To answer the question more generically so it applies to more use cases than just what the OP asked, consider this solution. I used jfs’s solution solution to help me. Here, we create two functions that help feed each other and can be used whether you know the exact replacements or not.
import numpy as np
import pandas as pd
class Utility:
@staticmethod
def rename_values_in_column(column: pd.Series, name_changes: dict = None) -> pd.Series:
"""
Renames the distinct names in a column. If no dictionary is provided for the exact name changes, it will default
to <column_name>_count. Ex. female_1, female_2, etc.
:param column: The column in your dataframe you would like to alter.
:param name_changes: A dictionary of the old values to the new values you would like to change.
Ex. {1234: "User A"} This would change all occurrences of 1234 to the string "User A" and leave the other values as they were.
By default, this is an empty dictionary.
:return: The same column with the replaced values
"""
name_changes = name_changes if name_changes else {}
new_column = column.replace(to_replace=name_changes)
return new_column
@staticmethod
def create_unique_values_for_column(column: pd.Series, except_values: list = None) -> dict:
"""
Creates a dictionary where the key is the existing column item and the value is the new item to replace it.
The returned dictionary can then be passed the pandas rename function to rename all the distinct values in a
column.
Ex. column ["statement"]["I", "am", "old"] would return
{"I": "statement_1", "am": "statement_2", "old": "statement_3"}
If you would like a value to remain the same, enter the values you would like to stay in the except_values.
Ex. except_values = ["I", "am"]
column ["statement"]["I", "am", "old"] would return
{"old", "statement_3"}
:param column: A pandas Series for the column with the values to replace.
:param except_values: A list of values you do not want to have changed.
:return: A dictionary that maps the old values their respective new values.
"""
except_values = except_values if except_values else []
column_name = column.name
distinct_values = np.unique(column)
name_mappings = {}
count = 1
for value in distinct_values:
if value not in except_values:
name_mappings[value] = f"{column_name}_{count}"
count += 1
return name_mappings
For the OP’s use case, it is simple enough to just use
w["female"] = Utility.rename_values_in_column(w["female"], name_changes = {"female": 0, "male":1}
However, it is not always so easy to know all of the different unique values within a data frame that you may want to rename. In my case, the string values for a column are hashed values so they hurt the readability. What I do instead is replace those hashed values with more readable strings thanks to the create_unique_values_for_column function.
df["user"] = Utility.rename_values_in_column(
df["user"],
Utility.create_unique_values_for_column(df["user"])
)
This will changed my user column values from ["1a2b3c", "a12b3c","1a2b3c"] to ["user_1", "user_2", "user_1]. Much easier to compare, right?
To answer the question more generically so it applies to more use cases than just what the OP asked, consider this solution. I used jfs’s solution solution to help me. Here, we create two functions that help feed each other and can be used whether you know the exact replacements or not.
import numpy as np
import pandas as pd
class Utility:
@staticmethod
def rename_values_in_column(column: pd.Series, name_changes: dict = None) -> pd.Series:
"""
Renames the distinct names in a column. If no dictionary is provided for the exact name changes, it will default
to <column_name>_count. Ex. female_1, female_2, etc.
:param column: The column in your dataframe you would like to alter.
:param name_changes: A dictionary of the old values to the new values you would like to change.
Ex. {1234: "User A"} This would change all occurrences of 1234 to the string "User A" and leave the other values as they were.
By default, this is an empty dictionary.
:return: The same column with the replaced values
"""
name_changes = name_changes if name_changes else {}
new_column = column.replace(to_replace=name_changes)
return new_column
@staticmethod
def create_unique_values_for_column(column: pd.Series, except_values: list = None) -> dict:
"""
Creates a dictionary where the key is the existing column item and the value is the new item to replace it.
The returned dictionary can then be passed the pandas rename function to rename all the distinct values in a
column.
Ex. column ["statement"]["I", "am", "old"] would return
{"I": "statement_1", "am": "statement_2", "old": "statement_3"}
If you would like a value to remain the same, enter the values you would like to stay in the except_values.
Ex. except_values = ["I", "am"]
column ["statement"]["I", "am", "old"] would return
{"old", "statement_3"}
:param column: A pandas Series for the column with the values to replace.
:param except_values: A list of values you do not want to have changed.
:return: A dictionary that maps the old values their respective new values.
