chrbar
Guest
-
#1
Hello,
I’m a newcomer with Proxmox.
I’ve installed «Proxmox VE 2 64 bits» on a «Debian Squeeze 64 bits» server.
I create different VM, and when I start them, I obtain «internal-error» as «Status»!
Do you think that is a hardware problem ou another problem (as Proxmox installation or settings)?
I’ve tried with different types of hardware settings (among the CPU, disk and network choices offer by the VM), I’ve tried different guest OS too.
If I create a CT with the Template «debian-6.0-standard_6.0-4_i386.tar.gz», this CT runs correctly.
Could you help me
Thanks a lot,
Chris
![]()
-
#2
Any hint in /var/log/syslog? Or /var/log/apache2/error.log
![]()
tom
Proxmox Staff Member
-
#3
and post your ‘pveversion -v’
chrbar
Guest
-
#4
Thanks for your help
Here my ‘pveversion -v’:
pve-manager: 2.1-14 (pve-manager/2.1/f32f3f46)
running kernel: 2.6.32-14-pve
proxmox-ve-2.6.32: 2.1-74
pve-kernel-2.6.32-10-pve: 2.6.32-63
pve-kernel-2.6.32-14-pve: 2.6.32-74
lvm2: 2.02.95-1pve2
clvm: 2.02.95-1pve2
corosync-pve: 1.4.3-1
openais-pve: 1.1.4-2
libqb: 0.10.1-2
redhat-cluster-pve: 3.1.92-3
resource-agents-pve: 3.9.2-3
fence-agents-pve: 3.1.8-1
pve-cluster: 1.0-27
qemu-server: 2.0-49
pve-firmware: 1.0-18
libpve-common-perl: 1.0-30
libpve-access-control: 1.0-24
libpve-storage-perl: 2.0-31
vncterm: 1.0-3
vzctl: 3.0.30-2pve5
vzprocps: 2.0.11-2
vzquota: 3.0.12-3
pve-qemu-kvm: 1.1-8
ksm-control-daemon: 1.1-1
I’ve checked and saw nothing special inside the logs (but I’m not a linux expert!).
I copie below the logs which appears in «/var/log/syslog» when I start a VM (and stop it 1 ou 2 mn after the «internal-error» appears):
Sep 8 19:14:54 xx-00000 pvedaemon[6853]: <root@pam> successful auth for user ‘root@pam’
Sep 8 19:15:21 xx-00000 pvedaemon[6853]: <root@pam> starting task UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam:
Sep 8 19:15:21 xx-00000 pvedaemon[18173]: start VM 100: UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam:
Sep 8 19:15:21 xx-00000 pvedaemon[6853]: <root@pam> end task UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam: OK
Sep 8 19:17:01 xx-00000 /USR/SBIN/CRON[18212]: (root) CMD ( cd / && run-parts —report /etc/cron.hourly)
Sep 8 19:17:59 xx-00000 pvedaemon[6387]: <root@pam> starting task UPID:sd-27060:00004734:0065368B:504B7DC7:qmstop:100:root@pam:
Sep 8 19:17:59 xx-00000 pvedaemon[18228]: stop VM 100: UPID:sd-27060:00004734:0065368B:504B7DC7:qmstop:100:root@pam:
Sep 8 19:18:00 xx-00000 pvedaemon[6387]: <root@pam> end task UPID:sd-27060:00004734:0065368B:504B7DC7:qmstop:100:root@pam: OK
Sep 8 19:18:47 xx-00000 pvedaemon[1422]: worker 6387 finished
Sep 8 19:18:47 xx-00000 pvedaemon[1422]: starting 1 worker(s)
Sep 8 19:18:47 xx-00000 pvedaemon[1422]: worker 18246 started
Same with logs from «/var/log/apache2/error.log»:
[Sat Sep 08 19:14:47 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:14:48 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:14:48 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:14:48 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:06 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:32 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:32 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:37 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:42 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:48 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:15:49 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:17:43 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:17:45 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:21:29 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:21:30 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
[Sat Sep 08 19:21:30 2012] [error] [client xx.xx.xx.xx] File does not exist: /usr/share/pve-manager/images/favicon.ico
I would be surprised that the problem comes from the «favicon.ico» file?
