Тест-дизайн – это этап процесса тестирования ПО, на котором проектируются и создаются тестовые случаи (тест-кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования.
Роли в тест дизайне:
- Тест-аналитик — определяет «ЧТО тестировать?».
- Тест-дизайнер — определяет «КАК тестировать?».
Попросту говоря, задача тест-аналитиков и дизайнеров сводится к тому, чтобы, используя различные стратегии и техники тест-дизайна, создать набор тестовых случаев, обеспечивающий оптимальное тестовое покрытие тестируемого приложения. На большинстве проектов эти роли выполняет QA инженер.
Тестовое покрытие — это одна из метрик оценки качества тестирования, представляющая из себя плотность покрытия тестами требований либо исполняемого кода.
Существуют следущее подходы к оценке и измерению тестового покрытия:
- Покрытие требований (Requirements Coverage) — оценка покрытия тестами функциональных и нефункциональных требований к продукту, путем построения матриц трассировки (traceability matrix).
- Покрытие кода (Code Coverage) — оценка покрытия исполняемого кода тестами, путем отслеживания непроверенных в процессе тестирования частей программного обеспечения.
- Тестовое покрытие на базе анализа потока управления — оценка покрытия основанная на определении путей выполнения кода программного модуля и создания выполняемых тест кейсов для покрытия этих путей.
Техники тест дизайна:
- Эквивалентное Разделение (Equivalence Partitioning — EP). Как пример, у Вас есть диапазон допустимых значений от 1 до 10, Вы должны выбрать одно верное значение внутри интервала, скажем, 5 и одно неверное значение вне интервала — 0.
- Анализ Граничных Значений (Boundary Value Analysis — BVA). Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10) и значения больше и меньше границ (0 и 11). Анализ Граничных значений может быть применен к полям, записям, файлам, или к любого рода сущностям, имеющим ограничения.
- Причина / Следствие (Cause/Effect — CE). Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие). Например, Вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого Вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем нажать кнопку «Добавить» — это «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
- Предугадывание ошибки (Error Guessing — EG). Когда тест-аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать», при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «Пользователь должен ввести код». Тест-аналитик, будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? » и так далее. Это и есть предугадывание ошибки.
- Исчерпывающее тестирование (Exhaustive Testing — ET) — это крайний случай. В пределах этой техники Вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным из-за огромного количества входных значений.
- Парное тестирование (Pairwise Testing — PT) — это техника формирования наборов тестовых данных. Сформулировать суть можно, например, таким образом: формирование таких наборов данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров.
Пример использования техники анализа классов эквивалентности:
Эквивалентное разделение, алгоритм использования техники:
- Необходимо определить класс эквивалентности. Это главный шаг техники. От него во многом зависит эффективность её применения.
- Затем нужно выбрать одного представителя от каждого класса. На этом шаге из каждого эквивалентного набора тестов мы выбираем один тест.
- Нужно выполнить тесты. На этом шаге мы выполняем тесты от каждого класса эквивалентности.
Можно разбивать тесты на классы эквивалентности по разным принципам. Например, если мы тестируем поле ввода, которое принимает максимум 5 символов, то можем выбрать разные принципы разбиения на классы эквивалентности:
- По количеству символов.
- По типу символов (цифры, буквы, спец символы).
Пример: функцию подсчета комиссии при отмене бронирования авиабилетов. Размер комиссии зависит от времени до вылета, когда совершена отмена:
- За 5 суток до вылета комиссия составляет 0%.
- Меньше 5 суток, но больше 24 часов – 50%.
- Меньше 24 часов, но до вылета – 75%.
- После вылета – 100%.
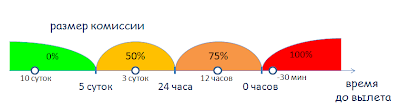
Рис. 5.1. Пример: функция подсчета комиссии при отмене бронирования авиабилетов
Шаги:
1. Определим классы эквивалентности:
(для каждого теста из этих классов мы ожидаем получить одинаковый результат):
- 1 класс: время до вылета > 5 суток.
- 2 класс: 24 часа < время до вылета < 5 суток.
- 3 класс: 0 часов < время до вылета < 24 часа.
- 4 класс: время до вылета < 0 часов (вылет уже состоялся).
2. Выберем представителя от каждого класса:
Здесь мы можем поступить так, как нам хочется и выбрать любые значения из класса. Ведь, если предположить, что мы правильно разбили на классы эквивалентности, то нет разницы, какое значение из диапазона мы выберем.
- время до вылета = 10 суток (тест из 1-го класса).
- время до вылета = 3 суток (тест из 2-го класса).
- время до вылета = 12 часов (тест из 3-го класса).
- время до вылета = -30 мин (тест из 4-го класса).
3. Выполним тесты:
- Отменим бронь за 10 суток до вылета и проверим, что комиссия составила 0%.
- Отменим бронь за 3 суток до вылета и проверим, что комиссия составила 50%.
- Отменим бронь за 12 часов до вылета и проверим, что комиссия составила 75%.
- Отменим бронь через 30 мин после вылета и проверим, что комиссия составила 100%.
Фактически, осталось всего 4 теста. А сколько возможных тестов существует? Даже если мы введем ограничение, что отмена бронирования может произойти в рамках 10 суток до вылета и 1 суток после вылета, то у нас будет около 950400 возможных тестов (количество секунд в 11 сутках).
Плюсы и минусы техники анализа классов эквивалентности
- К плюсам можно отнести заметное сокращение времени и улучшение структурированности тестирования.
- К минусам можно отнести то, что, при неправильном использовании техники, мы рискуем потерять баги.
Пример использования техники анализа граничных значений
Примерный алгоритм использования техники анализа граничных значений:
- Во-первых, нужно выделить классы эквивалентности. Опять же, это очень важный шаг и от правильности разбиения на классы эквивалентности зависит эффективность тестов граничных значений.
- Далее нужно определить граничные значения этих классов.
- Нам нужно понять, к какому классу будет относиться каждая граница.
- Для каждой границы нам нужно провести тесты по проверке значения до границы, на границе, и сразу после границы.
Пример: функцию подсчета комиссии при отмене бронирования авиабилетов. Размер комиссии зависит от времени до вылета, когда совершена отмена:
- За 5 суток до вылета комиссия составляет 0%.
- Меньше 5 суток, но больше 24 часов – 50%.
- Меньше 24 часов, но до вылета – 75%..
- После вылета – 100%
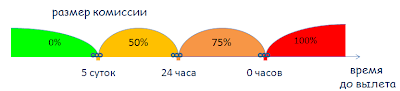
Рис. 5.2. Пример: функция подсчета комиссии при отмене бронирования авиабилетов
Шаги:
1. Выделим классы эквивалентности:
- 1 класс: время до вылета > 5 суток.
- 2 класс: 24 часа < время до вылета < 5 суток.
- 3 класс: 0 часов < время до вылета < 24 час.
- 4 класс: время до вылета < 0 часов (вылет уже состоялся).
2. Определим границы:
- 5 суток.
- 24 часа.
- 0 часов.
3. Определим, к какому классу относятся границы:
Примечание: На этом шаге был спорный момент, на который нужно обратить внимание. При составлении задачи я не подумал, какая логика должна быть на самих границах. Это типичный пример того, как составители требований не задумываются о границах. И поэтому программист может трактовать их по-своему.
- 5 суток – ко 2-му классу.
- 24 часа – к о2-му классу.
- 0 часов – к 4-му классу.
4. Протестируем значения на границах, до и после них:
- Отменим бронь за 5 суток + 1 секунду до вылета (или просто постараемся выполнить бронь как можно ближе к границе, но слева от нее) и проверим, что комиссия равна 0%.
- Отменим бронь ровно за 5 суток до вылета и проверим, что комиссия равна 50%.
- Отменим бронь за 5 суток – 1 секунду до вылета и проверим, что комиссия равна 50%.
- Отменим бронь за 24 часа + 1 секунду до вылета и проверим, что комиссия равна 50%.
- Отменим бронь ровно за 24 часа до вылета и проверим, что комиссия равна 50%.
- Отменим бронь за 24 часа — 1 секунду до вылета и проверим, что комиссия равна 75%.
- Отменим бронь за 1 секунду до вылета и проверим, что комиссия равна 75%.
- Отменим бронь ровно во время вылета и проверим, что комиссия равна 100%.
- Отменим бронь спустя 1 секунду после вылета и проверим, что комиссия равна 100%.
Мы получили 9 тестов, по 3 теста на каждую границу.
Если суммировать тесты, необходимые для проверки классов эквивалентности и граничных значений, получим 4 + 9 =13 тестов.
Плюсы и минусы техники анализа граничных значений
Эта техника добавляет в технику анализа классов эквивалентности ориентированность на конкретный тип ошибок.
То есть, техника анализа классов эквивалентности просто говорит нам о том, что нужно разбить все тесты на классы и провести тестирование всех классов. А техника граничных значений ориентирована на обнаружение конкретной проблемы – возникновения ошибок на границах классов эквивалентности.
Но, как и для техники анализа классов эквивалентности, эффективность техники анализа граничных значений зависит от правильности ее использования. Мы должны приложить усилия, чтобы правильно определить классы эквивалентности и их границы. Если мы отнесемся к этому поверхностно, то рискуем пропустить ошибки.
- Суть методики
- Особенности
- Что требуется, чтобы эффективно (пред)угадывать ошибки
- Примеры
- Преимущества и недостатки методики
Что это
Техники тест-дизайна — это то, чем должен хорошо владеть каждый тестировщик, даже стажер. Наиболее часто применяемые техники: эквивалентные классы, анализ граничных значений, и предугадывание ошибок.
В данной методике (типологически относится к тестированию черного ящика) нет какого-то специфического метода идентификации ошибок. Тестировщик действует, исходя из своего опыта и интуиции, пытаясь предугадать проблемные места в приложении. Поэтому успешность этой методики сильно зависит от опыта и скиллов, и глубины понимания тестируемого продукта.
Особенности
Как уже сказано, эффективность зависит от опыта, особенно с похожими приложениями ранее. Поэтому лучше и быстрее с такой задачей справляются QA-инженеры с опытом 1 год и более.
Методика направлена на поиск багов, не поддающихся другим методикам черного ящика. Поэтому стандартно выполняется уже после них.
Частыми ошибками в приложениях (следовательно, наиболее вероятными ошибками в тестируемом приложении) являются, например:
- Ввод некорректных (невалидных) параметров и символов
- Например, ввод пробела в “цифровые” поля, где это недопустимо
- Ошибка-исключение null pointer exception
- Деление на ноль
- Превышение максимального количества передаваемых файлов
- И подобные «типичные пользовательские» ошибки
Итак, цель предугадывания — найти ошибки, которые трудно “выловить” другими методиками черного ящика. Готовятся тест-кейсы, направленные на области наиболее вероятных ошибок; по возможности покрываются все проблемные места; но без избыточности.
Методика, разумеется, не является идеальной, способной обеспечить высокое качество — ведь она основана на интуиции, поэтому ограничена по умолчанию, зависит от умений и, главное, опытности QA-инженера. Она вовсе не гарантирует высокого покрытия, и должна сочетаться с другими методиками, дополнять их.
Что нужно, чтобы хорошо угадывать ошибки
- Интуиция тестировщика
- И его знание продукта
- Опыт прошлых проектов
- Чек-лист
- Риск-репорты
- Знание типичных проблем с интерфейсом
- Идеальное знание общих принципов тестирования
- Результаты предыдущих тестов
- Характерные ошибки, случавшиеся ранее
Примеры предугадывания ошибок
Пример 1
В приложении есть функция ввода номера телефона клиента, и он должен быть стандартной длины, то есть 10 цифр. Методика предугадывания ошибок в данном случае может проверить, например:
- Что случится, если ввести не цифру, а букву или пробел
- Если ввести только 8 цифр
- Если оставить поле пустым
- Если ввести не 10, а 12 цифр
Если такие невалидные значения введены, и функция ведёт себя как ожидается — то есть показывает ошибку, она расценивается как не имеющая багов; в противном случае заводится баг, и функция передается разработчикам, чтобы те устранили баг.
Пример 2
Счет на банковской карте настроен так, что принимает только суммы от 5000 до 7000 рублей (так нужно клиенту). Действуя по методике предугадывания ошибок, подбираем значения ввода, пытаясь добиться наибольшего покрытия:
| Значение | Результат |
| 6000 | ОК |
| 5500 | ОК |
| 4000 | Ошибка |
| 7200 | Ошибка |
| 7400 | Ошибка |
| 8000 | Ошибка |
| Пустое | Ошибка |
| 100$ | Ошибка |
| … | … |
| … и так далее |
Преимущества и недостатки методики
Преимущества
- Неплохой контроль возможных проблемных мест в проекте (они обычно стандартные)
- Отлично работает в сочетании с другими техниками тест-дизайна и дополняет их
- Позволяет довольно просто находить баги, которые доступны только при исчерпывающем тестировании (всех комбинаций ввода, что невозможно из-за недостатка времени)
Недостатки
- Является как бы ориентированной на личность тестировщика методикой, а не на процессы, что более правильно; то есть не является универсальной, а сильно зависит от скиллов тестировщика
- Не обеспечивает хорошее покрытие сама по себе
- Не очень подходит новичкам, неопытным, плохо знакомым с продуктом или областью его применения
***
The first documented approach to experience-based testing was error guessing [Myers 1979]. The people involved seem to have a knack for «smelling out» errors and faults. They practice, more often than not subconsciously, an approach to investigate certain probable types of faults and create test cases to try to expose these faults.
The value of Error Guessing lies in the unexpected: tests made up by guessing would otherwise not be considered. Based on the tester’s experience, he goes in search of fault-sensitive spots in the system and devises suitable test cases for these.
Experience here is a broad concept: it could be the professional tester who ‘smells’ the problems in certain complex screen processes, but it could also be the user or administrator who knows the exceptional situations from practice and wishes to test whether the new or amended system is dealing with them adequately.
The basic way of working is to think of possible faults and error-prone situations (for example by relying on past experiences) and to create and execute tests for that. The tests and results are mostly not documented. Therefore, we do not favor this approach, especially since exploratory testing is a much better alternative.

