Биостатистика
1.
Наука, которая занимается планированием
и анализом результатов медико-биологических
исследований, называется: статистика
2.
Дискретной переменной называется
величина, которая:может
принимать отдельные, изолированные
значения с определенными вероятностями.
3.
Ошибка среднего :
стандартное
отклонение выборочного среднего,
рассчитанное по выборке размера из
генеральной совокупности
4. При
статистическом анализе данных ошибка
I рода возникает: Ошибка
I рода показывает вероятность того, что
будет отвергнута истинная гипотеза,
5.
Функциональную зависимость между
значениями случайных величин и
вероятностями, с которыми они приобретают
эти значения, называют: Корреляция
6.
Какому закону распределения подчиняются
случайные события, как например:
количество вызовов скорой помощи за
определенный промежуток времени; очередь
к врачу в поликлинике; эпидемии?Случайной
величиной называется величина, которая
в результате опыта может принять то или
иное значение, неизвестно заранее, какое
именно
7.
Репрезентативной называется выборочная
совокупность, которая: имеющая
такое же распределение относительных
характеристик, что и генеральная
совокупность( совокупность всех объектов
(единиц), относительно которых учёный
намерен делать выводы при изучении
конкретной проблемы.)
8. Дана
выборочная совокупность: {113; 115; 115; 118;
119; 120; 120; 120; 125}. Определите медиану.119
9. На
что указывает знак коэффициента
корреляции при наличии корреляционной
связи?
10. Для
каких целей в статистических пакетах
используется F-критерий
Фишера?называют
любой статистический критерий, тестовая
статистика которого при выполнении
нулевой гипотезы имеет распределение
Фишера (F-распределение).
11. Как принято
называть медицинские данные, когда при
проведении клинических исследований
некоторые из испытуемых выбывают из
исследования по разным причинам?
12.
Величина, которая может принимать любые
числовые значения в заданном интервале,
называется:Дискретной
13.
Какие используются методы для выявления
линейной связи между парой изучаемых
признаков в случае нормального закона
распределения?Коэффициент
корреляции знаков , Линейный коэффициент
корреляции
14. При
статистическом анализе данных ошибка
II
рода возникает:ошибка
II рода – что будет принята ложная
гипотеза.
15.
Как принято называть
отдельные числовые значения
изменяющегося параметра в совокупности?
16.
Группа призывников, которые прошли
медицинское обследование в военкомате
на протяжении года, представляют собой:
17.
Коэффициент
корреляции между уровнем шума и снижением
слуха с учетом стажа у рабочих
механосборочного цеха равен r(xy)= + 0,91.
Установленная связь:Сильная
18.
Для каких целей может применяться
Т-критерий Стьюдента при статистическом
анализе данных?.
Наиболее частые случаи применения
t-критерия связаны с проверкой равенства
средних значений в двух выборках.
19.
Что характеризует значение по модулю
коэффициента корреляции стохастической
взаимосвязи случайных величин?
20. Как называется
вероятность, с которой может быть
отклонена нулевая гипотеза, в случае,
когда она является правильной?
21.
Как называются данные, которые просто
имеют названия, при этом их невозможно
содержательно упорядочить?
22.
Непрерывной случайной величиной
называется величина, которая:это
величина, которая принимает в результате
опыта одно из множества значений, причём
появление того или иного значения этой
величины до её измерения нельзя точно
предсказать.
23.
Чем определяется функция плотности
распределения вероятности при нормальном
законе распределения случайных величин?
24.
Размахом вариации случайной величины
называется: абсолютная
величина разности между максимальным
и минимальным значением
25.
При сравнении двух выборок нулевая
гипотеза отвергается на уровне значимости
р=0,01. Всегда ли можно ее отвергнуть если
критический уровень значимости р=0,05 ?
26.
Как называется набор значений
(Хі;Х2,…,Xn)
случайной
величины X
при проведении
n-количества
опытов?
вариационный
ряд
27.
Дана выборочная совокупность: {112;
115; 115; 115; 123;
123;
123;
120; 125}. Определить моду:115,123
28.
Какое основное требование необходимо
обеспечить к выборке при проведении
исследований?
29.
Значение коэффициента корреляции может
изменяться в пределах:0-1
30.
Для каких целей может применяться
критерий Хи-квадрат Пирсона?универсальный
метод проверки согласия результатов
эксперимента и используемой статистической
модели.
Соседние файлы в папке Мед информатика
- #
- #
- #
- #
- #
- #
- #
- #
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| |
Верная гипотеза | ||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
Ошибки, встроенные в систему: их роль в статистике
Время прочтения
6 мин
Просмотры 11K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):

Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
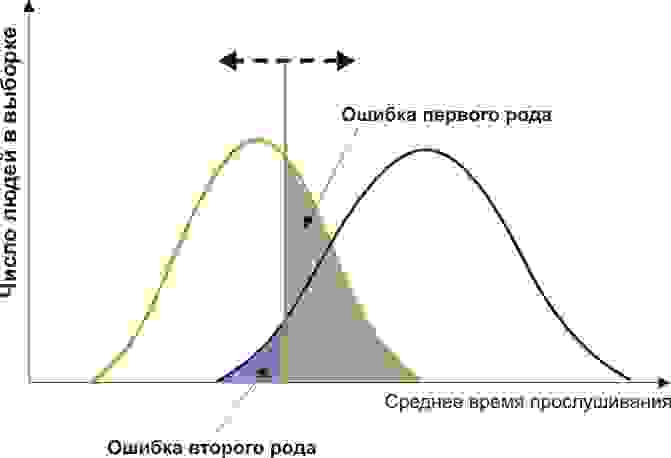
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
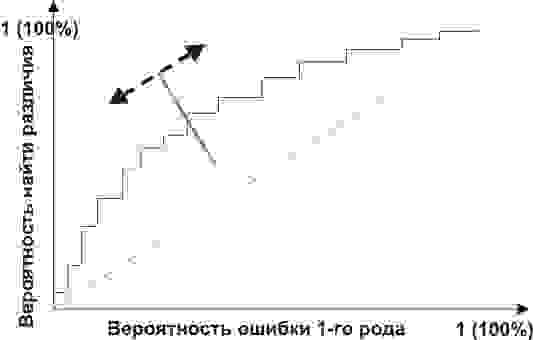
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]

The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed  . That is to say, the test statistic
. That is to say, the test statistic

In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve

According to change-of-units rule for the normal distribution. Referring to Z-table, we can get

Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as

which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]
The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed . That is to say, the test statistic
In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve
According to change-of-units rule for the normal distribution. Referring to Z-table, we can get
Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as
which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Радиолокация
- 4.2 Компьютеры
- 4.2.1 Компьютерная безопасность
- 4.2.2 Фильтрация спама
- 4.2.3 Вредоносное программное обеспечение
- 4.2.4 Поиск в компьютерных базах данных
- 4.2.5 Оптическое распознавание текстов (OCR)
- 4.2.6 Досмотр пассажиров и багажа
- 4.2.7 Биометрия
- 4.3 Массовая медицинская диагностика (скрининг)
- 4.4 Медицинское тестирование
- 4.5 Исследования сверхъестественных явлений
- 5 См. также
- 6 Примечания
Определения
Пусть дана выборка  из неизвестного совместного распределения
из неизвестного совместного распределения  , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:

