Содержание
- Dealing with errors in Power Query
- Step-level error
- Common step-level errors
- Can’t find the source — DataSource.Error
- The column of the table wasn’t found
- Other common step-level errors
- Cell-level error
- Handling errors at the cell level
- Remove errors
- Replace errors
- Keep errors
- Common cell-level errors
- Data type conversion errors
- Operation errors
- Nested values shown as errors
- Обработка ошибок
- Укажите альтернативное значение при поиске ошибок
- Укажите собственную логику условной ошибки
- Использование try с пользовательской логикой
- Использование try и catch использование пользовательской логики
Dealing with errors in Power Query
In Power Query, you can encounter two types of errors:
- Step-level errors
- Cell-level errors
This article provides suggestions for how to fix the most common errors you might find at each level, and describes the error reason, error message, and error detail for each.
Step-level error
A step-level error prevents the query from loading and displays the error components in a yellow pane.
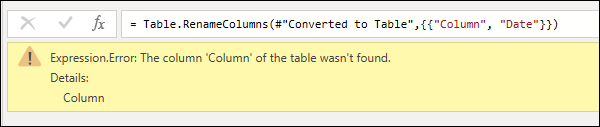
- Error reason: The first section before the colon. In the example above, the error reason is Expression.Error.
- Error message: The section directly after the reason. In the example above, the error message is The column ‘Column’ of the table wasn’t found.
- Error detail: The section directly after the Details: string. In the example above, the error detail is Column.
Common step-level errors
In all cases, we recommend that you take a close look at the error reason, error message, and error detail to understand what’s causing the error. You can select the Go to error button, if available, to view the first step where the error occurred.

Can’t find the source — DataSource.Error
This error commonly occurs when the data source is inaccessible by the user, the user doesn’t have the correct credentials to access the data source, or the source has been moved to a different place.
Example: You have a query from a text tile that was located in drive D and created by user A. User A shares the query with user B, who doesn’t have access to drive D. When this person tries to execute the query, they get a DataSource.Error because there’s no drive D in their environment.

Possible solutions: You can change the file path of the text file to a path that both users have access to. As user B, you can change the file path to be a local copy of the same text file. If the Edit settings button is available in the error pane, you can select it and change the file path.
The column of the table wasn’t found
This error is commonly triggered when a step makes a direct reference to a column name that doesn’t exist in the query.
Example: You have a query from a text file where one of the column names was Column. In your query, you have a step that renames that column to Date. But there was a change in the original text file, and it no longer has a column heading with the name Column because it was manually changed to Date. Power Query is unable to find a column heading named Column, so it can’t rename any columns. It displays the error shown in the following image.
Possible solutions: There are multiple solutions for this case, but they all depend on what you’d like to do. For this example, because the correct Date column header already comes from your text file, you can just remove the step that renames the column. This will allow your query to run without this error.
Other common step-level errors
When combining or merging data between multiple data sources, you might get a Formula.Firewall error such as the one shown in the following image.

This error can be caused by a number of reasons, such as the data privacy levels between data sources or the way that these data sources are being combined or merged. For more information about how to diagnose this issue, go to Data privacy firewall.
Cell-level error
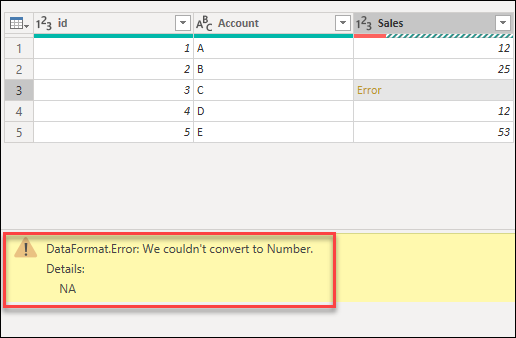
A cell-level error won’t prevent the query from loading, but displays error values as Error in the cell. Selecting the white space in the cell displays the error pane underneath the data preview.
The data profiling tools can help you more easily identify cell-level errors with the column quality feature. More information: Data profiling tools
Handling errors at the cell level
When encountering any cell-level errors, Power Query provides a set of functions to handle them either by removing, replacing, or keeping the errors.
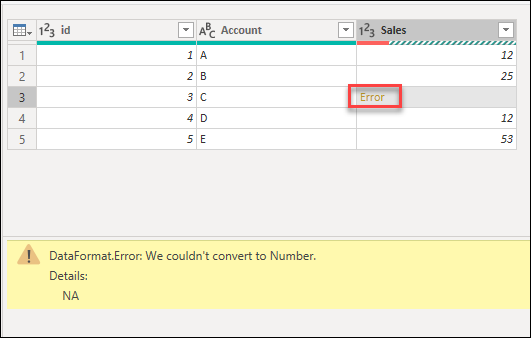
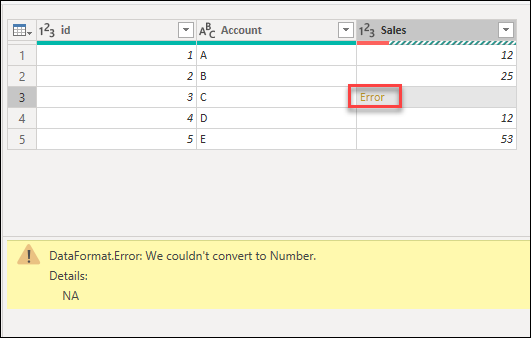
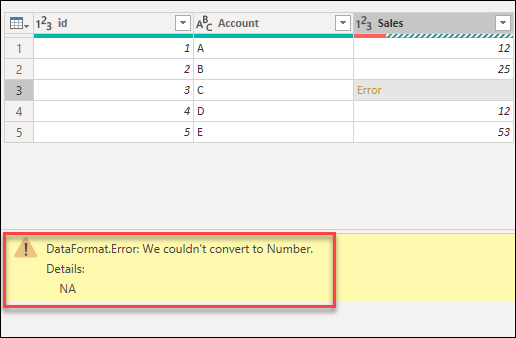
For the next sections, the provided examples will be using the same sample query as the start point. In this query, you have a Sales column that has one cell with an error caused by a conversion error. The value inside that cell was NA, but when you transformed that column to a whole number Power Query couldn’t convert NA to a number, so it displays the following error.
Remove errors
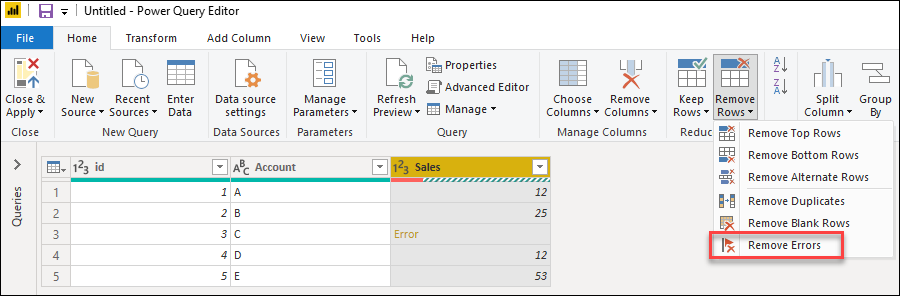
To remove rows with errors in Power Query, first select the column that contains errors. On the Home tab, in the Reduce rows group, select Remove rows. From the drop-down menu, select Remove errors.
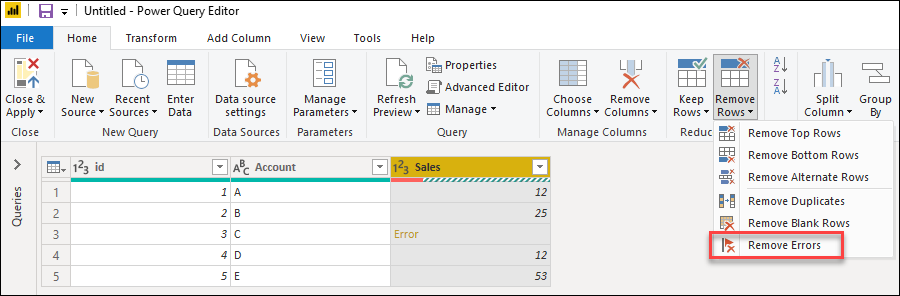
The result of that operation will give you the table that you’re looking for.
Replace errors
If instead of removing rows with errors, you want to replace the errors with a fixed value, you can do so as well. To replace rows that have errors, first select the column that contains errors. On the Transform tab, in the Any column group, select Replace values. From the drop-down menu, select Replace errors.
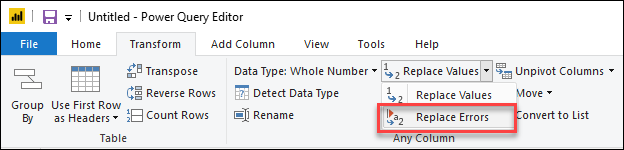
In the Replace errors dialog box, enter the value 10 because you want to replace all errors with the value 10.
The result of that operation will give you the table that you’re looking for.
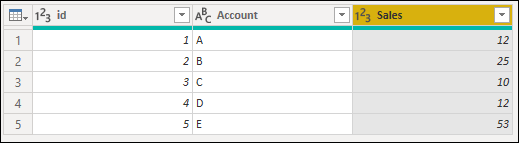
Keep errors
Power Query can serve as a good auditing tool to identify any rows with errors even if you don’t fix the errors. This is where Keep errors can be helpful. To keep rows that have errors, first select the column that contains errors. On the Home tab, in the Reduce rows group, select Keep rows. From the drop-down menu, select Keep errors.
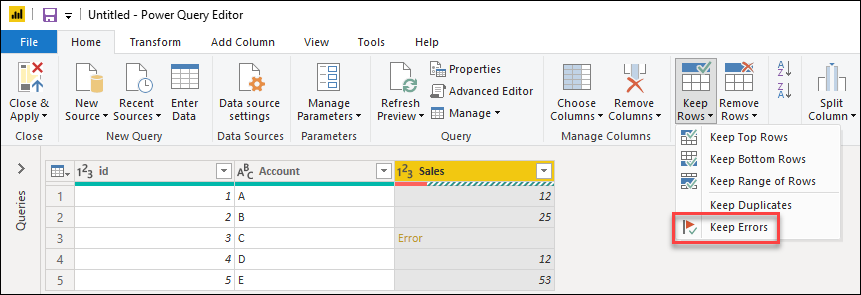
The result of that operation will give you the table that you’re looking for.

