Точность измерений
Никакое
измерение не может быть выполнено
абсолютно точно, всегда содержится та
или иная погрешность. Чем точнее метод
измерения и измерительный прибор тем
меньше величина погрешности. Принято
различать несколько видов погрешностей:
основная и дополнительная, абсолютная
и относительная, систематическая и
случайная, которые необходимо учитывать
при измерении в спорте.
Основная
погрешность
связана с методом измерения или
измерительного прибора, которая имеет
место в нормальных условиях их применения.
Например, точность измерения прыжка в
длину с помощью метра или рулетки;
точность измерения времени пробегания
короткой дистанции с помощью разных
(механического или электронного)
секундомеров будет не одинаковой и
определяется точностью самого средства
измерения. Эта погрешность, как правило,
указана в инструкции измерительного
прибора.
Дополнительная
погрешность
вызвана отклонением условий работы
измерительной системы от нормальных.
Например, при существенных колебаниях
(выше нормы) электрического напряжения
в сети может возникать погрешность
измерения. Другой пример — прибор,
предназначенный для работы при комнатной
температуре, будет давать неточные
показания, если пользоваться им в
условиях низких или высоких внешних
температур. К дополнительным погрешностям
относятся и так называемая динамическая
погрешность, обусловленная инерционностью
измерительного прибора и возникающая
в тех случаях, когда измеряемая величина
колеблется выше технических возможностей
регистрирующего устройства. Например,
некоторые пульсотахометры рассчитаны
на измерение средних величин ЧСС и не
способны улавливать непродолжительные
отклонения частоты от среднего уровня.
Величины
основной и дополнительной погрешности
могут быть представлены в абсолютных
и относительных единицах.
Абсолютная
погрешность равна
разности между показанием измерительного
пробора (А) и истинным значением измеряемой
величины
Она
измеряется в тех же единицах, что и
измеряемая величина.
Относительной
погрешностью называется
отношение абсолютной погрешности к
истинному значению измеряемой величины:
Поскольку
относительная погрешность измеряется
в процентах, то знак абсолютной погрешности
не учитывается.
Систематическая
погрешность
– это величина, которая не меняется от
измерения к измерению. Поэтому она часто
может быть предсказана заранее или, в
крайнем случае обнаружена и устранена
по окончании процесса измерения.
Определение систематической погрешности
измерения возможно способами: тарировки,
калибровки измерительной аппаратуры
или рандомизации.
Тарированием
называется
проверка показаний измерительных
приборов путем сравнения с показаниями
образцовых значений мер (эталонов) во
всем диапазоне измеряемой величины.
Калибровкой
называется
определение погрешностей или поправка
для совокупности мер. И при тарировке
и при калибровке к входу измерительной
системы подключается источник эталонного
сигнала известной величины. Например,
процедура проверки чувствительности
усилителя, заключающаяся в записи и
регулировке амплитуды ответов каналов
на подаваемое на вход напряжение,
сопоставляемое впоследствии с амплитудой
регистрируемых физиологических
параметров. Другой пример, – процедура
проверки скорости движения бумаги на
регистрирующем приборе с помощью
счетчика времени.
Рандомизацией
(от англ.
random – случайный) называется превращение
систематической погрешности в случайную.
По методу рандомизации измерение
изучаемой величины производится
несколько раз (например, многократные
исследования физической работоспособности
разными способами дозирования нагрузки).
По окончании всех измерений их результаты
усредняются по правилам математической
статистики.
Случайные
погрешности неустранимы
и возникают
под действием разнообразных факторов,
которые сложно заранее предсказать и
учесть. Единственно, с помощь методов
математической статистики можно оценить
величину случайной погрешности и учесть
ее при интерпретации результатов
измерения.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
 Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
Случайной Абсолютной
Абсолютной Основной
Основной Дополнительной
Дополнительной Систематической
Систематической Случайной
СлучайнойСТАТИСТИЧЕСКИЕ
ХАРАКТЕРИСТИКИ
Без
статистической обработки результаты
измерений не могут считаться достоверными.
Средняя
арифметическая характеризует
групповые свойства признака, занимает
центральное положение в общей массе
варьирующих признаков. Представляет
собой частное от деления суммы всех
вариант совокупности на их общее число.
Средняя арифметическая – величина
именованная, она выражается теми же
единицами измерения, что и характеризуемый
ею признак. Средняя арифметическая –
важнейшая статистическая характеристика,
но она ничего не говорит о величине
варьирования изучаемого признака.
Стандартное
или среднее квадратическое отклонение
(s) характеризует
вариации, или колеблемости признака.
Стандартное отклонение – величина
именованная, и выражается в тех же
единицах измерения, что и исследуемый
признак, т.е. характеризует степень
отклонения результатов от среднего
значения в абсолютных единицах. Этот
показатель не зависит от числа наблюдений,
и потому может использоваться для оценки
варьирования однородных признаков.
Однако для сравнения вариации двух и
более признаков, имеющих различные
единицы измерения (например, результаты
в беге на 100 м, прыжках в высоту, метаниях
гранаты и т.п.), эта характеристика не
пригодна. Для этого используется
коэффициент вариации.
Коэффициент
вариации (CV)
определяется как отношение стандартного
отклонения к среднему арифметическому,
выраженное в процентах. Коэффициент
вариации, будучи величиной относительной,
позволяет сравнивать между собой
колеблемость результатов измерений,
имеющих различные единицы измерения.
При нормальных распределениях CV обычно
не превышает 45-50%. В случаях асимметричных
распределений он может быть довольно
высоким (до 100% и выше). На практике
внутренняя вариабельность признака
считается небольшой при CV= 0-10%, средней
– 11-20% и большой – больше 20%.
Ошибка
средней арифметической (m) величина
не техническая, а статистическая, и
характеризует закономерные колебания
(вариации) средней арифметической
величины. Выборочная ошибка показывает
варьирование выборочных показателей
вокруг их генеральных параметров. Она
обладает теми же свойствами, что и
среднее квадратическое отклонение. Чем
больше объем выборки, тем точнее средний
результат, тем меньше выборочная средняя
будет отличаться от средней генеральной
совокупности. Следовательно, при
увеличении числа испытаний ошибка
выборочной средней будет уменьшаться.
Отсюда становится яснее значение
выборочной ошибки: она указывает на
точность, с какой определена сопровождаемая
ею средняя величина.
Оценка
по критерию Т-Стьюдента. В
спорте часто на одних и тех же спортсменах
проводится измерение через некоторое
время (например, в начале и в конце этапа
подготовки) или сравнение результатов
одной группы (контрольной) с другой
(экспериментальной). Во всех этих и
подобных случаях ставится, практически,
одна задача – достоверно или нет одни
результаты исследования отличаются от
других? Для этих целей используется
метод сравнения
двух выборочных средних арифметических
по критерию Т-Стьюдента. Принципиально
важным является то, что применение
указанного метода возможно лишь для
однородных признаков.
Ответом
на вопрос о достоверности различий
между признаками служит уровень
значимости (Р),
определяемый по таблице (стандартные
значения критерия Т-Стьюдента). При
уровне значимости Р<0,05 (что соответствует
95% вероятности события) можно говорить
о наличие достоверных различий между
сравниваемыми средними, при Р<0,01 и
особенно при Р<0,001 (когда 99,9% случаев
подлежат общей закономерности) можно
утверждать, что средние значения
отличаются друг от друга с высокой
вероятностью, или закономерностью.
Свидетельством отсутствия достоверных
(статистических) различий между средними
является Р>0,05 (т.е. менее 95% случаев
подлежат общей закономерности).
Корреляционный
анализ сводится
к измерению тесноты или степени
сопряженности между разнородными
признаками, а также к определению формы
и направления существующей между ними
связи. Критерием связи служит коэффициент
корреляции,
который имеет значения от 0 до 1. Чем
больше коэффициент корреляции приближается
к 1, тем теснее связь между признаками
и наоборот. Знак плюс или минус говорят
о направленности связи — положительной
(прямой) или отрицательной (обратной).
Коэффициент корреляции служит мерилом
только качественной связи между
изучаемыми признаками. С помощью
специальных расчетных процедур, в каждом
конкретном случае, устанавливается
форма (линейная, нелинейная) связи.
Существуют методы: парной и множественной
корреляции; для определения связи между
количесвенными и качественными признаками
(ранговая корреляция).
Регрессионный
анализ есть
продолжение корреляционного анализа,
где с помощью выведенного уравнения
регрессии можно показать количественную
степень связи (или взаимовлияния одного
признака на другой). Например, насколько
повысится результат в прыжках в длину
с разбега, если скорость бега на 30 м
увеличится на 2 м/с.
Дисперсионный
анализ позволяет
оценить влияние разнообразных факторов
на результат исследования. Например,
какие из факторов физической
подготовленности в большей мере влияют
на спортивный результат. Дисперсионный
анализ проводится как на малых, так и
на больших выборках, на однородных и
неоднородных признаках, на количественных
и качественных характеристиках. В основе
дисперсионного анализа лежит сравнение
выборочных дисперсий, или их отношений
с критическими значениями критерия
F-Фишера.
Более
подробно с методами математической
статистики можно ознакомиться в следующей
литературе.
1.
Ашмарин Б.А. Теория и методика педагогических
исследований в физическом воспитании.-
М.: ФиС, 1978.
2.
Бейл Н. Статистические методы в биологии.-
М.: Мир, 1964.
3.
Гласс Дж., Стэнли Дж. Статистические
методы в педагогике и психологии.- М.:
Прогресс, 1976.
4.
Друзь В.А. Моделирование процесса
спортивной тренировки.- Киев: Здоровье,
1976.
5.
Лакин Г.Ф. Биометрия: Учебник для
университетов и педагогических
институтов.- М.: Высшая школа, 1973.
6.
Основы общей и прикладной акмеологии.-
М.: ФиС, 1995. Плохинский Н.А. Биометрия.-
М.: МГУ, 1970.
7.
Рокицкий П.Ф. Биологическая статистика.-
Минск: Высшая школа, 1973.
8.Садовский
Л.Е., Садовский А.Л. Математика и спорт.-
М.: Наука, 1985.
9.
Фишер Р.А. Статистические методы для
исследователей / Перевод с англ. В.Н.
Перегудова – М.: Госстатиздат, 1958.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
|
7 |
|
|
8 |
|
|
9 |
|
 Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Относительную
Относительную Среднее
Среднее Закономерные
Закономерные Вариабельность
Вариабельность Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Определения
Определения Определения
Определения Определения
Определения Исследования
Исследования Р<0,01
Р<0,01 Р<0,05
Р<0,05 Р>0,05
Р>0,05 Р<0,001
Р<0,001Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
неустранимая ошибка
- неустранимая ошибка
-
неустранимая ошибка
Ошибка, последствия которой не могут быть устранены средствами системы и требуют вмешательства оператора, например, ошибка вызванная ненормальным завершением программы.
[Л.М. Невдяев. Телекоммуникационные технологии. Англо-русский толковый словарь-справочник. Под редакцией Ю.М. Горностаева. Москва, 2002]Тематики
- электросвязь, основные понятия
Справочник технического переводчика. – Интент.
2009-2013.
Смотреть что такое «неустранимая ошибка» в других словарях:
-
неустранимая погрешность — унаследованная ошибка — [Л.Г.Суменко. Англо русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.] Тематики информационные технологии в целом Синонимы унаследованная ошибка EN inherent error … Справочник технического переводчика
-
Синий экран смерти — В этой статье не хватает ссылок на источники информации. Информация должна быть проверяема, иначе она может быть поставлена под сомнение и удалена. Вы можете … Википедия
-
DNSBL — DNSBL DNS blacklist или DNS blocklist списки хостов, хранимые с использованием системы архитектуры DNS. Обычно используются для борьбы со спамом. Почтовый сервер обращается к DNSBL, и проверяет в нём наличие IP адреса клиента, с… … Википедия
-
Simple Mail Transfer Protocol — SMTP Название: Simple Mail Transfer Protocol Уровень (по модели OSI): Прикладной Семейство: TCP/IP Порт/ID: 25/TCP Назначение протокола: Отправка электронной почты Основные реализации (клиенты): MUA (The Bat!, MS Outlook, MS Outlook Express,… … Википедия
-
Российская Советская Федеративная Социалистическая Республика — РСФСР. I. Общие сведения РСФСР образована 25 октября (7 ноября) 1917. Граничит на С. З. с Норвегией и Финляндией, на З. с Польшей, на Ю. В. с Китаем, МНР и КНДР, а также с союзными республиками, входящими в состав СССР: на З. с… … Большая советская энциклопедия
Лекция 01. Погрешности вычислений
1.1. Погрешности и их учёт
Численное решение любой задачи, осуществляется приближённо, с различной точностью. Это может быть обусловлено неточностью исходных данных, конечной разрядностью вычислений и т. п.
Главная задача численных методов – фактическое нахождение решения с требуемой или, по крайней мере, оцениваемой точностью.
Отклонение истинного решения от приближённого называется погрешностью. Полная погрешность вычислений состоит из двух составляющих:
• неустранимая погрешность;
• устранимая погрешность.
Неустранимая погрешность обусловлена неточностью исходных данных и никаким образом не может быть уменьшена в процессе вычислений. Эти погрешности связаны с недостаточным знанием или упрощением исследуемых физических явлений. Т. е. причиной этого вида погрешности является неадекватность математической модели. Мера адекватности математической модели может быть оценена путём сравнения течения реального физического процесса и реализованной на ЭВМ модели процесса. Это очень сложная задача, т.к. реализация модели на ЭВМ включает много составляющих погрешностей, исследование реального процесса также происходит с погрешностью. Оценка погрешности математической модели выходит за рамки данного курса.
Устранимая погрешность может быть уменьшена выбором более точных методов и увеличением разрядности вычислений. К ним относятся:
• погрешность аппроксимации (погрешность дискретизации)– это погрешность от замены непрерывной модели дискретной; примером дискретизации является замена дифференциального уравнения системой алгебраических уравнений; решение системы алгебраических уравнений отличается от решения дифференциального уравнения, что и составляет погрешность дискретизации; обычно дискретная модель зависит от некоторых параметров, варьируя которые теоретически можно свести погрешность дискретизации к нулю; в приведённом примере, уменьшая шаг дискретизации (и увеличивая порядок системы алгебраических уравнений) можно заметно уменьшить погрешность дискретизации;
• трансформированная погрешность (погрешность искажения) – это погрешность, возникающая за счёт погрешности исходных данных, которые, как правило, являются результатом измерений некоторых физических величин, которые всегда производятся с некоторой погрешностью; кроме того, из-за ограниченной разрядности компьютеров возникает погрешность представления исходных данных (погрешность округления);многие задачи являются весьма чувствительными к погрешностям исходных данных и погрешностям, возникающим в ходе реализации алгоритма; в этом случае говорят, что задача является плохо обусловленной; для плохо обусловленной задачи погрешности исходных данных, даже при отсутствии погрешностей вычислений могут преобразоваться (трансформироваться) в значительные погрешности результата;
• методические погрешности возникают из-за применения приближённых алгоритмов; например, решая систему алгебраических уравнений итерационным методом, теоретически можно получить точное решение при бесконечно большом числе итераций; практически всегда число итераций приходится ограничивать, что приводит к погрешности метода;
• погрешности округления возникают из-за того, что все вычисления выполняются с ограниченным числом цифр, т.е. производится округление чисел; погрешности округления могут накапливаться и при плохой обусловленности задачи могут привести к очень большим погрешностям.
Как выбирать допустимые погрешности? В общем случае надо стремиться, чтобы все погрешности имели один и тот же порядок. Не следует очень точно решать задачу с неточными исходными данными. Точнее говоря, погрешность решения всей задачи (всей последовательности действий вычислительного эксперимента) должна быть соизмерима с погрешностью исходных данных.
В дальнейшем будем рассматривать только корректно поставленные задачи вычисления.
Задача вычисления называется корректно поставленной, если для любых входных данных из некоторого класса решение задачи существует, единственно и устойчиво по входным данным (т. е. непрерывно зависит от входных данных задачи).
В сформулированном понятии корректности учтены достаточно естественные требования, т. к. чтобы численно решать задачу, нужно быть уверенным, что её решение существует. Столь же естественны требования единственности и устойчивости решения.
Рассмотрим подробнее понятие устойчивости. Обычно нас интересует решение , соответствующее входным данным , т.е. . Реально мы имеем возмущённые входные данные с погрешностью, т.е. , и находим возмущённое решение.
Эта погрешность входных данных порождает неустранимую погрешность решения.
Если решение непрерывно зависит от входных данных, то при , задача называется устойчивой по входным данным.
Если – точное значение величины, а – приближённое значение, то абсолютная погрешность приближения определяется выражением.
Относительной погрешностью величины называется отношение абсолютной погрешности к модулю её точного значения:.
Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры (1, 2 и 9).
Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре.
Например, число равно, абсолютная погрешность числа равна . Тогда число а имеет четыре верных значащих цифры (1, 0, 3 и 0).
Одной из самых распространённых ошибок записи приближённых чисел является отбрасывание значащих нулей в конце числа. При этом верная значащая цифра не обязана совпадать с соответствующей цифрой точного числа.
Например число равно, абсолютная погрешность числа равна , тогда верными значащими цифрами являются все цифры после запятой, в то время как точное значение .
В общем случае , где – порядок (вес) старшей цифры, – число верных значащих цифр.
В нашем примере
Относительная погрешность связана с количеством верных цифр приближённого числа соотношением
где – старшая значащая цифра числа.
Для двоичного представления чисел имеем
Достаточно часто точное значение величины неизвестно, поэтому определяются границы погрешности:
(1.1)
(1.2)
причём числа и записываются с одинаковым количеством знаков после запятой, например,
Запись видаозначает, что число является приближённым значением числа с относительной погрешностью .
Отметим важную деталь. Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать (и часто весьма приближённо, обычно завышено) через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближённого решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например, точность решения системы алгебраических уравненийхарактеризуется невязкой, где – приближённое решение системы. Причём невязка достаточно сложным образом связана с погрешностью решения,при малой невязке, погрешность может быть значительной.
1.2. Погрешности округления
Рассмотрим подробнее погрешность округления чисел, участвующих в вычислениях. В позиционной системе счисления с основанием запись
(1.3)
означает, что
Здесь – целое число, большее единицы. Каждое из чисел может принимать одно из значений . Числа называются разрядами.
Запись вещественного числа в виде (1.3) называется также его представлением в форме числа с фиксированной запятой. В ЭВМ чаще всего используется представление чисел в форме с плавающей запятой. Так как наиболее часто в компьютерах применяется двоичная система с плавающей запятой, то вещественное число можно представить виде
(1.4)
где – основание системы счисления, – порядок числа , – мантисса числа, причём должно выполняться условие нормировки:
Большинство персональных компьютеров поддерживают IEEE-стандарт двоичной арифметики. Стандарт предусматривает два типа чисел с плавающей точкой: числа обычной точности (представляются 32 битами – 4 байтами):
• 1 бит – знак;
• 2 – 9 бит – порядок;
• 10 – 32 бит – мантисса.
Числа удвоенной точности (представляется 64 битами – 8 байтами):
• 1 бит – знак;
• 2 – 12 бит – порядок;
• 13 – 64 бит – мантисса.
IEEE-арифметика включает субнормальные числа–очень малые ненормализованные числа, находящиеся между 0 и наименьшим по абсолютной величине нормализованным числом. Наличие субнормальных чисел обеспечивает то, что малые числа не превращаются в машинный ноль. Например, равенствовозможно только при. IEEE-арифметика поддерживает специальные числа и .Число генерируются при переполнении. Правила для символа:
, ,
Любая операция, результат которой (конечный или бесконечный) не определён корректно, генерирует символ (Not a Number – НеЧисло). Например, символ генерируется при операциях:
, , , , где – любая операция.
Вычислительные системы(например MATLAB, SciLab) обрабатывают специальные символы, что позволяет обнаруживать и исправлять особые случаи,в которых программы на языках высокого уровня аварийно завершаются.
Из-за конечности разрядной сетки компьютера можно представить не все числа. Число , не представимое в компьютере, подвергается округлению, т.е. заменяется близким числом, представимым в компьютере точно.
Найдём границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где – цифры мантиссы.
Пусть под запись мантиссы отводитсядвоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Из условия нормировки получаем , поэтому всегда . Тогда и относительная погрешность равна .На практике применяют более точные методы округления и погрешность представления чисел равнат.е. точность представления чисел определяется разрядностью мантиссы.
Тогда приближённо представленное в компьютере число можно записать в виде, где– «машинный эпсилон» – относительная погрешность представления чисел.
1.3. Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Будем обозначать округлённое в системе с плавающей точкой число, соответствующее точному числу , через(от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой. Следовательно:
, где– любая арифметическая операция, а .
Рассмотрим трансформированные погрешности арифметических операций. Будем считать, что арифметические операции проводятся над приближёнными числами, ошибку арифметических операций учитывать не будем (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближённых чисел. Абсолютная погрешность алгебраической суммынескольких приближённых чисел не превосходит суммы абсолютных погрешностей слагаемых.
Действительно, пусть сумма точных чисел равна
сумма приближённых чисел равна
, где –абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
где – относительные погрешности представления чисел.
Из этого следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малыхвеличинаможет быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Отметим так же, что погрешности вычислений зависят от порядка вычислений.
Пример 1.1. Рассмотрим пример сложения трёх чисел.
При другой последовательности действий погрешность будет другой
Из сказанного видно, что результат выполнения некоторого алгоритма, искажённый погрешностями округления, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ и свести влияние погрешностей округления к возмущению исходных данных.
Т.е. можно записать:
, где
При умножении и делении приближённых чисел складываются и вычитаются их относительные погрешности.
с точностью величин второго порядка малости относительно .
Тогда
Если , то
При большом числе арифметических операций можно пользоваться приближённой статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков
, где
– суммарная погрешность,
– погрешность выполнения операций с плавающей точкой.
Лекция 02. Вычислительные алгоритмы и их погрешности
2.1. Трансформированная погрешность
Приведём несколько примеров иллюстрирующих приёмы уменьшения вычислительной погрешности путём алгебраических преобразований.Рассмотрим типичный пример, в котором порядок выполнения операций существенно влияет на погрешность результата.
Пример 2.1. Необходимо отыскать минимальный корень уравнения. Вычисления производим в десятичной системе счисления, причём в результате после округления оставляем четыре значимые цифры (разряда):
Рассмотрим другой алгоритм вычисления корня уравнения, для чего избавимся от иррациональности в числителе, помножив и числитель и знаменатель на :
Как видно из сравнения полученных результатов, применение «неудачного» алгоритма серьёзно влияет на полученный результат вычислений. Это явление в прикладной математике (в практике вычислений) называется потерей значащих цифр, и часто наблюдается при вычитании близких величин. Потеря значащих цифр, например, довольно часто приводит к существенному искажению результатов при решении даже сравнительно небольших систем линейных алгебраических уравнений.
Следовательно, для увеличения точности получаемого результата необходимо по возможности избегать вычитания близких по значению величин.
Пример 2.2. На машине с плавающей запятой необходимо вычислить значение суммы.
Эту сумму можно вычислить двумя способами:
Оказывается, для второго алгоритма вычислительная погрешность будет существенно меньше. Тестовые расчёты на одном и том же компьютере по первому и второму алгоритмам показали, что величина погрешности для обоих алгоритмов составляет и соответственно. Причина этого ясна, если вспомним, как числа представлены в ЭВМ (см. рис. 2.1).
Рис. 2.1. Представление чисел с плавающей точкой в типичном 32-бит формате.
а) Число; b) число 3; c) число ; d) число , представленное в машине с максимальной точностью (нормализованное); e) то же самое число , но представленное с тем же порядком, что и число 3; f) сумма чисел , которая эквивалентна 3.Этот пример ярко иллюстрирует и тот факт, что даже если оба слагаемых представлены в компьютере точно, то их сумма может быть представлена с погрешностью, особенно если слагаемые различаются на порядки.
Таким образом, в машинной арифметике, порядок выполнения операций значим и сложение чисел следует проводить по мере их возрастания.
Рассмотрим трансформированную погрешность вычисления значений функций. Абсолютная трансформированная погрешность дифференцируемой функции, вызываемая достаточно малой погрешностью аргумента , оценивается величиной .
Относительная погрешность:
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями аргументов оценивается величиной
Практически важно определять не только допустимую погрешность функции, но и допустимую погрешность аргумента. Эта задача имеет однозначное решение только для функций одной переменной:
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности то можно пренебречь погрешностью других аргументов
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Пример 2.3. Рассмотрим ещё один пример – использование рядов для вычисления значения функции в точке:
Выпишем разложение функции :
По признаку Лейбница, погрешность частичной суммы знакопеременного ряда по модулю не превышает значения первого отброшенного члена этого ряда.
Вычислим значение при (30º), не учитывая члены ряда, меньшие .
Это отличный результат в рамках принятой точности. Из курса математики известно, что данная функция определена для любого , посчитаем её значения для (390º).
Мы получили относительную погрешность 0,034, против ожидаемой 0,0001 по признаку Лейбница.
Применяя эту же формулу для вычисления при мы даже для очень высокой точности получим значение .
В программах, использующих степенные ряды для вычисления значений функции, для улучшения получаемого результата могут быть использованы различные подходы, одним из них может быть преобразование аргумента так, чтобы .
2.2. Оценка погрешностей с помощью графов вычислительных процессов
Применяя формулы, полученные в прошлой лекции для описания трансформации ошибок при выполнении арифметических операций, удобно для подсчёта распространения ошибок использовать граф. Граф следует читать снизу вверх по стрелкам. Сначала выполняются операции, расположенные на каком-либо нижнем горизонтальном уровне, затем операции более высокого уровня и т.д. Арифметические операции отображаются узлами графа. Рёбра графа снабжают весами в соответствии с формулами оценки относительных погрешностей для арифметических операций.
Относительная ошибка результата любой операции, отображаемой узлами графа, входит как слагаемое в результат следующей операции, умножаясь на коэффициент у стрелки, соединяющей эти две операции. Кроме того, необходимо учитывать погрешность, возникающую в каждой операции.
Пример 2.4.
Пусть вычисляется выражение . Сначала находится , затем
рис.2.1.
Граф, изображённый на рис.2.1, является только изображением самого вычислительного процесса. Для подсчёта общей погрешности результата необходимо дополнить этот граф коэффициентами, которые пишутся около стрелок согласно следующим правилам.
Сложение
Пусть две стрелки, которые входят в кружок сложения, выходят из двух кружков с величинами и . Эти величины могут быть как исходными, так и результатами предыдущих вычислений. Тогда стрелка, ведущая от к знаку «+» в кружке, получает коэффициент , стрелка же, ведущая отк знаку «+» в кружке, получает коэффициент.
Вычитание
Если выполняется операция , то соответствующие стрелки получают коэффициенты и .
Умножение
Обе стрелки, входящие в кружок умножения, получают коэффициент +1.
Деление
Если выполняется деление , то стрелка от к косой черте в кружке получает коэффициент +1, а стрелка от к косой черте в кружке получает коэффициент −1.
Смысл всех этих коэффициентов следующий: относительная ошибка результата любой операции (кружка) входит в результат следующей операции, умножаясь на коэффициенты у стрелки, соединяющей эти две операции.
Таким образом
Если все ошибки не превосходят, то
Пример 2.5.
Рассмотрим задачу сложения четырёх положительных чисел: , где . Граф этого процесса изображён на рис.2.2.
рис.2.2.
Предположим, что все исходные величины заданы точно и не имеют ошибок, и пусть, и являются относительными ошибками округления после каждой следующей операции сложения.
Последовательное применение правила для подсчёта полной ошибки окончательного результата приводит к формуле
Сокращая сумму в первом члене и умножая всё выражение на, получаем
Учитывая, что ошибка округления равна (в данном случае предполагается, что действительное число в ЭВМ представляется в виде десятичной дроби с значащими цифрами), окончательно имеем
Из этой формулы ясно, что максимально возможная ошибка (абсолютная или относительная), обусловленная округлением, становится меньше, если сначала складывать меньшие числа. Результат довольно удивительный, так как вся классическая математика основана на предположении, что при перемене мест слагаемых или их группировке сумма не изменяется. Разница заключается в том, что ЭВМ не может производить вычисления с бесконечно большой точностью, а именно такие вычисления рассматриваются в классической математике.
Рассмотрим вычитание двух почти равных чисел. Предположим, что необходимо вычислить . Тогда из формулы распространения ошибки при вычитании имеем
Предположим, кроме того, что и являются соответствующим образом округлёнными положительными числами, так что
и
Если разность мала, то относительная ошибка может стать большой, даже если абсолютная ошибка мала. Так как в дальнейших вычислениях эта большая относительная ошибка будет распространяться, то она может поставить под сомнение точность окончательного результата вычислений.
Пример 2.6.
Тогда
Зная и , мы можем написать
Как видим, относительные ошибки и малы. Однако
Эта относительная ошибка очень велика, и, что важнее всего, она будет распространяться в ходе последующих вычислений.
Граф вычислительного процесса даёт наглядное представление о структуре возникающей погрешности, однако с помощью графов нельзя оценивать погрешность циклических и итерационных вычислительных процессов.
На основании выше сказанного и рассмотренных примеров можно выработать следующие правила организации вычислительного процесса и округления полученных результатов:
• при сложении и вычитании приближённых чисел в результате следует сохранять столько десятичных знаков, сколько их в слагаемом с наименьшим числом десятичных знаков;
• при умножении и делении в результате следует сохранять столько значащих цифр, сколько их имеет приближённое данное с наименьшим числом значащих цифр;
• при возведении в квадрат или куб в результате следует сохранять столько значащих цифр, сколько их имеет возводимое в степень приближённое число ( последняя цифра квадрата и особенно куба при этом менее надёжна, чем последняя цифра основания);
• при вычислении квадратного и кубического корней в результате следует брать столько значащих цифр, сколько их имеет приближённое значение подкоренного числа (последняя цифра квадратного и особенно кубического корня при этом более надёжна, чем последняя цифра подкоренного числа);
• во всех промежуточных результатах следует сохранять на одну цифру больше, чем рекомендуют предыдущие правила; в окончательном результате последняя цифра отбрасывается;
• если некоторые данные имеют больше десятичных знаков (при сложении и вычитании) или больше значащих цифр (при умножении, делении, возведении в степень, извлечении корня), чем другие, то их предварительно следует округлить, сохраняя лишь одну лишнюю цифру;
• если необходимо произвести сложение-вычитание длинной последовательности чисел, следует начинать с меньших чисел;
• по возможности следует избегать вычитания двух почти равных чисел; формулы, содержащие такое вычитание, часто можно преобразовать так, чтобы избежать подобной операции;
• выражение вида можно представить в виде ;если числа в разности почти равны друг другу, следует производить вычитание до умножения или деления; при этом задача не будет осложнена дополнительными ошибками округления;
• в любом случае следует минимизировать число необходимых арифметических операций.
2.3. Методы оценки сложности алгоритмов
Анализ скорости выполнения алгоритмов
Есть несколько способов оценки сложности алгоритмов. Программисты обычно сосредотачивают внимание на скорости алгоритма, но важны и другие требования, например, к объёму оперативной памяти, свободному пространству дисковой памяти или другим ресурсам.
Многие алгоритмы предоставляют выбор между скоростью выполнения и используемыми программой ресурсами. Задача может выполняться быстрее, используя больше памяти, или наоборот, медленнее, заняв меньший объём памяти.
Хорошим примером в данном случае может служить алгоритм нахождения кратчайшего пути. Задав карту улиц города в виде графа, можно написать алгоритм, вычисляющий кратчайшее расстояние между любыми двумя точками в этогографа. Вместо того чтобы каждый раз заново пересчитывать кратчайшее расстояние между двумя заданными точками, можно заранее просчитать его для всех пар точек и сохранить результаты в таблице. Тогда, чтобы найти кратчайшее расстояние для двух заданных точек, достаточно будет просто взять готовое значение из таблицы.
При этом мы получим результат практически мгновенно, но это потребует большого объёма памяти. Карта улиц для большого города, такого как Москва или Лондон, может содержать сотни тысяч точек. Для такой сети таблица кратчайших расстояний содержала бы более 10 миллиардов записей. В этом случае выбор между временем исполнения и объёмом требуемой памяти очевиден: поставив дополнительные 10 гигабайт оперативной памяти, можно заставить программу выполняться гораздо быстрее.
Временная сложность алгоритма
Одним из важнейших качеств алгоритма является эффективность, характеризующая прежде всего время выполнения программыв зависимости от объёма входных данных (параметра ).
Нахождение точной зависимости для конкретной программы – задача достаточно сложная. По этой причине обычно ограничиваются асимптотическими оценками этой функции, то есть описанием её примерного поведения при больших значениях параметра . Чаще всего для асимптотических оценок используют традиционное отношение между двумя функциями .
Определение:– функции и имеют один порядок малости, если при существует конечный ненулевой .
Приведём некоторые примеры оценки сложности.
Пример 2.7. Рассмотрим программу нахождения факториала числа. Легко видеть, что количество операций, которые должны быть выполнены для нахождения факториала числа в первом приближении прямо пропорционально этому числу, ибо количество повторений цикла (итераций) в данной программе равно . В подобной ситуации принято говорить, что программа (или алгоритм) имеет линейную сложность (сложность).
Не менее интересен и пример вычисления -го числа Фибоначчи:.
Пример 2.8. Программа, печатающая -тое число Фибоначчи, которая имеет линейную сложность, (переменные и содержат значения двух последовательных чисел Фибоначчи).
static void Main () {
int n = int.Parse(Console.ReadLine());
if (n< 0) Console.WriteLine(«Не верно определено n»);
else if (n< 2)
Console.WriteLine(«{0} — е число Фибоначчи = {1}», n, n);
else {
long i = 0;
long j = 1;
long k;
int m = n;
while (—m > 0) {
k = j;
j += i;
i = k;
}
Console.WriteLine(«{0} — е число Фибоначчи = {1}», n, j);
}
}
}
Возникает вполне естественный вопрос: а можно ли находить числа Фибоначчи ещё быстрее? После изучения определённых разделов математики становится известной следующая формула для -ого числа Фибоначчи, которую легко проверить для небольших значений :
Может показаться, что основываясь на ней, легко написать программу со сложностью, не использующую итерации или рекурсии.
static void Main() {
int n = int.Parse(Console.ReadLine());
double f = (1.0 + Math.Sqrt(5.0)) / 2.0;
int j = (int)(Math.Pow(f, n) / Math.Sqrt(5.0) + 0.5);
Console.WriteLine(«{0} — ечислоФибоначчи = {1}», n, j);
}
На самом деле эта программа использует вызов функции возведения в степень Math.Pow(f,n), которая в лучшем случае имеет сложность .Таким образом, существенного выигрыша мы не получаем.
Про алгоритмы, в которых количество операций примерно пропорционально говорят, что они имеют логарифмическую сложность ().
В заключение приведём сравнительную таблицу времени выполнения алгоритмов с различной сложностью и объясним, почему с увеличением быстродействия компьютеров важность использования быстрых алгоритмов значительно возрастает.
Рассмотрим четыре алгоритма решения одной и той же задачи, имеющие сложности , , и соответственно. Предположим, что второй из этих алгоритмов требует для своего выполнения на некотором компьютере при значении параметра ровно одну минуту времени. Тогда времена выполнения всех этих четырёх алгоритмов на том же компьютере при различных значениях параметра будут примерно такими, как в таблице 1.