I’ve posted some printscreens from my VM, if you want to check it:
https://picasaweb.google.com/lh/sre…1121&authkey=Gv1sRgCLWNsqLptPOL-wE&feat=email
Thanks a lot for your help
chrbar
Guest
-
#5
Hi dietmar… I’ve sent log informations below, by replying to tom.
Thanks
Last edited by a moderator: Sep 9, 2012
udo
Famous Member
-
#6
Hi dietmar… I’ve sent log informations below, by replying to tom.
Thanks")
Hi,
and where is the output of «pveversion -v»?
Udo
chrbar
Guest
-
#7
Oupsss I thought my Reply (to tom) need to be validated by Moderator, but I saw that this reply was posted directly… it’s possible that I’ve canceled my reply to tom instead of send it
I’ll rewrite my reply to tom soon…
chrbar
Guest
-
#8
Hello,
Someone told me that the problem comes from IP Failover: there is not IP Failover set to virtual MAC address?
I didn’t set any IP Failover for my VM.
Does VM need an IP Failover to be able to run?
I though IP Failover was needed if you want to run your server directly on the Web.
But I thought we don’t need IP Failover settings if you just want to run VM via the Proxmox console.
Could you confirm to me I need to set an IP Failover to be able to run a VM?
Thanks for your help,
Chris
![]()
-
#9
Could you confirm to me I need to set an IP Failover to be able to run a VM?
No, you do not need IP Failover for that.
udo
Famous Member
-
#10
…
I’ve checked and saw nothing special inside the logs (but I’m not a linux expert!).
I copie below the logs which appears in «/var/log/syslog» when I start a VM (and stop it 1 ou 2 mn after the «internal-error» appears):
Sep 8 19:14:54 xx-00000 pvedaemon[6853]: <root@pam> successful auth for user ‘root@pam’
Sep 8 19:15:21 xx-00000 pvedaemon[6853]: <root@pam> starting task UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam:
Sep 8 19:15:21 xx-00000 pvedaemon[18173]: start VM 100: UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam:
Sep 8 19:15:21 xx-00000 pvedaemon[6853]: <root@pam> end task UPID:sd-27060:000046FD:0064F8B8:504B7D29:qmstart:100:root@pam: OK
…
Hi,
any error if you start the VM on the console with
Udo
VitaminJ
Guest
-
#11
Was this ever resolved? I have the same «internal-error»
/var/log/syslog
Code:
Mar 17 10:54:45 proxmox pvedaemon[2787]: <root@pam> starting task UPID:proxmox:00000B6B:0004CE1F:5145D935:qmstart:101:root@pam:
Mar 17 10:54:45 proxmox kernel: device tap101i0 entered promiscuous mode
Mar 17 10:54:45 proxmox kernel: vmbr0: port 4(tap101i0) entering forwarding state
Mar 17 10:54:46 proxmox pvedaemon[2787]: <root@pam> end task UPID:proxmox:00000B6B:0004CE1F:5145D935:qmstart:101:root@pam: OK
Mar 17 10:54:48 proxmox pvedaemon[2805]: <root@pam> successful auth for user 'root@pam'
Mar 17 10:54:48 proxmox pvedaemon[2944]: starting vnc proxy UPID:proxmox:00000B80:0004CF3A:5145D938:vncproxy:101:root@pam:
Mar 17 10:54:48 proxmox pvedaemon[2775]: <root@pam> starting task UPID:proxmox:00000B80:0004CF3A:5145D938:vncproxy:101:root@pam:
Mar 17 10:54:55 proxmox pvedaemon[2805]: <root@pam> successful auth for user 'root@pam'
Mar 17 10:54:56 proxmox kernel: tap101i0: no IPv6 routers presentCode:
root@proxmox:~# pveversion -v
pve-manager: 2.3-13 (pve-manager/2.3/7946f1f1)
running kernel: 2.6.32-18-pve
proxmox-ve-2.6.32: 2.3-88
pve-kernel-2.6.32-16-pve: 2.6.32-82
pve-kernel-2.6.32-18-pve: 2.6.32-88
lvm2: 2.02.95-1pve2
clvm: 2.02.95-1pve2
corosync-pve: 1.4.4-4
openais-pve: 1.1.4-2
libqb: 0.10.1-2
redhat-cluster-pve: 3.1.93-2
resource-agents-pve: 3.9.2-3
fence-agents-pve: 3.1.9-1
pve-cluster: 1.0-36
qemu-server: 2.3-18
pve-firmware: 1.0-21
libpve-common-perl: 1.0-48
libpve-access-control: 1.0-26
libpve-storage-perl: 2.3-6
vncterm: 1.0-3
vzctl: 4.0-1pve2
vzprocps: 2.0.11-2
vzquota: 3.1-1
pve-qemu-kvm: 1.4-8
