Содержание
- Мой первый опыт восстановления базы данных Postgres после сбоя (invalid page in block 4123007 of relatton base/16490)
- Подготовка к восстановлению
- Проверка файловой системы
- Попытка 1: zero_damaged_pages
- Попытка 2: reindex
- Попытка 3: SELECT, LIMIT, OFFSET
- Попытка 4: снять дамп в текстовом виде
- Попытка 5: SELECT, FROM, WHERE > Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному: for ((i=1; i /dev/null || echo $i; done
- Попытка 6: SELECT, FROM, WHERE id >= and id for ((i=1; i /dev/null || echo $i; done
- Счастливый финал
- Мой первый опыт восстановления базы данных Postgres после сбоя (invalid page in block 4123007 of relatton base/16490)
- Подготовка к восстановлению
- Проверка файловой системы
- Попытка 1: zero_damaged_pages
- Попытка 2: reindex
- Попытка 3: SELECT, LIMIT, OFFSET
- Попытка 4: снять дамп в текстовом виде
- Попытка 5: SELECT, FROM, WHERE > Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
Мой первый опыт восстановления базы данных Postgres после сбоя (invalid page in block 4123007 of relatton base/16490)
Хочу поделиться с вами моим первым успешным опытом восстановления полной работоспособности базы данных Postgres. С СУБД Postgres я познакомился пол года назад, до этого опыта администрирования баз данных у меня не было совсем. 
Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [. ]
pg_dunp: [parallel archtver] a worker process dled unexpectedly
Ошибка «invalid page in block» говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать FULL VACUUM с опцией zero_damaged_pages для решения данной проблемы. Что же, попрробеум…
Подготовка к восстановлению
ВНИМАНИЕ! Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите это.
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция -T, —exclude-table=TABLE в pg_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
Проверка файловой системы
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в «/srv» и тип был ext4.
Останавливаем базу данных: systemctl stop postgresql@9.5-main.service и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды lsof:
lsof +D /srv
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала «/srv». Далее я отмонтировал /srv (umount).
Проверка файловой системы была выполнена с помощью утилиты e2fsck с ключиком -f (Force checking even if filesystem is marked clean): 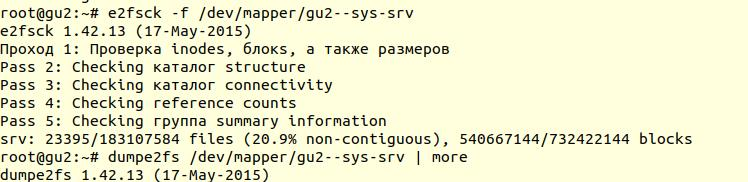
Далее с помощью утилиты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep checked) можно убедиться, что проверка действительно была произведена: 
e2fsck говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к vacuum full (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через smartctl -a /dev/XXX) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
Попытка 1: zero_damaged_pages
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию zero_damaged_pages может менять только он. В моём случае это postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опция zero_damaged_pages нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):
При выявлении повреждённого заголовка страницы Postgres Pro обычно сообщает об ошибке и прерывает текущую транзакцию. Если параметр zero_damaged_pages включён, вместо этого система выдаёт предупреждение, обнуляет повреждённую страницу в памяти и продолжает обработку. Это поведение разрушает данные, а именно все строки в повреждённой странице.
Включаем опцию и пробуем делать full vacuum таблицы:
VACUUM FULL VERBOSE 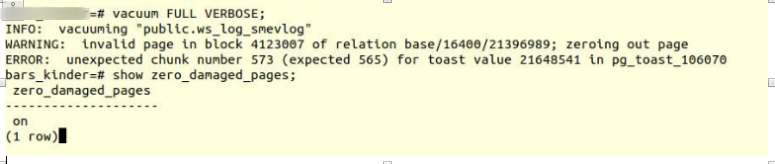
К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
INFO: vacuuming «“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast – механизм хранения «длинных данных» в Poetgres, если они не помещаются в одну страницу (по умолчанию 8кб).
Попытка 2: reindex
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать reindex повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:
reindex table ws_log_smevlog 
reindex завершился без проблем.
Однако это не помогло, VACUUM FULL аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную статью.
Попытка 3: SELECT, LIMIT, OFFSET
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
for ((i=0; i /dev/null || echo $i; done
В моём случае таблица содержала 1 628 991 строк! По-хорошему необходимо было позаботиться о партициирвоании данных, но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
for ((i=0; i /dev/null || echo $i; done
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
OFFSET указывает пропустить указанное число строк, прежде чем начать выдавать строки.
Если указано и OFFSET, и LIMIT, сначала система пропускает OFFSET строк, а затем начинает подсчитывать строки для ограничения LIMIT.
Применяя LIMIT, важно использовать также предложение ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк.
Очевидно, что вышенаписанная команда была ошибочной: во-первых, не было order by, результат мог получиться ошибочным. Во-вторых, Postgres сначала должен был просканировать и пропустить OFFSET-строк, и с возрастанием OFFSET производительность снижалась бы ещё сильнее.
Попытка 4: снять дамп в текстовом виде
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы ws_log_smevlog: 
В нашем случае у нас есть столбец «id», который содержал уникальный идентификатор (счётчик) строки. План был такой:
1) Начинаем снимать дамп в текстовом виде (в виде sql-команд)
2) В определённый момент времени снятия дампа бы прервалось из-за ошибки, но тектовый файл всё равно сохранился бы на диске
3) Смотрим конец текстового файла, тем самым мы находим идентификатор (id) последней строки, которая снялась успешно
Я начал снимать дамп в текстовом виде:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Далее через tail я просмотрел конец дампа (tail -5 ./my_dump.dump) обнаружил, что дамп прервался на строке с id 186 525. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«select * from ws_log_smevlog where обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удаленииизменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит autuvacuum и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимая, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
Попытка 5: SELECT, FROM, WHERE > Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
for ((i=1; i /dev/null || echo $i; done
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в /dev/null, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю id: 
А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в tmux и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
Попытка 6: SELECT, FROM, WHERE id >= and id for ((i=1; i /dev/null || echo $i; done
Тут можно было написать красивый и элегантный скрипт, но я выбрал наиболее быстрый способ распараллеливания: разбить диапазон 0-1628991 вручную на интервалы по 100 000 записей и запустить отдельно 16 команд вида:
for ((i=N; i /dev/null || echo $i; done
Но это не всё. По идее, подключение к базе данных тоже отнимает какое-то время и системные ресурсы. Подключать 1 628 991 было не очень разумно, согласитесь. Поэтому давайте при одном подключении извлекать 1000 строк вместо одной. В итоге команда преобразилоась в это:
for ((i=N; i =$i and id /dev/null || echo $i; done
Открываем 16 окон в сессии tmux и запускаем команды:
1) for ((i=0; i =$i and id /dev/null || echo $i; done
2) for ((i=100000; i =$i and id /dev/null || echo $i; done
…
15) for ((i=1400000; i =$i and id /dev/null || echo $i; done
16) for ((i=1500000; i =$i and id /dev/null || echo $i; done
Через день я получил первые результаты! А именно (значения XXX и ZZZ уже не сохранились):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000
Это значит, что у нас три строки содержат ошибку. id первой и второй проблемной записи находились между 829 000 и 830 000, id третьей – между 146 000 и 147 000. Далее нам предстояло просто найти точное значение id проблемных записей. Для этого просматриваем наш диапазон с проблемными записями с шагом 1 и идентифицируем id:
for ((i=829000; i /dev/null || echo $i; done
829417
ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070
829449
for ((i=146000; i /dev/null || echo $i; done
829417
ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070
146911
Счастливый финал
Мы нашли проблемные строки. Заходим в базу через psql и пробуем их удалить:
my_database=# delete from ws_log_smevlog where > DELETE 1
my_database=# delete from ws_log_smevlog where > DELETE 1
my_database=# delete from ws_log_smevlog where > DELETE 1
К моему удивлению, записи удалились без каких-либо проблем даже без опции zero_damaged_pages.
