Что такое валидатор файла robots.txt?
Инструмент проверки Robots.txt создан для того, чтобы показать, правильно ли составлен ваш файл robots.txt, нет ли в нем ошибок. Robots.txt — этот файл, который является частью вашего веб-сайта и описывает правила индексации для роботов поисковых машин, чтобы веб-сайт индексировался правильно, и первыми на сайте индексировались самые важные данные.Это очень простой инструмент, который создает отчет уже через несколько секунд сканирования: вам просто ввести в поле URL своего веб-сайта, через слэш /robots.txt (например, yourwebsite.com/robots.txt), а затем нажать на кнопку “проверить”. Наш инструмент для тестирования файлов robots.txt находит все ошибки (опечатки, синтаксические и “логические”) и выдает советы по оптимизации файла robots.txt.
Зачем нужно проверять файл robots.txt?
Проблемы с файлом robots.txt или его отсутствие могут негативно отразиться на SEO-оптимизации сайта: ваш сайт может не выдаваться на странице результатов выдачи поисковых машин (SERP). Это происходит из-за того, что нерелевантный контент может обходиться до или вместо важного контента.Проверить свой файл перед тем, как обходить контент важно, чтобы вы смогли избежать проблем, когда весь контент на сайте индексируется, а не только самый релевантный. Например, вы хотите, чтобы доступ к основному контенту вашего веб-сайта пользователи получали только после того, как заполнят форму подписки или войдут в свою учетную запись, но вы не исключаете ее в правилах файла robot.txt, и поэтому она может проиндексироваться.
Что означают ошибки и предупреждения?
Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.Ошибки, которые вы можете увидеть:Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.Предупреждения, которые вы можете увидеть:Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Как исправить ошибки в файле Robots.txt?
Насколько просто будет исправить ошибки в файле robots.txt? Зависит от платформы, которую вы используете. Если это WordPress, то лучше воспользоваться плагином типа WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключили свой веб-сайт к веб-службе Google Search Console, вы сможете редактировать свой файл robots.txt прямо в ней.Некоторые конструкторы веб-сайтов типа Wix не дают возможности редактировать файл robots.txt напрямую, но позволяют добавлять неиндексируемые теги для определенных страниц.
С помощью этого инструмента вы можете узнать, запрещает ли файл robots.txt поисковым роботам Google сканировать определенные URL на вашем сайте. Предположим, у вас есть изображение, которое не должно появляться в результатах поиска Google Картинок. Наш инструмент позволит вам проверить, закрыт ли роботу Googlebot-Image доступ к этому файлу.
Попробовать
Вам потребуется только указать нужный URL. После этого инструмент проверки обработает файл robots.txt так, как это сделал бы робот Googlebot, и определит, закрыт ли доступ к этому адресу.
Процедура проверки
- В Search Console выберите ваш сайт, перейдите к инструменту проверки и изучите код в файле
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в специальном текстовом поле.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в код, указанный в Search Console, и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененный код и добавьте его в файл robots.txt на вашем веб-сервере.
На что следует обратить внимание
- Инструмент работает только с ресурсами с префиксом в URL и несовместим с доменными ресурсами.
- Изменения, внесенные в редакторе, не сохраняются на веб-сервере. Необходимо скопировать полученный код и вставить его в файл
robots.txt. - Инструмент проверки файла robots.txt предоставляет результаты только для агентов пользователя Google и роботов, относящихся к Google (например, для робота Googlebot)
. Мы не можем гарантировать, что другие поисковые роботы будут обрабатывать код в вашем файлеrobots.txtаналогичным образом.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов
Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями
Disallow: /*? # запрет индексации результатов поиска на сайте
Allow: /wp-admin/admin-ajax.php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
# пустая строка
User-agent: Googlebot # правила только для ПС Google
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
Sitemap: # адрес файлаУчитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/
Disallow: /authors/
Disallow: /css/Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
-
1.
Зайдите в личный кабинет Яндекс.Вебмастер.
