Методы диагностики детско-родительских отношений.
В детстве
закладывается основа личности человека и его судьбы. Исследования показывают,
что современные родители, воспитывая детей, все больше нуждаются в помощи
специалистов. Консультации нужны не только родителям неблагополучных групп, но
и благополучным семьям.
Многие родители хотят научиться лучше воспитывать своих
детей и для этого им необходимы знания и методики. Совсем необязательно давать
родителям глубокие знания, но познакомить их с основными положениями,
подходами, показать, каким образом можно создать условия для гармоничного
развития ребенка, его личностного роста, необходимо.
Существует немало примеров, когда вмешательство психолога,
проведенная беседа с ребенком, консультация для родителей, приносили безусловную
пользу.
Эффективная работа психолога с семьей становится
предпосылкой к формированию новых отношений родителей и детей.
Выделяют следующие принципы построения и организации психодиагностической
деятельности психолога :
1. Соответствие выбранного подхода и конкретной методики целям и
задачам эффективного психологического сопровождения ребенка.
2. Результаты обследования должны быть сформулированы на
понятном для других языке, либо поддаваться переводу на понимаемый другими
язык.
3. Прогностичность используемых методов, то есть возможность
прогнозировать на их основе особенности развития ребенка на дальнейших этапах
обучения и воспитания.
4. Высокий развивающий потенциал метода.
5. Экономичность процедуры.
Хорошая методика должна быть короткой и
многофункциональной.
Обычно в практике по проблеме семейных отношений
используются такие методы исследования, как наблюдение, беседа, опрос,
анкетирование, тестирование, метод изучения продуктов деятельности, анализ
ранних детских воспоминаний.
Рассмотрим специфику данных методов.
1. Метод наблюдения в работе с семьей.
Наблюдение — это целенаправленное, специальным образом
организованное и фиксированное восприятие исследуемого объекта.
В работе с семьей, наблюдение позволяет выявить
психологические особенности ребенка и родителей в естественных для них
условиях. За ребенком можно наблюдать во время урока или игры со сверстниками,
за родителями — во время праздника, организованного в классе, причем наблюдатель
должен опираться на объективно наблюдаемые параметры поведения, а не
интерпретировать их.
Существуют ошибки, которые может допустить психолог во
время наблюдения:
— « Эффект ореола» — склонность к обобщению поведения наблюдаемого
(например, психолог, наблюдая за поведением ребенка во время урока, делает
вывод, что ребенок ведет себя так всегда).
— « Ложное согласие» — психолог-наблюдатель в оценке
поведения следует мнению окружающих, сложившемуся о ребенке («все так
говорят»).
— Ошибка «средней тенденции» — склонность ориентироваться
на типичные поведенческие проявления. Например, предположение о том, что в
неполных семьях невозможно полноценное воспитание, может быть ложным.
— Ошибка « первого впечатления» — возникает в результате
переноса сложившихся стереотипов восприятия на наблюдаемого. Для избежания
этих
ошибок
наблюдатель должен хорошо представлять, что, для чего и каким образом он
собирается наблюдать. До того, как приступить к наблюдению, необходимо
составить программу, определить параметры наблюдаемого поведения и способы их
фиксации.
В работе с семьей могут использоваться различные виды
наблюдения: внешнее, стандартизированное, включенное, стороннее…
2. Метод опроса.
Этот метод обеспечивает получение информации в процессе
непосредственного (беседа, интервью) или опосредованного (анкетирование,
опрос) общения.
Для грамотного проведения анкетирования и интервью важно
четкое формулирование вопросов. В психологии разработаны правила составления
вопросов (открытых и закрытых), расположения их в определенном порядке,
группировки на отдельные блоки.
Наиболее часто при составлении анкет и опросников
встречаются следующие ошибки: используются слова, непонятные опрашиваемому
(например, научные термины), в качестве значений признака применяются неконкретные,
общие понятия, в целях увлечь опрашиваемого, предлагаются неравноценные ответы
или используется сленг.
Для проведения беседы важна обстановка доверия между
психологом и семьей. Необходимо знать правила установления контакта, владеть
техниками эффективного общения, способами расположения к себе собеседника.
3. Использование тестов в работе с семьей.
Тесты — это стандартизированные задания, предназначенные
для измерения в сопоставимых величинах индивидуально-психологических свойств
личности, а также знаний, умений и навыков. Для психолога, полученные
результаты
тестирования, могут стать основой для проведения консультационной работы.
Наиболее распространенными в работе с детьми являются
рисуночные тесты, которые нередко служат единственным средством для развития общения
между психологом и ребенком. В рисунках содержится большое обилие «сигналов»
для психолога, которые можно использовать для построения диалога с
консультируемым.
Наиболее распространенными в работе с детьми являются такие
рисуночные тесты, как: «Дом-Дерево-Человек», «Автопортрет», « Кинетический
рисунок семьи».
