieve the best from both worlds. Experiments on standard benchmarks show that Padam can maintain fast convergence rate as Adam/Amsgrad while generalizing as well as SGD in training deep neural networks. These results would suggest practitioners pick up adaptive gradient methods once again for faster training of deep neural networks.
-
Specifically for triplet-loss models, there are a number of tricks which can improve training time and generalization. See: In training a triplet network, I first have a solid drop in loss, but eventually the loss slowly but consistently increases. What could cause this?
Regularization
Choosing and tuning network regularization is a key part of building a model that generalizes well (that is, a model that is not overfit to the training data). However, at the time that your network is struggling to decrease the loss on the training data — when the network is not learning — regularization can obscure what the problem is.
When my network doesn’t learn, I turn off all regularization and verify that the non-regularized network works correctly. Then I add each regularization piece back, and verify that each of those works along the way.
This tactic can pinpoint where some regularization might be poorly set. Some examples are
-
$L^2$ regularization (aka weight decay) or $L^1$ regularization is set too large, so the weights can’t move.
-
Two parts of regularization are in conflict. For example, it’s widely observed that layer normalization and dropout are difficult to use together. Since either on its own is very useful, understanding how to use both is an active area of research.
- «Understanding the Disharmony between Dropout and Batch Normalization by Variance Shift» by Xiang Li, Shuo Chen, Xiaolin Hu, Jian Yang
- «Adjusting for Dropout Variance in Batch Normalization and Weight Initialization» by Dan Hendrycks, Kevin Gimpel.
- «Self-Normalizing Neural Networks» by Günter Klambauer, Thomas Unterthiner, Andreas Mayr and Sepp Hochreiter
Keep a Logbook of Experiments
When I set up a neural network, I don’t hard-code any parameter settings. Instead, I do that in a configuration file (e.g., JSON) that is read and used to populate network configuration details at runtime. I keep all of these configuration files. If I make any parameter modification, I make a new configuration file. Finally, I append as comments all of the per-epoch losses for training and validation.
The reason that I’m so obsessive about retaining old results is that this makes it very easy to go back and review previous experiments. It also hedges against mistakenly repeating the same dead-end experiment. Psychologically, it also lets you look back and observe «Well, the project might not be where I want it to be today, but I am making progress compared to where I was $k$ weeks ago.»
As an example, I wanted to learn about LSTM language models, so I decided to make a Twitter bot that writes new tweets in response to other Twitter users. I worked on this in my free time, between grad school and my job. It took about a year, and I iterated over about 150 different models before getting to a model that did what I wanted: generate new English-language text that (sort of) makes sense. (One key sticking point, and part of the reason that it took so many attempts, is that it was not sufficient to simply get a low out-of-sample loss, since early low-loss models had managed to memorize the training data, so it was just reproducing germane blocks of text verbatim in reply to prompts — it took some tweaking to make the model more spontaneous and still have low loss.)

- Разработчикам
Рецепт обучения нейронных сетей
Поговорим о том, как можно избежать ошибок при обучении нейронной сети (или исправить их очень быстро).
Перевод “рецепта обучения нейронной сети” (с комментариями и замечаниями) – статьи из блога Andrej Karpathy О хакерском руководстве по нейронным сетям.
Пожалуй, это лучший практический материал по нейронным сетям в 2019 году. Рекомендуем к изучению и практическому использованию!

Несколько недель назад я опубликовал твит о «самых распространенных ошибках при обучении нейронных сетей», перечислив некоторые из них. Твит получил намного больший отклик, чем я ожидал (включая вебинар :)). Очевидно, что многие люди лично сталкивались с большим разрывом между утверждениями «вот как работает сверточная сеть» и «наша сеть достигает выдающихся результатов».
Поэтому я подумал, что было бы забавно отмахнуться от моего пыльного блога, и расширить мой твит до полной формы, которой заслуживает эта тема. При этом я не буду углубляться в перечисление наиболее распространенных ошибок или конкретизировать их. Вместо этого, я хотел бы копнуть немного глубже и поговорить о том, как можно вообще избежать этих ошибок (или исправить их очень быстро).
Рецепт заключается в том, чтобы следовать определенному процессу, который, насколько я могу судить, не очень часто документируется. Но сначала давайте начнем с двух важных наблюдений, которые это подтверждают.
1) Обучение нейронной сети – это уплывающая абстракция
Считается, что обучение нейронной сети легко начать. Многочисленные библиотеки и фреймворки гордятся 30-строчными чудо-фрагментами кода. Они решают ваши проблемы с данными, создавая ложное впечатление, что все это работает как «включи и играй».
