Many might have seen PostgreSQL issue the following error message: "ERROR: deadlock detected". But what does it really mean? How can we prevent a deadlock and how can we reproduce the problem? Let’s dive into PostgreSQL locking and understand what deadlock and deadlock_timeout really mean.
How does a deadlock happen?
Many people approach us because they want to understand what a deadlock is and how it can happen. They also want to understand how a deadlock can be avoided and what software developers can do about it.
If you want to understand how a deadlock occurs, all you need is a table containing two lines. That’s sufficient to explain the basic principle of deadlocks.
Here is some easy-to-use sample data:
test=# CREATE TABLE t_data (id int, data int); CREATE TABLE test=# INSERT INTO t_data VALUES (1, 100), (2, 200); INSERT 0 2 test=# TABLE t_data; id | data ----+------ 1 | 100 2 | 200 (2 rows)
The crux is that if data is updated in a different order, transactions might have to wait for one another to be finished. It is perfectly fine if transaction 1 has to wait for transaction 2. But what happens if transaction 1 has to wait for transaction 2 and transaction 2 has to wait for transaction 1? In that case, the system has two choices:
- Wait infinitely, or
- Abort one transaction and commit the other transaction.
As waiting infinitely is not an option, PostgreSQL will abort one of these transactions after some time (deadlock_timeout). Here is what happens:
| Transaction 1 | Transaction 2 | Comment |
BEGIN; |
BEGIN; |
|
UPDATE t_data |
UPDATE t_data |
works perfectly |
UPDATE t_data |
has to wait until transaction 2 releases the lock on the row containing id = 2 | |
| … waits … | UPDATE t_data |
wants to lock the row locked by transaction id: now both are supposed to wait |
| … deadlock timeout … | … deadlock timeout … | PostgreSQL waits (deadlock_timeout) and triggers deadlock detection after this timeout (not immediately) |
| update proceeds: “UPDATE 1” | ERROR: deadlock detected | a transaction has to die |
| COMMIT; | the rest commits normally |
The error message we will see is:
ERROR: deadlock detected
DETAIL: Process 70725 waits for ShareLock on transaction 891717; blocked by process 70713.
Process 70713 waits for ShareLock on transaction 891718; blocked by process 70725.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,1) in relation "t_data"
The reason is that transactions have to wait for one another. If two transactions are in a conflict, PostgreSQL will not resolve the problem immediately, rather it will wait for deadlock_timeout and then trigger the deadlock detection algorithm to resolve the problem.
Why does PostgreSQL wait for some time before it steps in and fixes things? The reason is that deadlock detection is quite expensive, and therefore not immediately triggering it makes sense. The default value here is 1 second, which is high enough to avoid pointless deadlock detection attempts, but is still short enough to fix the problem in a useful and timely manner.
How to fix and avoid deadlocks
The most important thing to know is: There is NO MAGIC CONFIGURATION PARAMETER to fix this problem. The problem does NOT depend on configuration. It depends on the execution order of operations. In other words, you cannot magically fix it without understanding the application and its underlying operations.
The only thing that can fix the problem is to change the execution order, as shown in the next listing:
test=# SELECT * FROM t_data ; id | data ----+------ 1 | 1000 2 | 2000 (2 rows)
This is the data you should see after committing the transaction that did not fail before. Thus we can see what happens if two transactions execute in a different order:
| Transaction 1 | Transaction 2 | Comment |
BEGIN; |
||
UPDATE t_data |
BEGIN; |
|
UPDATE t_data |
||
UPDATE t_data |
… wait … | |
COMMIT; |
… wait … | |
UPDATE t_data |
re-read the value and use the newly committed entries | |
UPDATE t_data |
re-read the value and use the newly committed entries | |
COMMIT; |
In this case, there is no deadlock. However, in a real work scenario it is hardly possible to simply swap the execution order. That’s why this is more of a theoretical solution to the problem than a practical one. However, there are no other options to fix the problem of deadlocks. In the case of deadlocks, being aware of how to prevent them is the best cure.
Finally …
Locking is really important. Deadlocks are not the only concern in this area. Performance might be equally important, therefore it makes sense to deal with performance-related locking effects as well. Stay tuned for more on this topic.
If you want to learn more about important features of PostgreSQL, you might want to check out a blog post about UPDATE which can be found here.
Please leave your comments below. In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
Содержание
- PostgreSQL: Decoding Deadlocks
- Identify tables involved
- Identify requested lock modes
- Putting it all together
- So…what was (probably) going on?
- Debugging deadlocks in PostgreSQL
- A simple deadlock example
- Setting the stage
- The deadlock
- How a deadlock appears in the log
- Why is debugging deadlocks difficult?
- The cause of the deadlock in our example
- Techniques for debugging deadlocks
- Debugging deadlocks by logging on the application side
- Debugging deadlocks by annotating queries on the application side
- Debugging deadlocks by logging on the database side
- The log file for our example would look as follows:
- Debugging deadlocks by increasing deadlock_timeout
- Conclusion
PostgreSQL: Decoding Deadlocks
At some point, a cryptic message like this one has probably popped up in your application logs:
And if you’re anything like me, several questions may have come to mind:
I know what a deadlock is…but what are all these numbers? What is an AccessExclusiveLock? Or AccessShareLock, for that matter? And, perhaps most importantly — what, if anything, can I do about it?
While it may seem intimidating to debug such an error, fear not! Essential information is packed into this message; you just need to know how to interpret it.
So, where to begin?
The DETAIL section of the error message above, once deconstructed, takes the following form:
Let’s start by filling in the blanks.
Identify tables involved
The error message actually pretty clearly indicates the impacted tables — in this case relation 17389 and relation 17309 — but they’re only identified by an integer. This isn’t just any integer though, it’s an OID (or “Object Identifier”) — a special type used internally by PostgreSQL for system table primary keys [1].
One nifty way of using the OID to retrieve the relation name is by casting it to regclass :
We can also get the same result by simply querying the pg_class system table directly [2]:
In most cases, either one of these queries is probably sufficient. But depending on the complexity of the database, additional context, like a schema, may be required to best narrow down the affected relations. This can be accomplished by JOINing on the pg_namespace system catalog [3]:
Similarly, the database referenced by database 16390 will be obvious most of the time. But, in case it isn’t, you can look that up too:
Now that we know what relations were involved, let’s examine the lock modes being requested.
Identify requested lock modes
The error message specifies a lock type that was requested, but not acquired by a given process. In the example, process 16121 requested a lock of type AccessExclusiveLock and process 15866 requested a lock of type AccessShareLock . Each of these lock types is associated with a corresponding lock mode.
The lock modes control concurrent access to the relation they are acquired on and determine the types of operations that can be performed.
While the entire chapter on Explicit Locking from the PostgreSQL documentation is worth a thorough read, for the purposes of this investigation, we will only focus on the two lock modes specifically indicated in the example error output: ACCESS EXCLUSIVE and ACCESS SHARE [4].
- Most restrictive lock mode (conflicts with all lock modes)
- Prevents all other transactions from accessing the table in any way for the duration the lock is held (typically until the end of the transaction)
- Only lock mode that blocks read-only access
- Acquired by most DDL statements ( ALTER TABLE , DROP TABLE ) and maintenance statements ( REINDEX , CLUSTER , VACUUM FULL )
- Least restrictive lock mode
- Only conflicts with ACCESS EXCLUSIVE
- Acquired by SELECT commands that are read-only (without FOR UPDATE )
Combining this knowledge with the process information from the error message, we can now deduce what sequence of operations might have resulted in the deadlock.
Putting it all together
For the sake of discussion, assume that the problematic relations were identified, using the previously demonstrated queries, as “author” (relation 17389) and “book” (relation 17309), both belonging to database “test” (database 16390).
Let’s take another look at the original error message, substituting these values:
To summarize simply:
Process 16121 is requesting an AccessExclusiveLock on “author” but is not able to acquire one because process 15866 is already holding a conflicting lock on “author”.
Process 15866 is requesting an AccessShareLock on “book” but is not able to acquire one because process 16121 is already holding a conflicting lock on “book”.
So, we know what locks are desired by each of these processes, but to really figure out what’s going on we’ll need to answer:
- What lock does process 15866 hold on table “author”?
- What lock does process 16121 hold on table “book”?
To answer these questions, we’ll start by reviewing the second line of the DETAIL:
What do we know?
- Process 15866 has asked for, but not acquired, a lock of type AccessShareLock
- The request for an AccessShareLock implies read-only operations will be performed on table “book”
- An AccessShareLock is only blocked by an AccessExclusiveLock
- Process 15866 is blocked by process 16121
Therefore, given this information, we can conclude that process 16121 must have already acquired an AccessExclusiveLock on table “book”.
Let’s go back to the first line of the DETAIL and list the knowns:
- Process 16121 has asked for, but not acquired, a lock of type AccessExclusiveLock
- The request for an AccessExclusiveLock implies a significant table modification/maintenance operation will be performed on table “author”
- An AccessExclusiveLock conflicts with all lock modes
- Process 16121 is blocked by process 15866
In this case, it is more challenging to deduce exactly what lock type was previously acquired by process 15866 because a range of possibilities exists, for example:
Consider a query like this one:
While executing the above transaction, the necessary AccessShareLock may have been acquired on “author”, but could not be acquired on “book” due to the conflicting transaction in process 16121.
Similarly, it is possible that the transaction in process 15866 was performing other tasks successfully before attempting to read from “book”. The lock previously obtained for the UPDATE on “author” would not be released immediately after the statement completed because locks are typically held until the end of the transaction.
To answer those outstanding questions:
- What lock does process 16121 hold on table “book”?
