Yes You are correct @CyberDem0n , I am using Spilo / Patroni images and using HELM chart for Kubernetes :
https://github.com/kubernetes/charts/tree/master/incubator/patroni
So server upgrades in this case is Kubernetes upgrades, and during those all pods are restarted. I noticed that after those upgrades , — my cluster stops working, only master pod is okay.
This is what pg_log provides :
2017-12-04 23:59:49.937 UTC,,,3195,,5a25e175.c7b,2,,2017-12-04 23:59:49 UTC,,0,LOG,00000,"startup process (PID 3197) exited with exit code 1",,,,,,,,,""
2017-12-04 23:59:49.937 UTC,,,3195,,5a25e175.c7b,3,,2017-12-04 23:59:49 UTC,,0,LOG,00000,"aborting startup due to startup process failure",,,,,,,,,""
2017-12-04 23:59:49.956 UTC,,,3195,,5a25e175.c7b,4,,2017-12-04 23:59:49 UTC,,0,LOG,00000,"database system is shut down",,,,,,,,,""
2017-12-04 23:59:59.794 UTC,,,3200,,5a25e17f.c80,1,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"ending log output to stderr",,"Future log output will go to log destination ""csvlog"".",,,,,,,""
2017-12-04 23:59:59.795 UTC,,,3202,,5a25e17f.c82,1,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"database system was interrupted while in recovery at log time 2017-11-10 14:48:38 UTC",,"If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.",,,,,,,""
2017-12-04 23:59:59.899 UTC,,,3202,,5a25e17f.c82,2,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"entering standby mode",,,,,,,,,""
2017-12-04 23:59:59.901 UTC,,,3202,,5a25e17f.c82,3,,2017-12-04 23:59:59 UTC,,0,FATAL,XX000,"requested timeline 2767 is not a child of this server's history","Latest checkpoint is at 163/C9000028 on timeline 2765, but in the history of the requested timeline, the server forked off from that timeline at 163/C8000098.",,,,,,,,""
2017-12-04 23:59:59.902 UTC,,,3200,,5a25e17f.c80,2,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"startup process (PID 3202) exited with exit code 1",,,,,,,,,""
2017-12-04 23:59:59.902 UTC,,,3200,,5a25e17f.c80,3,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"aborting startup due to startup process failure",,,,,,,,,""
2017-12-04 23:59:59.916 UTC,,,3200,,5a25e17f.c80,4,,2017-12-04 23:59:59 UTC,,0,LOG,00000,"database system is shut down",,,,,,,,,""
В PostgreSQL нет High Availability из коробки. Чтобы добиться HA, нужно что-то поставить, настроить — приложить усилия. Есть несколько инструментов, которые помогут повысить доступность PostgreSQL, и один из них — Patroni.
На первый взгляд, поставив Patroni в тестовой среде, можно увидеть, какой это прекрасный инструмент и как он легко обрабатывает наши попытки развалить кластер. Но на практике в production-среде не всегда всё происходит так красиво и элегантно. Data Egret начали использовать Patroni еще в конце 2018 года и накопили определенный опыт: как его диагностировать, настраивать, а когда вовсе не полагаться на автофейловер.
На HighLoad++ Алексей Лесовский обстоятельно, на примерах и с разбором логов рассказал о типовых проблемах, возникающих при работе с Patroni, и best practice для их преодоления.
В статье не будет: инструкций по установке Patroni и примеров конфигураций; проблем за пределами Patroni и PostgreSQL; историй, основанных на чужом опыте, а только те проблемы, с которыми в Data Egret разобрались сами.
О спикере: Алексей Лесовский (lesovsky) начинал системным администратором (Linux system administrator), работал в web-разработке (PostgreSQL database administrator). С 2014 года работает в Data Egret. Data Egret занимается консалтингом в сфере PostgreSQL, помогает многим-многим компаниям правильно использовать PostgreSQL и, конечно, накопила обширный опыт эксплуатации БД.
Доклад, на котором основана эта статья, называется «Patroni Failure Stories or How to crash your PostgreSQL cluster», здесь ссылка на презентацию.
Перед тем, как начать
Напомню, что такое Patroni, для чего предназначен и что умеет.
Patroni — это шаблон для построения HA из коробки. Так написано в документации и с моей точки зрения — это очень правильное уточнение. То есть Patroni — это не серебряная пуля, которую поставил и она решит все проблемы. Нужно приложить усилия, чтобы он начал работать и приносить пользу.
Patroni — агентская служба. Устанавливается на каждом сервере с базой данных и является своего рода init-системой для PostgreSQL: запускает, останавливает, перезапускает, меняет конфигурацию и топологию кластера.
Patroni хранит «состояние кластера» в DCS. Чтобы хранить состояние кластера, его текущее представление, нужно хранилище. Patroni хранит состояние во внешней системе — распределенном хранилище конфигураций. Это может быть один из вариантов: Etcd, Consul, ZooKeeper либо Etcd Kubernetes.
Автофейловер в Patroni включен по умолчанию. Вы получаете автофейловер из коробки, сразу же после установки Patroni.
Плюс есть много других вещей, таких как: обслуживание конфигураций, создание новых реплик, резервное копирование и т.д. Но в этот раз это останется за рамками доклада.
Основная задача Patroni — обеспечивать надежный автофейловер.
Patroni не должен следить за оборудованием, рассылать уведомления, делать сложные вещи по потенциальному предотвращению аварий и т.п. От него требуется, чтобы кластер оставался работоспособным и приложение могло продолжать работать с БД независимо от случившихся изменений в топологии кластера.
Но когда мы начинаем использовать Patroni с PostgreSQL, наша система становится чуть сложнее. Теперь, кроме самой БД, когда мастер или реплика выходят из строя, у нас может сломаться собственно Patroni, распределенное хранилище состояний кластера или сеть. Рассмотрим все варианты по мере их усложнения с точки зрения того, насколько трудно разобраться в их причинах.
Проблема 1. СУБД и DCS на одном кластере
Рассмотрим самый простой случай: взяли кластер баз данных и на этом же кластере развернули DCS. Эта распространенная ошибка связана не только с ошибками развертывания PostgreSQL и Patroni. Это ошибка вообще построения архитектур — совмещение множества разных компонентов в одном месте.
Итак, произошел фейловер. Начинаем разбираться с тем, что произошло. Здесь нас интересует, когда произошел фейловер, то есть момент времени, когда произошло изменение состояния кластера.
Когда произошел фейловер?
Фейловер не всегда происходит мгновенно, он может быть продолжительным по времени. Поэтому у него есть время начала и время завершения. Все события делятся на «до», «во время» и «после» фейловера.
Первым делом, когда произошел фейловер, мы ищем причину.
pgdb-2 patroni: INFO: promoted self to leader by acquiring session lock
pgdb-2 patroni: WARNING: Loop time exceeded, rescheduling immediately.
pgdb-2 patroni: INFO: Lock owner: pgdb-2; I am pgdb-2
pgdb-2 patroni: INFO: updated leader lock during promote
pgdb-2 patroni: server promoting
pgdb-2 patroni: INFO: cleared rewind state after becoming the leader
pgdb-2 patroni: INFO: Lock owner: pgdb-2; I am pgdb-2Выше стандартные логи Patroni, где он сообщает, что роль сервера изменилась и роль мастера перешла с другого на этот узел.
Почему произошел фейловер?
Дальше нужно понять, какие события заставили роль мастера перейти с одного узла на другой, что случилось со старым мастером.
pgdb-2 patroni: patroni.utils.RetryFailedError: 'Exceeded retry deadline'
pgdb-2 patroni: ERROR: Error communicating with DCS
pgdb-2 patroni: INFO: demoted self because DCS is not accessible and i was a leader
pgdb-2 patroni: WARNING: Loop time exceeded, rescheduling immediately.
В данном случае все просто: Error communicating with DCS — ошибка взаимодействия с системой хранения конфигураций. Мастер понял, что не может работать с DCS, и сказал, что он не может далее быть мастером и слагает с себя полномочия. demoted self говорит именно об этом.
Что предшествовало фейловеру?
Если посмотреть на события, которые предшествовали фейловеру, можно увидеть те самые причины, которые стали проблемой для продолжения работы мастера:
pgdb-2 patroni: ERROR: touch_member
... python trace
pgdb-2 patroni: socket.timeout: timed out
pgdb-2 patroni: During handling of the above exception, another exception occurred:
... python trace
pgdb-2 patroni: raise ReadTimeoutError(self, url, "Read timed out. (read timeout=%s)" % timeout_value)
pgdb-2 patroni: urllib3.exceptions.ReadTimeoutError: HTTPConnectionPool(host='127.0.0.1', port=8500): Read timed out. (read timeout=3.3333333333333335)
pgdb-2 patroni: During handling of the above exception, another exception occurred:
... python trace
pgdb-2 patroni: raise MaxRetryError(_pool, url, error or ResponseError(cause))
pgdb-2 patroni: urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='127.0.0.1', port=8500): Max retries exceeded with url: /v1/kv/service/pgdb/members/pgdb-2?acquire=19598b72-c0d5-f066-5d24-09c1a9ad61ee&dc=maindb (Caused by ReadTimeoutError("HTTPConnectionPool(host='127.0.0.1', port=8500): Read timed out. (read timeout=3.3333333333333335)",))
pgdb-2 patroni: INFO: no action. i am the leader with the lock
pgdb-2 patroni: WARNING: Loop time exceeded, rescheduling immediately.В логах Patroni видна масса разных ошибок, связанных с таймаутами. Агент Patroni не смог работать с DCS (в данном случае это Consul, port=8500). Patroni и база данных были запущены на одном хосте, и на этом же узле были запущены Consul-серверы. Создав нагрузку на сервере, мы создали проблемы и для сервера Consul, из-за которых они не смогли нормально общаться.
