Содержание
- Hidden dangers of duplicate key violations in PostgreSQL and how to avoid them
- Understanding the differences between INSERT and INSERT..ON CONFLICT
- Performance impact
- Bloat considerations
- Transaction ID usage acceleration and autovacuum impact
- Duplicate key with regular inserts
- Duplicate key with INSERT..ON CONFLICT
- Storage space considerations
- Duplicate key with regular inserts
- Duplicate key with INSERT..ON CONFLICT
- Summary
- About the Authors
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
For comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
The difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
We now observe five additional dead tuples generated:
This highlights that even though no rows were successfully inserted, there is an increase in dead tuples ( n_dead_tup ).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
Again, checking pg_stat_user_tables , we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row .
We used the following pgbench command to run it through multiple connections:
We observed multiple notice messages, because all were duplicate values:
For this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0 , to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.

On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
When we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log :
The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
Autovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
We ran the script on the instance in the following steps:
The preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.

There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
In our small instance, we went into Storage-full state during our script execution.

Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.

Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
Источник
Symptoms
You cannot start Confluence or create content, or perform another function. This can occur after an upgrade or randomly while the system is in use.
Some variation on the following appears in the atlassian-confluence.log:
atlassian-confluence.log
2011-07-21 11:58:11,153 ERROR [http-8080-3] [atlassian.confluence.servlet.ConfluenceServletDispatcher] sendError Could not execute action
-- referer: http://instance | url: /json/addlabelactivity.action | userName: admin
org.springframework.dao.DataIntegrityViolationException: Hibernate operation: could not insert: [bucket.search.persistence.IndexQueueEntry#26083335]; SQL []; ERROR: duplicate key value violates unique constraint "indexqueueentries_pkey"; nested exception is org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "indexqueueentries_pkey"
Caused by: org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "indexqueueentries_pkey"
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2102)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1835)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:257)
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:500)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeWithFlags(AbstractJdbc2Statement.java:388)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeUpdate(AbstractJdbc2Statement.java:334)
...atlassian-confluence.log
-- referer: https://confluence.mycompany.com.au/display/cspub/Page+Name | url: /pages/copypage.action | userName: userx | action: copypage
2015-09-02 21:47:44,468 ERROR [http-nio-443-exec-5] [sf.hibernate.util.JDBCExceptionReporter] logExceptions Violation of PRIMARY KEY constraint 'PK__CONTENT__1317CAA1114E8C1D'. Cannot insert duplicate key in object 'CONTENT'. The duplicate key value is (9469953).Cause and Diagnosis
This is caused by a problem with the hibernate_unique_key. This value is used to determine the next block of unique id numbers to create in the database. Most of Confluence’s tables use an id number as the primary key, and that number is determined by using the value in the hibernate_unique_key and applying a formula to it, and then incrementing it. This error can therefore occur for one of two reasons:
- There are two entries for the
hibernate_unique_key - The
hibernate_unique_keyis set to a value that is too low
To determine which is these is at fault, run this query against the database;
select * from hibernate_unique_key;There should be only one entry in this table, and the number must be higher than the highest id used in the database.
![]() If neither of those cases apply, and the
If neither of those cases apply, and the hibernate_unique_key value seems fine, there’s a similar problem that may produce this same behavior as well, due to a different root cause:
- Cannot create new Space due to «duplicate key value violates unique constraint [tablename]_pkey» error
Resolution
The resolution depends on the cause.
Solution One
If there are two entries in hibernate_unique_key, delete the lower number by issuing this command:
delete from hibernate_unique_key where next_hi = <the lower number>;Solution Two
If there is only one entry, we need to make Confluence calculate the correct value and reset it. There are two way to do this. Please test this in a testing environment first.
- Go to General Configuration > Backup & Restore and make an XML backup with attachments.
- Copy the XML backup zip from
atlassian_home/temptoatlassian_home/restore - Go to General Configuration > Backup & Restore again, and scroll to the bottom
- Choose the XML backup zip file and click Restore
The result will be that Confluence will regenerate a valid next_hi value.
or
- On the production instance, go to General Configuration > Backup & Restore and make an XML backup (no attachments.)
- Copy the XML backup zip from
atlassian_home/temptoatlassian_home/restoreon a test instance - On the test instance, go to General Configuration > Backup & Restore, and scroll to the bottom
- Choose the XML backup zip file and click Restore
- Run
select * from hibernate_unique_key;on the test instance database, and save thenext_hivalue - Shut down your production Confluence instance
- In your production database server, run
update hibernate_unique_key set next_hi = <value>;where <value> is the value from the test database server - Restart Confluence.
A common coding strategy is to have multiple application servers attempt to insert the same data into the same table at the same time and rely on the database unique constraint to prevent duplication. The “duplicate key violates unique constraint” error notifies the caller that a retry is needed. This seems like an intuitive approach, but relying on this optimistic insert can quickly have a negative performance impact on your database. In this post, we examine the performance impact, storage impact, and autovacuum considerations for both the normal INSERT and INSERT..ON CONFLICT clauses. This information applies to PostgreSQL whether self-managed or hosted in Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition.
Understanding the differences between INSERT and INSERT..ON CONFLICT
In PostgreSQL, an insert statement can contain several clauses, such as simple insert with the values to be put into a table, an insert with the ON CONFLICT DO NOTHING clause, or an insert with the ON CONFLICT DO UPDATE SET clause. The usage and requirements for all these types differ, and they all have a different impact on the performance of the database.
Let’s compare the case of attempting to insert a duplicate value with and without the ON CONFLICT DO NOTHING clause. The following table outlines the advantages of the ON CONFLICT DO NOTHING clause.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Dead tuples generated | Yes | No |
| Transaction ID used up | Yes | No |
| Autovacuum has more cleanup | Yes | No |
| FreeStorageSpace used up | Yes | No |
Let’s look at simple examples of each type of insert, starting with a regular INSERT:
postgres=> CREATE TABLE blog (
id int PRIMARY KEY,
name varchar(20)
);
CREATE TABLE
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1');
INSERT 0 1The INSERT 0 1 depicts that one row was inserted successfully.