AccessExclusiveLock - What lock does process 15866 hold on table “author”?
Could be any of them 🙁
So…what was (probably) going on?
In the real-world case that inspired this article, process 16121 was attempting a CREATE TABLE statement with foreign keys that required ACCESS EXCLUSIVE locks on both “author” and “book” tables. Simultaneously, process 15866 was executing a query very similar to the one shown in the AccessShareLock example above. This is a very common query pattern in our system. The “author” and “book” relations are often queried together but very rarely modified together, so a SELECT statement represented the most likely conflict with the ongoing table creation.
However, you’ll need to apply your own specific domain knowledge and experience with the particular application to narrow down the list of possibilities to those that seem most likely for your use case. Questions to consider:
- What kinds of operations are common in your application?
- What actions do you perform frequently or seldom/never?
- What are common query patterns?
Once a likely cause has been identified, is there anything that can be done to prevent deadlocks in the future?
In short, not really.
Occasional deadlocks are simply a fact of life, especially in highly concurrent systems, and are not usually a source for concern. After all, the data consistency and integrity that locks enforce is probably one of the reasons that you chose a relational database to begin with.
However, frequent deadlocks could highlight systemic issues that may need to be addressed. I would advise reviewing the lock monitoring techniques described here to learn more.
Источник
Debugging deadlocks in PostgreSQL

© Laurenz Albe 2022
Even if you understand what a deadlock is, debugging deadlocks can be tricky. This article shows some techniques on how to figure out the cause of a deadlock.
A simple deadlock example
Setting the stage
We will test our techniques for debugging deadlocks with the following example:
The deadlock
To provoke the deadlock, we run the following transactions in parallel. Each transaction adds a row to the child table and then tries to modify the corresponding row in parent .
How a deadlock appears in the log
The PostgreSQL log reveals more details:
Why is debugging deadlocks difficult?
The error message sent to the client does not contain any meaningful detail. That is because the SQL statement from the other sessions participating in the deadlock may contain data that you have no right to see. The PostgreSQL log contains more helpful data, but also not enough to understand the deadlock. To understand the cause of the deadlock, you would have to know all statements from the involved transactions, because locks are always held until the end of a transaction. The two statements from the error message alone could never cause a deadlock. So some earlier statement in these transactions must already have taken locks that are part of the problem. However, PostgreSQL does not retain any memory of these previous statements, so we have to find some other way to get the whole picture.
Usually you need help from the application’s developers. Perhaps you are lucky, the SQL statements from the error message are enough to identify the database transactions involved, and it is easy to reconstruct the SQL statements that were issued from each transaction. By examining the locks taken by these statements, you should be able to reconstruct the cause of the deadlock.
The cause of the deadlock in our example
If we know the statements from our transactions in the example above, we can deduce the following:
- The INSERT statements take a FOR KEY SHARE lock on the referenced rows in parent . That is necessary so that no concurrent transaction can delete the row referenced by our not yet committed INSERT . As you can see in the compatibility matrix, these locks don’t conflict with each other.
- The FOR UPDATE row locks from the SELECT . FOR UPDATE statements conflict with the FOR KEY SHARE locks from the other transaction, which leads to the deadlock.
Once we know that, the solution is simple: change “ SELECT . FOR UPDATE ” to “ SELECT . FOR NO KEY UPDATE “, and there will be no more lock conflicts and consequently no deadlock. Note that a FOR UPDATE row lock is only required if you want to DELETE a row, or if you intend to update a column with a unique or primary key constraint on it (a key). The lock name FOR UPDATE is counter-intuitive, since it suggests that this is the correct lock for an UPDATE , and it is a common trap for PostgreSQL beginners.
Great, with our complete knowledge we could fix the problem. But how do we get the statements from the transactions?
Techniques for debugging deadlocks
There are several approaches:
Debugging deadlocks by logging on the application side
If the application logs information about each error and each database transaction started, it is easy to determine the transactions that caused the problem. However, that requires that you either have control over the application code, or that the application has sufficiently well-designed tracing facilities. You are not always in that lucky position.
Debugging deadlocks by annotating queries on the application side
This is also a method that requires that you can modify the application. The trick here is to add a comment to the query, like
The information can be anything that allows you to tell which transaction the statement belongs to.
Debugging deadlocks by logging on the database side
In order to enable us to trace statements, we have to make sure that the process ID and transaction number are logged with each statement. With CSV logging, that is always the case, but with stderr logging, you have to change log_line_prefix :
Also, you have to log all statements:
Now the amount and performance impact of logging all statements may be forbidding for busy applications. PostgreSQL v12 introduced log_transaction_sample_rate , which allows you to log only a certain percentage of all transactions. However, in many cases that won’t be good enough, because you’ll typically only see the statements from one of the transactions involved.
The log file for our example would look as follows:
Note that the transaction ID is logged as 0 until after the first data modifying statement in the transaction. This is because PostgreSQL assigns transaction IDs lazily, only when they are needed.
Debugging deadlocks by increasing deadlock_timeout
The PostgreSQL deadlock detector doesn’t kick in immediately, but waits until after deadlock_timeout has passed. This is because the deadlock detector is a computationally expensive component, so we only want to activate it if there is very likely a problem. By default, the parameter is set to one second. Unfortunately, one second is much too short to debug the problem. Now if you can afford to let deadlocked sessions “hang” until you can debug them, you can increase the parameter. The maximum allowed value is almost 600 days, which is longer than you need. With proper monitoring, you could for example set deadlock_timeout to 15 minutes to catch deadlocks in the act.
Once you have an active deadlock, you can find client_addr and client_port from pg_stat_activity for the hanging sessions:
We sort by state_change , because other sessions might later get stuck behind the sessions that originally caused the deadlock. For that reason, you want to focus on the oldest entries.
Next, log into the client machine and find out which process has a TCP connection on port 49578:
Now you know that the client process is 3974, running the program myapp . You can now attach to the program with a debugger and see the current execution stack. That should give you a clue as to what is being executed, so you can figure out the SQL statements run in that transaction.
Needless to say, this is yet another method that requires control over the application code.
Conclusion
We have seen several methods for debugging deadlocks. Most of them require that you have control over the application code. Not all techniques are useful in every case: for example, you may not be able to afford logging all statements or leaving deadlocks hanging for a longer time.
For more information on deadlocks, see Hans’ blog on Understanding Deadlocks.
Please leave your comments below. In order to receive regular updates on important changes in PostgreSQL, subscribe to the CYBERTEC newsletter, or follow us on Twitter, Facebook, or LinkedIn
Laurenz Albe
Laurenz Albe is a senior consultant and support engineer at CYBERTEC. He has been working with and contributing to PostgreSQL since 2006.
Источник
This is the second post in a small series dedicated to analysing and dealing with deadlocks in PostgreSQL, and provides a general workflow to handle deadlock bugs and details on how to get information from PostgresSQL.
If you need a gentler introduction, take a look at the first article in this series.
Debugging a deadlock – a workflow
If you have to deal with a deadlock in a complex application, usually you’ll have a defect that appears in time-dependent, load-dependent and user-dependent way. It’s all too easy to get lost in hypotheses! To avoid that try to work in a scientific way and follow a strategy.
One such strategy is described below:
- look at Postgres logs first and try to get a rough idea of what is going on;
- determine what was going on at the exact time the deadlock happened. If you have a Web application, which page(s) were being loaded or submitted? If there are background jobs, were they running? If you have an API, were there clients using it? etc. Check all available logs as thoroughly as possible around the time the deadlock happened;
- if at all possible, try to trigger the problem in a reproducible way using information collected above. This might even be impossible in some cases, yet every effort should be taken to have the problem happening again predictably or you will not be able to validate any solution!
- based on information collected above, determine what transactions were in progress, what queries were completed before the deadlock and what queries were running at the time of the deadlock. In a big codebase this can be daunting, and ORMs such as Hibernate complicate things a lot by issuing automatically generated queries behind the scenes, yet you must, at some point, determine the active set of queries to have any chance;
- prototyping might help. You can, for example, attempt to write one or more test cases that exercise relevant code paths in your application and run them concurrently in order to better isolate affected components – see if you can get them deadlocking and check that the stack trace corresponds to the original. This has the advantage of automatically issue relevant queries to the RDBMS, which you can then figure out from logs (more on that in the next article);
- at this point, you should now ideally be able to reproduce the issue by manually issuing queries into different pgAdmin III windows or
psqlterminals; - from that, you can identify problematic tables and queries, and by this time it should not be hard to come up with a solution. Most probably you will want to change the ordering of queries, or if you can’t change the ordering, use
SELECT ... FOR UPDATEto get locks on whatever rows you need to change later.
How to do all that? Let’s see some practical tips.
Debugging a deadlock – interpreting logs
Typical deadlock error output, which can be found in /var/lib/pgsql/data/pg_log/*.log, looks like this:
ERROR: deadlock detected
DETAIL: Process 21535 waits for AccessExclusiveLock on relation 342640 of database 41454; blocked by process 21506.
Process 21506 waits for AccessExclusiveLock on relation 342637 of database 41454; blocked by process 21535.
HINT: See server log for query details.
CONTEXT: SQL statement "UPDATE ..."
Notable points:
AccessExclusiveLockis the kind of lock, in this case, a rather strict one. More on lock types later;- “relation 342640” and “relation 342637” refer to internal Postgres Object Identifiers. You can retrieve legible table names with the following query:
SELECT 342640::regclass, 342637::regclass; regclass | regclass
----------+----------
b | a
(1 row)
- the reported SQL statement after
CONTEXTis the one that has been interrupted and killed by Postgres. If there is more than one, then it represents the full “stack trace” of functions that were running at killing time;
In this case situation is pretty clear: a transaction in process 21535 wants to acquire an exclusive lock on table b, which is locked by a second transaction in process 21506 which in turn wants to lock a.