Таблица 1.
Сравнительная таблица времени выполнения алгоритмов
Сложность алгоритма
0,2 сек.
0,6 сек.
1,2 сек.
0,6 сек.
1 мин.
16,6 час.
6 сек.
16,6 час.
1902 года
1 мин.
лет
лет
С увеличением быстродействия компьютеров возрастают и значения параметров, для которых работа того или иного алгоритма завершается за приемлемое время. Таким образом, увеличивается среднее значение величины , и, следовательно, возрастает величина отношения времени выполнения быстрого и медленного алгоритмов. Чем быстрее компьютер, тем больше относительный проигрыш при использовании плохого алгоритма!
При сравнении различных алгоритмов важно понимать, как сложность алгоритма соотносится со сложностью решаемой задачи. При расчётах по одному алгоритму сортировка тысячи чисел может занять 1 секунду, а сортировка миллиона – 10 секунд, в то время как расчёты по другому алгоритму могут потребовать 2 и 5 секунд соответственно. В этом случае нельзя однозначно сказать, какая из двух программ лучше – это будет зависеть от исходных данных.
Лекция 03. Численные методы линейной алгебры
Выделяют четыре задачи линейной алгебры: решение системы линейных уравнений, вычисление определителя, нахождение обратной матрицы, определение собственных значений и собственных векторов матрицы.
Рассмотрим первую из перечисленных задач. Она является одной из важнейших и одной из наиболее распространённых задач вычислительной математики. К системе линейных алгебраических уравнений (СЛАУ) часто приходят при исследовании самых различных проблем науки и техники, в частности, приближённое решение обыкновенных дифференциальных уравнений и в частных производных сводится к решению алгебраических систем.
Рассмотрим систему линейных уравнений:
,
где – матрица – матрица коэффициентов левой части системы;
– вектор правой части,
– вектор решений системы уравнений.
Известно, что если , то система линейных неоднородных уравнений имеет единственное решение.
Для применения численных методов нахождения единственного решения системы линейных уравнений важна её устойчивость относительно погрешностей правой части.
Формально устойчивость существует, ибо при обратная матрица существует. Но если матрица имеет большие элементы, то можно указать такой вид погрешности исходных данных, который сильно изменит решение. У плохо обусловленной системы . Однако этот признак плохой обусловленности является необходимым, но недостаточным. Плохо обусловленная система геометрически соответствует почти параллельным прямым.
Число неизвестных в СЛАУ может достигать нескольких десятков, сотен и даже тысяч. Например, задача надёжного прогноза погоды в принципе сводится к решению систем линейных алгебраических уравнений с несколькими тысячами неизвестных. Один из методов решения систем линейных алгебраических уравнений был разработан в 1750 г. Г. Крамером. Если решать систему совместных уравнений по формулам Крамера (метод определителей), то можно подсчитать, что число только умножений и делений будет равно
,
например, для системы из десяти уравнений число этих операций будет
Разработке эффективных методов решения систем линейных уравнений уделяли и продолжают уделять внимание очень многие исследователи, однако только применение ЭВМ дало возможность решать системы при достаточно больших . Очень удачную схему вычисления методом исключения разработал К.Ф. Гаусс в 1849 г. По схеме Гаусса необходимо выполнить только
делений и умножений. При будем иметь всего лишь
,
т.е. почти в 84000 раз меньше чем . Однако необходимо учитывать не только время, требуемое для проведения большого количества умножений, делений и сложений в каком-либо методе, но и то, что накопление ошибок округления, появляющихся в результате большого числа операций, является очень серьёзной проблемой. Методы нахождения решения СЛАУ делятся на прямые, т.е. методы, которые представляют собой конечные алгоритмы для вычисления корней систем линейных уравнений и итерационные, которые дают решение системы как предел последовательных приближений вычисляемых по единообразной схеме.
Следует отметить, что вследствие неизбежных округлений результаты, полученные с помощью прямых методов, являются приближёнными, причём оценка погрешностей корней в общем случае затруднительна. Прямые методы применяются на практике для решения СЛАУ на ЭВМ, для .
3.1. Метод Гаусса для решения систем линейных уравнений
Пусть дана хорошо обусловленная система линейных уравнений, для которой существует единственное решение
Метод Гаусса – метод решения систем линейных алгебраических уравнений, состоит в том, что расширенная матрица системы (т.е. матрица, состоящая из коэффициентов системы и свободных членов ) преобразуется к треугольной матрице, все элементы которой ниже главной диагонали равны нулю. Выпишем формулы процесса для -того столбца. В этот момент ненулевые элементы ниже главной диагонали содержат уравнения
Умножим -ую строку на
и вычтем из -той строки.
т.о. производя такие операции для каждой строки исключим элементы -того столбца. В результате получим треугольную матрицу с ненулевыми элементами выше главной диагонали.
Замечания
Исключения нельзя производить, если на главной диагонали . Эту проблему можно решить перестановкой строк, т.к. все элементы -того столбца не могут быть нулевыми.
Для эффективного использования алгоритма каждый цикл алгоритма начинают с перестановки строк, находя среди элементов -того столбца наибольший по модулю и именно его помещая на главную диагональ.
Рассмотрим эти преобразования подробно. Проанализируем, например, коэффициенты первого столбца матрицы. Может оказаться, что максимальный коэффициент при находится, например, в пятом уравнении (т.е. это ). Если в системе алгебраических уравнений поменять любые два уравнения местами, то решение не изменится. Поэтому поменяем местами первое уравнение с тем уравнением, в котором находится максимальный коэффициент при , а затем уже будем исключать .
Возможен случай, когда максимальный элемент при находится в первом уравнении, тогда нет необходимости менять строки местами. В качестве примера мы рассмотрели переменную . Её будем исключать из второго, третьего, … , — го уравнений. В общем случае — я переменная исключается из — го, — го, … , — го уравнений. Ниже приводится описание алгоритма:
1. Из уравнений с номерами , ,…, выбираем то, в котором коэффициент при максимален по модулю, а точнее – определяем номер этого уравнения и поменяем местами -ое и -ое уравнения.
2. Разделим -ое уравнение на коэффициент при , т.е. на и вычтем его из уравнений с номерами больше , каждый раз предварительно домножая -ое уравнение на коэффициент при , уравнения из которого мы вычитаем.
Обратным ходом вычисляем :
1) .
2). Уравнение для определения имеет вид
Отсюда находим
где меняется от до 1.
Следует отметить, что количество арифметических действий прямого хода , обратного .
Пример 3.1. Решить систему линейных алгебраических уравнений методом Гаусса с выбором главных элементов
Решение:
В первом столбце максимальный по модулю элемент – , следовательно разделим на него второе уравнение и для удобства выпишем его первым в системе:
Теперь, домножим первое уравнение на коэффициент при во втором уравнении – и вычтем результат из второго уравнения:
Аналогично преобразуем третье и четвёртое уравнения:
Максимальный по модулю коэффициент при в четвёртом столбце, разделим на него четвёртое уравнение и выпишем его вторым:
Проведём преобразования, аналогичные предыдущим, домножая второе уравнение сначала на и вычитая его из третьего, а потом на и вычитая из четвёртого:
Аналогично система преобразовывается и относительно . Окончательно система приобретает вид:
Описанный выше алгоритм можно реализовать на языке C# в следующей программе:
static void Main () {
const int n = 4; // Размерность системы
double[,] a = {{1.87,5.38, 1.03, 1.17, 9.45},
{7.03,8.04,9.05,6.08,30.20},
{1.11,2.02,2.03,-.04,5.12},
{3.41,-4.52,7.28,5.18,11.35}};
double[] x = new double[n];
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i)
for (int j = i;j <= n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
double r = a[i, i];
for (int j = i;j <= n; j++)
a[i,j] /= r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j <= n; j++)
a[l,j] -= a[i,j]*r;
}
}
x[n-1] = a[n-1,n];
for (int i = n-1; i >= 0; i—){
x[i] = a[i,n];
for (int k = i+1; k < n; k++)
x[i] -= a[i,k]*x[k];
}
for (int i = 0; i < n; i++)
Console.WriteLine(«X({0}) = {1}», i + 1, x[i]);
}
Нетрудно заметить, что приведённая система имеет единичное решение. В результате выполнения программы получается следующее решение:
Отметим, что благодаря выбору наибольшего по модулю ведущего элемента, уменьшаются множители, используемые для преобразования уравнений, что способствует снижению погрешности вычислений.
Метод Гаусса целесообразно использовать для решения систем с плотно заполненной матрицей. Помимо аналитического решения СЛАУ, метод Гаусса также применяется для:
• нахождения матрицы, обратной к данной;
• определения ранга матрицы.
Рассмотрим подробнее вопрос о погрешностях решения СЛАУ методом Гаусса. Запишем систему в матричном виде . Решение этой системы можно представить в виде . Однако вычисленное решение отличается от точного решения из-за погрешностей округлений и ограниченности разрядной сетки компьютера. Существует две величины, характеризующие степень отклонения полученного решения от точного: погрешность и невязка .
Можно показать, что если одна из этих величин равна нулю, то и другая должна равняться нулю. Однако из малости одной величины не следует малость другой. При обычно , но обратное утверждение справедливо не всегда. В частности для плохо обусловленных систем при погрешность решения может быть большой. Вместе с тем, в практических расчётах, если система не является плохо обусловленной, контроль точности решения осуществляется с помощью невязки. Можно отметить, что метод Гаусса с выбором главного элемента в этих случаях даёт малые невязки.
3.2. Применение метода Гаусса для нахождения определителя матрицы
Непосредственное нахождение определителя матрицы требует большого объёма вычислений. Вместе с тем, легко вычислить определитель треугольной матрицы. Для приведения исходной матрицы к диагональному виду можно (и нужно!) использовать прямой ход метода Гаусса. В процессе исключения элементов абсолютное значение определителя матрицы не меняется. Знак же определителя меняется от перестановки его столбцов или строк. Следовательно, значение определителя матрицы , после приведения её к треугольному виду вычисляется по формуле:
Пример 3.2. Найти определитель матрицы методом Гаусса с выбором главных элементов.
Решение:
Максимальный по модулю элемент в первом столбце . Следовательно поменяем местами первую и вторую строки. Определитель в данный момент равен . Разделим все элементы первой строки на и домножая полученную строку на элемент в первом столбце поочерёдно второй, третьей и четвёртой строки вычтем первую строку:
Во втором столбце максимальный по модулю элемент находится в четвёртой строке, следовательно, меняем местами вторую и четвёртую строки. Полученную вторую строку делим на и вычитаем эту строку последовательно из третьей и четвёртой строки предварительно домножив сначала на (для третьей строки) и после на . Определитель становится равным . Матрица примет вид:
Аналогичные преобразования следует провести и для третьего столбца. В результате определитель станет равным , а матрица:
На последнем шаге определитель равен . Поскольку мы сделали чётное количество перестановок знак определителя менять не будем.
Модифицируем алгоритм, реализующий метод Гаусса, для получения определителя квадратной матрицы.
static void Main () {
const int n = 4; // Размерность системы
double[,] a = {{1.87,5.38, 1.03, 1.17},
{7.03,8.04,9.05,6.08},
{1.11,2.02,2.03,-.04},
{3.41,-4.52,7.28,5.18}};
int Перестановки = 0;
double Определитель = 1;
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i){
for (int j = i;j < n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
Перестановки++;
}
double r = a[i, i];
Определитель *= r;
for (int j = i;j < n; j++)
a[i,j] /= r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j < n; j++)
a[l,j] -= a[i,j]*r;
}
}
if ((Перестановки != 0) & (Перестановки % 2 == 1))
Определитель *=-1;
Console.WriteLine(«Определитель = {0}», Определитель);
}
Лекция 04. Вычисление обратной матрицы
Обратная матрица – это такая матрица , при умножении на которую исходная матрица даёт в результате единичную матрицу :
Квадратная матрица обратима тогда и только тогда, когда она невырожденная, то есть её определитель не равен нулю. Для неквадратных матриц и сингулярных матриц обратных матриц не существует.
Свойства обратной матрицы:
• .
• для любых двух обратимых матриц и .
• .
• для любого коэффициента .
• если необходимо решить систему линейных уравнений , (где – ненулевой вектор, а – искомый вектор), и если существует, то .
4.1. Метод Гаусса
Возьмём две квадратные матрицы одинаковой размерности: саму и единичную . Приведём матрицу к единичной матрице методом Гаусса. После применения каждой операции к первой матрице применим ту же операцию ко второй. Когда приведение первой матрицы к единичному виду будет завершено, вторая матрица окажется равной .
При использовании метода Гаусса первая матрица будет умножаться слева на одну из элементарных матриц (трансвекцию или диагональную матрицу с единицами на главной диагонали, кроме одной позиции):
Вторая матрица после применения всех операций станет равна , то есть будет искомой. Сложность алгоритма – .
Пример 4.1. Найти обратную матрицу методом Гаусса.
Решение:
На первом шаге
Умножив слева на , получим:
,а
,а
,а
На последнем шаге:
,а
Матрица и будет обратной к матрице .
Программа на языке C#, реализующая данный метод:
class Program {
const int n = 4; // Размерность системы
static void Main () {
double[,] Заданная = { { 1.87, 5.38, 1.03, 1.17 },
{ 7.03, 8.04, 9.05, 6.08 },
{ 1.11, 2.02, 2.03, -.04 },
{ 3.41, -4.52, 7.28, 5.18 } };
double[,] Обратная = new double[n, n];
for (int i = 0; i < n; i++)
Обратная[i, i] = 1.0;
for (int i = 0; i < n; i++) {
double[,] Вспомогательная = new double[n, n];
for (int j = 0; j < n; j++)
Вспомогательная[j, j] = 1.0;
for (int j = 0; j < n; j++)
if (j != i)
Вспомогательная[j, i] = -Заданная[j, i] / Заданная[i, i];
else
Вспомогательная[j, i] = 1 / Заданная[i, i];
Заданная = ПроизведениеМатриц(Вспомогательная, Заданная);
Обратная = ПроизведениеМатриц(Вспомогательная, Обратная);
}
for (int j = 0; j < n; j++, Console.WriteLine())
for (int k = 0; k < n; k++)
Console.Write(«{0} t», Обратная[j, k]);
}
static double[,] ПроизведениеМатриц (double[,] Левая, double[,] Правая) {
double[,] Результат = new double[n, n];
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++) {
double элемент = 0;
for (int t = 0; t < n; t++)
элемент += Левая[j, t] * Правая[t, k];
Результат[j, k] = элемент;
}
return (Результат);
}
}
4.2. Использование LU/LUP-разложения
Матричное уравнение для обратной матрицы можно рассматривать как совокупность систем вида . Обозначим -ый столбец матрицы через ; тогда , , поскольку -ым столбцом матрицы является единичный вектор , другими словами, нахождение обратной матрицы сводится к решению уравнений с одной матрицей и разными правыми частями. После выполнения LUP-разложения (время ) на решение каждого из уравнений нужно время , так что и эта часть работы требует времени .
Если матрица невырождена то для неё можно рассчитать LU-разложение . Пусть , . Тогда из свойств обратной матрицы можно записать: . Если умножить это равенство на и то можно получить два равенства вида и . Первое из этих равенств представляет собой систему из линейных уравнений для из которых известны правые части (из свойств треугольных матриц). Второе представляет также систему из линейных уравнений для из которых известны правые части (также из свойств треугольных матриц). Вместе они представляют собой систему из равенств. С помощью этих равенств можно рекуррентно определить все элементов матрицы . Тогда из равенства . получаем равенство .
Пример 4.2. Найти обратную матрицу с помощью метода LU-разложения.
Решение:
Обычно эту задачу разбивают на две части: нахождения LU-разложения матрицы и нахождения с помощью полученного разложения обратной матрицы. Покажем сначала разложение матрицы.
Матрица – нижнетреугольная матрица с единицами по главной диагонали, первый столбец этой матрицы получается из первого столбца заданной матрицы путём деления всех элементов на , матрица – верхнетреугольная, первая строка которой совпадает с первой строкой заданной матрицы. Выпишем известные элементы матриц и .
Неизвестные элементы матриц и найдём из соображений, что . Так, элемент найдём из уравнения . Подставив значения, , получаем . и находятся аналогично из уравнений: и . Следовательно, .
Так, после проведённых операций матрицы принимают следующий вид:
и
На следующем шаге можно найти из уравнения . Решив уравнение получим, что . Поскольку теперь известны все элементы третьей строки матрицы , можно найти все элементы третьей строки матрицы как решения уравнений и . Получаем, и .
и
Элемент найдём из уравнения: , , а элемент из , . А элемент из уравнения:
.
и
На втором этапе нам требуется найти обратные матрицы и . Матрица обратная к нижнетреугольной так же является нижнетреугольной и сохраняет единицы по главной диагонали. Выпишем
Неизвестные найдём из соображений, что . Получим систему однородных уравнений:
– умножение 2-ой строки матрицы на 1-ый столбец матрицы ;
– 3-ей строки матрицы на 1-ый столбец матрицы ;
– 3-ей строки матрицы на 2-ой столбец матрицы ;
Решая эту систему получаем: , , , . Таким образом:
Аналогичны рассуждения и для матрицы . Обратная для неё так же будет верхнетреугольной матрицей, элементы которой находятся как решения СЛАУ:
Произведение и даст нам матрицу, обратную к заданной.
Ниже представлен код на языке C# алгоритма обращения матрицы с помощью LU-разложения с комментариями.
Замечание: В алгоритме сознательно сделано LU разложение в разные матрицы, для наглядной демонстрации структуры этих матриц, однако в алгоритме используется и стандартное хранение этих матриц в виде вспомогательной матрицы С, в которой элементы ниже главной диагонали – это элементы матрицы L, а на главной диагонали и выше – элементы матрицы U.
static void Main () {
const int n = 4; //размерность исходной матрицы
double[,] A = {{1.87,5.38, 1.03, 1.17},
{7.03,8.04,9.05,6.08},
{1.11,2.02,2.03,-.04},
{3.41,-4.52,7.28,5.18}};
double[,] X = new double[n, n];
double[,] L = new double[n, n];
double[,] U = new double[n, n];
double[,] С = new double[n, n];
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++) {
U[0, i] = A[0, i];
L[i, 0] = A[i, 0] / U[0, 0];
double sum = 0;
for (int k = 0; k < i; k++)
sum += L[i, k] * U[k, j];
U[i, j] = A[i, j] — sum;
if (i > j)
L[j, i] = 0;
else {
sum = 0;
for (int k = 0; k < i; k++)
sum += L[j, k] * U[k, i];
L[j, i] = (A[j, i] — sum) / U[i, i];
}
}
}
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
С[i, j] = L[i, j];
for (int i = 0; i < n; i++)
for (int j = i; j < n; j++)
С[i, j] = U[i, j];
for (int k = n — 1; k >= 0; k—){
X[k,k] = 1;
for (int j = n — 1; j > k; j—)
X[k, k] -= С[k, j] * X[j, k];
X[k, k] /= С[k, k];
for (int i = k — 1; i >= 0; i—){
for (int j = n — 1; j > i; j—) {
X[i, k] -= С[i, j] * X[j, k];
X[k, i] -= С[j, i] * X[k, j];
}
X[i, k] /= С[i, i];
}
}
for (int i = 0; i < n; i++, Console.WriteLine() )
for (int j = 0; j < n; j++)
Console.Write(«{0}t», X[i, j]);
}
В случае использования LU-разложения не требуется перестановки столбцов матрицы , но решение может разойтись даже если матрица невырождена.
Сложность алгоритма – .
Использование LUP-разложения
Идея метода та же, что и в использовании LU разложения. Однако с целью уменьшения погрешности при нахождении LU разложения исходной матрицы, используется тот же приём, что и при выборе разрешающего элемента метода Гаусса. Сделанные перестановки строк запоминаются в матрице P, на которую и следует умножить полученную матрицу в завершении алгоритма.
4.3. Обновление обратной матрицы при изменении нескольких элементов матрицы A
В некоторых случаях надо решить такую задачу: есть матрица , которую мы обратили, получив . Затем мы изменили несколько элементов матрицы , получив матрицу , и нам требуется обратить матрицу .
Разумеется, эта задача может быть решена «в лоб» путём применения алгоритма обращения к матрице . Однако есть более эффективный алгоритм, позволяющий использовать тот факт, что у нас уже есть матрица , а матрица лишь незначительно отличается от матрицы .
Алгоритм обновления обратной матрицы
В основе алгоритма лежит формула Шермана-Моррисона:
Здесь – квадратная матрица размером , чья обратная матрица нам известна, а – столбец, а – строка высоты , задающие модификацию матрицы (к элементу добавляется ). Можно видеть, что для обновления обратной матрицы по этой формуле требуется порядка операций с вещественными числами, что в раз лучше, чем обращение более общим алгоритмом.
В зависимости от выбора векторов и возможны различные варианты модификации матрицы и обновления матрицы , выполняющиеся с различной трудоёмкостью. Рассмотрим основные варианты:
• если только -ая компонента вектора и -ая компонента вектора неравны нолю, то такой набор векторов обозначает добавление к элементу числа ;
• если -ая компонента вектора равна единице, а остальные равны нолю, то к -ой строке матрицы добавляется строка ;
• если -ая компонента вектора равна единице, а остальные равны нолю, то к -ому столбцу матрицы добавляется вектор ;
• если нет ограничений на компоненты векторов и , то это можно трактовать, как добавление строки (или столбца ) к разным строкам (столбцам) матрицы с разными множителями.
Различные варианты обновления могут быть осуществлены с разной эффективностью, учитывая особую структуру векторов и . Самым быстрым является обновление обратной матрицы при модификации только одного элемента исходной матрицы, поэтому имеет смысл выбрать его эталоном.
Обновление обратной матрицы при модификации строки или столбца исходной матрицы всего лишь в два раза медленнее (так что при модификации трёх и более элементов, расположенных в одном столбце или строке, оно является более выгодным, чем многократный вызов предыдущего алгоритма). Обновление обратной матрицы при произвольном выборе векторов и в три раза медленнее, чем обновление при модификации только одного элемента.
Замечание: Устойчивость алгоритма находится под вопросом, но как минимум один шаг алгоритма достаточно устойчив, если матрицы и хорошо обусловлены.
Пример 4.3. Пусть задана матрица
, обратная к ней
Найти обратную матрицу для .
Решение:
отличается от только элементом , который увеличился на 2 единицы. Обозначим это изменение .
Рассчитаем значение поправки: .
Преобразуем второй столбец матрицы , домножив его поэлементно на и разделив на .
Теперь возьмём третью строку матрицы , домножим её на первый полученный коэффициент и вычтем из первой строки матрицы , домножим на второй коэффициент и вычтем из второй строки, и домножив на тертий коэффициент вычтем из третьей строки.
Программная реализация приведена ниже.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int строка = 1;
int столбец = 2;
double Значение = 2.0;
double[] t1 = new double[n];
double[] t2 = new double[n];
for(int i = 0; i < n; i++)
t1[i] = ОбратнаяА[i, строка];
for(int i = 0; i < n ;i++)
t2[i] = ОбратнаяА[столбец, i];
double Поправка = Значение * ОбратнаяА[столбец, строка];
for(int i = 0; i < n; i++){
double vt = (Значение * t1[i]) / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] = ОбратнаяА[i, j] — vt * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Пример 4.4. В матрице предыдущего примера изменения затрагивают только элементы второй строки, т.е. . Найти .
Решение:
Строка изменений, т.е. строка поэлементно прибавленная к матрице имеет вид: .
Посчитаем столбец изменений :
Значение поправки (поскольку изменения вносятся во вторую строку).
Преобразуем второй столбец матрицы , разделив на :
Программная реализация данного алгоритма приведена ниже.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int НомерСтроки = 1;
double[ ] Строка = { 1.0, 2.0, 3.0 };
double[ ] t1 = new double[n];
double[ ] t2 = new double[n];
for (int i = 0; i < n; i++)
t1[i] = ОбратнаяА[i, НомерСтроки];
for (int j = 0; j < n; j++) {
double Пересчет = 0.0;
for (int i = 0; i < n; i++)
Пересчет += Строка[i] * ОбратнаяА[i, j];
t2[j] = Пересчет;
}
double Поправка = t2[НомерСтроки];
for(int i = 0; i < n; i++){
double Пересчет = t1[i] / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] -= Пересчет * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine() )
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Внесём изменение в каждый элемент одного столбца матрицы (в данном примере 1), и посчитаем новое значение обратной матрицы. Программная реализация приведена ниже, считаем, что каждый элемент второй строки заданной матрицы увеличили на единицу.
static void Main() {
double[,] ОбратнаяА = { { -0.1428571, -0.8571429, 1.4285714 },
{ 0.0, 1.0, -1.0 },
{ 0.2857143, -0.2857143, 0.1428571 } };
int n = 3;
int НомерСтолбца = 0;
double [] Столбец = {0.0,0.0,1.0};
double[ ] t1 = new double[n];
double[ ] t2 = new double[n];
for (int i = 0; i < n; i++) {
double vt = 0.0;
for (int j = 0; j < n; j++)
vt += ОбратнаяА[i, j] * Столбец[j];
t1[i] = vt;
}
double Поправка = t1[НомерСтолбца];
for(int j = 0; j < n; j++)
t2[j] = ОбратнаяА[НомерСтолбца, j];
for(int i = 0; i < n; i++){
double vt = t1[i] / (1 + Поправка);
for(int j = 0; j < n; j++)
ОбратнаяА[i, j] -= vt * t2[j];
}
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», ОбратнаяА[i, j]);
}
Лекция 05. Интерполяционные методы
5.1. Метод простых итераций
Пусть дана линейная система
Предполагая, что , разрешим первое уравнение относительно, второе уравнение относительно и т.д., тогда получим эквивалентную систему:
где Система называется системой, приведённой к нормальному виду. Считая и обозначая
система запишется в матрично-векторном виде:
Систему будем решать методом последовательных приближений. За нулевое приближение можно взять столбец свободных членов, . Далее последовательно строятся матрицы-столбцы: – первое приближение, – второе приближение и т.д.
Любое — е приближение вычисляется по формуле
Если последовательность приближений имеет предел , то этот предел является решением системы. В самом деле, переходя к пределу, будем иметь: или Предельный вектор является решением системы. Метод последовательных приближений, определённый формулой, носит название метода итераций.Заметим, что иногда лучше приводить систему к виду так, чтобы коэффициенты не были равными нулю. Например, можно положить: где. Тогда исходная система эквивалентна приведённой системе:
где. Существует множество способов приведения системы к нужному виду. Для того, чтобы последовательность приближений сходилась, необходимо выполнение условия, которое следует из принципа сжатых отображений:
Условие будет выполнено, если сделать следующие преобразования. Вычисляем . Если , то делим-е уравнение на , в противном случае делим -е уравнение на . То есть, мы делаем следующие преобразования: если ,то,при , .
Пример 5.1. Дана система линейных алгебраических уравнений:
Преобразовать исходную систему к нормальному видуи решить её методом простых итераций.
Решение:
Обозначим исходное приближение, а следующее приближение, которое вычисляется по формулам:
Вычисления продолжаются до тех пор, пока для всех , где – заданная точность вычислений. Если условие не выполнено по крайней мере для одного , то за исходное приближение на следующем шаге берём , т.е. полагаем и вычисляем очередное приближение по формуле приведённой выше.
Посчитаем значениепервой компоненты вектора .
Аналогично вычисляются остальные компоненты, . Вычислим элементы первой строки преобразованной матрицы: поскольку , , , , , .
Исходная система после преобразования к нормальному виду будет такой:
Взяв за начальное приближение вектор , на первом шаге получаем:
Поскольку модуль разности , полагаем и продолжаем вычисления по той же схеме.
Результаты реализации метода простых итераций:
Реализация данного алгоритма на языке C#:
staticvoidMain() {
constintn = 4; //размерность исходной матрицы
constdoubleeps = 0.001;
double[,] A = { { 5.38, 1.87, 1.03, 1.17 },
{ 1.03, 9.05, 1.04, 1.08 },
{ 1.11, 2.02, 7.04, 2.03, },
{ 1.41, 2.52, 2.18, 7.28 } };
double[ ] B = {11.32, 21.25, 14.22, 15.91};
double[ ] M = new double[n];
double[ ] X = { 0.0, 0.0, 0.0, 0.0 };
double[ ] TempX = new double[n];
double Norma;
for (int i = 0; i < n; i++) {
M[i] = Math.Abs(B[i]);
for (int j = 0; j < n; j++)
M[i] += Math.Abs(A[i, j]);
}
for (int i = 0; i < n; i++) {
int p;
if (A[i, i] < 0) p = 1;
else p = -1;
for (int j = 0; j < n; j++)
A[i, j] = p * A[i, j] / M[i];
B[i] = -p * B[i] / M[i];
A[i, i]++;
}
do {
for (int i = 0; i < n; i++) {
TempX[i] = B[i];
for (int g = 0; g < n; g++)
TempX[i] += A[i, g] * X[g];
}
Norma = Math.Abs(X[0] — TempX[0]);
for (int h = 0; h < n; h++) {
if (Math.Abs(X[h] — TempX[h]) > Norma)
Norma = Math.Abs(X[h] — TempX[h]);
X[h] = TempX[h];
}
} while (Norma > eps);
for (int i = 0; i < n; i++)
Console.WriteLine(«X{0} = {1}», i + 1, X[i]);
}
Следует отметить, что метод простых итераций (иногда называемый методом Якоби наиболее эффективен в случае матриц с преобладающими элементами по главной диагонали).
5.2. Метод Гаусса – Зейделя
Чтобы пояснить суть метода, перепишем задачу в виде:
Здесь в -м уравнении мы перенесли в правую часть все члены, содержащие , для . Эта запись может быть представлена:
где в принятых обозначениях означает матрицу, у которой на главной диагонали стоят соответствующие элементы матрицы , а все остальные нули; тогда как матрицы и содержат верхнюю и нижнюю треугольные части , на главной диагонали которых нули.
Итеративный процесс в методе Гаусса-Зейделя строится по формуле:
после выбора соответствующего начального приближения .
Метод Гаусса-Зейделя можно рассматривать как модификацию метода Якоби. Основная идея модификации состоит в том, что новые значения используются здесь сразу же по мере получения, в то время как в методе Якоби они не используются до следующей итерации:
где, ,
Таким образом,-тая компонента -го приближения вычисляется по формуле:
,
Условие сходимости
Пусть, где, – матрица, обратная к . Тогда при любом выборе начального приближения :
• метод Гаусса-Зейделя сходится;
• скорость сходимости метода равна скорости сходимости геометрической прогрессии со знаменателем ;
• верна оценка погрешности:.
Условие окончания
Условие окончания итерационного процесса Зейделя при достижении точности в упрощённой форме имеет вид:
Более точное условие окончания итерационного процесса имеет вид:
и требует больше вычислений. Хорошо подходит для разрежённых матриц.
Пример 5.2. Дана система линейных алгебраических уравнений:
Решить систему методом Гаусса – Зейделя с точностью 0,01.
Решение:
Обозначим за –решение полученное на -том шаге, а за –решение, получаемое на -ом шаге. За начальное приближение возьмём нулевой вектор.. И преобразуем систему:
Откуда:
На первом шаге получаем:
На втором шаге:
Текст программы на языке С#, реализующей метод Зейделя-Гаусса:
class Program {
const double eps = 0.001;
const int n = 4;
static void Main() {
double[,] A = { { 5.38, 1.87, 1.03, 1.17 },
{ 1.03, 9.05, 1.04, 1.08 },
{ 1.11, 2.02, 7.04, 2.03, },
{ 1.41, 2.52, 2.18, 7.28 } };
double[ ] B = { 11.32, 21.25, 14.22, 15.91 };
double[ ] P = new double [n];
double[ ] X = { 0.0, 0.0, 0.0, 0.0 };
do {
for (int i = 0; i < n; i++) {
double Сумма = 0;
for (int j = 0; j < n; j++)
if (j != i) { Сумма += (A[i, j] * X[j]); }
P[i] = X[i];
X[i] = (B[i] — Сумма) / A[i, i];
}
} while (Сходимость(X, P));
for (int j = 0; j < n; j++)
Console.Write(«{0} t», X[j]);
}
static bool Сходимость(double[] Xk, double[] Xkp){
bool b = false;
for (int i = 0; i < n; i++){
if (Math.Abs(Xk[i]-Xkp[i]) > eps){
b = true;
break;
}
}
return b;
}
}
5.3. Метод релаксации
Метод релаксации относится к итерационным методам, где на каждом шаге меняется значение только одной из компонент вектора приближения к решению.
Исходную систему уравнений (например, делением на диагональные элементы) преобразуем к виду
Возьмём начальное приближение. Подставляя его в преобразованную систему, получаем «невязки»
или в компактной форме
Выберем максимальную по модулю невязку и положим в очередном приближении
Очевидно, что
,
Среди найденных невязок вновь отыскиваем наибольшую по модулю и, положив , получаем
,
и т.д., до максимальной невязки в пределах заданной точности.
Пример 5.3. Дана система линейных алгебраических уравнений:
Решить систему методом релаксаций с точностью 0,01.
Решение:
Преобразуем систему, сразу выписав невязки и посчитаем их значения, взяв за начальное приближение единичный вектор:
Максимальная невязка в четвёртой строке, поэтому на следующей итерации вектор имеет вид: . Считаем новые невязки:
Так продолжаем до тех пор, пока все невязки не станут меньше 0,01. Программа, реализующаяданныйметод:
class Program {
const double eps = 0.001;
const int n = 3;
static void Main() {
double[,] A = { { 10.0, -2.0, -2.0 },
{ -1.0, 10.0, -2.0 },
{ -1.0, -1.0, 10.0}};
double[ ] B = { 6.0, 7.0, 8.0};
double[ ] Невязка = new double[n];
double[ ] X1 = { 0.0, 0.0, 0.0};
// Преобразуемсистему
for (int i = 0; i < n; i++) {
B[i] /= A[i, i];
for (int j = 0; j < n; j++)
if (i !=j) A[i, j] /= -A[i, i];
A[i, i] = -1;
}
// Считаемневязку
for (int i = 0; i < n; i++) {
Невязка[i] = B[i];
for (int j = 0; j < n; j++)
Невязка[i] += A[i, j] * X1[i];
}
while (true) {
double[ ] X2 = new double[n];
for (int i = 0; i < n; i++)
X2[i] = X1[i];
double Значение = Math.Abs(Невязка[0]);
int Номер = 0;
for (int i = 0; i < n; i++)
if (Math.Abs(Невязка[i]) >Значение) {
Значение = Math.Abs(Невязка[i]);
Номер = i;
}
X2[Номер] += Невязка[Номер];
double[ ] НевязкаНовая = newdouble[n];
НевязкаНовая[Номер] = 0;
for (int i = 0; i < n; i++)
if (i != Номер)
НевязкаНовая[i] = Невязка[i] + (A[i,Номер]*Невязка[Номер]);
if (Сходимость(X1, X2)) {
for (int i = 0; i < n; i++) {
X1[i] = X2[i];
Невязка[i] = НевязкаНовая[i];
}
continue;
}
else break;
}
for (int i = 0; i < n; i++)
Console.Write(«{0} t», X1[i]);
Console.WriteLine();
}
static bool Сходимость(double[] Xk, double[] Xkp){
bool b = false;
for (int i = 0; i < n; i++)
if (Math.Abs(Xk[i]-Xkp[i]) > eps){
b = true;
break;
}
return b;
}
}
Лекция 06. Проблема собственных значений матрицы
Если квадратная матрица -того порядка и при ,то называется собственным значением матрицы, а – соответствующим ему собственным вектором.
