Содержание:
1. Об ошибке при выполнении файловой операции
2. Устранение «Ошибки при выполнении файловой операции» в 1С 8.3
1. Об ошибке при выполнении файловой операции
Приветствую, коллеги! В данной статье будет описана ошибка «Ошибка при выполнении файловой операции», и подробно рассмотрены способы ее устранения.
Когда происходит обновление конфигураций в 1С 8, по завершении обновления, часто появляется ошибка, которая гласит «Ошибка при выполнении файловой операции – файл не содержит доступных обновлений».
2. Устранение «Ошибки при выполнении файловой операции» в 1С 8.3
Рассмотрим методы, при помощи которых, можно устранить ошибку при выполнении файловой операции в 1С.
Итак, первый способ – это попробовать сделать обновление при помощи файлов по обновлению вида «релиз 1с*.cfu». Если это не помогло, то можно попробовать обновить систему при помощи общего файла вида «полный релиз 1С*.cf».
Вторым способом будет проверка на соответствие общей версии системы 1С с минимальными требованиями версии конфигурации 1С, которую обновляем.
Третий способ устранения ошибки при выполнении файловой операции в 1С – более сложный, но действенный. Необходимо открыть в конфигурацию от поставщика в режиме Конфигуратора. Если ошибка всё так же появляется, то необходимо удалить конфигурацию поставщика, а затем опять установить. По сути, в данном варианте «вытягивается» последняя, рабочая версия данной конфигурации и обновление будет завершено без ошибок.
Рассмотрим подробнее третий способ. Пусть у нас уже есть некоторая конфигурация 1С KORG 1-ой версии, которая работает, но нужно поставить 2-ю версию, то есть обновить версию конфигурации 1С 8.3. Когда происходит обновление, всплывает ошибка «Ошибка при выполнении файловой конфигурации». Порядок действий в этом случае:
1. скачать релиз 1С KORG с версией 1*.cf;
2. копируем нашу базу данных;
3. в конфигураторе, который соответствует обновляемой базе, переходим по пути: «Конфигурация → Поддержка → Настройки поддержки → Снять с поддержки». В случае, если кнопка для снятия с поддержки недоступна, необходимо сперва включить возможные изменения. После этого нужно дать согласие, если система 1С будет уточнять что-либо или подтверждать действия;
4. Далее переходим по следующему пути: «Конфигурация → Сравнить и объединить с конфигурацией из файла…». Здесь необходимо выбрать файл «полный релиз 1С KORG версии 1*.cf»;
5. Далее перед нами появится окно, в котором система 1С будет запрашивать постановление на учёт для поддержки, на это уведомление обязательно отвечаем согласием;
6. В случае, если наша конфигурация является типовой, откроется окно по сравнению конфигураций. В нем обязательно убираем все «галочки». Далее последует объединение конфигураций;
7. В новом окне кликаем на «Сохранить изменения»;
8. Ещё раз сохраняем базу данных;
9. Обновляем конфигурацию 1С стандартным способом.
Если всё сделать, согласно инструкции выше, то в вашей конфигурации 1С 8.3 «Ошибка при выполнении файловой операции» больше не возникнет. Спасибо за внимание!
Специалист компании «Кодерлайн»
Айдар Фархутдинов
Обновлено 15.10.2020

Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов Рунета Pyatilistnik.org. В прошлый раз мы с вами разобрали, что из себя представляет файловая система raw, и как ее исправить, чтобы восстановить свои данные. Двигаемся дальше и поговорим сегодня на тему капризности 1С, точнее на капризную работу в рамках Windows Server 2016. Я рассмотрю причину и устранение периодически повторяющейся ошибки на сервере 1С 8.3 «Ошибка при выполнении файловой операции«. Ее я стал встречать после обновления с Windows Server 2012 R2 д 2016. Думаю мой опыт сэкономит вам часик серфинга по интернету.
Описание проблемы
В моей компании заканчивается обновление операционных систем у виртуальных серверов, с Windows Server 2012 R2 на Windows Server 2016, я понимаю, что поддержка первых еще будет несколько лет, но хочется уже не делать это в последний момент, а слегка опережать, да и уже давно пора стремиться к Windows Server 2019. Сервера 1С не были исключением, обновление происходило по быстрому варианты. Тут подразумевается накатывание более новой версии ОС по верх старой, тут мы убивали двух зайцев:
- Получали свежую версию ОС
- Оставляли весь софт на сервере, и не требовалась его переустановка
В случае чего всегда можно было откатиться из снапшота на момент проведения работ, благо ESXI 6.5 это помогает делать в два клика. Все прекрасно обновилось и сервер зажил новой жизнью. В какой-то момент при запуске клиента 1С 8.3 на RDS ферме, стала появляться ошибка:
Ошибка при выполнении файловой операции
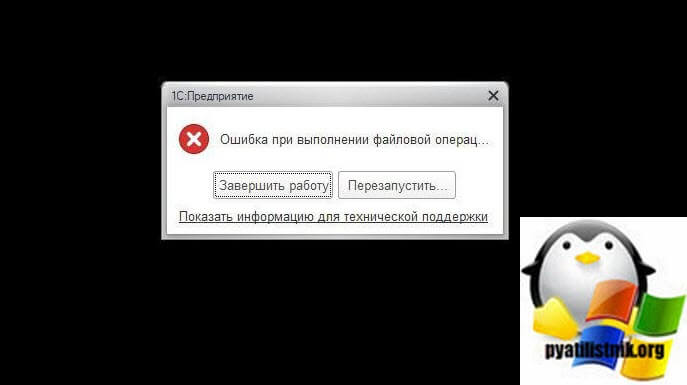
Устранение проблемы
Начав изучать данный вопрос мы не стали откатываться к бэкапу, так как данная проблема возникала не постоянно, а через некоторые промежутки и была вызвана явно не переходом на более новую версию операционной системы. Подняв исторические данные в системе заявок, я нашел похожую, где решением ошибки был перенос базы данных 1С на другой диск. Меня это заинтересовало и я стал прикидывать, что же могло быть в той ситуации. Через минут 20 я нашел одну закономерность, что на всех проблемных хостах был установлен компонент Windows дедупликации, как раз на тех дисках, где располагались базы данных 1С.
Я для тестирования отключил дедупликацию и вернул все в исходное состояние, и о чудо ошибка при выполнении файловой операции больше не появлялась. Все те же действия я произвел и на остальных серверах.
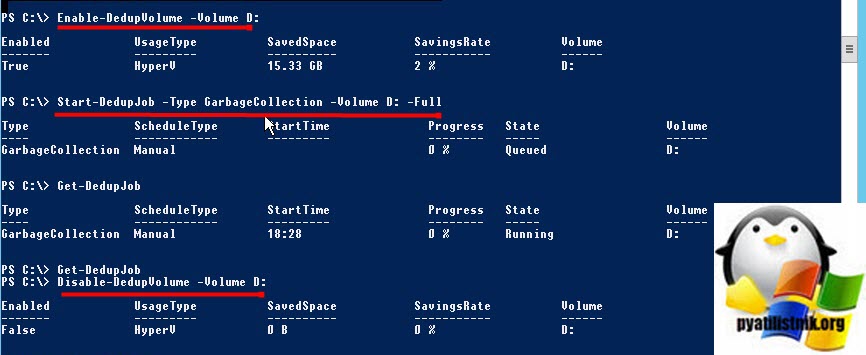
Вывод: Windows Дедупликация и 1С просто не совместимы друг с другом, это нужно запомнить
Из дополнительных методов я могу вам посоветовать еще очистку кэша 1С. Еще в на умных сайтах советуют на серверах, где используется 1С отключать протокол IPv6 на сетевых интерфейсах, но лично я не понимаю этого прикола, так как сама Microsoft советует по возможности этого не делать, в виду того, что очень многие ее сервисы и компоненты Windows в приоритете используют именно его, меньше будет проблем с DNS и Active Directory.
Вообще если у вас виртуальные сервера лежат на системе хранения данных, то у нее должна быть своя функция дедупликации и использовать лучше и правильнее ее. Если у вас есть другие варианты решения данной проблемы, то пишите их в комментариях. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Ошибка при выполнении файловой операции |
Я |
09.06.21 — 15:35
Приветствую, уважаемые форумчане.
Поделитесь, пожалуйста, опытом, может кто сталкивался. Из-за чего может возникать ошибка: «Ошибка при выполнении файловой операции ‘C:UsersUSR1CV8AppDataLocalTempv8_1BF4_352.mxl'». Ошибка происходит при попытке открыть элемент справочника. Ошибка не постоянная, может появиться, а может и нет. База на SQL. Сервер виртуальный. Очень напрягает такая ситуация, особенно, если непонятная причина.
1 — 09.06.21 — 15:37
смотри, что у тебя при открытии происходит, видимо коряво отчет формируется
2 — 10.06.21 — 11:05
(1) При открытии нашел место кода, где пишется в этот временный файл. Но проблема то несколько в ином, в том, что в один момент времени все без ошибок, а в другой момент времени выдает эту ошибку. Вот и хотим понять, на чьей стороне ошибка: диск виноват (хоть и виртуальный), права на каталог «тупят» (хотя всем дали полные) или что-то другое, неизвестное пока. Может был у кого прецедент и выяснили причину?
3 — 10.06.21 — 12:56
(2) Места хватает на сервере?
4 — 10.06.21 — 13:03
(3) Не зависит особо от этого. Бывает достаточно места, бывает мало остается, но ошибка в обоих случаях может появляться. Да и файл этот совсем небольшого размера же, для него уж места предостаточно.
5 — 10.06.21 — 13:04
(0) может файл занят а с ним какие то манипуляции хотите сделать. Когда он не занят, то работает, когда не успевает его освободить, тогда ошибку ловите.
6 — 10.06.21 — 13:06
(5) Так он вроде только при данном событии создается (при открытии элемента справочника, в смысле), а затем тут же удаляется.
7 — 10.06.21 — 13:08
(6) всегда с одним и тем же именем? А если двое отчет откроют?
8 — 10.06.21 — 13:10
(7) Видно же, что это временный файл…
9 — 10.06.21 — 13:11
(6) ругается при создании, или при удалении?
10 — 10.06.21 — 13:13
(6) если не секрет, для чего вы временный файл создаете, что там такого специфического, чего нельзя во временное хранилище пихнуть?
11 — 10.06.21 — 13:25
(7) Разный
12 — 10.06.21 — 13:26
(9) Пишет, что при вызове Write
13 — 10.06.21 — 13:27
(10) Конфигурация специализированная, 1С Отель. Разработчики так сделали
14 — 10.06.21 — 13:29
(13) а что на это говорят разработчики этого чудо решения?
15 — 10.06.21 — 13:32
(12) если код не большой, где этот временный файл создается, пишется и удаляется, то можете сюда кусок скинуть, либо на пастебин ссылкой. Возможно там где-нить в коде косяк.
16 — 10.06.21 — 13:58
(14) Отмалчиваются
17 — 10.06.21 — 13:58
(15)
Function cmGetAbsoluteColor(pColor) Export
If pColor.Type = ColorType.Absolute Then
Return pColor;
EndIf;
vSD = New SpreadsheetDocument;
vSD.Area(«R1C1»).BackColor = pColor;
vTF = GetTempFileName(«mxl»);
vSD.Write(vTF, SpreadsheetDocumentFileType.MXL7);
vSD.Read(vTF);
vColor = vSD.Area(«R1C1»).BackColor;
vSD = Undefined;
DeleteFiles(vTF);
Return vColor;
EndFunction
18 — 10.06.21 — 13:59
(17) расстрелять!
