Logical replication behaves similarly to normal DML operations in that the data will be updated even if it was changed locally on the subscriber node. If incoming data violates any constraints the replication will stop. This is referred to as a conflict. When replicating UPDATE or DELETE operations, missing data will not produce a conflict and such operations will simply be skipped.
Logical replication operations are performed with the privileges of the role which owns the subscription. Permissions failures on target tables will cause replication conflicts, as will enabled row-level security on target tables that the subscription owner is subject to, without regard to whether any policy would ordinarily reject the INSERT, UPDATE, DELETE or TRUNCATE which is being replicated. This restriction on row-level security may be lifted in a future version of PostgreSQL.
A conflict will produce an error and will stop the replication; it must be resolved manually by the user. Details about the conflict can be found in the subscriber’s server log.
The resolution can be done either by changing data or permissions on the subscriber so that it does not conflict with the incoming change or by skipping the transaction that conflicts with the existing data. When a conflict produces an error, the replication won’t proceed, and the logical replication worker will emit the following kind of message to the subscriber’s server log:
ERROR: duplicate key value violates unique constraint "test_pkey" DETAIL: Key (c)=(1) already exists. CONTEXT: processing remote data for replication origin "pg_16395" during "INSERT" for replication target relation "public.test" in transaction 725 finished at 0/14C0378
The LSN of the transaction that contains the change violating the constraint and the replication origin name can be found from the server log (LSN 0/14C0378 and replication origin pg_16395 in the above case). The transaction that produced the conflict can be skipped by using ALTER SUBSCRIPTION ... SKIP with the finish LSN (i.e., LSN 0/14C0378). The finish LSN could be an LSN at which the transaction is committed or prepared on the publisher. Alternatively, the transaction can also be skipped by calling the pg_replication_origin_advance() function. Before using this function, the subscription needs to be disabled temporarily either by ALTER SUBSCRIPTION ... DISABLE or, the subscription can be used with the disable_on_error option. Then, you can use pg_replication_origin_advance() function with the node_name (i.e., pg_16395) and the next LSN of the finish LSN (i.e., 0/14C0379). The current position of origins can be seen in the pg_replication_origin_status system view. Please note that skipping the whole transaction includes skipping changes that might not violate any constraint. This can easily make the subscriber inconsistent.
Содержание
- Postgresql logical replication error duplicate key value violates unique constraint
- Postgresql logical replication error duplicate key value violates unique constraint
- Postgresql logical replication error duplicate key value violates unique constraint
- Submit correction
- Postgresql logical replication error duplicate key value violates unique constraint
- Логическая репликация в PostgreSQL. Репликационные идентификаторы и популярные ошибки
- Задачи, решаемые логической репликацией
- Документация и примечания к выпускам
- Примечание
- Обновление до последней корректирующей (минорной) версии
- Создание ролей и строк аутентификации в pg_hba.conf
- Репликационные идентификаторы
- Что может выступать в качестве репликационного идентификатора
- Последовательности
- Первичные ключи и уникальные индексы
- Состав и порядок столбцов
- Склад грабель горизонтального хранения
- Если на мастере репликационные идентификаторы не заложены в бюджет
- . not find row.. .
- Лишний столбец на мастере
- Дубликаты значений в столбцах репликационных идентификаторов или «Раньше думать надо было!»
- Столбец NOT NULL без DEFAULT на реплике
- На мастере есть первичный ключ, на реплике он отсутствует
- На мастере и реплике первичные ключи или индексы построены на разных столбцах
- Фантомного индекса боль
- Непреобразуемые типы
- И такое может пригодиться, если что-то натворили непонятное
- Общие замечания
Postgresql logical replication error duplicate key value violates unique constraint
Логическая репликация работает подобно обычным операциям DML в том смысле, что данные будут изменены, даже если они независимо изменялись на стороне подписчика. Если входящие данные нарушат какие-либо ограничения, репликация остановится. Эта ситуация называется конфликтом. При репликации операций UPDATE или DELETE отсутствие данных не вызывает конфликта, так что такие операции просто пропускаются.
Операции логической репликации выполняются с правами роли, которой принадлежит подписка. Поэтому при отсутствии необходимых прав доступа к целевым таблицам возникнут конфликты репликации, как и при включённой для целевых таблиц защите на уровне строк, ограничивающей владельца подписки. При этом не имеет значения, существует ли политика, которая бы запрещала реплицируемые операции INSERT , UPDATE , DELETE или TRUNCATE . Ограничение, связанное с защитой на уровне строк, может быть убрано в следующих версиях PostgreSQL .
В случае конфликта выдаётся ошибка и репликация останавливается; разрешить возникшую проблему пользователь должен вручную. Подробности конфликта можно найти в журнале сервера-подписчика.
Разрешить конфликт можно, изменив данные или разрешения на стороне подписчика, чтобы они не конфликтовали с поступающими изменениями, или пропустив транзакцию, конфликтующую с существующими данными. Когда в случае конфликта выдаётся ошибка, репликация останавливается, а рабочий процесс логической репликации выводит в журнал сервера подписчика сообщение следующего вида:
В этом сообщении можно увидеть LSN транзакции, содержащей изменение, которое нарушает ограничение, и имя источника данных репликации (в данном случае LSN 0/14C0378 и pg_16395 , соответственно). Транзакцию, вызвавшую конфликт, можно пропустить, выполнив команду ALTER SUBSCRIPTION . SKIP с LSN её завершения (то есть LSN 0/14C0378). В качестве LSN завершения транзакции может задаваться LSN, с которым транзакция была зафиксирована или подготовлена на сервере публикации. Конфликтующую транзакцию также можно пропустить, вызвав функцию pg_replication_origin_advance() . Прежде чем вызывать эту функцию, нужно либо временно отключить подписку, выполнив ALTER SUBSCRIPTION . DISABLE , либо использовать подписку с параметром disable_on_error . Затем можно вызвать функцию pg_replication_origin_advance() , передав ей node_name (то есть pg_16395 ) и LSN, следующий за LSN завершения (то есть 0/14C0379). Текущие позиции источников репликации можно увидеть в системном представлении pg_replication_origin_status . Обратите внимание: когда пропускается вся транзакция, пропускаются все её изменения, в том числе не нарушающие никаких ограничений. В результате состояние подписчика легко можно оказаться несогласованным.
Источник
Postgresql logical replication error duplicate key value violates unique constraint
Логическая репликация работает подобно обычным операциям DML в том смысле, что данные будут изменены, даже если они независимо изменялись на стороне подписчика. Если входящие данные нарушат какие-либо ограничения, репликация остановится. Эта ситуация называется конфликтом. При репликации операций UPDATE или DELETE отсутствие данных не вызывает конфликта, так что такие операции просто пропускаются.
Операции логической репликации выполняются с правами роли, которой принадлежит подписка. Поэтому при отсутствии необходимых прав доступа к целевым таблицам возникнут конфликты репликации, как и при включённой для целевых таблиц защите на уровне строк, ограничивающей владельца подписки. При этом не имеет значения, существует ли политика, которая бы запрещала реплицируемые операции INSERT , UPDATE , DELETE или TRUNCATE . Ограничение, связанное с защитой на уровне строк, может быть убрано в следующих версиях PostgreSQL .
В случае конфликта выдаётся ошибка и репликация останавливается; разрешить возникшую проблему пользователь должен вручную. Подробности конфликта можно найти в журнале сервера-подписчика.
Разрешить конфликт можно, изменив данные или разрешения на стороне подписчика, чтобы они не конфликтовали с поступающими изменениями, или пропустив транзакцию, конфликтующую с существующими данными. Когда в случае конфликта выдаётся ошибка, репликация останавливается, а рабочий процесс логической репликации выводит в журнал сервера подписчика сообщение следующего вида:
В этом сообщении можно увидеть LSN транзакции, содержащей изменение, которое нарушает ограничение, и имя источника данных репликации (в данном случае LSN 0/14C0378 и pg_16395 , соответственно). Транзакцию, вызвавшую конфликт, можно пропустить, выполнив команду ALTER SUBSCRIPTION . SKIP с LSN её завершения (то есть LSN 0/14C0378). В качестве LSN завершения транзакции может задаваться LSN, с которым транзакция была зафиксирована или подготовлена на сервере публикации. Конфликтующую транзакцию также можно пропустить, вызвав функцию pg_replication_origin_advance() . Прежде чем вызывать эту функцию, нужно либо временно отключить подписку, выполнив ALTER SUBSCRIPTION . DISABLE , либо использовать подписку с параметром disable_on_error . Затем можно вызвать функцию pg_replication_origin_advance() , передав ей node_name (то есть pg_16395 ) и LSN, следующий за LSN завершения (то есть 0/14C0379). Текущие позиции источников репликации можно увидеть в системном представлении pg_replication_origin_status . Обратите внимание: когда пропускается вся транзакция, пропускаются все её изменения, в том числе не нарушающие никаких ограничений. В результате состояние подписчика легко можно оказаться несогласованным.
Источник
Postgresql logical replication error duplicate key value violates unique constraint
Logical replication behaves similarly to normal DML operations in that the data will be updated even if it was changed locally on the subscriber node. If incoming data violates any constraints the replication will stop. This is referred to as a conflict. When replicating UPDATE or DELETE operations, missing data will not produce a conflict and such operations will simply be skipped.
