-
#1
I’m new to Proxmox, not new to Linux or VMs.
Any time I start a new VM now, it freezes during the initial setup and Proxmox shows «Status: io-error». I only have a single LXC container and a single Ubuntu VM running right now. They definitely are not using the node’s entire disk drive space, or CPU or RAM.
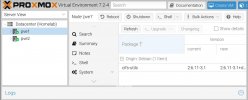
I saw somewhere online it could be due to the LVM being full. When looking at the node I see this
but honestly I can’t tell if that means I have the entirety of the disk reserved for Proxmox or the whole thing is in use. Looking at the node’s local storage and local-lvm storage, they both show only about 4% usage.
My only guess is it has something to do with VMs I have built and later removed through Proxmox. Maybe I didn’t remove their storage properly so there’s no more room on the disk for a new VM? I really have no clue, taking a shot in the dark.
What can I be looking for and what more info can I provide to help find this issue?
-
#2
Hi, i’m also new to proxmox, i got the same problem with one of my VMs (Pop!_OS).
This VM can’t boot properly, the same VM was all okay last sunday. Today when i got updates for my Proxmox host i wasn’t able to boot the VM.
I personally think that one of these updates is to blame for it.
One of these updates was for the LVM if i’m correct.
edit:
Just tried to create a new Linux (MX) VM and got an IO error again, but my Win 10 VM can boot normal, difference between this 3 VMs is just UEFI support (OVMF for Linux VMs ) / the Windows VM (SeaBios)
Last edited: Jun 4, 2022
-
#3
I don’t think I’ve updated Proxmox since setting it up. One of the VMs is ubuntu-live-server-amd64, and so is the new VM I’m trying to create.
Are you trying to say that a Proxmox update has just broken the ability to make VMs with one of the most common ISOs? Wouldn’t that just be breaking the entire function of Proxmox in the first place? There’s no way they’d push an update like that.
-
#4
Yeah you’re right about breaking the core function, but actually my migrated machines and also my attempt to install Ubuntu server 22.04 LTS got an IO error all over the day.
I tried Pop!_OS 21.10 live and it worked (tried all machines with UEFI / OVMF support).
So … i think it could be the Linux guest itself.
edit:
I encountered some strange behavior, some VMs booting and others not …, but in the end crashes all.
RAM is all Okay (ECC memory) …
I tried VM-disks on my CIFS Server and direct on the Host, all VMs with outsourced disks got an IO error, reboot of all my machines don’t helped.
Screenshot of one VM with disk on the network saved
When did you set up your Proxmox ?
Do you save your VMs on a NAS or Server in your network ?
Last edited: Jun 5, 2022
-
#5
I set up Proxmox with the current working VM and LXC like 2 weeks ago. I have all my VMs local, but I have tried storing the ISOs I’m using for boot both local and on a NAS.
-
#6
Okay, i tried the ISOs on the local machine but the VM-disks one time local and another time outsourced.
VM disk local = Function
VM disk in NAS / server storage = IO error
i know that saving a VM disk on network storage isn’t the best way, but for me it worked fine until yesterday.
What’s the output of syslog of your Proxmox ?
I found a message in the syslogs of my host machine, something like that and this causes me an IO error with outsourced VM disks
-
#7
So, that’s part of the problem and I should I have been more clear in my original post. How do I get syslog? I can’t find anything for logs other than under the firewall.
-
#8
You can access the syslog under Data center > «your Node» (eg. Proxmox) > syslog
-
#9
I should feel embarassed, I wass looking for it but mostly with the VM selected.
After watching the log I see i am getting the CIFS: VFS: error too.
After going througha nd making a VM again and looking carefully, I see it wasn’t the ISO, the «storage» was defaulting tosetting the disk to be on my NAS I have attached. Once I set that to local again it’s booting up fine. Of course that makes sense.
It should always default local, but I also should have caught that sooner.
-
#10
So in the end we both have the same Problem with CIFS / Samba Storage and outsourced VM Disks xDD
After all i think it is really something with an update for Proxmox, but to have IO errors ist just annoying.
I don’t know if this is a problem with Proxmox ( to be honest i use the non subscription repository for PVE updates ), but i hope for some fixes if its from an update….
I consider to reinstall proxmox complete on my Host an see if it’s a persistent error with the Repo.
-
#11
Well at least we got it figured out. Good thing my job hired me to be a Docker guy, not a Proxmox guy lol. I’m just doing this at home.
