Время прочтения
2 мин
Просмотры 34K
На hh/gt не нашел ни единого упоминания о этом замечательном расширении для Google Chrome. Хочу поделиться им с сообществом, потому как в последнее время оно помогает мне каждодневно экономить минут 10 — уж очень много скриншотов из социальных сетей на разных языках которые с помощью этого плагина переводятся в два клика.
Встречайте — Project Naptha (Chrome webstore).
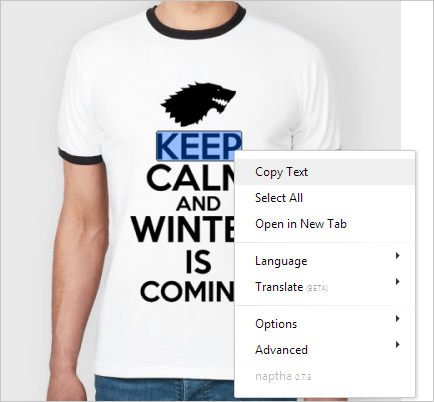
Список возможностей:
- копировать текст с картинки
- выделить весь текст
- гуглить выделенный текст
- переводить выделенное (бета)
- проговорить (TTS) выделенное
Проект был создан Kevin Kwok и представляет собой систему OCR (Optical character recognition), реализованную в JavaScript в виде браузерного расширения.
Project Naptha, несмотря на простоту для конечного пользователя, довольно сложный внутри.
Прежде всего, перед тем как непосредственно распознавание текста началось, нужно определить где собственно находятся блоки с текстом на картинке. Довольно нетривиальная задача, учитывая то, что текст может располагаться поверх совершенно разных фонов и сам по себе иметь разные цвета. Для реализации этого механизма Naptha использует проект Майкрософта Stroke Width Transform (SWT) — эффективный алгоритм, который отталкивается от того, что шрифты обычно имеют примерно равномерную толщину линий (font-weight) и, следовательно, легко отделить блоки текста от остального шума на картинке.
Оригинал:

После SWT:
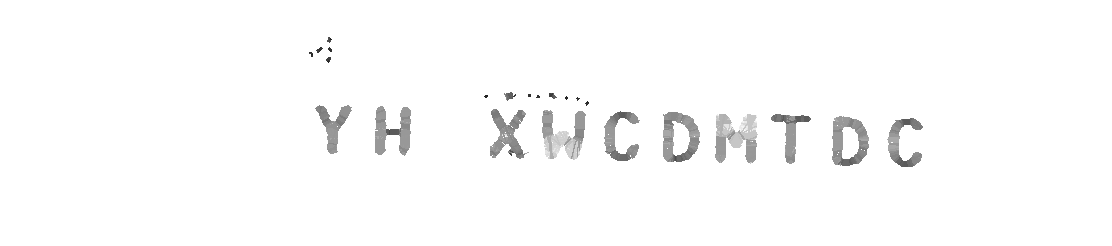
Naptha конечно же не распознает каждую картинку на открытой странице — это бы было крайне расточительно по отношению к ресурсам. Вместо этого начинает распознавание расположения блоков текста только после… нет, не наведения мыши на картинку (mouseover) как вы могли подумать, а предположения о том, что курсор будет над картинкой, основываясь на его движении. Дальше Web Workers (мультипоточность в фоне) работают над распознаванием расположения текста на картинке без какого-либо ощутимого торможения браузера.
Когда вы выбрали блок текста и клинкули “Copy Text” (Ctrl+C), он посылается на сервер с Ocrad OCR — движком с открытым кодом для распознавания текста. Ocrad попытается распознать кусок растровой картинки в текст, что может занять пару секунд, и после завершения вернет распознанный текст, который можно будет вставить обычным образом куда угодно (Ctrl+V).
Функция перевода пока что в бете, для того чтобы ее попробовать нужно отправить запрос на их электронный адрес. Предполагается что она будет работать схоже c уже работающим аналогом в Google Translate на мобильных устройствах:
Проект все еще находится в стадии тестирования, но даже на текущий момент он достаточно хорош чтобы использовать его в работе. Можно конечно придираться к деталям и возможным тормозам, но этот продукт, насколько я знаю, единственный в своем роде и он уже экономит мое время.
Google Chrome все больше берет курс на превращение чуть ли не в операционную систему, а браузерные приложения постепенно подменяют собой нативные. К счастью, про старые добрые расширения еще не окончательно забыли и иногда выдают весьма интересные экземпляры (например, захват видео с экрана). А сегодня мы расскажем про еще одно расширение, которое может похвастаться технологией распознавания текста на картинках.
