In this tutorial, you’ll learn how to parse a Python requests response as JSON and convert it to a Python dictionary. Whenever the requests library is used to make a request, a Response object is returned. The Python requests library provides a helpful method, json(), to convert a Response object to a Python dictionary.
By the end of this tutorial, you’ll have learned:
- How to parse a
requests.Responseto a Python dictionary using theResponse.json()method - How to convert a Python requests JSON response to a dictionary
- How to handle errors when parsing a Python requests JSON response
- How to convert a Python requests JSON object to a Pandas DataFrame
Parsing Python requests Response JSON Content
Every request that is made using the Python requests library returns a Response object. This is true for any type of request made, including GET, POST, and PUT requests. The requests library offers a number of different ways to access the content of a response object:
.contentreturns the actual content in bytes.textreturns the content converted to a string, using a character encoding such as UTF-8
Since you’re reading an article about how to parse the JSON from a response into a Python dictionary, the two options above may not be ideal. While you could use the json library to serialize the response, this adds an additional step and complexity to your code.
The requests library comes with a helpful method, .json(), that helps serialize the response of the request. In order to look at an example, let’s the public endpoints provided by the website reqres.in. These endpoints work without signing up, so following along with the tutorial is easy.
Let’s see how we can access the /users endpoint and serialize the response into a Python dictionary using the .json() method:
# Serializing a GET Request with .json()
import requests
resp = requests.get('https://reqres.in/api/users')
resp_dict = resp.json()
print(type(resp_dict))
# Returns: <class 'dict'>From the code above, we can see that applying the .json() method to our response created a Python dictionary. In the following section, you’ll learn how to work with the resulting dictionary to access some content.
How to Access Python requests Response Content as a Dictionary
After applying the .json() method to a response created by the requests library, we created a dictionary. This means that we can access the data in the dictionary using common dictionary methods, such as square-bracket indexing or the .get() method.
Let’s see how we can access the 'page' key in the data:
# Accessing Data in a Python Request Response
import requests
resp = requests.get('https://reqres.in/api/users')
resp_dict = resp.json()
print(resp_dict.get('page'))
# Returns: 1In the code above, we applied the .get() method to access the value corresponding with the key 'page'. Using the .get() method is a safer way of handling this operation. This is because the method will simply return None, if a key doesn’t exist.
How to Handle Errors When Parsing a JSON Response from Python requests
In some cases, the data that’s returned from a Response object can’t be serialized. In these cases, you’ll encounter a JSONDecodeError. You can safely handle these errors by wrapping your request in a try-except block.
Let’s see how we can safely handle a JSONDecodeError using the requests library:
# Handling a JSONDecodeError in Python
from json import JSONDecodeError
import requests
resp = requests.get('https://reqres.in/api/users/page4')
try:
resp_dict = resp.json()
except JSONDecodeError:
print('Response could not be serialized')How to Pretty Print a JSON Object From Python requests
In this section, we’ll take a look at how to pretty print a JSON object that is returned from using the Python requests library. Pretty printing a JSON file is made easy using the json.dumps() function.
Let’s see how we can pretty print a JSON object from the Python requests library:
import json
import requests
resp = requests.get('https://reqres.in/api/users')
resp_dict = resp.json()
pretty = json.dumps(resp_dict, indent=4)
print(pretty)
# Returns:
# {
# "page": 1,
# "per_page": 6,
# "total": 12,
# "total_pages": 2,
# "data": [
# {
# "id": 1,
# "email": "[email protected]",
# "first_name": "George",
# "last_name": "Bluth",
# "avatar": "https://reqres.in/img/faces/1-image.jpg"
# },
# ...
# {
# "id": 6,
# "email": "[email protected]",
# "first_name": "Tracey",
# "last_name": "Ramos",
# "avatar": "https://reqres.in/img/faces/6-image.jpg"
# }
# ],
# "support": {
# "url": "https://reqres.in/#support-heading",
# "text": "To keep ReqRes free, contributions towards server costs are appreciated!"
# }
# }Let’s break down what we did in the code above:
- We loaded the response the
GETrequest - We serialized the response using the
.json()method - We then used the
dumps()function with an indent of 4 to pretty print the response
How to Convert a Python requests JSON Object to a Pandas DataFrame
In this final section, we’ll take a look at how to convert a requests.Reponse object into a Pandas DataFrame. Because Pandas allows you to easily create DataFrames from a list of dictionaries, we can simply pass in part of our serialized response.
From the code above, we know that the data are stored in a key named 'data' as a list of dictionaries. We can easily pass this dictionary into a Pandas DataFrame constructor and convert it to a DataFrame:
# Converting JSON Data to a Pandas DataFrame
import requests
import pandas as pd
resp = requests.get('https://reqres.in/api/users')
resp_dict = resp.json()
df = pd.DataFrame(resp_dict.get('data'))
print(df)
# Returns:
# id email first_name last_name avatar
# 0 1 [email protected] George Bluth https://reqres.in/img/faces/1-image.jpg
# 1 2 [email protected] Janet Weaver https://reqres.in/img/faces/2-image.jpg
# 2 3 [email protected] Emma Wong https://reqres.in/img/faces/3-image.jpg
# 3 4 [email protected] Eve Holt https://reqres.in/img/faces/4-image.jpg
# 4 5 [email protected] Charles Morris https://reqres.in/img/faces/5-image.jpg
# 5 6 [email protected] Tracey Ramos https://reqres.in/img/faces/6-image.jpgIn the code above, we serialized our response to a dictionary. From there, we passed the values of the 'data' key into the pd.DataFrame constructor, which accepts a list of dictionaries.
Conclusion
In this tutorial, you learned how to use the Python requests library’s Response object and serialize the JSON data using the .json() method. You first learned how to use the .json() method. Then, you learned how to access data from the resulting dictionary. You also learned how to handle errors caused by this method, how to pretty print the resulting data, and how to load it into a Pandas DataFrame.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Python requests Response Object Explained
- Python requests: POST Request Explained
- Python requests: GET Request Explained
- How to Install requests Package in Python – Windows, macOS, and Linux
JSONDecodeError: Expecting value: line 1 column 1 (char 0) occurs while working with JSON (JavaScript Object Notation) format. You might be storing some data or trying to fetch JSON data from an API(Application Programming Interface). In this guide, we will discuss where it can creep in and how to resolve it.
JSONDecodeError means there is an incorrect JSON format being followed. For instance, the JSON data may be missing a curly bracket, have a key that does not have a value, and data not enclosed within double-quotes or some other syntactic error.
Generally, the error expecting value: line 1 column 1 (char 0) error can occur due to the following reasons.
- Non-JSON conforming quoting
- Empty JSON file
- XML output (that is, a string starting with <)
Let’s elaborate on the points stated above:
1. Non-JSON conforming quoting
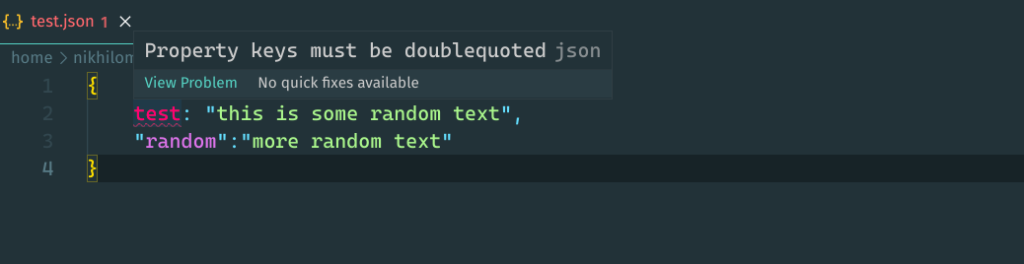
JSON or JavaScript Object Notation has a similar format to that of the python dictionary datatype. A dictionary requires a key or value to be enclosed in quotes if it is a string. Similarly, the JSON standard defines that keys need not be a string. However, keys should always be enclosed within double quotes. Not following this standard can also raise an error.

