В данной статье разберем, что делать с висячими узлами на сайте. Подписчик спрашивает: «Интересно узнать про висячие узлы. Так ли необходимо закрывать их или не так много веса по ним уходит?».
Что такое висячие узлы?
Если вы обойдете сайт каким-нибудь краулером (программой для сканирования сайта), он построит паутинку из ссылочных связей внутри сайта: страница А ссылается на страниц В, та в свою очередь на страницу С, а последняя жадничает и ни на кого не ссылается. И вот это вещь с нессылающейся ни на кого страницей называется «висячим узлом».
На данный момент висячии узлы встречается не так часто на реальных сайтах — просто потому, что структура стандартного построения сайта поменялась. Например, раньше, в двухтысячных годах, очень часто делали версию для печати. Нельзя было нормально печатать страницу, просто нажав на кнопку. Сейчас это можно сделать с помощью стилей, а тогда то ли нельзя было, то ли так не делали. И поэтому делалась отдельная страница для печати: то есть была какая-нибудь статья, и в уголке принтер был нарисован, на него кликали и попадали на страницу для печати. Так как эта страница была без обвязки — без менюшки, технических элементов, — то ссылок с нее обычно не было, то есть она как раз была висячим узлом. И таких страниц было очень много. И в те времена об этой проблеме можно было говорить.
Сейчас такие страницы обычно означают, что на сайте есть какая-нибудь проблема. Висячий узел — это признак того, что какая-то техническая страница попала на индексацию и никак не закрыта. И как правило это те, которые не должны ранжироваться.
Поэтому, если вы нашли у себя такой висячий узел, то сразу проверяете, нужна ли такая страница в поиске, будет ли она полезна пользователям. И обычно ответ — нет. И если так, то просто закрываете ее от индексации и дело с концом.
Влияют ли они на вес
Когда мы считаем условный классический PageRank, а именно сколько страниц вашего сайта накапливает на себе веса, который может передать дальше. Он ей помогает ранжироваться, и она передает его дальше. И что происходит в этот момент? Когда вы составили перелинковку страниц, то есть они у вас ссылаются друг на друга, то если говорить про классический PageRank, который имеет несколько проходов, происходит такой момент: страница А ссылается на В и передает ему вес с некоторым дисконтом. Грубо говоря: на А был вес ,она передала В 0,85, то есть чуть меньше. Когда страница В ссылается на С, то еще чуть меньше, но плюс свой вес. То есть таким образом с некоторым дисконтом оно начинает разгонять друг друга, и если много раз так происходит, то дисконтирование каждый такой круг передачи будет все меньше и меньше веса передавать. Поэтому, когда рассчитывается PageRank в разных анализаторах, то кто-то делает один проход (один такой круг), кто-то 2-3, но никто не делает 100, потому что смысла это не имеет, каждый раз будет затухание.
Что происходит, когда в этой красивой системе ссылок страниц друг на друга появляются висячие узлы? То есть, когда цикл прерывается, и страница С перестает ссылаться на А? Тогда страница С набирает на себя вес, но никому его не передает, и в этом случае цикличность перестает работать и не добавляет свой вклад в вес других страниц, на которые могла бы ссылаться. Причем, если брать вариант из 3 страниц, то здесь все понятно: все получили свой вес. Но когда сайт большой и много страниц, которые не передали другим свой вес, то в целом общий вес, который сосредоточен на сайте — немножко меньше. Не в 2-3 раза, а на 10%, например.
Формально это немного мешает продвижению: страницы на себя вес забрали, а другим не отдали. То есть, условная страница отдала 1/20 веса, а могла бы 119, если бы «жадины» среди них не было. А учитывая, что висячие узлы обычно ненужные для продвижения страницы, то вообще вес утек на них просто в никуда.
Поэтому сами эти страницы вес не уводят, но немного на них утекает, однако для продвижения это практически никак не заметно. Так что с точки зрения веса это проблем особых не приносит, а вот с точки зрения того, что это как правило мусорные страницы, которые в индексе не нужны — на это стоит обратить внимание. То есть висячие узлы — это не такая большая проблема, как принято об этом говорить.
[hi]
15 Основных Методов Повышающих Уровень Page Rank
Google pagerank alexa rank domain age — это алгоритм анализа ссылок, который используется поисковыми системами для того, чтобы оценить вес Ваших ссылок относительно других. Как Рассчитывается Page Rank? Page Rank рассчитывается через различные алгоритмы разработаны конкретные поисковые системы (Google, Yahoo и т. д.). В общем говоря, Page Rank рассчитывается на основе ссылок, связанных с Вашей страницей, в том числе:
Содержание:
- Pagerank висячий узел как исправить
- Как поднять pagerank сайта?
- Domain age alexa rank google pagerank seitend
[yw]Входящих ссылок Исходящих ссылок Ссылки между страницами на Вашем сайте Ссылка типа No-Follow Ссылки типа Do-Follow[/yw] Так как Google и другие поисковые системы, анализируют эти ссылки, чтобы назначить Вашему сайту Google pagerank alexa rank domain age от 1 до 10. Ниже я представлю 15 Основных Методов, Повышающих уровень Page Rank.
Как поднять pagerank сайта?
1.Высокое Качество Контента на Сайте В целях повышения google pagerank alexa rank domain age Вашей страницы, все тексты должны быть уникальными и хорошего качества. Должны быть так хороши, чтобы люди сами делились ими с другими. 2.Продвижение Сайта Если зависит на повышении google pagerank alexa rank domain age group, Ваш сайт должен иметь качественные ссылочные массы. Самый простой способ узнать как поднять pagerank сайта, чтобы реализовать это предположение, является добавление сайта в различные интернет-каталоги компаний. Отличной идеей является размещение интересных статей на страницах » Presell Pages. Не забудьте о добавлении ссылки на ваш веб-сайт в, или под статьей!
Вот некоторые каталоги в которые стоит добавить ваш сайт:
[yw]DMOZ Каталог компаний Onet.pl Каталог компаний wp.pl Каталог Gazeta.pl 3.Добавление комментария как гость[/yw] Это один из самых популярных методов, используемых для повышения pagerank. Большинство блогов имеют функцию публикации комментариев, к которым можно также добавить ссылку на Ваш блог. Получение таких ссылок очень помогает, особенно, если они связаны тематически с Вашей деятельностью. 4.Обмен Ссылками Один из старейших методов, но дальше работает. Для получения хорошего pagerank вы должны регулярно получать ссылки с других сайтов с высоким показателем PR. Влияет также положительно на количество людей, посещающих Вашу страницу.
Смотрите на эту же тему: Как поднять тиц самостоятельно
5. Активно обновляйте сайт
Google действительно любит и ценит сайты, которые имеют свежий и уникальный контент. Чем больше новостей вы размещаете, тем больше Google будет посещать ваш сайт, что в свою очередь увеличит Ваши шансы получить более высокий PR (pagerank). 6.Социальные Закладки Социальные Закладки, это очень эффективная методика, помогающая увеличить pagerank. Она заключается в обмене вашего сайта с помощью различных социальных сетей. Вы получите посещения благодаря тому, что размещаете бесплатные ссылки, а также улучшите движение на вашем веб-сайте. Вот некоторые из самых популярных социальных сетей для поднятия Google pagerank alexa rank domain age: Facebook Google Plus Stumble Upon 7. Высокое Качество Стороны
Domain age alexa rank google pagerank seiten
Если Ваш сайт загружается долго, Google может снизить его рейтинг. Всегда имейте в виду высокая доступность сайта. Позаботьтесь о чистом и исправном коде. 8.Используйте Низко конкурентные ключевые слова как это делается описано в этой статье Вы наверняка знаете, что люди в процессе поиска в Интернете используют ключевые слова, а не целые предложения. Старайтесь использовать эти слова для вашего сайта. Делай, но в меру! Слишком частое использование выбранных ключевых слов может принести больше вреда, чем пользы. 9.Продвижение Сайта Вы можете подготовить объявление или баннер Вашего сайта и рекламировать себя на других сайтах. Вы получите и хорошие бэк-ссылки, а также дополнительные источники новых посетителей. 10.Создайте Несколько Страниц Если описание каждой услуги будет находиться на отдельной странице сайта, вы увеличите силу внутренних ссылок и улучшит PageRank. 11.Участвуйте в Обсуждениях на Форумах Google любит форумы, так как они часто обновляются. Разместить ссылку на свой сайт в подписи и ведите живую беседу с другими пользователями. 12.Когда Google Обновляет Обновляет Page Rank? Google делает это от трех до пяти раз в год. Происходит это в среднем каждые 3 месяца. Существует много различных способов проверить pagerank стороны. Просто введите в поисковой системе page rank
13.Никогда Не Используйте Незаконных Методов
Применение незаконных тактики может повлечь за собой получение Бана от Google. Вопреки расхожему мнению, Google гораздо умнее, чем вы можете предположить. Никогда не думай, что удастся его обмануть. Рано или поздно каждый ощутит последствия применения незаконных методов. Что бы вы сделали, если бы Ваш сайт в один прекрасный день вылетела из Google? Ищете компанию которая отвечает за создание pagerank висячий узел как исправить, а также их продвижение? Оставьте свой комментарий в поле ниже. ]]>
Разбираем на примере трех проектов на Тильде
Внутренняя оптимизация помогает сайту с хорошим контентом занимать высокие позиции в поисковой выдаче. Но когда проект развивается и обрастает новыми страницами, можно допустить ошибки, которые негативно повлияют на рост позиций сайта. Как вовремя найти и исправить эти ошибки, расскажем в статье.
Зачем проверять настройки сайта для SEO
Чем выше позиции сайта в поисковой выдаче, тем людям проще его найти и тем больше посетителей может на него перейти. На позиции влияют разные факторы: контент, история сайта, количество упоминаний в других источниках и техническая оптимизация. Последняя играет большую роль в общем успехе продвижения в поисковых системах.
Технические настройки включают в себя настройку названий и описаний страниц (метатегов), заголовков, атрибутов у изображений, переадресаций, создание страницы для 404 ошибки и многое другое.
В Тильде все настройки можно сделать в интерфейсе. В справочном центре мы подготовили чек-лист по оптимизации сайта, который поможет проделать основную работу, связанную с SEO.
Когда вы только запускаете сайт, вы можете несколько раз проверить, чтобы все настройки были сделаны идеально. Когда проект развивается, постоянно создаются новые страницы, редактируются и удаляются старые, можно допустить ошибки, которые повлияют на продвижение. Чтобы этого не произошло, нужно периодически проводить проверку.
Руководитель турагентства открыл новое направление — фитнес-туры в Испанию. За полгода контент-менеджер Иван написал 10 статей для блога, которые нравятся читателям. Но он поставил у всех страниц со статьями одинаковые названия (метатег Title) и описания (метатег Description), а также не добавил заголовкам статьи теги H1 и H2. Статьи плохо ранжировались и не попали на первые страницы поисковой выдачи.
Иван посоветовался с SEO-специалистом и сделал все настройки. Несколько материалов поднялось на первую страницу поисковой выдачи по важным запросам: «как выбрать фитнес-тур», «фитнес-туры на море». За месяц их прочитала 1000 новых посетителей, а 10 из них заказали тур.
Краткий словарь SEO терминов
Чтобы было проще разобраться, что это за настройки и зачем они нужны, мы подготовили краткий словарь SEO терминов
Метатеги Title и Description — заголовок и описание страницы, которые отображаются в поисковой выдаче. На самой странице они не видны, но название отображается на вкладке браузера. Помимо этого, указанные вами Title и Description часто используются поисковыми системами для показа в результатах поиска.
Индексация — передача страниц и другого содержимого сайта (изображений, видео, ссылок и т. д.) роботом-пауком в индекс поисковой системы. Индекс представляет собой своеобразный список страниц, к которым поисковая система обращается во время поиска страниц, соответствующих запросам пользователей.
Код ответа сервера — трехзначное число, которым обозначается определённый статус запрашиваемой страницы. Даёт понять браузеру и поисковому роботу, как сайт отреагировал на запрос к определённой странице.
H1-H6 — шесть тегов, которые используются при создании HTML-страниц для структурирования и деления информации на блоки. Заголовок, обозначенный тегом H1, имеет наибольшую значимость для поисковых систем.
Альтернативный текст для изображений (тег ALT) — показывается на месте изображения, если само изображение не видно (например, в момент загрузки при медленном соединении). Кроме этого, поисковые системы воспринимают альтернативный текст как ключевые слова и учитывают их при индексации.
Глубина страницы — количество кликов, отделяющих страницу от главной.
Rel=canonical — атрибут, указывающий каноническую, приоритетную для индексации страницу. С его помощью все характеристики (ссылочный вес, поведенческий фактор и т. д.) передаются нужной версии документа, а копии отмечаются поисковым роботом как малозначительные и не попадают в индекс.
Внутренний PageRank — относительный показатель распределения ссылочного веса веса между страницами в пределах одного сайта. Вес передаётся при помощи ссылок с одной страницы на другую, а также атрибута rel=canonical и редиректов.
Какими бывают ошибки оптимизации и как их найти
В SEO существуют ошибки разной степени критичности, включая как очень важные, так и незначительные. Например, критическая ошибка — это дубли страниц. Если вы не указали в настройках при помощи атрибута Canonical, какая страница основная, а какую не нужно индексировать, поисковые системы могут понизить позиции обеих страниц.
![]()
Критические
- Важная страница закрыта от индексации
- Дубли страниц
- Бесконечный редирект
- Максимальная длина URL
- Нет адаптивной версии
- Наличие битых ссылок или битых изображений на сайте
- У страницы нет названия и/или описания (метатеги Tiltle и Description)
- Ссылка на логотипе в верхней части страницы ведет на другой сайт
- Купленный домен находится в черном списке