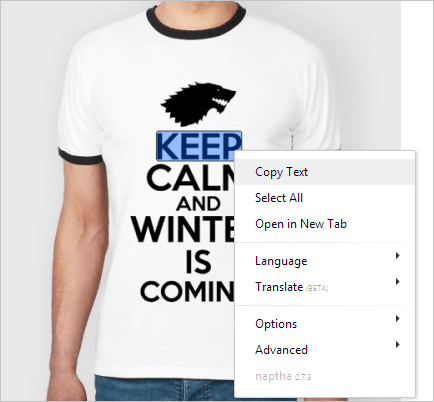
Думаю, вы уже наслышаны про OCR-программы (например, Abbyy Fine Reader), которые специализируется на переводе сканированных текстов в, собственно, текстовые файлы. Не знаю, как вы, но лично я воспринимал эту задачу настолько сложной, что даже и представить себе не мог реализацию оного через обычное расширение. И зря.
Расширение Project Naptha для Google Chrome анализирует картинки, которые загружаются в браузере, и позволяет работать с текстом этих изображений. Выглядит это примерно так. Вы просто выделяете текст на картинке при помощи мыши, будто делаете это в обычном текстовом редакторе, а потом можете скопировать его, отредактировать (прямо на картинке) или даже перевести на другой язык (при этом используются переводчики от Google, Яндекса и Microsoft). Кстати, копировать можно не только английский текст, но и, например, русский.
Качество, конечно, далеко от идеала. Если на чистых картинках с обычным шрифтом результат более-менее приемлем (т.е. в основном распознается верно, но правки нужны), то на картинках типа «капчи» все будет очень печально (в лучшем случае текст просто не будет найден). Но прежде чем критиковать качество подумайте вот о чем: расширение создано одним единственным студентом MIT в рамках хакатона (причем занял он там лишь второе место). Хотя технологии там используются уже известные. Например, технология выявления областей текста, созданная в 2008 году силами Microsoft Research.
Найти расширение можно в Chrome Web Store. А еще у проекта есть официальный сайт projectnaptha.com.
today 27.04.2014
 |
|
| Автор (ы) | Кевин Квок |
|---|---|
| Разработчик (и) | Google Chrome |
| Первый выпуск | апрель 2013 г.; 7 лет назад (2013-04) |
| Стабильный выпуск | Chrome: . 0.9.3 / 7 июля 2014 г.; 6 лет назад (07.07.2014) |
| Написано на | JavaScript |
| Операционная система | Chrome |
| Размер | 428 КБ |
| Тип | Расширение браузера |
| Веб-сайт | projectnaptha.com |
Project Naptha — это расширение браузера программное обеспечение для Google Chrome, которое позволяет пользователям выделять, копировать, редактировать и переводить текст из изображений. Он был создан разработчиком Кевином Квоком и выпущен в апреле 2014 года как надстройка Chrome. Это программное обеспечение сначала было доступно только в Google Chrome, его можно загрузить из Интернет-магазина Chrome. Затем он был доступен в Mozilla Firefox, загружался из репозитория Mozilla Firefox add-ons, но вскоре был удален. Причина удаления остается неизвестной.
Расширение веб-браузера использует передовые технологии обработки изображений. Подобные технологии также использовались для создания печатных копий и идентификации этих произведений.
За счет принятия нескольких алгоритмов оптического распознавания символов (OCR) , включая библиотеки, разработанные Microsoft Research и Google, текст автоматически идентифицируется на изображениях. OCR позволяет создавать модель текстовых областей, слов и букв из всех изображений.
Технология OCR, которую использует Project Naptha, представляет собой слегка отличающуюся технологию по сравнению с технологией используется таким программным обеспечением, как Google Drive и Microsoft OneNote для упрощения и анализа текста в изображениях. Project Naptha также использует метод под названием Stroke Width Transform (SWT), разработанный Microsoft Research в 2008 году в качестве формы обнаружения текста.
Содержание
- 1 Происхождение имени
- 1.1 Сложность перевода слов с изображений
- 2 История
- 3 Технические характеристики
- 4 Приложение
- 4.1 Комиксы
- 4.2 Фото
- 4.3 Снимки экрана
- 4.4 Редактирование текста на изображениях
- 5 Технические ограничения
- 6 Безопасность
- 6.1 Проблемы безопасности
- 6.2 Конфиденциальность
- 7 Будущие разработки
- 8 См. Также
- 9 Ссылки
Происхождение названия
Название Naptha происходит от Naphtha, общего термина, возникшего несколько тысяч лет назад и относящегося к воспламеняющимся жидким углеводородам. Процесс выделения текста также вдохновил на название проекта.
Сложность перевода слов с изображений
Процесс редактирования, копирования или цитирования текста внутри изображений был трудным до появления программного обеспечения, такого как Project Naptha. Раньше единственным способом поиска или копирования предложения из изображения было вручную расшифровать текст.
История
В мае 2012 года Кевин Квок читал о резьбе по швам, алгоритме, который мог изменять масштаб изображений без искажения или повреждения качество изображения. Квок заметил, что они имеют тенденцию сходиться и располагаться таким образом, чтобы прорезать промежутки между буквами. Особенно подробный комикс вдохновил его на разработку программного обеспечения, которое может считывать изображения (с canvas ), определять положение линий и букв и рисовать наложения выделения. чтобы успокоить распространенную привычку выделения текста.
