If you try to parse invalid JSON or decode an empty string as JSON, you will encounter the JSONDecodeError: Expecting value: line 1 column 1 (char 0). This error can occur if you read an empty file using json.load, read an empty JSON or receive an empty response from an API call.
You can use a try-except code block to catch the error and then check the contents of the JSON string or file before retrying.
This tutorial will go through the error in detail and how to solve it with code examples.
Table of contents
- JSONDecodeError: Expecting value: line 1 column 1 (char 0)
- Example #1: Incorrect use of json.loads()
- Solution
- Example #2: Empty JSON file
- Solution
- Example #3: Response Request
- Summary
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
In Python, JSONDecodeError occurs when there is an issue with the formatting of the JSON data. This specific error tells us the JSON decoder has encountered an empty JSON.
Example #1: Incorrect use of json.loads()
Let’s look at an example where we have a JSON file with the following contents:
[
{"margherita":7.99},
{"pepperoni":9.99},
{"four cheeses":10.99}
]
We want to read the data into a program using the json library. Let’s look at the code:
import json json_path = 'pizza.json' data = json.loads(json_path)
In the above code, we try to read the data in using json.loads(). Let’s run the code to see the result:
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The error occurs because json.loads() expects a JSON encoded string, not a filename. The string pizza.json is not a valid JSON encoded string.
Solution
We need to use json.load() instead of json.loads() to read a file. Let’s look at the revised code:
import json
json_path = 'pizza.json'
with open(json_path, 'r') as f:
data = json.loads(f.read())
print(data)
In the above code, we use the open() function to create a file object that json.load() can read and return the decoded data object. The with statement is a context manager that ensures that the file is closed once the code is complete. Let’s run the code to see the result:
[{'margherita': 7.99}, {'pepperoni': 9.99}, {'four cheeses': 10.99}]
Example #2: Empty JSON file
Let’s look at an example where we have an empty file, which we will try to read in using json.loads(). The file is called particles.json. Since the JSON file is empty, the JSON decoder will throw the JSONDecodeError when it tries to read the file’s contents. Let’s look at the code:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
contents = json.loads(f.read())
print(contents)
---------------------------------------------------------------------------
JSONDecodeError Traceback (most recent call last)
Input In [1], in <cell line: 5>()
3 filename = 'particles.json'
5 with open(filename, 'r') as f:
----> 6 contents = json.loads(f.read())
7 print(contents)
File ~/opt/anaconda3/lib/python3.8/json/__init__.py:357, in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
352 del kw['encoding']
354 if (cls is None and object_hook is None and
355 parse_int is None and parse_float is None and
356 parse_constant is None and object_pairs_hook is None and not kw):
--> 357 return _default_decoder.decode(s)
358 if cls is None:
359 cls = JSONDecoder
File ~/opt/anaconda3/lib/python3.8/json/decoder.py:337, in JSONDecoder.decode(self, s, _w)
332 def decode(self, s, _w=WHITESPACE.match):
333 """Return the Python representation of ``s`` (a ``str`` instance
334 containing a JSON document).
335
336 """
--> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end())
338 end = _w(s, end).end()
339 if end != len(s):
File ~/opt/anaconda3/lib/python3.8/json/decoder.py:355, in JSONDecoder.raw_decode(self, s, idx)
353 obj, end = self.scan_once(s, idx)
354 except StopIteration as err:
--> 355 raise JSONDecodeError("Expecting value", s, err.value) from None
356 return obj, end
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
Solution
If the file is empty, it is good practice to add a try-except statement to catch the JSONDecodeError. Let’s look at the code:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
try:
contents = json.loads(f.read())
print(contents)
except json.decoder.JSONDecodeError:
print('File is empty')
File is empty
Now we have verified the file is empty, we can add some content to the file. We will add three particle names together with their masses.
[
{"proton":938.3},
{"neutron":939.6},
{"electron":0.51}
]
Let’s try to read the JSON file into our program and print the contents to the console:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
try:
contents = json.loads(f.read())
print(contents)
except json.decoder.JSONDecodeError:
print('File is empty')
[{'proton': 938.3}, {'neutron': 939.6}, {'electron': 0.51}]
We successfully read the contents of the file into a list object.
Example #3: Response Request
Let’s look at an example where we want to parse a JSON response using the requests library. We will send a RESTful GET call to a server, and in return, we get a response in JSON format. The requests library has a built-in JSON decoder, response.json(), which provides the payload data in the JSON serialized format.
We may encounter a response that has an error status code or is not content-type application/json. We must check that the response status code is 200 (OK) before performing the JSON parse. Let’s look at the code to check the response has the 200 status code and has the valid content type. application/json.
import requests
from requests.exceptions import HTTPError
url = 'https://httpbin.org/get'
try:
response = requests.get(url)
status = response.status_code
if (status != 204 and response.headers["content-type"].strip().startswith("application/json")):
try:
json_response = response.json()
print(json_response)
except ValueError:
print('Bad Data from Server. Response content is not valid JSON')
elif (status != 204):
try:
print(response.text)
except ValueError:
print('Bad Data From Server. Reponse content is not valid text')
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
In the above example, we use httpbin.org to execute a GET call. Let’s run the code to get the result:
{'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.27.1', 'X-Amzn-Trace-Id': 'Root=1-6265a5c1-3b57327c02057a3a39ffe86d'}, 'origin': '90.206.95.191', 'url': 'https://httpbin.org/get'}
Summary
Congratulations on reading to the end of this tutorial! The JSONDecodeError: Expecting value: line 1 column 1 (char 0) occurs either when data is not present in a file, the JSON string is empty, or the payload from a RESTful call is empty.
You can resolve this error by checking the JSON file or string for valid content and using an if-statement when making a RESTful call to ensure the status code is 200 and the content type is application/json.
For further reading on errors involving JSON, go to the articles:
- How to Solve Python ValueError: Trailing data
- How to Solve Python JSONDecodeError: extra data
- How to Solve Python TypeError: Object of type datetime is not JSON serializable
- How to Solve Python JSONDecodeError: Expecting ‘,’ delimiter: line 1
Have fun and happy researching!
Содержание
- json — JSON encoder and decoder¶
- Basic Usage¶
- Encoders and Decoders¶
- Exceptions¶
- Standard Compliance and Interoperability¶
- Character Encodings¶
- Infinite and NaN Number Values¶
- Repeated Names Within an Object¶
- Top-level Non-Object, Non-Array Values¶
- Implementation Limitations¶
- Command Line Interface¶
- Command line options¶
json — JSON encoder and decoder¶
JSON (JavaScript Object Notation), specified by RFC 7159 (which obsoletes RFC 4627) and by ECMA-404, is a lightweight data interchange format inspired by JavaScript object literal syntax (although it is not a strict subset of JavaScript 1 ).