Together with exploratory testing, error guessing is rather a strange technique among test design techniques. Neither technique is based on any of the described basic techniques and therefore does not provide any specifiable coverage.
This very informal technique leaves the tester free to design the test cases in advance or to create them on the spot during the test execution. Documenting the test cases is optional. A point of focus when they are not documented is the reproducibility of the test. The tester often cannot quite remember under which circumstances a fault occurred. This may result in a developer not being able to investigate an anomaly, the tester not being able to retest a fix, and the test cannot be added to a regression test set. A possible measure for this is the taking of notes (a ‘test log’) during the test. Obviously, faults found with the test are documented. In those cases, great attention should be paid to the circumstances that have led to the fault, so that it will be reproducible.
The main downside of applying error guessing is the lack of documentation (as Myers states in his book “error
guessing is largely an intuitive and ad hoc process”). Therefore, tests are not reproducible. This may result in a developer not being able to investigate an anomaly, the tester not being able to retest a fix, and the test cannot be added to a regression test set.
Read more about the value of unstructured testing, here.
Tip
An aid for reproducing a fault is the activation of logging during the test, documenting the actions of the tester. A tool for automated test execution can be used for this.
The considerable freedom of the technique makes the area of application very broad. Error guessing can be applied to the testing of every quality characteristic and to every form of test basis.
Tip
Error guessing does not apply a structured approach to testing such as test design techniques, nor does it give any certainty about the coverage of functionality or risk. All known possibilities to solve this quickly result in moving to a checklist-based approach or to exploratory testing.
In more detail |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Error guessing is sometimes confused with exploratory testing (see «Exploratory Testing»). The table below sums up the differences:
|
Still, error guessing may be an efficient approach in specific situations, especially in a situation where a system is known to be of very low quality. In that case an experienced tester does not have to prepare any tests to be able to reveal so many anomalies in the IT system that the developers will quickly ask them to stop testing so they can first improve the quality. However, if a system is of good quality, error guessing is a very bad approach. In the case of good quality, the tester will try all sorts of tests but won’t find any anomalies.
The stakeholders will start doubting the quality of the testing, and rightfully so, because besides the fact that there are no anomalies found, the tester (with this unstructured, ad hoc and undocumented approach) will not be able to provide any insight in the quality and risks of the IT system and the stakeholders will not get the information they need to establish their confidence that the pursued business value can be reached with this system.
In more detail
In practice, error guessing is often cited for the applied test technique in the absence of a better name – ‘It’s not a common test design technique, therefore it is error guessing’. In particular, the testing of business processes by users, or the testing of requirements is often referred to as error guessing. However, the basic technique of «checklist» is used here, while with error guessing no specific basic technique is used.
The fact that tests are executed that otherwise would not be considered makes error guessing a valuable addition to the other test design techniques. However, since error guessing guarantees no coverage whatsoever, it is not a replacement.
By preference error guessing takes place later in the total testing process, when most normal and simple faults have already been removed with the regular techniques. Because of this, error guessing can focus on testing the real exceptions and difficult situations. From within the test strategy there should be made availalbe an amount of time (time box) for this activity.
When crowd testing is applied, there is often no control of the approach, techniques and tools the testers use. In practice, we see that these testers often only apply error guessing in trying to find low-hanging-fruit anomalies. To make crowd testing more effective, insight into and advice about the approaches used by the testers is of vital importance.
Points of focus in the steps
The steps can be performed both during the specification phase and during the test execution. The ‘tester’ usually does not document the results of the steps, but if great value is attached to showing evidence or transferability and reusability of the test, then this should be done.
1 — Identifying test situations
Prior to test execution, the ‘tester’ identifies the weak points on which the test should focus. These are often mistakes in the thought processes of others and things that have been forgotten. These aspects form the basis of the test cases to be executed. Examples are:
- Exceptional situations
- rare situations in the system operation, screen processing or business and other processes
- Fault handling
- forcing a fault situation during the handling of another fault situation, interrupting a process unexpectedly, etc.
- Non-permitted input
- negative amounts, zeros, excessive values, too-long names, empty (mandatory) fields, etc. (only useful if there is no syntactic test carried out on this part)
- Specific combinations, for example in the area of:
- Data: an as-yet untried combination of input values
- Sequence of transactions: e.g. «change – cancel change – change again – cancel – etc.» a number of times in succession
- Claiming too much of the system resources (memory, disk space, network)
- Complex parts of the system
- Often-changed parts of the system
- Parts of the system that often contained faults in the past (processes/functions) .
2 — Creating logical test cases
This step normally takes place only with more complex test cases. The tester may consider creating a logical test case that will cover the situation to be tested.
3 — Creating physical test cases
This step normally only takes place with more complex test cases. The tester may consider creating a physical test case for the logical test case.
4 — Establishing the starting point
During this activity, it may emerge that it is necessary to build a particular starting point for purposes of the test.
An overview of all featured Test Design Techniques can be found here.
Привет! Да-да, про тестирование ПО тут уже куча статей. Здесь я просто буду стараться структурировать как можно более полный охват данных из разных источников (чтобы по теории все основное было сразу в одном месте, и новичкам, например, было легче ориентироваться). При этом, чтобы статья не казалась слишком громоздкой, информация будет представлена без излишней детализации, как необходимая и достаточная для прохождения собеседования (согласно моему опыту), рассчитанное на стажеров/джунов.
ОСНОВНЫЕ ТЕРМИНЫ
Обеспечение качества (Quality Assurance) — изучение возможностей по изменению и улучшению процесса разработки, улучшению коммуникаций в команде, где тестирование является только одним из аспектов обеспечения качества.
Контроль качества (Quality Control) — анализ результатов тестирования и качества новых версий выпускаемого продукта.
Тестирование ПО (Software Testing) — проверка соответствия между реальным и ожидаемым поведением программы, проводится на наборе тестов, который выбирается некоторым образом.
Это одна из техник QC, включающая в себя:
-
планирование работ (Test Management)
-
проектирование тестов (Test Design)
-
выполнение тестирования (Test Execution)
-
анализ результатов (Test Analysis)
Как взаимосвязаны выше указанные термины хорошо объясняется в статье Разница между тестированием, QC и QA. Здесь я не буду слишком останавливаться на этом, потому что эта статья больше про тестирование ПО.
Основные цели тестирования:
-
техническая
Предоставление актуальной информации о состоянии продукта на данный момент.
-
коммерческая
Повышение лояльности к компании и продукту, т.к. любой обнаруженный дефект негативно влияет на доверие пользователей.
|
Верификация (verification) |
Валидация (validation) |
|
Соответствие продукта требованиям (спецификации) |
Соответствие продукта потребностям пользователей |
Дефект (баг) — это несоответствие фактического результата выполнения программы ожидаемому результату.
Следует уметь различать, что:
-
Error — это ошибка пользователя, то есть он пытается использовать программу иным способом (например, вводит буквы в поля, где требуется вводить цифры). В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message).
-
Bug (defect) — это ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так, как планировалось. Например, внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
-
Failure — это сбой в работе компонента, всей программы или системы (может быть как аппаратным, так и вызванным дефектом).
Жизненный цикл бага

Атрибуты дефекта
-
Серьезность (Severity) — характеризует влияние дефекта на работоспособность приложения. Выставляется тестировщиком.
Градация Серьезности дефекта
-
Blocker — ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна.
-
Крит (Critical) — неправильно работающая ключевая бизнес-логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие непрямые пути.
-
Major — часть основной бизнес логики работает некорректно, есть возможность для работы с тестируемой функцией, используя обходные пути.
-
Minor — незначительная ошибка, не нарушающая бизнес-логику тестируемой части приложения, очевидная проблема пользовательского интерфейса.
-
Тривиальная (Trivial) — ошибка, не касающаяся бизнес-логики приложения, не оказывающая никакого влияния на общее качество продукта.
-
Приоритет (Priority) — указывает на очередность выполнения задачи или устранения дефекта. Чем выше приоритет, тем быстрее нужно исправлять дефект. Выставляется менеджером, тимлидом или заказчиком.
Тест дизайн
Тест дизайн — это этап процесса тестирования ПО, на котором проектируются и создаются тестовые сценарии (тест кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования.
Ответственные за тест дизайн:
-
Тест аналитик — определяет «ЧТО тестировать?»
-
Тест дизайнер — определяет «КАК тестировать?»
ТЕХНИКИ ТЕСТ-ДИЗАЙНА
-
Эквивалентное Разделение (Equivalence Partitioning — EP). Как пример, есть диапазон допустимых значений от 1 до 10, выбирается одно верное значение внутри интервала (например, 5) и одно неверное значение вне интервала — 0.
-
Анализ Граничных Значений (Boundary Value Analysis — BVA). Если брать пример выше, в качестве значений для позитивного тестирования берется минимальная и максимальная границы (1 и 10), и значения больше и меньше границ (0 и 11). BVA может применяться к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
-
Причина / Следствие (Cause/Effect — CE). Подразумевается ввод условий, для получения ответа от системы (следствие).
-
Предугадывание ошибки (Error Guessing — EG). Это когда тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку.
-
Исчерпывающее тестирование (Exhaustive Testing — ET) — подразумевается проверка всех возможные комбинации входных значений. На практике не используется.
-
Попарное тестирование (Pairwise Testing) — это техника формирования наборов тестовых данных. Используется для тестирования сущностей с большими наборами входных данных (например, фильтры, сортировки). Преимущество данной техники в том, что она сокращает общее количество тест-кейсов, тем самым уменьшая время и расходы, затраченные на тестирование. Эта техника заслуживает отдельного внимания и более подробно рассматривается здесь. Также в конце данной статьи есть инструменты для автоматизации этой техники.
-
Таблица принятия решений (decision table) — инструмент для упорядочения сложных бизнес-требований, которые должны быть реализованы в продукте. В таблицах решений представлен набор условий, одновременное выполнение которых приводит к определенному действию.