-
2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
-
3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:

-
4.
Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:


Google Search Console
Чтобы сделать проверку с помощью Google:
-
1.
Перейдите на страницу инструмента проверки.
-
2.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
-
3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
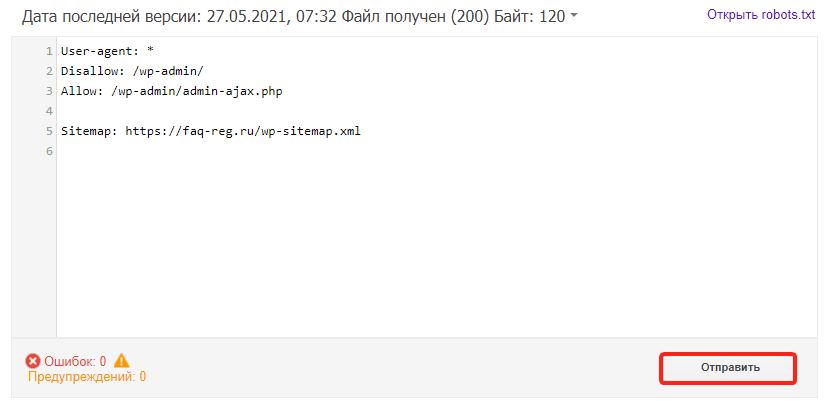

Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Файл robots.txt – это текстовый файл, размещаемый на веб-сайтах для информирования роботов поисковых систем (таких как Google), какие страницы в этом домене можно сканировать. . Если на вашем веб-сайте есть файл robots.txt, вы можете выполнить проверку с помощью нашего бесплатного генератора Robots.txt инструмента. Вы можете интегрировать ссылку на XML карту сайта в файл robots.txt.
Прежде чем боты поисковых систем просканируют ваш сайт, они сначала найдут файл robots.txt сайта. Таким образом, они увидят инструкции, какие страницы сайта можно индексировать, а какие не следует индексировать консолью поисковой системы.
С помощью этого простого файла вы можете настроить параметры сканирования и индексирования для роботов поисковых систем. И чтобы проверить, настроен ли на вашем сайте файл robots.txt, вы можете использовать наши бесплатные и простые инструменты для тестирования Robots.txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
Использование средства проверки robots.txt: пошаговое руководство
Тестирование файла robots.txt поможет вам протестировать файл robots.txt в вашем домене или любом другом домене, который вы хотите проанализировать.
Средство проверки robots.txt быстро обнаружит ошибки в настройках файла robots.txt. Наш инструмент проверки очень прост в использовании и может помочь даже неопытному профессионалу или веб-мастеру проверить файл Robots.txt на своем сайте. Вы получите результаты через несколько минут.
Шаг 1. Вставьте URL-адрес
Чтобы начать сканирование, все, что вам нужно сделать, это ввести интересующий URL-адрес в пустую строку и нажать кнопку с синей стрелкой. Затем инструмент начнет сканирование и выдаст результаты. Вам не нужно регистрироваться на нашем сайте, чтобы использовать его.
В качестве примера мы решили проанализировать наш сайт https://sitechecker.pro. На приведенных ниже снимках экрана вы можете увидеть процесс сканирования в нашем инструменте веб-сайта.
Шаг 2. Интерпретация результатов тестера Robots.txt
Затем, когда сканирование завершится, вы увидите, разрешает ли файл Robots.txt сканирование и индексирование конкретной доступной страницы. Таким образом, вы можете проверить, будет ли ваша веб-страница получать трафик из поисковой системы. Здесь вы также можете получить несколько полезных советов по мониторингу.