Эту же задачу можно переписать в виде
Нетривиальное решение существует, если выполняется следующее условие
Этот определитель является многочленом -той степени относительно , и его называют характеристическим многочленом. Значит, существует собственных значений – корней этого многочлена, возможно кратных. Каждому простому (не кратному) собственному значению соответствует один нормированный собственный вектор. Т.о. если все собственные значения простые, то им соответствуют линейно-независимые собственные вектора, образующие базис пространства.
Пример 6.1. Вычислить собственные значения и собственные вектора для матрицы
Решение:
Составим характеристический многочлен
Корни этого многочлена:
Для нахождения собственных векторов , соответствующих составим для каждого из них систему уравнений:
или в виде системы уравнений
После преобразований получим:
Поскольку уравнения линейно зависимы, получаем, что , и положив вычислим . Таким образом, собственный вектор, соответствующий собственному значению , или , где – единичные орты выбранной базисной системы.
Аналогично находим собственный вектор, соответствующий :
Отсюда , , .
В общем случае, для матриц высокого порядка, задача нахождения собственных значений матрицы и её собственных векторов не сводится к нахождению решения характеристического уравнения, поскольку осложнена хотя бы тем, что вычисление коэффициентов характеристического уравнения сопряжено со значительными сложностями, более того, зачастую, характеристический многочлен содержит кратные корни, что так же затрудняет применение вычислительных методов.
Задача нахождения собственных значения просто решается для матриц определённого вида: диагональной, треугольной или почти треугольной, трёх диагональной. Характеристический многочлен треугольной и диагональной матрицы равен произведению элементов, стоящих на главной диагонали, и следовательно, его собственные значения – это элементы главной диагонали матрицы.
Многие численные методы решения задач нахождения собственных значений связаны с приведением матриц к одному из перечисленных видов при помощи преобразования подобия.
Матрица называется подобной матрице , если существует невырожденная матрица , такая что: .
6.1. Метод Якоби
Метод Якоби применим только для симметрических матриц () и решает полную проблему собственных значений и собственных векторов таких матриц. Он основан на отыскании с помощью итерационных процедур матрицы в преобразовании подобия , а поскольку для симметрических матриц матрица преобразования подобия является ортогональной (), то , где – диагональная матрица с собственными значениями на главной диагонали
.
Пусть дана симметрическая матрица . Требуется для неё вычислить с точностью все собственные значения и соответствующие им собственные векторы. Изложем суть метода Якоби. Пусть известна матрица на — ой итерации, при этом для . Выбирается максимальный по модулю недиагональный элемент матрицы ( =) и ищется такая ортогональная матрица , чтобы в результате преобразования подобия произошло обнуление элемента матрицы . В качестве ортогональной матрицы выбирается матрица вращения, имеющая следующий вид:
,
В матрице вращения на пересечении — ой строки и — ого столбца находится элемент где – угол вращения, подлежащий определению. Симметрично относительно главной диагонали ( — ая строка, — ый столбец) расположен элемент ; Диагональные элементы и равны соответственно , ; другие диагональные элементы остальные элементы в матрице вращения равны нулю.
Угол вращения определяется из условия :
причём если то .
Высчитывается матрица в которой элемент
В качестве критерия окончания итерационного процесса используется условие малости суммы квадратов внедиагональных элементов:
Если то итерационный процесс продолжается. Если , то итерационный процесс останавливается, и в качестве искомых собственных значений принимаются .
Координатными столбцами собственных векторов матрицы в единичном базисе будут столбцы матрицы т.е.
причём эти собственные векторы будут ортогональны между собой, т.е.
Пример 6.2. С точностью вычислить собственные значения и собственные векторы матрицы
Решение:
Выбираем максимальный по модулю внедиагональный элемент матрицы , т.е. находим , такой что =. Им является элемент .
Находим соответствующую этому элементу матрицу вращения:
.
Вычисляем матрицу :
.
В полученной матрице с точностью до ошибок округления элемент .
, следовательно итерационный процесс необходимо продолжить.
Переходим к следующей итерации , максимальные внедиагональный элемент .
.
Переходим к следующей итерации . Максимальный элемент .
.
Переходим к следующей итерации . Максимальный элемент .
Таким образом в качестве искомых собственных значений могут быть приняты диагональные элементы матрицы :
Собственные векторы определяются из произведения
; .
Программная реализация этого метода выглядит следующим образом:
class Program {
const int n = 3;
const double e = 0.3; //погрешностьвычисления
public static double[,] A = { { 4.0, 2.0, 1.0 },
{ 2.0, 5.0, 3.0 },
{ 1.0, 3.0, 6.0 } };
static double Погрешность ( ) {
double Сумма = 0.0;
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
Сумма += Math.Pow(A[i, j], 2);
return (Math.Sqrt(Сумма));
}
static void Максимум (out int I, out int J){
I = 0;
J = 1;
double Значение = A[I, J];
for (int i = 0; i < n; i++)
for (int j = i + 1; j < n; j++)
if (Значение< Math.Abs(A[i,j])){
Значение = Math.Abs(A[i,j]);
I = i;
J = j;
}
}
static double[,] Произведение ( double[,] B, double[,] C ) {
double[,] Результат = new double[n, n];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
Результат[i, j] += B[i, k] * C[k, j];
return (Результат);
}
static double[,] МатрицаВращения ( int i, int j ) {
double[,] Результат = new double[n, n];
for (int k = 0; k < n; k++)
Результат[k, k] = 1.0;
double Fi;
if (A[i, i] != A[j, j])
Fi = 0.5 * Math.Atan(2.0 * A[i, j] / (A[i, i] — A[j, j]));
else
Fi = 0.5 * Math.Atan(Math.PI / 4.0);
Результат[i, i] = Результат[j, j] = Math.Cos(Fi);
Результат[i, j] = -Math.Sin(Fi);
Результат[j, i] = Math.Sin(Fi);
return (Результат);
}
static double[,] Транспонированная ( double[,] Матрица, int i, int j ) {
double[,] Результат = new double[n, n];
Array.Copy(Матрица, Результат, n * n);
Результат[i, j] *= -1;
Результат[j, i] *= -1;
return (Результат);
}
static void Main ( ) {
double[,] СобственныеВекторы = new double[n, n];
for (int i = 0; i < n; i++)
СобственныеВекторы[i, i] = 1.0;
do {
int I, J;
Максимум(out I, out J);
double[,] P = МатрицаВращения(I, J);
A = Произведение(Транспонированная(P, I, J), Произведение(A, P));
СобственныеВекторы = Произведение(СобственныеВекторы,P);
} while (Погрешность() > e);
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», A[i, j]);
for (int i = 0; i < n; i++, Console.WriteLine())
for (int j = 0; j < n; j++)
Console.Write(«{0}t», СобственныеВекторы[i, j]);
}
}
6.2. Метод вращений
Метод Якоби, рассмотренный в этой главе довольно неэффективем, поскольку является итерационным. Существует ряд методов, также основанных на использовании преобразования подобия, которые сводят заданную матрицу к матрице более сложной структуры, нежели диагональная матрица, но за конечное часло шагов. Одним из таких методов является метод вращения. Он позволяет привести исходную симметричную матрицу к трёхдиагональному виду и основан на специально подбираемом вращении системы координат в -мерном пространстве. Поскольку любое вращение можно заменить последовательностью плоских вращений, то решение задачи можно разбить на ряд шагов, на каждом из которых осуществляется плоское вращение. Таким образом, на каждом шаге выбираются две оси -тая и -тая и поворот производится в плоскости, проходящей через эти оси, остальные же оси остаются неподвижными.
По-прежнему, матрица вида
в которой отличны от единичных -тая и -тая строка и -тый и -тый столбец, так что – называется матрицей вращения. При этом, , а . Метод состоит в таком подборе матриц вращения, чтобы свести матрицу к трёхдиагональному виду. Угол поворота на каждом шаге выбирается таким, чтобы в преобразованной матрице обратился в ноль один элемент (в симметричной матрице – два)лежащий вне трёх диагоналей исходной матрицы. Преобразованная на — том шаге матрица , отличается от матрицы элементами строк и столбцов номерами и.
Обнуляя элемент коэффициенты и находятся по формулам:
Тогда элементы — ого и — ого столбца преобразовываются по формулам:
, для
Пример 6.3.Привести матрицу к трёхдиагональному виду.
3,31
4,71
-2,31
1,01
4,71
17,02
-5,58
9,61
-2,31
-5,58
9,99
-6,11
1,01
9,61
-6,11
12,01
Сначала, обнулим элементы и . Из этих соображений подбираем значения и в матрицу вращения , для этого умножим матрицу справа на и затем слева на . Получаем систему уравнений для определения параметров и .
Решая эту систему, находим
Используя эти значения можно вычислить значения элементов, в строках и столбцах с номерами , остальные элементы матрицы не изменились.
Остальные элементы матрицы остаются неизменными:
3,31
5,24
0,0
1,01
5,24
20,07
-0,64
11,31
0,0
-0,64
6,94
-1,26
1,01
11,31
-1,26
12,01
На следующем шаге будем обнулять элементы и , следовательно строим матрицу вращения и вычисляем элементы в строках и столбцах
3,31
5,34
0,0
0,0
5,34
23,98
-0,862
9.01
0,0
-0,86
6,94
-1,11
0,0
9.01
-1,11
8,1
На следующем шаге будем обнулять элементы и , следовательно, строим матрицу вращения и вычисляем элементы в строках и столбцах
3,31
5,34
0,0
0,0
5,34
23,98
9,05
0,0
0,0
9,05
8,29
0,98
0,0
0,0
0,98
6,74
static void Main() {
const int n = 4;
double[,] A = {{3.31,4.71,-2.31,1.01} ,{4.71,17.02,-5.58,9.61}, {-2.31,-5.58,9.99,-6.11}, {1.01,9.61,-6.11,12.01}};
for (int i = 1; i < n — 1; i++)
for (int j = i + 1; j < n; j++) {
double c, s, aki, akj, aii, ajj, aij;
c=A[i-1,i]/Math.Sqrt(Math.Pow(A[i-1,i],2.0)+Math.Pow(A[i-1,j],2.0));
s=A[i-1,j]/Math.Sqrt(Math.Pow(A[i-1,i],2.0)+Math.Pow(A[i-1,j],2.0));
Console.WriteLine(«c = {0} s = {1}», c,s);
for (int k = 0; k < n; k++)
if ((k != i) & (k != j)) {
aki = A[k, i];
akj = A[k, j];
A[k, i] = c * aki + s * akj;
A[i, k] = A[k, i];
A[k, j] = c * akj — s * aki;
A[j, k] = A[k, j];
}
aii = A[i, i];
ajj = A[j, j];
aij = A[i, j];
A[i, i] = c * c * aii + s * s * ajj + 2 * s * c * A[i, j];
A[j, j] = s * s * aii + c * c * ajj — 2 * s * c * A[i, j];
A[i, j] = aij * (c * c — s * s) + c * s * (ajj — aii);
A[j, i] = A[i, j];
for (int k = 0; k < n; k++, Console.WriteLine())
for (int t = 0; t < n; t++)
Console.Write(«{0} t», A[k, t]);
}
}
6.3. Вычисление характеристического полинома
После того, как заданная действительная симметричная матрица была сведена к трёхдиагональной форме, одним из способов отыскать её собственные значения становится прямое вычисление корней характеристического полинома . Эти корни можно найти методом факторизации.
Алгоритмы QR и QL
Основная идея алгоритма заключается в том, что любая действительная матрица может быть представлена в форме , где ортогональная, а – верхняя треугольная матрицы. Для матрицы общего вида это разложение строится применением алгоритма преобразования Хаусхолдера с целью уничтожения элементов столбцов матрицы ниже главной диагонали.
Теперь рассмотрим матрицу, сформированную произведением этих факторов в обратном порядке:
Поскольку ортогональна, получаем . Таким образом, . Видно, что является ортогональной трансформацией . Следует отметить, что -преобразование сохраняет симметрию и трёхдиагональность матрицы.
Алгоритм состоит из цепочки ортогональных преобразований:
Следующая теорема является основой для алгоритма в применении к матрице общего вида:
• Если имеет собственные значения, различные по модулю , то стремится к нижней треугольной форме при неограниченном возрастании . Собственные значения на диагонали при этом появляются в порядке возрастания модуля.
• Если имеет собственное значение кратности , то стремится к нижней треугольной форме, за исключением блока размерности , примыкающего к диагонали, собственные значения этого блока стремятся к .
Объём арифметических действий алгоритма имеет порядок на итерацию для матрицы общего вида, что является недопустимым. Однако для трёхдиагональной матрицы этот объём составляет на итерацию.
При доказательстве вышеупомянутой теоремы обнаруживается, что в целом наддиагональный элемент стремится к нулю как:
Хотя
сходимость может быть медленной при близости этих значений. Сходимость может быть ускорена методом сдвига: если – любая константа, то (), где – единичная матрица соответствующей размерности) имеет собственные значения (). Если разложить , так что , то скорость сходимости будет определяться отношением . Самое главное здесь выбрать на каждой стадии такое , чтобы максимально ускорить сходимость. На начальном этапе хорошим выбором является значение , близкое к , наименьшему собственному значению. В этом случае первая строка внедиагональных элементов будет быстро сведена к нулю. Однако, величина априорно неизвестна. На практике, очень эффективной стратегией (хотя и не доказано, что она оптимальна) является вычисление собственных значений начального минора размером () матрицы . После этого полагается равной тому собственному значению, которое ближе к .
Обобщая, представим, что уже найдены () собственных значений . Тогда матрицу можно уменьшить, обнулив первые () столбцов и строк:
Значение выбирается равным тому собственному значению ведущего минора размером (), которое ближе к . Можно показать, что скорость сходимости алгоритма при выборе этой стратегии обычно кубическая (и в худшем случае квадратичная при вырожденных собственных значениях). Эта исключительно быстрая сходимость делает алгоритм весьма привлекательным.
При использовании сдвига собственные значения уже не обязательно появляются на главной диагонали в порядке возрастания величины. Если это необходимо, следует отсортировать значения.
Как уже говорилось выше, -декомпозиция матрицы общего вида производится последовательностью преобразований Хаусхолдера.
QL-алгоритм с неявными сдвигами
Алгоритм, описанный выше, может быть очень эффективным. Однако когда элементы сильно различаются по порядку величины, вычитание большого из диагональных элементов может привести к потере точности для собственных значений с небольшой величиной. Эта трудность обходится применением – алгоритма с неявными сдвигами. Неявный – алгоритм математически эквивалентен исходному, однако при вычислениях не используется явное вычитание из .
Алгоритм основан на следующей лемме. Пусть – симметричная невырожденная матрица и , где – ортогональна, а – трёхдиагональна с положительными внедиагональными элементами. Тогда и полностью определяются на основании только последней строки .
Доказательство. Пусть обозначает -ую строку матрицы , а – -ый столбец матрицы . Соотношение может быть записано как
-ая строка этого матричного уравнения выглядит как
Поскольку матрица ортогональна, . Если теперь умножим обе части уравнения на , то найдём: , которая однозначно известна при заданном . Кроме того, из уравнения следует: , где обозначено , последняя величина также известна. Таким образом, , или , а также .(Поскольку согласно гипотезе ненулевое). Аналогично можно по индукции доказать, что если нам известны , , …, , а также все , и вплоть до уровня , то мы можем определить все значения на уровне (.
Для практического применения этой леммы предположим, что мы как-то нашли трёхдиагональную матрицу , такую что
, где
ортогональна и её последняя строка совпадает с последней строкой матрицы из оригинального — алгоритма. Тогда будем иметь и .
Далее, из оригинального алгоритма видно, что последняя строка совпадает с последней строкой . Но вспомним, что служит для плоской ротации с целью обнуления элемента матрицы . Простое вычисление показывает, что параметры и этой матрицы должны иметь вид:
Матрица является трёхдиагональной с двумя дополнительными элементами:
Она должна быть приведена к трёхдиагональной форме с помощью ортогональной матрицы, имеющей последнюю строку вида [0,0, …, 0,1]; таким образом, последняя строка останется равной строке . Это можно сделать последовательностью преобразований Хаусхолдера или Гивенса. Для матрицы указанного вида преобразование Гивенса эффективнее. Производим поворот в плоскости для обнуления элемента (по симметрии, будет также обнулен элемент ). После этого трёхдиагональная форма сохраняется за исключением дополнительных элементов и . Эти в свою очередь обнуляются поворотом в плоскости и т.д. Таким образом, требуется последовательность трансформаций Гивенса. В результате будем иметь:
, где
– матрицы трансформаций Гивенса, а – плоская ротация из оригинального алгоритма. По значению находим значение на новой итерации. Заметим, что сдвиг производится неявно при вычислении параметров и .
Пример 6.3: найти собственные значения трёхдиагональной матрицы предыдущего примера.
3,31
5,34
0,0
0,0
5,34
23,98
9,05
0,0
0,0
9,05
8,29
0,98
0,0
0,0
0,98
6,74
Решение:
Рассмотрим главный минор
3,31
5,34
5,34
23,98
Сформируем сдвиг
Реализация этого алгоритма на языке C# выглядит следующим образом:
class Program{
static double hipot( double x, double y ) {
return(Math.Sqrt(Math.Pow(x,2) + Math.Pow(y,2)));
}
staticvoidMain() {
int n = 3; //задали размерность матрицы
double[] d = {1.0, 2.0, 3.0 }; //элементы главной диагонали
double[] e = {1.0, 2.0, 0.0 }; //задали элементы поддиагонали,
int MAXITER = 30; // максимальное число итераций
for(intl = 0; l<n; l++) {
int iter = 0;
int m;
do {
for(m = l; m < n-1; m++) {
double dd = Math.Abs(d[m]) + Math.Abs(d[m + 1]);
if((Math.Abs(e[m] + dd) == dd)) break;
}
if(m != l) {
if( ++iter >= MAXITER) break;
double g = (d[l + 1] — d[l]) / (2.0 * e[l]);
double r = hipot(1.0, g);
if(g >= 0.0)
g += Math.Abs(r);
else
g -= Math.Abs(r);
g = d[m] — d[l] + e[l]/g;
double s = 1.0;
double c = 1.0;
double p = 0.0;
for(int i = m-1; i >= l; i—) {
double f = s * e[i];
double b = c * e[i];
e[i + 1] = r = hipot(f, g);
if(r == 0.0) {
d[i+1] -= p;
e[m]=0.0;
break;
}
s = f/r;
c = g/r;
g = d[i+1] — p;
r = (d[i] — g) * s + 2.0 * c * b;
d[i+1] = g +(p = s * r);
g = c * r — b;
}
if(r == 0.0 )
continue;
d[l] -= p; e[l] = g; e[m] = 0.0;
}
} while(m != l);
}
}
Лекция 07. Приближение функции. Вычисление значения функции
7.1. Понятие приближения функции
В вычислительной практике часто приходится встречаться с заменой функций более простыми, близкими к данным функциям в каком-либо смысле, с тем, чтобы найти с достаточной степенью точности более быстро простое решение.
Чаще всего в качестве приближающих функций берутся многочлены. Это связано с некоторыми свойствами многочленов в классе непрерывных функций:
• свойство полноты, которое выражается теоремой Вейерштрасса (1885г.)
Теорема. Если – непрерывная на конечном замкнутом промежутке функция, то для любого существует такой многочлен , что для .
• другое важное свойство многочленов – это функции простой природы; чтобы вычислить многочлен, нужно исполнить конечное число арифметических операций.
Теорема Вейерштрасса указывает лишь на возможность приближения функции многочленами, но не даёт способа построения такого многочлена. Существуют различные способы приближения функции при помощи многочленов. Большое распространение в вычислительной практике получил способ интерполирования функций.
Общая задача интерполирования заключается в построении функции, вообще говоря, отличной от данной, которая может быть известна, но задана слишком сложным аналитическим выражением, или неизвестна и задана в виде таблицы значений. Построенная функция должна принимать в заданных точках те же значения, что и данная функция . Таким образом мы сформулировали две задачи:
• построения для функции, имеющей аналитическое выражение, такой более простой функции, которая заменила бы данную в вычислениях;
• нахождения для функции, заданной таблицей, такой формулы, которая давала бы возможность находить значения функции для промежуточных значений аргумента.
Пусть на отрезке заданы точка:. Эти точки называются узлами интерполяции. И даны значения некоторой функции в этих точках .
Требуется построить функцию (интерполирующую функцию), принадлежащую определённому классу и принимающую в узлах интерполяции те же значения, что и , т.е. .
Геометрически это означает, что нужно найти кривую, некоторого определённого типа, проходящую через заданную систему точек .
В такой общей постановке задача может иметь бесконечное множество решений. Однако эта задача становится однозначной, если в качестве приближающей функции искать многочлен степени не выше , удовлетворяющий условиям . Полученную интерполяционную формулу обычно используют для приближённого вычисления значений данной функции . При этом различают интерполирование, когда, и экстраполирование, когда .
7.2. Вычисление значения многочлена
Займёмся общим многочленом вида:
Мы будем предполагать, что все коэффициенты известны, постоянны и записаны в массив. Это означает, что единственным входным данным для вычисления многочлена служит значение , а результатом программы должно быть значение многочлена в точке .
Программа, реализующая стандартный алгоритм вычисления выглядит так:
static void Main() {
double[] A = {1.56, 2.34, 4.07, 3.58, -1.43};
double X = 2.778;
double Результат = A[0] + A[1]*X;
double Степень = X;
for (int i = 2; i < A.Length; i++){
Степень *= X;
Результат += (A[i]*Степень);
}
Console.WriteLine(«{0}», Результат);
}
В цикле содержится два умножения, которые выполняются раз. Кроме того, одно умножение выполняется перед циклом, поэтому общее число умножений равно . В цикле выполняется также одно сложение, и одно сложение выполняется перед циклом, поэтому общее число сложений равно .
Вычисление по схеме Горнера оказывается более эффективным, причём оно не очень усложняется. Эта схема основывается на следующем представлении многочлена:
Можно легко проверить, что это представление задаёт тот же многочлен, что и выше.
Пример 7.1. Посчитать в точке значение полинома по схеме Горнера.
Решение:
На первом шаге значение полинома равно: . Далее полученный результат умножаем на и добавляем 4,07:, снова домножаем на и добавляем 2,34 : , и в последний раз домножаем на и добавляем 1,56. Значение полинома: 32,859.
Соответствующий алгоритм выглядит так:
staticvoidMain() {
double[] A = {1.56, 2.34, 4.07, 3.58, -1.43};
double X = 2.778;
double Результат = A[A.Length — 1];
for (int i = (A.Length — 2); i >=0; i—)
Результат = Результат * X + A[i];
Console.WriteLine(«{0}», Результат);
}
Цикл выполняется раз, причём внутри цикла есть одно умножение и одно сложение. Поэтому вычисление по схеме Горнера требует умножений и сложений – двукратное уменьшение числа умножений по сравнению со стандартным алгоритмом.
Результат можно даже улучшить, если обработать коэффициенты многочлена до начала работы алгоритма. Основная идея состоит в том, чтобы выразить многочлен через многочлены меньшей степени. Например, для вычисления значения можно воспользоваться таким же циклом, как в первом алгоритме этого раздела; в результате будет выполнено 255 умножений. Альтернативный подход состоит в том, чтобы положить Степень= x*x, а затем семь раз выполнить операцию Степень= Степень* Степень. После первого выполнения переменная Результат будет содержать, после второго , после третьего , после четвёртого , после пятого , после шестого , и после седьмого .
Для того, чтобы метод предварительной обработки коэффициентов работал, нужно, чтобы многочлен был унимодальным (то есть старший коэффициент должен равняться 1) , а степень многочлена должна быть на единицу меньше некоторой степени двойки ( для некоторого ). В таком случае многочлен можно представить в виде:
, где
В обоих многочленах и будет вдвое меньше членов, чем в . Для получения нужного результата мы вычислим по отдельности и , а затем сделаем одно дополнительное умножение и два сложения. Если при этом правильно выбрать значение , то оба многочлена и оказываются унимодальными, причем степень каждого из них позволяет применить к каждому из них ту же самую процедуру. Мы увидим, что её последовательное применение позволяет сэкономить вычисления.
Вместо того, чтобы вести речь о многочленах общего вида, обратимся к примеру.
Пример 7.2. Рассмотрим многочлен:
Определим сначала множитель . Степень многочлена равна 7, то есть, поэтому. Отсюда вытекает, что. Выберем значение таким образом, чтобы оба многочлена и были унимодальными. Для этого нужно посмотреть на коэффициенты в и положить . В нашем случае это означает, что . Теперь мы хотим найти значения и , удовлетворяющие уравнению:
Многочлены и совпадают соответственно с частным и остатком от деления на . Деление с остатком дает:
На следующем шаге мы можем применить ту же самую процедуру к каждому из многочленов и :
В результате получаем:
Посмотрев на этот многочлен, мы видим, что для вычисления требуется одно умножение; ещё одно умножение необходимо для подсчёта . Помимо этих двух умножений в вычислении правой части равенства участвуют ещё три умножения. Кроме того, выполняется 10 операций сложения. Применение подобного подхода целесообразно в случае, если значение полинома вычисляется много кратно в разных точках.
7.3. Интерполяционный многочлен Лагранжа
Пусть функция известна в узлах некоторой решётки – т. е. задана таблицей. Метод интерполяции заключается в упрощённом нахождении значений функции внутри интервала. Необходимо подобрать некоторую функцию которая близка в некотором смысле к . В методе интерполяции будем подбирать функцию из тех соображений, чтобы она совпадала с табличными значениями в узлах сетки.
Из которой можно получить параметры . Этот метод подбора называется интерполяцией Лагранжа. Если нелинейно зависит от параметров, то интерполяция называется нелинейной и нахождение параметров из системы может быть сильно затруднено. Рассмотрим линейную интерполяцию, когда линейно зависит от параметров т.е. представима в виде обобщённого многочлена
следует считать линейно-независимыми. Следовательно, необходимо найти решение системы
Чтобы задача интерполяции всегда имела единственное решение, необходимо, чтобы при любом расположении узлов (обязательно несовпадающих)
Система функций, удовлетворяющих этому условию, называется Чебышевской. Т.о. при линейной интерполяции необходимо строить обобщённый многочлен по какой-нибудь Чебышевской системе функций. В теории рассматриваются методы интерполирования тригонометрическими многочленами и экспонентами.
Рассмотрим систему , предложенную Лагранжем для вычисления таких многочленов. В этом случае
– определитель Вандермонда
и
где базисные полиномы определяются по формуле:
обладают следующими свойствами:
• являются многочленами степени ;
• ;
• при.
Отсюда следует, что , как линейная комбинация , может иметь степень не больше , и .
Пример 7.3. Дана функция в виде таблицы значений.
1.5
3.873
1.54
3.924
1.56
3.950
1.60
4.00
1.63
4.037
1.70
4.123
Требуется получить значение этой функции в точке, используя интерполяционный многочлен Лагранжа.
Решение:
Посчитаем значения базисных полиномов для точки .
Тогда значение функции в точке равно:
Программа для данного примера может быть такой:
classProgram {
// Функция, вычисляющая коэффициенты Лагранжа
static double L( double[] X, double xp, int n, int i ) {
double Числитель = 1;
double Знаменатель = 1;
for (int k = 0; k < n; k++ ){
if ( k == i ) continue;
Числитель *= xp — X[k];
}
for(int k = 0; k < n; k++){
if (X[i] == X[k]) continue;
Знаменатель *= X[i] — X[k];
}
return Числитель/Знаменатель;
}
staticvoidMain() {
double[] X = {1.5, 1.54, 1.56, 1.60,1.63, 1.70};
double[] Y = {3.873,3.924,3.950,4.00,4.037, 4.123};
int n = X.Length;
double Результат = 0;
double px = 1.55;
for (int i = 0; i < n; i++)
Результат += Y[i]*L(X, px, n, i);
Console.WriteLine(«Результат : {0} «,Результат);
}
}
Результаты выполнения программы: ,.
7.5. Интерполяционный многочлен Ньютон
Интерполяционные формулы Ньютона – формулы вычислительной математики, применяющиеся для полиномиального интерполирования.
Если узлы интерполяции равноотстоящие и упорядочены по величине, так что – const, то есть , то интерполяционный многочлен можно записать в форме Ньютона.
Интерполяционные полиномы в форме Ньютона удобно использовать, если точка интерполирования находится вблизи начала (прямая формула Ньютона) или конца таблицы (обратная формула Ньютона).
В случае равноудалённых центров интерполяции, находящихся на единичном расстоянии друг от друга, справедлива формула:
где – обобщённые на область действительных чисел биномиальные коэффициенты.
Прямая интерполяционная формула Ньютона:
где , , а выражения вида – конечные разности.
Обратная интерполяционная формула Ньютона:
где.
Определим разделённые разности
и т.д. – разделённые разности первого, второго и т.д. порядка. Разделённые разности обычно располагают в следующей таблице:
…
.
.
.
.
.
.
Эти разности дают приближённое значение производных. Эти разности любого порядка можно непосредственно вычислить через значение узлов сетки, но удобнее пользоваться рекуррентным соотношением. Проведя нехитрые преобразования получим формулу Ньютона
Пример 7.4.Посчитать значение функции, заданной в предыдущем примере в точке, с помощью интерполяционного многочлена Ньютона.
Решение:
Посчитать разделённые разности удобно в следующей таблице:
1.5
3.873
1.54
3.924
1.56
3.950
1.60
4.00
1.63
4.037
1.70
4.123
Программа на языке С#, реализующая приведённый метод может выглядеть например так:
static void Main() {
const int n = 6;
double[] X = {1.5, 1.54, 1.56, 1.60,1.63, 1.70};
double[] Y = {3.873,3.924,3.950,4.00,4.037, 4.123};
double Точка = 1.55;
double XX = 1.0;
double LN = Y[0];
for (int i = 1; i < n; i++) {
XX *= (Точка — X[i-1]);
double f = 0;
for (int j = 0; j <= i; j++){
double XXX = 1.0;
for (int k = 0; k <= i; k++){
if (k != j)
XXX *= X[j] — X[k];
}
f += Y[j] / XXX;
}
LN += XX * f;
}
Console.WriteLine(«{0}», LN);
}
7.6. Оценка погрешности
Погрешность удобно представлять в виде
Это погрешность заведомо равна нулю в узлах решетки. Будем считать, что функция имеет непрерывную производную. Введя дополнительную функцию, в которой играет роль параметра и принимает любое фиксированное значение, заметим, что эта функция обращается в ноль в узлах решётки и в точке . Из предположения, что имеет непрерывную производную следует, что на любом участке между нолями функции лежит ноль её производной. Последовательно пользуясь этим свойством, получим, что между крайними из нулей функции лежит нуль производной.
Если в какой-то точке , лежащей между указанными нулями, она обращается в нуль, то
заменим погрешность максимально возможной и получим
где максимум производной берётся по отрезку между наименьшим и наибольшим значением из значений сетки.
Оценить легче всего при постоянном шаге задания сетки. В этом случае имеет приблизительно такой вид: вблизи центрального узла интерполяции экстремумы невелики, вблизи крайних узлов – больше, а если выходит за крайние узлы интерполяции, то быстро растёт.
При равномерной сетке выгодно выбирать из таблицы узлы так, чтобы искомая точка попадала ближе к центру интерполяции – это обеспечит более высокую точность. Оценив погрешность на центральном интервале и преобразовав её, получаем окончательный результат:
если величины производных можно оценить, то отсюда легко определить число узлов, достаточное для получения заданной точности.
Более грубо можно сказать, что многочлен Ньютона имеет погрешность и обеспечивает порядок точности интерполяции.
Задачей обратного интерполирования называют задачу нахождения для произвольного , если задана таблица . Для монотонных функций между прямым и обратным интерполированием нет никакой разницы: можно считать таблицу, как задание . Единственное отличие будет в том, что «обратная» таблица будет иметь переменный шаг, даже если прямая таблица имела шаг постоянный.
Важный пример обратного интерполирования – решение уравнения . Вычислим несколько значений функции и запишем эти значения в виде . При помощи уже знакомого многочлена Ньютона вычислим приближённое значение .
Пример 7.5. Используя формулу Ньютона, найти решение уравнения:
Решение:
Составим таблицу 4 значений функции:
-1,500
0,000
0,540
-0,574
0,500
0,365
-0,076
0,797
1,000
Точное значение
Единственное существенное замечание: для повышения точности в этом способе целесообразно взять новые узлы, близко расположенные к грубо найденному корню, а не увеличивать число узлов.
Лекция 08. Нелинейная интерполяция
При повышении порядка точности на единицу при маленьком шаге погрешность уменьшается, а при достаточно большом шаге она может увеличиваться. Такое же явление мы наблюдаем, если производные быстро растут с увеличение порядка. Это чаще всего происходит при работе с быстро меняющимися функциями.
Пример 8.1.Найти значение функции заданной таблично в точке
1
1
11
10
2
121
110
50
3
1351
1230
560
170
Решение:
Этот ряд содержит быстро возрастающие члены и не похож на сходящийся, следовательно, вычислить с его помощью функцию не удастся.
Выяснив качественной поведение функции, обычно сравнивая её с графиками хорошо изученных элементарных функций, стараются подобрать такое преобразование переменных и , чтобы в новых переменных график мало отличался от прямой. Тогда в переменных интерполяция многочленом невысокой степени будет давать хорошую точность. Вычисления заключаются в составлении таблицы для новых переменных, интерполяции по ней и нахождении обратным преобразованием.
Можно заметить, что в приведённом выше примере зависимость близка к показательной , значит можно ввести переменные и. Составим новую таблицу:
0,0000
1
1,0414
1,0414
2
2,0828
1,0414
0,0000
3
3,1306
1,0478
0,0032
0,0011
теперь члены ряда быстро убывают, обеспечивая быструю сходимость и хорошую точность. Считая, что точность приблизительно равна порядку последнего слагаемого, обратным преобразованием получим
Удачно подобное выравнивание позволило получить высокую точность интерполяции.
Замечания:
Для каждой конкретной функции подбирают свой способ интерполяции. Для других функций этот вид будет давать плохую точность.
Оценка погрешности такой интерполяции содержит старшие производные , их трудно посчитать, поэтому на практике удобнее оценивать точность по скорости убывания членов ряда в формуле Ньютона.
Преобразования и должны выражаться несложными формулами, иначе этот метод будет мало пригодным на практике.
В исходных переменных интерполяция нелинейна относительно параметров. Однако в новых переменных она линейна. Такая интерполяция называется квазилинейной.
8.1. Метод наименьших квадратов
Будем считать, что значения некоторой функции получены экспериментально, и следовательно, эта функция задана таблично. Более того, проделана некоторая предварительная работа по анализу характера поведения искомой функции. Если значения функции пропорциональны значению аргумента, то ищем зависимость вида . Следовательно, задача сводится к определению коэффициента .Каждый отдельный опыт даёт свое значение
Можно получить среднее значение
Это самый простой, но не самый лучший способ. Изменим понимание проблемы. Будем считать, что результат опытов содержит некоторую ошибку . Которая приблизительно одинакова для любого значения . Тогда ошибка в значении тем больше, чем меньше . Найдём значение , при котором функция наилучшим способом соответствует опытным данным. Будем достигать этого минимизируя величину . В качестве меры общей ошибки будем рассматривать
Обратите внимание, что одна величинадобавляет в величину 100 единиц. В то же время, десять точек с ошибкой 1 добавит в только 10 единиц. Т.е. большие, но редкие ошибки сильнее влияют на значение ошибки, в то время, как много небольших ошибок мало влияют на эту величину.