Now if we insert the same value of id again, it errors out with a duplicate key violation because of the unique primary key:
postgres=> INSERT INTO blog
VALUES (1, 'AWS Blog1');
ERROR: duplicate key value violates unique constraint "blog_pkey"
DETAIL: Key (n)=(1) already exists.The following code shows how the INSERT… ON CONFLICT clause handles this violation error when inserting data:
postgres=> INSERT INTO blog
VALUES (1,'AWS Blog1')
ON CONFLICT DO NOTHING;
INSERT 0 0The INSERT 0 0 indicates that while nothing was inserted in the table, the query didn’t error out. Although the end results appear identical (no rows inserted), there are important differences when you use the ON CONFLICT DO NOTHING clause.
In the following sections, we examine the performance impact, bloat considerations, transaction ID acceleration and autovacuum impact, and finally storage impact of a regular INSERT vs. INSERT..ON CONFLICT.
Performance impact
The following excerpt of the commit message adding the INSERT..ON CONFLICT clause describes the improvement:
“This is implemented using a new infrastructure called ‘speculative insertion’. It is an optimistic variant of regular insertion that first does a pre-check for existing tuples and then attempts an insert. If a violating tuple was inserted concurrently, the speculatively inserted tuple is deleted and a new attempt is made. If the pre-check finds a matching tuple the alternative DO NOTHING or DO UPDATE action is taken. If the insertion succeeds without detecting a conflict, the tuple is deemed inserted.”
This pre-check avoids the overhead of inserting a tuple into the heap to later delete it in case it turns out to be a duplicate. The heap_insert () function is used to insert a tuple into a heap. Back in version 9.5, this code was modified (along with a lot of other code) to incorporate speculative inserts. HEAP_INSERT_IS_SPECULATIVE is used on so-called speculative insertions, which can be backed out afterwards without canceling the whole transaction. Other sessions can wait for the speculative insertion to be confirmed, turning it into a regular tuple, or canceled, as if it never existed and therefore never made visible. This change eliminates the overhead of performing the insert, finding out that it is a duplicate, and marking it as a dead tuple.
For example, the following is a simple select query on a table that attempted 1 million regular inserts that were duplicates:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 54.135 msFor comparison, the following is a simple select query on a table that used the INSERT..ON CONFLICT statement:
postgres=> SELECT count(*) FROM blog;
-[ RECORD 1 ]
count | 1
Time: 0.761 msThe difference in time is because of the 1 million dead tuples generated in the first case by the regular duplicate inserts. To count the actual visible rows, the entire table has to be scanned, and when it’s full of dead tuples, it takes considerably longer. On the other hand, in the case of INSERT..ON CONFLICT DO NOTHING, because of the pre-check, no dead tuples are generated, and the count(*) completes much faster, as expected for just one row in the table.
Bloat considerations
In PostgreSQL, when a row is updated, the actual process is to mark the original row deleted (old value) and then insert a new row (new value). This causes dead tuple generation, and if not cleared up by vacuum can cause bloat. This bloat can lead to unnecessary space utilization and performance loss as queries scan these dead rows.
As discussed earlier, in a regular insert, there is no duplicate key pre-check before attempting to insert the tuple into the heap. Therefore, if it’s a duplicate value, it’s similar to first inserting a row and then deleting it. The result is a dead tuple, which must then be handled by vacuum.
In this example, with the pg_stat_user_tables view, we can see these dead tuples are generated when an insert fails due to a duplicate key violation:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 4As we can see, n_dead_tup currently is 4. We attempt inserting five duplicate values:
postgres=> DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
DOWe now observe five additional dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9This highlights that even though no rows were successfully inserted, there is an increase in dead tuples (n_dead_tup).
Now, we run the following insert with the ON CONFLICT DO NOTHING clause five times:
DO $$
BEGIN
FOR r IN 1..5 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
END;
END LOOP;
END;
$$;Again, checking pg_stat_user_tables, we observe that there is no increase in n_dead_tup and therefore no dead tuples generated:
postgres=> SELECT relname, n_dead_tup, n_live_tup
FROM pg_stat_user_tables
WHERE relname = 'blog';
-[ RECORD 1 ]-------+-------
relname | blog
n_live_tup | 7
n_dead_tup | 9In the normal insert, we see dead tuples increasing, whereas no dead tuples are generated when we use the ON CONFLICT DO NOTHING clause. These dead tuples result in unnecessary table bloat as well as consumption of FreeStorageSpace.
Transaction ID usage acceleration and autovacuum impact
A PostgreSQL database can have two billion “in-flight” unvacuumed transactions before PostgreSQL takes dramatic action to avoid data loss. If the number of unvacuumed transactions reaches (2^31 – 10,000,000), the log starts warning that vacuuming is needed. If the number of unvacuumed transactions reaches (2^31 – 1,000,000), PostgreSQL sets the database to read-only mode and requires an offline, single-user, standalone vacuum. This is when the database reaches a “Transaction ID wraparound”, which is described in more detail in the PostgreSQL documentation. This vacuum requires multiple hours or days of downtime (depending on database size). More details on how to avoid this situation are described in Implement an Early Warning System for Transaction ID Wraparound in Amazon RDS for PostgreSQL.
Now let’s look at how these two different inserts impact the transaction ID usage by running some tests. All tests after this point are run on two different identical instances: one for regular INSERT testing and another one for the INSERT..ON CONFLICT clause.
Duplicate key with regular inserts
In the case of regular inserts, when the inserts error out, the transaction is canceled. This means if the application inserts 100 duplicate key values, 100 transaction IDs are consumed. This could lead to autovacuum runs to prevent wraparound in peak hours, which consumes resources that could otherwise be used for user workload.