Важные
- Цепочка переадресаций (редиректов)
- На странице отсутствует тег заголовка H1 Нет страницы 404 ошибки
- Большой размер изображений
- Системный URL вместо понятных слов
- Не прописан альтернативный текст у изображений
- Низкая скорость ответа сервера и загрузки страницы

Незначительные
- Короткий Title и/или Description
- Слишком длинный заголовок H1
- На сайте не настроено безопасное соединение по про протоколу HTTPS
Лучше устранять все виды ошибок, но к критическим нужно относиться особенно внимательно. Допустив их, вы можете упустить шанс оказаться в зоне видимости пользователя или серьёзно понизить уже имеющиеся позиции в выдаче. Вернуть всё назад будет сложно.
Чеклист для проверки сайта на ошибки
Поиск дубликатов страниц. Проверка настроек переадресации, канонического атрибута страницы
На сайте не должно присутствовать страниц с одинаковым контентом. Если нужно оставить страницы с частично или полностью повторяющимся контентом, у второстепенных страниц должен присутствовать атрибут rel=canonical.
Проверка доступности страниц для индексации. Проверка кодов ответа сервера
Страницы с важным контентом должны быть открыты для индексации и отдавать код ответа сервера 200 OK.
Проверка времени загрузки страниц сайта и скорости ответа сервера
Скорость ответа сервера должна быть меньше 500 мс.
Проверка метатегов Title и Description, тега заголовка H1
У каждой страницы должен быть уникальный Title и Description. Длина Title должна быть от 10 до 70 символов, Description — от 60 до 260 символов в среднем.
На каждой странице должен быть назначен тег H1 главному заголовку. Не рекомендуется делать его длиннее 65 символов.
Проверка структуры URL-адресов и глубины страниц
URL должны состоять из понятных слов. Глубина страниц — количества кликов, отделяющих страницу от главной. Рекомендуется, чтобы она не превышала 4.
Проверка оптимизации изображений
Оптимальный размер изображений — 100 кб. У изображений должен присутствовать альтернативный текст. Он должен соответствовать содержимому изображения и содержать от 70 до 250 символов.
Анализ внутреннего PageRank
PageRank — внутренний показатель распределения ссылочного веса между страницами в пределах одного сайта. На сайте не должно быть недостижимых страниц и страниц без исходящих ссылок.
Внутри Тильды есть встроенный инструмент для быстрой проверки следующих критических ошибок: наличие Title, Description, тега H1, читаемого URL, неопубликованных или закрытых от индексации страниц.
Чтобы запустить проверку, откройте Настройки сайта > SEO > SEO-рекомендации.

Проверка сайта на наличие технических ошибок
Чтобы наглядно показать, как искать ошибки, мы попросили Александру Метизу провести проверку трех разных проектов, сделанных на Тильде:
Сервис для клиентской поддержки Юздеск

Александра Метиза
Для проверки использовали Netpeak Spider — инструмент для комплексного внутреннего SEO-аудита сайта. Фактически программа «обходит» выбранные для сканирования страницы или весь сайт целиком, переходя по внутренним ссылкам.
В процессе Spider анализирует свойства страницы, проверяя метаданные, атрибуты, редиректы, инструкции для поисковых роботов, а также множество других данных, важных для поисковой оптимизации.
Выбор анализируемых параметров зависит от целей сканирования: можно выбрать их вручную, или воспользоваться одним из шаблонов.
1. Мастер-классы грузинской кухни Another Georgia
Сайт: another-georgia.com
Тип компании: малый бизнес
География: Москва
Краткое описание: практические мастер-классы по грузинской кухне

Контент и основные метаданные
Всего в сайте 16 страниц, ни одна из которых не дублируется. Важные проблемы были обнаружены всего на двух страницах: на них отсутствуют заголовки первого порядка H1, а длина Description — меньше рекомендованной.