Случаи, когда требуется проверка robots.txt
Проблемы с файлом robots.txt или его отсутствие могут негативно повлиять на ваш рейтинг в поисковых системах. Вы можете потерять рейтинговые очки в SERP. Анализ этого файла и его значения перед сканированием веб-сайта позволяет избежать проблем с сканированием. Кроме того, вы можете предотвратить добавление контента вашего веб-сайта на страницы исключения из индекса, которые вы не хотите сканировать. Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Вы можете создать файл с помощью простого текстового редактора. Во-первых, укажите пользовательский агент для выполнения инструкции и поместите директиву блокировки, например, disallow, noindex. После этого перечислите URL-адреса, для которых вы ограничиваете сканирование. Перед запуском файла убедитесь, что он правильный. Даже опечатка может привести к тому, что бот Googlebot проигнорирует ваши инструкции по проверке.
Какие инструменты проверки robots.txt могут помочь
Когда вы создаете файл robots.txt, вам необходимо проверить, не содержат ли они ошибок. Есть несколько инструментов, которые помогут вам справиться с этой задачей.
Консоль поиска Google
Теперь только в старой версии Google Search Console есть инструмент для тестирования файла robots. Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Старая версия Google Search Console > Сканировать > Тестер robots.txt
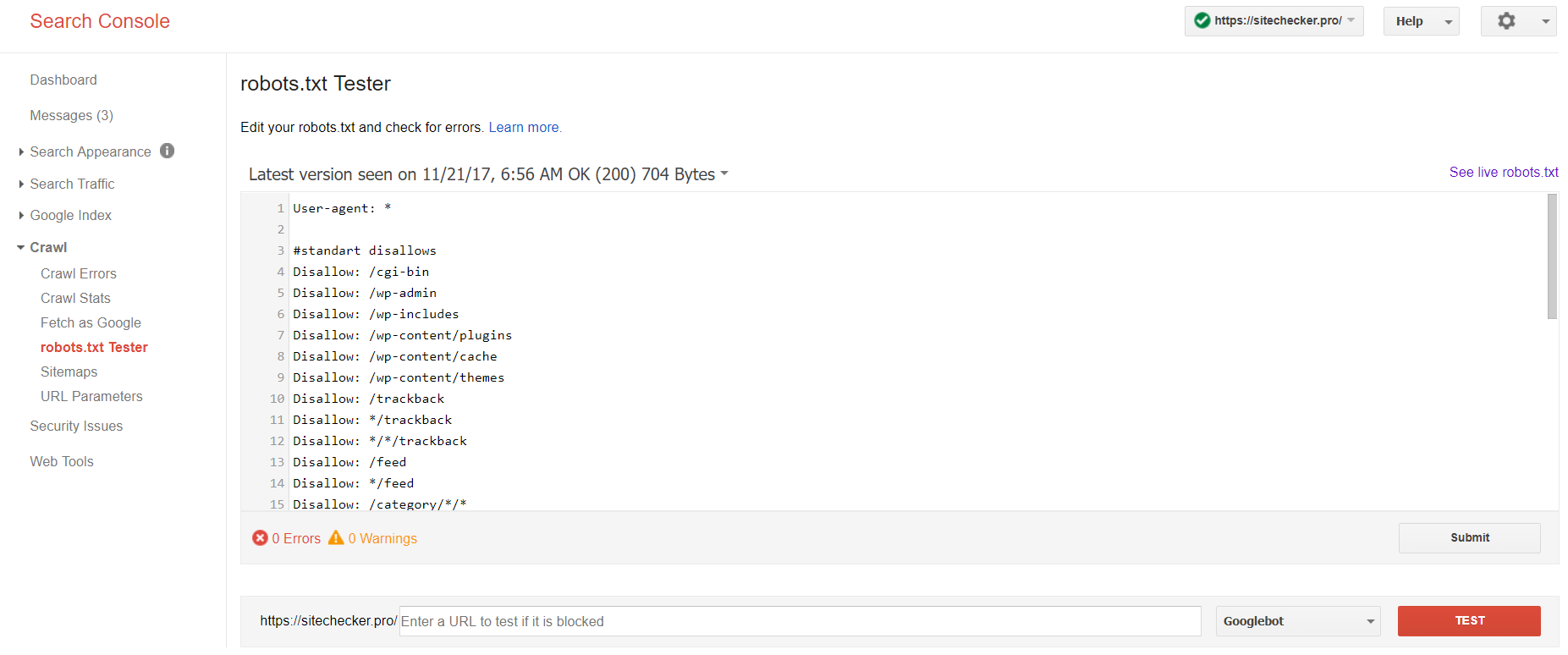
Этот тест robot.txt позволяет:
<ул>
Веб-мастер Яндекса
Войдите в аккаунт Яндекс Вебмастер с текущим сайтом и подтвержден на своей платформе и используйте этот путь, чтобы найти инструмент.