"""
except_values = except_values if except_values else []
column_name = column.name
distinct_values = np.unique(column)
name_mappings = {}
count = 1
for value in distinct_values:
if value not in except_values:
name_mappings[value] = f"{column_name}_{count}"
count += 1
return name_mappings
For the OP’s use case, it is simple enough to just use
w["female"] = Utility.rename_values_in_column(w["female"], name_changes = {"female": 0, "male":1}
However, it is not always so easy to know all of the different unique values within a data frame that you may want to rename. In my case, the string values for a column are hashed values so they hurt the readability. What I do instead is replace those hashed values with more readable strings thanks to the create_unique_values_for_column function.
df["user"] = Utility.rename_values_in_column(
df["user"],
Utility.create_unique_values_for_column(df["user"])
)
This will changed my user column values from ["1a2b3c", "a12b3c","1a2b3c"] to ["user_1", "user_2", "user_1]. Much easier to compare, right?
In this article, we are going to discuss the various methods to replace the values in the columns of a dataset in pandas with conditions. This can be done by many methods lets see all of those methods in detail.
Method 1 : Using dataframe.loc[] function
With this method, we can access a group of rows or columns with a condition or a boolean array. If we can access it we can also manipulate the values, Yes! this is our first method by the dataframe.loc[] function in pandas we can access a column and change its values with a condition.
Now, we are going to change all the “male” to 1 in the gender column.
Syntax: df.loc[ df[“column_name”] == “some_value”, “column_name”] = “value”
some_value = The value that needs to be replaced
value = The value that should be placed instead.
Note: You can also use other operators to construct the condition to change numerical values..
Example:
Python3
import pandas as pd
import numpy as np
Student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(Student)
df.loc[df["gender"] == "male", "gender"] = 1
Output:
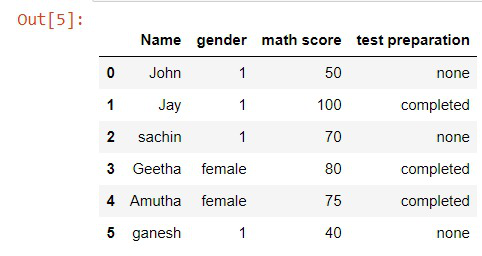
Method 2: Using NumPy.where() function
Another method we are going to see is with the NumPy library. NumPy is a very popular library used for calculations with 2d and 3d arrays. It gives us a very useful method where() to access the specific rows or columns with a condition. We can also use this function to change a specific value of the columns.
This numpy.where() function should be written with the condition followed by the value if the condition is true and a value if the condition is false. Now, we are going to change all the “female” to 0 and “male” to 1 in the gender column.
syntax: df[“column_name”] = np.where(df[“column_name”]==”some_value”, value_if_true, value_if_false)
Example:
Python3
import pandas as pd
import numpy as np
student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(student)
df["gender"] = np.where(df["gender"] == "female", 0, 1)
Output:
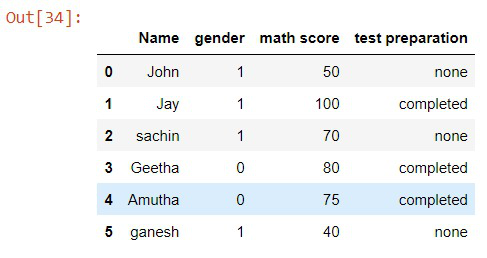
Method 3: Using pandas masking function
Pandas masking function is made for replacing the values of any row or a column with a condition. Now using this masking condition we are going to change all the “female” to 0 in the gender column.
syntax: df[‘column_name’].mask( df[‘column_name’] == ‘some_value’, value , inplace=True )
Example:
Python3
import pandas as pd
import numpy as np
student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(student)
df['gender'].mask(df['gender'] == 'female', 0, inplace=True)
Output:
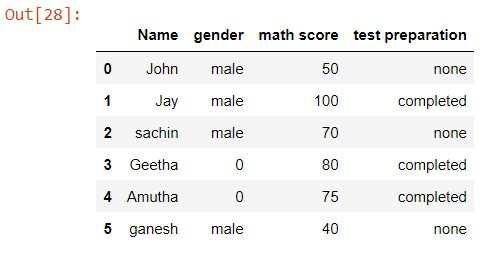
In this article, we are going to discuss the various methods to replace the values in the columns of a dataset in pandas with conditions. This can be done by many methods lets see all of those methods in detail.
