-
#1
Hi guys,
in PM 6 I got the «permission denied — invalid PVE ticket (401)» when using WEB GUI on one of the cluster nodes.
It logged me out of WEB GUI as soon as I started browsing the effected node via HTTP, even if I originally connected to another node.
Other nodes work fine.
I solved it by restarting services:
root@p37:~# systemctl restart pvedaemon pveproxy
It might be a bug. Seems i’m not the only with with the problem, but I guess writing the solution that worked for me, is the point of this forum post.
Here is the version info
Code:
proxmox-ve: 6.2-2 (running kernel: 5.4.65-1-pve)
pve-manager: 6.2-12 (running version: 6.2-12/b287dd27)
pve-kernel-5.4: 6.2-7
pve-kernel-helper: 6.2-7
pve-kernel-5.4.65-1-pve: 5.4.65-1
pve-kernel-5.4.34-1-pve: 5.4.34-2
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.0.4-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: 0.8.35+pve1
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.16-pve1
libproxmox-acme-perl: 1.0.5
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.0-3
libpve-common-perl: 6.2-2
libpve-guest-common-perl: 3.1-3
libpve-http-server-perl: 3.0-6
libpve-storage-perl: 6.2-8
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.3-1
lxcfs: 4.0.3-pve3
novnc-pve: 1.1.0-1
proxmox-backup-client: 0.9.0-2
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.3-1
pve-cluster: 6.2-1
pve-container: 3.2-2
pve-docs: 6.2-6
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.1-3
pve-ha-manager: 3.1-1
pve-i18n: 2.2-1
pve-qemu-kvm: 5.1.0-3
pve-xtermjs: 4.7.0-2
qemu-server: 6.2-15
smartmontools: 7.1-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 0.8.4-pve2
-
#2
is this not because of an accidental cache clear or session time-out ?
![]()
-
#3
usually it’s caused by the PVE node having the wrong time..
-
#4
My nodes have the same time, they use ntp. This is the first thing I checked.
-
#5
is this not because of an accidental cache clear or session time-out ?
No, I did try different browsers, cleared cache, different client PCs, .. etc
It did not work anywhere and started working everywhere after restart of those services on the host.
-
#6
Coworker got the same errors, while it worked for me. FYI He was able to fix it after manually removing cookies. No need to restart pve stuff.
-
#7
Now even our monitoring system get’s kicked out and then just works again.. something strange is happening.. i think we should open a bug…

-

1605806414060.png
60 KB
· Views: 23
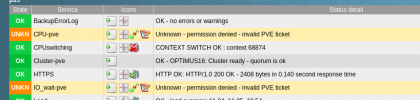
-
#8
As the problems were with only one node, I did systemctl restart pvedaemon pveproxy on that node and no more errors with logging in, not with our monitoring system or with our desktops. This for sure is a bug. Should I open a bug report? @fabian
Workaround would be, to do a cronjob restart of pvedaemon pveproxy every few hours…
-
#9
Got exactly same issue on 1 out of 4 nodes now. Definitely a bug.
Code:
proxmox-ve: 6.2-2 (running kernel: 5.4.65-1-pve)
pve-manager: 6.2-15 (running version: 6.2-15/48bd51b6)
pve-kernel-5.4: 6.2-7
pve-kernel-helper: 6.2-7
pve-kernel-5.3: 6.1-6
pve-kernel-5.4.65-1-pve: 5.4.65-1
pve-kernel-5.4.34-1-pve: 5.4.34-2
pve-kernel-5.3.18-3-pve: 5.3.18-3
pve-kernel-5.3.18-2-pve: 5.3.18-2
pve-kernel-5.3.10-1-pve: 5.3.10-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.0.4-pve1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: residual config
ifupdown2: 3.0.0-1+pve3
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.16-pve1
libproxmox-acme-perl: 1.0.5
libpve-access-control: 6.1-3
libpve-apiclient-perl: 3.0-3
libpve-common-perl: 6.2-2
libpve-guest-common-perl: 3.1-3
libpve-http-server-perl: 3.0-6
libpve-storage-perl: 6.2-9
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.3-1
lxcfs: 4.0.3-pve3
novnc-pve: 1.1.0-1
proxmox-backup-client: 0.9.4-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.3-6
pve-cluster: 6.2-1
pve-container: 3.2-2
pve-docs: 6.2-6
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-3
pve-firmware: 3.1-3
pve-ha-manager: 3.1-1
pve-i18n: 2.2-2
pve-qemu-kvm: 5.1.0-4
pve-xtermjs: 4.7.0-2
qemu-server: 6.2-18
smartmontools: 7.1-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 0.8.4-pve2Time is same/correct on all 4 nodes
Last edited: Nov 19, 2020
![]()
-
#10
could you check the logs of pvedaemon and pveproxy for anything suspicious? they should log once a day that the auth key got rotated, if you don’t see that message but a warning/error instead then the pmxcfs might have problems..