Первая попытка Квок была простой. Он спроецировал изображение на сторону, и была сформирована гистограмма изображения с вертикальным пикселем . Значимые впадины полученных гистограмм служили подписью концов текстовых строк. При обнаружении горизонтальных линий каждая линия автоматически обрезается, и процесс гистограммы повторяется до тех пор, пока не будут идентифицированы все горизонтальные линии на изображении. Чтобы определить положение буквы, был выполнен аналогичный процесс, но на этот раз вертикально. Однако выполнение процесса по вертикали не увенчалось успехом, так как созданные прогнозы не читались. Это было менее эффективно, доказывая, что этот процесс строго применим только к горизонтальному машинному напечатанному тексту. Столкнувшись с серьезными техническими трудностями, Квок решил отказаться от этого проекта в 2012 году.
Это было только до тех пор, пока Кевин Квок не продолжил обучение в Массачусетском технологическом институте (MIT) и поступил в хакатон, что он снова взялся за этот проект. Этот проект в итоге занял ему второе место. Для него выбор текстов на картинках был чем-то, что можно было осуществить на техническом уровне. Соответствующая технология существует и была легкодоступна в течение некоторого времени, но по необъяснимой причине она не была расширена для приложения перевода текстов с изображений. Как только Кевин Квок снова решил начать свой проект, технология транскрипции, перевода, стирания текста и модификации впоследствии стала естественным явлением.
Технические характеристики
Перед применением оптического распознавания символов (OCR) необходимо сначала определить, существуют ли блоки текста в изображении. После того, как блоки текстов идентифицированы, OCR позволяет построить модель текстовых областей, слов и букв из любых изображений. Эта функция предоставляет пользователям возможность копировать, переводить и даже изменять текст непосредственно в каждом изображении, в реальном времени и в их Google Chrome. browser.
Основная особенность Project Naptha — это функция обнаружения текста. Работая на алгоритме , называемом «преобразование ширины штриха», разработанном Microsoft Research в 2008 году, он обеспечивает возможность идентификации областей текста в независимой от языка манере и обнаружении наклонного текста и текст в изображениях. Это достигается за счет использования ширины линий, составляющих буквы, в качестве средства идентификации элементов, которые потенциально могут быть текстом, а не попытки определить заранее определенные отдельные элементы в качестве маркера текста.
В этом случае программа становится в высшей степени интуитивно понятной, похожей на людей, при этом нам не нужно понимать язык, чтобы распознавать письменный текст.
Project Naptha автоматически применяет самые современные алгоритмы компьютерного зрения к каждому изображению, доступному при просмотре веб-страниц, позволяя пользователям выделять, копировать и вставлять, редактировать и переводить текст, который ранее был заблокирован внутри изображения.
Применяется техника, аналогичная функции Photoshop «Заливка с учетом содержимого», под названием «inpainting ». Эти типы алгоритмов известны как часть Adobe Photoshop «Заливка с учетом содержимого». Она включает использование алгоритма , который автоматически заполняет пространство, ранее занимаемое текстом, цветами из окружающей области, соответствуя шрифту переведенного текста в стиле исходного изображения. Для этого сначала обнаруживается текст и извлекаются сплошные цвета из областей, окружающих текст. Затем цвета будут распространяться вокруг и внутрь, пока не будет заполнена вся область. Этот метод позволяет пользователю для восстановления изображений, а также для редактирования и удаления слов с изображения с захватом и обработкой независимых цветов из областей вокруг редактируемого текста.
Чтобы обеспечить беспроблемный и интуитивно понятный интерфейс для пользователя, расширение отслеживает движения курсора и другие Непрерывно экстраполирует на секунду вперед, основываясь на его положении и скорости, предсказывая, где на изображении могут быть блики. Затем программное обеспечение Project Naptha сканирует и запускает ресурсоемкие алгоритмы распознавания символов, обрабатывая потенциальный текст, который пользователи могут захотеть выделить на изображении, заранее.
Приложение
Project Naptha может использоваться в нескольких приложениях, позволяя пользователям копировать тексты с любых изображений, отображаемых в браузере. Сюда входят комиксы, фотографии, снимки экрана, изображения с наложенным текстом, например интернет-мемы, анимированные GIFS, отсканированные изображения, диаграммы с метками и переводы.
Комиксы
В октябре 2013 года был выпущен первый прототип расширения для комиксов. Потребность в расширении для комиксов возникла из-за использования комических шрифтов, которые являются более случайными и неформальными. Персонажи часто помещаются близко друг к другу, как если бы они были связаны, и если кто-то попытается скопировать и вставить текст из комикса, скопированный текст обычно будет выглядеть беспорядочно и нечетко.