4. Метод изучения продуктов деятельности.
Этот метод позволят собрать факты, опираясь на анализ
материализованных продуктов психической деятельности. Исследователь имеет дело
не с самим человеком, а с материальными продуктами его деятельности: учебной
(сочинение), игровой (придуманный ребенком сюжет игры), творческой (стихи,
сказки). Используя этот метод, важно попытаться воспроизвести процесс
изготовления продукта и благодаря этому обнаружить особенности личности.
5. Исследование семейной истории.
Биографический
метод сбор и анализ данных о жизненном пути личности. Исследование
жизненного стиля и сценария личности могут быть использованы для выявления
особенностей формирования жизненного стиля ребенка. Данный метод несет большую
терапевтическую и коррекционную нагрузку и может использоваться как в условиях
индивидуального, так и группового консультирования.
• Генограмма — используется для изучения хода семейной
истории, моделей поведения, передающихся из поколения в поколение, событий, которые
происходят в семье и влияют на развитие личности.
Генограмма представляет собой форму семейной родословной,
на которой записывается информация о членах семьи, по крайней мере, в трех поколениях.
Генограмма показывает семейную информацию графически, что позволяет быстро
охватить сложные системы взаимоотношений в ней. Изучая свою семью с помощью
генограммы, родители убеждаются в том, что то, какое положение они занимали в
своей семье, влияет на их актуальную ситуацию и на характер общения с ребенком.
Анализ ранних детских воспоминаний направлен на выявление
актуального жизненного стиля личности. Психолог предлагает назвать несколько
самых ранних детских воспоминаний, как можно более подробно их описать и
попытаться дать им название, начиная с фраз, типа: « Моя жизнь -это…». При
проведении методики важно фиксировать внимание на деталях воспоминания, на
эмоциональном отношении к происходящему в детстве…
Таким образом, в работе с семьей можно
использовать различные методы, применяя их в совокупности с другими, для более
подробного изучения семейных отношений и для получения наиболее достоверных
результатов.
Наблюдаемые свойства личности
-
Постоянные
Непостоянные
Эволюционирующие
Случайные
Типичные
Нетипичные
Существенные
Несущественные
Основные
Производные
Генетические
Актуальные
Структурные
Функциональные
Целостные
Локальные
Естественные
Вызванные
Динамические
Статические
Наблюдение может
предварять экспериментальное исследование
и психодиагностическую беседу, поскольку
позволяет выявлять те признаки поведения
и состояния, те признаки свойств личности,
которые должны быть измерены. Наблюдение
нередко завершает исследование,
подтверждая или внося уточнения в
полученную информацию. Результаты
наблюдения используются в качестве
внешних критериев, относительно которых
определяется валидность и надёжность
других методов.
Ограничения
в применении наблюдения в психологической
диагностике связаны с надёжностью
получаемых результатов, поскольку сам
наблюдатель может их серьёзно искажать
– например, совершая ошибки, обусловленные
индивидуальными особенностями восприятия
и обобщения перцептивной информации,
особенностями личного коммуникативного
опыта. Среди них наиболее часто
встречаются:
эффект ореола,
эффект «ложного
согласия»,
ошибка средней тенденции,
ошибка первого
впечатления.
Ошибка, названная
«эффект ореола»,
определяется способностью к обобщению
поведения наблюдаемого. Результаты
наблюдения за поведением человека в
нескольких жизненных ситуациях
переносятся на его же поведение вообще,
во всех ситуациях и всегда. Вокруг
человека возникают ореолы «умный»,
«порядочный», «общительный», «хвастливый»
и т.п. Не допускается, что один и тот же
человек бывает не только общительным,
но и замкнутым, не только тревожным, но
и спокойным и т.д. и т.п., а иногда может
вообще не походить на себя.
Ошибка, основанная на
эффекте «ложного
согласия»,
связанна с тем, что наблюдатель в оценке
поведения наблюдаемого следует мнению,
сложившемуся о человеке у окружающих
и выражающемуся формулой «все так
говорят». Эта установка ближайшего
окружения переносится на наблюдаемого
человека как его оценка и характеристика
многими или вообще всеми, что обычно не
соответствует действительности.
Ошибка «средней
тенденции»
связана со склонностью ориентироваться
в оценке человека на его типичное, так
называемое среднестатистическое
поведение, а не на особые, не свойственные
для него проявления, отклоняющиеся от
привычных.
Ошибка «первого
впечатления»
возникает в основном неосознанно в
результате переноса сложившихся
стереотипов восприятия на наблюдаемого
человека. Стереотипы существуют в
восприятии мужчин, женщин, определённых
национальностей, профессий, внешних
данных человека. Наиболее устойчивые
стереотипы, искажающие точность
наблюдения: «высокий лоб – признак
ума», «жёсткие волосы – признак жёсткого,
сурового характера», «красота женщины
– признак глупости», «все французы –
легкомысленны» и т.п. «Правдивость»
первого впечатления связана, прежде
всего, с его яркостью. Первая встреча с
незнакомым человеком оставляет самый
глубокий сенсорный след, самую сильную
ориентировочную реакцию.