Method 1 : Using dataframe.loc[] function
With this method, we can access a group of rows or columns with a condition or a boolean array. If we can access it we can also manipulate the values, Yes! this is our first method by the dataframe.loc[] function in pandas we can access a column and change its values with a condition.
Now, we are going to change all the “male” to 1 in the gender column.
Syntax: df.loc[ df[“column_name”] == “some_value”, “column_name”] = “value”
some_value = The value that needs to be replaced
value = The value that should be placed instead.
Note: You can also use other operators to construct the condition to change numerical values..
Example:
Python3
import pandas as pd
import numpy as np
Student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(Student)
df.loc[df["gender"] == "male", "gender"] = 1
Output:
Method 2: Using NumPy.where() function
Another method we are going to see is with the NumPy library. NumPy is a very popular library used for calculations with 2d and 3d arrays. It gives us a very useful method where() to access the specific rows or columns with a condition. We can also use this function to change a specific value of the columns.
This numpy.where() function should be written with the condition followed by the value if the condition is true and a value if the condition is false. Now, we are going to change all the “female” to 0 and “male” to 1 in the gender column.
syntax: df[“column_name”] = np.where(df[“column_name”]==”some_value”, value_if_true, value_if_false)
Example:
Python3
import pandas as pd
import numpy as np
student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(student)
df["gender"] = np.where(df["gender"] == "female", 0, 1)
Output:
Method 3: Using pandas masking function
Pandas masking function is made for replacing the values of any row or a column with a condition. Now using this masking condition we are going to change all the “female” to 0 in the gender column.
syntax: df[‘column_name’].mask( df[‘column_name’] == ‘some_value’, value , inplace=True )
Example:
Python3
import pandas as pd
import numpy as np
student = {
'Name': ['John', 'Jay', 'sachin', 'Geetha', 'Amutha', 'ganesh'],
'gender': ['male', 'male', 'male', 'female', 'female', 'male'],
'math score': [50, 100, 70, 80, 75, 40],
'test preparation': ['none', 'completed', 'none', 'completed',
'completed', 'none'],
}
df = pd.DataFrame(student)
df['gender'].mask(df['gender'] == 'female', 0, inplace=True)
Output:
Replace text is one of the most popular operation in Pandas DataFrames and columns. In this post we will see how to replace text in a Pandas.
The short answer of this questions is:
(1) Replace character in Pandas column
df['Depth'].str.replace('.',',')
(2) Replace text in the whole Pandas DataFrame
df.replace('.',',', regex=True)
We will see several practical examples on how to replace text in Pandas columns and DataFrames.
Suppose we have DataFrame like:
| Date | Time | Latitude | Longitude | Depth | Magnitude Type |
|---|---|---|---|---|---|
| 12/27/2016 | 23:20:56 | 45.7192 | 26.5230 | 97.0 | MWW |
| 12/28/2016 | 08:18:01 | 38.3754 | -118.8977 | 10.8 | ML |
| 12/28/2016 | 08:22:12 | 38.3917 | -118.8941 | 12.3 | ML |
| 12/28/2016 | 09:13:47 | 38.3777 | -118.8957 | 8.8 | ML |
| 12/28/2016 | 12:38:51 | 36.9179 | 140.4262 | 10.0 | MWW |
Replace single character in Pandas Column with .str.replace
First let’s start with the most simple example — replacing a single character in a single column. We are going to use the string method — replace:
df['Depth'].str.replace('.',',')
A warning message might be shown — for this one you can check the section below:
FutureWarning: The default value of regex will change from True to False in a future version.
If you are using regex than you can specify it by:
df['Depth'].str.replace('.',',', regex= True)
result:
23405 97
23406 10,8
23407 12,3
Replace regex pattern in Pandas Column
Let say that you would like to use a regex in order to replace specific text patterns in Pandas.
For example let’s change the date format of you Pandas DataFrame from:
- mm/dd/yyyy
to - yyyy-mm-dd
This can be done by using regex flag and using regex groups like:
df['Date'].str.replace(r'(d{2})/(d{2})/(d{4})', r"3-2-1", regex=True)
result:
23405 2016-27-12
23406 2016-28-12
23407 2016-28-12
How does the regex replace in Pandas work? . So this one is translated as (d{2}):
- 1st capturing group
(d{2})d— matches a digit (equivalent to [0-9])- {2} matches the previous token exactly 2 times
Then in the replacement part we are replaced by the group numbers — 1st group is 1.