For testing the impact of this, we ran a script using pgbench to repeatedly insert multiple key values into the blog table:
DO $$
BEGIN
FOR r in 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1');
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;The script runs the INSERT statement 1 million times, and if it throws an error, prints out duplicate row.
We used the following pgbench command to run it through multiple connections:
pgbench --host=iocblog.abcedfgxymxvb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script postgresWe observed multiple notice messages, because all were duplicate values:
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate row
NOTICE: duplicate rowFor this test, we modified some autovacuum parameters. First, we set log_autovacuum_min_duration to 0, to log all autovacuum actions. Secondly, we set rds.force_autovacuum_logging_level to debug5 in order to log detailed information about each run.
As the script did more and more loops, the transaction ID usage increased, as shown in the following visualization.
On this test instance, only our contrived workload was being run. We used Amazon CloudWatch to observe that as soon as MaximumUsedTransactionIds hit autovacuum_freeze_max_age (default 200 million), autovacuum worker was launched to prevent wraparound. The following is a snapshot of pg_stat_activity for that time:
postgres=> select * from pg_stat_activity where query like '%autovacuum%';
-[ RECORD 1 ]----+--------------------------------------------------------------------
datid | 14007
datname | postgres
pid | 3049
usesysid |
usename |
application_name |
client_addr |
client_hostname |
client_port |
backend_start | 2020-11-26 12:22:37.364145+00
xact_start | 2020-11-26 12:22:37.403818+00
query_start | 2020-11-26 12:22:37.403818+00
state_change | 2020-11-26 12:22:37.403818+00
wait_event_type | LWLock
wait_event | ProcArrayLock
state | active
backend_xid |
backend_xmin | 205602359
query | autovacuum: VACUUM public.blog (to prevent wraparound)
backend_type | autovacuum workerWhen we observe the query output and the graph, we can see that the autovacuum started at the time MaximumUsedTransactionIds reached 200 million (around 12:22 UTC; this was expected so as to prevent transaction ID wraparound). During the same time, we observed the following in postgresql.log:
2020-11-26 12:22:37 UTC::@:[3049]:DEBUG: blog: vac: 5971078 (threshold 50), anl: 0 (threshold 50)
.
.
2020-11-26 12:22:45 UTC::@:[3202]:WARNING: oldest xmin is far in the past
2020-11-26 12:22:45 UTC::@:[3202]:HINT: Close open transactions soon to avoid wraparound problems.
You might also need to commit or roll back old prepared transactions, or drop stale replication slots.The preceding code shows autovacuum running and having to act on 5.9 million dead tuples in the table. The warning about wraparound problems is because of the script generating the dead tuples, and advancing the transaction IDs. As time passed, autovacuum finally completed cleaning up the dead tuples:
2020-11-26 13:05:28 UTC::@:[62084]:LOG: automatic aggressive vacuum of table "postgres.public.blog": index scans: 2
pages: 0 removed, 1409317 remain, 48218 skipped due to pins, 0 skipped frozen
tuples: 115870210 removed, 96438 remain, 0 are dead but not yet removable, oldest xmin: 460304384
buffer usage: 4132095 hits, 21 misses, 1732480 dirtied
avg read rate: 0.000 MB/s, avg write rate: 37.730 MB/s
system usage: CPU: user: 22.71 s, system: 1.23 s, elapsed: 358.73 sAutovacuum had to act on approximately 115 million tuples. This is what we observed on an idle system with only a script running to insert duplicate values. The table here was pretty simple, with only two columns and two live rows. For bigger production tables, which realistically have more columns and more data, it could be much worse. Let’s now see how to avoid this by using INSERT..ON CONFLICT.
Duplicate key with INSERT..ON CONFLICT
We modified the same script as in the previous section to include the ON CONFLICT DO NOTHING clause:
DO $$
BEGIN
FOR r IN 1..1000000 LOOP
BEGIN
INSERT INTO blog VALUES (1, 'AWS Blog1') ON CONFLICT DO NOTHING;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
RAISE NOTICE 'duplicate row';
END;
END LOOP;
END;
$$;We ran the script on the instance in the following steps:
// Check the live rows in the table
postgres=> SELECT * FROM blog;
n | name
---+-----------
1 | AWS Blog1
2 | AWS Blog2
(2 rows)
postgres=> timing
Timing is on.
postgres=> SELECT now();
now
-------------------------------
2020-11-29 22:25:26.426271+00
(1 row)
Time: 2.689 ms
// Check the current transaction ID of the database (before running the script) :
postgres=> SELECT txid_current();
txid_current
--------------
16373267
(1 row)
//Run the script in another session as follows :
pgbench --host=iocblog2.abcdefghivb.eu-west-1.rds.amazonaws.com --port=5432 --username=postgres -c 1000 -f script2 postgres
Password:
starting vacuum...end.
//After some time later, go to previous session and check transaction ID along with pg_stat_activity. It increased by 4 transactions (which were the ones including our testing).
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:56:59.241092+00
Time: 8.692 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373271
Time: 234.526 ms
//The following query shows the 1001 active transactions which are active because of the script, but aren't causing a spike in transaction IDs.
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:44.373064+00
Time: 7.297 ms
postgres=> SELECT COUNT(*)
FROM pg_stat_activity
WHERE query like '%blog%'
AND backend_type='client backend';
-[ RECORD 1 ]
count | 1001
Time: 181.370 ms
postgres=> SELECT now();
-[ RECORD 1 ]----------------------
now | 2020-11-29 22:59:52.661102+00
Time: 6.212 ms
postgres=> SELECT txid_current();
-[ RECORD 1 ]+---------
txid_current | 16373273
Time: 741.437 msThe preceding testing shows that if we use INSERT..ON CONFLICT, the transaction IDs aren’t consumed. The following visualization shows the MaximumUsedTransactionIds metric.
There is still one more benefit to examine by using this clause: storage space.