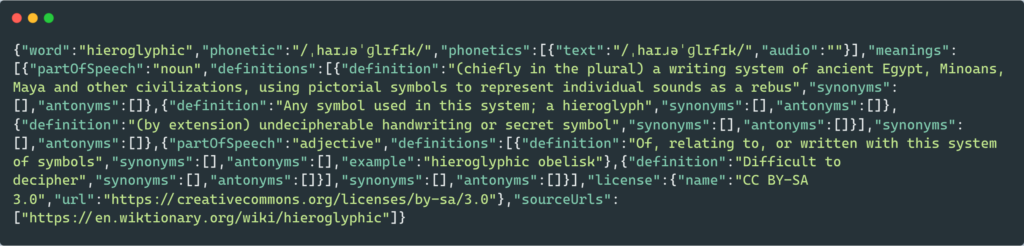
2. Empty JSON file
For this example, we have taken an empty JSON file named test.py and another file named test.py, which contains the code given below. Using context manager, we open the JSON file in reading mode and load it using the load method. However, an error is thrown because the JSON file is empty.
import json
with open("test.json", "r") as file:
data = json.load(file)
print("Data retrieved")

3. XML output (that is, a string starting with <)
The Extensible Markup Language, or simply XML, is a simple text-based format for representing structured information: documents, data, configuration, books, transactions, invoices, and much more. Similar to JSON, it is an older way of storing data. Earlier APIs used to return data in XML format; however, JSON is nowadays the preferred choice. Let’s see how we can face the expecting value: line 1 column 1 (char 0) type error in this case.
<part number="1976">
<name>Windscreen Wiper</name>
<description>The Windscreen wiper
automatically removes rain
from your windscreen, if it
should happen to splash there.
It has a rubber <ref part="1977">blade</ref>
which can be ordered separately
if you need to replace it.
</description>
</part>
import json
with open("test.xml", "r") as file:
data = json.load(file)
print("Data retrieved")
Let’s break down what is happening here.
- For ease of example, suppose API returns an XML format data, as shown above.
- Now, when we try to load that response from API, we will get a type error.

Resolving JSONDecodeError: Expecting value: line 1 column 1 (char 0)
1. Solution for Non-JSON conforming quoting
To resolve the type error in this case, you need to ensure that the keys and values are enclosed within the double quotes. This is necessary because it is a part of JSON syntax. It is important to realize that JSON only uses double quotes, not single quotes.
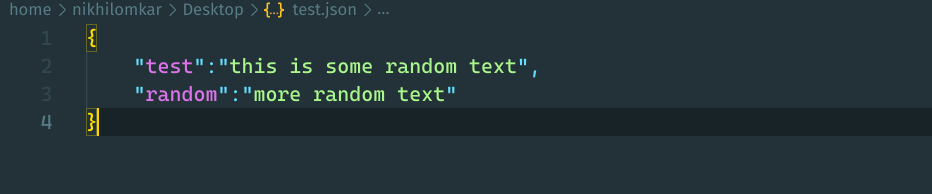
2. Solution for empty JSON file
The solution for this is self-evident in the name. To resolve the type error, in this case, make sure that the JSON file or the response from an API is not empty. If the file is empty, add content to it, and for a response from an API, use try-except to handle the error, which can be empty JSON or a 404 error, for instance.
import json
import requests
def main():
URL = "https://api.dictionaryapi.dev/api/v2/enties/en/"
word = input("Enter a word:")
data = requests.get(url + word)
data = data.text
try:
data_json = json.loads(data)
print(data_json)
except json.JSONDecodeError:
print("Empty response")
if __name__ == "__main__":
main()
The above code takes in a word and returns all the information related to it in a JSON format. Now in order to show how we can handle the Expecting value: line 1 column 1 (char 0) type error, we have altered the URL. entries have been changed to enties. Therefore we will get an invalid response which will not be of the JSON format. However, this is merely done to imitate the error when you might get an invalid response from an API.
- Now, if you try to run the code above, you will be prompted to enter a word. The response is saved into the data variable and later converted to a string.
- However, in the try block json.loads method, which parses JSON string to python dictionary raises an error.
- This is because the response sent by API is not of JSON format, hence can’t be parsed, resulting in JSONDecodeError.
- JSONDecodeError gets handled by the try-except block, and a “Response content is not valid JSON” gets printed as an outcome.


3. Solution for XML output(that is, a string starting with <)
To avoid type errors resulting from an XML format, we will convert it to a JSON format. However, firstly install this library.
pip install xmltodictimport json
import xmltodict
with open("test.xml", "r") as file:
data = xmltodict.parse(file.read())
file.close()
json_data = json.dumps(data)
with open("t.json", "w") as json_file:
json_file.write(json_data)
json_file.close()
print("Data retrieved")
print(data)
Let’s elaborate on the code above:
- We have imported two libraries, namely JSON and xmltodict.
- Using the context manager with, XML file test.xml is opened in read mode. Thereafter using the xmltodict parse method, it is converted to a dictionary type, and the file is closed.
- json.dumps() takes in a JSON object and returns a string of that object.
- Again using context manager with, a JSON file is created, XML data that was converted to a JSON string is written on it, and the file is closed.

JSONDecodeError: Expecting value: line 1 column 1 (char 0) Django
This issue is caused by the failure of Pipenv 2018.10.9. To resolve this issue, use Pipenv 2018.5.18. For more, read here.
Are you facing this error in Flask?
Many times, when you receive the data from HTTP requests, they are fetched as bytes. So, if you face JSONDecodeError, you might be dealing with a JSON in bytes. First, you need to decode the JSON by using response.decode('utf-8'). This will create a string, and then you can parse it.
FAQs
How to parse JSON in python?
json.loads() method can be used to parse JSON in python. For instance:import json
json_string = '{"a":"1", "b":"2", "c":"3"}'
json_to_dict = json.loads(json_string)
print(json_to_dict)
print(type(json_to_dict))
How to detect empty file/string before parsing JSON?
import os)
file_path = "/home/nikhilomkar/Desktop/test.json"
print("File is empty!" if os.stat(file_path).st_size == 0 else "File isn't empty!"
The following code checks if the file is empty and prints the File is empty! If true, else, the File isn’t empty!.
Conclusion JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The following article discussed the JSONDecodeError: Expecting value: line 1 column 1 (char 0). This error is due to various decoding and formatting errors. We looked at likely situations where it can occur and how to resolve it.
Trending Python Articles
-

“Other Commands Don’t Work After on_message” in Discord Bots
●February 5, 2023
-
Botocore.Exceptions.NoCredentialsError: Unable to Locate Credentials
by Rahul Kumar Yadav●February 5, 2023
-
[Resolved] NameError: Name _mysql is Not Defined
by Rahul Kumar Yadav●February 5, 2023
-
Best Ways to Implement Regex New Line in Python
by Rahul Kumar Yadav●February 5, 2023

![[Resolved] NameError: Name _mysql is Not Defined](https://www.pythonpool.com/wp-content/uploads/2023/01/nameerror-name-_mysql-is-not-defined-300x157.webp)

If you try to parse invalid JSON or decode an empty string as JSON, you will encounter the JSONDecodeError: Expecting value: line 1 column 1 (char 0). This error can occur if you read an empty file using json.load, read an empty JSON or receive an empty response from an API call.
You can use a try-except code block to catch the error and then check the contents of the JSON string or file before retrying.
This tutorial will go through the error in detail and how to solve it with code examples.
Table of contents
- JSONDecodeError: Expecting value: line 1 column 1 (char 0)
- Example #1: Incorrect use of json.loads()
- Solution
- Example #2: Empty JSON file
- Solution
- Example #3: Response Request
- Summary
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
In Python, JSONDecodeError occurs when there is an issue with the formatting of the JSON data. This specific error tells us the JSON decoder has encountered an empty JSON.
Example #1: Incorrect use of json.loads()
Let’s look at an example where we have a JSON file with the following contents:
[
{"margherita":7.99},
{"pepperoni":9.99},
{"four cheeses":10.99}
]
We want to read the data into a program using the json library. Let’s look at the code:
import json json_path = 'pizza.json' data = json.loads(json_path)
In the above code, we try to read the data in using json.loads(). Let’s run the code to see the result:
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
The error occurs because json.loads() expects a JSON encoded string, not a filename. The string pizza.json is not a valid JSON encoded string.