So you can try a simple exercise — to change the format to: dd mm ‘yy . The answer is below:
df['Date'].str.replace(r'(d{2})/(d{2})/d{2}(d{2})', r"2 1 '3", regex=True)
result:
23405 27 12 '16
23406 28 12 '16
23407 28 12 '16
If you like to replace values in all columns in your Pandas DataFrame then you can use syntax like:
df.replace('.',',', regex=True)
If you don’t specify the columns then the replace operation will be done over all columns and rows.
Replace text with conditions in Pandas with lambda and .apply/.applymap
.applymap is another option to replace text and string in Pandas. This one is useful if you have additional conditions — sometimes the regex might be too complex or to not work.
In this case the replacement can be done by lambda and .apply for columns:
df['Date'].apply(lambda x: x.replace('/', '-'))
result:
| Date | Time | Latitude | Longitude | Depth | Magnitude Type |
|---|---|---|---|---|---|
| 12/27/2016 | 23:20:56 | 45.7192 | 26.523 | 97 | MWW |
| 12/28/2016 | 08:18:01 | 38.3754 | -118.8977 | 10.8 | ML |
and .applymap for the whole DataFrame:
df.applymap(lambda x: x.replace('/', '-'))
result:
| Date | Time | Latitude | Longitude | Depth | Magnitude Type |
|---|---|---|---|---|---|
| 12/27/2016 | 23:20:56 | 45,7192 | 26,523 | 97 | MWW |
| 12/28/2016 | 08:18:01 | 38,3754 | -118,8977 | 10,8 | ML |
Note that this solution might be slower than the others.
Conditional replace in Pandas
If you like to apply condition to your replacement in Pandas you can use syntax like:
df['Date'].apply(lambda x: x.replace('/', '-') if '20' in x else x)
result:
23405 12-27-2016
23406 12-28-2016
23407 12-28-2016
Warning: FutureWarning: The default value of regex will change from True to False in a future version.
If you get an warning like:
FutureWarning: The default value of regex will change from True to False in a future version.
It means that you will need to explicitly set the regex parameter for replace method:
df.replace('.',',', regex=True)
The official documentation of method replace is:
`regex` -** bool, default True**
Determines if the passed-in pattern is a regular expression:
* If True, assumes the passed-in pattern is a regular expression.
* If False, treats the pattern as a literal string
Cannot be set to False if pat is a compiled regex or repl is a callable.
So the difference is how the passed pattern will be parsed — as a regex expression or not.
So in a practical example:
df.replace('.',',')
this will not change the values of the DataFrame:
45.7192
While the regex expression — '.' and regex=True:
df.replace('.',',', regex=True)
will change them:
45,7192
Resources
- Notebook
- pandas.Series.str.replace
- pandas.Series.replace
- pandas.Series.apply
- pandas.DataFrame.applymap
Вы можете использовать следующий базовый синтаксис для замены значений в столбце кадра данных pandas на основе условия:
#replace values in 'column1' that are greater than 10 with 20
df.loc[df['column1'] > 10, 'column1'] = 20
В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1. Замена значений в столбце на основе одного условия
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'position': ['G', 'G', 'F', 'F', 'G', 'G', 'F', 'F'],
'points': [5, 7, 7, 9, 12, 13, 9, 14],
'assists': [3, 8, 2, 6, 6, 5, 9, 5]})
#view DataFrame
df
team position points assists
0 A G 5 3
1 A G 7 8
2 A F 7 2
3 A F 9 6
4 B G 12 6
5 B G 13 5
6 B F 9 9
7 B F 14 5
Мы можем использовать следующий код, чтобы заменить каждое значение в столбце «точки», превышающее 10, значением 20:
#replace any values in 'points' column greater than 10 with 20
df.loc[df['points'] > 10, 'points'] = 20
#view updated DataFrame
df
team position points assists
0 A G 5 3
1 A G 7 8
2 A F 7 2
3 A F 9 6
4 B G 20 6
5 B G 20 5
6 B F 9 9
7 B F 20 5
Обратите внимание, что каждое из трех значений в столбце «точки», которые были больше 10, были заменены значением 20.