Storage space considerations
In the case of the normal insert, the dead tuples that are generated result in unnecessary space consumption. Even in our small test workload, we were able to quickly end up in a storage full situation. If this happens in a production system, a scale storage is required.
Duplicate key with regular inserts
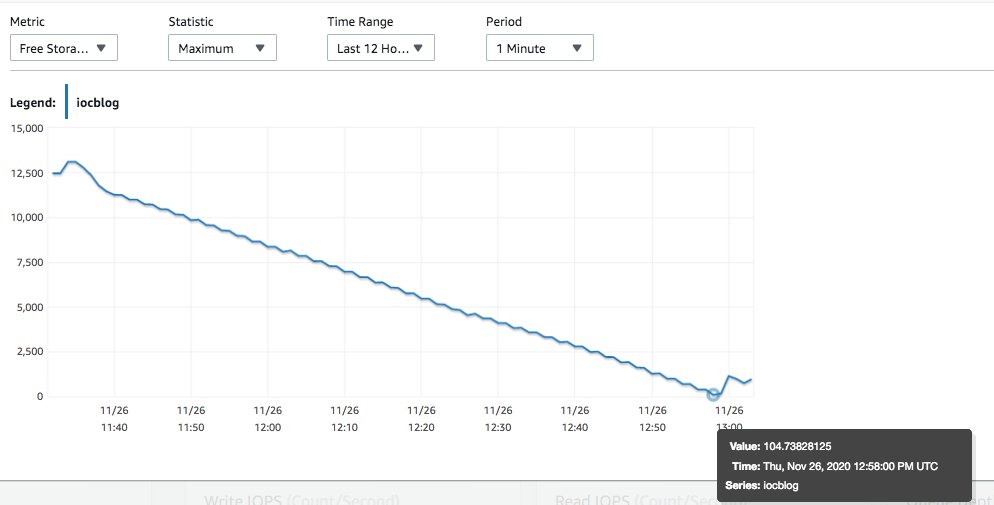
As discussed earlier, the tuples are inserted into the heap and checked if they are valid as per the constraint. If it fails, it’s marked as deleted. We can observe the impact on the FreeStorageSpace metric.
FreeStorageSpace went down all the way to a few MBs because these dead rows consume disk space. We used the following queries to monitor the script, they show that while there are only two visible tuples, space is consumed by the dead rows.
postgres=> select count(*) from blog;
-[ RECORD 1 ]
count | 2
postgres=> select pg_size_pretty (pg_table_size('blog'));
-[ RECORD 1 ]--+------
pg_size_pretty | 5718 MB
(1 row)In our small instance, we went into Storage-full state during our script execution.
Duplicate key with INSERT..ON CONFLICT
For comparison, when we ran the script using INSERT..ON CONFLICT, there was absolutely no drop in storage. This is because the transaction is prechecked and the tuple isn’t inserted in the table. With no dead tuples generated, no space is taken up by them, and the instance doesn’t run out of storage space due to duplicate inserts.
Summary
Let’s recap each of the considerations we discussed in the previous sections.
| .. | Regular INSERT | INSERT..ON CONFLICT DO NOTHING |
| Bloat considerations | Dead tuples generated for each conflicting tuples inserted in the relation. | Pre-check before inserting into the heap ensures no duplicates are inserted. Therefore, no dead tuples are generated. |
| Transaction ID considerations | Each failed insert causes the transaction to cancel, which causes consumption of 1 transaction ID. If too many duplicate values are inserted, this can spike up quickly. | The transaction can be backed out and not canceled in the case of a duplicate, and therefore, a transaction ID is not consumed. |
| Autovacuum Impact | As transaction IDs increase, autovacuum to prevent wraparound is triggered, consuming resources to clean up the dead rows. | No dead tuples, no transaction ID consumption, no autovacuum to prevent wraparound is triggered. |
| FreeStorageSpace considerations | The dead tuples also cause storage consumption. | No dead tuples generated, so no extra space is consumed. |
In this post, we showed you some of the issues that duplicate key violations can cause in a PostgreSQL database. They can cause wasted disk storage, high transaction ID usage and unnecessary Autovacuum work.
We offered an alternative approach using the “INSERT..ON CONFLICT“ clause which avoid these problems. It is recommended to use this alternative if you are constantly observing high volumes of the “duplicate key violates unique constraint” error in your logs. You might need to make some application code changes while using this option to see whether the INSERT succeeded or failed. This can not be determined by the error anymore (as there will be none generated) but by checking the number of rows affected with the insert query.
If you have any questions, let us know in the comments section.
About the Authors
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Shawn McCoy is a Senior Database Engineer for RDS & Aurora PostgreSQL. After being an Oracle DBA for many years he became one of the founding engineers for the launch of RDS PostgreSQL in 2013. Since then he has been improving the service to help customers succeed and scale their applications.
PostgreSQL — вставка данных с дублирующимися уникальными полями
В данной статье мы подробно рассмотрим процесс вставки данных. В том числе, как избежать ошибок при вставке дублирующихся данных. Все операции мы будем производить на тестовой базе PostgreSQL, дамп данной базы вы можете скачать по ссылке
В данной статье мы подробно рассмотрим процесс вставки данных. В том числе, как избежать ошибок при вставке дублирующихся данных. Все операции мы будем производить на тестовой базе PostgreSQL, дамп данной базы вы можете скачать по ссылке: https://www.postgresqltutorial.com/postgresql-sample-database/
Какой самый простой способ вставить данные в таблицу customer? Напомню, что синтаксис будет следующий:
INSERT INTO customer (active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id) VALUES (1, default, 10, default, 'test2@test.com', 'Andrey', 'Vasilyev', default, 2)
Для вставки нескольких значений, синтаксис будет следующим:
INSERT INTO customer (active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id) VALUES (1, default, 10, default, 'test2@test.com', 'Andrey', 'Vasilyev', default, 2), (1, default, 11, default, 'test4@test.com', 'Ivan', 'Ivanov', default, 2) returning customer_id;
Заметили в конце фразу «returning customer_id»? Она позволяет после вставки получить в ответ id добавленных записей.