Be cautious when parsing JSON data from untrusted sources. A malicious JSON string may cause the decoder to consume considerable CPU and memory resources. Limiting the size of data to be parsed is recommended.
json exposes an API familiar to users of the standard library marshal and pickle modules.
Encoding basic Python object hierarchies:
Specializing JSON object decoding:
Using json.tool from the shell to validate and pretty-print:
See Command Line Interface for detailed documentation.
JSON is a subset of YAML 1.2. The JSON produced by this module’s default settings (in particular, the default separators value) is also a subset of YAML 1.0 and 1.1. This module can thus also be used as a YAML serializer.
This module’s encoders and decoders preserve input and output order by default. Order is only lost if the underlying containers are unordered.
Basic Usage¶
Serialize obj as a JSON formatted stream to fp (a .write() -supporting file-like object ) using this conversion table .
If skipkeys is true (default: False ), then dict keys that are not of a basic type ( str , int , float , bool , None ) will be skipped instead of raising a TypeError .
The json module always produces str objects, not bytes objects. Therefore, fp.write() must support str input.
If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.
If check_circular is false (default: True ), then the circular reference check for container types will be skipped and a circular reference will result in a RecursionError (or worse).
If allow_nan is false (default: True ), then it will be a ValueError to serialize out of range float values ( nan , inf , -inf ) in strict compliance of the JSON specification. If allow_nan is true, their JavaScript equivalents ( NaN , Infinity , -Infinity ) will be used.
If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0, negative, or «» will only insert newlines. None (the default) selects the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a string (such as «t» ), that string is used to indent each level.
Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an (item_separator, key_separator) tuple. The default is (‘, ‘, ‘: ‘) if indent is None and (‘,’, ‘: ‘) otherwise. To get the most compact JSON representation, you should specify (‘,’, ‘:’) to eliminate whitespace.
Changed in version 3.4: Use (‘,’, ‘: ‘) as default if indent is not None .
If specified, default should be a function that gets called for objects that can’t otherwise be serialized. It should return a JSON encodable version of the object or raise a TypeError . If not specified, TypeError is raised.
If sort_keys is true (default: False ), then the output of dictionaries will be sorted by key.
To use a custom JSONEncoder subclass (e.g. one that overrides the default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
Changed in version 3.6: All optional parameters are now keyword-only .
Unlike pickle and marshal , JSON is not a framed protocol, so trying to serialize multiple objects with repeated calls to dump() using the same fp will result in an invalid JSON file.
Serialize obj to a JSON formatted str using this conversion table . The arguments have the same meaning as in dump() .
Keys in key/value pairs of JSON are always of the type str . When a dictionary is converted into JSON, all the keys of the dictionary are coerced to strings. As a result of this, if a dictionary is converted into JSON and then back into a dictionary, the dictionary may not equal the original one. That is, loads(dumps(x)) != x if x has non-string keys.
Deserialize fp (a .read() -supporting text file or binary file containing a JSON document) to a Python object using this conversion table .
object_hook is an optional function that will be called with the result of any object literal decoded (a dict ). The return value of object_hook will be used instead of the dict . This feature can be used to implement custom decoders (e.g. JSON-RPC class hinting).
object_pairs_hook is an optional function that will be called with the result of any object literal decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the dict . This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.
Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON float to be decoded. By default, this is equivalent to float(num_str) . This can be used to use another datatype or parser for JSON floats (e.g. decimal.Decimal ).
parse_int, if specified, will be called with the string of every JSON int to be decoded. By default, this is equivalent to int(num_str) . This can be used to use another datatype or parser for JSON integers (e.g. float ).
Changed in version 3.11: The default parse_int of int() now limits the maximum length of the integer string via the interpreter’s integer string conversion length limitation to help avoid denial of service attacks.
parse_constant, if specified, will be called with one of the following strings: ‘-Infinity’ , ‘Infinity’ , ‘NaN’ . This can be used to raise an exception if invalid JSON numbers are encountered.
Changed in version 3.1: parse_constant doesn’t get called on вЂnull’, вЂtrue’, вЂfalse’ anymore.
To use a custom JSONDecoder subclass, specify it with the cls kwarg; otherwise JSONDecoder is used. Additional keyword arguments will be passed to the constructor of the class.
If the data being deserialized is not a valid JSON document, a JSONDecodeError will be raised.
Changed in version 3.6: All optional parameters are now keyword-only .
Changed in version 3.6: fp can now be a binary file . The input encoding should be UTF-8, UTF-16 or UTF-32.
Deserialize s (a str , bytes or bytearray instance containing a JSON document) to a Python object using this conversion table .
The other arguments have the same meaning as in load() .
If the data being deserialized is not a valid JSON document, a JSONDecodeError will be raised.
Changed in version 3.6: s can now be of type bytes or bytearray . The input encoding should be UTF-8, UTF-16 or UTF-32.
Changed in version 3.9: The keyword argument encoding has been removed.
Encoders and Decoders¶
Simple JSON decoder.
Performs the following translations in decoding by default:
It also understands NaN , Infinity , and -Infinity as their corresponding float values, which is outside the JSON spec.
object_hook, if specified, will be called with the result of every JSON object decoded and its return value will be used in place of the given dict . This can be used to provide custom deserializations (e.g. to support JSON-RPC class hinting).
object_pairs_hook, if specified will be called with the result of every JSON object decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the dict . This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.
Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON float to be decoded. By default, this is equivalent to float(num_str) . This can be used to use another datatype or parser for JSON floats (e.g. decimal.Decimal ).
parse_int, if specified, will be called with the string of every JSON int to be decoded. By default, this is equivalent to int(num_str) . This can be used to use another datatype or parser for JSON integers (e.g. float ).
parse_constant, if specified, will be called with one of the following strings: ‘-Infinity’ , ‘Infinity’ , ‘NaN’ . This can be used to raise an exception if invalid JSON numbers are encountered.
If strict is false ( True is the default), then control characters will be allowed inside strings. Control characters in this context are those with character codes in the 0–31 range, including ‘t’ (tab), ‘n’ , ‘r’ and ‘’ .
If the data being deserialized is not a valid JSON document, a JSONDecodeError will be raised.
Changed in version 3.6: All parameters are now keyword-only .
Return the Python representation of s (a str instance containing a JSON document).
JSONDecodeError will be raised if the given JSON document is not valid.
Decode a JSON document from s (a str beginning with a JSON document) and return a 2-tuple of the Python representation and the index in s where the document ended.