That’s not the most common form of deadlock output, though. In most cases logs are more cryptic:
ERROR: deadlock detected
DETAIL: Process 5455 waits for ShareLock on transaction 44101; blocked by process 27458.
Process 27458 waits for ShareLock on transaction 43490; blocked by process 5455.
Process 5455: select * from rhn_channel.subscribe_server($1, $2, 1, $3) as result
Process 27458: select * from rhn_channel.update_needed_cache($1) as result
HINT: See server log for query details.
CONTEXT: SQL statement "UPDATE ..."
Notable points:
- in
DETAILyou can find the top-level queries that originated this deadlock,CONTEXTshows the stack trace (omitted here for brevity); - locks are of a different type with respect to the above case,
ShareLock. Again more on that later; - lock is not on a table and not even on a row, but on a transaction.
What’s the meaning of a transaction lock?
Transaction locks are really row locks
On a logical level, Postgres has two kinds of locks, table locks and row locks. Row locks obviously only apply to specific rows, while table locks lock the entire tables.
Implementation wise, it turns out that row locks are implemented on top of transaction locks. It’s actually an optimization, as transaction locks are less expensive than real row locks.
Here’s how it works:
- the very first thing every transaction does when it is created is to get an exclusive lock on itself. It will be released it upon completion;
- every table has a some extra system columns to implement MVCC, among those there’s
xmax; xmaxis an integer, which can be either 0 or a transaction ID;- if it is 0, then it means no transaction has
UPDATEd orDELETEd that row so far, in other words it has been freshlyINSERTed; - if it is not 0, then it is the ID of the transaction which last
UPDATEd that row; - whenever a transaction wants to
UPDATEorDELETEa row it will check itsxmaxfirst:- if it is 0, it can proceed by first updating the
xmaxvalue with its own ID and then the rest of the row; - if it is the ID of a transaction that has finished, it can proceed by overwriting
xmax; - if it is the ID of a transaction that has not finished yet, then the row is locked and it has to wait. The wait is implemented by requesting a lock on the transaction which ID is
xmax.
- if it is 0, it can proceed by first updating the
Since all transactions have exclusive locks on themselves, when the original transaction will finish it will release the lock and the row will be editable again.
Note that this “trick” only works for the first transaction that waits for a row. If two or more are waiting, ones beyond the first will get a regular row lock.
You can get a fuller explanation here for more details.
Debugging a deadlock – interpreting logs (cont’d)
Now we can explain the previous example:
DETAIL: Process 5455 waits for ShareLock on transaction 44101; blocked by process 27458.
Process 27458 waits for ShareLock on transaction 43490; blocked by process 5455.
This really means that transaction 43490 wants to edit some row previously edited by transaction 44101, while transaction 44101 wants to edit some row previously edited by transaction 43490. Being only two transactions, no “real” row lock is requested but only the less expensive transaction locks.
How can I determine what rows are causing this problem?
In general it is difficult as Postgres does not track that (see above). If you know what tables and queries are involved, you can try reproducing the situation manually and take a look at xmax values, for example:
SELECT id, name, xmax FROM rhnServer; id | name | xmax
------------+---------------------------------+---------
1000010000 | sles11swtest.lab.dus.novell.com | 2962002
(1 row)
You can retrieve transaction IDs by running this query:
susemanager=# SELECT txid_current();
txid_current
--------------
2962002
(1 row)
In this case, you can see that rhnServer‘s only row 1000010000 was updated by the current transaction.
Debugging a deadlock – live view on locks
If you have to figure out what locks were requested in some occasion, your best friend is pgAdmin III’s Tools -> Server Status window (full explanation with screenshot here).
Important things to notice are:
- that the Activity tab lists active processes/transactions;
- that the Locks table lists all currently active locks.
Note that this view does not show table names, just OIDs – you can use the following query to get roughly the same information with proper table names:
SELECT virtualtransaction, relation::regclass, locktype, page, tuple, mode, granted, transactionid FROM pg_locks ORDER BY granted, virtualtransaction;
You will probably be surprised when you check lock types. Lock names are actually very confusing – for example RowExclusive is actually the name of a table lock type! You are thus strongly encouraged to read the lock types page thoroughly from Postgres manual before thinking that it is doing something stupid. Usually, it doesn’t.
Debugging a deadlock – each-and-every-query logging
If you can reproduce a deadlock issue but still cannot comprehend how it works, you might be interested in having Postgres logging all queries and all of their parameters. Needless to say, this log level is a bit extreme and looking at the results might be overwhelming, still it can be useful.
To activate it edit /var/lib/pgsql/data/postgresql.conf and add the following line:
log_statement = 'all'
You might also be interested in the Process ID that originated each query to make sense of the flows. Then change the following line to:
log_line_prefix = '%t %d %u %p '
This is an example output:
2015-02-25 16:44:51 CET susemanager susemanager 31444 LOG: execute S_1: BEGIN
2015-02-25 16:44:51 CET susemanager susemanager 31444 LOG: execute <unnamed>: select * from logging.clear_log_id() as result
[...]
2015-02-25 16:44:52 CET susemanager susemanager 31445 LOG: execute S_1: BEGIN
2015-02-25 16:44:52 CET susemanager susemanager 31445 LOG: execute <unnamed>: select * from logging.clear_log_id() as result
Note that it could well be totally unreadable in normal conditions. You might want to stop background tasks to start with or, ideally, have some unit test code that can trigger the condition and stop everything else for best clarity.
The next post in this series will present a case study based on SUSE Manager and its upstream project Spacewalk.
We’ve got a web-based application. There are time-bound database operations (INSERTs and UPDATEs) in the application which take more time to complete, hence this particular flow has been changed into a Java Thread so it will not wait (block) for the complete database operation to be completed.
My problem is, if more than 1 user comes across this particular flow, I’m facing the following error thrown by PostgreSQL:
org.postgresql.util.PSQLException: ERROR: deadlock detected
Detail: Process 13560 waits for ShareLock on transaction 3147316424; blocked by process 13566.
Process 13566 waits for ShareLock on transaction 3147316408; blocked by process 13560.
The above error is consistently thrown in INSERT statements.
Additional Information:
1) I have PRIMARY KEY defined in this table.
2) There are FOREIGN KEY references in this table.
3) Separate database connection is passed to each Java Thread.
Technologies
Web Server: Tomcat v6.0.10
Java v1.6.0
Servlet
Database: PostgreSQL v8.2.3
Connection Management: pgpool II
![]()
xelco52
5,1974 gold badges39 silver badges56 bronze badges
asked Oct 5, 2009 at 14:23
![]()
1
One way to cope with deadlocks is to have a retry mechanism that waits for a random interval and tries to run the transaction again. The random interval is necessary so that the colliding transactions don’t continuously keep bumping into each other, causing what is called a live lock — something even nastier to debug. Actually most complex applications will need such a retry mechanism sooner or later when they need to handle transaction serialization failures.
Of course if you are able to determine the cause of the deadlock it’s usually much better to eliminate it or it will come back to bite you. For almost all cases, even when the deadlock condition is rare, the little bit of throughput and coding overhead to get the locks in deterministic order or get more coarse-grained locks is worth it to avoid the occasional large latency hit and the sudden performance cliff when scaling concurrency.
When you are consistently getting two INSERT statements deadlocking it’s most likely an unique index insert order issue. Try for example the following in two psql command windows:
Thread A | Thread B
BEGIN; | BEGIN;
| INSERT uniq=1;
INSERT uniq=2; |
| INSERT uniq=2;
| block waiting for thread A to commit or rollback, to
| see if this is an unique key error.
INSERT uniq=1; |
blocks waiting |
for thread B, |
DEADLOCK |
V
Usually the best course of action to resolve this is to figure out the parent objects that guard all such transactions. Most applications have one or two of primary entities, such as users or accounts, that are good candidates for this. Then all you need is for every transaction to get the locks on the primary entity it touches via SELECT … FOR UPDATE. Or if touches several, get locks on all of them but in the same order every time (order by primary key is a good choice).
answered Oct 5, 2009 at 16:50
![]()
Ants AasmaAnts Aasma
52.3k15 gold badges89 silver badges94 bronze badges
What PostgreSQL does here is covered in the documentation on Explicit Locking. The example in the «Deadlocks» section shows what you’re probably doing. The part you may not have expected is that when you UPDATE something, that acquires a lock on that row that continues until the transaction involved ends. If you have multiple clients all doing updates of more than one thing at once, you’ll inevitably end up with deadlocks unless you go out of your way to prevent them.
If you have multiple things that take out implicit locks like UPDATE, you should wrap the whole sequence in BEGIN/COMMIT transaction blocks, and make sure you’re consistent about the order they acquire locks (even the implicit ones like what UPDATE grabs) at everywhere. If you need to update something in table A then table B, and one part of the app does A then B while the other does B then A, you’re going to deadlock one day. Two UPDATEs against the same table are similarly destined to fail unless you can enforce some ordering of the two that’s repeatable among clients. Sorting by primary key once you have the set of records to update and always grabbing the «lower» one first is a common strategy.
It’s less likely your INSERTs are to blame here, those are much harder to get into a deadlocked situation, unless you violate a primary key as Ants already described.
