Содержание
- Error handling #1363
- Comments
- Spring Blog
- Stream Processing with Spring Cloud Stream and Apache Kafka Streams. Part 4 — Error Handling
- Handling Deserialization Exceptions
- Kafka Streams and the DLQ (Dead Letter Queue)
- Changing the default DLQ name generated by the binder:
- DLQ Topic and Partitions
- Handling producer errors
- Kafka Streams Binder Health Indicator and Metrics
- Summary
- Programmer Help
- Spring Cloud Stream exception handling
- Application Processing
- System Processing
- RetryTemplate
- blueedgenick/spring-cloud-stream-kafka-errors
- Sign In Required
- Launching GitHub Desktop
- Launching GitHub Desktop
- Launching Xcode
- Launching Visual Studio Code
- Latest commit
- Git stats
- Files
- README.md
- About
Error handling #1363
I am using spring cloud reactive stream and confused for error handling,
Currently I have the following logic with Kafaka
my exception when error happen the exception will be captured by retry, and retry again with the same message, but actually it retry again with another message !! , when using doOnError() , the stream is terminating and stop consume messaging, would you please provide advice ?
The text was updated successfully, but these errors were encountered:
Hi, @smaldini. In our recent sync-up, @artembilan had mentioned about a few improvements coming up in 3.2.0. In the meantime, do you have any suggestions on the best practices for the described scenario?
@azmym any chance you can post a sample app that fails somewhere in the github?
@olegz my current application is not failing but not meet business exception, currently business requirement is when an error has been happened during message processing, keep try with the same message and don’t process another message, but when using retry() and error happen, the application leave the current one (unacknowledged) and get the next message .
Now when IOException be fired, the main stream will resubscribe and process the next message, I wanna to keep try with the same message and fire the exception multi time so we can see that in mentoring screen and fix the problem /message before processing the next one ,
I hope this example illustrated my current case
@azmym We are in the process of a bit of a restructuring by bringing spring-cloud-function as a dependency to spring-cloud-stream. With that we’re bringing an improved reactive support, so stay tuned for updates. Current reactive support especially with retry is no as efficient since it is very simply and infinite (keep trying with no end). However, there are improvements in the pipeline with retryBackoff(..) etc.
That said, for your case you may find it a bit simpler (at least for now) to have a simple Message Handler instead of reactive. Keep in mind that re-try is already wired up via RetryTemplate in Message Listener Container. So your application should look as follows:
Also, as you can see you don’t need to manually convert the message since it will be automatically converted for you by the framework since application/json is the default content type since 2.0.
Please give it a try and let us know if you still have any more questions.
Источник
Spring Blog
Stream Processing with Spring Cloud Stream and Apache Kafka Streams. Part 4 — Error Handling
Continuing with the series on looking at the Spring Cloud Stream binder for Kafka Streams, in this blog post, we are looking at the various error-handling strategies that are available in the Kafka Streams binder.
The error handling in Kafka Streams is largely centered around errors that occur during deserialization on the inbound and during production on the outbound.
Handling Deserialization Exceptions
Kafka Streams lets you register deserialization exception handlers. The default behavior is that, when you have a deserialization exception, it logs that error and fails the application ( LogAndFailExceptionHandler ). It also lets you log and skip the record and continue the application ( LogAndContinueExceptionHandler ). Normally, you provide the corresponding classes as part of the configuration. By using the binder, you can set these exception handlers either at the binder level, which will be applicable for the entire application or at the binding level, which gives you more fine-grained control.
Here’s how you can set the deserialization exception handlers at the binder level:
If you have only a single processor with a single input, it is an easy way to set the deserialization exception handler on the binder as shown above. If you have multiple processors or inputs and if you want to control error handling on them separately, that needs to be set per input binding. Here is an example of doing so:
Notice that the handler is actually set on the input binding process-in-0 . If you have more such input bindings, then that has to be explicitly set.
Kafka Streams and the DLQ (Dead Letter Queue)
In addition to the two exception handlers that Kafka Streams provides, the binder provides a third option: a custom handler that lets you send the record in a deserialization error to a special DLQ. In order to activate this, you have to opt-in for this either at the binder or binding level, as explained above.