Фотографии
Алгоритм , используемый Project Naptha для фотографий, — это Stroke Width Transform, который был специально разработан для обнаружения текста в естественных сценах и фотографиях. Это связано с тем, что фотографии обычно сложнее и технически сложнее копировать текст по сравнению с большинством обычных изображений.
Снимки экрана
Для снимков экрана Project Naptha преобразует статические снимки экрана во что-то более похожее на интерактивный снимок экрана компьютера, каким он был во время захвата экрана. Курсор изменяется при наведении курсора на разные части, и блоки текста становятся доступными для выбора.
Редактирование текста на изображениях
Project Naptha позволяет стирать и редактировать тексты на изображениях с помощью технологии перевода. Эта технология перевода в основном использует «Inpainting ».
При изменении текста используется тот же прием, что и в переводе. Меню «Перевести» позволяет переводить текст в изображении на множество других языков, таких как английский, испанский, русский, французский, упрощенный китайский, традиционный китайский, японский или немецкий.
Технические ограничения
Есть несколько технических трудностей, с которыми Project Naptha все еще сталкивается, несмотря на постоянное улучшение программного обеспечения.
не зависящий от языка характер лежащего в основе алгоритма Project Naptha Stroke Width Transform позволяет ему обнаруживать маленькие волнистые линии как текст. Несмотря на то, что это положительный момент, поскольку он способен обнаруживать незначительные детали, он также может рассматриваться как ошибка, обнаруживая и включая слишком много нежелательных деталей.
Когда цвета текстов и фона изображения схожи, слова становятся сложными для распознавания, поскольку слова становятся менее отличительными от изображения. Это создает неточности при обнаружении и копировании текстов.
Из-за сегментации символов почерк особенно трудно обнаружить. Знаки в почерках часто пишутся слишком близко друг к другу, что затрудняет сегментирование знаков или разделение букв. Следовательно, копирование текстов из этих типов источников приведет к высокой неточности и с перебранными буквами.
В рамках функции улучшения Project Naptha начал работу над этим и позволяя ему поддерживать повернутый текст. Однако эта функция ограничена только примерно до 30 градусов. Любой текст с поворотом более 30 градусов может стать недоступным для копирования или перевода.
Для техник, использующих рисование, есть лазейки в том, что изображения вряд ли могут заменить оригинал и могут оставить следы его редактирования. Однако это будет выглядеть так, как будто слова были безупречно удалены с изображения на большом расстоянии.
Безопасность
Проблемы безопасности
Для любого другого программного обеспечения, которое используется на сайтах, одна из самых серьезных проблем связана с проблемами, возникающими в отношении баланса между пользовательским интерфейсом и конфиденциальность. Понятно, что разработчики Project Naptha делают все возможное, чтобы разрешить обработку на стороне клиента (т. Е. В браузере). Однако, поскольку текст, выбранный пользователями для извлечения из изображения, обрабатывается в облаке. Это означает, что для достижения более высокой точности перевода по-прежнему необходимо полагаться на более эффективную облачную обработку и, следовательно, подвергать риску конфиденциальность.
Существует значение по умолчанию настройка, которая помогает найти тонкий баланс между предоставлением всех функций и соблюдением конфиденциальности пользователей. По умолчанию, когда пользователи начинают выбирать текст, отправляется защищенный запрос HTTPS. Он содержит только URL-адрес конкретного изображения и ничего больше — никаких пользовательских токенов, никакой информации веб-сайта, никаких файлов cookie или аналитики, и запросы не регистрируются. Сервер отвечает списком существующих переводов и языков OCR, которые были выполнены. Это позволяет распознавать текст на изображении с гораздо большей точностью, чем это было возможно в противном случае.
В зависимости от предпочтений пользователей эту функцию по умолчанию можно отключить, установив флажок «Отключить поиск» в меню параметров.
Конфиденциальность
При установке Project Naptha требуются разрешения и полный доступ к информации пользователя. Эта информация будет запрошена в диалоговом окне установки. Чтобы обеспечить взаимодействие со всеми изображениями, требуется разрешение пользователя для программного обеспечения на чтение всех изображений со всех сайтов. С другой стороны, если пользователь не хочет разрешать доступ Project Naptha ко всем изображениям со всех сторон, он также может отключить эту функцию в диалоговом окне установки. В этом случае Project Naptha будет работать с очень низким уровнем доступа и, в идеале, является той функциональностью, которая изначально встроена в браузеры и операционные системы.
Расширение почти полностью написано на стороне клиента JavaScript, что позволяет расширению работать без доступа к удаленному серверу. Однако следует отметить, что онлайн-перевод, выполняемый в автономном режиме, является противоречивым, и неадекватный доступ к кэшированной службе OCR, работающей в облаке, будет означать компромисс и снижение производительности и более низкую точность транскрипции.
Наконец, из-за проблем с масштабируемостью функция перевода в настоящее время находится в ограниченном развертывании. Онлайн-сервисы OCR имеют учет для каждого пользователя, поэтому требуется токен уникального идентификатора . Этот токен является полностью анонимным и не связан с какой-либо личной информацией.