где  — нулевая гипотеза, а
— нулевая гипотеза, а  — альтернативная гипотеза. Предположим, что задан статистический критерий
— альтернативная гипотеза. Предположим, что задан статистический критерий
 ,
,
 ,
,сопоставляющий каждой реализации выборки  одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
 соответствует гипотезе
соответствует гипотезе  .
. .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. [1][2]
| Верная гипотеза | |||
|---|---|---|---|
| |
|
||
| Результат применения критерия |
|
верно принята |
неверно принята (Ошибка второго рода) |
| |
неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой  (отсюда название -errors).
(отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой  (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле
(отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле  . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
. Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Радиолокация
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда нарушители классифицируются как авторизованные пользователи (ошибки первого рода)
- когда авторизованные пользователи классифицируются как нарушители (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных
При поиске в базе данных к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[3]
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[4]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.[5] Самый низкий уровень наблюдается в Нидерландах, 1%.[6]
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[7]
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение.[8]
См. также
- Статистическая значимость
- Ложноположительный
- Атака второго рода
- Случаи ложного срабатывания систем предупреждения о ракетном нападении
- Receiver_operating_characteristic
Примечания
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения.». Стр. 26
- ↑ Valerie J. Easton, John H. McColl. Statistics Glossary: Hypothesis Testing.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95% женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research).
10 Sep 2020 |
SPSS
Источники:
- Наследов. SPSS Профессиональный статистический анализ данных.
- Дубина. Логика проверки статистических гипотез
0. Логика проверки гипотез
0.1 Базовые идеи
Связь может характеризоваться не только величиной (степенью связи) и направлением, но также и надежностью или статистической достоверности (statistical confidence).
Надежность определяется тем, насколько вероятно, что обнаруженная в выборке связь подтвердится (будет вновь обнаружена) на другой выборке той же генеральной совокупности.
0.2 Статистическая значимость и обоснованность
Пример: Проверяется гипотеза о том, что женщины тратят больше времени на разговоры по телефону, чем мужчины. Предположим, что в исследовании принимали участие 52 мужчины и 43 женщины. Среднее время разговора составило 37 мин. в день у мужчин и 41 мин. в день у женщин. На первый взгляд, различия обнаружены, и эти результаты подтверждают гипотезу.
Однако такой результат может быть получен случайно, даже если в генеральной совокупности различий нет, как и наоборот, когда различия на самом деле существуют.
Поэтому закономерен вопрос: достаточно ли полученного различия в средних значениях для того, чтобы утверждать, что вообще все женщины в среднем говорят по телефону дольше, чем все мужчины? Какова вероятность, что это не так? Является ли это различие статистически значимым?
Необходимо определить, достаточно ли велика разность между средними двух распределений для того, чтобы можно было объяснить ее действием независимой переменной, а не случайностью, связанной с малым объемом выборки
Методы статистики позволяют оценить вероятность случайного получения такого различия при условии, что на самом деле различий в генеральной совокупности нет
0.3 Статистические гипотезы
- Нулевая гипотеза (null hypothesis) – гипотеза об отсутствии различий (утверждение об отсутствии различий в значениях или об отсутствии связи в генеральной совокупности)
- Согласно нулевой гипотезе ((H_{0})), различие между значениями недостаточно значительно, а независимая переменная не оказывает никакого влияния.
- Альтернативная гипотеза (alternative hypothesis) – гипотеза о значимости различий (утверждает наличие различий или существование связи).
- Альтернативная гипотеза ((H_{A})) является «рабочей» гипотезой исследования. В соответствии с этой гипотезой, различия достаточно значимы и обусловлены влиянием независимой переменной.
- Нулевая и альтернативная гипотезы представляют полную группу несовместных событий: отклонение одной влечет принятие другой.
- Основной принцип метода проверки гипотез состоит в том, что выдвигается нулевая гипотеза (H_{0}), с тем чтобы попытаться опровергнуть ее и тем самым подтвердить альтернативную гипотезу (H_{A}). Если результаты статистического теста, используемого для анализа разницы между средними, окажутся таковы, что позволят отклонить (H_{0}), это будет означать, что верна (H_{1}), т.е. выдвинутая рабочая гипотеза подтверждается.
- Не можем отклонить нулевую гипотезу — не значит «принять» альтернативную (нулевая гипотеза никогда не может быть абсолютно подтверждена!)
0.4 Статистические ошибки при принятии решений Ошибки первого и второго рода
Статистическая ошибка первого рода (Type I Error) – ошибка обнаружить различия или связи, которые на самом деле не существуют «Истинная нулевая гипотеза отклоняется».
Статистическая ошибка второго рода (Type II Error) — не обнаружить различия или связи, которые на самом деле существуют «Ложная нулевая гипотеза не может быть отклонена».
Более «критичной» ошибкой считается статистическая ошибка первого рода.
Пример: «Судебная» аналогия: Вердикт «Не виновен» или «Виновен» Ошибка первого рода — невинный обвинен
Ошибка второго рода — виновный освобожден.
0.5 Уровни статистической значимости
Уровень значимости (level of significance) (уровень достоверности, уровень надежности, доверительный уровень, вероятностный порог) — это пороговая (критическая) вероятность ошибки, заключающейся в отклонении (не принятии) нулевой гипотезы, когда она верна. Другими словами, это допустимая (с точки зрения исследователя) вероятность совершения статистической ошибки первого рода – ошибки того, что различия сочтены существенными, а они на самом деле случайны.
Обычно используют уровни значимости (обозначаемые (alpha)), равные 0.05, 0.01 и 0.001.
Например, уровень значимости, равный 0,05, означает, что допускается не более чем 5%-ая вероятность ошибки. Т.е. нулевую гипотезу можно отвергнуть в пользу альтернативной гипотезы, если по результатам статистического теста вероятность ошибки, т.е. вероятность случайного возникновения обнаруженного различия (p-уровень) не превышает 5 из 100, т.е. имеется лишь 5 шансов из 100 ошибиться. Если же этот уровень значимости не достигается (вероятность ошибки выше 5%), считают, что разница вполне может быть случайной и поэтому нельзя отклонить нулевую гипотезу.
Таким образом, p-уровень значимости (p-value) соответствует риску совершения ошибки первого рода (отклонения истинной нулевой гипотезы). Если (p < alpha), (H_{0}) отклоняется.
| Уровень значимости | Решение | Возможный статистический вывод |
|---|---|---|
| p>0.1 | Но не может быть отклонена | «Статистически достоверные различия не обнаружены» |
| p <= 0.1 | сомнения в истинности Но, неопределенность | «Различия обнаружены на уровне ста- тистической тенденции» |
| p<=0.05 | значимость, отклонение Но | «Обнаружены статистически достоверные (значимые) различия» |
| p<=0.01 | высокая значимость, отклонение Но | «Различия обнаружены на высоком уровне статистической значимости» |
Для принятия решений о том, какую из гипотез (нулевую или альтернативную) следует принять, используют статистические критерии, которые включают в себя методы расчета определенного показателя, на основании которого принимается решение об отклонении или принятии гипотезы, а также правила (условия) принятия решения.
Этот показатель называется эмпирическим значением критерия. Это число сравнивается с известным (например, заданным таблично) эталонным числом, называемым критическим значением критерия.
Критические значения приводятся, как правило, для нескольких уровней значимости: 5% (0.05), 1% (0.01) или еще более высоких. Если полученное исследователем эмпирическое значение критерия оказывается меньше или равно критическому, то нулевая гипотеза не может быть отклонена – считается, что на заданном уровне значимости (то есть при том значении (a), для которого рассчитано критическое значение критерия) характеристики распределений совпадают.
Если эмпирическое значение критерия оказывается строго больше критического, то нулевая гипотеза отвергается и принимается альтернативная гипотеза – характеристики распределений считаются различными с достоверностью различий (1 – alpha). Например, если (alpha = 0.05) и принята альтернативная гипотеза, то достоверность различий равна 0.95 или 95%.
- Если эмпирическое значение критерия для данного числа степеней свободы ((df=n-1)) оказывается ниже критического уровня, соответствующего выбранному значению (alpha) (порогу вероятности), то нулевая гипотеза не может считаться опровергнутой, и это означает, что выявленная разница (или связь) недостоверна.
- Чем эмпирическое значение меньше критического значения критерия, тем больше степень совпадения характеристик сравниваемых объектов.
- Чем эмпирическое значение критерия больше критического значения, тем сильнее различаются характеристики сравниваемых объектов. Если эмпирическое значение критерия оказывается меньше или равно критическому, то можно сделать вывод, что характеристики экспериментальной и контрольной групп совпадают на уровне значимости (alpha).
- Если эмпирическое значение критерия оказывается строго больше критического, то можно сделать вывод, что достоверность различий характеристик экспериментальной и контрольной групп равна (alpha)
0.6 Процедура проверки статистической гипотезы
- Сформулировать нулевую и альтернативной гипотезы;
- Выбрать соответствующий статистический тест;
- Выбрать требуемый уровень значимости ((alpha = 0.05, 0.01, 0.025, …))
- Вычислить эмпирическое значение критерия по тесту;
- Сравнить с критическим значением критерия по тесту;
- Принять решение (для большинства тестов приемлемо правило: если вычисленное значение больше, чем критическое, нулевая гипотеза (H_{0}) отклоняется).
! Примечание: Выбор статистического метода также зависит от того, являются ли выборки, средние которых сравниваются, независимыми (т. е., например, взятыми из двух разных групп испытуемых) или зависимыми (т. е. отражающими результаты одной и той же группы испытуемых до и после воздействия или после двух различных воздействий).
1. Описательные статистики
Таблицы сопряженности и критерий (chi^{2})
Таблицы сопряженности служат для описания связи двух или более номинальных (категориальных) переменных. Примерами номинальных переменных являются: пол (женский, мужской), класс (А, Б, В), местность (город, пригород, село), ответ (да, нет) и т. д. Таблицы сопряженности неприменимы к непрерывным переменным, однако последние можно разбить на интервалы. Так, возраст человека, который следует считать непрерывным из-за большого числа его возможных значений, можно разделить на интервалы от 0 до 19 лет, от 20 до 39 лет, от 40 до 59 лет и т. д.
Критерий независимости (chi^{2})
Помимо частот (или наблюдаемых величин) SPSS может вычислять ожидаемые значения для каждой ячейки таблицы. Ожидаемое значение вычисляется в пред- положении, что две номинальные переменные независимы друг от друга. Рассмо- трим простой пример. Пусть в комнате находится 100 человек, из которых 30 являются мужчинами, а 70 — женщинами. Если известно, что из этих 100 человек 10 увлекаются искусством, в случае если увлечение не зависит от пола, следует ожидать, что из 10 увлекающихся искусством 3 являются мужчинами, а 7 — женщинами. Сопоставляя эти ожидаемые частоты с наблюдаемыми частотами, мы можем судить о том, действительно ли два номинальных признака независимы. Чем больше расхождение наблюдаемых и ожидаемых частот, тем сильнее эти два признака связаны друг с другом. Целью применения критерия независимости (chi^{2}) и является установление степени соответствия между наблюдаемыми и ожидаемыми значениями ячеек.
Вместе с (chi^{2}) вычисляется р-уровень значимости. При p > 0,05 считается, что различия между наблюдаемыми и ожидаемыми значениями незначительны. В противном случае предположение о независимости двух номинальных переменных отклоняется и делается вывод о том, что две классификации (переменные) зависят друг от друга. Т.е. если p < 0,05 различия значимы и две переменные зависят друг от друга.
О величине связи переменных можно судить по симметричным мерам — значени- ям показателей (phi) и (V) Крамера, которые аналогичны коэффициенту корреляции. Например, величина 0,392 свидетельствует об умеренной связи между переменными.
- Значение — для критерия (chi^{2}) значение тем больше, чем больше зависимость между переменными (как в нашем примере 15.02 для 2х df). Значения близкие к 0 свидетель- ствуют о независимости переменных.
- Асимпт. значимость — асимптотическая значимость, вероятность случайности связи или р-уровень значимости, то есть вероятность того, что связь является случайной. Чем меньше эта величина, тем выше статистическая значимость (достоверность) связи. Величина
p ≤ 0,05свидетельствует о статистически значимом результате, который достоин содержательной интерпретации. Асимптотическая значимость определяется по традиционному критерию (chi^{2}). - (phi) — коэффициент, являющийся мерой связи двух переменных, аналог корреляции Пирсона. Значение (φ) = 0,392 показывает умеренную связь между двумя переменными.
- (V) Крамера — как и коэффициент (phi), этот коэффициент является мерой связи между двумя переменными, однако отличается тем, что всегда принимает значения от 0 до 1 и более приемлем для таблиц с df > 2.
2. Корреляции
Корреляция представляет собой величину, заключенную в пределах от –1 до +1, и обозначается буквой r. Понятия корреляция и двумерная корреляция часто употребляются как синонимы; последнее означает «корреляция между двумя переменными» и подчеркивает, что рассматривается именно двумерное соотношение. Основной коэффициент корреляции r Пирсона предназначен для оценки связи между двумя переменными, измеренными в метрической шкале, распределение которых соответствует нормальному. Несмотря на то что величина r рассчитывается в предположении, что значения обеих переменных распределены по нормальному закону, формула для ее вычисления дает достаточно точные результаты и в случаях анормальных распределений, а также в случаях, когда одна из переменных является дискретной. Для распределений, не являющихся нормальными, предпочтительнее пользоваться ранговыми коэффициентами корреляции Спирмена или Кендалла. Команды подменю Корреляции позволяют вычислить как коэффициент Пирсона, так и коэффициенты Спирмена и Кендалла.
Понятие корреляции
Корреляция, или коэффициент корреляции, — это статистический показатель вероятностной связи между двумя переменными, измеренными в количественной шкале.
Величина коэффициента корреляции меняется от –1 до 1. Крайние значения соответствуют линейной функциональной связи между двумя переменными, 0 — отсутствию связи.
Линейная и криволинейная корреляции
Основной коэффициент корреляции r Пирсона является мерой прямолинейной связи между переменными: его значения достигают максимума, когда точки на графике двумерного рассеяния лежат на одной прямой линии. Если связь нелинейная, но монотонная, вместо r Пирсона следует использовать ранговые корреляции Спирмена или Кендалла.
Прежде чем оценивать корреляцию двух переменных, рекомендуется построить график зависимости между ними — график двумерного рассеяния. Если график демонстрирует монотонность связи, для вычисления корреляции можно использовать команды подменю Корреляции.
Ранговые корреляции
Необходимость в применении ранговых корреляций возникает в двух случаях:
- когда распределение хотя бы одной из двух переменных не соответствует нормальному
- когда связь между переменными является нелинейной (но монотонной).
В этих случаях вместо корреляции r Пирсона можно выбрать ранговые корреляции: r Спирмена либо τ (читается «тау») Кендалла. Ранговыми они являются потому, что программа предварительно ранжирует переменные, между которыми они вычисляются.
Значимость
При проверке статистической гипотезы результат имеет статистическую значимость, когда маловероятно, что он произошел с учетом нулевой гипотезы.
Напомним, что уровень значимости является мерой статистической достоверности результата вычислений, в данном случае — корреляции, и служит основанием для интерпретации. Если исследование показало, что уровень значимости корреляции не превышает 0,05 (р ≤ 0,05), то это означает, что корреляция является случайной с вероятностью не более 5 %. Обычно это является основанием для вывода о статистической достоверности корреляции. В противном случае (p > 0,05) связь признается статистически недостоверной и не подлежит содержательной интерпретации.
Частная корреляция
Понятие частной корреляции связано с ковариацией. Здесь мы упоминаем частную корреляцию лишь как одну из команд подменю Корреляции. Суть частной корреляции заключается в следующем. Если две переменные коррелируют, всегда можно предположить, что эта корреляция обусловлена влиянием третьей переменной, как общей причины совместной изменчивости первых двух переменных. Для проверки этого предположения достаточно исключить влияние этой третьей переменной и вычислить корреляцию двух переменных без учета влияния третьей переменой (при фиксированных ее значениях). Корреляция, вычисленная таким образом, и называется частной.
При вычисление парной корреляции в SPSS есть пунктик “Метить значимые корреляции (Falg significant correlations)”, корреляции, вычисленные с уровнем значимости от 0,01 до 0,05, будут помечены одной звездочкой (*), а от 0 до 0,01 — двумя звездочками(**)
Пример:

Значимая положительная корреляция в этой таблице наблюдается, в частности, между переменными кратковременная память (тест5) и отметка2 (r = 0.294, p = = 0.003). Это означает, что чем лучше кратковременная память, тем выше средняя отметка за выпускной класс.
3. Средние значения
Команда Средние предназначена для сравнения подгрупп наблюдений по таким показателям количественных переменных, как средние, медианы и пр.
Так, при помощи этой команды можно сравнить средние значения успеваемости (отметка1, отметка2) юношей и девушек (пол), учащихся разных классов (класс) и т. д.
Analyze -> Compare Means -> Means
Список независимых переменных служит для задания неколичественных (номи- нальных) переменных, градации которых определяют сравниваемые подгруппы объектов (пол, класс, вуз и т. п.)
Пример:

Сравнение средних отметок (непрерывная — dependent) для классов (номинальная — independent).
Анализ сравнения средних позволяет проводить однофакторный дисперсионный анализ

Для примера, сравним средние в группах Класс (Layer 1) и Пол (Layer 2).

Вычисленные средние значения (4,096, 4,167 и 4,408) различаются на уровне зна- чимости p < 0,001. Это свидетельствует о статистически достоверной зависимости успеваемости учащихся от класса.
Коэффициент Эта подобен корреляции и оценивает связь между двумя переменными: количе- ственной и номинативной. Коэффициент Эта в квадрате — мера влияния независи- мой переменной на дисперсию зависимой переменной. Величина 0,231 свидетельствует о том, что 23,1 % дисперсии зависимой переменной объясняются влиянием независимой переменной.
Попарно сравнить средние значения можно при помощи t-критерия Стьюдента.
4. Сравнение двух средних и t-критерий
Различные варианты обработки данных с применением t-критерия позволяют сделать вывод о различии двух средних значений. Например, в случае применения t-критерия для независимых выборок проверяется достоверность различия двух выборок по количественной переменной, измеренной у представителей этих двух выборок. Для этих выборок вычисляются средние значения количественной переменной, затем по t-критерию определяется статистическая значимость различия средних. Применение t-критерия позволяет ответить на простой вопрос: насколько существенны различия между двумя выборками по данной количественной переменной. Основное требование к данным для применения этого критерия — представление переменных, по которым сравниваются выборки, в метрической шкале измерения.
! SPSS позволяет применять 3 варианта t-критерия: t-критерий для независимых выборок, t-критерий для парных выборок, одновыборочный t-критерий.
- Первый из вариантов t-критерия, t-критерий для независимых выборок, предназначен для сравнения средних значений двух выборок. Для сравниваемых выборок должны быть определены значения одной и той же переменной. С помощью t-критерия для независимых выборок можно сравнить успеваемость студентов и студенток, степень удовлетворенности жизнью холостяков и женатых, средний рост футболистов двух команд и пр. Обязательным условием для проведения этого t-критерия является независимость выборок.
- Второй из t-критериев, t-критерий для парных или зависимых выборок, позволяет сравнить средние значения двух измерений одного признака для одной и той же выборки, например результаты первого и последнего экзаменов группы студентов или значения показателя до и после воздействия на группу. Обязательным условием применения t-критерия для зависимых выборок является наличие повторного измерения для одной выборки.
- Последний из t-критериев, одновыборочный t-критерий, позволяет сравнить среднее значение этой выборки с некоторой эталонной величиной. Например, отличается ли среднее значение некоторого теста для данной выборки от нормативной величины, отличается ли время, показанное бегунами во время соревнования, от 17 минут и т. д.
Уровень значимости
Результат сравнения средних значений с применением t-критерия оценивается по уровню значимости.
Напомним, что уровень значимости (р-уровень) является мерой статистической достоверности результата вычислений, в данном случае — различий средних, и служит основанием для интерпретации. Если исследование показало, что p-уровень значимости различий не превышает 0,05, это означает, что с вероятностью не более 5 % различия являются случайными. Обычно это яв- ляется основанием для вывода о статистической достоверности различий. В про- тивном случае (p > 0,05) различие признается статистически недостоверным и не подлежит содержательной интерпретации.
Применение t-критерия для независимых выборок
Сравнение средних -> T-критерий для независимых выборок
! Проверяемые переменные: Cами переменные должны быть метрического типа (переменные отметка1, отметка2, тест1 и т. п.)
! Группировать по: указывается имя переменной, значениям (градациям) которой соответствует две независимые выборки для t-критерия. Как правило, группирующая переменная дискретна и имеет две градации.