What you don’t want to do is try and duplicate locking in your app, which is going to turn into a giant scalability and reliability mess (and will likely still result in database deadlocks). If you can’t work around this within the confines of the standard database locking methods, consider using either the advisory lock facility or explicit LOCK TABLE to enforce what you need instead. That will save you a world of painful coding over trying to push all the locks onto the client side. If you have multiple updates against a table and can’t enforce the order they happen in, you have no choice but to lock the whole table while you execute them; that’s the only route that doesn’t introduce a potential for deadlock.
answered Oct 6, 2009 at 6:06
![]()
Greg SmithGreg Smith
16.3k1 gold badge33 silver badges27 bronze badges
Deadlock explained:
In a nutshell, what is happening is that a particular SQL statement (INSERT or other) is waiting on another statement to release a lock on a particular part of the database, before it can proceed. Until this lock is released, the first SQL statement, call it «statement A» will not allow itself to access this part of the database to do its job (= regular lock situation). But… statement A has also put a lock on another part of the database to ensure that no other users of the database access (for reading, or modifiying/deleting, depending on the type of lock). Now… the second SQL statement, is itself in need of accessing the data section marked by the lock of Statement A. That is a DEAD LOCK : both Statement will wait, ad infinitum, on one another.
The remedy…
This would require to know the specific SQL statement these various threads are running, and looking in there if there is a way to either:
a) removing some of the locks, or changing their types. For example, maybe the whole table is locked, whereby only a given row, or a page thereof would be necessary. b) preventing multiple of these queries to be submitted at a given time. This would be done by way of semaphores/locks (aka MUTEX) at the level of the multi-threading logic.
Beware that the «b)» approach, if not correctly implemented may just move the deadlock situation from within SQL to within the program/threads logic. The key would be to only create one mutex to be obtained first by any thread which is about to run one of these deadlock-prone queries.
answered Oct 5, 2009 at 14:38
![]()
mjvmjv
72.1k14 gold badges111 silver badges156 bronze badges
Your problem, probably, is the insert command is trying to lock one or both index and the indexes is locked for the other tread.
One common mistake is lock resources in different order on each thread. Check the orders and try to lock the resources in the same order in all threads.
answered Oct 5, 2009 at 14:37
![]()
1
In concurrent systems where resources are locked, two or more processes can end
up in a state in which each process is waiting for the other one. This state is
called a deadlock. Deadlocks are an important issues that can happen in any
database and can be scary when you encounter them for the first time.

In this article we will explore how deadlocks occur in PostgreSQL, what is the
deadlock timeout, and how to interpret the error raised by PostgreSQL in case of
a deadlock timeout.
Understanding How Deadlocks Occur in your Database
Before we dig into the details about deadlocks in PostgreSQL, it is important to
understand how they occur. Let’s observe the following example where two
concurrent processes end up in a deadlock.
process A: BEGIN;
process B: BEGIN;
process A: UPDATE users SET name = "Peter" WHERE id = 1;
process B: UPDATE users SET name = "Marko" WHERE id = 2;
-- Both process A and B acquired an exclusive lock in
-- their transactions. The lock will be released when
-- the transactions finishes.
process A: UPDATE users SET name = "John" WHERE id = 2;
-- process A tries to acquire an exclusive lock, but process B
-- already holds the lock for the record with id = 2
-- process A needs to wait till process B's transaction ends
process B: UPDATE users SET name = "John" WHERE id = 1;
-- process B tries to acquire an exclusive lock, but process A
-- already holds the lock for the record with id = 1
-- process B needs to wait till process A's transaction ends
At this point process A is waiting for process B, and process B is waiting for
process A. In other words, a deadlock has occurred. Neither of the two processes
can continue, and they will wait for each other indefinitely.
The Deadlock Timeout
To resolve the situation from the previous example, PostgreSQL raises a deadlock
error if it detects that two processes are waiting for each other. PostgreSQL
will wait for a given interval before it raises the error. This interval is
defined with deadlock_timeout configuration value.
Here is output one of the process would see after the deadlock timeout passes:
-- After a second, the deadlock timeout kicks in and raises an error
ERROR: deadlock detected
DETAIL: Process 12664 waits for ShareLock on transaction 1330;
blocked by process 12588.
Process 12588 waits for ShareLock on transaction 1331;
blocked by process 12664.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,31) in relation "users"
Rollbacks are of course not ideal, but they are a better solution than waiting
forever. If possible you should strive to design your application in a way that
prevents deadlocks in the first place. For example, if you are locking tables in
your application, you want to make sure that you always invoke the locking in
the same order.
In general, applications must be ready to handle deadlocks issue and retry the
transaction in case of a failure.
The best defense against deadlocks is generally to avoid them by being certain
that all applications using a database acquire locks on multiple objects in a
consistent order.
Adjusting the Deadlock Timeout
The deadlock timeout is the amount of time that PostgreSQL waits on a lock
before it checks for a deadlock. The deadlock check is an expensive operation so
it is not run every time a lock needs to wait. Deadlocks should not be common in
production environments and PostgreSQL will wait for a while before running the
expensive deadlock check.
The default timeout value in PostgreSQL is 1 second, and this is probably the
smallest time interval you would want to set in practice. If your database is
heavily loaded, you might want to raise this value to reduce the overhead on
your database servers.
Ideally, the deadlock_timeout should be a bit longer than your typical
transaction duration.
Did you like this article? Or, do you maybe have a helpful hint to share? Please
leave it in the comment section bellow.
Working with databases, concurrency control is the concept that ensures that database transactions are performed concurrently without violating data integrity.
There is a lot of theory and different approaches around this concept and how to accomplish it, but we will briefly refer to the way that PostgreSQL and MySQL (when using InnoDB) handle it, and a common problem that can arise in highly concurrent systems: deadlocks.
These engines implement concurrency control by using a method called MVCC (Multiversion Concurrency Control). In this method, when an item is being updated, the changes will not overwrite the original data, but instead, a new version of the item (with the changes) will be created. Thus we will have several versions of the item stored.
One of the main advantages of this model is that locks acquired for querying (reading) data do not conflict with locks acquired for writing data, and so reading never blocks writing, and writing never blocks reading.
But, if several versions of the same item are stored, which version of it will a transaction see? To answer that question we need to review the concept of transaction isolation. Transactions specify an isolation level, that defines the degree to which one transaction must be isolated from resource or data modifications made by other transactions. This degree is directly related with the locking generated by a transaction, and so, as it can be specified at transaction level, it can determine the impact that a running transaction can have over other running transactions.
This is a very interesting and long topic, although we will not go into too many details in this blog. We’d recommend the PostgreSQL and MySQL official documentation for further reading on this topic.
So, why are we going into the above topics when dealing with deadlocks? Because sql commands will automatically acquire locks to ensure the MVCC behavior, and the lock type acquired depends on the transaction isolation defined.
There are several types of locks (again another long and interesting topic to review for PostgreSQL and MySQL) but, the important thing about them, is how they interact (most exactly, how they conflict) with each other. Why is that? Because two transactions cannot hold locks of conflicting modes on the same object at the same time. And a non-minor detail, once acquired, a lock is normally held till end of the transaction.
This is a PostgreSQL example of how locking types conflict with each other:
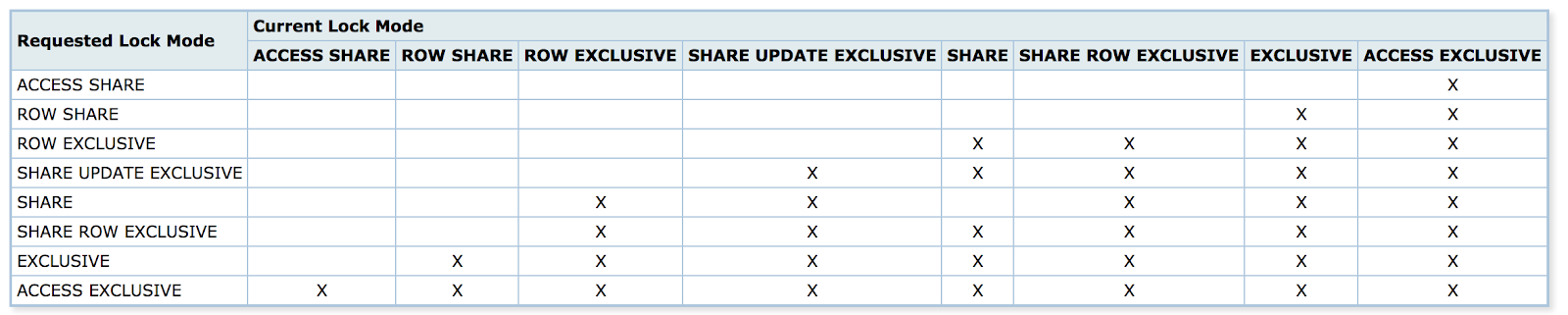
PostgreSQL Locking types conflict
And for MySQL:
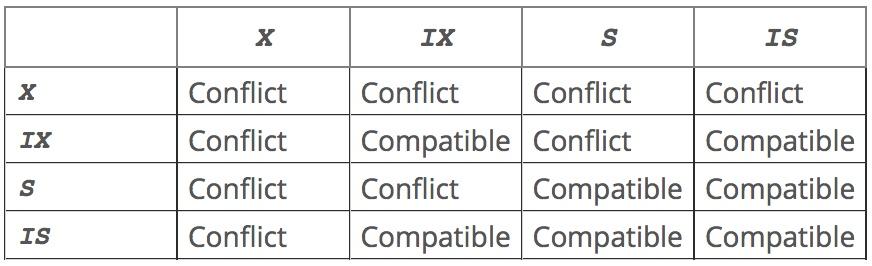
MySQL Locking types conflict
X= exclusive lock IX= intention exclusive lock
S= shared lock IS= intention shared lock
So what happens when I have two running transactions that want to hold conflicting locks on the same object at the same time? One of them will get the lock and the other will have to wait.