19 — 10.06.21 — 14:11
(17) И это все, для того чтобы вернуть цвет ячейки… Может у вас ошибка каждый раз когда pColor.Type <> ColorType.Absolute?
20 — 10.06.21 — 14:18
(0) Предлагаю, не писать этот файл 
21 — 10.06.21 — 14:21
(17) Этот ужас, где пишется?
На клиенте или Сервере?
22 — 10.06.21 — 14:23
(15)
Function cmGetAbsoluteColor(pColor) Export
//If pColor.Type = ColorType.Absolute Then
// Return pColor;
//EndIf;
//vSD = New SpreadsheetDocument;
//vSD.Area(«R1C1»).BackColor = pColor;
//vTF = GetTempFileName(«mxl»);
//vSD.Write(vTF, SpreadsheetDocumentFileType.MXL7);
//vSD.Read(vTF);
//vColor = vSD.Area(«R1C1»).BackColor;
//vSD = Undefined;
//DeleteFiles(vTF);
//Return vColor;
Возврат Новый Цвет(255, 255, 255);
EndFunction
С Вас сто рублёв
23 — 10.06.21 — 14:23
(22) -> (17)
24 — 10.06.21 — 14:30
(19) Проверил в отладчике. Когда не равен, проскакивает без ошибок.
25 — 10.06.21 — 14:32
(23) New Color() же)
26 — 10.06.21 — 14:32
(21) Это в общем модуле, на сервере
27 — 10.06.21 — 14:36
(25) не скрепно
28 — 10.06.21 — 14:39
(0) Ну народ, уже давно не пишут, все через память :)))
&НаСервере
Function cmGetAbsoluteColor(pColor) Export
If pColor.Вид = ВидЦвета.Абсолютный Then
Return pColor;
EndIf;
Поток = Новый ПотокВПамяти();
vSD = Новый ТабличныйДокумент;
vSD.Область(«R1C1»).ЦветФона = pColor;
vTF = ПолучитьИмяВременногоФайла («mxl»);
vSD.Записать(Поток, ТипФайлаТабличногоДокумента.MXL7);
Поток.Перейти(0,ПозицияВПотоке.Начало);
vSD.Прочитать(Поток, СпособЧтенияЗначенийТабличногоДокумента.Значение);
vColor = vSD.Область(«R1C1»).BackColor;
vSD = Неопределено;
//УдалитьФайлы(vTF);
Return vColor;
EndFunction
29 — 10.06.21 — 14:39
+(28) Ну поток уж сам закроешь
30 — 10.06.21 — 14:40
+ (0) Вот получше так…
&НаСервере
Function cmGetAbsoluteColor(pColor) Export
If pColor.Вид = ВидЦвета.Абсолютный Then
Return pColor;
EndIf;
Поток = Новый ПотокВПамяти();
vSD = Новый ТабличныйДокумент;
vSD.Область(«R1C1»).ЦветФона = pColor;
vSD.Записать(Поток, ТипФайлаТабличногоДокумента.MXL7);
Поток.Перейти(0,ПозицияВПотоке.Начало);
vSD.Прочитать(Поток, СпособЧтенияЗначенийТабличногоДокумента.Значение);
vColor = vSD.Область(«R1C1»).BackColor;
Поток.Закрыть();
Поток = Неопределено;
vSD = Неопределено;
//УдалитьФайлы(vTF);
Return vColor;
EndFunction
31 — 10.06.21 — 14:42
(29) ну это ладно, что mxl, а если бы xlsx был то в потоке уже так просто табдок не прочитаешь…
32 — 10.06.21 — 14:43
(31) У нас не ексель 
33 — 10.06.21 — 14:43
+ Вот будет ексель, тогда и поговорим про скорость
34 — 10.06.21 — 14:44
(33) я одного понять не могу, чем создателей webцвета не устроили или различные типовые стили?
35 — 10.06.21 — 14:45
(34) Ненаю, где там это используется, я вот еще не пойму, нак-зачемой по англиски писать
36 — 10.06.21 — 14:46
+ Потом даже модифицировать не могут
37 — 10.06.21 — 14:47
(35) может у индусов заказывали конфу?))
38 — 10.06.21 — 14:47
(35) Там вся конфа такая. Специально похоже, чтобы сложнее было понять, что они там разработали)
39 — 10.06.21 — 14:51
(38) Соболезную, держи пример, не мучайся хоть со справочником
40 — 10.06.21 — 14:53
Кстати, не только mxl пишут. Есть внешний ресурс Travelline, к которому 1С коненктится, забирает инфу и создает брони в 1С. При этом так же периодически ошибки вываливаются такого типа: «Failed to create reservation: Ошибка при выполнении файловой операции ‘C:UsersUSR1CV8AppDataLocalTempБронь_9719.pdf’; Booking №:20210613-19260-96172841».
41 — 10.06.21 — 14:54
Вопрос изначальный по идее так и остается. По какой причине то проходит запись в Temp, то нет. Бред какой-то происходит.
42 — 10.06.21 — 14:54
(40) Подвиг за день не должен превышать больше одного… Это вы дальше сами
43 — 10.06.21 — 14:54
(42)
44 — 10.06.21 — 14:55
(41) Если оба юзвера или много считывают, то может быть так, что у всех одно и тоже временное имя, 1С… что сказать
45 — 10.06.21 — 14:56
(40) тоже наверное можно без создания временного файла обойтись.
46 — 10.06.21 — 14:58
(44) Интересное предположение. Может так и происходит на самом деле
47 — 10.06.21 — 14:59
(46) Код покажи, вот этого (40) — Чисто в познавательных целях
48 — 10.06.21 — 14:59
(46) создайте свою папочку на серваке и дайте к ней доступ. Сами контролируйте уникальность файлов. Либо вообще поправьте код, чтобы избыточные временные файлы не создавались.
49 — 10.06.21 — 15:00
(41) Про антивирус уже писали?
50 — 10.06.21 — 15:00
(47) скорее всего возвращается ссылка на pdf брони созданной, а ее пытаются во временном файле записать)
51 — 10.06.21 — 15:01
+(46) Вот тебе генератор имен.
Функция УникальноеИмя(расширение)
Возврат «» + КаталогВременныхФайлов() + СокрЛП(Новый УникальныйИдентификатор())+».»+расширение;
КонецФункции
52 — 10.06.21 — 15:06
(51) а вот тут почитаешь и 1ска тебе тыкает, что так делать не надо, только для веб клиента)
https://its.1c.ru/db/v8std/content/542/hdoc
53 — 10.06.21 — 15:07
(52) тут понимаешь ли 1ской все гарантируется и должно работать)
54 — 10.06.21 — 15:09
(52) Если по каким-то причинам прикладной код не удалит созданный файл (например, между блоками создания и удаления временного файла возникнет штатное или нештатное исключение), этот файл так и останется в каталоге временных файлов.
…
А теперь вопрос, какой метод от 1С, удалит все временные файлы на сервере?
На сервере, где так же есть такая вещь, как КЭШ сервера
55 — 10.06.21 — 15:10
(54) вроде бы перезапуск службы 1с это делать должен)
56 — 10.06.21 — 15:11
(54) >>> Если по каким-то причинам прикладной код не удалит созданный файл
Файл в любом случаи останется
…Или 1С так же повторно заюзает этот файл?
57 — 10.06.21 — 15:11
(55) Что? Вы хотите сказать, что при рестарте службы, у многих пользователей автоматом гарантировано все ляжет? :)))
58 — 10.06.21 — 15:13
+(55) и тут же 1С разрешает этот код в (51) для вэба :))))
3.1. При выполнении кода веб-клиентом метод ПолучитьИмяВременногоФайла недоступен. Поэтому для формирования имен временных файлов и каталогов необходимо использовать функцию КаталогВременныхФайлов и объект УникальныйИдентификатор.
Неправильно:
Каталог = КаталогВременныхФайлов();
ИмяФайла = «TempDataFile.xml»;
ИмяПромежуточногоФайла = Каталог + ИмяФайла;
Данные.Записать(ИмяПромежуточногоФайла);
Правильно:
Каталог = КаталогВременныхФайлов();
ИмяФайла = Строка(Новый УникальныйИдентификатор) + «.xml»;
ИмяПромежуточногоФайла = Каталог + ИмяФайла;
Данные.Записать(ИмяПромежуточногоФайла);
59 — 10.06.21 — 15:16
(47) Вот этот кусок кода:
vConfirmationFileName = StrReplace(vDocObj.Ref.Metadata().Presentation() + » » + Format(vDocObj.GuestGroup.Code, «ND=12; NFD=0; NG=»), » «, «_») + «.pdf»;
vConfirmationFilePath = cmGetFullFileName(vConfirmationFileName, TempFilesDir());
vConfirmationSpreadsheet.Write(vConfirmationFilePath, SpreadsheetDocumentFileType.PDF);
60 — 10.06.21 — 15:16
(58) я про это и пишу, что для только для вэба и можно. По идее, когда сеанс перезапускается, который создавал временный файлы, то они подчищаются. Если же перезапустить службу 1ски, то все сеансы схлопнутся, все временные файлы созданные в этих сеансах должны удалиться платформой.
![]()
61 — 10.06.21 — 15:18
(59) а где гарантия, что vConfirmationFileName уникально? Если к примеру 2 человека одновременно этот кусок кода выполнят.
62 — 10.06.21 — 15:20
(59) может у вас действительно, что то с правами на серваке? Пробовали на другой машинке базу развернуть?
63 — 10.06.21 — 15:39
(62) К сожалению нет такой возможности.
64 — 10.06.21 — 17:12
(59) Проблемы, т.к. нам тут не видно.
1. Что это за код и до какой степени он уникален? «vDocObj.GuestGroup.Code»
2. Для чего это пишут в формате PDF?
3. Вопрос из (61), а где гарантия?
65 — 10.06.21 — 17:12
(60) Сколько раз перезапускал, такого не замечал
66 — 10.06.21 — 17:15
+(60) Если Автор (0) гарантирует, что будет удалять такие файлы САМ, то вероятность зависших файлов равна ничтожному проценту.
Т.е. парочка файлов просочится, но не более.
Учитывая, сколько раз мне приходилось чистить папку темп на сервере, для восстановления работоспособности баз, после динамической.обновы. и др. сбоев.
Вот все что там пишется, зависает, не стоит и ломаной десятины…
Главное Серверу 1С не жадничать дискового пространства под его временные файлы
67 — 10.06.21 — 17:17
+(59) А проверки на то, что файл уже есть, тоже присутствуют?
68 — 10.06.21 — 17:18
Кода мало, давай под 1000 строк
69 — 10.06.21 — 17:18
Не жадничай
70 — 10.06.21 — 17:58
(67) да какая там проверка, все же тут есть:
vConfirmationFilePath = cmGetFullFileName(vConfirmationFileName, TempFilesDir()); создали путь во временном каталоге
vConfirmationSpreadsheet.Write(vConfirmationFilePath, SpreadsheetDocumentFileType.PDF); записали табдок по этому пути в формате пдф.