ksm-control-daemon: 1.1-1root@proxmox:~# cat /etc/pve/qemu-server/101.conf
Code:
boot: dcn
bootdisk: sata0
cores: 2
ide2: local:iso/Hiren's.BootCD.15.2.iso,media=cdrom,size=609268K
memory: 1024
name: Windows7
net0: e1000=06:DA:A2:DF:E1:82,bridge=vmbr0
ostype: win7
sata0: local:101/vm-101-disk-1.raw,size=16G
sockets: 1I’m starting the machine from Hiren’s BootCD, and selecting the «Mini Windows XP option». As soon as I do that, the state changes from «running» to «internal-error» as below screenshots.
![]()
![]()
Curious about ‘boot: dcn’? What is that?
-
#12
same issue on a ubuntu guest — whats to do??
-
#14
server was moved from another proxmox installation.
storagecontroller is a lsi-controller raid1 and local only
-
#15
Were any of these resolved? I’m getting the exact same issue with ubuntu 13 server and desktop
-
#16
any relevant debugging information required? if so just ask
-
#18
I am having similar problems with new Ubuntu and Windows 2012 R2 too. What I actually do is to change the Video to Standard VGA, this helps a little. But not for mavarics, after 2nd reboot i get the Kernel backtrace. I think there is some issue with the emulated BIOS..
-
#19
I had same problem and my solution of fixing it was to disable KVM hardware virtualization. (Options > KVM hardware virtualization > No)
Hope it will be helpful.
-
#20
Yes it’s helps.
The VM is booting then blue screen of death.
Last edited: Nov 21, 2014
By default kvm running with options «-cpu kvm64,+lahf_lm,+sep,+kvm_pv_unhalt,+kvm_pv_eoi,enforce» (ps aux | grep kvm)
I manually run kvm with different «cpu» options:
# NO CPU OPTIONS (only -cpu kvm64), ALL WORKS GOOD, no error messages in dmesg
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64 -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
# PROXMOX’S 3.4 CPU OPTIONS, all works fine, in dmesg only this: kvm [18840]: vcpu0 unhandled rdmsr: 0xc001100d ; kvm [18840]: vcpu1 unhandled rdmsr: 0xc001100d
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64,+lahf_lm,+x2apic,+sep -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=»10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring»,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
# DEFAULT 4.1 CPU OPTIONS — FAIL
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64,+lahf_lm,+sep,+kvm_pv_unhalt,+kvm_pv_eoi,enforce -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=»10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring»,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
# DEFAULT 4.1 CPU OPTIONS WITHOUT «+kvm_pv_eoi»- FAIL
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64,+lahf_lm,+sep,+kvm_pv_unhalt,enforce -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=»10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring»,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
# DEFAULT 4.1 CPU OPTIONS WITHOUT «+kvm_pv_unhalt», ALL WORKS GOOD, in dmesg: kvm [18267]: vcpu0 unhandled rdmsr: 0xc001100d ; kvm [18267]: vcpu1 unhandled rdmsr: 0xc001100d
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64,+lahf_lm,+sep,+kvm_pv_eoi,enforce -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=»10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring»,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
