Challenge
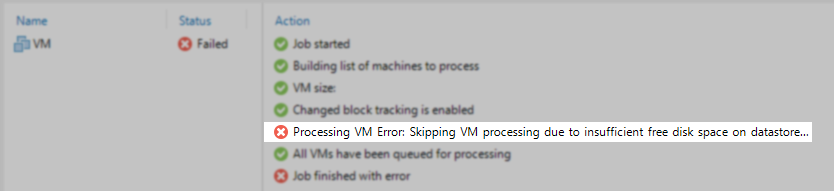
A Backup or Replication job fails with the messages:
Production datastore <datastore_name> is getting low on free space (xx GB left), and may run out of free disk space completely due to open snapshots.

Error: Skipping VM processing due to insufficient free disk space on datastore <datastore_name>.
Cause
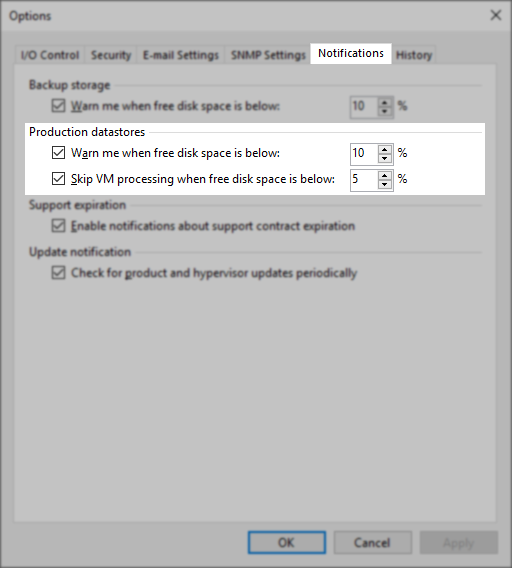
These notifications occur when a datastore associated with the VM being processed has free space less than the percentage configured within the Low Disk Space Notification settings.
Solution
Please investigate the datastore size and relative free space and adjust the notifications setting as needed. As the notifications are based on the percentage of free space and not a specific value, some environments with very large datastores may trigger these notifications sooner than expected. For example, with the default settings (warn=10%/skip=5%) in an environment with a 50TB datastore, the warning about free space will trigger when there is still 5TB of free space and begin skipping VMs at 2.5TB.
However, if the Datastore is actually low on free space, it is advisable to start by investigating whether any virtual machines using that datastore are running on a snapshot either user-created or one accidentally left behind by Veeam Backup & Replication. The snapshots created by Veeam Backup & Replication for vSphere environments will be named ‘VEEAM BACKUP TEMPORARY SNAPSHOT’, for Hyper-V environments, they are named ‘Veeam Recovery Snapshot’. These snapshots should only be present on a VM when a backup/replication job is actively processing that VM.
- VMware KB1004343: Determining if a virtual machine running on a snapshot
- VMware KB1003412: Troubleshooting ESXi datastore or VMFS volume that is full or near capacity
- For Hyper-V, use the following command to locate open checkpoints (snapshots).
get-vmsnapshot (get-vm)
Note: If the datastore is used to store replicas, remember that snapshots are used as restore points on replicas and should not be manually removed.
-
Veeam Backup & Replication User Guide: Low Disk Space Notification
More Information
Even if the «Skip VMs when free disk is below » option is disabled, Veeam Backup & Replication will terminate jobs if the amount of free space on the datastore is below 2 GB. This threshold limit is adjustable with the following registry value.
Key Location: HKLMSOFTWAREVeeamVeeam Backup and Replication
Value Name: BlockSnapshotThreshold
Value Type: DWORD (32-Bit) Value
Value Data (Default): 2
The Value Data is measured in Gigabytes (GB).
Critical Information
We strongly advise against lowering the threshold below 2GB unless you are absolutely certain and understand the ramifications.
This threshold is intended to prevent Veeam Backup & Replication from creating a snapshot that could grow to the point that the datastore becomes full. When a VMware Datastore becomes full, instabilities can occur, including VMs that are using thin provisioned disks becoming paused as they cannot expand further.
VMware KB1003412: Troubleshooting ESXi datastore or VMFS volume that is full or near capacity
To submit feedback regarding this article, please click this link: Send Article Feedback
To report a typo on this page, highlight the typo with your mouse and press CTRL + Enter.
Processing error skipping vm processing due to insufficient free disk space on datastore datastore1