Here’s how to do so:
Keep in mind that, when using this setting at the binder, this activates the DLQ at the global level, and this will be applied against all the input topics through their bindings. If that’s not what you want to happen, you have to enable it per input binding.
By default, the DLQ name is named error. . .
You can replace with the actual topic name. Note that this is not the binding name but the actual topic name.
If the input topic is topic-1 and the Kafka Streams application ID is my-application, the default DLQ name will be error.topic-1.my-application .
Changing the default DLQ name generated by the binder:
You can reset the default DLQ name, as follows:
spring.cloud.stream.bindings.process-in-0.consumer.dlqName=input-1-dlq (Replace process-in-0 with the actual binding name)
If it has the required permissions on the broker, the binder provisioner will create all the necessary DLQ topics. If that’s not the case, these topics have to be created manually before the application starts.
DLQ Topic and Partitions
By default, the binder assumes that the DLQ topic is provisioned with the same number of partitions as the input topic. If that’s not true (that is if the DLQ topic is provisioned with a different number of partitions), you have to tell the binder the partition to which to send the records by using a DlqPartitionFunction implementation, as follows:
There can only be one such bean present in the application. Therefore, you have to filter out the records by using a group (which is the same as the application ID when using the binder) in the event of multiple processors or inputs with separate DLQ topics.
Handling producer errors
All the exception handlers that we discussed so far deal only with errors surrounding deserialization of data. Kafka Streams also provides an ability to handle producer errors on the outbound. As of the 3.0. Release, the binder does not provide a first-class mechanism to support this. However, this doesn’t mean that you can’t use the producer exception handlers. You can use the various customizers that the binder relies on from Spring for Apache Kafka project to do that. These customizers are going to be the topic of our next blog post in this series.
Kafka Streams Binder Health Indicator and Metrics
Kafka Streams binder allows the monitoring of the health of the underlying streams thread and it exposes the health-indicator metrics through a Spring Boot actuator endpoint. You can find more details here. In addition to the health indicator, the binder also exposes Kafka Streams metrics through Micrometer meter-registry. All the basic metrics available through the KafkaStreams object is available in this registry. Here is where you can find more information on this.
Summary
In this blog post, we saw the various strategies Kafka Streams uses to enable handling deserialization exceptions. On top of these, the Kafka Streams binder also provides a handler that lets you send error-prone payloads to a DLQ topic. We saw that the binder provides fine-grained control of working with these DLQ topics.
Thank you for reading this far! In the next blog post, we are going to see how the binder enables further customizations.
Источник
Programmer Help
Where programmers get help
Spring Cloud Stream exception handling
Application Processing
When consumers process received messages, they may throw exceptions for some reasons. If we want to deal with the thrown exception, we need to adopt some exception handling methods, which can be divided into three ways: application level processing, system level processing and RetryTemplate processing.
In this section, we first introduce the common application-level anomaly handling methods, which are subdivided into local processing and global processing.
Stream-related configuration is as follows:
The so-called local processing is to deal with the specified channel. We need to define a method to handle exceptions, and add the @Service Activator annotation on this method. The annotation has an inputChannel attribute, which specifies which channel to process, in the form of ..errors. The code is as follows:
Global processing is able to handle all channel thrown exceptions, all channel thrown exceptions will generate an ErrorMessage object, that is, error messages. Error messages are placed in a dedicated channel, which is the error channel. So by listening to errorChannel, the global exception can be handled. The code is as follows:
System Processing
The way of system processing varies from message middleware to message middleware. If there is no configuration error handling at the application level, the error will be propagated to the binder, and the binder will send the error back to the message middleware. Message middleware can choose:
- Discard message: Error message will be discarded. Although acceptable in some cases, this method is generally not applicable to production.
- requeue
- Send the failed message to DLQ (Dead Letter Queue)
At present, RabbitMQ supports DLQ better. Take RabbitMQ as an example, only need to add DLQ related configuration:
When news consumption fails, it will be put into the dead letter queue. With a console operation, the dead letter can be put back into the message queue, so that the client can reprocess it.
If you want to get the exception stack of the original error, you can add the following configuration:
Rabbit and Kafka’s binder rely on RetryTemplate to retry messages, which improves the success rate of message processing. However, if spring.cloud.stream.bindings.input.consumer.max-attempts=1 is set, RetryTemplate will not try again. At this point, exceptions can be handled by requeue.