Solution
We need to use json.load() instead of json.loads() to read a file. Let’s look at the revised code:
import json
json_path = 'pizza.json'
with open(json_path, 'r') as f:
data = json.loads(f.read())
print(data)
In the above code, we use the open() function to create a file object that json.load() can read and return the decoded data object. The with statement is a context manager that ensures that the file is closed once the code is complete. Let’s run the code to see the result:
[{'margherita': 7.99}, {'pepperoni': 9.99}, {'four cheeses': 10.99}]
Example #2: Empty JSON file
Let’s look at an example where we have an empty file, which we will try to read in using json.loads(). The file is called particles.json. Since the JSON file is empty, the JSON decoder will throw the JSONDecodeError when it tries to read the file’s contents. Let’s look at the code:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
contents = json.loads(f.read())
print(contents)
---------------------------------------------------------------------------
JSONDecodeError Traceback (most recent call last)
Input In [1], in <cell line: 5>()
3 filename = 'particles.json'
5 with open(filename, 'r') as f:
----> 6 contents = json.loads(f.read())
7 print(contents)
File ~/opt/anaconda3/lib/python3.8/json/__init__.py:357, in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
352 del kw['encoding']
354 if (cls is None and object_hook is None and
355 parse_int is None and parse_float is None and
356 parse_constant is None and object_pairs_hook is None and not kw):
--> 357 return _default_decoder.decode(s)
358 if cls is None:
359 cls = JSONDecoder
File ~/opt/anaconda3/lib/python3.8/json/decoder.py:337, in JSONDecoder.decode(self, s, _w)
332 def decode(self, s, _w=WHITESPACE.match):
333 """Return the Python representation of ``s`` (a ``str`` instance
334 containing a JSON document).
335
336 """
--> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end())
338 end = _w(s, end).end()
339 if end != len(s):
File ~/opt/anaconda3/lib/python3.8/json/decoder.py:355, in JSONDecoder.raw_decode(self, s, idx)
353 obj, end = self.scan_once(s, idx)
354 except StopIteration as err:
--> 355 raise JSONDecodeError("Expecting value", s, err.value) from None
356 return obj, end
JSONDecodeError: Expecting value: line 1 column 1 (char 0)
Solution
If the file is empty, it is good practice to add a try-except statement to catch the JSONDecodeError. Let’s look at the code:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
try:
contents = json.loads(f.read())
print(contents)
except json.decoder.JSONDecodeError:
print('File is empty')
File is empty
Now we have verified the file is empty, we can add some content to the file. We will add three particle names together with their masses.
[
{"proton":938.3},
{"neutron":939.6},
{"electron":0.51}
]
Let’s try to read the JSON file into our program and print the contents to the console:
import json
filename = 'particles.json'
with open(filename, 'r') as f:
try:
contents = json.loads(f.read())
print(contents)
except json.decoder.JSONDecodeError:
print('File is empty')
[{'proton': 938.3}, {'neutron': 939.6}, {'electron': 0.51}]
We successfully read the contents of the file into a list object.
Example #3: Response Request
Let’s look at an example where we want to parse a JSON response using the requests library. We will send a RESTful GET call to a server, and in return, we get a response in JSON format. The requests library has a built-in JSON decoder, response.json(), which provides the payload data in the JSON serialized format.
We may encounter a response that has an error status code or is not content-type application/json. We must check that the response status code is 200 (OK) before performing the JSON parse. Let’s look at the code to check the response has the 200 status code and has the valid content type. application/json.
import requests
from requests.exceptions import HTTPError
url = 'https://httpbin.org/get'
try:
response = requests.get(url)
status = response.status_code
if (status != 204 and response.headers["content-type"].strip().startswith("application/json")):
try:
json_response = response.json()
print(json_response)
except ValueError:
print('Bad Data from Server. Response content is not valid JSON')
elif (status != 204):
try:
print(response.text)
except ValueError:
print('Bad Data From Server. Reponse content is not valid text')
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
In the above example, we use httpbin.org to execute a GET call. Let’s run the code to get the result:
{'args': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.27.1', 'X-Amzn-Trace-Id': 'Root=1-6265a5c1-3b57327c02057a3a39ffe86d'}, 'origin': '90.206.95.191', 'url': 'https://httpbin.org/get'}
Summary
Congratulations on reading to the end of this tutorial! The JSONDecodeError: Expecting value: line 1 column 1 (char 0) occurs either when data is not present in a file, the JSON string is empty, or the payload from a RESTful call is empty.
You can resolve this error by checking the JSON file or string for valid content and using an if-statement when making a RESTful call to ensure the status code is 200 and the content type is application/json.
For further reading on errors involving JSON, go to the articles:
- How to Solve Python ValueError: Trailing data
- How to Solve Python JSONDecodeError: extra data
- How to Solve Python TypeError: Object of type datetime is not JSON serializable
- How to Solve Python JSONDecodeError: Expecting ‘,’ delimiter: line 1
Have fun and happy researching!
Синтаксис:
import requests # создается в результате запроса к серверу Response = requests.get(...)
Параметры:
- нет.
Описание:
Объект requests.Response модуля requests содержит всю информацию ответа сервера на HTTP-запрос requests.get(), requests.post() и т.д.
Объект ответа сервера requests.Response генерируется после того, как библиотека requests получают ответ от сервера. Объект ответа Response содержит всю информацию,
возвращаемую сервером
, а также
объект запроса
, который создали изначально.
Атрибуты и методы объекта Response.
Response.apparent_encodingвозвращает кодировку, угаданнуюchardet,Response.close()освобождает соединение с пулом,Response.contentвозвращает контент в байтах,Response.cookiesвозвращаетcookies, установленные сервером,Response.elapsedвозвращает время, потраченное на запрос,Response.encodingустанавливает кодировку, для декодирования,Response.headersвозвращает заголовки сервера,Response.historyвозвращает историю перенаправлений,Response.is_permanent_redirectопределение постоянных редиректов,Response.is_redirectесть ли редирект,Response.iter_content()перебирает данные ответа кусками,Response.iter_lines()перебирает данные ответа, по одной строке,Response.json()возвращает ответ в виде JSON,Response.linksвозвращает ссылки заголовка ответа,Response.nextвозвращает объектPreparedRequest,Response.okTrue, еслиstatus_codeменьше 400,Response.raise_for_status()вызывает исключениеHTTPError,Response.rawвозвращает ответа в виде файлового объекта,Response.reasonвозвращает текстовое представление ответа,Response.requestвозвращает объектPreparedRequestзапроса,Response.status_codeвозвращает код ответа сервера,Response.textвозвращает контент ответа сервера в юникоде,Response.urlвозвращает URL-адрес, после перенаправлений.- Пример работы с объектом ответа сервера `Response.
Response.apparent_encoding:
Атрибут Response.apparent_encoding возвращает кодировку, определенную сторонним модулем chardet.
Response.close():
Метод Response.close() освобождает соединение с пулом. Как только этот метод был вызван, базовый необработанный объект больше не будет доступен.
Примечание: обычно не нужно вызывать явно.
Response.content:
Атрибут Response.content возвращает содержание ответа сервера, представленное в байтах.
Response.cookies = None:
Атрибут Response.cookies возвращает хранилище CookieJar файлов cookie, которые сервер отправил обратно.
Другими словами возвращает cookies, установленные сервером.
Response.elapsed = None:
Атрибут Response.elapsed возвращает время, прошедшее между отправкой запроса и получением ответа (в виде timedelta).
Это свойство специально измеряет время, затраченное между отправкой первого байта запроса и завершением анализа заголовков. Поэтому на него не влияет потребление содержимого ответа или значения ключевого аргумента stream.
Response.encoding = None:
Атрибут Response.encoding возвращает/устанавливает кодировку для декодирования контента при доступе к атрибуту Response.text.
Response.headers = None:
Атрибут Response.headers возвращает словарь без учета регистра, с заголовками сервера, которые он вернул во время ответа.
Например, заголовки [‘content-encoding’] вернут значение заголовка ответа Content-Encoding.
Response.history = None:
Атрибут Response.history возвращает список объектов ответа сервера из истории запроса. Здесь окажутся все перенаправленные ответы.
Список сортируется от самого старого до самого последнего запроса.
Response.is_permanent_redirect:
Атрибут Response.is_permanent_redirect возвращает True, если в этом ответе одна из постоянных версий перенаправления.