Затем я подключился к базе, сделал VACUUM FULL (думаю делать было необязательно), и, наконец, успешно снял бекап с помощью pg_dump. Дамп снялся без каких либо ошибок! Проблему удалось решить таким вот тупейшим способом. Радости не было предела, после стольких неудач удалось найти решение!
Источник
Мой первый опыт восстановления базы данных Postgres после сбоя (invalid page in block 4123007 of relatton base/16490)
Хочу поделиться с вами моим первым успешным опытом восстановления полной работоспособности базы данных Postgres. С СУБД Postgres я познакомился пол года назад, до этого опыта администрирования баз данных у меня не было совсем.

Я работаю полу-DevOps инженером в крупной IT-компании. Наша компания занимается разработкой программного обеспечения для высоконагруженных сервисов, я же отвечаю за работоспособность, сопровождение и деплой. Передо мной поставили стандартную задачу: обновить приложение на одном сервере. Приложение написано на Django, во время обновления выполняются миграции (изменение структуры базы данных), и перед этим процессом мы снимаем полный дамп базы данных через стандартную программу pg_dump на всякий случай.
Во время снятия дампа возникла непредвиденная ошибка (версия Postgres – 9.5):
Ошибка «invalid page in block» говорит о проблемах на уровне файловой системы, что очень нехорошо. На различных форумах предлагали сделать FULL VACUUM с опцией zero_damaged_pages для решения данной проблемы. Что же, попрробеум…
Подготовка к восстановлению
ВНИМАНИЕ! Обязательно сделайте резервную копию Postgres перед любой попыткой восстановить базу данных. Если у вас виртуальная машина, остановите базу данных и сделайте снепшот. Если нет возможности сделать снепшот, остановите базу и скопируйте содержимое каталога Postgres (включая wal-файлы) в надёжное место. Главное в нашем деле – не сделать хуже. Прочтите это.
Поскольку в целом база у меня работала, я ограничился обычным дампом базы данных, но исключил таблицу с повреждёнными данными (опция -T, —exclude-table=TABLE в pg_dump).
Сервер был физическим, снять снепшот было невозможно. Бекап снят, двигаемся дальше.
Проверка файловой системы
Перед попыткой восстановления базы данных необходимо убедиться, что у нас всё в порядке с самой файловой системой. И в случае ошибок исправить их, поскольку в противном случае можно сделать только хуже.
В моём случае файловая система с базой данных была примонтирована в «/srv» и тип был ext4.
Останавливаем базу данных: systemctl stop postgresql@9.5-main.service и проверяем, что файловая система никем не используется и её можно отмонтировать с помощью команды lsof:
lsof +D /srv
Мне пришлось ещё остановить базу данных redis, так как она тоже исползовала «/srv». Далее я отмонтировал /srv (umount).
Проверка файловой системы была выполнена с помощью утилиты e2fsck с ключиком -f (Force checking even if filesystem is marked clean):
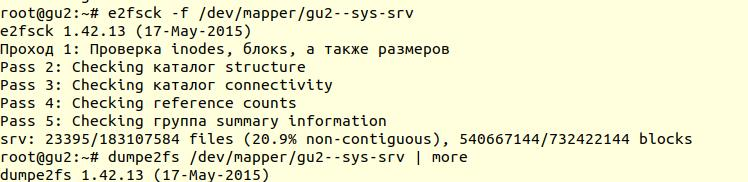
Далее с помощью утилиты dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep checked) можно убедиться, что проверка действительно была произведена:

e2fsck говорит, что проблем на уровне файловой системы ext4 не найдено, а это значит, что можно продолжать попытки восстановить базу данных, а точнее вернуться к vacuum full (само собой, необходимо примонтирвоать файловую систему обратно и запустить базу данных).
Если у вас сервер физический, то обязательно проверьте состояние дисков (через smartctl -a /dev/XXX) либо RAID-контроллера, чтобы убедиться, что проблема не на аппаратном уровне. В моём случае RAID оказался «железный», поэтому я попросил местного админа проверить состояние RAID (сервер был в нескольких сотнях километров от меня). Он сказал, что ошибок нет, а это значит, что мы точно можем начать восстановление.
Попытка 1: zero_damaged_pages
Подключаемся к базе через psql аккаунтом, обладающим правами суперпользователя. Нам нужен именно суперпользователь, т.к. опцию zero_damaged_pages может менять только он. В моём случае это postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
Опция zero_damaged_pages нужна для того, чтобы проигнорировать ошибки чтения (с сайта postgrespro):
При выявлении повреждённого заголовка страницы Postgres Pro обычно сообщает об ошибке и прерывает текущую транзакцию. Если параметр zero_damaged_pages включён, вместо этого система выдаёт предупреждение, обнуляет повреждённую страницу в памяти и продолжает обработку. Это поведение разрушает данные, а именно все строки в повреждённой странице.
Включаем опцию и пробуем делать full vacuum таблицы:

К сожалению, неудача.
Мы столкнулись с аналогичной ошибкой:
pg_toast – механизм хранения «длинных данных» в Postgres, если они не помещаются в одну страницу (по умолчанию 8кб).
Попытка 2: reindex
Первый совет из гугла не помог. После нескольких минут поиска я нашёл второй совет – сделать reindex повреждённой таблицы. Этот совет я встречал во многих местах, но он не внушал доверия. Сделаем reindex:

reindex завершился без проблем.
Однако это не помогло, VACUUM FULL аварийно завершался с аналогичной ошибкой. Поскольку я привык к неудачам, я стал искать советов в интернете дальше и наткнулся на довольно интересную статью.
Попытка 3: SELECT, LIMIT, OFFSET
В статье выше предлагали посмотреть таблицу построчно и удалить проблемные данные. Для начала необходимо было просмотреть все строки:
В моём случае таблица содержала 1 628 991 строк! По-хорошему необходимо было позаботиться о партициирвоании данных, но это тема для отдельного обсуждения. Была суббота, я запустил вот эту команду в tmux и пошёл спать:
К утру я решил проверить, как обстоят дела. К моему удивлению, я обнаружил, что за 20 часов было просканировано только 2% данных! Ждать 50 дней я не хотел. Очередной полный провал.
