- Build a wheel package need validation.py in the same folder with mk_
wheel.py
After adding this file (from /catboost folder):
F:Programspythoncatboost-mastercatboostpython-packagecatboost>F:Programs
pythonpython.exe F:Programspythoncatboost-mastercatboostpython-packagemk_
wheel.py -DPYTHON_INCLUDE=»/I F:Programspythoninclude» -DPYTHON_LIBRARIES=»F:
Programspythonlibspython27.lib»
F:Programspythonpython.exe F:Programspythoncatboost-master/ya make F:Prog
ramspythoncatboost-mastercatboostpython-packagecatboost —no-src-links -r —
-output c:userstestuserappdatalocaltemptmppst5fw -DUSE_ARCADIA_PYTHON=no —
DPYTHON_CONFIG=python-config -DPYTHON_INCLUDE=/I F:Programspythoninclude -DPY
THON_LIBRARIES=F:Programspythonlibspython27.lib -DPYTHON_INCLUDE=/I F:Progr
amspythoninclude -DPYTHON_LIBRARIES=F:Programspythonlibspython27.lib
Info: Attention! Using system user-defined compiler: cl.exe (check CC and CXX en
v vars).
Info: will fetch ‘YMake’ from sandbox
Traceback (most recent call last):
File «devtools/ya/entry/entry.py», line 157, in exit_interceptor
func()
File «devtools/ya/entry/entry.py», line 56, in
return lambda: wrapper(f)
File «devtools/ya/entry/entry.py», line 121, in f
res = func()
File «devtools/ya/entry/entry.py», line 250, in
run_main = lambda: do_main(args)
File «devtools/ya/entry/entry.py», line 49, in do_main
res = handler.handle(handler, args, prefix=[‘ya’])
File «devtools/ya/core/handler.py», line 157, in handle
return handler.handle(self, args[1:], prefix + [name])
File «devtools/ya/core/dispatch.py», line 37, in handle
return self.command().handle(root_handler, args, prefix)
File «devtools/ya/core/handler.py», line 337, in handle
return self._action(params)
File «devtools/ya/app.py», line 64, in helper
return action(ctx.params)
File «devtools/ya/build/build_handler.py», line 11, in do_ya_make
return YaMake(params, app_ctx).go()
File «devtools/ya/build/ya_make.py», line 519, in init
self.ctx = Context(self.opts, app_ctx=app_ctx, graph=graph, tests=tests, con
figure_errors=configure_errors, make_files=make_files)
File «devtools/ya/build/ya_make.py», line 347, in init
self.graph, self.tests, self.configure_errors, self.make_files = _build_grap
h_and_tests(self.opts, app_ctx)
File «devtools/ya/build/ya_make.py», line 282, in _build_graph_and_tests
graph, tests, gh, make_files = lg.build_graph_and_tests(opts, check=True, ev
_listener=ev_listener)
File «devtools/ya/build/graph.py», line 1372, in build_graph_and_tests
real_ymake_bin = ct.tool(‘ymake’)
File «devtools/ya/core/tools.py», line 214, in tool
return toolchain.find(name, with_params, for_platform)
File «devtools/ya/core/tools.py», line 152, in find
executable = cur_bottle[executable_name] # if executable_name is None it’s
Ok
File «devtools/ya/core/tools.py», line 60, in getitem
path = self.resolve()
File «devtools/ya/core/tools.py», line 42, in resolve
return self.__fetcher.fetch_if_need(self.__match, tared, binname).where
File «devtools/ya/yalibrary/fetcher/init.py», line 286, in fetch_if_need
self.__c[key] = self._fetch_if_need(*args, **kwargs)
File «devtools/ya/yalibrary/fetcher/init.py», line 296, in _fetch_if_need
if self._fetch(name, tared, lambda x: name.lower() in x.lower(), binname):
File «devtools/ya/yalibrary/fetcher/init.py», line 276, in _fetch
_install(self.where, do_install)
File «devtools/ya/yalibrary/fetcher/init.py», line 71, in _install
func(install_guard)
File «devtools/ya/yalibrary/fetcher/init.py», line 239, in do_install
http_client.download_file(url=config.mapping()[«resources»][by_platform[best
][«id»]], path=download_to)
File «devtools/ya/exts/retry.py», line 49, in wrapper
return retry(proxy_func, **retry_kwargs)
File «devtools/ya/exts/retry.py», line 22, in retry
return func()
File «devtools/ya/exts/retry.py», line 48, in
proxy_func = lambda: func(*args, **kwargs)
File «devtools/ya/exts/http_client.py», line 56, in download_file
res = urllib2.urlopen(request, timeout=timeout)
File «contrib/tools/python/src/Lib/urllib2.py», line 154, in urlopen
File «contrib/tools/python/src/Lib/urllib2.py», line 431, in open
File «contrib/tools/python/src/Lib/urllib2.py», line 449, in _open
File «contrib/tools/python/src/Lib/urllib2.py», line 409, in _call_chain
File «contrib/tools/python/src/Lib/urllib2.py», line 1227, in http_open
File «contrib/tools/python/src/Lib/urllib2.py», line 1194, in do_open
File «contrib/tools/python/src/Lib/httplib.py», line 1057, in request
File «contrib/tools/python/src/Lib/httplib.py», line 1097, in _send_request
File «contrib/tools/python/src/Lib/httplib.py», line 1053, in endheaders
File «contrib/tools/python/src/Lib/httplib.py», line 889, in _send_output
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xcd in position 16: ordinal
not in range(128)
Traceback (most recent call last):
File «F:Programspythoncatboost-mastercatboostpython-packagemk_wheel.py»,
line 102, in
wheel_name = build(arc_root, out_root, sys.argv[1:])
File «F:Programspythoncatboost-mastercatboostpython-packagemk_wheel.py»,
line 73, in build
subprocess.check_call(cmd)
File «F:Programspythonlibsubprocess.py», line 186, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command ‘[‘F:Programspythonpython.exe’, ‘F:
Programspythoncatboost-master/ya’, ‘make’, ‘F:Programspythoncatboost
-mastercatboostpython-packagecatboost’, ‘—no-src-links’, ‘-r’, ‘—output’
, ‘c:userstestuserappdatalocaltemptmppst5fw’, ‘-DUSE_ARCADIA_PYTHON=
no’, ‘-DPYTHON_CONFIG=python-config’, ‘-DPYTHON_INCLUDE=/I F:Programspython
include’, ‘-DPYTHON_LIBRARIES=F:Programspythonlibspython27.lib’, ‘-DPYT
HON_INCLUDE=/I F:Programspythoninclude’, ‘-DPYTHON_LIBRARIES=F:Programs
pythonlibspython27.lib’]’ returned non-zero exit status 1
Содержание
- No module named ‘_catboost’ #10
- Comments
- Footer
- pip installation? #5
- Comments
No module named ‘_catboost’ #10
Anaconda Windows x64, Python 3.5, install was ok:
pip install catboost
Jupiter Notebook code:
import numpy as np
from catboost import CatBoostClassifier
ImportError: No module named ‘_catboost’
ImportError: DLL load failed: Не найден указанный модуль.
The text was updated successfully, but these errors were encountered:
I have similar error on Anaconda Windows x64, Python 3.5:
got similar issue, Windows 10 x64, clean python 3.5, installed catboost through pip
This is because python 3.5 is specific, we load new version for python3.5 in pypi, try reinstall catboost:
pip install catboost —no-cache-dir
- Clone the repository:
git clone https://github.com/catboost/catboost.git - go to catboost/catboost/python-package
- run python mk_wheel.py
Here at the result you get some .whl file - run pip install catboost-. whl
After reinstall got «TypeError: the JSON object must be str, not ‘bytes’»
same as #2
This is because python 3.5 is specific, we load new version for python3.5 in pypi, try reinstall catboost:
pip install catboost —no-cache-dir
This helped, errors gone
New version has been uploaded to PyPi and to GitHub. Please try to reinstall CatBoost and check again.
I tried building from source on python 3.6.0 and also tried pip3 install catboost but I am getting same error:
Error Python 3 after installation catboost
/anaconda3/envs/dlaiwtpip/lib/python3.6/site-packages/catboost/__init__.py in —-> 1 from .core import FeaturesData, EFstrType, Pool, CatBoost, CatBoostClassifier, CatBoostRegressor, CatBoostError, cv, train, sum_models # noqa 2 from .version import VERSION as __version__ # noqa 3 __all__ = [‘FeaturesData’, ‘EFstrType’, ‘Pool’, ‘CatBoost’, ‘CatBoostClassifier’, ‘CatBoostRegressor’, ‘CatBoostError’, ‘CatboostError’, ‘cv’, ‘train’, ‘sum_models’] 4 5 # API compatibility alias.
/anaconda3/envs/dlaiwtpip/lib/python3.6/site-packages/catboost/core.py in 58 59 —> 60 _catboost = get_catboost_bin_module() 61 _PoolBase = _catboost._PoolBase 62 _CatBoost = _catboost._CatBoost
/anaconda3/envs/dlaiwtpip/lib/python3.6/site-packages/catboost/core.py in get_catboost_bin_module() 49 for so_path in so_paths: 50 try: —> 51 loaded_catboost = imp.load_dynamic(‘_catboost’, so_path) 52 sys.modules[‘catboost._catboost’] = loaded_catboost 53 return loaded_catboost
/anaconda3/envs/dlaiwtpip/lib/python3.6/imp.py in load_dynamic(name, path, file) 340 spec = importlib.machinery.ModuleSpec( 341 name=name, loader=loader, origin=path) —> 342 return _load(spec) 343 344 else: _catboost.pyx in init _catboost() AttributeError: type object ‘_catboost._FloatArrayWrapper’ has no attribute ‘__reduce_cython__’ «>
Anaconda Linux, Python 3.7, install was ok:
pip install catboost
Jupiter Notebook code:
import numpy as np
import catboost
ImportError: No module named ‘_catboost’
try this:
import sys
! -m pip install optuna
© 2023 GitHub, Inc.
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.
Источник
pip installation? #5
would be nice to be able install catboost with pip.
The text was updated successfully, but these errors were encountered:
pip install catboost doesn’t work?
it works, thanks! Sorry 🙂
the issue was, I’ve checked the installation page from https://tech.yandex.com/catboost/doc/dg/concepts/cli-installation-docpage/ and have not fount any pip installation. Reason for that is the page was about installation for R.
Doesn’t work. Windows7 python 2.7.
1.
F:ProgramspythonScripts>pip install catboost
Collecting catboost
Could not find a version that satisfies the requirement catboost (from version
s: )
No matching distribution found for catboost
- Downloading .whl file from https://pypi.python.org/pypi/catboost/0.1.1.3 didn’t help too (catboost-0.1.1.2-cp27-none-win_amd64.whl is not a supported wheel on this platfo
rm)
- Build from source
F:Programspythoncatboost-mastercatboostpython-packagecatboost>. ya
make -r -DUSE_ARCADIA_PYTHON=no -DPYTHON_INCLUDE=»/I F:Programspythoninclude
» -DPYTHON_LIBRARIES=»F:Programspythonlibspython27.lib»
Info: Attention! Using system user-defined compiler: cl.exe (check CC and CXX en
v vars).
Info: will fetch ‘YMake’ from sandbox
Traceback (most recent call last):
File «devtools/ya/entry/entry.py», line 157, in exit_interceptor
func()
File «devtools/ya/entry/entry.py», line 56, in
return lambda: wrapper(f)
File «devtools/ya/entry/entry.py», line 121, in f
res = func()
File «devtools/ya/entry/entry.py», line 250, in
run_main = lambda: do_main(args)
File «devtools/ya/entry/entry.py», line 49, in do_main
res = handler.handle(handler, args, prefix=[‘ya’])
File «devtools/ya/core/handler.py», line 157, in handle
return handler.handle(self, args[1:], prefix + [name])
File «devtools/ya/core/dispatch.py», line 37, in handle
return self.command().handle(root_handler, args, prefix)
File «devtools/ya/core/handler.py», line 337, in handle
return self._action(params)
File «devtools/ya/app.py», line 64, in helper
return action(ctx.params)
File «devtools/ya/build/build_handler.py», line 11, in do_ya_make
return YaMake(params, app_ctx).go()
File «devtools/ya/build/ya_make.py», line 519, in init
self.ctx = Context(self.opts, app_ctx=app_ctx, graph=graph, tests=tests, con
figure_errors=configure_errors, make_files=make_files)
File «devtools/ya/build/ya_make.py», line 347, in init
self.graph, self.tests, self.configure_errors, self.make_files = _build_grap
h_and_tests(self.opts, app_ctx)
File «devtools/ya/build/ya_make.py», line 282, in _build_graph_and_tests
graph, tests, gh, make_files = lg.build_graph_and_tests(opts, check=True, ev
_listener=ev_listener)
File «devtools/ya/build/graph.py», line 1372, in build_graph_and_tests
real_ymake_bin = ct.tool(‘ymake’)
File «devtools/ya/core/tools.py», line 214, in tool
return toolchain.find(name, with_params, for_platform)
File «devtools/ya/core/tools.py», line 152, in find
executable = cur_bottle[executable_name] # if executable_name is None it’s
Ok
File «devtools/ya/core/tools.py», line 60, in getitem
path = self.resolve()
File «devtools/ya/core/tools.py», line 42, in resolve
return self.__fetcher.fetch_if_need(self.__match, tared, binname).where
File «devtools/ya/yalibrary/fetcher/init.py», line 286, in fetch_if_need
self.__c[key] = self._fetch_if_need(*args, **kwargs)
File «devtools/ya/yalibrary/fetcher/init.py», line 296, in _fetch_if_need
if self._fetch(name, tared, lambda x: name.lower() in x.lower(), binname):
File «devtools/ya/yalibrary/fetcher/init.py», line 276, in _fetch
_install(self.where, do_install)
File «devtools/ya/yalibrary/fetcher/init.py», line 71, in _install
func(install_guard)
File «devtools/ya/yalibrary/fetcher/init.py», line 239, in do_install
http_client.download_file(url=config.mapping()[«resources»][by_platform[best
][«id»]], path=download_to)
File «devtools/ya/exts/retry.py», line 49, in wrapper
return retry(proxy_func, **retry_kwargs)
File «devtools/ya/exts/retry.py», line 22, in retry
return func()
File «devtools/ya/exts/retry.py», line 48, in
proxy_func = lambda: func(*args, **kwargs)
File «devtools/ya/exts/http_client.py», line 56, in download_file
res = urllib2.urlopen(request, timeout=timeout)
File «contrib/tools/python/src/Lib/urllib2.py», line 154, in urlopen
File «contrib/tools/python/src/Lib/urllib2.py», line 431, in open
File «contrib/tools/python/src/Lib/urllib2.py», line 449, in _open
File «contrib/tools/python/src/Lib/urllib2.py», line 409, in _call_chain
File «contrib/tools/python/src/Lib/urllib2.py», line 1227, in http_open
File «contrib/tools/python/src/Lib/urllib2.py», line 1194, in do_open
File «contrib/tools/python/src/Lib/httplib.py», line 1057, in request
File «contrib/tools/python/src/Lib/httplib.py», line 1097, in _send_request
File «contrib/tools/python/src/Lib/httplib.py», line 1053, in endheaders
File «contrib/tools/python/src/Lib/httplib.py», line 889, in _send_output
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xcd in position 16: ordinal
not in range(128)
- Build a wheel package need validation.py in the same folder with mk_
wheel.py
After adding this file (from /catboost folder):
F:Programspythoncatboost-mastercatboostpython-packagecatboost>F:Programs
pythonpython.exe F:Programspythoncatboost-mastercatboostpython-packagemk_
wheel.py -DPYTHON_INCLUDE=»/I F:Programspythoninclude» -DPYTHON_LIBRARIES=»F:
Programspythonlibspython27.lib»
F:Programspythonpython.exe F:Programspythoncatboost-master/ya make F:Prog
ramspythoncatboost-mastercatboostpython-packagecatboost —no-src-links -r —
-output c:userstestuserappdatalocaltemptmppst5fw -DUSE_ARCADIA_PYTHON=no —
DPYTHON_CONFIG=python-config -DPYTHON_INCLUDE=/I F:Programspythoninclude -DPY
THON_LIBRARIES=F:Programspythonlibspython27.lib -DPYTHON_INCLUDE=/I F:Progr
amspythoninclude -DPYTHON_LIBRARIES=F:Programspythonlibspython27.lib
Info: Attention! Using system user-defined compiler: cl.exe (check CC and CXX en
v vars).