Response.is_redirect:
Атрибут Response.is_redirect возвращает True если этот ответ является хорошо сформированным HTTP-перенаправлением, которое могло бы быть обработано автоматически (Session.resolve_redirects).
Response.iter_content(chunk_size=1, decode_unicode=False):
Метод Response.iter_content() перебирает данные ответа. Когда в запросе установлен stream=True, то это позволяет избежать одновременного чтения содержимого в память для больших ответов.
Размер блока chunk_size — это количество байтов, которые он должен считывать в память. Это не обязательно длина каждого возвращаемого элемента, т.к. может иметь место декодирование.
Аргумент chunk_size должен иметь тип int или None. Значение None будет функционировать по-разному в зависимости от значения stream. Если stream=True, то будет считывать данные по мере их поступления в любом размере полученных фрагментов. Если stream=False, то данные возвращаются как один фрагмент.
Если аргумент decode_unicode=True, то содержимое будет декодировано с использованием наилучшей доступной кодировки на основе ответа.
Response.iter_lines(chunk_size=512, decode_unicode=False, delimiter=None):
Метод Response.iter_lines() перебирает данные ответа, по одной строке за раз. Когда в запросе установлен stream=True, то это позволяет избежать одновременного чтения содержимого в память для больших ответов.
, что этот метод не является безопасным для повторного входа.
Response.json(**kwargs):
Метод Response.json() возвращает закодированное в json содержимое ответа, если таковое имеется.
Аргумент **kwargs это необязательные аргументы, которые принимает json.loads.
simplejson.JSONDecodeError— если тело ответа не содержит действительногоjsonи установленsimplejson.json.JSONDecodeError— если тело ответа не содержит допустимогоjsonиsimplejsonне установлен.
Response.links:
Атрибут Response.links возвращает проанализированные ссылки заголовка ответа, если таковые имеются.
Response.next:
Response.ok:
Атрибут Response.ok возвращает True, если status_code меньше 400, и False, если нет.
Этот атрибут проверяет, находится ли код состояния ответа в диапазоне от 400 до 600, чтобы проверить, была ли ошибка клиента или ошибка сервера. Если код состояния находится в диапазоне от 200 до 400, то этот атрибут вернет значение True.
Это не проверка кода ответа 200 OK.
Response.raise_for_status():
Метод Response.raise_for_status() вызывает исключение HTTPError, если таковой произошел.
Response.raw = None:
Атрибут Response.raw возвращает представление ответа в виде файлового объекта (для расширенного использования).
Использование Response.raw требует, чтобы в запросе был установлен stream=True. Это требование не распространяется на внутреннее использование запросов.
Response.reason = None:
Атрибут Response.reason возвращает текстовое представление ответа HTTP-статуса, например 'Not Found' или 'OK'.
Response.request = None:
Response.status_code = None:
Атрибут Response.status_code целочисленный код ответа HTTP-статуса, например 404 или 200.
Response.text:
Атрибут Response.text возвращает cодержание/контент ответа сервера в юникоде.
Если Response.encoding=None, то кодировка будет угадана с помощью модуля chardet.
Кодировка содержимого ответа определяется исключительно на основе HTTP-заголовков, следующих за RFC 2616. Если вы точно знаете кодировку сайта, а Response.text возвращает «крокозябры«, то тогда сначала следует установить Response.encoding в нужную кодировку, перед тем как вызвать Response.text.
Response.url = None:
Атрибут Response.url окончательный URL-адреса ответа, после перенаправлений, которые делал сервер.
Пример работы с объектом ответа сервера Response:
import requests resp = requests.get('https://httpbin.org/get', headers={'user-agent': 'my-agent-0.0.1'}, cookies={'one': 'true'}) if resp.ok: print('Заголовки ответа сервера:') print(resp.headers) print('ncookies, установленные сервером:') print(dict(resp.cookies)) print('nКонтент запрашиваемой страницы:') print(resp.text) print('nДоступ к параметрам нашего запроса `resp.request`:') print('- заголовки, которые отправил запрос:') print(resp.request.headers) print('- метод нашего запроса:') print(resp.request.method) # Заголовки ответа сервера: # {'Date': 'Wed, 31 Mar 2021 09:32:48 GMT', 'Content-Type': 'application/json', # 'Content-Length': '327', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', # 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'} # # cookies, установленные сервером: # {} # # Контент запрашиваемой страницы: # { # "args": {}, # "headers": { # "Accept": "*/*", # "Accept-Encoding": "gzip, deflate", # "Cookie": "one=true", # "Host": "httpbin.org", # "User-Agent": "my-agent-0.0.1", # "X-Amzn-Trace-Id": "Root=1-606441c0-674418047cacc3e2617e6449" # }, # "origin": "xxx.xxx.xxx.xxx", # "url": "https://httpbin.org/get" # } # # # Доступ к параметрам нашего запроса `resp.request`: # - заголовки, которые отправил запрос: # {'user-agent': 'my-agent-0.0.1', 'Accept-Encoding': 'gzip, deflate', # 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'one=true'} # - метод нашего запроса: # GET
Содержание
- Введение в тему
- Создание get и post запроса
- Передача параметров в url
- Содержимое ответа response
- Бинарное содержимое ответа
- Содержимое ответа в json
- Необработанное содержимое ответа
- Пользовательские заголовки
- Более сложные post запросы
- Post отправка multipart encoded файла
- Коды состояния ответа
- Заголовки ответов
- Cookies
- Редиректы и история
- Тайм ауты
- Ошибки и исключения
Введение в тему
Модуль python requests – это общепринятый стандарт для работы с запросами по протоколу HTTP.
Этот модуль избавляет Вас от необходимости работать с низкоуровневыми деталями. Работа с запросами становится простой и элегантной.
В этом уроке будут рассмотрены самые полезные функций библиотеки requests и различные способы их использования.
Перед использованием модуля его необходимо установить:
Создание get и post запроса
Сперва необходимо добавить модуль Requests в Ваш код:
Создадим запрос и получим ответ, содержащий страницу и все необходимые данные о ней.
import requests
response = requests.get('https://www.google.ru/')
В переменную response попадает ответ на запрос. Благодаря этому объекту можно использовать любую информацию, относящуюся к этому ответу.
Сделать POST запрос так же очень просто:
import requests
response = requests.post('https://www.google.ru/', data = {'foo':3})
Другие виды HTTP запросов, к примеру: PUT, DELETE, и прочих, выполнить ничуть не сложнее:
import requests
response = requests.put('https://www.google.ru/', data = {'foo':3})
response = requests.delete('https://www.google.ru/')
response = requests.head('https://www.google.ru/')
response = requests.options('https://www.google.ru/')
Передача параметров в url
Иногда может быть необходимо отправить различные данные вместе с запросом URL. При ручной настройке URL, параметры выглядят как пары ключ=значение после знака «?». Например, https://www.google.ru/search?q=Python. Модуль Requests предоставляет возможность передать эти параметры как словарь, применяя аргумент params. Если вы хотите передать q = Python и foo=’bar’ ресурсу google.ru/search, вы должны использовать следующий код:
import requests
params_dict = {'q':'Python', 'foo':'bar'}
response = requests.get('https://www.google.ru/search', params=params_dict)
print(response.url)
#Вывод:
https://www.google.ru/search?q=Python&foo=bar
Здесь мы видим, что URL был сформирован именно так, как это было задумано.
Пара ключ=значение, где значение равняется None, не будет добавлена к параметрам запроса URL.