Но я не стал сдаваться. Мне стало интересно, почему же сканирование шло так долго. Из документации (опять на postgrespro) я узнал:
OFFSET указывает пропустить указанное число строк, прежде чем начать выдавать строки.
Если указано и OFFSET, и LIMIT, сначала система пропускает OFFSET строк, а затем начинает подсчитывать строки для ограничения LIMIT.
Применяя LIMIT, важно использовать также предложение ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк.
Очевидно, что вышенаписанная команда была ошибочной: во-первых, не было order by, результат мог получиться ошибочным. Во-вторых, Postgres сначала должен был просканировать и пропустить OFFSET-строк, и с возрастанием OFFSET производительность снижалась бы ещё сильнее.
Попытка 4: снять дамп в текстовом виде
Далее мне в голову пришла, казалось бы, гениальная идея: снять дамп в текстовом виде и проанализировать последнюю записанную строку.
Но для начала, ознакомимся со структурой таблицы ws_log_smevlog:

В нашем случае у нас есть столбец «id», который содержал уникальный идентификатор (счётчик) строки. План был такой:
- Начинаем снимать дамп в текстовом виде (в виде sql-команд)
- В определённый момент времени снятия дампа бы прервалось из-за ошибки, но тектовый файл всё равно сохранился бы на диске
- Смотрим конец текстового файла, тем самым мы находим идентификатор (id) последней строки, которая снялась успешно
Я начал снимать дамп в текстовом виде:
Снятия дампа, как и ожидалось, прервался с той же самой ошибкой:
Далее через tail я просмотрел конец дампа (tail -5 ./my_dump.dump) обнаружил, что дамп прервался на строке с id 186 525. «Значит, проблема в строке с id 186 526, она битая, её и надо удалить!» – подумал я. Но, сделав запрос в базу данных:
«select * from ws_log_smevlog where обнаружилось, что с этой строкой всё нормально… Строки с индексами 186 530 — 186 540 тоже работали без проблем. Очередная «гениальная идея» провалилась. Позже я понял, почему так произошло: при удаленииизменении данных из таблицы они не удаляются физически, а помечаются как «мёртвые кортежи», далее приходит autovacuum и помечает эти строки удалёнными и разрешает использовать эти строки повторно. Для понимания, если данные в таблице меняются и включён autovacuum, то они не хранятся последовательно.
Попытка 5: SELECT, FROM, WHERE > Неудачи делают нас сильнее. Не стоит никогда сдаваться, нужно идти до конца и верить в себя и свои возможности. Поэтому я решил попробовать ешё один вариант: просто просмотреть все записи в базе данных по одному. Зная структуру моей таблицы (см. выше), у нас есть поле id, которое является уникальным (первичным ключом). В таблице у нас 1 628 991 строк и id идут по порядку, а это значит, что мы можем просто перербрать их по одному:
Если кто не понимает, команда работает следующим образом: просматривает построчно таблицу и отправляет stdout в /dev/null, но если команда SELECT проваливается, то выводится текст ошибки (stderr отправляется в консоль) и выводится строка, содержащая ошибку (благодаря ||, которая означает, что у select возникли проблемы (код возврата команды не 0)).
Мне повезло, у меня были созданы индексы по полю id:

А это значит, что нахождение строки с нужным id не должен занимать много времени. В теории должно сработать. Что же, запускаем команду в tmux и идём спать.
К утру я обнаружил, что просмотрено около 90 000 записей, что составляет чуть более 5%. Отличный результат, если сравнивать с предыдущим способом (2%)! Но ждать 20 дней не хотелось…
Источник
I’m getting an Error
ERROR: invalid page header in block 411 of relation "t_value_time"
in my PostgreSQL database. This keeps happening on different machines. Is there a way to prevent it from happening, or at least telling PSQL to ignore the data on the invalid block and move on?
I’d rather lose the data from the block and have him skip over it, reading the rest of the data. Is there a way to tell PSQL to skip this block?
![]()
pb2q
57.6k18 gold badges145 silver badges146 bronze badges
asked Mar 7, 2011 at 13:36
![]()
WARNING: You will lose some data!
We managed to get over it (crashed DEV VM) by issuing:
database=# SET zero_damaged_pages = on;
SET
database=# VACUUM FULL damaged_table;
WARNING: invalid page header in block xxx of relation base/yyy/zzz; zeroing out page
[..]
REINDEX TABLE damaged_table;
Fix via pwkg.ork.
answered Feb 18, 2013 at 15:31
![]()
VladVlad
10.5k2 gold badges34 silver badges38 bronze badges
2
Same block every time?
From what I’ve read, the most common cause of invalid blocks is hardware. Red Hat has a utility, pg_filedump, that formats «PostgreSQL heap, index, and control files into a human-readable form». I don’t think they support any PostgreSQL version greater than 8.4.0, but I could be wrong.
You want to prove your hardware is good by using tough, thorough disk, RAM, and NIC diagnostics.
answered Mar 7, 2011 at 14:44
![]()
There’s no simple way to do it, but it’s reasonably easy to do just by editing the data file directly (relfilenode of the pg_class entry gives the filename).
Just copy a block from elsewhere in the file over the bad block. Ideally, synthesise an empty block or update the one you’re overwriting to have no valid tuples in it.
Once you’ve got something that doesn’t produce that error, dump the table and reload it for safety.
answered Mar 7, 2011 at 18:18
![]()
araqnidaraqnid
123k23 gold badges153 silver badges133 bronze badges
these are almost always hardware problems btw. Verify and test RAM, disk, CPU. Make sure your environment is good (bad power input can cause problems as can overheating). That’s the best way to prevent it. Best way to address it is point in time recovery from a base backup.
answered Sep 28, 2012 at 12:53
![]()
Chris TraversChris Travers
25k6 gold badges63 silver badges181 bronze badges
If you have a slave, set hot_standby_feedback to ‘on’ on it if not already.
Do pg_dump and write it to /dev/null so that you don’t consume any space.
nohup pg_dump db_name -v -Fc -f /dev/null &
If the dump succeeds, then your slave is fine. Do a failover. There will be no data loss.
Another way to validate your slave is to do, explain select count(*) from table_name;
If it succeeds and if it is using a sequence scan, then your slave is good.
You may not have to consider this option if it is using index scan.
Note: This works only if your master is affected with storage level corruption.
I happened to face same issue just today and i was able to fix it.
answered Jul 11, 2019 at 12:50
![]()
27 февраля 2019 г. 10:16
Django и Python
2514
На VDS одного из проектов который я поддерживаю и который крутится на моем хостере по умолчанию (firstvds) недавно произошел сбой.
Сбои на VDS сами по себе явления необычные, а тут прям все «колом встало».
В результате разбора ситуации оказалось что сбойнула файловая система.