Common cell-level errors
As with any step-level error, we recommend that you take a close look at the error reasons, error messages, and error details provided at the cell level to understand what’s causing the errors. The following sections discuss some of the most frequent cell-level errors in Power Query.
Data type conversion errors
Commonly triggered when changing the data type of a column in a table. Some values found in the column could not be converted to the desired data type.
Example: You have a query that includes a column named Sales. One cell in that column has NA as a cell value, while the rest have whole numbers as values. You decide to convert the data type of the column from text to whole number, but the cell with the NA value causes an error.
Possible solutions: After identifying the row with the error, you can either modify the data source to reflect the correct value rather than NA, or you can apply a Replace error operation to provide a value for any NA values that cause an error.
Operation errors
When trying to apply an operation that isn’t supported, such as multiplying a text value by a numeric value, an error occurs.
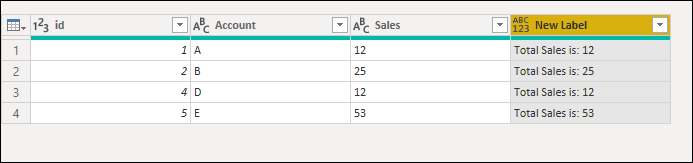
Example: You want to create a custom column for your query by creating a text string that contains the phrase «Total Sales: » concatenated with the value from the Sales column. An error occurs because the concatenation operation only supports text columns and not numeric ones.
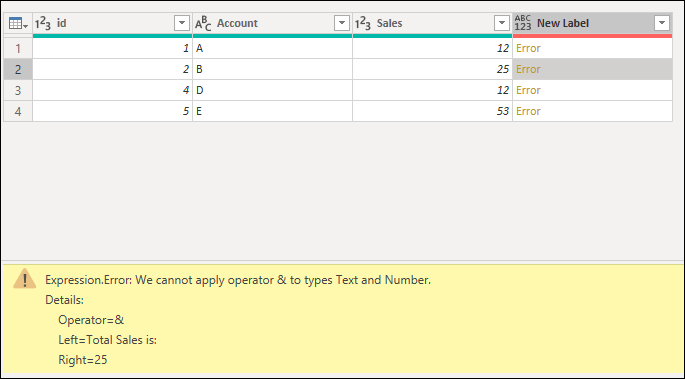
Possible solutions: Before creating this custom column, change the data type of the Sales column to be text.
Nested values shown as errors
When working with data that contains nested structured values (such as tables, lists, or records), you may sometimes encounter the following error:
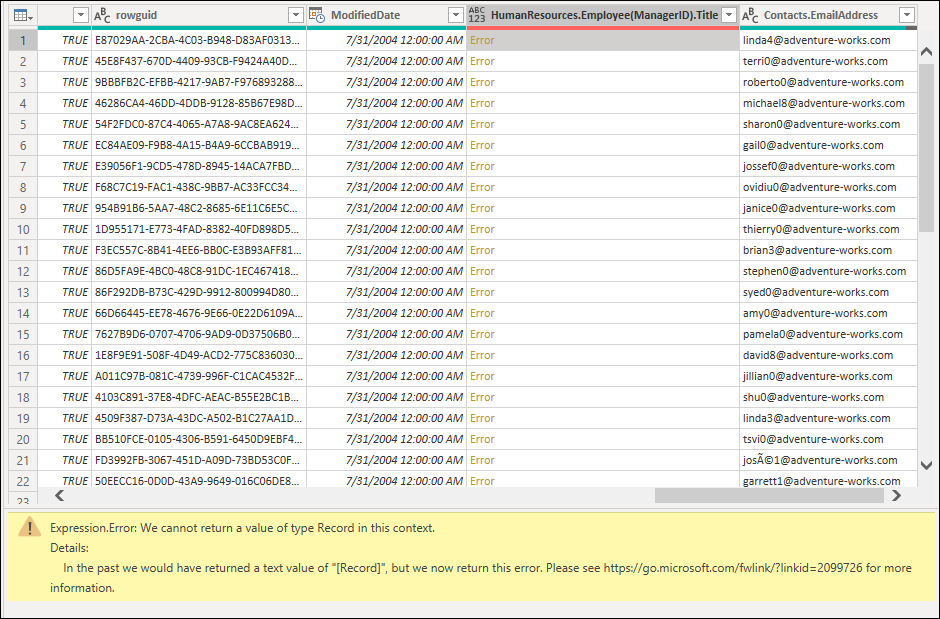
These errors usually occur for two reasons:
- When the Data Privacy Firewall buffers a data source, nested non-scalar values are automatically converted to errors.
- When a column defined with the Any data type contains non-scalar values, such values will be reported as errors during load (such as in a Workbook in Excel or the data model in Power BI Desktop).
Possible solutions:
- Remove the column that contains the error, or set a non- Any data type for such a column.
- Change the privacy levels of the data sources involved to one that allows them to be combined without being buffered.
- Flatten the tables before doing a merge to eliminate columns that contain nested structured values (such as table, record, or list).
Источник
Обработка ошибок
Аналогично тому, как в Excel и языке DAX есть IFERROR функция, Power Query имеет собственный синтаксис для тестирования и перехвата ошибок.
Как упоминалось в статье об ошибках в Power Query, ошибки могут отображаться на уровне шага или ячейки. В этой статье рассматриваются способы перехвата ошибок и управления ими на основе собственной логики.
Чтобы продемонстрировать эту концепцию, в этой статье будет использоваться книга Excel в качестве источника данных. Представленные здесь понятия применяются ко всем значениям в Power Query и не только к тем, которые поступают из книги Excel.
Пример источника данных для этой демонстрации — книга Excel со следующей таблицей.
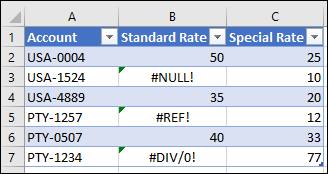
Эта таблица из книги Excel содержит ошибки Excel, такие как #NULL!, #REF!, и #DIV/0! в столбце «Стандартный тариф «. При импорте этой таблицы в редактор Power Query показано, как она будет выглядеть.
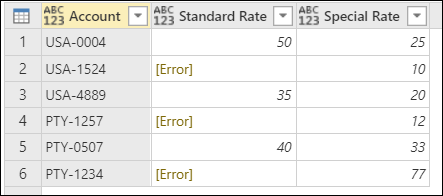
Обратите внимание, что ошибки из книги Excel отображаются со значением [Error] в каждой ячейке.
В этой статье вы узнаете, как заменить ошибку другим значением. Кроме того, вы узнаете, как перехватывать ошибку и использовать ее для собственной логики.
В этом случае цель состоит в создании нового столбца «Окончательная ставка «, который будет использовать значения из столбца «Стандартная ставка «. При возникновении ошибок он будет использовать значение из столбца «Специальный тариф » корреспондента.
Укажите альтернативное значение при поиске ошибок
В этом случае цель состоит в создании нового столбца «Окончательная ставка » в образце источника данных, который будет использовать значения из столбца «Стандартная ставка «. При возникновении ошибок оно будет использовать значение из соответствующего столбца «Специальная ставка «.
Чтобы создать новый настраиваемый столбец, перейдите в меню «Добавить столбец » и выберите «Настраиваемый столбец«. В окне «Настраиваемый столбец» введите формулу try [Standard Rate] otherwise [Special Rate] . Присвойт этому новому столбцу окончательную ставку.
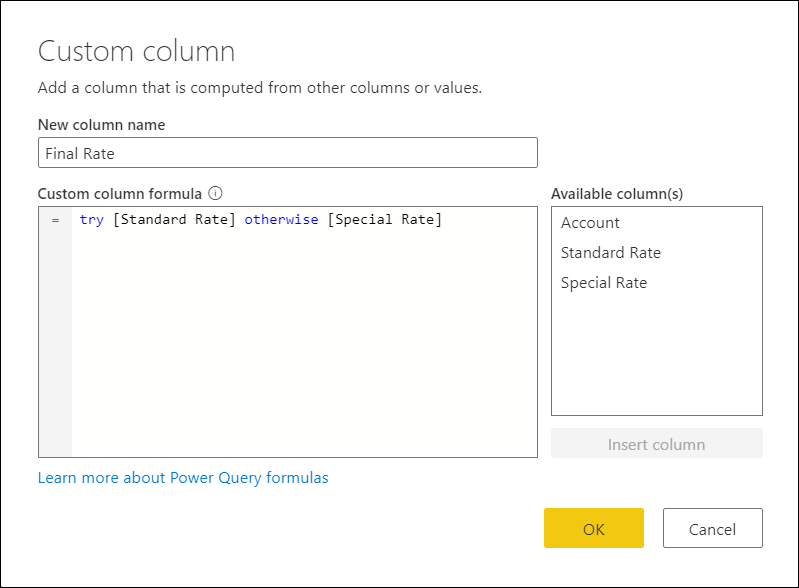
Приведенная выше формула попытается оценить столбец «Стандартная ставка» и выдаст его значение, если ошибки не найдены. Если ошибки найдены в столбце «Стандартная ставка «, выходные данные будут значениями, определенными после инструкции otherwise , которая в данном случае является столбцом «Специальная ставка «.
После добавления правильных типов данных во все столбцы таблицы на следующем рисунке показано, как выглядит окончательная таблица.
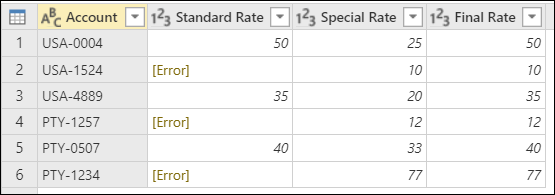
В качестве альтернативного подхода можно также ввести формулу try [Standard Rate] catch ()=> [Special Rate] , эквивалентную предыдущей формуле, но используя ключевое слово catch с функцией, для которой не требуются параметры.
Ключевое catch слово было введено в Power Query в мае 2022 года.
Укажите собственную логику условной ошибки
Используя тот же образец источника данных, что и в предыдущем разделе, новая цель — создать новый столбец для конечной ставки. Если значение из стандартной ставки существует, это значение будет использоваться. В противном случае будет использоваться значение из столбца «Специальная ставка «, за исключением строк с любой #REF! ошибкой.
Единственной целью исключения ошибки является демонстрация #REF! . В соответствии с основными понятиями, представленными в этой статье, вы можете выбрать любые поля из записи об ошибке.
При выборе любого из пробелов рядом со значением ошибки вы получите область сведений в нижней части экрана. Область сведений содержит как причину ошибки, DataFormat.Error так и сообщение об ошибке: Invalid cell value ‘#REF!’

Одновременно можно выделить только одну ячейку, чтобы можно было эффективно видеть только компоненты ошибки одного значения ошибки. Здесь вы создадите новый настраиваемый столбец и используйте try выражение.
Использование try с пользовательской логикой
Чтобы создать новый настраиваемый столбец, перейдите в меню «Добавить столбец » и выберите «Настраиваемый столбец«. В окне «Настраиваемый столбец» введите формулу try [Standard Rate] . Присвойт этому новому столбцу имя «Все ошибки«.

