Controlfile restoration issue has been resolved after adding No.restricstions file, but still i am facing the problem while restoring database!
abcbkp02:> rman target / catalog rman/xxxx@rman12
Recovery Manager: Release 12.1.0.2.0 — Production on Thu May 28 05:47:23 2015
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
connected to target database: DSTGEDV (not mounted)
connected to recovery catalog database
RMAN> run
{
set until time «to_date(‘2015/05/25 20:30:00′,’YYYY/MM/DD HH24:MI:SS’)»;
allocate channel ch1 type ‘sbt_tape’ parms=»ENV=(NB_ORA_CLASS=AIR_ABCDB12_DB_DSTGEDV_ONLINE, NB_ORA_SERV=abcbkp02, NB_ORA_CLIENT=abcdb12)»;
restore controlfile;
}
2> 3> 4> 5> 6>
executing command: SET until clause
allocated channel: ch1
channel ch1: SID=122 device type=SBT_TAPE
channel ch1: Veritas NetBackup for Oracle — Release 7.6 (2015021210)
Starting restore at 28-MAY-15
new media label is «@aaaah» for piece «c-2057956423-20150525-2a»
channel ch1: starting datafile backup set restore
channel ch1: restoring control file
channel ch1: reading from backup piece c-2057956423-20150525-2a
channel ch1: piece handle=c-2057956423-20150525-2a tag=TAG20150525T200244
channel ch1: restored backup piece 1
channel ch1: restore complete, elapsed time: 00:01:05
output file name=/u03/dstgedv/data01/control01.ctl
output file name=/u03/dstgedv/redo01/control02.ctl
output file name=/u03/dstgedv/redo02/control03.ctl
Finished restore at 28-MAY-15
released channel: ch1
RMAN> alter database mount;
Statement processed
RMAN> run
2> {
set until time «to_date(‘2015/05/25 20:30:00′,’YYYY/MM/DD HH24:MI:SS’)»;
3> 4> allocate channel ch1 type ‘sbt_tape’ parms=»ENV=(NB_ORA_CLASS=AIR_ABCDB12_DB_DSTGEDV_ARCH, NB_ORA_SERV=abcbkp02, NB_ORA_CLIENT=abcdb12)»;
5> allocate channel ch2 type ‘sbt_tape’ parms=»ENV=(NB_ORA_CLASS=AIR_ABCDB12_DB_DSTGEDV_ARCH, NB_ORA_SERV=abcbkp02, NB_ORA_CLIENT=abcdb12)»;
6> allocate channel ch3 type ‘sbt_tape’ parms=»ENV=(NB_ORA_CLASS=AIR_ABCDB12_DB_DSTGEDV_ARCH, NB_ORA_SERV=abcbkp02, NB_ORA_CLIENT=abcdb12)»;
7> restore database;}
executing command: SET until clause
allocated channel: ch1
channel ch1: SID=122 device type=SBT_TAPE
channel ch1: Veritas NetBackup for Oracle — Release 7.6 (2015021210)
allocated channel: ch2
channel ch2: SID=178 device type=SBT_TAPE
channel ch2: Veritas NetBackup for Oracle — Release 7.6 (2015021210)
allocated channel: ch3
channel ch3: SID=241 device type=SBT_TAPE
channel ch3: Veritas NetBackup for Oracle — Release 7.6 (2015021210)
Starting restore at 28-MAY-15
channel ch1: starting datafile backup set restore
channel ch1: specifying datafile(s) to restore from backup set
channel ch1: restoring datafile 00001 to /u03/dstgedv/data01/system01.dbf
channel ch1: restoring datafile 00006 to /u03/dstgedv/data01/users01.dbf
channel ch1: restoring datafile 00009 to /u03/dstgedv/data01/DSODBSPACE.dbf
channel ch1: reading from backup piece DSTGEDV_879778653_10307_1
channel ch2: starting datafile backup set restore
channel ch2: specifying datafile(s) to restore from backup set
channel ch2: restoring datafile 00002 to /u03/dstgedv/data01/iaspace.dbf
channel ch2: restoring datafile 00007 to /u03/dstgedv/data01/xmetasrsp.dbf
channel ch2: restoring datafile 00008 to /u03/dstgedv/data01/dseodb01.dbf
channel ch2: reading from backup piece DSTGEDV_879778653_10306_1
channel ch3: starting datafile backup set restore
channel ch3: specifying datafile(s) to restore from backup set
channel ch3: restoring datafile 00003 to /u03/dstgedv/data01/sysaux01.dbf
channel ch3: restoring datafile 00004 to /u03/dstgedv/undo01/undotbs01.dbf
channel ch3: restoring datafile 00005 to /u03/dstgedv/data01/xmetaspace.dbf
channel ch3: reading from backup piece DSTGEDV_879778653_10305_1
channel ch1: ORA-19870: error while restoring backup piece DSTGEDV_879778653_10307_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879778653_10307_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879778653_10307_1> not found in NetBackup catalog
channel ch2: ORA-19870: error while restoring backup piece DSTGEDV_879778653_10306_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879778653_10306_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879778653_10306_1> not found in NetBackup catalog
channel ch3: ORA-19870: error while restoring backup piece DSTGEDV_879778653_10305_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879778653_10305_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879778653_10305_1> not found in NetBackup catalog
failover to previous backup
channel ch1: starting datafile backup set restore
channel ch1: specifying datafile(s) to restore from backup set
channel ch1: restoring datafile 00001 to /u03/dstgedv/data01/system01.dbf
channel ch1: restoring datafile 00006 to /u03/dstgedv/data01/users01.dbf
channel ch1: restoring datafile 00009 to /u03/dstgedv/data01/DSODBSPACE.dbf
channel ch1: reading from backup piece DSTGEDV_879696472_10210_1
channel ch2: starting datafile backup set restore
channel ch2: specifying datafile(s) to restore from backup set
channel ch2: restoring datafile 00002 to /u03/dstgedv/data01/iaspace.dbf
channel ch2: restoring datafile 00007 to /u03/dstgedv/data01/xmetasrsp.dbf
channel ch2: restoring datafile 00008 to /u03/dstgedv/data01/dseodb01.dbf
channel ch2: reading from backup piece DSTGEDV_879696472_10209_1
channel ch3: starting datafile backup set restore
channel ch3: specifying datafile(s) to restore from backup set
channel ch3: restoring datafile 00003 to /u03/dstgedv/data01/sysaux01.dbf
channel ch3: restoring datafile 00004 to /u03/dstgedv/undo01/undotbs01.dbf
channel ch3: restoring datafile 00005 to /u03/dstgedv/data01/xmetaspace.dbf
channel ch3: reading from backup piece DSTGEDV_879696472_10208_1
channel ch1: ORA-19870: error while restoring backup piece DSTGEDV_879696472_10210_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879696472_10210_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879696472_10210_1> not found in NetBackup catalog
channel ch2: ORA-19870: error while restoring backup piece DSTGEDV_879696472_10209_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879696472_10209_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879696472_10209_1> not found in NetBackup catalog
channel ch3: ORA-19870: error while restoring backup piece DSTGEDV_879696472_10208_1
ORA-19507: failed to retrieve sequential file, handle=»DSTGEDV_879696472_10208_1″, parms=»»
ORA-27029: skgfrtrv: sbtrestore returned error
ORA-19511: non RMAN, but media manager or vendor specific failure, error text:
Backup file <DSTGEDV_879696472_10208_1> not found in NetBackup catalog
failover to previous backup
released channel: ch1
released channel: ch2
released channel: ch3
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of restore command at 05/28/2015 05:50:37
RMAN-06026: some targets not found — aborting restore
RMAN-06023: no backup or copy of datafile 6 found to restore
RMAN-06023: no backup or copy of datafile 4 found to restore
RMAN-06023: no backup or copy of datafile 3 found to restore
RMAN-06023: no backup or copy of datafile 1 found to restore
Please suggest what can be done to get out of this error.
A long time since my last post, and a lot of topics in the pipeline to be posted. So about time to get started.
In last years October I was part of a PoC which a customer initiated to find out if Solars SPARC together with a ZFS Storage Appliance might be a good platform to migrate and consolidate their systems to. A requirement was to have a Data Guard setup in place, so I needed to create the standby database from the primary. I use RMAN for this and since SPARC platforms typically benefit from heavy parallelization, I tried to use as much channels as possible.
RMAN> connect target sys/***@pocsrva:1521/pocdba RMAN> connect auxiliary sys/***@pocsrvb:1521/pocdbb RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 40 BACKUP TYPE TO BACKUPSET; RMAN> duplicate target database 2> for standby 3> from active database 4> spfile 5> set db_unique_name='POCDBB' 6> reset control_files 7> reset service_names 8> nofilenamecheck 9> dorecover;
Unfortunately this failed:
released channel: ORA_AUX_DISK_38 released channel: ORA_AUX_DISK_39 released channel: ORA_AUX_DISK_40 RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of Duplicate Db command at 10/18/2018 12:02:33 RMAN-05501: aborting duplication of target database RMAN-03015: error occurred in stored script Memory Script ORA-17619: max number of processes using I/O slaves in a instance reached
The documentation says:
$ oerr ora 17619 17619, 00000, "max number of processes using I/O slaves in a instance reached" // *Cause: An attempt was made to start large number of processes // requiring I/O slaves. // *Action: There can be a maximum of 35 processes that can have I/O // slaves at any given time in a instance.