Файловую систему оживил но уперся в другую проблему. Postgres отказался запускаться и писал что-то типа:
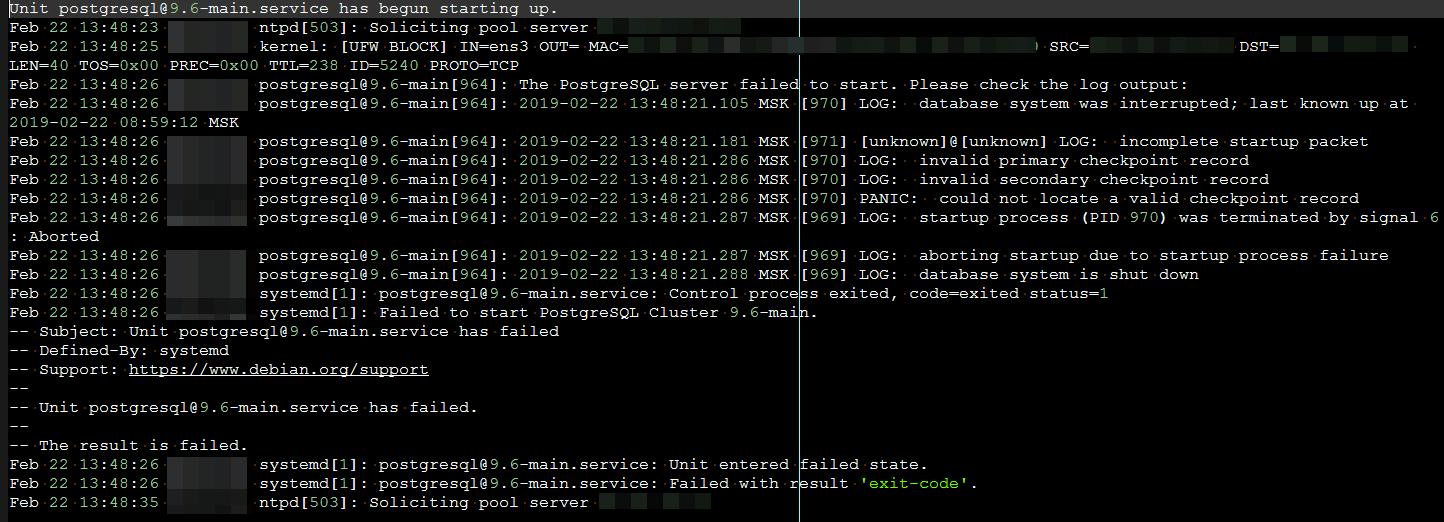
Эту проблему решил довольно быстро командой:
root$ pg_resetxlog DATADIR
И перезапуском postgresql.
Но в результате получил сбои при работе с базой проекта, обусловленные «битыми» индексами в одной из таблиц базы.
Выражалось это при любых попытках манипуляций с базой, ошибками вида:
ERROR: invalid page header in block XXXXX of relation base/XXXXX/XXXXXПри попытке сделать резервную копию базы получил ошибку вида:
pg_dump: SQL command failed pg_dump: Error message from server: ERROR: invalid page header in block XXXXX of relation base/XXXXX/XXXXX pg_dump: The command was: COPY public.samaged_table (column1, column2, column3, ...) TO stdout;Решение данной проблемы нагуглил не сразу и уже готовился к сносу данных и восстановлению из резервных копий.
Но случайно набрел на рекомендации от lxadm.com в следующем виде:
database=# SET zero_damaged_pages = on; SET database=# VACUUM FULL damaged_table; WARNING: invalid page header in block 13748 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13749 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13757 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13758 of relation base/16995/67484; zeroing out page (...) WARNING: index "damaged_table_site_id" contains 14697831 row versions, but table contains 14709258 row versions HINT: Rebuild the index with REINDEX. WARNING: invalid page header in block 13762 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13816 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13817 of relation base/16995/67484; zeroing out page WARNING: invalid page header in block 13818 of relation base/16995/67484; zeroing out page (...) WARNING: index "damaged_table_site_id" contains 14697498 row versions, but table contains 14709258 row versions HINT: Rebuild the index with REINDEX. VACUUM database=# REINDEX TABLE damaged_table;Все сработало и индексы в моём случае восстановились без потерь данных.
25.11.22 — 17:57
УТ 11.4 8.3.15.1534
Изначально крутится на postgreSQL.
Вечером делал обновление (буквально текст общего модуля поменял) и в этот момент сеанс оборвался. Запустил по новой и сразу сказал, что сеанс был прерван, обновить? Ответил да.
Обновился, но появилась ошибка типа
Ошибка СУБД: error: invalid page in block NNNNNNN of relatton base/NNNNN).
Так же крашится при открытии пользователя в конфигураторе.
Прогнал ТиИ — безрезультатно, выгрузил в файл, чекдбфл — так же.
Есть архив за пару дней до инцидента, там нет таких проблем.
Вижу пока вариант переносить новые документы в более старую работающую базу.
Или еще наткнулся на шаманство по типу
https://habr.com/ru/post/477248/
Может есть варианты по-проще?
1 — 25.11.22 — 18:06
win 64
2 — 25.11.22 — 18:09
У вас есть побмтая база данных в postgres.
Что-то пытаться нужно делать с ней,а также понять,что произошло.
Вылетел сеанс — это не причина,а следствие.
3 — 25.11.22 — 18:22
(0) Была аналогичная ситуёвина.
Выгрузил в дт. Развернул на файловой. Заработала. Выгрузил в дт из файловой. Снес базу в постгрес. Создал заново. Загрузил файловый дт-шник. Все заработало.
ПыСы. Вычистил все кэши изначально.
4 — 25.11.22 — 18:27
+ (3) Наперед смотри проблемы с файловой системой и далее на проблемы с железом (жесткие диски)
5 — 25.11.22 — 20:10
(1) говорят таблицу с конфигом можно из бэкапа взять — если только модули менялись
6 — 25.11.22 — 20:25
А диск,случаем,не ssd ?
7 — 25.11.22 — 22:21
(6) М.2 ssd самсунг
то ли 960 или 860
8 — 25.11.22 — 22:23
никогда не понимал, а что движет людьми, которые разворачивают рабочую базу на постриг?…
9 — 25.11.22 — 23:16
(8) Я когда-то так сделал. Клиент не хотел лицензий мелко-мягких. Но косяки возникли практически сразу же, и пришлось ставить тот же MS SQL Express, благо все было в рамках ограничений
10 — 25.11.22 — 23:20
(8) https://habr.com/ru/company/vk/blog/248845/ а тут наоборот, ставят постгри на уровень выше.
11 — 25.11.22 — 23:31
(10) Это прекрасно. Но в отличии от ВК, в 1С наиболее проработали и протестировали (освоили короче) вариант с MS SQL. А простые 1С-ники, в отличии от программистов ВК, могут только попытаться зарегистрировать ошибку в 1С.
ВК делает для себя, 1С — для всех.
Для 1с важно, чтобы было к кому обратиться (кроме себя) в случае возникновения ошибок с СУБД (так было, как минимум, до 2022 — сейчас я не уверен).
В общем, неоднозначно все. Я постгри лет пять уже даже не пытался использовать.