Выражение try преобразует значения и ошибки в значение записи, указывающее, обрабатывает ли try выражение ошибку или нет, а также правильное значение или запись ошибки.
Вы можете развернуть этот вновь созданный столбец со значениями записей и просмотреть доступные поля для развертывания, щелкнув значок рядом с заголовком столбца.
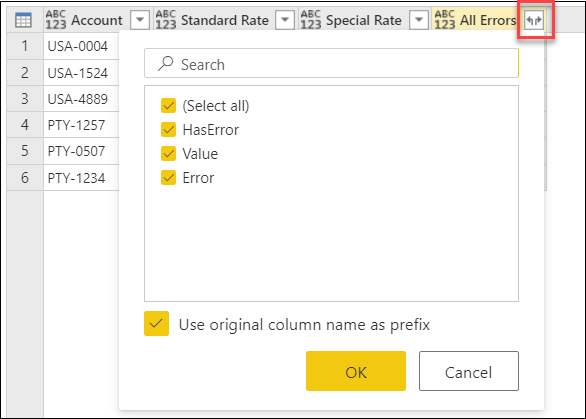
Эта операция предоставит три новых поля:
- Все ошибки.HasError — показывает, было ли значение из столбца «Стандартная ставка » ошибкой.
- Все ошибки.Значение— если значение из столбца «Стандартная ставка » не содержит ошибок, этот столбец будет отображать значение из столбца «Стандартная ставка «. Для значений с ошибками это поле будет недоступно, и во время операции развертывания этот столбец будет иметь null значения.
- Все ошибки.Error — если значение из столбца «Стандартная ставка » содержит ошибку, в этом столбце отображается запись об ошибке для значения из столбца «Стандартная ставка «. Для значений без ошибок это поле будет недоступно, и во время операции развертывания этот столбец будет иметь null значения.
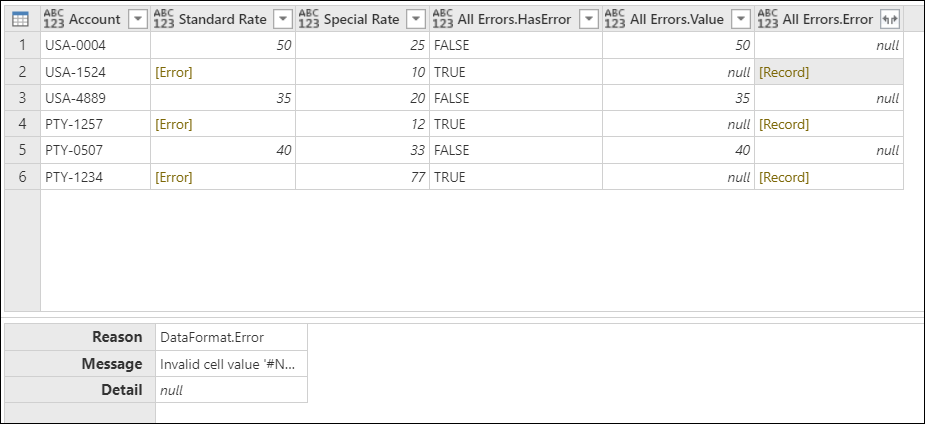
Для дальнейшего изучения можно развернуть столбец All Errors.Error , чтобы получить три компонента записи об ошибке:
- Причина ошибки
- Сообщение об ошибке
- Сведения об ошибках
После выполнения операции развертывания в поле All Errors.Error.Message отображается определенное сообщение об ошибке, сообщающее о том, какая ошибка Excel имеет каждая ячейка. Сообщение об ошибке является производным от поля сообщения об ошибке записи об ошибке.

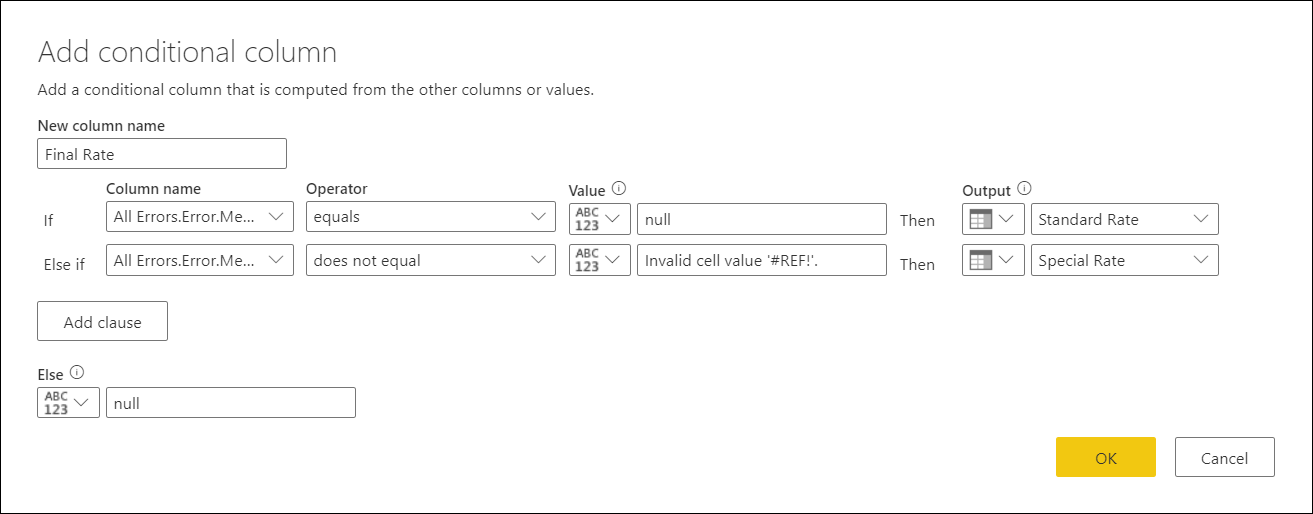
Теперь с каждым сообщением об ошибке в новом столбце можно создать новый условный столбец с именем Final Rate и следующими предложениями:
- Если значение в столбце All Errors.Errors.Message равно null , выходные данные будут иметь значение из столбца «Стандартная ставка «.
- В противном случае, если значение в столбце All Errors.Errors.Message равно Invalid cell value ‘#REF!’. , выходные данные будут значениями из столбца «Специальная ставка «.
- Else, null.
После сохранения только столбцов «Учетная запись«, «Стандартная ставка«, » Специальная ставка» и «Окончательная ставка » и добавления правильного типа данных для каждого столбца показано, как выглядит окончательная таблица.

Использование try и catch использование пользовательской логики
Кроме того, можно создать новый настраиваемый столбец с помощью try ключевых слов и catch ключевых слов.
try [Standard Rate] catch (r)=> if r[Message] <> «Invalid cell value ‘#REF!’.» then [Special Rate] else null
Источник
You’d often run into data sets with errors especially when the source is excel. If you have been working with Power Query you know that it doesn’t like error values and truncates the entire row which has an error in any column.
Sad. But you can obviously do Replace Errors and fix them with null values, however the challenge is that, the Replace Errors should automatically work on even the new columns added in data.
Video First ?
Consider this 3 column data
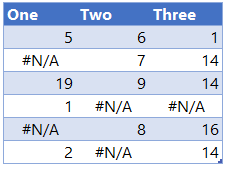
Now obviously when this is loaded in Power Query it will show error wherever #N/A (and for any other type of excel errors)
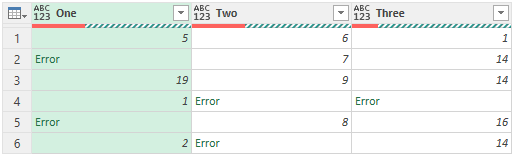
You can easily fix this
- Select all columns
- Transform Tab >> Replace Values Drop Down >> Replace Errors >> type null
- Done
But what if the 4th column is added and has error values, the Replace Errors will not automatically extend to the 4th column. Let’s do that!
Replace Error Values in Multiple Columns
Step 1 –
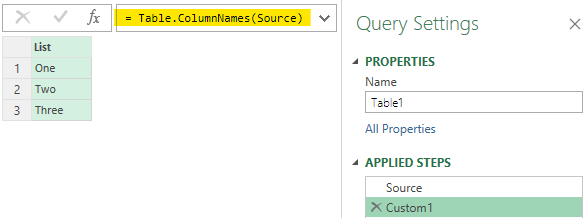
- I extract all the columns names as a list.
- Click on fx and write the M code below
- I do this as a second step after Source (data loading)
=Table.ColumnNames(Source)
Step 2 – Since a Table offers more options to work as compared to a List. Covert the List to a Table. Right click on the List (header) >> To Table.
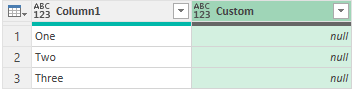
Step 3 – From the Add Columns Tab >> Custom Column >> type =null
- This will add a Custom Column will null values across all rows.
- I am doing this because I want to replace all error values with null.
The result looks like this
Step 4 – Next I will transpose this table. Transform Tab >> Transpose.
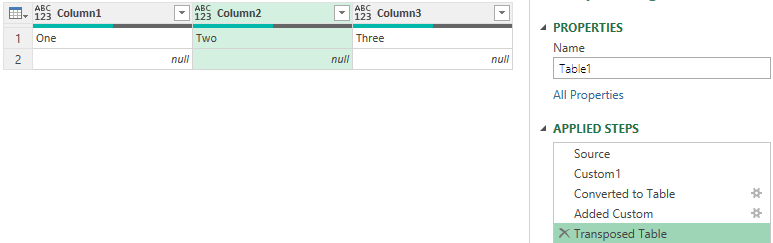
Understanding whats going on..
If you are still with me, so far you have blindly pursued the steps. Let me help you understand where are we headed.
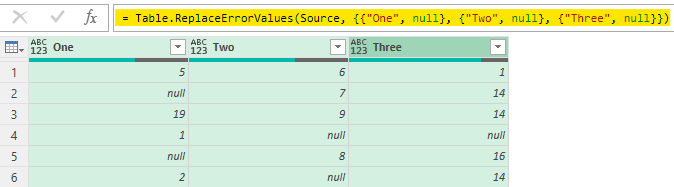
- When you do Replace Errors the highlighted (in yellow) code appears.
- Notice that column names – One, Two and Three are hard coded. They wont change if the column names changes or source data adds a new column.
- Also note that the column names are in double curly brackets {{ }}. Which means it’s a list inside a list.
- We are trying to create the same list of list with 2 parts – Column Name and null value. But a dynamic one!
- Let’s proceed
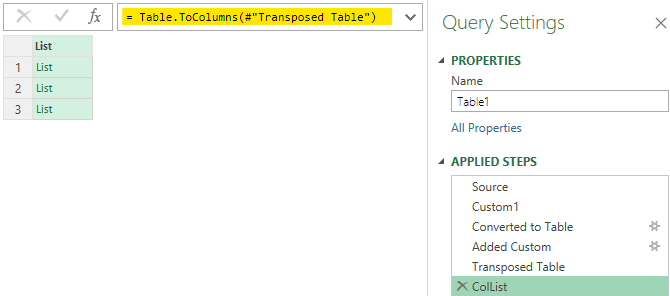
Step 5 – Convert the table into a list of list.
- Use the fx button to write a short M Code
- This will convert each column into a list and then make a single list of all lists
- Renamed the step to ColList (it’s optional but nice to have good labels across)
= Table.ToColumns(#'Transposed Table')
Step 6 – It’s time now to feed the list in Replace Errors
- Using the fx I’ll create a new Step
- Write the following Code. In the code Source is the Step (which has the table with error values) and ColList is our List of List which replaces all errors dynamically with null.
= Table.ReplaceErrorValues(Source, ColList)
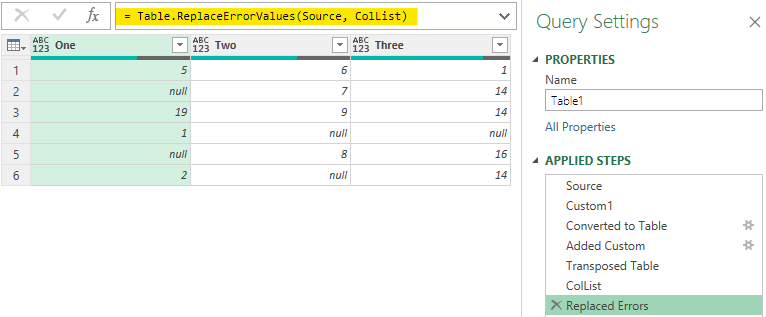
Bingo! 😎
Some more cool stuff on Power Query!
- Make Remove Other Columns Dynamic in Power Query
- Dynamic Column Renaming
- Running Total in Power Query
- Video – Combine Data from Multiple Excel File – With Dynamic Sheets and Columns
I have an awesome Course on Power Query, you must check it out..