Info: will fetch ‘YMake’ from sandbox
Traceback (most recent call last):
File «devtools/ya/entry/entry.py», line 157, in exit_interceptor
func()
File «devtools/ya/entry/entry.py», line 56, in
return lambda: wrapper(f)
File «devtools/ya/entry/entry.py», line 121, in f
res = func()
File «devtools/ya/entry/entry.py», line 250, in
run_main = lambda: do_main(args)
File «devtools/ya/entry/entry.py», line 49, in do_main
res = handler.handle(handler, args, prefix=[‘ya’])
File «devtools/ya/core/handler.py», line 157, in handle
return handler.handle(self, args[1:], prefix + [name])
File «devtools/ya/core/dispatch.py», line 37, in handle
return self.command().handle(root_handler, args, prefix)
File «devtools/ya/core/handler.py», line 337, in handle
return self._action(params)
File «devtools/ya/app.py», line 64, in helper
return action(ctx.params)
File «devtools/ya/build/build_handler.py», line 11, in do_ya_make
return YaMake(params, app_ctx).go()
File «devtools/ya/build/ya_make.py», line 519, in init
self.ctx = Context(self.opts, app_ctx=app_ctx, graph=graph, tests=tests, con
figure_errors=configure_errors, make_files=make_files)
File «devtools/ya/build/ya_make.py», line 347, in init
self.graph, self.tests, self.configure_errors, self.make_files = _build_grap
h_and_tests(self.opts, app_ctx)
File «devtools/ya/build/ya_make.py», line 282, in _build_graph_and_tests
graph, tests, gh, make_files = lg.build_graph_and_tests(opts, check=True, ev
_listener=ev_listener)
File «devtools/ya/build/graph.py», line 1372, in build_graph_and_tests
real_ymake_bin = ct.tool(‘ymake’)
File «devtools/ya/core/tools.py», line 214, in tool
return toolchain.find(name, with_params, for_platform)
File «devtools/ya/core/tools.py», line 152, in find
executable = cur_bottle[executable_name] # if executable_name is None it’s
Ok
File «devtools/ya/core/tools.py», line 60, in getitem
path = self.resolve()
File «devtools/ya/core/tools.py», line 42, in resolve
return self.__fetcher.fetch_if_need(self.__match, tared, binname).where
File «devtools/ya/yalibrary/fetcher/init.py», line 286, in fetch_if_need
self.__c[key] = self._fetch_if_need(*args, **kwargs)
File «devtools/ya/yalibrary/fetcher/init.py», line 296, in _fetch_if_need
if self._fetch(name, tared, lambda x: name.lower() in x.lower(), binname):
File «devtools/ya/yalibrary/fetcher/init.py», line 276, in _fetch
_install(self.where, do_install)
File «devtools/ya/yalibrary/fetcher/init.py», line 71, in _install
func(install_guard)
File «devtools/ya/yalibrary/fetcher/init.py», line 239, in do_install
http_client.download_file(url=config.mapping()[«resources»][by_platform[best
][«id»]], path=download_to)
File «devtools/ya/exts/retry.py», line 49, in wrapper
return retry(proxy_func, **retry_kwargs)
File «devtools/ya/exts/retry.py», line 22, in retry
return func()
File «devtools/ya/exts/retry.py», line 48, in
proxy_func = lambda: func(*args, **kwargs)
File «devtools/ya/exts/http_client.py», line 56, in download_file
res = urllib2.urlopen(request, timeout=timeout)
File «contrib/tools/python/src/Lib/urllib2.py», line 154, in urlopen
File «contrib/tools/python/src/Lib/urllib2.py», line 431, in open
File «contrib/tools/python/src/Lib/urllib2.py», line 449, in _open
File «contrib/tools/python/src/Lib/urllib2.py», line 409, in _call_chain
File «contrib/tools/python/src/Lib/urllib2.py», line 1227, in http_open
File «contrib/tools/python/src/Lib/urllib2.py», line 1194, in do_open
File «contrib/tools/python/src/Lib/httplib.py», line 1057, in request
File «contrib/tools/python/src/Lib/httplib.py», line 1097, in _send_request
File «contrib/tools/python/src/Lib/httplib.py», line 1053, in endheaders
File «contrib/tools/python/src/Lib/httplib.py», line 889, in _send_output
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xcd in position 16: ordinal
not in range(128)
Traceback (most recent call last):
File «F:Programspythoncatboost-mastercatboostpython-packagemk_wheel.py»,
line 102, in
wheel_name = build(arc_root, out_root, sys.argv[1:])
File «F:Programspythoncatboost-mastercatboostpython-packagemk_wheel.py»,
line 73, in build
subprocess.check_call(cmd)
File «F:Programspythonlibsubprocess.py», line 186, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command ‘[‘F:Programspythonpython.exe’, ‘F:
Programspythoncatboost-master/ya’, ‘make’, ‘F:Programspythoncatboost
-mastercatboostpython-packagecatboost’, ‘—no-src-links’, ‘-r’, ‘—output’
, ‘c:userstestuserappdatalocaltemptmppst5fw’, ‘-DUSE_ARCADIA_PYTHON=
no’, ‘-DPYTHON_CONFIG=python-config’, ‘-DPYTHON_INCLUDE=/I F:Programspython
include’, ‘-DPYTHON_LIBRARIES=F:Programspythonlibspython27.lib’, ‘-DPYT
HON_INCLUDE=/I F:Programspythoninclude’, ‘-DPYTHON_LIBRARIES=F:Programs
pythonlibspython27.lib’]’ returned non-zero exit status 1
That’s weird, pip install catboost works for me on both Python 2.7 and 3.6 on Windows as well as Linux.
I think my problem is version of python. Catboost is avaliable only for 64 bit python, but I have 32 bit ((
import sys
print sys.maxsize>2**32
False
same problem with malugina. Dear mxbi will You give responce for sys.getdefaultencoding() on Your system for check all environments? thnks
yes. pip install catboost works on Windows7, Python27 x64.
@ferrr can you look at the problem? Seems like ya cannot download binaries for 32bit system, maybe diagnostic should be improved.
We don’t support 32bit python, please try using 64bit version. Let us know if there are other problems.
Источник
Я успешно установил CatBoost через
pip install catboost
Но у меня возникли ошибки, когда я попробовал образец python script в Jupiter Notebook
import numpy as np
from catboost import CatBoostClassifier
ImportError: No module named '_catboost'
ImportError: DLL load failed: Не найден указанный модуль.
Ссылка на сайт CatBoost: https://catboost.yandex/
18 июль 2017, в 14:23
Поделиться
Источник
1 ответ
Если вы используете python 3.5, пип, возможно, загрузите не правильную версию колеса.
Вместо catboost-0.1.1.2-py3-none-win_amd64.whl вам нужно
catboost-0.1.1.2-cp35-none-win_amd64.whl.
Попробуйте переустановить catboost:
pip install catboost --no-cache-dir
Dmitry Donskov
18 июль 2017, в 17:06
Поделиться
Ещё вопросы
- 0Дочерний div рядом с родительским div, внизу
- 1Для каждого цикла, который неожиданно ведет себя с коллекцией LINQ
- 0Mysql подзапрос в concat
- 0Как запретить просмотр кода сайта
- 1Как найти, используя директивы
- 1Применить функцию к словарю данных
- 0FullCalendar: открыть событие gcal в новой вкладке / окне
- 1Изменение product.GetSeName () на Product.SeName Nopcommerce 2.40
- 1Android — сохранение состояния активности при запуске новой активности
- 0JQuery, если / еще предупреждение, изменить цвет в зависимости от ответа
- 0_mysql_exceptions.ProgrammingError 1064, «У вас есть ошибка в синтаксисе SQL; проверьте
- 1pip install производит «Не удалось найти версию, которая удовлетворяет требованию»
- 1ProgressDialog не появляется, пока не стало слишком поздно
- 0передать функцию видимости клонированной (и скомпилированной) угловой директиве
- 1Удаление определенного пользователя из массива javascript
- 0фильтр вложенных массивов с помощью angularjs-checkboxes-with-angularjs
- 1Как мне указать пункт назначения android.os.Message?
- 0Перезагрузить родительское окно Javascript возникла
- 0OpenCV VideoCapture :: set () возвращает false, но успешно
- 0Найти самую большую сумму из всех, она содержит числа и
- 1Pandas applymap метод с передачей имени столбца в качестве параметра
- 0как получить доступ к переменной $ _SESSION в symfony2
- 1То же действие по добавлению, но разные результаты в Javascript
- 0плагин проверки формы jquery с использованием селектора, а не формы
- 0Поиск с учетом регистра в SQL не работает
- 1Могу ли я воссоздать исходный код и файлы решения для веб-сайта ASP.NET?
- 1Извлечение индексов столбцов, где dtype это «объект» в Pandas
- 1Прото-сообщение, требующее использования параметра ref при попытке создать экземпляр
- 1Как найти устройства USB и общаться с ними, используя pySerial в Android?
- 1Firebase: User.photoUrl в строку
- 1Добавление TextViews в TableLayout «наращиваемый»
- 0Обнаружение изменения значения текстовой области
- 1Фильтр панд df по значениям
- 0Вложенные данные ng-repeat неправильно привязаны к директиве
- 0Распечатать массив в sendmail
- 0Бесконечный цикл с обработкой файлов и istringstreams
- 1В чем секрет хостинга пользовательских KML для использования в Google Maps Mobile?
- 1Использование Stimulreport на удаленной виртуальной машине
- 0Как убедиться, что все файлы CSS и JS на веб-странице или в приложении для Android загружены?
- 1Интерпретировать / dev / input / mice в Java
- 0Область действия ng-click на динамически создаваемой кнопке, не работающей на Google Map
- 0Как запустить угловой кодовый фрагмент в Ionic Framework
- 1Перехватить наOptionsItemSelected
- 0разбить строку, когда числа появляются впервые
- 1Файлы epub не загружаются [ANDROID]
- 0Получение номера ручки открытой на поток
- 0Создание объекта программно в ActionScript Error
- 0C ++ iostream не работает должным образом
- 1WebAssembly.Compile запрещен в основном потоке, если размер буфера больше 4 КБ
- 0Угловое обновление вар в сервисе

> What is CatBoost?¶
Catboost is an open-source machine learning library that provides a fast and reliable implementation of gradient boosting on decision trees algorithm (gradient boosted decision trees). Gradient boosted trees is a type of gradient booting machines algorithm where all estimators of ensemble are decision trees. It combines predictions of these weak tree learners to predict final output.
It can be used for classification, regression, ranking, and other machine learning tasks.
Catboost is developed by Yandex researchers and developers. It’s used by various companies for tasks like search, recommendation systems, personal assistants, self-driving cars, weather prediction, etc.
> Why Use «CatBoost» over Other Python Gradient Boosting Libraries?¶
Catboost provided support for handling categorical and text features of the data without the developer needing to handle them separately.
Catboost also provides support for grid search and randomized search which lets us try out a list of values for parameters to find the best combination of parameters that gives the best results.
Catboost algorithm gives quite a good accuracy with default parameter settings.
Apart from this, catboost also provides support for running the training process on GPU. It even lets us run the training process on multiple GPUs with simple configurations.
Catboost provides API in Python and R.
> What Can You Learn From This Article?¶
As a part of this tutorial, we have explained how to use Python library CatBoost to solve machine learning tasks (Classification & Regression). We have explained majority of CatBoost API with simple and easy-to-understand examples.
Apart from training models & making predictions, we have explained concepts like hyperparameters tuning, cross-validation, saving & loading model, recovering from interrupted training, early stopping to avoid overfitting, creating custom loss function, creating a custom evaluation metric, etc.
All our examples are trained on toy datasets (structured — tabular) available from scikit-learn to keep things simple and easy to grasp.
One of our sections at last also explains how to use CatBoost with text datasets.
Tutorial is designed to get individuals started with using CatBoost and learn end-to-end Python API of Catboost.
> Which Other Python Libraries Provides Implementation Of Gradient Boosted Trees?¶
- XGBoost
- LightGBM
- Scikit-Learn
> How to Install CatBoost?¶
- PIP
- pip install -U catboost
- Conda
- conda install catboost
Below, we have listed important sections of tutorial to give an overview of the material covered. We know that the list below is big but you can skip some sections of tutorial which has a theory or repeat example of some concepts. We have included NOTE in those sections so you can skip them to complete tutorial faster. You can then refer to those sections in your free time or as per need.
Important Sections Of Tutorial¶
- Load Datasets for Tutorial
- Boston Housing Dataset for Regression Tasks
- Breast Cancer Dataset for Binary Classification Tasks
- Wine Dataset for Multi-Class Classification Tasks
- CatBoost Models/Estimators at High-Level
- CatBoost: Regression Example
- 3.1 Train Simple CatBoost Model, Make Predictions, and Evaluate Performance of Model
- 3.2 Important Attributes & Methods of CatBoost Object
- 3.3 How to Perform Hyperparameters Tunning with CatBoost?
- Grid Search Example
- Random Search Example
- 3.4 Important Parameters of CatBoost() Constructor
- 3.5 Important Parameters of Catboost.fit() Methods
- CatBoost: Regression (Pool Data Structure to Represent Datasets)
- Important Parameters Of «Pool()» Constructor
- CatBoost: Binary Classification Example
- CatBoost: Multi-Class Classification Example
- CatBoostRegressor (Scikit-Learn Like API)
- CatBoostClassifier (Scikit-Learn Like API)
- Binary Classification Example
- Multi-Class Classification Example
- Cross Validation
- Saving and Loading Model
- Plotting Functionalities in CatBoost
- Visualize Training Loss and Metric Values
- Visualize Individual Tree of Ensemble using «plot_tree()»
- Visualize Important Statistics of Data Features using «calc_feature_statistics()»
- Visualize Individual Predictions using «plot_predictions()»
- Partial Dependence Plot of Features using «plot_partial_dependence()»
- Visualization to Compare Performance Of Different Models using «compare()»
- How to Compare Performance Of Different CatBoost Models?
- Recovering Interrupted Training using Snapshots
- Early Stop Training to Avoid Overfitting
- Monotonic Constraints
- Custom Evaluation Metric Function
- Custom Objective/Loss Function
- Text Data Example
- GPU Support
We’ll start by importing the necessary libraries.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import warnings warnings.filterwarnings("ignore") pd.set_option("display.max_columns", 50) import catboost import sklearn print("CatBoost Version : ", catboost.__version__) print("Scikit-Learn Version : ", sklearn.__version__)
CatBoost Version : 1.0.6 Scikit-Learn Version : 1.0.2
1. Load Datasets ¶
We’ll be using the below-mentioned three different datasets which are available from sklearn as a part of this tutorial for explanation purposes.