So now we are in a position to truly understand what is happening during a deadlock.
What is a deadlock then? As you can imagine, there are several definitions for a database deadlock, but I like the following for its simplicity.
A database deadlock is a situation in which two or more transactions are waiting for one another to give up locks.
So for example, the following situation will lead us to a deadlock:
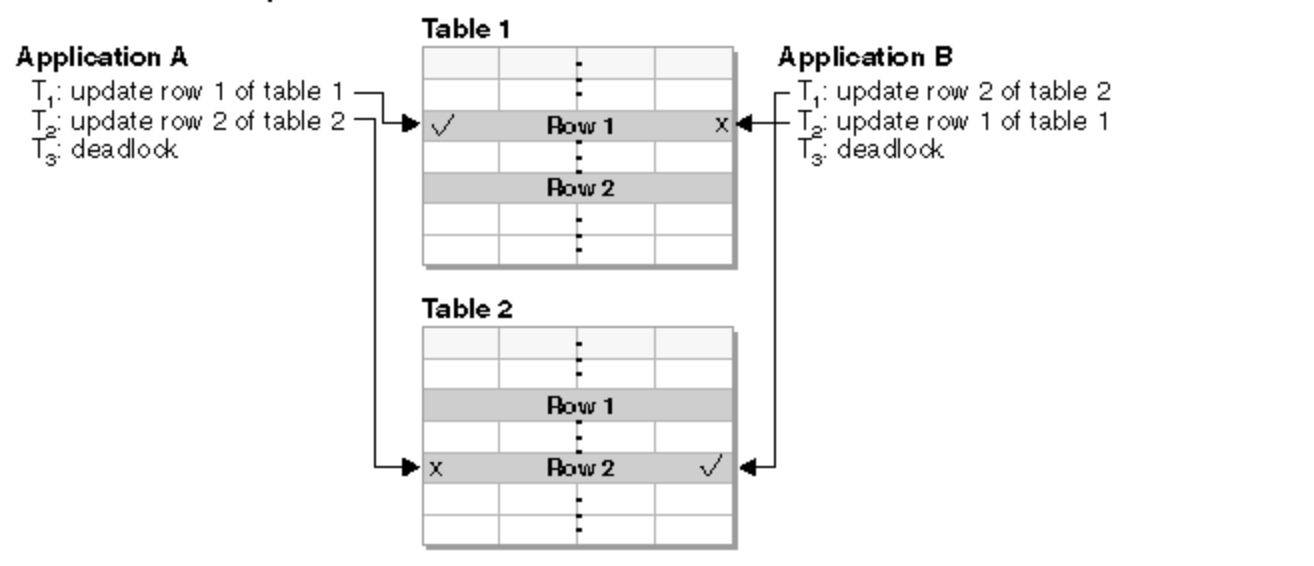
Deadlock example
Here, application A gets a lock on table 1 row 1 in order to make an update.
At the same time application B gets a lock on table 2 row 2.
Now application A needs to get a lock on table 2 row 2, in order to continue the execution and finish the transaction, but it cannot get the lock because it is held by application B. Application A needs to wait for application B to release it.
But application B needs to get a lock on table 1 row 1, in order to continue the execution and finish the transaction, but it cannot get the lock because it is held by application A.
So here we are in a deadlock situation. Application A is waiting for the resource held by application B in order to finish and application B is waiting for the resource held by application A. So, how to continue? The database engine will detect the deadlock and kill one of the transactions, unblocking the other one and raising a deadlock error on the killed one.
Let’s check some PostgreSQL and MySQL deadlock examples:
PostgreSQL
Suppose we have a test database with information from the countries of the world.
world=# SELECT code,region,population FROM country WHERE code IN ('NLD','AUS');
code | region | population
------+---------------------------+------------
NLD | Western Europe | 15864000
AUS | Australia and New Zealand | 18886000
(2 rows)We have two sessions that want to make changes to the database.
The first session will modify the region field for the NLD code, and the population field for the AUS code.
The second session will modify the region field for the AUS code, and the population field for the NLD code.
Table data:
code: NLD
region: Western Europe
population: 15864000code: AUS
region: Australia and New Zealand
population: 18886000Session 1:
world=# BEGIN;
BEGIN
world=# UPDATE country SET region='Europe' WHERE code='NLD';
UPDATE 1Session 2:
world=# BEGIN;
BEGIN
world=# UPDATE country SET region='Oceania' WHERE code='AUS';
UPDATE 1
world=# UPDATE country SET population=15864001 WHERE code='NLD';Session 2 will hang waiting for Session 1 to finish.
Session 1:
world=# UPDATE country SET population=18886001 WHERE code='AUS';
ERROR: deadlock detected
DETAIL: Process 1181 waits for ShareLock on transaction 579; blocked by process 1148.
Process 1148 waits for ShareLock on transaction 578; blocked by process 1181.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,15) in relation "country"Here we have our deadlock. The system detected the deadlock and killed session 1.
Session 2:
world=# BEGIN;
BEGIN
world=# UPDATE country SET region='Oceania' WHERE code='AUS';
UPDATE 1
world=# UPDATE country SET population=15864001 WHERE code='NLD';
UPDATE 1And we can check that the second session finished correctly after the deadlock was detected and the Session 1 was killed (thus, the lock was released).
To have more details we can see the log in our PostgreSQL server:
2018-05-16 12:56:38.520 -03 [1181] ERROR: deadlock detected
2018-05-16 12:56:38.520 -03 [1181] DETAIL: Process 1181 waits for ShareLock on transaction 579; blocked by process 1148.
Process 1148 waits for ShareLock on transaction 578; blocked by process 1181.
Process 1181: UPDATE country SET population=18886001 WHERE code='AUS';
Process 1148: UPDATE country SET population=15864001 WHERE code='NLD';
2018-05-16 12:56:38.520 -03 [1181] HINT: See server log for query details.
2018-05-16 12:56:38.520 -03 [1181] CONTEXT: while updating tuple (0,15) in relation "country"
2018-05-16 12:56:38.520 -03 [1181] STATEMENT: UPDATE country SET population=18886001 WHERE code='AUS';
2018-05-16 12:59:50.568 -03 [1181] ERROR: current transaction is aborted, commands ignored until end of transaction blockHere we will be able to see the actual commands that were detected on deadlock.
PostgreSQL Management & Automation with ClusterControl
Learn about what you need to know to deploy, monitor, manage and scale PostgreSQL
MySQL
To simulate a deadlock in MySQL we can do the following.
As with PostgreSQL, suppose we have a test database with information on actors and movies among other things.
mysql> SELECT first_name,last_name FROM actor WHERE actor_id IN (1,7);
+------------+-----------+
| first_name | last_name |
+------------+-----------+
| PENELOPE | GUINESS |
| GRACE | MOSTEL |
+------------+-----------+
2 rows in set (0.00 sec)We have two processes that want to make changes to the database.
The first process will modify the field first_name for actor_id 1, and the field last_name for actor_id 7.
The second process will modify the field first_name for actor_id 7, and the field last_name for actor_id 1.
Table data:
actor_id: 1
first_name: PENELOPE
last_name: GUINESSactor_id: 7
first_name: GRACE
last_name: MOSTELSession 1:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> UPDATE actor SET first_name='GUINESS' WHERE actor_id='1';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0Session 2:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> UPDATE actor SET first_name='MOSTEL' WHERE actor_id='7';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> UPDATE actor SET last_name='PENELOPE' WHERE actor_id='1';Session 2 will hang waiting for Session 1 to finish.
Session 1:
mysql> UPDATE actor SET last_name='GRACE' WHERE actor_id='7';
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transactionHere we have our deadlock. The system detected the deadlock and killed session 1.
Session 2:
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> UPDATE actor SET first_name='MOSTEL' WHERE actor_id='7';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0mysql> UPDATE actor SET last_name='PENELOPE' WHERE actor_id='1';
Query OK, 1 row affected (8.52 sec)
Rows matched: 1 Changed: 1 Warnings: 0As we can see in the error, as we saw for PostgreSQL, there is a deadlock between both processes.
For more details we can use the command SHOW ENGINE INNODB STATUSG:
mysql> SHOW ENGINE INNODB STATUSG
------------------------
LATEST DETECTED DEADLOCK
------------------------
2018-05-16 18:55:46 0x7f4c34128700
*** (1) TRANSACTION:
TRANSACTION 1456, ACTIVE 33 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 54, OS thread handle 139965388506880, query id 15876 localhost root updating
UPDATE actor SET last_name='PENELOPE' WHERE actor_id='1'
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1456 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0001; asc ;;
1: len 6; hex 0000000005af; asc ;;
2: len 7; hex 2d000001690110; asc - i ;;
3: len 7; hex 4755494e455353; asc GUINESS;;
4: len 7; hex 4755494e455353; asc GUINESS;;
5: len 4; hex 5afca8b3; asc Z ;;
*** (2) TRANSACTION:
TRANSACTION 1455, ACTIVE 47 sec starting index read, thread declared inside InnoDB 5000
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 53, OS thread handle 139965267871488, query id 16013 localhost root updating
UPDATE actor SET last_name='GRACE' WHERE actor_id='7'
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1455 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0001; asc ;;
1: len 6; hex 0000000005af; asc ;;
2: len 7; hex 2d000001690110; asc - i ;;
3: len 7; hex 4755494e455353; asc GUINESS;;
4: len 7; hex 4755494e455353; asc GUINESS;;
5: len 4; hex 5afca8b3; asc Z ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1455 lock_mode X locks rec but not gap waiting
Record lock, heap no 202 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0007; asc ;;
1: len 6; hex 0000000005b0; asc ;;
2: len 7; hex 2e0000016a0110; asc . j ;;
3: len 6; hex 4d4f5354454c; asc MOSTEL;;
4: len 6; hex 4d4f5354454c; asc MOSTEL;;
5: len 4; hex 5afca8c1; asc Z ;;
*** WE ROLL BACK TRANSACTION (2)Under the title “LATEST DETECTED DEADLOCK“, we can see details of our deadlock.
To see the detail of the deadlock in the mysql error log, we must enable the option innodb_print_all_deadlocks in our database.
mysql> set global innodb_print_all_deadlocks=1;
Query OK, 0 rows affected (0.00 sec)MySQL Log Error:
2018-05-17T18:36:58.341835Z 12 [Note] InnoDB: Transactions deadlock detected, dumping detailed information.