Course Details are here | Course Outline (pdf) is here

Chandeep
Welcome to Goodly! My name is Chandeep.
On this blog I actively share my learning on practical use of Excel and Power BI. There is a ton of stuff that I have written in the last few years. I am sure you’ll like browsing around.
Please drop me a comment, in case you are interested in my training / consulting services. Thanks for being around
Chandeep
|
Александр L  Пользователь Сообщений: 414 Александр |
Коллеги Всем привет , подскажите пжл возможно ли с помощь Try в Power Query при добавлении доп столбца формулой прописать аналог EСЛИОШИБКА ? |
|
PooHkrd  Пользователь Сообщений: 6602 Excel x64 О365 / 2016 / Online / Power BI |
#2 14.02.2019 13:37:57 try чего-то там otherwise что-то вместо ошибки
Изменено: PooHkrd — 14.02.2019 13:44:59 Вот горшок пустой, он предмет простой… |
||
|
Александр L Пользователь Сообщений: 414 Александр |
#3 14.02.2019 13:39:34
Так у меня вроде так и прописано когда создаю доп столбец но не работает Изменено: Александр L — 14.02.2019 13:40:20 |
||
|
Максим Зеленский  Пользователь Сообщений: 4646 Microsoft MVP |
#4 14.02.2019 13:42:15 Проще всего так:
Еще можно — создать столбец =[#»Количество (в базовых единицах), короба»]*[Вложения] и использовать в формуле его, чтобы не считать два раза, а потом удалить. F1 творит чудеса |
||
|
Максим Зеленский Пользователь Сообщений: 4646 Microsoft MVP |
#5 14.02.2019 13:44:00
Потому что деление на 0 это не совсем ошибка, которая стопорит запрос: F1 творит чудеса |
||
|
Александр L Пользователь Сообщений: 414 Александр |
А вы вот как обошли я тоже пробовал через If но применял три условия и вот не получалось(((. Спасибо сейчас попробую на массиве этот метод. |
|
А ещё есть null, деление на который даёт null, а не ошибку и не упомянутое выше |
|
|
Александр L Пользователь Сообщений: 414 Александр |
#8 14.02.2019 13:48:21 да с null я всегда пресекаю на начальном этапе))))) |
В М можно вызвать и обработать ошибки во время выполнения. Если из других языков программирования вы знакомы с идеей исключения, обработка ошибок Power Query отличается по крайней мере одним существенным моментом.[1]
Предыдущая заметка Следующая заметка
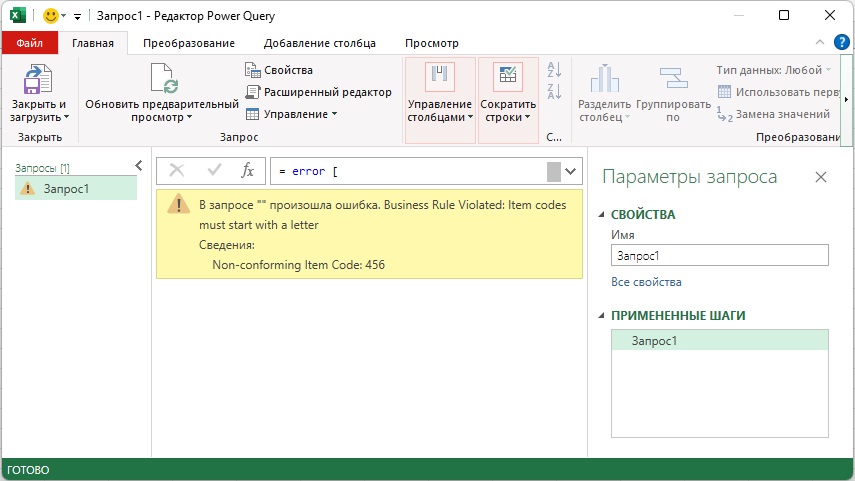
Рис. 1. Три поля записи error; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Скачать заметку в формате Word или pdf, примеры в формате Excel
Сообщение об ошибке
В Power Query каждое выражение должно что-то возвращать. Как правило, это значение. Но выражение также может вызвать ошибку – особый способ указать, что не получилось вернуть значение. Один из способов вызвать ошибку – создать запись с ключевым словом error. Такая запись имеет три поля: причина, сообщение и подробности. Поля с любыми другими именами будут проигнорированы.
Листинг 1[2]
|
= error [ Reason = «Business Rule Violated», Message = «Item codes must start with a letter», Detail = «Non-conforming Item Code: 456» ] |
Все три поля являются необязательными. Если поле Reason отсутствует, причина ошибки будет иметь значение по умолчанию – Expression.Error. Запись ошибки можно также создать с помощью функции Error.Record. В отличие от описанного выше подхода, в Error.Record атрибут Reason является обязательным.
Листинг 2
|
= error Error.Record( «Business Rule Violated», «Item codes must start with a letter», «Non-conforming Item Code: 456» ) |
Оба приведенных выше примера приводят к эквивалентной ошибке, изображенной на рис. 1 Глядя на рисунок, видно, как три поля/параметра соотносятся с отображаемым сообщением.
Вместо записи error также может принимать строку. Результирующее сообщение об ошибке будет иметь значение предоставленной строки, а его причина – значение Expression.Error.
Листинг 3
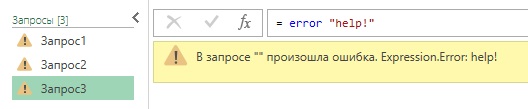
Рис. 2. Строка в error
Ярлык с многоточием
Существует также оператор быстрого доступа для создания ошибок, который пригодится во время разработки. Допустим, вы хотите протестировать запрос, часть кода которого еще не написана. Поскольку каждое выражение должно возвращать значение, или вызывать ошибку, вы не можете протестировать свой запрос, не поместив что-то в качестве заполнителя в нереализованные участки кода. Используйте оператор многоточия (…). При вызове … выдает ошибку Expression.Error: Значение не задано. Вот фрагмент кода, в котором не реализована ветвь else:
Листинг 4
|
let a = 6, Result = if a = 5 then true else ... in Result |
Когда условие (а = 5) принимает значение false, вызывается «…», что приводит к ошибке. Обратите внимание, ключевое слово error не используется. Оператор многоточия как определяет, так и вызывает ошибку.
Особое поведение
Что именно происходит, когда возникает ошибка? Какое поведение возвращает ошибку, а не значение? Рассмотрим выражение:
В обычных условиях сначала выполняется функция GetValue(). Затем полученное значение передается в someFunction(), которая возвращает финальный результат. Предположим, GetValue() выдает ошибку. Дальнейшее выполнение выражения прекращается. someFunction() не вызывается. Ошибка GetValue() становится итогом выражения. Такое поведение также известно, как повышение. Ошибка передается тому шагу, с которого была вызвана someFunction().
Дальнейшее зависит от того, предусмотрено ли в коде появление ошибки. Если да, запрос продолжит выполнение. Если нет, возникнет ошибка верхнего уровня. Запрос завершит работу и вернет значение ошибки.
Сдерживание ошибок
Если ошибка возникает в выражении, которое что-то определяет (поле записи, ячейку таблицы, переменную в выражении let, …), ошибка содержится в этом чём-то. Последствия ошибки ограничены этим чем-то и логикой, которая пытается получить доступ к значению этого чего-то. Ниже последствия ошибки GetValue содержатся в той части запроса, на которую она повлияла. Ошибка не остановила выполнение запроса. Запрос завершился успешно и вернул запись. Два поля – FieldB и FieldC – вернули ошибку, потому что они являются чем-то, затронутым ошибкой.
Листинг 5
|
let GetValue = () => error «Something bad happened!», DoSomething = (input) => input + 1, Result = [ FieldA = 25, FieldB = DoSomething(GetValue), FieldC = FieldA + FieldB ] in Result |
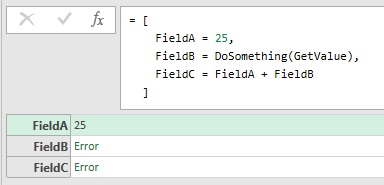
Рис. 3. Результат запроса
Сдерживание ошибок влечет за собой еще одну особенность. Ошибка сохраняется в чём-то, что ее содержит. Пока выполняется запрос, любая попытка получить доступ к значению этого чего-то приводит к повторному возникновению сохраненной ошибки. Когда происходит попытка доступа, логика, которая первоначально вызвала ошибку, не подвергается повторной оценке. Эта логика при повторном обращении могла бы вернуть допустимое значение. Но логика пропускается, и ранее сохраненная ошибка просто вызывается повторно.
Ниже функция GetDataFromWebService() вычисляется один раз, даже если к самим данным обращаются дважды. Если первое обращение вернуло ошибку, второе обращение тоже вернет ошибку, сохраненную ранее.
|
let Data = GetDataFromWebService() // повышенная ошибка in { List.Sum(Data[Amount]), List.Max(Data[TransactionDate]) } |
Ошибки верхнего уровня
Если ошибку не удалось сдержать, она передается из выражения в верхний уровень, как результат всего запроса. Далее в среду хоста и выполнение запроса останавливается. В следующем выражении ничто не содержит ошибку, поэтому её нельзя сдержать, и запрос завершается ошибкой:
Листинг 6
|
let GetValue= () => error «Something bad happened!», SomeFunction = (input) => input + 1 in SomeFunction(GetValue()) |
Сдерживание против исключения
Поведение Power Query по сдерживанию ошибок отличает его от большинства языков программирования, основанных на исключениях. В мире исключений ошибка автоматически распространяется вплоть до среды хоста, что приводит к завершению работы программы (если только в коде не будет предусмотрена обработка ошибок). В M ошибка локализуется, пока есть что-то, что ее содержит. Это позволяет успешно завершить запрос, даже если не удалось вычислить отдельные элементы.
Сдерживание ошибок – отличное поведение, учитывая цель использования M: обработка данных. Предположим, что выражение, определяющее значение столбца таблицы, содержит ошибку для одной ячейки из всей таблицы. В мире, основанном на исключениях, эта ошибка может привести к завершению всей обработки. В мире M ошибка просто влияет на эту единственную ячейку и любой код, который обращается к этой ячейке. Обработка продолжается, и будет получен результат.
На самом деле, из-за лени M, если к ячейке с ошибкой не будет обращений, то ошибка и не возникнет.
Листинг 7
|
let Data = #table({«Col1»}, {{«SomeValue»}, { error «bad» }}) in Table.RowCount(Data) // возвращает 2 |
Хотя одна ячейка и содержит ошибку, запрошенные данные (количество строк), не требуют вычисления значения ошибочной ячейки, поэтому выражение вернет значение 2.
Хотя сдерживание ошибок – отличное поведение по умолчанию, что, если оно не соответствует вашим потребностям? В частности, что делать с таблицами, если важно различать строки с ошибками и строки без ошибок? Возможно, вы не обращаетесь к содержимому строки напрямую, поэтому не делаете ничего, что могло бы вызвать распространение ошибок, но все же хотите знать, в каких строках есть ошибка, а в каких нет. Функции Table.SelectRowsWithErrors и Table.RemoveRowsWithErrors, то, что вам нужно.
Листинг 8
|
let Data = #table({«Col1»}, {{«SomeValue»}, { error «bad» }}) in [ RowsWithErrors = Table.RowCount(Table.SelectRowsWithErrors(Data)), RowsWithoutErrors = Table.RowCount(Table.RemoveRowsWithErrors(Data)) ] |
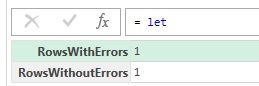
Рис. 4. Список, содержащий количество строк с ошибками и без
Обработка ошибок
Понимая, какие операции способны вызывать ошибку, вы можете использовать ключевое слово try, чтобы проверить, не возвращает ли выражение ошибку. try используется в двух вариантах…
|
try ExpressionToTry otherwise FallbackExpression |
… первый, try with otherwise, пытается выполнить ExpressionToTry. Если это выражение возвращает значение, всё Ok, переходим к следующему шагу запроса. Когда выражение выдает ошибку, вычисляется выражение otherwise и возвращается его значение.
|
try Number.FromText(input) otherwise 0 |