Для предотвращения
ошибок наблюдения следует придерживаться
определённых правил:
-
психолог-диагност
наблюдает внешние проявления человека
достаточно длительное время; -
наблюдаются поведенческие
проявления, соответствующие одному
какому-либо свойству личности, а не
личность в целом; -
наблюдаются внешние
проявления личностных свойств, на
основании которых делается заключение
о самом свойстве; -
при наблюдении
необходимо использовать унифицированный
перечень поведенческих проявлений,
характеризующих наблюдаемые свойства
личности, черты характера; -
необходимо присутствие
нескольких психологов, наблюдающих
поведение одного и того же человека; -
необходимо использовать
специальные средства для фиксации
наблюдаемых поведенческих проявлений
(специальные карты).
В настоящее время
известно большое количество карт
наблюдения. Например, карта Стотта для
наблюдения за дезадаптивными проявлениями
школьников. Карты наблюдения разнообразны
по своей форме и сложности. Наиболее
простая форма может служить для фиксации
наблюдаемого вербального и невербального
поведения и выглядит следующим образом.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Основными методами педагогической психологии являются следующие.
Наблюдение – целенаправленное, специальным образом организованное и фиксируемое восприятие исследуемого объекта. Наблюдение позволяет выявить психологические особенности ребенка, учителя или родителя в естественных для них условиях. За ребенком можно понаблюдать во время урока или игры со сверстниками, за родителем – во время праздника, организованного в классе, причем наблюдатель должен опираться на объективно наблюдаемые параметры поведения, а не интерпретировать их
Ошибки наблюдения, связанные с личностью наблюдателя:
- «эффект ореола» связан со склонностью наблюдателя к обобщению поведения наблюдаемого. Так, наблюдение за ребенком во время уроков переносится на его поведение вообще;
- ошибка «ложного согласия» состоит в том, что наблюдатель в оценке поведения следует мнению окружающих, сложившемуся о нем («все так говорят»);
- ошибка «средней тенденции» связана со склонностью ориентироваться на типичные, «среднестатистические» для каждого человека поведенческие проявления, а не отличные от обычных формы (представление о том, что мальчики в среднем более активны и энергичны, чем девочки, может повлиять на ход наблюдения за особенностями отношений детей разных полов);
- ошибка «первого впечатления» является результатом переноса сложившихся стереотипов восприятия на наблюдаемого человека.
Чтобы избежать указанных ошибок, желательно наблюдать за поведением конкретного человека длительное время, сопоставлять свои данные с результатами наблюдений других людей.
Наблюдатель должен хорошо представлять, что, для чего и каким образом он собирается наблюдать: должна быть создана программа, определены параметры наблюдаемого поведения, способы фиксации. В ином случае он будет фиксировать случайные факты.
Разновидностью наблюдения являются дневники, которые могут вести родители и педагоги, описывая особенности развития детей, их взаимоотношений с окружающими. Ценный материал психолог может получить из дневниковых записей и самоотчетов, которые ведут участники тренингов и групп личностного роста.
Самонаблюдение является разновидностью наблюдения и предполагает изучение психики на основе наблюдения за собственными психическими явлениями. Для его проведения у испытуемого должен быть сформирован высокий уровень абстрактно-логического мышления и способность к рефлексии. Дети-дошкольники легче нарисуют свое состояние, чем будут рассказывать о нем.
Эксперимент – метод сбора фактов в контролируемых и управляемых условиях, обеспечивающих активное проявление изучаемых психических явлений.
По форме проведения выделяют естественный и лабораторный эксперимент. Естественный эксперимент был предложен А.Ф. Лазурским в 1910 г. на I Всероссийском съезде по экспериментальной педагогике. Естественный эксперимент проводится в условиях привычной для испытуемого деятельности (на занятиях, в игре). Педагог может широко использовать этот метод в своей работе. В частности, изменяя формы и методы обучения, можно выявить, как они влияют на усвоение материала, особенности его понимания и запоминания. Такие известные в нашей стране педагоги, как В.А. Сухомлинский, А.С. Макаренко, Ш.А. Амонашвили, В.Ф. Шаталов, Е.А. Ямбург и др. добились высоких результатов в обучении и воспитании детей благодаря экспериментированию, созданию инновационных площадок в образовании.
Лабораторный эксперимент проводится в специально созданных условиях. В частности, особенности познавательных процессов (памяти, мышления, восприятия и др.) могут изучаться с помощью специально созданной аппаратуры. В педагогической психологии данный вид эксперимента практически не используется, так как возникает проблема переноса полученных в лабораторных условиях данных в реальную педагогическую практику.