The following configuration needs to be added:
In this way, the failed message will be resubmitted to the same handler for processing until the handler throws an AmqpRejectAndDontRequeueException exception.
RetryTemplate
RetryTemplate is mainly used for message retry and is also a means of error handling. There are two ways to configure, one is through the configuration file, as follows:
The other is through code configuration. In most scenarios, customizing retry behavior with configuration files can meet the requirements, but the configuration items supported in the configuration files may not meet some complex requirements. RetryTemplate can be configured in a code-based manner, as shown in the following example:
Finally, you need to add a configuration:
Note: Spring Cloud Stream 2.2 only supports retry-template-name settings
Posted on Sun, 11 Aug 2019 09:13:22 -0400 by alexcmm
Источник
blueedgenick/spring-cloud-stream-kafka-errors
Use Git or checkout with SVN using the web URL.
Work fast with our official CLI. Learn more.
Sign In Required
Please sign in to use Codespaces.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
An experiment with using the Spring Cloud Stream abstractions for producing messages to Apache Kafka.
Originally created to investigate:
the default Producer settings used by the Spring libraries
how error-handling can best be configured.
It’s a very basic Spring Boot app so dead simple to run — there’s only one class and it has a main method 😄 . I mostly chose to run it from within my IDE while testing.
You’ll need a Kafka Broker running somewhere for it to Produce messages to. If you’re not running that broker on localhost on the default port (9092) then you’ll need to adjust the spring.cloud.stream.kafka.binder.brokers entry in the application.yml file to reflect the location of your broker.
Notice that the entire set of Producer properties is, by default, logged when the app starts up. In particular, observe that the default number of retries is 0 and the default number of acks is set to 1.
Why this matters
This is generally considered a poor choice for clients writing to any kind of distributed data store, and that is equally true in the Kafka world. These kind of distributed systems rarely have a strictly-binary availability mode i.e. ‘up’ or ‘down’. Instead, by operating across a group or cluster of machines they seek to provide «at least some» availability, even when a subset of the cluster members are offline — perhaps as part of a rolling restart, for example. In these situations it is desirable to have clients retry an operation against a server which is currently unavailable as it’s responsibilities will generally be assumed by another member of the cluster in short order.
When working with Kafka it is therefore desirable to adjust the number of retries to a non-zero number. Note that recent versions of Kafka actually default this to MAX_INT (2147483647).
(For the curious, the time between retries is governed by a retry.backoff.ms value, set separately, default 100ms). Note that only so-called transient errors are retried.
Additionally, to ensure successful and durable recording of the messages your app is producing. it is desirable to set the number of acks (acknowledgements) to all . This will force your client to wait for acknowledgements from all of the brokers responsible for recording a copy of it’s messages before deeming them to have been durably saved. This can be important in several subtle but not uncommon edge cases, such as one broker or it’s network becoming overloaded and browning out its connections with the other brokers or with zookeeper. This can cause the rest of the cluster to ‘jettison’ this particular broker, with the result that messages it has recorded to disk but not yet replicated to other brokers may be lost when it re-joins the cluster.
Recommendations for reliable message producing
Add entries to your application.yml , under spring.cloud.stream.kafka.binder , for required-acks: all and producer-properties.retries: 2147483647 .
Familiarize yourself with the various producer properties related to durable message sending documented at (https://docs.confluent.io/current/installation/configuration/producer-configs.html). NOTE in particular the interaction of a non-zero value for the number of retries and the setting for max.in.flight.requests.per.connection , which you may want to adjust down to 1 in the event that you wish to preserve message ordering even in the face of transient non-delivery-and-retry situations.
Producer Error Handling
If an error occurs while producing a message to Kafka the default SCS behavior appears to be to write a log message and then continue processing anyway as if nothing had happened. You can easily simulate this by starting this test app, letting it run for a few seconds to send some messages, then stopping your local broker. After a brief timeout you should see something like this in the output
Sometimes however you want your application to be informed of this error and allow it a chance to take some specific action of your choosing. The good news is that, although somewhat non-obvious, this *is possible in SCS! You will need to make two changes in your app to have it be notified whenever a Producer error occurs:
- Add a handler method with the @ServiceActivator(inputChannel = «errorChannel») annotation. This will be invoked whenever an error occurs producing to any topic from your app. If you want to have separate handlers for writing to different topics, and you know some Spring Integration, this is also possible to set up but beyond what I have space to cover here.