Veeam Backup & Replication поможет справиться с новым поколением операционных проблем благодаря комплексному набору возможностей защиты данных корпоративного уровня. Veeam — эффективное и удобное решение, которое снижает непроизводительную нагрузку за счет гибких возможностей, отвечающих потребностям вашего бизнеса, и ведущих в отрасли показателей надежности.
Veeam Backup & Replication — простое, гибкое и надежное решение, которое обеспечивает доступность всех данных облачной, виртуальной и физической среды. Защита данных, находящихся в любых локациях, с помощью эффективных возможностей резервного копирования и мгновенного восстановления.
Эффективные передовые технологии защиты данных
Veeam Backup & Replication — решение 4-в-1 для резервного копирования и восстановления, которое позволяет защищать данные с помощью аппаратных снимков, резервных копий и реплик, а также обеспечивает непрерывную защиту данных. Veeam — лидер отрасли, который обеспечивает надежную и безопасную защиту облачных, виртуальных и физических систем.
НОВАЯ версия 11 включает более чем 150 новых возможностей и улучшений, что обеспечивает беспрецедентную отказоустойчивость решения при ее использовании в компаниях любого размера.
• Непрерывность бизнес-процессов для критически важных приложений и данных благодаря непрерывной защите данных Veeam
• Снижение затрат более чем в 20 раз за счет недорогого долгосрочного архивирования данных в облачных хранилищах AWS S3 Glacier и Azure Archive
• Надежная защита от программ-вымогателей благодаря неизменным резервным копиям в защищенном репозитории Linux
• Мгновенное восстановление NAS, Microsoft SQL и Oracle
Техническая документация Всего записей: 2 | Зарегистр. 18-04-2017 | Отправлено: 12:49 07-11-2017 | Исправлено: docNemo, 11:33 02-12-2022
| MACTEP
Advanced Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору dinohrom Цитата: точно и однозначно рефс- тк фаст клонинг Собственно, так и сделал, разметив сторадж с рекомендованным размером блока, а потом что-то засомневался. рефс- не дедуплицируемая на уровне файловой системы фс Но заявлено, что в серванте 2019 уже дедуплицируемая, вроде как? |
| Всего записей: 917 | Зарегистр. 11-04-2002 | Отправлено: 15:50 15-03-2020 |
| dinohrom
Newbie |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору отличие нтфс от рефс, среди прочего, отсутствие дудупа, ман по фс. дедуп заменен на фаст клон силами вима, что более эффективно. размер блока какой выставлен в рефс ? |
| Всего записей: 21 | Зарегистр. 06-01-2007 | Отправлено: 16:51 15-03-2020 |
| MACTEP
Advanced Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору dinohrom Цитата: размер блока какой выставлен в рефс ? 64k |
| Всего записей: 917 | Зарегистр. 11-04-2002 | Отправлено: 17:14 15-03-2020 |
| reff
Gold Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору MACTEP Поищите ответ на свой вопрос в блоге на хабре и ютубном канале veeam. |
| Всего записей: 6928 | Зарегистр. 04-09-2003 | Отправлено: 00:52 16-03-2020 |

| U2007
Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору MACTEP посмотрите на дисковую загрузку от дедупликации и вопрос отпадет. мое мнение — ну его на эту дедупликацию на винде в рамках бэкап репозитория — поскольку бэкапы ежедневные, то постдедупликация будет практически бесперерывная (хотя в 2019 допилили многопоток, может там дела лучше будут, не пробовал) |
| Всего записей: 339 | Зарегистр. 25-11-2008 | Отправлено: 16:22 16-03-2020 |
| MACTEP
Advanced Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Спасибо за инфу и подсказки! Соберу тогда рейд с размером страйпа 256к и форматну в рефс с 64к кластером. |
| Всего записей: 917 | Зарегистр. 11-04-2002 | Отправлено: 18:46 16-03-2020 |
| Chekhov
Newbie |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Можно настроить чтоб Veeam Agent для Microsoft Windows FREE делал бэкап раз в месяц? |
| Всего записей: 5 | Зарегистр. 23-05-2016 | Отправлено: 14:59 03-04-2020 |
| gegetthrjtyk
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Добрый день. Сегодня поставил VBR и сразу столкнулся с проблемой Processing VM Error: Skipping VM processing due to insufficient free disk space on datastore esxistorage. Не понимаю чего может не хватать, если под бэкап у меня есть 8ТБ свободного места, а на датасторе esxi — 800ГБ, и это при размере дисков ВМ 60ГБ. Почему вообще место требуется на датастре, да так, что аж более чем в 10 раз больше от размера ВМ не хватает ? |
| Всего записей: 45 | Зарегистр. 01-02-2016 | Отправлено: 18:36 25-05-2020 |
| U2007
Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору gegetthrjtyk 800ГБ — это сколько процентов от объема датастора? в VEEAM есть настройка зависящая от % свободного пространства на датасторе, страховка на случай заполнения стораджа от разросшихся снапшетов. |
| Всего записей: 339 | Зарегистр. 25-11-2008 | Отправлено: 19:00 25-05-2020 |
| gegetthrjtyk
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору U2007 Спасибо, идею понял. Это 2% с небольшим. UPD: Настройка skip VM processing в general options. |
| Всего записей: 45 | Зарегистр. 01-02-2016 | Отправлено: 15:37 26-05-2020 | Исправлено: gegetthrjtyk, 15:56 26-05-2020 |
| neyasyt9
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору del |
| Всего записей: 195 | Зарегистр. 19-01-2015 | Отправлено: 12:39 16-07-2020 | Исправлено: neyasyt9, 14:46 03-08-2020 |