Logical replication operations are performed with the privileges of the role which owns the subscription. Permissions failures on target tables will cause replication conflicts, as will enabled row-level security on target tables that the subscription owner is subject to, without regard to whether any policy would ordinarily reject the INSERT , UPDATE , DELETE or TRUNCATE which is being replicated. This restriction on row-level security may be lifted in a future version of PostgreSQL .
A conflict will produce an error and will stop the replication; it must be resolved manually by the user. Details about the conflict can be found in the subscriber’s server log.
The resolution can be done either by changing data or permissions on the subscriber so that it does not conflict with the incoming change or by skipping the transaction that conflicts with the existing data. When a conflict produces an error, the replication won’t proceed, and the logical replication worker will emit the following kind of message to the subscriber’s server log:
The LSN of the transaction that contains the change violating the constraint and the replication origin name can be found from the server log (LSN 0/14C0378 and replication origin pg_16395 in the above case). The transaction that produced the conflict can be skipped by using ALTER SUBSCRIPTION . SKIP with the finish LSN (i.e., LSN 0/14C0378). The finish LSN could be an LSN at which the transaction is committed or prepared on the publisher. Alternatively, the transaction can also be skipped by calling the pg_replication_origin_advance() function. Before using this function, the subscription needs to be disabled temporarily either by ALTER SUBSCRIPTION . DISABLE or, the subscription can be used with the disable_on_error option. Then, you can use pg_replication_origin_advance() function with the node_name (i.e., pg_16395 ) and the next LSN of the finish LSN (i.e., 0/14C0379). The current position of origins can be seen in the pg_replication_origin_status system view. Please note that skipping the whole transaction includes skipping changes that might not violate any constraint. This can easily make the subscriber inconsistent.
| Prev | Up | Next |
| 31.4. Column Lists | Home | 31.6. Restrictions |
Submit correction
If you see anything in the documentation that is not correct, does not match your experience with the particular feature or requires further clarification, please use this form to report a documentation issue.
Источник
Postgresql logical replication error duplicate key value violates unique constraint
Логическая репликация работает подобно обычным операциям DML в том смысле, что данные будут изменены, даже если они независимо изменялись на стороне подписчика. Если входящие данные нарушат какие-либо ограничения, репликация остановится. Эта ситуация называется конфликтом. При репликации операций UPDATE или DELETE отсутствие данных не вызывает конфликта, так что такие операции просто пропускаются.
Операции логической репликации выполняются с правами роли, которой принадлежит подписка. Поэтому при отсутствии необходимых прав доступа к целевым таблицам возникнут конфликты репликации, как и при включённой для целевых таблиц защите на уровне строк, ограничивающей владельца подписки. При этом не имеет значения, существует ли политика, которая бы запрещала реплицируемые операции INSERT , UPDATE , DELETE или TRUNCATE . Ограничение, связанное с защитой на уровне строк, может быть убрано в следующих версиях PostgreSQL .
В случае конфликта выдаётся ошибка и репликация останавливается; разрешить возникшую проблему пользователь должен вручную. Подробности конфликта можно найти в журнале сервера-подписчика.
Разрешить конфликт можно, изменив данные или разрешения на стороне подписчика, чтобы они не конфликтовали с поступающими изменениями, или пропустив транзакцию, конфликтующую с существующими данными. Когда в случае конфликта выдаётся ошибка, репликация останавливается, а рабочий процесс логической репликации выводит в журнал сервера подписчика сообщение следующего вида:
В этом сообщении можно увидеть LSN транзакции, содержащей изменение, которое нарушает ограничение, и имя источника данных репликации (в данном случае LSN 0/14C0378 и pg_16395 , соответственно). Транзакцию, вызвавшую конфликт, можно пропустить, выполнив команду ALTER SUBSCRIPTION . SKIP с LSN её завершения (то есть LSN 0/14C0378). В качестве LSN завершения транзакции может задаваться LSN, с которым транзакция была зафиксирована или подготовлена на сервере публикации. Конфликтующую транзакцию также можно пропустить, вызвав функцию pg_replication_origin_advance() . Прежде чем вызывать эту функцию, нужно либо временно отключить подписку, выполнив ALTER SUBSCRIPTION . DISABLE , либо использовать подписку с параметром disable_on_error . Затем можно вызвать функцию pg_replication_origin_advance() , передав ей node_name (то есть pg_16395 ) и LSN, следующий за LSN завершения (то есть 0/14C0379). Текущие позиции источников репликации можно увидеть в системном представлении pg_replication_origin_status . Обратите внимание: когда пропускается вся транзакция, пропускаются все её изменения, в том числе не нарушающие никаких ограничений. В результате состояние подписчика легко можно оказаться несогласованным.
Источник
Логическая репликация в PostgreSQL. Репликационные идентификаторы и популярные ошибки

Начиная с 10 версии, перенести данные с одной базы PostgreSQL на другую несложно, с обновлением, без обновления — неважно. Об этом немало сказано и сказанное сводится к следующему: на мастере, 10 версии и выше, устанавливаем параметр конфигурации wal_level=»logical» . В pg_hba.conf добавляем такую строку:
Затем рестартуем на мастере postgres и выполняем на реплике из-под пользователя postgres:
Теперь подключаемся на мастере пользователем postgres к базе db_name и создаём публикацию:
а на реплике создаём подписку:
По завершении репликации переключаем приложение или балансировщик на новую базу.
Теперь вы знаете постгрес (и с какой стороны доить слонеску) и можете идти устраиваться ДБА.
Для любознательных есть пара небольших деталей под катом.
Задачи, решаемые логической репликацией
Для чего может быть полезна логическая репликация, написано в документации:
- Передача подписчикам инкрементальных изменений в одной базе данных или подмножестве базы данных, когда они происходят.
- Срабатывание триггеров для отдельных изменений, когда их получает подписчик.
- Объединение нескольких баз данных в одну (например, для целей анализа).
- Репликация между разными основными версиями PostgreSQL.
- Репликация между экземплярами PostgreSQL на разных платформах (например, с Linux на Windows).
- Предоставление доступа к реплицированным данным другим группам пользователей.
- Разделение подмножества базы данных между несколькими базами данных.
Логическая репликация удобна тем, что вначале переносится схема данных. На ней можно тестировать возможность репликации заливкой данных с предварительно восстановленных резервных копий; проверять гипотезы по устранению возникающих при репликации проблем и имеющихся в базе ошибок проектирования. Также в этом случае появляется возможность внести и проверить такие изменения в схеме, которые на рабочей системе делать опасно.
Это тот момент, когда можно сказать — «А помните, мы хотели уменьшить объём базы за счёт выравнивания? Давайте сейчас столбцы и перераспределим!». Также на стороне реплики возможно, например, провести перераспределение данных из одного столбца типа JSON в несколько других столбцов, или даже таблиц, либо наоборот, после чего заполнять уже доработанную и протестированную базу, при необходимости обрабатывая данные напильником триггерами. Можно какие-то поля отправить в TOAST, а какие-то наоборот — достать. В некоторых пределах можно поменять типы значений в столбцах. Также причиной выбора является возможность провести практически бесшовное обновление, одновременно с котором допустимо некоторое изменение схемы данных, а при некотором усердии — кардинальное перекраивание схемы данных. В общем, к списку добавляется один пункт:
- Трансформация схемы данных, в определённых пределах, практически без перерыва в обслуживании.
Но, как и любой другой инструмент, логическая репликация имеет, помимо преимуществ, ещё и ограничения и недостатки. Знать их не помешает, ведь приведённый над катом пример будет работать без проблем только в сферической учебной БД.
Документация и примечания к выпускам
Надо помнить, что поведение СУБД в различных мажорных версиях может заметно разниться. Поэтому перед обновлением, да и вообще, важно ознакомиться с документацией и списком изменений (10, 11, 12, 13) и определить, какие из них могут изменить поведение вашей БД.
Здесь не будет рассказываться о создании публикаций и подписок, всё это есть в документации. Статья носит обзорный характер и не служит заменой документации.
Примечание
В статье приводится много примеров для воспроизведения которых лучше использовать psql , так как pgcli работает немного по-другому и перетащенный туда скрипт работает с ущербом для наглядности. Также создайте базу test , а в ней схему ts :
Не все скрипты можно перетаскивать как есть, в некоторых придётся поменять IP-адреса.
Приведённые примеры кода ни в коем случае не выполняйте на экземплярах СУБД, которые кем-либо используются. Некоторые примеры приведены для демонстрации падения СУБД и могут принести немало неприятностей. Лучше всего создать пару ВМ и экспериментировать на них.
Обновление до последней корректирующей (минорной) версии
Первое, что нужно запланировать и сделать при подготовке к использованию логической репликации — обновиться на последнюю минорную версию, особенно если в создаваемых публикациях планируется использовать предложение FOR ALL TABLES .
Почему стоит обновиться? Например, поэтому:
- В версиях 10.8 и 11.3 был исправлен баг с обработкой изменений, вносящихся во временные и нежурналируемые таблицы. Данные в таких таблицах в логической репликации не участвуют, поэтому им не требуется настройка репликационных идентификаторов, но, при попытке обновить в таких таблицах данные, сервер выдавал сообщение об ошибке: ERROR: cannot update table «logical_replication_test» because it does not have a replica identity and publishes updates и отменял транзакцию. Хорошего в этом мало, поэтому, если ваше приложение использует временные или нежурналируемые таблицы, то обновление обязательно;
- В версиях 10.11 и 11.6 был устранён вывод ошибки в случае, когда состав столбцов идентификации на мастере и на реплике различался. Правда и репликация изменения или удаления строк в таком случае прекращается;
- В версиях 10.12, 11.7, 12.2 был устранено несколько багов, которые приводили к невозможности значительно изменять схему таблиц на реплике по сравнению со схемой таблиц на мастере. Например, на реплике нельзя было создавать дополнительные столбцы с функцией в качестве значения по умолчанию («… clmname numeric DEFAULT random() . «).