71 — 11.06.21 — 06:34
(70) Если так, то это жесть :)))
zoran
72 — 22.06.21 — 09:02
Всем спасибо за обсуждение. В итоге, после общения с ТП конфигурации выяснилось, что запись на диск требуется для отправки печатных форм документов (бронирования, в частности) клиентам. И в настройках есть возможность отключить данную опцию. Далее понаблюдаем, исчезнут ли ошибки.
Продолжаем разговор об исключениях в C++.
- Гарантии безопасности
- Спецификации исключений в C++
- Стоит ли избегать исключений
- Как работают исключения
- Заключение
- Полезные ссылки

Георгий Осипов
Один из авторов курса «Разработчик C++» в Яндекс Практикуме, разработчик в Лаборатории компьютерной графики и мультимедиа ВМК МГУ
В первой части мы разобрали, как создавать исключения и работать с ними, а также какими они бывают. Разобрали ключевые слова try, catch и throw, синтаксис выбрасывания и обработки исключений, а ещё особые случаи, связанные с исключениями.
Вторая часть статьи больше подойдёт продвинутым программистам, которые хотят глубже разобраться в теме исключений. Однако никаких специальных знаний не требуется. Во второй части мы разберём:
- гарантии безопасности;
- спецификации исключений;
- как исключения влияют на скорость выполнения;
- как устроены исключения в C++ и как они работают.
Также рассмотрим философский вопрос о нужности исключений и альтернативных подходах, запустим три бенчмарка и в результате увидим, что иногда исключения не только не замедляют программу, а даже ускоряют.
Углубить и систематизировать знания C++ поможет курс «Разработчик C++» в Яндекс Практикуме. Для тех, кто знает C++, но желает изучить работу по сети, Docker, Linux и множество вспомогательных инструментов, есть курс «C++ для бэкенда».
Гарантии безопасности
Исключения — ситуация нештатная. Но они существуют для того, чтобы как-то обработать эту ситуацию и продолжить выполнение программы.
Чтобы было ясно, как исключительная ситуация может повлиять на работу, существует специальное понятие — гарантия безопасности исключений. Это описание вреда, который может нанести исключение, приводимое в документации к функции или методу.
Выделяют четыре уровня безопасности исключений:
- Гарантия отсутствия исключения. Самая сильная гарантия. Означает, что исключение возникнуть не может, а значит, ничего не сломает.
- Строгая гарантия безопасности. Исключение может возникнуть, но в этом случае всё будет возвращено к тому, как было до вызова соответствующей функции. Иными словами, операция не удалась, но можно сделать вид, как будто её и не было.
- Базовая гарантия безопасности. При возникновении ошибки мы не можем вернуть всё как было, но всё равно останемся в корректном состоянии. Все инварианты будут сохранены, все ненужные ресурсы освобождены, ничего не утечёт. С объектом, из-за которого возникло исключение, можно продолжать работать.
- Отсутствие безопасности. Не можем гарантировать ничего. Если исключение произошло, лучше поскорее завершить работу программы.
Рассмотрим пример. Напишем собственную операцию push_back для вставки в вектор.
Гарантия отсутствия безопасности
template<class T>
class Vector {
public:
void push_back_no_guarantee(T elem) {
T* old = mem;
// Возможное исключение в new не опасное:
// мы ещё ничего не успели испортить
mem = new T[size + 1];
size_t old_size = size++;
// Используем алгоритм move для перемещения всех
// элементов из старой памяти в новую.
// Тут может возникнуть исключение.
std::move(old, old + old_size, mem);
mem[old_size] = std::move(elem);
delete[] old;
}
private:
T* mem = nullptr;
size_t size = 0;
};
Вызов new не опасен в отличие от перемещения элементов: мы ничего не знаем про конструктор перемещения неизвестного объекта T. Он может выбрасывать исключение.
Эта реализация метода не даёт гарантий. Если во время перемещения объектов возникло исключение, то мы как минимум получим утечку памяти. Кроме того, у вектора будет неправильный размер, например, если перемещение прервалось на середине.
В примере мы использовали new для простоты и наглядности. Реальный вектор должен выделять сырую память без инициализации.
Базовая гарантия безопасности
Улучшим нашу функцию, чтобы подняться с четвёртого уровня безопасности на третий. Это минимальный уровень, который допустимо использовать в программах.
void push_back_basic_guarantee(T elem) {
T* old = mem;
mem = new T[size + 1];
size_t old_size = size;
size = 0;
try {
// Используем цикл, чтобы постоянно знать актуальный размер.
for (size_t i = 0; i < old_size; ++i) {
mem[i] = std::move(old[i]);
size++;
}
mem[old_size] = std::move(elem);
size++;
}
catch(...) {
// Предотвратим утечку ресурсов в случае исключения
delete[] old;
throw;
}
delete[] old;
}Уже лучше: размер вектора будет корректен, и мы не допустим утечки. Однако такая вставка может привести, например, к обнулению вектора, если исключение возникло в самом первом перемещении.
Строгая гарантия безопасности
Над строгой гарантией нужно потрудиться.
void push_back_strong_guarantee(T elem) {
// Идём другим путём: аллоцируем память, но не будем
// менять this->mem пока копирование не закончено.
T* new_mem = new T[size + 1];
try {
for (size_t i = 0; i < size; ++i) {
// Мы должны быть готовы всё вернуть как было, а значит,
// не можем перемещать элементы, чтобы не испортить
// старую память — придётся их копировать.
new_mem[i] = mem[i];
}
// Последний элемент можно переместить:
new_mem[size] = std::move(elem);
}
catch(...) {
delete[] new_mem;
throw;
}
// Выше мы вообще не меняли this.
// Теперь, когда всё точно готово, сделаем это.
T* old = mem;
mem = new_mem;
size++;
// Считаем, что деструктор не выбрасывает.
delete[] old;
}У строгой гарантии есть неприятный эффект: нам пришлось отказаться от перемещений в пользу копирований. Таким образом, она отрицательно влияет на эффективность.
Можно сделать всё эффективно, если есть уверенность, что перемещение объектов типа T не выбрасывает исключений. Стандартный std::vector так и делает.
Гарантия отсутствия исключения
И наконец, достигнем вершины — напишем метод без исключений:
// Теперь метод возвращает bool:
// true показывает, что вставка удалась,
// false свидетельствует об ошибке.
bool push_back_no_exception(T elem) {
T* new_mem;
// Теперь нужно поймать возможный std::bad_alloc или
// исключение в конструкторе
try {
new_mem = new T[size + 1];
}
catch(...) {
return false;
}
try {
for (size_t i = 0; i < size; ++i) {
new_mem[i] = mem[i];
}
new_mem[size] = std::move(elem);
}
catch(...) {
delete[] new_mem;
return false;
}
T* old = mem;
mem = new_mem;
size++;
// По-прежнему считаем, что деструктор не выбрасывает.
delete[] old;
return true;
}Возврат флага успеха — альтернатива исключениям. Функция очень похожа на предыдущий вариант. Однако при такой реализации мы ничего не сможем узнать о том, какая именно ошибка произошла.
Такой разный noexcept
Как говорилось выше, вставка в вектор может работать эффективнее, если есть гарантия, что перемещение объекта не выбрасывает исключений. Такую гарантию можно дать для произвольной функции, если пометить её словом noexcept:
// Функция извлечения корня будет возвращать пустое значение
// а не выбрасывать исключение. Чтобы показать, что она не выбрасывает
// мы пометили её как noexcept:
std::optional<double> SafeSqrt(double arg) noexcept {
return arg >= 0 ? sqrt(arg) : std::nullopt;
}Если же мы хотим явно сказать, что функция выбрасывает исключение, можно написать noexcept(false):
double UnsafeSqrt(double arg) noexcept(false) {
return arg >= 0
? sqrt(arg)
: throw std::invalid_argument("Попытка извлечь корень из отрицательного числа");
}Но это лишнее, ведь выбрасывающими по умолчанию считаются все функции, кроме деструкторов. Зато можно поместить внутрь скобок содержательное выражение времени компиляции:
int f() noexcept { return 42; }
int g() { throw 42; }
constexpr bool f_is_noexcept = true;
constexpr bool g_is_noexcept = false;
// h является noexcept, только когда и f и g таковые:
int h() noexcept(f_is_noexcept && g_is_noexcept) {
return f() + g();
}Тут мы явно написали, какая функция noexcept, а какая — нет, хотя могли бы вычислить. noexcept допустимо использовать как операцию, определяющую, может ли выбрасывать содержимое скобок:
#include <iostream>
int f() noexcept { return 42; }
int g() { throw 42; }
constexpr bool f_is_noexcept = noexcept(f());
constexpr bool g_is_noexcept = noexcept(g());
int h() noexcept(f_is_noexcept && g_is_noexcept) {
return f() + g();
}
int main() {
std::cout << "Функция f может выбрасывать исключения? " << (noexcept(f()) ? "нет" : "да") << std::endl;
std::cout << "Функция g может выбрасывать исключения? " << (noexcept(g()) ? "нет" : "да") << std::endl;
std::cout << "Функция h может выбрасывать исключения? " << (noexcept(h()) ? "нет" : "да") << std::endl;
std::cout << "Выражение f() + g() может выбрасывать исключения? " << (noexcept(f() + g()) ? "нет" : "да") << std::endl;
}Вывод программы будет таким:
Функция f может выбрасывать исключения? нет
Функция g может выбрасывать исключения? да
Функция h может выбрасывать исключения? да
Выражение f() + g() может выбрасывать исключения? даЗаметьте, что мы пишем noexcept(g()), а не noexcept(g). Последнее выражение всегда false, поскольку само по себе выражение g ничего не делает, а значит, ничего не выбрасывает.
Если в функции, помеченной как noexcept, всё же возникло исключение, то оно приведёт к вызову std::terminate и завершению программы.
А нужен ли noexcept?
Вряд ли что-то может ответить на поставленный вопрос красноречивее бенчмарка. В этом бенчмарке, который мы провели в сервисе QuickBench, созданы три практически одинаковых класса:
F_except, у которого есть обычный конструктор перемещения;
F_noexcept, у которого конструктор перемещения помечен какnoexcept;F_noexcept2— какF_noexcept, но с деструктором, помеченным какnoexcept(false). Деструктор нужно явно помечать какnoexcept(false), иначе он считается невыбрасывающим.
Объекты этих классов добавляются в std::vector. Его метод push_back обеспечивает строгую гарантию исключений. Как вы уже знаете, в этом случае перемещение вектора возможно только тогда, когда перемещение его элементов не выбрасывает исключений.