-
#11
Next time I notice logging out, I will grep syslog for pveproxy and pvedaemon.
-
#12
Coworker got the same errors, while it worked for me. FYI He was able to fix it after manually removing cookies.
No need to restart pve stuff.
There you go
Well, restarting a service does more than just that. It also reinitiates sessions and regenerates relevant ID’s. Much same as clearing cookies.
Could it be browser and services have a proxy in between which strips or rewrites part of the header ?
![]()
-
#13
There you go
Well, restarting a service does more than just that. It also reinitiates sessions and regenerates relevant ID’s. Much same as clearing cookies.
Could it be browser and services have a proxy in between which strips or rewrites part of the header ?
PVE does not have any session state server side..
-
#14
PVE does not have any session state server side..
Not even the session-id generated for the cookies ?
![]()
-
#15
there is no session-id generated for the cookies. PVE uses a signature based ticket mechanism for the cookies, which allows all nodes in a cluster to verify the tickets without needing per-session state that is synchronized.
-
#16
there is no session-id generated for the cookies. PVE uses a signature based ticket mechanism for the cookies, which allows all nodes in a cluster to verify the tickets without needing per-session state that is synchronized.
Thanks for explaining. If i understand correctly this implies the signature is valid across service restarts and no new tickets have to be issues after restart ?
![]()
-
#17
yes. the expiration of sessions is entirely time based.
-
#18
yes. the expiration of sessions is entirely time based.
now it is clear to me. As an admin i still call such a session albeit not based on a session-ID it does use a form of session identifier (ticket, right ?) Time based or not, as long as connectivity is permitted a session exists, although here purely in an permit window based on what i assume is the ticket stored in the cookie.
-
#19
Save Solution >>> Login per SSH in every Node and run:
service pve-cluster restart && service pvedaemon restart && service pvestatd restart && service pveproxy restart
-
#20
systemctl restart pvedaemon and pveproxy shuld suffice.
Содержание
- REST API: 401 Unauthorized: permission denied — invalid PVE ticket
- jan.svoboda
- Connection error 401: permission denied — invalid PVE ticket
- dcsapak
- dcsapak
- 4ps4all
- permission denied — invalid PVE ticket (401)
- T.Herrmann
- hallaji
- willprox
- chengkinhung
- RolandK
- RolandK
- 3 Node cluster «permission denied — invalid PVE ticket (401)»
- BugProgrammer
- Dominic
- BugProgrammer
- BugProgrammer
- hibouambigu
- hibouambigu
jan.svoboda
Member
I have some problems with authentication ticket. I know that there are multiple threads about the same issue. I tried to follow steps from those threads that worked for someone but nothing worked for me.
I use the REST API very extensively so it is crucial to have it working. I use proxmoxer 1.1.0 Python 3 library with HTTPS backend as a wrapper to the REST API.
I get HTTP 401 Unauthorized: permission denied — invalid PVE ticket while running a Python script using REST API very often and before the ticket’s 2 hours lifetime. Sometimes it doesn’t obtain the ticket at all.
It happens a few times a week. I searched for some clues in logs but I have never found the reason why this happens.
All nodes are NTP synchronized, I use the default systemd-timesyncd.
I would be very thankful if someone looks to attached logs and advise me what should I reconfigure or which other clues I should search for.
I have 5 Proxmox nodes in one cluster, all of them running the same version Proxmox VE 6.1-8.