>>> your_data = # вставьте свой потрясающий набор данных сюда
>>> model = SuperCrossValidator (SuperDuper.fit , your_data , ResNet50, SGDOptimizer)
# завоевать мир здесь
Эти библиотеки и примеры активируют ту часть нашего мозга, которая знакома со стандартным программированием, где часто используются чистые API и абстракции. Вам приводят библиотеку для демонстрации:
>>> r = reports.get (‘ https://api.github.com/user ‘, auth = (‘user’, ‘pass’))
>>> r.status_code
200
Это круто! Смелый разработчик взял на себя бремя понимания строк запросов, URL-адресов, запросов GET / POST, HTTP-соединений и т.д. И в значительной степени скрыл сложность за несколькими строками кода. Это то, что мы видим и ожидаем, но, к сожалению, нейронные сети работают не так. Они не являются готовой технологией, если вы немного отклонитесь от обучения классификатора ImageNet. Я попытался подчеркнуть это в своем посте «Да, вы должны понимать backprop», назвав backpropagation «уплывающей абстракцией».
К сожалению, ситуация гораздо более сложная. Backprop + SGD волшебным образом не заставят вашу сеть работать. Batchnorm волшебным образом не заставят сеть сходиться быстрее. RNN волшебным образом не позволит вам «получить» текст. И только потому, что вы можете сформулировать свою проблему как RL (Reinforcement Learning – обучение с подкреплением), не означает, что вы должны это делать. Если вы используете технологию, не понимая, как она работает, вы, скорее всего, потерпите неудачу. Что приводит меня к …
2) Обучение нейронной сети проваливается незаметно…
Когда в стандартном программировании вы нарушаете или неправильно конфигурируете код, вы обычно получаете сообщение об ошибке, как то: вы использовали целое число там, где ожидалась строка; функция имеет только три аргумента; импорт не удался; ключ не существует; количество элементов в двух списках разное. Кроме того, вы часто можете создать модульные тесты для тестирования функциональности.

В случае же обучения нейронных сетей это только начало. Синтаксически все может быть правильным, но все не правильно организовано, и это действительно трудно заметить. «Пространство возможных ошибок» является большим, логичным (в отличие от синтаксических) и очень сложным для модульного тестирования. Например, возможно, вы забыли перевернуть метки, когда вы переворачивали изображение влево-вправо во время аугментации данных. Ваша сеть все еще может (шокирующе) работать довольно хорошо, потому что ваша сеть может научиться обнаруживать перевернутые изображения, и также перевернуть свои прогнозы влево-вправо. Или, возможно, ваша авто-регрессионная модель случайно принимает то, что она пытается предсказать, в качестве входных данных из-за ошибки off-by-one (неучтенной единицы). Или вы пытались обрезать свои градиенты, но вместо этого обрезали loss, в результате чего во время тренировки игнорировались выбросы. Или вы инициализировали свои веса с предварительно обученной контрольной точки, но не использовали исходное среднее значение. Или вы просто испортили настройки регуляризации, скорости обучения, скорости затухания, размера модели и т.д. Поэтому ваша неправильно сконфигурированная нейронная сеть будет генерировать исключения, и то, если вам повезет. Она будет продолжать тренироваться, но незаметно будет работать все хуже и хуже.
В результате (и это reeaally трудно оценить) «быстрый и напористый» подход к обучению нейронных сетей не работает и приводит к ненужным мучениям. И эти мучения в итоге становятся естественной частью обучения нейронной сети. Но их можно уменьшить, если быть тщательным, параноидальным и одержимым визуализацией практически всего. По моему опыту, наиболее сильно коррелируют с успехами в глубоком обучении – это терпение и внимание к деталям.
Рецепт
В свете вышеупомянутых двух фактов я разработал для себя особый процесс, которому я следую, применяя нейронную сеть к новой проблеме. Вы увидите, что к двум вышеизложенным наблюдениям надо относиться очень серьезно. В частности, рецепт всегда строится от простого к сложному. На каждом этапе мы выдвигаем конкретные гипотезы о том, что произойдет, а затем либо проверяем их экспериментом, либо исследуем, пока не обнаружим какую-то проблему. То, что мы пытаемся предотвратить очень сложно, – это введение большого количества «непроверенных» усложнений одновременно, что неизбежно приводит к ошибкам / неправильной конфигурации. Чтобы написание кода нейронной сети было действительно похоже на обучение, нужно использовать очень небольшую скорость обучения и проводить полный набор тестов после каждой итерации.
1. Сроднитесь с данными
Первый шаг к обучению нейронной сети состоит в том, чтобы вообще не касаться кода нейронной сети, а вместо этого начать с тщательного изучения данных. Этот шаг очень важен. Мне нравится тратить огромное количество времени (измеряемое часами) на просмотр тысяч примеров, понимание их распределения и поиск шаблонов. К счастью, ваш мозг очень хорош в этом. Однажды я обнаружил, что данные содержат дубликаты примеров. В другой раз я нашел поврежденные изображения / метки. Я ищу дисбалансы данных и отклонения. Обычно я также применяю свой собственный процесс классификации данных, который намекает на типы архитектур, которые мы в конечном итоге рассмотрим. Например, достаточно ли локальных функций или нам нужен глобальный контекст? Сколько существует вариаций и в какой форме? Какой вариант является ложным и может быть предварительно отброшен? Имеет ли значение пространственное распределение или мы можем усреднить его? Насколько важны детали и как сильно мы можем уменьшить изображение? Насколько зашумлены метки?