Будущие разработки
Помимо текущего программного обеспечения, которое позволяет манипулировать текстами внутри изображений, есть экспериментальная функция, которая планирует расширить возможности программного обеспечения. В рамках этого экспериментального расширения программное обеспечение нацелено на то, чтобы позволить пользователям искать текст внутри изображений на текущей странице, что служит отличной функцией для всех пользователей.
Project Naptha также ищет различные способы улучшить свои ограничения. В настоящее время текст может иметь угол поворота не более 30 градусов, иначе он будет низкого качества. Project Naptha будет стремиться повысить качество своих будущих версий за счет использования лучше обученных моделей и алгоритмов. Также существует возможность включения служб транскрипции, которым будут помогать люди.
Кроме того, техника рисования может оставлять следы на исходном изображении, делая очевидным, что оно было отредактировано. Ожидается, что этот метод также улучшится, особенно с техникой обнаружения логики, помимо простого обнаружения шрифтов. В настоящее время inpainted читает шрифты таким образом — если прописные и полужирные, то шрифт Impact, если прописные, иначе шрифт XKCD, а для всего остального — Helvetica Neue.
Как признал Квок, Project Naptha все еще нуждается в улучшении многих своих функций. Основная причина заключается в том, что с точки зрения различных подкомпонентов и алгоритмов Project Naptha на несколько лет отстает от современного уровня техники. Тем не менее, он твердо уверен, что со временем функции распознавания, перевода и удаления текста можно будет развивать дальше, и этот огромный потенциал определенно будет захватывающим.
См. Также
- Copyfish — Copyfish расширение Google Chrome решает ту же проблему, но использует другой подход к пользовательскому интерфейсу.
Ссылки
Как распознать и перевести текст на картинке прямо в браузере
Благодаря Project Naptha мы получаем прямо в Chrome очень удобную и достаточно мощную систему распознавания текста на изображениях.

Если нам нужно ознакомиться с текстом на иностранном языке, которым мы, к сожалению, не владеем, то сделать это совсем не трудно. Мы просто копируем этот текст в буфер обмена, а далее в дело вступает его величество Google Translate, способный справиться и с китайским, и с греческим, и со всеми другими наречиями.
Но что делать, если текст размещён на картинке? Как перевести текст на диаграмме в научной статье, инфографике или просто на смешном демотиваторе? Во всех этих случаях нас спасёт специальное расширение для браузера Google Chrome под названием Project Naptha.
Project Naptha является системой распознавания текста, которая работает прямо в вашем браузере. Благодаря новой технологии Stroke Width Transform текст распознаётся гораздо легче и точнее, чем в обычных системах OCR. Для его использования необходимо установить одноимённое расширение из каталога Chrome Web Store.
После его установки вы получите возможность выделять текст на любой картинке с помощью курсора мыши. Сделайте правый клик по выделению, и вы увидите контекстное меню возможных действий. Здесь вы сможете скопировать текст, искать по выделенному слову, изменить некоторые опции расширения. Но наибольший интерес вызывает, несомненно, возможность мгновенного перевода. При этом расширение умеет не только предоставить перевод, но и аккуратно нанести его на изображение взамен исходного. Выглядит это очень эффектно, посмотрите на видео.
Расстраивает только то, что функция перевода находится в настоящее время в стадии тестирования и доступна только для ограниченного круга пользователей. Будем надеяться, что скоро эта функция будет включена в стандартный набор и доступна для всех желающих.
Очень полезно, что вы можете использовать распознавание текста и для локальных файлов. Для этого поставьте флажок возле опции «Разрешить открывать файлы по ссылкам» возле названия Project Naptha на странице расширений Google Chrome. После этого можете просто перетащить любую картинку с рабочего стола в окно программы и начинать выделять текст. Таким образом, благодаря Project Naptha мы получаем встроенную в Chrome очень удобную и достаточно мощную систему OCR.

 |
|
| Original author(s) | Kevin Kwok |
|---|---|
| Developer(s) | Google Chrome |
| Initial release | April 2013; 9 years ago |
| Stable release |
Chrome: |
| Written in | JavaScript |
| Operating system | Chrome |
| Size | 428KB |
| Type | Browser extension |
| Website | www.projectnaptha.com |
Project Naptha is a browser extension software for Google Chrome that allows users to highlight, copy, edit and translate text from within images.[1] It was created by developer Kevin Kwok,[2] and released in April 2014 as a Chrome add-on. This software was first made available only on Google Chrome, downloadable from the Chrome Web Store. It was then made available on Mozilla Firefox, downloadable from the Mozilla Firefox add-ons repository but was soon removed. The reason behind the removal remains unknown.[3]
The web browser extension uses advanced imaging technology.[4] Similar technologies have also been employed to produce hardcopy art, and the identification of these works.[5]
By adopting several Optical Character Recognition (OCR) algorithms, including libraries developed by Microsoft Research and Google, text is automatically identified in images. The OCR enables the build-up of a model of text regions, words and letters from all images.[6]
The OCR technology that Project Naptha adopts is a slightly differentiated technology in comparison to the technology used by software such as Google Drive and Microsoft OneNote to facilitate and analyse text within images. Project Naptha also makes use of a method called Stroke Width Transform (SWT),[7] developed by Microsoft Research in 2008 as a form of text detection.