Теперь давайте сделаем следующую очень распространённую вещь — сделаем поле email в этой таблице уникальным:
ALTER TABLE customer ADD CONSTRAINT email_unique UNIQUE (email);
И теперь давайте попробуем вставить уже существующую запись следующим образом:
INSERT INTO customer (active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id) SELECT active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id FROM customer WHERE customer_id = 10 returning customer_id
Т.е. данным запросом мы пытаемся вставить customer_id с номером 10. И при выполненгии данного запроса мы получим ошибку:
ERROR: duplicate key value violates unique constraint "email_unique"
Итак, теперь чтобы нам добавить нового пользователя, нужно выполнить перед инструкцией insert следующий запрос:
SELECT count(1) FROM customer WHERE email = 'test2@test.com'
Т.е. проверим, что пользователя с таким email нет в базе.
Однако, есть гораздо более простой способ сделать это. Попробуем следующий запрос:
INSERT INTO customer (active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id) VALUES (1, default, 19, default, 'helen.harris@sakilacustomer.org', 'Helen', 'Harris', default, 1) on conflict do nothing
И заметьте, что мы в ответ не получим никакой ошибки, запрос будет выполнен успешно, несмотря на то, что пользователь присутствует в базе.
У этого подхода есть ещё одно преимущество. Вместо того, чтобы просто ничего не делать при обнаружении дубликата, мы можем обновить запись. Например, представим ситуацию, что пользователь Helen сменил место жительства, т.е. переехал в другой город. И при попытке повторной регистрации нам требуется обновить адрес, а также имя и фамилию в случае если они также были изменены. Сделать нам это поможет следующий запрос:
INSERT INTO customer (active, activebool, address_id, create_date, email, first_name, last_name, last_update, store_id) VALUES (1, default, 20, default, 'helen.harris@sakilacustomer.org', 'Helena', 'Harry', default, 1) on conflict (email) do update set first_name = excluded.first_name, last_name = excluded.last_name, address_id = excluded.address_id returning customer_id
Заметим, что в этом запросе мы указали поле email, по которому мы проперяем по дубликаты, указываем действие, которые мы должны совершить (do update). И затем указываем маппинг, по которому мы обновляем поля (first_name = excluded.first_name, last_name = excluded.last_name, address_id = excluded.address_id). По ключевому слову excluded мы обращаемся к нашему новому вставляемому значению, обновляя тем самым значения поля. А фразой «returning customer_id» мы получаем в ответ id клиента.
Troubleshooting
Problem
The import of a configuration into an existing organisation failed.
Symptom
These errors were seen in the client.log during the time of the failed import.
ERROR o.h.engine.jdbc.spi.SqlExceptionHelper - ERROR: duplicate key value violates unique constraint "idx_muser_ldap_dn" Detail: Key (muser_ldap_dn)=(cn=A, User,ou=users,dc=domain,dc=com) already exists.
01:51:00.880 [http-nio-443-exec-3] ERROR o.h.engine.jdbc.spi.SqlExceptionHelper - ERROR: duplicate key value violates unique constraint "idx_muser_ldap_dn" Detail: Key (muser_ldap_dn)=(cn=A, User,ou=users,dc=domain,dc=com) already exists.
01:51:00.894 [http-nio-443-exec-3] INFO com.co3.web.rest.Co3ExceptionMapperBase - Mapping exception to REST
javax.persistence.PersistenceException: org.hibernate.exception.ConstraintViolationException: could not execute statement
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1763)
at org.hibernate.jpa.spi.AbstractEntityManagerImpl.convert(AbstractEntityManagerImpl.java:1677)
...
Caused by: org.hibernate.exception.ConstraintViolationException: could not execute statement
at org.hibernate.exception.internal.SQLStateConversionDelegate.convert(SQLStateConversionDelegate.java:129)
...
Caused by: org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "idx_muser_ldap_dn"
Detail: Key (muser_ldap_dn)=(cn=A, User,ou=users,dc=domain,dc=com) already exists.Cause
The LDAP distinguished name (cn=A, User,ou=users,dc=domain,dc=com) already exists within IBM Resilient, probably under a different email address, possibly an old account.
Diagnosing The Problem
Run the following query to find out of there is the same LDAP distinguished name within IBM Resilient
sudo -u postgres -i psql co3 -c «select p.principal_name, m.muser_id, m.muser_first_name, m.muser_last_name, m.muser_ldap_dn from monapp.musers m left join monapp.principals p on m.muser_id=p.principal_id where muser_ldap_dn in (select muser_ldap_dn from monapp.musers group by muser_ldap_dn having count(muser_ldap_dn) > 1);»
If this doesn’t return any results run the following query replacing xxx with part of the distinguished name shown in the client.log, for example «User.»
sudo -u postgres -i psql co3 -c «select p.principal_name, m.muser_id, m.muser_first_name, m.muser_last_name, m.muser_ldap_dn from monapp.musers m left join monapp.principals p on m.muser_id=p.principal_id where muser_ldap_dn in (select muser_ldap_dn from monapp.musers where muser_ldap_dn like ‘%xxx%’);»
This will return the user’s details helping you identify which user needs their distinguished name removed from IBM Resilient.
Resolving The Problem
After identifying the user details, remove their LDAP distinguished name from IBM Resilient.
sudo resutil resetuser -email <old email address> -clearldap
Try running the import again.
The above steps are useful in other circumstances where email addresses change but the user’s LDAP distinguished name remains the same. This can often affect users when logging in to IBM Resilient, if their email address has changed.