Если Number.FromText возвращает значение, оно и будет результатом выражения. Когда Number.FromText выдает ошибку, try обращается к части otherwise, и возвращает 0. Другими словами, если входные данные могут быть преобразованы в число, возвращается это число; в противном случае возвращается значение по умолчанию – 0.
Имейте в виду, что ошибки будут обработаны только в выражении, расположенном непосредственно справа от try. Если ошибку возвращает выражение otherwise, эта ошибка не будет обработана предшествующим try. Но… поскольку otherwise само по себе является выражением, try можно поместить внутрь него, чтобы обработать ошибку, вызванную otherwise.
|
try GetFromPrimary() otherwise try GetFromSecondary() otherwise «Возникли проблемы с обоими серверами. Возьми отгул на остаток дня :)» |
Проблема с конструкцией try with otherwise в том, что она неразборчива: любая ошибка возвращает альтернативное значение. Иногда последующие действия зависят от типа ошибки. Для этих ситуаций подойдет второй вариант – простое выражение try.
Эта форма всегда возвращает запись. Если выражение завершилось успешно, эта запись имеет вид:
|
[ HasError = false, Value = (значение выражения ExpressionToTry) ] |
Если выражение вызвало ошибку, возвращаемая запись выглядит следующим образом:
|
[ HasError = true, Error = (запись, описывающая возникшую ошибку) ] |
Например:
Листинг 9
|
let DoSomething = () => 45, Result = try DoSomething() in Result // [HasError = false, Value = 45] |
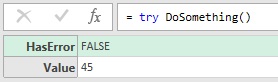
Рис. 5. Запись, возвращаемая try, если нет ошибки
Листинг 10
|
let DoSomething = () => error «bad», Result = try DoSomething() in Result // [HasError = true, Error = [Reason = «Expression.Error», Message = «bad», Details = null] |
Рис. 6. Запись, возвращаемая try, если есть ошибка
Запись, помещенная в поле Error, содержит ровно три поля: Reason, Message и Details.[3] Это верно, даже если в записи, первоначально использовавшейся для определения ошибки, отсутствовало одно или несколько из этих полей (помните, они необязательны при определении ошибки), или если она включала дополнительные поля.
Запись, возвращаемая try, может быть использована для реализации логики условного исправления. Следующий код обращается к вторичному источнику данных, если первичный выдает ошибку из-за недоступности сервера.
|
let Primary = try GetDataFromPrimary(), Source = if Primary[HasError] = false then Primary[Value] /* если Primary возвращает значение, используй его */ else if Primary[Error][Reason] = «External Source Error» and Primary[Error][Message] = «Server is unreachable» then GetDataFromSecondary() /* если ошибка Primary вызвана тем, что его источник недоступен, запроси данные с сервера Secondary */ else error Primary[Error] /* если Primary вернул иную ошибку, верни её в качестве результата запроса */ in Source |
Используя try with otherwise, мы бы запросили Secondary, если Primary выдаст любую ошибку, а не только когда основной сервер недоступен:
|
try GetDataFromPrimary() otherwise GetDataFromSecondary() |
Масштаб (область действия)
Обработка ошибок должна происходить на уровне, на котором они возникают. Нельзя обработать ошибки, содержащиеся на другом уровне.
|
let Data = #table({«Amount»}, {{10}, {error «help!»}, {error «save me!»}}) in try Data otherwise 0 |
try – бесполезный оператор в этом запросе. Возможно, разработчик надеялся с помощью try заменить ошибки нулями. Но в этом случае Data возвращает допустимую таблицу. Правда, в ней самой есть ячейки с ошибками, но эти ошибки содержатся на уровне ячеек. Поскольку они не влияют на выражение данных на уровне таблицы, try не дает эффекта.
try будет полезен в следующем случае, но его эффект может быть не таким, как предполагал разработчик.
Листинг 11
|
let Data = #table({«Amount»}, {{10}, {error «help!»}, {error «save me!»}}) in try List.Sum(Data[Amount]) otherwise 0 |
List.Sum суммирует значения в столбце [Amount] таблицы Data. Если выражение, определяющее значение элемента, вызывает ошибку, она повышается. List.Sum прекращает суммирование и возвращает ошибку. try обрабатывает эту ошибку, возвращая 0 вместо суммы элементов списка. Скорее всего, цель у разработчика была иная. Он хотел заменить элементы с ошибками на 0, и суммировать числовые значения. Необходимо применить try так, чтобы обработка ошибок велась на уровне ячеек таблицы. Кажется, что можно сделать так:
|
Table.TransformColumns(Data, (input) => try input otherwise 0) |
Однако, эта логика не улавливает ошибки, вызванные выражениями значений ячеек. Дело в том, что аргументы вычисляются до того, как их значения будут переданы в функцию. Если оценка приводит к ошибке, функция не вызывается. Вместо этого ошибка передается шагу, который вызвал функцию. В нашем случае, если выражение значения столбца выдает ошибку, функция преобразования (input) => … не вызывается, поэтому try не может обработать ошибку. Вместо этого ошибка передается обратно в Table.TransformColumns.
Проблема заключается в том, что выражение значения ячейки должно быть вычислено внутри try. Чтобы добиться этого, надо вернуться на уровень строки, и использовать функцию, которая получает строку. Затем внутри функции использовать ссылку на значение столбца строки и вот его подставить в try. Лишь тогда try сможет обработать ошибку. Чтобы реализовать это, нужно создать новый столбец, значения которого формировать путем проверки try. Затем можно удалить исходный столбец, а новому столбцу дать старое имя.
Листинг 12
|
let Data = #table({«Amount»}, {{10}, {error «help!»}, {error «save me!»}}), ErrorsReplacedWithZero = Table.AddColumn( Data, «NewAmount», (row) => try row[Amount] otherwise 0 ), RemoveOldAmount = Table.RemoveColumns(ErrorsReplacedWithZero, {«Amount»}), RenameNewAmount = Table.RenameColumns(RemoveOldAmount, {«NewAmount», «Amount»}) in List.Sum(RenameNewAmount[Amount]) // возвращает 10 |
Это довольно сложно. Но пример хорошо иллюстрирует общий подход к использованию try на уровне ячеек. Если же, как в нашем пример, вы просто хотите заменить любую ошибку значением по умолчанию, используйте Table.ReplaceErrorValues.
Листинг 13
|
let Data = #table({«Amount»}, {{10}, {error «help!»}, {error «save me!»}}), ErrorsReplacedWithZero = Table.ReplaceErrorValues( Data, {{«Amount», 0}} ) // заменяет ошибки в столбце Amount нулями in List.Sum(ErrorsReplacedWithZero[Amount]) // возвращает 10 |
Применить try к элементам списка сложнее. Для списков нет функции List.ReplaceErrorValues. Самым простым решением может быть преобразование списка в таблицу, обработка ошибки, а затем обратное преобразование таблицы в список.
Листинг 14
|
let Data = {10, error «help!», error «save me!»}, #»Преобразовано в таблицу» = Table.FromValue(Data), #»Замененные ошибки» = Table.ReplaceErrorValues(#»Преобразовано в таблицу», {{«Value», 0}}), Value = #»Замененные ошибки»[Value], #»Вычисленная сумма» = List.Sum(Value) in #»Вычисленная сумма» |
Рис. 7. Сумма элементов списка, содержащего ошибки
Нарушения правил
Вы можете использовать ошибки, как сигнал о несоответствиях. Допустим, вы обрабатываете CSV-файл, где значения в столбце ItemCode должны начинаться с буквы A. В начале запроса вы проверяете это, заменяя несоответствующие значения ошибками. Последующие этапы обработки, которые обращаются к столбцу, будут предупреждены, если они попытаются работать со значениями, нарушающими правила.
|
let Data = GetData(), // for testing use: #table({«ItemCode»}, {{«1»}, {«A2»}}) Validated = Table.TransformColumns( Data, { «ItemCode», each if Text.StartsWith(_, «A») then _ else error Error.Record( «Invalid Data», «ItemCode does not start with expected letter», _ ) } ) in Validated |
Такую проверку полезно применить в базовом запросе, на который будут ссылаться несколько других запросов. Это позволит вам выполнить проверку один раз (вспомните принцип Не повторяйся, Don’t repeat yourself), гарантируя, что пользователи, пытающиеся использовать ошибочные данные, будут предупреждены о наличии аномалий.
Другой вариант – добавить столбец со значениями true и false, в зависимости от того, соблюдается ли правило:
|
let Data = GetData(), // for testing use: #table({«ItemCode»}, {{«1»}, {«A2»}}) Validated = Table.AddColumn( Data, «ValidItemCode», each Text.StartsWith(_[ItemCode], «A»), type logical ) in Validated |
В этом примере логика заботится о том, является ли ItemCode допустимым. Если разработчик забудет выполнить проверку, неверные данные могут рассматриваться как действительные. В отличие от этого, подход замены несоответствующих данных ошибками гарантирует, что попытка получить доступ к недопустимому значению, закончится ошибкой. Пользователь будет вынужден поправить данные в источнике. Какой вариант выбрать, зависит от вашего контекста.
В следующей заметке
Я планирую рассказать о том, что остается за кулисами: организации разделов кода и о том, как M предоставляет возможность аннотировать значения дополнительной информацией (метаданными). Однако перед этим обсудим, как работает система типов в Power Query.
[1] Заметка написана на основе статьи Ben Gribaudo. Power Query M Primer (Part 15): Error Handling. Если вы впервые сталкиваетесь с Power Query, рекомендую начать с Марк Мур. Power Query.
[2] Номер листинга соответствует номеру запроса в приложенном Excel файле.
[3] Судя по рис. 6 современная реализация M создает пять полей.
Earlier this month I published a new and very practical Power BI app on Microsoft AppSource. The app audits Excel workbooks and detects changes and errors. To implement the app I needed to resolve key obstacles that are very common when you import Excel workbooks using Power Query. How do you import the data from Excel if you have formula errors in unpredictable cells?
In today’s tutorial, you will learn how to avoid these errors when you import the data from Excel to Power Query. As a bonus, you will also learn to detect the erroneous cells and find out the type of errors and their coordinates, so if needed, you can report back to the owners of the workbooks and ask them to fix these errors.
The Challenge
Let’s examine a very simple table in Excel as shown in the screenshot below (You can download it here). You can see that we have errors in the Price and Amount columns. Formula errors in Excel are very common. Sometimes, these errors are kept by design, sometimes, they are there by mistake.