# ONLY «+kvm_pv_unhalt» OPTION — FAIL
/usr/bin/kvm -id 100 -chardev socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait -mon chardev=qmp,mode=control -pidfile /var/run/qemu-server/100.pid -daemonize -smbios type=1,uuid=d75c86aa-3ad5-4731-b3fd-102da2038af8 -name ceph-test -smp 2,sockets=1,cores=2,maxcpus=2 -nodefaults -boot menu=on,strict=on,reboot-timeout=1000 -vga cirrus -vnc unix:/var/run/qemu-server/100.vnc,x509,password -cpu kvm64,+kvm_pv_unhalt -m 512 -k en-us -device pci-bridge,id=pci.1,chassis_nr=1,bus=pci.0,addr=0x1e -device pci-bridge,id=pci.2,chassis_nr=2,bus=pci.0,addr=0x1f -device piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2 -device usb-tablet,id=tablet,bus=uhci.0,port=1 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3 -iscsi initiator-name=iqn.1993-08.org.debian:01:5fd447b64e1 -drive if=none,id=drive-ide2,media=cdrom,aio=threads -device ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200 -drive file=rbdve_data/vm-100-disk-2:mon_host=»10.10.10.3;10.10.10.4;10.10.10.5:id=admin:auth_supported=cephx:keyring=/etc/pve/priv/ceph/my-ceph-pool.keyring»,if=none,id=drive-virtio1,format=raw,cache=none,aio=native,detect-zeroes=on -device virtio-blk-pci,drive=drive-virtio1,id=virtio1,bus=pci.0,addr=0xb -netdev type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown -device e1000,mac=66:63:34:64:31:66,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=100
In result the option «kvm_pv_unhalt» breaks all?
Maybe related to #24139
Different HTTP error code 500
ISSUE TYPE
- Bug Report
COMPONENT NAME
contrib/inventory/proxmox.py
ANSIBLE VERSION
ansible 2.3.0.0
config file = /etc/ansible/ansible.cfg
configured module search path = [u’/usr/lib/python2.7/site-packages/ansible/modules/extras’, u’/usr/lib/python2.7/site-packages/ansible/modules/core’]
python version = 2.7.5 (default, Nov 6 2016, 00:28:07) [GCC 4.8.5 20150623 (Red Hat 4.8.5-11)]
CONFIGURATION
nothing special
OS / ENVIRONMENT
CentOS 7.3
SUMMARY
STEPS TO REPRODUCE
--- - hosts: 127.0.0.1 connection: local vars: - proxmox_user: ansible@pve - proxmox_password: badpasswd - proxmox_host: 1.2.3.4 tasks: - proxmox: state: present # vmid: 103 # validate_certs: no node: 'pve' api_user: "{{ proxmox_user }}" api_password: "{{ proxmox_password }}" api_host: "{{ proxmox_host }}" # disk: 8 storage: 'pve-storage' # memory: 512 # swap: 512 password: evenbetterpasswd hostname: lxctest ostemplate: 'pve-templates:vztmpl/centos-7-default_20160205_amd64.tar.xz' # netif: '{"net0":"name=eth0,ip=dhcp,ip6=dhcp,bridge=vmbr0,tag=2"}'
EXPECTED RESULTS
LXC container created
ACTUAL RESULTS
5.6.7.8 - - [28/May/2017:20:15:57 +0200] "POST /api2/json/access/ticket HTTP/1.1" 200 663
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/version HTTP/1.1" 200 108
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/cluster/nextid HTTP/1.1" 200 14
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/cluster/resources?type=vm HTTP/1.1" 200 11
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/cluster/resources?type=vm HTTP/1.1" 200 11
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/nodes HTTP/1.1" 200 196
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "GET /api2/json/nodes/pve/storage/pve-templates/content HTTP/1.1" 200 492
5.6.7.8 - ansible@pve [28/May/2017:20:15:57 +0200] "POST /api2/json/nodes/pve/lxc HTTP/1.1" 500 13
fatal: [127.0.0.1]: FAILED! => {
"changed": false,
"failed": true,
"invocation": {
"module_args": {
"api_host": "192.168.1.10",
"api_password": "VALUE_SPECIFIED_IN_NO_LOG_PARAMETER",
"api_user": "ansible@pve",
"cpus": 1,
"cpuunits": 1000,
"disk": "3",
"force": false,
"hostname": "lxctest",
"ip_address": null,
"memory": 512,
"mounts": null,
"nameserver": null,
"netif": null,
"node": "pve",
"onboot": false,
"ostemplate": "pve-templates:vztmpl/centos-7-default_20160205_amd64.tar.xz",
"password": "VALUE_SPECIFIED_IN_NO_LOG_PARAMETER",
"pool": null,
"pubkey": null,
"searchdomain": null,
"state": "present",
"storage": "pve-storage",
"swap": 0,
"timeout": 30,
"unprivileged": false,
"validate_certs": false,
"vmid": null
}
},
"msg": "creation of lxc VM 103 failed with exception: 500 Internal Server Error"
Hi all,
Since a few days I get the error «io-error» message for one of my VMs when I try to boot it.