Так же есть возможность передавать в запрос список параметров:
import requests
params_dict = {'q':'Python', 'foo':['bar', 'eggs']}
response = requests.get('https://www.google.ru/search', params=params_dict)
print(response.url)
#Вывод:
https://www.google.ru/search?q=Python&foo=bar&foo=eggs
Содержимое ответа response
Код из предыдущего листинга создаёт объект Response, содержащий ответ сервера на наш запрос. Обратившись к его атрибуту .url можно просмотреть адрес, куда был направлен запрос. Атрибут .text позволяет просмотреть содержимое ответа. Вот как это работает:
import requests
params_dict = {'q':'Python'}
response = requests.get('https://www.google.ru/search', params=params_dict)
print(response.text)
#Вывод:<!doctype html><html lang="ru"><head><meta charset="UTF-8"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png"…
Библиотека автоматически пытается определить кодировку ответа основываясь на его заголовках. Узнать, какую кодировку выбрал модуль, можно следующим образом:
import requests
params_dict = {'q':'Python'}
response = requests.get('https://www.google.ru/search', params=params_dict)
print(response.encoding)
#Вывод:
windows-1251
Можно так же самостоятельно установить кодировку используя атрибут .encoding.
import requests
params_dict = {'q':'Python'}
response = requests.get('https://www.google.ru/search', params=params_dict)
response.encoding = 'utf-8' # указываем необходимую кодировку вручную
print(response.encoding)
#Вывод:
utf-8
Бинарное содержимое ответа
Существует возможность просмотра ответа в виде байтов:
import requests
params_dict = {'q':'Python'}
response = requests.get('https://www.google.ru/search', params=params_dict)
print(response.content)
#Вывод:
b'<!doctype html><html lang="ru"><head><meta charset="UTF-8"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" …
При передаче со сжатием ответ автоматически декодируется для Вас.
Содержимое ответа в json
Так же в Requests есть встроенная обработка ответов в формате JSON:
import requests
import json
response = requests.get(‘http://api.open-notify.org/astros.json’)
print(json.dumps(response.json(), sort_keys=True, indent=4))
#Вывод:
{
«message»: «success»,
«number»: 10,
«people»: [
{
«craft»: «ISS»,
«name»: «Mark Vande Hei»
},
{
«craft»: «ISS»,
«name»: «Oleg Novitskiy»
},
…
[/dm_code_snippet]
Если ответ не является JSON, то .json выбросит исключение:
import requests
import json
response = requests.get('https://www.google.ru/search')
print(json.dumps(response.json(), sort_keys=True, indent=4))
#Вывод:
…
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
Необработанное содержимое ответа
Если Вам нужно получить доступ к ответу сервера в чистом виде на уровне сокета, обратитесь к атрибуту .raw. Для этого необходимо указать параметр stream=True в запросе. Этот параметр заставляет модуль читать данные по мере их прибытия.
import requests
response = requests.get('https://www.google.ru/', stream=True)
print(response.raw)
print('Q'*10)
print(response.raw.read(15))
#Вывод:
<urllib3.response.HTTPResponse object at 0x000001E368771FA0>
QQQQQQQQQQ
b'x1fx8bx08x00x00x00x00x00x02xffxc5[[sxdb'
Так же можно использовать метод .iter_content. Этот метод итерирует данные потокового ответа и это позволяет избежать чтения содержимого сразу в память для больших ответов. Параметр chunk_size – это количество байтов, которые он должен прочитать в памяти. Параметр chunk_size можно произвольно менять.
import requests
response = requests.get('https://www.google.ru/', stream=True)
print(response.iter_content)
print('Q'*10)
print([i for i in response.iter_content(chunk_size=256)])
#Вывод:
<bound method Response.iter_content of <Response [200]>>
QQQQQQQQQQ
[b'<!doctype html><html itemscope="" itemtype="http://sche', b'ma.org/WebPage" lang="ru"><head><meta content=…
response.iter_content будет автоматически декодировать сжатый ответ. Response.raw — чистый набор байтов, неизменённое содержимое ответа.
Пользовательские заголовки
Если необходимо установить заголовки в HTTP запросе, передайте словарь с ними в параметр headers. Значения заголовка должны быть типа string, bytestring или unicode. Имена заголовков не чувствительны к регистру символов.
В следующем примере мы устанавливаем информацию об используемом браузере:
import requests
response = requests.get('https://www.google.ru/', headers={'user-agent': 'unknown_browser'})
print(response.request.headers)
# Вывод:
{'user-agent': 'unknown_browser', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
Более сложные post запросы
Существует способ отправить данные так, будто это результат заполнения формы на сайте:
import requests
response = requests.post('https://httpbin.org/post', data={'foo': 'bar'})
print(response.text)
# Вывод:
{
"args": {},
"data": "",
"files": {},
"form": {
"foo": "bar"
},
"headers": {
…
Параметр data может иметь произвольное количество значений для каждого ключа. Для этого необходимо указать data в формате кортежа, либо в виде dict со списками значений.
import requests
response = requests.post('https://httpbin.org/post', data={'foo':['bar', 'eggs']})
print(response.json()['form'])
print('|'*10)
response = requests.post('https://httpbin.org/post', data=[('foo', 'bar'), ('foo', 'eggs')])
print(response.json()['form'])
# Вывод:
{'foo': ['bar', 'eggs']}
||||||||||
{'foo': ['bar', 'eggs']}
Если нужно отправить данные, не закодированные как данные формы, то передайте в запрос строку вместо словаря. Тогда данные отправятся в изначальном виде.
import requests
response = requests.post('https://httpbin.org/post', data={'foo': 'bar'})
print('URL:', response.request.url)
print('Body:', response.request.body)
print('-' * 10)
response = requests.post('https://httpbin.org/post', data='foo=bar')
print('URL:', response.request.url)
print('Body:', response.request.body)
# Вывод:
URL: https://httpbin.org/post
URL: https://httpbin.org/post
Body: foo=bar
----------
URL: https://httpbin.org/post
Body: foo=bar
Post отправка multipart encoded файла
Запросы упрощают загрузку файлов с многостраничным кодированием (Multipart-Encoded):
import requests
url = 'https://httpbin.org/post'
files = {'file': open('report.xls', 'rb')}
response = requests.post(url, files=files)
print(response.text)
# Вывод:
{
...
"files": {
"file": "<censored...binary...data>"
},
...
}
Вы можете установить имя файла, content_type и заголовки в явном виде:
import requests
url = 'https://httpbin.org/post'
files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
response = requests.post(url, files=files)
print(response.text)
# Вывод:
{
...
"files": {
"file": "<censored...binary...data>"
},
...
}
Можете отправить строки, которые будут приняты в виде файлов:
import requests
url = 'https://httpbin.org/post'
files = {'file': ('report.csv', 'some,data,to,sendnanother,row,to,sendn')}
response = requests.post(url, files=files)
print(response.text)
# Вывод:
{
...
"files": {
"file": "some,data,to,send\nanother,row,to,send\n"
},
...
}
Коды состояния ответа
Возможно, наиболее важные данные (первые – уж точно), которые вы можете получить, используя библиотеку requests, является код состояния ответа.
Так, 200 статус означает, что запрос выполнен успешно, тогда как 404 статус означает, что ресурс не найден.
Важнее всего то, с какой цифры начинается код состояния:
- 1XX — информация
- 2XX — успешно
- 3XX — перенаправление
- 4XX — ошибка клиента (ошибка на нашей стороне)
- 5XX — ошибка сервера (самые страшные коды для разработчика)
Используя атрибут .status_code можно получить статус, который вернул сервер:
import requests
response = requests.get('https://www.google.ru/')
print(response.status_code)
# Вывод:
200
.status_code вернул 200 — это означает, что запрос успешно выполнен и сервер вернул запрашиваемые данные.
При желании, такую информацию можно применить в Вашем Пайтон скрипте для принятия решений:
import requests
response = requests.get('https://www.google.ru/')
if response.status_code == 200: print('Успех!')elif response.status_code == 404: print('Страница куда-то пропала…')
# Вывод:
Успех!
Если код состояния response равен 200, то скрипт выведет «Успех!», но, если он равен 404, то скрипт вернёт «Страница куда-то пропала…».
Если применить модуль Response в условном выражении и проверить логическое значение его экземпляра (if response) то он продемонстрирует значение True, если код ответа находится в диапазоне между 200 и 400, и False во всех остальных случаях.
Упростим код из предыдущего примера:
import requests
response = requests.get('https://www.google.ru/fake/')
if response:
print('Успех!')
else:
print('Хьюстон, у нас проблемы!')
# Вывод:
Хьюстон, у нас проблемы!
Данный способ не проверяет, что код состояния равен именно 200.
Причиной этого является то, что response с кодом в диапазоне от 200 до 400, такие как 204 и 304, тоже являются успешными, ведь они возвращают обрабатываемый ответ. Следовательно, этот подход делит все запросы на успешные и неуспешные – не более того. Во многих случаях Вам потребуется более детальная обработка кодов состояния запроса.