Document Location
Worldwide
[{«Business Unit»:{«code»:»BU059″,»label»:»IBM Software w/o TPS»},»Product»:{«code»:»SSIP9Q»,»label»:»IBM Security SOAR»},»ARM Category»:[{«code»:»a8m0z0000001gqlAAA»,»label»:»Authentication->LDAP»}],»ARM Case Number»:»TS003516765″,»Platform»:[{«code»:»PF043″,»label»:»Red Hat»}],»Version»:»All Versions»,»Edition»:»»,»Line of Business»:{«code»:»LOB24″,»label»:»Security Software»}}]
Postgres is one of the most advanced and widely used open-source RDBMS (Relational Database Management Systems) in the world. It’s particularly appreciated by the developer community because it supports both SQL and JSON querying, making it is both relational and non-relational compliant.
Yet, Postgres has some well-known issues, and one of the most annoying ones involves sequences. Specifically, Postgres sequences are prone to go out of sync, preventing you from inserting new rows. Postgres even returns a confusing error message when this happens.
In this article, we’ll teach you about the out-of-sync issue and show you how to solve it. We will learn about sequences, see what circumstances lead to the out-of-sync issue, learn how to diagnose the problem, and finally solve it. Let’s begin.
Delving into the out-of-sync sequence problem in Postgres
What is a Postgres sequence?
The official documentation explains that a sequence is nothing more than a number generator. In particular, Postgres uses a sequence to generate a progressive number, which usually represents an automatically incremented numeric primary key.
If you are familiar with MySQL, the result of having a sequence in Postgres is comparable to the AUTO_INCREMENT behavior. The main difference is that Postgres sequences can also be decremental. In detail, you can define a sequence with an initial value and let PostgreSQL decrement it for you at each INSERT.
You can define a sequence in Postgres with the CREATE SEQUENCE statement. Similarly, the special type SERIAL initializes an auto-incremental numeric primary key using a sequence behind the scene. Generally, you should use SERIAL when creating a new table with CREATE TABLE.
When do sequences go out of sync?
Based on my experience as a senior software developer, there are three reasons why a Postgres sequence can go out of sync. Specifically, this happens when:
- importing many rows with an
INSERTscript or restoring an extensive database; - manually setting the wrong value of a sequence with the
setval()function; - inserting a new record into a table by manually specifying the
idfield in theINSERTquery.
The last one is the most common cause and usually occurs because Postgres uses a sequence and automatically updates its value only when you omit the id field or use the DEFAULT keyword in the INSERT query.
How do I identify this issue?
Spotting this issue is straightforward. When you specify no value for the id column and manually launch an INSERT query or let your ORM (Object-Relational Mapping) do it for you, Postgres will always return a «duplicate key value violates unique constraint» error. Also, this will never happen when performing UPDATE queries.
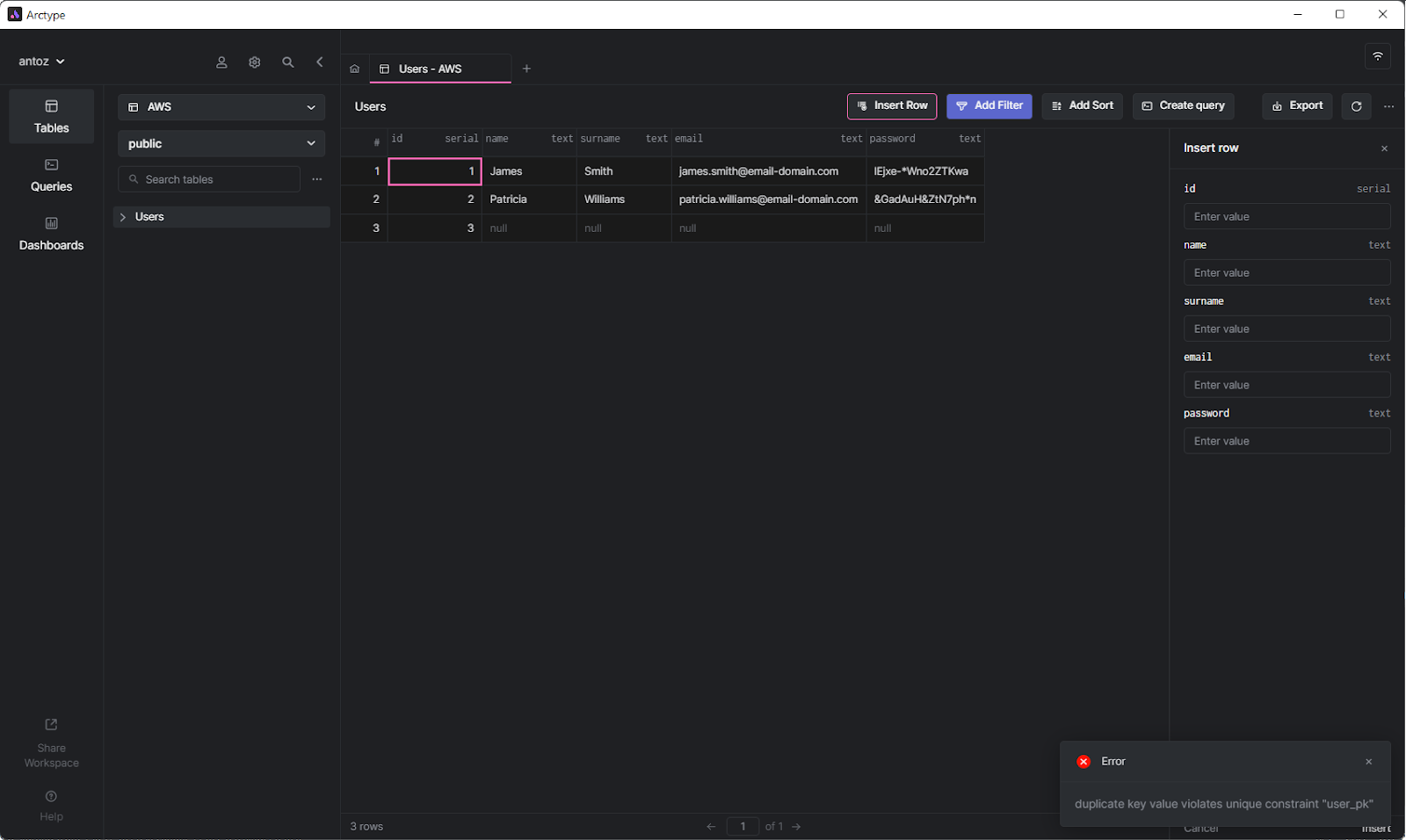
As you can imagine, the problem lies in the sequence related to the id column that went out of sync. Specifically, the error happens when the sequence returns a value for the id column that is already in use. And this leads to the aforementioned error because an ID must be unique by definition.