- В версиях 10.16, 11.11, 12.6 13.2 устранили утечки памяти в процессах walsender при передаче новых снимков для логического декодирования
Как видите, для снижения километража истрёпанных нервов, предпочтительнее обновиться, пусть это и займёт некоторое время.
Создание ролей и строк аутентификации в pg_hba.conf
После минорного обновления следует создать те роли, которые планируется использовать для создания публикации и подписки. При этом требования к ролям на мастере и реплике немного различаются.
В целом на реплике можно вообще не создавать отдельную роль, так как создание подписки разрешается только суперпользователям и применение полученных изменений происходит с правами суперпользователя. Поэтому на реплике можно пользоваться ролью postgres .
На мастере быть суперпользователем не обязательно, но если планируется обновление, то этот вариант удобнее. Конечно, можно обойтись и без выделенной роли, но на мастере роль предпочтительно создать для того, чтоб ограничить возможность подключения только тем сервером, на который происходит репликация.
Создать роль можно такой командой:
В pg_hba.conf на мастере нужно добавить две записи: одну для локального подключения, другую для подключения с реплики. Предпочтительно указывать точные адреса реплик — лучше сто записей в pg_hba, чем одна дыра в безопасности.
Обратите внимание что, несмотря на то что логическая репликация основана в значительной мере на потоковой, указывается не специальная запись replication , а имя базы или all — указание на все базы. Если указать replication , то создать подписку на реплике не получится из-за ошибки аутентификации.
После этого перезагружаем настройки из-под суперпользователя:
Репликационные идентификаторы
Весь процесс логической репликации в принципе строится на идее репликационных идентификаторов. Поэтому дальнейшая подготовка состоит в проверке наличия во всех реплицируемых таблицах либо первичного ключа, либо индекса, соответствующего некоторым минимальным требованиям и задействованного в REPLICA IDENTITY USING INDEX , либо назначении REPLICA IDENTITY FULL . То есть проверка наличия в таблицах репликационных идентификаторов. Они нужны для однозначной идентификации изменяемых или удаляемых строк при репликации команд UPDATE и DELETE и передаются на реплику в специальном поле для каждой записи.
Репликационные идентификаторы можно не настраивать, или даже отключить, если планируется реплицировать только команды INSERT . Главное не забыть правильно создать публикацию — исключить из неё команды UPDATE и DELETE . Но если вам на реплике нужны актуальные данные из активно изменяющихся таблиц, а первичные ключи или уникальные NOT NULL индексы в таблицах отсутствуют, то репликационные идентификаторы придётся настраивать с нуля. Не выполнив это условие, можно добиться того, что UPDATE и DELETE будут приводить к отмене транзакций на мастере, малоприятный факт на рабочей базе.
Что может выступать в качестве репликационного идентификатора
Как понятно из названия репликационных идентификаторов — они должны идентифицировать строки таблиц. Если в вашей таблице есть поле или комбинация полей, которая никогда не повторяется и поэтому позволяет идентифицировать строку, её следует либо объявить первичным ключом, либо создать по ней уникальный индекс.
Если столбцов пригодных к роли репликационных идентификаторов нет, что очень странно, то придётся их создавать. Каждое значение в таком столбце должно быть уникальным. В качестве источника уникальности могут выступать как естественные, так и искусственные ключи и их комбинации — зависит от архитектуры базы данных. При этом неважно что именно использовать в качестве естественных ключей, главное, чтоб они выполняли роль однозначного идентификатора. В качестве искусственных ключей используются, как правило, различные последовательности и типы UUID.
Последовательности
Использовать последовательности при создании репликационных идентификаторов можно двумя с половиной способами: ручное указание вызова функции получения следующего значения последовательности, например nextval ; назначение столбцу последовательного псевдотипа serial ; использование столбцов идентификации в соответствии со стандартом SQL. Вполне рабочим вариантом может быть отсутствие значения по умолчанию, ведь можно возложить эту обязанность на приложение, но столбец должен быть NOT NULL .
SEQUENCE и serial
Наиболее гибким и мощным является использование различных SEQUENCE . В таком случае, после создания последовательности, значения по умолчанию для столбцов необходимо прописывать самостоятельно. При необходимости назначить таблицу-владельца последовательности также придётся поработать руками.
Тип serial это синтаксический сахар для обычного способа создания последовательностей, этакий шаблон. Всё что нужно сделать, это назначить столбцу тип smallserial/serial/bigserial.
Использование типа serial менее гибко, но его использование позволяет избавиться от необходимости создавать последовательности вручную. Также такой последовательности автоматически назначается свойство OWNED BY . Это указание на столбец таблицы, при создании которого была создана последовательность.
Такую последовательность в дальнейшем нельзя удалить, не удалив это указание. И здесь кроется опасность — удалив такую последовательность с указанием ключевого слова CASCADE можно устроить локальный армагеддон. В привязанном к удалённой последовательности столбце останется включенным свойство NOT NULL , а вот свойство DEFAULT обнулится.
У полей serial есть ещё одна неприятная особенность — пользователь без права на использование автоматически созданной последовательности, и с правами на INSERT в таблицу, практически вставку выполнять не сможет, если только не укажет значение поля serial вручную. Если не укажет, то получит ошибку доступа к соответствующей последовательности. В принципе это не проблема, нужно не забывать давать права на использование последовательности вместе с правами на вставку в таблицу.
Несколько таблиц на одной последовательности
Если нужно подключить к одной последовательности несколько таблиц, — делать это нужно самостоятельно. Для этого задаётся получение nextval(нужная_последовательность) в свойстве DEFAULT интересующего вас столбца. Воспользоваться можно и той последовательностью, что была создана с использованием serial — никто не мешает вручную прописать её для других таблиц, разве что потом будут некоторые проблемы с удалением самой первой таблицы: нужно будет поменять или удалить ссылку на таблицу-владельца такой последовательности: ALTER SEQUENCE name_of_your_seq OWNED BY NONE .
Пришедшие из стандарта SQL cтолбцы идентификации задаются либо при создании таблицы, либо ими могут стать имеющиеся столбцы, либо можно добавить такие столбцы отдельно.
Последовательность, созданную для столбца идентификации, в отличие от первых полутора вариантов, не стоит использовать в других таблицах. В дальнейшем это помешает удалить исходную таблицу, а если удалить её с предложением CASCADE , то свойство DEFAULT у таблиц использовавших эту последовательность обнулится. При этом свойство NOT NULL никуда не денется.
В результате появится шанс наблюдать на мастере орды null value in column «i» violates not-null constraint . С последовательностями, созданными с помощью serial тоже такое бывает, но для них это исправимо — поменяйте принадлежность последовательности либо на нужный столбец нужной таблицы, либо сделайте её «бесхозяйной». С последовательностями столбцов идентификации это не работает.
Первичными ключами столбцы идентификации автоматически не становятся, это просто синтаксис назначения столбцу особых свойств, несколько отличающихся от обычных последовательностей. В частности, при типе serial вы можете спокойно проводить вставку любых произвольных значений в ключевые поля, за исключением имеющихся конечно (если на столбце включен PRIMARY KEY ).
Понятно, что это приведёт к тому, что однажды последовательность выдаст вставленные ранее произвольные значения и получившая их транзакция прервётся с ошибкой duplicate key . Использование столбцов идентификации позволит не беспокоиться о таком развитии событий — в столбцы идентификации, созданные с ключом ALWAYS , вставить произвольное число не так просто, нужно использовать специальную форму команды INSERT . При создании таких столбцов поддерживаются те же параметры, что и при создании обычной последовательности.
Universally Unique IDentifiers
Если назначить столбцу тип UUID, то значение для такого столбца не будет генерироваться автоматически. Для получения нового значения UUID необходимо пользоваться одним из двух дополнительных модулей: uuid-ossp или pgcrypto
В отличие от последовательностей UUID имеет длину не 16/32/64 бита, а 128 бит, — что нужно учитывать при расчётах нагрузки на сетевую подсистему. Зато у него есть то преимущество, что UUID генерирует такие строки, содержимое которых не повторяется в распределённых системах.
К слову, при использовании последовательностей можно использовать независимые последовательности с добавлением префикса, уникального для каждого участвующего во взаимообмене данными сервера. Столбец в таком случае придётся сделать текстовым, но даже так получится экономичнее.
В простейшем случае получать значения UUID можно через расширение pg_crypto . В нём есть только одна функция получения UUID:
Модуль uuid-ossp , в отличие от pg_crypto предоставляет больше возможностей по части выбора типа UUID. Если PostgreSQL установлен из пакетов, то можно сразу устанавливать расширение, только его имя обязательно нужно заключить в двойные кавычки, так как оно содержит дефис. Если собираете PostgreSQL из исходников, то нужно воспользоваться ключом —with-uuid=ossp (работает в Debian, как в RHEL — не знаю). Для этого, в дополнение к уже установленному постгресу, понадобится поставить несколько пакетов:
Первичные ключи и уникальные индексы
Определившись с источниками уникальности нужно указать какой столбец, или какие столбцы, надлежит использовать как репликационные идентификаторы. По умолчанию ими являются первичные ключи. Они, как и уникальные индексы, позволяют добавлять на стороне реплики произвольное число столбцов, не опасаясь приостановки репликации при операциях UPDATE и DELETE .