Для того чтобы найти при котором наименьшее, решим уравнение
Если , то будем искать в виде. В этом случае
Если бы уже было найдено, то должно было быть
Из этих двух условий получаем систему уравнений.
Поставим задачу шире, пусть функция задана таблицей значений, в точках . Используя метод наименьших квадратов, найдём многочлен – наилучшего среднеквадратичного приближения оптимальной степени. За оптимальное значение примем ту степень многочлена, для которой величина
минимальна.
Пример 8.2.Пусть функция задана следующей таблицей. Методом наименьших квадратов определить коэффициенты полиномов первой и второй степени, выбрать оптимальный из них.
-2.75
-2.0
-1.0
0.5
1.0
-0.2
-1.1
-2.3
0.1
1.1
Решение:
Многочлен первой степени ищем в виде . Следовательно, функция суммарной ошибки имеет вид . Продифференцировав её по и по и прировняв полученные производные к нулю значения и находим как решение системы уравнений
Посчитаем коэффициенты этих уравнений:
1
-2,75
-0,20
7,56
0,55
2
-2,00
-1,10
4,00
2,20
3
-1,00
-2,30
1,00
2,30
4
0,50
0,10
0,25
0,05
5
1,00
1,10
1,00
1,10
-4,25
-2,40
13,81
6,20
Решим систему уравнений:
Откуда , . Подставив эти значения в формулу посчитаем значение функции .
Многочлен второй степени будем искать в виде . Следовательно, функция суммарной ошибки имеет вид . Продифференцировав её по , и , и прировняв полученные производные к нулю, значения переменных находим как решение системы уравнений:
Необходимые коэффициенты этих уравнений приведены в следующей таблице:
1
-2,75
-0,20
7,56
-20,80
57,19
-1,51
0,55
2
-2,00
-1,10
4,00
-8,00
16,00
-4,40
2,20
3
-1,00
-2,30
1,00
-1,00
1,00
-2,30
2,30
4
0,50
0,10
0,25
0,13
0,06
0,03
0,05
5
1,00
1,10
1,00
1,00
1,00
1,10
1,10
-4,25
-2,40
13,81
-28,67
75,25
-7,09
6,20
Получаем систему уравнений:
Решив которую, получаем, что , , . Посчитаем значение функции .
Поскольку накопленная суммарная ошибка меньше для полинома второй степени, то его использование для аппроксимации функции предпочтительнее.
Программа, реализующая этот подход может выглядеть так:
namespace МетодНаименьшихКвадратов {
class Program {
static double[] МетодГаусса ( double[,] A,
double[] B){
int n = B.Length;
double[,] a = new double[n, n + 1];
double[] x = new double[n];
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++)
a[i,j] = A[i,j];
a[i,n] = B[i];
}
for (int i = 0; i < n; i++){
double m = Math.Abs(a[i, i]);
int k = i;
for (int j = i+1; j < n; j++)
if (Math.Abs(a[j,i]) > m) {
m = Math.Abs(a[j,i]);
k = j;
}
if (k != i)
for (int j = i;j <= n; j++){
double z = a[i, j];
a[i,j] = a[k,j];
a[k,j] = z;
}
double r = a[i, i];
for (int j = i;j <= n; j++)
a[i,j] /=r;
for (int l = i+1; l < n; l++){
r = a[l,i];
for (int j = i+1; j <= n; j++)
a[l,j] -= a[i,j]*r;
}
}
x[n-1] = a[n-1,n];
for (int i = n-1; i >= 0; i—){
x[i] = a[i,n];
for (int k = i+1; k < n; k++)
x[i] -=a[i,k]*x[k];
}
return(x);
}
static double[ ] МетодНК( double[ ] X,
double[ ] Y,
int n,
int m ) {
double[ ] B = new double[m + 1];
double[,] G = new double[m + 1, m + 1];
for (int j = 0; j <= m; j++) {
B[j] = 0;
for (int i = 0; i < n; i++)
B[j] += Y[i] * Math.Pow(X[i], j );
for (int k = 0; k <= m; k++) {
G[j, k] = 0;
for (int i = 0; i < n; i++)
G[j, k] += Math.Pow(X[i], k + j);
}
}
double[ ] коэффициенты = МетодГаусса(G, B);
return (коэффициенты);
}
static double ЗначениеПолинома(double[,] Коэффициенты,
int ПорядокПолинома,
double Точка ) {
double Значение = 0.0;
for (int i = 0; i <= ПорядокПолинома; i++)
Значение += Коэффициенты[ПорядокПолинома, i] * Math.Pow(Точка, i);
return (Значение);
}
static void Main() {
double[ ] X = { -2.75, -2.0, -1.0, 0.5, 1.0 };
double[ ] Y = { -0.2,-1.1, -2.3, 0.1, 1.1 };
int n = X.Length;
double[,] Коэффициенты = new double[n+1,n+1];
for (int i = 0; i <= n; i++) {
double[ ] Результат = МетодНК(X, Y, n, i);
for (int j = 0; j <= i; j++)
Коэффициенты[i,j] = Результат[j];
}
double МинимальнаяПогрешность = 0;
int Порядок = -1;
for (int i = 0; i <= n; i++){
double Погрешность = 0;
for (int j = 0; j < n; j++)
Погрешность += Math.Pow((ЗначениеПолинома(Коэффициенты, i, X[j]) — Y[j]),2);
Погрешность = Math.Sqrt(Погрешность/(n — i));
if ((МинимальнаяПогрешность ==0) || (МинимальнаяПогрешность > Погрешность)){
МинимальнаяПогрешность = Погрешность;
Порядок = i;
}
}
}
}
}
8.2. Интерполяция сплайнами
Если надо провести график функции по известным, но редким точкам, то можно воспользоваться гибкой металлической линейкой, изгибая её так, чтобы она проходила через известные точки. Таким способом часто пользуются инженеры-практики. Этот метод можно описать математически. Рассматривая гибкую линейку, как упругий брусок. Из курса сопротивления материалов известно, что уравнение свободного равновесия . Т.е. в промежутке между каждой парой соседних узлов интерполяционная функция задаётся многочленом третьей степени:
Интерполяция сплайнами третьего порядка – это быстрый, эффективный и устойчивый способ интерполяции функций.
В основе сплайн-интерполяции лежит следующий принцип. Интервал интерполяции разбивается на небольшие отрезки, на каждом из которых функция задаётся полиномом третьей степени. Коэффициенты полинома подбираются таким образом, чтобы выполнялись определённые условия (какие именно, зависит от способа интерполяции). Общие для всех типов сплайнов третьего порядка требования – непрерывность функции и, разумеется, прохождение через предписанные ей точки. Дополнительными требованиями могут быть линейность функции между узлами, непрерывность высших производных и т.д.
Основными достоинствами сплайн-интерполяции являются её устойчивость и малая трудоёмкость. Системы линейных уравнений, которые требуется решать для построения сплайнов, очень хорошо обусловлены, что позволяет получать коэффициенты полиномов с высокой точностью. В результате даже про очень больших вычислительная схема не теряет устойчивость. Построение таблицы коэффициентов сплайна требует операций, а вычисление значения сплайна в заданной точке – всего лишь .
Ниже рассмотрены различные типы интерполирующих сплайнов.
Линейный сплайн
Линейный сплайн – это сплайн, составленный из полиномов первой степени, т.е. из отрезков прямых линий. Точность интерполяции линейными сплайнами невысока, также следует отметить, что они не обеспечивают непрерывности даже первых производных. Однако в некоторых случаях кусочно-линейная аппроксимация функции может оказаться предпочтительнее, чем аппроксимация более высокого порядка. Например, линейный сплайн сохраняет монотонность переданного в него набора точек.
На графике приведён пример линейного сплайна, интерполирующего функцию на отрезке [-1, 1].
Таблица коэффициентов линейного сплайна строится следующей программой. С технической точки зрения, линейный сплайн реализован, как сплайн третьего порядка с коэффициентами при второй и третьей степенях равными нулю. Это сделано для обобщения программы вызова вычисления значения функции в точке.
Пример 8.3. Пусть функция задана следующей таблице. С помощью линейного сплайне посчитать значение этой функции в точке .
0,000
0,628
1,257
1,885
2,513
1,000
0,809
0,309
-0,309
-0,809
Решение:
Посчитаем значения сплайна по формуле и запишем третьей строкой таблицы:
1
2
3
4
5
0,000
0,628
1,257
1,885
2,513
1,000
0,809
0,309
-0,309
-0,809
-0,304
-0,796
-0,984
0,796
Значение в точке будем считать по формуле:
, где – номер узла сетки, наиболее близкого к точке слева. В нашем примере = 2.
Программа на С# строящая линейный сплайн приведена ниже.
staticdouble[ ] ПостроениеСплайна( double[ ] x,
double[ ] y,
int n ) {
double[ ] z;
int tblsize = 0;
tblsize = 3 + n + (n — 1) * 4;
z = new double[tblsize];
z[0] = tblsize;
z[1] = 3;
z[2] = n;
for (int i = 0; i < n; i++)
z[3 + i] = x[i];
for (int i = 0; i < n — 1; i++) {
z[3 + n + 4 * i + 0] = y[i];
z[3 + n + 4 * i + 1] = (y[i + 1] — y[i]) / (x[i + 1] — x[i]);
z[3 + n + 4 * i + 2] = 0.0;
z[3 + n + 4 * i + 3] = 0.0;
}
return (z);
}
Сплайн Эрмита
Сплайн Эрмита – это сплайн третьего порядка, производная которого принимает в узлах сплайна заданные значения. В каждом узле сплайна Эрмита задано не только значение функции, но и значение её первой производной. Сплайн Эрмита имеет непрерывную первую производную, но вторая производная у него разрывна.
На графике приведён пример сплайна Эрмита, интерполирующего функцию на отрезке [-1, 1]. Можно видеть, что точность интерполяции значительно лучше, чем у линейного сплайна.
Таблица коэффициентов сплайна Эрмита строится следующей подпрограммой:
static double[ ] ПостроениеСплайнаЭрмита( double[ ] x,
double[ ] y,
double[ ] d,// первая производная
int n ) {
double[ ] z;
int tblsize = 3 + n + (n — 1) * 4;
z = new double[tblsize];
z[0] = tblsize;
z[1] = 3;
z[2] = n;
for (int i = 0; i < n; i++)
z[3 + i] = x[i];
for (int i = 0; i < n — 1; i++) {
double delta = x[i + 1] — x[i];
double delta2 = Math.Sqrt(delta);
double delta3 = delta * delta2;
z[3 + n + 4 * i + 0] = y[i];
z[3 + n + 4 * i + 1] = d[i];
z[3 + n + 4 * i + 2] = (3 * (y[i + 1] — y[i]) — 2 * d[i] * delta — d[i + 1] * delta) / delta2;
z[3 + n + 4 * i + 3] = (2 * (y[i] — y[i + 1]) + d[i] * delta + d[i + 1] * delta) / delta3;
}
return (z);
}
Кубический сплайн
Все сплайны, рассмотренные в этомразделе, являются кубическими сплайнами – в том смысле, что они являются кусочно-кубическими функциями. Однако, когда говорят «кубический сплайн», то обычно имеют в виду конкретный вид кубического сплайна, который получается, если потребовать непрерывности первой и второй производных. Кубический сплайн задаётся значениями функции в узлах и значениями производных на границе отрезка интерполяции (либо первых, либо вторых производных).
Если известно точное значение первой производной на обеих границах, то такой сплайн называют фундаментальным. Погрешность интерполяции таким сплайном равна .
Если значение первой (или второй) производной на границе неизвестно, то можно задать т.н. естественные граничные условия, , и получить естественный сплайн. Погрешность интерполяции естественным сплайном составляет . Максимум погрешности наблюдается в окрестностях граничных узлов, во внутренних узлах точность интерполяции значительно выше.
Ещё одним видом граничного условия, которое можно использовать, если неизвестны граничные производные функции, является условие типа «сплайн, завершающийся параболой». В этом случае граничный отрезок сплайна представляется полиномом второй степени вместо третьей (для внутренних отрезков по-прежнему используются полиномы третьей степени). В ряде случаев это обеспечивает большую точность, чем естественные граничные условия.
Наконец, можно сочетать различные типы граничных условий на разных границах. Обычно так имеет смысл делать, если у нас есть только часть информации о поведении функции на границе (например, производная на левой границе – и никакой информации о производной на правой границе).
На графике приведён пример кубического сплайна, интерполирующего функцию на отрезке [-1, 1]. Можно видеть, что точность интерполяции близка к точности Эрмитова сплайна.
Таблица коэффициентов кубического сплайна строится следующей подпрограммой:
static double[] РешениеСистемы(double[] a,
double[] b,
double[] c,
double[] d,
int n){
double[] x = new double[n];
a[0] = 0;
c[n-1] = 0;
for(int k = 1; k <= n-1; k++) {
double t = a[k]/b[k-1];
b[k] = b[k]-t*c[k-1];
d[k] = d[k]-t*d[k-1];
}
x[n — 1] = d[n — 1]/b[n — 1];
for(int k = n — 2; k >= 0; k—)
x[k] = (d[k] — c[k] * x[k + 1]) / b[k];
return(x);
}
static double[] ПостроениеСплайна(double[] x,
double[] y,
int n,
int boundltype,
double boundl,
int boundrtype,
double boundr) {
double[] a1 = new double[n];
double[] a2 = new double[n];
double[] a3 = new double[n];
double[] b = new double[n];
int tblsize = 3 + n + (n — 1) * 4; ;
if( n==2 & boundltype==0 & boundrtype==0 ){
boundltype = 2;
boundl = 0;
boundrtype = 2;
boundr = 0;
}
switch (boundltype){
case 0:
a1[0] = 0;
a2[0] = 1;
a3[0] = 1;
b[0] = 2*(y[1]-y[0])/(x[1]-x[0]);
break;
case 1:
a1[0] = 0;
a2[0] = 1;
a3[0] = 0;
b[0] = boundl;
break;
case 2:
a1[0] = 0;
a2[0] = 2;
a3[0] = 1;
b[0] = 3*(y[1]-y[0])/(x[1]-x[0])-0.5*boundl*(x[1]-x[0]);
break;
}
for(int i = 1; i <= n — 2; i++){
a1[i] = x[i+1]-x[i];
a2[i] = 2*(x[i+1]-x[i-1]);
a3[i] = x[i]-x[i-1];
b[i] = 3*(y[i]-y[i-1])/(x[i]-x[i-1])*(x[i+1]-x[i])+3*(y[i+1]-
y[i])/(x[i+1]-x[i])*(x[i]-x[i-1]);
}
switch (boundrtype){
case 0:
a1[n-1] = 1;
a2[n-1] = 1;
a3[n-1] = 0;
b[n-1] = 2*(y[n-1]-y[n-2])/(x[n-1]-x[n-2]);
break;
case 1:
a1[n-1] = 0;
a2[n-1] = 1;
a3[n-1] = 0;
b[n-1] = boundr;
break;
case 2:
a1[n-1] = 1;
a2[n-1] = 2;
a3[n-1] = 0;
b[n-1] = 3*(y[n-1]-y[n-2])/(x[n-1]-x[n-2])+0.5*boundr*(x[n-1]-x[n-2]);
break;
}
double[] D = РешениеСистемы(a1, a2, a3, b, n);
double[ ] Z = ПостроениеСплайнаЭрмита(x, y, D, n);
return (Z);
}
Сплайн Акимы
Сплайн Акимы – это особый вид сплайна, устойчивый к выбросам. Недостатком кубических сплайнов является то, что они склонны осциллировать в окрестностях точки, существенно отличающейся от своих соседей. На графике справа приведён набор точек, содержащий один выброс. Зелёным цветом обозначен кубический сплайн с естественными граничными условиями. На отрезках интерполяции, граничащих с выбросом, сплайн заметно отклоняется от интерполируемой функции – сказывается влияние выброса. Красным цветом обозначен сплайн Акимы. Можно видеть, что, в отличие от кубического сплайна, сплайн Акимы в меньшей мере подвержен влиянию выбросов – на отрезках, граничащих с выбросом, практически отсутствуют признаки осцилляции.
Важным свойством сплайна Акимы является его локальность – значения функции на отрезке зависят только от . Вторым свойством, которое следует принимать во внимание, является нелинейность интерполяции сплайнами Акимы – результат интерполяции суммы двух функций не равен сумме интерполяционных схем, построенных на основе отдельных функций. Для построения сплайна Акимы требуется не менее 5 точек. Во внутренней области (т.е. между и ) погрешность интерполяции имеет порядок .
Таблица коэффициентов сплайна Акимы строится следующей подпрограммой:
static double Дифференцирование(double t,
double x0,
double f0,
double x1,
double f1,
double x2,
double f2 ) {
double result = 0;
double a = 0;
double b = 0;
t = t — x0;
x1 = x1 — x0;
x2 = x2 — x0;
a = (f2 — f0 — x2 / x1 * (f1 — f0)) / (Math.Sqrt(x2) — x1 * x2);
b = (f1 — f0 — a * Math.Sqrt(x1)) / x1;
return (2 * a * t + b);
}
static double[ ] ПостроениеСплайнаАкимы( double[ ] x,
double[ ] y,
int n ) {
double[ ] w = new double[n — 1];
double[ ] diff = new double[n — 1];
for (int i = 0; i < n — 1; i++)
diff[i] = (y[i + 1] — y[i]) / (x[i + 1] — x[i]);
for (int i = 1; i < n — 1; i++)
w[i] = Math.Abs(diff[i] — diff[i — 1]);
double[ ] d = new double[n];
for (int i = 2; i < n — 2; i++)
if (Math.Abs(w[i — 1]) + Math.Abs(w[i + 1]) != 0)
d[i] = (w[i + 1] * diff[i — 1] + w[i — 1] * diff[i]) / (w[i + 1] +
w[i — 1]);
else
d[i] = ((x[i + 1] — x[i]) * diff[i — 1] + (x[i] — x[i — 1]) *
diff[i]) / (x[i + 1] — x[i — 1]);
d[0] = Дифференцирование (x[0], x[0], y[0], x[1], y[1], x[2], y[2]);
d[1] = Дифференцирование (x[1], x[0], y[0], x[1], y[1], x[2], y[2]);
d[n — 2] = Дифференцирование(x[n — 2], x[n — 3], y[n — 3], x[n — 2],
y[n — 2], x[n — 1], y[n — 1]);
d[n — 1] = Дифференцирование (x[n — 1], x[n — 3], y[n — 3], x[n — 2],
y[n — 2], x[n — 1], y[n — 1]);
double[ ] z = ПостроениеСплайнаЭрмита(x, y, d, n);
return (z);
}
Вызов перечисленных программ, реализованный на языке С# выглядит следующим образом:
static void Main() {
double result = 0;
int n = 5; int l = 0; int r = 0; int m = 0;
double[ ] X = new double[n]; double[ ] Y = new double[n];
double Точка = 1.02;
if (n < 2) Console.WriteLine(» n < 2″);
else {
for (int i = 0; i < n; i++) {
X[i] = (i * Math.PI) / n;
Y[i] = Math.Cos(X[i]);
}
double[ ] Z = ПостроениеСплайна(X, Y, n);
l = 3;
r = 3 + n — 2 + 1;
while (l != r — 1) {
m = (l + r) / 2;
if (Z[m] >= Точка) r = m;
else l = m;
}
Точка -= Z[l];
m = 3 + n + 4 * (l — 3);
result = Z[m] + Точка * (Z[m + 1] + Точка * (Z[m + 2] + Точка * Z[m + 3]));
Console.WriteLine(«{0}», result);
}
Лекция 09. Понятие численного дифференцирования
9.1. Формулы приближённого дифференцирования, основанные на интерполяционной формуле Ньютона
Пусть дана функция , заданная в равноотстоящих точках отрезка . Обозначим . Для нахождения производных , и т.д., функцию приближённо заменим интерполяционным полиномом Ньютона, построенным для системы узлов , , … , .
Тогда
где , , , , – разделённые разности.
Производя перемножение биномов, получим:
Так как , то
.
Аналогично, так как
.
Таким же способом в случае необходимости можно найти производные любого порядка. Заметим, что при нахождении производных в фиксированной точке в качестве следует выбирать ближайшее табличное значение аргумента. Иногда требуется находить производные функции в основных табличных точках, т.е. в узлах . В этом случае формулы численного дифференцирования упрощаются. Так как каждое табличное значение можно считать за начальное, то положив , получаем . Тогда будем иметь:
Если – интерполяционный полином Ньютона, содержащий конечные разности до — того порядка включительно, то его погрешность выражается формулой:
Находим погрешность основной формулы:
Полагая и учитывая, что и
,
будем иметь
.
Так как, то
.
Пример 9.1. Пусть функция задана на отрезке [0,1] с шагом 0,2 следующей таблицей:
0,0
0,2
0,4
0,6
0,8
1,0
1,0
1,221
1,491
1,822
2,256
2,718
Посчитать значения первой и второй производной в точке с помощью многочлена Ньютона и оценить полученную погрешность.
Решение:
В данном случае удобнее воспользоваться формулой:
Где , a . Обозначим за , и посчитаем их значения:
0,0
1,0
0,221
0,049
0,012
0,028
0,005
0,2
1,221
0,270
0,061
0,04
0,033
0,4
1,491
0,331
0,101
0,073
0,6
1,822
0,434
0,028
0,8
2,256
0,462
1,0
2,718
Точное значение – 1,1051, следовательно, погрешность равна 0,0032.
Вторую производную посчитаем по формуле:
9.2. Дифференцирование функций, интерполированных полиномами Лагранжа
Пусть даны равноотстоящие точки , , … , , и известны значения некоторой функции в этих точках, , . Построим многочлен Лагранжа:
.
Полагая, получаем:
Следовательно, для многочлена Лагранжа в случае равноотстоящих узлов имеем выражение:
Для оценки погрешности воспользуемся известной формулой погрешности интерполяционной формулы Лагранжа.
.
.
Для узловых точек имеем:
Например, посчитаем формулу для первой производной в случае, когда известны значения функции в трёх точках. Выпишем многочлен Лагранжа
Тогда
Посчитаем значение
аналогично можно вывести формулы и для точек и .
.
Аналогично получаются формулы для случая четырёх узлов:
И для пяти узлов:
Обратим внимание, что при чётных наиболее простые выражения получаются для производных в центральных узлах. Так для произвольного узла при и формулы выглядят следующим образом:
Эти формулы часто используются на практике и называются апроксимацией производных с помощью центральных разностей.
Аналогично можно получить выражения и для второй производной:
• в случае трёх узлов:
• в случае четырёх узлов:
• в случае пяти узлов:
Аппроксимации вторых производных с помощью центральных разностей для чётных так же наиболее выгодно.
Пример 9.2. Пусть функция задана на отрезке [0,1] с шагом 0,25 следующей таблицей:
0,0
0,25
0,5
0,75
1,0
1,0
1,284
1,649
2,117
2,718
Посчитать значения первой и второй производной, используя формулы для пяти точек.
Решение:
Значения первой производной считаем по формулам:
Значения второй производной:
Численное дифференцирование необходимо также при решении дифференциальных уравнений с помощью разностных методов. Если узлов много, т.е. точек разбиения интервала много, то погрешность функции неограниченно убывает, а погрешность производной неограниченно растёт. Чтобы уменьшить погрешность дифференцирования, предварительно сглаживают кривую, обычно по методу наименьших квадратов. Формулы численного дифференцирования позволяют решать и более сложные задачи, такие как определение экстремальных точек или точек перегиба функции , заданной таблично. В этом случае полагаем соответственно , и решаем полученные алгебраические уравнения. Однако при этом следует проявлять осторожность, т.к. указанным путём мы найдём экстремальные точки или точки перегиба не самой функции, а интерполирующего многочлена.
9.3. Вычисление M – той производной с помощью полинома Чебышева
Для вычисления производных высших порядков существует метод, который позволяет эффективно посчитать производную произвольного порядка на основе произвольного числа точек . Единственный недостаток метода – он требует специального выбора точек вычисления функции, а именно размещения их в корнях полинома Чебышева — ой степени.
Метод использует свойство дискретной ортогональности полиномов Чебышева: если – полином Чебышева — ой степени, – его корни, а , то
Таким образом, узнав значения функции в указанных точках, легко построить её разложение по полиномам Чебышева, которое легко и быстро дифференцируется.
Замечание:
Есть два способа для повышения точности вычисления производной. Можно уменьшать шаг дифференцирования , а можно увеличивать число точек . Не рекомендуется делать слишком малым, особенно для производных высших порядков – начинают проявляться погрешности операций с вещественными числами. В таких случаях лучше увеличить число точек , оставив шаг довольно-таки большим.
Замечание:
Следует быть осторожным при вычислении производных высших порядков. С ростом порядка производной растёт число точек, которое требуется для её вычисления. Если вы вычисляете десятую производную, то будьте готовы, что для её вычисления вам потребуется двадцать точек, а при меньшем их числе погрешность будет слишком велика.
class Program {
static double f( double x ) {
return (Math.Cos(x));
}
static void Main() {
double result = 0;
double x = 1.02;
int n = 5;
int m = 4;
double h = 0.1;
double[ ] c = new double[0];
double[ ] p = new double[0];
double b1 = 0;
double b2 = 0;
double e = 0;
if (n == 0)
result = 0;
else
if (n == 1)
if (m == 0)
result = f(x);
else
result = 0;
else {
double[ ] fk = new double[n + 1];
for (int k = 1; k <= n; k++)
fk[k] = f(x + h * f(Math.PI * (k — 0.5) / n));
double[ ] Z = new double[n];
for (int j = 0; j <= n — 1; j++) {
Z[j] = 0;
for (int k = 1; k <= n; k++)
Z[j] = Z[j] + fk[k] * f(Math.PI * j * (k — 0.5) / n);
if (j == 0)
Z[j] = Z[j] / n;
else
Z[j] = 2 * Z[j] / n;
}
p = new double[n];
for (int t = 0; t <= n — 1; t++)
p[t] = 0;
double d = 0;
int i = 0;
do {
int k = i;
do {
e = p[k];
p[k] = 0;
if (i <= 1 & k == i)
p[k] = 1;
else {
if (i != 0)
p[k] = 2 * d;
if (k > i + 1)
p[k] = p[k] — p[k — 2];
}
d = e;
k++;
} while (k <= n — 1);
d = p[i];
e = 0;
k = i;
while (k <= n — 1) {
e = e + p[k] * Z[k];
k = k + 2;
}
p[i] = e;
i++;
} while (i <= n — 1);
if (m > n — 1)
result = 0;
else {
result = p[m];
for (int t = 1; t <= m; t++)
result *= t / h;
}
}
Console.WriteLine(«{0}», result);
}
}
9.4. Дифференцирование сплайнов
Уже хорошо известные нам сплайны также хорошо пригодны для нахождения производной. Следующая программа демонстрирует использование построенного сплайна Эрмита для нахождения первой и второй производной функции в точке:
class Program {
static double[ ] ПостроениеСплайнаЭрмита( double[ ] x,
double[ ] y,
double[ ] d,
int n )
static void Main() {
int n = 5;
double[ ] X = new double[n];
double[ ] Y = new double[n];
double[ ] D = new double[n];
double Точка = 1.02;
if (n < 2) Console.WriteLine(» n < 2″);
else {
for (int i = 0; i < n; i++) {
X[i] = (i * Math.PI) / n;
Y[i] = Math.Cos(X[i]);
D[i] = -Math.Sin(X[i]);
}
double[ ] Z = ПостроениеСплайнаЭрмита(X, Y, D, n);
int l = 3;
int r = 3+n-2+1;
while (l != r — 1) {
int t = (l + r) / 2;
if (Z[t] >= Точка)
r = t;
else
l = t;
}
Точка = Точка — Z[l];
int m = 3 + n + 4 * (l — 3);
double Функция = Z[m] + Точка * (Z[m + 1] + Точка * (Z[m + 2] +
Точка * Z[m + 3]));
double ПерваяПроизводная = Z[m + 1] + 2 * Точка* Z[m + 2] + 3 *
Math.Sqrt(Точка) * Z[m + 3];
double ВтораяПроизводная = 2 * Z[m + 2] + 6 * Точка * Z[m + 3];
Console.WriteLine(«{0} t {1} t {2}», Функция, ПерваяПроизводная,
ВтораяПроизводная);
}
}
}
Лекция 10. Понятие численного интегрирования
10.1. Метод прямоугольников
Собственное значение определённого интеграла
находится методом прямоугольников. Отрезок разбивается на частей, , …, с шагом . На каждом отрезке вычисляется значения интеграла по формуле прямоугольников, таким образом:
Пример 10.1. Посчитать методом прямоугольников с шагом 0,1 значение .
Решение:
Построим сначала таблицу значений подынтегральной функции:
0,00
1,000
0,35
0,885
0,70
0,613
0,05
0,998
0,40
0,852
0,75
0,570
0,10
0,990
0,45
0,817
0,80
0,527
0,15
0,978
0,50
0,779
0,85
0,486
0,20
0,960
0,55
0,739
0,90
0,445
0,25
0,939
0,60
0,698
0,95
0,406
0,30
0,913
0,65
0,655
1,00
0,368
Если точность вычисления не устраивает, количество точек разбиения удваивается и считается новое значение. Программа, реализующая данный метод:
classProgram {
staticdoublef(doublex){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
int n = 1;
double result = 0;
double h = b — a;
double s1 = 0;
double s2 = h * f((a + b)/2);
do {
n = 2 * n;
s1 = s2;
h /= 2;
s2 = 0;
int i = 1;
do {
s2 = s2 + f(a + h/2 + h * (i-1));
i++;
} while( i <= n );
s2 = s2 * h;
} while( Math.Abs(s2 — s1) > 3 * epsilon );
result = s2;
Console.WriteLine(«{0}», result);
}
}
10.2. Квадратурные формулы Ньютона – Котеса
Пусть для данной функции требуется вычислить интеграл . Квадратурные формулы Ньютона – Котеса получаются тогда, когда подынтегральную функцию заменяют интерполяционной формулой Лагранжа, т.е. . Чтобы построить формулу Лагранжа, выбираем шаг и строим систему равноотстоящих точек,, .
Вычисляем и используем формулу:
,
где .
Сделаем замену переменных, изменив и пределы интегрирования получаем:
Подставляя , получаем квадратурные формулы Ньютона – Котеса:
,
где
Постоянные называются коэффициентами Котеса. Эти коэффициенты не зависят от функции , а являются функцией только от – степени интерполяционного многочлена. Поэтому коэффициенты Котеса можно вычислить заранее для различных значений , что и сделано, и сведено в справочную таблицу.
10.3. Формула трапеций и её погрешность
Формула трапеций получается из квадратурных формул Ньютона – Котеса при , т.е. степень интерполяционного многочлена, которым заменяют подынтегральную функцию, равна единице. Посчитав коэффициенты Котеса для получаем:
, ,
подставив которые и получаем формулу трапеций
.
Фактически, в этом случае площадь под кривой заменяется площадью трапеции, поэтому соответствующая формула численного интегрирования получила название формулы трапеций.
Остаточный член или погрешность формулы трапеции равен
Предположим, что функция имеет вторую производную на интервале . Будем рассматривать как функцию шага. Тогда можно записать:
.
Дифференцируя последнее выражение по последовательно два раза, получим:
.
Интегральная теорема о среднем
Если функция и непрерывны на и на сохраняет знак, т.е. на или на , то в интервале существует такое число , такое что
.
Интегрируя по и используя интегральную теорему о среднем, последовательно выводим:
,
где
,
где.
Таким образом.
Из последнего утверждения, в частности, следует, что если то формула трапеции даёт значение интеграла с недостатком, в противном случае – с избытком. Сказанное проиллюстрировано на рисунках ниже.
Погрешность формулы трапеции обычно бывает очень велика. Эту погрешность можно значительно снизить, если применять формулу трапеций не сразу ко всему отрезку , а разбить его сначала и к каждой части в отдельности применять формулу трапеции. Если разбить отрезок на равных частей длины , обозначив через , ,…, последовательные ординаты, то получим обобщенную формулу трапеции:
Для уменьшения времени, затрачиваемого на вычисления в алгоритме при получении , используется формула:
Пример 10.2. Посчитать методом трапеций с шагом 0,1 значение .
Решение:
Воспользуемся таблицей значений подынтегральной функции примера 10.1
Если точность вычисление не устраивает можно удвоить количество узлов и повторить вычисления. Программа, реализующая данный метод:
classProgram {
staticdoublef(doublex){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
int n = 1;
double result = 0;
double h = b — a;
double s2 = h * (f(a) + f(b))/2;
double s1;
do {
s1 = s2;
s2 = 0;
int i = 1;
do {
s2 = s2 + f(a — h/2 + h * i);
i++;
} while( i <= n );
s2 = s1/2 + s2 * h/2;
n = 2 * n;
h = h / 2;
} while( Math.Abs(s2 — s1) > 3 * epsilon );
result = s2;
Console.WriteLine(«{0}», result);
}
}
10.4. Формула Симпсона и её погрешность
Формула Симпсона получается из квадратурных формул Ньютона – Котеса при , т.е. интерполяционный многочлен, которым заменяют подынтегральную функцию, многочлен второго порядка.
,
,
.
Подставив которые и получаем формулу Cимпсона.
Геометрически формула Симпсона получается в результате замены кривой параболой , проходящей через точки: , , .
Погрешность формулы Симпсона вычисляется из соображений
.
Предположим, что функция имеет четвёртую производную на . Аналогично тому, как это делалось для формулы трапеций, выведем более простое выражение для. Фиксируем среднюю точку и рассматриваем как функцию шага, будем иметь
.
Дифференцируя функциюпопоследовательно три раза, получим:
.
.
Теорема о среднем: Если функция непрерывна на и дифференцируема на , то в интервале существует такое число, что.
Применяя простую теорему о среднем для функции на получаем:, где . Кроме того, имеем:. Последовательно интегрируя и используя интегральную теорему о среднем, находим:
.
.
.
Где . Таким образом, окончательно имеем .
Из последней формулы видно, что она является точной для многочленов не только второй, но и третьей степени, т.е. формула Симпсона при относительно малом числе ординат обладает повышенной точностью.
Формула Симпсона также может быть применена не сразу ко всему отрезку, а к отдельным частям его. Если разобьём на равных частей c шагом , то получим обобщённую формулу Симпсона:
Введём обозначения: , .
Обобщённая формула Симпсона запишется в новых обозначениях так:
Пример 10.3. Посчитать методом Симпсона с шагом 0,1 значение .