| Serg0FFan
Silver Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Уважаемые, подскажите, что за беда такая с 10кой? Пытаюсь восстановить файлы из архива, Guest Files — Microsoft Windows. Выбираю архив, указываю причину восстановления, жму Finish, далее пишет что сейчас бэкап браузер откроется и вылетает вот эта ошибка. 09.12.2020 11:43:24 Error Выдано исключение типа «Veeam.Backup.AgentProvider.AgentClosedException». Причем на всех архивах виндовых. На Linux всё нормально, открывается браузер файлов и можно все восстановить. Причем на двух разных установках такая беда, последний патч 10а установил сегодня же и . ничего не поменялось. В логах, на сервере где установлен Veeam B&R10 такая запись есть: |
| Всего записей: 3031 | Зарегистр. 25-12-2002 | Отправлено: 18:36 09-12-2020 |

| CrazYViruS_CrazyNet
Member |
Редактировать | Профиль | Сообщение | ICQ | Цитировать | Сообщить модератору Доброго времени всем ! При попытке обновления а далее при «чистой установки» — «VeeamBackup&Replication_10.0.1.4854_20200723» возникает ошибка: «Адресат вызова создал исключение.» В логах: «BackupSrvLog.log» на данном этапе проблема: 1AppDataLocalTemp77ee83ac-a1b4-4e5f-b89c-b20da1ef6482Veeam.Backup.Setup.dll_x64′. 1AppDataLocalTemp77ee83ac-a1b4-4e5f-b89c-b20da1ef6482Veeam.Backup.Setup.dll_x64′. Error code: 0x80020009. Адресат вызова создал исключение. Собсно куда копать ? если RPC то проблема с портами ? но какой именно ? если wmi то счетчики или в самом wmi проблемы.. Как выяснилось у меня проблема со службой HTTP а именно не Биндятсья и не унбиндяться порты. А данная ошибка свидетельствует о наличии уже забинженого порта, можно в реестре увидеть — HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesHTTPParametersSslBindingInfo если у вас все по дефолту и порт равен 9401 то раздел 0.0.0.0:9401 будет там. Удалив этот раздел (0.0.0.0:9401) установка продолжиться но выдает новую ошибку: «VmWinError has been occurred. Error: 2» что свидетельствует об отсутствии раздела 0.0.0.0:9401 хотя если посмотреть через Procmon процесс установки, то установщик создает раздел и очевидно успешно но последующая проверка его присутствия не находит этот раздел и на этом ошибка. Вообщем ошибка «VmWinError has been occurred. Error: 2» гласит о том что я неправильно снял с привязки сертификат тоесть он файл с информацией о привязке по сути существовал — я выполнил это Netsh http delete sslcert ipport=0.0.0.0:9401. В логах получил: И после этой операции начинается следующая которая приводит опять к: Error code: 0x80020009. Адресат вызова создал исключение. Открыв Server64.msi в Orca я нашел таблицу VMCertificateCommand где есть три операции и две из них подряд биндят сертификат и переменные например порта у обоих совпадают: https://i.imgur.com/0E381JX.png Отсюда следует что обе команды привязки ссылаются на один и тот-же порт. И я решил закостылить это все дело. Понмиаю что с последующими обновлениями я буду получать теже самые грабли — но другого решения я не вижу, пока-что, у меня нет ошибок связанных со службной http, привязки вручную у меня проходят успешно, права на раздел в реестре с информацией о привязках я вообще выдал на «Все». |
| Всего записей: 340 | Зарегистр. 01-02-2010 | Отправлено: 22:26 31-12-2020 | Исправлено: CrazYViruS_CrazyNet, 15:06 02-01-2021 |