Кроме того, поскольку нейронная сеть фактически является сжатой /
скомпилированной версией вашего набора данных, вы сможете посмотреть на свои сетевые
(неправильные) прогнозы и понять, откуда они могут исходить. И если ваша сеть
дает вам какой-то прогноз, который не соответствует тому, что вы видели в
данных, что-то не так.
Как только у вас появляется качественное понимание данных, также хорошей идеей является написание простого кода для поиска / фильтрации / сортировки по параметрам, которые вы только можете придумать (например, тип метки, размер аннотаций, количество аннотаций и т.д.). Визуализируйте их распределение и выбросы вдоль какой-либо оси. Выбросы почти всегда обнаруживают некоторые ошибки в качестве данных или предварительной обработке.
2. Настройте сквозной скелет обучения / оценки + установите
базовые ориентиры
Теперь, когда мы понимаем наши данные, можем ли мы обратиться к нашему сверхумному мультимасштабному ASPP FPN ResNet и начать обучение потрясающих моделей? Ещё нет. Это будет дорога к мучениям. Наш следующий шаг – создать полный скелет обучения и оценки и обрести уверенность в его правильности с помощью серии экспериментов. На этом этапе лучше выбрать какую-нибудь простую модель, которую вы, возможно, не могли бы испортить, например, линейный классификатор или очень крошечный ConvNet. Мы хотим обучить его, визуализировать функцию потерь, любые другие метрики (например, точность), предсказания модели и выполнить серию отсекающих экспериментов с явными гипотезами.
Советы и рекомендации для этого этапа:
- Зафиксируйте random seed. Всегда используйте фиксированное случайное начальное число, чтобы гарантировать, что при повторном запуске вы получите тот же результат. Это устраняет фактор случайной вариации и удерживает нас в рамках здравого смысла. [Прим. Id-lab. Это, безусловно, полезно при тестировании / настройке вашей модели. Не забудьте только перед началом “боевого” обучения убрать фиксацию random seed. Иначе, обучение вашей сеть будет “страдать” от отсутствия вариативности.]
- Упрощайте. Обязательно отключите любые ненужные улучшения. В частности, обязательно отключите любую аугментацию данных на этом этапе. Аугментация данных – это стратегия регуляризации, которую мы можем использовать позже, но пока это еще одна возможность привнести какую-нибудь глупую ошибку.
- Делайте eval на значимом наборе тестовых данных. При построении функции потерь на тестовых данных выполните оценку по всему (большому) тестовому набору. Не смотрите тестовые потери только на партии (batch), полагаясь на их сглаживание в Tensorboard. Мы стремимся к правильности и очень хотим потратить время, чтобы оставаться в рамках здравого смысла.
- Подтвердите loss @ init. Убедитесь, что ваша функция потерь стартует с правильного значения. Например, если вы правильно инициализируете свой последний слой, вы должны получить -ln(1/n_classes) на моделях с softmax при инициализации. Те же значения по умолчанию могут быть получены для регрессии L2, функции Хьюбера и т.д.
- Инициализируйте верно. Инициализируйте веса последнего слоя правильно. Например, если вы регрессируете некоторые значения, которые имеют среднее значение 50, инициализируйте смещение (bias) последнего слоя значением 50. Если у вас есть несбалансированный набор данных с соотношением 1:10 положительных: отрицательных значений, установите смещение в logits так, чтобы ваша сеть предсказывала вероятность 0,1 при инициализации. Правильная их установка ускорит конвергенцию и устранит фактор «хоккейной клюшки», когда в течение первых нескольких итераций ваша сеть просто ищет правильное смещение (bias). [Прим. Id-lab. Верную начальную инициализацию весов и смещения сложно переоценить. Это важно не только для быстрой начальной сходимости модели. Неверная инициализация коэффициентов может в целом привести к фатальной ошибке, загнав модель в локальный минимум или «посадить» ее на плато, из которых невозможно выбраться. Также возможно получить слишком малые или слишком большие градиенты при backprop, что не позволит модели обучаться. Необходимо правильно установить начальный bias последнего слоя (bias внутренних слоёв можно инициализировать нулями) и веса всех уровней модели. Если ваши данные не содержат каких-либо особенностей и нормализованы со средним значением ноль, то веса также лучше инициализировать распределениями с нулевым средним. В частности, для нормализованных изображений очень хорошо подходит he_uniform. Для правильной установки смещения последнего слоя автор обоснованно предлагает использовать следующие соображения. Для задач классификации c выходной функцией активации softmax, когда все классы сбалансированы, при первом прогоне модель должна логично предсказывать для каждого класса значение 1/[число классов]. Для несбалансированной выборки оценку bias можно вывести из ожидаемого предсказания позитивного – pos (обычно меньшего, несбалансированного) класса: pos/(pos+neg) = 1/(1+exp(-bias)); bias = ln(pos/neg). Здесь мы разумно предполагаем, что при первом прогоне, модель должна просто транслировать на выход особенности входных данных x и выдать усредненные к нулю значения ядра: w.T * x. В этом случае именно bias последнего слоя должен определить верное значение z = w.T * x + bias для начального значения аргумента функции потерь.]