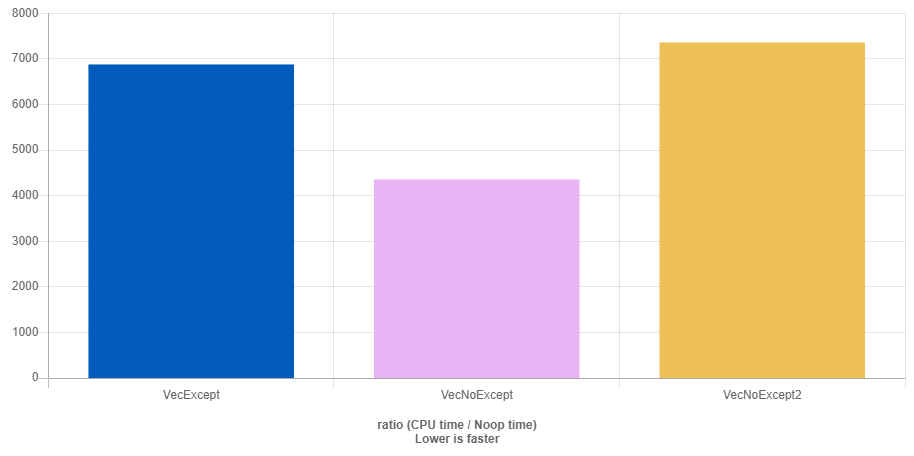
Добавление элемента в вектор в среднем в 1,6 раза быстрее, если конструктор перемещения элементов помечен как noexcept. Добавление замедляется, если деструктор элементов может выбрасывать
Отличие заметное, хотя не такое существенное из-за оптимизаций в std::vector. noexcept позволил выбрать более эффективный алгоритм, но только в том случае, когда он применялся и для конструктора перемещения, и для деструктора.
Волшебный default
Рассмотрим три класса:
class T1 {
public:
};
class T2 {
public:
T2() {}
};
class T3 {
public:
T4() = default;
};Казалось бы, разницы между ними нет, но попробуем изучить конструкцию T*() на предмет выбрасывания исключений:
class T1 {
public:
};
class T2 {
public:
T2() {}
};
class T3 {
public:
T4() = default;
};
class T4 {
public:
T4() noexcept {}
};
int main() {
std::cout << std::boolalpha;
std::cout << "T1() noexcept: " << noexcept(T1()) << std::endl;
std::cout << "T2() noexcept: " << noexcept(T2()) << std::endl;
std::cout << "T3() noexcept: " << noexcept(T3()) << std::endl;
std::cout << "T4() noexcept: " << noexcept(T4()) << std::endl;
}В этом примере мы также добавили четвёртый класс. Вывод программы такой:
T1() noexcept: true
T2() noexcept: false
T3() noexcept: true
T4() noexcept: trueНас подвёл только один вариант, в котором конструктор объявлен как T2() {}. Такой конструктор будет считаться выбрасывающим, хотя на вид он аналогичен записи T2() = default.
Невыбрасывающий конструктор часто позволяет получить более эффективный код и применить больше оптимизаций. В легковесных классах он вообще может не генерировать никаких инструкций, в то время как выбрасывающий потребует лишней работы. Предпочитайте конструкцию = default пустым скобкам.
Список исключений
В некоторых языках программирования c исключениями всё строже. Каждая функция снабжается списком исключений, которые она может выбрасывать. Была такая попытка и в C++ с самого момента его стандартизации:
#include <iostream>
#include <cmath>
class MyException{};
// Спецификация исключений для функции.
// Компилировать с флагом -std=c++03 или иным
// в зависимости от компилятора
int f(int x) throw(MyException) {
if (x < 0)
throw MyException();
return sqrt(x);
}
int main() {
f(15);
f(-3);
}У такого подхода есть преимущества:
- компилятор может убедиться, что все исключения обрабатываются;
- вы видите, что может, а что не может выбрасывать функция по её сигнатуре;
- обработчик можно искать в compile-time.
Однако на деле не всё так радужно. Всплыл ряд недостатков:
- Некоторые исключения, например,
std::bad_allocможет выбрасывать почти любая функция. Везде писатьthrow(std::bad_alloc)утомительно. - Непонятно, как быть с указателями на функции и
std::function. Если мы хотим заранее всё знать об исключениях, то спецификации исключений должны быть в типе функции. Тогда неясно, как их преобразовывать. - Можно сделать спецификации нестрогими, но тогда непонятно, что они дают.
С похожими недостатками сталкиваются и в других языках программирования. В C++ недостатки перевесили, и комитет по стандартизации решил от явных спецификаций отказаться, оставляя только noexcept. В Стандарте C++11 они объявлены устаревшими (deprecated), а позже вовсе исключены из языка.
Стоит ли избегать исключений
«Мы не используем исключения в C++», — cтайлгайд Google.
Не нужны или незаменимы
Исключения в C++ — удобный инструмент, не лишённый недостатков. Может быть, самый существенный из них — в том, что исключения прозрачны. Глядя на сигнатуру функции, нельзя понять, какие исключения она выбрасывает. Это можно понять, глядя в документацию. Но документация не проверяется автоматически, а значит, может ошибаться.
Код с исключениями иногда трудней читать и модифицировать. Может, где-то через функцию пролетает исключение, задуманное разработчиком, но узнать об этом, глядя на код, невозможно. Вы модифицируете функцию, внося, казалось бы, несущественные изменения, но тем самым нарушаете гарантии безопасности.
Вспомните пример с четырьмя реализациями push_back. Программисту, который не знал нашей мотивации — обеспечение гарантий безопасности, — будет совершенно неочевидно, почему мы обновили поле mem в начале функции, а не в другом месте. Ему покажется это прихотью, и он изменит способ на противоположный — просто для красоты кода. При этом корректная обработка исключений перестанет работать.
Но если пользоваться исключениями аккуратно, то данного недостатка можно избежать.
В некоторых местах без исключений трудно: например, это единственный способ прервать конструктор. Можно, конечно, ввести для объекта невалидное состояние, указывающее, что во время конструктора произошла ошибка. Но это будет усложнением класса.
Помимо конструкторов исключения практически незаменимы, когда вы делаете много похожих действий, каждое из которых может завершиться неудачей:
std::optional<PersonCard> ParseJSON(json raw_json, int idx) {
PersonCard result;
try {
result.first_name = raw_json["persons"][idx]["name"]["first"].as_string();
result.last_name = raw_json["persons"][idx]["name"]["last"].as_string();
result.phone = parse_phone(raw_json["persons"][idx]["phone"].as_string());
result.address = raw_json["persons"][idx]["address"];
}
catch(json::error e) {
std::cout << "Error in JSON at " << e.where() << ": " << e.what() << std::endl;
return std::nulltopt;
}
return result;
}Без исключений только первая строка блока try записывалась бы так:
if (!raw_json.is_object()) return std::nullopt;
if (!raw_json.has_key("persons")) return std::nullopt;
if (!raw_json["persons"].is_array()) return std::nullopt;
if (raw_json["persons"].length() >= idx) return std::nullopt;
if (!raw_json["persons"][idx].is_object()) return std::nullopt;
if (!raw_json["persons"][idx].has_key("name")) return std::nullopt;
if (!raw_json["persons"][idx]["name"].is_object()) return std::nullopt;
if (!raw_json["persons"][idx]["name"].has_key("first")) return std::nullopt;
if (!raw_json["persons"][idx]["name"]["first"].is_string()) return std::nullopt;При этом мы опустили вывод диагностики о местоположении ошибки и её сути. Конечно, можно было придумать сложный прокси-объект, который ведёт себя как JSON, но на самом деле находится в ошибочном состоянии и не выполняет никаких действий, и тем самым сократить количество строк.
Но решайте сами, следовать ли стайлгайду Google в этой части. Ещё один аргумент в пользу исключений в C++ вы найдёте ниже.
Строгий запрет
Некоторые компании и программисты предпочитают вообще не использовать исключения. Об этом лучше сказать компилятору специальной опцией. Это развяжет оптимизатору руки и позволит генерировать более простой и эффективный код в очень многих случаях.
Для GCC и clang это опция -fno-exceptions. Её использование не значит, что исключений не возникнет. В частности, никто не может избавить вас от std::bad_alloc и других исключений, выбрасываемых из библиотек. Однако чаще всего исключение будет приводить к вызову std::terminate.
Если на радикальные меры идти не хочется, ваш друг — noexcept. Он работает не хуже, чем -fno-exceptions, если его поставить везде, где нужно. noexcept также хорошо помогает оптимизатору и убирает оверхед при вызове функций, помеченных этим ключевым словом.
Назад в будущее
У исключений есть альтернатива, известная ещё корифеям, — возврат флага или ошибки из функции. Если вы пишете процедуру, то проще всего вернуть флаг успеха:
bool DoSomeOperation() {
if (!CanDoOperation())
return false;
DoUnchecked();
return true;
}Чтобы компилятор проверял, что вызывающая функция точно обрабатывает ошибку, добавим [[nodiscard]]:
[[nodiscard]] bool DoSomeOperation() …Подобного сервиса — проверки, что ошибка обрабатывается, — нет даже у исключений. Если булевого флага недостаточно, функция может возвращать объект ошибки, содержащий информацию о её причинах. В этом случае [[nodiscard]] можно поставить прямо в класс:
struct [[nodiscard]] ErrorInfo {
// Операция вернёт false, если ошибки не было.
operator bool() const {
return error_code != 0;
}
std::string what() const;
int error_code = 0;
}
ErrorInfo DoOperation();
int main() {
auto err = DoOperation();
if (err) {
std::cout << err.what() << std::endl;
return EXIT_FAILURE;
}
}Когда функция должна сама по себе вернуть значение, такой способ не подходит. Решение есть — специальный тип std::expected, но он будет добавлен в язык только в 2023 году. Предполагается, что этот объект будет хранить либо возвращённое значение, либо код ошибки, когда операция не удалась.
Универсальный солдат
Если ждать до 2023-го не хочется, можно реализовать expected самостоятельно или использовать простую замену: передать функции объект ошибки по ссылке, предлагая записать в него информацию.
Это самый универсальный и удобный способ для пользователя функции. Так мы предлагаем ему выбор: хочет ли он ловить исключение или предпочитает обрабатывать объект ошибки. Такой способ предусмотрен во многих библиотеках, в том числе в std. Рассмотрим примеры.
- std::filesystem. Функции работы с файловой системой часто могут завершаться с ошибкой. Например, вы хотите переименовать файл, но его только что удалили. В этом и подобных случаях выбрасывается
std::filesystem::filesystem_error, подклассstd::system_error, который в свою очередь расширяет подклассstd::runtime_errorиstd::exception.
Но если вы указали дополнительный параметр типаstd::error_code&, то исключение не будет выброшено — вместо этого ошибка запишется в переданный объект:std::error_code ec; std::filesystem::rename(old_path, new_path, ec); if (!ec) { std::cerr << "Ошибка переименования" << std::endl; } - Потоки ввода-вывода. Для них используется немного другой механизм. По умолчанию потоки не выбрасывают, и вы вынуждены проверять все операции на корректность.
Если вызвать метод потокаexceptions, то можно попросить поток сигнализировать при появлении флагов ошибок. Будет выбрасываться исключениеstd::ios_base::failure(также подвидstd::system_error). У метода есть эффект, даже если он вызван уже после возникновения ошибки:#include <iostream> #include <fstream> int main() { std::ifstream f("abracadabra"); try { f.exceptions(f.failbit); } catch (const std::ios_base::failure& e) { std::cout << "Ошибка потока: " << e.what() << 'n' << "Код: " << e.code() << 'n'; } }Передавать в метод
exceptionsфлагeofbitне рекомендуется. Достижение конца файла — штатная, а не исключительная ситуация. Последующие чтения всё равно установят флагfail.
А что со скоростью?