I can’t explain why this happened, this setup has been running the last 10 months without problems.
On the host I have installed Proxmox 6.1-7, the VM which has problems uses OpenMediaVault 4.1.x.
The host has 8 hard disks and one SSD installed, the hard disks are divided into two ZFS raids. (volume1 and volume2)
The VM itself was set up with two virtual disks. On one disk is the operating system, on the other disk there is only data.
The OS disk is located on the SSD and the data disk can be found on volume1. (vm-100-disk-0)
If I detache the data disk, I can boot the VM normally.
So my guess is there’s something wrong with the raid, but I can’t find anything out of the ordinary.
My second guess would be that the data disk on volume1 is somehow corrupt.
I’ve run a «zpool scrub» for voume1, but no error was found.
Here some info’s regarding the storage situation:
root@pve:/# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.1G 9.2M 3.1G 1% /run
/dev/mapper/pve-root 57G 7.2G 47G 14% /
tmpfs 16G 37M 16G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/nvme0n1p2 511M 304K 511M 1% /boot/efi
volume2 11T 256K 11T 1% /volume2
volume1 2.0M 256K 1.8M 13% /volume1
/dev/fuse 30M 16K 30M 1% /etc/pve
tmpfs 3.1G 0 3.1G 0% /run/user/0
root@pve:/# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data pve twi-aotz-- <147.38g 39.62 2.86
root pve -wi-ao---- 58.00g
swap pve -wi-ao---- 8.00g
vm-100-disk-0 pve Vwi-aotz-- 60.00g data 63.63
vm-101-disk-0 pve Vwi-aotz-- 25.00g data 80.86
root@pve:/# vgs
VG #PV #LV #SN Attr VSize VFree
pve 1 5 0 wz--n- 232.38g 16.00g
root@pve:/# pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p3 pve lvm2 a-- 232.38g 16.00g
root@pve:/# zpool list -v
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
volume1 36.2T 35.1T 1.13T - - 11% 96% 1.00x ONLINE -
raidz1 36.2T 35.1T 1.13T - - 11% 96.9% - ONLINE
sda - - - - - - - - ONLINE
sdb - - - - - - - - ONLINE
sdc - - - - - - - - ONLINE
sdd - - - - - - - - ONLINE
volume2 14.5T 53.3G 14.5T - - 0% 0% 1.00x ONLINE -
raidz1 14.5T 53.3G 14.5T - - 0% 0.35% - ONLINE
sde - - - - - - - - ONLINE
sdf - - - - - - - - ONLINE
sdg - - - - - - - - ONLINE
sdh - - - - - - - - ONLINE
root@pve:/# zpool status -v
pool: volume1
state: ONLINE
scan: scrub repaired 0B in 0 days 19:38:40 with 0 errors on Wed Feb 26 13:07:48 2020
config:
NAME STATE READ WRITE CKSUM
volume1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
sda ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
errors: No known data errors
pool: volume2
state: ONLINE
scan: scrub repaired 0B in 0 days 00:00:02 with 0 errors on Sun Feb 9 00:24:05 2020
config:
NAME STATE READ WRITE CKSUM
volume2 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
sde ONLINE 0 0 0
sdf ONLINE 0 0 0
sdg ONLINE 0 0 0
sdh ONLINE 0 0 0
errors: No known data errors
Something that seems strange to me, why does the command «df -h» show a much smaller size for volume1? Is the volume not mounted correctly?
Now to my question, what can i do to fix this problem? If it cannot be fixed, is there any way I can save my data?