Ok, there is a limit for I/O slaves per instance. By the way, this is all single instance, no RAC. So I reduced the amount of channels to 35 and tried again.
$ rman Recovery Manager: Release 12.1.0.2.0 - Production on Thu Oct 18 12:05:09 2018 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. RMAN> connect target sys/***@pocsrva:1521/pocdba RMAN> connect auxiliary sys/***@pocsrvb:1521/pocdbb RMAN> startup clone nomount force RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 35 BACKUP TYPE TO BACKUPSET; RMAN> duplicate target database 2> for standby 3> from active database 4> spfile 5> set db_unique_name='POCDBB' 6> reset control_files 7> reset service_names 8> nofilenamecheck 9> dorecover;
But soon the duplicate errored out again.
channel ORA_AUX_DISK_4: starting datafile backup set restore channel ORA_AUX_DISK_4: using network backup set from service olga9788:1521/eddppocb channel ORA_AUX_DISK_4: specifying datafile(s) to restore from backup set channel ORA_AUX_DISK_4: restoring datafile 00004 to /u02/app/oracle/oradata/POCDBB/datafile/o1_mf_sysaux__944906718442_.dbf PSDRPC returns significant error 1013. PSDRPC returns significant error 1013. RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of Duplicate Db command at 10/18/2018 12:09:13 RMAN-05501: aborting duplication of target database RMAN-03015: error occurred in stored script Memory Script ORA-19845: error in backupSetDatafile while communicating with remote database server ORA-17628: Oracle error 17619 returned by remote Oracle server ORA-17619: max number of processes using I/O slaves in a instance reached ORA-19660: some files in the backup set could not be verified ORA-19661: datafile 4 could not be verified ORA-19845: error in backupSetDatafile while communicating with remote database server ORA-17628: Oracle error 17619 returned by remote Oracle server ORA-17619: max number of processes using I/O slaves in a instance reached
Obviously the instance still tries to allocate to many I/O slaves. I asume, there are I/O slaves for normal channels as well as for auxiliary channels per instance. That’s why I tried again with a parallelism of 16 which would result in 32 I/O slaves.
RMAN> connect target sys/***@pocsrva:1521/pocdba RMAN> connect auxiliary sys/***@pocsrvb:1521/pocdbb RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 16 BACKUP TYPE TO BACKUPSET; RMAN> duplicate target database 2> for standby 3> from active database 4> spfile 5> set db_unique_name='POCDBB' 6> reset control_files 7> reset service_names 8> nofilenamecheck 9> dorecover;
With this configuration the duplicate went fine without any further issues. Parallelization is good, but it has it’s limits.
When using RMAN to restore a database to a new host, the recover database step fails with:
Crosschecked 43 objects PSDRPC returns significant error 3113. RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03002: failure of recover command at 03/18/2017 19:31:23 ORA-03113: end-of-file on communication channel
If you connect to the recovered database and check the database role, you find that the controlfiles have been restore for a physical standby:
SQL> select name, open_mode, database_role from v$database; NAME OPEN_MODE DATABASE_ROLE --------- -------------------- ---------------- NYC11 MOUNTED PHYSICAL STANDBY
The problem here is that if you use RMAN to restore the controlfiles to a new host, and you are connected to the RMAN catalog, the controlfiles are written as standby controlfiles.
Here how the controlfiles in this example were restored to the new host:
[oracle@rstemc64vm31 ~]$ rman target / catalog rman/rman@rcat Recovery Manager: Release 11.2.0.4.0 - Production on Sat Mar 18 19:29:57 2017 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: NYC11 (not mounted) connected to recovery catalog database RMAN> restore controlfile from tag CF_20170318_1435; Starting restore at 18-MAR-17 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=6 device type=DISK allocated channel: ORA_DISK_2 channel ORA_DISK_2: SID=63 device type=DISK allocated channel: ORA_DISK_3 channel ORA_DISK_3: SID=132 device type=DISK allocated channel: ORA_DISK_4 channel ORA_DISK_4: SID=191 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: restoring control file channel ORA_DISK_1: reading from backup piece /nfs_mount/dd0205_rman/nyc11/cf_NYC11_9471_1.rmn channel ORA_DISK_1: piece handle=/nfs_mount/dd0205_rman/nyc11/cf_NYC11_9471_1.rmn tag=CF_20170318_1435 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 output file name=+DATA/nyc11/controlfile/current.271.938979023 output file name=+FRA/nyc11/controlfile/current.338.938979023 Finished restore at 18-MAR-17
In order to avoid this problem, we need to restore the controlfiles while NOT connected to the RMAN catalog database. This means we cannot use the backup tag, but we can use the name of the backupset file:
[oracle@rstemc64vm31 dataguard]$ rman target / catalog rman/rman@rcat Recovery Manager: Release 11.2.0.4.0 - Production on Sat Mar 18 19:42:14 2017 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: NYC11 (DBID=334041916, not open) connected to recovery catalog database RMAN> list backup of controlfile completed after 'sysdate-(6/24)'; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398266 Incr 0 31.02M DISK 00:00:05 18-MAR-17 BP Key: 398276 Status: AVAILABLE Compressed: NO Tag: CF_20170318_1435 Piece Name: /nfs_mount/dd0205_rman/nyc11/cf_NYC11_9471_1.rmn Control File Included: Ckp SCN: 33220754 Ckp time: 18-MAR-17 BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398294 Full 31.05M DISK 00:00:01 18-MAR-17 BP Key: 398296 Status: AVAILABLE Compressed: NO Tag: TAG20170318T144723 Piece Name: +FRA/nyc11/autobackup/2017_03_18/s_938962043.287.938962043 Control File Included: Ckp SCN: 33221214 Ckp time: 18-MAR-17 BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398314 Full 31.02M DISK 00:00:02 18-MAR-17 BP Key: 398317 Status: AVAILABLE Compressed: NO Tag: TAG20170318T144728 Piece Name: /nfs_mount/dd0205_rman/nyc11/NYC11_controlfile_83rver40_1_1.ctl Control File Included: Ckp SCN: 33221259 Ckp time: 18-MAR-17 BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398325 Full 31.05M DISK 00:00:00 18-MAR-17 BP Key: 398327 Status: AVAILABLE Compressed: NO Tag: TAG20170318T144731 Piece Name: +FRA/nyc11/autobackup/2017_03_18/s_938962051.351.938962051 Control File Included: Ckp SCN: 33221273 Ckp time: 18-MAR-17 BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398462 Full 31.05M DISK 00:00:01 18-MAR-17 BP Key: 398478 Status: AVAILABLE Compressed: NO Tag: TAG20170318T144818 Piece Name: +FRA/nyc11/autobackup/2017_03_18/s_938962098.318.938962099 Control File Included: Ckp SCN: 33221554 Ckp time: 18-MAR-17 BS Key Type LV Size Device Type Elapsed Time Completion Time ------- ---- -- ---------- ----------- ------------ --------------- 398517 Full 31.05M DISK 00:00:00 18-MAR-17 BP Key: 398519 Status: AVAILABLE Compressed: NO Tag: TAG20170318T144827 Piece Name: +FRA/nyc11/autobackup/2017_03_18/s_938962107.395.938962107 Control File Included: Ckp SCN: 33221632 Ckp time: 18-MAR-17
The controlfile backed up with tag CF_20170318_1435 is in the backupset file /nfs_mount/dd0205_rman/nyc11/cf_NYC11_9471_1.rmn.
So exit RMAN, and start it again without the connection to the catalog:
[oracle@rstemc64vm31 dataguard]$ rman target / Recovery Manager: Release 11.2.0.4.0 - Production on Sat Mar 18 19:50:43 2017 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: NYC11 (not mounted) RMAN> restore controlfile from '/nfs_mount/dd0205_rman/nyc11/cf_NYC11_9471_1.rmn'; Starting restore at 18-MAR-17 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=69 device type=DISK channel ORA_DISK_1: restoring control file channel ORA_DISK_1: restore complete, elapsed time: 00:00:02 output file name=+DATA/nyc11/controlfile/current.271.938979023 output file name=+FRA/nyc11/controlfile/current.338.938979023 Finished restore at 18-MAR-17 RMAN> alter database mount; database mounted released channel: ORA_DISK_1
Connect to the database using SQL*Plus and verify that the database has mounted the correct controlfiles and that the database role is shown as PRIMARY.
SQL> show parameter control_files
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
control_files string +DATA/nyc11/controlfile/curren
t.271.938979023, +FRA/nyc11/co
ntrolfile/current.338.93897902
3
SQL> select name, open_mode, database_role from v$database;
NAME OPEN_MODE DATABASE_ROLE
--------- -------------------- ----------------
NYC11 MOUNTED PRIMARY
Once the correct type of control file has been restored, you can launch RMAN again and this time connect to the catalog to restore and recover the database to the new host.
8 августа 2022
![]()
Бесплатная консультация специалиста