Вы можете вызвать exception, если requests.get был неудачным. Такую конструкцию можно создать вызвав .raise_for_status() используя конструкцию try- except:
import requests
from requests.exceptions import HTTPError
for url in ['https://www.google.ru/', 'https://www.google.ru/invalid']:
try:
response = requests.get(url)
response.raise_for_status()
except HTTPError:
print(f'Возникла ошибка HTTP: {HTTPError}')
except Exception as err:
print(f'Возникла непредвиденная ошибка: {err}')
else:
print('Успех!')
# Вывод:
Успех!
Возникла ошибка HTTP: <class 'requests.exceptions.HTTPError'>
Заголовки ответов
Мы можем просматривать заголовки ответа сервера:
import requests
response = requests.get('https://www.google.ru/')
print(response.headers)
# Вывод:
{'Date': 'Sun, 27 Jun 2021 13:43:17 GMT', 'Expires': '-1', 'Cache-Control': 'private, max-age=0', 'Content-Type': 'text/html; charset=windows-1251', 'P3P': 'CP="This is not a P3P policy! See g.co/p3phelp for more info."', 'Content-Encoding': 'gzip', 'Server': 'gws', 'X-XSS-Protection': '0', 'X-Frame-Options': …
Cookies
Можно просмотреть файлы cookie, которые сервер отправляет вам обратно с помощью атрибута .cookies. Запросы также позволяют отправлять свои собственные cookie-файлы.
Чтобы добавить куки в запрос, Вы должны использовать dict, переданный в параметр cookie.
import requests
url = 'https://www.google.ru/'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
response = requests.get(url, headers=headers, cookies=cookies)
print(response.request.headers)
# Вывод:
{'user-agent': 'your-own-user-agent/0.0.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive', 'Cookie': 'visit-month=February'}
Редиректы и история
По умолчанию модуль Requests выполняет редиректы для всех HTTP глаголов, кроме HEAD.
Существует возможность использовать параметр history объекта Response, чтобы отслеживать редиректы.
Например, GitHub перенаправляет все запросы HTTP на HTTPS:
import requests
response = requests.get('https://www.google.ru/')
print(response.url)
print(response.status_code)
print(response.history)
# Вывод:
https://www.google.ru/
200
[]
Тайм ауты
Так же легко можно управлять тем, сколько программа будет ждать возврат response. Время ожидания задаётся параметром timeout. Это очень важный параметр, так как, если его не использовать, написанный Вами скрипт может «зависнуть» в вечном ожидании ответа от сервера. Используем предыдущий код:
import requests
response = requests.get(‘https://www.google.ru/’, timeout=0.001)
print(response.url)
print(response.status_code)
print(response.history)
# Вывод:…
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host=’www.google.ru’, port=443): Max retries exceeded with url: / (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x000001E331681C70>, ‘Connection to www.google.ru timed out. (connect timeout=0.001)’))
Модуль не ждёт полной загрузки ответа. Исключение возникает, если сервер не отвечает (хотя бы один байт) за указанное время.
Ошибки и исключения
Если возникнет непредвиденная ситуация – ошибка соединения, модуль Requests выбросит эксепшн ConnectionError.
response.raise_for_status() возвращает объект HTTPError, если в процессе произошла ошибка. Его применяют для отладки модуля и, поэтому, он является неотъемлемой частью запросов Python.
Если выйдет время запроса, вызывается исключение Timeout. Если слишком много перенаправлений, то появится исключение TooManyRedirects.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Making HTTP Requests With Python
The requests library is the de facto standard for making HTTP requests in Python. It abstracts the complexities of making requests behind a beautiful, simple API so that you can focus on interacting with services and consuming data in your application.
Throughout this article, you’ll see some of the most useful features that requests has to offer as well as how to customize and optimize those features for different situations you may come across. You’ll also learn how to use requests in an efficient way as well as how to prevent requests to external services from slowing down your application.
In this tutorial, you’ll learn how to:
- Make requests using the most common HTTP methods
- Customize your requests’ headers and data, using the query string and message body
- Inspect data from your requests and responses
- Make authenticated requests
- Configure your requests to help prevent your application from backing up or slowing down
Though I’ve tried to include as much information as you need to understand the features and examples included in this article, I do assume a very basic general knowledge of HTTP. That said, you still may be able to follow along fine anyway.
Now that that is out of the way, let’s dive in and see how you can use requests in your application!
Getting Started With requests
Let’s begin by installing the requests library. To do so, run the following command:
If you prefer to use Pipenv for managing Python packages, you can run the following:
$ pipenv install requests
Once requests is installed, you can use it in your application. Importing requests looks like this:
Now that you’re all set up, it’s time to begin your journey through requests. Your first goal will be learning how to make a GET request.
The GET Request
HTTP methods such as GET and POST, determine which action you’re trying to perform when making an HTTP request. Besides GET and POST, there are several other common methods that you’ll use later in this tutorial.
One of the most common HTTP methods is GET. The GET method indicates that you’re trying to get or retrieve data from a specified resource. To make a GET request, invoke requests.get().
To test this out, you can make a GET request to GitHub’s Root REST API by calling get() with the following URL:
>>>
>>> requests.get('https://api.github.com')
<Response [200]>
Congratulations! You’ve made your first request. Let’s dive a little deeper into the response of that request.
The Response
A Response is a powerful object for inspecting the results of the request. Let’s make that same request again, but this time store the return value in a variable so that you can get a closer look at its attributes and behaviors:
>>>
>>> response = requests.get('https://api.github.com')
In this example, you’ve captured the return value of get(), which is an instance of Response, and stored it in a variable called response. You can now use response to see a lot of information about the results of your GET request.
Status Codes
The first bit of information that you can gather from Response is the status code. A status code informs you of the status of the request.
For example, a 200 OK status means that your request was successful, whereas a 404 NOT FOUND status means that the resource you were looking for was not found. There are many other possible status codes as well to give you specific insights into what happened with your request.
By accessing .status_code, you can see the status code that the server returned:
>>>
>>> response.status_code
200
.status_code returned a 200, which means your request was successful and the server responded with the data you were requesting.
Sometimes, you might want to use this information to make decisions in your code:
if response.status_code == 200:
print('Success!')
elif response.status_code == 404:
print('Not Found.')
With this logic, if the server returns a 200 status code, your program will print Success!. If the result is a 404, your program will print Not Found.
requests goes one step further in simplifying this process for you. If you use a Response instance in a conditional expression, it will evaluate to True if the status code was between 200 and 400, and False otherwise.
Therefore, you can simplify the last example by rewriting the if statement:
if response:
print('Success!')
else:
print('An error has occurred.')
Keep in mind that this method is not verifying that the status code is equal to 200. The reason for this is that other status codes within the 200 to 400 range, such as 204 NO CONTENT and 304 NOT MODIFIED, are also considered successful in the sense that they provide some workable response.
For example, the 204 tells you that the response was successful, but there’s no content to return in the message body.
So, make sure you use this convenient shorthand only if you want to know if the request was generally successful and then, if necessary, handle the response appropriately based on the status code.
Let’s say you don’t want to check the response’s status code in an if statement. Instead, you want to raise an exception if the request was unsuccessful. You can do this using .raise_for_status():
import requests
from requests.exceptions import HTTPError
for url in ['https://api.github.com', 'https://api.github.com/invalid']:
try:
response = requests.get(url)
# If the response was successful, no Exception will be raised
response.raise_for_status()
except HTTPError as http_err:
print(f'HTTP error occurred: {http_err}') # Python 3.6
except Exception as err:
print(f'Other error occurred: {err}') # Python 3.6
else:
print('Success!')
If you invoke .raise_for_status(), an HTTPError will be raised for certain status codes. If the status code indicates a successful request, the program will proceed without that exception being raised.
Now, you know a lot about how to deal with the status code of the response you got back from the server. However, when you make a GET request, you rarely only care about the status code of the response. Usually, you want to see more. Next, you’ll see how to view the actual data that the server sent back in the body of the response.
Content
The response of a GET request often has some valuable information, known as a payload, in the message body. Using the attributes and methods of Response, you can view the payload in a variety of different formats.