| Softos
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Всем привет, пытался нагуглить свою проблему с VeeamBackup, но так и не смог ее толком описать в поисковике. Архивируется несколько ноутбуков, каждый вечер, все архивы складываются в один репозитарий на сервере бэкапов, каждый в свою папку с назвнанием ноутбука, Retention Policy для всех задана 2 дня, с синтетическими бэкапами по средам и субботам, все отлично работает и копиии переодически обрезаются до 2 дней в пятницу и понедельник. А теперь проблема: В какой-то момент бэкап одного из ноутбуков раздваивается, новая полная копия начинает делаться в новую папку с тем же названием +»_1″ в Backups сам Backup раздваивается и в нем образуются 2 бэкапа с одинаковым названием в одном все старые точки восстановления, а в другом одна полная новая и дальше бэкап продолжается в новой ветке, а старые точки восстановления остаются и не удаляются по Retention Policy. В свойствах нового бэкапа Owner менется на новый ID. Как лечу: Удаляю с диска старую ветку бэкапов, удаляю из конфигурации новую ветку бэкапов, переименовываю обратно папку с новым бэкапом, ресканирую репозитарий в джобах маплю новый бэкап на старое задание и все работает дальше до очередного такого сбоя. Вопрос: Что это? Как с этим бороться? Заранее спасибо. |
| Всего записей: 47 | Зарегистр. 20-03-2007 | Отправлено: 01:14 04-03-2021 |
| T49
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Спустя пол года, случайно нашел агента через который можно сделать несколько задач бэкапа. И что-то файловое резервное копирование меня разочаровало по скорости. В папке 989GB, в основном видео и местами немного картинок. Хотя ранее пробовал на папках 300 и 500гб, там последний оставал на незначительное время, 10-20 минут. |
| Всего записей: 59 | Зарегистр. 08-10-2017 | Отправлено: 18:49 18-03-2022 |
| HristNew
Junior Member |
Редактировать | Профиль | Сообщение | Цитировать | Сообщить модератору Добрый день комрады
попробовал протестить восстановление файлов из архива и наткнулся на ошибку Источник Adblock |

[SOLVED] Veeam Failed: Understanding disk space with Veeam and VM ?
-
Thread startervelocityg4
-
Start dateFeb 20, 2022