Пример 2. Замена значений в столбце на основе нескольких условий
Предположим, у нас есть следующие Pandas DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'position': ['G', 'G', 'F', 'F', 'G', 'G', 'F', 'F'],
'points': [5, 7, 7, 9, 12, 13, 9, 14],
'assists': [3, 8, 2, 6, 6, 5, 9, 5]})
#view DataFrame
df
team position points assists
0 A G 5 3
1 A G 7 8
2 A F 7 2
3 A F 9 6
4 B G 12 6
5 B G 13 5
6 B F 9 9
7 B F 14 5
Мы можем использовать следующий код, чтобы заменить каждое значение в столбце «позиция», где количество очков меньше 10 или где количество передач меньше 5, строкой «Плохо»:
#replace string in 'position' column with 'bad' if points < 10 or assists < 5
df.loc[(df['points'] < 10) |(df['assists'] < 5), 'position'] = 'Bad '
#view updated DataFrame
df
team position points assists
0 A Bad 5 3
1 A Bad 7 8
2 A Bad 7 2
3 A Bad 9 6
4 B G 20 6
5 B G 20 5
6 B Bad 9 9
7 B F 20 5
Точно так же мы можем использовать следующий код, чтобы заменить каждое значение в столбце «позиция», где количество очков меньше 10 и где количество передач меньше 5, строкой «Плохо»:
#replace string in 'position' column with 'bad' if points < 10 and assists < 5
df.loc[(df['points'] < 10) &(df['assists'] < 5), 'position'] = 'Bad '
#view updated DataFrame
df
team position points assists
0 A Bad 5 3
1 A G 7 8
2 A Bad 7 2
3 A F 9 6
4 B G 12 6
5 B G 13 5
6 B F 9 9
7 B F 14 5
Обратите внимание, что в двух строках, где количество очков было меньше 10, а количество передач меньше 5, значение «позиция» было заменено строкой «Плохо».
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как выбрать строки по нескольким условиям в Pandas
Как создать новый столбец на основе условия в Pandas
Как фильтровать кадр данных Pandas по нескольким условиям
Чтобы заменить значения в столбце на основе условия в Pandas DataFrame, вы можете использовать свойство DataFrame.loc, numpy.where() или DataFrame.where().
В этом руководстве мы рассмотрим все эти процессы на примерах программ.
Метод 1: в зависимости от условия
Чтобы заменить значения в столбце на основе условия с помощью DataFrame.loc, используйте следующий синтаксис.
DataFrame.loc[condition, column_name] = new_value
В следующей программе мы заменим те значения в столбце «a», которые удовлетворяют условию, что значение меньше нуля.
import pandas as pd df = pd.DataFrame([ [-10, -9, 8], [6, 2, -4], [-8, 5, 1]], columns=['a', 'b', 'c']) df.loc[(df.a < 0), 'a'] = 0 print(df)
Вывод:
a b c 0 0 -9 8 1 6 2 -4 2 0 5 1
Вы также можете заменить значения в нескольких значениях на основе одного условия. Передайте столбцы как кортеж в loc.
DataFrame.loc[condition, (column_1, column_2)] = new_value
В следующей программе мы заменим те значения в столбцах «a» и «b», которые удовлетворяют условию, что значение меньше нуля.
import pandas as pd
df = pd.DataFrame([
[-10, -9, 8],
[6, 2, -4],
[-8, 5, 1]],
columns=['a', 'b', 'c'])
df.loc[(df.a < 0), ('a', 'b')] = 0
print(df)
Вывод:
a b c 0 0 0 8 1 6 2 -4 2 0 0 1
Метод 2: с помощью where
Чтобы заменить значения в столбце на основе условия с помощью numpy.where, используйте следующий синтаксис.
DataFrame['column_name'] = numpy.where(condition, new_value, DataFrame.column_name)
В следующей программе мы воспользуемся методом numpy.where() и заменим те значения в столбце «a», которые удовлетворяют условию, что значение меньше нуля.
import pandas as pd import numpy as np df = pd.DataFrame([ [-10, -9, 8], [6, 2, -4], [-8, 5, 1]], columns=['a', 'b', 'c']) df['a'] = np.where((df.a < 0), 0, df.a) print(df)
Вывод:
a b c 0 0 -9 8 1 6 2 -4 2 0 5 1
Метод 3
Чтобы заменить значения в столбце на основе условия с помощью numpy.where, используйте следующий синтаксис.