Origin of name[edit]
The name Naptha is derived from Naphtha, which is a general term that originated few thousand years ago and refers to flammable liquid hydrocarbon. The process of highlighting texts also inspired the naming of the project.
Difficulty in translation of words from images[edit]
The process of editing, copying or quoting text inside images was difficult before software such as Project Naptha arrived. Previously, the only way to search or copy a sentence from an image was to manually transcribe the text.
History[edit]
In May 2012, Kevin Kwok[2] was reading about seam carving, an algorithm which was able to rescale images without distorting or damaging the quality of the image. Kwok noticed that they tend to converge and arrange themselves in a way that cut through the spaces in between letters. A particularly verbose comic inspired him to develop a software which can read images (with canvas), figure the positions of the lines and letters, and draw selection overlays to assuage a pervasive text-selection habit.
Kwok’s first attempt was simple. He projected the image onto the side and a vertical pixel image histogram was formed. The significant valleys of the resulting histograms served as a signature for the ends of text lines. When horizontal lines are detected, each lines are automatically cropped, and the histogram process repeats itself until all horizontal lines in the image have been identified. In order to determine the letter position, a similar process was carried out, but vertically this time. However, carrying out the process vertically was unsuccessful as projections created were not readable. It was less effective, proving that the process was strictly applicable only for horizontal machine printed text. Faced with high technical difficulties, Kwok decided to abandon this project in 2012.
It was only until Kevin Kwok went on to study at Massachusetts Institute of Technology(MIT) and entered a hackathon, that he picked up this project again. This project eventually won him second place. To him, selecting texts in pictures was something that was manageable on a technical level. The relevant technology exists and was readily available for quite some time, yet for inexplicable reason, it hadn’t been expanded for the application of translating texts from images. Once Kevin Kwok decided to start on his project again, the technology for transcription, translation, text erasure, and modification flowed naturally afterwards.
Technical Features[edit]
Before the Optical Character Recognition (OCR) can be applied, it has to first identify whether blocks of text exists in an image. Once the blocks of texts are identified, the OCR enables for the build-up of a model of text regions, words and letters from any images.[6] This function provides users with the option to copy, translate and even modify text directly in every image, in real-time and in their Google Chrome browser.[8]
The primary feature of Project Naptha is the text detection function. Running on an algorithm called the “Stroke Width Transform, developed by Microsoft Research in 2008,[7] it provides the capability of identifying regions of text in a language-agnostic manner and detecting angled text and text in images. This is done by using the width of the lines that make up letters as a means to identify elements that could potentially be text rather than trying to spot predetermined separate features as a marker of text.
In this case, the programme becomes highly intuitive, similar to humans whereby we do not need to understand a language in order to recognize a written text.[9]
Project Naptha automatically applies state-of-the-art computer vision algorithms on every image available when browsing the web, allowing users to highlight, copy and paste, edit and translate text which were formerly trapped within an image.
A technique similar to Photoshop’s «Content-Aware Fill» feature[10] called «inpainting” is adopted. These types of algorithms are famously known as a part of Adobe Photoshop’s “Content-Aware Fill” feature. It involves the using of an algorithm that automatically fills in the space previously occupied by text with colors from the surrounding area, matching the font of the translated text in the style of the original image. This is done so by, first, detecting the text and retrieving the solid colours from the regions surrounding the text. Following, the colours will be spread around and inwards till the entire area is filled up. This technique allows user to reconstruct images as well as to edit and remove words from an image with the capturing and processing of the independent colours from regions around the edited text.[8]
In order to provide a seamless and intuitive experience for the user, the extension technique tracks cursor movements and continuously extrapolates a second ahead based on its position and velocity, predicting where highlights might be made over an image.[1] The Project Naptha software then scans and runs a processor-intensive character recognition algorithms, processing potential text that users might want to pick out from an image, ahead of time.[11]
Application[edit]
Project Naptha can be used on a few applications, enabling users to copy texts from any images displayed in the browser. This includes comics, photos, screenshots, images with text overlays such as internet memes, animated GIFS, scans, diagrams with labels, and translations.[12]
Comics[edit]
In October 2013, the first prototype for the extension for comics was released. The need for an extension for comic was due to the use of comic fonts, which are more casual and informal. Characters are often placed closely together as if they are connected and if one tries to copy and paste text from a comic, the copied text will usually appear to be jumbled up and unclear.
Photos[edit]
The algorithm used by Project Naptha for photos is the Stroke Width Transform, which was specially designed for detecting text in natural scenes and photographs. This is because photographs are generally tougher and more technically challenging to copy texts from as compared to most regular images.