Output

Вывод: Из результатов следует, что выборка из 39 юношей имеет средний балл 4,13, выборка из 61 девушки — средний балл 4,28. Различия статистически достоверны на высоком уровне значимости (p = 0,009). Критерий равенства дисперсий Ливиня указывает на то, что дисперсии двух распределений статистически значимо не различаются (p = 0,807), следовательно, применение t-критерия корректно.
Применение t-критерия для парных выборок
Cравним отметки учащихся в 10 и 11 классах (отметка1 и отметка2).

Output

Вывод: Как видно из результатов, для выборки объемом N = 100 среднее значение пере- менной отметка2 (4,22) оказалось статистически значимо выше среднего значения переменной отметка1 (3,96) с уровнем значимости p < 0,001. Кроме того, между переменными отметка1 и отметка2 существует значительная корреляция (r = 0,434, p < 0,001), свидетельствующая о том, что данные переменные действительно мож- но считать зависимыми выборками.
Применение t-критерия для одной выборки
Сравнение средних -> Одновыборочный T-критерий
Иногда бывает необходимо сравнить среднее значение распределения с какой-либо фиксированной величиной. Представим себе следующую ситуацию. Исследователь решил проверить, отличаются ли данные его выборки от нормативных показателей. Предположим, нормативный показатель по выбранной переменной равен 10. Для того чтобы проверить результат выборки на соответствие норме, нужно вычислить среднее значение для выборки и сравнить его с числом 10.

Output

Вывод: Из таблиц видно, что среднее значение переменной тест2 (числовые ряды) составляет 10,35 и статистически достоверно не отличается от 10 ( p > 0,1). Среднее значение переменной тест3 (словарь) равно 11,96 и статистически достоверно отличается от 10 (p < 0,001).
Термины, используемые в выводе
- Стандартная ошибка — отношение стандартного отклонения к квадратному корню из размера выборки N. Является мерой стабильности среднего значения.
- F-критерий — величина, характеризующая соотношение дисперсий двух распределений.
- Значимость — значимость, или
р-уровень значимости. При сравнении дисперсии двух распределений, в зависимости от того, равны они или не равны, применяются различные виды статистических приближений. Величинаp > 0,05указывает на то, что дисперсии можно считать не различающимися. - t (t-критерий) — t-критерий определяется как отношение разности средних значений к стандартному отклонению.
- ст. св. — число степеней свободы, для t-критерия с независимыми выборками при равенстве дисперсий число степеней свободы равно разности числа объ- ектов и числа групп (100 – 2 = 98), а при различии дисперсий применяется более сложная формула, приводящая к дробному значению, равному 81,65. Для зависимых выборок и для одной выборки число степеней свободы для t-критерия определяется как 100 – 1 = 99.
- Значимость (2-сторонняя) — по отношению к t-критерию двусторонняя значимость означает вероятность того, что разность между средними значениями является случайной, а по отношению к коэффициенту корреляции — вероятность того, что связь между двумя переменными является случайной.
- Стд. отклонение — стандартное отклонение. Для t-критерия с зависимыми выборками это стандартное отклонение разности между значениями повторных измерений.
- Корреляция — мера связи двух переменных, а для зависимых выборок — мера связи парных переменных. Численно определяется коэффициентом корреля- ции; в данном примере использовался коэффициент Пирсона.
- 95% доверительный интервал — в случае t-критерия термин «доверительный интервал» относится к разности между средними значениями выборок.
5. Непараметрические критерии
Параметрический критерий — это метод статистического вывода, который применяется в отношении параметров генеральной совокупности. Самым главным условием для параметрических методов является нормальность распределения переменных и, как следствие, правомерность применения таких статистик, как среднее значение и стандартное отклонение.
Непараметрические методы методы предназначены для номинативных и ранговых переменных.
Восемь непараметрических методов перечислены ниже
- Сравнение двух независимых выборок (критерий Манна–Уитни) позволяет установить различия между двумя независимыми выборками по уровню выраженности порядковой переменной.
- Критерий знаков. Сравнение двух связанных (зависимых) выборок может проводиться по двум критериям. Критерий знаков основан на подсчете числа отрицательных и положительных разностей между повторными измерениями; критерий Уилкоксона в дополнение к знакам разностей учитывает их величину.
- Критерий серий определяет, является ли последовательность бинарных величин (событий) случайной или упорядоченной.
- Биномиальный критерий определяет, отличается ли распределение дихотомической величины от заданного соотношения.
- Критерий Колмогорова—Смирнова для одной выборки определяет отличие распределения переменной от нормального (равномерного, Пуассона и т. д.).
- Критерий хи-квадрат для одной выборки определяет степень отличия наблюдаемого распределения частот по градациям переменной от ожидаемого распределения.
- Сравнение К независимых выборок (критерий Н Крускала—Уоллеса) позволяет установить степень различия между тремя и более независимыми выборками по уровню выраженности порядковой переменной.
- Сравнение К связанных (зависимых) выборок (критерий Фридмана) позволяет установить степень различия между тремя и более зависимыми выборками по уровню выраженности порядковой переменной.
Примеры
5.1 Сравнение двух независимых выборок
Критерий Манна—Уитни (Mann-Whitney), или U-критерий, по назначению аналогичен t-критерию для независимых выборок. Разница заключается в том, что t-критерии ориентированы на нормальные и близкие к ним распределения, а критерий Манна–Уитни — на распределения, отличные от нормальных. В частном случае критерий Манна–Уитни можно применять и для нормально распределенных данных, однако он менее чувствителен к различиям (является менее мощным).
Пример: Выясним, различаются ли юноши и девушки по успеваемости в выпускном классе.

Output

Вывод: Средний ранг для девушек равен 56,21, а для юношей — 41,56. Это значит, что у девушек успеваемость выше, чем у юношей. Статистика U Манна-Уитни равна 841. Значение Z является нормализованным, связанным с уровнем значимости p = 0,014. Поскольку величина уровня значимости (Асимпт. знч (двухсторонняя)) меньше 0,05, мы можем быть уверены в статистической достоверности вывода о том, что успе- ваемость девушек действительно выше успеваемости юношей.
5.2 Сравнение двух связанных (зависимых) выборок
Основные методы, которые используются для сравнения двух зависимых выборок, — это критерий знаков и критерий Уилкоксона (Wilcoxon test).
5.2.a Критерий знаков
Критерий знаков позволяет сравнить два измерения переменной на одной выборке (например, «до» и «после») по уровню ее выраженности путем сопоставления количества положительных и отрицательных разностей (сдвигов) значений.
Пример: сравним результаты учащихся по второму (тест2) и четвертому (тест4) тестам

Output

Вывод: в 39 случаях значения переменной тест2 оказались меньшими, чем значения переменной тест4, в 57 случаях значе- ния переменной тест2 превысили значения переменной тест4, и 4 раза было уста- новлено равенство значений обеих переменных. Стандартизованное значение (Z) составляет –1,735, а уровень значимости p = 0,083. Это означает, что различия между результатами тестов тест4 и тест2 статистически недостоверны. Обратите внимание: поскольку переменные тест4 и тест2 являются метрическими, к ним предпочтительней применить t-критерий для парных выборок. Он показал бы, что средние значения тест4 и тест2 различаются с уровнем значимости p = 0,01. Таким образом, можно на практике убедиться в том, что статистические возможности t-критерия в отношении переменных значительно выше, чем возможности критерия знаков.
5.2.b Критерий Уилкоксона
Корректность применения этого критерия сомнительна, если переменная имеет небольшое число возможных значений, например, 3-балльная шкала.
Output

Вывод: Результаты применения критерия Уилкоксона и критерия знаков очень похожи. Частота каждого из трех исходов N осталась неизменной. Информация о каждом из исходов (кроме равенства) теперь включает также среднее и суммарное значе- ния для соответствующих рангов. Визуальный анализ исходных данных говорит о том, что значения теста 4 (осведомленность) в целом несколько превышают зна- чения теста 2 (числовые ряды). Это демонстрирует и величина Z = –2,493, которая значительно превосходит по модулю соответствующее значение, полученное ранее для критерия знаков. Уровень значимости p = 0,013, что говорит о статистической достоверности различий. Таким образом, мы убеждаемся в том, что критерий Уилкоксона является более чувствительным к различиям (более мощным), чем крите- рий знаков. Тем не менее он оказывается несколько хуже t-критерия, обеспечивающего уровень значимости 0,01, что подтверждает предпочтительность последнего для анализа метрических данных.
5.3 Критерий серий
Критерий серий применяется для анализа последовательности объектов (явлений, событий), упорядоченных во времени или в порядке возрастания (убывания) значений измеренного признака. Кроме того, критерий требует представления последовательности в виде бинарной переменной, то есть как чередования событий 0 и 1. Гипотеза о случайном распределении событий 1 среди событий 0 может быть отклонена, если количество серий либо слишком мало (однотипные события имеют тенденцию к группированию), либо слишком велико (события 0 и 1 имеют тенденцию к чередованию).
Пример: проверим гипотезу о неслучайном чередовании юношей и девушек (переменная пол).

Output

Вывод: Количество серий равно 49. В результаты включено значение точки деления, вве- денное в поле Задаваемое. Величина Z и соответствующая значимость зависят от числа серий. Число серий преобразуется к z-значению, для которого и определяется p-уровень. Большое значение p-уровня (0,929) свидетельствует о том, что чередование юношей и девушек в файле является случайным. Статистически значимый результат свидетельствовал бы о том, что чередование юношей и девушек в файле является неслучайным. Если при этом число серий было бы слишком велико, это свидетельствовало бы о том, что после юноши с высокой долей вероятности следует девушка (и наоборот). При малом значении числа серий можно было бы сделать вывод о том, что более вероятно группирование испытуемых в списке по половому признаку (после юноши чаще следует юноша, а после девушки — девушка).
5.4 Биномиальный критерий
Назначение биномиального критерия — определение вероятности того, что наблю- даемое распределение не отличается от ожидаемого (заданного) биномиального распределения. Свойством биномиального распределения является заранее задан- ное соотношение вероятностей двух взаимоисключающих событий (обычно — равновероятное). Например, при многократном подбрасывании «правильной» монеты вероятности выпадения «орлов» и «решек» подчиняется биномиальному распределению.
Пример: исследуем распределение юношей и девушек. Проверим, отличается ли статистически достоверно это распределение (наблюдаемое) от ожидаемого (теоретического) равновероятного соотношения.

Output

Вывод: Ожидаемая пропорция для биномиального теста равна 0,5 для обеих групп. На- блюдаемая пропорция для каждой из групп определяется как отношение размера группы (N ) к размеру выборки (100). Как можно видеть, наблюдаемые пропорции значительно отличаются от 0,5 и составляют 0,39 для мужчин и 0,61 для женщин. Уровень значимости, равный 0,035, свидетельствует о статистически достоверном отличии исследуемого распределения от биномиального (равновероятного).
5.5 Критерий Колмогорова–Смирнова для одной выборки
Критерий Колмогорова–Смирнова для одной выборки позволяет определить, отличается ли заданное распределение от нормального (эксцесс и асимметрия распределения равны 0), равномерного (значения распределены с одинаковой плотностью, например, как у целых чисел от 1 до 1000), Пуассона (среднее значение и дисперсия равны (lambda); при больших значениях (lambda) распределение Пуассона приближается к нормальному) или экспоненциального.
Пример: исследуем распределение значений переменной отметка1 на соответствие нормальному распределению.