Решение:
Воспользуемся таблицей значений подынтегральной функции примера 10.1
0,00
1,000
0,35
0,885
0,70
0,613
0,05
0,998
0,40
0,852
0,75
0,570
0,10
0,990
0,45
0,817
0,80
0,527
0,15
0,978
0,50
0,779
0,85
0,486
0,20
0,960
0,55
0,739
0,90
0,445
0,25
0,939
0,60
0,698
0,95
0,406
0,30
0,913
0,65
0,655
1,00
0,368
Если точность вычисление не устраивает можно удвоить количество узлов и повторить вычисления. Программа, реализующая данный метод:
classProgram {
staticdoublef( doublex ) {
return (Math.Exp(-Math.Pow(x, 2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
const double epsilon = 0.01;
double result = 0.0;
double h = b — a;
double x = 0.0;
double s1 = 0.0;
double s = 0.0;
double s2 = h * f((a + b) / 2);
double s3 = 0.0;
do {
s3 = s2;
h /= 2;
s1 = 0;
x = a + h;
do {
s1 = s1 + 2 * f(x);
x = x + 2 * h;
} while (x < b);
s = s + s1;
s2 = (s + s1) * h / 3;
x = Math.Abs(s3 — s2) / 15;
} while (x > epsilon);
result = s2;
Console.WriteLine(«{0}», result);
}
10.5. Погрешность формул Ньютона – Котеса
При вычислении приближённого значения интеграла допускается погрешность, которая зависит от шага разбиения и может быть представлена как . Трудно сравнить достоинства и недостатки различных методов интегрирования. Сравнение их точности ставит закономерный вопрос: «Что больше или ». Это зависит от подынтегральной функции и поведения её производных.
При изложении методов интегрирования, упоминался самый примитивный способ уточнения значений: удваивание количества точек разбиения.
Следует упомянуть другую схему уточнения значения интеграла – процесс Эйткена. Он даёт возможность оценить погрешность метода и указывает алгоритм уточнения результатов. Расчёт проводится три раза при различных значениях шага разбиения , и , таких что и в результате получены значения интегралов , и . Тогда уточнённое значение интеграла вычисляется по формуле:
.
Порядок точности используемого метода интегрирования оценивается соотношением
Лекция 11. Квадратурные формулы интегрирования
11.1. Квадратурные формулы Чебышева
Рассмотрим квадратурную формулу
где – постоянные коэффициенты. Чебышев предложил выбирать абсциссы таким образом, чтобы:
1) коэффициенты были равны между собой;
2) квадратурная формула являлась точной для всех полиномов до степени включительно.
Покажем, как могут быть найдены в этом случае величины и . Полагая , взяв, получаем:
. , следовательно .
Таким образом, квадратурная формула Чебышева имеет вид:
Для определения используем требование точности формулы для функций вида: . Подставляя эти функции в формулу, получим систему уравнений:
Из которой могут быть определены неизвестные .
Чебышев показал, что решение данной системы сводится к нахождению корней некоторого алгебраического уравнения — той степени. Узлы являются действительными при . При и среди узлов всегда имеются комплексные. В этом состоит принципиальный недостаток квадратурной формулы Чебышева. Свою формулу Чебышев П.Л. вывел в 1873 году.
Пример 11.1. Вывести формулу Чебышева с тремя ординатами .
Решение. Для определения имеем систему уравнений.
Определение. Многочлен называется симметрическим, если для любого множества значений значение этого многочлена не изменяется при какой угодно перестановки .
Элементарными симметрическими функциями от называются многочлены определяемые следующим образом:
. . . . . . . .
Каждый симметрический многочлен относительно может быть единственным образом записан, как многочлен относительно . Например, для квадратного многочлена, если и , то корни уравнения .
Так как в примере , то есть корни вспомогательного уравнения
,
Где симметрические функции корней:
.
.
.
Из первоначальной системы видно, что . Вычислим , для этого рассмотрим
.
Из последнего выражения находим.
.
Для нахождения рассмотрим
.
Отсюда находим
В результате получаем, что есть корни вспомогательного уравнения:
.
Решая его, находим: , , .
Таким образом, в данном случае формула Чебышева принимает вид:
.
Чтобы применить квадратурную формулу Чебышева к интегралу вида , следует сделать замену переменных , которая переводит отрезок в отрезок . Применяя к преобразованному интегралу формулу Чебышева, будем иметь:
где , .
Значения в формуле Чебышева для некоторых значений приведены в таблице.
2
1; 2
3
1; 3
2
4
1;4
2;3
5
1; 5
2; 4
3
Пример 11.2. Посчитать значение с использованием формулы Чебышева для .
Решение:
Вычисления удобно представить в следующей таблице:
1
-0,794654
2,2053
0,00772
2
-0,187592
2,8124
0,00037
3
0,187592
3,1876
0,00004
4
0,794654
3,7947
0,0000006
0,00813
Программная реализация этого метода может выглядеть следующим образом:
namespace МетодЧебышева {
class Program {
static double f(double x){
return (Math.Exp(Math.Pow(x,2)));
}
static void Main() {
const double a = 1.345;
const double b = 2.150;
double result = 0;
double s = 0.5 * (b + a);
double c = 0.5 * (b — a);
double t = 0;
int n = int.Parse(Console.ReadLine());
switch (n){
case 2:
t = Math.Sqrt(3)/3;
result = f(s + c * t) + f(s — c * t);
result *=(b — a)/2;
break;
case 3:
t = Math.Sqrt(2)/2;
result = f(s + c * t) + f(s)+f(s — c * t);
result *=(b — a)/3;
break;
case 4:
t = Math.Sqrt((Math.Sqrt(5) — 2)/(3 * Math.Sqrt(5)));
result = f(s + c * t)+f(s — c * t);
t = Math.Sqrt((Math.Sqrt(5) + 2)/(3*Math.Sqrt(5)));
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/4;
break;
case 5:
result = f(s);
t = 0.5 * Math.Sqrt((5 — Math.Sqrt(11))/3);
result = result + f(s + c * t) + f(s — c * t);
t = 0.5 * Math.Sqrt((5 + Math.Sqrt(11))/3);
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/5;
break;
case 6:
result = 0;
t = 0.866247;
result = result + f(s + c * t) + f(s — c * t);
t = 0.422519;
result +=f(s + c * t) + f(s — c * t);
t = 0.266635;
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/6;
break;
case 7:
result = f(s);
t = 0.883862;
result = result + f(s + c * t) + f(s — c * t);
t = 0.529657;
result += f(s + c * t) + f(s — c * t);
t = 0.323912;
result +=f(s + c * t) + f(s — c * t);
result *=(b — a)/7;
break;
case 9:
result = f(s);
t = 0.911589;
result +=f(s + c * t) + f(s — c * t);
t = 0.601019;
result += f(s + c * t) + f(s — c * t);
t = 0.528762;
result +=f(s + c * t) + f(s — c * t);
t = 0.167906;
result += f(s + c * t) + f(s — c * t);
result *= (b — a)/9;
break;
default:
result = 0;
break;
}
Console.WriteLine(«{0}», result);
}
}
}
11.2. Квадратурная формула Гаусса
За счёт выбора узлов можно получить квадратурные формулы, которые будут точны для алгебраического многочлена степени . В этом разделе нам потребуются некоторые сведения о полиномах Лежандра.
Определение. Полиномы вида , называются полиномами Лежандра.
Отметим важнейшие свойства полиномов Лежандра:
1). .
2). , где – любой многочлен степени , меньшей (свойство ортогональности).
3). Многочлен Лежандра имеет различных действительных корней, которые расположены на интервале .
Выпишем первые пять полиномов Лежандра:
.
.
.
.
.
Озвучив необходимую вспомогательную информацию, переходим к выводу квадратурной формулы Гаусса.
Рассмотрим функцию , заданную на промежутке . Общий случай легко свести к данному, путём линейной замены независимой переменной.
Поставим задачу: как нужно подобрать точки и коэффициенты , чтобы квадратурная формула была бы точной для всех полиномов наивысшей возможной степени .
Так как имеется постоянных и , а полином степени определяется константами, то эта наивысшая степень в общем случае, очевидно, равна . Для обеспечения равенства необходимо и достаточно, чтобы оно было верным при .
Полагая
и ,
будем иметь:
меняем порядок суммирования
.
Таким образом, учитывая соотношения:
для решения поставленной задачи достаточно определить и из системы уравнений.
Система является нелинейной и её решение обычным путём представляет большие математические трудности. Однако здесь можно применить следующий искусственный приём. Рассмотрим полиномы
Где – полином Лежандра. Так как степени этих полиномов не превышают , то на основании системы для них должна быть справедлива формула.
С другой стороны, в силу свойства ортогональности полиномов Лежандра (свойство 2) выполнимы равенства
поэтому
Равенства заведомо будут обеспечены при любых значениях , если положить .
Т.е. для достижения наивысшей точности квадратурной формулы в качестве точек достаточно взять нули соответствующего полинома Лежандра. Как известно (свойство 3), эти нули – корни действительны, различны и расположены на интервале .
Зная величины легко можно найти из линейной системы первых уравнений системы коэффициенты . Определитель этой подсистемы есть определитель Вандермонда , и, следовательно, определяются однозначно.
Формула , где – корни полинома Лежандра и определяются из системы, называется квадратурной формулой Гаусса.
Пример 11.2. Вывести квадратурную формулу Гаусса для случая трёх ординат .
Решение. Полином Лежандра 3 — й степени есть
.
приравниваем его нулю, находим корни.
Для определения коэффициентов из системы имеем:
Находим . Следовательно,
.
Значения и в формуле Гаусса для некоторых значений приведены в таблице.
1
1
2
2
1;2
1
3
1;3
2
4
1;4
2;3
Неудобство применения квадратурной формулы Гаусса состоит в том, что абсциссы точек и коэффициенты – вообще говоря, иррациональные числа. Этот недостаток отчасти искупается её высокой точностью при сравнительно малом числе ординат.
Рассмотрим теперь использование квадратурной формулы Гаусса для вычисления общего интеграла . Делая замену , получим:
.
Применяя к последнему интегралу квадратурную формулу Гаусса будем иметь:
,
где
— корни полинома Лежандра , т. е. .
Погрешность формулы Гаусса с узлами выражается следующей формулой:
.
Например
.
.
Пример 11.4. Найти значение интеграла используя квадратурную формулу Гаусса для .
Решение:
В данном случае
Для
Для
Для
Программная реализация этого метода может выглядеть следующим образом:
using System;
namespace МетодГауссаЛежандра {
class Program {
const double Epsilon = 0.001;
static double f( double x ) {
return (Math.Pow(Math.Cos(x),2));
}
static void ПересчетКоэффициентов( double a,
double b,
int n,
ref double[ ] x,
ref double[ ] w ) {
for (int i = 0; i <= n — 1; i++) {
x[i] = 0.5 * (x[i] + 1) * (b — a) + a;
w[i] = 0.5 * w[i] * (b — a);
}
}
static void ПостроениеМногочлена(int n,
ref double[ ] x,
ref double[ ] w ) {
double r = 0;
double r1 = 0;
double p1 = 0;
double p2 = 0;
double p3 = 0;
double dp3 = 0;
x = new double[n];
w = new double[n];
for (int i = 0; i <= (n + 1) / 2 — 1; i++) {
r = Math.Cos(Math.PI * (4 * i + 3) / (4 * n + 2));
do {
p2 = 0;
p3 = 1;
for (int j = 0; j <= n — 1; j++) {
p1 = p2;
p2 = p3;
p3 = ((2 * j + 1) * r * p2 — j * p1) / (j + 1);
}
dp3 = n * (r * p3 — p2) / (r * r — 1);
r1 = r;
r = r — p3 / dp3;
} while (Math.Abs(r — r1) >= Epsilon * (1 + Math.Abs(r)) * 100);
x[i] = r;
x[n — 1 — i] = -r;
w[i] = 2 / ((1 — r * r) * dp3 * dp3);
w[n — 1 — i] = 2 / ((1 — r * r) * dp3 * dp3);
}
}
static void Main( string[ ] args ) {
double a = -1;
double b = 1;
double[ ] x = new double[0];
double[ ] w = new double[0];
int n = 10;
double v1 = 0;
double v2 = 0;
double h = b — a;
double s = f(a) + f(b);
double s1 = 0;
double s2 = 1;
double s3 = 0;
double tx = 0;
int simpfunccalls = 2;
double nodedist = 0;
double nodesectstart = 0;
double nodesectend = 0;
double tmp = 0;
do {
s3 = s2;
h = h / 2;
s1 = 0;
tx = a + h;
do {
s1 = s1 + 2 * f(tx);
simpfunccalls = simpfunccalls + 1;
tx = tx + 2 * h;
} while (tx < b);
s = s + s1;
s2 = (s + s1) * h / 3;
tx = Math.Abs(s3 — s2) / 15;
} while (tx > Epsilon);
v1 = s2;
v2 = 0;
for (int i = 0; i <= n — 1; i++)
v2 = v2 + w[i] * f(x[i]);
a = 5.2;
b = 9.6;
v1 = 0;
simpfunccalls = 2;
s2 = 1;
h = b — a;
s = f(a) + f(b);
do {
s3 = s2;
h = h / 2;
s1 = 0;
tx = a + h;
do {
s1 = s1 + 2 * f(tx);
simpfunccalls = simpfunccalls + 1;
tx = tx + 2 * h;
}
while (tx < b);
s = s + s1;
s2 = (s + s1) * h / 3;
tx = Math.Abs(s3 — s2) / 15;
}
while (tx > Epsilon);
v1 = s2;
ПостроениеМногочлена(n, ref x, ref w);
ПересчетКоэффициентов(a, b, n, ref x, ref w);
v2 = 0;
for (int i = 0; i <= n — 1; i++) {
v2 = v2 + w[i] * f(x[i]);
}
n = 56;
ПостроениеМногочлена(n, ref x, ref w);
for (int i = 0; i <= n — 1; i++) {
for (int j = 0; j <= n — 2 — i; j++) {
if (x[j] >= x[j + 1]) {
tmp = x[j];
x[j] = x[j + 1];
x[j + 1] = tmp;
tmp = w[j];
w[j] = w[j + 1];
w[j + 1] = tmp;
}
}
}
for (int i = 0; i <= 4; i++) {
nodedist = x[n — 1] — x[0];
nodesectstart = nodedist * (0.2 * i — 0.5);
nodesectend = nodedist * (0.2 * (i + 1) — 0.5);
for (int j = 0; j <= n — 2; j++) {
if (x[j] >= nodesectstart & x[j] <= nodesectend | x[j + 1] >=
nodesectstart & x[j + 1] <= nodesectend) {
if (nodedist > x[j + 1] — x[j]) {
nodedist = x[j + 1] — x[j];
}
}
}
}
for (int i = 0; i <= 4; i++) {
tmp = x[n — 1] — x[0];
nodesectstart = tmp * (0.2 * i — 0.5);
nodesectend = tmp * (0.2 * (i + 1) — 0.5);
nodedist = 0;
for (int j = 0; j <= n — 1; j++) {
if (x[j] >= nodesectstart & x[j] <= nodesectend) {
if (nodedist < Math.Abs(w[j])) {
nodedist = Math.Abs(w[j]);
}
}
}
}
}
}
}
11.3. Некоторые замечания о применении квадратурных формул
Получен ряд квадратурных формул. Естественно возникает вопрос: какую квадратурную формулу целесообразно применять в том или ином случае? Ответ на этот вопрос зависит от ряда обстоятельств: от способа задания, свойств и поведения подынтегральной функции, от требуемой точности, с которой нужно получить приближённое значение интеграла. Если подынтегральная функция задана таблицей значений, то целесообразно использовать квадратурные формулы с узлами, в которых заданы значения функции.
Весьма существенно учесть свойства функции и её поведение на отрезке интегрирования. Если функция имеет малую гладкость, то нет смысла применять квадратурные формулы, погрешности которых содержат производные более высокого порядка, чем порядок имеющихся у функции производных. Так, например, для использования формулы трапеций подынтегральная функция должна принадлежать классу , формула Симпсона применима для функции, принадлежащей классу .
Как уже говорилось, постоянные Котеса зависят только от – степени интерполяционного многочлена. Они сосчитаны и сведены в таблицы. Так, например, если многочлен степени , то имеем:
Наиболее точной из рассмотренных квадратурных формул является формула Гаусса, которая при точках деления промежутка интегрирования обеспечивает совершенно точные результаты для многочлена — ой степени. Точки деления в формуле Гаусса берут уже не на равных расстояниях одна от другой. На практике также широко применяются квадратурная формула Чебышева, в которой точки деления (также неравномерные) выбраны так, чтобы вес всех значений был одним и тем же. Благодаря этой особенности формула Чебышева даёт наиболее обоснованные результаты при вычислении интегралов от функции , найденной экспериментально, когда вероятность погрешности каждого измерения одна и та же. Действительно, в этом случае нет никаких оснований различным значениям приписывать различные веса, как, например, в формуле Симпсона, где первое и последнее значения берутся с весом 1, все промежуточные значения с нечётными индексами – с весом 4, а с чётными индексами — с весом 2. Когда речь идёт о точности той или другой квадратурной формулы, то это понятие довольно условное, так как всегда можно выбрать надлежащим образом значение , получить результат с какой угодно степенью точности. Поэтому нельзя не согласиться со словами французского математика П.Лорана, что «эти формулы дают числовое значение искомого интеграла с точностью, которая главным образом зависит от терпения вычислителя».
Лекция 12. Решение нелинейных уравнений
12.1. Постановка задачи
Пусть задана непрерывная функция и требуется найти один или все корни уравнения .
Во-первых, надо исследовать количество, характер и расположение корней. Во-вторых, найти приближённое значение корней, выбрать интересующие нас корни и вычислить их с необходимой точностью.
Первая задача решается аналитически и графически. Например, многочлен имеет комплексных корней, и все корни лежат внутри круга, радиуса
Правда, эта оценка не оптимальная, и модули всех корней могут быть значительно меньше данной величины.
Когда ищутся только действительные корни, бывает полезно составить таблицу значений многочлена с некоторым шагом. Если в соседних узлах этой решетки значение функции меняет знак, то на данном участке обязательно имеется корень многочлена.
12.2.Метод дихотомии
Пусть, мы нашли такие точки , что , т.е. на отрезке лежит не менее одного корня уравнения. Найдём середину отрезка и вычислим значение функции в этой точке. Из двух половин отрезка выберем тот, для которого сохраняется условие разных знаков. Затем новый отрезок опять делим пополам и т.д. С помощью этого простого и надёжного метода, для любых непрерывных функций , в том числе недифференцируемых можно с любой наперёд заданной точностью найти корень уравнения. Данный метод устойчив к ошибкам округления. При этом невелика скорость сходимости, но сходимость гарантирована. Опишем недостатки метода:
• требуется найти интервал , если на этом отрезке несколько корней, то заранее неизвестно к какому из них метод сойдётся;
• метод неприменим к корням чётной кратности;
• для корней нечётной высокой кратности он сходится, но менее точен и хуже устойчив к ошибкам округления;
• на системы уравнения дихотомия не распространяется.
Недостаток дихотомии – сходимость неизвестно к какому корню (общий почти для всех итерационных методов) можно устранить удалением уже найденного корня. Если – простой корень уравнения , то функция непрерывна, при чём все нули функции и совпадают кроме корня , который не является корнем уравнения .
Т.о. на втором этапе мы ищем корни уравнения , и найдя один из корней снова удаляем его, получая новую функцию.
Поскольку мы находим лишь приближённое значение корня, то, учитывая возможность близкого расположения различных корней, необходимо вычислять удаляемые корни с очень высокой степенью точности. При этом в любом методе окончательные итерации вблизи определяемого корня рекомендуется делать по функции .
Пример 12.1. Найти на интервале [1; 1,5] решение уравнения с помощью метода дихотомии с точностью 0,01.
Решение:
№ итерации
1
1,0
1,5
0,205
-0.043
0,5
1,25
0,035
2
1,25
1,5
0,035
-0.043
0,25
1,375
-0,020
3
1,25
1,375
0,035
-0,020
0,125
1,313
0,020
4
1,313
1,375
0,020
-0,020
0,062
1,344
-0,01
5
1,313
1,344
0,020
-0,01
0,031
1,329
-0,004
6
1,313
1,329
0,020
-0,004
0,016
1,321
-0,001
7
1,313
1,321
0,020
-0,001
0,008
1,317
0,0005
Программа, реализующая данный метод:
class Program {
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double a = 1.0;
double b = 1.5;
double Eps = 0.00001;
double x, fa, fb, fx;
while (Math.Abc(b — a) > Eps){
x = (a + b )/2;
fa = f(a);
fb = f(b);
fx = f(x);
if (fa * fx < 0)
b = x;
else
a = x;
}
x = (a + b)/2;
Console.WriteLine(«{0}», x);
}
}
12.3. Метод секущих — хорд
Если на интервале непрерывная функция удовлетворяет условию , то корень уравнения может быть найден методом секущих:
Погрешность значения корня оценивается по формуле .
Пример 12.2. Найти на интервале [1; 1,5] решение уравнения с помощью метода секущих-хорд с точностью 0,01.
Решение:
2
1,0
1,5
0,205
-0.043
1,414
0,086
3
1,5
1,414
-0.043
-0.030
1,202
0,212
4
1,414
1,202
-0.030
0,058
1,341
0,139
5
1,202
1,341
0,058
-0,009
1,323
0,018
6
1,341
1,323
-0,009
-0,002
1,318
0,005
7
1,323
1,318
-0,002
0,00005
1,318
Программа, реализующая данный метод:
class Program {
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double Eps = 0.00001;
double x1 = 1.0;
double x2 = 1.5;
double x;
double x3 = 0;
while( Math.Abs(x1 — x2) > Eps){
x3 = x2 — f(x2)*(x2 — x1)/(f(x2) — f(x1));
x1 = x2;
x2 = x3;
}
x = x2;
Console.WriteLine(«{0}», x);
}
}
12.4. Метод Риддлера
Метод Риддлера применяется для поиска корней на отрезке , на котором функция меняет свой знак, т.е. . Метод прост в реализации, не требует знания производной функции и с некоторого шага удваивает число значащих цифр результата за каждые два вычисления функции, т.е. скорость сходимости квадратичная.
Пусть , , , , , .
Тогда ,
Перейдём к следующему шагу метода. Если , то полагаем , . В противном случае за берём тот из отрезков , на котором функция меняет знак.
Алгоритм останавливает работу, если достигнута заданная точность или выполнено указанное число итераций.
Пример 12.3. Найти на интервале [1; 1,5] решение уравнения с помощью метода Риддлера с точностью 0,01.
Решение:
№ итерации
1
1,0
1,5
1,25
0,205
-0.043
0,031
1,33
-0,005
2
1,25
1,33
1,29
0,031
-0,005
0,012
1,318
-0,0003
Программа, реализующая данный метод:
class Program {
const int itmax = 100;
const double epsilon = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double x3, x4, f1, f2, f3, f4;
double x = 0;
double x1 = 1.0;
double x2 = 1.5;
f1 = f(x1);
f2 = f(x2);
if( f1 * f2 >= 0 )
Console.WriteLine(«Неверно задан интервал»);
else{
int i = 1;
do {
if( Math.Abs(x2 — x1) < epsilon ){
if( Math.Abs(f1) > Math.Abs(f2) )
x = x1;
else
x = x2;
break;
}
else {
x3 = 0.5*(x1 + x2);
f3 = f(x3);
x4 = x3 + (x3 — x1) * Math.Sign(f1 — f2) * f3/Math.Sqrt(f3 * f3 –f1
* f2);
f4 = f(x4);
i++;
if( f3 * f4 <= 0 ){
x1 = x3;
f1 = f3;
x2 = x4;
f2 = f4;
}
else {
if(f1 * f4 <= 0){
x2 = x4;
f2 = f4;
}
else {
x1 = x4;
f1 = f4;
}
}
}
} while (i < itmax);
Console.WriteLine(«{0}», x);
}
}
12.5. Метод касательных (Ньютона)
Обычно начинают с нахождения грубого приближённого решения «нулевого приближения». Если решается физическая задача, то такое приближение часто известно из физического смысла задачи. Пусть это решение . Обозначим точное решение (нам ещё неизвестное) через и, пользуясь формулой Тейлора, получим
В силу постановки задачи, левая часть этого равенства должна быть равна 0, отбросим все члены высшего порядка малости и получим
, следовательно .
Обозначим правую часть через и получим первое приближение. Точно также можно получить второе, третье и т.д. приближение
Т.к. отбрасывание членов высокого порядка малости равносильно замене графика функции на касательную в точке , то геометрический смысл метода состоит в последовательном построении касательных к графику и нахождении пересечения этих касательных с осью .
Пример 12.4. Найти на интервале [1; 1,5] решение уравнения с помощью метода Ньютона с точностью 0,01.
Решение:
№ итерации
1
1
0,205
-0,839
1,245
2
1,245
0,034
-0,528
1,31
3
1,31
0,003
-0,419
1,318
class Program {
const double Eps = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static double dfdx(double x){
double sin = Math.Sin(x);
return(-2 * Math.Cos(x) * sin + sin/12);
}
static void Main() {
double x1 = 1;
double x = x1;
double a = f(x)/dfdx(x);
while(Math.Abs(a) > Eps){
x -= a;
a = f(x)/dfdx(x);
}
Console.WriteLine(«{0}», x);
}
}
12.6. Метод Ньютона с аппроксимацией производной
Если вычисление производной в методе Ньютона затруднено, можно заменить её вычисление оценкой.
class Program {
const double Eps = 0.00001;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double x = 1;
double h = 0.0001;
double fx = f(x);
double y = fx * h/(f(x + h) — fx);
while(Math.Abs(y) > Eps){
x = x — y;
fx = f(x);
y = fx * h/(f(x + h) — fx);
}
Console.WriteLine(«{0}», x);
}
}
12.7. Метод Брента
Метод Брента – метод поиска корней, окружённых на интервале (это значит, что ). Он сочетает в себе высокую скорость сходимости метода Риддлера с надёжностью метода дихотомии. В то время, как метод Риддлера быстр, но может очень сильно замедлиться на какой-нибудь сложной функции, скорость работы дихотомии не столь высока, но не зависит от обрабатываемой функции. Метод Брента сочетает в себе одновременно два подхода – на «хороших» функциях используется трёхточечная интерполяционная схема, дающая квадратичную скорость сходимости, а в случае слишком низкой скорости работы «продвинутого» подхода (или расходимости) используется деление отрезка на две части.
using System;
namespace МетодБрента {
class Program {
const double Eps = 0.00001;
const int itmax = 100;
static double f(double x){
return(Math.Pow(Math.Cos(x),2) — Math.Cos(x)/12 — 1/24);
}
static void Main() {
double a = 1.0;
double b = 1.5;
double fa = f(a);
double fb = f(b);
double fc = fb;
double x = 0.0;
double c = 0, d = 0, e = 0.0;
double min1, min2, min0;
double p, q, r, s;
double tol1, xm, iter = 1;
bool hasroot = false;
do {
if( fb * fc > 0 ){
c = a;
fc = fa;
d = b — a;
e = d;
}
if( Math.Abs(fc) < Math.Abs(fb) ){
a = b;
b = c;
c = a;
fa = fb;
fb = fc;
fc = fa;
}
tol1 = 2 * Eps * Math.Abs(b) + 0.5 * Eps;
xm = 0.5 * (c — b);
if( Math.Abs(xm) <= tol1 | fb == 0 ){
x = b;
hasroot = true;
break;
}
if(Math.Abs(fa) > Math.Abs(fb) ) {
s = fb / fa;
if(a == c) {
p = 2.0 * xm * s;
q = 1.0 — s;
}
else {
q = fa / fc;
r = fb / fc;
p = s * (2.0 * xm * q * (q — r) — (b — a) * (r — 1.0));
q = (q — 1.0) * (r — 1.0) * (s — 1.0);
}
if(p > 0)
q = -q;
p = Math.Abs(p);
min1 = 3 * xm * q — Math.Abs(tol1 * q);
min2 = Math.Abs(e * q);
if(min1 < min2)
min0 = min1;
else
min0 = min2;
if(2 * p < min0 ){
e = d;
d = p/q;
}
else {
d = xm;
e = d;
}
}
else {
d = xm;
e = d;
}
a = b;
fa = fb;
if( Math.Abs(d) > tol1 )
b = b + d;
else
if( xm > 0 )
b = b + Math.Abs(tol1);
else
b = b — Math.Abs(tol1);
fb = f(b);
iter++;
} while (iter <= itmax);
if (hasroot)
Console.WriteLine(«{0}», x);
else
Console.WriteLine(«Корень не найден»);
}
}
}
12.8. Безопасный метод Ньютона
Этот метод является аналогом метода Брента для случая, когда известна производная функции . Сочетая в себе гарантированную сходимость метода дихотомии с высокой скоростью сходимости обычного метода Ньютона, он требует не только знания производной функции, но и отрезка, на концах которого функция имеет разные знаки.
Сначала метод делает шаг по правилу Ньютона. Если сделанный шаг не укладывается в указанный отрезок или же сходимость слишком низкая, то делается один шаг метода дихотомии. Затем процесс повторяется.
using System;
namespace МетодБезопасныйНьютона {
class Program {
const int itmax = 100;
const double Eps = 0.00001;
static double f( double x ) {
return (Math.Pow(Math.Cos(x), 2) — Math.Cos(x) / 12 — 1 / 24);
}
static double dff( double x ) {
double sin = Math.Sin(x);
return (-2 * Math.Cos(x) * sin + sin / 12);
}
static void Main() {
double x1 = 1.0;
double x2 = 1.5;
double f0 = 0;
double xh = 0;
double xl = 0;
double root = 0;
bool hasroot = false;
double fl = f(x1);
double fh = f(x2);
double df = dff(xh);
if (fl * fh < 0) {
if (fl < 0) {
xl = x1;
xh = x2;
}
else {
xh = x1;
xl = x2;
double swap = fl;
fl = fh;
fh = swap;
}
double rts = 0.5 * (x1 + x2);
double dxold = Math.Abs(x2 — x1);
double dx = dxold;
f0 = f(rts);
df = dff(rts);
int j = 1;
while (j <= itmax) {
if (((rts — xh) * df — f0) * ((rts — xl) * df — f0) >= 0 |
Math.Abs(2 * f0) > Math.Abs(dxold * df)) {
dxold = dx;
dx = 0.5 * (xh — xl);
rts = xl + dx;
if (xl == rts) {
root = rts;
hasroot = true;
break;
}
}
else {
dxold = dx;
dx = f0 / df;
double temp = rts;
rts = rts — dx;
if (temp == rts) {
root = rts;
hasroot = true;
break;
}
}
if (Math.Abs(dx) < Eps) {
root = rts;
hasroot = true;
break;
}
f0 = f(rts);
df = dff(rts);
j++;
if (f0 < 0) {
xl = rts;
fl = f0;
}
else {
xh = rts;
fh = f0;
}
}
}
if (hasroot)
Console.WriteLine(«{0}», root);
else
Console.WriteLine(«Корни не найдены»);
}
}
}
}
Лекция 13. Решение систем нелинейных уравнений
В задачах проектирования и исследования поведения реальных объектов, процессов и систем (ОПС) математические модели должны отображать реальные физические нелинейные процессы. При этом эти процессы зависят, как правило, от многих переменных. В результате математические модели реальных ОПС описываются системами нелинейных уравнений.
Дана система нелинейных уравнений
Или
Необходимо решить эту систему, т.е. найти вектор , удовлетворяющий систему уравнений с точностью .
Вектор определяет точку в — мерном Евклидовом пространстве, т.е. принадлежит этому пространству и удовлетворяет всем уравнениям системы.
В отличие от систем линейных уравнений для систем нелинейных уравнений неизвестны прямые методы решения. При решении систем нелинейных уравнений используются итерационные методы. Эффективность всех итерационных методов зависит от выбора начального приближения (начальной точки), т.е. вектора .
Область, в которой начальное приближение сходится к искомому решению, называется областью сходимости . Если начальное приближение лежит за пределами , то решение системы получить не удаётся.
Выбор начальной точки во многом определяется интуицией и опытом специалиста.
13.1. Метод простых итераций
Для применения этого метода исходная система должна быть преобразована к виду
Или
Далее, выбрав начальное приближение и используя преобразованную систему, строим итерационный процесс поиска по схеме:
т.е. на — ом шаге поиска вектор переменных находим, используя значения переменных, полученных на шаге.
Итерационный процесс поиска прекращается, как только выполнится условие
Метод простых итераций используется для решения таких систем линейных уравнений, в которых выполняется условие сходимости итерационного процесса поиска, а именно:
т.е. сумма абсолютных величин частных производных всех преобразованных уравнений преобразованной системы по — ой переменной меньше единицы.
Пример 13.1. Дана система нелинейных уравнений:
Необходимо определить область сходимости системы, выбрать начальную точку и найти одно из решений системы.
Строим графики уравнений:
Преобразуем систему для решения методом итераций
Проверяем условие сходимости. Для заданной системы оно имеет вид:
Находим:
В результате условие сходимости будет иметь вид:
Определяем область сходимости .
Граница области сходимости определится при решении системы:
Отсюда
В результате область сходимости определится при и
На графике уравнений строим область сходимости :
Выбираем начальную точку , принадлежащую области сходимости . Используя выбранную начальную точку решаем заданную систему нелинейных уравнений.
Текст программы, реализующей данный метод приведён ниже:
using System;
namespace НелинейныеСистемыМетодИтераций {
class Program {
const double Eps = 0.00001;
static void f(double[] СтароеЗначение, out double[] НовоеЗначение) {
НовоеЗначение = new double[2];
НовоеЗначение[0] = Math.Sqrt(1 — СтароеЗначение[1]);
НовоеЗначение[1] = -0.5 — 0.5 * Math.Log(СтароеЗначение[0]);
}
static void Main( string[ ] args ) {
double[ ] СтароеЗначение = { 0.8, -0.6 };
double[ ] НовоеЗначение;
bool Продолжать = true;
while (Продолжать) {
f(СтароеЗначение, out НовоеЗначение );
Продолжать = false;
for (int i = 0; i < 2; i++)
if (Math.Abs(НовоеЗначение[i] — СтароеЗначение[i]) > Eps)
Продолжать = true;
for (int i = 0; i < 2; i++)
СтароеЗначение[i] = НовоеЗначение[i];
}
for (int i = 0; i < 2; i++)
Console.WriteLine(«{0}», СтароеЗначение[i]);
Console.ReadLine();
}
}
}
13.2. Метод Ньютона
Метод Ньютона наиболее распространённый метод решения систем нелинейных уравнений. Он обеспечивает более быструю сходимость по сравнению с методом итераций. В основе метода Ньютона лежит идея линеаризации всех нелинейных уравнений заданной системы. Для этого сообщим всей системе малые приращения и разложим каждое уравнение системы в ряд Тейлора:
— приращение по каждой ;
— остаточные нелинейные члены второго и более высоких порядков каждого ряда Тейлора.
Если приращения таковы, что переменные принимают значения близкие к корню, то будем считать, что левые части уравнений системы обращаются в нули. Тогда отбросив сведём задачу решения системы нелинейных уравнений к решению системы линейных уравнений, в которой неизвестными являются приращения ,
Система – система линейных уравнений с неизвестными ,. Запишем её в матричной форме
где
— матрица коэффициентов системы
— вектор свободных членов
— вектор неизвестных системы
Матрица , составленная из частных производных ; называется матрицей Якоби или Якобианом.
Метод Ньютона состоит из двух этапов:
На первом этапе реализации метода Ньютона необходимо построить систему линейных уравнений.
На втором этапе, начиная с начальной точки , необходимо решать систему на каждом шаге итерационного процесса поиска методом Гаусса. Найденные значения приращений используются как поправки к решению, полученному на предыдущем шаге поиска, т.е.
(5.7)
Или
Итерационный процесс прекращается, как только выполнится условие
(5.8)
по всем приращениям одновременно.