Но, тут появились новые веяния, и уход от буржуйских технологий может быть востребован и окупаться.
12 — 26.11.22 — 00:55
До сих пор не понял каким образом делался архив до манипуляций с базой. При нормальном архиве, как я понимаю, ветки бы не было
13 — 26.11.22 — 12:56
(12) архив в dt
перед самим обновлением, не делался
14 — 26.11.22 — 15:05
(13) Люди делятся на два вида: те, кто не делает бэкапы, и те, кто уже делает. (С) не мое
15 — 26.11.22 — 15:05
ИМХО постгря зло
16 — 26.11.22 — 15:24
(14) т.е. ты даже перед каждым обновлением (пусть даже модуль поменял), делаешь архив?
17 — 26.11.22 — 15:37
18 — 26.11.22 — 15:38
(8) постгрес бесплатный, на лицензиях экономия
19 — 26.11.22 — 17:10
(8) а с этим когда то были проблемы? Такая же работа как с мсом или ораклом
20 — 26.11.22 — 17:11
(19) Надо признать что PostgreSQL под Windows это легкий изврат в т.ч. с 1С
Вот под Linux оно супер
21 — 26.11.22 — 18:38
(19) на виндовых серверах, судя по веткам на мисте, это всегда проблема…
22 — 28.11.22 — 07:14
(16) Именно. При этом надо периодически проверять разворачиваемость бэкапов 
23 — 28.11.22 — 07:18
(14) и тех кто проверяет работоспособность бэкапов ))))
24 — 28.11.22 — 07:38
(0) настроить технологический журнал и глянуть, на запросе к какой таблице падает платформа. Далее в зависимости, что за таблица является проблемной — починить запросом/заменить корректной из бэкапа и т.п.
25 — 05.12.22 — 23:08
(17) полезная ссылочка, спасибо!
при вакууме ругается на такую таблицу _inforg20355_2, но ее в структуре БД не вижу, есть только _inforg20355 (регистр сведений).
Это как?
26 — 05.12.22 — 23:09
(25) Это индексы
John83
27 — 05.12.22 — 23:10
(26) реиндексировать?
|
При выгрузке базы данных стандартными средствами 1С вылетает ошибка: SQL State: XX001 Native: 7 Message: ERROR: invalid page header in block 19641 of relation "sc2256" Файл выгрузки не создается. Содержимое лога Postgre SQL после этой ошибки: LOG: система была отключена: 2008-03-22 19:32:39 MSK LOG: контрольная точка: 8/C8617E00 LOG: redo-запись: 8/C8617E00; undo-запись: 0/0; отключение: TRUE LOG: next transaction ID: 0/579962; next OID: 72130 LOG: next MultiXactId: 1; next MultiXactOffset: 0 LOG: система готова к использованию WARNING: nonstandard use of \ in a string literal на символе 75 ПОДСКАЗКА: Use the escape string syntax for backslashes, e.g., E'\'. WARNING: nonstandard use of \ in a string literal на символе 110 ПОДСКАЗКА: Use the escape string syntax for backslashes, e.g., E'\'. ERROR: статус транзакции 1900544 не доступен ПОДРОБНОСТИ: Could not open file "pg_clog/0001": Нет такого файла или каталога. КОМАНДА: FETCH FIRST IN dyn_cur_2997_028147D8 ERROR: current transaction is aborted, commands ignored until end of transaction block КОМАНДА: CLOSE dyn_cur_2997_028147D8 ERROR: current transaction is aborted, commands ignored until end of transaction block КОМАНДА: DECLARE dyn_cur_2997_028147D8 CURSOR WITH HOLD FOR SELECT * FROM SC2256 WHERE SP2259>=' C2 ECR ' AND SUBSTR (SP2259, 1, 13)=' C2 ECR ' ORDER BY SP2259, ROW_ID ERROR: current transaction is aborted, commands ignored until end of transaction block КОМАНДА: CLOSE dyn_cur_2997_026AB098 ERROR: курсор "dyn_cur_2997_028147d8" не существует КОМАНДА: CLOSE dyn_cur_2997_028147D8 WARNING: nonstandard use of \ in a string literal на символе 75 ПОДСКАЗКА: Use the escape string syntax for backslashes, e.g., E'\'. WARNING: nonstandard use of \ in a string literal на символе 110 ПОДСКАЗКА: Use the escape string syntax for backslashes, e.g., E'\'. ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98;DECLARE dyn_cur_3007_0205DA98 CURSOR WITH HOLD FOR SELECT * FROM _1SJOURN WHERE IDJOURNAL=409 AND DATE_TIME_IDDOC>=E'20080322 0 0 ' AND DATE_TIME_IDDOC<=E'20080322FHML6O 0 ' ORDER BY IDJOURNAL, DATE_TIME_IDDOC;MOVE LAST IN dyn_cur_3007_0205DA98;MOVE BACKWARD 0 IN dyn_cur_3007_0205DA98; ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH RELATIVE 0 IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH FIRST IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98;DECLARE dyn_cur_3007_0205DA98 CURSOR WITH HOLD FOR SELECT * FROM _1SJOURN WHERE IDJOURNAL=409 AND DATE_TIME_IDDOC>=E'20080322 0 0 ' AND DATE_TIME_IDDOC<=E'20080322FHML6O 0 ' ORDER BY IDJOURNAL, DATE_TIME_IDDOC;MOVE FORWARD 1 IN dyn_cur_3007_0205DA98; ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH RELATIVE 0 IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH FIRST IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98;DECLARE dyn_cur_3007_0205DA98 CURSOR WITH HOLD FOR SELECT * FROM _1SJOURN WHERE IDJOURNAL=409 AND DATE_TIME_IDDOC>=E'20080322 0 0 ' AND DATE_TIME_IDDOC<=E'20080322FHML6O 0 ' ORDER BY IDJOURNAL, DATE_TIME_IDDOC;MOVE FORWARD 1 IN dyn_cur_3007_0205DA98; ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH RELATIVE 0 IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH FIRST IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98;DECLARE dyn_cur_3007_0205DA98 CURSOR WITH HOLD FOR SELECT * FROM _1SJOURN WHERE IDJOURNAL=409 AND DATE_TIME_IDDOC>=E'20080322 0 0 ' AND DATE_TIME_IDDOC<=E'20080322FHML6O 0 ' ORDER BY IDJOURNAL, DATE_TIME_IDDOC;MOVE FORWARD 1 IN dyn_cur_3007_0205DA98; ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH RELATIVE 0 IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98;DECLARE dyn_cur_3007_0205DA98 CURSOR WITH HOLD FOR SELECT * FROM _1SJOURN WHERE IDJOURNAL=409 AND DATE_TIME_IDDOC>=E'20080322 0 0 ' AND DATE_TIME_IDDOC<=E'20080322FHML6O 0 ' ORDER BY IDJOURNAL, DATE_TIME_IDDOC;MOVE LAST IN dyn_cur_3007_0205DA98;MOVE BACKWARD -1 IN dyn_cur_3007_0205DA98; ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: FETCH RELATIVE 0 IN dyn_cur_3007_0205DA98 ERROR: курсор "dyn_cur_3007_0205da98" не существует КОМАНДА: CLOSE dyn_cur_3007_0205DA98 ERROR: invalid page header in block 3283 of relation "idd_sc2256" КОМАНДА: DECLARE dyn_cur_3018_020E3B08 CURSOR WITH HOLD FOR SELECT SC13.DESCR, RG99.SP4070, SC33.DESCR, SC33.PARENTID, RG99.SP101, SC31.DESCR, RG99.SP100, RG99.SP2269, 0, 0, RG99.SP2574, 0, 0, RG99.SP164, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, RG99.SP2270, SC3143.PARENTEXT, RG99.SP2847, SC2256.SP2259, 0, ' 0 ', ' ', ' ', RG99.SP2269, RG99.SP2574, RG99.SP164 FROM RG99 LEFT OUTER JOIN SC13 ON RG99.SP4070=SC13.ID LEFT OUTER JOIN SC33 ON RG99.SP101=SC33.ID LEFT OUTER JOIN SC31 ON RG99.SP100=SC31.ID LEFT OUTER JOIN SC2256 ON RG99.SP2270=SC2256.ID LEFT OUTER JOIN SC3143 ON SC2256.SP3184=SC3143.ID WHERE PERIOD='20061201' AND (((RG99.SP4070=' 1 '))) ERROR: курсор "dyn_cur_3018_020e3b08" не существует КОМАНДА: CLOSE dyn_cur_3018_020E3B08 ERROR: invalid page header in block 3283 of relation "idd_sc2256" КОМАНДА: DECLARE dyn_cur_3389_02693210 CURSOR WITH HOLD FOR SELECT SC13.DESCR, RG99.SP4070, SC33.DESCR, SC33.PARENTID, RG99.SP101, SC31.DESCR, RG99.SP100, RG99.SP2269, 0, 0, RG99.SP2574, 0, 0, RG99.SP164, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, RG99.SP2270, SC3143.PARENTEXT, RG99.SP2847, SC2256.SP2259, 0, ' 0 ', ' ', ' ', RG99.SP2269, RG99.SP2574, RG99.SP164 FROM RG99 LEFT OUTER JOIN SC13 ON RG99.SP4070=SC13.ID LEFT OUTER JOIN SC33 ON RG99.SP101=SC33.ID LEFT OUTER JOIN SC31 ON RG99.SP100=SC31.ID LEFT OUTER JOIN SC2256 ON RG99.SP2270=SC2256.ID LEFT OUTER JOIN SC3143 ON SC2256.SP3184=SC3143.ID WHERE PERIOD='20061201' AND (((RG99.SP4070=' 1 '))) ERROR: курсор "dyn_cur_3389_02693210" не существует КОМАНДА: CLOSE dyn_cur_3389_02693210 NOTICE: CREATE TABLE / PRIMARY KEY создаст подразумеваемый индекс "rgtemp0_pkey" для таблицы "rgtemp0" NOTICE: CREATE TABLE / PRIMARY KEY создаст подразумеваемый индекс "rgtemp0_pkey" для таблицы "rgtemp0" NOTICE: CREATE TABLE / PRIMARY KEY создаст подразумеваемый индекс "rgtemp0_pkey" для таблицы "rgtemp0" ERROR: invalid page header in block 19641 of relation "sc2256" КОМАНДА: DECLARE dyn_cur_3857_01C9A9B0 CURSOR WITH HOLD FOR SELECT * FROM SC2256 ORDER BY DESCR, ROW_ID ERROR: invalid page header in block 19641 of relation "sc2256" КОМАНДА: DECLARE dyn_cur_3885_01B765A8 CURSOR WITH HOLD FOR SELECT * FROM SC2256 ORDER BY DESCR, ROW_ID ERROR: invalid page header in block 19641 of relation "sc2256" КОМАНДА: DECLARE dyn_cur_4003_01CA4B28 SCROLL CURSOR WITH HOLD FOR SELECT * FROM SC2256 ORDER BY DESCR, ROW_ID ERROR: invalid page header in block 19641 of relation "sc2256" КОМАНДА: DECLARE dyn_cur_4042_01CA4B28 SCROLL CURSOR WITH HOLD FOR SELECT * FROM SC2256 ORDER BY DESCR, ROW_ID Подобная ошибка возникает и при загрузке базы стандартными средствами 1С, а также при работе с базой: при формировании некоторых отчетов и при проведении некоторых документов (особенно при формировании отчетов за большой промежуток времени: за год или полтора года).
Проблема "решилась" добавлением строки zero_damaged_pages = true в файл postgresql.conf. Не знаю пока, чего мне будет стоить добавление этого параметра, так что не считаю это решением проблемы. Но возможно это наведет на какие-то мысли по решению проблемы. После этого загрузка и выгрузка происходит без ошибок, правда значительно дольше. База объемом в 2.2 GB загружается 5 часов, а выгружается более 9. В MS SQL все эти процедуры выполняются в течение часа.
Какие итоги? Может есть смысл использовать новую сборку и версию СУБД 8,2,4 или 8,2,9?
(In reply to comment #3)
> Какие итоги? Может есть смысл использовать
> новую сборку и версию СУБД 8,2,4 или 8,2,9?
>
В данный момент базы загружаются и выгружаются корректно с версией 8.2.4 .
(In reply to comment #4)
> (In reply to comment #3)
> > Какие итоги? Может есть смысл использовать
> > новую сборку и версию СУБД 8,2,4 или 8,2,9?
> >
>
> В данный момент базы загружаются и
> выгружаются корректно с версией 8.2.4 .
Отлично, багу закрываю. Ждите скоро релиза ;)
|
Media failure is one of the crucial things that the database administrator should be aware of. Media failure is nothing but a physical problem reading or writing to files on the storage medium.
A typical example of media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, wal files, and control files.
This is the comprehensive post which focuses on disk failure in PostgreSQL and the ways you can retrieve the data from PostgreSQL Database after failure(other than restoring the backup).
In this post, we are going to do archaeology on the below error and will understand how to solve the error.
WARNING: page verification failed, calculated checksum 21135 but expected 3252
ERROR: invalid page in block 0 of relation base/13455/16395
During the process, you are going to learn a whole new bunch of stuff in PostgreSQL.