- Человеческий ориентир. Мониторьте показатели, помимо функции потерь, которые можно интерпретировать и проверить (например, точность). По возможности оцените свою (человеческую) точность и сравните с ней. В качестве альтернативы, аннотируйте тестовые данные дважды и для каждого примера рассматривайте одну аннотацию как прогноз, а другую как базис (ground truth).
- Исходно-независимая базовая линия. Обучите независимую от входа базовую линию (например, проще всего просто установить все ваши входы на ноль). Это должно работать хуже, чем когда вы фактически подключаете свои данные, не обнуляя их. Так ли это? Т.е. научилась ли ваша модель извлекать какую-либо информацию из входных данных вообще?
- Переобучите одну партию. Переобучите одну партию из нескольких примеров (например, всего двух). Для этого мы увеличиваем емкость нашей модели (например, добавляем слои или фильтры) и проверяем, что мы можем достичь наименьших достижимых потерь (например, ноль). Мне также нравится визуализировать на одном графике как метку, так и прогноз, и убедиться, что они в итоге выровняются идеально, как только мы достигнем минимальной потери. Если этого не происходит, где-то есть ошибка, и мы не можем перейти к следующему этапу.
- Проверьте уменьшение функции потерь при обучении. Надеемся, что на этом этапе вы будете не до обучать на своем наборе данных, поскольку работаете с игрушечной моделью. Попробуйте немного увеличить её мощность. Снизилась ли ваша функция потерь при обучении, как следовало бы?
- Визуализируйте данные прямо на входе сети. Однозначно правильное место для визуализации ваших данных находится непосредственно перед вашим y_hat = model(x) (или sess.run в tf ). То есть – вы хотите визуализировать именно то , что входит в вашу сеть, расшифровывая этот сырой тензор данных и меток в визуализации. Это единственный «источник правды». Я не могу сосчитать, сколько раз это спасло меня и выявило проблемы с предварительной обработкой и аугментации данных.
- Визуализируйте динамику прогнозирования. Мне нравится визуализировать прогнозы моделей для фиксированной тестовой партии в ходе обучения. «Динамика» того, как изменяются эти прогнозы, даст вам невероятно хорошую интуицию в том, как проходит обучение. Много раз можно почувствовать, что сеть «изо всех сил» приспосабливается к вашим данным, если она каким-то образом колеблется, выявляя нестабильность. Очень низкие или очень высокие показатели обучения также легко заметны по дрожанию.
- Используйте backprop для построения графиков зависимостей. Ваш код глубокого обучения часто будет содержать сложные, векторные и транслируемые операции. Относительно распространенная ошибка, с которой я сталкивался несколько раз, заключается в том, что люди ошибаются (например, они используют представление вместо транспонирования / перестановки где-либо) и непреднамеренно смешивают информацию в измерении пакета. Удручает тот факт, что ваша сеть, как правило, все еще работает нормально, потому что она научится игнорировать данные из других примеров. Один из способов отладки этого (и других связанных с этим проблем) состоит в том, чтобы установить потерю как нечто тривиальное, например, сумму всех выходных данных примера i, выполнить обратный проход до входа и убедиться, что вы получаете ненулевое значение градиента только на i-м входе. Та же самая стратегия может использоваться, например, чтобы гарантировать, что ваша модель авторегрессии в момент времени t зависит только от 1..t-1. В целом, градиенты дают вам информацию о том, что зависит от того, что находится в вашей сети, что может быть полезно для отладки.
- Обобщайте частный случай. Это немного более общий совет по кодированию, но я часто видел, как люди делают ошибки, когда они откусывают больше, чем могут прожевать, пишут относительно общую функциональность с нуля. Мне нравится писать очень специфическую функцию для того, что я делаю сейчас, заставить это работать, а затем обобщать ее позже, чтобы убедиться, что я получаю тот же результат. Часто это относится к векторному коду, где я почти всегда сначала записываю полностью зацикленную версию, а только затем преобразую ее в векторный код по одному циклу за раз.
3. Переобучение
На этом этапе у нас должно быть хорошее понимание набора данных, и у нас
работает полный конвейер обучения и оценки. Для любой данной модели мы можем
(воспроизводимо) вычислить метрики, которым мы доверяем. Мы также вооружены
нашей производительностью для независимой от ввода базовой линии,
производительностью нескольких простых базовых линий (мы должны улучшить их). У
нас также есть грубое представление о производительности человека (мы надеемся его
достичь). Теперь всё настроено для итераций на хорошей модели.