По целям проведения выделяют констатирующий и формирующий эксперимент. Цель констатирующего эксперимента – измерение наличного уровня развития (например, уровня развития абстрактно-логического мышления, степени сформированности моральных представлений). В этом случае разновидностью констатирующего эксперимента являются тесты. Полученные данные составляют основу формирующего эксперимента.
Формирующий эксперимент направлен на активное преобразование, развитие тех или иных сторон психики. Благодаря экспериментально-генетическому методу, созданному Л.С. Выготским, появилась возможность не только выявить качественные особенности развития высших психических функций, но и целенаправленно влиять на их формирование. В рамках формирующего эксперимента доказана возможность формирования у младших школьников научно-теоретического мышления, созданы условия для интенсивного изучения иностранного языка, обеспечено сближение учебной и профессиональной деятельности.
Специальной формой эксперимента является исследование при помощи тестов. Тесты – стандартизированные задания, предназначенные для измерения в сопоставимых величинах индивидуально-психологических свойств личности, а также знаний, умений и навыков. В педагогической практике впервые тесты стали использоваться в 1864 г. в Великобритании для проверки знаний учащихся. В конце XIX в. Ф. Гальтоном, основателем тестологии, был разработан ряд заданий для оценки индивидуальных особенностей человека. Термин «тест» был введен американским психологом Дж. М. Кеттелом (1890 г.). Им была создана серия тестов, направленных на определение уровня интеллектуального развития. Известны шкалы, созданные А. Бине в 1905 г. для обследования детей в возрасте 3-11 лет. Шкала включала в себя 30 заданий различной трудности и предназначалась для диагностики умственной отсталости. В 1911 г. В. Штерном введено понятие коэффициента интеллекта (IQ), измерение которого остается одной из целей тестирования.
В России тесты начали применяться в начале XX в. А.П. Болтуновым в 1928 г. была создана «измерительная шкала ума» на основе шкалы А. Бине.
В настоящее время тесты используются в системе профессионального отбора, при патопсихологической диагностике, для определения уровня готовности ребенка к поступлению в школу, для выявления особенностей сформированности познавательных процессов и личностных свойств (на этапе адаптации к школьному обучению, при переходе в среднее звено, при обследовании старшеклассников). Тестирование может быть использовано для выявления психологических особенностей ребенка, испытывающего трудности в общении, в обучении и т.д. Психолог может предложить педагогу пройти психологическое тестирование для выявления его психологических особенностей. Психологу эти данные помогут при проведении консультационной работы.
Качество теста определяется его надежностью (устойчивостью результатов тестирования), валидностью (соответствие теста целям диагностики), дифференцирующей силой задания (способностью теста подразделять испытуемых по степени выраженности исследуемой характеристики).
Разновидностью тестов являются проективные тесты, особенность которых заключается в исследовании личностных характеристик по непроизвольным реакциям (порождение свободных ассоциаций, интерпретация случайных конфигураций, описание картинок с неопределенным сюжетом, рисование на тему).
Тест свободных ассоциаций может быть проведен под видом игры «думаем вслух». Экспериментатор дает определенное слово, а ребенок называет десять ассоциаций, которые приходят ему в голову в связи с этим словом. Вначале предъявляются несколько камуфляжных слов-стимулов, а затем называются значимые слова, такие, как «твой отец», «твоя мать» и др.
Использование теста тематической апперцепции (ТАТ) может помочь собрать информацию о взаимоотношениях ребенка с окружающими. Набор сюжетных и бессюжетных картинок в черно-белом варианте позволяет испытуемым в зависимости от уровня развития мышления, речи, чувств и на основе предыдущего жизненного опыта (апперцепции) по-разному трактовать изображаемую ситуацию. Экспериментатор, используя такой тест, может решать диагностические и коррекционные задачи, обсуждая с испытуемым вопросы: «Кто изображен на картинке? Что происходит на картинке? Что думают и чувствуют персонажи картинки? Что привело к случившемуся? Что будет?».
Наиболее распространенным методом, используемым психологом образования, являются рисуночные техники. Еще в 1914 г. проф. А. Лазурский пытался использовать уроки рисования для исследования личности ребенка. Наиболее популярны эти техники стали в 1950-е гг. В настоящее время используются рисуночные тесты «Дом – дерево – человек», «Автопортрет», «Конструктивный рисунок человека из геометрических фигур», «Картина мира», «Свободный рисунок», «Рисунок семьи».
Некоторые психологи используют рисунок в психологической диагностике, опираясь на следующие принципы:
- создания рисунка, за возникновением которого можно было наблюдать;
- классификации рисунка с точки зрения уровня развития и с точки зрения необычных признаков;
- рассмотрения рисунка как результата полифункциональной деятельности. Эта деятельность может являться полем проекции интенсивных переживаний;
- по принципу, когда больше ошибок в психологической диагностике было вызвано преувеличенной проективной интерпретацией, чем опущением проективной интерпретации.