Главное, чтобы у добавленных столбцов не было назначено свойство NOT NULL с отсутствующим значением по умолчанию — при начальной репликации и репликации команды INSERT возникнет ошибка на стороне реплики, устранять которую возможно только на стороне реплики. На стороне мастера тут уже ничего не поделаешь, разве что удалить слот репликации — чтоб журнал предзаписи не переполнялся, и мастер не создавал каждые пять секунд процесс декодирования. Также можно запретить доступ через pg_hba.conf или на балансировщике, затем исправить неполадки на реплике и снова разрешить доступ.
Перед началом репликации таблицы первичные ключи должны быть настроены с обоих сторон, а имеющиеся в реплицируемой таблице столбцы, даже не являющиеся репликационными идентификаторами, должны присутствовать и в реплицированной таблице. То есть на мастере нельзя удалять столбцы, если они есть на реплике.
При непосредственном создании первичных ключей таблица блокируется на запись блокировкой SHARE ROW EXCLUSIVE . Поэтому предпочтительно использовать предварительное создание уникального индекса в режиме CONCURRENTLY и затем уже привязку его в качестве первичного ключа. Да — это ресурсоёмкая операция, зато доступность БД на запись не страдает.
Обратите внимание на то, что если вы создаёте первичный ключ на столбце, не имеющем свойства NOT NULL , то такое свойство будет создано автоматически, но после после удаления ограничения автоматически не удалится.
Наравне с первичными ключами можно использовать уникальные индексы, но их использование в качестве идентификатора репликации необходимо указывать явно с помощью предложения . REPLICA IDENTITY USING INDEX name_of_index . и с ними нужно быть поосторожнее. В отличие от первичных ключей столбцы, на которых строится индекс, нужно самостоятельно снабдить ограничением NOT NULL .
Требования к индексам перечислены в документации: индекс должен быть уникальным, не частичным, не отложенным и включать только столбцы, помеченные NOT NULL. Состав столбцов, по которым построен индекс на мастере, должен совпадать с их составом на реплике. Если в нужных таблицах в реплицируемой схеме нет первичных ключей — можно на мастере создать уникальный индекс, назначить его репликационным идентификатором, а после переноса схемы на реплику — создать там идентичный по составу и порядку столбцов первичный ключ. Можно и наоборот.
REPLICA IDENTITY FULL
В отличие от первичных ключей и индексов при REPLICA IDENTITY FULL идентификатором служит вся строка. В этом случае в журнал предзаписи попадает вся старая строка и по протоколу репликации также передаётся вся старая строка. Не передаются только значения полей TOAST — если изменения их не коснулись. Исходя из этого можно представить, насколько разрастается объём хранимых и передаваемых данных.
Поэтому от применения REPLICA IDENTITY FULL нужно максимально воздерживаться. Мало того — ошибки в его использовании могут привести к необходимости рестарта репликации. Когда используется REPLICA IDENTITY FULL , то состав столбцов в таблице на мастере и реплике преимущественно должен совпадать (порядок столбцов значения не имеет), иначе изменение и удаление данных реплицироваться не будет и последствия будут различаться в зависимости от того, где есть лишние столбцы — на мастере или на реплике.
Если лишние столбцы будут на мастере и публикация будет создана для команд UPDATE и DELETE — репликация приостановится до тех пор, пока на реплике будут отсутствовать нужные столбцы.
Вставка данных и начальная синхронизация не так строго ограничены по части состава столбцов — на реплике могут быть дополнительные столбцы, и они даже могут содержать какие-то данные. Но репликация будет идти благополучно для всех команд только если добавленные на реплике столбцы не содержат данных. Это связано с тем, что поля со значением NULL в идентификации строк не участвуют.
Однако пользы от такого способа добавления столбцов немного — при обычном добавлении столбцов, без данных, перезаписи таблицы не происходит, поэтому добавлять пустые столбцы можно и на рабочей базе.
Если же нужно менять данные на реплике, но на мастере нет возможности создать первичный ключ — его можно создать на реплике, тогда репликация всех команд будет происходить благополучно, хоть в дополнительных столбцах реплики и будут данные. Это работает, потому что в сообщениях протокола логической репликации, при REPLICA IDENTITY FULL на мастере, в качестве идентификатора отправляется вся строка старых данных и процесс применения сообщений выбирает из него значение того поля, которое на реплике является полем первичного ключа.
REPLICA IDENTITY FULL удобно использовать для трансляции небольших, редко изменяемых таблиц или для таблиц с небольшим размером строк — им не нужны индексы на мастере и данные очень быстро пишутся и отправляются. На реплике же можно и индексы строить, и первичные ключи создавать — вполне удобно. Но для обновляемых данных в масштабных таблицах применять его очень опрометчиво.
Включить для таблицы этот идентификатор крайне просто:
Если на мастере REPLICA IDENTITY FULL задана, то на реплике её наличие роли не играет — но только при условии, что состав столбцов таблицы на реплике идентичен таковому на мастере. Иначе на реплике будут применяться только команды INSERT , а если у вас 11 версия мастера — то и TRUNCATE . Команды UPDATE и DELETE будут применяться только если дополнительные столбцы в изменяемой/удаляемой строке будут равны NULL.
Если нужно реплицировать исторические данные или провести только начальную синхронизацию — можно вообще убрать идентификаторы репликации:
это снизит нагрузку на журнал предзаписи, декодирование и сеть. Но нужно обязательно создавать публикацию только для команд INSERT , иначе обновление и удаление в этой таблице работать перестанут, независимо от того — есть подписка или нет.
Состав и порядок столбцов
Вне зависимости от выбранных репликационных идентификаторов — порядок столбцов, даже ключевых — значения практически не имеет. Начальная синхронизация и репликация команд INSERT проходят без проблем, независимо от настройки репликационных идентификаторов — идентификаторы строк в этом случае не передаются.
Если же бездумно добавлять столбцы к таблице с той или другой стороны, то, например, при REPLICA IDENTITY FULL , придётся перезапускать репликацию для такой таблицы. Причём, в зависимости от способа прицеливания в ногу, можно либо добиться неконсистентности на реплике, либо ещё и раздуть на мастере журнал предзаписи до невероятных размеров. Что, в одном случае, не даст возможности восстановить согласованность данных в проблемной таблице на реплике и приведёт к необходимости перезаливки данных. Во втором случае такая возможность останется (условно) и реализуется автоматически — после выявления и устранения причины такой ситуации, однако целостность данных после этого всё равно останется под сомнением.
С первичными ключами и индексами ситуация значительно лучше. Хоть на реплике и нельзя удалять столбцы если такие есть на мастере, зато появляется возможность добавлять новые. И не просто добавлять, а различными способами заполнять их данными, без опаски получить остановку репликации или неконсистентность.
Склад грабель горизонтального хранения
Предупреждён — значит вооружен. Ниже приведены несколько самых распространённых сообщений об ошибках и просто общих рассуждений. Лучше прочитать эти сообщения здесь, чем на рабочих серверах — читаем и вооружаемся. Если у вас есть что-нибудь интересное на эту тему — расскажите в комментариях.
Если на мастере репликационные идентификаторы не заложены в бюджет
По умолчанию публикация создаётся для команд INSERT , UPDATE и DELETE (и TRUNCATE , начиная с 11 версии). При этом проверки идентификаторов репликации в целевых таблицах не происходит, от этого может получиться так, что они будут не у всех таблиц. Мало того — после создания публикации допускается сброс или удаление репликационного идентификатора:
Первое — сброс на значение по умолчанию, то есть на использование первичного ключа таблицы и если он есть — жить можно. Второе — отключение идентификаторов на таблице. Но если нет первичного ключа или идентификаторов вообще, то, при попытке выполнить на мастере обновление или удаление строк, будут получены соответствующие ошибки:
Так будет в случае, когда публикация не создана исключительно для команд INSERT и, для одиннадцатой версии — TRUNCATE . Вариантов исправления такой ситуации два — изменить подписку на publish=’insert’ или добавить репликационные идентификаторы.
. not find row.. .
Пример сообщений которые можно увидеть когда:
- на реплике добавили столбец и его значение не NULL ;
- на реплике по какой-либо причине строки отсутствуют, а на мастере они есть;
- на реплике были изменены строки;
- на реплике нет строки с переданным значением репликационного идентификатора
Если на реплике сложилась одна из приведённых ситуаций, то, при обычном значении параметра log_min_messages=warning , этих сообщений в логах реплики не появится. От того и о пропавших данных можно узнать, когда будет уже очень поздно. А можно и не узнать. С точки зрения СУБД в таком поведении нет ничего предосудительного, возможно таков был план. Но если это не был план, то для приложения это катастрофа, так что тут нужно быть предусмотрительным и внимательным.
Наблюдать эти сообщения в логах возможно при log_min_messages=debug1 . Однако так увеличится объём логов, но консистентности данных не прибавится — реплика, получив сообщение об изменениях, не смогла найти изменяемую/удаляемую строку и благополучно выкинула сообщение на свалку истории, а второго шанса ей не предоставится. Мастер не будет уведомлен об этом и в свои логи писать ничего не станет. Следует учесть, что в этом режиме в лог будет записываться строка подключения, вместе с именем пользователя и его паролем — сомнительное преимущество использования такого уровня сообщений журнала.