This can be used to decode a JSON document from a string that may have extraneous data at the end.
class json. JSONEncoder ( * , skipkeys = False , ensure_ascii = True , check_circular = True , allow_nan = True , sort_keys = False , indent = None , separators = None , default = None ) В¶
Extensible JSON encoder for Python data structures.
Supports the following objects and types by default:
int, float, int- & float-derived Enums
Changed in version 3.4: Added support for int- and float-derived Enum classes.
To extend this to recognize other objects, subclass and implement a default() method with another method that returns a serializable object for o if possible, otherwise it should call the superclass implementation (to raise TypeError ).
If skipkeys is false (the default), a TypeError will be raised when trying to encode keys that are not str , int , float or None . If skipkeys is true, such items are simply skipped.
If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.
If check_circular is true (the default), then lists, dicts, and custom encoded objects will be checked for circular references during encoding to prevent an infinite recursion (which would cause a RecursionError ). Otherwise, no such check takes place.
If allow_nan is true (the default), then NaN , Infinity , and -Infinity will be encoded as such. This behavior is not JSON specification compliant, but is consistent with most JavaScript based encoders and decoders. Otherwise, it will be a ValueError to encode such floats.
If sort_keys is true (default: False ), then the output of dictionaries will be sorted by key; this is useful for regression tests to ensure that JSON serializations can be compared on a day-to-day basis.
If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0, negative, or «» will only insert newlines. None (the default) selects the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a string (such as «t» ), that string is used to indent each level.
Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an (item_separator, key_separator) tuple. The default is (‘, ‘, ‘: ‘) if indent is None and (‘,’, ‘: ‘) otherwise. To get the most compact JSON representation, you should specify (‘,’, ‘:’) to eliminate whitespace.
Changed in version 3.4: Use (‘,’, ‘: ‘) as default if indent is not None .
If specified, default should be a function that gets called for objects that can’t otherwise be serialized. It should return a JSON encodable version of the object or raise a TypeError . If not specified, TypeError is raised.
Changed in version 3.6: All parameters are now keyword-only .
Implement this method in a subclass such that it returns a serializable object for o, or calls the base implementation (to raise a TypeError ).
For example, to support arbitrary iterators, you could implement default() like this:
Return a JSON string representation of a Python data structure, o. For example:
Encode the given object, o, and yield each string representation as available. For example:
Exceptions¶
Subclass of ValueError with the following additional attributes:
The unformatted error message.
The JSON document being parsed.
The start index of doc where parsing failed.
The line corresponding to pos.
The column corresponding to pos.
New in version 3.5.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by ECMA-404. This section details this module’s level of compliance with the RFC. For simplicity, JSONEncoder and JSONDecoder subclasses, and parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some extensions that are valid JavaScript but not valid JSON. In particular:
Infinite and NaN number values are accepted and output;
Repeated names within an object are accepted, and only the value of the last name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not RFC-compliant, this module’s deserializer is technically RFC-compliant under default settings.
Character Encodings¶
The RFC requires that JSON be represented using either UTF-8, UTF-16, or UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets ensure_ascii=True by default, thus escaping the output so that the resulting strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in terms of conversion between Python objects and Unicode strings , and thus does not otherwise directly address the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text, and this module’s serializer does not add a BOM to its output. The RFC permits, but does not require, JSON deserializers to ignore an initial BOM in their input. This module’s deserializer raises a ValueError when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16 surrogates), but it does note that they may cause interoperability problems. By default, this module accepts and outputs (when present in the original str ) code points for such sequences.
Infinite and NaN Number Values¶
The RFC does not permit the representation of infinite or NaN number values. Despite that, by default, this module accepts and outputs Infinity , -Infinity , and NaN as if they were valid JSON number literal values:
In the serializer, the allow_nan parameter can be used to alter this behavior. In the deserializer, the parse_constant parameter can be used to alter this behavior.
Repeated Names Within an Object¶
The RFC specifies that the names within a JSON object should be unique, but does not mandate how repeated names in JSON objects should be handled. By default, this module does not raise an exception; instead, it ignores all but the last name-value pair for a given name:
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values¶
The old version of JSON specified by the obsolete RFC 4627 required that the top-level value of a JSON text must be either a JSON object or array (Python dict or list ), and could not be a JSON null, boolean, number, or string value. RFC 7159 removed that restriction, and this module does not and has never implemented that restriction in either its serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere to the restriction yourself.
Implementation Limitations¶
Some JSON deserializer implementations may set limits on:
the size of accepted JSON texts
the maximum level of nesting of JSON objects and arrays
the range and precision of JSON numbers
the content and maximum length of JSON strings
This module does not impose any such limits beyond those of the relevant Python datatypes themselves or the Python interpreter itself.
When serializing to JSON, beware any such limitations in applications that may consume your JSON. In particular, it is common for JSON numbers to be deserialized into IEEE 754 double precision numbers and thus subject to that representation’s range and precision limitations. This is especially relevant when serializing Python int values of extremely large magnitude, or when serializing instances of “exotic” numerical types such as decimal.Decimal .
Command Line Interface¶
The json.tool module provides a simple command line interface to validate and pretty-print JSON objects.
If the optional infile and outfile arguments are not specified, sys.stdin and sys.stdout will be used respectively:
Changed in version 3.5: The output is now in the same order as the input. Use the —sort-keys option to sort the output of dictionaries alphabetically by key.
Command line options¶
The JSON file to be validated or pretty-printed:
If infile is not specified, read from sys.stdin .
Write the output of the infile to the given outfile. Otherwise, write it to sys.stdout .
Sort the output of dictionaries alphabetically by key.
New in version 3.5.
Disable escaping of non-ascii characters, see json.dumps() for more information.
New in version 3.9.
Parse every input line as separate JSON object.
New in version 3.8.
Mutually exclusive options for whitespace control.
New in version 3.9.
Show the help message.
As noted in the errata for RFC 7159, JSON permits literal U+2028 (LINE SEPARATOR) and U+2029 (PARAGRAPH SEPARATOR) characters in strings, whereas JavaScript (as of ECMAScript Edition 5.1) does not.
Источник
Are you looking for a simple way to fix Object of type ARandomClass is not JSON serializable where ARandomClass is a built-in Python object or a custom class you’ve defined on your own. You’re probably trying to encode a Python object to a JSON formatted string. In this article, we will show you a few cases where this error would happen, and how to avoid it in the future.
“Object of type is not JSON serializable” is a common error message in Python. It basically says that the built-in json module cannot transform the current object type into a JSON-formatted string.