- Crucially the annotated method alone is not enough — it won’t be invoked unless you also add another entry to the application.yml :
That’s it! Now your app will loudly cry for help on its STDOUT whenever Producer errors are encountered. (you were going to implement something smarter than my simple example here, weren’t you ? 😁 )
About
Demonstrate Producer error-handling when using Spring Cloud Stream with Kafka
Источник
Microsoft Dynamics 365 for Retail Management Solution is one of the best and popular ERP cloud solutions. It is a lot efficient and effective than a lot of other similar products that you can now find in the market. Even in the peak hours of the day, you can give the best customer experience to your clients. And the best part is that you can achieve this without gaps or duplication. It is one of the main reasons why a lot of business people rely on this ERP solution. It is easy to install and use this app.
However, if you are a new user, you might find it a little difficult to manage this application. Here’s how you should handle AX retail POS error.
Introduction:
In AX Retail POS, the Implementation Administrator created a new Windows user ID. But new user trying to open the Retail POS, he is getting error “Retail POS Cannot connect to a database. Try again Later or see your system administrator. “. As we all know for the online store required the Store channel database and store Massage database. The system administrator created this database from the Administrator user ID or Administrator Permission.
But still this Error occurred?
Error:
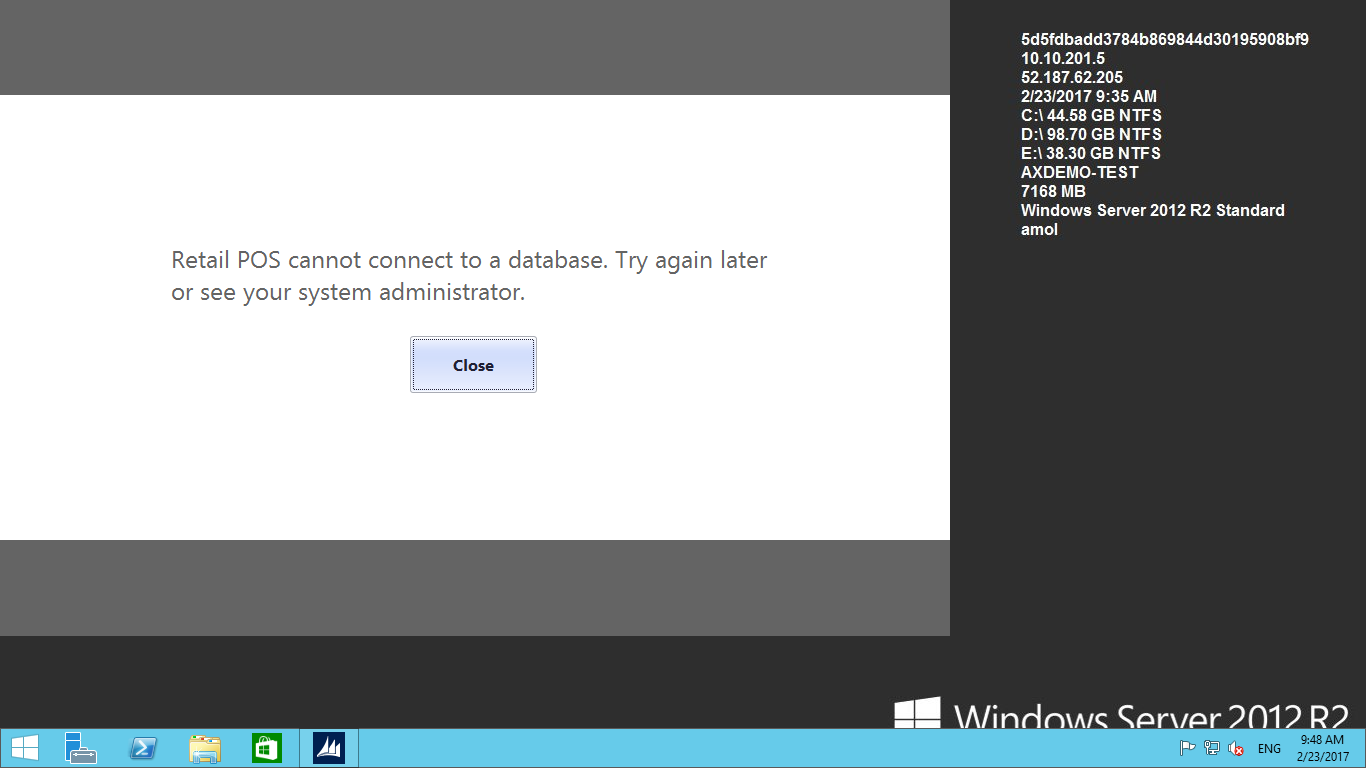
Why this error occurred?