Подход, который я предпочитаю использовать для поиска хорошей модели,
состоит из двух этапов: сначала постройте модель, достаточно большую, чтобы она
смогла переобучиться (то есть сосредоточьтесь на функции потерь при обучении). И
затем упорядочьте ее (регуляризуйте), улучшив функцию потерь при валидации (validation loss) в ущерб
функции потерь при обучении (training loss). Причина,
по которой мне нравятся эти два этапа, заключается в том, что если мы вообще не
cможем
достичь низкого уровня ошибок с какой-либо моделью, это может снова указать на
некоторые проблемы, ошибки или неправильную конфигурацию.
Несколько советов и рекомендаций для этого этапа:
- Выбирая модель . Чтобы достичь правильных значений функции потери при обучении, вы должны выбрать подходящую архитектуру модели. Когда дело доходит до этого выбора, мой совет № 1: не будь героем. Я видел много людей, которые хотят стать сумасшедшими и креативными, собирая лего-блоки из набора инструментов нейронной сети в различных экзотических архитектурах, которые имеют для них какой-то смысл. Сильно сопротивляйтесь этому искушению на ранних стадиях вашего проекта. Я всегда советую людям просто найти наиболее подходящую статью и скопировать оттуда простейшую архитектуру, которая обеспечивает хорошую производительность. Например, если вы классифицируете изображения, не будьте героем, просто скопируйте и вставьте ResNet-50 для первого запуска. Позже вы можете сделать что-то более нестандартное и улучшить результат.
- Адам это безопасно. На ранних этапах определения базовых уровней мне нравится использовать оптимизатор Адама со скоростью обучения (learning rate) 3e-4. По моему опыту, Адам гораздо более терпим к гиперпараметрам, в том числе к плохой скорости обучения. Для ConvNets хорошо настроенный SGD почти всегда немного опережает Адама, но область оптимальной скорости обучения гораздо более узкая и специфическая для задачи. (Примечание. Если вы используете RNN и связанные с ними модели последовательностей, то лучше пользуетесь Адамом. На начальном этапе вашего проекта, опять же, не будьте героем и следуйте тому, что предлагают в большинстве статей.)
- По одному усложнению за раз. Если у вас есть несколько сигналов для подключения к вашему классификатору, я бы посоветовал вам подключать их по одному. И каждый раз проверять, что вы получаете повышение производительности, которое ожидаете. Не топите вашу модель в сложностях с самого начала. Существуют и другие способы наращивания сложности – например, вы можете сначала попытаться использовать изображения меньшего размера, а потом увеличить их и т.д.
- Не используйте затухание для скорости обучения (learning rate) по умолчанию. Если вы используете код из какого-либо другого домена, всегда будьте очень осторожны с затуханием скорости обучения. Вы не только захотите использовать другой график затухания для своей задачи. В оригинальной реализации график основан на определенном количестве эпох, которое может сильно варьироваться в зависимости от размера вашего набора данных. Например, ImageNet будет затухать в 10 раз на каждой 30-й эпохе. Если вы не тренируете ImageNet, то вы почти наверняка этого не хотите. Если вы не будете осторожны, ваш код может незаметно снизить скорость обучения до нуля слишком рано, не позволяя вашей модели сойтись. В своей работе я всегда полностью отключаю затухание скорости обучения (использую постоянный learning rate) и настраиваю это только в самом конце.
4. Регуляризация
В идеале, мы сейчас находимся на этапе, где у нас есть большая модель,
которая хорошо обучается на тренировочных данных. Теперь пришло время его регуляризовать
и улучшить точность валидации, ухудшив точность обучения. Некоторые советы и
рекомендации:
- Увеличьте набор данных. Во-первых, самый лучший и предпочтительный способ регуляризовать модель с
практической точки зрения – это добавить больше реальных данных для обучения.
Это очень распространенная ошибка – тратить много инженерных циклов, пытаясь
выжать сок из небольшого набора данных, когда вместо этого нужно собрать больше
данных. Насколько я знаю, добавление большего количества данных – это практически
единственный гарантированный способ монотонного повышения производительности
хорошо сконфигурированной нейронной сети практически до бесконечности. Другой
будет ансамбль (если вы можете себе это позволить), но это возможно только после
примерно 5 моделей. - Аугментация данных. Следующее лучшее, что можно сделать после увеличения реальных данных, –
это синтезировать наполовину фальшивые данные – попробуйте более агрессивную
аугментацию данных. - Креативная аугментация. Если наполовину фальшивых данных недостаточно, фальшивые данные тоже
могут помочь. Люди находят творческие способы расширения наборов данных.