The built-in json module of Python can only handle basic Python objects such as dictionaries, lists, strings, numbers, None, etc. Below is a table of how native Python objects are translated to JSON.
| Python | JSON |
|---|---|
dict |
object |
list, tuple |
array |
str |
string |
int, long, float |
number |
True |
true |
False |
false |
None |
null |
Now you have two options to handle Object of type is not JSON serializable
- Create a custom JSON decoder for the object type of your choice. (https://pynative.com/make-python-class-json-serializable/)
- Fix your script so that it returns one of the Python primitives mentioned above.
Decode bytes to string before serialization
If you’re seeing something like “Object of type bytes is not JSON serializable”, it means that json module has failed to convert a bytes object into JSON formatted string. What you have to do is either removing string.encode() calls or adding string.decode() to make sure that json.dumps() only takes in raw string as input. Consider the code below:
Code language: Python (python)
import json bytes_object = 'mystring'.encode('utf-8') json_str = json.dumps({'message': bytes_object})
In the code snippet, we’ve tried passing a bytes object into json.dumps, which will eventually result in “TypeError: Object of type ‘bytes’ is not JSON serializable”. In order to get rid of it, we can either remove the string.encode() call or add a string.decode() call before actually serialize the object.
Also see: TypeError: list indices must be integers or slices not tuple – debugging and fixes
Writing a custom JSON encoder
The json module relies on its “encoders” to transform native Python objects to strings. By default, every single object is passed onto an instance of json.JSONEncoder class which must have encode(), default() and iterencode() methods to do the serialization.
In order to serialize your own object type, you would have to overload json.JSONEncoder and implement custom encode(), default() and iterencode() methods. Let’s look at an example where we define a new class and encode it to JSON:
import json from json import JSONEncoder class CustomData: def __init__(self, name, value): self.name = name self.value = value class CustomEncoder(json.JSONEncoder): def default(self, o): return o.__dict__ # Create an instance and serialize it with our new encoder the_value = CustomData("Paris", 120) jsonized = json.dumps(the_value, indent=4, cls=CustomEncoder) print(jsonized)
We’ll see something like this :
Code language: JSON / JSON with Comments (json)
{ "name": "Paris", "value": 120, }
Use jsonpickle
If you need a quick and dirty solution without involving in too much coding, then jsonpickle is made for you.
jsonpickle is a Python library for serialization and deserialization of complex Python objects to and from JSON.
jsonpickle is built so that it allows more complex data structure to be serialized right out of the box. Most of the time, jsonpickle can take almost any Python object and turn the object into JSON. Additionally, it can reconstitute the object back into Python.
Under the hood, jsonpickle uses the same toolset you’re already familiar with : stdlib’s json, simplejson, and demjson. By default, it uses built-in json library from stdlib, but you can choose another JSON backend as well as roll your own backend if you want.
Below is an example of how we would serialize an object with jsonpickle:
import jsonpickle class Thing(object): def __init__(self, name): self.name = name obj = Thing('Awesome') frozen = jsonpickle.encode(obj)
We hope that the information above helped you fix “Object of type is not JSON serializable” error message in Python. We’ve written a few other guides on troubleshooting other common Python problems such as Fix Python Unresolved Import in VSCode, Fix “Max retries exceeded with URL” error in Python requests library and Fix locale.Error: unsupported locale setting in Python.
If you have any suggestion, please feel free to leave a comment below.
JSONDecodeError: Expecting value: line 1 column 1 (char 0) occurs while working with JSON (JavaScript Object Notation) format. You might be storing some data or trying to fetch JSON data from an API(Application Programming Interface). In this guide, we will discuss where it can creep in and how to resolve it.
JSONDecodeError means there is an incorrect JSON format being followed. For instance, the JSON data may be missing a curly bracket, have a key that does not have a value, and data not enclosed within double-quotes or some other syntactic error.
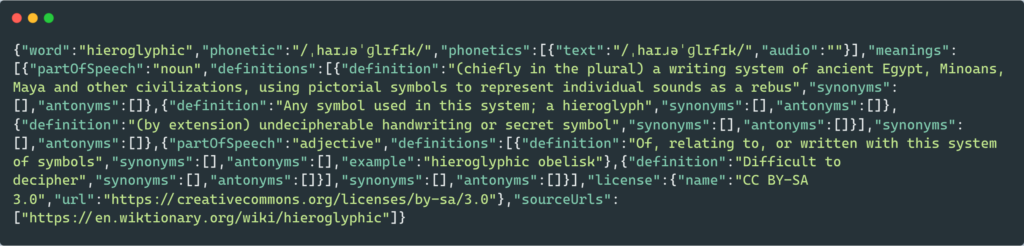
Generally, the error expecting value: line 1 column 1 (char 0) error can occur due to the following reasons.
- Non-JSON conforming quoting
- Empty JSON file
- XML output (that is, a string starting with <)
Let’s elaborate on the points stated above:
1. Non-JSON conforming quoting
JSON or JavaScript Object Notation has a similar format to that of the python dictionary datatype. A dictionary requires a key or value to be enclosed in quotes if it is a string. Similarly, the JSON standard defines that keys need not be a string. However, keys should always be enclosed within double quotes. Not following this standard can also raise an error.
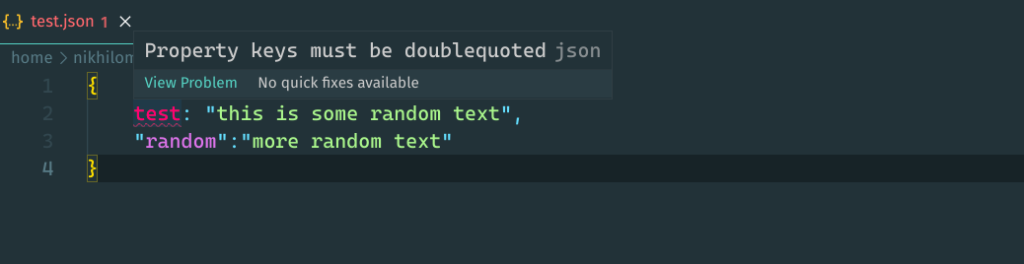

2. Empty JSON file
For this example, we have taken an empty JSON file named test.py and another file named test.py, which contains the code given below. Using context manager, we open the JSON file in reading mode and load it using the load method. However, an error is thrown because the JSON file is empty.
import json
with open("test.json", "r") as file:
data = json.load(file)
print("Data retrieved")

3. XML output (that is, a string starting with <)
The Extensible Markup Language, or simply XML, is a simple text-based format for representing structured information: documents, data, configuration, books, transactions, invoices, and much more. Similar to JSON, it is an older way of storing data. Earlier APIs used to return data in XML format; however, JSON is nowadays the preferred choice. Let’s see how we can face the expecting value: line 1 column 1 (char 0) type error in this case.
