Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Чтобы
судить о том, насколько точно проведенные
измерения отражают состав генеральной
совокупности, необходимо вычислить
стандартную ошибку средней арифметической
выборочной совокупности.
Стандартная
ошибка средней арифметической
характеризует степень отклонения
выборочной средней арифметической от
средней арифметической генеральной
совокупности.
Стандартная
ошибка средней арифметической вычисляется
по формуле:
![]() ,
,
где
– стандартное отклонение результатов
измерений, n
– объем выборки.
Зачастую
мы имеем дело с одной случайной выборкой
и с одной полученной при ее обработке
выборочной средней. Задача заключается
в суждении о величине неизвестной
генеральной средней по полученной
неточной величине случайной выборочной
средней.
Вычислим
среднюю ошибку найденного выборочного
среднего значения роста:
![]() 195
195
см; σ = 8,8 см;
![]() см.
см.
2,8 см
составляют не максимальную, а среднюю
возможную ошибку среднего. Отдельные
выборочные средние могут отклоняться
от генеральной как больше, так и меньше,
чем на 2,8 см.
Каковы
же пределы возможных ошибок случайной
выборки, какова ее максимальная ошибка?
Величина максимальной ошибки зависит
от величины средней ошибки и вычисляется
по формуле
![]() .
.
При
объеме выборки n
= 10:
![]() .
.
Все
случайные выборочные средние, которые
могут быть получены в подобных опытах
(в том числе и фактически полученная
выборочная средняя
![]() = 195 см), при своем варьировании около
= 195 см), при своем варьировании около
неизвестного генерального среднего в
подавляющем количестве группируются
около него так, что лишь ничтожный
процент их отклоняется от генеральной
средней более, чем на величину максимальной
ошибки.
Другими
словами, генеральная средняя определяется
как
![]() .
.
Эти пределы
колебаний значительно сужаются, если
средняя ошибка уменьшается благодаря
увеличению численности выборки.
Искомая
генеральная средняя лежит между
![]() и
и![]() .
.
Таким образом, при высокой точности
выполнения эксперимента и достаточно
большом числе измерений можно определить
среднюю арифметическую бесконечно
большого числа экспериментов.
До сих
пор мы определяли максимальную ошибку
выборочной средней, исходя из того, что
все остальные показатели известны. Если
же мы хотим достичь определенной
точности, определенного приближения к
генеральной средней, в этом случае
встает вопрос о численности выборки (о
том, сколько измерений, опытов необходимо
провести).
Допустим, что
максимальная ошибка должна быть равна
5 см. Сколько человек надо обследовать
(измерить) в нашем случае?
![]() .
.
Следовательно,
мы должны провести измерения роста у
36 баскетболистов высокого класса.
10. Достоверность различий
Следующим
важным вопросом практически для каждого
экспериментатора является умение
доказать достоверность различий между
двумя рядами признаков.
Проверку
достоверности различия двух рядов
измерений производят путем вычисления
критерия достоверности различия – t:
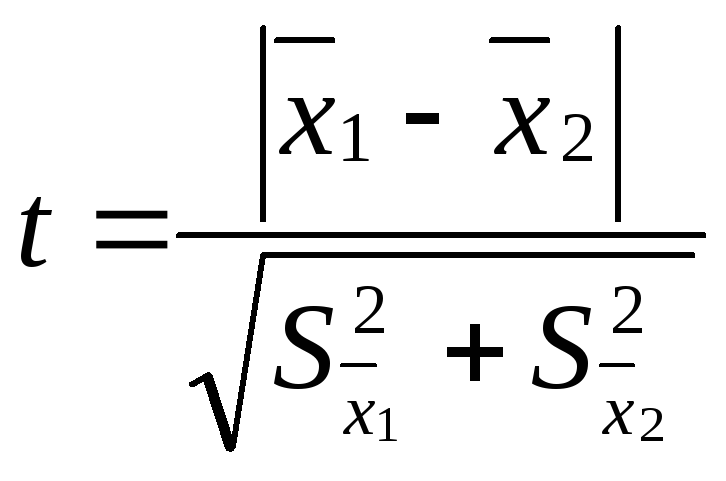 ,
,
где
![]() – средняя одной выборки;
– средняя одной выборки;![]() – средняя другой выборки;
– средняя другой выборки;![]() – средняя ошибка первой выборки;
– средняя ошибка первой выборки;![]() – второй выборки. Если t < 2, то различие
– второй выборки. Если t < 2, то различие
между двумя выборками считается
недостоверным, если t
2, то различие между двумя выборками
достоверно на 95%.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-

1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.

Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.

-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)

Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.

Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 996,116 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?
To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 996,116 times.
Did this article help you?
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
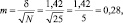 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 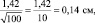 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
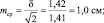
при объеме выборки N = 4 ошибка будет
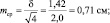
при объеме выборки N = 16 ошибка будет
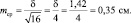
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 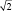 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 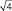 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 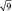 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 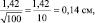 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 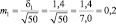 и
и 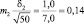 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 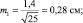
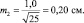 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
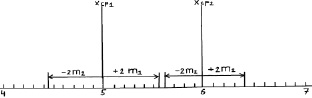
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
Средние ошибки повторной и бесповторной выборки
Средняя ошибка выборки
Средняя ошибка выборки представляет из себя такое расхождение между средними выборочной и генеральной совокупностями, которое не превышает ±б (дельта).
На основании теоремы Чебышева П. Л. величина средней ошибки при случайном повторном отборе в контрольных работах по статистике рассчитывается по формуле (для среднего количественного признака):

где числитель — дисперсия признака х в выборочной совокупности;
n — численность выборочной совокупности.
Для альтернативного признака формула средней ошибки выборки для доли по теореме Я. Бернулли рассчитывается по формуле:

где р(1- р) — дисперсия доли признака в генеральной совокупности;
n — объем выборки.
Вследствие, того что дисперсия признака в генеральной совокупности точно не известна, на практике используют значение дисперсии, которое рассчитано для выборочной совокупности на основании закона больших чисел. Согласно данному закону выборочная совокупность при большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности.
Поэтому расчетные формулы средней ошибки при случайном повторном отборе будут выглядеть таким образом:
1. Для среднего количественного признака:

где S^2 — дисперсия признака х в выборочной совокупности;
n — объем выборки.
2. Для доли (альтернативного признака):

где w (1 — w) — дисперсия доли изучаемого признака в выборочной совокупности.
В теории вероятностей было показано, что генеральная дисперсия выражается через выборочную согласно формуле:

В случаях малой выборки, когда её объем меньше 30, необходимо учитывать коэффициент n/(n-1). Тогда среднюю ошибку малой выборки рассчитывают по формуле:

Так как в процессе бесповторной выборки сокращается численность единиц генеральной совокупности, то в представленных выше формулах расчета средних ошибок выборки нужно подкоренное выражение умножить на 1- (n/N).
Расчетные формулы для такого вида выборки будут выглядеть так:
1. Для средней количественного признака:

где N — объем генеральной совокупности; n — объем выборки.
2. Для доли (альтернативного признака):