Бытует мнение, что исключения — это всегда медленно. Ведь у всех этих конструкций try наверняка большой оверхед. Даже если try-блоков нет, компилятор всё равно должен быть в любой момент готов обработать исключение при вызове любой функции, не помеченной как noexcept.
Проверим, так ли это. Лучший способ — бенчмарк. Будем измерять две функции, выполняющие похожую работу:
void f()— не помечена какnoexcept. Рекурсивно вызывает себя. После 10 миллионов вызовов выбрасывает исключение.bool g()— помечена какnoexcept. Рекурсивно вызывает себя. После 10 миллионов вызовов возвращаетfalse,и цепочка вызовов прерывается.
Результат во многом зависит от компилятора, оптимизаций и наличия у функций атрибута noinline. Но в большинстве случаев версия с исключениями по крайней мере не хуже. Вот бенчмарк, где версия с исключениями работает в полтора раза быстрее. При использовании clang преимущество скромнее — всего 10%.
Может показаться, что пример искусственный. В какой-то степени так и есть, но это не меняет тенденции. Без исключений в C++ нам нужно было проверять каждый результат возврата, а это дорогостоящая инструкция условного перехода. Трудно поверить, но при использовании исключений такая инструкция при вызове не требуется. Иногда это может дать неплохой выигрыш.
Сравним дизассемблер. Для наглядности добавим больше рекурсивных вызовов в каждую функцию. Так выглядит вариант с исключениями:

Каждый рекурсивный вызов превратился в одну инструкцию call, последний — в jmp
А вот начало функции с проверками. Не будем приводить код полностью:

Каждый рекурсивный вызов превратился в три инструкции — call, test и условный переход
Неудивительно, что исключения в этом случае победили. Однако не нужно думать, что так будет всегда. Главный минус исключений с точки зрения производительности — в том, что они мешают оптимизации.
Профессионалы советуют: везде, где можно, ставьте noexcept. Иначе производительность может сильно пострадать. Это причина, почему многие крупные компании вообще не используют исключения.
Как работают исключения
Исключения в компиляторах можно реализовать по-разному. Реализации стремятся к нулевому оверхеду, который формулируется так:
Мы не должны платить производительностью до тех пор, пока исключение не выбрасывается. Код, в котором исключение не произошло, должен работать так же быстро, как если бы исключение не могло произойти.
Современные компиляторы (а вернее, генераторы кода) в полной мере этому принципу не следуют, в чём можно убедиться, изучив ассемблерный код, который они выдают. Но возникающий оверхед минимальный, а где-то отсутствует вовсе. Подумаем, что обязан делать процессор для того, чтобы обеспечить возможность исключений.
Посадочные площадки
Исключение может возникнуть практически где угодно, а именно при любом вызове функции, не помеченной как noexcept. Во всех этих случаях компилятор должен знать, что ему делать дальше. Рассмотрим две строчки:
std::string s = "Имя гостя номер " + std::to_string(N) + " - " + guest_names.at(N);
std::cout << s << std::endl;Они могут прерваться в девяти местах:
- два раза — при конвертации
const char* в std::string; возможное исключениеbad_alloc; - три раза — при сложении строк; возможное исключение
bad_alloc; - один раз — в
std::to_string; возможное исключениеbad_alloc; - один раз — в
std::vector::at; возможное исключениеstd::out_of_range; - два раза — в
std::ostream::operator <<; возможное исключениеstd::ios_base::failure. Даже если мы не устанавливали для потока флаг выброса исключений, компилятор всё равно должен быть готов к такому повороту событий — операция<<не помечена какnoexcept.
Для этих девяти мест компилятор должен предусмотреть пути отхода. А именно установить, какие временные объекты он должен удалить в каждом случае и что делать дальше. Для этого в бинарном коде программы создаётся посадочная площадка (landing pad). Процессор приземляется на ней только в случае исключения.
Вызов функции обычно превращается в процессорную инструкцию call. При этом в стек кладётся адрес места, куда нужно вернуться после инструкции ret, завершающей вызов. Если вызываемая функция помечена как noexcept, то этого достаточно. Если нет, процессору нужно знать, куда идти, если в процессе выполнения вызова произошло непойманное исключение. Он идёт на посадочную площадку.
Таким образом для возможности обработки исключений каждый вызов требует максимум одну дополнительную инструкцию — запоминание адреса экстренной посадочной площадки. Сущая мелочь.
Выбор обработчика
Мы так увлеклись оверхедом, что совсем забыли: исключения нужны, чтобы их ловить. А ловят их обработчики. Чтобы исключение нашло свой обработчик, при выполнении raise нужно сохранить информацию о типе. Причём эта информация будет обрабатываться во время выполнения программы (run-time).
В C++ для этого есть свой механизм — динамическая идентификация типа данных, или RTTI. Чтобы мы могли поймать исключение по базовому типу, в run-time должна быть доступна информация обо всех предках выброшенного исключения.
Таким образом, raise делает следующее:
- сохраняет объект исключения;
- сохраняет информацию о типе;
- возможно, сохраняет что-то ещё (например, ссылку на деструктор объекта исключения);
- если надо, запускает
terminate; - если не надо, запускает раскрутку стека.
Раскрутка стека делает следующее:
- приземляется на посадочную площадку;
- удаляет временные и автоматические объекты;
- проверяет все доступные обработчики на соответствие типа;
- если надо, запускает
terminate; - если не надо (и обработчик не найден), продолжает раскрутку стека.
Обработчик делает следующее:
- выполняет пользовательский код;
- если исключение не переброшено, то деаллоцирует его.
И снова бенчмарк
Чтобы проверить, что информация о типе действительно обрабатывается в run-time, проведём ещё один любопытный бенчмарк. Создадим тип F очень простого вида:
struct F{};А также шаблон template<int> struct G. Его особенность — в том, что у типа G<0> очень много потомков, 2048 штук. В функции f всё просто: будем бросать исключение типа F и затем ловить исключение типа F. В функции g будем бросать исключение типа G<0>, а ловить по типу одного из его многочисленных потомков — G<1111>.
Если наше предположение верно, то программе потребуется гораздо меньше времени для поиска обработчика исключения типа F. Напротив, чтобы убедиться, что обработчик типа G<1111> соответствует выброшенному исключению типа G<0>, придётся потрудиться.
Запустим бенчмарк и убедимся в своей правоте:
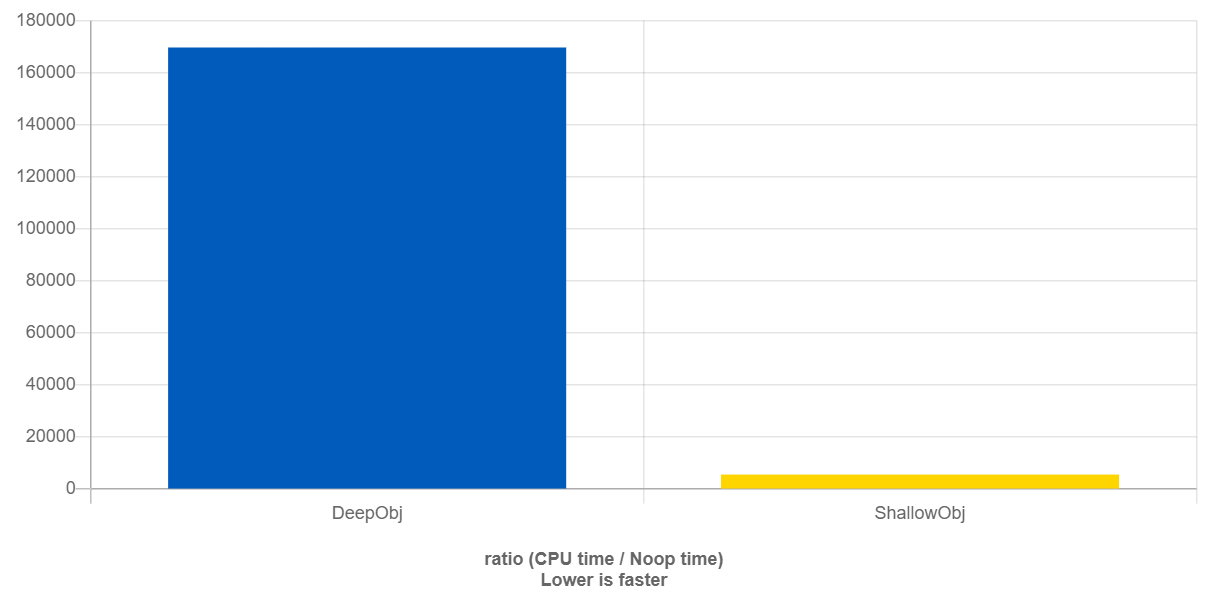
Слева обработка исключения типа G<0>, справа — типа F
Поимка объекта по глубокому производному классу заняла в 32 раза больше времени. Таким образом мы убедились, что проверка исключения на соответствие типу действительно происходит в run-time.
Мы рассмотрели подкапотную исключений и увидели, что часть важной работы происходит в run-time, что несвойственно для C++. Может быть, это даже не очень эффективно, но, как было сказано выше, при обработке исключений эффективность отодвигается на второй план. Ведь это исключительная ситуация, и в том, чтобы потратить несколько десятков тысяч лишних инструкций, нет ничего страшного.
Заключение
Мы проделали большую работу. Разобрались в тонкостях исключений в C++, гарантиях, спецификациях. Узнали, что, вопреки распространённому мнению, исключения — не всегда медленно.
Да, исключения мешают оптимизатору, но если не забыть noexcept для критически важных функций, то этот эффект сведётся к минимуму.
Некоторые компании избегают исключений в своём коде. Но только вам решать, отказываться от них или нет. При умелом использовании исключения не принесут вреда, а польза может быть огромна. В одном можете быть уверены: после прочтения этой статьи умелое использование исключений — в ваших руках.
Полезные ссылки
- Курс «Разработчик C++» в Яндекс Практикуме
- Дополнительный курс «C++ для бэкенда» в Яндекс Практикуме
- Блок try в энциклопедии cppreference
- Конструкция throw в энциклопедии cppreference
- Спецификации исключений в энциклопедии cppreference
- Стандартные типы исключений в энциклопедии cppreference
- Доклад «Исключения C++ через призму компиляторных оптимизаций» на конференции C++ Russia 2019 Piter
- Сервис микробенчмарков Quick C++ Benchmark
- Раздел «Исключения» стайлгайда Google
О чём тут не будет: напоминания базовых конструкций языка и основных моментов о том, как с ними работать; подробного разбора, как работают исключения (писали тут и тут); как грамотно спроектировать ваш класс/программу, чтобы не наломать дров в будущем с гарантией исключений (разве что совсем чуть-чуть, хотя я сам и не очень-то тук-тук).
О чём будет: разные способы обработки ошибок в C++, несколько советов от сообщества и немного заметок о различных жизненных (и не очень) ситуациях.
Текущее состояние дел
Перед тем, как посмотреть, что же есть в C++, давайте вспомним, как с ошибками жили C-программисты. Тут есть несколько опций:
-
возвращать код ошибки. Например заранее определить enum с возможными кодами ошибок:
enum err { OK = 0, UNEXPECTED };
err func(int x, int** result);-
использовать thread-local значения вроде
errno(для windowsGetLastError):
-
передавать отдельную переменную для ошибки:
int* func(int x, err* errcode);-
использовать setjmp/longjmp. В C++ стоит об этом категорически забыть (деструкторы и всё такое).