DataFrame['column_name'].where(~(condition), other=new_value, inplace=True)
- column_name – это столбец, в котором необходимо заменить значения.
- condition – это логическое выражение, которое применяется для каждого значения в столбце.
- new_value заменяет (поскольку inplace = True) существующее значение в указанном столбце на основе условия.
В следующей программе мы будем использовать метод DataFrame.where() и заменим те значения в столбце «a», которые удовлетворяют условию, что значение меньше нуля.
import pandas as pd df = pd.DataFrame([ [-10, -9, 8], [6, 2, -4], [-8, 5, 1]], columns=['a', 'b', 'c']) df['a'].where(~(df.a < 0), other=0, inplace=True) print(df)
Вывод:
a b c 0 0 -9 8 1 6 2 -4 2 0 5 1
В этом руководстве на примерах Python мы узнали, как заменить значения столбца в DataFrame новым значением в зависимости от условия.
Как заменить несколько значений?
Чтобы заменить несколько значений в DataFrame, вы можете использовать метод DataFrame.replace() со словарем различных замен, переданных в качестве аргумента.
Пример 1
Синтаксис для замены нескольких значений в столбце DataFrame:
DataFrame.replace({'column_name' : { old_value_1 : new_value_1, old_value_2 : new_value_2}})
В следующем примере мы будем использовать метод replace() для замены 1 на 11 и 2 на 22 в столбце a.
import pandas as pd
df = pd.DataFrame([
[4, -9, 8],
[1, 2, -4],
[2, 2, -8],
[0, 7, -4],
[2, 5, 1]],
columns=['a', 'b', 'c'])
df = df.replace({'a':{1:11, 2:22}})
print(df)
Вывод:
a b c 0 4 -9 8 1 11 2 -4 2 22 2 -8 3 0 7 -4 4 22 5 1
Пример 2
Синтаксис для замены нескольких значений в нескольких столбцах DataFrame:
DataFrame.replace({'column_name_1' : { old_value_1 : new_value_1, old_value_2 : new_value_2},
'column_name_2' : { old_value_1 : new_value_1, old_value_2 : new_value_2}})
В следующем примере мы воспользуемся методом replace() для замены 1 на 11 и 2 на 22 в столбце a; 5 с 55 и 2 с 22 в столбце b.
import pandas as pd
df = pd.DataFrame([
[4, -9, 8],
[1, 2, -4],
[2, 2, -8],
[0, 7, -4],
[2, 5, 1]],
columns=['a', 'b', 'c'])
df = df.replace({'a':{1:11, 2:22}, 'b':{5:55, 2:22}})
print(df)
Вывод:
a b c 0 4 -9 8 1 11 22 -4 2 22 22 -8 3 0 7 -4 4 22 55 1
В этом руководстве на примерах Python мы узнали, как заменить несколько значений в Pandas DataFrame в одном или нескольких столбцах.
When working with pandas dataframes, it might be handy to know how to quickly replace values. In this tutorial, we’ll look at how to replace values in a pandas dataframe through some examples.

The pandas dataframe replace() function is used to replace values in a pandas dataframe. It allows you the flexibility to replace a single value, multiple values, or even use regular expressions for regex substitutions. The following is its syntax:
df_rep = df.replace(to_replace, value)
Here, to_replace is the value or values to be replaced and value is the value to replace with. By default, the pandas dataframe replace() function returns a copy of the dataframe with the values replaced. If you want to replace the values in-place pass inplace=True
Examples
Let’s look at some of the different use-cases of the replace() function through some examples.
1. Replace values throughout the dataframe
The replace() function replaces all occurrences of the value with the desired value. See the example below:
import pandas as pd
# sample dataframe
df = pd.DataFrame({'A': ['a','b','c'], 'B':['b','c','d']})
print("Original DataFrame:n", df)
# replace b with e
df_rep = df.replace('b', 'e')
print("nAfter replacing:n", df_rep)
Output:
Original DataFrame:
A B
0 a b
1 b c
2 c d
After replacing:
A B
0 a e
1 e c
2 c d
In the above example, the replace() function is used to replace all the occurrences of b in the dataframe with e.