Определение матрицы Якоби
В методе Ньютона на каждом шаге итерационного процесса поиска необходимо формировать матрицу Якоби, при этом каждый элемент матрицы можно определить аналитически, как частную производную , методом численного дифференцирования, как отношение приращения функции к приращению аргумента, т.е.
В результате частная производная по первой координате определится как
а частная производная по координате определится как
где .
Лекция 14. Решение обыкновенных дифференциальных уравнений
14.1. Задача Коши и краевая задача для обыкновенных дифференциальных уравнений
Пусть дано обыкновенное дифференциальное уравнение первого порядка . Задача Коши для этого уравнения формулируется так: найти решение уравнения , удовлетворяющее начальному условию . Если функция непрерывна в области , определённой неравенствами , , то существует хотя бы одно решение дифференциального уравнения , определённое в некоторой окрестности , . Это решение единственное, если в выполнено условие Липшица: , где константа, зависящая в общем случае от ,. Если имеет ограниченную производную в , то можно положить . Для дифференциального уравнения — ого порядка задача Коши состоит в нахождении решения удовлетворяющего начальным условиям , , …, , где ,, , заданные числа.
14.2. Метод Эйлера
Пусть дано дифференциальное уравнение с начальными условиями , . Пусть – малый шаг, и . Искомую интегральную кривую , проходящую через точку , приближённо заменим ломаной с вершинами звенья которой прямолинейны между прямыми и имеют тангенс угла наклона . Звенья ломаной Эйлера к каждой вершине имеют направление , совпадающие с направлением касательной к интегральной кривой уравнения в точке . Значения могут быть определены выражением , . Метод Эйлера может быть распространён на системы дифференциальных уравнений и на дифференциальные уравнения высших порядков.
К достоинствам данного метода следует отнести его простоту, к недостаткам малую точность и систематическое накопление ошибок.
Метод Эйлера можно усовершенствовать следующим образом. Сначала определяется грубое приближение решения . Исходя из этого приближения находиться направление поля интегральных кривых . Затем приближенно полагаем . Этот подход ещё называется методом Эйлера — Коши. Программа, реализующая метод Эйлера:
using System;
namespace МетодЭйлераОДУ {
class Program {
static double f( double x, double y ) {
return (y / x + x * x);
}
static void Main( string[ ] args ) {
double x = 1;
double y = 0;
double x1 = 2;
int n = 10;
double h = (x1 — x) / n;
double y1 = y;
for (int i = 1; i <= n; i++) {
double f1 = f(x, y);
x += h;
y += f1 * h;
y = y1 + h * (f1 + f(x, y)) / 2;
y1 = y;
}
Console.WriteLine(«y = {0}», y);
Console.ReadLine();
}
}
}
Метод Рунге-Кутта
Пусть дано дифференциальное уравнение с начальным условием , . Пусть – шаг и , где . Пусть .
Рассмотрим числа
Согласно данному методу, последовательные значения находятся по формуле:
,
Метод Рунге — Кутта применим для решения систем обыкновенных дифференциальных уравнений. Пусть дана система дифференциальных уравнений и начальные условия . Задавшись некоторым шагом и введя обозначения и и , где
Положим
Согласно данному методу, последовательные значения находятся по формуле:
Погрешность этого метода пропорциональна , т.е. . Приведём программу, реализующую данный метод:
using System;
namespace МетодРунгеКуттаОДУ {
class Program {
static double f( double x, double y ) {
return (y / x + x * x);
}
static void Main( string[ ] args ) {
double x = 1;
double y = 0;
double x1 = 2;
int n = 10;
double h = (x1 — x) / n;
double y1 = y;
for (int i = 1; i <= n; i++) {
double k1 = h * f(x, y);
x += h / 2;
y = y1 + k1 / 2;
double k2 = f(x, y) * h;
y = y1 + k2 / 2;
double k3 = f(x, y) * h;
x += h / 2;
y = y1 + k3;
y = y1 + (k1 + 2*k2 + 2*k3 + f(x, y)*h)/6;
y1 = y;
}
Console.WriteLine(«y = {0}», y);
Console.ReadLine();
}
}
}
Методы Эйлера и Рунге-Кутта относятся к так называемым одношаговым методам, поскольку для вычисления значения функции в точке требуется знать только значение функции в одной предыдущей точке .
Метод Адамса
Многошаговые методы, называемые также методами Адамса, построены путём интерполирования по нескольким соседним точкам, для их использования необходимо знать значение функции в нескольких предыдущих точках. Достоинство многошаговых методов состоит в том, что независимо от порядка метода для вычисления значения функции в одной точке требуется один раз вычислить функцию .
Метод Адамса второго порядка записывается следующим образом:
где .
Методы Адамса третьего и четвёртого порядков имеют вид:
Погрешность решения найденного многошаговым методом оценивается равенством , где – порядок метода.
Таким образом, метод Рунге-Кутта 4-го порядка и метод Адамса четвёртого порядка имеют одинаковую оценку погрешности, но метод Адамса требует примерно вчетверо меньшего объёма вычислений.
При получении формулы Эйлера была использована замена производной правой конечной разностью , если использовать левую конечную разность получим уравнение в которое искомая величина входит нелинейным образом. Для решения такого уравнения можно использовать итерационные методы. Задавая начальное приближение и последовательно уточняя значение по формуле
получаем неявный метод Эйлера (или метод Эйлера с итерационной обработкой). Итерации выполняют до тех пор, пока не выполнится условие
Если после 3-х 4-х итераций требуемая точность не достигается, то производиться уменьшение шага .
Неявную схему можно применить и для методов высших порядков при этом получаются, так называемые, методы прогноза и коррекции.
Метод Эйлера — Коши можно рассматривать как один из простейших методов типа прогноза и коррекции, согласно которому вначале вычисляется грубое приближение по методу Эйлера, а затем оно используется для уточнения, причём коррекция может быть использована многократно:
Методы прогноза и коррекции можно получить на основе использования многошаговых методов:
метод второго порядка
метод третьего порядка
метод четвёртого порядка
Во всех этих формулах для вычисления используется значение полученное в текущем приближении
В методе Милна используются формулы прогноза и коррекции, построенные по разным точкам
7.3. Решение краевой задачи для обыкновенного дифференциального уравнения методом конечных разностей, методом прогонки и методом стрельбы
Рассмотрим случай, когда дифференциальное уравнение и краевые условия линейны. Такая краевая задача называется линейной краевой задачей. Линейное дифференциальное уравнение можно записать в следующем виде
где – линейный дифференциальный оператор
причём обычно предполагается, что и известные непрерывные функции на отрезке . Для простоты будем предполагать, что в краевые условия входят две абсциссы концы отрезка . Такие условия называют двухточечными.
Краевые условия называют линейными, если они имеют вид
, – заданные постоянные.
Линейная краевая задача состоит в нахождении функции , удовлетворяющей дифференциальному уравнению и краевым условиям, причём последние – линейно независимые.
Линейная краевая задача называется однородной, если:
1. ;
2.
в противном случае задача неоднородная.
Метод конечных разностей
Рассмотрим линейное дифференциальное уравнение
с двухточечными краевыми условиями
где – непрерывны на отрезке . Одним из самых простых способов решения данной задачи является сведение её к системе конечно-разностных уравнений. Для этого необходимо разбить отрезок на равных частей длины (шаг). Точками разбиения абсциссы будут , где , .
Значение функции в точках и её производных обозначим соответственно , , .
Введём следующие обозначения: , , .
Заменим производные конечно-разностными отношениями. Для внутренних точек отрезка , будем иметь:
при
Для крайних точек , , чтобы не выходить за концы отрезка , можно положить:
Однако, если функция достаточно гладкая, то более точные значения дают следующие формулы:
Таким образом, краевую задачу можно представить в виде:
Таким образом, получили систему линейных уравнений с неизвестными , решение которой позволяют найти значение искомой функции в точках . Система является трёхдиагональной и для её решения используется метод прогонки.
При использовании подстановок получаем систему линейных уравнений:
Для решения такой системы можно использовать какой-либо итерационный метод.
Лекция 15. Решение обыкновенных дифференциальных уравнений (продолжение)
Метод Галеркина
Основан на одной теореме из теории общих рядов Фурье.
Теорема. Пусть полная система функций ортогональных на интервале с ненулевой нормой. Если непрерывная функция ортогональна на ко всем функциям , то есть
при
то при
Пусть имеем двухточечную линейную краевую задачу , где
с линейными краевыми условиями
Выберем конечную систему базисных функций , составляющих часть некоторой полной системы, причём потребуем, чтобы удовлетворяла неоднородным краевым условиям
а остальные функции удовлетворяли однородным краевым условиям
Решение краевой задачи будем искать в виде
При таком выборе базисных функций функция очевидно удовлетворяет краевым условиям при любом выборе .
Если подставить в левую часть дифференциального уравнения выражение и вычесть из правую часть, то получим функцию невязки
Эта функция характеризует уклонение формы от действительного решения краевой задачи. Если форма при некоторых значениях коэффициентов совпадает с решением краевой задачи, то невязка будет равна нулю при , поэтому для получения приближённого решения, близкого к точному, нужно подобрать так, чтобы функция невязки была в каком-то смысле мала.
Согласно приведённой выше теореме для того, чтобы функция невязки была равна нулю необходимо, чтобы невязка была ортогональна ко всем базисным функциям
При достаточно большом это обеспечивает малость невязки в среднем, насколько приближённое решение будет при этом близко к точному вопрос остается открытым.
Используя выражение для невязки, после преобразований получим систему линейных уравнений вида
решив которую можно найти значения коэффициентов .
Согласно условиям теоремы используемая система функций должна быть полной и ортогональной, но на практике подобрать такую систему не всегда представляется возможным, поэтому при использовании этого метода требуют чтобы система функций была линейно-независимой на .
Метод коллокаций
В этом методе выбирают точек? принадлежащих рассматриваемому участку, , называемых точками коллокации, и требуют чтобы невязка в этих точках была равна нулю
После преобразований получим систему линейных уравнений
Следует иметь в виду, что получаемая система будет хорошо обусловленной, если точки коллокации являются корнями ортогональных многочленов (например многочленов Чебышева), при равноотстоящих точках получаемая система, особенно при большой размерности, может быть плохо обусловленной.
Метод экспоненциальной прогонки
Во многих приложениях, особенно в механике жидкости, при моделировании электрических цепей, химических реакций и в теории управления, возникают задачи с начальными данными, которым присуще свойство, называемое «жёсткостью». Жёсткие уравнения – это такие уравнения, решения которых имеют одновременно как быстрое, так и медленно изменяющиеся компоненты. Первые из них часто не представляют интереса, однако если используются классические методы интегрирования, то эти быстро затухающие компоненты могут привести к возникновению трудных вычислительных задач. Следовательно, важно создать подходящие численные методы для решения таких задач. С этой целью был предложен ряд схем.
Некоторые методы предназначаются для систем средней жесткости и требуют использования очень малых шагов в области быстрого изменения решения. Фактически это означает, что эффективность этих способов уменьшается с увеличением жесткости.
Для того чтобы показать, как пограничный слой может возникнуть в случае простых задач, мы приводим здесь пример линейной двухточечной краевой задачи с таким поведением.
Приведённые ниже восемь графиков иллюстрируют возникновение такого пограничного слоя по мере изменения коэффициента при второй производной от средних до малых значений. На этих рисунках приведены графики точных решений задачи
для восьми значений параметра .
В этой части мы рассмотрим двухточечные краевые задачи, являющиеся математическими моделями диффузионно – конвективных процессов или родственных физических явлений. Диффузионным членом является член, включающий производные второго порядка, а конвективный член включает производные первого порядка.
Решения указанного выше типа задач обычно не могут быть представлены в виде рядов по возрастающим степеням коэффициента диффузии. Таким образом, эти задачи не являются регулярными возмущениями соответствующих задач более низкого порядка. Они называются сингулярно-возмущёнными задачами. Так как в предельном случае при нулевом коэффициенте диффузии дифференциальные уравнения имеют более низкий порядок, некоторые из граничных условий станут излишними. Решение задачи может быстро изменяться вблизи граничных точек, что соответствует наличию пограничного слой.
При решении указанного выше типа задач стандартными численными методами возникают большие трудности. Часто причина этих трудностей заключается в неустойчивости численного процесса. Чтобы избавиться от неустойчивости, мы используем модифицированную дискретизацию диффузионного члена. Если нужно, то результирующие схемы могут быть представлены в консервативной форме.
Нельзя рассчитывать на то, что классические методы будут работать одинаково хорошо во всей области изменения величин и . Их использование аналогично аппроксимации экспоненциальной функции отрезком ряда Тейлора. Эти классические методы также требуют строгих ограничений на величину шага для обеспечения устойчивости при малых , за исключением специальных случаев. Например, хорошо известный метод направленных разностей приводит к схемам, не требующим наложения ограничений на величину шага для обеспечения устойчивости. Ошибка схемы с направленной разностью всегда содержит член порядка . Это приемлемо, если достаточно мало по сравнению с , но может быть неприемлемым в других случаях.
Рассмотрим задачу следующего вида:
где — малый параметр.
Случай, когда приводится к данной системе заменой независимой переменной на .
В случае, , схема решения задачи имеет следующий вид:
,
где ,
Приведённая система уравнений связывают три соседние точки искомого решения, её можно решать, например методом прогонки.
В случае, , схема решения задачи имеет следующий вид:
где выражаются теми же зависимостями, что и в случае .
Решение систем обыкновенных дифференциальных уравнений
Нормальной системой — ого порядка обыкновенных дифференциальных уравнений, называют систему:
где – независимая переменная; независимые функции. Систему, содержащую производные высших порядков и разрешённую относительно старших производных искомых функций, путём введения новых неизвестных функций, можно привести к представленному виду. Для дифференциального уравнения -ого порядка , полагая , , …, получим следующую систему:
систему можно записать в виде .
Под решением системы понимается любая совокупность функций которые будучи подставленными в уравнения обращают их в тождества т.к. система дифференциальных уравнений имеет бесчисленное множество решений, то для выделения одного конкретного решения, необходимы дополнительные условия, в простейшем случае задаются начальные условия . Это приводит к задаче Коши: Найти решения системы, удовлетворяющие заданным начальным условиям , где – фиксированное значение независимой переменной, а – заданная система чисел.
Система обыкновенных дифференциальных уравнений высшего порядка путём введения новых неизвестных может быть сведена к системе уравнений первого порядка. Рассмотрим такую систему
где ; ; . Метод Рунге-Кутта вычисляет по формуле:
где
– количество шагов интегрирования.
Точность измерений
Никакое
измерение не может быть выполнено
абсолютно точно, всегда содержится та
или иная погрешность. Чем точнее метод
измерения и измерительный прибор тем
меньше величина погрешности. Принято
различать несколько видов погрешностей:
основная и дополнительная, абсолютная
и относительная, систематическая и
случайная, которые необходимо учитывать
при измерении в спорте.
Основная
погрешность
связана с методом измерения или
измерительного прибора, которая имеет
место в нормальных условиях их применения.
Например, точность измерения прыжка в
длину с помощью метра или рулетки;
точность измерения времени пробегания
короткой дистанции с помощью разных
(механического или электронного)
секундомеров будет не одинаковой и
определяется точностью самого средства
измерения. Эта погрешность, как правило,
указана в инструкции измерительного
прибора.
Дополнительная
погрешность
вызвана отклонением условий работы
измерительной системы от нормальных.
Например, при существенных колебаниях
(выше нормы) электрического напряжения
в сети может возникать погрешность
измерения. Другой пример — прибор,
предназначенный для работы при комнатной
температуре, будет давать неточные
показания, если пользоваться им в
условиях низких или высоких внешних
температур. К дополнительным погрешностям
относятся и так называемая динамическая
погрешность, обусловленная инерционностью
измерительного прибора и возникающая
в тех случаях, когда измеряемая величина
колеблется выше технических возможностей
регистрирующего устройства. Например,
некоторые пульсотахометры рассчитаны
на измерение средних величин ЧСС и не
способны улавливать непродолжительные
отклонения частоты от среднего уровня.
Величины
основной и дополнительной погрешности
могут быть представлены в абсолютных
и относительных единицах.
Абсолютная
погрешность равна
разности между показанием измерительного
пробора (А) и истинным значением измеряемой
величины
Она
измеряется в тех же единицах, что и
измеряемая величина.
Относительной
погрешностью называется
отношение абсолютной погрешности к
истинному значению измеряемой величины:
Поскольку
относительная погрешность измеряется
в процентах, то знак абсолютной погрешности
не учитывается.
Систематическая
погрешность
– это величина, которая не меняется от
измерения к измерению. Поэтому она часто
может быть предсказана заранее или, в
крайнем случае обнаружена и устранена
по окончании процесса измерения.
Определение систематической погрешности
измерения возможно способами: тарировки,
калибровки измерительной аппаратуры
или рандомизации.
Тарированием
называется
проверка показаний измерительных
приборов путем сравнения с показаниями
образцовых значений мер (эталонов) во
всем диапазоне измеряемой величины.
Калибровкой
называется
определение погрешностей или поправка
для совокупности мер. И при тарировке
и при калибровке к входу измерительной
системы подключается источник эталонного
сигнала известной величины. Например,
процедура проверки чувствительности
усилителя, заключающаяся в записи и
регулировке амплитуды ответов каналов
на подаваемое на вход напряжение,
сопоставляемое впоследствии с амплитудой
регистрируемых физиологических
параметров. Другой пример, – процедура
проверки скорости движения бумаги на
регистрирующем приборе с помощью
счетчика времени.
Рандомизацией
(от англ.
random – случайный) называется превращение
систематической погрешности в случайную.
По методу рандомизации измерение
изучаемой величины производится
несколько раз (например, многократные
исследования физической работоспособности
разными способами дозирования нагрузки).
По окончании всех измерений их результаты
усредняются по правилам математической
статистики.
Случайные
погрешности неустранимы
и возникают
под действием разнообразных факторов,
которые сложно заранее предсказать и
учесть. Единственно, с помощь методов
математической статистики можно оценить
величину случайной погрешности и учесть
ее при интерпретации результатов
измерения.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
СТАТИСТИЧЕСКИЕ
ХАРАКТЕРИСТИКИ
Без
статистической обработки результаты
измерений не могут считаться достоверными.
Средняя
арифметическая характеризует
групповые свойства признака, занимает
центральное положение в общей массе
варьирующих признаков. Представляет
собой частное от деления суммы всех
вариант совокупности на их общее число.
Средняя арифметическая – величина
именованная, она выражается теми же
единицами измерения, что и характеризуемый
ею признак. Средняя арифметическая –
важнейшая статистическая характеристика,
но она ничего не говорит о величине
варьирования изучаемого признака.
Стандартное
или среднее квадратическое отклонение
(s) характеризует
вариации, или колеблемости признака.
Стандартное отклонение – величина
именованная, и выражается в тех же
единицах измерения, что и исследуемый
признак, т.е. характеризует степень
отклонения результатов от среднего
значения в абсолютных единицах. Этот
показатель не зависит от числа наблюдений,
и потому может использоваться для оценки
варьирования однородных признаков.
Однако для сравнения вариации двух и
более признаков, имеющих различные
единицы измерения (например, результаты
в беге на 100 м, прыжках в высоту, метаниях
гранаты и т.п.), эта характеристика не
пригодна. Для этого используется
коэффициент вариации.
Коэффициент
вариации (CV)
определяется как отношение стандартного
отклонения к среднему арифметическому,
выраженное в процентах. Коэффициент
вариации, будучи величиной относительной,
позволяет сравнивать между собой
колеблемость результатов измерений,
имеющих различные единицы измерения.
При нормальных распределениях CV обычно
не превышает 45-50%. В случаях асимметричных
распределений он может быть довольно
высоким (до 100% и выше). На практике
внутренняя вариабельность признака
считается небольшой при CV= 0-10%, средней
– 11-20% и большой – больше 20%.
Ошибка
средней арифметической (m) величина
не техническая, а статистическая, и
характеризует закономерные колебания
(вариации) средней арифметической
величины. Выборочная ошибка показывает
варьирование выборочных показателей
вокруг их генеральных параметров. Она
обладает теми же свойствами, что и
среднее квадратическое отклонение. Чем
больше объем выборки, тем точнее средний
результат, тем меньше выборочная средняя
будет отличаться от средней генеральной
совокупности. Следовательно, при
увеличении числа испытаний ошибка
выборочной средней будет уменьшаться.
Отсюда становится яснее значение
выборочной ошибки: она указывает на
точность, с какой определена сопровождаемая
ею средняя величина.
Оценка
по критерию Т-Стьюдента. В
спорте часто на одних и тех же спортсменах
проводится измерение через некоторое
время (например, в начале и в конце этапа
подготовки) или сравнение результатов
одной группы (контрольной) с другой
(экспериментальной). Во всех этих и
подобных случаях ставится, практически,
одна задача – достоверно или нет одни
результаты исследования отличаются от
других? Для этих целей используется
метод сравнения
двух выборочных средних арифметических
по критерию Т-Стьюдента. Принципиально
важным является то, что применение
указанного метода возможно лишь для
однородных признаков.
Ответом
на вопрос о достоверности различий
между признаками служит уровень
значимости (Р),
определяемый по таблице (стандартные
значения критерия Т-Стьюдента). При
уровне значимости Р<0,05 (что соответствует
95% вероятности события) можно говорить
о наличие достоверных различий между
сравниваемыми средними, при Р<0,01 и
особенно при Р<0,001 (когда 99,9% случаев
подлежат общей закономерности) можно
утверждать, что средние значения
отличаются друг от друга с высокой
вероятностью, или закономерностью.
Свидетельством отсутствия достоверных
(статистических) различий между средними
является Р>0,05 (т.е. менее 95% случаев
подлежат общей закономерности).
Корреляционный
анализ сводится
к измерению тесноты или степени
сопряженности между разнородными
признаками, а также к определению формы
и направления существующей между ними
связи. Критерием связи служит коэффициент
корреляции,
который имеет значения от 0 до 1. Чем
больше коэффициент корреляции приближается
к 1, тем теснее связь между признаками
и наоборот. Знак плюс или минус говорят
о направленности связи — положительной
(прямой) или отрицательной (обратной).
Коэффициент корреляции служит мерилом
только качественной связи между
изучаемыми признаками. С помощью
специальных расчетных процедур, в каждом
конкретном случае, устанавливается
форма (линейная, нелинейная) связи.
Существуют методы: парной и множественной
корреляции; для определения связи между
количесвенными и качественными признаками
(ранговая корреляция).
Регрессионный
анализ есть
продолжение корреляционного анализа,
где с помощью выведенного уравнения
регрессии можно показать количественную
степень связи (или взаимовлияния одного
признака на другой). Например, насколько
повысится результат в прыжках в длину
с разбега, если скорость бега на 30 м
увеличится на 2 м/с.
Дисперсионный
анализ позволяет
оценить влияние разнообразных факторов
на результат исследования. Например,
какие из факторов физической
подготовленности в большей мере влияют
на спортивный результат. Дисперсионный
анализ проводится как на малых, так и
на больших выборках, на однородных и
неоднородных признаках, на количественных
и качественных характеристиках. В основе
дисперсионного анализа лежит сравнение
выборочных дисперсий, или их отношений
с критическими значениями критерия
F-Фишера.
Более
подробно с методами математической
статистики можно ознакомиться в следующей
литературе.
1.
Ашмарин Б.А. Теория и методика педагогических
исследований в физическом воспитании.-
М.: ФиС, 1978.
2.
Бейл Н. Статистические методы в биологии.-
М.: Мир, 1964.
3.
Гласс Дж., Стэнли Дж. Статистические
методы в педагогике и психологии.- М.:
Прогресс, 1976.
4.
Друзь В.А. Моделирование процесса
спортивной тренировки.- Киев: Здоровье,
1976.
5.
Лакин Г.Ф. Биометрия: Учебник для
университетов и педагогических
институтов.- М.: Высшая школа, 1973.
6.
Основы общей и прикладной акмеологии.-
М.: ФиС, 1995. Плохинский Н.А. Биометрия.-
М.: МГУ, 1970.
7.
Рокицкий П.Ф. Биологическая статистика.-
Минск: Высшая школа, 1973.
8.Садовский
Л.Е., Садовский А.Л. Математика и спорт.-
М.: Наука, 1985.
9.
Фишер Р.А. Статистические методы для
исследователей / Перевод с англ. В.Н.
Перегудова – М.: Госстатиздат, 1958.
|
1 |
|
|
2 |
|
|
3 |
|
|
4 |
|
|
5 |
|
|
6 |
|
|
7 |
|
|
8 |
|
|
9 |
|
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка калибровки датчика
Калибровка датчика – определение его индивидуальныхкоэффициентов общей формы передаточной функции.
Производится еслипроизводственные допуски на датчик превышают требуемую точность измерения.Например, требуется измерить температуру с точностью ±0.5°С датчиком, посправочным данным обладающим погрешностью ±1?С. Это можно сделать только послепроведения калибровки этого конкретного датчика, т.е. после нахождения егоиндивидуальной передаточной функции.
Математическое описание передаточнойфункции необходимо знать до начала проведения калибровки. Если выражение дляпередаточной функции является линейным, в процессе калибровки определяюткоэффициенты а и b, если экспоненциальным — токоэффициенты а и к т.д.
Пример для линейной передаточнойфункции. Поскольку для определения коэффициентов, описывающих прямую линию,необходимо иметь два уравнения, придется проводить калибровку, как минимум, вдвух точках.
Передаточная функция: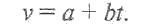
Для определения а и b датчик необходимо поместить в две среды: одну стемпературой t1, другую с температурой t2 и измерить значения двух соответствующих напряжений: v1, и v2 После чего надо подставить эти величиныв выражение передаточной функции: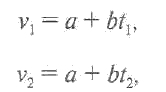
и найти значения констант:
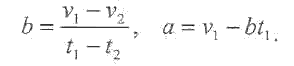
Дляполучения температуры из выходного напряжения, значение измеренного напряжениянеобходимо подставить в инверсное выражение передаточной функции:
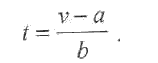
В некоторых случаях одна из констант может быть заранее определена с достаточнойстепенью точности, тогда калибровка проводится в одной точке. Например длядатчика температуры с р-n переходом наклон передаточной функции b дляопределенного типа полупроводников обычно является хорошо воспроизводимойвеличиной.
Длянелинейных функций калибровку требуется проводить более чем в двух точках.Количество необходимых калибровок диктуется видом математического выражения.Если передаточная функция моделируется полиноминальной зависимостью, числокалибровочных точек выбирается в зависимости от требуемой точности. Поскольку,как правило, процесс калибровки занимает довольно много времени, для снижениястоимости изготовления датчиков на производстве количество калибровочных точекзадается минимальным.
Другойподход к калибровке нелинейных датчиков — применение кусочно-линейной аппроксимации:любую кривую в пределах достаточно небольшого интервала всегда можно заменитьлинейной функцией. Поэтому нелинейную передаточную функцию можно представить ввиде комбинации линейных отрезков, каждый из которых обладает своимисобственными коэффициентами а и b.
Дляпроведения калибровки датчиков важно иметь точные физические эталоны,позволяющие моделировать соответствующие внешние воздействия. Например, прикалибровке контактного датчика температуры его необходимо помещать либо врезервуар с водой, либо в «сухой колодец», в которых есть возможность точнорегулировать температуру. При калибровке инфракрасных датчиков требуетсяналичие черного тела, а для калибровки гигрометров — набор насыщенных растворовсолей, используемых для поддержания постоянной относительной влажности взакрытом контейнере и т.д.
Следовательноточность последующих измерений напрямую связана с точностью проведения калибровкии ошибка калибровочных эталонов должна включаться в полную ошибку измерений.
Ошибка калибровки — это погрешность, допущеннаяпроизводителем при проведениикалибровки датчика на заводе. Эта погрешность является систематический и добавляется ко всем реальнымпередаточным функциям.
This article is about assessing the accuracy of a measurement device, like a scale or a ruler. For the statistical concept, see Calibration (statistics).
In measurement technology and metrology, calibration is the comparison of measurement values delivered by a device under test with those of a calibration standard of known accuracy. Such a standard could be another measurement device of known accuracy, a device generating the quantity to be measured such as a voltage, a sound tone, or a physical artifact, such as a meter ruler.
The outcome of the comparison can result in one of the following:
- no significant error being noted on the device under test
- a significant error being noted but no adjustment made
- an adjustment made to correct the error to an acceptable level
Strictly speaking, the term «calibration» means just the act of comparison and does not include any subsequent adjustment.
The calibration standard is normally traceable to a national or international standard held by a metrology body.
BIPM Definition[edit]
The formal definition of calibration by the International Bureau of Weights and Measures (BIPM) is the following: «Operation that, under specified conditions, in a first step, establishes a relation between the quantity values with measurement uncertainties provided by measurement standards and corresponding indications with associated measurement uncertainties (of the calibrated instrument or secondary standard) and, in a second step, uses this information to establish a relation for obtaining a measurement result from an indication.»[1]
This definition states that the calibration process is purely a comparison, but introduces the concept of measurement uncertainty in relating the accuracies of the device under test and the standard.
Modern calibration processes[edit]
The increasing need for known accuracy and uncertainty and the need to have consistent and comparable standards internationally has led to the establishment of national laboratories. In many countries a National Metrology Institute (NMI) will exist which will maintain primary standards of measurement (the main SI units plus a number of derived units) which will be used to provide traceability to customer’s instruments by calibration.
The NMI supports the metrological infrastructure in that country (and often others) by establishing an unbroken chain, from the top level of standards to an instrument used for measurement. Examples of National Metrology Institutes are NPL in the UK, NIST in the United States, PTB in Germany and many others. Since the Mutual Recognition Agreement was signed it is now straightforward to take traceability from any participating NMI and it is no longer necessary for a company to obtain traceability for measurements from the NMI of the country in which it is situated, such as the National Physical Laboratory in the UK.
Quality[edit]
To improve the quality of the calibration and have the results accepted by outside organizations it is desirable for the calibration and subsequent measurements to be «traceable» to the internationally defined measurement units. Establishing traceability is accomplished by a formal comparison to a standard which is directly or indirectly related to national standards (such as NIST in the USA), international standards, or certified reference materials. This may be done by national standards laboratories operated by the government or by private firms offering metrology services.
Quality management systems call for an effective metrology system which includes formal, periodic, and documented calibration of all measuring instruments. ISO 9000[2] and ISO 17025[3] standards require that these traceable actions are to a high level and set out how they can be quantified.
To communicate the quality of a calibration the calibration value is often accompanied by a traceable uncertainty statement to a stated confidence level. This is evaluated through careful uncertainty analysis.
Some times a DFS (Departure From Spec) is required to operate machinery in a degraded state. Whenever this does happen, it must be in writing and authorized by a manager with the technical assistance of a calibration technician.
Measuring devices and instruments are categorized according to the physical quantities they are designed to measure. These vary internationally, e.g., NIST 150-2G in the U.S.[4] and NABL-141 in India.[5] Together, these standards cover instruments that measure various physical quantities such as electromagnetic radiation (RF probes), sound (sound level meter or noise dosimeter), time and frequency (intervalometer), ionizing radiation (Geiger counter), light (light meter), mechanical quantities (limit switch, pressure gauge, pressure switch), and, thermodynamic or thermal properties (thermometer, temperature controller). The standard instrument for each test device varies accordingly, e.g., a dead weight tester for pressure gauge calibration and a dry block temperature tester for temperature gauge calibration.
Instrument calibration prompts[edit]
Calibration may be required for the following reasons:
- a new instrument
- after an instrument has been repaired or modified
- moving from one location to another location
- when a specified time period has elapsed
- when a specified usage (operating hours) has elapsed
- before and/or after a critical measurement
- after an event, for example
- after an instrument has been exposed to a shock, vibration, or physical damage, which might potentially have compromised the integrity of its calibration
- sudden changes in weather
- whenever observations appear questionable or instrument indications do not match the output of surrogate instruments
- as specified by a requirement, e.g., customer specification, instrument manufacturer recommendation.
In general use, calibration is often regarded as including the process of adjusting the output or indication on a measurement instrument to agree with value of the applied standard, within a specified accuracy. For example, a thermometer could be calibrated so the error of indication or the correction is determined, and adjusted (e.g. via calibration constants) so that it shows the true temperature in Celsius at specific points on the scale. This is the perception of the instrument’s end-user. However, very few instruments can be adjusted to exactly match the standards they are compared to. For the vast majority of calibrations, the calibration process is actually the comparison of an unknown to a known and recording the results.
Basic calibration process[edit]
Purpose and scope[edit]
The calibration process begins with the design of the measuring instrument that needs to be calibrated. The design has to be able to «hold a calibration» through its calibration interval. In other words, the design has to be capable of measurements that are «within engineering tolerance» when used within the stated environmental conditions over some reasonable period of time.[6] Having a design with these characteristics increases the likelihood of the actual measuring instruments performing as expected.
Basically, the purpose of calibration is for maintaining the quality of measurement as well as to ensure the proper working of particular instrument.
Frequency[edit]
The exact mechanism for assigning tolerance values varies by country and as per the industry type. The measuring of equipment is manufacturer generally assigns the measurement tolerance, suggests a calibration interval (CI) and specifies the environmental range of use and storage. The using organization generally assigns the actual calibration interval, which is dependent on this specific measuring equipment’s likely usage level. The assignment of calibration intervals can be a formal process based on the results of previous calibrations. The standards themselves are not clear on recommended CI values:[7]
- ISO 17025[3]
- «A calibration certificate (or calibration label) shall not contain any recommendation on the calibration interval except where this has been agreed with the customer. This requirement may be superseded by legal regulations.”
- ANSI/NCSL Z540[8]
- «…shall be calibrated or verified at periodic intervals established and maintained to assure acceptable reliability…»
- ISO-9001[2]
- «Where necessary to ensure valid results, measuring equipment shall…be calibrated or verified at specified intervals, or prior to use…”
- MIL-STD-45662A[9]
- «… shall be calibrated at periodic intervals established and maintained to assure acceptable accuracy and reliability…Intervals shall be shortened or may be lengthened, by the contractor, when the results of previous calibrations indicate that such action is appropriate to maintain acceptable reliability.»
Standards required and accuracy[edit]
The next step is defining the calibration process. The selection of a standard or standards is the most visible part of the calibration process. Ideally, the standard has less than 1/4 of the measurement uncertainty of the device being calibrated. When this goal is met, the accumulated measurement uncertainty of all of the standards involved is considered to be insignificant when the final measurement is also made with the 4:1 ratio.[10] This ratio was probably first formalized in Handbook 52 that accompanied MIL-STD-45662A, an early US Department of Defense metrology program specification. It was 10:1 from its inception in the 1950s until the 1970s, when advancing technology made 10:1 impossible for most electronic measurements.[11]
Maintaining a 4:1 accuracy ratio with modern equipment is difficult. The test equipment being calibrated can be just as accurate as the working standard.[10] If the accuracy ratio is less than 4:1, then the calibration tolerance can be reduced to compensate. When 1:1 is reached, only an exact match between the standard and the device being calibrated is a completely correct calibration. Another common method for dealing with this capability mismatch is to reduce the accuracy of the device being calibrated.