Инженер перезвонит
за 15 минут

Аккредитованный сервисный центр Эвотор

Удаленно устраняем ошибки на кассе
Ошибка 1013 на Эвотор возникает на старых версиях кассовых устройств и связана с фискальным накопителем. В данной статье вы узнаете, как решить эту проблему.
Устраним на Эвотор ошибку чтения реквизита
Бесплатная консультация специалиста8 (800) 700 50 85


Как устранить ошибку 1013 на Эвотор
При возникновении этой ошибки большое значение имеет то, какие операции на ККТ вы совершаете в данный момент. Суть в том, что все причины возникновения рассматриваются в индивидуальном порядке. Например, при совершении какой-то операции на кассе вы запрашиваете реквизит у фискального накопителя, а у него его нет. Это может случиться, если архив фискального накопителя закрыт или ФН не активирован, а также и в других случаях.
Очень важно отследить, при каких условиях возникла ошибка и доверить решение проблемы специалистам. Вы можете обратиться на горячую линию ЭвоКлаб.
Варианты решения проблемы:
- Замена ФН
- Замена ККТ
Исправность работы накопителя крайне важна для работы самого терминала и законности всей торговли. Не оттягивайте с этим, чтобы не получить штраф налоговой.
Иногда проблема может быть в неисправности самой ККТ. В таком случае единственный вариант решения проблемы — приобрести новый терминал. Наши специалисты проведут диагностику работы кассы и точно скажут, нужна ли замена.
Мы не рекомендуем пытаться справиться с данной проблемой самостоятельно, так как любое неправильное действие с фискальным накопителем может привести к его неисправности.
Устраним на Эвотор ошибку чтения реквизита
Бесплатная консультация специалиста8 (800) 700 50 85
Другие записи блога
Как сделать разные списки товаров для разных магазинов на Эвотор
Как сделать общий список товаров для нескольких Эвоторов
Предупреждение «Проверка компонентов» на Эвотор
Смарт-карта не отображается в «Кассовых сервисах»
30 сентября 2022
Такая проблема часто встречалась на кассах со старой прошивкой. Если долгое время не обновлять ККТ, это будет вызывать проблемы с ОС и фискальным накопителем. Далее рассказываем, что делать, если на Эвотор ошибка чтения реквизита.

Содержание
Причины ошибки чтения реквизита 1013 на Эвотор
Смарт-терминал состоит из фискальной и планшетной части. В фискальной находится ФН, который принимает, записывает, хранит и отправляет информацию о продажах в ОФД и налоговую.
Во время проведения операций ККТ запрашивает определенные реквизиты у фискальника. Реквизитом может быть, например, номер чека. Ошибка чтения реквизита 1013 на Эвотор возникает из-за того, что накопитель не может предоставить информацию по запросу. Почему такое происходит:
- Архив ФН закрыт
- Новый накопитель еще не успели активировать
- Неисправность кассы (очень редко)
Как понять, в чем причина ошибки?
Чтобы точно понять, в каком статусе у вас находится накопитель, проведите простой тест — выключите и включите терминал. Если при включении возникает ошибка 211 с текстом «Ошибка ЭКЛЗ/ФН», это говорит о том, что в кассе установлен ФН с закрытым архивом.
В зависимости от причины, решение будет разное. Далее рассказываем подробно.
Исправим ошибку в реквизитах Эвотор
Оставьте заявку или позвоните сами8 (800) 700 40 85


Как устранить на Эвотор ошибку чтения реквизита
Заменить фискальный накопитель
Это нужно сделать в любом случае. Когда у накопителя закрыт архив, он блокируется и больше не выполняет свои функции, даже если он все еще подключен к кассе. А если вы еще не зарегистрировали фискальник в налоговой, то есть не активировали его, то он также не принимает и не отправляет данные в налоговую.
Если после этого проблема не исчезает и на Эвотор ошибка чтения реквизита все равно возникает, то необходимо провести полную диагностику ККТ. Вероятно, проблема возникает из-за поломки самого устройства. Мы все проверим и точно скажем, нужна ли замена или достаточно только ремонта в АСЦ.
Другие записи блога
Ошибка z3 на терминале оплаты Эвотор
Как подключить Эвотор к интернету — инструкция
Как подключить банковский терминал к кассе Эвотор
Переполнение памяти ФН на Эвотор
Содержание
- Русские Блоги
- Орученная ошибка — ORA-03113: решения для файлов для каналов связи
- Проблема
- Растворы
- PostScript
- Интеллектуальная рекомендация
- IView CDN Загрузка значка шрифта нормальная, а значок шрифта не может быть загружен при локальной загрузке JS и CSS
- Критическое: ошибка настройки прослушивателя приложения класса org.springframework.web.context.ContextLoaderLis
- 1086 Не скажу (15 баллов)
- Pandas применяют параллельный процесс приложения, многоядерная скорость очистки данных
- PureMVC Learning (Tucao) Примечания
- Вылетает запрос с ошибкой ORA-03113 : Oracle
- ORA-03113: end of file on communication channel
- Answers
Русские Блоги
Орученная ошибка — ORA-03113: решения для файлов для каналов связи
Я часто слежу за ними, посадка PL/SQL Сделайте неудачу, произошла ошибка ORA-01034 «с участием» ORA-27101 «Как показано:

Затем вы пройдете через командную строку. Oracle Посмотрите, что происходит, то проблема дальше, ошибки » ORA-03113: Конец канала связи процесс ID:6320 отвечать ID :191 серийный номер: 3 ”。

Проблема
Oracle Есть ошибка, поэтому перейдите к неправильному журналу, чтобы найти корня проблемы: e:appkangdiagrdbmsoracleoracletrace Файл под папкой oracle_ora_6320.trc Документ, откройте журнал ошибок дисплея:
- Trace filee:appkangdiagrdbmsoracleoracletraceoracle_ora_6320.trc
- Oracle Database 11gEnterprise Edition Release 11.2.0.1.0 — 64bit Production
- With thePartitioning, OLAP, Data Mining and Real Application Testing options
- Windows NT VersionV6.1 Service Pack 1
- CPU : 4 — type 8664, 2 PhysicalCores
- Process Affinity : 0x0x0000000000000000
- Memory (Avail/Total):Ph:2805M/6087M, Ph+PgF:6761M/12173M
- Instance name: oracle
- Redo thread mountedby this instance: 1
- Oracle processnumber: 19
- Windows thread id:6320, image: ORACLE.EXE (SHAD)
- *** 2014-08-1608:18:55.461
- *** SESSIONID:(191.3) 2014-08-16 08:18:55.461
- *** CLIENT ID:()2014-08-16 08:18:55.461
- *** SERVICE NAME:()2014-08-16 08:18:55.461
- *** MODULENAME:(sqlplus.exe) 2014-08-16 08:18:55.461
- *** ACTION NAME:()2014-08-16 08:18:55.461
- ORA-19815: Предупреждение: DB_RECOVERY_FILE_DEST_SIZE BYTES (BYTES 4102029312). Доступны 0 байтов. Быть
- ************************************************************************
- You have followingchoices to free up space from recovery area:
- 1. Consider changingRMAN RETENTION POLICY. If you are using Data Guard,
- then consider changing RMAN ARCHIVELOGDELETION POLICY.
- 2. Back up files totertiary device such as tape using RMAN
- BACKUP RECOVERY AREA command.
- 3. Add disk space andincrease db_recovery_file_dest_size parameter to
- reflect the new space.
- 4. Delete unnecessaryfiles using RMAN DELETE command. If an operating
- system command was used to delete files,then use RMAN CROSSCHECK and
- DELETE EXPIRED commands.
- ************************************************************************
- ORA-19809: предел количества файлов восстановления
- ORA-19804: невозможно восстановить 33961984 байтовое дисковое пространство (от 4102029312 Limited)
- *** 2014-08-1608:18:55.502 4132 krsh.c
- ARCH: Error 19809Creating archive log file to’E:APPKANGFLASH_RECOVERY_AREAORACLEARCHIVELOG2014_08_16O1_MF_1_159_%U_.ARC’
- *** 2014-08-1608:18:55.502 2747 krsi.c
- krsi_dst_fail: dest:1err:19809 force:0 blast:1
- DDE: Problem Key ‘ORA312’ was flood controlled (0x1) (no incident)
- ORA-00312: Онлайн журнал 3 нить 1: ‘e: app kang oradata Oracle Redo03.log’
- ORA-16038: Журнал 3 Правила # 159 Невозможно архивировать
- ORA-19809: предел количества файлов восстановления
- ORA-00312: Онлайн журнал 3 нить 1: ‘e: app kang oradata Oracle Redo03.log’
- *** 2014-08-1608:18:55.565
- USER (ospid: 6320):terminating the instance due to error 16038
Отсюда мы открываем корень проблемы: »
ORA-19815: Предупреждение: DB_RECOVERY_FILE_DEST_SIZE BYTES (BYTES 4102029312). Доступны 0 байтов. ” да db_recovery_file_dest_size Также легко найти корневую причину архива журнала пространства. Легко решить проблему.
Растворы
Небольшое пространство, то, как мы находимся перед нами, так это то, что нужно установить пространство, другой — удалить дополнительные файлы, то мы используем эти два способа.
По окну команды:
——— Установите размер архива журнала пространства
- sqlplus / as sysdba
- shutdown abort —- Закрыть процесс
- startup mount —- Загрузка базы данных
- select * from v$recovery_file_dest; — Запрос архив журнала
- db_recovery_file_dest_size=10737418240; — Установите пространство журнала архива до 10 г
- Exit — Размер пространства здесь был установлен
——— Удалить архивный журнал
- rmantarget / —— введите окно инструментов RMAN
- RMAN>crosscheckarchivelog all ; — Запустите эту команду, может отметить недействительный истекший архивес.
- RMAN>deletenoprompt archivelog until time «sysdate -3» ; — — То есть удалить журнал архива 3 дня назад
Здесь тщательно ok NS. Следующий Re-откройте базу данных: нормальное использование 。
В файле удаления архива есть небольшое внимание, отображающее файл архива через окно команд. E:appkangflash_recovery_areaoracleARCHIVELOG Под, но мы не можем напрямую удалить эти файлы напрямую, это связано с соответствующей информацией каждого архивелога в ControlFile, когда мы удаляем эти файлы в ОС, мы все еще записываем их в нашем Controlfile. Информация о архивелоге, есть также эти журналы в Oracle OEM-менеджер. Поскольку, когда мы обрабатываем файлы в каталоге архива, эти записи не очищаются нами от ControlFile, то есть Oracle не знает, что эти файлы не существуют. Таким образом, вы все еще должны выполнить команду, чтобы удалить эти файлы через окно команд.
PostScript
Журнал архива фактически используется для нас, чтобы использовать его при восстановлении базы данных, но иногда эти архивные бревна на самом деле приведут нам немного неприятностей, поэтому эти архивные журналы все еще нуждаются в нас, чтобы обратить внимание.
Интеллектуальная рекомендация

IView CDN Загрузка значка шрифта нормальная, а значок шрифта не может быть загружен при локальной загрузке JS и CSS
Используйте iview, чтобы сделать небольшой инструмент. Чтобы не затронуть другие платформы, загрузите JS и CSS CDN на локальные ссылки. В результате значок шрифта не может быть загружен. Просмо.

Критическое: ошибка настройки прослушивателя приложения класса org.springframework.web.context.ContextLoaderLis
1 Обзор Серверная программа, которая обычно запускалась раньше, открылась сегодня, и неожиданно появилась эта ошибка. Интуитивно понятно, что не хватает связанных с Spring пакетов, но после удаления п.

1086 Не скажу (15 баллов)
При выполнении домашнего задания друг, сидящий рядом с ним, спросил вас: «Сколько будет пять умножить на семь?» Вы должны вежливо улыбнуться и сказать ему: «Пятьдесят три». Это.

Pandas применяют параллельный процесс приложения, многоядерная скорость очистки данных
В конкурсе Algorith Algorith Algorith Algorith Algorith 2019 года используется многофункциональная уборка номера ускорения. Будет использовать панды. Но сама панда, кажется, не имеет механизма для мно.