Например, рандомизация доменов, использование симуляции, умные гибриды, такие как вставка (потенциально симулированная)
данных в сцены или даже GAN. - Предобученная сеть. Очень часто помогает использовать предварительно обученную сеть, даже
если у вас достаточно данных. - Используйте обучение с учителем. Не увлекайтесь неконтролируемым обучением (без
учителя). Несмотря на то, что утверждается в том известном посте за 2008 год,
насколько я знаю, ни одна из последующих реализаций не добилась сильных
результатах в современном компьютерном зрении (хотя NLP, похоже, в настоящее время неплохо
справляется с BERT и подобными сетями, вероятно, из-за более предопределенного
характера текстовых данных и более высокого отношения сигнал / шум). - Меньшая размерность входных данных. Удалите функции, которые могут содержать ложный
сигнал. Любые добавленные ложные данные – это просто еще одна возможность переобучения,
если ваш набор данных небольшой. Точно так же, если детали низкого уровня не
имеют большого значения, попробуйте использовать изображения меньшего размера. - Меньший размер модели. Во многих случаях вы можете использовать знание ограничений предметной
области, чтобы уменьшить размер сети. Например, раньше было модно использовать
слои Fully Connected в верхней части магистралей для ImageNet, но с тех пор они
были заменены простым средним пулированием, что исключило кучу ненужных параметров
из процесса. - Меньший размер партии (batch). Из-за нормализации, применяемой внутри партии,
меньший размер партии в некоторой степени соответствует более сильной
регуляризации. Это связано с тем, что эмпирическое среднее значение / отклонение
партии являются приблизительной версией полного среднего значения / отклонения,
поэтому масштаб и смещение «раскачивают» вашу партию сильнее.
[Прим. Id–lab. Эта рекомендация несколько
противоречит общепринятой практике использовать партии максимально возможного
размера. Больший размер партии, очевидно, способствует более быстрой сходимости
сети. В тоже время, уменьшение размера партии заставляет сеть обучаться медленнее,
но из-за более сильной «раскачки» это может привести в итоге к лучшему
результату.]
- Используйте drop. Применяйте dropout2d (пространственное выпадение) для ConvNets. Делайте это экономно / осторожно, потому что выпадение не очень хорошо сочетается с нормализацией партии.
- Затухание весов. Увеличьте штраф за затухание весов.
- Ранняя остановка (Early stopping). Прекращайте обучение, основываясь на изменениях функции потерь при валидации, чтобы поймать вашу модель, как только она собирается переобучиться.
- Попробуйте большую модель. Я упоминаю об этом в последний раз и только после средства ранней остановки. Но в прошлом я несколько раз обнаруживал, что большие модели в конечном итоге, могут переобучаться гораздо легче, но их «ранняя остановка» часто намного лучше, чем у меньших моделей.
Наконец, чтобы получить дополнительную уверенность в том, что ваша сеть
является разумным классификатором, мне нравится визуализировать веса первого
уровня сети и убедиться, что вы получите хорошие параметры, которые имеют
смысл. Если ваши фильтры первого слоя выглядят как шум, значит, что-то не так.
Аналогичным образом, уровни активация внутри сети могут иногда отображать
странные артефакты и указывать на проблемы.
5. Настройка
На этом этапе вы должны полностью владеть вашим набором данных, исследовав
широкий набор возможных моделей, которые дают низкое значение функции потерь
при валидации. Вот несколько советов для этого шага:
- Случайный поиск по сетке. Для одновременной настройки нескольких гипер-параметров
может показаться заманчивым использование поиска по сетке для обеспечения
охвата всех настроек, но имейте в виду, что вместо этого лучше
использовать случайный поиск. Интуитивно это объясняется тем, что нейронные сети
часто гораздо более чувствительны к одним параметрам, чем к другим. Например,
если параметр a имеет значение, а изменение b недает
никакого эффекта, вы бы предпочли более точную настройку по a, чем в нескольких фиксированных
точках. - Оптимизация гипер-параметров. Есть большое количество привлекательных байесовских
наборов инструментов для оптимизации гипер-параметров, и некоторые из моих
друзей говорили об успехе при работе с ними. Мой личный опыт заключается в том,
что современный подход к исследованию широкого пространства моделей и гипер-параметров
это использовать стажера :). Просто шучу.
6. Последняя капля
Когда вы уже нашли лучшие типы архитектур и гипер-параметров, вы все равно можете
использовать еще несколько приемов, чтобы выжать из системы последние капли
сока:
- Ансамбли. Модельные
ансамбли – это в значительной степени гарантированный способ улучшить точность
на 2% по всем показателям. Если вы не можете позволить себе вычисления во время
тестирования, изучите возможность объединения вашего ансамбля в сеть с
использованием темных знаний . - Продолжайте обучение. Я часто видел людей, прекращающих обучение модели, когда функция потерь
при валидации перестает уменьшаться. По моему опыту, сети продолжают
тренироваться интуитивно долгое время. Однажды я случайно оставил модель
обучаться на время зимних каникул, и когда я вернулся в январе, это был шедевр.