-
#12
Well yeah i’m an Electrician for all things over PC to Networking and Linux, but working actually as signal technician xD , i’m doing this at home to virtualize multiple machines and splitting some services from my storage server etc.
-
#13
Well, a friend of mine sends me a screenshot about his Proxmox nodes and upgradable packages an there is a package for Cifs-utils.
-

signal-2022-06-06-082229_001.jpeg
193.9 KB
· Views: 21
-
#14
Yeah i found the cause ,…. the I/O error over the network storage is based on the newer Kernel
![]()
fiona
Proxmox Staff Member
-
#15
Hi,
I can reproduce the issue here and am looking for the root cause. Apart from downgrading the kernel, a workaround seems to be to switch your VM’s disk away from io_uring to threads or native (advanced disk settings in the UI).
-
#16
@Fabian_E Haha nice, thanks, i just tried the old 5.4 kernel just for fun and that’s it.
I would like to know why we get kernel messages about CIFS /VFS in the syslog as i described above in thread #6 and i’ll try to switch my VM disks away from IO_uring as you mentioned.
![]()
fiona
Proxmox Staff Member
-
#17
@Fabian_E Haha nice, thanks, i just tried the old 5.4 kernel just for fun and that’s it.
I would like to know why we get kernel messages about CIFS /VFS in the syslog as i described above in thread #6 and i’ll try to switch my VM disks away from IO_uring as you mentioned.
I’m still trying to figure out the cause. It might be that the issue is in the CIFS kernel code and using IO uring makes the issue more likely to appear, but it might also be a problem in IO uring itself.
-
#18
So… i switched the Disk to Nativ as you mentioned earlier, now with the new kernel it seems to work as usually.
-
#19
So .. today i got again the I/O Error message but this time with nativ VM disk option.
The other VMs working normally without issues, but Deepin and Linux Mint don’t wanna go the right way.

![]()
fiona
Proxmox Staff Member
-
#20
So .. today i got again the I/O Error message but this time with nativ VM disk option.
The other VMs working normally without issues, but Deepin and Linux Mint don’t wanna go the right way.
View attachment 38798
Hmm, as said maybe using io_uring just makes it more likely to trigger. Can you please check /var/log/syslog from around the time the issue happened? Is it the same Error -512 sending data on socket to server error?
I’m currently testing a commit that’s potentially fixing the issue suggested by kernel developers.
Содержание
- io-error how to identify, fix and check?
- eiger3970
- eiger3970
- [SOLVED] Crash VM with io-error
- carcella
- carcella
- carcella
- carcella
- VM shows io-error and locks up
- Sandbo
- VM I/O error when mounting a RAIDZ partition
- VM Status: io-error ZFS full
- wowkisame
- LnxBil
- wowkisame
- Dunuin
- wowkisame
- Dunuin
- wowkisame
- Dunuin
- wowkisame
- itNGO
- LnxBil
io-error how to identify, fix and check?
eiger3970
Active Member
Hello, I’ve received an io-error. I would like to know how to pinpoint what the cause of the problem is, to address the correct issue and avoid repeats.
I ran some tests
I’m guessing the hard drive is faulty, but would like to confirm which hard drive, before physically replacing.
Also, how do I check all the hard drives in the server without physically opening up the machine?
I would like to confirm harddrives running Proxmox and if or what hard drives are running the servers, such as CentOS where the io-error appeared on the GUI. The Proxmox GUI also showed the CPU usage at 101.5%, but was running fine, until I logged in and saw the io-error.
Famous Member
Hi,
where do you see the io-error?
For looking at your hdds use smartmontools.
Which storage do you use for your VM? Which cache settings?
eiger3970
Active Member
Thank you for the reply.
The io-error is in VM 4 and 5 on the Proxmox GUI > Server View > Datacenter > proxmox > VM > Summary > Status > Status > io-error.
I’ve had a look at smartmontools and it looks like I install on the Proxmox machine.
The storage used is a hard disk drive (virtio0) local:VMID/vm-VMID-disk-1.raw,format=raw,size=50G.
Cache (memory?): 2.00GB.
VMs 1 — 3 run fine.
VMs 4 — 5 had the io-errors.
I deleted VMs 4 — 5, then restored VMs 4 — 5.
VM 4 has the same error. Odd as the restore is from 20160313, but VM 4 worked until 20160319.
Yes, I have run the fsck manually, however after fixing issues, a reboot returns to the same error.
Actually, I ran the fsck manually on the restore, and it’s fixed.
So, how can I avoid this.
I guess setting up RAID or knowing what causes the io-error would be good.