Output

Вывод: В строке Разности экстремумов приведены Модуль, а также Положительные и Отрицательные отклонения исследуемого распределения от теоретического (в данном случае, нормального). Строка Статистика Z Колмогорова-Смирнова содержит z-значение, уровень значимости которого равен 0,685 (последняя строка). Это означает, что распределение значений переменной отметка1 статистически не отличается от нормального (p > 0,05).
5.6 Критерий хи-квадрат (chi^{2}) для одной выборки
В данном случае в качестве ожидаемого (теоретического) распределения обычно выступает равномерное распределение объектов по градациям перемен- ной, в отношении которой применяется критерий. Далее будет приведен пример применения критерия (chi^{2}) к переменной вуз. Поскольку число объектов (N) равно 100, а переменная вуз имеет 4 градации, ожидаемые частоты для каждой градации равны 100/4 = 25. Применение рассматриваемого критерия допускает задание не только равномерного ожидаемого распределения, но и любого другого. Например, можно проверить гипотезу о том, что соотношение учащихся, предпочитающих 4 категории специализаций, соотносятся как 20:20:30:30. Для этого в группе Ожидаемые значения следует установить переключатель Значения, а затем при помощи поля и кнопки Добавить последовательно ввести в список значения 20, 20, 30, 30. После этих действий ожидаемые частоты изменятся в соответствии с заданными пропорциями.

Output

Вывод: Первая из таблиц демонстрирует заметные различия наблюдаемых и ожидаемых частот. Остаток — это разность между наблюдаемыми и ожидаемыми частотами. Число степеней свободы (ст.св.) определяется как число значений (градаций) переменной, уменьшенное на 1. Уровень значимости ( p = 0,002) свидетельствует о статистически достоверном отличии наблюдаемого распределения предпочтений от равномерного распределения.
5.7 Сравнение К независимых выборок и критерий Крускала–Уоллеса
Для сравнения более двух независимых выборок по уровню выраженности переменной применяется несколько критериев: H-критерий Крускала—Уоллеса, критерий медианы, критерий Джонкира—Терпстра. Из них наибольшей чувствительностью к различиям обладает H-критерий Крускала—Уоллеса. Этот критерий является непараметрическим аналогом однофакторного дисперсионного анализа, отличаясь от него в двух отношениях. Во-первых, критерий Крускала—Уоллеса основан не на сравнении средних значений и дисперсий переменных, а на сравнении средних рангов. Во-вторых, вместо вычисления F-критерия на основе сравнения средних рангов с ожидаемыми значениями вычисляется критерий хи-квадрат. Для нормальных распределений однофакторный дисперсионный анализ обеспечивает более точные результаты, чем критерий Крускала—Уоллеса, однако применение последнего рекомендуется для распределений, отличающихся от нормального.
H-критерий Крускала—Уоллеса «по идее» сходен с U-критерием Манна—Уитни. Как и последний, он оценивает степень пересечения (совпадения) нескольких рядов значений измеренного признака. Чем меньше совпадений, тем больше различаются ряды, соответствующие сравниваемым выборкам. Основная идея H-критерия Крускала—Уоллеса основана на представлении всех значений сравниваемых выборок в виде одной общей последовательности упорядоченных (ранжированных) значений с последующим вычислением среднего ранга для каждой из выборок. Если выполняется статистическая гипотеза об отсутствии различий, можно ожидать, что все средние ранги примерно равны и близки к общему среднему рангу.
Пример: проведем сравнение трех групп учащихся, отличающихся внешкольными увлечениями (переменная хобби) и успеваемостью в выпускном классе (переменная отметка2).

Output

Вывод: В первой таблице для каждой группы представлена ее численность и средний ранг. Во второй таблице указано значение критерия (chi^{2}), число степеней свободы и уровень статистической значимости. Результаты обработки показывают статистически достоверную связь внешкольных увлечений учащихся с успеваемостью в выпускном классе.
5.8 Сравнение нескольких зависимых выборок и критерий Фридмана
Критерий Фридмана является непараметрическим аналогом однофакторного дис- персионного анализа для повторных измерений. Он позволяет проверять гипотезы о различии более двух зависимых выборок (повторных измерений) по уровню выраженности изучаемой переменной. Критерий Фридмана может быть более эффективен, чем его метрический аналог однофакторный дисперсионный анализ в случаях повторных измерений изучаемого признака на небольших выборках и при отличии распределения от нормального. Если выполняется статистическая гипотеза об отсутствии различий между повторными измерениями, можно ожидать примерного равенства сумм рангов для этих условий. Чем больше различаются зависимые выборки по изучаемому признаку, тем больше эмпирическое значение вычисляемого значения критерия (chi^{2}), по которому определяется p-уровень значимости.
Пример: сравним результаты тестов тест1, тест2, тест3, тест4 и тест5 для всех учащихся.

Output

Вывод: Средние ранги определяются следующим образом: сначала для каждого наблюдения значения сравниваемых переменных ранжируются (по строке). Затем для каждой из сравниваемых переменных вычисляется средний ранг по всем объектам. Определяемый по критерию (chi^{2}) уровень значимости Асимпт. знч. < 0.001. Он свидетельствует о статистически значимой разнице между пятью результатами тестирования. Различаться может любая пара переменных, и без попарного сравнения невозможно выяснить, какие именно пары вносят значимый вклад в факт статистической достоверности результата.
6. Однофакторный дисперсионный анализ
Дисперсионный анализ (Analysis Of Variances, ANOVA — общепринятое обозначение метода) — это процедура сравнения средних значений выборок, на основании которой можно сделать вывод о соотношении средних значений генеральных совокупностей. Ближайшим и более простым аналогом ANOVA является t-критерий. В отличие от t-критерия дисперсионный анализ предназначен для сравнения не двух, а нескольких выборок. Слово «дисперсионный» в названии указывает на то, что в процессе анализа сопоставляются компоненты дисперсии изучаемой переменной. Общая изменчивость переменной раскладывается на две составляющие: межгрупповую (факторную), обусловленную различием групп (средних значений), и внутригрупповую (ошибки), обусловленную случайными (неучтенными) причинами. Чем больше частное от деления межгрупповой и внутригрупповой изменчивости (F-отношение), тем больше различаются средние значения сравниваемых выборок и тем выше статистическая значимость этого различия.
В ANOVA можно задать единственную зависимую переменную (при этом она обязательно должна быть количественного, а точнее метрического типа) и единственную независимую переменную (всегда номинальную, имеющую несколько градаций).
При однофакторном дисперсионном анализе сравниваются между собой средние значения каждой выборки и вычисляется общий уровень значимости различий. Вывод по результатам ANOVA касается общего различия всех сравниваемых средних без конкретизации того, какие именно выборки различаются, а какие нет. Для идентификации пар выборок, отличающихся друг от друга средними значениями, используются апостериорные критерии парных сравнений (Post Hoc), а для более сложных сопоставлений — метод контрастов (Contrasts).
Зависимые переменные должны быть метрического типа.
Фактор, в котором нужно указать единственную независимую переменную, имеющую несколько градаций (в нашем случае — хобби).
Пример: в роли зависимой переменной выступит переменная тест1, а независимая переменная класс разделит объекты на три выборки, средние значения которых мы будем сравнивать.
Однофакторный дисперсионный анализ
Мы будем сравнивать между собой средние значения переменной тест1 для каждой из выборок по уровням переменной хобби.
Флажок Описательные статистики приведет к включению в выводимые данные всех средних значений, стандартных отклонений, стандартных ошибок, границ доверительных интервалов в 95 %, а также минимумов и максимумов выборок. Флажок Проверка однородности дисперсии позволяет вывести информацию о степени пригодности данных к дисперсионному анализу, а с помощью флажка График средних можно построить диаграмму, на которой будут изображены средние значения для каждой выборки.

Output

Вывод: Самым важным в этой таблице является уровень значимости (p = 0.002). Он указывает на то, что разность между средними значениями переменной тест1 для трех групп статистически достоверна. Знаком звездочки помечены те пары выборок, для которых разность средних значений статистически достоверна, то есть со значением уровня значимости 0,05 и меньше. Из полученных данных можно сделать вывод, что результаты теста 1 для тех, кто увлекается компьютером, статистически выше значимы, чем для тех, кто увлекается спортом и искусством. Те же, кто увлекаются спортом и искусством, по результатам теста 1 статистически достоверно не различаются.
Критерий однородности дисперсии Ливиня со значимостью 0,161 показал, что дисперсии для каждой из групп статистически достоверно не различаются. Следовательно, результаты ANOVA могут быть признаны корректными. Если бы результат применения критерия Ливиня оказался статистически достоверным, то это послужило бы основанием для сомнения в корректности применения ANOVA.
7. Многофакторный дисперсионный анализ
ANOVA с двумя и более факторами.
- Единственная зависимая переменная должна быть метрической.
- Несколько независимых переменных, каждая из которых должна быть номинальна, то есть иметь несколько градаций, или уровней.
В многофакторном дисперсионном анализе появляется проблема взаимодействия факторов. Выполним двух- и трехфакторный дисперсионный анализ с учетом влияния ковариаты.
Дисперсионный анализ (ANOVA) определяет статистическую достоверность различия между выборками путем сравнения их средних значений.
7.1 Дисперсионный анализ с двумя факторами
Попытаемся определить степень влияния переменных Интонация (Инт), Часть ряда (Ч_ряда) и их взаимодействия Инт × Ч_ряда на распределение значений переменной Слова. Такая схема анализа может быть лаконично обозначена как ANOVA 2 × 3 (Интонация × Часть ряда). Исследование позволит получить ответы на перечисленные ниже вопросы.
- Существует ли главный эффект фактора Инт, то есть существует ли значимое различие в продуктивности воспроизведения всего ряда из 24 слов в зависимости от интонационного выделения середины ряда и какова степень этого различия?
- Существует ли главный эффект фактора Ч_ряда, то есть существует ли зна- чимое различие в продуктивности воспроизведения трех частей ряда (начала, середины и конца) и какова степень этого различия?
- Существует ли взаимодействие переменных Инт и Ч_ряда, то есть зависит ли влияние одной из этих переменных от уровней (значений, градаций) другой?
7.2 Дисперсионный анализ с тремя и более факторами
Предположим, изучается влияние на переменную Слова трех факторов: Инт, Ч_ряда и Отсрочка.
- Существует ли главный эффект фактора Инт, то есть существует ли значимое различие в продуктивности воспроизведения всего ряда из 24 слов в зависимости от интонационного выделения середины ряда и какова степень этого различия?
- Существует ли главный эффект фактора Ч_ряда, то есть существует ли зна- чимое различие в продуктивности воспроизведения трех частей ряда (начала, середины и конца) и какова степень этого различия?
- Существует ли главный эффект фактора Отсрочка, то есть существует ли зна- чимое различие в продуктивности воспроизведения всего ряда в зависимости от отсрочки?
- Существует ли взаимодействие переменных Инт и Ч_ряда, то есть зависит ли влияние одной из этих переменных от уровней (значений, градаций) другой?
- Существует ли взаимодействие переменных Инт и Отсрочка, то есть зависит ли влияние одной из этих переменных от градаций другой?
- Существует ли взаимодействие переменных Ч_ряда и Отсрочка, то есть зависит ли влияние одной из этих переменных от градаций другой?
- Существует ли взаимодействие переменных Инт, Ч_ряда и Отсрочка, то есть за- висит ли взаимодействие двух из этих переменных от градаций третьей?
Трехфакторный дисперсионный анализ предполагает проверку уже семи гипотез.
7.3. Влияние ковариат
Ковариаты используются для исключения влияния количественной переменной на зависимую переменную. Ковариату проще всего представить как переменную, значительно коррелирующую с зависимой переменной и позволяющую умень- шить ее дисперсию. За счет включения в анализ ковариаты дисперсия зависимой переменной уменьшается, что позволяет сделать более очевидным влияние анали- зируемых факторов. В нашем исследовании в качестве ковариаты будет использоваться переменная Знач. Эта переменная (эмоциональная значимость предъявляемого ряда слов) в существенной степени коррелирует с продуктивностью воспроизведения этого ряда (Слова).