Все вернулось, как было
Через некоторое время, когда нагрузка спала, наш Patroni смог снова общаться с агентами, все возобновилось:
pgdb-2 patroni: INFO: promoted self to leader by acquiring session lock
pgdb-2 patroni: WARNING: Loop time exceeded, rescheduling immediately.
pgdb-2 patroni: INFO: Lock owner: pgdb-2; I am pgdb-2
pgdb-2 patroni: INFO: updated leader lock during promote
pgdb-2 patroni: server promoting
pgdb-2 patroni: INFO: cleared rewind state after becoming the leader
pgdb-2 patroni: INFO: Lock owner: pgdb-2; I am pgdb-2Тот же самый сервер pgdb-2 снова стал мастером. Был небольшой “флип” — за относительно короткое время он сложил с себя полномочия мастера, потом снова взял их на себя.
Это можно расценивать либо как ложное срабатывание, либо как то, что Patroni сделал все правильно.
Решение
Мы решили для себя, что проблема в том, что Consul-серверы находятся на том же оборудовании, что и базы. Соответственно любая нагрузка на CPU и на диски (тяжелый запрос по IO, временные файлы, автовакуумы, миграции, бэкап и т.п.) также влияет на взаимодействие с кластером Consul. Мы решили, что это не должно жить на одном оборудовании с БД, и выделили отдельный кластер для Consul.
В качестве альтернативы можно покрутить параметры ttl, loop_wait, retry_timeout, попытаться за счет их увеличения пережить кратковременные пики нагрузки. Но если нагрузка будет продолжительной, мы выйдем за пределы этих параметров, и способ не сработает.
Проблема 2. Перебои в сети
Вторая проблема похожа на первую тем, что у нас снова есть проблемы взаимодействия с системой DCS:
maindb-1 patroni: ERROR: get_cluster
maindb-1 patroni: Traceback (most recent call last):
... python trace
maindb-1 patroni: RetryFailedError: 'Exceeded retry deadline'
maindb-1 patroni: ERROR: Error communicating with DCS
maindb-1 patroni: INFO: closed patroni connection to the postgresql cluster
maindb-1 patroni: INFO: postmaster pid=214121
...
...
maindb-1 patroni: INFO: demoted self because DCS is not accessible and i was a leader
maindb-1 patroni: WARNING: Loop time exceeded, rescheduling immediately.Patroni снова говорит, что не может взаимодействовать с DCS, поэтому текущий мастер перестает быть мастером и переходит в режим реплики. Старый мастер становится репликой:
maindb-1 patroni: INFO: Lock owner: maindb-2; I am maindb-1
maindb-1 patroni: INFO: does not have lock
maindb-1 patroni: INFO: running pg_rewind from maindb-2
maindb-1 patroni: INFO: running pg_rewind from user=postgres host=192.168.11.18 port=5432 ...
maindb-1 patroni: servers diverged at WAL location 1FA/A38FF4F8 on timeline 6
maindb-1 patroni: rewinding from last common checkpoint at 1FA/A38FF450 on timeline 6
maindb-1 patroni: INFO: Lock owner: maindb-2; I am maindb-1
maindb-1 patroni: INFO: running pg_rewind from maindb-2 in progress
maindb-1 patroni: Done!
Здесь Patroni отрабатывает как и положено — запускает pg_rewind, чтобы отмотать журнал транзакций, потом подключиться к новому мастеру и уже догнать новый мастер.
Что предшествовало фейловеру?
Давайте, найдем первое, что предшествовало фейловеру, — ошибки, которые послужили его причиной. В этом плане удобны логи Patroni: он с определенным интервалом пишет одни и те же сообщения. Можно их быстро промотать и увидеть, когда поменялись логи. В этот момент начались какие-то проблемы.
В нормальной ситуации логи Patroni выглядят примерно так:
maindb-1 patroni: INFO: Lock owner: maindb-1; I am maindb-1
maindb-1 patroni: INFO: no action. i am the leader with the lock
maindb-1 patroni: INFO: Lock owner: maindb-1; I am maindb-1
maindb-1 patroni: INFO: no action. i am the leader with the lockПроверяется владелец блокировки, если он поменяется, могут наступить события, на которые Patroni должен отреагировать. В данном случае у нас все в порядке.
Промотав до того места, когда ошибки начали появляться, мы видим, что произошел автофейловер. Раз ошибки были связаны со взаимодействием с DCS, мы заодно смотрим и в логи Consul — что происходило там. Примерно сопоставив время фейловера и время в логах Consul, видим, что соседи по Consul-кластеру стали сомневаться в существовании других участников:
maindb-2 consul[11581]: serf: EventMemberFailed: maindb-1 192.168.11.19
maindb-2 consul[11581]: [INFO] serf: EventMemberFailed: maindb-1 192.168.11.19
maindb-2 consul[11581]: memberlist: Suspect maindb-1 has failed, no acks received
maindb-2 consul[11581]: [INFO] memberlist: Suspect maindb-1 has failed, no acks receivedЕсли посмотреть на логи других Consul-агентов, то там тоже видно, что происходит сетевой коллапс: все участники Consul-кластера сомневаются в существовании друг друга. Это и послужило толчком к фейловеру.
Если посмотрим еще более ранние записи, увидим, что Consul-система для агента PostgreSQL испытывает сложности с коммуникацией (deadline reached, RPC failed):
maindb-1 consul: memberlist: Suspect lbs-4 has failed, no acks received
maindb-1 consul: [ERR] yamux: keepalive failed: i/o deadline reached
maindb-1 consul: yamux: keepalive failed: i/o deadline reached
maindb-1 consul: [ERR] consul: "KVS.List" RPC failed to server 192.168.11.115:8300: rpc error making call: EOF
maindb-1 consul: [ERR] http: Request GET /v1/kv/service/sam_prod/?recurse=1, error: rpc error making call: EOF from=192.168.11.19
maindb-1 consul: [ERR] consul: "KVS.List" RPC failed to server 192.168.11.115:8300: rpc error making call: EOF
maindb-1 consul: [ERR] agent: Coordinate update error: rpc error making call: EOF
maindb-1 consul: [ERR] http: Request GET /v1/kv/service/sam_prod/?recurse=1, error: rpc error making call: EOF from=192.168.11.19Решение
Самый простой ответ — это чинить сеть. Это легко советовать, но обстоятельства могут складываться по-разному, и не всегда это возможно. Система может жить в дата-центре, где мы не можем влиять на оборудование. Нужны другие варианты.
Варианты решения без работы с сетью есть:
- Отключить Consul-проверки —
checks: [].
Это самый простой вариант, который и написан в документации. Можно передать пустой массив, то есть сказать Consul-агенту не использовать никакие проверки. За счет этого можно игнорировать сетевые штормы и не инициировать фейловер. - Перепроверить
raft_multiplier.
Это параметр самого Consul-сервера, который по умолчанию равен 5 (это значение в документации рекомендуется для staging-окружения). Параметр влияет на скорость обмена сообщениями между участниками Consul-кластера. Для продакшен-окружения его рекомендуется уменьшить. - Использовать
renice -n -10 consul.
Здесь мы хотим увеличить приоритет для планировщика процессов ОС. Параметр renice определяет приоритет процессов. Мы выбрали именно такой вариант и просто уменьшили приоритет Consul-агентам, чтобы ОС давала этому процессу больше времени на работу и исполнение своего кода. - Не использовать consul?
Consul-агент должен быть запущен на каждом узле с базой данных. Patroni взаимодействует с Consul-кластером через этот самый агент, и он становится узким местом: если с агентом что-то происходит, то Patroni уже не может работать с кластером. Если использовать etcd, то такой проблемы не возникнет, потому что в etcd никакого агента нет. Patroni может напрямую работать со списком etcd-серверов. Мы же как компания-консультант ограничены тем, что выбрал и использует клиент, пока так получается, что чаще всего это Consul. - Пересмотреть значения параметров
ttl, loop_wait, retry_timeout.
Можно увеличить эти параметры в надежде, что кратковременные сетевые проблемы не выйдут за выставленные значения. Таким образом уменьшается агрессивность Patroni в выполнении автофейловера в случае сетевых проблем.
Проблема 3. Потеря узла
Если вы используете Patroni, то знакомы с командой patronictl list, которая показывает текущее состояние кластера:
$ patronictl list
+-----------------+-------------------------+--------------+--------+---------+-----------+
| Cluster | Member | Host | Role | State | Lag in MB |
+-----------------+-------------------------+--------------+--------+---------+-----------+
| patroni_cluster | pg01.dev.zirconus.local | 10.202.1.101 | | running | 0.0 |
| patroni_cluster | pg03.dev.zirconus.local | 10.202.1.103 | Leader | running | 0.0 |
+-----------------+-------------------------+--------------+--------+---------+-----------+
На первый взгляд такой вывод может показаться нормальным — есть мастер, реплики, а лага репликации нет. Но эта картина нормальна ровно до тех пор, пока мы не знаем, что в этом кластере должно быть 3 узла, а не 2.