Источник
[SOLVED] Crash VM with io-error
carcella
New Member

Proxmox Staff Member
Best regards,
Mira
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
carcella
New Member
# pveversion -v
proxmox-ve: 7.3-1 (running kernel: 5.11.22-7-pve)
pve-manager: 7.3-3 (running version: 7.3-3/c3928077)
pve-kernel-5.15: 7.2-14
pve-kernel-helper: 7.2-14
pve-kernel-5.13: 7.1-9
pve-kernel-5.15.74-1-pve: 5.15.74-1
pve-kernel-5.15.64-1-pve: 5.15.64-1
pve-kernel-5.13.19-6-pve: 5.13.19-15
pve-kernel-5.13.19-2-pve: 5.13.19-4
pve-kernel-5.11.22-7-pve: 5.11.22-12
ceph-fuse: 15.2.15-pve1
corosync: 3.1.7-pve1
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.24-pve2
libproxmox-acme-perl: 1.4.2
libproxmox-backup-qemu0: 1.3.1-1
libpve-access-control: 7.2-5
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.3-1
libpve-guest-common-perl: 4.2-3
libpve-http-server-perl: 4.1-5
libpve-storage-perl: 7.3-1
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 5.0.0-3
lxcfs: 4.0.12-pve1
novnc-pve: 1.3.0-3
proxmox-backup-client: 2.2.7-1
proxmox-backup-file-restore: 2.2.7-1
proxmox-mini-journalreader: 1.3-1
proxmox-offline-mirror-helper: 0.5.0-1
proxmox-widget-toolkit: 3.5.3
pve-cluster: 7.3-1
pve-container: 4.4-2
pve-docs: 7.3-1
pve-edk2-firmware: 3.20220526-1
pve-firewall: 4.2-7
pve-firmware: 3.5-6
pve-ha-manager: 3.5.1
pve-i18n: 2.8-1
pve-qemu-kvm: 7.1.0-4
pve-xtermjs: 4.16.0-1
qemu-server: 7.3-1
smartmontools: 7.2-pve3
spiceterm: 3.2-2
swtpm: 0.8.0
bpo11+2
vncterm: 1.7-1
zfsutils-linux: 2.1.6-pve1
root@pve:
carcella
New Member
# qm config 100
boot: order=ide0;ide2;net0
cores: 2
description: administrator / AzPan!c02020
ide0: local-lvm:vm-100-disk-0,size=62G
ide2: cdrom,media=cdrom
machine: pc-i440fx-6.1
memory: 6144
meta: creation-qemu=6.1.0,ctime=1642289339
name: Win19srv
net0: e1000=A2:4F:4C:1D:A1 2,bridge=vmbr0,firewall=1
numa: 0
ostype: win10
parent: win2019_18122022
scsihw: virtio-scsi-pci
smbios1: uuid=ecd0cefd-2aa5-45c1-b123-f3c00946843d
sockets: 3
usb0: spice,usb3=1
vga: qxl
vmgenid: 284cb1d3-c3bc-4298-8495-4606211b5504
carcella
New Member
Proxmox Staff Member
Best regards,
Mira
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Источник
VM shows io-error and locks up
Sandbo
Member
I am setting up one VM to do plotting for Chia, it has the following disks:
-3 pass-through 1TB SSDs
-5 SATA 400GB SSDs as RAID0 in Proxmox, used as a directory and is assigned as virtual hard disk to the VM (volume set was 1800 GiB, after checking df -BGiB in Proxmox shell)
-1 PCI-E RAID card (LSI 9266-8i)
After some times, can be a day or some times as short as a couple hours, the VM becomes unresponsive to SSH. By logging in to the GUI, the console simply says «Guest disabled display», and there is a yellow «!» saying «io-error». The OS is completely frozen and I can only reboot it, and it does work after the reboot but can freeze later. I checked and when it locks up, the SATA arrays are at most at 80% and are not yet full.
May I know where to start to look into the issue? As I have a few IO devices, can I see which one of the above three is the cause?
Update 1: Adding some context after some tests. Turns out it was caused by the SATA drives as I isolate them one by one.
They are 5*400GB SATA SSDs (Intel DC S3700 400 GB) attached to the mainboard directly (X399 Taichi). I set them up as ZFS RAID 0 and created a directory under /CSCP2. I checked by «df -BGiB» that the volume is (for example, not when it had the error)
CSCP2 1802GiB 343GiB 1459GiB 20% /CSCP2
So I assigned to VM as a harddisk with 1800 GiB. As the drive is being filled, and before it has been fully filled, it threw the io-error at some point, seemingly up to 80% use of the drive as indicated from df from host.