When you import data from Excel using Power Query, you may find in the preview pane the errors. But oftentimes, when you deal with a very large dataset, you may completely miss them.

Import the Excel (here), convert the type of the Price column to Fixed decimal number (or let the auto-detection of column types work its black-magic), and apply any filter on Price. For example, in the screenshot below, I applied a greater than 100 filter.





I am sure you have seen these errors before. In the next sections, we will discuss possible solutions.
Removing Rows with Errors
One of the common approaches to resolve the errors is to filter out rows with errors. To do it, you can right-click on the headers of the columns with the errors (In our case, Price and Amount), and select Remove Errors in the shortcut menu.

This step will remove rows that have errors in the selected columns. This approach may be too harsh. Oftentimes, you may know the root cause for the errors and apply some logic that to workaround the errors instead of ignoring the entire rows.
Still, let’s assume that you have no options, and need to remove the errors. We can make your challenge more interesting, and say that you need to remove rows if you find errors in ANY column. How would you approach it?
Looking at the M formula after you removed the errors for columns Price and Amount, you can see that the column names were explicitly called out in the formula, using a list.
= Table.RemoveRowsWithErrors(#"Changed Type", {"Price", "Amount"})To remove rows with errors for any columns, you can replace the static list with the function Table.ColumnNames. Here is the modified formula:
= Table.RemoveRowsWithErrors(#"Changed Type", Table.ColumnNames(#"Changed Type"))Note that in the formula above, in my example, I had #”Changed Type” as the last step in Applied Steps, so I used it as the parameter for Table.ColumnNames. When you apply this technique on your own data, you will have a different step name and will need to copy it as the relevant parameter.
Replacing Errors with other Values
A more common approach to handle errors in Power Query and avoid the refresh errors, is to replace the errors with values. For example, you will oftentimes want to replace the errors with nulls.
Replacing the errors for a single column is very discoverable. You right-click on the column’s header and select Replace Errors in the

But in our example, we have two columns with errors. See, what happens when you select both Price and Amount. Right-clicking on one of their headers, will not have an option for Replace Errors. But when something is missing in one UI element, it doesn’t mean that this functionality is not supported. Let’s look for it in the ribbon.



You can see in the formula bar the following line:
= Table.ReplaceErrorValues(#"Changed Type", {{"Price", null}, {"Amount", null}})We now have a different format in M to replace the errors. You can see a list of pairs. Each pair includes the column name and the null value.
What would you do to replace errors with nulls when you don’t know in which columns you have the errors? Here is the solution using Table.ColumnNames and List.Transform.
= Table.ReplaceErrorValues(#"Changed Type", List.Transform(Table.ColumnNames(#"Changed Type"), each {_,null}))The formula above gets the list of column names and transform them into the required pairs of column name and null. If you are not sure how it works, don’t worry. You can apply it to any table you have in the future, by clicking the fx button in the formula bar, and then copy the formula above. Don’t forget to replace the two occurrences of #”Changed Type” with the last step name of your table. If you have spaces or special characters in the last step, use the #”…” wrapper.
Detecting Errors
So far we have learned to remove formula errors or replace the errors with values. Now, let’s move to a more advanced scenario. Imagine that after you resolved the errors, you still want to dynamically detect these errors and report them to the Excel workbook’s owner.
In this section, you will learn how to do it.
Note: if this use-case has a very high value for you, you can install my Excel Compare app from AppSource here, and use it to report the errors in Excel.
If you are an advanced Power Query user and wish to detect Excel formula errors in Power Query across many workbooks, you can create the following custom function in Power Query:
(tbl) =>
let
#"Unpivoted Columns" = Table.UnpivotOtherColumns(tbl, {"ID"}, "Column", "Value"),
#"Kept Errors" = Table.SelectRowsWithErrors(#"Unpivoted Columns", {"Value"}),
#"Added Custom" = Table.AddColumn(#"Kept Errors", "Custom", each try [Value]),
#"Removed Columns" = Table.RemoveColumns(#"Added Custom",{"Value"}),
#"Expanded Custom" = Table.ExpandRecordColumn(#"Removed Columns", "Custom", {"Error"}, {"Error"}),
#"Expanded Error" = Table.ExpandRecordColumn(#"Expanded Custom", "Error", {"Reason", "Message", "Detail"}, {"Reason", "Message", "Detail"})
in
#"Expanded Error"Name the custom function FnDetectErrorsInWorksheet.
Before you use the function, make sure you have a column ID in the table. If you don’t have one, you can create it using the Add Index button in Add Column tab. To apply the function on your table, you can invoke the FnDetectErrorsInWorksheet on your table. For example, if the table with the errors is represented in the Table query, this formula will do the trick.
= FnDetectErrorsInWorksheet(Table)

How to detect errors step by step
If you want to learn how to detect the errors without the custom function above, let’s show you the steps in the UI. You will find it very easy.
On the Queries pane, select the query with the errors. Right-click on it and select Reference in the shortcut menu. Name the new query Detect Errors.
Right-click on the header of ID column, and select Unpivot Other Columns. Now, all the data in the Excel table is rebuilt as the value and its coordinates. ID represents the row. The Attribute column represents the column name, and the Value column represents the value in the original Excel table. You can see that the Value column contains the errors.

Right-click on the header of the Value column.
In Home tab, select Keep Rows, and then select Keep Errors.

You are now left with the errors only. You already know at this stage where errors are located.
But can you tell what kind of errors were detected? To do it, we will add a custom column. In Add Column tab, click Custom Column.

In the Custom Column dialog box, enter the formula:
try [Value]This formula returns a record with the details of the error. You can learn more about the try statement here and check out the latest official error handling article here.
It’s time to move on. Click OK and close the Custom Column dialog box.

Click the expand control in the Custom column header.

Select HasError and Error fields and click OK.

Click the expand control in the Error column header. Select the fields Reason, Message, and Detail, and then click OK.

You can now see that we extracted the specific Excel formula errors in the Message column. From here, you only need to load the Detect Errors query and build a nice report to notify your colleagues when they have errors in Excel.

Did you find this tutorial helpful? Do you want to learn more?
Schedule a very special Power BI or Power Query training for your team. Learn more here.