PureMVC Learning (Tucao) Примечания
Справочная статья:Введение подробного PrueMVC Использованная литература:Дело UnityPureMvc Основная цель этой статьи состоит в том, чтобы организовать соответствующие ресурсы о PureMVC. Что касается Pu.
Источник
Вылетает запрос с ошибкой ORA-03113 : Oracle
Есть самописная программа, все работало до определенного момента, потом стала вылетать с ошибкой ORA-03113: end-of-file on communication channel
стал разбираться, выяснилось вылетает на запросе абсолютно безобидном запросе:
SELECT TREE, NAME
FROM SUPERMAG.SACARDCLASS
WHERE TREE LIKE ‘16.7.2.%’
AND INSTR( TREE,’.’,1,4 ) > 0
AND INSTR( TREE,’.’,1,5 ) = 0
дальше выяснилось, что если в тексте добавить или убрать пробел
запрос замечательно выполняется.
Растолкуйте, почему? и как с этим бороться?
в запросе меняешь например
было: AND INSTR( TREE,’.’,1,4 ) > 0
меняешь на: AND INSTR(TREE,’.’,1,4 ) > 0
и все работает
вылет мгновенный при запуске запроса например из девелопера
нажал выполнить, девелопер отвалился от базы :)))
а в алерте я не нашел цитат на этот момент 🙁
сейчас с ораклом дела практически не имею — просто у меня ранее было подобное на тяжелых запросах — коннект к ораклу был через одбс — отваливало по таймауту соединения — лечил установкой в реестре параметра ConnectionTimeout в ноль — не разрывать коннект до окончания выполнения
также — из загашников 🙂 — нытырил пока свою проблемау не разрешил
==================================================
ORA-03113: end-of-file on communication channel
Cause: The connection between Client and Server process was broken. It may also happen if the external agent extproc crashes for some reason.
Action: There was a communication error that requires further investigation. First, check for network problems and review the SQL*Net setup.
Also, look in the alert.log file for any errors. Finally, test to see whether the server process is dead and whether a trace file was generated
at failure time. There may be some system calls in the .NET function which might terminate the process. Remove such calls.
==================================================
На самом деле 3113 часто (не всегда) является следствием каких-либо багов Oracle, так что вопрос может потребовать более детального исследования вплоть до обращения в техподдержку Oracle.
Ну а alert.log в подобных случаях желательно посмотреть в любом случае
Оказывается одним из способов решения этой проблемы является простое удаление статистики. Именно статистики, а не индексов.
В случае, если это не помогло, ее всегда можно восстановить средствами Оракл
==================================================
Обычно связана с аппаратными сбоями, при этом нередко имеет
динамический характер: то есть, то нет. При возникновении нужно
искать соответствующий trace file и анализировать его.
Посмотрите хватает операционке памяти и т. п.
Возможно ваш запрос съел большую часть ресурсов и оракл не поймал их.
Скорей всего это вопрос к админам (пусть ставят патчи).
6.2.34 ORA-03113: End-of-File on Communication Channel
Cause: This error can occur under several circumstances and indicates that the
Oracle server process has failed.
Action: There is one case that may be encountered during an upgrade that has a
known solution. When running on certain 64-bit platforms, the RDBMS bug 2614728
may cause the defnavpg.sql script to fail. If you are on a 64-bit platform, check
your upgrade log file to see if the problem is encountered in the following
context:
#— Beginning inner script: wwd/defnavpg
# Create seeded navigation pages for page groups declare
*
ERROR at line 1:
ORA-03113: end-of-file on communication channel
If it is in this context, apply the patch for bug 2614728 for your platform.
Restore from your backup, and run the upgrade again.
==================================================
упс, упустил — еще непосредственно установка ODBCTimeout на сам запрос перед выполнением в 0 — тоже где то в реестре есть, но мне так проще было
Источник
ORA-03113: end of file on communication channel
Hi there, I am new to Oracle database and have been working on a test installation of oracle 11g that my employer wants me to practise on. My oracle instance was working fine, and then I logged in and found the following error when I try to start the instance.
SQL> startup
ORACLE instance started.
Total System Global Area 1653518336 bytes
Fixed Size 2176288 bytes
Variable Size 1006635744 bytes
Database Buffers 637534208 bytes
Redo Buffers 7172096 bytes
ORA-03113: end-of-file on communication channel
Process ID: 5736
Session ID: 191 Serial number: 1
I get the same error if I try start with RMAN:
RMAN> startup mount
Oracle instance started
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of startup command at 03/07/2012 15:18:29
ORA-03113: end-of-file on communication channel
Process ID: 7256
Session ID: 192 Serial number: 5
In Enterprise Manager I can see the instance is down, the listener is up and in the section Agent Connection to Instance it says:
Status
Failed
Details ORA-12505: TNS:listener does not currently know of SID given in connect descriptor (DBD ERROR: OCIServerAttach)
Ok, so for both these errors ORA-12505 and ORA-03113 I can find plenty of information on the net, but I have not been able to make any progress and just feel like I am going around in circles, hence my post here. The last thing I did when the instance was working was switch to archive logging mode. Then the next day started getting these errors. Any help much appreciated. but at this point I am not sure what to do next!
Answers
Do you use data guard? Most likely the archivelog destination is invalid.
Try to start up the database again. Then post the last 10 lines in alert.log.
Edited by: AliD on 6/03/2012 18:57
what Operating System name & version?
find OS directory folder named «alert» & then file within it called «log.xml»
post last 200 or so line from this file.
What is ORACLE_SID for your database?
what does the alert log says.
how about the shared memory management. can you post it. I think this would be shared memory problem.
please also check your spfile.
possibly there are some invalid entry inside there.
try to startup using pfile
Thanks very much for all your replies. Here are the results of some of the things I looked into based on those replies.
4 digit Oracle version? 11.2.0.1.0 — 64bit Production — installed on a windows 7 box (sorry, I should have mentioned this at the outset)
What were the steps you took to switch to archive logging mode? I did the following:
SQL> alter system set log_archive_dest_1=’location=/app/DBA/archivelog’ scope=spfile;
then I shutdown the database and then did startup mount, then:
SQL>
alter database archivelog;
Do you use data guard? Most likely the archivelog destination is invalid.
Not using data guard. The archivelog destination is valid and is not full.
Try to start up the database again. Then post the last 10 lines in alert.log.
Here are the results of last startup from end of alert log:
Thu Mar 08 10:50:14 2012
Starting ORACLE instance (normal)
LICENSE_MAX_SESSION = 0
LICENSE_SESSIONS_WARNING = 0
Picked latch-free SCN scheme 3
Autotune of undo retention is turned on.
IMODE=BR
ILAT =27
LICENSE_MAX_USERS = 0
SYS auditing is disabled
Starting up:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 — 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options.
Using parameter settings in server-side spfile C:APPDBAPRODUCT11.2.0DBHOME_1DATABASESPFILEORCL.ORA
System parameters with non-default values:
processes = 150
memory_target = 1584M
control_files = «C:APPDBAORADATAORCLCONTROL01.CTL»
control_files = «C:APPDBAFLASH_RECOVERY_AREAORCLCONTROL02.CTL»
db_block_size = 8192
compatible = «11.2.0.0.0»
log_archive_dest_1 = «location=/app/DBA/archivelog»
db_recovery_file_dest = «C:appDBAflash_recovery_area»
db_recovery_file_dest_size= 3912M
undo_tablespace = «UNDOTBS1»
remote_login_passwordfile= «EXCLUSIVE»
db_domain = «»
dispatchers = «(PROTOCOL=TCP) (SERVICE=orclXDB)»