ВИДЫ ТЕСТИРОВАНИЯ

Функциональное тестирование рассматривает заранее указанное поведение и основывается на анализе спецификации компонента или системы в целом.
Нефункциональные виды тестирования
-
Тестирование пользовательского интерфейса (GUI Testing) — функциональная проверка интерфейса на соответствие требованиям (размер, шрифт, цвет, consistent behavior).
-
Тестирование удобства пользования (Usability Testing) — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Сюда также входит:
User eXperience (UX) — ощущение, испытываемое пользователем во время использования цифрового продукта, в то время как User interface — это инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс». -
Тестирование безопасности — это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
-
Тестирование установки (Installation testing) направленно на проверку успешной инсталляции и настройки, а также обновления или удаления программного обеспечения.
-
Конфигурационное тестирование (Configuration Testing) — специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
-
Тестирование взаимодействия (Interoperability Testing) — это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами и включающее в себя тестирование совместимости (compatibility testing) и интеграционное тестирование
-
Тестирование на отказ и восстановление (Failover and Recovery Testing) проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети). Целью данного вида тестирования является проверка систем восстановления (или дублирующих основной функционал систем), которые, в случае возникновения сбоев, обеспечат сохранность и целостность данных тестируемого продукта.
-
Нагрузочное тестирование — это автоматизированное тестирование, имитирующее работу определенного количества бизнес пользователей на каком-либо общем (разделяемом ими) ресурсе.
-
Тестирование стабильности или надежности (Stability / Reliability Testing). Задачей тестирования стабильности (надежности) является проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
-
Стрессовое тестирование (Stress Testing) позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса. Стрессом в данном контексте может быть повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера. Также одной из задач при стрессовом тестировании может быть оценка деградации производительности, таким образом цели стрессового тестирования могут пересекаться с целями тестирования производительности.
-
Объемное тестирование (Volume Testing). Задачей объемного тестирования является получение оценки производительности при увеличении объемов данных в базе данных приложения
По виду Тестовых Сценариев:
-
Позитивный тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
-
Негативный тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций (срабатывание валидаторов), а также проверяет, что вызываемая приложением функция не выполняется при срабатывании валидатора.
По Уровню Тестирования:
-
Модульное тестирование (Unit Testing) Компонентное — проверяет функциональность и ищет дефекты в частях приложения, которые доступны и могут быть протестированы по-отдельности (модули программ, объекты, классы, функции и т.д.).
-
Интеграционное тестирование (Integration Testing) Проверяется взаимодействие между компонентами системы после проведения компонентного тестирования.
Подходы к интеграционному тестированию
-
Снизу вверх (Bottom Up Integration) Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
-
Сверху вниз (Top Down Integration) Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами.
-
Большой взрыв («Big Bang» Integration) Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
-
Системное тестирование (System Testing) Основной задачей системного тестирования является проверка как функциональных, так и не функциональных требований в системе в целом. При этом выявляются дефекты, такие как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования и т.д.
-
Операционное тестирование (Release Testing). Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации. Поэтому так важно провести операционное тестирование как финальный шаг валидации. Кроме этого, тестирование в среде эксплуатации позволяет выявить и нефункциональные проблемы, такие как: конфликт с другими системами, смежными в области бизнеса или в программных и электронных окружениях и др. Очевидно, что нахождение подобных вещей на стадии внедрения — критичная и дорогостоящая проблема.
Cтатическое и динамическое тестирование
Статическое тестирование отличается от динамического тем, что производится без запуска программного кода продукта. Тестирование осуществляется путем анализа программного кода (code review) или скомпилированного кода. Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к статическому тестированию относится тестирования спецификации и прочей документации.
Исследовательское / ad-hoc тестирование
Простейшее определение исследовательского тестирования — это разработка и выполнения тестов в одно и то же время. Что является противоположностью сценарного подхода (с его предопределенными процедурами тестирования, неважно ручными или автоматизированными). Исследовательские тесты, в отличие от сценарных тестов, не определены заранее и не выполняются в точном соответствии с планом.
Разница между ad hoc и exploratory testing в том, что теоретически, ad hoc может провести кто угодно, а для проведения exploratory необходимо мастерство и владение определенными техниками.
Дымовое (Smoke) тестирование рассматривается как короткий цикл тестов, выполняемый для подтверждения того, что после сборки кода (нового или исправленного) устанавливаемое приложение, стартует и выполняет основные функции.
Тестирование сборки (Build Verification Test) — тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования. По своим целям является аналогом Дымового Тестирования, направленного на приемку новой версии в дальнейшее тестирование или эксплуатацию. Вглубь оно может проникать дальше, в зависимости от требований к качеству выпущенной версии.
Повторное тестирование — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок. В чем разница между regression testing и re-testing? Re-testing — проверяется исправление багов Regression testing — проверяется то, что исправление багов, а также любые изменения в коде приложения, не повлияли на другие модули ПО и не вызвало новых багов.
Регрессионное тестирование — это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде. Регрессионными могут быть как функциональные, так и нефункциональные тесты.
Санитарное тестирование — это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружающей среде. Обычно выполняется вручную.
ДОКУМЕНТАЦИЯ
Требования — это спецификация (описание) того, что должно быть реализовано. Требования описывают то, что необходимо реализовать, без детализации технической стороны решения.
Основные атрибуты требований:
-
Полнота — в требовании должна содержаться вся необходимая для реализации функциональности информация.
-
Непротиворечивость — требование не должно содержать внутренних противоречий и противоречий другим требованиям и документам.
-
Недвусмысленность — требование должно содержать однозначные формулировки.
-
Проверяемость (тестопригодность) — формулировка требований таким образом, чтобы можно было выставить однозначный вердикт, выполнено все в соответствии с требованиями или нет.
-
Приоритетность — у каждого требования должен быть приоритет (количественная оценка степени значимости требования).
Тест план (Test Plan) — документ, описывающий весь объем работ по тестированию ( а также необходимое в процессе работы оборудование, специальные знания, оценки рисков с вариантами их разрешения). Отвечает на вопросы:
-
Что нужно тестировать?
-
Как будет тестироваться?
-
Когда будет тестироваться?
-
Критерии начала тестирования.
-
Критерии окончания тестирования.
Основные пункты из которых может состоять тест-план перечислены в стандарте IEEE 829.
Неотъемлемой частью тест-плана является Traceability matrix — Матрица соответствия требований (МСТ) — это таблица, содержащая соответствие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases). В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки. МСТ используется для валидации покрытия продукта тестами.
|
Функциональные требования |
functional requirement 1 |
functional requirement 2 |
functional requirement 3 |
… |
|
Тестовые сценарии |
||||
|
test case 1 |
+ |
|||
|
test case 2 |
+ |
+ |
||
|
… |
Чек-лист (check list) — это документ, описывающий что должно быть протестировано. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта. Чаще всего, в ЧЛ содержатся только действия, без ожидаемого результата. ЧЛ менее формализован, чем тестовый сценарий, ассоциируется с гибкими подходами в тестировании.
Тестовый сценарий (Test Case) — это документ, в котором содержатся условия, шаги и другие параметры для проверки реализации тестируемой функции или её части.
Тест-кейс состоит из:
-
Названия
-
Более подробного описания сути проводимого кейса (для более сложных кейсов)
-
Описания окружения
-
Указания тестируемого компонента приложения
-
Предусловия — PreConditions (не всегда используются) — действий, которые приводят систему к состоянию пригодному для проведения проверки, либо список условий, выполнение которых говорит о том, что система находится в нужном для состоянии основного теста
-
Шагов — Steps — cписок действий, переводящих систему из одного состояния в другое, для получения результата
-
Ожидаемый результат, на основании которого можно делать вывод о удовлетворении реализации, поставленным требованиям
-
и иногда Постусловия — PostConditions — для перевода системы в первоначальное состояние, как до проведения теста (initial state)
Из тестовых сценариев, сгруппированных по некоему признаку (например, тестируемой функциональности), получаются некоторые наборы. Они могут быть как зависящими от последовательности выполнения (результат выполнения предыдущего является предварительным условием для следующего — этоTest script), так и независимыми (Test suite).
Наиболее часто выделяются наборы для:
-
Smoke тестирования
-
приёмо-сдаточных испытаний.
Баг Репорт (Bug Report) — это документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе функциональности.
|
Шапка |
Название — Короткое описание (Summary), составляется по схеме WWW (What? Where? When?) или ЧТО ГДЕ КОГДА (при каких условиях) |
|
Автор (Author) баг репорта |
|
|
Назначен на (Assigned To) сотрудника, который будет с ним разбираться |
|
|
Статус (Status) бага в соответствии с workflow |
|
|
Проект (Project) |
|
|
Компонент приложения (Component) — название тестируемой функции или ее части |
|
|
Информация по сборке, на которой была найдена ошибка — Номер версии (Version) |
|
|
Информация об окружении — ОС + версия / и т.д… |
|
|
Серьезность (Severity) |
|
|
Приоритет (Priority) |
|
|
Описание |
Предусловия — PreConditions — действий, которые приводят систему к состоянию пригодному для проведения проверки (не всегда требуются) |
|
Шаги воспроизведения (Steps to Reproduce), по которым воспроизводится ситуация, приведшая к ошибке |
|
|
Фактический Результат (Result), полученный после прохождения шагов воспроизведения, часто = название (Summary) + расшифровка чего-либо (например, ошибки по коду), если нужно |
|
|
Ожидаемый результат (Expected Result) — который правильный |
|
|
Прикрепленные файлы |
(Attachment) Файл с логами, скриншот или видео каст либо их комбинация для прояснения причины ошибки |
Огромное спасибо @alexlobach и @Gennadii_M за статьи! Большая часть информации взята именно оттуда.
UPD: статья пополняется. Спасибо @yakoeka
Тестовое
Покрытие (Test Coverage)
Тестовое
Покрытие
— это одна из метрик оценки качества
тестирования, представляющая из себя
плотность покрытия тестами требований
либо исполняемого кода.
Если
рассматривать тестирование как «проверку
соответствия между реальным и ожидаемым
поведением программы, осуществляемая
на конечном наборе тестов», то именно
этот конечный набор тестов и будет
определять тестовое покрытие:
Чем
выше требуемый уровень тестового
покрытия, тем больше тестов будет
выбрано, для проверки тестируемых
требований или исполняемого кода.
Сложность
современного программного обеспечения
и инфраструктуры сделало невыполнимой
задачу проведения тестирования со 100%
тестовым покрытием. Поэтому для разработки
набора тестов, обеспечивающего более
менее высокий уровень покрытия можно
использовать специальные инструменты
либо техники тест дизайна.
Существует
2 широко применяемых подхода к оценке
и измерению тестового покрытия:
-
Покрытие
требований (Requirements Coverage)
— оценка покрытия тестами функциональных
и нефункциональных требований к продукту
путем построения матриц трассировки
(traceability matrix). -
Покрытие
кода (Code Coverage)
— оценка покрытия исполняемого кода
тестами, путем отслеживания непроверенных
в процессе тестирования частей
программного обеспечения.
Различия:
Метод
покрытия требований сосредоточен на
проверке соответствия набора проводимых
тестов требованиям к продукту, в то
время как анализ покрытия кода — на
полноте проверки тестами, разработанной
части продукта (исходного кода).
Ограничения:
Метод
оценки покрытия кода не выявит
нереализованные требования, так как
работает не с конечным продуктом, а с
существующим исходным кодом.
Метод
покрытия требований может оставить
непроверенными некоторые участки кода,
потому что не учитывает конечную
реализацию.
Покрытие
требований (Requirements Coverage)
Расчет
тестового покрытия относительно
требований проводится по формуле:
Tcov
= (Lcov/Ltotal) * 100%
где:
Tcov
— тестовое покрытие
Lcov
— количество требований, проверяемых
тест кейсами
Ltotal
— общее количество требований
Для
измерения покрытия требований, необходимо
проанализировать требования к продукту
и разбить их на пункты. Опционально
каждый пункт связывается с тест кейсами,
проверяющими его. Совокупность этих
связей — и является матрицей трассировки.
Проследив связи, можно понять какие
именно требования проверяет тестовый
случай.
Тесты
не связанные с требованиями не имеют
смысла. Требования, не связанные с
тестами — это «белые пятна», т.е.
выполнив все созданные тест кейсы,
нельзя дать ответ реализовано данное
требование в продукте или нет.
Для
оптимизации тестового покрытия при
тестировании на основании требований,
наилучшим способом будет использование
стандартных техник тест дизайна. Пример
разработки тестовых случаев по имеющимся
требованиям рассмотрен в разделе:
«Практическое
применение техник тест дизайна при
разработке тест кейсов«
Покрытие
кода (Code Coverage)
Расчет
тестового покрытия относительно
исполняемого кода программного
обеспечения проводится по формуле:
Tcov
= (Ltc/Lcode) * 100%
где:
Tcov
— тестовое покрытие
Ltc
— кол-ва строк кода, покрытых тестами
Lcode
— общее кол-во строк кода.
В
настоящее время существует инструментарий
(например: Clover),
позволяющий проанализировать в какие
строки были вхождения во время проведения
тестирования, благодаря чему можно
значительно увеличить покрытие, добавив
новые тесты для конкретных случаев, а
также избавиться от дублирующих тестов.
Проведение такого анализа кода и
последующая оптимизация покрытия
достаточно легко реализуется в рамках
тестирования белого ящика (white-box testing)
при модульном, интеграционном и системном
тестировании; при тестировании же
черного ящика (black-box testing) задача становится
довольно дорогостоящей, так как требует
много времени и ресурсов на установку,
конфигурацию и анализ результатов
работы, как со стороны тестировщиков,
так и разработчиков.
Техники
тест
дизайна
(Test Design Technics)
Многие
люди тестируют и пишут тестовые
случаи (test cases),
но не многие пользуются специальными
техниками
тест дизайна.
Постепенно, набираясь опыта они осознают,
что постоянно делают одну и ту же работу,
поддающуюся конкретным правилам. И
тогда они находят, что все эти правила
уже описаны.
Предлагаем
вам ознакомиться с кратким описанием
наиболее распространенных техник тест
дизайна:
-
Эквивалентное
Разделение
(Equivalence
Partitioning — EP).
Как
пример, у вас есть диапазон допустимых
значений от 1 до 10, вы должны выбрать
одно верное значение внутри интервала,
скажем, 5, и одно неверное значение вне
интервала — 0. -
Анализ
Граничных Значений
(Boundary
Value Analysis — BVA).
Если взять пример выше, в качестве
значений для позитивного тестирования
выберем минимальную и максимальную
границы (1 и 10), и значения больше и меньше
границ (0 и 11). Анализ Граничный значений
может быть применен к полям, записям,
файлам, или к любого рода сущностям
имеющим ограничения. -
Причина
/ Следствие
(Cause/Effect
— CE).
Это, как правило, ввод комбинаций условий
(причин), для получения ответа от системы
(Следствие). Например, вы проверяете
возможность добавлять клиента, используя
определенную экранную форму. Для этого
вам необходимо будет ввести несколько
полей, таких как «Имя», «Адрес»,
«Номер Телефона» а затем, нажать
кнопку «Добавить» — эта «Причина».
После нажатия кнопки «Добавить»,
система добавляет клиента в базу данных
и показывает его номер на экране — это
«Следствие». -
Предугадывание
ошибки
(Error
Guessing — EG).
Это когда тест аналитик использует
свои знания системы и способность к
интерпретации спецификации на предмет
того, чтобы «предугадать» при каких
входных условиях система может выдать
ошибку. Например, спецификация говорит:
«пользователь должен ввести код».
Тест аналитик, будет думать: «Что,
если я не введу код?», «Что, если я
введу неправильный код? «, и так далее.
Это и есть предугадывание ошибки. -
Исчерпывающее
тестирование
(Exhaustive
Testing — ET)
— это крайний случай. В пределах этой
техники вы должны проверить все возможные
комбинации входных значений, и в
принципе, это должно найти все проблемы.
На практике применение этого метода
не представляется возможным, из-за
огромного количества входных значений.
Практическое
применение техник тест дизайна при
разработке тест кейсов
Многие
знают что такое тест дизайн, но не все
умеют его применять. Чтобы немного
прояснить ситуацию, мы решили предложить
Вашему вниманию последовательный подход
к разработке тестовых
случаев (тест кейсов),
используя самые простейшие техники
тест дизайна:
-
Эквивалентное
Разделение (Equivalence Partitioning),
далее в тексте — EP -
Анализ
Граничных Значений (Boundary Value Analysis),
далее в тексте — BVA -
Предугадывание
ошибки (Error Guessing),
далее в тексте — EG -
Причина
/ Следствие (Cause/Effect),
далее в тексте — CE
План
разработки тест кейсов
предлагается следующий:
-
Анализ
требований. -
Определение
набора тестовых данных на основании
EP,
BVA,
EG. -
Разработка
шаблона теста на основании CE. -
Написание
тест кейсов на основании первоначальных
требований, тестовых данных и шагов
теста.
Далее
на примере, рассмотрим предложенный
подход.
Пример:
Протестировать
функциональность формы приема заявок,
требования к которой предоставлены в
следующей таблице:
|
Элемент |
Тип |
Требования |
|
Тип |
combobox |
Набор
* |
|
Контактное |
editbox |
1.
2. 3. |
|
Контактный |
editbox |
|
|
Сообщение |
text |
1. 2. |
|
Отправить |
button |
Состояние:
1.
2.
Действия
1.
2. |
Вариант
использования (иногда
его может и не быть):
Читаем,
анализируем требования и выделяем для
себя следующие нюансы:
-
какие
из полей обязательные для заполнения? -
имеют
ли поля ограничения по длине или по
размерности (границы)? -
какие
из полей имеют специальные форматы?
2.Определение набора тестовых данных
Отталкиваясь
от требований к полям, используя техники
тест дизайна начинаем определение
набора тестовых данных:
-
в
зависимости от того обязательное поле
или нет, определим какие поля необходимо
проверить на пустое значение, так как
оно может вызывать ошибку (В результирующей
таблице оранжевый
цвет) -
т.к.
исчерпывающее тестирование не
представляется возможным из-за
огромного числа всевозможных комбинаций
значений,
в первую очередь необходимо определить
минимальный
набор данных.
Это можно сделать используя такие
техники,
как EP
и BVA.
(В результирующей таблице голубой
цвет) -
На
форме присутствует поле, имеющее
составной тип (цифры используются
совместно с символами), обладает
специальным форматом данных и поэтому
выделение тестовых данных для него —
это достаточно трудоемкая задача. В
пределах данной статьи ограничимся
только простой проверкой форматов и
основных требований описанных в форме
приема заявок. -
По
завершению генерации данных используя
стандартные техники, можно добавить
некоторое количество значений на
основании личного опыта (техника
EG)
— это будет использование спец. символов,
очень длинных строк, разных форматов
данных, регистров в строках (Upper, Lowwer,
Mixed cases), отрицательные и нулевые значения,
кейворды Null — NaN — Infinity и т.д. Сюда можно
включить все, что вы полагаете может
вывести приложение из строя (В
результирующей таблице фиолетовый
цвет)
Примечание:
Отметим,
что количество тестовых данных после
окончательной генерации будет достаточно
большим, даже при использовании
специальных техник тест дизайна. Поэтому
ограничимся лишь несколькими значениями
для каждого поля, так как цель данной
статьи показать именно процесс
создания тест кейсов,
а не процесс получения конкретных
тестовых данных.
2.1 Выбор тестовых данных для каждого отдельно взятого поля
-
Поле
Тип
обращения.
Так как все данные входят в 1 класс
эквивалентности, то есть не изменяют
сам процесс выполнения приема заявки,
берем любою (1-ю) позицию в листе с
ожидаемым пезультатом ОК. Но т.к.
реализовано поле как лист, имеет также
смысл рассмотреть и граничные условия
(техника BVA), т.е. берем первый и последний
элементы. Итого: 1-я и последняя позиции
в листе. Ожидаемый результат при
использовании — ОК. -
Поле
Контактное
лицо.
Это обязательное поле размером от 1 до
25 символов (включая границы). Проверка
на обязательность добавляет к тестовым
данным пустое значение. Проведем анализ
граничных условий (BVA), получим набор:
0, 1, 2, 24, 25 и 26 символов. Пустое значение
(0 символов) уже было добавлено при
анализе обязательности поля для ввода,
поэтому при BVA мы не будем добавлять
его еще раз. (если его добавить второй
раз, произойдет дублирование тестовых
данных, которое не приведет к нахождению
новых дефектов, а значит повторное
добавление в домен не имеет смысла). В
связи с тем, что значения 2 и 24 символа
являются, с нашей точки зрения,
некритичными, их можно не добавлять. В
итоге получаем, что минимальный набор
данных для тестирования поля — это
строки 1 и 25 — ОК, и 0 (пустое значение),
26 символов — NOK. -
поле
Контактный
телефон
состоит из нескольких частей: код
страны, код оператора, номер телефон
(который может быть составной и
разделенный дефисами). Для определения
правильного набора тестовых данных
необходимо рассматривать каждую
составную часть по-отдельности. Применяя
BVA и EP, получим:-
для
номеров с плюсом
По
BVA получим номера с 10, 11, 12 и 14, 15, 16
цифрами, где 10 и 16 — NOK, а 11, 12, 14, 15 —
OK
Рассматривая полученные данные с
позиции EP выделим, что 11, 12, 14, 15 входят
в один класс эквивалентности. Поэтому
при тестировании мы можем использовать
любое из них, но так как 11 и 15 — это
границы интервала, то на наш взгляд их
пропускать нельзя. Следовательно мы
можем уменьшить набор значений до
двух, исключив 12 и 14, а оставив 11 и 15 для
проверки граничных условий.
Итого
имеем:
11 и 15 цифр — OK, (+12345678901,
+123456789012345)
10 и 16 цифр — NOK; (+1234567890,
+1234567890123456) -
для
номеров без плюса:
По
BVA получим номера с 4, 5, 6 и 9, 10, 11
цифрами.
Действуя аналогично примеру
для номеров телефонов с плюсом, исключим
значения 6 и 9, оставив 5 и 10.
Итого
имеем:
5 и 10 цифр — OK, (12345, 1234567890)
4 и
11 цифр — NOK; (1234, 12345678901)
-
-
поле
Сообщение.
подбор данных проводим по аналогии с
полем Контактное лицо. На выходе получаем
значения: строки 1 и 1024 — ОК, и 1025 символов
— NOK.
Результирующая
таблица данных, для использования при
последующем составлении тест кейсов
|
Поле |
OK/NOK |
Значение |
Комментарий |
|
Тип |
OK |
Консультация |
первый |
|
Ошибка |
последний |
||
|
NOK |
|||
|
Контактное |
OK |
йцукенгшщзйцукенгшщзйцуке |
25 |
|
a |
1 |
||
|
ЙЦУКЕНГШЩЗФЫВАПРОЛДЖЯЧСМИ |
25 |
||
|
ЙЦУКЕНГШЩЗфывапролджЯЧСМИ |
25 |
||
|
NOK |
пустое значение |
||
|
йцукенгшщзйцукенгшщзйцукей |
длина |
||
|
@#$%^&;.?,>|/№»!()_{}[<~ |
спец. |
||
|
1234567890123456789012345 |
только |
||
|
adsadasdasdas |
очень |
||
|
Контактный |
OK |
+12345678901 |
с |
|
+123456789012345 |
с |
||
|
12345 |
без |
||
|
1234567890 |
без |
||
|
NOK |
пустое |
||
|
+1234567890 |
с |
||
|
+1234567890123456 |
с |
||
|
1234 |
без |
||
|
12345678901 |
без |
||
|
+YYYXXXyyyxxzz |
с |
||
|
yyyxxxxzz |
без |
||
|
+###-$$$-%^-&^-&! |
спец. |
||
|
1232312323123213231232(…)99 |
очень |
||
|
Сообщение |
OK |
йццуйцуйц(…)йцу |
максимальная |
|
NOK |
пустое |
||
|
йццуйцуйц(…)йцуц |
длина |
||
|
adsadasdasdas |
очень |
||
|
@##$$$%^&^& |
только |
Соседние файлы в папке 03.11.13_1
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Тестирование. Фундаментальная теория +13
Тестирование IT-систем
Рекомендация: подборка платных и бесплатных курсов создания сайтов — https://katalog-kursov.ru/
Доброго времени суток!
Хочу собрать всю самую необходимую теорию по тестирвоанию, которую спрашивают на собеседованиях у trainee, junior и немножко middle. Собственно, я собрал уже не мало. Цель сего поста в том, чтобы сообща добавить упущенное и исправить/перефразировать/добавить/сделатьЧтоТоЕщё с тем, что уже есть, чтобы стало хорошо и можно было взять всё это и повторить перед очередным собеседованием про всяк случай. Вообщем, коллеги, прошу под кат, кому почерпнуть что-то новое, кому систематизировать старое, а кому внести свою лепту.
В итоге должна получиться исчерпывающая шпаргалка, которую нужно перечитать по дороге на собеседование.
Всё ниже перечисленное не выдумано мной лично, а взято с разных источников, где мне лично формулировка и определение понравилось больше. В конце список источников.
В теме: определение тестирования, качество, верификация / валидация, цели, этапы, тест план, пункты тест плана, тест дизайн, техники тест дизайна, traceability matrix, tets case, чек-лист, дефект, error/deffect/failure, баг репорт, severity vs priority, уровни тестирования, виды / типы, подходы к интеграционному тестированию, принципы тестирования, статическое и динамическое тестирование, исследовательское / ad-hoc тестирование, требования, жизненный цикл бага, стадии разработки ПО, decision table, qa/qc/test engineer, диаграмма связей.
Поехали!
Тестирование программного обеспечения — проверка соответствия между реальным и ожидаемым поведением программы, осуществляемая на конечном наборе тестов, выбранном определенным образом. В более широком смысле, тестирование — это одна из техник контроля качества, включающая в себя активности по планированию работ (Test Management), проектированию тестов (Test Design), выполнению тестирования (Test Execution) и анализу полученных результатов (Test Analysis).
Качество программного обеспечения (Software Quality) — это совокупность характеристик программного обеспечения, относящихся к его способности удовлетворять установленные и предполагаемые потребности. [ISO 8402:1994 Quality management and quality assurance]
Верификация (verification) — это процесс оценки системы или её компонентов с целью определения удовлетворяют ли результаты текущего этапа разработки условиям, сформированным в начале этого этапа[IEEE]. Т.е. выполняются ли наши цели, сроки, задачи по разработке проекта, определенные в начале текущей фазы.
Валидация (validation) — это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, требованиям к системе [BS7925-1].
Также можно встретить иную интерпритацию:
Процесс оценки соответствия продукта явным требованиям (спецификациям) и есть верификация (verification), в то же время оценка соответствия продукта ожиданиям и требованиям пользователей — есть валидация (validation). Также часто можно встретить следующее определение этих понятий:
Validation — ’is this the right specification?’.
Verification — ’is the system correct to specification?’.
Цели тестирвоания
Повысить вероятность того, что приложение, предназначенное для тестирования, будет работать правильно при любых обстоятельствах.
Повысить вероятность того, что приложение, предназначенное для тестирования, будет соответствовать всем описанным требованиям.
Предоставление актуальной информации о состоянии продукта на данный момент.
Этапы тестирования:
1. Анализ
2. Разработка стратегии тестирования
и планирование процедур контроля качества
3. Работа с требованиями
4. Создание тестовой документации
5. Тестирование прототипа
6. Основное тестирование
7. Стабилизация
8. Эксплуатация
Тест план (Test Plan) — это документ, описывающий весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков с вариантами их разрешения.
Отвечает на вопросы:
Что надо тестировать?
Что будете тестировать?
Как будете тестировать?
Когда будете тестировать?
Критерии начала тестирования.
Критерии окончания тестирования.
Основные пункты тест плана
В стандарте IEEE 829 перечислены пункты, из которых должен (пусть — может) состоять тест-план:
a) Test plan identifier;
b) Introduction;
c) Test items;
d) Features to be tested;
e) Features not to be tested;
f) Approach;
g) Item pass/fail criteria;
h) Suspension criteria and resumption requirements;
i) Test deliverables;
j) Testing tasks;
k) Environmental needs;
l) Responsibilities;
m) Staf?ng and training needs;
n) Schedule;
o) Risks and contingencies;
p) Approvals.
Тест дизайн — это этап процесса тестирования ПО, на котором проектируются и создаются тестовые случаи (тест кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования.
Роли, ответственные за тест дизайн:
• Тест аналитик — определяет «ЧТО тестировать?»
• Тест дизайнер — определяет «КАК тестировать?»
Техники тест дизайна
• Эквивалентное Разделение (Equivalence Partitioning — EP). Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0.
• Анализ Граничных Значений (Boundary Value Analysis — BVA). Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10), и значения больше и меньше границ (0 и 11). Анализ Граничный значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
• Причина / Следствие (Cause/Effect — CE). Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие). Например, вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем, нажать кнопку «Добавить» — эта «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
• Предугадывание ошибки (Error Guessing — EG). Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тест аналитик, будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.
• Исчерпывающее тестирование (Exhaustive Testing — ET) — это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным, из-за огромного количества входных значений.
Traceability matrix — Матрица соответствия требований — это двумерная таблица, содержащая соответсвие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases). В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки.
Матрица соответсвия требований используется QA-инженерами для валидации покрытия продукта тестами. МСТ является неотъемлемой частью тест-плана.
Тестовый случай (Test Case) — это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Пример:
Action Expected Result Test Result
(passed/failed/blocked)
Open page «login» Login page is opened Passed
Каждый тест кейс должен иметь 3 части:
PreConditions Список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
Test Case Description Список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям
PostConditions Список действий, переводящих систему в первоначальное состояние (состояние до проведения теста — initial state)
Виды Тестовых Случаев:
Тест кейсы разделяются по ожидаемому результату на позитивные и негативные:
• Позитивный тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
• Негативный тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций (срабатывание валидаторов), а также проверяет, что вызываемая приложением функция не выполняется при срабатывании валидатора.
Чек-лист (check list) — это документ, описывающий что должно быть протестировано. При этом чек-лист может быть абсолютно разного уровня детализации. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта.
Как правило, чек-лист содержит только действия (шаги), без ожидаемого результата. Чек-лист менее формализован чем тестовый сценарий. Его уместно использовать тогда, когда тестовые сценарии будут избыточны. Также чек-лист ассоциируются с гибкими подходами в тестировании.
Дефект (он же баг) — это несоответствие фактического результата выполнения программы ожидаемому результату. Дефекты обнаруживаются на этапе тестирования программного обеспечения (ПО), когда тестировщик проводит сравнение полученных результатов работы программы (компонента или дизайна) с ожидаемым результатом, описанным в спецификации требований.
Error — ошибка пользователя, то есть он пытается использовать программу иным способом.
Пример — вводит буквы в поля, где требуется вводить цифры (возраст, количество товара и т.п.).
В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message), с красным крестиком которые.
Bug (defect) — ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так как планировалось и программа выходит из-под контроля. Например, когда никак не контроллируется ввод пользователя, в результате неверные данные вызывают краши или иные «радости» в работе программы. Либо внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
Failure — сбой (причём не обязательно аппаратный) в работе компонента, всей программы или системы. То есть, существуют такие дефекты, которые приводят к сбоям (A defect caused the failure) и существуют такие, которые не приводят. UI-дефекты например. Но аппаратный сбой, никак не связанный с software, тоже является failure.
Баг Репорт (Bug Report) — это документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Шапка
Короткое описание (Summary) Короткое описание проблемы, явно указывающее на причину и тип ошибочной ситуации.
Проект (Project) Название тестируемого проекта
Компонент приложения (Component) Название части или функции тестируемого продукта
Номер версии (Version) Версия на которой была найдена ошибка
Серьезность (Severity) Наиболее распространена пятиуровневая система градации серьезности дефекта:
• S1 Блокирующий (Blocker)
• S2 Критический (Critical)
• S3 Значительный (Major)
• S4 Незначительный (Minor)
• S5 Тривиальный (Trivial)
Приоритет (Priority) Приоритет дефекта:
• P1 Высокий (High)
• P2 Средний (Medium)
• P3 Низкий (Low)
Статус (Status) Статус бага. Зависит от используемой процедуры и жизненного цикла бага (bug workflow and life cycle)
Автор (Author) Создатель баг репорта
Назначен на (Assigned To) Имя сотрудника, назначенного на решение проблемы
Окружение
ОС / Сервис Пак и т.д. / Браузера + версия /… Информация об окружении, на котором был найден баг: операционная система, сервис пак, для WEB тестирования — имя и версия браузера и т.д.
…
Описание
Шаги воспроизведения (Steps to Reproduce) Шаги, по которым можно легко воспроизвести ситуацию, приведшую к ошибке.
Фактический Результат (Result) Результат, полученный после прохождения шагов к воспроизведению
Ожидаемый результат (Expected Result) Ожидаемый правильный результат
Дополнения
Прикрепленный файл (Attachment) Файл с логами, скриншот или любой другой документ, который может помочь прояснить причину ошибки или указать на способ решения проблемы.
Severity vs Priority
Серьезность (Severity) — это атрибут, характеризующий влияние дефекта на работоспособность приложения.
Приоритет (Priority) — это атрибут, указывающий на очередность выполнения задачи или устранения дефекта. Можно сказать, что это инструмент менеджера по планированию работ. Чем выше приоритет, тем быстрее нужно исправить дефект.
Severity выставляется тестировщиком
Priority — менеджером, тимлидом или заказчиком
Градация Серьезности дефекта (Severity)
S1 Блокирующая (Blocker)
Блокирующая ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна. Решение проблемы необходимо для дальнейшего функционирования системы.
S2 Критическая (Critical)
Критическая ошибка, неправильно работающая ключевая бизнес логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие входные точки. Решение проблемы необходимо для дальнейшей работы с ключевыми функциями тестируемой системой.
S3 Значительная (Major)
Значительная ошибка, часть основной бизнес логики работает некорректно. Ошибка не критична или есть возможность для работы с тестируемой функцией, используя другие входные точки.
S4 Незначительная (Minor)
Незначительная ошибка, не нарушающая бизнес логику тестируемой части приложения, очевидная проблема пользовательского интерфейса.
S5 Тривиальная (Trivial)
Тривиальная ошибка, не касающаяся бизнес логики приложения, плохо воспроизводимая проблема, малозаметная посредствам пользовательского интерфейса, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Градация Приоритета дефекта (Priority)
P1 Высокий (High)
Ошибка должна быть исправлена как можно быстрее, т.к. ее наличие является критической для проекта.
P2 Средний (Medium)
Ошибка должна быть исправлена, ее наличие не является критичной, но требует обязательного решения.
P3 Низкий (Low)
Ошибка должна быть исправлена, ее наличие не является критичной, и не требует срочного решения.
Уровни Тестирования
1. Модульное тестирование (Unit Testing)
Компонентное (модульное) тестирование проверяет функциональность и ищет дефекты в частях приложения, которые доступны и могут быть протестированы по-отдельности (модули программ, объекты, классы, функции и т.д.).
2. Интеграционное тестирование (Integration Testing)
Проверяется взаимодействие между компонентами системы после проведения компонентного тестирования.
3. Системное тестирование (System Testing)
Основной задачей системного тестирования является проверка как функциональных, так и не функциональных требований в системе в целом. При этом выявляются дефекты, такие как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность, неудобство использования и т.д.
4. Операционное тестирование (Release Testing).
Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации, как это было определено в бизнес моделе системы. Следует учесть, что и бизнес модель может содержать ошибки. Поэтому так важно провести операционное тестирование как финальный шаг валидации. Кроме этого, тестирование в среде эксплуатации позволяет выявить и нефункциональные проблемы, такие как: конфликт с другими системами, смежными в области бизнеса или в программных и электронных окружениях; недостаточная производительность системы в среде эксплуатации и др. Очевидно, что нахождение подобных вещей на стадии внедрения — критичная и дорогостоящая проблема. Поэтому так важно проведение не только верификации, но и валидации, с самых ранних этапов разработки ПО.
5. Приемочное тестирование (Acceptance Testing)
Формальный процесс тестирования, который проверяет соответствие системы требованиям и проводится с целью:
• определения удовлетворяет ли система приемочным критериям;
• вынесения решения заказчиком или другим уполномоченным лицом принимается приложение или нет.
Виды / типы тестирования
Функциональные виды тестирования
• Функциональное тестирование (Functional testing)
• Тестирование безопасности (Security and Access Control Testing)
• Тестирование взаимодействия (Interoperability Testing)
Нефункциональные виды тестирования
• Все виды тестирования производительности:
o нагрузочное тестирование (Performance and Load Testing)
o стрессовое тестирование (Stress Testing)
o тестирование стабильности или надежности (Stability / Reliability Testing)
o объемное тестирование (Volume Testing)
• Тестирование установки (Installation testing)
• Тестирование удобства пользования (Usability Testing)
• Тестирование на отказ и восстановление (Failover and Recovery Testing)
• Конфигурационное тестирование (Configuration Testing)
Связанные с изменениями виды тестирования
• Дымовое тестирование (Smoke Testing)
• Регрессионное тестирование (Regression Testing)
• Повторное тестирование (Re-testing)
• Тестирование сборки (Build Verification Test)
• Санитарное тестирование или проверка согласованности/исправности (Sanity Testing)
Функциональное тестирование рассматривает заранее указанное поведение и основывается на анализе спецификаций функциональности компонента или системы в целом.
Тестирование безопасности — это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
Тестирование взаимодействия (Interoperability Testing) — это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами и включающее в себя тестирование совместимости (compatibility testing) и интеграционное тестирование
Нагрузочное тестирование — это автоматизированное тестирование, имитирующее работу определенного количества бизнес пользователей на каком-либо общем (разделяемом ими) ресурсе.
Стрессовое тестирование (Stress Testing) позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса. Стрессом в данном контексте может быть повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера. Также одной из задач при стрессовом тестировании может быть оценка деградации производительности, таким образом цели стрессового тестирования могут пересекаться с целями тестирования производительности.
Объемное тестирование (Volume Testing). Задачей объемного тестирования является получение оценки производительности при увеличении объемов данных в базе данных приложения
Тестирование стабильности или надежности (Stability / Reliability Testing). Задачей тестирования стабильности (надежности) является проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
Тестирование установки направленно на проверку успешной инсталляции и настройки, а также обновления или удаления программного обеспечения.
Тестирование удобства пользования — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Сюда также входит:
Тестирование пользовательского интерфейса (англ. UI Testing) — это вид тестирования исследования, выполняемого с целью определения, удобен ли некоторый искусственный объект (такой как веб-страница, пользовательский интерфейс или устройство) для его предполагаемого применения.
User eXperience (UX) — ощущение, испытываемое пользователем во время использования цифрового продукта, в то время как User interface — это инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс».
Тестирование на отказ и восстановление (Failover and Recovery Testing) проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети). Целью данного вида тестирования является проверка систем восстановления (или дублирующих основной функционал систем), которые, в случае возникновения сбоев, обеспечат сохранность и целостность данных тестируемого продукта.
Конфигурационное тестирование (Configuration Testing) — специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
Дымовое (Smoke) тестирование рассматривается как короткий цикл тестов, выполняемый для подтверждения того, что после сборки кода (нового или исправленного) устанавливаемое приложение, стартует и выполняет основные функции.
Регрессионное тестирование — это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде. Регрессионными могут быть как функциональные, так и нефункциональные тесты.
Повторное тестирование — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
В чем разница между regression testing и re-testing?
Re-testing — проверяется исправление багов
Regression testing — проверяется то, что исправление багов не повлияло на другие модули ПО и не вызвало новых багов.
Тестирование сборки или Build Verification Test — тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования. По своим целям является аналогом Дымового Тестирования, направленного на приемку новой версии в дальнейшее тестирование или эксплуатацию. Вглубь оно может проникать дальше, в зависимости от требований к качеству выпущенной версии.
Санитарное тестирование — это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружающей среде. Обычно выполняется вручную.
Предугадывание ошибки (Error Guessing — EG). Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тест аналитик, будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.