2018-05-17T18:36:58.341869Z 12 [Note] InnoDB:
*** (1) TRANSACTION:
TRANSACTION 1812, ACTIVE 42 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 11, OS thread handle 140515492943616, query id 8467 localhost root updating
UPDATE actor SET last_name='PENELOPE' WHERE actor_id='1'
2018-05-17T18:36:58.341945Z 12 [Note] InnoDB: *** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1812 lock_mode X locks rec but not gap waiting
Record lock, heap no 204 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0001; asc ;;
1: len 6; hex 000000000713; asc ;;
2: len 7; hex 330000016b0110; asc 3 k ;;
3: len 7; hex 4755494e455353; asc GUINESS;;
4: len 7; hex 4755494e455353; asc GUINESS;;
5: len 4; hex 5afdcb89; asc Z ;;
2018-05-17T18:36:58.342347Z 12 [Note] InnoDB: *** (2) TRANSACTION:
TRANSACTION 1811, ACTIVE 65 sec starting index read, thread declared inside InnoDB 5000
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 12, OS thread handle 140515492677376, query id 9075 localhost root updating
UPDATE actor SET last_name='GRACE' WHERE actor_id='7'
2018-05-17T18:36:58.342409Z 12 [Note] InnoDB: *** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1811 lock_mode X locks rec but not gap
Record lock, heap no 204 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0001; asc ;;
1: len 6; hex 000000000713; asc ;;
2: len 7; hex 330000016b0110; asc 3 k ;;
3: len 7; hex 4755494e455353; asc GUINESS;;
4: len 7; hex 4755494e455353; asc GUINESS;;
5: len 4; hex 5afdcb89; asc Z ;;
2018-05-17T18:36:58.342793Z 12 [Note] InnoDB: *** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 23 page no 3 n bits 272 index PRIMARY of table `sakila`.`actor` trx id 1811 lock_mode X locks rec but not gap waiting
Record lock, heap no 205 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
0: len 2; hex 0007; asc ;;
1: len 6; hex 000000000714; asc ;;
2: len 7; hex 340000016c0110; asc 4 l ;;
3: len 6; hex 4d4f5354454c; asc MOSTEL;;
4: len 6; hex 4d4f5354454c; asc MOSTEL;;
5: len 4; hex 5afdcba0; asc Z ;;
2018-05-17T18:36:58.343105Z 12 [Note] InnoDB: *** WE ROLL BACK TRANSACTION (2)Taking into account what we have learned above about why deadlocks happen, you can see that there is not much we can do on the database side to avoid them. Anyway, as DBAs it is our duty to actually catch them, analyze them, and provide feedback to the developers.
The reality is that these errors are particular to each application, so you will need to check them one by one and there is not guide to tell you how to troubleshoot this. Keeping this in mind, there are some things you can look for.
Tips for investigating and avoiding deadlocks
Search for long-running transactions. As the locks are usually held until the end of a transaction, the longer the transaction, the longer the locks over the resources. If it is possible, try to split long-running transactions into smaller/faster ones.
Sometimes it is not possible to actually split the transactions, so the work should focus on trying to execute those operations in a consistent order each time, so transactions form well-defined queues and do not deadlock.
One workaround that you can also propose is to add retry logic into the application (of course, try to solve the underlying issue first) in a way that, if a deadlock happens, the application will run the same commands again.
Check the isolation levels used, sometimes you try by changing them. Look for commands like SELECT FOR UPDATE, and SELECT FOR SHARE, as they generate explicit locks, and evaluate if they are really needed or you can work with an older snapshot of the data. One thing you can try if you cannot remove these commands is using a lower isolation level such as READ COMMITTED.
Of course, always add well-chosen indexes to your tables. Then your queries need to scan fewer index records and consequently set fewer locks.
On a higher level, as a DBA you can take some precautions to minimize locking in general. To name one example, in this case for PostgreSQL, you can avoid adding a default value in the same command that you will add a column. Altering a table will get a really aggressive lock, and setting a default value for it will actually update the existing rows that have null values, making this operation take really long. So if you split this operation into several commands, adding the column, adding the default, updating the null values, you will minimize the locking impact.
Of course, there are tons of tips like this that the DBAs get with the practice (creating indexes concurrently, creating the pk index separately before adding the pk, and so on), but the important thing is to learn and understand this “way of thinking” and always to minimize the lock impact of the operations we are doing.
Summary
Hopefully, this blog has provided you with helpful information on database deadlocks and how to overcome them. Since there isn’t a sure-fire way to avoid deadlocks, knowing how they work can help you catch them before they do harm to your database instances. Software solutions like ClusterControl can help you ensure that your databases always stay in shape. ClusterControl has already helped hundreds of enterprises – will yours be next? Download your free trial of ClusterControl today to see if it’s the right fit for your database needs.
Мы уже поговорили о некоторых блокировках на уровне объектов (в частности — о блокировках отношений), а также о блокировках на уровне строк, их связи с блокировками объектов и об очереди ожидания, не всегда честной.
Сегодня у нас сборная солянка. Начнем с взаимоблокировок (вообще-то я собирался рассказать о них еще в прошлый раз, но та статья и так получилась неприлично длинной), затем пробежимся по оставшимся блокировкам объектов, и в заключение поговорим про предикатные блокировки.
Взаимоблокировки
При использовании блокировок возможна ситуация взаимоблокировки (или тупика). Она возникает, когда одна транзакция пытается захватить ресурс, уже захваченные другой транзакцией, в то время как другая транзакция пытается захватить ресурс, захваченный первой. Это проиллюстрировано на левом рисунке ниже: сплошные стрелки показывают захваченные ресурсы, пунктирные — попытки захватить уже занятый ресурс.
Визуально взаимоблокировку удобно представлять, построив граф ожиданий. Для этого мы убираем конкретные ресурсы и оставляем только транзакции, отмечая, какая транзакция какую ожидает. Если в графе есть контур (из вершины можно по стрелкам добраться до нее же самой) — это взаимоблокировка.

Конечно, взаимоблокировка возможна не только для двух транзакций, но и для любого большего числа.
Если взаимоблокировка возникла, участвующие в ней транзакции не могут ничего с этим сделать — они будут ждать бесконечно. Поэтому все СУБД, и PostgreSQL тоже, автоматически отслеживают взаимоблокировки.
Однако проверка требует определенных усилий, которые не хочется прилагать всякий раз, когда запрашивается новая блокировка (все-таки взаимоблокировки достаточно редки). Поэтому когда процесс пытается захватить блокировку и не может, он встает в очередь и засыпает, но взводит таймер на значение, указанное в параметре deadlock_timeout (по умолчанию — 1 секунда). Если ресурс освобождается раньше, то и хорошо, мы сэкономили на проверке. А вот если по истечении deadlock_timeout ожидание продолжается, тогда ожидающий процесс будет разбужен и инициирует проверку.
Если проверка (которая состоит в построении графа ожиданий и поиска в нем контуров) не выявила взаимоблокировок, то процесс продолжает спать — теперь уже до победного конца.
Ранее в комментариях меня справедливо упрекнули в том, что я ничего не сказал про параметр lock_timeout, который действует на любой оператор и позволяет избежать неопределенно долгого ожидания: если блокировку не удалось получить за указанное время, оператор завершается с ошибкой lock_not_available. Его не стоит путать с параметром statement_timeout, который ограничивает общее время выполнения оператора, неважно, ожидает ли он блокировку или просто выполняет работу.
Если же взаимоблокировка выявлена, то одна из транзакций (в большинстве случаев — та, которая инициировала проверку) принудительно обрывается. При этом освобождаются захваченные ей блокировки и остальные транзакции могут продолжать работу.
Взаимоблокировки обычно означают, что приложение спроектировано неправильно. Обнаружить такие ситуации можно двумя способами: во-первых, будут появляться сообщения в журнале сервера, и во-вторых, будет увеличиваться значение pg_stat_database.deadlocks.
Пример взаимоблокировки
Обычная причина возникновения взаимоблокировок — разный порядок блокирования строк таблиц.
Простой пример. Первая транзакция намерена перенести 100 рублей с первого счета на второй. Для этого она сначала уменьшает первый счет:
=> BEGIN;
=> UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
В это же время вторая транзакция намерена перенести 10 рублей со второго счета на первый. Она начинает с того, что уменьшает второй счет:
| => BEGIN;
| => UPDATE accounts SET amount = amount - 10.00 WHERE acc_no = 2;
| UPDATE 1
Теперь первая транзакция пытается увеличить второй счет, но обнаруживает, что строка заблокирована.