Answer: Store channel is the database where all retail POS transaction data stored Like ( sales Transaction, shift details, POS profile, store and terminal details…etc.). User ID can to connected to this Database or user ID does available for store channel database in SQL. Because of this reason when new user tries to run the Retail POS application, he gets this error message.
How to solve this issue?
Follow the below steps:
-
- Login Point of Sales system from administrator. Then Open the store SQL server.
- After opening SQL, In Object Explorer go to Security -> logins
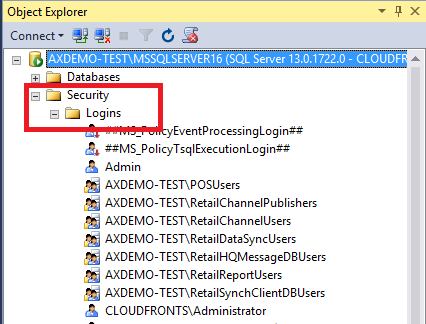
-
- Right Click on Logins and select New Login option
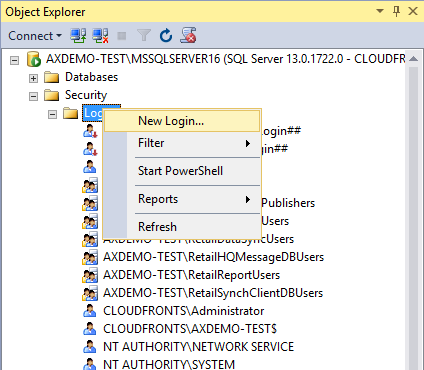
-
- In the General tab, select the Windows authentication option and after that click on the Search button.
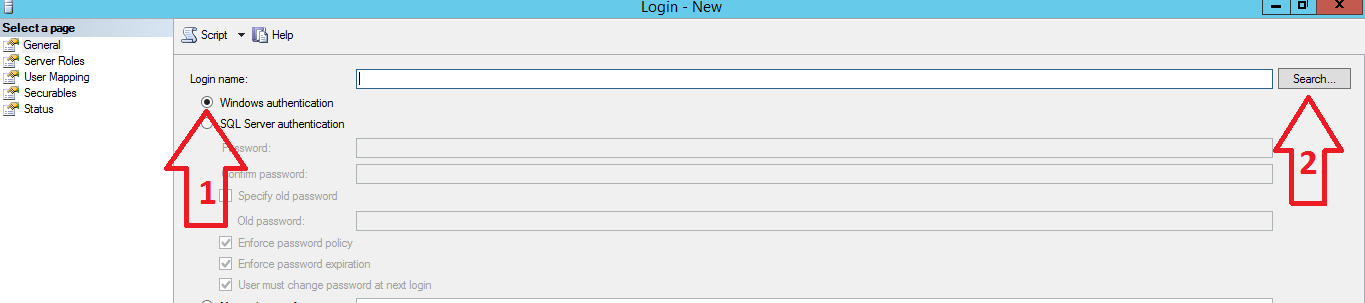
-
- Add the new user ID. <Domain Name><New User ID> (Note:- Make sure that your system should be in the domain while adding new user).
For demo use, I am using my domain
CloudFrontsAmol - Select User Mapping Page, In User Mapping Page Map Store Channel Database and Store message database.
- Add the new user ID. <Domain Name><New User ID> (Note:- Make sure that your system should be in the domain while adding new user).