# pveversion -v
pve-manager: 6.1-8 (running version: 6.1-8/806edfe1)
pve-kernel-helper: 6.1-7
pve-kernel-5.3: 6.1-6
pve-kernel-5.3.18-3-pve: 5.3.18-3
pve-kernel-5.3.18-2-pve: 5.3.18-2
pve-kernel-5.3.10-1-pve: 5.3.10-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.0.3-pve1
criu: 3.11-3
glusterfs-client: 7.4-1
ifupdown: residual config
ifupdown2: 2.0.1-1+pve8
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.15-pve1
libpve-access-control: 6.0-6
libpve-apiclient-perl: 3.0-3
libpve-common-perl: 6.0-17
libpve-guest-common-perl: 3.0-5
libpve-http-server-perl: 3.0-5
libpve-storage-perl: 6.1-5
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4
pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 3.2.1-1
lxcfs: 4.0.1-pve1
novnc-pve: 1.1.0-1
openvswitch-switch: 2.12.0-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.1-3
pve-cluster: 6.1-4
pve-container: 3.0-23
pve-docs: 6.1-6
pve-edk2-firmware: 2.20200229-1
pve-firewall: 4.0-10
pve-firmware: 3.0-6
pve-ha-manager: 3.0-9
pve-i18n: 2.0-4
pve-qemu-kvm: 4.1.1-4
pve-xtermjs: 4.3.0-1
qemu-server: 6.1-7
smartmontools: 7.1-pve2
spiceterm: 3.1-1
vncterm: 1.6-1
zfsutils-linux: 0.8.3-pve1
# timedatectl
Local time: Wed 2020-06-17 10:43:41 CEST
Universal time: Wed 2020-06-17 08:43:41 UTC
RTC time: Wed 2020-06-17 08:43:41
Time zone: Europe/Prague (CEST, +0200)
System clock synchronized: yes
NTP service: active
RTC in local TZ: no
# systemctl status -l systemd-timesyncd
● systemd-timesyncd.service — Network Time Synchronization
Loaded: loaded (/lib/systemd/system/systemd-timesyncd.service; enabled; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/systemd-timesyncd.service.d
└─disable-with-time-daemon.conf
Active: active (running) since Mon 2020-06-15 15:25:07 CEST; 1 day 19h ago
Docs: man:systemd-timesyncd.service(8)
Main PID: 4020 (systemd-timesyn)
Status: «Synchronized to time server for the first time 89.221.212.46:123 (0.debian.pool.ntp.org).»
Tasks: 2 (limit: 7372)
Memory: 6.5M
CGroup: /system.slice/systemd-timesyncd.service
└─4020 /lib/systemd/systemd-timesyncd
Jun 15 15:25:06 devel1 systemd[1]: Starting Network Time Synchronization.
Jun 15 15:25:07 devel1 systemd[1]: Started Network Time Synchronization.
Jun 15 15:25:07 devel1 systemd-timesyncd[4020]: Synchronized to time server for the first time 89.221.210.188:123 (0.debian.pool.ntp.org).
Jun 15 15:44:31 devel1 systemd-timesyncd[4020]: Timed out waiting for reply from 89.221.210.188:123 (0.debian.pool.ntp.org).
Jun 15 15:44:31 devel1 systemd-timesyncd[4020]: Synchronized to time server for the first time 89.221.212.46:123 (0.debian.pool.ntp.org).
# systemctl status -l corosync
● corosync.service — Corosync Cluster Engine
Loaded: loaded (/lib/systemd/system/corosync.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-06-15 15:46:01 CEST; 1 day 18h ago
Docs: man:corosync
man:corosync.conf
man:corosync_overview
Main PID: 8412 (corosync)
Tasks: 9 (limit: 7372)
Memory: 147.6M
CGroup: /system.slice/corosync.service
└─8412 /usr/sbin/corosync -f
Jun 15 15:46:24 devel1 corosync[8412]: [KNET ] rx: host: 4 link: 0 is up
Jun 15 15:46:24 devel1 corosync[8412]: [KNET ] host: host: 4 (passive) best link: 0 (pri: 1)
Jun 15 15:46:25 devel1 corosync[8412]: [TOTEM ] A new membership (1.1860e) was formed. Members joined: 4
Jun 15 15:46:25 devel1 corosync[8412]: [CPG ] downlist left_list: 0 received
Jun 15 15:46:25 devel1 corosync[8412]: [CPG ] downlist left_list: 0 received
Jun 15 15:46:25 devel1 corosync[8412]: [CPG ] downlist left_list: 0 received
Jun 15 15:46:25 devel1 corosync[8412]: [CPG ] downlist left_list: 0 received
Jun 15 15:46:25 devel1 corosync[8412]: [CPG ] downlist left_list: 0 received
Jun 15 15:46:25 devel1 corosync[8412]: [QUORUM] Members[5]: 1 2 3 4 5
Jun 15 15:46:25 devel1 corosync[8412]: [MAIN ] Completed service synchronization, ready to provide service.