Файлы к уроку:
- Для спонсоров Boosty
- Для спонсоров VK
Ссылки:
- Страница курса
- Плейлист YouTube
- Плейлист ВК
Описание
В нашей таблице 2 столбца. В первом находится название категории и даты, а во втором суммы остатков.
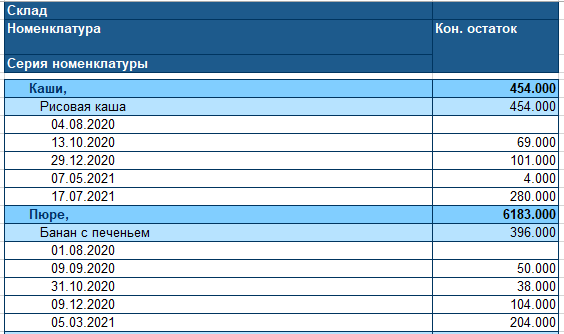
Нам нужно разделить первый столбец на два, чтобы в одном были только даты, а в другом только названия товаров. Строки с итоговыми цифрами нужно убрать.
Решение
Сначала нам понадобится создать дубликат столбца, который предстоит делить. Оригинал мы оставим, чтобы оставить в нем потом только текст, а в копии мы получим значения дат.
Значения копии столбца мы преобразуем в дату. В исходном столбце мы заменим значения таким образом, чтобы они превратились в null в случае, когда в копии находится дата.
Далее останется лишь удалить лишние строки и переупорядочить столбцы.
Примененные функции
- Excel.Workbook
- File.Contents
- Table.SelectColumns
- Table.ExpandTableColumn
- Table.PromoteHeaders
- Table.Skip
- Table.DuplicateColumn
- Table.TransformColumnTypes
- Table.ReplaceErrorValues
- Table.ReplaceValue
- Replacer.ReplaceValue
- Table.FillDown
Код
let
source = Excel.Workbook(File.Contents(path), null, true),
cols_select = Table.SelectColumns(source, {"Data"}),
col_expand_table = Table.ExpandTableColumn(
cols_select,
"Data",
{"Column1", "Column2"}
),
table_promote_headers = Table.PromoteHeaders(
col_expand_table,
[PromoteAllScalars = true]
),
table_skip_rows = Table.Skip(table_promote_headers, 8),
table_promote_headers_2 = Table.PromoteHeaders(
table_skip_rows,
[PromoteAllScalars = true]
),
col_duplicate = Table.DuplicateColumn(
table_promote_headers_2,
"Номенклатура",
"Дата"
),
types = Table.TransformColumnTypes(col_duplicate, {{"Дата", type date}}),
col_replace_errors = Table.ReplaceErrorValues(types, {{"Дата", null}}),
col_replace_values = Table.ReplaceValue(
col_replace_errors,
each [Номенклатура],
each if [Дата] = null then [Номенклатура] else null,
Replacer.ReplaceValue,
{"Номенклатура"}
),
table_fill_down = Table.FillDown(col_replace_values, {"Номенклатура"}),
types_2 = Table.TransformColumnTypes(
table_fill_down,
{{"Кон. остаток", type number}},
"en-US"
),
col_replace_values_2 = Table.ReplaceValue(
types_2,
null,
0,
Replacer.ReplaceValue,
{"Кон. остаток"}
),
rows_select = Table.SelectRows(
col_replace_values_2,
each ([Дата] <> null)
),
table_reorder_cols = Table.ReorderColumns(
rows_select,
{"Дата", "Номенклатура", "Кон. остаток"}
)
in
table_reorder_colsЭтот урок входит в Практический курс Power Query
| Номер урока | Урок | Описание |
|---|---|---|
| 1 | Обработка типичной выписки | В этом уроке мы обработаем типичную банковскую выписку. |
| 2 | Интересная консолидация | В этом уроке мы будем практиковать объединение таблиц по вертикали. |
| 3 | Множественная консолидация при несовпадении заголовков | Объединим таблицы по вертикали, когда заголовки таблиц не совпадают, но порядок всегда одинаков. |
| 4 | Таблица дат | Для построения отчетов в модели данных Excel вам нужно создать таблицу дат. Сейчас вы узнаете как это сделать в Power Query. |
| 5 | Продажи год назад | В этом уроке мы узнаем как в Power Query получить таблицу с продажами прошлого года напротив текущих. |
| 6 | Консолидация книг и листов одновременно | В этом уроке мы научимся объединять все листы всех книг, т. е. выполним двухуровневую консолидацию. |
| 7 | Столбец общей суммы в PQ и PP | В этом уроке мы создадим столбец, в котором будет находиться общая сумма всех строк таблицы. Так же разберем эту же операцию в Power Pivot. |
| 8 | Скученные данные 3 | В этом уроке мы обработаем еще один файл со скученными данными. На этот раз в одном столбце находятся даты и номенклатура. Нужно разбить этот столбец на два. |
| 9 | Строки преобразовать в столбцы | У нас есть таблица, в которой один столбец имеет скученные данные. Нам нужно скученный столбец преобразовать в столбцы. |
| 10 | Пивот, анпивот, группировка | В этом уроке мы попрактикуем анпивот, условную логику и группировку. |
| 11 | Нужные столбцы с нужного листа | В этом уроке мы научимся извлекать нужные столбцы с нужного листа не используя название самого листа. |
| 12 | Объединение, группировка, транспонирование, анпивот | В этом уроке на очень интересном примере из реальной жизни попрактикуем несколько техник Power Query: группировка, анпивот, объединение таблиц по горизонтали, транспонирование. |
| 13 | Нарастающий итог 4, много группировок | В этом уроке мы изучим еще 1 способ создать столбец нарастающего итога в Power Query. В отличие от других способов здесь мы не будем пользоваться формулами. Все сделаем при помощи пользовательского интерфейса. |
| 14 | Количество позиций в строке | В этом уроке мы посчитаем количество наименований, перечисленных в одной ячейке. |
| 15 | List Contains, Пользовательская функция | В этом уроке повторим создание пользовательских функций и рассмотрим еще 1 пример использования функции List.Contains. |
| 16 | ABC анализ | Научимся выполнять ABC анализ в Power Query. |
Замените все значения ошибок для всех столбцов после импорта данных (при сохранении строк)
Вопрос:
Таблица Excel в качестве источника данных может содержать значения ошибок (#NA, # DIV/0), которые могут нарушить некоторые последующие этапы процесса преобразования в Power Query.
В зависимости от следующих шагов мы можем получить не вывод, а ошибку. Так как же справиться с этим делом?
Я нашел два стандартных шага в Power Query, чтобы поймать их:
- Удалить ошибки (интерфейс: Главная/Удалить строки/Удалить ошибки) → все строки с ошибками будут удалены
- Заменить значения ошибок (UI: Transform/Replace Errors) → столбцы должны быть сначала выбраны для выполнения этих операций.
Первая возможность для меня не является решением, так как я хочу сохранить строки и просто заменить значения ошибок.
В моем случае моя таблица данных будет меняться со временем, это означает, что имя столбца может измениться (например, годы) или появятся новые столбцы. Так что вторая возможность слишком статична, так как я не хочу каждый раз менять скрипт.
Поэтому я попытался получить динамический способ очистки всех столбцов, независимо от имен столбцов (и количества столбцов). Он заменяет ошибки на нулевое значение.
let
Source = Excel.CurrentWorkbook(){[Name="Tabelle1"]}[Content],
//Remove errors of all columns of the data source. ColumnName doesn't play any role
Cols = Table.ColumnNames(Source),
ColumnListWithParameter = Table.FromColumns({Cols, List.Repeat({""}, List.Count(Cols))}, {"ColName" as text, "ErrorHandling" as text}),
ParameterList = Table.ToRows(ColumnListWithParameter ),
ReplaceErrorSource = Table.ReplaceErrorValues(Source, ParameterList)
in
ReplaceErrorSource
Вот разные три сообщения с запросами, после того как я добавил два новых столбца (с ошибками) к источнику: 
Если у кого-то есть другое решение для такой очистки данных, напишите здесь.
Лучший ответ:
let
src = Excel.CurrentWorkbook(){[Name="Tabelle1"]}[Content],
cols = Table.ColumnNames(src),
replace = Table.ReplaceErrorValues(src, List.Transform(cols, each {_, "!"}))
in
replace
Replace Error Values in Multiple Columns
You’d often run into data sets with errors especially when the source is excel. If you have been working with Power Query you know that it doesn’t like error values and truncates the entire row which has an error in any column.
Sad. But you can obviously do Replace Errors and fix them with null values, however the challenge is that, the Replace Errors should automatically work on even the new columns added in data.
Video First ?
Consider this 3 column data
Now obviously when this is loaded in Power Query it will show error wherever #N/A (and for any other type of excel errors)
You can easily fix this
- Select all columns
- Transform Tab >> Replace Values Drop Down >> Replace Errors >> type null
- Done
But what if the 4th column is added and has error values, the Replace Errors will not automatically extend to the 4th column. Let’s do that!
Replace Error Values in Multiple Columns
Step 1 –
- I extract all the columns names as a list.
- Click on fx and write the M code below
- I do this as a second step after Source (data loading)
Step 2 – Since a Table offers more options to work as compared to a List. Covert the List to a Table. Right click on the List (header) >> To Table.
Step 3 – From the Add Columns Tab >> Custom Column >> type =null
- This will add a Custom Column will null values across all rows.
- I am doing this because I want to replace all error values with null.
The result looks like this
Step 4 – Next I will transpose this table. Transform Tab >> Transpose.
![]()
Understanding whats going on..
If you are still with me, so far you have blindly pursued the steps. Let me help you understand where are we headed.
- When you do Replace Errors the highlighted (in yellow) code appears.
- Notice that column names – One, Two and Three are hard coded. They wont change if the column names changes or source data adds a new column.
- Also note that the column names are in double curly brackets << >>. Which means it’s a list inside a list.
- We are trying to create the same list of list with 2 parts – Column Name and null value. But a dynamic one!
- Let’s proceed
Step 5 – Convert the table into a list of list.
- Use the fx button to write a short M Code
- This will convert each column into a list and then make a single list of all lists
- Renamed the step to ColList (it’s optional but nice to have good labels across)
Step 6 – It’s time now to feed the list in Replace Errors
- Using the fx I’ll create a new Step
- Write the following Code. In the code Source is the Step (which has the table with error values) and ColList is our List of List which replaces all errors dynamically with null.
Источник
Обработка ошибок
Аналогично тому, как в Excel и языке DAX есть IFERROR функция, Power Query имеет собственный синтаксис для тестирования и перехвата ошибок.
Как упоминалось в статье об ошибках в Power Query, ошибки могут отображаться на уровне шага или ячейки. В этой статье рассматриваются способы перехвата ошибок и управления ими на основе собственной логики.
Чтобы продемонстрировать эту концепцию, в этой статье будет использоваться книга Excel в качестве источника данных. Представленные здесь понятия применяются ко всем значениям в Power Query и не только к тем, которые поступают из книги Excel.
Пример источника данных для этой демонстрации — книга Excel со следующей таблицей.
Эта таблица из книги Excel содержит ошибки Excel, такие как #NULL!, #REF!, и #DIV/0! в столбце «Стандартный тариф «. При импорте этой таблицы в редактор Power Query показано, как она будет выглядеть.
Обратите внимание, что ошибки из книги Excel отображаются со значением [Error] в каждой ячейке.
В этой статье вы узнаете, как заменить ошибку другим значением. Кроме того, вы узнаете, как перехватывать ошибку и использовать ее для собственной логики.
В этом случае цель состоит в создании нового столбца «Окончательная ставка «, который будет использовать значения из столбца «Стандартная ставка «. При возникновении ошибок он будет использовать значение из столбца «Специальный тариф » корреспондента.
Укажите альтернативное значение при поиске ошибок
В этом случае цель состоит в создании нового столбца «Окончательная ставка » в образце источника данных, который будет использовать значения из столбца «Стандартная ставка «. При возникновении ошибок оно будет использовать значение из соответствующего столбца «Специальная ставка «.
Чтобы создать новый настраиваемый столбец, перейдите в меню «Добавить столбец » и выберите «Настраиваемый столбец«. В окне «Настраиваемый столбец» введите формулу try [Standard Rate] otherwise [Special Rate] . Присвойт этому новому столбцу окончательную ставку.
Приведенная выше формула попытается оценить столбец «Стандартная ставка» и выдаст его значение, если ошибки не найдены. Если ошибки найдены в столбце «Стандартная ставка «, выходные данные будут значениями, определенными после инструкции otherwise , которая в данном случае является столбцом «Специальная ставка «.
После добавления правильных типов данных во все столбцы таблицы на следующем рисунке показано, как выглядит окончательная таблица.
В качестве альтернативного подхода можно также ввести формулу try [Standard Rate] catch ()=> [Special Rate] , эквивалентную предыдущей формуле, но используя ключевое слово catch с функцией, для которой не требуются параметры.
Ключевое catch слово было введено в Power Query в мае 2022 года.
Укажите собственную логику условной ошибки
Используя тот же образец источника данных, что и в предыдущем разделе, новая цель — создать новый столбец для конечной ставки. Если значение из стандартной ставки существует, это значение будет использоваться. В противном случае будет использоваться значение из столбца «Специальная ставка «, за исключением строк с любой #REF! ошибкой.
Единственной целью исключения ошибки является демонстрация #REF! . В соответствии с основными понятиями, представленными в этой статье, вы можете выбрать любые поля из записи об ошибке.
При выборе любого из пробелов рядом со значением ошибки вы получите область сведений в нижней части экрана. Область сведений содержит как причину ошибки, DataFormat.Error так и сообщение об ошибке: Invalid cell value ‘#REF!’
Одновременно можно выделить только одну ячейку, чтобы можно было эффективно видеть только компоненты ошибки одного значения ошибки. Здесь вы создадите новый настраиваемый столбец и используйте try выражение.
Использование try с пользовательской логикой
Чтобы создать новый настраиваемый столбец, перейдите в меню «Добавить столбец » и выберите «Настраиваемый столбец«. В окне «Настраиваемый столбец» введите формулу try [Standard Rate] . Присвойт этому новому столбцу имя «Все ошибки«.
Выражение try преобразует значения и ошибки в значение записи, указывающее, обрабатывает ли try выражение ошибку или нет, а также правильное значение или запись ошибки.
Вы можете развернуть этот вновь созданный столбец со значениями записей и просмотреть доступные поля для развертывания, щелкнув значок рядом с заголовком столбца.
Эта операция предоставит три новых поля:
- Все ошибки.HasError — показывает, было ли значение из столбца «Стандартная ставка » ошибкой.
- Все ошибки.Значение— если значение из столбца «Стандартная ставка » не содержит ошибок, этот столбец будет отображать значение из столбца «Стандартная ставка «. Для значений с ошибками это поле будет недоступно, и во время операции развертывания этот столбец будет иметь null значения.
- Все ошибки.Error — если значение из столбца «Стандартная ставка » содержит ошибку, в этом столбце отображается запись об ошибке для значения из столбца «Стандартная ставка «. Для значений без ошибок это поле будет недоступно, и во время операции развертывания этот столбец будет иметь null значения.
Для дальнейшего изучения можно развернуть столбец All Errors.Error , чтобы получить три компонента записи об ошибке:
- Причина ошибки
- Сообщение об ошибке
- Сведения об ошибках
После выполнения операции развертывания в поле All Errors.Error.Message отображается определенное сообщение об ошибке, сообщающее о том, какая ошибка Excel имеет каждая ячейка. Сообщение об ошибке является производным от поля сообщения об ошибке записи об ошибке.
Теперь с каждым сообщением об ошибке в новом столбце можно создать новый условный столбец с именем Final Rate и следующими предложениями:
- Если значение в столбце All Errors.Errors.Message равно null , выходные данные будут иметь значение из столбца «Стандартная ставка «.
- В противном случае, если значение в столбце All Errors.Errors.Message равно Invalid cell value ‘#REF!’. , выходные данные будут значениями из столбца «Специальная ставка «.
- Else, null.
После сохранения только столбцов «Учетная запись«, «Стандартная ставка«, » Специальная ставка» и «Окончательная ставка » и добавления правильного типа данных для каждого столбца показано, как выглядит окончательная таблица.
Использование try и catch использование пользовательской логики
Кроме того, можно создать новый настраиваемый столбец с помощью try ключевых слов и catch ключевых слов.
try [Standard Rate] catch (r)=> if r[Message] <> «Invalid cell value ‘#REF!’.» then [Special Rate] else null
Источник
Работа с ошибками в Power Query
В Power Query можно столкнуться с двумя типами ошибок:
- Ошибки на уровне шага
- Ошибки на уровне ячеек
В этой статье приводятся рекомендации по устранению наиболее распространенных ошибок, которые можно найти на каждом уровне, а также описывает причину ошибки, сообщение об ошибке и подробные сведения об ошибке для каждого из них.
Ошибка на уровне шага
Пошаговая ошибка предотвращает загрузку запроса и отображает компоненты ошибок на желтой панели.
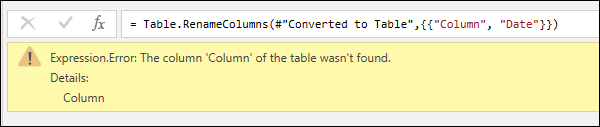
- Причина ошибки: первый раздел перед двоеточием. В приведенном выше примере причина ошибки — Expression.Error.
- Сообщение об ошибке: раздел непосредственно после причины. В приведенном выше примере сообщение об ошибке — столбец «Столбец» таблицы не найден.
- Сведения об ошибке: раздел непосредственно после строки Details: В приведенном выше примере сведения об ошибке — «Столбец«.
Распространенные ошибки на уровне шага
Во всех случаях рекомендуется внимательно ознакомиться с причиной ошибки, сообщением об ошибке и подробными сведениями об ошибке, чтобы понять, что вызывает ошибку. Вы можете нажать кнопку «Перейти к ошибке» , если она доступна, чтобы просмотреть первый шаг, в котором произошла ошибка.