- Boston Housing Dataset: It’s a regression problem dataset which has information about the various attribute of houses in Boston and their price in dollar. This will be used for regression tasks.
- Breast Cancer Dataset: It’s a classification dataset which has information about two different types of tumor. It’ll be used for explaining binary classification tasks.
- Wine Dataset — It’s a classification dataset which has information about ingredients used in three different types of wines. It’ll be used for explaining multi-class classification tasks.
We have loaded all three datasets mentioned one by one below. We have printed descriptions of datasets which gives us an overview of dataset features and size. We have even loaded each dataset as a pandas data frame and displayed the first few samples of data.
Boston Housing Dataset¶
from sklearn.datasets import load_boston boston = load_boston() for line in boston.DESCR.split("n")[5:29]: print(line) boston_df = pd.DataFrame(data=boston.data, columns = boston.feature_names) boston_df["Price"] = boston.target boston_df.head()
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | Price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Breast Cancer Dataset¶
from sklearn.datasets import load_breast_cancer breast_cancer = load_breast_cancer() for line in breast_cancer.DESCR.split("n")[5:31]: print(line) breast_cancer_df = pd.DataFrame(data=breast_cancer.data, columns = breast_cancer.feature_names) breast_cancer_df["TumorType"] = breast_cancer.target breast_cancer_df.head()
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 3 is Mean Radius, field
13 is Radius SE, field 23 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | radius error | texture error | perimeter error | area error | smoothness error | compactness error | concavity error | concave points error | symmetry error | fractal dimension error | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | TumorType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | 1.0950 | 0.9053 | 8.589 | 153.40 | 0.006399 | 0.04904 | 0.05373 | 0.01587 | 0.03003 | 0.006193 | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | 0.5435 | 0.7339 | 3.398 | 74.08 | 0.005225 | 0.01308 | 0.01860 | 0.01340 | 0.01389 | 0.003532 | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | 0.7456 | 0.7869 | 4.585 | 94.03 | 0.006150 | 0.04006 | 0.03832 | 0.02058 | 0.02250 | 0.004571 | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | 0.4956 | 1.1560 | 3.445 | 27.23 | 0.009110 | 0.07458 | 0.05661 | 0.01867 | 0.05963 | 0.009208 | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | 0.7572 | 0.7813 | 5.438 | 94.44 | 0.011490 | 0.02461 | 0.05688 | 0.01885 | 0.01756 | 0.005115 | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Wine Dataset¶
from sklearn.datasets import load_wine wine = load_wine() for line in wine.DESCR.split("n")[5:29]: print(line) wine_df = pd.DataFrame(data=wine.data, columns = wine.feature_names) wine_df["WineType"] = wine.target wine_df.head()
**Data Set Characteristics:**
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | WineType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
2. CatBoost Models at High-Level (High-Level API)¶
CatBoost provides three different estimators to perform classification and regression tasks.
- CatBoost — It’s a universal estimator which can handle both classification and regression datasets with settings.
- CatBoostRegressor — It is an estimator with scikit-learn like API designed to work with regression datasets.
- CatBoostClassifier — It is an estimator with scikit-learn like API designed to work with classification datasets.
3. CatBoost: Regression Example ¶
The simplest way to train a model in Catboost is by initializing the CatBoost estimator. The CatBoost constructor accepts only one parameter named params which is a dictionary of parameters to be used to create an estimator. It has one main parameter named loss_function based on the value of this parameter it determines whether the task is regression or classification. We can create a CatBoost estimator without passing any parameter and it’ll create an estimator with loss function as root mean squared error which is used for regression tasks. All the parameters have some defined default values which we’ll list down at the end of this section. By default, the CatBoost estimator trains for 1000 iterations creating 1000 trees. It’s an alias to the n_estimators parameter which limits the number of trees.
3.1 Train Simple CatBoost Model, Make Predictions and Evaluate Performance ¶
Below we have created our first CatBoost estimator using the RMSE loss function. We have passed an iteration value of 100 to train it for 100 iterations. The verbose value of 10 will print results at every 10 iterations. The training process will create an ensemble of 100 trees.
In the next cell, we have divided the Boston housing dataset into the train (90%) and test (10%) sets using scikit-learn’s train_test_split() function.
from catboost import CatBoost booster = CatBoost(params={'iterations':100, 'verbose':10, 'loss_function':'RMSE'}) booster
<catboost.core.CatBoost at 0x7fa71fbd9978>
from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) X_train.shape, X_test.shape, Y_train.shape, Y_test.shape
((455, 13), (51, 13), (455,), (51,))
We are now training our gradient boosting estimator created from previous steps by calling the fit() method on it passing it train data and labels. The fit() method accepts many other parameters which we’ll explain as we go ahead with the tutorial. We have then called the set_feature_names() method which can be used to set feature names for each column of data.
booster.fit(X_train, Y_train) booster.set_feature_names(boston.feature_names)
Learning rate set to 0.195221 0: learn: 7.9013401 total: 49.9ms remaining: 4.94s 10: learn: 3.5505266 total: 71.7ms remaining: 580ms 20: learn: 2.5639279 total: 87.4ms remaining: 329ms 30: learn: 2.1352590 total: 96.8ms remaining: 215ms 40: learn: 1.8986418 total: 104ms remaining: 150ms 50: learn: 1.7054125 total: 110ms remaining: 106ms 60: learn: 1.5124150 total: 116ms remaining: 73.9ms 70: learn: 1.3810154 total: 122ms remaining: 49.7ms 80: learn: 1.2817508 total: 127ms remaining: 29.9ms 90: learn: 1.1909646 total: 133ms remaining: 13.2ms 99: learn: 1.0946543 total: 138ms remaining: 0us
The CatBoost estimator provides the method predict() which accepts feature values and returns model predictions. We have below calculated predictions for train and test datasets.
test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) test_preds[:5], train_preds[:5]
(array([27.31252602, 25.46937914, 48.40820072, 17.59846592, 31.75154109]), array([29.06693798, 20.01352158, 10.58013016, 20.45851082, 14.61395818]))
We can evaluate model performance using the eval_metric() method available from the utils module of catboost. The method accepts actual labels, predictions, and a list of metrics to evaluate. We’ll later list down a list of available metrics with catboost. We have evaluated the R2 metric on both train and test sets below.
from catboost.utils import eval_metric print("Test R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Test R2 : 0.83 Train R2 : 0.99
3.2 Important Attributes & Methods of «CatBoost» Object ¶
We’ll now list down a list of important attributes and methods of the CatBoost estimator. Please make a note that this is not a list of all possible attributes and methods. There are many more methods which we’ll cover later as well.
Attributes¶
- best_score_ — It returns the best score of the model.
- classes_ — It returns list of classes for classification problem.
- feature_names_ — It returns list of feature names.
- feature_importances_ — It returns the importance of each feature per algorithm.
- learning_rate_ — It returns the learning rate of the algorithm.
- random_seed_ — It returns a random seed from which initial model weights were assigned.
- tree_count_ — It returns the number of trees in the ensemble.
- n_features_in_ — It returns the number of features used to train the model.
- evals_result — It returns dictionary of evaluation. If we have provided an evaluation set then evaluation results for it will be included.
print("Best Score : ",booster.best_score_) print("nList of Target Classses : ",booster.classes_) print("nData Feature Names : ",booster.feature_names_) print("nFeature Importance : ", booster.feature_importances_) print("nLearning Rate : ",booster.learning_rate_) print("nRandom Seed : ",booster.random_seed_) print("nNumber of Trees : ",booster.tree_count_) print("nNumber of Features : ",booster.n_features_in_)
Best Score : {'learn': {'RMSE': 1.0946543114564808}}
List of Target Classses : []
Data Feature Names : ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
Feature Importance : [ 5.92222613 0.63347651 1.30753294 0.51512493 4.23171093 36.80942036
4.56455622 6.41080691 1.84345698 2.59364321 6.58149125 2.74532378
25.84122985]
Learning Rate : 0.19522100687026978
Random Seed : 0
Number of Trees : 100
Number of Features : 13
Methods¶
- get_best_score() — It returns best score of the estimator.
- get_params() — It returns parameters which were given as dictionary when creating CatBoost estimator and their values as dictionary.
- get_all_params() — It returns list of all parameters of CatBoost estimator and their values as dictionary.
- get_cat_feature_indices() — It returns list of indices which has categorical features.
- get_feature_importance() — It returns feature importance of individual feature according to trained model.
- shrink(ntree_end, ntree_start=0) — It accepts two arguments which are end tree and starts tree to shrink ensemble to include only trees that come in that index range discarding all other trees.
- set_params() — It can be used to set parameters of the estimator. Please make a note that this method will only work before the training model.
- calc_leaf_indexes(data, ntree_start=0,ntree_end=0) — It takes as input data and returns index of leaf in each tree which was used to make prediction for sample. The output of this function will be n_samples x n_trees. It’ll return all trees’ leaf index for a sample.
- get_leaf_values() — It returns actual leaf values of the trees in ensemble.
- get_leaf_weights() — It returns leaf weights for each leaf of the trees in the ensemble.
leaf_indices = booster.calc_leaf_indexes(X_train) print("Leaf Indices Size : ",leaf_indices.shape) leaf_indices[:2]
Leaf Indices Size : (455, 100)
array([[33, 16, 4, 8, 35, 9, 10, 9, 42, 35, 21, 6, 7, 20, 55, 26,
22, 33, 16, 10, 18, 1, 54, 27, 17, 4, 20, 2, 45, 9, 12, 19,
11, 32, 21, 35, 36, 33, 25, 8, 1, 45, 1, 21, 23, 27, 40, 13,
17, 5, 26, 21, 4, 16, 8, 13, 37, 17, 47, 9, 5, 4, 12, 50,
36, 61, 33, 5, 51, 4, 9, 24, 17, 37, 33, 5, 33, 8, 33, 0,
45, 2, 48, 14, 22, 10, 61, 14, 58, 15, 10, 13, 12, 32, 38, 11,
0, 5, 36, 33],
[36, 34, 20, 28, 51, 25, 34, 41, 42, 27, 53, 6, 35, 4, 55, 26,
54, 23, 4, 10, 31, 43, 46, 27, 5, 3, 61, 2, 39, 9, 8, 25,
11, 9, 21, 43, 6, 45, 25, 9, 49, 45, 35, 23, 23, 27, 63, 13,
17, 53, 58, 21, 12, 51, 8, 29, 37, 17, 51, 43, 53, 24, 15, 50,
36, 61, 33, 37, 35, 45, 9, 24, 49, 61, 33, 61, 35, 8, 33, 56,
61, 37, 53, 9, 62, 58, 61, 14, 57, 15, 10, 13, 36, 32, 46, 63,
2, 37, 36, 33]], dtype=uint32)
print("Parameters Passed When Creating Model : ",booster.get_params()) print("nAll Model Parameters : ",booster.get_all_params())
Parameters Passed When Creating Model : {'iterations': 100, 'verbose': 10, 'loss_function': 'RMSE'}
All Model Parameters : {'nan_mode': 'Min', 'eval_metric': 'RMSE', 'iterations': 100, 'sampling_frequency': 'PerTree', 'leaf_estimation_method': 'Newton', 'grow_policy': 'SymmetricTree', 'penalties_coefficient': 1, 'boosting_type': 'Plain', 'model_shrink_mode': 'Constant', 'feature_border_type': 'GreedyLogSum', 'bayesian_matrix_reg': 0.10000000149011612, 'l2_leaf_reg': 3, 'random_strength': 1, 'rsm': 1, 'boost_from_average': True, 'model_size_reg': 0.5, 'subsample': 0.800000011920929, 'use_best_model': False, 'random_seed': 0, 'depth': 6, 'posterior_sampling': False, 'border_count': 254, 'classes_count': 0, 'auto_class_weights': 'None', 'sparse_features_conflict_fraction': 0, 'leaf_estimation_backtracking': 'AnyImprovement', 'best_model_min_trees': 1, 'model_shrink_rate': 0, 'min_data_in_leaf': 1, 'loss_function': 'RMSE', 'learning_rate': 0.19522100687026975, 'score_function': 'Cosine', 'task_type': 'CPU', 'leaf_estimation_iterations': 1, 'bootstrap_type': 'MVS', 'max_leaves': 64}
print("nBest Score : ",booster.get_best_score()) print("nCategorical Feature Indices : ",booster.get_cat_feature_indices()) print("nFeature Importances : ",booster.get_feature_importance())
Best Score : {'learn': {'RMSE': 1.0946543114564808}}
Categorical Feature Indices : []
Feature Importances : [ 5.92222613 0.63347651 1.30753294 0.51512493 4.23171093 36.80942036
4.56455622 6.41080691 1.84345698 2.59364321 6.58149125 2.74532378
25.84122985]
print("nLeaf Values Shape : ", booster.get_leaf_values().shape) print("nLeaf Values : ", booster.get_leaf_values()[:10]) print("nLeaft Weights Shape : ",booster.get_leaf_weights().shape) print("nLeaft Weights : ",booster.get_leaf_weights()[:10])
Leaf Values Shape : (6400,) Leaf Values : [ 0. -0.13355947 0. 0. 0. 0. 0. 0. 0. -0.48615764] Leaft Weights Shape : (6400,) Leaft Weights : [0. 4. 0. 0. 0. 0. 0. 0. 0. 3.]
Shrink Estimator by Reducing Number of Trees in Ensemble¶
Below we have explained how we can use the shrink() method. We have reduced our original ensemble from 100 to 50 trees. We have then evaluated the R2 metric on the train and test sets. We can notice a visible change in the R2 score by decreasing the number of trees in the ensemble.
booster.shrink(ntree_end=50) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("Test R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Test R2 : 0.81 Train R2 : 0.96
3.3 How to Perform Hyperparameters Tunning with CatBoost? ¶
3.3.1 Grid Search¶
The CatBoost estimator lets us perform grid search as well using the grid_search() method of the estimator. In order to do a grid search, we need to create an estimator without setting parameters that we want to try. We then call the grid_search() method on the estimator instance by giving it parameters dictionary and data to try different parameter combinations.
If you are interested in learning about grid search and randomized search from scikit-learn then please feel free to check our tutorial on the same.
- Scikit-Learn: Cross-Validation and Hyperparameter Tunning using Grid Search
Important Parameters of «grid_search()»¶
- param_grid — It accepts a dictionary of parameter names and a list of values to try for that parameters.
- X — It accepts numpy array, pandas dataframe, ‘catboost.Pool’ data structure which has feature values.
- y — It accepts target labels of data. If we are using the catboost.Pool data structure which has labels info then we don’t need to pass this parameter value.
- cv — It accepts integer or sklearn data splitter classes (KFold, StratifiedKFold, ShuffleSplit, StratifiedShuffleSplit). If we give an integer as input then that many folds of data will be created for training. The default value of the parameter is 3.
- calc_cv_statistics — It accepts boolean value specifying whether to calculate cross-validation statistics. The default is True.
- refit — It accepts boolean values specifying whether to train a model using the best parameter setting found using cross-validation. The default is True.
- stratified — It performs stratified partition of the dataset so that class proportion is maintained in sets. The default is True.