Источник
VM I/O error when mounting a RAIDZ partition
New Member
First of all, I should say I’m a total beginner regarding these matters, so please bear with me for a moment. Thank you.
My company accidentally fill one RAIDZ partition (sdb1) up to 100% of its capacity yesterday causing the VM in which such partition was originally mounted to go unresponsive.
We stopped and then started the VM succesfully, but the part is now unmounted as it is absent in df (see below). 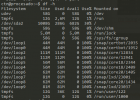
When checking with lsblk I can see the disk and its partition without a mount point indeed (see figure below for details). 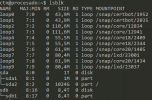
The problem is that when I try to mount the partition from the console using the typical mount /dev/sdb1 , the terminal hangs indefinitely, and when checking it out in the proxmox VE dashboard the VM appears with a warning icon indicating io-error, although apparently the VM is still running as indicated in the Status flag (I don’t know why it says that, because it effectively goes unresponsive). The figure below shows the specific error. 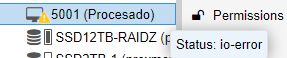
I assume the problem comes from the lack of any free space in the partition, so, do you have any ideas about how can I proceed without losing the data? I have searched and searched for solutions and had no luck yet. The fact I’m only a begginer does not help at all, to be honest.
Thank you very much in advance for your time!
Источник
VM Status: io-error ZFS full
wowkisame
New Member
Since yesterday I had a VM with status : io-error. I can’t find a way to make free space on it . When I check my ZFS pool :
root@pve:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
rpool 222G 115G 107G — — 68% 51% 1.00x ONLINE —
stockage 43.6T 42.3T 1.36T — — 10% 96% 1.00x ONLINE —
ZFS list :
root@pve:
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 115G 100G 104K /rpool
rpool/ROOT 4.34G 100G 96K /rpool/ROOT
rpool/ROOT/pve-1 4.34G 100G 4.34G /
rpool/data 110G 100G 96K /rpool/data
rpool/data/vm-100-disk-0 1.74G 100G 1.74G —
rpool/data/vm-101-disk-0 108G 100G 108G —
rpool/data/vm-105-disk-0 56K 100G 56K —
stockage 30.7T 0B 140K /stockage
stockage/vm-101-disk-0 30.7T 0B 30.7T —
I think that the free space in zpool is use to parity for raidz, so ZFS don’t have any space.
I can start a live Linux on the VM but when I try to mount the filesystem, the VM freeze and I got status : io-error in Proxmox.
I don’t know if is-it possible to mount the filesystem directly to the host proxmox and make some cleanup .
Any others ideas ?
LnxBil
Famous Member
No, the free space is unusable, therefore you cannot store anything new on it.
First, I’d look for any refreservation values, then I’d see if there are any snapshots that can be deleted, then I’d temporarily send/receive one dataset to another pool and delete the source . and do your maintenance stuff.
wowkisame
New Member
Hi LnxBil,
First of all, thanks for your time.
Unfortunately, no snapshot, no reservation, no quota (may be there are others commands ?) :
Could you explain this part please ?
Of course I will create an alert for storage next time .
Dunuin
Famous Member
Better you set a quota too and not just an alarm. In general its recommended to keep around 20% of your ZFS pool always empty because the pool will become slower when the pool gets full. I always set a quota of 90% for the entire pool and set a alarm when 80% is exceeded to clean up stuff to bring it under 80% again. That way you can’t run into such a situation where your pools gets full to a point where it stops working.
And you only checked «reservation» but not «refreservation».
Output of zfs list -o space stockage or even zfs list -o space would be useful too. Then you also see snapshot and refreservation space usage.
wowkisame
New Member
Thanks for your time and your answer.
I don’t understand the «Sending and Receiving ZFS Data» part. I can only send a part of stockage to rpool/data for exemple ?
Dunuin
Famous Member
Thanks for your time and your answer.
wowkisame
New Member
I don’t have 31+TB to copy my volume. So I don’t have any solution to clean or reduce the volume
Dunuin
Famous Member
wowkisame
New Member
Oh
May be someone else have others ideas ?

itNGO
Well-Known Member
Oh
May be someone else have others ideas ?
LnxBil
Famous Member
The problem is that you have only one zvol stored on your pool stockage without any snapshots or any kind of reservation and you ran out of space. The send/receive route is not a viable option, because you only have one volume.