Почему произошел фейловер?
Мы понимаем, что произошел автофейловер и после этого пропала одна реплика. Нужно выяснить, почему она пропала, и вернуть ее обратно.
Снова изучаем логи, чтобы понять, почему произошел автофейловер:
pg02 patroni[1425]: ERROR: failed to update leader lock
pg02 patroni[1425]: INFO: demoted self because failed to update leader lock in DCS
pg02 patroni[1425]: WARNING: Loop time exceeded, rescheduling immediately.
pg02 patroni[1425]: INFO: Lock owner: None; I am pg02.dev.zirconus.local
pg02 patroni[1425]: INFO: not healthy enough for leader race
pg02 patroni[1425]: INFO: starting after demotion in progress
Мастер pg02 не смог обновить мастер-ключ — ERROR: failed to update leader lock.
Тогда мастером стала вторая реплика db03, здесь все в порядке:
pg03 patroni[9648]: INFO: promoted self to leader by acquiring session lock
pg03 patroni[9648]: server promoting
pg03 patroni[9648]: INFO: cleared rewind state after becoming the leaderЧто со старым мастером?
pg02, решив стать репликой, начал с перемотки журнала транзакций. Здесь нам нужно уже смотреть логи реплики, которой нет в кластере. Открываем логи Patroni и смотрим, что в процессе подключения к кластеру возникла проблема на стадии pg_rewind.
pg02 patroni[1425]: INFO: running pg_rewind from pg03
pg02 patroni[1425]: INFO: running pg_rewind from user=postgres host=10.202.1.103 port=5432 ...
pg02 patroni[1425]: servers diverged at WAL location 33F/68E6AD10 on timeline 28
pg02 patroni[1425]: could not open file "/data/pgdb/11/pg_wal/0000001C0000033F00000059": No such file or directory
pg02 patroni[1425]: could not find previous WAL record at 33F/59FFE368 pg02 patroni[1425]: Failure, exiting
pg02 patroni[1425]: ERROR: Failed to rewind from healty master: pg03
pg02 patroni[1425]: WARNING: Postgresql is not running.
Чтобы подключиться к кластеру, узел должен запросить журнал транзакций у мастера и по нему догнать мастера. В данном случае журнала транзакций нет (No such file or directory), и реплика не может запуститься. Соответственно PostgreSQL останавливается с ошибкой. Надо понять, почему не оказалось журнала транзакций.
Посмотрим, что в WAL у нового мастера:
LOG: checkpoint complete:
wrote 62928 buffers (16.0%); 0 WAL file(s) added, 0 removed, 23 recycled;
write=12.872 s, sync=0.020 s, total=13.001 s;
sync files=16, longest=0.009 s, average=0.001 s;
distance=520220 kB, estimate=520220 kB
Оказывается, в то время, когда выполнялся pg_rewind, произошел чекпоинт, и часть старых журналов транзакций была переименована. Когда старый мастер попытался подключиться к новому мастеру и запросить эти логи, они уже были переименованы, их попросту не было.
По timestamp время между этими событиями буквально в 150 мс.
2019-08-26 00:06:11,369 LOG: checkpoint complete
2019-08-26 00:06:11,517 INFO: running pg_rewindНо этого хватило, чтобы реплика не смогла подключиться и заработать.
Решение
Изначально мы использовали слоты репликации. Это решение казалось нам хорошим, хотя на первом этапе эксплуатации мы слоты отключали. Мы думали, что если слоты будут копить много wal-сегментов, мастер может упасть. Помучившись какое-то время без слотов, мы поняли, что они нужны, и вернули их.
Проблема в том, что мастер при переходе в состояние реплики удаляет слоты и вместе с ними wal-сегменты. Чтобы нивелировать эту проблему, мы увеличили параметр wal_keep_segments. По умолчанию он равен 8 сегментов, мы подняли wal_keep_segments до 1000. Мы выделили 16 Гбайт на wal_keep_segments, и теперь при переключении у нас всегда на всех узлах есть запас 16 Гбайтов журналов транзакций.
Это актуально и для продолжительных maintenance-задач. Допустим, нужно обновить одну из реплик (софт, ОС, еще что-то), и мы хотим ее выключить. Когда мы выключаем реплику, для нее также удаляется слот. Если использовать маленькое значение параметра wal_keep_segments, то при продолжительном отсутствии реплики она запросит те журналы транзакций, которых на мастере уже может и не оказаться — тогда реплика не сможет подключиться. Поэтому мы держим большой запас журналов.
Проблема 4. Потеря данных
Произошел фейловер на production-базе. Проверили кластер: всё в порядке, все реплики на месте, лага репликации нет, ошибок по журналам тоже нет. Но продуктовая команда сообщает, что в базе не хватает данных — в одном источнике они есть, а в базе нет. Необходимо понять, что с ними произошло.
Мы сразу поняли, что это pg_rewind их затер, но нужно выяснить, почему.
Когда произошел фейловер?
В логах мы всегда можем найти, когда произошел фейловер, кто стал новым мастером, кто был мастером до этого и когда он захотел стать репликой.
pgdb-1 patroni[17836]: INFO: promoted self to leader by acquiring session lock
pgdb-1 patroni[17836]: server promoting
pgdb-1 patroni[17836]: INFO: cleared rewind state after becoming the leader
pgdb-1 patroni[17836]: INFO: Lock owner: pgdb-1; I am pgdb-1По логам мы можем определить, какой объем журналов транзакций был потерян.
Дело было так: старый мастер перезагрузился, после его перезагрузки автозапуском был запущен Patroni, который следом запустил PostgreSQL. PostgreSQL решил стать участником Patroni-кластера и запустил процесс pg_rewind, который в свою очередь стер часть журналов транзакций, скачал новые и подключился.
Patroni отработал совершенно так, как и было задумано. Кластер восстановился: было 3 узла, после фейловера 3 узла и осталось. Но часть данных потеряна, и нужно понять, какая это часть.
Найдем в логах старого мастера момент, когда происходил pg_rewind:
pgdb-2 patroni[4149]: INFO: running pg_rewind from pgdb-1
pgdb-2 patroni[4149]: Lock owner: pgdb-1; I am pgdb-2
pgdb-2 patroni[4149]: Deregister service pgdb/pgdb-2
pgdb-2 patroni[4149]: running pg_rewind from pgdb-1 in progress
pgdb-2 patroni[4149]: running pg_rewind from user=replica host=10.10.1.31 port=5432 ...
pgdb-2 patroni[4149]: servers diverged at WAL location 0/5AD1BFD8 on timeline 66
pgdb-2 patroni[4149]: rewinding from last common checkpoint at 0/59DD1070 on timeline 66
pgdb-2 patroni[4149]: Done!Нужно найти позицию в журнале транзакций, на которой остановился старый мастер.
pgdb-2 patroni[4149]: INFO: Local timeline=66 lsn=0/5BDA8EB8
pgdb-2 patroni[4149]: INFO: master_timeline=67
...
pgdb-2 patroni[4149]: servers diverged at WAL location 0/5AD1BFD8 on timeline 66
postgres=# select pg_wal_lsn_diff('0/5BDA8EB8','0/5AD1BFD8');
pg_wal_lsn_diff
----------------
17354464
В данном случае это отметка 0/5BDA8EB8. Вторая отметка — 0/5AD1BFD8 — нужна, чтобы найти расстояние, на которое отличается старый мастер от нового. С помощью функции pg_wal_lsn_diff сравниваем эти две отметки, получаем 17 Мбайт.
Большая ли потеря 17 Мбайт данных, каждый для себя решает сам. Для кого-то это незначительно, а для кого-то недопустимо много. Каждый для себя индивидуально определяет в соответствии с потребностями бизнеса.
Решение
Прежде всего необходимо решить, всегда ли нужен автозапуск Patroni после перезагрузки системы. Чаще всего мы должны зайти на старый мастер, посмотреть, насколько он отличается от актуального состояния, возможно, проинспектировать сегменты журнала транзакций. Нужно понять, можно ли эти данные потерять, либо нужно в standalone-режиме запустить старый мастер, чтобы вытащить данные. Только уже после этого принять решение, что делать с данными, и подключить этот узел в качестве реплики в наш кластер.
Помимо этого есть параметр maximum_lag_on_failover, по умолчанию его значение 1 Мб. Он работает так: если реплика отстает на 1 Мб данных по лагу репликации, то эта реплика не принимает участия в выборах. Если вдруг происходит фейловер, Patroni смотрит, какие реплики отстают, и те из них, которые отстают на большое количество журналов транзакций, не могут стать мастером. Это хорошая защитная функция, которая позволяет не потерять слишком много данных.