Яндекс для веб-мастеров > Инструменты > Анализ robots.txt
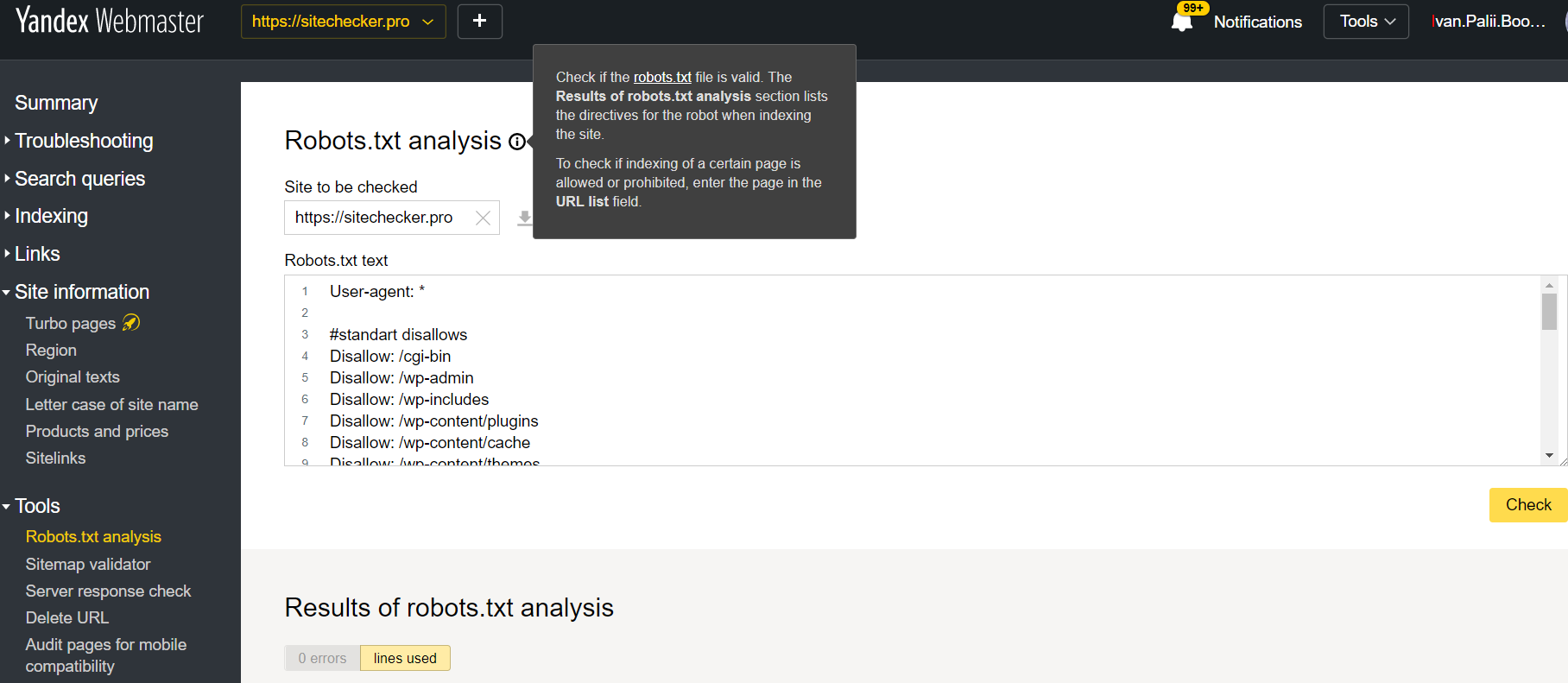
Этот тестер предлагает почти такие же возможности для проверки, как и описанный выше. Разница заключается в:
<ул>
Сканер проверки сайта
Это решение для массовой проверки, если вам нужно просканировать веб-сайт. Наш краулер помогает проверить весь сайт и определить, какие URL-адреса запрещены в robots.txt, а какие закрыты от индексации с помощью метатега noindex.