Thanks in advance for your help!
Sorry if I forgot to add some important information.
Добрый день, с недавнего времени стали автоматически отключаться VM, без определенной последовательности, рандомно. (Proxmox 7.2-7, Debian 11.4)
В логе только это:
Jul 21 09:04:34 Line-host QEMU[2643325]: KVM: entry failed, hardware error 0x80000021
Jul 21 09:04:34 Line-host QEMU[2643325]: If you're running a guest on an Intel machine without unrestricted mode
Jul 21 09:04:34 Line-host QEMU[2643325]: support, the failure can be most likely due to the guest entering an invalid
Jul 21 09:04:34 Line-host QEMU[2643325]: state for Intel VT. For example, the guest maybe running in big real mode
Jul 21 09:04:34 Line-host QEMU[2643325]: which is not supported on less recent Intel processors.
Jul 21 09:04:34 Line-host kernel: set kvm_intel.dump_invalid_vmcs=1 to dump internal KVM state.
Jul 21 09:04:34 Line-host QEMU[2643325]: EAX=00000000 EBX=d8b26010 ECX=00000000 EDX=d8b79948
Jul 21 09:04:34 Line-host QEMU[2643325]: ESI=d00c7320 EDI=00000000 EBP=47ce5f80 ESP=35731fb0
Jul 21 09:04:34 Line-host QEMU[2643325]: EIP=00008000 EFL=00000002 [-------] CPL=0 II=0 A20=1 SMM=1 HLT=0
Jul 21 09:04:34 Line-host QEMU[2643325]: ES =0000 00000000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: CS =be00 7ffbe000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: SS =0000 00000000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: DS =0000 00000000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: FS =0000 00000000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: GS =0000 00000000 ffffffff 00809300
Jul 21 09:04:34 Line-host QEMU[2643325]: LDT=0000 00000000 000fffff 00000000
Jul 21 09:04:34 Line-host QEMU[2643325]: TR =0040 35726000 00000067 00008b00
Jul 21 09:04:34 Line-host QEMU[2643325]: GDT= 35727fb0 00000057
Jul 21 09:04:34 Line-host QEMU[2643325]: IDT= 00000000 00000000
Jul 21 09:04:34 Line-host QEMU[2643325]: CR0=00050032 CR2=f24d525a CR3=cea5b000 CR4=00000000
Jul 21 09:04:34 Line-host QEMU[2643325]: DR0=0000000000000000 DR1=0000000000000000 DR2=0000000000000000 DR3=0000000000000000
Jul 21 09:04:34 Line-host QEMU[2643325]: DR6=00000000ffff0ff0 DR7=0000000000000400
Jul 21 09:04:34 Line-host QEMU[2643325]: EFER=0000000000000000
Jul 21 09:04:34 Line-host QEMU[2643325]: Code=kvm: ../hw/core/cpu-sysemu.c:77: cpu_asidx_from_attrs: Assertion `ret < cpu->num_ases && ret >= 0' failed.При запуски появляется ошибка:
kvm: -drive file=/var/lib/vz/images/100/vm-100-disk-1.qcow2,if=none,id=drive-ide0,format=qcow2,aio=native,cache=none,detect-zeroes=on: file system may not support O_DIRECT