Но есть проблема: лаг репликации обновляется с определенным интервалом, значение ttl по умолчанию 30 с. Вполне возможна ситуация, когда значение лага репликации для реплик в DCS одно, а на самом деле оно совершенно другое или лага вообще нет. Это не real-time значение, оно не всегда отражает реальную картину и завязывать на него сложную логику не стоит.
Риск «потеряшек» всегда остается:
- В худшем случае:
maximum_lag_on_failover + ttl. - В среднем случае:
maximum_lag_on_failover + (loop_wait / 2).
Когда планируете внедрение Patroni и оцениваете, сколько данных можно потерять, учитывайте эти формулы, чтобы примерно представлять возможные потери.
Хорошая новость — в «потеряшках» могут быть WAL от фоновых процессов. Эти данные можно запросто игнорировать и потерять, в этом нет никакой проблемы.
Так выглядят логи в случае, если выставлен maximum_lag_on_failover, произошел фейловер и нужно выбрать нового мастера:
pgdb-1 patroni[6202]: INFO: Lock owner: None; I am pgdb-1
pgdb-1 patroni[6202]: INFO: not healthy enough for leader race
pgdb-1 patroni[6202]: INFO: changing primary_conninfo and restarting in progress
...
pgdb-1 patroni[6202]: INFO: following a different leader because i am not the healthiest node
pgdb-1 patroni[6202]: INFO: following a different leader because i am not the healthiest node
Реплика просто видит, что она not healthy enough for leader race, и отказывается от участия в гонке за лидерство. Поэтому просто ждет, когда будет выбран новый мастер, чтобы к нему подключиться. Это дополнительная мера от потери данных.
Проблема 5. Диски
Продуктовая команда написала, что приложение испытывает проблемы при работе с PostgreSQL. При этом на мастер нельзя зайти, потому что он недоступен по SSH, но и автофейловер тоже не происходит. Тогда хост принудительно перезагрузили и таким образом запустили автофейловер. Хотя можно было сделать и ручной фейловер.
После перезагрузки идем смотреть, что было с мастером.
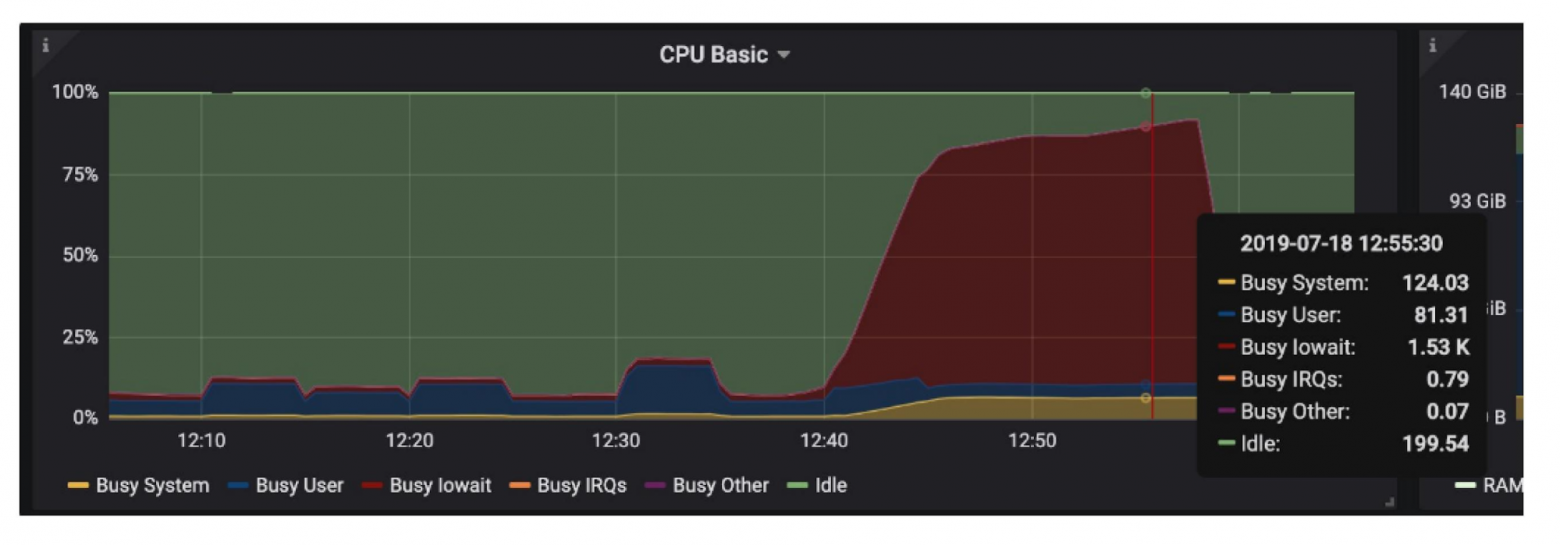
Нам заранее было известно о проблемах с дисками, по мониторингу мы знали, где копать.
В логах PostgreSQL видим следующее:
[COMMIT] LOG: duration: 1138.868 ms statement: COMMIT
...
[] WARNING: autovacuum worker started without a worker entry
...
[SELECT] LOG: temporary file: path "base/pgsql_tmp/pgsql_tmp11247.983", size 532996096
...На лицо все показатели проблем с дисками: коммиты, которые длятся секунды, autovacuum запускается очень долго и странно и временные файлы на диске.
Мы заглянули в системный dmesg — лог сообщений ядра, и увидели проблему с одним из дисков:
md/raid10:md2: sde3: rescheduling sector 351273392
blk_update_request: I/O error, dev sde, sector 64404728
md/raid10:md2: sde3: rescheduling sector 63161592
blk_update_request: I/O error, dev sde, sector 64404760
...
md2 : active raid10 sda3[0] sdc3[2] sdd3[3] sdb3[1] sdh3[7] sdf3[5] sdg3[6]
15623340032 blocks super 1.2 512K chunks 2 near-copies [8/7] [UUUUUUU_]
bitmap: 58/59 pages [232KB], 131072KB chunk
Дисковая подсистема на сервере представляла собой софтверный Raid из 8 дисков, но одного не хватало. В строке sda3[0] sdc3[2] sdd3[3] sdb3[1] sdh3[7] sdf3[5] sdg3[6] не хватает sde[4]. Условно говоря, выпал один диск, это вызвало дисковые проблемы, и у приложения возникли проблемы при работе с кластером PostgreSQL.
Решение
В данном случае Patroni никак бы не смог помочь, потому что у Patroni нет задачи отслеживать состояние сервера и дисков. Во время проблем Patroni продолжал взаимодействовать с кластером DCS и не видел никаких трудностей. Для таких ситуаций нужен внешний мониторинг.
Проблема 6. Кластер-симулянт
Это одна из самых странных проблем. Я её исследовал очень долго, перечитал много логов и назвал «Кластер-симулянт».
Проблема заключалась в том, что старый мастер не мог стать нормальной репликой. Patroni его запускал, показывал, что этот узел присутствует как реплика, но в то же время он не был нормальной репликой, сейчас увидите, почему.
Все началось, как и в предыдущем случае, с проблем с дисками:
14:48:55.601 [COMMIT] LOG: duration: 1478.118 ms statement: COMMIT
14:48:56.287 [COMMIT] LOG: duration: 1290.203 ms statement: COMMIT
14:48:56.287 [COMMIT] LOG: duration: 1778.465 ms statement: COMMIT
14:48:56.287 [COMMIT] LOG: duration: 1778.449 ms statement: COMMITБыли обрывы соединений:
14:48:58.078 [idle in transaction] LOG: could not send data to client: Broken pipe
14:48:58.078 [idle] LOG: could not send data to client: Broken pipe
14:48:58.078 [idle] FATAL: connection to client lost
14:48:58.107 [idle in transaction] FATAL: connection to client lostБыли долгие ожидания ответа и блокировки разной степени тяжести:
14:49:26.929 [UPDATE waiting] LOG: process 4298 acquired ExclusiveLock on tuple (2,10) of relation 52082 of database 50587 after 52487.463 ms
14:49:26.929 [UPDATE waiting] STATEMENT: UPDATE sessions SET lastaccess='1565005714' WHERE sessionid=...
14:49:27.929 [UPDATE waiting] LOG: process 4298 still waiting for ShareLock on transaction 364118337 after 1000.088 ms
14:49:27.929 [UPDATE waiting] DETAIL: Process holding the lock: 4294. Wait queue: 4298.В общем, явные проблемы с дисками, включая снова временные файлы.
Но самое загадочное для меня — это прилетевший immediate shutdown request:
14:49:34.102 MSK 5335 @ from [] LOG: received immediate shutdown request
14:49:34.689 [authentication] WARNING: terminating connection because of crash of another server process
14:49:34.689 [authentication] DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memoryУ PostgreSQL есть три режима выключения:
- Graceful, когда мы ждем, когда все клиенты отключатся самостоятельно.
- Fast, когда мы говорим клиентам отключаться, потому что идем на выключение.
- Immediate, которые не сообщает клиентам, что нужно отключиться, а просто выключает и всем клиентам отправляет сообщение RST (TCP-сигнал, что соединение прервано).
Фоновые процессы PostgreSQL друг другу сигналы immediate shutdown request не посылают, а только на них реагируют. Это экстренный перезапуск, и кто его послал, непонятно. Если бы это был kill -9, то я бы увидел это в логах, но там этого не было.