Output

Вывод: Таблица Оценка эффеков межгрупповых факторов содержит результаты проверки трех основных гипотез двухфакторного дисперсионного анализа:
- Переменная Ч_ряда не оказывает статистически достоверное влияние на распре- деление зависимой переменной Слова (средние значения для начала, середины и конца ряда составили соответственно 3,08, 3,70 и 3,28, F = 2,364, p = 0,099).
- Переменная Инт не оказывает статистически значимого влияния на распределе- ние зависимой переменной Слова (средние значения для групп «нет» и «есть» составили соответственно 3,45 и 3,25, F = 0,696, p = 0,406).
- Обнаружено статистически достоверное взаимодействие на высоком уровне статистической значимости между независимыми переменными Ч_ряда и Инт (F = 8,543, p < 0,001).
Влияние ковариаты. Таблицы Оценка эффектов межгрупповых факторов
Ковариата ЗНАЧ оказывает значительное влияние на разброс зависимой переменной Слова: значение (eta^{2}) составляет 0,265, то есть 26,5 % дисперсии переменной Слова обусловлено влиянием ковариаты. Дисперсия скорректированной модели представляет собой сумму всех сумм квадратов дисперсий, обусловленных влияниями независимых переменных и их взаимодействий.
Двухфакторный дисперсионный анализ с зависимой переменной Слова, независимыми переменными Инт и Ч_ряда и ковариатой «`ЗНАЧ« дал следующие результаты:
- Ковариата
ЗНАЧоказывает статистически достоверное влияние на зависимую переменнуюСлова(F = 40,73, p < 0,001). - Переменная
Интоказывает статистическое влияние на распределение зависимой переменнойСлова(F = 4,429, p =0,038). - Переменная
Ч_рядаоказывает статистически значимое влияние на распределение зависимой переменнойСлова(F = 3,188, p = 0,045). - Обнаружено статистически достоверное взаимодействие между независимыми переменными
Ч_рядаиИнт(F = 11,52, p < 0,001).
8. Простая линейная регрессия (стр239)
Рассмотрим такие понятия, как прогнозируемые значения зависимой переменной и уравнение регрессии, покажем связь между простой регрессией и корреляцией двух переменных, рассмотрим влияние одной переменной на дисперсию другой, а также ознакомимся с оценкой криволинейности связи двух переменных.
Пример: есть датасет с переменными трев и тест. Гипотеза о линейности отношения этих двух переменных говорит о том, что чем выше нервная возбудимость студента, тем выше его результативность (например, потому, что спокойных студентов меньше волнуют их знания, а тревожные студенты проводят больше времени за подготовкой к зачету).
- Зависимая переменная (критерий) — переменная
тест, - Независимая переменная (предиктор) — переменная
трев.
Уравнение регрессии: ({тест}_{истина} = константа + коэфициент*трев + остаток)
В результате применения линейного регрессионного анализа константа оказалась равной 9.3114, а коэффициент регрессии 0.6751. Соответственно, уравнение для прогноза результата зачетного тестирования выглядит следующим образом:
[{тест}_{прогноз} = 9.3114 + 0.6751*трев]
[{тест}_{истина} = тест_{прогноз} + остаток]
Прогнозируемое значение будет отличаться от истинного значения. Чтобы получить истинный результат, необходимо ввести в уравнение член, равный разности прогнозируемого и реального значений. Этот член и называют остатком.
[РеальноеЗначение = ПрогнозируемоеЗначение + остаток]
Величины, которые вычисляются при проведении регрессионного анализа:
- (R) — Коэффициент корреляции. Коэфициент, характеризующий связь между значениями зависимой и независимой переменных.
- (p-ур.знач.) — (p < 0.05) свидетельствует о значимой корреляции переменных. При (p > 0.05) вероятность случайности результата считается слишком высокой, и в этом случае говорят, что связь между переменными слабая или не обнаружена.
- (R^{2}) — характеризует долю дисперсии одной переменной, обусловленной воздействием другой переменной. Так, для переменных
тревитестзначение (R = 0.546), а (R^{2}) = 0.298. Это означает, что 29.8 % дисперсии переменнойтестобъясняется влиянием независимой переменнойтрев.
Оценка криволинейности
В приведенном ранее примере мы видим значительную корреляцию между переменными трев и тест ((R = 0.546), (p < 0.001)), однако возможная ошибка прогноза велика (только 29.8 % дисперсии переменной тест объясняется влиянием переменной трев). Можно предположить, что если изменить вид общего уравнения (например, включить в него квадрат переменной трев), прогнозируемые значения будут ближе к реальным.
Построим график рассеяния переменных тест и трев

Чтобы статистически оценить криволинейность, в подменю Регрессия есть Подгонка кривых. Там необходимо задать зависимую переменную (тест), независимую переменную (трев) и установить флажки Линейная и Квадратичная.

Output

В результаты включены значения коэффициентов B регрессии (Константа b0, b1, b2), поэтому не сложно составить линейное и квадратичное уравнения регрессии для прогнозируемых значений.
Для линейной уравнение имеет вид: ({тест}_{прогноз} = 9.3114 + 0.6751 times трев)
Для квадратичной уравнение имеет вид: ({тест}_{прогноз} = 0.1615 + 4.4896 times трев — 0.3381 times (трев)^{2})

В случае линейной регрессии величина (R^{2}) (столбец R квадрат в таблице выводимых результатов) равна 0.298, то есть 29.8 % дисперсии переменной тест обусловлено воздействием со стороны переменной трев. В то же время для квадратичной регрессии, которая учитывает и линейную, и криволинейную связи, (R^{2} = 0.675), то есть она обусловливает 67.5 % дисперсии переменной тест. Малый p-уровень для обоих уравнений свидетельствует об очень высокой статистической достоверности полученных результатов. Очевидно, что квадратичная регрессия описывает отношения между переменными тест и трев более адекватно, чем линейная. Значения F-критерия и соответствующие значимости (для F и t) говорят о сильном воздействии на зависимую переменную как обеих независимых переменных, так и каждой переменной в отдельности.
9. Множественный регрессионный анализ
Множественная регрессия исследует влияние двух и более предикторов на критерий.
Переменные

Простая регрессия. Переменная помощь представляет время (в секундах), потраченное человеком на оказание помощи своему партнеру, и ее значения имеют нормальное распределение (среднее равно 30, стандартное отклонение — 10). Переменная симпатия отражает оценку симпатии к партнеру в баллах от 1 до 20. На примере этих двух переменных мы продемонстрируем простую регрессию. В качестве зависимой выступит переменная помощь, а в качестве независимой — переменная симпатия (предполагается, что симпатия и сочувствие заставляют человека оказывать помощь, а не наоборот). Как показал анализ, коэффициент корреляции между переменными помощь и симпатия составляет 0.416 при значимости p = 0.004, что говорит о значительной связи между этими переменными. Константа и коэффициент регрессии составили соответственно 14.739 и 1.547. Таким образом, уравнение регрессии имеет следующий вид:
[{помощь}_{прогноз} = 14.739 + 1.547 times (симпатия)]
Множественная регрессия. Множественный регрессионный анализ показал следующие коэффициенты при каждой из переменных: (B(симпатия) = 1.0328), (B(агрессия) = 1.1676), (B(польза) = 1.2569) , (константа = –5.3147). Уравнение регрессии для множественного анализа имеет следующий вид:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times (симпатия) + 1.1676 times (агрессия) + 1,2569 times (польза)]
Возьмем объект с номером 7 и рассчитаем для него прогнозируемое значение переменной помощь:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times 2 + 1.1676 times 10 + 1.2569 times 9 = 19.74]
Таким образом, человек, имеющий низкий показатель симпатии и средние показатели агрессивности и самооценки полезности, должен, согласно прогнозу, оказывать незначительную помощь. Фактическое значение переменной помощь для объекта 7 составило 21, что свидетельствует о высокой точности нашего прогноза.
9.1. Коэффициент детерминации и пошаговые методы
Коэффициент (R) является мерой связи всей совокупности независимых переменных и зависимой переменной. Часто его называют коэффициентом множественной корреляции. Величина(R^{2}) равна доле дисперсии зависимой переменной, обусловленной влиянием со стороны независимых переменных, и называется коэффициентом детерминации. Для регрессионного анализа с тремя независимыми переменными, речь о котором шла выше, значение (R = 0.571), а (R^{2} = 0.326). Это означает, что 32.6 % дисперсии переменной помощь определяется совокупным воздействием переменных агрессия, симпатия и польза.
Множественный регрессионный анализ позволяет использовать любое количество предикторов, но присутствие большого числа независимых переменных не всегда удобно. Было бы предпочтительно иметь в качестве предикторов как можно больше переменных, оказывающих значимое влияние на критерий, и как можно меньше переменных, не оказывающих такого влияния. В процедуру множественной регрессии SPSS включены методы, позволяющие производить пошаговый отбор в регрессионное уравнение только значимых независимых переменных. Одним из них является метод Включение, суть которого заключается в следующем. Сначала процедура вычисляет, какая из независимых переменных имеет наибольший коэффициент корреляции с зависимой переменной, а затем составляет уравнение регрессии с участием этой переменной. Далее из числа оставшихся предикторов выбирается тот, который имеет наибольший коэффициент (beta), при условии, что (beta) является значимым. Выбранный предиктор также включается в уравнение регрессии. Процесс продолжается до тех пор, пока не будут выбраны все предикторы, оказывающие значимое воздействие на зависимую переменную (имеющие статистически достоверные коэффициенты (beta)). По умолчанию SPSS продолжает выбирать независимые переменные до тех пор, пока уровень значимости ((p)) коэффициентов (beta) не превысит значения 0.05. Разумеется, при желании вы можете изменить величину порогового уровня значимости.
Рассмотрим основные условия, выполнение которых способствует получению действительно ценных результатов анализа:
-
Распределение значений предикторов должно быть близким к нормальному. Желательно, чтобы значения асимметрий и эксцессов по модулю не превосходили 1. Тем не менее можно получить весьма точные результаты, если это требование не выполняется строго для каждого из предикторов, и даже в случае, если в анализ входит дискретная переменная с небольшим числом значений. Нормальность распределения зависимой переменной также желательна, однако допустимы как отклонения от нормальности, так и использование дискретных переменных с малым числом значений.
-
Наиболее жестким требованием является запрет на использование зависимых переменных, корреляции между которыми близки к 1 (–1). Для проверки это- го требования можно использовать статистики коллинеарности.
Выполнение

! Важно. Раскрывающийся список Метод. Пункты этого списка определяют алгоритмы включения независимых переменных в уравнение регрессии.
- Принудительное включение — метод, применяющийся по умолчанию. Все независимые переменные включаются в уравнение независимо от степени их корреляции с переменной-критерием.
- Включение — пошаговое включение переменных с проверкой на значимость их частной корреляции с критерием. В результате в уравнение включаются все переменные, имеющие значимую частную корреляцию с переменной-критерием. Включение производится в порядке возрастания p-уровня.
- Исключение — пошаговый метод, сначала включающий в уравнение регрессии все независимые переменные, а затем поочередно удаляющий все переменные, чья корреляция с критерием имеет уровень значимости выше заданного порогового значения. Как правило, пороговым значением является p = 0,1.
- Шаговый отбор — комбинация пошаговых методов включения и исключения. Основной идеей является изменение доли влияния независимой переменной на критерий при появлении в уравнении других независимых переменных. Если влияние какой-либо из включенных переменных становится слишком слабым, она исключается из уравнения. Подобный метод используется при регрессионном анализе наиболее часто.
- Блочное исключение — это метод принудительного удаления переменных. Он требует предварительного задания метода Включение в качестве предыдущего блока, например Блок 1 из 1. При задании следующего блока, в данном случае Блок 2 из 2, в список Независимые переменные вы сможете ввести те независимые переменные, которые хотите исключить из уравнения регрессии. При выполнении команды вы получите результат со всеми заданными переменными, а затем — результат с удаленными переменными. Если в анализе участвуют несколько блоков, то можно задавать операцию удаления после каждого из них.
Кнопка Переменная отбора наблюдений — возможность выбрать группирующую переменную для задания подгруппы наблюдений.
! Окно Линейная регрессия: Статистики. Наиболее важные флажки.
- Доверительные интервалы — включает в вывод для коэффициентов (B) доверительный интервал в 95 %.
- Матрица ковариаций — генерирует таблицу, под главной диагональю которой расположены ковариации, на главной диагонали — дисперсии, а над главной диагональю — корреляции.
- Изменение (R-квадрата) — для методов
ВключениеиШаговый отборуказывает изменения коэффициента (R^{2}) при введении новых переменных в уравнение регрессии. - Описательные статистики — включает средние значения переменных, стандартные отклонения, а также корреляционную матрицу.
- Диагностика коллинеарности — устанавливает наличие коллинеарностей (корреляций, близких к 1) между переменными.
! Окно Линейная регрессия: Сохраниение. Наиболее важные флажки.
Данное окно позволяет создать в файле данных новые переменные, содержащие значения, соответствующие установленным флажкам.
- В группе Предсказанные значения имеются 4 флажка. Флажок Нестандартизованные генерирует прогнозируемые значения, которые бывает полезно сравнить с фактическими значениями для оценки адекватности уравнения регрессии. Флажок Стандартизованные позволяет рассчитывать стандартизированные прогнозируемые значения (в z-значениях).
- Флажки в группе Статистики влияния позволяют исключать из выборки те или иные объекты. Так, если в команде спортсменов-бегунов один пробегает дистанцию гораздо хуже или гораздо лучше других, его результаты значительно искажают статистические показатели всей команды. Иногда подобные значения («выбросы») желательно исключать из анализа. К сожалению, подробное изложение этой процедуры выходит за пределы темы данной книги.
Пример 1: МРА с участием зависимой переменной помощь и пяти предикторов: симпатия, проблема, эмпатия, польза и агрессия. C методом Принудительное включение.

Output

Вывод: В уравнение регрессии включены все пять предикторов. Коэффициент множественной корреляции (R) отражает связь зависимой переменной помощь с совокупностью независимых переменных и равен 0.598. Значение (R^{2}) составляет 0.358 и показывает, что 35.8 % дисперсии переменной помощь обусловлено влиянием предикторов. Стандартные коэффициенты регрессии (beta) отражают относительную степень влияния каждого из предикторов, но ни один из них не достигает статистической значимости ( (p > 0.05)). Следовательно, вклад предикторов в оценку зависимой переменной не может быть проинтерпретирован, и результат имеет сомнительную ценность.
Пример 2: МРА с участием зависимой переменной помощь и пяти предикторов: симпатия, проблема, эмпатия, польза и агрессия. C методом Шаговый отбор.
Будем использовать метод Шаговый отбор, включим в результат статистики для коэффициентов (B), описательные статистики и характеристики модели.