В данном случае можно радоваться хотя бы тому, что на мастере такое поведение почти никак не скажется. В этом случае реплика получает сообщения репликации, затем, не применив их, отчитывается мастеру, что всё хорошо и журнал предзаписи не разрастается. Конечно, после такого инцидента придётся выправлять сложившееся положение дел:
- На мастере исключать таблицу из публикации;
- На реплике обновлять подписку и вычищать таблицу;
- Привести состав столбцов к единому виду;
- Включать на мастере таблицу в публикацию;
- Обновлять подписку на реплике и ждать перезаливки данных.
А всего нужно было — не добавлять столбцы в таблицу на стороне реплики если используется REPLICA IDENTITY FULL или не изменять, бездумно, данные на реплике.
В отличие от UPDATE и DELETE , операция INSERT и начальная синхронизация будут нормально обрабатываться, даже если на реплике есть столбцы отсутствующие на мастере.
Лишний столбец на мастере
Если же случилось так, что кто-то удосужился создать лишний столбец на мастере, то на реплике начнёт появляться множество таких сообщений:
А на мастере множество таких:
То есть вставка, изменение и удаление строк не принимается репликой, ведь на стороне реплики нет столбцов для поступивших данных. О сложившейся ситуации мастер «информируется». В этом случае на реплике постоянно создаётся и уничтожается новый процесс репликации для сбойной подписки.
В результате на мастере начнёт раздувать журнал предзаписи независимо от типа операции. Так можно довести и до останова сервера, не заметив вовремя разбухание журнала. Удаление столбца на стороне мастера не спасёт — логическое декодирование будет использовать записи из журнала предзаписи, а там добавленный столбец есть и никуда не денется. Также не спасёт и удаление таблицы из публикации — это связано с тем, что публикацией может пользоваться несколько подписок и такое лекарство окажется опаснее болезни, потому и возможность такую не реализовали.
Лично я считаю, что для публикаций с одним подписчиком не помешает добавить такую возможность — но пока что разработчики так не думают. В общем имеется три варианта:
- Добавить на реплику недостающий столбец и надеяться, что на обоих серверах их содержимое совпадает (x6c6f6c), иначе все операции UPDATE и DELETE по несовпадающим строкам пропадут и оставят после себя уже знакомые записи в логе » . not find row for . » — это относится к REPLICA IDENTITY FULL .
Отсутствие в добавленном столбце данных, имеющихся на мастере, приведет к тому, что пробка, конечно, рассосётся — только вот накопившиеся операции INSERT данных попадут в таблицу на реплике, а UPDATE и DELETE — нет. Потому что идентификатором строки будет вся строка, а в одном из столбцов данные не совпадают.
Выбор так себе, но так можно относительно безопасно разгрести журнал предзаписи на мастере и не доводить до второго способа. Ну а далее — чистим публикацию от проблемной таблицы, обновляем подписку, добавляем таблицу обратно в публикацию, добавляем в таблицу недостающие столбцы, обновляем подписку, ждём. Если же на обоих серверах нормальные репликационные идентификаторы — первичный ключ или уникальный индекс — репликация восстановится без потерь данных.
Дубликаты значений в столбцах репликационных идентификаторов или «Раньше думать надо было!»
Возникают такие ошибки потому, что с мастера на реплику приходит новая строка с имеющимся на реплике значением репликационного идентификатора на основе первичного ключа или уникального индекса. При обновлении логической репликацией или простом переносе данных такие ошибки не появляются. Они появляются если база находится в доступе на запись для пользователей или приложений и те этим пользуются. По сути, это не ошибка PostgreSQL, это ошибка проектирования и вопросы нужно задавать себе.
Исправлять такие инциденты не так уж и просто — сначала необходимо определить какая из двух конфликтующих строк неправильная, и насколько. Если неправильным является содержимое строки на реплике, то репликация продолжится после удаления с реплики такой строки.
Совсем другое дело, когда неправильной является строка, пришедшая с мастера. В этом случае всё равно придётся либо удалять строку на реплике, либо назначать ей заведомо большой идентификатор; ждать завершения загрузки с мастера отставших транзакций; заменять пришедшую с мастера строку старой строкой с реплики.
Ситуация в обоих случаях усугубляется тем, что лишних строк может быть очень много. Настолько, что новые транзакции будут выполняться быстрее, чем будут разбираться конфликтные ситуации. И всё время, пока расследуется инцидент, размер журнала предзаписи будет разрастаться, а пользователи реплики не будут иметь возможности получать актуальные данные.
Если предполагается использовать логическую репликацию не для обновления, а для обмена данными между различными базами — следует очень внимательно проработать вопрос об идентификации строк. Так как для идентификации, обычно, используются последовательности, то можно посоветовать пробежаться по слайдам доклада CTO Stickeroid Ai, Камиля Исламова о способах применения последовательностей в PostgreSQL и документацию по последовательностям, затем перепроектировать их в сбойной системе баз данных.
Столбец NOT NULL без DEFAULT на реплике
Для любых столбцов на реплике не должно быть установлено свойство NOT NULL без указания значения по умолчанию. Особенно это касается тех столбцов, которые есть на мастере, потому что на реплике для них значение DEFAULT подставляться не будет — как пришел NULL , так и будет записываться.
Если в дополнительные NOT NULL столбцы значение по умолчанию не поставить, то репликация приостановится с приведённой выше ошибкой. Как только удалите такой столбец, зададите ему значение по умолчанию или удалите ограничение NOT NULL — репликация возобновится без потери данных.
Если в реплицируемой таблице на стороне мастера изначально есть значения NULL — сначала необходимо заполнить такие поля, либо удалить ограничение NOT NULL на реплике.
При появлении такой ошибки в начале репликации можно узнать из логов название проблемной таблицы, но не схему в которой она расположена:
Если же начальная синхронизация давно закончилась и репликация идёт полным ходом, то в логах записи о таблице не будет — придётся искать вручную.
На мастере есть первичный ключ, на реплике он отсутствует
Ошибка наблюдается при репликации команд UPDATE и DELETE , если в таблице на реплике отсутствует первичный ключ, который есть на мастере. Повторяется до тех пор, пока на реплике не будет создан соответствующий первичный ключ. Репликация при этом приостанавливается и продолжается после устранения причины ошибки. Состав столбцов на обоих серверах либо идентичен, либо на реплике могут быть дополнительные столбцы; порядок столбцов может различаться.
На мастере и реплике первичные ключи или индексы построены на разных столбцах
Ошибка появляется при репликации команд UPDATE и DELETE , если в таблице на реплике первичный ключ (индекс) построен не на том столбце, на котором построен первичный ключ (индекс) на мастере. Повторяется до тех пор, пока на реплике не будет удалён неправильный и не будет создан правильный первичный ключ (индекс).
Репликация при этом приостанавливается и продолжается после устранения причины ошибки. На реплике могут быть дополнительные столбцы, порядок столбцов может различаться.
Фантомного индекса боль
Ошибка очень интересная и наблюдается на мастере при выполнении команд UPDATE и DELETE , если в таблице на мастере в качестве репликационного идентификатора использовался уникальный индекс, который потом удалили, например потому, что создали взамен первичный ключ, или просто так удалили (всяко быват, уж мы их ругам-ругам, ничо не помогат).
Ошибку эту можно получить только на мастере и только на таблицах, включенных в публикации, поддерживающие UPDATE и DELETE . Вообще эта ошибка означает именно отсутствие любого репликационного идентификатора, но в данном случае всё немного интереснее — идентификатором остаётся индекс, который удалили.
Чтоб исправить ошибку нужно вернуть REPLICA IDENTITY DEFAULT , перенацелив тем самым поиcк идентификатора туда, где он есть — на первичный ключ. Также можно воссоздать индекс и снова перенацелиться на него, так как oid у него будет уже другой, и система не будет его видеть.
Если же нет времени строить индексы и первичные ключи — включаем REPLICA IDENTITY FULL , а уж затем восстанавливаем индексы и так далее. В рабочих системах начинать изменения нужно с реплики, иначе вылезут другие ошибки.
Идентифицировать именно такой вариант развития событий не так уж и просто, хотя бы потому, что никому такое в голову не придёт. И, не приведи вселенная, если ещё до вас кто-то удалил и снова создал индекс — выявить причину происходящего будет практически невозможно.
Непреобразуемые типы
Ошибка наблюдается на любом этапе репликации, если в таблице на реплике есть хотя бы один столбец, в тип которого нельзя преобразовать полученный с мастера тип данных. Повторяется до тех пор, пока на реплике не будет исправлена таблица. Репликация при этом приостанавливается и продолжается после устранения причины ошибки.
И здесь снова неполная информация о том, в какой таблице произошла ошибка. То есть при начальной синхронизации в строке с контекстом есть информация о таблице, но не о схеме. Но, если уже после начальной синхронизации столбец был изменён, то информация будет полноценной.
И такое может пригодиться, если что-то натворили непонятное
Общие замечания
Лучше первичных ключей нет на свете репликационных идентификаторов. В случае, когда в таблице отсутствует PRIMARY KEY и его добавление невозможно, то всегда имеется возможность создать его используя неблокирующее построение индекса с последующим назначением его ограничением первичного ключа.
Выполнять создание индексов желательно до переноса схемы данных, с тем, чтоб они перенеслись на реплику в составе схемы БД, ну или не забыть создать их и на реплике. К тому же на реплике возможно сразу создать первичный ключ с аналогичным составом столбцов ещё до начала репликации.