<part number="1976">
<name>Windscreen Wiper</name>
<description>The Windscreen wiper
automatically removes rain
from your windscreen, if it
should happen to splash there.
It has a rubber <ref part="1977">blade</ref>
which can be ordered separately
if you need to replace it.
</description>
</part>
import json
with open("test.xml", "r") as file:
data = json.load(file)
print("Data retrieved")
Let’s break down what is happening here.
- For ease of example, suppose API returns an XML format data, as shown above.
- Now, when we try to load that response from API, we will get a type error.

Resolving JSONDecodeError: Expecting value: line 1 column 1 (char 0)
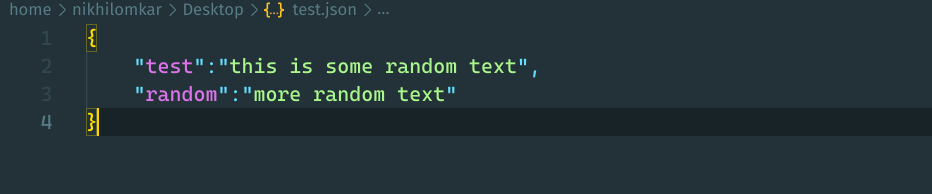
1. Solution for Non-JSON conforming quoting
To resolve the type error in this case, you need to ensure that the keys and values are enclosed within the double quotes. This is necessary because it is a part of JSON syntax. It is important to realize that JSON only uses double quotes, not single quotes.
2. Solution for empty JSON file
The solution for this is self-evident in the name. To resolve the type error, in this case, make sure that the JSON file or the response from an API is not empty. If the file is empty, add content to it, and for a response from an API, use try-except to handle the error, which can be empty JSON or a 404 error, for instance.
import json
import requests
def main():
URL = "https://api.dictionaryapi.dev/api/v2/enties/en/"
word = input("Enter a word:")
data = requests.get(url + word)
data = data.text
try:
data_json = json.loads(data)
print(data_json)
except json.JSONDecodeError:
print("Empty response")
if __name__ == "__main__":
main()
The above code takes in a word and returns all the information related to it in a JSON format. Now in order to show how we can handle the Expecting value: line 1 column 1 (char 0) type error, we have altered the URL. entries have been changed to enties. Therefore we will get an invalid response which will not be of the JSON format. However, this is merely done to imitate the error when you might get an invalid response from an API.
- Now, if you try to run the code above, you will be prompted to enter a word. The response is saved into the data variable and later converted to a string.
- However, in the try block json.loads method, which parses JSON string to python dictionary raises an error.
- This is because the response sent by API is not of JSON format, hence can’t be parsed, resulting in JSONDecodeError.
- JSONDecodeError gets handled by the try-except block, and a “Response content is not valid JSON” gets printed as an outcome.


3. Solution for XML output(that is, a string starting with <)
To avoid type errors resulting from an XML format, we will convert it to a JSON format. However, firstly install this library.
pip install xmltodictimport json
import xmltodict
with open("test.xml", "r") as file:
data = xmltodict.parse(file.read())
file.close()
json_data = json.dumps(data)
with open("t.json", "w") as json_file:
json_file.write(json_data)
json_file.close()
print("Data retrieved")
print(data)
Let’s elaborate on the code above:
- We have imported two libraries, namely JSON and xmltodict.
- Using the context manager with, XML file test.xml is opened in read mode. Thereafter using the xmltodict parse method, it is converted to a dictionary type, and the file is closed.
- json.dumps() takes in a JSON object and returns a string of that object.
- Again using context manager with, a JSON file is created, XML data that was converted to a JSON string is written on it, and the file is closed.

JSONDecodeError: Expecting value: line 1 column 1 (char 0) Django
This issue is caused by the failure of Pipenv 2018.10.9. To resolve this issue, use Pipenv 2018.5.18. For more, read here.
Are you facing this error in Flask?
Many times, when you receive the data from HTTP requests, they are fetched as bytes. So, if you face JSONDecodeError, you might be dealing with a JSON in bytes. First, you need to decode the JSON by using response.decode('utf-8'). This will create a string, and then you can parse it.
FAQs
How to parse JSON in python?
json.loads() method can be used to parse JSON in python. For instance:import json
json_string = '{"a":"1", "b":"2", "c":"3"}'
json_to_dict = json.loads(json_string)
print(json_to_dict)
print(type(json_to_dict))
How to detect empty file/string before parsing JSON?
import os)
file_path = "/home/nikhilomkar/Desktop/test.json"
print("File is empty!" if os.stat(file_path).st_size == 0 else "File isn't empty!"
The following code checks if the file is empty and prints the File is empty! If true, else, the File isn’t empty!.
Conclusion JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The following article discussed the JSONDecodeError: Expecting value: line 1 column 1 (char 0). This error is due to various decoding and formatting errors. We looked at likely situations where it can occur and how to resolve it.
Trending Python Articles
-

“Other Commands Don’t Work After on_message” in Discord Bots
●February 5, 2023
-
Botocore.Exceptions.NoCredentialsError: Unable to Locate Credentials
by Rahul Kumar Yadav●February 5, 2023
-
[Resolved] NameError: Name _mysql is Not Defined
by Rahul Kumar Yadav●February 5, 2023
-
Best Ways to Implement Regex New Line in Python
by Rahul Kumar Yadav●February 5, 2023

![[Resolved] NameError: Name _mysql is Not Defined](https://www.pythonpool.com/wp-content/uploads/2023/01/nameerror-name-_mysql-is-not-defined-300x157.webp)

Source code:Lib/json/__init__.py
JSON (JavaScript Object Notation), specified by RFC 7159 (which obsoletes RFC 4627) and by ECMA-404, is a lightweight data interchange format inspired by JavaScript object literal syntax (although it is not a strict subset of JavaScript 1 ).
Warning
Be cautious when parsing JSON data from untrusted sources. A malicious JSON string may cause the decoder to consume considerable CPU and memory resources. Limiting the size of data to be parsed is recommended.
json exposes an API familiar to users of the standard library marshal and pickle modules.