The problem with freeing up used space is that this probably needs to write in order to clean it up a bit, which is not real option. Yet, as you’ve already descibed, you already ran out of space and the guest noticed that, so you’re already a filesystem with errors on it. As you described, you cannot mount the disk in a live system due to the space problem, so cleaning it now won’t help — or maybe it does.
Источник
Hi all,
Since a few days I get the error «io-error» message for one of my VMs when I try to boot it.
I can’t explain why this happened, this setup has been running the last 10 months without problems.
On the host I have installed Proxmox 6.1-7, the VM which has problems uses OpenMediaVault 4.1.x.
The host has 8 hard disks and one SSD installed, the hard disks are divided into two ZFS raids. (volume1 and volume2)
The VM itself was set up with two virtual disks. On one disk is the operating system, on the other disk there is only data.
The OS disk is located on the SSD and the data disk can be found on volume1. (vm-100-disk-0)
If I detache the data disk, I can boot the VM normally.
So my guess is there’s something wrong with the raid, but I can’t find anything out of the ordinary.
My second guess would be that the data disk on volume1 is somehow corrupt.
I’ve run a «zpool scrub» for voume1, but no error was found.
Here some info’s regarding the storage situation:
root@pve:/# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.1G 9.2M 3.1G 1% /run
/dev/mapper/pve-root 57G 7.2G 47G 14% /
tmpfs 16G 37M 16G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/nvme0n1p2 511M 304K 511M 1% /boot/efi
volume2 11T 256K 11T 1% /volume2
volume1 2.0M 256K 1.8M 13% /volume1
/dev/fuse 30M 16K 30M 1% /etc/pve
tmpfs 3.1G 0 3.1G 0% /run/user/0
root@pve:/# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
data pve twi-aotz-- <147.38g 39.62 2.86
root pve -wi-ao---- 58.00g
swap pve -wi-ao---- 8.00g
vm-100-disk-0 pve Vwi-aotz-- 60.00g data 63.63
vm-101-disk-0 pve Vwi-aotz-- 25.00g data 80.86
root@pve:/# vgs
VG #PV #LV #SN Attr VSize VFree
pve 1 5 0 wz--n- 232.38g 16.00g
root@pve:/# pvs
PV VG Fmt Attr PSize PFree
/dev/nvme0n1p3 pve lvm2 a-- 232.38g 16.00g
root@pve:/# zpool list -v
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
volume1 36.2T 35.1T 1.13T - - 11% 96% 1.00x ONLINE -
raidz1 36.2T 35.1T 1.13T - - 11% 96.9% - ONLINE
sda - - - - - - - - ONLINE
sdb - - - - - - - - ONLINE
sdc - - - - - - - - ONLINE
sdd - - - - - - - - ONLINE
volume2 14.5T 53.3G 14.5T - - 0% 0% 1.00x ONLINE -
raidz1 14.5T 53.3G 14.5T - - 0% 0.35% - ONLINE
sde - - - - - - - - ONLINE
sdf - - - - - - - - ONLINE
sdg - - - - - - - - ONLINE
sdh - - - - - - - - ONLINE
root@pve:/# zpool status -v
pool: volume1
state: ONLINE
scan: scrub repaired 0B in 0 days 19:38:40 with 0 errors on Wed Feb 26 13:07:48 2020
config:
NAME STATE READ WRITE CKSUM
volume1 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
sda ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
errors: No known data errors
pool: volume2
state: ONLINE
scan: scrub repaired 0B in 0 days 00:00:02 with 0 errors on Sun Feb 9 00:24:05 2020
config:
NAME STATE READ WRITE CKSUM
volume2 ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
sde ONLINE 0 0 0
sdf ONLINE 0 0 0
sdg ONLINE 0 0 0
sdh ONLINE 0 0 0
errors: No known data errors
Something that seems strange to me, why does the command «df -h» show a much smaller size for volume1? Is the volume not mounted correctly?
Now to my question, what can i do to fix this problem? If it cannot be fixed, is there any way I can save my data?
Thanks in advance for your help!
Sorry if I forgot to add some important information.
io-error how to identify, fix and check?
eiger3970
Active Member
Hello, I’ve received an io-error. I would like to know how to pinpoint what the cause of the problem is, to address the correct issue and avoid repeats.
I ran some tests
I’m guessing the hard drive is faulty, but would like to confirm which hard drive, before physically replacing.
Also, how do I check all the hard drives in the server without physically opening up the machine?