Отсюда:
- рисунок не следует использовать в качестве единственного отправного пункта проективной интерпретации;
- проективные тенденции следует проверять при помощи исследований, сопоставления с результатами дальнейших испытаний, в разговоре с родителями и т.п.;
- рисунок может явиться индикатором не только творческих способностей, но и патологических процессов (функциональных и органических).
К основным аспектам интерпретации рисунка семьи относятся:
- структура рисунка семьи;
- особенности нарисованных членов семьи;
- процесс рисования.
Метод изучения продуктов деятельности позволяет собрать факты, опираясь на анализ материализованных продуктов психической деятельности. Исследователь, используя данный метод, имеет дело не с самим человеком, а с материальными продуктами его деятельности: учебной (сочинение, решенная задача), игровой (сюжет придуманной ребенком игры, построенный из кубиков дом), творческой (стихи, рассказы, сказки). При осуществлении этого метода важно попытаться воспроизвести процесс изготовления продукта и тем самым обнаружить особенности личности.
Требования к методу:
- анализируя продукты деятельности, следует установить, являются ли они результатом типичной, характерной для данного человека деятельности или созданы случайно;
- необходимо знать, в каких условиях протекала деятельность;
- анализировать не единичные, а многие продукты деятельности.
Метод опроса обеспечивает получение информации в процессе непосредственного (беседа, интервью) или опосредованного (анкетирование, опрос) общения. Для грамотного проведения анкетирования и интервью важно четкое формулирование вопросов, так, чтобы их однозначно понимали испытуемые. В психологии разработаны правила составления вопросов (открытых и закрытых), расположения их в нужном порядке, группировки в отдельные блоки.
Наиболее часто при составлении анкет и опросников встречаются следующие ошибки:
- используются слова, являющиеся научными терминами или непонятными опрашиваемому;
- в качестве значений признака применяются неконкретные и общие понятия («часто – редко», «много – мало»), их следует конкретизировать (регулярно – «раз в неделю», «раз в месяц», «раз в год» и т.д.);
- психолог пытается увлечь опрашиваемого, предлагая неравноценные ответы или используя сленг.
Для проведения беседы важна обстановка доверия между психологом и тем, кого он опрашивает. Необходимо знать правила установления контакта, владеть техниками эффективного общения, способами расположения к себе собеседника.
Социометрия – метод изучения особенностей межличностных отношений в малых группах. Он состоит в том, что основным измерительным приемом является вопрос, отвечая на который каждый член группы проявляет свое отношение к другим. Результаты заносятся на социограмму – график, на котором стрелками указаны выборы (отвержения) членов группы, либо в таблицу, в которой подсчитывается число выборов, полученное каждым членом группы. Положительный статус характеризует лидерскую позицию члена группы. Негативный – дезорганизующие тенденции в поведении личности. Используются групповые и индивидуальные формы социометрии, а также модификации в виде игры, рисуночных тестов и др.
Биографический метод – сбор и анализ данных о жизненном пути личности. Исследование жизненного стиля и сценария личности (метод генограммы, анализа ранних детских воспоминаний) может быть использовано для выявления особенностей формирования жизненного стиля ребенка. Данный метод несет большую терапевтическую и коррекционную нагрузку как в условиях индивидуального, так и группового консультирования.
Генограмма представляет собой форму семейной родословной, на которой записывается информация о членах семьи, по крайней мере в трех поколениях. Генограмма показывает семейную информацию графически, что позволяет быстро визуализировать сложные семейные паттерны. Генограмма служит также источником гипотез о том, как актуальные проблемы связаны с семейным контекстом и развитием во времени.
Анализ ранних детских воспоминаний направлен на выявление актуального жизненного стиля личности. Психолог предлагает как можно более подробно описать несколько самых ранних детских воспоминаний и попытаться дать им название, начиная с фраз типа «Моя жизнь – это…», «Жить – это значит…». При проведении методики важно фиксировать внимание на деталях воспоминаний, на эмоциональном отношении к происходящему в детстве, к особенностям людей, представленных в воспоминании.
В рамках трансактного анализа предложены процедуры исследования жизненного сценария. Психолог стимулирует в ходе беседы с испытуемым обсуждение таких вопросов, как: «В честь кого вас назвали? Каким вы были ребенком в семье (первым, вторым…) и как повлияло появление второго ребенка на вас? Какие пословицы или поговорки могут отразить ценности, отстаиваемые вашей семьей? Как планировали ваше будущее родители?» и т.д.
Математические методы в психолого-педагогическом исследовании используются как вспомогательные при планировании и обработке результатов эксперимента, тестовых обследований, анкетирования и опроса.