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 2;
Затем вторая транзакция пытается увеличить первый счет, но тоже блокируется.
| => UPDATE accounts SET amount = amount + 10.00 WHERE acc_no = 1;
Возникает циклическое ожидание, который никогда не завершится само по себе. Через секунду первая транзакция, не получив доступ к ресурсу, инициирует проверку взаимоблокировки и обрывается сервером.
ERROR: deadlock detected
DETAIL: Process 16477 waits for ShareLock on transaction 530695; blocked by process 16513.
Process 16513 waits for ShareLock on transaction 530694; blocked by process 16477.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,2) in relation "accounts"
Теперь вторая транзакция может продолжить работу.
| UPDATE 1
| => ROLLBACK;
=> ROLLBACK;
Правильный способ выполнения таких операций — блокирование ресурсов в одном и том же порядке. Например, в данном случае можно блокировать счета в порядке возрастания их номеров.
Взаимоблокировка двух команд UPDATE
Иногда можно получить взаимоблокировку там, где, казалось бы, ее быть никак не должно. Например, удобно и привычно воспринимать команды SQL как атомарные, но возьмем UPDATE — эта команда блокирует строки по мере их обновления. Это происходит не одномоментно. Поэтому если одна команда будет обновлять строки в одном порядке, а другая — в другом, они могут взаимозаблокироваться.
Получить такую ситуацию маловероятно, но тем не менее она может встретиться. Для воспроизведения мы создадим индекс по столбцу amount, построенный по убыванию суммы:
=> CREATE INDEX ON accounts(amount DESC);
Чтобы успеть увидеть происходящее, напишем функцию, увеличивающую переданное значение, но мееедленно-мееедленно, целую секунду:
=> CREATE FUNCTION inc_slow(n numeric) RETURNS numeric AS $$
SELECT pg_sleep(1);
SELECT n + 100.00;
$$ LANGUAGE SQL;
Еще нам понадобится расширение pgrowlocks.
=> CREATE EXTENSION pgrowlocks;
Первая команда UPDATE будет обновлять всю таблицу. План выполнения очевиден — последовательный просмотр:
| => EXPLAIN (costs off)
| UPDATE accounts SET amount = inc_slow(amount);
| QUERY PLAN
| ----------------------------
| Update on accounts
| -> Seq Scan on accounts
| (2 rows)
Поскольку версии строк на странице нашей таблицы лежат в порядке возрастания суммы (ровно так, как мы их добавляли), они и обновляться будут в том же порядке. Запускаем обновление работать.
| => UPDATE accounts SET amount = inc_slow(amount);
А в это время в другом сеансе мы запретим использование последовательного сканирования:
|| => SET enable_seqscan = off;
В этом случае для следующего оператора UPDATE планировщик решает использовать сканирование индекса:
|| => EXPLAIN (costs off)
|| UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
|| QUERY PLAN
|| --------------------------------------------------------
|| Update on accounts
|| -> Index Scan using accounts_amount_idx on accounts
|| Index Cond: (amount > 100.00)
|| (3 rows)
Под условие попадают вторая и третья строки, а, поскольку индекс построен по убыванию суммы, строки будут обновляться в обратном порядке.
Запускаем следующее обновление.
|| => UPDATE accounts SET amount = inc_slow(amount) WHERE amount > 100.00;
Быстрый взгляд в табличную страницу показывает, что первый оператор уже успел обновить первую строку (0,1), а второй — последнюю (0,3):
=> SELECT * FROM pgrowlocks('accounts') gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- первый
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,3)
locker | 530700 <- второй
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
Проходит еще секунда. Первый оператор обновил вторую строку, а второй хотел бы это сделать, но не может.
=> SELECT * FROM pgrowlocks('accounts') gx
-[ RECORD 1 ]-----------------
locked_row | (0,1)
locker | 530699 <- первый
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 2 ]-----------------
locked_row | (0,2)
locker | 530699 <- первый успел раньше
multi | f
xids | {530699}
modes | {"No Key Update"}
pids | {16513}
-[ RECORD 3 ]-----------------
locked_row | (0,3)
locker | 530700 <- второй
multi | f
xids | {530700}
modes | {"No Key Update"}
pids | {16549}
Теперь первый оператор хотел бы обновить последнюю строку таблицы, но она уже заблокирована вторым. Вот и взаимоблокировка.
Одна из транзакций прерывается:
|| ERROR: deadlock detected
|| DETAIL: Process 16549 waits for ShareLock on transaction 530699; blocked by process 16513.
|| Process 16513 waits for ShareLock on transaction 530700; blocked by process 16549.
|| HINT: See server log for query details.
|| CONTEXT: while updating tuple (0,2) in relation "accounts"
А другая завершает выполнение:
| UPDATE 3
Занимательные подробности об обнаружении и предотвращении взаимоблокировок можно почерпнуть из README менеджера блокировок.
На этом про взаимоблокировки все, а мы приступаем к оставшимся блокировкам объектов.

Блокировки не-отношений
Когда требуется заблокировать ресурс, не являющийся отношением в понимании PostgreSQL, используются блокировки типа object. Таким ресурсом может быть почти все, что угодно: табличные пространства, подписки, схемы, роли, перечислимые типы данных… Грубо говоря все, что только можно найти в системном каталоге.
Посмотрим на простом примере. Начинаем транзакцию и создаем в ней таблицу:
=> BEGIN;
=> CREATE TABLE example(n integer);
Теперь посмотрим, какие блокировки типа object появились в pg_locks:
=> SELECT
database,
(SELECT datname FROM pg_database WHERE oid = l.database) AS dbname,
classid,
(SELECT relname FROM pg_class WHERE oid = l.classid) AS classname,
objid,
mode,
granted
FROM pg_locks l
WHERE l.locktype = 'object' AND l.pid = pg_backend_pid();
database | dbname | classid | classname | objid | mode | granted
----------+--------+---------+--------------+-------+-----------------+---------
0 | | 1260 | pg_authid | 16384 | AccessShareLock | t
16386 | test | 2615 | pg_namespace | 2200 | AccessShareLock | t
(2 rows)
Чтобы разобраться, что именно тут блокируется, надо смотреть на три поля: database, classid и objid. Начнем с первой строки.
Database — это OID базы данных, к которой относится блокируемый ресурс. В нашем случае в этом столбце ноль. Это означает, что мы имеем дело с глобальным объектом, который не принадлежит к какой-либо конкретной базе.
Classid содержит OID из pg_class, который соответствует имени таблицы системного каталога, которая и определяет тип ресурса. В нашем случае — pg_authid, то есть ресурсом является роль (пользователь).
Objid содержит OID из той таблицы системного каталога, которую нам указал classid.
=> SELECT rolname FROM pg_authid WHERE oid = 16384;
rolname
---------
student
(1 row)
Таким образом, заблокирована роль student, из-под которой мы работаем.
Теперь разберемся со второй строкой. База данных указана, и это база test, к которой мы подключены.
Classid указывает на таблицу pg_namespace, которая содержит схемы.
=> SELECT nspname FROM pg_namespace WHERE oid = 2200;
nspname
---------
public
(1 row)
Таким образом, заблокирована схема public.
Итак, мы увидели, что при создании объекта блокируются (в разделяемом режиме) роль-владелец и схема, в которой создается объект. Что и логично: иначе кто-нибудь мог бы удалить роль или схему, пока транзакция еще не завершена.
=> ROLLBACK;
Блокировка расширения отношения
Когда число строк в отношении (то есть в таблице, индексе, материализованном представлении) растет, PostgreSQL может использовать для вставки свободное место в имеющихся страницах, но, очевидно, в какой-то момент приходится добавлять и новые страницы. Физически они добавляются в конец соответствующего файла. Это и понимается под расширением отношения.
Чтобы два процесса не кинулись добавлять страницы одновременно, этот процесс защищен специальной блокировкой с типом extend. Та же блокировка используется и при очистке индексов, чтобы другие процессы не могли добавлять страницы во время сканирования.
Конечно, эта блокировка снимается, не дожидаясь конца транзакции.
Раньше таблицы расширялись только на одну страницу за раз. Это вызывало проблемы при одновременной вставке строк несколькими процессами, поэтому в версии PostgreSQL 9.6 сделали так, чтобы к таблицам добавлялось сразу несколько страниц (пропорционально числу ожидающих блокировку процессов, но не более 512).
Блокировка страниц
Блокировка с типом page на уровне страницы применяется в единственном случае (если не считать предикатных блокировок, о которых позже).
GIN-индексы позволяют ускорять поиск в составных значениях, например, слов в текстовых документах (или элементов в массивах). Такие индексы в первом приближении можно представить как обычное B-дерево, в котором хранятся не сами документы, а отдельные слова этих документов. Поэтому при добавлении нового документа индекс приходится перестраивать довольно сильно, внося в него каждое слово, входящее в документ.
Чтобы улучшить производительность, GIN-индексы обладают возможностью отложенной вставки, которая включается параметром хранения fastupdate. Новые слова сначала по-быстрому добавляются в неупорядоченный список ожидания (pending list), а спустя какое-то время все накопившееся перемещается в основную индексную структуру. Экономия происходит за счет того, что разные документы с большой вероятностью содержат повторяющиеся слова.
Чтобы исключить перемещение из списка ожидания в основной индекс одновременно несколькими процессами, на время переноса метастраница индекса блокируется в исключительном режиме. Это не мешает использованию индекса в обычном режиме.
Рекомендательные блокировки
В отличие от других блокировок (таких, как блокировки отношений), рекомендательные блокировки (advisory locks) никогда не устанавливаются автоматически, ими управляет разработчик приложения. Их удобно использовать, например, если приложению для каких-то целей требуется логика блокирования, не вписывающаяся в стандартную логику обычных блокировок.