# systemctl status -l pveproxy
● pveproxy.service — PVE API Proxy Server
Loaded: loaded (/lib/systemd/system/pveproxy.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2020-06-16 15:51:44 CEST; 18h ago
Process: 16677 ExecStartPre=/usr/bin/pvecm updatecerts —silent (code=exited, status=0/SUCCESS)
Process: 16686 ExecStart=/usr/bin/pveproxy start (code=exited, status=0/SUCCESS)
Process: 18296 ExecReload=/usr/bin/pveproxy restart (code=exited, status=0/SUCCESS)
Main PID: 16688 (pveproxy)
Tasks: 5 (limit: 7372)
Memory: 288.8M
CGroup: /system.slice/pveproxy.service
├─ 1561 pveproxy worker
├─ 1812 pveproxy worker
├─ 2197 pveproxy worker
├─16688 pveproxy
└─36856 pveproxy worker (shutdown)
Jun 17 10:38:49 devel1 pveproxy[16688]: starting 1 worker(s)
Jun 17 10:38:49 devel1 pveproxy[16688]: worker 1812 started
Jun 17 10:38:49 devel1 pveproxy[1812]: Clearing outdated entries from certificate cache
Jun 17 10:39:31 devel1 pveproxy[48057]: worker exit
Jun 17 10:40:48 devel1 pveproxy[16688]: worker 1386 finished
Jun 17 10:40:48 devel1 pveproxy[16688]: starting 1 worker(s)
Jun 17 10:40:48 devel1 pveproxy[16688]: worker 2197 started
Jun 17 10:40:49 devel1 pveproxy[2196]: got inotify poll request in wrong process — disabling inotify
Jun 17 10:40:49 devel1 pveproxy[2197]: Clearing outdated entries from certificate cache
Jun 17 10:40:50 devel1 pveproxy[2196]: worker exit
# systemctl status -l pvedaemon
● pvedaemon.service — PVE API Daemon
Loaded: loaded (/lib/systemd/system/pvedaemon.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2020-06-16 15:51:50 CEST; 18h ago
Process: 16725 ExecStart=/usr/bin/pvedaemon start (code=exited, status=0/SUCCESS)
Main PID: 16728 (pvedaemon)
Tasks: 6 (limit: 7372)
Memory: 298.7M
CGroup: /system.slice/pvedaemon.service
├─ 827 pvedaemon worker
├─16728 pvedaemon
├─36835 task UPID:devel1:00008FE3:1265C8BA:5EE9C7CB:vncproxy:261:zima@ldap:
├─36837 /usr/bin/perl /usr/sbin/qm vncproxy 261
├─47263 pvedaemon worker
└─48069 pvedaemon worker
Jun 17 10:40:56 devel1 pvedaemon[47263]: successful auth for user ‘icinga@pve’
Jun 17 10:41:01 devel1 pvedaemon[47263]: successful auth for user ‘icinga@pve’
Jun 17 10:41:04 devel1 pvedaemon[48069]: successful auth for user ‘icinga@pve’
Jun 17 10:41:04 devel1 pvedaemon[827]: successful auth for user ‘icinga@pve’
Jun 17 10:41:14 devel1 pvedaemon[827]: successful auth for user ‘icinga@pve’
Jun 17 10:41:22 devel1 pvedaemon[47263]: successful auth for user ‘icinga@pve’
Jun 17 10:41:39 devel1 pvedaemon[48069]: successful auth for user ‘ @ldap’
Jun 17 10:41:50 devel1 pvedaemon[827]: successful auth for user ‘ @ldap’
Jun 17 10:41:50 devel1 pvedaemon[48069]: successful auth for user ‘icinga@pve’
Jun 17 10:41:52 devel1 pvedaemon[47263]: successful auth for user ‘icinga@pve’
Источник
Connection error 401: permission denied — invalid PVE ticket
Active Member
HI,
since a couple of hours I do get this message at the proxmox gui on cluster host 1
but on cluster host 5 everything is fine.