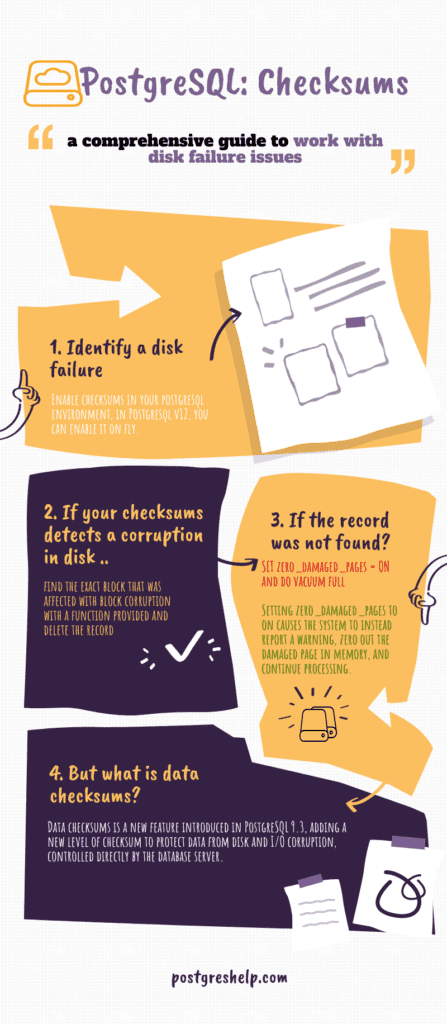
PostgreSQL Checksum: The definitive guide
- Chapter 1: What is a checksum?
- Chapter 2: PostgreSQL checksum: Practical implementation
- Chapter 3: How to resolve the PostgreSQL corrupted page issue?
With v9.3, PostgreSQL introduced a feature known as data checksums and it has undergone many changes since then. Now we have a well-sophisticated view in PostgreSQL v12 to find the checksums called pg_checksums.
But what is a PostgreSQL checksum?
When the checksum is enabled, a small integer checksum is written to each “page” of data that Postgres stores on your hard drive. Upon reading that block, the checksum value is recomputed and compared to the stored one.
This detects data corruption, which (without checksums) could be silently lurking in your database for a long time.
Good, checksum, when enabled, detects data corruption.
How does PostgreSQL checksum work?
PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
Also read: A comprehensive guide – PostgreSQL Caching
From here we understood that the PostgreSQL page has to pass through OS Cache before it leaves or enters into shared buffers. So page validity happens before leaving the shared buffers and before entering the shared buffers.
when PostgreSQL tries to copy the page into its buffer cache then it will (if possible) detect that something is wrong, and it will not allow page to enter into shared buffers with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message
ERROR: invalid page in block 0 of relation base/13455/16395
If you already have a block with invalid data at disk-level and its page version at buffer level, during the next checkpoint, while page out, it will update invalid checksum details but which is rarely possible in real-time environments.
confused, bear with me.
And finally,
If the invalid byte is part of the PostgreSQL database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; Some times you will get an error and sometimes you may end up with wrong data.
How PostgreSQL Checks Page Validity?
In a typical page, if data checksums are enabled, information is stored in a 2-byte field containing flag bits after the page header.
Also Read: A comprehensive guide on PostgreSQL: page header
This is followed by three 2-byte integer fields (pd_lower, pd_upper, and pd_special). These contain byte offsets from the page start to the start of unallocated space, to the end of unallocated space, and to the start of the special space.
The checksum value typically begins with zero and every time reading that block, the checksum value is recomputed and compared to the stored one. This detects data corruption.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that when you do page inspect on a page which is already in the buffer, you may not get the actual checksum. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache.
Also read: A comprehensive guide – PostgreSQL Caching
Let’s work on the practical understanding of whatever we learned so far.
I have a table check_corruption wherein I am going to do all the garbage work.
- my table size is 8 kB.
- has 5 records.
- the version I am using is PostgreSQL v12.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) postgres=# SELECT * FROM page_header(get_raw_page(‘check_corruption’,0)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid ——————+—————+————+————+————+—————+—————+—————+—————— 0/17EFCA0 | 0 | 0 | 44 | 7552 | 8192 | 8192 | 4 | 0 (1 row) postgres=# dt+ check_corruption List of relations Schema | Name | Type | Owner | Size | Description ————+—————————+————+—————+——————+——————— public | check_corruption | table | postgres | 8192 bytes | (1 row) postgres=# select pg_relation_filepath(‘check_corruption’); pg_relation_filepath ——————————— base/13455/16490 (1 row) postgres=# |
First, check whether the checksum is enabled or not?
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 0
[postgres@stagdb ~]$
It is disabled.
Let me enable the page checksum in PostgreSQL v12.
Syntax: pg_checksums -D /u01/pgsql/data –enable –progress –verbose
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —enable —progress —verbose pg_checksums: checksums enabled in file «/u01/pgsql/data/global/2847» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/1260_fsm» pg_checksums: checksums enabled in file «/u01/pgsql/data/global/4175» .. .. 23/23 MB (100%) computed Checksum operation completed Files scanned: 969 Blocks scanned: 3006 pg_checksums: syncing data directory pg_checksums: updating control file Data checksum version: 1 Checksums enabled in cluster |
Again, check the status of checksums in PostgreSQL
[postgres@stagdb ~]$
[postgres@stagdb ~]$ pg_controldata -D /u01/pgsql/data | grep checksum
Data page checksum version: 1
[postgres@stagdb ~]$
we can disable the checksums with –disable option
|
[postgres@stagdb ~]$ [postgres@stagdb ~]$ pg_checksums —D /u01/pgsql/data —disable pg_checksums: syncing data directory pg_checksums: updating control file Checksums disabled in cluster [postgres@stagdb ~]$ |
Let’s first check the current data directory for errors, then play with data.
To check the PostgreSQL page errors, we use the following command.
pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb ~]$ pg_checksums -D /u01/pgsql/data –check
Checksum operation completed
Files scanned: 969
Blocks scanned: 3006
Bad checksums: 0
Data checksum version: 1
[postgres@stagdb ~]$
Warning!! Do not perform the below case study in your production machine.
As the table check_corruption data file is 16490, I am going to corrupt the file with the Operating system’s dd command.
dd bs=8192 count=1 seek=1 of=16490 if=16490
[postgres@stagdb 13455]$ dd bs=8192 count=1 seek=1 of=16490 if=16490
Now, log in and get the result
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
I got the result, but why?
I got the result from shared buffers. Let me restart the cluster and fetch the same.
/usr/local/pgsql/bin/pg_ctl restart -D /u01/pgsql/data
|
postgres=# select * from check_corruption; aid | bid | abalance | filler ———+———+—————+——————————————————————————————————————————— 1 | 1 | 0 | This is checksum example, checksum is for computing block corruption 2 | 1 | 0 | This is checksum example, checksum is for computing block corruption 3 | 1 | 0 | This is checksum example, checksum is for computing block corruption 4 | 1 | 0 | This is checksum example, checksum is for computing block corruption 5 | 1 | 0 | This is checksum example, checksum is for computing block corruption (5 rows) |
But again why?
As we discussed earlier, during restart my PostgreSQL has replaced error checksum with the value of shared buffer.
How can we trigger a checksum warning?
We need to get that row out of shared buffers. The quickest way to do so in this test scenario is to restart the database, then make sure we do not even look at (e.g. SELECT) the table before we make our on-disk modification. Once that is done, the checksum will fail and we will, as expected, receive a checksum error:
i.e., stop the server, corrupt the disk and start it.