Методы оказания психологической помощи и поддержки субъектам образовательного процесса направлены на создание условий для целостного психологического развития школьников и на решение конкретных проблем, возникающих в процессе развития. К ним относятся: активное социальное обучение (тренинг), индивидуальное и групповое консультирование, психологическая коррекция.
Активное социальное обучение (тренинг) – это совокупность методов, направленных на развитие знаний, социальных установок, умений и навыков самопознания и саморегуляции, общения и межличностного взаимодействия. Приемы, которые использует психолог при проведении тренинга: ролевая игра, групповая дискуссия, психогимнастика, тренировка поведенческих навыков, анализ ситуаций, элементы психодиагностики и др. Для получения участниками тренинга обратной связи может быть использована аудио- и видеоаппаратура. К настоящему времени в арсенале педагогической психологии накоплено большое количество программ активного социального обучения, обеспечивающих работу психолога с детьми, с педагогами и родителями.
Целью психологического консультирования является культурно-продуктивная личность, обладающая чувством перспективы, действующая осознанно, способная разрабатывать различные стратегии поведения и анализировать ситуацию с различных точек зрения. При консультировании школы как организации психолог ориентирован на оптимизацию организационных и управленческих структур. Психолог может выступать как консультант по организационному развитию, направляя свои действия на изменение социальных отношений, взглядов людей и структуры организации с целью улучшения ее функционирования и обеспечения развития. Консультирование может проводиться в индивидуальной и групповой формах. Методологическая и теоретическая подготовленность психолога, ориентированность в основных подходах к пониманию целей и средств консультирования, специфика заявленной проблемы обусловливают основания его работы с личностью или группой. В практике работы школьного психолога наиболее успешно используются поведенческий, транзактный, гуманистический и когнитивно-ориентированный подходы, элементы гештальт-терапии, психосинтеза, телесно-ориентированной терапии.
Психологическая коррекция – направленное психологическое воздействие на те или иные психологические структуры с целью обеспечения полноценного развития и функционирования личности. В арсенале школьных психологов много программ, направленных на развитие и коррекцию познавательной области учащихся, эмоционально-личностной сферы.
Что такое смещение центральной тенденции?
17 авг. 2022 г.
читать 2 мин
Смещение центральной тенденции относится к склонности человека ставить большинству пунктов опроса среднюю оценку по шкале оценок.
Этот тип предвзятости чаще всего возникает при внутренних опросах, когда менеджеры должны оценивать своих сотрудников. Например, по 10-балльной шкале менеджеры могут поставить сотрудникам от 6 до 8 баллов по большинству категорий.
Менеджеры могут делать это, потому что они хотят избежать предоставления преференциального отношения к определенным сотрудникам или просто избежать негативной реакции со стороны сотрудников за то, что они ставят оценки на крайних концах шкалы.
Этот тип предвзятости встречается реже, когда клиенты заполняют опросы для компании, потому что ставки ниже.
Клиенты не оценивают напрямую людей, которых они знают и с которыми общаются ежедневно, поэтому они более склонны ставить чрезвычайно высокие или крайне низкие оценки, когда чувствуют в этом необходимость.
Проблема смещения центральной тенденции
Есть две проблемы, вызванные смещением центральной тенденции:
1. Данные могут быть неточными.
Если менеджеры оценивают каждого сотрудника в середине рейтинговой шкалы просто потому, что боятся давать чрезмерные оценки, это означает, что данные, собранные в ходе опроса, будут неточными и не будут отражать реальную производительность сотрудников.
2. Данные будут бесполезны.
Если менеджеры оценивают каждого сотрудника в середине рейтинговой шкалы для каждой категории, то производительность всех сотрудников будет казаться в основном одинаковой. Это затрудняет определение лиц, которые должны быть повышены в должности или должны получить премию.
Как избежать смещения центральной тенденции
Есть три способа избежать смещения центральной тенденции в опросах:
1. Не требуйте от менеджеров обоснования своих оценок.
Иногда менеджеры не хотят ставить оценки в нижней или верхней части шкалы просто потому, что от них требуется предоставить обоснование для необычно низких или высоких оценок.
Не требуя от менеджеров обоснования своих оценок, они с большей вероятностью будут честны в отношении того, следует ли оценивать сотрудника выше или ниже, потому что им не нужно выполнять дополнительную работу по предоставлению обоснования.
Преимущество этого подхода заключается в том, что вы, скорее всего, получите более точные данные, но недостатком является то, что вы на самом деле не понимаете причин особенно низких или высоких оценок.
2. Разрешить ранжирование.
Вместо того, чтобы просить менеджера поставить оценку от 1 до 10 для каждого отдельного сотрудника по общей производительности, вы можете вместо этого попросить его ранжировать сотрудников от наименее продуктивных до наиболее продуктивных.