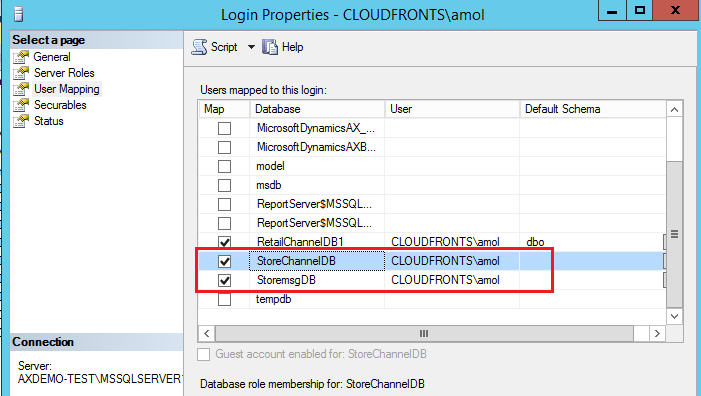
- Select Database Role membership for Store channel database and store message Database.
Role should be db_accessadmin, db_datareader, db_datawriter, db_excutore and click on OK button. - Restart the Async client Service and run the Retail POS.
Conclusion:
Adding User with permission in SQL for Store channel database and Store Message Database, allow windows users to interact with the database from Retail POS application.
Related posts:
Introduction
An experiment with using the Spring Cloud Stream abstractions for producing messages to Apache Kafka.
Originally created to investigate:
-
the default Producer settings used by the Spring libraries
-
how error-handling can best be configured.
Running
It’s a very basic Spring Boot app so dead simple to run — there’s only one class and it has a main method 😄. I mostly chose to run it from within my IDE while testing.
You’ll need a Kafka Broker running somewhere for it to Produce messages to. If you’re not running that broker on localhost on the default port (9092) then you’ll need to adjust the
spring.cloud.stream.kafka.binder.brokers entry in the application.yml file to reflect the location of your broker.
Producer settings
Notice that the entire set of Producer properties is, by default, logged when the app starts up. In particular, observe that the default number of retries is 0 and the default number of acks is set to 1.
Why this matters
This is generally considered a poor choice for clients writing to any kind of distributed data store,
and that is equally true in the Kafka world.
These kind of distributed systems rarely have a strictly-binary availability mode i.e. ‘up’ or ‘down’.
Instead, by operating across a group or cluster of machines they seek to provide «at least some» availability, even when a subset of the cluster members are offline — perhaps as part of a rolling restart, for example.
In these situations it is desirable to have clients retry an operation against a server which is currently unavailable as it’s responsibilities will generally be assumed by another member of the cluster in short order.
When working with Kafka it is therefore desirable to adjust the number of retries to a non-zero number.
Note that recent versions of Kafka actually default this to MAX_INT (2147483647).
(For the curious, the time between retries is governed by a retry.backoff.ms value, set separately, default 100ms).
Note that only so-called transient errors are retried.
Additionally, to ensure successful and durable recording of the messages your app is producing.
it is desirable to set the number of acks (acknowledgements) to all.
This will force your client to wait for acknowledgements from all of the brokers responsible for recording a copy of it’s messages before deeming them to have been durably saved. This can be important in several subtle but not uncommon edge cases, such as one broker or it’s network becoming overloaded and browning out its connections with the other brokers or with zookeeper. This can cause the rest of the cluster to ‘jettison’ this particular broker, with the result that messages it has recorded to disk but not yet replicated to other brokers may be lost when it re-joins the cluster.
Recommendations for reliable message producing
Add entries to your application.yml, under spring.cloud.stream.kafka.binder, for required-acks: all and producer-properties.retries: 2147483647.
kafka: binder: brokers: localhost required-acks: all producer-properties: retries: 2
Familiarize yourself with the various producer properties related to durable message sending documented at
(https://docs.confluent.io/current/installation/configuration/producer-configs.html). NOTE in particular the interaction of
a non-zero value for the number of retries and the setting for max.in.flight.requests.per.connection, which you may want to adjust down to 1
in the event that you wish to preserve message ordering even in the face of transient non-delivery-and-retry situations.
Producer Error Handling
If an error occurs while producing a message to Kafka the default SCS behavior appears to be to write a log message and then continue processing anyway as if nothing had happened.