I would like to confirm harddrives running Proxmox and if or what hard drives are running the servers, such as CentOS where the io-error appeared on the GUI. The Proxmox GUI also showed the CPU usage at 101.5%, but was running fine, until I logged in and saw the io-error.
Famous Member
Hi,
where do you see the io-error?
For looking at your hdds use smartmontools.
Which storage do you use for your VM? Which cache settings?
eiger3970
Active Member
Thank you for the reply.
The io-error is in VM 4 and 5 on the Proxmox GUI > Server View > Datacenter > proxmox > VM > Summary > Status > Status > io-error.
I’ve had a look at smartmontools and it looks like I install on the Proxmox machine.
The storage used is a hard disk drive (virtio0) local:VMID/vm-VMID-disk-1.raw,format=raw,size=50G.
Cache (memory?): 2.00GB.
VMs 1 — 3 run fine.
VMs 4 — 5 had the io-errors.
I deleted VMs 4 — 5, then restored VMs 4 — 5.
VM 4 has the same error. Odd as the restore is from 20160313, but VM 4 worked until 20160319.
Yes, I have run the fsck manually, however after fixing issues, a reboot returns to the same error.
Actually, I ran the fsck manually on the restore, and it’s fixed.
So, how can I avoid this.
I guess setting up RAID or knowing what causes the io-error would be good.
Источник
[SOLVED] Crash VM with io-error
carcella
New Member
Proxmox Staff Member
Best regards,
Mira
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
carcella
New Member
# pveversion -v
proxmox-ve: 7.3-1 (running kernel: 5.11.22-7-pve)
pve-manager: 7.3-3 (running version: 7.3-3/c3928077)
pve-kernel-5.15: 7.2-14
pve-kernel-helper: 7.2-14
pve-kernel-5.13: 7.1-9
pve-kernel-5.15.74-1-pve: 5.15.74-1
pve-kernel-5.15.64-1-pve: 5.15.64-1
pve-kernel-5.13.19-6-pve: 5.13.19-15
pve-kernel-5.13.19-2-pve: 5.13.19-4
pve-kernel-5.11.22-7-pve: 5.11.22-12
ceph-fuse: 15.2.15-pve1
corosync: 3.1.7-pve1
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.24-pve2
libproxmox-acme-perl: 1.4.2
libproxmox-backup-qemu0: 1.3.1-1
libpve-access-control: 7.2-5
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.3-1
libpve-guest-common-perl: 4.2-3
libpve-http-server-perl: 4.1-5
libpve-storage-perl: 7.3-1
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 5.0.0-3
lxcfs: 4.0.12-pve1
novnc-pve: 1.3.0-3
proxmox-backup-client: 2.2.7-1
proxmox-backup-file-restore: 2.2.7-1
proxmox-mini-journalreader: 1.3-1
proxmox-offline-mirror-helper: 0.5.0-1
proxmox-widget-toolkit: 3.5.3
pve-cluster: 7.3-1
pve-container: 4.4-2
pve-docs: 7.3-1
pve-edk2-firmware: 3.20220526-1
pve-firewall: 4.2-7
pve-firmware: 3.5-6
pve-ha-manager: 3.5.1
pve-i18n: 2.8-1
pve-qemu-kvm: 7.1.0-4
pve-xtermjs: 4.16.0-1
qemu-server: 7.3-1
smartmontools: 7.2-pve3
spiceterm: 3.2-2
swtpm: 0.8.0
bpo11+2
vncterm: 1.7-1
zfsutils-linux: 2.1.6-pve1
root@pve:
carcella
New Member
# qm config 100
boot: order=ide0;ide2;net0
cores: 2
description: administrator / AzPan!c02020
ide0: local-lvm:vm-100-disk-0,size=62G
ide2: cdrom,media=cdrom
machine: pc-i440fx-6.1
memory: 6144
meta: creation-qemu=6.1.0,ctime=1642289339
name: Win19srv
net0: e1000=A2:4F:4C:1D:A1 2,bridge=vmbr0,firewall=1
numa: 0
ostype: win10
parent: win2019_18122022
scsihw: virtio-scsi-pci
smbios1: uuid=ecd0cefd-2aa5-45c1-b123-f3c00946843d
sockets: 3
usb0: spice,usb3=1
vga: qxl
vmgenid: 284cb1d3-c3bc-4298-8495-4606211b5504
carcella
New Member
Proxmox Staff Member
Best regards,
Mira
Do you already have a Commercial Support Subscription? — If not, Buy now and read the documentation
Источник
VM shows io-error and locks up
Sandbo
Member
I am setting up one VM to do plotting for Chia, it has the following disks:
-3 pass-through 1TB SSDs
-5 SATA 400GB SSDs as RAID0 in Proxmox, used as a directory and is assigned as virtual hard disk to the VM (volume set was 1800 GiB, after checking df -BGiB in Proxmox shell)
-1 PCI-E RAID card (LSI 9266-8i)
After some times, can be a day or some times as short as a couple hours, the VM becomes unresponsive to SSH. By logging in to the GUI, the console simply says «Guest disabled display», and there is a yellow «!» saying «io-error». The OS is completely frozen and I can only reboot it, and it does work after the reboot but can freeze later. I checked and when it locks up, the SATA arrays are at most at 80% and are not yet full.