The method returns a dictionary with two keys.
- Best parameter settings.
- Cross-validation results.
Below we are explaining how we can perform a grid search with an example. We are trying different values of parameters iterations, learning_rate and booststrap_type. We are using training data created from the Boston dataset earlier. We have then evaluated the performance of the estimator with the best setting by calculating the R2 score on the train and test dataset.
booster = CatBoost() params = { 'iterations':[10,50], 'learning_rate':[0.01, 0.1], 'bootstrap_type':['Bayesian', 'Bernoulli', 'No'] } search_results = booster.grid_search(params, X_train, Y_train, cv=5) print("nBest Params : ", search_results['params']) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
bestTest = 21.55239476
bestIteration = 9
0: loss: 21.5523948 best: 21.5523948 (0) total: 124ms remaining: 1.36s
bestTest = 21.55702996
bestIteration = 9
1: loss: 21.5570300 best: 21.5523948 (0) total: 148ms remaining: 740ms
bestTest = 21.55128989
bestIteration = 9
2: loss: 21.5512899 best: 21.5512899 (2) total: 160ms remaining: 479ms
bestTest = 10.92908795
bestIteration = 9
3: loss: 10.9290879 best: 10.9290879 (3) total: 175ms remaining: 349ms
bestTest = 10.95387453
bestIteration = 9
4: loss: 10.9538745 best: 10.9290879 (3) total: 181ms remaining: 253ms
bestTest = 10.7457616
bestIteration = 9
5: loss: 10.7457616 best: 10.7457616 (5) total: 187ms remaining: 187ms
bestTest = 15.92112385
bestIteration = 49
6: loss: 15.9211238 best: 10.7457616 (5) total: 216ms remaining: 154ms
bestTest = 15.8017972
bestIteration = 49
7: loss: 15.8017972 best: 10.7457616 (5) total: 244ms remaining: 122ms
bestTest = 15.81644278
bestIteration = 49
8: loss: 15.8164428 best: 10.7457616 (5) total: 272ms remaining: 90.5ms
bestTest = 3.788368224
bestIteration = 49
9: loss: 3.7883682 best: 3.7883682 (9) total: 300ms remaining: 60ms
bestTest = 3.654791242
bestIteration = 49
10: loss: 3.6547912 best: 3.6547912 (10) total: 335ms remaining: 30.5ms
bestTest = 3.452184786
bestIteration = 49
11: loss: 3.4521848 best: 3.4521848 (11) total: 386ms remaining: 0us
Estimating final quality...
Best Params : {'iterations': 50, 'learning_rate': 0.1, 'bootstrap_type': 'No'}
Test R2 : 0.81
Train R2 : 0.93
cv_results = pd.DataFrame(search_results["cv_results"]) cv_results.head()
| iterations | test-RMSE-mean | test-RMSE-std | train-RMSE-mean | train-RMSE-std | |
|---|---|---|---|---|---|
| 0 | 0 | 22.014214 | 0.786907 | 21.983740 | 0.187981 |
| 1 | 1 | 20.292298 | 0.793154 | 20.237792 | 0.174227 |
| 2 | 2 | 18.777471 | 0.791517 | 18.663837 | 0.157903 |
| 3 | 3 | 17.340791 | 0.751594 | 17.184659 | 0.135167 |
| 4 | 4 | 16.026837 | 0.745211 | 15.853864 | 0.120795 |
3.3.2 Randomized Search¶
The CatBoost also lets us perform a randomized search which is faster compared to grid search which only tries a few parameter settings than trying all possible combinations. We can perform a randomized search using randomized_search() of the CatBoost estimator. The randomized_search() method has the same API as that of the grid_search() method with one extra parameter named n_iter which accepts integer values specifying how many random combinations of parameters to try. The default value of this parameter is 10.
Below we have explained how we can perform a randomized search. We are trying different values of parameters iterations, learning_rate and booststrap_type. We are using training data created from the Boston dataset earlier. We have then evaluated the performance of an estimator with the best setting by calculating the R2 score on the train and test dataset.
booster = CatBoost() params = { 'iterations':[5,10,50,100], 'learning_rate':[0.01, 0.03, 0.1,1.0], 'bootstrap_type':['Bayesian', 'Bernoulli', 'MVS', 'No'] } search_results = booster.randomized_search(params, X_train, Y_train, cv=5, n_iter=8) print("nBest Params : ", search_results['params']) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
bestTest = 15.6936908
bestIteration = 4
0: loss: 15.6936908 best: 15.6936908 (0) total: 106ms remaining: 745ms
bestTest = 8.345542698
bestIteration = 49
1: loss: 8.3455427 best: 8.3455427 (1) total: 211ms remaining: 633ms
bestTest = 8.147224095
bestIteration = 49
2: loss: 8.1472241 best: 8.1472241 (2) total: 264ms remaining: 440ms
bestTest = 3.452184786
bestIteration = 49
3: loss: 3.4521848 best: 3.4521848 (3) total: 294ms remaining: 294ms
bestTest = 4.563786442
bestIteration = 13
4: loss: 4.5637864 best: 3.4521848 (3) total: 329ms remaining: 197ms
bestTest = 5.044662741
bestIteration = 29
5: loss: 5.0446627 best: 3.4521848 (3) total: 370ms remaining: 123ms
bestTest = 3.425305309
bestIteration = 99
6: loss: 3.4253053 best: 3.4253053 (6) total: 428ms remaining: 61.2ms
bestTest = 4.563786442
bestIteration = 13
7: loss: 4.5637864 best: 3.4253053 (6) total: 485ms remaining: 0us
Estimating final quality...
Best Params : {'iterations': 100, 'learning_rate': 0.1, 'bootstrap_type': 'Bayesian'}
Test R2 : 0.80
Train R2 : 0.96
cv_results = pd.DataFrame(search_results["cv_results"]) cv_results.head()
| iterations | test-RMSE-mean | test-RMSE-std | train-RMSE-mean | train-RMSE-std | |
|---|---|---|---|---|---|
| 0 | 0 | 22.125040 | 0.844848 | 22.066620 | 0.202171 |
| 1 | 1 | 20.439970 | 0.852782 | 20.330457 | 0.198279 |
| 2 | 2 | 18.920182 | 0.867940 | 18.736814 | 0.218151 |
| 3 | 3 | 17.532082 | 0.865926 | 17.304811 | 0.211505 |
| 4 | 4 | 16.242792 | 0.824299 | 15.961548 | 0.199420 |
3.4 Important Parameters of CatBoost Model ¶
NOTE: Please feel free to skip this section if you are in hurry. It is a theoretical section listing parameters of «CatBoost()» constructor. You can refer to them later as you need to tweak model.
Below we have listed down important parameters of gradient boosting algorithm which we can pass to CatBoost constructor in a dictionary when creating an estimator. These parameters will be available in CatBoostRegressor and CatBoostClassifier constructor as well.
- loss_function — It accepts string specifying metric used during training. The gradient boosting algorithm will try to minimize/maximize loss function output depending on the situation. Below we have given some commonly used loss functions.
- RMSE
- MAE
- Logloss
- CrossEntropy
- MultiClass
- MultiClassOneVsAll
- Other Available Loss Functions
- custom_metric — It’s the same as the above parameter and the output of the function specified here will be printed during training. We can specify a single metric or even a list of metrics.
- eval_metric — It accepts string specifying metric to evaluate on evaluation set given during training. It has the same options as that of loss_function.
- iterations — It accepts integers specifying the number of trees to train. The default is 1000.
- learning_rate — It specifies the learning rate during the training process. The default is 0.03.
- l2_leaf_reg — It accepts float specifying coefficient of L2 regularization of a loss function. The default value is 3.
- bootstrap_type — It accepts string specifying bootstrap type. Below is a list of possible values.
- Bayesian
- Bernoulli
- MVS
- Poisson — Only works when training on GPU
- No
- class_names — It accepts a list of string specifying class names for classification tasks.
- classes_count — It accepts integer specifying the number of classes in target for multi-class classification problem.
- depth/max_depth — It accepts integer specifying maximum allowed tree depth in an ensemble. The default is 6.
- min_data_in_leaf — It accepts an integer specifying a minimum number of training samples per leaf of a tree. The default is 1.
- max_leaves — It accepts an integer specifying the minimum number of leaves in a tree. The default is 31.
- leaf_estimation_method — It accepts the string specifying method used to calculate values in leaves. Below is a list of possible options.
- Newton
- Gradient
- Exact
- monotone_constraints — It accepts list of integers of length n_features. Each entry in the list has a value of either 1,0 or -1 specifying increasing, none, or decreasing monotone relation of a feature with the target. We can even give a list of strings or a dictionary of mapping from feature names to relation types.
- early_stopping_rounds — It accepts an integer that instructs the algorithm to stop training if the last evaluation set in the list has not improved for that many rounds.
- thread_count — It accepts integer specifying the number of threads to use during training. The default is -1 which means to use all cores on the system.
- used_ram_limit — It accepts string specifying the size of RAM to use when training. It accepts values in KB, MB, and GB.
- gpu_ram_part — It accepts float between 0-1 specifying how much GPU ram to use. The default is 0.95 which means 95% of RAM.
- task_type — It accepts one of the below options specifying whether to run the task on CPU or GPU.
- CPU
- GPU
- devices — It accepts string specifying IDs of GPUs to use for training. Below are possible options
- Single GPU — [id1] — It’ll use GPU with id1 for training.
- List of GPUs — [id1]:[id3]:[id5] — It’ll use GPU with id1, id3 and id5 for training.
- Range of GPUs — [id1]:[id3] — It’ll use GPU with id1, id2 and id3 for taining.
- train_dir — It accepts string specifying where to store info generated during training. The default is catboost_info.
Please make a note that the above-mentioned list is not all possible parameters available in CatBoost. The above list includes important parameters which are generally tuned for good performance. Below we have given a list of all possible parameters available.
- All Boosting Training Parameters
3.5 Important Parameters of «Catboost.fit()» Methods ¶
NOTE: Please feel free to skip this section if you are in hurry. It is a theoretical section listing parameters of «CatBoost()» constructor. You can refer to them later as you need to tweak model.
- cat_features — It accepts a list of integer specifying indices of data that has categorical features.
- text_features — — It accepts a list of integer specifying indices of data that has text features.
- embedding_features — — It accepts a list of integer specifying indices of data that has embedding features.
- eval_set — It accepts a list of below options as input to be used as an evaluation set.
- catboost.Pool
- pandas dataframe
- numpy tuple of features and target labels.
- early_stopping_rounds — It accepts an integer that instructs the algorithm to stop training if the last evaluation set in the list has not improved for that many rounds.
- plot — It accepts boolean value specifying whether to generate a plot of training results.
- save_snapshot — It accepts boolean value specifying whether to store a snapshot of training at a specified interval so that interrupted training can be resumed later from that point rather than from the beginning.
- snapshot_file — It accepts string specifying file name where to stop snapshots during training.
- snapshot_interval — It accepts integer specifying interval in seconds at which snapshots are saved.
4. CatBoost: Regression («Pool» Data Structure to Represent Datasets) ¶
As a part of this section, we are explaining how we can use the catboost internal data structure named Pool for maintaining data. We have even explained how we can create a CatBoost estimator using the train() method of the catboost library. Please make a note that catboost.train() has almost all parameters same as that of CatBoost.fit() method.
The Pool is an internal data structure of catboost that wraps our data and target values. It can make training faster.
4.1 Important Parameters Of «Pool()» Constructor¶
Below we have given important parameters of the Pool constructor.
- data — It accepts numpy array, pandas dataframe, or list which has features values.
- label — It accepts numpy array, pandas dataframe, or list which has target labels.
- cat_features — It accepts a list of integer specifying indices of data that has categorical features.
- text_features -It accepts a list of integer specifying indices of data that has text features.
Below we have explained how we can use the Pool data structure with the train() method to generate the CatBoost estimator.
from catboost import Pool X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) train_data = Pool(X_train, Y_train) test_data = Pool(X_test, Y_test) booster = catboost.train(pool=train_data,params={'iterations':100, 'verbose':10, 'loss_function':'RMSE', }) print() print(booster) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(test_data) train_preds = booster.predict(train_data) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.195221 0: learn: 7.9013401 total: 2.71ms remaining: 269ms 10: learn: 3.5505266 total: 9.11ms remaining: 73.7ms 20: learn: 2.5639279 total: 14.9ms remaining: 56.1ms 30: learn: 2.1352590 total: 20.6ms remaining: 45.9ms 40: learn: 1.8986418 total: 26.3ms remaining: 37.9ms 50: learn: 1.7054125 total: 32ms remaining: 30.7ms 60: learn: 1.5124150 total: 37.6ms remaining: 24.1ms 70: learn: 1.3810154 total: 43.3ms remaining: 17.7ms 80: learn: 1.2817508 total: 49.1ms remaining: 11.5ms 90: learn: 1.1909646 total: 54.8ms remaining: 5.41ms 99: learn: 1.0946543 total: 59.8ms remaining: 0us <catboost.core.CatBoost object at 0x7f21de94e828> Test R2 : 0.83 Train R2 : 0.99
Below we have given another example where we have explained how we can give an evaluation set that will be evaluated during training.
from catboost import Pool from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) train_data = Pool(X_train, Y_train) test_data = Pool(X_test, Y_test) booster = CatBoost({'verbose':10, 'iterations':100}) booster.fit(train_data, eval_set=(test_data)) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(test_data) train_preds = booster.predict(train_data) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.166668 0: learn: 8.0520453 test: 10.1798347 best: 10.1798347 (0) total: 2.65ms remaining: 262ms 10: learn: 3.8810707 test: 6.4769275 best: 6.4769275 (10) total: 26.7ms remaining: 216ms 20: learn: 2.7929439 test: 5.4534123 best: 5.4534123 (20) total: 45.9ms remaining: 173ms 30: learn: 2.3461951 test: 5.1077987 best: 5.1077987 (30) total: 63.9ms remaining: 142ms 40: learn: 2.0812703 test: 4.8640181 best: 4.8640181 (40) total: 79.8ms remaining: 115ms 50: learn: 1.8649713 test: 4.7165995 best: 4.7052137 (48) total: 92.1ms remaining: 88.5ms 60: learn: 1.6934276 test: 4.6191067 best: 4.6191067 (60) total: 103ms remaining: 65.6ms 70: learn: 1.5620403 test: 4.5825150 best: 4.5825150 (70) total: 111ms remaining: 45.2ms 80: learn: 1.4340285 test: 4.5732299 best: 4.5389627 (74) total: 117ms remaining: 27.4ms 90: learn: 1.3495901 test: 4.5714853 best: 4.5389627 (74) total: 123ms remaining: 12.2ms 99: learn: 1.2619128 test: 4.5646310 best: 4.5389627 (74) total: 133ms remaining: 0us bestTest = 4.538962725 bestIteration = 74 Shrink model to first 75 iterations. Test R2 : 0.82 Train R2 : 0.97
Catboost has a method named to_regressor() which takes CatBoost instance and converts it to CatBoostRegressor instance.
catboost.to_regressor(booster)
<catboost.core.CatBoostRegressor at 0x7f21dfac4358>
5. CatBoost: Binary Classification Example ¶
As a part of this section, we have explained how we can use CatBoost for binary classification problems. We have divided breast cancer data into train and test sets. We have created the CatBoost instance with the LogLoss loss function and then trained the model on train data. We have then evaluated it on test data as well as printing its accuracy.