You can easily simulate this by starting this test app, letting it run for a few seconds to send some messages, then stopping your local broker. After a brief timeout you should see something like this in the output
2019-08-27 21:22:42.526 ERROR 8588 --- [ad | producer-2] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key='null' and payload='{123, 34, 116, 101, 120, 116, 34, 58, 34, 72, 101, 108, 108, 111, 32, 83, 67, 83, 32, 87, 111, 114, ...' to topic scstest:
org.apache.kafka.common.errors.TimeoutException: Expiring 30 record(s) for scstest-0: 30014 ms has passed since batch creation plus linger time
Sometimes however you want your application to be informed of this error and allow it a chance to take some specific action of your choosing.
The good news is that, although somewhat non-obvious, this *is possible in SCS!
You will need to make two changes in your app to have it be notified whenever a Producer error occurs:
- Add a handler method with the
@ServiceActivator(inputChannel = "errorChannel")annotation. This will be invoked whenever an error occurs producing to any topic from your app. If you want to have separate handlers for writing to different topics, and you know some Spring Integration, this is also possible to set up but beyond what I have space to cover here.
/** * Callback function invoked whenever a Producer error occurs. * * @param em structured error object containing both the failing message and error details */ @ServiceActivator(inputChannel = "errorChannel") public void handle(final ErrorMessage em) { System.out.println("** help me! **"); }
- Crucially the annotated method alone is not enough — it won’t be invoked unless you also add another entry to the
application.yml:
spring: cloud: stream: bindings: output: producer: error-channel-enabled: true
That’s it! Now your app will loudly cry for help on its STDOUT whenever Producer errors are encountered. (you were going to implement something smarter than my simple example here, weren’t you ? 😁)
Application Processing
When consumers process received messages, they may throw exceptions for some reasons. If we want to deal with the thrown exception, we need to adopt some exception handling methods, which can be divided into three ways: application level processing, system level processing and RetryTemplate processing.
In this section, we first introduce the common application-level anomaly handling methods, which are subdivided into local processing and global processing.
Local processing
Stream-related configuration is as follows:
spring:
cloud:
stream:
rocketmq:
binder:
name-server: 192.168.190.129:9876
bindings:
input:
destination: stream-test-topic
group: binder-group
The so-called local processing is to deal with the specified channel. We need to define a method to handle exceptions, and add the @Service Activator annotation on this method. The annotation has an inputChannel attribute, which specifies which channel to process, in the form of {destination}.{group}.errors. The code is as follows:
package com.zj.node.usercenter.rocketmq;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.integration.annotation.ServiceActivator;
import org.springframework.messaging.Message;
import org.springframework.messaging.support.ErrorMessage;
import org.springframework.stereotype.Service;
/**
* Consumer
*
* @author 01
* @date 2019-08-10
**/
@Slf4j
@Service
public class TestStreamConsumer {
@StreamListener(Sink.INPUT)
public void receive1(String messageBody) {
log.info("Consumer news, messageBody = {}", messageBody);
throw new IllegalArgumentException("Parameter error");
}
/**
* Method of dealing with local anomalies
*
* @param errorMessage Exception message object
*/
@ServiceActivator(
// Specify which channel exception to handle through a specific format
inputChannel = "stream-test-topic.binder-group.errors"
)
public void handleError(ErrorMessage errorMessage) {
// Getting exception objects
Throwable errorMessagePayload = errorMessage.getPayload();
log.error("exception occurred", errorMessagePayload);
// Get message body
Message<?> originalMessage = errorMessage.getOriginalMessage();
if (originalMessage != null) {
log.error("Message Body: {}", originalMessage.getPayload());
} else {
log.error("The message body is empty");
}
}
}
Global processing
Global processing is able to handle all channel thrown exceptions, all channel thrown exceptions will generate an ErrorMessage object, that is, error messages. Error messages are placed in a dedicated channel, which is the error channel. So by listening to errorChannel, the global exception can be handled. The code is as follows:
@StreamListener(Sink.INPUT)
public void receive1(String messageBody) {
log.info("Consumer news, messageBody = {}", messageBody);
throw new IllegalArgumentException("Parameter error");
}
/**
* A Method of Handling Global Exceptions
*
* @param errorMessage Exception message object
*/
@StreamListener("errorChannel")
public void handleError(ErrorMessage errorMessage) {
log.error("exception occurred. errorMessage = {}", errorMessage);
}
System Processing
The way of system processing varies from message middleware to message middleware. If there is no configuration error handling at the application level, the error will be propagated to the binder, and the binder will send the error back to the message middleware. Message middleware can choose:
- Discard message: Error message will be discarded. Although acceptable in some cases, this method is generally not applicable to production.