Разбираясь дальше, я увидел, что Patroni не писал в лог довольно долго — 54 секунды сообщений просто не было. За это время одна из реплик сделала «promote» и произошел автофейловер:
pgsql03 patroni: 14:48:25,000 INFO: Lock owner: pgsql03; I am pgsql03
pgsql03 patroni: 14:48:25,013 INFO: no action. i am the leader with the lock
pgsql03 patroni: 14:48:37,159 INFO: Lock owner: pgsql03; I am pgsql03
pgsql03 patroni: 14:49:31,155 WARNING: Exception hened during processing of request from 10.1.0.12
pgsql03 patroni: 14:49:31,297 WARNING: Exception hened during processing of request from 10.1.0.11
pgsql03 patroni: 14:49:31,298 WARNING: Exception hened during processing of request from 10.1.0.11Patroni здесь снова отработал прекрасно, старый мастер был недоступен, поэтому начались выборы нового мастера.
pgsql01 patroni: 14:48:57,136 INFO: promoted self to leader by acquiring session lock
pgsql01 patroni: server promoting
pgsql01 patroni: 14:48:57,214 INFO: cleared rewind state after becoming the leader
pgsql01 patroni: 14:49:05,013 INFO: Lock owner: pgsql01; I am pgsql01
pgsql01 patroni: 14:49:05,023 INFO: updated leader lock during promotepgsql01 стал новым лидером, а со второй репликой как раз были проблемы. Она честно пыталась переконфигурироваться:
pgsql02 patroni: 14:48:57,124 INFO: Could not take out TTL lock
pgsql02 patroni: 14:48:57,137 INFO: following new leader after trying and failing to obtain lock
pgsql02 patroni: 14:49:05,014 INFO: Lock owner: pgsql01; I am pgsql02
pgsql02 patroni: 14:49:05,025 INFO: changing primary_conninfo and restarting in progress
pgsql02 patroni: 14:49:15,011 INFO: Lock owner: pgsql01; I am pgsql02
pgsql02 patroni: 14:49:15,014 INFO: changing primary_conninfo and restarting in progress
pgsql02 patroni: 14:49:25,011 INFO: Lock owner: pgsql01; I am pgsql02
pgsql02 patroni: 14:49:25,014 INFO: changing primary_conninfo and restarting in progress
pgsql02 patroni: 14:49:35,011 INFO: Lock owner: pgsql01; I am pgsql02
pgsql02 patroni: 14:49:35,014 INFO: changing primary_conninfo and restarting in progressОна пыталась поменять recovery.conf, перезапустить PostgreSQL, подключиться к новому мастеру. Каждые 10 секунд идут сообщения, что она пытается, но никак не может.
Тем временем на старый мастер прилетел тот самый immediate-shutdown-сигнал. Мастер начал аварийную перезагрузку, recovery также прекращается. Реплика не может подключиться к мастеру, потому что он в режиме выключения.
14:49:34.293 [idle] LOG: received replication command: IDENTIFY_SYSTEM
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
14:49:35.232 FATAL: could not receive data from WAL stream: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
14:49:35.232 LOG: record with incorrect prev-link 142D46/315602C at 14CF/CF38C160
14:49:35.305 FATAL: could not connect to the primary server: FATAL: the database system is shutting down
14:49:40.241 FATAL: could not connect to the primary server: FATAL: the database system is shutting downВ какой-то момент реплика заработала, но репликация при этом не запустилась.
14:50:14.024 [] LOG: record with incorrect prev-link 142D46/315602C at 14CF/CF38C160
14:50:14.028 [] LOG: fetching timeline history file for timeline 72 from primary server
14:50:14.104 [] FATAL: could not start WAL streaming: ERROR: requested starting point 14CF/CF000000 on timeline 71 is not in this server's history
DETAIL: This server's history forked from timeline 71 at 14CF/CEC32E40.
14:50:14.104 [] LOG: new timeline 72 forked off current database system timeline 71 before current recovery point 14CF/CF38C160У меня есть единственная гипотеза: в recovery.conf был адрес старого мастера. Когда уже появился новый мастер, вторая реплика пыталась подключиться к старому мастеру. Когда Patroni запустился на второй реплике, узел запустился, но не смог подключиться по репликации. Образовался лаг репликации, который выглядел примерно так:
+-----------------+----------+--------------+--------+---------+-----------+
| Cluster | Member | Host | Role | State | Lag in MB |
+-----------------+----------+--------------+--------+---------+-----------+
| patroni_cluster | pgsql01 | 10.2.200.151 | Leader | running | 0.0 |
| patroni_cluster | pgsql02 | 10.2.200.152 | | running | 9153.0 |
| patroni_cluster | pgsql03 | 10.2.200.153 | | running | 0.0 |
+-----------------+----------+--------------+--------+---------+-----------+То есть все три узла были на месте, но второй узел отставал. Репликация не могла запуститься, потому что журналы транзакций отличались. Журналы транзакций, которые предлагал мастер, указанные в recovery.conf, просто не подходили текущему узлу. PostgreSQL каждые 5 секунд сообщал об ошибке
14:50:44.143 FATAL: could not start WAL streaming: ERROR: requested starting point 14CF/CF000000 on timeline 71 is not in this server's history
DETAIL: This server's history forked from timeline 71 at 14CF/CEC32E40.
14:50:44.143 LOG: new timeline 72 forked off current database system timeline 71 before current recovery point 14CF/ CF38C160Здесь я допустил ошибку и не проверил свою гипотезу, что мы подключаемся не к тому мастеру. Я просто перезапустил Patroni на реплике. Честно говоря, я уже поставил на ней крест и думал, что придется её переналивать, но все равно решил попробовать перезапустить.
15:14:13.511 LOG: consistent recovery state reached at 14CF/A3F657B0
15:14:13.511 LOG: database system is ready to accept read only connectionsЗапустился recovery, и даже база открылась, она была готова принимать соединение, репликация запустилась:
15:14:17.072 LOG: record with incorrect prev-link 142D46/315602C at 14CF/CF38C160
15:14:17.077 LOG: started streaming WAL from primary at 14CF/CF000000 on timeline 72
15:14:17.536 LOG: invalid record length at 14CF/CF38C160: wanted 24, got 1
Но через минуту отвалилась с ошибкой terminating walreceiver process due to administrator command — реплика сказала, что ей не подходят журналы транзакций.
15:15:27.823 FATAL: terminating walreceiver process due to administrator command
15:15:27.895 LOG: invalid record length at 14CF/CF38C160: wanted 24, got 1
15:15:27.895 LOG: invalid record length at 14CF/CF38C160: wanted 24, got 1Причем я не перезапускал PostgreSQL, а перезапускал именно Patroni в надежде, что он магическим образом запустит базу. Репликация снова запустилась, но база открылась на том же месте:
15:17:33.553 LOG: consistent recovery state reached at 14CF/A3F657B0
15:17:33.554 LOG: database system is ready to accept read only connectionsОтметки в журнале транзакций отличались, они были другими, чем в предыдущей попытке запуска — позиция журнала транзакция была раньше:
15:17:37.299 LOG: invalid contrecord length 5913 at 14CF/CEFFF7B0
15:17:37.304 LOG: started streaming WAL from primary at 14CF/CE000000 on timeline 72Репликация снова остановилась, причем сообщение об ошибке было другое и снова не особо информативное:
15:18:12.208 FATAL: terminating walreceiver process due to administrator command
15:18:12.240 LOG: record with incorrect prev-link 60995000/589DF000 at 14CF/CEFFF7B0
15:18:12.240 LOG: record with incorrect prev-link 60995000/589DF000 at 14CF/CEFFF7B0Для эксперимента рестартанул снова, база открывалась на том же месте:
15:21:25.135 LOG: consistent recovery state reached at 14CF/A3F657B0
15:21:25.135 LOG: database system is ready to accept read only connectionsТут мне пришла идея: что если я перезапущу PostgreSQL, в этот момент на текущем мастере сделаю чекпойнт, чтобы подвинуть точку в журнале транзакций чуть-чуть вперед и recovery началось с другого момента.
Запустил Patroni, сделал пару чекпоинтов на мастере, пару рестарт-пойнтов на реплике, когда она открылась:
15:22:43.727 LOG: invalid record length at 14D1/BCF3610: wanted 24, got 0
15:22:43.731 LOG: started streaming WAL from primary at 14D1/B000000 on timeline 72Это сработало — репликация запустилась уже с другого места и больше не рвалась. Но для меня это одна из наиболее загадочных проблем, над которой я до сих пор ломаю голову. Особенно тот странный immediate shutdown request.
Из этого можно сделать вывод: Patroni может отработать, как задумано и без ошибок, но это не стопроцентная гарантия того, что все на самом деле в порядке. После фейловера всегда нужно перепроверить, что с кластером все хорошо: нужное количество реплик, нет лага репликации.
Итоги
На основе этих и многих других подобных проблем я сформулировал общие рекомендации, которые советую иметь в виду при эксплуатации Patroni.
- Когда вы используете Patroni, у вас обязательно должен быть мониторинг. Всегда нужно знать, когда произошел автофейловер, потому что если вы не знаете, что у вас случился автофейловер, вы не контролируете кластер.