For example, a gauge with 3% manufacturer-stated accuracy can be changed to 4% so that a 1% accuracy standard can be used at 4:1. If the gauge is used in an application requiring 16% accuracy, having the gauge accuracy reduced to 4% will not affect the accuracy of the final measurements. This is called a limited calibration. But if the final measurement requires 10% accuracy, then the 3% gauge never can be better than 3.3:1. Then perhaps adjusting the calibration tolerance for the gauge would be a better solution. If the calibration is performed at 100 units, the 1% standard would actually be anywhere between 99 and 101 units. The acceptable values of calibrations where the test equipment is at the 4:1 ratio would be 96 to 104 units, inclusive. Changing the acceptable range to 97 to 103 units would remove the potential contribution of all of the standards and preserve a 3.3:1 ratio. Continuing, a further change to the acceptable range to 98 to 102 restores more than a 4:1 final ratio.
This is a simplified example. The mathematics of the example can be challenged. It is important that whatever thinking guided this process in an actual calibration be recorded and accessible. Informality contributes to tolerance stacks and other difficult to diagnose post calibration problems.
Also in the example above, ideally the calibration value of 100 units would be the best point in the gauge’s range to perform a single-point calibration. It may be the manufacturer’s recommendation or it may be the way similar devices are already being calibrated. Multiple point calibrations are also used. Depending on the device, a zero unit state, the absence of the phenomenon being measured, may also be a calibration point. Or zero may be resettable by the user-there are several variations possible. Again, the points to use during calibration should be recorded.
There may be specific connection techniques between the standard and the device being calibrated that may influence the calibration. For example, in electronic calibrations involving analog phenomena, the impedance of the cable connections can directly influence the result.
Manual and automatic calibrations[edit]
Calibration methods for modern devices can be manual or automatic.

Manual calibration — US serviceman calibrating a pressure gauge. The device under test is on his left and the test standard on his right.
As an example, a manual process may be used for calibration of a pressure gauge. The procedure requires multiple steps,[12] to connect the gauge under test to a reference master gauge and an adjustable pressure source, to apply fluid pressure to both reference and test gauges at definite points over the span of the gauge, and to compare the readings of the two. The gauge under test may be adjusted to ensure its zero point and response to pressure comply as closely as possible to the intended accuracy. Each step of the process requires manual record keeping.

Automatic calibration — A U.S. serviceman using a 3666C auto pressure calibrator
An automatic pressure calibrator [13] is a device that combines an electronic control unit, a pressure intensifier used to compress a gas such as Nitrogen, a pressure transducer used to detect desired levels in a hydraulic accumulator, and accessories such as liquid traps and gauge fittings. An automatic system may also include data collection facilities to automate the gathering of data for record keeping.
Process description and documentation[edit]
All of the information above is collected in a calibration procedure, which is a specific test method. These procedures capture all of the steps needed to perform a successful calibration. The manufacturer may provide one or the organization may prepare one that also captures all of the organization’s other requirements. There are clearinghouses for calibration procedures such as the Government-Industry Data Exchange Program (GIDEP) in the United States.
This exact process is repeated for each of the standards used until transfer standards, certified reference materials and/or natural physical constants, the measurement standards with the least uncertainty in the laboratory, are reached. This establishes the traceability of the calibration.
See Metrology for other factors that are considered during calibration process development.
After all of this, individual instruments of the specific type discussed above can finally be calibrated. The process generally begins with a basic damage check. Some organizations such as nuclear power plants collect «as-found» calibration data before any routine maintenance is performed. After routine maintenance and deficiencies detected during calibration are addressed, an «as-left» calibration is performed.
More commonly, a calibration technician is entrusted with the entire process and signs the calibration certificate, which documents the completion of a successful calibration.
The basic process outlined above is a difficult and expensive challenge. The cost for ordinary equipment support is generally about 10% of the original purchase price on a yearly basis, as a commonly accepted rule-of-thumb. Exotic devices such as scanning electron microscopes, gas chromatograph systems and laser interferometer devices can be even more costly to maintain.
The ‘single measurement’ device used in the basic calibration process description above does exist. But, depending on the organization, the majority of the devices that need calibration can have several ranges and many functionalities in a single instrument. A good example is a common modern oscilloscope. There easily could be 200,000 combinations of settings to completely calibrate and limitations on how much of an all-inclusive calibration can be automated.

An instrument rack with tamper-indicating seals
To prevent unauthorized access to an instrument tamper-proof seals are usually applied after calibration. The picture of the oscilloscope rack shows these, and prove that the instrument has not been removed since it was last calibrated as they will possible unauthorized to the adjusting elements of the instrument. There also are labels showing the date of the last calibration and when the calibration interval dictates when the next one is needed. Some organizations also assign unique identification to each instrument to standardize the record keeping and keep track of accessories that are integral to a specific calibration condition.
When the instruments being calibrated are integrated with computers, the integrated computer programs and any calibration corrections are also under control.
Historical development[edit]
Origins[edit]
The words «calibrate» and «calibration» entered the English language as recently as the American Civil War,[14] in descriptions of artillery, thought to be derived from a measurement of the calibre of a gun.
Some of the earliest known systems of measurement and calibration seem to have been created between the ancient civilizations of Egypt, Mesopotamia and the Indus Valley, with excavations revealing the use of angular gradations for construction.[15] The term «calibration» was likely first associated with the precise division of linear distance and angles using a dividing engine and the measurement of gravitational mass using a weighing scale. These two forms of measurement alone and their direct derivatives supported nearly all commerce and technology development from the earliest civilizations until about AD 1800.[16]
Calibration of weights and distances (c. 1100 CE)[edit]

An example of a weighing scale with a ½ ounce calibration error at zero. This is a «zeroing error» which is inherently indicated, and can normally be adjusted by the user, but may be due to the string and rubber band in this case
Early measurement devices were direct, i.e. they had the same units as the quantity being measured. Examples include length using a yardstick and mass using a weighing scale. At the beginning of the twelfth century, during the reign of Henry I (1100-1135), it was decreed that a yard be «the distance from the tip of the King’s nose to the end of his outstretched thumb.»[17] However, it wasn’t until the reign of Richard I (1197) that we find documented evidence.[18]
- Assize of Measures
- «Throughout the realm there shall be the same yard of the same size and it should be of iron.»
Other standardization attempts followed, such as the Magna Carta (1225) for liquid measures, until the Mètre des Archives from France and the establishment of the Metric system.
The early calibration of pressure instruments[edit]
Direct reading design of a U-tube manometer
One of the earliest pressure measurement devices was the Mercury barometer, credited to Torricelli (1643),[19] which read atmospheric pressure using Mercury. Soon after, water-filled manometers were designed. All these would have linear calibrations using gravimetric principles, where the difference in levels was proportional to pressure. The normal units of measure would be the convenient inches of mercury or water.
In the direct reading hydrostatic manometer design on the right, applied pressure Pa pushes the liquid down the right side of the manometer U-tube, while a length scale next to the tube measures the difference of levels. The resulting height difference «H» is a direct measurement of the pressure or vacuum with respect to atmospheric pressure. In the absence of differential pressure both levels would be equal, and this would be used as the zero point.
The Industrial Revolution saw the adoption of «indirect» pressure measuring devices, which were more practical than the manometer.[20]
An example is in high pressure (up to 50 psi) steam engines, where mercury was used to reduce the scale length to about 60 inches, but such a manometer was expensive and prone to damage.[21] This stimulated the development of indirect reading instruments, of which the Bourdon tube invented by Eugène Bourdon is a notable example.


Indirect reading design showing a Bourdon tube from the front (left) and the rear (right).
In the front and back views of a Bourdon gauge on the right, applied pressure at the bottom fitting reduces the curl on the flattened pipe proportionally to pressure. This moves the free end of the tube which is linked to the pointer. The instrument would be calibrated against a manometer, which would be the calibration standard. For measurement of indirect quantities of pressure per unit area, the calibration uncertainty would be dependent on the density of the manometer fluid, and the means of measuring the height difference. From this other units such as pounds per square inch could be inferred and marked on the scale.
See also[edit]
![]()
Look up calibration in Wiktionary, the free dictionary.
- Calibration curve
- Calibrated geometry
- Calibration (statistics)
- Color calibration – used to calibrate a computer monitor or display.
- Deadweight tester
- EURAMET Association of European NMIs
- Measurement Microphone Calibration
- Measurement uncertainty
- Musical tuning – tuning, in music, means calibrating musical instruments into playing the right pitch.
- Precision measurement equipment laboratory
- Scale test car – a device used to calibrate weighing scales that weigh railroad cars.
- Systems of measurement
References[edit]
- ^ JCGM 200:2008 International vocabulary of metrology Archived 2019-10-31 at the Wayback Machine — Basic and general concepts and associated terms (VIM)
- ^ a b ISO 9001: «Quality management systems — Requirements» (2008), section 7.6.
- ^ a b ISO 17025: «General requirements for the competence of testing and calibration laboratories» (2005), section 5.
- ^ Faison, C. Douglas; Brickenkamp, Carroll S. (March 2004). «Calibration Laboratories: Technical Guide for Mechanical Measurements» (PDF). NIST Handbook 150-2G. NIST. Retrieved 14 June 2015.
- ^ «Metrology, Pressure, Thermal & Eletrotechnical Measurement and Calibration». Fluid Control Research Institute (FCRI), Ministry of Heavy Industries & Public Enterprises, Govt. of India. Archived from the original on 14 June 2015. Retrieved 14 June 2015.
- ^ Haider, Syed Imtiaz; Asif, Syed Erfan (16 February 2011). Quality Control Training Manual: Comprehensive Training Guide for API, Finished Pharmaceutical and Biotechnologies Laboratories. CRC Press. p. 49. ISBN 978-1-4398-4994-1.
- ^ Bare, Allen (2006). Simplified Calibration Interval Analysis (PDF). Aiken, SC: NCSL International Workshop and Symposium, under contract with the Office of Scientific and Technical Information, U.S. Department of Energy. pp. 1–2. Archived (PDF) from the original on 2007-04-18. Retrieved 28 November 2014.
- ^ «ANSI/NCSL Z540.3-2006 (R2013)». The National Conference of Standards Laboratories (NCSL) International. Archived from the original on 2014-11-20. Retrieved 28 November 2014.
- ^ «Calibration Systems Requirements (Military Standard)» (PDF). Washington, DC: U.S. Department of Defense. 1 August 1998. Archived from the original (PDF) on 2005-10-30. Retrieved 28 November 2014.
- ^ a b Ligowski, M.; Jabłoński, Ryszard; Tabe, M. (2011), Jabłoński, Ryszard; Březina, Tomaš (eds.), Procedure for Calibrating Kelvin Probe Force Microscope, Mechatronics: Recent Technological and Scientific Advances, p. 227, doi:10.1007/978-3-642-23244-2, ISBN 978-3-642-23244-2, LCCN 2011935381
- ^ Military Handbook: Evaluation of Contractor’s Calibration System (PDF). U.S. Department of Defense. 17 August 1984. p. 7. Archived (PDF) from the original on 2014-12-04. Retrieved 28 November 2014.
- ^ Procedure for calibrating pressure gauges (USBR 1040) (PDF). U.S. Department of the Interior, Bureau of Reclamation. pp. 70–73. Archived (PDF) from the original on 2013-05-12. Retrieved 28 November 2014.
- ^ «KNC Model 3666 Automatic Pressure Calibration System» (PDF). King Nutronics Corporation. Archived from the original (PDF) on 2014-12-04. Retrieved 28 November 2014.
- ^ «the definition of calibrate». Dictionary.com. Retrieved 18 March 2018.
- ^ Baber, Zaheer (1996). The Science of Empire: Scientific Knowledge, Civilization, and Colonial Rule in India. SUNY Press. pp. 23–24. ISBN 978-0-7914-2919-8.
- ^ Franceschini, Fiorenzo; Galetto, Maurizio; Maisano, Domenico; Mastrogiacomo, Luca; Pralio, Barbara (6 June 2011). Distributed Large-Scale Dimensional Metrology: New Insights. Springer Science & Business Media. pp. 117–118. ISBN 978-0-85729-543-9.
- ^ Ackroyd, Peter (16 October 2012). Foundation: The History of England from Its Earliest Beginnings to the Tudors. St. Martin’s Press. pp. 133–134. ISBN 978-1-250-01367-5.
- ^ Bland, Alfred Edward; Tawney, Richard Henry (1919). English Economic History: Select Documents. Macmillan Company. pp. 154–155.
- ^ Tilford, Charles R (1992). «Pressure and vacuum measurements» (PDF). Physical Methods of Chemistry: 106–173. Archived from the original (PDF) on 2014-12-05. Retrieved 28 November 2014.
- ^ Fridman, A. E.; Sabak, Andrew; Makinen, Paul (23 November 2011). The Quality of Measurements: A Metrological Reference. Springer Science & Business Media. pp. 10–11. ISBN 978-1-4614-1478-0.
- ^ Cuscó, Laurence (1998). Guide to the Measurement of Pressure and Vacuum. London: The Institute of Measurement and Control. p. 5. ISBN 0-904457-29-X.
Sources[edit]
- Crouch, Stanley & Skoog, Douglas A. (2007). Principles of Instrumental Analysis. Pacific Grove: Brooks Cole. ISBN 0-495-01201-7.
This article is about assessing the accuracy of a measurement device, like a scale or a ruler. For the statistical concept, see Calibration (statistics).
In measurement technology and metrology, calibration is the comparison of measurement values delivered by a device under test with those of a calibration standard of known accuracy. Such a standard could be another measurement device of known accuracy, a device generating the quantity to be measured such as a voltage, a sound tone, or a physical artifact, such as a meter ruler.
The outcome of the comparison can result in one of the following:
- no significant error being noted on the device under test
- a significant error being noted but no adjustment made
- an adjustment made to correct the error to an acceptable level
Strictly speaking, the term «calibration» means just the act of comparison and does not include any subsequent adjustment.
The calibration standard is normally traceable to a national or international standard held by a metrology body.
BIPM Definition[edit]
The formal definition of calibration by the International Bureau of Weights and Measures (BIPM) is the following: «Operation that, under specified conditions, in a first step, establishes a relation between the quantity values with measurement uncertainties provided by measurement standards and corresponding indications with associated measurement uncertainties (of the calibrated instrument or secondary standard) and, in a second step, uses this information to establish a relation for obtaining a measurement result from an indication.»[1]
This definition states that the calibration process is purely a comparison, but introduces the concept of measurement uncertainty in relating the accuracies of the device under test and the standard.
Modern calibration processes[edit]
The increasing need for known accuracy and uncertainty and the need to have consistent and comparable standards internationally has led to the establishment of national laboratories. In many countries a National Metrology Institute (NMI) will exist which will maintain primary standards of measurement (the main SI units plus a number of derived units) which will be used to provide traceability to customer’s instruments by calibration.
The NMI supports the metrological infrastructure in that country (and often others) by establishing an unbroken chain, from the top level of standards to an instrument used for measurement. Examples of National Metrology Institutes are NPL in the UK, NIST in the United States, PTB in Germany and many others. Since the Mutual Recognition Agreement was signed it is now straightforward to take traceability from any participating NMI and it is no longer necessary for a company to obtain traceability for measurements from the NMI of the country in which it is situated, such as the National Physical Laboratory in the UK.
Quality[edit]
To improve the quality of the calibration and have the results accepted by outside organizations it is desirable for the calibration and subsequent measurements to be «traceable» to the internationally defined measurement units. Establishing traceability is accomplished by a formal comparison to a standard which is directly or indirectly related to national standards (such as NIST in the USA), international standards, or certified reference materials. This may be done by national standards laboratories operated by the government or by private firms offering metrology services.
Quality management systems call for an effective metrology system which includes formal, periodic, and documented calibration of all measuring instruments. ISO 9000[2] and ISO 17025[3] standards require that these traceable actions are to a high level and set out how they can be quantified.
To communicate the quality of a calibration the calibration value is often accompanied by a traceable uncertainty statement to a stated confidence level. This is evaluated through careful uncertainty analysis.
Some times a DFS (Departure From Spec) is required to operate machinery in a degraded state. Whenever this does happen, it must be in writing and authorized by a manager with the technical assistance of a calibration technician.
Measuring devices and instruments are categorized according to the physical quantities they are designed to measure. These vary internationally, e.g., NIST 150-2G in the U.S.[4] and NABL-141 in India.[5] Together, these standards cover instruments that measure various physical quantities such as electromagnetic radiation (RF probes), sound (sound level meter or noise dosimeter), time and frequency (intervalometer), ionizing radiation (Geiger counter), light (light meter), mechanical quantities (limit switch, pressure gauge, pressure switch), and, thermodynamic or thermal properties (thermometer, temperature controller). The standard instrument for each test device varies accordingly, e.g., a dead weight tester for pressure gauge calibration and a dry block temperature tester for temperature gauge calibration.
Instrument calibration prompts[edit]
Calibration may be required for the following reasons:
- a new instrument
- after an instrument has been repaired or modified
- moving from one location to another location
- when a specified time period has elapsed
- when a specified usage (operating hours) has elapsed
- before and/or after a critical measurement
- after an event, for example
- after an instrument has been exposed to a shock, vibration, or physical damage, which might potentially have compromised the integrity of its calibration
- sudden changes in weather
- whenever observations appear questionable or instrument indications do not match the output of surrogate instruments
- as specified by a requirement, e.g., customer specification, instrument manufacturer recommendation.
In general use, calibration is often regarded as including the process of adjusting the output or indication on a measurement instrument to agree with value of the applied standard, within a specified accuracy. For example, a thermometer could be calibrated so the error of indication or the correction is determined, and adjusted (e.g. via calibration constants) so that it shows the true temperature in Celsius at specific points on the scale. This is the perception of the instrument’s end-user. However, very few instruments can be adjusted to exactly match the standards they are compared to. For the vast majority of calibrations, the calibration process is actually the comparison of an unknown to a known and recording the results.
Basic calibration process[edit]
Purpose and scope[edit]
The calibration process begins with the design of the measuring instrument that needs to be calibrated. The design has to be able to «hold a calibration» through its calibration interval. In other words, the design has to be capable of measurements that are «within engineering tolerance» when used within the stated environmental conditions over some reasonable period of time.[6] Having a design with these characteristics increases the likelihood of the actual measuring instruments performing as expected.
Basically, the purpose of calibration is for maintaining the quality of measurement as well as to ensure the proper working of particular instrument.
Frequency[edit]
The exact mechanism for assigning tolerance values varies by country and as per the industry type. The measuring of equipment is manufacturer generally assigns the measurement tolerance, suggests a calibration interval (CI) and specifies the environmental range of use and storage. The using organization generally assigns the actual calibration interval, which is dependent on this specific measuring equipment’s likely usage level. The assignment of calibration intervals can be a formal process based on the results of previous calibrations. The standards themselves are not clear on recommended CI values:[7]
- ISO 17025[3]
- «A calibration certificate (or calibration label) shall not contain any recommendation on the calibration interval except where this has been agreed with the customer. This requirement may be superseded by legal regulations.”
- ANSI/NCSL Z540[8]
- «…shall be calibrated or verified at periodic intervals established and maintained to assure acceptable reliability…»
- ISO-9001[2]
- «Where necessary to ensure valid results, measuring equipment shall…be calibrated or verified at specified intervals, or prior to use…”
- MIL-STD-45662A[9]
- «… shall be calibrated at periodic intervals established and maintained to assure acceptable accuracy and reliability…Intervals shall be shortened or may be lengthened, by the contractor, when the results of previous calibrations indicate that such action is appropriate to maintain acceptable reliability.»
Standards required and accuracy[edit]
The next step is defining the calibration process. The selection of a standard or standards is the most visible part of the calibration process. Ideally, the standard has less than 1/4 of the measurement uncertainty of the device being calibrated. When this goal is met, the accumulated measurement uncertainty of all of the standards involved is considered to be insignificant when the final measurement is also made with the 4:1 ratio.[10] This ratio was probably first formalized in Handbook 52 that accompanied MIL-STD-45662A, an early US Department of Defense metrology program specification. It was 10:1 from its inception in the 1950s until the 1970s, when advancing technology made 10:1 impossible for most electronic measurements.[11]
Maintaining a 4:1 accuracy ratio with modern equipment is difficult. The test equipment being calibrated can be just as accurate as the working standard.[10] If the accuracy ratio is less than 4:1, then the calibration tolerance can be reduced to compensate. When 1:1 is reached, only an exact match between the standard and the device being calibrated is a completely correct calibration. Another common method for dealing with this capability mismatch is to reduce the accuracy of the device being calibrated.
For example, a gauge with 3% manufacturer-stated accuracy can be changed to 4% so that a 1% accuracy standard can be used at 4:1. If the gauge is used in an application requiring 16% accuracy, having the gauge accuracy reduced to 4% will not affect the accuracy of the final measurements. This is called a limited calibration. But if the final measurement requires 10% accuracy, then the 3% gauge never can be better than 3.3:1. Then perhaps adjusting the calibration tolerance for the gauge would be a better solution. If the calibration is performed at 100 units, the 1% standard would actually be anywhere between 99 and 101 units. The acceptable values of calibrations where the test equipment is at the 4:1 ratio would be 96 to 104 units, inclusive. Changing the acceptable range to 97 to 103 units would remove the potential contribution of all of the standards and preserve a 3.3:1 ratio. Continuing, a further change to the acceptable range to 98 to 102 restores more than a 4:1 final ratio.
This is a simplified example. The mathematics of the example can be challenged. It is important that whatever thinking guided this process in an actual calibration be recorded and accessible. Informality contributes to tolerance stacks and other difficult to diagnose post calibration problems.
Also in the example above, ideally the calibration value of 100 units would be the best point in the gauge’s range to perform a single-point calibration. It may be the manufacturer’s recommendation or it may be the way similar devices are already being calibrated. Multiple point calibrations are also used. Depending on the device, a zero unit state, the absence of the phenomenon being measured, may also be a calibration point. Or zero may be resettable by the user-there are several variations possible. Again, the points to use during calibration should be recorded.
There may be specific connection techniques between the standard and the device being calibrated that may influence the calibration. For example, in electronic calibrations involving analog phenomena, the impedance of the cable connections can directly influence the result.
Manual and automatic calibrations[edit]
Calibration methods for modern devices can be manual or automatic.
Manual calibration — US serviceman calibrating a pressure gauge. The device under test is on his left and the test standard on his right.
As an example, a manual process may be used for calibration of a pressure gauge. The procedure requires multiple steps,[12] to connect the gauge under test to a reference master gauge and an adjustable pressure source, to apply fluid pressure to both reference and test gauges at definite points over the span of the gauge, and to compare the readings of the two. The gauge under test may be adjusted to ensure its zero point and response to pressure comply as closely as possible to the intended accuracy. Each step of the process requires manual record keeping.
Automatic calibration — A U.S. serviceman using a 3666C auto pressure calibrator
An automatic pressure calibrator [13] is a device that combines an electronic control unit, a pressure intensifier used to compress a gas such as Nitrogen, a pressure transducer used to detect desired levels in a hydraulic accumulator, and accessories such as liquid traps and gauge fittings. An automatic system may also include data collection facilities to automate the gathering of data for record keeping.
Process description and documentation[edit]
All of the information above is collected in a calibration procedure, which is a specific test method. These procedures capture all of the steps needed to perform a successful calibration. The manufacturer may provide one or the organization may prepare one that also captures all of the organization’s other requirements. There are clearinghouses for calibration procedures such as the Government-Industry Data Exchange Program (GIDEP) in the United States.
This exact process is repeated for each of the standards used until transfer standards, certified reference materials and/or natural physical constants, the measurement standards with the least uncertainty in the laboratory, are reached. This establishes the traceability of the calibration.
See Metrology for other factors that are considered during calibration process development.
After all of this, individual instruments of the specific type discussed above can finally be calibrated. The process generally begins with a basic damage check. Some organizations such as nuclear power plants collect «as-found» calibration data before any routine maintenance is performed. After routine maintenance and deficiencies detected during calibration are addressed, an «as-left» calibration is performed.
More commonly, a calibration technician is entrusted with the entire process and signs the calibration certificate, which documents the completion of a successful calibration.
The basic process outlined above is a difficult and expensive challenge. The cost for ordinary equipment support is generally about 10% of the original purchase price on a yearly basis, as a commonly accepted rule-of-thumb. Exotic devices such as scanning electron microscopes, gas chromatograph systems and laser interferometer devices can be even more costly to maintain.
The ‘single measurement’ device used in the basic calibration process description above does exist. But, depending on the organization, the majority of the devices that need calibration can have several ranges and many functionalities in a single instrument. A good example is a common modern oscilloscope. There easily could be 200,000 combinations of settings to completely calibrate and limitations on how much of an all-inclusive calibration can be automated.
An instrument rack with tamper-indicating seals
To prevent unauthorized access to an instrument tamper-proof seals are usually applied after calibration. The picture of the oscilloscope rack shows these, and prove that the instrument has not been removed since it was last calibrated as they will possible unauthorized to the adjusting elements of the instrument. There also are labels showing the date of the last calibration and when the calibration interval dictates when the next one is needed. Some organizations also assign unique identification to each instrument to standardize the record keeping and keep track of accessories that are integral to a specific calibration condition.
When the instruments being calibrated are integrated with computers, the integrated computer programs and any calibration corrections are also under control.
Historical development[edit]
Origins[edit]
The words «calibrate» and «calibration» entered the English language as recently as the American Civil War,[14] in descriptions of artillery, thought to be derived from a measurement of the calibre of a gun.
Some of the earliest known systems of measurement and calibration seem to have been created between the ancient civilizations of Egypt, Mesopotamia and the Indus Valley, with excavations revealing the use of angular gradations for construction.[15] The term «calibration» was likely first associated with the precise division of linear distance and angles using a dividing engine and the measurement of gravitational mass using a weighing scale. These two forms of measurement alone and their direct derivatives supported nearly all commerce and technology development from the earliest civilizations until about AD 1800.[16]
Calibration of weights and distances (c. 1100 CE)[edit]
An example of a weighing scale with a ½ ounce calibration error at zero. This is a «zeroing error» which is inherently indicated, and can normally be adjusted by the user, but may be due to the string and rubber band in this case
Early measurement devices were direct, i.e. they had the same units as the quantity being measured. Examples include length using a yardstick and mass using a weighing scale. At the beginning of the twelfth century, during the reign of Henry I (1100-1135), it was decreed that a yard be «the distance from the tip of the King’s nose to the end of his outstretched thumb.»[17] However, it wasn’t until the reign of Richard I (1197) that we find documented evidence.[18]
- Assize of Measures
- «Throughout the realm there shall be the same yard of the same size and it should be of iron.»
Other standardization attempts followed, such as the Magna Carta (1225) for liquid measures, until the Mètre des Archives from France and the establishment of the Metric system.
The early calibration of pressure instruments[edit]
Direct reading design of a U-tube manometer
One of the earliest pressure measurement devices was the Mercury barometer, credited to Torricelli (1643),[19] which read atmospheric pressure using Mercury. Soon after, water-filled manometers were designed. All these would have linear calibrations using gravimetric principles, where the difference in levels was proportional to pressure. The normal units of measure would be the convenient inches of mercury or water.
In the direct reading hydrostatic manometer design on the right, applied pressure Pa pushes the liquid down the right side of the manometer U-tube, while a length scale next to the tube measures the difference of levels. The resulting height difference «H» is a direct measurement of the pressure or vacuum with respect to atmospheric pressure. In the absence of differential pressure both levels would be equal, and this would be used as the zero point.
The Industrial Revolution saw the adoption of «indirect» pressure measuring devices, which were more practical than the manometer.[20]
An example is in high pressure (up to 50 psi) steam engines, where mercury was used to reduce the scale length to about 60 inches, but such a manometer was expensive and prone to damage.[21] This stimulated the development of indirect reading instruments, of which the Bourdon tube invented by Eugène Bourdon is a notable example.
Indirect reading design showing a Bourdon tube from the front (left) and the rear (right).
In the front and back views of a Bourdon gauge on the right, applied pressure at the bottom fitting reduces the curl on the flattened pipe proportionally to pressure. This moves the free end of the tube which is linked to the pointer. The instrument would be calibrated against a manometer, which would be the calibration standard. For measurement of indirect quantities of pressure per unit area, the calibration uncertainty would be dependent on the density of the manometer fluid, and the means of measuring the height difference. From this other units such as pounds per square inch could be inferred and marked on the scale.
See also[edit]
![]()
Look up calibration in Wiktionary, the free dictionary.
- Calibration curve
- Calibrated geometry
- Calibration (statistics)
- Color calibration – used to calibrate a computer monitor or display.
- Deadweight tester
- EURAMET Association of European NMIs
- Measurement Microphone Calibration
- Measurement uncertainty
- Musical tuning – tuning, in music, means calibrating musical instruments into playing the right pitch.
- Precision measurement equipment laboratory
- Scale test car – a device used to calibrate weighing scales that weigh railroad cars.
- Systems of measurement
References[edit]
- ^ JCGM 200:2008 International vocabulary of metrology Archived 2019-10-31 at the Wayback Machine — Basic and general concepts and associated terms (VIM)
- ^ a b ISO 9001: «Quality management systems — Requirements» (2008), section 7.6.
- ^ a b ISO 17025: «General requirements for the competence of testing and calibration laboratories» (2005), section 5.
- ^ Faison, C. Douglas; Brickenkamp, Carroll S. (March 2004). «Calibration Laboratories: Technical Guide for Mechanical Measurements» (PDF). NIST Handbook 150-2G. NIST. Retrieved 14 June 2015.
- ^ «Metrology, Pressure, Thermal & Eletrotechnical Measurement and Calibration». Fluid Control Research Institute (FCRI), Ministry of Heavy Industries & Public Enterprises, Govt. of India. Archived from the original on 14 June 2015. Retrieved 14 June 2015.
- ^ Haider, Syed Imtiaz; Asif, Syed Erfan (16 February 2011). Quality Control Training Manual: Comprehensive Training Guide for API, Finished Pharmaceutical and Biotechnologies Laboratories. CRC Press. p. 49. ISBN 978-1-4398-4994-1.
- ^ Bare, Allen (2006). Simplified Calibration Interval Analysis (PDF). Aiken, SC: NCSL International Workshop and Symposium, under contract with the Office of Scientific and Technical Information, U.S. Department of Energy. pp. 1–2. Archived (PDF) from the original on 2007-04-18. Retrieved 28 November 2014.
- ^ «ANSI/NCSL Z540.3-2006 (R2013)». The National Conference of Standards Laboratories (NCSL) International. Archived from the original on 2014-11-20. Retrieved 28 November 2014.
- ^ «Calibration Systems Requirements (Military Standard)» (PDF). Washington, DC: U.S. Department of Defense. 1 August 1998. Archived from the original (PDF) on 2005-10-30. Retrieved 28 November 2014.
- ^ a b Ligowski, M.; Jabłoński, Ryszard; Tabe, M. (2011), Jabłoński, Ryszard; Březina, Tomaš (eds.), Procedure for Calibrating Kelvin Probe Force Microscope, Mechatronics: Recent Technological and Scientific Advances, p. 227, doi:10.1007/978-3-642-23244-2, ISBN 978-3-642-23244-2, LCCN 2011935381
- ^ Military Handbook: Evaluation of Contractor’s Calibration System (PDF). U.S. Department of Defense. 17 August 1984. p. 7. Archived (PDF) from the original on 2014-12-04. Retrieved 28 November 2014.
- ^ Procedure for calibrating pressure gauges (USBR 1040) (PDF). U.S. Department of the Interior, Bureau of Reclamation. pp. 70–73. Archived (PDF) from the original on 2013-05-12. Retrieved 28 November 2014.
- ^ «KNC Model 3666 Automatic Pressure Calibration System» (PDF). King Nutronics Corporation. Archived from the original (PDF) on 2014-12-04. Retrieved 28 November 2014.
- ^ «the definition of calibrate». Dictionary.com. Retrieved 18 March 2018.
- ^ Baber, Zaheer (1996). The Science of Empire: Scientific Knowledge, Civilization, and Colonial Rule in India. SUNY Press. pp. 23–24. ISBN 978-0-7914-2919-8.
- ^ Franceschini, Fiorenzo; Galetto, Maurizio; Maisano, Domenico; Mastrogiacomo, Luca; Pralio, Barbara (6 June 2011). Distributed Large-Scale Dimensional Metrology: New Insights. Springer Science & Business Media. pp. 117–118. ISBN 978-0-85729-543-9.
- ^ Ackroyd, Peter (16 October 2012). Foundation: The History of England from Its Earliest Beginnings to the Tudors. St. Martin’s Press. pp. 133–134. ISBN 978-1-250-01367-5.
- ^ Bland, Alfred Edward; Tawney, Richard Henry (1919). English Economic History: Select Documents. Macmillan Company. pp. 154–155.
- ^ Tilford, Charles R (1992). «Pressure and vacuum measurements» (PDF). Physical Methods of Chemistry: 106–173. Archived from the original (PDF) on 2014-12-05. Retrieved 28 November 2014.
- ^ Fridman, A. E.; Sabak, Andrew; Makinen, Paul (23 November 2011). The Quality of Measurements: A Metrological Reference. Springer Science & Business Media. pp. 10–11. ISBN 978-1-4614-1478-0.
- ^ Cuscó, Laurence (1998). Guide to the Measurement of Pressure and Vacuum. London: The Institute of Measurement and Control. p. 5. ISBN 0-904457-29-X.
Sources[edit]
- Crouch, Stanley & Skoog, Douglas A. (2007). Principles of Instrumental Analysis. Pacific Grove: Brooks Cole. ISBN 0-495-01201-7.

 Рассмотрим смысл этих терминов на примере системы сбора данных и подключенного к ней внешнего датчика, когда система сбора данных измеряет на своих входах значение электрической величины, а датчик является преобразователем определённой физической величины в электрическую.
Рассмотрим смысл этих терминов на примере системы сбора данных и подключенного к ней внешнего датчика, когда система сбора данных измеряет на своих входах значение электрической величины, а датчик является преобразователем определённой физической величины в электрическую.
- В данном примере термин калибровка относят к системе сбора данных, термин градуировка относят к датчику, а термин тарировка – ко всей рассматриваемой системе.
- Далее, рассмотрим подробнее технический смысл этих терминов.
- Калибровка – это устранение большей части систематической погрешности прибора путём задания коэффициентов коррекции данных для штатной операции коррекции данных, которая должна действовать в процессе работы этого прибора.
В большинстве случаев применяется линейная функция коррекции данных с двумя коэффициентами коррекции смещения нуля и коэффициента передачи, В любом случае, прибор должен сохранять калибровочные коэффициенты в энергонезависимой памяти, а сама операция коррекции данных может делаться как средствами самого прибора, так и средствами штатного ПО, поставляемого для этого прибора.
Производители приборов используют калибровку в целях уменьшения стоимости прибора, поскольку, в противном случае, пришлось бы применять высокопрецизионные компоненты и дорогостоящие технологические решения, которые сразу «от момента рождения» прибора обеспечивали бы требуемую величину систематической погрешности.
Для Средства Измерения операция калибровки делается метрологической службой в соответствии с Методикой поверки. В любом случае, важно отметить, что калибровка – это не пользовательская операция, которая, как правило, делается на предприятии изготовителе или аккредитованной организацией, для достижения заявленных производителем метрологических свойств.
Градуировка в рассматриваемом случае датчика – это заявленная производителем датчика зависимость выходной величины от входной в виде формул и таблиц. Когда речь идёт о стандартных датчиках (например, термопарах, термопреобразователях), изготовленных по стандартным технологическим параметрам, то градуировочные зависимости описываются в соответствующих ГОСТах на эти типы датчиков.