Сгенерированы данные, позволяющие судить о том, какая из независимых переменных оказывает наибольшее влияние на критерий. При составлении уравнения регрессии сначала в него включаются переменные, чья частная корреляция ((β)) с зависимой переменной имеет уровень значимости не выше 0.05. Если затем обнаружится, что из включенных переменных какие-либо обнаруживают новый уровень значимости, превышающий значение 0.1, они исключаются из уравнения. Кроме того, в результате выполнения процедуры будет создана переменная для хранения прогнозируемых значений переменной помощь, рассчитанных по составленному уравнению регрессии. В окне вывода можно найти корреляционную матрицу для всех переменных и описательные статистики.
Output

Вывод: в результате применения пошагового метода из пяти предикторов в уравнение регрессии включены лишь три (модель 3): симпатия, агрессия и польза. Коэффициент множественной корреляции R отражает связь зависимой переменной помощь с совокупностью независимых переменных и равен 0.571. Значение (R^{2}) составляет 0.326 и показывает, что 32.6 % дисперсии переменной помощь обусловлено влиянием предикторов. Стандартные коэффициенты регрессии (beta) являются статистически достоверными, что позволяет интерпретировать относительную степень влияния каждого из предикторов; для переменной симпатия (beta = 0.278), а для переменных агрессия и польза соответственно (beta = 0.276) и (beta = 0.269). Каждая из независимых переменных вносит примерно одинаковый вклад в оценку зависимой переменной и коррелирует с ней положительно.
Терминология вывода:
- Вероятность F-включения — максимальный уровень значимости переменных, вводимых в уравнение регрессии, в данном случае равный (p = 0.050).
- R — коэффициент множественной корреляции, отражающий связь совокупности предикторов
симпатия,агрессияипользас критериемпомощь. - R-квадрат — коэффициент детерминации ((R^{2})), равный доле дисперсии зависимой переменной
помощь, обусловленной влиянием независимых переменныхсимпатия,агрессияипольза. - Скорректированный R-квадрат — исправленная величина (R^{2}). Величина (R^{2}), используемая в расчетах, на практике оказывается несколько завышенной. Исправленная величина (R^{2}) ближе к реальным результатам.
- Стд. ошибка оценки — в таблице Сводка для модели стандартное отклонение ожидаемого значения переменной
помощь. Как видно из приводимых данных, с добавлением каждой новой независимой переменной в уравнение регрессии эта величина уменьшается. - Регрессия — статистика, отражающая влияние предикторов на зависимую переменную.
- Остаток — статистика, отражающая внешнее (не обусловленное предикторами) влияние на независимую переменную.
- B — нестандартизированные коэффициенты и константа уравнения регрессии, связывающего критерий и предикторы:
[{помощь}_{прогноз} = –5.3147 + 1.0328 times (симпатия) + 1.1676 times (агрессия) + 1.2569 times (польза)]
- Стд. ошибка — в таблице Коэффициенты является мерой стабильности коэффициентов (B) и равна стандартному отклонению их значений, рассчитанных для большого числа выборок.
- Бета — стандартизованный коэффициент регрессии ((beta)), представляющий собой коэффициенты (B) для независимых переменных, представленных в z-шкале. Для линейных взаимодействий (beta) по абсолютному значению не превосходит 1; для криволинейных взаимодействий это условие не является обязательным.
- t — отношение коэффициента (B) к своей стандартной ошибке.
- Бета включения — значения коэффициента (beta) для переменных, не включенных в уравнение регрессии в предположении, что они в него включены.
- Частная корреляция — коэффициенты частной корреляции для переменных, входящих в уравнение регрессии. Наличие в этом уравнении нескольких коррелирующих переменных взаимно снижает их частную корреляцию.
10. Факторный анализ
Факторный анализ дает возможность количественно определить нечто, непосредственно неизмеряемое, исходя из нескольких доступных измерению переменных. Например, характеристики «посещает развлекательные мероприятия», «много разговаривает».
Факторный анализ позволяет установить для большого числа исходных признаков сравнительно узкий набор «свойств», характеризующих связь между группами этих признаков и называемых факторами.
Этапы факторного анализа
- Вычисление корреляционной матрицы для всех переменных, участвующих в анализе.
- Извлечение факторов.
- Вращение факторов для создания упрощенной структуры.
- Интерпретация факторов.
10.1 Вычисление корреляционной матрицы
Без комментариев
10.2. Извлечение факторов
С математической точки зрения извлечение факторов имеет определенную аналогию с множественным регрессионным анализом. Первым шагом множественного регрессионного анализа является выбор той независимой переменной, которая обусловливает наибольшую долю дисперсии зависимой переменной. Затем операция повторяется для оставшихся независимых переменных до тех пор, пока добавляемая доля дисперсии не перестанет быть значимой. В факторном анализе существует аналогичная процедура.
Извлечение фактора начинается с подсчета суммарного разброса значений всех участвующих в анализе переменных (данная величина чем-то похожа на общую сумму квадратов). Для этого «суммарного разброса» непросто подобрать логическую интерпретацию, однако он является вполне строго определенной математической величиной. Первой задачей факторного анализа является выбор взаимодействующих переменных, чья взаимная корреляция обусловливает наибольшую долю общей дисперсии. Эти переменные образуют первый фактор. Затем первый фактор исключается и из оставшегося множества переменных снова выбираются те, чье взаимодействие определяет наибольшую долю оставшейся общей дисперсии. Эти переменные образуют второй фактор. Процедура извлечения факторов продолжается до тех пор, пока не будет исчерпана вся общая дисперсия переменных.
10.3. Выбор и вращение факторов
Целью факторного анализа является сокращение исходного набора переменных. Итак, нужно принять решение, какие из факторов следует оставить для дальнейшего анализа. Здесь, в первую очередь, рекомендуется руководствоваться здравым смыслом и оставлять те факторы, которые имеют понятную теоретическую или логическую интерпретацию. Однако не всегда представляется возможным заранее установить назначение каждого фактора, и поэтому исследователи на первом этапе обычно используют формальные критерии. При выполнении факторного анализа с установками по умолчанию все факторы, чьи собственные значения превышают единицу, сохраняются для дальнейшего анализа. Поскольку число факторов равно числу переменных, лишь для небольшого количества факторов собственные значения оказываются больше единицы, а значит, выполнение команды с параметрами по умолчанию позволяет радикально сократить числофакторов. Существуют и другие критерии выделения факторов (например, критерий «каменистой осыпи» Р. Кеттелла); кроме того, вы можете выбирать факторы, основываясь на известных вам особенностях конкретного файла данных. В любом случае, окончательное решение о числе факторов обычно принимается после интерпретации факторов, следовательно, факторный анализ предполагает неоднократное выделение различного числа факторов. В разделе пошаговых процедур рассмотрены несколько вариантов выполнения факторного анализа, отличные от принятого по умолчанию.
Следующим шагом после выделения факторов является их вращение. Вращение требуется потому, что изначально структура факторов, будучи математически корректной, как правило, трудна для интерпретации. Целью вращения является получение простой структуры, которой соответствует большое значение нагрузки каждой переменной только по одному фактору и малое по всем остальным факторам. Нагрузка отражает связь между переменной и фактором, являясь подобием коэффициента корреляции. Значение нагрузки лежит в пределах от –1 до 1. Идеальная простая структура предполагает, что каждая переменная имеет нулевые значения нагрузок для всех факторов, кроме одного, для которого нагрузка этой переменной близка к 1 (–1). До вращения (слева) точки, соответствующие переменным, расположены на удалении от осей факторов. После поворота осей (справа) переменные оказываются вблизи осей, что соответствует максимальной нагрузке каждой переменной только по одному фактору. На практике строгая ориентация переменных вдоль осей факторов обычно не достигается, однако операция поворота позволяет приблизиться к желательному результату.

10.4. Интерпретация факторов
Итак, пусть в некоторой ситуации (близкой к идеальной) путем вращения мы добились того, что значение нагрузки для рассматриваемого фактора является большим (более 0,5), а для остальных факторов — малым (менее 0,2); кроме того, мы четко представляем смысл нашего фактора, то есть то, что он измеряет. Разумеется, в большинстве исследований переменные могут взаимодействовать с «ненужным» фактором, а нередко таких факторов может быть несколько. Как правило, исследователь не ограничивается только числовыми результатами факторного анализа; необходимым условием успеха факторного анализа является понимание содержательной специфики конкретных данных и взаимосвязей между ними.
Для факторного анализа мы будем использовать данные реального тестирования интеллекта 46 школьников. Тест включал в себя 11 субтестов (переменные и1, и2, …, и11). Предпо лагалось, что эти 11 субтестов позволят измерить 3 и более обобщенные интеллектуальные характеристики: математические, вербальные и невербальные (образные). Факторный анализ должен был установить соотношение субтестов и факторов.
Число объектов (N) равно 46.
Простейший вариант факторного анализа, в котором используются значения по умолчанию для всех параметров:

Output


Что произошло:
- Вычисление корреляционной матрицы для 11 заданных переменных.
- Извлечение 11 факторов методом главных компонентов.
- Выбор для вращения всех факторов, чьи собственные значения не меньше 1.
- Вращение факторов по методу Варимакс.
- Вывод матрицы факторных нагрузок после вращения и других результатов.
Вывод: фвыывфыв
Второй вариант, напротив, включает многие из действий, упомянутых ранее в этой главе:
Теперь зададим некоторые дополнительные параметры. Включим в вывод одномерные описательные статистики всех переменных, коэффициенты корреляции, а также применим критерии многомерной нормальности и адекватности выборки. Для извлечения факторов будет использоваться метод главных компонентов, а для отображения — график собственных значений. Вращение факторов будет производиться методом Варимакс. Наконец, отсортируем переменные по величине их нагрузок по факторам и отобразим те нагрузки, абсолютная величина которых не менее 0.3.




Output

Величина КМО демонстрирует приемлемую адекватность выборки для факторного анализа. Критерий сферичности Бартлетта показывает статистически достоверный результат ( p < 0,05): данные вполне приемлемы для факторного анализа.

В первой из двух таблиц перечислены имена переменных и общности. Столбцы второй таблицы содержат характеристики выделенных факторов: их порядковые номера (с 1 по 3), суммы квадратов нагрузок, процент общей дисперсии, обусловленной фактором, и соответствующий кумулятивный (накопленный) процент (до и после вращения).
Чем больше процент дисперсии, обусловленной фактором, тем больший вес имеет данный фактор. А чем больше кумулятивный процент, накопленный к последнему фактору, тем более состоятельным является факторное решение. Если этот накопленный процент менее 50 %, следует либо сократить количество переменных, либо увеличить количество факторов. В данном случае накопленный процент дисперсии вполне приемлем.
Диаграмма называется графиком собственных значений, или диаграммой каменистой осыпи.

Точками показаны соответствующие собственные значения в пространстве двух координат. Этот тип диаграммы обычно используется при определении достаточного числа факторов перед вращением. При этом руководствуются следующим правилом: оставлять нужно лишь те факторы, которым соответствуют первые точки на графике до того, как кривая станет более пологой. В данном примере число таких факторов равно 3, а в соответствие с упомянутым правилом нужно было бы взять не три, а четыре фактора.