Encoding basic Python object hierarchies:
>>> import json >>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}]) '["foo", {"bar": ["baz", null, 1.0, 2]}]' >>> print(json.dumps(""foobar")) ""foobar" >>> print(json.dumps('u1234')) "u1234" >>> print(json.dumps('\')) "\" >>> print(json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)) {"a": 0, "b": 0, "c": 0} >>> from io import StringIO >>> io = StringIO() >>> json.dump(['streaming API'], io) >>> io.getvalue() '["streaming API"]'
Compact encoding:
>>> import json >>> json.dumps([1, 2, 3, {'4': 5, '6': 7}], separators=(',', ':')) '[1,2,3,{"4":5,"6":7}]'
Pretty printing:
>>> import json >>> print(json.dumps({'4': 5, '6': 7}, sort_keys=True, indent=4)) { "4": 5, "6": 7 }
Decoding JSON:
>>> import json >>> json.loads('["foo", {"bar":["baz", null, 1.0, 2]}]') ['foo', {'bar': ['baz', None, 1.0, 2]}] >>> json.loads('"\"foo\bar"') '"foox08ar' >>> from io import StringIO >>> io = StringIO('["streaming API"]') >>> json.load(io) ['streaming API']
Specializing JSON object decoding:
>>> import json >>> def as_complex(dct): ... if '__complex__' in dct: ... return complex(dct['real'], dct['imag']) ... return dct ... >>> json.loads('{"__complex__": true, "real": 1, "imag": 2}', ... object_hook=as_complex) (1+2j) >>> import decimal >>> json.loads('1.1', parse_float=decimal.Decimal) Decimal('1.1')
Extending JSONEncoder:
>>> import json >>> class ComplexEncoder(json.JSONEncoder): ... def default(self, obj): ... if isinstance(obj, complex): ... return [obj.real, obj.imag] ... ... return json.JSONEncoder.default(self, obj) ... >>> json.dumps(2 + 1j, cls=ComplexEncoder) '[2.0, 1.0]' >>> ComplexEncoder().encode(2 + 1j) '[2.0, 1.0]' >>> list(ComplexEncoder().iterencode(2 + 1j)) ['[2.0', ', 1.0', ']']
Using json.tool from the shell to validate and pretty-print:
$ echo '{"json":"obj"}' | python -m json.tool { "json": "obj" } $ echo '{1.2:3.4}' | python -m json.tool Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
See Command Line Interface for detailed documentation.
Note
JSON is a subset of YAML 1.2. The JSON produced by this module’s default settings (in particular, the default separators value) is also a subset of YAML 1.0 and 1.1. This module can thus also be used as a YAML serializer.
Note
This module’s encoders and decoders preserve input and output order by default. Order is only lost if the underlying containers are unordered.
Basic Usage
-
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) -
Serialize obj as a JSON formatted stream to fp (a
.write()-supporting file-like object) using this conversion table.If skipkeys is true (default:
False), then dict keys that are not of a basic type (str,int,float,bool,None) will be skipped instead of raising aTypeError.The
jsonmodule always producesstrobjects, notbytesobjects. Therefore,fp.write()must supportstrinput.If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.
If check_circular is false (default:
True), then the circular reference check for container types will be skipped and a circular reference will result in aRecursionError(or worse).If allow_nan is false (default:
True), then it will be aValueErrorto serialize out of rangefloatvalues (nan,inf,-inf) in strict compliance of the JSON specification. If allow_nan is true, their JavaScript equivalents (NaN,Infinity,-Infinity) will be used.If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0, negative, or
""will only insert newlines.None(the default) selects the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a string (such as"t"), that string is used to indent each level.Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an
(item_separator, key_separator)tuple. The default is(', ', ': ')if indent isNoneand(',', ': ')otherwise. To get the most compact JSON representation, you should specify(',', ':')to eliminate whitespace.Changed in version 3.4: Use
(',', ': ')as default if indent is notNone.If specified, default should be a function that gets called for objects that can’t otherwise be serialized. It should return a JSON encodable version of the object or raise a
TypeError. If not specified,TypeErroris raised.If sort_keys is true (default:
False), then the output of dictionaries will be sorted by key.To use a custom
JSONEncodersubclass (e.g. one that overrides thedefault()method to serialize additional types), specify it with the cls kwarg; otherwiseJSONEncoderis used.Changed in version 3.6: All optional parameters are now keyword-only.
Note
Unlike
pickleandmarshal, JSON is not a framed protocol, so trying to serialize multiple objects with repeated calls todump()using the same fp will result in an invalid JSON file.
-
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) -
Serialize obj to a JSON formatted
strusing this conversion table. The arguments have the same meaning as indump().Note
Keys in key/value pairs of JSON are always of the type
str. When a dictionary is converted into JSON, all the keys of the dictionary are coerced to strings. As a result of this, if a dictionary is converted into JSON and then back into a dictionary, the dictionary may not equal the original one. That is,loads(dumps(x)) != xif x has non-string keys.
-
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) -
Deserialize fp (a
.read()-supporting text file or binary file containing a JSON document) to a Python object using this conversion table.object_hook is an optional function that will be called with the result of any object literal decoded (a
dict). The return value of object_hook will be used instead of thedict. This feature can be used to implement custom decoders (e.g. JSON-RPC class hinting).object_pairs_hook is an optional function that will be called with the result of any object literal decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the
dict. This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON float to be decoded. By default, this is equivalent to
float(num_str). This can be used to use another datatype or parser for JSON floats (e.g.decimal.Decimal).parse_int, if specified, will be called with the string of every JSON int to be decoded. By default, this is equivalent to
int(num_str). This can be used to use another datatype or parser for JSON integers (e.g.float).Changed in version 3.11: The default parse_int of
int()now limits the maximum length of the integer string via the interpreter’s integer string conversion length limitation to help avoid denial of service attacks.parse_constant, if specified, will be called with one of the following strings:
'-Infinity','Infinity','NaN'. This can be used to raise an exception if invalid JSON numbers are encountered.Changed in version 3.1: parse_constant doesn’t get called on ‘null’, ‘true’, ‘false’ anymore.
To use a custom
JSONDecodersubclass, specify it with theclskwarg; otherwiseJSONDecoderis used. Additional keyword arguments will be passed to the constructor of the class.If the data being deserialized is not a valid JSON document, a
JSONDecodeErrorwill be raised.Changed in version 3.6: All optional parameters are now keyword-only.
Changed in version 3.6: fp can now be a binary file. The input encoding should be UTF-8, UTF-16 or UTF-32.
-
json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) -
Deserialize s (a
str,bytesorbytearrayinstance containing a JSON document) to a Python object using this conversion table.The other arguments have the same meaning as in
load().If the data being deserialized is not a valid JSON document, a
JSONDecodeErrorwill be raised.Changed in version 3.6: s can now be of type
bytesorbytearray. The input encoding should be UTF-8, UTF-16 or UTF-32.Changed in version 3.9: The keyword argument encoding has been removed.
Encoders and Decoders
-
class json.JSONDecoder(*, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None) -
Simple JSON decoder.