What could be the reason and which steps have to be done to narrow it down
I looked into pveproxy where I guess are the pve tickets from and saw some
Nov 11 13:15:51 prox01 pveproxy[18082]: got inotify poll request in wrong process — disabling inotify
and a few
Nov 11 13:20:39 prox01 pveproxy[8722]: 2020-11-11 13:20:39.497791 +0100 error AnyEvent::Util: Runtime error in AnyEvent::guard callback: Can’t call method «_put_session» on an undefined value at /usr/lib/x86_64-linux-gnu/perl5/5.28/AnyEvent/Handle.pm line 2259 during global destruction.
Active Member

dcsapak
Proxmox Staff Member
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Active Member
# timedatectl timesync-status
Server: ntp1
Poll interval: 34min 8s (min: 32s; max 34min 8s)
Leap: normal
Version: 4
Stratum: 1
Reference: PPS
Precision: 2us (-19)
Root distance: 442us (max: 5s)
Offset: +1.527ms
Delay: 3.383ms
Jitter: 3.488ms
Packet count: 5068
Frequency: +20,113ppm
root@prox01:/var/log# timedatectl timesync-status
Server: ntp1
Poll interval: 34min 8s (min: 32s; max 34min 8s)
Leap: normal
Version: 4
Stratum: 1
Reference: PPS
Precision: 2us (-19)
Root distance: 411us (max: 5s)
Offset: +39us
Delay: 5.539ms
Jitter: 2.028ms
Packet count: 5070
Frequency: +2,812ppm
dcsapak
Proxmox Staff Member
also the time of the client (browser)?
anything else in the syslog?
Best regards,
Dominik
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
4ps4all
New Member
I’m getting same problem since today, I can’t login through proxmox gui in a single proxmox node (ssh works).
I used lastly pve-promox-backup.iso in another proxmox node, but the two nodes are not in a cluster.
The single node I can’t login through proxmox gui should have done vm and ct backups in the other node, I hope so.
pve version:
pve-manager/6.2-15/48bd51b6 (running kernel: 5.4.65-1-pve)
Источник
permission denied — invalid PVE ticket (401)
T.Herrmann
Active Member
Maybe but please test it. My experience with this «Round up» order was good until now.
service pve-cluster restart && service pvedaemon restart && service pvestatd restart && service pveproxy restart
service pvedaemon restart && service pveproxy restart
hallaji
New Member
willprox
New Member
delete authkey.pub then restart that nodes have problems.
chengkinhung
Active Member
Hi, I just encounter this issue in PVE 6.4-15, I have 5 nodes in cluster, found only one node got «permission denied», can not read stat from all the other nodes, I can till login this node directly, but can not read all the other nodes’s stata from this node too. So I check the pveproxy service and found it was not working well, so I just restart the pveproxy service on this node and solve this issue:
RolandK
Active Member
i also get intermittend «Connection error 401: permission denied — invalid PVE ticket» in our 6.4 cluster
typically, this goes away after a while without any action.
how can i debug this ?
RolandK
Active Member
apparently, the authkey.pub had been changed
the problem went away after doing «touch /etc/pve/authkey.pub»
what was going wrong here ?
i’d be interested why an outdated timestamp on authkey.pub causing intermittend «invalid pve ticket» tickets and logouts in browser.
you can do some action and then another action fails. connecting to console of a VM works and then fails again. reloading browser window fixes it for some action and short after, you get invalid pve ticket again.
why does a simple timestamp update on that file fix such issue?
why does browser behave so weird and non-forseeable?
for me looks a little like buggy behaviour, espectially because it happens out of nowhere. (i have no timesync problem and i did not find any errors in the logs)
Источник
3 Node cluster «permission denied — invalid PVE ticket (401)»
BugProgrammer
New Member
Tried to create a 3 node cluster with a fresh proxmox ve 6.0-4 install.