Преобразованная матрица факторных нагрузок после вращения. Именно эта матрица является главным итогом факторного анализа и подлежит содержательной интерпретации.
Первый из факторов соответствует предполагаемым математическим способностям, так как объединяет субтесты «счет в уме», «аналогии», «числовые ряды» и «умозаключения». Во второй фактор попали три субтеста, относящиеся к вербальным способностям: «заучивание слов», «осведомленность», «пропущенные слова», а в третий фактор — три субтеста, относящиеся к невербальным способностям: «скрытые фигуры», «геометрическое сложение», «исключение изображений». К «странностям» результатов можно отнести разве что распределение переменной «исключение изображений» между вторым и третьим фактором и попадание переменной «понятливость» в третий фактор. Подобные отклонения обычно требуют отдельного изучения. В частности, можно увеличить число факторов или исключить «неопределенные» переменные и повторить анализ. Целью приведенного примера было показать, каким образом факторный анализ группирует переменные, объединяя их по факторам. Каждый фактор интерпретируется как причина совместной изменчивости (корреляции) группы переменных. После получения приемлемого решения можно вычислить факторные оценки для объектов как новые переменные для дальнейшего анализа.
Критериям KMO и Барлетта: КМО (мера выборочной адекватности Кайзера–Мейера–Олкина) — величина, характеризующая степень применимости факторного анализа к данной выборке:
- более 0.9 — безусловная адекватность;
- более 0.8 — высокая адекватность;
- более 0.7 — приемлемая адекватность;
- более 0.6 — удовлетворительная адекватность;
- более 0.5 — низкая адекватность;
- менее 0.5 — факторный анализ неприменим к выборке.
- Критерий сферичности Барлетта — критерий многомерной нормальности для распределения переменных. С его помощью проверяют, отличаются ли корреляции от 0. Значение p-уровня, меньшее 0.05, указывает на то, что данные вполне приемлемы для проведения факторного анализа.
Матрица повернутых компонент — матрица факторных нагрузок после вращения, основной результат факторного анализа для содержательной интерпретации.
11. Кластерный анализ
Программа SPSS реализует три метода кластерного анализа: Двухэтапный кластерный анализ (TwoStep), Кластеризация К-средними (K-means) и Иерархическая кластеризация (Hierarchical).
- Двухэтапный кластерный анализ позволяет выявить группы (кластеры) объектов по заданным переменным, если эти группы действительно существуют. При этом программа автоматически определяет количество существующих кластеров.
- Кластеризация К-средними разбивает по заданным переменным все множество объектов на заданное пользователем число кластеров так, чтобы средние значения для кластеров по каждой из переменных максимально различались.
- Иерархическая кластеризация, как наиболее гибкий из рассматриваемых методов, позволяет детально исследовать структуру различий между объектами и выбрать наиболее оптимальное число кластеров.
11.1. Сравнение кластерного и факторного анализов
Главное сходство между кластерным и факторным анализами заключается в том, что тот и другой предназначены для перехода от исходной совокупности множества переменных (или объектов) к существенно меньшему числу факторов (кластеров).
-
Целью факторного анализа является замена большого числа исходных переменных меньшим числом факторов. Кластерный анализ, как правило, применяется для того, чтобы уменьшить число объектов путем их группировки.
-
В факторном анализе на каждом этапе извлечения фактора для каждой переменной подсчитывается доля дисперсии, которая обусловлена влиянием данного фактора. При кластерном анализе вычисляется расстояние между текущим объектом и всеми остальными объектами, и кластер образует та пара, для которой расстояние оказалось наименьшим. Подобным образом каждый объект группируется либо с другим объектом, либо включается в состав существующего кластера. Процесс кластеризации конечен и продолжается до тех пор, пока все объекты не будут объединены в один кластер.
11.2. Этапы кластерного анализа
Для демонстрации кластерного анализа будем кластеризовать данные о 15 подержанных автомобилях
Этапы:
-
Выбор переменных-критериев для кластеризации. В данном случае, это будут:
цена,т_сост(экспертная оценка технического состояния по 10-балльной шкале),возраст(количество лет эксплуатации),пробег(пройденный километраж с начала эксплуатации). -
Выбор способа измерения расстояния между объектами, или кластерами (изначально считается, что каждый объект соответствует одному кластеру). По умолчанию используется квадрат Евклидова расстояния. Предположим, что марка автомобиля A имеет показатели технического состояния и возраста 5 и 6, а марка B — соответственно 7 и 4. Тогда по этим двум переменным (координатам) расстояние между марками А и В вычисляется следующим образом: ({(5 – 7)}^{2} + {(6 – 4)}^{2} = 8). Помимо Евклидова существуют и другие виды расстояний, вычисляемые по другим формулам. Относительно вычисления расстояния может возникнуть следующий вопрос: будет ли адекватным результат кластерного анализа в том случае, если переменные имеют различные шкалы измерения? Так, все переменные файла cars. sav имеют самые разные шкалы. Для решения проблемы шкалирования в SPSS используется стандартизация, в частности ее простой метод — нормализация переменных, приводящая все переменные к стандартной z-шкале (среднее равно 0, стандартное отклонение — 1). При нормализации всех переменных при проведении кластерного их веса становятся одинаковыми. В случае если все исходные данные имеют одну и ту же шкалу измерения либо веса переменных по смыслу должны быть разными, стандартизацию переменных проводить не нужно.
-
Формирование кластеров. Существует два основных метода формирования кластеров: метод слияния и метод дробления. В первом случае исходные кластеры увеличиваются путем объединения до тех пор, пока не будет сформирован единственный кластер, содержащий все данные. Метод дробления основан на обратной операции: сначала все данные объединяются в один кластер, который затем делится на части до тех пор, пока не будет достигнут желаемый результат.
-
Интерпретация результатов. Как и в случае факторного анализа, желаемое число кластеров и оценка результатов анализа зависят от целей исследователя. Для рассматриваемого примера нам представляется наиболее предпочтительным число кластеров, равное 3. Как показывает анализ, все марки можно разделить на 3 группы: первая группа имеет высокую стоимость (среднее значение — 15 230), небольшой срок эксплуатации (4 года) и средний пробег (85 400 км). Вторая группа имеет среднюю стоимость, небольшой пробег, наибольший воз- раст, но хорошее техническое состояние. Третья группа содержит недорогие модели с большим пробегом и невысоким рейтингом технического состояния.
Анализ выберите команду Классификация -> Иерархическая кластеризация.
Если вместо переключателя Наблюдения в группе Кластеризовать установить переключатель Переменные, в списке Переменные потребуется указать кластеризуемые переменные, а поле Метить значениями останется пустым.
Процедура стандартизации выбирается в раскрывающемся списке Стандартизация. По умолчанию выбран пункт Нет, однако в случаях, когда переменные представлены в разных шкалах (единицах измерения) стандартизация необходима, и чаще всего выбирают пункт z-значения.
Последняя из четырех функциональных кнопок окна Иерархический кластерный анализ — кнопка Сохранить. С помощью этого окна можно создавать новые переменные, значения которых будут указывать принадлежность наблюдений кластерам.
Пример 1: Класетризуем авто. В кластеризации участвуют объекты.


Output


Вывод:
В таблице Шаги агломерации вторая колонка Кластер объединен с содержит первый (Кластер 1) и второй (Кластер 2) столбцы, которые соответствуют номерам кластеров, объединяемых на данном шаге. После объединения кластеру присваивается номер, соответствующий номеру в колонке Кластер 1. Так, на первом шаге объединяются объекты 5 и 14, и кластеру присваивается номер 5, далее этот кластер на шаге 3 объединяется с элементом 4, и новому кластеру присваивается номер 4 и т. д. Следующая колонка Коэффициент содержит значение расстояния между кластерами, которые объединяются на данном шаге. Колонка Этап первого появления кластера показывает, на каком шаге до этого появлялся первый и второй из объединяемых кластеров. Последняя колонка Следующий этап показывает, на каком шаге снова появится кластер, образованный на этом шаге.
Выбор числа кластеров. По таблице шагов агломерации можно предварительно оценить число кластеров. Для этого необходимо проследить динамику увеличения расстояний по шагам кластеризации и определить шаг, на котором отмечается резкое возрастание расстояний. Оптимальному числу классов соответствует разность между числом объектов и порядковым номером шага, на котором было обнаружено резкое возрастание расстояний. Так, в нашем примере это обнаруживается при переходе от шага 12 к шагу 13. Следовательно, наиболее оптимальное количество кластеров должно быть получено на шаге 12 или 13. Оно равно численности объектов минус номер шага, то есть (15 – 12 = 3) или (15 – 13 = 2), то есть 3 или 2 кластера.
Дендрограмма показывает, что в результате кластеризации переменные группируются в три кластера, состав которых идентичен факторам, полученным в отношении тех же данных при факторном анализе.
Пример 2: testIQ, содержащий 11 переменных. В кластеризации участвуют переменные.
Нас интересуют взаимосвязи между переменными, и мы хотим сравнить результаты с факторным анализом, в качестве меры близости целесообразно выбрать корреляцию.

Output

12. Дискриминантный анализ
Дискриминантный анализ позволяет предсказать принадлежность объектов к двум или более непересекающимся группам. Исходными данными для дискриминантного анализа является множество объектов, разделенных на группы так, что каждый объект может быть отнесен только к одной группе. Допускается при этом, что некоторые объекты не относятся ни к какой группе (являются «неизвестными»).
Для каждого из объектов имеются данные по ряду количественных переменных. Такие переменные называются дискриминантными переменными, или предикторами.
Задачами дискриминантного анализа является определение:
- решающих правил, позволяющих по значениям дискриминантных переменных (предикторов) отнести каждый объект (в том числе и «неизвестный») к одной из известных групп;
- «веса» каждой дискриминантной переменной для разделения объектов на группы.
Существует множество ситуаций, в которых было бы весьма желательно вычислить вероятность того или иного исхода в зависимости от совокупности измеряемых переменных: например, подходит ли соискатель работы на ту или иную должность, страдает психически больной человек шизофренией или психозом, вернется заключенный в тюрьму или к нормальной жизни после выхода на свободу, ка- кие факторы влияют на увеличение риска пациента получить сердечный приступ и т. п. Во всех перечисленных ситуациях есть две общие черты: во-первых, для некоторых субъектов (не для всех) есть информация об их принадлежности к той или иной группе; во-вторых, о каждом субъекте имеется дополнительная информация для создания формулы, которая позволит спрогнозировать принадлежность субъекта к той или иной группе.
Дискриминантный анализ имеет определенное сходство с кластерным анализом; сходство заключается в том, что исследователь в обоих случаях ставит перед собой цель разделить совокупность объектов (а не переменных) на несколько более мелких (значимых) групп. Тем не менее процесс классификации в двух видах анализа принципиально различен. В кластерном анализе объекты классифицируются на основе их различий без какой-либо предварительной информации о количестве и составе классов. В дискриминантном анализе изначально заданы количество и состав классов, и основная задача заключается в определении того, насколько точно можно предсказать принадлежность объектов к классам при помощи данного набора дискриминантных переменных (предикторов).
Дискриминантный анализ представляет собой альтернативу множественного регрессионного анализа для случая, когда зависимая переменная представляет собой не количественную, а номинальную переменную. При этом дискриминантный анализ решает, по сути, те же задачи, что и множественный регрессионный анализ: предсказание значений «зависимой» перемененной (в данном случае — категорий номинального признака) и определение того, какие «независимые» переменные лучше всего подходят для такого предсказания. Дискриминантный анализ основан на составлении уравнения регрессии, использующего номинальную зависимую переменную (обратите внимание на то, что она не является количественной, как в случае регрессионного анализа). Уравнение регрессии составляется на основе тех объектов, о которых известна групповая принадлежность, что позволяет максимально точно подобрать его коэффициенты. После того как уравнение регрессии получено, его можно использовать для группировки интересующих нас объектов в целях прогнозирования их принадлежности к какому-либо классу.
Как и для большинства сложных статистических операций, параметры дискриминантного анализа в основном определяются особенностями данных, а также задачами исследователя. Как всегда, мы рассмотрим пример (на этот раз единственный) проведения дискриминантного анализа в разделе пошаговых процедур, а раздел «Представление результатов» посвятим интерпретации выводимых данных.
Для демонстрации дискриминантного анализа мы рассмотрим пример прогнозирования успешности обучения на основе предварительного тестирования. Файл class.sav содержит данные о 46 учащихся (объекты с 1 по 46), юношей и девушек (переменная пол), закончивших курс обучения, в отношении которых известны оценки успешности обучения — для этого используется переменная оценка (1 — низкая, 2 — высокая). Кроме того, в файл включены данные предварительного тестирования этих учащихся до начала обучения (13 переменных):
и1, ..., и11— 11 показателей теста интеллекта;э_и— показатель экстраверсии по тесту Г. Айзенка (H. Eysenck);н— показатель нейротизма по тесту Г. Айзенка.
Еще для 10 претендентов на курс обучения (объекты с 47 по 56) известны лишь результаты их предварительного тестирования (13 перечисленных переменных). Значения переменной оценка для них, разумеется, неизвестны, и в файле данных им соответствуют пустые ячейки. В процессе дискриминантного анализа мы, в частности, попытаемся спрогнозировать успешность обучения этих 10 претендентов в предположении, что выборки закончивших обучение и претендентов идентичны.
Этапы дискриминантного анализа
-
Выбор переменных-предикторов. Необходимо составить список переменных, которые могут повлиять на результат группировки (переменную-критерий). В рассматриваемом файле помимо переменной-критерия (оценка) содержится 13 переменных, характеризующих каждого учащегося; это позволяет нам сделать все 13 переменных предикторами и включить их в уравнение регрессии. Если бы число переменных было велико (например, несколько сотен), было бы невозможно применить дискриминантный анализ ко всем переменным одновременно. Обычно на начальном этапе дискриминантного анализа для предикторов формируется корреляционная матрица. В данном контексте она имеет особый смысл, называется общей внутригрупповой корреляционной матрицей и содержит средние коэффициенты корреляции для двух или более корреляционных матриц (каждая для одной группы). Помимо общей внутригрупповой корреляционной матрицы можно также вычислить ковариационные матрицы для отдельных групп, для всей выборки либо общую внутригрупповую ковариационную матрицу. Нередко исследователи применяют серию t-критериев между двумя группами для каждой переменной либо однофакторный дисперсионный анализ, если число групп оказывается больше двух. Поскольку целью дискриминантного анализа является составление наилучшего уравнения регрессии, дополнительный анализ исходных данных никогда не является лишним. Так, в результате применения t-критериев для данных нашего примера были найдены значимые различия между двумя уровнями переменной оценка для 8 из 13 предикторов. Мы рассмотрим один из наиболее распространенных вариантов дискриминантного анализа, при проведении которого программа автоматически исключает несущественные для предсказания предикторы, но по критериям, которые устанавливает сам исследователь.
-
Выбор параметров. По умолчанию программа реализует метод, который основан на принудительном включении в регрессионное уравнение всех предикторов, указанных исследователем. В другом варианте используется метод Уилкса (Wilks), относящийся к категории пошаговых методов и основанный на минимизации коэффициента Уилкса ((lambda)) после включения в уравнение регрессии каждого нового предиктора. Так же как и в случае множественного регрессионного анализа, существует критерий для включения предикторов в уравнение регрессии (по умолчанию таким критерием является (F > 3.84)) и критерий для исключения предикторов из уравнения регрессии (по умолчанию (F < 2.71)). Коэффициент (lambda) представляет собой отношение внутригрупповой суммы квадратов к общей сумме квадратов и характеризует долю влияния предиктора на дисперсию критерия. Со значением (lambda) связаны величины (F) и (p), характеризующие его значимость. Более полное описание вы можете найти в разделе «Представление результатов».
-
Интерпретация результатов. Целью дискриминантного анализа является составление уравнения регрессии с использованием выборки, для которой известны значения и предикторов, и критерия. Это уравнение позволяет по известным значениям предикторов определить неизвестные значения критерия для другой выборки. Разумеется, точность рассчитываемых значений критерия для второй выборки в общем случае не выше, чем для исходной. Так, в нашем примере регрессионное уравнение обеспечило около 90 % корректных результатов для той выборки, с помощью которой оно было создано. Соответственно, точность предсказания успешности обучения для 10 претендентов может достигать 90 % лишь в том случае, если выборка претендентов совершенно идентична тем 46 учащимся, данные для которых послужили основой для прогноза.
Пример: дискриминантный анализ для зависимой переменной оценка, имеющей два уровня, и 13 предикторов. Предикторы добавляются в дискриминантное уравнение пошаговым методом (Уилкса) с установками, отличающимися от предлагаемых по умолчанию: для включения предикторов в уравнение (F = 1.125), а для исключения — значение (F = 1). Для анализа зависимости между предикторами вычисляются все описательные статистики. Кроме того, мы включаем в окно вывода нестандартные коэффициенты дискриминантного уравнения, результаты для каждого объекта и итоговую таблицу.
Кнопка Сохранить позволяет сохранять в качестве новых переменных следующие величины для каждого объекта (в том числе, «неизвестного»):
- прогнозируемый номер группы;
- оценки дискриминантных функций;
- вероятность принадлежности к каждой группе.
Поскольку переменная оценка, используемая в нашем примере как зависимая, имеет лишь два уровня (1 и 2), их следует указать в полях Минимум и Максимум. Если число уровней группирующей переменной больше двух, описанная операция позволит задать любой диапазон уровней.