Please make a note that the predict() method has a parameter named prediction_type which accepts the below-mentioned value to generate different predictions.
- RawFormulaVal — It generates raw output from a gradient boosting algorithm.
- Class — It returns class number for classification problems.
- Probability — It returns probability for classification problem.
X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target, train_size=0.9, stratify=breast_cancer.target, random_state=123) booster = CatBoost(params={'iterations':100, 'verbose':10, 'loss_function':'Logloss'}) booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(breast_cancer.feature_names) test_preds = booster.predict(X_test, prediction_type="Class") train_preds = booster.predict(X_train, prediction_type="Class") from catboost.utils import eval_metric print("nTest Accuracy : %.2f"%eval_metric(Y_test, test_preds, "Accuracy")[0]) print("Train Accuracy : %.2f"%eval_metric(Y_train, train_preds, "Accuracy")[0])
Learning rate set to 0.073131 0: learn: 0.5730087 test: 0.5715369 best: 0.5715369 (0) total: 92.6ms remaining: 9.17s 10: learn: 0.1564599 test: 0.1748713 best: 0.1748713 (10) total: 120ms remaining: 973ms 20: learn: 0.0811663 test: 0.1047480 best: 0.1047480 (20) total: 144ms remaining: 540ms 30: learn: 0.0522608 test: 0.0798318 best: 0.0798318 (30) total: 167ms remaining: 372ms 40: learn: 0.0391529 test: 0.0681539 best: 0.0681539 (40) total: 191ms remaining: 275ms 50: learn: 0.0296856 test: 0.0594379 best: 0.0590864 (49) total: 225ms remaining: 216ms 60: learn: 0.0242369 test: 0.0543715 best: 0.0543715 (60) total: 261ms remaining: 167ms 70: learn: 0.0188321 test: 0.0501147 best: 0.0501147 (70) total: 285ms remaining: 117ms 80: learn: 0.0160430 test: 0.0495876 best: 0.0484613 (77) total: 309ms remaining: 72.4ms 90: learn: 0.0133933 test: 0.0439943 best: 0.0439943 (90) total: 332ms remaining: 32.9ms 99: learn: 0.0115672 test: 0.0413455 best: 0.0413455 (99) total: 354ms remaining: 0us bestTest = 0.04134545311 bestIteration = 99 Test Accuracy : 0.98 Train Accuracy : 1.00
Below we have explained how we can generate probabilities with the predict() function.
booster.predict(X_test, prediction_type="Probability")[:5]
array([[9.98702599e-01, 1.29740117e-03],
[7.61900642e-03, 9.92380994e-01],
[9.99418319e-01, 5.81681361e-04],
[4.00919216e-03, 9.95990808e-01],
[1.43614433e-03, 9.98563856e-01]])
Catboost has method named to_classifier() which takes CatBoost instance and converts it to CatBoostClassifier instance.
catboost.to_classifier(booster)
<catboost.core.CatBoostClassifier at 0x7f21de936d30>
6. CatBoost: Multi-Class Classification Example ¶
NOTE: Please feel free to skip this section if you are in hurry and have already understood how to use catboost for classification tasks using our previous «binary classification» example.
As a part of this section, we have explained how we can use CatBoost for multi-class classification problems. We have used the wine dataset for this section as it has three classes to predict.
X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target, train_size=0.9, stratify=wine.target, random_state=123) booster = CatBoost(params={'iterations':100, 'verbose':10, 'loss_function':'MultiClass', 'classes_count':3}) booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(wine.feature_names) test_preds = booster.predict(X_test, prediction_type="Class").flatten() train_preds = booster.predict(X_train, prediction_type="Class").flatten() from catboost.utils import eval_metric print("nTest Accuracy : %.2f"%eval_metric(Y_test, test_preds, "Accuracy")[0]) print("Train Accuracy : %.2f"%eval_metric(Y_train, train_preds, "Accuracy")[0])
Learning rate set to 0.250848 0: learn: 0.8810930 test: 0.9177696 best: 0.9177696 (0) total: 4.67ms remaining: 463ms 10: learn: 0.2073324 test: 0.3310180 best: 0.3310180 (10) total: 31.5ms remaining: 255ms 20: learn: 0.0968205 test: 0.2342860 best: 0.2342860 (20) total: 56.1ms remaining: 211ms 30: learn: 0.0585815 test: 0.1975512 best: 0.1969462 (29) total: 79ms remaining: 176ms 40: learn: 0.0403924 test: 0.1881050 best: 0.1881050 (40) total: 97.5ms remaining: 140ms 50: learn: 0.0295660 test: 0.1741516 best: 0.1741516 (50) total: 110ms remaining: 106ms 60: learn: 0.0231273 test: 0.1707485 best: 0.1683297 (58) total: 121ms remaining: 77.3ms 70: learn: 0.0188628 test: 0.1692754 best: 0.1683297 (58) total: 130ms remaining: 53.1ms 80: learn: 0.0156153 test: 0.1676627 best: 0.1658585 (78) total: 138ms remaining: 32.4ms 90: learn: 0.0135755 test: 0.1636182 best: 0.1635633 (87) total: 145ms remaining: 14.4ms 99: learn: 0.0121369 test: 0.1616905 best: 0.1616905 (99) total: 152ms remaining: 0us bestTest = 0.1616905315 bestIteration = 99 Test Accuracy : 0.94 Train Accuracy : 1.00
booster.predict(X_test, prediction_type="Probability")[:5]
array([[0.01434538, 0.01599883, 0.96965578],
[0.00373846, 0.99234009, 0.00392145],
[0.06538219, 0.91376836, 0.02084945],
[0.87954488, 0.0982254 , 0.02222972],
[0.00157402, 0.99693869, 0.00148729]])
7. CatBoostRegressor (Scikit-Learn Like API) ¶
The catboost provides an estimator named CatBoostRegressor which can be used directly for regression problems. It accepts the same parameters that were given to CatBoost as a dictionary directly. Below we have explained how we can use it with a simple example using the Boston dataset.
from catboost import CatBoostRegressor X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(iterations=100, verbose=10) booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) from catboost.utils import eval_metric print("nTest R2 : %.2f"%booster.score(X_test, Y_test)) print("Train R2 : %.2f"%booster.score(X_train, Y_train))
Learning rate set to 0.166668 0: learn: 8.0520453 test: 10.1798347 best: 10.1798347 (0) total: 2.77ms remaining: 274ms 10: learn: 3.8810707 test: 6.4769275 best: 6.4769275 (10) total: 27ms remaining: 219ms 20: learn: 2.7929439 test: 5.4534123 best: 5.4534123 (20) total: 47.3ms remaining: 178ms 30: learn: 2.3461951 test: 5.1077987 best: 5.1077987 (30) total: 65.6ms remaining: 146ms 40: learn: 2.0812703 test: 4.8640181 best: 4.8640181 (40) total: 83.1ms remaining: 120ms 50: learn: 1.8649713 test: 4.7165995 best: 4.7052137 (48) total: 99.9ms remaining: 95.9ms 60: learn: 1.6934276 test: 4.6191067 best: 4.6191067 (60) total: 116ms remaining: 74.5ms 70: learn: 1.5620403 test: 4.5825150 best: 4.5825150 (70) total: 130ms remaining: 52.9ms 80: learn: 1.4340285 test: 4.5732299 best: 4.5389627 (74) total: 140ms remaining: 32.7ms 90: learn: 1.3495901 test: 4.5714853 best: 4.5389627 (74) total: 148ms remaining: 14.6ms 99: learn: 1.2619128 test: 4.5646310 best: 4.5389627 (74) total: 155ms remaining: 0us bestTest = 4.538962725 bestIteration = 74 Shrink model to first 75 iterations. Test R2 : 0.82 Train R2 : 0.97
Important Attributes & Methods of «CatBoostRegressor»¶
It has the same attributes and methods which are available with the CatBoost estimator.
Hyperparameters Tunning: Grid Search¶
NOTE: Please feel free to skip this section if you are in hurry and have already understood how to perform a grid search with Catboost from earlier examples.
The CatBoostRegressor also has a grid_search() method which can be used to perform grid search with it. We have explained it below with a simple example.
booster = CatBoostRegressor() params = { 'iterations':[10,50], 'learning_rate':[0.01, 0.1], 'bootstrap_type':['Bayesian', 'No'] } search_results = booster.grid_search(params, X_train, Y_train, cv=5, ) print("nBest Params : ", search_results['params'])
bestTest = 21.55239476
bestIteration = 9
0: loss: 21.5523948 best: 21.5523948 (0) total: 173ms remaining: 1.21s
bestTest = 21.55128989
bestIteration = 9
1: loss: 21.5512899 best: 21.5512899 (1) total: 211ms remaining: 632ms
bestTest = 10.92908795
bestIteration = 9
2: loss: 10.9290879 best: 10.9290879 (2) total: 236ms remaining: 394ms
bestTest = 10.7457616
bestIteration = 9
3: loss: 10.7457616 best: 10.7457616 (3) total: 262ms remaining: 262ms
bestTest = 15.92112385
bestIteration = 49
4: loss: 15.9211238 best: 10.7457616 (3) total: 336ms remaining: 201ms
bestTest = 15.81644278
bestIteration = 49
5: loss: 15.8164428 best: 10.7457616 (3) total: 368ms remaining: 123ms
bestTest = 3.788368224
bestIteration = 49
6: loss: 3.7883682 best: 3.7883682 (6) total: 409ms remaining: 58.5ms
bestTest = 3.452184786
bestIteration = 49
7: loss: 3.4521848 best: 3.4521848 (7) total: 456ms remaining: 0us
Estimating final quality...
Best Params : {'iterations': 50, 'learning_rate': 0.1, 'bootstrap_type': 'No'}
Hyperparameters Tunning: Randomized Search¶
NOTE: Please feel free to skip this section if you are in hurry and have already understood how to perform a randomized search with Catboost from earlier examples.
The CatBoostRegressor also has a randomized_search() method which can be used to perform a randomized search with it. We have explained it below with a simple example.
booster = CatBoostRegressor() params = { 'iterations':[5,50,], 'learning_rate':[0.01, 0.1], 'bootstrap_type':['Bayesian', 'Bernoulli', 'MVS'] } search_results = booster.randomized_search(params, X_train, Y_train, cv=5, n_iter=8) print("nBest Params : ", search_results['params'])
bestTest = 22.43710864
bestIteration = 4
0: loss: 22.4371086 best: 22.4371086 (0) total: 112ms remaining: 783ms
bestTest = 22.43544339
bestIteration = 4
1: loss: 22.4354434 best: 22.4354434 (1) total: 123ms remaining: 370ms
bestTest = 22.43002952
bestIteration = 4
2: loss: 22.4300295 best: 22.4300295 (2) total: 135ms remaining: 224ms
bestTest = 15.67950464
bestIteration = 4
3: loss: 15.6795046 best: 15.6795046 (3) total: 145ms remaining: 145ms
bestTest = 15.6064376
bestIteration = 4
4: loss: 15.6064376 best: 15.6064376 (4) total: 155ms remaining: 93ms
bestTest = 15.6936908
bestIteration = 4
5: loss: 15.6936908 best: 15.6064376 (4) total: 165ms remaining: 54.9ms
bestTest = 15.92112385
bestIteration = 49
6: loss: 15.9211238 best: 15.6064376 (4) total: 263ms remaining: 37.6ms
bestTest = 3.654791242
bestIteration = 49
7: loss: 3.6547912 best: 3.6547912 (7) total: 292ms remaining: 0us
Estimating final quality...
Best Params : {'iterations': 50, 'learning_rate': 0.1, 'bootstrap_type': 'Bernoulli'}
8. CatBoostClassifier (Scikit-Learn Like API) ¶
The catboost provides an estimator named CatBoostClassifier which can be used directly for regression problems. It accepts the same parameters that were given to CatBoost as a dictionary directly.
8.1 Binary Classification Example¶
Below we have explained how we can perform binary classification using CatBoostClassifier.
from catboost import CatBoostClassifier X_train, X_test, Y_train, Y_test = train_test_split(breast_cancer.data, breast_cancer.target, train_size=0.9, stratify=breast_cancer.target, random_state=123) booster = CatBoostClassifier(iterations=100, verbose=10) booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(breast_cancer.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest Accuracy : %.2f"%booster.score(X_test, Y_test)) print("Train Accuracy : %.2f"%booster.score(X_train, Y_train))
Learning rate set to 0.073131 0: learn: 0.5730087 test: 0.5715369 best: 0.5715369 (0) total: 7.87ms remaining: 779ms 10: learn: 0.1564599 test: 0.1748713 best: 0.1748713 (10) total: 104ms remaining: 842ms 20: learn: 0.0811663 test: 0.1047480 best: 0.1047480 (20) total: 146ms remaining: 548ms 30: learn: 0.0522608 test: 0.0798318 best: 0.0798318 (30) total: 170ms remaining: 379ms 40: learn: 0.0391529 test: 0.0681539 best: 0.0681539 (40) total: 194ms remaining: 279ms 50: learn: 0.0296856 test: 0.0594379 best: 0.0590864 (49) total: 234ms remaining: 225ms 60: learn: 0.0242369 test: 0.0543715 best: 0.0543715 (60) total: 263ms remaining: 168ms 70: learn: 0.0188321 test: 0.0501147 best: 0.0501147 (70) total: 287ms remaining: 117ms 80: learn: 0.0160430 test: 0.0495876 best: 0.0484613 (77) total: 316ms remaining: 74.1ms 90: learn: 0.0133933 test: 0.0439943 best: 0.0439943 (90) total: 345ms remaining: 34.1ms 99: learn: 0.0115672 test: 0.0413455 best: 0.0413455 (99) total: 379ms remaining: 0us bestTest = 0.04134545311 bestIteration = 99 Test Accuracy : 0.98 Train Accuracy : 1.00
The CatBoostClassifier provides a method named predict_proba() which can be used to generate output as a list of probabilities.
booster.predict_proba(X_test)[:5]
array([[9.98702599e-01, 1.29740117e-03],
[7.61900642e-03, 9.92380994e-01],
[9.99418319e-01, 5.81681361e-04],
[4.00919216e-03, 9.95990808e-01],
[1.43614433e-03, 9.98563856e-01]])
booster.predict_log_proba(X_test)[:5]
array([[-1.29824353e-03, -6.64739211e+00],
[-4.87710931e+00, -7.64817932e-03],
[-5.81850604e-04, -7.44958775e+00],
[-5.51916551e+00, -4.01725051e-03],
[-6.54579330e+00, -1.43717657e-03]])
Important Attributes & Methods of «CatBoostClassifier»¶
It has the same attributes and methods which are available with the CatBoost estimator.
Hyperparameters Tunning: Grid Search & Randomized Search¶
The CatBoostClassifier also has grid_search() and randomized_search() methods which work exactly the same way as CatBoost and CatBoostRegresor hence we have not repeated the code again to explain it.
8.2 Multi-Class Classification Example¶
NOTE: Please feel free to skip this section if you are in hurry and have already understood how to use «CatBoostClassifier» for classification tasks using our previous «binary classification» example.