Cluster creation works and adding a second node works aswell, but after i added the 3rd node i get «permission denied — invalid PVE ticket (401)» (only for the third the other 2 are still working).
In the webinterface i can access Node 1 and 2, but 3 aborts with this message. Node 3 can’t access any node.

Dominic
Proxmox Retired Staff
Best regards,
Dominic
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
BugProgrammer
New Member
What i tried until now:
-use another browser/workstation to access
-separate the 3rd node and use delnode on the other clients then readd
-tried the above and before readd i cleared all reverences i could find on the 2 working nodes
-checked timedatectl and synced the time and timezone between all nodes
-reinstalled node 3 & synced the time and added it to the cluster again (before i cleared all references from the other nodes)
Nothing of this worked. After «pvecm add ip-of-the-first-node» it says successful and the webpanel shows the node in the cluster with it’s local and local lvm. When i expand it i get «permission denied — invalid PVE ticket (401)».
No idea what i should try next.
BugProgrammer
New Member
hibouambigu
Member
Same thing is happening to me too. Fourth cluster I’ve built, but first time using the GUI and separate corosync network to do so (now with 6.0.4)
Hosts can all ping one-another on corosync network, and all went fine until joining node #2 and #3 via GUI.
Is the corosync cluster network supposed to be able to reach the NTP server directly from that separate network?
EDIT: more detail:
2/3 nodes seem to be ok. The 3rd node has joined the cluster and is visible in the other 2 nodes management windows via web UI.
Node 3 asks for login each time it is visited. Nothing works from this node’s web UI, but it does believe it is joined to the cluster (node 1 and 2 are visible, but clicking anything throws errors. 401: no ticket in shell, and «NaN» repeatedly in other fields within the cluster management).
hibouambigu
Member
Same thing is happening to me too. Fourth cluster I’ve built, but first time using the GUI and separate corosync network to do so (now with 6.0.4)
Hosts can all ping one-another on corosync network, and all went fine until joining node #2 and #3 via GUI.
Is the corosync cluster network supposed to be able to reach the NTP server directly from that separate network?
EDIT: more detail:
2/3 nodes seem to be ok. The 3rd node has joined the cluster and is visible in the other 2 nodes management windows via web UI.
Node 3 asks for login each time it is visited. Nothing works from this node’s web UI, but it does believe it is joined to the cluster (node 1 and 2 are visible, but clicking anything throws errors. 401: no ticket in shell, and «NaN» repeatedly in other fields within the cluster management).
For anyone else knocking about with this.
Seem to have solved it for now. Still not sure why the error happened during cluster creation!
2.) restarted nodes.
3.) cleared browser cookies for all three nodes.
..still had the errors, until the web browser itself was purged of cache, closed and restarted.
Источник
The problem
Exactly two hours after restarting HA, Proxmox integration no longer works with error: 401 Unauthorized: permission denied — invalid PVE ticket
Environment
- Home Assistant Core release with the issue: 0.111.3
- Last working Home Assistant Core release (if known): 0.110.x
- Operating environment (Home Assistant/Supervised/Docker/venv): Home Assistant
- Integration causing this issue: Proxmox VE
- Link to integration documentation on our website: https://www.home-assistant.io/integrations/proxmoxve/
Problem-relevant configuration.yaml
proxmoxve: - host: <ip address> username: <user> password: <pwd> verify_ssl: false realm: pam nodes: - node: pve vms: - 100 - 102 - 103 containers: - 101
Traceback/Error logs
Logger: homeassistant.helpers.entity
Source: components/proxmoxve/binary_sensor.py:96
First occurred: 17:40:58 (1026 occurrences)
Last logged: 19:53:10
Update for binary_sensor.pve_hassio_running fails
Update for binary_sensor.pve_omv_running fails
Update for binary_sensor.pve_hassio_test_running fails
Update for binary_sensor.pve_lamp_running fails
Traceback (most recent call last):
File "/usr/src/homeassistant/homeassistant/helpers/entity.py", line 279, in async_update_ha_state
await self.async_device_update()
File "/usr/src/homeassistant/homeassistant/helpers/entity.py", line 472, in async_device_update
await self.hass.async_add_executor_job(self.update)
File "/usr/local/lib/python3.7/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/usr/src/homeassistant/homeassistant/components/proxmoxve/binary_sensor.py", line 83, in update
item = self.poll_item()
File "/usr/src/homeassistant/homeassistant/components/proxmoxve/binary_sensor.py", line 96, in poll_item
.get(self._item_type.name)
File "/usr/local/lib/python3.7/site-packages/proxmoxer/core.py", line 105, in get
return self(args)._request("GET", params=params)
File "/usr/local/lib/python3.7/site-packages/proxmoxer/core.py", line 94, in _request
resp.reason, resp.content))
proxmoxer.core.ResourceException: 401 Unauthorized: permission denied - invalid PVE ticket - b''
Additional information
HassOS is a proxmox virtual machine
0
1
Сталкивался кто, не получается сделать кластер с 2х нод в разных сетях.