Output
Таблица Критерии равенства групповых средних. Наиболее важная для исследователя информация относится к величинам F-критерия и уровням значимости, поскольку именно по ним можно судить, для каких переменных различие двух групп является значимым.

Таблица Введенные/исключенные переменные иллюстрирует пошаговый процесс составления дискриминантного уравнения. В него поочередно вводятся предикторы на основе заданного критерия включения (по умолчанию критерием является F ≥ 3,84, в нашем случае — F ≥ 1,25), а также исключаются из уравнения те предикторы, которые удовлетворяют критерию исключения (по умолчанию таким критерием является F ≤ 2,71, в нашем случае — F ≤ 1).

В таблицах Собственные значения и Лямбда Уилкса в графе Функция значение 1 говорит о том, что в процессе дискриминантного анализа была получена одна дискриминантная функция. Если бы зависимая переменная имела не 2, а 3 уровня, то было бы составлено две дискриминантные функции. Чем больше значение Хи-квадрат (chi^{2}), тем сильнее дискриминантная функция различает группы и тем лучше она соответствует своему назначению. О ее состоятельности свидетельствует статистическая значимость Знч., заметно меньшая 0.05.

Таблица Коэффициенты канонической дискриминантной функции — список нестандартизованных коэффициентов и константа дискриминантного уравнения. Это уравнение подобно линейному уравнению множественной регрессии и применяется для предсказания. Значение функции для каждого объекта подсчитывается по этому уравнению.

Таблица Нормированных коэффициентов канонической дискриминантной функции. Эти коэффициенты служат для определения относительного вклада каждой переменной в значение дискриминантной функции, с учетом влияния остальных переменных. Чем больше абсолютное значение коэффициента, тем больше относительный вклад данной переменной в значение дискриминантной фунциии, разделяющей классы.

Таблица Поточечные статистики содержит информацию о фактической и прогнозируемой группах для каждого объекта, вероятности его принадлежности к группе, а также значения (баллы) дискриминантной функции. Для объектов, отмеченных двумя звездочками (**), фактическая и прогнозируемая группы не совпали. Всего таких объектов 5 из 46. В отношении последних 10 объектов, для которых принадлежность к группе не была известна, в таблице представлены результаты предсказания, полученные при помощи уравнения дискриминантной функции.


Таблица Результаты классификации показывает, при данном наборе дискриминантных переменных точность классификации составляет 89,13% (41 из 46 правильных предсказаний в отношении «известных» объектов).

13. Многомерное шкалирование (332)
Основное достоинство многомерного шкалирования — представление больших массивов данных о различии объектов в наглядном, доступном для интерпретации графическом виде. При многомерном шкалировании матрица различий между объектами (вычисленными, например, по их экспертным оценкам) представляется в виде одно-, двух- или трехмерного графического изображения взаимного расположения этих объектов.
Основным преимуществом многомерного шкалирования является возможность очень наглядного визуального сравнения объектов анализа. Если две точки на изображении удалены друг от друга, то между соответствующими объектами имеется значительное расхождение; и наоборот, близость точек говорит о сходстве объектов.
Рассмотрим наиболее известную процедуру многомерного шкалирования ALSCAL.
Представим себе, что преподаватель решил создать идеальную психологическую обстановку в группе во время занятия, рассадив учащихся так, чтобы ни один из них не оказался рядом с тем, кто ему не нравится. Для этого каждому из 12 студентов было предложено оценить степень своей симпатии к своим однокурсникам по пятибалльной шкале (от 1 до 5, где 1 — максимум симпатии, а 5 — максимум антипатии). Результаты этого вымышленного опроса мы поместили в файл данных mds1.sav. Чтобы добиться желаемого результата, преподавателю необходимо максимально далеко рассадить негативно настроенных в отношении друг друга учащихся. Здесь весьма полезной окажется диаграмма, на которой удаленность точек будет соответствовать отношениям между учащимися. Для построения диаграммы мы воспользуемся средствами многомерного шкалирования.
Первое, что необходимо сделать для решения задачи, — создать квадратную (12 × 12) матрицу различий. Позже на основе этой матрицы будет построено двумерное изображение, иллюстрирующее взаимоотношения студентов. В ходе многомерного шкалирования исходная матрица 12 × 12 преобразуется в гораздо более простую матрицу 12 × 2 (где 2 — количество измерений или шкал), содержащую координаты точек для изображения. Исходную матрицу называют квадратной асимметричной матрицей различий. Поясним, что означают составляющие это определение термины.
- Квадратная матрица — это матрица, строки и столбцы которой представляют один и тот же набор объектов. В данном случае этим набором объектов является группа учащихся.
- Асимметричная матрица — это матрица, для которой отношение двух объектов друг к другу может быть разным. Так, например, симпатия Петра к Ирине не означает, что Ирине Петр тоже симпатичен. Визуально асимметричность матрицы выражается в том, что как минимум для одной пары ячеек, симметрично расположенных относительно главной диагонали матрицы, значения различны.
- Матрица различий — матрица, данные которой представляют меру различия. В данном случае значения матрицы отражают степень отличия отношения одного студента к другому от идеального; чем больше значение, тем больше различие.
Пример 1: Обработаем гипотетическую социограмму для группы учащихся, при этом количественные оценки их взаимоотношений будут преобразованы в соответствующее графическое изображение.
Данные имеют вид




Output

Значения, записанные в столбце S-stress, характеризуют отклонение результата от идеального (точно соответствующего матрице отличий) на различных итерациях применения модели. SPSS применяет заданную модель столько раз, сколько необходимо для получения достаточно низкого значения в столбце S-stress. Если число итераций оказывается больше 30, то это, как правило, указывает на проблемы в исходных данных.
Стрессы и квадраты коэффициентов корреляции
Для каждой строки асимметричной матрицы различий, для каждой матрицы мо- дели индивидуальных различий, а также для всей модели при многомерном шка- лировании вычисляются стресс и коэффициент (R^{2}). Стресс по своему смыслу схож со стрессом предыдущей модели, однако для его расчета используется другое уравнение, позволяющее упростить вычислительный процесс сравнения различий. Коэффициент (R^{2}) (столбец RSQ) характеризует долю дисперсии в матрице различий, обусловленную данной моделью. Чем лучше модель, тем выше значение коэффициента (R^{2}).

Координаты стимулов
Для каждого шкалируемого объекта указываются его координаты по каждой шкале. Это сделано для того, чтобы вы могли на основе этих координат построить собственное графическое изображение или использовать координаты для дальнейшего анализа. В данном случае столбец 1 соответствует координате x, а столбец 2 — координате y.


Диаграмма представляет собой итог применения модели многомерного шкалирования. Она отображает взаимоотношения 12-ти студентов таким образом, что чем больше различия между учащимися в исходной матрице, тем дальше они находятся друг от друга на диаграмме. На ней видно, что в исследуемой группе выделяются три относительно компактные подгруппы, самая крупная из которых состоит из пяти человек и располагается в правом верхнем углу диаграммы. Отношения внутри каждой из группировок характеризуются симпатией (точки расположены близко), чего не скажешь об отношениях между группами. В данном случае смысл каждой из шкал не имеет значения; главным является взаимное расположение точек.
Пример 2: Рассмотрим результаты тестирования учащихся по пяти показателям и покажем различия между ними графически на плоском изображении.
Данные имеют вид



Output
Пример 3: Небольшое исследование восприятия и понимания студентами пяти многомерных методов статистического анализа. Рассмотрим пример двумерного шкалирования с использованием нескольких квадратных симметричных матриц и модели индивидуальных различий.
Данные имеют вид



14. Логистическая регрессия
Логистическая регрессия представляет собой расширение множественной регрессии и отличается от последней тем, что в качестве зависимой переменной используется дихотомическая переменная, имеющая лишь два возможных значения. Как правило, эти два значения символизируют принадлежность или не принадлежность объекта какой-либо группе, ответ типа «да» или «нет» и т. п.
Логистическая регрессия прогнозирует вероятность некоторого события, находящуюся в пределах от 0 до 1. Кроме того, при помощи индикаторной схемы кодирования допускается использование в качестве предикторов категориальных (номинативных) переменных. Категориальный предиктор может быть представлен серией бинарных переменных — по одной на каждую категорию предиктора. Этим бинарным переменным присваиваются значения 1 или 0 в зависимости от того, к какой категории относится объект.
Будем прогнозировать мнение партнера о том, полезна или нет оказанная ему помощь.
Уравнение логистической регресии (имеет две формы)
[{P}_{help}=frac{1}{1+e^{-B_{0}} times e^{-B_{1} x_{1}} times e^{-B_{2} x_{2} }times e^{-B_{3} x_{3} }}]
[lnleft [ frac{P_{help}}{1-P_{help}} right ]=B_{0}+B_1x_1+B_2x_2+B_3x_3]

Регрессия -> Логистическая
Метод Включение: ОП (ОП — отношение правдоподобия) предполагает пошаговое включение в уравнение предикторов, оказывающих наибольшее воздействие на за- висимую переменную, до последнего предиктора, чье воздействие окажется значимым.
Если в вашем анализе используется категориальные предикторы, то после задания всех предикторов в списке Ковариаты следует воспользоваться кнопкой Категориальные.


Классификационная таблица
В классификационной таблице сравниваются прогнозируемые значения зависимой переменной, рассчитанные по уравнению регрессии, и фактические наблюдаемые значения. Как показывают данные крайнего правого столбца таблицы, для 78.3 % объектов результаты прогноза оказались верными.

Переменные в уравнении
Таблица демонстрирует эффекты включения переменных в уравнение на каждом шаге его построения. Строка Константа для каждого шага соответствует константе (B0) регрессионного уравнения.

Фактическая группировка и прогнозируемые вероятности
В диаграмме используются первые буквы градаций зависимой переменной: е (есть — помощь оказана) и н (нет — помощь не оказана). По горизонтальной оси отложены значения прогнозируемой вероятности, вычисляемые по уравнению регрессии, а по вертикальной оси — частоты. Таким образом, каждый столбик на диаграмме соответствует определенной предсказанной вероятности, а его высота — количеству объектов, для которых предсказана данная вероятность. В случае идеальной логистической регрессии все буквы н окажутся левее букв е, а разделять их будет вероятность 0,5. Как видно из диаграммы, некоторые столбики включают в себя обе буквы, что свидетельствует об ошибках предсказания (высота в два символа соответствует одному объекту). Символам н в правой части диаграммы и символам е в левой части диаграммы соответствуют неправильные предсказания относительно оказания помощи. О количестве правильных и неправильных предсказаний позволяет судить классификационная таблица.

Другие термины при выводе:
- (B) — коэффициенты регрессионного уравнения, отражающие влияние соответ- ствующих предикторов на зависимую переменную. Так, переменная агрессия оказывает положительное влияние на вероятность оказания помощи.
- (Вальд) — критерий значимости Вальда коэффициента (B) для соответствующего предиктора. Чем выше его значение (вместе с числом степеней свободы), тем выше значимость.
- (Exp(B)) — величина ((eB)), которая может использоваться для интерпретации результатов анализа наравне с коэффициентом (B) (вспомните о двух формах регрессионного уравнения, в одной из которых используются коэффициенты (B), а в другой — (eB)).