Это заставит менеджеров идентифицировать низкопродуктивных и высокопродуктивных сотрудников просто потому, что не каждый сотрудник может быть наименее продуктивным или наиболее продуктивным.
3. Убедитесь, что вопросы понятны.
Еще один очевидный способ избежать систематической ошибки, связанной с центральной тенденцией, — убедиться, что вопросы опроса ясны. Часто, когда вопросы неясны, менеджеры просто присваивают средний рейтинг, потому что они не уверены в заданном вопросе.
Например, рассмотрим следующий опрос с неясными вопросами:
- Насколько ответственен сотрудник X по шкале от 1 до 10?
- Как бы вы оценили лидерство сотрудника X по шкале от 1 до 10?
Теперь рассмотрим пересмотренный опрос с четкими вопросами:
- Оцените ответственность сотрудника X по шкале от 1 до 10, где 1 означает, что он никоим образом не несет ответственности, а 10 означает, что он полностью отвечает за свои действия и свою работу.
- Оцените лидерство сотрудника X по шкале от 1 до 10, где 1 означает, что он никогда не брал на себя руководящую роль в проекте и не проявляет каких-либо лидерских качеств, а 10 указывает на то, что он всегда берет на себя роль лидера и проявляет лидерские качества в проекте. все проекты по мере необходимости.
Пересмотренный опрос, скорее всего, даст точные данные, потому что они гораздо яснее показывают, за что менеджер должен давать оценки.
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
- Среднеквадратичная ошибка (Mean Squared Error)
- Корень из среднеквадратичной ошибки (Root Mean Squared Error)
- Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error)
- Cредняя абсолютная ошибка (Mean Absolute Error)
- Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error)
- Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error)
- Средняя абсолютная масштабированная ошибка (Mean absolute scaled error)
- Средняя относительная ошибка (Mean Relative Error)
- Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error
- R-квадрат
- Скорректированный R-квадрат
- Сравнение метрик
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Средняя ошибка аппроксимации
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
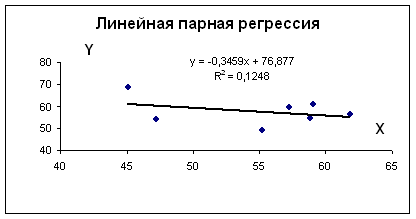
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Задача №3. Расчёт параметров регрессии и корреляции с помощью Excel
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R 2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов |

Остаточная сумма квадратов


Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Средней ошибки аппроксимации качество уравнений
Оценка этой формы связи по коэффициенту множественной корреляции и средней ошибке аппроксимации показывает, что адекватность данной модели не подтверждается. Действительно, хотя значение коэффициента достаточно высокое (0,92), средняя ошибка аппроксимации составляет более 10% (I = 14,5%). Поэтому данная форма должна быть исключена из перебора известных уравнений регрессии. [c.29]
Анализ полученной формы связи по той же причине, что и в первом случае, позволяет сделать вывод о непригодности и этой модели. Коэффициент множественной корреляции хотя и имеет более высокое значение, чем в линейной зависимости (0,93), но по величине средней ошибки аппроксимации (б = 12,4%) это уравнение регрессии подлежит исключению из дальнейшего перебора. [c.29]
Последняя модель себестоимости добычи нефти, как показывает оценка ее по известным критериям, удовлетворяет условиям адекватности. Коэффициент множественной корреляции R составляет 0,98, что свидетельствует о том, что колеблемость исследуемого показателя более чем на 96 % определяется факторами, включенными в эту модель. При оценке по f-критерию (t R = 30,5) можно утверждать, что с вероятностью 0,99 факторы, включенные в модель, имеют существенную связь с исследуемым показателем (t a n = 2,58). Средняя ошибка аппроксимации составляет всего лишь 2,9 %, а F-критерий, характеризующий уровень остаточной дисперсии, превышает критическое (табличное) значение в четыре раза. К этому следует добавить, что полученная модель себестоимости добычи нефти представляет собой достаточно простую форму связи, легко решается и поддается экономической интерпретации. [c.30]
Оценка полученной модели по статистическим характеристикам показывает, что колеблемость затрат исследуемой подсистемы на 85 % обусловлена колеблемостью факторов, включенных в модель, коэффициент множественной корреляции высокий (/ = 0,92) и существенный (f = = 39,8), модель является адекватной, средняя ошибка аппроксимации (ё = 5,7%) меньше 10%. [c.39]
Статистический анализ показывает, что уравнение значимо Рф = 5,054 при /»табл = 3,01, корреляционное отношение равно 0,9959, ее»стандартная ошибка равна 0,0015. Среднее квадратическое отклонение расчетной себестоимости от фактической равно 0,018. Средняя ошибка аппроксимации 1,1%. [c.90]
Средняя ошибка аппроксимации [c.94]
Средняя ошибка аппроксимации. [c.95]