audit_file_dest = «C:APPDBAADMINORCLADUMP»
audit_trail = «DB»
db_name = «orcl»
open_cursors = 300
diagnostic_dest = «C:APPDBA»
Thu Mar 08 10:50:17 2012
VKTM started with pid=3, OS at elevated priority
Thu Mar 08 10:50:17 2012
PMON started with pid=2, OS
Thu Mar 08 10:50:17 2012
GEN0 started with pid=4, OS
Thu Mar 08 10:50:17 2012
DIAG started with pid=5, OS
Thu Mar 08 10:50:17 2012
DBRM started with pid=6, OS
Thu Mar 08 10:50:17 2012
PSP0 started with pid=7, OS
Thu Mar 08 10:50:17 2012
DIA0 started with pid=8, OS
Thu Mar 08 10:50:17 2012
MMAN started with pid=9, OS
VKTM running at (10)millisec precision with DBRM quantum (100)ms
Thu Mar 08 10:50:18 2012
DBW0 started with pid=10, OS
Thu Mar 08 10:50:18 2012
LGWR started with pid=11, OS
Thu Mar 08 10:50:18 2012
CKPT started with pid=12, OS
Thu Mar 08 10:50:18 2012
SMON started with pid=13, OS
Thu Mar 08 10:50:18 2012
RECO started with pid=14, OS
Thu Mar 08 10:50:18 2012
MMON started with pid=15, OS
Thu Mar 08 10:50:18 2012
MMNL started with pid=16, OS
starting up 1 dispatcher(s) for network address ‘(ADDRESS=(PARTIAL=YES)(PROTOCOL=TCP))’.
starting up 1 shared server(s) .
ORACLE_BASE from environment = C:appDBA
Thu Mar 08 10:50:19 2012
ALTER DATABASE MOUNT
USER (ospid: 4016): terminating the instance
Instance terminated by USER, pid = 4016
please also check your spfile. possibly there are some invalid entry inside there. try to startup using pfile
Источник
Hello
*Setup :*
Primary DB : EZPRDEBS1 , EZPRDEBS2 , EZPRDEBS3
Standby DB (single instance) : PRDEBSDR
Second Standby DB (single instance) : EZPRDEBSDR
[oraprod@prd-db-601 ~]$ rman target /
Recovery Manager: Release 12.1.0.2.0 — Production on Thu Nov 28 08:48:18
2019
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
connected to target database: EZPRDEBS (DBID=2217119773)
RMAN> show all;
using target database control file instead of recovery catalog
RMAN configuration parameters for database with db_unique_name EZPRDEBS are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 7;
CONFIGURE BACKUP OPTIMIZATION OFF; # default
CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default
CONFIGURE CONTROLFILE AUTOBACKUP OFF;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; #
default
CONFIGURE DEVICE TYPE DISK BACKUP TYPE TO COMPRESSED BACKUPSET PARALLELISM
16;
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE MAXSETSIZE TO 32 G;
CONFIGURE ENCRYPTION FOR DATABASE OFF; # default
CONFIGURE ENCRYPTION ALGORITHM ‘AES128’; # default
CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE
FOR LOAD TRUE ; # default
CONFIGURE RMAN OUTPUT TO KEEP FOR 7 DAYS;
CONFIGURE ARCHIVELOG DELETION POLICY TO SHIPPED TO ALL STANDBY;
CONFIGURE SNAPSHOT CONTROLFILE NAME TO
‘+HYB_FRA/EZPRDEBS/snapcf_EZPRDEBS.f’;
CONFIGURE SNAPSHOT CONTROLFILE NAME TO
‘+HYB_FRA/EZPRDEBS/snapcf_ezprdebs.f’;
RMAN> exit
===================Standby PRDEBSDR====================================
RMAN> show all;
using target database control file instead of recovery catalog
RMAN configuration parameters for database with db_unique_name PRDEBSDR are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 7;
CONFIGURE BACKUP OPTIMIZATION OFF; # default
CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default
CONFIGURE CONTROLFILE AUTOBACKUP OFF;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; #
default
CONFIGURE DEVICE TYPE DISK BACKUP TYPE TO COMPRESSED BACKUPSET PARALLELISM
48;
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE MAXSETSIZE TO 16 G;
CONFIGURE ENCRYPTION FOR DATABASE OFF; # default
CONFIGURE ENCRYPTION ALGORITHM ‘AES128’; # default
CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE
FOR LOAD TRUE ; # default
CONFIGURE RMAN OUTPUT TO KEEP FOR 7 DAYS; # default
CONFIGURE ARCHIVELOG DELETION POLICY TO APPLIED ON ALL STANDBY;
CONFIGURE SNAPSHOT CONTROLFILE NAME TO
‘+DATA/EZPRDEBSDR/snapcf_EZPRDEBSDR.f’;
RMAN>
=============STANDBY
EZPRDEBSDR===============================================
RMAN> show all;
RMAN configuration parameters for database with db_unique_name EZPRDEBSDR
are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 7;
CONFIGURE BACKUP OPTIMIZATION OFF; # default
CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default
CONFIGURE CONTROLFILE AUTOBACKUP OFF;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; #
default
CONFIGURE DEVICE TYPE DISK BACKUP TYPE TO COMPRESSED BACKUPSET PARALLELISM
48;
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE MAXSETSIZE TO 16 G;
CONFIGURE ENCRYPTION FOR DATABASE OFF; # default
CONFIGURE ENCRYPTION ALGORITHM ‘AES128’; # default
CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE
FOR LOAD TRUE ; # default
CONFIGURE RMAN OUTPUT TO KEEP FOR 7 DAYS; # default
CONFIGURE ARCHIVELOG DELETION POLICY TO APPLIED ON ALL STANDBY;
CONFIGURE SNAPSHOT CONTROLFILE NAME TO
‘+DATA/EZPRDEBSDR/snapcf_EZPRDEBSDR.f’;
RMAN>
Set up below cronjob to delete archive log on a daily basis on both standby
server.
RMAN command «delete archivelog all completed before ‘sysdate -3’;» .
While deleting archivelog from either of the standby DB’s for past 3 days
(delete archivelog all completed before ‘sysdate -3’) throws below error
PSDRPC returns significant error 1013.
PSDRPC returns significant error 1013.
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03009: failure of delete command on ORA_DISK_30 channel at 11/28/2019
09:04:08
ORA-15028: ASM file
‘+DATA/EZPRDEBSDR/ARCHIVELOG/2019_11_23/thread_2_seq_260708.767.1025066629’
not dropped; currently being accessed
Recovery Manager complete.
Upon checking the standby database for this thread
thread_2_seq_260708.767.1025066629′ it shows its already applied on 23rd
Nov and completed, also for the other standby this thread does not exist
anymore (probably this got deleted)
*****************************************************************************************************
DR-DB-801:
===========
SQL> select NAME,APPLIED,STATUS,COMPLETION_TIME from v$archived_log where
name like ‘%thread_2_seq_260708.767.1025066629%’;
NAME
———————————————————————————
APPLIED S COMPLETIO
——— — ———
+DATA/EZPRDEBSDR/ARCHIVELOG/2019_11_23/thread_2_seq_260708.767.1025066629
YES A 23-NOV-19
*****************************************************************************************************
Second Standby: dr-db-803
SQL> select name from v$archived_log where name like
‘%thread_2_seq_260708.767.1025066629%’;
no rows selected
Did below to resolve but no luck
1. ASMCMD LSOF does not list any files that are currently being accessed.
2. Tried restarting ASM instance
Cheers,
Sameer
—
This is an email from Ezidebit Pty Ltd. The email and any attachments may
be confidential, legally privileged and/or subject to copyright. If you are
not the intended recipient, you must not disclose or use the information
contained in this e-mail. If you have received this email in error, please
notify us immediately and delete the email and all copies. We do not
guarantee that this email and any attachments are free from virus or other
errors. We will not be responsible for loss or damage resulting (either
directly or indirectly) from any such virus or error. We will only be
responsible for a change to a document if we made the change. The content
of and opinions expressed in non-business emails are not that of Ezidebit
Pty Ltd and are that of the sender.
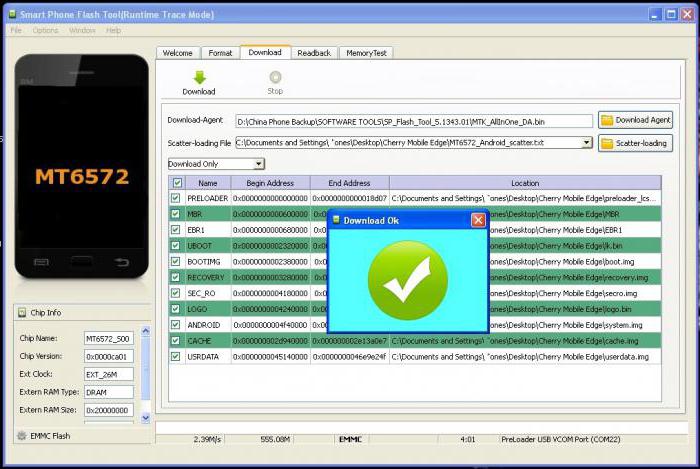
Одной из самых популярных на сегодняшний день аппаратных платформ, на которой строятся современные смартфоны и планшетные ПК, является решение, созданное и развиваемое компанией Mediatek. MTK-аппараты, особенно бюджетного сегмента, буквально заполонили весь мир благодаря усилиям огромного количества производителей из Китая. Такое разнообразие различных девайсов привело к появлению большого числа самых разнообразных программных решений, которые появляются в смартфонах и планшетах на базе МТК в результате так называемой прошивки, т. е. переноса файлов в разделы памяти девайсов при помощи специальных программ.