- После каждого фейловера всегда проверяйте кластер. Необходимо убедиться, что: реплик всегда актуальное количество; нет лага репликации; в логах нет ошибок, связанных с потоковой репликацией, с Patroni, с системой DCS.
Patroni — очень хороший инструмент, но это как ни крути не серебряная пуля. Автоматика может успешно отработать, но при этом объекты автоматики могут находиться в полурабочем состоянии. Все равно нужно иметь представление о том: как работает PostgreSQL и репликация, как Patroni управляет PostgreSQL и как обеспечивается взаимодействие между узлами. Это нужно для того, чтобы уметь чинить руками возникающие проблемы.
Этапы диагностики
Так сложилось, что мы работаем с разными клиентами, стека ELK по больше части у них нет, и приходится разбираться в логах, открыв 2 вкладки и 6 консолей: в одной вкладке Patroni для каждого узла, в другой — логи Consul либо PostgreSQL. Диагностировать все это тяжело.
Я выработал следующий подход. Я всегда смотрю, когда произошел фейловер. Для меня это некий водораздел. Я смотрю, что произошло до, во время и после фейловера. Фейловер имеет два timestamp — начало и конец. В логах я смотрю, что предшествовало фейловеру, то есть ищу причины. Это дает понимание картины, что происходило и что можно сделать в будущем, чтобы фейловер при таких же обстоятельствах не происходил.
Для этого я смотрю:
- Первым делом логи Patroni.
- Дальше логи PostgreSQL или логи DCS в зависимости от того, что нашлось в логах Patroni.
- Логи системы — они тоже иногда помогают понять, что послужило причиной фейловера.
Послесловие
Есть много других продуктов для автофейловера: stolon, repmgr, pg_auto_failover, PAF. Я пробовал все 4 инструмента и на мой взгляд Patroni — лучшее, что есть сегодня на рынке.
Рекомендую ли я Patroni? Определенно, да, потому что Patroni мне нравится, как мне кажется, я научился его готовить.
Если вам интересно посмотреть, какие еще бывают проблемы с Patroni, кроме описанных в статье, вы всегда можете зайти на страницу https://github.com/zalando/patroni/issues. Там много разных историй. Несмотря на то, что половина из них от неграмотных пользователей, которые задают глупые вопросы не удосужившись озаботиться простым поиском, там обсуждаются и интересные проблемы и по итогу обсуждений при необходимости открываются задачи на исправление багов.
Спасибо компании Zalando за то, что они развивают этот проект, а также двум людям, которые начинали работать над этим продуктом: Александру Кукушкину и Алексею Клюкину. Большое спасибо вообще всем контрибьюторам Patroni.
После этого доклада мы записали небольшое интервью, в котором Алексей попытался уместить свой доклад в один совет и рассказал, зачем участвовать и выступать на конференциях. Берите на вооружение и приходите проверять подход на Saint HighLoad++.
Питерский HighLoad++ запланирован на 6-7 апреля. Мы тщательно мониторим ситуацию с коронавирусом, изучаем рекомендации компетентных источников. В данный момент мы планируем провести конференцию в назначенные даты, предприняв целый ряд профилактических и информационных мер (каких именно, перечислили на специальной странице). В случае ухудшения ситуации или форс-мажоров мы перенесём конференцию с сохранением всех билетов, партнёрских опций, докладчиков и всех других обязательств, которые мы на себя берём.
Поэтому ждём вас на Saint HighLoad++! Тем более в программе, как всегда, много полезных докладов относятся к PostgreSQL: Олег Бартунов расскажет, что уже есть в PostgreSQL для работы с JSON и что скоро появится; Иван Панченко познакомит с фичами PostgreSQL 13, повышающими производительность; Николай Самохвалов разберёт распространённые ошибки изменения схемы БД.
I am learning Postgres and I have installed 3 VMs as follows:
node1 — Installed Postgres and etcd here
node2 — Installed Postgres and etcd here
node3 — Installed etcd here
I have setup streaming replication between node1 and node2 and it worked fine (even etcd health showed as fine for all 3 nodes).
Then I installed and configured Patroni on node1 and node2 and when I first started it node2 was promoted to master and node1 was acting as a slave. At the time I could access psql from both nodes but a change (I inserted a row in a table) I did in the master was not propagated to the slave.
I then stopped Patroni on node1 (slave) and restarted it but postgres on the slave is not starting and I cannot access psql on the slave either now. I don’t know whether I should be able to access the DB from the slave or not when using Patroni (I could with streaming replication), i.e. should the postgres service remain switched off by design on the slave when you have Patroni? As from my understanding if it finds that there is a master holding a lock, postgres on the slave will fail to start.
I then stopped postgres on master as I thought that it will failover to node 1 (and node1 to become a master) but no automatic failover occurred. Furthermore, postgres service is not starting on either now (not even on node2 — but I can connect using psql on node2 — which still seems to be the master). Should postgres service be showing as running on the master or it also fails to start by design and one should only check the status of Patroni? Patroni is active and running on both nodes.

When I try to start postgres on node2 (the node holding the lock):

Log on node1 (the slave):

etcd is working fine:

From my research I found that pg_rewind might help to get the slave in sync with my master, however, I’m not sure whether that is even my issue.
What do I need to do to fix this situation?
- I mainly need to start postgres on the master (I have no idea how I can use psql but postgres service is failing to start on the master).
- I need the slave to be able to promote itself to master (through Patroni), if the master fails.
My config files seem fine (especially since it was working fine prior to trying to switch off one instance for a failover to occur)
Recommend Projects
-

React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
I have follow this tutorial: https://linode.com/docs/databases/postgresql/create-a-highly-available-postgresql-cluster-using-patroni-and-haproxy/ , in order to set up Highly Available PostgreSQL Cluster Using Patroni and HAProxy.
But when I try to start patroni I get this error:
ubuntu@sudo patroni /etc/patroni.yml
2018-05-31 09:49:37,159 INFO: Failed to import patroni.dcs.consul
2018-05-31 09:49:37,166 INFO: Selected new etcd server http://privateetcdIP:2379
2018-05-31 09:49:37,173 INFO: Lock owner: None; I am postgresqlm
2018-05-31 09:49:37,175 INFO: trying to bootstrap a new cluster
pg_ctl: cannot be run as root
Please log in (using, e.g., "su") as the (unprivileged) user that will
own the server process.
2018-05-31 09:49:37,185 INFO: removing initialize key after failed attempt to bootstrap the cluster
2018-05-31 09:49:37,673 INFO: Lock owner: None; I am postgresqlm
Traceback (most recent call last):
File "/usr/local/bin/patroni", line 9, in <module>
load_entry_point('patroni==1.4.4', 'console_scripts', 'patroni')()
File "/usr/local/lib/python2.7/dist-packages/patroni/__init__.py", line 176, in main
return patroni_main()
File "/usr/local/lib/python2.7/dist-packages/patroni/__init__.py", line 145, in patroni_main
patroni.run()
File "/usr/local/lib/python2.7/dist-packages/patroni/__init__.py", line 114, in run
logger.info(self.ha.run_cycle())
File "/usr/local/lib/python2.7/dist-packages/patroni/ha.py", line 1164, in run_cycle
info = self._run_cycle()
File "/usr/local/lib/python2.7/dist-packages/patroni/ha.py", line 1077, in _run_cycle
return self.post_bootstrap()
File "/usr/local/lib/python2.7/dist-packages/patroni/ha.py", line 976, in post_bootstrap
self.cancel_initialization()
File "/usr/local/lib/python2.7/dist-packages/patroni/ha.py", line 971, in cancel_initialization
raise PatroniException('Failed to bootstrap cluster')
The configuration of /etc/patroni.yml is:
scope: postgres
namespace: /db/
name: postgresqlm
restapi:
listen: privateIPoffirstnode:8008
connect_address: privateIPoffirstnode:8008
etcd:
host: privateIPofetcd:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
max_connections: 100
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host replication replicator 127.0.0.1/32 md5
- host replication replicator privateIPoffirstnode/0 md5
- host replication replicator privateIPofsecondnode/0 md5
- host replication replicator privateIPofthirdnode/0 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: privateIPoffirstnode:5432
connect_address: privateIPoffirstnode:5432
data_dir: /data/patroni
pgpass: /tmp/pgpass
bin_dir: /usr/lib/postgresql/9.5/bin
authentication:
replication:
username: replicator
password: rep-pass
superuser:
username: postgres
password: '12345'
parameters:
unix_socket_directories: '.'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
The configuration of /etc/systemd/system/patroni.service is:
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /etc/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=multi-user.targ
etcd congiguration:
ETCD_LISTEN_PEER_URLS="http://privateIPofetcd:2380"
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://privateIPofetcd:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://privateIPofetcd:2380"
ETCD_INITIAL_CLUSTER="etcd0=http://privateIPofetcd:2380,"
ETCD_ADVERTISE_CLIENT_URLS="http://privateIPofetcd:2379"
ETCD_INITIAL_CLUSTER_TOKEN="cluster1"
ETCD_INITIAL_CLUSTER_STATE="new"
Of course, I have the real ips in privateIPoffirstnode, privateIPofsecondnode etc.