2. Replace values in a particular column
The pandas dataframe replace() function allows you the flexibility to replace values in specific columns without affecting values in other columns.
import pandas as pd
# sample dataframe
df = pd.DataFrame({'A': ['a','b','c'], 'B':['b','c','d']})
print("Original DataFrame:n", df)
# replace b with e
df_rep = df.replace({'A': 'b'}, 'e')
print("nAfter replacing:n", df_rep)
Output:
Original DataFrame:
A B
0 a b
1 b c
2 c d
After replacing:
A B
0 a b
1 e c
2 c d
In the above example, we replace the occurrences of b in just the column A of the dataframe. For this, we pass a dictionary to the to_replace parameter. Here the dictionary {'A': 'b'} tells the replace function that we want to replace the value b in the column A. And the 'e' passed to the value parameter use is used to replace all relevant matches.
3. Replace multiple values together
You can also have multiple replacements together. For example, if you want to replace a with b, b with c and c with d in the above dataframe, you can pass just a single dictionary to the replace function.
import pandas as pd
# sample dataframe
df = pd.DataFrame({'A': ['a','b','c'], 'B':['b','c','d']})
print("Original DataFrame:n", df)
# replace a with b, b with c, and c with d
df_rep = df.replace({'a':'b', 'b':'c', 'c':'d'})
print("nAfter replacing:n", df_rep)
Output:
Original DataFrame:
A B
0 a b
1 b c
2 c d
After replacing:
A B
0 b c
1 c d
2 d d
In the above example, we only pass a single dictionary to the replace() function. The function infers the dictionary keys as values to replace in the dataframe and the corresponding keys as the values to replace them with.
4. Replace using Regex match
To replace values within a dataframe via a regular expression match, pass regex=True to the replace function. Keep in mind that you pass the regular expression string to the to_replace parameter and the value to replace the matches to the value parameter. Also, note that regular expressions will only substitute for strings.
import pandas as pd
# sample dataframe
df = pd.DataFrame({'A': ['tap','cap','map'], 'B':['cap','map', 'tap']})
print("Original DataFrame:n", df)
# replace ap with op
df_rep = df.replace(to_replace='ap', value='op', regex=True)
print("nAfter replacing:n", df_rep)
Output:
Original DataFrame:
A B
0 tap cap
1 cap map
2 map tap
After replacing:
A B
0 top cop
1 cop mop
2 mop top
In the above example, the regular expression looks for the occurrences of ap and replaces them with op.
For more on the Pandas dataframe replace function, refer to its official documentation.
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
More on Pandas DataFrames –
- Pandas – Sort a DataFrame
- Change Order of Columns of a Pandas DataFrame
- Pandas DataFrame to a List in Python
- Pandas – Count of Unique Values in Each Column
- Pandas – Replace Values in a DataFrame
- Pandas – Filter DataFrame for multiple conditions
- Pandas – Random Sample of Rows
- Pandas – Random Sample of Columns
- Save Pandas DataFrame to a CSV file
- Pandas – Save DataFrame to an Excel file
- Create a Pandas DataFrame from Dictionary
- Convert Pandas DataFrame to a Dictionary
- Drop Duplicates from a Pandas DataFrame
- Concat DataFrames in Pandas
- Append Rows to a Pandas DataFrame
- Compare Two DataFrames for Equality in Pandas
- Get Column Names as List in Pandas DataFrame
- Select One or More Columns in Pandas
- Pandas – Rename Column Names
- Pandas – Drop one or more Columns from a Dataframe
- Pandas – Iterate over Rows of a Dataframe
- How to Reset Index of a Pandas DataFrame?
- Read CSV files using Pandas – With Examples
- Apply a Function to a Pandas DataFrame
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. In the past, he’s worked as a Data Scientist for ZS and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts

In this post, you’ll learn how to use the Pandas .replace() method to replace data in your dataframe. The Pandas dataframe.replace() function can be used to replace a string, values, and even regular expressions (regex) in your dataframe. It’s an immensely powerful function – so let’s dive right in!
Loading Sample Dataframe
To start things off, let’s begin by loading a Pandas dataframe. We’ll keep things simple so it’s easier to follow exactly what we’re replacing.
import pandas as pd
df = pd.DataFrame.from_dict(
{
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['F', 'F', 'M', 'M']
}
)
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Jane 23 London F
1 Melissa 45 Paris F
2 John 35 Toronto M
3 Matt 64 Atlanta M
Check out some other Python tutorials on datagy, including our complete guide to styling Pandas and our comprehensive overview of Pivot Tables in Pandas!