May I know where to start to look into the issue? As I have a few IO devices, can I see which one of the above three is the cause?
Update 1: Adding some context after some tests. Turns out it was caused by the SATA drives as I isolate them one by one.
They are 5*400GB SATA SSDs (Intel DC S3700 400 GB) attached to the mainboard directly (X399 Taichi). I set them up as ZFS RAID 0 and created a directory under /CSCP2. I checked by «df -BGiB» that the volume is (for example, not when it had the error)
CSCP2 1802GiB 343GiB 1459GiB 20% /CSCP2
So I assigned to VM as a harddisk with 1800 GiB. As the drive is being filled, and before it has been fully filled, it threw the io-error at some point, seemingly up to 80% use of the drive as indicated from df from host.
Источник
VM I/O error when mounting a RAIDZ partition
New Member
First of all, I should say I’m a total beginner regarding these matters, so please bear with me for a moment. Thank you.
My company accidentally fill one RAIDZ partition (sdb1) up to 100% of its capacity yesterday causing the VM in which such partition was originally mounted to go unresponsive.
We stopped and then started the VM succesfully, but the part is now unmounted as it is absent in df (see below).
When checking with lsblk I can see the disk and its partition without a mount point indeed (see figure below for details).
The problem is that when I try to mount the partition from the console using the typical mount /dev/sdb1 , the terminal hangs indefinitely, and when checking it out in the proxmox VE dashboard the VM appears with a warning icon indicating io-error, although apparently the VM is still running as indicated in the Status flag (I don’t know why it says that, because it effectively goes unresponsive). The figure below shows the specific error.
I assume the problem comes from the lack of any free space in the partition, so, do you have any ideas about how can I proceed without losing the data? I have searched and searched for solutions and had no luck yet. The fact I’m only a begginer does not help at all, to be honest.
Thank you very much in advance for your time!
Источник
VM Status: io-error ZFS full
wowkisame
New Member
Since yesterday I had a VM with status : io-error. I can’t find a way to make free space on it . When I check my ZFS pool :
root@pve:
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
rpool 222G 115G 107G — — 68% 51% 1.00x ONLINE —
stockage 43.6T 42.3T 1.36T — — 10% 96% 1.00x ONLINE —
ZFS list :
root@pve:
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
rpool 115G 100G 104K /rpool
rpool/ROOT 4.34G 100G 96K /rpool/ROOT
rpool/ROOT/pve-1 4.34G 100G 4.34G /
rpool/data 110G 100G 96K /rpool/data
rpool/data/vm-100-disk-0 1.74G 100G 1.74G —
rpool/data/vm-101-disk-0 108G 100G 108G —
rpool/data/vm-105-disk-0 56K 100G 56K —
stockage 30.7T 0B 140K /stockage
stockage/vm-101-disk-0 30.7T 0B 30.7T —
I think that the free space in zpool is use to parity for raidz, so ZFS don’t have any space.
I can start a live Linux on the VM but when I try to mount the filesystem, the VM freeze and I got status : io-error in Proxmox.
I don’t know if is-it possible to mount the filesystem directly to the host proxmox and make some cleanup .
Any others ideas ?
LnxBil
Famous Member
No, the free space is unusable, therefore you cannot store anything new on it.
First, I’d look for any refreservation values, then I’d see if there are any snapshots that can be deleted, then I’d temporarily send/receive one dataset to another pool and delete the source . and do your maintenance stuff.
wowkisame
New Member
Hi LnxBil,
First of all, thanks for your time.
Unfortunately, no snapshot, no reservation, no quota (may be there are others commands ?) :
Could you explain this part please ?
Of course I will create an alert for storage next time .