How to solve the problem
It is now time to see how to address the out-of-sync problem and solve it once and for all. This problem can be addressed in a few ways. Here are two approaches.
Method 1: Single table solution
Suppose you want to fix the sequence associated with the id column of your Users table. You can achieve this by running the following query:
SELECT SETVAL('public."Users_id_seq"', COALESCE(MAX(id), 1)) FROM public."Users";Such query will update the Users_id_seq sequence by setting its current value to the result of COALESCE(MAX(id), 1). Notice how the name of the sequences in Postgres follows this notation:
"<table-name>_<column-name>_seq"The COALESCE function returns the first non-null value, and it is required because if Users were empty, MAX(id) would return NULL. So, by using COALESCE, you are sure that the value assigned to Users_id_seq will be MAX(id) when Users is not null, and 1 when Users is null. In both cases, that query sets the desired value.
Method 2: Fixing all your sequences with one script
If you wanted to fix all your sequences with one query, you could use the following script coming from the official Postgres Wiki:
SELECT 'SELECT SETVAL(' ||
quote_literal(quote_ident(PGT.schemaname) || '.' || quote_ident(S.relname)) ||
', COALESCE(MAX(' ||quote_ident(C.attname)|| '), 1) ) FROM ' ||
quote_ident(PGT.schemaname)|| '.'||quote_ident(T.relname)|| ';'
FROM pg_class AS S,
pg_depend AS D,
pg_class AS T,
pg_attribute AS C,
pg_tables AS PGT
WHERE S.relkind = 'S'
AND S.oid = D.objid
AND D.refobjid = T.oid
AND D.refobjid = C.attrelid
AND D.refobjsubid = C.attnum
AND T.relname = PGT.tablename
ORDER BY S.relname;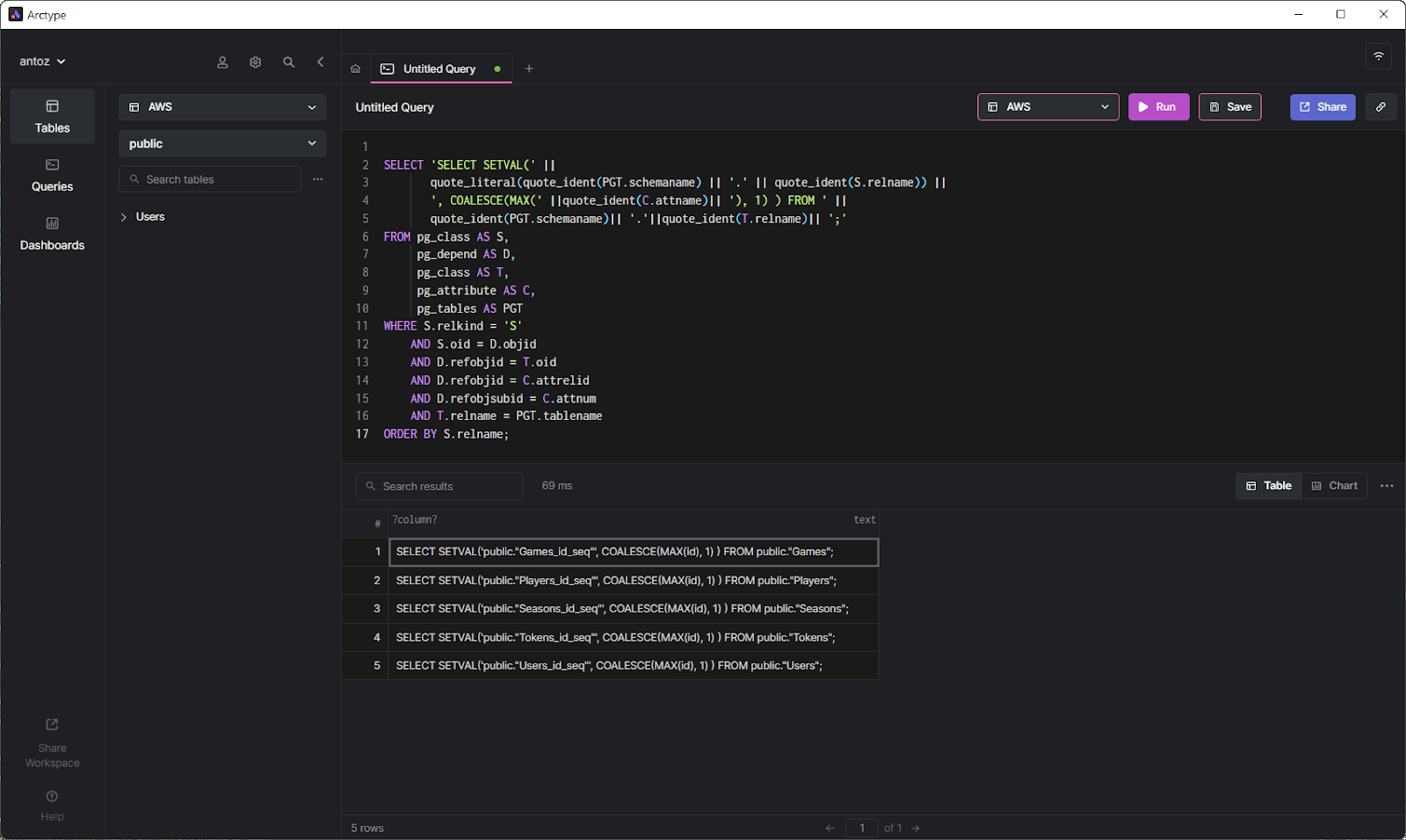
id of each tableThis query returns the set of queries required to fix each of your sequences when executed. As stated in the Wiki, you should use this query as follows:
- Save the query in a
fix_sequences.sqlfile. - Run the query contained in the
fix_sequences.sqlfile and store the result in atempfile. Then, run the queries contained in thetempfile. Finally, delete thetempfile. You can achieve this with the following three commands:
bash
psql -Atq -f fix_sequences.sql -o temp
psql -f temp
rm temptemp fileHow to verify that the problem was fixed
Now, all you have to do to verify that your sequence is no longer out-of-sync is to insert a new record in the same table where you initially experienced the issue.