Градуировочные зависимости могут быть нелинейными, При применении такого датчика совместно с системой сбора данных на верхнем программном уровне должна быть применена соответствующая градуировочная функция этого датчика. Важно отметить, что применение градуировочной функции не устраняет полностью систематическую погрешность конкретного экземпляра датчика, а устраняет лишь большую часть этой погрешности.
Для чего нужна калибровка?
Что же такое калибровка? — Калибровка представляет собой набор действий, определяющих взаимосвязь между значениями измеряемой величины, указанной калибруемым измерительным прибором, и соответствующими значениями физических величин, осуществляемых с помощью стандартных единиц измерения и с учетом неопределенности измерения.
В простейшем случае эта процедура заключается в определении разницы между показанием стандарта и показанием калибруемого прибора с учетом неопределенности измерений. Целью калибровки является определение метрологических свойств калибруемого прибора, определение его пригодности для проведения измерений или подтверждение того, что калиброванный прибор соответствует определенным метрологическим требованиям (поверка).
Доказательством, подтверждающим метрологические свойства откалиброванного прибора, является документ, выданный лабораторией, и именуемый как сертификат о калибровке (поверке) с указанными символами аккредитации. Во время калибровки необходимо поддерживать согласованность измерений, также известную как прослеживаемость, составляющую непрерывную привязку калибруемого прибора по национальному или международному стандарту.
Что такое Тарировочная таблица?
Тарировка — что это за непонятное слово? Что подразумевается под тарировкой? Для чего нужна тарировка? Эти вопросы не дают покоя многим людям, кто впервые сталкивается с системами спутникового мониторинга транспорта и контроля топлива и впервые слышит данный термин.
- Большой толковый словарь современного русского языка Д.Н. Ушакова на эту тему сообщает: » Тарировать — проверить (проверять) показания каких-нибудь приборов путем сличения с показаниями контрольных приборов.»
- Словарь русских синонимов сообщает: » Тарировать — калибровать, градуировать»
- В Викисловаре находим: » Тарировка — градуировка измерительных приборов и регулирующих устройств», » Калибровка — проверка или измерение шкалы делений какого-нибудь измерительного прибора, сопоставление делений инструментальной шкалы со значениями измеряемой величины»
Теперь термин «тарировка» стал понятен и уже не вызывает вопросов. Осталось разобраться, какую роль играет тарировка в спутниковом мониторинге транспорта при помощи систем ГЛОНАСС и GPS. И в этом случае, оказывается, всё достаточно просто. Все датчики уровня топлива универсальны и подходят под любой топливный бак.
ДУТ различаются лишь длиной трубок. Но все баки разные по форме и объему. Два разных бака могут быть, например, одинаковой высоты, но разной длины. В связи с этим их объемы будут сильно отличаться. Так вот, чтобы диспетчер видел точное количество топлива в баках ДУТ необходимо откалибровать или тарировать,
Чтобы в итоге получить тарировочную таблицу, Тарировочная таблица — таблица, составляемая в процессе тарировки. Содержит в одной колонке данные, выдаваемые ДУТ, а во второй колонке соответствующие им значения в литрах.
Чем отличается калибровка от тарировки?
Термины: Калибровка, тарировка, градуировка В данном примере термин калибровка относят к системе сбора данных, термин градуировка относят к датчику, а термин тарировка – ко всей рассматриваемой системе.
Что такое слово калибровка?
Подстройка, проверка или измерение шкалы делений какого-нибудь измерительного прибора, сопоставление делений инструментальной шкалы со значениями измеряемой величины ◆ Калибровка термометра.
Для чего нужна тарировка?
Тарировка баков с «Ресурсконтроль» — Тарировка топливных баков в «Ресурсконтроль» осуществляется с помощью мобильных тарировочных станций. Тарировочная станция – это передвижной комплекс оборудования для тарирования, позволяющий проводить процедуру тарировки максимально быстро и в любой точке без привязки к АЗС или наличию 220В.
- Станция оборудована ёмкостью 1000 литров, генератором, насосом и мерными ёмкостями.
- С мобильной тарировочной станцией процесс тарировки максимально автоматизирован и происходит без использования дополнительного оборудования.
- Топливо из бака откачивается в ёмкость еврокуба, после чего порциями заливается обратно в бак, проходя через счётчик, который предварительно калибруется и проверяется.
тарировка производится по удобному для клиента адресу и не требует привлечения ответственных лиц со стороны клиента.
Как пользоваться Тарировочной таблицей?
Для топливомера ПТ-041 нужны следующие замеры: — 1. «Пустой бак» (при замере включать топливомер не нужно) – установите направляющую топливомера на горловину, как показано на рисунке. Упорная планка должна лежать на плоскости горловины, чтобы измерительная линейка располагалась к поверхности топлива под тем же углом, что и горловина.  2. «Полный бак» — с помощью канцелярской линейки замерьте длину горловины в миллиметрах в средней её части. Прибавьте 35 миллиметров (высота направляющей топливомера) и запишите показатель в графу «Полный бак». Замеры «Пустой бак» и «Полный бак» привязывают геометрию бака и топливомера друг к другу.3.
2. «Полный бак» — с помощью канцелярской линейки замерьте длину горловины в миллиметрах в средней её части. Прибавьте 35 миллиметров (высота направляющей топливомера) и запишите показатель в графу «Полный бак». Замеры «Пустой бак» и «Полный бак» привязывают геометрию бака и топливомера друг к другу.3.  Остальные графы в бланке заполнять не обязательно, они могут служить для удобства распознавания — какой машине какая таблица соответствует.
Остальные графы в бланке заполнять не обязательно, они могут служить для удобства распознавания — какой машине какая таблица соответствует.
Как измерить уровень топлива в баке линейкой?
16.06.2017 Как измерить количество топлива, оставшегося в баке автомобиля? Датчик на приборной панели не дает точной информации о количестве топлива. Самый простой способ узнать точную цифру – это опустить палку или линейку в топливный бак, а затем измерить значение и определить остаток по таблице.
- Специально для этого мы подготовили для вас тарировку топливного бака DAF (ДАФ).
- Если вы хотите узнать объём топливного бака DAF вам необходимо измерить линейкой топливный бак DAF и сравнить данные с таблицами указанные ниже.
- Мы разместили самые популярные размеры и объёмы топливных баков DAF (ДАФ), данные таблицы топливных баков DAF носят исключительно информативный характер.
Данные в тарировачных таблицах DAF могут иметь погрешность. Технология измерения проста. Берёте линейку и опускаете её в топливную горловину. Вытаскиваете линейку и смотрите сколько сантиметров линейки находилось в баке с топливом. Смотрите сантиметры в таблице объёмов бака и сравниваете значение с вашим топливным баком. На автомобиле были установлены 2 бака объемом 560 литров: На автомобиле установлено 2 бака объемом 850 и 430 литров, их тарировка: На автомобиле установлен бак объемом 850 литров, его тарировка: Тарировка баков 690 л, 400 л, 620 л и 750 л: На автомобиле установлены баки объемом 995 и 500 литров, их тарировка: На автомобиле установлен бак объемом 870 литров, его тарировка: На автомобиле установлен бак объемом 600 литров, его тарировка:
Что такое поверка и калибровка?
Калибровка и поверка. Разбираемся в понятиях — Специалистов белорусских лабораторий давно интересует вопрос: в чем заключается разница между калибровкой и поверкой? Эту разницу пытаются объяснить специалисты государственной метрологической службы, но для многих вопрос остается.
- И когда приходит время принять решение поверять или калибровать средства измерений, большинство специалистов задумываются и не могут однозначно ответить для себя на этот вопрос.
- Давайте попробуем разобраться.
- А разбираться начнем с понятий.
- Что же такое калибровка? А что такое поверка? На национальном уровне понятия калибровка и поверка закреплены в Законе Республики Беларусь об обеспечении единства измерений,
На международном уровне понятие калибровка закреплено в международном словаре по метрологии JCGM 200:2008,, Сравнение понятия приведено в таблице 1. Таблица 1 – Сравнение понятий «калибровка» и «поверка»  1. Основное отличие понятий «калибровка» и «поверка» заключается в том, что при калибровке устанавливают характеристики, а при поверке подтверждают их соответствие требованиям законодательства. Однако, подтверждение без установления невозможно. Чтобы сделать заключение о соответствии характеристик (подтвердить) требованиям, нужно сначала их оценить (установить).
1. Основное отличие понятий «калибровка» и «поверка» заключается в том, что при калибровке устанавливают характеристики, а при поверке подтверждают их соответствие требованиям законодательства. Однако, подтверждение без установления невозможно. Чтобы сделать заключение о соответствии характеристик (подтвердить) требованиям, нужно сначала их оценить (установить).
Получается понятие «поверка» включает в себя процедуры, предусмотренные при калибровке. РАЗРАБОТКА/ВАЛИДАЦИЯ МЕТОДИК Выполним работы по разработке Методик выполнения измерений ПОДРОБНЕЕ ОБ УСЛУГЕ С другой стороны, просто устанавливать характеристики без дальнейшего принятия решений бессмысленно. Измерительные устройства и эталоны, к которым может применяться процедура калибровки, предназначены для получения результатов измерений с заданной точностью.
Характеристики, которые устанавливаются при калибровке, напрямую влияют на точность и надежность получаемых результатов измерений. Поэтому на основании результатов калибровки специалист, использующий при измерении измерительные устройства или эталоны, должен принять решение: «а пригодно ли мое средство измерений (эталон, испытательное оборудование, измерительные системы) для получения надежного результата измерений (с требуемой точностью)?».2.
Что подлежит калибровке?
Средства измерений, подлежащие обязательной калибровке: — В обязательном порядке сертификация проводится для средств измерений, попадающих в одну из следующих групп:
КИП, обеспечивающие безопасный технологический процесс; приборы, применяемые в процессе совершения торговых, коммерческих и учетных операций; СИ, использование которых оказывает непосредственное влияние на качество продукции; образцовые и эталонные средства измерений. Они в обязательном порядке проходят сертификацию в государственных органах контроля, а также периодические поверки представителями этих инстанций; СИ, применение которых влияет на экологическую безопасность.
Если предприятие или индивидуальный предприниматель проводят добровольную калибровку, они могут получить аккредитацию в Госстандарте. В то же время, делать это не обязательно, так как проведение процедуры в собственных целях не требует какой-либо квалификации.
Как делается калибровка?
1. Средства измерений, не предназначенные для применения в сфере государственного регулирования обеспечения единства измерений, могут в добровольном порядке подвергаться калибровке. Калибровка средств измерений выполняется с использованием эталонов единиц величин, прослеживаемых к государственным первичным эталонам соответствующих единиц величин, а при отсутствии соответствующих государственных первичных эталонов единиц величин — к национальным эталонам единиц величин иностранных государств.2.
- Выполняющие калибровку средств измерений юридические лица и индивидуальные предприниматели в добровольном порядке могут быть аккредитованы в области обеспечения единства измерений.3.
- Результаты калибровки средств измерений, выполненной юридическими лицами или индивидуальными предпринимателями, аккредитованными в соответствии с законодательством Российской Федерации об аккредитации в национальной системе аккредитации, могут быть использованы при поверке средств измерений в сфере государственного регулирования обеспечения единства измерений.
Порядок признания результатов калибровки при поверке средств измерений в сфере государственного регулирования обеспечения единства измерений и требования к содержанию сертификата калибровки, включая прослеживаемость, устанавливаются Правительством Российской Федерации.
Что такое калибровка в психологии?
Раньше говорили — очень внимательный собеседник, наблюдательный, замечает в разговоре все! Теперь говорят о том же самом: «отлично калибрует»! Калибровка — это внимательное наблюдение за мелкими деталями состояния и поведения человека, уточняющие наше видение его состояния.
- Калибровка используется для более эффективной подстройки и ведения, данные калибровки помогают лучше понять, что на самом деле думает и чувствует человека, даже если он не расположен о своем состоянии рассказывать или тем более ведет двойную игру.
- Что дает калибровка? Лучше всего привести цитаты и примеры из работ студентов Университета практической психологии, которые они написали как отчеты по результатам тренировки этого замечательного навыка.
Пишет Б. Неля Моя младшая дочь, ей 14 лет, подняла перед зеркалом футболочку и громким голосом, привлекая мое внимание, говорит: мама, я такая толстая! Что я наблюдаю: зона Гюльчатай 1: центр бровей приподнят (некое удивление ), морщинки между бровей (усиливает момент), носик вздернут, уголки губ опущены вниз.
Глаза любопытные и хитроватые. В них уже заготовлен ответ для меня: ну что ж ты Яночка, ты худенькая и красивая. Ставлю эксперимент, отвечаю: сейчас позвоню в фитнес клуб, узнаю во сколько свободен тренер. Дальше картина маслом: первая реакция недоумение, складки на лбу горизонтальные, глаза большие и круглые (не то ожидала услышать), рот приоткрыт.
Удивление и недоумение. Пишет Л. Сергей В качестве калибруемых я выбрал жену, директора и администратора. Мы в браке 30 лет, что нового я смогу увидеть в своей жене? Интуитивно, неосознанно даже по микродвижениям, по первому слову я знаю, что и зачем она говорит.
- Но понаблюдав осознанно за её мимикой и жестами я понял, что ещё многое о ней не знаю.
- Она может говорить ласково, правильные слова и глаза могут быть добрыми, но если увижу складочку на лбу – значит она сердится; если добавляется жестикуляция (обычно указующая, но бывает просто суетность движений) значит, она возмущена и хочет активно влиять.
Когда она что то анализирует, глаза её сужаются и начинают бегать из стороны в сторону. Удовольствие выражается в лёгкой улыбке без обнажения зубов, уголки губ сильно вверх, под глазами складочка, щеки поднимаются вверх, в наружных углах глаз образуются так называемые гусиные лапки.
При удивлении глаза округляются, появляются складки на лбу и слегка приоткрывается рот. Когда она не верит мне её лицо как бы собирается к центру: губы в трубочку, щеки подтянуты, нос сморщен, глаза прищурены, на лбу складки. Пишет М. Светлана Отдел вневедомственной охраны, жду около кабинета окончание послеобеденного перерыва.
Время истекло, но никого нет. Минут через двадцать появляется женщина и замечает меня, ожидающую ее прихода. Движения рук становятся суетливыми, плечи немного сутулятся, голова втягивается в плечи. Лицо напрягается, на лбу появляются морщинки, брови немного сведены к переносице.
Что такое калибровка на телефоне?
Калибровка тачскрина Android через приложение — Для устройств, которые не имеют встроенных средств калибровки экрана, существуют специальные приложения. В Google Play их очень много. Порекомендуем два: 
Touchscreen Calibration, Простое приложение для ручной калибровки экрана Android. Позволяет настроить силу нажатия, двойного нажатия, длительного нажатия, зума, скроллинга. Quick TuneUp, Для автоматической калибровки всех сенсоров телефона. Просто откройте приложение, выберите пункт Display Calibration, и программа автоматически откалибрует все датчики экрана.
Читайте также :
Как открыть скрытые функции Android Как работает ЖК-дисплей? Просто о сложном Как защитить дисплей смартфона с помощью жидкого стекла
Фото: Android Central, Google Play
Для чего калибруют приборы?
Весовое оборудование калибруют, чтобы оценить, как оно работает. Настройку выполняют, чтобы внести необходимые изменения в работу прибора. Такая очередность важна, поскольку нельзя менять настройки оборудования для взвешивания, не оценив сначала его работу.
Для чего нужна калибровка экрана?
Что такое калибровка экрана — Калибровка экрана — это настройка сенсора для верной работы команд при касании пальцами или стилусом. В основном калибровка требуется в последствии падения телефона, даже из-за самых мелких повреждений может потребоваться настройка экрана.
Проверить нужна ли данная процедура достаточно просто. Сначала нужно снять защитную плёнку, для того чтобы касания воспринимались правильно и четко. Далее попробуйте ввести любую букву или цифру, если вы нажали одно, а на экране высветилось совсем другое, можете быть уверены в необходимости калибровки.
А значит нужно прочесть подробную статью как на андроид сделать калибровку экрана, далее расскажем вкратце.
Для чего нужна калибровка анализатора?
Краткое вступление — Все, кто работает с векторными анализаторами электрических цепей знают, что перед тем как начинать измерения, анализатор цепей необходимо откалибровать, Точность калибровки напрямую влияет на точность всех последующих измерений векторного анализатора цепей (ВАЦ), поэтому выполнять её надо грамотно и аккуратно.
Правильная калибровка сводит к минимуму погрешности (неопределённости) всей измерительной системы, которая, кроме самого анализатора, обычно включает два фазостабильных кабеля и, в некоторых случаях, переходные адаптеры. Также во время калибровки определяется место расположения опорной плоскости, которая будет использоваться для всех измерений фазы.
На этой странице подробно рассказано о разных методах калибровки и показан пример калибровки ВАЦ Anritsu MS46122A по методу SOLT.
Обновлено: 12.02.2023
Имя журнала: System
Источник: Microsoft-Windows-WHEA-Logger
Дата: 06.03.2011 11:15:01
Код события: 18
Категория задачи:Отсутствует
Уровень: Ошибка
Ключевые слова:
Пользователь: LOCAL SERVICE
Компьютер: LesenyshPC
Описание:
Произошла неустранимая аппаратная ошибка.
Сообщивший компонент: ядро процессора
Источник ошибки: Исключение проверки компьютера
Тип ошибки: Ошибка иерархии кэша
ИД процесса: 0
Дополнительные сведения содержатся в подробном представлении этой записи.
Xml события:
<Event xmlns http://schemas.microsoft.com/win/2004/08/events/event» target=»_blank» rel=»noreferrer nofollow»>http://schemas.microsoft.com/win/2004/08/events/event»>
<System>
<Provider Name=»Microsoft-Windows-WHEA-Logger» Guid=»» />
<EventID>18</EventID>
<Version>0</Version>
<Level>2</Level>
<Task>0</Task>
<Opcode>0</Opcode>
<Keywords>0x8000000000000000</Keywords>
<TimeCreated SystemTime=»2011-03-06T08:15:01.459526500Z» />
<EventRecordID>2860</EventRecordID>
<Correlation ActivityID=»» />
<Execution ProcessID=»1608″ ThreadID=»1864″ />
<Channel>System</Channel>
<Computer>LesenyshPC</Computer>
<Security UserID=»S-1-5-19″ />
</System>
<EventData>
<Data Name=»ErrorSource»>3</Data>
<Data Name=»ApicId»>0</Data>
<Data Name=»MCABank»>8</Data>
<Data Name=»MciStat»>0xee2000000003110a</Data>
<Data Name=»MciAddr»>0xff7fff40</Data>
<Data Name=»MciMisc»>0x1040000086</Data>
<Data Name=»ErrorType»>9</Data>
<Data Name=»TransactionType»>2</Data>
<Data Name=»Participation»>256</Data>
<Data Name=»RequestType»>0</Data>
<Data Name=»MemorIO»>256</Data>
<Data Name=»MemHierarchyLvl»>2</Data>
<Data Name=»Timeout»>256</Data>
<Data Name=»OperationType»>256</Data>
<Data Name=»Channel»>256</Data>
<Data Name=»Length»>928</Data>
<Data Name=»RawData»>435045521002FFFFFFFF03000100000002000000A0030000370D080006030B140000000000000000000000000000000000000000000000000000000000000000BDC407CF89B7184EB3C41F732CB57131FE6FF5E89C91C54CBA8865ABE14913BB4827C16BD6DBCB0102000000000000000000000000000000000000000000000058010000C00000000102000001000000ADCC7698B447DB4BB65E16F193C4F3DB0000000000000000000000000000000001000000000000000000000000000000000000000000000018020000800000000102000000000000B0A03EDC44A19747B95B53FA242B6E1D0000000000000000000000000000000001000000000000000000000000000000000000000000000098020000080100000102000000000000011D1E8AF94257459C33565E5CC3F7E8000000000000000000000000000000000100000000000000000000000000000000000000000000007F010000000000000002010000020000A70602000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000007000000000000000000000000000000A706020000081000BFE3BA1DFFFBEBBF0000000000000000000000000000000000000000000000000000000000000000F50157A5EFE3DE43AC72249B573FAD2C03000000000000009F0082260000000040FF7FFF00000000000000000000000000000000000000000000000000000000010000000100000073107E6FD6DBCB010000000000000000000000000000000000000000080000000A110300000020EE40FF7FFF0000000086000040100000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000</Data>
</EventData>
</Event>
№3 и 4 источник: DistributedCOM
№5 источник: Application Error
Имя сбойного приложения: LogonUI.exe, версия: 6.1.7600.16385, отметка времени: 0x4a5bc8ba
Имя сбойного модуля: ImageReog.dll_unloaded, версия: 0.0.0.0, отметка времени 0x4ab5cc8c
Код исключения: 0xc0000005
Смещение ошибки: 0x0000000180006b20
Идентификатор сбойного процесса: 0xb98
Время запуска сбойного приложения: 0x01cbdb65c4fb5f20
Путь сбойного приложения: C:windowssystem32LogonUI.exe
Путь сбойного модуля: ImageReog.dll
Код отчета: 42add5e6-4759-11e0-81a4-889ffae6ad1c
№6 источник: SideBySide
Ошибка создания контекста архивации для «c:program files (x86)windows livephoto galleryMovieMaker.Exe». Ошибка в файле манифеста или политики «c:program files (x86)windows livephoto galleryWLMFDS.DLL» в строке 8. Идентификатор компонента в файле манифеста не соответствует запрошенному идентификатору компонента. Ссылка — WLMFDS,processorArchitecture=»AMD64″,type=»win32″,version=»1.0.0.1″. Определение — WLMFDS,processorArchitecture=»x86″,type=»win32″,version=»1.0.0.1″. Используйте sxstrace.exe для подробной диагностики.
Ошибка создания контекста архивации для «c:program files (x86)microsoftsearch enhancement packsearch helpersearchhelper.dll». Ошибка в файле манифеста или политики «c:program files (x86)microsoftsearch enhancement packsearch helpersearchhelper.dll» в строке 2. Синтаксическая ошибка в XML.
№7 Источник: Service Control Manager
Сбой при запуске службы «ReadyComm.DirectRouter» из-за ошибки
Не удается найти указанный файл.
Служба «Установщик модулей Windows» завершена из-за ошибки
№ 8 источник: LanguagePackSetup
Не удалось запустить мастер установки языкового пакета. Перезагрузите систему и заново запустите мастер.
Шина:Устройство:Функция: 0x0:0x1C:0x4
ИД поставщика:ИД устройства: 0x8086:0xA114
Код класса: 0x30400
Дополнительные сведения содержатся в подробностях этой записи.
| [ Name] | Microsoft-Windows-WHEA-Logger |
| UncorrectableErrorStatus | 0x0 |
| CorrectableErrorStatus | 0x1000 |
| HeaderLog | 00000000000000000000000000000000 |
| RawData | 435045521002FFFFFFFF02000200000002000000A002000026110A00050112140000000000000000000000000000000000000000000000000000000000000000BDC407CF89B7184EB3C41F732CB571311FC093CF161AFC4DB8BC9C4DAF67C1046C2594DAEE85D30100000000000000000000000000000000000000000000000010010000D0000000000300000100000054E995D9C1BB0F43AD91B44DCB3C6F3500000000000000000000000000000000020000000000000000000000000000000000000000000000E0010000C00000000003000000000000ADCC7698B447DB4BB65E16F193C4F3DB00000000000000000000000000000000030000000000000000000000000000000000000000000000DF0000000000000004000000010100001000060400000000868014A1000403041C00000000000000000000000000000000000000108042010180000027001100234872054200223000FD440000004000080000000000000037080000100400000000000000000000000000000000000001000114000000000000000011000600001000000020000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000043010000000000000002000000000000E306050000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 |
Что было сделано.
Далее были скачаны все официальные последние драйвера с сайтов производителей.
Видеокарту с GeForce, Чипсет HM170 с сайта Intel и остальное так же. Так же без ошибок, все обновилось.
Если персональные компьютеры пользователей при своем функционировании испытывают определенные сложности и затруднения с определенными составными аппаратными компонентами устройств, то в данном руководстве мы подробно рассмотрим разнообразные способы осуществления проверки состояния используемого оборудования и представим действенные варианты устранения наиболее распространенных проблем.
Введение
Востребованность среди пользователей современных персональных компьютерных устройств для своевременного и полноценного исполнения множества разнообразных, по уровню трудоемкости и прилагаемых усилий, процессов довольно высока, и, с каждым днем, ее уровень постоянно увеличивается. Массовое внедрение и широкое применение устройств способствует развитию продвинутых и более мощных составных комплектующих, используемых в различных комбинаторных вариациях для окончательного формирования готовых компьютерных изделий. Наибольшее распространение в мире, как для делового и профессионального использования, так и для индивидуальных личных целей, получили стационарные настольные персональные компьютеры и ноутбуки различной конечной формы и конфигурации исполнения.
Отдельным важным и незаменимым элементом, без которого невозможно достичь существующей популярности и массовости представления, контролирующим любые запущенные процессы компьютерного устройства, обеспечивающим полноценное управление и корректное функционирование компьютера, организовывающим должный уровень взаимодействия пользователей с устройством и многообразием используемого массива разнообразной информации, безусловно является операционная система.
Среди предлагаемых образцов программных решений различных мировых доверенных разработчиков, особо выделяется операционная система «Windows» от производителя «Microsoft» , приверженность к которой подтверждена наибольшей представленностью на пользовательских компьютерах и ноутбуках. Данный программный инструмент управления обладает не только удачным и привлекательным для пользователей интерфейсом, но и позволяет устанавливать множественные сторонние приложения, а также способен контролировать и обслуживать подавляющее большинство внутренних и внешних образцов аппаратного оборудования, успешно объединяя их в единый комплекс и полноценно раскрывая, заложенный производителями, потенциал.
В операционной системе «Windows» , представленной на сегодняшний день своей новейшей прогрессивной версией «Windows 10» , присутствуют ответственные службы, следящие за исправностью, подключенного к пользовательскому персональному компьютеру, оборудования (клавиатура, мышь, материнская плата, процессор, память и т.д.).
Если пользователи замечают отдельные неполадки с определенным оборудованием или на мониторе персонального компьютера отображаются предупреждения с желтым восклицательным знаком, красной буквой «X» или стрелкой вниз, то понимание его рабочего состояния должно быть одним из первых шагов для успешной диагностики и устранения проблем.
В данном руководстве по представлению, заложенных разработчиками, возможностях операционной системы «Windows 10» мы непосредственно расскажем о шагах, позволяющих определить исходное состояние оборудования, установленного на пользовательском компьютере, а также представим порядок действий, направленных на устранение неполадок и исправление распространенных неисправностей.
Как проверить состояние оборудования с помощью встроенного приложения «Диспетчер устройств» ?
Чтобы проверить состояние аппаратного оборудования, установленного на персональном компьютере, пользователям предстоит выполнить, представленный далее, простой упорядоченный алгоритм последовательных действий.
Статус, доступного на персональном компьютере, оборудования пользователи могут определить из системного приложения «Диспетчер устройств» , непосредственный доступ к которому в операционной системе «Windows 10» можно получить многими разными способами. Задействуйте любой известный вариант запуска и откройте востребованное приложение. Например, нажмите на «Панели задач» в нижнем левом углу рабочего стола на кнопку «Пуск» , и откройте главное пользовательское меню операционной системы. В основной панели меню, содержащей упорядоченный по алфавиту перечень установленных на компьютере системных приложений и программ сторонних разработчиков, задействуя для перемещения колесо вращения компьютерной мыши или ползунок полосы прокрутки, отыщите и откройте раздел «Средства администрирования Windows» .
Не могу локализовать ошибку, проявляется по разному, но итог один — тормоза на терминальном сервере. Извиняюсь за многобукв.
Имеем сервер :
Мать — ASRock EP2C612D8 (был ранее заменена по гарантии на идентичную, после замены ОС не переустанавливали)
ОЗУ — 64 Гб
Процессор — Intel Xeon E5-2620 v3, 2,4 Ггц
RAID контроллер — LSI MegaRAID SAS 9271-8i
На сервере крутится
Windows Server 2008R2
Терминалы
MS SQL 2012
Сервер 1С
УТ 10.3
80 Гб
Пользователей до 20-25, в основном работают в УТ, забивают заявки и и тд.
В штатном режиме работы процессор загружен до 15 процентов, чаще всего до 10.
Сегодня пользователи пожаловались на тормоза, в диспетчере задач увидел загруженность процессора под 60%, причем понять что именно грузило не возможно, поочередно процессор то SQL, то платформа, то rphost, то другое по, хотя показатели по оперативной памяти и дисковой активности были в норме.
В событиях красовалась ошибка :
Неустранимая аппаратная ошибка.
Источник : WHEA-Logger
Компонент: Порт PCI Express Root
Источник ошибки: BOOT
Шина:Устройство:Функция: 0x0:0x3:0x2
ИД поставщика:ИД устройства: 0x8086:0x2f0a
Код класса: 0x604
Согласно ИД устройства это
Intel(R) Xeon(R) E7 v3/Xeon(R) E5 v3/Core i7 PCI Express Root Port 3 — 2F0A
Подобная ошибка и тормоза выскакивали не первый раз, помогало обычная перезагрузка.
Пробовал обновить драйвера на материнской плате — безуспешно, до следующих тормозов могло пройти 2-3 недели.
Сегодня перезагрузка не решила, процессор был загружен изначально, помогло только вкл/выкл.
После загрузки снова выскочила ошибка, но уже ссылалось на другое ИД оборудования
Intel(R) Xeon(R) E7 v3/Xeon(R) E5 v3/Core i7 DMI2 — 2F00
С подобным дел не имел, теряюсь в догадках.
Провернуть глобальные вещи нет возможности, так как на сервер свободен только 6 часов. Банально даже систему переставить не успею толком.
Завтра буду ставить вопрос перед руководителем о приобретении мощного ПК, на который можно все это будет временно перенести. (i7,SSD все дела).
Железо не под задачи да и само по себе не очень надежное.
У тебя идет банальный «перегрев» мамки при работе/нагрузке и это еще осложнено старой осью с не совсем правильными драйверами.
Обновление биоса/оси/дров может помочь но совершенно не факт.
Ищите другой сервак и выносите на него одну из баз чтобы снизить нагрузку, заодно и резерв будет.
БП3 дико прожорлива в терминале, если рабочие компы позволяют то в тонкие клиенты ее.
(2) «БП3 дико прожорлива в терминале» // Речь о толстом клиенте в терминале?
(3) > Речь о толстом клиенте в терминале?
У автора УТ-шка 10.3. А она разве в тонком клиенте, а не в толстом на обычных формах?
Вообще идея смешивания сервера терминалов с СУБД и сервером приложения на одном компе не самая лучшая.
По возможности надо сервер терминалов отдельно выносить, оставив только СУБД+1С. Для 25 пользователей самое то.
Начать можно с того, что пользователей с нормальными по характеристикам клиентскими компами вообще выкинуть с терминального сервера.
(0) У вас этот сервер стоит в отдельном, хорошо охлаждаемом помещении? Если нет, то можно попросить руководство обеспечить серверу необходимые условия эксплуатации. И туда же потом поставить еще I7 с SSD и всеми делами.
(0) Обновляй биосы мамки и рейд контроллера.
PS это еще одна отрицательная сторона серверного оборудования — необкатанность прошивок и драйверов.
(2) В БУХ работает 1-2 человека, как правило это переброс документов из УТ и перепроверенные их в отчетные периоды.
В УТ 10.3 днем работает пару бухгалтеров, разносят приходники и c 12 до 21 остальные пользователи забивают до 1000 РТУ.
В штатном режиме таких проблем не было, процессор загружается от 0 до 10 процентов и не более. Время отклика и длина очереди дисковой системы в норме. Я понимаю что сервер не хватает с небес звезды, но с нагрузкой справлялся.
А тут даже после перезагрузки тормозил сервер целиком, даже банальное сворачивание окна проводника происходило не спеша и небрежно.
(6)
1. Виртуальных серверов нет.
2. Температура процессоров и материнской была в норме, температура в серверной не превышала 25 градусов, сегодня включил принудительное охлаждение.
3. Длина очереди к дискам и время отклика на удивление были в норме. Отклик порядка 10 мс.
4. Изучу вопрос.
(7) Тоже склонен глобально заняться этим вопросом, но смогу только после переноса текущего ПО на другую площадку. Выделят ли для этого хоть какие-то средства — большая загадка. Планировал приобрести i7 c максимальной частотой на ядро, оперативы 32/64 и воткнуть пару SSD от самсунг. Как раз будет некий резерв, куда можно будет переносить базы, так и машина на которой можно будет шустрее поорбрезать базы.
(4) Основная часть клиентов УТ 10.3 работают через аппаратные тонкие клиенты, грузятся по сети (WTware).
Напрямую по RDP с компьютеров подключается 3 бухгалтера да и компьютеры у них так себе (4Гб ОЗУ и прочее), не думаю что они что-то решат.
Отделить терминалы от 1С+SQL это хорошо, но увы не располагаю такими ресурсами, просто тупо некуда. Особенность предприятия — минимальные затраты на АйТи, а лучше чтоб их вообще не было. Сложно что-то объяснить человеку, если он не слушает, ну это так . эмоции.
Склонен все же выбить производительный системник (писал выше), обновить биос, прошивку контролера обновить, сделать ТО серверу, переустановить ОС и там будет понятно, решаемая эта проблема или нет.
(10) «Особенность предприятия — минимальные затраты на АйТи, а лучше чтоб их вообще не было. Сложно что-то объяснить человеку, если он не слушает» // Так ты пади объяснять не умеешь, лезешь с какой-нибудь технической хней.
Ты в понятиях управленца попробуй разъяснить, что если не вкладывать в ИТ, то будет то-то и то-то (столько-то часов / дней простоя, например)
(11) Это скажем так «особенность» руководителя. Он считает что ИТ вообще лишнее и с ним он мирится как с необходимым злом, что-то вкладывать это как переступить через себя.
Чтоб понимать насколько неохотно выделяются средства — приведу пример. Ежемесячно предприятие тратит
15 т.р. на заправки картриджей и мелкий ремонт техники(блоки питания, батареи ИБП, мышки и прочая мелочевка). Даже при таких минимальных тратах я оказался под подозрением. Получил звание — Директор по расходам. В итоге провел анализ своих затрат за 3 года и подготовил докладную записку, в которой на цифрах, что за 3 года цена на заправку не изменились и остались на прежнем уровне. Вроде как этот вопрос закрыл.
В мае взял отпуск на 1 рабочую неделю и как по закону подлости произошел вот такой же баг как я и описывал в (0). Был в горах, вне зоны GSM.
Два дня водили админов со всего города и на второй день решились перезагрузить сервер и все вернулось на круги своя. Что было потом, сложно описать приличными словами. В итоге шеф признал, что резерв нужен, что бы не было простоев, но платить полную стоимость аналогичного сервера он не готов. Мол ищите иной хитрый способ.
Ничего иного кроме мощного ПК на SSD дисках я не придумал.
(9) >А тут даже после перезагрузки тормозил сервер целиком, даже банальное сворачивание окна проводника происходило не спеша и небрежно.
Читайте также:
- Как называется компьютер похожий на папку
- Есть ли на playstation 5 трассировка лучей
- Как получить информацию о свойствах объекта в компьютере
- Настройка компьютеров в чехове
- Как обклеить ноутбук пленкой