Screenshots[edit]
For Screenshots, Project Naptha transforms static screenshots into something more similar to an interactive snapshot of the computer as it was when the screen was captured. The cursor changes when hovering over different parts, and blocks of text become selectable.
Editing Text on Images[edit]
Project Naptha allows one to erase and edit texts on an image by using the translation technology. This translation technology essentially makes use of “Inpainting”.
During the changing of a text, it uses the same trick that translation uses. The Translate menu includes the capability to translate in-image text to many other different languages such as English, Spanish, Russian, French, Chinese Simplified, Chinese Traditional, Japanese, or German.[8]
Technical Limitations[edit]
There are a few technical difficulties that Project Naptha still faces despite the constant improvements made to the software.
The language-agnostic nature of Project Naptha’s underlying Stroke Width Transform algorithm allows it detect the little squiggles as text. Despite it being a plus point since it is capable of detecting minor details, it can also end up to be seen as a bug by detecting and including too many unwanted details.
When the colours of the texts and background of an image are similar, it becomes challenging for words to be detected, as words become less distinctive from the image. This creates inaccuracies in the detection and copying of texts.[12]
Due to character segmentation, handwritings are especially tough for detection. The characters in handwritings are often written too close to each other, making it difficult to segment the characters or to separate the letters apart. Hence, copying texts from these types of sources will result in high inaccuracy and with jumbled letters.[12]
As part of an improvement feature, Project Naptha started work on it and enabling it to support rotated text. However, this function is only limited only up to about 30 degrees. Any text with rotation of more than 30 degrees may become incapable of being copied or translated.
For techniques that make use of inpainting, present loopholes to it is that images may hardly be a substitute for the original and can leave marks of it being edited. It will however, look as though the words have been flawlessly removed from the image from a distance away.
Security[edit]
Security Concerns[edit]
For any other software that is used on sites, one of the greatest concerns is due to issues arising regarding the balance between user experience and privacy. It is understood that the developers of Project Naptha are doing their best in attempting to allow the processing on the client side (i.e., within the browser). However, as text selected by users for extraction from the image are being processed in the cloud. This means that in order to achieve higher translation accuracy, there is still a need to rely on greater cloud processing and hence compromising on privacy.[4]
There is a default setting which helps to strike a delicate balance between having all the functionality made available and respecting user privacy. By default, when users begin selecting a text, a secure HTTPS request is sent. This is only contains the URL of the specific image and nothing else – no User Tokens, no Website Information, no Cookies or analytics and the requests are not logged. The server responds with a list of existing translations and OCR languages that have been done. This allows you to recognize text from an image with much more accuracy than otherwise possible.
Depending on the preference of the users, this default function can be disabled by checking on the “Disable Lookup” item under the Options Menu.
Privacy[edit]
When installed, Project Naptha requires the permissions and sweeping access to user’s information. This informations would be requested in the installation dialog. In order to allow for the interaction with all images, it requires the permission from the user for the software to read all images from all sites. On another hand, if the user does not want to allow access for Project Naptha to all images on all sides, they can also disable this function under the installation dialog. In this case, Project Naptha will be operating at a very low level of access, and is ideally the kind of functionality that gets built into browsers and operating systems natively.
The extension is almost entirely written in client side JavaScript, allowing the extension to function without an access to a remote server. However a point to take note is that an online translation running offline is contradicting and the inadequate access to a cached OCR service running in the cloud would mean a compromise and reduction in performance and lower transcription accuracy.
Lastly due to scalability issues, the translation feature is currently in limited rollout. The online OCR services has per-user metering, hence requires a unique identifier token. This token is completely anonymous and is not linked with any personally identifiable information.
Future Developments[edit]
Apart from the current software that allows one to manipulate texts inside the images, there is an experimental feature that plans to widen the ability of the software. Under this experimental extension, the software aims to allow users to search for texts inside images on a current page, serving as a great feature for all users.[4]
Project Naptha has also been looking at different ways to improve on its limitations. Currently, text can only be of a rotation angle of not more than 30 degrees[13] otherwise it would be of inferior quality. Project Naptha will aim to increase the quality in its future versions by using better-trained models and algorithms. There is also a possibility of the inclusion of transcription services that will be assisted by humans.
Also, the techniques of inpainting may leave marks on the original image, making it obvious that it has been edited. This technique is expected to improve as well, especially with a technique of detecting logic besides simply detecting fonts. Currently, inpainted reads fonts in this manner — if uppercase and super bold, then Impact font, if uppercase otherwise then XKCD font, and for everything else, Helvetica Neue.
As acknowledged by Kwok, Project Naptha still has to improve on many of its functionality. The main reason is because in terms of its various subcomponents and algorithms, Project Naptha is a few years behind the state of the art. However, he firmly believes that over time, text recognition, translation and deletion can all be developed further and this immense potential is definitely one that will be exciting.