Подходы к интеграционному тестированию:
• Снизу вверх (Bottom Up Integration)
Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
• Сверху вниз (Top Down Integration)
Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
• Большой взрыв («Big Bang» Integration)
Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
Принципы тестирования
Принцип 1 — Тестирование демонстрирует наличие дефектов (Testing shows presence of defects)
Тестирование может показать, что дефекты присутствуют, но не может доказать, что их нет. Тестирование снижает вероятность наличия дефектов, находящихся в программном обеспечении, но, даже если дефекты не были обнаружены, это не доказывает его корректности.
Принцип 2 — Исчерпывающее тестирование недостижимо (Exhaustive testing is impossible)
Полное тестирование с использованием всех комбинаций вводов и предусловий физически невыполнимо, за исключением тривиальных случаев. Вместо исчерпывающего тестирования должны использоваться анализ рисков и расстановка приоритетов, чтобы более точно сфокусировать усилия по тестированию.
Принцип 3 — Раннее тестирование (Early testing)
Чтобы найти дефекты как можно раньше, активности по тестированию должны быть начаты как можно раньше в жизненном цикле разработки программного обеспечения или системы, и должны быть сфокусированы на определенных целях.
Принцип 4 — Скопление дефектов (Defects clustering)
Усилия тестирования должны быть сосредоточены пропорционально ожидаемой, а позже реальной плотности дефектов по модулям. Как правило, большая часть дефектов, обнаруженных при тестировании или повлекших за собой основное количество сбоев системы, содержится в небольшом количестве модулей.
Принцип 5 — Парадокс пестицида (Pesticide paradox)
Если одни и те же тесты будут прогоняться много раз, в конечном счете этот набор тестовых сценариев больше не будет находить новых дефектов. Чтобы преодолеть этот «парадокс пестицида», тестовые сценарии должны регулярно рецензироваться и корректироваться, новые тесты должны быть разносторонними, чтобы охватить все компоненты программного обеспечения, или системы, и найти как можно больше дефектов.
Принцип 6 — Тестирование зависит от контекста (Testing is concept depending)
Тестирование выполняется по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем сайт электронной коммерции.
Принцип 7 — Заблуждение об отсутствии ошибок (Absence-of-errors fallacy)
Обнаружение и исправление дефектов не помогут, если созданная система не подходит пользователю и не удовлетворяет его ожиданиям и потребностям.
Cтатическое и динамическое тестирование
Статическое тестирование отличается от динамического тем, что производится без запуска программного кода продукта. Тестирование осуществляется путем анализа программного кода (code review) или скомпилированного кода. Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к статическому тестирвоанию относится тестирования спецификации и прочей документации.
Исследовательское / ad-hoc тестирование
Простейшее определение исследовательского тестирования — это разработка и выполнения тестов в одно и то же время. Что является противоположностью сценарного подхода (с его предопределенными процедурами тестирования, неважно ручными или автоматизированными). Исследовательские тесты, в отличие от сценарных тестов, не определены заранее и не выполняются в точном соответствии с планом.
Разница между ad hoc и exploratory testing в том, что теоретически, ad hoc может провести кто угодно, а для проведения exploratory необходимо мастерство и владение определенными техниками. Обратите внимание, что определенные техники это не только техники тестирования.
Требования — это спецификация (описание) того, что должно быть реализовано.
Требования описывают то, что необходимо реализовать, без детализации технической стороны решения. Что, а не как.
Требования к требованиям:
• Корректность
• Недвусмысленность
• Полнота набора требований
• Непротиворечивость набора требований
• Проверяемость (тестопригодность)
• Трассируемость
• Понимаемость
Жизненный цикл бага