To see the response’s content in bytes, you use .content:
>>>
>>> response = requests.get('https://api.github.com')
>>> response.content
b'{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'
While .content gives you access to the raw bytes of the response payload, you will often want to convert them into a string using a character encoding such as UTF-8. response will do that for you when you access .text:
>>>
>>> response.text
'{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'
Because the decoding of bytes to a str requires an encoding scheme, requests will try to guess the encoding based on the response’s headers if you do not specify one. You can provide an explicit encoding by setting .encoding before accessing .text:
>>>
>>> response.encoding = 'utf-8' # Optional: requests infers this internally
>>> response.text
'{"current_user_url":"https://api.github.com/user","current_user_authorizations_html_url":"https://github.com/settings/connections/applications{/client_id}","authorizations_url":"https://api.github.com/authorizations","code_search_url":"https://api.github.com/search/code?q={query}{&page,per_page,sort,order}","commit_search_url":"https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}","emails_url":"https://api.github.com/user/emails","emojis_url":"https://api.github.com/emojis","events_url":"https://api.github.com/events","feeds_url":"https://api.github.com/feeds","followers_url":"https://api.github.com/user/followers","following_url":"https://api.github.com/user/following{/target}","gists_url":"https://api.github.com/gists{/gist_id}","hub_url":"https://api.github.com/hub","issue_search_url":"https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}","issues_url":"https://api.github.com/issues","keys_url":"https://api.github.com/user/keys","notifications_url":"https://api.github.com/notifications","organization_repositories_url":"https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}","organization_url":"https://api.github.com/orgs/{org}","public_gists_url":"https://api.github.com/gists/public","rate_limit_url":"https://api.github.com/rate_limit","repository_url":"https://api.github.com/repos/{owner}/{repo}","repository_search_url":"https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}","current_user_repositories_url":"https://api.github.com/user/repos{?type,page,per_page,sort}","starred_url":"https://api.github.com/user/starred{/owner}{/repo}","starred_gists_url":"https://api.github.com/gists/starred","team_url":"https://api.github.com/teams","user_url":"https://api.github.com/users/{user}","user_organizations_url":"https://api.github.com/user/orgs","user_repositories_url":"https://api.github.com/users/{user}/repos{?type,page,per_page,sort}","user_search_url":"https://api.github.com/search/users?q={query}{&page,per_page,sort,order}"}'
If you take a look at the response, you’ll see that it is actually serialized JSON content. To get a dictionary, you could take the str you retrieved from .text and deserialize it using json.loads(). However, a simpler way to accomplish this task is to use .json():
>>>
>>> response.json()
{'current_user_url': 'https://api.github.com/user', 'current_user_authorizations_html_url': 'https://github.com/settings/connections/applications{/client_id}', 'authorizations_url': 'https://api.github.com/authorizations', 'code_search_url': 'https://api.github.com/search/code?q={query}{&page,per_page,sort,order}', 'commit_search_url': 'https://api.github.com/search/commits?q={query}{&page,per_page,sort,order}', 'emails_url': 'https://api.github.com/user/emails', 'emojis_url': 'https://api.github.com/emojis', 'events_url': 'https://api.github.com/events', 'feeds_url': 'https://api.github.com/feeds', 'followers_url': 'https://api.github.com/user/followers', 'following_url': 'https://api.github.com/user/following{/target}', 'gists_url': 'https://api.github.com/gists{/gist_id}', 'hub_url': 'https://api.github.com/hub', 'issue_search_url': 'https://api.github.com/search/issues?q={query}{&page,per_page,sort,order}', 'issues_url': 'https://api.github.com/issues', 'keys_url': 'https://api.github.com/user/keys', 'notifications_url': 'https://api.github.com/notifications', 'organization_repositories_url': 'https://api.github.com/orgs/{org}/repos{?type,page,per_page,sort}', 'organization_url': 'https://api.github.com/orgs/{org}', 'public_gists_url': 'https://api.github.com/gists/public', 'rate_limit_url': 'https://api.github.com/rate_limit', 'repository_url': 'https://api.github.com/repos/{owner}/{repo}', 'repository_search_url': 'https://api.github.com/search/repositories?q={query}{&page,per_page,sort,order}', 'current_user_repositories_url': 'https://api.github.com/user/repos{?type,page,per_page,sort}', 'starred_url': 'https://api.github.com/user/starred{/owner}{/repo}', 'starred_gists_url': 'https://api.github.com/gists/starred', 'team_url': 'https://api.github.com/teams', 'user_url': 'https://api.github.com/users/{user}', 'user_organizations_url': 'https://api.github.com/user/orgs', 'user_repositories_url': 'https://api.github.com/users/{user}/repos{?type,page,per_page,sort}', 'user_search_url': 'https://api.github.com/search/users?q={query}{&page,per_page,sort,order}'}
The type of the return value of .json() is a dictionary, so you can access values in the object by key.
You can do a lot with status codes and message bodies. But, if you need more information, like metadata about the response itself, you’ll need to look at the response’s headers.
Query String Parameters
One common way to customize a GET request is to pass values through query string parameters in the URL. To do this using get(), you pass data to params. For example, you can use GitHub’s Search API to look for the requests library:
import requests
# Search GitHub's repositories for requests
response = requests.get(
'https://api.github.com/search/repositories',
params={'q': 'requests+language:python'},
)
# Inspect some attributes of the `requests` repository
json_response = response.json()
repository = json_response['items'][0]
print(f'Repository name: {repository["name"]}') # Python 3.6+
print(f'Repository description: {repository["description"]}') # Python 3.6+
By passing the dictionary {'q': 'requests+language:python'} to the params parameter of .get(), you are able to modify the results that come back from the Search API.
You can pass params to get() in the form of a dictionary, as you have just done, or as a list of tuples:
>>>
>>> requests.get(
... 'https://api.github.com/search/repositories',
... params=[('q', 'requests+language:python')],
... )
<Response [200]>
You can even pass the values as bytes:
>>>
>>> requests.get(
... 'https://api.github.com/search/repositories',
... params=b'q=requests+language:python',
... )
<Response [200]>
Query strings are useful for parameterizing GET requests. You can also customize your requests by adding or modifying the headers you send.
Other HTTP Methods
Aside from GET, other popular HTTP methods include POST, PUT, DELETE, HEAD, PATCH, and OPTIONS. requests provides a method, with a similar signature to get(), for each of these HTTP methods:
>>>
>>> requests.post('https://httpbin.org/post', data={'key':'value'})
>>> requests.put('https://httpbin.org/put', data={'key':'value'})
>>> requests.delete('https://httpbin.org/delete')
>>> requests.head('https://httpbin.org/get')
>>> requests.patch('https://httpbin.org/patch', data={'key':'value'})
>>> requests.options('https://httpbin.org/get')
Each function call makes a request to the httpbin service using the corresponding HTTP method. For each method, you can inspect their responses in the same way you did before:
>>>
>>> response = requests.head('https://httpbin.org/get')
>>> response.headers['Content-Type']
'application/json'
>>> response = requests.delete('https://httpbin.org/delete')
>>> json_response = response.json()
>>> json_response['args']
{}
Headers, response bodies, status codes, and more are returned in the Response for each method. Next you’ll take a closer look at the POST, PUT, and PATCH methods and learn how they differ from the other request types.
The Message Body
According to the HTTP specification, POST, PUT, and the less common PATCH requests pass their data through the message body rather than through parameters in the query string. Using requests, you’ll pass the payload to the corresponding function’s data parameter.
data takes a dictionary, a list of tuples, bytes, or a file-like object. You’ll want to adapt the data you send in the body of your request to the specific needs of the service you’re interacting with.
For example, if your request’s content type is application/x-www-form-urlencoded, you can send the form data as a dictionary:
>>>
>>> requests.post('https://httpbin.org/post', data={'key':'value'})
<Response [200]>
You can also send that same data as a list of tuples:
>>>
>>> requests.post('https://httpbin.org/post', data=[('key', 'value')])
<Response [200]>
If, however, you need to send JSON data, you can use the json parameter. When you pass JSON data via json, requests will serialize your data and add the correct Content-Type header for you.
httpbin.org is a great resource created by the author of requests, Kenneth Reitz. It’s a service that accepts test requests and responds with data about the requests. For instance, you can use it to inspect a basic POST request:
>>>
>>> response = requests.post('https://httpbin.org/post', json={'key':'value'})
>>> json_response = response.json()
>>> json_response['data']
'{"key": "value"}'
>>> json_response['headers']['Content-Type']
'application/json'
You can see from the response that the server received your request data and headers as you sent them. requests also provides this information to you in the form of a PreparedRequest.