Как исправить
Добавить тег H1 к заголовкам на страницах.
Инструкция →
Составить более развёрнутый Description (Описание) и указать его в настройках страницы.
Инструкция →
Настройки переадресации и атрибут Canonical
На сайте используются серверные редиректы, которые перенаправляют на зеркала без слеша в конце. Но отсутствует переадресация на единую версию с префиксом www. или без него. Есть вероятность, что это повлечёт за собой появление дублей, которые крайне негативно воспринимаются поисковыми системами. Поисковые роботы воспринимают атрибут rel=»canonical» не как строгую директиву, а как рекомендацию, то есть указанный URL может быть проигнорирован.
Нет переадресации и на HTTP-версию сайта при попытке ввести адрес сайта с https://, хотя имеется ведущий на неё атрибут Canonical.

Как исправить
В настройках сайта настроить переадресацию: Настройки > SEO > Редиректы страниц.
Инструкция →
Проверка кодов ответа сервера. Открытость к индексации
Ни одна из стратегически важных страниц не была закрыта от поисковых роботов: все отдают код ответа 200 OK, а значит, могут быть проиндексированы поисковыми роботами. Исключение составляют несколько служебных страниц.

Время загрузки страниц сайта и скорость ответа сервера
Время ответа сервера в пределах сайта варьируется от 93 до 234 мс, скорость загрузки контента — от 1 до 108 мс. Показатели близки к идеалу.

Структура URL и глубина страниц
Все URL составлены грамотно: их вид отвечает структуре сайта и смыслу каждой отдельно взятой страницы. Нет проблем ни с кодировкой, ни с излишней глубиной: до любой страницы сайта можно добраться в 2 клика.
Распределение внутреннего PageRank
Внутренний PageRank распределяется между страницами равномерно. Перелинковка сделана грамотно, тупиковых страниц нет. Нет таких проблем, как «Висячий узел», «Отсутствуют связи», «Отсутствуют исходящие ссылки».
Висячий узел. Так определяются страницы, на которые ведут ссылки, но на них самих отсутствуют исходящие ссылки, из-за чего нарушается естественное распределение ссылочного веса по сайту.
Отсутствуют связи. Это страницы, на которые не было найдено ни одной входящей ссылки.
Отсутствуют исходящие ссылки. Показывает URL, у которых не были найдены исходящие ссылки.
На сайте не было обнаружено проблем с оптимизацией изображений. Но у 15 из них не прописан атрибут ALT, который мог бы поспособствовать продвижению сайта в поиске по картинках.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
2. Интернет-магазин пряностей Kitchen Ceremony

Контент и основные метаданные
Первая проблема, которая бросается в глаза по итогу сканирования сайта, — несколько битых ссылок, отдающих 404 код ответа.
Кликнув по одной из обнаруженных ссылок, мы неизменно попадаем на страницу «Пряности», однако битый URL не меняется на http://www.kitchenceremony.com/spices/.
В действительности абсолютно нормальная страница имеет код ответа сервера 404 Not Found, что подтверждает даже консоль разработчика в Chrome. Возможно, всё дело в том, что владельцы сайта не создали выделенную страницу для 404 ошибки и назначили на её роль страницу «Пряности».

Как исправить
Создать отдельную страницу 404 ошибки и указать её в настройках сайта: Настройки > Еще > Страница 404.
Инструкция →
Следующая проблема — обилие дубликатов. Netpeak Spider обнаружил несколько одинаковых Title, Description и заголовков первого порядка, использованных для страниц с несколькими разными рецептами и товарами.
Также, просматривая ссылки с дублями, мы обнаружили, что страницы /decor/05 и /decor/06 фактически дублируют друг друга: программа не определила их как полные дубли только потому, что в тексте есть несущественное различие, которое можно обнаружить лишь целенаправленно.
Как исправить
Создать для всех страниц уникальный Title и Description.
Инструкция →
Удалить дубликаты страниц.
Также на некоторых страницах были обнаружены слишком короткие или слишком длинные H1, Description и Title. Эти проблемы имеют низкий уровень критичности, но лучше не оставлять их без внимания.
Как исправить
Привести H1, Title и Description к нужной длине:
- Title — от 10 до 70 символов,
- Description — от 60 до 260 символов в среднем,
- H1 — не более 65 символов.
Настройки переадресации и атрибут Canonical
Не настроены серверные редиректы на одну основную версию сайта, так что внутри сайта смешиваются страницы с префиксом www. и без него.
Страница «Пряности» отдаёт разный код ответа в зависимости от наличия слеша и префикса в адресе. На этом, кстати, проблемы страницы не завершаются: её каноническая версия (http://www.kitchenceremony.com/spices/) закрыта при помощи запрещающей директивы Disallow в robots.txt. Это происходит из-за того, что страница «Пряности» установлена в качестве страницы 404 ошибки.
Как исправить
Настроить редирект с версии сайта без www. на версию с www., или наоборот.
Инструкция →
Создать отдельную страницу 404 ошибки и указать её в настройках сайта: Настройки > Еще > Страница 404.
Инструкция →
Проверка кодов ответа сервера. Открытость к индексации
Согласно результатам сканирования, 77,3% процента обнаруженных на сайте страниц могут быть проиндексированы. Это те страницы, которые открыты для индексации, отдают код ответа 200 OK и не перенаправляют поисковых роботов на канонические URL-адреса. Большинство стратегически важных страниц попадают в их число, но всё же результат мог бы быть значительно лучше.

Скорость ответа сервера и загрузки контента
Минимальное время ответа сервера составляет 49 мс, максимальное — 578 мс, что незначительно превышает допустимую норму. Время загрузки контента также колеблется в рекомендуемых пределах — от 0 до 540 мс.
Структура URL и глубина страниц
Как и в случае с Another Georgia, URL на сайте формируются согласно иерархии страниц. В большинстве случаев адреса страниц включают в себя краткие версии русскоязычных заголовков, прописанных латиницей. Почти на всех из них можно попасть в 2 клика. Но есть и исключения, которые портят идеальную картину.
Как исправить
Проставить ссылки на страницы с глубоким уровнем вложенности таким образом, чтобы «сократить» к ним путь от главной.
Распределение внутреннего PageRank
На сайте есть некоторые проблемы с распределением внутреннего PageRank:
Внутри сайта есть недостижимые страницы
Это касается товарных страниц с описаниями кориандра, хмели-сунели и жёлтого цветка. Клик по миниатюрам этих товаров из каталога специй не перенаправляет пользователя на страницу — он просто добавляет артикул в корзину.
Как исправить
Добавить ссылки на недостижимые страницы. Например, можно добавить ссылки на описание специй в статьи с рецептами.
Страницы, отдающие 404 код ответа, создают так называемые «висячие узлы»
«Висячие узлы», на которых не только теряется ссылочный вес, но и «тормозятся» поисковые роботы. И наличие подобных страниц может негативно сказаться на пользовательском опыте.
Как исправить
Добавить на тупиковые страницы исходящие ссылки, например, на главную или на другие связанные страницы.
Размер имеющихся на сайте изображений не превышает рекомендуемой нормы. Но в то же время у большинства картинок отсутствует атрибут ALT, необходимый для ранжирования в поиске.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
Сайт: usedesk.ru
Тип компании: онлайн-сервис
География: международный рынок
Краткое описание: сервис для общения с клиентами во всех цифровых каналах (чат на сайте, электронная почта, мессенджеры, соцсети).