Почему этого недостаточно? Код возврата/параметр очень легко проигнорировать. Как часто вы проверяли, что вернули scanf/printf? Установку errno ещё легче.
Из-за этих (и ряда других) причин в С++ появились исключения. Их преимущества:
-
код не замусоривается обработкой кодов ошибок. Обработка исключений более менее отделена от логики приложения (если не говнокодить) + на каждый код возврата у вас нет лишнего бранча, который иногда может быть не очень просто предсказать;
-
исключения сложно игнорировать.
И недостатки:
-
flow кода может быть непредсказуем;
-
некоторый оверхед на поддержку исключений. Причём он есть, даже если вы исключения не используете (и не сделали что-то для того, чтобы его не было).
Кроме исключений ещё есть продвинутые коды возвратов. Тут не только значения, но и категории значений, чтобы можно было проверять, относится ли код к какой-то группе (прям как ловить базовый класс исключения вместо конкретных наследников):
std::error_code ec { MY_ERRC, std::errc::not_enough_memory};
...
if (ec == std::errc::not_enough_memory) {…}Спорить о том, что же удобнее и эффективнее, – не самое продуктивное занятие. В языке есть оба инструмента, которые нужно применять исходя из ваших нужд и требований (даже Bjarne Stroustrup писал, что исключения не замена другим возможным техникам обработки). Самый простой пример – исполнение в constexpr-контексте. При выполнении кода с бросанием исключений в constexpr-контексте вы получите ошибку компиляции (это даже как чит используется). Однако вы можете захотеть уметь в compile time обрабатывать ошибки. Тут вам и помогут коды возвратов. Только не std::error_code: эти ребята в constexpr не умеют.
Ещё, грубо говоря, std::optional тоже своего рода механизм обработки ошибок, но семантически его часто используют не для исключительных ситуаций, а для приемлемых ситуаций. Так что well yes but actually no.
Светлое будущее
Следующим шагом для стандартного C++ является пропозал по введению std::expected<T, E> (аналог Result<T, E> из Rust). Здесь возвращается либо результат, либо сконструированное исключение (или std::error_code, int, MyErrorClass и что угодно ещё). Есть хороший доклад Andrei Alexandrescu на CppCon2018 про это. Можно посмотреть вариант базовой реализации.
Всё новое хорошо забытое старое…
Вообще подобные штуки можно было делать и раньше, например с помощью std::exception_ptr, std::current_exception и std::rethrow_exception. Ловите ваше исключение и работаете с ним, как объектом, пока не нужно бросить его дальше. Но идея std::expected это всё-таки уровень повыше: у вас всегда пара значений, в которой есть только что-то одно.
Мне нравятся варианты с корутинами, если не обращать внимания на неприятные глазу приставки co_ к половине операторов. Например такой, где они совмещаются со std::expected и всё это варится в виде монад, что позволяет напрямую не обрабатывать ошибки без необходимости:
struct error {
int code;
};
expected<int, error> f1() { return 7; }
expected<double, error> f2(int x) { return 2.0 * x; }
expected<int, error> f3(int x, double y) { return error{42}; }
auto test_expected_coroutine() {
return []() -> expected<int, error> {
auto x = co_await f1();
auto y = co_await f2(x);
auto z = co_await f3(x, y);
co_return z;
}();
}Или вот замечательный доклад про подобное в другом виде. Хотя конечно на практике такое не очень используется, потому что могут быть проблемы с производительностью.
Рядом с пропозалом о std::expected ещё есть пропозал об operator try() (что-то вроде operator ? из Rust), который помогает писать меньше кода. Автор предлагает ввести понятную конструкцию, чтобы не приходилось абузить корутины для достижения таких же результатов. Правда она в перспективе не дойдёт до стандарта до C++29.
Самой конфетой является предложение Herb Sutter про использование статических исключений. Пример из пропозала:
string f() throws {
if (flip_a_coin()) throw arithmetic_error::something;
return “xyzzy”s + “plover”; // any dynamic exception is translated to error
}
string g() throws { return f() + “plugh”; } // any dynamic exception is translated to error
int main() {
try {
auto result = g();
cout << “success, result is: ” << result;
}
catch(error err) { // catch by value is fine
cout << “failed, error is: ” << err.error();
}
}
Появляется новое ключевое слово throws, которое означает, что функция возвращает на самом деле (грубо говоря) std::expected<T, error_code>, а все throw в функции — на самом деле return, который возвращает код ошибки. И теперь можно будет писать всегда либо throws, либо noexcept. Ещё тут предлагается расширить кейсы использования ключевого слова try: использовать вместе с/вместо return, при инициализации, использовать при передаче аргументов функций. Немного синтаксического сахара при использовании catch. А ещё предлагаемая модель является real-time safe (это когда время работы инструмента/механизма ограничено сверху известной величиной) в отличие от текущей реализации исключений. Однако работа над этим пропозалом не велась с 2019, и что с ним и как непонятно.
Как альтернатива есть статья James Renwick о другой реализации такого же механизма, как у Herb Sutter, но она подразумевает слом ABI, что почти наверняка в ближайшие годы не случится.
Набросы
Часто считается плохой практикой бросать что-то не унаследованное от стандартных ошибок. И тут (как и со своими типами) стоит быть аккуратным:
struct e1 : std::exception {};
struct e2 : std::exception {};
struct e3 : ex1, ex2 {};
int main() {
try { throw_e3(); }
catch(std::exception& e) {}
catch(...) {}
}Т.к. у e3 несколько предков std::exception => компилятор не сможет понять, к какому именно std::exception нужно привести объект e3, потому это исключение будет отловлено в catch(...). При виртуальном наследовании e1, e2 от std::exception всё работает как ожидается.
Знатные маслины можно ловить при бросании исключений откуда не надо. Например, у стандартной библиотеки есть некоторые инварианты, без которых написание кода стало бы ужасной мукой (а может и вовсе невозможным). Одним из них является предположение, что деструкторы, операции удаления и swap не бросают исключений, потому хорошо бы помечать их noexcept. Если по каким-то причинам внутри что-то может вылететь, на месте (прям до выхода из функции/методов) ловите исключения и пытайтесь исправить ситуацию, чтобы состояние программы осталось валидным. По-хорошему ещё и move-операции должны быть небросающими, т.к. это открывает путь к более эффективному коду (классический пример это использование std::move_if_noexcept в std::vector).
Собственно с деструкторами и начинается самый флекс: если исключение вылетает при раскрутке стека, вы сразу ловите std::terminate. Бороться с такими проблемами можно разными способами. Самый хороший – не бросать исключения из деструкторов. Если очень хочется, юзайте noexcept(false), но лучше отбросьте эти богохульные мысли и идите спать. Чуть больше про это можно почитать вот тут.
Интересные штуки ещё можно делать со статическими переменными. Во-первых, их инициализация происходит атомарно. Во-вторых, только один раз. Т.е. если вы хотите выполнить какой-то единожды, вы можете сделать следующее:
[[maybe_unused]] static bool unused = [] {
std::cout << "printed once" << std::endl;
return true;
}();А что, если хочется выполнить какой-то код ровно n раз? Тут можно воспользоваться фактом, что, если при инициализации вылетает исключение, переменная не инициализируется и попытается инициализироваться в следующий раз:
struct Throwed {};
constexpr int n = 3;
void init() {
try {
[[maybe_unused]] static bool unused = [] {
static int called = 0;
std::cout << "123" << std::endl;
if (++called < n) {
throw Throwed{};
}
return true;
}();
} catch (Throwed) {}
}Но это тоже говнокод ¯_(ツ)_/¯.
Какие-то рекомендации
Набросы из личного опыта и советов из интернетов, которые, к сожалению, получилось прочувствовать на себе:
-
Исключения задумывались в мире, где существуют деструкторы, а значит и RAII. Используйте эту идиому максимально, если речь идёт об освобождении ресурсов.
Если для ситуации RAII подходит недостаточно (нужно совершить не очистку ресурсов, а просто набор действий), сообразите что-то вроде gsl::finally.
-
Используйте исключения, если в конструкторе объекта становится понятно, что объект создать невозможно (раз, два). Тут так-то других вариантов особо и нет: возвращаемое значение у конструкторов не предусмотрено. Можно конечно завести условный метод
IsValidи обмазаться конструкциями сif, но имхо не оч удобно. -
Можно использовать исключения для проверки пред-/постусловий.
-
В силу непредсказуемости flow выполнения вашего кода из-за исключений, можно с ними знатные приколы мутить. Встречались кейсы, когда исключения использовались для выхода из глубокой рекурсии, нескольких циклов сразу или, внезапно, даже возврата значения из функции. Не делайте так. Исключения они на то и исключения, чтобы детектить ошибки. Exceptions are for exceptional.
-
Но не переусердствуйте с ловлей исключений. Хорошо, когда вы ожидаете какую-то конкретную ошибку и ловите именно её. Думаю, вы тоже видели код с конструкциями вида
catch (...) {}, потому что “ну там какие-то исключения вылетают, а падать не хочется”. Разберитесь с этим и контролируйте (может у вас есть действительно хорошие примеры, где это наилучшее решение; тогда расскажите в комментариях). -
Если не можете обработать исключение, делайте аборт (
std::abort/std::terminate/std::exit/std::quick_exit). -
Старайтесь ловить исключения так, чтобы они копировались минимальное количество раз (с помощью ссылок/указателей/
exception_ptr). В идеале ноль.
Ещё немного набросов
В некоторых проектах исключения вообще стараются не использовать, т.к. это не очень эффективно (размотка стека и проблемы с некоторыми оптимизациями). В таких случаях применяются другие подходы обработки ошибок (например падение). Тут же есть практики постоянно писать noexcept. Это хорошая практика, но всё же стоит быть осторожным, т.к. это часть интерфейса. Короче пользуйтесь с умом.
Если вы точно не хотите использовать исключения, можно компилировать ваш проект с -fno-exceptions, что позволяет не поддерживать исключения при компиляции -> открыть возможности для новых оптимизаций (будьте готовы к разным неожиданным эффектам; например стандартная библиотека станет падать там, где раньше вылетали исключения).
Вы можете использовать function-try-block для ловли исключений из всей функции/конструкторов со списками инициализации:
struct S {
MyClass x;
S(MyClass& x) try : x(x) {
} catch (MyClassInitializationException& ex) {...}
};Но имейте в виду некоторые возможные проблемы.
Мне нравится как принято работать с ошибками в Golang: вы словили её, добавили к сообщению какую-то информацию и бросили дальше, чтобы в итоге сообщение у ошибки получилось примерно такое: “topFunc: secondFunc: firstFunc: some error text”. Довольно удобно (по крайней мере в Go), если у вас похожая парадигма работы с ошибками и нет stacktrace рядом с исключениями. Однако в C++ стоит быть осторожным, потому что есть механизм std::throw_with_nested, который совсем о другом. Концептуально тут всё просто: у исключений может быть вложенное исключение, которое можно достать из родительского исключения. Получается, можно сделать дерево в виде цепочки из исключений (прямо как в Java есть cause у исключений, но там этот механизм чуть шире и делать так принято). Имхо если вы такое используете, у вас какие-то архитектурные проблемы, так что перед написанием новых велосипедов, задумайтесь, всё ли в порядке.