Способы прошивки
Безусловно, для такой сложной процедуры, как установка операционной системы «Андроид» в смартфоны и планшеты, необходимо применение специализированных программных инструментов — утилит-прошивальщиков. Несмотря на то что есть способы прошивки, не подразумевающие использования Windows-приложений, а работающие с памятью практически напрямую (например, ADB и Fastboot) или осуществляющие манипуляции прямо из Android, без подключения девайса к ПК, самым популярным методом проведения прошивки MTK-устройств является фирменное приложение, созданное программистами Mediatek – SP Flash Tool. Именно об этой замечательной программе пойдет речь ниже. Более подробно остановимся на ошибках «Флештула», которые могут помешать достижению нужного пользователю результата, то есть безупречно работающего смартфона или планшета.

SP Flash Tool
Популярность приложения обусловлена высокой эффективностью, а также относительной простотой реализации управления процессом прошивки. Действительно, после того как SP Flash Tool стал доступен для загрузки любым владельцем MTK-аппарата, прошивать собственные телефоны стали очень многие пользователи. Несмотря на аскетичный интерфейс приложения, следует отметить, что утилита является очень мощным решением и способна выполнять большое количество операций. Практически все возможные процедуры, предусматривающие манипуляции с памятью «Андроид»-девайсов, в основе которых лежит аппаратная платформа Mediatek, осуществимы с помощью SP Flash Tool. Бывают случаи, когда возникают ошибки «Флештула», что делает осуществление процесса установки ОС в смартфон или планшет невозможным. При этом стоит учитывать, что большинство ошибок устранимы достаточно легко.
Особенности
Как и любой другой программный инструмент, SP Flash Tool нельзя назвать на 100% действенным инструментом, с помощью которого осуществляется прошивка «Андроид»-устройств на процессоре MTK. Ввиду огромного разнообразия смартфонов и планшетов, вероятно, невозможно создать универсальный вариант, который будет работать абсолютно со всеми устройствами без проблем. Ошибки «Флештула», которые программа может генерировать в процессе переноса файлов в память девайса или при других манипуляциях с аппаратной частью, часто вызывают раздражение и недовольство пользователей и жалобы на несовершенство решения программистов Mediatek. При этом нужно учитывать, что остановка процесса может являться своеобразным срабатыванием защиты, заложенной в программу. Другими словами, программа защищает сопряженное устройство от повреждения аппаратной части.
Общие рекомендации
Прежде чем переходить к процессу прошивки смартфона или планшета через SP Flash Tool, следует тщательно изучить инструкции, а также особенности работы с программой при манипуляциях с конкретной моделью «Андроид»-девайса. В этом вопросе неоценимую помощь окажут тематические ресурсы по прошивке, которые пользуются популярностью в Глобальной сети. Взвешенный подход позволит избежать многих проблем и ошибок «Флештула», а также сделает процесс установки различного ПО в смартфон простым, понятным и эффективным. Не следует забывать также о вдумчивом подходе при поиске и загрузке необходимых файлов. Пакеты, предназначенные для установки с помощью SP Flash Tool, должны быть получены из проверенных источников, в идеальном случае – с официального сайта производителя, выпустившего устройство.
Распространенные ошибки
Существует довольно большое количество проблем, которые могут возникнуть в процессе работы с рассматриваемой программой. Часто встречающиеся ошибки «Флештула» и рекомендации по их преодолению будут рассмотрены ниже. В целом, нужно отметить, что в появлении сбоев в большинстве случаев виновата совсем не программа. Перед тем как переходить к кардинальным действиям, нужно проверить достоверность используемых файлов прошивок, качество соединения USB-кабеля, применимость используемой версии SP Flash Tool к конкретной модели аппарата, корректность установки драйверов. Что же делать, если все проверено, а «Флештул» выдает ошибку вновь и вновь? Придется разбираться с каждым конкретным сбоем приложения, используя номер ошибки, демонстрируемый пользователю в окне-сообщении при ее проявлении.

Ошибка 3149
Начнем рассмотрение конкретных сбоев с ошибки, которая может быть решена в результате выполнения одного из множества действий. Ошибка «Флештула» 3149 является довольно распространенной и характеризуется широким перечнем способов ее устранения. Итак, если возникает ошибка 3149, следует попробовать:
- Использовать другую версию SP Flash Tool. То есть если ошибка возникает в третьей версии программы, нужно использовать пятую, и наоборот.
- Провести процесс прошивки в режиме Format all + Download.
- Переустановить драйвера девайса с целью получения такой ситуации, когда в Диспетчере устройств прошиваемый смартфон отображается как MTK USB PORT.
- Записать отдельно раздел PRELOADER в режиме Download.
- Предварительно отформатировать память девайса, прибегнув к возможностям раздела Format в программе, затем прошить только раздел PRELOADER и только потом (в случае удачной записи PRELOADER) записывать все остальные разделы.
Ошибка 8417
Также весьма распространенная, но при этом легко решаемая ошибка. В том случае, если ошибка «Флештула» 8417 мешает процессу проведения установки «Андроида» в девайс, нужно всего лишь проверить путь к файлам с программой и прошивкой. Сбой происходит в том случае, если один из этих путей содержит русские буквы. Для устранения ошибки следует переименовать папки, не используя кириллицу, перезапустить SP Flash Tool и повторить процесс сначала. В целом, отсутствие кириллических символов, а также пробелов в названиях каталогов по пути к файлам программы и прошивки – одно из первых и главных требований для обеспечения бессбойной работы приложения при манипуляциях с разделами памяти «Андроид»-устройств.
Ошибка 4001
Ошибка «Флештула» 4001, как и многие другие ошибки, не имеет однозначного трактования, а значит, может быть решена одним из нескольких методов. При возникновении ошибки 4001 необходимо провести действия, представленные:
- Сменой USB-порта (подключать девайс для прошивки следует исключительно к задней панели материнской платы ПК!).
- Переносом файлов программы в корень системного раздела (диска C:).
Кроме прочего, рассматриваемая ошибка может свидетельствовать об отсутствии информации о процессоре и/или флеш-памяти в файле DA. В этом случае нужно попробовать использовать более свежую версию «Флештула».
Также при проявлении ошибки 4001 не следует исключать наличия аппаратных проблем у сопряженного устройства. Эта ошибка часто проявляется, если флеш-память аппарата вышла из строя.
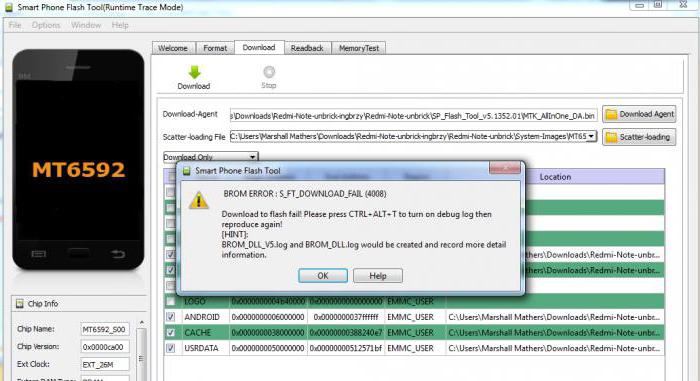
Ошибка 1013
Неисправный ЮСБ-кабель очень часто может привести к появлению сбоев в работе. Ошибка «Флештула» 1013 обычно решается именно в результате смены используемого кабеля на более качественный. Кроме того, при поиске способа устранить ошибку 1013 следует проверить:
- Версию приложения. Ошибка практически не возникает в пятой версии SP Flash Tool, а вот при использовании третьей версии – довольно распространена.
- БИОС ПК на предмет наличия отключенных COM-портов.
- Наличие неисправностей USB-порта (необходимо использовать другой разъем).
Кроме прочего, можно попробовать произвести запуск «Флештула» от имени Администратора.
Ошибка 5069
К сожалению, при работе с SP Flash Tool возникают проблемы, которые решаются путем серьёзных усилий либо не решаются вообще. Примером таких неприятностей является появление ошибки «Флештула» 5069.
Данная ошибка проявляется в результате невозможности взаимодействия приложения с флеш-памятью девайса, имеющей определенные аппаратные особенности. Такое положение вещей обусловлено широким распространением типов и видов микросхем памяти, используемой при создании различных «Андроид»-девайсов. Не все производители чипов могут обеспечить полное соответствие своих решений общепринятым стандартам. Если при прошивке возникает ошибка 5069, вероятно, от использования SP Flash Tool придется отказаться и прибегнуть к использованию других методов и программных инструментов.