-
- Nov 21, 2006
-
- 5,356
-
- 459
-
- 43,390
- 1,521
-
#1
I’ve got a server running VMWare ESXi 6.7.0. Guest OS is Windows Server 2016 standard. I’m new to Veeam and VMWare ESXi. I’m just used to a straight Windows Server without running off a VM. So, this is all different than I expected.
Issue: Veeam Backup is spitting out the error «Processing (VM Name) Error: Skipping VM processing due to insufficient free disk space on datastore (VM Hard Disk)»
I’m aware I can uncheck «Skip VM Processing when free disk space is below 5%»
Background: This is an existing server. I added an NVMe SSD. Then I went into VMWare and added it as additional storage in VMWare for the Windows Server Guest. I set the virtual storage size (VMFS) to fill the entire SSD (actually 1.8TB of 1.82TB).
In Windows I formatted the drive and used the entire virtual drive.
Actual data on the drive is 601GB of 1.79TB.
Questions: Which formatting is the problem for Veeam and the SSD? Real data used is only 601GB on a 2TB SSD. Which is well above the 5% threshold. So, I’m confused where Veeam is trying to toss the snapshots.
Do I need to recreate the VM storage space? This’ll be a big hassle. As I’ll have to go onsite and take the VM offline. As I don’t believe I can remove a virtual drive while the VM is live.
What’s the danger of «Skip VM Processing when free disk space is below 5%»? In my mind there’s over 50% free. The best I can figure is Veeam wants to place snapshots outside the formatted space on the SSD. Which makes no sense to me.
Edit: Just saw the Prebuilt and Enterprise subforum. If this is better suited there. Then mods please move.
Edit 2: Just found this entry from Veeam about tuning VSphere. I’m guessing this means I need to toast the virtual drive I made then redo it?
- Allocate enough space for snapshots. VMware vSphere 5.x puts the snapshot VMDK on the same datastore with the parent VMDK. If a VM has virtual disks on multiple datastores, each datastore must have enough space to hold the snapshots for their volume. Take into consideration the possibility of running multiple snapshots on a single datastore. According to the best practices, it is strongly recommended to have 10% free space within a datastore for a general use VM, and at least 20% free space within a datastore for a VM with high change rate (SQL server, Exchange server, and others).
Note: This is the default behavior that can be changed as explained in VMware KB Article 1002929.
Last edited: Feb 20, 2022
-
- Nov 21, 2006
-
- 5,356
-
- 459
-
- 43,390
- 1,521
-
#2
-
- Nov 21, 2006
-
- 5,356
-
- 459
-
- 43,390
- 1,521
-
#2
- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics
Dear All,
Lately we cannot take a backup of our VM on using VEEAM backup and replication
the error is Processing Error: Skipping VM processing due to insufficient free disk space on datastore Data.
I’ve looked on the Data Store of the VM which has a less storage and want to change default snapshot of the VM to a different storage.
we are using ESXI 6.5 and found this article regarding this.
Creating snapshots in a different location than default virtual machine directory for VMware ESXi an…
however when I download the .vmx file of the VM I can’t seem to find the workingdir. the below is the .vm file of the VM.
Can someone please advise how to fix this ? a big thank you all.
.encoding = «UTF-8»
config.version = «8»
virtualHW.version = «13»
vmci0.present = «TRUE»
floppy0.present = «FALSE»
numvcpus = «4»
memSize = «4096»
sched.cpu.units = «mhz»
scsi0.virtualDev = «lsisas1068»
scsi0.present = «TRUE»
scsi0:0.deviceType = «scsi-hardDisk»
scsi0:0.fileName = «DC.vmdk»
scsi0:0.present = «TRUE»
displayName = «DC»
guestOS = «windows8srv-64»
toolScripts.afterPowerOn = «TRUE»
toolScripts.afterResume = «TRUE»
toolScripts.beforeSuspend = «TRUE»
toolScripts.beforePowerOff = «TRUE»
uuid.bios = «56 4d d9 7f a4 40 10 a1-78 83 f9 05 05 14 81 2f»
uuid.location = «56 4d d9 7f a4 40 10 a1-78 83 f9 05 05 14 81 2f»
vc.uuid = «52 64 8f 31 39 1c 55 84-6b a0 c6 fc c2 ba 17 7f»
chipset.onlineStandby = «FALSE»
sched.cpu.min = «0»
sched.cpu.shares = «normal»
sched.mem.min = «0»
sched.mem.minSize = «0»
sched.mem.shares = «normal»
vmci0.id = «85229871»
cleanShutdown = «TRUE»
tools.syncTime = «FALSE»
extendedConfigFile = «DC.vmxf»
scsi0:1.deviceType = «scsi-hardDisk»
scsi0:1.fileName = «/vmfs/volumes/56fb479c-62b92216-f691-6805ca40b402/DC/DC_1.vmdk»
scsi0:1.present = «true»
sched.cpu.affinity = «all»
sched.scsi0:0.shares = «normal»
sched.scsi0:1.shares = «normal»
sched.scsi0:0.throughputCap = «off»
sched.scsi0:1.throughputCap = «off»
svga.vramSize = «16777216»
tools.upgrade.policy = «manual»
ethernet0.virtualDev = «vmxnet3»
ethernet0.networkName = «VM Network»
ethernet0.addressType = «generated»
ethernet0.wakeOnPcktRcv = «FALSE»
ethernet0.uptCompatibility = «TRUE»
ethernet0.present = «TRUE»
ethernet0.generatedAddress = «00:0c:29:14:81:2f»
tools.guest.desktop.autolock = «FALSE»
sched.cpu.latencySensitivity = «normal»
nvram = «DC.nvram»
pciBridge0.present = «TRUE»
svga.present = «TRUE»
pciBridge4.present = «TRUE»
pciBridge4.virtualDev = «pcieRootPort»
pciBridge4.functions = «8»
pciBridge5.present = «TRUE»
pciBridge5.virtualDev = «pcieRootPort»
pciBridge5.functions = «8»
pciBridge6.present = «TRUE»
pciBridge6.virtualDev = «pcieRootPort»
pciBridge6.functions = «8»
pciBridge7.present = «TRUE»
pciBridge7.virtualDev = «pcieRootPort»
pciBridge7.functions = «8»
hpet0.present = «TRUE»
cpuid.coresPerSocket = «2»
svga.autodetect = «TRUE»
vmci0.unrestricted = «TRUE»
disk.EnableUUID = «TRUE»
virtualHW.productCompatibility = «hosted»
sched.swap.derivedName = «/vmfs/volumes/56fb3860-5c070484-4bad-6805ca40b402/DC/DC-44b389b7.vswp»
replay.supported = «false»
pciBridge0.pciSlotNumber = «17»
pciBridge4.pciSlotNumber = «21»
pciBridge5.pciSlotNumber = «22»
pciBridge6.pciSlotNumber = «23»
pciBridge7.pciSlotNumber = «24»
scsi0.pciSlotNumber = «160»
ethernet0.pciSlotNumber = «192»
vmci0.pciSlotNumber = «32»
scsi0.sasWWID = «50 05 05 6f a4 40 10 a0″ddd
ethernet0.generatedAddressOffset = «0»
vm.genid = «-7868119124044379321»
vm.genidX = «2509724875556312798»
monitor.phys_bits_used = «43»
vmotion.checkpointFBSize = «4194304»
vmotion.checkpointSVGAPrimarySize = «16777216»
softPowerOff = «TRUE»
toolsInstallManager.lastInstallError = «0»
svga.guestBackedPrimaryAware = «TRUE»
tools.remindInstall = «FALSE»
toolsInstallManager.updateCounter = «6»
numa.autosize.vcpu.maxPerVirtualNode = «4»
numa.autosize.cookie = «40001»
acpi.smbiosVersion2.7 = «FALSE»
acpi.mouseVMW0003 = «FALSE»
migrate.hostLog = «./DC-44b389b7.hlog»
scsi0:1.redo = «»
scsi0:0.redo = «»
SCSI0:0.ctkEnabled = «true»
SCSI0:1.ctkEnabled = «true»
ctkEnabled = «TRUE»
Troubleshooting ESXi Datastore or VMFS Insufficient Disk Space and Pausing Virtual Machines (VMs) Issue
January 6, 2017
1. Objective
In this document will describe how to troubleshoot the issue that virtual machines (VMs) had been paused because of the datastore or VMFS on ESXi host is full or nearly full of disk space capacity.
2. Problem Description
-
- Every day the datastore disk pace on ESXi host keep increasing from 5GB to 20GB and can potentially to consumed almost of all the available disk space or can even run out of disk space very soon. This happen when the virtual machines (VMs) have a tree of active snapshots and creating double VMDKs which they are the original VMDKs and snapshot VMDKs.
- As the space on the virtual machines (VMs) keep growing, the space of he snapshot VMDK is growing too and can easily exceed all the available disk space in the datastore.
- As soon as the space on the datastore is full, the ESXi host will pause the running virtual machines (VMs) or some of the running virtual machines (VMs) will be crushed with the following error message “There is no more space for vitual disk MV-Name_x-00000x.vmdk. You might be able to continue this session by freeing disk space on the relevant volume, and clicking Retry.“