Использовать REPLICA IDENTITY FULL стоит только если строки в таблице незначительного размера и редко изменяются. При использовании такого типа идентификатора желательно воздержаться от изменения структуры принимающей таблицы.
Если после переноса схемы вам необходимо поменять в ней некоторые таблицы, то возможно проверять безопасность изменений в новой базе используя специально восстановленную резервную копию мастера как источник данных и устанавливая log_min_messages=debug1 для проверки правильности работы репликации по части UPDATE и DELETE . Изменение этого параметра не требует перезапуска сервера, поэтому возможно его переключать в любое время, например на время проверки внесенных изменений.
После начала репликации на мастере нельзя добавлять столбцы, а если добавлять, то начинать надо с реплики.
Новые столбцы с NOT NULL на реплике хороши только если в комплекте идёт DEFAULT .
Ошибки могут случаться, но в большинстве случаев они некритичные и легко устраняются, только нужно с умом подойти к выбору репликационных идентификаторов. Если речь идёт не об обновлении, а о более сложных схемах применения логической репликации, то к проектированию системы в целом нужно подойти очень ответственно, иначе можно отправить всё в нокдаун или потерять данные.
И на сладкое: можно добиться того, что системные каталоги на реплике сохранят информацию о подписках, которые, как казалось, были удалены. Тут может помочь только реинициализация кластера БД. В таком случае команда dRs показывает наличие подписки, а SELECT * FROM pg_subscription; — нет. При этом на реплике все необходимые для обслуживания процессы запускаются, но ничего полезного не делают, кроме множества ошибок в логах (не можем подключиться, слота нет. ), даже при специально повторно созданных объектах и слотах. То есть было утеряно некоторое количество внутренней информации о подписке. За месяц экспериментов такое положение дел было достигнуто только два раза, и оба раза это произошло после отправки хоста тестовых виртуалок в ждущий или спящий режим. Хоть и получалось так не всегда — не делайте так. Но случиться такое с хост-системой всё-таки может, так что про такую вероятность нужно знать.
Источник
Logical replication is widely used as an easy and flexible way to replicate data. And now PostgreSQL makes it even easier by providing some mechanisms to handle replication conflicts. Let me show you how.

While physical replication copies whole clusters and accepts read-only queries on the standby if required, logical replication gives more fine-grained and flexible control over data replication.
Before we start
Logical replication is a method of selective data replication. While physical replication copies whole clusters and accepts read-only queries on the standby if required1, logical replication gives more fine-grained and flexible control over data replication. Some of the capabilities available in logical replication are:
- Selection of target tables and operations
- Direct writes on the subscriber
- Complex topology between publications and subscriptions
In logical replication, data is applied on the subscriber by subscription worker process, which operates in a similar way to conduct DML operations on the node. So, if new incoming data violates any constraints on the subscriber, the replication stops with error.
This is referred to as conflict2, and requires manual intervention from the user so that it can proceed.
Contents
> So, what changes in PostgreSQL 15?
> Improvements to logical replication and new features
> Resolving conflicts by skipping a failing transaction
> What can go wrong if I specify the wrong parameters?
> Wrapping up
> If you would like to learn more
So, what changes in PostgreSQL 15?
In PostgreSQL 15, the PostgreSQL community is introducing improvements and new features useful to tackle logical replication conflicts. I’ll describe these improvements and how you can apply them to handle conflicts.
In this post, the resolution is achieved by skipping the transaction that conflicts with existing data. Regarding the auto-disabling feature (disable_on_error option) described in this post, I also worked as one of the developers in the community. The figure below illustrates how a conflict may happen during apply.
Disclaimer: In this post I’ve used the development version of PostgreSQL, and the community can either decide to change its design or completely revert those.
Conflict during logical replication
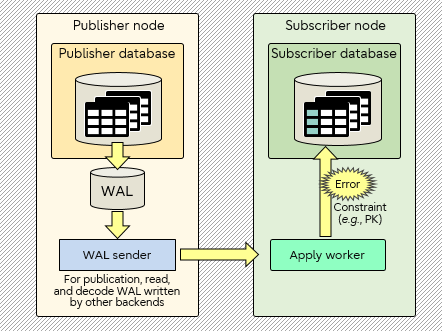
Improvements to logical replication and new features
The community has been working really hard to make sure that Postgres provides a reliable, efficient, and easy measure in terms of logical replication. Part of this effort are the commit of the features and improvements below:
- New system view pg_stat_subscription_stats3 for subscription statistics
Each record of this view refers to a subscription. In this view, we have implemented two types of failure counters: one for failure in initial table synchronization, and another for failure in application of changes.
- New subscription option disable_on_error4
When a conflict occurs, the logical replication worker gets stuck in an error loop by default. The reason is that when the worker fails to apply a change, it exits with an error, restarts, and tries to apply the same change repeatedly in the background. But with this new option, the subscription worker can break the loop by disabling the subscription automatically on error. After that, users can choose what to do next. Failures during initial table synchronization also disable the subscription. The default value is false and setting it to false repeats the same error on conflict.
- Extended error context information of subscription worker error
The error context message now includes 2 new pieces of information conditionally5:
- Finish LSN. In general, LSN is a pointer to a location in the WAL. Here, finish LSN will indicate commit_lsn for committed transactions, and prepare_lsn for prepared transactions.
- Replication origin name6. This will contain the name of replication origin that keeps track of replication progress. For logical replication, each corresponding replication origin is created automatically, along with the subscription definition.
Both pieces of information above will be useful when users need to use the pg_replication_origin_advance function7.
Resolving conflicts by skipping a failing transaction
We have checked each enhancement for this theme. So, in this section, I’ll emulate one conflict scenario. Keep in mind that skipping a transaction by calling pg_replication_origin_advance is just one of the resolutions that users can choose, users can also change data or permissions on the subscriber to solve the conflict.
1 On the publisher side, create a table and a publication.
postgres=# CREATE TABLE tab (id integer);
CREATE TABLE
postgres=# INSERT INTO tab VALUES (5);
INSERT 0 1
postgres=# CREATE PUBLICATION mypub FOR TABLE tab;
CREATE PUBLICATION
We now have one record for initial table synchronization.
2 On the subscriber side, create a table with a unique constraint and a subscription.
postgres=# CREATE TABLE tab (id integer UNIQUE);
CREATE TABLE
postgres=# CREATE SUBSCRIPTION mysub CONNECTION ‘…’ PUBLICATION mypub WITH (disable_on_error = true);
NOTICE: created replication slot «mysub» on publisher
CREATE SUBSCRIPTION
We have now created a subscription with the disable_on_error option enabled. At the same time, this definition causes the initial table synchronization in the background, which will succeed without any issues.
3 On the publisher side, execute three transactions in succession after the table synchronization.
postgres=# BEGIN; — Txn1
BEGIN
postgres=*# INSERT INTO tab VALUES (1);
INSERT 0 1
postgres=*# COMMIT;
COMMIT
postgres=# BEGIN; — Txn2
BEGIN
postgres=*# INSERT INTO tab VALUES (generate_series(2, 4));
INSERT 0 3
postgres=*# INSERT INTO tab VALUES (5);
INSERT 0 1
postgres=*# INSERT INTO tab VALUES (generate_series(6, 8));
INSERT 0 3
postgres=*# COMMIT;
COMMIT
postgres=# BEGIN; — Txn3
BEGIN
postgres=*# INSERT INTO tab VALUES (9);
INSERT 0 1
postgres=*# COMMIT;
COMMIT
postgres=# SELECT * FROM tab;
id
—-
5
1
2
3
4
5
6
7
8
9
(10 rows)
Txn1 can be replayed successfully. But the second statement of Txn2 (highlighted in blue above) includes a duplicated value same as the table synchronization (also highlighted in blue in the first command section). On the subscriber, this violates the unique constraint on the table. Therefore, it will cause a conflict and disable the subscription. As a result, the subscription will stop here. Txn3 won’t be replayed until the conflict is addressed, as per the steps below.
4 On the subscriber side, check the current replication status.
postgres=# SELECT * FROM pg_stat_subscription_stats;
subid | subname | apply_error_count | sync_error_count | stats_reset
——-+———+——————-+——————+————-
16389 | mysub | 1 | 0 |
(1 row)
postgres=# SELECT oid, subname, subenabled, subdisableonerr FROM pg_subscription;
oid | subname | subenabled | subdisableonerr
——-+———+————+——————
16389 | mysub | f | t
(1 row)
postgres=# SELECT * FROM tab;
id
—-
5
1
(2 rows)
Before skipping a transaction, we’ll have a look at the current status.
There was no failure during initial table synchronization, but there was one during apply phase. That is what pg_stat_subscription_stats shows so far. Furthermore, since we created the subscription with the disable_on_error option set to true, the subscription mysub has been disabled due to the failure. The table tab has the data replicated up to Txn1, which we have successfully replayed.
5 On the subscriber side, check the error message of this conflict and the log message of the disable_on_error option.
ERROR: duplicate key value violates unique constraint «tab_id_key»
DETAIL: Key (id)=(5) already exists.
CONTEXT: processing remote data for replication origin «pg_16389» during «INSERT»
for replication target relation «public.tab» in transaction 730 finished at 0/1566D10
LOG: logical replication subscription «mysub» has been disabled due to an error
Above we can see the replication origin name and the LSN that indicates commit_lsn. I’ll utilize those to skip Txn2 as below.