Inspecting Your Request
When you make a request, the requests library prepares the request before actually sending it to the destination server. Request preparation includes things like validating headers and serializing JSON content.
You can view the PreparedRequest by accessing .request:
>>>
>>> response = requests.post('https://httpbin.org/post', json={'key':'value'})
>>> response.request.headers['Content-Type']
'application/json'
>>> response.request.url
'https://httpbin.org/post'
>>> response.request.body
b'{"key": "value"}'
Inspecting the PreparedRequest gives you access to all kinds of information about the request being made such as payload, URL, headers, authentication, and more.
So far, you’ve made a lot of different kinds of requests, but they’ve all had one thing in common: they’re unauthenticated requests to public APIs. Many services you may come across will want you to authenticate in some way.
Authentication
Authentication helps a service understand who you are. Typically, you provide your credentials to a server by passing data through the Authorization header or a custom header defined by the service. All the request functions you’ve seen to this point provide a parameter called auth, which allows you to pass your credentials.
One example of an API that requires authentication is GitHub’s Authenticated User API. This endpoint provides information about the authenticated user’s profile. To make a request to the Authenticated User API, you can pass your GitHub username and password in a tuple to get():
>>>
>>> from getpass import getpass
>>> requests.get('https://api.github.com/user', auth=('username', getpass()))
<Response [200]>
The request succeeded if the credentials you passed in the tuple to auth are valid. If you try to make this request with no credentials, you’ll see that the status code is 401 Unauthorized:
>>>
>>> requests.get('https://api.github.com/user')
<Response [401]>
When you pass your username and password in a tuple to the auth parameter, requests is applying the credentials using HTTP’s Basic access authentication scheme under the hood.
Therefore, you could make the same request by passing explicit Basic authentication credentials using HTTPBasicAuth:
>>>
>>> from requests.auth import HTTPBasicAuth
>>> from getpass import getpass
>>> requests.get(
... 'https://api.github.com/user',
... auth=HTTPBasicAuth('username', getpass())
... )
<Response [200]>
Though you don’t need to be explicit for Basic authentication, you may want to authenticate using another method. requests provides other methods of authentication out of the box such as HTTPDigestAuth and HTTPProxyAuth.
You can even supply your own authentication mechanism. To do so, you must first create a subclass of AuthBase. Then, you implement __call__():
import requests
from requests.auth import AuthBase
class TokenAuth(AuthBase):
"""Implements a custom authentication scheme."""
def __init__(self, token):
self.token = token
def __call__(self, r):
"""Attach an API token to a custom auth header."""
r.headers['X-TokenAuth'] = f'{self.token}' # Python 3.6+
return r
requests.get('https://httpbin.org/get', auth=TokenAuth('12345abcde-token'))
Here, your custom TokenAuth mechanism receives a token, then includes that token in the X-TokenAuth header of your request.
Bad authentication mechanisms can lead to security vulnerabilities, so unless a service requires a custom authentication mechanism for some reason, you’ll always want to use a tried-and-true auth scheme like Basic or OAuth.
While you’re thinking about security, let’s consider dealing with SSL Certificates using requests.
SSL Certificate Verification
Any time the data you are trying to send or receive is sensitive, security is important. The way that you communicate with secure sites over HTTP is by establishing an encrypted connection using SSL, which means that verifying the target server’s SSL Certificate is critical.
The good news is that requests does this for you by default. However, there are some cases where you might want to change this behavior.
If you want to disable SSL Certificate verification, you pass False to the verify parameter of the request function:
>>>
>>> requests.get('https://api.github.com', verify=False)
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
<Response [200]>
requests even warns you when you’re making an insecure request to help you keep your data safe!
Performance
When using requests, especially in a production application environment, it’s important to consider performance implications. Features like timeout control, sessions, and retry limits can help you keep your application running smoothly.
Timeouts
When you make an inline request to an external service, your system will need to wait upon the response before moving on. If your application waits too long for that response, requests to your service could back up, your user experience could suffer, or your background jobs could hang.
By default, requests will wait indefinitely on the response, so you should almost always specify a timeout duration to prevent these things from happening. To set the request’s timeout, use the timeout parameter. timeout can be an integer or float representing the number of seconds to wait on a response before timing out:
>>>
>>> requests.get('https://api.github.com', timeout=1)
<Response [200]>
>>> requests.get('https://api.github.com', timeout=3.05)
<Response [200]>
In the first request, the request will timeout after 1 second. In the second request, the request will timeout after 3.05 seconds.
You can also pass a tuple to timeout with the first element being a connect timeout (the time it allows for the client to establish a connection to the server), and the second being a read timeout (the time it will wait on a response once your client has established a connection):
>>>
>>> requests.get('https://api.github.com', timeout=(2, 5))
<Response [200]>
If the request establishes a connection within 2 seconds and receives data within 5 seconds of the connection being established, then the response will be returned as it was before. If the request times out, then the function will raise a Timeout exception:
import requests
from requests.exceptions import Timeout
try:
response = requests.get('https://api.github.com', timeout=1)
except Timeout:
print('The request timed out')
else:
print('The request did not time out')
Your program can catch the Timeout exception and respond accordingly.
The Session Object
Until now, you’ve been dealing with high level requests APIs such as get() and post(). These functions are abstractions of what’s going on when you make your requests. They hide implementation details such as how connections are managed so that you don’t have to worry about them.
Underneath those abstractions is a class called Session. If you need to fine-tune your control over how requests are being made or improve the performance of your requests, you may need to use a Session instance directly.
Sessions are used to persist parameters across requests. For example, if you want to use the same authentication across multiple requests, you could use a session:
import requests
from getpass import getpass
# By using a context manager, you can ensure the resources used by
# the session will be released after use
with requests.Session() as session:
session.auth = ('username', getpass())
# Instead of requests.get(), you'll use session.get()
response = session.get('https://api.github.com/user')
# You can inspect the response just like you did before
print(response.headers)
print(response.json())
Each time you make a request with session, once it has been initialized with authentication credentials, the credentials will be persisted.
The primary performance optimization of sessions comes in the form of persistent connections. When your app makes a connection to a server using a Session, it keeps that connection around in a connection pool. When your app wants to connect to the same server again, it will reuse a connection from the pool rather than establishing a new one.
Max Retries
When a request fails, you may want your application to retry the same request. However, requests will not do this for you by default. To apply this functionality, you need to implement a custom Transport Adapter.
Transport Adapters let you define a set of configurations per service you’re interacting with. For example, let’s say you want all requests to https://api.github.com to retry three times before finally raising a ConnectionError. You would build a Transport Adapter, set its max_retries parameter, and mount it to an existing Session:
import requests
from requests.adapters import HTTPAdapter
from requests.exceptions import ConnectionError
github_adapter = HTTPAdapter(max_retries=3)
session = requests.Session()
# Use `github_adapter` for all requests to endpoints that start with this URL
session.mount('https://api.github.com', github_adapter)
try:
session.get('https://api.github.com')
except ConnectionError as ce:
print(ce)
When you mount the HTTPAdapter, github_adapter, to session, session will adhere to its configuration for each request to https://api.github.com.
Timeouts, Transport Adapters, and sessions are for keeping your code efficient and your application resilient.
Conclusion
You’ve come a long way in learning about Python’s powerful requests library.
You’re now able to:
- Make requests using a variety of different HTTP methods such as
GET,POST, andPUT - Customize your requests by modifying headers, authentication, query strings, and message bodies
- Inspect the data you send to the server and the data the server sends back to you
- Work with SSL Certificate verification
- Use
requestseffectively usingmax_retries,timeout, Sessions, and Transport Adapters
Because you learned how to use requests, you’re equipped to explore the wide world of web services and build awesome applications using the fascinating data they provide.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Making HTTP Requests With Python