Вывод
Раз вы добрались до этого этапа, у вас должны быть все составляющие для успеха: у вас есть глубокое понимание технологии, набора данных и задачи, вы создали всю инфраструктуру обучения / оценки и достигли высокой уверенности в ее точности. Вы исследовали разные сложные модели, улучшая производительность способами, которые вы контролировали на каждом этапе. Теперь вы готовы прочитать много статей, провести большое количество экспериментов и получить результаты на уровне произведений искусства. Удачи!

Библиографическое описание:
Кураева, Е. С. Проблемы обучения нейронных сетей / Е. С. Кураева. — Текст : непосредственный // Молодой ученый. — 2020. — № 14 (304). — С. 72-74. — URL: https://moluch.ru/archive/304/68605/ (дата обращения: 12.02.2023).
В данной статье рассматриваются проблемы, которые могут возникнуть при работе с нейронными сетями, а также способы их устранения.
Ключевые слова: нейронные сети, обучение, подготовка начальных значений весовых коэффициентов, планирование выходных значений.
Нейронные сети не всегда работают так, как запланировано. Необходимо спланировать тренировочные данные и начальные значения весов, а также спланировать выходные значения. Факторы, которые влияют на незапланированную работу нейронной сети и будут рассмотрены в данной работе.
Распространенной проблемой является насыщение сети. Она возникает, если присутствуют большие значения сигналов, часто спровоцированные большими начальными весовыми коэффициентами. Таким образом сигналы попадут в область близких к нулю градиенту функции активации. Что в свою очередь влияет на способность к обучению, а именно на подбор лучших коэффициентов.
- Входные значения
Если использовать в качестве функции активации — сигмоиду, то при слишком больших значениях входных данных, прямая будет выглядеть, как прямая. Поэтому рекомендуется задавать небольшие значения. Однако слишком маленькие значения также будут плохо сказываться на обучение, так как точность компьютерных вычислений снижается. Поэтому советуется выбирать значения входных данных от 0.0 до 1.0. При этом можно ввести смещение равное 0.01. [2, c. 124].
На рисунке 1 видно, что при увеличении входных данных, способность нейронной сети к обучению снижается, так как сигмоида почти выпрямляется.
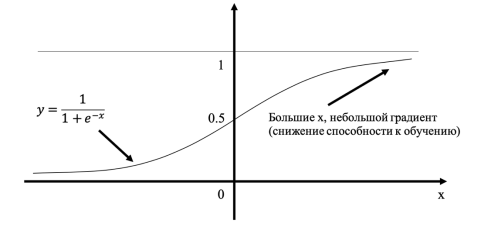
Рис. 1. Подготовка входных данных
- Выходные значения
Выходные значения следует подбирать, в зависимости от выбранной функции активации. Если она не способна обеспечивать значения свыше 1.0, но выходные значения мы хотим получить больше 1.0, то весовые коэффициенты будут увеличиваться, чтобы подстроиться под ситуацию. Но ничего не выйдет, выходные значения все равно не будут больше максимального значения функции активации. Поэтому выходные значения следует масштабировать в пределах от 0.0 до 1.0. Так как граничные значения не достигаются, то советуется выбирать значения от 0.01 до 0.99. На рис. 2 продемонстрировано данное правило.
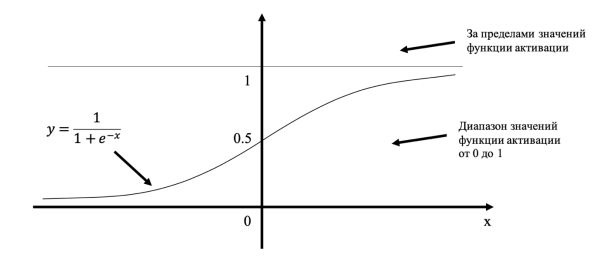
Рис. 2. Ограничение по выходных значениям
- Случайные начальные значения весовых коэффициентов
Самый простой вариант в выборе начальных значений весовых коэффициентов — выбирать их из диапазона от -1.0 до +1.0.
Но существуют подходы, которые позволяют определить коэффициенты в зависимости от конфигурации сети. Цель заключается в том, чтобы если на узел сети поступает множество сигналов и их поведение известно, то весовые коэффициенты не должны нарушать их состояние. То есть веса не должна нарушать тщательную подготовку входных и выходных значений, описанный в пунктах 1 и 2.
Если грубо описать правило, то оно звучит так: «Весовые коэффициенты инициализируются числами, случайно выбираемыми из диапазона, которые определяются обратной величиной квадратного корня из количества связей, ведущих к узлу» [2, с. 126].
На рис. 3 иллюстрируются подходы для выбора начальных весов.
Рис. 3. Подходы к выбору весовых коэффициентов
Советуется не задавать одинаковые веса. Таким образом бы в узлы пришли бы одинаковые сигналы и выходные значения получились бы одинаковыми. И после обновления весов, их значения все равно будут равными.
Также нельзя задавать нулевые значения для весовых коэффициентов, так как входные значения в этом случае «теряют свою силу».