So, does anyone know what this error means?
 Обновлено: 26.09.2022
Обновлено: 26.09.2022
Опубликовано: 31.07.2022
Используемые термины: Patroni, Consul.
Кластер Postgresql, созданный штатными средствами не совсем удобен в эксплуатации — у него сложные механизмы отслеживания проблем с репликацией, нет возможности автоматического переключения с основной ноды на резервную и обратно, сложный процесс восстановления после падения. Приложение Patroni позволяет сделать процесс управления кластером Postgresql проще. Оно хранит данные кластера в базе типа key-value и ориентируется на работоспособность системы с помощью DCS (Distributed Control Service). В качестве таких систем для Patroni могут выступать:
- Consul Hashicorp.
- Kubernetes.
- Zookeeper.
- etcd.
В данной инструкции мы рассмотрим процесс установки и настройки Patroni с Consul.
Предполагается, что у нас уже есть кластер consul, а также серверы с установленным Postgresql (чистыми без полезных данных). На последних также должны быть установлены consul в режиме агента или сервера. Ссылки на необходимые материалы будут приведены в конце данной инструкции.
Подготовка системы
Установка и настройка
Политика для ACL на consul
Устранение проблем
Дополнительная информация
Предварительная настройка
Прежде чем перейти к настройке patroni и кластера, подготовим наши серверы баз данных.
Настройка брандмауэра
Если на наших серверах используется брандмауэр, то нам нужно открыть порт 5432, по которому работает postgresql, а также порт 8008 для patroni.
Вводим команды:
iptables -I INPUT -p tcp —dport 5432 -j ACCEPT
iptables -I INPUT -p tcp —dport 8008 -j ACCEPT
Для сохранения правил вводим:
apt install iptables-persistent
netfilter-persistent save
Подготовка СУБД
Patroni самостоятельно инициализирует базу и настройки, поэтому наш каталог с данными Postgresql должен быть чист, а сервис postgresql находится в выключенном состоянии.
Если на вашем сервере баз данных есть ценная информация, действия ниже приведут к ее потере. В этом случае стоит развернуть кластер на других серверах и перенести данные.
На наших серверах СУБД смотрим путь до каталога с данными:
su — postgres -c «psql -c ‘SHOW data_directory;'»
В моем случае для обоих серверов путь был /var/lib/postgresql/14/main — сохраняем путь. Скоро он нам понадобиться.
Останавливаем сервис postgres и запрещаем его автозапуск:
systemctl disable postgresql —now
Удаляем содержимое каталога с данными, путь до которого нам вернула команда SHOW data_directory:
rm -rf /var/lib/postgresql/14/main/*
Готово. Можно переходить к установке и настройке Patroni.
Установка и настройка Patroni
Данное приложение разработано на Python и требует установки как последнего, так и некоторых его компонентов.
Выполняем команду:
apt install python3 python3-pip python3-psycopg2
* в нашем примере мы будем работать с python версии 3. Также нам нужна библиотека для работы с postgresql python3-psycopg2.
Теперь ставим сам patroni, как приложение python:
pip3 install patroni[consul]
Установка завершена. Переходим к настройке.
Создадим каталог для хранения конфигурации:
mkdir /etc/patroni
И сам конфигурационный файл:
vi /etc/patroni/patroni.yml
name: postgres01.dmosk.local
scope: pgdb
watchdog:
mode: off
consul:
host: «localhost:8500»
register_service: true
#token: <consul-acl-token>
restapi:
listen: 0.0.0.0:8008
connect_address: «192.168.0.11:8008»
auth: ‘patrest:password’
bootstrap:
dcs:
ttl: 30
loop_wait: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
archive_mode: «on»
wal_level: hot_standby
max_wal_senders: 10
wal_keep_segments: 8
archive_timeout: 1800s
max_replication_slots: 5
hot_standby: «on»
wal_log_hints: «on»
initdb:
— encoding: UTF8
— data-checksums
pg_hba:
— local all all trust
— host replication replicator 192.168.0.0/24 md5
— host replication replicator 127.0.0.1/32 trust
— host all all 0.0.0.0/0 md5
postgresql:
pgpass: /var/lib/postgresql/14/.pgpass
listen: 0.0.0.0:5432
connect_address: «192.168.0.11:5432»
data_dir: /var/lib/postgresql/14/main/
bin_dir: /usr/lib/postgresql/14/bin/
pg_rewind:
username: postgres
password: password
pg_hba:
— local all all trust
— host replication replicator 192.168.0.0/24 md5
— host replication replicator 127.0.0.1/32 trust
— host all all 0.0.0.0/0 md5
replication:
username: replicator
password: password
superuser:
username: postgres
password: password
* данные конфигурационные файлы на разных серверах будут немного различаться. Опишем подробнее опции, на которые нам нужно обратить внимание:
- name — имя узла, на котором настраивается данный конфиг.
- scope — имя кластера. Его мы будем использовать при обращении к ресурсу, а также под этим именем будет зарегистрирован сервис в consul.
- consul — token — если наш кластер consul использует ACL, необходимо указать токен.
- restapi — connect_address — адрес на настраиваемом сервере, на который будут приходить подключения к patroni.
- restapi — auth — логин и пароль для аутентификации на интерфейсе API.
- pg_hba — блок конфигурации pg_hba для разрешения подключения к СУБД и ее базам. Необходимо обратить внимание на подсеть для строки host replication replicator. Она должна соответствовать той, которая используется в вашей инфраструктуре.
- postgresql — pgpass — путь до файла, который создаст патрони. В нем будет храниться пароль для подключения к postgresql.
- postgresql — connect_address — адрес и порт, которые будут использоваться для подключения к СУДБ.
- postgresql — data_dir — путь до файлов с данными базы.
- postgresql — bin_dir — путь до бинарников postgresql.
- pg_rewind, replication, superuser — логины и пароли, которые будут созданы для базы.
Создадим юнит в systemd для patroni:
vi /lib/systemd/system/patroni.service
[Unit]
Description=Patroni service
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /etc/patroni/patroni.yml
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=multi-user.target
* обратите внимание, что в официальной документации предлагается не перезапускать автоматически службу (Restart=no). Это дает возможность разобраться в причине падения базы.
Перечитываем конфигурацию systemd:
systemctl daemon-reload
Разрешаем автозапуск и стартуем сервис:
systemctl enable patroni —now
Проверяем статусы сервиса на обоих серверах:
systemctl status patroni
Посмотреть список нод
patronictl -c /etc/patroni/patroni.yml list pgdb
* где pgdb — имя нашей базы (указана с использованием директивы scope в конфигурационном файле patroni).
Мы должны увидеть что-то на подобие:
+————————+—————+———+———+—-+————+
| Member | Host | Role | State | TL | Lag in MB |
+ Cluster: pgdb (7126124696482454785) —+———+———+—-+————+
| postgres01.dmosk.local | 192.168.0.11 | Leader | running | 1 | |
| postgres02.dmosk.local | 192.168.0.12 | Replica | running | 1 | 0 |
+————————+—————+———+———+—-+————+
Можно проверить, что сервер консул разрешает имена кластера:
nslookup -port=8600 master.pgdb.service.consul 127.0.0.1
nslookup -port=8600 replica.pgdb.service.consul 127.0.0.1
* где consul — настроенный в consul домен.
Команды нам должны вернуть адреса соответствующих серверов — лидера и реплики.
Наш кластер в рабочем состоянии.
Использование ACL на сервере Consul
Как было сказано выше, если сервер консула использует проверку доступа на основе ACL, необходимо прописать token. Рассмотрим процесс подробнее.
Сначала на сервере консул создаем файл для политики:
cd /var/lib/consul
vi patroni-policy.json
service_prefix «» {
policy = «write»
}
session_prefix «» {
policy = «write»
}
key_prefix «» {
policy = «write»
}
node_prefix «» {
policy = «read»
}
agent_prefix «» {
policy = «read»
}
Для ее применения вводим команду:
consul acl policy create -name «patroni-policy» -rules @patroni-policy.json
Теперь создаем токен с привязкой к созданной политике:
consul acl token create -description «Token for Patroni» -policy-name patroni-policy
Мы должны увидеть что-то на подобие:
…
SecretID: 5adb466f-b6ee-9048-6458-e8edbffc42a3
…
Это и есть токен, который нужно прописать в конфигурационном файле patroni:
vi /etc/patroni/patroni.yml
…
consul:
…
token: 5adb466f-b6ee-9048-6458-e8edbffc42a3
Возможные ошибки
Рассмотрим некоторые ошибки, с которым пришлось столкнуться автору.
password authentication failed
При запуске службы на вторичном сервере (slave) не выполняется репликация и мы можем увидеть в логе сообщение:
pg_basebackup: error: FATAL: password authentication failed for user «replicator»
Причина: не создана учетная запись replicator на сервере postgresql.
Решение: переходим на master сервер. Заходим под пользователем postgres:
su — postgres
Создаем учетную запись для репликации:
createuser —replication -P replicator
Система потребует ввести пароль, который будет использоваться для учетной записи. В нашем примере в конфигурационном файле мы используем password, поэтому нужно ввести именно его.