6 On the subscriber side, execute pg_replication_origin_advance and then enable the subscription.
postgres=# SELECT pg_replication_origin_advance(‘pg_16389‘, ‘0/1566D11‘::pg_lsn);
pg_replication_origin_advance
——————————-
(1 row)
postgres=# ALTER SUBSCRIPTION mysub ENABLE;
ALTER SUBSCRIPTION
postgres=# SELECT * FROM tab;
id
—-
5
1
9
(3 rows)
After making the origin advance, I enabled the subscription to re-activate it — immediately, we can see the replicated data for Txn3.
Here, note that some other data irrelevant to the direct cause of the conflict in Txn2, regardless of the timing within the same transaction (remember, we performed other inserts in Txn2, highlighted in red), was not replicated — the whole transaction Txn2 was skipped.
The sequence of events here is as follows:
- We used pg_replication_origin_advance and enabled the subscription.
- Enabling the subscription launched the apply worker and it sent the LSN passed via pg_replication_origin_advance to the walsender process on the publisher.
- This walsender process evaluated whether transaction Txn2 should be sent or skipped at decoding commit, by comparing the related LSNs.
- The walsender concluded that transaction Txn2 should be skipped.
Lastly, I emphasize we must pay attention to pass an appropriate LSN to pg_replication_origin_advance. Although the possibility is becoming quite low because of the new community’s improvements described in this blog, it can easily skip other transactions unrelated to the conflict if it’s misused.
What can go wrong if I specify the wrong parameters?
 For reference, we provide an example of what would happen if we use pg_replication_origin_advance incorrectly.
For reference, we provide an example of what would happen if we use pg_replication_origin_advance incorrectly.
Below, I re-executed the above scenario with one more transaction Txn4 to insert 10 after Txn3. Then, as the argument of pg_replication_origin_advance, I set a LSN bigger than that of Txn3’s commit record but smaller than that of Txn4’s commit record (retrieved by pg_waldump8). After I enabled the subscription, I got the replicated data without the value of Txn3.
Result on the subscriber side of using pg_replication_origin_advance incorrectly is as follows.
postgres=# SELECT * FROM tab;
id
—-
5
1
10
(3 rows)
As shown above, we can never be too careful when manually intervening in the replication to solve conflicts.
On this point, the community has already introduced a different feature (ALTER SUBSCRIPTION SKIP) separately.
This feature is one step ahead of pg_replication_origin_advance in the aspect of handling
logical replication conflicts. Please have a look at my next post that describes the detail.
Wrapping up
As logical replication becomes more widely adopted in enterprises, the need for handling practical problems like conflicts becomes ever more important. For this reason, the improvements added to PostgreSQL are essential.
The PostgreSQL community has been hardening the database, and in this blog post I have described an easy way to handle logical replication conflicts. Still, we have to be careful to provide the correct information for the tool being used, in this case pg_replication_origin_advance.
If you would like to learn more
If you would like to read more about logical replication and its mechanics in PostgreSQL, I wrote the blog post How to gain insight into the pg_stat_replication_slots view by examining logical replication. And my colleague Ajin Cherian wrote a blog post on Logical decoding of two-phase commits in PostgreSQL 14 in case you would like to learn more about logical decoding and how PostgreSQL performs it for two-phase commits.
References in this post:
Subscribe to be notified of future blog posts
If you would like to be notified of my next blog posts and other PostgreSQL-related articles, fill the form here.
We also have a series of technical articles for PostgreSQL enthusiasts of all stripes, with tips and how-to’s.

Topics:
PostgreSQL,
PostgreSQL community,
Logical replication
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
postgres=> CREATE TABLE blog (
id int PRIMARY KEY,
name varchar(20)
);
CREATE TABLE
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1');
INSERT 0 1The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
postgres=> INSERT INTO blog
VALUES (1, 'AWS Blog1');
ERROR: duplicate key value violates unique constraint "blog_pkey"
DETAIL: Key (n)=(1) already exists.The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1')
ON CONFLICT DO NOTHING;
INSERT 0 0The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 54.135 msFor comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 0.761 msThe difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 4As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
postgres=> DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
DOWe now observe five additional dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9This highlights that even though no rows were successfully inserted, there is an increase in dead tuples (n_dead_tup).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
END;
END LOOP;
END;
$$;Again, checking pg_stat_user_tables, we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
DO $$
BEGIN
FOR r in 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row.
We used the following pgbench command to run it through multiple connections:
pgbench --host=iocblog.abcedfgxymxvb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script postgresWe observed multiple notice messages, because all were duplicate values:
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate rowFor this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0, to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.

On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
postgres=> select * from pg_stat_activity where query like '%autovacuum%';
-[ RECORD 1 ]----+--------------------------------------------------------------------
datid | 14007
datname | postgres
pid | 3049
usesysid |
usename |
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2020-11-26 12:22:37.364145+00
xact_start | 2020-11-26 12:22:37.403818+00
query_start | 2020-11-26 12:22:37.403818+00
state_change | 2020-11-26 12:22:37.403818+00
wait_event_type | LWLock
wait_event | ProcArrayLock
state | active
backend_xid |
backend_xmin | 205602359
query | autovacuum: VACUUM public.blog (to prevent wraparound)
backend_type | autovacuum workerWhen we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log:
2020-11-26 12:22:37 UTC::@:[3049]:DEBUG: blog: vac: 5971078 (threshold 50), anl: 0 (threshold 50)
.
.
2020-11-26 12:22:45 UTC::@:[3202]:WARNING: oldest xmin is far in the past
2020-11-26 12:22:45 UTC::@:[3202]:HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
2020-11-26 13:05:28 UTC::@:[62084]:LOG: automatic aggressive vacuum of table "postgres.public.blog": index scans: 2
pages: 0 removed, 1409317 remain, 48218 skipped due to pins, 0 skipped frozen
tuples: 115870210 removed, 96438 remain, 0 are dead but not yet removable, oldest xmin: 460304384
buffer usage: 4132095 hits, 21 misses, 1732480 dirtied
avg read rate: 0.000 MB/s, avg write rate: 37.730 MB/s
system usage: CPU: user: 22.71 s, system: 1.23 s, elapsed: 358.73 sAutovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
DO $$
BEGIN
FOR r IN 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;We ran the script on the instance in the following steps:
// Check the live rows in the table
postgres=> SELECT * FROM blog;
n | name
---+-----------
1 | AWS Blog1
2 | AWS Blog2
(2 rows)
postgres=> timing
Timing is on.
postgres=> SELECT now();
now
-------------------------------
2020-11-29 22:25:26.426271+00
(1 row)
Time: 2.689 ms
// Check the current transaction ID of the database (before running the script) :
postgres=> SELECT txid_current();
txid_current
--------------
16373267
(1 row)
//Run the script in another session as follows :
pgbench --host=iocblog2.abcdefghivb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script2 postgres
Password:
starting vacuum...end.
//After some time later, go to previous session and check transaction ID along with pg_stat_activity. It increased by 4 transactions (which were the ones including our testing).
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:56:59.241092+00
Time: 8.692 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373271
Time: 234.526 ms
//The following query shows the 1001 active transactions which are active because of the script, but aren't causing a spike in transaction IDs.
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:44.373064+00
Time: 7.297 ms
postgres=> SELECT COUNT(*)
FROM pg_stat_activity
WHERE query like '%blog%'
AND backend_type='client backend';
-[ RECORD 1 ]
count | 1001
Time: 181.370 ms
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:52.661102+00
Time: 6.212 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373273
Time: 741.437 msThe preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.

There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
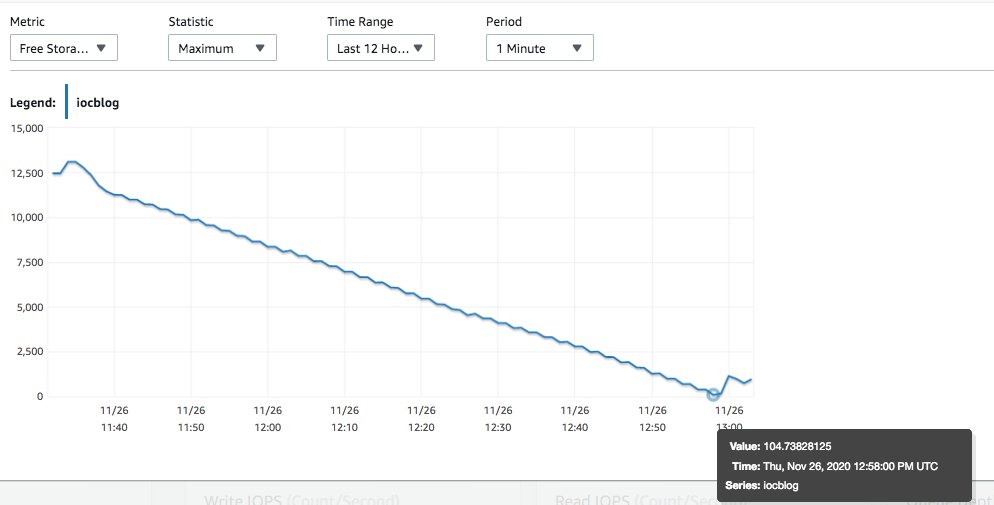
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
postgres=> select count(*) from blog;
-[ RECORD 1 ]
count | 2
postgres=> select pg_size_pretty (pg_table_size('blog'));
-[ RECORD 1 ]--+------
pg_size_pretty | 5718 MB
(1 row)In our small instance, we went into Storage-full state during our script execution.

Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.

Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
About the Authors
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
When you need to upgrade PostgreSQL, there are a variety of approaches that you can use. To avoid application downtime, then not all of the options to upgrade postgres are suitable. When avoiding downtime is essential, then you might consider using replication as a means of upgrade, and depending on your scenario, you can choose to approach this task using either logical replication or physical (streaming) replication. Here, we take a look at the difference between logical and physical replication in PostgreSQL. Then we explore how to accomplish an upgrade using logical replication in more detail, and by doing so, avoid application downtime. In a subsequent article, we’ll investigate physical replication.
We have already discussed about a few methods available to perform PostgreSQL upgrades in our previous blog posts – PostgreSQL Upgrade Using pg_dumpall and PostgreSQL Upgrade Using pg_dump/pg_restore – as part of our Upgrading or Migrating Your Legacy PostgreSQL to Newer PostgreSQL Versions series. However, both of these methods involve downtime to application.
Types of logical replication
Here we’ll cover two types of replication you could implement:
- Replication between PostgreSQL 10 and 11 versions using built-in logical replication.
- Replication between PostgreSQL 9.4 or (< PG 11) to PostgreSQL 11 using an extension named pglogical .
We might opt to implement replication as a method of upgrade to minimize downtime for the application. Once all the data to date has been replicated to another PostgreSQL server on the latest version, you can simply switch your application to the new server with a minimal downtime… though of course this does depends on the complexity of your application stack.
Logical replication in PostgreSQL allows users to perform a selective replication of a few tables and open a standby for writes. Whereas physical replication in PostgreSQL is a block level replication. In this case, each database in the master is replicated to a standby, and the standby is not open for writes. Going forward, we’ll refer to physical replication as streaming replication.
With logical replication, a standby can have replication enabled from multiple masters. This could be helpful in situations where you need to replicate data from several PostgreSQL databases (OLTP) to a single PostgreSQL server for reporting and data warehousing.
One of the biggest advantages of logical over streaming replication is that logical replication allows us to replicate changes from an older version PostgreSQL to a later version. Streaming replication works only when both the master and standby are of the same major version. We’d recommend they have same minor version too for best practice.
Replication between PostgreSQL 10 and 11 versions
Starting from PostgreSQL 10, logical replication is available with the PostgreSQL source by default. So, you could easily replicate a PostgreSQL 10 database to PostgreSQL 11. Logical Replication uses a publish and subscribe model. The node that sends the changes becomes a publisher. And the node that subscribes to those changes becomes a subscriber. You may have one or more subscriptions to a publication.
Publication
Publication is a set of changes generated from a group of tables. It is referred to as a change set or replication set. Publications can only contains tables and cannot contain any other objects. DMLs on these tables can be replicated but not DDLs.
In a publication, you can choose what type of DML to replicate: INSERT or DELETE or UPDATE or ALL. By default, it is ALL. You must have a replica identity set on the table being published to replicate UPDATES and DELETES to a subscriber. A replica identity set helps in identifying the rows to be updated or deleted.
The primary key of a table is its default replica identity. You can also make a unique index with NO NULL values as a replica identity. If there is no primary key or a unique index with NO NULLs, then you can set the replica_identity to FULL. When a replica identity is set to FULL, postgres uses the entire row as a key. Of course, this may be inefficient.
You might see ERRORS if a table with no primary key and a non-default replica identity has been added to a publication after an UPDATE or a DELETE operation.
Subscription
A subscriber can subscribe to one or more publications. Before adding the subscription, you must ensure that the tables being replicated have been created in the subscriber node. In order to achieve that, you can perform a schema-only dump from publisher to subscriber node.
An example of logical replication
The following example steps work for logical replication between PostgreSQL 10 and 11 versions only.
On the publishing node, create a publication. You can either add all tables or choose to add selected tables to the publication.
|
— For adding ALL Tables in Database CREATE PUBLICATION percpub FOR ALL TABLES; — For adding Selected Tables in Database CREATE PUBLICATION percpub FOR TABLE scott.employee scott.departments; |
On the subscriber node, create a subscription that refers to the publication on the publisher node. Perform a DDL dump of the tables to the subscriber node before creating the subscription, as mentioned above,
|
$ pg_dump —h publisher_server_ip —p 5432 —d percona —Fc —s —U postgres | pg_restore —d percona —h subscriber_node_ip —p 5432 —U postgres CREATE SUBSCRIPTION percsub CONNECTION ‘host=publisher_server_ip dbname=percona user=postgres password=secret port=5432’ PUBLICATION percpub; |
The above command also copies the pre-existing data from the tables. If you want to disable the copy of the pre-existing data, you can use the following syntax. It will then only start copying the changes to the publisher after you run this command.
|
CREATE SUBSCRIPTION percsub CONNECTION ‘host=publisher_server_ip dbname=percona user=postgres password=oracle port=5432’ PUBLICATION percpub WITH (copy_data = false); |
Monitor the replication using the following command on the publishing node.
|
$ psql x select * from pg_stat_replication; |
Replication between PostgreSQL 9.4 and PostgreSQL 11
Now, what about the versions that are older than PostgreSQL 10? For this purpose, there is an extension named
pglogical that works for versions from 9.4 until 11. Using pglogical, you can easily replicate PostgreSQL 9.4 to PostgreSQL 11.
The following sequence of steps demonstrates a high-level procedure to setup replication between PG 9.4 and PG 11 using pglogical extension.
Step 1 : Consider pgserver_94 to be the source server with a database : percona_94 running on PostgreSQL 9.4. Create the following extensions.
|
[pgserver_94:] $psql —d percona_94 —c «CREATE EXTENSION pglogical_origin» CREATE EXTENSION [pgserver_94:] $psql —d percona_94 —c «CREATE EXTENSION pglogical» CREATE EXTENSION |
Step 2 : Now, you can go ahead and add either selected tables or all the tables in a schema or multiple schemas for replication. In the following example, you can see an error when there is no primary key on one of the tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[pgserver_94:] $psql —d percona_94 psql (9.4.21) Type «help» for help. percona_94=# SELECT pglogical.create_node(node_name := ‘provider1’,dsn := ‘host=192.168.0.24 port=5432 dbname=percona_94’); create_node ————- 2976894835 (1 row) percona_94=# SELECT pglogical.replication_set_add_all_tables(‘default’, ARRAY[‘public’]); ERROR: table pgbench_history cannot be added to replication set default DETAIL: table does not have PRIMARY KEY and given replication set is configured to replicate UPDATEs and/or DELETEs HINT: Add a PRIMARY KEY to the table percona_94=# ALTER TABLE pgbench_history ADD PRIMARY KEY (tid,aid,delta); ALTER TABLE percona_94=# SELECT pglogical.replication_set_add_all_tables(‘default’, ARRAY[‘public’]); replication_set_add_all_tables ——————————— t (1 row) |
Step 3
On the subscriber node, which is our PostgreSQL 11 database, you can run similar commands as follows.
|
[pgserver_11:] $psql —d percona_11 psql (11.2) Type «help» for help. percona_11=# SELECT pglogical.create_node(node_name := ‘subscriber1’,dsn := ‘host=127.0.0.1 port=5432 dbname=percona_11 password=secret’); create_node ————- 330520249 (1 row) percona_11=# SELECT pglogical.create_subscription(subscription_name := ‘subscription1’,provider_dsn := ‘host=192.168.0.24 port=5432 dbname=percona_94 password=secret’); create_subscription ——————— 1763399739 (1 row) |
Step 4 You can then validate the replication status by querying a few tables pglogical always updates:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
percona_11=# select * from pglogical.local_sync_status; sync_kind | sync_subid | sync_nspname | sync_relname | sync_status | sync_statuslsn ————+————+—————+——————+————-+—————- f | 1763399739 | public | pgbench_accounts | r | 0/2EB7D48 f | 1763399739 | public | pgbench_history | r | 0/2EB7D48 f | 1763399739 | public | pgbench_tellers | r | 0/2EB7D48 f | 1763399739 | public | pgbench_branches | r | 0/2EB7D48 d | 1763399739 | | | r | 0/0 (5 rows) percona_11=# select * from pglogical.subscription; sub_id | sub_name | sub_origin | sub_target | sub_origin_if | sub_target_if | sub_enabled | sub_slot_name | sub_rep lication_sets | sub_forward_origins | sub_apply_delay ————+—————+————+————+—————+—————+————-+—————————————-+—————- ————————+———————+—————— 1763399739 | subscription1 | 2976894835 | 330520249 | 2402836775 | 2049915666 | t | pgl_percona_11_provider1_subscription1 | {default,defaul t_insert_only,ddl_sql} | {all} | 00:00:00 (1 row) |
Primary key selection
At step 2, you saw how all the tables of schema : public got added to a replication set by creating a primary key on the table that doesn’t currently have one. The primary key I chose may not be the right one for that table as it is just for demonstration. However, when you choose a primary key, make sure that you are selecting the right one. It needs to be always unique and use column(s) that don’t normally contain NULLs. If you don’t research primary key selection thoroughly, you could cause downtime to your application. Here’s an example error that you could encounter:
|
[pgserver_94:] $pgbench —c 10 —T 300 —n percona_94 Client 7 aborted in state 12: ERROR: duplicate key value violates unique constraint «pgbench_history_pkey» DETAIL: Key (tid, aid, delta)=(7, 63268, 2491) already exists. |
So far we have seen how you can use pglogical to create replication between an older version to a newer version PostgreSQL. After you have set up replication, you can easily switch your applications to the latest version with a lower downtime.