Вывод
Чтобы нейронные сети работали удовлетворительно, необходимо входные и выходные данные, а также начальные значения весовых коэффициентов задавать в зависимости от структуры нейронной сети. Также преградой для наилучшего обучения сети являются нулевые значения сигналов и весов. А значения весовых коэффициентов должны отличаться друг от друга.
Входные и выходные значения должна быть масштабированными.
Литература:
1. Хайкин С. Нейронные сети. — М.: Вильямс, 2006.
2. Рашид Т. Создает нейронную сеть. — М.: Диалектика, 2019.
Основные термины (генерируются автоматически): выходной, коэффициент, нейронная сеть, данные.
нейронные сети, обучение, подготовка начальных значений весовых коэффициентов, планирование выходных значений
Похожие статьи
Использование искусственных нейронных сетей для…
нейронная сеть, обратное распространение ошибки, сеть, коэффициент корреляции, прямой проход, левый желудочек, корреляционный анализ, диастолическая дисфункция, гиперболический тангенс… Исследование и сравнительный анализ работы нейронных сетей…
Нейросетевые технологии и их применение при прогнозировании…
Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение.
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
Ключевые слова: сеть, нейронная сеть, искусственный интеллект, язык программирования, протон, python, сигмоида, входной слой, скрытый слой, выходной слой, функция активации, jupiter notebook. Структура нейронной сети пришла в мир программирования из биологии.
Исследование и сравнительный анализ работы нейронных сетей…
Каждая нейронная сеть, подключенная к группе, генерирует случайные весовые коэффициенты, затем каждая сеть обучается отдельно на
Для объединения выходных данных группы нейронных сетей используется усредненную простую группировку.
Анализ и классификация погрешностей обучения…
Нейронная сеть, решающая задачу прогнозирования фронта пика, состоит из входного и выходного слоев с одним нейроном и 4-х слоёв по 50 нейронов в. Анализ и классификация погрешностей обучения информационно-измерительных систем на базе нейронных сетей.
Исследование возможностей использования нейронных сетей
В данной статье рассматриваются теоретические основы нейронных сетей, исследование их видов и описание их математической модели. Целью данной статьи является исследование возможностей использования нейронных сетей.
Модель математической нейронной сети | Статья в журнале…
Выходные данные передаем дальше.
Тренировочный сет— это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1…
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
Ключевые слова: нейронная сеть, интеллектуальные технологии, анализ
Нейронная сеть — это система, состоящая из многих простых вычислительных элементов, или нейронов
Для построения нейросетевой модели использовано 6 входных факторов ( ), 1 выходное значение…
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
После загруженных данных, нейронная сеть начинает свое обучение с помощью выбранного алгоритма управляемого обучения.
нейронная сеть, слой, карт признаков, изображение, результат работы сети, машинное обучение, выходной слой, математическая модель, буква…
Похожие статьи
Использование искусственных нейронных сетей для…
нейронная сеть, обратное распространение ошибки, сеть, коэффициент корреляции, прямой проход, левый желудочек, корреляционный анализ, диастолическая дисфункция, гиперболический тангенс… Исследование и сравнительный анализ работы нейронных сетей…
Нейросетевые технологии и их применение при прогнозировании…
Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение.
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
Ключевые слова: сеть, нейронная сеть, искусственный интеллект, язык программирования, протон, python, сигмоида, входной слой, скрытый слой, выходной слой, функция активации, jupiter notebook. Структура нейронной сети пришла в мир программирования из биологии.
Исследование и сравнительный анализ работы нейронных сетей…
Каждая нейронная сеть, подключенная к группе, генерирует случайные весовые коэффициенты, затем каждая сеть обучается отдельно на
Для объединения выходных данных группы нейронных сетей используется усредненную простую группировку.
Анализ и классификация погрешностей обучения…
Нейронная сеть, решающая задачу прогнозирования фронта пика, состоит из входного и выходного слоев с одним нейроном и 4-х слоёв по 50 нейронов в. Анализ и классификация погрешностей обучения информационно-измерительных систем на базе нейронных сетей.
Исследование возможностей использования нейронных сетей
В данной статье рассматриваются теоретические основы нейронных сетей, исследование их видов и описание их математической модели. Целью данной статьи является исследование возможностей использования нейронных сетей.
Модель математической нейронной сети | Статья в журнале…
Выходные данные передаем дальше.
Тренировочный сет— это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1…
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
Ключевые слова: нейронная сеть, интеллектуальные технологии, анализ
Нейронная сеть — это система, состоящая из многих простых вычислительных элементов, или нейронов
Для построения нейросетевой модели использовано 6 входных факторов ( ), 1 выходное значение…
нейронная сеть, сеть, эта, нейрон, данные, архитектура…
После загруженных данных, нейронная сеть начинает свое обучение с помощью выбранного алгоритма управляемого обучения.
нейронная сеть, слой, карт признаков, изображение, результат работы сети, машинное обучение, выходной слой, математическая модель, буква…