Стадии разработки ПО — это этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широко круга пользователей. Разработка ПО начинается с первоначального этапа разработки (стадия «пре-альфа») и продолжается стадиями, на которых продукт дорабатывается и модернизируется. Финальным этапом этого процесса становится выпуск на рынок окончательной версии программного обеспечения («общедоступного релиза»).
Программный продукт проходит следующие стадии:
• анализ требований к проекту;
• проектирование;
• реализация;
• тестирование продукта;
• внедрение и поддержка.
Каждой стадии разработки ПО присваивается определенный порядковый номер. Также каждый этап имеет свое собственное название, которое характеризует готовность продукта на этой стадии.
Жизненный цикл разработки ПО:
• Пре-альфа
• Альфа
• Бета
• Релиз-кандидат
• Релиз
• Пост-релиз
Таблица принятия решений (decision table) — великолепный инструмент для упорядочения сложных бизнес требований, которые должны быть реализованы в продукте. В таблицах решений представлен набор условий, одновременное выполнение которых должно привести к определенному действию.
QA/QC/Test Engineer
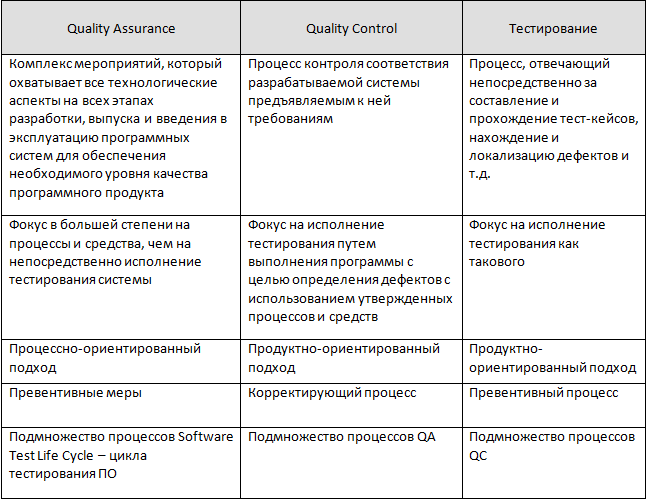
Таким образом, мы можем построить модель иерархии процессов обеспечения качества: Тестирование — часть QC. QC — часть QA.
Диаграмма связей — это инструмент управления качеством, основанный на определении логических взаимосвязей между различными данными. Применяется этот инструмент для сопоставления причин и следствий по исследуемой проблеме.

Источники: www.protesting.ru, www.bugscatcher.net, www.qalight.com.ua, www.thinkingintests.wordpress.com, книга ISTQB, www.quizful.net, www.bugsclock.blogspot.com, www.zeelabs.com, www.devopswiki.net, www.hvorostovoz.blogspot.com.
Продолжаем говорить о техниках тест-дизайна. Сегодня речь пойдет о технике предугадывания ошибок. Она подойдет в том случае, когда мы уже знакомы с продуктом и имеем определенный опыт в тестировании подобного функционала.
Суть техники в том, что чтобы найти все способы, которые могут сломать тестируемый продукт.
По традиции начну с определения. Немного информации из ISTQB:
Предположение об ошибках – это способ предотвращения ошибок, дефектов и отказов, основанный на знаниях тестировщика, включающих:
— Историю работы приложения в прошлом.
— Наиболее вероятные типы дефектов, допускаемых при разработке.
— Типы дефектов, которые были обнаружены в схожих приложениях.
Структурированный подход к предположению об ошибках предполагает создание списка всех возможных ошибок, дефектов и отказов с последующей разработкой тестов, направленных на поиск дефектов из этого списка. Списки отказов и дефектов могут быть построены на основе опыта, исторических данных об отказах и ошибках, а также на общих знаниях о причинах отказа программ.
Получается, что предугадывание ошибки — это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку.
Например, в программе я вижу: «для подтверждения заказа введите свой номер телефона в формате +7(…)… ….» И я, как тестировщик, начинаю думать: «А если не вводить телефон?», «А если ввести в формате не +7, а просто 8? «, и так далее. Это и есть предугадывание ошибки.
Давайте посмотрим на конкретных примерах, как можно использовать этот метод.
Уже знакомая нам игра с молокозаводом
Возьмем объекты, которые нам необходимо построить. Например, каким образом можно сломать курятник на этапе покупки?
- Можно попробовать поставить его на другой объект

2. Или за границу доступного поля

3. За границей поля тоже не получается.. А давайте попробуем поставить на воду? Вдруг разработчики не учли этот момент?

Тоже никак, все работает как надо… Ладно поставим пока курятник на место. Теперь попробуем проверить, все ли нормально с его работой.
4. В курятник можно покупать и сажать кур. А что если попробовать вместо кур поместить коров?

5. Или попробовать кур поместить на территорию вне курятника

6. Или попробовать зайти в магазин, пока покупаем кур

«Ладно, видимо не в этот раз» — говорим мы себе и закрываем игру…
Таким образом, путем предугадывания ошибок, мы с вами нашли 6 случаев, при которых возможны проблемы в работе приложения.
А теперь посмотрим на примере сайта
Возьмем один из элементов сайта — форму регистрации. Посмотрим на нее внимательно и подумаем, как мы можем ее «сломать».

Мне на ум приходят вот какие варианты:
- Указать e-mail c несуществующим доменом на конце.
- Указать e-mail без знака «@».
- Заполнить поле «Пароль» без использования обязательных символов. Например, если программа требует, чтобы в пароле были заглавные и строчные буквы, то пробуем ввести пароль без использования заглавных букв.
- В поле «Пароль еще раз» ввести символы отличные от символов в поле «Пароль».
- Снять галочку «Я принимаю условия Пользовательского соглашения».
- Ввести неверные символы с картинки.
- Оставить одно поле незаполненным.
________________________________
Таким образом, суть данного метода заключается в том, чтобы найти как можно больше ошибок, попытаться сломать работающий функционал. Название техники уже говорит само за себя.
________________________________
В предугадывании ошибок нет четкой и логической схемы, которая позволила бы нам составить тест-кейсы. Т.е. нельзя сказать, что сделав сначала Шаг №1, затем Шаг №2 и т.д. мы на выходе получим готовые проверки с максимально полным покрытием.
Наоборот, эта техника основывается на опыте тестировщика и на его умении думать креативно и деструктивно.
Теория тестирования
Тестирование
Тестирование ПО (Software Testing) — проверка соответствия между реальным и ожидаемым поведением программы, осуществляемая на конечном наборе тестов, выбранном определенным образом.
Пирамида тестирования