Контент и основные метаданные
На сайте есть несколько битых ссылок. Некоторые размещены на важных лидогенерирующих страницах. Нужно заменить их корректными рабочими ссылками без потери смысловой связи.
Как исправить
Заменить битые ссылки на соответствующие рабочие.
На сайте существует сразу несколько вариантов ссылок с разными GET-параметрами на страницы авторизации и регистрации, которые открыты для индексации. Они могут определяться поисковыми роботами как дубли из-за того, что страницах не настроен атрибут Canonical. К тому же, на этих же страницах отсутствуют метатеги Description.
Как исправить
Настроить атрибут Canonical, указав в качестве канонических страницы авторизации и регистрации без GET-параметров и дополнительных атрибутов в адресе.
Инструкция →
Прописать Description.
Инструкция →
Примерно у десятка страниц Description короче, чем рекомендуется.
Редиректы и атрибут Canonical
На сайте исправно работают редиректы на основное зеркало сайта (с HTTPS, без слеша и префикса www.).
Директивы по индексации. Индексируемость страниц
В robots. txt от индексации закрыто всего несколько страниц, хотя по большому счёту, нет особенного смысла скрывать их от поисковых роботов.
Все ссылки на страницах, связанных с клиентами компании, и ещё нескольких лендингах закрыты при помощи rel=nofollow, хотя в данный момент в этом нет необходимости. Атрибут nofollow больше не помогает «сохранить» ссылочный вес от передачи другим сайтам.
Скорость ответа сервера и загрузки контента
Время ответа сервера для абсолютного большинства страниц варьируется в рекомендуемых пределах от 47 до 496 мс. Всего 2 страницы составили исключение и превысили планку в 600 мс.
Структура URL и глубина страниц
URL в большинстве случаев отвечают принципу ЧПУ (человеко-понятные URL), а их строение соответствует общей структуре сайта. Средняя глубина страниц составляет от 1 до 4, что не превышает допустимой нормы.
Распределение внутреннего PageRank
Использование вышеупомянутого атрибута rel=nofollow на нескольких десятках страниц привело к неравномерному распределению внутреннего PageRank. Как следствие, 8 страниц сайта были определены краулером как «Висячие узлы», то есть, как страницы без открытых исходящих ссылок.
Как исправить
Убрать атрибут rel=nofollow и добавить на тупиковые страницы исходящие ссылки, например, на главную или на другие связанные страницы.
Все изображения на сайте имеют размер не более 100 кбайт, но при этом ни у одного из них нет сопутствующего атрибута ALT.
Как исправить
Добавить альтернативный текст к изображениям.
Инструкция →
Мы провели базовый аудит трёх работающих сайтов. У двух из них выявили критические ошибки, которые влияют на потенциальную индексацию и ранжирование в поисковой выдаче. Но исправить их можно довольно быстро.
Чтобы избежать проблем с ранжированием сайта, для каждой новой страницы не забывайте делать необходимые настройки по чек-листу и проверяйте весь сайт на критические ошибки не реже раза в месяц.
Текст: Александра Метиза, Роман Яковенко
Верстка, дизайн и иллюстрации: Юля Засс
Если материал вам понравился, поставьте лайк — это помогает другим узнать о нем и других статьях Tilda Education и поддерживает наш проект. Спасибо!
*Компания Meta Platforms Inc., владеющая социальными сетями Facebook и Instagram, по решению суда от 21.03.2022 признана экстремистской организацией, ее деятельность на территории России запрещена.
Показываем, как с помощью рассчитанной на основе алгоритма PageRank перелинковки и рассчитанных на основе алгоритма BM25 текстов повысить позиции сайта по ключевым словам и привлечь больше трафика.
Техника 1. Перелинковка сайта на основе PageRank
Перед перелинковкой мы внимательно изучили статью Александра Садовского «Растолкованный PageRank» и решили применить знания на сайте клиента.
Внутренняя перелинковка — это метод внутренней оптимизации сайта, выполняемый для перераспределения ссылочного веса сайта на продвигаемые страницы. Статический вес сайта всегда равен 100%. Когда одна страница ссылается на другую, она передает некоторую часть своего веса, так называемый ссылочный сок. Таким образом, чем больше ссылочного сока передается страницам, тем более важными они считаются и для посетителей, и для поисковых систем.
Проще говоря, перелинковка выполняет две задачи.
- Внутренние ссылки передают вес с одной страницы на другую.
- Направляют посетителей на важные и ценные страницы.
Алгоритм перелинковки сайта
Рассмотрим алгоритм перелинковки на примере сайта производителя плитки ПВХ для промышленных и спортивных помещений.
1. Выбираем страницы, которые хотим видеть в топе поисковых систем.
В нашем случае это:
- главная;
- полы ПВХ для цеха, склада, производства;
- плитка ПВХ для тренажерного зала;
- полы для гаража, автосервиса и паркинга;
- полы для бассейна, душевой, ванной комнаты;
- плитка ПВХ для офиса;
- полы для кафе и ресторанов;
- полы для ледовых дворцов;
- полы для магазинов и супермаркетов;
- плитка ПВХ для автосервиса;
- полы для технических этажей.
2. Далее узнаём по каждой странице, какие ссылки ведут на страницу и со страницы.
Для этого можно использовать различные сервисы, например: сервис saitreport.ru или программы Xenu1 и PageWeight. Не забываем, что нам нужны только открытые для индексации ссылки, никаких тегов nofollow и noindex там быть не должно. Закрытые ссылки не участвуют в передаче внутреннего веса и нужны исключительно для удобства пользователя, помогая найти нужный раздел, склонить к прочтению дополнительной информации и уменьшить количество отказов.
3. Теперь рассчитываем текущее распределение веса по всему сайту.
Берём отчёт по внутренним ссылкам, которые мы получили в Xenu1 или PageWeight, и вносим данные в таблицу. Мы использовали отчёт по ссылкам в Saitereport.
Так выглядит отчёт по внутренним ссылкам в Excel с Saitereport.
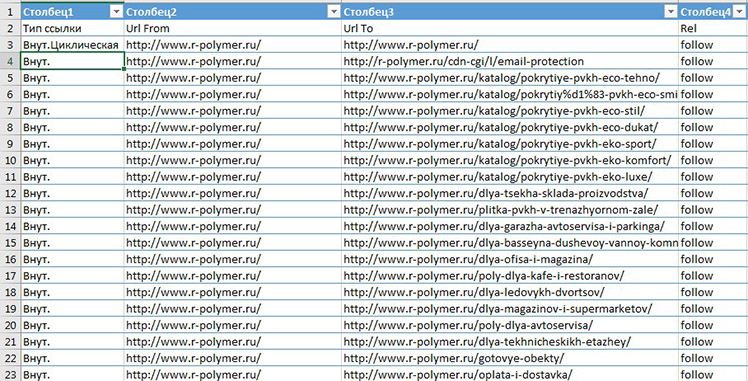
Отчёт по внутренним ссылкам
Для этого используем Excel. Открываем калькулятор, по горизонтали и вертикали вносим все страницы, которые есть на сайте. Для удобства это можно сделать по определённой иерархии. Таких страниц 45 с каждой стороны.

Текущее распределение ссылочного веса по сайту
Заполнили таблицу и получили PageRank для каждой страницы. Квадратики с заливкой показывают, что на определённую страницу ссылаются отдельные страницы. На скриншоте видно, что вес всех страниц практически одинаковый, все страницы ссылаются друг на друга в приблизительно одинаковом количестве, а некоторые не продвигаемые страницы имеют непомерно высокий вес.
Наша задача — сделать такую перелинковку на сайте, чтобы вес был самым высоким на продвигаемых страницах.
Выполнять нужную перелинковку нам поможет та же таблица в Excel.
Запомним, каких ссылок быть не должно:
- Висячих узлов: страниц без исходящих ссылок.
- Зацикливающих страниц: ссылающихся на самих себя.
- Дублирующих ссылок.
- Ссылок на не продвигаемые и страницы с ответом 404.
- Несвязных узлов: страницы без входящих ссылок.
После нескольких итераций у нас получилось такое распределение веса: главная и продвигаемые страницы получили в среднем 7,6% ссылочного веса, в сумме — почти 84% всего PageRank сайта. Остальные страницы сайта получили около 0,5%. То есть модель перелинковки, согласно теории PageRank, сделана правильно. Вес сосредоточен на продвигаемых страницах!