See also[edit]
- Copyfish — The Copyfish Google Chrome extension solves the same problem, but takes a different user interface approach.
References[edit]
- ^ a b Stu, Robarts (24 April 2014). «New Google Chrome extension lets you copy and delete text in images». Gizmag. Retrieved 7 April 2015.
- ^ a b Kwok, Kevin. «Profile». Google+. Retrieved 7 April 2015.
- ^ Brinkmann, Martin (26 September 2014). «Project Naptha text on image recognition technology comes to Firefox». ghacks.net. Retrieved 2 April 2015.
- ^ a b c Hoffman, Chris (26 June 2014). «Edit Image Text With Chrome’s Project Naptha: What It Is & How To Use It». Makeuseof. Retrieved 7 April 2015.
- ^ Narelle, Jarry (1996). «Computer Imaging Technology: The Process of Identification». The Book and Paper Group. The American Institute for Conservation. Retrieved 2 April 2015.
- ^ a b Brian, Matt. «This Chrome add-on lets you copy and erase text inside any image on the web». Engadget. Retrieved 7 April 2015.
- ^ a b «Stroke Width Transform». Stroke Width Transform. Retrieved 7 April 2015.
- ^ a b c Chacos, Brad. «Meet Project Naptha, an amazing Chrome extension for modifying text in web images». PCWorld. Retrieved 7 April 2015.
- ^ Starr, Michelle. «Chrome extension lets you copy text from images». CNET. Retrieved 2 April 2015.
- ^ Wollman, Dana. «Adobe unveils Photoshop CS6 beta with redesigned UI and 65 new features, download it for free today». Engadget. Retrieved 30 March 2015.
- ^ Chan, Norman. «In Brief: Project Naptha OCRs Web Images». Tested. Retrieved 2 April 2015.
- ^ a b c «Project Naptha». Project Naptha. Retrieved 7 April 2015.
- ^ Khaw, Cassandra (23 April 2014). «Edit Image Text with the useful Chrome extension». TheVerge. Retrieved 2 April 2015.
 Имели ли Вы когда-либо проблему с тем, чтобы увидеть перевод текста с картинки? Или же просто скопировать текст с изображения? То есть, конечно же, можно сделать просто: прочесть и вбить в переводчик или просто перепечатать. Но если же текста на изображении куда больше, чем пара строк? Теперь для того, чтобы узнать перевод или просто скопировать текст изображения больше не нужно долго печатать смотря на картинку. Для этого стоит добавить только одно расширение- Project Naptha. Сейчас оно доступно для браузеров Opera и Chrome.
Имели ли Вы когда-либо проблему с тем, чтобы увидеть перевод текста с картинки? Или же просто скопировать текст с изображения? То есть, конечно же, можно сделать просто: прочесть и вбить в переводчик или просто перепечатать. Но если же текста на изображении куда больше, чем пара строк? Теперь для того, чтобы узнать перевод или просто скопировать текст изображения больше не нужно долго печатать смотря на картинку. Для этого стоит добавить только одно расширение- Project Naptha. Сейчас оно доступно для браузеров Opera и Chrome.
Первый взгляд и как пользоваться расширением
Сейчас стоит рассмотреть на что вообще способно данное расширение на примере браузера Chrome. Самая главная и наиболее стабильная функция- выделение текста на изображении:

Как же его выделять? Все очень просто: при наведении на текст стрелка указателя мыши изменит себя на бегунок текста. То есть интуитивно понятно, что на изображении уже распознан текст. Примечательно то, что расширение позволяет выделать большие объемы текста на картинке, но иногда не может распознать и пары строк, если текст внутри изображения имеет большой размер шрифта. Но стоит отдать должное, что расширение, находясь еще в бета версии, достаточно неплохо справляется с выделением текста и копирование текста происходит стандартными действиями: либо через Ctrl+C Ctrl+V, либо правой кнопкой по выделенному тексту и копироватьвставить.
Следующая функция позволяет искать в Google выделенный текст. По сути, все делается стандартно как и в любом браузере: выделяем текст, правой кнопкой нажимаем по выделенному тексту, далее выбираем искать в Google.
Третья и очень забавная «плюшка» данного приложения- это перевод и озвучка текста. Почему же она забавная? Перевод не работает вовсе, так как расширение выдает ошибку о том, что оно в бета версии. Озвучка работает только английская, при чем, если сравнить с озвучкой текста в Google, очень монотонная, практически не разборчивая и без интонационная.
Вывод
Из серьезных минусов можно сказать то, что сейчас Project Naptha работает далеко не со всеми языками, часто не распознает текст даже на самом четком изображении или же может распознать его не полностью. Но данное расширение все-таки помогает сэкономить время и поскольку находится на стадии беты, в скором времени можно уже ожидать улучшений в работе.
Вам может быть интересно:
Расширение Skyload — основные возможности и установка
Преобразование речи в текст с помощью онлайн-сервисов
Браузер Комета – веб-обозреватель на движке Chromium