Performs the following translations in decoding by default:
JSON
Python
object
dict
array
list
string
str
number (int)
int
number (real)
float
true
True
false
False
null
None
It also understands
NaN,Infinity, and-Infinityas their correspondingfloatvalues, which is outside the JSON spec.object_hook, if specified, will be called with the result of every JSON object decoded and its return value will be used in place of the given
dict. This can be used to provide custom deserializations (e.g. to support JSON-RPC class hinting).object_pairs_hook, if specified will be called with the result of every JSON object decoded with an ordered list of pairs. The return value of object_pairs_hook will be used instead of the
dict. This feature can be used to implement custom decoders. If object_hook is also defined, the object_pairs_hook takes priority.Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON float to be decoded. By default, this is equivalent to
float(num_str). This can be used to use another datatype or parser for JSON floats (e.g.decimal.Decimal).parse_int, if specified, will be called with the string of every JSON int to be decoded. By default, this is equivalent to
int(num_str). This can be used to use another datatype or parser for JSON integers (e.g.float).parse_constant, if specified, will be called with one of the following strings:
'-Infinity','Infinity','NaN'. This can be used to raise an exception if invalid JSON numbers are encountered.If strict is false (
Trueis the default), then control characters will be allowed inside strings. Control characters in this context are those with character codes in the 0–31 range, including't'(tab),'n','r'and''.If the data being deserialized is not a valid JSON document, a
JSONDecodeErrorwill be raised.Changed in version 3.6: All parameters are now keyword-only.
-
decode(s) -
Return the Python representation of s (a
strinstance containing a JSON document).JSONDecodeErrorwill be raised if the given JSON document is not valid.
-
raw_decode(s) -
Decode a JSON document from s (a
strbeginning with a JSON document) and return a 2-tuple of the Python representation and the index in s where the document ended.This can be used to decode a JSON document from a string that may have extraneous data at the end.
-
-
class json.JSONEncoder(*, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None) -
Extensible JSON encoder for Python data structures.
Supports the following objects and types by default:
Python
JSON
dict
object
list, tuple
array
str
string
int, float, int- & float-derived Enums
number
True
true
False
false
None
null
Changed in version 3.4: Added support for int- and float-derived Enum classes.
To extend this to recognize other objects, subclass and implement a
default()method with another method that returns a serializable object foroif possible, otherwise it should call the superclass implementation (to raiseTypeError).If skipkeys is false (the default), a
TypeErrorwill be raised when trying to encode keys that are notstr,int,floatorNone. If skipkeys is true, such items are simply skipped.If ensure_ascii is true (the default), the output is guaranteed to have all incoming non-ASCII characters escaped. If ensure_ascii is false, these characters will be output as-is.
If check_circular is true (the default), then lists, dicts, and custom encoded objects will be checked for circular references during encoding to prevent an infinite recursion (which would cause a
RecursionError). Otherwise, no such check takes place.If allow_nan is true (the default), then
NaN,Infinity, and-Infinitywill be encoded as such. This behavior is not JSON specification compliant, but is consistent with most JavaScript based encoders and decoders. Otherwise, it will be aValueErrorto encode such floats.If sort_keys is true (default:
False), then the output of dictionaries will be sorted by key; this is useful for regression tests to ensure that JSON serializations can be compared on a day-to-day basis.If indent is a non-negative integer or string, then JSON array elements and object members will be pretty-printed with that indent level. An indent level of 0, negative, or
""will only insert newlines.None(the default) selects the most compact representation. Using a positive integer indent indents that many spaces per level. If indent is a string (such as"t"), that string is used to indent each level.Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an
(item_separator, key_separator)tuple. The default is(', ', ': ')if indent isNoneand(',', ': ')otherwise. To get the most compact JSON representation, you should specify(',', ':')to eliminate whitespace.Changed in version 3.4: Use
(',', ': ')as default if indent is notNone.If specified, default should be a function that gets called for objects that can’t otherwise be serialized. It should return a JSON encodable version of the object or raise a
TypeError. If not specified,TypeErroris raised.Changed in version 3.6: All parameters are now keyword-only.
-
default(o) -
Implement this method in a subclass such that it returns a serializable object for o, or calls the base implementation (to raise a
TypeError).For example, to support arbitrary iterators, you could implement
default()like this:def default(self, o): try: iterable = iter(o) except TypeError: pass else: return list(iterable) return json.JSONEncoder.default(self, o)
-
encode(o) -
Return a JSON string representation of a Python data structure, o. For example:
>>> json.JSONEncoder().encode({"foo": ["bar", "baz"]}) '{"foo": ["bar", "baz"]}'
-
iterencode(o) -
Encode the given object, o, and yield each string representation as available. For example:
for chunk in json.JSONEncoder().iterencode(bigobject): mysocket.write(chunk)
-
© 2001–2022 Python Software Foundation
Licensed under the PSF License.
https://docs.python.org/3.11/library/json.html
Python
3.11
-
itertools — Functions creating iterators for efficient looping
This module implements a number of iterator building blocks inspired by constructs from APL, Haskell, and SML.
-
Itertools Recipes
This section shows recipes for creating an extended toolset using the existing itertools as building blocks.
-
Exceptions
Subclass of ValueError with the following additional attributes: The unformatted error message.
-
keyword — Testing for Python keywords
Source code: Lib/keyword.py This module allows Python program to determine if string keyword soft Return True if s is a Python keyword.
You are here because when you try to dump or encode Python set into JSON, you received an error, TypeError: Object of type set is not JSON serializable.
The built-in json module of Python can only handle Python primitives types that have a direct JSON equivalent. i.e., The fundamental problem is that the JSON encoder json.dump() and json.dumps() only knows how to serialize the basic types by default (e.g., dictionary, lists, strings, numbers, None, etc.). To solve this, we need to build a custom encoder to make set JSON serializable.
In this article, we will see how to JSON Serialize Set. There are multiple ways to accomplish this.
Use the jsonpickle module to make Python set JSON serializable
jsonpickle is a Python library designed to work with complex Python Objects. You can use jsonpickle for serialization complex Python objects into JSON. Also, and deserialization from JSON to complex Python objects. jsonpickle allows more complex data structures to be serialized to JSON. jsonpickle is highly configurable and extendable.
Steps:
- Install jsonpickle using pip.
pip install jsonpickle - Execute
jsonpickle.encode(object)to serialize custom Python Object.