Бесполезный (но забавный) факт. Вот такой код вполне себе корректен: throw nothrow.
Несмешная нешутка.
*шутка про то, что C++ – ошибка, которую не сумели правильно обработать*
Реклама.
Можете подписаться на канал о C++ и программировании в целом в тг: t.me/thisnotes.
Определено в заголовке <filesystem> |
||
|---|---|---|
class filesystem_error; |
(since C++17) |
Класс std::filesystem::filesystem_error определяет объект исключения, который генерируется при сбое из-за перегрузки функций в библиотеке файловой системы.
Member functions
| объект исключения (функция публичного члена) |
|
| заменяет объект исключения (функция публичного члена) |
|
| возвращает пути,которые были задействованы в операции,вызвавшей ошибку. (функция публичного члена) |
|
| возвращает пояснительную строку (функция публичного члена) |
Наследуется от std :: system_error
Member functions
| код ошибки возврата (открытая функция-член std::system_error ) |
|
|
[virtual] |
возвращает пояснительную строку (виртуальная общедоступная функция-член std::system_error ) |
Унаследовано от std::runtime_error
Наследуется от std :: exception
Member functions
|
[virtual] |
уничтожает объект исключения (виртуальная публичная функция-член std::exception ) |
|
[virtual] |
возвращает пояснительную строку (виртуальная публичная функция-член std::exception ) |
Notes
Чтобы гарантировать, что функции копирования filesystem_error системы_ошибки не являются исключением, типичные реализации хранят объект, содержащий возвращаемое значение what() , и два объекта std::filesystem::path , на которые ссылаются path1() и path2() соответственно, в отдельно выделенном хранилище с подсчетом ссылок.
В настоящее время реализация MS STL не соответствует требованиям: упомянутые выше объекты хранятся непосредственно в объекте filesystem , что делает функции копирования не нулевыми.
Example
#include <system_error> #include <filesystem> #include <iostream> int main() { const std::filesystem::path from{"/nonexistent1/a"}, to{"/nonexistent2/b"}; try { std::filesystem::copy_file(from, to); } catch(std::filesystem::filesystem_error const& ex) { std::cout << "what(): " << ex.what() << 'n' << "path1(): " << ex.path1() << 'n' << "path2(): " << ex.path2() << 'n' << "code().value(): " << ex.code().value() << 'n' << "code().message(): " << ex.code().message() << 'n' << "code().category(): " << ex.code().category().name() << 'n'; } std::error_code ec; std::filesystem::copy_file(from, to, ec); std::cout << "nnon-throwing form sets error_code: " << ec.message() << 'n'; }
Possible output:
what(): filesystem error: cannot copy file: No such file or directory [/nonexistent1/a] [/nonexistent2/b] path1(): "/nonexistent1/a" path2(): "/nonexistent2/b" code().value(): 2 code().message(): No such file or directory code().category(): generic non-throwing form sets error_code: No such file or directory
C++
-
std::filesystem::file_time_type
Представляет время файла.
-
std::filesystem::file_type
file_type определяет константы,указывающие путь к каталогу или директории,к которой относится Возможный вывод:
-
std::filesystem::filesystem_error::filesystem_error
Создает новый объект filesystem_error.
-
std::filesystem::filesystem_error::operator=
Присваивает содержимое с содержимым других.
Содержание
- C++ — Урок 011. Исключения
- Инварианты
- Виды исключений
- std::logic_error
- std::invalid_argument
- std::domain_error
- std::length_error
- std::out_of_range
- std::future_error
- std::runtime_error
- std::range_error
- std::overflow_error
- std::underflow_error
- std::system_error
- std::ios_base::failure
- std::bad_typeid
- std::bad_cast
- std::bad_weak_ptr
- std::bad_function_call
- std::bad_alloc
- std::bad_array_new_length
- std::bad_exception
- 20.5 – Исключения, классы и наследование
- Исключения и функции-члены
- Когда конструкторы дают сбой
- Классы исключений
- Исключения и наследование
- std::exception
- Использование стандартных исключений напрямую
- Создание собственных классов, производных от std::exception или std::runtime_error
C++ — Урок 011. Исключения
Что такое исключение? Это ситуация, которая не предусмотрена стандартным поведением программы. Например, попытка доступа к элементу в классе Vector (который мы разбирали в статье про классы ), который не существует. То есть происходит выход за пределы вектора. В данном случае можно воспользоваться исключениями, чтобы прервать выполнение программы. Это необходимо потому, что
- Как правило в таких случаях, автор класса Vector не знает, как пользователь захочет использовать его класс, а также не знает в какой программе этот класс будет использоваться.
- Пользователь класса Vector не может всегда контролировать правильность работы этого класса, поэтому ему нужно сообщить о том, что что-то пошло не так.
Для разрешения таких ситуация в C++ можно использовать технику исключений.
Рассмотрим, как написать вызов исключения в случае попытки доступа к элементу по индексу, который не существует в классе Vector.
Здесь применяется исключение out_of_range. Данное исключение определено в заголовочном файле .
Оператор throw передаёт контроль обработчику для исключений типа out_of_range в некоторой функции, которая прямо или косвенно вызывает Vector::operator . Для того, чтобы обработать исключения необходимо воспользоваться блоком операторов try catch.
Инварианты
Также блоки try catch позволяют производить обработку нескольких различных исключений, что вносит инвариантность в работу механизма исключений C++.
Например, класс вектор при создании может получить неправильный размер вектора или не найти свободную память для элементов, которые он будет содержать.
Данный конструктор может выбросить исключение в двух случаях:
- Если в качестве аргумента size будет передано отрицательное значение
- Если оператор new не сможет выделить память
length_error — это стандартный оператор исключений, поскольку библиотека std часто использует данные исключения при своей работе.
Обработка исключений будет выглядеть следующим образом:
Также можно выделить свои собственные исключения.
Виды исключений
Все исключения стандартной библиотеки наследуются от std::exception.
На данный момент существуют следующие виды исключений:
- logic_error
- invalid_argument
- domain_error
- length_error
- out_of_range
- future_error (C++11)
- runtime_error
- range_error
- overflow_error
- underflow_error
- system_error (C++11)
- ios_base::failure (начиная с C++11)
- bad_typeid
- bad_cast
- bad_weak_ptr (C++11)
- bad_function_call (C++11)
- bad_alloc
- bad_array_new_length (C++11)
- bad_exception
- ios_base::failure (до C++11)
std::logic_error
Исключение определено в заголовочном файле
Определяет тип объекта, который будет брошен как исключение. Он сообщает об ошибках, которые являются следствием неправильной логики в рамках программы, такие как нарушение логической предпосылки или класс инвариантов, которые возможно предотвратить.
Этот класс используется как основа для ошибок, которые могут быть определены только во время выполнения программы.
std::invalid_argument
Исключение определено в заголовочном файле
Наследован от std::logic_error. Определяет исключение, которое должно быть брошено в случае неправильного аргумента.
Например, на MSDN приведён пример, когда в объект класса bitset из стандартной библиотеки
В данном примере передаётся неправильная строка, внутри которой имеется символ ‘b’, который будет ошибочным.
std::domain_error
Исключение определено в заголовочном файле
Наследован от std::logic_error. Определяет исключение, которое должно быть брошено в случае если математическая функция не определена для того аргумента, который ей передаётся, например:
std::length_error
Исключение определено в заголовочном файле
Наследован от std::logic_error. Определяет исключение, которое должно быть броше в том случае, когда осуществляется попытка реализации превышения допустим пределов для объекта. Как это было показано для размера вектора в начале статьи.
std::out_of_range
Исключение определено в заголовочном файле
Наследован от std::logic_error. Определяет исключение, которое должно быть брошено в том случае, когда происходит выход за пределы допустимого диапазона значений объекта. Как это было показано для диапазона значений ветора в начале статьи.
std::future_error
Исключение определено в заголовочном файле
Наследован от std::logic_error. Данное исключение может быть выброшено в том случае, если не удалось выполнить функцию, которая работает в асинхронном режиме и зависит от библиотеки потоков. Это исключение несет код ошибки совместимый с std::error_code .
std::runtime_error
Исключение определено в заголовочном файле
Является базовым исключением для исключений, которые не могут быть легко предсказаны и должны быть брошены во время выполнения программы.
std::range_error
Исключение определено в заголовочном файле
Исключение используется при ошибках при вычислении значений с плавающей запятой, когда компьютер не может обработать значение, поскольку оно является либо слишком большим, либо слишком маленьким. Если значение является значение интегрального типа, то должны использоваться исключения underflow_error или overflow_error .
std::overflow_error
Исключение определено в заголовочном файле
Исключение используется при ошибках при вычислении значений с плавающей запятой интегрального типа, когда число имеет слишком большое положительное значение, положительную бесконечность, при которой происходит потеря точности, т.е. результат настолько большой, что не может быть представлен числом в формате IEEE754.
std::underflow_error
Исключение определено в заголовочном файле
Исключение используется при ошибках при вычислении значений с плавающей запятой интегрального типа, при которой происходит потеря точности, т.е. результат настолько мал, что не может быть представлен числом в формате IEEE754.
std::system_error
Исключение определено в заголовочном файле
std::system_error — это тип исключения, которое вызывается различными функциями стандартной библиотеки (как правило, функции, которые взаимодействуют с операционной системой, например, конструктор std::thread ), при этом исключение имеет соответствующий std::error_code .
std::ios_base::failure
Исключение определено в заголовочном файле
Отвечает за исключения, которые выбрасываются при ошибках функций ввода вывода.
std::bad_typeid
Исключение определено в заголовочном файле
Исключение этого типа возникает, когда оператор typeid применяется к нулевому указателю полиморфного типа.
std::bad_cast
Исключение определено в заголовочном файле
Данное исключение возникает в том случае, когда производится попытка каста объекта в тот тип объекта, который не входит с ним отношения наследования.
std::bad_weak_ptr
Исключение определено в заголовочном файле
std::bad_weak_ptr – тип объекта, генерируемый в качестве исключения конструкторами std::shared_ptr , которые принимают std::weak_ptr в качестве аргумента, когда std::weak_ptr ссылается на уже удаленный объект.
std::bad_function_call
Исключение определено в заголовочном файле
Данное исключение генерируется в том случае, если был вызван метод std::function::operator() объекта std::function , который не получил объекта функции, то есть ему был передан в качестве инициализатора nullptr, например, а объект функции так и не был передан.
std::bad_alloc
Исключение определено в заголовочном файле
Вызывается в том случае, когда не удаётся выделить память.
std::bad_array_new_length
Исключение определено в заголовочном файле
Исключение вызывается в следующих случаях:
- Массив имеет отрицательный размер
- Общий размер нового массива превысил максимальное значение, определяемое реализацией
- Количество элементов инициализации превышает предлагаемое количество инициализирующих элементов
std::bad_exception
Исключение определено в заголовочном файле
std::bad_exception — это тип исключения в C++, которое выполняется в следующих ситуациях:
- Если нарушается динамическая спецификация исключений
- Если std::exception_ptr хранит копию пойманного исключения, и если конструктор копирования объекта исключения поймал current_exception, тогда генерируется исключение захваченных исключений.