Below we have given a simple example which explains how CatBoostClassifier can be used for multi-class classification problems.
from catboost import CatBoostClassifier X_train, X_test, Y_train, Y_test = train_test_split(wine.data, wine.target, train_size=0.9, stratify=wine.target, random_state=123) booster = CatBoostClassifier(iterations=100, verbose=10) booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(wine.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest Accuracy : %.2f"%booster.score(X_test, Y_test)) print("Train Accuracy : %.2f"%booster.score(X_train, Y_train))
Learning rate set to 0.250848 0: learn: 0.8810930 test: 0.9177696 best: 0.9177696 (0) total: 3.75ms remaining: 371ms 10: learn: 0.2073324 test: 0.3310180 best: 0.3310180 (10) total: 30.7ms remaining: 249ms 20: learn: 0.0968205 test: 0.2342860 best: 0.2342860 (20) total: 55ms remaining: 207ms 30: learn: 0.0585815 test: 0.1975512 best: 0.1969462 (29) total: 78ms remaining: 174ms 40: learn: 0.0403924 test: 0.1881050 best: 0.1881050 (40) total: 99.7ms remaining: 144ms 50: learn: 0.0295660 test: 0.1741516 best: 0.1741516 (50) total: 121ms remaining: 117ms 60: learn: 0.0231273 test: 0.1707485 best: 0.1683297 (58) total: 137ms remaining: 87.5ms 70: learn: 0.0188628 test: 0.1692754 best: 0.1683297 (58) total: 148ms remaining: 60.6ms 80: learn: 0.0156153 test: 0.1676627 best: 0.1658585 (78) total: 158ms remaining: 37.1ms 90: learn: 0.0135755 test: 0.1636182 best: 0.1635633 (87) total: 166ms remaining: 16.5ms 99: learn: 0.0121369 test: 0.1616905 best: 0.1616905 (99) total: 174ms remaining: 0us bestTest = 0.1616905315 bestIteration = 99 Test Accuracy : 0.94 Train Accuracy : 1.00
booster.predict_proba(X_test)[:5]
array([[0.01434538, 0.01599883, 0.96965578],
[0.00373846, 0.99234009, 0.00392145],
[0.06538219, 0.91376836, 0.02084945],
[0.87954488, 0.0982254 , 0.02222972],
[0.00157402, 0.99693869, 0.00148729]])
9. Cross Validation Example ¶
The catboost provides a method named cv() which can be used to perform cross-validation on data. Below we have explained with few examples of how we can perform cross-validation in catboost.
from catboost import cv, Pool data = Pool(boston.data, boston.target) cv(data, params={'iterations':10, 'loss_function':'RMSE'}, nfold=5)
0: learn: 23.7392457 test: 23.7214209 best: 23.7214209 (0) total: 1.45s remaining: 13.1s 1: learn: 23.1657012 test: 23.1529352 best: 23.1529352 (1) total: 3.09s remaining: 12.4s 2: learn: 22.5952486 test: 22.5993739 best: 22.5993739 (2) total: 4.65s remaining: 10.9s 3: learn: 22.0752979 test: 22.0892861 best: 22.0892861 (3) total: 6.2s remaining: 9.3s 4: learn: 21.5334643 test: 21.5535213 best: 21.5535213 (4) total: 7.73s remaining: 7.73s 5: learn: 21.0432351 test: 21.0794070 best: 21.0794070 (5) total: 9.42s remaining: 6.28s 6: learn: 20.5481253 test: 20.5972173 best: 20.5972173 (6) total: 10.9s remaining: 4.66s 7: learn: 20.0763160 test: 20.1390519 best: 20.1390519 (7) total: 12.4s remaining: 3.1s 8: learn: 19.6266408 test: 19.6996881 best: 19.6996881 (8) total: 13.9s remaining: 1.55s 9: learn: 19.1627362 test: 19.2500695 best: 19.2500695 (9) total: 15.3s remaining: 0us
| iterations | test-RMSE-mean | test-RMSE-std | train-RMSE-mean | train-RMSE-std | |
|---|---|---|---|---|---|
| 0 | 0 | 23.721421 | 1.368552 | 23.739246 | 0.332811 |
| 1 | 1 | 23.152935 | 1.371173 | 23.165701 | 0.323821 |
| 2 | 2 | 22.599374 | 1.366576 | 22.595249 | 0.316548 |
| 3 | 3 | 22.089286 | 1.360462 | 22.075298 | 0.308760 |
| 4 | 4 | 21.553521 | 1.349079 | 21.533464 | 0.301004 |
| 5 | 5 | 21.079407 | 1.339058 | 21.043235 | 0.292612 |
| 6 | 6 | 20.597217 | 1.339418 | 20.548125 | 0.287159 |
| 7 | 7 | 20.139052 | 1.336868 | 20.076316 | 0.281062 |
| 8 | 8 | 19.699688 | 1.325541 | 19.626641 | 0.280764 |
| 9 | 9 | 19.250069 | 1.307312 | 19.162736 | 0.269559 |
from catboost import cv, Pool data = Pool(breast_cancer.data, breast_cancer.target) cv(data, params={'iterations':10, 'loss_function':'CrossEntropy'}, nfold=5)
0: learn: 0.6443925 test: 0.6464482 best: 0.6464482 (0) total: 1.79s remaining: 16.1s 1: learn: 0.5999487 test: 0.6040791 best: 0.6040791 (1) total: 3.35s remaining: 13.4s 2: learn: 0.5593831 test: 0.5650989 best: 0.5650989 (2) total: 5.01s remaining: 11.7s 3: learn: 0.5240421 test: 0.5317291 best: 0.5317291 (3) total: 6.56s remaining: 9.85s 4: learn: 0.4873987 test: 0.4971399 best: 0.4971399 (4) total: 8.14s remaining: 8.14s 5: learn: 0.4602370 test: 0.4709405 best: 0.4709405 (5) total: 9.72s remaining: 6.48s 6: learn: 0.4290721 test: 0.4404948 best: 0.4404948 (6) total: 11.3s remaining: 4.83s 7: learn: 0.4036246 test: 0.4172114 best: 0.4172114 (7) total: 12.8s remaining: 3.2s 8: learn: 0.3767254 test: 0.3908014 best: 0.3908014 (8) total: 14.4s remaining: 1.59s 9: learn: 0.3558123 test: 0.3714315 best: 0.3714315 (9) total: 15.9s remaining: 0us
| iterations | test-CrossEntropy-mean | test-CrossEntropy-std | train-CrossEntropy-mean | train-CrossEntropy-std | |
|---|---|---|---|---|---|
| 0 | 0 | 0.646448 | 0.007269 | 0.644393 | 0.004051 |
| 1 | 1 | 0.604079 | 0.009152 | 0.599949 | 0.005777 |
| 2 | 2 | 0.565099 | 0.007957 | 0.559383 | 0.004786 |
| 3 | 3 | 0.531729 | 0.008418 | 0.524042 | 0.004339 |
| 4 | 4 | 0.497140 | 0.011098 | 0.487399 | 0.004073 |
| 5 | 5 | 0.470941 | 0.010447 | 0.460237 | 0.004030 |
| 6 | 6 | 0.440495 | 0.011888 | 0.429072 | 0.004206 |
| 7 | 7 | 0.417211 | 0.012052 | 0.403625 | 0.005801 |
| 8 | 8 | 0.390801 | 0.012969 | 0.376725 | 0.006292 |
| 9 | 9 | 0.371432 | 0.013297 | 0.355812 | 0.007268 |
10. Saving and Loading Model ¶
Each catboost estimator(CatBoost, CatBoostClassifier & CatBoostRegressor) provides method named save_model() and load_model() which can be used to save trained model and reload saved model.
Below we have explained with a simple example of how we can save and load the catboost model. We have even evaluated the loaded model again to verify.
from catboost import Pool, CatBoost from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoost({'verbose':10, 'iterations':100}) booster.fit(X_train,Y_train, eval_set=(X_test,Y_test)) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.166668 0: learn: 8.0520453 test: 10.1798347 best: 10.1798347 (0) total: 2.36ms remaining: 234ms 10: learn: 3.8810707 test: 6.4769275 best: 6.4769275 (10) total: 24ms remaining: 194ms 20: learn: 2.7929439 test: 5.4534123 best: 5.4534123 (20) total: 38.6ms remaining: 145ms 30: learn: 2.3461951 test: 5.1077987 best: 5.1077987 (30) total: 47.5ms remaining: 106ms 40: learn: 2.0812703 test: 4.8640181 best: 4.8640181 (40) total: 54.5ms remaining: 78.4ms 50: learn: 1.8649713 test: 4.7165995 best: 4.7052137 (48) total: 60.5ms remaining: 58.2ms 60: learn: 1.6934276 test: 4.6191067 best: 4.6191067 (60) total: 66.3ms remaining: 42.4ms 70: learn: 1.5620403 test: 4.5825150 best: 4.5825150 (70) total: 72ms remaining: 29.4ms 80: learn: 1.4340285 test: 4.5732299 best: 4.5389627 (74) total: 77.7ms remaining: 18.2ms 90: learn: 1.3495901 test: 4.5714853 best: 4.5389627 (74) total: 83.4ms remaining: 8.25ms 99: learn: 1.2619128 test: 4.5646310 best: 4.5389627 (74) total: 88.6ms remaining: 0us bestTest = 4.538962725 bestIteration = 74 Shrink model to first 75 iterations. Test R2 : 0.82 Train R2 : 0.97
How to Save «CatBoost» Model using «save_model()» Method?¶
booster.save_model("catboost_regressor.model")
How to Load «CatBoost» Model using «load_model()» Method?¶
loaded_booster = CatBoost() loaded_booster.load_model("catboost_regressor.model")
<catboost.core.CatBoost at 0x7f21dfa427f0>
test_preds = loaded_booster.predict(X_test) train_preds = loaded_booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Test R2 : 0.82 Train R2 : 0.97
11. Plotting Functionalities in CatBoost ¶
11.1 Visualize Training Loss and Metric Values¶
Catboost provides us with a few simple plotting functionalities which can be useful to analyze model performance. The catboost estimator’s fit() method has a parameter named plot which is set to True will plot the result of the training process. We have explained below how we can plot the training process.
The grid_search() and randomized_search() methods of the estimator’s also had plot parameter which if set to True will generate a plot for them.
from catboost import Pool, CatBoost from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoost({'verbose':0, 'iterations':100}) booster.fit(X_train,Y_train, eval_set=(X_test,Y_test), plot=True); booster.set_feature_names(boston.feature_names) #test_preds = booster.predict(X_test) #train_preds = booster.predict(X_train) #print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) #print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
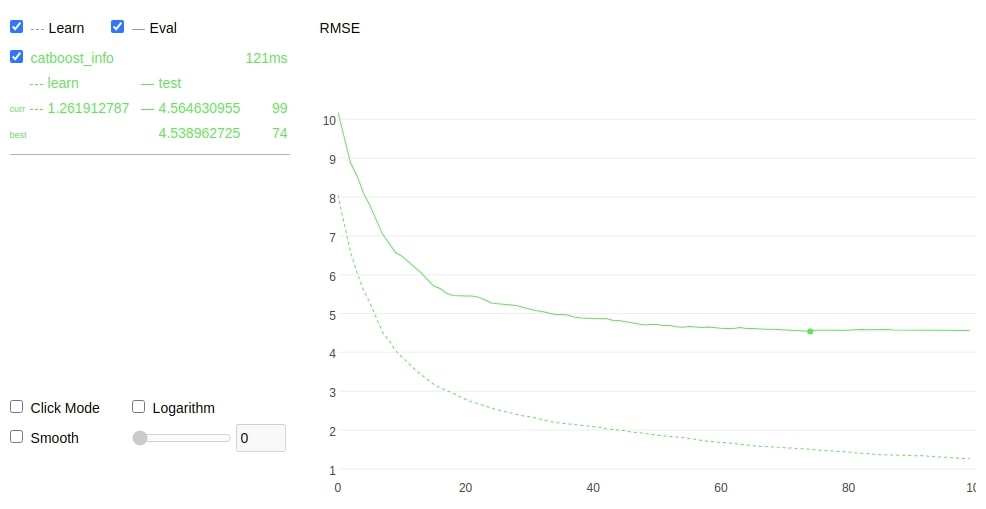
The cv() method of catboost also has a plot parameter which if set to True will generate a plot for cross-validation. We have explained the usage of the same below.
from catboost import cv data = Pool(breast_cancer.data, breast_cancer.target) cv(data, params={'iterations':10, 'loss_function':'CrossEntropy'}, nfold=5, plot=True, verbose=False);
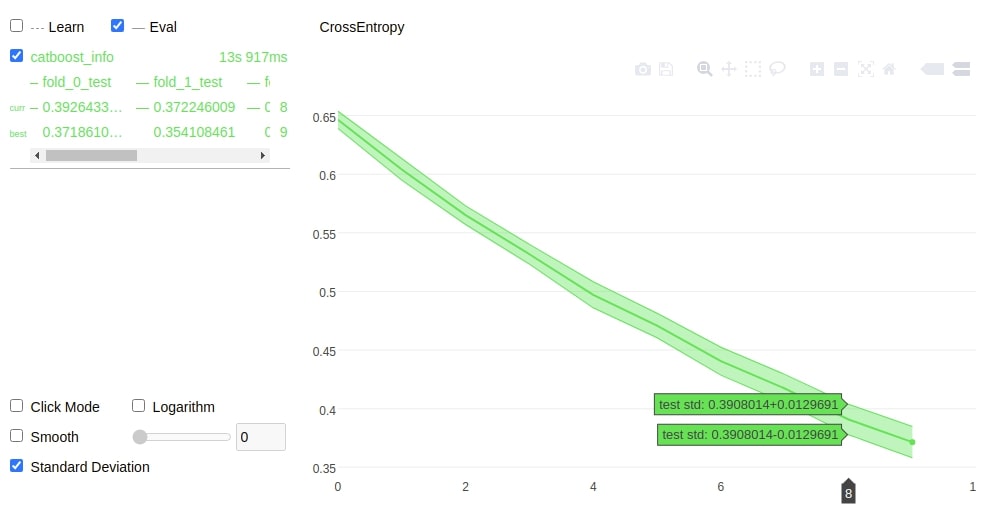
11.2 Visualize Individual Tree of Ensemble using «plot_tree()»¶
Each catboost estimators have a method named plot_tree() which accepts integer and plots tree with that index from an ensemble of trees. Below we have plotted the 2nd tree. The output of the method is graphviz graph which we have saved.
out = booster.plot_tree(1) out.render('tree', format="png") out

11.3 Visualize Important Statistics of Data Features using «calc_feature_statistics()»¶
The calc_feature_statistics() method estimator takes as input data, target labels and feature names. It then generated a chart showing statistics of the feature using a trained model, dataset, and target labels.