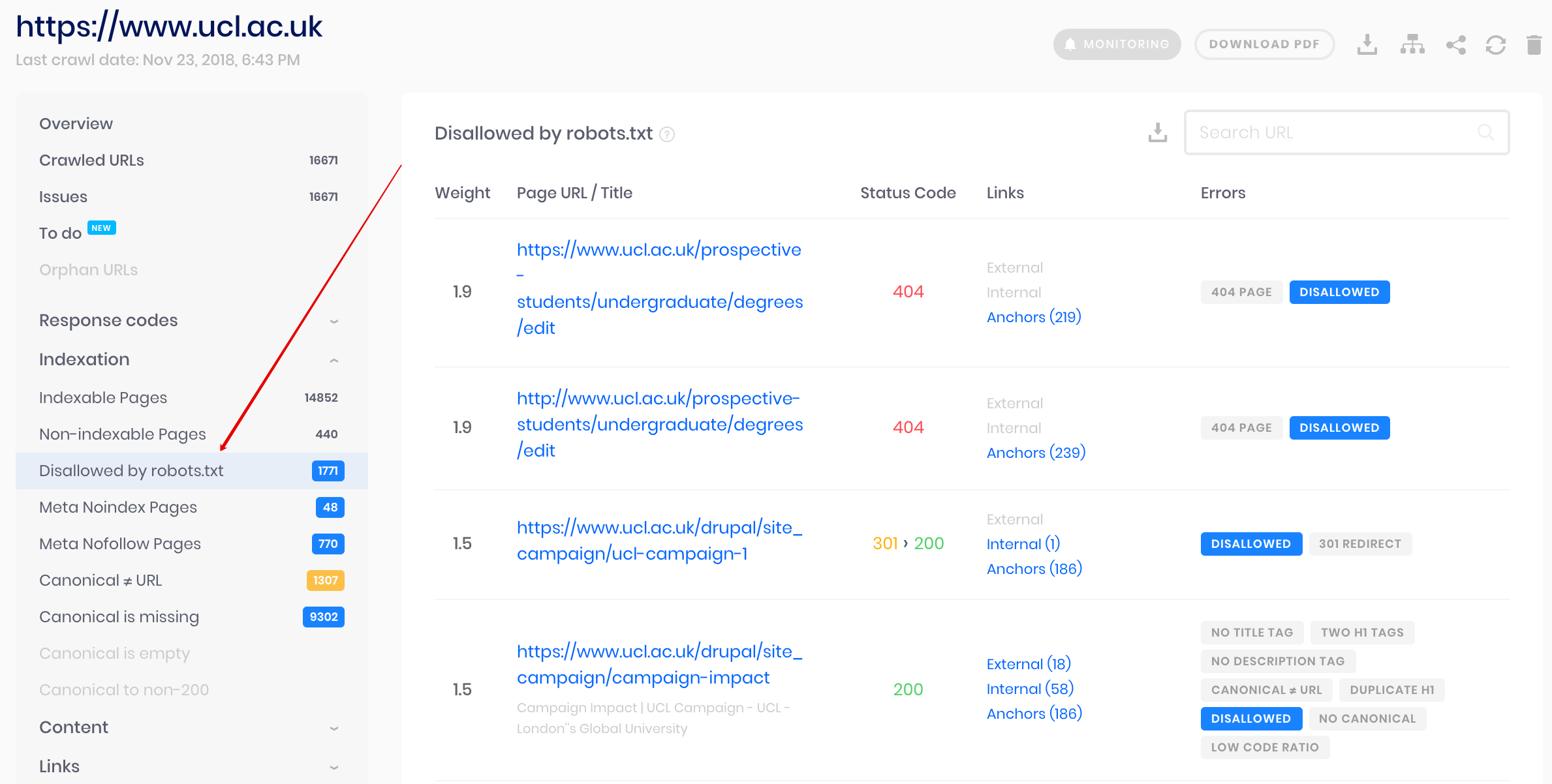
Внимание: для обнаружения запрещенных страниц необходимо просканировать веб-сайт с настройкой игнорировать robots.txt.