В случаях, когда трудно обосновать форму зависимости, решение задачи можно провести по разным моделям и сравнить полученные результаты. Адекватность разных моделей фактическим зависимостям проверяется по критерию Фишера, показателю средней ошибки аппроксимации и величине множественного коэффициента детерминации, о которых речь пойдет несколько позже (см. 7.4). [c.144]
Эти сведения вводятся в ПЭВМ и рассчитываются матрицы парных и частных коэффициентов корреляции, уравнение множественной регрессии, а также показатели, с помощью которых оценивается надежность коэффициентов корреляции и уравнения связи критерий Стьюдента, критерий Фишера, средняя ошибка аппроксимации, множественные коэффициенты корреляции и детерминации. [c.145]
Для того чтобы убедиться в надежности уравнения связи и правомерности его использования для практической цели, необходимо дать статистическую оценку надежности показателей связи. Для этого используются критерий Фишера (F-отношение), средняя ошибка аппроксимации ( ), коэффициенты множественной корреляции (/ ) и детерминации (D). [c.151]
Для статистической оценки точности уравнения связи используется также средняя ошибка аппроксимации [c.152]
Чем меньше теоретическая линия регрессии (рассчитанная по уравнению) отклоняется от фактической (эмпиричной), тем меньше средняя ошибка аппроксимации. В нашем примере она составляет 0,0364, или 3,64 %. Учитывая, что в экономических расчетах допускается погрешность 5-8 %, можно сделать вывод, что исследуемое уравнение связи довольно точно описывает изучаемые зависимости. [c.152]
После построения уравнения регрессии необходимо сделать проверку его значимости с помощью специальных критериев установить, не является ли полученная зависимость, выраженная уравнением регрессии, случайной, т.е. можно ли ее использовать в прогнозных целях и для факторного анализа. В статистике разработаны методики строгой проверки значимости коэффициентов регрессии с помощью дисперсионного анализа и расчета специальных критериев (например, F-критерия). Нестрогая проверка может быть выполнена путем расчета среднего относительного линейного отклонения (ё), называемого средней ошибкой аппроксимации [c.123]
Модель считается адекватной, т.е. пригодной для практического использования, если средняя ошибка аппроксимации не превосходит 15%. [c.123]
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации. [c.6]
Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических [c.6]
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата ух. По ним рассчитаем показатели тесноты связи — индекс корреляции рху и среднюю ошибку аппроксимации 7, [c.13]
Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации. [c.16]
Это означает, что 52% вариации заработной латы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума. Качество модели определяет средняя ошибка аппроксимации [c.18]
Оцените с помощью средней ошибки аппроксимации качество уравнений. [c.38]
Оцените качество уравнений с помощью средней ошибки аппроксимации. [c.42]
Оцените качество уравнения через среднюю ошибку аппроксимации. [c.92]
Оцените качество каждого тренда через среднюю ошибку аппроксимации, линейный коэффициент автокорреляции отклонений. [c.166]
СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ [c.87]
Представим расчет средней ошибки аппроксимации для уравнения ух = 9,876 + 5,129 hue в табл. 2.7. А = — 7,3 = 1,2%, что [c.88]
Расчет средней ошибки аппроксимации [c.88]
В стандартных программах чаще используется первая формула для расчета Средней ошибки аппроксимации. [c.88]
В чем смысл средней ошибки аппроксимации и как она определяется [c.89]
Средняя ошибка аппроксимации [c.10]
Выбор вида модели основан на логическом анализе изучаемых показателей, сравнении статистических характеристик (средняя ошибка аппроксимации, критерий Фишера, коэффициенты множественной корреляции и детерминации), рассчитанных для различных функций по одним и тем же первичным данным. [c.31]
Проверка приведенной в формуле (154) себестоимости по фактическим данным 103 СМУ показала, что средняя ошибка аппроксимации, определяющая степень соответствия расчетных значений фактическим, составила всего 1,5%, что вполне допустимо. [c.227]
Исчисляемый коэффициент детерминации получился равным 0,869. Это говорит о том, что размер заработной платы водителей на 86,9% зависит от Р и Л ри на 13,1% — от неучтенных в модели факторов. Средняя ошибка аппроксимации составила всего лишь 0,17%. Модель была получена на основе конкретных показателей ряда автотранспортных предприятий Владимирского транспортного управления, поэтому она может -быть использована в практической работе только на этих предприятиях. Предлагаемая же методика может быть использована в любом транспортном управлении, министерстве при планировании и анализе себестоимости автомобильных перевозок и установлении нормативов по заработной плате водителей за время работы на линии. [c.36]
источники:
http://ecson.ru/economics/econometrics/zadacha-3.raschyot-parametrov-regressii-i-korrelyatsii-s-pomoschju-excel.html
http://economy-ru.info/info/119599/