Заключение
Конечно же, перечень вышеописанных ошибок не претендует на звание полного. В процессе работы с «Андроид»-устройствами пользователь может столкнуться и со многими другими проблемами. При этом подход в решении остается единым: изначально следует проверить исправность всех аппаратных компонентов как компьютера, так и «Андроид»-девайса, а также соответствие версий, используемых при прошивке файлов модели устройства. В большинстве случаев проблема лежит на поверхности и решается довольно просто.
Когда я вчера вечером вышел с работы, я собирался закрыть базу данных ORACLE на виртуальной машине машины, а затем собирался уйти с работы, но был вызван тем, что мой SecureCRT открыл несколько окон, и результат был случайным и небрежным. Затем я выполнил немедленную команду shutdown на производственном сервере. Примерно через 6–7 секунд я обнаружил, что на команду нет ответа, и обнаружил, что выполнение этой команды было неправильным на сервере. В шоке я даже не подумал о том, что сочетание клавиш CTRL + C может прервать эту операцию . Следующим образом:
SQL> shutdown immeidate;
SP2-0717: illegal SHUTDOWN option
SQL> shutdown immediate;
^C^C^C^C^C
ORA-01013: user requested cancel of current operation

Поэтому я проверил файл журнала сигналов тревоги в другом окне и обнаружил, что в базе данных были закрыты некоторые процессы. Общая ситуация такова
tail -40f alert_SCM2.log
Wed Aug 6 17:54:37 2014
ARCH shutting down
ARC8: Archival stopped
Wed Aug 6 17:54:42 2014
ARCH shutting down
ARC7: Archival stopped
Wed Aug 6 17:54:47 2014
ARCH shutting down
ARC6: Archival stopped
Wed Aug 6 17:54:52 2014
ARCH shutting down
ARC5: Archival stopped
Wed Aug 6 17:54:57 2014
ARCH shutting down
ARC4: Archival stopped
Wed Aug 6 17:55:05 2014
CLOSE: Error 1013 during database close
Wed Aug 6 17:55:05 2014
SMON: enabling cache recovery
SMON: enabling tx recovery
Wed Aug 6 17:55:05 2014
ORA-1013 signalled during: ALTER DATABASE CLOSE NORMAL...
Wed Aug 6 17:55:07 2014
ARCH shutting down
ARC2: Archival stopped
Wed Aug 6 17:55:12 2014
ARCH shutting down
ARC1: Archival stopped
Wed Aug 6 17:55:17 2014
ARC3: Becoming the heartbeat ARCH
ARC3: Archiving disabled
ARCH shutting down
ARC3: Archival stopped
Wed Aug 6 17:55:17 2014
ARCH shutting down
Wed Aug 6 17:55:17 2014
ARC0: Archival stopped
Wed Aug 6 17:55:18 2014
Thread 1 closed at log sequence 97562
Successful close of redo thread 1
^C
Поэтому немедленно проверьте состояние базы данных, чтобы убедиться, что он нормальный, результат следующий, есть такие ошибки, как ORA-00604, ORA-00376 и ORA-01110.
SQL> SQL> SQL> select status from v$instance;
select status from v$instance
*
ERROR at line 1:
ORA-00604: error occurred at recursive SQL level 2
ORA-00376: file 1 cannot be read at this time
ORA-01110: data file 1: ‘/u01/oradata/SCM2/system01.dbf’

В шоке, я сразу же вышел из сеанса и снова вошел в систему (в то время я не был очень спокоен и поспешно замолчал)
sqlplus / as sysdba
SQL*Plus: Release 10.2.0.4.0 — Production on Wed Aug 6 17:57:11 2014
Copyright (c) 1982, 2007, Oracle. All Rights Reserved.
Connected.
SQL> select status from v$instacne;
select status from v$instacne
*
ERROR at line 1:
ORA-01012: not logged on
SQL> shutdown immdeiate;
SP2-0717: illegal SHUTDOWN option
SQL> exit
Disconnected
SQL> shutdwon immeidiate;
SP2-0734: unknown command beginning «shutdwon i…» — rest of line ignored.
SQL> shutdown immediate;
ORA-24324: service handle not initialized
ORA-24323: value not allowed
ORA-01089: immediate shutdown in progress — no operations are permitted

На данный момент таких ошибок в журнале тревог очень много.

В отчаянии я мог использовать только команду shutdown abort и вместо этого успокоился. Однако возникла ошибка ORA-01031: недостаточно прав. После выхода и повторного входа в систему база данных была закрыта и перезапущена.
SQL> shutdown abort
ORA-01031: insufficient privileges
sqlplus / as sysdba
SQL*Plus: Release 10.2.0.4.0 — Production on Wed Aug 6 18:15:00 2014
Copyright (c) 1982, 2007, Oracle. All Rights Reserved.
Connected.
SQL> shutdown abort
ORACLE instance shut down.
SQL> startup
ORACLE instance started.
Total System Global Area 7516192768 bytes
Fixed Size 2095640 bytes
Variable Size 5167384040 bytes
Database Buffers 2298478592 bytes
Redo Buffers 48234496 bytes
Database mounted.
Database opened.
SQL> exit
После перезапуска просмотрите журнал сигналов тревоги и убедитесь, что нет никаких отклонений от нормы. После проверки по очереди обнаружите, что проблема не возникает, и зависшее сердце успокаивается. Но давайте резюмируем: это ошибка низкого уровня и ошибка, которая производит глубокое впечатление. Причина, по которой я хочу записать ее, заключается в том, что это тоже случай, а во-вторых, я должен запомнить В душе. На протяжении всего процесса я не чувствовал себя спокойным и нерешительным. Фактически, база данных уже была отключена, поэтому мы должны спокойно проанализировать, перезапускается ли она после закрытия базы данных или , чтобы прервать процесс. Сама база данных ORACLE закрыла некоторые процессы. Если в этот момент процесс shutdown прерывается, это, очевидно, неразумное решение. Неправильное решение привело к возникновению ряда последующих проблем, типовой ремонтной базы не хватило! В электронном письме от начальника мне было сказано, что мне нужно расслабиться, успокоиться и в следующий раз быть осторожным. Иметь ввиду.