Remember to give the id column the DEFAULT value or omit it entirely in the INSERT query. This way, Postgres will use the Users_id_seq sequence behind the scene to retrieve the correct value to give to id.
For example, run the following query, and you should no longer receive the “duplicate key value violates unique constraint” error message:
INSERT INTO "Users"("id", "name", "surname", "email", "password")
VALUES (DEFAULT, 'Jennifer', 'Jones', 'jennifer.jones@email-domain.com', 'pBHxe*cWnC2ZJKHw');Instead, this query will insert a new record in the Users table as expected.
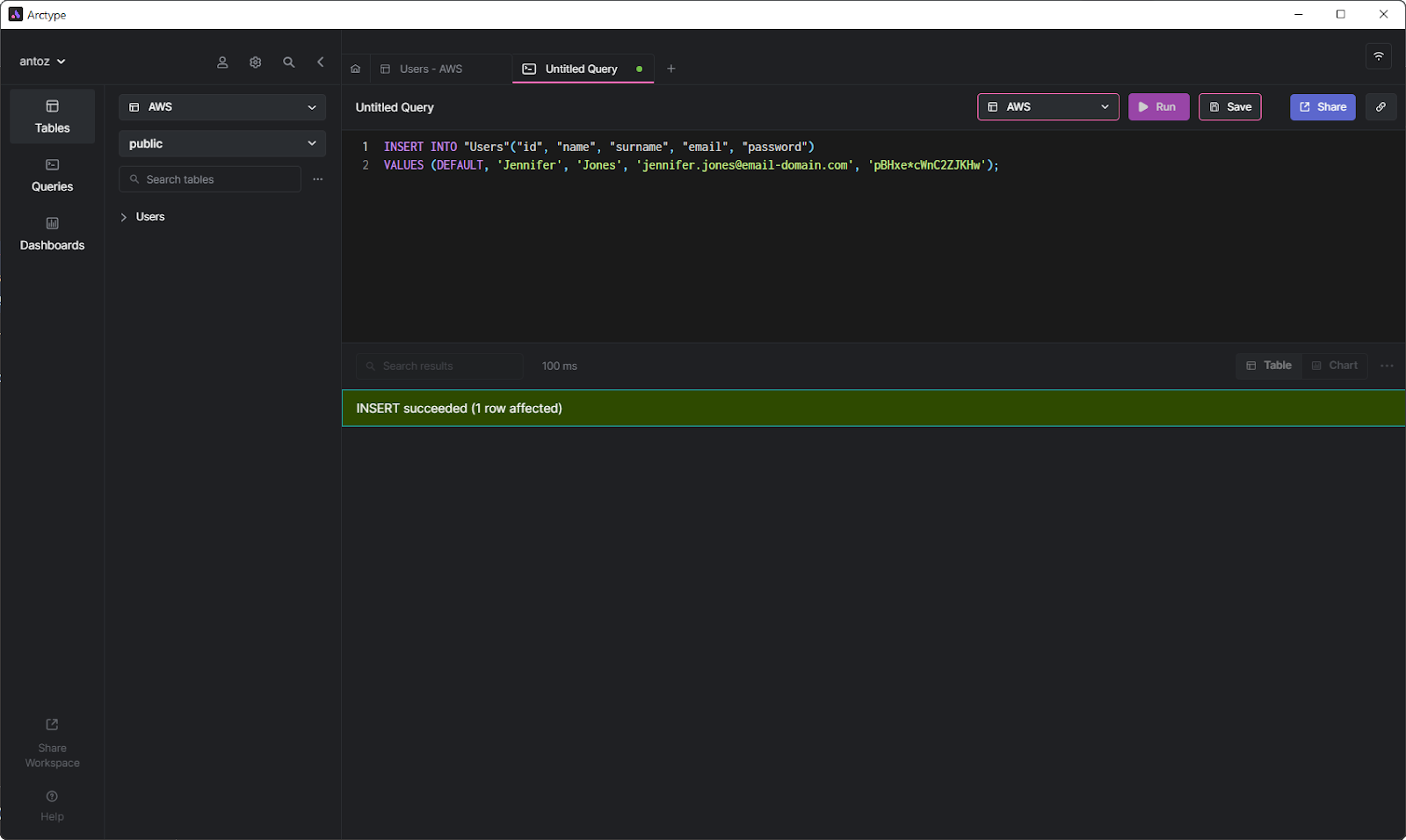
INSERT query now works as expected
Conclusion
Postgres is undoubtedly a great RDBMS. At the same time, it has a few issues that can waste your time. This is especially true if you aren’t aware of them, don’t know how to identify them, and don’t address them accordingly. In this article, we looked at the tricky out-of-sync issue. Out-of-sync sequence errors are tricky because it leads to a «duplicate key value violates unique constraint» message error, which is also associated with other problems. But that won’t fool you anymore, because now you know why it occurs, how to detect it, and how to fix it!