где 1- (n/N) — доля единиц генеральной совокупности, не попавших в выборку.
Поскольку n всегда меньше N, то дополнительный множитель 1 — (n/N) всегда будет меньше единицы. Это означает, что средняя ошибка при бесповторном отборе всегда будет меньше, чем при повторном. Когда доля единиц генеральной совокупности, которые не попали в выборку, существенная, то величина 1 — (n/N) близка к единице и тогда расчет средней ошибки производится по общей формуле.
Средняя ошибка зависит от следующих факторов:
1. При выполнении принципа случайного отбора средняя ошибка выборки определяется во-первых объемом выборки: чем больше численность, тем меньше величины средней ошибки выборки. Генеральная совокупность характеризуется точнее тогда, когда больше единиц данной совокупности охватывает выборочное наблюдение
2. Средняя ошибка также зависит от степени варьирования признака. Степень варьирования характеризуется дисперсией. Чем меньше вариация признака (дисперсия), тем меньше средняя ошибка выборки. При нулевой дисперсии (признак не варьируется) средняя ошибка выборки равна нулю, таким образом, любая единица генеральной совокупности будет характеризовать всю совокупность по этому признаку.
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Стандартное отклонение (SD), измеряет количество изменчивости или дисперсии, из отдельных значений данных, к среднему значению, в то время как стандартная ошибка среднего (SEM) мер, как далеко образец среднее (среднее) данных, вероятно, будет от истинного среднего значения населения. SEM всегда меньше SD.
Ключевые выводы
- Стандартное отклонение (SD) измеряет разброс набора данных относительно его среднего значения.
- Стандартная ошибка среднего (SEM) измеряет, насколько вероятно расхождение между средним значением выборки по сравнению со средним значением генеральной совокупности.
- SEM берет SD и делит его на квадратный корень из размера выборки.
SEM против SD
Стандартное отклонение и стандартная ошибка используются во всех типах статистических исследований, включая исследования в области финансов, медицины, биологии, инженерии, психологии и т. Д. В этих исследованиях стандартное отклонение (SD) и расчетная стандартная ошибка среднего (SEM) ) используются для представления характеристик данных выборки и объяснения результатов статистического анализа. Однако некоторые исследователи иногда путают SD и SEM. Таким исследователям следует помнить, что расчеты SD и SEM включают разные статистические выводы, каждый из которых имеет свое значение. SD – это разброс отдельных значений данных.
Другими словами, SD указывает, насколько точно среднее значение представляет данные выборки. Однако значение SEM включает статистический вывод, основанный на распределении выборки. SEM – это стандартное отклонение теоретического распределения выборочных средних (выборочное распределение).
Расчет стандартного отклонения