Dunuin
Famous Member
Better you set a quota too and not just an alarm. In general its recommended to keep around 20% of your ZFS pool always empty because the pool will become slower when the pool gets full. I always set a quota of 90% for the entire pool and set a alarm when 80% is exceeded to clean up stuff to bring it under 80% again. That way you can’t run into such a situation where your pools gets full to a point where it stops working.
And you only checked «reservation» but not «refreservation».
Output of zfs list -o space stockage or even zfs list -o space would be useful too. Then you also see snapshot and refreservation space usage.
wowkisame
New Member
Thanks for your time and your answer.
I don’t understand the «Sending and Receiving ZFS Data» part. I can only send a part of stockage to rpool/data for exemple ?
Dunuin
Famous Member
Thanks for your time and your answer.
wowkisame
New Member
I don’t have 31+TB to copy my volume. So I don’t have any solution to clean or reduce the volume
Dunuin
Famous Member
wowkisame
New Member
Oh
May be someone else have others ideas ?
itNGO
Well-Known Member
Oh
May be someone else have others ideas ?
LnxBil
Famous Member
The problem is that you have only one zvol stored on your pool stockage without any snapshots or any kind of reservation and you ran out of space. The send/receive route is not a viable option, because you only have one volume.
The problem with freeing up used space is that this probably needs to write in order to clean it up a bit, which is not real option. Yet, as you’ve already descibed, you already ran out of space and the guest noticed that, so you’re already a filesystem with errors on it. As you described, you cannot mount the disk in a live system due to the space problem, so cleaning it now won’t help — or maybe it does.
Источник
-

-
July 18 2013, 13:44
Приветствую.
Debian x64 (Proxmox), 2.6.32 на Hp Prolliant G6. Контроллер Hewlett-Packard Company Smart Array G6 controllers. В dmesg валятся такие ошибки:
ext3_orphan_cleanup: deleting unreferenced inode 2712868
ext3_orphan_cleanup: deleting unreferenced inode 2712867
ext3_orphan_cleanup: deleting unreferenced inode 2712866
lost page write due to I/O error on dm-5
Buffer I/O error on device dm-5, logical block 23265409
lost page write due to I/O error on dm-5
EXT3-fs error (device dm-5): ext3_get_inode_loc: unable to read inode block — inode=11075712, block=44302345
EXT3-fs error (device dm-5): ext3_get_inode_loc: unable to read inode block — inode=8503794, block=34013217
EXT3-fs error (device dm-5): ext3_get_inode_loc: unable to read inode block — inode=11075586, block=44302338
EXT3-fs error (device dm-5): ext3_get_inode_loc: unable to read inode block — inode=5818417, block=23265413
JBD: I/O error detected when updating journal superblock for dm-5
EXT3-fs (dm-5): error: ext3_journal_start_sb: Detected aborted journal
EXT3-fs (dm-5): error: remounting filesystem read-only
Не могу найти, какой раздел он перемонтировал в RO и не пойму, что такое dm-5?
# ls /dev/dm*
/dev/dm-0 /dev/dm-1 /dev/dm-2 /dev/dm-3 /dev/dm-4
root@reserv:/dev/mapper# ls -l
total 0
crw——- 1 root root 10, 61 Jun 5 21:18 control
lrwxrwxrwx 1 root root 7 Jul 17 23:03 pve-data -> ../dm-4
lrwxrwxrwx 1 root root 7 Jun 5 21:18 pve-root -> ../dm-0
lrwxrwxrwx 1 root root 7 Jul 18 10:26 pve-swap -> ../dm-3
lrwxrwxrwx 1 root root 7 Jul 18 10:26 storage1-backups -> ../dm-2
lrwxrwxrwx 1 root root 7 Jul 18 10:26 storage1-iso -> ../dm-1
HPшная утилитка говорит, что с винтами всё OK.
# hpacucli ctrl slot=0 pd all show
Smart Array P410i in Slot 0 (Embedded)
array A
physicaldrive 1I:1:3 (port 1I:box 1:bay 3, SAS, 300 GB, OK)
physicaldrive 1I:1:4 (port 1I:box 1:bay 4, SAS, 300 GB, OK)
array B
physicaldrive 1I:1:1 (port 1I:box 1:bay 1, SAS, 500 GB, OK)
physicaldrive 1I:1:2 (port 1I:box 1:bay 2, SAS, 500 GB, OK)
Так же I/O errors валятся в одной из гостевых kvm-виртуалок, (файловый образ в формате RAW). Может кто-нибудь пояснить, где повреждена FS, в гостевой или в хост-системе, и как это вообще всё локализовать?