Допустим, у нас есть условный ресурс, не соответствующий никакому объекту базы данных (который мы могли бы заблокировать командами типа SELECT FOR или LOCK TABLE). Нужно придумать для него числовой идентификатор. Если у ресурса есть уникальное имя, то простой вариант — взять от него хеш-код:
=> SELECT hashtext('ресурс1');
hashtext
-----------
243773337
(1 row)
Вот таким образом мы захватываем блокировку:
=> BEGIN;
=> SELECT pg_advisory_lock(hashtext('ресурс1'));
Как обычно, информация о блокировках доступна в pg_locks:
=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 243773337 | ExclusiveLock | t
(1 row)
Чтобы блокирование действительно работало, другие процессы также должны получать его блокировку, прежде чем обращаться к ресурсу,. Соблюдение этого правила, очевидно, должно обеспечиваться приложением.
В приведенном примере блокировка действует до конца сеанса, а не транзакции, как обычно.
=> COMMIT;
=> SELECT locktype, objid, mode, granted
FROM pg_locks WHERE locktype = 'advisory' AND pid = pg_backend_pid();
locktype | objid | mode | granted
----------+-----------+---------------+---------
advisory | 243773337 | ExclusiveLock | t
(1 row)
Ее нужно освобождать явно:
=> SELECT pg_advisory_unlock(hashtext('ресурс1'));
Существуют большой набор функций для работы с рекомендательными блокировками на все случаи жизни:
- pg_advisory_lock_shared полечает разделяемую блокировку,
- pg_advisory_xact_lock (и pg_advisory_xact_lock_shared) получает блокировку до конца транзакции,
- pg_try_advisory_lock (а также pg_try_advisory_xact_lock и pg_try_advisory_xact_lock_shared) не ожидает получения блокировки, а возвращает ложное значение, если блокировку не удалось получить немедленно.
Набор try-функций представляет еще один способ не ждать блокировку, в дополнение к перечисленным в прошлой статье.
Предикатные блокировки
Термин предикатная блокировка появился давно, при первых попытках реализовать полную изоляцию на основе блокировок в ранних СУБД (уровень Serializable, хотя стандарта SQL в те времена еще не существовало). Проблема, с которой тогда столкнулись, состояла в том, что даже блокировка всех прочитанных и измененных строк не дает полной изоляции: в таблице могут появиться новые строки, попадающие под те же условия отбора, что приводит к появлению фантомов (см. статью про изоляцию).
Идея предикатных блокировок состояла в блокировке не строк, а предикатов. Если при выполнении запроса с условием a > 10 заблокировать предикат a > 10, это не даст добавить в таблицу новые строки, попадающие под условие и позволит избежать фантомов. Проблема в том, что в общем случае это вычислительно сложная задача; на практике ее можно решить только для предикатов, имеющих очень простой вид.
В PostgreSQL уровень Serializable реализован иначе, поверх существующей изоляции на основе снимков данных. Термин предикатная блокировка остался, но смысл его в корне изменился. Фактически такие «блокировки» ничего не блокируют, а используются для отслеживания зависимостей по данным между транзакциями.
Доказано, что изоляция на основе снимков допускает аномалию несогласованной записи и аномалию только читающей транзакции, но никакие другие аномалии невозможны. Чтобы понять, что мы имеем дело с одной из двух перечисленных аномалией, мы можем анализировать зависимости между транзакциями и находить в них определенные закономерности.
Нас интересуют зависимости двух видов:
- одна транзакция читает строку, которая затем изменяется другой транзакцией (RW-зависимость),
- одна транзакция изменяет строку, которую затем читает другая транзакция (WR-зависимость).
WR-зависимости можно отследить, используя уже имеющиеся обычные блокировки, а вот RW-зависимости как раз приходится отслеживать дополнительно.
Еще раз повторюсь: несмотря на название, предикатные блокировки ничего не блокируют. Вместо этого при фиксации транзакции выполняется проверка и, если обнаруживается «нехорошая» последовательность зависимостей, которая может свидетельствовать об аномалии, транзакция обрывается.
Давайте посмотрим, как происходит установка предикатных блокировок. Для этого создадим таблицу с достаточно большим числом строк и индекс на ней.
=> CREATE TABLE pred(n integer);
=> INSERT INTO pred(n) SELECT g.n FROM generate_series(1,10000) g(n);
=> CREATE INDEX ON pred(n) WITH (fillfactor = 10);
=> ANALYZE pred;
Если запрос выполняется с помощью последовательного сканирования всей таблицы, то предикатная блокировка устанавливается на всю таблицу (даже если под условия фильтрации попадают не все строки).
| => SELECT pg_backend_pid();
| pg_backend_pid
| ----------------
| 12763
| (1 row)
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n > 100;
| QUERY PLAN
| ----------------------------------------------------------------
| Seq Scan on pred (actual time=0.047..12.709 rows=9900 loops=1)
| Filter: (n > 100)
| Rows Removed by Filter: 100
| Planning Time: 0.190 ms
| Execution Time: 15.244 ms
| (5 rows)
Любые предикатные блокировки всегда захватываются в одном специальном режиме SIReadLock (Serializable Isolation Read):
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+----------+------+-------
relation | pred | |
(1 row)
| => ROLLBACK;
А вот если запрос выполняется с помощью индексного сканирования, ситуация меняется в лучшую сторону. Если говорить о B-дереве, то достаточно установить блокировку на прочитанные табличные строки и на просмотренные листовые страницы индекса — тем самым мы блокируем не только конкретные значения, но и весь прочитанный диапазон.
| => BEGIN ISOLATION LEVEL SERIALIZABLE;
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1001;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.122..0.131 rows=2 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1001))
| Heap Fetches: 2
| Planning Time: 0.096 ms
| Execution Time: 0.153 ms
| (5 rows)
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
tuple | pred | 3 | 236
tuple | pred | 3 | 235
page | pred_n_idx | 22 |
(3 rows)
Можно заметить несколько сложностей.
Во-первых, на каждую прочитанную версию строки создается отдельная блокировка, но потенциально таких версий может быть очень много. Общее число предикатных блокировок в системе ограничено произведением значений параметров max_pred_locks_per_transaction × max_connections (значения по умолчанию — 64 и 100 соответственно). Память под такие блокировки отводится при запуске сервера; попытка превысить это число будет приводить к ошибкам.
Поэтому для предикатных блокировок (и только для них!) используется повышение уровня. До версии PostgreSQL 10 действовали жестко зашитые в код ограничения, а начиная с нее повышением уровня можно управлять параметрами. Если число блокировок версий строк, относящихся к одной странице, превышает max_pred_locks_per_page, такие блокировки заменяются на одну блокировку уровня страницы. Вот пример:
=> SHOW max_pred_locks_per_page;
max_pred_locks_per_page
-------------------------
2
(1 row)
| => EXPLAIN (analyze, costs off)
| SELECT * FROM pred WHERE n BETWEEN 1000 AND 1002;
| QUERY PLAN
| ------------------------------------------------------------------------------------
| Index Only Scan using pred_n_idx on pred (actual time=0.019..0.039 rows=3 loops=1)
| Index Cond: ((n >= 1000) AND (n <= 1002))
| Heap Fetches: 3
| Planning Time: 0.069 ms
| Execution Time: 0.057 ms
| (5 rows)
Вместо трех блокировок типа tuple видим одну типа page:
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 22 |
(2 rows)
Аналогично, если число блокировок страниц, относящихся к одному отношению, превышает max_pred_locks_per_relation, такие блокировки заменяются на одну блокировку уровня отношения.
Других уровней не бывает: предикатные блокировки захватываются только для отношений, страниц или версий строк, и всегда с режимом SIReadLock.
Конечно, повышение уровня блокировок неизбежно приводит к тому, что большее число транзакций будет ложно завершаться ошибкой сериализации и в итоге пропускная способность системы будет снижаться. Здесь нужно искать баланс между расходом оперативной памяти и производительностью.
Вторая сложность состоит в том, что при различных операциях с индексом (например, из-за расщепления индексных страниц при вставке новых строк) число листовых страниц, покрывающих прочитанный диапазон, может измениться. Но реализация это учитывает:
=> INSERT INTO pred SELECT 1001 FROM generate_series(1,1000);
=> SELECT locktype, relation::regclass, page, tuple
FROM pg_locks WHERE mode = 'SIReadLock' AND pid = 12763;
locktype | relation | page | tuple
----------+------------+------+-------
page | pred | 3 |
page | pred_n_idx | 211 |
page | pred_n_idx | 212 |
page | pred_n_idx | 22 |
(4 rows)
| => ROLLBACK;
К слову, предикатные блокировки не всегда снимаются сразу по завершению транзакции, ведь они нужны, чтобы отслеживать зависимости между несколькими транзакциями. Но в любом случае управление ими происходит автоматически.
Далеко не все типы индексов в PostgreSQL поддерживают предикатные блокировки. Раньше этим могли похвастать только B-деревья, но в версии PostgreSQL 11 ситуация улучшилась: к списку добавились хеш-индексы, GiST и GIN. Если используется индексный доступ, а индекс не работает с предикатными блокировками, то блокировка накладывается на весь индекс целиком. Конечно, это тоже увеличивает число ложных обрывов транзакций.
В заключение отмечу, что именно с использованием предикатных блокировок связано ограничение, что для гарантий полной изоляции все транзакции должны работать на уровне Serializable. Если какая-либо транзакция будет использовать другой уровень, она просто не будет устанавливать (и проверять) предикатные блокировки.
По традиции оставлю ссылку на README по предикатным блокировкам, с которого можно начинать изучение исходного кода.
Продолжение следует.