Формула SD требует нескольких шагов:
- Во-первых, возьмите квадрат разницы между каждой точкой данных и средним значением выборки, найдя сумму этих значений.
- Затем разделите эту сумму на размер выборки минус один, который представляет собой дисперсию.
- Наконец, извлеките квадратный корень из дисперсии, чтобы получить стандартное отклонение.
Стандартная ошибка среднего
SEM рассчитывается путем деления стандартного отклонения на квадратный корень из размера выборки.
Стандартная ошибка дает точность выборочного среднего путем измерения изменчивости выборочного среднего от образца к образцу. SEM описывает, насколько точное среднее значение выборки является оценкой истинного среднего значения совокупности. По мере увеличения размера выборки данных SEM уменьшается по сравнению с SD; следовательно, по мере увеличения размера выборки среднее значение выборки оценивает истинное среднее значение генеральной совокупности с большей точностью. Напротив, увеличение размера выборки не обязательно делает SD больше или меньше, это просто становится более точной оценкой SD населения.
Стандартная ошибка и стандартное отклонение в финансах
В финансах стандартная ошибка средней дневной доходности актива измеряет точность выборочного среднего как оценки долгосрочной (постоянной) средней дневной доходности актива.
С другой стороны, стандартное отклонение доходности измеряет отклонения индивидуальных доходов от среднего значения. Таким образом, SD является мерой волатильности и может использоваться в качестве меры риска для инвестиций. Активы с более высокими ежедневными движениями цен имеют более высокое SD, чем активы с меньшими ежедневными движениями. Предполагая нормальное распределение, около 68% дневных изменений цен находятся в пределах одного стандартного отклонения от среднего, при этом около 95% дневных изменений цен находятся в пределах двух стандартных значений среднего.
© Г. П. Тихова, 2013 УДК 616-07-092.41.9
Значение и интерпретация ошибки среднего в клиническом исследовании и эксперименте
Г. П. Тихова
ООО «ИнтелТекЛаб», Петрозаводск
Importance and interpretation of standard error of mean in clinical study and trial
G. P. Tikhova
IntelTeck Lab Ltd, Petrozavodsk
В статье рассмотрен содержательный смысл и различие между стандартной ошибкой среднего и среднеквадратическим отклонением, изложены факторы, влияющие на величину этих статистических параметров. Ключевые слова: обработка клинических данных, ошибка среднего, стандартное отклонение.
This paper highlighted the meaning and difference between standard error of mean and standard deviation as well as describes the factors that affect the values of this statistical parameters. Key words: clinical data processing, standard error of mean, standard deviation.
Прежде чем погрузиться в тонкости различных методов статистической обработки данных, зададимся вопросом: что мы собственно считаем с их помощью? Как рассчитанные на нашей выборке статистические параметры связаны с описанием исследуемой нами популяции?
Для примера рассмотрим числовую случайную величину с нормальным законом распределения -ударный объем у здоровых беременных женщин со сроком гестации не менее 30 недель.
Итак, во-первых, мы четко определяем интересующую нас популяцию — здоровые беременные женщины со сроком гестации 30 недель и более. Представим мысленно, что мы можем измерить ударный объем у всех без исключения членов этой популяции. (Конечно, на самом деле это сделать нереально!) Регистрируем ударный объем у 1-й беременной и получаем, допустим, 60 мл, затем у 2-й — 55 мл, у 3-й — 78 мл и т. д. В конечном итоге мы получаем бесконечное множество реализаций случайной величины под названием ударный объем. Можем ли мы посчитать среднее значение всех полученных измерений? Конечно, можем. Что же это будет за величина? Это будет точное среднее значение ударного объема, присущее популяции беременных со сроком от 30 недель и более. Подчеркну, именно точное среднее значение, без всякой ошибки, потому что по условию нашего мысленного эксперимента мы измерили ударный объем у всех без исключения членов популяции. Поскольку мы перебрали всех членов популяции, то откуда же взяться ошибке? Мы
не оставили никакой неопределенности, включив в расчет всю популяцию, поэтому и смогли посчитать точное среднее значение без всякой ошибки. Но из этого следует, что в рассматриваемой популяции среднее значение — это объективная реальность, а не придуманная математиками величина. Причем это среднее значение равно вполне конкретному числу, присущему именно этой популяции. В другой популяции оно, вообще говоря, может быть другим, и если это так, то по показателю ударного объема эти две популяции различаются, и данный показатель может служить признаком отличия этих популяций друг от друга. Точно также, имея полученные измерения, мы можем подсчитать точное значение стандартного отклонения ударного объема в этой популяции. Это же касается и медианы, и моды, и всех остальных статистик, которые обычно рассчитываются для числовой случайной величины. Что же получается? Все эти интегральные параметры случайной величины -не искусственное изобретение, а вполне реальные свойства, имеющие точные значения в конкретной популяции. Можно сказать, точные значения этих параметров определяются особенностями конкретной популяции и в свою очередь характеризуют ее, как отличительные признаки, присущие только ей. Когда мы проводим реальное исследование, то вынуждены довольствоваться выборкой, т. е. лишь частью (и, как правило, далеко не большей частью) интересующей нас популяции. Однако мы все-таки рассчитываем и среднее значение, и стандартное отклонение, и другие статистики в условиях,