Обнаружение и анализ не только файла robots.txt, но и других проблем SEO на вашем сайте!
Проведите полный аудит, чтобы выяснить и исправить проблемы с вашим сайтом, чтобы улучшить результаты поисковой выдачи.



Часто задаваемые вопросы
Зачем мне проверять файл robots.txt?
Robots.txt показывает поисковым системам, какие URL-адреса на вашем сайте они могут сканировать и индексировать, в основном, чтобы не перегружать ваш сайт запросами. Проверка этого действительного файла рекомендуется, чтобы убедиться, что он работает правильно.
Является ли нарушение файла Robots.txt незаконным?
Сегодня нет закона, требующего строго следовать инструкциям в файле. Это не обязывающий договор между поисковыми системами и веб-сайтами.
Что делает файл robots.txt?
Robots.txt показывает агентам поисковых систем, какие страницы вашего сайта можно сканировать и индексировать, а какие страницы были исключены из просмотра. Разрешение поисковым системам сканировать и индексировать некоторые страницы вашего сайта — это возможность контролировать конфиденциальность некоторых страниц. Это необходимо для поисковой оптимизации вашего сайта.
Является ли Robot.txt безопасным?
Файл robots.txt не ставит под угрозу безопасность вашего сайта, поэтому его правильное использование может быть отличным способом защитить конфиденциальные страницы вашего сайта. Тем не менее, не ожидайте, что все сканеры поисковых систем будут следовать инструкциям в этом файле. Злоумышленники смогут отключать инструкции и сканировать запрещенные страницы.
The robots.txt file
The robots.txt file is a simple text file used to inform Googlebot about the areas of a domain that may be crawled by the search engine’s crawler and those that may not. In addition, a reference to the XML sitemap can also be included in the robots.txt file.
Before the search engine bot starts indexing, it first searches the root directory for the robots.txt file and reads the specifications given there. For this purpose, the text file must be saved in the root directory of the domain and given the name: robots.txt.

The robots.txt file can simply be created using a text editor. Every file consists of two blocks. First, one specifies the user agent to which the instruction should apply, then follows a “Disallow” command after which the URLs to be excluded from the crawling are listed.
The user should always check the correctness of the robots.txt file before uploading it to the root directory of the website. Even the slightest of errors can cause the bot to disregard the specifications and possibly include pages that should not appear in the search engine index.
This free tool from Ryte enables you to test your robots.txt file. You only need to enter the corresponding URL and the select the respective user agent. Upon clicking on “Start test”, the tool checks if crawling on your given URL is allowed or not. You can also use Ryte FREE to test many other factors on your website! You can analyze and optimize up to 100 URLs using Ryte FREE. Simply click here to get your FREE account »
The simplest structure of the robots.txt file is as follows:
User-agent: *
Disallow:
This code gives Googlebot permission to crawl all pages. In order to prevent the bot from crawling the entire web presence, you should add the following in the robots.txt file:
User-agent: *
Disallow: /
Example: If you want to prevent the /info/ directory from being crawled by Googlebot, you should enter the following command in the robots.txt file:
User-agent: Googlebot
Disallow: /info/
More information about the robots.txt file can be found here:
- Ryte Wiki: Robots.txt
- Wikipedia: Robots Exclusion Standard
- The Web Robots Pages