нода1 — 1.2.3.4
нода2 — 8.7.6.5
на первой pvecm create clust — создается кластер.
на второй pvecm add 1.2.3.4 — спрашивает пароль, а потом
Dec 17 14:57:55 m11617 pmxcfs[7483]: [quorum] crit: quorum_initialize failed: 2
Dec 17 14:57:55 m11617 pmxcfs[7483]: [confdb] crit: cmap_initialize failed: 2
Dec 17 14:57:55 m11617 pmxcfs[7483]: [dcdb] crit: cpg_initialize failed: 2
Dec 17 14:57:55 m11617 pmxcfs[7483]: [status] crit: cpg_initialize failed: 2
Dec 17 14:58:00 m11617 systemd[1]: Starting Proxmox VE replication runner...
Dec 17 14:58:00 m11617 pvesr[8863]: error with cfs lock 'file-replication_cfg': no quorum!
Dec 17 14:58:00 m11617 systemd[1]: pvesr.service: Main process exited, code=exited, status=2/INVALIDARGUMENT
Dec 17 14:58:00 m11617 systemd[1]: Failed to start Proxmox VE replication runner.
Dec 17 14:58:00 m11617 systemd[1]: pvesr.service: Unit entered failed state.
Dec 17 14:58:00 m11617 systemd[1]: pvesr.service: Failed with result 'exit-code'.
Dec 17 14:58:01 m11617 pmxcfs[7483]: [quorum] crit: quorum_initialize failed: 2
Dec 17 14:58:01 m11617 pmxcfs[7483]: [confdb] crit: cmap_initialize failed: 2
Dec 17 14:58:01 m11617 pmxcfs[7483]: [dcdb] crit: cpg_initialize failed: 2
Dec 17 14:58:01 m11617 pmxcfs[7483]: [status] crit: cpg_initialize failed: 2
Dec 17 14:58:01 m11617 cron[3211]: (*system*vzdump) CAN'T OPEN SYMLINK (/etc/cron.d/vzdump)
Dec 17 14:58:07 m11617 pmxcfs[7483]: [quorum] crit: quorum_initialize failed: 2
Dec 17 14:58:07 m11617 pmxcfs[7483]: [confdb] crit: cmap_initialize failed: 2
Dec 17 14:58:07 m11617 pmxcfs[7483]: [dcdb] crit: cpg_initialize failed: 2
Dec 17 14:58:07 m11617 pmxcfs[7483]: [status] crit: cpg_initialize failed: 2
Dec 17 14:58:13 m11617 pmxcfs[7483]: [quorum] crit: quorum_initialize failed: 2
Dec 17 14:58:13 m11617 pmxcfs[7483]: [confdb] crit: cmap_initialize failed: 2
Dec 17 14:58:13 m11617 pmxcfs[7483]: [dcdb] crit: cpg_initialize failed: 2
Dec 17 14:58:13 m11617 pmxcfs[7483]: [status] crit: cpg_initialize failed: 2
вот такая ругня…
при чем в кластер нода как-бы добавляется и показывается, но доступа к ней нет.
proxmox 5.3-5