Готовая модель перелинковки
Техника 2. Подготовка текстов на основе алгоритма семантического анализа
Следующий этап — это проведение оптимизации текстов по вхождению ключевых слов.
Для этого мы выполнили семантический анализ всех текстов: определили соответствие поискового запроса документу как на продвигаемых, так и на служебных страницах. Мы применили метод оценки релевантности TF-IDF.
Метод заключается в следующем: чем больше частота запроса в документе, тем значимей будет данный текст по отношению к запросу. То есть вероятность показа этого текста по запросу возрастает. Например:
| Предложения в тексте | Всего слов | Плитка | ПВХ | Покрытие | ||
|---|---|---|---|---|---|---|
| Текстура плитки ПВХ ЭКО-ТЕХНО имеет выступающие прямоугольники | 7 | 1 | 1 | |||
| Плитка обеспечивает сцепление для транспортных средств и для пешеходов | 9 | 1 | ||||
| ПВХ-покрытия не взаимодействуют с кислотами, щёлочами, маслами, бензином и другой активной «химией» | 11 | 1 | 1 | |||
| Плитка ПВХ легко режется | 4 | 1 | 1 | |||
| Итого | 31 | 3 | 3 | 1 |
Например, из этой таблицы мы понимаем, что запрос «покрытие» используется 1 раз, в то время как «плитка» и «ПВХ» используется по 3 раза. Мы можем заменить вхождение слова «плитка» на слово «покрытие». В таком случае не будет заспамленности, и эту страницу можно будет продвигать по двум запросам — «плитка ПВХ» и «покрытие ПВХ».
В текстах мы выявили чрезмерную заспамленность по ключевым словам. Чтобы уменьшить вхождение фраз, а также расширить его, мы воспользовались подбором ключевых слов Yandex.Wordstat, выделили нужные ключевые запросы и внедрили их в тексты, а чрезмерное количество одинаковых ключевиков — уменьшили. Затем написали подробное техническое задание копирайтеру. Полное ТЗ находится в GoogleDocs. Не все ключевые слова были использованы копирайтером в тексте, так как текст был бы слишком ими перенасыщен. А тексты в первую очередь должны быть написаны для людей.
Результат
В среднем трафик с поисковых систем увеличился на 16% в июне по сравнению с апрелем. Сравнивали с апрелем, потому что в апреле такое же количество дней, как в июне, и столько же праздников. К тому же, в мае и происходили все действия, которые могли повлиять на точность данных. В итоге грамотная внутренняя перелинковка и написанные для людей уникальные тексты, ранжирование которых можно улучшить при помощи TF-IDF, дают прирост органического трафика.
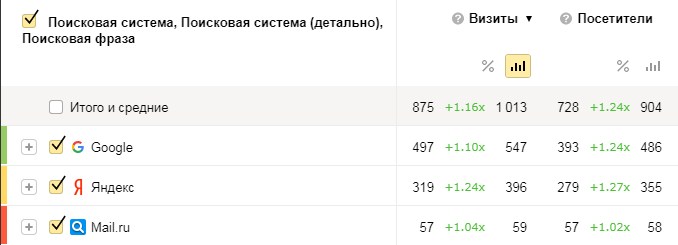
Сравнение поискового трафика
Также выросли позиции по основным ключевым словам. Многие запросы стали видны в топ-100.
- Зелёный цвет — позиции выросли.
- Красный — снизились.
- Без заливки — остались неизменными.
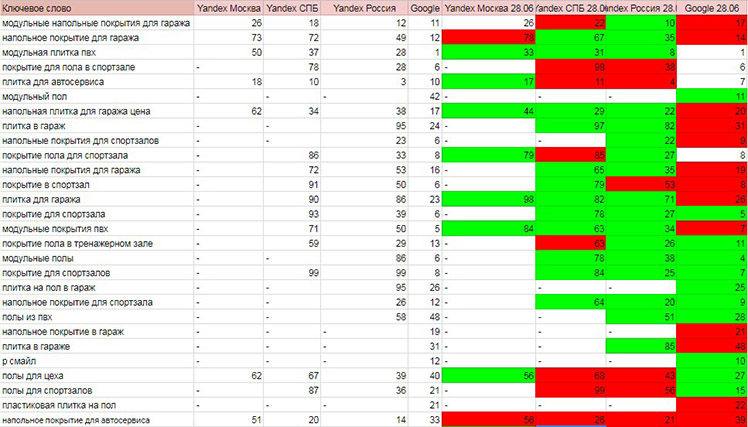
Позиции в поисковой системе
Вывод
Даже если у вас на сайте выполнена базовая внутренняя оптимизация сайта: прописаны title и description, написаны уникальные тексты, грамотная перелинковка сайта всё равно может быть полезна. Она принесёт увеличение органического трафика уже при первой полной переиндексации сайта. Главное помнить, что перелинковка должна быть удобной и пользователям и не создаваться исключительно для перераспределения веса.
Что касается текстов — пишите их в первую очередь для людей и только потом, применяя метод TF-IDF, отрабатывайте их для поисковых систем. Такой подход точно даст результат, так как тексты будут читабельными и поисковый робот будет их правильно трактовать.
Читайте также: 11 советов SEO-шнику, которому попался сложный клиент
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
С того момента, когда PageRank был впервые представлен в 1998 году, было потрачено немало усилий, чтобы улучшить его качество и скорость вычисления. В этой обзорной и достаточно популярной статье я опишу основные направления исследований вокруг PageRank и варианты алгоритма.
Я разрабатываю систему оценки важности web-страниц на основе входящих и исходящих ссылок в компании Нигма, поэтому смотрю на PageRank с математической стороны, со стороны разработчика а не seo.
Я не буду пересказывать здесь многократно описанные основы PageRank. Предполагается, что читатель знает, что это вообще такое. Если же нет, то для начала могу порекомендовать статью Растолкованный PageRank.
На следующей картинке схематически представлены основные направления исследований, окруживших PageRank. Каждому овалу на схеме будет соответствовать отдельная глава статьи.

PageRank с математической стороны
PageRank основан на математической модели случайного блуждания «пользователя» в сети интернет. В некоторый момент он находится на одной странице, затем случайным образом выбирает одну из ссылок и переходит по ней на другую. «Пользователь» произвольно выбирает ссылки, не отдавая предпочтение каким-либо из них.
PageRank страницы – это вероятность того, что блуждающий «пользователь» находится на данной странице.
Сделаем небольшой набросок того, как рассчитать эту вероятность.
Пронумеруем web-страницы целыми числами от 1 до N.
Сформируем матрицу переходов P, содержащую вероятность перехода «пользователя» с одной страницы на другую. Пусть deg(i) – количество исходящих ссылок на странице i. В таком случае, вероятность перехода со страницы i на страницу j равна:
P[i, j] = 1 / deg(i), если i ссылается на j
P[i, j] = 0, если i не ссылается на j
Пусть p(k) – это вектор, содержащий для каждой страницы вероятность того, что в момент k на ней находится «пользователь». Этот вектор – распределение вероятностей местоположения «пользователя».
Предположим, что «пользователь» может начать своё бесцельное блуждание с любой страницы. То есть, начальное распределение вероятностей равномерно.
Зная распределение вероятностей в момент k, мы можем узнать распределение вероятностей в момент k+1 по следующей формуле:

В основе этой формулы не более чем правила сложения и умножения вероятностей.
Математически мы пришли к цепи Маркова с матрицей переходов P, где каждая web-страница представляет собой одно из состояний цепи.
Но нам нужно знать вероятность нахождения «пользователя» на странице независимо от того, сколько шагов k он сделал от точки начала блуждания.
Мы берём начальное распределение вероятностей p(0). Считаем по представленной выше формуле распределение p(1). Затем по той же формуле считаем p(2), затем p(3) и т.д. до тех пор, пока некие p(k-1) и p(k) не будут отличаться лишь незначительно (полное равенство будет достигнуто при k стремящемся к бесконечности).
Таким образом, последовательность p(1), p(2), p(3) … сойдётся к некому вектору p = p(k). Интересно, что вектор p на самом деле не зависит от начального распределения (т.е. от того, с какой страницы начал своё блуждание воображаемый «пользователь»).
Вектор p таков, что в любой момент (начиная с некоторого момента k), вероятность того, что «пользователь» находится на странице i, равна p[i]. Это и есть искомый PageRank.
Этот алгоритм называется методом степеней (power method). Он сойдётся только в том случае, если выполняются два условия: граф страниц должен быть сильно связным и апериодическим. Как достигается выполнение первого условия, будет рассмотрено далее. Второе же без дополнительных усилий справедливо для структуры web.
Примечание
При выполнении условий сильной связности и апериодичности, согласно эргодической теореме, цепь Маркова с матрицей перехода P имеет единственное стационарное распределение p:

PageRank и является стационарным распределением цепи Маркова.
Также это выражение представляет собой собственную систему, а вектор p — собственный вектор матрицы A. Поэтому и применяется метод степеней — численный метод для поиска собственных векторов.
Висячие узлы (dangling nodes)
Висячие узлы – это страницы, которые не имеют исходящих ссылок. Страница может не иметь исходящих ссылок просто потому, что у неё их нет, либо потому, что она не была прокраулена (crawled) – т.е. страница попала в базу, т.к. на неё ссылаются другие прокрауленные страницы, но сама прокраулена не была, и о её исходящих ссылках ничего не известно.
Для вычисления PageRank в графе страниц не должно быть висячих узлов. Сумма каждого ряда матрицы переходов должна быть равна единице (row-stochastic), для висячих же узлов она окажется равной 0 – входные данные алгоритма будут некорректными.
По статистике, даже если поисковая система имеет достаточно большой индекс, 60% страниц оказывается висячими. Поэтому то, как с ними поступать, оказывает большое влияние на ранжирование.
Метод удаления
Изначальный подход, предложенный Пэйджем, заключается в том, чтобы удалить висячие узлы перед вычислением PageRank. В качестве обоснования предлагается то, что висячие узлы не оказывают влияния на другие страницы. Но это не совсем так – удаляя их, мы уменьшаем количество исходящих ссылок страниц, которые на них ссылаются. Тем самым мы увеличиваем значение PageRank, которое эти страницы передают через свои ссылки.
Кроме того, удаление висячих узлов, может создать новые висячие узлы. Таким образом, требуется проделать несколько итераций удаления (обычно 5 или что-то около того).
В качестве развития этого подхода, было предложено после вычисления PageRank возвращать удалённые узлы назад в граф и проделывать ещё столько же итераций алгоритма PageRank, сколько было проделано итераций удаления. Это позволяет получить значение PageRank и для висячих узлов.
Считать связанными со всеми другими страницами
Наиболее популярный трюк заключается в том, чтобы считать висячие узлы связанными со всеми другими страницами. В модели случайного блуждания данный метод находит подходящее объяснение: попав на страницу без исходящих ссылок, «пользователь» перескакивает на любую другую страницу сети случайным образом.
Можно считать вероятность попадания «пользователя» на страницу из висячего узла в результате такого перескока распределённой равномерно среди всех страниц сети. Но можно и не считать её таковой. Например, можно исключить попадание из висячего узла на другой висячий узел. Или распределить вероятность между страницами по аналогии с аристократическим вектором телепортации, о котором будет рассказано ниже в главе Телепортация.
Матрица переходов модифицируется следующим образом:

d[i] = 1, если i – висячий узел, и 0 в противном случае
v[j] – вероятность попадания «пользователя» на страницу j из висячего узла
Шаг назад (step back)
Проблему висячих узлов можно решить, добавив каждому такому узлу обратные ссылки на страницы, которые на него ссылаются. В модели блуждания это соответствует нажатию кнопки назад в браузере «пользователем», попавшим на страницу без исходящих ссылок. Этот метод критикуют за то, что он поощряет страницы с большим количеством ссылок на висячие узлы. Однако в некоторых моих экспериментах такой подход давал лучшее ранжирование.
Петля (self-link)
Упомяну кратко ещё один способ. Каждому висячему узлу можно добавить ссылку на самого себя – это приведёт в порядок матрицу переходов. Но после вычисления PageRank, результат придётся определённым образом скорректировать. Подробности описаны в G. Jeh and J.Widom “Scaling Personalized Web Search.”
Телепортация
Решение проблемы висячих узлов ещё не даёт сильную связность графа. Поэтому вводится телепортация.
В модели случайного блуждания это выглядит так: «пользователь», находясь на некоторой странице, с вероятностью c переходит по одной из её ссылок и с вероятностью (1 – c) * v[j] перескакивает (телепортируется) на страницу j. Стохастический вектор v описывает вероятность телепортации на ту или иную страницу и называется вектором телепортации.
c как правило выбирается в диапазоне 0.85 – 0.9. Большие значения дают более точные результаты, но более медленную сходимость. Меньшие значения – быструю сходимость, но менее точные результаты.
Плюс ко всему, чем меньше значение с, тем больше возможностей для поискового спама – достаточно создать на сайте огромное количество страниц и они будут, как зонтик, собирать значительный PageRank, получаемый за счёт телепортации.
Существует два способа выбора вектора телепортации: демократический и аристократический. Демократический вектор содержит одинаковые значения вероятности для всех страниц. Это стандартный вариант. Аристократический содержит низкую вероятность для обычных страниц и более высокую для избранных достоверно качественных неспамерских страниц. Последний способ явно поощряет избранные страницы в ущерб остальным, зато более устойчив к поисковому спаму.
В одной из статей предлагалось делать более высокую вероятность телепортации для главных страниц сайтов, но мне не известно, каковы были результаты.
Значение v[j] не должно быть равно 0. Иначе может оказаться, что j недосягаема из некой другой страницы, что означает нарушение сильной связности.
Телепортация модифицирует матрицу переходов следующим образом:

v – вектор телепортации
Мы ещё вернёмся к вектору телепортации, когда будем обсуждать персонализацию PageRank.
Ускорение метода степеней
Многие исследователи пытались ускорить сходимость метода степеней. Посмотрим на самые удачные способы.
Для удобства повторю формулу, которую мы используем на каждой итерации. Назовём её формулой А:
Метод Гаусса-Зейделя (Gauss-Seidel method)
На каждой итерации в методе степеней мы используем значения элементов вектора p(k) чтобы рассчитать вектор p(k+1). Отличие метода Гаусса-Зейделя в том, что мы сразу используем значения вычисленных элементов вектора p(k+1) для вычисления его остальных элементов.
В методе Гаусса-Зейделя мы последовательно элемент за элементом вычисляем вектор p(k+1). При это там где, согласно формуле А, нам нужно использовать значение p(k)[i] мы используем p(k+1)[i], если этот элемент вектора уже был вычислен.
Согласно экспериментам этот метод способен сократить необходимое количество итераций на 40%. Его недостаток в том, что его достаточно сложно вычислять параллельно.
Методы экстраполяции (Extrapolation methods)
В этой группе методов мы проделываем некоторое количество d обычных итераций метода степеней. Затем на основе результатов этих итераций строим аппроксимацию решения и используем её вместо p(k) для следующей итерации. Через следующие d итераций повторяем трюк. И так далее пока алгоритм не сойдётся.
Исследователям удавалось достичь сокращения необходимого количества итераций на 30%.
Адаптивный метод (Adaptive method)
Этот метод основан на наблюдении, что значительная часть элементов вектора p сходится гораздо быстрее остальных и затем почти не меняется. Ускорение в этом методе достигается за счёт того, что мы не пересчитываем значения таких элементов.
Если в какой-то момент k для некоторого элемента i обнаруживается что p(k+1)[i] — p(k)[i] меньше определённого порога, мы считаем, что значение PageRank для страницы i найдено и более не пересчитываем i-тый элемент вектора p.
Исследователям удавалось достичь сокращения времени работы метода степеней на 20% при помощи этого трюка.
Однако данный метод требует периодически переупорядочивать данные, чтобы избежать вычисления тех элементов, значения которых считаются уже найденными. Поэтому адаптивный метод плохо подходит для больших графов – переупорядочить огромный объём данных становится слишком дорогой задачей.
Метод блочной структуры (Block Structure Method)
Web имеет блочную структуру. Это открытие столь интересно, что я намерен посвятить ему отдельный пост. Там же и обсудим этот метод.
UPD: пост о блочной структуре web.
Численные методы
Вычисляя значение PageRank, мы ищем такой вектор p, что
Это выражение является так называемой собственной системой, а p – собственный вектор матрицы A. Задача поиска собственного вектора может быть представлена системой линейных уравнений. В нашем случае это будет огромная, но всё же обычная система, которая может быть решена при помощи численных методов линейной алгебры.
Тем не менее, вычисление PageRank численными методами ещё находится в экспериментальной области. Каковы будут характеристики и свойства этих методов на реальных графах web пока не понятно.
Стоит отметить, что существуют уже готовые решения для параллельного вычисления крупных линейных систем.
Параллелизация
Вычисление PageRank параллельно на нескольких машинах позволяет существенно ускорить работу.
По сути методы параллелизации можно разделит на два типа.
Первые разделяют граф страниц на плотно связные компоненты – группы страниц плотно связанных ссылками между собой и имеющие относительно немного ссылок на страницы вне группы. PageRank для каждой такой группы вычисляется параллельно. Процессы/потоки периодически обмениваются информацией, когда дело доходит до ссылок между страницами разных групп.
Ко второму типу относятся методы, использующие блочную структуру web. О них мы поговорим в уже обещанном выше посте о блочной структуре.
UPD: пост о блочной структуре web.
Оптимизация ввода-вывода
Это довольно интересная тема, которую я приберегу для одного из следующих постов. Я представлю три алгоритма, которые будут интересны не только с точки зрения вычисления PageRank, но и вообще с точки зрения обработки больших объёмов информации.
Эволюция графа
Довольно естественной кажется идея не пересчитывать PageRank для всех страниц целиком, а найти способ обновлять его по мере эволюции графа страниц (по мере эволюции web).
В «Incremental Page Rank Computation on Evolving Graphs» Prasanna Desikan и др. предлагают следующий способ.
Сперва выделить часть графа, состоящую из страниц, до которых не существует путей от новых страниц, исчезнувших страниц, либо страниц, ссылки которых были изменены. Удалить эту часть графа, оставив только граничные узлы (т.к. они влияют на PageRank оставшихся страниц). Посчитать PageRank для оставшегося графа. Затем отмасштабировать значения PageRank с учётом общего количества страниц – т.к. количество страниц влияет на часть PageRank, получаемую за счёт телепортации.
Замечу, что полученный в результате PageRank не является точным, а всё же некой аппроксимацией.
По различным данным от 25% до 40% ссылок между web-страницами меняются в интернет в течение недели. Такая скорость изменения, на мой взгляд, оправдывает полный пересчёт PageRank всех страниц.
Персонализация
Представление о важности той или ной страницы во многом субъективно. То, что покажется одному отбросом, другой сочтёт изумрудом. Пусть есть очень качественная страница об игре керлинг, но я совершенно не хочу, чтобы она вылезала лично мне в топ. Чтобы учитывать в ранжировании интересы конкретного человека был придуман персонализированный PageRank.
Выбирается какое-то количество категорий, по которым можно классифицировать тематику тех или иных страниц (или сайтов). Например: культура, спорт, политика и т.п.
Пусть T[j] – множество страниц, принадлежащих к категории j (или расположенных на сайте, принадлежащем к данной категории).
Для каждой категории формируется особый вектор телепортации v (см. главу Телепортация).
v[i] очень мало, если страница i не принадлежит T[j], и значительно больше если принадлежит.
Для каждого тематического вектора телепортации вычисляется тематический PageRank pj. Вычислить сто тематических PageRank для ста категорий вполне реально.
Допустим, у нас есть вектор k, сумма элементов которого равна единице. Значение k[j] отражает степень заинтересованности пользователя (реального, а не того из модели блуждания) в категории j.
Степень заинтересованности пользователя может быть указана явно, или она может быть сохранена в его профиле. Или она может быть выведена исходя из того, какие слова входят в запрос. Например, если запрос содержит слово fairtrade то можно вывести, что пользователь заинтересован на 0.4 в теме общество, на 0.4 в теме экономика и на 0.2 в теме политика.
Во время ранжирования результатов запроса пользователя для страниц используется следующее итоговое значение PageRank:
k[0] * p0 + k[1] * p1 + … + k[n] * pn , где n – количество категорий
Таким образом, рейтинг страницы будет зависеть от того, что реально интересно пользователю.
Темы, которые будут рассмотрены в следующих постах
Оптимизация ввода-вывода
Это довольно интересная тема, которую я приберегу для одного из следующих постов. Я представлю три алгоритма, которые будут интересны не только с точки зрения вычисления PageRank, но и вообще с точки зрения обработки больших объёмов информации.
Siterank
UPD: Эта тема освещена в посте о блочной структуре web.
18.07.2017
9 224
9
Время чтения: 3 минуты
Рейтинг статьи:
![]() Загрузка…
Загрузка…
Зачем нужен внутренний аудит? Ваш сайт скрывает много неиспользуемых возможностей. Важно их найти и задействовать, чтобы подняться в поисковой выдаче. Это в свою очередь повысит трафик и конверсию. Поэтому не спешите закупаться ссылками, сперва определите состояние вашего сайта.
Desktop vs. SaaS — что выбрать?
Когда речь заходит о внутреннем аудите своими руками, вам не обойтись без хорошего ПО. Выбор лежит между SaaS и desktop продуктом. Конкретно под внутреннюю оптимизацию лучше заточены десктопы в силу своей скорости и детальности анализа. Их сейчас немало, но отличия существенны: начиная от места обработки информации (только на операционке, только на жёстком диске или на операционке и жёстком — это напрямую влияет на скорость аудита), заканчивая адекватным юзабилити. В этой статье мы рассмотрим внутренний аудит с помощью одного из десктопов — Netpeak Spider.
Структура страниц
Сперва рекомендуем провести мониторинг архитектуры сайта:
- Расстояние между главной и основными страницами должно исчисляться 1 кликом.
- Глубина сайта должна быть продумана (пользователь не проходит квесты в поиске нужной страницы). Волшебной формулы расчёта нет. Просто постарайтесь максимально упростить задачу пользователя в поиске информации.