Зачем тестировать ПО
Цели тестирования:
- Повысить вероятность того, что приложение, будет работать правильно при любых обстоятельствах.
- Повысить вероятность того, что приложение, будет соответствовать всем описанным требованиям.
- Предоставление актуальной информации о состоянии продукта на данный момент.
Этапы тестирования
Этапы:
- Анализ продукта
- Работа с требованиями
- Разработка стратегии тестирования
и планирование процедур контроля качества - Создание тестовой документации
- Тестирование прототипа
- Основное тестирование
- Стабилизация
- Эксплуатация
Типы тестирования
По целям:
- Безопасности
- Функциональное
- Нефункциональное
- UI
- Совместимости
- Производительности
- Нагрузочное
- Стабильности
- Стресс
По знанию системы:
- Белый ящик
- Серый ящик
- Чёрный ящик
По хронологии выполнения:
- Входное (Smoke/intake)
- Повторное
- Регрессионное
По степени автомтизации
По исполнению кода
Уровни тестирования
-
Модульное/Компонентное (unit/component testing)* — тестирование наименьших элементов ПО, которые могут быть протестированы по-отдельности (модули, объекты, классы, функции).
Задача модульного тестирования — выявление локализованных в модуле ошибок реализации алгоритмов, а также определение степени готовности системы к переходу на следующий уровень разработки и тестирования. -
Интеграционное (integration testing) — тестирование части системы, состоящей из двух и более модулей.
Задача интеграционного тестирования — поиск дефектов, связанных с ошибками реализации и интерпретации интерфейсного взаимодействия между модулями, а также ошибок взаимодействия с другими частями системы (ОС, оборудованием). -
Системное (system testing) — процесс тестирования системы в целом с целью проверки того, что она соответствует установленным требованиям.
Задача системного тестирования — выявление дефектов, связанных с общей работой системы, таких как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность, неудобство в применении и т.д. -
Приёмочное (acceptance testing) — формальный процесс тестирования, который проверяет соответствие системы потребностям, требованиям и бизнес процессам пользователя, и проводится для вынесения решения заказчиком (внутренним или внешним) или другим уполномоченным лицом принимается приложение или нет.
Техники тест-дизайна
-
Эквивалентное Разделение/Классы эквивалентности (Equivalence Partitioning — EP). Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0, получив таким образом два значения относящиеся к разным классам.
-
Анализ Граничных Значений (Boundary Value Analysis — BVA). Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10), и значения больше и меньше границ (0 и 11). Анализ Граничный значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
Ценность: ошибки часто встречаются как раз на границах разных групп значений. -
Попарное тестирование (Pairwise Testing) — техника формирования наборов тестовых данных. Сформулировать суть можно так: формирование таких наборов данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров.
-
Причина/Следствие (Cause/Effect — CE). Это, как правило, ввод комбинаций условий (Причин), для получения ответа от системы (Следствие). Например, вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем, нажать кнопку «Добавить» — это «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
-
Предугадывание ошибки (Error Guessing — EG). Это когда тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тестировщик будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.
-
Исчерпывающее тестирование (Exhaustive Testing — ET) — крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным, из-за огромного количества входных значений.
Что такое Regression и Confirmation тестирование, какая между ними разница
Повторное/Подтверждающее тестирование (re-testing/confirmation testing) — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
Регрессионное тестирование (regression testing) — тестирование уже протестированной программы после модификации для уверенности в том, что процесс модификации не внес или не активизировал ошибки в областях, не подвергавшихся изменениям. Проводится после изменений в коде ПО или его окружения.
Частота регрессионного тестирования
Стоит делать по возможности и в зависимости от частоты вмешательства в релизы.
Виды интеграционного тестирования
-
Снизу вверх (Bottom Up Integration). Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
-
Сверху вниз (Top Down Integration). Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
-
Большой взрыв («Big Bang» Integration). Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
Configuration Testing
Конфигурационное тестирование (configuration testing) — тестирование, направленное на проверку работы ПО при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и системного ПО и т.д.).
Exploratory Testing
Исследовательское тестирование (exploratory testing) — неформальный метод, при котором тестировщик активно контролирует проектирование тестов, в то время как эти тесты выполняются, и использует полученную информацию для проектирования новых улучшенных тестов. Такое тестирование определяется как одновременное обучение, проектирование теста и его исполнение.
Black/Grey/White Box Testing
-
Тестирование белого ящика (white box testing) — тестирование, основанное на анализе внутренней структуры компонента или системы и на знании исходного кода, к которому тестировщик (как правило, это программист) имеет полный доступ.
-
Тестирование серого ящика (gray box testing) — тестирование, ориентированное на имитацию работы пользователей, в условиях, когда часть внутренней структуры программы известна.
-
Тестирование чёрного ящика (black box testing) — тестирование, основанное на анализе функциональной или нефункциональной спецификации системы, при котором программа рассматривается как объект, внутренняя структура которого неизвестна.
Performance Testing
Тестирование производительности (performance testing) — определение степени, с которой система выполняет заложенные в нее функции в установленных рамках на время обработки и пропускную способность. Достаточно часто при тестировании производительности проверяется сразу несколько его подвидов.
Smoke и Sanity тестирование и какая между ними разница
Санитарное тестирование или проверка согласованности/исправности (sanity testing) — узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружении. Обычно выполняется вручную.
Дымовое/входное тестировние (smoke/intake test) — специальный тест (короткий цикл тестов) для принятия решения, готов ли компонент или система для дальнейшего детального тестирования. Выполняется для подтверждения того, что после сборки кода (нового или исправленного) приложение, стартует и выполняет основные функции.
Traceability Matrix
Матрица соответствия требований (traceability matrix) — двумерная таблица, содержащая соответсвие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases).
В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки.
Матрица соответсвия требований используется QA-инженерами для валидации покрытия продукта тестами. МСТ является неотъемлемой частью тест-плана.
End-to-End тест
End-to-End тесты — такие интеграционные тесты, которые воздействуют на систему через ее самые внешние интерфейсы и проверяют ожидаемую реакцию системы через эти же интерфейсы.
Почему именно интеграционные? Потому, что это единственное, что можно о них сказать наверняка: они по определению не могут быть модульными тестами. А все остальное: являются ли они одновременно приемочными, нагрузочными или еще какими — зависит только от общих плана/стратегии тестирования и той роли, которые эти тесты в них играют.
Тестирование безопасности
Тестирование безопасноcти/защищённости (security testing) – тестирование ПО с целью определить его защищённость.
Основные понятия, которые должны быть охвачены тестированием: конфиденциальность, целостность и сохранность данных, аутентификация, авторизация и невозможность отказа от авторства.
Испытание на основе рисков
Тестирование на основе рисков/Риск-тестирование (risk-based testing) — метод тестирования ПО, который базируется на вероятности рисков. Их вероятность определяется путем анализа, в котором учитываются сложность программы, критичность функции для бизнеса, частота ее использования и количество возможных дефектов. При тестировании на основе рисков наибольший приоритет получает проверка самых важных и потенциально имеющих недостатки функций.
Динамическое тестирование
Динамическое тестирование (dynamic testing) — тестирование, проводимое во время выполнения ПО, компонента или системы.
«Парадокс пестицида»
Парадокс пестицида — эффект, при котором при регулярном прогоне тестовых сценариев ошибки перестают находиться. Происходит из-за того, что ошибки которые ловились данными тестами уже пойманы, а остальные оказываются не попадающими в тестовые сценариями.
Основные фазы STLC? Дайте определение Entry и Exit Criteria.
Жизненный цикл тестирования ПО(STLC) определяет, какие действия выполнять при тестировании и когда их выполнять.
Фазы:
- Анализ требований
- Планирование тестирования
- Дизайн теста
- Настройка тестовой среды
- Выполнение теста
- Завершение теста
Критерии входа (Entry Criteria) — содержат обязательные элементы, которые необходимо выполнить, прежде чем можно будет начать тестирование.
Критерии выхода (Exit Criteria) — определяют элементы, которые должны быть выполнены до завершения тестирования.
Что такое Bug, Error, Failure, Fault
Bug (defect/fault) — ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так как планировалось и программа выходит из-под контроля. Например, когда никак не контроллируется ввод пользователя, в результате неверные данные вызывают краши или иные «радости» в работе программы. Либо внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
Error — ошибка пользователя, то есть он пытается использовать программу иным способом.
Пример — вводит буквы в поля, где требуется вводить цифры (возраст, количество товара и т.п.).
В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message).
Failure — сбой (причём не обязательно аппаратный) в работе компонента, всей программы или системы. То есть, существуют такие дефекты, которые приводят к сбоям (A defect caused the failure) и существуют такие, которые не приводят. UI-дефекты например. Но аппаратный сбой, никак не связанный с software, тоже является failure.
Атрибуты баг-репорта? Какие основные поля для заполнения
Баг Репорт (Bug Report) — документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Атрибуты:
- Короткое описание (Summary/Title) — выжимка информации явно указывающая на причину и тип проблемы.
- Номер версии (Version) — версия на которой была найдена ошибка
- Серьезность (Severity):
- S1 Блокирующий (Blocker)
- S2 Критический (Critical)
- S3 Значительный (Major)
- S4 Незначительный (Minor)
- S5 Тривиальный (Trivial)
- Приоритет (Priority):
- P1 Высокий (High)
- P2 Средний (Medium)
- P3 Низкий (Low)
- Статус (Status) — текущий статус бага. Зависит от используемой процедуры и жизненного цикла бага (bug workflow and life cycle)
- Окружение (Environment) — ОС / Браузер + версия и т.п. Информация об окружении, на котором был найден баг.
- Шаги воспроизведения (Steps to Reproduce) — действия, по которым можно легко воспроизвести ситуацию, приведшую к ошибке.
- Фактический Результат (Actual Result) — результат, полученный после прохождения шагов к воспроизведению
- Ожидаемый результат (Expected Result) — ожидаемый правильный результат
Разница между приоритетом и серьезностью
Серьезность (Severity) — атрибут, характеризующий влияние дефекта на работоспособность приложения.
Приоритет (Priority) — атрибут, указывающий на очередность выполнения задачи или устранения дефекта. Больше инструмент менеджера по планированию работ. Чем выше приоритет, тем быстрее нужно исправить дефект
Обычно Severity выставляется тестировщиком, а Priority — менеджером, тимлидом или заказчиком.
Приведите примеры серьезного, но не приоритетного бага.
На Андроиде 4.4 приложение при первом запуске падает. В последующие запуски работает нормально. Т.к. пользователей с этой версией ОС у нас около 0,5%, то приоретет можно поставить низкий или вообще проигнорировать.
В чем разница между валидацией и верификацией
Верификация (verification) — это процесс оценки системы или её компонентов с целью определения удовлетворяют ли результаты текущего этапа разработки условиям, сформированным в начале этого этапа. Т.е. выполняются ли наши цели, сроки, задачи по разработке проекта, определенные в начале текущей фазы.
Валидация (validation) — это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, требованиям к системе.
Validation — ’is this the right specification?’.
Verification — ’is the system correct to specification?’.
Зачем нужна тестовая документация? Какие её виды
https://habr.com/ru/company/otus/blog/588923/
Тестовая документация — набор документов, создаваемых перед началом процесса тестирования и непосредственно в процессе. Эти документы описывают покрытие тестами и процесс выполнения тестов, в них указываются необходимые для тестирования вещи, приводится основная терминология и т. д. В тестовой документации любой член команды может найти полную информацию обо всех действиях, связанных с тестированием (и об уже выполненных, и о запланированных). Тестовая документация определяет, что для нас важно и почему, какие действия мы должны выполнить и сколько времени у нас есть. Наконец, в документации обозначено, чего должна достичь команда и что сигнализирует об окончании процесса.
Виды:
- План тестирования (test plan)
- Чеклист (checklist)
- Тестовый сценарий (Test Case)
- Баг-репорт (Bug Report)
- Отчёт о тестировании (Test Report)
- Инструкция (Manual)
Тест-план? Какие элементы у него есть
План тестирования (Test Plan) — документ, описывающий весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков с вариантами их разрешения.
В стандарте IEEE 829 перечислены пункты, из которых может/должен состоять тест-план:
- Test plan identifier
- Introduction
- Test items
- Features to be tested
- Features not to be tested
- Approach
- Item pass/fail criteria
- Suspension criteria and resumption requirements
- Test deliverables
- Testing tasks
- Environmental needs
- Responsibilities
- Staffing and training needs
- Schedule
- Risks and contingencies
- Approvals
Какую обязательную информацию должен содержать тест-план? Как правильно его использовать, поддерживать и нужен ли он вообще для большинства проектов
Должен отвечать на вопросы:
- Что надо тестировать?
- Что будете тестировать?
- Как будете тестировать?
- Когда будете тестировать?
- Критерии начала тестирования.
- Критерии окончания тестирования.
Составляется до начала этапа тестирования. Для проектов использующих agile подходы тест-план может быстро устаревать, т.к. условия и требования могут регулярно менятся. Соответственно потребуются трудозатраты по его обновлению.
Разница между чеклистом и тест-кейсами
Чек-лист (check list) — артефакт, описывающий что должно быть протестировано. При этом чек-лист может быть абсолютно разного уровня детализации. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта.
Как правило, чек-лист содержит только действия (шаги), без ожидаемого результата. Чек-лист менее формализован чем тестовый сценарий. Его уместно использовать тогда, когда тестовые сценарии будут избыточны. Также чек-лист ассоциируется с гибкими подходами в тестировании.
Тестовый кейс/сценарий (Test Case) — артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Должен иметь 3 части:
- PreConditions — список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
- Test Case Description — список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям
- PostConditions — список действий, переводящих систему в первоначальное состояние (состояние до проведения теста — initial state)
Тест кейсы разделяют на позитивные и негативные:
- Позитивный тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
- Негативный тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций (срабатывание валидаторов), а также проверяет, что вызываемая приложением функция не выполняется при срабатывании валидатора.
AQA (Automation QA)
Программирование
Что такое ООП? Назовите его принципы с примерами
Объектно-ориентированное программирование (ООП) — подход, при котором вся программа рассматривается как набор взаимодействующих друг с другом объектов. При этом нам важно знать их характеристики.
Основные понятия ООП:
Класс – способ описания сущности, определяющий состояние и поведение, зависящее от этого состояния, а также правила для взаимодействия с данной сущностью (контракт).
С точки зрения программирования класс можно рассматривать как набор данных (полей, атрибутов, членов класса) и функций для работы с ними (методов).
С точки зрения структуры программы, класс является сложным типом данных.
Объект (экземпляр) – отдельный представитель класса, имеющий конкретное состояние и поведение, полностью определяемое классом.
Говоря простым языком, объект имеет конкретные значения атрибутов и методы, работающие с этими значениями на основе правил, заданных в классе.
Интерфейс – набор методов класса, доступных для использования другими классами.
Абстрагирование – способ выделить набор значимых характеристик объекта, исключая из рассмотрения незначимые. Соответственно, абстракция – это набор всех таких характеристик.
Инкапсуляция – свойство системы, позволяющее объединить данные и методы, работающие с ними, в классе и скрыть детали реализации от пользователя.
Полиморфизм – свойство системы использовать объекты с одинаковым интерфейсом без информации о типе и внутренней структуре объекта.
Наследование – свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствующейся функциональностью. Класс, от которого производится наследование, называется базовым или родительским. Новый класс – потомком, наследником или производным классом.
SHORT VERSION
Базовые принципы ООП:
- Абстракция — отделение концепции от ее экземпляра
- Полиморфизм — реализация задач одной и той же идеи разными способами
- Наследование — способность объекта или класса базироваться на другом объекте или классе. Это главный механизм для повторного использования кода. Наследственное отношение классов четко определяет их иерархию
- Инкапсуляция — размещение одного объекта или класса внутри другого для разграничения доступа к ним
Используйте следующее вместе с наследованием:
- Делегация — перепоручение задачи от внешнего объекта внутреннему
- Композиция — включение объектом-контейнером объекта-содержимого и управление его поведением; последний не может существовать вне первого
- Агрегация — включение объектом-контейнером ссылки на объект-содержимое; при уничтожении первого последний продолжает существование
Интерфейс? Абстрактный класс? Чем они отличаются
Абстрактный класс — класс, у которого не реализован один или больше методов (некоторые языки требуют такие методы помечать специальными ключевыми словами). Абстрактный класс необходим, когда нужно семейство классов, у которых есть много общего. Конечно, можно применить и интерфейс, но тогда нужно будет писать много идентичного кода.
Интерфейс — абстрактный класс, у которого ни один метод не реализован, все они публичные и нет переменных класса. Интерфейс используется, когда, например, один класс хочет дать другому возможность доступа к некоторым своим методам, но не хочет себя «раскрывать». Поэтому он просто реализует интерфейс.
Что такое SOLID? Приведите примеры
SOLID — 5 правил разработки ПО задающие принципы, которым стоит следовать, когда пишешь программы, чтобы их проще было масштабировать и поддерживать.
S — Single Responsibility (Принцип единственной обязанности)
Для каждого класса должно быть определено единственное назначение. Все ресурсы, необходимые для его осуществления, должны быть инкапсулированы в этот класс и подчинены только этой задаче.

O — Open-Closed (Принцип открытости/закрытости)
Сущности программы должны быть открыты для расширения, но закрыты для изменения.

L — Liskov Substitution (Принцип подстановки Барбары Лисков)
Должна быть возможность вместо базового типа подставить любой его подтип.

I — Interface Segregation (Принцип разделения интерфейсов)
Клиенты не должны вынужденно зависеть от методов, которыми не пользуются.

D — Dependency Inversion (Принцип инверсии зависимостей)
Модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те и другие должны зависеть от абстракций.
Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.

Что такое DRY, KISS, YAGNI
DRY (Don’t Repeat Yourself — Не повторяйся)
Избегайте повторного написания кода, вынося в абстракции часто используемые задачи и данные. Каждая часть вашего кода или информации должна находиться в единственном числе в единственном доступном месте. Это один из принципов читаемого кода.
KISS (Keep It Simple, Stupid/Keep It Simple and Straightforward — Будь проще)
Не придумывайте к задаче более сложного решения, чем ей требуется. Простота кода – превыше всего, потому что простой код – наиболее понятный.
YAGNI (You Aren’t Gonna Need It — Вам это не понадобится)
Если пишете код, то будьте уверены, что он вам понадобится. Не пишите код, если думаете, что он пригодится позже. Если вы занимаетесь рефакторингом метода, класса или файла, не бойтесь удалять лишние методы. Даже если раньше они были полезны – теперь они не нужны.
Какие паттерны GOF вам известны? Приведите примеры их использования.
Стратегия (Strategy) — предлагает определить семейство схожих алгоритмов, которые часто изменяются или расширяются, и вынести их в собственные классы, называемые стратегиями.
Пример: способ построения маршрута в навигаторе (для авто, пешехода, велосипедиста, на общественном транспорте)
Строитель (Builder) — разделяет создание сложного объекта и инициализацию его состояния так, что одинаковый процесс построения может создать объекты с разным состоянием.
Пример: избавление от лишних опций конструктора (Lombok и создание экземпляров класса), StringBuilder
Итератор (Iterator) — предоставляет способ последовательного доступа к элементам множества независимо от его внутреннего устройства.
Пример: foreach
Одиночка (Singleton) — гарантирует, что класс имеет только один экземпляр и предоставляет глобальную току доступа к нему.
Пример: общий доступ к базе данных из разных частей программы, selenium driver
Фабричный метод (Factory Method) — определяет интерфейс для создания объекта, но позволяет подклассам решать, какой класс инстанцировать. Позволяет делегировать создание объекта подклассам.
Абстрактная фабрика (Abstarct Factory) — предоставляет интерфейс для создания групп связанных или зависимых объектов, не указывая их конкретный класс.
PageObject и PageFactory
Page Object — паттерн при котором для каждой страницы тестируемого приложения создаётся отдельный объект, методы которого инкапсулируют логику работы с отдельными элементами. Позволяет уменьшить количество кода и упростить его поддержку.
Page Factory — реализация паттерна Factory для создания экземпляров страниц встроенная в Selenium.
Какая иерархия Collections
Интерфейсы:
- Collection
- List
- Set
- Map
- Sorted Set
- Sorted Map
- Queue
Классы:
- Lists:
- ArrayList
- LinkedList
- Vector(deprecated)
- Sets
- HashSet
- LinkedHashSet
- TreeSet
- Maps
- HashMap
- TreeMap
- HashTable (deprecated)
- LinkedHashMap
- Queue
- Priority Queue