Не удается найти источник — DataSource.Error
Эта ошибка обычно возникает, когда источник данных недоступен пользователем, у пользователя нет правильных учетных данных для доступа к источнику данных или источник был перемещен в другое место.
Пример. У вас есть запрос из текстовой плитки, которая была расположена на диске D и создана пользователем A. Пользователь A предоставляет общий доступ к запросу пользователю B, у которого нет доступа к диску D. Когда этот пользователь пытается выполнить запрос, он получает dataSource.Error , так как в своей среде нет диска D.

Возможные решения. Вы можете изменить путь к файлу текстового файла на путь, к которому у обоих пользователей есть доступ. Как пользователь Б, вы можете изменить путь к файлу, чтобы он был локальной копией того же текстового файла. Если кнопка «Изменить параметры» доступна в области ошибок, ее можно выбрать и изменить путь к файлу.
Столбец таблицы не найден
Эта ошибка обычно активируется, когда шаг создает прямую ссылку на имя столбца, которое не существует в запросе.
Пример. У вас есть запрос из текстового файла, в котором одно из имен столбцов — Column. В запросе есть шаг, который переименовывает этот столбец в date. Но в исходном текстовом файле произошло изменение, и у него больше нет заголовка столбца с именем Column , так как он был изменен вручную на Date. Power Query не удается найти заголовок столбца с именем Column, поэтому он не может переименовать столбцы. Отображается ошибка, показанная на следующем рисунке.
Возможные решения: существует несколько решений для этого случая, но все они зависят от того, что вы хотите сделать. В этом примере, так как правильный заголовок столбца Date уже поступает из текстового файла, можно просто удалить шаг, который переименовывает столбец. Это позволит выполнять запрос без этой ошибки.
Другие распространенные ошибки на уровне шага
При объединении или объединении данных между несколькими источниками данных может возникнуть ошибка Formula.Firewall , например, показанная на следующем рисунке.

Эта ошибка может быть вызвана рядом причин, таких как уровни конфиденциальности данных между источниками данных или способом объединения или объединения этих источников данных. Дополнительные сведения о диагностике этой проблемы см. в брандмауэре конфиденциальности данных.
Ошибка уровня ячейки
Ошибка на уровне ячейки не препятствует загрузке запроса, но отображает значения ошибок в ячейке. При выборе пробела в ячейке отображается область ошибок под предварительным просмотром данных.
Средства профилирования данных помогают более легко выявлять ошибки на уровне ячеек с помощью функции качества столбца. Дополнительные сведения: средства профилирования данных
Обработка ошибок на уровне ячейки
При возникновении ошибок на уровне ячеек Power Query предоставляет набор функций для их обработки путем удаления, замены или сохранения ошибок.
В следующих разделах указанные примеры будут использовать тот же пример запроса, что и начальная точка. В этом запросе есть столбец Sales с одной ячейкой с ошибкой, вызванной ошибкой преобразования. Значение внутри этой ячейки было NA, но при преобразовании этого столбца в целое число Power Query не удалось преобразовать НС в число, поэтому отображается следующая ошибка.
Удаление ошибок
Чтобы удалить строки с ошибками в Power Query, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Удалить строки«. В раскрывающемся меню выберите «Удалить ошибки«.
Результат этой операции даст вам таблицу, которую вы ищете.
Замена ошибок
Если вместо удаления строк с ошибками необходимо заменить ошибки фиксированным значением, это также можно сделать. Чтобы заменить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Преобразование» в группе «Любой столбец » выберите «Заменить значения«. В раскрывающемся меню выберите «Заменить ошибки«.
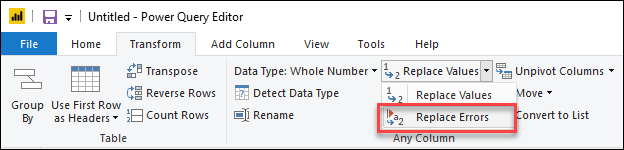
В диалоговом окне «Замена ошибок » введите значение 10 , так как вы хотите заменить все ошибки значением 10.

Результат этой операции даст вам таблицу, которую вы ищете.
Сохранение ошибок
Power Query может служить хорошим средством аудита для выявления строк с ошибками, даже если вы не исправите ошибки. Здесь могут быть полезны ошибки keep . Чтобы сохранить строки с ошибками, сначала выберите столбец, содержащий ошибки. На вкладке «Главная» в группе «Уменьшить строки» выберите «Сохранить строки«. В раскрывающемся меню выберите «Сохранить ошибки«.
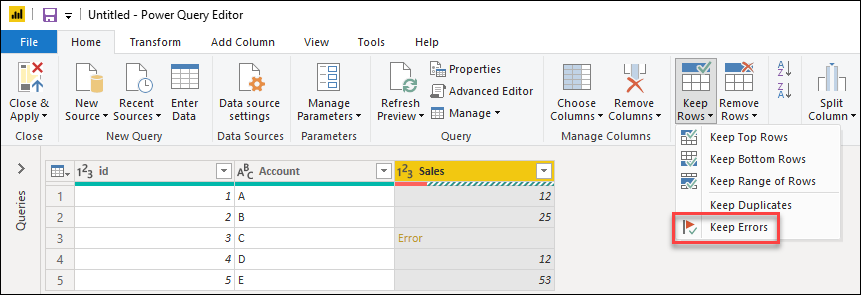
Результат этой операции даст вам таблицу, которую вы ищете.

Распространенные ошибки на уровне ячеек
Как и в случае с любой ошибкой на уровне шага, мы рекомендуем внимательно изучить причины ошибок, сообщения об ошибках и сведения об ошибках, предоставленные на уровне ячейки, чтобы понять, что вызывает ошибки. В следующих разделах рассматриваются некоторые наиболее частые ошибки на уровне ячеек в Power Query.
Ошибки преобразования типов данных
Обычно активируется при изменении типа данных столбца в таблице. Некоторые значения, найденные в столбце, не удалось преобразовать в нужный тип данных.
Пример. У вас есть запрос, содержащий столбец с именем Sales. Одна ячейка в этом столбце содержит значение NA в качестве значения ячейки, а остальные имеют целые числа в качестве значений. Вы решили преобразовать тип данных столбца из текста в целое число, но ячейка со значением NA приводит к ошибке.
Возможные решения. После идентификации строки с ошибкой можно либо изменить источник данных, чтобы отразить правильное значение, а не NA, либо применить операцию «Заменить» , чтобы указать значение для любых значений NA , вызывающих ошибку.
Ошибки операций
При попытке применить операцию, которая не поддерживается, например умножение текстового значения на числовое значение, возникает ошибка.
Пример. Вы хотите создать настраиваемый столбец для запроса, создав текстовую строку, содержащую фразу «Total Sales: » сцеплено со значением из столбца Sales . Ошибка возникает из-за того, что операция объединения поддерживает только текстовые столбцы, а не числовые.

Возможные решения. Перед созданием этого настраиваемого столбца измените тип данных столбца Sales на текст.
Источник