kvm: -drive file=/var/lib/vz/images/100/vm-100-disk-1.qcow2,if=none,id=drive-ide0,format=qcow2,aio=native,cache=none,detect-zeroes=on: could not open disk image /var/lib/vz/images/100/vm-100-disk-1.qcow2: Could not open ‘/var/lib/vz/images/100/vm-100-disk-1.qcow2’: Invalid argument
TASK ERROR: start failed: command ‘/usr/bin/kvm -id 100 -chardev ‘socket,id=qmp,path=/var/run/qemu-server/100.qmp,server,nowait’ -mon ‘chardev=qmp,mode=control’ -vnc unix:/var/run/qemu-server/100.vnc,x509,password -pidfile /var/run/qemu-server/100.pid -daemonize -smbios ‘type=1,uuid=23f1d264-91c8-408e-bb84-9ac94cf529fc’ -name TServer -smp ‘4,sockets=1,cores=4,maxcpus=4’ -nodefaults -boot ‘menu=on,strict=on,reboot-timeout=1000’ -vga cirrus -cpu kvm64,+lahf_lm,+x2apic,+sep -m 10240 -k en-us -cpuunits 1000 -device ‘piix3-usb-uhci,id=uhci,bus=pci.0,addr=0x1.0x2’ -device ‘usb-tablet,id=tablet,bus=uhci.0,port=1’ -device ‘virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x3’ -iscsi ‘initiator-name=iqn.1993-08.org.debian:01:5ed3e1eb441e’ -drive ‘file=/var/lib/vz/template/iso/debian-8.0.0-amd64-DVD-1.iso,if=none,id=drive-ide2,media=cdrom,aio=native’ -device ‘ide-cd,bus=ide.1,unit=0,drive=drive-ide2,id=ide2,bootindex=200’ -drive ‘file=/var/lib/vz/images/100/vm-100-disk-1.qcow2,if=none,id=drive-ide0,format=qcow2,aio=native,cache=none,detect-zeroes=on’ -device ‘ide-hd,bus=ide.0,unit=0,drive=drive-ide0,id=ide0,bootindex=100’ -netdev ‘type=tap,id=net0,ifname=tap100i0,script=/var/lib/qemu-server/pve-bridge,downscript=/var/lib/qemu-server/pve-bridgedown’ -device ‘e1000,mac=E6:03:E9:F0:74:81,netdev=net0,bus=pci.0,addr=0x12,id=net0,bootindex=300» failed: exit code 1
В консоле показывает:
root@pve:~# kvm
Could not initialize SDL(No available video device) — exiting
root@pve:~# lspci | grep VGA
07:0b.0 VGA compatible controller: ASPEED Technology, Inc. ASPEED Graphics Family (rev 10)
Сервер DELL PowerEdge 1100, никто с такой проблемой не сталкивался?
14
Посты
2
Пользователи
0
Likes
1,671
Просмотры

(@2013okt112)
Active Member
Присоединился: 2 года назад
https://ibb.co/M9kXgyy
незнаю как вставить фото, поэтому вот
(@2013okt112)
Active Member
Присоединился: 2 года назад
вообще новичек в этом и даже непонимаю как что оттуда восстановить и что надо делать

(@zerox)
Prominent Member
Присоединился: 9 лет назад
Во время загрузки сервера попробуй выбрать предыдущее ядро. Это можно сделать на этом экране — 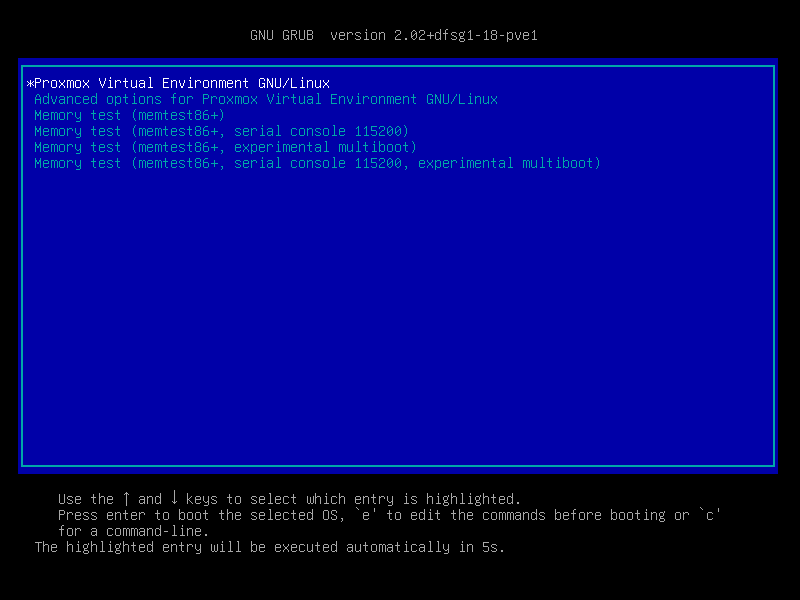
Если не ошибаюсь, во втором разделе меню можно это сделать.