3. Problem Resolution
There are some workarounds with above issue that we can do as below.
-
Increase Datastore Disk Space Capacity
For some storage model there is a features that it is possible to extend more space to the datastore. So, we can increasing disk space on the datastore.
-
Move Virtual machines (VMs) to Another Datastore
In case that there is no feature on the storage to extend additional space to the datastore, check disk space of the ESXi host if there is some more disk space available. Then, create another datastore and move some virtual machines (VMs) to there.
-
Move Virtual machines (VMs) to Another ESXi Host
If the ESXi host is also running out disk space, we can move the virtual machines (VMs) to another ESXi host by export virtual machines (VMs) to an OVF format file.We need to shutdown virtual machines (VMs) first. Select the virtual machines (VMs) that we want to export and then go to “File” choose “Export” click on “Export OVF Template…”

Then, use the exported OVF file to deploy it in the new ESXi host. On the new ESXi host from vSphere client go to “File” option and click “Deploy OVF Template…”

-
Remove the Tree of Snapshots, The Permanent Solution
After we had performed some actions as above, we should have some available space now. However, the datastore space still keep increasing so fast. To permanently fix this issue, we need to delete the tree of all the active snapshots.On vSphere client, right click on the virtual machines (VMs) that we want to delete the snapshot then go to “Snapshot” and click “Snapshot Manager…” and finally click on “Delete All”

After the tree of snapshots had been removed, check the space of the datastore again. That should free up a lots of space.

After enough space is available, the pause or crushed virtual machines (VMs) will be up and running as normal automatically. We don’t need to manually power on them.
Comments
comments