- requeue
- Send the failed message to DLQ (Dead Letter Queue)
DLQ
At present, RabbitMQ supports DLQ better. Take RabbitMQ as an example, only need to add DLQ related configuration:
spring:
cloud:
stream:
bindings:
input:
destination: stream-test-topic
group: binder-group
rabbit:
bindings:
input:
consumer:
# Automatically send failed messages to DLQ
auto-bind-dlq: true
When news consumption fails, it will be put into the dead letter queue. With a console operation, the dead letter can be put back into the message queue, so that the client can reprocess it.
If you want to get the exception stack of the original error, you can add the following configuration:
spring:
cloud:
stream:
rabbit:
bindings:
input:
consumer:
republish-to-dlq: true
requeue
Rabbit and Kafka’s binder rely on RetryTemplate to retry messages, which improves the success rate of message processing. However, if spring.cloud.stream.bindings.input.consumer.max-attempts=1 is set, RetryTemplate will not try again. At this point, exceptions can be handled by requeue.
The following configuration needs to be added:
# Default is 3, set to 1 to disable retry spring.cloud.stream.bindings.<input channel Name>.consumer.max-attempts=1 # Message indicating whether requeue is rejected (i.e. requeue handles failed messages) spring.cloud.stream.rabbit.bindings.input.consumer.requeue-rejected=true
In this way, the failed message will be resubmitted to the same handler for processing until the handler throws an AmqpRejectAndDontRequeueException exception.
RetryTemplate
RetryTemplate is mainly used for message retry and is also a means of error handling. There are two ways to configure, one is through the configuration file, as follows:
spring:
cloud:
stream:
bindings:
<input channel Name>:
consumer:
# Up to a few attempts, default 3
maxAttempts: 3
# Initial backoff interval at retry, unit milliseconds, default 1000
backOffInitialInterval: 1000
# Maximum backoff interval, unit milliseconds, default 10000
backOffMaxInterval: 10000
# Backoff multiplier, default 2.0
backOffMultiplier: 2.0
# Whether to retry when listen throws an exception not listed in retryableExceptions
defaultRetryable: true
# Are exceptions allowed to retry map mappings
retryableExceptions:
java.lang.RuntimeException: true
java.lang.IllegalStateException: false
The other is through code configuration. In most scenarios, customizing retry behavior with configuration files can meet the requirements, but the configuration items supported in the configuration files may not meet some complex requirements. RetryTemplate can be configured in a code-based manner, as shown in the following example:
@Configuration
class RetryConfiguration {
@StreamRetryTemplate
public RetryTemplate sinkConsumerRetryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
retryTemplate.setRetryPolicy(retryPolicy());
retryTemplate.setBackOffPolicy(backOffPolicy());
return retryTemplate;
}
private ExceptionClassifierRetryPolicy retryPolicy() {
BinaryExceptionClassifier keepRetryingClassifier = new BinaryExceptionClassifier(
Collections.singletonList(IllegalAccessException.class
));
keepRetryingClassifier.setTraverseCauses(true);
SimpleRetryPolicy simpleRetryPolicy = new SimpleRetryPolicy(3);
AlwaysRetryPolicy alwaysRetryPolicy = new AlwaysRetryPolicy();
ExceptionClassifierRetryPolicy retryPolicy = new ExceptionClassifierRetryPolicy();
retryPolicy.setExceptionClassifier(
classifiable -> keepRetryingClassifier.classify(classifiable) ?
alwaysRetryPolicy : simpleRetryPolicy);
return retryPolicy;
}
private FixedBackOffPolicy backOffPolicy() {
final FixedBackOffPolicy backOffPolicy = new FixedBackOffPolicy();
backOffPolicy.setBackOffPeriod(2);
return backOffPolicy;
}
}
Finally, you need to add a configuration:
spring.cloud.stream.bindings.<input channel Name>.consumer.retry-template-name=myRetryTemplate
Note: Spring Cloud Stream 2.2 only supports retry-template-name settings