Программное исполнение
- Код ответа сервера: 200, 301/302, 4xx, 5xx. Очень часто случается, что склейку страницы проводят с помощью 302 редиректа — не надо так. Постоянное перенаправление проводим с помощью 301-го, временное — 302-го. Совсем «не ок», когда внутренние ссылки на вашем сайте ведут к несуществующей странице с 404-й ошибкой.
- Дубли. Даже самый качественный контент можно убить, не проставив на частично похожих или повторяющихся страницах canonical. В таком случае вас ожидает ухудшение индексации, выявление нерелевантной страницы роботом (он выбирает на своё усмотрение), утрата доли естественных ссылок (пользователи ссылаются на дублированную страницу).
- Sitemap. Поисковому роботу нередко тяжело проиндексировать весь сайт (в особенности, если у вас крупный интернет-магазин). В таком случае направьте его, указав с помощью sitemap, что именно нужно индексировать.

- Robots.txt. Неверно прописанный robots.txt может закрыть доступ к целым тематическим категориям. И тогда вам не поможет ни уникальный контент, ни правильная разметка — всё это тщетно, если страницы скрыты от поисковых роботов.
- Висячие узлы. Внутренние ссылки позволяют пользователю ориентироваться в структуре сайта, направляют по его страницам. Висячими узлами называют ссылки на такие страницы, которые сами никуда не ведут. В итоге вы теряете ссылочный вес и повышаете вероятность потери пользователей, которые просто уйдут на другие сайты.

- Внутренний PageRank. Вам нужно знать, как распределяется ссылочный вес в пределах вашего сайта. Так вы пойметес, какие страницы, являясь неважными, напрасно получают избыточный вес. Грамотная схема перелинковки внутри сайта может сэкономить приличный бюджет.
Проверить PageRank можно так:


Контент
- Заголовки h1-h6. Здесь важно избегать дублирования заголовков, наличия нескольких сразу или полного их отсутствия.
Это не критические ошибки, но ваш контент наверняка направлен на информирование и привлечение пользователей. Скорее всего, не видя заголовка и не понимая, о чём статья, юзер просто закроет страницу. О спам-заголовках и вовсе промолчим. Здесь и так всё понятно: ни в коем случае.

- Оформление текста. Даже если у вас уникальный и крутой контент, это не гарантирует, что пользователь его прочтёт. Ему может просто не понравиться оформление текста. Так что структурируйте его, выделяйте заголовки, подзаголовки, прикрепляйте изображения. Помните: вы пишете для людей.
- Заспамленность. Проводя «сео-оптимизацию своего сайта бесплатно за 2 минуты», помните, что «сео-оптимизация сайта бесплатно за 2 минуты» должна обходиться без избытка ключевых слов.
- Изображения. Отсутствие атрибута ALT (подписи к изображению), непроработанные километровые инфографики без сжатия, замедляющие загрузку страницы, — это не понравится ни вашим пользователям, ни поисковикам.

Подытожим. Проводя внутренний аудит, обязательно проверяйте:
- структуру сайта, глубину ключевых для продвижения страниц;
- дубли, коды ответа сервера, robots.txt, sitemap, висячие узлы;
- оформление и заспамленность контента;
- распределение ссылочного веса с помощью внутреннего PageRank.
Не забывайте, что внутренний аудит следует проводить регулярно. Проверяйте изменения в перелинковке сайта, возможном дублировании страниц и их canonical — всё это непосредственно влияет на место вашего сайта в поисковой выдаче. В этой статье мы рассмотрели некоторые важные параметры, однако внутри программы Netpeak Spider их больше 60-ти. Изучайте их, экспериментируйте, применяйте.
А как считаете вы, какие параметры аудита заслуживают первостепенного внимания?
Что такое алгоритм PageRank?
Алгоритм 1.pagerank — это алгоритм оценки стоимости сайта на основе случайных прогулок.
Почему?
Можно доказать, что вероятность того, что узел случайно выбран из сети и расположен в узле i после прохождения K шагов вдоль направленного края,
Он равен значению PR узла i, полученному после k шагов алгоритма PageRank.
Этот вывод очень убедителен. Он не должен быть ошибочным в книге. Если в книге нет никаких доказательств, сначала примите этот вывод как черный ящик и сначала запишите его.
Основная идея алгоритма 2.pagerank
Важность страницы в Интернете зависит от количества и качества других страниц, указывающих на нее.
Первоначально назначьте одинаковое значение для всех страниц в сети. Если имеется N страниц, важность каждой страницы составляет 1 / N
Абстрагируйте всю сеть как ориентированный граф, страницу как вершину и гиперссылки на странице как направленные ребра
Если на странице 3 гиперссылки, указывающие на другие 3 страницы, то этот узел имеет три направленных ребра, указывающих на три узла, представляющих соответствующую страницу.
После первоначального выделения всей сети она входит в итерацию, и итерационная сходимость = до итерации равна после итерации (можно использовать метод сохранения десятичных дробей)
Вопрос сейчас:
- Как определить исходную ситуацию?
- Как перебрать?
- Как определяется условие завершения алгоритма? (Обсуждается позже)
# 1. Определение исходной ситуации (базовый алгоритм PageRank)
Учитывая начальное значение PageRank для всех узлов (значение PR для краткости, значения PR используются ниже), удовлетворить

Часть рисунка ниже означает значение PR 0-й итерации (начальный случай)

Как правило, начальное значение PR присваивается каждому узлу. Для четырех узлов начальное значение PR каждого узла составляет 1/4.
# 2. Итерационные методы
Для каждой итерации значения PR всех узлов в предыдущей версии изменяются один раз.
Метод модификации заключается в следующем
Запишите выходные данные каждого узла как:
 Означает степень вывода i-го узла
Означает степень вывода i-го узла
Выполните итерацию по каждому узлу и разделите значение PR текущего узла поровну на те узлы, которые указаны направленным краем этой точки
Значение: текущая страница имеет значение PR.Если текущая страница имеет три гиперссылки, указывающие на три страницы, значение PR текущей страницы делится поровну между этими тремя страницами для каждой итерации.
Имеет следующую итерационную формулу

Означает, что значение PR K-й итерации i-узла равно
Все остальные узлы, после разделения, значение PR, поступающее в этот узел
Среди них Значение в матрице смежности, ребро между узлом j и узлом i равно 1, а несуществование равно 0.
Значение в матрице смежности, ребро между узлом j и узлом i равно 1, а несуществование равно 0.
Вы можете узнать основную идею PageRank после небольшого вкуса.
Некорректированная реализация алгоритма PageRank
Анализ против следующих ориентированных графов
 (Рисунок 1, следующий эксперимент для этой фигуры)
(Рисунок 1, следующий эксперимент для этой фигуры)
Числа на рисунке — это последние итерации, которые сходятся, переходят в устойчивое состояние и, наконец, значение PR каждого узла.
Значение PR каждого узла в начале составляет 1/8
Определение базовой матрицы Google