- /usr/local/pgsql/bin/pg_ctl stop -D /u01/pgsql/data
- dd bs=8192 count=1 seek=1 of=16490 if=16490
- /usr/local/pgsql/bin/pg_ctl start -D /u01/pgsql/data
During the next fetch, I got below error
postgres=# select * from check_corruption;
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427
WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:06:17.434 IST [25218] ERROR: invalid page in block 1 of relation base/13455/16490
2020-02-06 19:06:17.434 IST [25218] STATEMENT: select * from check_corruption;
ERROR: invalid page in block 1 of relation base/13455/16490
Let us dig deeper into the issue and confirm that the block is corrupted
There are a couple of ways you can find the issue which includes Linux commands like
- dd
- od
- hexdump
Usind dd command : dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -1
[postgres@stagdb 13455]$ dd if=16490 bs=8192 count=1 skip=1 | od -A d -t x1z -w16 | head -2
1+0 records in
1+0 records out
8192 bytes (8.2 kB) copied, 4.5e-05 seconds, 182 MB/s
0000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d >……~…..,…<
here,
00 00 00 00 a0 fc 7e 01 the first 8 bytes indicate pd_lsn and the next two bytes
03 9a indicates checksums.
Using hexdump : hexdump -C 16490 | head -1
[postgres@stagdb 13455]$ hexdump -C 16490 | head -1
00000000 00 00 00 00 a0 fc 7e 01 03 9a 00 00 2c 00 80 1d |……~…..,…|
[postgres@stagdb 13455]$
Both hexdump and dd returned same result.
Let’s understand what our PostgreSQL very own pg_checksums has to say?
command: pg_checksums -D /u01/pgsql/data –check
[postgres@stagdb 13455]$ pg_checksums -D /u01/pgsql/data –check
pg_checksums: error: checksum verification failed in file “/u01/pgsql/data/base/13455/16490”, block 1: calculated checksum 9A04 but block contains 9A03
Checksum operation completed
Files scanned: 968
Blocks scanned: 3013
Bad checksums: 1
Data checksum version: 1
[postgres@stagdb 13455]$
here, according to pg_checksums checksum 9A03 is matching with that of hexdump’s checksum 9A03.
Converting Hex 9A03 to decimals, I got 39427
which is matching the error
2020-02-06 19:06:17.433 IST [25218] WARNING: page verification failed, calculated checksum 39428 but expected 39427

How to resolve the PostgreSQL corrupted page issue?
use the below function to find the exact location where the page is corrupted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
CREATE OR REPLACE FUNCTION find_bad_row(tableName TEXT) RETURNS tid as $find_bad_row$ DECLARE result tid; curs REFCURSOR; row1 RECORD; row2 RECORD; tabName TEXT; count BIGINT := 0; BEGIN SELECT reverse(split_part(reverse($1), ‘.’, 1)) INTO tabName; OPEN curs FOR EXECUTE ‘SELECT ctid FROM ‘ || tableName; count := 1; FETCH curs INTO row1; WHILE row1.ctid IS NOT NULL LOOP result = row1.ctid; count := count + 1; FETCH curs INTO row1; EXECUTE ‘SELECT (each(hstore(‘ || tabName || ‘))).* FROM ‘ || tableName || ‘ WHERE ctid = $1’ INTO row2 USING row1.ctid; IF count % 100000 = 0 THEN RAISE NOTICE ‘rows processed: %’, count; END IF; END LOOP; CLOSE curs; RETURN row1.ctid; EXCEPTION WHEN OTHERS THEN RAISE NOTICE ‘LAST CTID: %’, result; RAISE NOTICE ‘%: %’, SQLSTATE, SQLERRM; RETURN result; END $find_bad_row$ LANGUAGE plpgsql; |
Now, using the function find_bad_row(), you can find the ctid of the corrupted location.
you need hstore extension to use the function
postgres=# CREATE EXTENSION hstore;
CREATE EXTENSION
postgres=#
postgres=# select find_bad_row(‘check_corruption’);
2020-02-06 19:44:24.227 IST [25929] WARNING: page verification failed, calculated checksum 39428 but expected 39427
2020-02-06 19:44:24.227 IST [25929] CONTEXT: PL/pgSQL function find_bad_row(text) line 21 at FETCH
WARNING: page verification failed, calculated checksum 39428 but expected 39427
NOTICE: LAST CTID: (0,5)
NOTICE: XX001: invalid page in block 1 of relation base/13455/16490
find_bad_row
————–
(0,5)
(1 row)
Deleting that particular CTID will resolve the issue
postgres=# delete from check_corruption where ctid='(0,6)’;
DELETE 1
postgres=#
If deleting ctid has not worked for you, you have an alternative solution which is setting zero_damaged_pages parameter.
Example.,
postgres=# select * from master;
WARNING: page verification failed, calculated checksum 8770 but expected 8769
ERROR: invalid page in block 1 of relation base/13455/16770
postgres=#
I can’t access the data from table master as block is corrupted.
Solution:
postgres=# SET zero_damaged_pages = on;
SET
postgres=# vacuum full master;
|
postgres=# select * from master; WARNING: page verification failed, calculated checksum 8770 but expected 8769 WARNING: invalid page in block 1 of relation base/13455/16770; zeroing out page id | name | city ——+—————+—————— 1 | Orson | hyderabad 2 | Colin | chennai 3 | Leonard | newyork |
here, it cleared the damaged page and gave the rest of the result.
What your document has to say?
zero_damaged_pages (boolean): Detection of a damaged page header normally causes PostgreSQL to report an error, aborting the current transaction. Setting zero_damaged_pages to on causes the system to instead report a warning, zero out the damaged page in memory, and continue processing. This behavior will destroy data, namely all the rows on the damaged page. However, it does allow you to get past the error and retrieve rows from any undamaged pages that might be present in the table. It is useful for recovering data if corruption has occurred due to a hardware or software error. You should generally not set this on until you have given up hope of recovering data from the damaged pages of a table. Zeroed-out pages are not forced to disk so it is recommended to recreate the table or the index before turning this parameter off again. The default setting is off, and it can only be changed by a superuser.
There are a couple of things to be aware when using this feature though. First, using checksums has a cost in performance as it introduces extra calculations for each data page (8kB by default), so be aware of the tradeoff between data security and performance when using it.
There are many factors that influence how much slower things are when checksums are enabled, including:
- How likely things are to be read from shared_buffers, which depends on how large shared_buffers is set, and how much of your active database fits inside of it
- How fast your server is in general, and how well it (and your compiler) are able to optimize the checksum calculation
- How many data pages you have (which can be influenced by your data types)
- How often you are writing new pages (via COPY, INSERT, or UPDATE)
- How often you are reading values (via SELECT)
The more that shared buffers are used (and using them efficiently is a good general goal), the less checksumming is done, and the less the impact of checksums on database performance will be. On an average if you enable checksum the performance cost would be more than 2% and for inserts, the average difference was 6%. For selects, that jumps to 19%. Complete computation benchmark test can be found here
Bonus
You can dump the content of the file with pg_filedump before and after the test and can use diff command to analyze data corruption
- pg_filedump -if 16770 > before_corrupt.txt
- corrupt the disk block
- pg_filedump -if 16770 > before_corrupt.txt
- diff or beyond compare both the files.
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out to the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestions/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.