Below we have generated feature statistics for the LSTAT feature.
booster.calc_feature_statistics(X_train, Y_train, feature="LSTAT");
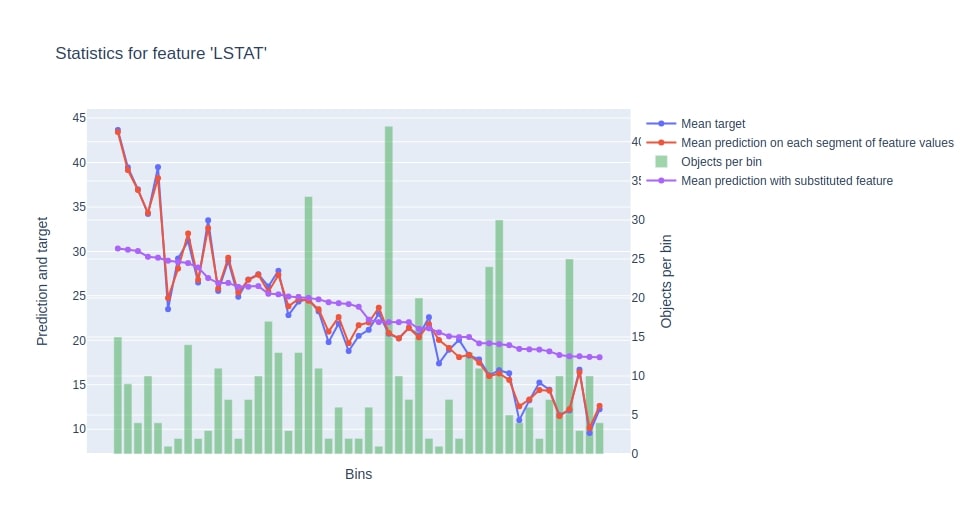
11.4 Visualize Individual Predictions using «plot_predictions()»¶
The plot_predictions() function takes as input dataset and list of features names/feature indices. It then sequentially vary the value of given features and calculate predictions.
booster.plot_predictions(X_test[:5], features_to_change=["LSTAT"]);

11.5 Partial Dependence Plot of Features using «plot_partial_dependence()»¶
It generates a partial dependence plot of the feature based on given data.
booster.plot_partial_dependence(Pool(X_train, Y_train) , features=["LSTAT"]);

11.6 Visualization to Compare Performance Of Different Models using «compare()» Method¶
The catboost estimators have a method named compare() which takes as input another estimator and a list of metrics to compare the performance of both models on a specified list of metrics. Below we have explained how we can compare the performance of two different catboost estimators using the compare() method. We have used metrics R2, RMSE, and MAE for it.
from catboost import Pool, CatBoost from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster1 = CatBoost({'verbose':0, 'iterations':100, 'learning_rate':0.1, 'bootstrap_type':'Bayesian'}) booster1.fit(X_train,Y_train, eval_set=(X_test,Y_test)) booster1.set_feature_names(boston.feature_names) test_preds = booster1.predict(X_test) train_preds = booster1.predict(X_train) print("Model-1") print("Test R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0]) booster2 = CatBoost({'verbose':0, 'iterations':100, 'learning_rate':0.3, 'bootstrap_type':'No'}) booster2.fit(X_train,Y_train, eval_set=(X_test,Y_test)) booster2.set_feature_names(boston.feature_names) test_preds = booster2.predict(X_test) train_preds = booster2.predict(X_train) print("nModel-2") print("Test R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Model-1 Test R2 : 0.80 Train R2 : 0.96 Model-2 Test R2 : 0.87 Train R2 : 0.99
How to Compare Performance of Different CatBoost Models?¶
booster1.compare(booster2, data=Pool(X_test,Y_test), metrics=["R2", "RMSE", "MAE"])

12. Recovering Interrupted Training using Snapshots ¶
Catboost provides support for saving the training process and recovering the training process if it was interrupted. It provides us with parameters named save_snapshot, snapshot_file, and snapshot_interval which save training results at particular intervals. We can then rerun training from the interrupted part rather than from the beginning using these parameters.
Below we are training CatBoostRegressor for 15000 iterations so that it takes time to complete. We are then interrupting training after a few seconds. We have set the save_snapshot parameter of the fit() method to True so that it takes a snapshot during training. The snapshot_interval is set to 1 so that snapshots are taken every 1 minute. The snapshots are saved in a file named catboost_snapshots.temp.
from catboost import Pool from catboost.utils import eval_metric from catboost import CatBoost, CatBoostClassifier, CatBoostRegressor from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(verbose=1000, iterations=15000) booster.fit(X_train, Y_train,save_snapshot=True, snapshot_file="catboost_snapshots.temp",snapshot_interval=1) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.004332 0: learn: 8.9345986 total: 817us remaining: 12.3s 1000: learn: 2.4437755 total: 613ms remaining: 8.57s 2000: learn: 1.7841487 total: 1.33s remaining: 8.63s 3000: learn: 1.4364310 total: 1.92s remaining: 7.66s 4000: learn: 1.1695109 total: 2.56s remaining: 7.04s 5000: learn: 0.9645754 total: 3.22s remaining: 6.45s 6000: learn: 0.8062126 total: 3.8s remaining: 5.7s
--------------------------------------------------------------------------- KeyboardInterrupt Traceback (most recent call last) ~/anaconda3/lib/python3.7/site-packages/catboost/core.py in _fit(self, X, y, cat_features, text_features, embedding_features, pairs, sample_weight, group_id, group_weight, subgroup_id, pairs_weight, baseline, use_best_model, eval_set, verbose, logging_level, plot, column_description, verbose_eval, metric_period, silent, early_stopping_rounds, save_snapshot, snapshot_file, snapshot_interval, init_model) 1808 allow_clear_pool, -> 1809 train_params["init_model"] 1810 ) ~/anaconda3/lib/python3.7/site-packages/catboost/core.py in _train(self, train_pool, test_pool, params, allow_clear_pool, init_model) 1257 def _train(self, train_pool, test_pool, params, allow_clear_pool, init_model): -> 1258 self._object._train(train_pool, test_pool, params, allow_clear_pool, init_model._object if init_model else None) 1259 self._set_trained_model_attributes() _catboost.pyx in _catboost._CatBoost._train() _catboost.pyx in _catboost._CatBoost._train() KeyboardInterrupt: During handling of the above exception, another exception occurred: KeyboardInterrupt Traceback (most recent call last) <ipython-input-22-19031eb2f180> in <module> 8 booster = CatBoostRegressor(verbose=1000, iterations=15000) 9 ---> 10 booster.fit(X_train, Y_train,save_snapshot=True, snapshot_file="catboost_snapshots.temp",snapshot_interval=1) 11 booster.set_feature_names(boston.feature_names) 12 ~/anaconda3/lib/python3.7/site-packages/catboost/core.py in fit(self, X, y, cat_features, sample_weight, baseline, use_best_model, eval_set, verbose, logging_level, plot, column_description, verbose_eval, metric_period, silent, early_stopping_rounds, save_snapshot, snapshot_file, snapshot_interval, init_model) 4848 use_best_model, eval_set, verbose, logging_level, plot, column_description, 4849 verbose_eval, metric_period, silent, early_stopping_rounds, -> 4850 save_snapshot, snapshot_file, snapshot_interval, init_model) 4851 4852 def predict(self, data, prediction_type=None, ntree_start=0, ntree_end=0, thread_count=-1, verbose=None): ~/anaconda3/lib/python3.7/site-packages/catboost/core.py in _fit(self, X, y, cat_features, text_features, embedding_features, pairs, sample_weight, group_id, group_weight, subgroup_id, pairs_weight, baseline, use_best_model, eval_set, verbose, logging_level, plot, column_description, verbose_eval, metric_period, silent, early_stopping_rounds, save_snapshot, snapshot_file, snapshot_interval, init_model) 1807 params, 1808 allow_clear_pool, -> 1809 train_params["init_model"] 1810 ) 1811 KeyboardInterrupt:
Below we are again starting the training process after interruption and we can notice that it has started from where the last snapshot was taken.
X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(verbose=1000, iterations=15000) booster.fit(X_train, Y_train, save_snapshot=True, snapshot_file="catboost_snapshots.temp",snapshot_interval=1) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.004332 7000: learn: 0.6827440 total: 3.83s remaining: 0us 8000: learn: 0.5833276 total: 3.83s remaining: 0us 9000: learn: 0.5005558 total: 3.83s remaining: 0us 10000: learn: 0.4320653 total: 3.83s remaining: 0us 11000: learn: 0.3751506 total: 3.83s remaining: 0us 12000: learn: 0.3275477 total: 3.83s remaining: 0us 13000: learn: 0.2869134 total: 3.83s remaining: 0us 14000: learn: 0.2523760 total: 3.83s remaining: 0us 14999: learn: 0.2222595 total: 3.83s remaining: 0us Test R2 : 0.86 Train R2 : 1.00
13. Early Stop Training to Avoid Overfitting ¶
The catboost provides a parameter named early_stopping_rounds in the fit() method of all estimators which can be set to some integer. The training process will stop if the training loss function output is not improving constantly for a specified number of rounds (specified using the early_stopping_rounds parameter).
Below we have explained with a simple example of how we can use early_stopping_rounds. We can notice that training stops when it does improve loss for 5 consecutive rounds.
from catboost import Pool from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoost({'verbose':10, 'iterations':100}) booster.fit(X_train, Y_train, eval_set=(test_data), early_stopping_rounds=5) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0]) print("nNumber of Trees in Ensemble : ", booster.tree_count_)
Learning rate set to 0.166668 0: learn: 8.0520453 test: 10.1798347 best: 10.1798347 (0) total: 791us remaining: 78.4ms 10: learn: 3.8810707 test: 6.4769275 best: 6.4769275 (10) total: 8.54ms remaining: 69.1ms 20: learn: 2.7929439 test: 5.4534123 best: 5.4534123 (20) total: 14.2ms remaining: 53.6ms 30: learn: 2.3461951 test: 5.1077987 best: 5.1077987 (30) total: 19.9ms remaining: 44.3ms 40: learn: 2.0812703 test: 4.8640181 best: 4.8640181 (40) total: 25.6ms remaining: 36.8ms 50: learn: 1.8649713 test: 4.7165995 best: 4.7052137 (48) total: 31.2ms remaining: 30ms 60: learn: 1.6934276 test: 4.6191067 best: 4.6191067 (60) total: 36.8ms remaining: 23.6ms 70: learn: 1.5620403 test: 4.5825150 best: 4.5825150 (70) total: 43.1ms remaining: 17.6ms Stopped by overfitting detector (5 iterations wait) bestTest = 4.538962725 bestIteration = 74 Shrink model to first 75 iterations. Test R2 : 0.82 Train R2 : 0.97 Number of Trees in Ensemble : 75
14. Monotonic Constraints ¶
The monotonic constraints let us specify the increasing, decreasing, or no monotone relation of a feature with a target. We can specify a monotone value of 1,0 or -1 for each feature to show the increasing, none, and decreasing relation of the feature with the target by setting the monotone_constraints parameter. Below we have explained the usage of monotonic constraints for regression tasks using the Boston dataset.
Please make a note that the below estimator is not giving a good R2 score because we have randomly set monotonic constraints values just for explanation purposes.
from catboost import Pool from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoost({'verbose':10, 'iterations':100, 'monotone_constraints':[1,0,0,-1,1,-1,0,-1,0,0, -1, 0,1]}) booster.fit(X_train, Y_train, eval_set=(test_data)) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0]) print("nNumber of Trees in Ensemble : ", booster.tree_count_)
Learning rate set to 0.166668 0: learn: 8.4082824 test: 10.6123467 best: 10.6123467 (0) total: 4.76ms remaining: 472ms 10: learn: 6.1844246 test: 9.1819333 best: 9.1819333 (10) total: 42.9ms remaining: 347ms 20: learn: 5.4849113 test: 8.7248760 best: 8.7248760 (20) total: 80.1ms remaining: 301ms 30: learn: 5.0819403 test: 8.4086976 best: 8.4086976 (30) total: 118ms remaining: 262ms 40: learn: 4.7705217 test: 8.0945726 best: 8.0945726 (40) total: 155ms remaining: 223ms 50: learn: 4.4499139 test: 8.0709417 best: 8.0296328 (42) total: 192ms remaining: 184ms 60: learn: 4.1723597 test: 8.0705261 best: 8.0296328 (42) total: 245ms remaining: 157ms 70: learn: 3.9376692 test: 7.9487736 best: 7.9395332 (69) total: 284ms remaining: 116ms 80: learn: 3.7828106 test: 7.9343475 best: 7.8989299 (78) total: 321ms remaining: 75.4ms 90: learn: 3.6612582 test: 7.8562065 best: 7.8512619 (89) total: 359ms remaining: 35.6ms 99: learn: 3.4974324 test: 7.7380102 best: 7.7302591 (98) total: 394ms remaining: 0us bestTest = 7.73025906 bestIteration = 98 Shrink model to first 99 iterations. Test R2 : 0.48 Train R2 : 0.85 Number of Trees in Ensemble : 99
15. Custom Evaluation Metric ¶
As a part of this section, we’ll explain how we can use a custom evaluation metric with catboost. We can design a class that can be used as a custom evaluation metric but it should have below mentioned three methods included in it.
- is_max_optimal() — This method returns True if we want to maximize metric else False.
- evaluate() — This method returns an error and total weight for a list of prediction and target labels. The logic of calculating error for a list of values should be included here.
- get_final_error() — This method returns actual metric value based on total error and total weight. The logic of calculating the final error based on weights should be included here.
Below we have created a simple mean absolute error metric. We have then given the same metric to the eval_metric method of CatBoostRegressor. We can notice from the training results that it is printing mean absolute error at every 10 iterations for the evaluation dataset which is a test set in our case.
class MeanAbsoluteError(object): def is_max_optimal(self): ## Return True if We want to Maximize metric else false if want to minimize ## We have passed False because we want to decrease metric return False def evaluate(self, approxes, target, weight): error = 0 weight_sum = 0 for i in range(len(approxes[0])): w = 1.0 if weight is None else weight[i] error += w* (target[i] - approxes[0][i]) weight_sum += w return error, 1.0 if weight is None else weight_sum def get_final_error(self, error, weight): # Returns final value of metric based on error and weight return error / weight
from catboost.utils import eval_metric from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(verbose=10, iterations=100, eval_metric=MeanAbsoluteError(), ) booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test)]) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.166668 0: learn: 24.2600634 test: 136.0999662 best: 136.0999662 (0) total: 3.17ms remaining: 314ms 10: learn: 97.7562849 test: 68.6856874 best: 68.6856874 (10) total: 29.2ms remaining: 236ms 20: learn: 52.6252278 test: 30.4887092 best: 30.4887092 (20) total: 44.4ms remaining: 167ms 30: learn: 18.7700885 test: 18.4446486 best: 18.4446486 (30) total: 53.9ms remaining: 120ms 40: learn: 11.3055473 test: 9.4733398 best: 9.4733398 (40) total: 62.9ms remaining: 90.5ms 50: learn: 6.2744321 test: 5.7102511 best: 5.2957340 (49) total: 71.2ms remaining: 68.4ms 60: learn: 2.7441574 test: 3.7928502 best: 3.7928502 (60) total: 89.9ms remaining: 57.5ms 70: learn: 2.1414438 test: 2.3408031 best: 2.3408031 (70) total: 97.3ms remaining: 39.7ms 80: learn: 2.1668637 test: 0.0583625 best: 0.0583625 (80) total: 105ms remaining: 24.6ms 90: learn: -1.0705412 test: -1.2272650 best: -1.2272650 (90) total: 112ms remaining: 11.1ms 99: learn: 2.3224568 test: -1.3544445 best: -1.3544445 (99) total: 119ms remaining: 0us bestTest = -1.354444507 bestIteration = 99 Test R2 : 0.82 Train R2 : 0.98
16. Custom Objective/Loss Function ¶
As a part of this section, we’ll explain how we can use the custom loss function with catboost. We can create a class that can be used as a custom loss function but it should have one method named calc_ders_range(). This method takes as an input list of predictions, actual target labels, and weights. It then returns a list of tuples where the first value in the tuple is the first derivative of the loss function and the second value is the second derivative of a loss function. The list of tuple must have the same length as the list of predictions and target labels passed to it.