Разница между Thread class и Runnable interface
Многопоточность программы в Java организуется с помощью интерфейса Runnable и класса Thread, который наследуется от Runnable. Первый способ более гибкий, второй – проще.
Когда пользовательский класс должен наследоваться от другого класса (не Thread), приходится использовать наследование от интерфейса Runnable, т.к. в Java нет множественного наследования классов.
Разница между String, Stringbuffer и Stringbuilder
String
Строки в Java иммутабельны (не могут быть изменены). При изменении объекта String в Java каждый раз создается совершенно новый объект.
При использовании оператора new для создания в памяти кучи каждый раз будет создаваться новый объект String. При использовании литерала объекта («some string»), если такой объект уже существует в куче, новый объект не появится, а ссылочная переменная будет указывать на существующий объект.
StringBuilder
Класс StringBuilder представляет собой альтернативу классу String, поскольку создает мутабельный (изменяемый) набор символов.
Класс StringBuilder не обеспечивает синхронизацию: экземпляры класса StringBuilder не могут совместно использоваться несколькими потоками. Для операций со строками в среде, не являющейся многопоточной, стоит использовать StringBuilder, потому что он быстрее, чем StringBuffer.
StringBuffer
Класс StringBuffer также создает изменяемый строковый объект и содержит те же методы, что и StringBuilder.
Разница между ними в том, что класс StringBuffer — потокобезопасный и синхронизированный: экземпляры класса StringBuffer могут совместно использоваться несколькими потоками. Для операций со строками в многопоточных средах стоит использовать StringBuffer.
Разница между final, finally и finalize
final – модификатор, который применяется к переменным, полям, методам и классам. Переменная или поле становится неизменяемым и требует инициализации. Финальный метод нельзя переопределить в наследниках. Финальный класс не может иметь наследников вообще.
finally – часть языковой конструкции try-catch-finally.
finalize — метод класса Object. Сборщик мусора вызывает его для объектов, на которые больше нет ссылок и которые помечены для сбора мусора. Deprecated с Java 9.
Selenium
Что такое Selenium и зачем его используют
Selenium — это набор программ с открытым исходным кодом, которые применяют для тестирования веб-приложений и администрирования сайтов локально и в сети. Программы Selenium позволяют автоматизировать действия браузера.
- Selenium IDE — плагин для браузера Firefoх для записи действий пользователя.
- Selenium RC — устаревшая библиотека для управления браузерами.
- Selenium WebDriver — современная библиотека для управления браузерами.
- Selenium Server — сервер для управления браузером удаленно по сети.
- Selenium Grid — кластер Selenium-серверов для управления браузерами на разных компьютерах в сети.
Что такое Selenium Grid
Selenium Grid — кластер, состоящий из нескольких Selenium-серверов. Предназначен для организации распределённой сети, позволяющей параллельно запускать много браузеров на большом количестве машин. Имеется выделенный сервер, который носит название «хаб» или «коммутатор», а остальные сервера называются «ноды» или «узлы».
Драйвер браузера
Драйвер браузера — не имеющая пользовательского интерфейса программная библиотека, которая позволяет различным программам взаимодействовать с браузером, управлять его поведением, получать от браузера данные и заставлять браузер выполнять команды.
Какие виды локаторов страницы существуют? Каковы их преимущества и недостатки
id=<element_id> — соответствует элементу, у которого атрибут id равен значению element_id. Cледует отметить, что данный вид локаторов является одним из самых быстрых в нахождении и одним из самых уникальных.
name=<element_name> — соответствует элементу, у которого атрибут name равен значению element_name. Эффективно применяется при работе с полями ввода формы (кнопки, текстовые поля, выпадающие списки). Данный тип локаторов тоже является достаточно быстрым в нахождении, но менее уникальным, так как на странице может быть несколько форм, у которых могут быть элементы с одинаковым именем.
dom=<dom_object> — данный тип локатора позволяет обращаться к элементу так же, как и в DHTML используя DOM-структуру. Данный тип локатора используется нечасто, так как обычно находятся более удобные аналоги, но тем не менее данная возможность есть.
link=<link_text> — специально для ссылок используется отдельно зарезервированный тип локаторов, который находит нужную ссылку по ее тексту. Это сделано отчасти потому, что ссылки как правило не имеют таких атрибутов как ID или name. Также у ссылки есть фиксированная часть и есть часть, которая может варьироваться. В этом случае мы можем использовать wildcards, в частности ‘*’.
xpath=<xpath_locator> — наиболее универсальный тип локаторов. HTML представляет собой различное сочетание тегов, которые выстраиваются в определенную иерархию, наподобие структуры каталогов в файловой системе. Задача XPath — отразить подобный путь к нужному элементу, с учетом иерархии. У XPath есть много удобств, но есть и основной недостаток — низкая скорость нахождения объекта. В таких случаях рекомендуется воспользоваться CSS-локаторами, но в некоторых случаях от XPath уйти не получится.
css=<css_path> — данный тип локаторов основан на описаниях таблиц стилей (CSS). В отличие от локаторов по ID, по имени или по тексту ссылки, данный тип локаторов может учитывать иерархию объектов, а также значения атрибутов, что делает его ближайшим аналогом XPath. А в силу того, что объект находится по данному локатору быстрее, чем XPath, рекомендуется прибегать к помощи CSS вместо XPath.
Selenium Waits? Какие есть и чем отличаются
Implicit Wait (неявное ожидание) — пожалуй, самый популярный способ ожидания в Selenium благодаря своей легкости в использовании. Использование:
- установить его всего 1 раз
- указать вручную лимит ожидания
Explicit wait (явное ожидание) — чаще используется для ожидания определенного условия, которое должно быть выполнено прежде, чем тест пойдет дальше. Стоит помнить следующие вещи:
- ожидание сработает именно там, где оно указано
- как и неявному ожиданию, ему необходимо указать лимит времени
- ожидает выполнения необходимого условия
- ждет завершения Ajax request
Какие exceptions может бросить Selenium? Что они означают и как их обрабатывать
ElementClickInterceptedException — команда [Клик] не могла быть выполнена должным образом, так как элемент, получающий команду каким-то образом скрыт (например, перекрыт другим элементом).
ElementNotVisibleException — выдается, когда веб-элемент присутствует, но не виден. Поскольку элемент не виден, любое взаимодействие с ним невозможно.
NoSuchElementException — бросается, когда локатор, используемый для доступа к элементу, недействителен или предпринимается попытка выполнить действие над элементом, которого нет в DOM. В любом из этих случаев элемент не будет найден.
TimeoutException — происходит, когда команда, выполняемая в данный момент, не завершается в течение ожидаемого периода времени.
WebDriverException — возникает из-за несовместимости Selenium WebDriver и целевого веб-браузера.
Исключения в Selenium обрабатываются посредством использования try-catch блока
Для чего используют JavascriptExecutor? Приведите примеры.
JavascriptExecutor — это интерфейс Selenium, который позволяет выполнить JavaScript код. Например, ввести текст, сделать щёлчок по элементу и т.п.
Способы click и send keys Selenium
Через методы Селениума или через использование JavaScriptExecutor.
Как вы запускаете параллельное выполнение тестов? Что такое ThreadLocal
maven-surefire-plugin -> thread-count
Параллелизация сьютов между агентами на CI сервере
jUnit5
-Djunit.jupiter.execution.parallel.enabled=true
-Djunit.jupiter.execution.parallel.mode.default=concurrent
TestNG
TestNG(xmlSuite.setParallel(XmlSuite.ParallelMode.CLASSES))
TestNG(xmlSuite.setThreadCount(<n>) + xmlSuite.setDataProviderThreadCount(<m>))
java.lang.ThreadLocal — класс используется для хранения переменных, которые должны быть доступны для всего потока. Фактически это нечто вроде ещё одной области видимости переменных. Класс ThreadLocal имеет методы get и set, которые позволяют получить текущее значение и установить новое значение.
Обычно экземпляры ThreadLocal объявляются как приватные статические переменные в классе. Каждый поток получает из метода get своё значение и устанавливает через set тоже своё значение, изолированное от других потоков.
Разница между Action и Actions
Action — интерфейс, который представляет одно действие пользователя. Содержит один из наиболее широко используемых методов perform().
Actions — класс ориентированный на пользователя API для эмуляции сложных пользовательских действий. Класс Actions реализует паттерн Builder, который может создавать CompositeAction, содержащий все действия, указанные вызовами метода.
Как написать метод isElementPresent
public boolean isElementPresent(By by) { return driver.findElement(by).isDisplayed(); }
Как вычитать данные из динамической веб-таблицы
Необходимо сначала определить количество колонок и столбцов в данный момент с помощью xPath и тэгов <td>, <tr>, а затем обращаться к определённой ячейке или итеративно получить данные из всех ячеек.
Можете ли вы назвать 10 интерфейсов в Selenium
- WebDriver
- Options
- Capabilities
- Timeouts
- JavascriptExecutor
- Action
- LocalStorage
- Logs
- WrapsDriver
- WrapsElement
Я не вижу практического применения в заучивании названий интерфейсов.
2 способа, позволяющих автоматизировать капчу
- Боты с поддержкой оптического распознавания символов (OCR) — в этом подходе КАПЧА решается автоматически с помощью бота.
- Услуги по решению капчи реальными людьми — в сервисе есть сотрудники, которые постоянно доступны онлайн для решения капчи. Когда вы отправляете свою КАПЧУ, компания пересылает ее работникам, которые ее решают, и отправляет обратно решения.
Типы команд Selenium
- Действия – функциональное действие над тестируемым веб-приложением в браузере. Например, заполнение полей, нажатие на кнопку и т.п.
- Проверки – выполнение проверок на тестируемой странице. Например, проверка того, что определенное поле формы имеет указанное значение, или проверка заголовка окна.
- Ожидания – организация того как, сколько и какого события будет дожидаться Selenium (ожидания загрузки страницы, ajax и т.д.).
Как найти поврежденные ссылки в Selenium WebDriver
- Собрать все ссылки на веб-странице на основе тега <a>.
- Отправить HTTP-запрос для первой ссылки.
- Получить HTTP-код ответа и узнать, является ли ссылка действительной или нет.
- Повторить это для всех захваченных ссылок.
TestNG/JUnit
Для чего нужны TestNG/JUnit
Это фреймворки автоматического тестирования. Нужны чтобы не писать свой велосипед для тех же задач по конфигурированию тестов, аннотаций для них, дата-провайдеров и т.д.
Какие аннотации используются в TestNG/JUnit
TestNG:
- @BeforeSuite / @AfterSuite
- @BeforeTest / @AfterTest
- @BeforeClass / @AfterClass
- @BeforeGroups / @AfterGroups
- @BeforeMethod / @AfterMethod
- @Test
- @DataProvider
- @Factory
- @Parameters
- @Listener
jUnit 5:
- @BeforeAll / @AfterAll
- @BeforeEach / @AfterEach
- @Test
- @Disable
- @Nested
- @Tag
- @TestFactory
- @Suite / @SelectClasses / @SelectPackages / @IncludePackages / @ExcludePackages
- @IncludeClassNamePatterns / @ExcludeClassNamePatterns / @IncludeTags / @ExcludeTags
Какие assertions есть в TestNG/JUnit
TestNG:
- assertEquals() / assertNotEquals()
- assertTrue() / assertFalse()
- assertNull() / assertNotNull()
- assertSame() / assertNotSame()
- assertEqualsNoOrder()
- fail()
jUnit 5:
- assertTrue() / assertFalse()
- assertEquals() / assertNotEquals()
- assertArrayEquals()
- assertIterableEquals()
- assertLinesMatch()
- assertNull() / assertNotNull()
- assertSame() / assertNotSame()
- assertTimeout() / assertTimeoutPreemptively()
- assertThrows()
- fail()
Как выполнять тесты параллельно TestNG/JUnit
Перевести драйвер браузера на ThreadLocal!
TestNG
TestNG (xmlSuite.setParallel(XmlSuite.ParallelMode.CLASSES))
TestNG (xmlSuite.setThreadCount(<n>) + xmlSuite.setDataProviderThreadCount(<m>))
jUnit 5
-Djunit.jupiter.execution.parallel.enabled=true
-Djunit.jupiter.execution.parallel.mode.default=concurrent
Git
Для чего используют системы контроля версий
Система контроля версий (Version Control System/VCS) — позволяет хранить несколько версий одного и того же документа, при необходимости возвращаться к более ранним версиям, определять, кто и когда сделал то или иное изменение, и многое другое.
VCS позволяет изменять одни и те же файлы нескольким разработчикам одновременно. При этом все варианты изменений сохраняются отдельно, и можно сделать разные варианты одного и того же файла с учетом разных правок от разных людей. Если же несколько изменений затрагивают один и тот же фрагмент документа, то система предложит выбрать нужный вариант.
Что такое Git? Каков принцип его работы
Git — одна из VCS. Набор консольных утилит, которые отслеживают и фиксируют изменения в файлах.
Принцип работы —
Что такое commits, branches в Git
Коммит (commit) — снимок изменений в репозитории.
Бранч (branch) — ветка или копия проекта, в которую можно вносить любые изменения и они не повлияют на основной проект.
Для чего нужны GitHub, GitLab и другие, базирующиеся на Git, вебхостинги проектов
Для общего доступа к коду проекта, его скачиванию, обновлению и правке.
CI
Что такое CI/CD/CD
Непрерывная интеграция (Continuous Integration/CI) — методология разработки и набор практик, при которых в код вносятся небольшие изменения с частыми коммитами. Поскольку большинство современных приложений разрабатываются с использованием различных платформ и инструментов, то появляется необходимость в механизме интеграции и тестировании вносимых изменений.
Цель CI — обеспечить последовательный и автоматизированный способ сборки, упаковки и тестирования приложений.
Непрерывная поставка (Continuous Delivery/CD) — основывается на автоматизации сборки и тестирования, которую вводит непрерывная интеграция. Она предполагает перевод ручных шагов, необходимых для выпуска сборки приложения в продакшн, на автоматизированный процесс.
Непрерывное развёртывание (Continuous Deployment/CD) — после автоматизации релиза остаётся один ручной этап: одобрение и запуск развёртывания в продакшен. Практика непрерывного развёртывания упраздняет это, не требуя непосредственного утверждения со стороны разработчика. Все изменения развёртываются автоматически.
Последовательность выполнения CI/CD процесса на проекте
- Написание кода
- Сборка
- Тестирование
- Релиз
- Развертывание
- Поддержка и мониторинг
- Планирование

Как автоматическое тестирование интегрируется в CI
Непрерывная интеграция и непрерывная поставка нуждаются в непрерывном тестировании. Непрерывное тестирование часто реализуется в виде набора различных автоматизированных тестов (регрессионных, производительности и других), которые выполняются в CI/CD-конвейере.
Какие инструменты для генерации репорта после выполнения автоматических тестов вы знаете
Allure, Serenity
Какую информацию должен содержать отчет о выполнении автоматических тестов
Исходя из приоритетов целевой аудитории, мы должны определить, какую информацию должен содержать отчёт. Соответственно, в ходе проекта, информация должна консолидироваться по тому направлению, которое необходимо отразить.
Мы можем выделить три группы целевых аудиторий:
- Технические пользователи — Test-manager. Для них приоритетно понимание хода тестирования, какие возникают проблемы, как они решаются, построение самого процесса тестирования, описание применяемых методов и технологий.
- Product Manager, они же Менеджеры продукта. Их фокус сконцентрирован на сроках выполнения, выжимках из результатов тестирования без излишних технических подробностей и на общей статистике (цифровые и сравнительные метрики).
- Бизнес-пользователи. Обычно это и есть те люди, которые принимают решения по завершению тестирования. Они же определяют качество проделанной работы. Для них, в первую очередь, важен конечный результат в максимально кратком и ясном формате (данет), наглядное представление информации (графики, диаграммы), экспертное мнение о возможности выпуска продукта в промышленную среду и т. п., без углубления в детали.
WEB
Клиент-серверная архитектура