Рекомендуем хостинг TIMEWEB
Рекомендуемые статьи по этой тематике
Источник
20.5 – Исключения, классы и наследование
Исключения и функции-члены
До этого момента в данном руководстве вы видели исключения, используемые только в функциях, не являющихся членами. Однако исключения также полезны в функциях-членах и тем более в перегруженных операторах. Рассмотрим следующий перегруженный оператор [] как часть простого класса целочисленного массива:
Хотя эта функция будет отлично работать, пока index является допустимым индексом массива, ей очень не хватает проверки на ошибку. Мы могли бы добавить инструкцию assert , чтобы убедиться, что index корректен:
Теперь, если пользователь передаст недопустимый индекс, программа вызовет ошибку утверждения. К сожалению, поскольку перегруженные операторы предъявляют особые требования к количеству и типу параметров, которые они могут принимать и возвращать, у них нет гибкости для передачи кодов ошибок или логических значений в вызывающую функцию для обработки. Однако, поскольку исключения не изменяют сигнатуру функции, они могут быть здесь очень полезны. Например:
Теперь, если пользователь передает недопустимый индекс, operator[] вызовет исключение типа int .
Когда конструкторы дают сбой
Конструкторы – это еще одна область классов, в которой исключения могут быть очень полезны. Если по какой-либо причине конструктор может дать сбой (например, пользователь передал недопустимые входные данные), просто выбросите исключение, чтобы указать, что объект не удалось создать. В таком случае создание объекта прерывается, и все члены класса (которые уже были созданы и инициализированы до выполнения тела конструктора) уничтожаются как обычно.
Однако деструктор класса в этом случае никогда не вызывается (потому что объект так и не завершил построение). Поскольку деструктор никогда не выполняется, вы не можете полагаться на этот деструктор в освобождении любых ресурсов, которые уже были выделены.
Это приводит к вопросу о том, что мы должны делать, если мы выделили ресурсы в нашем конструкторе, а затем возникает исключение до завершения конструктора. Как обеспечить правильное освобождение уже выделенных ресурсов? Один из способов – обернуть любой код, который может дать сбой в блок try , использовать соответствующий блок catch для перехвата исключения и выполнить любую необходимую очистку, а затем повторно выбросить исключение (эту тему мы обсудим в уроке «20.6 – Повторное выбрасывание исключений»). Однако это добавляет много бардака, и здесь легко ошибиться, особенно если ваш класс выделяет несколько ресурсов.
К счастью, есть способ получше. Воспользовавшись тем фактом, что члены класса уничтожаются, даже если конструктор завершается сбоем, если вы выполняете размещение ресурсов внутри членов класса (а не в самом конструкторе), эти члены, когда они уничтожаются, могут выполнять после себя очистку.
Этот код печатает:
В приведенной выше программе, когда класс A выдает исключение, все члены A уничтожаются. Вызывается деструктор m_member , который дает возможность освободить все выделенные им ресурсы.
Это одна из причин того, что RAII (метод, описанный в уроке «12.9 – Деструкторы») так широко пропагандируется – даже в исключительных обстоятельствах классы, реализующие RAII, могут выполнять после себя очистку.
Однако создание пользовательского класса, такого как Member , для управления размещением ресурсов неэффективно. К счастью, стандартная библиотека C++ поставляется с RAII-совместимыми классами для управления распространенными типами ресурсов, такими как файлы ( std::fstream , рассмотренные в уроке «23.6 – Основы файлового ввода/вывода») и динамическая память ( std::unique_ptr и другие умные указатели, описанные в «M.1 – Введение в умные указатели и семантику перемещения»).
Например, вместо этого:
В первом случае, если конструктор Foo завершится со сбоем после того, как ptr выделил свою динамическую память, Foo будет отвечать за очистку, что может быть сложной задачей. Во втором случае, если конструктор Foo завершится со сбоем после того, как ptr выделил свою динамическую память, деструктор ptr выполнит и вернет эту память в систему. Foo не должен выполнять какую-либо явную очистку, когда обработка ресурсов делегируется членам, совместимым с RAII!
Классы исключений
Одна из основных проблем с использованием базовых типов данных (таких как int ) в качестве типов исключений заключается в том, что они по своей сути непонятны. Еще бо́льшая проблема – это разрешение неоднозначности того, что означает исключение, когда в блоке try есть несколько инструкций или вызовов функций.
В этом примере, если бы мы перехватили исключение типа int , о чем это нам сказало бы? Был ли один из индексов массива вне допустимого диапазона? operator+ вызвал целочисленное переполнение? Сбой оператора new из-за нехватки памяти? К сожалению, в этом случае нет простого способа устранить неоднозначность. Хотя мы можем генерировать исключения const char* для решения проблемы определения, ЧТО пошло не так, это всё же не дает нам возможности обрабатывать исключения из разных источников по-разному.
Один из способов решить эту проблему – использовать классы исключений. Класс исключения – это просто обычный класс, специально созданный для выдачи исключения. Давайте спроектируем простой класс исключения, который будет использоваться с нашим классом IntArray :
Вот полный код программы, использующей этот класс:
Используя такой класс, мы можем сделать так, чтобы исключение вернуло описание возникшей проблемы, которое предоставляет контекст для того, что пошло не так. А поскольку ArrayException – это собственный уникальный тип, мы можем специально перехватывать исключения, создаваемые классом массива, и при желании обрабатывать их иначе, чем другие исключения.
Обратите внимание, что обработчики исключений должны перехватывать объекты класса исключения по ссылке, а не по значению. Это предотвращает создание компилятором копии исключения, что может быть дорогостоящим, если исключение является объектом класса, и предотвращает обрезку объекта при работе с производными классами исключений (о которых мы поговорим чуть позже). Как правило, следует избегать перехвата исключений по указателю, если для этого нет особых причин.
Исключения и наследование
Поскольку можно выбрасывать объекты классов, в качестве исключений, а классы могут быть производными от других классов, нам необходимо учитывать, что происходит, когда в качестве исключений мы используем наследованные классы. Оказывается, обработчики исключений будут не только соответствовать классам определенного типа, они также будут соответствовать классам, производным от этого конкретного типа! Рассмотрим следующий пример:
В приведенном выше примере мы генерируем исключение типа Derived . Однако результат этой программы:
Во-первых, как упоминалось выше, производные классы будут перехвачены обработчиками базового типа. Поскольку Derived является производным от Base , Derived «является» Base (между ними есть связь «является чем-либо»). Во-вторых, когда C++ пытается найти обработчик возникшего исключения, он делает это последовательно. Следовательно, первое, что делает C++, – это проверяет, соответствует ли обработчик исключений для Base исключению Derived . Поскольку Derived «является» Base , ответ – да, и он выполняет блок catch для типа Base ! Блок catch для Derived в этом случае даже не проверяется.
Чтобы этот пример работал, как задумывалось, нам нужно изменить порядок блоков catch :
Таким образом, обработчик Derived получит первым шанс перехватить объекты типа Derived (до того, как это сделает обработчик для Base ). Объекты типа Base не будут соответствовать обработчику Derived ( Derived «является» Base , но Base не является Derived ) и, таким образом, «провалятся вниз» до обработчика Base .
Правило
Обработчики для исключений производных классов должны быть идти перед обработчиками для базовых классов.
Возможность использовать обработчик для перехвата исключений производных типов с помощью обработчика для базового класса может быть чрезвычайно полезной.
std::exception
Многие классы и операторы в стандартной библиотеке в случае сбоя выдают исключения с объектами классов. Например, оператор new может выбросить std::bad_alloc , если не может выделить достаточно памяти. Неудачный dynamic_cast вызовет std::bad_cast . И так далее. Начиная с C++20, существует 28 различных классов исключений, которые могут быть сгенерированы, и в каждом последующем стандарте языка добавляется еще больше.
Хорошая новость заключается в том, что все эти классы исключений являются производными от одного класса std::exception . std::exception – это небольшой интерфейсный класс, предназначенный для использования в качестве базового класса для любого исключения, создаваемого стандартной библиотекой C++.
В большинстве случаев, когда стандартная библиотека генерирует исключение, нас не волнует, неудачное ли это выделение памяти, неправильное приведение или что-то еще. Нас просто волнует, что что-то катастрофически пошло не так, и теперь наша программа дает сбой. Благодаря std::exception мы можем настроить обработчик исключений для перехвата исключений типа std::exception , и в итоге мы перехватим и std::exception , и все производные исключения в одном месте. Всё просто!
Приведенная выше программа печатает:
Приведенный выше пример довольно простой. В нем стоит отметить одну вещь: std::exception имеет виртуальную функцию-член what() , которая возвращает строку в стиле C с описанием исключения. Большинство производных классов переопределяют функцию what() для изменения этого сообщения. Обратите внимание, что эта строка предназначена для использования только для описательного текста – не используйте ее для сравнений, поскольку не гарантируется, что она будет одинаковой для разных компиляторов.
Иногда нам нужно обрабатывать определенный тип исключения по-другому. В этом случае мы можем добавить обработчик для этого конкретного типа и позволить всем остальным «проваливаться вниз» до обработчика базового типа. Рассмотрим следующий код:
В этом примере исключения типа std::length_error будут перехвачены и обработаны первым обработчиком. Исключения типа std::exception и всех других производных классов будут перехвачены вторым обработчиком.
Такие иерархии наследования позволяют нам использовать определенные обработчики для нацеливания на определенные производные классы исключений или использовать обработчики базовых классов для перехвата всей иерархии исключений. Это позволяет нам точно контролировать, какие исключения мы хотим обрабатывать, и при этом нам не нужно делать слишком много работы, чтобы отловить «всё остальное» в иерархии.
Использование стандартных исключений напрямую
Ничто напрямую не вызывает std::exception , и вы тоже. Однако вы можете свободно использовать другие стандартные классы исключений из стандартной библиотеки, если они адекватно соответствуют вашим потребностям. Список всех стандартных исключений вы можете найти на cppreference.
std::runtime_error (включен как часть заголовка stdexcept ) выбирается часто потому, что он имеет обобщенное название, а его конструктор принимает настраиваемое сообщение:
Этот код печатает:
Создание собственных классов, производных от std::exception или std::runtime_error
Конечно, вы можете наследовать свои классы от std::exception и переопределять виртуальную константную функцию-член what() . Вот та же программа, что и выше, но с исключением ArrayException , производным от std::exception :
Обратите внимание, что виртуальная функция what() имеет спецификатор noexcept (что означает, что эта функция обещает не генерировать исключения). Следовательно, у нашего переопределения также должен быть спецификатор noexcept .
Поскольку std::runtime_error уже имеет возможности обработки строк, он также популярен в качестве базового класса для производных классов исключений. Вот тот же пример, использующий std::runtime_error :
Вам решать, хотите ли вы создать свои собственные автономные классы исключений, использовать стандартные классы исключений или наследовать свои классы исключений от std::exception или std::runtime_error . Все эти подходы допустимы и зависят от ваших целей.
Источник
Выбор правильной стратегии обработки ошибок (части 1 и 2) +20
C++, Блог компании Mail.Ru Group, Проектирование и рефакторинг, Совершенный код, Анализ и проектирование систем
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.