когда подавляющее большинство членов популяции оказываются за рамками нашего исследования. Что же мы делаем и что получаем в итоге? Поскольку мы включаем в наш расчет лишь часть популяции, привносим некоторую неопределенность, неточность в расчет среднего и других статистик и в итоге получаем не точные значения, а лишь ОЦЕНКИ этих параметров. Такие оценки называют выборочными оценками, потому что они рассчитаны по конкретной выборке и в некоторой степени зависят от ее особенностей. Если мы повторим исследование, наберем другую выборку из этой же популяции, и снова рассчитаем среднее, то это новое рассчитанное значение, скорее всего, будет отличаться от первого, хотя, по сути, мы рассчитали то же самое. Почему нам следуем ожидать этого несовпадения? Потому что на выборке мы получаем лишь оценку точного значения, а не само популяционное значение статистики, и эта оценка, полученная на выборке, всегда, подчеркну, всегда без исключения имеет ошибку. Ошибка эта называется статистической, потому что она обусловлена случайными факторами. В отличие от коварной и вредоносной ошибки смещения, статистическая ошибка, можно сказать, безобидна, т. к. ее всегда можно рассчитать и сделать на нее поправку. Она всегда явная и точно известна по величине. Но если ошибки смещения можно попытаться избежать, то статистическая ошибка — это неотъемлемая часть выборочной оценки. При расчете любого параметра на выборке, статистическая ошибка будет иметь место и от нее никуда не деться.
Таким образом, рассчитывая на нашей выборке среднее значение, стандартное отклонение и другие параметры числовой случайной величины, мы на самом деле проводим оценивание их реальных точных значений в популяции, из которой эта выборка была взята. Оценка, как мы уже упоминали, может быть более или менее точной, но необходимо смириться с тем, что на выборке мы никогда не получим абсолютно точной величины, которая имеет место в данной исследуемой популяции. А это значит, что, вообще говоря, каждую рассчитанную на выборке статистику мы должны сопровождать ее ошибкой, чтобы можно было понять, с какой точностью оценен тот или иной параметр. На практике однако принято указывать ошибки не всех рассчитываемых статистических параметров, а лишь наиболее важных для сравнения выборок. Так, например, как правило, указывают ошибку среднего. О ней и поговорим поподробнее.
Поскольку ошибка среднего рассчитывается по очень простой формуле непосредственно из стандартного отклонения, то ее часто путают с этим последним. В научных статьях принято
указывать рядом со средним значением либо ошибку среднего, либо стандартное отклонение, но это только потому, что, зная одно, мы легко можем вычислить другое при известном объеме выборки. Из этого однако не следует, что ошибка среднего и стандартное отклонение — это одно и то же. Указанные два параметра описывают совершенно разные свойства исследуемого показателя. Ошибка среднего характеризует точность выборочной оценки среднего значения исследуемого показателя в заданной популяции и зависит от вариабельности, объективно присущей этому показателю в условиях данной популяции, и репрезентативности выборки:
— чем чище и больше наша выборка, тем меньше ошибка;
— чем меньше вариабельность исследуемого показателя, тем меньше ошибка.
Иными словами, ошибка среднего дает нам понять, насколько сильно мы отклоняемся в своих расчетах от точного значения среднего в популяции. Если бы наши расчеты охватили всю заданную популяцию, то ошибка среднего была бы равна нулю, т. е. отсутствовала бы полностью.
Что касается стандартного отклонения, то по своему смыслу к точности оценки среднего оно не имеет никакого отношения. Как мы уже разобрали ранее, стандартное отклонение характеризует объективно существующую вариабельность исследуемого показателя, и поскольку мы здесь обсуждаем только случайные величины с нормальным вероятностным распределением, эта статистика не может обращаться в ноль ни при каких обстоятельствах, даже в случае охвата всей популяции. Стандартное отклонение, рассчитанное по выборке, само является приближенной оценкой точного популяционного значения стандартного отклонения и, соответственно, тоже имеет статистическую ошибку, величина которой определяется теми же условиями, что и ошибка среднего. Просто эту ошибку, как правило, не указывают. В критериях сравнения она не играет такой важной роли, как ошибка среднего.
Таким образом, стандартное отклонение характеризует объективную природу данных, с которыми мы имеем дело в исследовании, а ошибка среднего отражает точность и адекватность нашего исследования и полученных результатов. С увеличением объема выборки ошибка среднего стремится к нулю, а стандартное отклонение -к определенному числу, являющемуся точным значением стандартного отклонения этого показателя в популяции.