Pandas Replace Method Syntax
The Pandas .replace() method takes a number of different parameters. Let’s take a look at them:
DataFrame.replace(
to_replace=None,
value=None,
inplace=False,
limit=None,
regex=False,
method='pad')Let’s take a closer look at what these actually mean:
- to_replace: take a string, list, dictionary, regex, int, float, etc. and describes the values to replace
- value: The value to replace with
- inplace: whether to perform the operation in place
- limit: the maximum size gap to backward or forward fill
- regex: whether to interpret to_replace and/or value as regex
- method: the method to use for replacement
Replace a Single Value in Pandas
Let’s learn how to replace a single value in a Pandas column.
In the example below, we’ll look to replace the value Jane with Joan:
df['Name'] = df['Name'].replace(to_replace='Jane', value='Joan')
print(df)This returns the following dataframe:
Name Age Birth City Gender
0 Joan 23 London F
1 Melissa 45 Paris F
2 John 35 Toronto M
3 Matt 64 Atlanta M
Replace Multiple Values with the Same Value in Pandas
Now, you may want to replace multiple values with the same value. This is also extremely easy to do using the .replace() method.
Of course, you could simply run the method twice, but there’s a much more efficient way to accomplish this. Here, we’ll look to replace London and Paris with Europe:
df['Birth City'] = df['Birth City'].replace(
to_replace=['London', 'Paris'],
value='Europe')
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Jane 23 Europe F
1 Melissa 45 Europe F
2 John 35 Toronto M
3 Matt 64 Atlanta M
Now let’s take a look at how to replace multiple values with different values.
Replace Multiple Values with Different Values in Pandas
Similar to the example above, you can replace a list of multiple values with a list of different values.
This is as easy as loading in a list into each of the to_replace and values parameters. It’s important to note that the lists must be the same length.
In the example below, we’ll replace London with England and Paris with France:
df['Birth City'] = df['Birth City'].replace(
to_replace=['London', 'Paris'],
value=['England', 'France'])
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Jane 23 England F
1 Melissa 45 France F
2 John 35 Toronto M
3 Matt 64 Atlanta M
Replace Values in the Entire Dataframe
In the previous examples, you learned how to replace values in a single column. Similar to those examples, we can easily replace values in the entire dataframe.
Let’s take a look at replacing the letter F with P in the entire dataframe:
df = df.replace(
to_replace='M',
value='P')
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Jane 23 London F
1 Melissa 45 Paris F
2 John 35 Toronto P
3 Matt 64 Atlanta P
We can see that this didn’t return the expected results.
In order to replace substrings (such as in Melissa), we simply pass in regex=True:
df = df.replace(
to_replace='M',
value='P',
regex=True)
print(df)
This returns the expected dataframe:
Name Age Birth City Gender
0 Jane 23 London F
1 Pelissa 45 Paris F
2 John 35 Toronto P
3 Patt 64 Atlanta P
Finally, let’s take a closer look at more complex regular expression replacements.
Replacing Values with Regex (Regular Expressions)
We can use regular expressions to make complex replacements.
We’ll cover off a fairly simple example, where we replace any four letter word in the Name column with “Four letter name”.
The following .replace() method call does just that:
df = df.replace(
to_replace=r'bw{4}b',
value='Four letter name',
regex=True)
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Four letter name 23 London F
1 Melissa 45 Paris F
2 Four letter name 35 Toronto M
3 Four letter name 64 Atlanta M
Replace Values In Place with Pandas
We can also replace values inplace, rather than having to re-assign them. This is done simply by setting inplace= to True.
Let’s re-visit an earlier example:
df['Birth City'].replace(
to_replace='Paris',
value='France',
inplace=True)
print(df)
This returns the following dataframe:
Name Age Birth City Gender
0 Jane 23 London F
1 Melissa 45 France F
2 John 35 Toronto M
3 Matt 64 Atlanta M
Conclusion
In this post, you learned how to use the Pandas replace method to, well, replace values in a Pandas dataframe. The .replace() method is extremely powerful and lets you replace values across a single column, multiple columns, and an entire dataframe. The method also incorporates regular expressions to make complex replacements easier.
To learn more about the Pandas .replace() method, check out the official documentation here.