Читайте также
Другие инструкции, имеющие отношение к кластеризации Postgres:
1. Установка и запуск PostgreSQL на Ubuntu.
2. Установка и настройка кластера Consul Hashicorp на Linux Ubuntu.
3. Установка агента Consul и примеры регистрации сервисов.
4. Настройка потоковой репликации PostgreSQL.
5. Мониторинг репликации PostgreSQL в Zabbix.
Patroni Troubleshooting
Generally once you have a Patroni cluster up and running, there is not much else that needs to be done for day to day operations and maintenance. However, High Availability is a complex topic, and there can be many subtle ways for a cluster to fail, eventually leading to an outage. This article will outline general tips and suggestions for common Patroni maintenance related tasks, as well as considerations and steps on how to recover from more serious issues. Check out the official Patroni Documentation for more in-depth details on how Patroni works.
Useful Maintenance Commands
Most of the time, you will be interacting with Patroni directly through their CLI application patronictl. When you run patronictl, you will get the following:
Usage: patronictl [OPTIONS] COMMAND [ARGS]...
Options:
-c, --config-file TEXT Configuration file
-d, --dcs TEXT Use this DCS
-k, --insecure Allow connections to SSL sites without certs
--help Show this message and exit.
Commands:
configure Create configuration file
dsn Generate a dsn for the provided member,...
edit-config Edit cluster configuration
failover Failover to a replica
flush Flush scheduled events
list List the Patroni members for a given Patroni
pause Disable auto failover
query Query a Patroni PostgreSQL member
reinit Reinitialize cluster member
reload Reload cluster member configuration
remove Remove cluster from DCS
restart Restart cluster member
resume Resume auto failover
scaffold Create a structure for the cluster in DCS
show-config Show cluster configuration
switchover Switchover to a replica
version Output version of patronictl command or a running Patroni...
The key commands you will want to be familiar with patronictl are:
failoverhistorylistpausereinitresumeversion
General Diagnosis Steps
Normally the first thing you would need to do on a Patroni cluster is to figure out if the cluster itself is reporting an issue or not. You can get an overall view of the state of the cluster with patronictl list. An example output is as follows:
$ patronictl list
+---------+------------------+----------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+------------------+----------------+--------+---------+----+-----------+
| master | patroni-master-0 | 192.168.0.1 | Leader | running | 7 | 0 |
| master | patroni-master-1 | 192.168.0.2 | | running | 7 | 0 |
| master | patroni-master-2 | 192.168.0.3 | | running | 7 | 0 |
+---------+------------------+----------------+--------+---------+----+-----------+
The columns you will care about the most are Role, State, TL and Lag in MB. The above output example shows a healthy cluster because:
- Only one pod is marked as Leader/Master under Role
- All pods are running under State
- All timelines are the same number as the Leader/Master under TL
- All values under Lag in MB are 0
If your cluster does not match the above 4 signals, you will need to determine next steps on how to repair a degraded cluster.
Partial Cluster Failure Recovery
Normally when one of the nodes in the cluster is not behaving correctly, you will be able to easily tell which one it is either through patronictl list or through the Pod overview in the OpenShift console. There can be many things that can make a Patroni node fail (WAL recovery corruption, general table inconsistencies, etc). A general rule of thumb is that as long as one of the nodes in the cluster is acting as master and behaving correctly, you can force a misbehaving node to reset and synchronize with the current leader.
To reset a specific node, run patronictl reinit <cluster_name> and then follow the CLI prompts. It will ask you to select which member needs to be reinitialized. After choosing, in nearly all cases, the defective node will reboot and align itself to the current Patroni timeline. Unless a spurious error appears, your cluster should now be restored.
Total Cluster Failure Recovery
While total cluster failure is an exceedingly rare situation in a container environment, it can sometimes happen such as with this incident. In this specific incident, our team was unfortunately not able to detect the initial Patroni cluster degredation incident and resolve it as outlined in the previous section. We ended up getting total cluster failure because of a series of cluster degredations over the span of a few days.
Analysis
As mentioned in the Root Cause of the incident report, we had a defective patroni-master-0 pod already for some extended amount of time. While this alone did not take down the cluster, it did leave it vulnerable. Since our StatefulSet had .spec.podManagementPolicy configured to OrderedReady, our StatefulSet would only deploy pods in sequential ascending order. When patroni-master-2 went down due to expected maintenance, it was unable to come back up because patroni-master-0 was still crash-looping. This left the cluster with only patroni-master-1 being the functional leader and no available replicas. When patroni-master-1 crashed, it was also unable to recover because patroni-master-0 was crash-looping (it never passed any health checks).
Recovery Plan
For this specific incident, we learned the following symptoms:
- Health checks (liveness/readiness probes) caused patroni-master-0 to endlessly crash-loop
- The StatefulSet being in
OrderedReadymode meant higher numbered pods would not be able to refresh while patroni-master-0 was defective - We were able to discover (based off of Kibana logs from the platform) that patroni-master-1 had our most recent «source of truth».
As such, our effective goal was to get patroni-master-1 online again and have it act as the leader/master. Once that was done, we could leverage that node to reinitialize and reset the other degraded nodes to restore the cluster.
Recovery Steps
The following are the general steps we performed in order to resolve the incident. The notes in italics provide the context and rationale for why each step is done.
- Connect a debug pod as patroni-master-0, and run
patronictl pauseon it.- Since none of the cluster members are functional, and we want to prevent patroni from automatically selecting a leader, we need to pause it.
- Modify the StatefulSet replica count to 0, and remove the liveness/readiness probes from the StatefulSet.
- We need to temporarily remove the health checks to prevent the pods from crash looping. The entire cluster must be shut down first to ensure the health check definitions disappear.
- Modify the StatefulSet replica count to 3.
- We want all patroni pods to be up, and a replica count of 3 will achieve this.
- At this time, we can expect no Postgres DB instances should be running because Patroni is paused.
- In the event this is not the case, you can manually run
pg_ctl -D /home/postgres/pgdata/pgroot/data stopto kill the database instance(s).
- Identify which of the patroni instances was the most recent master.
- This step will take a bit of guesswork, but we need to know which was the right master in order to recover correctly without losing data
- One way to determine this is to manually start up Postgres out of band with
pg_ctl -D /home/postgres/pgdata/pgroot/data start. - If the node is able to start up without showing any errors, it is possible that node was formerly the master node. If it crashes or exhibits any other errors, it’s likely that node is a corrupted replica.
- If there are still Kibana logs, you could search in there to try and determine which was the master before the cluster failed as an alternative.
- Restart the Postgres DB manually on patroni-master-1 with
patronictl restart master patroni-master-1- We want to make sure ONLY patroni-master-1 database is running.
- While the
pg_ctlcommand can spin up the database, we need Patroni to be the one spinning it up so that it can be managed correctly. - Make sure that if you did spin up Postgres manually, you tell it to stop before running the
patronictl restartcommand.
- Force Patroni to failover to patroni-master-1 if it is not already flagged as the leader.
- This is where we tell the cluster to make patroni-master-1 to be the master manully
- At this point, you will likely want to verify the data integrity of patroni-master-1 before proceeding. One of the ways you can do this is with
oc port-forwardand using a local machine DB tool of your choosing to inspect.
- Restore Patroni cluster management with
patroni resume.- With patroni-master-1 as the elected leader, we can let Patroni manage things again
- After running this command, some of the other cluster nodes will hopefully realign with the elected leader. Use
patronictl listfrequently to keep tabs on the situation.
- Hard reset the defective patroni-master-0 with
patronictl reinit master patroni-master-0.- We can now safely tell the defective node to reset to the timeline that patroni-master-1 is on and rebuild
- Run
patronictl listto check the status of the cluster. You want to ensure that all nodes are online and on the same timeline.
- Force a failover to patroni-master-0 with
patronictl failover master patroni-master-0.- As our StatefulSet spins up in OrderedReady configuration, node 0 will always be the first one to come up.
- By setting the master to node 0, we can ensure that when we shut down Patroni and reboot it later, it will be the rightful master instance.
- Modify the StatefulSet replica count to 0, and restore the liveness/readiness probes in the StatefulSet.
- In order to restore the health checks, we need to shut down the entire cluster again
- Modify the StatefulSet replica count to 3, and verify cluster health.
- Once the health check definitions are back, restart the cluster in full and verify that it is working as intended
- By the end of this step, you should have a fully operational Patroni database again with hopefully no data loss during the outage.
Prevention
One of the key lessons with this incident is that while Patroni High Availability is actually quite resilient the way it is designed, it can easily also mask degredation symptoms within the cluster. If these signals are not caught and dealt with early enough, you can end up in a total cluster failure situation. Going forwards, we can avoid this situation by being more vigilant with periodically checking that our Patroni clusters are healthy manually.
Down the road, it is more beneficial to have some form of monitoring and alerting system in place to inform the team when a pod in the cluster has become defective. One potential avenue for furthere exploration is to leverage the Patroni REST API and periodically probe that for statuses. Another avenue of consideration is to change the StatefulSet to be Parallel instead of OrderedReady. While this would prevent this specific incident from happening, there is a potential for a different class of issues (multiple leaders, deadlocks, etc) which could occur. More research will need to be done in order to evaluate the risk of both StatefulSet approaches.