Мы можем разделить каждую строку ориентированного графа на степень точки, чтобы получить эту матрицу Google
Правило итерации можно записать следующим образом

Из которых
 Является вектором из n строк и 1 столбца. Предыдущая итерация изменяется посредством транспонирования матрицы Google, и результат этой итерации ожидается.
Является вектором из n строк и 1 столбца. Предыдущая итерация изменяется посредством транспонирования матрицы Google, и результат этой итерации ожидается.
Каждая строка матрицы Google является результатом деления пополам соответствующей точки
После транспонирования каждая точка делится поровну на степень оттока, а доля значения PR, поступающего в точку, неизвестна.
Вы можете взять первый пункт и проверить его в своей голове.
Идея кода заключается в следующем:
1.c = функция pagerank (A, n), передать начальную матрицу смежности и размер матрицы и вернуть окончательный вектор значения PR в c
# 1. Рассчитать выход каждой точки
# 2. Получить гугл матрицу
# 3. Инициализировать вектор PR
# 4. Введите итерацию
2. Итерационный алгоритм вынесен отдельно, чтобы сделать функцию runpagerrank
c = runpagerank (A1, PR) Введите матрицу Google и значение PR в предыдущей версии и получите новое значение PR после исправления матрицы Google
3.c = код страницы (A, n) выглядит следующим образом:
function c = pagerank (A, n)% входящего графа смежности A и масштаба сети n
% 1. Рассчитать выходную степень каждой точки
outDegree=zeros(n,1);
for i=1:n
current_outDegree=0;
for j=1:n
if A(i,j)>0
current_outDegree=current_outDegree+1;
end
end
outDegree(i,1)=current_outDegree;
end
% 2. Основной алгоритм PageRank, матрица Google A1 получена следующим образом
A1=A;
for i=1:n
for j=1:n
if outDegree (i, 1) == 0% Если степень точки равна 0, чтобы эта точка не рассеивала значение PR всей сети, если эта точка не подключена, она будет случайным образом переходить на другие сети
A1(i,j)=1/n;
else
A1(i,j)=A1(i,j)/outDegree(i,1);
end
end
end
A1
% 3. Инициализируйте вектор PR, чтобы вероятность просмотра каждой страницы была одинаковой
PR=zeros(n,1);
for i=1:n
PR(i,1)=1/n;
end
PR
% 4. Переставим гугл матрицу А1, умножим справа на матрицу PR, это итерация
% Итерационная конвергенция означает, что эта итерация и следующий результат итерации совпадают, остановка
num=0;
runpagerank(A1,PR)
while 1
если round (PR, 4) == round (runpagerank (A1, PR), 4)% Если вы не используете оценку здесь (top 4), вы не можете завершить алгоритм все время
c=PR;
break;
else
PR=runpagerank(A1,PR);
PR
num=num+1
end
end
4.runpagerank (A1, PR) код выглядит следующим образом
function c=runpagerank(A1,PR)
c=A1'*PR;5. Экспериментальные результаты
Построить матрицу смежности A на рисунке 1 снаружи
Вызов страницы (A, размер (A, 1))

Проверьте 1 узел 4/13 =?

Полученный результат верен
3. Какие проблемы с реализацией алгоритма PageRank?
1. Висячий узел
После нескольких итераций алгоритма PageRank значения PR всех узлов во всей сети равны 0.
Если точка на рисунке имеет степень превышения 0, то есть на странице нет гиперссылок, указывающих на другие страницы.
При использовании алгоритма PR для одной итерации значение PR в этой точке будет рассеиваться
Таким образом, вся сеть будет передавать некоторые значения PR в эту точку с выходом 0 каждый раз, и эта точка с выходом 0 не сможет вернуть свое собственное значение PR всей сети. И, наконец, полностью ГГ Смитт.
2. Выход приводит к тому, что значение PR алгоритма полностью поглощается выходом.

Небольшая система (система, состоящая из узла 6 и узла 7), как показано вышеДепартаментТакже нет способа вернуть значение PR в систему. Весь вывод будет запрашивать только систему и не будет возвращать систему обратно. Это просто подонок. Наконец, вывод будет поглощать все значения PR системы после нескольких итераций. Некоторые значения PR равны нулю.
3. Кольцевая сеть заставляет алгоритм продолжать работать в цикле и не может сходиться

Исходя из рисунка выше, если начальное значение PR

(Почему не все начальные значения PR установлены одинаково? Здесь я просто хочу объяснить этот процесс непрерывного цикла
Если все настройки одинаковы, все будут равны 1/5 на следующей итерации, и это будет сразу же ошибочно оценено как конвергенция. )
Тогда итерационный процесс значения PR выглядит следующим образом:

(Игнорировать мозаику в правом верхнем углу)
В конце концов, он продолжает цикл и не может сходиться. Условия сходимости в моем алгоритме — это первые четыре цифры значения RP до и после итерации.
В-четвертых, пересмотренная реализация алгоритма PageRank
Модифицированная модель случайных серферов:
Предположим, что в Интернете есть случайный пользователь, который начинает просматривать случайно выбранную страницу.
Если выходные данные текущей страницы больше нуля, то случайным образом щелкните гипертекстовую ссылку на текущей странице с вероятностью s (0 <s <1), чтобы перейти на следующую страницу.
В то же время, страница будет случайным образом выбираться на всем WWW с вероятностью 1 с в качестве следующей страницы для просмотра. (Смотрите как повторный ввод URL для просмотра)
Если выходные данные текущей страницы равны нулю, тогда страница случайным образом выбирается в качестве следующей страницы для просмотра. (Похоже, что текущая страница не имеет гиперссылок, указывающих на другие страницы, поэтому вы можете только ввести URL-адрес в адресной строке для следующего шага)
1. Итерационные правила для модифицированной модели

Это означает, что значение PR i-узла повторяется на шаге K. Оно выполняется с вероятностью s предыдущим способом, а случайный просмотр выполняется с вероятностью (1-с)
здесь Представляется следующим образом:
Представляется следующим образом:

Означает, что степень больше 0 и не изменяется
Степень выхода равна 0, затем случайный просмотр
Определите размер значения 2.s
Можно представить, что размер значения s является скользящим значением, которое определяет, будет ли модель просматриваться в соответствии с предыдущим шаблоном или случайным образом.
Если s = 0, первая половина формулы равна 0, а последняя равна 1 / N.
Это означает, что все страницы не нажимают свои собственные гиперссылки, и они выбирают для просмотра, набрав URL в строке URL.
Если s = 1, вторая половина формулы равна 0, и расчет PR выполняется полностью в соответствии с неизмененной моделью.
Когда Пейдж и Брин первоначально предложили алгоритм PageRank, было предложено принять s = 0,85.
Результат 0,85 неизвестно, сколько работы они проделали, и неизвестно, как они наконец предложили быть 0,85.
Во всяком случае, играть с 0,85 сейчас …
3. Алгоритм реализации
Просто слегка измените логику матрицы Google предыдущего алгоритма.
Небольшое изменение во второй части
функция c = pagerank1 (A, n)% графа входящего смежности A и масштаба сети n
% 1. Рассчитать выходную степень каждой точки
outDegree=zeros(n,1);
for i=1:n
current_outDegree=0;
for j=1:n
if A(i,j)>0
current_outDegree=current_outDegree+1;
end
end
outDegree(i,1)=current_outDegree;
end
% 2. После пересмотренного алгоритма PageRank полученная матрица Google A1 выглядит следующим образом
A1=A;
for i=1:n
for j=1:n
if outDegree (i, 1) == 0% Если степень точки равна 0, чтобы эта точка не рассеивала значение PR всей сети, если эта точка не подключена, она будет случайным образом переходить на другие сети
A1(i,j)=1/n;
else
A1(i,j)=A1(i,j)/outDegree(i,1);
end
end
end
A1 = 0,85 * A1 + 0,15 * 1 / n * единиц (n)% исправить матрицу Google
% 3. Инициализируйте вектор PR, чтобы вероятность просмотра каждой страницы была одинаковой
PR=zeros(n,1);
for i=1:n
PR(i,1)=1/n;
end
PR
% 4. Переставим гугл матрицу А1, умножим справа на матрицу PR, это итерация
% Итерационная конвергенция означает, что эта итерация и следующий результат итерации совпадают, остановка
num=0;
runpagerank(A1,PR)
while 1
if round(PR,4)==round(runpagerank(A1,PR),4)
c=PR;
break;
else
PR=runpagerank(A1,PR);
PR
num=num+1
end
if num==73
break;
end
end
V. Резюме

Левое изображение — это модифицированный результат PageRank, а правое изображение — это не исправленный результат PageRank.
Вы можете видеть, что результаты неплохие, но скорость итерации намного выше.