Иными словами, стандартное отклонение определяется объективной природой исследуемых данных, а ошибка среднего зависит:
— от объективной природы данных (исследуемой случайной величины), а именно ее вариабельности, выражаемой в стандартном отклонении;
— субъективной особенности конкретного исследования — объема выборки.
Мы очень подробно рассмотрели выборочную оценку среднего и его ошибку, но другие статистики, рассчитанные на выборке, также обладают некоторой статистической ошибкой в силу тех же причин, что и выборочное среднее значение. Из этого следует, что, указывая полученное в ходе расчетов значение статистического параметра, мы должны указать и его статистическую ошибку. Все в точности так же, как это принято для выборочного среднего значения. Это касается всех рассчитываемых статистик независимо от типа исследуемого показателя. По популярности расчета следом за средним значением идет оценка частот или долей для качественных, а иногда и порядковых показателей, поэтому на одном таком примере мы и рассмотрим, как правильно описывать такие результаты.
В исследовании, посвященном спинальной анестезии у беременных, необходимо было определить долю различных вариантов интраоперацион-ной тошноты и рвоты (ИОТР), а именно:
— сколько процентов пациенток не имели никаких осложнений,
— у какой доли беременных отмечалась гипотония во время операции,
— сколько процентов пациенток жаловались на тошноту,
— у какой доли наблюдаемых развилась интра-операционная рвота.
Исследуемая популяция определена как беременные со сроком гестации более 35 недель (беременность без патологий), спинальная анестезия проводилась по поводу планового кесарева сечения. Понятно, что в этой популяции мы исследуем качественный признак ИОТР, который является случайной величиной, принимающей в каждом конкретном случае одно из перечисленных значений, и во всей популяции доля каждого из вариантов вполне определена и имеет точное значение. Всю популяцию мы охватить в своем исследовании не можем, поэтому довольствуемся выборкой и, следовательно, полученные процентные доли (или частоты осложнений) будут лишь оценками точных популяционных величин. Что из этого следует? То, что все полученные числа, выборочные значения долей, будут иметь статистические ошибки, которые мы также должны рассчитать
и указать. В качестве примера приведена табл., взятая из работы А. М. Погодина и Е. М. Шифмана, напечатанной в 1-м номере нашего журнала за 2009 г. [1].
Частота эпизодов ИОТР в исследуемых группах
Группа* Частота ИОТР (доля ± ошибка доли, %)
I (n = 35) 17,1 ± 2,4
II (n = 33) 18,2 ± 2,6
III (n = 36) 11,1 ± 1,6
Всего (n = 104) 15,4 ± 1,3
* Стратификация пациентов на 3 группы производилась в соответствии с антиэметиком, применявшимся в составе премедикации.
Если мы выделим из той же популяции выборку большего объема, то выборочные значения долей у нас буду ближе к реальным, а ошибки — меньше. Независимо от того, что и на каких данных вы считаете, поведение всех расчетных статистических параметров будет одинаково:
— если параметр отражает объективную реальность, то его выборочные оценки с увеличением объема выборки будут приближаться к конкретным числам — точным значениям в популяции;
— если параметр характеризует точность и адекватность исследования, то с увеличением объема выборки его значение будет неуклонно уменьшаться и стремиться к нулю.
Все статистические ошибки с ростом объема выборки снижаются и стремятся к нулю.
Процентные доли не являются исключением, поэтому при указании результатов в процентных долях необходимо записывать полученное выборочное значение с его статистической ошибкой (ошибкой доли), поскольку сравнение долей требует такой же математической строгости, как и сравнение средних значений. Нельзя утверждать, что одна доля больше другой лишь на том основании, что мы получили два числа, одно больше другого. Их разность может укладываться в статистическую ошибку одного из них (или обоих) и они могут быть просто неточными, приближенными, оценками одного и того же точного попу-ляционного значения. Например, в приведенной табл. в группе I частота ИОТР составила 17,1%, а в группе II — 18,2%, однако мы не можем утверждать, что в I группе частота меньше, чем во II, поскольку ошибки этих долей покрывают оба этих значения, указывая на то, что они с точки зрения статистики равны, а их различие — просто случайная неточность оценки, которую привносит данная, не очень большая, выборка и природная вариабельность данных.
Вопросы, которые мы здесь разобрали, порой кажутся второстепенными и мелкими, но на самом деле они требуют пристального внимания
исследователя при интерпретации результатов, полученных в ходе статистической обработки клинических данных. Глубокое понимание природы и источников статистической ошибки, а также строгий контроль ее величины позволят избежать неправомерных выводов: обнаружить эффект там, где его нет, или влияние фактора, когда в реальности оно отсутствует.
Литература
1. Погодин А. М., Шифман Е. М. Профилактика тошноты и рвоты при спинномозговой анестезии во время операции кесарева сечения // Регионарная анестезия и лечения острой боли. 2009; 1: 11-14.