В промежутках могут находиться балансировщики, если используется несколько серверов или БД.
Что может выступать в роли клиента
Клиент — это рабочая станция с одной выходной точкой – конечный пользователь. В его обязанности входит отправка запросов и получение ответа.
Что такое REST, SOAP? В чем разница
SOAP и REST — это два стиля API, которые подходят к вопросу передачи данных с разных точек зрения.
SOAP (Simple Object Access Protocol) — это стандартизированный протокол, который отправляет сообщения с использованием других протоколов, таких как HTTP и SMTP. Спецификации SOAP являются официальными веб-стандартами, которые поддерживаются и разрабатываются Консорциумом World Wide Web (W3C).
REST (Representational State Transfer) — это не протокол, в отличие от SOAP, а архитектурный стиль. Архитектура REST устанавливает набор рекомендаций, которым необходимо следовать, если вы хотите построить веб-службу RESTful, например, сервисы без сохранения промежуточного состояния или использование HTTP-кодов состояния.
Какие протоколы передачи данных знаете
IP (Internet Protocol) — протокол передачи, который первым объединил отдельные компьютеры в единую сеть. Один из самых простых. Он является ненадёжным, т.е. не подтверждает доставку пакетов получателю и не контролирует целостность данных. По протоколу IP передача данных осуществляется без установки соединения.
TCP/IP (Transmission Control Protocol/Internet Protocol) — стек протоколов TCP и IP. Первый обеспечивает и контролирует надёжную передачу данных и следит за её целостностью. Второй же отвечает за маршрутизацию для отправки данных.
UDP (User Datagram Protocol) — протокол, обеспечивающий передачу данных без предварительного создания соединения. Этот протокол является ненадёжным. В нём пакеты могут не только не дойти, но и прийти не по порядку или вовсе продублироваться. Основное его преимущество заключается в скорости доставки данных. Именно поэтому чувствительные к сетевым задержкам приложения часто используют этот тип передачи данных.
FTP (File Transfer Protocol) — протокол передачи файлов. Использовали ещё в 1971 году — задолго до появления протокола IP. На текущий момент этим протоколом пользуются при удалённом доступе к хостингам. FTP является надёжным протоколом, поэтому гарантирует передачу данных. Работает по принципу клиент-серверной архитектуры. Пользователь проходит аутентификацию (хотя может подключаться и анонимно) и получает доступ к файловой системе сервера.
HTTP (HyperText Transfer Protocol) — изначально протокол передачи HTML-документов. Сейчас же он используется для передачи произвольных данных в интернете. Он является протоколом клиент-серверного взаимодействия без сохранения промежуточного состояния. В роли клиента чаще всего выступает веб-браузер, хотя может быть и, например, поисковый робот. Для обмена информацией протокол HTTP в большинстве случаев использует TCP/IP. HTTP имеет расширение HTTPS (HTTP over TLS), которое поддерживает шифрование.
SSH (Secure Shell) — протокол удалённого управления ОС с использованием TCP. В SSH шифруется весь трафик, с возможностью выбора алгоритма шифрования. В основном это нужно для передачи паролей и другой важной информации. Также SSH позволяет обрабатывать любые другие протоколы передачи. Это значит, что кроме удалённого управления компьютером, через протокол можно пропускать любые файлы или даже аудио/видео поток. SSH часто применяется при работе с хостингами.
Какие способы взаимодействия с API существуют? В чем разница между ними
-
SOAP (Simple Object Access Protocol) — Простой Протокол Доступа к Объектам. Клиент и сервер обмениваются сообщениями посредством XML. Это менее гибкий API, который был более популярен в прошлом.
-
RPC (Remote Procedure Call) — Удалённый Вызов Процедур. Клиент выполняет функцию (или процедуру) на сервере, и сервер отправляет результат обратно клиенту.
-
Websocket – современная разработка web API, которая использует объекты JSON для передачи данных. WebSocket поддерживает двустороннюю связь между клиентскими приложениями и сервером. Сервер может отправлять сообщения обратного вызова подключенным клиентам, что делает его более эффективным, чем REST.
-
REST — на сегодняшний день это самые популярные и гибкие API-интерфейсы в Интернете. Клиент отправляет запросы на сервер в виде данных. Сервер использует этот клиентский ввод для запуска внутренних функций и возвращает выходные данные обратно клиенту.
Как можно протестировать API, что там нужно проверять
Убедиться, что API работает правильно можно с помощью функционального тестирования.
Основные задачи:
- убедиться, что реализация API работает правильно, как и ожидалось
- гарантировать, что реализация API работает в соответствии со спецификацией требований
- предотвратить регрессии между написанным кодом и релизом
Проверка спецификации:
- эндпоинты правильно именованы
- ресурсы и их типы правильно отражают объектную модель
- нет отсутствующей или дублирующей функциональности
- отношения между ресурсами правильно отражаются в API
Этапы тестирования API
Каждый тест состоит из атомарных действий, которые должны выполняться в каждом потоке тестирования API. Для каждого запроса API тест должен будет выполнить следующие действия:
- Корректность кода состояния HTTP (создание ресурса должно возвращать 201 CREATED, а запрещенные запросы должны возвращать 403 FORBIDDEN и т.д.)
- Полезная нагрузка ответа (правильность тела JSON, имен, типов и значений полей ответа, в том числе в ответах на ошибочные запросы)
- Заголовки ответа (заголовки HTTP-сервера влияют как на безопасность, так и на производительность)
- Правильность состояния приложения (применяется в основном к ручному тестированию или когда пользовательский интерфейс или другой интерфейс можно легко проверить)
- Базовая работоспособность (если операция была завершена успешно, но заняла неоправданно много времени, тест не пройден)
Форматы передачи данных
- JSON (JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript, но при этом независим от JS.
- XML (eXtensible Markup Language/расширяемый язык разметки) — используется для хранения и передачи данных. формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому часто используется для передачи данных по API. Единственно возможный формат входных и выходных данных в SOAP.
- CSV (Comma-Separated Values/значения, разделенные запятыми) – текстовый формат, предназначенный для представления табличных данных с фиксированным количеством столбцов. Каждая строка файла — это одна строка таблицы.
- YAML (YAML Ain’t markup language/YAML не язык разметки; ранее Yet Another Markup Language) — язык для сериализации данных, который позволяет хранить сложноорганизованные данные в компактном и читаемом формате. Похож на XML и JSON, но использует более минималистичный синтаксис при сохранении аналогичных возможностей.
Отличия между XML и JSON
XML — язык разметки.
JSON — формат для обмена данными, обычно реализуемый, как массив данных.
Ключевые различия:
- Объект JSON имеет тип, тогда как объекты XML не содержат типов
- В JSON проще получить объект нежели в XML (данные XML должны быть проанализированы)
- Читабельность JSON файла выше по сравнению с XML
- JSON не обеспечивает поддержку пространства имен, в то время как XML обеспечивает
- JSON не имеет возможностей отображения, тогда как XML имеет такую возможность
- JSON менее защищен, тогда как XML более безопасен по сравнению с JSON
- JSON поддерживает только кодировку UTF-8, тогда как XML поддерживает различные кодировки
Как происходит шифрование
Симметричное — используется лишь один пароль/ключ.
В системе шифрования предусмотрен некий математический алгоритм. На его цифровой «вход» подается исходный ключ и исходные данные. Далее информация шифруется и отправляется.
При получении срабатывает обратный алгоритм и проходит процедура дешифровки с использованием того самого ключа.
Если знать ключ, то безопасность симметричного шифрования стремится к нулю. Поэтому ключ должен быть максимально сложным и запутанным. Несмотря на определенные ограничения, симметричное шифрование очень распространено из-за простоты и быстродействия.
Ассиметричное — используются два ключа: открытый/публичный и закрытый/приватный. Преимущество ассиметричного шифрования в том, что один из ключей всегда остается на устройстве и не передается.
Схема передачи данных между двумя субъектами (А и Б) выглядит следующим образом:
- Субъект А генерирует пару ключей, публичный и приватный.
- Субъект А передает публичный ключ субъекту Б. Передача может осуществляться по незащищенным каналам.
- Субъект Б шифрует пакет данных при помощи полученного публичного ключа и передает его А. Передача может осуществляться по незащищенным каналам.
- Субъект А расшифровывает полученную от Б информацию при помощи приватного ключа.
Какие бывают виды БД
https://proglib.io/p/11-tipov-sovremennyh-baz-dannyh-kratkie-opisaniya-shemy-i-primery-bd-2020-01-07
- Простейшие типы БД
- Текстовые файлы, csv-файлы
- Иерархические (файловые системы, DNS, LDAP)
- Сетевые (IDMS)
-
Реляционные БД (MySQL, PostgreSQL..)
-
NoSQL БД
- «Ключ-значение» (Redis, memcached)
- Документные (MongoDB, RethinkDB)
- Графовые (Neo4j, Dgraph)
- Колоночные (Cassandra, HBase)
- БД временных рядов (OpenTSDB, TimescaleDB)
- Комбинированные типы БД
- NewSQL (MemSQL, VoltDB, CockroachDB)
- Многомодельные (OrientDB, Couchbase)
Охарактеризуйте каждый класс HTTP status code (1хх; 2xx; 3xx; 4xx; 5xx).
- 1xx: Informational (информационные)
- 2xx: Success (успешно)
- 3xx: Redirection (перенаправление)
- 4xx: Client Error (ошибка клиента)
- 5xx: Server Error (ошибка сервера)
Расшифровка CRUD
CRUD — акроним, обозначающий четыре базовые функции, используемые при работе с постоянными хранилищами данных: создание (create), чтение (read), модификация (update), удаление (delete).
Какие есть HTTP-методы
GET — запрашивает информацию из указанного источника и не влияет на его содержимое. Запрос доступен для кеширования данных и добавления в закладки.
POST — используется для отправки данных, что может оказывать влияние на содержимое ресурса. В отличие от метода GET запросы POST не могут быть кешированы, они не остаются в истории браузера и их нельзя добавить в закладки.
HEAD — аналогичен методу GET, однако в ответе сервера содержится только заголовок, без тела. Обычно применяется для того, чтобы проверить, существует ли ресурс по указанному адресу, а также не изменился ли он с момента последнего обращения.
PUT — Загружает содержимое запроса на указанный в запросе URI. Если по заданному URI ресурса нет, то сервер создает его, возвращая статус 201 (Created).
PATCH — Используется для частичного изменения ресурса. В PATCH вложенный объект содержит набор инструкций, описывающих, как ресурс, должен быть модифицирован для создания новой версии. А в PUT содержится новая версия ресурса целиком.
DELETE — Удаляет указанный ресурс.
OPTIONS — Используется для описания параметров коммуникации между клиентом и сервером.
CONNECT — Преобразует соединение запроса в прозрачный TCP/IP-туннель.
Отличия GET от POST

Разница между методами PUT, POST, PATCH
POST — создание новой сущности. Может создавать коллекцию сущностей.
PUT — создание новой или полное обновление существующей сущности. Может работать только с одой сущностью.
PATCH — частичное обновление существующей сущности.
Какие знаете Web elements
Кнопки, лейблы, поля ввода, выпадающие списки, чекбоксы, радиобатоны, фреймы
Для чего необходимы инструменты разработчика в браузере (Chrome DevTools) и как они помогают в тестировании
- Переопределение геолокации и подмена User-Agent
- Определение JS пути к строке
- Изменение HTML-кода и стилей CSS у элементов
- Тестирование производительности и неиспользуемых CSS и Javascript в вёрстке
- Debug JavaScript
- Имитация медленного сетевого соединения
- Мониторинг сетевых запросов
- Информация о cookies во вкладке applications
Что такое кэш
Кэш — промежуточный буфер с быстрым доступом к нему, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удалённого источника, однако его объём существенно ограничен по сравнению с хранилищем исходных данных.
Кэш браузера — буфер между браузером и интернетом, в котором сохраняются посещённые пользователем страницы. Вместо того, чтобы скачивать их из интернета, браузер может «достать» страницы из кэша, что значительно сокращает скорость загрузки страниц. Проблема может возникнуть, если на сервере страница обновится, а браузер продолжит подгружать старую версию из кэша.
Что такое сессия
Cессия — механизм, позволяющий однозначно идентифицировать браузер и создающий для этого браузера файл на сервере, в котором хранятся переменные сеанса.
Зачем нужны cookies
Cookies — текстовые файлы небольшого размера со служебной информацией для браузера. Часто в таких файлах хранится статистика посещений, логин и пароль от сайтов или сервисов, индивидуальные настройки пользователя — регион, дизайн оформления и прочее.
iFrame и как с ним работать в Selenium
Фрейм (Frame/iFrame) — самостоятельный документ, который отображается в отдельном окне браузера и представляет собой полностью законченную HTML-страницу. Простыми словами, фрейм — разделитель браузерных окон на отдельные области.
Способы переключаться на iframe:
- По индексу
driver.switchTo().frame(i); - По имени или идентификатору
driver.switchTo().frame("a077aa5e"); - По веб-элементу
driver.switchTo().frame(driver.findElement(By.cssSelector("#modal>iframe"));
Что такое HTML/CSS/JavaScript
HTML (HyperText Markup Language/язык гипертекстовой разметки) — стандартизированный язык разметки документов для просмотра веб-страниц в браузере.
CSS (Cascading Style Sheets/каскадные таблицы стилей) — формальный язык описания внешнего вида документа (веб-страницы), написанного с использованием языка разметки (чаще всего HTML или XHTML). Также может применяться к любым XML-документам, например, к SVG или XUL.
JavaScript — мультипарадигменный язык программирования. Поддерживает объектно-ориентированный, императивный и функциональный стили. Часто используется как встраиваемый язык для программного доступа к объектам приложений. Наиболее широкое применение находит в браузерах как язык сценариев для придания интерактивности веб-страницам.
Какую структуру имеет веб-страница
- Заголовок: <header>
- Навигационное меню: <nav>.
- Основное содержимое: <main>, с различными подразделами содержимого, представленными элементами <article>, <section> и <div>.
- Боковая панель: <aside>, обычно располагается внутри <main>.
- Нижний колонтитул: <footer>.
Зачем чистить кэш
Веб-страницы могут отображаться некорректно в связи с тем, что в них были внесены изменения, а браузер продолжает использовать устаревшие данные из кэша. Также устаревший кэш может занимать место на ЖД.
Что такое AJAX
AJAX (Asynchronous JavaScript and XML/асинхронный JavaScript и XML) — технология описывающая как можно получать данные с сервера в фоновом режиме и использовать их для обновления страницы (без перезагрузки). Основная цель AJAX – это сделать сайты и веб-приложения более удобными, быстрыми и отзывчивыми.
Асинхронный потому, что действие выполняется в фоне (не в основном потоке), таким образом, что оно не мешает пользователю взаимодействовать со страницей.
JavaScript отвечает за создание и настройку запроса, отправку его на сервер, получение ответа и его разбор, обновление страницы.
Преимущества использования AJAX:
- снижение трафика (уменьшения объёма передаваемых данных между клиентом и сервером)
- уменьшение нагрузки на сервер (перегенерируется только часть страницы, которую нужно обновить)
- увеличение быстродействия и отзывчивости (нет необходимости в полной перезагрузке страницы, достаточно обновить содержимое отдельных блоков)
- повышение интерактивности (с помощью AJAX можно сразу отображать результаты и сделать ресурс более удобным для пользования)
Mobile
Какие мобильные платформы существуют
- Android
- iOS
Какие версии Android и iOS используются на рынке (минимальные и максимальные)
Взят min в 1%
Android: 4.4 — 13
iOS: 12 — 15
Типы мобильных приложений
- Игры для смартфона
- Промо-приложения
- Контентные сервисы
- Социальные сети
Что такое ADB
ADB (Android Debug Bridge) — клиент-серверное приложение, которое предоставляет доступ к работающему эмулятору или устройству. С его помощью можно копировать файлы, устанавливать скомпилированные программные пакеты и запускать консольные команды.
Состоит из трёх компонентов:
- фоновой службы (демона), работающей в эмуляторе
- сервиса, запущенного на компьютере разработчика
- клиентской программы (наподобие DDMS), которая связывается со службой через Сервис
Как снять логи с Android/IOS
Android:
- Подсоедините ваше устройство
- Подтвердите, что согласны подключить устройство к компьютеру (на устройстве)
- Откройте командную строку Windows
- adb devices
- adb -s <device ID> logcat -> log.log
- Воспроизведите проблему
- Остановите процесс подключения (ctrl+c) или просто отсоедините устройство
- В папке, из которой вы запустили командную строку, вы найдете файл log.log.
iOS (нужен MAC):
- Запустите Xcode.
- Подсоедините ваше устройство.
- Нажмите на вкладку Window — выберите в выпадающем списке «Устройства».
- Выберите ваше устройство.
- Воспроизведите проблему.
- Выберите log файл нажатием клавиш cmd+A
- Сохраните файл.
Что такое Appium
Appium — бесплатный кроссплатформенный инструмент с открытым исходным кодом, который помогает автоматизировать приложения как для Android, так и для iOS. Appium придерживается того же подхода, что и Selenium WebDriver, который получает HTTP-запросы в формате JSON от клиентов и преобразует их в зависимости от платформы, на которой он работает.
Требования для Android:
- Java (version >= 7)
- Android SDK API (version >= 17)
- Android Virtual Device (AVD) / real device
- Intel Hardware Accelerated Execution Manager
Требования для iOS:
- Mac OS X (version >= 10.7)
- Xcode (version >= 5.1)
- Java (version >= 7)
- Homebrew
- NodeJS
- npm
Как запускать тесты Android без Appium
- Espresso — официальный фреймворк для UI-тестирования, но тесты с его использованием работают по модели белого ящика (white-box). Espresso поддерживает Android API с 10 версии.
- UiAutomator — официальный фреймворк для тестирования. Как GUI-драйвер он служит для поиска элементов интерфейса на экране девайса и эмуляции различных действий: кликов, тачей, свайпов, ввода текста, проверок на видимость. Позволяет писать тесты по модели черного ящика (black-box). Он живет в собственном процессе и работает без доступа к исходному коду приложения. Тест с его использованием может взаимодействовать практически с любыми приложениями, в том числе системными.
- Robolectric — позволяет писать особые unit-тесты на основе JUnit с использованием Android API. Мокирует часть Android SDK, предоставляя пользователю так называемые shadow-объекты. Robolectric берет на себя такие задачи, как inflate view, загрузка ресурсов, и множество других, которые имеют нативную С-реализацию на Android-девайсах. Поэтому Robolectric позволяет писать тесты, имеющие зависимости на Android, но запускать их не на эмуляторе или реальном девайсе, а на десктопной JVM. Это существенно ускоряет процесс сборки, запуска и выполнения тестов.
- Robotium
- Selendroid