You can refer to Jsonpickle Documentation for more detail. Let’s see the jsonpickle example to make a set JSON serializable.
import json
import jsonpickle
from json import JSONEncoder
sampleSet = {25, 45, 65, 85}
print("Encode set into JSON using jsonpickle")
sampleJson = jsonpickle.encode(sampleSet)
print(sampleJson)
# Pass sampleJson to json.dump() if you want to write it in file
print("Decode JSON into set using jsonpickle")
decodedSet = jsonpickle.decode(sampleJson)
print(decodedSet)
# to check if we got set after decoding
decodedSet.add(95)
print(decodedSet)Output:
Encode set into JSON using jsonpickle
{"py/set": [65, 25, 85, 45]}
Decode JSON into set using jsonpickle
{65, 45, 85, 25}
{65, 45, 85, 25, 95}
Use custom JSON Encoder to make Python set JSON serializable
Let’ see how to write custom encoder to JSON serializable Python set. Python json module provides a JSONEncoder to encode python types into JSON. We can extend by implementing its default() method that can JSON serializable set.
In default() method we will convert set into list using list(setObj)
The json.dump() and json.dumps() methods of the json module has a cls kwarg. Using this argument, you can pass a custom JSON Encoder, which tells dump or dumps method how to encode set into JSON formatted data.
JSONEncoder class has a default() method which will be used when we execute JSONEncoder.encode(object). This method converts only basic types into JSON.
Your custom JSONEncoder subclass will override the default() method to serialize additional types. Specify it with the cls kwarg in json.dumps() method; otherwise, default JSONEncoder is used. Example: json.dumps(cls=CustomEncoder).
import json
from json import JSONEncoder
# subclass JSONEncoder
class setEncoder(JSONEncoder):
def default(self, obj):
return list(obj)
sampleSet = {25, 45, 65, 85}
print("Encode Set and Printing to check how it will look like")
print(setEncoder().encode(sampleSet))
print("Encode Set nto JSON formatted Data using custom JSONEncoder")
jsonData = json.dumps(sampleSet, indent=4, cls=setEncoder)
print(jsonData)
# Let's load it using the load method to check if we can decode it or not.
setObj = json.loads(jsonData, object_hook=customSetDecoder)
print("Decode JSON formatted Data")
print(setObj)
Output:
Encode Set and Printing to check how it will look like
[65, 25, 85, 45]
Encode Set nto JSON formatted Data using custom JSONEncoder
[
65,
25,
85,
45
]
Decode JSON formatted Data
[65, 25, 85, 45]
So What Do You Think?
I want to hear from you. What do you think of this article? Or maybe I missed one of the ways to JSON serialize Python set, Either way, let me know by leaving a comment below.
Also, try to solve the Python JSON Exercise to have a better understanding of Working with JSON Data in Python.
Python Exercises and Quizzes
Free coding exercises and quizzes cover Python basics, data structure, data analytics, and more.
- 15+ Topic-specific Exercises and Quizzes
- Each Exercise contains 10 questions
- Each Quiz contains 12-15 MCQ

When working with URLs and APIs in Pythons, you often have to use the urllib and json libraries. More importantly, the json library helps with processing JSON data which is the default way to transfer data, especially with APIs.
Within the json library, there is a method, loads(), that returns the JSONDecodeError error. In this article, we will discuss how to resolve such errors and deal with them appropriately.
Use try to Solve raise JSONDecodeError("Expecting value", s, err.value) from None in Python
Before dealing with JSON, we often had to receive data via the urllib package. However, when working with the urllib package, it is important to understand how to import such a package into your code as it could result in errors.
For us to make use of the urllib package, we have to import it. Often, people might import it as below.
import urllib
queryString = { 'name' : 'Jhon', 'age' : '18'}
urllib.parse.urlencode(queryString)
The output of the code above will give an AttributeError:
Traceback (most recent call last):
File "c:UsersakinlDocumentsHTMLpythontest.py", line 3, in <module>
urllib.parse.urlencode(queryString)
AttributeError: module 'urllib' has no attribute 'parse'
The correct way to import the urllib can be seen below.
import urllib.parse
queryString = {'name': 'Jhon', 'age': '18'}
urllib.parse.urlencode(queryString)
Alternatively, you can use the as keyword and your alias (often shorter) to make it easier to write your Python code.
import urllib.parse as urlp
queryString = {'name': 'Jhon', 'age': '18'}
urlp.urlencode(queryString)
All of the above works for request, error, and robotparser:
import urllib.request
import urllib.error
import urllib.robotparser
With these common errors out of the way, we can deal further with the function that often works with the urllib library when working with URLs that throws the JSONDecodeError error, as seen earlier, which is the json.load() function.
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The load() method parses valid JSON string that it receives as an argument and converts it into a Python dictionary for manipulation. The error message shows that it expected a JSON value but did not receive one.
That means your code did not parse JSON string or parse an empty string to the load() method. A quick code snippet can easily verify this.
import json
data = ""
js = json.loads(data)
The output of the code:
Traceback (most recent call last):
File "c:UsersakinlDocumentspythontexts.py", line 4, in <module>
js = json.loads(data)
File "C:Python310libjson__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "C:Python310libjsondecoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:Python310libjsondecoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The same error message is present, and we can ascertain that the error came from an empty string argument.
For a more detailed example, let us try to access a Google Map API and collect user location, e.g., US or NG, but it does not return any value.
import urllib.parse
import urllib.request
import json
googleURL = 'http://maps.googleapis.com/maps/api/geocode/json?'
while True:
address = input('Enter location: ')
if address == "exit":
break
if len(address) < 1:
break
url = googleURL + urllib.parse.urlencode({'sensor': 'false',
'address': address})
print('Retrieving', url)
uReq = urllib.request.urlopen(url)
data = uReq.read()
print('Returned', len(data), 'characters')
js = json.loads(data)
print(js)
The output of the code:
Traceback (most recent call last):
File "C:UsersakinlDocumentshtmlpythonjsonArt.py", line 18, in <module>
js = json.loads(str(data))
File "C:Python310libjson__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "C:Python310libjsondecoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:Python310libjsondecoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
We obtained the same error. However, to catch such errors and prevent breakdown, we can use the try/except logic to safeguard our code.
Therefore, if the API does not return any JSON value at a point of request, we can return another expression and not an error.
The above code becomes:
import urllib.parse
import urllib.request
import json
googleURL = 'http://maps.googleapis.com/maps/api/geocode/json?'
while True:
address = input('Enter location: ')
if address == "exit":
break
if len(address) < 1:
break
url = googleURL + urllib.parse.urlencode({'sensor': 'false',
'address': address})
print('Retrieving', url)
uReq = urllib.request.urlopen(url)
data = uReq.read()
print('Returned', len(data), 'characters')
try:
js = json.loads(str(data))
except:
print("no json returned")
The output of the code when we enter location as US:
Enter location: US
Retrieving http://maps.googleapis.com/maps/api/geocode/json?sensor=false&address=US
Returned 237 characters
no json returned
Because no JSON value was returned, the code prints no json returned. Because the error is more a non-presence of argument that cannot be controlled, the use of try/except is important.