We can then pass this class to the loss_function parameter of estimators. Below we have created a simple mean squared error loss function and explained usage of it with a simple example in the next cell.
class MeanSquaredErrorLoss(object): def calc_ders_range(self, approxes, targets, weights): # This function should return a list of pairs (der1, der2), where # der1 is the first derivative of the loss function with respect # to the predicted value, and der2 is the second derivative. result = [] for index in range(len(targets)): der1 = 2*(targets[index] - approxes[index]) ## First Derivative of Loss Function der2 = -1 ## Second Derivative of Loss Function result.append((der1, der2)) return result
from catboost.utils import eval_metric from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(verbose=10, iterations=100, loss_function=MeanSquaredErrorLoss(), eval_metric="R2" ) booster.fit(X_train, Y_train, eval_set=[(X_test, Y_test)]) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
0: learn: -5.4810607 test: -4.9178567 best: -4.9178567 (0) total: 1.06ms remaining: 105ms 10: learn: -1.5021091 test: -1.6297951 best: -1.6297951 (10) total: 14.7ms remaining: 119ms 20: learn: -0.0371187 test: -0.2945356 best: -0.2945356 (20) total: 23.8ms remaining: 89.6ms 30: learn: 0.5014831 test: 0.2272055 best: 0.2272055 (30) total: 32.1ms remaining: 71.5ms 40: learn: 0.7173740 test: 0.4787453 best: 0.4787453 (40) total: 41.1ms remaining: 59.2ms 50: learn: 0.8195089 test: 0.6193570 best: 0.6193570 (50) total: 50.3ms remaining: 48.3ms 60: learn: 0.8656855 test: 0.6928399 best: 0.6928399 (60) total: 59.9ms remaining: 38.3ms 70: learn: 0.8906273 test: 0.7310830 best: 0.7310830 (70) total: 69ms remaining: 28.2ms 80: learn: 0.9081062 test: 0.7554555 best: 0.7554555 (80) total: 78.1ms remaining: 18.3ms 90: learn: 0.9210548 test: 0.7773323 best: 0.7773323 (90) total: 87.3ms remaining: 8.64ms 99: learn: 0.9290782 test: 0.7905164 best: 0.7905164 (99) total: 95.8ms remaining: 0us bestTest = 0.7905163648 bestIteration = 99 Test R2 : 0.79 Train R2 : 0.93
17. How to Use CatBoost with Text Data? ¶
NOTE: Please feel free to skip this section if you are working with tabular data. You can refer it later when you want to learn about how to use Catboost for tasks involving text datasets.
As a part of this section, we’ll explain with a simple example of how we can handle text data with catboost. We’ll start by loading the spam/ham dataset available from the UCI website. We have included the code below to download it. We have then loaded the dataset as a list of text and labels.
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip !unzip smsspamcollection.zip
--2020-11-29 22:01:42-- https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip Resolving archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.252 Connecting to archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.252|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 203415 (199K) [application/x-httpd-php] Saving to: ‘smsspamcollection.zip’ smsspamcollection.z 100%[===================>] 198.65K 52.8KB/s in 3.8s 2020-11-29 22:01:48 (52.8 KB/s) - ‘smsspamcollection.zip’ saved [203415/203415] Archive: smsspamcollection.zip inflating: SMSSpamCollection inflating: readme
import collections with open('SMSSpamCollection') as f: data = [line.strip().split('t') for line in f.readlines()] y, text = zip(*data) collections.Counter(y)
Counter({'ham': 4827, 'spam': 747})
Example 1¶
The simplest way to work with text data is to let catboost handle the column with text data by itself. Catboost will tokenize data and convert it to a float array by itself. We’ll be using catboost’s internal Pool data structure for this purpose. The Pool data structure has an argument named text_features which accepts a list of indices in data that holds text data. As our dataset only has text data, we have given 0 in that list. We have then normally created the CatBoostClassifier instance and trained it on train data. We have later evaluated it on test data to check accuracy as well which is very impressive.
The catboost estimators have a parameter named text_processing which has some default JSON values which are responsible for handling text data. The default value is available at this link.
from catboost import CatBoostClassifier, Pool from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(pd.DataFrame(text), y, train_size=0.9, stratify=y, random_state=123) train_data = Pool(X_train, Y_train, text_features=[0]) test_data = Pool(X_test, Y_test, text_features=[0]) booster = CatBoostClassifier(iterations=10, learning_rate=0.03, eval_metric='Accuracy') booster.fit(train_data, eval_set=test_data) print("nTest Accuracy : %.2f"%booster.score(train_data)) print("Train Accuracy : %.2f"%booster.score(test_data))
0: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 55.2ms remaining: 497ms 1: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 99.8ms remaining: 399ms 2: learn: 0.9748804 test: 0.9892473 best: 0.9892473 (2) total: 146ms remaining: 340ms 3: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 191ms remaining: 287ms 4: learn: 0.9742823 test: 0.9856631 best: 0.9892473 (2) total: 237ms remaining: 237ms 5: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 307ms remaining: 205ms 6: learn: 0.9752791 test: 0.9892473 best: 0.9892473 (2) total: 358ms remaining: 153ms 7: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 403ms remaining: 101ms 8: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 448ms remaining: 49.7ms 9: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 493ms remaining: 0us bestTest = 0.9892473118 bestIteration = 2 Shrink model to first 3 iterations. Test Accuracy : 0.99 Train Accuracy : 0.99
Example 2¶
As a part of our second example, we have explained how we can specify the value for the text_processing parameter if we want to impose a different way of handling text data.
from catboost import CatBoostClassifier, Pool from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(pd.DataFrame(text), y, train_size=0.9, stratify=y, random_state=123) train_data = Pool(X_train, Y_train, text_features=[0]) test_data = Pool(X_test, Y_test, text_features=[0]) booster = CatBoostClassifier(iterations=10, learning_rate=0.03, eval_metric='Accuracy', text_processing=['NaiveBayes+Word|BoW+Word:min_token_occurrence=5']) booster.fit(train_data, eval_set=test_data) print("nTest Accuracy : %.2f"%booster.score(train_data)) print("Train Accuracy : %.2f"%booster.score(test_data))
0: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 45.3ms remaining: 408ms 1: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 91.1ms remaining: 364ms 2: learn: 0.9748804 test: 0.9892473 best: 0.9892473 (2) total: 138ms remaining: 322ms 3: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 184ms remaining: 276ms 4: learn: 0.9742823 test: 0.9856631 best: 0.9892473 (2) total: 230ms remaining: 230ms 5: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 302ms remaining: 201ms 6: learn: 0.9752791 test: 0.9892473 best: 0.9892473 (2) total: 353ms remaining: 151ms 7: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 399ms remaining: 99.6ms 8: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 444ms remaining: 49.4ms 9: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 490ms remaining: 0us bestTest = 0.9892473118 bestIteration = 2 Shrink model to first 3 iterations. Test Accuracy : 0.99 Train Accuracy : 0.99
Example 3¶
Our third example for text data gives us another example of handling text data with the text_processing parameter.
from catboost import CatBoostClassifier, Pool from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(pd.DataFrame(text), y, train_size=0.9, stratify=y, random_state=123) train_data = Pool(X_train, Y_train, text_features=[0]) test_data = Pool(X_test, Y_test, text_features=[0]) booster = CatBoostClassifier(iterations=10, learning_rate=0.03, eval_metric='Accuracy', text_processing=['NaiveBayes+Word,BiGram|BoW:token_level_type=Word,top_tokens_count=1000+Word,BiGram']) booster.fit(train_data, eval_set=test_data) print("nTest Accuracy : %.2f"%booster.score(train_data)) print("Train Accuracy : %.2f"%booster.score(test_data))
0: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 46.2ms remaining: 416ms 1: learn: 0.9742823 test: 0.9856631 best: 0.9856631 (0) total: 92.9ms remaining: 371ms 2: learn: 0.9748804 test: 0.9892473 best: 0.9892473 (2) total: 139ms remaining: 324ms 3: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 185ms remaining: 277ms 4: learn: 0.9742823 test: 0.9856631 best: 0.9892473 (2) total: 231ms remaining: 231ms 5: learn: 0.9744817 test: 0.9856631 best: 0.9892473 (2) total: 293ms remaining: 195ms 6: learn: 0.9752791 test: 0.9892473 best: 0.9892473 (2) total: 352ms remaining: 151ms 7: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 399ms remaining: 99.7ms 8: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 445ms remaining: 49.4ms 9: learn: 0.9750797 test: 0.9874552 best: 0.9892473 (2) total: 490ms remaining: 0us bestTest = 0.9892473118 bestIteration = 2 Shrink model to first 3 iterations. Test Accuracy : 0.99 Train Accuracy : 0.99
Example 4¶
As a part of our fourth example for handling text data, we have used the TF-IDF vectorizer available from scikit-learn to transform our text data to float. All other parts of the code are almost the same as previous examples with the only difference that we are using TF-IDF transformed arrays for training and evaluation now.
If you are interested in learning about feature extraction from text data using scikit-learn then please feel free to check our tutorial on the same to get an in-depth idea about it.
- Feature Extraction from Text Data using Scikit-Learn
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer X_train, X_test, Y_train, Y_test = train_test_split(text, y, train_size=0.50, stratify=y, random_state=123) vectorizer = TfidfVectorizer(max_features=500) X_train_vect = vectorizer.fit_transform(X_train) X_test_vect = vectorizer.transform(X_test) train_data = Pool(X_train_vect.toarray(), Y_train) ## toarray() is added to prevent catboost from failing (to avoid sparse array error) test_data = Pool(X_test_vect.toarray(), Y_test) ## toarray() is added to prevent catboost from failing (to avoid sparse array error) booster = CatBoostClassifier(iterations=10) booster.fit(train_data, eval_set=test_data) print("nTest Accuracy : %.2f"%booster.score(train_data)) print("Train Accuracy : %.2f"%booster.score(test_data))
Learning rate set to 0.302592 0: learn: 0.4257491 test: 0.4246194 best: 0.4246194 (0) total: 9.53ms remaining: 85.8ms 1: learn: 0.2937232 test: 0.2930775 best: 0.2930775 (1) total: 18.7ms remaining: 74.7ms 2: learn: 0.2358165 test: 0.2344989 best: 0.2344989 (2) total: 27.5ms remaining: 64.1ms 3: learn: 0.2026422 test: 0.1992495 best: 0.1992495 (3) total: 36.2ms remaining: 54.4ms 4: learn: 0.1799321 test: 0.1799717 best: 0.1799717 (4) total: 44.8ms remaining: 44.8ms 5: learn: 0.1612395 test: 0.1644169 best: 0.1644169 (5) total: 53.5ms remaining: 35.7ms 6: learn: 0.1459207 test: 0.1504466 best: 0.1504466 (6) total: 62ms remaining: 26.6ms 7: learn: 0.1345363 test: 0.1389994 best: 0.1389994 (7) total: 70.3ms remaining: 17.6ms 8: learn: 0.1250743 test: 0.1316323 best: 0.1316323 (8) total: 78.8ms remaining: 8.76ms 9: learn: 0.1180861 test: 0.1258048 best: 0.1258048 (9) total: 87.5ms remaining: 0us bestTest = 0.1258048004 bestIteration = 9 Test Accuracy : 0.97 Train Accuracy : 0.97
18. How to Train CatBoost Model on GPU? ¶
Catboost let us run the training process on GPU. It lets us run the training process on a single GPU or even on multiple GPUs in parallel.
In order to run training on GPU, we need to set the task_type parameter of estimators to GPU. We can provide the devices parameter with a list of the below-mentioned values to run the training process on single/multiple GPUs.
- Single GPU — [id1] — e.g : «1» — It’ll use GPU with id 1 for training.
- List of GPUs — [id1]:[id3]:[id5] — e.g : «1:3:5» — It’ll use GPUs with id 1, 3 and 5 for training.
- Range of GPUs — [id1]:[id3] — e.g : «1-3» — It’ll use GPUs with id 1, 2 and 3 for training.
We can get the count of GPUs present on the system using the get_gpu_device_count() method of the utils module.
from catboost import utils gpu_cnt = utils.get_gpu_device_count() print("Number of GPU Count : ",gpu_cnt)
Below we have explained with simple examples of how we can use GPU for the training process.
from catboost import Pool from catboost.utils import eval_metric X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) train_data = Pool(X_train, Y_train) test_data = Pool(X_test, Y_test) booster = CatBoost({'verbose':10, 'iterations':100, 'task_type':"GPU", 'devices':'0'}) booster.fit(train_data) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%eval_metric(Y_test, test_preds, "R2")[0]) print("Train R2 : %.2f"%eval_metric(Y_train, train_preds, "R2")[0])
Learning rate set to 0.250194 0: learn: 7.5374429 total: 16.6ms remaining: 1.65s 10: learn: 2.7801408 total: 65.7ms remaining: 532ms 20: learn: 2.0818499 total: 114ms remaining: 429ms 30: learn: 1.7069672 total: 163ms remaining: 363ms 40: learn: 1.5225117 total: 212ms remaining: 305ms 50: learn: 1.3526526 total: 263ms remaining: 253ms 60: learn: 1.1985452 total: 312ms remaining: 200ms 70: learn: 1.0589672 total: 361ms remaining: 147ms 80: learn: 0.9428833 total: 410ms remaining: 96.1ms 90: learn: 0.8402823 total: 458ms remaining: 45.3ms 99: learn: 0.7629917 total: 504ms remaining: 0us Test R2 : 0.86 Train R2 : 0.99
from catboost import CatBoostRegressor X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, train_size=0.9, random_state=123) booster = CatBoostRegressor(iterations=100, verbose=10, task_type="GPU", devices="0") booster.fit(X_train, Y_train, eval_set=(X_test, Y_test)) booster.set_feature_names(boston.feature_names) test_preds = booster.predict(X_test) train_preds = booster.predict(X_train) print("nTest R2 : %.2f"%booster.score(X_test, Y_test)) print("Train R2 : %.2f"%booster.score(X_train, Y_train))
Learning rate set to 0.191091 0: learn: 7.8653512 test: 10.0828261 best: 10.0828261 (0) total: 56.8ms remaining: 5.62s 10: learn: 3.1914457 test: 5.2116555 best: 5.2116555 (10) total: 431ms remaining: 3.48s 20: learn: 2.3058749 test: 4.4116229 best: 4.4116229 (20) total: 602ms remaining: 2.27s 30: learn: 1.9493499 test: 4.2799673 best: 4.2799673 (30) total: 690ms remaining: 1.54s 40: learn: 1.7352761 test: 4.1593650 best: 4.1593650 (40) total: 787ms remaining: 1.13s 50: learn: 1.5262644 test: 4.1012897 best: 4.0934527 (47) total: 881ms remaining: 847ms 60: learn: 1.3843874 test: 4.0436441 best: 4.0436441 (60) total: 978ms remaining: 625ms 70: learn: 1.3190212 test: 4.0293323 best: 4.0293323 (70) total: 1.09s remaining: 446ms 80: learn: 1.2506546 test: 4.0181813 best: 4.0037107 (75) total: 1.19s remaining: 279ms 90: learn: 1.1381610 test: 4.0142571 best: 3.9918756 (86) total: 1.31s remaining: 130ms 99: learn: 1.0572261 test: 4.0196702 best: 3.9918756 (86) total: 1.37s remaining: 0us bestTest = 3.991875569 bestIteration = 86 Shrink model to first 87 iterations. Test R2 : 0.86 Train R2 : 0.98